ES2908978T3 - Nuevas entidades químicas simples y métodos para la administración de oligonucleótidos - Google Patents
Nuevas entidades químicas simples y métodos para la administración de oligonucleótidos Download PDFInfo
- Publication number
- ES2908978T3 ES2908978T3 ES18182352T ES18182352T ES2908978T3 ES 2908978 T3 ES2908978 T3 ES 2908978T3 ES 18182352 T ES18182352 T ES 18182352T ES 18182352 T ES18182352 T ES 18182352T ES 2908978 T3 ES2908978 T3 ES 2908978T3
- Authority
- ES
- Spain
- Prior art keywords
- seq
- sirna
- peptides
- oligonucleotide
- strand
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 108091034117 Oligonucleotide Proteins 0.000 title description 45
- 238000000034 method Methods 0.000 title description 34
- 150000005829 chemical entities Chemical class 0.000 title description 2
- 108090000765 processed proteins & peptides Proteins 0.000 claims abstract description 50
- 108020004459 Small interfering RNA Proteins 0.000 claims abstract description 39
- 239000000203 mixture Substances 0.000 claims abstract description 35
- 102000004196 processed proteins & peptides Human genes 0.000 claims abstract description 31
- 125000000548 ribosyl group Chemical group C1([C@H](O)[C@H](O)[C@H](O1)CO)* 0.000 claims abstract description 11
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 claims description 26
- 235000012000 cholesterol Nutrition 0.000 claims description 13
- ZHNUHDYFZUAESO-UHFFFAOYSA-N Formamide Chemical compound NC=O ZHNUHDYFZUAESO-UHFFFAOYSA-N 0.000 description 40
- 230000008685 targeting Effects 0.000 description 33
- 239000003446 ligand Substances 0.000 description 30
- 150000002632 lipids Chemical class 0.000 description 30
- 125000005647 linker group Chemical group 0.000 description 24
- 210000004027 cell Anatomy 0.000 description 23
- 150000001875 compounds Chemical class 0.000 description 21
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 20
- 230000003381 solubilizing effect Effects 0.000 description 19
- -1 GalNAc 2 and GalNAc3 Chemical compound 0.000 description 14
- 239000007983 Tris buffer Substances 0.000 description 13
- LENZDBCJOHFCAS-UHFFFAOYSA-N tris Chemical compound OCC(N)(CO)CO LENZDBCJOHFCAS-UHFFFAOYSA-N 0.000 description 13
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 12
- 108020004999 messenger RNA Proteins 0.000 description 12
- 239000007787 solid Substances 0.000 description 12
- 239000011541 reaction mixture Substances 0.000 description 11
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 10
- 238000012925 biological evaluation Methods 0.000 description 10
- 238000006243 chemical reaction Methods 0.000 description 9
- 108090000623 proteins and genes Proteins 0.000 description 9
- 108010051109 Cell-Penetrating Peptides Proteins 0.000 description 8
- 102000020313 Cell-Penetrating Peptides Human genes 0.000 description 8
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 description 8
- 238000004458 analytical method Methods 0.000 description 8
- 239000012528 membrane Substances 0.000 description 8
- 239000000243 solution Substances 0.000 description 8
- WQZGKKKJIJFFOK-SVZMEOIVSA-N (+)-Galactose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-SVZMEOIVSA-N 0.000 description 6
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N Silicium dioxide Chemical compound O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 description 6
- 239000000872 buffer Substances 0.000 description 6
- 238000005119 centrifugation Methods 0.000 description 6
- 239000003795 chemical substances by application Substances 0.000 description 6
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 6
- 150000003573 thiols Chemical class 0.000 description 6
- ZMANZCXQSJIPKH-UHFFFAOYSA-N Triethylamine Chemical compound CCN(CC)CC ZMANZCXQSJIPKH-UHFFFAOYSA-N 0.000 description 5
- 230000004048 modification Effects 0.000 description 5
- 238000012986 modification Methods 0.000 description 5
- 239000002773 nucleotide Substances 0.000 description 5
- 125000003729 nucleotide group Chemical group 0.000 description 5
- 229920001223 polyethylene glycol Polymers 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- IYMAXBFPHPZYIK-BQBZGAKWSA-N Arg-Gly-Asp Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CC(O)=O)C(O)=O IYMAXBFPHPZYIK-BQBZGAKWSA-N 0.000 description 4
- 102000004506 Blood Proteins Human genes 0.000 description 4
- 108010017384 Blood Proteins Proteins 0.000 description 4
- BWGNESOTFCXPMA-UHFFFAOYSA-N Dihydrogen disulfide Chemical compound SS BWGNESOTFCXPMA-UHFFFAOYSA-N 0.000 description 4
- 108010072041 arginyl-glycyl-aspartic acid Proteins 0.000 description 4
- 229920001577 copolymer Polymers 0.000 description 4
- 201000010099 disease Diseases 0.000 description 4
- 230000000021 endosomolytic effect Effects 0.000 description 4
- 238000009472 formulation Methods 0.000 description 4
- BAZAXWOYCMUHIX-UHFFFAOYSA-M sodium perchlorate Chemical compound [Na+].[O-]Cl(=O)(=O)=O BAZAXWOYCMUHIX-UHFFFAOYSA-M 0.000 description 4
- 229910001488 sodium perchlorate Inorganic materials 0.000 description 4
- 239000002904 solvent Substances 0.000 description 4
- 238000002305 strong-anion-exchange chromatography Methods 0.000 description 4
- 102000040650 (ribonucleotides)n+m Human genes 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 description 3
- 229910017855 NH 4 F Inorganic materials 0.000 description 3
- 238000012228 RNA interference-mediated gene silencing Methods 0.000 description 3
- 125000002777 acetyl group Chemical group [H]C([H])([H])C(*)=O 0.000 description 3
- 125000000217 alkyl group Chemical group 0.000 description 3
- 150000001408 amides Chemical class 0.000 description 3
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical group [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 3
- 239000012455 biphasic mixture Substances 0.000 description 3
- 230000004700 cellular uptake Effects 0.000 description 3
- 230000021615 conjugation Effects 0.000 description 3
- XUJNEKJLAYXESH-UHFFFAOYSA-N cysteine Natural products SCC(N)C(O)=O XUJNEKJLAYXESH-UHFFFAOYSA-N 0.000 description 3
- 235000018417 cysteine Nutrition 0.000 description 3
- 235000014113 dietary fatty acids Nutrition 0.000 description 3
- 150000002019 disulfides Chemical class 0.000 description 3
- 150000002148 esters Chemical group 0.000 description 3
- 229930195729 fatty acid Natural products 0.000 description 3
- 239000000194 fatty acid Substances 0.000 description 3
- 150000004665 fatty acids Chemical class 0.000 description 3
- 229940014144 folate Drugs 0.000 description 3
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 3
- 235000019152 folic acid Nutrition 0.000 description 3
- 239000011724 folic acid Substances 0.000 description 3
- 230000009368 gene silencing by RNA Effects 0.000 description 3
- 238000004895 liquid chromatography mass spectrometry Methods 0.000 description 3
- 229910052760 oxygen Inorganic materials 0.000 description 3
- 239000001301 oxygen Substances 0.000 description 3
- 230000008569 process Effects 0.000 description 3
- 235000018102 proteins Nutrition 0.000 description 3
- 102000004169 proteins and genes Human genes 0.000 description 3
- 108020003175 receptors Proteins 0.000 description 3
- 102000005962 receptors Human genes 0.000 description 3
- 239000000377 silicon dioxide Substances 0.000 description 3
- 239000000126 substance Substances 0.000 description 3
- 229910052717 sulfur Inorganic materials 0.000 description 3
- AVBGNFCMKJOFIN-UHFFFAOYSA-N triethylammonium acetate Chemical compound CC(O)=O.CCN(CC)CC AVBGNFCMKJOFIN-UHFFFAOYSA-N 0.000 description 3
- GVJHHUAWPYXKBD-UHFFFAOYSA-N (±)-α-Tocopherol Chemical compound OC1=C(C)C(C)=C2OC(CCCC(C)CCCC(C)CCCC(C)C)(C)CCC2=C1C GVJHHUAWPYXKBD-UHFFFAOYSA-N 0.000 description 2
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 description 2
- BSYNRYMUTXBXSQ-UHFFFAOYSA-N Aspirin Chemical compound CC(=O)OC1=CC=CC=C1C(O)=O BSYNRYMUTXBXSQ-UHFFFAOYSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 2
- WQZGKKKJIJFFOK-QTVWNMPRSA-N D-mannopyranose Chemical compound OC[C@H]1OC(O)[C@@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-QTVWNMPRSA-N 0.000 description 2
- XEKOWRVHYACXOJ-UHFFFAOYSA-N Ethyl acetate Chemical compound CCOC(C)=O XEKOWRVHYACXOJ-UHFFFAOYSA-N 0.000 description 2
- 102000015779 HDL Lipoproteins Human genes 0.000 description 2
- 108010010234 HDL Lipoproteins Proteins 0.000 description 2
- 102000008100 Human Serum Albumin Human genes 0.000 description 2
- 108091006905 Human Serum Albumin Proteins 0.000 description 2
- HEFNNWSXXWATRW-UHFFFAOYSA-N Ibuprofen Chemical compound CC(C)CC1=CC=C(C(C)C(O)=O)C=C1 HEFNNWSXXWATRW-UHFFFAOYSA-N 0.000 description 2
- 102000007330 LDL Lipoproteins Human genes 0.000 description 2
- 108010007622 LDL Lipoproteins Proteins 0.000 description 2
- 108010001831 LDL receptors Proteins 0.000 description 2
- 102000000853 LDL receptors Human genes 0.000 description 2
- 108090001030 Lipoproteins Proteins 0.000 description 2
- 102000004895 Lipoproteins Human genes 0.000 description 2
- SMEROWZSTRWXGI-UHFFFAOYSA-N Lithocholsaeure Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)CC2 SMEROWZSTRWXGI-UHFFFAOYSA-N 0.000 description 2
- 241000124008 Mammalia Species 0.000 description 2
- OVRNDRQMDRJTHS-CBQIKETKSA-N N-Acetyl-D-Galactosamine Chemical compound CC(=O)N[C@H]1[C@@H](O)O[C@H](CO)[C@H](O)[C@@H]1O OVRNDRQMDRJTHS-CBQIKETKSA-N 0.000 description 2
- MBLBDJOUHNCFQT-UHFFFAOYSA-N N-acetyl-D-galactosamine Natural products CC(=O)NC(C=O)C(O)C(O)C(O)CO MBLBDJOUHNCFQT-UHFFFAOYSA-N 0.000 description 2
- CMWTZPSULFXXJA-UHFFFAOYSA-N Naproxen Natural products C1=C(C(C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-UHFFFAOYSA-N 0.000 description 2
- 229910019142 PO4 Inorganic materials 0.000 description 2
- 108010039918 Polylysine Proteins 0.000 description 2
- 239000004372 Polyvinyl alcohol Substances 0.000 description 2
- NINIDFKCEFEMDL-UHFFFAOYSA-N Sulfur Chemical compound [S] NINIDFKCEFEMDL-UHFFFAOYSA-N 0.000 description 2
- 229960001138 acetylsalicylic acid Drugs 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 150000001720 carbohydrates Chemical class 0.000 description 2
- 235000014633 carbohydrates Nutrition 0.000 description 2
- 229910052799 carbon Inorganic materials 0.000 description 2
- 210000000170 cell membrane Anatomy 0.000 description 2
- 238000000502 dialysis Methods 0.000 description 2
- 208000035475 disorder Diseases 0.000 description 2
- 229940079593 drug Drugs 0.000 description 2
- 239000003814 drug Substances 0.000 description 2
- 230000030279 gene silencing Effects 0.000 description 2
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 2
- 229960001680 ibuprofen Drugs 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- SMEROWZSTRWXGI-HVATVPOCSA-N lithocholic acid Chemical compound C([C@H]1CC2)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(O)=O)C)[C@@]2(C)CC1 SMEROWZSTRWXGI-HVATVPOCSA-N 0.000 description 2
- 230000002132 lysosomal effect Effects 0.000 description 2
- VLKZOEOYAKHREP-UHFFFAOYSA-N n-Hexane Chemical class CCCCCC VLKZOEOYAKHREP-UHFFFAOYSA-N 0.000 description 2
- 229960002009 naproxen Drugs 0.000 description 2
- CMWTZPSULFXXJA-VIFPVBQESA-N naproxen Chemical compound C1=C([C@H](C)C(O)=O)C=CC2=CC(OC)=CC=C21 CMWTZPSULFXXJA-VIFPVBQESA-N 0.000 description 2
- 229910052757 nitrogen Inorganic materials 0.000 description 2
- 125000004433 nitrogen atom Chemical group N* 0.000 description 2
- 230000000149 penetrating effect Effects 0.000 description 2
- 239000000816 peptidomimetic Substances 0.000 description 2
- 235000021317 phosphate Nutrition 0.000 description 2
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 2
- 125000004437 phosphorous atom Chemical group 0.000 description 2
- 229920001308 poly(aminoacid) Polymers 0.000 description 2
- 229920000656 polylysine Polymers 0.000 description 2
- 229920000642 polymer Polymers 0.000 description 2
- 229920002451 polyvinyl alcohol Polymers 0.000 description 2
- 239000000843 powder Substances 0.000 description 2
- 238000004007 reversed phase HPLC Methods 0.000 description 2
- 101150112274 ssb gene Proteins 0.000 description 2
- 239000011593 sulfur Substances 0.000 description 2
- 230000032258 transport Effects 0.000 description 2
- NOOLISFMXDJSKH-UTLUCORTSA-N (+)-Neomenthol Chemical group CC(C)[C@@H]1CC[C@@H](C)C[C@@H]1O NOOLISFMXDJSKH-UTLUCORTSA-N 0.000 description 1
- DTGKSKDOIYIVQL-WEDXCCLWSA-N (+)-borneol Chemical group C1C[C@@]2(C)[C@@H](O)C[C@@H]1C2(C)C DTGKSKDOIYIVQL-WEDXCCLWSA-N 0.000 description 1
- DNIAPMSPPWPWGF-VKHMYHEASA-N (+)-propylene glycol Chemical group C[C@H](O)CO DNIAPMSPPWPWGF-VKHMYHEASA-N 0.000 description 1
- REPVLJRCJUVQFA-UHFFFAOYSA-N (-)-isopinocampheol Chemical group C1C(O)C(C)C2C(C)(C)C1C2 REPVLJRCJUVQFA-UHFFFAOYSA-N 0.000 description 1
- KIUKXJAPPMFGSW-DNGZLQJQSA-N (2S,3S,4S,5R,6R)-6-[(2S,3R,4R,5S,6R)-3-Acetamido-2-[(2S,3S,4R,5R,6R)-6-[(2R,3R,4R,5S,6R)-3-acetamido-2,5-dihydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-2-carboxy-4,5-dihydroxyoxan-3-yl]oxy-5-hydroxy-6-(hydroxymethyl)oxan-4-yl]oxy-3,4,5-trihydroxyoxane-2-carboxylic acid Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O[C@H]1[C@H](O)[C@@H](O)[C@H](O[C@H]2[C@@H]([C@@H](O[C@H]3[C@@H]([C@@H](O)[C@H](O)[C@H](O3)C(O)=O)O)[C@H](O)[C@@H](CO)O2)NC(C)=O)[C@@H](C(O)=O)O1 KIUKXJAPPMFGSW-DNGZLQJQSA-N 0.000 description 1
- XUNKPNYCNUKOAU-VXJRNSOOSA-N (2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-[[(2s)-2-amino-5-(diaminomethylideneamino)pentanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]amino]-5-(diaminomethylideneamino)pentanoyl]a Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O XUNKPNYCNUKOAU-VXJRNSOOSA-N 0.000 description 1
- HSINOMROUCMIEA-FGVHQWLLSA-N (2s,4r)-4-[(3r,5s,6r,7r,8s,9s,10s,13r,14s,17r)-6-ethyl-3,7-dihydroxy-10,13-dimethyl-2,3,4,5,6,7,8,9,11,12,14,15,16,17-tetradecahydro-1h-cyclopenta[a]phenanthren-17-yl]-2-methylpentanoic acid Chemical compound C([C@@]12C)C[C@@H](O)C[C@H]1[C@@H](CC)[C@@H](O)[C@@H]1[C@@H]2CC[C@]2(C)[C@@H]([C@H](C)C[C@H](C)C(O)=O)CC[C@H]21 HSINOMROUCMIEA-FGVHQWLLSA-N 0.000 description 1
- BHQCQFFYRZLCQQ-UHFFFAOYSA-N (3alpha,5alpha,7alpha,12alpha)-3,7,12-trihydroxy-cholan-24-oic acid Natural products OC1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 BHQCQFFYRZLCQQ-UHFFFAOYSA-N 0.000 description 1
- YPFDHNVEDLHUCE-UHFFFAOYSA-N 1,3-propanediol Chemical group OCCCO YPFDHNVEDLHUCE-UHFFFAOYSA-N 0.000 description 1
- 229940035437 1,3-propanediol Drugs 0.000 description 1
- MZMNEDXVUJLQAF-UHFFFAOYSA-N 1-o-tert-butyl 2-o-methyl 4-hydroxypyrrolidine-1,2-dicarboxylate Chemical compound COC(=O)C1CC(O)CN1C(=O)OC(C)(C)C MZMNEDXVUJLQAF-UHFFFAOYSA-N 0.000 description 1
- TZMSYXZUNZXBOL-UHFFFAOYSA-N 10H-phenoxazine Chemical compound C1=CC=C2NC3=CC=CC=C3OC2=C1 TZMSYXZUNZXBOL-UHFFFAOYSA-N 0.000 description 1
- NVKAWKQGWWIWPM-ABEVXSGRSA-N 17-β-hydroxy-5-α-Androstan-3-one Chemical compound C1C(=O)CC[C@]2(C)[C@H]3CC[C@](C)([C@H](CC4)O)[C@@H]4[C@@H]3CC[C@H]21 NVKAWKQGWWIWPM-ABEVXSGRSA-N 0.000 description 1
- HIAJCGFYHIANNA-QIZZZRFXSA-N 3b-Hydroxy-5-cholenoic acid Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@@H](CCC(O)=O)C)[C@@]1(C)CC2 HIAJCGFYHIANNA-QIZZZRFXSA-N 0.000 description 1
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 description 1
- 101800002011 Amphipathic peptide Proteins 0.000 description 1
- 108091023037 Aptamer Proteins 0.000 description 1
- 229940122361 Bisphosphonate Drugs 0.000 description 1
- 229920002101 Chitin Polymers 0.000 description 1
- 229920001661 Chitosan Polymers 0.000 description 1
- 239000004380 Cholic acid Substances 0.000 description 1
- 229920000858 Cyclodextrin Polymers 0.000 description 1
- 150000008574 D-amino acids Chemical class 0.000 description 1
- NOOLISFMXDJSKH-UHFFFAOYSA-N DL-menthol Chemical group CC(C)C1CCC(C)CC1O NOOLISFMXDJSKH-UHFFFAOYSA-N 0.000 description 1
- 229920002307 Dextran Polymers 0.000 description 1
- 229930091371 Fructose Natural products 0.000 description 1
- 239000005715 Fructose Substances 0.000 description 1
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 1
- 102000006395 Globulins Human genes 0.000 description 1
- 108010044091 Globulins Proteins 0.000 description 1
- 229920001202 Inulin Polymers 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- 108010061306 Lipoprotein Receptors Proteins 0.000 description 1
- 102000011965 Lipoprotein Receptors Human genes 0.000 description 1
- 108010007013 Melanocyte-Stimulating Hormones Proteins 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 108010063954 Mucins Proteins 0.000 description 1
- OVRNDRQMDRJTHS-UHFFFAOYSA-N N-acelyl-D-glucosamine Natural products CC(=O)NC1C(O)OC(CO)C(O)C1O OVRNDRQMDRJTHS-UHFFFAOYSA-N 0.000 description 1
- OVRNDRQMDRJTHS-FMDGEEDCSA-N N-acetyl-beta-D-glucosamine Chemical compound CC(=O)N[C@H]1[C@H](O)O[C@H](CO)[C@@H](O)[C@@H]1O OVRNDRQMDRJTHS-FMDGEEDCSA-N 0.000 description 1
- MBLBDJOUHNCFQT-LXGUWJNJSA-N N-acetylglucosamine Natural products CC(=O)N[C@@H](C=O)[C@@H](O)[C@H](O)[C@H](O)CO MBLBDJOUHNCFQT-LXGUWJNJSA-N 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 101710163270 Nuclease Proteins 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- 108091093037 Peptide nucleic acid Proteins 0.000 description 1
- 239000002202 Polyethylene glycol Substances 0.000 description 1
- 108010020346 Polyglutamic Acid Proteins 0.000 description 1
- 239000004373 Pullulan Substances 0.000 description 1
- 229920001218 Pullulan Polymers 0.000 description 1
- 102000007615 Pulmonary Surfactant-Associated Protein A Human genes 0.000 description 1
- 108010007100 Pulmonary Surfactant-Associated Protein A Proteins 0.000 description 1
- 108091005487 SCARB1 Proteins 0.000 description 1
- 108010004487 SS-B antigen Proteins 0.000 description 1
- 208000021386 Sjogren Syndrome Diseases 0.000 description 1
- 229930182558 Sterol Natural products 0.000 description 1
- PZBFGYYEXUXCOF-UHFFFAOYSA-N TCEP Chemical compound OC(=O)CCP(CCC(O)=O)CCC(O)=O PZBFGYYEXUXCOF-UHFFFAOYSA-N 0.000 description 1
- 101000588258 Taenia solium Paramyosin Proteins 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-N Thiophosphoric acid Chemical group OP(O)(S)=O RYYWUUFWQRZTIU-UHFFFAOYSA-N 0.000 description 1
- 102000011923 Thyrotropin Human genes 0.000 description 1
- 108010061174 Thyrotropin Proteins 0.000 description 1
- 102000004338 Transferrin Human genes 0.000 description 1
- 108090000901 Transferrin Proteins 0.000 description 1
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 1
- 229930003779 Vitamin B12 Natural products 0.000 description 1
- 229930003427 Vitamin E Natural products 0.000 description 1
- QNEPTKZEXBPDLF-JDTILAPWSA-N [(3s,8s,9s,10r,13r,14s,17r)-10,13-dimethyl-17-[(2r)-6-methylheptan-2-yl]-2,3,4,7,8,9,11,12,14,15,16,17-dodecahydro-1h-cyclopenta[a]phenanthren-3-yl] carbonochloridate Chemical compound C1C=C2C[C@@H](OC(Cl)=O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 QNEPTKZEXBPDLF-JDTILAPWSA-N 0.000 description 1
- DBIVGJQOBUBAMS-UHFFFAOYSA-N [N-]=[N+]=NSSN=[N+]=[N-] Chemical class [N-]=[N+]=NSSN=[N+]=[N-] DBIVGJQOBUBAMS-UHFFFAOYSA-N 0.000 description 1
- XVIYCJDWYLJQBG-UHFFFAOYSA-N acetic acid;adamantane Chemical compound CC(O)=O.C1C(C2)CC3CC1CC2C3 XVIYCJDWYLJQBG-UHFFFAOYSA-N 0.000 description 1
- 230000009471 action Effects 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- WQZGKKKJIJFFOK-PHYPRBDBSA-N alpha-D-galactose Chemical compound OC[C@H]1O[C@H](O)[C@H](O)[C@@H](O)[C@H]1O WQZGKKKJIJFFOK-PHYPRBDBSA-N 0.000 description 1
- 125000003368 amide group Chemical group 0.000 description 1
- 229960003473 androstanolone Drugs 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 230000003466 anti-cipated effect Effects 0.000 description 1
- 230000000692 anti-sense effect Effects 0.000 description 1
- ICCBZGUDUOMNOF-UHFFFAOYSA-N azidoamine Chemical compound NN=[N+]=[N-] ICCBZGUDUOMNOF-UHFFFAOYSA-N 0.000 description 1
- 239000003012 bilayer membrane Substances 0.000 description 1
- 239000003613 bile acid Substances 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 150000004663 bisphosphonates Chemical class 0.000 description 1
- CKDOCTFBFTVPSN-UHFFFAOYSA-N borneol Chemical group C1CC2(C)C(C)CC1C2(C)C CKDOCTFBFTVPSN-UHFFFAOYSA-N 0.000 description 1
- 229940116229 borneol Drugs 0.000 description 1
- 201000011510 cancer Diseases 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 125000002091 cationic group Chemical group 0.000 description 1
- BHQCQFFYRZLCQQ-OELDTZBJSA-N cholic acid Chemical compound C([C@H]1C[C@H]2O)[C@H](O)CC[C@]1(C)[C@@H]1[C@@H]2[C@@H]2CC[C@H]([C@@H](CCC(O)=O)C)[C@@]2(C)[C@@H](O)C1 BHQCQFFYRZLCQQ-OELDTZBJSA-N 0.000 description 1
- 235000019416 cholic acid Nutrition 0.000 description 1
- 229960002471 cholic acid Drugs 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- FDJOLVPMNUYSCM-WZHZPDAFSA-L cobalt(3+);[(2r,3s,4r,5s)-5-(5,6-dimethylbenzimidazol-1-yl)-4-hydroxy-2-(hydroxymethyl)oxolan-3-yl] [(2r)-1-[3-[(1r,2r,3r,4z,7s,9z,12s,13s,14z,17s,18s,19r)-2,13,18-tris(2-amino-2-oxoethyl)-7,12,17-tris(3-amino-3-oxopropyl)-3,5,8,8,13,15,18,19-octamethyl-2 Chemical compound [Co+3].N#[C-].N([C@@H]([C@]1(C)[N-]\C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C(\C)/C1=N/C([C@H]([C@@]1(CC(N)=O)C)CCC(N)=O)=C\C1=N\C([C@H](C1(C)C)CCC(N)=O)=C/1C)[C@@H]2CC(N)=O)=C\1[C@]2(C)CCC(=O)NC[C@@H](C)OP([O-])(=O)O[C@H]1[C@@H](O)[C@@H](N2C3=CC(C)=C(C)C=C3N=C2)O[C@@H]1CO FDJOLVPMNUYSCM-WZHZPDAFSA-L 0.000 description 1
- 230000001268 conjugating effect Effects 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 125000004122 cyclic group Chemical group 0.000 description 1
- OOTFVKOQINZBBF-UHFFFAOYSA-N cystamine Chemical compound CCSSCCN OOTFVKOQINZBBF-UHFFFAOYSA-N 0.000 description 1
- 229940099500 cystamine Drugs 0.000 description 1
- 210000000805 cytoplasm Anatomy 0.000 description 1
- 230000001086 cytosolic effect Effects 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- KXGVEGMKQFWNSR-UHFFFAOYSA-N deoxycholic acid Natural products C1CC2CC(O)CCC2(C)C2C1C1CCC(C(CCC(O)=O)C)C1(C)C(O)C2 KXGVEGMKQFWNSR-UHFFFAOYSA-N 0.000 description 1
- 230000001419 dependent effect Effects 0.000 description 1
- 238000011033 desalting Methods 0.000 description 1
- DTGKSKDOIYIVQL-UHFFFAOYSA-N dl-isoborneol Chemical group C1CC2(C)C(O)CC1C2(C)C DTGKSKDOIYIVQL-UHFFFAOYSA-N 0.000 description 1
- 230000003828 downregulation Effects 0.000 description 1
- 230000000694 effects Effects 0.000 description 1
- 238000005538 encapsulation Methods 0.000 description 1
- 210000001163 endosome Anatomy 0.000 description 1
- RTZKZFJDLAIYFH-UHFFFAOYSA-N ether Substances CCOCC RTZKZFJDLAIYFH-UHFFFAOYSA-N 0.000 description 1
- 125000001033 ether group Chemical group 0.000 description 1
- 235000019439 ethyl acetate Nutrition 0.000 description 1
- 229930182830 galactose Natural products 0.000 description 1
- 229920000370 gamma-poly(glutamate) polymer Polymers 0.000 description 1
- WIGCFUFOHFEKBI-UHFFFAOYSA-N gamma-tocopherol Natural products CC(C)CCCC(C)CCCC(C)CCCC1CCC2C(C)C(O)C(C)C(C)C2O1 WIGCFUFOHFEKBI-UHFFFAOYSA-N 0.000 description 1
- GNOIPBMMFNIUFM-UHFFFAOYSA-N hexamethylphosphoric triamide Chemical compound CN(C)P(=O)(N(C)C)N(C)C GNOIPBMMFNIUFM-UHFFFAOYSA-N 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 229920002674 hyaluronan Polymers 0.000 description 1
- 229960003160 hyaluronic acid Drugs 0.000 description 1
- BHEPBYXIRTUNPN-UHFFFAOYSA-N hydridophosphorus(.) (triplet) Chemical compound [PH] BHEPBYXIRTUNPN-UHFFFAOYSA-N 0.000 description 1
- 150000002433 hydrophilic molecules Chemical class 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 125000004356 hydroxy functional group Chemical group O* 0.000 description 1
- 230000002401 inhibitory effect Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 230000010189 intracellular transport Effects 0.000 description 1
- JYJIGFIDKWBXDU-MNNPPOADSA-N inulin Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)OC[C@]1(OC[C@]2(OC[C@]3(OC[C@]4(OC[C@]5(OC[C@]6(OC[C@]7(OC[C@]8(OC[C@]9(OC[C@]%10(OC[C@]%11(OC[C@]%12(OC[C@]%13(OC[C@]%14(OC[C@]%15(OC[C@]%16(OC[C@]%17(OC[C@]%18(OC[C@]%19(OC[C@]%20(OC[C@]%21(OC[C@]%22(OC[C@]%23(OC[C@]%24(OC[C@]%25(OC[C@]%26(OC[C@]%27(OC[C@]%28(OC[C@]%29(OC[C@]%30(OC[C@]%31(OC[C@]%32(OC[C@]%33(OC[C@]%34(OC[C@]%35(OC[C@]%36(O[C@@H]%37[C@@H]([C@@H](O)[C@H](O)[C@@H](CO)O%37)O)[C@H]([C@H](O)[C@@H](CO)O%36)O)[C@H]([C@H](O)[C@@H](CO)O%35)O)[C@H]([C@H](O)[C@@H](CO)O%34)O)[C@H]([C@H](O)[C@@H](CO)O%33)O)[C@H]([C@H](O)[C@@H](CO)O%32)O)[C@H]([C@H](O)[C@@H](CO)O%31)O)[C@H]([C@H](O)[C@@H](CO)O%30)O)[C@H]([C@H](O)[C@@H](CO)O%29)O)[C@H]([C@H](O)[C@@H](CO)O%28)O)[C@H]([C@H](O)[C@@H](CO)O%27)O)[C@H]([C@H](O)[C@@H](CO)O%26)O)[C@H]([C@H](O)[C@@H](CO)O%25)O)[C@H]([C@H](O)[C@@H](CO)O%24)O)[C@H]([C@H](O)[C@@H](CO)O%23)O)[C@H]([C@H](O)[C@@H](CO)O%22)O)[C@H]([C@H](O)[C@@H](CO)O%21)O)[C@H]([C@H](O)[C@@H](CO)O%20)O)[C@H]([C@H](O)[C@@H](CO)O%19)O)[C@H]([C@H](O)[C@@H](CO)O%18)O)[C@H]([C@H](O)[C@@H](CO)O%17)O)[C@H]([C@H](O)[C@@H](CO)O%16)O)[C@H]([C@H](O)[C@@H](CO)O%15)O)[C@H]([C@H](O)[C@@H](CO)O%14)O)[C@H]([C@H](O)[C@@H](CO)O%13)O)[C@H]([C@H](O)[C@@H](CO)O%12)O)[C@H]([C@H](O)[C@@H](CO)O%11)O)[C@H]([C@H](O)[C@@H](CO)O%10)O)[C@H]([C@H](O)[C@@H](CO)O9)O)[C@H]([C@H](O)[C@@H](CO)O8)O)[C@H]([C@H](O)[C@@H](CO)O7)O)[C@H]([C@H](O)[C@@H](CO)O6)O)[C@H]([C@H](O)[C@@H](CO)O5)O)[C@H]([C@H](O)[C@@H](CO)O4)O)[C@H]([C@H](O)[C@@H](CO)O3)O)[C@H]([C@H](O)[C@@H](CO)O2)O)[C@@H](O)[C@H](O)[C@@H](CO)O1 JYJIGFIDKWBXDU-MNNPPOADSA-N 0.000 description 1
- 229940029339 inulin Drugs 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 125000002960 margaryl group Chemical group [H]C([*])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])C([H])([H])[H] 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 229940041616 menthol Drugs 0.000 description 1
- 108091070501 miRNA Proteins 0.000 description 1
- 239000002679 microRNA Substances 0.000 description 1
- 230000003278 mimic effect Effects 0.000 description 1
- OKPYIWASQZGASP-UHFFFAOYSA-N n-(2-hydroxypropyl)-2-methylprop-2-enamide Chemical compound CC(O)CNC(=O)C(C)=C OKPYIWASQZGASP-UHFFFAOYSA-N 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- 229950006780 n-acetylglucosamine Drugs 0.000 description 1
- QNILTEGFHQSKFF-UHFFFAOYSA-N n-propan-2-ylprop-2-enamide Chemical compound CC(C)NC(=O)C=C QNILTEGFHQSKFF-UHFFFAOYSA-N 0.000 description 1
- 239000002105 nanoparticle Substances 0.000 description 1
- 239000005445 natural material Substances 0.000 description 1
- QTNLALDFXILRQO-UHFFFAOYSA-N nonadecane-1,2,3-triol Chemical group CCCCCCCCCCCCCCCCC(O)C(O)CO QTNLALDFXILRQO-UHFFFAOYSA-N 0.000 description 1
- 108020004707 nucleic acids Proteins 0.000 description 1
- 102000039446 nucleic acids Human genes 0.000 description 1
- 150000007523 nucleic acids Chemical class 0.000 description 1
- 125000004430 oxygen atom Chemical group O* 0.000 description 1
- 108010043655 penetratin Proteins 0.000 description 1
- MCYTYTUNNNZWOK-LCLOTLQISA-N penetratin Chemical compound C([C@H](NC(=O)[C@H](CC=1C2=CC=CC=C2NC=1)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCNC(N)=N)[C@@H](C)CC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC=1C2=CC=CC=C2NC=1)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCCCN)C(N)=O)C1=CC=CC=C1 MCYTYTUNNNZWOK-LCLOTLQISA-N 0.000 description 1
- 125000001151 peptidyl group Chemical group 0.000 description 1
- 239000012071 phase Substances 0.000 description 1
- 239000010452 phosphate Substances 0.000 description 1
- 150000004713 phosphodiesters Chemical class 0.000 description 1
- 150000003904 phospholipids Chemical class 0.000 description 1
- 150000003013 phosphoric acid derivatives Chemical class 0.000 description 1
- 229920002627 poly(phosphazenes) Polymers 0.000 description 1
- 108010064470 polyaspartate Proteins 0.000 description 1
- 229920002643 polyglutamic acid Polymers 0.000 description 1
- 229920000166 polytrimethylene carbonate Chemical group 0.000 description 1
- 229920002635 polyurethane Polymers 0.000 description 1
- 239000004814 polyurethane Substances 0.000 description 1
- 125000002924 primary amino group Chemical group [H]N([H])* 0.000 description 1
- 235000019423 pullulan Nutrition 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 239000002516 radical scavenger Substances 0.000 description 1
- 239000000376 reactant Substances 0.000 description 1
- 210000001525 retina Anatomy 0.000 description 1
- 238000012552 review Methods 0.000 description 1
- HFHDHCJBZVLPGP-UHFFFAOYSA-N schardinger α-dextrin Chemical compound O1C(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC(C(O)C2O)C(CO)OC2OC(C(C2O)O)C(CO)OC2OC2C(O)C(O)C1OC2CO HFHDHCJBZVLPGP-UHFFFAOYSA-N 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 238000003252 siRNA assay Methods 0.000 description 1
- 230000001743 silencing effect Effects 0.000 description 1
- SUKJFIGYRHOWBL-UHFFFAOYSA-N sodium hypochlorite Chemical compound [Na+].Cl[O-] SUKJFIGYRHOWBL-UHFFFAOYSA-N 0.000 description 1
- 239000007790 solid phase Substances 0.000 description 1
- 150000003408 sphingolipids Chemical class 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 150000003432 sterols Chemical class 0.000 description 1
- 235000003702 sterols Nutrition 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 229920001059 synthetic polymer Polymers 0.000 description 1
- 238000007910 systemic administration Methods 0.000 description 1
- 238000012360 testing method Methods 0.000 description 1
- TUNFSRHWOTWDNC-HKGQFRNVSA-N tetradecanoic acid Chemical compound CCCCCCCCCCCCC[14C](O)=O TUNFSRHWOTWDNC-HKGQFRNVSA-N 0.000 description 1
- 230000001225 therapeutic effect Effects 0.000 description 1
- 229960000874 thyrotropin Drugs 0.000 description 1
- 230000001748 thyrotropin Effects 0.000 description 1
- 210000001519 tissue Anatomy 0.000 description 1
- 239000012581 transferrin Substances 0.000 description 1
- 230000005945 translocation Effects 0.000 description 1
- 229960000834 vinyl ether Drugs 0.000 description 1
- 235000019163 vitamin B12 Nutrition 0.000 description 1
- 239000011715 vitamin B12 Substances 0.000 description 1
- 235000019165 vitamin E Nutrition 0.000 description 1
- 229940046009 vitamin E Drugs 0.000 description 1
- 239000011709 vitamin E Substances 0.000 description 1
- SFVVQRJOGUKCEG-OPQSFPLASA-N β-MSH Chemical compound C1C[C@@H](O)[C@H]2C(COC(=O)[C@@](O)([C@@H](C)O)C(C)C)=CCN21 SFVVQRJOGUKCEG-OPQSFPLASA-N 0.000 description 1
Classifications
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/62—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being a protein, peptide or polyamino acid
- A61K47/64—Drug-peptide, drug-protein or drug-polyamino acid conjugates, i.e. the modifying agent being a peptide, protein or polyamino acid which is covalently bonded or complexed to a therapeutically active agent
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/113—Non-coding nucleic acids modulating the expression of genes, e.g. antisense oligonucleotides; Antisense DNA or RNA; Triplex- forming oligonucleotides; Catalytic nucleic acids, e.g. ribozymes; Nucleic acids used in co-suppression or gene silencing
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/30—Macromolecular organic or inorganic compounds, e.g. inorganic polyphosphates
- A61K47/42—Proteins; Polypeptides; Degradation products thereof; Derivatives thereof, e.g. albumin, gelatin or zein
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K48/00—Medicinal preparations containing genetic material which is inserted into cells of the living body to treat genetic diseases; Gene therapy
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/111—General methods applicable to biologically active non-coding nucleic acids
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/87—Introduction of foreign genetic material using processes not otherwise provided for, e.g. co-transformation
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/10—Type of nucleic acid
- C12N2310/14—Type of nucleic acid interfering nucleic acids [NA]
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3513—Protein; Peptide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2310/00—Structure or type of the nucleic acid
- C12N2310/30—Chemical structure
- C12N2310/35—Nature of the modification
- C12N2310/351—Conjugate
- C12N2310/3515—Lipophilic moiety, e.g. cholesterol
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N2320/00—Applications; Uses
- C12N2320/30—Special therapeutic applications
- C12N2320/32—Special delivery means, e.g. tissue-specific
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Biomedical Technology (AREA)
- Chemical & Material Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Molecular Biology (AREA)
- Biotechnology (AREA)
- Organic Chemistry (AREA)
- General Engineering & Computer Science (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- General Health & Medical Sciences (AREA)
- Biophysics (AREA)
- Microbiology (AREA)
- Biochemistry (AREA)
- Plant Pathology (AREA)
- Physics & Mathematics (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Public Health (AREA)
- Epidemiology (AREA)
- Animal Behavior & Ethology (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Medicinal Chemistry (AREA)
- Inorganic Chemistry (AREA)
- Pharmaceuticals Containing Other Organic And Inorganic Compounds (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Peptides Or Proteins (AREA)
- Medicinal Preparation (AREA)
Abstract
Una composición modular que comprende 1) un siRNA; 2) uno o más conectores, que pueden ser iguales o diferentes, seleccionados de la Tabla 2, donde los conectores están unidos a la hebra guía del siRNA en la posición 2' de los anillos de ribosa excluyendo las posiciones terminales 3' y/o 5' de la hebra guía, o donde los conectores están unidos a la hebra retardada del siRNA en la posición 2' de los anillos de ribosa excluyendo las posiciones terminales 3' y/o 5' de la hebra retardada; y 3) uno o más péptidos, que pueden ser iguales o diferentes, seleccionados de SEQ ID NO: 28, 29, 33, 36, 40, 50, 51, 52, 53, 54, 55, 56, 57, 58 y 59, en donde los péptidos están unidos a los conectores.
Description
DESCRIPCIÓN
Nuevas entidades químicas simples y métodos para la administración de oligonucleótidos
La presente invención se refiere a composiciones modulares que comprenden un siRNA y uno o más péptidos que están unidos al siRNA a través de uno o más conectores.
Los esfuerzos científicos centrados en la administración sistémica de oligonucleótidos con fines terapéuticos son continuos. Tres enfoques destacados para la administración de oligonucleótidos incluyen 1) encapsulación en nanopartículas lipídicas (LNP), 2) conjugación con polímeros y 3) conjugación química simple. La conjugación química simple normalmente emplea un ligando direccionador o un lípido o un grupo solubilizante o un péptido endosomolítico o un péptido de penetración celular y/o una combinación de dos o los cuatro unidos a un oligonucleótido. Los conectores pueden estar presentes en el conjugado así como en otras funcionalidades. Se conocen conjugados químicos simples y la unión del oligonucleótido se produce en el extremo 5' o 3' del oligonucleótido, en ambos extremos, o internamente. Véase WO2005/041859; WO2008/036825, WO2009/126933, US2010/0076056 y WO2010/039548.
En este contexto, Gaglione y Messere (Gaglione, M. y Messere, A.; Mini-Reviews in Medicinal Chemistry, 10; 2010; págs. 578-595) describe siRNA modificados químicamente con perfiles de aplicación mejorados. Además, WO 2010/039548 A2 describe compuestos y procesos para conjugar ligandos con oligonucleótidos, así como conjugados respectivos y usos de los mismos. Es más, WO 2007/069068 A2 describe conjugados de péptido de penetración celular-ácido nucleico y usos de los mismos. Más aún, WO 2008/109105 A2 describe composiciones de RNA bicatenario conectado, modificado químicamente, y usos de las mismas. Finalmente, WO 2004/090105 A2 describe métodos y composiciones para realizar interferencia de RNA, usando siRNA estabilizados.
Una cantidad considerable de evidencia bibliográfica respalda la hipótesis de que los principales obstáculos para la administración de oligonucleótidos son la captación celular y el escape endosómico. Para mejorar la eficacia de la administración, pueden ser necesarios péptidos promotores de la captación y/o péptidos endosomolíticos y/o grupos protectores de carga en una topología muy condensada. En este sentido, las plataformas multifuncionales y las modificaciones internas ofrecen oportunidades únicas para cumplir con este requisito.
La presente invención se refiere a los siguientes apartados:
1. Una composición modular que comprende
1) un siRNA;
2) uno o más conectores, que pueden ser iguales o diferentes, seleccionados de la Tabla 2, donde los conectores están unidos a la hebra guía del siRNA en la posición 2' de los anillos de ribosa excluyendo las posiciones terminales 3' y/o 5 ' de la hebra guía, o donde los conectores están unidos a la hebra retardada del siRNA en la posición 2' de los anillos de ribosa excluyendo las posiciones terminales 3' y/o 5' de la hebra retardada; y 3) uno o más péptidos, que pueden ser iguales o diferentes, seleccionados de SEQ ID NO: 28, 29, 33, 36, 40, 50, 51,52, 53, 54, 55, 56, 57, 58 y 59, en donde los péptidos están unidos a los conectores.
2. La composición modular según el apartado 1 que comprende además colesterol, en la que el colesterol está unido al siRNA en la posición 2' de los anillos de ribosa o en la posición 3' del siRNA.
3. La composición modular según el apartado 1 que comprende además colesterol, en la que el colesterol está unido al siRNA en la posición 2' de los anillos de ribosa y/o en las posiciones terminales 3' y/o 5' del siRNA. Las figuras muestran:
Fig. 1 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C4-1.
Fig. 2 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C4-5.
Fig. 3 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C4-8.
Fig. 4 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C4-10.
Fig. 5 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C6-1.
Fig. 6 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C6-2.
Fig. 7 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C7-1.
Fig. 8 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C8-1.
Fig. 9 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C10-7.
Fig. 10 Niveles de mRNA de SSB en células HeLa tratadas con el compuesto C10-8.
Fig. 11 Niveles de mRNA de SSB en retina de rata.
Para ilustrar la invención a través de representaciones gráficas, aquí se muestra una composición modular que comprende un oligonucleótido ([O1][O2][O3].....[On]), uno o más conectores (L), uno o más péptidos (P) y uno o más lípidos opcionales (X), uno o más ligandos direccionadores (X) y/o uno o más grupos solubilizantes (X).
En una realización, la composición modular puede tener la fórmula:
P-L-[O1][O2][O3]......[On] -L-P.
En otra realización, la composición modular puede tener la fórmula:
P-L-[O1][O2][O3].... [On] -X.
Ejemplos de composiciones modulares son:
Hebra retardada

Hebra guía
Hebra retardada

Hebra guía
Hebra retardada

Hebra guía
Hebra retardada

Hebra guía
Otra representación de una composición modular es:
Hebra retardada

Hebra guía
Estos ejemplos son orientativos. Un experto en la técnica reconocerá que existe una variedad de permutaciones para colocar los componentes deseados en la hebra guía y la hebra retardada.
Se puede unir al oligonucleótido cualquier número de conectores y, por lo tanto, cualquier número de péptidos. Un intervalo preferido de número de conectores es de 1 a 8. Un intervalo más preferido de número de conectores es de 1 a 4. Un intervalo preferido de número de péptidos es de 1 a 8. Un intervalo más preferido de número de péptidos es de 1 a 4.
Las dos hebras contienen n y n' nucleótidos respectivamente. Los números n y n' pueden ser iguales o diferentes. Los números son números enteros que van del 8 al 50. Preferiblemente, los números son números enteros que van del 12 al 28. Más preferiblemente, los números son números enteros que van del 19 al 21.
Como ejemplo, cada nucleótido [On] o [On], que contiene un conector (L-P y/o L-X) tiene estructuras genéricas que se muestran en la siguiente representación gráfica:

Para cada nucleótido, 1) E = oxígeno (O) o azufre (S); 2) Base = A, U, G o C, que puede estar modificada o no modificada; 3) D es el punto de conexión entre el anillo de ribosa y el conector L, D = oxígeno (O), azufre (S, S(O) o S(O)2), nitrógeno (N-R, donde R = H, alquilo, L-P o L-X), carbono (CH-R, donde R = H, alquilo, L-P o L-X), o fósforo (P(O)R o P(O)(OR), donde R = alquilo, L-P o L-X). Preferiblemente, D = oxígeno (O).
Los dos nucleótidos [On-1] y [On] o [On-1] y [On] están conectados a través de enlaces fosfodiéster o tio-fosfodiéster.
Cuando el oligonucleótido es un oligonucleótido bicatenario, el "P-L" y el lípido, el ligando direccionador y/o el grupo solubilizante pueden ubicarse en la misma hebra o en hebras diferentes.
En algunas realizaciones, el "P-L" y el lípido, el ligando direccionador y/o el grupo solubilizante están en la misma hebra.
En algunas realizaciones, el "P-L" y el lípido, el ligando direccionador y/o el grupo solubilizante están en la hebra retardada.
En algunas realizaciones, el "P-L" y el lípido, el ligando direccionador y/o el grupo solubilizante están en la hebra guía.
En algunas realizaciones, el "P-L" y el lípido, el ligando direccionador y/o el grupo solubilizante están ubicados en hebras diferentes.
En algunas realizaciones, el "P-L" está en la hebra retardada mientras que el lípido, el ligando direccionador y/o el grupo solubilizante están en la hebra guía.
En algunas realizaciones, el "P-L" y el lípido, el ligando direccionador y/o el grupo solubilizante están en hebras diferentes pero en el mismo extremo terminal del oligonucleótido bicatenario.
En algunas realizaciones, el "P-L" y el lípido, el ligando direccionador y/o el grupo solubilizante están en hebras diferentes y en los extremos terminales opuestos del oligonucleótido bicatenario.
En algunas realizaciones, se puede usar un "P-L" adicional de naturaleza idéntica o diferente en lugar del lípido, el ligando direccionador y/o el grupo solubilizante indicado en las realizaciones anteriores.
En algunas realizaciones, el "P-L" se puede ubicar en múltiples extremos terminales de la hebra retardada o de la hebra guía y el lípido, el ligando de direccionamiento y/o el grupo solubilizante se pueden ubicar en los extremos terminales restantes de las hebras retardada y guía.
En algunas realizaciones, un "P-L" y dos o más lípidos, ligandos direccionadores y/o grupos solubilizantes están presentes en el oligonucleótido.
En algunas realizaciones, dos o más "P-L" y dos o más lípidos, ligandos direccionadores y/o grupos solubilizantes están presentes en el oligonucleótido.
En algunas realizaciones, cuando el oligonucleótido es un oligonucleótido bicatenario y están presentes una pluralidad de componentes "P-L" y/o lípidos, ligandos direccionadores y/o grupos solubilizantes, tal pluralidad de componentes "P-L" y/o lípidos, ligandos direccionadores y/o grupos solubilizantes pueden estar todos presentes en una hebra o en ambas hebras del oligonucleótido bicatenario.
Cuando están presentes una pluralidad de componentes "P-L" y/o lípidos, ligandos direccionadores y/o grupos solubilizantes, todos pueden ser iguales o diferentes.
En algunas realizaciones, los "P-L" están solo en los nucleótidos internos (es decir, excluyendo los extremos 3' y 5' terminales del oligonucleótido).
En el presente documento se describe un método para administrar un oligonucleótido a una célula. El método incluye (a) proporcionar u obtener una composición modular de la invención; (b) poner en contacto una célula con la composición modular; y (c) permitir que la célula incorpore la composición modular.
El método se puede realizar in vitro, ex vivo o in vivo, por ejemplo, para tratar a un sujeto identificado como necesitado de un oligonucleótido, por ejemplo, un ser humano, que necesita tener la expresión de uno o más genes, por ejemplo, un gen relacionado con un trastorno, regulada a la baja o silenciada.
En un aspecto, aquí se describe un método para inhibir la expresión de uno o más genes. El método comprende poner en contacto una o más células con una cantidad eficaz de un oligonucleótido, en el que la cantidad eficaz es una cantidad que suprime la expresión del uno o más genes. El método se puede realizar in vitro, ex vivo o in vivo.
Los métodos y composiciones descritos en este documento, por ejemplo, la composición modular descrita en este documento, se pueden usar con cualesquier oligonucleótidos conocidos en la técnica. Además, los métodos y composiciones descritos en el presente documento se pueden usar para el tratamiento de cualquier enfermedad o trastorno conocido en la técnica y para el tratamiento de cualquier sujeto, por ejemplo, cualquier animal, cualquier mamífero, como un ser humano. Un experto normal en la técnica también reconocerá que los métodos y composiciones descritos en el presente documento pueden usarse para el tratamiento de cualquier enfermedad que se beneficiaría de la regulación a la baja o silenciamiento de uno o más genes.
Los métodos y composiciones descritos en el presente documento, por ejemplo, la composición modular descrita en el presente documento, se pueden usar con cualquier dosificación y/o formulación descrita en el presente documento, o cualquier dosificación o formulación conocida en la técnica. Además de las vías de administración descritas en el presente documento, un experto en la técnica también apreciará que se pueden usar otras vías de administración para administrar la composición modular de la invención.
Oligonucleótido
Un "oligonucleótido", como se usa en el presente documento, es un RNA, PNA o DNA policatenario, bicatenario o monocatenario, no modificado o modificado. Los ejemplos de RNA modificados incluyen aquellos que tienen mayor resistencia a la degradación por nucleasas que los RNA no modificados. Otros ejemplos incluyen aquellos que tienen una modificación de azúcar en 2', una modificación de base, una modificación en un saliente monocatenario, por ejemplo, un saliente monocatenario en 3' o, particularmente si es monocatenario, una modificación en 5' que incluye uno o más fosfatos. grupos o uno o más análogos de un grupo fosfato. Se pueden encontrar ejemplos y una descripción adicional de los oligonucleótidos en WO2009/126933.
En una realización, un oligonucleótido es un miRNA o siRNA antisentido. El oligonucleótido preferido es un siRNA. Otro oligonucleótido preferido es la hebra retardada de un siRNA. Otro oligonucleótido preferido es la hebra guía de un siRNA. siRNA
siRNA dirige el silenciamiento específico de secuencia de mRNA a través de un proceso conocido como interferencia por RNA (RNAi). El proceso ocurre en una amplia variedad de organismos, incluidos los mamíferos y otros vertebrados. Se conocen métodos para preparar y administrar siRNA y su uso para inactivar específicamente la función génica. siRNA incluye siRNA modificado y no modificado. Se pueden encontrar ejemplos y una descripción adicional de siRNA en WO2009/126933.
Se conocen varios ejemplos de rutas de administración que pueden usarse para administrar siRNA a un sujeto. Además, el siRNA se puede formular de acuerdo con cualquier ejemplo de método conocido en la técnica. Se pueden encontrar ejemplos y una descripción adicional de la formulación y administración de siRNA en WO2009/126933.
Péptidos
Para los fármacos macromoleculares y las moléculas de fármacos hidrofílicos, que no pueden cruzar fácilmente las membranas de la bicapa, se cree que el atrapamiento en los compartimentos endosómicos/lisosómicos de la célula es el mayor obstáculo para la entrega eficaz en su sitio de acción. Sin desear limitarse a ninguna teoría, se cree que el uso de péptidos facilitará el escape de oligonucleótidos de estos compartimentos endosómicos/lisosómicos o la traslocación de oligonucleótidos a través de una membrana celular y su liberación en el compartimento citosólico. En ciertas realizaciones, los péptidos pueden ser péptidos policatiónicos, anfifílicos o polianiónicos o peptidomiméticos que muestran actividad de membrana y/o fusogenicidad dependiente del pH. Un peptidomimético puede ser una pequeña cadena similar a una proteína diseñada para mimetizar un péptido.
En algunas realizaciones, el péptido es un agente de penetración celular, preferiblemente un agente de penetración celular helicoidal. Estos péptidos se denominan comúnmente péptidos de penetración celular. Véase, por ejemplo, "Handbook of Cell Penetrating Peptides" Ed. Langel, U.; 2007, CRC Press, Boca Raton, Florida. Preferiblemente, el componente es anfipático. El agente helicoidal es preferiblemente un agente alfa-helicoidal, que preferiblemente tiene una fase lipófila y otra lipófoba. Un agente de penetración celular puede ser, por ejemplo, un péptido de penetración celular, un péptido catiónico, un péptido anfipático o un péptido hidrofóbico, p.ej. que consiste principalmente en Tyr, Trp y Phe, un péptido dendrímero, un péptido restringido o un péptido reticulado. Los ejemplos de péptidos de penetración celular incluyen Tat, Penetratin y MPG. Para la presente invención, se cree que los péptidos que penetran en las células pueden ser un péptido de "entrega", que puede transportar moléculas polares grandes que incluyen péptidos, oligonucleótidos y proteínas a través de las membranas celulares. Los péptidos de penetración celular pueden ser lineales o cíclicos, e incluyen D-aminoácidos, secuencias "retro-inversas", enlaces no peptídicos o pseudopeptídicos, miméticos de peptidilo. Además, los péptidos y los miméticos de péptidos pueden estar modificados, p.ej. glicosilados, pegilados o metilados. Se pueden encontrar ejemplos y una descripción más detallada de los péptidos en WO2009/126933.
Los péptidos pueden conjugarse en cualquiera de los extremos o en ambos extremos mediante la adición de una cisteína u otro resto que contiene tiol al extremo C- o N-terminal. Cuando no están funcionalizados en el extremo N-terminal, los péptidos pueden rematarse con un grupo acetilo o pueden rematarse con un lípido, un PEG o un resto direccionador. Cuando el extremo C-terminal de los péptidos no está conjugado o funcionalizado, se puede rematar como una amida o se puede rematar con un lípido, un PEG o un resto direccionador.
Los péptidos descritos en este documento son:
HFHHFFHHFFHFFHHFFHHF (SEQ ID NO: 1);
WHHWWWHWWHHWWHHW (SEQ ID NO: 2);
HWHHLLHHLLHLLHHLLHHL (SEQ ID NO: 3);
HLHHWLHHLLHLLHHLLHHL (SEQ ID NO: 4);
HLHHLWHHLLHLLHHLLHHL (SEQ ID NO: 5);
HLHHLLHHLWHLLHHLLHHL (SEQ ID NO: 6);
HLHHLLHHLLHWLHHLLHHL (SEQ ID NO: 7);
HLHHLLHHLLHLLHHWLHHL (SEQ ID NO: 8);
HLHHLLHHLLHLLHHLWHHL (SEQ ID NO: 9);
HPHHLLHHLLHLLHHLLHHL (SEQ ID NO: 10);
HLHHPLHHLLHLLHHLLHHL (SEQ ID NO: 11);
HLHHLPHHLLHLLHHLLHHL (SEQ ID NO: 12);
HLHHLLHHLPHLLHHLLHHL (SEQ ID NO: 13);
HLHHLLHHLLHLLHHLPHHL (SEQ ID NO: 14);
HLHHLLHHLLHLLHHLLHHP (SEQ ID NO: 15);
ELEELLEELLHLLHHLLHHL (SEQ ID NO: 16);
ELHHLLHELLHLLHELLHHL (SEQ ID NO: 17);
GLWRALWRLLRSLWRLLWRAC (SEQ ID NO: 18);
GLFEAIEGFIENGWEGMIDGWYGYGRKKRRQRR (SEQ ID NO: 19);
HLHHLLHHLLHLLHHLLHHL (SEQ ID NO: 20);
HWHHWWHHWWWHWWHHWWHHW (SEQ ID NO: 21);
HLHHLLHHWLHLLHHLLHHL (SEQ ID NO: 22);
HLHHLLHHLLHLWHHLLHHL (SEQ ID NO: 23);
HLHHLLHHLLHLLHHLLHHW (SEQ ID NO: 24);
HHHHHHHHHHLLLLLLLLLLLL (SEQ ID NO: 25);
HHHHHHHLLLLLLL (SEQ ID NO: 26);
LTTLLTLLTTLLTTL (SEQ ID NO: 27);
KLLKLLKLWLKLLKLLLKLL (SEQ ID NO: 28);
LHLLHHLLHHLHHLLHHLLHLLHHLLHHL (SEQ ID NO: 29);
FLGGIISFFKRLF (SEQ ID NO: 30);
FIGGIISFIKKLF (SEQ ID NO: 31);
FIGGIISLIKKLF (SEQ ID NO: 32);
HLLHLLLHLWLHLLHLLLHLL (SEQ ID NO: 33);
GIGGAVLKVLTTGLPALISWIKRKRQQ (SEQ ID NO: 34);
RQIKIWFQNRRMKWKKGG (SEQ ID NO: 35);
RKKRRQRRRPPQ (SEQ ID NO: 36);
GALFLGWLGAAGSTMGAPKKKRKV (SEQ ID NO: 37);
GGGARKKAAKAARKKAAKAARKKAAKAARKKAAKAAK (SEQ ID NO: 38); GWTLNSAGYLLGKINLKALAALAKKIL (SEQ ID NO: 39);
RRRRRRRRR (SEQ ID NO: 40);
WEAKLAKALAKALAKHILAKALAKALKACEA (SEQ ID NO: 41); WEAALAEALAEALAEHLAEALAEAEALEALAA (SEQ ID NO: 42);
D(NHC12H25)NleKNleKNleHNleKNleHNle (SEQ ID NO: 43);
KLLKLLLKLWLKLLKLLLKLL (SEQ ID NO: 44);
GLFEAIAGFIENGWEGMIDGWYG (SEQ ID NO: 45);
GLFHAIAAHFIHGGWHGLIHGWYG (SEQ ID NO: 46);
GLFEAIAEFIEGGWEGLIEGWYG (SEQ ID NO: 47);
GLFEAIEGFIENGWEGMIDGWYG (SEQ ID NO: 48);
GLFKAIAKFIKGGWKGLIKGWYG (SEQ ID NO: 49);
GLFEAIAGFIENGWEGMIDGWYGYGRKKRRQRR (SEQ ID NO: 50);
GLFEAIAGFIENGWEGMIDGWYGRQIKIWFQNRRMKWKKGG (SEQ ID NO: 51);
GLFHAIAAHFIHGGWHGLIHGWYGYGRKKRRQRR (SEQ ID NO: 52);
GLFEAIAEFIEGGWEGLIEGWYGYGRKKRRQRR (SEQ ID NO: 53);
GLFEAIEGFIENGWEGMIDGWYGYGRKKRRQRR (SEQ ID NO: 54);
GLFKAIAKFIKGGWKGLIKGWYGYGRKKRRQRR (SEQ ID NO: 55);
GFFALIPKIISSPLFKTLLSAVGSALSSSGEQE (SEQ ID NO: 56);
LHLLHHLLHHLHHLLHHLLHLLHHLLHHLGGGRKKRRQRRRRPPQ (SEQ ID NO: 57);
RKKRRQRRRPPQGGGLHLLHHLLHHLHHLLHHLLHLLHHLLHHL (SEQ ID NO: 58); y
LIRLWSHIHIWFQWRRLKWKKK (SEQ ID NO: 59);
donde los péptidos se conjugan opcionalmente en cualquiera de los extremos mediante la adición de una cisteína u otro resto que contiene tiol al extremo C- o N-terminal; o cuando no están funcionalizados en el extremo N-terminal, los péptidos opcionalmente se rematan con un grupo acetilo, lípido, peg o un resto direccionador; o cuando no están funcionalizados en el extremo C-terminal, los péptidos opcionalmente se rematan con una amida, lípido, peg o un resto direccionador.
Los péptidos (P) preferidos son:
GLFEAIEGFIENGWEGMIDGWYGYGRKKRRQRR (SEQ ID NO: 19);
KLLKLLLKLWLKLLKLLLKLL (SEQ ID NO: 28);
LHLLHHLLHHLHHLLHHLLHLLHHLLHHL (SEQ ID NO: 29);
HLLHLLLHLWLHLLHLLLHLL (SEQ ID NO: 33);
RKKRRQRRRPPQ (SEQ ID NO: 36);
RQIKIWFQNRRMKWKKGG (SEQ ID NO: 40);
GLFEAIAGFIENGWEGMIDGWYGYGRKKRRQRR (SEQ ID NO: 50);
GLFEAIAGFIENGWEGMIDGWYGRQIKIWFQNRRMKWKKGG (SEQ ID NO: 51);
GLFHAIAAHFIHGGWHGLIHGWYGYGRKKRRQRR (SEQ ID NO: 52);
GLFEAIAEFIEGGWEGLIEGWYGYGRKKRRQRR (SEQ ID NO: 53);
GLFEAIEGFIENGWEGMIDGWYGYGRKKRRQRR (SEQ ID NO: 54);
GLFKAIAKFIKGGWKGLIKGWYGYGRKKRRQRR (SEQ ID NO: 55);
GFFALIPKIISSPLFKTLLSAVGSALSSSGEQE (SEQ ID NO: 56);
LHLLHHLLHHLHHLLHHLLHLLHHLLHHLGGGRKKRRQRRRRPPQ (SEQ ID NO: 57);
RKKRRQRRRPPQGGGLHLLHHLLHHLHHLLHHLLHLLHHLLHHL (SEQ ID NO: 58); y
LIRLWSHIHIWFQWRRLKWKKK (SEQ ID NO: 59);
donde los péptidos se conjugan opcionalmente en cualquiera de los extremos mediante la adición de una cisteína u otro resto que contiene tiol al extremo C- o N-terminal; o cuando no están funcionalizados en el extremo N-terminal, los péptidos opcionalmente se rematan con un grupo acetilo, lípido, peg o un resto direccionador; o cuando no están funcionalizados en el extremo C-terminal, los péptidos opcionalmente se rematan con una amida, lípido, peg o un resto direccionador.
Conectores
Los enlaces covalentes entre el péptido y el oligonucleótido de la composición modular descrita en el presente documento están mediados por un conector. Este conector puede ser escindible o no escindible, según la aplicación. En ciertas realizaciones, se puede usar un conector escindible para liberar el oligonucleótido después del transporte desde el endosoma al citoplasma. La naturaleza prevista de la interacción por conjugación o acoplamiento, o el efecto biológico deseado, determinará la elección del grupo conector. Los grupos conectores pueden combinarse o ramificarse para proporcionar arquitecturas más complejas. Se pueden encontrar ejemplos y una descripción adicional de los conectores en WO2009/126933.
Los conectores descritos en este documento se muestran en la Tabla 1: Tabla 1

n = O a 750
Los conectores comerciales están disponibles a partir de varios proveedores tales como Pierce o Quanta Biodesign que incluyen combinaciones de dichos conectores. Los conectores también se pueden combinar para producir arquitecturas ramificadas más complejas que acomodan de 1 a 8 péptidos, como se ilustra en uno de estos ejemplos a continuación:

Ligandos direccionadores
Las composiciones modulares descritas en el presente documento pueden comprender un ligando direccionador. En algunas realizaciones, este ligando direccionador puede dirigir la composición modular a una célula particular. Por ejemplo, el ligando direccionador puede unirse de forma específica o no específica con una molécula en la superficie de una célula objetivo. El resto direccionador puede ser una molécula con una afinidad específica por una célula objetivo. Los restos direccionadores pueden incluir anticuerpos dirigidos contra una proteína que se encuentra en la superficie de una célula diana, o el ligando o una porción de unión al receptor de un ligando para una molécula que se encuentra en la superficie de una célula diana. Se pueden encontrar ejemplos y una descripción adicional de ligandos direccionadores en WO2009/126933.
Los ligandos direccionadores se seleccionan del grupo que consiste en un anticuerpo, una porción de unión a ligando de un receptor, un ligando para un receptor, un aptámero, D-galactosa, N-acetil-D-galactosa (GalNAc), N-acitil-D-galactosa multivalente, D-manosa, colesterol, un ácido graso, una lipoproteína, folato, tirotropina, melanotropina, proteína surfactante A, mucina, carbohidrato, lactosa multivalente, galactosa multivalente, N-acetil-galactosamina, N-acetil-glucosamina, manosa multivalente, fructosa multivalente, poliaminoácidos glicosilados, transferina, bisfosfonato, poliglutamato, poliaspartato, una fracción lipófila que mejora la unión a proteínas plasmáticas, un esteroide, ácido biliar, vitamina B12, biotina, un péptido RGD, un mimético del péptido RGD, ibuprofeno, naproxeno, aspirina, folato y análogos y derivados de los mismos.
Los ligandos direccionadores preferidos se seleccionan del grupo que consiste en un péptido RGD, un mimético del péptido RGD, D-galactosa, N-acetil-D-galactosamina (GalNAc), GalNAc2 y GalNAc3, colesterol, folato, y análogos y derivados de los mismos.
Lípidos
Los restos lipófilos, como el colesterol o los ácidos grasos, cuando se unen a moléculas altamente hidrófilas, como los ácidos nucleicos, pueden mejorar sustancialmente la unión a proteínas plasmáticas y, en consecuencia, la semivida en circulación. Además, los grupos lipofílicos pueden aumentar la captación celular. Por ejemplo, los lípidos pueden unirse a ciertas proteínas plasmáticas, como las lipoproteínas, que, en consecuencia, se ha demostrado que aumentan la captación en tejidos específicos que expresan los receptores de lipoproteínas correspondientes (p. ej., el receptor de LDL o el receptor eliminador SR-B1). Los conjugados lipofílicos también se pueden considerar como un enfoque de administración dirigida y su tráfico intracelular podría mejorarse potencialmente mediante la combinación con agentes endosomolíticos.
Ejemplos de restos lipofílicos que mejoran la unión a proteínas plasmáticas incluyen, entre otros, esteróles, colesterol, ácidos grasos, ácido cólico, ácido litocolico, dialquilglicéridos, diacilglicérido, fosfolípidos, esfingolípidos, ácido adamantano acético, ácido 1-pirenobutírico, dihidrotestosterona, 1,3-bis-O(hexadecil)glicerol, grupo geraniloxihexilo, hexadecilglicerol, borneol, mentol, 1,3-propanodiol, grupo heptadecilo, ácido palmítico, ácido mirístico, ácido O3-(oleoil)litocólico, ácido O3-(oleoil)colénico, dimetoxitritilo, fenoxazina, aspirina, naproxeno, ibuprofeno, vitamina E y biotina, etc. Se pueden encontrar ejemplos y una descripción adicional de los lípidos en WO2009/126933.
Ejemplos de lípidos incluyen:

El lípido preferido es el colesterol.
Agentes Solubilizantes
La composición modular puede comprender uno o más restos/ligandos que pueden mejorar la solubilidad acuosa, la semivida en circulación y/o la captación celular. Estos pueden incluir sustancias naturales, como una proteína (p. ej., albúmina sérica humana (HSA), lipoproteína de baja densidad (LDL), lipoproteína de alta densidad (HDL) o globulina); o un carbohidrato (por ejemplo, un dextrano, pululano, quitina, quitosano, inulina, ciclodextrina o ácido hialurónico). Estos restos también pueden ser una molécula recombinante o sintética, como un polímero sintético o poliaminoácidos sintéticos. Los ejemplos incluyen polilisina (PLL), poli(ácido L-aspártico), poli(ácido L-glutámico), copolímero de estireno-anhídrido de ácido maleico, copolímero de poli(L-lactida-co-glicolida), copolímero de divinil éter-anhídrido maleico, copolímero de N-(2-hidroxipropil)metacrilamida (HMPA), polietilenglicol (p Eg , por ejemplo, PEG-0.5K, PEG-2K, PEG-5K, PEG-10K, PEG-12K, PEG-15K, PEG-20K, PEG-40K), metil-PEG (mPEG), [mPEG]2 , poli(alcohol vinílico) (PVA), poliuretano, poli(ácido 2-etilacrílico), polímeros de N-isopropilacrilamida, o polifosfazina. Se pueden encontrar ejemplos y una descripción adicional de los agentes solubilizantes en WO2009/126933.
El grupo solubilizante preferido es PEG de 0,5K a 30K.
Método de tratamiento
En el presente documento se describe un método para tratar a un sujeto en riesgo o afectado por una enfermedad que puede beneficiarse de la administración de la composición modular de la invención. El método comprende administrar la composición modular de la invención a un sujeto que lo necesita, tratando así al sujeto. El oligonucleótido que se administra dependerá de la enfermedad que se ha de tratar. Por ejemplo, los conjugados de la presente invención son útiles para el tratamiento del cáncer. Véase WO2009/126933 para obtener detalles adicionales sobre los métodos de tratamiento para indicaciones específicas.
Formulación
Existen numerosos métodos para preparar conjugados de compuestos de oligonucleótidos. Los expertos en la materia estarán familiarizados con esas técnicas. Una referencia útil para tales reacciones es Bioconjugate Techniques, Hermanson, G.T., Academic Press, San Diego, CA, 1996. Otras referencias incluyen WO2005/041859; WO2008/036825 y WO2009/126933.
Ejemplos
La invención se ilustra adicionalmente mediante los siguientes ejemplos, que no deben interpretarse como una limitación adicional. Los siRNA descritos en el presente documento se diseñaron para dirigirse al gen SSB expresado
de forma ubicua (antígeno B del síndrome de Sjogren; NM_009278.4).
La síntesis de oligonucleótidos es bien conocida en la técnica. (Véanse las solicitudes de patentes de EE. UU.: US 2006/0083780, US 2006/0240554, US 2008/0020058, US 2009/0263407 y US 2009/0285881 y solicitudes de patente PCT: WO 2009/086558, WO2009/127060, WO2009/132131, WO2010/042877, WO2010/054384, WO2010/054401, WO2010/054405 y WO2010/054406). Los siRNA descritos y utilizados en los Ejemplos se sintetizaron mediante procedimientos estándar en fase sólida.
Los grupos conectores pueden estar conectados a la(s) hebra(s) de oligonucleótidos en un punto de unión de enlace (LAP, por sus siglas en inglés) y pueden incluir cualquier resto que contiene carbono, en algunas realizaciones que tienen al menos un átomo de oxígeno, al menos un átomo de fósforo y/o al menos un átomo de nitrógeno. En algunas realizaciones, el átomo de fósforo forma parte de un grupo fosfato o fosforotioato terminal en el grupo conector, que puede servir como punto de conexión para la hebra de oligonucleótidos. En determinadas realizaciones, el átomo de nitrógeno forma parte de un grupo terminal éter, éster, amino o amido (NHC(O)-) en el grupo conector, que puede servir como punto de conexión para los conectores de interés, la unidad endosomolítica, el péptido de penetración celular, el grupo solubilizante, el lípido, el grupo direccionador o conectores adicionales de interés. Estos grupos de conectores terminales incluyen, pero no se limitan a, un resto hexilo C6, hidroxi secundario C5, tiol C3 o resto tiol C6. Un ejemplo de las secuencias de RNA descritas a continuación es hexilo C6: [(CH2)6 NH2].
Ejemplo 1
A una solución de éster de NHS L-2 (100,0 mg, 0,320 mmol) en 0,5 ml de DCE anhidro se añadió azidoamina L-1 (253,0 mg, 0,480 mmol) en 0,5 ml de DCE anhidro, seguido de la adición de 1,5 eq. de trietilamina. La solución resultante se agitó durante 1 h a temperatura ambiente y la mezcla de reacción se cargó en una columna de sílice, que se eluyó con MeOH/DCM = 0/100 a 10/90 durante 25 min. La fracción recolectada de L-3 se sometió a análisis LC-MS y el resultado indicó que el producto tenía una pureza >95 %.
Siguiendo procedimientos análogos, se prepararon azido disulfuros L-4 a L-6 con una pureza por HPLC >95%, L-7 se preparó a partir de éster de SPDP-PEG-NHS polidisperso.
Ejemplo 2
El oligonucleótido bruto R-1, 15 mg, se trató con azido-peg9-SPDP L-3 (25,3 mg, 0,035 mmol) y CuBrMe2S (0,760 mg, 3,70 gmol) en 3 mL de DMA/Agua=3/1. La mezcla de reacción resultante se agitó durante 48 h a temperatura ambiente, seguido de la adición de 2,0 ml de NH4 F al 40 %/agua =1/1. La mezcla bifásica se agitó a 65 °C durante 1 h, luego se purificó con cartuchos C18 para dar un sólido blanco bruto R-2 ~ 5 mg.
Siguiendo procedimientos análogos, se prepararon los disulfuros de RNA R-3 - R-11 respectivamente.





Ejemplo 3
El oligonucleótido bruto R-12, 50 mg, se trató con azido-peg9-SPDP L-3 (40,0 mg, 0,055 mmol) y CuBr-Me2S (2,50 mg, 12 gmol) en 4 mL de DMA/Agua=3/1. La mezcla de reacción resultante se agitó durante 48 h a temperatura ambiente, seguido de la adición de 2,0 ml de NH4 F al 40 %/agua=1/1. La mezcla bifásica se agitó a 65 °C durante 1 h, luego se purificó con cartuchos C18 para dar un sólido blanco bruto R-13 ~ 15 mg.
Siguiendo procedimientos análogos, se prepararon los disulfuros de RNA R-14 - R-18 respectivamente.




Ejemplo 4
El compuesto R-2 (1,50 mg, 0,211 pmol) en 400 pl de formamida/tampón Tris de pH=6,8 =3/1 se trató con el péptido SEQ ID NO: 19 (1,724 mg, 0,423 pmol) en 400 pl del mismo tampón y la mezcla de reacción resultante se agitó durante 1 h. La reacción se diluyó mediante la adición de formamida/tampón Tris de pH=6,8=3/1 hasta un volumen total de 2,5 ml y se purificó mediante cromatografía de intercambio aniónico fuerte en una columna Resource Q (25-75% B en A, A: formamida/H2O=1/1, 20 mmol Tris-HCl, pH=7,4, B: formamida/H2O=1/1, 20 mmol Tris-HCl, 400 mmol NaClO4, pH=7,4). Las fracciones de producto combinadas se diluyeron con agua y se dializaron por centrifugación 4 veces frente a agua con una membrana de corte de peso molecular 10.000. El dialito se liofilizó para proporcionar R-19 como un sólido blanco, masa = 11063.
Se mezcló una cantidad equimolar de la hebra guía G1 con el compuesto R-19 para producir el correspondiente dúplex C4-1 bicatenario. La integridad del dúplex se comprobó mediante análisis CE y el conjugado se sometió a evaluaciones biológicas.
Siguiendo procedimientos análogos, se prepararon los conjugados de disulfuro de RNA C4-2 a C4-14 respectivamente y se sometieron a evaluaciones biológicas.





Ejemplo 5
El péptido SEQ ID NO: 19 (10,0 mg, 2,45 pmol) se disolvió en 500 pl de tampón TEAA pH=6,5 y se añadió gota a gota al conector L-8 (38,4 mg, 0,074 mmol) en 500 pl de tampón TEAA pH=6,5. La reacción se agitó durante 2 h y se purificó mediante RP HPLC 10-90 % MeCN/agua durante 20 min. Las fracciones recogidas se liofilizaron para dar un sólido blanco SEQ ID NO: 19-1 que tenía una pureza >95 % mediante análisis LC-MS.
El agente reaccionante R-3 (2,00 mg, 0,282 pmol) y TCEP (0,808 mg, 2,82 pmol) se disolvieron en 0,5 ml de tampón Tris de pH=6,8 y se agitaron durante 2 h. El rastro de LC-MS indicó la escisión del enlace disulfuro R-3, luego la mezcla de reacción se cargó en una columna de desalinización PD-10. Las fracciones recolectadas se liofilizaron para dar un sólido blanco R-20 y se usaron para la siguiente reacción sin purificación adicional.
El compuesto R-20 (2,00 mg, 0,286 pmol) en 300 pl de formamida/tampón Tris de pH=6,8 = 3/1 se trató con el péptido SEQ ID NO: 19-1 (3,95 mg, 0,859 pmol) en 300 pl del mismo tampón y la mezcla de reacción resultante se agitó durante 1 h. La reacción se diluyó mediante la adición de formamida/tampón Tris de pH=6,8 = 3/1 hasta un volumen total de 2,5 ml y se purificó mediante cromatografía de intercambio aniónico fuerte en una columna Resource Q (25 75 % B en A, A: formamida/H2O=1/1,20 mmol Tris-HCl, pH=7,4, B: formamida/H2O=1/1,20 mmol Tris-HCl, 400 mmol NaClO4, pH=7,4). Las fracciones de producto combinadas se diluyeron con agua y se dializaron por centrifugación 4 veces frente a agua con una membrana de corte de peso molecular 10.000. El dialito se liofilizó para proporcionar R-21 (0,71 mg, 21,4%, >95 % de pureza) como un sólido blanco.
Se mezcló una cantidad equimolar de la hebra guía G1 con el compuesto R-21 para producir el correspondiente dúplex C5-1 bicatenario. La integridad del dúplex se comprobó mediante análisis CE y el conjugado se sometió a evaluaciones biológicas.

El compuesto R-13 (3,00 mg, 0,382 pmol) en 300 pl de formamida/tampón T ris de pH=6,8 = 3/1 se trató con el péptido SEQ ID NO: 19 (4,98 mg, 1,222 pmol) en 300 pl del mismo tampón y la mezcla de reacción resultante se agitó durante 1 h. La reacción se diluyó mediante la adición de formamida/tampón Tris de pH=6,8 = 3/1 hasta un volumen total de 2,5 ml y se purificó mediante cromatografía de intercambio aniónico fuerte en una columna Resource Q (25-75 % B en A, A: formamida/H2O=1/1,20 mmol Tris-HCl, pH=7,4, B: formamida/H2O=1/1,20 mmol Tris-HCl, 400 mmol NaClO4, pH=7,4). Las fracciones de producto combinadas se diluyeron con agua y se dializaron por centrifugación 4 veces frente a agua con una membrana de corte de peso molecular 10.000. El dialito se liofilizó para proporcionar R-22 (>90 % de pureza) como un sólido blanco.
Se mezcló una cantidad equimolar de la hebra guía G1 con el compuesto R-22 para producir el correspondiente dúplex C6-1 bicatenario. La integridad del dúplex se comprobó mediante análisis CE y el conjugado se envió para evaluaciones biológicas.
Siguiendo procedimientos análogos, se prepararon conjugados de disulfuro de RNA C6-2 a C6-6 y se sometieron a evaluaciones biológicas.
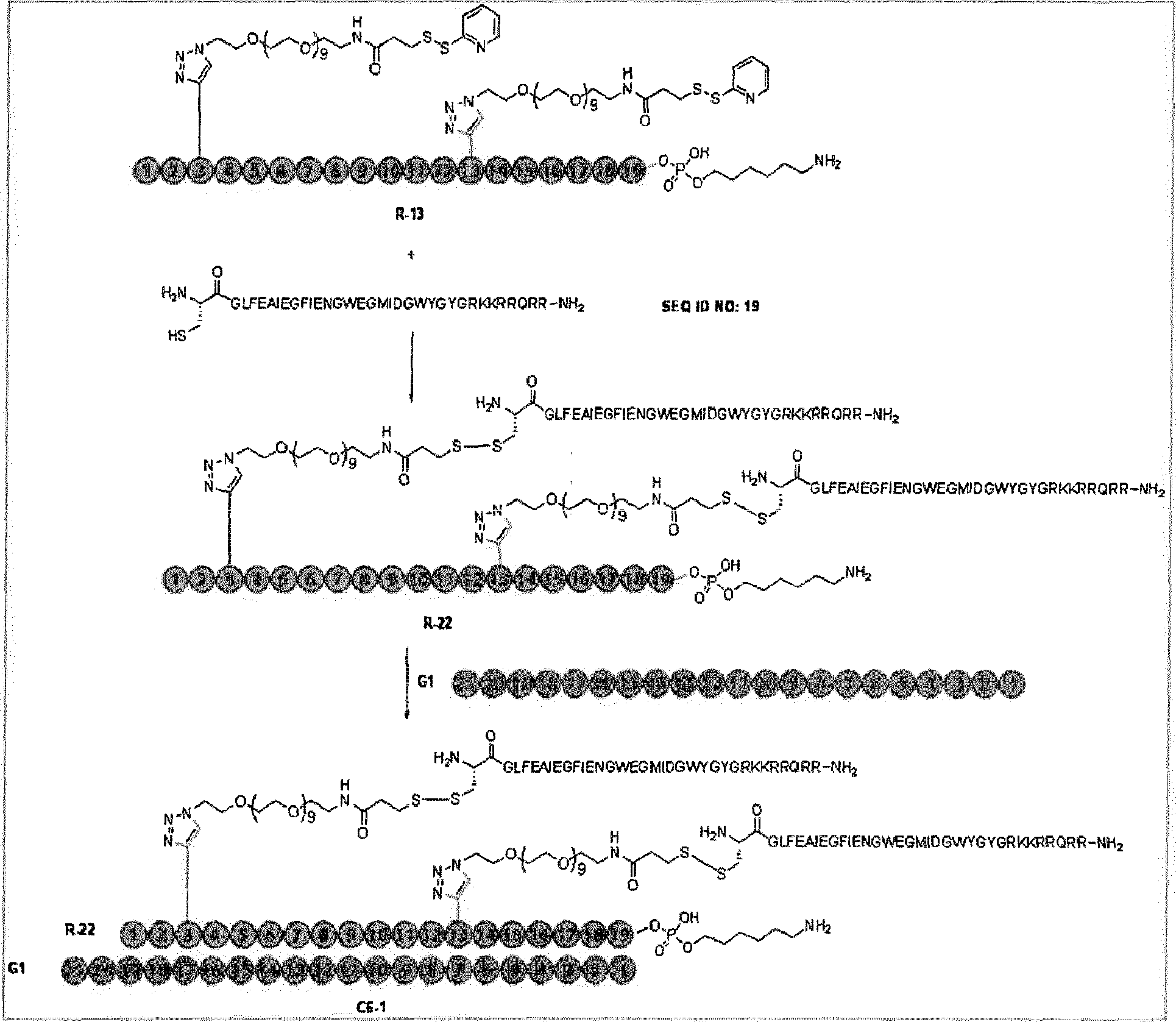


Ejemplo 7
Se disolvieron cistamina (1,13 g, 5,02 mmol) y cloroformiato de colesterol (4,96 g, 11,04 mmol) en 20 ml de DCM, seguido de la adición de TEA (3,50 ml, 25,09 mmol) a 0 °C. La mezcla de reacción se calentó a temperatura ambiente y se agitó durante 1 h. Se separó el disolvente y el residuo se purificó mediante columna de sílice (EtOAc/hexanos = 0/100 a 50/50 durante 25 min) para proporcionar L-9 como un sólido blanco (2,44 g, 50%).
L-9 (440 mg, 0,450 mmol) y DTT (174 mg, 1,125 mmol) se disolvieron en THF/agua = 20/1 y se agitaron durante la noche. Se eliminó el disolvente y el residuo se purificó mediante columna de sílice para proporcionar tiol L-10 (300 mg, 68%) como un sólido blanco.
R-3 (3,00 mg, 0,423 pmol) y L-10 (2,071 mg, 4,23 pmol) se disolvieron en THF/tampón Tris pH=6,8 = 10/1 600 pL y se agitó durante 3 h. La mezcla de reacción se purificó por C4 RP HPLC con TEAA como aditivo. Las fracciones recogidas se dializaron 3 veces frente a una membrana 3k y se liofilizaron para dar un sólido blanco R-23 (0,61 mg, 19 %, >95 % de pureza).
Se mezcló una cantidad equimolar de la hebra guía G1 con el compuesto R-23 para producir el correspondiente dúplex C7-1 bicatenario. La integridad del dúplex se comprobó mediante análisis CE y el conjugado se envió para evaluaciones biológicas.

Ejemplo 8
Una solución de R-2 (5,00 mg, 0,705 pmol) en 0,3 ml de tampón Tris de pH=8 se enfrió a 0 °C y se trató con una solución de L-11 (2,76 mg, 4,93 pmol) en 0,3 ml de MeCN. La solución resultante se agitó a temperatura ambiente durante 0,5 h. La reacción bruta se diluyó con 18 ml de agua y se dializó por centrifugación cuatro veces contra agua
usando una membrana de diálisis MW 3K. El dialito se liofilizó para proporcionar el producto deseado R-24 como un polvo amorfo blanco esponjoso, masa medida = 7540.
Una solución de R-24 (1,0 mg, 0,133 pmol) en 400 pL de formamida/tampón Tris de pH=6,8 = 3/1 se trató con una solución de SEQ ID NO: 19 (2,164 mg, 0,530 pmol) en 400 pL de formamida/tampón Tris de pH=6,8 = 3/1 y la solución resultante se agitó a temperatura ambiente durante 1,0 h. La reacción bruta se purificó mediante cromatografía de intercambio aniónico preparatoria en un aparato Gilson utilizando una columna ResourceQ de 6 ml y un gradiente lineal de A sobre B al 25-70 % (A = TrisHCl 20 mM, formamida al 50 %, pH = 7,4; B = TrisHCl 20 mM, NaClO4400 mM, formamida al 50%, pH=7,4). El pico del producto se diluyó con agua y se dializó por centrifugación cuatro veces frente a agua usando una membrana de diálisis de PM 10K. El dialito se liofilizó para proporcionar 0,32 mg del conjugado R-25 deseado como un polvo amorfo blanco esponjoso.
Se mezcló una cantidad equimolar de la hebra guía G1 con el compuesto R-25 para producir el correspondiente dúplex bicatenario C8-1 . La integridad del dúplex se comprobó mediante análisis CE y el conjugado se sometió a evaluaciones biológicas.
Siguiendo procedimientos análogos, se prepararon los conjugados de disulfuro de RNA C8-2 a C8-6 y se sometieron a evaluaciones biológicas.



Ejemplo 9
El oligonucleótido G3 bruto, 50 mg, se trató con azido-peg9-SPDP L-3 (38,6 mg, 0,053 mmol) y CuBrMe2S (2,74 mg, 0,013 mmol) en 3 mL de DMA/Agua=3/1. La mezcla de reacción resultante se agitó durante 48 h a temperatura
ambiente, seguido de la adición de 2,0 ml de NH4F al 40 %/agua=1/1. La mezcla bifásica se agitó a 65 °C durante 1 h, luego se purificó utilizando cartuchos C18 para dar un sólido blanco bruto G4.
Siguiendo procedimientos análogos, se prepararon los disulfuros de RNA G5 y G6 respectivamente.

Ejemplo 10
El compuesto G4 (3,00 mg, 0,391 pmol) en 300 pl de formamida/tampón Tris de pH=6,8 = 3/1 se trató con el péptido SEQ ID NO: 19 (3,19 mg, 0,782 pmol) en 300 pl del mismo tampón y la mezcla de reacción resultante se agitó durante 0,5 h. La reacción se diluyó mediante la adición de formamida/tampón Tris de pH=6,8 = 3/1 hasta un volumen total de 2,5 ml y se purificó mediante cromatografía de intercambio aniónico fuerte en una columna Resource Q (25-75 % B en A, A: formamida/ H2O=1/1,20 mmol Tris-HCl, pH=7,4, B: formamida/H2O=1/1,20 mmol Tris-HCl, 400 mmol NaClO4, pH=7,4). Las fracciones de producto combinadas se diluyeron con agua y se dializaron por centrifugación 4 veces frente a agua con una membrana de corte de peso molecular de 10.000. El dialito se liofilizó para proporcionar 3,5 mg de G7 como un sólido blanco, masa = 11640.
Se mezcló una cantidad equimolar de la hebra guía G7 con la hebra retardada R-28 para producir el correspondiente dúplex C10-1 de doble hebra. La integridad del dúplex se comprobó mediante análisis CE y el conjugado se sometió a evaluaciones biológicas.
Siguiendo procedimientos análogos, se prepararon los conjugados de disulfuro de RNA C10-2 a C10-8 respectivamente y se sometieron a evaluaciones biológicas.



Ensayos
Protocolo general de ensayo de siRNA
Los siRNA descritos en el presente documento se diseñaron para dirigirse al gen SSB expresado de forma ubicua (antígeno B del síndrome de Sjogren; NM_009278.4). La secuencia del siRNA utilizada es homóloga en transcritos humanos, de ratón y de rata. Para probar la actividad silenciadora de los conjugados de siRNA, se sembraron células
Claims (3)
1. Una composición modular que comprende
1) un siRNA;
2) uno o más conectores, que pueden ser iguales o diferentes, seleccionados de la Tabla 2, donde los conectores están unidos a la hebra guía del siRNA en la posición 2' de los anillos de ribosa excluyendo las posiciones terminales 3' y/o 5' de la hebra guía, o donde los conectores están unidos a la hebra retardada del siRNA en la posición 2' de los anillos de ribosa excluyendo las posiciones terminales 3' y/o 5' de la hebra retardada; y 3) uno o más péptidos, que pueden ser iguales o diferentes, seleccionados de SEQ ID NO: 28, 29, 33, 36, 40, 50, 51,52, 53, 54, 55, 56, 57, 58 y 59, en donde los péptidos están unidos a los conectores.
2. La composición modular según la reivindicación 1, que comprende además colesterol, en la que el colesterol está unido al siRNA en la posición 2' de los anillos de ribosa o en la posición 3' del siRNA.
3. La composición modular según la reivindicación 1, que comprende además colesterol, en la que el colesterol está unido al siRNA en la posición 2' de los anillos de ribosa y/o en las posiciones terminales 3' y/o 5' del siRNA.
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US37860910P | 2010-08-31 | 2010-08-31 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2908978T3 true ES2908978T3 (es) | 2022-05-04 |
Family
ID=45773456
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES18182352T Active ES2908978T3 (es) | 2010-08-31 | 2011-08-29 | Nuevas entidades químicas simples y métodos para la administración de oligonucleótidos |
Country Status (9)
| Country | Link |
|---|---|
| US (3) | US20130253168A1 (es) |
| EP (2) | EP3406730B1 (es) |
| JP (1) | JP2013541510A (es) |
| KR (1) | KR20130100278A (es) |
| CN (1) | CN103221549A (es) |
| AU (1) | AU2011296268A1 (es) |
| CA (1) | CA2809439A1 (es) |
| ES (1) | ES2908978T3 (es) |
| WO (1) | WO2012030683A2 (es) |
Families Citing this family (52)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| RU2572826C2 (ru) | 2008-12-02 | 2016-01-20 | Чиралджен, Лтд. | Способ синтеза модифицированных по атому фосфора нуклеиновых кислот |
| SG10201403841QA (en) | 2009-07-06 | 2014-09-26 | Ontorii Inc | Novel nucleic acid prodrugs and methods of use thereof |
| CA2807552A1 (en) | 2010-08-06 | 2012-02-09 | Moderna Therapeutics, Inc. | Engineered nucleic acids and methods of use thereof |
| JP5868324B2 (ja) | 2010-09-24 | 2016-02-24 | 株式会社Wave Life Sciences Japan | 不斉補助基 |
| LT4108671T (lt) | 2010-10-01 | 2025-01-10 | Modernatx, Inc. | Modifikuoti nukleozidai, nukleotidai, nukleorūgštys bei jų panaudojimas |
| US8710200B2 (en) | 2011-03-31 | 2014-04-29 | Moderna Therapeutics, Inc. | Engineered nucleic acids encoding a modified erythropoietin and their expression |
| CN107365339A (zh) | 2011-07-19 | 2017-11-21 | 波涛生命科学有限公司 | 合成官能化核酸的方法 |
| US9464124B2 (en) | 2011-09-12 | 2016-10-11 | Moderna Therapeutics, Inc. | Engineered nucleic acids and methods of use thereof |
| SMT202200229T1 (it) | 2011-10-03 | 2022-07-21 | Modernatx Inc | Nucleosidi, nucleotidi e acidi nucleici modificati e loro usi |
| RU2649364C2 (ru) | 2011-12-16 | 2018-04-02 | Модерна Терапьютикс, Инк. | Составы на основе модифицированного нуклеозида, нуклеотида и нуклеиновой кислоты |
| US9283287B2 (en) | 2012-04-02 | 2016-03-15 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of nuclear proteins |
| AU2013243954A1 (en) | 2012-04-02 | 2014-10-30 | Moderna Therapeutics, Inc. | Modified polynucleotides for the production of cosmetic proteins and peptides |
| US9572897B2 (en) | 2012-04-02 | 2017-02-21 | Modernatx, Inc. | Modified polynucleotides for the production of cytoplasmic and cytoskeletal proteins |
| US10501512B2 (en) | 2012-04-02 | 2019-12-10 | Modernatx, Inc. | Modified polynucleotides |
| RU2693381C2 (ru) | 2012-07-13 | 2019-07-02 | Уэйв Лайф Сайенсес Лтд. | Асимметричная вспомогательная группа |
| EP2872147B1 (en) | 2012-07-13 | 2022-12-21 | Wave Life Sciences Ltd. | Method for making chiral oligonucleotides |
| WO2014010718A1 (ja) | 2012-07-13 | 2014-01-16 | 株式会社新日本科学 | キラル核酸アジュバント |
| HRP20220607T1 (hr) | 2012-11-26 | 2022-06-24 | Modernatx, Inc. | Terminalno modificirana rna |
| US8980864B2 (en) | 2013-03-15 | 2015-03-17 | Moderna Therapeutics, Inc. | Compositions and methods of altering cholesterol levels |
| EP2786766A1 (en) * | 2013-04-05 | 2014-10-08 | Ufpeptides S.r.l. | Supramolecular aggregates comprising maleimido cores |
| US20160194625A1 (en) | 2013-09-03 | 2016-07-07 | Moderna Therapeutics, Inc. | Chimeric polynucleotides |
| EP3041938A1 (en) | 2013-09-03 | 2016-07-13 | Moderna Therapeutics, Inc. | Circular polynucleotides |
| US10023626B2 (en) | 2013-09-30 | 2018-07-17 | Modernatx, Inc. | Polynucleotides encoding immune modulating polypeptides |
| BR112016007255A2 (pt) | 2013-10-03 | 2017-09-12 | Moderna Therapeutics Inc | polinucleotídeos que codificam receptor de lipoproteína de baixa densidade |
| WO2015069586A2 (en) | 2013-11-06 | 2015-05-14 | Merck Sharp & Dohme Corp. | Dual molecular delivery of oligonucleotides and peptide containing conjugates |
| KR102357337B1 (ko) | 2013-12-27 | 2022-01-28 | 가부시키가이샤 보낙 | 유전자 발현 제어를 위한 인공 매치형 miRNA 및 그 용도 |
| EP3095459A4 (en) | 2014-01-15 | 2017-08-23 | Shin Nippon Biomedical Laboratories, Ltd. | Chiral nucleic acid adjuvant having antitumor effect and antitumor agent |
| JPWO2015108047A1 (ja) | 2014-01-15 | 2017-03-23 | 株式会社新日本科学 | 免疫誘導活性を有するキラル核酸アジュバンド及び免疫誘導活性剤 |
| JPWO2015108046A1 (ja) | 2014-01-15 | 2017-03-23 | 株式会社新日本科学 | 抗アレルギー作用を有するキラル核酸アジュバンド及び抗アレルギー剤 |
| CA2936712A1 (en) | 2014-01-16 | 2015-07-23 | Meena | Chiral design |
| DK4023249T3 (da) | 2014-04-23 | 2025-01-13 | Modernatx Inc | Nukleinsyrevacciner |
| EP3169693B1 (en) | 2014-07-16 | 2022-03-09 | ModernaTX, Inc. | Chimeric polynucleotides |
| WO2016100401A1 (en) | 2014-12-15 | 2016-06-23 | Dicerna Pharmaceuticals, Inc. | Ligand-modified double-stranded nucleic acids |
| RU2740032C2 (ru) | 2014-12-27 | 2020-12-30 | Бонак Корпорейшн | ВСТРЕЧАЮЩИЕСЯ В ПРИРОДЕ миРНК ДЛЯ КОНТРОЛИРОВАНИЯ ЭКСПРЕССИИ ГЕНОВ И ИХ ПРИМЕНЕНИЕ |
| ES2926369T3 (es) | 2015-03-27 | 2022-10-25 | Bonac Corp | Molécula de ácido nucleico monocatenario que tiene función de suministro y capacidad de control de la expresión génica |
| CR20180107A (es) | 2015-07-22 | 2018-04-03 | Wave Life Sciences Ltd | Composiciones de oligonucleótidos y métodos de los mismos |
| JP7104462B2 (ja) * | 2015-08-06 | 2022-07-21 | シティ・オブ・ホープ | 細胞透過性タンパク質-抗体コンジュゲートおよび使用方法 |
| US10384511B2 (en) * | 2017-01-27 | 2019-08-20 | Ford Global Technologies, Llc | Method to control battery cooling using the battery coolant pump in electrified vehicles |
| SG11202010910QA (en) | 2018-05-07 | 2020-12-30 | Alnylam Pharmaceuticals Inc | Extrahepatic delivery |
| CA3124090A1 (en) * | 2018-12-19 | 2020-06-25 | Alnylam Pharmaceuticals, Inc. | Amyloid precursor protein (app) rnai agent compositions and methods of use thereof |
| MX2022005220A (es) * | 2019-11-06 | 2022-08-11 | Alnylam Pharmaceuticals Inc | Suministro extrahepático. |
| CN115885042A (zh) | 2020-05-22 | 2023-03-31 | 波涛生命科学有限公司 | 双链寡核苷酸组合物及其相关方法 |
| AU2021409740A1 (en) | 2020-12-23 | 2023-07-06 | Flagship Pioneering Innovations Vi, Llc | Compositions of modified trems and uses thereof |
| US20250270575A1 (en) | 2021-04-07 | 2025-08-28 | Neoplants Sas | Compositions and methods for indoor air remediation |
| CA3233097A1 (en) | 2021-09-30 | 2023-04-06 | Katherine Diane GRIBBLE | Compositions and methods for treating kcnq4-associated hearing loss |
| MX2024006238A (es) * | 2021-11-23 | 2024-07-19 | Univ California | Composicion de administracion celular y metodos de uso de esta. |
| WO2023250112A1 (en) | 2022-06-22 | 2023-12-28 | Flagship Pioneering Innovations Vi, Llc | Compositions of modified trems and uses thereof |
| WO2024112809A2 (en) * | 2022-11-21 | 2024-05-30 | Pepgen Inc. | Cell-penetrating peptides, conjugates thereof, and methods of their use |
| WO2024197242A1 (en) | 2023-03-23 | 2024-09-26 | Carbon Biosciences, Inc. | Protoparvovirus compositions comprising a protoparvovirus variant vp1 capsid polypeptide and related methods |
| WO2024196965A1 (en) | 2023-03-23 | 2024-09-26 | Carbon Biosciences, Inc. | Parvovirus compositions and related methods for gene therapy |
| AU2024369609A1 (en) | 2023-10-31 | 2025-12-11 | Korro Bio, Inc. | Oligonucleotides comprising phosphoramidate internucleotide linkages |
| WO2026050243A1 (en) | 2024-08-26 | 2026-03-05 | Korro Bio, Inc. | Galnac conjugated oligonucleotides for rna editing |
Family Cites Families (25)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20030056538A (ko) * | 2001-12-28 | 2003-07-04 | 주식회사 웰진 | 리본형 안티센스 올리고뉴클레오티드에 의한 형질전이성장 인자-β1의 효과적 저해제 개발 |
| WO2004090105A2 (en) * | 2003-04-02 | 2004-10-21 | Dharmacon, Inc. | Modified polynucleotides for use in rna interference |
| AU2004227414A1 (en) * | 2003-04-03 | 2004-10-21 | Alnylam Pharmaceuticals | iRNA conjugates |
| US8017762B2 (en) | 2003-04-17 | 2011-09-13 | Alnylam Pharmaceuticals, Inc. | Modified iRNA agents |
| EP3222294A1 (en) | 2003-04-30 | 2017-09-27 | Sirna Therapeutics, Inc. | Conjugates and compositions for cellular delivery |
| CA2569645C (en) | 2004-06-07 | 2014-10-28 | Protiva Biotherapeutics, Inc. | Cationic lipids and methods of use |
| CA2597724A1 (en) | 2005-02-14 | 2007-08-02 | Sirna Therapeutics, Inc. | Cationic lipids and formulated molecular compositions containing them |
| US7404969B2 (en) | 2005-02-14 | 2008-07-29 | Sirna Therapeutics, Inc. | Lipid nanoparticle based compositions and methods for the delivery of biologically active molecules |
| JP2009519033A (ja) | 2005-12-16 | 2009-05-14 | ディアト | 核酸を細胞に送達するための細胞貫通ペプチド結合体 |
| US8252755B2 (en) | 2006-09-22 | 2012-08-28 | Dharmacon, Inc. | Duplex oligonucleotide complexes and methods for gene silencing by RNA interference |
| WO2008109105A2 (en) * | 2007-03-06 | 2008-09-12 | Flagship Ventures | Methods and compositions for improved therapeutic effects with sirna |
| JP5476304B2 (ja) * | 2007-09-05 | 2014-04-23 | ノボ・ノルデイスク・エー/エス | グルカゴン様ペプチド−1誘導体及びそれらの医薬用途 |
| EP2224912B1 (en) | 2008-01-02 | 2016-05-11 | TEKMIRA Pharmaceuticals Corporation | Improved compositions and methods for the delivery of nucleic acids |
| JP5788312B2 (ja) | 2008-04-11 | 2015-09-30 | アルニラム ファーマスーティカルズ インコーポレイテッドAlnylam Pharmaceuticals, Inc. | 標的リガンドをエンドソーム分解性成分と組み合わせることによる核酸の部位特異的送達 |
| PL2279254T3 (pl) | 2008-04-15 | 2017-11-30 | Protiva Biotherapeutics Inc. | Nowe preparaty lipidowe do dostarczania kwasów nukleinowych |
| US20090285881A1 (en) | 2008-04-16 | 2009-11-19 | Abbott Laboratories | Cationic lipids and uses thereof |
| US20090263407A1 (en) | 2008-04-16 | 2009-10-22 | Abbott Laboratories | Cationic Lipids and Uses Thereof |
| WO2009132131A1 (en) | 2008-04-22 | 2009-10-29 | Alnylam Pharmaceuticals, Inc. | Amino lipid based improved lipid formulation |
| WO2010021720A1 (en) * | 2008-08-19 | 2010-02-25 | Nektar Therapeutics | Conjugates of small-interfering nucleic acids |
| EP3587434A1 (en) | 2008-09-23 | 2020-01-01 | Alnylam Pharmaceuticals Inc. | Chemical modifications of monomers and oligonucleotides with click components for conjugation with ligands |
| EP2743265B1 (en) | 2008-10-09 | 2017-03-15 | Arbutus Biopharma Corporation | Improved amino lipids and methods for the delivery of nucleic acids |
| CA3029724A1 (en) | 2008-11-10 | 2010-05-14 | Muthiah Manoharan | Lipids and compositions for the delivery of therapeutics |
| US8722082B2 (en) | 2008-11-10 | 2014-05-13 | Tekmira Pharmaceuticals Corporation | Lipids and compositions for the delivery of therapeutics |
| WO2011126974A1 (en) * | 2010-04-09 | 2011-10-13 | Merck Sharp & Dohme Corp. | Novel single chemical entities and methods for delivery of oligonucleotides |
| AR090905A1 (es) * | 2012-05-02 | 2014-12-17 | Merck Sharp & Dohme | Conjugados que contienen tetragalnac y peptidos y procedimientos para la administracion de oligonucleotidos, composicion farmaceutica |
-
2011
- 2011-08-29 ES ES18182352T patent/ES2908978T3/es active Active
- 2011-08-29 AU AU2011296268A patent/AU2011296268A1/en not_active Abandoned
- 2011-08-29 EP EP18182352.7A patent/EP3406730B1/en active Active
- 2011-08-29 CN CN2011800416670A patent/CN103221549A/zh active Pending
- 2011-08-29 WO PCT/US2011/049479 patent/WO2012030683A2/en not_active Ceased
- 2011-08-29 EP EP11822416.1A patent/EP2611927B1/en active Active
- 2011-08-29 JP JP2013526197A patent/JP2013541510A/ja not_active Withdrawn
- 2011-08-29 KR KR1020137005059A patent/KR20130100278A/ko not_active Withdrawn
- 2011-08-29 US US13/819,578 patent/US20130253168A1/en not_active Abandoned
- 2011-08-29 CA CA2809439A patent/CA2809439A1/en not_active Abandoned
-
2015
- 2015-09-08 US US14/848,118 patent/US20160074525A1/en not_active Abandoned
-
2017
- 2017-01-19 US US15/409,819 patent/US20170137815A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| CN103221549A (zh) | 2013-07-24 |
| EP2611927A4 (en) | 2014-12-31 |
| US20130253168A1 (en) | 2013-09-26 |
| EP3406730B1 (en) | 2022-02-23 |
| AU2011296268A1 (en) | 2013-02-21 |
| US20160074525A1 (en) | 2016-03-17 |
| EP3406730A1 (en) | 2018-11-28 |
| CA2809439A1 (en) | 2012-03-08 |
| EP2611927A1 (en) | 2013-07-10 |
| KR20130100278A (ko) | 2013-09-10 |
| EP2611927B1 (en) | 2018-08-01 |
| JP2013541510A (ja) | 2013-11-14 |
| WO2012030683A2 (en) | 2012-03-08 |
| US20170137815A1 (en) | 2017-05-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2908978T3 (es) | Nuevas entidades químicas simples y métodos para la administración de oligonucleótidos | |
| AU2013256341B2 (en) | Novel tetraGalNAc and peptide containing conjugates and methods for delivery of oligonucleotides | |
| US8691580B2 (en) | Single chemical entities and methods for delivery of oligonucleotides | |
| JP2012513953A5 (es) | ||
| KR20140037449A (ko) | 히알루론산-핵산 접합체 및 이를 포함하는 핵산 전달용 조성물 | |
| AU2020319911A1 (en) | Subcutaneous delivery of multimeric oligonucleotides with enhanced bioactivity | |
| KR20220115579A (ko) | 표적화된 핵산 전달을 위한 펩티드 도킹 비히클 | |
| WO2021026490A1 (en) | Cns targeting with multimeric oligonucleotides | |
| WO2011135140A1 (es) | Método para la administración de oligonucleótidos | |
| Patwa et al. | Lipid oligonucleotide bioconjugates: applications in medicinal chemistry |