ES2955417T3 - Variante fosforribosil pirofosfato amidotransferasa y método para producir nucleótido de purina usando la misma - Google Patents
Variante fosforribosil pirofosfato amidotransferasa y método para producir nucleótido de purina usando la misma Download PDFInfo
- Publication number
- ES2955417T3 ES2955417T3 ES19762700T ES19762700T ES2955417T3 ES 2955417 T3 ES2955417 T3 ES 2955417T3 ES 19762700 T ES19762700 T ES 19762700T ES 19762700 T ES19762700 T ES 19762700T ES 2955417 T3 ES2955417 T3 ES 2955417T3
- Authority
- ES
- Spain
- Prior art keywords
- amino acid
- microorganism
- purf
- seq
- purine nucleotide
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 239000002213 purine nucleotide Substances 0.000 title claims abstract description 75
- 102100039239 Amidophosphoribosyltransferase Human genes 0.000 title claims abstract description 71
- 108010039224 Amidophosphoribosyltransferase Proteins 0.000 title claims abstract description 71
- 125000000561 purinyl group Chemical class N1=C(N=C2N=CNC2=C1)* 0.000 title claims abstract description 7
- 238000004519 manufacturing process Methods 0.000 title abstract description 21
- 244000005700 microbiome Species 0.000 claims abstract description 83
- 108091033319 polynucleotide Proteins 0.000 claims description 54
- 239000002157 polynucleotide Substances 0.000 claims description 54
- 102000040430 polynucleotide Human genes 0.000 claims description 54
- 239000013598 vector Substances 0.000 claims description 48
- 238000006467 substitution reaction Methods 0.000 claims description 41
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 38
- 238000000034 method Methods 0.000 claims description 32
- 241000186216 Corynebacterium Species 0.000 claims description 22
- 239000004475 Arginine Substances 0.000 claims description 16
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 claims description 16
- 229930182817 methionine Natural products 0.000 claims description 15
- 241000186308 Corynebacterium stationis Species 0.000 claims description 10
- 125000000637 arginyl group Chemical group N[C@@H](CCCNC(N)=N)C(=O)* 0.000 claims description 3
- 238000012258 culturing Methods 0.000 claims description 3
- 125000001360 methionine group Chemical group N[C@@H](CCSC)C(=O)* 0.000 claims description 3
- 125000003275 alpha amino acid group Chemical group 0.000 claims 5
- 238000013519 translation Methods 0.000 abstract description 6
- 150000001413 amino acids Chemical group 0.000 description 108
- 150000003212 purines Chemical class 0.000 description 68
- 235000001014 amino acid Nutrition 0.000 description 62
- 229940024606 amino acid Drugs 0.000 description 59
- 230000035772 mutation Effects 0.000 description 49
- GRSZFWQUAKGDAV-KQYNXXCUSA-N IMP Chemical compound O[C@@H]1[C@H](O)[C@@H](COP(O)(O)=O)O[C@H]1N1C(NC=NC2=O)=C2N=C1 GRSZFWQUAKGDAV-KQYNXXCUSA-N 0.000 description 48
- GRSZFWQUAKGDAV-UHFFFAOYSA-N Inosinic acid Natural products OC1C(O)C(COP(O)(O)=O)OC1N1C(NC=NC2=O)=C2N=C1 GRSZFWQUAKGDAV-UHFFFAOYSA-N 0.000 description 48
- RQFCJASXJCIDSX-UHFFFAOYSA-N 14C-Guanosin-5'-monophosphat Natural products C1=2NC(N)=NC(=O)C=2N=CN1C1OC(COP(O)(O)=O)C(O)C1O RQFCJASXJCIDSX-UHFFFAOYSA-N 0.000 description 44
- 235000013902 inosinic acid Nutrition 0.000 description 44
- 108090000623 proteins and genes Proteins 0.000 description 36
- 229920001184 polypeptide Polymers 0.000 description 32
- 108090000765 processed proteins & peptides Proteins 0.000 description 32
- 102000004196 processed proteins & peptides Human genes 0.000 description 32
- 101150076045 purF gene Proteins 0.000 description 31
- 230000000694 effects Effects 0.000 description 24
- DCTLYFZHFGENCW-UUOKFMHZSA-N 5'-xanthylic acid Chemical compound O[C@@H]1[C@H](O)[C@@H](COP(O)(O)=O)O[C@H]1N1C(NC(=O)NC2=O)=C2N=C1 DCTLYFZHFGENCW-UUOKFMHZSA-N 0.000 description 23
- 108020004414 DNA Proteins 0.000 description 20
- 102000004169 proteins and genes Human genes 0.000 description 19
- 239000002609 medium Substances 0.000 description 17
- 235000018102 proteins Nutrition 0.000 description 17
- 210000004027 cell Anatomy 0.000 description 16
- 239000000203 mixture Substances 0.000 description 14
- 230000006872 improvement Effects 0.000 description 13
- 238000002360 preparation method Methods 0.000 description 13
- 108090000790 Enzymes Proteins 0.000 description 12
- 239000002773 nucleotide Substances 0.000 description 12
- 125000003729 nucleotide group Chemical group 0.000 description 12
- 102000004190 Enzymes Human genes 0.000 description 11
- 239000012634 fragment Substances 0.000 description 11
- 238000012163 sequencing technique Methods 0.000 description 11
- 108020004705 Codon Proteins 0.000 description 10
- 210000000349 chromosome Anatomy 0.000 description 10
- 238000000855 fermentation Methods 0.000 description 10
- 230000004151 fermentation Effects 0.000 description 10
- 238000003780 insertion Methods 0.000 description 10
- 230000037431 insertion Effects 0.000 description 10
- 101150035744 guaB gene Proteins 0.000 description 9
- 150000002742 methionines Chemical class 0.000 description 9
- KDCGOANMDULRCW-UHFFFAOYSA-N 7H-purine Chemical compound N1=CNC2=NC=NC2=C1 KDCGOANMDULRCW-UHFFFAOYSA-N 0.000 description 8
- 101100126053 Dictyostelium discoideum impdh gene Proteins 0.000 description 8
- 150000007523 nucleic acids Chemical class 0.000 description 8
- 150000001484 arginines Chemical class 0.000 description 7
- 230000000295 complement effect Effects 0.000 description 7
- 230000000875 corresponding effect Effects 0.000 description 7
- 238000009396 hybridization Methods 0.000 description 7
- 229930027917 kanamycin Natural products 0.000 description 7
- SBUJHOSQTJFQJX-NOAMYHISSA-N kanamycin Chemical compound O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CN)O[C@@H]1O[C@H]1[C@H](O)[C@@H](O[C@@H]2[C@@H]([C@@H](N)[C@H](O)[C@@H](CO)O2)O)[C@H](N)C[C@@H]1N SBUJHOSQTJFQJX-NOAMYHISSA-N 0.000 description 7
- 229960000318 kanamycin Drugs 0.000 description 7
- 229930182823 kanamycin A Natural products 0.000 description 7
- 239000000463 material Substances 0.000 description 7
- 101150002764 purA gene Proteins 0.000 description 7
- 238000011218 seed culture Methods 0.000 description 7
- 239000001963 growth medium Substances 0.000 description 6
- 238000002744 homologous recombination Methods 0.000 description 6
- 230000006801 homologous recombination Effects 0.000 description 6
- 230000004048 modification Effects 0.000 description 6
- 238000012986 modification Methods 0.000 description 6
- 102000039446 nucleic acids Human genes 0.000 description 6
- 108020004707 nucleic acids Proteins 0.000 description 6
- 230000003287 optical effect Effects 0.000 description 6
- 239000000126 substance Substances 0.000 description 5
- HMUNWXXNJPVALC-UHFFFAOYSA-N 1-[4-[2-(2,3-dihydro-1H-inden-2-ylamino)pyrimidin-5-yl]piperazin-1-yl]-2-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)ethanone Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)N1CCN(CC1)C(CN1CC2=C(CC1)NN=N2)=O HMUNWXXNJPVALC-UHFFFAOYSA-N 0.000 description 4
- NLXLAEXVIDQMFP-UHFFFAOYSA-N Ammonia chloride Chemical compound [NH4+].[Cl-] NLXLAEXVIDQMFP-UHFFFAOYSA-N 0.000 description 4
- 241000588724 Escherichia coli Species 0.000 description 4
- CSNNHWWHGAXBCP-UHFFFAOYSA-L Magnesium sulfate Chemical compound [Mg+2].[O-][S+2]([O-])([O-])[O-] CSNNHWWHGAXBCP-UHFFFAOYSA-L 0.000 description 4
- NBIIXXVUZAFLBC-UHFFFAOYSA-N Phosphoric acid Chemical compound OP(O)(O)=O NBIIXXVUZAFLBC-UHFFFAOYSA-N 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 108091081024 Start codon Proteins 0.000 description 4
- 239000002253 acid Substances 0.000 description 4
- 238000007792 addition Methods 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- -1 aromatic amino acids Chemical class 0.000 description 4
- 238000011156 evaluation Methods 0.000 description 4
- 239000000796 flavoring agent Substances 0.000 description 4
- 235000019634 flavors Nutrition 0.000 description 4
- UYTPUPDQBNUYGX-UHFFFAOYSA-N guanine Chemical compound O=C1NC(N)=NC2=C1N=CN2 UYTPUPDQBNUYGX-UHFFFAOYSA-N 0.000 description 4
- 230000000813 microbial effect Effects 0.000 description 4
- 239000000047 product Substances 0.000 description 4
- 238000013518 transcription Methods 0.000 description 4
- 230000035897 transcription Effects 0.000 description 4
- 230000009466 transformation Effects 0.000 description 4
- VZSRBBMJRBPUNF-UHFFFAOYSA-N 2-(2,3-dihydro-1H-inden-2-ylamino)-N-[3-oxo-3-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)propyl]pyrimidine-5-carboxamide Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)C(=O)NCCC(N1CC2=C(CC1)NN=N2)=O VZSRBBMJRBPUNF-UHFFFAOYSA-N 0.000 description 3
- PQGCEDQWHSBAJP-TXICZTDVSA-N 5-O-phosphono-alpha-D-ribofuranosyl diphosphate Chemical compound O[C@H]1[C@@H](O)[C@@H](O[P@](O)(=O)OP(O)(O)=O)O[C@@H]1COP(O)(O)=O PQGCEDQWHSBAJP-TXICZTDVSA-N 0.000 description 3
- QTBSBXVTEAMEQO-UHFFFAOYSA-N Acetic acid Chemical compound CC(O)=O QTBSBXVTEAMEQO-UHFFFAOYSA-N 0.000 description 3
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 description 3
- 206010064571 Gene mutation Diseases 0.000 description 3
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Natural products OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- FFEARJCKVFRZRR-BYPYZUCNSA-N L-methionine Chemical compound CSCC[C@H](N)C(O)=O FFEARJCKVFRZRR-BYPYZUCNSA-N 0.000 description 3
- 108091028043 Nucleic acid sequence Proteins 0.000 description 3
- 239000001888 Peptone Substances 0.000 description 3
- 108010080698 Peptones Proteins 0.000 description 3
- KWYUFKZDYYNOTN-UHFFFAOYSA-M Potassium hydroxide Chemical compound [OH-].[K+] KWYUFKZDYYNOTN-UHFFFAOYSA-M 0.000 description 3
- HEMHJVSKTPXQMS-UHFFFAOYSA-M Sodium hydroxide Chemical compound [OH-].[Na+] HEMHJVSKTPXQMS-UHFFFAOYSA-M 0.000 description 3
- 150000007513 acids Chemical class 0.000 description 3
- WQZGKKKJIJFFOK-VFUOTHLCSA-N beta-D-glucose Chemical compound OC[C@H]1O[C@@H](O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-VFUOTHLCSA-N 0.000 description 3
- 230000015572 biosynthetic process Effects 0.000 description 3
- 229940041514 candida albicans extract Drugs 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 238000004925 denaturation Methods 0.000 description 3
- 230000036425 denaturation Effects 0.000 description 3
- 238000004520 electroporation Methods 0.000 description 3
- 239000000284 extract Substances 0.000 description 3
- 235000013305 food Nutrition 0.000 description 3
- 235000013373 food additive Nutrition 0.000 description 3
- 239000002778 food additive Substances 0.000 description 3
- 230000006870 function Effects 0.000 description 3
- 239000008103 glucose Substances 0.000 description 3
- 239000011159 matrix material Substances 0.000 description 3
- 235000013372 meat Nutrition 0.000 description 3
- 235000019319 peptone Nutrition 0.000 description 3
- 239000013612 plasmid Substances 0.000 description 3
- 238000000746 purification Methods 0.000 description 3
- 108091008146 restriction endonucleases Proteins 0.000 description 3
- 150000003839 salts Chemical class 0.000 description 3
- 239000012138 yeast extract Substances 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- UKAUYVFTDYCKQA-UHFFFAOYSA-N -2-Amino-4-hydroxybutanoic acid Natural products OC(=O)C(N)CCO UKAUYVFTDYCKQA-UHFFFAOYSA-N 0.000 description 2
- YLZOPXRUQYQQID-UHFFFAOYSA-N 3-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)-1-[4-[2-[[3-(trifluoromethoxy)phenyl]methylamino]pyrimidin-5-yl]piperazin-1-yl]propan-1-one Chemical compound N1N=NC=2CN(CCC=21)CCC(=O)N1CCN(CC1)C=1C=NC(=NC=1)NCC1=CC(=CC=C1)OC(F)(F)F YLZOPXRUQYQQID-UHFFFAOYSA-N 0.000 description 2
- 229930024421 Adenine Natural products 0.000 description 2
- GFFGJBXGBJISGV-UHFFFAOYSA-N Adenine Chemical compound NC1=NC=NC2=C1N=CN2 GFFGJBXGBJISGV-UHFFFAOYSA-N 0.000 description 2
- 108010056443 Adenylosuccinate synthase Proteins 0.000 description 2
- QGZKDVFQNNGYKY-UHFFFAOYSA-N Ammonia Chemical compound N QGZKDVFQNNGYKY-UHFFFAOYSA-N 0.000 description 2
- IJGRMHOSHXDMSA-UHFFFAOYSA-N Atomic nitrogen Chemical compound N#N IJGRMHOSHXDMSA-UHFFFAOYSA-N 0.000 description 2
- 241000186226 Corynebacterium glutamicum Species 0.000 description 2
- 229930091371 Fructose Natural products 0.000 description 2
- RFSUNEUAIZKAJO-ARQDHWQXSA-N Fructose Chemical compound OC[C@H]1O[C@](O)(CO)[C@@H](O)[C@@H]1O RFSUNEUAIZKAJO-ARQDHWQXSA-N 0.000 description 2
- 239000005715 Fructose Substances 0.000 description 2
- VEXZGXHMUGYJMC-UHFFFAOYSA-N Hydrochloric acid Chemical compound Cl VEXZGXHMUGYJMC-UHFFFAOYSA-N 0.000 description 2
- QNAYBMKLOCPYGJ-REOHCLBHSA-N L-alanine Chemical compound C[C@H](N)C(O)=O QNAYBMKLOCPYGJ-REOHCLBHSA-N 0.000 description 2
- UKAUYVFTDYCKQA-VKHMYHEASA-N L-homoserine Chemical compound OC(=O)[C@@H](N)CCO UKAUYVFTDYCKQA-VKHMYHEASA-N 0.000 description 2
- COLNVLDHVKWLRT-QMMMGPOBSA-N L-phenylalanine Chemical compound OC(=O)[C@@H](N)CC1=CC=CC=C1 COLNVLDHVKWLRT-QMMMGPOBSA-N 0.000 description 2
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 2
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 2
- 108090000364 Ligases Proteins 0.000 description 2
- 102000003960 Ligases Human genes 0.000 description 2
- PVNIIMVLHYAWGP-UHFFFAOYSA-N Niacin Chemical compound OC(=O)C1=CC=CN=C1 PVNIIMVLHYAWGP-UHFFFAOYSA-N 0.000 description 2
- 108700026244 Open Reading Frames Proteins 0.000 description 2
- QAOWNCQODCNURD-UHFFFAOYSA-N Sulfuric acid Chemical compound OS(O)(=O)=O QAOWNCQODCNURD-UHFFFAOYSA-N 0.000 description 2
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 2
- XSQUKJJJFZCRTK-UHFFFAOYSA-N Urea Chemical compound NC(N)=O XSQUKJJJFZCRTK-UHFFFAOYSA-N 0.000 description 2
- 229960000643 adenine Drugs 0.000 description 2
- OIRDTQYFTABQOQ-KQYNXXCUSA-N adenosine Chemical compound C1=NC=2C(N)=NC=NC=2N1[C@@H]1O[C@H](CO)[C@@H](O)[C@H]1O OIRDTQYFTABQOQ-KQYNXXCUSA-N 0.000 description 2
- 102000005130 adenylosuccinate synthetase Human genes 0.000 description 2
- 235000004279 alanine Nutrition 0.000 description 2
- 229910000147 aluminium phosphate Inorganic materials 0.000 description 2
- 235000019270 ammonium chloride Nutrition 0.000 description 2
- 238000000137 annealing Methods 0.000 description 2
- QVGXLLKOCUKJST-UHFFFAOYSA-N atomic oxygen Chemical compound [O] QVGXLLKOCUKJST-UHFFFAOYSA-N 0.000 description 2
- 230000006696 biosynthetic metabolic pathway Effects 0.000 description 2
- 230000006652 catabolic pathway Effects 0.000 description 2
- 235000013409 condiments Nutrition 0.000 description 2
- OPTASPLRGRRNAP-UHFFFAOYSA-N cytosine Chemical compound NC=1C=CNC(=O)N=1 OPTASPLRGRRNAP-UHFFFAOYSA-N 0.000 description 2
- 238000012239 gene modification Methods 0.000 description 2
- 230000005017 genetic modification Effects 0.000 description 2
- 235000013617 genetically modified food Nutrition 0.000 description 2
- RQFCJASXJCIDSX-UUOKFMHZSA-N guanosine 5'-monophosphate Chemical compound C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP(O)(O)=O)[C@@H](O)[C@H]1O RQFCJASXJCIDSX-UUOKFMHZSA-N 0.000 description 2
- 235000013928 guanylic acid Nutrition 0.000 description 2
- 239000004226 guanylic acid Substances 0.000 description 2
- IPCSVZSSVZVIGE-UHFFFAOYSA-N hexadecanoic acid Chemical compound CCCCCCCCCCCCCCCC(O)=O IPCSVZSSVZVIGE-UHFFFAOYSA-N 0.000 description 2
- 238000004128 high performance liquid chromatography Methods 0.000 description 2
- 229910000358 iron sulfate Inorganic materials 0.000 description 2
- BAUYGSIQEAFULO-UHFFFAOYSA-L iron(2+) sulfate (anhydrous) Chemical compound [Fe+2].[O-]S([O-])(=O)=O BAUYGSIQEAFULO-UHFFFAOYSA-L 0.000 description 2
- 229910052943 magnesium sulfate Inorganic materials 0.000 description 2
- 235000019341 magnesium sulphate Nutrition 0.000 description 2
- 239000003550 marker Substances 0.000 description 2
- 108020004999 messenger RNA Proteins 0.000 description 2
- 235000013923 monosodium glutamate Nutrition 0.000 description 2
- 235000015097 nutrients Nutrition 0.000 description 2
- 239000001301 oxygen Substances 0.000 description 2
- 229910052760 oxygen Inorganic materials 0.000 description 2
- 239000000546 pharmaceutical excipient Substances 0.000 description 2
- COLNVLDHVKWLRT-UHFFFAOYSA-N phenylalanine Natural products OC(=O)C(N)CC1=CC=CC=C1 COLNVLDHVKWLRT-UHFFFAOYSA-N 0.000 description 2
- 238000002708 random mutagenesis Methods 0.000 description 2
- 238000011160 research Methods 0.000 description 2
- 239000000523 sample Substances 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 238000012360 testing method Methods 0.000 description 2
- RWQNBRDOKXIBIV-UHFFFAOYSA-N thymine Chemical compound CC1=CNC(=O)NC1=O RWQNBRDOKXIBIV-UHFFFAOYSA-N 0.000 description 2
- OUYCCCASQSFEME-UHFFFAOYSA-N tyrosine Natural products OC(=O)C(N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-UHFFFAOYSA-N 0.000 description 2
- 239000004474 valine Substances 0.000 description 2
- UVZZAUIWJCQWEO-DFWYDOINSA-N (2s)-2-aminopentanedioic acid;sodium Chemical compound [Na].OC(=O)[C@@H](N)CCC(O)=O UVZZAUIWJCQWEO-DFWYDOINSA-N 0.000 description 1
- OWEGMIWEEQEYGQ-UHFFFAOYSA-N 100676-05-9 Natural products OC1C(O)C(O)C(CO)OC1OCC1C(O)C(O)C(O)C(OC2C(OC(O)C(O)C2O)CO)O1 OWEGMIWEEQEYGQ-UHFFFAOYSA-N 0.000 description 1
- LDXJRKWFNNFDSA-UHFFFAOYSA-N 2-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)-1-[4-[2-[[3-(trifluoromethoxy)phenyl]methylamino]pyrimidin-5-yl]piperazin-1-yl]ethanone Chemical compound C1CN(CC2=NNN=C21)CC(=O)N3CCN(CC3)C4=CN=C(N=C4)NCC5=CC(=CC=C5)OC(F)(F)F LDXJRKWFNNFDSA-UHFFFAOYSA-N 0.000 description 1
- PAWQVTBBRAZDMG-UHFFFAOYSA-N 2-(3-bromo-2-fluorophenyl)acetic acid Chemical compound OC(=O)CC1=CC=CC(Br)=C1F PAWQVTBBRAZDMG-UHFFFAOYSA-N 0.000 description 1
- WZFUQSJFWNHZHM-UHFFFAOYSA-N 2-[4-[2-(2,3-dihydro-1H-inden-2-ylamino)pyrimidin-5-yl]piperazin-1-yl]-1-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)ethanone Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)N1CCN(CC1)CC(=O)N1CC2=C(CC1)NN=N2 WZFUQSJFWNHZHM-UHFFFAOYSA-N 0.000 description 1
- PWKSKIMOESPYIA-UHFFFAOYSA-N 2-acetamido-3-sulfanylpropanoic acid Chemical compound CC(=O)NC(CS)C(O)=O PWKSKIMOESPYIA-UHFFFAOYSA-N 0.000 description 1
- CONKBQPVFMXDOV-QHCPKHFHSA-N 6-[(5S)-5-[[4-[2-(2,3-dihydro-1H-inden-2-ylamino)pyrimidin-5-yl]piperazin-1-yl]methyl]-2-oxo-1,3-oxazolidin-3-yl]-3H-1,3-benzoxazol-2-one Chemical compound C1C(CC2=CC=CC=C12)NC1=NC=C(C=N1)N1CCN(CC1)C[C@H]1CN(C(O1)=O)C1=CC2=C(NC(O2)=O)C=C1 CONKBQPVFMXDOV-QHCPKHFHSA-N 0.000 description 1
- OYFLINJPCLMDLX-QOOXTFGASA-N 9-[(2R,3R,4S,5R)-3,4-dihydroxy-5-(hydroxymethyl)oxolan-2-yl]-6-oxopurine-5-carboxylic acid Chemical compound [C@@H]1([C@H](O)[C@H](O)[C@@H](CO)O1)N1C=NC2(C(=O)N=CN=C12)C(=O)O OYFLINJPCLMDLX-QOOXTFGASA-N 0.000 description 1
- 229920001817 Agar Polymers 0.000 description 1
- GUBGYTABKSRVRQ-XLOQQCSPSA-N Alpha-Lactose Chemical compound O[C@@H]1[C@@H](O)[C@@H](O)[C@@H](CO)O[C@H]1O[C@@H]1[C@@H](CO)O[C@H](O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-XLOQQCSPSA-N 0.000 description 1
- ATRRKUHOCOJYRX-UHFFFAOYSA-N Ammonium bicarbonate Chemical compound [NH4+].OC([O-])=O ATRRKUHOCOJYRX-UHFFFAOYSA-N 0.000 description 1
- 239000004254 Ammonium phosphate Substances 0.000 description 1
- 239000002126 C01EB10 - Adenosine Substances 0.000 description 1
- UXVMQQNJUSDDNG-UHFFFAOYSA-L Calcium chloride Chemical compound [Cl-].[Cl-].[Ca+2] UXVMQQNJUSDDNG-UHFFFAOYSA-L 0.000 description 1
- OKTJSMMVPCPJKN-UHFFFAOYSA-N Carbon Chemical compound [C] OKTJSMMVPCPJKN-UHFFFAOYSA-N 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 241000186145 Corynebacterium ammoniagenes Species 0.000 description 1
- 241001644925 Corynebacterium efficiens Species 0.000 description 1
- 241000186249 Corynebacterium sp. Species 0.000 description 1
- 241000337023 Corynebacterium thermoaminogenes Species 0.000 description 1
- 101710088194 Dehydrogenase Proteins 0.000 description 1
- 206010059866 Drug resistance Diseases 0.000 description 1
- 101001078247 Escherichia coli (strain K12) dITP/XTP pyrophosphatase Proteins 0.000 description 1
- 108090000926 GMP synthase (glutamine-hydrolyzing) Proteins 0.000 description 1
- 102100033452 GMP synthase [glutamine-hydrolyzing] Human genes 0.000 description 1
- WHUUTDBJXJRKMK-UHFFFAOYSA-N Glutamic acid Natural products OC(=O)C(N)CCC(O)=O WHUUTDBJXJRKMK-UHFFFAOYSA-N 0.000 description 1
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Natural products NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 244000068988 Glycine max Species 0.000 description 1
- 235000010469 Glycine max Nutrition 0.000 description 1
- 108010087227 IMP Dehydrogenase Proteins 0.000 description 1
- 102000006674 IMP dehydrogenase Human genes 0.000 description 1
- HAEJPQIATWHALX-KQYNXXCUSA-N ITP Chemical compound O[C@@H]1[C@H](O)[C@@H](COP(O)(=O)OP(O)(=O)OP(O)(O)=O)O[C@H]1N1C(N=CNC2=O)=C2N=C1 HAEJPQIATWHALX-KQYNXXCUSA-N 0.000 description 1
- 229930010555 Inosine Natural products 0.000 description 1
- UGQMRVRMYYASKQ-KQYNXXCUSA-N Inosine Chemical compound O[C@@H]1[C@H](O)[C@@H](CO)O[C@H]1N1C2=NC=NC(O)=C2N=C1 UGQMRVRMYYASKQ-KQYNXXCUSA-N 0.000 description 1
- 102000016600 Inosine-5'-monophosphate dehydrogenases Human genes 0.000 description 1
- 108050006182 Inosine-5'-monophosphate dehydrogenases Proteins 0.000 description 1
- 150000008575 L-amino acids Chemical class 0.000 description 1
- ODKSFYDXXFIFQN-BYPYZUCNSA-P L-argininium(2+) Chemical compound NC(=[NH2+])NCCC[C@H]([NH3+])C(O)=O ODKSFYDXXFIFQN-BYPYZUCNSA-P 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- WHUUTDBJXJRKMK-VKHMYHEASA-N L-glutamic acid Chemical compound OC(=O)[C@@H](N)CCC(O)=O WHUUTDBJXJRKMK-VKHMYHEASA-N 0.000 description 1
- HNDVDQJCIGZPNO-YFKPBYRVSA-N L-histidine Chemical compound OC(=O)[C@@H](N)CC1=CN=CN1 HNDVDQJCIGZPNO-YFKPBYRVSA-N 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-YFKPBYRVSA-N L-leucine Chemical compound CC(C)C[C@H](N)C(O)=O ROHFNLRQFUQHCH-YFKPBYRVSA-N 0.000 description 1
- KDXKERNSBIXSRK-YFKPBYRVSA-N L-lysine Chemical compound NCCCC[C@H](N)C(O)=O KDXKERNSBIXSRK-YFKPBYRVSA-N 0.000 description 1
- KZSNJWFQEVHDMF-BYPYZUCNSA-N L-valine Chemical compound CC(C)[C@H](N)C(O)=O KZSNJWFQEVHDMF-BYPYZUCNSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QKKXKWKRSA-N Lactose Natural products OC[C@H]1O[C@@H](O[C@H]2[C@H](O)[C@@H](O)C(O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@H]1O GUBGYTABKSRVRQ-QKKXKWKRSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- OYHQOLUKZRVURQ-HZJYTTRNSA-N Linoleic acid Chemical compound CCCCC\C=C/C\C=C/CCCCCCCC(O)=O OYHQOLUKZRVURQ-HZJYTTRNSA-N 0.000 description 1
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- GUBGYTABKSRVRQ-PICCSMPSSA-N Maltose Natural products O[C@@H]1[C@@H](O)[C@H](O)[C@@H](CO)O[C@@H]1O[C@@H]1[C@@H](CO)OC(O)[C@H](O)[C@H]1O GUBGYTABKSRVRQ-PICCSMPSSA-N 0.000 description 1
- 102000018697 Membrane Proteins Human genes 0.000 description 1
- 108010052285 Membrane Proteins Proteins 0.000 description 1
- NIPNSKYNPDTRPC-UHFFFAOYSA-N N-[2-oxo-2-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)ethyl]-2-[[3-(trifluoromethoxy)phenyl]methylamino]pyrimidine-5-carboxamide Chemical compound O=C(CNC(=O)C=1C=NC(=NC=1)NCC1=CC(=CC=C1)OC(F)(F)F)N1CC2=C(CC1)NN=N2 NIPNSKYNPDTRPC-UHFFFAOYSA-N 0.000 description 1
- AFCARXCZXQIEQB-UHFFFAOYSA-N N-[3-oxo-3-(2,4,6,7-tetrahydrotriazolo[4,5-c]pyridin-5-yl)propyl]-2-[[3-(trifluoromethoxy)phenyl]methylamino]pyrimidine-5-carboxamide Chemical compound O=C(CCNC(=O)C=1C=NC(=NC=1)NCC1=CC(=CC=C1)OC(F)(F)F)N1CC2=C(CC1)NN=N2 AFCARXCZXQIEQB-UHFFFAOYSA-N 0.000 description 1
- PYUSHNKNPOHWEZ-YFKPBYRVSA-N N-formyl-L-methionine Chemical compound CSCC[C@@H](C(O)=O)NC=O PYUSHNKNPOHWEZ-YFKPBYRVSA-N 0.000 description 1
- 238000009004 PCR Kit Methods 0.000 description 1
- 235000021314 Palmitic acid Nutrition 0.000 description 1
- 235000019483 Peanut oil Nutrition 0.000 description 1
- OAICVXFJPJFONN-UHFFFAOYSA-N Phosphorus Chemical compound [P] OAICVXFJPJFONN-UHFFFAOYSA-N 0.000 description 1
- 101001074199 Rattus norvegicus Glycerol kinase Proteins 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 235000019764 Soybean Meal Nutrition 0.000 description 1
- 229920002472 Starch Polymers 0.000 description 1
- 235000021355 Stearic acid Nutrition 0.000 description 1
- 229930006000 Sucrose Natural products 0.000 description 1
- CZMRCDWAGMRECN-UGDNZRGBSA-N Sucrose Chemical compound O[C@H]1[C@H](O)[C@@H](CO)O[C@@]1(CO)O[C@@H]1[C@H](O)[C@@H](O)[C@H](O)[C@@H](CO)O1 CZMRCDWAGMRECN-UGDNZRGBSA-N 0.000 description 1
- 235000019486 Sunflower oil Nutrition 0.000 description 1
- JZRWCGZRTZMZEH-UHFFFAOYSA-N Thiamine Natural products CC1=C(CCO)SC=[N+]1CC1=CN=C(C)N=C1N JZRWCGZRTZMZEH-UHFFFAOYSA-N 0.000 description 1
- KZSNJWFQEVHDMF-UHFFFAOYSA-N Valine Natural products CC(C)C(N)C(O)=O KZSNJWFQEVHDMF-UHFFFAOYSA-N 0.000 description 1
- 241000700605 Viruses Species 0.000 description 1
- 240000008042 Zea mays Species 0.000 description 1
- 235000005824 Zea mays ssp. parviglumis Nutrition 0.000 description 1
- 235000002017 Zea mays subsp mays Nutrition 0.000 description 1
- 241000319304 [Brevibacterium] flavum Species 0.000 description 1
- 239000000654 additive Substances 0.000 description 1
- 230000000996 additive effect Effects 0.000 description 1
- 229960005305 adenosine Drugs 0.000 description 1
- 239000008272 agar Substances 0.000 description 1
- 150000001298 alcohols Chemical class 0.000 description 1
- 229910021529 ammonia Inorganic materials 0.000 description 1
- 239000001099 ammonium carbonate Substances 0.000 description 1
- 235000012501 ammonium carbonate Nutrition 0.000 description 1
- 229910000148 ammonium phosphate Inorganic materials 0.000 description 1
- 235000019289 ammonium phosphates Nutrition 0.000 description 1
- BFNBIHQBYMNNAN-UHFFFAOYSA-N ammonium sulfate Chemical compound N.N.OS(O)(=O)=O BFNBIHQBYMNNAN-UHFFFAOYSA-N 0.000 description 1
- 229910052921 ammonium sulfate Inorganic materials 0.000 description 1
- 235000011130 ammonium sulphate Nutrition 0.000 description 1
- 235000019730 animal feed additive Nutrition 0.000 description 1
- 238000005571 anion exchange chromatography Methods 0.000 description 1
- 235000003704 aspartic acid Nutrition 0.000 description 1
- 150000007514 bases Chemical class 0.000 description 1
- 235000015278 beef Nutrition 0.000 description 1
- OQFSQFPPLPISGP-UHFFFAOYSA-N beta-carboxyaspartic acid Natural products OC(=O)C(N)C(C(O)=O)C(O)=O OQFSQFPPLPISGP-UHFFFAOYSA-N 0.000 description 1
- GUBGYTABKSRVRQ-QUYVBRFLSA-N beta-maltose Chemical compound OC[C@H]1O[C@H](O[C@H]2[C@H](O)[C@@H](O)[C@H](O)O[C@@H]2CO)[C@H](O)[C@@H](O)[C@@H]1O GUBGYTABKSRVRQ-QUYVBRFLSA-N 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 239000001110 calcium chloride Substances 0.000 description 1
- 229910001628 calcium chloride Inorganic materials 0.000 description 1
- 235000013900 calcium guanylate Nutrition 0.000 description 1
- 239000004244 calcium guanylate Substances 0.000 description 1
- KAFMRSAFJZENBN-GWTDSMLYSA-L calcium guanylate Chemical compound [Ca+2].C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP([O-])([O-])=O)[C@@H](O)[C@H]1O KAFMRSAFJZENBN-GWTDSMLYSA-L 0.000 description 1
- 239000004202 carbamide Substances 0.000 description 1
- 150000001720 carbohydrates Chemical class 0.000 description 1
- 235000014633 carbohydrates Nutrition 0.000 description 1
- 229910052799 carbon Inorganic materials 0.000 description 1
- 239000001913 cellulose Substances 0.000 description 1
- 229920002678 cellulose Polymers 0.000 description 1
- 235000010980 cellulose Nutrition 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 230000008859 change Effects 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000003795 chemical substances by application Substances 0.000 description 1
- 230000002759 chromosomal effect Effects 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 239000003240 coconut oil Substances 0.000 description 1
- 235000019864 coconut oil Nutrition 0.000 description 1
- 229910000365 copper sulfate Inorganic materials 0.000 description 1
- ARUVKPQLZAKDPS-UHFFFAOYSA-L copper(II) sulfate Chemical compound [Cu+2].[O-][S+2]([O-])([O-])[O-] ARUVKPQLZAKDPS-UHFFFAOYSA-L 0.000 description 1
- 235000005822 corn Nutrition 0.000 description 1
- 239000013601 cosmid vector Substances 0.000 description 1
- 238000002425 crystallisation Methods 0.000 description 1
- 230000008025 crystallization Effects 0.000 description 1
- 238000012136 culture method Methods 0.000 description 1
- 239000012228 culture supernatant Substances 0.000 description 1
- 229940104302 cytosine Drugs 0.000 description 1
- 229940127089 cytotoxic agent Drugs 0.000 description 1
- 239000002254 cytotoxic agent Substances 0.000 description 1
- 231100000599 cytotoxic agent Toxicity 0.000 description 1
- MNNHAPBLZZVQHP-UHFFFAOYSA-N diammonium hydrogen phosphate Chemical compound [NH4+].[NH4+].OP([O-])([O-])=O MNNHAPBLZZVQHP-UHFFFAOYSA-N 0.000 description 1
- 235000014113 dietary fatty acids Nutrition 0.000 description 1
- 235000013898 dipotassium guanylate Nutrition 0.000 description 1
- 239000004192 dipotassium guanylate Substances 0.000 description 1
- BCQFRUIIFOQGFI-LGVAUZIVSA-L dipotassium guanylate Chemical compound [K+].[K+].C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP([O-])([O-])=O)[C@@H](O)[C@H]1O BCQFRUIIFOQGFI-LGVAUZIVSA-L 0.000 description 1
- ZPWVASYFFYYZEW-UHFFFAOYSA-L dipotassium hydrogen phosphate Chemical compound [K+].[K+].OP([O-])([O-])=O ZPWVASYFFYYZEW-UHFFFAOYSA-L 0.000 description 1
- PVBRXXAAPNGWGE-LGVAUZIVSA-L disodium 5'-guanylate Chemical compound [Na+].[Na+].C1=2NC(N)=NC(=O)C=2N=CN1[C@@H]1O[C@H](COP([O-])([O-])=O)[C@@H](O)[C@H]1O PVBRXXAAPNGWGE-LGVAUZIVSA-L 0.000 description 1
- 239000002270 dispersing agent Substances 0.000 description 1
- 239000012153 distilled water Substances 0.000 description 1
- 229940079593 drug Drugs 0.000 description 1
- 239000003814 drug Substances 0.000 description 1
- 238000009510 drug design Methods 0.000 description 1
- 230000007515 enzymatic degradation Effects 0.000 description 1
- 230000009088 enzymatic function Effects 0.000 description 1
- 239000013604 expression vector Substances 0.000 description 1
- 229930195729 fatty acid Natural products 0.000 description 1
- 239000000194 fatty acid Substances 0.000 description 1
- 150000004665 fatty acids Chemical class 0.000 description 1
- 238000001914 filtration Methods 0.000 description 1
- 235000019264 food flavour enhancer Nutrition 0.000 description 1
- 235000011194 food seasoning agent Nutrition 0.000 description 1
- 239000007789 gas Substances 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 235000013922 glutamic acid Nutrition 0.000 description 1
- 239000004220 glutamic acid Substances 0.000 description 1
- 125000003630 glycyl group Chemical group [H]N([H])C([H])([H])C(*)=O 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 230000002209 hydrophobic effect Effects 0.000 description 1
- 230000002779 inactivation Effects 0.000 description 1
- 150000002484 inorganic compounds Chemical class 0.000 description 1
- 229910010272 inorganic material Inorganic materials 0.000 description 1
- 229960003786 inosine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 239000008101 lactose Substances 0.000 description 1
- 235000020778 linoleic acid Nutrition 0.000 description 1
- OYHQOLUKZRVURQ-IXWMQOLASA-N linoleic acid Natural products CCCCC\C=C/C\C=C\CCCCCCCC(O)=O OYHQOLUKZRVURQ-IXWMQOLASA-N 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 229940099596 manganese sulfate Drugs 0.000 description 1
- 239000011702 manganese sulphate Substances 0.000 description 1
- 235000007079 manganese sulphate Nutrition 0.000 description 1
- SQQMAOCOWKFBNP-UHFFFAOYSA-L manganese(II) sulfate Chemical compound [Mn+2].[O-]S([O-])(=O)=O SQQMAOCOWKFBNP-UHFFFAOYSA-L 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 229940127554 medical product Drugs 0.000 description 1
- 230000002503 metabolic effect Effects 0.000 description 1
- 229910052751 metal Inorganic materials 0.000 description 1
- 239000002184 metal Substances 0.000 description 1
- CAAULPUQFIIOTL-UHFFFAOYSA-N methyl dihydrogen phosphate Chemical compound COP(O)(O)=O CAAULPUQFIIOTL-UHFFFAOYSA-N 0.000 description 1
- 108091005573 modified proteins Proteins 0.000 description 1
- 102000035118 modified proteins Human genes 0.000 description 1
- 235000013379 molasses Nutrition 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 229910000402 monopotassium phosphate Inorganic materials 0.000 description 1
- 235000019796 monopotassium phosphate Nutrition 0.000 description 1
- LPUQAYUQRXPFSQ-DFWYDOINSA-M monosodium L-glutamate Chemical compound [Na+].[O-]C(=O)[C@@H](N)CCC(O)=O LPUQAYUQRXPFSQ-DFWYDOINSA-M 0.000 description 1
- WQEPLUUGTLDZJY-UHFFFAOYSA-N n-Pentadecanoic acid Natural products CCCCCCCCCCCCCCC(O)=O WQEPLUUGTLDZJY-UHFFFAOYSA-N 0.000 description 1
- 235000001968 nicotinic acid Nutrition 0.000 description 1
- 229960003512 nicotinic acid Drugs 0.000 description 1
- 239000011664 nicotinic acid Substances 0.000 description 1
- 229910052757 nitrogen Inorganic materials 0.000 description 1
- QIQXTHQIDYTFRH-UHFFFAOYSA-N octadecanoic acid Chemical compound CCCCCCCCCCCCCCCCCC(O)=O QIQXTHQIDYTFRH-UHFFFAOYSA-N 0.000 description 1
- OQCDKBAXFALNLD-UHFFFAOYSA-N octadecanoic acid Natural products CCCCCCCC(C)CCCCCCCCC(O)=O OQCDKBAXFALNLD-UHFFFAOYSA-N 0.000 description 1
- 239000003921 oil Substances 0.000 description 1
- 235000019198 oils Nutrition 0.000 description 1
- 235000014593 oils and fats Nutrition 0.000 description 1
- 150000007524 organic acids Chemical class 0.000 description 1
- 235000005985 organic acids Nutrition 0.000 description 1
- 239000000312 peanut oil Substances 0.000 description 1
- PJNZPQUBCPKICU-UHFFFAOYSA-N phosphoric acid;potassium Chemical compound [K].OP(O)(O)=O PJNZPQUBCPKICU-UHFFFAOYSA-N 0.000 description 1
- 229910052698 phosphorus Inorganic materials 0.000 description 1
- 239000011574 phosphorus Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 239000013600 plasmid vector Substances 0.000 description 1
- 229920000642 polymer Polymers 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 230000001323 posttranslational effect Effects 0.000 description 1
- 239000002243 precursor Substances 0.000 description 1
- 239000003755 preservative agent Substances 0.000 description 1
- 230000002335 preservative effect Effects 0.000 description 1
- 230000008569 process Effects 0.000 description 1
- 230000004144 purine metabolism Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000001105 regulatory effect Effects 0.000 description 1
- 229920002477 rna polymer Polymers 0.000 description 1
- 238000000926 separation method Methods 0.000 description 1
- 230000037432 silent mutation Effects 0.000 description 1
- 238000002741 site-directed mutagenesis Methods 0.000 description 1
- 229940073490 sodium glutamate Drugs 0.000 description 1
- 159000000000 sodium salts Chemical class 0.000 description 1
- 239000007787 solid Substances 0.000 description 1
- 239000004455 soybean meal Substances 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 239000008107 starch Substances 0.000 description 1
- 235000019698 starch Nutrition 0.000 description 1
- 239000008117 stearic acid Substances 0.000 description 1
- 239000000758 substrate Substances 0.000 description 1
- 239000005720 sucrose Substances 0.000 description 1
- 235000000346 sugar Nutrition 0.000 description 1
- 150000008163 sugars Chemical class 0.000 description 1
- 239000002600 sunflower oil Substances 0.000 description 1
- 239000000375 suspending agent Substances 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000003786 synthesis reaction Methods 0.000 description 1
- 235000019157 thiamine Nutrition 0.000 description 1
- KYMBYSLLVAOCFI-UHFFFAOYSA-N thiamine Chemical compound CC1=C(CCO)SCN1CC1=CN=C(C)N=C1N KYMBYSLLVAOCFI-UHFFFAOYSA-N 0.000 description 1
- 229960003495 thiamine Drugs 0.000 description 1
- 239000011721 thiamine Substances 0.000 description 1
- 229940113082 thymine Drugs 0.000 description 1
- 238000004448 titration Methods 0.000 description 1
- 230000005030 transcription termination Effects 0.000 description 1
- 238000012546 transfer Methods 0.000 description 1
- 241001515965 unidentified phage Species 0.000 description 1
- 239000011782 vitamin Substances 0.000 description 1
- 235000013343 vitamin Nutrition 0.000 description 1
- 229940088594 vitamin Drugs 0.000 description 1
- 229930003231 vitamin Natural products 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Chemical compound O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 230000003313 weakening effect Effects 0.000 description 1
- 239000000080 wetting agent Substances 0.000 description 1
- 210000005253 yeast cell Anatomy 0.000 description 1
- NWONKYPBYAMBJT-UHFFFAOYSA-L zinc sulfate Chemical compound [Zn+2].[O-]S([O-])(=O)=O NWONKYPBYAMBJT-UHFFFAOYSA-L 0.000 description 1
- 229910000368 zinc sulfate Inorganic materials 0.000 description 1
- 229960001763 zinc sulfate Drugs 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P19/00—Preparation of compounds containing saccharide radicals
- C12P19/26—Preparation of nitrogen-containing carbohydrates
- C12P19/28—N-glycosides
- C12P19/30—Nucleotides
- C12P19/32—Nucleotides having a condensed ring system containing a six-membered ring having two N-atoms in the same ring, e.g. purine nucleotides, nicotineamide-adenine dinucleotide
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/10—Transferases (2.)
- C12N9/1048—Glycosyltransferases (2.4)
- C12N9/1077—Pentosyltransferases (2.4.2)
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/52—Genes encoding for enzymes or proenzymes
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/63—Introduction of foreign genetic material using vectors; Vectors; Use of hosts therefor; Regulation of expression
- C12N15/74—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora
- C12N15/77—Vectors or expression systems specially adapted for prokaryotic hosts other than E. coli, e.g. Lactobacillus, Micromonospora for Corynebacterium; for Brevibacterium
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y204/00—Glycosyltransferases (2.4)
- C12Y204/02—Pentosyltransferases (2.4.2)
- C12Y204/02014—Amidophosphoribosyltransferase (2.4.2.14)
Landscapes
- Health & Medical Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Genetics & Genomics (AREA)
- Engineering & Computer Science (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Molecular Biology (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Plant Pathology (AREA)
- Biophysics (AREA)
- Physics & Mathematics (AREA)
- Medicinal Chemistry (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Enzymes And Modification Thereof (AREA)
Abstract
La presente solicitud se refiere a una variante de fosforribosilpirofosfato amidotransferasa, a un microorganismo que la comprende y a un método para producir un nucleótido de purina usando la misma. (Traducción automática con Google Translate, sin valor legal)
Description
DESCRIPCIÓN
Variante fosforribosil pirofosfato amidotransferasa y método para producir nucleótido de purina usando la misma [Campo técnico]
La presente descripción se refiere a una fosforribosilpirofosfato amidotransferasa, a un microorganismo que incluye la misma, a un método para preparar un nucleótido de purina mediante el uso de la misma. También se describe en el presente documento una composición para producir un nucleótido de purina, un método para aumentar la producción de un nucleótido de purina, o el uso de la variante fosforribosilpirofosfato amidotransferasa.
[Técnica anterior]
Ácido 5'-inosínico (monofosfato de 5'-inosina; en lo sucesivo denominado IMP), que es un material a base de nucleótidos, es un material intermedio del sistema metabólico de la biosíntesis de ácidos nucleicos, y se usa en una variedad de campos, tales como productos médicos y aplicaciones médicas. El IMP es un material muy utilizado como aditivo condimentario o para alimentos, junto con el ácido 5-guanílico (monofosfato de 5'-guanina; en lo sucesivo denominado GMP). Se sabe que el IMP en sí tiene sabor a carne de vacuno y que potencia el sabor del ácido glutámico monosódico (glutamato monosódico (MSG)), al igual que el GMP. Por lo tanto, IMP ha recibido mucha atención como condimento de sabor basado en nucleótidos.
Los métodos de preparación de IMP incluyen un método de degradación enzimática de ácidos ribonucleicos extraídos de células de levadura, un método de fosforilación química de inosina producida por fermentación (Agri. Biol. Chem., 36, 1511(1972), etc.), un método de cultivo de un microorganismo capaz de producir directamente IMP y de recuperación posterior de IMP en un cultivo del mismo, etc. Entre estos métodos, el más usado es el método de utilización de un microorganismo capaz de producir directamente IMP.
Además, los métodos de preparación de GMP incluyen un método de conversión de ácido 5'-xantílico (monofosfato de 5'-xantosina; en lo sucesivo denominado XMP) producido por fermentación microbiana en GMP mediante el uso de un microorganismo corineforme, y un método de conversión de XMP producido por fermentación microbiana en GMP mediante el uso de Escherichia coli. Según los métodos, cuando se produce XMP y luego se convierte en GMP, es necesario aumentar la productividad de XMP, que es un precursor de la reacción de conversión durante la fermentación microbiana, y se requiere evitar la pérdida de GMP que ya se ha producido a lo largo de la reacción de conversión, así como de XMP producido.
Mientras tanto, las enzimas en su estado natural no siempre presentan propiedades óptimas en cuanto a actividad, estabilidad, especificidad de sustrato para isómeros ópticos, etc., que son necesarias en las aplicaciones industriales. Por tanto, se han hecho diversos intentos de mejorar las enzimas mediante variaciones de sus secuencias de aminoácidos, etc., de forma que resulten adecuadas para el uso previsto. De estos, se han aplicado diseño racional y mutagénesis dirigida al sitio de enzimas para mejorar las funciones enzimáticas. Sin embargo, en muchos casos, existe el inconveniente de que la información sobre la estructura de una enzima diana no es suficiente, o la relación estructura-función no está clara, por lo que los métodos no pueden aplicarse eficazmente. A este respecto, se informa de que la mejora de la enzima se intenta mediante un método de evolución dirigida de selección de una enzima de un rasgo deseado a partir de una biblioteca de enzimas mutantes que se construye mediante mutagénesis aleatoria del gen de la enzima, lo que conduce a la mejora de su actividad.
[Descripción]
[Problema técnico]
Los presentes inventores han llevado a cabo amplios estudios para producir un nucleótido de purina con un alto rendimiento mediante un método de producción del nucleótido de purina a través de fermentación microbiana, e identificaron una variante de una proteína que tiene una mayor productividad de nucleótidos de purina, completando así la presente descripción.
[Solución técnica]
La invención se expone en el conjunto de reivindicaciones adjuntas.
Un objeto de la presente descripción es proporcionar una fosforribosilpirofosfato amidotransferasa tal como se reivindica en la reivindicación 1.
Otro objeto de la presente descripción es proporcionar un polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa.
Otro objeto más de la presente descripción es proporcionar un vector que incluya el polinucleótido.
Otro objeto más de la presente descripción es proporcionar un microorganismo del género Corynebacterium que produzca un nucleótido de purina, incluyendo el microorganismo la fosforribosilpirofosfato amidotransferasa o el vector.
Otro objeto más de la presente descripción es proporcionar un método para preparar un nucleótido de purina, incluyendo el método la etapa de cultivar un microorganismo del género Corynebacterium en un medio.
También se describe en el presente documento, pero no se reivindica, una composición para producir un nucleótido de purina, que comprende la variante fosforribosilpirofosfato amidotransferasa de la presente descripción.
Además, se describe en el presente documento, pero no se reivindica, un método para aumentar la producción de un nucleótido de purina, que comprende la variante fosforribosilpirofosfato amidotransferasa de la presente descripción.
También se describe en el presente documento, pero no se reivindica, el uso de la variante fosforribosilpirofosfato amidotransferasa para la producción de un nucleótido de purina.
También se describe en el presente documento, pero no se reivindica, un uso del polinucleótido para la producción de un nucleótido de purina.
También se describe en el presente documento, pero no se reivindica, un uso del microorganismo del género Corynebacterium para la producción de un nucleótido de purina.
[Efectos ventajosos]
Cuando una fosforribosilpirofosfato amidotransferasa de la presente descripción tal como se reivindica en la reivindicación 1 se usa para cultivar un microorganismo del género Corynebacterium, es posible producir un nucleótido de purina con un alto rendimiento. Además, el nucleótido de purina preparado puede aplicarse no sólo a alimentos para animales o aditivos para alimentos para animales, sino también a diversos productos tales como alimentos para humanos o aditivos alimentarios, condimentos, medicamentos, etc.
[Mejor modo]
Una descripción detallada es la siguiente.
En el presente documento se describe, pero no se reivindica, una variante fosforribosilpirofosfato amidotransferasa que tiene un polipéptido que incluye la sustitución de uno o más aminoácidos en una secuencia de aminoácidos de SEQ ID NO: 2. Específicamente, la presente descripción proporciona la variante fosforribosilpirofosfato amidotransferasa que tiene el polipéptido que incluye la sustitución de uno o más aminoácidos en la secuencia de aminoácidos de SEQ ID NO: 2, en donde la sustitución de aminoácidos incluye la sustitución de un aminoácido en la posición 2 y/o la sustitución de un aminoácido en la posición 445 desde el extremo N-terminal de SEQ ID NO: 2.
Para lograr los objetos anteriores, un aspecto de la presente descripción proporciona una variante fosforribosilpirofosfato amidotransferasa, en donde i) el aminoácido en la posición 2 se sustituye por metionina, ii) el aminoácido en la posición 455 se sustituye por arginina, o iii) el aminoácido en la posición 2 se sustituye por metionina y el aminoácido en la posición 455 se sustituye por arginina a partir del extremo N-terminal de la secuencia de aminoácidos de SEQ ID NO: 2 y en donde la fosforribosilpirofosfato amidotransferasa tiene al menos un 80 % de identidad con la secuencia de aminoácidos de SEQ ID NO: 2.
Tal como se usa en el presente documento, el término “ fosforribosilpirofosfato amidotransferasa” se refiere a una enzima que tiene un papel importante en la biosíntesis de purinas. Con respecto a los objetos de la presente descripción, la enzima se refiere a una proteína implicada en la producción de nucleótidos de purina.
En la presente descripción, SEQ ID NO: 2 se refiere a una secuencia de aminoácidos que tiene actividad fosforribosilpirofosfato amidotransferasa. Específicamente, SEQ ID NO: 2 es una secuencia de una proteína que tiene actividad fosforribosilpirofosfato amidotransferasa, que está codificada por el gen purF. La secuencia de aminoácidos de SEQ ID NO: 2 puede obtenerse de NCBI GenBank, que es una base de datos pública. Por ejemplo, la secuencia de aminoácidos de SEQ ID NO: 2 puede derivarse del género Corynebacterium (Corynebacterium sp.), y puede incluir cualquier secuencia que tenga la misma actividad que la de la secuencia de aminoácidos anterior sin limitación. Además, el alcance de la secuencia de aminoácidos de SEQ ID NO: 2 puede incluir una secuencia de aminoácidos que tenga actividad fosforribosilpirofosfato amidotransferasa de SEQ ID NO: 2 o una secuencia de aminoácidos que tenga un 80 % o más de homología o identidad con la misma. La secuencia de aminoácidos incluye la secuencia de aminoácidos de SEQ ID NO: 2 o una secuencia de aminoácidos que tenga al menos 80 %, 85 %, 90 %, 95 %, 96 %, 97 %, 98 %, o 99 % o más de homología o identidad con la secuencia de aminoácidos de SEQ ID NO: 2. La secuencia de aminoácidos que tiene homología o identidad puede ser las que excluyen una
secuencia que tiene el 100 % de identidad del rango anterior, o puede ser una secuencia que tiene menos del 100 % de identidad. Además, es evidente que una proteína que tenga una secuencia de aminoácidos con supresión, modificación, sustitución o adición de algunos aminoácidos también entra dentro del ámbito de la presente invención, siempre que tenga la homología o identidad y muestre una eficacia correspondiente a la de la proteína anterior.
Tal como se usa en el presente documento, el término “ fosforribosilpirofosfato amidotransferasa” puede utilizarse indistintamente con polipéptido que produce nucleótidos de purina, un polipéptido productor de nucleótidos de purina, un polipéptido que produce un nucleótido de purina, un polipéptido con actividad fosforribosilpirofosfato amidotransferasa, una fosforribosilpirofosfato amidotransferasa, etc.
La fosforribosilpirofosfato amidotransferasa incluye variación(es) en la posición 2 y/o en la posición 445 desde el N-terminal en la secuencia de aminoácidos de SEQ ID NO: 2. La fosforribosilpirofosfato amidotransferasa puede tener la sustitución de otro(s) aminoácido(s) por el(los) aminoácido(s) en la posición 2 y/o en la posición 445 en la secuencia de aminoácidos de SEQ ID NO: 2 y una actividad mejorada, en comparación con las que incluyen la secuencia de aminoácidos de SEQ ID NO: 2 o una fosforribosilpirofosfato amidotransferasa no modificada derivada del microorganismo de tipo natural. Dicha variante de fosforribosilpirofosfato amidotransferasa significa aquellas que tienen variación del aminoácido en la posición 2 o en la posición 445 desde el N-terminal de la SEQ ID NO: 2 y/o una secuencia de aminoácidos que tiene al menos 80 %, 85 %, 90 %, 95 %, 96 %, 97 %, 98 %, o 99 % o más de homología o identidad con la SEQ ID NO: 2, tal como se ha descrito anteriormente.
La fosforribosilpirofosfato amidotransferasa tiene i) sustitución de metionina por el aminoácido en la posición 2, ii) la sustitución de arginina por el aminoácido en la posición 445, o iii) la sustitución de metionina por el aminoácido en la posición 2 y la sustitución de arginina por el aminoácido en la posición 445 en la secuencia de aminoácidos de SEQ ID NO: 2, y puede tener una actividad fosforribosilpirofosfato amidotransferasa potenciada, en comparación con el polipéptido que incluye la secuencia de aminoácidos de SEQ ID NO: 2.
Con respecto a los objetos de la presente descripción, un microorganismo que incluye la fosforribosilpirofosfato amidotransferasa tiene una productividad más alta de nucleótidos de purina que un microorganismo de tipo natural, un microorganismo que incluye la fosforribosilpirofosfato amidotransferasa de tipo natural, o un microorganismo que no incluye fosforribosilpirofosfato amidotransferasa. La presente descripción es de importancia porque la producción de nucleótidos de purina por microorganismos puede aumentarse mediante el uso de la fosforribosilpirofosfato amidotransferasa de la presente descripción, mientras que la cepa de tipo natural del género Corynebacterium no puede producir nucleótidos de purina o, aunque produce nucleótidos de purina, es capaz de producir cantidades traza de los mismos.
La fosforribosilpirofosfato amidotransferasa incluye una secuencia de aminoácidos que tiene sustitución de otro(s) aminoácido(s) para el (los) aminoácido (s) en la posición 2 y/o en la posición 445 como sigue: i) la sustitución de metionina por el aminoácido en la posición 2, ii) la sustitución de arginina por el aminoácido en la posición 445, o iii) la sustitución de metionina por el aminoácido en la posición 2 y la sustitución de arginina por el aminoácido en la posición 445 desde el extremo N-terminal en la secuencia de aminoácidos de SEQ ID NO: 2. Además, la fosforribosilpirofosfato amidotransferasa incluye una secuencia de aminoácidos en la que otro(s) aminoácido(s) se sustituye(n) por el(los) aminoácido(s) en la posición 2 y/o en la posición 445 desde el N-terminal en la secuencia de aminoácidos de SEQ ID NO: 2, o una secuencia de aminoácidos que tiene un 80 % o más de homología o identidad con la misma. Específicamente, la fosforribosilpirofosfato amidotransferasa de la presente descripción puede incluir un polipéptido que tenga al menos 80 %, 85 %, 90 %, 95 %, 96 %, 97 %, 98 %, o 99 % o más de homología o identidad con la secuencia de aminoácidos que tiene sustitución de metionina por el aminoácido en la posición 2 o sustitución de arginina por el aminoácido en la posición 445 en la secuencia de aminoácidos de SEQ ID NO: 2.
En otras palabras, aunque la presente descripción describe una 'proteína o polipéptido que tiene una secuencia de aminoácidos representada por una SEQ ID NO: particular', es evidente pero no se reivindica que una proteína que tiene una secuencia de aminoácidos con supresión, modificación, sustitución, sustitución conservativa o adición de algunos aminoácidos también puede utilizarse en la presente descripción, siempre que tenga una actividad idéntica o correspondiente a la del polipéptido que tiene la secuencia de aminoácidos de la s Eq ID NO: correspondiente. Por ejemplo, mientras una proteína tenga la actividad idéntica o correspondiente a la de la fosforribosilpirofosfato amidotransferasa, no excluye la adición de secuencia, la mutación natural, la mutación silenciosa o la sustitución conservadora de la misma que no altere la función de la proteína, antes y después de la secuencia de aminoácidos.
Por “ sustitución conservadora” se entiende la sustitución de un aminoácido por otro aminoácido con propiedades estructurales y/o químicas similares. Esta sustitución de aminoácidos puede realizarse generalmente sobre la base de la similitud en polaridad, carga, solubilidad, hidrofobicidad, hidrofilicidad y/o naturaleza antipática. Por ejemplo, los aminoácidos cargados positivamente (básicos) incluyen arginina, lisina e histidina; los aminoácidos cargados negativamente (ácidos), incluyen ácido glutámico y ácido aspártico; los aminoácidos aromáticos incluyen fenilalanina, triptófano y tirosina; y los aminoácidos hidrófobos incluyen alanina, valina, isoleucina, leucina, metionina, fenilalanina, tirosina y triptófano.
La “variante” puede incluir además la sustitución y/o modificación conservadora de uno o más aminoácidos en “ una proteína o polipéptido que tenga una secuencia de aminoácidos representada por una SEQ ID NO: particular” . Por ejemplo, determinadas variantes pueden incluir variantes en las que se han eliminado una o más porciones, tales como una secuencia líder N-terminal o un dominio transmembrana. Otra variante puede incluir variantes en las que se ha eliminado una porción del N- y/o C-terminal de la proteína madura. La variante también puede incluir otras modificaciones, incluida la supresión o adición de aminoácidos, que tienen efectos mínimos sobre las propiedades y la estructura secundaria del polipéptido. Por ejemplo, el polipéptido puede conjugarse con una secuencia señal (o líder) en el extremo N-terminal de una proteína que dirige la transferencia de la proteína de forma co-traduccional o post-traduccional. El polipéptido también puede conjugarse con otra secuencia o un enlazador para facilitar la identificación, purificación o síntesis del polipéptido. El término “variante” puede utilizarse indistintamente con modificación, proteína modificada, polipéptido modificado, mutante, muteína, divergente, etc., y puede emplearse cualquier término sin limitación, siempre que se utilice en el sentido de ser modificado.
Homología e identidad significan un grado de parentesco entre dos secuencias dadas de aminoácidos o secuencias de nucleótidos, y pueden expresarse en porcentaje. Los términos homología e identidad pueden utilizarse indistintamente.
La homología o identidad de secuencias de un polinucleótido o polipéptido conservado puede determinarse mediante un algoritmo de alineación estándar utilizado con penalizaciones de separación predeterminadas establecidas por un programa que se vaya a utilizar. Sustancialmente, las secuencias homólogas o idénticas pueden hibridar en condiciones moderada o altamente estrictas a lo largo de toda su secuencia o en al menos aproximadamente un 50 %, aproximadamente un 60 %, aproximadamente un 70 %, aproximadamente un 80 % o aproximadamente un 90 % de toda su longitud. Con respecto a los polinucleótidos a hibridar, también pueden contemplarse polinucleótidos que incluyan un codón degenerado en lugar de un codón.
En general, como codón define qué aminoácido debe codificarse, un codón se forma emparejando tres secuencias de nucleótidos. Existen más tipos de codones en comparación con el del aminoácido a codificar, y el tipo de aminoácido a producir difiere de acuerdo con la combinación de codones. La traducción comienza a partir de un codón de iniciación y el primer aminoácido a traducir puede ser fMet. Generalmente, la traducción procede transportando fMET para el codón del ARNm correspondiente a la secuencia atg del ADN. Sin embargo, la traducción puede proceder transportando fMET cuando el primer ADN del ARNm ORF (marco abierto de lectura) es gtg o ttg. Es decir, el codón de iniciación puede ser atg, gtg o ttg.
Si dos secuencias polinucleotídicas o polipeptídicas tienen homología, similitud o identidad puede determinarse, por ejemplo, mediante un algoritmo informático conocido, como el programa “ FASTA” , utilizando parámetros predeterminados tal como en Pearson y col. (1988) [Proc. Natl. Acad. Sci. USA 85]: 2444, y alternativamente, determinado mediante el algoritmo Needleman-Wunsch (Needleman y Wunsch, 1970, J. Mol. Biol. 48: 443-453) tal como se aplica en el programa Needleman del paquete EMBOSS (EMBOSS: The European Molecular Biology Open Software Suite, Rice y col., 2000, Trends Genet. 16: 276-277) (versión 5.0.0 o posterior) [incluyendo el paquete de programas GCG (Devereux, J., y col., Nucleic Acids Research 12: 387 (1984)), BlASTP, BlAs Tn , FASTA (Atschul, [S.] [F.,] [Y COL, J MOLEC BIOL 215]: 403 (1990); Guide to Huge Computers, Martin J. Bishop, [ED.,] Academic Press, San Diego, 1994, and [CARILLO ETN.](1988) SIAM J Applied Math 48: 1073). Por ejemplo, la homología, la similitud o la identidad pueden determinarse utilizando BLAST o ClustalW del National Center for Biotechnology Information.
La homología, similitud o identidad de polinucleótidos o polipéptidos puede determinarse comparando la información de secuencias mediante un programa informático GAP, por ejemplo, Needleman y col. (1970), J Mol Biol.48: 443, tal como se describe en Smith y Waterman, Adv. Appl. Math (1981) 2:482. Brevemente, el programa GAP define la similitud como el número de símbolos alineados (es decir, nucleótidos o aminoácidos) que son similares, dividido por el número total de símbolos en la más corta de las dos secuencias. Los parámetros por defecto del programa GAP pueden incluir: (1) una matriz de comparación unaria (que contiene un valor de 1 para identidades y 0 para no identidades) y la matriz de comparación ponderada (o matriz de sustitución EDNAFULl (versión EMBOSS de NCBI NUC4.4)) de Gribskov y col. (1986) Nucl. Acids Res. 14: 6745, tal como se describe en Schwartz y Dayhoff, eds., Atlas Of Protein Sequence And Structure, National Biomedical Research Foundation, págs. 353-358 (1979); (2) una penalización de 3,0 para cada espacio y una penalización de 0,10 adicional para cada símbolo en cada espacio (o penalización por apertura de hueco 10, penalización por extensión de hueco 0,5); y (3) ninguna penalización para los espacios finales. Por tanto, el término “ homología” o “ identidad” , tal como se utiliza en el presente documento, representa la relevancia entre secuencias.
Debido a la degeneración de codones, es evidente que también puede incluirse un polinucleótido para traducirse en el polipéptido que tenga sustitución de otro(s) aminoácido(s) por el(los) aminoácido(s) en la posición 2 y/o en la posición 445 desde el N-terminal de la secuencia de aminoácidos de SEQ ID NO: 2, o un polipéptido que tenga homología o identidad con el mismo. Además, mediante hibridación en condiciones rigurosas con una sonda preparada a partir de una secuencia génica conocida, por ejemplo, una secuencia complementaria a toda o parte de la secuencia de nucleótidos, se incluye una secuencia polinucleotídica que codifica la fosforribosilpirofosfato amidotransferasa que incluye la secuencia de aminoácidos en la que i) sustitución de metionina por el aminoácido en la posición 2 ii) sustitución de arginina por el aminoácido en la posición 445, o iii) sustitución de metionina por
el aminoácido en la posición 2 y sustitución de arginina por el aminoácido en la posición 445 en la secuencia de aminoácidos de SEQ ID NO: 2.
Tal como se usa en el presente documento, el término “ polinucleótido” se refiere a una cadena de ADN o ARN que tiene más de una longitud determinada como polímero nucleotídico, que es una cadena larga de monómeros nucleotídicos conectados por enlaces covalentes, y más específicamente, a un fragmento polinucleotídico que codifica un polipéptido.
El polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa de la presente descripción puede incluir cualquier secuencia polinucleotídica sin limitación, siempre y cuando codifique el polipéptido que tiene actividad fosforribosilpirofosfato amidotransferasa de la presente descripción como se reivindica en la reivindicación 1. En la presente descripción, un gen que codifica la secuencia de aminoácidos de la fosforribosilpirofosfato amidotransferasa es el gen purF, y específicamente, el gen puede derivarse de Corynebacterium stationis.
Específicamente, debido a la degeneración de codones o al considerar codones preferidos por un microorganismo en el que se permite que el polipéptido se exprese, pueden realizarse diversas modificaciones en la región codificante del polinucleótido de la presente descripción dentro del alcance que no cambia la secuencia de aminoácidos del polipéptido. Puede incluirse cualquier secuencia polinucleotídica sin limitación siempre que codifique la variante fosforribosilpirofosfato amidotransferasa que tiene sustitución de metionina por el aminoácido en la posición 2 o de arginina por el aminoácido en la posición 445 en la secuencia de aminoácidos de SEQ ID NO: 2. Por ejemplo, el polinucleótido de la presente descripción puede incluir una secuencia que tenga alguna secuencia modificada en SEQ ID NO: 1.
Además, mediante hibridación en condiciones estrictas con una sonda preparada a partir de una secuencia genética conocida, por ejemplo, una secuencia complementaria a toda o parte de la secuencia de nucleótidos, se incluye una secuencia que codifica una proteína que tiene actividad de la fosforribosilpirofosfato amidotransferasa con sustitución de metionina por el aminoácido en la posición 2 o de arginina por el aminoácido en la posición 445 en la secuencia de aminoácidos de SEQ ID NO: 2. Por “ condiciones estrictas” se entienden las condiciones que permiten la hibridación específica entre polinucleótidos. Tales condiciones se describen detalladamente en la bibliografía (por ejemplo, J. Sambroo y col., anteriormente). Las condiciones estrictas pueden incluir condiciones en las que los genes que tienen homología o identidad alta, por ejemplo, genes que tienen 40 % o más, específicamente 85 % o más, 90 % o más, más específicamente 95 % o más, aún más específicamente 97 % o más, particularmente específicamente 99 % o más de homología o identidad son capaces de hibridarse entre sí, y los genes que tienen homología o identidad más baja no son capaces de hibridarse entre sí, o condiciones que son condiciones de lavado comunes para la hibridación Southern, por ejemplo una concentración de sal y una temperatura correspondientes a 60 °C, 1*SSC, 0,1 % SDS, específicamente 60 °C, 0,1*SSC, 0,1 % SDS, más específicamente 68 °C, 0,1*SSC, 0,1 % SDS, una vez, específicamente, dos o tres veces.
La hibridación requiere que dos ácidos nucleicos tengan secuencias complementarias, aunque son posibles apareamientos erróneos entre bases dependiendo del grado de rigor de la hibridación. El término “ complementario” se utiliza para describir la relación entre bases nucleotídicas capaces de hibridarse entre sí. Por ejemplo, con respecto al ADN, la adenosina es complementaria a la timina y la citosina es complementaria a la guanina. Por consiguiente, la presente descripción también puede incluir fragmentos aislados de ácido nucleico complementarios a las secuencias completas, así como secuencias de ácido nucleico sustancialmente similares.
Específicamente, un polinucleótido que tenga homología o identidad puede detectarse mediante condiciones de hibridación que incluyan una etapa de hibridación a Tm de 55 °C y utilizando las condiciones descritas anteriormente. Además, el valor de Tm puede ser de 60 °C, 63 °C o 65 °C y puede ser controlado adecuadamente por los expertos en la técnica según el propósito.
La rigurosidad apropiada para hibridar polinucleótidos depende de la longitud de los polinucleótidos y el grado de complementación, y variables bien conocidas en la técnica (véase Sambrook y col, anteriormente, 9.50-9.51, 11.7-11.8).
En la presente descripción, el gen que codifica la secuencia de aminoácidos de la fosforribosilpirofosfato amidotransferasa es el gen purF, y un polinucleótido que codifica el mismo es el mismo descrito anteriormente.
En la presente descripción, el polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa también es el mismo que se ha descrito anteriormente.
Otro aspecto más de la presente descripción proporciona un polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa, o un vector que incluye el polinucleótido.
Tal como se usa en el presente documento, el término “vector” se refiere a una construcción de ADN que contiene la secuencia nucleotídica del polinucleótido que codifica el polipéptido deseado y que está unido de forma operable a una secuencia de control adecuada, de manera que el polipéptido deseado se expresa en un huésped adecuado. Las secuencias de control pueden incluir un promotor para dirigir la transcripción, una secuencia operadora determinada para controlar dicha transcripción, una secuencia que codifique un sitio adecuado de unión al ribosoma
en el ARNm y una secuencia para controlar la terminación de la transcripción y la traducción. Una vez transformado en un hospedador adecuado, el vector puede replicarse o funcionar independientemente del genoma del hospedador, o puede integrarse en el propio genoma.
El vector usado en la presente descripción es replicable en la célula huésped, y puede utilizarse cualquier vector conocido en la técnica. Los ejemplos del vector comúnmente usado pueden incluir plásmidos, cósmidos, virus y bacteriófagos naturales o recombinantes. Por ejemplo, como vector fago o vector cósmido, pueden utilizarse pWE15, M13, MBL3, MBL4, IXII, ASHII, APII, t10, t11, Charon4A, Charon21A, etc., y como vector plásmido, pueden utilizarse los basados en pBR, pUC, pBluescriptII, pGEM, pTZ, pCL, pET, etc. Específicamente, pueden utilizarse pDZ, pACYC177, pACYC184, pCL, pECCG117, pUC19, pBR322, μMW118, el vector pCClBAC, etc.
Por ejemplo, el polinucleótido que codifica el polipéptido deseado puede insertarse en el cromosoma a través de un vector de inserción cromosómica en una célula. La inserción del polinucleótido en el cromosoma puede realizarse mediante cualquier método conocido en la técnica, por ejemplo, por recombinación homóloga. Se puede incluir adicionalmente un marcador de selección para confirmar la inserción del vector en el cromosoma. El marcador de selección se utiliza para la selección de células transformadas con el vector, es decir, para confirmar si se ha insertado la molécula de ácido nucleico deseada, y pueden utilizarse marcadores capaces de proporcionar fenotipos seleccionables tales como resistencia a fármacos, auxotrofia, resistencia a agentes citotóxicos y expresión de proteínas de superficie. En las circunstancias en las que se tratan los agentes selectivos, sólo las células capaces de expresar los marcadores de selección pueden sobrevivir o expresar otros rasgos fenotípicos, por lo que las células transformadas pueden ser seleccionadas.
Otro aspecto más de la presente descripción proporciona un microorganismo productor de un nucleótido de purina, incluyendo el microorganismo la fosforribosilpirofosfato amidotransferasa como se reivindica en la reivindicación 1 o el polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa. Específicamente, el microorganismo que incluye la fosforribosilpirofosfato amidotransferasa y/o el polinucleótido que la codifica puede ser un microorganismo preparado por transformación con un vector que incluye el polinucleótido.
Tal como se utiliza en el presente documento, el término “ transformación” se refiere a un proceso de introducción de un vector que incluye un polinucleótido que codifica una proteína diana en una célula huésped, de forma que la proteína codificada por el polinucleótido pueda expresarse en la célula huésped. No importa si el polinucleótido transformado se inserta en el cromosoma de una célula huésped y se localiza en él o se localiza fuera del cromosoma, siempre que el polinucleótido transformado pueda expresarse en la célula huésped. Además, el polinucleótido puede incluir ADN y ARN que codifiquen la proteína diana. El polinucleótido puede introducirse en cualquier forma, siempre que el polinucleótido pueda introducirse en la célula huésped y expresarse en ella. Por ejemplo, el polinucleótido puede introducirse en la célula huésped en forma de un casete de expresión, que es un constructo génico que incluye todos los elementos necesarios para la expresión autónoma. El casete de expresión puede incluir un promotor, una señal de terminación de la transcripción, un sitio de unión al ribosoma y una señal de terminación de la traducción que pueden estar unidos de forma operable al polinucleótido. El casete de expresión puede estar en forma de un vector de expresión que realiza autorreplicación. Además, el polinucleótido puede ser introducido en la célula huésped como tal para ser enlazado operablemente a la secuencia requerida para la expresión en la célula huésped.
Además, la expresión “ unido operablemente” se refiere a una unión funcional entre una secuencia génica y una secuencia promotora que inicia y media la transcripción del polinucleótido que codifica el polipéptido deseado de la presente descripción.
La expresión “ microorganismo que incluye el polipéptido” o “ microorganismo que incluye la fosforribosilpirofosfato amidotransferasa” , tal como se utiliza en el presente documento, se refiere a un microorganismo preparado proporcionando productividad de nucleótidos de purina a un microorganismo que tiene una productividad de nucleótidos de purina naturalmente débil o a una cepa madre que no tiene productividad de nucleótidos de purina. El microorganismo es un microorganismo que expresa la t fosforribosilpirofosfato amidotransferasa que tiene el polipéptido que incluye la sustitución de uno o más aminoácidos en la secuencia de aminoácidos de SEQ ID NO: 2, en el que la sustitución de aminoácidos incluye la sustitución de metionina por el aminoácido en la posición 2 y/o la sustitución de arginina por el aminoácido en la posición 445 del N-terminal de SEQ ID NO: 2, en el que la fosforribosilpirofosfato amidotransferasa tiene al menos un 80 % de identidad con la secuencia de aminoácidos de SEQ ID NO: 2. También se describe un microorganismo que puede ser un microorganismo que expresa el polipéptido variante, en el que el microorganismo tiene actividad fosforribosilpirofosfato amidotransferasa debido a la sustitución de otro(s) aminoácido(s) por el(los) aminoácido(s) en la posición 2 y/o en la posición 445 en la secuencia de aminoácidos de SEQ ID NO: 2.
El microorganismo puede ser una célula o un microorganismo que puede incluir el polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa, o puede transformarse con el vector que incluye el polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa para expresar la misma.
En la presente descripción, el microorganismo productor de un nucleótido de purina puede utilizarse indistintamente con un microorganismo productor de nucleótidos de purina o un microorganismo con productividad de nucleótidos de purina.
Con respecto a los objetos de la presente descripción, el “ nucleótido de purina” significa un nucleótido que incluye una estructura de purina. Los ejemplos de los mismos pueden incluir IMP, XMP o GMP.
Específicamente, el término “ IMP (monofosfato de 5'-inosina)” es un material a base de ácido nucleico que se compone de la siguiente fórmula química 1:

El IMP tiene el nombre IUPAC de monofosfato de 5'-inosina o ácido 5'-inosínico, y se utiliza ampliamente en los alimentos como potenciador del sabor, junto con el XMP o el GMP.
El término “ GMP (5'-guanina monofosfato)” es un material a base de ácido nucleico compuesto por la siguiente fórmula química 2:

GMP tiene el nombre IUPAC de [(2R,3S,4R,5R)-5-(2-amino-6-oxo-1,6-dihidro-9H-purin-9-il)-3,4-dihidroxitetrahidro-2-furanil]dihidrógeno fosfato de metilo, y también se denomina ácido 5'-guanidílico, ácido 5'-guanílico o ácido guanílico.
GMP en forma de sus sales, tales como guanilato de sodio, guanilato de dipotasio y guanilato de calcio, se usa ampliamente como aditivo alimenticio. Cuando se usa como aditivo junto con IMP, g Mp exhibe un efecto sinérgico para mejorar el sabor. GMP puede prepararse convirtiéndose a partir de XMP. Tal como se confirma en una realización de la presente descripción, el polipéptido de la presente descripción puede aumentar la producción de XMP, y a partir del aumento de la producción de XMP, se puede convertir el GMP y aumentar su producción. Por consiguiente, es evidente que GMP también se incluye en el alcance de la presente descripción.
El término “ XMP (monofosfato de 5'-xantosina)” es un material intermedio del metabolismo de las purinas y está compuesto por la siguiente fórmula química 3. El XMP tiene el nombre IUPAC de monofosfato de 5'-inosina o ácido 5'-xantílico. El XMP puede formarse a partir de IMP por acción de la IMP deshidrogenasa, o el XMP puede convertirse en GMP por acción de la GMP sintetasa. Además, el XMP puede formarse a partir del XTP mediante la desoxirribonucleósido trifosfato pirofosfohidrolasa, que es una enzima con actividad XTPasa.

Tal como se usa en el presente documento, la expresión “ microorganismo productor de un nucleótido de purina” puede ser un microorganismo en el que se produce una modificación genética o se potencia la actividad para producir el nucleótido de purina deseado, incluido todo un microorganismo de tipo natural o un microorganismo en el que se produce una modificación genética de forma natural o artificial, y el microorganismo puede ser un microorganismo en el que un mecanismo particular se debilita o potencia mediante la inserción de un gen exógeno o mediante la potenciación o inactivación de la actividad de un gen endógeno. Con respecto a los objetos de la presente descripción, el microorganismo productor de un nucleótido de purina puede caracterizarse en que el microorganismo incluye la fosforribosilpirofosfato amidotransferasa para tener una mayor productividad de un nucleótido de purina deseado, y el microorganismo es un microorganismo del género Corynebacterium. Específicamente, en la presente descripción, el microorganismo productor de un nucleótido de purina o el microorganismo con productividad de nucleótidos de purina puede ser un microorganismo en el que algunos de los genes implicados en la vía de biosíntesis de nucleótidos de purina están potenciados o debilitados, o algunos de los genes implicados en la vía de degradación de nucleótidos de purina están potenciados o debilitados. Por ejemplo, el microorganismo puede ser un microorganismo en el que la expresión del gen purA que codifica la adenilosuccinato sintetasa esté debilitada. Además, la expresión de guaB, que es un gen que codifica la inosina-5'-monofosfato deshidrogenasa presente en la vía de degradación del IMP, puede regularse en función del nucleótido de purina. Específicamente, cuando el nucleótido de purina es IMP, la expresión de guaB puede debilitarse, o cuando el nucleótido de purina es XMP o GMP, la expresión de guaB puede potenciarse.
Tal como se usa en el presente documento, la expresión “ microorganismo del género Corynebacterium que produce un nucleótido de purina” se refiere a un microorganismo del género Corynebacterium que tiene productividad de nucleótidos de purina de forma natural o por mutación. Específicamente, tal como se utiliza en el presente documento, el microorganismo del género Corynebacterium que tiene productividad de nucleótidos de purina puede ser un microorganismo del género Corynebacterium que ha mejorado la productividad de nucleótidos de purina debido a una mayor actividad del gen purF que codifica la fosforribosilpirofosfato amidotransferasa. Más concretamente, tal como se usa en el presente documento, el microorganismo del género Corynebacterium con productividad de nucleótidos de purina se refiere a un microorganismo del género Corynebacterium que ha mejorado la productividad de nucleótidos de purina debido a la inclusión de la fosforribosilpirofosfato amidotransferasa o el polinucleótido que codifica la misma, o debido a la transformación con el vector que incluye el polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa. El “ microorganismo del género Corynebacterium que ha mejorado la productividad de nucleótidos de purina” se refiere a un microorganismo que ha mejorado la productividad de nucleótidos de purina, en comparación con una cepa parental antes de la transformación o con un microorganismo no modificado. El “ microorganismo no modificado” se refiere a una cepa de tipo natural propiamente dicha, o a un microorganismo que no incluye la variante de nucleótido de purina productora de proteínas, o a un microorganismo que no se transforma con el vector que incluye el polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa.
Tal como se usa en el presente documento, el “ microorganismo del género Corynebacterium” puede ser específicamente Corynebacterium glutamicum, Corynebacterium ammoniagenes, Brevibacterium lactofermentum, Brevibacterium flavum, Corynebacterium thermoaminogenes, Corynebacterium efficiens, Corynebacterium stationis, etc.
Otro aspecto más de la presente descripción proporciona un método para preparar un nucleótido de purina, incluyendo el método la etapa de cultivar el microorganismo del género Corynebacterium que produce un nucleótido de purina en un medio. Por ejemplo, el método de la presente descripción puede incluir además la etapa de recuperar el nucleótido de purina del microorganismo o del medio después de la etapa de cultivo.
En el método, la etapa de cultivo del microorganismo puede realizarse mediante un cultivo por lotes conocido, un cultivo continuo, un cultivo por lotes alimentado, etc. A este respecto, las condiciones de cultivo son un pH óptimo
(por ejemplo, pH 5 a pH 9, específicamente pH 6 a pH 8, y más específicamente pH 6,8) puede ajustarse utilizando un compuesto básico (por ejemplo, hidróxido de sodio, hidróxido de potasio o amoníaco) o un compuesto ácido (por ejemplo, ácido fosfórico o ácido sulfúrico). Se puede mantener una condición aeróbica añadiendo oxígeno o una mezcla gaseosa que contenga oxígeno al cultivo. La temperatura de cultivo puede mantenerse entre 20 °C y 45 °C, y específicamente entre 25 °C y 40 °C, y el cultivo puede realizarse durante entre aproximadamente 10 horas y aproximadamente 160 horas. El nucleótido de purina producido por el cultivo puede segregarse al medio o permanecer dentro de las células.
Además, en un medio de cultivo a utilizar, como fuente de carbono, azúcares e hidratos de carbono (por ejemplo, glucosa, sacarosa, lactosa, fructosa, maltosa, melaza, almidón y celulosa), aceites y grasas (por ejemplo, aceite de soja, aceite de girasol, aceite de cacahuete y aceite de coco), ácidos grasos (por ejemplo, ácido palmítico, ácido esteárico y ácido linoleico), alcoholes (por ejemplo, glicerol y etanol), ácidos orgánicos (por ejemplo, ácido acético), etc., pueden utilizarse individualmente o mezclados. Como fuente de nitrógeno, puede utilizarse un compuesto orgánico que contenga nitrógeno (por ejemplo, peptona, extracto de levadura, extracto de carne, extracto de malta, licor de remojo de maíz, harina de soja y urea), o un compuesto inorgánico (por ejemplo, sulfato de amonio, cloruro de amonio, fosfato de amonio, carbonato de amonio y nitrato de amonio), etc., individualmente o en una mezcla. Como fuente de fósforo, pueden utilizarse dihidrogenofosfato potásico, hidrogenofosfato dipotásico, la sal sódica correspondiente, etc., individualmente o en una mezcla. El medio también puede incluir materiales esenciales que promuevan el crecimiento, tales como otras sales metálicas (por ejemplo, sulfato de magnesio o sulfato de hierro), aminoácidos y vitaminas.
Un método de recuperación del nucleótido de purina producido en la etapa de cultivo de la presente descripción consiste en recoger el nucleótido de purina deseado del medio de cultivo utilizando un método apropiado conocido en la técnica según el método de cultivo. Por ejemplo, puede utilizarse centrifugación, filtración, cromatografía de intercambio aniónico, cristalización, HPLC, etc., y el nucleótido de purina deseado puede recuperarse del medio o microorganismo utilizando un método apropiado conocido en la técnica.
Además, la etapa de recuperación puede incluir un proceso de purificación. El proceso de purificación puede realizarse mediante el uso de un método apropiado conocido en la técnica. Por tanto, el nucleótido de purina recuperado puede ser una forma purificada o un líquido de fermentación de microorganismos que incluya el nucleótido de purina (Introduction to Biotechnology and Genetic Engineering, A. J. Nair., 2008).
También se describe en el presente documento, pero no se reivindica, una composición para producir un nucleótido de purina, que comprende la variante fosforribosilpirofosfato amidotransferasa.
La composición para producir un nucleótido de purina se refiere a una composición capaz de producir un nucleótido de purina por el polinucleótido de la presente descripción. Por ejemplo, la composición comprende el polinucleótido, y además puede comprender, sin limitación, una constitución capaz de hacer funcionar el polinucleótido. El polinucleótido puede estar en una forma incluida en un vector para expresar un gen vinculado operablemente a la célula huésped introducida.
Además, la composición puede comprender además cualquier excipiente adecuado utilizado convencionalmente en una composición para producir un nucleótido de purina. Dicho excipiente puede ser, por ejemplo, un conservante, un agente humectante, un agente dispersante, un agente de suspensión, un tampón, un agente estabilizador o un agente isotónico.
También se describe en el presente documento, pero no se reivindica, un método para aumentar la producción de un nucleótido de purina, que comprende la etapa de cultivo de la fosforribosilpirofosfato amidotransferasa en un microorganismo del género Corynebacterium.
Los términos “ fosforribosilpirofosfato amidotransferasa” , “ microorganismo del género Corynebacterium” , “ cultivo” , “ homoserina o L-aminoácido derivado de la homoserina” son los descritos anteriormente.
También se describe en el presente documento, pero no se reivindica, un uso de la fosforribosilpirofosfato amidotransferasa para la producción de un nucleótido de purina, o la preparación de una composición para producir un nucleótido de purina.
También se describe en el presente documento, pero no se reivindica, un uso del polinucleótido para la producción de un nucleótido de purina, o la preparación de una composición para producir un nucleótido de purina.
También se describe en el presente documento, pero no se reivindica, el uso del microorganismo del género Corynebacterium para la producción de un nucleótido de purina, o la preparación de una composición para producir un nucleótido de purina.
[Modo para la invención]
De aquí en adelante, la presente descripción se describirá con más detalle con referencia a los ejemplos. No obstante, es evidente para los expertos en la técnica a la que se refiere la presente descripción que estos ejemplos tienen únicamente fines ilustrativos.
Ejemplo 1: Preparación de la cepa productora de IMP de tipo natural
Las cepas de tipo natural del género Corynebacterium no pueden producir IMP, o pueden producirlo en cantidades muy pequeñas. Por tanto, se preparó una cepa productora de IMP basada en Corynebacterium stationis ATCC6872 de tipo natural. Específicamente, la cepa productora de IMP se preparó debilitando la actividad de purA, que codifica la adenilosuccinato sintetasa, y la actividad de guaB, que codifica la deshidrogenasa del ácido 5-inosínico.
Ejemplo 1-1: Preparación de la cepa debilitada purA
Para preparar una cepa en la que se cambiara el codón de inicio de purA, se preparó primero un vector de inserción que contenía purA. Para clonar el gen purA en el vector de inserción, se realizó una PCR utilizando el ADN genómico de Corynebacterium stationis ATCC6872 como molde y los cebadores de SEQ ID NO: 3 y 4 y SEQ ID NO: 5 y 6 durante 30 ciclos de desnaturalización a 94 °C durante 30 s, recocido a 55 °C durante 30 s y extensión a 72 °C durante 2 min. La PCR se realizó utilizando dos fragmentos de ADN obtenidos por la PCR anterior como molde y los cebadores de SEQ ID NO: 3 y 6 durante 30 ciclos de desnaturalización a 94 °C durante 30 s, recocido a 55 °C durante 30 s y extensión a 72 °C durante 2 min para obtener un fragmento de ADN. El fragmento de ADN obtenido se digirió con la enzima de restricción XbaI y se clonó en un vector pDZ (patente coreana n.° 10-0924065 y publicación internacional de patente n.° 2008-033001) que había sido digerido con la misma enzima. El vector preparado por el método anterior se designó como pDZ-purA-alt.
[Tabla 1

El vector recombinante pDZ-purA-alt se transformó en la cepa Corynebacterium stationis ATCC6872 por electroporación y, a continuación, las cepas en las que se insertó el vector en el cromosoma por recombinación homóloga se seleccionaron en un medio que contenía 25 mg/l de kanamicina. Las cepas primarias así seleccionadas se sometieron a un cruce secundario y, a continuación, las cepas seleccionadas se sometieron a secuenciación, con lo que se seleccionó una cepa final en la que se introdujo la mutación. Esta cepa se designó ATCC6872-purA(alt).
Ejemplo 1-2: Preparación de la cepa debilitada guaB
Para preparar una cepa en la que se cambiara el codón de inicio de guaB, primero se preparó un vector de inserción que contenía guaB. Para clonar el gen guaB en el vector de inserción, se realizó una p Cr utilizando el ADN genómico de Corynebacterium stationis ATCC6872 como molde y los cebadores de SEQ ID NO: 7 y 8 y SEQ ID NO: 9 y 10. La PCR también se realizó usando los productos de PCR anteriores como molde y cebadores de SEQ ID NO: 7 y 10. El fragmento de ADN obtenido se clonó de la misma manera que en el ejemplo 1-1. El vector preparado se designó pDZ-guaB-alt.
[Tabla 2]

El vector recombinante pDZ-guaB-alt se transformó en la cepa ATCC6872-purA(alt) preparada en el ejemplo 1-1 por electroporación, y luego las cepas en las que el vector se insertó en el cromosoma por recombinación homóloga se seleccionaron en un medio que contenía 25 mg/l de kanamicina. Las cepas primarias así seleccionadas se sometieron a un cruce secundario y, a continuación, las cepas seleccionadas se sometieron a secuenciación, con lo que se seleccionó una cepa final en la que se introdujo la mutación.
La cepa productora de IMP finalmente seleccionada, basada en Corynebacterium stationis ATCC6872 de tipo natural, se designó CJI9088.
Ejemplo 1-3: Prueba de titulación de fermentación de CJI9088
Se dispensaron 2 ml de un medio de cultivo de semillas en tubos de ensayo de 18 mm de diámetro y se esterilizaron en autoclave a presión. Se inocularon sendos ATCC6872 y CJI9088 y se incubaron a 30 °C durante 24 h con agitación para utilizarlos como cultivos semilla. Se dispensaron 29 ml de un medio de fermentación en matraces Erlenmeyer agitados de 250 ml y se esterilizaron en autoclave bajo presión a 121 °C durante 15 min, y se inocularon 2 ml del cultivo semilla y se incubaron durante 3 días. Las condiciones de cultivo se ajustaron a una velocidad de rotación de 170 rpm, una temperatura de 30 °C y un pH de 7,5.
Después de completar el cultivo, la producción de IMP se midió por HPLC (SHIMAZDU LC20A), y los resultados de cultivo son como en la siguiente tabla 3. Los siguientes resultados sugieren que las cepas debilitadas por purA y guaB tienen productividad IMP.
[Tabla 3]
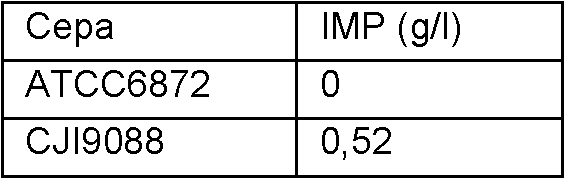
- Medio de cultivo de semillas: glucosa al 1 %, peptona al 1 %, extracto de carne al 1 %, extracto de levadura al 1 %, cloruro de sodio al 0,25 %, 100 mg/l de adenina, 100 mg/l de guanina, pH 7,5
- Medio de fermentación: glutamato de sodio al 0,1 %, cloruro de amonio al 1 %, sulfato de magnesio al 1,2 %, cloruro de calcio al 0,01 %, 20 mg/l de sulfato de hierro, 20 mg/l de sulfato de manganeso, 20 mg/l de sulfato de zinc, 5 mg/l de sulfato de cobre, 23 mg/l de L-cisteína, 24 mg/l de alanina, 8 mg/l de ácido nicotínico, 45 μg/l de biotina, 5 mg/l de tiamina ácido clorhídrico, 30 mg/l de adenina, ácido fosfórico al 1,9 %(85 %), glucosa al 2,55 %, fructosa al 1,45 %.
Ejemplo 2: Identificación de la variante mejorada fosforribosilpirofosfato amidotransferasa
Con el fin de mejorar la actividad de la fosforribosilpirofosfato amidotransferasa, que es la primera enzima en la vía biosintética de IMP, para la mejora de la productividad de IMP, se preparó una biblioteca mutante de purF, que es un gen que codifica la fosforribosilpirofosfato amidotransferasa, y se identificó una mutación que mejora la productividad de IMP.
Ejemplo 2-1: Preparación del vector que contiene purF
Para preparar una biblioteca de mutantes purF, primero se preparó un vector recombinante que contenía purF. Se realizó una PCR utilizando el ADN genómico de Corynebacterium stationis ATCC6872 como molde y los cebadores de SEQ ID NO: 11 y SEQ ID NO: 12, y se clonó un producto de la PCR en el vector pCR2.1 de E. coli utilizando un kit de clonación TOPO (Invitrogen) para obtener pCR-purF.
[Tabla 4]

Ejemplo 2-2: Preparación de la biblioteca de mutantes purF
Se preparó una biblioteca de mutantes purF basada en el vector preparado en el ejemplo 2-1. La biblioteca se preparó utilizando un kit de PCR propenso a errores (clontech Diversify® PCR Random Mutagenesis Kit). En condiciones en las que pueden producirse mutaciones, se realizó la PCR utilizando los cebadores de SEQ ID NO: 13 y SEQ ID NO: 14. Concretamente, en condiciones en las que pueden producirse de 0 a 3 mutaciones por 1000 pb, se realizó un precalentamiento a 94 °C durante 30 s, seguido de 25 ciclos de 94 °C durante 30 s y 68 °C durante 1 min 30 s. Un producto de PCR así obtenido se sometió a PCR utilizando un megaprimer (500 ng a 125 ng) durante 25 ciclos de 95 °C durante 50 s, 60 °C durante 50 s y 68 °C durante 12 min, y después se trató con DpnI, y se transformó en E. coli DH5a y se extendió en un medio sólido LB que contenía kanamicina (25 mg/l). Se seleccionaron 20 tipos de colonias transformadas y, a continuación, se obtuvieron plásmidos, seguidos de un análisis de secuenciación. Como resultado, se confirmó que las mutaciones se introducían en distintos sitios con una frecuencia de 2 mutaciones/kb. Se tomaron aproximadamente 20.000 colonias de E. coli transformadas y se extrajeron de ellas plásmidos, que se designaron como biblioteca pTOPO-purF.
[Tabla 5]

Ejemplo 2-3: Evaluación de la biblioteca preparada y selección de la cepa
La biblioteca pTOPO-purF preparada en el ejemplo 2-2 se transformó en la cepa CJI9088 preparada en el ejemplo 1 por electroporación, y luego se extendió en un medio nutritivo que contenía 25 mg/l de kanamicina para obtener 10.000 colonias en las que se insertó el gen mutante. Las colonias se designaron como CJI9088_pPO_purF(mt)1 a CJI9088_pPO_purF(mt)10000.
- Medio nutritivo: peptona al 1 %, extracto de carne al 1 %, cloruro de sodio al 0,25 %, extracto de levadura al 1 %, agar al 2 %, pH 7,2.
Cada una de las 10.000 colonias obtenidas se inoculó en 200 pl de un medio de cultivo semilla esterilizado en autoclave a presión, y se cultivó en una placa de 96 pocillos profundos con agitación a 30 °C y 1.200 rpm durante 24 h utilizando un agitador de microplacas (TAITEC), y después se utilizó como cultivo semilla. Se dispensaron 290 pl de medio de fermentación esterilizado en autoclave a presión en una placa de 96 pocillos profundos y se inocularon en ella 20 pl de cada uno de los cultivos de semillas, tras lo cual se procedió al cultivo con agitación en las mismas condiciones anteriores durante 72 h.
Para analizar la producción de ácido 5'-inosínico en el medio de cultivo, una vez finalizado el cultivo, se transfirieron 3 pl de sobrenadante del cultivo a una placa UV de 96 pocillos, cada uno de los cuales contenía 197 pl de agua destilada. A continuación, se utilizó un lector de microplacas para realizar la agitación durante 30 s y un espectrofotómetro para medir la densidad óptica a 25 °C y 270 nm y se comparó con la densidad óptica de la cepa CJI9088 para seleccionar 50 colonias de la cepa mutante que mostraran un aumento del 10 % o más en la densidad óptica. Otras colonias mostraron una densidad óptica similar o inferior a la del control.
Las densidades ópticas de las 50 cepas seleccionadas se midieron del mismo modo que en el caso anterior para examinar repetidamente las cantidades de producción de ácido 5'-inosínico. Se seleccionaron dos cepas CJI9088_pTOPO_purF(mt)201 y CJI9088_pTOPO_purF (mt)5674, que mostraron una notable mejora en la productividad del ácido 5'-inosínico en comparación con la cepa CJI9088.
Ejemplo 2-4: Identificación de mutación mediante secuenciación
Para identificar las mutaciones genéticas de las cepas mutantes, cada una de las cepas CJI9088_pTOPO_purF(mt)201 y CJI9088_pTOPO_guaB(mt)5674 se sometió a PCR utilizando cebadores de SEQ ID NO: 15 y 16, seguido de secuenciación. Sus genes purF se compararon con los de las cepas ATCC6872 y CJI9088 que contenían el gen purF de tipo natural.
Como resultado, se descubrió que ambas cepas incluían la mutación del gen purF en sitios diferentes.
En concreto, se confirmó que la cepa CJI9088_pTOPO_purF(mt)201 tiene una mutación de sustitución de metionina por valina en la posición 2 de la secuencia de aminoácidos purF representada por la SEQ ID NO: 2, y la cepa CJI9088_pTOPO_purF(mt)5674 tiene una mutación de sustitución de arginina por glicina en la posición 445 de la secuencia de aminoácidos purF representada por la SEQ ID NO: 2.
[Tabla 6]

En los ejemplos 3 y 4 siguientes, se examinó si las mutaciones mencionadas afectaban a la producción de IMP del microorganismo del género Corynebacterium.
Ejemplo 3: Examen de la productividad de IMP en CJI9088
Las mutaciones identificadas en el ejemplo 2 se introdujeron en CJI9088, que es una cepa productora de IMP derivada de ATCC6872, y se examinó la productividad de IMP.
Ejemplo 3-1: Preparación del vector de inserción que contiene la mutación purF
Para introducir cepas con la mutación seleccionada en el ejemplo 2, se preparó un vector de inserción. Se prepara un vector para la introducción de la mutación purF de la siguiente manera.
La PCR se realizó utilizando el ADN genómico del ATCC6872 como molde y los cebadores de SEQ ID NO: 17 y 18 y SEQ ID NO: 19 y 20. La PCR se realizó por desnaturalización a 94 °C durante 5 min, y luego, durante 20 ciclos de a 94 °C durante 30 s, a 55 °C durante 30 s, a 72 °C durante 1 min, seguido de polimerización a 72 °C durante 5 min. La PCR se realizó utilizando cada uno de los fragmentos de ADN resultantes como molde y los cebadores de SEQ ID NO: 17 y SEQ ID NO: 20. El fragmento de ADN resultante se digirió con Xbal. Usando ligasa T4, el fragmento de ADN se clonó en un vector pDZ lineal que se había digerido con la enzima de restricción XbaI y, por lo tanto, se preparó pDZ-purF (V2M). La PCR se realizó usando cebadores de SEQ ID NO: 21 y 22 y SEQ ID n O: 23 y 24 de la misma manera que anteriormente. La PCR se realizó utilizando cada uno de los fragmentos de ADN resultantes como molde y los cebadores de SEQ ID NO: 21 y SEQ ID NO: 24. El fragmento de ADN resultante se digirió con XbaI. Usando ligasa T4, el fragmento de ADN se clonó en un vector pDZ lineal que se había digerido con la enzima de restricción XbaI y, por lo tanto, se preparó pDZ-purF(G445R).
[Tabla 7]

Ejemplo 3-2: Introducción del mutante en la cepa CJI9088 y evaluación
CJI9088 se transformó con cada uno de los vectores pDZ-purF(V2M) y pDZ-purF(G445R) preparados en el ejemplo 3-1, y las cepas en las que el vector se insertó en el cromosoma por recombinación homóloga se seleccionaron en un medio que contenía 25 mg/l de kanamicina. Las cepas primarias así seleccionadas se sometieron a un cruzamiento secundario para seleccionar cepas en las que se introdujo la mutación del gen diana. La introducción de la mutación genética en las cepas transformadas finales se examinó mediante PCR utilizando los cebadores de SEQ ID NO: 15 y SEQ ID NO: 16, y después se realizó la secuenciación para confirmar la introducción de la mutación en las cepas. Específicamente, la cepa introducida con la mutación V2M del gen purF se designó como CJI9088_purF_m1, y la cepa introducida con la mutación G445R del gen purF se designó como CJI9088_purF_m2. Además, para preparar una cepa mutante que tuviera las mutaciones V2M y G445R, se transformó la cepa CJI9088_purF_m1 con el vector pDZ-purF(G445R), y se obtuvieron colonias de la misma manera que en el caso anterior. Mediante el análisis de secuenciación de las colonias obtenidas, se seleccionó una cepa introducida con las mutaciones V2M y G445R del gen purF y se designó como CJI9088_purF_m1m2.
Tal como se muestra en los resultados a continuación, la cepa CJI9088_purF_m1 o CJI9088_purF_m2 con la mutación V2M o la mutación G445R en el gen purF mostró una concentración de IMP de 0,15 g/l (128 %) o 0,09 g/l (117 %), respectivamente, lo que indica una mejora en comparación con la cepa CJI9088 de control. Además, la cepa CJI9088_purF_m1m2 con las mutaciones V2M y G445R mostró una mejora de la concentración de IMP de 0,31 g/l (159 %), lo que indica que cuando se incluyen las dos mutaciones, se puede obtener la mejora más eficaz en la concentración de IMP.
[Tabla 8]

Ejemplo 4: Examen de la productividad de IMP en la cepa productora de IMP derivada de ATCC6872
Para examinar el efecto del mutante purF que se identificó en el ejemplo 2, basado en una cepa que produce una alta concentración de IMP, se introdujo el mutante en CJI0323 (n.° de registro KCCM12151P, n.° de patente coreana 10-1904675), que es una cepa que produce una alta concentración de IMP, y se examinó la productividad de IMP.
Ejemplo 4-1: Introducción del mutante en la cepa CJI0323 y evaluación
CJI0323 se transformó con cada uno de los vectores pDZ-purF(V2M) y pDZ-purF(G445R) preparados en el ejemplo 3-1, y las cepas en las que el vector se insertó en el cromosoma por recombinación homóloga se seleccionaron en un medio que contenía 25 mg/l de kanamicina. Las cepas primarias así seleccionadas se sometieron a un cruzamiento secundario para seleccionar cepas en las que se introdujo la mutación del gen diana. La introducción de la mutación genética en las cepas transformadas finales se examinó mediante PCR utilizando los cebadores de SEQ ID NO: 15 y SEQ ID NO: 16, y después se realizó la secuenciación para confirmar la introducción de la mutación en las cepas. Específicamente, la cepa introducida con la mutación V2M del gen purF se designó como CJI0323_purF_m1, y la cepa introducida con la mutación G445R del gen purF se designó como CJI0323_purF_m2. Además, para preparar una cepa mutante que tuviera las mutaciones V2M y G445R, se transformó la cepa CJI0323_purF_m1 con el vector pDZ-purF(G445R), y se obtuvieron colonias de la misma manera que en el caso anterior. Mediante el análisis de secuenciación de las colonias obtenidas, se seleccionó una cepa introducida con las mutaciones V2M y G445R del gen purF y se designó como CJI0323_purF_m1m2.
El CJI0323_purF_m1 fue denominado CJI2353, depositado en el Centro Coreano de Cultivo de Microorganismos el 10 de septiembre de 2018, en virtud de las disposiciones del Tratado de Budapest, y se le asignó el número de registro KCCM12316P. Además, el preparado CJI0323_purF_m2 se denominó CJI2354, se depositó en el Centro Coreano de Cultivo de Microorganismos el 10 de septiembre de 2018, en virtud de las disposiciones del Tratado de Budapest, y se le asignó el número de registro KCCM12317P.
Como se muestra en los resultados a continuación, la cepa CJI0323_purF_m1 o CJI0323_purF_m2 con la mutación V2M o la mutación G445R en el gen purF mostraron una concentración de IMP de 1,9 g/l (119 %) o 0,95 g/l (109 %), respectivamente, lo que indica una mejora en comparación con la cepa CJI0323 de control. Además, la cepa CJI0323_purF_m1m2 con las mutaciones V2M y G445R mostró una mejora de la concentración de IMP de 3,33 g/l (134 %), lo que indica que cuando se incluyen las dos mutaciones, se puede obtener la mejora más eficaz en la concentración de IMP.
[Tabla 9]

Ejemplo 5: Examen de la productividad del ácido 5'-xantílico del mutante purF
Para examinar el efecto del mutante purF que se identificó en el ejemplo 2, basado en una cepa productora de XMP, se introdujo el mutante en KCCM10530 (publicación de patente coreana n.° 10-2005-0056670), que es una cepa productora de una alta concentración de XMP, y se examinó la productividad de XMP.
Ejemplo 5-1: Introducción del mutante en la cepa KCCM10530 y evaluación
KCCM10530 se transformó con cada uno de los vectores pDZ-purF(V2M) y pDZ-purF(G445R) preparados en el ejemplo 3-1, y las cepas en las que el vector se insertó en el cromosoma por recombinación homóloga se seleccionaron en un medio que contenía 25 mg/l de kanamicina. Las cepas primarias así seleccionadas se sometieron a un cruzamiento secundario para seleccionar cepas en las que se introdujo la mutación del gen diana. La introducción de la mutación genética en las cepas transformadas finales se examinó mediante PCR utilizando los cebadores de SEQ ID NO: 15 y SEQ ID NO: 16, y después se realizó la secuenciación para confirmar la introducción de la mutación en las cepas. Específicamente, la cepa introducida con la mutación V2M del gen purF se designó como KCCM10530_purF_m1, y la cepa introducida con la mutación G445R del gen purF se designó como KCCM10530_purF_m2. Además, para preparar una cepa mutante que tuviera las mutaciones V2M y G445R, se transformó la cepa KCCM10530_purF_m1 con el vector pDZ-purF(G445R), y se obtuvieron colonias de la misma manera que en el caso anterior. Mediante el análisis de secuenciación de las colonias obtenidas, se seleccionó una cepa introducida con las mutaciones V2M y G445R del gen purF y se designó como KCCM10530_purF_m1m2.
El KCCM10530_purF_m1 fue denominado CJX1681, depositado en el Centro Coreano de Cultivo de Microorganismos el 10 de septiembre de 2018, en virtud de las disposiciones del Tratado de Budapest, y se le asignó el número de registro KCCM12312P. Además, el preparado KCCM10530_purF_m2 se denominó CJX1682, se depositó en el Centro Coreano de Cultivo de Microorganismos el 10 de septiembre de 2018, en virtud de las disposiciones del Tratado de Budapest, y se le asignó el número de registro KCCM12313P.
Tal como se muestra en los resultados a continuación, la cepa KCCM10530_purF_m1 o KCCM10530_purF_m2 con la mutación V2M o la mutación G445R en el gen purF mostraron una concentración de XMP de 1,77 g/l (115 %) o
0,8 g/l (107 %), respectivamente, lo que indica una mejora, en comparación con la cepa KCCM10530 de control. Además, la cepa KCCM10530_purF_m1m2 con las mutaciones V2M y G445R mostró una mejora de la concentración de XMP de 2,36 g/l (120 %), lo que indica que cuando se incluyen las dos mutaciones, se puede obtener la mejora más eficaz en la concentración de XMP.
[Tabla 10]

Claims (8)
1. Una fosforribosilpirofosfato amidotransferasa, que comprende o bien;
i) una metionina en la posición 2 desde el extremo N-terminal de la secuencia de aminoácidos de SEQ ID NO: 2,
ii) una arginina en la posición 445 desde el extremo N-terminal de la secuencia de aminoácidos de SEQ ID NO: 2, o
iii) una metionina en la posición 2 y una arginina en la posición 445 desde el extremo N-terminal de la secuencia de aminoácidos de SEQ ID NO: 2,
en donde dicha fosforribosilpirofosfato amidotransferasa tiene al menos el 80 % de identidad con la secuencia de aminoácidos de SEQ ID NO: 2, y en donde dicha fosforribosilpirofosfato amidotransferasa que tiene dicha sustitución, o dichas sustituciones, tiene una mayor productividad de nucleótidos de purina que la fosforribosilpirofosfato amidotransferasa que tiene la secuencia de aminoácidos de SEQ ID NO: 2.
2. Un polinucleótido que codifica la fosforribosilpirofosfato amidotransferasa de la reivindicación 1.
3. Un vector que comprende el polinucleótido de la reivindicación 2.
4. Un microorganismo del género Corynebacteriumque produce un nucleótido de purina, en donde dicho microorganismo comprende la fosforribosilpirofosfato amidotransferasa de la reivindicación 1.
5. El microorganismo según la reivindicación 4, en donde dicho microorganismo es Corynebacterium stationis.
6. Un método para preparar un nucleótido de purina, que comprende la etapa de cultivar el microorganismo de la reivindicación 4 en un medio.
7. El método según la reivindicación 6, que comprende además la etapa de recuperar el nucleótido de purina del microorganismo o del medio después de la etapa de cultivo.
8. El método según la reivindicación 6, en donde dicho microorganismo es Corynebacterium stationis.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020190035683A KR102006977B1 (ko) | 2019-03-28 | 2019-03-28 | 변이형 포스포리보실피로포스페이트 아미도트랜스퍼라아제 및 이를 이용한 퓨린 뉴클레오티드 제조방법 |
| PCT/KR2019/008924 WO2020196993A1 (ko) | 2019-03-28 | 2019-07-19 | 변이형 포스포리보실피로포스페이트 아미도트랜스퍼라아제 및 이를 이용한 퓨린 뉴클레오티드 제조방법 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| ES2955417T3 true ES2955417T3 (es) | 2023-11-30 |
Family
ID=67616121
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| ES19762700T Active ES2955417T3 (es) | 2019-03-28 | 2019-07-19 | Variante fosforribosil pirofosfato amidotransferasa y método para producir nucleótido de purina usando la misma |
Country Status (18)
| Country | Link |
|---|---|
| US (1) | US11008599B2 (es) |
| EP (1) | EP3739044B1 (es) |
| JP (1) | JP6891292B2 (es) |
| KR (1) | KR102006977B1 (es) |
| CN (1) | CN112004926B (es) |
| AU (1) | AU2019226146B2 (es) |
| BR (1) | BR112019020178B1 (es) |
| ES (1) | ES2955417T3 (es) |
| HU (1) | HUE063033T2 (es) |
| MX (1) | MX2019011479A (es) |
| MY (1) | MY192935A (es) |
| PL (1) | PL3739044T3 (es) |
| PT (1) | PT3739044T (es) |
| RU (1) | RU2736372C1 (es) |
| SG (1) | SG11201907885WA (es) |
| TW (1) | TWI738050B (es) |
| WO (1) | WO2020196993A1 (es) |
| ZA (1) | ZA201905668B (es) |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100771511B1 (ko) * | 2006-03-09 | 2007-10-30 | 삼성코닝 주식회사 | 분할 구동용 백 라이트 유닛 및 그 백 라이트 유닛의비대칭 발광 다이오드 렌즈 |
| KR102013873B1 (ko) | 2018-01-25 | 2019-08-23 | 씨제이제일제당 주식회사 | 퓨린 뉴클레오티드를 생산하는 코리네박테리움 속 미생물 및 이를 이용한 퓨린 뉴클레오티드의 생산방법 |
| CN113106080B (zh) * | 2021-03-31 | 2022-02-25 | 深圳希吉亚生物技术有限公司 | 烟酰胺磷酸核糖转移酶突变体及其应用 |
| KR102277410B1 (ko) * | 2021-04-29 | 2021-07-14 | 씨제이제일제당 주식회사 | 신규한 이중기능성 pyr 오페론 전사조절자/우라실 포스포리보실 전달 효소 변이체 및 이를 이용한 IMP 생산 방법 |
| US12247849B2 (en) | 2021-08-27 | 2025-03-11 | Stmicroelectronics S.R.L. | Enhanced human activity recognition |
| KR102837216B1 (ko) | 2022-11-01 | 2025-07-23 | 씨제이제일제당 주식회사 | 퓨린 뉴클레오티드를 생산하는 미생물 및 이를 이용한 퓨린 뉴클레오티드의 생산 방법 |
| KR102830911B1 (ko) * | 2023-02-28 | 2025-07-08 | 씨제이제일제당 주식회사 | 5'-구아닌산 생산 균주 및 이를 이용한 5'-구아닌산 생산 방법 |
Family Cites Families (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP1004663B1 (en) * | 1997-07-18 | 2007-02-07 | Ajinomoto Co., Inc. | Process and microorganism for producing purine nucleosides via fermentation |
| RU2326170C2 (ru) * | 1999-07-01 | 2008-06-10 | Басф Акциенгезелльшафт | Гены corynebacterium glutamicum, кодирующие белки системы фосфоенолпируват-сахар-фосфотрансферазы |
| KR100542568B1 (ko) | 2003-12-10 | 2006-01-11 | 씨제이 주식회사 | 5'-크산틸산을 생산하는 미생물 |
| WO2006092449A2 (en) * | 2005-03-02 | 2006-09-08 | Metanomics Gmbh | Process for the production of fine chemicals |
| KR20070056491A (ko) * | 2005-11-30 | 2007-06-04 | 씨제이 주식회사 | 포스포리보실 피로포스페이트 아미도트랜스퍼라제 코딩유전자가 도입된 미생물 및 이를 사용한 5’-크산틸산의생산방법 |
| WO2008033001A1 (en) | 2006-09-15 | 2008-03-20 | Cj Cheiljedang Corporation | A corynebacteria having enhanced l-lysine productivity and a method of producing l-lysine using the same |
| KR101166027B1 (ko) * | 2009-04-01 | 2012-07-19 | 씨제이제일제당 (주) | 5'-이노신산 생산성이 향상된 코리네박테리움 속 미생물 및 이를 이용한 핵산의 생산방법 |
| CN103952422B (zh) * | 2014-04-15 | 2016-06-29 | 天津大学 | 枯草芽孢杆菌编码PRPP转酰胺酶突变基因purF及应用 |
| KR101904675B1 (ko) | 2017-12-15 | 2018-10-04 | 씨제이제일제당 (주) | 5'-이노신산을 생산하는 미생물 및 이를 이용한 5'-이노신산의 생산 방법 |
| KR101950141B1 (ko) * | 2018-08-01 | 2019-02-19 | 씨제이제일제당 (주) | 신규 아데닐로석시네이트 신세타아제 및 이를 이용한 퓨린 뉴클레오티드 생산방법 |
-
2019
- 2019-03-28 KR KR1020190035683A patent/KR102006977B1/ko active Active
- 2019-07-19 WO PCT/KR2019/008924 patent/WO2020196993A1/ko not_active Ceased
- 2019-07-19 HU HUE19762700A patent/HUE063033T2/hu unknown
- 2019-07-19 AU AU2019226146A patent/AU2019226146B2/en active Active
- 2019-07-19 MX MX2019011479A patent/MX2019011479A/es unknown
- 2019-07-19 CN CN201980002191.6A patent/CN112004926B/zh active Active
- 2019-07-19 EP EP19762700.3A patent/EP3739044B1/en active Active
- 2019-07-19 JP JP2019549374A patent/JP6891292B2/ja active Active
- 2019-07-19 BR BR112019020178-5A patent/BR112019020178B1/pt active IP Right Grant
- 2019-07-19 PT PT197627003T patent/PT3739044T/pt unknown
- 2019-07-19 PL PL19762700.3T patent/PL3739044T3/pl unknown
- 2019-07-19 SG SG11201907885WA patent/SG11201907885WA/en unknown
- 2019-07-19 US US16/493,661 patent/US11008599B2/en active Active
- 2019-07-19 ES ES19762700T patent/ES2955417T3/es active Active
- 2019-07-19 RU RU2019127999A patent/RU2736372C1/ru active
- 2019-08-28 ZA ZA2019/05668A patent/ZA201905668B/en unknown
- 2019-08-29 MY MYPI2019004993A patent/MY192935A/en unknown
- 2019-09-04 TW TW108131886A patent/TWI738050B/zh active
Also Published As
| Publication number | Publication date |
|---|---|
| MX2019011479A (es) | 2020-11-13 |
| CN112004926A (zh) | 2020-11-27 |
| HUE063033T2 (hu) | 2024-01-28 |
| AU2019226146A1 (en) | 2020-10-15 |
| JP2021512586A (ja) | 2021-05-20 |
| US20210047666A1 (en) | 2021-02-18 |
| PT3739044T (pt) | 2023-09-13 |
| RU2736372C1 (ru) | 2020-11-16 |
| MY192935A (en) | 2022-09-15 |
| SG11201907885WA (en) | 2020-11-27 |
| ZA201905668B (en) | 2020-05-27 |
| BR112019020178B1 (pt) | 2022-11-01 |
| US11008599B2 (en) | 2021-05-18 |
| TWI738050B (zh) | 2021-09-01 |
| EP3739044B1 (en) | 2023-07-12 |
| TW202035686A (zh) | 2020-10-01 |
| JP6891292B2 (ja) | 2021-06-18 |
| EP3739044A4 (en) | 2021-01-27 |
| AU2019226146B2 (en) | 2021-10-28 |
| PL3739044T3 (pl) | 2023-10-30 |
| CN112004926B (zh) | 2021-11-12 |
| KR102006977B1 (ko) | 2019-08-05 |
| EP3739044A1 (en) | 2020-11-18 |
| BR112019020178A2 (pt) | 2021-10-26 |
| WO2020196993A1 (ko) | 2020-10-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| ES2955417T3 (es) | Variante fosforribosil pirofosfato amidotransferasa y método para producir nucleótido de purina usando la misma | |
| ES2926648T3 (es) | Promotor novedoso y método de producción de nucleótidos de purina mediante el uso del mismo | |
| RU2770464C1 (ru) | Новая аденилосукцинат-синтетаза и способ получения нуклеотидов пурина с ее использованием | |
| US11384124B2 (en) | Polypeptide and method of producing IMP using the same | |
| BR122020018773B1 (pt) | Polipeptídeo modificado tendo atividade de citrato sintase, microrganismo do gênero corynebacterium e método para produzir um l-aminoácido | |
| CA3051217C (en) | Novel 5'-inosinic acid dehydrogenase and method of preparing 5'-inosinic acid using the same | |
| ES3050106T3 (en) | Microorganism having enhanced activity of 3-methyl-2-oxobutanoate hydroxymethyltransferase and uses thereof | |
| BR112019020183B1 (pt) | Variante de aceto-hidroxiácido sintase, micro-organismo que compreende a mesma e método de produção de aminoácido de cadeia ramificada l com o uso da mesma | |
| ES2992349T3 (es) | Variante novedosa de GMP sintasa que hidroliza glutamina y método para producir nucleótidos de purina usando la misma | |
| BR112022008745B1 (pt) | Microrganismo com atividade aumentada da 3-metil-2-oxobutanoato hidroximetiltransferase e utilização do mesmo | |
| CN117431197A (zh) | 具有增强的l-精氨酸或l-瓜氨酸生产力的棒状杆菌属微生物及其相关方法 | |
| HK40035066B (en) | Variant phosphoribosyl pyrophosphate amidotransferase and method of preparing purine nucleotide using the same | |
| HK40035066A (en) | Variant phosphoribosyl pyrophosphate amidotransferase and method of preparing purine nucleotide using the same | |
| BR112019016462B1 (pt) | Polipeptídeo modificado tendo atividade de citrato sintase, microrganismo do gênero corynebacterium e método para produzir um laminoácido | |
| BR112020001762A2 (pt) | variante de atp fosforribosiltransferase, polinucleotídeo, vetor, micro-organismo do gênero corynebacterium, e, método para produzir histidina. | |
| HK40027606A (en) | Novel 5'-inosine monophosphate dehydrogenase and 5'-inosine monophosphate production method using same |