FR2784383A1 - Polypeptides capables d'interagir avec les mutants oncogeniques de la proteine p53 - Google Patents
Polypeptides capables d'interagir avec les mutants oncogeniques de la proteine p53 Download PDFInfo
- Publication number
- FR2784383A1 FR2784383A1 FR9812754A FR9812754A FR2784383A1 FR 2784383 A1 FR2784383 A1 FR 2784383A1 FR 9812754 A FR9812754 A FR 9812754A FR 9812754 A FR9812754 A FR 9812754A FR 2784383 A1 FR2784383 A1 FR 2784383A1
- Authority
- FR
- France
- Prior art keywords
- sep
- polypeptide
- protein
- seq
- oncogenic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 108090000765 processed proteins & peptides Proteins 0.000 title claims abstract description 121
- 102000004196 processed proteins & peptides Human genes 0.000 title claims abstract description 108
- 229920001184 polypeptide Polymers 0.000 title claims abstract description 106
- 230000010261 cell growth Effects 0.000 title claims abstract description 22
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 title description 134
- 101000721661 Homo sapiens Cellular tumor antigen p53 Proteins 0.000 title description 131
- 239000002246 antineoplastic agent Substances 0.000 title 1
- 230000002246 oncogenic effect Effects 0.000 claims abstract description 53
- 230000003993 interaction Effects 0.000 claims abstract description 51
- 231100000590 oncogenic Toxicity 0.000 claims abstract description 48
- 108091034117 Oligonucleotide Proteins 0.000 claims abstract description 33
- 238000000034 method Methods 0.000 claims abstract description 32
- 239000012634 fragment Substances 0.000 claims abstract description 30
- 230000000694 effects Effects 0.000 claims abstract description 25
- 239000013598 vector Substances 0.000 claims abstract description 25
- 150000001875 compounds Chemical class 0.000 claims abstract description 18
- 108020004999 messenger RNA Proteins 0.000 claims abstract description 14
- 238000004519 manufacturing process Methods 0.000 claims abstract description 11
- 150000007523 nucleic acids Chemical class 0.000 claims abstract description 11
- 108020004707 nucleic acids Proteins 0.000 claims abstract description 6
- 102000039446 nucleic acids Human genes 0.000 claims abstract description 6
- 230000001028 anti-proliverative effect Effects 0.000 claims abstract description 5
- 239000008194 pharmaceutical composition Substances 0.000 claims abstract description 5
- 238000002360 preparation method Methods 0.000 claims abstract description 5
- 239000002773 nucleotide Substances 0.000 claims description 49
- 125000003729 nucleotide group Chemical group 0.000 claims description 49
- 239000000523 sample Substances 0.000 claims description 23
- 230000027455 binding Effects 0.000 claims description 16
- 206010028980 Neoplasm Diseases 0.000 claims description 14
- 239000003446 ligand Substances 0.000 claims description 10
- 239000000203 mixture Substances 0.000 claims description 10
- 102000008394 Immunoglobulin Fragments Human genes 0.000 claims description 9
- 108010021625 Immunoglobulin Fragments Proteins 0.000 claims description 9
- 230000000903 blocking effect Effects 0.000 claims description 9
- 238000011282 treatment Methods 0.000 claims description 9
- 241000700605 Viruses Species 0.000 claims description 8
- 230000022131 cell cycle Effects 0.000 claims description 8
- 230000002401 inhibitory effect Effects 0.000 claims description 7
- 230000008569 process Effects 0.000 claims description 7
- 230000004064 dysfunction Effects 0.000 claims description 5
- 238000012360 testing method Methods 0.000 claims description 5
- 239000000074 antisense oligonucleotide Substances 0.000 claims description 4
- 238000012230 antisense oligonucleotides Methods 0.000 claims description 4
- 230000002950 deficient Effects 0.000 claims description 3
- 201000010099 disease Diseases 0.000 claims description 3
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 3
- 239000003814 drug Substances 0.000 claims description 3
- 230000004936 stimulating effect Effects 0.000 claims description 3
- 239000004480 active ingredient Substances 0.000 claims description 2
- 230000010076 replication Effects 0.000 claims description 2
- 238000006073 displacement reaction Methods 0.000 claims 1
- 230000005764 inhibitory process Effects 0.000 claims 1
- 239000013600 plasmid vector Substances 0.000 claims 1
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 abstract description 12
- 230000000692 anti-sense effect Effects 0.000 abstract description 6
- 108020004711 Nucleic Acid Probes Proteins 0.000 abstract 1
- 238000012258 culturing Methods 0.000 abstract 1
- 239000002853 nucleic acid probe Substances 0.000 abstract 1
- 108090000623 proteins and genes Proteins 0.000 description 188
- 102000004169 proteins and genes Human genes 0.000 description 182
- 239000013612 plasmid Substances 0.000 description 45
- 210000004027 cell Anatomy 0.000 description 38
- 241001529936 Murinae Species 0.000 description 33
- 239000002299 complementary DNA Substances 0.000 description 32
- 238000002474 experimental method Methods 0.000 description 31
- 238000010276 construction Methods 0.000 description 27
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 20
- 235000014680 Saccharomyces cerevisiae Nutrition 0.000 description 20
- 108091028043 Nucleic acid sequence Proteins 0.000 description 19
- 230000006870 function Effects 0.000 description 17
- 210000004962 mammalian cell Anatomy 0.000 description 17
- 230000035772 mutation Effects 0.000 description 17
- 150000001413 amino acids Chemical class 0.000 description 16
- 108020004635 Complementary DNA Proteins 0.000 description 15
- 108700020796 Oncogene Proteins 0.000 description 15
- 108010001515 Galectin 4 Proteins 0.000 description 14
- 102100039556 Galectin-4 Human genes 0.000 description 14
- 102000047918 Myelin Basic Human genes 0.000 description 14
- 210000001519 tissue Anatomy 0.000 description 14
- 239000013613 expression plasmid Substances 0.000 description 13
- 108010034065 fibulin 2 Proteins 0.000 description 13
- 238000001890 transfection Methods 0.000 description 13
- 102100031813 Fibulin-2 Human genes 0.000 description 12
- 239000000047 product Substances 0.000 description 12
- 102000016914 ras Proteins Human genes 0.000 description 12
- 101710135898 Myc proto-oncogene protein Proteins 0.000 description 11
- 102100038895 Myc proto-oncogene protein Human genes 0.000 description 11
- 101710150448 Transcriptional regulator Myc Proteins 0.000 description 11
- 230000001413 cellular effect Effects 0.000 description 11
- 108010014186 ras Proteins Proteins 0.000 description 11
- 101710110798 Mannose-binding protein C Proteins 0.000 description 10
- 230000004568 DNA-binding Effects 0.000 description 9
- 241000699666 Mus <mouse, genus> Species 0.000 description 9
- 101100137555 Mus musculus Prg2 gene Proteins 0.000 description 9
- 229930193140 Neomycin Natural products 0.000 description 9
- 238000012512 characterization method Methods 0.000 description 9
- 238000010367 cloning Methods 0.000 description 9
- 238000001514 detection method Methods 0.000 description 9
- 239000013604 expression vector Substances 0.000 description 9
- 238000002955 isolation Methods 0.000 description 9
- 229960004927 neomycin Drugs 0.000 description 9
- 210000004881 tumor cell Anatomy 0.000 description 9
- 230000003321 amplification Effects 0.000 description 8
- 239000000872 buffer Substances 0.000 description 8
- 230000002068 genetic effect Effects 0.000 description 8
- 239000012528 membrane Substances 0.000 description 8
- 230000004048 modification Effects 0.000 description 8
- 238000012986 modification Methods 0.000 description 8
- 238000003199 nucleic acid amplification method Methods 0.000 description 8
- 108091008146 restriction endonucleases Proteins 0.000 description 8
- 210000002950 fibroblast Anatomy 0.000 description 7
- 230000002062 proliferating effect Effects 0.000 description 7
- 238000012216 screening Methods 0.000 description 7
- 241000700159 Rattus Species 0.000 description 6
- 238000006243 chemical reaction Methods 0.000 description 6
- 239000002609 medium Substances 0.000 description 6
- 238000013518 transcription Methods 0.000 description 6
- 230000035897 transcription Effects 0.000 description 6
- 108700028369 Alleles Proteins 0.000 description 5
- 108091003079 Bovine Serum Albumin Proteins 0.000 description 5
- 230000004913 activation Effects 0.000 description 5
- 230000004927 fusion Effects 0.000 description 5
- 238000009396 hybridization Methods 0.000 description 5
- 230000001965 increasing effect Effects 0.000 description 5
- 239000000126 substance Substances 0.000 description 5
- 230000009466 transformation Effects 0.000 description 5
- 239000006144 Dulbecco’s modified Eagle's medium Substances 0.000 description 4
- 102100031181 Glyceraldehyde-3-phosphate dehydrogenase Human genes 0.000 description 4
- 101001056128 Homo sapiens Mannose-binding protein C Proteins 0.000 description 4
- 108700028031 Myelin Basic Proteins 0.000 description 4
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 4
- 201000011510 cancer Diseases 0.000 description 4
- 230000010307 cell transformation Effects 0.000 description 4
- 239000012894 fetal calf serum Substances 0.000 description 4
- 108020001507 fusion proteins Proteins 0.000 description 4
- 102000037865 fusion proteins Human genes 0.000 description 4
- BRZYSWJRSDMWLG-CAXSIQPQSA-N geneticin Chemical compound O1C[C@@](O)(C)[C@H](NC)[C@@H](O)[C@H]1O[C@@H]1[C@@H](O)[C@H](O[C@@H]2[C@@H]([C@@H](O)[C@H](O)[C@@H](C(C)O)O2)N)[C@@H](N)C[C@H]1N BRZYSWJRSDMWLG-CAXSIQPQSA-N 0.000 description 4
- 108020004445 glyceraldehyde-3-phosphate dehydrogenase Proteins 0.000 description 4
- 210000001161 mammalian embryo Anatomy 0.000 description 4
- 238000002703 mutagenesis Methods 0.000 description 4
- 231100000350 mutagenesis Toxicity 0.000 description 4
- 210000001550 testis Anatomy 0.000 description 4
- 238000013519 translation Methods 0.000 description 4
- 101100239628 Danio rerio myca gene Proteins 0.000 description 3
- PEDCQBHIVMGVHV-UHFFFAOYSA-N Glycerine Chemical compound OCC(O)CO PEDCQBHIVMGVHV-UHFFFAOYSA-N 0.000 description 3
- 101000584310 Homo sapiens C-myc promoter-binding protein Proteins 0.000 description 3
- 101001018318 Homo sapiens Myelin basic protein Proteins 0.000 description 3
- 241000701044 Human gammaherpesvirus 4 Species 0.000 description 3
- 241000699670 Mus sp. Species 0.000 description 3
- 102000043276 Oncogene Human genes 0.000 description 3
- 108091023040 Transcription factor Proteins 0.000 description 3
- 102000040945 Transcription factor Human genes 0.000 description 3
- 230000009471 action Effects 0.000 description 3
- 210000004899 c-terminal region Anatomy 0.000 description 3
- 230000000052 comparative effect Effects 0.000 description 3
- 238000012217 deletion Methods 0.000 description 3
- 230000037430 deletion Effects 0.000 description 3
- 102000044581 human DENND4A Human genes 0.000 description 3
- 102000054064 human MBP Human genes 0.000 description 3
- 238000000338 in vitro Methods 0.000 description 3
- 108700025694 p53 Genes Proteins 0.000 description 3
- 230000036961 partial effect Effects 0.000 description 3
- 230000008092 positive effect Effects 0.000 description 3
- 230000003362 replicative effect Effects 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 2
- 102000012199 E3 ubiquitin-protein ligase Mdm2 Human genes 0.000 description 2
- 101150007452 EBNA-LP gene Proteins 0.000 description 2
- 241000588724 Escherichia coli Species 0.000 description 2
- 241000233866 Fungi Species 0.000 description 2
- DHMQDGOQFOQNFH-UHFFFAOYSA-N Glycine Chemical compound NCC(O)=O DHMQDGOQFOQNFH-UHFFFAOYSA-N 0.000 description 2
- 241000341655 Human papillomavirus type 16 Species 0.000 description 2
- 101150010283 MBP1 gene Proteins 0.000 description 2
- 101100244348 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) pma-1 gene Proteins 0.000 description 2
- 108010077850 Nuclear Localization Signals Proteins 0.000 description 2
- 241000235648 Pichia Species 0.000 description 2
- 101710152606 Protein lin-2 Proteins 0.000 description 2
- 101000702488 Rattus norvegicus High affinity cationic amino acid transporter 1 Proteins 0.000 description 2
- 108091081024 Start codon Proteins 0.000 description 2
- 239000002253 acid Substances 0.000 description 2
- 150000007513 acids Chemical class 0.000 description 2
- 230000003213 activating effect Effects 0.000 description 2
- 238000007792 addition Methods 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 210000004102 animal cell Anatomy 0.000 description 2
- 239000000427 antigen Substances 0.000 description 2
- 108091007433 antigens Proteins 0.000 description 2
- 102000036639 antigens Human genes 0.000 description 2
- 238000013459 approach Methods 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- 230000033228 biological regulation Effects 0.000 description 2
- 210000004900 c-terminal fragment Anatomy 0.000 description 2
- 231100000504 carcinogenesis Toxicity 0.000 description 2
- 239000003153 chemical reaction reagent Substances 0.000 description 2
- 239000003795 chemical substances by application Substances 0.000 description 2
- 230000005757 colony formation Effects 0.000 description 2
- 230000001332 colony forming effect Effects 0.000 description 2
- 238000011161 development Methods 0.000 description 2
- 230000018109 developmental process Effects 0.000 description 2
- 229940042399 direct acting antivirals protease inhibitors Drugs 0.000 description 2
- 230000002255 enzymatic effect Effects 0.000 description 2
- 230000012010 growth Effects 0.000 description 2
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 2
- 238000001114 immunoprecipitation Methods 0.000 description 2
- 238000001727 in vivo Methods 0.000 description 2
- 208000017482 infantile neuronal ceroid lipofuscinosis Diseases 0.000 description 2
- 210000004072 lung Anatomy 0.000 description 2
- 101150024228 mdm2 gene Proteins 0.000 description 2
- 230000007246 mechanism Effects 0.000 description 2
- 230000010309 neoplastic transformation Effects 0.000 description 2
- 238000006384 oligomerization reaction Methods 0.000 description 2
- 239000000137 peptide hydrolase inhibitor Substances 0.000 description 2
- 230000029279 positive regulation of transcription, DNA-dependent Effects 0.000 description 2
- 230000004481 post-translational protein modification Effects 0.000 description 2
- 230000017854 proteolysis Effects 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 210000002966 serum Anatomy 0.000 description 2
- 239000011780 sodium chloride Substances 0.000 description 2
- 238000006467 substitution reaction Methods 0.000 description 2
- 238000003786 synthesis reaction Methods 0.000 description 2
- 230000001225 therapeutic effect Effects 0.000 description 2
- 238000012546 transfer Methods 0.000 description 2
- 230000014621 translational initiation Effects 0.000 description 2
- 239000013603 viral vector Substances 0.000 description 2
- JKMHFZQWWAIEOD-UHFFFAOYSA-N 2-[4-(2-hydroxyethyl)piperazin-1-yl]ethanesulfonic acid Chemical compound OCC[NH+]1CCN(CCS([O-])(=O)=O)CC1 JKMHFZQWWAIEOD-UHFFFAOYSA-N 0.000 description 1
- QKNYBSVHEMOAJP-UHFFFAOYSA-N 2-amino-2-(hydroxymethyl)propane-1,3-diol;hydron;chloride Chemical compound Cl.OCC(N)(CO)CO QKNYBSVHEMOAJP-UHFFFAOYSA-N 0.000 description 1
- AXDJCCTWPBKUKL-UHFFFAOYSA-N 4-[(4-aminophenyl)-(4-imino-3-methylcyclohexa-2,5-dien-1-ylidene)methyl]aniline;hydron;chloride Chemical compound Cl.C1=CC(=N)C(C)=CC1=C(C=1C=CC(N)=CC=1)C1=CC=C(N)C=C1 AXDJCCTWPBKUKL-UHFFFAOYSA-N 0.000 description 1
- WRDABNWSWOHGMS-UHFFFAOYSA-N AEBSF hydrochloride Chemical compound Cl.NCCC1=CC=C(S(F)(=O)=O)C=C1 WRDABNWSWOHGMS-UHFFFAOYSA-N 0.000 description 1
- HRPVXLWXLXDGHG-UHFFFAOYSA-N Acrylamide Chemical compound NC(=O)C=C HRPVXLWXLXDGHG-UHFFFAOYSA-N 0.000 description 1
- 101001051799 Aedes aegypti Molybdenum cofactor sulfurase 3 Proteins 0.000 description 1
- 108020000948 Antisense Oligonucleotides Proteins 0.000 description 1
- 108010039627 Aprotinin Proteins 0.000 description 1
- 239000004475 Arginine Substances 0.000 description 1
- 241000228212 Aspergillus Species 0.000 description 1
- 241000193830 Bacillus <bacterium> Species 0.000 description 1
- 241000894006 Bacteria Species 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 108091033380 Coding strand Proteins 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 108050006400 Cyclin Proteins 0.000 description 1
- 108020004414 DNA Proteins 0.000 description 1
- 230000033616 DNA repair Effects 0.000 description 1
- 241000702421 Dependoparvovirus Species 0.000 description 1
- 102000004190 Enzymes Human genes 0.000 description 1
- 108090000790 Enzymes Proteins 0.000 description 1
- 230000010190 G1 phase Effects 0.000 description 1
- 239000004471 Glycine Substances 0.000 description 1
- 101150009006 HIS3 gene Proteins 0.000 description 1
- 241000238631 Hexapoda Species 0.000 description 1
- 101000944380 Homo sapiens Cyclin-dependent kinase inhibitor 1 Proteins 0.000 description 1
- 101000804764 Homo sapiens Lymphotactin Proteins 0.000 description 1
- 101000861454 Homo sapiens Protein c-Fos Proteins 0.000 description 1
- 241000701806 Human papillomavirus Species 0.000 description 1
- 206010020751 Hypersensitivity Diseases 0.000 description 1
- 102100023408 KH domain-containing, RNA-binding, signal transduction-associated protein 1 Human genes 0.000 description 1
- 101710094958 KH domain-containing, RNA-binding, signal transduction-associated protein 1 Proteins 0.000 description 1
- 241000235649 Kluyveromyces Species 0.000 description 1
- CKLJMWTZIZZHCS-REOHCLBHSA-N L-aspartic acid Chemical compound OC(=O)[C@@H](N)CC(O)=O CKLJMWTZIZZHCS-REOHCLBHSA-N 0.000 description 1
- QIVBCDIJIAJPQS-VIFPVBQESA-N L-tryptophane Chemical compound C1=CC=C2C(C[C@H](N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-VIFPVBQESA-N 0.000 description 1
- GDBQQVLCIARPGH-UHFFFAOYSA-N Leupeptin Natural products CC(C)CC(NC(C)=O)C(=O)NC(CC(C)C)C(=O)NC(C=O)CCCN=C(N)N GDBQQVLCIARPGH-UHFFFAOYSA-N 0.000 description 1
- 102100035304 Lymphotactin Human genes 0.000 description 1
- 206010064912 Malignant transformation Diseases 0.000 description 1
- 241001465754 Metazoa Species 0.000 description 1
- 108010021466 Mutant Proteins Proteins 0.000 description 1
- 102000008300 Mutant Proteins Human genes 0.000 description 1
- 206010029260 Neuroblastoma Diseases 0.000 description 1
- 238000000636 Northern blotting Methods 0.000 description 1
- 102000008297 Nuclear Matrix-Associated Proteins Human genes 0.000 description 1
- 108010035916 Nuclear Matrix-Associated Proteins Proteins 0.000 description 1
- 238000011672 OFA rat Methods 0.000 description 1
- 239000012124 Opti-MEM Substances 0.000 description 1
- 241000283973 Oryctolagus cuniculus Species 0.000 description 1
- 239000002033 PVDF binder Substances 0.000 description 1
- 241000337661 Parada Species 0.000 description 1
- 229920001213 Polysorbate 20 Polymers 0.000 description 1
- 102100036691 Proliferating cell nuclear antigen Human genes 0.000 description 1
- 102000001253 Protein Kinase Human genes 0.000 description 1
- 102000052575 Proto-Oncogene Human genes 0.000 description 1
- 108700020978 Proto-Oncogene Proteins 0.000 description 1
- 102000009092 Proto-Oncogene Proteins c-myc Human genes 0.000 description 1
- 108010087705 Proto-Oncogene Proteins c-myc Proteins 0.000 description 1
- 230000004570 RNA-binding Effects 0.000 description 1
- 101100394989 Rhodopseudomonas palustris (strain ATCC BAA-98 / CGA009) hisI gene Proteins 0.000 description 1
- 241000235070 Saccharomyces Species 0.000 description 1
- 241000311088 Schwanniomyces Species 0.000 description 1
- 241000187747 Streptomyces Species 0.000 description 1
- 241000223259 Trichoderma Species 0.000 description 1
- 239000013504 Triton X-100 Substances 0.000 description 1
- 229920004890 Triton X-100 Polymers 0.000 description 1
- QIVBCDIJIAJPQS-UHFFFAOYSA-N Tryptophan Natural products C1=CC=C2C(CC(N)C(O)=O)=CNC2=C1 QIVBCDIJIAJPQS-UHFFFAOYSA-N 0.000 description 1
- 108010040002 Tumor Suppressor Proteins Proteins 0.000 description 1
- 102000001742 Tumor Suppressor Proteins Human genes 0.000 description 1
- 108090000848 Ubiquitin Proteins 0.000 description 1
- 102000044159 Ubiquitin Human genes 0.000 description 1
- 241000700618 Vaccinia virus Species 0.000 description 1
- 108010067390 Viral Proteins Proteins 0.000 description 1
- 241000607479 Yersinia pestis Species 0.000 description 1
- 230000005856 abnormality Effects 0.000 description 1
- 239000012190 activator Substances 0.000 description 1
- 239000000556 agonist Substances 0.000 description 1
- 208000026935 allergic disease Diseases 0.000 description 1
- 239000005557 antagonist Substances 0.000 description 1
- 230000001093 anti-cancer Effects 0.000 description 1
- 229940124650 anti-cancer therapies Drugs 0.000 description 1
- 238000011319 anticancer therapy Methods 0.000 description 1
- 238000003782 apoptosis assay Methods 0.000 description 1
- 230000006907 apoptotic process Effects 0.000 description 1
- 229960004405 aprotinin Drugs 0.000 description 1
- ODKSFYDXXFIFQN-UHFFFAOYSA-N arginine Natural products OC(=O)C(N)CCCNC(N)=N ODKSFYDXXFIFQN-UHFFFAOYSA-N 0.000 description 1
- 210000004507 artificial chromosome Anatomy 0.000 description 1
- 238000000376 autoradiography Methods 0.000 description 1
- 230000004071 biological effect Effects 0.000 description 1
- 230000008827 biological function Effects 0.000 description 1
- 230000015572 biosynthetic process Effects 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 210000004369 blood Anatomy 0.000 description 1
- 239000008280 blood Substances 0.000 description 1
- 230000015556 catabolic process Effects 0.000 description 1
- 238000005119 centrifugation Methods 0.000 description 1
- 210000004978 chinese hamster ovary cell Anatomy 0.000 description 1
- 238000004587 chromatography analysis Methods 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 238000000749 co-immunoprecipitation Methods 0.000 description 1
- 230000000295 complement effect Effects 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 238000006731 degradation reaction Methods 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 230000001687 destabilization Effects 0.000 description 1
- 230000008034 disappearance Effects 0.000 description 1
- 230000013020 embryo development Effects 0.000 description 1
- 230000009144 enzymatic modification Effects 0.000 description 1
- 230000001747 exhibiting effect Effects 0.000 description 1
- 238000013467 fragmentation Methods 0.000 description 1
- 238000006062 fragmentation reaction Methods 0.000 description 1
- 230000013595 glycosylation Effects 0.000 description 1
- 238000006206 glycosylation reaction Methods 0.000 description 1
- 230000006801 homologous recombination Effects 0.000 description 1
- 238000002744 homologous recombination Methods 0.000 description 1
- 102000047278 human FOS Human genes 0.000 description 1
- 210000004408 hybridoma Anatomy 0.000 description 1
- 230000009610 hypersensitivity Effects 0.000 description 1
- 230000003053 immunization Effects 0.000 description 1
- 230000000984 immunochemical effect Effects 0.000 description 1
- 238000011534 incubation Methods 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- ZPNFWUPYTFPOJU-LPYSRVMUSA-N iniprol Chemical compound C([C@H]1C(=O)NCC(=O)NCC(=O)N[C@H]2CSSC[C@H]3C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@H](C(N[C@H](C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC=4C=CC=CC=4)C(=O)N[C@@H](CC=4C=CC(O)=CC=4)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC=4C=CC=CC=4)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CCCCN)NC(=O)[C@H](C)NC(=O)[C@H](CCCNC(N)=N)NC2=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CSSC[C@H](NC(=O)[C@H](CC=2C=CC=CC=2)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H]2N(CCC2)C(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(=O)N2[C@@H](CCC2)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC(O)=CC=2)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N2[C@@H](CCC2)C(=O)N3)C(=O)NCC(=O)NCC(=O)N[C@@H](C)C(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@H](C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@H](C(=O)N1)C(C)C)[C@@H](C)O)[C@@H](C)CC)=O)[C@@H](C)CC)C1=CC=C(O)C=C1 ZPNFWUPYTFPOJU-LPYSRVMUSA-N 0.000 description 1
- 230000010354 integration Effects 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- GDBQQVLCIARPGH-ULQDDVLXSA-N leupeptin Chemical compound CC(C)C[C@H](NC(C)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C=O)CCCN=C(N)N GDBQQVLCIARPGH-ULQDDVLXSA-N 0.000 description 1
- 108010052968 leupeptin Proteins 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 101150109301 lys2 gene Proteins 0.000 description 1
- 239000012139 lysis buffer Substances 0.000 description 1
- 230000007257 malfunction Effects 0.000 description 1
- 230000036212 malign transformation Effects 0.000 description 1
- 230000001404 mediated effect Effects 0.000 description 1
- 238000013508 migration Methods 0.000 description 1
- 230000005012 migration Effects 0.000 description 1
- 238000001823 molecular biology technique Methods 0.000 description 1
- 230000000877 morphologic effect Effects 0.000 description 1
- 230000000869 mutational effect Effects 0.000 description 1
- 208000002154 non-small cell lung carcinoma Diseases 0.000 description 1
- 231100001221 nontumorigenic Toxicity 0.000 description 1
- 210000000299 nuclear matrix Anatomy 0.000 description 1
- QYSGYZVSCZSLHT-UHFFFAOYSA-N octafluoropropane Chemical compound FC(F)(F)C(F)(F)C(F)(F)F QYSGYZVSCZSLHT-UHFFFAOYSA-N 0.000 description 1
- 230000006548 oncogenic transformation Effects 0.000 description 1
- 239000008188 pellet Substances 0.000 description 1
- 229950000964 pepstatin Drugs 0.000 description 1
- 108010091212 pepstatin Proteins 0.000 description 1
- FAXGPCHRFPCXOO-LXTPJMTPSA-N pepstatin A Chemical compound OC(=O)C[C@H](O)[C@H](CC(C)C)NC(=O)[C@H](C)NC(=O)C[C@H](O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)NC(=O)[C@H](C(C)C)NC(=O)CC(C)C FAXGPCHRFPCXOO-LXTPJMTPSA-N 0.000 description 1
- 239000008177 pharmaceutical agent Substances 0.000 description 1
- 230000026731 phosphorylation Effects 0.000 description 1
- 238000006366 phosphorylation reaction Methods 0.000 description 1
- 210000002826 placenta Anatomy 0.000 description 1
- 229920002401 polyacrylamide Polymers 0.000 description 1
- 239000000256 polyoxyethylene sorbitan monolaurate Substances 0.000 description 1
- 235000010486 polyoxyethylene sorbitan monolaurate Nutrition 0.000 description 1
- 229920002981 polyvinylidene fluoride Polymers 0.000 description 1
- 230000023603 positive regulation of transcription initiation, DNA-dependent Effects 0.000 description 1
- 230000005522 programmed cell death Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108060006633 protein kinase Proteins 0.000 description 1
- 230000004850 protein–protein interaction Effects 0.000 description 1
- 238000000746 purification Methods 0.000 description 1
- 238000011002 quantification Methods 0.000 description 1
- 238000000163 radioactive labelling Methods 0.000 description 1
- 230000007115 recruitment Effects 0.000 description 1
- 230000008439 repair process Effects 0.000 description 1
- 238000011160 research Methods 0.000 description 1
- 230000004044 response Effects 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 230000003248 secreting effect Effects 0.000 description 1
- 239000003724 sodium stearoyl-2-lactylate Substances 0.000 description 1
- 238000010186 staining Methods 0.000 description 1
- 239000006228 supernatant Substances 0.000 description 1
- 208000011580 syndromic disease Diseases 0.000 description 1
- 230000002195 synergetic effect Effects 0.000 description 1
- 238000010257 thawing Methods 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000003146 transient transfection Methods 0.000 description 1
- 208000029729 tumor suppressor gene on chromosome 11 Diseases 0.000 description 1
- 241000701161 unidentified adenovirus Species 0.000 description 1
- 241001529453 unidentified herpesvirus Species 0.000 description 1
- 241001430294 unidentified retrovirus Species 0.000 description 1
- 238000011144 upstream manufacturing Methods 0.000 description 1
- 230000003612 virological effect Effects 0.000 description 1
- 238000005406 washing Methods 0.000 description 1
- 238000001262 western blot Methods 0.000 description 1
Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/78—Connective tissue peptides, e.g. collagen, elastin, laminin, fibronectin, vitronectin or cold insoluble globulin [CIG]
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P35/00—Antineoplastic agents
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/46—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates
- C07K14/47—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals
- C07K14/4701—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used
- C07K14/4746—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans from vertebrates from mammals not used p53
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Medicinal Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Biophysics (AREA)
- Biochemistry (AREA)
- Genetics & Genomics (AREA)
- Gastroenterology & Hepatology (AREA)
- Molecular Biology (AREA)
- Zoology (AREA)
- Toxicology (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Peptides Or Proteins (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
Abstract
La présente invention concerne le domaine de la biologie et de la régulation du cycle cellulaire. Plus particulièrement, la présente invention concerne de nouveaux polypeptides capables d'interagir spécifiquement avec les formes oncogéniques de la protéine p53.
Description
<Desc/Clms Page number 1>
POLYPEPTIDES CAPABLES D'INTERAGIR AVEC LES MUTANTS
ONCOGENIQUES DE LA PROTEINE P53
La présente invention concerne le domaine de la biologie et de la régulation du cycle cellulaire. Plus particulièrement, la présente invention concerne de nouveaux polypeptides capables d'interagir spécifiquement avec les formes oncogéniques de la protéine p53.
ONCOGENIQUES DE LA PROTEINE P53
La présente invention concerne le domaine de la biologie et de la régulation du cycle cellulaire. Plus particulièrement, la présente invention concerne de nouveaux polypeptides capables d'interagir spécifiquement avec les formes oncogéniques de la protéine p53.
La protéine p53 sauvage intervient dans la régulation du cycle cellulaire et dans le maintien de l'intégrité du génome de la cellule. Cette protéine, dont la fonction principale est d'être un activateur de la transcription de certains gènes, est susceptible de bloquer la cellule en phase G1 du cycle cellulaire lors de l'apparition de mutations au cours de la réplication du génome, et d'enclencher un certains nombre de processus de réparation de l'ADN. Ce blocage en phase Gl est dû principalement à l'activation du gène p21/WAF1. De plus, en cas de mauvais fonctionnement de ces processus de réparation ou en cas d'apparition d'évènements mutationnels trop nombreux pour être corrigés, cette protéine est capable d'induire le phénomène de mort cellulaire programmée, appelé apoptose.
De cette façon, la protéine p53 agit comme un supresseur de tumeur, en éliminant les cellules anormalement différenciées ou dont le génome a été endommagé.
La protéine p53 comporte 393 acides aminés, qui définissent 5 domaines fonctionnels (voir Figure 1) : - le domaine activateur de la transcription, constitué par les acides aminés 1 à 73, capable de lier certains facteurs de la machinerie générale de transcription comme la protéine TBP. Ce domaine est aussi le siège d'un certain nombre de modifications post-traductionnelles. Il est également le siège d'interactions nombreuses de la protéine p53 avec de nombreuses autres protéines et notamment avec la protéine cellulaire mdm2 ou la protéine EBNA5 du virus d'Epstein-Barr (EBV), capables de
<Desc/Clms Page number 2>
bloquer la fonction de la protéine sauvage. De plus, ce domaine possède des séquences d'acides aminés dites PEST de susceptibilité à la dégradation protéolytique.
- le domaine de liaison à l'ADN, localisé entre les acides aminés 73 et 315. La conformation de ce domaine central de p53 régule la reconnaissance de séquences d'ADN spécifiques de la protéine p53. Ce domaine est le siège de deux types d'altérations affectant la fonction de la protéine sauvage : (i) l'interaction avec des protéines bloquant la fonction de la p53 comme l'antigène 'grand T' du virus SV40 ou les protéines virales E6 des virus HPV16 et HPV18 capables de provoquer sa dégradation par le système de l'ubiquitine. Cette dernière interaction ne peut se faire qu'en présence de la protéine cellulaire E6ap (enzyme E3 de la cascade de l'ubiquitinilation).
(ii) les mutations ponctuelles qui affectent la fonction de la p53 et dont la quasi-totalité observée dans les cancers humains sont localisées dans cette région.
- le signal de localisation nucléaire, constitué des acides aminés 315à 325, indispensable au bon adressage de la protéine dans le compartiment où elle va exercer sa principale fonction.
- le domaine d'oligomérisation, constitué des acides aminés 325 à 355. Cette région 325 à 355 forme une structure de type : feuillet ss (326-334) -coude (335-336) - hélice a (337-355). Les altérations de fonctions localisées dans cette région sont essentiellement dues à l'interaction de la protéine sauvage avec les différentes formes mutantes qui peuvent conduire à des effets variables sur la fonction de la protéine sauvage.
- le domaine de régulation, constitué des acides aminés 365 à 393, qui est le siège d'un certain nombre de modifications post-traductionnelles (glycosylations, phosphorylations, fixation d'ARN,...) qui modulent la fonction de la protéine p53 de façon positive ou négative. Ce domaine joue un rôle extrêmement important dans la
<Desc/Clms Page number 3>
modulation de l'activité de la protéine sauvage.
Le fonctionnement de la protéine p53 peut être perturbé de différentes façons : - blocage de sa fonction par un certain nombre de facteurs comme par exemple l'antigène 'grand T' du virus SV40, la protéine EBNA5 du virus d'Epstein-Barr, ou la protéine cellulaire mdm2.
- déstabilisation de la protéine par augmentation de sa susceptibilité à la protéolyse, notamment par interaction avec la protéine E6 des virus du papillome humain HPV16 et HPV18, qui favorise l'entrée de la p53 dans le cycle d'ubiquitinilation. Dans ce cas l'interaction entre ces deux protéines ne peut se faire que par la fixation préalable d'une protéine cellulaire, la protéine E6ap dont le site de fixation est mal connu.
- mutations ponctuelles au niveau du gène de la p53.
- délétion d'un ou des deux allèles de la p53
Les deux derniers types de modifications sont retrouvés dans environ 50% des différents types de cancer. A cet égard, les mutations du gène de la p53 repertoriées dans les cellules cancéreuses touchent une très grande partie du gène codant pour cette protéine, et ont pour résultats des modifications variables du fonctionnement de cette protéine. On peut cependant noter que ces mutations sont en grande majorité localisées dans la partie centrale de la protéine p53 dont on sait qu'elle est la région de contact avec les séquences génomiques spécifiques de la protéine p53. Ceci explique pourquoi la plupart des mutants de la protéine p53 ont comme principale caractéristique de ne plus pouvoir se fixer aux séquences d'ADN que reconnait la protéine sauvage et ainsi de ne plus pouvoir exercer leur rôle de facteur de transcription.
Les deux derniers types de modifications sont retrouvés dans environ 50% des différents types de cancer. A cet égard, les mutations du gène de la p53 repertoriées dans les cellules cancéreuses touchent une très grande partie du gène codant pour cette protéine, et ont pour résultats des modifications variables du fonctionnement de cette protéine. On peut cependant noter que ces mutations sont en grande majorité localisées dans la partie centrale de la protéine p53 dont on sait qu'elle est la région de contact avec les séquences génomiques spécifiques de la protéine p53. Ceci explique pourquoi la plupart des mutants de la protéine p53 ont comme principale caractéristique de ne plus pouvoir se fixer aux séquences d'ADN que reconnait la protéine sauvage et ainsi de ne plus pouvoir exercer leur rôle de facteur de transcription.
On regroupe actuellement l'ensemble de ces modifications dans deux catégories :
<Desc/Clms Page number 4>
- les mutants dits faibles, dont le produit est une protéine non-fonctionnelle, qui, dans le cas de mutation sur un seul des deux allèles, n'affecte pas le fonctionnement de la protéine sauvage codée par l'autre allèle. Le principal représentant de cette catégorie est le mutant H273 spécifique du syndrome familial de Li-Fraumeni d'hypersensibilité aux affections cancéreuses.
- les mutants dominant-oncogéniques, dont le produit est une protéine qui a perdu la capacité de se lier à l'ADN et qui participe activement à la transformation néoplasique. Les mutants de cette catégorie ont perdu leur capacité transactivatrice et sont plus stables que la protéine sauvage. Ils sont incapables d'inhiber la transformation des fibroblastes embryonnaires de rat et ils fonctionnent comme oncogènes en coopérant avec la forme activée de RAS dans la transformation de fibroblastes embryonnaires de rat (Eliyahu et al, Nature 312 (1984) 646 / Parada et al, Nature 312 (1984) 649). Ce comportement peut être expliqué par deux mécanismes différents non exclusifs l'un de l'autre ; (i) ces mutants génèrent une protéine non-fonctionnelle, qui, dans le cas de mutation sur un seul des deux allèles et par interaction avec la protéine sauvage, est capable de bloquer le fonctionnement de celle-ci par formation d'oligomères mixtes non-actifs qui ne peuvent plus se fixer aux séquences d'ADN spécifiques de la protéine sauvage. Un tel mécanisme est invoqué dans le cas où l'on observe la transformation maligne des cellules après transfection des mutants en présence de p53 endogène.
(ii) ces mutants peuvent de plus présenter un phénotype "gain de fonction". Leur expression dans des cellules non tumorigènes n'exprimant pas de p53 endogène conduit à l'apparition de tumeurs chez la souris athymique (Dittmer et al, Nature Genetics 4 (1993) 42). Ils sont capables d'activer la trancription des gènes comme MDR ou PCNA n'ayant pas de séquences consensus reconnues par p53, activation qui se fait probablement par recrutement des facteurs de transcription spécifiques des mutants et qui peut participer à l'apparition du phénotype tumoral
<Desc/Clms Page number 5>
(Chin et al, Science 255 (1992) 459 ; Deb et al, J. Virol. 66 (1992) 6164). Enfin, il a été rapporté récemment que ces mutants peuvent perturber l'attachement de certaines régions de l'ADN (MAR/SAR) au réseau de la matrice nucléaire (Müller et al, Oncogene 12(1996) 1941).
De nombreux partenaires cellulaires ont été décrits pour p53. Certains intéragissent aussi bien avec les conformations sauvage et mutées de la protéine et d'autres sont spécifiques de l'une ou l'autre des conformations (Iwabuchi et al, Proc.
Natl. Acad. Sci. USA 91 (1994) 6098). Il est concevable que certaines de ces propriétés 'gain de fonction' puissent être médiées par des partenaires protéiques spécifiques des mutants de p53, cependant de tels partenaires n'ont encore jamais été identifiés. L'identification de tels partenaires permettrait de nouvelles approches dans les thérapies anti-cancéreuses basées sur la modification ou le contrôle de ces interactions et sur l'obtention de composés capables d'interférer dans l'interaction de ces partenaires protéiques avec les différentes formes de p53. La présente invention satisfait ce besoin et apporte en outre d'autres avantages.
Dans le but d'étudier ce phénotype "gain de fonction" susceptible d'impliquer des interactions protéine-protéine spécifiques de ce type de mutant, le système double-hybride a été utilisé pour rechercher des partenaires spécifiques potentiels du mutant H175, principal représentant de cette catégorie de mutants. Une banque de cDNA d'embryon de souris, fusionnée à la séquence du domaine de transactivation de G.AL4 (TA), a été criblée dans la souche de levure YCM17 en utilisant comme protéine appât le domaine 73-393 du mutant H 175 fusionné au domaine de liaison à l'ADN de Gal4 (DB). Ce criblage a permis d'isoler deux cDNA codant pour deux protéines différentes.
Les interactions entre ces deux protéines et le mutant H175 de la protéine p53 ont pu être confirmées en cellules mammifères et des effets fonctionnels ont pu être démontrés, aussi bien sur des propriétés de la forme mutée de la p53 que sur des propriétés de la forme sauvage.
<Desc/Clms Page number 6>
La présente invention résulte donc de la mise en évidence par la demanderesse de nouveaux polypeptides capables d'interagir spécifiquement avec différentes formes de la protéine p53. Plus précisément la présente invention résulte de l'identification, l'isolement et la caractérisation d'une nouvelle protéine et du gène correspondant, la dite protéine étant caractérisée en ce qu'elle est capable d'interagir spécifiquement avec les formes oncogéniques de p53 et avec les mutants H 175 et G281 en particulier. Cette protéine est appelée MBP1pour p53 Mutant Binding Protein. La présente invention résulte également de la mise en évidence qu'une autre protéine, la fibuline2, est capable d'interagir spécifiquement avec les formes oncogéniques de p53 et avec les mutants H175 et G281 en particulier.
La présente invention résulte également de la découverte des propriétés particulières de ces nouveaux partenaires protéiques de p53 qui de manière inattendue s'avèrent également être capables de bloquer les effets anti-prolifératifs de la forme sauvage de p53.
Ces nouveaux partenaires protéiques de p53 présentent en outre une synergie d'action très importante avec les mutants oncogéniques de p53, cette synergie s'exerce aussi bien pour la coopération oncogénique avec la forme activée de la protéine Ras que sur l'effet prolifératif des formes mutées de p53.
De plus et indépendamment de toute interaction avec p53, ces polypeptides présentent un effet positif sur la croissance cellulaire. En outre, un de ces partenaires, la protéine MBP1, présente les caractéristiques d'un oncogène immortalisant en coopérant avec la forme activée de la protéine Ras pour la transformation cellulaire.
De part la spécificité et les effets synergiques que présentent ces nouveaux partenaires de p53 vis à vis de certaines formes mutées de p53, ces polypeptides constituent une cible thérapeutique de choix pour le traitement des cancers liés aux mutations de la protéine p53.
En outre, ces polypeptides qui présentent des propriétés oncogéniques
<Desc/Clms Page number 7>
intrinsèques, constituent de nouvelles cibles potentielles pour le traitement du cancer en général.
Un premier objet de l'invention concerne donc des polypeptides capables d'interagir spécifiquement avec les formes oncogéniques de p53. Ces polypeptides sont en outre capables de stimuler la croissance cellulaire et de bloquer les effets anti- prolifératifs de la forme sauvage de p53.
Selon un premier mode de réalisation, ces polypeptides comprennent tout ou partie d'une séquence choisie parmi les séquences polypeptidiques SEQ ID N 8 ou SEQ ID N 22 ou un dérivé de celles-ci.
Selon un autre mode de réalisation, ces polypeptides comprennent tout ou partie d'une séquence choisie parmi les séquences polypeptidiques SEQ ID N 26 ou SEQ ID N 23 ou un dérivé de celles-ci.
Enfin selon encore un autre mode de réalisation, ces polypeptides comprennent tout ou partie de la séquence polypeptidique SEQ ID N 9 ou un dérivé de celle-ci.
De manière préférée les polypeptides de l'invention sont représentés par la séquence polypeptidique SEQ ID N 23 ou ses dérivées
Au sens de la présente invention, le terme séquence polypeptidique dérivée désigne toute séquence polypeptidique différant de la séquence considérée, obtenue par une ou plusieurs modifications de nature génétique et/ou chimique, et possédant la capacité d'interagir avec les formes mutées oncogéniques de p53. Par modification de nature génétique et/ou chimique, on peut entendre toute mutation, substitution, délétion, addition et/ou modification d'un ou plusieurs résidus. De tels dérivés peuvent être générés dans des buts différents, tels que notamment celui de modifier
Au sens de la présente invention, le terme séquence polypeptidique dérivée désigne toute séquence polypeptidique différant de la séquence considérée, obtenue par une ou plusieurs modifications de nature génétique et/ou chimique, et possédant la capacité d'interagir avec les formes mutées oncogéniques de p53. Par modification de nature génétique et/ou chimique, on peut entendre toute mutation, substitution, délétion, addition et/ou modification d'un ou plusieurs résidus. De tels dérivés peuvent être générés dans des buts différents, tels que notamment celui de modifier
<Desc/Clms Page number 8>
leurs propriétés de liaison au formes mutées oncogéniques de p53, ou d'augmenter leur efficacité thérapeutique ou de réduire leurs effets secondaires, ou celui de leur conférer de nouvelles propriétés pharmacocinétiques et/ou biologiques.
A cet égard, un autre objet de l'invention concerne les séquences polypeptidiques qui présentent des fonctions biologiques comparables à celles des polypeptides selon l'invention et notamment la capacité à interagir avec les formes mutées oncogéniques de p53 et qui présentent un degré d'identité d'au moins 80 % et de préférence au moins 90 % avec la séquence polypeptidique SEQ ID N 22 ou la séquence polypeptidique SEQ ID N 23 ou la séquence polypeptidique SEQ ID N 9.
De préférence, les séquences polypeptidiques selon l'invention présentent au moins 95 % et de préférence encore au moins 97 % d'identité avec la séquence polypeptidique SEQ ID N 22 ou la séquence polypeptidique SEQ ID N 23 ou la séquence polypeptidique SEQ ID N 9.
De manière plus particulièrement préférée, les séquences polypeptidiques selon l'invention présentent au moins 98 % d'identité et de préférence encore au moins 99 % d'identité avec la séquence polypeptidique SEQ ID N 22 ou la séquence polypeptidique SEQ ID N 23 ou la séquence polypeptidique SEQ ID N 9.
Le terme séquence polypeptidique dérivée comprend également les fragments des séquences polypeptidiques indiquées ci-dessus. De tels fragments peuvent être générés de différentes façons. En particulier, ils peuvent être synthétisés par voie chimique, sur la base des séquences données dans la présente demande, en utilisant les synthétiseurs peptidiques connus de l'homme du métier. Ils peuvent également être synthétisés par voie génétique, par expression dans un hôte cellulaire d'une séquence nucléotidique codant pour le peptide recherché. Dans ce cas, la séquence nucléotidique peut être préparée chimiquement en utilisant un synthétiseur d'oligonucléotides, sur la base de la séquence peptidique donnée dans la présente demande et du code génétique. La séquence nucléotidique peut également être
<Desc/Clms Page number 9>
préparée à partir des séquences données dans la présente demande, par coupures enzymatiques, ligature, clonage, etc, selon les techniques connues de l'homme du métier, ou par criblage de banques d'ADN avec des sondes élaborées à partir de ces séquences.
Un autre objet de la présente invention concerne les séquences nucléotidiques codant pour les séquences polypeptidiques présentées dans les séquences SEQ ID N 22, ou SEQ ID N 23 ou SEQ ID N 9.
Selon un mode particulier de l'invention, les séquences nucléotidiques comprennent tout ou partie de la séquence SEQ ID N 16 ou SEQ ID N 21 ou de leurs dérivées.
Selon un autre mode de l'invention, les séquences nucléotidiques comprennent tout ou partie de la séquence nucléotidique SEQ ID N 9 ou de ses dérivées.
Selon encore un autre mode, les séquences nucléotidiques comprennent la séquence SEQ ID N 15, ou la séquence SEQ ID N 26.
Selon un mode préféré, la séquence nucléotidique est représentée par la séquence SEQ ID N 21ou ses dérivées.
Au sens de la présente invention, le terme séquence nucléotidique dérivée désigne toute séquence différant de la séquence considérée en raison de la dégénérescence du code génétique, obtenue par une ou plusieurs modifications de nature génétique et/ou chimique, ainsi que toute séquence hybridant avec ces séquences ou des fragments de celles-ci et codant pour un polypeptide selon l'invention. Par modification de nature génétique et/ou chimique, on peut entendre toute mutation, substitution, délétion, addition et/ou modification d'un ou plusieurs résidus.
<Desc/Clms Page number 10>
Le terme séquence nucléotidique dérivée comprend également les séquences homologues à la séquence considérée, issues d'autres sources cellulaires et notamment de cellules d'origine humaine, ou d'autres organismes.
A cet égard la présente invention concerne toute séquence nucléotidique qui présente au moins 70 % d'identité et de préférence au moins 85 % d'identité avec la séquence nucléotidique SEQ ID N 23 ou la séquence nucléotidique SED ID N 22 ou la séquence nucléotidique SEQ ID N 9.
De préférence, la séquence nucléotidique selon l'invention présente au moins 90 % et de préférence encore au moins 93 % d'identité avec la séquence nucléotidique SEQ ID N 23 ou la séquence nucléotidique SED ID N 22 ou la séquence nucléotidique SEQ ID N 9.
De manière plus particulièrement préférée, les séquences selon l'invention présentent au moins 95 % et de préférence encore 97 %, voire 98 % ou même 99 % d'identité avec la séquence nucléotidique SEQ ID N 23 ou la séquence nucléotidique SED ID N 22 ou la séquence nucléotidique SEQ ID N 9.
De telles séquences homologues peuvent être obtenues par des expériences d'hybridation. Les hybridations peuvent être réalisées à partir de banques d'acides nucléiques, en utilisant comme sonde, la séquence native ou un fragment de celle-ci, dans des conditions variables d'hybridation.
Un autre objet de l'invention concerne des séquences nucléotidiques capables de s'hybrider dans des conditions de stringence élevée avec les séquences nucléotidiques définies ci-avant.
A cet égard, le terme condition de stringence élevée signifie que l'hybridation se produit si les séquences nucléotidiques présentent au moins 95 % et préféretiellement au moins 97 % d'identité.
<Desc/Clms Page number 11>
Comme indiqué ci-avant, de telles séquences peuvent être notamment utilisées comme sondes de détection avec du RNA ou du cDNA ou du DNA génomique pour isoler des séquences nucléotidiques codant pour des polypeptides selon l'invention. De telles sondes ont généralement au moins 15 bases. De préférence, ces sondes font au moins 30 bases et peuvent avoir plus de 50 bases. De manière préférée, ces sondes ont entre 30 et 50 bases.
Les séquences nucléotidiques selon l'invention peuvent être d'origine artificielle ou non. Il peut s'agir de séquences génomiques, d'ADNc, d'ARN, de séquences hybrides ou de séquences synthétiques ou semi-synthétiques. Ces séquences peuvent être obtenues par exemple par criblage de banques d'ADN (banque d'ADNc, banque d'ADN génomique) au moyen de sondes élaborées sur la base de séquences présentées ci-avant. De telles banques peuvent être préparées à partir de cellules de différentes origine par des techniques classiques de biologie moléculaire connues de l'homme du métier. Les séquences nucléotidiques de l'invention peuvent également être préparées par synthèse chimique ou encore par des méthodes mixtes incluant la modification chimique ou enzymatique de séquences obtenues par criblage de banques. D'une manière générale les acides nucléiques de l'invention peuvent être préparés selon toute technique connue de l'homme du métier.
Au sens de la présente invention la dénomination formes oncogéniques ou forme mutées oncogéniques de p53 désigne les mutants dominant-oncogéniques, dont le produit est une protéine qui a perdu la capacité de se lier à l'ADN et qui participe activement à la transformation néoplasique. Les mutants de cette catégorie ont perdu leur capacité transactivatrice et sont plus stables que la protéine sauvage.
Les représentants de cette catégorie de mutants de p53 sont notamment les formes mutantes H 175, G281, W248, et A 143.
Un autre objet de la présente invention concerne un procédé de préparation des polypeptides selon l'invention selon lequel on cultive une cellule contenant une
<Desc/Clms Page number 12>
séquence nucléotidique selon l'invention, dans des conditions d'expression de ladite séquence et on récupère le polypeptide produit. Dans ce cas, la partie codant pour ledit polypeptide est généralement placée sous le contrôle de signaux permettant son expression dans un hôte cellulaire. Le choix de ces signaux (promoteurs, terminateurs, séquence leader de sécrétion, etc. ) peut varier en fonction de l'hôte cellulaire utilisé. Par ailleurs, les séquences nucléotidiques de l'invention peuvent faire partie d'un vecteur qui peut être à réplication autonome ou intégratif. Plus particulièrement, des vecteurs à réplication autonome peuvent être préparés en utilisant des séquences à réplication autonome chez l'hôte choisi. S'agissant de vecteurs intégratifs, ceux-ci peuvent être préparés, par exemple, en utilisant des séquences homologues à certaines régions du génome de l'hôte, permettant, par recombinaison homologue, l'intégration du vecteur.
La présente invention a également pour objet des cellules hôtes transformées avec un acide nucléique comportant une séquence nucléotidique selon l'invention.
Les hôtes cellulaires utilisables pour la production des peptides de l'invention par voie recombinante sont aussi bien des hôtes eucaryotes que procaryotes. Parmi les hôtes eucaryotes qui conviennent, on peut citer les cellules animales, les levures, ou les champignons. En particulier, s'agissant de levures, on peut citer les levures du genre Saccharomyces, Kluyveromyces, Pichia, Schwanniomyces, ou Hansenula.
S'agissant de cellules animales, on peut citer les cellules d'insectes (SF9 ou SF21), les cellules COS, CHO, C127, de neuroblastomes humains etc. Parmi les champignons, on peut citer plus particulièrement Aspergillus ssp. ou Trichoderma ssp. Comme hôtes procaryotes, on préfère utiliser les bactéries suivantes E.coli, Bacillus, ou Streptomyces.
Selon un mode préféré, les cellules hôtes sont avantageusement représentées par des souches de levures recombinantes pour l'expression des acides nucléiques de l'invention ainsi que la production des protéines dérivées de ceux-ci.
<Desc/Clms Page number 13>
Préférentiellement, les cellules hôtes comprennent au moins une séquence ou un fragment de séquence choisis parmi les séquences nucléotidiques SEQ ID N 16, N 21, N 9, N 15 et N 26 pour la production des polypeptides selon l'invention.
Une autre application des séquences d'acides nucléiques selon l'invention est la réalisation d'oligonucléotides antisens ou d'antisens génétiques utilisables comme agents pharmaceutiques. Les séquences antisens sont des oligonucléotides de petite taille, complémentaires du brin codant d'un gène donné, et de ce fait capables d'hybrider spécifiquement avec l'ARNm transcrit, inhibant la traduction en protéine.
L'invention a ainsi pour objet les séquences antisens capables d'inhiber, au moins partiellement , l'expression de polypeptides capables d'interagir avec la p53 comme la protéine MBP1ou la fibuline2. De telles séquences peuvent être constituées par tout ou partie des séquences nucléotidiques définies ci-avant et peuvent être obtenus par fragmentation, etc. ou par synthèse chimique.
Les séquences nucléotidiques selon l'invention peuvent être utilisées pour le transfert et la production in vitro, in vivo ou ex vivo de séquences antisens ou pour l'expression de protéines ou de polypeptides capables d'interagir avec la protéine p53.
A cet égard les séquences nucléotidiques selon l'invention peuvent être incorporées dans des vecteurs viraux ou non viraux, permettant leur administration in vitro, in vivo ou ex vivo.
Un autre objet de l'invention concerne en outre tout vecteur comprenant une séquence nucléotidique définie ci-avant. Le vecteur de l'invention peut être par exemple un plasmide, un cosmide ou tout ADN non encapsidé par un virus, un phage, un chromosome artificiel, un virus recombinant etc. Il s'agit de préférence d'un plasmide ou d'un virus recombinant.
<Desc/Clms Page number 14>
A titre de vecteurs viraux conformes à l'invention on peut tout particulièrement citer les vecteurs de type adénovirus, rétrovirus, virus adéno- associés, virus de l'herpès ou virus de la vaccine. La présente demande a également pour objet des virus recombinants défectifs comprenant une séquence nucléique hétérologue codant pour un polypeptide selon l'invention.
L'invention permet également la réalisation de sondes nucléotidiques, synthétiques ou non, capables de s'hybrider avec les séquences nucléotidiques définies ci-avant ou des ARNm correspondants. De telles sondes peuvent être utilisées in vitro comme outil de diagnostic, pour la détection des polypeptides selon l'invention et notamment de la protéine MBP1humaine ou de la fibuline 2. Ces sondes peuvent également être utilisées pour la mise en évidence d'anomalies génétiques (mauvais épissage, polymorphisme, mutations ponctuelles, etc). Ces sondes peuvent ausi être utilisées pour la mise en évidence et l'isolement de séquences d'acides nucléiques homologues codant pour les polypeptides tels que définis précédemment, à partir d'autres sources cellulaires et préférentiellement de cellules d'origines humaines. Les sondes de l'invention comportent généralement au moins 10 nucléotides, de préférence au moins 15 nucléotides, et de préférence encore au moins 20 nucléotides. Préférentiellement, ces sondes sont marquées préalablement à leur utilisation. Pour cela, différentes techniques connues de l'homme du métier peuvent être employées (marquage radioactif, enzymatique, etc).
Un autre objet de l'invention réside dans des anticorps ou fragments d'anticorps polyclonaux ou monoclonaux dirigés contre un polypeptide tel que défini ci-avant. De tels anticorps peuvent être générés par des méthodes connues de l'homme du métier. En particulier ces anticorps peuvent être préparés par immunisation d'un animal contre un polypeptide dont la séquence est choisie parmi les séquences SEQ ID N 8 ou SEQ ID N 26 ou les séquences polypeptidiques SEQ ID N 23 ou SEQ ID N 9 ou tout fragment ou dérivé de celles-ci, puis prélèvement du
<Desc/Clms Page number 15>
sang et isolement des anticorps. Ces anticorps peuvent également être générés par préparation d'hybridomes selon les techniques connues de l'homme de l'art.
L'invention a également pour objet des anticorps simple chaîne ScFv dérivés des anticorps monoclonaux définis ci-avant. De tel anticorps simple chaîne peuvent être obtenus selon les techniques décrites dans les brevet US 4,946,778, US 5,132,405 et US 5,476,786.
Les anticorps ou fragments d'anticorps selon l'invention peuvent notamment être utilisés pour inhiber et/ ou révéler l'interaction entre la p53 et les polypeptides tels que définis ci-avant.
Un autre objet de la présente invention concerne un procédé d'identification de composés capables de se lier aux polypeptides selon l'invention. La mise en évidence et/ou l'isolement de ces composés, peut-être réalisée selon les étapes suivantes : - on met en contact une molécule ou un mélange contenant différentes molécules, éventuellement non-identifiées, avec un polypeptide de l'invention dans des conditions permettant l'interaction entre ledit polypeptide et ladite molécule dans le cas où celle-ci posséderait une affinité pour ledit polypeptide, et, - on détecte et/ou isole les molécules liées au dit polypeptide de l'invention.
Selon un mode particulier, un tel procédé permet d'identifier des molécules capables de s'opposer ou de bloquer l'activité de stimulation de la croissance cellulaire des polypeptides selon l'invention et notamment de la protéine MBP1 humaine ou Fibuline 2 ou des fragments dérivés de ces protéines. Ces molécules sont également susceptibles de présenter des propriétés anti-cancéreuses et de s'opposer à la fonction d'oncogènes immortalisants que présentent MBP1ou les polypeptides
<Desc/Clms Page number 16>
dérivés de MBP1qui coopèrent avec la forme activée de la protéine Ras pour la transformation cellulaire.
A cet égard, un autre objet de l'invention concerne l'utilisation d'un ligand identifié et/ou obtenu selon le procédé décrit ci-avant comme médicament. De tels ligands sont en effet susceptibles de traiter certaines affections impliquant un dysfonctionnement du cycle cellulaire et notamment les cancers.
Un autre objet de la présente invention concerne un procédé d'identification de composés capables de moduler ou d'inhiber totalement ou partiellement l'interaction entre les formes mutées oncogènes de p53 et les polypeptides selon l'invention.
La mise en évidence et/ou l'isolement de modulateurs ou de ligands capables de moduler ou d'inhiber totalement ou partiellement l'interaction entre les formes mutées oncogènes de p53 et les polypeptides selon l'invention, peut-être réalisée selon les étapes suivantes : - on réalise la liaison d'une forme mutée de p53 ou d'un fragment de celle-ci à un polypeptide selon l'invention ; il peut s'agir des formes mutées de p53 telles que H 175, G281, W248, ou A 143 ou d'un fragment de celles-ci, il s'agit préférentiellement de la forme H 175 ou encore de la forme G281.
- on ajoute un composé à tester pour sa capacité à inhiber la liaison entre la forme mutée de p53 et les polypeptides selon l'invention ; - on détermine si la forme mutée de p53 ou les polypeptides selon l'invention sont déplacés de la liaison ou empêchés de se lier ; - on détecte et/ou isole les composés qui empêchent ou qui gênent la liaison entre la forme mutée de p53 et les polypeptides selon l'invention.
<Desc/Clms Page number 17>
Dans un mode particulier, ce procédé de l'invention est adapté à la mise en évidence et/ou l'isolement d'agonistes et d'antagonistes de l'interaction entre les formes mutées de p53 et les polypeptides de l'invention. Toujours selon un mode particulier, l'invention fournit un procédé d'identification de molécules capables de bloquer l'interaction entre les formes mutées de p53 et la protéine MBP1humaine ou fibuline 2 humaine. Un tel procédé permet d'identifier des molécules capables de s'opposer aux effets de l'action des polypeptides selon l'invention avec les formes mutées de p53. En particulier de tels composés sont susceptibles de prévenir la coopération oncogénique entre la protéine MBP1 et les formes mutantes oncogéniques de p53 telle notamment H175.
A cet égard, un autre objet de l'invention concerne l'utilisation d'un ligand ou d'un modulateur identifié et/ou obtenu selon le procédé décrit ci-avant comme médicament. De tels ligands ou modulateurs sont en effet susceptibles de traiter certaines affections impliquant un dysfonctionnement du cycle cellulaire et notamment des cancers.
L'invention fournit également des composés non peptidiques ou non exclusivement peptidiques utilisables pharmaceutiquement. Il est en effet possible, à partir des motifs protéiques actifs décrits dans la présente demande, de réaliser des molécules inhibitrices de l'interaction de MBP1 ou de la fibuline2 avec les formes mutées oncogéniques de p53, ces molécules étant non exclusivement peptidiques et compatibles avec une utilisation pharmaceutique. A cet égard, l'invention concerne l'utilisation d'un polypeptide de l'invention tel que décrit ci-avant pour la préparation de molécules non-peptidiques, ou non exclusivement peptidiques, actives pharmacologiquement, par détermination des éléments structuraux de ce polypeptide qui sont importants pour son activité et reproduction de ces éléments par des structures non-peptidiques ou non exclusivement peptidiques. L'invention a aussi pour objet des compositions pharmaceutiques comprenant une ou plusieurs molécules ainsi préparées.
<Desc/Clms Page number 18>
L'invention a encore pour objet toute composition pharmaceutique comprenant comme principe actif au moins un ligand obtenu selon l'un et/ou l'autre des procédés décrit ci-avant, et/ou au moins un anticorps ou fragment d'anticorps, et/ou un oligonucléotide antisens, et/ou un composé non exclusivement peptidiques tels que décrits ci-avant.
Les compositions selon l'invention peuvent être utilisées pour moduler l'interaction des formes mutées oncogènes de p53 avec les polypeptides MBP 1 ou Fibuline 2 et de ce fait peuvent être utilisées pour moduler la prolifération de certain type cellulaires. Plus particulièrement ces compositions pharmaceutiques sont destinées au traitement des maladies impliquant un dysfonctionnement du cycle cellulaire et notamment au traitement des cancers. Il s'agit en particulier des cancers associés à la présence de mutants oncogéniques de p53.
D'autres avantages de la présente invention apparaîtront à la lecture des exemples qui suivent et qui doivent être considérés comme illustratifs et non limitatifs.
Légende des Figures Figure 1 : Domaines fonctionnels de la protéine p53 sauvage. TA : Domaine activateur de la transcription ; domaine de liaison à l'ADN; NLS : signal de localisation nucléaire ; domaine d'oligomérisation; REG : domaine de régulation.
Figure 2 : entre la protéine C-mbpl et les protéines p53 et H 175 en cellules mammifères.
Figure 3 : entre la protéine C-fibulin2 et les protéines p53 et H175 en cellules mammifères.
Figure 4 : Comparaison des séquences protéiques codées par les ADNc mMBP
<Desc/Clms Page number 19>
(murine) et hMBP1 (humaine).
Figure 5 : Effetscomparés des protéines C-mbpl et mbp murine sur la croissance cellulaire de cellules tumorales.
Figure 6 : Expression de l'ARNm codant pour la protéine MBP1chez la souris.
Figure 7 : de l'ARNm codant pour la protéine MBP1 dans différents tissus humains.
Exemple 1 - Construction des différents fragments nucléotidiques nécessaires au criblage
1-a - Construction du cDNA codant pour la p53 sauvage humaine
Le gène de la p53 humaine a été cloné par réaction d'amplification en chaine (PCR) sur de l'ADN d'une banque de placenta humain (Clontech) en utilisant les oligonucléotides 5'-l et 3'-393.
1-a - Construction du cDNA codant pour la p53 sauvage humaine
Le gène de la p53 humaine a été cloné par réaction d'amplification en chaine (PCR) sur de l'ADN d'une banque de placenta humain (Clontech) en utilisant les oligonucléotides 5'-l et 3'-393.
Oligonucléotide 5'-1(SEQ ID N 1) :
AGATCTGTATGGAGGAGCCGCAG
Oligonucléotide 3'-393 (SEQ ID N 2) :
AGATCTCATCAGTCTGAGTCAGGCCCTTC
Ce produit a ensuite été cloné directement après PCR dans le vecteur pCRII (Invitrogène).
AGATCTGTATGGAGGAGCCGCAG
Oligonucléotide 3'-393 (SEQ ID N 2) :
AGATCTCATCAGTCTGAGTCAGGCCCTTC
Ce produit a ensuite été cloné directement après PCR dans le vecteur pCRII (Invitrogène).
1-b - Construction des cDNA codant pour les différentes formes mutées de la p53 humaine
<Desc/Clms Page number 20>
1-b.(i) - Construction du cDNA codant pour le mutant H 175 de la p53 humaine Le cDNA portant une mutation ponctuelle sur l'acide aminé 175 de la protéine p53 humaine (Arginine-> Histidine) a été obtenu par mutagénèse dirigée sur l'ADN de p53 (décrit dans l'exemple 1-a) au moyen du kit Amersham, en utilisant l'oligonucléotide H175 de séquence : Oligonucléotide H 175 3' (SEQ ID N 3) :
GGGGCAGTGCCTCAC Ce fragment a été désigné H175.
GGGGCAGTGCCTCAC Ce fragment a été désigné H175.
1-b. (ii) - Construction du cDNA codant pour le mutant W248 de la p53 humaine Le cDNA portant une mutation ponctuelle sur l'acide aminé 248 de la protéine p53 humaine (Arginine-> Tryptophane) a été obtenu par mutagénèse dirigée sur l'ADN de p53 (décrit dans l'exemple 1-a) au moyen du kit Amersham, en utilisant l'oligonucléotide W248 de séquence : Oligonucléotide W248 3' (SEQ ID N 4) :
GGGCCTCCAGTTCAT Ce fragment a été désigné W248.
GGGCCTCCAGTTCAT Ce fragment a été désigné W248.
1-b (iii) - Construction du cDNA codant pour le mutant H273 de la p53 humaine
Le cDNA portant une mutation ponctuelle sur l'acide aminé 273 de la protéine p53 humaine (Aspartate-> Histidine) a été obtenu par mutagénèse dirigée sur l'ADN de p53 (décrit dans l'exemple 1-a) au moyen du kit Amersham, en utilisant l'oligonucléotide H273 de séquence :
Le cDNA portant une mutation ponctuelle sur l'acide aminé 273 de la protéine p53 humaine (Aspartate-> Histidine) a été obtenu par mutagénèse dirigée sur l'ADN de p53 (décrit dans l'exemple 1-a) au moyen du kit Amersham, en utilisant l'oligonucléotide H273 de séquence :
<Desc/Clms Page number 21>
Oligonucléotide H273 3' (SEQ ID N 5) :
ACAAACATGCACCTC Ce fragment a été désigné H273.
ACAAACATGCACCTC Ce fragment a été désigné H273.
1-b (iv) - Construction du cDNA codant pour le mutant G281 de la p53 humaine Le cDNA portant une mutation ponctuelle sur l'acide aminé 281 de la protéine p53 humaine (Asparagine-> Glycine) a été obtenu par mutagénèse dirigée sur l'ADN de p53 (décrit dans l'exemple 1-a) au moyen du kit Amersham, en utilisant l'oligonucléotide G281 de séquence : Oligonucléotide G281 3' (SEQ ID N 6) :
GCGCCGGCCTCTCCC Ce fragment a été désigné G28 1.
GCGCCGGCCTCTCCC Ce fragment a été désigné G28 1.
1-c - Construction des cDNA codant pour les fragments 73-393 de la p53 humaine sauvage et du mutant H175
1-c (i) - Construction du cDNA codant pour le fragment 73-393 de la p53 humaine sauvage Cet exemple décrit la construction d'un cDNA codant pour les acides aminés 73 à 393 de la protéine p53 humaine sauvage (73-393wt).
1-c (i) - Construction du cDNA codant pour le fragment 73-393 de la p53 humaine sauvage Cet exemple décrit la construction d'un cDNA codant pour les acides aminés 73 à 393 de la protéine p53 humaine sauvage (73-393wt).
Ce cDNA a été obtenu par réaction d'amplification en chaine (PCR) sur l'ADN de p53 (décrit dans l'exemple 1-a) avec l'oligonucléotide 3'-393 (SEQ ID N 2) et l'oligonucléotide 5'-73 suivant : 5'-73 (SEQ ID N 7) :
AGATCTGTGTGGCCCCTGCACCA
AGATCTGTGTGGCCCCTGCACCA
<Desc/Clms Page number 22>
1-c (ii) - Construction du cDNA codant pour le fragment 73-393 du mutant H175 Cet exemple décrit la construction d'un cDNA codant pour les acides aminés 73 à 393 du mutant H 175 de la protéine p53 humaine (73-393H 175).
Ce cDNA a été obtenu par réaction d'amplification en chaine (PCR) sur l'ADN du mutant (décrit dans l'exemple 1-b) avec les oligonucléotides 3'-393 (SEQ ID N 2) et 5'-73 (SEQ ID N 7).
Exemple 2 - Construction des vecteurs d'expression dans la levure des fragments 73-393wt et 73-393H175 fusionnés au domaine de liaison à l'ADN de la protéine Gal4 et des différentes formes de la p53 humaine entière (sauvage et mutée) fusionnées au domaine d'activation de la transcription de la protéine Gal4
Cet exemple décrit la construction de vecteurs permettant l'expression dans la levure des fragments 73-393wt et 73-393H175 sous forme d'une fusion avec le domaine de liaison à l'ADN de la protéine Gal4 (DB) de la levure S. cerevisiae pour leur utilisation dans le système double-hybride et pour le criblage de banques de cDNA fusionnés au domaine d'activation de la transcription (transactivateur) de la même protéine Gal4 (TA).
Cet exemple décrit la construction de vecteurs permettant l'expression dans la levure des fragments 73-393wt et 73-393H175 sous forme d'une fusion avec le domaine de liaison à l'ADN de la protéine Gal4 (DB) de la levure S. cerevisiae pour leur utilisation dans le système double-hybride et pour le criblage de banques de cDNA fusionnés au domaine d'activation de la transcription (transactivateur) de la même protéine Gal4 (TA).
2-a - Construction des vecteurs d'expression de levure des fragments 73-393wt et 73-393H175 fusionnés au domaine de liaison à l'ADN de la protéine Gal4 Les fragments 73-393wt et 73-393H175 ont été clonés dans le vecteur pPC97 (Chevray et al, Proc. Natl. Acad. Sci. USA 89 (1992) 5789) en utilisant le site de reconnaissance par l'enzyme de restriction Bgl II.
Les produits de ces constructions portent les noms suivants:
<Desc/Clms Page number 23>
73-393wt dans pPC97 --> (plasmide pMA 1 ) --> DB-wt
73-393H 175 dans pPC97 --> (plasmide pEC 16)--> DB-H 175 2-b - Construction des vecteurs d'expression de levure des différentes formes de la p53 humaine entière (sauvage et mutée) fusionnées au domaine d'activation de la transcription de la protéine Gal4 Les différentes formes de la p53 humaine entière (sauvage et mutée) ont été clonés dans le vecteur pPC86 (Chevray et al, Proc. Natl. Acad. Sci. USA 89 (1992) 5789) en utilisant le site de reconnaissance par l'enzyme de restriction Bgl II.
73-393H 175 dans pPC97 --> (plasmide pEC 16)--> DB-H 175 2-b - Construction des vecteurs d'expression de levure des différentes formes de la p53 humaine entière (sauvage et mutée) fusionnées au domaine d'activation de la transcription de la protéine Gal4 Les différentes formes de la p53 humaine entière (sauvage et mutée) ont été clonés dans le vecteur pPC86 (Chevray et al, Proc. Natl. Acad. Sci. USA 89 (1992) 5789) en utilisant le site de reconnaissance par l'enzyme de restriction Bgl II.
Les produits de ces constructions portent les noms suivants:

p53 dans pPC86 --> (plasmide pEC 10)--> TA-wt H175 dans pPC86 --> (plasmide pEC20)--> TA-H175 H273 dans pPC86 --> (plasmide pEC87)--> TA-H273 G281 dans pPC86 --> (plasmide pEC88)--> TA-G281 Exemple 3 - Clonage par le système double-hybride des partenaires de la protéine H175, et caractérisation de cette interaction en terme de spécificité dans la levure
Cet exemple décrit l'obtention des partenaires de la protéine H175 par le système double-hybride en utilisant la banque de cDNA d'embryon de souris pPC67 (Chevray et al, Proc. Natl. Acad. Sci. USA 89 (1992) 5789), et la caractérisation, à l'aide du même système double-hybride, de ces partenaires en terme de spécificité d'interaction avec les différentes formes de la protéine p53 humaine (sauvage et mutée).
p53 dans pPC86 --> (plasmide pEC 10)--> TA-wt H175 dans pPC86 --> (plasmide pEC20)--> TA-H175 H273 dans pPC86 --> (plasmide pEC87)--> TA-H273 G281 dans pPC86 --> (plasmide pEC88)--> TA-G281 Exemple 3 - Clonage par le système double-hybride des partenaires de la protéine H175, et caractérisation de cette interaction en terme de spécificité dans la levure
Cet exemple décrit l'obtention des partenaires de la protéine H175 par le système double-hybride en utilisant la banque de cDNA d'embryon de souris pPC67 (Chevray et al, Proc. Natl. Acad. Sci. USA 89 (1992) 5789), et la caractérisation, à l'aide du même système double-hybride, de ces partenaires en terme de spécificité d'interaction avec les différentes formes de la protéine p53 humaine (sauvage et mutée).
3-a - Isolement des partenaires de la protéine H175
3-a (i) - Génotype de la souche YCM 17
3-a (i) - Génotype de la souche YCM 17
<Desc/Clms Page number 24>
La souche YCM17 utilisée pour l'isolement des partenaires et pour la caractérisation de leur interaction avec les différentes formes de la protéine p53 humaine par le système double-hybride est une souche de levure du genre Saccharomyces cerevisiae qui possède le génotype suivant: MATa. #gal4. #gal80, lys2, his3, trpl, leu2, ade2, ura3, canl, met16::URA3 pGALl- 10 LacZ.
Cette souche de levure permet de détecter une réponse positive en système double-hybride par l'apparition du phénotype Ura+ et/ou du double phénotype Ura+/LacZ+.
3-a (ii) - Génotype de la souche TG La souche TG1 utilisée pour la purification des ADN plasmidiques est une souche de bactérie du genre E.coli qui possède le génotype suivant: supE, hsdD5, thi, D(lac-proAB), F'[tra D36 proA+B+ lacIq lacZDM15]
3-a (iii) - Construction de la souche YMA1 La souche YCM17 a été transformée par la méthode de Gietz et al (Yeast Il(1995) 355) avec 1 g du plasmide pMA1permettant ainsi l'obtention de la souche YMA1 qui exprime la protéine DB-H175.
3-a (iii) - Construction de la souche YMA1 La souche YCM17 a été transformée par la méthode de Gietz et al (Yeast Il(1995) 355) avec 1 g du plasmide pMA1permettant ainsi l'obtention de la souche YMA1 qui exprime la protéine DB-H175.
3-a (iv) - Isolement des partenaires de la protéine Hl 75 La souche YMA1 a été transformée par la même méthode que celle utilisée dans l'exemple CI.3en utilisant 100 g d'ADN de la banque pPC67, permettant l'obtention de 3,5.10 transformants parmi lesquels 404 présentent le phénotype Ura+ et 14 le double phénotype Ura+/LacZ+.
L'ADN plasmidique contenu dans les 14 clones présentant le double phénotype Ura+/LacZ+ a été isolé par la méthode de Ward (Nucl. Acids Res. 18 (1990) 5319)
<Desc/Clms Page number 25>
avant d'être utilisé pour transformer la souche TG1. Les plasmides correspondants issus de la banque ont ensuite été purifiés et regroupés en deux sous-groupes de plasmides différents contenant chacun un cDNA codant pour deux protéines différentes : - un cDNA codant pour la partie C-terminale (SEQ ID N 8) d'un nouveau gène.
- un cDNA codant pour la partie C-terminale de la fibuline 2 murine (acides aminés 863 à 1195 (SEQ ID N 9)) (Pan et al, J. Cell. Biol. 123 (1993) 1269).
Les protéines codées par ces deux cDNA sont appelées respectivement C-mbpl(mbp = 'p53 Mutant Binding Protein') et C-fibuline2, les protéines de fusion avec le domaine d'activation de la transcription de Gal4, TA-C-mbplet TA-C-fibuline2 et les plasmides correspondants TA -C-MBP 1 et TA-C-FIB2 3 - b - Caractérisation de l'interaction entre les protéines C-mbpl et C-fibuline2 et la protéine H175 en terme de spécificité dans la levure
3 - b (i) - Caractérisation de la spécificité de l'interaction entre la protéine DB- H175 et les protéines TA-C-mbplet TA-C-fibuline2 Dans le but de tester la spécificité des interactions décrites dans l'exemple 3-a (iv), les plasmides pPC86, TA-C-MBP 1 et TA-C-FIB2 ont été réintroduits dans la souche YCM17 par co-transformation avec différents plasmides : le plasmide pPC97 codant pour la protéine DB, le plasmide pMA1codant pour la protéine DB-H175, le plasmide pEC 10 codant pour la protéine DB-wt et le plasmide pPC76 codant pour une protéine de fusion entre le domaine de liason à l'ADN de la protéine Gal4 et un fragment de la protéine Fos humaine (acides aminés 132 à 211) (Chevray et al, Proc.
3 - b (i) - Caractérisation de la spécificité de l'interaction entre la protéine DB- H175 et les protéines TA-C-mbplet TA-C-fibuline2 Dans le but de tester la spécificité des interactions décrites dans l'exemple 3-a (iv), les plasmides pPC86, TA-C-MBP 1 et TA-C-FIB2 ont été réintroduits dans la souche YCM17 par co-transformation avec différents plasmides : le plasmide pPC97 codant pour la protéine DB, le plasmide pMA1codant pour la protéine DB-H175, le plasmide pEC 10 codant pour la protéine DB-wt et le plasmide pPC76 codant pour une protéine de fusion entre le domaine de liason à l'ADN de la protéine Gal4 et un fragment de la protéine Fos humaine (acides aminés 132 à 211) (Chevray et al, Proc.
Natl. Acad. Sci. USA, 89 (1992) 5789) (DB-Fos). Après la co-transformation, les différents clones obtenus ont été testés pour les phénotypes associés aux gènes URA3 et LacZ
<Desc/Clms Page number 26>
Les résultats de cette expérience sont présentés dans le Tableau 1.
Tableau 1: Spécificité de l'interaction entre la protéine DB-H175 et les protéines TAC-mbp1 et TA-C-fibuline2

<tb> TA <SEP> TA-C-mbpl <SEP> TA-C-fibuline2
<tb>
<tb> DB <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP>
<tb>
<tb> DB-H175 <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura <SEP> + <SEP> / <SEP> LacZ+ <SEP> Ura <SEP> + <SEP> / <SEP> LacZ+ <SEP>
<tb>
<tb> DB-wt <SEP> Ura-/LacZ- <SEP> Ura-/LacZ- <SEP> Ura-/LacZ-
<tb>
<tb> DB-Fos <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura-/LacZ- <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP>
<tb>
<tb>
<tb> DB <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP>
<tb>
<tb> DB-H175 <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura <SEP> + <SEP> / <SEP> LacZ+ <SEP> Ura <SEP> + <SEP> / <SEP> LacZ+ <SEP>
<tb>
<tb> DB-wt <SEP> Ura-/LacZ- <SEP> Ura-/LacZ- <SEP> Ura-/LacZ-
<tb>
<tb> DB-Fos <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP> Ura-/LacZ- <SEP> Ura <SEP> - <SEP> / <SEP> LacZ- <SEP>
<tb>
Ces résultats montrent que l'interaction entre la protéine DB-H175 et les protéines TA-C-mbpl et TA-C-fibuline2 est spécifique et qu'une telle interaction ne peut être obtenue ni avec la protéine DB seule, ni avec la protéine DB-wt ni avec la protéine contrôle DB-Fos.
3-b (ii) - Construction de protéines de fusion entre le domaine liaison à l'ADN de Gal4 et les protéines C-mbpl et C-fibuline2
Les cDNA codant pour C-mbpl et C-fibuline2 ont été extraits des plasmides TA-C-MBPI et TA-C-FIB2, puis clonés dans le vecteur pPC97 en utilisant les sites de reconnaissance par les enzymes de restriction Sal I et Not I.
Les cDNA codant pour C-mbpl et C-fibuline2 ont été extraits des plasmides TA-C-MBPI et TA-C-FIB2, puis clonés dans le vecteur pPC97 en utilisant les sites de reconnaissance par les enzymes de restriction Sal I et Not I.
Les protéines de fusion avec le domaine de liaison à l'ADN de Gal4 ainsi obtenues sont appelées respectivement DB-C-mbpl et DB-C-fibuline2 et les plasmides correspondants DB-C-MBP1et DB-C-FIB2.
<Desc/Clms Page number 27>
3-b (iii) Caractérisation de la spécificité de l'interaction entre les DB-C-mbpl et DB-C-fibuline2 et les protéines TA-H175 et TA-G281
Dans le but de vérifier que l'interaction potentielle entre les protéines C-mbpl et C-fibuline2 et la protéine H 175 n'est pas un artefact dû à la fusion de l'un ou l'autre des partenaires avec l'un ou l'autre des domaines de Gal4, et de confirmer la spécificité de l'interaction avec la forme mutante de la protéine p53, une nouvelle expérience d'interaction dans la levure a été effectuée en utilisant des fusions différentes de celles de l'exemple 3-b (i).
Dans le but de vérifier que l'interaction potentielle entre les protéines C-mbpl et C-fibuline2 et la protéine H 175 n'est pas un artefact dû à la fusion de l'un ou l'autre des partenaires avec l'un ou l'autre des domaines de Gal4, et de confirmer la spécificité de l'interaction avec la forme mutante de la protéine p53, une nouvelle expérience d'interaction dans la levure a été effectuée en utilisant des fusions différentes de celles de l'exemple 3-b (i).
Dans cette expérience, les protéines DB-C-mbp 1 et DB-C-fibuline2 ont été testées contre les fusions du domaine d'activation de la transcription de Gal4 avec les formes entières de la protéine p53 (sauvage ou mutante) décrites dans l'exemple 2-b, en utilisant une souche de levure différente de la souche YCM17, la souche PCY2 (Chevray et al, Proc. Natl. Acad. Sci. USA 89 (1992) 5789).
Les résultats de cette expérience sont présentés dans le Tableau 2.
Tableau 2 : de l'interaction entre les protéines DB-C-mbpl et DB-C- fibuline2 et les protéines TA-H175 et TA-G281

<tb> TA <SEP> TA-wt <SEP> TA-H175 <SEP> TA-H273 <SEP> TA-G281
<tb>
<tb> DB <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP>
<tb>
<tb> DB-C-mbpl <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> + <SEP> LacZ <SEP> - <SEP> LacZ <SEP> +
<tb>
<tb> DB-C- <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> + <SEP> LacZ <SEP> - <SEP> LacZ <SEP> +
<tb>
<tb> fibuline2
<tb>
Ces résultats permettent d'une part de confirmer l'interaction observée lors du
<tb>
<tb> DB <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP>
<tb>
<tb> DB-C-mbpl <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> + <SEP> LacZ <SEP> - <SEP> LacZ <SEP> +
<tb>
<tb> DB-C- <SEP> LacZ <SEP> - <SEP> LacZ <SEP> - <SEP> LacZ <SEP> + <SEP> LacZ <SEP> - <SEP> LacZ <SEP> +
<tb>
<tb> fibuline2
<tb>
Ces résultats permettent d'une part de confirmer l'interaction observée lors du
<Desc/Clms Page number 28>
criblage. D'autre part, ces résultats mettent en évidence, la spécificité de l'interaction entre les protéines C-mbpl et C-fibuline2 et certaines formes mutées de la protéine p53. En ce qui concerne cette spécificité, il est intéressant de noter, que ces protéines n'interagissent pas avec le mutant H273. En effet, ce mutant présente une conformation équivalente à celle de la protéine p53 sauvage car il est reconnu par l'anticorps PAb 1620 qui est spécifique de la forme sauvage et pas par l'anticorps PAb 240 qui est spécifique de la forme mutée (Medcalf et al, Oncogene 7 (1992) 71).
Ainsi, l'ensemble des données obtenues dans la levures montrent clairement que les deux protéines C-mbpl et C-fibuline2 sont des partenaires potentiels spécifiques des mutants oncogéniques de la protéine p53.
Exemple 4 - Interaction entre les protéines C-mbpl, C-fibuline2 et les différentes formes de la protéine p53 en cellules mammifères Cet exemple décrit la construction de plasmides pour l'expression des différentes protéines en cellules mammifères et la caractérisation de l'interaction entre les protéines C-mbpl et C-fibuline2 et les différentes formes de la protéine p53 en cellules mammifères.
4-a Construction des plasmides d'expression des différentes protéines en cellules mammifères
4-a (i) Construction du vecteur d'expression pBFA 107
Cet exemple décrit la construction d'un vecteur permettant l'expression dans des cellules mammifères de protéines portant une étiquette dérivée de la protéine cmyc (acides aminés 410-419) et reconnue par l'anticorps 9E10 (Oncogene Science). Cette construction a été effectuée en utilisant comme vecteur de base le vecteur d'expression mammifère pSV2, décrit dans DNA Cloning, A practical approach Vol. 2, D. M. Glover (Ed) IRL Press, Oxford, Washington DC, 1985.
4-a (i) Construction du vecteur d'expression pBFA 107
Cet exemple décrit la construction d'un vecteur permettant l'expression dans des cellules mammifères de protéines portant une étiquette dérivée de la protéine cmyc (acides aminés 410-419) et reconnue par l'anticorps 9E10 (Oncogene Science). Cette construction a été effectuée en utilisant comme vecteur de base le vecteur d'expression mammifère pSV2, décrit dans DNA Cloning, A practical approach Vol. 2, D. M. Glover (Ed) IRL Press, Oxford, Washington DC, 1985.
<Desc/Clms Page number 29>
Le cDNA comprenant la séquence codant pour l'étiquette c-myc ainsi qu'un multisite de clonage (MCS) a été construit à partir des 4 oligonucléotides suivants : c-myc5'(SEQIDN 10):
GATCCATGGAGCAGAAGCTGATCTCCGAGGAGGACCTGA c-myc3'(SEQIDN ll):
GATCTCAGGTCCTCCTCGGAGATCAGCTTCTGCTCCATG MCS 5' (SEQ ID N 12):
GATCTCGGTCGACCTGCATGCAATTCCCGGGTGCGGCCGCGAGCT MCS 3' (SEQ ID N 13):
CGCGGCCGCACCCGGGAATTGCATGCAGGTCGACCGA
Ces quatre oligonucléotides présentent des complémentarités deux à deux (c- myc 5' / c-myc 3', MCS 5' / MCS 3') et des complémentarités chevauchantes (c-myc 3' / MCS 5') permettant l'obtention de la séquence nucléotidique désirée par simple hybridation et ligation. Ces oligonucléotides ont été phosphorylés à l'aide de la T4 kinase, puis hybridés tous ensemble et insérés dans le vecteur d'expression pSV2 préalablement digéré par les enzymes de restriction Bgl II et Sac I. Le vecteur résultant est le vecteur pBFA 107.
GATCCATGGAGCAGAAGCTGATCTCCGAGGAGGACCTGA c-myc3'(SEQIDN ll):
GATCTCAGGTCCTCCTCGGAGATCAGCTTCTGCTCCATG MCS 5' (SEQ ID N 12):
GATCTCGGTCGACCTGCATGCAATTCCCGGGTGCGGCCGCGAGCT MCS 3' (SEQ ID N 13):
CGCGGCCGCACCCGGGAATTGCATGCAGGTCGACCGA
Ces quatre oligonucléotides présentent des complémentarités deux à deux (c- myc 5' / c-myc 3', MCS 5' / MCS 3') et des complémentarités chevauchantes (c-myc 3' / MCS 5') permettant l'obtention de la séquence nucléotidique désirée par simple hybridation et ligation. Ces oligonucléotides ont été phosphorylés à l'aide de la T4 kinase, puis hybridés tous ensemble et insérés dans le vecteur d'expression pSV2 préalablement digéré par les enzymes de restriction Bgl II et Sac I. Le vecteur résultant est le vecteur pBFA 107.
4-a (ii) - Construction des plasmides d'expression des protéines C-mbpl et C- fibuline2 étiquetées
Les cDNA codant pour les protéines C-mbpl et C-fibuline2 ont été extraits des plasmides TA-C-MBPI et TA-C-FIB2 et clonés dans le vecteur d'expression mammifère pBFA 107 en utilisant les sites de reconnaissance par les enzymes de restriction Sal I et Not I. On obtient ainsi les plasmides pBFA107-C-MBPl et pBFA107-C-FIB2
Les cDNA codant pour les protéines C-mbpl et C-fibuline2 ont été extraits des plasmides TA-C-MBPI et TA-C-FIB2 et clonés dans le vecteur d'expression mammifère pBFA 107 en utilisant les sites de reconnaissance par les enzymes de restriction Sal I et Not I. On obtient ainsi les plasmides pBFA107-C-MBPl et pBFA107-C-FIB2
<Desc/Clms Page number 30>
4-a (iii) Construction des plasmides d'expression des différentes formes de la protéine p53
Les cDNA codant pour les différentes formes de la protéine p53 (wt, H 175, H273 et G281) ont été insérés dans les vecteurs d'expression pSV2 et pcDNA3 (Invitrogen) en utilisant le site de reconnaissance par l'enzyme de restriction Bgl II.
Les cDNA codant pour les différentes formes de la protéine p53 (wt, H 175, H273 et G281) ont été insérés dans les vecteurs d'expression pSV2 et pcDNA3 (Invitrogen) en utilisant le site de reconnaissance par l'enzyme de restriction Bgl II.
4 b - Interaction entre les protéines C-mbpl et C-fibuline2 et les différentes formes de la protéine p53 en cellules mammifères
Cet exemple décrit la mise en évidence dans des cellules mammifères de l'interaction entre les protéines C-mbpl et C-fibuline2 et les différentes formes de la protéine p53. Ces expériences ont été effectuées par transfection transitoire et co- immunoprécipitation dans les cellules H 1299 (cellules tumorales de type 'Non Small Cell Lung Cancer') déficientes pour les deux allèles de la protéine p53 (Mitsudomi et al, Oncogene 1 (1992) 171).
Cet exemple décrit la mise en évidence dans des cellules mammifères de l'interaction entre les protéines C-mbpl et C-fibuline2 et les différentes formes de la protéine p53. Ces expériences ont été effectuées par transfection transitoire et co- immunoprécipitation dans les cellules H 1299 (cellules tumorales de type 'Non Small Cell Lung Cancer') déficientes pour les deux allèles de la protéine p53 (Mitsudomi et al, Oncogene 1 (1992) 171).
Les cellules (106) sont ensemencées dans des boites de Pétri de 10 cm de diamètre contenant 8 ml de milieu DMEM (Gibco BRL) additioné de 10% de sérum de veau foetal inactivé à la chaleur, et cultivées sur la nuit dans un incubateur à CO2 (5%) à 37 C. Les différentes constructions sont alors transfectées en utilisant la lipofectAMINE (Gibco BRL) comme agent de transfection de la façon suivante : 6ug de plasmide total (3 g de chaque plasmide codant pour chacun des deux partenaires) sont incubés avec 20 l de lipofectAMINE (Gibco BRL) pendant 30 min avec 3 ml de milieu Opti-MEM (Gibco BRL) (mélange de transfection). Pendant ce temps, les cellules sont rincées deux fois au PBS puis incubées 4 h à 37 C avec le mélange de transfection, après quoi celui-ci est aspiré et remplacé par 8 ml de milieu DMEM additionné de 10% de sérum de veau foetal inactivé à la chaleur et les cellules remises à pousser à 37 C.
<Desc/Clms Page number 31>
Vingt quatre heures après la transfection, les cellules sont lavées une fois en PBS puis gratées, lavées de nouveau deux fois en PBS et remises en suspension dans 200 l de tampon de lyse (HNTG: Hepes 50 mM pH 7,5, NaCl 150 mM, Triton X-100
1%, glycérol 10%) additioné d'inhibiteurs de protéases (Aprotinine 2 g/ml, pepstatine 1 ug/ml, leupeptine 1 g/ml, E64 2 g/ml et Pefabloc 1 mM), incubées 30 min à 4 C et centrifugées 15 min à 15. 000 rpm et 4 C. L'extrait cellulaire ainsi obtenu est soumis à une étape de 'pré-clearing' par incubation 1h à 4 C avec 16 l d'un sérum de lapin pré-immun, puis 30 min à 4 C avec 200 l d'immunoprecipitin (Gibco BRL) préparée selon les recommandations du fournisseur. Par la suite, l'extrait cellulaire ainsi nettoyé est séparé en 3 lots égaux dont chacun est incubé la nuit à 4 C avec un anticorps différent; 3 g d'anticorps 9E 10 (anti myc), 1 g d'anticorps DO1 (anti p53) (Oncogene Science) et 1 g d'anticorps PAb416 (anti SV40 T-Ag, utilisé comme anticorps contrôle) (Oncogene Science). Ce mélange [extrait cellulaire/anticorps] est ensuite additionné de 30 l d'immunoprecipitin et incubé 30 min à 4 C avant d'être centrifugé 30 sec à 15. 000 rpm. Le culot contenant l'immunoprecipitin est ensuite lavé deux fois par 1 ml de tampon HNTG additionné d'inhibiteurs de protéases, puis resuspendu dans 30 l de tampon de dépot sur gel d'acrylamide (Laemmli, Nature 227 (1970) 680) et incubé 5 min à 95 C. Après centrigugation 15sec à 15. 000 rpm, les surnageants sont déposés sur gel de polyacrylamide en milieu dénaturant (Novex) et les protéines séparées en utilisant le système de migration XCell II (Novex) suivant les recommandations du fournisseur, puis transférées sur membrane de PVDF (NEN Life Science Products) à l'aide du même système XCell II.
1%, glycérol 10%) additioné d'inhibiteurs de protéases (Aprotinine 2 g/ml, pepstatine 1 ug/ml, leupeptine 1 g/ml, E64 2 g/ml et Pefabloc 1 mM), incubées 30 min à 4 C et centrifugées 15 min à 15. 000 rpm et 4 C. L'extrait cellulaire ainsi obtenu est soumis à une étape de 'pré-clearing' par incubation 1h à 4 C avec 16 l d'un sérum de lapin pré-immun, puis 30 min à 4 C avec 200 l d'immunoprecipitin (Gibco BRL) préparée selon les recommandations du fournisseur. Par la suite, l'extrait cellulaire ainsi nettoyé est séparé en 3 lots égaux dont chacun est incubé la nuit à 4 C avec un anticorps différent; 3 g d'anticorps 9E 10 (anti myc), 1 g d'anticorps DO1 (anti p53) (Oncogene Science) et 1 g d'anticorps PAb416 (anti SV40 T-Ag, utilisé comme anticorps contrôle) (Oncogene Science). Ce mélange [extrait cellulaire/anticorps] est ensuite additionné de 30 l d'immunoprecipitin et incubé 30 min à 4 C avant d'être centrifugé 30 sec à 15. 000 rpm. Le culot contenant l'immunoprecipitin est ensuite lavé deux fois par 1 ml de tampon HNTG additionné d'inhibiteurs de protéases, puis resuspendu dans 30 l de tampon de dépot sur gel d'acrylamide (Laemmli, Nature 227 (1970) 680) et incubé 5 min à 95 C. Après centrigugation 15sec à 15. 000 rpm, les surnageants sont déposés sur gel de polyacrylamide en milieu dénaturant (Novex) et les protéines séparées en utilisant le système de migration XCell II (Novex) suivant les recommandations du fournisseur, puis transférées sur membrane de PVDF (NEN Life Science Products) à l'aide du même système XCell II.
Les anticorps 9E 10 et DO1utilisés pour la révélation des protéines transférées sont couplés à la biotine LCnHS (Pierce) suivant les recommandations du fournisseur.
Les membranes de transfert sont tout d'abord incubées 1 h à 4 C dans 10 ml de tampon TTBSN (Tris-HCI 20 mM, pH 7,5, NaCI 150 mM, NaN3 0,02%, Tween 20 0,1%) additionné de 3% d'albumine bovine sérique (BSA) (TTBSN-BSA), puis 2 h à température ambiante avec 10 ml d'une solution de TTBSN-BSA contenant
<Desc/Clms Page number 32>
l'anticorps 9E10 biotinylé (1 ug/ml). Après 6 lavages par 10 ml de tampon TTBSN, les membranes sont ensuite incubées 1 h à température ambiante avec 10 ml d'une solution de TTBSN-BSA contenant de l'ExtrAvidin-Peroxidase (Sigma Immuno Chemicals) au 1/5000e, lavées de nouveau 6 fois au TTBSN et traitées au réactif ECL (Amersham) pour la révélation des protéines par chemiluminescence. Les mêmes membranes sont ensuite traitées par l'anticorps DO1 biotinylé après avoir été préalablement deshybridées (Ellis et al, Nature 343 (1990) 377) et en suivant le même protocole que pour l'anticorps 9E10.
4 - b (i) - Interaction entre la protéine C-mbp1 et les différentes formes de la protéine p53 en cellules mammifères
Dans cet exemple, les cellules H 1299 ont été transfectées avec les combinaisons de plasmides suivantes avant immunoprécipitation et Western-blot : pBFA107 / pBFA107-C-MBP1 (3 g) + pSV2 / pSV2-p53 (sauvage ou mutant) (3 ug) De plus la combinaison suivante servant de contrôle a été effectuée : pBFA107-Sam68 (3 g) + pSV2-H175 (3 g)
Ce contrôle sert à examiner si H 175 peut ou non interagir soit avec l'étiquette myc soit avec une fusion entre l'étiquette myc et une protéine quelconque, la protéine Sam68 décrite par Lock et al (Cell 84 (1996)23), n'étant pas censée interagir avec les différentes formes de la protéine p53.
Dans cet exemple, les cellules H 1299 ont été transfectées avec les combinaisons de plasmides suivantes avant immunoprécipitation et Western-blot : pBFA107 / pBFA107-C-MBP1 (3 g) + pSV2 / pSV2-p53 (sauvage ou mutant) (3 ug) De plus la combinaison suivante servant de contrôle a été effectuée : pBFA107-Sam68 (3 g) + pSV2-H175 (3 g)
Ce contrôle sert à examiner si H 175 peut ou non interagir soit avec l'étiquette myc soit avec une fusion entre l'étiquette myc et une protéine quelconque, la protéine Sam68 décrite par Lock et al (Cell 84 (1996)23), n'étant pas censée interagir avec les différentes formes de la protéine p53.
Les résultats de cette expérience qui sont présentés dans la Figure 2 montrent que : - la protéine C-mbpl peut interagir avec la protéine H 175 dans des cellules mammifères
<Desc/Clms Page number 33>
- cette interaction est bien spécifique de la protéine C-mbpl car la protéine H175 n'intéragit pas avec le contrôle myc-Sam68
4-b (ii) - Interaction entre la protéine C-fibuline2 et les différentes formes de la protéine p53 en cellules mammifères
Dans cet exemple, les cellules H 1299 ont été transfectées avec les combinaisons de plasmides suivantes avant immunoprécipitation et Westem-blot : pBFA107 / pBFAI07-C-FIB2 (3 g) + pSV2 / pSV2-p53 (sauvage ou mutant) (3 ug)
Les résultats de cette expérience qui sont présentés dans la Figure 3 montrent que la protéine C-fibuline2 peut interagir spécifiquement avec la protéine H175 dans des cellules mammifères.
4-b (ii) - Interaction entre la protéine C-fibuline2 et les différentes formes de la protéine p53 en cellules mammifères
Dans cet exemple, les cellules H 1299 ont été transfectées avec les combinaisons de plasmides suivantes avant immunoprécipitation et Westem-blot : pBFA107 / pBFAI07-C-FIB2 (3 g) + pSV2 / pSV2-p53 (sauvage ou mutant) (3 ug)
Les résultats de cette expérience qui sont présentés dans la Figure 3 montrent que la protéine C-fibuline2 peut interagir spécifiquement avec la protéine H175 dans des cellules mammifères.
La conclusion générale de ces expériences est que les protéines C-mbp 1 et Cfibuline2 sont capables d'interagir spécifiquement en cellules mammifères avec la protéines H175. Ces résultats de même que ceux obtenus dans la levure (exemple 3) sont en accord avec :
1/ la classification des mutants de la protéine p53 : - H175 et G281: dominants oncogéniques - H273 : faible
2/ la classification des différentes formes de la protéine p53 en terme de conformation et de reconnaissance par des anticorps conformationnels : - H 175 et G281 : mutante, PAb 1620 - / PAb 240 + - p53 et H273 : conformationsauvage, PAb 1620 + / Pab 240 -
L'ensemble des ces données montrent que les protéines C-mbpl et C-fibuline2 interagissent avec les formes de la protéine p53 présentant une conformation mutée, et qu'elles sont susceptibles d'avoir un effet sur des fonctions spécifiques des formes
1/ la classification des mutants de la protéine p53 : - H175 et G281: dominants oncogéniques - H273 : faible
2/ la classification des différentes formes de la protéine p53 en terme de conformation et de reconnaissance par des anticorps conformationnels : - H 175 et G281 : mutante, PAb 1620 - / PAb 240 + - p53 et H273 : conformationsauvage, PAb 1620 + / Pab 240 -
L'ensemble des ces données montrent que les protéines C-mbpl et C-fibuline2 interagissent avec les formes de la protéine p53 présentant une conformation mutée, et qu'elles sont susceptibles d'avoir un effet sur des fonctions spécifiques des formes
<Desc/Clms Page number 34>
mutées de la protéine p53.
De plus, de par la littérature, on sait qu'une fraction de la protéine p53 peut exhiber une conformation mutante dans les cellules mammifères, en particulier :
1/ la protéine p53, capable de se lier à l'ADN (Hupp et al, Nucl. Acids Res. 21 (1993) 3167), peut adopter une conformation mutante lorsqu'elle se lie à l'ADN (Halazonetis et al, EMBO J. 12 (1993) 1021)
2/ la protéine p53 peut adopter deux conformations différentes au cours du cycle cellulaire; la conformation dite 'suppresseur' (conformation sauvage, PAb 1620 + / PAb 240-) et la conformation dite 'promoteur' (conformation mutante, PAb 1620 - / PAb 240 +) (Milner & Watson, Oncogene 2 (1990) 1683).
1/ la protéine p53, capable de se lier à l'ADN (Hupp et al, Nucl. Acids Res. 21 (1993) 3167), peut adopter une conformation mutante lorsqu'elle se lie à l'ADN (Halazonetis et al, EMBO J. 12 (1993) 1021)
2/ la protéine p53 peut adopter deux conformations différentes au cours du cycle cellulaire; la conformation dite 'suppresseur' (conformation sauvage, PAb 1620 + / PAb 240-) et la conformation dite 'promoteur' (conformation mutante, PAb 1620 - / PAb 240 +) (Milner & Watson, Oncogene 2 (1990) 1683).
On peut donc supposer que les protéines C-mbp1 et C-fibuline 2 sont également susceptibles d'avoir un effet sur des fonctions spécifiques de la forme sauvage de la protéine p53.
Exemple 5 - Effet de la protéine C-mbpl sur la coopération oncogénique entre la protéine H175 et la protéine Ras-Vall2
Cet exemple décrit les effets de la protéine C-mbplsur une propriété du mutant oncogénique H175, sa capacité à coopérer avec la forme mutée du proto- oncogène Ras (Ras-Va112) dans la transformation oncogénique de fibroblastes embryonnaires de rat
Les fibroblastes embryonnaires de rat (REF) ont été préparés à partir de rats OFA (IFA-CREDO) selon la méthode décrite par C. Finlay (Methods in Enzymology 255 (1995) 389). Après décongélation, les cellules (1,5.106) sont ensemencées dans des boites de Pétri de 10 cm de diamètre contenant 8 ml de milieu DMEM (Gibco BRL) additioné de 10% de sérum de veau foetal et cultivées sur la nuit dans un incubateur à CO, (5%) à 37 C, puis sont transfectées par les différents mélanges de plasmides (21 g d'ADN) en utilisant le réactif CellPhect (Pharmacia) suivant les recommandations du fournisseur. 24 h après la fin de la transfection, les cellules
Cet exemple décrit les effets de la protéine C-mbplsur une propriété du mutant oncogénique H175, sa capacité à coopérer avec la forme mutée du proto- oncogène Ras (Ras-Va112) dans la transformation oncogénique de fibroblastes embryonnaires de rat
Les fibroblastes embryonnaires de rat (REF) ont été préparés à partir de rats OFA (IFA-CREDO) selon la méthode décrite par C. Finlay (Methods in Enzymology 255 (1995) 389). Après décongélation, les cellules (1,5.106) sont ensemencées dans des boites de Pétri de 10 cm de diamètre contenant 8 ml de milieu DMEM (Gibco BRL) additioné de 10% de sérum de veau foetal et cultivées sur la nuit dans un incubateur à CO, (5%) à 37 C, puis sont transfectées par les différents mélanges de plasmides (21 g d'ADN) en utilisant le réactif CellPhect (Pharmacia) suivant les recommandations du fournisseur. 24 h après la fin de la transfection, les cellules
<Desc/Clms Page number 35>
contenues dans chacune des boites sont grattées puis réensemencées sur trois boites de Pétri de 10 cm et cultivées pendant 15jours avant d'être colorées au cristal violet suivant le protocole décrit par C. Finlay (Methods in Enzymology 255 (1995) 389).
Les foyers de transformation sont alors visualisés et comptés.
Les plasmides utilisés au cours de cette série d'expériences sont les suivants: - plasmide tampon : pSG5 (Stratagene) - plasmide d'expression de la protéine Ras-Va112: pEJ-Ras (Shih & Weinberg, Cell 29 (1982) 161) - plasmide d'expression de la protéine c-myc entière: pSVc-mycl(Land et al, Nature 304 (1983) 596) - plasmide d'expression de la protéine H175: pSV2-H175 (exemple 4-a (iii)) - plasmide d'expression de la protéine C-mbpl: pBFA107-C-MBP1(exemple 4-a (ii))
Chaque point de transfection contient un mélange de trois plasmides à raison de 7 g de chaque plasmide. Les résultats de deux expériences indépendantes sont reportés dans le Tableau 3.
Chaque point de transfection contient un mélange de trois plasmides à raison de 7 g de chaque plasmide. Les résultats de deux expériences indépendantes sont reportés dans le Tableau 3.
<Desc/Clms Page number 36>
Tableau 3. Effet de la protéine C-mbpl sur la coopération oncogénique entre la protéine H 175 et la protéine Ras-Val12
Expérience 1 Expérience 2

Expérience 1 Expérience 2
<tb> contrôle <SEP> 0 <SEP> 0
<tb>
<tb> Ras-Val <SEP> 12 <SEP> 0 <SEP> 0
<tb> c-myc <SEP> 0 <SEP> NT
<tb> H175 <SEP> 0 <SEP> NT
<tb> C-mbp <SEP> 0 <SEP> NT
<tb>
<tb> Ras-Vall2 <SEP> + <SEP> c-myc <SEP> 111 <SEP> 16
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> c-myc <SEP> + <SEP> C-mbp <SEP> 1 <SEP> 113 <SEP> 12 <SEP> *
<tb>
<tb> Ras-Val12 <SEP> + <SEP> H175 <SEP> 0 <SEP> 16
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> C-mbpl <SEP> 0 <SEP> 3
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> H <SEP> 175 <SEP> + <SEP> C-mbp <SEP> 1 <SEP> 13 <SEP> 30
<tb>
NT : non testé * : effectuée avec 3 g de plasmide pSVc-myc 1 Les résultats de ces expériences montrent que : - C-mbplpeut coopérer avec la forme activée de Ras pour la transformation des REF - il existe une synergie entre les protéines H 175 et C-mbpl dans la coopération oncogénique avec Ras qui est spécifique de cette association car C-mbplne présente aucun effet sur la coopération oncogénique Ras/ c-myc.
<tb>
<tb> Ras-Val <SEP> 12 <SEP> 0 <SEP> 0
<tb> c-myc <SEP> 0 <SEP> NT
<tb> H175 <SEP> 0 <SEP> NT
<tb> C-mbp <SEP> 0 <SEP> NT
<tb>
<tb> Ras-Vall2 <SEP> + <SEP> c-myc <SEP> 111 <SEP> 16
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> c-myc <SEP> + <SEP> C-mbp <SEP> 1 <SEP> 113 <SEP> 12 <SEP> *
<tb>
<tb> Ras-Val12 <SEP> + <SEP> H175 <SEP> 0 <SEP> 16
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> C-mbpl <SEP> 0 <SEP> 3
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> H <SEP> 175 <SEP> + <SEP> C-mbp <SEP> 1 <SEP> 13 <SEP> 30
<tb>
NT : non testé * : effectuée avec 3 g de plasmide pSVc-myc 1 Les résultats de ces expériences montrent que : - C-mbplpeut coopérer avec la forme activée de Ras pour la transformation des REF - il existe une synergie entre les protéines H 175 et C-mbpl dans la coopération oncogénique avec Ras qui est spécifique de cette association car C-mbplne présente aucun effet sur la coopération oncogénique Ras/ c-myc.
Exemple 6 - Effet des protéines C-mbpl et C-fibuline2 et relation avec les effets des différentes formes de la protéine p53 sur la croissance cellulaire des cellules tumorales
<Desc/Clms Page number 37>
Cet exemple décrit les effets des protéines C-mbpl et C-fibuline2 sur la croissance cellulaire des cellules tumorales et leur relation avec les effets des différentes formes de la protéine p53 sur cette même croissance cellulaire.
Ces effets des protéines C-mbpl et C-fibuline2 sur la croissance cellulaire ont été testés sur la lignée cellulaire H 1299 dans une expérience de formation de colonies résistantes à la néomycine suite à la transfection par des plasmides exprimant ces protéines.
Ces expériences de transfection ont été effectuées selon le protocole décrit dans l'exemple 4-b en utilisant 105cellules par point et 1,5 g d'ADN total.
Les plasmides utilisés au cours de cette série d'expériences sont les suivants: - plasmides d'expression des protéines p53 et H175: pSV2-p53 et pSV2-H175.
- plasmide d'expression de la protéine C-mbp 1: pBFA107-C-MBP (exemple 4-a (ii)) - plasmide d'expression de la protéine C-fibuline2: pBFAI07-C-FIB2 (exemple 4-a (ii)) - plasmide conférant la résistance à la néomycine : pSV2-Neo pour une quantité totale de 0,4 g Protocole de formation de colonies résistantes à la néomycine : 48h après transfection, les cellules sont grattées et transférées dans 2 boites de Pétri de 10 cm de diamètre et remises en culture avec 10 ml de milieu DMEM additionné de 10% de sérum de veau foetal inactivé à la chaleur et contenant 400 g/ml de généticine (G418). Après une sélection de 15 jours en présence de G418, le nombre de colonies NeoR est déterminé par comptage après coloration à la fuchsine.
Les résultat de ces expériences sont reportés dans les Tableaux 4 et 5.
<Desc/Clms Page number 38>
Tableau 4 : de la protéine C-mbpl sur la croissance cellulaire de cellules tumorales
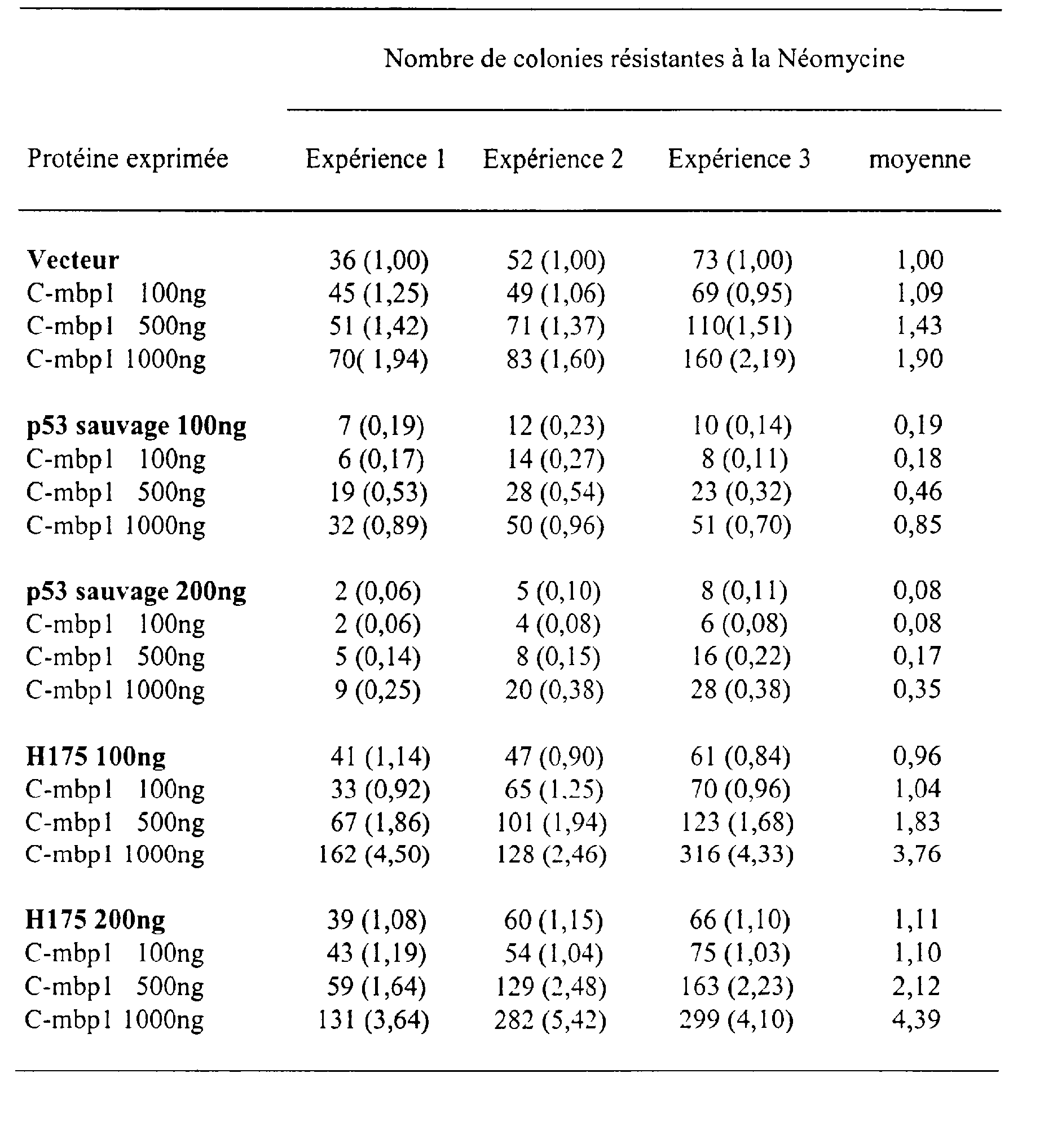
<tb> Nombre <SEP> de <SEP> colonies <SEP> résistantes <SEP> à <SEP> la <SEP> Néomycine
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Protéine <SEP> exprimée <SEP> Expérience <SEP> 1 <SEP> Expérience <SEP> 2 <SEP> Expérience <SEP> 3 <SEP> moyenne
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Vecteur <SEP> 36 <SEP> (1,00) <SEP> 52(1,00) <SEP> 73 <SEP> (1,00) <SEP> 1,00
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 100ng <SEP> 45(1,25) <SEP> 49 <SEP> (1,06) <SEP> 69(0,95) <SEP> 1,09
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 51(1,42) <SEP> 71 <SEP> (1,37) <SEP> 110(1,51) <SEP> 1,43
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1000ng <SEP> 70( <SEP> 1,94) <SEP> 83 <SEP> (1,60) <SEP> 160 <SEP> (2,19) <SEP> 1,90
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> lOOng <SEP> 7(0,19) <SEP> 12 <SEP> (0,23) <SEP> 10 <SEP> (0,14) <SEP> 0,19
<tb>
<tb>
<tb>
<tb> C-mbp <SEP> lOOng <SEP> 6 <SEP> (0,17) <SEP> 14 <SEP> (0,27) <SEP> 8(0,11) <SEP> 0,18
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 19(0,53) <SEP> 28(0,54) <SEP> 23(0,32) <SEP> 0,46
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1 <SEP> 1000ng <SEP> 32 <SEP> (0,89) <SEP> 50(0,96) <SEP> 51(0,70) <SEP> 0,85
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> 200ng <SEP> 2 <SEP> (0,06) <SEP> 5(0,10) <SEP> 8(0,11) <SEP> 0,08
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 100ng <SEP> 2 <SEP> (0,06) <SEP> 4(0,08) <SEP> 6 <SEP> (0,08) <SEP> 0,08
<tb>
<tb>
<tb> C-mbp <SEP> 500ng <SEP> 5(0,14) <SEP> 8(0,15) <SEP> 16 <SEP> (0,22) <SEP> 0,17
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1 <SEP> 1000ng <SEP> 9(0,25) <SEP> 20 <SEP> (0,38) <SEP> 28(0,38) <SEP> 0,35
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 100ng <SEP> 41(1,14) <SEP> 47(0,90) <SEP> 61 <SEP> (0,84) <SEP> 0,96
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> lOOng <SEP> 33 <SEP> (0,92) <SEP> 65(1.25) <SEP> 70 <SEP> (0,96) <SEP> 1,04
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 67 <SEP> (1,86) <SEP> 101 <SEP> (1,94) <SEP> 123 <SEP> (1,68) <SEP> 1,83
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1000ng <SEP> 162 <SEP> (4,50) <SEP> 128(2,46) <SEP> 316 <SEP> (4,33) <SEP> 3,76
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 200ng <SEP> 39(1,08) <SEP> 60(1,15) <SEP> 66(1,10) <SEP> 1,11
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 100ng <SEP> 43(1,19) <SEP> 54(1,04) <SEP> 75(1,03) <SEP> 1,10
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 59(1,64) <SEP> 129(2,48) <SEP> 163(2,23) <SEP> 2,12
<tb>
<tb>
<tb>
<tb> C-mbp <SEP> 1 <SEP> 1000ng <SEP> 131 <SEP> (3,64) <SEP> 282(5,42) <SEP> 299 <SEP> (4,10) <SEP> 4,39
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Protéine <SEP> exprimée <SEP> Expérience <SEP> 1 <SEP> Expérience <SEP> 2 <SEP> Expérience <SEP> 3 <SEP> moyenne
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Vecteur <SEP> 36 <SEP> (1,00) <SEP> 52(1,00) <SEP> 73 <SEP> (1,00) <SEP> 1,00
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 100ng <SEP> 45(1,25) <SEP> 49 <SEP> (1,06) <SEP> 69(0,95) <SEP> 1,09
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 51(1,42) <SEP> 71 <SEP> (1,37) <SEP> 110(1,51) <SEP> 1,43
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1000ng <SEP> 70( <SEP> 1,94) <SEP> 83 <SEP> (1,60) <SEP> 160 <SEP> (2,19) <SEP> 1,90
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> lOOng <SEP> 7(0,19) <SEP> 12 <SEP> (0,23) <SEP> 10 <SEP> (0,14) <SEP> 0,19
<tb>
<tb>
<tb>
<tb> C-mbp <SEP> lOOng <SEP> 6 <SEP> (0,17) <SEP> 14 <SEP> (0,27) <SEP> 8(0,11) <SEP> 0,18
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 19(0,53) <SEP> 28(0,54) <SEP> 23(0,32) <SEP> 0,46
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1 <SEP> 1000ng <SEP> 32 <SEP> (0,89) <SEP> 50(0,96) <SEP> 51(0,70) <SEP> 0,85
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> 200ng <SEP> 2 <SEP> (0,06) <SEP> 5(0,10) <SEP> 8(0,11) <SEP> 0,08
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 100ng <SEP> 2 <SEP> (0,06) <SEP> 4(0,08) <SEP> 6 <SEP> (0,08) <SEP> 0,08
<tb>
<tb>
<tb> C-mbp <SEP> 500ng <SEP> 5(0,14) <SEP> 8(0,15) <SEP> 16 <SEP> (0,22) <SEP> 0,17
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1 <SEP> 1000ng <SEP> 9(0,25) <SEP> 20 <SEP> (0,38) <SEP> 28(0,38) <SEP> 0,35
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 100ng <SEP> 41(1,14) <SEP> 47(0,90) <SEP> 61 <SEP> (0,84) <SEP> 0,96
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> lOOng <SEP> 33 <SEP> (0,92) <SEP> 65(1.25) <SEP> 70 <SEP> (0,96) <SEP> 1,04
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 67 <SEP> (1,86) <SEP> 101 <SEP> (1,94) <SEP> 123 <SEP> (1,68) <SEP> 1,83
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 1000ng <SEP> 162 <SEP> (4,50) <SEP> 128(2,46) <SEP> 316 <SEP> (4,33) <SEP> 3,76
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 200ng <SEP> 39(1,08) <SEP> 60(1,15) <SEP> 66(1,10) <SEP> 1,11
<tb>
<tb>
<tb>
<tb> C-mbpl <SEP> 100ng <SEP> 43(1,19) <SEP> 54(1,04) <SEP> 75(1,03) <SEP> 1,10
<tb>
<tb>
<tb> C-mbpl <SEP> 500ng <SEP> 59(1,64) <SEP> 129(2,48) <SEP> 163(2,23) <SEP> 2,12
<tb>
<tb>
<tb>
<tb> C-mbp <SEP> 1 <SEP> 1000ng <SEP> 131 <SEP> (3,64) <SEP> 282(5,42) <SEP> 299 <SEP> (4,10) <SEP> 4,39
<tb>
<Desc/Clms Page number 39>
Tableau 5 : Effet de la protéine C-fibuline2 sur la croissance cellulaire de cellules tumorales

<tb> Nombre <SEP> de <SEP> colonies <SEP> résistantes <SEP> à <SEP> la <SEP> Néomycine
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Protéine <SEP> exprimée <SEP> Expérience <SEP> 1 <SEP> Expérience <SEP> 2 <SEP> Expérience <SEP> 3 <SEP> moyenne
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Vecteur <SEP> 36(1,00) <SEP> 52(1,00) <SEP> 73(1,00) <SEP> 1,00
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 35 <SEP> (0,97) <SEP> 56 <SEP> (1,08) <SEP> 80 <SEP> (1,10) <SEP> 1,05
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 48(1,33) <SEP> 68(1,31) <SEP> 102(1,40) <SEP> 1,35
<tb>
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 60( <SEP> 1,67) <SEP> 87 <SEP> (1,67) <SEP> 194 <SEP> (2,66) <SEP> 2,00
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> lOOng <SEP> 7(0,19) <SEP> 12(0,23) <SEP> 10(0,14) <SEP> 0,19
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 10 <SEP> (0,28) <SEP> Il <SEP> (0,21) <SEP> 13 <SEP> (0,18) <SEP> 0,22
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 15 <SEP> (0,42) <SEP> 30 <SEP> (0,58) <SEP> 26 <SEP> (0,36) <SEP> 0,45
<tb>
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 35 <SEP> (0,97) <SEP> 44 <SEP> (0,85) <SEP> 45 <SEP> (0,62) <SEP> 0,81
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> 200ng <SEP> 2 <SEP> (0,06) <SEP> 5(0,10) <SEP> 8(0,11) <SEP> 0,09
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 3(0,08) <SEP> 6 <SEP> (0,12) <SEP> 6 <SEP> (0,08) <SEP> 0,09
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 4(0,11) <SEP> 10 <SEP> (0,19) <SEP> 16(0,22) <SEP> 0,16
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 10 <SEP> (0,28) <SEP> 18 <SEP> (0,35) <SEP> 28(0,38) <SEP> 0,34
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 100ng <SEP> 41 <SEP> (1,14) <SEP> 47 <SEP> (0,90) <SEP> 61 <SEP> (0,84) <SEP> 0,96
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 47(1,31) <SEP> 54(1,04) <SEP> 84(1,15) <SEP> 1,17
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 84 <SEP> (2,33) <SEP> 95(1,83) <SEP> 156 <SEP> (2,14) <SEP> 2,10
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 143 <SEP> (3,97) <SEP> 138 <SEP> (2,65) <SEP> 270 <SEP> (3,70) <SEP> 3,44
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 200ng <SEP> 39(1,08) <SEP> 60(1,15) <SEP> 66(1,10) <SEP> 1,11
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 51 <SEP> (1,42) <SEP> 63 <SEP> (1,21) <SEP> 80 <SEP> (1,10) <SEP> 1,24
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 74 <SEP> (2,06) <SEP> 146 <SEP> (2,81) <SEP> 142 <SEP> (1,95) <SEP> 2,27
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 158 <SEP> (4,39) <SEP> 230(4,42) <SEP> 284 <SEP> (3,89) <SEP> 4,23
<tb>
Les résultats de ces expériences montrent que : - les protéines C-mbplet C-fibuline2 ont un effet positif sur la croissance cellulaire - les protéines C-mbplet C-fibuline2 sont capables de bloquer l'effet anti- prolifératif de la protéine p53, et ce indépendamment de leur effet prolifératif
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Protéine <SEP> exprimée <SEP> Expérience <SEP> 1 <SEP> Expérience <SEP> 2 <SEP> Expérience <SEP> 3 <SEP> moyenne
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> Vecteur <SEP> 36(1,00) <SEP> 52(1,00) <SEP> 73(1,00) <SEP> 1,00
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 35 <SEP> (0,97) <SEP> 56 <SEP> (1,08) <SEP> 80 <SEP> (1,10) <SEP> 1,05
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 48(1,33) <SEP> 68(1,31) <SEP> 102(1,40) <SEP> 1,35
<tb>
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 60( <SEP> 1,67) <SEP> 87 <SEP> (1,67) <SEP> 194 <SEP> (2,66) <SEP> 2,00
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> lOOng <SEP> 7(0,19) <SEP> 12(0,23) <SEP> 10(0,14) <SEP> 0,19
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 10 <SEP> (0,28) <SEP> Il <SEP> (0,21) <SEP> 13 <SEP> (0,18) <SEP> 0,22
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 15 <SEP> (0,42) <SEP> 30 <SEP> (0,58) <SEP> 26 <SEP> (0,36) <SEP> 0,45
<tb>
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 35 <SEP> (0,97) <SEP> 44 <SEP> (0,85) <SEP> 45 <SEP> (0,62) <SEP> 0,81
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> p53 <SEP> sauvage <SEP> 200ng <SEP> 2 <SEP> (0,06) <SEP> 5(0,10) <SEP> 8(0,11) <SEP> 0,09
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 3(0,08) <SEP> 6 <SEP> (0,12) <SEP> 6 <SEP> (0,08) <SEP> 0,09
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 4(0,11) <SEP> 10 <SEP> (0,19) <SEP> 16(0,22) <SEP> 0,16
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 10 <SEP> (0,28) <SEP> 18 <SEP> (0,35) <SEP> 28(0,38) <SEP> 0,34
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 100ng <SEP> 41 <SEP> (1,14) <SEP> 47 <SEP> (0,90) <SEP> 61 <SEP> (0,84) <SEP> 0,96
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 47(1,31) <SEP> 54(1,04) <SEP> 84(1,15) <SEP> 1,17
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 84 <SEP> (2,33) <SEP> 95(1,83) <SEP> 156 <SEP> (2,14) <SEP> 2,10
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 143 <SEP> (3,97) <SEP> 138 <SEP> (2,65) <SEP> 270 <SEP> (3,70) <SEP> 3,44
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb>
<tb> H175 <SEP> 200ng <SEP> 39(1,08) <SEP> 60(1,15) <SEP> 66(1,10) <SEP> 1,11
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 100ng <SEP> 51 <SEP> (1,42) <SEP> 63 <SEP> (1,21) <SEP> 80 <SEP> (1,10) <SEP> 1,24
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 500ng <SEP> 74 <SEP> (2,06) <SEP> 146 <SEP> (2,81) <SEP> 142 <SEP> (1,95) <SEP> 2,27
<tb>
<tb>
<tb>
<tb> C-fibuline2 <SEP> 1000ng <SEP> 158 <SEP> (4,39) <SEP> 230(4,42) <SEP> 284 <SEP> (3,89) <SEP> 4,23
<tb>
Les résultats de ces expériences montrent que : - les protéines C-mbplet C-fibuline2 ont un effet positif sur la croissance cellulaire - les protéines C-mbplet C-fibuline2 sont capables de bloquer l'effet anti- prolifératif de la protéine p53, et ce indépendamment de leur effet prolifératif
<Desc/Clms Page number 40>
- l'effet prolifératif des protéines C-mbpl et C-fibuline2 est fortement augmenté en présence de la protéine H175 Exemple 7 - Clonage des ADNc codant pour la forme entière des protéines mbpl murine et humaine.
Cet exemple décrit le clonage des ADNc codant pour la protéine mbpl murine entière et l'utilisation de ces données pour le clonage d'un homologue humain de MBP1.
7 a - Clonage de l'ADNc codant pour la forme entière de la protéine mbpl murine
L'ADNc codant pour la partie C-terminale de la protéine mbplmurine a été cloné par réaction d'amplification en chaine (PCR) sur l'ADN de la banque SuperScript d'embryon murin (8,5 jours) (Gibco BRL) en utilisant l'oligonucléotide 3'-mMBP 1 et l'oligonucléotide SP6 (Gibco BRL).
L'ADNc codant pour la partie C-terminale de la protéine mbplmurine a été cloné par réaction d'amplification en chaine (PCR) sur l'ADN de la banque SuperScript d'embryon murin (8,5 jours) (Gibco BRL) en utilisant l'oligonucléotide 3'-mMBP 1 et l'oligonucléotide SP6 (Gibco BRL).
Oligonucléotide 3'-mMBPl (SEQ ID N 14) : CGGTACTGGCAGAGGTAACTGG
Cette amplification a permis d'obtenir un produit unique présentant une taille d'environ 800 paires de bases qui a ensuite été cloné directement après PCR dans le vecteur pCRII (Invitrogene) et séquence. La séquence ainsi obtenue (SEQ ID N 15) montre un recouvrement de 368 paires de bases avec C-MBP (SEQ ID N 8) avec une identité stricte de séquence sur cette partie commune. De plus, en 5' de cette partie commune, on trouve une séquence additionnelle de 445 paires de bases présentant une phase de lecture ouverte et un codon d'initiation de la traduction.
Cette amplification a permis d'obtenir un produit unique présentant une taille d'environ 800 paires de bases qui a ensuite été cloné directement après PCR dans le vecteur pCRII (Invitrogene) et séquence. La séquence ainsi obtenue (SEQ ID N 15) montre un recouvrement de 368 paires de bases avec C-MBP (SEQ ID N 8) avec une identité stricte de séquence sur cette partie commune. De plus, en 5' de cette partie commune, on trouve une séquence additionnelle de 445 paires de bases présentant une phase de lecture ouverte et un codon d'initiation de la traduction.
Les deux fragments représentés par ces séquences ont ensuite été rassemblés par une ligation à trois partenaires en utilisant les sites de reconnaissance par les enzymes de restriction EcoR I, Pst I et Not I et le plasmide pBC-SK+
<Desc/Clms Page number 41>
(STRATAGENE) permettant ainsi la reconstitution de l'ADNc MBP 1murin entier (mMBP1) (SEQ ID N 16).
7-b Clonage de l'ADNc codant pour la forme entière de la protéine mbpl humaine
La séquence du gène murin MBP1 a été utilisée pour une recherche d'homologie dans Genbank. Cette recherche a permis de montrer une forte homologie avec la séquence d'une EST humaine (g 1548384). A partir de cette séquence, deux fragments d'ADNc ont été clonés par réaction d'amplification en chaine (PCR) sur l'ADN de la banque SuperScript de testicule humain (Gibco BRL) en utilisant les oligonucléotides 3'-hMBPI et SP6 (Gibco BRL) d'une part, et les oligonucléotides 5'- hMBPl et T7 (Gibco BRL) d'autre part.
La séquence du gène murin MBP1 a été utilisée pour une recherche d'homologie dans Genbank. Cette recherche a permis de montrer une forte homologie avec la séquence d'une EST humaine (g 1548384). A partir de cette séquence, deux fragments d'ADNc ont été clonés par réaction d'amplification en chaine (PCR) sur l'ADN de la banque SuperScript de testicule humain (Gibco BRL) en utilisant les oligonucléotides 3'-hMBPI et SP6 (Gibco BRL) d'une part, et les oligonucléotides 5'- hMBPl et T7 (Gibco BRL) d'autre part.
Oligonucléotide 3'-hMBP1 (SEQ ID N 17) :
CTCCGCTCCGAGGTGATGGTC
Oligonucléotide 5'-hMBPl (SEQ ID N 18) :
TGTAGCTACTCCAGCTACCTC
Ces amplifications ont permis d'obtenir deux produits présentant des tailles d'environ 1100 et 700 paires de bases qui ont ensuite été clonés directement après PCR dans le vecteur pCRII (Invitrogene) et séquences. Les séquences ainsi obtenues (SEQ ID N 19 et SEQ ID N 20) montrent un recouvrement de 325 paires avec une identité stricte de séquence sur cette partie commune.
CTCCGCTCCGAGGTGATGGTC
Oligonucléotide 5'-hMBPl (SEQ ID N 18) :
TGTAGCTACTCCAGCTACCTC
Ces amplifications ont permis d'obtenir deux produits présentant des tailles d'environ 1100 et 700 paires de bases qui ont ensuite été clonés directement après PCR dans le vecteur pCRII (Invitrogene) et séquences. Les séquences ainsi obtenues (SEQ ID N 19 et SEQ ID N 20) montrent un recouvrement de 325 paires avec une identité stricte de séquence sur cette partie commune.
Les deux fragments représentés par ces séquences ont ensuite été rassemblés par une ligation à trois partenaires en utilisant les sites de reconnaissance par les enzymes de restriction EcoR I, Nco 1 et Not 1 et le plasmide pBC-SK+ (STRATAGENE) permettant ainsi la reconstitution de l'ADNc MBP1 humain entier (hMBPl) (SEQ ID N 21) présentant une phase de lecture ouverte et un codon d'initiation de la traduction.
<Desc/Clms Page number 42>
La comparaison des séquences protéiques correspondant aux ADNc précédemment obtenus (Exemples 7-a et 7-b) (Figure 4) montre une identité stricte de 95% dans la phase ouverte de lecture supposée (après le site de démarrage de la traduction (ATG) supposé). Par contre, une absence d'identité et une très mauvaise homologie sont observées entre les régions situées en amont de ce site de démarage de la traduction (ATG) putatif. Ces données permettent donc de confirmer cette position comme démarage de la traduction et par là même que ces deux ADNc codent bien pour les formes entières des protéines mbpl humaine et murine (SEQ ID N 23 et SEQ ID N 22).
7 - c Construction des plasmides d'expression en cellules mammifères des formes murine et humaine de la protéine mbpl
Les ADNc codant pour les formes murine et humaine de la protéine mbp1 contenus dans le vecteur pBC SK+, ont été insérés dans les vecteurs d'expression pSV2 et pcDNA3 (Invitrogen) en utilisant les sites de reconnaissance par les enzymes de restriction Hind III et Not I.
Les ADNc codant pour les formes murine et humaine de la protéine mbp1 contenus dans le vecteur pBC SK+, ont été insérés dans les vecteurs d'expression pSV2 et pcDNA3 (Invitrogen) en utilisant les sites de reconnaissance par les enzymes de restriction Hind III et Not I.
Exemple 8 - Effets comparés des protéines C-mbpl et mbpl murine sur la croissance cellulaire des cellules tumorales
Cet exemple décrit les effets comparés des protéines C-mbp 1 et mbp 1 murine sur la croissance cellulaire des cellules tumorales et leur relation avec les effets de la protéine H 175 sur cette même croissance cellulaire.
Cet exemple décrit les effets comparés des protéines C-mbp 1 et mbp 1 murine sur la croissance cellulaire des cellules tumorales et leur relation avec les effets de la protéine H 175 sur cette même croissance cellulaire.
Ces effets de la protéine mbp1 murine sur la croissance cellulaire ont été testés sur la lignée cellulaire H1299 dans une expérience de formation de colonies résistantes à la néomycine suite à la transfection par des plasmides portant les ADNc codant pour ces protéines.
Ces expériences de transfection ont été effectuées selon le protocole décrit dans l'exemple D2 en utilisant 105cellules par point et 1,5 g d'ADN total.
<Desc/Clms Page number 43>
Les plasmides utilisés au cours de cette série d'expériences sont les suivants : - plasmide d'expression de la protéine H175: pSV2-H175.
- plasmide d'expression de la protéine C-mbpl: pBFA107-C-MBP1(exemple 4-a (ii)) - plasmide d'expression de la protéine mbpl murine: pSV2-mMBPI (exemple 7-c) - plasmide conférant la résistance à la néomycine : pSV2-Neo pour une quantité totale de 0,4 g
Le protocole de formation de colonies résistantes à la néomycine utilisé est celui décrit dans l'exemple 6. Les résultat de cette expérience sont présentés dans le Tableau 6 et la Figure 5.
Le protocole de formation de colonies résistantes à la néomycine utilisé est celui décrit dans l'exemple 6. Les résultat de cette expérience sont présentés dans le Tableau 6 et la Figure 5.
Tableau 6 : comparés des protéines C-mbpl et mbpl murine sur la croissance cellulaire de cellules tumorales

<tb> Nombre <SEP> de <SEP> colonies <SEP> résistantes <SEP> à <SEP> la <SEP> Néomycine
<tb>
<tb> Protéine <SEP> exprimée <SEP> Expérience <SEP> 1 <SEP> Expérience <SEP> 2
<tb>
<tb>
<tb> Vecteur <SEP> 61 <SEP> ( <SEP> 1,00) <SEP> 71 <SEP> ( <SEP> 1,00)
<tb> C-mbp <SEP> lOOng <SEP> 67 <SEP> ( <SEP> 1,10) <SEP>
<tb> C-mbpl <SEP> 500ng <SEP> 96 <SEP> ( <SEP> 1,57) <SEP>
<tb> C-mbp <SEP> lOOOng <SEP> 278 <SEP> ( <SEP> 4,56) <SEP> 239 <SEP> ( <SEP> 3,37) <SEP>
<tb>
<tb> mbp <SEP> lOOng <SEP> 94 <SEP> ( <SEP> 1,54) <SEP>
<tb> mbp <SEP> 500ng <SEP> 128 <SEP> ( <SEP> 2,10) <SEP>
<tb> mbp <SEP> lOOOng <SEP> 419 <SEP> ( <SEP> 6,87) <SEP> 562 <SEP> ( <SEP> 7,92) <SEP>
<tb>
<tb>
<tb> H175 <SEP> 200ng <SEP> 65 <SEP> ( <SEP> 1,07) <SEP> 69 <SEP> ( <SEP> 0,97) <SEP>
<tb> C-mbpl <SEP> lOOng <SEP> 72 <SEP> ( <SEP> 1,18) <SEP>
<tb> C-mbpl <SEP> 500ng <SEP> 134 <SEP> ( <SEP> 2,20) <SEP>
<tb> C-mbp <SEP> lOOOng <SEP> 397(6,51) <SEP> 341 <SEP> ( <SEP> 4,80) <SEP>
<tb>
<tb> mbpl <SEP> lOOng <SEP> 81 <SEP> ( <SEP> 1,33) <SEP>
<tb> mbp <SEP> 500ng <SEP> 206 <SEP> ( <SEP> 3,38) <SEP>
<tb> mbpl <SEP> lOOOng <SEP> 729(11,95) <SEP> 1215(17,11)
<tb>
<tb>
<tb> Protéine <SEP> exprimée <SEP> Expérience <SEP> 1 <SEP> Expérience <SEP> 2
<tb>
<tb>
<tb> Vecteur <SEP> 61 <SEP> ( <SEP> 1,00) <SEP> 71 <SEP> ( <SEP> 1,00)
<tb> C-mbp <SEP> lOOng <SEP> 67 <SEP> ( <SEP> 1,10) <SEP>
<tb> C-mbpl <SEP> 500ng <SEP> 96 <SEP> ( <SEP> 1,57) <SEP>
<tb> C-mbp <SEP> lOOOng <SEP> 278 <SEP> ( <SEP> 4,56) <SEP> 239 <SEP> ( <SEP> 3,37) <SEP>
<tb>
<tb> mbp <SEP> lOOng <SEP> 94 <SEP> ( <SEP> 1,54) <SEP>
<tb> mbp <SEP> 500ng <SEP> 128 <SEP> ( <SEP> 2,10) <SEP>
<tb> mbp <SEP> lOOOng <SEP> 419 <SEP> ( <SEP> 6,87) <SEP> 562 <SEP> ( <SEP> 7,92) <SEP>
<tb>
<tb>
<tb> H175 <SEP> 200ng <SEP> 65 <SEP> ( <SEP> 1,07) <SEP> 69 <SEP> ( <SEP> 0,97) <SEP>
<tb> C-mbpl <SEP> lOOng <SEP> 72 <SEP> ( <SEP> 1,18) <SEP>
<tb> C-mbpl <SEP> 500ng <SEP> 134 <SEP> ( <SEP> 2,20) <SEP>
<tb> C-mbp <SEP> lOOOng <SEP> 397(6,51) <SEP> 341 <SEP> ( <SEP> 4,80) <SEP>
<tb>
<tb> mbpl <SEP> lOOng <SEP> 81 <SEP> ( <SEP> 1,33) <SEP>
<tb> mbp <SEP> 500ng <SEP> 206 <SEP> ( <SEP> 3,38) <SEP>
<tb> mbpl <SEP> lOOOng <SEP> 729(11,95) <SEP> 1215(17,11)
<tb>
<Desc/Clms Page number 44>
Les résultats de cette expérience montrent que la protéine mbp1murine présente les mêmes caractéristiques que la protéine C-mbpl, à savoir un effet positif sur la croissance cellulaire qui est fortement augmenté en présence de la protéine H175.
De plus cet effet de la protéine mbp1 est très fortement augmenté par rapport à la protéine tronquée C-mbpl.
Exemple 8 bis - Coopération oncogénique des protéines C-mbpl et mbpl murine et mbpl humaine avec la protéine Ras-Vall2
Cet exemple décrit les effets comparés des protéines C-mbp 1, mbp1 murine et mbp1 humaine dans une expérience de coopération oncogénique avec la protéine Ras- Va)12.
Cet exemple décrit les effets comparés des protéines C-mbp 1, mbp1 murine et mbp1 humaine dans une expérience de coopération oncogénique avec la protéine Ras- Va)12.
Cette coopération oncogénique a été testée sur des fibroblastes embryonnaires de rat suite à la transfection par des plasmides portant les ADNc codant pour ces protéines et suivant le protocole décrit dans l'exemple 5.
Les résultat de cette expérience sont présentés dans le Tableau 7.
Tableau 7 : oncogénique des protéines C-mbpl, mbpl murine et mbpl humaine avec la protéine Ras-Val12
<Desc/Clms Page number 45>
Expérience 1 Expérience 2

<tb> contrôle <SEP> 0 <SEP> 0
<tb>
<tb> Ras-Val <SEP> 12 <SEP> 0 <SEP> 0
<tb> c-myc <SEP> 0 <SEP> 0
<tb> H175 <SEP> 0 <SEP> 0
<tb> C-mbpl <SEP> 0 <SEP> 0
<tb> mbp <SEP> 0 <SEP> 0
<tb>
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> c-myc <SEP> 31 <SEP> 42
<tb>
<tb> Ras-Vall2 <SEP> + <SEP> H175 <SEP> 10 <SEP> 15
<tb> Ras-Vall2 <SEP> + <SEP> C-mbpl <SEP> 4 <SEP> 4
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> mbpl <SEP> murine <SEP> 5 <SEP> 7
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> mbp <SEP> 1 <SEP> humaine <SEP> 6 <SEP> 6
<tb>
<tb>
<tb> Ras-Val <SEP> 12 <SEP> 0 <SEP> 0
<tb> c-myc <SEP> 0 <SEP> 0
<tb> H175 <SEP> 0 <SEP> 0
<tb> C-mbpl <SEP> 0 <SEP> 0
<tb> mbp <SEP> 0 <SEP> 0
<tb>
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> c-myc <SEP> 31 <SEP> 42
<tb>
<tb> Ras-Vall2 <SEP> + <SEP> H175 <SEP> 10 <SEP> 15
<tb> Ras-Vall2 <SEP> + <SEP> C-mbpl <SEP> 4 <SEP> 4
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> mbpl <SEP> murine <SEP> 5 <SEP> 7
<tb> Ras-Val <SEP> 12 <SEP> + <SEP> mbp <SEP> 1 <SEP> humaine <SEP> 6 <SEP> 6
<tb>
Les résultats de cette expérience montrent que les protéine mbp1 murine et mbp humaine présentent les mêmes caractéristiques que la protéine C-mbpl, à savoir la capacité de coopérer avec la protéine Ras-Va112 pour la transformation de fibroblastes embryonnaires de rat.
De façon intéressante, on note aussi que les fibroblastes ainsi transformés présentent un aspect morphologique tout à fait particulier qui diffère de celui obtenu avec l'oncogène c-myc.
Exemple 9 - Expression de la protéine mbpl chez la souris et dans les tissus humains
Cet exemple décrit l'étude de l'expression de l'ARN messager de MBP 1 chez la souris et dans différents tissus humains.
Cet exemple décrit l'étude de l'expression de l'ARN messager de MBP 1 chez la souris et dans différents tissus humains.
<Desc/Clms Page number 46>
9-a Préparation des sondes
Les sondes mMBP 1 et hMBP 1 sont constituées par les ADNc correspondants.
Les sondes mMBP 1 et hMBP 1 sont constituées par les ADNc correspondants.
La sonde GAPDH (contrôle) a été générée par réaction d'amplification en chaine (PCR) sur l'ADN de la banque SuperScript de testicule humain (Gibco BRL) (GAPDH) en utilisant les oligonucléotides suivants :
Oligonucléotide sens-GAPDH (SEQ ID N 24) :
CGGAGTCAACGGATTTGGTCGTAT
Oligonucléotide antisens-GAPDH(SEQ ID N 25) :
AGCCTTCTCCATGGTGGTGAAGAC
Les sondes ont été radiomarquées au 32P-dCTP en utilisant le kit Rediprime (Amersham) et les recommandations du fournisseur, et les nucléotides non incorporés ont été éliminés par chromatographie sur des colonnes MicroSpin G-25 (Pharmacia Biotech). Les Northern blots utilisés lors de cette expérience ont été obtenus chez Clontech. Les membranes ont été préhybridées avec la solution ExpressHyb (Clontech) 45 minutes à 65 c, puis incubées 2 heures avec les sondes radiomarquées à 65 C, lavées trois fois avec du tampon 2xSSC deux fois avec du tampon 2xSSC additionné de 0,1% de SDS et enfin lavées avec du tampon 0,2xSSC additionné de 0,1% de SDS jusqu'à disparition du bruit de fond. Les membranes ont ensuite été soumises a autoradiographie et une quantification du signal a été effectuée à l'aide d'un instantimager (Packard instruments).
Oligonucléotide sens-GAPDH (SEQ ID N 24) :
CGGAGTCAACGGATTTGGTCGTAT
Oligonucléotide antisens-GAPDH(SEQ ID N 25) :
AGCCTTCTCCATGGTGGTGAAGAC
Les sondes ont été radiomarquées au 32P-dCTP en utilisant le kit Rediprime (Amersham) et les recommandations du fournisseur, et les nucléotides non incorporés ont été éliminés par chromatographie sur des colonnes MicroSpin G-25 (Pharmacia Biotech). Les Northern blots utilisés lors de cette expérience ont été obtenus chez Clontech. Les membranes ont été préhybridées avec la solution ExpressHyb (Clontech) 45 minutes à 65 c, puis incubées 2 heures avec les sondes radiomarquées à 65 C, lavées trois fois avec du tampon 2xSSC deux fois avec du tampon 2xSSC additionné de 0,1% de SDS et enfin lavées avec du tampon 0,2xSSC additionné de 0,1% de SDS jusqu'à disparition du bruit de fond. Les membranes ont ensuite été soumises a autoradiographie et une quantification du signal a été effectuée à l'aide d'un instantimager (Packard instruments).
9-b Expression de la protéine mbpl chez la souris
Cet exemple décrit l'étude de l'expression de l'ARN messager de MBP1chez la souris.
Cet exemple décrit l'étude de l'expression de l'ARN messager de MBP1chez la souris.
<Desc/Clms Page number 47>
Les sondes utilisées dans cette expérience sont les sondes mMBP1et GAPDH . Les membranes utilisées dans cette expérience contiennent l'une des ARNm d'embryon de souris obtenus à différents stages du développement, et l'autre des ARNm représentatifs de différents tissus de souris adulte.
Les résultats de cette expérience (Figure 6) indiquent clairement que:
1 - un transcript unique de 1,8 kb est détécté aussi bien dans les ARNm d'embryon de souris que dans les tissus de souris adulte.
1 - un transcript unique de 1,8 kb est détécté aussi bien dans les ARNm d'embryon de souris que dans les tissus de souris adulte.
2 - ce messager présente des variations de niveaux d'expression au cours du développement, avec une forte abondance dans les stades précoces (7 jours) puis une diminution importante (11jours) pour atteindre un niveau apparement constant.
3 - ce messager est modérément exprimé dans l'ensemble des tissus adultes testé à l'exception d'une expression importante dans le poumon et les testicules.
Un tel niveau d'expression de transcript élevée dans une phase du développement embryonnaire ainsi que dans des tissus présentant un taux de croissance élevé, confirme l'implication du produit du gène MBP1 dans les processus de croissance cellulaire mise en évidence dans les exemples 5, 6 et 7.
9-c Expression de la protéine mbpl dans les tissus humains
Cet exemple décrit l'étude de l'expression de l'ARN messager de MBP1 dans différents tissus humains.
Cet exemple décrit l'étude de l'expression de l'ARN messager de MBP1 dans différents tissus humains.
Les sondes utilisées dans cette expérience sont les sondes hMBP1 et GAPDH .
Les membranes utilisées contiennent des ARNm représentatifs de différents tissus humain.
Les résultats de cette expérience (Figure 7) indiquent clairement que: 1 - deux transcripts de 1,5 et 1,8 kb sont détectés dans les tissus humains.
<Desc/Clms Page number 48>
2 - ces messagers sont modérément exprimés dans l'ensemble des tissus testés et leur profil d'expression est comparable à celui du messager murin (forte expression dans le poumon et les testicules).
Ces résultats montrent que: - il peut exister deux formes différentes de la protéine mbpl humaine avec possibilité d'épissage alternatif du messager.
- les ARNm codant pour la(les) protéine (s) mbp1 humaine(s) tout comme leur homologue murin présentent un niveau d'expression élevé dans des tissus à taux de croissance élevé, et que le(s) produit(s) du gène MBP1humain pourrait(ent) donc aussi être impliqué(s) dans les processus de croissance cellulaire.
Les résultats présentés dans les différents exemples montrent que les protéines C-mbpl, mbplet C-fibuline2 interagissent spécifiquement avec les formes mutantes de la protéine p53 et que ces interactions conduisent à une synergie entre ces protéines et les mutants oncogéniques de la protéine p53 que ce soit pour la coopération oncogénique avec la forme activée de la protéine Ras ou pour l'effet prolifératif.
De plus, les protéines C-mbpl, mbpl et C-fibuline2 présentent une activité proliférative intrinsèque, et la protéine C-mbpl agit comme un oncogène immortalisant en coopérant avec la forme activée de la protéine Ras pour la transformation cellulaire.
Les résultats présentés dans les différents exemples montrent que les protéines ou polypeptides C-mbpl, mbpl et C-fibuline2 interagissent spécifiquement avec les formes mutantes de la protéine p53 et que ces interactions conduisent à une synergie entre ces protéines et les mutants oncogéniques de la protéine p53 que ce soit pour la coopération oncogénique avec la forme activée de la protéine Ras ou pour l'effet prolifératif.
<Desc/Clms Page number 49>
De plus, les protéines C-mbpl, mbpl et C-fibuline2 présentent une activité proliférative intrinsèque, et les protéines C-mbpl et mbpl agissent comme des oncogènes immortalisants en coopérant avec la forme activée de la protéine Ras pour la transformation cellulaire.
Ces propriétés confèrent à mbp un rôle potentiel d'oncogène. Dans au moins un des test (exemple 8 bis) la protéine mbpl présente des propriétés oncogéniques accrues par rapport au polypeptide c-MBP 1.
Enfin, la forte homologie présentée par les protéines mbp1humaine et murine (95% d'identité stricte), et la similarité d'expression tissulaire de leurs messagers respectifs, permettent de conclure que la protéine mbp humaine, qui pourrait être présente sous forme de deux variants différents (2 messagers distincts), possède(ent) des propriétés analogues à celles de son homologue murine.
En conclusion, ces résultats décrivent la caractérisation d'une nouvelle protéine murine, mbpl, et de son(ses) homologue(s) humaine (s), qui présente des propriétés oncogéniques et qui intéragit spécifiquement avec les formes mutées de la protéine p53. Cette interaction qui se traduit par un accroissement des propriétés oncogéniques de mbpl, pourrait constituer un élément fondamental de la capacité oncogénique de ces mutants de la protéine p53.
De telles propriétés semblent aussi partagées par une autre protéine présentant des homologies avec mbp l, la fibuline 2. Cette protéine faisant partie d'une famille plus large, on peut envisager que ces propriétés puissent être étendues à l'ensemble des membres de la famille des fibulines.
Ces interactions montrant une forte synergie entre les pouvoirs oncogéniques des protéines mbpl, fibuline2 et mutants p53, elles constituent un point d'action potentiel dans le traitement des cancers liés aux mutations de la protéine p53. De plus, les protéines mbpl et fibuline2 qui présentent des propriétés oncogéniques intrinsèques constituent des cibles potentielles pour le traitement du cancer en général.
<Desc/Clms Page number 50>
LISTE DE SEQUENCES
SEQ ID N 1 : AGATCTGTATGGAGGAGCCGCAG
SEQ ID N 2: AGATCTCATCAGTCTGAGTCAGGCCCTTC SEQ ID N 3: GGGGCAGTGCCTCAC SEQ ID N 4: GGGCCTCCAGTTCAT SEQ ID N 5 : ACAAACATGCACCTC SEQ ID N 6 : GCGCCGGCCTCTCCC SEQ ID N 7 : AGATCTGTGTGGCCCCTGCACCA SEQ ID N 8 : séquence nucléotidique et polypeptidique fragment C-term de MBP1 murine SEQ ID N 8: 1/1 31/11 TGC ACC TGC CCT GAT GGT TAC CGA AAA ATT GGA CCC GAA TGT GTG GAC ATA GAT GAG TGT CTCPDGYRKIGPECVDIDEC 61/21 91/31 CGT TAC CGC TAT TGC CAG CAT CGA TGT GTG AAC CTG CCG GGC TCC TTT CGA TGC CAG TGT R Y R Y C Q H R C V N L P G F R C Q 121/41 151/51 GAG CCA GGC TTC CAG TTG GGA CCT AAC AAC CGC TCT TGT GTG GAT GTG AAT GAG TGT GAC EPGFQLGPNNRSCVDVNECD D 181/61 211/71 ATG GGA GCC CCA TGT GAG CAG CGC TGC TTC AAC TCC TAT GGG ACC TTC CTG TGT CGC TGT MGAPCEQRCFNSYGTFLCRC
SEQ ID N 1 : AGATCTGTATGGAGGAGCCGCAG
SEQ ID N 2: AGATCTCATCAGTCTGAGTCAGGCCCTTC SEQ ID N 3: GGGGCAGTGCCTCAC SEQ ID N 4: GGGCCTCCAGTTCAT SEQ ID N 5 : ACAAACATGCACCTC SEQ ID N 6 : GCGCCGGCCTCTCCC SEQ ID N 7 : AGATCTGTGTGGCCCCTGCACCA SEQ ID N 8 : séquence nucléotidique et polypeptidique fragment C-term de MBP1 murine SEQ ID N 8: 1/1 31/11 TGC ACC TGC CCT GAT GGT TAC CGA AAA ATT GGA CCC GAA TGT GTG GAC ATA GAT GAG TGT CTCPDGYRKIGPECVDIDEC 61/21 91/31 CGT TAC CGC TAT TGC CAG CAT CGA TGT GTG AAC CTG CCG GGC TCC TTT CGA TGC CAG TGT R Y R Y C Q H R C V N L P G F R C Q 121/41 151/51 GAG CCA GGC TTC CAG TTG GGA CCT AAC AAC CGC TCT TGT GTG GAT GTG AAT GAG TGT GAC EPGFQLGPNNRSCVDVNECD D 181/61 211/71 ATG GGA GCC CCA TGT GAG CAG CGC TGC TTC AAC TCC TAT GGG ACC TTC CTG TGT CGC TGT MGAPCEQRCFNSYGTFLCRC
<Desc/Clms Page number 51>
241/81 271/91
AAC CAG GGC TAT GAG CTG CAC CGG GAT GGC TTC TCC TGC AGC GAT ATC GAT GAG TGC GGC NQGYELHRDGFSCSDIDECG G
301/101 331/111
TAC TCC AGT TAC CTC TGC CAG TAC CGC TGT GTC AAC GAG CCA GGC CGA TTC TCC TGT CAC Y S SYLCQYRCVNEPGRFSCH H
361/121 391/131
TGC CCA CAA GGC TAC CAG CTG CTG GCT ACA AGG CTC TGC CAA GAT ATT GAC GAG TGT GAA CPQGYQLLATRLCQDIDECE
421/141 451/151
ACA GGT GCA CAC CAA TGT TCT GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG GGT TAC CGC TGAHQCSEAQTCVNFHGGYR R
481/161 511/171
TGT GTG GAC ACC AAC CGT TGT GTG GAG CCC TAT GTC CAA GTG TCA GAC AAC CGC TGC CTC CVDTNRCVEPYVQVSDNRCL L
541/181 571/191
TGC CCT GCC TCC AAT CCC CTT TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC CGC TAC ATG CPASNPLCREQPSSIVHRYM
601/201 631/211 AGC ATC ACC TCA GAG CGA AGT GTG CCT GCT GAC GTG TTT CAG ATC CAG GCA ACC TCT GTC SITSERSVPADVFQIQATSV 661/221 691/231 TAC CCT GGT GCC TAC AAT GCC TTT CAG ATC CGT TCT GGA AAC ACA CAG GGG GAC TTC TAC YPGAYNAFQIRSGNTQGDFY 721/241 751/251 ATT AGG CAA ATC AAC AAT GTC AGC GCC ATG CTG GTC CTC GCC AGG CCA GTG ACG GGA CCC IRQINNVSAMLVLARPVTGP 781/261 811/271 CGG GAG TAC GTG CTG GAC CTG GAG ATG GTC ACC ATG AAT TCC CTT ATG AGC TAC CGG GCC REYVLDLEMVTMNSLMSYRA 841/281 871/291 AGC TCT GTA CTG AGA CTC ACG GTC TTT GTG GGA GCC TAT ACC TTC TGA AGACCCTCAGGGAAGG SSVLRLTVFVGAYTF* GCCATGTGGGGGCCCCTTCCCCCTCCCATAGCTTAAGCAGCCCCGGGGGCCTAGGGATGACCGTTCTGCTTAAAGGAACT ATGATGTGAAGGACAATAAAGGGAGAAAGAAGGAAAA SEQ ID N 9: séquence nucléotidique et polypeptidique fragment C-term de fibuline 2 murine SEQ ID N 9 : 1/1 31/11
AAC CAG GGC TAT GAG CTG CAC CGG GAT GGC TTC TCC TGC AGC GAT ATC GAT GAG TGC GGC NQGYELHRDGFSCSDIDECG G
301/101 331/111
TAC TCC AGT TAC CTC TGC CAG TAC CGC TGT GTC AAC GAG CCA GGC CGA TTC TCC TGT CAC Y S SYLCQYRCVNEPGRFSCH H
361/121 391/131
TGC CCA CAA GGC TAC CAG CTG CTG GCT ACA AGG CTC TGC CAA GAT ATT GAC GAG TGT GAA CPQGYQLLATRLCQDIDECE
421/141 451/151
ACA GGT GCA CAC CAA TGT TCT GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG GGT TAC CGC TGAHQCSEAQTCVNFHGGYR R
481/161 511/171
TGT GTG GAC ACC AAC CGT TGT GTG GAG CCC TAT GTC CAA GTG TCA GAC AAC CGC TGC CTC CVDTNRCVEPYVQVSDNRCL L
541/181 571/191
TGC CCT GCC TCC AAT CCC CTT TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC CGC TAC ATG CPASNPLCREQPSSIVHRYM
601/201 631/211 AGC ATC ACC TCA GAG CGA AGT GTG CCT GCT GAC GTG TTT CAG ATC CAG GCA ACC TCT GTC SITSERSVPADVFQIQATSV 661/221 691/231 TAC CCT GGT GCC TAC AAT GCC TTT CAG ATC CGT TCT GGA AAC ACA CAG GGG GAC TTC TAC YPGAYNAFQIRSGNTQGDFY 721/241 751/251 ATT AGG CAA ATC AAC AAT GTC AGC GCC ATG CTG GTC CTC GCC AGG CCA GTG ACG GGA CCC IRQINNVSAMLVLARPVTGP 781/261 811/271 CGG GAG TAC GTG CTG GAC CTG GAG ATG GTC ACC ATG AAT TCC CTT ATG AGC TAC CGG GCC REYVLDLEMVTMNSLMSYRA 841/281 871/291 AGC TCT GTA CTG AGA CTC ACG GTC TTT GTG GGA GCC TAT ACC TTC TGA AGACCCTCAGGGAAGG SSVLRLTVFVGAYTF* GCCATGTGGGGGCCCCTTCCCCCTCCCATAGCTTAAGCAGCCCCGGGGGCCTAGGGATGACCGTTCTGCTTAAAGGAACT ATGATGTGAAGGACAATAAAGGGAGAAAGAAGGAAAA SEQ ID N 9: séquence nucléotidique et polypeptidique fragment C-term de fibuline 2 murine SEQ ID N 9 : 1/1 31/11
<Desc/Clms Page number 52>
GAG GGC TCT GAA TGT GTG GAT GTG AAT GAG TGT GAG ACA GGT GTG CAT CGC TGT GGC GAG EGSECVDVNECETGVHRCGE
61/21 91/31
GGC CAA CTG TGC TAT AAC CTC CCT GGA TCC TAC CGC TGT GAC TGC AAG CCC GGC TTC CAG GQLCYNLPGSYRCDCKPGFQ Q
121/41 151/51
AGG GAT GCA TTC GGC AGG ACT TGC ATT GAT GTG AAC GAA TGC TGG GTC TCG CCG GGC CGC R D A F G R T C I D V N E C W V S P G R R
181/61 211/71
CTG TGC CAG CAC ACA TGT GAG AAC ACA CCG GGC TCC TAC CGC TGC TCC TGC GCT GCT GGC LCQHTCENTPGSYRCSCAAG
241/81 271/91 TTC CTT TTG GCC GCA GAT GGC AAA CAT TGT GAA GAT GTG AAC GAG TGC GAG ACT CGG CGC FLLAADGKHCEDVNECETRR
301/101 331/111 TGC AGC CAG GAA TGT GCC AAC ATC TAT GGC TCC TAT CAG TGC TAC TGC CGT CAG GGC TAC CSQECANIYGSYQCYCRQGY
361/121 391/131 CAG CTG GCA GAG GAT GGG CAT ACC TGC ACA GAC ATC GAT GAG TGT GCA CAG GGC GCG GGC QLAEDGHTCTDIDECAQGAG 421/141 451/151 ATT CTC TGT ACC TTC CGC TGT GTC AAC GTG CCT GGG AGC TAC CAG TGT GCA TGC CCA GAG ILCTFRCVNVPGSYQCACPE E 481/161 511/171 CAA GGG TAT ACA ATG ATG GCC AAC GGG AGG TCC TGC AAG GAC CTG GAT GAG TGT GCA CTG QGYTMMANGRSCKDLDECAL 541/181 571/191 GGC ACC CAC AAC TGC TCT GAG GCT GAG ACC TGC CAC AAT ATC CAG GGG AGT TTC CGC TGC GTHNCSEAETCHNIQGSFRC 601/201 631/211 CTG CGC TTT GAT TGT CCA CCC AAC TAT GTC CGT GTC TCA CAA ACG AAG TGC GAG CGC ACC L R F D C P P N Y V R V S Q T K C E R T 661/221 691/231 ACA TGC CAG GAT ATC ACG GAA TGT CAA ACC TCA CCA GCT CGC ATC ACG CAC TAC CAG CTC TCQDITECQTSPARITHYQL L 721/241 751/251 AAT TTC CAG ACA GGC CTA CTG GTA CCT GCA CAT ATC TTC CGC ATC GGC CCT GCT CCC GCC NFQTGLLVPAHIFRIGPAPA 781/261 811/271 TTT GCT GGG GAC ACC ATC TCC CTG ACC ATC ACG AAG GGC AAT GAG GAG GGC TAC TTC GTC FAGDTISLTITKGNEEGYFV 841/281 871/291 ACA CGC AGA CTC AAT GCC TAC ACT GGT GTG GTA TCC CTG CAG CGG TCT GTT CTG GAG CCG TRRLNAYTGVVSLQRSVLEP
61/21 91/31
GGC CAA CTG TGC TAT AAC CTC CCT GGA TCC TAC CGC TGT GAC TGC AAG CCC GGC TTC CAG GQLCYNLPGSYRCDCKPGFQ Q
121/41 151/51
AGG GAT GCA TTC GGC AGG ACT TGC ATT GAT GTG AAC GAA TGC TGG GTC TCG CCG GGC CGC R D A F G R T C I D V N E C W V S P G R R
181/61 211/71
CTG TGC CAG CAC ACA TGT GAG AAC ACA CCG GGC TCC TAC CGC TGC TCC TGC GCT GCT GGC LCQHTCENTPGSYRCSCAAG
241/81 271/91 TTC CTT TTG GCC GCA GAT GGC AAA CAT TGT GAA GAT GTG AAC GAG TGC GAG ACT CGG CGC FLLAADGKHCEDVNECETRR
301/101 331/111 TGC AGC CAG GAA TGT GCC AAC ATC TAT GGC TCC TAT CAG TGC TAC TGC CGT CAG GGC TAC CSQECANIYGSYQCYCRQGY
361/121 391/131 CAG CTG GCA GAG GAT GGG CAT ACC TGC ACA GAC ATC GAT GAG TGT GCA CAG GGC GCG GGC QLAEDGHTCTDIDECAQGAG 421/141 451/151 ATT CTC TGT ACC TTC CGC TGT GTC AAC GTG CCT GGG AGC TAC CAG TGT GCA TGC CCA GAG ILCTFRCVNVPGSYQCACPE E 481/161 511/171 CAA GGG TAT ACA ATG ATG GCC AAC GGG AGG TCC TGC AAG GAC CTG GAT GAG TGT GCA CTG QGYTMMANGRSCKDLDECAL 541/181 571/191 GGC ACC CAC AAC TGC TCT GAG GCT GAG ACC TGC CAC AAT ATC CAG GGG AGT TTC CGC TGC GTHNCSEAETCHNIQGSFRC 601/201 631/211 CTG CGC TTT GAT TGT CCA CCC AAC TAT GTC CGT GTC TCA CAA ACG AAG TGC GAG CGC ACC L R F D C P P N Y V R V S Q T K C E R T 661/221 691/231 ACA TGC CAG GAT ATC ACG GAA TGT CAA ACC TCA CCA GCT CGC ATC ACG CAC TAC CAG CTC TCQDITECQTSPARITHYQL L 721/241 751/251 AAT TTC CAG ACA GGC CTA CTG GTA CCT GCA CAT ATC TTC CGC ATC GGC CCT GCT CCC GCC NFQTGLLVPAHIFRIGPAPA 781/261 811/271 TTT GCT GGG GAC ACC ATC TCC CTG ACC ATC ACG AAG GGC AAT GAG GAG GGC TAC TTC GTC FAGDTISLTITKGNEEGYFV 841/281 871/291 ACA CGC AGA CTC AAT GCC TAC ACT GGT GTG GTA TCC CTG CAG CGG TCT GTT CTG GAG CCG TRRLNAYTGVVSLQRSVLEP
<Desc/Clms Page number 53>
901/301 931/311
CGG GAC TTT GCC CTA GAT GTG GAG ATG AAG CTT TGG CGC CAG GGC TCT GTC ACT ACC TTC RDFALDVEMKLWRQGSVTTF F
961/321 991/331
CTG GCC AAG ATG TAC ATC TTC TTC ACC ACT TTT GCC CCA TGA GGTGACATGTCAGGCAATCCCTCC LAKMYIFFTTFAP*
AGGTGATGCCTGGGCGGTGGGCAGCTGCGCCACTCCTAAGTGGCTTTTTGCTGTGACTCTGTAACTTAACTTAATCATGC
TGAGCTGGTTGGTCTTGAGTCTCTACCCTAGAGGGAGGGAGATGCACCCCAGCAGGCACTGAGTACAGGCCAGGGTCACC
CGAGGCTAGATGGTGACCTGCAAACTGGAAACAGCCATAGGGGGCTTCTGAACTCCACTCCTCAACTATGGCTACAGCTG
ACATTCCATTCCTTCATCCACTGTGTTCCTCAATTAAAAAAAAAAATCAGCTGTGCATGGTAGCACAGACCTTTAATCCT AGCACTGGGGAGGCAGAGGTAGGTAGATCTCTGAGTTCCAGGCCAGCCTGGTCTACACTGGGAGTTCTAACCAGCCAGAG
CTACATAGAGAGACCCTATCTCAACAAGGAAAAAACGAAAGAAATCTCTGTGAGTTCCAGGCCAGCCTGGTCTACGCTGG GAGTTCTAACCAGCCAGAGCTACATAGAGAGATCCTATCTCAACAAGGAAAAATGAAAGAAATCATTTTAAAAGGTTTTT TTTTTTGCTGTTGTTGTTTAATGATAAGAGTAGCACATATACATTATTAAAAATGATCAAATAGCACAGAAAGGTTA SEQ ID N 10: GATCCATGGAGCAGAAGCTGATCTCCGAGGAGGACCTGA SEQ ID N 11: GATCTCAGGTCCTCCTCGGAGATCAGCTTCTGCTCCATG SEQ ID N 12: GATCTCGGTCGACCTGCATGCAATTCCCGGGTGCGGCCGCGAGCT SEQ ID N 13: CGCGGCCGCACCCGGGAATTGCATGCAGGTCGACCGA SEQ ID N 14 : CGGTACTGGCAGAGGTAACTGG SEQ ID N 15: séquence nucléotidique partielle MBP1 murine SEQ ID N 15 : GCTGTGGCAGAAACCCCTGACTTCTGCCCACCACCTCCCAGCCTCAGGATGCTCCCTTTTGCCTCCTGCCTCCCCGGGTCTTTGCT GCTCTGGGCGTTTCTGCTGTTGCTCTTGGGAGCAGCGTCCCCACAGGATCCCGAGGAGCCGGACAGCTACACGGAATGCACAGATG GCTATGAGTGGGATGCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGCCTGACCATCCCGGAGGCTTGCAAGGGTGAGATGAAA TGCATCAACCACTACGGGGGTTATTTGTGTCTGCCTCGCTCTGCTGCCGTCATCAGTGATCTCCATGGTGAAGGACCTCCACCGCC AGCGGCCCATGCTCAACAACCAAACCCTTGCCCGCAGGGCTACGAGCCTGATGAACAGGAGAGCTGTGTGGATGTGGACGAGTGTA CCCAGGCTTTGCATGACTGTCGCCCTAGTCAGGACTGCCATAACCTTCCTGGCTCCTACCAGTGCACCTGCCCTGATGGTTACCGA AAAATTGGACCCGAATGTGTGGACATAGATGAGTGTCGTTACCGCTATTGCCAGCATCGATGTGTGAACCTGCCGGGCTCTTTTCG ATGCCAGTGTGAGCCAGGCTTCCAGTTGGGACCTAACAACCGCTCTTGTGTGGATGTGAATGAGTGTGACATGGGAGCCCCATGTG AGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGTAACCAGGGCTATGAGCTGCACCGGGATGGCTTCTCCTGCAGC GATATCGATGAGTGCGGCTACTCCAGTTACCTCTGCCAGTACC
CGG GAC TTT GCC CTA GAT GTG GAG ATG AAG CTT TGG CGC CAG GGC TCT GTC ACT ACC TTC RDFALDVEMKLWRQGSVTTF F
961/321 991/331
CTG GCC AAG ATG TAC ATC TTC TTC ACC ACT TTT GCC CCA TGA GGTGACATGTCAGGCAATCCCTCC LAKMYIFFTTFAP*
AGGTGATGCCTGGGCGGTGGGCAGCTGCGCCACTCCTAAGTGGCTTTTTGCTGTGACTCTGTAACTTAACTTAATCATGC
TGAGCTGGTTGGTCTTGAGTCTCTACCCTAGAGGGAGGGAGATGCACCCCAGCAGGCACTGAGTACAGGCCAGGGTCACC
CGAGGCTAGATGGTGACCTGCAAACTGGAAACAGCCATAGGGGGCTTCTGAACTCCACTCCTCAACTATGGCTACAGCTG
ACATTCCATTCCTTCATCCACTGTGTTCCTCAATTAAAAAAAAAAATCAGCTGTGCATGGTAGCACAGACCTTTAATCCT AGCACTGGGGAGGCAGAGGTAGGTAGATCTCTGAGTTCCAGGCCAGCCTGGTCTACACTGGGAGTTCTAACCAGCCAGAG
CTACATAGAGAGACCCTATCTCAACAAGGAAAAAACGAAAGAAATCTCTGTGAGTTCCAGGCCAGCCTGGTCTACGCTGG GAGTTCTAACCAGCCAGAGCTACATAGAGAGATCCTATCTCAACAAGGAAAAATGAAAGAAATCATTTTAAAAGGTTTTT TTTTTTGCTGTTGTTGTTTAATGATAAGAGTAGCACATATACATTATTAAAAATGATCAAATAGCACAGAAAGGTTA SEQ ID N 10: GATCCATGGAGCAGAAGCTGATCTCCGAGGAGGACCTGA SEQ ID N 11: GATCTCAGGTCCTCCTCGGAGATCAGCTTCTGCTCCATG SEQ ID N 12: GATCTCGGTCGACCTGCATGCAATTCCCGGGTGCGGCCGCGAGCT SEQ ID N 13: CGCGGCCGCACCCGGGAATTGCATGCAGGTCGACCGA SEQ ID N 14 : CGGTACTGGCAGAGGTAACTGG SEQ ID N 15: séquence nucléotidique partielle MBP1 murine SEQ ID N 15 : GCTGTGGCAGAAACCCCTGACTTCTGCCCACCACCTCCCAGCCTCAGGATGCTCCCTTTTGCCTCCTGCCTCCCCGGGTCTTTGCT GCTCTGGGCGTTTCTGCTGTTGCTCTTGGGAGCAGCGTCCCCACAGGATCCCGAGGAGCCGGACAGCTACACGGAATGCACAGATG GCTATGAGTGGGATGCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGCCTGACCATCCCGGAGGCTTGCAAGGGTGAGATGAAA TGCATCAACCACTACGGGGGTTATTTGTGTCTGCCTCGCTCTGCTGCCGTCATCAGTGATCTCCATGGTGAAGGACCTCCACCGCC AGCGGCCCATGCTCAACAACCAAACCCTTGCCCGCAGGGCTACGAGCCTGATGAACAGGAGAGCTGTGTGGATGTGGACGAGTGTA CCCAGGCTTTGCATGACTGTCGCCCTAGTCAGGACTGCCATAACCTTCCTGGCTCCTACCAGTGCACCTGCCCTGATGGTTACCGA AAAATTGGACCCGAATGTGTGGACATAGATGAGTGTCGTTACCGCTATTGCCAGCATCGATGTGTGAACCTGCCGGGCTCTTTTCG ATGCCAGTGTGAGCCAGGCTTCCAGTTGGGACCTAACAACCGCTCTTGTGTGGATGTGAATGAGTGTGACATGGGAGCCCCATGTG AGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGTAACCAGGGCTATGAGCTGCACCGGGATGGCTTCTCCTGCAGC GATATCGATGAGTGCGGCTACTCCAGTTACCTCTGCCAGTACC
<Desc/Clms Page number 54>
SEQ ID N 16: séquence nucléotidique MBP1 murine
SEQ ID N 16 :
GCTGTGGCAGAAACCCCTGACTTCTGCCCACCACCTCCCAGCCTCAGGATGCTCCCTTTTGCCTCCTGCCTCCCCGGGTCTTTGCT GCTCTGGGCGTTTCTGCTGTTGCTCTTGGGAGCAGCGTCCCCACAGGATCCCGAGGAGCCGGACAGCTACACGGAATGCACAGATG
GCTATGAGTGGGATGCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGCCTGACCATCCCGGAGGCTTGCAAGGGTGAGATGAAA
TGCATCAACCACTACGGGGGTTATTTGTGTCTGCCTCGCTCTGCTGCCGTCATCAGTGATCTCCATGGTGAAGGACCTCCACCGCC
AGCGGCCCATGCTCAACAACCAAACCCTTGCCCGCAGGGCTACGAGCCTGATGAACAGGAGAGCTGTGTGGATGTGGACGAGTGTA
CCCAGGCTTTGCATGACTGTCGCCCTAGTCAGGACTGCCATAACCTTCCTGGCTCCTACCAGTGCACCTGCCCTGATGGTTACCGA
AAAATTGGACCCGAATGTGTGGACATAGATGAGTGTCGTTACCGCTATTGCCAGCATCGATGTGTGAACCTGCCGGGCTCTTTTCG
ATGCCAGTGTGAGCCAGGCTTCCAGTTGGGACCTAACAACCGCTCTTGTGTGGATGTGAATGAGTGTGACATGGGAGCCCCATGTG
AGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGTAACCAGGGCTATGAGCTGCACCGGGATGGCTTCTCCTGCAGC
GATATCGATGAGTGCGGCTACTCCAGTTACCTCTGCCAGTACCGCTGTGTCAACGAGCCAGGCCGATTCTCCTGTCACTGCCCACA
AGGCTACCAGCTGCTGGCTACAAGGCTCTGCCAAGATATTGACGAGTGTGAAACAGGTGCACACCAATGTTCTGAGGCCCAAACCT
GTGTCAACTTCCATGGGGGTTACCGCTGTGTGGACACCAACCGTTGTGTGGAGCCCTATGTCCAAGTGTCAGACAACCGCTGCCTC TGCCCTGCCTCCAATCCCCTTTGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGAGCATCACCTCAGAGCGAAGTGTGCC TGCTGACGTGTTTCAGATCCAGGCAACCTCTGTCTACCCTGGTGCCTACAATGCCTTTCAGATCCGTTCTGGAAACACACAGGGGG ACTTCTACATTAGGCAAATCAACAATGTCAGCGCCATGCTGGTCCTCGCCAGGCCAGTGACGGGACCCCGGGAGTACGTGCTGGAC CTGGAGATGGTCACCATGAATTCCCTTATGAGCTACCGGGCCAGCTCTGTACTGAGACTCACGGTCTTTGTGGGAGCCTATACCTT CTGAAGACCCTCAGGGAAGGGCCATGTGGGGGCCCCTTCCCCCTCCCATAGCTTAAGCAGCCCCGGGGGCCTAGGGATGACCGTTC TGCTTAAAGGAACTATGATGTGAAGGACAATAAAGGGAGAAAGAAGGAAAA SEQ ID N 17 : CTCCGCTCCGAGGTGATGGTC SEQ ID N 18: TGTAGCTACTCCAGCTACCTC SEQ ID N 19: séquence nucléotidique partielle MBP1 humaine SEQ ID N 19 : AAGCCAGCCGAGCCGCCAGAGCCGCGGGCCGCGGGGGTGTCGCGGGCCCAACCCCAGGATGCTCCCCTGCGCCTCCTGCCTACCCG GGTCTCTACTGCTCTGGGCGCTGCTACTGTTGCTCTTGGGATCAGCTTCTCCTCAGGATTCTGAAGAGCCCGACAGCTACACGGAA TGCACAGATGGCTATGAGTGGGACCCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGTCTGACCATCCCTGAGGCCTGCAAGGG GGAAATGAAGTGCATCAACCACTACGGGGGCTACTTGTGCCTGCCCCGCTCCGCTGCCGTCATCAACGACCTACACGGCGAGGGAC CCCCGCCACCAGTGCCTCCCGCTCAACACCCCAACCCCTGCCCACCAGGCTATGAGCCCGACGATCAGGACAGCTGTGTGGATGTG GACGAGTGTGCCCAGGCCCTGCACGACTGTCGCCCCAGCCAGGACTGCCATAACTTGCCTGGCTCCTATCAGTGCACCTGCCCTGA TGGTTACCGCAAGATCGGGCCCGAGTGTGTGGACATAGACGAGTGCCGCTACCGCTACTGCCAGCACCGCTGCGTGAACCTGCCTG GCTCCTTCCGCTGCCAGTGCGAGCCGGGCTTCCAGCTGGGGCCTAACAACCGCTCCTGTGTTGATGTGAACGAGTGTGACATGGGG GCCCCATGCGAGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGCCACCAGGGCTATGAGCTGCATCGGGATGGCTT CTCCTGCAGTGATATTGATGAGTGTAGCTACTCCAGCTACCTCTGTCAGTACCGCTGCGTCAACGAGCCAGGCCGTTTCTCCTGCC
SEQ ID N 16 :
GCTGTGGCAGAAACCCCTGACTTCTGCCCACCACCTCCCAGCCTCAGGATGCTCCCTTTTGCCTCCTGCCTCCCCGGGTCTTTGCT GCTCTGGGCGTTTCTGCTGTTGCTCTTGGGAGCAGCGTCCCCACAGGATCCCGAGGAGCCGGACAGCTACACGGAATGCACAGATG
GCTATGAGTGGGATGCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGCCTGACCATCCCGGAGGCTTGCAAGGGTGAGATGAAA
TGCATCAACCACTACGGGGGTTATTTGTGTCTGCCTCGCTCTGCTGCCGTCATCAGTGATCTCCATGGTGAAGGACCTCCACCGCC
AGCGGCCCATGCTCAACAACCAAACCCTTGCCCGCAGGGCTACGAGCCTGATGAACAGGAGAGCTGTGTGGATGTGGACGAGTGTA
CCCAGGCTTTGCATGACTGTCGCCCTAGTCAGGACTGCCATAACCTTCCTGGCTCCTACCAGTGCACCTGCCCTGATGGTTACCGA
AAAATTGGACCCGAATGTGTGGACATAGATGAGTGTCGTTACCGCTATTGCCAGCATCGATGTGTGAACCTGCCGGGCTCTTTTCG
ATGCCAGTGTGAGCCAGGCTTCCAGTTGGGACCTAACAACCGCTCTTGTGTGGATGTGAATGAGTGTGACATGGGAGCCCCATGTG
AGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGTAACCAGGGCTATGAGCTGCACCGGGATGGCTTCTCCTGCAGC
GATATCGATGAGTGCGGCTACTCCAGTTACCTCTGCCAGTACCGCTGTGTCAACGAGCCAGGCCGATTCTCCTGTCACTGCCCACA
AGGCTACCAGCTGCTGGCTACAAGGCTCTGCCAAGATATTGACGAGTGTGAAACAGGTGCACACCAATGTTCTGAGGCCCAAACCT
GTGTCAACTTCCATGGGGGTTACCGCTGTGTGGACACCAACCGTTGTGTGGAGCCCTATGTCCAAGTGTCAGACAACCGCTGCCTC TGCCCTGCCTCCAATCCCCTTTGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGAGCATCACCTCAGAGCGAAGTGTGCC TGCTGACGTGTTTCAGATCCAGGCAACCTCTGTCTACCCTGGTGCCTACAATGCCTTTCAGATCCGTTCTGGAAACACACAGGGGG ACTTCTACATTAGGCAAATCAACAATGTCAGCGCCATGCTGGTCCTCGCCAGGCCAGTGACGGGACCCCGGGAGTACGTGCTGGAC CTGGAGATGGTCACCATGAATTCCCTTATGAGCTACCGGGCCAGCTCTGTACTGAGACTCACGGTCTTTGTGGGAGCCTATACCTT CTGAAGACCCTCAGGGAAGGGCCATGTGGGGGCCCCTTCCCCCTCCCATAGCTTAAGCAGCCCCGGGGGCCTAGGGATGACCGTTC TGCTTAAAGGAACTATGATGTGAAGGACAATAAAGGGAGAAAGAAGGAAAA SEQ ID N 17 : CTCCGCTCCGAGGTGATGGTC SEQ ID N 18: TGTAGCTACTCCAGCTACCTC SEQ ID N 19: séquence nucléotidique partielle MBP1 humaine SEQ ID N 19 : AAGCCAGCCGAGCCGCCAGAGCCGCGGGCCGCGGGGGTGTCGCGGGCCCAACCCCAGGATGCTCCCCTGCGCCTCCTGCCTACCCG GGTCTCTACTGCTCTGGGCGCTGCTACTGTTGCTCTTGGGATCAGCTTCTCCTCAGGATTCTGAAGAGCCCGACAGCTACACGGAA TGCACAGATGGCTATGAGTGGGACCCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGTCTGACCATCCCTGAGGCCTGCAAGGG GGAAATGAAGTGCATCAACCACTACGGGGGCTACTTGTGCCTGCCCCGCTCCGCTGCCGTCATCAACGACCTACACGGCGAGGGAC CCCCGCCACCAGTGCCTCCCGCTCAACACCCCAACCCCTGCCCACCAGGCTATGAGCCCGACGATCAGGACAGCTGTGTGGATGTG GACGAGTGTGCCCAGGCCCTGCACGACTGTCGCCCCAGCCAGGACTGCCATAACTTGCCTGGCTCCTATCAGTGCACCTGCCCTGA TGGTTACCGCAAGATCGGGCCCGAGTGTGTGGACATAGACGAGTGCCGCTACCGCTACTGCCAGCACCGCTGCGTGAACCTGCCTG GCTCCTTCCGCTGCCAGTGCGAGCCGGGCTTCCAGCTGGGGCCTAACAACCGCTCCTGTGTTGATGTGAACGAGTGTGACATGGGG GCCCCATGCGAGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGCCACCAGGGCTATGAGCTGCATCGGGATGGCTT CTCCTGCAGTGATATTGATGAGTGTAGCTACTCCAGCTACCTCTGTCAGTACCGCTGCGTCAACGAGCCAGGCCGTTTCTCCTGCC
<Desc/Clms Page number 55>
ACTGCCCACAGGGTTACCAGCTGCTGGCCACACGCCTCTGCCAAGACATTGATGAGTGTGAGTCTGGTGCGCACCAGTGCTCCGAG
GCCCAAACCTGTGTCAACTTCCATGGGGGCTACCGCTGCGTGGACACCAACCGCTGCGTGGAGCCCTACATCCAGGTCTCTGAGAA
CCGCTGTCTCTGCCCGGCCTCCAACCCTCTATGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGACCATCACCTCGGAGC
GGAG
SEQ ID N 20 : séquence nucléotidique partielle MBP1 humaine
SEQ ID N 20 : TGTAGCTACTCCAGCTACCTCTGTCAGTACCGCTGCGTCAACGAGCCAGGCCGTTTCTCCTGCCACTGCCCACAGGGTTACCAGCT GCTGGCCACACGCCTCTGCCAAGACATTGATGAGTGTGAGTCTGGTGCGCACCAGTGCTCCGAGGCCCAAACCTGTGTCAACTTCC ATGGGGGCTACCGCTGCGTGGACACCAACCGCTGCGTGGAGCCCTACATCCAGGTCTCTGAGAACCGCTGTCTCTGCCCGGCCTCC AACCCTCTATGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGACCATCACCTCGGAGCGGAGCGTGCCCGCTGACGTGTT CCAGATCCAGGCGACCTCCGTCTACCCCGGTGCCTACAATGCCTTTCAGATCCGTGCTGGAAACTCGCAGGGGGACTTTTACATTA GGCAAATCAACAACGTCAGCGCCATGCTGGTCCTCGCCCGGCCGGTGACGGGCCCCCGGGAGTACGTGCTGGACCTGGAGATGGTC ACCATGAATTCCCTCATGAGCTACCGGGCCAGCTCTGTACTGAGGCTCACCGTCTTTGTAGGGGCCTACACCTTCTGAGGAGCAGG AGGGAGCCACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAAGGCAATAAAGGGAGAAAG SEQ ID N 21 : séquence nucléotidique MBP1 humaine SEQ ID N 21 : AAGCCAGCCGAGCCGCCAGAGCCGCGGGCCGCGGGGGTGTCGCGGGCCCAACCCCAGGATGCTCCCCTGCGCCTCCTGCCTACCCG GGTCTCTACTGCTCTGGGCGCTGCTACTGTTGCTCTTGGGATCAGCTTCTCCTCAGGATTCTGAAGAGCCCGACAGCTACACGGAA TGCACAGATGGCTATGAGTGGGACCCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGTCTGACCATCCCTGAGGCCTGCAAGGG GGAAATGAAGTGCATCAACCACTACGGGGGCTACTTGTGCCTGCCCCGCTCCGCTGCCGTCATCAACGACCTACACGGCGAGGGAC CCCCGCCACCAGTGCCTCCCGCTCAACACCCCAACCCCTGCCCACCAGGCTATGAGCCCGACGATCAGGACAGCTGTGTGGATGTG GACGAGTGTGCCCAGGCCCTGCACGACTGTCGCCCCAGCCAGGACTGCCATAACTTGCCTGGCTCCTATCAGTGCACCTGCCCTGA TGGTTACCGCAAGATCGGGCCCGAGTGTGTGGACATAGACGAGTGCCGCTACCGCTACTGCCAGCACCGCTGCGTGAACCTGCCTG GCTCCTTCCGCTGCCAGTGCGAGCCGGGCTTCCAGCTGGGGCCTAACAACCGCTCCTGTGTTGATGTGAACGAGTGTGACATGGGG GCCCCATGCGAGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGCCACCAGGGCTATGAGCTGCATCGGGATGGCTT CTCCTGCAGTGATATTGATGAGTGTAGCTACTCCAGCTACCTCTGTCAGTACCGCTGCGTCAACGAGCCAGGCCGTTTCTCCTGCC ACTGCCCACAGGGTTACCAGCTGCTGGCCACACGCCTCTGCCAAGACATTGATGAGTGTGAGTCTGGTGCGCACCAGTGCTCCGAG GCCCAAACCTGTGTCAACTTCCATGGGGGCTACCGCTGCGTGGACACCAACCGCTGCGTGGAGCCCTACATCCAGGTCTCTGAGAA CCGCTGTCTCTGCCCGGCCTCCAACCCTCTATGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGACCATCACCTCGGAGC GGAGCGTGCCCGCTGACGTGTTCCAGATCCAGGCGACCTCCGTCTACCCCGGTGCCTACAATGCCTTTCAGATCCGTGCTGGAAAC TCGCAGGGGGACTTTTACATTAGGCAAATCAACAACGTCAGCGCCATGCTGGTCCTCGCCCGGCCGGTGACGGGCCCCCGGGAGTA CGTGCTGGACCTGGAGATGGTCACCATGAATTCCCTCATGAGCTACCGGGCCAGCTCTGTACTGAGGCTCACCGTCTTTGTAGGGG CCTACACCTTCTGAGGAGCAGGAGGGAGCCACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAA GGCAATAAAGGGAGAAAG SEQ ID N 22 : séquence nucléotidique et polypeptidique MBP murine SEQ ID N 22 :
GCCCAAACCTGTGTCAACTTCCATGGGGGCTACCGCTGCGTGGACACCAACCGCTGCGTGGAGCCCTACATCCAGGTCTCTGAGAA
CCGCTGTCTCTGCCCGGCCTCCAACCCTCTATGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGACCATCACCTCGGAGC
GGAG
SEQ ID N 20 : séquence nucléotidique partielle MBP1 humaine
SEQ ID N 20 : TGTAGCTACTCCAGCTACCTCTGTCAGTACCGCTGCGTCAACGAGCCAGGCCGTTTCTCCTGCCACTGCCCACAGGGTTACCAGCT GCTGGCCACACGCCTCTGCCAAGACATTGATGAGTGTGAGTCTGGTGCGCACCAGTGCTCCGAGGCCCAAACCTGTGTCAACTTCC ATGGGGGCTACCGCTGCGTGGACACCAACCGCTGCGTGGAGCCCTACATCCAGGTCTCTGAGAACCGCTGTCTCTGCCCGGCCTCC AACCCTCTATGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGACCATCACCTCGGAGCGGAGCGTGCCCGCTGACGTGTT CCAGATCCAGGCGACCTCCGTCTACCCCGGTGCCTACAATGCCTTTCAGATCCGTGCTGGAAACTCGCAGGGGGACTTTTACATTA GGCAAATCAACAACGTCAGCGCCATGCTGGTCCTCGCCCGGCCGGTGACGGGCCCCCGGGAGTACGTGCTGGACCTGGAGATGGTC ACCATGAATTCCCTCATGAGCTACCGGGCCAGCTCTGTACTGAGGCTCACCGTCTTTGTAGGGGCCTACACCTTCTGAGGAGCAGG AGGGAGCCACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAAGGCAATAAAGGGAGAAAG SEQ ID N 21 : séquence nucléotidique MBP1 humaine SEQ ID N 21 : AAGCCAGCCGAGCCGCCAGAGCCGCGGGCCGCGGGGGTGTCGCGGGCCCAACCCCAGGATGCTCCCCTGCGCCTCCTGCCTACCCG GGTCTCTACTGCTCTGGGCGCTGCTACTGTTGCTCTTGGGATCAGCTTCTCCTCAGGATTCTGAAGAGCCCGACAGCTACACGGAA TGCACAGATGGCTATGAGTGGGACCCAGACAGCCAGCACTGCCGGGATGTCAACGAGTGTCTGACCATCCCTGAGGCCTGCAAGGG GGAAATGAAGTGCATCAACCACTACGGGGGCTACTTGTGCCTGCCCCGCTCCGCTGCCGTCATCAACGACCTACACGGCGAGGGAC CCCCGCCACCAGTGCCTCCCGCTCAACACCCCAACCCCTGCCCACCAGGCTATGAGCCCGACGATCAGGACAGCTGTGTGGATGTG GACGAGTGTGCCCAGGCCCTGCACGACTGTCGCCCCAGCCAGGACTGCCATAACTTGCCTGGCTCCTATCAGTGCACCTGCCCTGA TGGTTACCGCAAGATCGGGCCCGAGTGTGTGGACATAGACGAGTGCCGCTACCGCTACTGCCAGCACCGCTGCGTGAACCTGCCTG GCTCCTTCCGCTGCCAGTGCGAGCCGGGCTTCCAGCTGGGGCCTAACAACCGCTCCTGTGTTGATGTGAACGAGTGTGACATGGGG GCCCCATGCGAGCAGCGCTGCTTCAACTCCTATGGGACCTTCCTGTGTCGCTGCCACCAGGGCTATGAGCTGCATCGGGATGGCTT CTCCTGCAGTGATATTGATGAGTGTAGCTACTCCAGCTACCTCTGTCAGTACCGCTGCGTCAACGAGCCAGGCCGTTTCTCCTGCC ACTGCCCACAGGGTTACCAGCTGCTGGCCACACGCCTCTGCCAAGACATTGATGAGTGTGAGTCTGGTGCGCACCAGTGCTCCGAG GCCCAAACCTGTGTCAACTTCCATGGGGGCTACCGCTGCGTGGACACCAACCGCTGCGTGGAGCCCTACATCCAGGTCTCTGAGAA CCGCTGTCTCTGCCCGGCCTCCAACCCTCTATGTCGAGAGCAGCCTTCATCCATTGTGCACCGCTACATGACCATCACCTCGGAGC GGAGCGTGCCCGCTGACGTGTTCCAGATCCAGGCGACCTCCGTCTACCCCGGTGCCTACAATGCCTTTCAGATCCGTGCTGGAAAC TCGCAGGGGGACTTTTACATTAGGCAAATCAACAACGTCAGCGCCATGCTGGTCCTCGCCCGGCCGGTGACGGGCCCCCGGGAGTA CGTGCTGGACCTGGAGATGGTCACCATGAATTCCCTCATGAGCTACCGGGCCAGCTCTGTACTGAGGCTCACCGTCTTTGTAGGGG CCTACACCTTCTGAGGAGCAGGAGGGAGCCACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAA GGCAATAAAGGGAGAAAG SEQ ID N 22 : séquence nucléotidique et polypeptidique MBP murine SEQ ID N 22 :
<Desc/Clms Page number 56>
1/1 GCTGTGGCAGAAACCCCTGACTTCTGCCCACCACCTCCCAGCCTCAGG ATG CTC CCT TTT GCC TCC TGC CTC MLPFASCL L 25/9 55/19 CCC GGG TCT TTG CTG CTC TGG GCG TTT CTG CTG TTG CTC TTG GGA GCA GCG TCC CCA CAG PGSLLLWAFLLLLLGAASPQ Q 85/29 115/39 GAT CCC GAG GAG CCG GAC AGC TAC ACG GAA TGC ACA GAT GGC TAT GAG TGG GAT GCA GAC DPEEPDSYTECTDGYEWDAD D 145/49 175/59 AGC CAG CAC TGC CGG GAT GTC AAC GAG TGC CTG ACC ATC CCG GAG GCT TGC AAG GGT GAG SQHCRDVNECLTIPEACKGE E 205/69 235/79 ATG AAA TGC ATC AAC CAC TAC GGG GGT TAT TTG TGT CTG CCT CGC TCT GCT GCC GTC ATC MKCINHYGGYLCLPRSAAVI 265/89 295/99 AGT GAT CTC CAT GGT GAA GGA CCT CCA CCG CCA GCG GCC CAT GCT CAA CAA CCA AAC CCT SDLHGEGPPPPAAHAQQPNP 325/109 355/119 TGC CCG CAG GGC TAC GAG CCT GAT GAA CAG GAG AGC TGT GTG GAT GTG GAC GAG TGT ACC CPQGYEPDEQESCVDVDECT T 385/129 415/139 CAG GCT TTG CAT GAC TGT CGC CCT AGT CAG GAC TGC CAT AAC CTT CCT GGC TCC TAC CAG QALHDCRPSQDCHNLPGSYQ Q 445/149 475/159 TGC ACC TGC CCT GAT GGT TAC CGA AAA ATT GGA CCC GAA TGT GTG GAC ATA GAT GAG TGT CTCPDGYRKIGPECVDIDEC 505/169 535/179 CGT TAC CGC TAT TGC CAG CAT CGA TGT GTG AAC CTG CCG GGC TCT TTT CGA TGC CAG TGT R Y R Y C Q H R C V N L P G F R C Q 565/189 595/199 GAG CCA GGC TTC CAG TTG GGA CCT AAC AAC CGC TCT TGT GTG GAT GTG AAT GAG TGT GAC EPGFQLGPNNRSCVDVNECD D 625/209 655/219 ATG GGA GCC CCA TGT GAG CAG CGC TGC TTC AAC TCC TAT GGG ACC TTC CTG TGT CGC TGT MGAPCEQRCFNSYGTFLCRC 685/229 715/239 AAC CAG GGC TAT GAG CTG CAC CGG GAT GGC TTC TCC TGC AGC GAT ATC GAT GAG TGC GGC NQGYELHRDGFSCSDIDECG 745/249 775/259 TAC TCC AGT TAC CTC TGC CAG TAC CGC TGT GTC AAC GAG CCA GGC CGA TTC TCC TGT CAC YSSYLCQYRCVNEPGRFSCH H 805/269 835/279 TGC CCA CAA GGC TAC CAG CTG CTG GCT ACA AGG CTC TGC CAA GAT ATT GAC GAG TGT GAA
<Desc/Clms Page number 57>
CPQGYQLLATRLCQDIDECE
865/289 895/289
ACA GGT GCA CAC CAA TGT TCT GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG GGT TAC CGC TGAHQCSEAQTCVNFHGGYR R
925/309 955/319
TGT GTG GAC ACC AAC CGT TGT GTG GAG CCC TAT GTC CAA GTG TCA GAC AAC CGC TGC CTC CVDTNRCVEPYVQVSDNRCL L
985/329 1015/339
TGC CCT GCC TCC AAT CCC CTT TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC CGC TAC ATG
C P A S N P L C R E Q P S S I V H R Y M
1045/349 1075/359 AGC ATC ACC TCA GAG CGA AGT GTG CCT GCT GAC GTG TTT CAG ATC CAG GCA ACC TCT GTC
S ITSERSVPADVFQIQATSV
1105/369 1135/379 TAC CCT GGT GCC TAC AAT GCC TTT CAG ATC CGT TCT GGA AAC ACA CAG GGG GAC TTC TAC YPGAYNAFQIRSGNTQGDFY
1165/389 1195/399 ATT AGG CAA ATC AAC AAT GTC AGC GCC ATG CTG GTC CTC GCC AGG CCA GTG ACG GGA CCC IRQINNVSAMLVLARPVTGP
1225/409 1255/419 CGG GAG TAC GTG CTG GAC CTG GAG ATG GTC ACC ATG AAT TCC CTT ATG AGC TAC CGG GCC REYVLDLEMVTMNSLMSYRA
1285/429 1315/439 AGC TCT GTA CTG AGA CTC ACG GTC TTT GTG GGA GCC TAT ACC TTC TGA AGACCCTCAGGGAAG SSVLRLTVFVGAYTF* GGCCATGTGGGGGCCCCCTTCCCCCTCCCATAGCTTAAGCAGCCCTGGGGGCCTAGGGATGACCGTTCTGCTTAAAGGA ACTATGATGTGAAGGACAATAAAGGGAGAAAGAAGGAAAA SEQ ID N 23 : séquence nucléotidique et polypeptidique MBP 1 humaine SEQ ID N 23 :
1/1 AAGCCAGCCGAGCCGCCAGAGCCGCGGGCCGCGGGGGTGTCGCGGGCCCAACCCCAGG ATG CTC CCC TGC GCC
M L P C A 16/6 46/16 TCC TGC CTA CCC GGG TCT CTA CTG CTC TGG GCG CTG CTA CTG TTG CTC TTG GGA TCA GCT S C L P G S L L L W A L L L L L L G S A 76/26 106/36 TCT CCT CAG GAT TCT GAA GAG CCC GAC AGC TAC ACG GAA TGC ACA GAT GGC TAT GAG TGG SPQDSEEPDSYTECTDGYEW 136/46 166/56 GAC CCA GAC AGC CAG CAC TGC CGG GAT GTC AAC GAG TGT CTG ACC ATC CCT GAG GCC TGC
865/289 895/289
ACA GGT GCA CAC CAA TGT TCT GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG GGT TAC CGC TGAHQCSEAQTCVNFHGGYR R
925/309 955/319
TGT GTG GAC ACC AAC CGT TGT GTG GAG CCC TAT GTC CAA GTG TCA GAC AAC CGC TGC CTC CVDTNRCVEPYVQVSDNRCL L
985/329 1015/339
TGC CCT GCC TCC AAT CCC CTT TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC CGC TAC ATG
C P A S N P L C R E Q P S S I V H R Y M
1045/349 1075/359 AGC ATC ACC TCA GAG CGA AGT GTG CCT GCT GAC GTG TTT CAG ATC CAG GCA ACC TCT GTC
S ITSERSVPADVFQIQATSV
1105/369 1135/379 TAC CCT GGT GCC TAC AAT GCC TTT CAG ATC CGT TCT GGA AAC ACA CAG GGG GAC TTC TAC YPGAYNAFQIRSGNTQGDFY
1165/389 1195/399 ATT AGG CAA ATC AAC AAT GTC AGC GCC ATG CTG GTC CTC GCC AGG CCA GTG ACG GGA CCC IRQINNVSAMLVLARPVTGP
1225/409 1255/419 CGG GAG TAC GTG CTG GAC CTG GAG ATG GTC ACC ATG AAT TCC CTT ATG AGC TAC CGG GCC REYVLDLEMVTMNSLMSYRA
1285/429 1315/439 AGC TCT GTA CTG AGA CTC ACG GTC TTT GTG GGA GCC TAT ACC TTC TGA AGACCCTCAGGGAAG SSVLRLTVFVGAYTF* GGCCATGTGGGGGCCCCCTTCCCCCTCCCATAGCTTAAGCAGCCCTGGGGGCCTAGGGATGACCGTTCTGCTTAAAGGA ACTATGATGTGAAGGACAATAAAGGGAGAAAGAAGGAAAA SEQ ID N 23 : séquence nucléotidique et polypeptidique MBP 1 humaine SEQ ID N 23 :
1/1 AAGCCAGCCGAGCCGCCAGAGCCGCGGGCCGCGGGGGTGTCGCGGGCCCAACCCCAGG ATG CTC CCC TGC GCC
M L P C A 16/6 46/16 TCC TGC CTA CCC GGG TCT CTA CTG CTC TGG GCG CTG CTA CTG TTG CTC TTG GGA TCA GCT S C L P G S L L L W A L L L L L L G S A 76/26 106/36 TCT CCT CAG GAT TCT GAA GAG CCC GAC AGC TAC ACG GAA TGC ACA GAT GGC TAT GAG TGG SPQDSEEPDSYTECTDGYEW 136/46 166/56 GAC CCA GAC AGC CAG CAC TGC CGG GAT GTC AAC GAG TGT CTG ACC ATC CCT GAG GCC TGC
<Desc/Clms Page number 58>
DPDSQHCRDVNECLTIPEAC
206/66 236/76
AAG GGG GAA ATG AAG TGC ATC AAC CAC TAC GGG GGC TAC TTG TGC CTG CCC CGC TCC GCT KGEMKCINHYGGYLCLPRSA
266/86 296/96
GCC GTC ATC AAC GAC CTA CAC GGC GAG GGA CCC CCG CCA CCA GTG CCT CCC GCT CAA CAC AVINDLHGEGPPPPVPPAQH H
326/106 356/116
CCC AAC CCC TGC CCA CCA GGC TAT GAG CCC GAC GAT CAG GAC AGC TGT GTG GAT GTG GAC PNPCPPGYEPDDQDSCVDVD D
356/126 416/136 GAG TGT GCC CAG GCC CTG CAC GAC TGT CGC CCC AGC CAG GAC TGC CAT AAC TTG CCT GGC ECAQALHDCRPSQDCHNLPG
416/146 476/156 TCC TAT CAG TGC ACC TGC CCT GAT GGT TAC CGC AAG ATC GGG CCC GAG TGT GTG GAC ATA SYQCTCPDGYRKIGPECVDI 506/166 536/176 GAC GAG TGC CGC TAC CGC TAC TGC CAG CAC CGC TGC GTG AAC CTG CCT GGC TCC TTC CGC DECRYRYCQHRCVNLPGSFR 566/186 596/196 TGC CAG TGC GAG CCG GGC TTC CAG CTG GGG CCT AAC AAC CGC TCC TGT GTT GAT GTG AAC C Q C E PGFQLGPNNRSCVDVN 626/206 656/216 GAG TGT GAC ATG GGG GCC CCA TGC GAG CAG CGC TGC TTC AAC TCC TAT GGG ACC TTC CTG ECDMGAPCEQRCFNSYGTFL L 686/226 716/236 TGT CGC TGC CAC CAG GGC TAT GAG CTG CAT CGG GAT GGC TTC TCC TGC AGT GAT ATT GAT CRCHQGYELHRDGFSCSDID D 746/246 776/256 GAG TGT AGC TAC TCC AGC TAC CTC TGT CAG TAC CGC TGC GTC AAC GAG CCA GGC CGT TTC ECSYSSYLCQYRCVNEPGRF F 806/266 836/276 TCC TGC CAC TGC CCA CAG GGT TAC CAG CTG CTG GCC ACA CGC CTC TGC CAA GAC ATT GAT SCHCPQGYQLLATRLCQDID D 866/286 896/296 GAG TGT GAG TCT GGT GCG CAC CAG TGC TCC GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG ECESGAHQCSEAQTCVNFHG G 926/306 956/316 GGC TAC CGC TGC GTG GAC ACC AAC CGC TGC GTG GAG CCC TAC ATC CAG GTC TCT GAG AAC GYRCVDTNRCVEPYIQVSEN 986/326 1016/336 CGC TGT CTC TGC CCG GCC TCC AAC CCT CTA TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC RCLCPASNPLCREQPSSIVH H 1046/346 1076/356
206/66 236/76
AAG GGG GAA ATG AAG TGC ATC AAC CAC TAC GGG GGC TAC TTG TGC CTG CCC CGC TCC GCT KGEMKCINHYGGYLCLPRSA
266/86 296/96
GCC GTC ATC AAC GAC CTA CAC GGC GAG GGA CCC CCG CCA CCA GTG CCT CCC GCT CAA CAC AVINDLHGEGPPPPVPPAQH H
326/106 356/116
CCC AAC CCC TGC CCA CCA GGC TAT GAG CCC GAC GAT CAG GAC AGC TGT GTG GAT GTG GAC PNPCPPGYEPDDQDSCVDVD D
356/126 416/136 GAG TGT GCC CAG GCC CTG CAC GAC TGT CGC CCC AGC CAG GAC TGC CAT AAC TTG CCT GGC ECAQALHDCRPSQDCHNLPG
416/146 476/156 TCC TAT CAG TGC ACC TGC CCT GAT GGT TAC CGC AAG ATC GGG CCC GAG TGT GTG GAC ATA SYQCTCPDGYRKIGPECVDI 506/166 536/176 GAC GAG TGC CGC TAC CGC TAC TGC CAG CAC CGC TGC GTG AAC CTG CCT GGC TCC TTC CGC DECRYRYCQHRCVNLPGSFR 566/186 596/196 TGC CAG TGC GAG CCG GGC TTC CAG CTG GGG CCT AAC AAC CGC TCC TGT GTT GAT GTG AAC C Q C E PGFQLGPNNRSCVDVN 626/206 656/216 GAG TGT GAC ATG GGG GCC CCA TGC GAG CAG CGC TGC TTC AAC TCC TAT GGG ACC TTC CTG ECDMGAPCEQRCFNSYGTFL L 686/226 716/236 TGT CGC TGC CAC CAG GGC TAT GAG CTG CAT CGG GAT GGC TTC TCC TGC AGT GAT ATT GAT CRCHQGYELHRDGFSCSDID D 746/246 776/256 GAG TGT AGC TAC TCC AGC TAC CTC TGT CAG TAC CGC TGC GTC AAC GAG CCA GGC CGT TTC ECSYSSYLCQYRCVNEPGRF F 806/266 836/276 TCC TGC CAC TGC CCA CAG GGT TAC CAG CTG CTG GCC ACA CGC CTC TGC CAA GAC ATT GAT SCHCPQGYQLLATRLCQDID D 866/286 896/296 GAG TGT GAG TCT GGT GCG CAC CAG TGC TCC GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG ECESGAHQCSEAQTCVNFHG G 926/306 956/316 GGC TAC CGC TGC GTG GAC ACC AAC CGC TGC GTG GAG CCC TAC ATC CAG GTC TCT GAG AAC GYRCVDTNRCVEPYIQVSEN 986/326 1016/336 CGC TGT CTC TGC CCG GCC TCC AAC CCT CTA TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC RCLCPASNPLCREQPSSIVH H 1046/346 1076/356
<Desc/Clms Page number 59>
CGC TAC ATG ACC ATC ACC TCG GAG CGG AGC GTG CCC GCT GAC GTG TTC CAG ATC CAG GCG RYMTITSERSVPADVFQIQA
1106/366 1136/376
ACC TCC GTC TAC CCC GGT GCC TAC AAT GCC TTT CAG ATC CGT GCT GGA AAC TCG CAG GGG TSVYPGAYNAFQIRAGNSQG G
1166/386 1196/396
GAC TTT TAC ATT AGG CAA ATC AAC AAC GTC AGC GCC ATG CTG GTC CTC GCC CGG CCG GTG DFYIRQINNVSAMLVLARPV
1226/406 1256/416
ACG GGC CCC CGG GAG TAC GTG CTG GAC CTG GAG ATG GTC ACC ATG AAT TCC CTC ATG AGC TGPREYVLDLEMVTMNSLMS
1286/426 1316/436
TAC CGG GCC AGC TCT GTA CTG AGG CTC ACC GTC TTT GTA GGG GCC TAC ACC TTC TGA GGA YRASSVLRLTVFVGAYTF* GCAGGAGGGAGCCACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAAGGCAATAAAG
GGAGAAAG
SEQ ID N 24 :
CGGAGTCAACGGATTTGGTCGTAT
SEQ ID N 25 :
AGCCTTCTCCATGGTGGTGAAGAC
SEQ ID N 26 (fragment C-terminal de hMBPl correspondant au fragment C-terminal murin isolé double-hybride)
1/1 31/11
TGC ACC TGC CCT GAT GGT TAC CGC AAG ATC GGG CCC GAG TGT GTG GAC ATA GAC GAG TGC CTCPDGYRKIGPECVDIDEC
61/21 91/31
CGC TAC CGC TAC TGC CAG CAC CGC TGC GTG AAC CTG CCT GGC TCC TTC CGC TGC CAG TGC RYRYCQHRCVNLPGSFRCQC
121/41 151/51
GAG CCG GGC TTC CAG CTG GGG CCT AAC AAC CGC TCC TGT GTT GAT GTG AAC GAG TGT GAC EPGFQLGPNNRSCVDVNE C D D
181/61 211/71
ATG GGG GCC CCA TGC GAG CAG CGC TGC TTC AAC TCC TAT GGG ACC TTC CTG TGT CGC TGC MGAPCEQRCFNSYGTFLCRC
241/81 271/91
CAC CAG GGC TAT GAG CTG CAT CGG GAT GGC TTC TCC TGC AGT GAT ATT GAT GAG TGT AGC HQGYELHRDGFSCSDIDECS
301/101 331/111
TAC TCC AGC TAC CTC TGT CAG TAC CGC TGC GTC AAC GAG CCA GGC CGT TTC TCC TGC CAC YSSYLCQYRCVNEPGRFSCH H
361/121 391/131
TGC CCA CAG GGT TAC CAG CTG CTG GCC ACA CGC CTC TGC CAA GAC ATT GAT GAG TGT GAG CPQGYQLLATRLCQDIDECE
421/141 451/151
TCT GGT GCG CAC CAG TGC TCC GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG GGC TAC CGC
1106/366 1136/376
ACC TCC GTC TAC CCC GGT GCC TAC AAT GCC TTT CAG ATC CGT GCT GGA AAC TCG CAG GGG TSVYPGAYNAFQIRAGNSQG G
1166/386 1196/396
GAC TTT TAC ATT AGG CAA ATC AAC AAC GTC AGC GCC ATG CTG GTC CTC GCC CGG CCG GTG DFYIRQINNVSAMLVLARPV
1226/406 1256/416
ACG GGC CCC CGG GAG TAC GTG CTG GAC CTG GAG ATG GTC ACC ATG AAT TCC CTC ATG AGC TGPREYVLDLEMVTMNSLMS
1286/426 1316/436
TAC CGG GCC AGC TCT GTA CTG AGG CTC ACC GTC TTT GTA GGG GCC TAC ACC TTC TGA GGA YRASSVLRLTVFVGAYTF* GCAGGAGGGAGCCACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAAGGCAATAAAG
GGAGAAAG
SEQ ID N 24 :
CGGAGTCAACGGATTTGGTCGTAT
SEQ ID N 25 :
AGCCTTCTCCATGGTGGTGAAGAC
SEQ ID N 26 (fragment C-terminal de hMBPl correspondant au fragment C-terminal murin isolé double-hybride)
1/1 31/11
TGC ACC TGC CCT GAT GGT TAC CGC AAG ATC GGG CCC GAG TGT GTG GAC ATA GAC GAG TGC CTCPDGYRKIGPECVDIDEC
61/21 91/31
CGC TAC CGC TAC TGC CAG CAC CGC TGC GTG AAC CTG CCT GGC TCC TTC CGC TGC CAG TGC RYRYCQHRCVNLPGSFRCQC
121/41 151/51
GAG CCG GGC TTC CAG CTG GGG CCT AAC AAC CGC TCC TGT GTT GAT GTG AAC GAG TGT GAC EPGFQLGPNNRSCVDVNE C D D
181/61 211/71
ATG GGG GCC CCA TGC GAG CAG CGC TGC TTC AAC TCC TAT GGG ACC TTC CTG TGT CGC TGC MGAPCEQRCFNSYGTFLCRC
241/81 271/91
CAC CAG GGC TAT GAG CTG CAT CGG GAT GGC TTC TCC TGC AGT GAT ATT GAT GAG TGT AGC HQGYELHRDGFSCSDIDECS
301/101 331/111
TAC TCC AGC TAC CTC TGT CAG TAC CGC TGC GTC AAC GAG CCA GGC CGT TTC TCC TGC CAC YSSYLCQYRCVNEPGRFSCH H
361/121 391/131
TGC CCA CAG GGT TAC CAG CTG CTG GCC ACA CGC CTC TGC CAA GAC ATT GAT GAG TGT GAG CPQGYQLLATRLCQDIDECE
421/141 451/151
TCT GGT GCG CAC CAG TGC TCC GAG GCC CAA ACC TGT GTC AAC TTC CAT GGG GGC TAC CGC
<Desc/Clms Page number 60>
SGAHQCSEAQTCVNFHGGYR R
481/161 511/171
TGC GTG GAC ACC AAC CGC TGC GTG GAG CCC TAC ATC CAG GTC TCT GAG AAC CGC TGT CTC CVDTNRCVEPYIQVSENRCL L
541/181 571/191 TGC CCG GCC TCC AAC CCT CTA TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC CGC TAC ATG CPASNPLCREQPSSIVHRYM
601/201 631/211 ACC ATC ACC TCG GAG CGG AGc GtG CCC GCT GAC GTG TTC CAG ATC CAG GCG ACC TCC GTC TITSERSVPADVFQIQATSV
661/221 691/231 TAC CCC GGT GCC TAC AAT GCC TTT CAG ATC CGT GCT GGA AAC TCG CAG GGG GAC TTT TAC YPGAYNAFQIRAGNSQGDFY 721/241 751/251 ATT AGG CAA ATC AAC AAC GTC AGC GCC ATG cTG GTC CTC GCC CGG CCG GTG ACG GGC CCC IRQINNVSAMLVLARPVTGP 781/261 811/271 CGG GAG TAC GTG CTG GAc CTG GAG ATG GTC ACC ATG AAT TCC CTC ATG AGC TAC CGG GCC REYVLDLEMVTMNSLMSYRA 841/281 871/291 AGC TcT GTA cTG AGG CTC ACC GTc TTT GTA GGG GCC TAC ACC TTc TGA GGAGCAGGAGGGAGC S SVLRLTVFVGAYTF F * CACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAAGGCAATAAAGGGAGAAAGAAAG TCCTGGTGGCTGAGGTGGGCGGGTCACACTGCAGGAAGCCTCAGGCTGGGGCAGGGTGGCACTTGGGGGGGCAGGCCAA GTTCACCTAAATGGGGGTCTCTATATGTTCAGGCCCAGGGGCCCCCATTGACAGGAGCTGGGAGCTCTGCACCACGAGC TTCAGTCACCCCGAGAGGAGAGGAGGTAACGAGGAGGGCGGACTCCAGGCCCCGGCCCAGAGATTTGGACTTGGCTGGC TTGCAGGGGTCCTAAGAAACTCCACTCTGGACAGCGCCAGGAGGCCCTGGGTTCCATTCCTAACTCTGCCTCAAACTGT ACATTTGGATAAGCCCTAGTAGTTCCCTGGGCCTGTTTTTCTATAAAACGAGGCAACTGG
481/161 511/171
TGC GTG GAC ACC AAC CGC TGC GTG GAG CCC TAC ATC CAG GTC TCT GAG AAC CGC TGT CTC CVDTNRCVEPYIQVSENRCL L
541/181 571/191 TGC CCG GCC TCC AAC CCT CTA TGT CGA GAG CAG CCT TCA TCC ATT GTG CAC CGC TAC ATG CPASNPLCREQPSSIVHRYM
601/201 631/211 ACC ATC ACC TCG GAG CGG AGc GtG CCC GCT GAC GTG TTC CAG ATC CAG GCG ACC TCC GTC TITSERSVPADVFQIQATSV
661/221 691/231 TAC CCC GGT GCC TAC AAT GCC TTT CAG ATC CGT GCT GGA AAC TCG CAG GGG GAC TTT TAC YPGAYNAFQIRAGNSQGDFY 721/241 751/251 ATT AGG CAA ATC AAC AAC GTC AGC GCC ATG cTG GTC CTC GCC CGG CCG GTG ACG GGC CCC IRQINNVSAMLVLARPVTGP 781/261 811/271 CGG GAG TAC GTG CTG GAc CTG GAG ATG GTC ACC ATG AAT TCC CTC ATG AGC TAC CGG GCC REYVLDLEMVTMNSLMSYRA 841/281 871/291 AGC TcT GTA cTG AGG CTC ACC GTc TTT GTA GGG GCC TAC ACC TTc TGA GGAGCAGGAGGGAGC S SVLRLTVFVGAYTF F * CACCCTCCCTGCAGCTACCCTAGCTGAGGAGCCTGTTGTGAGGGGCAGAATGAGAAAGGCAATAAAGGGAGAAAGAAAG TCCTGGTGGCTGAGGTGGGCGGGTCACACTGCAGGAAGCCTCAGGCTGGGGCAGGGTGGCACTTGGGGGGGCAGGCCAA GTTCACCTAAATGGGGGTCTCTATATGTTCAGGCCCAGGGGCCCCCATTGACAGGAGCTGGGAGCTCTGCACCACGAGC TTCAGTCACCCCGAGAGGAGAGGAGGTAACGAGGAGGGCGGACTCCAGGCCCCGGCCCAGAGATTTGGACTTGGCTGGC TTGCAGGGGTCCTAAGAAACTCCACTCTGGACAGCGCCAGGAGGCCCTGGGTTCCATTCCTAACTCTGCCTCAAACTGT ACATTTGGATAAGCCCTAGTAGTTCCCTGGGCCTGTTTTTCTATAAAACGAGGCAACTGG
Claims (30)
1. Polypeptide capable d'interagir spécifiquement avec les formes oncogéniques de p53, de stimuler la croissance cellulaire et de bloquer les effets anti- prolifératifs de la forme sauvage de p53.
2. Polypeptide selon la revendication 1, caractérisé en ce qu'il comprend tout ou partie d'une séquence choisie parmi les séquences polypeptidiques SEQ ID N 8 ou SEQ ID N 22 ou un dérivé de celles-ci.
3. Polypeptide selon la revendication 1, caractérisé en ce qu'il comprend tout ou partie d'une séquence choisie parmi les séquences polypeptidiques SEQ ID N 26 ou SEQ ID N 23 ou un dérivé de celles-ci.
4. Polypeptide selon la revendication 1, caractérisé en ce qu'il comprend tout ou partie de la séquence polypeptidique SEQ ID N 9 ou un dérivé de celle-ci.
5. Polypeptide selon la revendication 3, caractérisé en ce qu'il est représenté par la séquence polypeptidique SEQ ID N 23.
6. Séquence nucléotidique codant pour un polypeptide tel que défini selon l'une des revendications 1 à 5.
7. Séquence nucléotidique selon la revendication 6 caractérisée en ce qu'elle comprend tout ou partie de la séquence SEQ ID N 16 ou de la SEQ ID N 21 ou de leurs dérivées.
8. Séquence nucléotidique selon la revendication 6 caractérisée en ce qu'elle comprend tout ou partie de la séquence nucléotidique SEQ ID N 9 ou de ses dérivées.
<Desc/Clms Page number 62>
9. Séquence nucléotidique selon la revendication 6 ou 7 caractérisée en ce qu'elle comprend la séquence SEQ ID N 15 ou la séquence SEQ ID N 26.
10. Séquence nucléotidique selon la revendication 6,7 ou 9 caractérisée en ce qu'elle est représentée en SEQ ID N 21.
11. Cellule hôte pour la production de polypeptide selon l'une des revendications 1 à 5, caractérisée en ce qu'elle a été transformée avec un acide nucléique comportant une séquence nucléotidique selon l'une des revendications 6 à
10.
12. Procédé de préparation d'un polypeptide selon l'une des revendications 1 à 5 caractérisé en ce que l'on cultive une cellule contenant une séquence nucléotidique selon l'une des revendications 6 à 10 dans des conditions d'expression de ladite séquence et on récupère le polypeptide produit.
13. Cassette d'expression comprenant une séquence nucléotidique codant pour un polypeptide selon l'une des revendications 6 à 10.
14. Vecteur comprenant une séquence nucléotidique selon l'une des revendications 6 à 10.
15. Vecteur selon la revendication 14 caractérisé en ce qu'il s'agit d'un vecteur plasmidique, d'un cosmide ou de tout ADN non encapsidé par un virus.
16. Vecteur selon la revendication 14 caractérisé en ce qu'il s'agit d'un virus recombinant, et de préférence d'un virus recombinant défectif pour la réplication.
17. Oligonucléotide antisens d'une séquence selon la revendication 7 à 10 capable d'inhiber au moins partiellement la production de polypeptides selon l'une des revendications 1 à 5.
<Desc/Clms Page number 63>
18. Sonde nucléotidique capable de s'hybrider avec une séquence nucléotidique selon l'une des revendications 7 à 10 ou l'ARNm correspondant.
19. Anticorps ou fragment d'anticorps dirigé contre un polypeptide selon l'une des revendications 1 à 5.
20. Anticorps ou fragment d'anticorps selon la revendication 19 caractérisé en ce qu'il est dirigé contre une séquence choisie parmi les séquences peptidiques présentées en SEQ ID N 8 ou SEQ ID N 9 ou SEQ ID N 26.
21. Anticorps ou fragment d'anticorps selon la revendication 19 ou 20 caractérisé en ce qu'il possède la faculté de prévenir l'interaction entre les formes oncogéniques de p53 et un polypeptide selon l'une des revendications 1 à 5.
22. Procédé de mise en évidence ou d'identification de composés capables de se lier avec un polypeptide tel que défini selon l'une des revendications 1 à 5, caractérisé en ce que l'on réalise les étapes suivantes : a - on met en contact une molécule ou un mélange contenant différentes molécules, éventuellement non-identifiées, avec un polypeptide tel que défini selon l'une des revendications 1à5 dans des conditions permettant l'interaction entre ledit polypeptide et ladite molécule dans le cas où celle-ci possèderait une affinité pour ledit polypeptide, et, b - on détecte et/ou isole les molécules liées au dit polypeptide.
23. Procédé de mise en évidence ou d'identification de composés capables de moduler ou d'inhiber l'interaction entre entre les formes oncogéniques de p53 et un polypeptide selon l'une des revendications 1 à 5, caractérisé en ce que l'on réalise les étapes suivantes : a - on réalise la liaison de la forme oncogénique de p53 ou d'un fragment de celle ci avec ledit polypeptide ;
<Desc/Clms Page number 64>
24. Ligand d'un polypeptide tel que défini selon les revendications 1 à 5, susceptible d'être obtenu selon le procédé de la revendication 22.
- on ajoute un composé à tester pour sa capacité à inhiber la liaison entre la forme oncogénique de p53 et ledit polypeptide , - on détermine le déplacement ou l'inhibition de la liaison entre la forme oncogénique de p53 ; - on détecte et/ou isole les composés qui empêchent ou qui gênent la liaison entre la forme oncogénique de p53 et ledit polypeptide ;
25. Ligand capable de moduler ou d'inhiber l'interaction entre les formes oncogéniques de p53 et un polypeptide tel que défini selon les revendications 1 à 5, susceptible d'être obtenu selon le procédé de la revendication 23.
26. Utilisation d'un ligand selon la revendication 24 ou 25 pour la préparation d'un médicament destiné au traitement traitement des maladies impliquant un dysfonctionnement du cycle cellulaire.
27. Utilisation d'un polypeptide capable d'interagir avec les formes mutées oncogéniques de p53 et comprenant tout ou partie d'une séquence peptidique choisie parmi les séquences SEQ ID N 8, N 9, N 26, ou N 23 ou d'un dérivé de celle -ci, selon l'une des revendications 1 à 5 pour la réalisation d'un composé non peptidique ou non exclusivement peptidique capable d'interagir avec les formes mutées oncogéniques de p53, par détermination des éléments structuraux de ce polypeptide qui sont importants pour son activité et reproduction de ces éléments par des structures non peptidiques ou non exclusivement peptidiques.
28. Composition pharmaceutique comprenant comme principe actif au moins un anticorps ou fragment d'anticorps selon l'une des revendications 19 à 21, et/ou un
<Desc/Clms Page number 65>
oligonucléotide antisens selon la revendication 17 et/ou un ligand selon l'une des revendications 24 ou 25 et/ou un composé selon la revendication 27.
29. Composition selon la revendication 28 destinée au traitement des maladies impliquant un dysfonctionnement du cycle cellulaire.
30. Composition selon la revendication 29 destinée au traitement des cancers.
Priority Applications (8)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9812754A FR2784383B1 (fr) | 1998-10-12 | 1998-10-12 | Polypeptides capables d'interagir avec les mutants oncogeniques de la proteine p53 |
| AU60958/99A AU6095899A (en) | 1998-10-12 | 1999-10-12 | (mbp1) polypeptides capable of interacting with oncogenic mutants of the p53 protein |
| PCT/FR1999/002465 WO2000022120A1 (fr) | 1998-10-12 | 1999-10-12 | Polypeptides (mbp1) capables d'interagir avec les mutants oncogeniques de la proteine p53 |
| CA002347121A CA2347121A1 (fr) | 1998-10-12 | 1999-10-12 | Polypeptides (mbp1) capables d'interagir avec les mutants oncogeniques de la proteine p53 |
| JP2000576010A JP2002527063A (ja) | 1998-10-12 | 1999-10-12 | p53タンパク質の発癌性突然変異体と相互作用することが可能な(MBP1)ポリペプチド |
| EP99947556A EP1121427A1 (fr) | 1998-10-12 | 1999-10-12 | Polypeptide (mbp1) capable d'interagir avec les mutants oncogeniques de la proteine p53 |
| US09/829,936 US20030049699A1 (en) | 1998-10-12 | 2001-04-11 | Polypeptide (MBP1) capable of interacting with oncogenic mutants of the P53 protein |
| US10/759,256 US20050129698A1 (en) | 1998-10-12 | 2004-01-20 | Polypeptides (MBP1) capable of interacting with oncogenic mutants of the p53 protein |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR9812754A FR2784383B1 (fr) | 1998-10-12 | 1998-10-12 | Polypeptides capables d'interagir avec les mutants oncogeniques de la proteine p53 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| FR2784383A1 true FR2784383A1 (fr) | 2000-04-14 |
| FR2784383B1 FR2784383B1 (fr) | 2003-02-07 |
Family
ID=9531448
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| FR9812754A Expired - Fee Related FR2784383B1 (fr) | 1998-10-12 | 1998-10-12 | Polypeptides capables d'interagir avec les mutants oncogeniques de la proteine p53 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US20050129698A1 (fr) |
| FR (1) | FR2784383B1 (fr) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1997038012A1 (fr) * | 1996-04-10 | 1997-10-16 | Human Genome Sciences, Inc. | Facteur de croissance extracellulaire/epidermique hcaba58x |
Family Cites Families (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4946778A (en) * | 1987-09-21 | 1990-08-07 | Genex Corporation | Single polypeptide chain binding molecules |
| US5132405A (en) * | 1987-05-21 | 1992-07-21 | Creative Biomolecules, Inc. | Biosynthetic antibody binding sites |
| ATE243754T1 (de) * | 1987-05-21 | 2003-07-15 | Micromet Ag | Multifunktionelle proteine mit vorbestimmter zielsetzung |
-
1998
- 1998-10-12 FR FR9812754A patent/FR2784383B1/fr not_active Expired - Fee Related
-
2004
- 2004-01-20 US US10/759,256 patent/US20050129698A1/en not_active Abandoned
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1997038012A1 (fr) * | 1996-04-10 | 1997-10-16 | Human Genome Sciences, Inc. | Facteur de croissance extracellulaire/epidermique hcaba58x |
Non-Patent Citations (3)
| Title |
|---|
| CHEN J ET AL: "MAPPING OF THE P53 AND MDM-2 INTERACTION DOMAINS", MOLECULAR AND CELLULAR BIOLOGY, vol. 13, no. 7, 1 July 1993 (1993-07-01), pages 4107 - 4114, XP000571629, ISSN: 0270-7306 * |
| GALLAGHER W M ET AL.: "MBP1: a novel mutant p53-specific protein partner with oncogenic properties", ONCOGENE, vol. 18, no. 24, 17 June 1999 (1999-06-17), pages 3608 - 3616, XP002109119 * |
| PAN T-C ET AL.: "Structure and expression of fibulin-2, a novel extracellular matrix protein with multiple EGF-like repeats and consensus motifs for calcium binding", JOURNAL OF CELL BIOLOGY, vol. 123, no. 5, December 1993 (1993-12-01), pages 1269 - 1277, XP002109118 * |
Also Published As
| Publication number | Publication date |
|---|---|
| US20050129698A1 (en) | 2005-06-16 |
| FR2784383B1 (fr) | 2003-02-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN108271364A (zh) | 用于降解错误折叠的蛋白质的组合物和方法 | |
| US20080220455A1 (en) | p53-DEPENDENT APOPTOSIS-INDUCING PROTEIN AND METHOD OF SCREENING FOR APOPTOSIS REGULATOR | |
| JP2008037870A (ja) | 心臓病及び心不全の治療のためのホスホランバン活性の阻害方法 | |
| EP0839194B1 (fr) | Variants de la proteine p53 et utilisations therapeutiques | |
| CA2148258A1 (fr) | Facteur de transcription dp-1 | |
| EP0637334A1 (fr) | Peptides ayant une activite de facteur d'echange du gdp, sequences d'acides nucleiques codant pour ces peptides, preparation et utilisation | |
| CA2305809A1 (fr) | Utilisation du gene suppresseur de tumeur p33ing1 pour moduler l'activite de la p53 et diagnostiquer une tumeur | |
| CA2240449A1 (fr) | Sequences nucleotidiques, proteines, medicaments et agents diagnostiques utiles dans le traitement du cancer | |
| EP1049775B1 (fr) | Proteine humaine btrcp | |
| JP4005135B2 (ja) | 神経アポトーシス抑制性蛋白質(naip)の使用 | |
| FR2691475A1 (fr) | Séquence d'ADN des produits de fusion résultant de la translocation chromosomique récurrente t(11;22) (q24;q12) associée au développement d'un groupe de tumeurs cancéreuses. | |
| EP0877758A2 (fr) | PROTEINE PURIFIEE SR-p70 | |
| JP2003508011A (ja) | ヒトfez1遺伝子である新規ガン抑制遺伝子に関する組成物、キットおよび方法 | |
| FR2740454A1 (fr) | Peptides capables d'inhiber l'endocytose de l'app et sequences nucleotidiques correspondantes | |
| WO2000008147A1 (fr) | Genes impliques dans les voies moleculaires de la suppression tumorale et/ou la resistance aux virus | |
| KR100820526B1 (ko) | Iren 단백질, 이의 제조 및 용도 | |
| FR2784383A1 (fr) | Polypeptides capables d'interagir avec les mutants oncogeniques de la proteine p53 | |
| EP1121427A1 (fr) | Polypeptide (mbp1) capable d'interagir avec les mutants oncogeniques de la proteine p53 | |
| FR2881429A1 (fr) | Motif de la proteine beclin interagissant avec les membres anti-apoptotiques de la famille de proteines bcl-2 et utilisations | |
| CA2219861A1 (fr) | .delta.p62, ses variants, sequences nucleiques et leurs utilisations | |
| AU2004202608B2 (en) | (MBP1) polypeptides capable of interacting with oncogenic mutants of the p53 protein | |
| EP1254225A2 (fr) | Nouvelle famille de proteines, denommees atip, les sequences nucleiques codant pour lesdites proteines et leurs applications | |
| FR2782084A1 (fr) | Sequences nucleiques codant pour tout ou partie d'une proteine interagissant avec le recepteur at2 et leurs applications | |
| FR2772046A1 (fr) | Sequences codant pour une proteine kin17 et leurs applications | |
| FR2805266A1 (fr) | Compositions utilisables pour reguler l'activite de la parkine |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| CD | Change of name or company name | ||
| ST | Notification of lapse |
Effective date: 20110630 |