FR2827974A1 - Procede pour la compression d'un code interprete par analyse semantique - Google Patents
Procede pour la compression d'un code interprete par analyse semantique Download PDFInfo
- Publication number
- FR2827974A1 FR2827974A1 FR0110210A FR0110210A FR2827974A1 FR 2827974 A1 FR2827974 A1 FR 2827974A1 FR 0110210 A FR0110210 A FR 0110210A FR 0110210 A FR0110210 A FR 0110210A FR 2827974 A1 FR2827974 A1 FR 2827974A1
- Authority
- FR
- France
- Prior art keywords
- program
- instructions
- code
- apdu
- applet
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/41—Compilation
- G06F8/44—Encoding
- G06F8/443—Optimisation
- G06F8/4434—Reducing the memory space required by the program code
Landscapes
- Engineering & Computer Science (AREA)
- General Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Devices For Executing Special Programs (AREA)
- Stored Programmes (AREA)
Abstract
Le procédé selon l'invention est utilisable au compactage de programmes en code objet intermédiaire exécutable dans un système embarqué à faibles ressources matérielles. Il comprend l'exploitation d'une information sémantique pour modifier le code objet intermédiaire du programme et l'élimination des instructions du code objet intermédiaire du programme devenues inutiles du fait de cette modification.
Description
<Desc/Clms Page number 1>
La présente invention concerne un procédé de compression de code objet intermédiaire par analyse sémantique utilisable, notamment mais non exclusivement, au compactage de programmes en code objet intermédiaire exécutable dans un système embarqué à faibles ressources matérielles tel qu'une carte à puce ou qu'un terminal de paiement comportant un microprocesseur et un environnement matériel et logiciel incluant notamment : - un compilateur servant à obtenir le code objet intermédiaire à partir d'un programme source, et - un interpréteur qui effectue une interprétation logicielle des instructions standard du code objet intermédiaire en instructions directement exécutables par le microprocesseur.
D'une manière générale, on sait que, par opposition à l'analyse syntaxique, l'analyse sémantique est un ensemble de techniques permettant d'extraire des propriétés concernant l'exécution d'un programme. Cette technique, qui repose sur des bases théoriques bien connues [CC77]"Patrick Cousot & Radhia Cousot. Abstract interpretation : a unified lattice model for static analysis of programs by construction or approximation of fixpoints. In Conference Record of the Fourth Annual CM GIGPLAN-SIGACT Symposium on Principles of Programming Languages, pages 238--252, Los Angeles, California, 1977. ACM Press, New York, NY, USA.", consiste à construire
<Desc/Clms Page number 2>
un modèle mathématique de l'exécution du programme sous forme d'équations, dites sémantiques, et à appliquer des algorithmes de résolution automatique de ces équations permettant d'extraire l'information désirée. Les techniques d'analyse sémantique permettent par exemple de calculer les intervalles de variation des variables scalaires d'un programme, information utile à des fins de vérification pour prédire les erreurs de dépassement de bornes de tableaux ; elles permettent également de déduire les objets référencés (accédés ou modifiés) à des points de programme donnés.
L'analyse syntaxique est, quant à elle, un ensemble de techniques permettant d'extraire des propriétés concernant la syntaxe d'un programme. Les techniques d'analyse syntaxique permettent par exemple de détecter des répétitions de séquences d'instructions données dans un programme. Contrairement aux analyses sémantiques, les analyses syntaxiques ne reposent pas sur des modèles d'exécution des programmes et n'apportent pas d'informations de nature opérationnelle.
Il s'avère qu'à l'heure actuelle, toutes les techniques existantes en matière de compression de code reposent sur des analyses syntaxiques : Le code objet du programme est traité comme une donnée brute à compresser mais la sémantique du programme (ou son modèle d'exécution) n'intervent jamais dans ces procédés de compression. Certains de ces procédés, tels que par exemple celui qui se trouve décrit dans le brevet FR 2 785 695, reposent sur la recherche de motifs syntaxiques dans le code et sur une factorisation de ces motifs.
Au contraire, l'invention propose d'effectuer une compression en exploitant une information sémantique pour modifier le code objet intermédiaire du programme et éliminer les instructions du code intermédiaire devenues inutiles du fait de cette modification.
<Desc/Clms Page number 3>
Plus particulièrement, le procédé selon l'invention consiste à identifier les accès aux objets manipulés par le programme par une analyse sémantique du code objet du programme et à utiliser cette information pour remplacer dans le code du programme les groupes d'instructions accédant à ces objets par des instructions spécialisées permettant un accès direct aux objets considérés. La réduction de la taille du code provient du remplacement d'un groupe d'instructions par une instruction spécialisée de taille inférieure et/ou par élimination dans le code du programme d'instructions devenues inutiles du fait de l'introduction des instructions spécialisées précédentes.
Les instructions spécialisées employées par ce procédé doivent être intégrées dans l'interpréteur du langage s'il n'en dispose pas.
Conformément au procédé selon l'invention, la compression de programmes code objet exécutable par un interpréteur se décompose en deux parties.
Premièrement, s'il n'en dispose pas déjà, on étend l'interpréteur avec des registres spécifiques et des versions spécialisées de certaines instructions de l'interpréteur qui opèrent implicitement sur ces registres spécifiques plutôt que sur leurs arguments ordinaires (y compris les instructions de simples lecture et écriture d'objets).
Deuxièmement, étant donné un interpréteur disposant de registres spécifiques et de versions spécialisées de certaines instructions de l'interpréteur qui opèrent implicitement sur ces registres spécifiques plutôt que sur leurs arguments ordinaires (y compris les instructions de simples lecture et écriture d'objets), le procédé de compression d'un programme code objet exécutable par cet interpréteur est défini par les étapes suivantes :
<Desc/Clms Page number 4>
- une première étape dans laquelle on effectue une analyse sémantique du programme qui met en évidence les objets accédés en chaque point du programme, - une deuxième étape dans laquelle, à l'aide de l'information calculée par l'analyse sémantique de la première étape, pour tout objet manipulé par le programme, on identifie dans le programme les occurrences de différents groupes d'instructions qui opèrent sur cet objet (c'est-à-dire qui le lisent et éventuellement le transforment) et dont on dispose d'une version spécialisée (c'est-à-dire de sémantique équivalente) en terme d'un registre spécifique dans le jeu d'instruction de l'interpréteur, - une troisième étape dans laquelle on soumet lesdits objets à un test de comparaison de supériorité d'une fonction d'au moins le nombre d'occurrences des groupes d'instructions correspondants dans ledit programme (comme déterminé à la deuxième étape) à une valeur de référence et, sur réponse positive audit test, pour chaque objet satisfaisant à ladite étape de test, - une quatrième étape dans laquelle, en un point du programme qui précède, dans toutes les exécutions possibles du programme, les occurrences de groupes d'instructions associées audit objet, on introduit le code correspondant à l'affectation dudit objet dans un des registres spécifiques de l'interpréteur, - une cinquième étape dans laquelle on remplace dans le programme les groupes d'instruction à chacune desdites occurrences par l'instruction spécialisée par rapport audit registre qui leur correspond, - une sixième étape dans laquelle on élimine du code du programme les instructions et les constructions qui sont rendues inutiles ou redondantes du fait des transformations du programme indiquées aux quatrième et cinquième étapes.
<Desc/Clms Page number 5>
La taille du programme ainsi transformé est inférieure à celle du programme initial, cette propriété étant garantie par le procédé de choix utilisé dans la troisième étape.
Un mode de mise en oeuvre du procédé selon l'invention sur des programmes JavaCard destinés à des cartes à puce sera décrit ci-après, à titre d'exemples non limitatifs, avec référence aux dessins annexés dans lesquels :
La figure 1 est un organigramme du procédé de compression selon l'invention ;
La figure 2 est une représentation schématique représentant l'état de l'interpréteur JCVM juste avant l'exécution de l'appel de sendBytes dans la méthode setBalance.
La figure 1 est un organigramme du procédé de compression selon l'invention ;
La figure 2 est une représentation schématique représentant l'état de l'interpréteur JCVM juste avant l'exécution de l'appel de sendBytes dans la méthode setBalance.
Il convient de noter tout d'abord que JavaCard est une architecture logicielle complète (incluant un langage de programmation de haut niveau orienté objet, un code objet interprété, un interpréteur de code objet de type machine à pile, un environnement d'exécution, des bibliothèques standard et un système d'interactions sécurisé entre applets hébergées sur une même carte) pour l'exécution de programmes sur des cartes à puce dans un contexte multiapplications. Ce langage est mis en oeuvre à l'aide d'une machine virtuelle qui interprète un programme en code objet (le bytecode JavaCard) dans un environnement sécurisé. Un programme JavaCard est appelé une applet. C'est un programme réactif passif qui interagit avec le terminal auquel la carte est connectée sous la forme d'envoi de messages de type commande-réponse, les commandes étant émises par le terminal uniquement, l'applet renvoyant une réponse pour chaque commande reçue. Une carte à puce peut contenir différentes applets qui peuvent interagir. Les applets peuvent être introduites sur la carte en usine lors de la production en série, ou téléchargées en phase d'utilisation par le possesseur de la carte.
<Desc/Clms Page number 6>
Le langage code objet intermédiaire ici considéré est le bytecode JavaCard.
L'interpréteur de bytecode est la machine virtuelle JavaCard (JCVM) qui est embarquée sur les cartes à puce. Les objets manipulés par une applet sont soit les objets JavaCard créés par l'applet elle-même, soit les objets créés par l'environnement d'exécution ou retournés par les méthodes de l'API (Application Programming Interface). L'API définit l'interface d'utilisation d'une bibliothèque donnée (dans ce document c'est l'interface logicielle avec l'environnement d'exécution JavaCard). Elle contient la définition des bibliothèques de types abstraits, leurs fonctionnalités et leur mode d'utilisation. Les analyses sémantiques préalables utilisées pour déterminer les accès aux objets s'inscrivent quant à elles dans le cadre classique des analyses de pointeurs ou analyses d'alias [De95]"Semantic Models and Abstract Interpretation Techniques for Inductive Data Structures and Pointers, Alain Deutsch. PEPM95-Proc. ACM SIGPLAN Symposium on Partial evaluation and semantics-based program manipulation June 21-23, 1995, La Jolla, CA USA". L'analyse de pointeurs est une analyse sémantique qui décrit l'évolution de la mémoire au cours de l'exécution d'un programme. Ce type d'analyse calcule à chaque instruction du programme l'ensemble des objets qui peuvent être référencés par chaque variable de type pointeur et/ou l'ensemble des variables de type pointeur qui référencent le même objet (on appelle deux pointeurs qui référencent le même objet des alias). Dans toute cette section on considèrera une syntaxe simplifiée du bytecode JavaCard afin de faciliter la lecture, sans que cela fausse la description en quoi que ce soit.
Dans cet exemple, le protocole de communication entre la carte à puce et le terminal qui l'héberge repose sur un format standardisé [IS07816]"ISO/IEC 7816. First Edition 1995-09-01 Information Technology-Identification Cards-Integrated Circuit (s) Cards with Contacts"de paquets de données : les APDU. Les commandes envoyées par le terminal aussi bien que les réponses de l'applet sont codées dans des APDU. Pour gérer cela
<Desc/Clms Page number 7>
l'environnement d'exécution JavaCard (JCRE) met à la disposition des programmeurs un type de données APDU ainsi qu'un unique objet de ce type qui est créé par l'environnement lui-même et qui est utilisé par l'applet aussi bien pour lire les commandes émises par le terminal que pour écrire les données de la réponse. Les données de l'objet APDU sont stockées dans un buffer qui lui est associé. Chaque applet possède nécessairement une méthode process qui prend en argument cet objet de type APDU, une méthode étant le nom d'un sous-programme attaché à un type de données dont il définit une fonctionnalité. Au début de l'exécution de la méthode process, cet objet contient la commande émise par le terminal, à la fin de l'exécution de la méthode, il contient la réponse renvoyée par l'applet.
Comme illustré par l'organigramme représenté sur la figure 1, la première étape de l'organigramme consiste en une analyse sémantique comprenant une propagation interprocédurale des références à l'objet APDU et à son buffer associé, c'est-à-dire une analyse qui permet d'identifier les références à l'instance de la classe APDU contenue dans l'environnement d'exécution JCRE et son unique buffer associé dans toutes les méthodes de l'applet. La source de l'objet APDU est l'unique argument de la méthode process de l'applet. C'est cette valeur qui est propagée dans tout le programme en explorant le graphe d'appel du programme depuis process.
Cette première étape comprend également l'identification des références au buffer de l'APDU par les appels de la méthode getBuffer de la classe APDU sur une référence à l'objet APDU du JCRE.
L'étape 2 identifie les groupes d'instructions qui lisent ou transforment l'un ou l'autre de ces deux objets (APDU et buffer), le buffer n'étant accessible que par l'intermédiaire de l'APDU.
<Desc/Clms Page number 8>
En fait, l'analyse détermine en chaque point du bytecode JavaCard de l'applet quelles sont les variables locales et les entrées dans la pile qui contiennent une référence à l'APDU ou à son buffer. Différentes optimisations sont alors possibles à partir de cette information (choix de l'objet et du buffer APDU à l'étape 3 de l'organigramme).
En utilisant deux registres de l'interpréteur, on peut accéder directement à l'APDU ou au buffer de l'APDU. Il faut pour cela insérer des opérations d'initialisation de ces registres dans le code de l'applet, par exemple au début de la méthode process (étape 4 d'introduction d'une instruction stockant l'objet dans un registre). Un style couramment utilisé dans les applets JavaCard est de passer une référence sur ces deux objets aux méthodes internes de l'applet appelées par process. La compression consiste alors (étape 5) à remplacer dans ces méthodes les lectures des variables locales (c'est-à-dire les paramètres de la méthode) contenant ces objets et les opérations qui les suivent par les opérations spécialisées correspondantes (portant sur les deux registres). Il est aussi possible d'éliminer ces deux arguments de la définition de la méthode, puisqu'ils ne sont plus utilisés (étape 6 d'élimination du code inutile). Le gain en espace est ainsi obtenu non seulement par l'emploi d'instructions spécialisées (plus compactes) mais aussi par élimination des instructions d'empilement de ces références lors de chaque appel aux méthodes concernées qui deviennent alors inutiles.
Les étapes du procédé précédemment défini seront illustrées ci-après par les exemples suivants, à savoir : - un exemple de compression des opérations sur l'objet et le buffer APDU dans une application bancaire de type porte-monnaie électronique (Exemple 1),
<Desc/Clms Page number 9>
- une extension de l'exemple précédent au cas d'applications GSM ("Global
System for Mobile Communication"système de radiotéléphonie mobile à transmission numérique) (Exemple 2),

- un exemple de compression des chemins d'accès à des objets créés par l'applet (Exemple 3), - un exemple de compression des appels de méthodes internes de l'applet (Exemple 4).
System for Mobile Communication"système de radiotéléphonie mobile à transmission numérique) (Exemple 2),
- un exemple de compression des chemins d'accès à des objets créés par l'applet (Exemple 3), - un exemple de compression des appels de méthodes internes de l'applet (Exemple 4).
Ces exemples font appel aux termes techniques suivants dont les définitions fournies dans le glossaire ci-après tiennent compte de leur contexte : Bytecode : terme anglo-saxon synonyme de code objet interprété. Ce terme fait référence ici au code objet interprété sous-jacent à la machine virtuelle JavaCard.
Chemin d'accès : séquence d'opérations de sélection de champ dans des données structurées qui permet de référencer un objet du programme qui n'est pas accessible directement depuis une variable.
Classe : dans un langage orienté objet une classe est la définition d'un type de données et des méthodes qui lui sont associées.
EEPROM : mémoire non volatile et réinscriptible embarquée sur une carte à puce. Les objets non volatiles créés par une applet JavaCard sont stockés dans cette mémoire.
JavaCard : langage et environnement de programmation conçus par Sun Microsystems pour l'exécution de programmes sur des cartes à puce.
JCRE : Acronyme de JavaCard Runtime Environment. C'est l'environnement d'exécution de l'architecture JavaCard qui est embarqué sur une carte à puce.
<Desc/Clms Page number 10>
Cet environnement contient l'interpréteur de bytecode (la JCVM), les bibliothèques standard, le protocole d'échange de données entre la carte et le terminal ainsi que le système chargé de la sécurité lors des interactions entre applets (pare-feu).
JCVM : Acronyme de JavaCard Virtual Machine. Nom de l'interpréteur de code JavaCard (bytecode). Cet interpréteur est un composant du JCRE.
Objet : Zone mémoire munie d'une structure qui est définie par un type de données dans le programme.
Exemple 1 Dans cet exemple, on suppose que : a) la méthode process de l'applet a la forme classique suivante en JavaCard : public void process (APDU apdu) { byte [] buffer = apdu. getBuffer () ; switch (buffer[IS07816. 0FFSET INS]) { case SET BALANCE : { setBalance (apdu, buffer) ; return ; } case...

} } et que,
<Desc/Clms Page number 11>
b) la méthode setBalance qui modifie le solde du porte-monnaie a la forme suivante :

private void setBalance (APDU apdu, byte [] buffer) { short currency = buffer [OFFSETCURRENCY] ; short amount = Util. getShort (buffer, OFFSET-AMOUNT) ; apdu. sendBytes ( (short) O, (short) 2) ; //new balance } La méthode process décode la commande stockée dans le buffer de l'objet APDU et, en fonction du code de la commande (donné notamment par l'octet situé à l'index IS07816. OFFSET INS du buffer de l'APDU), appelle différentes méthodes internes qui sont chargées de traiter chaque commande.
private void setBalance (APDU apdu, byte [] buffer) { short currency = buffer [OFFSETCURRENCY] ; short amount = Util. getShort (buffer, OFFSET-AMOUNT) ; apdu. sendBytes ( (short) O, (short) 2) ; //new balance } La méthode process décode la commande stockée dans le buffer de l'objet APDU et, en fonction du code de la commande (donné notamment par l'octet situé à l'index IS07816. OFFSET INS du buffer de l'APDU), appelle différentes méthodes internes qui sont chargées de traiter chaque commande.
Ces méthodes internes reçoivent en argument à la fois l'objet APDU et son buffer afin de pouvoir lire les paramètres de la commande et écrire la réponse.
Cette méthode setBalance n'a pas été détaillée dans son intégralité, seules ont été reprises quelques lignes qui lisent dans le buffer le type de monnaie (à

l'index OFFSET- CURRENCY) et le montant à créditer au porte-monnaie électronique (à l'index OFFTMOMVT). Après compilation de l'applet en bytecode la méthode process a typiquement la forme suivante (les commentaires sont précédés du symbole ) aload 1 invokevirtual"getBufferO" astore 2 aload 2 sconst 1 IS07816. OFFSET-INS baload
l'index OFFSET- CURRENCY) et le montant à créditer au porte-monnaie électronique (à l'index OFFTMOMVT). Après compilation de l'applet en bytecode la méthode process a typiquement la forme suivante (les commentaires sont précédés du symbole ) aload 1 invokevirtual"getBufferO" astore 2 aload 2 sconst 1 IS07816. OFFSET-INS baload
<Desc/Clms Page number 12>
switch... aload 0 aload 1 aload 2 invokespecial"setBalance (APDU, byte []) return Après compilation en bytecode, la méthode setBalance a la forme suivante : aload 2 sconst OFFSETCURRENCY baload sstore 3 aload 2 sconst OFFSET AMOUNT invokestatic"Util. getShort (byte[], short) " sstore 4 aload 1 sconst 2 sconst 0 invokevirtual"sendBytes (short, short)" return La machine virtuelle JavaCard utilise une pile pour stocker les arguments et les résultats de calculs ainsi que des variables JCVM numérotées permettant à la fois de stocker les arguments des méthodes et de stocker des résultats dont la durée de vie est supérieure à celle de la pile. Chaque variable dans le
<Desc/Clms Page number 13>
programme JavaCard (variable locale ou argument) est traduite comme une variable JCVM dans le bytecode.
Dans la méthode process, le paramètre apdu est stocké dans la variable JCVM 1, la variable JavaCard buffer dans la variable JCVM 2 et la référence à l'objet applet dans la variable JCVM 0. Dans la méthode setBalance le paramètre apdu est stocké dans la variable JCVM 1, le paramètre buffer dans la variable JCVM 2, la variable JavaCard currency dans la variable JCVM 3, la variable JavaCard amount dans la variable JCVM 4, et la référence à l'objet applet dans la variable JCVM 0.
L'instruction aload n empile la valeur de la variable JCVM n, l'instruction store n écrit dans la variable JCVM n la valeur de type objet se trouvant au sommet de la pile d'opérandes, et l'instruction sstore n écrit dans la variable JCVM n la valeur de type entier se trouvant au sommet de la pile, l'instruction sconst c empile la constante c, les instructions invokevirtual et invokespecial représentent des appels de méthode selon divers modes non détaillés ici, l'instruction baload est l'instruction de lecture d'un élément de tableau, les instructions switch et return représentent respectivement le choix multiple et le retour de méthode. Toutes les instructions du bytecode JavaCard prennent leurs arguments sur la pile d'opérandes.
La figure 2 est une représentation schématique montrant l'état de l'interpréteur JCVM juste avant l'exécution de l'appel de sendBytes dans la méthode setBalance.
Selon cette représentation : - le bloc 1 représente la mémoire allouée à l'interpréteur qui comporte ici l'objet applet qui correspond au programme en cours d'exécution, l'objet
APDU et le buffer associé à l'APDU,
APDU et le buffer associé à l'APDU,
<Desc/Clms Page number 14>
- le bloc 2 est la pile d'opérandes, - le bloc 3 représente les variables JCVM 0 à JCVM 4 utilisées par la méthode setBalance, et - le bloc 4 montre les variables JCVM 0 et JCVM 1 utilisées par la méthode process.
La pile d'opérandes (bloc 2) contient trois valeurs en partant du bas de la pile : une référence sur l'objet APDU, l'entier 2 et l'entier 0.
Chaque appel de méthode engendre un environnement d'exécution qui définit des variables JCVM utilisées par la méthode.
Que ce soit pour la pile d'opérandes ou pour les environnements d'exécution des méthodes, on a représenté par des flèches les références aux objets se trouvant en mémoire.
Dans le cas où l'analyse sémantique préalable (étape 1 du procédé) a

déterminé qu'en tout point de la méthode setBalance la variable JCVM 1 contenait une référence à l'APDU et la variable JCVM 2 une référence au buffer de l'APDU, l'étape 2 détermine alors notamment, parmi les instructions mentionnées ci-dessus, les occurrences de groupes d'instructions qui opèrent sur l'objet et le buffer APDU. Dans le cas où ces deux objets sont choisis à l'étape 3, alors, selon la suite du procédé, ces objets vont être stockés dans deux registres de l'interpréteur, notés A et B. Les instructions qui effectuent la lecture des registres correspondants sont notées aload A et aload B. De même, sont notées astore-A, astore-B les instructions qui affectent à ces mêmes registres une référence stockée sur la pile d'opérandes.
déterminé qu'en tout point de la méthode setBalance la variable JCVM 1 contenait une référence à l'APDU et la variable JCVM 2 une référence au buffer de l'APDU, l'étape 2 détermine alors notamment, parmi les instructions mentionnées ci-dessus, les occurrences de groupes d'instructions qui opèrent sur l'objet et le buffer APDU. Dans le cas où ces deux objets sont choisis à l'étape 3, alors, selon la suite du procédé, ces objets vont être stockés dans deux registres de l'interpréteur, notés A et B. Les instructions qui effectuent la lecture des registres correspondants sont notées aload A et aload B. De même, sont notées astore-A, astore-B les instructions qui affectent à ces mêmes registres une référence stockée sur la pile d'opérandes.
Selon l'étape 4 du procédé, on insère au début de la méthode process la séquence de bytecode qui initialise les registres globaux A et B. Le début de la méthode process devient :
<Desc/Clms Page number 15>
aload 1 astore~A aload 1 invokevirtual "getBuffer ()" astore 2 aload 2 as tore B Selon l'étape 5 du procédé, on remplace les occurrences des groupes d'instruction accédant à l'objet et au buffer APDU par les instructions de lecture spécialisées correspondantes, aussi bien dans process :

aload B sconst 1 IS07816. OFFSET-INS baload switch... aload 0 aload A aload B invokespecial"setBalance (APDU, byte [])" return que dans setBalance : aload B sconst OFFSET CURRENCY baload sstore 3
aload B sconst 1 IS07816. OFFSET-INS baload switch... aload 0 aload A aload B invokespecial"setBalance (APDU, byte [])" return que dans setBalance : aload B sconst OFFSET CURRENCY baload sstore 3
<Desc/Clms Page number 16>
aload B sconst OFFSET AMOUNT invokestatic"Util. getShort (byte [], short)" sstore 4 aload A sconst 2 sconst 0 invokevirtual"sendBytes (short, short)" return Enfin, selon l'étape 6 du procédé, le programme est simplifié par élimination des arguments désormais inutiles de la méthode setBalance. L'appel de cette méthode dans process devient : aload 0 invokespecial"setBalance ()" return et la signature de la méthode setBalance est modifiée par suppression de ses arguments.
On obtient un gain en taille du fait de l'élimination des instructions d'empilement des arguments de la méthode setBalance au moment de son appel.
Spécialisation d'opérations sur les tableaux Les instructions de manipulation de tableaux bastore (écriture d'un élément) et baload (lecture d'un élément) sont fréquemment utilisées pour accéder au
<Desc/Clms Page number 17>
buffer de l'APDU. Créer des instructions spécialisées qui manipulent directement le buffer stocké dans un registre permet d'éliminer l'opération d'empilement de la référence à ce buffer avant chaque bastorelbaload.
Ainsi, si dans l'étape 3 du procédé on prend en compte également la lecture du tableau dans la méthode setBalance parmi les groupes d'instructions opérant sur le buffer de l'APDU, l'étape 5 récrit setBalance de la manière suivante : sconst OFFSET CURRENCY baload B sstore 3 L'instruction de lecture d'un élément du tableau a été spécialisée en l'instruction baloadB qui lit son argument dans le registre B, l'empilement du buffer APDU a été économisé.
Spécialisation sur l'objet d'appels virtuels à l'API Un appel virtuel consiste à appeler une méthode sur un objet dont elle définit une fonctionnalité.
Certaines méthodes de l'API comme javacard. framework. APDUsendBytes (envoi de données au terminal auquel est reliée la carte) sont toujours appelées sur l'objet APDU. On peut employer une instruction spécialisée pour faire de tels appels et ainsi éviter d'empiler la référence à l'APDU avant l'appel de la méthode virtuelle.
Ainsi, si dans l'étape 3 du procédé on prend en compte également l'appel virtuel à sendBytes dans la méthode setBalance parmi les groupes d'instructions opérant sur l'objet APDU, l'étape 5 récrit setBalance de la manière suivante :
<Desc/Clms Page number 18>
sconst 2 sconst 0 invokevirtualA "sendBytes (short, short)" return L'instruction d'appel de méthode virtuelle a été spécialisée en l'instruction invokevirtualA qui va lire l'objet sur lequel la méthode est appelée dans le registre A, on économise ainsi l'empilement de l'objet APDU.
Spécialisation sur les arguments d'appels à l'API Certaines méthodes de l'API comme javacardframework. Util. getShort (lecture d'un entier 16 bits dans un tableau d'octets) ou

javacard. framework. Util. arrayCopy (copie d'un tableau d'octets) sont souvent utilisées avec le buffer de l'APDU en argument. On peut créer des instructions spécialisées qui évitent d'empiler la référence au buffer pour l'argument correspondant.
javacard. framework. Util. arrayCopy (copie d'un tableau d'octets) sont souvent utilisées avec le buffer de l'APDU en argument. On peut créer des instructions spécialisées qui évitent d'empiler la référence au buffer pour l'argument correspondant.
Ainsi, si dans l'étape 3 du procédé on prend en compte également l'appel à

getShort dans la méthode setBalance parmi les groupes d'instructions opérant sur le buffer APDU, l'étape 5 récrit setBalance de la manière suivante : sconst OFFSET AMOUNT invokestatic-B"Util. getShort (byte [], short)" sstore 4 L'instruction d'appel de méthode statique a été spécialisée en instruction invokestatic~B qui lit son premier argument dans le registre B, on économise ainsi l'empilement du buffer APDU.
getShort dans la méthode setBalance parmi les groupes d'instructions opérant sur le buffer APDU, l'étape 5 récrit setBalance de la manière suivante : sconst OFFSET AMOUNT invokestatic-B"Util. getShort (byte [], short)" sstore 4 L'instruction d'appel de méthode statique a été spécialisée en instruction invokestatic~B qui lit son premier argument dans le registre B, on économise ainsi l'empilement du buffer APDU.
<Desc/Clms Page number 19>
Exemple 2 Les applications GSM n'utilisent pas le protocole classique d'échanges d'APDU mais une API de plus haut niveau qui prend en charge les différents échanges d'APDU. Cette API repose sur quatre classes qui représentent les différents types de messages que la carte peut échanger avec le terminal (ici un téléphone mobile) :

EnvelopeHandler . EnvelopeResponseHandler 'jE'Mve/e ? ee ? oe7'M/e ' ProactiveHandler * ProactiveResponseHandler Ces types de données sont utilisés de la même façon que le type APDU pour échanger des données entre le terminal et la carte. Il n'existe qu'une seule instance de chacune de ces classes qui est construite et gérée par l'API. Une référence à ces différentes instances peut être obtenue à l'aide de la méthode getTheHandler qui est implantée par chacune de ces classes. Toutes les techniques de compression décrites dans la section précédente pour l'APDU et son buffer peuvent donc se transposer directement au cadre des applications GSM. L'analyse sémantique est de la même façon une propagation de références interprocédurale qui se charge d'identifier les références à ces différents objets dans tout le code de l'applet.
EnvelopeHandler . EnvelopeResponseHandler 'jE'Mve/e ? ee ? oe7'M/e ' ProactiveHandler * ProactiveResponseHandler Ces types de données sont utilisés de la même façon que le type APDU pour échanger des données entre le terminal et la carte. Il n'existe qu'une seule instance de chacune de ces classes qui est construite et gérée par l'API. Une référence à ces différentes instances peut être obtenue à l'aide de la méthode getTheHandler qui est implantée par chacune de ces classes. Toutes les techniques de compression décrites dans la section précédente pour l'APDU et son buffer peuvent donc se transposer directement au cadre des applications GSM. L'analyse sémantique est de la même façon une propagation de références interprocédurale qui se charge d'identifier les références à ces différents objets dans tout le code de l'applet.
Exemple 3 Compression des chemins d'accès à des objets créés par l'applet Typiquement une applet peut créer des objets en EEPROM au moment de son installation sur la carte et les stocker dans des variables de l'applet. L'analyse sémantique permet d'associer à chaque groupe de bytecodes qui accèdent à un
<Desc/Clms Page number 20>
objet quel est l'objet accédé chaque fois qu'elle le peut (cela dépend de la puissance et de la précision de l'analyse sémantique utilisée). Lorsque l'analyse permet de déterminer quel est l'objet accédé, on peut remplacer le groupe d'opérations utilisées pour y accéder par une seule opération. Pour ce faire, on peut utiliser un registre dans lequel on stocke une référence à l'objet et remplacer le groupe de bytecodes par une opération de lecture de ce registre.
Cette méthode nécessite de déterminer une position dans le corps de l'applet où insérer l'opération d'initialisation du registre à l'objet en question dans ses différents contextes d'utilisation. Cette position doit satisfaire deux contraintes : elle doit précéder tout accès à la valeur de l'objet concerné et elle ne doit précéder elle-même aucune modification de la valeur de l'objet. Il s'agit donc d'une position dans le programme où l'objet a acquis sa valeur définitive (une valeur qui restera constante jusqu'à la fin du programme) et où il n'a pas encore été accédé. Le calcul de telles positions dans le programme relève des techniques standard d'analyse statique.
A titre d'exemple d'application, on considère le cas de la méthode install qui est appelée une seule fois dans la durée de vie de chaque applet au moment de sa création sur la carte. Cette méthode se charge de mettre en place toutes les données qui vont être utilisées par l'applet. En général tous les objets manipulés par l'applet sont créés dans cette méthode. On se place dans ce cas de figure et on suppose que l'analyse sémantique permet de déterminer les chemins d'accès aux objets issus des variables de l'applet qui ne sont plus modifiables après exécution de la méthode install. Dans ce cas, il est licite de stocker les valeurs de ces chemins dans des registres en insérant les opérations appropriées au début de la méthode process.
Soit le fragment de code JavaCard suivant :
<Desc/Clms Page number 21>
this. f. array[O] = 1 ; this. f. array [l] = 2 ; Le bytecode correspondant après compilation a la forme suivante : getfield~this "f" getfield"array" sconst 0 sconst 1 sastore getfield~this"f" getfield"array" sconst 1 sconst 2 sastore Les instructions getfield et getfield~this empilent la valeur de champs d'objets (de champs de l'objet applet courant pourgeldthis) et l'instruction sastore écrit un entier dans un tableau.
Si l'analyse sémantique a permis de déterminer que l'objet référencé par thisfarray est uniquement déterminé après installation de l'applet et s'il est stocké dans le registre A, alors en reprenant les notations de l'exemple 1, le code obtenu après compaction a la forme suivante (en reprenant les notations de l'Exemple 1) : aload A sconst 0 sconst 1 sastore aload A
<Desc/Clms Page number 22>
sconst 1 sconst 2 sastore Il faut également insérer à l'endroit approprié (au début de la méthode process par exemple) la séquence d'initialisation suivante : getfield~this"f" getfield "array" as tore A Il est à noter que cette optimisation en espace est aussi une optimisation en temps de calcul, car il y a moins d'accès à la mémoire dans la forme compactée du bytecode.
Exemple 4 On trouve généralement dans le corps de l'applet de nombreux appels aux méthodes internes de l'applet. Ces appels de méthodes (par l'opération invokespecial) nécessitent l'empilement de la référence à l'objet applet par l'intermédiaire de l'instruction aload 0 (en JavaCard la référence à l'applet est par convention toujours stockée dans la variable 0 de chaque méthode de l'applet). La méthode de compaction proposée concerne les méthodes internes de l'applet qui ne sont pas accessibles directement ou indirectement depuis une autre applet. En effet dans un contexte multi-application une méthode qui est utilisable depuis un autre contexte (ici une autre applet) ne peut pas subir de modifications qui intègrent des spécificités du contexte de l'applet qui la définit.
Le système de compaction opère alors comme suit :
<Desc/Clms Page number 23>
* On utilise un registre A pour enregistrer la référence à l'objet applet.
* On remplace dans chacune des méthodes candidates chaque opération aload 0 qui fait référence à l'applet par l'opération de lecture du registre A.
* Dans toutes les autres méthodes de l'applet, on identifie les groupes de bytecodes qui correspondent à un appel à une des méthodes ainsi transformées. Dans chacun de ces groupes : a. On élimine l'instruction aload 0 qui correspond à l'empilement de la référence à l'objet applet courant ; b. On remplace l'instruction invokespecial par une nouvelle instruction invokespecialjplet qui possède la même sémantique, à la seule différence que la référence à l'objet applet est lue non pas dans la pile mais dans le registre A.
* On insère une opération d'initialisation du registre A dans le code de l'applet, par exemple au début de la méthode process.
Soit le groupe de bytecodes suivant correspondant à un appel de méthode interne : aload 0 aload 2 sconst 23
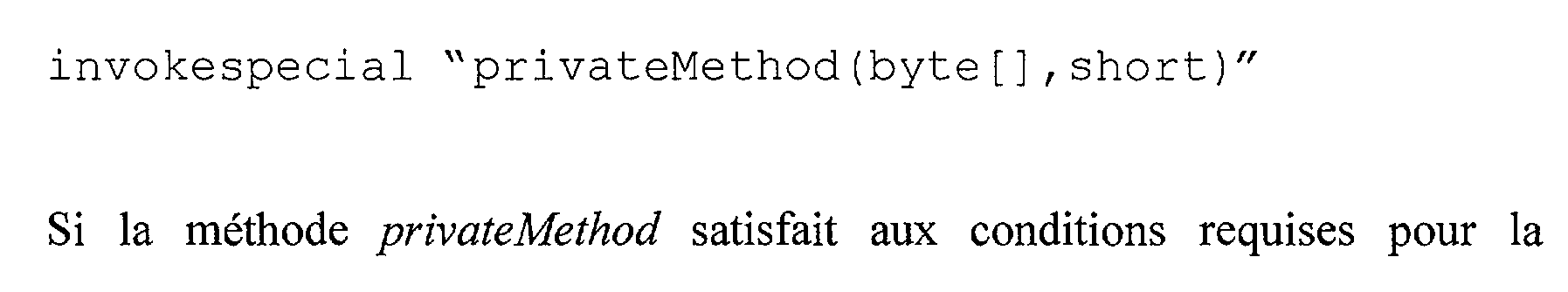
invokespecial"privateMethod (byte [], short)" Si la méthode privateMethod satisfait aux conditions requises pour la compression, ce groupe de bytecodes devient après application de la compression :
invokespecial"privateMethod (byte [], short)" Si la méthode privateMethod satisfait aux conditions requises pour la compression, ce groupe de bytecodes devient après application de la compression :
<Desc/Clms Page number 24>
aload 2 sconst 23 invokespecialapplet"privateMethod (byte [], short) Sachant que, dans la méthode privateMethod, toutes les instructions aload 0 ont été remplacées par des instructions de lecture de registre aload A (en reprenant les notations de l'exemple 1), et qu'on a inséré au début de la méthode process la séquence de bytecode suivante : aload 0 as tore A
Claims (8)
1. Procédé pour la compression du code d'un programme en code objet intermédiaire, ce procédé étant utilisable au compactage de programmes en code objet intermédiaire exécutable dans un système embarqué à faibles ressources matérielles, caractérisé en ce qu'il comprend l'exploitation d'une information sémantique pour modifier le code objet intermédiaire du programme et l'élimination des instructions du code objet intermédiaire du programme devenues inutiles du fait de cette modification.
2. Procédé selon la revendication 1, caractérisé en ce qu'il comprend l'identification des accès aux objets manipulés par le programme par une analyse sémantique du code objet du programme et l'utilisation de cette information pour remplacer dans le code du programme les groupes d'instructions accédant à ces objets par des instructions spécialisées permettant un accès direct aux objets considérés.
3. Procédé selon la revendication 2, caractérisé en ce que les susdites instructions spécialisées sont intégrées dans l'interpréteur servant à effectuer une interprétation logicielle des instructions standard du code intermédiaire en instructions directement exécutables par un microprocesseur, dans le cas où cet interpréteur n'en dispose pas.
4. Procédé selon la revendication 3, caractérisé en ce que l'interpréteur est étendu avec des registres spécifiques et des versions spécialisées de certaines instructions de l'interpréteur qui opèrent implicitement sur ces registres spécifiques plutôt que sur leurs arguments ordinaires.
<Desc/Clms Page number 26>
5. Procédé selon la revendication 4, caractérisé en ce qu'il comprend les étapes suivantes : - une première étape dans laquelle on effectue une analyse sémantique du programme qui met en évidence les objets accédés en chaque point du programme, - une deuxième étape dans laquelle, à l'aide de l'information calculée par l'analyse sémantique de la première étape, pour tout objet manipulé par le programme, on identifie dans le programme les occurrences de différents groupes d'instructions qui opèrent sur cet objet et dont on dispose une version spécialisée en terme d'un registre spécifique dans le jeu d'instruction de l'interpréteur, - une troisième étape dans laquelle on soumet lesdits objets à un test de comparaison de supériorité d'une fonction d'au moins le nombre d'occurrences des groupes d'instructions correspondants dans ledit programme, comme déterminé à la deuxième étape, à une valeur de référence et, sur réponse positive audit test, pour chaque objet satisfaisant à ladite étape de test, - une quatrième étape dans laquelle, en un point du programme qui précède, dans toutes les exécutions possibles du programme, les occurrences de groupes d'instructions associées audit objet, on introduit le code correspondant à l'affectation dudit objet dans un des registres spécifiques de l'interpréteur, - une cinquième étape dans laquelle on remplace dans le programme les groupes d'instruction à chacune desdites occurrences par l'instruction spécialisée par rapport audit registre qui leur correspond, - une sixième étape dans laquelle on élimine du code du programme les instructions et les constructions qui sont rendues inutiles ou redondantes du fait des transformations du programme indiquées aux quatrième et cinquième étapes.
<Desc/Clms Page number 27>
6. Procédé selon l'une des revendications précédentes, caractérisé en ce que dans le cas d'un compactage d'un programme en code objet intermédiaire JavaCard exécutable dans le cadre des échanges entre une carte à puce et un terminal de lecture, l'analyse sémantique consiste en une propagation interprocédurale des références à l'objet APDU, analyse qui permet d'identifier les références de l'unique instance de la classe APDU contenue dans le JCRE et son unique buffer associé dans toutes les méthodes de l'applet, cette analyse déterminant en chaque point du bytecode JavaCard de l'applet quelles sont les variables locales et les entrées dans la pile qui contiennent une référence à l'APDU ou à son buffer.
7. Procédé selon la revendication 6, caractérisé en ce que l'interpréteur comprend deux registres permettant d'accéder directement à l'APDU ou au buffer de l'APDU en insérant des opérations d'initialisation de ces registres dans le code de l'applet.
8. Procédé selon l'une des revendications précédentes, caractérisé en ce que la compression consiste à remplacer dans les méthodes internes de l'applet, les lectures des variables locales contenant ces objets et les opérations qui les suivent par les opérations spécialisées correspondantes.
Priority Applications (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR0110210A FR2827974B1 (fr) | 2001-07-26 | 2001-07-26 | Procede pour la compression d'un code interprete par analyse semantique |
| PCT/FR2002/002607 WO2003010666A1 (fr) | 2001-07-26 | 2002-07-22 | Procede pour la compression d'un code interprete par analyse semantique |
| US10/484,849 US7467376B2 (en) | 2001-07-26 | 2002-07-22 | Semantic analysis based compression of interpreted code by replacing object instruction groups with special instruction specifying a register representing the object |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR0110210A FR2827974B1 (fr) | 2001-07-26 | 2001-07-26 | Procede pour la compression d'un code interprete par analyse semantique |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| FR2827974A1 true FR2827974A1 (fr) | 2003-01-31 |
| FR2827974B1 FR2827974B1 (fr) | 2005-02-11 |
Family
ID=8866096
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| FR0110210A Expired - Fee Related FR2827974B1 (fr) | 2001-07-26 | 2001-07-26 | Procede pour la compression d'un code interprete par analyse semantique |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US7467376B2 (fr) |
| FR (1) | FR2827974B1 (fr) |
| WO (1) | WO2003010666A1 (fr) |
Families Citing this family (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7464370B2 (en) * | 2003-12-04 | 2008-12-09 | International Business Machines Corporation | Creating a method from a block of code |
| DE10357257A1 (de) * | 2003-12-08 | 2005-06-30 | Giesecke & Devrient Gmbh | Java Smart Card Chip mit für globale Variablen reserviertem Speicherbereich |
| KR100597413B1 (ko) * | 2004-09-24 | 2006-07-05 | 삼성전자주식회사 | 자바 바이트코드 변환 방법 및 상기 변환을 수행하는 자바인터프리터 |
| KR100902461B1 (ko) | 2005-02-03 | 2009-06-11 | 미쓰비시덴키 가부시키가이샤 | 프로그램 코드 생성 지원 장치 및 방법, 프로그램실행장치와 방법, 프로그램 코드 압축 처리 장치 및 방법과그들의 프로그램 |
| KR100683853B1 (ko) * | 2005-02-04 | 2007-02-16 | 삼성전기주식회사 | 프리 컴파일링 장치 |
| GB0510657D0 (en) * | 2005-05-25 | 2005-06-29 | Ibm | Generating an application software library |
| US7827537B2 (en) * | 2006-05-26 | 2010-11-02 | Oracle America, Inc | Searching computer programs that use different semantics |
| US8341597B2 (en) * | 2007-01-17 | 2012-12-25 | International Business Machines Corporation | Editing source code |
| US8059126B2 (en) * | 2007-03-30 | 2011-11-15 | Computer Associates Think, Inc. | System and method for indicating special characters to be interpreted literally |
| US8924921B2 (en) * | 2009-04-20 | 2014-12-30 | International Business Machines Corporation | Abstracting business logic into centralized database controls |
| JP5110111B2 (ja) * | 2010-03-23 | 2012-12-26 | 株式会社デンソー | 中間モジュールの生成方法及び支援装置 |
| US8375373B2 (en) * | 2010-04-19 | 2013-02-12 | Microsoft Corporation | Intermediate language support for change resilience |
| US8689200B1 (en) * | 2011-01-12 | 2014-04-01 | Google Inc. | Method and system for optimizing an executable program by generating special operations for identical program entities |
| US8683455B1 (en) | 2011-01-12 | 2014-03-25 | Google Inc. | Method and system for optimizing an executable program by selectively merging identical program entities |
| CA2741212C (fr) | 2011-05-27 | 2020-12-08 | Ibm Canada Limited - Ibm Canada Limitee | Soutien aux utilisateurs de libre-service automatise fondee sur l'analyse ontologique |
| US10157049B2 (en) | 2011-10-26 | 2018-12-18 | International Business Machines Corporation | Static analysis with input reduction |
| CA2767676C (fr) * | 2012-02-08 | 2022-03-01 | Ibm Canada Limited - Ibm Canada Limitee | Attribution reposant sur l'analyse semantique |
| US9274772B2 (en) | 2012-08-13 | 2016-03-01 | Microsoft Technology Licensing, Llc. | Compact type layouts |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5613121A (en) * | 1994-10-19 | 1997-03-18 | International Business Machines Corporation | Method and system of generating combined storage references |
| EP0778521A2 (fr) * | 1995-12-08 | 1997-06-11 | Sun Microsystems, Inc. | Système et méthode pour l'optimisation en temps d'exécution d'appels de fonction à des variables privées dans un interprétateur sûr |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2360101A (en) * | 2000-03-08 | 2001-09-12 | Nokia Mobile Phones Ltd | An optimised method of compiling code in an object oriented programming language |
-
2001
- 2001-07-26 FR FR0110210A patent/FR2827974B1/fr not_active Expired - Fee Related
-
2002
- 2002-07-22 WO PCT/FR2002/002607 patent/WO2003010666A1/fr not_active Ceased
- 2002-07-22 US US10/484,849 patent/US7467376B2/en not_active Expired - Fee Related
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5613121A (en) * | 1994-10-19 | 1997-03-18 | International Business Machines Corporation | Method and system of generating combined storage references |
| EP0778521A2 (fr) * | 1995-12-08 | 1997-06-11 | Sun Microsystems, Inc. | Système et méthode pour l'optimisation en temps d'exécution d'appels de fonction à des variables privées dans un interprétateur sûr |
Also Published As
| Publication number | Publication date |
|---|---|
| WO2003010666B1 (fr) | 2003-10-02 |
| US20040221282A1 (en) | 2004-11-04 |
| WO2003010666A1 (fr) | 2003-02-06 |
| US7467376B2 (en) | 2008-12-16 |
| FR2827974B1 (fr) | 2005-02-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| FR2827974A1 (fr) | Procede pour la compression d'un code interprete par analyse semantique | |
| AU771699B2 (en) | Token-based linking | |
| US20250199778A1 (en) | Implementing reflection mechanism in blockchain | |
| AU764398B2 (en) | Object-oriented instruction set for resource-constrained devices | |
| KR20000052759A (ko) | 마이크로컨트롤러를 이용한 고급 프로그래밍 언어 사용 | |
| US8818967B2 (en) | Method for compressing identifiers | |
| US8805801B2 (en) | Method for compressing a .net file | |
| WO2004006088A2 (fr) | Securisation d'application telechargee notamment dans une carte a puce | |
| EP1782191B1 (fr) | Procede de chargement d'un logiciel en langage intermediaire oriente objet dans un appareil portatif | |
| WO2025020395A1 (fr) | Procédé d'optimisation de code à octets wasm, procédé d'exécution, dispositif informatique et support de stockage | |
| CN114327482B (zh) | 应用格式转换方法、装置、设备及存储介质 | |
| CN101208690A (zh) | 计算环境中翻译表达式 | |
| CN116700629B (zh) | 数据处理方法和装置 | |
| CN116932149A (zh) | 数据处理方法和装置 | |
| CN116680014A (zh) | 数据处理方法和装置 | |
| CN113495727B (zh) | 业务组件开发方法、装置、电子设备及介质 | |
| CN116700840B (zh) | 文件执行方法、装置、电子设备及可读存储介质 | |
| KR20070088160A (ko) | 메소드 호출 방법 및 이를 이용한 자바 가상 머신 | |
| WO2003017097A2 (fr) | Procede de compression de code objet interprete par factorisation d'expressions arborescentes | |
| EP1405180A2 (fr) | Procedes et appareils ameliores destines a l'inclusion par reference de valeurs constantes numeriques dans des machines virtuelles | |
| CN117149155A (zh) | 服务接口的代码校验方法、装置、设备及存储介质 | |
| CN118012400A (zh) | 针对程序的方法集合获取方法和装置 | |
| CN116955209A (zh) | WebAssembly虚拟机的测试方法和装置 | |
| CN119127075A (zh) | 运行时内存管理方法、装置、操作系统、虚拟机、设备、及终端 | |
| AU2001290842B2 (en) | Remote incremental program binary compatibility verification using API definitions |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PLFP | Fee payment |
Year of fee payment: 16 |
|
| PLFP | Fee payment |
Year of fee payment: 17 |
|
| PLFP | Fee payment |
Year of fee payment: 18 |
|
| PLFP | Fee payment |
Year of fee payment: 19 |
|
| ST | Notification of lapse |
Effective date: 20210305 |