JP2004013680A - Character code compression/decompression device and method - Google Patents
Character code compression/decompression device and method Download PDFInfo
- Publication number
- JP2004013680A JP2004013680A JP2002168638A JP2002168638A JP2004013680A JP 2004013680 A JP2004013680 A JP 2004013680A JP 2002168638 A JP2002168638 A JP 2002168638A JP 2002168638 A JP2002168638 A JP 2002168638A JP 2004013680 A JP2004013680 A JP 2004013680A
- Authority
- JP
- Japan
- Prior art keywords
- character code
- character
- compression
- delimiter
- information
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
- 238000007906 compression Methods 0.000 title claims abstract description 56
- 230000006835 compression Effects 0.000 title claims abstract description 56
- 238000000034 method Methods 0.000 title claims abstract description 26
- 230000006837 decompression Effects 0.000 title claims abstract description 24
- 238000006243 chemical reaction Methods 0.000 claims abstract description 65
- 238000000926 separation method Methods 0.000 abstract description 7
- 238000010586 diagram Methods 0.000 description 5
- 238000013144 data compression Methods 0.000 description 4
- 230000000694 effects Effects 0.000 description 4
- 239000000284 extract Substances 0.000 description 2
- 238000012986 modification Methods 0.000 description 1
- 230000004048 modification Effects 0.000 description 1
- 238000005192 partition Methods 0.000 description 1
- 230000002441 reversible effect Effects 0.000 description 1
Images





Landscapes
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
Abstract
Description
【0001】
【発明の属する技術分野】
本発明は、文字コード圧縮・復元装置および同方法に関する。さらに詳述すると、本発明は、頻繁に使用される文字コードを短いビットに割り当てて全体の記憶容量を削減する文字コード圧縮・復元装置および同方法に関する。
【0002】
【従来の技術】
従来、文字コード圧縮・復元装置および同方法は、たとえば、記憶装置に適用される。従来は、入力装置から得た文字コードをそのまま記憶装置に格納したり、出力装置から外部に流したりしている。
【0003】
例えば、文字「ABCDE」の場合について、より具体的な処理手順例を以下に説明する。本文字例を、通常のビット列(8bit ASCII)で表した場合の、文字/ビット列、の関係は以下となる。
A/01000001、B/01000010、C/01000011、
D/01000100、E/01000101
【0004】
上記の従来例によれば、下記の特徴がある。
1)1文字を常に8bitで表しているため、文字の区切りを示す必要がない。
2)必要なビット数は、8bit×5文字=40bit、である。
【0005】
本発明と技術分野の類似する先願発明例1として、特開平11−85459号公報の「文字データ符号化方法および記録媒体」がある。本先願発明例1では、基本的にはASCIIコード表に従って、1文字を1つのコードに符号化するが、複数文字からなる特定のキーワードについては、制御文字用に用意された領域コードを用いて符号化する。即ち、文字数とその出現頻度とを考慮して、データ圧縮効果の高いものから順に選択された16個のキーワードを、コード10H〜1fHに符号化する。これにより、より少ない記憶容量にて効率よく記憶媒体に格納可能なように文字データを符号化するとしている。
【0006】
先願発明例2として、特開平11−55125号公報の「文字データの圧縮・復元方法」がある。本先願発明例2では、原データを判別して内部番号列に変換して符号化する。また、内部番号に変換された文字列が辞書に保持されていない場合には、2つのグループに分け、ひらがな、漢字等の文字を符号化し、グループを表すビットを付して出力する。これにより、小さいデータでも高い圧縮率を得ることができる、としている。
【0007】
先願発明例3として、特開平9−69785号公報の「データ圧縮方法及びデータ圧縮装置」がある。本先願発明例3では、特定文字のコードデータとその圧縮コードデータとを対応付けた対応一覧表を用意しておき、圧縮対象データから取り出した1文字分の文字コードデータがその対応一覧表に存在するか否かを検索する。その結果、当該データが対応する一覧表に存在する場合には、その圧縮コードデータを対応一覧表から読み出し、存在しない場合には、当該データをそのまま出力する。これにより、効果的なデータ圧縮を行うとしている。
【0008】
【発明が解決しようとする課題】
しかしながら、従来の文字コード圧縮・復元装置および同方法では、入力装置から得た文字コードをそのまま記憶装置に格納している。このため、1文字当たり常に1バイト(8ビット)の容量を使用しており、文章全体に渡って無駄なビットが記憶容量の多くを占めているという問題を伴う。
【0009】
本発明は、頻繁に使用される文字コードを短いビットに割り当て、全体の記憶容量を削減する文字コード圧縮・復元装置および同方法を提供することを目的とする。
【0010】
【課題を解決するための手段】
かかる目的を達成するため、本発明の文字コード圧縮・復元装置は、入力された文字の文字コードを圧縮変換し、該文字コードの区切りの情報を生成し、圧縮変換結果と区切り情報とを結合するデータ処理装置と、文字の各ビット列に対応する文字コード情報を予め記憶している変換テーブルを使用して変換された文字コード、および該変換結果の区切り位置を示す区切りの情報を格納する記憶装置とを有し、文字の出現頻度順にビット数の少ない所に割り当てた変換テーブルを作成し、文字コードの変換効率を高めたことを特徴としている。
【0011】
また、上記の記憶装置は、文字コードを変換する時に使用する変換テーブル記憶部と、圧縮変換した結果を格納する圧縮情報記憶部と、変換結果の区切り位置を示す区切り情報を格納する区切り情報記憶部とを備え、変換テーブル記憶部は、各アルファベットに対応するビット列の情報をあらかじめ記憶している記憶部とするとよい。
【0012】
本発明の文字コード圧縮・復元方法は、入力された文字の文字コードを圧縮変換し、該文字コードの区切りの情報を生成し、圧縮変換結果と区切り情報とを結合するデータ処理工程と、文字の各ビット列に対応する文字コード情報を予め記憶している変換テーブルを使用して変換された文字コード、および該変換結果の区切り位置を示す区切りの情報を格納する記憶工程とを有し、文字の出現頻度順にビット数の少ない所に割り当てた変換テーブルを作成し、文字コードの変換効率を高めたことを特徴としている。
【0013】
また、上記の記憶工程は、文字コードを変換する時に使用する変換テーブル記憶工程と、圧縮変換した結果を格納する圧縮情報記憶工程と、変換結果の区切り位置を示す区切り情報を格納する区切り情報記憶工程とを備え、変換テーブル記憶工程は、各アルファベットに対応するビット列の情報をあらかじめ記憶している記憶工程とするとよい。
【0014】
【発明の実施の形態】
次に、添付図面を参照して本発明による文字コード圧縮・復元装置および同方法の実施の形態を詳細に説明する。図1から図8を参照すると、本発明の文字コード圧縮・復元装置および同方法の一実施形態が示されている。
【0015】
本発明の文字コード圧縮・復元装置および同方法は、アルファベットとして使用されている文字コードが有しているビットサイズを減少することで、文章などで使用している文字列全体のビット数の削減を図り、全体として使用するデータの容量を圧縮するものである。また、可逆的な復元方式を用いることで、圧縮した情報から、元の文字コードへの復元動作も可能とする。
【0016】
更に、1文字ずつ順番に圧縮・復元できる方式の為、先頭から1文字ずつ入力される場合や末尾の文字を1文字削除するなどと言った場合でも、その影響範囲を該当文字の部分だけに押さえ込むことを可能とする。本構成の内容を以下に詳述する。
【0017】
(構成例)
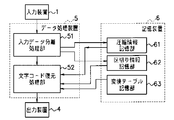
図1および図2は、本発明の文字コード圧縮・復元装置および同方法の実施形態に適用される文字コード圧縮・復元装置の構成例を示すブロック図である。
図1を参照すると、文字コード圧縮装置であり、文字コード圧縮時に適用される機能部を示している。本機能部は、キーボードなどの入力装置1と、プログラム制御により動作するデータ処理装置2と、情報を記憶する記憶装置3と、情報を外部に取り出す為の出力装置4とを含む。
【0018】
データ処理装置2は、入力装置1より入力された文字コードを圧縮する文字コード圧縮処理部21と、文字コードの区切りの情報を生成する区切り情報生成処理部22と、外部に出力する際に変換結果と区切り情報を結合する情報結合処理部23とを備えている。
【0019】
記憶装置3は、文字コードを変換する時に使用する変換テーブル記憶部31と、圧縮変換した結果を格納する圧縮情報記憶部32と、変換結果の区切り位置を示す区切り情報を格納する区切り情報記憶部33とを備えている。変換テーブル記憶部31は、各アルファベットに対応するビット列の情報を、あらかじめ記憶している。
【0020】
次に、図2を参照すると、本実施例は、文字コードを復元する時のものであり、先の図1にて圧縮した情報を外部から入力する為の入力装置1と、プログラム制御により動作するデータ処理装置5と、情報を記憶する記憶装置6と、情報を外部に取り出す為の出力装置4とを含む。
【0021】
記憶装置6は、文字コードの圧縮情報部分を記憶する圧縮情報記憶部61と、区切り情報部分を記憶する区切り情報記憶部62と、文字コードを復元する時に使用する変換テーブル記憶部63とを備える。なお、この変換テーブル記憶部63は、各ビット列に対応する文字コードの情報を、あらかじめ記憶している。
【0022】
データ処理装置5は、入力装置1から得た情報を、文字コードの圧縮情報と区切り情報に分離する入力データ分離処理部51と、記憶装置6の情報を元の文字コードに復元する文字コード復元処理部52とを備える。
【0023】
(動作例)
次に、図1〜図7を参照して、本実施例の動作について詳細に説明する。なお、図3は、記憶装置3および記憶装置6に記憶された変換テーブルの構成例を示す。図4は、文字列、文字のビット列、および文字の区切りビット列の構成例を示す。図5は、文字列例に対応する圧縮ビット列、区切りビット列、および従来のコード例を表した図である。図6および図7は、処理手順例を示すフローチャートである。
【0024】
これらの図において、図1および図6は、文字コードから圧縮データへ圧縮する処理例を、図2および図7では、圧縮されたデータから元の文字コードへの復元を行う処理例を表している。
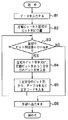
【0025】
先ず、文字コードを入力する(ステップA1)。入力が未終了の場合は(ステップA2/NO)、入力文字を圧縮ビット列に変換し(ステップA3)、変換後のビット列から区切りビット列を生成する(ステップA4)。
入力が終了した場合は(ステップA2/YES)、圧縮ビット列と区切りビット列の結合を実行し(ステップA5)、実行後の結合されたビット列を外部へ出力する(ステップA6)。
【0026】
図1の入力装置1から与えられた文字コードは(ステップA1)、データ処理装置2により記憶装置3を参照して、別のビット列に置き換える(ステップA3、A4、A5)。記憶装置3は、図3に示す通り、各文字に対応したビット列を保持し、それをテーブルとして記憶している。
【0027】
データ処理装置2は、入力された文字コードを、記憶装置3を元にしたビット列に置き換える(ステップA3、A4、A5)。その際、データ処理装置2では、文字コードを置き換えたビット列の区切り情報を記憶するために、文字の区切り部分識別のためのビット列を生成する(ステップA4)。
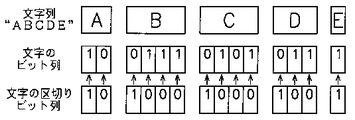
【0028】
図4は、文字列“ABCDE”と、文字ビット列と、文字の区切りビット列とを示している。本図4に示す通り、置き換えたビット列の先頭ビットは“1”、残りのビットは“0”に相当するビット列を生成する。これにより、区切りビット列のビットが“1”の所に該当する圧縮ビット列のビットが、圧縮した文字コードの先頭ビットとなり、続く“0”のビット列の部分が、圧縮した文字コードの残りの部分となる。
【0029】
図6に示す通り、上記の処理を入力が終了するまで行い、入力が終了した時点で、データ処理装置2にて、圧縮ビット列と区切りビット列の結合を行い、出力装置4にて出力を行う。
【0030】
次に、図2の入力装置1から与えられたデータは、データ処理装置5の入力データ分離処理部51で、圧縮情報データと区切り情報データの2つに分割を行う。分割したこれらのデータはそれぞれ、圧縮情報記憶部61と区切り情報記憶部62に格納する。次に、データ処理装置5の文字コード復元処理部52では、記憶装置6の圧縮情報記憶部61と区切り情報記憶部62と変換テーブル記憶部63のデータを、元の文字コードへの復元処理を行う。データ処理装置5は、区切り情報記憶部62から文字の区切り情報として、ビット“1”とそれに続くビット“0”を、次にビット“1”が現れるか、区切りデータが末尾になるまで順に取り出す。その時に、何ビット取り出したかをカウントしておく。
【0031】
次に、文字コード復元処理部52は、先ほどカウントした数の分だけ、圧縮情報記憶部61から圧縮情報のビットを取り出す。次に、文字コード復元処理部52は、取り出した圧縮情報のビットを、変換テーブル記憶部63のテーブルで検索し、該当するビット列に相当する文字コードを入手する。
【0032】
図3に示す通り、変換テーブル記憶部63が記憶する変換テーブルは、文字コードとビット列のテーブルとなっており、ビット列を順に検索することで、そのビット列に相当する文字コードを割り出すことが出来る。取り出した文字コードは、出力装置4により外部に取り出す。
【0033】
図7に示す通り、先ずデータを入力する(ステップB1)。入力したデータを、圧縮ビット列と区切りビット列に分離する(ステップB2)。区切りビット列が残っている場合は(ステップB3/YES)、区切りビット列を元に、圧縮ビット列から1文字分のビット列を入手し(ステップB4)、1文字分のビット列から、テーブルを元に文字コードを入手する(ステップB5)。圧縮ビット列から1文字分のビット列入手(ステップB4)と、文字コード入手(ステップB5)は、区切りビット列が無くなるまで繰り返し実行される(ステップB3/NO)。
【0034】
このように、区切り情報記憶部62に区切り情報が残っている場合には(ステップB3/YES)、再度、区切り情報記憶部62から取り出した情報を元に、圧縮情報記憶部61から圧縮情報を取り出し(ステップB4)、変換テーブル記憶部63のテーブルから文字コードを割り出す(ステップB5)。
1文字分のビット列から入手した文字コードは、出力装置4により、外部に取り出すものとする(ステップB6)。
【0035】
図8の変換テーブルによるビット列で表した場合の、文字/ビット列、の関係は、以下となる。
A/10、 B/0111、 C/0101、
D/011、 E/1
上記の具体例では、1文字を可変長で表しているため、文字の区切りの位置を示す必要がある。そのため、区切り識別用のビット列を設けることとする。
【0036】
例えば、区切りの識別子には、先頭ビットが“1”、残りのビットが“0”としたものを使用する。一例を、以下に示す。以下の、文字/ビット列、の関係の具体例は、図8のテーブルを使用した場合に該当している。
3)文字列; A B C D E
4)文字のビット列; 10 0111 0101 011 1 14bit
5)区切り用ビット列;10 1000 1000 100 1 14bit
上に掲げた具体例では、合計が28bitとなる。この場合のビット数を上述した従来の処理例と比較すると、本例/従来例が28/40=70%となる。
【0037】
(実施例の効果)
第1の効果は、通常8ビットで表現される文字コードを、最低2ビット〜最悪8ビットで表わすことで文章全体で使用する容量を削減でき、少ないメモリで多くの文字が記憶できる。また、ネットワークなどで送受信する際にも、流すデータ量が削減され、転送速度の向上とトラフィックの軽減がなされる。
【0038】
なお、図4に示した通り、単純な「ABCDE」といった文字列の場合には、70%の圧縮率となっている。しかし、通常の文書中に頻繁に使用される文字を割り出し、その文字を頻度順にビット数の少ない所に割り当てるようなテーブルを作成することで、更に圧縮率を高めることが可能となる。
【0039】
(他の実施例)
図1の変換テーブル記憶部31のテーブルの内容を、当事者間で了解され、外部に知らせていない独自なテーブルを使用することで、入出力データが外部に漏洩した際にも、データが暗号化された状態となり、機密保持を行うことが出来る。
【0040】
なお、上述の実施形態は本発明の好適な実施の一例である。ただし、これに限定されるものではなく、本発明の要旨を逸脱しない範囲内において種々変形実施が可能である。
【0041】
【発明の効果】
以上の説明より明らかなように、本発明の文字コード圧縮・復元装置および同方法は、入力された文字の文字コードを圧縮変換し、該文字コードの区切りの情報を生成し、圧縮変換結果と区切り情報とを結合し、文字の各ビット列に対応する文字コード情報を予め記憶している。また、変換テーブルを使用して変換された文字コード、および該変換結果の区切り位置を示す区切りの情報を格納し、文字の出現頻度順にビット数の少ない所に割り当てた変換テーブルを作成して、文字コードの変換効率を高めている。
【図面の簡単な説明】
【図1】本発明の文字コード圧縮・復元装置の実施形態に適用され、文字コード圧縮時に使用される機能部の構成例を示すブロック図である。
【図2】本発明の文字コード圧縮・復元方法の実施形態に適用され、文字コード復元時に使用される機能部の構成例を示すブロック図である。
【図3】記憶装置3および記憶装置6に記憶された変換テーブルの構成例を示す。
【図4】文字列、文字のビット列、および文字の区切りビット列の構成例を示す。
【図5】文字列例に対応する圧縮ビット列、区切りビット列、および従来のコード例を表した図である。
【図6】処理手順例を示す第1のフローチャートである。
【図7】処理手順例を示す第2のフローチャートである。
【図8】変換テーブルの構成例を示している。
【符号の説明】
1 入力装置
2 データ処理装置
3 記憶装置
4 出力装置
5 データ処理装置
6 記憶装置
21 文字コード圧縮処理部
22 区切り情報生成処理部
23 情報結合処理部
31 変換テーブル記憶部
32 圧縮情報記憶部
33 区切情報記憶部
51 入力データ分離処理部
52 文字コード復元処理部
61 圧縮情報記憶部
62 区切り情報記憶部
63 変換テーブル記憶部[0001]
TECHNICAL FIELD OF THE INVENTION
The present invention relates to a character code compression / decompression device and method. More specifically, the present invention relates to a character code compression / decompression apparatus and method for assigning frequently used character codes to short bits to reduce the overall storage capacity.
[0002]
[Prior art]
Conventionally, a character code compression / decompression device and method are applied to, for example, a storage device. Conventionally, a character code obtained from an input device is stored in a storage device as it is, or is sent to an external device from an output device.
[0003]
For example, in the case of the character “ABCDE”, a more specific processing procedure example will be described below. When this character example is represented by a normal bit string (8-bit ASCII), the relationship between the character and the bit string is as follows.
A / 01000001, B / 01000010, C / 01000011,
D / 01000100, E / 01000101
[0004]
According to the above conventional example, the following features are provided.
1) Since one character is always represented by 8 bits, there is no need to indicate a character delimiter.
2) The required number of bits is 8 bits × 5 characters = 40 bits.
[0005]
Japanese Patent Application Laid-Open No. H11-85459 discloses "Character data encoding method and recording medium" as a first example of the prior application similar to the present invention in the technical field. In Inventive Example 1 of the prior application, one character is basically encoded into one code in accordance with the ASCII code table. For a specific keyword including a plurality of characters, an area code prepared for a control character is used. Encoding. That is, in consideration of the number of characters and the appearance frequency, 16 keywords selected in order from the one with the highest data compression effect are encoded into codes 10H to 1fH. Thereby, the character data is encoded so that it can be efficiently stored in a storage medium with a smaller storage capacity.
[0006]
Japanese Patent Application Laid-Open No. H11-55125 discloses a "method of compressing and restoring character data" as Invention Example 2 of the prior application. In Inventive Invention Example 2, the original data is discriminated, converted into an internal number sequence, and encoded. If the character string converted to the internal number is not stored in the dictionary, the character string is divided into two groups, and characters such as hiragana and kanji are encoded and output with bits indicating the group. It states that a high compression ratio can be obtained even with small data.
[0007]
Japanese Patent Application Laid-Open No. 9-69785 discloses "Data Compression Method and Data Compression Apparatus". In Inventive Example 3, a correspondence list in which code data of a specific character is associated with its compression code data is prepared, and the character code data for one character extracted from the data to be compressed is stored in the correspondence list. Search whether it exists in. As a result, if the data exists in the corresponding list, the compressed code data is read from the corresponding list, and if not, the data is output as it is. Thereby, effective data compression is performed.
[0008]
[Problems to be solved by the invention]
However, in the conventional character code compression / decompression device and method, the character code obtained from the input device is stored in the storage device as it is. Therefore, one byte (8 bits) is always used for one character, and there is a problem that useless bits occupy a large part of the storage capacity over the entire text.
[0009]
SUMMARY OF THE INVENTION It is an object of the present invention to provide a character code compression / decompression apparatus and method for allocating frequently used character codes to short bits and reducing the overall storage capacity.
[0010]
[Means for Solving the Problems]
In order to achieve this object, the character code compression / decompression device of the present invention compresses and converts the character code of an input character, generates information of the character code delimiter, and combines the compression conversion result with the delimiter information. A data processing device that stores character codes converted by using a conversion table that stores character code information corresponding to each bit string of characters in advance, and storage for storing delimiter information indicating a delimiter position of the conversion result A conversion table assigned to places where the number of bits is small in the order of appearance frequency of characters, thereby improving the conversion efficiency of character codes.
[0011]
Further, the storage device includes a conversion table storage unit used when converting a character code, a compression information storage unit that stores a result of compression conversion, and a delimiter information storage that stores delimiter information indicating a delimiter position of the conversion result. The conversion table storage unit may be a storage unit that stores bit string information corresponding to each alphabet in advance.
[0012]
A character code compression / decompression method according to the present invention includes a data processing step of compressing and converting a character code of an input character, generating information of a delimiter of the character code, and combining the compression conversion result with the delimiter information; Storing a character code converted using a conversion table that stores character code information corresponding to each bit string in advance, and delimiter information indicating a delimiter position of the conversion result. A conversion table assigned to places with a small number of bits in the order of appearance frequency is created to enhance the conversion efficiency of character codes.
[0013]
Further, the storage step includes a conversion table storage step used when converting a character code, a compression information storage step storing a result of compression conversion, and a delimiter information storage storing delimiter information indicating a delimiter position of the conversion result. The conversion table storage step may be a storage step in which bit string information corresponding to each alphabet is stored in advance.
[0014]
BEST MODE FOR CARRYING OUT THE INVENTION
Next, an embodiment of a character code compressing / decompressing apparatus and method according to the present invention will be described in detail with reference to the accompanying drawings. 1 to 8, there is shown an embodiment of a character code compression / decompression apparatus and method according to the present invention.
[0015]
The character code compression / decompression device and method of the present invention reduce the bit size of a character code used as an alphabet, thereby reducing the number of bits of the entire character string used in a sentence or the like. In order to reduce the amount of data used as a whole. Further, by using a reversible restoration method, a restoration operation from compressed information to an original character code can be performed.
[0016]
Furthermore, since the compression / decompression method can be used in order one character at a time, even if the characters are input one by one from the beginning or the last character is deleted, the affected area is limited to the relevant character part only. It is possible to hold down. The contents of this configuration will be described in detail below.
[0017]
(Configuration example)
FIGS. 1 and 2 are block diagrams showing a configuration example of a character code compression / decompression device applied to an embodiment of the character code compression / decompression device and the method according to the present invention.
FIG. 1 shows a character code compression apparatus, which shows a functional unit applied at the time of character code compression. This functional unit includes an
[0018]
The
[0019]
The
[0020]
Next, referring to FIG. 2, this embodiment is for restoring a character code, and operates by an
[0021]
The
[0022]
The
[0023]
(Operation example)
Next, the operation of this embodiment will be described in detail with reference to FIGS. FIG. 3 shows a configuration example of the conversion table stored in the
[0024]
In these figures, FIGS. 1 and 6 show examples of processing for compressing character codes into compressed data, and FIGS. 2 and 7 show examples of processing for restoring compressed data to the original character codes. I have.
[0025]
First, a character code is input (step A1). If the input has not been completed (step A2 / NO), the input character is converted into a compressed bit string (step A3), and a delimiter bit string is generated from the converted bit string (step A4).
When the input is completed (step A2 / YES), the compression bit string and the delimiter bit string are combined (step A5), and the combined bit string after execution is output to the outside (step A6).
[0026]
The character code given from the
[0027]
The
[0028]
FIG. 4 shows a character string “ABCDE”, a character bit string, and a character separation bit string. As shown in FIG. 4, the first bit of the replaced bit string is "1", and the remaining bits generate a bit string corresponding to "0". As a result, the bit of the compressed bit string corresponding to the place where the bit of the delimiter bit string is “1” becomes the leading bit of the compressed character code, and the bit string of “0” that follows becomes the remaining bit of the compressed character code. Become.
[0029]
As shown in FIG. 6, the above processing is performed until the input is completed, and when the input is completed, the
[0030]
Next, the data provided from the
[0031]
Next, the character code restoration processing unit 52 extracts the bits of the compressed information from the compressed
[0032]
As shown in FIG. 3, the conversion table stored in the conversion table storage section 63 is a table of character codes and bit strings, and by sequentially searching the bit strings, a character code corresponding to the bit string can be determined. The extracted character code is extracted by the output device 4 to the outside.
[0033]
As shown in FIG. 7, data is input first (step B1). The input data is separated into a compressed bit string and a separating bit string (step B2). If the delimiter bit string remains (step B3 / YES), a bit string for one character is obtained from the compressed bit string based on the delimiter bit string (step B4), and a character code is obtained from the bit string for one character based on the table. (Step B5). The acquisition of the bit string for one character from the compressed bit string (step B4) and the acquisition of the character code (step B5) are repeatedly executed until there is no more delimiter bit string (step B3 / NO).
[0034]
As described above, when the delimiter information remains in the delimiter information storage unit 62 (step B3 / YES), the compression information is again stored in the decompression
The character code obtained from the bit string for one character is taken out to the outside by the output device 4 (step B6).
[0035]
The relationship between a character and a bit string when represented by a bit string according to the conversion table of FIG. 8 is as follows.
A / 10, B / 0111, C / 0101,
D / 011, E / 1
In the above specific example, since one character is represented by a variable length, it is necessary to indicate the position of the character delimiter. Therefore, a bit string for delimiter identification is provided.
[0036]
For example, as the delimiter identifier, the one whose first bit is “1” and whose remaining bits are “0” is used. An example is shown below. The following specific example of the relationship between the character / bit string corresponds to the case where the table of FIG. 8 is used.
3) Character string; ABCDE
4) Character bit string; 10 0111 0101 011 1 14 bits
5) Delimiter bit string; 10 1000 1000 100 1 14 bits
In the above specific example, the total is 28 bits. When the number of bits in this case is compared with the above-described conventional processing example, the present example / conventional example is 28/40 = 70%.
[0037]
(Effects of the embodiment)
The first effect is that a character code normally expressed by 8 bits is expressed by at least 2 bits to 8 bits at worst, so that the capacity used for the entire text can be reduced, and many characters can be stored with a small memory. Also, when transmitting and receiving over a network or the like, the amount of data to be transmitted is reduced, so that the transfer speed is improved and traffic is reduced.
[0038]
As shown in FIG. 4, in the case of a simple character string such as "ABCDE", the compression ratio is 70%. However, it is possible to further increase the compression ratio by creating a table in which characters that are frequently used in a normal document are allocated and the characters are assigned to places having a small number of bits in order of frequency.
[0039]
(Other embodiments)
The contents of the table in the conversion table storage unit 31 shown in FIG. 1 can be encrypted even when input / output data leaks to the outside by using a unique table which is understood by the parties and is not notified to the outside. And the confidentiality can be maintained.
[0040]
The above embodiment is an example of a preferred embodiment of the present invention. However, the present invention is not limited to this, and various modifications can be made without departing from the scope of the present invention.
[0041]
【The invention's effect】
As is clear from the above description, the character code compression / decompression apparatus and method of the present invention compresses and converts the character code of an input character, generates information on the delimitation of the character code, and generates a result of the compression conversion. The character code information corresponding to each bit string of the character is stored in advance by combining with the delimiter information. In addition, a character code converted by using the conversion table, and information of a delimiter indicating a delimiter position of the conversion result is stored, and a conversion table allocated to a place where the number of bits is small in the order of character appearance frequency is created. The efficiency of character code conversion is improved.
[Brief description of the drawings]
FIG. 1 is a block diagram illustrating a configuration example of a functional unit used at the time of character code compression applied to an embodiment of a character code compression / decompression device of the present invention.
FIG. 2 is a block diagram illustrating a configuration example of a functional unit used at the time of character code decompression applied to the embodiment of the character code compression / decompression method of the present invention.
FIG. 3 shows a configuration example of a conversion table stored in a
FIG. 4 shows a configuration example of a character string, a character bit string, and a character delimiter bit string.
FIG. 5 is a diagram illustrating a compressed bit string, a delimiter bit string, and a conventional code example corresponding to a character string example.
FIG. 6 is a first flowchart illustrating an example of a processing procedure.
FIG. 7 is a second flowchart illustrating an example of a processing procedure.
FIG. 8 shows a configuration example of a conversion table.
[Explanation of symbols]
REFERENCE SIGNS
Claims (6)
前記文字の各ビット列に対応する文字コード情報を予め記憶している変換テーブルを使用して変換された文字コード、および該変換結果の区切り位置を示す前記区切りの情報を格納する記憶装置とを有し、
前記文字の出現頻度順にビット数の少ない所に割り当てた前記変換テーブルを作成し、前記文字コードの変換効率を高めたことを特徴とする文字コード圧縮・復元装置。A data processing device that compresses and converts a character code of an input character, generates information of a delimiter of the character code, and combines the compression conversion result and the delimiter information,
A storage device for storing a character code converted using a conversion table in which character code information corresponding to each bit string of the character is stored in advance, and the delimiter information indicating a delimiter position of the conversion result. And
A character code compression / decompression device, wherein the conversion table allocated to places having a small number of bits in the order of the appearance frequency of the character is created to increase the conversion efficiency of the character code.
前記文字の各ビット列に対応する文字コード情報を予め記憶している変換テーブルを使用して変換された文字コード、および該変換結果の区切り位置を示す前記区切りの情報を格納する記憶工程とを有し、
前記文字の出現頻度順にビット数の少ない所に割り当てた前記変換テーブルを作成し、前記文字コードの変換効率を高めたことを特徴とする文字コード圧縮・復元方法。A data processing step of compressing and converting a character code of an input character, generating information of a delimiter of the character code, and combining the compression conversion result and the delimiter information;
Storing a character code converted using a conversion table in which character code information corresponding to each bit string of the character is stored in advance, and the delimiter information indicating a delimiter position of the conversion result. And
A character code compression / decompression method, wherein the conversion table allocated to places having a small number of bits in the order of the appearance frequency of the character is created, and the conversion efficiency of the character code is increased.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2002168638A JP2004013680A (en) | 2002-06-10 | 2002-06-10 | Character code compression/decompression device and method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2002168638A JP2004013680A (en) | 2002-06-10 | 2002-06-10 | Character code compression/decompression device and method |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2004013680A true JP2004013680A (en) | 2004-01-15 |
Family
ID=30435494
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2002168638A Pending JP2004013680A (en) | 2002-06-10 | 2002-06-10 | Character code compression/decompression device and method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2004013680A (en) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5149454B1 (en) * | 2012-07-28 | 2013-02-20 | 義尚 神山 | Recording medium on which YKM format compression program is recorded |
| WO2014002281A1 (en) * | 2012-06-29 | 2014-01-03 | 株式会社エス・ケイ・ケイ | Document processing system, electronic document, document processing method, and program |
| EP3506126A1 (en) | 2017-12-28 | 2019-07-03 | Fujitsu Limited | Encoding program, creating program, encoding method, creating method, encoding device, and decoding device |
-
2002
- 2002-06-10 JP JP2002168638A patent/JP2004013680A/en active Pending
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2014002281A1 (en) * | 2012-06-29 | 2014-01-03 | 株式会社エス・ケイ・ケイ | Document processing system, electronic document, document processing method, and program |
| JP5467155B1 (en) * | 2012-06-29 | 2014-04-09 | 株式会社エス・ケイ・ケイ | Document processing system, document processing method and program |
| JP5149454B1 (en) * | 2012-07-28 | 2013-02-20 | 義尚 神山 | Recording medium on which YKM format compression program is recorded |
| EP3506126A1 (en) | 2017-12-28 | 2019-07-03 | Fujitsu Limited | Encoding program, creating program, encoding method, creating method, encoding device, and decoding device |
| US10404275B2 (en) | 2017-12-28 | 2019-09-03 | Fujitsu Limited | Non-transitory computer readable recording medium, encoding method, creating method, encoding device, and decoding device |
| EP4053730A1 (en) | 2017-12-28 | 2022-09-07 | Fujitsu Limited | Decoding program creating dynamic dictionary associating codes to words for extraction |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| AU702207B2 (en) | Method of and apparatus for compressing and decompressing data and data processing apparatus and network system using the same | |
| JP3278297B2 (en) | Data compression method, data decompression method, data compression device, and data decompression device | |
| CN101800556B (en) | Method and apparatus for adaptive data compression | |
| JP3009727B2 (en) | Improved data compression device | |
| JP3421700B2 (en) | Data compression device and decompression device and method thereof | |
| JP3499671B2 (en) | Data compression device and data decompression device | |
| JP3778087B2 (en) | Data encoding apparatus and data decoding apparatus | |
| TW538599B (en) | A method of performing Huffman decoding | |
| JP6680126B2 (en) | Encoding program, encoding device, encoding method, and search method | |
| JP4003854B2 (en) | Data compression apparatus, decompression apparatus and method thereof | |
| JPS59231683A (en) | Data compression system | |
| JP6447161B2 (en) | Semantic structure search program, semantic structure search apparatus, and semantic structure search method | |
| Nandi et al. | A compression technique based on optimality of LZW code (OLZW) | |
| US6834283B1 (en) | Data compression/decompression apparatus using additional code and method thereof | |
| JP2013125445A (en) | Transposition index preparation method for ciphered document and retrieval method using transposition index | |
| US8463759B2 (en) | Method and system for compressing data | |
| JP2004013680A (en) | Character code compression/decompression device and method | |
| JPH10261969A (en) | Data compression method and apparatus | |
| Anto et al. | A Compression System for Unicode Files Using an Enhanced Lzw Method. | |
| JPH09219650A (en) | Data encoding device, data decoding device and method thereof | |
| JP4953145B2 (en) | Character string data compression apparatus and method, and character string data restoration apparatus and method | |
| JP5928201B2 (en) | RESTORE PROGRAM, COMPRESSION PROGRAM, RESTORE DEVICE, COMPRESSION DEVICE, RESTORE METHOD, AND COMPRESSION METHOD | |
| JP7006462B2 (en) | Data generation program, data generation method and information processing equipment | |
| US10915559B2 (en) | Data generation method, information processing device, and recording medium | |
| Bharathi et al. | A plain-text incremental compression (pic) technique with fast lookup ability |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20050517 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20080128 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080205 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080407 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20080701 |