JP2004509406A - 医療および他の用途に用いる化合物の発見および創製のための方法、システム、装置、および機器 - Google Patents
医療および他の用途に用いる化合物の発見および創製のための方法、システム、装置、および機器 Download PDFInfo
- Publication number
- JP2004509406A JP2004509406A JP2002527795A JP2002527795A JP2004509406A JP 2004509406 A JP2004509406 A JP 2004509406A JP 2002527795 A JP2002527795 A JP 2002527795A JP 2002527795 A JP2002527795 A JP 2002527795A JP 2004509406 A JP2004509406 A JP 2004509406A
- Authority
- JP
- Japan
- Prior art keywords
- protein
- compound
- partial
- interaction
- proteins
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- 150000001875 compounds Chemical class 0.000 title claims abstract description 596
- 238000000034 method Methods 0.000 title claims abstract description 261
- 108090000623 proteins and genes Proteins 0.000 claims abstract description 1044
- 102000004169 proteins and genes Human genes 0.000 claims abstract description 996
- 230000003993 interaction Effects 0.000 claims abstract description 257
- 239000003814 drug Substances 0.000 claims abstract description 41
- 239000000126 substance Substances 0.000 claims abstract description 21
- 230000001225 therapeutic effect Effects 0.000 claims abstract description 20
- 238000007876 drug discovery Methods 0.000 claims abstract description 18
- 230000036961 partial effect Effects 0.000 claims description 272
- 210000004027 cell Anatomy 0.000 claims description 130
- 230000027455 binding Effects 0.000 claims description 76
- 230000000694 effects Effects 0.000 claims description 70
- 239000007787 solid Substances 0.000 claims description 64
- 230000006870 function Effects 0.000 claims description 53
- 229940079593 drug Drugs 0.000 claims description 42
- 150000003384 small molecules Chemical class 0.000 claims description 42
- 230000004850 protein–protein interaction Effects 0.000 claims description 37
- 230000001988 toxicity Effects 0.000 claims description 37
- 231100000419 toxicity Toxicity 0.000 claims description 37
- 230000008859 change Effects 0.000 claims description 33
- 239000000203 mixture Substances 0.000 claims description 33
- 230000000144 pharmacologic effect Effects 0.000 claims description 28
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 26
- 238000011156 evaluation Methods 0.000 claims description 24
- 239000003596 drug target Substances 0.000 claims description 21
- 238000007418 data mining Methods 0.000 claims description 20
- 239000002299 complementary DNA Substances 0.000 claims description 19
- 108091028043 Nucleic acid sequence Proteins 0.000 claims description 18
- 238000007385 chemical modification Methods 0.000 claims description 17
- 230000000051 modifying effect Effects 0.000 claims description 17
- 238000012360 testing method Methods 0.000 claims description 17
- 125000000539 amino acid group Chemical group 0.000 claims description 16
- 238000010494 dissociation reaction Methods 0.000 claims description 16
- 230000005593 dissociations Effects 0.000 claims description 16
- 238000000926 separation method Methods 0.000 claims description 16
- 239000000556 agonist Substances 0.000 claims description 15
- 239000005557 antagonist Substances 0.000 claims description 15
- 238000005259 measurement Methods 0.000 claims description 15
- 241000894007 species Species 0.000 claims description 15
- 238000013518 transcription Methods 0.000 claims description 15
- 230000035897 transcription Effects 0.000 claims description 15
- 108010052285 Membrane Proteins Proteins 0.000 claims description 14
- 108091023040 Transcription factor Proteins 0.000 claims description 14
- 102000040945 Transcription factor Human genes 0.000 claims description 14
- 239000012528 membrane Substances 0.000 claims description 14
- 102000018697 Membrane Proteins Human genes 0.000 claims description 13
- 230000009133 cooperative interaction Effects 0.000 claims description 12
- 238000011160 research Methods 0.000 claims description 12
- 241001465754 Metazoa Species 0.000 claims description 11
- 238000004587 chromatography analysis Methods 0.000 claims description 11
- 229910052739 hydrogen Inorganic materials 0.000 claims description 11
- 239000001257 hydrogen Substances 0.000 claims description 11
- 230000033001 locomotion Effects 0.000 claims description 11
- 108020004999 messenger RNA Proteins 0.000 claims description 11
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 11
- 238000012216 screening Methods 0.000 claims description 11
- 102000003688 G-Protein-Coupled Receptors Human genes 0.000 claims description 10
- 108090000045 G-Protein-Coupled Receptors Proteins 0.000 claims description 10
- 230000009918 complex formation Effects 0.000 claims description 10
- 238000010828 elution Methods 0.000 claims description 10
- 230000004807 localization Effects 0.000 claims description 10
- 210000001519 tissue Anatomy 0.000 claims description 10
- 210000002845 virion Anatomy 0.000 claims description 10
- 238000002474 experimental method Methods 0.000 claims description 9
- 238000001042 affinity chromatography Methods 0.000 claims description 8
- 239000011324 bead Substances 0.000 claims description 8
- 238000004949 mass spectrometry Methods 0.000 claims description 8
- 210000000056 organ Anatomy 0.000 claims description 8
- 239000004094 surface-active agent Substances 0.000 claims description 8
- 102000004190 Enzymes Human genes 0.000 claims description 7
- 108090000790 Enzymes Proteins 0.000 claims description 7
- 230000008827 biological function Effects 0.000 claims description 7
- 239000013592 cell lysate Substances 0.000 claims description 7
- 238000005194 fractionation Methods 0.000 claims description 7
- 238000002523 gelfiltration Methods 0.000 claims description 7
- 230000003834 intracellular effect Effects 0.000 claims description 7
- 239000011159 matrix material Substances 0.000 claims description 7
- 230000004660 morphological change Effects 0.000 claims description 7
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 7
- 238000006467 substitution reaction Methods 0.000 claims description 7
- 238000000108 ultra-filtration Methods 0.000 claims description 7
- 238000005406 washing Methods 0.000 claims description 7
- WEVYAHXRMPXWCK-UHFFFAOYSA-N Acetonitrile Chemical compound CC#N WEVYAHXRMPXWCK-UHFFFAOYSA-N 0.000 claims description 6
- OKKJLVBELUTLKV-UHFFFAOYSA-N Methanol Chemical compound OC OKKJLVBELUTLKV-UHFFFAOYSA-N 0.000 claims description 6
- 108091000080 Phosphotransferase Proteins 0.000 claims description 6
- 230000000692 anti-sense effect Effects 0.000 claims description 6
- 230000005684 electric field Effects 0.000 claims description 6
- 238000001819 mass spectrum Methods 0.000 claims description 6
- 102000020233 phosphotransferase Human genes 0.000 claims description 6
- 238000002198 surface plasmon resonance spectroscopy Methods 0.000 claims description 6
- 239000003440 toxic substance Substances 0.000 claims description 6
- 241000701447 unidentified baculovirus Species 0.000 claims description 6
- LFQSCWFLJHTTHZ-UHFFFAOYSA-N Ethanol Chemical compound CCO LFQSCWFLJHTTHZ-UHFFFAOYSA-N 0.000 claims description 5
- 150000001413 amino acids Chemical class 0.000 claims description 5
- 238000003556 assay Methods 0.000 claims description 5
- 230000015572 biosynthetic process Effects 0.000 claims description 5
- 238000005251 capillar electrophoresis Methods 0.000 claims description 5
- 239000000470 constituent Substances 0.000 claims description 5
- 238000002447 crystallographic data Methods 0.000 claims description 5
- 230000009881 electrostatic interaction Effects 0.000 claims description 5
- 239000000284 extract Substances 0.000 claims description 5
- 238000010353 genetic engineering Methods 0.000 claims description 5
- 238000004519 manufacturing process Methods 0.000 claims description 5
- 229920001184 polypeptide Polymers 0.000 claims description 5
- LVTJOONKWUXEFR-FZRMHRINSA-N protoneodioscin Natural products O(C[C@@H](CC[C@]1(O)[C@H](C)[C@@H]2[C@]3(C)[C@H]([C@H]4[C@@H]([C@]5(C)C(=CC4)C[C@@H](O[C@@H]4[C@H](O[C@H]6[C@@H](O)[C@@H](O)[C@@H](O)[C@H](C)O6)[C@@H](O)[C@H](O[C@H]6[C@@H](O)[C@@H](O)[C@@H](O)[C@H](C)O6)[C@H](CO)O4)CC5)CC3)C[C@@H]2O1)C)[C@H]1[C@H](O)[C@H](O)[C@H](O)[C@@H](CO)O1 LVTJOONKWUXEFR-FZRMHRINSA-N 0.000 claims description 5
- 238000000746 purification Methods 0.000 claims description 5
- 231100000331 toxic Toxicity 0.000 claims description 5
- 231100000167 toxic agent Toxicity 0.000 claims description 5
- 230000002588 toxic effect Effects 0.000 claims description 5
- 238000012546 transfer Methods 0.000 claims description 5
- 102000004127 Cytokines Human genes 0.000 claims description 4
- 108090000695 Cytokines Proteins 0.000 claims description 4
- IAZDPXIOMUYVGZ-UHFFFAOYSA-N Dimethylsulphoxide Chemical compound CS(C)=O IAZDPXIOMUYVGZ-UHFFFAOYSA-N 0.000 claims description 4
- 108700024394 Exon Proteins 0.000 claims description 4
- 241000124008 Mammalia Species 0.000 claims description 4
- WYURNTSHIVDZCO-UHFFFAOYSA-N Tetrahydrofuran Chemical compound C1CCOC1 WYURNTSHIVDZCO-UHFFFAOYSA-N 0.000 claims description 4
- DTQVDTLACAAQTR-UHFFFAOYSA-N Trifluoroacetic acid Chemical compound OC(=O)C(F)(F)F DTQVDTLACAAQTR-UHFFFAOYSA-N 0.000 claims description 4
- 230000002411 adverse Effects 0.000 claims description 4
- 239000003153 chemical reaction reagent Substances 0.000 claims description 4
- 230000009146 cooperative binding Effects 0.000 claims description 4
- 210000000805 cytoplasm Anatomy 0.000 claims description 4
- 238000000605 extraction Methods 0.000 claims description 4
- 230000004927 fusion Effects 0.000 claims description 4
- 230000002209 hydrophobic effect Effects 0.000 claims description 4
- 244000005700 microbiome Species 0.000 claims description 4
- 210000004940 nucleus Anatomy 0.000 claims description 4
- 230000003287 optical effect Effects 0.000 claims description 4
- 108091005981 phosphorylated proteins Proteins 0.000 claims description 4
- 239000011148 porous material Substances 0.000 claims description 4
- 238000002360 preparation method Methods 0.000 claims description 4
- 230000002829 reductive effect Effects 0.000 claims description 4
- 238000003786 synthesis reaction Methods 0.000 claims description 4
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 claims description 4
- OYPRJOBELJOOCE-UHFFFAOYSA-N Calcium Chemical compound [Ca] OYPRJOBELJOOCE-UHFFFAOYSA-N 0.000 claims description 3
- IVOMOUWHDPKRLL-KQYNXXCUSA-N Cyclic adenosine monophosphate Chemical compound C([C@H]1O2)OP(O)(=O)O[C@H]1[C@@H](O)[C@@H]2N1C(N=CN=C2N)=C2N=C1 IVOMOUWHDPKRLL-KQYNXXCUSA-N 0.000 claims description 3
- 102000015696 Interleukins Human genes 0.000 claims description 3
- 108010063738 Interleukins Proteins 0.000 claims description 3
- 108020005497 Nuclear hormone receptor Proteins 0.000 claims description 3
- 108091005804 Peptidases Proteins 0.000 claims description 3
- 102000035195 Peptidases Human genes 0.000 claims description 3
- IVOMOUWHDPKRLL-UHFFFAOYSA-N UNPD107823 Natural products O1C2COP(O)(=O)OC2C(O)C1N1C(N=CN=C2N)=C2N=C1 IVOMOUWHDPKRLL-UHFFFAOYSA-N 0.000 claims description 3
- 229910052791 calcium Inorganic materials 0.000 claims description 3
- 239000011575 calcium Substances 0.000 claims description 3
- 230000001914 calming effect Effects 0.000 claims description 3
- 238000012512 characterization method Methods 0.000 claims description 3
- 238000006243 chemical reaction Methods 0.000 claims description 3
- 238000005094 computer simulation Methods 0.000 claims description 3
- 229940095074 cyclic amp Drugs 0.000 claims description 3
- 238000001514 detection method Methods 0.000 claims description 3
- 238000000502 dialysis Methods 0.000 claims description 3
- 230000007613 environmental effect Effects 0.000 claims description 3
- 108020004017 nuclear receptors Proteins 0.000 claims description 3
- 239000003960 organic solvent Substances 0.000 claims description 3
- 230000004481 post-translational protein modification Effects 0.000 claims description 3
- 235000019833 protease Nutrition 0.000 claims description 3
- 230000006916 protein interaction Effects 0.000 claims description 3
- 238000011002 quantification Methods 0.000 claims description 3
- 230000004044 response Effects 0.000 claims description 3
- 238000010897 surface acoustic wave method Methods 0.000 claims description 3
- 210000003855 cell nucleus Anatomy 0.000 claims description 2
- 210000004671 cell-free system Anatomy 0.000 claims description 2
- 230000002757 inflammatory effect Effects 0.000 claims description 2
- 239000006166 lysate Substances 0.000 claims description 2
- BDERNNFJNOPAEC-UHFFFAOYSA-N propan-1-ol Chemical compound CCCO BDERNNFJNOPAEC-UHFFFAOYSA-N 0.000 claims description 2
- 238000005549 size reduction Methods 0.000 claims description 2
- 238000001542 size-exclusion chromatography Methods 0.000 claims description 2
- 230000004960 subcellular localization Effects 0.000 claims description 2
- 230000002194 synthesizing effect Effects 0.000 claims description 2
- YLQBMQCUIZJEEH-UHFFFAOYSA-N tetrahydrofuran Natural products C=1C=COC=1 YLQBMQCUIZJEEH-UHFFFAOYSA-N 0.000 claims description 2
- 238000013480 data collection Methods 0.000 claims 26
- 241000238631 Hexapoda Species 0.000 claims 4
- 230000001747 exhibiting effect Effects 0.000 claims 4
- 239000010453 quartz Substances 0.000 claims 4
- VYPSYNLAJGMNEJ-UHFFFAOYSA-N silicon dioxide Inorganic materials O=[Si]=O VYPSYNLAJGMNEJ-UHFFFAOYSA-N 0.000 claims 4
- LYCAIKOWRPUZTN-UHFFFAOYSA-N Ethylene glycol Chemical compound OCCO LYCAIKOWRPUZTN-UHFFFAOYSA-N 0.000 claims 2
- 108091036060 Linker DNA Proteins 0.000 claims 2
- 101710177166 Phosphoprotein Proteins 0.000 claims 2
- 239000008186 active pharmaceutical agent Substances 0.000 claims 2
- 230000004075 alteration Effects 0.000 claims 2
- 210000002390 cell membrane structure Anatomy 0.000 claims 2
- 230000002255 enzymatic effect Effects 0.000 claims 2
- 238000004811 liquid chromatography Methods 0.000 claims 2
- 230000002934 lysing effect Effects 0.000 claims 2
- 241000196324 Embryophyta Species 0.000 claims 1
- 102000007399 Nuclear hormone receptor Human genes 0.000 claims 1
- 102000001253 Protein Kinase Human genes 0.000 claims 1
- 230000002508 compound effect Effects 0.000 claims 1
- 230000002950 deficient Effects 0.000 claims 1
- 230000001627 detrimental effect Effects 0.000 claims 1
- WGCNASOHLSPBMP-UHFFFAOYSA-N hydroxyacetaldehyde Natural products OCC=O WGCNASOHLSPBMP-UHFFFAOYSA-N 0.000 claims 1
- 230000000813 microbial effect Effects 0.000 claims 1
- 108060006633 protein kinase Proteins 0.000 claims 1
- 238000001814 protein method Methods 0.000 claims 1
- 238000013459 approach Methods 0.000 abstract description 23
- 239000002547 new drug Substances 0.000 abstract description 9
- 230000002441 reversible effect Effects 0.000 abstract description 3
- 239000003905 agrochemical Substances 0.000 abstract description 2
- 239000002778 food additive Substances 0.000 abstract 1
- 235000013373 food additive Nutrition 0.000 abstract 1
- 239000000243 solution Substances 0.000 description 12
- 101150071146 COX2 gene Proteins 0.000 description 9
- 101100114534 Caenorhabditis elegans ctc-2 gene Proteins 0.000 description 9
- 101150000187 PTGS2 gene Proteins 0.000 description 9
- 239000000523 sample Substances 0.000 description 8
- 230000008901 benefit Effects 0.000 description 7
- 108091007999 druggable proteins Proteins 0.000 description 7
- 102000038037 druggable proteins Human genes 0.000 description 7
- 230000001965 increasing effect Effects 0.000 description 7
- 230000004048 modification Effects 0.000 description 7
- 238000012986 modification Methods 0.000 description 7
- 239000002904 solvent Substances 0.000 description 7
- 101100496968 Caenorhabditis elegans ctc-1 gene Proteins 0.000 description 6
- 101100221647 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) cox-1 gene Proteins 0.000 description 6
- 101150062589 PTGS1 gene Proteins 0.000 description 6
- 239000003446 ligand Substances 0.000 description 6
- -1 small molecule compound Chemical class 0.000 description 6
- 238000005457 optimization Methods 0.000 description 5
- 230000008569 process Effects 0.000 description 5
- 102000005962 receptors Human genes 0.000 description 5
- 108020003175 receptors Proteins 0.000 description 5
- 108020004414 DNA Proteins 0.000 description 4
- NTYJJOPFIAHURM-UHFFFAOYSA-N Histamine Chemical compound NCCC1=CN=CN1 NTYJJOPFIAHURM-UHFFFAOYSA-N 0.000 description 4
- 241000282412 Homo Species 0.000 description 4
- 238000004458 analytical method Methods 0.000 description 4
- YZXBAPSDXZZRGB-DOFZRALJSA-N arachidonic acid Chemical compound CCCCC\C=C/C\C=C/C\C=C/C\C=C/CCCC(O)=O YZXBAPSDXZZRGB-DOFZRALJSA-N 0.000 description 4
- 201000010099 disease Diseases 0.000 description 4
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 239000003112 inhibitor Substances 0.000 description 4
- 230000005764 inhibitory process Effects 0.000 description 4
- 229940021182 non-steroidal anti-inflammatory drug Drugs 0.000 description 4
- 230000001105 regulatory effect Effects 0.000 description 4
- 108091008743 testicular receptors 4 Proteins 0.000 description 4
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 3
- 108010041952 Calmodulin Proteins 0.000 description 3
- 108010016183 Human immunodeficiency virus 1 p16 protease Proteins 0.000 description 3
- 102100026888 Mitogen-activated protein kinase kinase kinase 7 Human genes 0.000 description 3
- 210000000170 cell membrane Anatomy 0.000 description 3
- 238000013461 design Methods 0.000 description 3
- 125000001165 hydrophobic group Chemical group 0.000 description 3
- 238000001727 in vivo Methods 0.000 description 3
- 238000003032 molecular docking Methods 0.000 description 3
- 230000035772 mutation Effects 0.000 description 3
- 230000004853 protein function Effects 0.000 description 3
- 239000012460 protein solution Substances 0.000 description 3
- 238000012552 review Methods 0.000 description 3
- 125000006850 spacer group Chemical group 0.000 description 3
- 239000000758 substrate Substances 0.000 description 3
- 238000011144 upstream manufacturing Methods 0.000 description 3
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 2
- 102000000584 Calmodulin Human genes 0.000 description 2
- 102100025064 Cellular tumor antigen p53 Human genes 0.000 description 2
- 108010085220 Multiprotein Complexes Proteins 0.000 description 2
- 102000007474 Multiprotein Complexes Human genes 0.000 description 2
- 102000007079 Peptide Fragments Human genes 0.000 description 2
- 108010033276 Peptide Fragments Proteins 0.000 description 2
- 229920002684 Sepharose Polymers 0.000 description 2
- 102000004887 Transforming Growth Factor beta Human genes 0.000 description 2
- 108090001012 Transforming Growth Factor beta Proteins 0.000 description 2
- 241000700605 Viruses Species 0.000 description 2
- 230000009471 action Effects 0.000 description 2
- 230000003281 allosteric effect Effects 0.000 description 2
- 239000002249 anxiolytic agent Substances 0.000 description 2
- 239000007864 aqueous solution Substances 0.000 description 2
- 229940114079 arachidonic acid Drugs 0.000 description 2
- 235000021342 arachidonic acid Nutrition 0.000 description 2
- 229940049706 benzodiazepine Drugs 0.000 description 2
- 150000001557 benzodiazepines Chemical class 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- HVYWMOMLDIMFJA-DPAQBDIFSA-N cholesterol Chemical compound C1C=C2C[C@@H](O)CC[C@]2(C)[C@@H]2[C@@H]1[C@@H]1CC[C@H]([C@H](C)CCCC(C)C)[C@@]1(C)CC2 HVYWMOMLDIMFJA-DPAQBDIFSA-N 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 230000006854 communication Effects 0.000 description 2
- 230000009073 conformational modification Effects 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 230000008878 coupling Effects 0.000 description 2
- 238000010168 coupling process Methods 0.000 description 2
- 238000005859 coupling reaction Methods 0.000 description 2
- AAOVKJBEBIDNHE-UHFFFAOYSA-N diazepam Chemical compound N=1CC(=O)N(C)C2=CC=C(Cl)C=C2C=1C1=CC=CC=C1 AAOVKJBEBIDNHE-UHFFFAOYSA-N 0.000 description 2
- 229960003529 diazepam Drugs 0.000 description 2
- 239000003623 enhancer Substances 0.000 description 2
- 238000000855 fermentation Methods 0.000 description 2
- 230000004151 fermentation Effects 0.000 description 2
- 235000013305 food Nutrition 0.000 description 2
- 108020001507 fusion proteins Proteins 0.000 description 2
- 102000037865 fusion proteins Human genes 0.000 description 2
- 238000013537 high throughput screening Methods 0.000 description 2
- 229960001340 histamine Drugs 0.000 description 2
- CGIGDMFJXJATDK-UHFFFAOYSA-N indomethacin Chemical compound CC1=C(CC(O)=O)C2=CC(OC)=CC=C2N1C(=O)C1=CC=C(Cl)C=C1 CGIGDMFJXJATDK-UHFFFAOYSA-N 0.000 description 2
- 230000002401 inhibitory effect Effects 0.000 description 2
- 210000004020 intracellular membrane Anatomy 0.000 description 2
- 108091005573 modified proteins Proteins 0.000 description 2
- 102000035118 modified proteins Human genes 0.000 description 2
- 230000000877 morphologic effect Effects 0.000 description 2
- 102000006255 nuclear receptors Human genes 0.000 description 2
- 239000000575 pesticide Substances 0.000 description 2
- 230000004962 physiological condition Effects 0.000 description 2
- 102000038041 potential drug target proteins Human genes 0.000 description 2
- 108091008002 potential drug target proteins Proteins 0.000 description 2
- 230000019491 signal transduction Effects 0.000 description 2
- 150000003431 steroids Chemical class 0.000 description 2
- SVUOLADPCWQTTE-UHFFFAOYSA-N 1h-1,2-benzodiazepine Chemical compound N1N=CC=CC2=CC=CC=C12 SVUOLADPCWQTTE-UHFFFAOYSA-N 0.000 description 1
- ZOOGRGPOEVQQDX-UUOKFMHZSA-N 3',5'-cyclic GMP Chemical compound C([C@H]1O2)OP(O)(=O)O[C@H]1[C@@H](O)[C@@H]2N1C(N=C(NC2=O)N)=C2N=C1 ZOOGRGPOEVQQDX-UUOKFMHZSA-N 0.000 description 1
- QFVHZQCOUORWEI-UHFFFAOYSA-N 4-[(4-anilino-5-sulfonaphthalen-1-yl)diazenyl]-5-hydroxynaphthalene-2,7-disulfonic acid Chemical compound C=12C(O)=CC(S(O)(=O)=O)=CC2=CC(S(O)(=O)=O)=CC=1N=NC(C1=CC=CC(=C11)S(O)(=O)=O)=CC=C1NC1=CC=CC=C1 QFVHZQCOUORWEI-UHFFFAOYSA-N 0.000 description 1
- 241001203868 Autographa californica Species 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- 238000012492 Biacore method Methods 0.000 description 1
- 102000000844 Cell Surface Receptors Human genes 0.000 description 1
- 108010001857 Cell Surface Receptors Proteins 0.000 description 1
- 108010077544 Chromatin Proteins 0.000 description 1
- 108020004635 Complementary DNA Proteins 0.000 description 1
- 229940126062 Compound A Drugs 0.000 description 1
- 108091035707 Consensus sequence Proteins 0.000 description 1
- 241000255581 Drosophila <fruit fly, genus> Species 0.000 description 1
- NLDMNSXOCDLTTB-UHFFFAOYSA-N Heterophylliin A Natural products O1C2COC(=O)C3=CC(O)=C(O)C(O)=C3C3=C(O)C(O)=C(O)C=C3C(=O)OC2C(OC(=O)C=2C=C(O)C(O)=C(O)C=2)C(O)C1OC(=O)C1=CC(O)=C(O)C(O)=C1 NLDMNSXOCDLTTB-UHFFFAOYSA-N 0.000 description 1
- 101000959437 Homo sapiens Beta-2 adrenergic receptor Proteins 0.000 description 1
- UFHFLCQGNIYNRP-UHFFFAOYSA-N Hydrogen Chemical compound [H][H] UFHFLCQGNIYNRP-UHFFFAOYSA-N 0.000 description 1
- 102000004310 Ion Channels Human genes 0.000 description 1
- 108090000862 Ion Channels Proteins 0.000 description 1
- AGPKZVBTJJNPAG-WHFBIAKZSA-N L-isoleucine Chemical compound CC[C@H](C)[C@H](N)C(O)=O AGPKZVBTJJNPAG-WHFBIAKZSA-N 0.000 description 1
- ROHFNLRQFUQHCH-UHFFFAOYSA-N Leucine Natural products CC(C)CC(N)C(O)=O ROHFNLRQFUQHCH-UHFFFAOYSA-N 0.000 description 1
- 241000244206 Nematoda Species 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 102000004005 Prostaglandin-endoperoxide synthases Human genes 0.000 description 1
- 108090000459 Prostaglandin-endoperoxide synthases Proteins 0.000 description 1
- 102000009572 RNA Polymerase II Human genes 0.000 description 1
- 108010009460 RNA Polymerase II Proteins 0.000 description 1
- 240000004808 Saccharomyces cerevisiae Species 0.000 description 1
- 238000012300 Sequence Analysis Methods 0.000 description 1
- 241000256251 Spodoptera frugiperda Species 0.000 description 1
- 101710100170 Unknown protein Proteins 0.000 description 1
- 238000005411 Van der Waals force Methods 0.000 description 1
- QYSXJUFSXHHAJI-XFEUOLMDSA-N Vitamin D3 Natural products C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@H](C)CCCC(C)C)=C/C=C1\C[C@@H](O)CCC1=C QYSXJUFSXHHAJI-XFEUOLMDSA-N 0.000 description 1
- 238000002441 X-ray diffraction Methods 0.000 description 1
- 238000010521 absorption reaction Methods 0.000 description 1
- 238000012382 advanced drug delivery Methods 0.000 description 1
- SHGAZHPCJJPHSC-YCNIQYBTSA-N all-trans-retinoic acid Chemical compound OC(=O)\C=C(/C)\C=C\C=C(/C)\C=C\C1=C(C)CCCC1(C)C SHGAZHPCJJPHSC-YCNIQYBTSA-N 0.000 description 1
- 229940024606 amino acid Drugs 0.000 description 1
- 238000003277 amino acid sequence analysis Methods 0.000 description 1
- 125000003277 amino group Chemical group 0.000 description 1
- 239000003242 anti bacterial agent Substances 0.000 description 1
- 230000003276 anti-hypertensive effect Effects 0.000 description 1
- 230000003110 anti-inflammatory effect Effects 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 230000000949 anxiolytic effect Effects 0.000 description 1
- 239000003125 aqueous solvent Substances 0.000 description 1
- 238000003491 array Methods 0.000 description 1
- 238000012925 biological evaluation Methods 0.000 description 1
- 229960002685 biotin Drugs 0.000 description 1
- 235000020958 biotin Nutrition 0.000 description 1
- 239000011616 biotin Substances 0.000 description 1
- 230000000740 bleeding effect Effects 0.000 description 1
- 125000003178 carboxy group Chemical group [H]OC(*)=O 0.000 description 1
- 239000000969 carrier Substances 0.000 description 1
- 210000003483 chromatin Anatomy 0.000 description 1
- 238000003776 cleavage reaction Methods 0.000 description 1
- 230000007012 clinical effect Effects 0.000 description 1
- 231100000313 clinical toxicology Toxicity 0.000 description 1
- 230000002860 competitive effect Effects 0.000 description 1
- 238000004590 computer program Methods 0.000 description 1
- 239000000356 contaminant Substances 0.000 description 1
- 229940111134 coxibs Drugs 0.000 description 1
- 239000013078 crystal Substances 0.000 description 1
- 238000012866 crystallographic experiment Methods 0.000 description 1
- ATDGTVJJHBUTRL-UHFFFAOYSA-N cyanogen bromide Chemical compound BrC#N ATDGTVJJHBUTRL-UHFFFAOYSA-N 0.000 description 1
- ZOOGRGPOEVQQDX-UHFFFAOYSA-N cyclic GMP Natural products O1C2COP(O)(=O)OC2C(O)C1N1C=NC2=C1NC(N)=NC2=O ZOOGRGPOEVQQDX-UHFFFAOYSA-N 0.000 description 1
- 230000006735 deficit Effects 0.000 description 1
- 238000011161 development Methods 0.000 description 1
- 229940000406 drug candidate Drugs 0.000 description 1
- 238000009510 drug design Methods 0.000 description 1
- 238000007877 drug screening Methods 0.000 description 1
- 208000000718 duodenal ulcer Diseases 0.000 description 1
- 239000012156 elution solvent Substances 0.000 description 1
- 239000003256 environmental substance Substances 0.000 description 1
- 210000003527 eukaryotic cell Anatomy 0.000 description 1
- 238000011049 filling Methods 0.000 description 1
- SYTBZMRGLBWNTM-UHFFFAOYSA-N flurbiprofen Chemical compound FC1=CC(C(C(O)=O)C)=CC=C1C1=CC=CC=C1 SYTBZMRGLBWNTM-UHFFFAOYSA-N 0.000 description 1
- 230000002496 gastric effect Effects 0.000 description 1
- 238000001502 gel electrophoresis Methods 0.000 description 1
- 108091006104 gene-regulatory proteins Proteins 0.000 description 1
- 102000034356 gene-regulatory proteins Human genes 0.000 description 1
- 150000002334 glycols Chemical class 0.000 description 1
- 210000002288 golgi apparatus Anatomy 0.000 description 1
- 230000005484 gravity Effects 0.000 description 1
- 230000012010 growth Effects 0.000 description 1
- 229910052736 halogen Inorganic materials 0.000 description 1
- 150000002367 halogens Chemical class 0.000 description 1
- 239000000383 hazardous chemical Substances 0.000 description 1
- 230000035876 healing Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 125000000623 heterocyclic group Chemical group 0.000 description 1
- HNDVDQJCIGZPNO-UHFFFAOYSA-N histidine Natural products OC(=O)C(N)CC1=CN=CN1 HNDVDQJCIGZPNO-UHFFFAOYSA-N 0.000 description 1
- 239000000710 homodimer Substances 0.000 description 1
- 230000001771 impaired effect Effects 0.000 description 1
- 230000001976 improved effect Effects 0.000 description 1
- 238000000338 in vitro Methods 0.000 description 1
- 125000001041 indolyl group Chemical group 0.000 description 1
- 229960000905 indomethacin Drugs 0.000 description 1
- 230000001939 inductive effect Effects 0.000 description 1
- 230000028709 inflammatory response Effects 0.000 description 1
- 239000003999 initiator Substances 0.000 description 1
- 230000002452 interceptive effect Effects 0.000 description 1
- 229940047122 interleukins Drugs 0.000 description 1
- 229960000310 isoleucine Drugs 0.000 description 1
- AGPKZVBTJJNPAG-UHFFFAOYSA-N isoleucine Natural products CCC(C)C(N)C(O)=O AGPKZVBTJJNPAG-UHFFFAOYSA-N 0.000 description 1
- 125000001909 leucine group Chemical class [H]N(*)C(C(*)=O)C([H])([H])C(C([H])([H])[H])C([H])([H])[H] 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 239000007788 liquid Substances 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 238000000691 measurement method Methods 0.000 description 1
- 230000007246 mechanism Effects 0.000 description 1
- 230000010534 mechanism of action Effects 0.000 description 1
- 238000002156 mixing Methods 0.000 description 1
- 230000009149 molecular binding Effects 0.000 description 1
- 238000012544 monitoring process Methods 0.000 description 1
- 239000000178 monomer Substances 0.000 description 1
- 210000000865 mononuclear phagocyte system Anatomy 0.000 description 1
- 238000002418 nanoflow liquid chromatography-electrospray ionisation mass spectrometry Methods 0.000 description 1
- 229930014626 natural product Natural products 0.000 description 1
- 239000002858 neurotransmitter agent Substances 0.000 description 1
- 230000009871 nonspecific binding Effects 0.000 description 1
- 210000000633 nuclear envelope Anatomy 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 239000002773 nucleotide Substances 0.000 description 1
- 125000003729 nucleotide group Chemical group 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 230000035479 physiological effects, processes and functions Effects 0.000 description 1
- 231100000614 poison Toxicity 0.000 description 1
- 230000001323 posttranslational effect Effects 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 230000001737 promoting effect Effects 0.000 description 1
- 238000007634 remodeling Methods 0.000 description 1
- 238000003571 reporter gene assay Methods 0.000 description 1
- 229930002330 retinoic acid Natural products 0.000 description 1
- 230000007017 scission Effects 0.000 description 1
- 230000028327 secretion Effects 0.000 description 1
- 238000007614 solvation Methods 0.000 description 1
- 230000009870 specific binding Effects 0.000 description 1
- 230000004936 stimulating effect Effects 0.000 description 1
- 210000002784 stomach Anatomy 0.000 description 1
- 238000012916 structural analysis Methods 0.000 description 1
- 230000008093 supporting effect Effects 0.000 description 1
- 238000010381 tandem affinity purification Methods 0.000 description 1
- 238000004885 tandem mass spectrometry Methods 0.000 description 1
- 229940126585 therapeutic drug Drugs 0.000 description 1
- 150000003573 thiols Chemical class 0.000 description 1
- 231100000440 toxicity profile Toxicity 0.000 description 1
- 230000002103 transcriptional effect Effects 0.000 description 1
- 238000013519 translation Methods 0.000 description 1
- 229960001727 tretinoin Drugs 0.000 description 1
- 238000012795 verification Methods 0.000 description 1
- 230000000007 visual effect Effects 0.000 description 1
- QYSXJUFSXHHAJI-YRZJJWOYSA-N vitamin D3 Chemical compound C1(/[C@@H]2CC[C@@H]([C@]2(CCC1)C)[C@H](C)CCCC(C)C)=C\C=C1\C[C@@H](O)CCC1=C QYSXJUFSXHHAJI-YRZJJWOYSA-N 0.000 description 1
- 235000005282 vitamin D3 Nutrition 0.000 description 1
- 239000011647 vitamin D3 Substances 0.000 description 1
- 229940021056 vitamin d3 Drugs 0.000 description 1
Images



Classifications
-
- C—CHEMISTRY; METALLURGY
- C40—COMBINATORIAL TECHNOLOGY
- C40B—COMBINATORIAL CHEMISTRY; LIBRARIES, e.g. CHEMICAL LIBRARIES
- C40B30/00—Methods of screening libraries
- C40B30/04—Methods of screening libraries by measuring the ability to specifically bind a target molecule, e.g. antibody-antigen binding, receptor-ligand binding
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P43/00—Drugs for specific purposes, not provided for in groups A61P1/00-A61P41/00
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6803—General methods of protein analysis not limited to specific proteins or families of proteins
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6803—General methods of protein analysis not limited to specific proteins or families of proteins
- G01N33/6845—Methods of identifying protein-protein interactions in protein mixtures
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Chemical & Material Sciences (AREA)
- Immunology (AREA)
- Urology & Nephrology (AREA)
- Hematology (AREA)
- Biomedical Technology (AREA)
- Physics & Mathematics (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Organic Chemistry (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Biotechnology (AREA)
- Pathology (AREA)
- Biophysics (AREA)
- Bioinformatics & Computational Biology (AREA)
- Cell Biology (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Microbiology (AREA)
- General Physics & Mathematics (AREA)
- Food Science & Technology (AREA)
- Analytical Chemistry (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Pharmacology & Pharmacy (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Investigating Or Analysing Biological Materials (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
- Organic Low-Molecular-Weight Compounds And Preparation Thereof (AREA)
Abstract
Description
技術分野
本発明は、医療および他の用途に用いる化合物の発見および創製のための方法、システム、装置、および機器に関する。他の用途としては、農薬、食品、環境、発酵、獣医学分野を含むが、これに限定しない。
【0002】
背景となる技術
新規薬物の発見および開発のための研究は、薬物標的を探索してその候補を同定し、これがどのようなものか明らかにした後、検証することに始まる。本明細書では、以後「標的の同定」という語句は、それがどのようなものか明らかにされた後の標的の同定を意味する。
【0003】
現在人気がある創薬研究の方法は、ヒトおよび他の生物のゲノムを研究し、転写および翻訳後に蛋白質を生ずる特定の遺伝子を同定し(ゲノム科学の仕事)、蛋白質の機能を特定し(プロテオミクスの仕事)、ある蛋白質が薬物標的であるらしいと考えられる場合には、多数の化合物についてその蛋白質の機能を修飾する活性の有無と強さをスクリーニングするというものである。ゲノム科学とプロテオミクスにおける最近の進歩によって、そのような薬物標的の同定が加速され、最終的には、これまで医療用として考慮されていない新規薬物の発見が可能になると期待されている。これは上流から下流への一方通行的ゲノム科学/プロテオミクス・アプローチと呼ぶことができる。しかしながら、ヒトゲノムの90%より多くのDNA配列が知られるようになったとはいえ、ゲノム中に埋め込まれている遺伝子の大部分は未同定であり、遺伝子によってコードされる蛋白質の機能が明らかにされる必要があり、さらに蛋白質間の相互作用がどのようなものかについても明らかにされる必要がある。ヒト以外の哺乳動物のゲノムに関する我々の知識も少ない。プロテオミクスは未だ胚芽期にある。したがって、現在、一方通行的ゲノム科学/プロテオミクス・アプローチによって効果的に薬物標的の候補を見出すことができる段階に到達したと言明することは困難である。
【0004】
もう一つの一般的アプローチは、先に述べた一方通行的ゲノム科学/プロテオミクス・アプローチ以外の研究によってある蛋白質の機能が知られるようになった場合に、その蛋白質を薬物標的蛋白質として選択するものである。本明細書ではしばしば薬物標的蛋白質という表現を標的蛋白質または薬物標的のように略記する。酵素およびイオン・チャネル、神経伝達物質およびサイトカインの細胞表面受容体、ステロイド、レチノイン酸およびビタミンD3に対する核内受容体などはその例である。シグナル伝達に関与する蛋白質(特に種々のキナーゼ)、転写過程に関与する蛋白質(転写因子を含む)もそのような薬物標的蛋白質の候補と考えられている。推定されたものであれ、立証されたものであれ、そのような薬物標的の同定には、生理学、生化学、分子生物学、薬理学など、生物研究にかかわる種々の学問が貢献してきた。
【0005】
後者を伝統的なアプローチと呼ぶなら、ゲノム科学/プロテオミクスからのアプローチは新しいアプローチということになろう。恐らく、伝統的なアプローチと新しいアプローチとを組み合わせることによって最も効率的なアプローチとなると考えられる。
【0006】
標的蛋白質が推定されたものであれ立証されたものであれ同定されても、創薬研究の話が終わるわけではない。次の段階では、特定の標的蛋白質を選択し、化合物ライブラリーと称する多数の化合物の集団をスクリーニングして、そのなかのいくつかの化合物が標的蛋白質の機能を望ましい方向に修飾するかどうか調べなければならない。これを高速度で行う、最近採用されている過程はハイスループット・スクリーニング(HTS)と呼ばれている。これは、化合物について多様性と数を増せば、良いヒットが見つかり、そのヒットから新規薬物、ときにはブロックバスターとなるような新規薬物が生まれるという考えである。ここでは、化合物は矢にたとえられる。つまり、矢の種類と数を無限に増やすことができれば、少なくともいくつかの矢は的に当たるはずだということが、現在考えられている。しかしながら、そのようなスクリーニングの後で、結局良いヒットが一つも見つからなかったということを、しばしば、特に、製薬会社に入手可能である化合物ライブラリーが対象のときに経験している。一般的には、入手可能な化合物の多様性と数が足らない為と失敗の理由づけがなされている。天然物を含めて異なる起源に由来する化合物ライブラリーを組合せて、ライブラリーについて数と多様性を拡大すべく、必死の努力がなされてきた。しかし、本発明者から見ると、この種の努力は必ずしもより高い成功率を生んだとはいえない。そこで製薬会社の最近の傾向は、むしろ可能な限り多くの標的を研究室に持ち込み、彼らが手にしている化合物を次々に異なる標的に対してスクリーニングにかけることであるようにみえる。この種の努力を、望むらくは効率的に行うために、いわゆる「偏った(biased)」または「絞り込まれた(focused)」ライブラリーを構築する工夫がなされている。ここで、答えられるべき質問は、このようなアプローチが成功を約束するかどうか、また、もしそうであるならば、どの程度の成功を約束するかである。
【0007】
発明の開示
本発明の開示の記載は、どのような組合せであっても、本出願の特許請求の範囲を構成しうる。
【0008】
本発明は、そもそも、入手可能な化合物には数の点でも多様性の点でも限界があり、化合物は決して無限には存在しえないという認識に基づいている。この認識は、一製薬会社が薬物スクリーニングに供しうる化合物の数が購入可能な化合物を加えてもどの程度存在するかを考えれば明らかであろう。製薬会社に購入可能な化合物ライブラリーの多様性についての限界も自明である。さらに、化合物ライブラリーについて別種の制約も考慮しなければならない。この制約は、薬物らしさ(drug−likeness)という概念から生ずる。これは、薬物の毒性と、その作用部位への到達性から考えられた概念である(総説としてはClark, D.E.およびPicket, S.D. Drug Discovery Today (2000), 5: 49−58を見よ)。薬物らしさの一面を定義する、Lipinsky, C.A.らによって提唱された「5の規則(rule of five)」はよく知られている(Advanced Drug Delivery Reviews (1997) 23: 3−25)。例えば、いくらか誇張した言い方ではあるが、その規則の一つでは、ある化合物が薬物様(drug−like)の分子であるためには分子量が500を超えてはならないと言われている。それ以外にも、ある分子が薬物様であるために要求される条件はいろいろある。したがって、薬物様の分子だけを考えるなら、世界中の製薬会社すべてを考慮してもスクリーニングに供すべき化合物の数と多様性には限界があることが明らかである。この文脈の中で認識されるべき重要な事実は、保健機関によって治療用として承認された既知の薬物は、薬物らしさのための要件を歴史的に満たしてきたということである。(抗生物質を含めて少数の例外はある。)
【0009】
本発明の真髄は、矢と標的の役割の逆転にある。ここでは、矢、すなわち化合物が標的の役割をつとめ、逆に、標的、すなわち蛋白質が矢の役割を果たす。化合物は、その構造が知られているということ、その入手に限界があるということから、現在のゲノム科学およびプロテオミクスの知識からすると無限に将来的入手可能性を有すると考えられる、機能未知の蛋白質より価値が高いとみなされる。より具体的には、薬物様の化合物は蛋白質より価値が高いとみなされる。さらに、標的化合物として最も価値の高い化合物は治療用に承認された薬物である。なぜなら、すでに述べたように、そのような薬物は、薬物らしさのための要件を満足しているからである。本発明のスキームでは、標的化合物を選定した後で、その各々に対して、蛋白質ライブラリーと呼ばれる集められた種々の蛋白質の親和性が同時に試験される。そのような蛋白質ライブラリーは、構成要素である蛋白質のクラス、活性、または局在性に関して、偏っているかまたは絞り込まれていてよい。局在性については、細胞表面、細胞質、および核といった区別が重要なこともあるので、例えば、細胞表面蛋白質だけのライブラリーが構築されてもよい。方法が有効であるならば、より絞り込んだライブラリー、例えば特定の細胞がもつ全てのGPCR (G蛋白質共役受容体)蛋白質を含むようなライブラリーを構築してもよい。すなわち、絞込みの高度なライブラリーは、クラスまたは活性(この例ではGPCR)と局在(この例では特定の細胞)の組合せによって構築できる。検討されるべき化合物の分子量は、先述のLipinskyの「5の規則」にしたがえば、500未満となるが、分子量による制約は絶対的なものではないので、この値を600未満、1,000未満、または1,600未満というように大きくしてよい。また、分子量が固定された値(例えば600)より大きい化合物において、その構造の特定の一部だけが蛋白質との相互作用に関与することがあり得、従って、対応する部分構造も同定したいと考える。これが、分子量についての制約を緩和するもう一つの理由である。分子量の上限として1,600という数値を導入した。これは、医療用における承認薬物のほとんどが分子量50〜1,600の範囲に収まるからである(Hirayama, N.、私信)。
【0010】
つぎに、標的化合物に対して所望の親和性および特異性をもつ蛋白質が選択される。そして、例えばNCBI や EMBLのような適当なデータベースの検索によって、まず、それらの蛋白質の構造(例えば、アミノ酸配列)が調べられ、つぎにそれらの機能が明らかにされる。ある種の事前情報があれば、そのような蛋白質の機能を実験的に明らかにすることも可能である。このようにして、そのような蛋白質のうちのあるものを追求すべき興味ある治療的標的として、新たに特定することができる。我々はすでに特定の化合物Xo(オリジネーター(originator)であることを意味する)が、前記蛋白質に一定の親和性および特異性を有することを知っているので、Xoの構造が検討される。そのような検討に基づき、Xoの化学的な修飾を通じて親和性、活性、および特異性の最適化が図られ、まったく新しい作用メカニズムをもつ薬物が発見される。公知の標的蛋白質をもつ周知の薬物が、他の蛋白質に対してもある程度の親和性をもち、そのような他の蛋白質のうちのあるものは、これまでの知識から考えられない、明らかに異なる治療的標的であったということが発見される可能性は十分ありうる。観察された親和性および特異性は重要な要素ではあるが、Xoに、最適化のための化学的な修飾の余地が残されているかどうかも考慮されなければならない。
【0011】
上に述べたゲノム科学/プロテオミクス研究からの知識が蓄積するにつれて、治療的標的として魅力的な蛋白質が同定される機会は益々増大すると期待される。特記すべき事実は、完全に機能的な蛋白質をコードする、数多くの、かつ多様な全長cDNA分子が、近い将来、知られるようになるか、入手可能なようになることである。一個人あるいは一企業が、化合物と蛋白質間の種々の相互作用をカバーする私有のデータベースを手にしているならば、データが得られた時点で後者の機能が未知であっても、その個人または企業は他者に対して競合的な優位性をもっているといえる。なぜなら、その私有のデータベースに含まれている蛋白質のあるものについて機能が明らかにされ、非常に魅力的であることが判明したとき、その個人または企業は、直ちにオリジネーターXoを最適化する工程を開始して、価値ある新規薬物を得ることができるか、あるいは、その蛋白質に対して所望の親和性および特異性を有する、またはそう期待される化合物の実在するプールまたは仮想的なプールをすでに持っていて、そこから薬物として適する化合物を選び出せばよいという段階に達しているかもしれないからである。
【0012】
さらに、ある低分子化合物1個を選び、この世界に存在するほとんどの蛋白質が入手可能であるという状況を仮定すると、上述のアプローチは、この化合物に結合する、ほとんどすべての蛋白質のカタログまたはデータベースを生み出すことになる。そのようにして選択された化合物(Xo)が既承認の治療用(即ち医療用)の薬物であって、蛋白質がヒトまたは哺乳動物由来であるとすれば、そのようなカタログまたはデータベースは、それに対してXoの親和性および特異性が化学的修飾によって最適化されるべき、ほとんどすべての薬物標的蛋白質候補を収載していることになる。ヒトまたは哺乳動物の蛋白質をコードする全長cDNA分子が益々手に入りやすくなっていることは、このアプローチを現実的なものにしている。加えて、分画化されたものでも分画化されていないものでもよいが、細胞溶解液を使うことが可能であり、これによって使用する蛋白質資源を拡大し、完全に近い形にすることができる。
【0013】
そのような蛋白質のうちの一つがXoの毒性または副作用の原因となっている蛋白質であるということが判明することもありうる。ここで、Xoは必ずしも既知の薬物でなくともよく、創薬研究の過程で得られた化合物でもよい。これが観察されたときには、Xoは化学的に修飾されて、その蛋白質に対する親和性が極小化され、治療的標的蛋白質に対しては所望の特異性と親和性を有するが、毒性または副作用が減少した、より良い薬物を生ずる。このアプローチは、有毒な産業化合物または環境物質に拡大できる。この世界に存在するほとんどすべての蛋白質をこのような物質の親和性に基づいて調べるならば、前記物質の毒性の原因となる蛋白質を同定するのに役立つであろう。そのような蛋白質が同定されたとき、産業または環境上の危険を低下させる手段をとることが可能となり、その手段とは、例えば、毒性物質の化学的修飾によって、その蛋白質に対して親和性が低下した代替物を見出すことである。
【0014】
さらに、この世界に存在するほとんどすべてのヒトおよび哺乳動物蛋白質を入手した上で、Xoとして既存の承認された治療用薬物のすべてを選ぶなら、想像もできないほど大きい薬物標的蛋白質プールを確保する良い機会を得る。そして、そのような薬物標的蛋白質のそれぞれに対応するXoの親和性および特異性を化学的修飾によって最適化することができ、それにより実に多くの改良された新規薬物、またはこれまでに考えることができなかった新規薬物を得ることができる。ここで、このような既承認薬物は、薬物らしさの要件を満足したものであることに注意してほしい。長い創薬研究の歴史の結果として、化合物が薬物として備えるべき要件を満足する必須の化学構造のほとんどすべては既に同定されていると考えられるため、ここに述べたアプローチによって、ヒトまたは哺乳動物起源の潜在的薬物標的蛋白質のほとんどすべてを同定するという成果が得られる可能性がある。そのような同定作業によって、ほとんどすべての潜在的薬物標的蛋白質に関するカタログまたはデータベースが作られる。
【0015】
計算化学的合成技術の進歩によって、さらに、Xoから誘導可能な、仮想的(virtual)に合成される薬物様のほとんどすべての化合物のリストを作成することが可能となる。このことは上述のアプローチによって、既知であろうと未知であろうと、最終的には薬物として潜在的に有用なすべての化合物を同定することが可能なことを意味する。この場合も同様に、カタログまたはデータベースが作られる。承認される薬物の数が増えるにつれ、Xoのリストに評価されるべき新しい承認薬物を加えることによって、新規の価値ある薬物の発見がさらに進むことが期待される。
【0016】
上記および下記の蛋白質と化合物の相互作用の記述全体は、ペプチドとして分離されているかどうかにかかわりなく、ドメイン、モチーフ、リガンド、リガンド部分、断片、ペプチド、ポリペプチドのように表現される蛋白質の「部分」の相互作用についても同等に当てはまる。ここで単数形の部分とは、すべて対応する単数形のドメイン、モチーフ、リガンド、リガンド部分、断片、ペプチド、ポリペプチドを意味する。全長cDNA分子は対応する機能的蛋白質を生ずることが潜在的に可能であるが、全長でないcDNA分子もそのような蛋白質の部分の提供源として重要である。さらに、上記および下記の蛋白質と化合物の相互作用の記述全体は、翻訳後の、あるいは蛋白質−蛋白質相互作用の結果として、または他の様式での、修飾を受けた蛋白質の相互作用についても同等に当てはまる。
【0017】
すべての承認薬物を選択する代わりに、代表的な薬物を選択することも可能である。このアプローチによって、これまで述べた親和性評価工程による薬物標的蛋白質の良質なプールを得るという作業において重複が少なくなることが期待される。代表的な薬物は化学構造、作用機序、薬理学的効果、その薬物の適応とされる疾病・症状を基礎に選択することができる。例えば、マイナー・トランキライザーという用語は抗不安作用をもつ化合物を意味する。これらの薬物は異なった化学構造をもつ化合物群を含む。一群の化合物はベンゾジアゼピンとして分類される。ここでの代表的薬物はジアゼパムかもしれない。それゆえ、すべての既承認のベンゾジアゼピン薬物を試験する代わりに、親和性評価に用いるべきベンゾジアゼピン・クラスの代表的マイナー・トランキライザーとしてジアゼパムを選択することになるかもしれない。H2ブロッカーは代表的化合物を選択することが難しい例である。当初、化学的修飾をヒスタミンから開始したが、その後薬理学的プロファイルの改善に向けて継続的な努力が払われた結果、最終的にはヒスタミンと類似していない種々の構造を有する化合物を生む結果となった。そのような場合には、そのクラスの既承認薬物の大部分を試験したいと考えるかもしれない。
【0018】
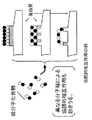
通常、単一の低分子化合物を用いて蛋白質−蛋白質相互作用に介入したり、またはそれを修飾することは難しい。なぜなら、そのような相互作用は、二つの蛋白質の両側の表面積、それが前記化合物によって被いきれないほど広い表面積における蛋白質同士の接触の結果だからである。しかしながら、二つ以上の異なる化合物が、蛋白質の対のうち少なくとも片方の接触面積の異なった部位に結合することが分かったなら、治療目的にそのような化合物の組み合わせを用いて、その蛋白質−蛋白質相互作用に介入したり、またはそれを修飾することが可能かもしれない。この原理を図1および図2に示す。図1の上段は、蛋白質−蛋白質相互作用の結果、右側の蛋白質に例えば形態学的な変化(頭状構造の背部の鼻と顎のような突起を見よ)が生じ、それがある種の効果を生ずるか、またはさらに別のセットの蛋白質−蛋白質相互作用を誘導することを示している。図1の下段は、単一の低分子化合物ではこの相互作用に影響を与えることができないことを示している。しかしながら、図2に示すように、異なる結合部位をもつ二つの違う化合物を用いれば、この相互作用の発現が阻害される。相互作用表面の部位に化合物が結合しなくても、化合物が相互作用表面以外の部位に結合することでアロステリックな形態的変化が蛋白質の一つに生ずることによって、蛋白質−蛋白質相互作用に介入し、それを修飾することは可能である。異なる結合部位(相互作用表面上か否かは問わない)をもつ異なる化合物の組み合わせを治療目的に用いれば、蛋白質−蛋白質相互作用への介入または修飾をより効果的に誘導することが原理的には可能である。
【0019】
本発明に記載されたアプローチにより、どのような化合物の組み合わせを、あるセットの蛋白質−蛋白質相互作用への介入または修飾のために評価すべきかについて指針が与えられる。なぜなら、本発明のアプローチはその相互作用に関与する蛋白質の各々にどのような化合物が結合するかについての情報を与えるからである。また、そのような指針は、カタログあるいはデータベースの構築を可能にする。この種の評価には注意が必要である。同一または類似の部位に化合物が結合するとき、競合現象が起きて、用いられた一つまたはそれ以上の化合物の介入作用あるいは修飾作用の減少がありうるからである。
【0020】
本明細書に既に記載の段落において、化合物が相互作用表面に存在する部位に結合することなく、アロステリックな形態的変化が蛋白質の一つに生じ、その結果、蛋白質−蛋白質相互作用が修飾される可能性があることを記載した。本発明者らは議論を蛋白質−蛋白質相互作用に限定せずに、この側面を次段落以降でさらに考慮する。
【0021】
蛋白質分子のコンフォメーションは低分子化合物との相互作用によって、様々な修飾を受ける。例えば、ある化合物は蛋白質または蛋白質の一部の可動構造に運動への障害物として作用する。そのような可動構造は、いわゆる活性部位と直接つながっているとは限らない。図3にはそのような修飾の例として、蛋白質分子の蝶番様または関節様構造のなかに挿入されてクサビとして作用する低分子化合物が示されている。すなわち、低分子は、幅(ギャップ)を閉じる(狭める)(図3.[a])ことができ、幅(ギャップ)を開く(ひろげる)こともできる(図3.[b])。この型の修飾は標的蛋白質の機能の増強あるいは阻害を誘導することができる。例えば、ある蛋白質がアミノ酸配列の一部の変異によって機能的な障害を受けていて、その障害が蛋白質の正常な機能に必要なギャップが狭窄された結果であるとすれば、モード[b]のように働く低分子は、ギャップを広げて正常な機能を回復するのに有効であろう。低分子による、このような型あるいは他の型のコンフォメーション修飾は、その結果として、一連の蛋白質−蛋白質相互作用を増強、回復、および阻害することが期待される。
【0022】
コンフォメーション修飾のいくつかの型を前段落で記載したが、それらは単一分子によって引き起こされるものに限定されない。正常であれば蛋白質の運動を許す蝶番様または関節様の構造の内部または近傍の異なる部位にいくつかの異なる分子が結合することによって所望のコンフォメーション変化を協調して引き起こすこともできる。
【0023】
単一の低分子ではなくて、複数の低分子が組み合わせられる場合は、いわゆる「協調的相互作用」も考慮しなければならない。図4は同一低分子種による協調的相互作用の例を示している。括弧内に示したように、協調的相互作用は異なる低分子種の混合物によっても起き得る。ここで、構成要素である単一分子と蛋白質分子上の結合部位との相互作用を単位相互作用と呼ぶ。すなわち、そのような単位相互作用は弱くても、このような同一または異なる低分子種の混合物は全体としての協調的相互作用によって、蛋白質分子と強い相互作用(結合)を持ち得るのである。本明細書の記述にしたがって低分子−蛋白質相互作用を探索すれば、種々の単位相互作用を発見することができる。本明細書の記述にしたがって低分子−蛋白質相互作用を探索すれば、異なる分子種ではなく単一の多数の分子種によって生じる種々の協調的相互作用を発見することもできる。後者は、蛋白質濃度を一定に保ち、研究されるべき低分子の濃度(または異なる低分子においてはそれぞれの濃度)を変えたときの、親和性パラメター対濃度曲線における結合の鋭い上昇によって明らかとなる。さらに、最初の研究で見出されたような、異なる低分子種による弱い単位相互作用を組み合わせることによって、特定の蛋白質に対する、より強い協調的相互作用を得ることが可能である。
【0024】
ある化合物が蛋白質の運動を妨げることによって蛋白質の機能を阻害する一つの例は、HIV−1プロテアーゼの蝶番様構造とポリオキソメタレートとの相互作用である(Judd, D.A.ら、J. Am. Chem. Soc. (2001) 123: 886−897)。調べられたポリオキソメタレートの分子量は大きく、即ち約4,500であるが、相当小さな分子でも蝶番運動の阻害の原理はあてはまると考えられる。コンフォメーション変化が引き起こされたもう一つの例は、変異p53がDNAに結合できるようにすることによって、その機能を回復したと報告されている「分子かすがい」である(Foster, B.A.ら、Science (1999): 286, 2507−2510)。この研究では、10万個より多くの合成化合物がスクリーニングされ、複数のクラスの低分子化合物(300から500ダルトン)がスクリーニングに有効とされた。そのうちの一つの化合物CP−31398は、日量100 mg kg−1で自然変異p53をもつヒト腫瘍の小さな異種移植片の成長を有効に阻害することが認められた。しかしリポーター遺伝子アッセイ法の濃度−反応データからは、そのような阻害が協調的相互作用のある型のものを含むかどうか明らかでない。
【0025】
本発明は細胞表面蛋白質の探索法を含む。このような蛋白質はその機能がしばしばコンフォメーションの変化に敏感である。この理由から、化合物と細胞表面蛋白質との相互作用を、細胞表面蛋白質が細胞表面上にインタクトの状態であるようにして得ることが望ましい。それゆえ、本発明には細胞そのものが特定の細胞表面蛋白質のキャリアーとして使用される場合が含まれる。
【0026】
本発明はまた、細胞表面または細胞内の膜構造と結合した蛋白質について探索する方法を含む。膜に結合した蛋白質はその機能がコンフォメーションの変化に敏感である。したがって、化合物とそのようなインタクトな蛋白質との相互作用を観察するとき、蛋白質が細胞膜に結合した状態のまま観察することが望ましい。それゆえ、本発明には細胞外ヴィリオンが特定の膜結合蛋白質のキャリアーとして用いられる場合が含まれる。
【0027】
膜結合蛋白質は緩和な界面活性剤または緩和な界面活性剤の混合物を含む溶液中で細胞を処理することによって物理化学的にも得られる。
【0028】
ここで、注意しておかなければならないことがある。認識できるように本発明で用いられるアプローチは主として親和性に基づいている。標的蛋白質に対してある化合物が高い親和性を示すからといって、後者の機能を修飾する効果があるということにはならないことを理解すべきである。例えば、標的蛋白質のある機能の阻害物質を見出すことが望まれる場合に、その阻害作用を確認できる生物学的評価系をさらに構築する必要があると考えられる。そのような評価系は、細胞によるもの、組織によるもの、器官によるもの、または動物全体を用いたものであってもよい。そのような評価系の組み合わせを付加的に用いることが薦められる。
【0029】
ある化合物が少数の特定の蛋白質に比較的高い結合定数をもって(すなわち、ある程度の特異性と親和性をもって)結合することが見出されたとき、そのような結合が生物学的に意義があるかどうかを知りたいと考える。同じことは、特定の複数の蛋白質に対する親和性を共有している一群の化合物が組み合わされて、各蛋白質の機能を修飾するために用いられる場合にも当てはまる。特に、蛋白質−蛋白質相互作用に関わるパートナー蛋白質の片方または双方への親和性を共有する化合物の組み合わせが生物学的な系の機能を修飾する点で有意義な結果を生じるかどうかを知りたいと考えるであろう。そのような化合物−蛋白質相互作用が生物学的に有意義であるかどうかを知る一つの方法が後述の実施例によって示されている。
【0030】
一旦、ある化合物−蛋白質相互作用が生物学的に有意義であることが見出されたら、その相互作用に関与する蛋白質の機能次第で、化合物はアゴニストとして刺激的に作用するか、またはアンタゴニストとして阻害的に作用するかのいずれかであると結論づけられる。ハイスループットであるかどうかはともかくとして、多くのスクリーニング法を構築することが可能となる。その場合、この相互作用に関与する蛋白質は新規の薬物標的としての役割を担う。スクリーニング法としては、本発明に開示された親和性評価法、ならびに細胞によるもの、組織によるもの、器官によるもの、および動物全体によるものがあり、それらを別々に、あるいは組み合わせて用いることができる。蛋白質の機能が知られているか、知られるようになったとき、細胞外および細胞内のpH、細胞外および細胞内のカルシウム、サイクリックAMP、その他生物学的意義がある物質の濃度、光学的変化、形態学的変化、ならびに電気生理学的変化を機能インディケーターとして用いることによって、対象となる蛋白質と相互作用する化合物の各々がアゴニストまたはアンタゴニストとして作用するかどうかを確認するために、適当なアッセイ法を考案することができる。機能インディケーターは、無細胞の系または細胞による系のどちらであるかにかかわりなく、対象となる蛋白質の活性を表わす任意のインディケーターとして定義されている。ある化合物がアゴニストとして作用するか、またはアンタゴニストとして作用するかを知る方法の例を後述の実施例10に示す。そこでは、mRNAレベルにおける発現プロファイルを調べる際のアンチセンス分子(AS)の使用が含まれる。化合物によって生ずる発現プロファイルが、蛋白質に対応するASによって生ずるものと類似であることが見出された場合、その化合物は蛋白質に対してアンタゴニストとして作用すると仮定される。発現プロファイルが逆方向、即ち、例えばある種の遺伝子がダウンレギュレーションされる代わりにアップレギュレーションされるような場合は、その化合物はアゴニストと仮定される。このような方法および他の方法によって、化合物はアゴニストかアンタゴニストのいずれかに分類される。
【0031】
つぎに、親和性に関するデータの意味について説明する。
【0032】
最初に、一組の親和性データから何が推論されるかを考える。特に、Cと名づけたある化合物に関する一組の親和性データを考える。同時に、蛋白質−低分子相互作用における特定の対が生物学的意義をもつかどうかを証明する方法を持っていると仮定する。そのような方法のいくつかは以下の実施例に記載されている。そのような相互作用をB (広い(broad))とL (限定されている(limited))の二つのクラスに分類する。クラスBの相互作用では、化合物Cは多様な蛋白質に親和性をもつ。クラスLの相互作用では、化合物Cは限定された数またはクラスの蛋白質としか親和性をもたない。ここで、結合定数で定義される親和性と、各々の相互作用の生物学的意義の有無に基づく2x2行列を作る(表1)。
【0033】
クラスBの相互作用を考える。Cがそのクラスにかかわりなく多数の蛋白質に結合し、かつ、観察される結合定数が大であり、さらに、そのような相互作用の大部分に生物学的意義があるが、特異性がないなら、Cは毒性が高いと推論される。しかしながら、そのような結合がいずれも生物学的に意義を持たないならば、Cはヒトに投与されたとき薬物として有効ではなく、単に身体内部に広く分布するだけであろう。結合定数が小さい場合には、そのような結合に一定の生物学的意義があっても、Cが薬物となる機会は無視できるほどであると推論できる。さらに、結合定数が小さく、その結合に生物学的意義がないなら、同様にCが薬物となる機会はないものと結論されると思われる。
【0034】
つぎに、クラスLの相互作用を考える。Cが限定された数あるいはクラスの蛋白質にのみ結合し、かつ、その結合定数が大であり、さらに、そのような相互作用に生物学的意義があるなら、Cは有効な薬物か、または毒性物質になる可能性が大きいと推論される。しかしながら、いずれの相互作用も生物学的意義を有さないなら、Cはヒトによって摂取されても薬物として有効とならず、また毒性物質としても有害とならないであろう。Cが限定された数またはクラスの蛋白質にのみ結合し、かつ、その結合定数が小であるけれども、そのような相互作用に生物学的意義がある場合には特別の注意が必要である。この場合には、Cに化学的修飾を加えて特定の蛋白質または所望のクラスの蛋白質への結合定数を高める(特異性と親和性の両面から改良する)ことによって良い薬物を得るという機会があると推論する。Cが環境にとって有害であるなら、その毒性を減じるために反対の方向の化学的修飾を行えばよいだろう。最後に、結合定数が小で、かつ、いずれの相互作用も生物学的意義を有さないなら、Cは薬物にも毒性物質にもならないであろう。
【0035】
さらに、ある化合物と、ある蛋白質との相互作用(すなわち、結合)に生物学的意義のあることが見出され、その相互作用に関与する蛋白質の機能が知られているか、知られるようになるなら、つぎのことが可能となる。
(1)化合物の薬理学的活性または毒性を定義すること。
(2)化合物に化学的修飾を加えて、特異性と親和性を最適化すること。この操作において、蛋白質の機能に関する知識は必ずしも要求されないことに注意。
(3)表2に示すように、既知の化合物と既知の蛋白質の相互作用に関するデータを用いて作成されたモデル行列に基づいて、被検物質の薬理学的活性と毒性を予測すること。すなわち、被検化合物の親和性プロファイルを、既知の化合物と既知の蛋白質の相互作用に関するデータを用いて作られた親和性プロファイルのモデル行列と比較することによって、被検化合物の薬理学的活性と毒性を予測する方法がある。先の場合と同様に、この場合も必ずしも蛋白質の機能に関する知識は必要とされない。
【0036】
化合物−蛋白質相互作用について、さらに別の局面を述べる。そのような相互作用を評価するために考案された新規の方法についても記載する。
【0037】
最近の研究によると、細胞内では驚くべき生化学が起きていることが分かっている。典型的な例は蛋白質の非常に大きな複合体が形成される転写装置である。真核細胞では、RNAポリメラーゼIIが転写の仕事を開始して、ゲノムDNAから初期RNA転写物を作るために、転写因子と総称される種々の調節蛋白質が協調して、きわめて大きな複合体を形成する必要がある。エンハンサーを含んでいるそのような複合体の一種に、「エンハンセオゾーム(enhanceosome)」と呼ばれるものがある(Lewin, B., Genes VII, p 639, Oxford University Press, 2,000)。クロマチンのリモデリングもまた、大きな蛋白質複合体の形成を必要とすることが知られている。シグナル伝達経路は、実際には経路ではなくて、むしろ異なる蛋白質、および/または形成済みの異なる蛋白質複合体の(恐らく連続的な)結合によって構築される大きな複合体の形成であるという証拠がある。(この文脈において、例えば、ホモダイマーを形成する各モノマーも互いに「異なる」と呼ばれる。)例えば、餌(bait)として作用するTAK 1により、TGFβで細胞を刺激したとき餌であるTAK 1を含めて20種より多くの異なる蛋白質を含む複合体がプルダウンされることが見出された(Natsume, T.、私信)。したがって、本発明で開示された蛋白質−低分子相互作用の意義は、この観点から考慮される必要がある。蛋白質への低分子の結合は、その蛋白質ともう一つの蛋白質との結合を阻害するかもしれないし、または強化するかもしれない。転じて、そのことは自然状態で形成される大きな複合体の形成に影響するかもしれない。異なる低分子の各々が複合体を構成する異なる蛋白質と結合して、その蛋白質複合体の機能を阻害したり、または強化することもあり得る。恐らく、各分子種が異なる蛋白質の各々と結合するように異なる低分子をコンビナトリアルに用いるなら、単一の分子を用いて一対の蛋白質−蛋白質相互作用のみに影響を与える場合より、蛋白質複合体の機能を変化させるのに有効であろう。異なる低分子のこのようなコンビナトリアルな使用によって各分子種を複合体の異なる蛋白質の各々に生物学的に有意義な様式で結合させるという考え方は、特定の疾病の治療にまで拡大することができる。
【0038】
このような考察は本発明に対して二つの効果をもたらす。一つは、蛋白質−低分子相互作用の評価方法に対してであり、もう一つは特定の蛋白質−低分子相互作用の生物学的意義を評価する方法に対してである。
【0039】
蛋白質−低分子相互作用の評価方法に関して、ある化合物が評価対象として選ばれたとき、その化合物をすでに形成された複合体と相互作用させるか、または複合体形成にあずかる蛋白質の混合液と相互作用させる。後者の場合、その複合体の形成に必要な構成蛋白質を評価系に加えるか、または複合体形成に必要な試薬を加えるのかのいずれかによって、複合体形成を開始させることができる。後者の例は、複合体形成にキナーゼが関与する場合にATPを外から加える場合である。この評価方法は、複合体形成に関与する蛋白質の各々を完全に精製するか、または部分的に精製して用いるイン・ヴィトロ系で行い得る。この様式は再構成実験と呼び得る。細胞溶解液の使用も再構成実験である。相互作用の有無、および相互作用が存在する場合の定量的側面は、表面プラズモン共鳴技術を含めて、実施例に記載されている種々の方法によってモニターされる。
【0040】
もう一つの評価様式は細胞そのものを利用するもの、すなわち、イン・ヴィヴォ様式である。先に引用した夏目の研究では、TAK 1遺伝子がまずカルモデュリン遺伝子と融合され、さらに、特定のペプチダーゼによって開裂するペプチドをコードするリンカー配列を介してプロテインA遺伝子と融合されている。この融合遺伝子は適当なベクター配列と結合されて、細胞をトランスフェクトするのに用いられた。融合遺伝子に対応する融合蛋白質が細胞内で発現された。この細胞がつぎにTGFβによって刺激された。このとき、TAK 1を「ドメイン」として含む融合蛋白質が蛋白質複合体を形成することが期待された。細胞は溶解され、想定された複合体が適当なアフィニティ・クロマトグラフィーの使用によりプルダウンされた。最初はプロテインAに対するアフィニティ・クロマトグラフィーが使用され、リンカー・ペプチドが開裂されたのち、カルモデュリンに対して第二のアフィニティ・クロマトグラフィーが使用された。プロテインAまたはカルモデュリンのような蛋白質またはポリペプチドを本発明では、アフィニティ・クロマトグラフィーにおいて特異的な「かぎ(hook)」としての働きをするため、「アフィニティかぎ」と称する。この様式の精製を「タンデム・アフィニティ精製」と呼ぶことがある。この精製された想定複合体は、ナノスケール液体クロマトグラフィー−エレクトロスプレーイオン化−タンデム質量分析(nanoLC−ESI−MS/MS)にかけられた。この分析は、事実、20より多くの蛋白質を含む複合体が形成されることを明らかにした。この実験は蛋白質−低分子相互作用を評価するのに細胞をどのように使用すれば良いかの例を示している。すなわち、はじめに細胞を選択された化合物で処理し、その後、夏目によって用いられたものと同様のプロトコールに従う。プルダウンされた複合体(複合体でなく単一分子の場合もある)の蛋白質組成が、その化合物なしで得られた複合体の蛋白質組成と異なるなら、複合体形成に関与する少なくとも1個の蛋白質もしくは一対の蛋白質と低分子との間に直接的相互作用があったと結論するか、または低分子に複合体形成への間接的影響があったと結論する。つぎに単一あるいは複数の再構成実験を行って、直接的な場合と間接的な場合を弁別し、低分子との相互作用に関わった1つまたは複数の蛋白質を同定する。一部再構成実験、一部イン・ヴィヴォといった混合様式の実験もあり得るであろう。
【0041】
ある特定の蛋白質−低分子相互作用に生物学的意義があるかどうかを決定する方法に関しては、上述の細胞を用いた評価(イン・ヴィヴォ)においてプルダウウンされた複合体の蛋白質組成が選択された化合物の有無に応じて違っていて、かつ、関与している蛋白質のうちの少なくとも一つがその化合物と相互作用することが知られているとき、生物学的意義があるという直接的な証拠となる。どのような生物学的意義が、どのような点で存在するかを知るのには、さらなる知識または情報が必要である。
【0042】
細胞の使用は、蛋白質−低分子相互作用評価を別の側面に拡張できる。タグをもつ遺伝子(タグ付きの遺伝子と称する)を有する適当なベクターで、まず、細胞をトランスフェクトする。ヒスチジン・タグはその1例である。得られた細胞は、そのタグをもつ蛋白質を発現していると予想され、この細胞を選択された化合物で処理する。この処理の後、細胞を溶解する。溶解液について直接または適当な精製過程を加えたのち、化合物が蛋白質から分離しない条件下で、タグに対するアフィニティ分離を(バッチ的またはクロマトグラフィー的に)行う。そのような化合物の分離を避けるために、生理的条件またはそれに近い条件が望ましい。つぎに、溶出液を質量分析に付す。この溶出液で化合物と蛋白質が結合していることは、もはや必要ではない。得られたマス・スペクトルを化合物で処理せずに得られたマス・スペクトルと比較する。この操作では、蛋白質と化合物両方のマス・スペクトルが得られ、両者の量が明らかにされるので、相互作用の定性面だけでなく定量面も検討することができる。タグつきの蛋白質を発現した細胞を化合物一種のみでなく、化合物の混合物で処理しても差し支えない。マス・スペクトルを比較することにより、タグつき蛋白質がどの化合物と、どの程度相互作用するかの情報を得ることができる。この方法の利点は自然環境に近い状態で相互作用を同定することができるという点である。タグを付しても、大抵の場合に自然の蛋白質のフォールディングが残っていると期待される。このスキームのもとでは、翻訳後修飾のような、細胞内修飾を受けた蛋白質と化合物との相互作用も同定することができる。さらに、タグつき蛋白質を構成成分として含む蛋白質複合体と化合物との相互作用を同定することも可能である。
【0043】
データベースまたはカタログの構築のために集められるべきデータの種類は、つぎの通り要約される。
(1)基礎的データ
Ci: 化合物i (修飾された化合物は異なる化合物としてカウントされる)
Pj: 蛋白質j (翻訳後修飾または他の修飾を受けた蛋白質は異なる蛋白質としてカウントされ、同じ蛋白質でも製法が異なれば、異なる蛋白質としてカウントされる。ある蛋白質の一部も異なる蛋白質としてカウントされる)
Ek: 親和性評価の環境k (親和性測定法、溶媒、pH、イオン強度、細胞内、細胞膜結合状態など)
Aijk: 親和性測定値(カイネティックな条件下、平衡時、定量的、半定量的、定性的などの任意の測定条件下)
(2)構造的データ
SCi: Ci の化学構造(1D−, 2D−または3D−; Dは次元の意)
SPj: Pj の構造(1D−, 2D−または3D−)
SCik: 環境k におけるCi の構造
SPjk: 環境k におけるPj の構造
(3)他の属性 (下つき添字省略)
FC, FP: 機能(FC は化合物の薬理学的活性、毒性および副作用、ならびにその化合物の対象疾患または病態など)
GC, GP: Cまたは P がどのように得られたか (すなわち、製法など)
TC, TP: それが知られているとき 、C またはP の標的蛋白質 (C またはP の標的蛋白質とは、C またはP が直接相互作用する相手の蛋白質を意味する)
MC, MP: 上記以外の種々の属性 (これらはさらにサブカテゴリーに分類され、別途命名してよい)
【0044】
つぎの段階はデータベースを構築し、予測を行うためのものである。
【0045】
第1段階: Aijk データの配列化とその比較
1.化合物Ci に対して、定められた値より高い親和性値をもつ蛋白質のAijk データを並べ、それらの蛋白質の構造を比較する。
2.蛋白質Pjに対して、定められた値より高い親和性値をもつ化合物のAijk データを並べ、それらの化合物の構造を比較する。
3.化合物と蛋白質に関してAijk データを以下のようにクラスタリングして配列する。
1)親和性測定のために各化合物が化学的な修飾を受けたか否かを無視する。
2)化合物の製法(合成法および抽出法を含む)を無視する。
3)各蛋白質が翻訳後修飾または蛋白質−蛋白質相互作用などにより修飾を受けたか否かを無視する。
4)蛋白質の製法の違いを無視する。
5)親和性測定の環境(条件)の違いを無視する。
6)化合物に関して、共通の構造および生物学的活性にしたがう。
7)蛋白質に関して、共通の構造および生物学的機能にしたがう。
8)上記のいずれかの組み合わせを行う。
【0046】
第2段階:蛋白質および化合物のコンセンサス部分配列およびコンセンサス部分構造を見出すこと。コンセンサス相当部分配列およびコンセンサス相当部分構造の発見を含む。
【0047】
第1段階で得られた配列データについて、蛋白質のコンセンサス部分配列および化合物のコンセンサス部分構造を、目視による比較および/または適当なコンピューター・プログラムの使用によって、検索する。この操作は、コンセンサス相当部分配列およびコンセンサス相当部分構造の発見を含む。例えば、蛋白質の一部のアミノ酸配列が別のアミノ酸配列に機能上重大な損失を蒙ることなく置換できると想定されるとき、双方の配列は互いにコンセンサス相当と見なされる。ロイシンからイソロイシンへの置換はその例である。この型のアミノ酸置換を行うのに、PAM250 (Dayhoff percent accepted mutation matrix 250)やBLOSUM62 (blosum substitution matrix 62)などが利用できる。相当という用語は絶対的ではないので、相当の程度をこれらの行列によって与えられる固定したスコア値によって定義することが可能である。「相当」という概念は局所的配列の比較に限定されることはなく、3次元構造、すなわち、空間における構造要素の位置の比較にまで拡張することが可能である。したがって、例えば、占有体積、ファン・デル・ワールス力、水素結合、および静電気的力などの点で、あるアミノ酸配列と、別のアミノ酸配列が同一または類似の3次元構造をとるなら、これら二つの配列はコンセンサス相当であるといわれる。「相当」の概念は異なる化合物の比較の場合にも適用される。このような化合物の比較は1次元構造または2次元構造の比較のみでなく、3次元構造の比較をも含む。本明細書の別の個所に「共通の」および「類似の」という表現が用いられるが、これらはそれぞれ、コンセンサスおよびコンセンサス相当を意味する。
【0048】
この第2段階はつぎの仮定に基づく。
1)低分子との結合に関与できる蛋白質上の部位は、数の上でも多様性の観点からも限られている。そのような部位は蛋白質の部分配列または部分構造によって表わすことができる。このような配列は1箇所でのひと続きのアミノ酸配列として同定できる場合もあれば、異なる場所に分離した複数のアミノ酸配列として同定できる場合もある。
2)蛋白質との結合に関与できる化合物上の部位は、数の上でも多様性の観点からも限られている。そのような部位は化合物の部分構造、骨格、その他の構造的特徴によって表わされる。
【0049】
先の段落において、単一分子または複数の同一もしくは異なる分子の組み合わせが、正常であれば蛋白質の運動を許す蝶番様または関節様の構造の内部または近傍の1つもしくは複数の部位に結合することによって、所望のコンフォメーション変化を引き起こすことができるということを記述した。そのような蝶番様または関節様の構造の内部または近傍の1つもしくは複数の部位に局在するコンセンサス部分アミノ酸配列を見出すことが可能である。ある種の蛋白質については蝶番様または関節様の構造は、HIV−1プロテアーゼの場合のように同定されている(Judd, D.A.ら、J. Am. Chem. Soc. (2001) 123: 886−897)。蛋白質の構造解析の進歩に伴って、そのような可動構造とこれに関与するアミノ酸配列に関する知識はさらに得られるであろう。この第2段階で見出されたコンセンサス配列のいくつかが可動構造に関与するアミノ酸配列に対応することが分かれば、すでに得られている蛋白質−低分子相互作用のデータに基づいて標的蛋白質のコンフォメーション上の変化を通じてその機能を阻害したり、回復したり、または強化するのに望ましい化合物を設計することが可能となる。
【0050】
第3段階:第2段階の知見の検証、および蛋白質と化合物に関する必須部分構造および必須骨格の発見
【0051】
第3段階はつぎのようになされる。
1)検証−対象化合物の構造に大きさの減少、置換、または大きさの拡大のような化学修飾を段階的に加えてAijkにおける変化を検討する。同様に、対象蛋白質にアミノ酸残基の置換のような変異を段階的に加えてAijkにおける変化を検討する。
2)必須の部分構造、骨格、および3次元構造の発見−上記1)での知見からこれらを同定する。
【0052】
これらの段階の最終目標は、薬物の効果面を考えるとき、選ばれた標的蛋白質に対する親和性および特異性を最大化するような化合物の構造を予測することである。一方、毒性面を考えるとき、選ばれた標的蛋白質に対する親和性および特異性を最小化するような化合物の構造を予測することである。そのような予測は、予測によって得られた化合物を創製し(すなわち合成し)、実験的に、選ばれた蛋白質への親和性を評価し、親和性の生物学的意義を研究することによって検証される。
【0053】
データベース、ユーザーインタフェース、ならびにこれらのデータベースおよびユーザーインタフェースの利用方法について以下の段落で詳細に述べる。
【0054】
ある蛋白質または部分蛋白質と、分子量1,600未満、1,000未満、600未満、または500未満の化合物の集団から選ばれた化合物との間の相互作用を記述して表化することによって、データベースが構築される。これらの化合物は、医療用として承認されていてもよいし、されていなくてもよい。そのようなデータベース中の蛋白質または部分蛋白質は、細胞溶解液から得られたもの、遺伝子工学的に人工的に調製されたもの、全長cDNAから発現されたもの、クラス、酵素活性のような活性、細胞表面、細胞質、核のような局在性、細胞型、起源の組織、起源の器官、細胞の膜構造への結合(この注意すべき例はGPCRである)、細胞外ヴィリオンに発現したもの、緩和な界面活性剤、または緩和な界面活性剤を含む溶液によって物理化学的に細胞を処理することによって得られたものといったような観点で絞り込まれたものを含む。
【0055】
そのようなデータベースにおいて、相互作用は、そのような相互作用の有無および親和性の強さのパラメター(適当な場合、親和性という用語は相互作用という用語と互換的に用いられる)、および/または、相互作用の様式および/または相互作用の構造的要素によって定義される。親和性の強さのパラメターには、 (a) 結合速度定数および/または解離速度定数、ならびに(b)平衡時の結合定数および/または平衡時の解離定数が含まれる。相互作用様式としては、ファン・デル・ワールス力による相互作用、水素結合、静電気的相互作用、チャージ・トランスファー、疎水的、親水的、親油的相互作用、および協調的結合または協調的相互作用が含まれる。相互作用の構造的要素には相互作用部位、相互作用部位の構造、相互作用する群、相互作用するアミノ酸残基、相互作用する原子、相互作用表面、および相互作用する群、相互作用するアミノ酸残基、相互作用する原子、相互作用表面の1次元、2次元または3次元空間における相対的な位置が含まれる。
【0056】
複数の蛋白質または部分蛋白質の各々と、複数の化合物との相互作用に関する記述を表化してデータベースを構築すると便利である。同様に複数の化合物の各々と、複数の蛋白質または部分蛋白質との相互作用に関する記述を表化してデータベースを構築すると便利である。そのように集合的に構築されたデータベースは、既述した親和性の強さのパラメターおよび/または相互作用の様式および/または相互作用の構造的要素をも含むことができる。そのようなデータベースは、(a)化合物との相互作用に関与する蛋白質の発現を制御しているゲノムDNA配列上の制御領域および/または (b) その蛋白質をコードする遺伝子の転写を開始する転写因子のゲノムDNA配列上の結合位置および/または (c) 該制御領域によって制御される遺伝子および/または (d) この遺伝子によってコードされる蛋白質についての表化された記述を含むことができる。ゲノムDNAの制御領域はプロモーターおよびエンハンサーを含む。そのようなデータベースは既述した親和性の強さのパラメターおよび/または相互作用の様式および/または相互作用の構造的要素をも含むことができる。そのようなデータベースは、化合物のいずれかまたはそのいずれかの組み合わせを投与したときにその発現が影響を受ける蛋白質または部分蛋白質の表化された記述を含むこともできる。その場合、化合物のいずれかまたはそのいずれかの組み合わせの投与は無細胞の系、細胞による系、組織による系、器官による系、および動物全体による系のアッセイ法のいずれか、またはそのいずれの組み合わせにおいて行われていてもよい。
【0057】
さらに、SNPs(単塩基多型マーカー)を表化した形で記述してデータベースが構築される。その場合SNPsは、その蛋白質をコードする遺伝子のエクソン内および/またはその蛋白質をコードする遺伝子を制御する制御領域内および/またはその蛋白質をコードする遺伝子の転写を開始する転写因子が結合するゲノムDNA配列上の部位内にあってよい。さらに、その蛋白質をコードする遺伝子のエクソン内におけるSNPsの位置および/もしくは型ならびに/または各SNPが対応する蛋白質のアミノ酸残基の変化を起こすかどうかならびに/またはそのようなアミノ酸残基の変化が蛋白質の3次元構造および/もしくは生物学的機能に影響するかどうかの記述も含められる。同様に、その蛋白質をコードする遺伝子を制御する制御領域内におけるSNPsの位置および/もしくは型、ならびに/またはその蛋白質をコードする遺伝子の転写を開始する転写因子のゲノムDNA配列上の結合部位を表化した形で記述してデータベースを作成することができる。
【0058】
上記のすべてのデータベースは蛋白質または部分蛋白質をコードする遺伝子から転写されるスプライス・ヴァリアントmRNAの表化された記述を含むことができる。上記のデータベースはさらに、上記mRNAのRNA配列、これらのRNA配列から翻訳されるアミノ酸配列、および/またはこれらのアミノ酸配列からフォールディングによって生ずる3次元構造を含み得る。本発明のデータベースは薬理学的活性および臨床的適応のような化合物の属性を含むことができ、プロファイルの形で表化できる。臨床的適応とは、医学的な目的のために化合物が用いられる疾患や症状ばかりでなく、十二指腸潰瘍の治癒促進、血漿コレステロールの低下のような臨床的効果をも意味する。薬理学的活性には臨床薬理学的活性を含むことができ、場合により臨床的適応と同義となりうる。さらに薬理学的活性の有無および/または薬理学的活性の程度を表の形で記述した、そのような薬理学的活性プロファイルのデータベースは多数の化合物についてのデータを収めた別のデータベースに集約することができる。同様に、本発明のデータベースはプロファイルの形で表化された毒性および有害な副作用のような化合物の他の属性を含むことができる。毒性には臨床的毒性を含むことができ、これは有害な副作用と同義としてよい。さらに毒性の有無および/または毒性の程度を表の形で記述した、そのような毒性プロファイルのデータベースは多数の化合物についてのデータを収めた別のデータベースに集約することができる。蛋白質−蛋白質相互作用に関与する蛋白質の少なくとも一つが分子量1,600未満、1,000未満、600未満、または500未満の化合物および/または医療用として承認された化合物と相互作用できるとき、そのような蛋白質−蛋白質相互作用を表化して記述することを特徴とするデータベースを構築することができる。また、複数の蛋白質または部分蛋白質の少なくとも一つが分子量1,600未満、1,000未満、600未満、または500未満の化合物および/または医療用として承認された化合物と相互作用できるとき、複数の蛋白質または部分蛋白質間の相互作用のネットワークを表化あるいはグラフ化した記述を特徴とするデータベースを構築することができる。
【0059】
上記のデータベースのいずれかまたはそのいずれかの組み合わせからの出力を表化またはグラフ化した形で提示するユーザーインターフェースが構築される。
【0060】
上記のデータベースのいずれかまたはそのいずれかの組み合わせを用いることを特徴とする化合物についての情報を検索する方法であって、その化合物と相互作用する蛋白質もしくは部分蛋白質、および/または他の蛋白質もしくは他の部分蛋白質と相互作用できる蛋白質もしくは部分蛋白質、および/または、その化合物によって発現が影響を受ける蛋白質もしくは部分蛋白質、および/または蛋白質もしくは部分蛋白質の一部またはすべてとその化合物が含まれる相互作用のネットワーク、および/または、その化合物に関する情報およびその相互作用ネットワークに含まれる蛋白質もしくは部分蛋白質に関する情報を検索する方法があると便利である。
【0061】
これまでの段落の中で記載された方法を用いることによって得られる出力を表化および/またはグラフ化した形で提示するユーザーインターフェースを構築するとさらに便利である。相互作用を提示するそのようなユーザーインターフェースは、化合物と蛋白質もしくは部分蛋白質の間を線で結び、蛋白質もしくは部分蛋白質と他の蛋白質もしくは他の部分蛋白質の間を別の線で結び、各化合物および各蛋白質もしくは各部分蛋白質を結節として相互作用ネットワークのなかに表現することによって、より便利にすることができる。そのようなユーザーインターフェースは、相互作用ネットワークのなかに相互作用の強度を、望ましくは結合および/または解離速度定数および/または平衡時結合定数として表したものを提示したり、相互作用ネットワークに含まれる蛋白質の発現にその相互作用が与える影響の程度を提示することによって、さらに便利なものとなりうる。これらのユーザーインターフェースは、蛋白質をコードする遺伝子のエクソン内のSNPsおよび/またはその蛋白質をコードする遺伝子を制御する制御領域内のSNPsおよび/またはその蛋白質をコードする遺伝子の転写を開始する転写因子が結合するゲノムDNA配列上の部位内のSNPsに関する情報を表化および/またはグラフ化した形で収めることができる。これらのユーザーインターフェースは、さらに、この蛋白質をコードする遺伝子のエクソン内におけるSNPsの位置および/もしくは型ならびに/または各SNPが対応する蛋白質のアミノ酸残基の変化を起こすかどうか、ならびに/またはそのようなアミノ酸残基の変化が蛋白質の3次元構造および/もしくは生物学的機能に影響するかどうかに関する情報も表化および/またはグラフ化した形で収めることができる。これらのユーザーインターフェースのいくつかは、その蛋白質をコードする遺伝子を制御する制御領域内のSNPsの位置および/もしくは型、ならびに/またはその蛋白質をコードする遺伝子の転写を開始する転写因子のゲノムDNA配列上の結合部位に関する情報を表化および/またはグラフ化した形で収めることもできる。
【0062】
上記のデータベースのいずれかまたはそのいずれかの組み合わせを用いることを特徴とする、蛋白質または部分蛋白質(まとめて「質問対象蛋白質」と呼ぶ)についての情報を検索する方法であって、その質問対象蛋白質と相互作用する化合物、および/または該質問対象蛋白質と相互作用できる他の蛋白質もしくは他の部分蛋白質、および/または、該質問対象蛋白質によって発現が影響を受ける蛋白質、および/または、該質問対象蛋白質を含む蛋白質もしくは部分蛋白質の一部あるいはすべてならびにその化合物が関与する相互作用ネットワーク、および/または、相互作用ネットワークに含まれる化合物の各々に関する情報およびその相互作用ネットワークに含まれる蛋白質もしくは部分蛋白質の各々に関する情報を検索する方法もあると便利である。
【0063】
上記の方法を用いることから得られる出力を表化および/またはグラフ化した形で提示するユーザーインターフェースが構築される。
【0064】
上記のデータベースおよびユーザーインターフェースのいくつかまたはその組み合わせを用いることによって、蛋白質または部分蛋白質との相互作用の強度(望ましくは、結合および/または解離速度定数および/または平衡時結合定数として表わされる)が同一もしくは類似のプロファイルを持つ化合物としてどのようなものがあるかを検索したり、および/またはそのような化合物の各々についての情報を検索したりする方法を考案することが可能である。同様に、上記のデータベースおよびユーザーインターフェースのいくつかまたはその組み合わせを用いることによって、化合物との相互作用の強度(望ましくは、結合および/または解離速度定数および/または平衡時結合定数として表わされる)が同一もしくは類似のプロファイルを持つ蛋白質もしくは部分蛋白質としてどのようなものがあるかを検索したり、および/またはそのような蛋白質もしくは部分蛋白質の各々についての情報を検索したりする方法を考案することが可能である。
【0065】
上記の方法を用いることから得られる出力を表化および/またはグラフ化した形で提示するユーザーインターフェースが構築される。
【0066】
上記のデータベースおよびユーザーインターフェースのいくつかまたはその組み合わせを用いることによって、薬理学的活性および臨床的適応の点で同一もしくは類似のプロファイルを持つ化合物としてどのようなものがあるかを検索したり、および/またはそのような化合物の各々についての情報を検索したりする方法を考案することが可能である。同様に、上記のデータベースおよびユーザーインターフェースのいくつかまたはその組み合わせを用いることによって、毒性および副作用の点で同一もしくは類似のプロファイルを持つ化合物としてどのようなものがあるかを検索したり、および/またはそのような化合物の各々についての情報を検索したりする方法を考案することが可能である。
【0067】
上記の方法を用いることから得られる出力を表化および/またはグラフ化した形で提示するユーザーインターフェースが構築される。
【0068】
上記のデータベースおよびユーザーインターフェースのいくつかまたはその組み合わせを用いることによって、薬理学的活性および毒性の両方の点で同一もしくは類似のプロファイルを持つ化合物としてどのようなものがあるかを検索したり、および/またはそのような化合物の各々についての情報を検索したりする方法を考案することがもちろん可能である。
【0069】
上記の方法を用いることから得られる出力を表化および/またはグラフ化した形で提示するユーザーインターフェースが構築される。
【0070】
(a) 化合物と蛋白質または部分蛋白質との相互作用と (b) その化合物の薬理学的活性および/または毒性との関係を抽出するデータマイニングの方法を考案することが必要である。これは、蛋白質または部分蛋白質との相互作用に関するその化合物のプロファイルと、薬理学的活性および/または毒性に関するその化合物のプロファイルを比較することによって達成される。これらのプロファイルは既述のデータベースおよびユーザーインターフェースに記録されている。両者の関係のそのような抽出作業は、対象化合物に対して高い親和性を有する蛋白質もしくは部分蛋白質が対象化合物の薬理学的活性および/または毒性の原因となっているという仮定に基づくことができる。その化合物のプロファイルにおける蛋白質への親和性の強度のデータ、その蛋白質の機能に関する付加的情報、およびその蛋白質がどのような組織や細胞から得られるかという情報は特定の薬理学的活性および/または毒性の原因となっている単数または複数の蛋白質を同定するために用いられる。
【0071】
互いに親和性をもつ(a) 化合物と (b) 蛋白質または部分蛋白質の構造における関係を抽出するデータマイニングの方法を考案することも必要である。これは化合物の構造的カテゴリー(定義は下を見よ)と蛋白質または部分蛋白質の1次元、2次元、および3次元構造を、上記のデータベースおよびユーザーインターフェースに記録されている相互作用(親和性)のプロファイルと比較することによって達成される。
【0072】
この側面のデータマイニングはつぎの三つのカテゴリーに分けられる。各々を詳述する。
(1)単一蛋白質に対して複数の異なる化合物が親和性をもつ(複数化合物対単一蛋白質モード)
(2)単一化合物に対して複数の異なる蛋白質が親和性をもつ(複数蛋白質対単一化合物モード)
(3)複数の異なる化合物の各々が複数の異なる蛋白質の各々に親和性をもつ(複数対複数モード)
【0073】
第1番目は、(a)「被検索化合物」と称される複数の異なる化合物の各々が(b)単一蛋白質または単一部分蛋白質に対して親和性をもつときの(a)と(b)の構造における関係を抽出することである。これは被検索化合物の構造的カテゴリーを比較し、共通または類似の構造的カテゴリーを抽出することによって達成される。上述のデータベースおよびユーザーインターフェースは各化合物の属性として構造的カテゴリーをある程度収納しているのであるが、さらに便宜を図るためには別種のデータベースおよびユーザーインターフェースを構築する必要があるかもしれない。ここで、構造的カテゴリーとは、一群の異なる化合物から共通または類似する構造または下位構造を抽出しようとする試みから生まれるカテゴリーのすべてをいう。構造的カテゴリーには、カルボキシル基、アミノ基、ハロゲン、ならびにステロイド骨格およびインドール骨格のような部分構造または原子が含まれる。これは、構造中に特定の同項環または異項環を含むことを意味することもありうる。IUPACおよびIUPAC−IUB命名法の規則はそのような構造的カテゴリーを定義することができ、非常に有用であるが、これらの規則だけでは本発明の目的のためには不十分である。構造的カテゴリーは大きさ(次元)と形(シート、球、棒などとその組み合わせ)によって定義される特定の疎水性基の空間における位置によって定義されるかもしれない。いくつかのそのような疎水性基の空間における相対的位置が、その各々の大きさや形とともに重要かもしれない。(陽性または陰性に)荷電した原子または原子団については、1個あるいは複数の疎水性基とのその相対的位置、その大きさ、および静電力が届く距離(電場)が重要かもしれない。異なるグループを連結する鎖構造についてはどのようなものでもその長さと柔軟性が考慮される。回転に対する自由度も考慮される。水素結合を可能にする原子団の存在とその相対的位置は重要かもしれないし、さらにこの考慮は水分子による溶媒和に拡張されるかもしれない。これらのすべてと他の構造記述子は組み合わされ、異なる化合物が共有する共通性あるいは類似性の階層を形成することができる。そのような階層は、異なる構造的側面のどれに重要性の優先順位をつけるかによって、いくつかの異なる方法で構築される。また、構造的記述子の組み合わせから非階層的カテゴリーが生まれ、そのようなカテゴリーが異なる化合物で共通であったり、または類似であったりすることもあり得る。換言すれば、一群の異なる化合物の構造から抽出される共通の属性または類似の属性は、任意のレベルおよび任意の側面で、構造的カテゴリーと言うことができる。我々は、ある蛋白質に親和性をもっている一群の複数の化合物に特異的な構造的カテゴリーを抽出したいのであるから、異なる化合物のランダムなサンプルにしばしば見られる「非特異的構造的カテゴリー」と呼ばれる構造的カテゴリーは除いておく必要がある。これは、無作為に選んだ化合物のサンプルから共通の(類似のではない)構造的カテゴリーを抽出することによって実施される。そのようなサンプルの大きさは重要である。偏りを避けるためには複数のサンプルを利用する。非特異的構造的カテゴリーの集合は、サンプルの大きさ、用いられた無作為サンプルの数、およびこの目的のために選択された各無作為サンプルの化合物の多様性における特徴によって異なったレベルのものが構築される。一般に、サンプルが大きく、サンプル数が多いと、抽出される非特異的構造的カテゴリーの数は少なくなる。抽出カテゴリーの数が小さいそのような集合を「低いレベルの集合」と呼ぶ。本発明で使用する「構造的カテゴリー」という用語は、非特異的カテゴリーを含まない。選ばれたセットの化合物に特異的に結びついている構造的カテゴリーを見逃したくはないので、共通または類似の構造的カテゴリーから非特異的カテゴリーを除去するのに最初は低いレベルの集合を用い、段階的に集合のレベルを上げて行くのがよい。クラスタリングは別の用語で、これはある集合の要素を分割して、各下位集合の要素は互いに共通あるいは類似しているが他の下位集合の要素とは異なるような下位集合に分類する操作を意味する。谷本の類似性指標、PPP−三角法およびそのダイナミック版への変種、CoMFAおよびその他の方法がこの目的のために利用されている。多数の化合物についての複数の構造的記述子を用いたクラスタリングについては、総説がある (Brown, R. および Martin, Y. C., J. Chem. Inf. Comput. Sci. (1966) 36: 572−584 および同, (1997) 37: 1−9)。そのような構造的記述子を組み合わせることによって、各クラスターが一定の構造的カテゴリーを共有する多次元のクラスターが生ずる。対象蛋白質または部分蛋白質に親和性(すなわち、一定レベルより高い親和性)を共有する化合物から、そのような共通もしくは類似の構造的カテゴリーが抽出されれば、それらの構造的カテゴリーは、それらの化合物とその蛋白質または部分蛋白質との相互作用に関与している構造的カテゴリーの候補となる。この種のデータマイニングの目的の一つは、蛋白質との相互作用に関与していると想定される種々の構造的カテゴリーによって対象蛋白質をプローブし、かつ、被検索化合物を「化学的プローブ」として用いることによってその蛋白質を特徴付けることである。事前に共通のあるいは類似の構造的カテゴリーを抽出しないで、複数の化合物を用いて蛋白質を「化学的にプローブすること」については、後ほど Cox−1 および Cox−2 の基質と阻害剤について述べる際に、その(3)から(5)として記載される。一旦、強い相互作用が対象蛋白質とある種の化合物の各々との間に見出されたなら、それらの化合物から共通あるいは類似の構造的カテゴリーの抽出が試みられる。
【0074】
第1番目とは逆に、第2番目では、(a)まとめて「被検索蛋白質」と称される複数の異なる蛋白質または部分蛋白質の各々が(b)単一化合物に対して親和性をもつときの(a)と(b)の構造における関係を抽出する。これは最初に上述のデータベースおよびユーザーインターフェースに記録されている被検索蛋白質のアミノ酸配列を比較することによって達成される。対象化合物に対して親和性(すなわち、一定レベルより高い親和性)を共有する被検索蛋白質のあるものには共通(コンセンサス)または類似(コンセンサス相当)の部分配列を見ることができるかもしれない。そのような共通または類似の部分配列は、比較された複数の全長配列のなかでいくつかの個所に見出されることがあり得る。そのような共通または類似の部分配列および単一残基を含む鎖、そこではリンカーの位置にある配列は比較的重要でないのだが、そのような鎖が対象化合物に対して高い親和性をもつ異なる蛋白質の配列のなかに見出されるかもしれない。その場合、鎖の中での共通または類似の部分配列や単一残基の並び方は必ずしも同一でなくともよい。蛋白質もしくは部分蛋白質がその化合物に結合する際にそのような共通または類似の部分配列や残基が全体としてあるいは部分的に関与していると想定するのである。さらに、そのような配列や残基が全体としてあるいは部分的に蛋白質もしくは部分蛋白質の表面に化合物を適切に落着かせるための場所を、点、隆起など(または場合により低分子を引きつけたり、追いやったりする荷電した凹部)の形で作っていると想定するのである。最も信頼できるデータとしては同一またはそれと類似の化合物と蛋白質の複合体のX線結晶学的解析によって得られたデータ、最も信頼性が薄いデータとしてはそのような複合体のコンピューターによるモデリングによって得られたデータがあるが、これらを利用することにより、これらの落着きサイトの2次元または3次元マップを構築することもできるし、さらに、電場の特定と特徴づけ、分子間結合に寄与している水素結合の位置およびファン・デル・ワールス接触についての情報を得ることもできる。さらに、蛋白質上の低分子結合サイトの構造は、ねじれていて(つまり、ストレスを受けて)ポケットを形成し、熱力学的には不安定であるが、低分子をドックするには適しているという可能性もある。結合ポケットは、例えば、HIV−1プロテアーゼ(Judd, D.A.ら、J. Am. Chem. Soc. (2001) 123: 886−897) やCox−2 (Kurumbail, R. G.ら、Nature (1996) 384: 644−648)において観察されている。なんらかの理由で、これらの一見不安定な構造は実際には十分安定なのかもしれないし、便利なモデュールとして進化的に保存され、種々の生物によって利用されてきたのかもしれない。互いに構造の異なるそのようなモデュールがいくつかあるのかもしれない。熱力学的な制約があるので、これらのモデュールは数(したがって、種類)が限られてきたに違いない。それゆえ、進化を通じて生物はそれらの各々を利用して、多数の異なる蛋白質を作ってきた可能性がある。したがって、同一のモデュールが単一種の生物で多数の異なる蛋白質に見出されるかもしれない。同一のモデュールを共通にもつこれらの蛋白質は、類似の、関係ある、または異なった機能をもち得る。単一種の生物について、ある低分子に親和性をもつ広範囲の蛋白質について検索を行うなら、これらの進化的に保存されたモデュール、各々は先に述べた共通または類似の部分配列および残基を含む鎖で表わされているのであるが、そのようなモデュールは複数の蛋白質とその低分子との相互作用に共通に関与しているものとして同定し得る。そのような同定の機会は、種を越えて広範囲の異なる生物種について同様の検索を行ったときに増えるであろう。さらに、モデュールの各々について、落着きサイトの2次元または3次元マップを構築することもできるし、さらに、電場、分子間結合に寄与している水素結合の位置および/またはファン・デル・ワールス接触の同定と特徴づけも行うことが可能であろう。「化学的にプローブすること」によって、これらすべてが可能となるか、可能になり易くなると考えられる。
【0075】
最後に、(a)「被検索化合物」と称される複数の異なる化合物の各々が(b)まとめて「被検索蛋白質」と称される複数の異なる蛋白質または部分蛋白質の各々に対して親和性をもつときの(a)と(b)の構造における関係を抽出する。これは、複数対複数モードのデータマイニングであって、「化学的プロービング」の最も実り多い応用である。
【0076】
以下簡単のために、他の定義がないかぎり、蛋白質は蛋白質および部分蛋白質の両者を意味する。複数対複数モードのデータマイニングに関する記載は、部分的に、複数化合物対単一蛋白質モードおよび複数蛋白質対単一化合物モードのデータマイニングにも当てはまる。
【0077】
複数対複数モードのデータマイニングは、被検索蛋白質の各々に対して、例えばあるカットオフ点A0より大きい平衡時結合定数Aijによって表記される親和性をもつ被検索化合物の構造的カテゴリーを比較することによって共通あるいは類似の構造的カテゴリーを抽出することから始まる。つぎに、被検索蛋白質の各々に対応する共通または類似の構造的カテゴリー(以下、単に構造的カテゴリーと称する)をリストアップした表を作る。例えば、蛋白質P3は構造的カテゴリーH4、H7およびH8と結びついており、蛋白質P5はH2、H7およびH8と結びついているなどであるとき、そのような結合の存在を+記号で示した次の表を作成する。

【0078】
共通(コンセンサス)または類似(コンセンサス相当)の部分配列の抽出も同様になされるが、方法はより複雑である。まず、化合物Ciと蛋白質Pjの間の相互作用を示す、つぎのような表を作成する。ここで、+ 記号は、例えば親和性を平衡時結合定数Aijで表わしたとき、それがカットオフ点A0より大きいときに相互作用の存在を示す。
【0079】
共通または類似のワードをピックアップするとき、すでに化合物について行った非特異的構造的カテゴリーの除去と同じように、非特異的なワードを除去しておくという考え方があり得る。これは可能であるが、注意して行うべきである。本発明で定義される配列鎖は一つの文のようなものである。文においてしばしば出現する言葉が重要であるということは理解されよう。その出現の頻度が高いにもかかわらず、である。
【0080】
化合物の共通または類似の構造的カテゴリーからのアプローチと、蛋白質の共通および類似の配列ならびに3次元構造からのアプローチの、両方のアプローチの結果を合わせるなら、最も実り多い推論を得ることが期待できる。この議論を単純化するために、特定の化合物−蛋白質対の相互作用を考え、その構造的観点および様式を支持する豊富な周辺データが他の複数の化合物−蛋白質対における相互作用の評価からすでに得られているものとする。そのような状況下では、この相互作用に関与するものとして同定された化合物側の構造的カテゴリーと蛋白質側の部分配列は、その3次元構造とともに、高い確度で正しいものと考えてよいだろう。この高い確度での正しさ自体、価値がある。しかし、さらに価値が高いのは、すでに同定された配列と同じか類似の部分配列が、新しく発見された蛋白質にも認められるなら、その新しい蛋白質もその化合物に対して親和性があると、より高い確度で言えることである。その上に価値が高いのは、これまで述べた解析から定義される構造的カテゴリーと相互作用に関与する配列鎖の3次元構造に基づいて、特異的な結合サイトに高い親和性をもつ化合物の構造を設計することが容易となることである。結晶学的データから電場、水素結合および/またはファン・デル・ワールス接触に関して結合サイトが明らかになれば、そのような設計はさらに容易になるであろう。特に、薬物設計分野における多かれ少なかれ試行錯誤の現況から見れば、これは大きな進歩である。
【0081】
Cox−1 および Cox−2の基質と阻害剤に関する物語は上述の分析に洞察を与える。アラキドン酸はCox−1とCox−2の両方の基質である。非ステロイド性抗炎症剤(NSAIDs)はCox−1およびCox−2のサイクロオキシゲナーゼ活性部位に特異性なしに作用する。そのため胃に副作用が生ずる。これと対照的に、Cox−2に選択的ないくつかの阻害剤が強力な抗炎症作用をもち、胃への副作用が少ないものとして同定されてきた。この二つの酵素は約60%の配列同一性を示し、全体の3次元構造は高度に保存されている。このような事実と、すでに述べた進化的に保存されたモデュールに関する議論から、いくつかのことが言える。(1)アラキドン酸、フルビプロフェンおよびインドメサシンのようなNSAIDs、ならびにCox−2−選択的阻害剤であるSC−558のように、構造的に明らかに異なる低分子が同一の活性部位に結合する。(2)したがって、複数の低分子化合物が構造が違っていても、それらに対して蛋白質が同一あるいは同一に近い結合部位を有する場合があると仮定することができる。(3)そのような部位はそれらの分子をドックするための1個または複数のポケットを含み、それは単一のモデュールまたは数個の異なるモデュールの集合を含む。Kurumbail, R. G.らの結晶学的研究(前出)ならびにNSAIDsおよびSC−558とCox−1 およびCox−2の複合体に関する結晶学的研究は、そのような数個の異なるモデュールの集合の存在を示唆している。(4)同一の蛋白質に、構造が異なるにもかかわらず複数の低分子が高い親和性をもって結合することが見出されたとき、それらが同一あるいは同一に近い部位に結合するとの仮定は魅力的である(これは上述の(2)の逆である)。ただし、ここでファン・デル・ワールス接触および/または静電気的相互作用によるような非特異的な結合が優勢な場合は除く。(5)さらに、異なる低分子に対するそのような共通の結合部位が大抵の場合に一見熱力学的に不安定な構造であるポケットの形をしていて、それが進化的に保存された単一のモデュールまたは複数のモデュールの集合を含むとの仮定も魅力的である。(6)低分子のある集団が特定の異なる蛋白質の集団に高い親和性をもって結合することが見出されたとき、それらの蛋白質は同一または同一に近い結合部位をそれらの低分子に対して共通に持っているということを示している可能性がある。(7)その場合、これらの蛋白質のアミノ酸配列を比較すれば、共通または類似の部分配列および残基を同定できるかもしれない。これは既述の単一化合物が複数の蛋白質と相互作用する場合と同様である。(8)これらの共通または類似の部分配列および残基やそれらからなる単数または複数の配列鎖が進化的に保存されてきた単一モデュールや複数のモデュールの集合を構成している可能性がある。同時に、そのようなモデュールが低分子をドックするのに適したポケットを形作る可能性もある。(9)同一の低分子の集合に対して高い親和性をもつ進化的に関連した蛋白質の配列を異なる種の間で比較すれば、進化的に保存されたモデュールという考え方、ひいては進化的に保存されたポケットという考え方がさらに支持されるであろう。(10)Cox−1と Cox−2の場合のように近縁の蛋白質に対して化合物の分子間結合の親和性に大きな違いがあるという事実は、特定のモデュールおよび対応するポケットがそれぞれの蛋白質に存在していたり、欠如しているということを示唆する(例えば、前出Kurumbail, R. G.らが見出したCox−2におけるSC−558特異的ポケットの存在を見よ)。(文献上、ポケットの大きさについて明確な区別はない。大きいポケットは、より小さい複数のポケットを含むという可能性はある。そのような区別は、とくに明示しなかったが、上述の議論のなかに含まれる。)
【0082】
上述の方法を使用してできるデータベースは容易に構築される。上記の方法および/またはこれらの方法の使用によって構築されたデータベースを用いることから得られる出力を表化および/またはグラフ化した形で提示するユーザーインターフェースも同様に構築される。
【0083】
最後に、(a) 蛋白質または部分蛋白質と化合物の相互作用と、(b)蛋白質または部分蛋白質と他の蛋白質または部分蛋白質の相互作用の間にある関係を抽出するデータマイニングの方法を案出する必要がある。これは、上述のデータベースおよびユーザーインターフェースに記録されている蛋白質または部分蛋白質と化合物の相互作用のプロファイルと、蛋白質または部分蛋白質と他の蛋白質または部分蛋白質の相互作用のプロファイルとを比較することによって達成される。データベースおよびユーザーインターフェースはこれから構築される。
【0084】
上述のすべてを可能にするソフトウエアは、既存の知識と技術に基づいて容易に書かれうる。現在入手可能な技術を用いて、上述のデータベース、ユーザーインターフェース、およびソフトウエアを記録するフロッピー・ディスク、CD、CD−ROM、およびMDのような媒体は容易に作成される。上述のデータベース、ユーザーインターフェース、ソフトウエア、および媒体の使用に関連したサービスは容易に入手可能である。
【0085】
本発明の第一の利点は、薬物標的として有望な蛋白質のプールを確保する力にあるということが強調される。本発明のさらに重要な利点として、オリジネーター化合物が既知であるから、このオリジネーターの最適化によって直接新規かつ価値ある薬物を発見ならびに創製する効率的な方法を与える点が強調される。本発明の原理は、化学物質と蛋白質の相互作用が関心の対象である農薬、食品、環境、発酵、および畜産のような他の産業分野にも当てはまる。
【0086】
本発明によって開示された創薬の技術は、「ケモ−プロテオミクス」または「リバース・プロテオミクス」と名づけることができる。これは、一方通行の上流から下流へのゲノム科学/プロテオミクス・アプローチとは逆のアプローチである。それは、終点(化合物)から始まり、ゲノムの方向、すなわち上流に行くものである。
【0087】
本明細書に引用される全ての特許、特許出願、および刊行物は、参照として本明細書に組み入れられる。
【0088】
本発明は下記の実施例によってさらに示される。ただし、本発明はこれらの実施例によって制限されるものではない。
【0089】
実施例1.化合物結合型固相支持体、その蛋白質分離と新規薬物の発見・創製における利用
研究対象の化合物(オリジネーター)を、好ましくは共有結合によって、適当な反応および/または適当なスペーサー/リンカー物質(以後スペーサーと称する)の使用によりビーズのような固相支持体に結合する。低分子を化学反応によって結合することができる種々の固相支持体が商業的に入手可能である。それらは例えばPharmaciaから得られ、例えばCNBr−活性化セファロースや活性化チオールセファロースなどがあり、その場合、スペーサーのサイズは0から10原子の範囲である。未反応の対象化合物と試薬などの共雑物を除くために固相支持体を適当な溶液を用いて洗浄し、適当なクロマトグラフィー・カラムに適当な溶媒を用いて充填する。未知の蛋白質を含みうる蛋白質の混合物を適当な水溶液に溶かし、先のクロマトグラフィー・カラムに加える。カラムの洗浄は、対象化合物に十分な親和性をもたない蛋白質が洗浄除去されるように、適当な水溶液を用いてなされる。溶出は、固相支持体に結合させた対象化合物のフリー体溶液を用いることによってなされる。対象化合物のフリー体は固相支持体に結合した蛋白質への結合を求めて競合し、固相支持体から蛋白質を遊離させると考えられる。加えて、pHおよびイオン強度の点でそれぞれ特定の範囲にある適当な水性溶媒も用いうる。溶出は、対象化合物の濃度を段階的に変化させた溶液ならびに/またはpHおよびイオン強度を段階的に変化させた溶媒を用いることによって段階的に行うこともできる。溶出液は分取され、濃縮される。その場合、例えばミクロフィルターが使用される。各分画は蛋白質濃度に関して適宜調整され、ゲル電気泳動に付される。ゲル上の蛋白質は例えばクーマシー・ブルーを用いて染色され、可視化される。各バンドは標準分子量マーカーのバンドと比較され、溶出され、アミノ酸配列解析にかけられる。直接的に各蛋白質のアミノ酸配列データに基づいて、あるいは、間接的にcDNA配列のデータに基づいて、その蛋白質についての情報をNCBIまたはEMBLのようなデータベースから検索する。cDNA配列のデータは、アミノ酸配列データから適当な核酸プローブを設計し、適当なcDNAライブラリーからそのプローブにハイブリダイズするcDNA分子を得て、cDNA分子の配列解析を行うことによって得られる。その蛋白質が興味ある薬物標的であることがわかったら、オリジネーターの構造の基づき、より高い親和性および特異性を持つ化合物を得るための最適化過程が開始される。最適化過程は、既述のように、親和性以外の適当な評価方法により実施することもできる。オリジネーターのそのような最適化は新規で価値ある薬物の発見と創製につながることが期待される。仮に、データベースの検索によってその蛋白質が同定できないとき、データを保存しておき、後に追加的情報が手に入ったときにその蛋白質を薬物標的になりそうかどうか再評価する。ある化合物に対して所望の親和性をもつ蛋白質を得るのに洗浄に用いる溶媒のpHおよびイオン強度を適宜調整するという方法で得ることもできる。例えば、イオン強度が低いほど、その化合物への親和性が低い蛋白質がクロマトグラフィー・カラムに残りやすいと考えられる。結合した蛋白質を完全に溶出するためにイオン強度は高くすることができるが、望ましければ親和性の強さに応じて蛋白質が段階的に溶出するようにイオン強度を段階的に変化させることができる。
【0090】
固相支持体に結合した化合物をいわば蛋白質への餌として用いる限り、どのような変更も可能である。例えば、固相支持体はプレートの形であってもよい。蛋白質溶液が化合物を固定したプレートの上を流れるようにするか、または蛋白質溶液にプレートを浸した後、プレートを洗って、所望の親和性をもつ蛋白質をプレートから溶出することができる。プレートはウェルの形であってもよい。
【0091】
固相支持体に結合した化合物の溶液によって溶出がなされるとき、異なる化合物が結合されているビーズの混合品をクロマトグラフィー・カラムに充填することもできる。例えば、化合物A、B、Cを結合したビーズを混ぜるか、または作成して一本のカラムに充填する。次に蛋白質の混合溶液をカラムに加え、洗浄し、最初はAを含む溶液で溶出し、二番目にBを含む溶液で溶出し、それからCを含む溶液で溶出する。すると、最初の溶出液は化合物Aに対して親和性がある蛋白質を含んでいることが期待され、二番目の溶出液は化合物Bに対して親和性がある蛋白質を含んでいることが期待され、最後の溶出液は化合物Cに対して親和性がある蛋白質を含んでいることが期待される。このモードによる蛋白質の溶出を「異なる化合物のフリー体溶液の段階的適用による分別溶出」と呼ぶ。このやり方は、異なる化合物が同時に結合しているプレートやウェルのような他の形の固相支持体にも適用可能である。
【0092】
実施例2.化学物質結合型固相支持体を含む多重システムおよびその蛋白質分離への利用
例えば96穴型のような複数のウェルをもつプレートは複数の異なる化合物を収容できる。複数の蛋白質の混合物を含む溶液をそのようなプレート全体に接触させ、プレート全体を洗浄溶媒で洗浄後、溶出は個々のウェル毎に行う。これは、溶出溶媒をウェルに自動的に充填し、蛋白質と化合物との分離が行われるようにしばらく放置した後、各ウェルの内容物を自動的に吸引することにより便利に行われる。各ウェルから溶出液を集めるには、各ウェルに小孔を開け、別の受け容器の各ウェルに溶出液が重力により滴下するようにすることもできる。この場合、ガイドピンを用いれば、滴下はより効率的に受け器の各々に誘導される。洗浄および溶出のための溶媒の調製は個々のウェル毎にマニュアルで行うこともできるが、装置をコンピューター・プログラム化して自動化することにより、より便利に行うことができる。
【0093】
もう一つの型は多重化したミニ−クロマトグラフィー・カラムを含むプレートである。一定の厚さをもつプレートに多数の小孔をうがつ。プレートの底面を、溶媒を通すフィルターとしての働きと化合物を結合した固体を載せておく支持体としての働きの両方をもつシート状のもので緊密に覆う。各小孔には結合した化合物の異なる化合物結合固相支持体を充填する。この場合も、蛋白質の混合物を含む溶液がプレートの上方から化合物結合固相支持体に接触し、ついで洗浄と溶出が全小孔一度に、または小孔毎に分離して行われる。
【0094】
実施例3.固相支持体を用いて細胞表面上に存在する蛋白質を捕捉する方法および装置
実施例1に記載の方法にしたがって化合物をビーズ、プレートもしくはウェルに結合し、細胞を実施例1の単一物質型か、または実施例2の多重化型の固相支持体に捕捉せしめる。既知の細胞表面蛋白質に対する抗体を用いれば、対象化合物に結合した、異なる細胞表面蛋白質を区別できる。用いられた抗体に反応する蛋白質をその表面にもつ細胞は固相支持体から遊離するので、どのような細胞表面蛋白質が対象化合物に対して親和性を有していたかが明らかとなる。この操作を行う前に細胞をそのクラス、起源、および機能に応じて分別しておくこともできる。このような準備的手続は得られた結果の不確定性の度合いを減じる。蛋白質の同定を効率的に行うには、抗体の混合品を二分しておき、それぞれを最初の試験に用いて、その二つの混合品のどちらか陽性であったほうをさらに二分して(実際には事前に調製しておく)試験を行い、この工程を単一の抗原蛋白質が同定されるまで繰り返す。二分法以外の分け方も用いうる。ただし、抗体は全能ではないことに気をつけなければならない。ある蛋白質を通じて対象化合物に結合した細胞が必ず対応する抗体によって遊離するとは限らない。それは対象化合物と蛋白質との結合の部位または様式(例えば、静電気的あるいは他の)が抗体とその蛋白質との結合の部位または様式と異なる可能性があるからである。
【0095】
実施例4.遺伝子工学的に特定の蛋白質を高濃度に細胞表面上に発現するように調製された細胞の利用
既知蛋白質を高濃度に細胞表面に発現する。このような細胞を実施例3の化合物多重化型固相支持体に適用し、どの化合物がその細胞に対して親和性をもつか調べる。あるいは、異なる蛋白質を発現している細胞のパネルを調製し、これを実施例3の化合物結合固相支持体に適用する。 細胞表面発現蛋白質の区別は実施例3に述べた抗体を使用して行う。
【0096】
実施例5. 分別された蛋白質混合品の使用
文献にしたがって、クラス、細胞内局在、機能に関して分別された蛋白質の集合(すなわち、蛋白質ライブラリー)を得ることが実際上可能である。例えば、本條ら(米国特許第5,525,486号)、ジェイコブズ(米国特許第5,536,637号)、土屋ら(国際公開公報第99/60113号)の方法によって、分泌可能および細胞表面蛋白質をコードするcDNA分子をまとめて得ることができる。これらのcDNA分子は、全長のものでない場合は、適当な操作を加えて全長cDNAを得て、分泌可能および細胞表面蛋白質のライブラリーが得られる。同様に、細胞内の核に移行することができる蛋白質のライブラリーを、植木および矢野の方法(日本特許出願である特開2000−50882)によって得たcDNA分子から作ることができる。文献によれば、その機能および/またはリガンドが知られているかどうかにかかわらず、GPCR蛋白質をコードする多数のcDNA分子がすでに単離されている。そのようなcDNA分子はGPCR蛋白質ライブラリーを調製するために用いられる。マレイニミド化したビオチンで燐酸化蛋白質をビオチン化しておき、アヴィディン・カラムを用いてビオチン化した分子をアフィニティ分離することによりキナーゼのような燐酸化蛋白質のライブラリーを作ることも可能である。サイトカインおよびインターロイキンのように炎症性反応に関与する蛋白質が多数知られているが、これらもまた炎症性蛋白質のライブラリーを作るのに利用できる。
【0097】
実施例6.細胞外ヴィリオンの形で膜結合蛋白質を得る方法
ある種のウイルスを遺伝子工学的に変えて、異なる生物のものありながら本来の機能を保持している膜結合蛋白質を発現せしめることができる。一例は組換えバキュロ・ウイルス(Autographa californica multiple nuclear polyhedrosis virus)によって感染を受けたSpodoptera frugiperda (Sf9)細胞の使用である(Bouvier, M.ら、国際公開公報第98/46777号; Loisel, T.P.ら、 Nature Biotechnology (1997) 15:1300−1304)。これらの研究者はヒトのβ2−アドレナリン作動性受容体cDNAをコードする組換えバキュロ・ウイルスの感染を受けたSf9細胞から遊離されたウイルス粒子が生物活性のある糖鎖をもった対応する受容体を含んでいることを見出した。彼らはさらにM1−ムスカリン作動性またはD1−ドパミン作動性受容体をコードするバキュロ・ウイルスの感染を受けた細胞から由来したウイルス粒子が対応する受容体を含んでいることを示した。彼らはさらに、GPCRをコードするバキュロ・ウイルスの感染を受けたSf9細胞から細胞外ヴィリオンを集める方法は生物学的に活性の受容体を大量に作るための容易かつ一般的に適応しうる方法であるかもしれないこと、およびこの方法は不活性の(ミスフォールドされた)受容体を除くためのアフィニティ・クロマトグラフィー段階を必要とする粗製Sf9膜標品を用いるような精製方式に対して利点ある別法となるかもしれないことをコメントしている(Bouvier, M.ら、 Current Opinion in Biotechnology (1998) 9:522−527)。細網内皮系、核膜、およびゴルジ装置のような細胞内膜構造に存在していた生物学的に活性な膜蛋白質で外来性のものを発現することができるウイルス−細胞系もありうる。
【0098】
実施例7.ビアコア法および類似の方法の利用
固相支持体による親和性評価のより洗練された方法の一つは表面プラズモン共鳴測定によって可能となる。有名な例はBIACORE International ABによって商業化されているもので親和性の定量的データを容易に出すことができる。定量的情報を生み出すことができるビアコアに類似の装置もまた利用することができる。この場合、化合物(主として低分子)を固相支持体に結合させる様式と蛋白質のほうを固相支持体に結合させる様式のどちらもある。
【0099】
実施例8.化合物の化学的修飾を必要としない親和性評価方法
固相支持体を用いる親和性評価は、固相支持体に低分子化合物を結合させるために該化合物の化学的修飾が必要である。そのような化学的修飾は常に容易とは限らない。これを避けて化学的修飾を必要としない方法を用いることができる。その方法の一つはゲルろ過、ウルトラフィルトレーション、または透析法の使用によるサイズ・フラクショネーションである。蛋白質または部分蛋白質と化合物との相互作用を評価する方法は以下の連続的な段階を含む。
(1)評価対象の化合物を複数の蛋白質および/または部分蛋白質を含むライブラリーと混合し、相互作用が起きるようにいくらかの時間放置して、対象化合物とライブラリー中の蛋白質または部分蛋白質の解離が避けられるような条件でゲルろ過またはウルトラフィルトレーションにかける。
(2)段階(1)を繰り返して、ライブラリー中の大部分の蛋白質または部分蛋白質が分画されて、各分画には一種の蛋白質または一種の部分蛋白質しか含まないようにする。
(3)段階(1)および(2)で得られた、一種の蛋白質または一種の部分蛋白質を含む各分画をライブラリーの蛋白質または部分蛋白質から化合物を効果的に遊離させる条件に置き、さらにゲルろ過、ウルトラフィルトレーション、または透析法にかける。
(4)段階(3)から得られた各分画について対象化合物が存在するかどうかを調べ、存在する場合には、該化合物は一種の蛋白質または部分蛋白質に結合すると結論される。
(5)段階(4)で得られる対象化合物量の総和を段階(3)で得られる対応分画におけるもとの濃度に変換する。この濃度と段階(3)で得られた各分画における対応する一種の蛋白質または部分蛋白質の濃度から該化合物のその一種の蛋白質または部分蛋白質への親和性の強度に関する定量的情報が得られる。
【0100】
対象化合物が蛋白質または部分蛋白質から遊離することを避けるために、生理学的条件あるいはそれに近い条件が望ましい。蛋白質からの該化合物の効果的遊離は、 pHの調整、高イオン強度の適用、ならびにグリコール類、メタノール、エタノール、プロパノール、アセトニトリル、ジメチル・スルフォキサイド、テトラヒドロフラン、およびトリフルオロ酢酸などのような水と混合できる有機溶媒の使用を単一または組み合わせて行う。ゲルろ過(サイズ・エクスクルージョン・クロマトグラフィー)は蛋白質を先に排除するものであるし、ウルトラフィルトレーションは低分子を先にろ過するものであるので、段階(1)および(2)では前者を使用することが、段階(3)では低分子が遊離した後に後者を使用することが、この二つの技術を用いる場合には、望ましいかもしれない。遊離した化合物はUV吸収または他の検出もしくは定量手段により容易にモニターされる。複数の化合物を区別して検出または定量する手段があるなら、複数の化合物を混ぜたものと蛋白質ライブラリーとの相互作用を行わせる混合物対混合物モードが可能である。
【0101】
実施例9.固相支持体に結合した蛋白質の使用
化合物−蛋白質相互作用の検討のためには、固相支持体に、化合物を結合させる代わりに蛋白質を結合させることが可能である。例えば、実施例2に記載のシステムをこのスキームで用いることができる。ウェルまたはミニ−クロマトグラフィー・カラムを洗浄後、化合物を遊離させる条件を適用して対象化合物の遊離の有無を各ウェルまたはミニ−クロマトグラフィー・カラムについて検討する。いわゆるプロテイン・チップもこのような使用に適合させることができる。この蛋白質結合固相支持体のスキームのもとでのビアコア法またはそれに類似の方法の使用は、実施例7で述べたように化合物遊離の段階を必要としないので、有利である。
【0102】
実施例10.化合物−蛋白質相互作用に生物学的意義があるかどうかを評価する方法
説明のために、相互作用に関与する化合物と蛋白質をそれぞれ該化合物および該蛋白質と呼ぶことにする。
【0103】
細胞株を含めて多種類の細胞をすぐに使える状態にあることが望ましい。これらの細胞(試験細胞)は酵母、線虫、ショウジョウバエおよび他の動物、例えば哺乳動物、特にヒトからのものであってよい(環境や農薬を目的とする場合は微生物および植物からのものを含む)。さらに試験細胞としてすぐ使える状態にあるとよいものは、形態学的、物理化学的、ならびに/または特徴的な低分子リガンド、ペプチド、および蛋白質などの分泌を含む生化学的性質を示すことが知られている細胞である。さらに有利なのは、細胞外はもちろん細胞内のパラメターの変化をモニターする手段を持っていることである。そのような物理化学的および/または生化学的パラメターの例は、pH、カルシウム、サイクリックAMP、およびサイクリックGMPの濃度を含む。光学的な変化や電気生理学的変化もモニターしてよい。該蛋白質がどのクラスに属するかについての知識がない状態でさえ行うことができる最初のことは、毒性を示す濃度以下の濃度の該化合物で試験細胞を処理して、mRNAレベルにおける発現プロファイルに何が起きるかを、そのような処理をしていない細胞の場合(対照)と比較して、調べることである。そこである種の違いが認められても、該化合物が該蛋白質に対して有意に高い親和性および特異性をもっていて、かつ先の発現プロファイルにおける該化合物の濃度が十分低濃度でなければ、その違いは今評価している相互作用に基づくとは必ずしも言えない。これを明確にするには、該化合物の代わりに今評価している該蛋白質に対応するアンチセンス分子(AS)を用いる。ASで試験細胞を処理した場合の発現プロファイルの変化が、該化合物でその細胞を処理した場合の変化と類似または反対の方向の変化を生ずるならば、すでにアゴニストおよびアンタゴニストの項で述べたように、相互作用は生物学的に有意義であると結論される。加えて技術的には大変だが、評価対象蛋白質の発現を欠くノックアウト細胞およびそれを過剰発現する細胞も有用でありうる。これらの細胞は、対応する正常細胞において該化合物によって起こされた生物学的変化がこれらの遺伝子工学的に作られた細胞のいずれかに生じる変化と類似あるいは反対の方向かどうかを見るのに用いられる。配列情報を用いてデータベースを検索して該蛋白質を分類または同定しておくことはきわめて有用である。該蛋白質のクラスにしたがって、次のような評価がなされる。
【0104】
1.酵素(キナーゼを含む):酵素活性を測定する方法を工夫するか、または既存の方法を使用して、評価対象化合物の存在および非存在下での活性を比較する。
2.分泌蛋白質:評価対象蛋白質の機能が知られている場合には、評価対象化合物の存在によって機能が影響を受けるかどうかを調べる適当なアッセイ法を工夫する。該蛋白質の機能が知られていない場合には、該蛋白質の存在下で試験細胞の形態、物理化学的性質(例えばpH)、生化学的性質、電気生理学的性質、またはmRNAレベルにおける発現プロファイルのような分子生物学的性質に何が起きるかを見出しておく必要がある。一旦、ある変化が同定されたら、そのような変化が評価対象化合物の存在によって影響を受けるかどうかを検討する。さらに、以下に述べられる細胞表面膜結合蛋白質に対する方法も使用できる。
3.細胞表面膜結合蛋白質:評価対象化合物の存在および非存在下で試験細胞のmRNAレベルにおける発現プロファイルを比較する。該化合物が該細胞膜結合蛋白質に対して有意に高い親和性および特異性をもち、十分低い化合物濃度での実験であれば、発現プロファイルにおける変化は、それが観察されたとき、該化合物と該蛋白質の間の想定された相互作用の結果であり、そのような相互作用は生物学的に有意義であると予備的に推論することができる。この推論をさらに確かめるためには、該化合物の存在下での発現プロファイルと該蛋白質の代わりにそれに対応するASの存在下での発現プロファイルを比較することが必要である。もし評価対象相互作用が有意義であるなら、ASは類似の発現プロファイルか、またはその反対の発現プロファイルを生ずることが期待される。評価対象蛋白質と配列が類似している蛋白質が知られていて、さらにその類似蛋白質に対するアゴニストおよび/またはアンタゴニストが知られているならば、そのような物質の少なくとも一つによる変化が、該化合物による場合と類似の方向か反対の方向かを調べる実験を無細胞系および細胞系のどちらかで行う。そのような変化が観察されたら、それは評価対象の相互作用に生物学的意義があることの陽性の指標となる。
4.核内受容体:細胞表面膜結合蛋白質について記載されたものと同じ方法を用いる。
5.細胞内シグナル蛋白質:細胞表面膜結合蛋白質について記載されたものと同じ方法を用いる。
6.転写因子および転写に関係する蛋白質:細胞表面膜結合蛋白質について記載されたものと同じ方法を用いる。
7.分類不能または同定不能の蛋白質を含む他の蛋白質:細胞表面膜結合蛋白質について記載された方法のいずれかを用いる。
【0105】
実施例11.化合物と蛋白質の間の相互作用を検出または定量化する他の方法
化合物と蛋白質の間の相互作用を検出または定量化する他の方法としては、水晶発振子の共鳴振動数の変化を測定するもの、表面弾性波の変化を測定するもの、および質量分析を用いるものが含まれる。
【0106】
実施例12.蛋白質の分離におけるキャピラリー電気泳動の使用
一般的に化合物と結合している蛋白質は結合していない対応する蛋白質(つまりフリー体)と異なる泳動速度をもつので、結合体を対応するフリー体と区別して分離、検出、または定量することが可能である。この方法は化合物と蛋白質または部分蛋白質との間の相互作用を研究するために用いることができる。
【0107】
【表1】化合物Cの親和性データに基づく予測
クラスB相互作用:Cが多数かつ多種の蛋白質に親和性を示す場合
【表2】既知化合物および既知蛋白質間の相互作用データを用いて作成されたモデル行列の例
【図面の簡単な説明】
【図1】左側の蛋白質が右側の蛋白質に結合する蛋白質−蛋白質相互作用の結果、右側の蛋白質に形態学的な変化(頭状構造の背部の鼻と顎のような突起)が生じる。この形態学的(コンフォメーション)変化は、ある種の効果を生ずるか、さらに別の蛋白質−蛋白質相互作用を誘導することができる。
【図2】異なる結合部位をもつ二つの違う化合物を組合わせて用いれば、右側の蛋白質の形態学的変化が生じない。
【図3】蛋白質の運動は、ある種の低分子化合物がその蛋白質の可動構造に存在することによって制限を受ける。このような運動の制限によって、蛋白質の機能の阻害が生じうる。ここでは、蛋白質分子の蝶番様または関節様構造のなかに挿入されて低分子化合物がクサビとして作用する例を示している。
【図4】低分子化合物−蛋白質間の協調的相互作用の例。この図は、同一低分子種による協調的相互作用の例を示しているが、同様の協調的相互作用は異なる低分子種の組合せによっても起こすことができ、その場合のほうが強い効果を示すことがありうる。
Claims (259)
- 蛋白質または部分蛋白質と化合物との相互作用に関するデータの集まり、データベースまたはカタログ。
- 蛋白質または部分蛋白質と化合物との相互作用の表化された記載を特徴とする、請求項1に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が分子量1,600未満の化合物からなる集団から選択される、請求項1または請求項2に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が分子量1,000未満の化合物からなる集団から選択される、請求項1または請求項2に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が分子量600未満の化合物からなる集団から選択される、請求項1または請求項2に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が分子量500未満の化合物からなる集団から選択される、請求項1または請求項2に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が医療用として承認された薬物の集団から選択されたものである、請求項1から請求項6のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該相互作用の有無の記載が含まれる、請求項1から請求項7のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該相互作用が親和性の強度のパラメターおよび/または相互作用の様式および/または相互作用の構造的要素によって定義される、請求項1から請求項8のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 親和性の強度の該パラメターが(a)結合速度定数および/もしくは解離速度定数、ならびに/または(b)平衡時の結合定数および/もしくは平衡時の解離定数を意味する、請求項9に記載のデータの集まり、データベースまたはカタログ。
- 該相互作用様式がファン・デル・ワールス力による相互作用、水素結合、静電気的相互作用、チャージ・トランスファー、疎水的、親水的、親油的相互作用、および協調的結合もしくは協調的相互作用のいずれかまたはそのいずれかの組み合わせを意味する、請求項9または請求項10に記載のデータの集まり、データベースまたはカタログ。
- 相互作用の該構造的要素が、相互作用部位、相互作用部位の構造、相互作用する群、相互作用するアミノ酸残基、相互作用する原子、相互作用表面、ならびに相互作用する群、相互作用するアミノ酸残基、相互作用する原子および/もしくは相互作用表面の、1次元、2次元もしくは3次元空間における相対的な位置のいずれかまたはそのいずれかの組み合わせを意味する、請求項9から請求項11のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 単一蛋白質または単一部分蛋白質と複数の化合物の各々との相互作用に関するデータの集まり、データベースまたはカタログ。
- 単一蛋白質または単一部分蛋白質と複数の化合物の各々との相互作用の表化された記載を特徴とする、請求項13に記載のデータの集まり、データベースまたはカタログ。
- 複数の蛋白質または複数の部分蛋白質の各々と単一化合物との相互作用に関するデータの集まり、データベースまたはカタログ。
- 複数の蛋白質または複数の部分蛋白質の各々と単一化合物との相互作用の表化された記載を特徴とする、請求項15に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が請求項3から請求項6のいずれか一項によって定義される、請求項13から請求項16のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が請求項7によって定義される、請求項17に記載のデータの集まり、データベースまたはカタログ。
- 該相互作用の有無の記載が含まれる、請求項13から請求項18のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該相互作用が親和性の強度のパラメターおよび/または相互作用の様式および/または相互作用の構造的要素によって定義される、請求項13から請求項19のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 親和性の強度の該パラメターが(a)結合速度定数および/もしくは解離速度定数、ならびに/または(b)平衡時の結合定数および/もしくは平衡時の解離定数を意味する、請求項20に記載のデータの集まり、データベースまたはカタログ。
- 該相互作用様式がファン・デル・ワールス力による相互作用、水素結合、静電気的相互作用、チャージ・トランスファー、疎水的、親水的、親油的相互作用、および協調的結合もしくは協調的相互作用のいずれかまたはそのいずれかの組み合わせを意味する、請求項20または請求項21記載のデータの集まり、データベースまたはカタログ。
- 相互作用の該構造的要素が、相互作用部位、相互作用部位の構造、相互作用する群、相互作用するアミノ酸残基、相互作用する原子、相互作用表面、ならびに相互作用する群、相互作用するアミノ酸残基、相互作用する原子および/もしくは相互作用表面の、1次元、2次元もしくは3次元空間における相対的な位置のいずれかまたはそのいずれかの組み合わせを意味する、請求項20から請求項22のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質が細胞溶解液に由来するものである、請求項1から請求項23のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質が遺伝子工学的に人工的に調製されたものである、請求項1から請求項24のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質が全長cDNAから発現されたものである、請求項1から請求項25のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質がクラス、活性または局在性に関して焦点をあてたものである、請求項1から請求項26のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該活性が酵素的である、請求項27に記載のデータの集まり、データベースまたはカタログ。
- 該局在性が細胞表面、細胞質または核のいずれかである、請求項27に記載のデータの集まり、データベースまたはカタログ。
- 該局在性が細胞型、起源の組織および/または起源の器官である、請求項27に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質が細胞の膜構造に結合しているものである、請求項1から請求項26のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質がGPCRであるか、またはそれに由来するものである、請求項31に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質が細胞外ヴィリオンに発現したものである、請求項31または請求項32に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質が、緩和な界面活性剤または緩和な界面活性剤の混合物を含む溶液によって物理化学的に細胞を処理することによって得られたものである、請求項31から請求項33のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 化合物が分子量1,600未満の化合物からなる集団から選択されることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 化合物が分子量1,000未満の化合物からなる集団から選択されることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 化合物が分子量600未満の化合物からなる集団から選択されることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 化合物が分子量500未満の化合物からなる集団から選択されることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 化合物が医療用として承認された薬物の集団から選択されたものであることを特徴とする、請求項35から請求項38のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質が細胞溶解液に由来することを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質が遺伝子工学的に人工的に調製されたものであることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質が全長cDNAから発現されたものであることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質がクラス、活性または局在性に関して焦点をあてたものであることを特徴とする、請求項40から請求項42のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 該活性が酵素的であることを特徴とする、請求項43に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 該局在性が細胞表面、細胞質または核のいずれかであることを特徴とする、請求項43に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 該局在性が細胞型、起源の組織および/または起源の器官であることを特徴とする、請求項43に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質が細胞の膜構造に結合しているものであることを特徴とする、請求項40から請求項42のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質がGPCRであるか、またはそれに由来するものであることを特徴とする、請求項47に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質のキャリアーが細胞であることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質のキャリアーが細胞外ヴィリオンであることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質が、緩和な界面活性剤または緩和な界面活性剤の混合物を含む溶液によって物理化学的に細胞を処理することによって得られたものであることを特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 相互作用が親和性の強度のパラメターおよび/または相互作用の様式および/または相互作用の構造的要素によって定義される、請求項35から請求項51のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 親和性の強度の該パラメターが(a)結合速度定数および/もしくは解離速度定数、ならびに/または(b)平衡時の結合定数および/もしくは平衡時の解離定数を意味する、請求項52に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 相互作用様式がファン・デル・ワールス力による相互作用、水素結合、静電気的相互作用、チャージ・トランスファー、疎水的、親水的、親油的相互作用、および協調的結合もしくは協調的相互作用のいずれかまたはそのいずれかの組み合わせを意味する、請求項52または請求項53に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 相互作用の該構造的要素が、相互作用部位、相互作用部位の構造、相互作用する群、相互作用するアミノ酸残基、相互作用する原子、相互作用表面、ならびに相互作用する群、相互作用するアミノ酸残基、相互作用する原子および/もしくは相互作用表面の、1次元、2次元もしくは3次元空間における相対的な位置のいずれかまたはそのいずれかの組み合わせを意味する、請求項52から請求項54のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 以下の段階を含む、新規の薬物標的として適当である蛋白質または部分蛋白質を同定する方法:
(1)選択された標的化合物に対して所望の親和性および特異性をもつ複数の蛋白質または部分蛋白質を選択する段階;
(2)該蛋白質または該部分蛋白質の構造および機能を特定する段階;および
(3)所望の機能をもつ単一蛋白質または単一部分蛋白質を選択する段階。 - 以下の段階を含む、薬物の発見方法:
(1)請求項56に記載の方法を用いて選択された該標的化合物の化学構造を検討する段階;および
(2)選択された該標的化合物の構造を化学的に修飾して、請求項56に記載の新規の薬物標的として適当である該蛋白質または該部分蛋白質に対して、修飾された化合物の親和性および特異性を最適化する段階。 - 選択された該標的化合物の分子量が1,600未満である、請求項56に記載の新規の薬物標的として適当である蛋白質または部分蛋白質の同定方法。
- 選択された該標的化合物の分子量が1,000未満である、請求項56に記載の新規の薬物標的として適当である蛋白質または部分蛋白質の同定方法。
- 選択された該標的化合物の分子量が600未満である、請求項56に記載の新規の薬物標的として適当である蛋白質または部分蛋白質の同定方法。
- 選択された該標的化合物の分子量が500未満である新規の薬物標的として適当である、請求項56に記載の蛋白質または部分蛋白質の同定方法。
- 選択された該標的化合物が医療用として承認されたものである、請求項56に記載の新規の薬物標的として適当である蛋白質または部分蛋白質の同定方法。
- 選択された該標的化合物が医療用として承認されたものである、請求項58から請求項61のいずれか一項に記載の新規の薬物標的として適当である蛋白質または部分蛋白質の同定方法。
- 選択された該標的化合物の分子量が1,600未満である、請求項57に記載の薬物の発見方法。
- 選択された該標的化合物の分子量が1,000未満である、請求項57に記載の薬物の発見方法。
- 選択された該標的化合物の分子量が600未満である、請求項57に記載の薬物の発見方法。
- 選択された該標的化合物の分子量が500未満である、請求項57に記載の薬物の発見方法。
- 選択された該標的化合物が医療用として承認されたものである、請求項57に記載の薬物の発見方法。
- 選択された該標的化合物が医療用として承認されたものである、請求項64から請求項67のいずれか一項に記載の薬物の発見方法。
- 該蛋白質または該部分蛋白質が微生物、植物、動物、昆虫、哺乳動物またはヒトを起源とするものである、請求項1から請求項34のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該蛋白質または該部分蛋白質が微生物、植物、動物、昆虫、哺乳動物またはヒトを起源とするものである、請求項35から請求項55のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用の評価方法。
- 該蛋白質または該部分蛋白質が微生物、植物、動物、昆虫、哺乳動物またはヒトを起源とするものである、請求項56および請求項58から請求項63のいずれか一項に記載の新規の薬物標的として適当である蛋白質または部分蛋白質の同定方法。
- 該蛋白質または該部分蛋白質が微生物、植物、動物、昆虫、哺乳動物またはヒトを起源とするものである、請求項57および請求項64から請求項69のいずれか一項に記載の薬物の発見方法。
- 該化合物が創薬研究の過程で得られたものである、請求項1から請求項34および請求項70のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- 該化合物が創薬研究の過程で得られたものである、請求項35から請求項55のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用の評価方法。
- 選択された該標的化合物が創薬研究の過程で得られたものである、請求項56および請求項58から請求項63のいずれか一項に記載の新規の薬物標的として適当である蛋白質または部分蛋白質の同定方法。
- 選択された該標的化合物が創薬研究の過程で得られたものである、請求項57および請求項64から請求項69のいずれか一項に記載の薬物の発見方法。
- 以下の段階を含む、化合物の毒性または副作用の原因となる蛋白質または部分蛋白質を同定する方法:
(1)該化合物に対して高い親和性および特異性をもつ複数の蛋白質または部分蛋白質を選択する段階;
(2)該蛋白質または該部分蛋白質の構造および機能を特定する段階;および
(3)該化合物の毒性または副作用の原因となる単一蛋白質または単一部分蛋白質を選択する段階。 - 以下の段階を含む、毒性および副作用が低減した化合物を発見する方法:
(1)請求項78に記載の方法に用いられた該化合物の化学構造を検討する段階;および
(2)該化合物の構造を化学的に修飾して修飾された化合物の毒性または副作用の原因となる蛋白質への親和性を最小化する段階。 - 該化合物が創薬研究の過程で得られたものであるか、または環境にとって有害なものである、請求項78に記載の化合物の毒性または副作用の原因となる蛋白質または部分蛋白質の同定方法。
- 該化合物が創薬研究の過程で得られたものであるか、または環境にとって有害なものである、請求項79に記載の毒性および副作用が低減した化合物を発見する方法。
- 1つまたは複数の該化合物が環境にとって有害なものである、請求項1から請求項34および請求項70のいずれか一項に記載のデータの集まり、データベースまたはカタログ。
- (a) 請求項56および請求項58から請求項63のいずれか一項に記載の方法を用いて選択された該標的化合物の化学構造を検討する段階;および(b) 計算化学的合成技術を用いることによって選択された該標的化合物から誘導可能な薬物様(drug−like)の化合物を仮想的に合成する段階を特徴とする、薬物様の化合物のリストの作成方法。
- 請求項83に記載の方法の使用によって構築されたデータの集まり、データベースまたはカタログ。
- 蛋白質または部分蛋白質の可動構造の運動に対する障害物として作用する化合物の使用を特徴とする、蛋白質または部分蛋白質の活性の修飾方法。
- 蛋白質の蝶番様または関節様構造のなかに挿入されてクサビとして作用する化合物による蛋白質または部分蛋白質の活性の修飾方法。
- 蛋白質または部分蛋白質に協調的に結合する、異なる化合物の組み合わせの使用を特徴とする、蛋白質または部分蛋白質の活性の修飾方法。
- 異なる化合物の組み合わせの使用を特徴とする、蛋白質−蛋白質相互作用の修飾方法。
- 複数の該化合物が複数の蛋白質の相互作用表面の異なる部位に結合するものである、請求項88に記載の蛋白質−蛋白質相互作用の修飾方法。
- 少なくとも1つの該化合物がいずれかの蛋白質の相互作用表面には存在しない部位に結合するものである、請求項88に記載の蛋白質−蛋白質相互作用の修飾方法。
- いずれかの蛋白質の可動構造の運動に対する障害物として作用する少なくとも1つの該化合物の使用を特徴とする、請求項88に記載の蛋白質−蛋白質相互作用の修飾方法。
- 少なくとも1つの該化合物がいずれかの蛋白質の蝶番様または関節様構造のなかに挿入されてクサビとして作用する、請求項88に記載の蛋白質−蛋白質相互作用の修飾方法。
- 複数の該化合物がいずれか一方の蛋白質または両方の蛋白質に協調的に結合するものである、請求項88に記載の蛋白質−蛋白質相互作用の修飾方法。
- 請求項85から請求項93のいずれか一項またはそのいずれかの組み合わせに記載の方法の治療的使用。
- 蛋白質または部分蛋白質の可動構造の運動に対する障害物として作用して該蛋白質の活性を修飾する、化合物の治療的使用。
- 蛋白質の蝶番様または関節様構造のなかに挿入されてクサビとして作用して蛋白質の活性を修飾する、化合物の治療的使用。
- 蛋白質に協調的に結合して蛋白質の活性を修飾する複数の異なる化合物の組み合わせの治療的使用。
- 蛋白質−蛋白質相互作用を修飾する複数の異なる化合物の組み合わせの治療的使用。
- 複数の該化合物が複数の蛋白質の相互作用表面の複数の異なる結合部位に結合するものである、請求項98に記載の複数の異なる化合物の組み合わせの治療的使用。
- 少なくとも1つの該化合物がいずれかの蛋白質の相互作用表面には存在しない部位に結合するものである、請求項98または請求項99に記載の複数の異なる化合物の組み合わせの治療的使用。
- 少なくとも1つの該化合物がいずれかの蛋白質の可動構造の運動に対する障害物として作用するものである、請求項98から請求項100のいずれか一項に記載の複数の異なる化合物の組み合わせの治療的使用。
- 少なくとも1つの該化合物がいずれかの蛋白質の蝶番様または関節様構造のなかに挿入されてクサビとして作用するものである、請求項98から請求項101のいずれか一項に記載の複数の異なる化合物の組み合わせの治療的使用。
- 複数の該化合物がいずれか一方の蛋白質または両方の蛋白質に協調的に結合するものである、請求項98から請求項102のいずれか一項に記載の複数の異なる化合物の組み合わせの治療的使用。
- 単一蛋白質または単一部分蛋白質に共通して結合する複数の化合物をリストアップしている、データの集まり、データベースまたはカタログ。
- 蛋白質−蛋白質相互作用に関与するいずれかの蛋白質またはいずれかの部分蛋白質に結合する複数の化合物をリストアップしている、データの集まり、データベースまたはカタログ。
- 以下の段階を含む、化合物と蛋白質との相互作用の生物学的意義を評価する方法:
(1)化合物が蛋白質に対して有意に高い親和性および特異性をもっている場合に、十分に低濃度の化合物で処理された試験細胞のmRNAレベルにおける発現プロファイルを対照の発現プロファイルと比較する段階、および/または
(2)該化合物の代わりに該蛋白質に対応するアンチセンス分子(AS)を用いて、アンチセンス分子を該細胞に処理した場合の発現プロファイルの変化が、該化合物を該細胞に処理した場合の変化と類似または反対の方向かどうかを調べる段階、および/または
(3)該蛋白質の発現を欠くノックアウト細胞または該蛋白質を過剰発現する細胞を用いて、対応する正常細胞において該化合物によって起こされた生物学的変化がこれらの遺伝子工学的に作成された細胞のいずれかに生じる変化と類似または反対の方向かどうかを調べる段階、および/または
(4)配列情報を用いてデータベースを検索することにより、該蛋白質を分類または同定する段階、および/または
(5)該蛋白質のクラスにしたがって以下の評価を行う段階:
1)酵素(キナーゼを含む):酵素活性を測定する方法を工夫するか、または既存の方法を使用して、評価すべき該化合物の存在および非存在下での活性を比較する;
2)分泌蛋白質:(a) 該蛋白質の機能が知られている場合には、該化合物の存在によって機能が影響を受けるかどうかを調べる適当なアッセイ法を工夫し、(b) 該蛋白質の機能が知られていない場合には、最初に該蛋白質の存在下で試験細胞の形態、物理化学的性質、生化学的性質、光学的変化、または電気生理学的性質に何が生じるかを見出し、ある変化が同定されたら、そのような変化が該化合物の存在によって影響を受けるかどうかを検討し、さらにまたはその代わりに、細胞表面膜結合蛋白質について記載の方法を使用する;
3)細胞表面膜結合蛋白質:評価すべき該蛋白質と配列が類似の蛋白質が知られている場合には、さらにその類似蛋白質に対するアゴニストまたはアンタゴニストが知られている場合には、無細胞系または細胞系のいずれかにおいて該化合物の存在とアゴニストまたはアンタゴニストの存在が生ずる変化が類似または反対の方向かどうかを調べる実験を行う;
4)核内受容体、細胞内シグナル蛋白質、転写因子および転写に関係する蛋白質:細胞表面膜結合蛋白質について記載されたものと同じ方法を用いる。 - 限定された数またはクラスの蛋白質または部分蛋白質に対して生物学的に有意義な親和性をもつ化合物を選択する段階を特徴とする、薬物または毒性物質の候補を同定する方法。
- 請求項107の方法によって同定された蛋白質への親和性を該候補の化学的修飾によってそれぞれ最適化するかまたは最小化することを特徴とする、薬物または毒性物質の無毒化代替物の発見方法。
- 化合物が生物学的に有意義な様式で相互作用する蛋白質の機能を同定することを特徴とする、化合物の薬理学的性質または毒性を定義する方法。
- 被検化合物の親和性プロファイルを、既知の化合物と既知の蛋白質との相互作用に関するデータを用いて作成された親和性プロファイルのモデル行列と比較する段階を特徴とする、被検化合物の薬理学的活性と毒性を予測する方法。
- 蛋白質−化合物相互作用が生物学的に有意義であることを特徴とする、蛋白質−化合物相互作用に関与する蛋白質の機能に関して化合物をアゴニストまたはアンタゴニストのいずれかとして同定する方法。
- 生物学的に有意義な蛋白質−化合物相互作用に関与する蛋白質を薬物標的として用いることを特徴とする、化合物のスクリーニング方法。
- 生物学的に有意義な蛋白質−化合物相互作用に関与する蛋白質を薬物標的として用いて該蛋白質の機能に関してアゴニストまたはアンタゴニストのいずれかを見出すことを特徴とする、化合物のスクリーニング方法。
- 親和性評価が用いられる、請求項112または請求項113に記載の化合物のスクリーニング方法。
- 細胞による系、組織による系、器官による系、および動物全体による系を別々に、またはその組み合わせて用いるものである、請求項112から請求項114のいずれか一項に記載の化合物のスクリーニング方法。
- 機能インディケーターを用いる評価法の使用を特徴とする、請求項112から請求項115のいずれか一項に記載のスクリーニング方法の使用によって見出された化合物をアゴニストまたはアンタゴニストのいずれかとして同定する方法。
- 請求項112から請求項115のいずれか一項に記載のスクリーニング方法の使用によって見出された化合物を請求項116に記載のアゴニストまたはアンタゴニストのいずれかとして同定する方法であって、該機能インディケーターが(a) 細胞外および/または細胞内pH、(b) 細胞外および/または細胞内の(b1) カルシウム、(b2) サイクリックAMPおよび/または(b3) その他生物学的意義がある物質の濃度、(c) 光学的変化、(d) 形態学的変化、ならびに(e) 電気生理学的変化のいずれかまたはそのいずれかの組み合わせである方法。
- 化合物の使用によって得られたmRNAレベルの発現プロファイルを、蛋白質―化合物相互作用に関与する蛋白質に対応するアンチセンス分子の使用によって得られたものと比較する段階を特徴とする、生物学的に有意義な蛋白質−化合物相互作用に関与する化合物をアゴニストまたはアンタゴニストのいずれかとして同定する方法。
- 化合物の使用によって得られたmRNAレベルの発現プロファイルを蛋白質―化合物相互作用に関与する蛋白質に対応するアンチセンス分子の使用によって得られたものと比較する段階を特徴とする、請求項112から請求項115のいずれか一項に記載のスクリーニング方法の使用によって見出された化合物をアゴニストまたはアンタゴニストのいずれかとして同定する方法。
- 化合物に対して親和性を有する蛋白質および/または部分蛋白質の分離における、該化合物を結合した固相支持体の使用。
- 該固相支持体がビーズの形であってクロマトグラフィー・カラムに充填されるものである、請求項120に記載の化合物を結合した固相支持体の使用。
- 該固相支持体がプレートの形である、請求項120に記載の化合物を結合した固相支持体の使用。
- 該固相支持体がウェルの形である、請求項122に記載の化合物を結合した固相支持体の使用。
- 化合物に親和性をもつ蛋白質または部分蛋白質の溶出が該化合物のフリー体溶液を用いることによってなされるものである、請求項120から請求項123のいずれか一項またはそのいずれかの組み合わせに記載の該化合物に親和性を有する蛋白質および/または部分蛋白質の分離における該化合物を結合した固相支持体の使用。
- 複数の化合物が結合している固相支持体を含む多重システムであって、結合している化合物の各々が分離して配置されているシステム。
- 複数の化合物が結合している固相支持体を含む多重システムであって、請求項125に記載の固相支持体が多重化したウェルの形であるシステム。
- 複数の化合物が結合している固相支持体を含む多重システムであって、請求項126に記載の親和性反応が終了した後各ウェルに単数または複数の小孔が作られるものであるシステム。
- 複数の化合物が結合している固相支持体を含む多重システムであって、請求項125に記載の固相支持体が多重化したミニ−クロマトグラフィー・カラムからなるプレートの形であるシステム。
- 結合している複数の化合物に親和性をもつ蛋白質または部分蛋白質の分離における請求項126から請求項128のいずれか一項またはそのいずれかの組み合わせに記載の多重システムの使用。
- 複数の異なる化合物に親和性がある蛋白質または部分蛋白質の分別分離における、異なる化合物の混合物を結合した固相支持体の使用。
- 蛋白質または部分蛋白質の分別溶出が複数の化合物のフリー体溶液を段階的に適用することによってなされるものである、請求項130に記載の複数の異なる化合物に親和性がある蛋白質または部分蛋白質の分別分離における異なる化合物の混合物を結合した固相支持体の使用。
- 固相支持体がビーズの形であり各種類のビーズは単一化合物を結合していてクロマトグラフィー・カラムに充填されるものである、請求項130もしくは請求項131またはその組み合わせに記載の複数の異なる化合物に親和性がある蛋白質または部分蛋白質の分別分離における複数の異なる化合物の混合物を結合した固相支持体の使用。
- 固相支持体がプレートの形である、請求項130もしくは請求項131またはその組み合わせに記載の複数の異なる化合物に親和性がある蛋白質または部分蛋白質の分別分離における複数の異なる化合物の混合物を結合した固相支持体の使用。
- 固相支持体がウェルの形である、請求項130もしくは請求項131またはその組み合わせに記載の複数の異なる化合物に親和性がある蛋白質または部分蛋白質の分別分離における複数の異なる化合物の混合物を結合した固相支持体の使用。
- 細胞表面上に蛋白質または部分蛋白質をもつ細胞を捕捉するための化合物結合固相支持体の使用。
- 固相支持体が多重システムである、請求項135に記載の細胞表面上に蛋白質または部分蛋白質をもつ細胞を捕捉するための化合物結合固相支持体の使用。
- 固相支持体がビーズ、プレート、またはウェルのいずれかの形である、請求項135または請求項136に記載の細胞表面上に蛋白質または部分蛋白質をもつ細胞を捕捉するための化合物結合固相支持体の使用。
- 細胞が遺伝子工学的に特定の蛋白質を高濃度に細胞表面上に発現するように調製されたものである、請求項135から請求項137のいずれか一項またはそのいずれかの組み合わせに記載の細胞表面上に蛋白質または部分蛋白質をもつ細胞を捕捉するための化合物結合固相支持体の使用。
- 請求項135から請求項138のいずれか一項またはそのいずれかの組み合わせに記載の細胞表面上に蛋白質または部分蛋白質をもつ細胞を捕捉するための化合物結合固相支持体の使用において、該蛋白質または該部分蛋白質をもつ結合した細胞を遊離させるための細胞表面上に存在する該蛋白質または該部分蛋白質に対する抗体の使用。
- 蛋白質または部分蛋白質と化合物との相互作用評価における、クラス、細胞内局在および/または機能に関して分別された蛋白質混合物の使用。
- 分別された該蛋白質混合物が分泌可能蛋白質またはその部分蛋白質、細胞表面蛋白質またはその部分蛋白質、細胞内の核に移行することができる蛋白質またはその部分蛋白質、GPCR蛋白質またはその部分蛋白質、燐酸化蛋白質またはその部分蛋白質、キナーゼまたは部分キナーゼ、ビオチン化した燐酸化蛋白質またはその部分蛋白質、炎症性蛋白質またはその部分蛋白質、サイトカインまたは部分サイトカイン、およびインターロイキンまたは部分インターロイキンのいずれかまたはそのいずれかの組み合わせである、請求項140に記載の分別された蛋白質混合物の使用。
- 細胞外ヴィリオンがバキュロ・ウイルスに由来するものである、請求項33に記載のデータの集まり、データベースまたはカタログ。
- 細胞外ヴィリオンがバキュロ・ウイルスに由来するものである、請求項50に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 蛋白質または部分蛋白質と化合物との相互作用の評価における蛋白質または化合物のいずれかが固相支持体に結合している場合の表面プラズモン共鳴測定の使用。
- 化合物の化学的修飾を必要としない蛋白質または部分蛋白質と該化合物との相互作用を評価する方法。
- サイズ・フラクショネーションの技術が用いられるものである、請求項145に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 以下の連続的な段階における請求項145または請求項146に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法:
(1)評価対象の化合物を複数の蛋白質および/または部分蛋白質を含むライブラリーと混合し、相互作用が起きるようにいくらかの時間放置して、対象化合物とライブラリー中の蛋白質または部分蛋白質の解離が避けられるような条件でゲルろ過またはウルトラフィルトレーションにかける;
(2)段階(1)を繰り返して、ライブラリー中の大部分の蛋白質または部分蛋白質が分画されて、各分画には一種の蛋白質または部分蛋白質しか含まないようにする;
(3)段階(1)および(2)で得られた、一種の蛋白質または一種の部分蛋白質を含む各分画を、ライブラリーの蛋白質または部分蛋白質から化合物を効果的に遊離させる条件に置き、さらにゲルろ過、ウルトラフィルトレーション、または透析法にかける;
(4)段階(3)から得られた各分画について対象化合物が存在するかどうかを調べ、存在する場合には、該化合物は一種の蛋白質または部分蛋白質に結合すると結論される;
(5)段階(4)で得られる対象化合物量の総和を段階(3)で得られる対応分画におけるもとの濃度に変換し、このもとの濃度と段階(3)で得られる各分画における対応する一種の蛋白質または部分蛋白質の濃度から該化合物のその一種の蛋白質または部分蛋白質への親和性の強度に関する定量的情報が得られる。 - 化合物を蛋白質から効果的に遊離する条件がpHの調整、高イオン強度の適用、および水と混合できる有機溶媒の使用を、単一または組み合わせて行うものである、請求項147に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 水と混合できる該有機溶媒がグリコール、メタノール、エタノール、プロパノール、アセトニトリル、ジメチル・スルフォキサイド、テトラヒドロフラン、およびトリフルオロ酢酸のいずれかまたはいずれかの組み合わせである、請求項148に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- ゲルろ過を含むサイズ・エクスクルージョン・クロマトグラフィーが段階(1)および/または(2)において用いられ、ウルトラフィルトレーションが段階(3)で用いられるものである、請求項147から請求項149のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 評価が混合物対混合物モードでなされる、請求項146から請求項150のいずれか一項に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 一群の異なる化合物を区別して検出または定量する手段が用いられるものである、請求項151に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 固相支持体に結合した蛋白質または部分蛋白質の使用を特徴とする、蛋白質または部分蛋白質と化合物との相互作用を評価する方法。
- 相互作用完了後に、蛋白質または部分蛋白質が結合したウェルまたはミニ−クロマトグラフィー・カラムに、
(1)洗浄段階、
(2)化合物を遊離させる条件を適用する段階、および
(3)遊離した化合物を評価する段階
を行うものである、請求項153に記載の蛋白質または部分蛋白質と化合物との相互作用を評価する方法。 - 化合物と蛋白質または部分蛋白質の間の相互作用を検出または定量化することにおける水晶発振子の共鳴振動数変化の測定、または表面弾性波変化の測定の使用。
- 請求項35から請求項55、請求項71、請求項75、請求項120から請求項141、請求項143、および請求項145から請求項154のいずれか一項に記載の方法、使用およびシステムにおける請求項155に記載の化合物と蛋白質または部分蛋白質の間の相互作用を検出または定量化することにおける水晶発振子の共鳴振動数変化の測定、または表面弾性波変化の測定の使用。
- 請求項35から請求項55、請求項71、請求項75、請求項120から請求項141、請求項143、および請求項145から請求項154のいずれか一項に記載の方法、使用およびシステムにおける請求項144に記載の蛋白質または部分蛋白質と化合物との相互作用の評価における蛋白質または化合物のいずれかが固相支持体に結合している場合の表面プラズモン共鳴測定の使用。
- 化合物と蛋白質または部分蛋白質の相互作用評価における蛋白質または部分蛋白質を分離するためのキャピラリー電気泳動の使用。
- 請求項35から請求項55、請求項71、請求項75、請求項143、および請求項145のいずれか一項に記載の方法における請求項158に記載の化合物と蛋白質または部分蛋白質の相互作用評価における蛋白質または部分蛋白質を分離するためのキャピラリー電気泳動の使用。
- 化合物と蛋白質または部分蛋白質の相互作用評価における検出または定量化のための質量分析の使用。
- 請求項35から請求項55、請求項71、請求項75、請求項120から請求項141、請求項143から請求項154、請求項158、および請求項159のいずれか一項に記載の方法、使用およびシステムにおける請求項160に記載の化合物と蛋白質または部分蛋白質の相互作用の評価における検出または定量化のための質量分析の使用。
- 化合物をすでに形成された複合体と相互作用させるか、または複合体を形成すべき蛋白質を含む混合液と相互作用させることを特徴とする、化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 複合体の形成を開始させるのに構成蛋白質を加えるか、または該複合体の形成に必要な試薬を加えることを特徴とする、請求項162に記載の化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 該試薬がATPである、請求項163に記載の化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 細胞を利用することを特徴とする化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 餌(bait)として作用する蛋白質をコードするDNA配列で細胞をトランスフェクトし、該蛋白質が該細胞中で発現された後、該蛋白質に対するアフィニティ・クロマトグラフィーを用いて該細胞の溶解液から該蛋白質をプル・ダウンすることを特徴とする請求項165に記載の細胞を利用することを特徴とする、化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 餌として作用する蛋白質をコードするDNA配列、アフィニティかぎとして作用する蛋白質またはポリペプチドをコードするDNA配列、および特異的なペプチダーゼによって開裂するペプチドをコードするリンカーDNA配列を含む融合遺伝子で細胞をトランスフェクトすることを特徴とする請求項166に記載の細胞を利用することを特徴とする、化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 該融合遺伝子が、餌として作用する蛋白質をコードするDNA配列、アフィニティかぎとして作用する複数の蛋白質および/またはポリペプチドをコードするDNA配列、およびそれぞれが特異的なペプチダーゼによって開裂する複数のペプチドをコードするリンカーDNA配列を含む、請求項167に記載の細胞を利用することを特徴とする化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 該複合体の組成が該化合物の存在下および非存在下で比較されるものである、請求項162から請求項168のいずれか一項に記載の化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 化合物の存在下および非存在下での複合体の組成の比較を特徴とする、化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果の生物学的意義を評価する方法。
- 該比較が細胞を用いて行われるものである、請求項170に記載の化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果の生物学的意義を評価する方法。
- 複合体の異なる構成蛋白質に結合する異なる低分子のコンビナトリアルな使用を特徴とする、複数の異なる蛋白質を含む複合体の機能を変化させる方法。
- 複合体の異なる構成蛋白質に結合する異なる低分子を組み合わせて用いるものである、請求項172に記載の方法の治療的使用。
- 治療的使用のための複合体の異なる構成蛋白質に結合する異なる低分子の組み合わせ。
- 化合物結合固相支持体、蛋白質結合固相支持体、サイズ・フラクショネーション、液体クロマトグラフィー、アフィニティ・クロマトグラフィー、キャピラリー電気泳動、表面プラズモン共鳴測定、水晶発信子の共鳴振動数変化の測定、表面弾性波変化の測定、および質量分析の使用のいずれかまたはいずれかの組み合わせの使用を特徴とする、請求項162から請求項169のいずれか一項に記載の化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果を評価する方法。
- 化合物結合固相支持体、蛋白質結合固相支持体、サイズ・フラクショネーション、液体クロマトグラフィー、アフィニティ・クロマトグラフィー、キャピラリー電気泳動、表面プラズモン共鳴測定、水晶発信子の共鳴振動数変化の測定、表面弾性波変化の測定、および質量分析の使用のいずれかまたはいずれかの組み合わせの使用を特徴とする、請求項170または請求項171に記載の化合物の蛋白質−蛋白質相互作用への効果または複数の異なる蛋白質を含む複合体への効果の生物学的意義を評価する方法。
- 以下の連続的な段階を含む、蛋白質または部分蛋白質と化合物の相互作用を評価する方法:
(1)タグつきの遺伝子をもつベクターで細胞をトランスフェクトする段階;
(2)該細胞に対応するタグをもつ対応する蛋白質を発現させる段階;
(3)該細胞を化合物で処理する段階;
(4)該細胞を溶解する段階;
(5)生じた細胞溶解液を直接または蛋白質分画のための適当な精製段階を踏んだ後バッチ的にまたはクロマトグラフィーによって該タグに対するアフィニティ分離にかけて該化合物の蛋白質からの解離が避けられる条件で溶出液を得て、
(6)段階(5)から生じた該溶出液を質量分析にかける段階;および
(7)生じたマス・スペクトルを該化合物による処理を行なわないで得られたものと比較する段階。 - 以下の連続的な段階を含む、蛋白質または部分蛋白質と複数の異なる化合物の相互作用を評価する方法:
(1)タグつきの遺伝子をもつベクターで細胞をトランスフェクトする段階;
(2)該細胞に対応するタグをもつ対応する蛋白質を発現させる段階;
(3)該細胞を該複数の異なる化合物で処理する段階;
(4)該細胞を溶解する段階;
(5)生じた細胞溶解液を直接または蛋白質分画のための適当な精製段階を踏んだ後バッチ的にまたはクロマトグラフィーによって該タグに対するアフィニティ分離にかけて該複数の化合物の蛋白質からの解離が避けられる条件で溶出液を得る段階;
(6)段階(5)から生じた該溶出液を質量分析にかける段階;および
(7)生じたマス・スペクトルを該複数の化合物による処理を行なわないで得られたものと比較する段階。 - 化合物の識別表示Ci 、蛋白質または部分蛋白質の識別表示Pj 、親和性測定の環境Ek 、測定された親和性Aijk 、Ciの化学構造SCi 、Pjの構造SPj 、Ciの環境kにおける構造SCik 、Pjの環境kにおける構造SPjk 、Ciの機能FCi 、Pjの機能FPj 、 Ciがどのように得られたかGCi、 Pjがどのように得られたかGPj、 Ciの標的蛋白質TCi、Pjの標的蛋白質TPj、ならびにその他の化合物および蛋白質または部分蛋白質にかかわるすべてまたは部分的な情報の集まりであることを特徴とする、データベースまたはカタログを構築するための蛋白質または部分蛋白質と化合物の相互作用評価から得られたデータの収集方法。
- 請求項179に記載の方法によって構築されたデータベースもしくはカタログ、または請求項35から請求項69、請求項71から請求項73、請求項75から請求項81、請求項106から請求項141、請求項143から請求項172、請求項175から請求項178のいずれか一項またはそのいずれかの組み合わせに記載の方法、使用、およびシステムの使用によって得られたデータから構築されたデータベースまたはカタログ。
- 以下のいずれかまたはいずれかの組み合わせによって構築されたデータベースまたはカタログ:
1.化合物Ciに対して定められた値より高い親和性値をもつ蛋白質もしくは部分蛋白質のAijkデータを並べることおよび/または該蛋白質もしくは部分蛋白質の構造を比較すること;
2.蛋白質または部分蛋白質Pjに対して定められた値より高い親和性値をもつ化合物のAijkデータを並べることおよび/または該化合物の構造を比較すること;
3.化合物と蛋白質または部分蛋白質に関してAijk データを以下のような様式でクラスタリングして配列すること:
1)親和性測定のために各化合物が化学的な修飾を受けたか否かを無視する;
2)化合物の製法(合成法および抽出法を含む)の違いを無視する;
3)各蛋白質または部分蛋白質が翻訳後修飾または蛋白質−蛋白質相互作用などにより修飾を受けたか否かを無視する;
4)蛋白質または部分蛋白質の製法の違いを無視する;
5)親和性測定の環境の違いを無視する;
6)化合物に関して、共通の構造および生物学的機能にしたがう;
7)蛋白質または部分蛋白質に関して、共通の構造および生物学的機能にしたがう;
8)上記のいずれかの組み合わせを行なう。 - 蛋白質または部分蛋白質のコンセンサス部分またはコンセンサス相当部分アミノ酸配列および/または構造が単一化合物に対して共通して高い親和性をもつことの原因でありうるという概念の使用。
- 化合物のコンセンサスまたはコンセンサス相当部分構造および/または骨格が単一の蛋白質または部分蛋白質に対して共通して高い親和性をもつことの原因でありうるという概念の使用。
- 請求項180または請求項181に記載のデータベースまたはカタログの検索を特徴とする、複数の蛋白質または部分蛋白質が単一化合物に対して高い親和性を共通してもつことの原因でありうるコンセンサスまたはコンセンサス相当部分アミノ酸配列または構造の同定方法。
- 請求項180または請求項181に記載のデータベースまたはカタログの検索を特徴とする、複数の化合物が単一蛋白質または部分蛋白質に対して高い親和性を共通してもつことの原因でありうるコンセンサスまたはコンセンサス相当部分構造および/または骨格の同定方法。
- 該部分アミノ酸配列が該蛋白質または部分蛋白質の可動構造に関係したものである、請求項184または請求項185に記載の複数の蛋白質または部分蛋白質が単一化合物に対して高い親和性を共通してもつことの原因でありうるコンセンサスまたはコンセンサス相当部分アミノ酸配列または構造の同定方法。
- 対象化合物の構造に大きさの減少、置換、大きさの拡大の化学的修飾を段階的に加えてAijk における変化を調べることを特徴とする、複数の化合物が単一蛋白質または部分蛋白質に対して高い親和性を共通してもつことの原因でありうる必須のコンセンサスまたはコンセンサス相当部分構造または骨格の検証または発見方法。
- 対象蛋白質または部分蛋白質にアミノ酸残基の段階的置換を加えてAijk における変化を調べることを特徴とする、複数の蛋白質または部分蛋白質が単一化合物に対して高い親和性を共通してもつことの原因でありうる必須のコンセンサスまたはコンセンサス相当部分アミノ酸配列または構造の検証または発見方法。
- 請求項182から請求項188のいずれか一項に記載の方法および概念のいずれかまたはそのいずれかの組み合わせの使用を特徴とする選択された標的蛋白質に対して親和性および特異性を最大化または最小化する化合物の化学構造の予測方法。
- (a)該蛋白質の発現を制御しているゲノムDNA配列上の制御領域および/または (b)該蛋白質をコードする遺伝子の転写を開始する転写因子のゲノムDNA配列上の結合位置および/または (c) 該制御領域によって制御される遺伝子および/または (d) 該遺伝子によってコードされる蛋白質が表化して記述されるものである、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180および請求項181のいずれか一項に記載のデータベース。
- 無細胞の系、細胞による系、組織による系、器官による系、および動物全体による系のアッセイ法のいずれかまたはいずれかの組み合わせにおいて化合物を単数または複数の組み合わせで投与したときに発現が影響を受ける蛋白質または部分蛋白質の表化された記述をさらに特徴とする、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181および請求項189のいずれか一項に記載のデータベース。
- 該蛋白質をコードする遺伝子のエクソン内のSNPsおよび/または該蛋白質をコードする遺伝子を制御する制御領域内のSNPsおよび/または該蛋白質をコードする遺伝子の転写を開始する転写因子が結合するゲノムDNA配列上の部位内のSNPsの表化した記述をさらに特徴とする、請求項190または請求項191に記載のデータベース。
- 該蛋白質をコードする遺伝子のエクソン内における該SNPsの位置および/または該蛋白質をコードする遺伝子のエクソン内における該SNPsの型および/または該SNPの各々が対応する蛋白質のアミノ酸残基の変化を起こすかどうかおよび/またはアミノ酸残基の該変化が該蛋白質の3次元構造および/または生物学的機能に影響するかどうかの表化された記述をさらに特徴とする、請求項192に記載データベース。
- 該蛋白質をコードする遺伝子を制御する制御領域内のSNPsの位置および/もしくは型、ならびに/または該蛋白質をコードする遺伝子の転写を開始する転写因子のゲノムDNA配列上の結合部位の表化した記述をさらに特徴とする、請求項192または請求項193に記載のデータベース。
- 該蛋白質または部分蛋白質をコードする遺伝子から転写されるスプライス・ヴァリアントmRNAの表化した記述を追加したことをさらに特徴とする、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181および請求項190から請求項194のいずれか一項に記載のデータベース。
- 該スプライス・ヴァリアントmRNAのRNA配列、該RNA配列から翻訳されるアミノ酸配列、および/または該アミノ酸配列のフォールディングから生ずる3次元構造の表化した記述をさらに特徴とする、請求項195に記載のデータベース。
- 蛋白質との該相互作用に関与する化合物の薬理学的活性および/または臨床的適応がプロファイルの形で表化されたものである、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181および請求項190から請求項196のいずれか一項に記載のデータベース。
- 請求項197に記載のデータベースから誘導される薬理学的活性の有無および/または薬理学的活性の程度の表化した記述をさらに特徴とする多数の化合物についてのプロファイルのデータベース。
- 蛋白質との該相互作用に関与する化合物の毒性および有害な副作用がプロファイルの形で表化されたものである、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181および請求項190から請求項198のいずれか一項に記載のデータベース。
- 請求項199に記載のデータベースから誘導される毒性および有害な副作用の有無ならびに/または毒性および有害な副作用の程度の表化した記述をさらに特徴とする多数の化合物についてのプロファイルのデータベース。
- 蛋白質−蛋白質相互作用の表化された記述を特徴とするデータベースであって、該相互作用に関与する少なくとも1つの蛋白質または少なくとも1つの部分蛋白質が分子量1,600未満、1,000未満、600未満、または500未満の化合物および/または医療用として承認された化合物と相互作用することができるものであるデータベース。
- 多数の蛋白質または部分蛋白質間の相互作用のネットワークを表化および/またはグラフ化して記述してあることを特徴とするデータベースであって、少なくとも1つの該蛋白質または少なくとも1つの部分蛋白質が分子量1,600未満、1,000未満、600未満、または500未満の化合物および/または医療用として承認された化合物と相互作用することができるものであるデータベース。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181および請求項190から請求項202のいずれか一項に記載のデータベースまたはそのいずれかの組み合わせからの出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181および請求項190から請求項203のいずれか一項に記載のデータベースおよびユーザーインターフェースまたはそのいずれかの組み合わせを用いることを特徴とする、化合物と相互作用する蛋白質もしくは部分蛋白質および/または他の蛋白質もしくは部分蛋白質と相互作用することができる蛋白質もしくは部分蛋白質および/または該化合物によって発現が影響を受ける蛋白質もしくは部分蛋白質および/または該蛋白質もしくは該部分蛋白質と該化合物が関与する相互作用のネットワークおよび/または相互作用の該ネットワークに関与する該化合物および蛋白質または部分蛋白質に関する情報に関して該化合物についての情報を探索する方法。
- 請求項204に記載の方法を用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 化合物と蛋白質または部分蛋白質の間を線で結び、蛋白質または部分蛋白質と他の蛋白質または他の部分蛋白質の間を別の線で結び、各化合物および蛋白質または部分蛋白質を結節として相互作用ネットワークのなかに表現することをさらに特徴とする、請求項204に記載のユーザーインターフェース。
- 望ましくは結合および/または解離速度定数および/または平衡時結合定数として相互作用の強度を表したものを提示し、さらに相互作用ネットワークに含まれる蛋白質の発現に該相互作用が与える影響の程度を提示することをさらに特徴とする、請求項205または請求項206に記載のユーザーインターフェース。
- 蛋白質をコードする遺伝子のエクソン内のSNPsおよび/または該蛋白質をコードする遺伝子を制御する制御領域内のSNPsおよび/または該蛋白質をコードする遺伝子の転写を開始する転写因子が結合するゲノムDNA配列上の部位内のSNPsに関する情報を表化および/またはグラフ化したフォーマットでさらに提示する、請求項205から請求項207のいずれか一項またはそのいずれかの組み合わせに記載のユーザーインターフェース。
- 蛋白質をコードする遺伝子のエクソン内におけるSNPsの位置および/または該蛋白質をコードする遺伝子のエクソン内におけるSNPsの型および/または各SNPが対応する蛋白質のアミノ酸残基の変化を起こすかどうか、および/またはアミノ酸残基の該変化が該蛋白質の3次元構造および/または生物学的機能に影響するかどうかに関する情報を表化および/またはグラフ化したフォーマットでさらに提示する、請求項205から請求項208のいずれか一項またはそのいずれかの組み合わせに記載のユーザーインターフェース。
- 蛋白質をコードする遺伝子を制御する制御領域内のSNPsの位置および/もしくは型、ならびに/または該蛋白質をコードする遺伝子の転写を開始する転写因子のゲノムDNA配列上の結合部位に関する情報を表化および/またはグラフ化したフォーマットでさらに提示する、請求項205から請求項209のいずれか一項またはそのいずれかの組み合わせに記載のユーザーインターフェース。
- まとめて「質問対象蛋白質」と呼ばれる蛋白質または部分蛋白質についての情報を検索する方法であって、該質問対象蛋白質と相互作用する複数の化合物、および/または該質問対象蛋白質と相互作用できる他の蛋白質もしくは他の部分蛋白質、および/または、該質問対象蛋白質によって発現が影響を受ける蛋白質、および/または、該質問対象蛋白質を含む該蛋白質もしくは部分蛋白質の一部またはすべてと該化合物を含む相互作用ネットワーク、および/または相互作用ネットワークに含まれる化合物の各々に関する情報および該相互作用ネットワークに含まれる蛋白質または部分蛋白質の各々に関して請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203および請求項205から請求項210のいずれか一項に記載のデータベースおよびユーザーインターフェースまたはそのいずれかの組み合わせを用いることを特徴とする情報検索方法。
- 請求項211に記載の方法を用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 蛋白質または部分蛋白質との望ましくは結合および/または解離速度定数および/または平衡時結合定数として表わした相互作用の強度が同一または類似のプロファイルを持つ異なる化合物を検索し、かつ/または該化合物の各々についての情報を検索する方法であって、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210および請求項212のいずれか一項に記載のデータベースおよびユーザーインターフェースまたはそのいずれかの組み合わせを用いることを特徴とする情報検索方法。
- 化合物との望ましくは結合および/または解離速度定数および/または平衡時結合定数として表わした相互作用の強度が同一または類似のプロファイルを持つ異なる蛋白質または異なる部分蛋白質を検索し、かつ/または該蛋白質または部分蛋白質の各々についての情報を検索する方法であって、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210および請求項212のいずれか一項に記載のデータベースおよびユーザーインターフェースまたはそのいずれかの組み合わせを用いることを特徴とする情報検索方法。
- 請求項213および/または請求項214に記載の方法を用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 薬理学的活性および臨床的適応の点で同一または類似のプロファイルを持つ異なる化合物を検索し、かつ/または該化合物の各々についての情報を検索する方法であって、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212および請求項215のいずれか一項に記載のデータベースおよびユーザーインターフェースまたはそのいずれかの組み合わせを用いることを特徴とする情報検索方法。
- 毒性および副作用の点で同一または類似のプロファイルを持つ異なる化合物を検索し、かつ/または該化合物の各々についての情報を検索する方法であって、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212および請求項215のいずれか一項に記載のデータベースおよびユーザーインターフェースまたはそのいずれかの組み合わせを用いることを特徴とする情報検索方法。
- 請求項216および/または請求項217に記載の方法を用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 薬理学的活性および毒性の両方の点で同一または類似のプロファイルを持つ異なる化合物を検索し、かつ/または該化合物の各々についての情報を検索する方法であって、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215および請求項218のいずれか一項に記載のデータベースおよびユーザーインターフェースまたはそのいずれかの組み合わせを用いることを特徴とする情報検索方法。
- 請求項219に記載の方法を用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218および請求項220のいずれか一項またはそのいずれかの組み合わせに記載のデータベースおよびユーザーインターフェースに記録された化合物の蛋白質または部分蛋白質との相互作用に関するプロファイルと、薬理学的活性および/または毒性に関するプロファイルを比較することによって(a) 該化合物と蛋白質または部分蛋白質との相互作用と (b) 該化合物の薬理学的活性および/または毒性との関係を抽出するデータマイニングの方法。
- 化合物のプロファイルにおける蛋白質への親和性の強度のデータ、該蛋白質の機能の情報、該蛋白質がどのような組織および細胞から得られるかという情報が特定の薬理学的活性および/または毒性の原因となっている単数または複数の蛋白質を同定するために用いられるものである、請求項221に記載のデータマイニングの方法。
- 請求項221または請求項222に記載の方法を用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 一つのグループの異なる化合物の構造から共通の属性または類似の属性(構造的カテゴリーと呼ぶ)を任意のレベルおよび任意の側面で抽出し、非特異的構造的カテゴリーを除く構造的カテゴリーをリストアップすることによって作られる表化されたデータベースの構築方法。
- 該グループの各化合物の蛋白質または部分蛋白質に対する親和性が特定のレベルより高いものである、請求項224に記載の構造的カテゴリーの表化されたデータベースを構築する方法。
- 複数の該グループに対して請求項225に記載の方法によって構築されたデータベースのいずれかの組み合わせによって作られる構造的カテゴリー・データベースの表化構築方法。
- 請求項224から請求項226のいずれか一項に記載の方法を用いて構築された構造的カテゴリーのデータベース。
- 請求項224から請求項226のいずれか一項に記載の方法および/または請求項227に記載のデータベースを用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 蛋白質、化合物および/または構造的カテゴリーを特定した問合せに対する請求項227に記載のデータベースからの回答および/または請求項228に記載のユーザーインターフェースからの回答を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 化合物の構造的カテゴリーと蛋白質または部分蛋白質の1次元、2次元、および3次元構造を、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218、請求項220、請求項223および請求項227から請求項229のいずれか一項またはそのいずれかの組み合わせに記載のデータベースおよびユーザーインターフェースに記録された相互作用のプロファイルと比較することを特徴とする、互いに親和性をもつ(a) 複数の化合物と (b) 複数の蛋白質または部分蛋白質の構造における関係を抽出するデータマイニングの方法。
- 請求項227から請求項229のいずれか一項に記載のデータベースおよびユーザーインターフェースを用いることを特徴とする、 (a)複数の異なる化合物の各々が(b)単一蛋白質または部分蛋白質に対して親和性をもつ場合の(a)と(b)の構造における関係を抽出するデータマイニングの方法。
- 請求項230または請求項231に記載の方法を用いて構築されたデータベース。
- 請求項230または請求項231に記載の方法および/または請求項232に記載のデータベースを用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 蛋白質と親和性をもつ種々の化合物を用いて蛋白質をプローブし、該蛋白質を該化合物に共通または類似の構造的カテゴリーによって特定する方法。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218、請求項220、請求項223、請求項227から請求項229、請求項232および請求項233のいずれか一項またはそのいずれかの組み合わせに記載のデータベースおよびユーザーインターフェースを用いることを特徴とする、(a)複数の異なる蛋白質または部分蛋白質の各々が(b)単一化合物に対して親和性をもつ場合の(a)と(b)の構造における関係を抽出するデータマイニングの方法。
- (a)複数の異なる蛋白質または部分蛋白質の各々が(b)単一化合物に対して親和性をもつ場合の(a)と(b)の構造における関係を抽出する請求項235に記載のデータマイニングの方法であって、該蛋白質のアミノ酸配列を比較して該蛋白質間で共通または類似の部分配列および残基を抽出することを特徴とするものである方法。
- (a)複数の異なる蛋白質または部分蛋白質の各々が(b)単一化合物に対して親和性をもつ場合の(a)と(b)の構造における関係を抽出する請求項236に記載のデータマイニングの方法であって、該蛋白質間で共通または類似の部分配列および残基を含む配列鎖を見出すことを特徴とするものである方法。
- 関係する電場、水素結合の位置および/またはファン・デル・ワールス接触についての結晶学的データおよび/またはコンピューター・モデリングの使用による同定と特徴づけがある場合またはない場合における、化合物のための落着きサイトの2次元または3次元マップを構築する方法であって、該落着きサイトが請求項236に記載の該部分配列および残基または請求項237に記載の該配列鎖を含む方法。
- 複数の蛋白質と低分子との相互作用に共通に関与しているものとして請求項237に記載の方法によって見出される進化的に保存された、共通または類似の部分配列および残基を含む配列鎖の全体または部分で表わされるモデュールの同定方法であって、単一種について該化合物に親和性をもつ蛋白質を広汎に検索することを特徴とするものである方法。
- 請求項239に記載の進化的に保存されたモデュールの同定方法であって、種を越えて広範囲の異なる種について検索することをさらに特徴とするものである方法。
- 関係する電場、水素結合の位置および/またはファン・デル・ワールス接触についての結晶学的データおよび/またはコンピューター・モデリングの使用による同定と特徴づけがある場合またはない場合における、請求項239または請求項240に記載の方法によって見出された進化的に保存されたモデュールに対応する落着きサイトの2次元または3次元マップを構築する方法。
- 請求項234から請求項241のいずれか一項に記載の方法を用いて構築されたデータベース。
- 請求項234から請求項241のいずれか一項に記載の方法および/または請求項242に記載のデータベースを用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- (a)複数の異なる化合物の各々が(b)複数の異なる蛋白質または部分蛋白質の各々に対して親和性をもつときの(a)と(b)の構造における関係を抽出するデータマイニングの方法であって、以下の段階の実施を特徴とする方法:
(1)該蛋白質の各々に対して、事前に定められたカットオフ点より大きい親和性を有する化合物の共通または類似の構造的カテゴリーを抽出する段階;
(2)該蛋白質の各々と結合する化合物の共通または類似の構造的カテゴリーをリストアップした結合プロファイルと称する表を作成する段階;および
(3)一組の構造的カテゴリーに対して同一または類似の結合プロファイルを示す蛋白質がその組の構造的カテゴリーを示す化合物に対して親和性をもつということ、および、該複数の蛋白質が該化合物に対して互いに共通または類似する少なくとも一つの結合サイトを持っているということを予測する段階。 - 該蛋白質の各々と該組の構造的カテゴリーを示す別の組の化合物との間の相互作用を検討することを特徴とする、請求項244に記載の方法を用いることによりなされる予測を検証する方法。
- (a)複数の異なる化合物の各々が(b)複数の異なる蛋白質または部分蛋白質の各々に対して親和性をもつときの(a)と(b)の構造における関係を抽出するデータマイニングの方法であって、該化合物と該蛋白質からなる2x2表を作成し、事前に定められたカットオフ点より高い親和性を示す化合物−蛋白質対の交差ボックスに記号を付し、または該表を作成せずに以下の段階を実施することを特徴とする方法:
(1)各化合物に対して該カットオフ点より高い親和性を示す蛋白質の配列からコンセンサスまたはコンセンサス相当部分配列を抽出する段階;
(2)複数の該蛋白質のすべての配列のコンセンサスまたはコンセンサス相当部分配列からワードと称する連続したアミノ酸コードの連なりを摘出する段階;
(3)複数の該蛋白質が該カットオフ点より高い親和性を示す化合物の各々に対して複数の該蛋白質から摘出されたワードをリストアップする別の2x2表を構築する段階、このとき起源となる蛋白質についての情報と起源となる蛋白質の配列における各ワードの位置の情報を保存しておく;および
(4)複数の該蛋白質の間で類似の位置にあって単一蛋白質内に共存するワードを含む配列鎖を化合物−蛋白質相互作用に関与しているものとして帰属させる段階。 - (a)複数の異なる化合物の各々が(b)複数の異なる蛋白質または部分蛋白質の各々に対して親和性をもつときの(a)と(b)の構造における関係を抽出する請求項246に記載のデータマイニングの方法であって、ワードの組の不完全な一致によって配列鎖が帰属されるものである方法。
- 請求項246または請求項247に記載の方法の使用によって帰属される配列鎖の3次元構造を構築する方法であって、類似の配列鎖をもち結晶学的データが入手可能なモデル蛋白質を検索し該データを参照することを特徴とするものである方法。
- 請求項244から請求項248のいずれか一項に記載の方法を用いて構築されたデータベース。
- 請求項244から請求項248のいずれか一項に記載の方法および/または請求項249に記載のデータベースを用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- (a)蛋白質または部分蛋白質と化合物の相互作用と(b)蛋白質または部分蛋白質と他の蛋白質または部分蛋白質の相互作用との関係を抽出するデータマイニングの方法であって、請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218、請求項220、請求項223、請求項227から請求項229、請求項232、請求項233、請求項242、請求項243、請求項249および請求項250のいずれか一項またはそのいずれかの組み合わせに記載のデータベースおよびユーザーインターフェースに記録されている蛋白質または部分蛋白質と化合物の相互作用のプロファイルと、蛋白質または部分蛋白質と他の蛋白質または部分蛋白質の相互作用のプロファイルとを比較することを特徴とするものである方法。
- 請求項251に記載の方法を用いて構築されたデータベース。
- 請求項251に記載の方法および/または請求項252に記載のデータベースを用いて得られる出力を表化および/またはグラフ化したフォーマットで提示するユーザーインターフェース。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218、請求項220、請求項223、請求項227から請求項229、請求項232、請求項233、請求項242、請求項243、請求項249、請求項250、請求項252および請求項253のいずれか一項またはそのいずれかの組み合わせに記載のデータベースおよびユーザーインターフェースを構築するソフトウエア。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218、請求項220、請求項223、請求項227から請求項229、請求項232、請求項233、請求項242、請求項243、請求項249、請求項250、請求項252および請求項253のいずれか一項またはそのいずれかの組み合わせに記載のデータベースおよびユーザーインターフェースの使用のためのソフトウエア。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218、請求項220、請求項223、請求項227から請求項229、請求項232、請求項233、請求項242、請求項243、請求項249、請求項250および請求項252から請求項255のいずれか一項またはそのいずれかの組み合わせに記載のデータベース、ユーザーインターフェース、およびソフトウエアを記録した媒体。
- 請求項1から請求項34、請求項70、請求項74、請求項82、請求項84、請求項104、請求項105、請求項142、請求項180、請求項181、請求項190から請求項203、請求項205から請求項210、請求項212、請求項215、請求項218、請求項220、請求項223、請求項227から請求項229、請求項232、請求項233、請求項242、請求項243、請求項249、請求項250および請求項252から請求項256のいずれか一項またはそのいずれかの組み合わせに記載のデータベース、ユーザーインターフェース、ソフトウエア、および媒体の使用に関連したサービス。
- 該部分蛋白質が相当する非全長cDNA 分子から発現したものである、請求項1から請求項257のいずれか一項に記載のデータベース、ユーザーインターフェース、方法、ソフトウエア、媒体、およびサービス。
- 該蛋白質が相当する完全長cDNA分子から発現され、翻訳後または別の様式で修飾されたものである、請求項1から請求項257のいずれか一項に記載のデータベース、ユーザーインターフェース、方法、ソフトウエア、媒体、およびサービス。
Applications Claiming Priority (11)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US23262600P | 2000-09-14 | 2000-09-14 | |
| US60/232,626 | 2000-09-14 | ||
| US26086701P | 2001-01-12 | 2001-01-12 | |
| US60/260,867 | 2001-01-12 | ||
| US27277401P | 2001-03-05 | 2001-03-05 | |
| US60/272,774 | 2001-03-05 | ||
| US29456301P | 2001-06-01 | 2001-06-01 | |
| US60/294,563 | 2001-06-01 | ||
| US29890001P | 2001-06-19 | 2001-06-19 | |
| US60/298,900 | 2001-06-19 | ||
| PCT/JP2001/008009 WO2002023199A2 (en) | 2000-09-14 | 2001-09-14 | Method, system, apparatus and device for discovering and preparing chemical compounds |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2004509406A true JP2004509406A (ja) | 2004-03-25 |
| JP2004509406A5 JP2004509406A5 (ja) | 2008-11-06 |
| JP5021143B2 JP5021143B2 (ja) | 2012-09-05 |
Family
ID=27540004
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2002527795A Expired - Lifetime JP5021143B2 (ja) | 2000-09-14 | 2001-09-14 | 医療および他の用途に用いる化合物の発見および創製のための方法 |
Country Status (5)
| Country | Link |
|---|---|
| US (1) | US20090156413A1 (ja) |
| EP (2) | EP2071481A3 (ja) |
| JP (1) | JP5021143B2 (ja) |
| AU (1) | AU2001286252A1 (ja) |
| WO (1) | WO2002023199A2 (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8058009B2 (en) | 2004-11-09 | 2011-11-15 | Reverse Proteomics Research Institute Co., Ltd. | Target protein and target gene in drug designing and screening method |
| US8153385B2 (en) | 2004-10-18 | 2012-04-10 | Reverse Proteomics Research Institute Co., Ltd. | Target protein and target gene in drug designing and screening method |
| US8178077B2 (en) | 2004-10-19 | 2012-05-15 | Reverse Proteomics Research Institute Co., Ltd. | Drug development target protein and target gene, and method of screening |
| JP2012108925A (ja) * | 2003-10-14 | 2012-06-07 | Verseon | リード分子交差反応の予測・最適化システム |
| KR101533745B1 (ko) * | 2013-07-30 | 2015-07-03 | 주식회사 엘지화학 | 정량적 검색이 가능한 분자 오비탈 데이터베이스 구축 방법 및 이를 이용하는 시스템 |
| KR20180031980A (ko) * | 2016-09-21 | 2018-03-29 | 전주대학교 산학협력단 | 마이크로 rna의 데이터 마이닝을 통한 마이크로 rna id의 분석방법 |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004170195A (ja) * | 2002-11-19 | 2004-06-17 | Reverse Proteomics Research Institute Co Ltd | タンパク質の固定化方法 |
| EP1730530A1 (en) * | 2004-03-03 | 2006-12-13 | Bayer Technology Services GmbH | Analytical platform and method for generating protein expression profiles of cell populations |
| CN104897826B (zh) * | 2015-06-16 | 2016-06-22 | 广西师范大学 | 一种用于细胞原位检测小分子化合物与靶蛋白相互作用的方法 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2879303B2 (ja) | 1993-01-14 | 1999-04-05 | 佑 本庶 | cDNAライブラリーの作製方法、および新規なポリペプチドとそれをコードするDNA |
| US5536637A (en) | 1993-04-07 | 1996-07-16 | Genetics Institute, Inc. | Method of screening for cDNA encoding novel secreted mammalian proteins in yeast |
| FR2761994B1 (fr) | 1997-04-11 | 1999-06-18 | Centre Nat Rech Scient | Preparation de recepteurs membranaires a partir de baculovirus extracellulaires |
| WO1999060113A1 (en) | 1998-05-20 | 1999-11-25 | Chugai Seiyaku Kabushiki Kaisha | Novel method for isolating gene |
| JP2000050882A (ja) | 1998-06-05 | 2000-02-22 | Herikkusu Kenkyusho:Kk | 核移行活性を有するペプチド |
| US6406921B1 (en) * | 1998-07-14 | 2002-06-18 | Zyomyx, Incorporated | Protein arrays for high-throughput screening |
| JP2003044349A (ja) * | 2001-07-30 | 2003-02-14 | Elpida Memory Inc | レジスタ及び信号生成方法 |
| US7659426B2 (en) * | 2003-12-01 | 2010-02-09 | Reverse Proteomics Research Institute Co., Ltd. | Target protein of anticancer agent and novel anticancer agent (spnal) corresponding thereto |
| WO2005054468A1 (ja) * | 2003-12-01 | 2005-06-16 | Reverse Proteomics Research Institute Co., Ltd. | 抗糖尿病剤の標的タンパク質及び対応する新規抗糖尿病剤「インスフル」 |
| JP4975444B2 (ja) * | 2004-11-09 | 2012-07-11 | 株式会社リバース・プロテオミクス研究所 | 創薬標的タンパク質及び標的遺伝子、並びにスクリーニング方法 |
| JPWO2006101272A1 (ja) * | 2005-03-25 | 2008-09-04 | 株式会社リバース・プロテオミクス研究所 | 創薬標的タンパク質及び標的遺伝子、並びにスクリーニング方法 |
| JPWO2007026969A1 (ja) * | 2005-09-02 | 2009-03-12 | 株式会社リバース・プロテオミクス研究所 | 創薬標的タンパク質及び標的遺伝子、並びにスクリーニング方法 |
-
2001
- 2001-09-14 JP JP2002527795A patent/JP5021143B2/ja not_active Expired - Lifetime
- 2001-09-14 EP EP09153661A patent/EP2071481A3/en not_active Withdrawn
- 2001-09-14 AU AU2001286252A patent/AU2001286252A1/en not_active Abandoned
- 2001-09-14 WO PCT/JP2001/008009 patent/WO2002023199A2/en not_active Ceased
- 2001-09-14 EP EP01965662A patent/EP1402449A2/en not_active Withdrawn
-
2009
- 2009-02-10 US US12/320,961 patent/US20090156413A1/en not_active Abandoned
Cited By (9)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012108925A (ja) * | 2003-10-14 | 2012-06-07 | Verseon | リード分子交差反応の予測・最適化システム |
| JP2015072691A (ja) * | 2003-10-14 | 2015-04-16 | バーセオン | リード分子交差反応の予測・最適化システム |
| JP2017123169A (ja) * | 2003-10-14 | 2017-07-13 | バーセオン | リード分子交差反応の予測・最適化システム |
| US8153385B2 (en) | 2004-10-18 | 2012-04-10 | Reverse Proteomics Research Institute Co., Ltd. | Target protein and target gene in drug designing and screening method |
| US8178077B2 (en) | 2004-10-19 | 2012-05-15 | Reverse Proteomics Research Institute Co., Ltd. | Drug development target protein and target gene, and method of screening |
| US8058009B2 (en) | 2004-11-09 | 2011-11-15 | Reverse Proteomics Research Institute Co., Ltd. | Target protein and target gene in drug designing and screening method |
| KR101533745B1 (ko) * | 2013-07-30 | 2015-07-03 | 주식회사 엘지화학 | 정량적 검색이 가능한 분자 오비탈 데이터베이스 구축 방법 및 이를 이용하는 시스템 |
| KR20180031980A (ko) * | 2016-09-21 | 2018-03-29 | 전주대학교 산학협력단 | 마이크로 rna의 데이터 마이닝을 통한 마이크로 rna id의 분석방법 |
| KR101884073B1 (ko) | 2016-09-21 | 2018-07-31 | 전주대학교 산학협력단 | 마이크로 rna의 데이터 마이닝을 통한 마이크로 rna id의 분석방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| AU2001286252A1 (en) | 2002-03-26 |
| WO2002023199A8 (en) | 2003-12-31 |
| JP5021143B2 (ja) | 2012-09-05 |
| WO2002023199A2 (en) | 2002-03-21 |
| EP1402449A2 (en) | 2004-03-31 |
| EP2071481A2 (en) | 2009-06-17 |
| EP2071481A3 (en) | 2009-09-02 |
| US20090156413A1 (en) | 2009-06-18 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Emili et al. | Large-scale functional analysis using peptide or protein arrays | |
| Chanda et al. | Fulfilling the promise: drug discovery in the post-genomic era | |
| Stelzl et al. | The value of high quality protein–protein interaction networks for systems biology | |
| Lian et al. | Screening bicyclic peptide libraries for protein–protein interaction inhibitors: discovery of a tumor necrosis factor-α antagonist | |
| Duffner et al. | A pipeline for ligand discovery using small-molecule microarrays | |
| Hackler et al. | Off-DNA DNA-encoded library affinity screening | |
| DE60120713T2 (de) | Funktionelles protein array | |
| Grünenfelder et al. | Treasures and traps in genome-wide data sets: case examples from yeast | |
| Shi et al. | Selecting a DNA-encoded chemical library against non-immobilized proteins using a “ligate–cross-link–purify” strategy | |
| Wright | Signal initiation in biological systems: the properties and detection of transient extracellularprotein interactions | |
| US20090156413A1 (en) | Method, system, apparatus and device for discovering and preparing chemical compounds for medical and other uses | |
| Neamati | New paradigms in drug design and discovery | |
| US20090221436A1 (en) | Process for determining target function and identifying drug leads | |
| Kraemer et al. | Crossing the halfway point: aptamer-based, highly multiplexed assay for the assessment of the proteome | |
| JP2016500255A (ja) | ハイスループットなレセプター:リガンド同定の方法 | |
| Chung et al. | Chemogenetic minitool for dissecting the roles of protein phase separation | |
| Rappleye et al. | Optogenetic microwell array screening system: a high-throughput engineering platform for genetically encoded fluorescent indicators | |
| US20030027223A1 (en) | Specimen-linked G protein coupled receptor database | |
| He et al. | Rapid discovery of protein interactions by cell-free protein technologies | |
| Gui et al. | A Functional Assay for Mining Noninhibitory Enzyme Ligands from One Bead One Compound Libraries: Application to E3 Ubiquitin Ligases | |
| US20040115726A1 (en) | Method, system, apparatus and device for discovering and preparing chemical compounds for medical and other uses. | |
| US20250093362A1 (en) | High-throughput engineering of molecular glues | |
| JP2004509406A5 (ja) | ||
| Chen et al. | Ensemble modified aptamer based pattern recognition for adaptive target identification | |
| Reddy et al. | Proteomics in transfusion medicine. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD04 | Notification of resignation of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7424 Effective date: 20080520 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20080912 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080912 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110421 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110617 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120227 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120426 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120528 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120614 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150622 Year of fee payment: 3 |
|
| S801 | Written request for registration of abandonment of right |
Free format text: JAPANESE INTERMEDIATE CODE: R311801 |
|
| ABAN | Cancellation due to abandonment | ||
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |