JP2007207117A - 性能監視装置、性能監視方法及びプログラム - Google Patents
性能監視装置、性能監視方法及びプログラム Download PDFInfo
- Publication number
- JP2007207117A JP2007207117A JP2006027622A JP2006027622A JP2007207117A JP 2007207117 A JP2007207117 A JP 2007207117A JP 2006027622 A JP2006027622 A JP 2006027622A JP 2006027622 A JP2006027622 A JP 2006027622A JP 2007207117 A JP2007207117 A JP 2007207117A
- Authority
- JP
- Japan
- Prior art keywords
- countermeasure
- information
- model
- state
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images










Landscapes
- Debugging And Monitoring (AREA)
- Computer And Data Communications (AREA)
- Stored Programmes (AREA)
Abstract
【解決手段】モニタ部101は、AC環境及び非AC環境の状態に係る状態情報を取得し、分析部103又はモデル診断部106は、取得された状態情報に基づいて、AC環境の装置の状態を判定する。シミュレーション部108は、その判定結果に対応する対策リストを参照し、対策リストに含まれる少なくとも一つの対策夫々によるシミュレーション処理を実行し、各対策の効果を評価する。
【選択図】図1
Description
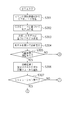
(1)先ず、コンピュータシステムを監視してハードウェア、ソフトウェアの挙動をログデータとして集約
(2)集約したものを分析して状況を把握
(3)目的達成のための対策を立てる
(4)計画を実行・制御する
本発明の性能監視方法は、少なくとも一つの外部装置と通信回線を介して接続される性能監視装置による性能監視方法であって、前記外部装置の状態に係る状態情報を取得する取得ステップと、前記取得ステップにより取得される前記状態情報に基づいて、前記外部装置の状態を判定する判定ステップと、前記判定ステップによる判定結果に対応する対策リストを参照し、前記対策リストに含まれる少なくとも一つの対策情報夫々による前記外部装置の状態に係るシミュレーション処理を実行し、前記各対策情報により示される対策の効果を評価するシミュレーションステップとを含むことを特徴とする。
本発明のプログラムは、前記性能監視方法をコンピュータに実行させることを特徴とする。
従って、本発明によれば、その評価結果に基づいて、様々な形態で発生する外部装置の事象に対して、最も的確な対策を選択・策定することが可能となる。
「ポリシー」とは、後述するオートノミック・コンピューティング環境(以下AC環境とする)の運用に関する指針である。ポリシーの一例としては、「CPU使用率が0〜10%であれば余剰である、CPU使用率が11〜80%であれば正常である、CPU使用率が81%以上であれば過負荷である」、「CPU使用率が過負荷の場合は、シミュレーションを実行して最適な結果を残した対策を選択する」、「システムの応答がない場合は、即座に再起動する」等が挙げられる。
「対策リスト」とは、AC環境内の装置に生じ得る各事象に紐つけられる対策の集合であり、事象と対策とはm:nで対応付けられている。なお、m=nであってもよく、m≠nであってもよい。対策リストの一例としては、「CPU使用率が閾値を超えている」という事象に対して「対策1.CPUを1つ追加、対策2.CPUを2つ追加、対策3.サーバ追加による負荷分散」で構成された対策リスト等が挙げられる。
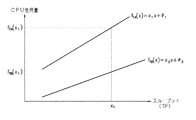
「モデル」とは、AC環境及び後述する非AC環境から取得する監視データに基づいて、AC環境内の各装置について特徴を抽出したものである。その一例として、AC環境内におけるAPサーバからCPU使用率を示す監視データを取得した場合には、その線形近似式を求めることによってCPU使用率の時系列変化を表す以下のモデルが抽出できる。
f(t)=at+b
f(t):CPU使用率、t:時間、a,b:実値
(1)CPUを1つ追加
(2)CPUを2つ追加
(3)サーバ追加による負荷分散(処理分散パターンA)
(4)サーバ追加による負荷分散(処理分散パターンB)
(5)サーバ追加による負荷分散(処理分散パターンC)
(6)サーバ追加による負荷分散(処理分散パターンD)
対策(1)の結果:CPU使用率85%
対策(2)の結果:CPU使用率なし(実現不可能な構成と判断されたため)
対策(3)の結果:CPU使用率40%
対策(4)の結果:CPU使用率55%
対策(5)の結果:CPU使用率55%
対策(6)の結果:CPU使用率65%
先ず、図4(a)において、前回モデル1042を抽出した時点(時間2)から所定時間が経過し、モデル抽出部105は、時間1及び時間2の監視データとともに、新たに時間3の監視データを今回取得する。ここで取得する監視データは、図4(a)に示すように、CPU使用率を示す監視データとスループットを示す監視データとであるものとする。
101:モニタ部
102:イベント情報蓄積部
103:分析部
104:知識情報蓄積部
105:モデル抽出部
106:モデル診断部
107:計画部
108:シミュレーション部
109:計画実行部
110:対策探索部
1001:サーバ類
1002:ストレージ類
1003:ネットワーク装置類
1004:非AC環境
1041:ポリシー
1042:モデル
1043:対策リスト
Claims (8)
- 少なくとも一つの外部装置と通信回線を介して接続される性能監視装置であって、
前記外部装置の状態に係る状態情報を取得する取得手段と、
前記取得手段により取得される前記状態情報に基づいて、前記外部装置の状態を判定する判定手段と、
前記判定手段による判定結果に対応する対策リストを参照し、前記対策リストに含まれる少なくとも一つの対策情報夫々による前記外部装置の状態に係るシミュレーション処理を実行し、前記各対策情報により示される対策の効果を評価するシミュレーション手段とを有することを特徴とする性能監視装置。 - 前記取得手段により取得される前記状態情報を外部又は内部の記録媒体内に蓄積する蓄積手段と、
前記記録媒体内に蓄積される前記状態情報の履歴に基づいて、前記外部装置の状態を表すモデル情報を抽出するモデル抽出手段とを更に有し、
前記判定手段は、前記モデル情報に基づいて前記外部装置の状態を判定することを特徴とする請求項1に記載の性能監視装置。 - 前記判定手段は、前記モデル情報と、更に前記状態情報の種類に応じた前記外部装置の運用に係るポリシー情報とに基づいて、前記外部装置の状態を判定することを特徴とする請求項2に記載の性能監視装置。
- 前記シミュレーション手段による前記各対策の効果の評価結果に基づいて、前記対策リストから一つの対策情報を決定する対策決定手段を更に有することを特徴とする請求項1乃至3の何れか1項に記載の性能監視装置。
- 前記対策決定手段により前記評価結果に基づいて前記対策リストから一つの対策情報を決定することができなかった場合、前記対策リストに含まれない他の対策情報を探索する探索手段を更に有し、
前記シミュレーション手段は、前記他の対策情報による前記外部装置の状態に係るシミュレーション処理を実行し、前記他の対策情報により示される対策の効果を評価することを特徴とする請求項4に記載の性能監視装置。 - 前記探索手段は、前記対策決定手段が前記他の対策情報により示される対策の効果の評価結果に基づいて前記他の対策情報を決定した場合、前記他の対策情報を前記判定結果に対応付けることを特徴とする請求項5に記載の性能監視装置。
- 少なくとも一つの外部装置と通信回線を介して接続される性能監視装置による性能監視方法であって、
前記外部装置の状態に係る状態情報を取得する取得ステップと、
前記取得ステップにより取得される前記状態情報に基づいて、前記外部装置の状態を判定する判定ステップと、
前記判定ステップによる判定結果に対応する対策リストを参照し、前記対策リストに含まれる少なくとも一つの対策情報夫々による前記外部装置の状態に係るシミュレーション処理を実行し、前記各対策情報により示される対策の効果を評価するシミュレーションステップとを含むことを特徴とする性能監視方法。 - 請求項7に記載の性能監視方法をコンピュータに実行させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006027622A JP4705484B2 (ja) | 2006-02-03 | 2006-02-03 | 性能監視装置、性能監視方法及びプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006027622A JP4705484B2 (ja) | 2006-02-03 | 2006-02-03 | 性能監視装置、性能監視方法及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007207117A true JP2007207117A (ja) | 2007-08-16 |
| JP4705484B2 JP4705484B2 (ja) | 2011-06-22 |
Family
ID=38486511
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006027622A Expired - Lifetime JP4705484B2 (ja) | 2006-02-03 | 2006-02-03 | 性能監視装置、性能監視方法及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4705484B2 (ja) |
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2010032701A1 (ja) * | 2008-09-18 | 2010-03-25 | 日本電気株式会社 | 運用管理装置、運用管理方法、および運用管理プログラム |
| JP2010218000A (ja) * | 2009-03-13 | 2010-09-30 | Nec Corp | システム性能分析装置、システム性能分析方法、及びプログラム |
| WO2011068015A1 (ja) * | 2009-12-02 | 2011-06-09 | コニカミノルタホールディングス株式会社 | システム構築支援方法 |
| US7975186B2 (en) | 2008-02-25 | 2011-07-05 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| US8225144B2 (en) | 2008-02-25 | 2012-07-17 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| WO2013141018A1 (ja) * | 2012-03-21 | 2013-09-26 | 日本電気株式会社 | 最適システム設計支援装置 |
| JP2018206245A (ja) * | 2017-06-08 | 2018-12-27 | コニカミノルタ株式会社 | 状態予測装置、状態予測方法および状態予測プログラム |
| US11275044B2 (en) | 2018-08-31 | 2022-03-15 | Nuflare Technology, Inc. | Anomaly determination method and writing apparatus |
| CN114531333A (zh) * | 2022-01-28 | 2022-05-24 | 新华三技术有限公司 | 一种管理运维数据的方法、云平台和ac |
| CN115297035A (zh) * | 2022-08-04 | 2022-11-04 | 杭州杰牌传动科技有限公司 | 一种边云协同智能运维系统 |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08314751A (ja) * | 1995-05-18 | 1996-11-29 | Hitachi Ltd | 障害対策支援方法 |
| JP2002268922A (ja) * | 2001-03-09 | 2002-09-20 | Ntt Data Corp | Wwwサイトの性能監視装置 |
| JP2005099973A (ja) * | 2003-09-24 | 2005-04-14 | Hitachi Ltd | 運用管理システム |
| JP2005346331A (ja) * | 2004-06-02 | 2005-12-15 | Nec Corp | 障害復旧装置および障害復旧方法、マネージャ装置並びにプログラム |
-
2006
- 2006-02-03 JP JP2006027622A patent/JP4705484B2/ja not_active Expired - Lifetime
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH08314751A (ja) * | 1995-05-18 | 1996-11-29 | Hitachi Ltd | 障害対策支援方法 |
| JP2002268922A (ja) * | 2001-03-09 | 2002-09-20 | Ntt Data Corp | Wwwサイトの性能監視装置 |
| JP2005099973A (ja) * | 2003-09-24 | 2005-04-14 | Hitachi Ltd | 運用管理システム |
| JP2005346331A (ja) * | 2004-06-02 | 2005-12-15 | Nec Corp | 障害復旧装置および障害復旧方法、マネージャ装置並びにプログラム |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7975186B2 (en) | 2008-02-25 | 2011-07-05 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| US8621284B2 (en) | 2008-02-25 | 2013-12-31 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| US8225144B2 (en) | 2008-02-25 | 2012-07-17 | Nec Corporation | Operations management apparatus, operations management system, data processing method, and operations management program |
| JP5375829B2 (ja) * | 2008-09-18 | 2013-12-25 | 日本電気株式会社 | 運用管理装置、運用管理方法、および運用管理プログラム |
| WO2010032701A1 (ja) * | 2008-09-18 | 2010-03-25 | 日本電気株式会社 | 運用管理装置、運用管理方法、および運用管理プログラム |
| US8700953B2 (en) | 2008-09-18 | 2014-04-15 | Nec Corporation | Operation management device, operation management method, and operation management program |
| CN102099795B (zh) * | 2008-09-18 | 2014-08-13 | 日本电气株式会社 | 运用管理装置、运用管理方法和运用管理程序 |
| JP2010218000A (ja) * | 2009-03-13 | 2010-09-30 | Nec Corp | システム性能分析装置、システム性能分析方法、及びプログラム |
| WO2011068015A1 (ja) * | 2009-12-02 | 2011-06-09 | コニカミノルタホールディングス株式会社 | システム構築支援方法 |
| WO2013141018A1 (ja) * | 2012-03-21 | 2013-09-26 | 日本電気株式会社 | 最適システム設計支援装置 |
| JP2018206245A (ja) * | 2017-06-08 | 2018-12-27 | コニカミノルタ株式会社 | 状態予測装置、状態予測方法および状態予測プログラム |
| US11275044B2 (en) | 2018-08-31 | 2022-03-15 | Nuflare Technology, Inc. | Anomaly determination method and writing apparatus |
| CN114531333A (zh) * | 2022-01-28 | 2022-05-24 | 新华三技术有限公司 | 一种管理运维数据的方法、云平台和ac |
| CN114531333B (zh) * | 2022-01-28 | 2023-09-15 | 新华三技术有限公司 | 一种管理运维数据的方法、云平台和ac |
| CN115297035A (zh) * | 2022-08-04 | 2022-11-04 | 杭州杰牌传动科技有限公司 | 一种边云协同智能运维系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP4705484B2 (ja) | 2011-06-22 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7702485B2 (en) | Method and apparatus for predicting remaining useful life for a computer system | |
| JP4980581B2 (ja) | 性能監視装置、性能監視方法及びプログラム | |
| JP4756675B2 (ja) | コンピュータ資源のキャパシティを予測するためのシステム、方法およびプログラム | |
| JP4859558B2 (ja) | コンピュータシステムの制御方法及びコンピュータシステム | |
| Urunuela et al. | Storm a simulation tool for real-time multiprocessor scheduling evaluation | |
| US20130318022A1 (en) | Predictive Analytics for Information Technology Systems | |
| Soualhia et al. | Predicting scheduling failures in the cloud: A case study with google clusters and hadoop on amazon EMR | |
| Nadeem et al. | Modeling and predicting execution time of scientific workflows in the grid using radial basis function neural network | |
| JP4705484B2 (ja) | 性能監視装置、性能監視方法及びプログラム | |
| CN119513207B (zh) | 虚拟仿真平台的任务仿真方法、装置和计算机设备 | |
| Cheng et al. | Improving architecture-based self-adaptation through resource prediction | |
| CN111861012B (zh) | 一种测试任务执行时间预测方法及最优执行节点选择方法 | |
| Brosch et al. | Parameterized reliability prediction for component-based software architectures | |
| JP6777142B2 (ja) | システム分析装置、システム分析方法、及び、プログラム | |
| JP2005099973A (ja) | 運用管理システム | |
| GB2516357A (en) | Methods and apparatus for monitoring conditions prevailing in a distributed system | |
| Sedaghatbaf et al. | A method for dependability evaluation of software architectures | |
| Foroni et al. | Moira: A goal-oriented incremental machine learning approach to dynamic resource cost estimation in distributed stream processing systems | |
| US20140361978A1 (en) | Portable computer monitoring | |
| JP7107991B2 (ja) | 運用管理装置及び運用管理方法 | |
| JP2006185055A (ja) | 計算機システムの設計支援システムおよび設計支援プログラム | |
| Lewis et al. | Chaotic attractor prediction for server run-time energy consumption | |
| JP2018041296A (ja) | 計算機システムおよびジョブ実行計画変更方法 | |
| JP2008191849A (ja) | 稼働管理装置、情報処理装置、稼働管理装置の制御方法、情報処理装置の制御方法及びプログラム | |
| Brandt et al. | Using probabilistic characterization to reduce runtime faults in HPC systems |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20090128 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20100824 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20100914 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20101112 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110301 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110311 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4705484 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| EXPY | Cancellation because of completion of term |