JP2007538331A - 集積回路及びバッファリング方法 - Google Patents
集積回路及びバッファリング方法 Download PDFInfo
- Publication number
- JP2007538331A JP2007538331A JP2007517554A JP2007517554A JP2007538331A JP 2007538331 A JP2007538331 A JP 2007538331A JP 2007517554 A JP2007517554 A JP 2007517554A JP 2007517554 A JP2007517554 A JP 2007517554A JP 2007538331 A JP2007538331 A JP 2007538331A
- Authority
- JP
- Japan
- Prior art keywords
- data
- buffered
- processing module
- integrated circuit
- amount
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images

Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F13/00—Interconnection of, or transfer of information or other signals between, memories, input/output devices or central processing units
- G06F13/38—Information transfer, e.g. on bus
- G06F13/42—Bus transfer protocol, e.g. handshake; Synchronisation
- G06F13/4204—Bus transfer protocol, e.g. handshake; Synchronisation on a parallel bus
- G06F13/4208—Bus transfer protocol, e.g. handshake; Synchronisation on a parallel bus being a system bus, e.g. VME bus, Futurebus, Multibus
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
- Information Transfer Systems (AREA)
- Multi Processors (AREA)
- Communication Control (AREA)
Abstract
Description
Claims (14)
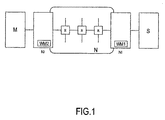
- インターコネクト手段に接続されている多数の処理モジュールを有する集積回路であって、第1の処理モジュールがトランザクションを用いて第2の処理モジュールと通信する前記集積回路が、
第1の量のデータがバッファされるまで、インターコネクト手段を介して転送すべき前記第2の処理モジュールからのデータをバッファリングするように前記第2の処理モジュールに関連付けた第1のラッパー手段を具え、バッファされたデータは、前記第1の量のデータがバッファされたときに転送されるようにした、
ことを特徴とする集積回路。 - 第2の量のデータがバッファされるまで、インターコネクト手段を介して転送すべき前記第1の処理モジュールからのデータをバッファリングするように前記第1の処理モジュールに関連付けた第2のラッパー手段をさらに具え、バッファされたデータは、前記第2の量のデータがバッファされたときに転送されるようにした、
ことを特徴とする請求項1に記載の集積回路。 - 前記第1及び第2のラッパー手段にバッファされたデータ量が前記第1及び第2の量より少なくても、それぞれ第1及び第2のアンバッファ信号または信号のグループの第1及び第2の組合せに応答して、バッファされたデータを転送するように前記第1及び第2のラッパー手段を適合させた、
ことを特徴とする請求項1または2に記載の集積回路。 - 前記第1及び第2のラッパー手段にバッファされたデータ量が前記第1及び第2のデータ量より少なくても、それぞれ第1及び第2のアンバッファフラグに従って、バッファされたデータを転送するように前記第1及び第2のラッパー手段を適合させた、
ことを特徴とする請求項1または2に記載の集積回路。 - 前記第1及び第2のラッパー手段の少なくとも1つが、前記第1と第2の処理モジュール間の通信の通信特性に従って、バッファすべきデータの最適な第1または第2の量を決定する決定ユニットを具える、
ことを特徴とする請求項1または2に記載の集積回路。 - 前記第1及び第2のラッパー手段の少なくとも1つが、前記第1と第2の処理モジュール間の通信の通信特性に従って、前記第1及び第2のラッパー手段のデータを送信する最適な瞬時を決定する決定ユニットを具える、
ことを特徴とする請求項1または2に記載の集積回路。 - 前記第1のアンバッファ信号を前記第2の処理モジュールによって起動させ、かつ、前記第2のアンバッファ信号を前記第1の処理モジュールによって起動させるようにした、
ことを特徴とする請求項3に記載の集積回路。 - 前記第1のアンバッファフラグの設定を前記第2の処理モジュールによって開始させ、かつ、前記第2の非バッファフラグの設定を前記第1の処理モジュールによって開始させるようにした、
ことを特徴とする請求項4に記載の集積回路。 - 前記第1及び/または前記第2のアンバッファ信号を起動させるように前記第1の処理モジュールを適合させた、
ことを特徴とする請求項3または4に記載の集積回路。 - 前記第1及び/または前記第2のアンバッファフラグの設定を開始するように前記第1の処理モジュールを適合させた、
ことを特徴とする請求項4に記載の集積回路。 - 前記第1及び第2の処理モジュールが、メッセージ伝達通信スキームを用いて互いに通信し、メッセージがメッセージヘッダを含み、
前記第1及び第2のラッパー手段にバッファされたデータの量が、前記第1及び第2の量より少なくても、前記メッセージヘッダにおける情報に応答して、バッファされたデータを転送するように前記第1及び第2のラッパー手段をそれぞれ適合させた、
ことを特徴とする請求項1または2に記載の集積回路。 - 前記第1及び第2の処理モジュールが、パケットに基づく通信スキームを用いて互いに通信し、パケットがパケットヘッダを含み、
前記第1及び第2のラッパー手段にバッファされたデータの量が、前記第1及び第2の量より少なくても、前記パケットヘッダにおける情報に応答して、バッファされたデータを転送するように前記第1及び第2のラッパー手段をそれぞれ適合させた、
ことを特徴とする請求項1または2に記載の集積回路。 - インターコネクト手段に接続される多数の処理モジュールを有する集積回路内でデータをバッファリングする方法であって、第1の処理モジュールがトランザクションを用いて第2の処理モジュールと通信する前記バッファリング方法が、
第1の量のデータがバッファされるまで、インターコネクト手段を介して転送すべき前記第2の処理モジュールからのデータをバッファリングし、バッファされたデータは、前記第1の量のデータがバッファされたときに転送するステップを含む、
ことを特徴とするバッファリング方法。 - インターコネクト手段に接続される多数の処理モジュールを具えるデータ処理システムであって、第1の処理モジュールがトランザクションを用いて第2の処理モジュールと通信する前記データ処理システムが、
第1の量のデータがバッファされるまで、インターコネクト手段を介して転送すべき前記第2の処理モジュールからのデータをバッファリングするように前記第2の処理モジュールに関連付けた第1のラッパー手段を具え、バッファされたデータは、前記第1の量のデータがバッファされたときに転送されるようにした、
ことを特徴とするデータ処理システム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| EP04102189 | 2004-05-18 | ||
| PCT/IB2005/051580 WO2005111823A1 (en) | 2004-05-18 | 2005-05-13 | Integrated circuit and method for buffering to optimize burst length in networks on chips |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2007538331A true JP2007538331A (ja) | 2007-12-27 |
Family
ID=34967297
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2007517554A Pending JP2007538331A (ja) | 2004-05-18 | 2005-05-13 | 集積回路及びバッファリング方法 |
Country Status (7)
| Country | Link |
|---|---|
| US (1) | US8086800B2 (ja) |
| EP (1) | EP1751667B1 (ja) |
| JP (1) | JP2007538331A (ja) |
| CN (1) | CN100445977C (ja) |
| AT (1) | ATE396454T1 (ja) |
| DE (1) | DE602005007014D1 (ja) |
| WO (1) | WO2005111823A1 (ja) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8254913B2 (en) | 2005-08-18 | 2012-08-28 | Smartsky Networks LLC | Terrestrial based high speed data communications mesh network |
| KR100653087B1 (ko) * | 2005-10-17 | 2006-12-01 | 삼성전자주식회사 | AXI가 적용된 NoC 시스템 및 그 인터리빙 방법 |
| EP1791366A1 (en) * | 2005-11-28 | 2007-05-30 | Alcatel Lucent | Avoiding interruptions in the reproduction of audio/video by storing enough data in advance at a mobile terminal |
| US8261025B2 (en) | 2007-11-12 | 2012-09-04 | International Business Machines Corporation | Software pipelining on a network on chip |
| EP2063581A1 (en) * | 2007-11-20 | 2009-05-27 | STMicroelectronics (Grenoble) SAS | Transferring a stream of data between first and second electronic devices via a network on-chip |
| US8526422B2 (en) | 2007-11-27 | 2013-09-03 | International Business Machines Corporation | Network on chip with partitions |
| US8490110B2 (en) * | 2008-02-15 | 2013-07-16 | International Business Machines Corporation | Network on chip with a low latency, high bandwidth application messaging interconnect |
| US8423715B2 (en) | 2008-05-01 | 2013-04-16 | International Business Machines Corporation | Memory management among levels of cache in a memory hierarchy |
| US8494833B2 (en) | 2008-05-09 | 2013-07-23 | International Business Machines Corporation | Emulating a computer run time environment |
| US8392664B2 (en) | 2008-05-09 | 2013-03-05 | International Business Machines Corporation | Network on chip |
| US8438578B2 (en) | 2008-06-09 | 2013-05-07 | International Business Machines Corporation | Network on chip with an I/O accelerator |
| US8195884B2 (en) | 2008-09-18 | 2012-06-05 | International Business Machines Corporation | Network on chip with caching restrictions for pages of computer memory |
| US9110668B2 (en) * | 2012-01-31 | 2015-08-18 | Broadcom Corporation | Enhanced buffer-batch management for energy efficient networking based on a power mode of a network interface |
| US10983910B2 (en) * | 2018-02-22 | 2021-04-20 | Netspeed Systems, Inc. | Bandwidth weighting mechanism based network-on-chip (NoC) configuration |
| US11782865B1 (en) * | 2021-06-02 | 2023-10-10 | Amazon Technologies, Inc. | Flexible data handling |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07123118A (ja) * | 1993-10-21 | 1995-05-12 | Fuji Xerox Co Ltd | フレーム送信回路 |
| JP2000209652A (ja) * | 1999-01-18 | 2000-07-28 | Kobe Steel Ltd | 無線電話装置 |
| JP2002084289A (ja) * | 2000-09-07 | 2002-03-22 | Kddi Corp | Tcp通信方法 |
| WO2004034173A2 (en) * | 2002-10-08 | 2004-04-22 | Koninklijke Philips Electronics N.V. | Integrated circuit and method for exchanging data |
Family Cites Families (14)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4228496A (en) * | 1976-09-07 | 1980-10-14 | Tandem Computers Incorporated | Multiprocessor system |
| US4253144A (en) * | 1978-12-21 | 1981-02-24 | Burroughs Corporation | Multi-processor communication network |
| US5522050A (en) * | 1993-05-28 | 1996-05-28 | International Business Machines Corporation | Bus-to-bus bridge for a multiple bus information handling system that optimizes data transfers between a system bus and a peripheral bus |
| US5987552A (en) | 1998-01-26 | 1999-11-16 | Intel Corporation | Bus protocol for atomic transactions |
| US6397287B1 (en) * | 1999-01-27 | 2002-05-28 | 3Com Corporation | Method and apparatus for dynamic bus request and burst-length control |
| US6393500B1 (en) | 1999-08-12 | 2002-05-21 | Mips Technologies, Inc. | Burst-configurable data bus |
| US6493776B1 (en) | 1999-08-12 | 2002-12-10 | Mips Technologies, Inc. | Scalable on-chip system bus |
| US6629253B1 (en) | 1999-12-30 | 2003-09-30 | Intel Corporation | System for efficient management of memory access requests from a planar video overlay data stream using a time delay |
| US6668308B2 (en) * | 2000-06-10 | 2003-12-23 | Hewlett-Packard Development Company, L.P. | Scalable architecture based on single-chip multiprocessing |
| GB2373595B (en) | 2001-03-15 | 2005-09-07 | Italtel Spa | A system of distributed microprocessor interfaces toward macro-cell based designs implemented as ASIC or FPGA bread boarding and relative common bus protocol |
| US7012893B2 (en) * | 2001-06-12 | 2006-03-14 | Smartpackets, Inc. | Adaptive control of data packet size in networks |
| GB0315504D0 (en) * | 2003-07-02 | 2003-08-06 | Advanced Risc Mach Ltd | Coherent multi-processing system |
| EP1671233B1 (en) | 2003-09-04 | 2011-11-16 | Koninklijke Philips Electronics N.V. | Tree-like data processing system accessing a memory |
| US7257665B2 (en) * | 2003-09-29 | 2007-08-14 | Intel Corporation | Branch-aware FIFO for interprocessor data sharing |
-
2005
- 2005-05-13 JP JP2007517554A patent/JP2007538331A/ja active Pending
- 2005-05-13 US US11/569,083 patent/US8086800B2/en active Active
- 2005-05-13 AT AT05739743T patent/ATE396454T1/de not_active IP Right Cessation
- 2005-05-13 DE DE602005007014T patent/DE602005007014D1/de not_active Expired - Lifetime
- 2005-05-13 CN CNB2005800158550A patent/CN100445977C/zh not_active Expired - Fee Related
- 2005-05-13 EP EP05739743A patent/EP1751667B1/en not_active Expired - Lifetime
- 2005-05-13 WO PCT/IB2005/051580 patent/WO2005111823A1/en not_active Ceased
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH07123118A (ja) * | 1993-10-21 | 1995-05-12 | Fuji Xerox Co Ltd | フレーム送信回路 |
| JP2000209652A (ja) * | 1999-01-18 | 2000-07-28 | Kobe Steel Ltd | 無線電話装置 |
| JP2002084289A (ja) * | 2000-09-07 | 2002-03-22 | Kddi Corp | Tcp通信方法 |
| WO2004034173A2 (en) * | 2002-10-08 | 2004-04-22 | Koninklijke Philips Electronics N.V. | Integrated circuit and method for exchanging data |
Also Published As
| Publication number | Publication date |
|---|---|
| EP1751667B1 (en) | 2008-05-21 |
| US8086800B2 (en) | 2011-12-27 |
| EP1751667A1 (en) | 2007-02-14 |
| WO2005111823A1 (en) | 2005-11-24 |
| US20070226407A1 (en) | 2007-09-27 |
| CN100445977C (zh) | 2008-12-24 |
| ATE396454T1 (de) | 2008-06-15 |
| DE602005007014D1 (de) | 2008-07-03 |
| CN1954306A (zh) | 2007-04-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US8285912B2 (en) | Communication infrastructure for a data processing apparatus and a method of operation of such a communication infrastructure | |
| US7594052B2 (en) | Integrated circuit and method of communication service mapping | |
| KR100687659B1 (ko) | Axi 프로토콜에 따른 락 오퍼레이션을 제어하는네트워크 인터페이스, 상기 네트워크 인터페이스가 포함된패킷 데이터 통신 온칩 인터커넥트 시스템, 및 상기네트워크 인터페이스의 동작 방법 | |
| EP1552669B1 (en) | Integrated circuit and method for establishing transactions | |
| JP2007538331A (ja) | 集積回路及びバッファリング方法 | |
| KR101699784B1 (ko) | 버스 시스템 및 그것의 동작 방법 | |
| US20110286422A1 (en) | Electronic device and method of communication resource allocation | |
| JP2004525449A (ja) | 相互接続システム | |
| CN102449614A (zh) | 用于耦合代理的分组化接口 | |
| US7613849B2 (en) | Integrated circuit and method for transaction abortion | |
| CN100583819C (zh) | 用于分组交换控制的集成电路和方法 | |
| US7978693B2 (en) | Integrated circuit and method for packet switching control | |
| JP2008520119A (ja) | 電子デバイスおよび通信資源割り当て方法 | |
| CN103152275A (zh) | 一种适用于片上网络的可配置交换机制的路由器 | |
| EP1733309B1 (en) | Integrated circuit and method for transaction retraction | |
| JP5146454B2 (ja) | 情報処理装置及び情報処理方法 | |
| KR20100137326A (ko) | 버스 시스템 및 그 제어 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080512 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20080904 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20110114 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110125 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110425 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20110802 |