本発明は、画像処理方法及び装置に関し、特に、画像処理機能を有するデジタルインスタントカメラを開示する。
本発明は、さらに、デジタルカメラ技術の分野に関し、特に、一体型カラープリンタ付きのデジタルカメラを開示する。
従来のカメラ技術は、長年に亘り、感光性フィルムに映し出される画像のネガに依存する光学処理システムの設備に依存してきている。この感光性フィルムは、“定着(fix)”して、原画像の再生を行うポジプリントの作成を許容するために後で化学的処理される。そのような画像処理技術は、標準的になってきていたけれども、画像のフルカラー処理においては不経済で困難な技術が必要とされるため、過度に複雑になり得る。近年、デジタルカメラが利用可能になってきている。これらのカメラは、標準的には、際立った画像を検知するための電荷結合素子(CCD)の利用に依存している。該カメラは標準的には、続けて行う画像処理(manipulation)や印刷のためにコンピュータ装置に画像を転送するためのコネクターに加え、検知したシーンのストレージのためのストレージ・メディアを有する。
そのような装置は、全ての画像がカメラによって保存されており、しばらく後でないと印刷できないという点で不便である。また、該カメラは、多数の画像の保存のために十分なストレージ能力を有していなければならず、加えて、カメラのユーザは、画像のダウンロードやコンピュータ・プリンターによる印刷等のためにコンピュータシステムにアクセスしなければならない。
さらに、インスタント画像の生成を可能にするポラロイド(登録商標)タイプのインスタントカメラは、しばらくの間、使用されてきた。しかしながら、このタイプのカメラは、限定されたサイズの画像のみの作成に限られていて、また、化学物質の使用には多くの問題があり、特に、これらのタイプのカメラで作られた写真は劣化する。
このような装置や他の画像キャプチャー装置を使用する場合、写真撮影の際、音声ひや他の環境の情報を適切に取り込めることが望ましい。
さらに、左眼に与えられる第1画像と右眼に与えられる第2画像とで三次元面の錯覚を起こすという立体視の生成が、よく知られている。しかしながら、従前のシステム複雑な準備を必要とし、現物に極めて近い画像(ハイファイ画像)は通常不可能であった。さらに、画像の一般的な選択は、特別に準備された画像のみに限定されている。
現物に極めて近い立体画像(ハイファイ立体画像)を要求に応じて生成できること、特に、立体画像を自由に撮影することのできるポータブル・カメラ装置によって画像を作成することが一般的に必要である。
さらに、カメラ装置によってキャプチャーされた画像を片面に有すると共に、もう片面に郵便料金払い済み印と住所を有する、自動的にカスタマイズされた葉書を、そのようなカメラ写真画像作成システムが作成できれば、非常に便利だろう。
近年、画像の長い“パノラマ”ビューを作成する写真再生技術については、ますます一般的になってきている。これらの画像は写真用紙などの上に作成される。また、さらなる“パノラマ”のタイプのビューを作成するため、画像の構成は、幅に比べて長さが長くされる。残念ながら、画像が形成される写真用紙は、小径のロールの状態で保存されていた場合に問題が発生する。
近年、フィルターを配置して、人気のある芸術的な絵のスタイルに似せた効果を画像に生じさせるようにすることがかなり一般的になってきている。これらのフィルターは、画像を撮影すると共に、芸術的なスタイルの一つについての芸術的演出を最初の画像に与えて第2の画像を得るように設計されている。現代において極めて人気のある芸術家の一人は、ビンセント・ファン・ゴッホである。彼の絵画のフラット・エリアにおけるブラッシュストローク(筆さばき)の方向が、その絵画における主要な物のエッジの方向を積極的にたどるというのが、この芸術家の芸術作品の一つの特徴である。例えば、“糸杉と星の見える道”や“星月夜”や“医師ガッシュ”と題された彼の作品は、この処理の説明に役立つ実例である。入力されてきた任意の画像に“ファン・ゴッホ”効果を自動的に生じさせ、それを携帯用カメラシステムから出力するというコンピュータ・アルゴリズムの提供が望まれるだろう。
残念ながら、ワーピングのシステムは、ハイエンドコンピュータにて使用されることが一般的であり、画像をコンピュータの中にスキャンすることやプリントアウトすることは一般には不便である。携帯用カメラ等を使って画像を取得するような場合は、取得画像を画像処理のためにコンピュータシステムに後で転送し、次に、要求に従ってそれらの画像を処理するという必要があるため、一般的には特に不便である。
さらに、多様な画法を真似るという効果に大きな価値があるとしばしば考えられる。さらに進んで、1つの簡単な形態の中にこれらの効果を組み入れることができれば、それらの効果は、デジタル撮影能力を有する携帯用カメラ装置と合体させるのに適切であり、それによって、カメラ装置で撮影されるシーンについて、所望のフィルター処理された画像を生成することができるだろう。
残念ながら、今日 製造されるカメラにおいて厄介なシステムの要求である、デジタル画像変換技術やフィルター交換技術は、明らかに、未だ利用できない技術を利用することができず、今までのところ、創造も着想もできていないフィルターを利用することもできない。
カメラ技術の極めて一般的な方式の一つは、伝統的なネガフィルムとポジプリント写真である。このケースでは、ネガフィルムにシーンを撮影するためにカメラが使用され、該ネガフィルムは陰画を定着させるために処理される。続いて一連のプリントがネガフィルムから作成される。さらに、一連のプリントはネガからどんなときにでも直ぐに作成されることができる。残念ながら、デジタルカメラ(本願にて提案されるものも含む)では、後においてさらなる画像のコピーが要求されるなら、キャプチャーされ印刷される写真をデジタル形式で永久的に保存することが必要であろう。“写真”のコピーが単に最初のプリントを必要とするということは一般的には不便かも知れない。もちろん、その代わりに、高品質なカラー写真コピー装置を使用してコピーしても差し支えない。残念ながら、そのような装置はコピー能力に限界があり、そのようなコピーの形態が行われるとき、しばしば信号の劣化が生じる。明らかに、カメラプリントのコピーを作成する、より好適な形態が望まれる。
さらに、下塗りの際のメディアの選択に起因して色が制限され、風景についてのほとんど全ての芸術的絵画は限定的な色域(gamut)を使用している。このような制限は、様々な芸術的効果を生じさせるために芸術家によってしばしば使われる。この処理の古典的な見本は、次のような周知の芸術作品を含む:
− カミーユ・ピサロ “L’le Lacroix−Rouen、霧の効果” 1888年、フィラデルフィア美術館
− シャルル・アングラン “セーヌ河、朝”−1889年、プティ・パレ・コレクション、ジュネーブ
− アンリ・ヴァン・ド・ヴェルド “Crepuscule” −1892年、クレラー=ミュラー国立美術館、オッテルロー
− ジョルジョ・スーラ “バ=ビュタンの砂浜、オンフルール”1886年−トゥルーネ美術館
任意の入力画像から、上記リストのそれと似たような効果や特性を持つ出力画像を作成することが望ましい。
何らかの衣服が創造されるとき多くの創造的な判断がなされる。初めに、衣服の形状やスタイルであり、加えて、布の色や種類である。しばしは、ファッションデザイナーは、衣服を完成させる前に、多くの異なる代替案にトライし、最終的なファッションの製品を描こうとする。
このようなプロセスは、衣服の迅速かつ柔軟な変更や、ファッション製品の最終外観の迅速な判断機会のためには一般的に不十分である。
双眼鏡や望遠鏡は良く知られている。特に、双眼鏡を例にすると、該装置は、ユーザの視力の能力を高めるために景色の望遠の拡大を提供する。さらに、夜間用双眼鏡等のような装置も、また、ユーザの視力の能力を高めるために使われる。残念ながら、これらのシステムは、リアルタイムの、アナログの光学部品に依存し、見えた景色の永久記録は困難である。シーンの永久コピーの記録に適していると思われる1つの方法は、シーンを取得するCCD等のようなセンサー装置を取り付けることと、後に行う印刷のためにストレージデバイスに保存することである。残念ながら、そのような構造は、野外で、携行性に富む状態での双眼鏡の使用が望まれる場合には特に邪魔となる。
圧縮した状態での情報のストレージについては、多くの形態のものが周知である。例えば、コンピュータ装置の分野では、固定された、或いは携行できる磁気ディスク装置の使用は一般的である。携行できるディスクについては、“フロッピーディスク”や“ジップディスク”や、ポータブル磁気ストレージメディアの他の方式が、市場において大量に受け入れられている。携帯可能なストレージの他の形式は、一連の細長いピット(螺旋状のトラックに沿って配置されたものであり、レーザビーム装置によって読み取られるもの)を利用するコンパクトディスク“CD”である。CDの利用は、ストレージについての極めて低コストの形態を提供する。しかしながら、必要とされる技術はかなり複雑であり、書き換え可能なCDタイプの装置の使用は極めて限定される。
ストレージの他の方式としては磁気カードがあり、しばしばクレジットカードや同種のものに使用される。これらのカードは、標準的には、カードのユーザに関連する情報を記録するため、裏面に磁気の帯を有している。近年、集積回路タイプの装置をカードに組み込むというスマートカード技術の形で、磁気カードの利便性が伸びてきている。残念ながら、そのような装置のコストはしばしば高く、使用される技術の複雑さもまた著しい。
従来の銀塩カメラの処理システムは、多数のプリントの作成のため、周知の“ネガ”の使用を生じさせてきた。そのネガは、標準的にはプリントの生産源となり、その実施は、連続使用のためのケアや保護のために成長してきた。
フォールトトレラント方法にて検知される符号化システムでは、効率的な復号化が可能となる符号化がどのようにすれば可能かという、重要な懸案がある。したがって、効率的な符号化システムの提供が望まれる。
本発明の概要
本発明は、一体型カラープリンタ付きデジタルカメラを備えたカメラシステムの代替形態の提供に関する。加えて、該カメラは、イメージ・センシング・システムの見かけの解像度を増加させ、様々な“芸術的なスタイル”やグラフィック強化(graphic enhancement)に画像を変換するためのハードウェア及びソフトウェアを備える。
本発明のさらなる態様に従って、シーンを撮像するための少なくとも1つのエリアイメージセンサーと、前記撮像されたシーンを所定のシーン変換要求に従って処理するためのカメラ処理装置(camera processor means)と、前記処理された画像のシーンをプリントメディアに印刷するためのプリンターと、前記カメラシステム内部の一つの取り外し可能なモジュールに収納されたプリントメディア及び印刷用インクと、を備えたカメラシステムが提供される。該カメラシステムは、前記エリアイメージセンサーによるシーンの撮像、及び前記プリンターによって前記シーンを印刷したものを前記カメラシステムから直接出力するためのハンドヘルドユニットを備える。
前記カメラシステムは、好ましくは、プリントメディアの保管のためのプリントロールと、前記プリンターにより使用される印刷用インクを備えている。該プリントロールは前記カメラシステムから取り外し可能である。さらに、該プリントロールが前記カメラシステムに挿入されたときに認証が実行されるように、該プリントロールは、認証情報を含む認証チップを備え、前記カメラ処理装置は該認証チップを確認(interrogate)するように適合されている。
さらに、前記プリンターは、ドロップ・オン・デマンドのインクプリンターと、印刷された写真の分離のための裁断装置とを含む。
本発明の第1態様に従って、シーンを撮像するための少なくとも1つのエリアイメージセンサーと、前記撮像されたシーンを所定のシーン変換要求に従って処理するためのカメラ処理装置と、前記処理された画像のシーンをプリントメディアに印刷するためのプリンターと、前記カメラシステム内部の一つの取り外し可能なモジュールに収納されたプリントメディア及び印刷用インクと、を有するカメラシステムが提供される。該カメラシステムは、前記エリアイメージセンサーによるシーンの撮像、及び前記プリンターによって前記シーンを印刷したものを前記カメラシステムから直接出力するためのハンドヘルドユニットを備える。
好ましくは、該カメラシステムは、前記プリンターにより使用されるプリントメディア及び印刷用インクを収納するためのプリントロールを備えている。該プリントロールは前記カメラシステムから取り外しが可能である。さらに、該プリントロールが前記カメラシステムに挿入されたときに認証が実行されるように、該プリントロールは、認証情報を含む認証チップを備え、前記カメラ処理装置は該認証チップを確認(interrogate)するように適合されている。
さらに、前記プリンターは、ドロップ・オン・デマンドのインクプリンターと、印刷された写真の分離のための裁断装置とを含む。
本発明のさらなる態様に従って、装置を操作するためのユーザ・インターフェースが提供される。該ユーザ・インターフェースは、装置に挿入されるカードを有しており、該カードの表面には、前記装置の出力に関して該カードが有する効果について目に見える説明が含まれている。
本発明のさらなる態様に従って、
シーンを撮像するための少なくとも1つのエリアイメージセンサーと;
前記撮像されたシーンを所定のシーン変換要求に従って処理するためのカメラ処理装置と;
前記処理された画像のシーンをプリントメディアに印刷するためのプリンターと;
前記プリンターのための前記プリントメディアと印刷用インクとを収納するための取り外し可能なモジュールと;
を備えたカメラシステムが提供される。該カメラシステムは、前記エリアイメージセンサーによるシーンの撮像、及び前記プリンターによって前記シーンを印刷したものを前記カメラシステムから直接出力するためのハンドヘルドユニットを備える。
本発明のさらなる態様に従って、
画像を検知するセンサー装置(sensor means)と;
検知された画像を所定の処理要求に従って処理するための処理装置と;
もしあるならば、音声信号を検知画像に関連付けて一致させるための音声録音装置と;
前記カメラシステムで供給されるプリントメディアの第1エリアに処理された検知画像を印刷し、前記プリントメディアの第2エリアに前記音声信号の符号化されたバージョンを印刷するための印刷装置と;
を備えたカメラシステムが提供される。好ましくは、該検知画像は前記プリントメディアの第1面に印刷され、前記音声信号の符号化されたバージョンは該プリントメディアの第2面に印刷される。
本発明に従って、
画像を検知するエリアイメージセンサー装置と;
該検知した画像を保管するための画像ストレージ装置と;
画像検知時におけるカメラの向きを検出する定位装置と;
検知したカメラの向きを使用して前記検知画像を処理するための処理装置と;
を備えたカメラシステムが提供される。
本発明のさらなる態様に従って、
焦点調整技術を使用して画像をキャプチャーし;
画像における構成の位置の指示器として焦点設定を利用し;
該焦点設定に特有の効果を生成するために該焦点設定を利用して画像を処理し;
その画像を印刷すること;
からなるデジタル画像処理方法が提供される。
好ましくは、前記画像はズーム技術を使用してキャプチャーされ、そのズーム設定は、前記画像の部分を処理するように発見的な方法で使用される。
本発明のさらなる態様に従って、アイポジション検知装置付きデジタルカメラにて撮影された画像を処理する方法が提供される。該方法は、空間的に変化するsense(アイポジション情報に依存するもの)で画像を処理するため、検知画像にアイポジション情報を使用するステップを含む。
前記ステップは、興味のあるエリアの位置を前記検知画像の中で特定するためにアイポジション情報を使用することを含む。その処理は、画像への吹き出しの配置や、画像への特定のゆがみの適用を含むことができる。代わりに、その処理は、前記アイポジション情報のエリアに、より細かい画像のためにブラッシュストロークフィルターを適用することも含む。理想的には、前記カメラは、処理の結果を大体直ぐに印刷することができる。
本発明のさらなる態様に従って、自動露出設定を有するデジタルカメラで撮影された画像の処理方法が提供され、該処理方法は、検知画像を処理するために前記情報を使用するステップを含む。
上述の、情報を使用するステップは、画像中の色が前記自動露出設定の計算に変換されてなる補正画像を生成するため、画像中の色のリマッピングを決定するために自動露出設定を使用することを含む。その処理は、露出設定が暗い状態を示すときは、リマッピングされる画像の色が、より深く、より鮮やかになるようにし、露出設定が明るい状態を示すときは、リマッピングされる画像の色が、より明るく、より飽和するようにする。
最近、デジタルカメラはますます一般的になってきている。これらのカメラは、標準的には、電荷結合素子(CCD)配列を使用した所望の画像の取得、並びに、撮像されたシーンの電子ストレージメディアへの保存(続けて行う画像処理や印刷のために、コンピュータシステムに後で行われるダウンロードのためのもの)を行う。標準的に、画像を印刷するためにコンピュータシステムを使用するとき、洗練されたソフトウェアが、要求に従って画像を処理するために使用される。
残念ながら、そのようなシステムは、キャプチャーされた画像の重要な後処理を必要とし、通常は、撮影された向きに画像を提示し、キャプチャーされた画像の必要な修正又は要求された修正を実行するため、後処理工程に依存する。さらに、写真が撮影される際の多くの環境情報が失われる。
本発明のさらなる態様に従って、デジタルカメラ及びフラッシュを使用してキャプチャーされた画像の処理方法が提供され、該方法は、以下のステップを含む。
(a) 前記フラッシュの使用に起因した、前記キャプチャーされた画像のゆがみ(ディストーション、distortion)の発見(特定)
(b) 前記ゆがみの影響を局部的に減少させるように前記画像の修正
本発明の第2の態様に従って、キャプチャーされた画像におけるフラッシュのゆがみ(distortion)の影響を減少させるデジタルカメラであって、
(a) 画像のキャプチャーのために画像をキャプチャーするデジタル画像キャプチャー装置と;
(b) フラッシュが誘発した色のゆがみの、前記キャプチャー画像内での位置を探すためのゆがみ位置決定装置と;
(c) 該ゆがみ位置決定装置及び前記デジタル画像キャプチャー装置に接続されて、前記ゆがみの影響を減少させるように前記キャプチャー画像を処理するように適合された画像ゆがみ是正装置と;
(d) 表示のために前記画像ゆがみ是正装置に接続されている表示装置と;
を備えたデジタルカメラが提供される。
本発明のさらなる態様に従って立体写真画像を作り出す方法が提供され、該方法は、
(a) シーンを立体画像的に撮像するためにカメラ装置を使用し;
(b) レンズシステムが第2面に形成された透明なプリントメディアにおける第1面部分の所定位置に、一体的に形成された画像のような立体撮影画像を印刷して、該印刷された立体撮影画像の観察者の左右の眼が前記シーンを立体画像的に見るようにする;
ことを含む。
本発明のさらなる態様に従って、プリントメディア及びインク供給装置が提供される。該供給装置は、インクと該インク付着用のプリントメディアとをプリント装置に供給するように適合されている。該供給装置は、メディア・フォーマーの上に巻かれた、ロール状のメディアを内部に有している。また、該供給装置は、前記メディア及びインク供給装置の内部に一体的に形成されると共に、インク及びプリントメディアの前記プリント装置への供給のために前記プリント装置に接続されるように適合された少なくとも1つのインク・リザーバを有している。
本発明のさらなる態様に従って、カメラ画像システムにて使用されるプリントロールであって、フォーマットされた多数の葉書情報が、所定の間隔で裏面に印刷されてなるプリントロールが提供される。
本発明の第2の態様に従って、カスタマイズされた葉書の作成方法が提供される。該作成方法は、次のステップを含む。すなわち、フォーマットされた多数の葉書情報区域を所定位置に有する裏面を備えるプリントロールを備えるカメラ装置の使用と、該プリントロールの対応する画像面へのカスタマイズされた画像の撮像と、該カメラ装置によって葉書を作成するための前記プリントロールの使用。
本発明の第3の態様に従って、カメラ画像を有する葉書を郵便制度を通じて送る方法が提供され、該方法は、次のステップを含む。すなわち、前払いの郵便料金が含まれているプリントロールを売るステップと、葉書を作成するために該プリントロールをカメラシステムで使用するステップと、該前払いした葉書を郵便で送るステップ。
本発明は、さらに、一体型プリンター装置付きカメラシステムを対象とする。そのプリントメディアは、カメラシステムから取り外し自在であり、該プリントメディアに関する重要な情報を保存するための装置を含む。
本発明は、さらに、一体型プリンター装置付きカメラシステムを対象とする。そのプリントメディアは、カメラシステムから取り外し自在であり、該プリントメディアへの認証アクセスを提供する。
本発明のさらなる態様に従って、使用に際してカールする度合いが低い、平らなプリントメディアが提供される。該プリントメディアは、前記平面の方向に異方性の剛性を有している。本発明の第2の態様に従って、異方性剛性を有する平らなプリントメディアにプリントされた画像においてカールを減少させる方法が提供される。該方法は、前記プリントメディアの部分に局所的な圧力を与えるものである。
本発明はさらに、一体型プリンター装置を有するカメラシステムを対象とする。該カメラシステムは、プリンターに残っている画像の数のインジケータを有する。該インジケータは、多くの異なるモードで、残っているプリントの数を表示することができる。
本発明のさらなる態様に従って画像の自動処理方法が提供される。該処理方法は、高い空間的な変化を持つ特徴を、画像の中で位置特定し、高い空間的な変化を持つそれらの領域から放射する一連のブラッシュストロークを画像に描くことを含む。好ましくは、そのブラッシュストロークは、重要な特徴付けるものの近傍ではサイズが小さい。加えて、ブラッシュストロークの所定部分の位置はジッタリングの下になる。
本発明のさらなる態様に従って、入力画像を歪ませるようなワーピング方法が提供される。該方法は、
所定の寸法A×Bである任意の出力画像のためのワープマップであって、該ワープマップの各要素は、理論上の入力画像における対応領域を、前記要素の座標位置に対応した前記任意の出力画像の画素位置にマッピングするワープマップを入力するステップと;
縮小されたワープマップを形成するためにワープマップをワープ画像の次元に縮小するステップと;
該縮小されたワープマップの各要素のため、該要素の値と隣接する要素の値とから前記入力画像における貢献領域を計算するステップと;
該貢献領域から前記要素に対応するワープ画像の画素のため、出力画像の色を決定するステップと;
を含む。
本発明のさらなる態様に従って、センサー装置によって読み取るため、メディアに保存されたデータの復元力を増加させる方法が提供される。該方法は、
(a) 回復可能な方法で保存されているデータを、高周波成分を有する変調信号にて変調するステップと;
(b) 前記データを変調された形式で前記メディアに保存するステップと;
(c) 該変調され保存されているデータを前記センサー装置によって検知するステップと;
(d) 変調され前記メディアに保存されているデータの位置の分離を探知するため、変調され保存されているデータの変調を中立化するステップと;
(e) 保存データの内の変調されていないものを、保存データの内の変調されているものから回収するステップと;
を含む。
本発明の好適な実施例は、カメラシステムの中に設けられたシステムであって、後で復号化が行えるように、CCDタイプの装置を介してデータを読み込むためのカード読み取りシステムに関して説明される。さらに、該好適な実施例の説明は、誤差制御システムの分野に大きく依存する。したがって、この仕様が案内される人は、誤差制御システムのエキスパートになるべきである。特に、“デジタル・コミュニケーションやストレージのための誤差制御システム”ステファン.B.ウィッカー著、プレティス・ホール社出版、1995年、特にリード・ソロモン・コードの考察のような標準的なテキストや他の標準的なテキストにしっかりと精通すべきである。
本発明の目的は、スキャンされた画素を含むスキャンされた画像を、対応するビットマップイメージに変換する方法を提供することであって、該方法は、ビットマップイメージにおける各ビットのために、次のステップを有する。すなわち、
a.スキャンされた画像における周囲のビットの位置から現在のビットにおけるスキャンされた画像での予期された位置を決定するステップ、
b.前記スキャンされた画像における期待された対応画素の位置での値から前記ビットの適当な値を決定するステップ、
c.前記予期された位置での予期された強度の中心の重心の寸法を決定するステップ、
d.前記スキャンされた画像における現在のビットの周囲に近接した画素のため、重心の寸法を決定するステップ、
e.前記重心の寸法が前記予期された位置に関連して伸びる場合、伸びた重心の寸法を有する画素に該予期された位置を調整するステップ、
とを有する。
本発明のさらなる態様に従って、
画像を検知できるデジタルカメラ装置と;
該画像を処理すべく該デジタルカメラ装置に挿入されて該デジタルカメラ装置に画像処理の指示(画像にテキストを付加する指示)を与えるように適合された画像処理データ入力カードと;
前記画像に付加する新たなテキスト文字を作成するために、前記画像処理指示に関連して前記デジタルカメラ装置により使用される一連の非ローマ・フォント文字を有するテキスト入力装置であって、前記画像に付加する前記文字を入力するために前記デジタルカメラ装置に接続されるテキスト入力装置と;
を備えた、画像を編集する、テキストのための装置が提供される。
望ましくは、前記新しいテキスト文字を作成するために前記画像処理指示に従って前記装置により要求された場合に、フォント文字が前記デジタルカメラ装置に送られる。前記画像処理データ入力カードは、ローマフォント文字のセットと、ヘブライ語、キリル文字、アラビア語、漢字及び中国文字(chinese character)の少なくとも1つを含む非ローマ文字とを含む。
本発明のさらなる態様に従って、
画像を検知できるデジタルカメラ装置と;
該画像を処理すべく該デジタルカメラ装置に挿入されて該デジタルカメラ装置に画像処理の指示(画像にテキストを付加する指示)を与えるように適合された画像処理データ入力カードと;
前記画像に付加する新たなテキスト文字を作成するために、前記画像処理指示に関連して前記デジタルカメラ装置により使用される一連の非ローマ・フォント文字を有するテキスト入力装置であって、前記画像に付加する前記文字を入力するために前記デジタルカメラ装置に接続されるテキスト入力装置と;
を備えた、画像を編集する、テキストのための装置が提供される。
本発明の目的は、作り出される新しいフィルターの利点、及び、プリントアウトするデジタル画像の処理のための柔軟性のある方法の利点に加えて、アップデートされる技術の利点を利用することである。
本発明のさらなる態様に従って、一連のインクドットからなる入力画像の再生のための画像コピー装置が提供され、該装置は、
(a) 対応した見本画像を作成するため、前記ドットの周波数よりも高いサンプリングレートで前記入力画像を撮像するイメージング・アレイ装置と;
(b) 前記見本画像中の印刷ドットの位置を決定するために前記画像を処理する処理装置と;
(c) 前記印刷ドットの位置に対応する、プリントメディア上の位置にインクドットを印刷するプリント装置と;
を含む。
2. 前記コピー装置が前記入力画像のフルカラーコピーを印刷する、請求項1に記載された画像コピー装置。
本発明のさらなる態様に従って、ボケ修正画像を出力するためのカメラシステムが提供される。該カメラシステムは、
画像を検知するイメージ・センサーと;
外部環境に関連した前記画像の何らかの動きを検知して、その動きを示す速度出力を生成するための速度検出手段と;
それらのイメージ・センサーや速度検出手段に接続されると共に、前記画像のボケ修正を行ってボケ修正画像を出力するように適合されたプロセッサー手段と;
を備えている。
望ましくは、前記カメラシステムは、前記ボケ修正画像を直ぐに出力するために印刷装置に接続されるものであって、携帯用のハンドヘルドユニットである。前記速度検出手段は、微小電気機械(MEMS)装置のような加速度計を含むことができる。
本発明のさらなる態様に従って、フォトセンサー読み取り形成品が提供され、該形成品は、
(a) 発光素子の挿入のための、一連の発光体収納部と;
(b) 前記一連の発光素子から発光された光を、撮像されるべきオブジェクトの表面に焦点を合わせるための発光素子合焦装置と;
(c) 一連のフォトセンサー列を挿入するためのフォトセンサー収納部と;
(d) 撮像されるべきオブジェクトからの反射光を、前記CCD列の特徴的な部分に焦点を合わせる合焦装置と;
を備える。
本発明の態様に従って、コンピュータシステムに接続されるプリンター装置が提供される。該プリンター装置は、プリントメディアに画像を印刷するためのインクジェット・プリントヘッドからなるプリントヘッドユニットを備え、さらに、消耗財であるプリントロールユニットを挿入するための空洞を有する。該プリントロールユニットは、該空洞に挿入される消耗財であるプリントメディアとインクとを含み、該インクは前記プリントメディアに画像を印刷するため、前記インクジェット・プリントヘッドにより使用される。
本発明のさらなる態様に従って、
画像を検知するセンサー装置(sensing means)と;
カメラに入力される修正指示に従って前記検知した画像を修正する修正装置と;
該修正された画像を出力するための出力装置と;
を備えたデジタルカメラシステムであって、前記修正装置が、中央のクロスバー・スイッチの周りに配列された一連のPE(Processing element)であるものが提供される。望ましくは、該PEは、書き込み可能なコントロール・ストアを有するマイクロコード・ストアの制御下で動作する算術論理演算ユニット(ALU)を有する。前記PEは、該素子にて使用される画素データを保存するための内部入出力FIFOを含むことができ、前記修正装置は、該装置へ画像の画素データを書き込んだり読み込んだりするための読み書きFIFOに接続されている。
それぞれのPEは輪になるように配置されることができ、また、それぞれのPEは最も近い隣のPEに単独で接続される。前記ALUは、内部クロスバースイッチを介してALU内の一連の中央演算装置に接続された一連の入力を受け、テンポラリーデータのストレージのための多くの内部レジスターを有する。該中央演算装置は、乗算器、加算器及びバレル・シフターの内の少なくとも1つを有している。
前記PEはさらに、該PEに画素データを転送するためのコモン・データバスに接続されている。該データバスはデータキャッシュに接続され、該データキャッシュは前記PEと、画像を保管するメモリーストアとの間で中間キャッシュとして機能する。
本発明のさらなる態様に従って、カードに高ピッチレートで保存された検知画像データを、リアルタイムで短時間に復号化する方法が提供され、該方法は、
前記画像データの初期位置を検出するステップと;
該画像データの対応するビットパターンを決定すべく、該画像データを復号化するステップと;
を含む。
本発明のさらなる態様に従って、カードに高ピッチレートで保存されて回転やワーピングやマーキングがされる検知画像データをフォールトトレラント方法によって短時間で復号化する方法が提供され、該方法は、
前記画像データの開始の初期位置を決定するステップと;
前記ピッチレートよりも高いサンプリングレートで前記画像データを検知するステップと;
カラム処理によってカラム中の検知画像データを処理し、次のカラムの各ドットの中心(重心)の期待される位置をキープし、期待される次の重心の位置をアップデートするように、各カラムを処理する場合に該重心の微細な調整を行うステップと;
を有する。
本発明のさらなる態様に従って、ドット配列からなり、画素配列を形成するため、該ドット配列のピッチ周波数よりも高いレートでサンプリングされた検知画像データのドットの値を正確に検出する方法が提供され、該方法は、
前記画素配列の内で、期待された重心位置に対応した、期待された中央画素を決定するステップと;
前記画素の位置を中心とするドットの値を出力するルックアップテーブルのインデックスとして、前記中央画素の検知値、及び、多くの隣接画素の検知値を使用するステップと;
からなる。
本発明のさらなる態様に従って、カードに高ピッチレートで保存され、回転やワーピングやマーキングの効果を前提とする検知画像データのドットの位置を正確に決定する方法が提供され、該方法は、
カラム中の前記画像データをカラム形式によって処理するステップと;
画素の前記処理されたカラムのドットパターンを記録するステップと;
前記処理された画素の記録されたドットパターンから、期待されたドットパターンを最新のカラム位置にするステップと;
前記期待されたドットパターンを、前記最新のカラム位置での検知画像データの実際のドットパターンと比較するステップと;
その比較が所定の誤差内である場合に、新しい実際のドット位置を生成するため、前記期待されたドットパターンに適合させるため、実際のドット位置を前記最新のカラム位置に帰るように前記最新のカラム位置を使用するステップと;
次のカラムのドット位置を決定する際に、最新のカラム位置にて前記実際のドット位置を利用するステップと;
を含む。
本発明のさらなる態様に従って、画像に絵画の効果を擬態するために画像バンプマップを結合させる方法が提供され、該方法は、
絵の具が塗られる表面を生じさせる、画像キャンバスバンプマップを規定し、
該表面に描かれるオブジェクトのペイントバンプマップを規定し、
前記画像キャンバスバンプマップによる、前記ペイントバンプマップの修正の程度を決定する剛性因子を使用し、最終的な結合バンプマップを作成するために前記画像キャンバスバンプマップと前記ペイントバンプマップとを結合すること、
を含む。
本発明のさらなる態様に従って、芸術的な効果を生じさせるため、入力されてきた画像を自動的に処理する方法が提供され、該方法は、
目的とする芸術的効果を作成するため、所定の出力ガモットへの入力ガモットのマッピングを決定し、
所定の出力ガモットを有する出力画像に前記入力画像をマップするマッピングを利用する、
ことを含む。
望ましくは、前記方法は、さらに、ブラッシュストローク・フィルターを使用した、出力画像の後処理のステップを含む。
さらに、望ましくは、前記出力ガモットは、所定数の入力ガモット値を、対応する出力色ガモット値にマッピングすると共に、入力ガモット値から出力色ガモット値へのマッピングの維持を挿入することによって形成される。その挿入プロセスは、出力色ガモット値への入力ガモット値の所定数のマッピングの加重和を含む。
本発明の第2の態様に従って、出力色ガモットに入るように入力色ガモットを圧縮する方法が提供され、該方法は、
現在の入力色の強さにてゼロクロミナンス値を決定するステップと;
前記ゼロクロミナンス値から前記入力色ガモットのエッジまでの距離であるソース距離を決定するステップと;
前記出力色ガモットの好適なエッジを決定するステップと;
前記ゼロクロミナンス値から前記出力色ガモットのエッジまでの距離であるターゲット距離を決定するステップと;
前記ソース距離と前記ターゲット距離との比から導き出される因子により、現在の入力色強さを計るステップと、
を備える。
好ましくは、前記現在の入力色強さは、前記ゼロクロミナンス値ポイントからの前記現在の入力色の距離に基づく因子により計られる。
本発明のさらなる態様に従って、カメラによって検知された画像の出力のための携帯用カメラが提供され、該カメラは、
画像を検知するためのセンサー装置(sensing means)と;
タイル状画像を作成すべく、検知された画像にタイル効果を付与するタイル装置と;
該タイル状画像を表示するための表示装置と;
を備えている。
本発明のさらなる態様に従って、カメラによって検知された画像の出力のための携帯用カメラが提供され、該カメラは、
画像を検知するためのセンサー装置(sensing means)と;
テクスチャが付加された画像を作成すべく、検知された画像にテクスチャ効果を付与するテクスチャマッピング装置と;
該テクスチャが付加された画像を表示するための表示装置と;
を備える。
本発明のさらなる態様に従って、カメラにより検知された画像を出力するための携帯用カメラが提供され、該カメラは、
画像を検知するためのセンサー装置(sensor means)と;
該検知された画像にて光を放つ光源の効果を真似たイルミネーション画像を作成すべく、検知画像に照明効果を付与する照明装置と;
該イルミネーション画像を表示するためのディスプレイ装置と;
を備えている。
本発明のさらなる態様に従って、
検知画像の特徴を有する布製衣料を描くディスプレイ装置への出力のため、前記検知画像の処理のためにカメラそうちに入力される一連の入力トークン信号と;
前記出力画像を形成するために、前記入力トークン信号を読み、画像を検知し、読み込んだ入力トークン信号に従って該画像を処理するように適合されたカメラ装置と;
前記出力画像を表示するように適合されたディスプレイ装置と;
からなる衣類創作システムが提供される。
本発明のさらなる態様に従って、画像センサー装置と画像表示装置とを有し、画像センサー装置によって検知された任意の画像の部分を衣類にマッピングして、前記画像表示装置にて表示する衣類創作システムが提供される。
本発明のさらなる態様に従って、処理された画像を形成する方法が提供され、該方法は、一連のカメラ処理ユニット(camera manipulation unit)を接続することを含み、それぞれのカメラ処理ユニットは、処理された出力画像を形成すべく、入力画像に画像処理を与えるものである。それらのカメラ処理ユニットの最初の1つは周囲から画像を検知し、それらのカメラ処理ユニットの少なくとも最後の1つは、色落ちしない出力画像を形成する。
本発明のさらなる態様に従って、遠い所にある被写体を眺めるための携帯用撮像装置が提供され、該撮像装置は、
遠く離れたところに見える被写体を拡大するための光学レンズシステムと;
該被写体を同時に検知するための検知システムと;
該検知された画像を処理してプリンター装置に送るために前記検知システムに接続される処理装置と;
要求に応じて前記携帯用撮像装置により検知された画像をプリントメディアに印刷するため前記処理装置に接続されたプリンター装置と;
を備えている。
好ましくは、前記システムは、さらに、前記プリンター装置にロール状のプリントメディアとインクとを供給するため、前記プリンター装置に接続される、取り外し可能なモジュールに配置された、取り外し可能なプリントメディア供給装置を有する。
前記プリンター装置は、検知した画像を出力するための、フルカラープリンターを提供する、インクジェットプリント装置を備えることができる。
さらに、好ましい実施例は、遠い所の被写体を前記検知システムに投影するためのビームスプリッタ装置を備えた双眼鏡システムとして実施される。
本発明のさらなる態様に従って、カードに印刷された一連のドットとして、フォールトトレラント方法により符号化されている録音済み音声を再生するシステムが提供される。該システムは、
録音済み音声の目に見える形式のスキャニングのためのオプティカル・スキャナー装置と;
スキャンされた音声符号を復号化して音声信号を生成するように、該オプティカル・スキャナー装置に接続された処理装置と;
要求に応じて該音声信号を再生するように、該処理装置に接続された音声エミッター装置と;
を備える。
前記符号化は、録音済み音声のリード・ソロモン符号化を含むことができ、スキャニングを補助するために高周波変調されたインクドット列を含むことができる。
前記システムは、前記カードを挿入するための細長い穴を有する棒状のアームを備える。
本発明のさらなる態様に従って、印刷されたカードに情報を担持させる方法を提供するものであって、該方法は、
カードの表面を多くの所定のエリアに分割するステップと;
該所定のエリアの内の第1エリアに格納されるべき第1のデータを印刷するステップと;
前記カードに保存されている情報を読み取るときに前記印刷された第1の所定エリアを使用するステップと;
該カードに保存された情報をアップデートするときに、該カードに保存されるさらなる情報が印刷される、データの印刷に使用されていない第2の所定エリアを決定するステップと;
を有する。
望ましくは、それらのエリアは、予め決められた順番で選択される。また、例えば、データのリード・ソロモン符号化によってもたらされるフォールトトレラントを有するデータを印刷するため、高解像度のインクドットプリンターを使用して印刷される。前記エリアのボーダーの線引きをするボーダー領域が印刷されて提供され、さらに、該ボーダー領域の位置を示すのに役立つ、多数のボーダー・ターゲット・マーカーが提供される。それらのボーダー・ターゲットは、第1色の大きなエリアと、該エリアの中心に配置される、第2色の小さなエリアとからなる。
望ましくは、前記データは、市松模様パターンのような高周波変調信号を使用して印刷されている。その印刷されたものは、1インチにつき約1200ドットよりも大きい解像度のドット配列であり、好ましくは、1インチにつき少なくとも1600ドットよりも大きい解像度を有するドット配列である。該所定のエリアは、該カードの表面にて標準の配列に配列することができ、該カードは、一般的な長方形のクレジットカードのようなサイズ及び形状にすることができる。
本発明のさらなる態様に従って、画像処理のための一連の指示を作成する方法が提供される。該方法は、
ユーザが選択するため、見本画像の初期配列を表示するステップと;
該見本画像の少なくとも1つをユーザが選択することを受諾するステップと;
見本画像のさらなる配列を作成するため、その選択結果を利用するステップと;
ユーザが最終的な最適画像を少なくとも1つ選択するまで、上述のステップを繰り返して適用するステップと;
前記一連の指示に従って見本画像を作成するステップと;
該一連の指示を出力するステップと;
を含む。
さらに、前記方法は、ユーザの写真をスキャンすることと、各見本画像の作成のための初期画像として該スキャンされた写真を使用すること、を含む。前記指示は、前記カードの第2面に視覚表示されるように印刷されるのに加えて、第1面にエンコード形式で印刷されることができる。加えて、処理画像自体は印刷される。
前記配列を形成するため、遺伝的アルゴリズムや遺伝的プログラミング技術を含む画像の形成に様々な技術が使用され得る。さらに、さらなる画像の形成において、‘これまでのところベスト(best so far)’の画像が使用のために保存される。
望ましくは、カードや写真を販売する自動販売機に組み込まれたコンピュータシステムにこの方法が実行される。
本発明のさらなる態様に従って、挿入されたカードに情報を保存するための情報保存装置が提供され、該装置は、
カードの面に印刷されたパターンであって、カードの所定数の可能動作領域(possible active area)に配置されたパターンを検知するセンサー装置と;
該検知したパターンを対応するデータに復号化するためのデコード装置と;
カード表面であって前記活動領域の1つにドットパターンを印刷するための印刷装置と;
前記センサー装置及び前記印刷装置の公知の相対位置に、検知されるカードを配置する位置決め装置と;
を備え、
前記検知装置は、前記カードの最新の動作プリント領域にて印刷されたパターンを検知するように適合され、
前記デコード装置は、該検知したパターンを対応する最新のデータに復号化するように適合化され、
前記印刷装置は、最新のデータのアップデートが要求された場合に、カードの正確な位置決めのために位置決め装置が駆動された後、前記活動領域の内の最新の1つに、アップデートされた最新データをプリントするように適合される。
前記印刷装置は、望ましくは、1度にカード幅の印刷が可能なカード幅プリントヘッドからなるインクジェットプリンタ装置を備える。前記位置決め装置は、カードを挟んでカードの移動をコントロールするための一連のピンチローラーを備えることができる。前記印刷されたパターンは、例えば、リードソロモン復号化を使用して、フォールトトレラント方法により配列され、前記デコード装置は、該フォールトトレラントパターンのために好適なデコーダを有する。
本発明のさらなる態様に従って、
画像を検知するイメージ・センサーと;
検知画像及び関連するシステム構成を保存するためのストレージ装置と;
前記検知画像を修正するために画像修正データモジュールを入力するためのデータ入力装置と;
前記検知画像の処理に加えて前記カメラシステムのコントロールのために、前記イメージ・センサーや前記ストレージ装置や前記データ入力装置に接続された処理装置と;
供給されるプリントメディアに、要求に応じて前記検知画像を印刷するための印刷装置と;
を備えたデジタルカメラシステム、並びに、
さらなる画像修正モジュールの挿入に基づき、前記デジタルカメラシステムの操作の修正を前記処理装置にさせるように適合された、画像修正データモジュールの提供方法が提供される。
望ましくは、符号化されたデータをその表面に有するカードを前記画像修正データモジュールが有し、そのデータの符号化は印刷により行われ、前記データ入力装置は、カード表面をスキャンするための光学スキャナーを有する。操作の修正は、繰り返し、同じ画像に、一連の画像修正モジュールが挿入される順にそれぞれ画像修正を行う。
本発明のさらなる態様に従って、
画像を検知するイメージ・センサーと;
検知画像及び関連するシステム構成を保存するためのストレージ装置と;
前記検知画像を修正するために画像修正データモジュールを入力するためのデータ入力装置と;
前記検知画像の処理に加えて前記カメラシステムのコントロールのために、前記イメージ・センサーや前記ストレージ装置や前記データ入力装置に接続された処理装置と;
供給されるプリントメディアに、要求に応じて前記検知画像を印刷するための印刷装置と;
を備え、画像修正データモジュールは、デジタルカメラシステムにて一連の診断テストの実施、及び前記印刷装置を介した結果の印刷を前記処理装置が行うように適合されたデジタルカメラシステムが提供される。
望ましくは、符号化された指示データをその一面に有するカードを前記画像修正データモジュールが有し、前記処理装置は、該カードに符号化された指示データを読み取るための装置を有する。前記診断テストは、連続した全てが黒の帯を印刷するなどによって、プリンター装置の操作を向上させるため、プリンター装置のためのクリーニングサイクルを有することもできる。代わりに、インクジェットプリンターの操作を向上させるため、前記診断テストがノズルの調節を含むこともできる。加えて、カメラシステムの様々な内部操作パラメータを印刷することもできる。重力衝撃センサーをカメラシステムに装備した場合には、前記診断テストは、該センサーの局地を印刷することもできる。
本発明のさらなる態様に従って、画像を生成するためのカメラシステムが提供され、該カメラシステムは、画像を検知するセンサーと;何らかの所定の処理要求に従って前記検知画像を処理するための処理装置と;プリントメディアの面に前記検知画像を印刷するための印刷装置と;前記プリントメディアに形成された磁気感受性面に関連情報を記録するための磁気記録装置とを備える。前記関連情報は、検知画像に関連した音声情報を含み、前記印刷装置は、望ましくは、検知画像を前記プリントメディアの第1面に印刷し、前記磁気記録装置は前記プリントメディアの第2面に前記関連情報を記録する。前記プリントメディアは、前記カメラシステムの内部の取り外し可能なロールに収納されることができる。1つの実施例では、前記磁気感受性面は、前記プリントメディアの裏面に貼り付けられた帯片を含むことができる。
本発明のさらなる態様に従って、携帯用カメラ装置のイメージセンサーにキャプチャーされた画像の、色落ちしないコピーを作る方法が提供される。前記携帯用カメラ装置は、該カメラ装置に格納されているプリントメディアに印刷するための一体型コンピュータ装置と一体型プリンター装置とを備えており、前記方法は、前記イメージセンサーにて画像を検知するステップと;フォールトトレラントの符号性質を持つ符号化形式に前記画像を変換するステップと;前記一体型プリンター装置を使用して画像の色落ちしない記録としての画像の符号化形式を印刷するステップとからなる。
好ましくは、前記一体型プリンター装置は、プリントメディアの第1面及び第2面に印刷するための装置を備え、前記検知画像やその視覚的な処理は第1面に印刷され、符号化された形式は第2面に印刷される。検知画像のサムネイルは、前記画像のエンコード形式の横に印刷されることができる。また、そのフォールト・トレラント符号化は、永久的な録音が、反復可能な高周波スペクトラル成分を有する符号化形式に市松模様のような高周波変調信号を適用するのに加えて、画像のリードソロモン符号化バージョンを形成することも含む。
本発明の第1の態様に従って、カメラ装置で使用される画像処理カードの販売のための販売システムが提供される。該カメラ装置は、画像処理カードの挿入のためのカード処理インターフェースを有する。該画像処理カードは、前記カメラ装置での画像の処理のためのものである。前記販売システムは、
画像処理カードを出力するための複数の印刷装置と;
該画像処理カードの作成のために必要な一連の画像処理カードデータのストレージのために、それぞれの印刷装置が対応するコンピュータシステムに接続されている。
望ましくは、前記コンピュータシステムは、コンピュータ・ネットワークを介してキャッシュされる方法で、一連の画像処理カードデータを保存する。そして、カード配布コンピュータは、新しい画像処理カードをコンピュータシステムへ配布する。
前記画像処理カードにイベントカード(季節ごとのイベントに利用すべくカードをプリントアウトするため、前記コンピュータシステムに分配される季節ごとのカード)が含まれる場合、本発明は特定用途を有する。
本発明のさらなる態様に従って、オブジェクトの表面に符号化された、一連のブロックデータ領域を有するデータ構成が提供され、それぞれのブロックデータ領域は、
符号化された形式に復号化されるデータを含む符号化データ領域と;
該符号化データ領域の第1の周辺部を囲むように配置された、一連のクロックマーク構成と;
該符号化データ領域の第2の周辺部を囲むように配置された、一連の、簡単に特定できるターゲット構成と;
からなる。
前記ブロックデータ領域は、さらに、前記符号化データ領域の第3の周辺部の周りに配置された方向データ構成(orientation data structure)を含む。該方向データ構成は、前記周辺部のエッジに沿った、等データ点の線(a line of equal data points)を含むことができる。
前記クロックマーク構成は、符号化データ領域のエッジに沿って配置されたデータ点の実質的近接第2の線(a substantially adjacent second line)に加えて、等データ点の第1の線を有することができる。該クロックマーク構成は、符号化データ領域の反対側に配置されることができる。
前記ターゲット構成は、間隙を有するように配置された一連のデータポイントブロック(data points blocks)のセットを有し、該データポイントは、中央部以外では、第1の大きさ(magunitude)の定値を有し、中央部では、前記第1の大きさとは逆の大きさを有する。前記ブロックのセットは、さらに、前記逆の大きさの連続群の値を有する、ターゲット数表示構成を含む。
前記データ構成は、理想的には基材表面に印刷された一連のドットにて活用される。
本発明の第2の態様に従って、オブジェクトの表面に符号化されたデータ構成を復号化する方法が提供され、該データ構成は一連のブロックデータ領域を有し、それぞれのブロックデータ領域は、
符号化された形式に復号化されるデータを含む符号化データ領域と;
該符号化データ領域の第1の周辺部を囲むように配置された、一連のクロックマーク構成と;
該符号化データ領域の第2の周辺部を囲むように配置された、一連の、簡単に特定できるターゲット構成と;
からなり、前記方法は、
(a) 前記データ構成をスキャンするステップと;
(b) 前記データ構成のスタートの位置を探すステップと;
(c) 前記ターゲット構成の最新の方向を判断して該ターゲット構成の位置を探すステップと;
(d) 前記ターゲット構成の位置から前記クロックマーク構成の位置を探すステップと;
(e) 前記符号化データ領域のビットデータの期待される位置を決定するために前記クロックマーク構成を使用するステップと;
(f) 各ビットデータのために期待されるデータ値を決定するステップと;
を有する。
前記クロックマーク構成は、符号化データ領域のエッジに沿って配置されたデータ点の実質的近接第2の線(a substantially adjacent second line)に加えて、等データ点の第1の線を有することができる。前記(e) の、使用するステップは、前記クロックマーク構成中の最新の位置を維持するため、疑似位相ロックループタイプのアルゴリズムを使用してデータポイントの第2の線に沿ってランすることも含む。
さらに、決定するステップ(f)
は、
検知したビット値を3つの隣接する領域(すなわち、中央領域、第1のlower extreme 領域、及び第2のupper extreme 領域)に分けることを含み、
第1の領域にそれらの値が含まれ、該第1の領域に対応するビット値を決定し;
第2の領域にそれらの値が含まれ、該第2の領域に対応するビット値を決定し;
前記中央領域にそれらの値が含まれ、その値が第1の値か第2の値かを決定するために空間的に囲まれる値を使用する。
本発明のさらなる態様に従って、検知データの出力データ値を決定する方法が提供され、該方法は、
(a) 検知されたデータ値を3つの隣接する領域(すなわち、中央領域、第1のlower extreme 領域、及び第2のupper extreme 領域)に分けることを含み、
第1の領域にそれらの値が含まれ、該第1の領域に対応するビット値を決定し;
第2の領域にそれらの値が含まれ、該第2の領域に対応するビット値を決定し;
前記中央領域にそれらの値が含まれ、その値が第1の値か第2の値かを決定するために空間的に囲まれる値を使用する。
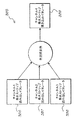
本発明のさらなる態様に従って、複数の異なる供給スロットに複数の異なる流体を供給するための流体供給装置が提供される。該供給スロットは、交互に配置するという方法で周期的な間隔を置いて配置され、前記流体供給装置は、
複数の異なる流体のそれぞれのための流体注入口装置と;
異なる流体のそれぞれのための流路であって、前記供給スロットのそれぞれに接続されたメインチャンネル流路と;
前記供給スロットのそれぞれを、対応するメインチャンネル流路に接続するサブチャンネル流路と;
を備えている。流体の数は2よりも多く、成形された流体供給ユニットの第1面に少なくとも2本のメインチャンネル流体装置が形成され、他のメインチャンネル流体装置は、成形品の表面を貫通する貫通孔を介して前記スロットに接続されたサブチャンネル流路で該成形品の上面に形成される。
望ましくは、前記供給装置は、プラスチック射出成形されており、前記スロットのピッチレートは、1インチ当たり1000に等しいか、1000よりも少ない。さらに、スロットの集合が、写真の幅に形成される。望ましくは、前記流体供給装置は、1又はそれ以上のピンチローラーを収容するためのローラースロット装置を複数有しており、前記流体はインクからなり、前記ローラーは、前記スロットに接続されたプリントヘッドをプリントメディアが横切るように制御される。前記スロットは、カラムに配置された一連のカラースロットに分割される。
好ましくは、前記流体供給装置の少なくとも1つのチャンネルは、製造時に露出され、該露出面をシーリングテープにてシールされている。有利なことには、前記流体供給装置は、テープによる自動結合されたワイヤを得るため、TABスロットにより提供される。
本発明のさらなる態様に従って、インク供給路を介して供給するインク吐出装置を少なくとも1つ使用する画像印刷用プリンター装置が提供され、該装置は、
前記プリンターへのインク供給のためのインク供給装置に連動するように適合された、1つの出力色につき1つで一連のインク供給口と;
前記プリンター装置の外表面に沿った、一連の導電性コネクタパッドと;
インクを吐出させる一連のインク吐出装置を有するページ幅プリントヘッドと;
前記インク供給口から前記ページ幅プリントヘッドの前記インク吐出装置にインクを供給するインク供給システムと;
前記ページ幅プリントヘッドを前記導電性コネクタパッドに接続する、複数の相互接続ワイヤと;
を備え、
前記プリンター装置は、ハウジング装置の中に取り外し可能に挿入されるように適合され、該ハウジングは、前記導電性コネクタパッドとの相互接続のための相互接続部や、前記インク供給装置によるインクの供給のため、前記インク供給口との相互接続のためのインク供給コネクタを有している。
望ましくは、前記複数の相互接続ワイヤは、前記プリンター装置の外面を包み込むと共に、導電性コネクターパッドに接続されたテープ自動ボンディング・シートを形成する。該相互接続されたワイヤーは、
前記導電性コネクターパッドに相互接続されると共に、プリントヘッドの全長に沿って互いにほぼ平行な配置された第1のセットのワイヤーと、
該プリントヘッドの表面から互いにほぼ平行に配置された第2のセットのワイヤーと、
を有している。第1のセットのワイヤーのそれぞれは、第2のセットのワイヤの多くに接続されている。前記インク供給口は、薄いダイアフラム部を有している。該ダイアフラム部は、前記インク供給コネクタが前記ハウジング装置に挿入されることに基づき穴が開けられている。
前記ページ幅プリントヘッドは、それぞれに所定数のインク吐出装置を有する、実質的に等しく繰り返し可能なユニット(substantially identical repeatable unit)を多数備えることができる。該ユニットは、所定数の接続ワイヤを有する標準インターフェースを有し、各標準インターフェース装置は、導電性コネクタパッドにグループで接続される。該プリントヘッド自体は、シリコンウェハから作成されることができ、ページ幅ストリップに分離される。
本発明のさらなる態様に従って、電流の変動をモニターするという方法によって集積回路のモニタリングに対する抵抗を与える方法が提供され、前記方法は、前記集積回路の一部であるスプリアスノイズ発生回路を形成するステップを含む。
前記ノイズ発生回路はLFSR(リニア・フィードバック・シフト・レジスタ)のような乱数発生器を含むことができる。
本発明のさらなる態様に従って、低消費電力のCMOS回路が提供される。該回路は、第1のクロックと入力とに接続されたゲートを有するpタイプのトランジスタ、及び、第2のクロックと入力とに接続されたnタイプのトランジスタを備え、該CMOS回路は、オーバーラップしない方法により前記第1及び第2のクロックが切り換えられることに稼動される。
該回路は、高出力スイッチング特性(high power switching characteristics)を持つ第2の回路に実質的に隣接されることができる。該第2の回路は、ノイズ発生回路を有することができる。
本発明のさらなる態様に従って、異なる出力状態に対応する複数のレベル状態を有する、メモリー回路のモニタリングに対する抵抗を与える方法が提供され、該方法は、有効な出力状態のためだけに中間状態を利用することを含む。該メモリーはフラッシュメモリーにすることができ、さらに、1かそれ以上のパリティビットを有することができる。
本発明のさらなる態様に従って、集積回路に手を加える攻撃(attempt)をモニターするため、ランダムノイズ発生器に取り付けられた回路(circuit path)を使用する、前記集積回路に手を加えることに対する抵抗を与える方法が提供される。
前記回路(circuit
path)は、互いに逆であって、様々な回路に接続され、リセット出力信号を生成するための排他的OR回路となる、第1パス及び第2パスを有する。
本発明の第2の態様に従って、接地された大きな抵抗に一端が接続され、電源に接続された第2の大きな抵抗に他端が接続されたタンパー検出ラインが提供される。該タンパー検出ラインは、さらに、期待される電圧が所定の許容範囲内にあるかを比較するコンパレータに接続される。一連のテストに接続される抵抗の中間には、そのテストの1つによってタンパリングが検出された場合にコンパレータがリセット信号を出力するように大きな抵抗が出力される。
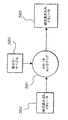
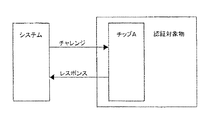
本発明のさらなる態様に従って、認証されるべき付属ユニットの有効性を判断するための認証システムが提供され、該システムは、
第1及び第2のセキュアキーの確認のための中央システムユニットと;
該中央システムユニットに取り付けられた第1及び第2のセキュアキーを保持するオブジェクトと;
を備え、
第2のセキュアキーを保持するオブジェクトは取り外せないような方法で取り付けられ、
前記中央システムユニットは、
第1のレスポンスを決定するために前記第1のセキュアキーを保持するオブジェクトに問い合わせを行い、
第2のレスポンスを決定するために前記第2のセキュアキーを保持するオブジェクトに問い合わせを行うために前記第1のレスポンスを利用し、
さらに、
前記第2のセキュアキーを保持するオブジェクトが、有効な取り付けユニットに取り付けられているかどうかを判断するために、前記第1のレスポンスと前記第2のレスポンスを比較するように適合されている。
前記取り付けユニットの所定の使用の後に該ユニットが作動を止めるように、前記第2のセキュアキーを保持するオブジェクトは、さらに、効果的に単調減少するマグニチュード・ファクターを有するレスポンスを含む。したがって、取り付けられたユニットは、消耗品を含むことができる。
さらに、前記中央システムユニットは、前記第1のレスポンスを受け取った数を前記第1のセキュアキーを保持するオブジェクトに問い合わせることができ、そのとき、該中央システムユニットは、第2のレスポンスの判断のための前記第2のセキュアキーを保持するオブジェクトへの問い合わせに際して前記第1のレスポンスを使用し、該中央システムユニットは、前記第2のレスポンスの有効範囲を判断するため、前記第1のセキュアキーを保持するユニットに問い合わせを行うために前記第2のレスポンスを使用する。
該システムは、理想的には、インクジェットプリンターにおけるインクのように、プリンターの消耗品を認証するために使用される。
実際に、内蔵型インクジェットプリンターを有するカメラシステムにおいて、消耗品であるインクに関連して、好ましい実施例が論じられるだろうけれども、本発明がそのことに限定されるものではない。
好適なその他の実施例の説明
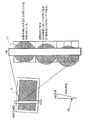
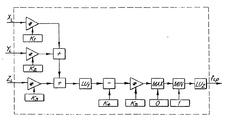
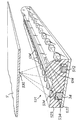
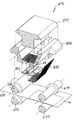
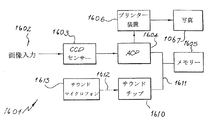
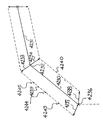
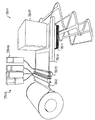
好適な実施例により構成されたデジタル画像処理カメラシステムは、図1に示されている。カメラユニット1は、一体的なプリントロール(図示しない)を挿入する手段を含む。カメラユニット1は、カメラによって撮影される像3を検出するエリアイメージセンサ2を含む。オプションとして、シーン3を映像化し、オプション的に立体画法の出力効果の生成物を得るため、第2のエリアイメージセンサを搭載してもよい。
カメラ1は、センサ2によって検出された像を表示するためのオプションのカラーディスプレイ5を含む。シンプルな像がディスプレイ5に表示されるとき、ボタン6を押下することが可能であり、その結果、印刷された画像8がカメラユニット1によって出力される。以下では、Artcard(アートカード)9と呼ばれる一連のカードは、一方の面に符号化された情報を含み、もう一方の面に、Artcard9により生成された特定の効果によって歪められた画像を含む。Artcard9は、カメラ1の側面にあるArtcardリーダー10に挿入され、挿入されると、Artcard9の面に現れた歪みと同じ方法で歪められた出力画像8が得られる。したがって、この簡単なユーザインタフェースを使用することにより、特定の効果を生じさせることを望むユーザは、多数のArtcard9のうちの一枚をArtcardリーダー10に挿入し、像3の写真を撮影するためボタン19を利用することが可能であり、その結果、対応した歪んだ出力画像8が得られる。
カメラユニット1は、カメラユニットの内部プリントロールに残っているプリントアウトの数を含む説明情報を表示するための簡単なLCD出力ディスプレイ15に加えて、多数の他の制御ボタン13、14を含み得る。更に、様々な出力フォーマットがCHPスイッチ17によって制御され得る。
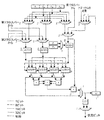
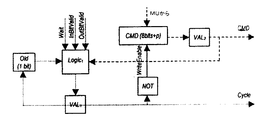
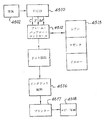
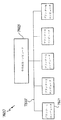
次に図2を参照すると、カメラ1の内部ハードウェアの概略図が示されている。内部ハードウェアは、Artcam(アートカム)中央プロセッサユニット(ACP)31を中心としている。
Artcam中央プロセッサ31
Artcam中央プロセッサ31は、システムの心臓部を形成する多数の機能を提供する。ACP31は、好ましくは、複雑な高速CMOSシステムオンチップとして実現される。一部のフルカスタム領域を有する標準的なセル設計を利用することが推奨される。0.25ミクロンCMOSプロセス上の製作は、合理的に小さいダイ面積と共に、要求され
る密度及び速度を実現する。
ACP31によって与えられる機能には次の機能が含まれる:
1. エリアイメージセンサ2の制御及びデジタル化。ACPの3次元立体視バージョンは、第2のオプションのイメージセンサ4が立体視効果のために設けられた二つのエリアイメージセンサインタフェースを必要とする;
2. エリアイメージセンサ補償、再フォーマッティング、及び画像強調;
3. 記憶装置33に対するメモリインタフェース及び管理;
4. Artcard9からのデータの読み出しのために設けられたArtcardリーダーのリニアイメージセンサ34のインタフェース、制御及びアナログ・デジタル変換;
5. デジタル化された符号化Artcard画像からの未加工Artcardデータの抽出;
6. Artcardの符号化データのリード・ソロモン誤差検出及び訂正。Artcard9の符号化された面は、Artcard9の画像歪み面に表示された効果を生成するためどのように画像を処理するかに関する情報を含む。この情報は、以下では、「Varkスクリプト」と呼ばれるスクリプトの形式である。Varkスクリプトは、望ましい効果を生成するためACP31内で実行されるインタープリタによって利用される;
7. Artcard9上のVarkスクリプトの解釈;
8. Varkスクリプトによって指定されたとおりの画像処理動作の実行;
9. 用紙輸送36、ズームレンズ38、自動焦点39、及びArtcardドライバ37のための様々なモーターの制御;
10. プリントロール42からの写真8を裁断する裁断機41の動作用の裁断機アクチュエータ40の制御;
11. 印刷用画像データの中間調化;
12. 適当な時におけるプリントヘッド44へのプリントデータの供給;
13. プリントヘッド44の制御;
14. プリントヘッド44へのインク圧送の制御;
15. オプションのフラッシュユニット56の制御;
16. 方位センサ46、自動焦点47及びArtcard挿入センサ49を含むカメラ内の様々なセンサの読み出し及びそれに基づく処置;
17. ユーザインタフェースボタン6、13、14の読み出し及びそれに基づく処置。
18. 状態ディスプレイ15の制御;
19. ビューファインダー及びプレビュー画像のカラーディスプレイ5への供給;
20. 電力管理回路51によるACP電力消費を含むシステム電力消費の制御;
21. 汎用コンピュータへの外部通信52の提供(パートUSBを使用);
22. プリントロール認証チップ53の情報の読み出し及び保存;
23. カメラ認証チップ54の情報の読み出し及び保存;
24. テキスト修正用のオプションのミニキーボード57との通信。
水晶振動子58
水晶振動子58は、システムクロック用の周波数基準として使用される。システムクロックは非常に高いため、ACP31は水晶58から得られた周波数を増大させるため位相ロックループクロック回路を含む。
イメージセンシング
エリアイメージセンサ2
エリアイメージセンサ2は、そのレンズを通る像を電気信号へ変換する。エリアイメージセンサは、電荷結合素子(CCD)でもよく、アクティブ画素センサ(APS)CMOSイメージセンサでもよい。現在のところ、利用可能なCCDは、通常、かなり高い画質を有するが、CMOSイメージャの開発は、現在、非常に盛んに行われている。CMOSイメージャは、最終的には、画素数の少ないCCDよりも実質的に安価になり、駆動回路及び信号処理を組み込み得ることが予想される。CMOSイメージャは、12インチウェハーに移行しているCMOS製造技術で製作することが可能である。したがって、CCDとCMOSイメージャの間の製造コストの差は増加し、徐々にCMOSイメージャの方が支持される可能性が高い。しかし、現在のところ、CCDは、最良の選択肢である。
Artcamユニットは、1500×1000型のエリアイメージセンサで適切な結果を生じるであろう。しかし、例えば、750×700型のような小型のセンサも、様々な市場で適切であろう。Artcamは、従来のデジタルカメラと比べると、イメージセンサの解像度に対する感度が低い。その理由は、Artcard9に入っている殆どのスタイルは、解像度の不足をわかりにくくするように画像を処理するからである。例えば、画像が印象派の絵画へ変換される効果をシミュレートするため歪められる場合、原画像の低解像度は最小の影響で使用可能である。低解像度入力画像が典型的に気付かれない更なる例には、極めて歪んだ画像を生じる画像ワープ、画像の複数の縮写(例えば、パスポート写真)、ベースレリーフメタルルックのためのバンプマッピングのようなテクスチャ処理、及び構造化されたシーンへの写真合成が含まれる。
このように低解像度イメージセンサを許容することは、Artcamユニット1カメラの製造コストを低下させる重要なファクタである。低コストの750×500型イメージセンサを用いるArtcamは、しばしば、非常に高価な1500×1000型イメージセンサを用いる従来のデジタルカメラよりも優れた結果を生じる。
オプションの立体視3次元イメージセンサ4
Artcamユニット1の3次元バージョンは、立体視動作のため補助イメージセンサ4を備える。このイメージセンサは、主イメージセンサと同一である。オプションのイメージセンサを駆動する回路は、設計コストの増大を低減するため、ACPチップ31の標準部品として収容してもよい。或いは、別個の3次元Artcam
ACPを設計してもよい。このオプションは、主流の単一センサ型のArtcamの製造コストを削減する。
プリントロール認証チップ53
小型チップ53は、各プリントロール42に収容される。このチップは、APS(新写真システム)フィルムカートリッジのような他の形態のカメラフィルムユニット上のバーコード、光学センサ及びホイール、並びに、ISO/ASAセンサの機能を置き換える。
認証チップは、以下のその他の機能も提供する:
1. APSロールから機械的及び光学的に検出されるデータではなく、データの保存;
2. 高解像度の正確さの媒体の残りの長さの表示;
3. 粗悪な模造プリントロールコピーを防止するための認証情報。
認証チップ53は、1024ビットのフラッシュメモリを含み、1024ビットのうちの128ビットは認証鍵であり、512ビットは認証情報である。更に、認証鍵が直接アクセスされないことを保証するため、暗号化回路が収容される。
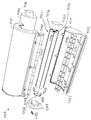
プリントヘッド44
Artcamユニット1は、十分に小規模、十分に低電力、十分に高速、十分に高品質、及び十分に低コストであり、プリントロールに適合したどのようなカラー印刷技術でも利用可能である。以下、当該印刷ヘッドについて具体的に説明する。
インクジェットヘッドの仕様は以下の通りである。
オプションのインク圧コントローラ(図示せず)
インク圧コントローラの機能は、Artcamに組み込まれたインクジェットプリントヘッド44のタイプに依存する。一部のタイプのインクジェットでは、インク圧は単純に大気圧であるため、インク圧コントローラを使用しなくても済む。他のタイプのプリントヘッドは、安定化した正のインク圧を必要とする。この場合、インプレッシャ・コントローラは、ポンプ及び圧力トランスデューサを含む。
その他のプリントヘッドは、インク圧力に、典型的に約100KHzの規則的な振動を生じさせるため超音波トランスデューサが必要である。この場合、ACP31は、これらの振動の周波数位相及び振幅を制御する。
用紙輸送モーター36
用紙輸送モーター36は、プリントロール42内からプリントヘッドの傍を通して、一定速度で用紙を移動させる。モーター36は、用紙を移動させるローラーを駆動するため適切な速度までギアダウンされた小型モーターである。機械的なガタ又はその他の振動が印刷されたドット行間隔に影響を与えるので、高画質を実現するためには、高品質モーターと機械式ギアが必要である。
用紙輸送モータードライバ60
モータードライバ60は、APC31からのデジタルモーター制御信号をモーター36の駆動に適切なレベルまで増幅する小型回路である。
用紙プルセンサ
用紙プルセンサ50は、印刷プロセス中にユーザによるカメラユニットからの写真の引っ張りを検出する。APC31は、このセンサ50を読み出し、この状況を検出した場合、裁断機41を作動する。用紙プルセンサ50は、動作中にカメラをより絶対確実にするために組み込まれる。ユーザが印刷中に強引に用紙を引き出そうとした場合、プリント機構44又はプリントロール42は、(極端なケースでは)破損するであろう。ポッドが完全に排出される前にポラロイド式カメラからポッドを引き出すことが許されるので、一般の人々はこのような動作を行うことに慣れている。したがって、一般の人々は、用紙を引き出してはならないという印刷された指示に留意しない可能性が高い。
Artcamは、好ましくは、引っ張り検出後に裁断機41が用紙を裁断した後、写真印刷プロセスを再開する。
引っ張りセンサは、歪みゲージセンサとして実現してもよく、又は用紙が引っ張られたときに用紙ドライブローラーに発生するトルクによって偏向される小さいプラスチック製のフラグを検出する光学センサとして実現してもよい。後者の実現形態は、低コストのため推奨される。
用紙裁断機アクチュエータ40
用紙裁断機アクチュエータ40は、写真の終わりに、又は用紙引っ張りセンサ50が作動されたときに、裁断機41に用紙を裁断させる小型アクチュエータである。
用紙裁断機アクチュエータ40は、APCからの裁断機制御信号をアクチュエータ41によって要求されるレベルまで増幅する小型回路である。
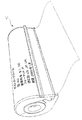
Artcard9
Artcard9はArtcamユニット用のプログラム記憶媒体である。前述の通り、プログラムは、Varkスクリプトの形式である。Varkは、特に、Artcamユニットのため開発された強力な画像処理言語である。各Artcard9は一つのVarkスクリプトを格納し、これによって、一つの画像処理スタイルを規定する。
好ましくは、VARK言語は高度に画像処理専用である。高度に画像処理専用とすることにより、カード上に詳細を記憶するために要する記憶容量は実質的に減少する。更に、機能強化された効果を含む新しいプログラムを作成できる簡便さは、実質的に向上する。好ましくは、この言語は、ワープマップによる画像ワーピング、コンボリューション、カラールックアップテーブル、画像のポスタリゼーション、画像へのノイズ付加、画像強調フィルタ、ペインティングアルゴリズム、ブラシジッタリング及び操作エッジ検出フィルタ、タイリング、光源による照明、バンプマップ、テキスト、顔検出及び物体検出属性、3次元フォントを含むフォント、並びに、任意の複合予備レンダリングアイコンを含む多数の画像処理機能を取り扱う機能を含む。Vark言語インタープリタの動作のより詳細な内容は以下に記載される。
したがって、作成された言語によって定義されるような言語構造を利用することにより、任意の画像に対する新しい影響を作成し、Artcard上の安価な記憶装置のために構築し、その後、カメラの所有者に配布することが可能である。更に、カードの片面には、カードのもう一方の面に記憶された特定のVARKスクリプトが任意の撮影像に与える影響を説明する例が設けられる。
このようなシステムを利用することにより、VARKインタープリタがカメラ装置に組み込まれているならば、装置に依存しないシナリオが与えられ、その結果として、根本的な技術が長期のうちに完全に変えられるという点で、カメラ技術は、著しく陳腐化する虞を伴わずに普及させることができる。更に、新しいフィルタが作成され、カード読み出し用の簡単なカードを用いるような、安価な方式で配布されたときに、Varkスクリプトを更新することが可能である。
Artcard9は、クレジットカード(長さ86mm、幅54mm)と同一フォーマットの薄い白色プラスチック製の片である。Artcardは、高解像度インクジェットプリンタを使用して両面印刷されている。このインクジェットプリンタ技術は、1600dpi(63dpmm)の解像度のArtcamに使用される技術と同じ技術であると考えられる。Artcard9の主要な特徴は、安価な製造コストである。Artcardは、プラスチックフィルムの幅広いウェブと同様に高速で製造可能である。プラスチックウェブは、親水性の染料固着層で両面を覆われる。ウェブは、ページ幅のカラーインクジェットプリンタを用いて両面同時に印刷される。次に、ウェブは、個別のカードに切断され打ち抜かれる。カードの一方の面は、Artcard9が検出された像に与える影響を人が読める形で表現したものが印刷される。これは、カードの裏面に記憶されたVarkスクリプトを使用して処理された単純な標準画像でもよい。
カードの裏面には、画像処理シーケンスを定義するVarkスクリプトに復号化され得るドットの配列が印刷される。この印刷面積は80mm×50mmであり、全部で15876000ドットがある。このドットの配列は、少なくとも1.89MByteのデータを表現することができる。高信頼性を実現するため、広範な誤り検出及び訂正がドットの配列に組み込まれる。これにより、カードの実質的な部分が汚損され、損耗され、皺を付けられ、或いは、汚されても、データの完全性に影響が及ばないようにすることができる。使用されるデータ符号化方式はリード・ソロモン符号化であり、データの半分が誤り訂正のために用いられる。これにより、各Artcard9には、誤り訂正された967Kbyteのデータを記憶させることができる。
リニアイメージセンサ34
Artcardリニアセンサ34は、上記のArtcardデータ画像を電気信号へ変換する。エリアイメージセンサ2、4の場合と同様に、リニアイメージセンサは、CCD又はAPS
CMOS技術を用いて製造可能である。イメージセンサ34の有効長さは50mmであり、Artcard9上のデータ配列の幅と一致する。ナイキストのサンプリング定理を充たすため、リニアイメージセンサ34の解像度は、イメージセンサに到達するArtcard光学像の最高空間周波数の少なくとも2倍でなければならない。実際上、データ検出は、イメージセンサ解像度がこれよりも実質的に高くなった場合、より簡単になる。4900dpi(180dpmm)の解像度が選ばれた場合、全部で9450画素が与えられる。この解像度は、5.3μmの画素センサピッチを必要とする。これは、千鳥状にされた4行の20μm画素センサを使用することによって簡単に実現することができる。
リニアイメージセンサは、ライトパイプ(図示せず)によってArtcard9を照明するためのLED65を含む特殊なパッケージに装着される。
Artcardリーダーのライトパイプは、以下の数機能を備えた成形ライトパイプでもよい:
1. ライトパイプは、全ての内部反射ファセットを使用してカードの幅に亘ってLEDからの光を拡散する。
2. ライトパイプは、集積化されたシリンドリカルレンズを使用してArtcard9の16μm幅のストリップ上に光を集める。
3. ライトパイプは、成形されたマイクロレンズの配列を使用してArtcardから反射された光をリニアイメージセンサの画素に集める。
次に、Artcardリーダーの動作を説明する。
Artcardリーダーモーター37
Artcardリーダーモーターは、比較的一定の速度でArtcardを進めてリニアイメージセンサ34を通過させる。厳密な精度の機械コンポーネントをArtcardリーダーに収容することは費用対効果がよくないので、モーター37は、Artcard9を動かすローラーのペアを駆動するため適切な速度までギアダウンされた標準的な小型モーターである。速度変動、ガタ、及びその他の振動は、未加工の画像データに影響を与えるので、APC31内の回路は、Artcardデータを確実に読むためこれらの効果の広範な補償を行う。
モーター37は、Artcardを取り出すとき、逆向きに駆動される。
Artcardモータードライバ61
Artcardモータードライバ61は、モーター37を駆動するために適切なレベルまでAPC31からのデジタルモーター制御信号を増幅する小型回路である。
カード挿入センサ49
カード挿入センサ49は、カードリーダー34に挿入されているカードの有無を検出する光学センサである。このセンサ49からの信号の後、APC31はカード読み出しプロセスを開始し、そのプロセスには、Artcardリーダーモーター37の作動が含まれる。
カードイジェクトボタン16
カードイジェクトボタン16(図1)は、現在のArtcardを取り出すためユーザによって使用され、他のArtcardを挿入できるようになる。APC31は、ボタンの押下を検出し、カードを取り出すため、Artcardリーダーモーター37を反転させる。
カード状態インジケータ66
カード状態インジケータ66は、Artcard読み出しプロセスの状態をユーザへ報せるために設けられる。これは、標準的な2色(赤/緑)LEDでもよい。カードが正しく読み出され、データの完全性が検証されたとき、LEDは連続的に緑色で発光する。カードが不良である場合、LEDは赤色で発光する。
カメラが3Vのバッテリではなく1.5Vのバッテリから給電される場合、電源電圧は、緑色LEDの前向き電圧降下よりも小さく、LEDは発光しない。この場合、赤色LEDが使用されるか、又はそのLEDは、より高い電圧を必要とするArtcam内の他の回路に給電する電圧ポンプから給電される。
64MビットDRAM33
多種多様な画像処理効果を実行するため、カメラは8Mbyteのメモリ33を利用する。これは、単一の64Mビットメモリチップによって設けることができる。勿論、メモリ技術の変化に伴って、より大容量のDRAM記憶容量サイズで置き換えても構わない。
メモリチップへの高速アクセスが要求される。これは、Rambus
DRAM(毎秒500メガバイトのバーストアクセス速度)、又はダブルデータレート(DDR)SDRAM又はシンクリンク(SyncLink)DRAMチップを使用することによって達成できる。
カメラ認証チップ
カメラ認証チップ54は、異なる情報を記憶している点を除くと、プリントロール認証チップ53と同一のものである。カメラ認証チップ54には、以下の三つの主要な目的がある:
1. 認証コードをプリントロール認証チップと比較するセキュア手段を設けること;
2. カメラの製造番号のような製造情報用の記憶装置を設けること;
3. ユーザ情報の記憶用の小容量の不揮発性メモリを設けること。
ディスプレイ
Artcamは、オプションのカラーディスプレイ5及び小型状態ディスプレイ15を含む。最低コストの民生用カメラは、ある種のデジタルカメラ及びビデオカメラで見られるような小型TFT
LCD5のようなカラー画像ディスプレイを含む。カラーディスプレイ5は、これらのバージョンのArtcamの主要なコストのかかる要素であり、バックライトを加えたディスプレイ5は主要な電力消費元である。
状態ディスプレイ15
状態ディスプレイ15は、小型の受動セグメントに基づくLCDであり、現在のハロゲン化銀式カメラ及びデジタルカメラに設けられているLCDと類似している。その主要な機能は、プリントロール42に残っているプリントの数と、フラッシュ状態及びバッテリ状態のような様々な標準的なカメラ機能に対するアイコンと、を表示することである。
カラーディスプレイ5
カラーディスプレイは、完全動画像ディスプレイであり、ビューファインダーとして、印刷される画像の確認として、及びユーザインタフェースディスプレイとして動作する。ディスプレイ5のコストは、その面積にほぼ比例するので、大型ディスプレイ(例えば、4インチ対角)ユニットは、Artcamユニットの高価なバージョンに限定される。例えば、カラービデオカメラの約1インチのビューファインダーTFTのようなより小さいディスプレイは、中程度のArtcamに有効である。
ズームレンズ(図示せず)
Artcamはズームレンズを含むことができる。これは、標準的な電子カメラに使用されるズームレンズと同一であり、ポケットカメラのズームレンズに類似している標準的な電子制御ズームレンズでもよい。Artcamユニットの好適なバージョンは、標準的な交換可能な35mmSLRレンズを含む。
自動焦点モーター39
自動焦点モーター39はズームレンズの焦点を変更する。モーターは、自動焦点機構を駆動するため適切な速度にギアダウンされた小型モーターである。
自動焦点モータードライバ63
自動焦点モータードライバ63は、モーター39を駆動するため適切なレベルまでAPC31からのデジタルモーター制御信号を増幅する小型回路である。
ズームモーター38
ズームモーター38は、ズームのフロントレンズを出入りするように動かす。モーターは、ズーム機構を駆動するため適切な速度にギアダウンされた小型モーターである。
ズームモータードライバ62
ズームモータードライバ62は、モーターを駆動するため適切なレベルまでAPC31からのデジタルモーター制御信号を増幅する小型回路である。
通信
ACP31は、パーソナルコンピュータとの通信用のユニバーサルシリアルバス(USB)インタフェース52を含む。必ずしも全てのArtcamモデルがUSBコネクタを組み込むことを予定されているわけではない。しかし、USB回路52のために必要なシリコン面積は小さいので、インタフェースを標準的なACPに収容することが可能である。
オプションのキーボード57
Artcamユニットは、Artcardによって指定されたテキストをカスタマイズするオプションの小型キーボード57を含む。Artcard画像に現れるあらゆるテキストは、複雑なメタリック3次元フォントの形である場合でも編集可能である。小型キーボードは、元のテキストと編集されたテキストを表示するため単一ラインの英数字LCDを含む。このキーボードは標準装備品でもよい。
ACP31は、小型キーボートとの間でデータを転送するシリアル通信回路を含む。
電源
Artcamユニットは、バッテリ48を使用する。Artcamのオプションに依存して、このバッテリは、3Vのリチウム電池、1.5VのAAアルカリ電池、又はその他のバッテリ装置のいずれでもよい。
電源管理ユニット51
電源消費は、Artcamにおける重要な設計制約条件である。標準的なカメラバッテリ(例えば、3Vのリチウムバッテリ)又は標準的なAA若しくはAAAアルカリ電池の何れかが使用可能であることが望ましい。Artcamユニットの電子回路の複雑さの程度は35mm写真カメラよりも著しく高いが、電力消費量が相応に高いとは限らない。Artcamの電源は、全てのユニットが未使用時には電源をオフされるように慎重に管理される。
最も重大な電力浪費元は、APC31、エリアイメージセンサ2及び4、プリンタ44の様々なモーター、フラッシュユニット56、並びに、オプションのカラーディスプレイ5である。次に各部品について別々に取り扱う:
1. ACP:0.25μmのCMOSを使用して製造され、1.5Vで動作するならば、ACP電力消費は非常に小さくすることができる。ACPチップの様々な部品へのクロックも非常に小さくすることができる。ACPチップの様々な部品へのクロックは、未使用時にオフにすることができ、スタンバイ電流消費を殆ど取り除く。ACPは、印刷される写真毎に約4秒間だけ完全に使用される;
2. エリアイメージセンサ:電力は、ユーザがボタンに指を置いたときに限りエリアイメージセンサに供給される;
3. プリンタ電力は、実際に印刷しているときに限りプリンタへ供給される。これは、1枚の写真につき約2秒間である。たとえそうであっても、適度に低い電力消費印刷が使用されるべきである;
4. Artcamで必要になるモーターは、全て低電力小型モーターであり、典型的に、1枚の写真について数秒間だけ作動される;
5. フラッシュユニット45は、一部の写真だけに対して使用される。その電力消費は、妥当なバッテリ寿命の3Vのリチウムバッテリによって容易に供給される。
6. オプションのカラーディスプレイ5は、次の二つの理由から主要な電流浪費元である。カラーディスプレイは、カメラの使用中の全ての時間に亘ってオンにする必要があり、液晶ディスプレイが使用された場合には、バックライトが必要になる。カラーディスプレイを組み込むカメラは、許容可能なバッテリ寿命を達成するため、より大型のバッテリを要求する。
フラッシュユニット56
フラッシュユニット56は民生用カメラの標準的な小型電子フラッシュである。
ACP31の概要
図3は、Artcam中央プロセッサ(ACP)31を詳細に示す図である。Artcam中央プロセッサは、Artcamの処理能力の全てを提供する。ACPは、0.25ミクロンCMOSプロセス用に設計され、約150万個のトランジスタと、約50mm2の面積を有する。ACP31の設計は複雑であるが、設計の手間は、データパスコンパイレーション技術、マクロセル、及びIPコアを使用することによって軽減できる。ACP31は、
RISC型CPUコア72と、
4ウェイVLIWベクトルプロセッサ74と、
ダイレクトRAMbus(ラムバス)インタフェース81と、
CMOSイメージセンサインタフェース83と、
CMOSリニアイメージセンサインタフェース88と、
USBシリアルインタフェース52と、
赤外線キーボードインタフェース55と、
数字LCDインタフェース84と、
カラーTFT LCDインタフェース88と、
プログラム記憶装置70用4Mバイトフラッシュメモリ70と、
を含む。RISC型CPU、ダイレクRAMbusインタフェース81、CMOSセンサインタフェース83、及びUSBシリアルインタフェース52は、ベンダーによって供給されるコアでもよい。ACP31は、電力消費を最小限に抑えるため、外部3V及び内部1.5Vに基づいて200MHzのクロック速度で動作することが意図されている。CPUコアは100MHzで動作すればよい。以下の二つのブロック図、即ち、
単独のACP31の説明図、及び
Artcamの残りのハードウェアに接続されたACP31の上位レベルの図を与える例示的なArtcam、
はACP31の2通りの見方を与える。
画像アクセス
前述の通り、DRAMインタフェース81は、ACPチップの他のクライアント部と、ラムバスDRAMとの間を接続する役割を担う。実際上、DRAMインタフェース内の各モジュールはアドレス生成器である。
ACPによって操作される画像には三つの論理タイプがある。それらは、
−CCDから撮影された入力像であるCCD画像と、
−Artcam装置によって内部的に利用される画像フォーマットである内部画像フォーマットと、
−Artcamによって印刷される出力画像フォーマットである印刷画像と、
である。
これらの画像は、典型的に、色空間、解像度、並びに、カメラ間で変動のあり得る出力及び入力色空間の点で相違する。例えば、低価格カメラのCCD画像は、高価格カメラで使用されるものとは異なる解像度、又は異なる色特性を揺する。しかし、あらゆる内部画像フォーマットは、全てのカメラを通じて色空間の点で同一フォーマットである。
その上、3種類の画像タイプは、どちらの方向が「上向き」であるかに関しても異なり得る。カメラの物理的な向きは、人物像であるか、又は風景像であるかについての観念を生じさせ、この観念は処理全体を通じて維持されるべきである。このため、内部画像は常に正しく向きを決められ、印刷動作中にCCDから獲得された画像に対して回転が実行される。
CPUコア(CPU)72
ACP31は、Vark画像処理言語インタープリタを動作させ、Artcamの汎用オペレーティングシステムの役割を実行するため32ビットRISC型CPU72を内蔵する。多種多様なCPUコアが適当であり、要求されたコア計算及び制御機能を消費者の期待を満足する十分な速さで実行するために足りる処理能力を備えていればどのようなプロセッサコアでも構わない。適当なコアの例には、LSIロジック社のMIPS
R4000、Strong ARMコアが含まれる。異なるArtcamモデルの間で命令セットの継続性を維持する必要はない。Artcardの互換性は、将来のプロセッサの進歩及び変更とは無関係に維持される。なぜならば、Varkインタープリタは、新しい命令セット毎に再コンパイルをするだけで済むからである。したがって、ACP31のアーキテクチャは、自由に進化させることができる。種々の製造者は、CPUコアの使用許諾や移植をすることなく、様々なACP31チップ設計を製造することができる。この装置非依存性によって、PC市場においてインテル社が行っているようなチップベンダーのロックインが避けられる。CPUは100MHzで動作し、単一サイクルタイムは10nsである。このCPUは、VLIWベクトルプロセッサ74が時間的に重大な演算を担うとしても、Varkインタープリタを実行するために十分な高速性が必要である。
プログラムキャッシュ72
プログラムコードがオンチップフラッシュメモリ70に保存されるとしても、ウェルパックされたフラッシュメモリ70がCPUによって要求される10nsのサイクルタイムで動作できる可能性は低い。したがって、優れた性能のために小規模のキャッシュが要求される。各々が32バイトの16個のキャッシュラインは、全部で512バイトになり、十分な大きさである。プログラムキャッシュ72は、プログラムキャッシュ72という名前の章に規定されている。
データキャッシュ76
小規模のデータキャッシュ76が優れた性能のために要求される。この要求は、概して、ラムバスDRAMを使用しているために生じる。ラムバスDRAMは、高速データをバーストで提供することができるが、単一バイトのアクセスには不十分である。CPUは、CPUデータキャッシュ76のサイズをフレキシブルに操作することを可能にさせるメモリキャッシングシステムにアクセスする。最小限で16個のキャッシュライン(512バイト)が優れた性能のために推奨される。
CPUメモリモデル
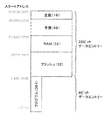
ArtcamのCPUメモリモデルは、32MBのエリアにより構成される。Artcamの基本モデルでは、CPUメモリモデルは、8MBの物理的RDRAMオフチップにより構成され、最大で16MBのオフチップメモリが設けられる。ACP31にはプログラム記憶用に4MBのフラッシュメモリ70が存在し、最終的に、4MBのアドレス空間がACP31の様々なレジスタ及びコントロールに割り当てられる。したがって、Artcam用のメモリマップは以下の通りである。
アドレスをデコードする簡単な方法は、アドレスビット23−24を使用することである。即ち、
ビット24がクリアされている場合、アドレスは下位側16MBのレンジに含まれるので、DRAM及びデータキャッシュ76から充たされる。殆どの場合に、DRAMは8MBに過ぎないが、より上位のメモリモデルArtcamを考慮に入れるため16MBが割り当てられる。
ビット24がセットされ、ビット23がクリアされている場合、アドレスは、フラッシュメモリ70の4Mバイトレンジを表現し、プログラムキャッシュ72によって充たされる。
ビット24=1及びビット23=1である場合、アドレスは、CPUメモリデコーダ68によって、低速バス経由によるAC内の要求されたコンポーネントへのアクセスに変換される。
フラッシュメモリ70
ACP31は、Artcamプログラムを記憶する4Mバイトのフラッシュメモリ70を含む。フラッシュメモリ70はマスクROMよりも高い充填率を有し、カメラプログラムコードを試験するためより高いフレキシビリティを許容することが想定される。フラッシュメモリ70の弱点はアクセス時間であり、このアクセス時間はCPUの100MHzの動作速度(10nsのサイクルタイム)に対して十分に高速であるとはいえない。したがって、高速プログラム命令キャッシュ77が、CPUと低速のフラッシュメモリ70との間のインタフェースとして作用する。
プログラムキャッシュ72
優れたCPU性能のために小型キャッシュが要求される。この要求は、プログラムコードを記憶するフラッシュメモリ70が低速であることに起因する。各々が32バイトの16個のキャッシュラインは、全部で512バイトになり、十分な大きさである。プログラムキャッシュ72は読み出し専用キャッシュである。CPUプログラムによって使用されるデータは、CPUメモリデコーダ68を通過し、アドレスがDRAM内にある場合、汎用データキャッシュ76を通る。分離によって、CPUをVLIWベクトルプロセッサ74とは独立して動作させることができる。所定のプロセスに対するデータ要求量が少ない場合、結果的に、そのプロセスは完全にキャッシュによって動作し得る。
最後に、プログラムキャッシュ72は、CPUによって純粋にプログラム命令としてではなく、データとして読み出すことが可能である。これにより、テーブル、即ち、VLIWのためのマイクロコード等をフラッシュメモリ70からロードすることが可能になる。ビット24がセットされ、ビット23がクリアされているアドレスは、プログラムキャッシュ72から充足される。
CPUメモリデコーダ68
CPUメモリデコーダ68は、CPUデータアクセスに沿う簡単なデコーダである。デコーダは、データアドレスを、内部低速バスによる内部ACPレジスタアクセスに変換し、これにより、ACPレジスタのメモリマップドI/Oを可能にさせる。CPUメモリデコーダ68は、ビット24がセットされ、ビット23がクリアされているアドレスだけを解釈する。CPUメモリデコーダ68内ではキャッシングは行われない。
DRAMインタフェース81
Artcamによって使用されるDRAMは、1.6GB/秒で動作する単一チャンネルの64Mビット(8Mバイト)RAMbus(ラムバス)RDRAMである。RDRAMアクセスは、単一チャンネル(16ビットデータパス)コントローラによる。RDRAMは、低電力動作用の数種の有効な動作モードを有する。ラムバス仕様書には、95%以上の効率を達成可能であるようなランダムな32バイト転送のあるシステムが記載されているが、これは、32バイトのうちの一部しか使用されない場合には成り立たない。同一のデバイスに対する2回の読み出しに続いて2回の書き込みを行うことによって86%以上の効率が得られる。基礎的なレイテンシーは、書き込みから読み出しへ変化するバスのターンアラウンドのために必要であり、遅延書き込み機構が存在するので、効率を更に改善することが可能である。書き込みに関して、書き込みマスクは、特定のバイトのサブセットへの書き込みを可能にさせる。これらの書き込みマスクは、内部キャッシュの「ダーティビット」によってセットされるであろう。ラムバスダイレクトRDRAMは、要するに、1GB/秒を超えるスループットを簡単に達成可能であり、32バイトの転送知識を十分に利用する知的アルゴリズムと組み合わされ(殆どのプロセスで)書き込み毎に複数回の読み出しを伴い、1.3GB/秒を超える転送レートが期待されるということである。10ns毎に、コアとの間で16バイトを転送することができる。
DRAM構成
基本モデル(8MB RDRAM)のArtcam用のDRAM構成を次に示す。
注:非圧縮形式の印刷画像は4.5MB(1チャンネル当たり1.5MB)を必要とする。他の対象を8MBモデルに収容するため、印刷画像は圧縮されるべきである。クロミナンスチャンネルが4:1に圧縮された場合、各クロミナンスチャンネルは0.375MBしか必要としない。
ここで説明されるメモリモデルは、単一の8MBのRDRAMを想定している。Artcamのその他のモデルの中にはより多くのメモリを具備し、印刷画像を圧縮しなくてもよいものがある。その上、メモリ量が増加すると、最終画像の大部分を同時に操作できるようになり、速度が向上する可能性がある。
Artcardの取り出し又は挿入は、印刷画像、拡大された写真画像の1チャンネル、及び画像ピラミッドを保持する5.5MBエリアを無効にすることに注意すべきである。この空間は、Artcardデータを復号化するためArtcardインタフェースによって安全に使用される。
データキャッシュ76
ACP31は、専用CPU命令キャッシュ77及び汎用データキャッシュ76を含む。データキャッシュ76は、CPU、VLIWベクトルプロセッサ74及びディスプレイコントローラ88からの全てのDRAM要求(データの読み出し及び書き込み)を取り扱う。これらの要求は、メモリ使用量及びアルゴリズム的タイミング必要条件の点で非常に異なる側面を有する。例えば、VLIWプロセスは、リニアメモリ内の画像を処理し、画像内の値毎にテーブルの値をルックアップする。画像の大半をキャッシュする必要な殆ど無いが、実際のメモリアクセスが必要ではないように、ルックアップテーブル全体をキャッシュすることが望ましい。このように必要条件が相違しているため、データキャッシュ76は、キャッシングを知的に定義することが可能である。
ラムバスDRAMインタフェース81は、非常に高速のメモリアクセス能力を備えているが(平均スループットは25nsで32バイト)、単一バイトの要求を処理するためには不十分である。実効的なメモリレイテンシーを低下させるため、ACP31は、128個のキャッシュラインを含む。各キャッシュラインは32バイト幅である。このようにして、データキャッシュ76の総容量は4096バイト(4KB)である。128個のキャッシュラインは、16個のプログラム可能なサイズのグループに構成される。16個のグループの各々は、連続したキャッシュラインのセットでなければならない。CPUは、各グループに割り付けるキャッシュラインの個数を決定する役割を担う。各グループ内で、キャッシュラインは、簡単なLRU(最低使用頻度)アルゴリズムに従って詰められる。CPUデータ要求に関して、データキャッシュ76は、アドレスビット24がクリアされたメモリアクセス要求を取り扱う。ビット24がクリアされている場合、アドレスは下位側16MBのレンジに収まるので、DRAM及びデータキャッシュ76から応じることができる。殆どの場合に、DRAMは、8MBしかないが、よりメモリ量の多いモデルのArtcamを考慮に入れて16MBが割り付けられる。ビット24がセットされている場合、アドレスはデータキャッシュ76によって無視される。
全てのCPUデータ要求はキャッシュグループ0から応じられる。優れたCPU性能のためには16個の最小のキャッシュラインが推奨されるが、CPUは、(0個以外の)任意の個数のキャッシュラインをキャッシュグループ0に割り当てることができる。残りのキャッシュグループ(1から15)は、現在の必要条件に従って割り付けられる。これは、VLIWベクトルプロセッサ74プログラム又はディスプレイコントローラ88への割付を意味することもある。例えば、常時利用可能であることが要求される256バイトのルックアップテーブルは、8個のキャッシュラインが必要であろう。順次画像を書き出すためには、(生成されたレコードのサイズと、書き込み要求が多数のサイクルに亘って書き込み遅延されているかどうかと、に応じて)2から4個のキャッシュラインだけが必要であろう。各キャッシュラインのバイトには、メモリをDRAMへ書き込む際に書き込みマスクを作成するため使用されるダーティビットが関連付けられる。各キャッシュラインには別のダーティビットが関連付けられ、このダーティビットは、キャッシュラインのバイトの何れかに書き込みがされたかどうか(したがって、DRAMを再使用する前に、キャッシュラインをDRAMへ書き戻さなければならないかどうか)を示す。二つの異なるキャッシュグループがメモリの同じアドレスをアクセスし、同期が外れる可能性があることに注意する必要がある。VLIWプログラムライターは、これが問題にならないことを保証する役割を担う。例えば、あるキャッシュグループには画像を読み出す役割を与え、別のキャッシュグループには変更された画像をメモリに書き戻す役割を与えることは完全に合理的である。画像が順番に読み出し又は書き込みされる場合、キャッシュラインをこのようにして割り付けることは有利である。全部で8本のバス182は、VLIWベクトルプロセッサ74をデータキャッシュ76へ接続する。各バスは、I/Oアドレス生成器に接続される。(1個の処理ユニット178当たりに2個のI/Oアドレス生成器189及び190が存在し、VLIWベクトルプロセッサ74には4個の処理ユニットが存在する。したがって、バスの総数は8本である。)
所与のサイクルにおいて、CPUのキャッシュグループ(グループ0)への単一の32ビット(4バイト)アクセスの他に、残りのキャッシュグループへの16ビット(2バイト)の四つ同時のアクセスが8本のVLIWプロセッサ74のバス上で許容される。データキャッシュ76は要求を公平に処理する役割がある。ある所与のサイクルで、特定のキャッシュグループへのたった一つの要求が処理される。VLIWベクトルプロセッサ74に8個のアドレス生成器189、190が存在する場合、アドレス生成器の各々は個別のキャッシュグループを参照する可能性がある。しかし、2個以上のアドレス生成器189、190が同じキャッシュグループにアクセスする可能性があり、場合によっては、その方が合理的である。CPUは、キャッシュグループに正確なキャッシュラインの個数が割り付けられることを保証し、VLIWベクトルプロセッサ74の様々なアドレス生成器189、190が特定のキャッシュグループを正確に参照することを保証する役割を担う。上述のようにデータキャッシュ76は、ディスプレイコントローラ88及びVLIWベクトルプロセッサ74が同時に動作状態になることを許容する。これらの二つのコンポーネントの動作が決して同時に出現しないと考えられるならば、全部で9個のキャッシュグループがあれば足りる。CPUはキャッシュグループ0を使用し、VLIWベクトルプロセッサ74及びディスプレイコントローラ88は残りの8個のキャッシュグループを共用し、(4ビットではなく)3ビットだけで特定の要求に応じるキャッシュグループを定めることができる。
JTAGインタフェース85
標準的なJTAG(ジョイントテスト部会)インタフェースはテスト目的用にACP31に収容される。チップの複雑さのため、BIST(ビルトインセルフテスト)及び機能的ブロック分離等を含む様々なテスト技術が必要である。チップ面積の10%のオーバーヘッドが全チップテスト回路のため想定される。テスト回路は本文書の範囲外の事項である。
シリアルインタフェース
USBシリアルポートインタフェース52
これは標準的なUSBシリアルポートであり、内部チップの低速バスに接続されるので、CPUがそれを制御することができる。
キーボードインタフェース65
これは標準的な低速シリアルポートであり、内部チップ低速バスに接続されるので、CPUがそれを制御することができる。キーボードインタフェースは、プリントをカスタマイズするための簡単なデータ入力を許容するためオプション的にキーボードへ接続できるように設計される。
認証チップシリアルインタフェース64
これらは、二つの標準的な低速シリアルポートであり、内部チップ低速バスに接続されるので、CPUがこれらを制御できる。二つのポートを具備する理由は、別個のラインを使用して、オンカメラ認証チップとプリントロール認証チップの両方に接続するためである。1個のラインしか使用しない場合、模造プリントロールの製造者は、認証コードを生成するのではなく、カメラの認証チップによって生成されたコードを使用するようにカメラを誤動作させるチップを設計することができる。
パラレルインタフェース67
パラレルインタフェースはACP31を個別の静的な電気信号に接続する。CPUは、低速バスを介して、メモリマップドI/Oとしてこれらの配線の各々を制御することができる。以下の表は、パラレルインタフェースへの配線の一覧である。
VLIW入力及び出力FIFO78、79
VLIW入出力FIFOは、プロセスとVLIWベクトルプロセッサ74との間を接続するため使用される8ビット幅のFIFOである。両方のFIFOはVLIWベクトルプロセッサ74によって制御されるが、CPUによってクリアしたり、(例えば、状態について)問い合わせをしたりすることができる。
VLIW入力FIFO78
クライアントは、VLIWベクトルプロセッサ74にデータを処理させるため、8ビットデータをVLIW入力FIFO78に書き込む。クライアントには、イメージセンサインタフェース、Artcardインタフェース、及びCPUが含まれる。これらのプロセスの各々は、単にデータをFIFOに書き込み、VLIWベクトルプロセッサ74に重い仕事の全ての実行を任せることによって、処理から解放される。クライアントによるVLIW入力FIFO78の使用を用いる一例は、イメージセンサインタフェース(ISI83)である。イメージセンサインタフェース83は、イメージセンサからデータを取得し、そのデータをFIFOに書き込む。VLIWプロセスは、FIFOからデータを取得し、データを正しい画像データフォーマットへ変換し、それをDRAMへ書き出す。イメージセンサインタフェース83は、その結果として、非常に簡単化される。
VLIW出力FIFO79
VLIWベクトルプロセッサ74は、8ビットデータをVLIW出力FIFO79に書き込み、クライアントはVLIW出力FIFOでデータを読み出すことができる。クライアントには、プリントヘッドインタフェース及びCPUが含まれる。これらのクライアントの両方は、単にFIFOから処理済みのデータを読み出し、VLIWベクトルプロセッサ74に重い仕事の全ての実行を任せることにより、処理から解放される。CPUは、データがVLIW出力FIFO79に収容されたときはいつでも中断させることができ、FIFOを絶えずポーリングするのではなく、データが利用可能になったときに限りそのデータを処理できるようになる。クライアントによるVLIW出力FIFO79の使用を用いる一例は、プリントヘッドインタフェース(PHI62)である。VLIWプロセスは、画像を取得し、画像を正しい向きへ回転し、色変換を行い、プリントヘッド必要条件に応じて得られた画像をディザリングする。プリントヘッドインタフェース62は、VLIW出力FIFO79からディザリングされたフォーマット後の8ビットデータを読み出し、その8ビットデータをACP31の外部にあるプリントヘッドに渡すだけでよい。プリントヘッドインタフェース62はその結果として非常に簡単化される。
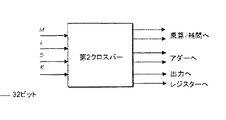
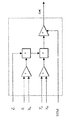
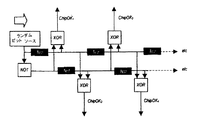
VLIWベクトルプロセッサ74
Artcamの高い処理要求を実現するため、ACP31は、VLIW(超長命令語)ベクトルプロセッサを含む。VLIWプロセッサは、クロスバースイッチ183によって接続され並列に動作する4個の同一処理ユニット(例えば、PU178)の組である。各処理ユニット、例えば、PU178は、各サイクルに、4回の8ビット乗算、8回の8ビット加算、3回の32ビット加算、I/O処理、及び様々な論理演算を実行することができる。処理ユニット、例えば、PU178はマイクロコード化され、各々は、2個のアドレス生成器189、190を具備し、データ処理のため利用可能なサイクルを完全に使用できる。4個の処理ユニット、例えば、PU178は、通常、密接に相互作用するVLIWプロセッサを実現するため同期させられる。200MHzのクロックにより、VLIWベクトルプロセッサ74は、12Gop(毎秒120億回の演算速度)で動作する。命令は、ワーピング、芸術的なブラッシング、複雑な合成照明、色変換、画像フィルタリング、及び合成のような画像処理機能のために調整される。これらは、デスクトップコンピュータよりも2桁加速されている。
図3(a)に詳細に示されるように、VLIWベクトルプロセッサ74は、クロスバースイッチ183によって接続された4個の処理ユニット、例えば、PU178であり、各処理ユニット、例えば、PU178は、クロスバースイッチ183へ2入力を供給し、クロスバースイッチ183からの2出力を取得する。2個の共通レジスタは、処理ユニット、例えば、PU178のための制御及び同期機構を形成する。8本のキャッシュバス182は、データキャッシュ76を介してDRAMへの接続を可能にさせ、2本のバスは各処理ユニット、例えば、PU178へ至る(I/Oアドレス生成器毎に1本のバス)。各処理ユニット、例えば、PU178は、(データを処理するための多数のレジスタ及びある種の算術論理を格納する)ALU(算術論理ユニット)188と、ある種のマイクロコードRAM196と、外界(他のALUを含む)への配線と、を具備する。ローカルPU状態機械は、マイクロコードで動き、この手段によって処理ユニット、例えば、PU178が制御される。各処理ユニット、例えば、PU178は、DRAM(データキャッシュ76経由)とALU188(入力FIFO及び出力FIFO経由)の間のデータフローを制御する二つのI/Oアドレス生成器189、190を含む。アドレス生成器は、データ(特に、様々なフォーマットの画像)、並びに、DRAM内のテーブル及びシミュレーティッドFIFOを読み書きすることが可能である。フォーマットはソフトウェア制御の下でカスタマイズ可能であるが、マイクロコード化されない。データキャッシュ76から取得されたデータは、16ビット幅の入力FIFOを介してALU188へ転送される。出力データは、16ビット幅の出力FIFOに書き込まれ、そこからデータキャッシュ76へ書き込まれる。最後に、全ての処理ユニット、例えば、PU178は、単一の8ビット幅VLIW入力FIFO78と、単一の8ビット幅VLIW出力FIFO79を共用する。低速データバス接続によって、CPUは、処理ユニット、例えば、PU178のレジスタを読み書きし、マイクロコードを更新し、VLIWベクトルプロセッサ74の全ての処理ユニット、例えば、PU178によって共用される共通レジスタを読み書きすることが可能になる。次に、図4を参照すると、単独の処理ユニット、例えば、PU178の内部のより詳細が示され、以下では、コンポーネント及び制御信号を詳述する。
マイクロコード
各処理ユニット、例えば、PU178は、その特定の処理ユニット、例えば、PU178用のプログラムを保持するマイクロコードRAM196を含む。マイクロコードをROMに収容するのではなく、マイクロコードはRAMに収容され、CPUはマイクロコードをアップロードする役割を担う。チップ上の同じ空間であるため、このトレードオフは、ある一つの機能の最大サイズをRAM196のサイズまで縮小するが、マイクロコードに書き込まれる機能の数は無制限である。マイクロコードを用いて実現された機能は、Varkアクセラレーション、Artcard読み取り、及び印刷を含む。VLIWベクトルプロセッサ74の方式は、ACP31のケースでは、以下の幾つかの利点がある:
ハードウェア設計の複雑さが低減される;
ハードウェアのリスクは複雑さの低減によって低減する;
ハードウェア設計時間は、専用シリコンに組み込まれる全てのVark機能に依存しない;
チップ上の空間が全体的に縮小される(多数のプロセスをマイクロコードとして組み込むことができるため);
ハードウェア設計時間に影響を与えることなく、(マイクロコードによって)Varkに機能を加えることができる。
サイズ及び内容
各処理ユニット、例えば、PU178を制御するCPUによってロードされたマイクロコードRAM196は128ワードであり、各ワードは96ビット幅である。処理ユニット、例えば、PU178の様々なユニットを制御するためのマイクロコードサイズの概要は以下の表に掲載されている。
128個の命令ワードによって、処理ユニット、例えば、PU178毎の全マイクロコードRAM196は、12288ビット、即ち、正確に1.5KBである。VLIWベクトルプロセッサ74は、4個の同一の処理ユニット、例えば、PU178により構成されるので、これは、6144バイト、即ち、正確に6KBと一致する。マイクロコードワード内の一部のビットは、制御ビットとしてそのまま使用され、一方、他のビットはデコードされる。マイクロコードワードのビットの各々の解釈を詳細に記述する種々のユニット説明を参照せよ。
処理ユニット、例えば、PU178の間の同期
各処理ユニット、例えば、PU178は、4ビット同期レジスタ197を含む。それは、一体的に動作する処理ユニット、例えば、PU178を決定するため使用されるマスクであり、単一プロセスとして機能する対応した処理ユニット、例えば、PU178の各々に対して1ビットがセットされる。例えば、全ての処理ユニット、例えば、PU178が単一プロセスとして機能する場合、4個の同期レジスタ197の各々は、全て4ビットがセットされるであろう。2個の処理ユニット、例えば、PU178毎に二つの同期プロセスが存在するならば、2個の処理ユニット、例えば、PU178は、(そのPU自体に対応した)同期レジスタ内の2ビットがセットされ、他の2個の処理ユニットは、(そのPU自体に対応した)同期レジスタ内の別の2ビットがセットされる:
同期レジスタ197は、以下の二つの基本的な方式で使用される;
同期した所定のプロセスを停止及び開始する;
プロセス内で実行を一時停止する。
停止及び開始プロセス
CPUは、マイクロコードRAM196にロードし、第1の命令の実行アドレス(通常は0)をロードする役割を担う。CPUがマイクロコードを実行し始めるとき、マイクロコードは指定されたアドレスから始まる。
マイクロコードが実行されるのは、同期レジスタ197の全てのビットが共通同期レジスタ197にもセットされたときに限られる。したがって、CPUは、全ての処理ユニット、例えば、PU178をセットアップし、次に、共通同期レジスタ197への1回の書き込みでプロセスを開始又は停止する。
この同期方式は、複数のプロセスが処理ユニット、例えば、PU178上で非同期的に実行されることを可能にさせ、同時に1個の処理ユニット、例えば、PU178としてではなく、プロセスとして停止及び開始される、
プロセス内の実行の一時停止
所与のサイクルにおいて、処理ユニット、例えば、PU178は、(現在のマイクロコード命令のオペレーションコードに基づいて)FIFOからの読み出し、又はFIFOへの書き込みのために必要である。FIFOが読み出し要求時にエンプティであるか、又は書き込み要求時にフルである場合、FIFO要求は完了し得ない。処理ユニット、例えば、PU178は、したがって、プロセス一時停止制御信号198をアサートする。全ての処理ユニット、例えば、PU178からのプロセス一時停止信号は、全ての処理ユニット、例えば、PU178へフィードバックされる。同期レジスタ197は、4個のプロセス一時停止ビットと論理積演算され、結果が非零であるならば、処理ユニット、例えば、PU178のレジスタのライトイネーブル、又はFIFOストローブはセットされない。したがって、そのタスクを終了できなかった処理ユニット、例えば、PU178と同じプロセスグループを形成する処理ユニット、例えば、PU178の中に、自分のレジスタ又はFIFOがそのサイクル中に更新された処理ユニットは存在しない。この簡単な技術は、所定のプロセスグループを同期状態に保つ。後の各サイクルで、処理ユニット、例えば、PU178の状態機械は、同じアドレスのこのマイクロコード命令を再実行することを試み、成功するまでそのようにし続ける。勿論、共通同期レジスタ197は、必要に応じてプロセス全体を停止させるため、CPUによって書き込むことができる。この同期方式は、任意の処理ユニット、例えば、PU178の組み合わせが一体となって動作することを可能にさせ、各グループは、データを読み書きする準備ができていないことを原因とする一時停止に関しては、協働して動作する処理ユニットだけに影響を与える。
制御及び分岐
各サイクル中、処理ユニット、例えば、PU178のALU188内の4個の基本入力及び計算ユニットの各々(読み出し、アダー/ロジック、乗算/補間、及びバレルシフタ)は、そのサイクル中の演算結果が0であるか又は負であるかを示す零フラグ及び負フラグの二つの状態ビットを生成する。各サイクルに、これらの4個の状態ビットのうちの一つが、処理ユニット、例えば、PU178から出力されるマイクロコード命令によって選択される。4個の状態ビット(一つの処理ユニット、例えば、PU178のALU188について1個)が4ビット共通状態レジスタ200に組み合わされる。次のサイクル中に、各処理ユニット、例えば、PU178のマイクロコードプログラムは、共通状態レジスタ200からのビットのうちの1ビットを選択し、状態ビットの値に依存して別のマイクロコードアドレスへ分岐することが可能である。
状態ビット
各処理ユニット、例えば、PU178のALU188は、多数の入力及び計算ユニットを含む。各ユニットは、負フラグと零フラグの二つの状態ビットを生成する。これらの状態ビットのうちの一つは、特別なユニットが1ビット3状態の状態ビットバス上の値をアサートするときに、処理ユニット、例えば、PU178から出力される。一つの状態ビットが処理ユニット、例えば、PU178から出力され、次に、共通状態レジスタ200を更新するため、他の処理ユニット、例えば、PU178の状態ビットと組み合わされる。出力状態ビットを決定するマイクロコードは以下の形式をとる。
ALU188内で、2ビット選択プロセッサブロック値は、4個の1ビットイネーブルビットにデコードされ、異なるイネーブルビットが各プロセッサユニットブロックへ送信される。状態選択ビット(零又は負を選択する)は、状態ビットバスへ出力されるべきビットを決定するため全てのユニットへ渡される。
マイクロコード内の分岐
各処理ユニット、例えば、PU178は、実行中の現在のマイクロコードアドレスを保持する7ビットプログラムカウンタ(PC)を含む。普通のプログラム実行はリニアであり、即ち、あるサイクルのアドレスNから次のサイクルのアドレスN+1へ進む。しかし、サイクル毎に、マイクロコードプログラムは、異なる場所へ分岐する能力、又は共通状態レジスタ200からの状態ビットをテストして分岐する能力を備えている。次の実行アドレスを決定するマイクロコードは以下の形式をとる。
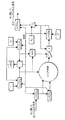
ALU188
図5はALU188を詳細に示す図である。ALU188内部には、多数の専用処理ブロックが存在し、マイクロコードプログラムによって制御される。専用処理ブロックには、
入力FIFOからのデータを受け取る読み出しブロック202と、
出力FIFOを介してデータを送り出す書き込みブロック203と、
加算及び減算と、比較及び論理演算のためのアダー/ロジックブロック204と、
乗算タイプの補間及び乗算/累算のための乗算/補間ブロック205と、
要求に応じてデータをシフトするバレルシフトブロック206と、
外部クロスバースイッチ183からのデータを受け取る入力ブロック207と、
外部クロスバースイッチ183へデータを送り出す出力ブロック208と、
一次記憶装置にデータを保持するレジスタブロック215と、
が含まれる。
4個の専用32ビットレジスタは、4個の主要な処理ブロックの結果を保持する:
Mレジスタ209は、乗算/補間ブロックの結果を保持する;
Lレジスタ209は、アダー/ロジックブロックの結果を保持する;
Sレジスタ209は、バレルシフタブロックの結果を保持する;
Rレジスタ209は、読み出しブロック202の結果を保持する。
更に、データ転送用の二つの内部クロスバースイッチ213及び214が存在する。多様な処理ブロックは、各ブロックに属するマイクロコード定義と共に後続のセクションで更に展開される。尚、マイクロコードは、内部の様々なユニットへ制御信号を供給するためブロック内でデコードされる。
処理ユニット、例えば、PU178間のデータ転送
各処理ユニット、例えば、PU178は、外部クロスバーを介してデータを交換することができる。処理ユニット、例えば、PU178は、二つの入力を取得し、2個の値を外部クロスバーへ出力する。このようにして、処理用の2個のオペランドが単一サイクルで獲得できるが、実際には、次のサイクルまで演算に使用されない。
入力207
このブロックは図6に示され、外部クロスバーからのデータを受け取る2個のレジスタIn1及びIn2を含む。レジスタはサイクル毎にロードすることが可能であり、又はそのままの状態を保つことが可能である。8入力から選択するための選択ビットは、外部クロスバースイッチ183へ出力される。マイクロコードは以下の形式をとる。
出力208
入力は出力208によって補完される。出力ブロックは図7に詳細に示されている。出力は、Out
1及びOut
2の2個のレジスタを含み、両方のレジスタは、他の処理ユニット、例えば、PU178によって使用するためサイクル毎に外部クロスバーへ出力される。また、書き込みユニットは、Out
1とOut
2のうちの一方を、ALU188に取り付けられた出力FIFOの一つに書き込むことが可能である。最終的に、両方のレジスタは、第1クロスバー213への入力として利用可能であり、第1クロスバー213は、そのレジスタ値がALU188内の他のユニットへの入力として利用できるようにする。各サイクルで、2個のレジスタのうち何れか一方は、マイクロコード選択に応じて更新することができる。指定されたレジスタにロードされたデータは、(第1クロスバー213から選択された)D
0−D
3のうちの一つ、(第2クロスバー214から選択された)M、L、S及びRのうちの一つ、2個のプログラマブル定数のうちの一つ、又は固定値0若しくは1である。出力用のマイクロコードは以下の形式をとる。
ALU188内のローカルレジスタ及びデータ転送
前述の通り、ALU188は、以下の4個のブロックの結果を保持するため、4個の専用32ビットレジスタを含む:
Mレジスタ209は乗算/補間ブロックの結果を保持する;
Lレジスタ209はアダー/ロジックブロックの結果を保持する;
Sレジスタ209はバレルシフタブロックの結果を保持する;
Rレジスタ209は読み出しブロック202の結果を保持する。
CPUはこれらのレジスタに直接アクセスを行い、他のユニットは、第2クロスバー214経由の入力としてそれらを選択することができる。場合によっては、演算を1サイクル以上遅延させる必要がある。レジスタブロックは、4個の32ビットレジスタD0−D3を含み、処理中の一時変数を保持する。各サイクルに、レジスタのうちの一つを更新可能であり、一方、全てのレジスタは、他のユニットが(同様に、In1、In2、Out1及びOut2を含む)第1クロスバー213を介して使用するために出力される。CPUはこれらのレジスタへ直接アクセスを行う。指定されたレジスタにロードされたデータは、(第1クロスバー213から選択された)D0−D3のうちの一つ、(第2クロスバー214から選択された)M、L、S及びRのうちの一つ、2個のプログラマブル定数のうちの一つ、又は固定値0若しくは1である。レジスタブロック215は図8に詳細に示されている。レジスタ用のマイクロコードは以下の形式をとる。
第1クロスバー213
第1クロスバー213は図9に詳細に示されている。第1クロスバー213は、入力In
1、In
2、Out
1、Out
2、D
0−D
3から選択するため使用される。7個の出力が第1クロスバー213から発生され、3個が乗算/補間ユニットへ、2個がアダーユニットへ、1個がレジスタユニットへ、1個が出力ユニットへ向けられる。第1クロスバー213用の制御信号は、クロスバー入力を使用する様々なユニットから到来する。第1クロスバー213のため分離された特定のマイクロコードは存在しない。
第2クロスバー214
第2クロスバー214は図10に詳細に示されている。第2クロスバー214は、汎用ALU188レジスタM、L、S及びRから選択するため使用される。6個の出力が第1クロスバー213から発生され、2個が乗算/補間ユニットへ、2個がアダーユニットへ、1個がレジスタユニットへ、1個が出力ユニットへ向けられる。第2クロスバー214用の制御信号は、クロスバー入力を使用する様々なユニットから到来する。第2クロスバー214のため分離された特定のマイクロコードは存在しない。
処理ユニット、例えば、PU178とDRAM又は外部プロセスとの間のデータ転送
図4を参照すると、処理ユニット、例えば、PU178は、外部クロスバーを介して、直接的に相互にデータを共有する。また、処理ユニットは、外部プロセス並びにDRAMとの間でデータを転送する。各処理ユニット、例えば、PU178は、2個のI/Oアドレス生成器189及び190を含み、DRAMとの間でデータを転送する。処理ユニット、例えば、PU178は、I/Oアドレス生成器の出力FIFO、例えば、186を介してDRAMへデータを送出し、又はI/Oアドレス生成器の入力FIFO187を介して、DRAMからデータを受け取る。これらのFIFOは、処理ユニット、例えば、PU178に局在する。また、外部プロセスとの間で、全てのALUによって共有される共通VLIW入力FIFO78及び共通VLIW出力FIFO79の形でデータを送受する機構が存在する。VLIW入力及び出力FIFOは、8ビット幅しかなく、印刷、Artcard読み出し、CPU等へのデータ転送に使用される。ローカル入力及び出力FIFOは16ビット幅である。
読み出し
図5の読み出しプロセスブロック202は、ALU188のRレジスタ209を更新する役割を担い、Rレジスタは、VLIWマイクロコード化プロセスへの外部入力データを表現する。サイクル毎に、読み出しユニットは、共通VLIW入力FIFO78(8ビット)、又は2個のローカル入力FIFO(16ビット)のうちの何れかから読み出すことが可能である。32ビット値が生成され、そのデータの全部又は一部がRレジスタ209へ転送される。プロセスは図11に示されている。読み出し用のマイクロコードは以下の表に掲載されている。一部のビットパターンの解釈はデコーディングを補助するため意図的に選択される。
書き込み
書き込みプロセスブロックは、各サイクルに、共通VLIW出力FIFO79、又は2個のローカル出力FIFOの一方の何れかへの書き込みを行うことができる。所与のサイクル中に書き込まれるFIFOは1個しかないので、1個の16ビット値が全てのFIFOへ出力され、下位8ビットがVLIW出力FIFO79へ達することに注意する必要がある。マイクロコードは、どのFIFOがその値を受け付けるかを制御する。データ選択のプロセスは図12により詳細に示されている。ソース値Out
1及びOut
2は出力ブロックから到来する。それらは、単に2個のレジスタである。書き込み用のマイクロコードは以下の形式をとる。
計算ブロック
各ALU188は、2個の計算プロセスブロック、即ち、アダー/ロジックプロセスブロック204と、乗算/補間プロセスブロック205と、を含む。更に、これらの計算ブロックを補助するためバレルシフタブロックが設けられる。レジスタブロック215からのレジスタは、パイプライン演算中に一時記憶装置として使用することも可能である。
バレルシフタ
バレルシフタプロセスブロック206は図13に詳細に示され、その入力は、アダー/ロジック、若しくは、乗算/補間プロセスブロックの出力、又はそれらのブロック(ALUレジスタL及びM)の前のサイクルの結果から得られる。選択された32ビットは、(必要に応じて符号を拡張して)何れかの向きに任意のビット数だけバレルシフトされ、ALU188のSレジスタ209へ出力される。バレルシフトプロセスブロック用のマイクロコードは以下の表に記載されている。一部のビットパターンの解釈はデコーディングを助けるため意図的に選択されることに注意する必要がある。
アダー/ロジック204
アダー/ロジックプロセスブロックは、図14により詳細に示され、簡単な32ビット加算/減算、比較、及び論理演算用に設計されている。単一サイクルで、1回の加算、比較、又は論理演算を実行することができ、その結果はALU188のLレジスタ209に保存される。二つの主オペランドA及びBが存在し、これらは、二つのクロスバーの何れか、又は4個の定数レジスタから選択される。一方のクロスバーの選択によって、前のサイクルの算術演算の結果を使用することが可能になり、もう一方は、このALU又は他のALU188によって前に計算されたオペランドへアクセスする。CPUは、4個の定数(K
1−K
4)にアクセスする唯一のユニットである。例えば、(A+B)×4のような演算が要求される場合、アダーからの直接出力は、バレルシフタへの入力として使用可能であり、先にLレジスタ209にラッチしなくても2個分だけ左シフトさせることができる。アダーからの出力は、乗算−累算演算のため乗算ユニットで利用することができる。アダー/ロジックプロセスブロック用のマイクロコードは以下の表に掲載されている。一部のビットパターンの解釈はデコーディングを補助するため意図的に選択される。
アダー/ロジックユニット用のマイクロコードビット解釈
乗算/補間205
乗算/補間プロセスブロックは、図15に詳細に示され、4個の8×8形補間ユニットのセットであり、4個の8×8形補間ユニットは、1サイクル毎に4回の別個の8×8形補間を実行する能力を備えているか、又は1回の16×16形乗算を実行するため組み合わせることができる。これは、単一サイクル中に最大で4回のリニア補間、1回のバイリニア補間、又はトライリニア補間の半分を実行可能であることを示す。補間又は乗算の結果はALU188のMレジスタ209に保存される。二つの主オペランドA及びBは、ALU188の汎用レジスタの何れかから選択されるか、又は乗算/補間プロセスブロックの内部にある4個のプログラマブル定数から選択される。各補間ブロックは、簡単な8ビット補間器[結果=A+(B−A)f]として機能するか、又は簡単な8×8形乗算[結果=A*B]として機能する。演算が補間である場合、A及びBは、4個の8ビット数値A
0からA
3(A0は下位バイトである)、及びB
0からB
3として取り扱われる。AGEN、BGEN及びFGENは、実行される演算に適合するように補間ユニットへの入力を並べる役目を果たす。例えば、バイリニア補間を実行するため、4個の値の各々は、異なる係数によって乗算され、その結果が加算され、一方、16×16形の乗算は、係数を0にする必要がある。アダー/ロジックプロセスブロック用のマイクロコードは、以下の表に掲載されている。尚、一部のビットパターンの解釈はデコーディングを補助するため意図的に選択される。
同じ4ビットがV及びfの選択のために使用されるが、Vの直前の4個の選択肢は、一般的にf値として意味をなさない。1又は0の係数を用いる補間は無意味であり、前の乗算若しくは現在の結果がfに対する有意な値である可能性は少ない。
I/Oアドレス生成器189と190
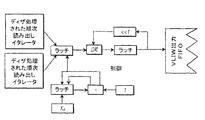
I/Oアドレス生成器は図16に詳細に示されている。VLIWプロセスはDRAMに直接アクセスしない。アクセスは2個のI/Oアドレス生成器189、190を介して行われ、各々のI/Oアドレス生成器は固有の入力FIFO及び出力FIFOを含む。処理ユニット、例えば、PU178は、2個のローカル入力FIFOの一方からデータを読み出し、2個のローカル出力FIFOの一方にデータを書き込む。各I/Oアドレス生成器は、DRAMからデータを読み出し、そのデータを入力FIFOに入れる責任があり、その入力FIFOにおいて、データは処理ユニット、例えば、PU178によって読み出すことができる。各I/Oアドレス生成器は、その出力FIFOから(処理ユニット、たとえば、PU178によって入れられた)データを取り出し、それをDRAMに書き込む役割を担う。I/Oアドレス生成器は、データキャッシュ76を介してDRAMのデータを取得及び記憶するためのアドレスを生成し制御を行う状態機械である。それは、CPUソフトウェア制御の下でカスタマイズ可能であるが、マイクロコード化できない。アドレス生成器は、
多種多様な方式で画像の画素の最初から最後までを繰り返すため(読み、書き、もしくはその両方)使用される画像イタレータと、
画像の画素、テーブルのデータをランダムにアクセスし、DRAMのFIFOをシミュレートするため使用されるテーブルI/Oと、
の二つに大別されるアドレスを生成する。
I/Oアドレス生成器189と190の各々は、データキャッシュ76への固有のバス配線を具備し、1個の処理ユニット、例えば、PU178について2本のバス配線があり、VLIWベクトルプロセッサ74全体で合計8本のバスがある。データキャッシュ76は、サイクル毎に、4個の処理ユニット、例えば、PU178からの最大で8個の要求のうちの4個のために作用することが可能である。入力FIFO及び出力FIFOは、深さが8エントリーで、幅が16ビットのFIFOである。多種多様のアドレス生成(画像イタレータ及びテーブルI/O)が後のセクションで説明される。
レジスタ
I/Oアドレス生成器は、アドレス生成を制御するため使用されるレジスタの組を有する。また、アドレッシングモードは、データがどのようにフォーマットされ、ローカル入力FIFOへ送られるか、並びに、データが出力FIFOからどのように解釈されるかを決定する。CPUは、低速バスを介して、I/Oアドレス生成器のレジスタにアクセス可能である。第1のレジスタの組は、I/O生成器のためのハウスキーピングパラメータを定義する。
キャッシュ処理
複数のレジスタがキャッシュ処理機構を制御するため使用され、入力、出力等に使用するキャッシュグループを指定する。キャッシュグループのより詳細な情報についてはデータキャッシュ76に関するセクションを参照のこと。
画像イタレータ=順次自動画素アクセス
ソフトウェア及びハードウェアアルゴリズム用の主な画像絵素アクセス方法は画像イタレータによる。画像イタレータは、画像チャンネル内の画素のキャッシュのアドレッシング及びアクセスの全てを実行し、それらのクライアントのため画素を読み出し、書き込み、或いは、読み書きする。読み出しイタレータは、そのクライアントのための特定の順序で画素を読み出し、書き込みイタレータはそのクライアントのための特定の順序で画素を書き込む。イタレータのクライアントは、ローカル入力FIFOから画素を読み出し、又はローカル出力FIFOを介して画素を書き込む。
読み出し画像イタレータは、特定の順序で画像の中を読み、画素データをローカル入力FIFOに入れる。クライアントが入力FIFOから画素を読み出す毎に、読み出しイタレータは(データキャッシュ76経由で)画像からの次の画素をFIFOに入れる。
書き込み画像イタレータは、画像全体を書き出すため、特定の順序で画素を書き込む。クライアントは画素を出力バッファに書き込み、この出力バッファが次に書き込み画像イタレータによって読み出され、データキャッシュ76を介してDRAMに書き込まれる。
典型的に、VLIWプロセッサは、読み出しイタレータに結合された入力と、対応した書き込みイタレータに結合された出力と、を有する。処理ユニット、例えば、PU178のマイクロプログラムの観点では、FIFOは、DRAMへの効率的なインタフェースである。記憶を(データの論理的な順序ではなく)実際に実行する方法は無関係である。FIFOは、長さが実質的に制限されていると考えられるが、実際上、FIFOは長さが有限であり、特に、複数のメモリアクセスが競合する場合、データをソートし、取り出す遅延が生じる。画像処理アルゴリズムの最も一般的なアドレッシング必要条件に対処する様々な画像イタレータが存在する。殆どの場合に、各読み出しイタレータには、対応した書き込みイタレータが存在する。種々のイタレータが以下の表に掲載されている。
4ビットアドレスモードレジスタがイタレータタイプを決定するため使用される。
フラグレジスタ(アクセス専用1)は、データの読み出し及び書き込みに影響を与える要因を決定する多数のフラグを含む。フラグレジスタは以下のように構成される。
読み出しイネーブル及び書き込みイネーブルに関する注意:
読み出しイネーブルがセットされたとき、I/Oアドレス生成器は読み出しイタレータとして動作するので、特定の順序で画像を読み出し、画素を入力FIFOに収容する。
書き込みイネーブルがセットされたとき、I/Oアドレス生成器は書き込みイタレータとして動作するので、特定の順序で画像を書き込み、出力FIFOから画素を取り出す。
読み出しイネーブルと書き込みイネーブルの両方がセットされたとき、I/Oアドレス生成器は、読み出しイタレータ及び書き込みイタレータとして動作し、入力FIFO内の画素を読み出し、出力FIFOからの画素を書き込む。画素は読み出された後に限り書き込まれる。即ち、書き込みイタレータは読み出しイタレータよりも先に進むことはない。このモードが使用されるときには、VLIWマイクロコードによる入力処理と出力処理の間のバランスを確保するように注意すべきである。尚、CasheGroup1とキャッシュグループ2に異なる値をロードすることによって、別々のキャッシュグループを読み出しと書き込みに関して指定することも可能である。
PassX及びPassYに関する注意:
PassXとPassYの両方がセットされた場合、Y縦座標はX縦座標よりも前に入力FIFOに収容される。
PassX及びPassYは、読み出しイネーブルビットがクリアされたときに限りセットされる。縦座標をアドレス生成器に渡すのではなく、縦座標は入力FIFOに直接収容される。縦座標はFIFOから取り出されるときに前進する。
書き込みイネーブルビットがセットされた場合、VLIWプログラムは、入力FIFOからの縦座標の読み出しを、出力FIFOへの書き込みと確実にバランスさせる必要がある。なぜならば、書き込みは、縦座標までしか発生しないからである(読み出しイネーブル及び書き込みイネーブルに関する上記の注意を参照せよ。)
ループに関する注意:
ループビットがセットされた場合、読み出しは、一旦[最終画素、最終行]に達すると、[開始画素、開始行]で再開する。これは、データを繰り返し読み出す必要があるコンボリューションカーネルやディザセルマトリックスのような構造体を処理する場合に理想的である。
読み出しイネーブル及び書き込みイネーブルがセットされた状態のループ処理は、単一ラインの履歴を維持する環境で役に立ち得るが、書き込みの前に読み出しが行われる場合に限り有効である。(長さに制約のある形式で書き込みが読み出しの前に行われる)FIFOの効果がある場合、画像イタレータではなく、適切なテーブルI/Oアドレッシングモードが使用される。
書き込みイネーブルだけがセットされたループ処理は、直前のN画素の書き込み窓を作成する。これは、窓からデータを読み出す非同期的プロセスを用いて使用される。Artcard読み出しアルゴリズムは、このモードを利用する。
順次読み出し及び書き込みイタレータ
図17は、画素データフォーマットの説明図である。最も簡単な画像イタレータは、順次読み出しイタレータ、及び対応した順次書き込みイタレータである。順次読み出しイタレータは、チャンネルからの画素を、同時に1行ずつ、上から下に示し、同じ行内では、画素は左から右へ示される。パディングバイトはクライアントに示されない。これは、画像からの各画素にある種のプロセスを実行する必要があるが、処理される画素の順序を問題にしないか、又はデータが特にこの順序であることを要求するアルゴリズムにとって最も有益な点である。順次読み出しイタレータを補完するのは、順次書き込みイタレータである。クライアントは出力FIFOに画素を書き込む。順次書き込みイタレータは、適切なキャッシュ処理及び適切なパディングバイトを使用して、有効画像を書き出す。各順次イタレータは、2本のキャッシュラインへのアクセスを必要とする。読み出し時に、32画素が1本のキャッシュラインから示されるが、他のキャッシュラインはメモリからロードされ得る。書き込み時、32画素は1本のキャッシュラインに書き込まれるが、他の画素はメモリに書き込まれる。画像の各画素に独立に演算を実行するプロセスは、典型的に、画素を得るために順次読み出しイタレータを使用し、新しい画素値を目的画像内の対応した場所に書き込むため順次書き込みイタレータを使用するであろう。このような処理は図18に示されている。
殆どの場合に、原画像及び目的画像は異なり、2個のI/Oアドレス生成器189と190によって表現される。しかし、原画像と目的画像を一致させることも有効である。なぜならば、ある種の入力画像は1回しか読み出されないからである。その場合、同じイタレータを入力と出力の両方に使用することが可能であり、読み出しイネーブルレジスタ及び書き込みイネーブルレジスタの両方が適切にセットされる。最大効率の場合、読み出し用と書き込み用の2個の異なるキャッシュグループを使用することが必要である。データがVLIWプロセスによって作成され、順次書き込みイタレータによって書き込まれるべき場合、PassXフラグ及びPassYフラグは座標を生成するため使用され、その座標は、次に、入力FIFOへ伝えられる。VLIWプロセスは、これらの座標を使用し、出力データを適切に作成することができる。
ボックス読み出しイタレータ
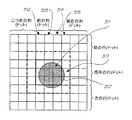
ボックス読み出しイタレータは、汎用フィルタ及びコンボルブのような演算を実行するため最も便利な順序で画素を提示するため使用される。このイタレータは、順次に読み出された画素の周りの正方形のボックス内の画素値を提示する。このボックスは、X及びYの方向の幅が1、3、5又は7画素になるように制限される(Xボックスサイズ及びYボックスサイズは同じ値であるか、一方の次元の値が1であり、他方の次元の値が3、5又は7である)。この処理は図19に示されている。
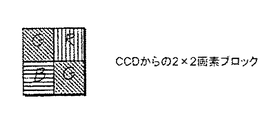
ボックスオフセット:この専用レジスタは、どの入力画素がボックスの中心として使用されるかに関してサブサンプリングを決定するため使用される。通常値は1であり、これは、各画素がボックスの中心として使用されることを意味する。”2”という値は、画像ピラミッドを構築する場合のように画像を4:1に縮小する際に便利である。上記の図からの画素アドレスを使用すると、ボックスは、画素0、2、8及び10の順に中心が置かれる。ボックス読み出しイタレータは、最大で14(2×7)本のキャッシュラインにアクセスする必要がある。画素が7本のラインの中の1組から提示される間に、他のキャッシュラインはメモリからロードすることが可能である。
ボックス書き込みイタレータ
対応するボックス書き込みイタレータは存在しない。なぜならば、画素の複製は入力時だけに要求されるからである。入力用のボックス読み出しイタレータを使用するプロセスは、殆ど確実に、同期しているので出力用の順次書き込みイタレータを使用するであろう。その良い例はコンボルバである。コンボルバでは、N個の入力画素が1個の出力画素を計算するため読み出される。そのプロセスフローは、図20に示されているようなフローである。ボックス読み出しイタレータを使用するとき、原画像及び目的画像は同じメモリを使ってはならない。なぜならば、後続の画像のラインが(新たに計算されたものではなく)元の値を必要とするからである。
垂直ストリップ読み出し及び書き込みイタレータ
ある種の例では、画像を出力画素の順序で書き込む必要があるが、出力画素に対する入力画素のコヒーレンスの方向がわからない。その一例は回転である。画像が90度回転され、出力画像を水平方向に処理する場合、キャッシュコヒーレンスの完全に失われる。これに対して、出力画像を処理する同時に1本のキャッシュラインの幅の画素に基づいて出力画像を処理し、(同じライン上の次のキャッシュラインに相当する画素へ進むのではなく)次のラインへ進む場合、入力画像の画素に対するキャッシュコヒーレンスが得られる。入力画素に(色コヒーレンスのような)既知の「ブロック」コヒーレンスが存在する場合も同様であり、この場合、読み出しが処理順序を支配し、同期させられるべき書き込みは、同じ画素順序に従わなければならない。入力として提示された画素の順序(垂直ストリップ読み出し)、又は出力に予想される順序(垂直ストリップ書き込み)は同一である。順序は、ライン0の画素0から画素31、次に、ライン1の画素9から画素31、以下、画像の全てのラインに対して同様であり、次に、ライン0の画素32から63というように続く。最後の垂直ストリップでは、正確に32画素が存在しないかもしれない。この場合、画像の実際の画素だけが入力として、提示されるか、又は予定される。この処理は図21に示されている。
垂直ストリップ書き込みイタレータだけを必要とするプロセスは、典型的に、出力画素座標が与えられた場合に入力画素座標をマッピングする方法を備えている。そのプロセスは、このマッピングに従って入力画像の画素にアクセスし、コヒーレンスは、入力画像用の「ランダムアクセス」リーダー上に十分なキャッシュラインを設けることによって決定される。図22のプロセス概要に示されるように、座標は、典型的に、垂直ストリップ書き込みイタレータのPassXフラグ及びPassYフラグをセットすることによって生成される。
書き込みイタレータを順次読み出しイタレータ又はボックス読み出しイタレータとペアにすることは重要ではないが、垂直ストリップ書き込みイタレータは、入力座標と出力座標の間に重要なマッピングが存在するとき、性能に著しい改良を加える。
垂直ストリップ読み取りイタレータと垂直ストリップ書き込みイタレータをペアにすることは重要である。この場合、入力画像と出力画像が同じであるならば、垂直ストリップ読み取りイタレータと垂直ストリップ書き込みイタレータを一つのALU188に割り当てることが可能である。座標が必要であるならば、更なるイタレータをセットされたPassXフラグ及びPassYフラグと共に使用しなければならない。垂直ストリップ読み取り/書き込みイタレータは、入力FIFOに画素を提示し、出力FIFOからの出力画素を受け取る。適切なパディングバイトが書き込み時に挿入される。入力及び出力の各々は、優れた性能のために少なくとも2本のキャッシュラインを必要とする。
テーブルI/Oアドレッシングモード
(画像のような)テーブル内の値を調べることはしばしば必要になる。テーブルI/Oアドレッシングモードは、この機能を提供し、クライアントがインデックスを出力FIFOに入れることを要求する。I/Oアドレス生成器は、インデックスを保有し、適切にデータを調べ、VLIWクライアントによる後の処理のため、調べた値を入力FIFOに返す。
1次元、2次元及び3次元のテーブルがサポートされ、特定のモードは補間を対象としている。VLIWのクライアント側の複雑さを軽減するため、インデックス値は、固定小数点の数値として取り扱われ、アクセス専用レジスタは、固定小数点を定め、インデックスの整数部として取り扱われるべきビットを定める。データフォーマットは、画素オフセットレジスタが無視される点で、汎用画像特徴の制限された形式であり、データは行内で連続していると仮定され、データ要素毎に、8ビット又は16ビット(1バイト又は2バイト)だけが許容される。4ビットのアドレスモードレジスタはI/Oタイプを決定するため使用される。
FractX、FractY及びFractZは、インデックスに基づいてアドレスを生成し、有意ビット及び整数/小数コンポーネントに関するインデックスのフォーマットを解釈するため使用される。種々のパラメータは、索引付けされたテーブルの次元数によって必要に応じて定められる。1次元テーブルは、FractXだけが必要であり、2次元テーブルは、FractX及びFractYを必要とする。各Fract値は、対応したインデックスの小数ビットの個数により構成される。例えば、Xインデックスは、5:3のフォーマットである。これは、整数が5ビットで、小数が3ビットであることを示す。したがって、FractXは3にセットされる。簡単な1次元ルックアップは、8:0のフォーマットであり、即ち、小数コンポーネントが全く無い。FractXは0になる。零オフセットは、3次元ルックアップの場合に限り必要になり、2種類の解釈を採用する。これは3次元テーブルルックアップのセクションに詳述されている。フラグレジスタ(アクセス専用1)は、データの読み取り(あるケースでは、書き込み)に影響を与える要因を決定するため使用される多数のフラグを含む。フラグレジスタは以下のように構成される。
1次元直接ルックアップとDRAMのFIFOを除くと、全てのテーブルI/Oモードは、読み出しだけをサポートし、書き込みをサポートしていない。したがって、上記の二つのモードを除く全てのI/Oモードでは、読み出しイネーブルビットはセットされ、書き込みイネーブルビットはクリアされる。1次元直接ルックアップは、
読み出しイネーブルビットがセットされ、書き込みイネーブルビットがクリアされている読み出し専用と、
読み出しイネーブルビットがクリアされ、書き込みイネーブルビットがクリアされている書き込み専用と、
読み出しイネーブルビットと書き込みイネーブルビットの両方がセットされているリード・モディファイ・ライトと、
の3モードをサポートする。
異なるモードは、以下の1次元ルックアップのセクションに記載されている。DRAM
FIFOモードは、
読み出しイネーブルビットと書き込みイネーブルビットの両方がセットされているライト・リード・モード
という一つのモードだけをサポートする。
このモードは、以下のDRAM FIFOのセクションに記載されている。DataSizeフラグは、テーブルの各データ要素のサイズが8ビットであるか、16ビットであるかを決定する。2種類のデータサイズだけがサポートされる。32ビットの要素は、プロセスの必要条件に依存して、以下の2種類の方法の何れかで作成することができる:
二つの16ビットテーブルから同時に読み出し、その結果を合成する。これは、タイミングが問題となるときに都合が良いが、二つのI/Oアドレス生成器189と190を無駄に使用する点で欠点があり、各32ビット要素はCPUによって32ビットのエンティティとして読むことができない;
16ビットテーブから2回に亘って読み出し、その結果を合成する。これは、一つのルックアップだけが使用されるので都合が良いが、異なるインデックスを生成し、ルックアップへ伝えなければならない。
1次元構造
直接ルックアップ
直接ルックアップは、1次元ルックアップテーブルへの簡単なインデキシングである。クライアントは、フラグレジスタに適切なビットをセットすることにより、三つのアクセスモード、即ち、
読み出し専用
書き込み専用
リード・モディファイ・ライト
の間で選択可能である。
読み出し専用
クライアントは、固定小数点インデックスXを出力FIFOに送り、テーブル[Int(X)]の8又は16ビット値が入力FIFOに返される。インデックスXの小数コンポーネントは完全に無視される。インデックスが範囲外である場合、エッジ繰り返しフラグは、エッジ画素が返されるか、一定画素が返されるかを決定する。アドレス生成は、次のように簡単である:
データサイズが8ビットを示す場合、Xは右へバレルシフトされたFractXのビットであり、結果はテーブルのベースアドレスImageStartに加算される;
データサイズが16ビットを示す場合、Xは右へバレルシフトされたFractXのビットであり、左へ1ビットシフトされた(ビット0が0になる)結果は、テーブルのベースアドレスImageStartに加算される。
結果として得られたアドレスにおける8又は16ビットデータ値は入力FIFOに入れられる。アドレス生成には1サイクルを要し、要求されたデータをキャッシュから出力FIFOへ転送するためにも(キャッシュヒットを仮定したとき)1サイクルを要する。例えば、各エントリーが16ビットであり、インデックスが12ビットの8:4の固定小数点フォーマットである256エントリーのテーブルの値を引く場合を想定すると、FractXは4であり、データサイズは1である。インデックスがルックアップへ渡されたとき、4ビットだけ右へシフトし、その結果を1ビットだけ左へシフトし、ImageStartに加算する。
書き込み専用
クライアントは、固定小数点インデックスXを出力FIFOへ渡し、その後、テーブルの指定された場所へ書き込まれるべき8又は16ビット値を渡す。完全な転送には最低でも2サイクル、即ち、アドレス生成のための1サイクルと、FIFOからDRAMへのデータ転送のための1サイクルを要する。VLIWプロセスがインデックスをFIFOに収容してから書き込まれるべき値をFIFOに収容するまでの間に任意の数のサイクル数を設けることができる。アドレス生成は、読み出し専用モードと同様に行われるが、データがそのアドレスから読み出されるのではなく、出力FIFOからのデータがそのアドレスに書き込まれる。アドレスがテーブルの範囲外である場合、そのデータはFIFOから削除され、DRAMには書き込まれない。
リード・モディファイ・ライト
クライアントは、固定小数点インデックスXを出力FIFOに送り、テーブル[Int(X)]の8又は16ビット値が入力FIFOへ返される。出力FIFOに収容された次の値は、テーブル[Int(X)]に書き込まれ、前に返された値を置き換える。汎用処理ループは、ある場所から値を読み出し、値を変更し、その値を書き戻すプロセスである。全体的な時間は、
インデックスからアドレスを生成するサイクルと、
テーブルからの値を返却するサイクルと、
ある種の方法で値を変更するサイクルと、
変更した値をテーブルへ書き戻すサイクルと、
の4サイクルである。
クライアントが「Xからの読み出し」又は「Xへの書き込み」を表すフラグを提示する特定の読み出し/書き込みモードは存在しない。クライアントは、元の値を書き込むことにより「Xからの読み出し」のシミュレーションを行い、返された値をただ無視することによって「Xへの書き込み」のシミュレーションを行うことができる。しかし、このようなモードの使用が促進されることはない。なぜならば、各動作は、最低でも3サイクル(モディファイは必要ではない)を使用し、特定の読み出し及び書き込みモードによって行われるような1回のアクセスではなく2回のデータアクセスを使用するからである。
補間テーブル
これは、所定の固定小数点インデックスXに対して、1個の値ではなく2個の値が返される点を除くと、読み出しモードにおける直接ルックアップと同じである。返される値は、テーブル[Int(X)]とテーブル[Int(X)+1]である。いずれかのインデックスが範囲外である場合、エッジ繰り返しフラグは、エッジ画素が返されるか、一定画素が返されるかを決定する。アドレス生成は、8ビットデータであるか16ビットデータであるかに応じて、2番目のアドレスが単に(1番目のアドレス+1)又は(1番目のアドレス+2)である点を除くと、直接ルックアップと同じである。要求されたデータを出力FIFOへ転送するためには2サイクルを要するが(キャッシュヒットを想定)、1回の16ビットフェッチによって2個の8ビット値がキャッシュからアドレス生成器へ実際に返される。
DRAM FIFO
読み出し/書き込み1次元テーブルの特殊なケースは、DRAM FIFOである。DRAM及び付随したキャッシュを使用して所定の長さのFIFOをシミュレーションすることがしばしば必要である。DRAMのFIFOによって、クライアントは、テーブルに明示的に索引付けをせずに、あたかもFIFOの一方の端であるかのようにして出力FIFOへ書き込み、同じ論理的FIFOのもう一方の端であるかのようにして入力FIFOから読み出す。2個のカウンタがシミュレーティッドFIFOの入力位置と出力位置を追跡し、必要に応じてDRAMへキャッシュする。クライアントは、フラグレジスタの読み出しイネーブルビットと書き込みイネーブルビットの両方を見る必要がある。
DRAM FIFOの用法の一例は、ある値のシングルライン履歴を保持することである。初期履歴は処理が始まる前に書き込まれる。一般的なプロセスがラインを完了するとき、前のラインの値がFIFOから獲得され、このラインの値はFIFOに入れられる(このラインは、次のラインを処理するときには前のラインになる)。入力と出力が平均的に相互に一致する限り、出力FIFOは常に一杯である。その結果として、この種のFIFOの場合、アクセス遅延が無く効率的である(但し、FIFO全長が非常に短い場合、例えば、3又は4バイトの場合を除くが、その場合にはFIFOの目的を損なうであろう)。
2次元テーブル
直接ルックアップ
2次元直接ルックアップはサポートされていない。2次元ルックアップの全てのケースはバイリニア補間のためアクセスされることが予定されているので、特別なバイリニアルックアップが実現された。
バイリニアルックアップ
この種のルックアップは、2次元テーブルからのデータのバイリニア補間のために必要である。固定小数点X座標及びY座標が与えられた場合(Y、Xの順に出力FIFOに入れられた場合)、4個の値がルックアップ後に返される。それらの値は(順番に):
Table[Int(X), Int(Y)]
Table[Int(X)+1, Int(Y)]
Table[Int(X), Int(Y)+1]
Table[Int(X)+1, Int(Y)+1]
である。
返される値の順序は、最良のキャッシュコヒーレンスを与える。データが8ビットである場合、2個の値が2サイクルの間のサイクル毎に返され、下位バイトは第1のデータ要素である。データが16ビットである場合、1サイクル毎に1エントリーずつで、4個の値が4サイクルに返される。アドレス生成には2サイクルを要する。第1サイクルでは、FractYビットだけ右へバレルシフトされたインデックス(Y)がRowOffsetによって乗算され、その結果がImageStartに加えられる。第2サイクルは、XインデックスをFractXビットだけ右へシフトし、(8ビットデータの場合)その結果、又は(16ビットデータの場合)その結果を1ビットだけ左へシフトしたものの何れかが第1サイクルからの結果に加算される。これにより、アドレスAdrは、Table[Int(X),
Int(Y)]のアドレスである:
Adr = ImageStart
+ ShiftRight(Y, FractY)*RowOffset
+ ShiftRight(X, FractX)
Adrのコピーは後続のエントリーをフェッチするためAdrOldに保持される:
データが8ビットであるならば、タイミングは、アドレス生成の2サイクルであり、その後、データが返却される2サイクルが続く(1サイクル毎に2個のテーブルエントリー);
データが16ビットであるならば、タイミングはアドレス生成の2サイクルであり、その後、データが返却される4サイクルが続く(1サイクル毎に1エントリー)。
以下の二つの表は、8ビットデータサイズ及び16ビットデータサイズ用のアドレス計算方法を示している。
両方のケースにおいて、アドレス生成の第1サイクルは、XインデックスのFIFOへの挿入と重なってもよく、実効タイミングは、アドレス生成のための1サイクル、及び返却データの4サイクルと同程度に低い。インデックスの生成がその結果よりも2ステップ進んでいる場合、実効アドレス生成時間は無く、データは単に適切なレート(1セット毎に2サイクル又は4サイクル)で生成される。
3次元ルックアップ
直接ルックアップ
2次元ルックアップの全てのケースはトライリニア補間のためアクセスされることが予想されるので、二つの特別なトライリニアルックアップが実現される。1番目は単純なルックアップテーブルであり、2番目は画像ピラミッドからのトライリニア補間用である。
トライリニアルックアップ
このタイプのルックアップは、色変換テーブルのような3次元データテーブルに有効である。標準的な画像パラメータは、データの単一のXY平面を定義し、即ち、各平面は、ImageHight個の行により構成され、各行は、RowOffset個のバイトを含む。殆どの環境において、連続した平面を想定すると、一つのXY平面は、ImageHight×RowOffsetバイトの連なりである。このオフセットを仮定又は計算するのではなく、CPUによるソフトウェアは、そのオフセットを12ビットZOffsetレジスタの形で提供しなければならない。この形式のルックアップの場合、Z、Y、Xの順の3個の固定小数点インデックスが与えらると、ルックアップテーブルから8個の値:
Table[Int(X), Int(Y), Int(Z)]
Table[Int(X)+1, Int(Y), Int(Z)]
Table[Int(X), Int(Y)+1, Int(Z)]
Table[Int(X)+1, Int(Y)+1, Int(Z)]
Table[Int(X), Int(Y), Int(Z)+1]
Table[Int(X)+1, Int(Y), Int(Z)+1]
Table[Int(X), Int(Y)+1, Int(Z)+1]
Table[Int(X)+1, Int(Y)+1, Int(Z)+1]
が順番に返される。
返される値の順序は、最良のキャッシュコヒーレンスを与える。データが8ビットである場合、2個の値が4サイクルの間のサイクル毎に返され、下位バイトは第1のデータ要素である。データが16ビットである場合、1サイクル毎に1エントリーずつで、4個の値が8サイクルに返される。アドレス生成には3サイクルを要する。第1サイクルでは、FractZビットだけ右へバレルシフトされたインデックス(Z)が12ビットのZOffsetによって乗算され、ImageStartに加えられる。第2サイクルでは、FractYビットだけ右へバレルシフトされたインデックス(Y)がRowOffsetによって乗算され、その結果が前のサイクルの結果に加算される。第2サイクルは、XインデックスをFractXビットだけ右へシフトし、(8ビットデータの場合)その結果、又は(16ビットデータの場合)その結果を1ビットだけ左へシフトしたものの何れかが第2サイクルからの結果に加算される。これにより、アドレスAdrは、Table[Int(X),
Int(Y), Int(Z)]のアドレスである:
Adr = ImageStart
+ (ShiftRight(Z, FractZ)*ZOffset)
+ (ShiftRight(Y, FractY)*RowOffset)
+ ShiftRight(X, FractX)
Adrのコピーは後続のエントリーをフェッチするためAdrOldに保持される:
データが8ビットであるならば、タイミングは、アドレス生成の2サイクルであり、その後、データが返却される2サイクルが続く(1サイクル毎に2個のテーブルエントリー);
データが16ビットであるならば、タイミングはアドレス生成の2サイクルであり、その後、データが返却される4サイクルが続く(1サイクル毎に1エントリー)。
以下の二つの表は8ビットデータサイズ及び16ビットデータサイズ用のアドレス計算方法を示している。
両方のケースにおいて、アドレス生成のサイクルは、XインデックスのFIFOへの挿入と重なってもよく、単一の1回限りのルックアップの実効タイミングは、アドレス生成のための1サイクル、及び返却データの4サイクルと同程度に低い。インデックスの生成がその結果よりも2ステップ進んでいる場合、実効アドレス生成時間は無く、データは単に適切なレート(1セット毎に4サイクル又は8サイクル)で生成される。
画像ピラミッドルックアップ
ブラッシング、タイリング及びワーピングの間に、画像の特定エリアの平均カラーを計
算することが必要である。所与のエリア毎に値を計算するのではなく、これらの機能は画像ピラミッドを利用する。画像ピラミッドの説明及び構造は、この文書のDRAMインタフェース81の章の内部画像フォーマットに関するセクションに詳述される。このセクションは、順序付きの3個の固定小数点インデックス:レベル(Z)、Y、及びXに関して、ピラミッド内の所与の画素をアドレッシングする方法に関連する。画像ピラミッドルックアップは8ビットのデータエントリーを想定するので、DataSizeフラグは完全に無視される。Z、Y、及びXの指定後、以下の8画素:
[Int(X), Int(Y)]のレベルInt(Z)の画素
[Int(X)+1, Int(Y)]のレベルInt(Z)の画素
[Int(X), Int(Y)+1]のレベルInt(Z)の画素
[Int(X)+1, Int(Y)+1]のレベルInt(Z)の画素
[Int(X), Int(Y)]のレベルInt(Z)+1の画素
[Int(X)+1, Int(Y)]のレベルInt(Z)+1の画素
[Int(X), Int(Y)+1]のレベルInt(Z)+1の画素
[Int(X)+1, Int(Y)+1]のレベルInt(Z)+1の画素
が入力FIFOを介して返される。
8個の画素は4×16ビットのエントリーとして返却され、XエントリーとX+1エントリーはハイ/ローに合成される。例えば、拡大縮小された(X,Y)座標が(10.4,12.7)であるならば、最初に返される4個の画素は、(10,12)、(11,12)、(10,13)及び(11,13)であろう。座標が有効レンジ外であるとき、クライアントは、エッジ画素繰り返し及び定数画素レジスタ(下位8ビットだけが使用される)によって、エッジ画素繰り返し、又は定数カラー値の返却を選択することができる。画像ビラミッドが構築されたとき、レベル0の座標からレベルZの座標までの簡単なマッピングが存在する。この方法は、単に、X又はY座標をZビットだけ右へシフトさせる。これは、座標の整数部を獲得するため既にシフトされたビット数(即ち、X座標に対するFractXビットの右シフト及びY座標に対するFractYの右シフト)に加えて行う必要がある。画像ピラミッドの所与のレベルに対するImageStart及びRowOffsetを見つけるため、24ビットのZOffsetレジスタがレベル情報テーブルへのポインタとして使用される。このテーブルは、レコードの配列であり、各レコードは、レベル数によって順序付けられた所与のピラミッドのレベルを表現する。各レコードは、ImageStartからそのピラミッドのレベルまでの16ビットのオフセットZOffset(オフセットの下位6ビットのような64バイトの整列したアドレスは存在しない)と、そのレベルのための12ビットのZRowOffsetと、により構成される。テーブルの要素0は、ZOffsetが0であり、単にフルサイズ画像を指示するとき、ZRowOffsetが汎用レジスタRowOffsetと一致する。テーブルの要素NにおけるZoffset値は、画像ピラミッドのレベルNの実効ImageStartを得るため、ImageStartに加算されるであろう。テーブルの要素NのRowOffset値は、レベルNに対するRowOffset値を格納する。CPU上で動かされるソフトウェアは、このアドレッシングモードを使用する前にテーブルを適切にセットアップしなければならない。実際のアドレス生成の概要は、以下で1サイクル毎に説明される。
上述のアドレス生成は、単一のバレルシフタ、2個のアダー、及び24ビットを生じる単一の16×16乗算/加算ユニットを使用して実現できる。一部のサイクルには2回のシフトが含まれるが、それらは、シフト値が同じであるか(即ち、バレルシフタの出力が2回使用されるか)、又はシフトが1ビットであるかのどちらかであり、ハードワイヤード可能である。次の内部レジスタ:ZAdr, Adr, ZInt, YInt, XInt, ZRowOffset, ZImageStartが必要である。_Int形のレジスタは最大で8ビットだけが必要であるが、他のレジスタは最大24ビットになり得る。このアクセス方法は、画像ピラミッドから読み出すだけであり、画像ピラミッドへ書き込まないので、キャッシュグループ2(CacheGroup2)が(Zadrを用いて)画像ピラミッドアドレステーブルをルックアップするため使用される。CacheGroup1は、(Adrを用いて)画像ピラミッド自体をルックアップするため使用される。アドレステーブルは、(原画像サイズに応じて)約22エントリーがあり、各エントリーは4バイトである。したがって、3又は4本のキャッシュラインをキャッシュグループ2に割り付けるべきであり、できるだけ多数のキャッシュラインをCasheGroup1に割り付けるべきである。データのセットを返すためのタイミングは8サイクルであり、サイクル8とサイクル0は動作が重なり合うと考えられ、即ち、次の要求のサイクル0はサイクル8の間に生じる。これが許される理由は、サイクル0がメモリにアクセスせず、サイクル8が特定の演算を含まないからである。
VLIWベクトルプロセッサ74を用いる座標の生成
書き込みイタレータにリンクされた一部の関数は、処理パイプラインの一部で処理されている現在画素のX及び/又はY座標を必要とする。特定の処理は、処理されている各行又は列の最後に行われる必要がある。殆どの場合に、PassX及びPassYフラグは全ての座標を完全に生成するために十分である。しかし、特別な必要条件が存在する場合、以下の関数を使用することができる。この計算は、単一サイクル生成のため多数のALUに展開することが可能であり、或いは、多数サイクル生成のため単一のALU188内で行ってもよい。
シーケンシャル[X,Y]生成
プロセスが順次読み出しイタレータに従って順次に画素を処理するとき(又は、画素を生成し、順次書き込みイタレータへその画素を書き出すとき)、以下のプロセスは、図23に示されるように、PassXフラグ/PassYフラグの代わりに、X、Y座標を生成するため使用可能である。
座標生成器は、X座標に関して画像幅ImageWidthまでカウントアップし、ImageWidth個の画素毎に1回ずつY座標をインクリメントする。実際のプロセスは図24に示され、以下の定数がソフトウェアによってセットされる。
以下のレジスタは一時変数を保持するため使用される。
垂直ストリップ[X,Y]生成
プロセスが、画素を垂直ストリップ書き込みイタレータへ書くために画素を処理し、ある種の理由からPassXフラグ/PassYフラグを使用できないとき、図25に示されるようなプロセスがX、Y座標を生成するため使用できる。この座標生成器は、X座標に関して画像幅ImageWidthまでカウントアップし、ImageWidth個の画素毎に1回ずつY座標をインクリメントするだけである。実際のプロセスは図26に示され、以下の定数がソフトウェアによってセットされる。
以下のレジスタは一時変数を保持するため使用される。
垂直ストリップ毎に1回ずつ出現する計算(2回の加算、そのうち一つはMIN演算と関連付けられている)は、一般的なタイミング統計量に含まれない。なぜならば、それらは、画素タイミング毎の実際の一部ではないからである。しかし、それらは、特定の関数用のマイクロコードのプログラミングに考慮しなければならない。
イメージセンサインタフェース(ISI83)
イメージセンサインタフェース(ISI83)は、CMOSイメージセンサからデータを取得し、データをDRAMに蓄積するため利用できるようにする。イメージセンサは、3:2のアスペクト比をもち、典型的な解像度は750×500サンプルであり、375K(1画素当たり8ビット)を生ずる。2×2画素ブロックの各々は、図27に示されるような構造を有する。ISI83は、画像を読み出すため、フレーム同期パルス及びPixelClockパルスを含む制御情報をイメージセンサへ送信する状態機械である。画素は、イメージセンサから読み出され、VLIW入力FIFO78に入れられる。VLIWは、次に、画素を処理及び/又は蓄積することが可能である。これは図28に示されている。ISI83は、検出された写真画像をDRAMに蓄積するVLIWプログラムと組み合わせて使用される。処理は次の2ステップで行われる:
小規模VLIWプログラムはFIFOから画素を読み出し、順次書き込みイタレータを介して画素をDRAMへ書き込む;
DRAM内の写真画像は、写真が撮影されたときのカメラの向きに応じて90、180又は270度回転させられる。
回転が0度である場合、ステップ1は、写真画像を最終的な写真画像格納場所へ書き出すだけであり、ステップ2は実行されない。回転が0度以外である場合、画像は一時エリア(例えば、プリント画像記憶エリア)に書き込まれ、次に、ステップ2の間に、回転させられ最終的な写真画像格納場所へ入れられる。ステップ1は、非常に簡単なマイクロコードであり、VLIW入力FIFO78からデータを取り出し、そのデータを順次書き込みイタレータに書き込む。ステップ2の回転は、加速Varkアフィン変換関数を用いて実行される。処理は、設計の複雑さを軽減し、画像のために既に必要とされたVarkアフィン変換回転ロジックを再使用するため、2ステップで行われる。これが許容できる理由は、両方のステップが、Artcamのオペレータにとってごくわずかな時間である約0.03秒内に終了するからである。たとえそうであったとしても、読み出しプロセスは、センサ速度による制限を受け、フレーム全体を読み出すために0.02秒を要し、画像を回転するため約0.01秒を要する。
検出された写真画像と内部フォーマット画像との間で変換を行うために向きは重要である。なぜならば、R画素、G画素及びB画素の相対位置は向きと共に変化するからである。処理された画像は、印刷のため正しい向きにするために、印刷プロセス中に回転させる必要がある。Artcamの3次元モデルは、2個のイメージセンサを具備し、それらの入力は単一のISI83(マイクロコードは異なるが、ACP31は同一)に多重化される。各センサはフレーム蓄積型であるため、両方の画像を同時に取得し、同時にメモリへ転送することができる。
ディスプレイコントローラ88
Artcam上の「撮影」ボタンが半押しされたとき、TFTはイメージセンサからの(簡単なVLIWプロセスによって変換された)現在の像を表示する。撮影ボタンが完全に押下されたとき、撮影像が表示される。ユーザが印刷ボタンを押下し、画像処理が始まると、TFTはターンオフされる。画像が印刷されると、TFTは再度ターンオンされる。ディスプレイコントローラ88は、フラットパネルディスプレイを内蔵するArtcamモデルで使用される。例示的なディスプレイは、240×160画素の解像度を有するTFT型LCDである。ディスプレイコントローラ88の構成は図29に示されている。ディスプレイコントローラ88の状態機械はレジスタを含み、レジスタは同期生成のタイミングを制御し、表示画像はそこから(特定のキャッシュグループによるデータキャッシュ76を介してDRAMに)取得され、レジスタは、TFTをその時点で(TFTイネーブルを用いて)動作可能状態にすべきであるかどうかを制御する。CPUは、低速バスを介してこれらのレジスタへ書き込むことが可能である。240×160画素の画像をRGB方式TFTに表示するためには、1画素当たりに3個のコンポーネントが必要になる。DRAMから取得された画像は3個のDACを介して表示され、DACは、R、G及びBの出力信号の各々に対して1個ずつ設けられる。毎秒30フレーム(毎秒60フィールド)の画像リフレッシュレートで、ディスプレイコントローラ88は、
240×160×3×30=3.5MB/秒
のデータ転送速度を必要とする。
このデータ速度は、システムの他の部分よりも低速である。しかし、集約的な画像処理中にVLIWプログラムを減速させるためには十分に高い。TFT動作の一般的な原理はこれを反映している。
画像データフォーマット
上述の通り、DRAMインタフェース81は、ACPチップの他のクライアント部と、RAMBUS
DRAMとの間を接続する。事実上、DRAMインタフェース内の各モジュールはアドレス生成器である:
ACPによって操作される画像には3種類の論理的タイプがある。それらは、
−CCDから捕捉された入力像であるCCD像
−Artcam装置によって内部的に利用される内部画像フォーマット
−Artcamによって印刷される出力画像フォーマットである印刷画像
である。
これらの画像は、典型的に、色空間、解像度、並びに、カメラ間で変動し得る出力及び入力色空間が相違する。例えば、低価格カメラのCCD像は、高価格カメラで使用されるCCDとは、解像度やカラー特性が異なる。しかし、全ての内部画像フォーマットは、あらゆるカメラの中で色空間に関して同一フォーマットである。
その上、3種類の画像タイプは、どちらの方向が「上向き」であるかに関して異なる可能性がある。カメラの物理的な向きは、人物像であるか、又は風景像であるかについての観念を生じさせ、この観念は処理全体を通じて維持されるべきである。このため、内部画像は常に正しく向きを決められ、印刷動作中にCCDから獲得された画像に対して回転が実行される。
CCD像編成
多種多様なCCDイメージセンサを利用可能であるが、CCD自体は750×500形イメージセンサであり、375000バイト(1画素当たり8ビット)を生成する場合を想定する。2×2画素ブロックの各々は図30に示されるような構造を有する。
DRAMに蓄積されたときのCCD像は、メモリ内で隣接している所定のラインと連続した画素を有する。各ラインは、次々に蓄積される。イメージセンサインタフェース83は、CCDからデータを取得し、そのデータを正しい向きでDRAMに格納する役割を担う。このようにして、回転0度のCCD像は、G、R、G、R、G、R...のような第1ラインを含み、B、G、B、G、B、G...のような第2ラインを含む。CCD像が人物像であり、90度回転されているならば、第1ラインはR、G、R、G、R、Gであり、第2ラインはG、B、G、B、G、B、...(以下同様に続く)となるであろう。
画素は、インターリーブ形式で蓄積される。なぜならば、全てのカラーコンポーネントが内部画像フォーマットを変換するために必要になるからである。
ACP31はCCD画素フォーマットに関して仮説を立てないことに注意する必要がある。なぜならば、イメージング用の実際のCCDは、Artcamの間で経時的に変化し得るからである。ハードウェアによって行われる全ての処理は、ACP31の有用性を拡大するために主要なマイクロコードによって制御される。
内部画像編成
内部画像は、典型的に、多数のチャンネルにより構成される。Vark画像には、
Lab
Labα
LabΔ
αΔ
L
が含まれるが、これらに限定されるものではない。
L、a及びbは、Lab色空間のコンポーネントに対応し、αは(コンポジットのため使用される)マットチャンネルであり、Δは(ブラッシング、タイリング、及びイルミネーティングの間に使用される)バンプマップチャンネルである。
VLIWプロセッサ74は、画像が平面的な構造で編成されることを要求する。そのため、Lab画像は、三つの別個のメモリブロック、即ち、
Lチャンネル用の1ブロック
aチャンネル用の1ブロック
bチャンネル用の1ブロック
として記憶される。
各チャンネルのブロック内において、画素は(幾つかのオプションのパディングバイトと共に)所定の行に対し隣接して記憶され、行は次々に記憶される。
図31には、論理的画像100の記憶形式の一例が示されている。論理的画像100は、逐次記憶されたカラーコンポーネントL101、a102及びb103を有する平面形式で記憶される。或いは、論理的画像100は、非圧縮Lコンポーネント101と、圧縮Aコンポーネント105及び圧縮Bコンポーネント106を有する圧縮フォーマットで記憶してもよい。
図32を参照すると、ラインn(110)の画素は、ラインn+1(111)の画素の前に一緒に格納されている。画像は単一チャンネル内の隣接したメモリに記憶されている。
8MBメモリモデルの場合、全処理の終了後の最終的な印刷画像は、クロミナンスチャンネルにおいて圧縮する必要がある。クロミナンスチャンネルの圧縮は、4:1にすることができ、全体的な圧縮は12:6又は2:1になる。
最終的な印刷画像を除くと、Artcamの画像は典型的に圧縮されない。メモリ制約のため、ソフトウェアは、クロミナンスチャンネルの最終的な印刷画像を、これらのチャンネルの各々を2:1でスケーリングすることによって圧縮することを選択してもよい。これが行われた後、画像を印刷するために利用されるプリントVark関数は、圧縮されたものとして指定されたクロミナンスチャンネルを取り扱うように指示されるべきである。プリント関数は、圧縮されたクロミナンスを取り扱う方法を知っている唯一の関数であるが、たとえそうであるとしても、プリント関数は、固定の2:1圧縮比で処理するだけである。
画像を圧縮し、次に、最終印刷画像を作成するため圧縮画像に基づいて動作することは可能であるが、これは、解像度の損失を生ずるので推奨できない。その上、画像は、プリントアウト前の最終段階として一回だけ圧縮されるべきである。1回の圧縮は実質的には気付かれないのに対し、多数回の圧縮はかなりの画像劣化を生じさせる。
クリップ画像編成
Artcardに記憶されたクリップ画像はACP31によって明示的にはサポートされない。ソフトウェアは、現在のArtcardから画像を取り出し、ACPで認識できる形式にデータを編成する役割を担う。画像がArtcard上に圧縮形式で記憶されているならば、ソフトウェアは、それらを伸長する役割を担う。なぜならば、Artcard画像の伸長をサポートする特定のハードウェアは存在しないからである。
画像ピラミッド編成
画像を操作するため利用されるブラッシング、タイリング、及びワーピングプロセス中に、しばしば、画像の特定のエリアの平均カラーを計算することが必要である。所与の各エリアの値を計算するのではなく、これらの関数は、画像ピラミッドを利用する。図33に示されるように、画像ピラミッドは、事実上の多重解像度画素マップである。原画像115は1:1表現である。各次元におけるローパスフィルタリング及び2:1のサブサンプリングによって、元のサイズの1/4の画像116が得られる。このプロセスは、画像全体が単一画素によって表現されるまで続けられる。画像ピラミッドは、原始的な内部フォーマット画像から構築され、原画像が占めていたサイズの1/3(1/4+1/16+1/64+...)を使用する。1500×1000の原画像の場合、対応した画像ピラミッドは約1/2MBである。画像ピラミッドは特定のVark関数によって構築され、他のVark関数のパラメータとして使用される。
印刷画像編成
処理画像全体は、それを印刷するため同時に必要になる。しかし、印刷画像出力は、CMYディザ画像を含み、唯一の一時的な画像フォーマットであり、印刷画像機能内で使用される。しかし、内部色空間から印刷色空間への色変換が必要であることに注意しなければならない。その上、色変換は、インク特性の異なるカメラのプリントロールの種類毎に別々に調整することができる。例えば、セピア出力は特定のセピア調色Artcardを使用して実行され、又はセピア色調プリントロールを使用して実行される(したがって、全てのArtcardはセピア色調で機能する)。
色空間
上述の通り、Artcamでは、画像タイプの種類に対応して三つの色空間が使用される。
ACPは、特定の色空間についての直接的な知識を持たない。その代わりに、ACPは、CCD色空間、内部色空間、及びプリンタ色空間、即ち、
CCD色空間:RGBと、
内部色空間:Labと、
プリンタ色空間:CMYと、
の間の変換のためクライアントの色空間変換テーブルに依存する;
ACP31から色空間変換を取り除くことによって、
−様々なカメラで様々なCCDを使用すること
−同じカメラで(長期間に異なるプリントロールの)異なるインクを使用すること
−ACP設計パスからCCD選定を分離すること
−正確なカラー処理のため内部色空間を巧く定義すること
が可能になる。
Artcardインタフェース87
Artcardインタフェース(AI)は、Artcardがリニアイメージセンサの下を通過するときに、リニアイメージセンサからデータを取得し、どのデータをDRAMに記憶するため利用する。イメージセンサは、1走査線当たりに11000個の8ビットサンプルを生成し、Artcardを4800dpiでサンプリングする。AIは、画像を読み出すため、LineSyncパルス及びPixelClockパルスを含む制御情報をリニアセンサへ送る状態機械である。画素は、リニアセンサから読み出され、VLIW入力FIFO78に収容される。VLIWは、次に、画素を処理する、及び/又は、画素を蓄積することが可能である。AIは以下の数個のレジスタを含む。
尚、CPUは、走査を始動する前にVLIW入力FIFO78をクリアしなければならない。状態レジスタは以下のように解釈されるビットを有する。
Artcardインタフェース(AI)87
Artcardインタフェース(AI)87は、Ardcardリーダー34からArtcard画像を取得し、それをオリジナルデータ(通常は、Varkスクリプト)に復号化する役割を担う。特に、AI87は、ArtcardスキャナリニアCCD34から信号を受け取り、カードに印刷されたビットパターンを検出し、ビットパターンをオリジナルデータに変換し、読み出しエラーを訂正する。
Artcard9が挿入されていない場合、Artcamから印刷された画像は、任意の標準的な画像処理ルーチンによって整理された検出写真画像に過ぎない。Artcard9は、ユーザがプリントアウトする前に写真を修正するための手段である。特定のArtcard9をArtcamに挿入するという簡単なタスクによって、ユーザは、写真画像に対して実行される複雑な画像処理を定義することができる。
Artcardが挿入されていない場合、写真画像は、印刷画像を作成するため通常の方法で処理される。1枚のArtcard9がArtcamに挿入されているとき、そのArtcardの効果は、印刷画像を生成するため写真画像に適用される。Artcard9が取り外されたとき(取り出されたとき)、印刷された画像は標準的な方法で処理された写真画像に戻る。ユーザがArtcardを取り出すためボタンを押下したとき、Artcam中央プロセッサ31で実行されるオペレーティングシステムによって維持されるイベントキューにイベントが収容される。イベントが処理されるとき(例えば、現在のプリントが行われた後)、以下の状況が発生する。
現在のArtcardが有効であるならば、印刷画像は無効としてマークされ、「プロセス標準」イベントがイベントキューに入れられる。イベントが最終的に処理されたとき、印刷画像を生成するため、写真画像に標準的な画像処理演算が加えられる。
モーターはArtcardを取り出すため始動され、時間的に規定された「モーター停止」イベントがイベントキューに追加される。
アートカードの挿入
ユーザがArtcard9を挿入したとき、Artcardセンサ49はそれを検知し、ACP72へ報せる。これにより、ソフトウェアは、「Artcard挿入済み」イベントをイベントキューに挿入する。このイベントが処理されると、以下の数個の状況が発生する:
現在のArtcardは無効としてマークされる(「無し」ではない);
印刷画像は無効としてマークされる;
Artcardモーター37はArtcardを取り込むため始動される;
Artcardインタフェース87はArtcardを読み取るように命令される;
Artcardインタフェース87は、ArtcardスキャナリニアCCD34から信号を受け取り、カードに印刷されたビットパターンを検出し、検出されたビットパターンの誤りを訂正し、有効ArtcardデータブロックをDRAMに生成する。
ArtcardCCDからのデータ読み出し−一般的考察
図34に示されるように、データカード読み出しプロセスは、画素データがカードから読み出される間に4フェーズを有する。フェーズは以下の通りである:
フェーズ1 Artcard上のデータエリア検出
フェーズ2 CCD画素に基づくArtcardからのビットパターン検出と、バイトとしての書き込み
フェーズ3 バイトパターンのスクランブル解除及びXOR演算
フェーズ4 データ復号化(リード・ソロモン復号)。
図35に示されるように、Artcard9は、ナイキストの定理を充足するため、少なくとも印刷された解像度の2倍でサンプリングされなければならない。実際には、これよりも高いレートでサンプリングする方がよい。好ましくは、画素は、各次元で印刷されたドットの解像度の3倍でサンプリングされ(237)、1個のドットを定義するために9個の画素が必要になる。したがって、Artcard9の解像度が1600dpiであり、センサ34の解像度が4800dpiである場合、50mmのCCDイメージセンサを使用することにより、1列毎に9450画素が得られる。即ち、2MBのドットデータ(1ドット当たり9画素の場合)が必要であるならば、2MB*8*9/9450=15978列=約16000列が必要になる。勿論、ドットがサンプリングCCDと厳密に揃えられていないならば、考えられる最悪のケースでは、ドットは16(4×4)画素エリア(231)で検出されるであろう。
Artcard9は、熱損傷のため多少歪みが生じ、Artcardリーダーへの挿入のばらつきによって僅かに(最大で、例えば、1度)回転し、リーダーモーター37の速度の変動を原因として真のデータレートに僅かな偏差が現れる可能性がある。これらの変化のために、カードからのデータの列は、対応した画素データの列として読み出せなくなる。図36に示されるように、Artcard9の1度の回転によって、カード上のある列からの画素は、166列に亘る画素として読み出されることになる。
最後に、Artcard9は、人間のオペレータにとって合理的な時間内に読み取られなければならない。Artcard上のデータはArtcard表面の大部分を覆っているので、タイミングの問題はArtcardデータ自体に制限され得る。1.5秒の読み出し時間は、Artcard読み出しとして適切である。
Artcardは1.5秒内に取り込まれなければならない。したがって、16000列の全ての画素データがCCD34から1.5秒以内に、即ち、1秒当たり10667列で読み出される必要がある。したがって、1列を読み取るために利用できる時間は1/10667秒、即ち、93747ナノ秒である。画素データは画素データを読み出すプロセスとは完全に独立に、同時に1列ずつDRAMへ書き込むことが可能である。
1列のデータ(1画素当たり4ビット、したがって、1バイト当たりに2×4ビット画素の読み出しが可能であるので、9450/2バイト)をDRAMへ書き込むための時間は、8個のキャッシュラインを使用することによって短縮される。4ラインが同時に書き込まれるならば、4バンクを独立にかきこむことが可能であり、オーバーラップレイテンシーが短縮される。この場合、4725バイトは11840ns(4725/128*320ns)で書き込み可能である。このようにして、所定の列データをDRAMへ書き込むために要する時間は、利用可能な帯域幅の13%未満しか使用しない。
Artcardの復号化
単純にデータサイズを見ると、リニアCCD34によって読み取られるようなArtcard画素データ全体(各ビットが3×3配列として読まれるならば140MB)が維持される場合、プロセスを8MBのメモリ33に適合させることは不可能に思われる。このため、リニアCCDの読み取り、ビットマップの復号化、及びアンビットマッププロセスは、(Artcard9がリニアCCD34の傍を通過する間に)リアルタイムで行われるべきであり、これらのプロセスは、全ての画像データ蓄積が利用可能にされなくても効率的に作用しなければならない。
Artcard9が挿入されたとき、古い蓄積された印刷画像と拡大された写真画像は無効になる。新しいArtcard9は、現在の撮影写真画像に基づいて新しい画像を作成する命令を含み得る。古い印刷画像は無効であり、拡大された写真画像及び画像ピラミッドを保持するエリアは無効であり、読み出しプロセス中にスクラッチメモリとして使用できる5MBよりも多くの量が残される。厳密に説明すると、Artcardの新しい生データが書き込まれるべき1MBのエリアは、最終的なリード・ソロモン復号化が行われるときまで、Artcard読み出しプロセス中にスクラッチデータとして使用可能であり、その1MBエリアが再度開放される。ここで説明している読み出しプロセスは、(データの最終的な宛先としての利用を除いて)余分な1MBエリアを利用しない。
また、スクランブル解除プロセスは、スクランブル解除を所定の場所で行うことができないので、2組の2MBのメモリエリアを必要とすることに注意すべきである。幸運にも、5MBのスクラッチエリアはこの目的のために十分なスペースを含む。
図37を参照すると、Artcardデータを復号化するために必要なステップのフローチャート220が示されている。これらのステップには、Artcard221を読み込むステップと、対応した符号化され、XOR演算され、スクランブル処理されたビットマップデータ223を生成するため、読まれたデータを復号化するステップと、を含む。次に、符号化され、スクランブル処理されたデータ224を生成するため、チェッカーボードXOR演算がそのデータに適用される。このデータは、次に、データ225を生成するためにスクランブル解除227され、その後、このデータは、元の生データ226を生成するため、リード・ソロモン復号化を受ける。或いは、スクランブル解除及びXOR演算プロセスは、一緒に行ってもよく、別々のデータのパスを必要としない。上記のステップの各々は、以下で詳述される。図37を参照して説明したように、Artcardインタフェースは、4フェーズを有し、そのうちの最初の二つは、時間的に重大であり、画素データがCCDから読み出される間に行われなければならない:
フェーズ1 Artcard上のデータエリア検出
フェーズ2 CCD画素に基づくArtcardからのビットパターン検出と、バイトとしての書き込み
フェーズ3 バイトパターンのスクランブル解除及びXOR演算
フェーズ4 データ復号化(リード・ソロモン復号)。
これらの4フェーズを次に詳細に説明する。
フェーズ1:Artcard9がCCD34を通過するとき、AIは、データエリアの左側でArrcard上の特別ターゲットを確実に検出することにより、データエリアのスタートを検出しなければならない。特別ターゲットが検出され得なかった場合、カードは無効としてマークされる。この検出は、Artcard9がCCD34を通過する間に、リアルタイムで行われる必要がある。
必要に応じて、回転不変性が与えられる。この場合、ターゲットは、Artcardの右側で繰り返されるが、上隅ではなく、下右隅に関連している。このようにして、もし、カードが「間違った」やり方で挿入された場合、ターゲットは、結局、正しい向きにされる。後述のフェーズ3は、データの向きを検出し、回転の可能性を考慮するように変更してもよい。
フェーズ2:データが一旦決定されると、主たる読み出しプロセスが始まり、CCDからの画素データを「Artcardデータ窓」に入れ、この窓からのビットを検出し、検出されたビットをバイトに組み立て、DRAMにバイトイメージを構築する。これは、ArtcardがCCDを通過する間に全て行われる必要がある。
フェーズ3:全ての画素がArtcardデータエリアから読み出されると、Artcardモーター37は停止させられ、バイトイメージはスクランブル解除され、XOR演算される。リアルタイム性能は要求されないが、このプロセスは、人間のオペレータを煩わせない程度に高速でなければならない。このプロセスは、2MBのスクランブル化されたビットイメージを取得し、スクランブル加除され/XOR演算されたビットイメージを別々の2MBイメージに書き込む。
フェーズ4:Artcard読み出しプロセスの最終フェーズは、リード・ソロモン復号化プロセスであり、2MBビットイメージが1MBの有効Artcardデータエリアに復号化される。再び、リアルタイム性能は要求されないが、人間のオペレータからみて素早く復号化を行うことが必要である。復号プロセスが有効であるならば、カードは有効としてマークされる。復号に失敗した場合、ビットイメージ内のデータの複製の復号化が試みられ、プロセスは、成功するか、又はビットイメージ内にデータの複製イメージが存在しなくなるまで繰り返される。
上記の4フェーズプロセスは、4.5MBのDRAMを必要とする。2MBはフェーズ2の出力のために確保され、0.5MBはフェーズ1及び2の間のスクラッチデータ用に確保される。残りの2MBのスペースは、1列当たりに4725バイトとして440列以上を保持することができる。実際上、読み出されている画素データはフェーズ1のアルゴリズムよりも数列分だけ先行しており、最悪のケースでは、約180列だけフェーズ2よりも遅れるが、440列の限界の範囲内に十分に収まる。
次に、各フェーズの実際の動作を詳細に説明する。
フェーズ1−Artcard上のデータエリア検出
このフェーズは、Artcard9上のデータエリアの左側を確実に検出することと関係がある。データエリアの正確な検出は、カードの左側に印刷された特殊ターゲットの正確な検出によって実現される。これらのターゲットは、特に、最大1度までの回転がある場合でも簡単に検出できるように設計されている。
図38を参照すると、Artcard9の左側の拡大図が示されている。このカードの左側は16個のバンド239に分割され、ターゲット、例えば、241は各バンドの中心に設けられる。バンドは、バンドを分離するための線が引かれていないという点で論理的である。図39には、1個のターゲットが示されている。ターゲット241は、単一の白色ドットを含む印刷された黒色正方形である。この考え方は、最初にできるだけ多数のターゲット241を検出し、次に、少なくとも8個の検出された白色ドットの場所を単一の論理的な直線に繋ぎ合わせるというものである。この考え方が実行できれば、データエリア243のスタートは、この論理的な直線から一定距離になる。実行できない場合、カードは無効であるとして拒否される。
図38に示されるように、カード9の高さは3150ドットである。ターゲット(Target0)241は、データエリアの左上隅244から24ドットの一定距離だけ離れた場所に置かれるので、ターゲットは、192ドット(576画素)の等しいサイズの16個の領域のうちの最初の領域239の範囲に巧く収まり、カードの最後の画素領域にターゲットは存在しない。ターゲット241は、簡単に検出できるように十分に大きくしなければならないが、カードが1度回転したときに領域の外側へ出る程に大きくしてはならない。ターゲットの適当なサイズは、白色ドット242を含む31×31ドット(93×93個の検出画素)の黒色正方形241である。
最悪の1度の回転がある場合、1列分のシフトは57画素毎に起こる。したがって、590画素のサイズのバンドの場合、カードが最悪の回転状態であるならば、このシンボルの何れかの部分を、上部若しくは下部の12画素、又はバンドのその場所に配置することは不可能であり、或いは、シンボルはCCD読み出し時に間違ったバンドで検出されるであろう。
したがって、矩形の黒色部分が57画素の高さ(19ドット)である場合、少なくとも9.5個の黒色画素は、CCDによって同一列で確実に読み出すことができる(画素の半分が1列に収まり、あとの半分が次の列に収まる最悪ケース)。同一列で少なくとも10個の黒色ドットが確実に読み出されるようにするため、高さを20ドットにする必要がある。黒色ドットのスタートのエッジでの誤検出に備えて、ドットの個数を31まで増加させ、ターゲットのローカル座標(15,15)に置かれた白色ドットの両側に15ドットずつを置く。31ドットは91画素であり、列内のシフトは最大でも3画素であり、576画素のバンドの範囲内に容易に収まる。
このように、各ターゲットは、31×31ドット(93×93画素)のブロックであり、各ターゲットは、
各列に31個の黒色ドットを含む15列(93画素のうちの45画素幅の列)と、
15個の黒色ドット(45画素)、1個の白色ドット(3画素)、及び更なる15個の黒色ドット(45画素)を含む1列と、
各列が31個の黒色ドットを含む15列(93画素のうちの45画素幅の列)と、
により構成される。
ターゲット検出
ターゲットは、ドットを検出するのではなく、同時に1列ずつ画素の列を読み出すことにより検出される。所定のバンド内で、ターゲットの左側を構築する多数の隣接した黒色画素により構成された多数の列を探索することが必要である。次に、更なる黒色列の中心で白色領域を見つけることが期待され、最後に、ターゲットの中心の左側で黒色列が見つけられる。
画素の読み出しの際に優れたキャッシュ性能を得るためには8個のキャッシュラインが必要である。論理的な読み出し毎に、4回のサブ読み出しによって4個のキャッシュラインが満たされ、一方、その他の4個のキャッシュラインは使用される。これは、利用可能なDRAM帯域幅の13%までを効率的に使用する。
図40に示されるように、ターゲットを検出する検出機構FIFOは、フィルタ245、ランレングスエンコーダ246、及びランダムアクセスのため最上部3要素(S1、S2及びS3)の特別な配線を必要とするFIFO247を含む。
入力画素の列は、全てのターゲットが検出されるか、又は指定された数の列が処理されるまで、同時に1列ずつ処理される。列を処理するため、画素はDRAMから読み出され、0又は1を検出するためフィルタ245の中を通され、次に、ランレングス符号化246される。ビット値、及び同じ値の隣接したビットの個数は、FIFO247に入れられる。FIFO249の個々のエントリーは8ビットに収まり、7ビット250はランレングスを保持し、1ビット249は検出されたビットの値を保持する。
ランレングスエンコーダ246は、576画素(192ドット)領域内の隣接した画素だけを符号化する。
FIFO247の最上部3要素は、ランダムな順序でアクセス252され得る。これらのエントリーの(画素の)ランレングスは、以下の表に従って、ショート、ミディアム、及びロングの3個の値にフィルタ処理される。
FIFO247の最上部の3個のエントリーに着目すると、3種類の興味深い特殊ケースが存在する。
好ましくは、領域バンド毎に以下の情報が保持される。
全部で7バイトが与えられる。合計が8バイトであるならば、アドレス生成が簡単化される。そこで、16個のエントリーは、16*8=128バイトが必要であり、これは、4個のキャッシュラインとぴったり合う。アドレスレンジは、0.5MBのDRAMエリアのスクラッチの内側に入るべきである。なぜならば、他のフェーズが残りの4MBデータエリアを利用するからである。
所定の画素列を処理し始めるとき、レジスタ値S2StartPixel254は0にリセットされる。FIFO内のエントリーがS2からS1へ進むとき、それらは、既存のS2StartPixel値に加算され(255)、現在S2で定義されているランの正確な位置を与える。FIFO内の3個の興味深いケースの各々を調べると、S2StartPixelはターゲットの黒色エリアのスタートを判定するため使用可能であり(ケース1及び2)、ターゲットの中心にある白色ドットのスタートを判定するため使用可能である(ケース3)。列を処理するアルゴリズムは以下のように表される。
列の処理に関与するステップ(プロセスColumn)は以下の通りである。
3種類のケース(処理ケース)の各々に対する処理は以下の通りである。
ケース1:
ケース2:
ケース3を識別するためPrevCaseWasCase2フラグ(前のケースはケース2であった)をセットする以外に特別な処理は記録されない(上記の列を処理するステップ3を参照)。
ケース3:
所与の列を処理する最後に、現在の列がターゲット検出のための列の最大番号と比較される。許容された列の番号を超えたとき、検出されたターゲットの個数をチェックする必要がある。検出されたものが8個未満であるならば、カードは無効であると見なされる。
プロセス ターゲット
ターゲットが検出された後、ターゲットを処理する必要がある。全部のターゲットが利用可能であるか、又は一部のターゲットだけが利用可能である。一部のターゲットは誤って検出された可能性もある。
この処理のフェーズは、できるだけ多数のターゲットの中心を通る数学的な直線を決定する。その直線が通過するターゲットの個数が多いほど、より高い信頼度でターゲット位置が検出される。限界は8ターゲットに設定される。直線が少なくとも8個のターゲットを通過する場合、正しい直線である見なされる。
力ずくではあるが、簡単なアプローチを採用することは差し支えない。なぜならば、そのように行うための時間があり(以下を参照)、複雑さを低減することによりテストが簡単化されるからである。Target0とTarget1(両方のターゲットが有効であると見なされる場合)の間で直線を決定し、この直線上にあるターゲットの個数を決定する必要がある。次に、Target0とターゲット2の間の直線を決定し、このプロセスを繰り返す。最終的に、Target1と2の間の直線、1と3の間の直線等に同じプロセスを実行し、以下同様に続き、最終的に、Target14とTarget15の間の直線に同じプロセスを実行する。全てのターゲットが検出された場合を想定すると、15+14+13+...=90回の計算(各計算の組は16回のテストを必要とするので、実際には、1440回の計算)を実行し、その直線に沿って最大個数のターゲットが検出された直線を選択する必要がある。ターゲット位置を見つけるためのアルゴリズムは、例えば、以下のようになる:
図34に示されるように、上記アルゴリズムにおて、TargetA261及びTargetBからCurrentLine260を決定するため、ターゲット261、262と、ターゲットAの位置との間でΔrow(264)及びΔcolumn(263)を計算することが必要である。Δrow及びΔcolumnを加算することにより、Target0からTarget1、以下同様、へ移動することが可能になる。検出された(実際に検出されたならば)TargetNの位置は、直線上のTargetNの計算された予測位置と比較することができ、許容範囲内に収まるならば、TargetNは直線上にあることが判定される。
Δrow及びΔcolumnは、
Δrow = (rowTargetA
- rowTargetB)/(B - A)
Δcolumn =
(columnTargetA- columnTargetB)/(B-A)
により計算される。次に、Target0の位置を、
row = rowTargetA - (A * Δrow)
column = columnTargetA - (A * Δcolumn)
により計算する。
また、(row,
column)を実際のrowTarget0及びcolumnTarget0と比較する。ある予測ターゲットから次のターゲット(例えば、Target0からTarget1)へ移動するためには、Δrow及びΔcolumnをそれぞれrow及びcolumnに加算すればよい。各ターゲットが直線上にあるかどうかをチェックするため、Target0の予測位置を計算し、次に、各ターゲットの座標に対して1回の加算及び1回の比較を実行することが必要である。
16個全てのターゲットと最大で90本の直線との比較の終了後、得られる結果は有効ターゲットを通る最良直線である。その直線が少なくとも8個のターゲットを通過するならば(即ち、MaxFound >= 8)、直線を形成するために十分なターゲットが検出されたことが認められるので、カードを処理することができる。最良直線の通過するターゲットが8個未満であるならば、カードは無効であると見なされる。
結果として生じるアルゴリズムは、Δrow及びΔcolumnを計算するための180回の除算と、Target0の位置を計算するための180回の乗算/加算と、2880回の加算/比較と、を要する。この処理を実行するための時間は、36列の画素データを読み出すために要する時間、即ち、3374892nsである。加算は除算よりも所要時間が短いという事実までを考慮しない場合、3240回の数学的演算を3374892ns内に実行しなければならない。これは、1演算当たりに約1040ns、即ち、104サイクルに相当する。したがって、CPUは、ターゲットの全ての処理を無事に実行することが可能であり、設計の複雑さは低減される。
データエッジ境界及びクロックマークに基づく重心の更新
ステップ0:データエリアの位置検出
Target0(図38の241)からデータエリアの左上境界244までの行及び列に関する距離は所定の固定距離であり、更に、垂直クロックマーク276までには1ドットの列がある。したがって、前の段階で見つかったTargetA、Δrow及びΔcolumn(Δrow及びΔcolumnはターゲット間の距離を表す)は、上述のようにTarget0の重心又は予測位置を計算するため使用される。
Target0からデータエリアまでの固定画素オフセットはターゲット間の距離(ターゲット間は192ドット、Target0とデータエリア243の間は24ドット)と関連付けられるので、単に、Δrow/8をTarget0の重心の列座標に加算すればよい(ドットのアスペクト比は1:1)。最上部座標は、
(columnDotColumnTop= columnTarget0
+ (Δrow/8)
(rowDorColumnTop= rowTarget0
+ (Δcolumn/8)
として定義される。
次のΔrow及びΔcolumnは、ターゲット間のドット数によってそれらを除算することにより、(ターゲット間ではなく)単一列内のドット間の画素数を与えるために更新される:
Δrow = Δrow/192
Δcolumn = Δcolumn/192
更に、currentColumnレジスタ(フェーズ2を参照)には−1をセットすることにより、ステップ2の後、フェーズ2が開始したとき、currentColumnレジスタは−1から0へインクリメントする。
ステップ1:初期重心デルタ(Δ)及びビット履歴の書き出し
これは、フェーズ2のために必要なセットアップ情報を書き込むだけである。
これは、各行のすべてのΔrow及びΔcolumnのエントリーと、ビット履歴に0を書き込むことによって実現できる。ビット履歴は実際には予測ビット履歴である。なぜならば、クロックマーク列276の左側には境界列277があり、その前には、白色エリアが存在することがわかっているからである。したがって、ビット履歴は、011、010、011、010等である。
ステップ2:読み出された実際の画素に基づく重心の更新
ビット履歴は、予測クロックマーク及びデータ境界に従ってステップ1でセットアップされる。各ドット行の実際の重心は、予測データを実際の画素値と比較することによって、より正確にセットされる(初期的には0である)。重心更新機構は、フェーズ2のステップ3を実行するだけで実現される。
フェーズ2−読み出された画素に基づくArtcardからのビットパターン検出及びバイトとしての書き込み
Artcard9からのドットは、3列に亘って検出された少なくとも9個の画素が提示されることを要求するので、検出された画素列毎にドット検出計算を実行するポイントは殆ど無い。処理に要する時間は、平均ドット出現に亘って平均化し、利用可能な処理時間を最大化した方がよい。これにより、Artcard9からのドットの列の処理を、Artcardから3列のデータを読み出すために要する時間内に収めることが可能になる。最も可能性の高いケースでは、ドットを提示するために4列を要するが、4番目の列は、あるドットの最後の列であり、且つ次のドットの最初の列である。したがって、処理は3列だけに制限されるべきである。
CCDからの画素は、利用可能な時間の13%内でDRAMに書き込まれるので、83%の時間、即ち、93747*3の83%=281241nsの83%=233430nsは、ドットの1列を処理するために利用可能である。
利用可能な時間内に、3150ドットを検出し、それらのビット値をメモリの生データエリアに書き込むことが必要である。したがって、この処理は以下のステップを必要とする:
Artcard上のドットの列毎に、
ステップ0:次のドット列へ進む;
ステップ1:Artcardドット列の上端及び下端を検出する(クロックマークをチェックする);
ステップ2:ドット列を処理し、ビットを検出し、ビットを適切に記憶する;
ステップ3:重心を更新する。
Artcardの論理的なドット列を処理し、論理的なドット列は165画素に亘ってシフトする可能性があるので、最悪のケースでは、少なくとも165列がDRAMに読み込まれるまで、最初の列を処理できない。したがって、フェーズ2は、読み出しプロセスが終了した後、同じ時間で終了する。最悪ケースの時間は、165*93747ns=15468255ns、即ち、0.015秒である。
ステップ0:次のドットへ前進
次のドットの列へ進むため、Δrow及びΔcolumnをdotColumnTopに加算し、列の上端のドットの重心を得る。最初にこれを行うとき、ビットイメージ画像データエリアの左側のクロックマーク列276の所にいるので、第1のデータ列へ進む。Δrow及びΔcolumnは、1列内のドット間の距離を表すので、ドット列の間を移動するために、ΔrowをcolumndotColumnTopに加算し、ΔcolumnをrowdotColumnTopに加算することが必要である。
処理中の列番号を追跡するため、列番号は、CurrentCoulmnという名称のレジスタに記録される。センサが次のドット列へ進むたびに、CurrentColumnレジスタをインクリメントする必要がある。CurrentColumnレジスタが最初にインクリメントされとき、それは、−1から0へインクリメントされる(フェーズ1のステップ0を参照)。CurrentColumnレジスタは、(maxColumnsに達したときに)読み出しプロセスを終了するときを決定し、(8ドット列毎に1回ずつ)8ビット全部がバイトに書き込まれた後、DataOutPointerを次のバイト情報の列へ進めるために使用される。下位3ビットは、現在のバイトにどのビットまで入るかを決定する。
ステップ1:Artcardドット列の上端及び下端の検出
Artcardからのドット列を処理するため、列の上端及び下端を検出することが必要である。列は、(局所的な歪み等を除いて)列の上端と下端の間に直線を形成すべきである。初期的に、dotCoulumnTopはクロックマーク列276を指定する。予測値をトグルさせ、予測値をビット履歴に書き込み、ステップ2へ進むだけでよく、その最初のタスクは、列の最初のデータドットに到達するため、Δrow及びΔcolumnの値をdotColumnTopに加算することである。
ステップ2:Artcardのドット列を処理
列の上端及び下端の重心が画素座標に与えられたならば、列は、それらの間に歪み等を原因とする変動ができる限り少ない直線を形成する。
処理が列の上端(上端重心座標)でスタートし、列の下端へ下がる場合を想定すると、後続の予測ドット重心は、
rownext= row + Δrow
columnnext= column + Δcolumn
として与えられる。
これは、列の次のドットの予測重心のアドレスを与える。しかし、局部的な歪み及び誤差を考慮するため、直前に所定の行で検出したドットに基づく別のΔrow及びΔcolumnを加算する。このようにして、列の上端から下端を繋ぎ合わせる直線からあるパーセンテージの最大のドリフトに累積する小さいドリフトを考慮することができる。
したがって、行毎に2個の値を保持するが、行履歴はこのフェーズのステップ3で使用されるので、それらの2個の値は別々のテーブルに格納する:
*Δrow及びΔcolumn(それぞれ2@4ビット=1バイト);
*行履歴 (1行毎に3ビット、1バイト当たり2行が格納される)。
行毎に、重心への変化を決定するため、Δrow及びΔcolumnを読み出すことが必要である。読み出しプロセスは、帯域幅の5%と2個のキャッシュラインを要する:
76*(3150/32)+2*3150=13824ns=帯域幅の5%。
重心が決定されると、重心の周辺画素は、ドットの状態、即ち、ビットの値を検出するために調べられる。換言すると、ドットは、4×4画素のエリアを覆う。しかし、ドットの解像度の3倍の解像度でサンプリングしているので、ドットの状態、即ち、ビットの値を検出するために必要な画素数はこれよりも遙かに少ない。1回につきアクセスすべき画素列は、3列に過ぎない。
1%の回転による画素ドリフトのある最悪ケースでは、重心は57画素行毎に1列ずつシフトするが、ドットの直径が3ドットであるため、ある列は、171画素行(3*57)に対して有効であろう。1バイトは2画素を含むので、各バッファ読み出し(4個のキャッシュライン)で有効なバイト数は、最悪の場合に(128の読み出しのうちの)86であろう。
ビットが検出されると、ビットはDRAMへ書き出すことが必要である。DRAM遅延を最小限に抑えるため、8列からのビットが隣接したバイトのセットとして格納される。所与のドット列からの全てのビットは、データバイト内の次のビット位置に対応するので、そのバイトの古い値を読み出し、新しいビット内でシフトしOR演算し、そのバイトを書き戻すことが可能である。
読み出し/シフト及びOR演算/書き込みプロセスは2個のキャッシュラインを必要とする。
所定の行に対するビット履歴を更新するとき、そのビット履歴を読み出し、書き込むことが必要である。1行当たりに必要なビット履歴は3ビットだけであり、2行の履歴を単一バイトに格納することが可能である。読み出し/シフト及びOR演算/書き込みプロセスは2個のキャッシュラインを必要とする。
ビット検出及び蓄積のために要する総帯域幅は以下の表に掲載されている。
ドットの検出
重心を与えるドットの値(即ち、ビットの値)を検出するプロセスは、3個の画素値を検査し、ルックアップテーブルから結果を取得することによって実現される。この処理は、かなり簡単であり、図42に示されている。ドット290の半径は約1.5画素である。したがって、重心を支える画素291は、その画素内の重心の実際の位置とは無関係に、完全にそのドット値であろう。重心が画素291の中心と正確に一致するならば、重心画素の上画素292及び下画素293、並びに、重心画素の左画素294及び右画素295は、大部分そのドット値であろう。重心が画素295の正確な中心から離れているならば、中心画素以外の画素がそのドットによって100%覆われる可能性が高い。
図42には、中心の左及び下へ偏っている重心だけが示されているが、同じ関係が中心の上側及び右側の重心に対しても成り立つことは明白である。ケース1では、重心は、中央画素295の中心と正確に一致する。中心画素295はそのドットによって完全に覆われ、上、下、左、及び右の画素もそのドットによって十分に覆われている。ケース2では、重心は、中央画素291の中心の左側にある。中心画素は、依然としてドットによって完全に覆われ、中心の左の画素294はドットによって完全に覆われている。上画素292及び下画素293は依然として十分に覆われている。ケース3では、重心は、中央画素291の中心の下側にある。中心画素291は、依然としてドット291によって完全に覆われ、中心の左の画素はドットによって完全に覆われている。中心の左画素294及び右画素295は依然として十分に覆われている。ケース4では、重心は中央画素の中心の左下にある。中心画素291は依然としてドット291によって完全に覆われ、中心の左画素294、及び中心の下画素294はドットによって完全に覆われている。
重心を更新するアルゴリズムは、以下の3個の代表的な画素を選択し、ドットの値を決定するため、中央画素291の中心から重心までの距離を使用する:
第1画素:重心を含む画素
第2画素:重心のX座標(列値)が<1/2である場合、第1画素の左側の画素であり、さもなければ、第1画素の右側の画素
第3画素:重心のY座標(行値)が<1/2である場合、第1画素の上側の画素であり、さもなければ、第1画素の下側の画素。
図43に示されるように、各画素の値は、予め計算されたルックアップテーブル301へ出力される。3個の画素は12ビットのルックアップテーブルへ供給され、このルックアップテーブルはドットの値、即ち、オン又はオフを示す単一ビットを出力する。ルックアップテーブル301は、チップ定義時に構築され、約500ゲートにまとめられる。ルックアップテーブルは、簡単な閾値テーブルでもよいが、但し、中心画素(第1画素)は重く重み付けされる。
ステップ3:列において行毎に重心Δsの更新
Δs処理の考え方は、現在列において、行毎に予測重心位置で完全なドットを生成するため、前のビット履歴を使用することである。実際の(CCDからの)画素は、予測完全画素と比較される。両方が一致する場合、実際の重心位置は正確に予測位置に含まれるので、重心Δsは有効であり、更新する必要がない。さもなければ、予測重心位置を実際のデータに最も良く適合させるため、重心Δsを更新するプロセスを行うことが必要である。新しい重心Δsは次の列のドットを処理するために使用される。
重心Δsの更新は、下記の理由で、ステップ2からの後続のプロセスとして実行される:なぜならば、
設計の複雑さを軽減し、それにより、十分な帯域幅が残っているフェーズ1のステップ2として実行でき、DRAMバッファを再使用できるようになり、
重心更新に必要な全てのデータが特殊なパイプライン化を行うことなく、プロセスのスタート時に利用できることが保証されるからである。
重心Δは、複雑さを低減するため、Δcolumn及びΔrowとして処理される。
所与のドットは直径が3ドットであるが、4×4の画素エリアに出現する可能性が高い。しかし、あるドットのエッジは、結果的に、次のドットのエッジと同じ画素に含まれる。このため、重心更新のためには、所与の単一ドットに関する情報以外の情報が必要である。
図44には、前の列からの単一のドット310が所与の重心311と共に示されている。本例では、ドット310は、4個の画素列312から315の範囲にΔが広がり、実際上、前のドット列のドット(座標=(Prevcolumn,
CurrentRow))の一部は、現在行のドットの現在列に入り込んでいる。現在の行及び列のドットが白色であるならば、前の列のドットからのドット情報(現在の列のドットは白色)しか存在しないので、前のドット列から最も右側にある画素列314は小さい値であると予測される。このことから、この画素列315における画素値が高くなればなるほど、重心がより右側になることがわかる。勿論、右側のドットも黒色であるならば、サブピクセルから情報を獲得できないので、重心を調整することができる。同様のことは、ドット座標(Prevcolumn, CurrentRow)における左、上及び下のドットについても成り立つ。
このことから、最大で5個の画素列及び画素行が必要であることがわかる。行及び列の重心Δsを別々に考慮し、それらを90度だけ回転した同じ問題として取り扱うことにより、状況を簡単化することが可能である。
水平方向のケースを最初に説明すると、予測画素が検出画素と一致しない場合、列重心Δsを変更することが必要である。ビット履歴から、現在ドット列の現在行に対して見つかったビットの値、直前のドット列、及び二つ前のドット列がわかる。予測重心位置もわかっている。これらの二組の情報を使用することにより、読み出しが完全であるならば、20ビットの予測ビットパターンを生成することが可能である。20ビットのビットパターンは水平方向次元で5画素毎の予測Δ値を表現する。1番目のニブルは、最も左側のドットの最も右側の画素を表現する。次の3個のニブルは、前の列からドット310の中心を通る3画素を表現し、最後のニブルは(現在列から)最も右側のドットの最も左側の画素317を表現する。
予測重心が画素の中心である場合、20ビットパターンは以下の表に基づくことが予測される。
中心ドットの左側及び右側の画素は、ビットが0であるか、又は1であるかに応じて、それぞれ、0又はDである。中心の3画素は、ビットが0であるか、又は1であるかに応じて、それぞれ、000又はDFDである。これらの値は、所与の画素に対してドットによって占められた物理的なエリアに基づいている。画素の正確な中心から重心までの距離に依存して、僅かにシフトしたデータを予測し、これは、実際に中心画素の両側の画素だけに影響を与える。16通りの可能性があるので、中心からの距離を16で除算し、予測画素をシフトさせるためその量を使用することができる。
20ビットの5個の画素予測値が決定されると、それは読み出された実際の画素と比較される。これは、画素単位で、読み出された実際の画素から予測画素を減算し、最後に、予測Δ値からの距離を獲得するため、それらの差をまとめて加算することにより行われる。
図45は、上記アルゴリズムを実現する一形態の説明図であり、ビット履歴322及び重心小数コンポーネント323を受け取り、対応した20ビットの数324を出力するルックアップテーブル320が含まれ、20ビットの数324は、中心画素入力326から減算321され、画素差327が生成される。
このプロセスは、予測重心に関して、Δcolumnの量1による重心の左シフト及び右シフトに対して1回ずつ実行される。実際の画素からの差が最も小さい重心は、「勝者」であると見なされ、それに応じてΔcolumnが更新される(「変更無し」が望ましい)。その結果として、Δcolumnは、ドット列毎に1よりも大きく変更されることはない。
このプロセスは垂直方向画素に対しても繰り返され、その結果としてΔrowが更新される。
ここで、並列化できる見通しはかなり高い。ACPユニット31に対して選択されたクロックのレートに依存して、これらのユニットは直列に配置することができ(これにより、3種類のΔのテストは連続したクロックサイクルで行われる)、又は並列に配置することができ、これにより、3種類のテストを同時に行うことができる。クロックレートが十分に高速であるならば、並列化の必要性はない。
帯域幅初期化
Δsの古いΔを読み出し、それらを再度書き出すことが必要である。これは、帯域幅の10%を要する:
2*(76(3150/32)+2*3150)=27648ns=帯域幅の10%。
Δsを更新するとき、所与の列のビット履歴を読み出すことが必要である。各バイトは2個の行のビット履歴を含むので、帯域幅の2.5%を要する:
76((3150/32)/2)32)+2*(3150/2)=4085ns=帯域幅の2.5%。
1%の回転によって画素がドリフトする最悪ケースでは、重心は57画素行毎に1列だけシフトするが、ドットの直径は3画素であるため、所与の画素列は、181画素行(3*57)に対して有効である。バイトは2画素を収容するので、キャッシュ読み出しにおいて有効なバイト数は最悪のケースで(128回の読み出しのうちの)86である。5列に対する最悪ケースのタイミングは、したがって、31%帯域幅である:
5*(((9450/(128*2))*320)*128/86)=88112ns=帯域幅の31%。
重心Δを更新するために必要な総帯域幅は以下の表に掲載されている。
フェーズ2のメモリ使用量
2MBのビットイメージDRAMエリアは、フェーズ2処理中に読み書きされる。2MB画素データDRAMエリアは読まれる。
0.5MBのスクラッチDRAMエリアは行データを格納するため使用される。即ち、
フェーズ3−生データのスクランブル解除及びXOR演算
図37を参照すると、復号化の次のステップは、生データのスクランブル解除及びXOR演算である。Artcardから取得されるような2MBバイト画像は、スクランブル処理され、XOR演算された形式である。これは、フェーズ4におけるリード・ソロモンデコーダに必要なビットイメージを得るためにスクランブル解除及び再XOR演算を必要とする。
図46を参照すると、スクランブル解除プロセス330は、2MBのスクランブル付きのバイト画像331を取得し、スクランブル解除された2MB画像332を書き込む。このプロセスは、同じ場所で合理的に実行することが不可能であるため、2組の2MBエリアが利用される。スクランブル付きのデータ331は、16×16配列に並べられたシンボルブロック順であり、シンボルブロック0(334)は、ランダムな順序の、あらゆる符号語からの全てのシンボル0を含む。シンボルブロック1は、ランダムな順序で全ての符号語からの全てのシンボル1を含み、以下同様である。255個のシンボルしかないので、256番目のシンボルブロックは、現時点では使用されない。
線形フィードバックシフトレジスタは、シンボルブロック、例えば、シンボルブロック334内の位置と、そのシンボルブロックが由来する符号語、例えば、符号語355との間の関係を決定するため使用される。これは、元のArtcard画像を生成したときと同じシードが使用される限り機能する。時間のボトルネックは、DRAMの非順次アドレスへの読み出し/書き込みの準備完了を待機することであるため、他のソースラインからのバイトと、0xAA及び0x55とのXOR演算は、(時間的に)実質的に制約がない。
スクランブル解除及びXOR演算プロセスのタイミングは、実質的に、2MBのランダムバイト読み出しと、2MBのランダムバイト書き込みであり、即ち、
2*(2MB*76ns+2MB*2ns)=327155712ns、つまり、約0.33秒である。このタイミングはキャッシュ処理を想定していない。
フェーズ4−リード・ソロモン復号
このフェーズはループであり、ビットイメージ内のデータのコピーに対して繰り返され、復号が成功するか、又は復号しようとするコピーが無くなるまで、データのコピーをリード・ソロモン復号モジュールへ送る。
使用されるリード・ソロモンデコーダは、適切にプログラミングされたVLIWプロセッサでもよく、或いは、LSIロジックのL64712のような別個のハードワイヤードでもよい。L64712は、1秒当たり50Mビット(毎秒約6.25MB)のスループットを備えているので、時間は、2MBの読み出し及び1MBの書き込みのためのメモリアクセス時間(順次アクセスの場合500MB/秒)ではなく、むしろ、リード・ソロモンデコーダの速度によって制約される。最悪ケースで要する時間は、2/6.25秒=約0.32秒である。
フェーズ5 Varkスクリプトの実行
Artcard9を読み出し、それを復号化するために要する総時間は、約2.15秒である。ユーザにとっての明らかな遅れは、実際には、0.65秒(フェーズ3及び4の合計)に過ぎない。なぜならば、Artcardは、1.5秒後に動きを止めるからである。
Artcardがロードされると、Artvarkスクリプトは解釈される。直ちにスクリプトを実行するのではなく、スクリプトは、「プリント」」ボタン13(図1)を押したときに限り実行される。スクリプトを実行するために取られる措置は、スクリプトの複雑さに大きく依存し、プリントボタン及び実際のプリントボタンを押下し、実際のプリントが行われるまでの間に認識される遅れを考慮しなければならない。
代替Artcardフォーマット
勿論、他のartcardのフォーマットも考えられる。以下では、多数の好適な特徴を備えたこのような新しい代替artcardフォーマットについて説明する。以下では、代替Artcardデータフォーマット、ユーザデータを代替Artcard上のドットにマッピングする機構、及びリソースが不足している組込型システムで使用するための高速代替Artcard読み出しアルゴリズムを説明する。
代替Artcardの概要
代替Artcardは、組込型アプリケーション及びPC型アプリケーションの両方で使用され、大容量のデータ又はコンフィギュレーション情報への使い易いインタフェースを提供する。
代替Artcardの裏面は(データを保存するので)アプリケーションとは無関係に同一の外観を有するが、代替Artcardの表面はアプリケーションに依存している。表面はアプリケーションとの関係においてユーザに意味がなければならない。
代替Artcard技術は、印刷解像度とは独立にすることができる。カード上にドットとしてデータを保存する考え方は、(解像度を上げることによって)同じ空間により多くのドットを配置することができるならば、それらのドットがより多くのデータを表現し得るということを意味するに過ぎない。好適な実施例は、例示的なArtcardとしての86mm×55mmカード上で1600dpiの印刷を利用することを想定するが、他の等価的なレイアウト、他のカードサイズのためのデータサイズ、及び/又は、他の印刷解像度に決定することは容易である。印刷解像度とは無関係に、読み出し技術はそのまま維持される。全ての復号化及びその他のオーバーヘッドを考慮した後、代替Artcardは、1600dpiまでの印刷解像度で、最大で1メガバイトのデータを保存することが可能である。代替Artcardは、1600dpiを超える印刷解像度で、数メガバイトのデータを保存することが可能である。以下の二つの表は、ある印刷解像度に対する代替Artcardの実効データ記憶容量を要約するものである。
代替Artcardのフォーマット
代替Artcard上のデータ構造は、データの復元を補助するため特別に設計されている。このセクションは代替Artcardのデータ(裏)面のフォーマットを説明する。
ドット
代替Artcardのデータ面のドットはモノクロでもよい。例えば、黒色ドットが、所定の望ましい印刷解像度で白色背景に印刷される。その結果として、「黒色ドット」は物理的に「白色ドット」から区別される。図47には、黒色ドット及び白色ドットの拡大図の様々な例が示されている。白色背景上の黒色ドットのモノクロ方式は、好ましくは、ブラー効果のある読み出し環境においてダイナミックレンジを最大にするために選択される。黒色ドットが特定のピッチ(例えば、1600dpi)で印刷されているとしても、ドット自体は、ドットが隣接させて印刷されたときに、隣接した直線が作成されるように、少し大きくされる。ドットは、実際には滲みの結果として一つに併合されるかもしれないが、図47の例示的な画像では併合されていない。黒色のキザキザはもっと取り除かれるであろう。好適な実施例に記述された代替Artcardは、ドットサイズの柔軟に変化することを許容するが、最良の結果を得るためには、正確なドットサイズ、及び特定の印刷技術用のインク/印刷動作をより詳細に調べるべきである。
このArtcardの実施例の説明中、用語ドットは、代替Artcard上に物理的に印刷されたドット(インク、熱、電子写真、ハロゲン化銀等)を意味する。代替Artcardリーダーが代替Artcardを走査するとき、ドットは、ナイキストの定理を充たすために、少なくとも印刷された解像度の2倍でサンプリングされる必要がある。用語画素は、代替Artcardリーダー装置からのサンプル値を意味する。例えば、1600dpiのドットが4800dpiで走査されるとき、ドットの各次元に3個の画素、即ち、1ドット当たりに9個の画素が存在する。サンプリングプロセスは後述される。
図48を参照すると、典型的な代替Artcardのデータ面1101が示されている。各代替Artcardは、白色境界領域1103によって囲まれた「アクティブ」領域1102により構成される。白色境界1103は、データ情報を格納しないが、代替Artcardリーダーによってホワイトレベルを較正するため使用される。アクティブ領域は、データブロック、例えば、1104の配列であり、各データブロックは、8個の白色ドット、例えば、1106のギャップによって隣のデータブロックから分離されている。印刷解像度に依存して、代替Artcard上のデータブロック数は変化する。1600dpiの代替Artcard上で、配列は8×8でもよい。各データブロック1104は、627×394ドットの次元を有する。ブロック間ギャップ1106が8白色ドットである場合、代替Artcardのアクティブエリアは、5072×3208ドット(1600dpiのとき、8.1mm×5.1mm)である。
データブロック
図49を参照すると、単一のデータブロック1107が示されている。代替Artcardのアクティブ領域は、同一構造のデータブロック1107の配列により構成される。各データブロックの構造は、クロックマーク1109によって囲まれたデータ領域1108と、境界1110と、Target1111である。データ領域は、符号化データだけを含み、クロックマーク、境界、及びターゲットは、特に、データ領域の位置検出を補助し、領域内からのデータの正確な復元を保証するために設けられる。
各データブロック1107の次元は、627×934ドットである。この中で、595×384ドットの中央エリアはデータ領域1108である。周囲ドットは、クロックマーク、境界、及びターゲットを保持するため使用される。
境界及びクロックマーク
図50はデータブロックを示し、図51及び図52は、そのデータブロックの拡大エッジ部分を示す。図51及び図52に示されるように、二つの5ドット高の境界及びクロックマーク領域1170及び1177が各データブロックに存在し、一方はデータ領域の上方に、もう一方はデータ領域の下側にある。例えば、上端の5ドット高領域は、(データブロックの長辺を引き延ばす)外側黒色ドット境界線1112と、(境界線が独立していることを保証する)白色ドット分離線1113と、3ドット高のクロックマークの組1114と、により構成される。クロックマークは、白色及び黒色行の間で交互に代わり、黒色ブロックの両端から8番目の列で黒色クロックマークから始まる。クロックマークドットとデータ領域内のドットとの間は分離されていない。
クロックマークは、代替Artcardが180度回転させて挿入された場合に、同じ相対的な境界/クロックマーク領域が出現するという点で対称性がある。境界1112、1113は、データがデータ領域から読み出されるときに、垂直方向に追従するため、代替Artcardが使用することを意図されている。クロックマーク1114は、データがデータ領域から読み出されるときに、水平方向に追跡することが意図されている。白色のドット直線による境界とクロックマークの分離は、読み取り中にブラー効果が発生する結果として望ましい。境界は、このようにして、両側が白色の黒色直線になり、読み出し時の周波数応答の改良に役立つ。白色と黒色の間で交互に代わるクロックマークは、垂直次元ではなく、水平次元である点を除いて、類似した結果を生ずる。任意の代替Artcardは、追跡のために使用することを意図しているならば、クロックマーク及び境界の位置を見つけなければならない。次のセクションは、クロックマーク、境界及びデータへの方向を示すため設計されたターゲットを取り扱う。
ターゲット領域内のターゲット
図54に示されるように、二つの15ドット幅のターゲット領域1116及び1117が各データブロックに存在する。一方はデータ領域の左側に存在し、他方はデータ領域の右側に存在する。ターゲット領域は、方位のため使用される1列のドットによってデータ領域から分離される。ターゲット領域1116及び1117の目的は、クロックマーク、境界、及びデータ領域までの進み方を指定することである。各ターゲット領域は、6個のターゲット、例えば、1118を含み、6個のターゲットは、代替Artcardリーダーによって簡単に検出できるように設計される。次に、図53を参照すると、単一Target1120の構造が示されている。各Target1120は、15×15ドットの黒色正方形であり、中心構造1121とランレングス符号化ターゲット番号1122と、を含む。中心構造1121は、単純な白色十字であり、ターゲット番号コンポーネント1122は、単純な2列の白色ドットであり、各列はターゲット番号の各部分に対し2ドットの長さである。したがって、ターゲット番号1のターゲットidの1122は2ドットの長さであり、ターゲット番号2のターゲットidの1122は4ドット幅であり、以下同様に続く。
図54に示されるように、ターゲットは、カード挿入に関して回転不変性を有するように配置される。即ち、左のターゲットと右のターゲットは、180度回転している点を除いて同じである。左のターゲット領域1116において、ターゲットは、Target1から6が上端から下端へそれぞれ位置決めされるように配置される。右のターゲット領域において、ターゲットは、ターゲット番号1から6が下端から上端へ位置決めされるように配置される。ターゲット番号idは、常に、データ領域までの半分のところにある。図54の拡大部分図は、右のターゲットが、180度回転している点を除いて、左のターゲットと同一である様子を明瞭に示している。
図55に示されるように、Target1124及び1125は、特に、中心が55ドット離されてターゲット領域内に配置される。その上、Target1(1124)の中心から上部クロックマーク領域の第1のクロックマークドット1126までの距離は55ドットであり、ターゲットの中心から下部クロックマーク領域の第1のクロックマークドット(図示せず)までの距離は55ドットである。両方の領域の第1の黒色クロックマークは、ターゲット中心とちょうど一致して始まる(8番目のドット位置は15ドット幅のターゲットの中心である)。
図55の略構成図には、ターゲット中心の間の距離と、上部境界/クロックマーク領域内オンTarget1(1124)から第1の黒色クロックマーク(1126)の第1のドットまでの距離が示されている。上部及び下部の両方のターゲットからクロックマークまでの距離は55ドットであり、代替Artcardの両側は対称性があるため(180度回転しているため)、カードは、左から右へ、又は右から左へ読み出される。読み出し方向とは無関係に、方位はデータ領域からデータを抽出するため決定する必要がない。
方位列
図56に示されるように、各データブロックには2個の1ドット幅の方位列1127及び1128が存在する。一方はデータ領域の直ぐ左側にあり、他方はデータ領域の直ぐ右側にある。方位列は、代替Artcardリーダーに方向情報を与えるため設けられる。(左ターゲットの右にある)データ領域の左側には、単一の白色ドット列1127が隣接する。(右ターゲットの左にある)データ領域の右側には、単一の黒色ドット列1128が隣接する。ターゲットは回転不変性があるので、これらの二つのドット列によって、代替Artcardリーダーは、代替Artcardの方向、即ち、カードが正しく挿入されたか、又は逆向きに挿入されたかを決定できるようになる。代替Artcardの観点からは、ドットの劣化が無いと仮定すると、次の二つの可能性が存在する。即ち:
*データ領域の左側のドット列が白色であり、データ領域の右側の列が黒色であるならば、リーダーは、カードが書き込まれたときと同じように挿入されたことを認識する;
*データ領域の左側のドット列が黒色であり、データ領域の右側の列が白色であるならば、リーダーは、カードが後ろ向きに挿入され、データ領域がそれに応じて回転していることを認識する。リーダーは、代替Artcardから正しく情報を復元するため、適切な動作を選択しなければならない。
データ領域
図57に示されるように、データブロックのデータ領域は、各列が384ドットを含む595列により構成され、全部で228480ドットがある。これらのドットは、原データを得るために、解釈され、復号化される。各ドットは単一ビットを表現するので、228480ドットは228480ビット、即ち、28560バイトを表現する。各ドットの解釈は以下の通りである。
しかし、ドットから得られたビットの実際の解釈は、原データから代替Artcardのデータ領域内のドットへのマッピングの理解が必要である。
原データのデータ領域ドットへのマッピング
次に、最大サイズが910082バイトの原データファイルを取得し、それを、1600dpi代替Artcard上の64個のデータブロックのデータ領域内のドットへマッピングするプロセスを説明する。代替Artcardリーダーは、代替Artcard上のドットから原データを抽出するためこのプロセスを逆転するであろう。一見して、データをドットにマッピングすることは簡単なことに思われ、即ち、2値データは1と0により構成されるので、黒色ドット及び白色ドットを簡単にカードに書き込むことができるであろう。しかし、この方式は、インクがフェイドし、カードの一部がごみ、汚れ、或いは、場合によっては傷によって損なわれることを許容しない。誤り検出符号化を行わない限り、カードから取得されたデータが正確であるかどうかを検出する方法は無い。更に、冗長符号化を行わない限り、検出された誤りを正す方法はない。したがって、マッピングプロセスの目的は、データ復元を非常に確実に行い、代替Artcardリーダーに、データを正しく読み出したことを認識する能力を与えることである。
原データファイルをデータ領域ドットへマッピングするために、以下の三つの基本的なステップが関係する:
*原データを冗長符号化する;
*局部的に生じた代替Artcardの損傷の影響を低減するため、符号化データをシ決定論的にャッフルする;
*シャッフルされた符号化データをドットとして代替Artcardのデータブロックに書き込む。
これらの各ステップは以下のセクションで詳細に考察される。
リード・ソロモン符号化を使用する冗長符号
データの代替Artcardへのマッピングは、冗長符号化を利用する方法に大きく依存している。バースト誤りを取り扱い、最小限の冗長性で効率的に誤りを検出し訂正する能力を備えているリード・ソロモン符号化を選択する方が好ましい。リード・ソロモン符号化は、Wicker,
S. と Bhargava,
V. による''Reed−Solomon Codes and
their Application'',IEEE Press, 1994、Rorabaugh,
Cによる''Error Coding Cookbook'',McGraw−Hill,
1994、及びLyppens, H.による''Reed−Solomon Error
Correction'',De. Dobb's Journal,
Volume 22,
Issue 1,
January 1997のような標準的なテキストで適切に説明されている。
リード・ソロモン符号化用の様々なパラメータを使用することが可能であり、異なるシンボルサイズ及び異なる冗長性レベルが含まれる。好ましくは、以下の符号化パラメータ、
*m=8
*t=64
が使用される。
m=8とすることは、シンボルサイズが8ビット(1バイト)であることを意味する。また、リード・ソロモン符号化されたブロックサイズnは255バイト(28−1シンボル)であることを意味する。最大でt個のシンボルの訂正を行うため、最終的なブロックサイズで2t個のシンボルが冗長シンボルを用いて採用されなければならない。t=64とすることは、誤りがある場合に、1ブロック毎に64バイト(シンボル)を訂正可能であることを意味する。255バイトの各ブロックは、128(2×64)冗長バイトを有し、残りの127バイト(k=127)は原データを保持するため使用される。このようにして、
*n=255
*k=127
である。
実際の結果では、127バイトの原データが符号化され、255バイトブロックのリード・ソロモン符号化データが得られる。符号化された255バイトブロックは、代替Artcard上に記憶され、その後、代替Artcardリーダーの復号化によって元の127バイトに戻される。データブロックのデータ領域の単一列内の384ドットは、48バイト(384/8)を保持し得る。595列は28560バイトを保持し得る。これは、112個のリード・ソロモンブロックに達する(各ブロックは255バイトを含む)。完全な代替Artcardの64個のデータブロックは、全部で7168個のリード・ソロモンブロック(1リード・ソロモンブロック当たりに255バイトのとき、1827840バイト)を保持し得る。7168個のリード・ソロモンブロックのうちの2個は、制御情報のため確保されるが、残りの7166個はデータを記憶するため使用される。各リード・ソロモンブロックは127バイトの実際のデータを保持し、代替Artcard上に記憶できるデータの総量は910082バイト(7166×27)である。原データがこの総量未満である場合、データは、正確な個数のリード・ソロモンブロックに適合させるため、符号化することができ、次に、符号化されたブロックは、7166個の全てが使用されるまで複製可能である。図58は利用される符号化の全体的な形態の説明図である。
2個の制御ブロック1132及び1133の各々は、残りの7166個のリード・ソロモンブロックを復号化するために必要な同じ符号化情報、即ち、
フルメッセージ(16ビット格納ロー/ハイ)中のリード・ソロモンブロックの個数と、メッセージ(8ビット)の最後のリード・ソロモンブロック内のデータバイトの個数と、を収容する。
これらの2個の数は、32回繰り返され(96バイトを消費)、残りの31バイトは確保され、0にセットされる。各制御ブロックは、次に、リード・ソロモン符号化され、127バイトの制御情報は255バイトのリード・ソロモン符号化データに変換される。
制御ブロックは、生き残る可能性を高くするため2回記憶される。その上、制御ブロック内のデータの繰り返しは、リード・ソロモン符号を使用する場合に特に重要である。間違いの無いリード・ソロモン符号化ブロックにおいて、データの最初の127バイトは、正しく原データであり、もし、制御ブロックが復号化に失敗したとき(64個を超えるシンボルに誤りがあるとき)、原メッセージを復元するために参照することができる。このようにして、制御ブロックが復号化に失敗した場合、2個の復号化パラメータの最も確からしい値を決定するために、3バイトのセットを検査することができる。復元可能であることは保証されないが、冗長性によって可能性は高くなる。例えば、制御ブロックの最後の159バイトが破壊され、最初の96バイトは完全に大丈夫である。最初の96バイトを参照すると、数字の繰り返しセットが見つかる。これらの数字は、残りの7166個のリード・ソロモンブロックにあるメッセージの残りの部分を復号化するため巧く利用することができる。
一例として、正確に9967バイトのデータを含むデータファイルを想定する。必要なリード・ソロモンブロックの数は79個である。最初の78個のリード・ソロモンブロックは完全に利用され、9906バイト(78×127)が使用される。79番目のブロックには、61バイトのデータしか含まれない(残りの66バイトは全て0である)。
代替Artcardは、7168個のリード・ソロモンブロックにより構成される。最初の2ブロックは制御ブロックであり、次の79ブロックは符号化データであり、次の79ブロックは符号化データの複製であり、次の79ブロックは符号化データの別の複製であり、以下同様に続く。79個のリード・ソロモンブロックを90回記憶した後、残りの56個のリード・ソロモンブロックは、79ブロックの符号化データのうちの最初の56ブロックの別の複製である(符号化データの最後の23ブロックは、代替Artcard上に十分な場所が存在しないので、これ以上記憶されない)。リード・ソロモン符号化される前の各制御ブロックデータ内の127バイトの16進表現が図59に示されている。
符号化データのスクランブル処理
全ての符号化ブロックがメモリ内に隣接して格納されているならば、最大で1827840バイトのデータ(2個の制御ブロックと、7166個の情報ブロックとを合わせて全部で7168個のリード・ソロモン符号化ブロック)を代替Artcard上に記憶することができる。好ましくは、データは、この段階で代替Artcard上にそのまま記憶されるのではなく、即ち、1個のリード・ソロモンブロックの255バイトの全てがカード上で物理的に一体として記憶されるのではない。カードに物理的な破損を生じさせるごみ、汚れ、又は歪みは、一つのリード・ソロモンブロック内の64バイト以上を破壊する可能性があり、そのブロックは復元できなくなる。リード・ソロモンブロックの複製が無い場合、代替Artcardの全体を復号化し得ないことになる。
これに対するソリューションは、代替Artcard上に多数のバイトが存在し、代替Artcardは合理的な物理サイズを有するという点を活かすことである。したがって、データはスクランブル処理され、一つのリード・ソロモンブロックからのシンボルが相互に接近しないことが保証される。勿論、カードが劣化する異状ケースでは、リード・ソロモンブロックを復元することは不可能であるが、平均的に、データのスクランブル処理によってカードを非常に頑強にすることができる。選択されたスクランブル方式は単純であり、図14に概略的に示されている。リード・ソロモンブロックからのバイト0の全ては、まとめて配置され(1136)、次に、全てのバイト1等も同様である。したがって、7168個のバイト0と、7168個のバイト1等が存在する。代替Artcard上の各データブロックは28560バイトを記憶することができる。この結果として、代替Artcard上の64個のデータブロックの各々に、各リード・ソロモンブロックからの約4バイトが収容される。
このスクランブル方式の下では、代替Artcard上の16個のデータブロック全体に対する完全なダメージによって、1リード・ソロモンブロック毎に64個のシンボル誤りが生じる。即ち、代替Artcardにその他のダメージが無い場合、たとえデータの複製が無くても、全てのデータは完全に復元可能である。
スクランブル処理された符号化データを代替Artcardへ書き込み
原データがリード・ソロモン符号化され、複製され、スクランブル処理されると、1827840バイトのデータを代替Artcardに記憶する必要がある。代替Artcard上の64個のデータブロックの各々は、28560バイトを記憶する。
データは、単純に代替Artcardのデータブロックへ書き出されるので、第1のデータブロックはスクランブル付きデータのうちの最初の28560バイトを格納し、第2のデータブロックは次の28560バイトを格納し、以下同様に続く。
図61に示されるように、データブロック内で、データは列に関して左から右へ書き込まれる。このため、データブロック内の最も左側の列は、28560バイトのスクランブル付きデータのうちの最初の48バイトを格納し、最後の列は、28560バイトのスクランブル付きデータのうちの最後の48バイトを格納する。列内では、バイトは、ビット7から始めて、同時に1ビットずつ、上から下へ書き込まれ、ビット0で終了する。ビットがセット(1)されている場合、黒色ドットが代替Artcardに配置され、ビットがクリア(0)されている場合、ドットは配置されず、カードの白色背景カラーのまま残される。
例えば、1827840バイトのデータの組は、代替Artcardに記憶されるべき7168個のリード・ソロモン符号化ブロックをスクランブル処理することによって作成できる。最初の28560バイトのデータは最初のデータブロックに書き込まれる。最初の28560バイトのうちの最初の48バイトはデータブロックの最初の列に書き込まれ、次の48バイトは次の列に書き込まれ、以下同様に続く。28560バイトのうちの最初の2バイトが16進のD3
5Fである場合を想定する。バイト0のビット7が最初に格納され、次にビット6が格納され、以下同様に続く。次に、バイト1のビット7からバイト1のビット0までが格納される。各「1」は黒色ドットとして格納され、各「0」は白色ドットして格納されるので、これらの2バイトは、代替Artcard上では、以下のドットの組として表現され、
*D3(1101 0011)は、黒、黒、白、黒、白、白、黒、黒になり、
*5F(0101 1111)は、白、黒、白、黒、黒、黒、黒、黒になる。
代替Artcardの復号化
このセクションは、代替Artcardから正確かつ確実な形で原データを抽出する処理を取り扱う。特に、前の章で説明した代替Artcardのフォーマットを前提として、代替Artcardから元の予め符号化されたデータを抽出する方法を説明する。
代替Artcardを復号化する前提の一部として多数の一般的な考察が存在する。
ユーザ
代替Artcardの目的は、様々なアプリケーションで使用するためのデータを保存することである。ユーザは、代替Artcardを代替Artcardリーダーに挿入し、データが「妥当な時間」内にロードされることを期待する。ユーザの観点からは、モーター輸送が代替Artcardを代替Artcardリーダーへ動かす。これは、問題となる遅れとしては認識されない。なぜならば、代替Artcardは動いているからである。代替Artcardが停止した後の時間は遅延として認識され、代替Artcard読み出し方式において最低限に短縮されるべきである。理想的な状態では、代替Artcardの全体が移動中に読み出され、これにより、カードの移動が停止した後に遅延が認識されない。
好適な実施例の目的のため、代替Artcardを物理的にロードするための妥当な時間は1.5秒に決める。代替Artcardの移動が停止した後の付加的な復号化のための時間を最低限に短縮すべきである。代替Artcardのアクティブ領域は代替Artcardの表面の大部分を覆うので、時間的な関心をその領域に限定することができる。
ドットのサンプリング
代替Artcard上のドットは、ナイキストの定理(Nyguist‘s
Theorem)を充たすため、少なくとも印刷された解像度の2倍でCCDリーダー等によってサンプリングしなければならない。実際には、これよりも高いレートでサンプリングする方がよい。代替Artcardリーダーの環境では、ドットは、好ましくは、各次元に関してドットが印刷された解像度、即ち、単一ドットを定義するために9画素を必要とする解像度の3倍の解像度でサンプリングされる。代替Artcardのドットの解像度が1600dpiである場合、代替Artcardリーダーのイメージセンサは、4800dpiで画素を走査しなければならない。勿論、ドットがイメージセンサと正確に位置合わせされていない場合、図62に示されるような最悪の最も起こり易いケースでは、ドットは4×4画素エリアに亘って検出されるであろう。
サンプリングされる各画素は1バイト(8ビット)である。各画素の下位2ビットは、有意なノイズを含む可能性がある。したがって、復号化アルゴリズムは、耐ノイズ性が要求される。
位置合わせ/回転
ユーザが代替Artcardを回転なしに完全に位置合わせされた状態で代替Artcardリーダーに挿入する可能性は極めて低い。リーダーの入口及びモーター輸送のグリップにおけるある種の物理的制約は、挿入された後、代替ArtcardがCCDに対して挿入時の最初の角度で保たれることを保証する。好ましくは、この回転角度は、図63に示されるように最大で1度である。読み出しプロセス中にジッタ及びモーターのガタによって角度が僅かに外れる可能性はあるが、基本的に1度の限界内に収まると考えられる。
代替Artcardの物理的寸法は86mm×55mmである。1度の回転は、86mmがCCDの下を通過したとき、カードの実効高さを1.5mm(86sin1°)だけ長くするので、必要なCCD長に影響を与える。
代替Artcardの読み出しに対する1度の回転の影響は、CCDからの1本の走査線が代替Artcardからの多数の異なるドット列を含むことである。これは、画素の列に対するドットのドリフトを表した図63に拡大された形態で示されている。同図では誇張されているが、実際のドリフトは、57画素毎に最大で1画素列になる。
代替Artcardが回転していないとき、単一のドット列は3本の画素走査線によって読むことができる。代替Artcardの回転が大きくなると、局部的な影響が増加する。読み出されるドットの数が増加すると、回転の影響が加わる時間が長くなる。これらの要因のうちのいずれかが増大すると、代替Artcard上の単一列から所定のドットの組を得るために読み出す必要がある画素走査線の数が増加する。以下の表は、特定の代替Artcard構造において単一のドット列のために必要な画素走査線の本数を示している。
代替Artcardの全体を読むため、87mm(86mmと1°の回転による1mmの和)を読む必要がある。4800dpiの場合、これは、16252列の画素列に相当する。
CCD(又はその他のリニアイメージセンサ)の長さ
CCD自体の長さは、
−代替Artcardの物理的高さ(55mm)
−物理的な代替Artcardの挿入時の垂直方向動き(1mm)
−最大1°の挿入時回転(86sin1°=1.5mm)
に適合しなければならない。
これらの要因を組み合わせると、全体の長さは57.5mmになる。
代替Artcardリーダーの代替ArtcardイメージセンサCCDが4800dpiで走査するとき、1本の走査線は10866画素である。簡単のため、この数字を11000画素に切り上げる。代替Artcardのアクティブ領域の高さは3208ドット、即ち、9624画素である。データ領域の高さは384ドット、即ち、1152画素である。
DRAMサイズ
代替Artcardの読み出し及び復号化に必要なメモリ量は、理想的には最低限に削減される。典型的な代替Artcardリーダーの配置は、内蔵型システムであり、その場合、メモリリソースは貴重である。このことは、回転の影響によって更に重大な問題になる。上述の通り、代替Artcardの回転が大きくなると、原ドットを効率的に復元するために要する走査線の数が増加する。
アルゴリズムの複雑さと、ユーザの認知する遅延と、頑強性と、メモリ使用量との間にはトレードオフがある。最も簡単なリーダーアルゴリズムの一つは、単に代替Artcardの全体を走査し、次に、リアルタイムの制約無しに全データを処理することであろう。これは、大規模のメモリ容量を必要とするだけではなく、代替Artcardの読み出しプロセスと並行に行われるリーダーアルゴリズムよりも長時間を要するであろう。
代替Artcardの読み出し及び復号化のために実際に必要なメモリ量は、符号化されたデータを、少量のスクラッチ空間(1から2KB)と共に保持するために必要なスペースの量の2倍である。1600dpiの代替Artcardの場合、これは、4MBのメモリ必要量を意味する。実際のメモリ使用量は以下のアルゴリズムの説明で詳述される。
転送レート
DRAM帯域幅の前提条件は、タイミングを考慮するために行う必要があり、特に、代替Artcardリーダーは、典型的に、内蔵型システムの一部であるので、アルゴリズム設計にある程度の影響を与える。
Rambus Incの''Direct Rambus
Technology Disclosure'', Oct 1997に記載されているような標準的なRambus
Direct(ラムバスダイレクト)RDRAMアーキテクチャが想定され、ピークデータ転送レートは1.6GB/秒である。75%の効率(容易に実現できる)を想定すると、平均で1.2GB/秒のデータ転送レートが得られる。したがって、16バイトのブロックにアクセスするために要する平均時間は12nsである。
汚染データ
物理的に破損した代替Artcardがリーダーに挿入されることがあり得る。代替Artcardは、傷を付けられるか、汚れ若しくはごみによって歪みを生じるかもしれない。代替Artcardリーダーが全てを完全に読み出すことは想定できない。汚染データの影響は、ブラー効果によって更に悪化させられる。なぜならば、汚染データが周囲のきれいなドットに影響を与えるからである。
ブラー効果環境
ブラー効果は、次の2種類の経路で代替Artcard読み取り環境に組み込まれる:*代替ArtcardからCCD間での距離の特性を原因とする自然的なブラー効果;
*代替Artcardの歪み。
代替Artcard像の自然的なブラー効果は、CCDから検出されたデータのオーバーラップが存在するときに生じる。ブラー効果は役に立つ場合がある。なぜならば、ブラー効果は、検出データに高周波数が存在しないこと、及びCCDによって失われたデータが存在しないことを保証するからである。しかし、CCD画素によって覆われたエリアが非常に広い場合、非常に多くのブラー効果が現れ、データを復元するために要するサンプリングの条件が充たされない。図64は検出データの重なり合いの略説明図である。
別の形態のブラー効果は、代替Artcardが熱ダメージのために僅かに歪むときに生じる。垂直方向の次元に歪みがあるとき、代替ArtcardとCCDの間の距離は一定ではなく、ブラー効果のレベルはそのエリアの中で変化する。
黒色ドット及び白色ドットは、代替Artcardがブラー効果のある読み出し環境で最良のダイナミックレンジを与えるように選択された。ブラー効果は、所与のドットが黒色であるか、又は白色であるかを決定するときに問題を生じる。
ブラー効果が増大すると、所与のドットは周辺ドットから受ける影響が大きくなる。その結果として、特定のドットのダイナミックレンジは減少する。白色ドット及び黒色ドットの各々が起こり得るあらゆるドットの組によって囲まれる場合を考える。9個のドットにブラー効果が現れ、中央ドットがサンプリングされる。図65は、黒色ドット及び白色ドットに対して得られた中央ドット値の分布の説明図である。
この図は、典型的なブラー効果を意図している。0から約180までの曲線1140は黒色ドットのレンジを示す。75から250までの曲線1141は白色ドットのレンジを示す。しかし、ブラー効果が大きくなると、2本の曲線はレンジの中央の方へ向かってシフトし、交わるエリアが増大し、所与のドットが黒色であるか、白色であるかを判定することがより困難になる。交わりの中心点での画素値は曖昧であり、ドットが黒色である可能性と白色である可能性は等しい。
ブラー効果が増大すると、読み出しビット誤りの確率が増加する。都合良く、リード・ソロモン復号化アルゴリズムは、t個のシンボル誤りまで正常にこれらに対処することができる。図65は、特定のシンボル誤り率の場合に復元できない代替Artcardのリード・ソロモンブロックの予測数のグラフである。リード・ソロモン復号化方式が優れた性能を示し、次に、実質的に低下することに注意すべきである。リード・ソロモンブロックの複製が無い場合、1ブロックに誤りが生じるだけでデータを復元できなくなる。勿論、ブロック複製を行った場合、代替Artcard復号化の機会が増加する。
図66は、誤りのあるリード・ソロモンブロックの個数に対応するシンボル(バイト)誤りだけを示している。対処可能なブラー効果の量と、カードに生じたダメージの量との間にはトレードオフが存在する。全ての誤り検出及び訂正はリード・ソロモンデコーダによって行われるので、リード・ソロモンデータブロック毎に対処可能な誤りの個数は有限である。ブラー効果によって取り込まれる誤りが増加すると、代替Artcardのダメージによる誤りの中で対処可能な誤りの個数は減少する。
代替Artcard復号化の概要
上述の通り、ユーザが代替Artcardを代替Artcard読み取りユニットに挿入するとき、モーター輸送は、理想的には、代替Artcardを運び、モノクロリニアCCDイメージセンサの傍らを通過させる。カードは次元毎に印刷された解像度の3倍の解像度でサンプリングされる。代替Artcard読み取りハードウェア及びソフトウェアは、1度までの回転と、モーター輸送によって生じるジッタ及び振動と、代替ArtcardからCCDまでの距離の変動によって生じるブラー効果を補正する。データのデジタルビットイメージが、以下に説明される複雑な方法によって、サンプリングされた像から抽出される。リード・ソロモン復号化は、代替Artcard上の生データの25%までの任意に分布したデータコラプションを訂正する。約1MBの訂正データが1600dpiカードから抽出される。
復号化に関連するステップは図67に示されるようなステップである。
復号化プロセスに必要なステップは、
*印刷された解像度の3倍の解像度で代替Artcardを走査する(例えば、4800dpiで1600dpiの代替Artcardを走査する)ステップ1144と、
*カード上で走査されたドットからデータビットマップを抽出するステップ1145と、
*代替Artcardが逆向きに挿入された場合に、ビットマップを反転するステップ1146と、
*符号化データをスクランブル解除するステップ1147と、
*ビットマップからのデータをリード・ソロモン復号化するステップ1148と、
である。
アルゴリズムの概要
フェーズ1−リアルタイムExtractingBitImage
利用可能なメモリ(4MB)と、1600dpiの代替Artcardの走査された全画素を保持するための必要メモリ(172.5MB)との簡単な比較によって、カードが複数回読み出されない限り(現実的な選択肢ではない)、画素データからのビットマップの抽出は、代替ArtcardがCCDの傍を通過させられる間に、オンザフライ方式でリアルタイムに実行する必要がある。このフェーズでは、二つのタスク、即ち、
*代替Artcardを4800dpiで走査するタスク
*カード上で走査されたドットからデータビットマップを抽出するタスク
を実行しなければならない。
ビットイメージの回転及びスクランブル解除は、ビットイメージ全体が抽出されるまで行えない。したがって、抽出されたビットイメージを保持するためにメモリ領域を割り当てることが必要である。ビットイメージは、2MBの範囲内で容易に収容され、抽出プロセスで使用するための2MBが確保される。
CCDからの現在の走査線だけを調べる間にビットイメージを抽出するのではなく、窓として機能するバッファを代替Artcardに割り付け、最新のN本の走査線読み出しを記憶することが可能である。メモリ必要量は、代替Artcardの全体がこのようにして記憶されることは許容しないが(172.5MBが必要になるであろう)、190画素列を記憶するため2MBを割り付けることは(各走査線は11000バイト以上を必要としない)、ExtractingBitImageプロセスを簡単化させる。
したがって、4MBメモリの使用法は以下の通りである:
*抽出されたビットイメージのための2MB;
*走査された画素のための〜2MB;
*フェーズ1のスクラッチデータのために1.5KB(アルゴリズムによる要求次第)。
フェーズ1に要する時間は1.5秒である。なぜならば、この時間は、代替ArtcardがCCDの傍を通過し、物理的にロードされるために要する時間であるからである。
フェーズ2−ビットイメージからのデータ抽出
ビットイメージが抽出されると、ビットイメージはスクランブル解除され、場合によっては180°回転させることが必要である。ビットイメージは次に復号化される。フェーズ2は、Artcardの動きが停止している点でリアルタイム必要条件が無く、ユーザが時間経過を認識することだけが問題である。したがって、フェーズ2は、代替Artcardを復号化する残りのタスクに関係する。即ち、
*ビットイメージを再編成し、代替Artcardが逆向きに挿入された場合には反転する;
*符号化されたデータをスクランブル解除する;
*ビットイメージからのデータをリード・ソロモン復号化する。
フェーズ2への入力は2MBビットイメージバッファである。スクランブル解除及び回転は、その場では実行し得ないので、第2の2MBバッファが必要である。フェーズ1で走査された画素を保持するため使用される2MBバッファは不要になっているので、回転させられたスクランブル無しデータを記憶するため使用可能である。
リード・ソロモン復号化タスクは、スクランブル無しのビットイメージを取得し、それを910082バイトに復号化する。復号化は元の位置で実行可能であるが、指定された別の場所で実行してもよい。復号化プロセスは、補助的なメモリバッファを必要としない。
したがって、4MBのメモリの使用法は以下の通りである:
*(フェーズ1からの)抽出されたビットイメージのための2MB;
*スクランブル無しの、回転された可能性のあるビットイメージのための〜2MB;
*フェーズ2のスクラッチデータのための<1KB(アルゴリズムによる要求次第)。
フェーズ2に要する時間はハードウェアに依存し、リード・ソロモン復号化のために要する時間によって制限される。LSIロジックのL64712のような専用コア、又は等価的なCPU/DSPの組み合わせを使用することにより、フェーズ2は0.32秒を要することが推定される。
フェーズ1−ExtractingBitImage
これは、アルゴリズムのリアルタイムフェーズであり、CCDによって走査されたような代替Artcardからビットイメージを抽出することに関連する。
図68に示されるように、フェーズ1は、二つの非同期的なプロセスストリームに分解することができる。そのうちの第1のストリームは、単に、CCDからの代替Artcardの画素をリアルタイムで読み出し、その画素をDRAMへ書き込む。第2のストリームは、画素を参照し、ビットを抽出する。第2のプロセスストリームは、それ自体が二つのプロセスに分解される。第1のプロセスは、大域的なプロセスであり、代替Artcardのスタートの位置検出に関する。第2のフェーズはExtractingBitImage固有である。
図69は、データ/プロセスの観点からのデータフロー説明図である。
タイミング
1600dpi代替Artcardの全体に対して、最大で16252画素列を読み出すことが必要である。代替Artcardの全体に対する合計時間が1.5秒である場合、これは、様々なプロセスの経過中に、1画素列当たりの最大時間が92296nsであることを意味する。
プロセス1−CCDからの画素読み出し
CCDは、代替Artcardを4800dpiで走査し、1列当たりに11000個の1バイト画素を生成する。このプロセスは、CCDからデータを取得し、それをDRAMへ書き込むだけであり、DRAMから画素データを読み出している他のプロセスからは完全に独立している。図70には関連したステップが示されている。
画素は、190列の全画素列を保持し得る2MBバッファに連続して書き込まれる。バッファは、常に、最近に読み出された190列を保持する。その結果として、画素データを読み出そうとするプロセス(例えば、プロセス2及びプロセス3)は、最初に、所定の列が探索する場所を知る必要があり、次に、要求されたデータが実際にバッファ内に存在することが確実であるように十分に高速でなければならない。
プロセス1は、現在のCurrentScanLineが他のプロセスから利用できるようにさせるので、他のプロセスは、未だ読み出されていない走査線からの画素へのアクセスを試みないことを保証することができる。
単一のデータ列(11000バイト)をDRAMへ書き出すために要する時間は、11000/16*12=8256nsである。
プロセス1は、したがって、利用可能なDRAM帯域幅の9%未満(8256/92296)しか使用しない。
プロセス2−代替Artcardのスタート検出
このプロセスは、走査された代替Artcard上のアクティブエリアの位置検出と関連している。このステージへの入力はDRAM(プロセス1によってそこに収容された)からの画素データである。出力は、代替Artcard上の最初の8個のデータブロックに対する境界の組であり、プロセス3への入力として要求される。プロセス3の上位レベル概要が図71に示されている。
代替Artcardは、挿入時に垂直方向の動きが1mmある。1度の回転によって、更に、1.5mm(86sin1°)の垂直方向の動きが生じる。その結果として、全部で垂直方向の動きは2.5mmである。1600dpiのとき、これは、約160ドットの動きに相当する。単一のデータブロックの高さは394ドットに過ぎないので、この動きは、データブロックの半分よりも少し少ない。データブロックが存在する場所をより良く推定するためには、代替Artcard自体を検出しなければならない。
したがって、プロセス2は、
*代替Artcardのスタートを位置検出する部分と、もし、検出されたならば、
*代替Artcardのスタートに基づいて最初の8個のデータブロックの境界を計算する部分と、
を含む。
代替Artcardのスタート位置検出
代替Artcardエリアの外側で走査された画素は黒色である(表面は黒色のプラスチック、又はその他の非反射型表面でもよい)。代替Artcardエリアの境界は白色である。画素列を1列ずつ処理し、画素を黒色又は白色の何れかに関してフィルタ処理するならば、黒色から白色への変化点は、代替Artcard上のスタートを特徴付ける。最高レベルのプロセスは以下の通りである:
ProcessColumn関数は単純である。走査された列の二つのエリアからの画素は、それらが黒色又は白色のどちらであるかを判定するため閾値フィルタに通される。一定数の白色画素を待ち、所定の個数が検出されたとき、代替Artcardのスタートを報せることが可能である。画素列を処理するロジックは以下の疑似コードに示されている。列中に代替Artcardが検出されなかった場合、0が返される。さもなければ、検出された位置の画素数が返される:
データブロック境界の計算
このステージでは、代替Artcardが検出されている。代替Artcardの回転に応じて、代替Artcardの上部又は代替Artcardの下部の何れかが検出されている。プロセス2の第2ステップはどちらが検出されたかを判定し、フェーズ3のためのデータブロック境界を適切にセットする。
フェーズ3を見ると、フェーズ3はデータブロックセグメント境界に関して動作することがわかる。各データブロックは、データブロックのデータ領域を位置検出するためにターゲットを探索すべき場所を決定するため、StartPixel及びEndPixelを含む。
画素値がカードの上半分に存在する場合、それを第1のStartPixel境界としてそのまま使用することができる。画素値がカードの下半分に存在する場合、画素値が最後のセグメントのEndPixel境界になるように逆行させることが可能である。代替Artcardのデータサイズの幅で前進又は後退し、各セグメントに適切な境界をセットする。これにより、代替Artcardからのデータ抽出を開始する準備が整う:
MaxPixel値はプロセス3で定義され、SetBounds関数は、0及びMaxPixelに対するStartPixel及びEndPixelクリッピングをセットするだけである。
プロセス3−画素からのビットデータ抽出
これは代替Artcardリーダーアルゴリズムの心臓部である。このプロセスは、CCD画素データからのビットデータ抽出処理に関係する。このプロセスは、本質的に、プロセス2によって作成され、プロセス3によって維持されたスクラッチ情報に基づいて、画素データからビットイメージを作成する。このプロセスの上位レベル概要は図72に示されている。
単に代替Artcardの画素列を読み出し、どの画素がどのデータブロックに属しているかを判定するのではなく、プロセス3は、その逆の作用をする。プロセス3は、所定のデータブロックの画素を探索すべき場所がわかっている。プロセス3は、これを行うため、論理的な代替Artcardを8個のセグメントに分割する。各セグメントは、図73に示されるように8個のデータブロックを含む。
図示されたセグメントは論理的な代替Artcardと一致する。物理的に、代替Artcardはある量だけ回転させられている可能性が高い。セグメントは、論理的な代替Artcard構造に固定されたままであるため、回転に依存しない。あるセグメントは、以下の2状態のうちの一方をとり得る:
*LookingForTaregets:この状態では、このセグメントの正確なデータブロック位置は未だ決定されていない。ターゲットは、セグメント境界によって指定された境界内の画素列データを走査することによって位置検出されている。ターゲット、並びに、黒色及び白色のためにセットされた境界を用いてデータブロックが位置検出されると、状態は、ExtractingBitImageへ変化する;
*ExtractingBitImage:この状態では、データブロックは正確に位置検出されており、データビットは同時に1ドット列ずつ抽出され、代替Artcardビットイメージに書き込まれる。データブロッククロックマークの追跡は、回転とは無関係に正確なドット復元を与えるので、セグメント境界は無視される。データブロック全体が抽出されると、新しいセグメント境界が、現在位置に基づいて次のデータブロックに対して計算される。状態は、LookingForTargetsへ変化する。
このプロセスは、各領域から8個ずつの64データブロックの全てが抽出されたときに終了する。
各データブロックは595のデータ列により構成され、各データ列は48バイトである。好ましくは、データブロック用の2個の方位列がそれぞれ48バイト毎に抽出され、全部で1データブロック当たりに28656バイトが抽出される。簡単のため、2MBのメモリを64×32Kのチャンクに分割することができる。所定のセグメントのn番目のデータブロックは、
SrartBuffer + (256k*n)
で表される場所に格納される。
セグメントのデータ構造
8個のセグメントの各々は、データ構造が関連付けられる。各セグメントを定義するデータ構造は、スクラッチデータエリアに格納される。その構造は以下の表に列挙することができる。
プロセス3の上位レベル
プロセス3は、各セグメントに対して繰り返して、セグメントの現在状態に依存して単一ラインの処理を実行するだけである。擬似コードは以下のように簡潔である:
プロセス3は、指定された時間が経過しても終了しない場合には、外部制御プロセスによって停止される必要がある。これは、データが抽出できなかった場合に限られるであろう。簡単な仕組みは、プロセス1が代替Artcardの読み出しを終了した後にカウントダウンを開始する仕組みである。プロセス3がその時間までに終了しなかった場合、代替Artcardからのデータは復元不可能である。
CurrentState =LookingForTargets
ターゲットは、同時に1画素列ずつ画素の列を読み出すことによって検出されるのであって、(StartPixelとEndPixelの間にある)所定の画素のバンド内のドットを検出することによって画素のある種のパターンが検出されるのではない。画素列は、全てのターゲットが検出されるか、又は指定された数の列が処理されるまで、同時に1列ずつ処理される。その時点で、ターゲットを処理することが可能であり、データはクロックマークを用いて位置検出される。状態は、データを抽出する時であることを示すためExtractingBitImageに変更される。十分な数の有効ターゲットを位置検出できなかった場合、データブロックは無視され、失敗したデータブロック内の列を確実にスキップし、次のデータブロック内でターゲットを探索するプロセスを再開する。これは以下の擬似コードで表すことができる:
ProcessPixelColumn関数
各画素列は、ターゲットを識別するある種の画素のパターンを探索するため、指定された境界内(StartPixelとEndPixelの間)で処理される。単一ターゲット(ターゲット番号2)の構造は、既に図54に示されている通りである。
画素の観点から、ターゲットは、以下の事項によって識別することができる:
*左の黒色領域:これは、多数の隣接した黒色画素により構成された多数の画素列であり、ターゲットの最初の部分を構築する;
*ターゲット中心:これは、更なる黒色列の中心にある白色領域である;
*ターゲット番号:これは、黒色で囲まれた白色領域であり、白色領域はその長さによってターゲット番号を定義する;
*第3の黒色領域:これは、ターゲット番号の後の二つの黒色ドット領域である。
要求されるプロセスの概要は図74に示されている。
識別は黒色又は白色画素だけに基づいているので、各列からの画素1150は、黒色又は白色を検出するためフィルタ1151を通され、次に、ランレングス符号化1152される。ランレングスは、次に、状態機械1153へ送られ、状態機械は、最後の3個のランレングスと、最後から4番目の色を取得する。これらの値に基づいて、ターゲット候補は、識別ステージの各々を通過する。
最大及び最小収集プロセスGatherMin&Max1155は、セグメントの処理中に見つかった最小値及び最大値を保持するだけである。これらは、ターゲットが位置検出されたとき、BlackMax、WhiteMin、及びMidRange値をセットするため使用される。
各セグメントは、ターゲットの探索においてターゲット構造体の組を保持する。ターゲット構造体自体はメモリ内を動き回らないが、幾つかのセグメント変数はこれらのターゲット構造体へのポインタのリストを指示する。これらの3個のポインタリストを再度示す。
これらのリストポインタの各々と関連したカウンタ、即ち、TargetsFound、PossibleTargetCount、及びAvailableTargetCountが存在する。
代替Artcardがロードされる前に、TargetsFound及びPossibleTargetCountは0にセットされ、AvailableTargetCountは28(ターゲット境界の最小サイズは40画素であり、データエリアは約1152画素であるので、調査中のターゲット構造体候補の最大数)にセットされる。ターゲットポインタレイアウトの一例は図75に示される。
新しいターゲット候補が検出されるとき、それらは、AvailableTargetsリスト1157から取得され、ターゲットデータ構造体は更新され、この構造体へのポインタはPossibleTargetsリスト1158に追加される。ターゲットが完全に検証されたとき、そのターゲットはLocatedTargetsリスト1159へ追加される。ターゲット候補が最終的にターゲットではないことが判明した場合、ターゲット候補はAvailableTargetsリスト1157へ戻される。この結果として、いつでも循環している28個のターゲットポインタが常に存在し、リストの間を移動している。
ターゲットデータ構造体1160は以下の形式をとり得る。
ターゲット検出モジュール1162(図74)内のProcessPixelColumn関数は、全てのランレングスを一つずつ調べ、(StartPixelによって)ランを既存のターゲット候補と比較するか、又は今までに知られていないターゲット候補が検出された場合に、新しいターゲット候補を作成する。全てのケースにおいて、比較はS0.colorが白色であり、S1.colorが黒色である場合に限り行われる。
次に、ProcessPixelColumnの擬似コードを示す。第1のターゲットが肯定的に識別された場合、ターゲットをチェックすべき最後の列は、そこから最大距離の範囲内にあるとして決定される。1°の回転がある場合、最大距離は18画素列である:
AddToTargetはターゲット検出モジュール内の関数であり、特定のランを所与のターゲットに加算することができるかどうかを判定する:
*ランがターゲットの開始位置の許容範囲内に入るならば、そのランは現在のターゲットと直接的に関連付けられるので、それに適用することが可能である;
*ランがターゲットの前で始まる場合、既存のターゲットが依然としてOKであり、そのランとは関係がないと想定する。したがって、ターゲットはそのままの状態で残され、返値FALSEは、ランが適用されなかったことを呼び出し元へ通知する。呼び出し元は、引き続いてランをチェックして、ランがその固有の全く新しいターゲットを開始するかどうかを調べる;
*ランがターゲットの後で始まる場合、そのターゲットが候補ターゲットではなくなったと考える。状態は、NotATargetに変更され、返値TRUEが返される;
ランをターゲットに適用すべき場合、特別の動作が現在の状態と、S1、S2及びS3のランの組に基づいて実行される。AddToTargetの擬似コードは以下の通りである:
画素ランのタイプはDeterminRunTypeにおいて以下のように識別される。
状態推定手続EvaluateStateは現在の状態及びランタイプに依存して動作する。
その動作は以下に表形式で示される。
ターゲット処理
位置検出されたターゲット(LocatedTargetsリスト内)は、位置検出された順序で記憶される。代替Artcardの回転に依存して、これらのターゲットは、画素昇順又は画素降順である。その上、ターゲットから復元されたターゲット番号は、誤りがあるかもしれない。また、間違ったターゲットを復元したかもしれない。クロックマーク推定量が取得できる前に、ターゲットは、無効ターゲットが確実に廃棄されるように処理する必要があり、有効ターゲットは、間違っているならばターゲット番号が修復される(例えば、ごみのために破損されたターゲット番号)。二つの主要なステップが関連している:
*ターゲットを画素昇順にソートするステップ;
*誤りのあるターゲット番号を見つけ、修復するステップ。
最初のステップは簡単である。ターゲット検索の性質は、データが画素昇順又は画素降順の何れかで常に記憶されるべきことを意味する。簡単なスワップソートは、6個のターゲットが既に正しくソートされているならば、最大で14回の比較がスワップ無しに行われる。データがソートされていない場合、14回の比較は3回の3回のスワップと共に行われる。以下の擬似コードはソーティングプロセスを示す:
誤ったターゲット番号を位置検出し修復することは、多少複雑になる。順番に、検出されたN個のターゲットの各々が正しいと仮定される。他のターゲットは、この「正しい」ターゲットと比較され、TargetNが正しい場合に変更を必要とするターゲットの個数がカウントされる。変更の回数が0であるならば、全てのターゲットは既に正しい筈である。さもなければ、他のターゲットに対して要求する変更の回数が最も少ないターゲットが変更の基準として使用される。所与のターゲットのターゲット番号及び画素位置が、「正しい」ターゲットの画素位置及びターゲット番号と比較されたときに、相互に関連しないならば、変更が登録される。この変更は、ターゲットのターゲット番号の更新を意味し、或いは、ターゲットの削除を意味する。上昇するターゲットは、(既にソートされているので)昇順の画素を有すると仮定することができる:
多くの場合、この関数は
bestChanges = 0
で終了しており、これは変更が要求されないことを意味している。そうでない場合、変更を適用する必要がある。変更を適用する機能は、targetNumber との比較までは、(上述の擬似コードにおいて)変更をカウントすることと同一である。変更アプリケーションは以下の通りである:
変更ループの最後に、LocatedTargetsリストをコンパクトにして、全てのヌルターゲットを削除する必要がある。
この手続の最後に、数個のターゲットが存在する可能性がある。残っている全てのターゲット(少なくとも2個のターゲットが必要である)は、クロックマーク及びデータ領域の位置を検出するため使用される。
図55に示されるように、上側領域の第1のクロックマークドット1126は、第1のTarget1124の中心から55ドット離れている(これはターゲット中心間の距離と同じである)。クロックマークドットの中心は更に1ドット遠ざかり、黒色境界線1123は第1のクロックマークドットから更に4ドット離れている。下側領域の第1のクロックマークドットは、上側領域の第1のクロックマークドット1126から正確に7ターゲットの距離(7×55ドット)離れている。
Target1及び6が見つかっていると仮定し得ないので、最も上側のターゲット及び最も下側のターゲットを使用する必要があり、どのターゲットが使用されているかを判定するためターゲット番号を使用する。この時点で少なくとも2個のターゲットが必要である。その上、ターゲット中心は、実際のターゲット中心の推定値に過ぎない。それは、ターゲット中心をより正確に位置検出することである。ターゲットの中心は、黒色に囲まれた白色である。したがって、画素次元と列次元の両方で極大を見つけることが望ましい。これには、連続した画像を再構築することが必要である。なぜならば、最大値が整数バウンダリ(本例の推定値)に厳密に合わせられる可能性は殆ど無いからである。
連続した画像をターゲットの中心の周りに構築する前に、2個のターゲット中心のより良い推定値を作成することが必要である。既存のターゲット中心は、実施には、ターゲット中心の境界ボックスの左上座標である。ターゲットの中心を画成するエリアを見つけるため各画素を一つずつ調べ、最高値を有する画素を検出することは、簡単なプロセスである。同じ最高画素値を有する画素は2個以上存在する場合もあるが、中心値の推定には1個の画素があればよい。
擬似コードは簡単であり、2個のターゲットの各々に対して実行される:
このプロセスの最後に、ターゲット中心座標は、実際の中心の1画素の範囲に収まるべきターゲットの最も白い画素を指示する。ターゲット中心のより正確な位置を構築するプロセスには、推定されたターゲット中心の両側に3個ずつで、ターゲットの7個の走査線スライスの連続信号を再構築することが含まれる。検出された7個の最大値(上記の画素スライスの各々につき1個ずつ)は、列次元において連続信号を再構築し、次に、その次元における最大値の位置を検出するために使用される:
FindMaxは、元の1次元信号に基づくサンプル点を再構築し、最大値の位置及び検出された最大値を返す関数である。使用される信号再構築/再サンプリング方法は、図76に示されるように、Lanczos3窓sinc関数である。
Lancoz3窓sinc関数は、再構築された次元から、推定位置Xの周りに集められた、即ち、X−3、X−2、X−1、X、X+1、X+2、X+3にある7(画素)サンプルを取得する。X−1からX+1の間に、0.1の間隔で点を再構築し、最大となる点を決定する。最大値である位置が新しい中心になる。カーネルの性質上、XとX+1の間の点に対してコンボリューションカーネルに必要なエントリーは6個だけである。X−1からXに対して6個の点と使用し、XからX+1に対して6個の点を使用し、X−1からX+1間での画素値を得るために全体として7点が必要である。なぜならば、要求された画素の一部は一致するからである。
最も上側のターゲットから最も下側のターゲットまでに正確な推定値が与えられた場合、上側領域及び下側領域に対して第1のクロックマークドットの位置を以下のようにして計算することができる:
これにより第1のクロックマークドットが得られる。列位置は、クロックマークの中心へ到達するため、データエリアから更に1ドット遠くへ動かすことが必要である。また、画素位置は、境界線の中心へ到達するため、更に4ドット遠ざける必要がある。deltaColumn及びdeltaPixelの疑似コード値は、55ドットの距離(ターゲット間の距離)に基づいているので、これらのデルタは、クロックマーク座標に適用される前に、それぞれ、1/55及び4/55によって縮小しなければならない。これは以下の通りに表現される:
kDeltaDotFactor =
1/DOTS_BETWEEN_TARGET_CENTRES
deltaColumn *= kDeltaDotFactor
deltaPixel *= 4 * kDelteDotFactor
UpperClock.pixel -= deltaPixel
UpperClock.column -= deltaColumn
LowerClock.pixel += deltaPixel
LowerClock.column += deltaColumn
UpperClock及びLowerClockは、ターゲットの中心とちょうど合致した第1のクロックマークに対する有効クロックマーク推定値である。
黒色及び白色画素/ドットレンジの設定
データをデータエリアから抽出する前に、黒色及び白色ドットの画素レンジを確認する必要がある。LookingForTaregets中に現れた最小値及び最大値は、それぞれ、WhiteMin及びBlackMaxに保存されているが、これらは、データ抽出に関してこれらの変数の有効な値を表現していない。それらは、単に、記憶の便宜上、使用されるだけである。以下の疑似コードは、出現した最小画素及び最大画素に基づいてWhiteMin及びBlackMaxの良い値を獲得する方法を示している:
MinPixel = WhiteMin
MaxPixel = BlackMax
MidRange = (MinPixel + MaxPixel)/2
WhiteMin = MaxPixel - 105
BlackMax = MinPixel + 84
CurrentState = ExtractingBitImage
ExtractingBitImage状態は、データブロックが、ターゲットによって既に正確に位置検出された状態であり、ビットデータは、同時に1ドット列毎に抽出中であり、代替Artcardビットイメージに書き込まれている。データブロッククロックマーク/境界の追跡によって、回転とは無関係に正確なドット復元が行われ、セグメント境界は無視される。データブロック全体(595個のデータ列と2個の方位列を併せて、48バイトずつの597列)が抽出されると、新しいセグメント境界が現在位置に基づいて次のデータブロックのために計算される。この状態は、LookingForTargets状態に変更される。
所与のドット列の処理には以下の二つのタスクが必要である:
*第1のタスクは、クロックマークを用いて特定のデータのドット列の位置を検出することである;
*第2のタスクは、ドット列を追跡して、1ドットにつき1ビットずつビット値を集めることである。
これらの二つのタスクは、列のデータが代替Artcardから読み出され、DRAMへ転送された場合に限り行うことができる。これは、プロセス1がどの走査線まで到達しているかをチェックし、それをクロックマーク列と比較することによって判定される。ドットデータがDRAMに存在するとき、クロックマークを更新し、クロックマークを次のドット列に対する推定値へ進める前に、列からデータを抽出することが可能である。このプロセスの概要は、以下の疑似コードに示されている。具体的な関数については後述する:
ドット列の位置検出
所定のドット列は、ドットを読み出し、データを抽出する前に、位置検出されなければならない。これは、データブロックの上側及び下側境界に沿ってクロックマーク/境界線を追跡することによって実現される。位相ロックループと等価的なソフトウェアが使用され、たとえクロックマークが破損されていても、クロックマーク位置の良い推定が確実に行われる。図77は、例示的なデータブロックの左上の説明図であり、そのデータブロックのコーナーには、ターゲットエリアの外側へ広がる3ドット高のクロックマーク1166と、白色行と、黒色境界線と、が現されている。
初期的に、第1の黒色クロックマークの位置の推定値が(ターゲット位置に基づいて)提供される。正確な垂直位置(画素)を得るため黒色境界が使用され、正確な水平位置(列)を得るため、例えば、クロックマーク1166が使用される。これらは、UpperClock及びLowerClockの位置に反映される。
クロックマーク推定値が取得され、その近傍の画素を調べることにより、連続した信号が再構築され、正確な中心が決定される。2次元をクロックマークと境界に分解しているので、これは、簡単な1次元プロセスであり、2回実行する必要がある。しかし、これは、位置合わせの相手側の黒色クロックマークが存在するとき、2ドット列について1回だけ行われる。白色クロックマークの場合、単に推定値を使用し、推定値はそのままにしておく。或いは、(常に存在するので)ドット列毎に境界に基づいて画素座標を更新してもよい。実際上、(黒色クロックマークを含む)1列おきに両方の座標を更新すれば十分である。なぜならば、この動作中の解像度は非常に精細だからである。したがって、このプロセスは次のようになる:
所定の許容度(MAX_CLOCKMARK_DEVIATION)を上回る偏差が存在する場合、検出された信号は無視され、推定値からの最大許容度に収まる偏差だけが許容される。この点に関して、この機能はフェーズロックループの機能と類似している。したがって、DetermineAccurateUpperDotCenter関数は以下の疑似コードによって実現される:
また、DetermineAccurateLowerDotCenter関数は、境界からクロックマークまでの向きが負方向である(+3ドットではなく、−3ドットである)点を除くと同様である。
GetAccuratePixel及びGetAccurateColumnは、座標が与えられた場合に、一次元だけの観点で正確なドット中心を決定する関数である。正確なドット中心の決定は、信号を再構成し、最小信号値が検出された位置を見つけるプロセスである(これは、ターゲット中心は黒色ではなく白色であるために、信号の最大値の位置を検出することによりターゲット中心の位置を検出するプロセスとは異なる)。このアプリケーションの信号再構成/再サンプリングのために選択された方法は、図76を参照して説明したようなLanczos3窓sinc関数である。
クロックマーク又は境界は何らかの方法で、おそらくは、ひっかきによって、傷つけられている可能性がある。再サンプリングによって得られた新しい中心値と推定値との差が許容量を超える場合、中心値は最大許容量だけ動かされる。それが無効な位置である場合、データ回復に使用するために十分に接近しているはずであり、更なるクロックマークはその位置に再度合わせられる。
第1のデータドットの中心と後続のドットへのデルタの決定
正確なUpperClock及びLowerClock位置が決定されると、第1のデータドットの中心(CurrentDot)と、列内の後続のドットへ進めるためにその中心位置に加算されるべきデルタ量(DataDelta)とを計算することができる。
最初に行うべきことは、ドット列のデルタを計算することである。これは、単に、LowerClockからUpperClockを減算し、2点間のドット数で除算することによって実現される。実際にはドット数の逆数を乗算することが可能である。なぜならば、ドット数は代替Artcardに関して定数であり、且つ乗算の方が高速に行われるからである。画素次元のデルタと列次元のデルタを獲得するため、異なる定数を使用することが可能である。画素のデルタは二つの境界間の距離であり、列のデルタは二つのクロックマークの中心間である。このようにして、関数DeternineDataInfoは二つの部分からなる。第1の部分は次の擬似コードによって表される:
kDeltaColumnFactor =
1/(DOTS_PER_DATA_COLUMN+2+2-1)
kDeltaPixelFactor =
1/(DOTS_PER_DATA_COLUMN+5+5-1)
delta = LowerClock.column -
UpperClock.column
DataDelta.column = delta *
kDeltaColumnFactor
delta = LowerClock.pixel - UpperClock.pixel
DataDelta.pixel = delta * kDeltaPixelFactor
次に、列の第1のデータの中心を決定することが可能である。クロックマークの中心から第1のデータドットの中心までの距離は2ドットであり、境界の中心から第1のデータドットの中心までの距離は5ドットである。この関数の第2の部分は次の擬似コードによって表される:
CurrentDot.column = UpperClock.column + (2*DataDelta.column)
CurrentDot.pixel = UpperClock.pixel +
(5*DataDelta.pixel)
ドット列の追跡
ドット列はクロックマークに追従する位相ロックループから見つけられたので、残っていることは、その列を下って各ドットの中心でドット列をサンプリングすることだけである。変数CurrentDot点は現在列の第1のドットの中心に決定される。列の次のドットへ進むためには、DataDeltaを加算するだけでよい(2回の加算:1回は列座標のため、もう1回は画素座標のため)。所定の座標におけるドットのサンプリング(バイリニア補間)が行われ、ドットの中心を表現する画素値が決定される。画素値は、次に、そのドットのビット値を決定するため使用される。しかし、より良いビット判定を行うため、同一ドットライン上の2個の周辺ドットに対する中心値と関連して、その画素値を使用することが可能である。
抽出されたドット列内のドットに対する全ての画素はこの時点でDRAMにロードされていると仮定してもよい。なぜならば、ラインの両端(クロックマーク)がDRAMに存在するならば、これらの2個のクロックマークの間のドットも間違いなくDRAMに存在するからである。更に、データブロック高さは十分に低いので(384ドット高にすぎない)、単なるデルタだけがラインの全長を越えるために十分であることが保証される。カードが8個のデータブロック高さに分割されている理由の一つは、単一のデータブロックに関して行うことができる保証と同じ厳格な保証を、カードの全高に亘って行うことが不可能だからである。
単一ラインのデータ(48バイト)を抽出する上位レベルプロセスは、以下の疑似コードで表される。データバッファポインタは、各バイトが保存されるのに伴ってインクリメントされ、連続したバイト及びデータの列が確実に連続的に保存される:
GetPixel関数はドット座標(固定小数点)を取得し、バイリニア補間によって中心画素値に達するため、4個のCCD画素をサンプリングする。
DetermineCenterDot関数は、ビット値が決定されたドットの両側にあるドット中心を表現する画素値を取得し、その中心ドットのビット値の値を知的に推定することを試みる。図64の一般化されたブラー効果曲線から、以下の三つの一般的なケースが考えられる:*ドットの中心画素値はWhiteMinよりも小さいので、確実に黒色ドットである。したがって、ビット値は必ず1である;
*ドットの中心値はBlackMaxよりも大きいので、確実に白色ドットである。したがって、ビット値は必ず0である;
*ドットの中心値は、BlackMaxとWhiteMinの間のどこかにある。ドットは黒色かもしれないし、白色かもしれない。したがって、このビットの値が問題になる。ビットの値を合理的に推定するため、多数の方式が考えられている。これらの方式は、精度に対して複雑さのバランスを取り、ある種のケースでは、保証された解決策が存在しないことを考慮する必要がある。誤ったビット判定を行うケースでは、ビットのリード・ソロモンシンボルに誤りが生じ、フェーズ2のリード・ソロモン復号化ステージで訂正しなければならない。
画素値がBlackMaxとWhiteMinの間に入るときにドットの値を決定するため使用される方式は、あまり複雑ではないが、優れた結果を与える。この方式は、門対となっているドットの左及び右にあるドット中心の画素値を使用して、中心ドットのよりもっともらしい値を決定する。即ち、
*両側の2個のドットがMidRange(平均ドット値)の白色側に存在する場合、中心ドットが白色であるならば、「確実に」白色であると推定することができる。その中心ドットが不確実な領域に存在するということは、そのドットが黒色であり、その値をより不確実にするため周辺の白色ドットによる影響を受けたということを示す。したがって、そのドット値は黒色であると考えられるので、そのビット値は1である;
*両側の2個のドットがMidRangeの黒色側に存在する場合、中心ドットが黒色であるならば、「確実に」黒色であると推定することができる。その中心ドットが不確実な領域に存在するということは、そのドットが白色であり、その値をより不確実にするため周辺の黒色ドットによる影響を受けたということを示す。したがって、そのドット値は白色であると考えられるので、そのビット値は0である;
*一方のドットがMidRangeの黒色側に存在し、もう一方のドットがMidRangeの白色側に存在するならば、中心ドット値をそのまま使用して決定する。中心ドットがMidRangeの黒色側に存在するならば、黒色(ビット値1)を選択する。さもなければ、白色(ビット値0)を選択する。
このロジックは以下のように表現される:
ここから、周辺画素値の使用は、中心ドットの状態の優れた指標を与え得ることが認められる。ここで説明した方式は、同じ行からのドットだけを使用しているが、単一のドットライン履歴(前のドットライン)の使用は、明らかに代替的な構成になるであろう。
次の列のためのクロックマーク更新
ある列の第1のデータドットの中心が決定されると、クロックマーク値は不要になる。それらは、その列に対するデータが獲得された後、次の列の準備のため更新する方が好都合である。クロックマークの向きは、ドット列に沿って下りるドットの追跡方向に対して垂直であるため、列を更新するため画素デルタを使用し、両方のクロックの画素を更新するため列デルタを使用することが可能である:
UpperClock.column += DataDelta.pixel
LowerClock.column += DataDelta.pixel
UpperClock.pixel -= DataDelta.column
LowerClock.pixel -= DataDelta.column
この時点で、次のドット列の推定値が得られる。
タイミング
タイミングの必要条件は、DRAM利用率が100%を超えない限り充たされ、並列アルゴリズムの追加によってタイミングが増大されるがDRAM利用率は100%を超えない。DRAM利用率はプロセス1に関して特定され、このプロセス1は各画素を1回ずつ連続的に書き込み、DRAM帯域幅の9%を消費する。
このセクションに記載されるようなタイミングは、DRAMが代替Artcardリー
ダーアルゴリズムの要求に容易に対処し得ることを示す。したがって、タイミングのボトルネックは、DRAMアクセスではなく、ロジック速度に関するアルゴリズムの実装であろう。しかし、アルゴリズムは、アーキテクチャの単純さに留意して設計され、メモリサイクル毎に最小限の個数の論理演算しか要求しない。この点で、実装された状態機械又は等価的なCPU/DSPアーキテクチャが以下のサブセクションに記載されているように実行可能である限り、目標速度は達成されるであろう。
ターゲット位置検出
ターゲットは画素列の境界内の画素を読み出すことによって位置検出される。各画素は高々1個ずつ読み出される。ランレングスエンコーダが十分高速に動作する場合を考えると、ターゲットの位置検出の限界はメモリアクセスである。したがって、アクセスはプロセス1のタイミング、即ち、DRAM帯域幅の9%利用率よりは悪化しないであろう。
したがって、ターゲット位置検出中の(プロセス1を含む)DRAMの総利用率は18%であり、ターゲットロケータは、常に、代替Artcardのイメージセンサ画素リーダーに追従している。
ターゲットの処理
ターゲット番号をソートしチェックするためのタイミングは取るに足らない。2個のターゲット中心の各々のより良い推定値を見つけるためには、12組の12画素の読み出し、即ち、全部で144回の読み出しを必要とする。しかし、正確なターゲット中心の修復は些細ではなく、2組の推定を必要とする。各ターゲット中心の調整には、8組の20種類の6エントリー型コンボリューションカーネルが必要である。このようにして、その合計は、8×20×6回の乗算−累算=960に達する。その上、7組の7画素を獲得するため49回のメモリアクセスが必要である。したがって、1ターゲット当たりの総数は、144+960+49=1153であり、これは、画素の列内の画素数(1152)とほぼ同数である。このように、各ターゲット推定は、1行の画素を処理するために要する時間を消費する。ターゲットが2個の場合、実質的に2列の画素列に要する時間を消費する。
ターゲットは、第1の画素列上でターゲット番号の後に確実に識別される。方位列の前には2列のドット列が存在するので、6列の画素列が存在する。ターゲット位置検出プロセスは、最初の画素列を使い果たすが、残りの5列の画素列は全く処理されない。したがって、データエリアは、他のプロセス時間に影響を与えることなく、利用可能な時間の2/5内に位置検出することができる。
利用可能な時間の残りの3/5は、白色及び黒色画素のレンジを割り当てる些細なタスクのために十分であり、1タスクは高々2から3マシーンサイクルを使用する。
データ抽出
タイミングに関して、次の二つの部分を考慮すべきである:
*正確なクロックマーク及び境界値を取得すること;
*ドット値を抽出すること。
クロックマーク及び境界値は、1ドット列おきにしか収集されない。しかし、より正確にするためにクロックマーク推定値を更新する毎に、20種類の6エントリー型コンボリューションカーネルを評価しなければならない。平均的に、1ドット列当たりにそのうちの2個が存在する(2ドット列毎に4個)。境界に基づいて画素座標を更新するためには、同じ画素走査線からの7画素だけが必要である。しかし、列座標を更新するためには、異なる列、即ち、異なる走査線からの7画素が必要である。走査線エントリー毎に1回のキャッシュミスが生じ、同じ走査線内の画素に対して2回のキャッシュミスが生じる最悪ケースの状況を想定すると、全部で8回のキャッシュミスが起こる。
ドット情報を抽出するためには、1ドット毎に(ドットを定義する平均9個ではなく)4画素だけを読み出す。1152画素(384ドット)のデータエリアを想定すると、せいぜい、これは、9画素ドットではなく4画素ドットを読み出すことによって、72回のキャッシュ読み出しを節約するに過ぎない。最悪ケースは、57画素毎に1列だけ移動する1°の回転であるが、節約の程度が僅かに悪化するだけである。
最悪の場合、読み出すキャッシュラインの数は、データエリア内の画素によって使われたキャッシュラインよりも少なくなる、といっても構わない。したがって、アクセスはプロセス1、即ち、DRAM帯域幅の9%利用率よりも悪化することはない。
したがって、データ抽出中(プロセス1を含む)のDRAM総利用率は18%であり、データ抽出部は、常に、代替Artcardのイメージセンサ画素リーダーに追従する。これにより実装されるターゲット処理プロセスでは、ターゲットの処理は、かなり非効率的な方法によって実行されるが、依然として、必要に応じて、データ抽出プロセス中に迅速に追従する。
フェーズ2−ビットイメージ復号
フェーズ2は、代替Artcardのデータ復元アルゴリズムの非リアルタイムフェーズである。フェーズ2の先頭で、ビットイメージは代替Artcardから抽出されている。ビットイメージは、代替Artcardのデータ領域から読み出されたビットを表現する。一部のビットには誤りがあり、おそらく、代替Artcardは挿入時に回転させられているので、データ全体は180°回転している。フェーズ2は、この符号化されたビットイメージから原データを確実に抽出することに関係している。基本的に、図79に示されるように3ステップが実行される:
*代替Artcardが逆向きに挿入されているならば反転して、ビットイメージを再編成する;
*符号化されたデータをスクランブル解除する;
*ビットイメージからのデータをリード・ソロモン復号化する。
3ステップの各々は別個のプロセスとして定義され、あるプロセスの出力は次のプロセルの入力として要求されるので、連続して実行される。最初の2ステップを単一プロセスに併合することは簡単であるが、説明の便宜上、ここでは、別個のプロセスとして取り扱う。
データ/プロセスの観点からみると、フェーズ2は図80に示されるような構造を有する。
プロセス1及び2のタイミングは無視することが可能であり、その間に1/1000秒未満しか消費しない。プロセス3(リード・ソロモン復号)は、約0.32秒を消費し、これがフェーズ2のために必要な合計時間になる。
ビットイメージ再編成、必要に応じて反転
DRAM内のビットマップは、この時点で、代替Artcardから取得されたデータを表現する。しかし、ビットイメージは連続していない。ビットイメージは64個の32k単位のチャンクに分割され、データブロック毎に1チャンクがある。32kチャンクの各々は、28656個の有効バイトだけ、即ち、
最も左側の方位列からの48バイトと、
真のデータ領域からの28560バイトと、
最も右側の方位列からの48バイトと、
未使用の4112バイトと、
を格納する。
画素データ(フェーズ1のプロセス1によって格納)のために使用される2MBバッファは、再編成されたビットイメージを保持するために使用可能である。なぜならば、画素データはフェーズ2の間では要求されないからである。再編成の最後に、正しく向きを与えられた連続したビットイメージは、2MB画素バッファに収容され、リード・ソロモン復号化のための準備ができている。
カードの向きが正しい場合、最も左側の方位列は白色であり、最も右側の方位列は黒色である。カードが180°回転している場合、最も左側の方位列は黒色であり、最も右側の方位列は白色である。
カードが正しい向きにされているかどうかを判定する簡単な方法は、白色ビットに対する黒色ビットの比率が圧倒的であるブロックが見つかるまで、各データブロックを一つずつ使用して、データの最初及び最後の48バイトをチェックすることである。以下の擬似コードはこの方法を例示し、カードが正しい向きに置かれているときTRUEを返し、そうではなければFALSEを返す:
データは、この時点で、カードが正しい向きであるかどうかに基づいて認識できるはずである。最も簡単なケースは、カードが正しい向きにされている場合である。この場合、データは、方位列を除去し、データ全体を連続させるために、少しだけ動かす必要がある。これは、以下の擬似コードに示されるように元の位置で非常に簡単に実現される:
それ以外の場合は、データを実際に反転させる必要がある。データを反転させるアルゴリズムは非常に簡単であるが、簡単にするために、256バイトのテーブルReverseを用いる。ここで、Reverse[N]の値はNのビット反転である:
両方のプロセスのタイミングは無視することが可能であり、1/1000秒未満しか消費しない:
*2MB連続読み出し(2048/16×12ns=1536ns);
*2MB実効的連続バイト書き込み(2048/16×12ns=1536ns)。
符号化画像のスクランブル解除
ビットイメージは、1827840個の連続した、正しい向きにされた、スクランブル付きのバイトである。バイトは、1ブロックが255バイト長からなる7168個のリード・ソロモンブロックを生成するために、スクランブル解除されなければならない。スクランブル解除プロセスは非常に簡単であるが、スクランブル解除処理は元の場所で実行できないので、別個の出力バッファを必要とする。図80は、スクランブル解除プロセスが行われるメモリの説明図である。
以下の疑似コードはスクランブル解除プロセスの実行方法を規定する:
このプロセスのためのタイミングは無視することが可能であり、1/1000秒未満しか消費しない:
*2MB連続読み出し(2048/16×12ns=1536ns);
*2MB非連続バイト書き込み(2048×12ns=24576ns)。
このプロセスの終了時、スクランブル無しデータがリード・ソロモン復号化のために準備できる。
リード・ソロモン復号化
代替Artcardの読み出しの最後の部分は、リード・ソロモン復号化プロセスであり、ここでは、約2MBのスクランブル無しデータが約1MBの有効代替Artcardデータに復号化される。
このアルゴリズムは、同時に一つのリード・ソロモンブロックを復号化し、(必要であれば)元の場所で実行可能である。なぜならば、符号化されたブロックは復号化されたブロックよりも大きく、冗長バイトがデータバイトの後に格納されているからである。
最初の2個のリード・ソロモンブロックは制御ブロックであり、ビットイメージから抽出されるべきデータのサイズに関する情報を含んでいる。このメタ情報は、最初に復号化する必要があり、得られた情報が真のデータを復号化するため使用される。真のデータの復号化は、単に同時に一つずつデータブロックを復号化する問題である。特定のブロックの復号化が失敗した場合、控えのデータブロックを使用することが可能である。
最上位レベルのリード・ソロモン復号化を疑似コードで提示する:
DecodeBlockは、標準的なリード・ソロモンブロックデコーダであり、m=8及びt=64を使用する。
GetControlData関数は、復号化エラーが生じない限り簡単である。この関数は、成功するまで、同時に一つの制御ブロックを復号化するためDecodeBlockを呼び出すだけである。制御パラメータは、復号化されたデータの最初の3バイトから抽出することができる(destBlocksはバイト0及び1に格納され、lastBlock
はバイト2に格納される)。復号化エラーが存在する場合、この関数は、32組の3バイトをトラバースし、最も確からしい値の組を決定しなければならない。一つの簡単な方法は、3バイトの中から2個の連続した等しいコピーを見つけ、これらの値が正しい値であるとして決めることである。他の方法は、出現する3バイトの組の種類数をカウントし、最もよく出現する組が正しい組であると決める。
リード・ソロモン復号化に要する時間は実装に依存する。リード・ソロモン復号化プロセスを実行するために専用コア(例えば、LSIロジックのL64712)を使用可能であるが、アプリケーションに応じて(通常、復号化されたデータを用いて何かを実行するために)内蔵型システムの全体でより汎用的に使用できるCPU/DSPの組み合わせを選択する方が好ましい。勿論、復号化時間はCPU/DSPの組み合わせの場合にも十分に高速でなければならない。
L64712は、毎秒50Mビット(毎秒約6.25MB)のスループットがあるので、時間は、最大で2MB読み出し及び1MB書き込みのメモリアクセス時間ではなく、リード・ソロモンデコーダの速度によって制約される。最悪のケース(全ての2MBが復号化を必要とするケース)に要する時間は、従って、2/6.25秒=約0.32秒である。勿論、以下の改良を含む多数の改良を考えることができる。
読み出し環境のブラー効果が大きいほど、所定のドットは周辺ドットからより大きい影響を受ける。好適な実施例による現在の読み出しアルゴリズムは、ドット値に関してより優れた決定を行うため、同一列内の周辺ドットを使用する能力を備えている。前の列のドットは既に復号化されているので、前の列のドット履歴は、画素値が不確実なレンジに含まれるドットの値を決定する際に役に立つ。
初期ステージに関する別の可能性は、それを完全に取り除き、データブロックの初期境界を必要とされる境界よりも広くし、ターゲット処理関数をより知的にすることである。これは、全体的な複雑さを軽減する。データブロックの独立性を維持するために注意する必要がある。
制御ブロック機構はより頑強にすることができる:
*制御ブロックは、(本例のケースのように)隣接させるのではなく、最初のブロック及び最後のブロックでもよい。これは、ある種の異常なダメージ状況に対する保護を高めるであろう;
*第2の改良は、リード・ソロモン復号化ステップが失敗した場合に使用される補助的なレベルの冗長性/誤り検出を制御ブロック構造に取り入れることである。パリティのような簡単な仕組みは、リード・ソロモンステージが失敗した場合に、制御情報のもっともらしさを改良する。
フェーズ5 Varkスクリプト実行
Artcard9を読み出し、それを復号化するために要する総時間は、したがって、約2.15秒である。ユーザがはっきりとわかる遅延は、実際には0.65秒(フェーズ3及び4の合計)に過ぎない。なぜならば、Artcardは1.5秒後に移動を停止するからである。
Artcardがロードされると、Artvarkスクリプトを解釈しなければならない。スクリプトを直ちに実行するのではなく、スクリプトは「プリント」ボタン13(図1)が押下されたときだけに実行される。スクリプトを実行するための所要時間は、スクリプトの複雑さに応じて変化し、プリントボタンの押下と、実際のプリントボタンと、実際の印刷動作との間で認識される遅延を考慮しなければならない。
上述の通り、VLIWプロセッサ74は、コンピュータ利用の費用がかかるVark関数を加速するデジタル処理システムである。CPUコア72によってソフトウェアで実行される関数と、VLIWプロセッサ74によってハードウェアで実行される関数のバランスは、実装に依存する。VLIWプロセッサ74の目的は、全てのArtcardスタイルがユーザからみて遅いと感じられない時間内で実行することを助けることである。CPUが高速で強力になると共に、ハードウェア加速を必要とする関数の数は減少し続ける。VLIWプロセッサは、以下の時間的に重要な関数の汎用ハードウェア高速化を可能にさせるマイクロコード化されたALUサブシステムを含む:
1)汎用ソフトウェア処理のための画像アクセス機構
2)画像コンボルバ
3)データ駆動型画像ワーパー
4)画像スケーリング
5)画像モザイク
6)アフィン変換
7)画像コンポジッター
8)色空間変換
9)ヒストグラムコレクタ
10)画像の照明
11)ブラシスタンパー
12)ヒストグラムコレクタ
13)CCDイメージから内部画像への変換
14)画像ピラミッドの構築(ワーパーによってブラッシングのため使用される)。
以下の表は、ALUモデルに実装された場合の各Vark演算の所要時間を要約したものである。ALUモデルを使用する関数を実装する方法は後述される。
例えば、CCD画像を変換するため、ヒストグラム収集、及び(画像強調用)ルックアップ色置換のために1画素当たりに9+2+0.5サイクル、即ち、11.5サイクルを要する。1500×1000画像の場合、これは、172500000、即ち、1コンポーネント当たりに約0.2秒、即ち、全3コンポーネント当たりに0.6秒である。簡単なワープを追加すると、全体で、0.6+0.36、即ち、ほぼ1秒になる。
画像コンボルバ
コンボルブは中心画素周りの重み付き平均化である。この平均は、単純な加算でもよく、絶対値の和でもよく、和の絶対値でもよく、或いは、0で丸められた和でもよい。
画像コンボルバは汎用コンボルバであり、可変サイズ係数カーネル内の値を変えることによって様々な関数を実現できる。サポートされるカーネルサイズは、3×3、5×5、及び7×7だけである。
図82を参照すると、コンボリューションプロセスの一例340が示されている。コンボルバプロセス341に供給される画素コンポーネント値は、ボックス読み出しイタレータ342から与えられる。イタレータ342は行単位で画像データを供給し、各行内では、画素毎に画像データを供給する。コンボルバ341からの出力は、順次書き込みイタレータ344へ送られ、順次書き込みイタレータ344は有効画像フォーマットで合成画像を格納する。
係数カーネル346は、DRAM内のルックアップテーブルである。カーネルは、ボックス読み出しイタレータ342と同じ順序に係数が並べられる。各係数エントリーは8ビットである。単純な順次読み出しイタレータは、カーネル346を指定し、係数を与えるため使用される。これは、カーネルサイズと一致する画像幅ImageWidthの画像をシミュレーションし、ループオプションがセットされるので、カーネルは連続して供給される。
ALUユニット上のコンボルブプロセスの一実施形態は図81に示されている。以下の定数がソフトウェアによってセットされる。
制御ロジックは、1画素当たりの乗算/加算の回数をカウントダウンするため使用される。カウント(ラッチ2に累算)が0に達するとき、生成される制御信号は(ラッチ1からの)現在のコンボルブ値を書き出し、カウントをリセットするため使用される。このようにして、一つの制御ロジックブロックは、多数の並列コンボルブストリームのために使用される。
各サイクルに、乗算ALUは、画素の適切な部分を組み込むため、1回の乗算/加算を実行することができる。全ての値を総計するために要するサイクル数は、したがって、カーネル内のエントリーの個数である。これは計算制約であるため、画像を複数のセクションに分割し、それらを異なるALUユニットで並列に処理することが適切である。
7×7カーネル上で、各画素に要する時間は49サイクル、即ち、490nsである。各キャッシュラインは32画素を保持するので、メモリアクセスのために利用可能な時間は、((32−7+1)×490ns)、即ち、12740nsである。7本のキャッシュラインを読み出し、1本を書き込むために要する時間は、より悪いケースであって、1120ns(全てのアクセスが同じDRAMバンクへのアクセスであるとして、8*140ns)である。その結果として、リソースが無制限であるならば、最大10画素を並列に処理することが可能である。ALUの個数が限定されている場合、最高で4画素を並列に処理することができる。従って、7×7カーネルを使用してコンボリューションを実行するために要する時間は、0.18375秒(1500*1000*490ns/4=183750000ns)である。
5×5カーネル上で、各画素に要する時間は25サイクル、即ち、250nsである。各キャッシュラインは32画素を保持するので、メモリアクセスのために利用可能な時間は、((32−5+1)×250ns)、即ち、7000nsである。5本のキャッシュラインを読み出し、1本を書き込むために要する時間は、より悪いケースであって、840ns(全てのアクセスが同じDRAMバンクへのアクセスであるとして、6*140ns)である。その結果として、リソースが無制限であるならば、最大7画素を並列に処理することが可能である。ALUの個数が限定されている場合、最高で4画素を並列に処理することができる。従って、5×5カーネルを使用してコンボリューションを実行するために要する時間は、0.09375秒(1500*1000*250ns/4=93750000ns)である。
3×3カーネル上で、各画素に要する時間は9サイクル、即ち、90nsである。各キャッシュラインは32画素を保持するので、メモリアクセスのために利用可能な時間は、((32−3+1)×90ns)、即ち、2700nsである。3本のキャッシュラインを読み出し、1本を書き込むために要する時間は、より悪いケースであって、560ns(全てのアクセスが同じDRAMバンクへのアクセスであるとして、4*140ns)である。その結果として、リソースが無制限であるならば、最大10画素を並列に処理することが可能である。ALU及び読み出し/書き込みイタレータの個数が限定されている場合、最高で4画素を並列に処理することができる。従って、3×3カーネルを使用してコンボリューションを実行するために要する時間は、0.03375秒(1500*1000*90ns/4=33750000ns)である。この結果として、各出力画素は、計算をするためにカーネルサイズ/3サイクルを要する。実際のタイミングは以下の表に要約されている。
画像コンポジッター
コンポジット処理は、最終画像における前景及び背景の適切な比率を制御するため、マット又はチャンネルを使用して前景画像を後景画像に加算することである。好ましくは、通常コンポジット処理及び付随コンポジット処理の二つのスタイルのコンポジット処理がサポートされる。二つのスタイルの規則は、
通常コンポジット処理:新しい値=前景+(背景−前景)a
付随コンポジット処理:新しい値=前景+(1−a)背景
である。
相違点は、付随コンポジット処理の場合、前景はマットによって予め乗算されているのに対して、通常コンポジット処理の場合、そのようにされていないことである。コンポジットプロセスの一例は図83に示されている。
アルファチャネルは、レンジ0から1に対応した0から255の値をとる。
通常コンポジット
通常コンポジットは、
背景+(背景−前景)*α/255
として実装される。
X/255による除算は、257X/65536によって近似される。コンポジットプ
ロセスの実装例は図84に詳細に示され、以下の定数がソフトウェアによってセットされる。
4個のイタレータが必要であるため、コンポジットプロセスは1画素当たりに1サイクルを要し、ALUの半分しか利用しない。コンポジットプロセスは一つのチャンネルだけで実行される。3チャンネル画像を互いにコンポジットするためには、コンポジッターは、各チャンネルに1回ずつの合計3回実行されなければならない。
フルサイズの単一チャンネルをコンポジットするための所要時間は、0.015秒(1500*1000*1*10ns)であり、3チャンネル全てをコンポジットするために0.045秒を要する。
255による除算を近似するため、257倍した後に65536で除算する。これは、1回の加算(256*x+x)と、その結果の最後の16ビットの無視(丸めの目的を除く)とによっても実現可能である。
図42に示されるように、コンポジットプロセスは、3個の順次読み出しイタレータ351−353と、1個の順次書き出しイタレータ355とを必要とし、乗算器ALUと共にアダーALUと共にアダーを使用するマイクロコードとして実装される。コンポジット時間は1画素当たり1サイクル(10ns)である。付随コンポジット処理と通常コンポジット処理は別々のマイクロコードを必要とするが、1画素当たりの平均時間は同じである。
コンポジット処理は単一チャンネルだけで実行される。一つの3チャンネル画像を互いにコンポジットするために、コンポジッターは、チャンネル毎に1回ずつ、併せて3回実行される。aチャンネルは各コンポジットに対して同一であるため、それは毎回読み出される必要がある。しかし、最良ケースでの4×32バイトのキャッシュラインの転送(読み出し又は書き込み)は320nsを要する。パイプラインは、平均で1画素コンポジット当たりに1サイクルを与え、32画素をコンポジットするために32サイクル、即ち、320ns(100MHz)を要するので、チャンネルは実質的に無制限で読み出される。したがって、全チャンネルは、
1500/32*1000*320ns=15040000ns=0.015秒
でコンポジットされる。
フルサイズの3チャンネル画像をコンポジットするための所要時間は0.045秒である。
画像ピラミッド構築
ワーピング、タイリング、及びブラッシングのような幾つかの関数は、所定の画素のエリアの平均値を必要とする。所与の各エリアの値を計算するのではなく、これらの関数は、好ましくは、画像ピラミッドを利用する。既に図33に示されたように、画像ピラミッド360は、実質的に多重解像度画素マップである。原画像は1:1表現である。各次元での2:1によるサブサンプリングは、元のサイズの1/4の画像を生成する。このプロセスは画像全体が単一画素によって表現されるまで続く。
画像ピラミッドは原画像から構築され、原画像によって占められたサイズの1/3(1/4+1/16+1/64+...)を使う。原画像が1500×1000である場合、対応した画像ピラミッドは約1/2MBである。
画像ピラミッドは、コンボルブのカーネルを各次元で2画素ずつ前進させるワン・イン・フォー入力画像に基づいて実行される3×3コンボルブによって構築することができる。3×3コンボルブは、単純な4画素の平均化よりも高い精度を生じ、異なるピラミッドレベルの座標の差が1レベル毎に1ビットだけシフトすることによって得られるという付加的な利点がある。
ピラミッド全体の構築は、ピラミッドの各レベルで1回ずつピラミッドレベル構築関数を呼び出すソフトウェアループに依拠している。
ピラミッドの1レベルを生成するためのタイミングは、入力画像の解像度の(9/4)*(1/4)である。なぜならば、原画像の1/4のサイズの画像を生成しているからである。このようにして、1500×1000画像に対して、
ピラミッドのレベル1を生成するためのタイミング=9/4*750*500=843750サイクルであり、
ピラミッドのレベル2を生成するためのタイミング=9/4*375*250=210938サイクルであり、
ピラミッドのレベル3を生成するためのタイミング=9/4*188*125=52735サイクルであり、
以下同様に続く。
総時間は、原画像1画素当たりに3/4サイクル(画像ピラミッドは原画像サイズの1/3であり、各画素は計算に9/4サイクルを要し、即ち、(1/3)*(9/4)=3/4)である。1500×1000画像の場合、(100MHz)で1125000サイクル、即ち、0.011秒である。このタイミングは単一色チャンネルに対するタイミングであり、3色チャンネルは0.034秒の処理時間を要する。
汎用データ駆動型画像ワーパー
ACP31は、入力画像の画像ワーピング操作を実行可能である。画像ワーピングの原理は理論的に周知である。ワーピングのプロセスに関する一つの完全な教科書は、Geroge
Wolbergによる''Digital Image Warping'', IEEE Computer Society Press,
Los Alamitos,
California,
1990である。ワーピングプロセスは、Artcard9によって供給されたデータの一部を形成するワープマップを使用する。ワープマップは、必要条件に応じて任意的に寸法を決めることができ、入力画素の出力画素へのマッピングの情報を提供する。残念なことに、任意的に寸法を決められたワープマップの利用は、画像ワーパーによって解決されるべき多数の問題を生じる。
図85を参照すると、A×B次元のワープマップ365は、ある大きさ(例えば、0から255の8ビット値)の配列値により構成され、この配列値は理論的な入力画像の座標を表現し、理論的な入力画像の座標は同じ配列座標インデックスを有する対応した「理論的な」出力画像へマップされる。残念ながら、出力画像、例えば、出力画像366は固有の次元C×Dを有し、これは、固有の次元E×Fを有する入力画像とは全く異なる。したがって、出力画像366が、出力画素毎に、対応した入力画像のエリア又は領域を決定できるように、ワープマップ365のマッピングを容易に行えるようにする必要がある。出力画素色データは、対応した入力画像のエリア又は領域から構築される。出力画像366内の各出力画素に対して、最初に、ワープマップ365から対応したワープマップ値を決定することが必要である。このため、出力画像画素がワープマップテーブル365内の小数位置にマッピングされるときに、周辺ワープマップ値をバイリニア補間することが必要である。このプロセスの結果は、ワープマップ365内の各データ値のサイズによって寸法が決められる「理論的な」画像内での入力画像画素の位置を与える。これらの値は、理論的な画像を対応した実際の入力画像367へマッピングするため再度スケーリングしなければならない。
実際の値を決定するため、出力画像画素はエイリアシング効果を回避するように選ばれるべきであり、最終的な出力画像画素値に寄与する入力画像画素367の領域を決定するために隣接した出力画像画素を調べる必要がある。この点に関して、以下でより明らかにされるように、画像ピラミッドが利用される。
画像ワーパーは画像をワープさせるため以下の幾つかのタスクを実行する:
−出力画像サイズに一致するようにワープマップをスケーリングする;
−各出力画素に表現される入力画像画素の領域のスパンを決定する;
−入力画像ピラミッドからトライリニア補間によって最終的な出力画素値を計算する。
ワープマップスケーリング
前述の通り、データ駆動型ワープでは、ワープマップは、出力画素毎に、対応した入力画像マップの中心を記述することが必要である。前述のように単一ワープマップを用いる代わりに、インターリーブされたx及びy値情報を格納すると、X座標及びY座標を別個のチャンネルとして取り扱うことが可能である。
その結果として、好ましくは、二つのワープマップが設けられ、XワープマップはX座標のワーピングを表し、YワープマップはY座標のワーピングを示す。前述のように、ワープマップ365は、スケーリング中の画像とは異なる空間解像度でもよい(例えば、32×32ワープマップ365は、1500×1000画像366のワープを適切に記述する)。その上、ワープマップは、ワープ中の画像のサイズに対応した8又は16ビット値によって表現可能である。
所定のワープマップから入力画像空間に点を生成するために幾つかのステップが含まれる:
1.出力画像に対してワープマップ内に対応した位置を決定する;
2.次のステップのため、ワープマップから値をフェッチする(これは、ワープマップがほんの8ビット値である場合に、解像度ドメインにおけるスケーリングを必要とする);
3.実際の値を決定するためワープマップのバイリニア補間を行う;
4.入力画像ドメインに対応するように値をスケーリングする。
最初のステップは、出力画像における現在のX/Y座標にスケール倍率(XとYで異なる場合がある)を乗算することにより実行される。例えば、出力画像が1500×1000であるならば、ワープマップは150×100であり、XとYの両方は1/10によってスケーリングされている。
ワープマップから値をフェッチするためには、二つのルックアップテーブルにアクセスすることが必要である。一方のルックアップテーブルは、ルックアップテーブルから8又は16ビットのエントリーを読み出し、常に16ビット値を返す(元の値が8ビットしかない場合、上位8ビットをクリアする)。
パイプラインの次のステップは、参照されたワープマップ値をバイリニア補間することである。
最後に、バイリニア補間からの結果がスケーリングされ、ワープされるべき画像と同じドメインに収容される。このようにして、ワープマップのレンジが0から255である場合、Xを1500/255でスケーリングし、Yを1000/255でスケーリングする。
補間プロセスは図86に示されているようなプロセスであり、以下の定数がソフトウェアによってセットされる。
スパン計算
ワープマップ365からの点は入力画像367内の画素領域の中心の位置を示す。隣接した出力画像画素の入力画像画素の間の距離は領域のサイズを示し、この距離は、スパン計算によって近似することができる。
図87を参照すると、ワープマップP1の所定の現在点に対して、同じライン上の前のポイントはP0であり、前のラインの同じ位置にあるポイントはP2である。P1とP0の間、並びに、P1とP2の間で、X及びYの絶対距離を決定する。X又はYの最大距離は、実際の形状を近似する正方形であるスパンになる。
好ましくは、点は、垂直方向ストリップの出力順に処理され、P0はストリップ内の同じ線で先行する点であり、P1がストリップ内の最初の点であるとき、P0は、前のストリップの対応した線の最後の点を表す。P2は同一ストリップ内の前の線の点であるため、32エントリーの履歴バッファに保持され得る。スパン計算プロセスの原理は図88に示され、そのプロセスの詳細は図89に示されている。
以下のDRAMのFIFOが使用される。
32ビット精度のスパン履歴が保持されるので、1500画素幅の画像がワープされる場合、12000バイトの一時記憶が必要になる。
スパン364の計算は、二つのアダーALU(一方はスパン計算用であり、もう一方はP0及びP2の履歴をループしカウントするためのものである)を使用し、以下のように7サイクルを要する。
履歴バッファ365、366は、キャッシュ型のDRAMである。「前のライン」(P2履歴の場合)バッファ366は、32エントリーのスパン精度である。「前の点」(P0履歴の場合)バッファ365は、(ストリップの線の点1から31の計算のため)殆どの場合に使用される1個のレジスタを必要とし、DRAMにバッファされた履歴値の組はストリップの線の点0の計算に使用される。
スパン履歴の32ビット精度は、P2履歴を保持するため4本のキャッシュラインと、P0履歴のための2本のキャッシュラインと、を必要とする。P0の履歴は、32画素からなる8本の線毎に1回ずつ、(ImageHeight*4)バイトの一時記憶空間に書き込まれ、読み出される。このようにして、1500画素の高さの画像がワープされるとき、6000バイトの一時記憶が必要であり、全部で6本のキャッシュラインが必要である。
トライリニア補間
平均化されるべき入力画像からエリアの中心及びスパンを決定した後、ワーププロセスの最終部分は、出力画素の値を決定することである。単一の出力画素は、理論的に入力画像全体によって表現できるので、出力画素に寄与する入力画像の特定のエリアを実際に読み出し平均化するためには、非常に時間を消費する可能性がある。その代わりとして、入力画像の画像ピラミッドを使用することにより画素値を近似することができる。
スパンが1以下である場合、所与の座標の周辺で原画像の画素を読み出し、バイリニア補間を実行するだけでよい。スパンが1よりも大きい場合、二つの適切なレベルの画像ピラミッドを読み出し、トライリニア補間を実行する必要がある。二つのレベルの画像ピラミッドの間にリニア補間を実行することは、厳密に正確ではないが、許容可能な結果を与える(それは結果画像にブラー効果が生じる側で判断を誤る)。
図90を参照すると、一般的には、あるスパン「s」が与えられた場合に、ln2s(370)及びln2s+1(371)によって与えられる画像ピラミッドレベルを読み出すことが必要である。Ln2sは、sの上位ビットセットを復号化するだけである。ピラミッドの二つのレベル370、371の各々で画素値の値を決定するためバイリニア補間を実行し、レベル間で補間を実行しなければならない。
図91に示されるように、最終的な出力値373を得るため、ピラミッドレベル間で補間を行う前に、最初に各画素ピラミッドレベルのX及びYに関して補間を行うことが必要である。
画像ピラミッドアドレスモードは、ピラミッドレベルs及びs+1上の(x,y)における画素座標に対するアドレスを生成する。各レベルの画像ピラミッドは、xの方向に連続した画素を格納する。したがって、xに関する読み出しはキャッシュヒットする可能性が高い。
適度なキャッシュヒットのコヒーレンスは、出力画像の局所領域が典型的に入力画像と局所的にコヒーレントである(おそらく、スケールは異なるが、同じスケールでコヒーレントである)ときに獲得される。入力画像と出力画像との関係を知ることはできないが、出力画素は、キャッシュコヒーレンスを最大限に利用するため、(垂直ストリップイタレータによって)確実に垂直ストリップに書き込まれる。
トライリニア補間は、パイプラインとして4個の乗算ALU及び4個全てのアダーALUを使用し、メモリアクセスの必要がない場合を想定すると、平均的に2サイクル程度で完了し得る。しかし、全ての補間値は画像ピラミッドから得られるので、補間速度はキャッシュコヒーレンスに完全に依存する(その他のユニットはワープマップスケーリング及びスパン計算を実行するためビジーであることは言うまでもない)。できるだけ多数のキャッシュラインを画像ピラミッド読み出しのために利用できるべきである。最良の速度は、2個の乗算ALUを使用して8サイクルである。
出力画素は、二つのキャッシュラインを使用する垂直ストリップ書き込みイタレータによってDRAMに書き込まれる。この速度は、従って、1出力画素当たりに8サイクルの最小値で制限される。ワープマップのスケーリングに必要なサイクルが8サイクル以下であるならば、全体的な速度は変化しない。さもなければ、スループットはワープマップをスケーリングするために要する時間である。殆どの場合に、ワープマップは写真のサイズと適合するまで拡大される。
1画素当たりに必要なサイクル数が8サイクル以下のワープマップをスケーリングする場合、画像の1個のカラーコンポーネントを変換するための所要時間は0.12秒(1500*1000*8サイクル*1サイクル当たりに10ns)である。
ヒストグラムコレクタ
ヒストグラムコレクタは、入力として画像チャンネルを取得し、出力としてヒストグラムを生成するマイクロコードプログラムである。チャンネルの画素の各々は、レンジ0−255に収まる値をとる。その結果として、ヒストグラムテーブルには全部で256画素が存在し、各エントリーは32ビットであり、1500×1000の全画像のカウントを十分に収容することができる。
図92に示されるように、ヒストグラムは全画像の要約を表現するので、順次読み出しイタレータ378は入力として十分にである。ヒストグラム自体は、完全にキャッシュされ、32個のキャッシュライン(1K)を必要とする。
マイクロコードは二つのパスを有し、初期化パスでは、全てカウントを0にセットし、次に、「カウント」ステージは、画像から読み出された各画素の適切なカウンタをインクリメントする。第1のステージは、アドレスユニットと単一のアダーALUとを必要とし、ヒストグラムテーブル377のアドレスを初期化する。
第2のステージは、画像からの実際の画素を処理し、4個のアダーALUを使用する。
アダー2のサイクル2からの零フラグは、入力画素が同じである間、マイクロコードアドレス2に留まるため使用される。入力画素が変化したとき、新しいカウントはマイクロコードアドレス3に書き出され、処理はマイクロコードアドレス2で再開する。マイクロコードアドレス4は最後に使用され、それ以上読み出される画素は存在しない。
ステージ1は、256サイクル、即ち、2560nsを要する。ステージ2は、画素の値に応じて変わる。ルックアップテーブル置換のための最悪ケースの時間は、あらゆる画素がその近傍と同じではない場合に、1画像画素当たりに2サイクルである。単一カラーのルックアップに要する時間は0.03秒(1500×1000×1画素当たり2サイクル×1サイクル当たり10ns=30000000ns)である。3個のカラーコンポーネントに要する時間はこの量の3倍、即ち、0.09秒である。
色変換
色変換は、
ルックアップテーブル置換、及び
色空間変換
の二つの主要な方法で実現される。
ルックアップテーブル置換
図86に示されるように、画素の色を変換するための最も簡単な方法の一つは、任意に複雑な変換関数をルックアップテーブル380にエンコードすることである。画素のコンポーネントカラー値は、画素の新しいコンポーネント値をルックアップ381するため使用される。順次読み出しイタレータから読み出された画素毎に、その新しい値が新カラーテーブル380から読み出され、順次書き込みイタレータ383へ書き込まれる。入力画像は、メモリ帯域幅を効率的に利用するため、半分ずつ同時に処理される。以下のルックアップテーブルが使用される。
総プロセスは、二つの順次読み出しイタレータ及び二つの順次書き込みイタレータを必要とする。二つの新カラーテーブルは、256バイト(1バイトからなる256個のエントリー)を保持するため、各々に8個のキャッシュラインが必要である。
したがって、ルックアップテーブル置換に要する平均時間は1画像画素当たり1/2サイクルである。単一カラーのルックアップに要する時間は0.0075秒(1500×1000×1画素当たり1/2サイクル×1サイクル当たり10ns=7500000ns)である。三つのカラーコンポーネントのための所要時間はこの量の3倍、即ち、0.0225秒である。各カラーコンポーネントは、ソフトウェアの制御下で次々に処理される。
色空間変換
色空間変換は、色空間の間を動くときに限り必要である。CCD画像はRGB色空間で撮影され、印刷はCMY色空間で行われ、一方、ACP31のクライアントは、Lab色空間で画像を処理する可能性が高い。入力色空間チャンネルの全ては、典型的に、各出力チャンネルのコンポーネント値を決定するために要求される。このような論理的プロセスが図94の385に示されている。
簡潔に言うと、Lab、RGB及びCMYの間の変換は、かなり簡単である。しかし、特定の装置の個別の色プロファイルは著しく変化し得る。その結果として、将来のCCD、インク、及びプリンタを可能にさせるため、ACP31は、色空間変換ルックアップテーブルからのトライリニア補間によって色空間変換を実行する。
色コヒーレンスは、線ベースではなく、エリアベースである傾向がある。トライリニア補間ルックアップ中にキャッシュコヒーレンスを補助するため、画像を垂直ストリップで処理することが最良である。このようにして、読み出しイタレータ386−388及び書き出しイタレータ389は、垂直ストリップイタレータである。
トライリニア色空間変換
各出力カラーコンポーネントに対して、入力色空間を出力色空間へマッピングする単一の3次元テーブルが必要になる。例えば、CCD画像をRGBからLabへ変換するため、CCDの物理的特性に較正された3個のテーブル、即ち、
RGB->L
RGB->a
RGB->b
が必要になる。
LabからCMYへ変換するため、インク/プリンタの物理的特性に較正された3個のテーブル、即ち、
Lab->C
Lab->M
Lab->Y
が必要になる。
8ビット入力カラーコンポーネントは、変換テーブルへのインデックス付けのため、固定小数点数(3:5)として取り扱われる。整数の3ビットはインデックスを与え、小数の5ビットは補間として使用される。3ビットは8個の値を与えるので、3次元で512エントリー(8×8×8)が得られる。各エントリーのサイズは1ビットであり、1テーブル当たり512バイトが必要である。
したがって、色空間変換プロセスは図95に示されるように実装され、以下のルックアップテーブルが使用される。
トライリニア補間は、8個の値の間の補間を返す。ルックアップから各8ビット値を返すために1サイクルを要し、全部で8サイクルを要する。トライリニア補間は、1サイクル当たり2個の乗算ALUが使用されたとき、8サイクルを使用する。一般的なトライリニア補間情報はこの文書のALUセクションに記載されている。ルックアップテーブル用の512バイトは16個のキャッシュラインに詰め込まれる。
画像の単一のカラーコンポーネントを変換するための時間は0.105秒(1500*1000*7サイクル*1サイクル当たり10ns)である。3コンポーネントを変換するため、0.415秒を要する。都合良く、プリントアウト用の色空間変換は、プリントアウト中にオンザフライ方式で行われる。
カラーコンポーネントが別々に変換される場合、それらは入力色空間コンポーネントを上書きしなければならない。なぜならば、入力色空間からの全てのカラーコンポーネントは各コンポーネントを変換するために必要になるからである。
補間を実行するために1個の乗算ユニットだけが使用されるので、Lab->CMY変換の全体を単一パスとして行うことが可能である。このためには、三つの垂直ストリップ読み出しイタレータと、三つの垂直ストリップ書き込みイタレータと、が必要であり、3個の変換テーブルに同時にアクセスする。その場合、入力画像へ書き戻し、余分なメモリを使用しないことも可能である。しかし、3個の変換テーブルへのアクセスは、各々に対するキャッシュ処理の1/3に相当し、プロセス全体では高いレイテンシーを生じることになる。
アフィン変換
写真を用いて画像をコンポジットする前に、画像を回転、スケーリング、及び並進することが必要である。画像が並進だけされている場合、直接的なサブピクセル平行移動関数を使用する方が高速になる。しかし、回転、拡大、及び並進は、単一のアフィン変換に組み込むことができる。
汎用アフィン変換は、加速関数として組み込みことが可能である。アフィン変換は2次元に制限され、縮小される場合、入力画像はスケール関数によって予めスケーリングされるべきである。汎用アフィン変換を備えることにより、出力画像を同時に1ブロックずつ構築することが可能になり、画像に対して多数の変換を実行するために要する時間を削減できる。なぜならば、多数の変換の全てを同時に適用できるからである。
変換行列はクライアントによって与えられる必要があり、行列は、望まれる変換の逆行列でなければならない。即ち、その行列を出力画素座標に適用することによって入力座標が得られる。
2次元行列は、通常、以下の3×3配列、即ち、
第3列は常に[0,0,1]であるため、クライアントはそれを指定しなくてもよい。その代わりに、クライアントはa,b,c,d,e,fを指定する。
左上画像画素の座標が(0,0)として表される入力画像内の座標(x,y)が与えられた場合、入力座標は、(ax+cy+e,bx+dy+f)によって指定される。入力座標が決定されると、入力画像は、その画素値に達するためサンプリングされる。入力画像画素のバイリニア補間は、計算された座標における画素の値を決定するため使用される。アフィン変換は平行線を保存するので、画像は、最高の平均入力画像キャッシュコヒーレンスを得るため32画素幅の出力垂直ストリップで処理される。
3個の乗算ALUは、バイリニア補間を2サイクル内で実行するために必要である。乗算ALU1及び2は、線Y及び線Y+1のそれぞれについてXに関してリニア補間を実行し、乗算ALU3は、乗算ALU1及び2によって出力された値の間でYに関するリニア補間を実行する。
Xに関して出力線を横切って右へ移動するとき、2個のアダーALUは、「a」を現在のX値に加算し、「b」を現在のY値に加算することによって、実際の入力画像座標を計算する。次の線(最大で32画素を処理した後の垂直ストリップ内の次の線、又は新しい垂直ストリップの最初の線)へ進んだとき、X及びYを所与のブロックに対する予め計算されたスタート座標値定数に更新する。
入力座標を計算するプロセスは図96に示され、同図では、以下の定数がソフトウェアによってセットされる。
画素計算
入力画像座標が得られると、入力画像をサンプリングする必要がある。ルックアップテーブルは、バイリニア補間の準備として指定された座標における値を返すため使用される。基本プロセスは図97に示され、以下のルックアップテーブルが使用される。
アフィン変換は、全部で4個の乗算ALU及び全部で4個のアダーALUを必要とし、良好なキャッシュコヒーレンスがある場合、1出力画素当たり平均2サイクルでアフィン変換を実行できる。このタイミングは優れたキャッシュコヒーレンスを前提とし、この前提は画像に歪みが無い場合には成立する。最悪ケースでは、画像がかなり歪み、重要なVarkスクリプトが含まれている可能性は低い。
128×128画像を変換するために要する時間は、0.00033秒(32768サイクル)である。これが4チャンネル(aチャンネルを含む)を備えたクリップ画像である場合、必要な総時間は0.00131秒(131072サイクル)である。
垂直ストリップ書き込みイタレータは画素を出力するため必要である。読み出しイタレータは不要である。しかし、アフィン変換アクセラレータは、入力画像画素にアクセスするために要する時間によって制約されるので、できるだけ多数のキャッシュラインが入力画像からの画素の読み出しに割り付けられるべきである。少なくとも32が利用可能であり、好ましくは、64以上が利用可能である。
スケーリング
スケーリングは、基本的に画像の再サンプリングである。画像の拡大はアフィン変換関数を用いて実行できる。縮小を含む一般化された画像のスケーリングは、ハードウェア加速型スケール関数によって行われる。スケーリングはX及びYに関して独立に行われるので、異なるスケール倍率を各次元で使用することができる。一般化されたスケールユニットは、位置合わせに関して、アフィン変換スケール関数と適合しなければならない。
一般化されたスケーリングプロセスは図98に示されている。Xに関するスケールは図99に示されるようにFantの再サンプリングアルゴリズムによって達成される。
以下の定数がソフトウェアによってセットされる。
以下のレジスタは一時変数を保持するため使用される。
Yに関するスケールプロセスは図100に示され、X画素の順番の処理を考慮するためFantの再サンプリングアルゴリズムの僅かに変更されたバージョンによっても実現される。
以下の定数がソフトウェアによってセットされる。
以下のレジスタが一時変数を保持するため使用される。
画像モザイク処理
画像のモザイク処理はタイリングの一形態である。モザイク処理は、特別に設計された「タイル」を、水平方向及び垂直方向に複数回、第2の(通常はより大きい)画像空間へコピーする処理を含む。モザイク処理されたとき、小さいタイルは継ぎ目のないピクチャーを形成する。この一例は、レンガ壁の区画の小さいタイルである。それは、モザイク処理されたときに、完全なレンガ壁を形成するように設計される。尚、モザイク処理には、スケーリング、又はサブピクセル平行移動が含まれないことに注意すべきである。
モザイク処理を行うために最もキャッシュコヒーレントな方法は、画像をライン毎に順次に出力し、同じ入力画像のラインを、そのラインの区間の間、繰り返すことである。ラインが終了したとき、入力画像は次のラインへ進められるべきである(出力ラインをはさんで複数回それを繰り返すべきである)。
モザイク関数の概要は図101の390に示されている。順次読み出しイタレータ392は入力タイルの単一ラインを連続して読み出すようにセットアップされる(スタートラインは0であり、エンドラインは1である)。各入力画素は、書き込みイタレータ393−395の三つ全てに書き込まれる。アダーALUのカウンタ397は、出力ライン中の画素数をカウントダウンし、ラインの最後にシーケンスを終了する。
ラインの処理の最後に、小さいソフトウェアルーチンは、マイクロコード及び順次読み出しイタレータ(これは、FIFOをクリアし、タイルのライン2を繰り返す)を再始動する前に、順次読み出しイタレータのスタートライン及びエンドラインレジスタを更新する。書き込みイタレータ393−395は更新されず、出力画像の対応した部分へ書き込み続けるだけである。正味の効果として、タイルが出力ラインをはさんで1ライン繰り返され、タイルが垂直方向に繰り返される。
このプロセスはメモリ帯域幅を完全には使用しない。なぜならば、入力画像におけるキャッシュコヒーレンスは優れているが、モザイク処理を他のサイズのタイルと共に機能させることができないからである。このプロセスは、1個のアダーALUを使用する。3個の書き込みイタレータ393−395の各々が、画像の1/3に書き込む(画像をタイルサイズの境界に分割する)ならば、モザイクプロセスの全体は1出力画像画素当たり1/3サイクルの平均速度で行われる。1500×1000の画像の場合、これは、0.005秒(5000000ns)と一致する。
サブピクセルトランスレータ
画像を背景とコンポジットする前に、X及びYの両方に関してサブピクセル量で画像を平行移動させることが必要である。サブピクセル平行移動は、各次元に1画素ずつ画像のサイズを増加することができる。画像の外側の領域の値は、定数値(例えば、黒色)又はエッジ画素繰り返しのようなクライアントによって決定される値である。典型的に、黒色を使用する方がよい。
サブピクセル平行移動プロセスは図102に示されている。所定の次元のサブピクセル平行移動は、
Pixelout = Pixelin *
(1-Translation) + Pixelin-1 *
Translation
によって定義される。
これは、補間の形式、即ち、
Pixelout= Pixelin-1 +
(Pixelin - Pixelin-1)
* Translation
として表現することができる。
単一の乗算ALU及び単一のアダーALUを組み合わせて使用する単一(又は平均)サイクル補間エンジンの実装は簡単である。X及びYの両方に関するサブピクセル平行移動は、二つの補間エンジンを必要とする。
Yに関するサブピクセル平行移動を行うため、二つの順次読み出しイタレータ400、401が必要になり(一方は、同じ画像から他の画像よりも進んでいるラインを読み出す)、一つの順次書き込みイタレータ403が必要になる。
第1の補間エンジン(Yに関する補間)は、二つのストリームからのデータペアを受け取り、それらの間を線形に補間する。第2の補間エンジン(Xに関する補間)は、単一の1次元ストリームとしてそのデータを受け取り、値の間を線形に補間する。両方のエンジンは平均として1サイクルで補間を行う。
各補間エンジン405、406は、平均的に1出力画素当たり1サイクルでサブピクセル平行移動を実行する能力を備えている。したがって、全体的な時間は1出力画素当たり1サイクルであり、2個の乗算ALUと2個のアダーALUが必要である。
サブピクセル平行移動関数から32画素を出力するために要する時間は、平均で320ns(32サイクル)である。これは、DRAMへの完全な4個のキャッシュラインアクセスに十分な時間であり、3個の順次イタレータの使用はタイミング原価以内に十分に収まる。
画像をサブピクセル平行移動するために要する総時間は、したがって、出力画像の1画素当たり1サイクルである。サブピクセル平行移動されるべき典型的な画像は、サイズ128*128のタイルである。出力画像サイズは129*129である。このプロセスは、129*129*10ns=166410nsである。
画像タイル貼り関数もサブピクセル平行移動アルゴリズムを使用するが、サブピクセル平行移動処理されたデータを書き出す必要はなく、そのデータを更に処理する。
画像タイルタイラー
画像をタイル貼りする上位レベルアルゴリズムはソフトウェアで実行される。タイルの配置が決定されると、適切な着色タイルを合成しなければならない。各タイルの画像への実際のコンポジット処理は、マイクロコード化されたALUによってハードウェアで行われる。タイルのコンポジット処理は、背景画像へのテクスチャ貼り付けとカラー貼り付けの両方を含む。ある種のケースでは、背景に加えられる実際のテクスチャ量と、予定されたテクスチャ量とを比較し、貼り付けられるカラーをスケーリングするためこれを使用することが望ましい。これらのケースでは、テクスチャを先に貼り付けることが必要である。
カラー貼り付け機能及びテクスチャ貼り付け機能はある程度独立しているので、これらはサブ関数に分離される。
種々のテクスチャスタイル及びカラーリングスタイルのための4チャンネルタイルコンポジット当たりのサイクル数は以下の表に要約されている。
タイルカラーリング及びコンポジット処理
タイルは、(タイル全体に)一定色を具備するか、又は入力画像から各画素値を取るようにセットされる。これらの両方のケースは、不透明度を拡大縮小するため、テクスチャ処理ステージからのフィードバックがある(シニングペイントと同様)。
4ケースに対するステップは以下のように要約できる:
−タイルの不透明度値をサブピクセル平行移動する;
−(テクスチャ貼り付けからのフィードバックが有効である場合)タイルの不透明度を選択的にスケーリングする;
−画素の色を(一定に、又は画像マップから)決定する;
−画素を背景画像上でコンポジットする。
4ケースの各々は、関数を実行するために要する時間を最小限に抑えるため、別々に取り扱われる。単一カラーチャンネルのカラーコンポジット処理スタイル当たりの時間は以下の表に要約されている。
一定色
この場合、タイルは、ソフトウェアによって決定された一定色を具備する。ACP31が一つのタイルを設置する間に、ソフトウェアは次のタイルの配置及びカラーリングを決定することができる。
タイルの色は、タイル貼りされている画像をスケーリングした画像へのバイリニア補間によって決定することが可能である。スケーリングされた画像は、作成し、画像ピラミッドの所定の位置に保存することが可能であり、タイル演算の全体に対して1回だけ実行すればよい。サイズが128×128である場合、画像は、各次元に関して、128:1で縮小される。
フィードバック無し
タイルのテクスチャ処理からのフィードバックが無いとき、タイルは、指定された座標に設置されるだけである。タイル色は、画素の色毎に使用され、コンポジットのための不透明度は、タイルのサブピクセル平行移動処理された不透明度チャンネルから由来する。このケースでは、カラーチャンネル及びテクスチャチャンネルは、タイル貼りパスの間に完全に独立して処理可能である。
プロセスの概要は図103に示されている。タイルのサブピクセル平行移動410は、1出力画素当たり1サイクルの平均時間の場合、2個の乗算ALU及び2個のアダーALUを使用して実行することができる。サブピクセル平行移動からの出力は、背景順次読み出しイタレータからの背景画像で一定タイル色412をコンポジット処理411する際に使用されるべきマスクである。
コンポジット処理は、1コンポジット当たり1サイクルの平均時間の場合、1個の乗算ALU及び1個のアダーALUを用いて実行できる。したがって、必要条件は、3個の乗算ALU及び3個のアダーALUである。4個の順次イタレータ413−416が必要であり、それらの内容を読み書きするために320nsを要する。サブピクセル並行移動及びコンポジットのために要する1画素当たりの平均サイクル数の場合、バッファを読み書きするための十分な時間がある。
フィードバック付き
タイルのテクスチャ処理からのフィードバックがあるとき、タイルは指定された座標に配置される。タイル色は、画素の色毎に使用され、コンポジットのための不透明度は、フィードバックパラメータによってスケーリングされたサブピクセル平行移動処理された不透明度チャンネルから由来する。このようにして、テクスチャ値は、カラー値が貼り付けられる前に計算しなければならない。
プロセスの概要は図97に示されている。タイルのサブピクセル平行移動は、1出力画素当たり1サイクルの平均時間の場合、2個の乗算ALU及び2個のアダーALUを使用して実行することができる。サブピクセル平行移動からの出力は、フィードバック順次読み出しイタレータ420から読み出されたフィードバックに応じてスケーリングされるべきマスクである。このフィードバックはスケーラ(1個の乗算ALU)421へ送られる。
コンポジット処理426は、1コンポジット当たり1サイクルの平均時間の場合、1個の乗算ALU及び1個のアダーALUを用いて実行できる。したがって、必要条件は、4個の乗算ALU及び4個のアダーALUである。プロセス全体は、平均的に1サイクル内で完了可能であるが、ボトルネックはメモリアクセスである。なぜならば、5個の順次イタレータが必要になるからである。十分なバッファリングが行われる場合、平均時間は1画素当たり1.25サイクルである。
入力画像からの色
タイルの画素に着色する一つの方法は、入力画像の画素から色を取り出すことである。ここでも、コンポジット処理には、テクスチャ処理からのフィードバック付きとフィードバック無しの二つの可能性がある。
フィードバック無し
この場合、タイル色は、入力画像内の対応する画素から簡単にもたらされる。コンポジット処理用の不透明度は、サブピクセルシフトされたタイルの不透明度チャンネルに由来する。
プロセスの概要は図105に示されている。タイルのサブピクセル平行移動425は、1出力画素当たり1サイクルの平均時間の場合、2個の乗算ALU及び2個のアダーAL
Uを使用して実行することができる。サブピクセル平行移動からの出力は、(入力画像428から読み出された)タイルの画素色を背景画像429とコンポジット処理426する際に使用されるべきマスクである。このフィードバックは、スケーラ(1個の乗算ALU)431へ送られる。
コンポジット処理434は、1コンポジット当たり1サイクルの平均時間の場合、1個の乗算ALU及び1個のアダーALUを用いて実行できる。したがって、必要条件は、3個の乗算ALU及び3個のアダーALUである。プロセス全体は平均して1サイクル以内に完了可能であるが、ボトルネックはメモリアクセスである。なぜならば、5個の順次イタレータが必要になるからである。十分なバッファリングが行われる場合、平均時間は1画素当たり1.25サイクルである。
フィードバック付き
この場合、タイル色は、やはり入力画像内の対応する画素から簡単にもたらされるが、コンポジット処理用の不透明度は、テクスチャ処理パス中に実際に適用されたテクスチャ高さの相対的な量による影響を受ける。このプロセスは図106に示されている。
タイルのサブピクセル平行移動431は、1出力画素当たり1サイクルの平均時間の場合、2個の乗算ALU及び2個のアダーALUを使用して実行することができる。サブピクセル平行移動からの出力は、フィードバック順次読み出しイタレータ432から読み出されたフィードバックに応じてスケーリング431されるべきマスクである。
コンポジット処理は、1コンポジット当たり1サイクルの平均時間の場合、1個の乗算ALU及び1個のアダーALUを用いて実行できる。
したがって、必要条件は、4個の乗算ALU及び3個のアダーALUである。プロセス全体は平均して1サイクル以内に完了可能であるが、ボトルネックはメモリアクセスである。なぜならば、6個の順次イタレータが必要になるからである。十分なバッファリングが行われる場合、平均時間は1画素当たり1.5サイクルである。
タイルテクスチャ処理
各タイルはそのテクスチャチャンネルによって定義される表面テクスチャを有する。テクスチャは、サブピクセルへ移行移動され、次に、出力画像に貼り付けられる。テクスチャコンポジット処理には、
テクスチャ配置と、
25%背景+タイルのテクスチャと、
平均高さアルゴリズムと、
の3種類のスタイルがある。
更に、平均高さアルゴリズムはカラーコンポジット処理のためのフィードバックパラメータを節約する。
テクスチャコンポジット処理スタイル毎に要する時間は以下の表に要約される。
テクスチャ置換
このケースでは、タイルからのテクスチャは、図107に示されるように、画像のテクスチャチャンネルを置き換える。タイルのテクスチャのサブピクセル平行移動436は、1出力画素当たり1サイクルの平均時間で、2個の乗算ALU及び2個のアダーALUを使用して実行できる。サブピクセル平行移動からの出力は、順次書き込みイタレータ437へそのまま供給される。
テクスチャ置換コンポジット処理に要する時間は1画素当たり1サイクルである。テクスチャ値の100%が常に背景に貼り付けられるので、フィードバックは無い。したがって、チャンネルを特定の順序で処理する必要はない。
25%背景+タイルのテクスチャ
この例では、タイルからのテクスチャは既存テクスチャ値の25%に加えられる。新しい値は元の値以上でなければならない。その上、テクスチャチャンネルは8ビットしかないので、新しいテクスチャ値は255でクリップされる。利用されるプロセスは図108に示されている。
タイルのテクスチャのサブピクセル平行移動440は、1出力画素当たり1サイクルの平均時間で、2個の乗算ALU及び2個のアダーALUを使用して実行できる。サブピクセル平行移動440からの出力は、アダー441へ供給され、背景テクスチャ値の1/4
442に加算される。最小値及び最大値関数444は、サブピクセル平行移動のために使用されない2個のアダーによって設けられ、出力は順次書き込みイタレータ445に書き込まれる。
このスタイルのテクスチャコンポジット処理のために要する時間は1画素当たり1サイクルである。テクスチャ値の100%は、(たとえ、255でクリッピングされたとしても)背景に貼り付けられたと考えられるので、フィードバックは無い。したがって、チャンネルを特定の順序で処理する必要はない。
平均高さアルゴリズム
このテクスチャ貼り付けアルゴリズムでは、タイルに基づいて平均高さが計算され、各画像の高さは平均高さと比較される。画素の高さが平均よりも小さい場合、ストローク高さが背景高さに加えられる。画素の高さが平均以上である場合、ストローク高さが平均高さに加えられる。このようにして、背景ピークはストロークを細くする。この高さは、背景がストローク貼り付けを0まで細くすることを避けるため、最小限の量で増加するように拘束される(しかし、最小限の量は0になり得る)。高さは、テクスチャチャンネルが8ビット解像度であるため、255で切り取られる。
貼り付けられたテクスチャと貼り付けられる予測量との差のフィードバックが存在し得る。フィードバック量は、タイルの色の貼り付けの際に倍率として使用可能である。
両方のケースで、平均テクスチャは、ソフトウェアによって提供され、スケーリングされたテクスチャマップに関するバイレベル補間を実行することにより計算される。ソフトウェアは、現在のタイルが貼り付けられている間に、次のタイルの平均テクスチャ高さを決定する。ソフトウェアは、付加する最小限の厚さを与え、この最小限の厚さは、典型的に、タイル貼り付けプロセスの全体で一定である。
フィードバック無し
フィードバックが無い場合、テクスチャは、図109に示されるように、背景テクスチャに貼り付けられるだけである。
4個の順次イタレータが必要であり、これは、プロセスが1サイクルの間でパイプライン化できるならば、メモリの高速性が遅れないために十分であることを意味する。
タイルのテクスチャのサブピクセル平行移動450は、1出力画素当たり1サイクルの平均時間で、2個の乗算ALU及び2個のアダーALUを使用して実行できる。最小値及び最大値関数451、452は、1サイクル以内に全演算を完了するため、別個のアダーALUを必要とする。テクスチャのサブピクセル平行移動によって既に2が使用されているので、1サイクル平均時間のために十分な残り時間が無い。
したがって、1画素のテクスチャを処理するための平均時間は2サイクルである。フィードバックが存在せず、コンポジット処理のカラーチャンネルの順序は無関係であることに注意する必要がある。
フィードバック付き
これは、概念的にはフィードバック無しの場合と同じであるが、但し、標準的なテクスチャ貼り付けアルゴリズムの処理の他に、実際に貼り付けられたテクスチャの割合を記録しなければならない。この割合は、引き続きタイルの色を背景画像にコンポジット処理するための倍率として使用可能である。フローチャートは図110に示され、以下のルックアップテーブルが使用される。
ソフトウェアで設けられた1/Nテーブル460の256個のエントリーの各々は16ビットであり、連続して保持するため16個のキャッシュラインが必要である。
タイルのテクスチャのサブピクセル平行移動461は、1出力画素当たり1サイクルの平均時間で、2個の乗算ALU及び2個のアダーALUを使用して実行できる。最小値関数462及び最大値関数463の各々は、1サイクル以内に全演算を完了するため、別個のアダーALUを必要とする。テクスチャのサブピクセル平行移動によって既に2が使用されているので、1サイクル平均時間のために十分な残り時間が無い。
したがって、1画素のテクスチャを処理するための平均時間は2サイクルである。フィードバックデータエリア(タイルサイズの画像チャンネル)のために十分な空間を割り付けるべきである。テクスチャは、タイルの色が貼り付けられる前に貼り付けられるべきである。なぜならば、フィードバックがタイルの不透明度をスケーリングするため使用されるからである。
CCD画像インターポレータ
ISI83(図3)によってCCDから獲得される像は750×500画素である。像がISIによって撮影されたときのカメラの向きは、画像の上部が「上」に対応するように、画素を0、90、180又は270度回転させるために使用される。全ての画素は、(最大で3というよりも)R、G又はBカラーコンポーネントだけを有するので、これらが回転しているという事実は、画素値を解釈する際に考慮されなければならない。カメラの向きに応じて、2×2画素ブロックの各々は、図111に示されたコンフィギュレーションの何れかを有する。
CCD撮影された像を処理のために有用な形式に変換するために、CCD撮影された像に以下の幾つかの処理を行うことが必要である:
−CCD像の低サンプルレートカラーコンポーネントのアップ補間(画素の正しい向きを解釈);
RGBから内部色空間への色変換;
−750×500から1500×1000へ内部空間画像をスケーリング;
−プレーナーフォーマットで像を書き込み。
像のチャンネル全体は、ワーピングを可能にさせるため、同時に利用できることが必要である。小規模メモリモデル(8MB)の場合、一時的オブジェクトとして全解像度で単一のチャンネルを保持するための空間しかない。このため、色変換は単一のカラーチャンネルへの変換である。このプロセスに関する制約要因は色変換である。なぜならば、色変換は、RGBから内部色空間へのトライリニア補間を含み、このトライリニア補間は、1チャンネル当たり0.026ns(750×500×1画素当たり7サイクル×1サイクル当たり10ns=26250000ns)を要するプロセスだからである。
内部色空間画像をスケーリングする前に色変換を実行することが重要である。なぜならば、これは、スケーリングされる画素数(したがって、全体のプロセス時間)を4の倍率で削減するからである。
全ての変換に対する必要条件がALUスキームに当てはまる訳ではない。変換は、したがって、以下の二つのフェーズに分解される:
フェーズ1:CCD像の低サンプルレートカラーコンポーネントのアップ補間(画素の正しい向きを解釈);
RGBから内部色空間への色変換;
プレーナーフォーマットでの像の書き込み;
フェーズ2:750×500から1500×1000へ内部空間画像をスケーリング。
スケール関数の分離は、小さい色変換後の画像は大きい画像と同時にメモリ内に存在すべきであることを意味する。フェーズ1からの出力(0.5MB)は、通常、画像ピラミッド(1MB)のために確保されたメモリエリアに安全に書き込まれる。フェーズ2からの出力は、一般的な拡大されたCCD像である。スケーリングの分離によって、更に、スケーリングをアフィン変換によって実現することが可能になり、これは、簡単な1:2の拡大ではない様々なCCD解像度を許容する。
フェーズ1:低サンプルレートカラーコンポーネントのアップ補間
3カラーコンポーネント(R、G及びB)の各々は、所与の画素に対して色変換を実行するためアップ補間される必要がある。色変換は7サイクルを使用するので、補間を実行するため1画素当たりに7サイクルがある。
Gの補間は簡単であり、図112に示されている。向きに応じて、実際の画素値Gは、
奇数ライン上の奇数画素及び偶数ライン上の偶数画素と、偶数ライン上の奇数画素及び奇数ライン上の偶数画素との間で交互に代わる。両方のケースで、リニア補間が要求される全てである。Rコンポーネント及びBコンポーネントの補間は、図113及び図113に示されるようにもっと複雑である。なぜならば、水平方向及び垂直方向において、同図から分かるように、3行の画素に同時にアクセスすることが要求されるので、3個の順次読み出しイタレータが必要であり、各順次読み出しイタレータは単一行によってオフセットされる。その上、各行のためのラッチを用いて、同じ行の前の画素へアクセスする。
したがって、各画素は、CCDからの1個のコンポーネントと、他の2個のアップ補間されたコンポーネントと、を格納する。一方のコンポーネントがバイリニア補間されているとき、他方はリニア補間されている。補間係数は定数0.5であるため、補間は、加算及び1ビット右シフトによって(1サイクル以内に)計算することが可能であり、係数0.5のバイリニア補間は、3回の加算及び2ビット右シフト(3サイクル)によって計算可能である。必要な総サイクル数は、単一の乗算ALUを使用した場合4である。
図115は、回転0の偶数ライン偶数画素(EL,EP)及び奇数ライン奇数画素(OL,EP)のケースを示し、図116は、回転0の偶数ライン奇数画素(EL,OP)及び奇数ライン偶数画素(OL,OP)のケースを示している。他の回転は、これらの2個の表現の少し異なる形式である。
色変換
RGBからLabへの色空間変換は、汎用色空間変換関数に関して説明された方法と同じ方法を使用して実現され、1画素当たり8サイクルを要するプロセスである。フェーズ1の処理は図117を参照して説明される。
RGBのアップ補間は4サイクル(1個の乗算ALU)を必要とするが、色空間の変換は、ルックアップ転送時間のため、1画素当たり8サイクル(2個の乗算ALU)を必要とする。
フェーズ2
画像スケーリング
このフェーズは、CCD解像度(750×500)から作業用写真解像度(1500×1000)への画像のアップ補間と関係する。スケーリングは、1:2の縮尺のアフィン変換を実行させることにより行われる。汎用アフィン変換のタイミングは1出力画素当たり2サイクルであり、本ケースでは、0.03秒のスケーリング時間の経過を意味する。
画像照明
画像が処理された後、画像を一つ以上の光源によって照明することができる。光源は以下の何れの型でもよい:
1.指向性型−無限の距離があるので、単一方向へ平行光を投じる;
2.オムニ型−全方向へ非焦点光を投じる;
3.スポット型−特定の目標点へ焦点ビームを投光する。スポット光に関連した円錐及び半影部が存在する。
シーンは、反射角を変化させるため関連したバンプマップを有する。周辺光も選択的に照明されたシーンに存在する。
加速された照明のプロセスでは、単一の光源によって一つの画像チャンネルを照明することに関心がある。多数の光源を、1光源当たりに1パスの多数のパスとして、単一の画像チャンネルに適用することが可能である。多数のチャンネルは、バンプマップがある場
合も無い場合も、同時に一つずつ処理可能である。
ある画素における法線表面ベクトル(N)は、もし存在するならば、バンプマップから計算される。バンプマップが存在しない場合、デフォルト法線ベクトルは、画像面に垂直、即ち、N=[0,0,1]である。
ビューイングベクトルVは、常に、画像平面に垂直、即ち、V=[0,0,1]である。
指向性光源の場合、画素から光源への光源ベクトル(L)は、画像全体中で一定であり、画像全体に対して1回計算される。(有限の距離にある)オムニ光源の場合、光源ベクトルは、画素毎に独立に計算される。
周辺光の画素の反射は、IakaOdに従って計算される。
光源の画素の散乱及び鏡面反射は、Phongモデル:
fattIp[kdOd(N・L) + ksOs(R・V)n]
に従って計算される。
光源が無限大である場合、光源強度は画像全体に亘って一定である。
各光源は1画素当たりに3個の寄与度、即ち、
周辺光寄与度
散光寄与度
鏡面寄与度
を有する。
光源は以下の変数を用いて定義される。
同じ反射係数(k
a,k
s,k
d)がカラーコンポーネント毎に使用される。
所与の画素の値は、周辺光寄与と、各光の拡散寄与及び鏡面寄与の合計との和に一致する。
照明計算のサブプロセス
散光寄与度を計算するため、様々なその他の計算が必要である。それらの計算の中には、
1/ΔX
N
L
N・L
R・V
fatt
fcp
の計算が含まれる;
サブプロセスは、
周辺光
散光
鏡面
の寄与度を計算するためにも定義される。
サブプロセスは、光源の全体的な照度を計算するために使用できる。4個の乗算ALUしか存在しないので、特定のタイプの光源に対するマイクロコードは、性能のため適切に混ぜられたサブプロセスを含み得る。
1/√Xの計算
Vark照明モデルはベクトルを使用する。殆どの場合に、正規化の目的のため、ベクトルの長さの逆数を計算することが重要である。長さの逆数を計算するためには、1/([x]の平方根)の計算が必要である。
論理的に、このプロセスは、図118に示されるような入力及び出力を有するプロセスとして表現可能である。図119を参照すると、この計算は、推定値をルックアップし、次に、以下の関数:
Vn+1 = 1/2 Vn(3-XVn 2)
を1回繰り返すことによって行うことが可能である。
繰り返しの回数は、要求される精度に応じる。このケースでは、16ビットの精度が必要である。したがって、テーブルは、8ビットの精度であり、1回の繰り返しだけが必要である。以下の定数はソフトウェアによってセットされる。
Nの計算
Nは表面法線ベクトルである。バンプマップが存在しない場合、Nは一定である。バンプマップが存在する場合、Nは画素毎に計算しなければならない。
バンプマップ無し
バンプマップが無いとき、固定法線Nは、以下の性質、即ち、
N=[XN,YN,ZN]=[0,0,1]
||N||=1
1/||N||=1
正規化されたN=N
を有する。
これらの性質は、具体的に法線ベクトル及び1/||N||を計算する代わりに使用することが可能であり、他の計算を最適化することができる。
バンプマップ有り
図120に示されるように、バンプマップが存在する場合、Nは、X次元とY次元のバンプマップ値を比較することによって計算される。図120は、同じ行及び列における画素に関して画素P1に対するNの計算を示しているが、P1自体での値も含まれる。Nの計算は、スケール倍率(X及びYで同じ倍率)で乗算することにより、解像度に依存しないようにされる。このプロセスは、図121に示されるような入力及び出力(ZNは常に1である)を有するプロセスとして表現できる。
ZNは常に1である。XN及びYNは未だ正規化されていない(なぜならば、ZN=1である)。Nの正規化は、N.Lが計算されるまで遅延されるので、1/||N||による乗算は、3回ではなく1回である。
Nを計算する実際のプロセスは図122に示されている。
以下の定数がソフトウェアによってセットされる。
Lの計算
指向性光
光源が無限遠であるとき、光源は実効的な一定光ベクトルLを有する。Lは、
L=[X
L, Y
L, Z
L]
||L||=1
1/||L||=1
のようにソフトウェアによって正規化され、計算される。
これらの性質は、具体的にL及び1/||L||を計算する代わりに使用することが可能であり、他の計算を最適化することができる。このプロセスは図123に示されている。
オムニ光及びスポット光
光源が無限遠ではないとき、Lは現在点Pから光源PLまでのベクトルである。P=[XP,
YP, 0]であるため、Lは、
L=[XL, YL, ZL]
XL=XP−XPL
YL=YP−YPL
ZL=−ZPL
によって与えられる。1/||L||を乗算することにより、XL、YL、及びZLの各々を正規化する。(後で正規化の際に使用される)1/||L||の計算は、
V=XL 2+YL 2+ZL 2
を計算し、次に、
V−1/2
を計算することによって実行される。
このケースでは、Lの計算は、図124に示されるような入力及び出力を有するプロセスとして表現可能である。
XP及びYPは照度が計算されている画像の座標である、ZPは常に0である。
Lを計算する実際のプロセスは図125に示されている。
以下の定数がソフトウェアによってセットされる。
N.Lの計算
ベクトルNとベクトルLの内積の計算は、
X
NX
L+Y
NY
L+Z
NZ
L
によって定義される。
バンプマップ無し
バンプマップが無いとき、Nは一定[0,0,1]である。したがって、N.LはZLに簡約化される。
バンプマップ有り
バンプマップが存在するとき、内積を直接計算する必要がある。正規化されたNコンポーネントを取り込むのではなく、正規化されていないNと正規化されたLの内積を得た後に正規化を行う。Lは、(一定であるとき)ソフトウェアによって正規化されるか、又はL計算プロセスによって正規化される。このプロセスは図126に示されている。
ZNは、1になるように定義されているので、入力として不要である。しかし、その代わりに、結果を正規化するために1/||N||が必要とされる。N.Lを計算する実際の一プロセスは、図127に示されている。
R・Vの計算
R・Vは鏡面寄与度の計算への入力として必要である。V=[0,0,1]であるため、Zコンポーネントだけが必要である。したがって、R・Vは、
R・V=2ZN(N.L)−ZL
に簡約化される。
加えて、非正規化ZN=1であるため、正規化ZN=1/||N||である。
バンプマップ無し
最も簡単な実装は、Nが一定(即ち、バンプマップ無し)のときである。N及びVは定数であるため、N.L及びR・Vは、
V=[0, 0,
1]
N=[0, 0,
1]
L=[XL, YL, ZL]
N.L=ZL
R・V=2ZN(N.L)−ZL
=2ZL−ZL
=ZL
として簡単化される。
Lが一定(指向性光源)であるとき、正規化ZLは、R・Vが要求されるときに、定数の形で与えることができる。Lが変化するとき(オムニ光及びスポット光のとき)、正規化ZLはオンザフライ方式で計算しなければならない。それは、L計算プロセスの出力として獲得される。
バンプマップ有り
Nが一定ではないとき、R・Vを計算するプロセスは、一般化された式、即ち、
R・V=2ZN(N.L)−ZL
を実施するだけである。入力及び出力は図128に示され、実際の実装は図129に示されている。
減衰定数の計算
指向性光
光源が無限遠であるとき、光の強度は画像一面で変化しない。したがって、減衰定数fattは1である。この定数は、無限遠光源の照明計算を最適化するために使用可能である。
オムニ光及びスポット光
光源が無限遠ではないとき、光の強度は次式、
fatt=f0+f1/d+f2/d2
に従って変化する。
係数f0、f1及びf2を適切にセットすることにより、光強度を一定に、距離に関して線形に、或いは、距離の平方によって減衰させることができる。
d=||L||であるため、fattの計算は、図130に示されるような入力及び出力を有するプロセスとして表現可能である。
fattを計算する実際のプロセスは図131に定義される。
以下の定数がソフトウェアによってセットされる。
円錐及び半影ファクタの計算
指向性光及びオムニ光
これらの二つの光源は集光されないので、円錐又は半影を持たない。円錐−半影スケーリングファクタf
cpは1である。この定数は、指向性光源及びオムニ光源の照明計算を最適化するために使用できる。
スポット光
スポット光は特定の目標点(PT)に集光する。スポット光の強度は、像の特定の点が円錐内にあるか、半影にあるか、又は円錐/半影領域の外側にあるかによって変化する。
図132を参照すると、半影一に対するfcpのグラフが示されている。円錐の内部470でfcpは1であり、半影の外部471でfcpは0である。円錐のエッジから半影の終わりまで、光強度は3次関数472に従って変化する。
半影475及び円錐476の計算のための様々なベクトルが図133及び図134に示されている。
図134に示されているように1次元に関して像の表面を調べることにより、3個の角A、B及びCが定義される。Aは、目標点479と光源478と円錐の終端480の間の角度である。Cは、目標点479と光源478と半影の終端481の間の角度である。これらの両方は所与の光源に対して一定である。Bは、目標点479と光源478と計算対象一482の間の角度であり、像上で計算される点毎に変化する。
ここで、レンジAからCを0から1に正規化し、Bが、次式、
(B−A)/(C−A)
によってその角度レンジの間に収まる距離を見つける。
そのレンジは0から1のレンジに丸められ、この値は、fcpの3次近似のためのルックアップとして使用される。
したがって、fattの計算は、図135に示されるような入力及び出力を有するプロセスとして表現可能であり、fcpを計算する実際のプロセスは図136に示され、以下の定数がソフトウェアによってセットされる。
周辺光寄与の計算
像に当てられる光の数とは無関係に、周辺光寄与が各画素に対して1回ずつ実行され、バンプマップには依存しない。
周辺光計算プロセスは図131に示されるような入力及び出力を備えたプロセスとして表現可能である。このプロセスを実装するためには、図138に示されるように入力画像からの各画素(Od)を定数値(Iaka)によって乗算することが必要であり、以下の定数がソフトウェアによってセットされる。
散光寄与の計算
表面に当てられた各光は拡散照明を生じる。拡散照明は、次式、
散光=k
dO
d(N.L)
によって表される。2種類の実装形態を考えることができる。
実装例1−定数N及びL
N及びLの両方が定数であるとき(指向性光でバンプマップが無いとき)、
N.L=ZL
である。したがって、
散光=kdOdZL
である。
Odだけが変数であるため、散光寄与を計算する実際のプロセスは図139に示されるようなものであり、以下の定数がソフトウェアによってセットされる。
実装例2−非定数N及びL
N又はLの何れかが非定数であるとき(ビットマップ、又はオムニ光若しくはスポット光からの照明であるとき)、散光計算は、次式、
散光=k
dO
d(N.L)
に従って直接実行される。
散光計算プロセスは図140に示されるような入力を備えたプロセスとして表現可能である。N.Lは、N.L計算プロセスを使用して計算するか、又は定数として与えられる。散光寄与を計算する実際のプロセスは図141に示されるようなプロセスであり、以下の定数がソフトウェアによってセットされる。
鏡面寄与の計算
表面に当てられた各光は鏡面照明を生ずる。鏡面照明は、次式、
鏡面光= k
sO
s(R・V)
n
によって表される。ここで、
O
s=k
scO
d+(1−k
sc)I
p
である。
鏡面光計算プロセスは二つの実装形態がある。
実装例1−定数N及びL
第1の実装例は、N及びLの両方が定数であるとき(指向性光でバンプマップ無し)である。N、L及びVは一定であるので、N.L及びR・Vも一定である:
V=[0, 0,
1]
N=[0, 0,
1]
L=[XL, YL, ZL]
N.L=ZL
R・V=2ZN(N.L)−ZL
=2ZL−ZL
=ZL
このようにして、鏡面光計算は、
鏡面光=ksOsZL n
=ksZL n(kscOd+(1−ksc)Ip)
=kskscZL nOd+(1−ksc)IpksZL n
として簡略化される。
鏡面光計算ではOdだけが変数であるため、鏡面光寄与の計算は、図142に示されるような入力及び出力を備えたプロセスとして表現可能であり、鏡面光寄与を計算する実際のプロセスは図143に示され、以下の定数がソフトウェアによってセットされる。
実装例2−非定数N及びL
この実装例は、N又はLの何れかが一定ではないとき(ビットマップ、又はオムニ光若しくはスポット光からの照明であるとき)である。これは、R・Vを与える必要があることを意味し、R・V
nを計算しなければならない。
鏡面光計算プロセスは、図144に示されるような入力及び出力を備えたプロセスとして表現可能である。図145は、鏡面光寄与を計算する実際のプロセスを表し、以下の定数がソフトウェアによってセットされる。
周辺光が唯一の照明であるとき
周辺光寄与が唯一の光源である場合、このプロセスは非常に簡単である。なぜならば、図146に示されているようなプロセス全体で周辺光を加える必要がないからである。像は、垂直方向に二つの区画に分割し、周辺光ロジックを複製することにより、半分の各々を同時に処理することが可能である(このようにして、全部で2個の乗算ALU及び4個の順次イタレータを使用する)。したがって、タイミングは、周辺光を適用する1画素当たり1/2サイクルである。
典型的な照明のケースは、一つ以上の光によって照らされるシーンである。これらのケースでは、周辺光計算は非常に手軽であるため、周辺光計算は各光源の処理と共に収容される。処理されるべき最初の光は、正確なIaka設定値を持つべきであり、後続の光は、Iakaの値を0にすべきである(多重の周辺光寄与を避けるため)。
周辺光が別個のパスとして(第1のパスではなく)処理されるならば、周辺光を現在の計算値に加えることが必要である(同じアドレスへの読み書きが必要である)。プロセスの概要は図147に示されている。
このプロセスは、3個の像イタレータと1個の乗算ALUを使用し、平均で1画素当たり1サイクルを要する。
無限光源
無限光源のケースでは、像全体で一定の光源強度が得られる。L及びfattの両方は定数である。
バンプマップ無し
バンプマップが無いとき、一定法線ベクトルN[0,0,1]が存在する。照明の複雑さは、N、L及びfattが一定であることによって著しく軽減される。バンプマップ無しの単一の指向性光を当てるプロセスは図147に示され、以下の定数がソフトウェアによってセットされる。
単一の無限光源の場合、図148に示されるような論理演算を実行することが求められ、ここで、K
1からK
4は以下の値をもつ定数である。
このプロセスは、K
2、K
3及びK
4が定数であるため簡単化することができる。基本的に(乗算ALUのうちの3個を使用する)鏡面光寄与と散光寄与の計算が複雑であるため、周辺光計算を4番目の乗算ALUとして安全に加えることが可能である。処理される第1の無限光源は、真の周辺光パラメータI
ak
aを備え、後続の全ての無限光は、I
ak
aに0をセットすることができる。周辺光計算は実質的に無くなる。
無限光源が照射される第1の光である場合、他の光源による既存の寄与度を取り込む必要はなく、その状況は図149に示され、定数は以下の値をとる。
無限光源が照射される第1の光ではない場合、先行して処理された光によって生成された既存の寄与度を取り込む必要があり(同じ定数が当てはまる)、状況は図148に示されている。
第1のケースでは、2個の順次イタレータ490、491が必要であり、第2のケースでは、3個の順次イタレータ490、491、492が必要である(余分のイタレータは先行の光の寄与度を読み出すために必要である)。両方のケースで、バンプマップ無しの無限光源の適用は1画素当たり1サイクルを要し、オプションとして周辺光の適用が含まれる。
バンプマップ有り
バンプマップが存在するとき、法線ベクトルNは画素毎に計算することが必要であり、一定光源ベクトルLに適用される。1/||N||はR・Vを計算するために使用され、R・Vは鏡面光計算2プロセスへの入力として要求される。以下の定数がソフトウェアによってセットされる。
バンプマップ順次読み出しイタレータ490は、バンプマップの現在ラインを読み出す役割を担う。現在ラインは、Xに関するスロープを決定するため入力として与えられる。バンプマップ順次読み出しイタレータ491、492は、現在ラインの上下のラインを読み出す役割を担う。それらはYに関するスロープを決定するため入力を提供する。
オムニ光
オムニ光源のケースでは、光ベクトルL及び減衰定数fattは像の中で画素毎に変化する。したがって、L及びfattの両方は画素毎に計算しなければならない。
バンプマップ無し
バンプマップが無いとき、一定法線ベクトルN[0,0,1]が存在する。Lは画素毎に計算しなければならないが、N.L及びR・Vの両方は、ZLに簡単化される。バンプナップが無いとき、オムニ光の適用は図149に示されるように計算され、以下の定数がソフトウェアによってセットされる。
このアルゴリズムは、オプションとして、先行の光源からの寄与を取り込み、周辺光計算を含む。周辺光は1回だけ取り込めばよい。他の全ての光パスに対して、周辺光計算プロセスにおける適切な定数は0にセットされるべきである。
図示されるようなアルゴリズムは全部で19回の乗算/累算を必要とする。ルックアップのために必要な時間は、Lの計算中の1サイクルと、鏡面光寄与計算中の4サイクルである。したがって、5サイクルの処理時間が実現可能な最良のものである。その関数のためにALUを最適にマイクロコード化できない場合には、必要な時間は6サイクルまで増加する。オムニ光を関連したビットマップの無い像へ適用するための速度は1画素当たり6サイクルである。
バンプマップ有り
オムニ光が関連したバンプマップを備えた像に照射されるとき、N、L、N.L及びR・Vの計算は全てが必要である。オムニ光を関連したバンプマップを備えた像に適用するプロセスは図150に示され、以下の定数がソフトウェアによってセットされる。
このアルゴリズムは、オプションとして、先行の光源からの寄与を取り込み、周辺光計算を含む。周辺光は1回だけ取り込むことが必要である。他の全ての光パスに対し、周辺光計算プロセス内の適切な定数は0にセットされるべきである。
図示されるようなアルゴリズムは全部で32回の乗算/累算を必要とする。ルックアップのために要する時間は、LとNの両方の計算中に1サイクルずつと、鏡面光寄与計算のための4サイクルである。しかし、NとLのために必要なルックアップは同じである(したがって、2個のLUが3個のLUを実装する)。8サイクルの処理時間が適切である。その関数のためのALUを最適にマイクロコード化できない場合、必要な時間は9サイクルまで延長される。オムニ光を関連したビットマップ付きの像に適用する速度は1画素当たり9サイクルである。
スポット光
スポット光はオムニ光と類似しているが、減衰定数fattが、目標の周りに効率的に光を集める円錐/半影ファクタfcpによって変更されている点が相違する。
バンプマップ無し
バンプマップが無いとき、一定法線ベクトルN[0,0,1]が存在する。Lは画素毎に計算しなければならないが、N.L及びR・Vの両方は、ZLに簡単化される。図151は、像へのスポット光の照射の説明図であり、以下の定数がソフトウェアによってセットされる。
このアルゴリズムは、オプションとして、先行の光源からの寄与を取り込み、周辺光計算を含む。周辺光は1回だけ取り込めばよい。他の全ての光パスに対して、周辺光計算プロセスにおける適切な定数は0にセットされるべきである。
図示されるようなアルゴリズムは全部で30回の乗算/累算を必要とする。ルックアップのために必要な時間は、Lの計算中の1サイクルと、鏡面光寄与計算中の4サイクルと、円錐/半影計算における2組の4サイクルルックアップである。
バンプマップ有り
スポット光が関連したバンプマップを備えた像に照射されるとき、N、L、N.L及びR・Vの計算は全てが必要である。単一のスポット光を関連したバンプマップを備えた像に適用するプロセスは図152に示され、以下の定数がソフトウェアによってセットされる。
このアルゴリズムは、オプションとして、先行の光源からの寄与を取り込み、周辺光計算を含む。周辺光は1回だけ取り込むことが必要である。他の全ての光パスに対し、周辺光計算プロセス内の適切な定数は0にセットされるべきである。図示されるようなアルゴリズムは全部で41回の乗算/累算を必要とする。
プリントヘッド44
図153は、論理的に8セグメントにより構成され、各々がページの一部分に2層のシアン、マゼンタ、及びイエローを印刷する単一のプリントヘッドの論理的レイアウトの説明図である。
印刷用セグメントのローディング
何かを印刷する前に、プリントヘッドの8セグメントの各々は、最終出力画像における以下の相対的な行に対応した6行のデータがロードされなければならない:
行0=ラインN、イエロー、偶数ドット0、2、4、6,8、...
行1=ラインN+8、イエロー、奇数ドット1、3、5、7、...
行2=ラインN+10、マゼンタ、偶数ドット0、2、4、6,8、...
行3=ラインN+18、マゼンタ、奇数ドット1、3、5、7、...
行4=ラインN+20、シアン、偶数ドット0、2、4、6,8、...
行5=ラインN+28、シアン、奇数ドット1、3、5、7、...
各セグメントは、ページの異なる部分にドットを印刷する。各セグメントは、1色の750ドット、即ち、ある行に375個の偶数ドットと、別の行に375個の奇数ドットを印刷する。8個のセグメントは、位置に対応したドットを含む。
各ドットは、プリントヘッドセグメントに1ビットで表現される。データは、データをセグメントのBitValue(ビット値)ピンに置くことによって、同時に1ビットだけロードされ、BitClock(ビットクロック)に従ってそのセグメントのシフトレジスタへクロック供給されなければならない。データは単一のレジスタにロードされるので、ビットをローディングする順序は正しい筈である。データは10MHzの最大レートでプリントヘッドにクロック供給することができる。
全てのビットがロードされると、ビットはプリントヘッド出力バッファへ並列に転送され、印刷の準備が完了する。この転送はセグメントのParallelXferClockピン上の1個のパルスによって実行される。
印刷制御
電力を節約するため、プリントヘッドの全てを必ずしも同時に印刷しなくてもよい。制御ラインの組は、特定のドットの印刷を可能にさせる。ACPのような外部コントローラは、速度及び/又は電力の必要条件に応じて、同時に印刷されるドット数、並びに、プリントパルスの間隔を変更することが可能である。
各セグメントは、5本のNozzelSelect(ノズル選択)ラインを含み、ノズル選択ラインは1行当たり32組のノズルを選択するため復号化される。各行には375個のノズルがあるので、各組には12個のノズルがある。更に、色の偶数行と奇数行に1本ずつの、2本のBankEnable(バンクイネーブル)ラインが設けられる。最後に、各セグメントは、Cカラー、Mカラー及びYカラーの各々に1本ずつの、3本のColorEnable(カラーイネーブル)ラインを含む。あるColorEnableライン上のパルスは、カラーの指定行の指定されたノズルに印刷を行わせる。パルスは、典型的に、2
sの間隔である。
全てのセグメントが、NozzelSelectラインと、BankEnableラインと、ColorEnableライン(プリントヘッドへ外部から配線されている)の同じ組によって制御される場合、以下の事項が成立する。
奇数バンク及び偶数バンクの両方が同時に印刷をする場合(両方のBankEnableビットがセットされている場合)、1セグメント当たり24個のノズル、即ち、全部で192個のノズルが同時に発射し、5.7ワットを消費する。
奇数バンクと偶数バンクが独立に印刷をする場合、1セグメント当たり12個のノズルだけが、即ち、全部で96個が同時に発射し、2.85ワットを消費する。
印刷ヘッドインタフェース62
印刷ヘッドインタフェース62は、ACPをプリントヘッドに接続し、データと適切な信号の両方を外部プリントヘッドへ供給する。プリントヘッドインタフェース62は、VLIWプロセッサ74と、CPU上で実行されるソフトウェアアルゴリズムの両方と協働して動作し、約2秒のうちに写真を印刷する。
プリントヘッドインタフェースへの入出力の概要は図154に示されている。アドレス及びデータバスがCPUによって使用され、プリントヘッドインタフェースの種々のレジスタのアドレスを指定する。単一のBitClock出力ラインは、プリントヘッド上の8セグメントの全てに繋がる。8本のDataBits(データビット)ラインは、1本ずつが各セグメントに接続され、(BitClockパルスに基づいて)プリントヘッドの8セグメントへ同時にクロックインされる。例えば、同時に、ドット0はセグメント0へ転送され、ドット750はセグメント1へ転送され、ドット1500はセグメント2へ転送され、以下同様である。
VLIW出力FIFOは、ディザ処理された2レベルC、M及びYの6000×9000解像度印刷画像を、8本のDataBitsラインへ出力するために正しい順序で格納する。ParallelXferClockは、プリントヘッドの8セグメントの各々へ接続されるので、単一パルスによって、全てのセグメントがそれぞれのビットを同時に転送する。最後に、NozzleSelectライン、BankEnableライン及びColorEnableラインが8セグメントの各々へ接続され、プリントヘッドインタフェースは、C、M及びYドロップパルスの間隔、並びに、各パルスで印刷されるドロップの数を制御できるようになる。プリントヘッドインタフェースのレジスタは、0から6μsのパルス間隔、典型的に2μsの間隔を指定することができる。
画像印刷
画像がArtcamのユーザの管理下に置かれる前に、以下の2フェーズ、即ち、
1.印刷されるべき画像の準備
2.準備された画像の印刷
を行うことが必要である。
画像の準備は1回だけ実行すればよい。画像印刷は必要に応じて何回で実行できる。
画像準備
印刷用の画像の準備には、
1.写真画像の印刷画像への変換
2.プリンタの向きの出力に揃えるために印刷画像(内部色空間)の回転
3.(必要に応じて)圧縮されたチャンネルのアップ補間
4.内部色空間から特定のプリンタ及びインクに適したCMY色空間への色変換が含まれる。
画像準備の最後に、4.5MBの正しく向きを決められた1000×1500CMY色空間画像の印刷準備が完了する。
写真画像の印刷画像への変換
写真画像を印刷画像へ変換するためには、画像処理を実行するためVarkスクリプトを実行することが必要である。このスクリプトは、デフォルト画像強調スクリプト、又は現在挿入中のArtcardから取り出されたVarkスクリプトである。Varkスクリプトは、CPUによって実行され、VLIWベクトルプロセッサによって実行される関数で加速される。
印刷画像の回転
メモリ内の画像は、最初、上端が上向きになるように方向を合わされる。これにより、Vark処理を簡単にすることができる。画像が印刷される前に、画像は、プリントロールの向きと揃えられなければならない。再アライメントは1回だけ実行すればよい。印刷画像の引き続くプリントは、予め適切に回転されているであろう。
適用されるべき変換は、ユーザがArtcamの「撮像」ボタンを押したときに、CCDからの捕捉中に適用された変換の単に逆変換である。元の回転が0であるならば、変換は不要である。元の回転が+90度であるならば、印刷前に−90度(270度と同じである)回転する必要がある。この回転を適用するために使用される方法は、Vark加速されたアフィン変換関数である。アフィン変換エンジンは、各カラーチャンネルを独立に回転させるため呼び出される。カラーチャンネルは元の位置で回転できないことに注意する必要がある。その代わりに、カラーチャンネルは、拡大された単一チャンネル(1.5MB)のために先に使用されたスペースを利用することが可能である。
図155は、Lab画像の回転の一例の説明図であり、aチャンネル及びbチャンネルは4:1に圧縮されている。Lチャンネルは、不要になったスペース(単一チャンネルエリア)へ回転させられ、次に、aチャンネルは、Lの後に残された空きスペースに回転させられ、最後に、bを回転させることができる。三つのチャンネルを回転するために要する総時間は0.09秒である。これは、最初の画像印刷の前に許容可能な時間の経過である。後続のプリントは、このオーバーヘッドを生じない。
アップ補間及び色変換
Lab画像は、印刷前にCMYへ変換しなければならない。Lab画像のaチャンネル及びbチャンネルが圧縮されているかどうかに応じて、様々な処理が行われる。Lab画像が圧縮されているならば、aチャンネル及びbチャンネルは色変換が行われる前に伸長されなければならない。Lab画像が圧縮されていないならば、色変換は唯一の必要なステップである。Lab画像は、(aチャンネル及びbチャンネルが圧縮されているならば)アップ補間し、CMY画像へ変換される。スケール及び色変換を組み合わせた単一のVLIWプロセスを使用することができる。
色変換を実行するために使用される方法は、Vark加速型色変換関数である。アフィン変換エンジンは、各カラーチャンネルを独立に回転させるため呼び出し可能である。カラーチャンネルはそのままの位置で回転できない。その代わりに、カラーチャンネルは拡大された単一チャンネル(1.5MB)のために先に使用されたスペースを利用することが可能である。
画像印刷処理
画像印刷処理は、正しい向きに置かれた1000×1500CMY画像を取り込み、外部プリントヘッドへ送信されるべきデータ及び信号を生成することに関係する。このプロセスは、VLIWプロセス及びプリントヘッドインタフェースと協働するCPUを必要とする。
Artcam内の画像の解像度は1000×1500である。印刷された画像は、6000×9000ドットの解像度があり、非常に簡単な関係:1画素=6×6=36ドットが得られる。図156に示されるように、各ドットは16.6μmであるため、6×6平方ドットは100平方μmである。各ドットは2レベルであるため、出力をディザ処理する必要がある。
画像は約2秒で印刷されるべきである。9000行のドットの場合、これは、各行を印刷する間の時間が222μsの時間であることを意味する。プリントヘッドインタフェースは、この時間内に6000ドットを生成しなければならず、平均して1ドット毎に37nsである。しかし、各ドットは3色により構成されるので、プリントヘッドインタフェースは、約12ns内に、即ち、ACPの1クロックサイクル(100MHzで10ns)のうちに各カラーコンポーネントを生成しなければならない。一つのVLIWプロセスは、印刷されるべき次の6000ドットのラインを計算する役割を担う。奇数と偶数のC、M及びYドットは、6種類の1000×1500画像ラインからの入力をディザ処理することによって生成される。第2のVLIWプロセスは、先に計算された6000ドットのラインを取り込み、1回の転送でプリントヘッドインタフェースからプリントヘッドへ転送されるべき8個のセグメントのための8ビットのデータを正確に生成する役割がある。
CPUプロセスは、プリントライン毎に3回ずつ(1カラーコンポーネント当たり1回ずつ=2秒間に27000回)第1のVLIWプロセス3内のレジスタを更新し、第2のVLIWプロセス内のレジスタをプリントライン毎に1回ずつ(2秒間に9000回)更新する。CPUは、これを行うために、VLIWプロセスよりも1ラインだけ先に進んでいる。
最後に、プリントヘッドインタフェースは、VLIW出力FIFOから8ビットデータを取り込み、それをそのままプリントヘッドへ出力し、BitClock信号を適切に生成する。全てのデータの転送が終わった後、ParallelXferClock信号が次のプリントラインのデータをロードするため生成される。データのプリントヘッドへの転送と連動して、別個のタイマーが、プリントヘッドインタフェース内部レジスタによって指定されたNozzleSelectライン、ColorEnableライン及びBankEnableラインを使用して、プリントヘッドの異なるプリントサイクルのための信号を生成する。
更に、CPUは、印刷プロセス中にパラレルインタフェースを介して種々のモーター及び裁断機を制御する。
C、M及びYドット生成
このプロセスへの入力は、印刷のため正しい向きに置かれた1000×1500CMY画像である。この画像は圧縮されていない。図157に示されるように、VLIWマイクロコードプログラムは、CMY画像を取り込み、プリントヘッドインタフェースによって要求された、ディザ処理されるC、M及びY画素を生成する。
このプロセスは、三つのカラーコンポーネントの各々に対して1回ずつの3回実行される。このプロセスは、並列に実行される二つのサブプロセスを含未、一方は奇数ドットを生成し、他方は偶数ドットを生成する。各サブプロセスは入力画像から1画素を取り込み、3個の出力ドットを生成する(なぜならば、1画素=6出力ドットであり、各サブプロセスは偶数ドットと奇数ドットの何れかに関連しているからである)。1個の出力ドットが1サイクル毎に生成されるが、入力画素は3サイクル毎に1回だけ読み出される。
元のディザセルは64×64形のセルであり、各エントリーは8ビットである。この元のセルは、奇数セルと偶数セルに分割されるので、各々は64の高さのままであるが、32エントリーの幅しかない。偶数ディザセルは、元のディザセル画素0、2、4等を格納し、一方、奇数ディザセルは、元のディザセル画素1、3、5等を格納する。ディザセルはラインを超えて繰り返されるので、2個のディザセルの各々の単一の32バイトラインは、ライン全体の間に必要であり、したがって、完全にキャッシュすることができる。単一のプロセスラインのうちの奇数ライン及び偶数ラインは、8ドットラインだけ離して交互にされるので、奇数ディザセルの8ライン毎に回転させることが好都合である。したがって、奇数ディザセルと偶数ディザセルの両方に同じオフセットを使用することが可能である。この結果として、偶数ディザセルのラインは元のディザセルのラインLの偶数エントリーに対応し、奇数ディザセルのラインは元のディザセルのラインL+8の奇数エントリーに対応する。
このプロセスは、カラーコンポーネントの各々に対して1回ずつの3回実行される。CPUソフトウェアルーチンは、奇数ライン及び偶数ライン用の順次読み出しイタレータがプリントヘッドに対応した正しい画像ラインを確実に指定しなければならない。例えば、1組の18000ドット(3組の6000ドット)を生成するため、
・イエロー偶数ドットライン=0、したがって、入力イエロー画像ライン=0/6=0
・イエロー奇数ドットライン=8、したがって、入力イエロー画像ライン=8/6=1
・マゼンタ偶数ドットライン=10、したがって、入力マゼンタ画像ライン=10/6=1
・マゼンタ奇数ドットライン=18、したがって、入力マゼンタ画像ライン=18/6=3
・シアン偶数ドットライン=20、したがって、入力シアン画像ライン=20/6=3
・シアン奇数ドットライン=28、したがって、入力シアン画像ライン=28/6=4
である。この後に続く入力画像ラインの組は、
・Y=[0,1], M=[1,3], C=[3,4]
・Y=[0,1], M=[1,3], C=[3,4]
・Y=[0,1], M=[2,3], C=[3,5]
・Y=[0,1], M=[2,3], C=[3,5]
・Y=[0,2], M=[2,3], C=[4,5]
である。
しかし、ディザセルデータはカラーコンポーネント毎に更新しなくてもよい。3カラーのディザセルは同じになるが、コンポーネント毎に2ドットラインずつオフセットしている。
ディザ処理された出力は順次書き込みイタレータに書き込まれ、奇数及び偶数のディザ処理されたドットは2個の別々の出力に書き込まれる。同じ2個の書き込みイタレータが3個の全てのカラーコンポーネントに対して使用されるので、それらは、奇数及び偶数ドットの分割の範囲内で連続的である。
1組のドットがプリントラインに対して生成される間に、先に生成されたドットの組が、次のセクションで説明されるような第2のVLIWプロセスによって併合される。
併合8ビットドット出力生成
このプロセスは、図158に示されるように、1ラインのディザ処理されたドットを取り込み、VLIW出力FIFOを介してプリントヘッドインタフェースへ出力するための8ビットのデータストリームを生成する。このプロセスは、ライン全体が準備されることを必要とする。なぜならば、このプロセスは、ディザ処理されたラインの殆どを同時に準ランダムアクセスする必要があるからである。以下の定数がソフトウェアによってセットされる。
順次読み出しイタレータは、前に生成されたドットのラインを指定し、イタレータのレジスタは単一カラーコンポーネントへのアクセスを制限するためセットアップされている。後続の画素の間の距離は375であり、あるラインと次のラインとの間の距離は1バイトになるように与えられる。その結果として、8個のエントリーが「ライン」毎に読み出される。単一の「ライン」は、プリントヘッドへロードされる8ビットに対応する。画像の「ライン」総数は375にセットされる。少なくとも8個のキャッシュラインを順次読み出しイタレータに割り当てることにより、完全なキャッシュコヒーレンスが維持される。8ビットをカウントする代わりに、8個のマイクロコードステップが暗黙的にカウントを行う。
生成プロセスは、最初に、偶数ドットから全てのエントリーを読み出し、8個のエントリーを1バイトに合成し、その1バイトをVLIW出力FIFOへ出力する。3000個の全部の偶数ドットが読み出された後、3000個の奇数ドットが読み出され、処理される。ソフトウェアルーチンは、1カラーコンポーネント毎に1回ずつ、即ち、1ライン毎に3回ずつ奇数及び偶数の順次読み出しイタレータのドットのアドレスを更新しなければならない。二つのVLIWプロセスは、全部で8個のALUとVLIW出力FIFOを必要とする。CPUが上述のように二つのプロセスでレジスタを更新できる限り、VLIWプロセッサは、プリンタに追従するために十分な速さでディザ処理された画像ドットを生成し得る。
データカードリーダー
図159は、読み出すためArtcard9を挿入することができるカードリーダー500の一形態を示す図である。図158は図159のリーダーの分解斜視図である。カードリーダーはコンピュータシステムに相互連結され、CCD読み出し機構35を含む。カードリーダーは、挿入されたArtcard9を挟むピンチローラー506及び507を含む。一方のローラー、例えば、ローラー506は、二つのローラー506及び507の間のカード9を一様な速度で前進させるためのArtcardモーター37によって駆動される。Artcard9は、一連のLEDライト512の上を通過させられ、一連のLEDライトは、半円形の断面を有する透明なプラスチックモールド514内に収容される。この断面は、例えば、LED512からの光を、カード9がLED512の傍を通過するときに、カード9の表面に集める。その表面から、光は、約480dpiの解像度に構成された高解像度リニアCCD34へ反射される。Artcard9の表面は、約1600dpiのレベルまでエンコードされているので、リニアCCD34は、約3倍の乗数でArtcard表面をスーパーサンプルする。Artcard9は、リニアCCD34が1インチ当たり約4800回の読み出しのレートでArtcardの移動方向にスーパーサンプルできるような速度で更に駆動される。走査されたArtcardのCCDデータはArtcardリーダーからACP31へ送られ処理される。光センサにより構成できるセンサ49は、カード13の有無を検出するために機能する。
CCDリーダーは、下側基板516と、透明な成形されたプラスチックを含む上側基板514と、を有する。二つの基板の間に、半導体製造プロセスによって製作された薄く長いリニアCCDアレイを含むリニアCCDアレイ34が挿入される。
図160を参照すると、CCDリーダーユニットの一構成例の部分断面斜視側面図が示されている。一連のLED、例えば、LED512は、カード9がCCDリーダー34の表面を通過するときに発光するように動作する。放出された光は、上側基板523の一部分を透過する。この基板は、LED512から放出された光を、カード9上の表面上の点、例えば、点532に集めるように湾曲した周囲を有する部分、例えば、部分529を含む。焦点が合わされた光は、点532から、CCDアレイ34の方へ反射される。誇張されて示された一連のマイクロレンズ、例えば、マイクロレンズ534は、上側基板523の表面に形成される。マイクロレンズ523は、表面全体から受光した光を、CCDアレイ34の感光部に入射する光を検知するCCDリーダー34の表面上の点に対応した下の焦点536に集めるように作用する。
上記の装置には多数の改良が考えられる。例えば、リニアCCD34上の感知デバイスは千鳥状でもよい。対応したマイクロレンズ34は、千鳥状のCCDセンサに対応するように、光を千鳥状の一連のスポットへ集光させるために相応に形成することができる。
読み出しを助けるため、Artcard9のデータ表面エリアは、図38を参照して既に説明したように、チェッカー盤のようなパターンで変調させてもよい。その他の形態の高周波変調も実現可能である。
Artcardプリンタが記憶装置Artcard上のデータをプリントアウトするものとして提供できることは明らかである。したがって、Artcardシステムは、Artcam装置の外部に情報を配信する一般的な形態として利用することが可能である。Artcardプリンタは、Artcardを高品質印刷面にプリントアウトすることが可能であり、多数のArtcardを同じ用紙に印刷し、後で分離することができる。Artcard9の第2の面には、引き続く記憶のために、Artcard9に記憶されたファイル等に関する情報を印刷することができる。
したがって、Artcardシステムは、CD−ROM、磁気ディスク等の他の形態の記憶装置の代わりに使用するために適した簡単化された形態の記憶装置を可能にさせる。Artcard9は、大量生産可能であり、そのため、再分配用に実質的に低価格の形態で生産できる。
プリントロール
図162には、Artcamのプリントロール42及びプリントヘッド部が示されている。用紙/フィルム611は、連続した「ウェブのような」プロセスで、印刷機構15へ送られ、印刷機構15は、更なるピンチローラー616−619、及びプリントヘッド44を含む。
ピンチローラー613は、駆動機構(図示せず)に連結され、プリントローラー613の回転時に、フィルム611の形態の「用紙」は、印刷機構615の中へ通され、ピクチャー出力スロット6から出される。回転式裁断機構(図示せず)は、要求された写真サイズで用紙611のロールを切断するために利用される。
したがって、プリンタロール42は、写真用にイメージ化されたピクチャーを印刷する印刷機構615に「用紙」611を供給する役割を果たすことが明白である。
図163には、プリントロール42の分解斜視図が示されている。プリントロール42は、ピンチローラー612、613の動作の下で出力される出力プリンタ用紙611を含む。
次に、図164には、「用紙」フィルムロールが除かれた図163のプリントロール42のより完全な分解斜視図が示されている。プリントロール42は、インク貯蔵セクション620、用紙ロールセクション622、623、及び外側ケーシングセクション626、627からなる三つの主要部品を含む。
最初にインク貯蔵セクション620を参照すると、インクリザーバ又はインク供給セクション633が設けられている。印刷用インクは、三つのブラダー型の容器630から632に収容される。プリンタロール42は、フルカラー出力インクを提供するものとする。したがって、第1のインクリザーバ又はブラダー容器630はシアン色インクを収容する。第2のリザーバ631はマゼンタ色インクを収容し、第3のリザーバ632はイエロー色インクを収容する。リザーバ630から632の各々は、容積寸法が異なっているかもしれないが、実質的に同じ容積サイズを有するように設計される。
インク貯蔵セクション621、633は、カバー624と共に、プラスチックセクションから製作することが可能であり、ヒートシール、紫外線照射等を用いて一体的にできるように設計される。サイズが等しくされたインクリザーバ630から632の各々は、対応したインクチャンネル639から641に連結され、リザーバ630から632より対応したインク出力ポート635から637へのインクの流れを可能にさせる。インクリザーバ632はインクチャンネル641及び出力ポート637を具備し、インクリザーバ631はインクチャンネル640及び出力ポート636を具備し、インクリザーバ630はインクチャンネル639及び出力ポート7637を具備する。
動作中に、インクリザーバ630から632は、対応したインクで充たされ、セクション633はセクション621に接合される。インク貯蔵セクション630から632は、折り畳み可能なブラダーでもよく、インクがインクチャンネル639−641を行き来できるようにさせ、インク出力ポート635から637と流体的に連通される。更に、必要に応じて、空気取り入れ口が設けられ、インクチャンネルリザーバ630から632に関連した圧力を要求通りに維持することができる。
キャップ624は、空気圧取り入れ口からアクセス可能な加圧型キャビティを形成するため、インク貯蔵セクション620に接合することができる。
インク貯蔵セクション621、633及び624は、一体的なユニットとして一つに連結され、プリンタロールセクション622、623の内側へ挿入できるように設計される。プリンタロールセクション622、623は、対応したメス型部分(図示せず)と結合するオス型部分645から647を用いてスナップフィットによって一体的に結合されるように設計される。同様に、メス型部分654から656は、対応したオス型部分660から662と結合するように設計される。用紙ロールセクション622、623は、したがって、一体的にスナップで留められるように設計される。ロール内のフィルムの一端は、二つのセクション622、623が一つに接合されたとき、二つのセクション622、623の間で締め付けられる。プリントフィルムは、必要に応じて、プリントロールセクション622、625上で回転させることができる。
前述の通り、インク貯蔵セクション620、621、633、624は、用紙ロールセクション622、623の内側に挿入できるように設計される。プリンタロールセクション622、623は、オンデマンドでフィルムを与えるため、静止したインク貯蔵セクション621、633及び624の周りで回転することができる。
外側ケーシングセクション626及び627は、更に、プリントロールセクション622、623の周りで結合できるように設計される。更に、ピンチローラー、例えば、612、613のそれぞれの端は、カバー626、627内で対応したキャビティ、例えば、670に留められるように設計され、ローラー613は、プリントフィルムを供給し、プリントロールから排出するため外部(図示せず)から駆動される。
最後に、キャビティ677は、プリントロール42に関連した情報を記憶するためのシリコンチップ集積回路型装置53を挿入し案内するため、インク貯蔵セクション620、621に設けることが可能である。
図155及び図164に示されるように、プリントロール42は、Artcamカメラ装置に挿入され、カップリングユニット680と結合するように設計され、カップリングユニット680は、シリコンチップ53との配線を行うコネクタパッド681を含む。更に、コネクタ680は、インク供給ポート635から637との4個の接続用のエンドコネクタを含む。インク供給ポートは、次に、インク供給ライン、例えば、682へ接続され、インク供給ラインは、次に、プリントヘッド供給ポート、例えば、687へ相互連結され、必要に応じてインクをプリントヘッド44へ流す。
ロールを形成するため利用される「メディア」611は、適当な画像を上に印刷するために設計された様々な材料により構成することが可能である。例えば、不透明な回転可能なプラスチック材料が利用され、透明なプラスチックシートを使用することにより透明性が使用され、メタリックシートフィルムの利用によってメタリック印刷が行われ得る。更に、プリンタロール42内に布を利用し、布に画像を印刷することも可能であるが、適当な剛性又は適当な裏当てを有する材料だけが利用できることに注意する必要がある。
印刷メディアがプラスチックであるとき、インクを定着させ、吸収する層でその印刷メディアを覆うことが可能である。更に、幾つかのタイプの印刷メディア、例えば、不透明白色マット、透明フィルム、艶消し透明フィルム、3次元立体印刷用のレンチキュラーアレイフィルム、金属化フィルム、格子又はホログラムのようなエンボス方式の光学的に可変のデバイス、裏面に予め印刷が施されたメディア、及び磁気記録層を含むメディア、を使用できる。金属泊を利用するとき、金属泊は、ポリマーベースをもつことが可能であり、薄い(数ミクロンの)アルミニウム又はその他の金属の蒸着層で覆われ、次に、インクプリンタ機構を介してインクを受容するように適合した透明な保護層で覆われる。
使用されるプリントロール42は、カメラ装置の内部に挿入され、要求に応じて画像の印刷用のインク及び用紙を提供できるように設計される。インク出力ポート635から637は、カメラ装置内の対応したポートと適合する。ピンチローラー672、673は、カメラ装置の制御下で用紙をカメラ装置へ供給できるように作動される。
図164に示されるように、実装されたシリコンチップ53は、プリントロール42の一方の端に挿入される。図165では、認証チップ53がより詳細に示され、この認証チップ53は、チップ53からチップが挿入されている対応したカメラへ詳細を通信する4本の通信リード線680から683を含む。
図165を参照すると、チップは、小型集積回路687をエポキシに入れ、ボンディングリード線、例えば、688を外部通信リード線680から683へ繋ぐことにより、単独で作成され得る。集積チップ687は、約400平方ミクロンであり、スクライブ境界は100ミクロンである。続いて、チップは、プリントロール42のキャビティの適切な表面に貼り付けられる。図165の装置の分解図である図166には、ボンディングパッド681、682に相互連結された集積回路67が示されている。
図164Aから164Eにおいて、参照番号1100は、全体的にプリントカートリッジ1100を示す。プリントカートリッジ1100は、本発明によれば、インクカートリッジ1102を含む。
プリントカートリッジ1100はハウジング1104を含む。図2により詳細に示されているように、ハウジング1104は、上側成形部品1106及び下側成形部品1108によって画成される。成形部品1106及び1108は、クリップ1110によって挟まれる。ハウジング1104はラベル1112によって被われ、ラベル1112はカートリッジ1100に魅力的な外観を与える。ラベル1112は、ユーザがカートリッジ1100を使えるようにするための情報を搭載する。
ハウジング1104はチャンバー1114を画成し、チャンバー内にインクカートリッジ1102が収まる。インクカートリッジ1102は、ハウジング1104のチャンバー1114に固定して担持される。
フォーマーに巻き付けられたフィルム/メディア1118のロール1126を含むプリントメディア1116の補給品はハウジング1104のチャンバー1114に収容される。フォーマー1120は、インクカートリッジ1102に摺動自在に収容され、インクカートリッジに対して回転自在である。
図164Bに示されるように、上側成形部品1106及び下側成形部品1108は一体としてクリップされ、出口スロット1122が画成され、用紙1118の舌状部は出口スロットを通して排出される。
カートリッジ1100はローラー組立体1124を含み、ローラー組立体1124は、用紙1118がロール1126から供給されるときに用紙1118のカールを取り除くために役立ち、スロット1122を介して用紙1118を押し出すために役立つ。ローラー組立体1124は、駆動ローラー1128と、2個の従動ローラー1130と、を含む。従動ローラー1130は、リブ1132に回転自在に支持され、リブ1132は、ハウジング1104の下側成形部品1108のフロア1134から盛り上がっている。ローラー1130は、駆動ローラー1128と一体となって、用紙1118がハウジング1104から排出されるときに、用紙1118の速度及び位置を制御するため、用紙1118に正のトラクションを与える。ローラー1130は、ポリスチレンのような適当な合成プラスチック材料の射出成形部品である。この点に関して、上側成形部品1106及び下側成形部品1108は、同様に、ポリスチレンのような適当な合成プラスチック材料の射出成形部品である。
駆動ローラー1128は、ハウジング1104の上側成形部品1106及び下側成形部品1108の各々の側壁に画成された合わせリセス1138及び1140の間に回転自在式に係留されている駆動シャフト1136を含む。駆動ローラー1128の反対側の端1142は、ハウジング1140の上側成形部品1106と下側成形部品1108に適当な構成(図示せず)で回転自在に保持されている。
駆動ローラー1128は、ツーショット射出成形部品であり、高衝撃ポリスチレン製のシャフト1136を含み、シャフト1136の上に、エラストマ又はゴムローラー部分1144の形をした軸受手段が成形されている。これらの部分1144は、用紙1118を確実に係止し、用紙1118がカートリッジ1100から供給されるときに、用紙1118の滑りを防止する。
ハウジング1104から突起するローラー1128の端は、十字形構造体1146(図164A)の形をした係合体を有し、この十字形構造体は、プリントカートリッジ1100が取り付けられるカメラのような装置のプリントヘッド組立体の歯車付き駆動インタフェース(図示せず)と結合する。この構造体は、用紙1118がプリントヘッドに供給される速度を、プリントヘッドによる印刷と確実に同期させるので、インクが用紙1118上で正確に位置合わせされることを保証する。
インクカートリッジ1102は、直円柱押出成形部品の形をした容器1148を含む。この容器1148は、ポリスチレンのような適当な合成プラスチック材料から押出成形される。
本発明の好適な実施形態において、プリントカートリッジ1100が共に使用されるプリントヘッドは、多色プリントヘッドである。したがって、容器1148は、複数の、より詳細には、4個のコンパートメント、即ち、リザーバ1150に分割される。各リザーバ1150は、異なる色、又は異なるタイプのインクを収容する。一実施形態では、リザーバ1150に収容されるインクは、シアンインク、マゼンタインク、イエローインク、及びブラックインクである。本発明の他の実施形態では、3種類の有色インクであるシアンインク、マゼンタインク及びイエローインクがリザーバ1150のうちの3個に収容され、4番目のリザーバ1150は、赤外線スペクトルだけで可視化されるインクを収容する。
図164C及び164Dに明瞭に示されているように、容器1148の一端は、エンドキャップ1152によって閉じられる。エンドキャップ1152は複数の開口1154が画成されている。開口1154は各リザーバ1150と関連付けられているので、エンドキャップ1152が設けられた容器1148の端でリザーバ1150内は大気圧で維持される。
シール構造体1156は、エンドキャップ1152が設けられている端側で容器1148に設けられる。シール構造体1156は、各リザーバ1150に摺動自在に受容されたゲル状材料からなる四分円形ペレット1158を含む。ペレット1158のゲル状材料は、熱硬化性ゴムと炭化水素からなる化合物である。炭化水素は白色鉱物油である。熱硬化性ゴムは、ペレット1158が通常の動作温度でその形状を維持し、同時に、ペレット1158がその関連したリザーバ1150内で摺動できるように、鉱物油に十分な剛性を与える共重合体である。適当な熱硬化性ゴムは、シェル石油会社によって「Karton」(登録商標)の名前で販売されている熱硬化性ゴムである。共重合体は、ゲルのような粘度を各ペレット1158に与えるために十分な量でその化合物内に存在する。典型的に、共重合体は、使用されるタイプに応じて、約3%から20%の重量パーセントの量で存在するであろう。
使用中に、この化合物は加熱され、その結果として流体になる。各リザーバ1150に特定のタイプのインクが詰められると、溶融状態の化合物は各リザーバ1150に注入され、化合物はペレット1158を形成するため固まる。ペレット1158の裏側の大気圧、即ち、エンドキャップ1152と向かい合うペレットの端における大気圧は、インクがリザーバ1150から引き出されるときに、自動注油式であるペレット1148が容器1148の反対側へ向かって滑ることを保証する。ペレット1158は、逆さにされた容器からインクが出て空になることを止め、リザーバ1150内のインクが汚れることを妨げ、リザーバ1150内のインクが乾燥することを妨げる。更に、ペレット1158は、リザーバ1150からのインクの漏れを防止するため疎水性である。
容器1148の反対側の端は、インク鍔成形部品1160によって閉じられる。成形部品1160に支持されたバッフル1162は、エラストマーシール成形部品1164を受容する。疎水性であるエラストマーシール成形部品1164は、内部にシーリング幕1166が画成されている。各シーリング幕1166にはスリット1168が設けられているので、プリントヘッド組立体からの合わせピン(図示せず)は、スリット1168を通して挿入可能であり、容器1148のリザーバ1150と流体的に連通される。中空突起1170は、インク鍔成形部品1160の反対側から突起する。各突起1170は、関連したリザーバ1150とぴったり合うように成形され、インク鍔成形部品を容器1148の端に位置決めする。
図164Cを参照すると、インク鍔成形部品1160は、キャリア又は隠し板成形部品1172によって正しい位置に維持される。隠し板成形部品1172には、四つ葉のクローバー形状の窓1174が画成され、この窓1174を介して、エラストマーシール成形部品1164へアクセスすることができる。隠し板成形部品1172は、ハウジング1104の上側成形部品1106と下側成形部品1108との間に係留される。隠し板成形部品1174と、ハウジング1104の上側成形部品1106及び下側成形部品1108のそれぞれの内面から延びるウェブ1176及び1178は、コンパートメント1180を画成する。エアーフィルタ1182はコンパートメント1180に収容され、端部成形部品1174によって正しい位置に保たれる。エアーフィルタ1182はプリントヘッド組立体と協働する。エアーは、プリントヘッド組立体のノズルガードの至る所へ吹き付けられ、ノズルガードのクリーニングを行う。このエアーは、隠し板1172内の入口側開口1184に収容されたピン(図示せず)を用いてエアーフィルタ1182を通して引き出すことによって濾過される。
エアーフィルタ1182は、図164Eに更に詳細に示されている。エアーフィルタ1182はフィルタ媒体1192を含む。フィルタ媒体1192は、合成ファイバに基づくものであり、フィルタリング目的のため利用可能な表面積を増加させるため溝付きの形で配置される。紙ベースのフィルタ媒体1192の代わりに、他の繊維性芯材を使用してもよい。
フィルタ媒体1192は密閉容器1194に収容される。密閉容器1194は、底成形部品1196及び蓋1198を含む。ハウジング1104のコンパートメント1180に収容するために、密閉容器1194は、部分的に環状、即ち、馬蹄形にされる。このようにして、密閉容器1194は、一対の対向端1200を有する。吸気開口1202が各端1200に画成される。
排気開口1204は蓋1198に画成される。排気開口1204は、最初、フィルム、又は膜1206によって閉鎖されている。フィルタ1182がコンパートメント1180の正しい位置に取り付けられたとき、排気開口1204は隠し板成形部品1172の開口1184と位置合わせされる。プリントヘッド組立体からのピンがフィルム1206を貫通し、エアーがノズルガードとプリントヘッド組立体のプリントヘッドに吹き付けられる前に、エアーフィルタ1182を介して雰囲気からエアーを引き込む。
底成形部品1194は、密閉容器1194の正しい位置にフィルタ媒体1192を設置するための位置決め構造体1208及び1210を含む。位置決め構造体1208は複数のピンの形をなし、一方、位置決め構造体1210は、フィルタ媒体1192の端1214を係止するリブの形をしている。
フィルタ媒体1192が底成形部品1196の正しい位置に設置された後、蓋1198は、蓋1198で底成形部品1196を密閉するため超音波溶接、又は類似した方法によって、底成形部品1196に固定される。
プリントカートリッジ1100が組み立てられたとき、膜又はフィルム1186は、窓1174を閉鎖するために隠れ板成形部品1172の外側端に被せられる。この膜又はフィルム1186は、使用するために、ピンによって孔を開けられ、又は破裂されられる。フィルム1186は、破片がインクリザーバ1150に侵入することを防止する。
認証チップ1188の形の認証手段は、隠れ板成形部品1172の開口1190に収容される。認証チップ1188は、プリントカートリッジ1100が装置のプリントヘッド組立体と互換性があり、準拠していることを保証するため、プリントヘッド組立体1188による問い合わせを受ける。
認証チップ
認証チップ53
好適な実施形態の認証チップ53は、正しく製造されたプリントロールだけがカメラシステムで利用されることを保証する責任がある。認証チップ53は、プリントロールシステムに限定されない任意の消耗品に関して利用されるときに一般的に有用である技術を利用する。消耗品を必要とする(トナーカートリッジを必要とするレーザープリンタのような)他のシステムの製造者は、消耗品を認証する問題で苦労し、成功のレベルは様々である。その殆どは、専用化されたパッケージングに頼っている。しかし、これは、家庭での詰め替え作業や複製品製造を抑えない。コピー作成を防止することは、不完全に製造された代用消耗品が基本システムを損傷することを防ぐために重要である。例えば、濾過が不十分なインクは、インクジェットプリンタのプリントノズルを詰まらせ、消費者はシステム製造者に責任を負わせ、許可されていない消耗品の使用を認めない。
認証の問題を解決するために、認証チップ53は、認証コードと、コピー防止のために特別に設計された回路と、を含む。このチップは、標準的なフラッシュメモリ製造プロセスを使用して製造され、インク及びトナーカートリッジのような消耗品に組み込むことができる程度に低価格である。一旦プログラミングされると、認証チップは、後述するように、NSA持ち出し(エクスポート)ガイドラインに準拠する。認証は、非常に大規模であり、且つ常に成長している分野である。以下の説明は、消耗品の認証だけに関連している。
記号名
以下の記号名が本実施形態の説明を通じて使用される。
基本用語
Mで示されたメッセージは平文である。Mを、Mの実体が隠された暗号文Cに変換するプロセスは、暗号化と呼ばれる。CをMへ逆変換するプロセスは、復号化と呼ばれる。暗号化関数をEで表し、復号化関数をDで表すことにより、以下の恒等式:
E[M]=C
D[C]=M
が得られる。したがって、以下の恒等式:
D[E[M]]=M
が成り立つ。
対称暗号化方式
対称暗号化アルゴリズムとは:
暗号化関数Eが鍵K1に依存する;
復号化関数Dが鍵K2に依存する;
K2はK1から導出可能である;
K1はK2から導出可能である;
というアルゴリズムである。
殆どの対称アルゴリズムにおいて、K1は通常K2と等しい。しかし、K1がK2と等しくない場合であっても、一方の鍵がもう一方の鍵から導出可能であるならば、数学的な定義のためには単一の鍵があれば十分である。したがって、
EK[M]=C
DK[C]=M
と表せる。
誰でも知っている教科書から洗練された現代のアルゴリズムまでの非常に多数の対称アルゴリズムが存在する。それらの殆どは、現在の暗号解読技術がKを導出し得る程度で攻撃に成功し得るという点において不確かである。特定の対称アルゴリズムの安全性は、通常、アルゴリズムの強度、及び鍵の長さからなる二つの事項の関数である。以下のアルゴリズムは、認証チップに利用するために適した特徴を含んでいる:
DES;
ブローフィッシュ(Blowfish);
RC5;
IDEA。
DES
DES(データ暗号化規格)は米国及び国際規格であり、暗号化と復号化に同じ鍵が使用される。鍵の長さは56ビットである。これは、ハードウェアとソフトウェアで実装されるが、当初の設計はハードウェア専用であった。DESで使用される当初のアルゴリズムは、米国特許第3962539号に記載されている。トリプルDESの変形と称されるDESの変形はより安全性が高いが、3個の鍵:K1、K2及びK3を必要とする。これらの鍵は、
EK3[DK2[EK1[M]]]=C
DK3[EK2[DK1[C]]]=M
という形で使用される。
トリプルDESの主な利点は、既存のDESの実装を使用して単一鍵のDESよりも安全性を高くすることができる点である。特に、トリプルDESは、112ビットの鍵の長さと等価的な保護を与える。トリプルDESは、単純に期待されるような168ビット鍵(3×56)と等価的な保護を与えるものではない。トリプルDESの復号化及び/又は符号化を実行する機器は米国から持ち出すことができない。
ブローフィッシュ(Blowfish)
Blowfishは、1994年にSchneierによって最初に提案された対称ブロック暗号方式である。これは、32ビットから448ビットまでの可変長鍵を使用する。更に、これはDESよりもかなり高速である。Blowfishアルゴリズムは、鍵拡張部と、データ暗号化部の二つの部分により構成される。鍵拡張は、最大で448ビットの鍵を、全部で4168バイトの複数のサブ鍵配列へ変換する。データ暗号化は、16ラウンドのFeistelネットワークによって行われる。全ての演算は、32ビット語上でのXORと加算であり、1ラウンド当たりに4回のインデックス配列ルックアップを含む。復号化は、サブ鍵が逆順に使用されることを除いて暗号化と同じである点に注意する必要がある。したがって、実装の複雑さは、このような対称性をもたない他のアルゴリズムよりも低減される。
RC5
1995年にRon Rivestによって設計されたRC5は、ブロックサイズ、鍵のサイズ、及びラウンド回数が可変である。しかし、典型的に、RC5は、64ビットのブロックサイズと128ビットの鍵を使用する。RC5アルゴリズムは、鍵拡張部と、データ暗号化部の二つの部分により構成される。鍵拡張は、鍵を2r+2個のサブ鍵(ここで、r=ラウンド回数である。)に変換し、各サブ鍵はwビットである。64ビットのブロックサイズで、16回のラウンドの場合(w=32,r=16)、サブ鍵配列は全部で136バイトである。データ復号化は、モジュロー2wの加算と、XORと、ビット回転と、を使用する。
IDEA
1990年にLai及びMasseyによって開発されたIDEA暗号方式の最初の具体化された形はPESと呼ばれる。1991年にBiham及びShamirによって差分解読法が発見された後、このアルゴリズムは強化され、その結果は1992年にIDEAとして発表された。IDEAは、64ビットの平文ブロックを操作するために128ビット鍵を使用する。暗号化と復号化のために同じアルゴリズムが使用される。このアルゴリズムは、一般的に、現在利用可能な最も安全なブロックアルゴリズムであると考えられている。これは、1993年に発行された米国特許第5214703号に記載されている。
非対称暗号化方式
他に使用できるアルゴリズムは非対称アルゴリズムである。非対称暗号化アルゴリズムとは:
暗号化関数Eが鍵K1に依存する;
復号化関数Dが鍵K2に依存する;
K2は合理的な時間内にK1から導出不能である;
K1は合理的な時間内にK2から導出不能である;
というアルゴリズムである。
したがって、
EK1[M]=C
DK2[C]=M
である。
これらのアルゴリズムは、一方の鍵K1が公開されるので、公開鍵とも称される。したがって、誰でも(K1を使用して)メッセージを暗号化し得るが、対応した復号鍵(K2)を持っている人だけがそのメッセージを復号化して読むことができる。殆どの場合に、以下の恒等式:
EK2[M]=C
DK1[C]=M
が成立する。
この恒等式は非常に重要である。なぜならば、公開鍵K1を所持する人は誰でもMを見ることができ、そのMはK2の所有者からのものであることが分かるからである。他の人はCを生成することができない。なぜならば、Cを生成し得ることは、K2を知っていることを意味するからである。合理的な時間内にK2からK1を導出できないこと、並びに、その逆にK1からK2を導出できないことは、当然、合理的な時間という概念によって曖昧になる。再々実証されているように、長時間を要することが予想される計算は、より高速化されたコンピュータ、新しいアルゴリズム等の導入によって実現可能になる。非対称アルゴリズムの安全性は、大きい数(より具体的には、二つの大きい素数の積である大きい数)を素因数分解すること、及び有限において離散対数関数を計算することの困難さの二つの問題のうちの一方の困難さに基づいている。大きい数の素因数分解は、現代の数学の理解においては難問であることが推測される。しかし、素因数分解は予測されるよりも速く容易になっているということが問題である。Ron
Rivestは、1977年に、125桁の素因数分解には40000兆年かかると言っていた。1994年に129桁の素因数分解が行われた。Schneierによれば、1980年代における512ビットの数から得られた安全性のレベルを現在得るためには、1024ビットの数が必要であるとされている。その鍵が数年続くとすると、1024ビットでも十分ではない。Rivestは1990年に鍵の長さの評価を改め、2005年まで高い安全性を維持するためには1628ビットを提唱し、2015年まで持ちこたえる高い安全性のためには1884ビットを提唱している。一方、Schneierは、2015年まで企業及び政府からの保護を得るためには2048ビットが必要であることを示唆している。
多数の公開鍵暗号化アルゴリズムが存在する。その殆どは実際には実装不可能であり、その多くは、所与のMに対して非常に大きいCを生成するか、又は巨大な鍵を必要とする。更に、その他のものは、たとえ安全であるとしても、非常に低速であるため数年の間には実施できない。このため、多数の公開鍵システムは、ハイブリッド方式であり、公開鍵の仕組みは対称セッション鍵を送信するために使用され、セッション鍵が実際のメッセージのために使用される。全てのアルゴリズムは、鍵選択の点で問題がある。乱数はどうしても安全性が不十分である。大きい素数p及びqは慎重に選ぶことが必要であり、ある種の組み合わせは簡単に素因数分解できるという弱点がある(一部の弱い鍵は検査することができる)。しかし、それにもかかわらず、鍵選択は、例えば、単に、1024ビットをランダムに選択するというような単純なことではない。その結果として、鍵選択プロセスも安全でなければならない。
公開の精査の下で使用中の実際的なアルゴリズムの中で、以下のアルゴリズム:
RSA;
DSA;
EIGamal;
は利用するために適している。
RSA
Rivest、Shamir及びAdlemanの名前にちなんで命名されたRSA暗号システムは、最も広く使用されている公開鍵暗合システムであり、世界中の多くで事実上の標準である。RSAの安全性は、2個の素数(p及びq)の積である大きい数の素因数分解の困難さに依存していると考えられる。p及びqの生成には多数の制約がある。それらは、両方共に大きいことが必要であり、ビット数が同じであり、しかも、互いに近似していてはならない(そうでなければ、pqは√pqと近似する)。その上、多くの場合に、p及びqは強い素数でなければならないことが指摘されている。RSAアルゴリズムの特許は1983年に発行された(米国特許第4405829号)。
DSA
DSA(デジタル署名規格)は、デジタル署名標準(DSS)の一部として設計されたアルゴリズムである。規定されているとおり、このアルゴリズムは一般的な暗号化には使用できない。その上、RSAに対して、DSAは署名検証の際に10から40倍速度が遅い。DSAは、SHA−1ハッシュアルゴリズム(以下の一方向関数の定義を参照せよ。)を明示的に使用する。DSA鍵生成は、qがp−1を割り切るような2個の素数p及びqの検出に依拠している。Schneierによれば、1024ビットのp値が長期間のDSA安全性のために必要である。しかし、DSA標準は、pの値が1024ビットよりも大きくなることを認めていない(pは、更に、64ビットの倍数でなければならない)。米国政府はDSAアルゴリズムを所有し、少なくとも一つの関連特許(1993年に発行された米国特許第5231688号)を保持する。
EIGamal
EIGamal方式は、暗号化とデジタル署名の両方に使用される。その安全性は有界で離散対数関数を計算することの困難さに依拠している。鍵選択には、g及びxがpよりも小さくなるような、素数pと2個の乱数g及びxの選択が必要である。次に、y=gx
mod pを計算する。公開鍵は、y、g及びpである。秘密鍵はxである。
暗号によるチャレンジ−レスポンスプロトコル及びゼロ知識証明
チャレンジ−レスポンスプロトコルの一般的な原理は、カメラシステムに適したアイデンティティ認証を提供することである。チャレンジ−レスポンスの最も簡単な形態は秘密パスワードの形態をとる。AはBに秘密パスワードを尋ね、Bが正しいパスワードで応答したとき、AはBが真正であることを表明する。この種の簡単なプロトコルには三つの主要な問題点がある。第一に、一旦Bがパスワードを公表すると、任意のオブサーバCはパスワードが何であるかを知る。第二に、Aはパスワードを検証するためにパスワードを知ることが必要である。第三に、CがAになりすました場合、Bは(CがAであると思い)Cにパスワードを与え、これにより、Bを危険にさらす。著作権のあるテキスト(例えば、俳句)を使用することは、弱い代用である。なぜならば、(例えば、知的所有権が遵守されない国では)誰でもパスワードをコピーすることができると考えられるからである。暗号によるチャレンジ−レスポンスプロトコルの考え方は、唯一のエンティティ(要求者)が、そのエンティティに関して知られている秘密情報の知識を実証することによって、プロトコル中に秘密情報自体を検証者に明かすことなく、自分のアイデンティティを他者(検証者)へ渡すことである。暗号によるチャレンジ−レスポンスプロトコルの一般化されたケースでは、ある種の方式により検証者はその秘密情報を知り、それ以外の場合には、その秘密情報は検証者にさえ知られていない。この実施形態の説明は、特に認証に関係しているので、認証の試し要される実際の暗号によるチャレンジ−レスポンスプロトコルは、適当なセクションで詳述される。しかし、ゼロ知識証明の概念はここで説明する。最初に、Feige、Fiat及びShamirによって明らかにされたゼロ知識証明プロトコルは、認証目的用のスマートカードで広く使用されている。このプロトコルの有効性は、未知の素因数分解による大きい合成整数の平方根モジュローの計算がコンピュータの能力で実施不可能である、という仮定に基づいている。これは、おそらく、大きい整数の素因数分解が困難であるという仮定と等価であろう。尚、要求者は著しい計算パワーをもっていなくてもよいことに注意する必要がある。スマートカードは、数回のモジュロー乗算だけを使用してこの種の認証を実現する。ゼロ知識証明プロトコルは米国特許第4747668号に記載されている。
一方向関数
一方向関数Fは、入力Xに作用し、XがF[X]から判定できないようなF[X]を返す。Xのフォーマットに制限が無く、F[X]がXよりも少ないビットを格納する場合、衝突が存在する筈である。衝突は、同じF[X]値を生ずる2個の異なるX値、即ち、X1≠X2であり、しかも、F[X1]=F[X2]となるようなX1及びX2として定義される。XがF[X]よりも多数のビットを格納する場合、入力は、出力を生成するために何らかの方法で圧縮されなければならない。殆どの場合に、Xは、特定のサイズのブロックに分割され、多数のラウンドに亘って圧縮され、あるラウンドの出力が次のラウンドへの入力である。このハッシュ関数の出力は、Xが使い尽くされた後の最後の出力である。圧縮関数CFの疑似衝突は、2個の異なる初期値V1及びV2として定義され、2個の入力X1及びX2(同一であるかもしれない)は、CF(V1,X1)=
CF(V2,X2)となるように与えられる。疑似衝突が存在しても、所与のX1に対するX2の計算が簡単になるわけではないことに注意する必要がある。
高速に計算できる一方向関数だけに関心がある。更に、様々な実装において再現可能である決定論的な一方向関数だけに関心がある。一例として、F[X]がFの呼び出しの間の時間であるFを考える。所与のF[X]に対して、Xは決定可能である。なぜならば、XはFによって均等に使用されないからである。しかし、Fからの出力は様々な実装において異なる。したがって、この種のFに興味はない。
本実施形態の認証チップの実装の説明の範囲では、以下の形式の一方向関数:
未知鍵を使用する暗号化;
乱数シーケンス;
ハッシュ関数;
メッセージ認証コード;
だけに関心がある。
未知鍵を使用する暗号化
メッセージが未知鍵Kを使用して暗号化されたとき、暗号化関数Eは事実上一方向性である。この鍵が無い場合、EK[M]からMをK無しに獲得することはコンピュータ能力的に実施不能である。暗号化関数は、鍵が隠されている限り一方向性である。暗号化アルゴリズムは衝突を生成しない。なぜならば、Eは、関数Dを使用してMを再構築できないようなEK[M]を生成するからである。この結果として、F[X]は、一方向関数FがEであるならば、少なくともXと同数のビットを格納する(情報は失われない)。(上記の)対称暗号化アルゴリズムは、暗号化に基づく一方向関数を生成する非対称アルゴリズムよりも有利である。その理由は、
所定の強さの暗号化アルゴリズム用の鍵は、非対称アルゴリズムよりも対称アルゴリズムの方が短くなり、
対称アルゴリズムの方が高速に計算でき、必要なソフトウェア/シリコンが少ない、からである。
優れた鍵の選択は選択された暗号化アルゴリズムに依存する。ある種の鍵は特定の暗号化アルゴリズムの場合に強くないので、全ての鍵の強さをテストすることが必要である。鍵選択のために実行されるべきテストの回数が増えるほど、その鍵が隠された状態を保つ可能性が低くなる。
乱数シーケンス
乱数シーケンスR0,R1,...,Ri,Ri+1を考える。F[X]が乱数シーケンス内のX番目の乱数を返すような一方向関数を定義する。しかし、F[X]は様々な実装において所定のXに関して再現可能であることを保証しなければならない。したがって、乱数シーケンスは、本当の意味でランダムではない。その代わりに、乱数シーケンスは疑似乱数であり、生成器は特殊なシードを利用する。
優れた乱数生成器の定義に関して多数の問題がある。Knuthは、生成器を「良くする」要因(統計的テストを含む)、生成器の構築に関する一般的な問題を説明している。大半の乱数生成器は、i−1番目の状態からi番目の乱数を生成し、i番目の数を決定するための唯一の方法は、0番目の数からi番目の数までを繰り返すことである。iが大きい場合、i回の繰り返しを待つことは実際的ではない。しかし、あるタイプの乱数生成器はランダムアクセスを許可しない。Blum、Blum及びShubは、理想的な生成器に関して、「短いシードから、校正なコインの連続的な反転によって完全に発生させられたように見える長い(ビットの)シーケンスを素早く生成するためには疑似ランダムシーケンス生成器が好ましい」のように定義している。彼らは、X2
mod n型の生成器、一般的には、BBS生成器と呼ばれる生成器を定義した。現在の暗号化方式が依拠しているある種の仮定を前提とした場合、BBS生成器は非常に厳しい統計的テストに合格することを示した。
BBS生成器は、Blum整数であるnの選択に依拠している(n=pqであり、p及びqは大きい素数であり、p≠qであり、p
mod 4=3であり、q
mod 4=3である)。生成器の初期状態は、x0によって与えられ、ここで、x0=x2
mod nであり、xは、nよりも相対的に優良なランダム整数である。i番目の疑似ランダムビットは、xiの最下位ビットであり、xi=xi−1 2
mod nである。付加的な性質として、p及びqの知識は、xi=x0 y
mod n、但し、y=2i
mod ((p−1)(q−1))によって、シーケンス内のi番目の数の直接的な計算を可能にさせる。
p及びqの知識がない場合、生成器は、繰り返しを実行しなければならない(計算の安全性は大きい数の素因数分解の困難さに依存する)。当初定義されたとき、BBS生成器に関する主要な問題は、単一の出力ビットのために必要な作業量であった。このアルゴリズムは、殆どのアプリケーションに対して遅すぎると考えられていた。しかし、モンゴメリ型リダクション演算の出現によって、より実際的な実装形態が生じた。その上、Vazirani及びVaziraniは、nのサイズに依存して、生成器の安全性を譲歩することなく、より多数のビットをxiから安全に取り出せることを示した。xi毎に1ビットだけが必要であるとするならば、Nビット(したがって、ビット生成器関数のN回の反復)がNビット乱数を発生させるために必要である。外部オブザーバーにとって、特定のビットの組が与えられた場合に、半々の確率以外で次のビットを決定する方法は無い。x、p及びqが秘密にされている場合、それらは鍵として作用し、出力ビットストリームを取り出し、x、p及びqを計算することはコンピュータ能力的に実施不能である。また、所定の疑似ランダムビットの組を発生させるために使用されたiの値を決定することは、コンピュータ能力的に実施不能である。この最後の特徴によって、生成器は一方向性になる。異なるiの値が、所定の長さの同じビットシーケンス(例えば、32ビットのランダムビット)を生じさせる可能性がある。たとえ、x、p及びqが既知であるとしても、予定のF[i]に対して、iは確率の組として導出できるだけであり、特定の値として導出できない。(勿論、iのドメインが既知であるならば、確率の組は更に限定される)。しかし、良好なp及びqと、良好なシードxの選択に関して問題がある。特に、Ritterは、xを選択する際の問題について記述している。この問題の性質は、BBS生成器が既知長さの単一のサイクルを生成しないことである。その代わりに、BBS生成器は、縮退(長さゼロ)サイクルを含む様々な長さのサイクルを生成する。このように、BBS生成器は、短いサイクルかもしれないランダム状態を用いて初期化することが不可能である。
ハッシュ関数
ハッシュ関数として知られている特殊な一方向関数は、任意長さのメッセージを固定長さのハッシュ値へマップする。ハッシュ関数はH[M]のように表される。入力は任意長さであるため、ハッシュ関数は固定長さの出力を生ずるため圧縮コンポーネントを有する。また、ハッシュ関数は、衝突の検出を困難にさせ、H[M]からMに関する情報の決定を困難にさせるため、オブファスケイションコンポーネントを含む。衝突は実際に存在するので、殆どのアプリケーションは、所与のX1に対して、H[X1]=H[X2]となるようなX2を見つけることが困難であるという点で、ハッシュアルゴリズムが耐プレイメージ性であることを必要とする。その上、殆どのアプリケーションは、ハッシュアルゴリズムが耐衝突性である(即ち、H[X1]=H[X2]となるような2個のメッセージX1及びX2を見つけることが困難である)ことを要求する。耐衝突性のあるハッシュ関数が理想的な意味で存在し得るかどうかは、未確定の問題である。ハッシュ関数の主なアプリケーションは、デジタル署名アルゴリズムを適用する前に、入力メッセージをデジタル「指紋」に変形することである。デジタル署名との衝突の一つの問題は以下の例に示されている。
Aは、「私はBに100ドルの借りがある。」という長いメッセージM1を持っている。Aは、自分の秘密鍵を用いてH[M1]を署名する。どん欲なBは、H[M2]=H[M1]であり、M2がBにとって有利であるような衝突メッセージM2、例えば、「私はBに100万ドルの借りがある。」を探索する。明らかに、このようなM2を見つけることが困難であることを保証することはAの利益である。
耐衝突性のある一方向ハッシュ関数の例は、SHA−1、MD5、及びRIPEMD−160であり、これらは全てMD4から導かれる。
MD4
Ron Rivestは1990年にMD4を発表した。他の全ての一方向ハッシュ関数はMD4から何らかの方法によって導出されるので、ここでは、MD4を説明する。MD4は、衝突を探索されるのではなく、計算可能であるという点で、現在では、完全に破られたと考えられている。上記の例において、Bは、元のメッセージM1と同じハッシュ値を用いて、代わりのメッセージM2を普通に発生させることができる。
MD5
Ron Rivestは1991年に、安全性の高まったMD4として、MD5を発表した。MD4と同様に、MD5は128ビットのハッシュ値を生成する。Dobbertinは、最近の攻撃後のMD5の状態を説明している。彼は、MD5において疑似衝突を見つける方法を説明し、圧縮関数の弱点を指摘し、つい最近、衝突が発見された。即ち、MD5は、衝突の存在がひどい結果を招くデジタル署名スキームの圧縮に使用されるべきではない。しかし、MD5は、一方向関数として依然として使用することができる。その上、HMAC−MD5の構造は、これらの最近の攻撃による影響を受けない。
SHA−1
SHA−1はMD5と非常に類似しているが、160ビットのハッシュ値を有する(MD5は128ビットのハッシュ値しかない)。SHA−1は、デジタル署名標準(DSS)で使用するため、NIST及びNSAによって設計され発表された。最初に発表された説明はSHAと呼ばれたが、その後直ぐに、おそらくSHAの安全性の欠陥を訂正するために改訂され、SHA−1となった(但し、NSAは変更の原因となった数学的な理由を発表していない)。SHA−1に対する暗号攻撃は知られていない。また、SHA−1は、単にハッシュ結果が長くなったという理由で、力ずくの攻撃に対する耐性がMD4又はMD5よりも強い。米国政府は、SHA−1及びDSAアルゴリズム(DSSの一部として定められたデジタル署名認証アルゴリズム)を保有し、少なくとも一つの関連特許(1993年に発行された米国特許5231688号)を保持する。
RIPEMD−160
RIPEMD−160は、その前進であるRIPEMD(1992年に欧州委員会のRIPEプロジェクトのために開発された)から導出されたハッシュ関数である。その名前から分かるように、RIPEMD−160は、160ビットのハッシュ結果を生成する。32ビットアーキテクチャのソフトウェア実装のため合わされたRIPEMD−160は、10年間以上に亘って高いセキュリティレベルを提供することを予定されている。RIPEMD−160に対する攻撃の成功例は存在しないが、RIPEMD−160は比較的新しく、大規模に解読されていない。最初のRIPEMDアルゴリズムは、従来のMD4に対する暗号攻撃に対抗するために特に設計された。最近のMD5に対する攻撃は、RIPEMDの128ビットハッシュ関数においても類似した弱点を明らかにした。この攻撃は理論的な弱点を示しただけであるが、Dobbertin、Preneel及びBosselaersは、RIPEMDを新しいアルゴリズムRIPEMD−160へ更に強化した。
メッセージ認証コード
メッセージ認証の問題は以下のようにまとめることができる:
Aは、Bからのメッセージであると推測されるメッセージが本当にBからのメッセージであることをどのようにして確信するか?
メッセージ認証はエンティティ認証とは異なる。エンティティ認証の場合、一つのエンティティ(要求者)は、自分のアイデンティティを他者(検証者)に対して照明する。メッセージ認証の場合、所定のメッセージが自分の思う人からのメッセージであることを保証すること、即ち、メッセージが発信元から宛先までの途中で改ざんされていないことを保証することに関係する。一方向ハッシュ関数はメッセージに対する保護が十分ではない。MD5のようなハッシュ関数は、元の入力を代表するハッシュ値を発生させ、元の入力がハッシュ値から導出できないことに基づいている。AとBの間にいるEからの簡単な攻撃は、Bからのメッセージを途中で盗み、自分のメッセージで置き換えることである。たとえ、Aが元のメッセージのハッシュを送信したとしても、Eは自分の新しいメッセージのハッシュで簡単に置き換えることができる。一方向ハッシュだけを使用した場合、AはBのメッセージが変更されたかどうかを知る方法がない。メッセージ認証の問題に対する一つのソリューションは、メッセージ認証コード、即ち、MACだえる。BがメッセージMを送信するとき、Bは、受信者にMが本当にBからのメッセージであることがわかるようにMAC[M]を送信する。これを実現するため、BだけがMのMACを生成可能であり、更に、AはMAC[M]と対照してMを検証し得ることが必要である。これは、Mを秘密にする必要がないときに、M−MACの暗号化が有効であることとは異なることに注意する必要がある。ハッシュ関数からMACを構築する最も簡単な方法は、対称アルゴリズムを用いてハッシュ値を暗号化すること、即ち、
入力メッセージをハッシュ化 H[M]
ハッシュを暗号化 EK[H[M]]
である。
これは、最初にメッセージを暗号化して、次に、暗号化されたメッセージをハッシュ化するよりも安全性が高い。任意の対称又は非対称暗号化関数を使用することができる。しかし、(上記のような)暗号化を使用する技術の代わりに、鍵依存型の一方向ハッシュ関数を使用する方が以下の幾つかの点で有利である:
速度:一方向ハッシュ関数は一般的に暗号化よりも高速に動作するため;
メッセージサイズ:EK[H[M]]は少なくともMと同じサイズであるが、H[M]は固定サイズ(通常、Mよりもかなり小さい)であるため;
ハードウェア/ソフトウェア必要条件:鍵付きの一方向ハッシュ関数は、典型的に、それらの暗号ベースの代案よりも遙かに複雑さが抑えられている;
一方向ハッシュ関数の実装は、暗号化装置又は復号化装置であるとはみなされないので、米国の国外持ち出し規制の対象ではない。
尚、ハッシュ関数は、当初は、鍵を格納したり、メッセージ認証をサポートしたりするためには設計されていなかったことに注意する必要がある。その結果として、メッセージを秘密プレフィックス、サフィックス、又は両方と連結する種々の関数を含む、メッセージ認証を実行するためにハッシュ関数を使用する、ある種のアドホックな方法が提案されている。これらのアドホックな方法の殆どは、洗練された手段によって巧く攻撃された。付加的なMACは、XORスキーム及びテプリッツ(Toeplitz)行列に基づいて提案されている(LFSRベース構造の特殊なケースを含む)。
HMAC
特にHMAC構造は、インターネットメッセージ認証セキュリティプロトコル用のソリューションとして認められ始めている。HAMC構造は、基礎となるハッシュ関数をブラックボックス的に使用して、ラッパーとして作用する。ハッシュ関数の置換は、安全性又は性能上の理由から求められるならば、簡単に行われる。しかし、HMAC構造の主要な利点は、基礎となるハッシュ関数がある程度の合理的な暗号強度を有するならば、HMAC構造は安全であることが証明できること、即ち、HMACの強度は、ハッシュ関数の強度と直接的に関連していることである。HMAC構造はラッパーであるため、任意の反復ハッシュ関数をHMACで使用することが可能である。その例には、HMAC−MD5、HMAC−SHA1、HMAC−RIPEMD160等が含まれる。以下のような定義:
H=ハッシュ関数(例えば、MD5又はSHA−1)
n=Hから出力されたビット数(例えば、SHA−1の場合160ビット、MD5の場合128ビット)
M=MAC関数が適用されるべきデータ
K=2当事者によって共有される秘密鍵
ipad=0x36の反復64回
opad=0x5Cの反復64回
を与えると、HMACアルゴリズムは:
0x00バイトをKの最後に付加することによってKを64バイトへ拡張する;
(1)で作成された64バイト文字列をipadでXOR演算する;
(2)で作成された64バイトにデータストリームMを付加する;
(3)で発生されたストリームにHを適用する;
(1)で作成された64バイト文字列をopadでXOR演算する;
(4)からの結果Hを(5)からの結果である64バイトに付加する;
(6)の出力にHを適用し、結果を出力する;
のようになる。したがって、
HMAC[M]=H[(KAopad)|H[(KAipad)|M]]
である。
推奨される鍵長さは少なくともnビットであるが、64バイト(ハッシュ化ブロックの長さ)よりも長くなってはならない。nビットよりも長い鍵は、関数の安全性を上乗せしない。HMACは、オプションとして、最終的な出力の丸め、例えば、160ビットから128ビットへの丸めを行うことできる。HMAC設計者の規約(RFC)は、このアルゴリズムが最初に発表された1年後の1997年に発行された。設計者は、HMACに対する既知の最強の攻撃は、ハッシュ関数Hに対する衝突の頻度に基づく攻撃であり、最低限度で適当なハッシュ関数に対して全く実際的ではないということを公表している。より最近では、リプレイ防止機能付きHMACプロトコルが、所定の時間内でのM、HMAC[M]コンビネーションの捕捉及び再生を防止するために規定されている。
乱数及び時変性メッセージ
一方向関数としての乱数生成器の使用については既に説明した。しかし、乱数生成器の理論は、暗号法、セキュリティ、及び認証と非常に絡み合っている。優れた乱数生成器の定義に関して多数の問題がある。Knuthは、生成器をよくするもの(統計的テストを含む)、及び生成器の構築に関する一般的な問題を説明している。乱数の用法の一つは、メッセージが時間的に変化することを保証することである。Aがコマンドを暗号化し、それをBへ送信するシステムを想定する。暗号化アルゴリズムが所与の入力と同じ出力を生成する場合、攻撃者は、簡単にメッセージを記録し、Bを欺くためにそれを再生することが可能である。攻撃者は、暗号化機構を破壊する必要がなく、(Aになりすましている間に)Bに対して再生すべきメッセージがわかれればよい。その結果として、メッセージは、しばしば、そのメッセージ(したがって、その暗号化された対応部分)が常に変化することを保証するため、乱数及びタイムスタンプを含む。乱数生成器は、しばしば、鍵を生成するためにも使用される。したがって、現時点では、全ての生成器は、この目的のためには不確かであると言って差し支えない。例えば、Berlekamp−Masseyアルゴリズムは、LFSR乱数生成器に対する従来の攻撃法である。LFSRの長さがnであるならば、2nビットのシーケンスは、鍵生成器を構成するLFSRを決定するために十分である。しかし、乱数生成器の唯一の役目は、メッセージが時間的に変化することを保証することであるならば、生成器及びシードのセキュリティは、セッション鍵生成の場合のように重要ではない。しかし、乱数シード生成器が危険にさらされ、攻撃者が未来の「乱数」を計算可能であるならば、一部のプロトコルが攻撃者に対して開放されたままにされ得る。新しいプロトコルはこの状況に関して検討されるべきである。要求される実際のタイプの乱数生成器は、インプリメンテーションと、その生成器の使用目的と、に依存するであろう。生成器には、Ron
RivestによるRC4のようなBlum、Blum、及びShubストリーム暗号、SHA−1及びRIPEMD−160のようなハッシュ関数、並びに、LFSR(線形フィードバックシフトレジスタ)及びそれらのより最近の対応物であるFCSR(キャリー付きフィードバックシフトレジスタ)のような従来の生成器が含まれる。
攻撃
このセクションは、認証チップのような認証暗号システムを破るために行われる可能性のある様々なタイプの攻撃を説明する。攻撃は、物理的な攻撃と論理的な攻撃に大別される。物理的な攻撃は、暗号システムの物理的な実装を破壊する(例えば、鍵を取り出すためにチップを壊して開ける)方法を表し、論理的な攻撃は、実装に依存しない暗号システムへの攻撃を含む。論理的なタイプの攻撃は、プロトコル又はアルゴリズムに対して機能し、以下の三つのうちの何れかを実行しようとする:
認証プロセスを完全に回避する;
あらゆる質問に回答できるように、力ずく又は推論によって秘密鍵を取得する;
鍵を用いることなく各質問に正しい回答を与えるため、認証用の質問及び回答の性質を十分に検出する。
次に、攻撃のスタイル及び形式を詳細に説明する。セキュリティチップによって使用されるアルゴリズム及びプロトコルとは無関係に、チップの認証部の回路は物理的な攻撃を受ける可能性がある。物理的な攻撃は、以下の4つの主要な形で現れるが、攻撃の形態は変化し得る:
認証チップを完全に回避する;
動作中にチップを物理的に検査する(破壊的及び非破壊的);
チップを物理的に分解する;
チップを物理的に改変する。
次に、攻撃のスタイル及び形式を詳細に説明する。このセクションは、これらの攻撃に対するソリューションを提案するものではない。このセクションは、各攻撃タイプを説明するだけである。調査は、(インターネット認証のような他のある種のシステムではなく)あるシステムに取り付けられた認証チップ53の状況に限定されている。
論理的な攻撃
これらの攻撃は、暗号システムの物理的な実装形態に依存しない。これらは、プロトコル、アルゴリズムの安全性、及び乱数生成器に作用する。
暗号文だけの攻撃
これは、攻撃者が、全て同じアルゴリズムを使用して暗号化された一つ以上の暗号化メッセージをもつ場合である。攻撃者の目的は暗号化メッセージから平文メッセージを獲得することである。理想的には、鍵を復元することが可能であり、その結果、将来のすべてのメッセージを復元可能である。
既知平文攻撃
これは、攻撃者が、平文と、平文の暗号化形式の両方をもつ場合である。認証チップの場合、既知の平文の攻撃は、攻撃者がシステムと認証チップの間のでーたフローを見ることができる場合である。入力及び出力は(攻撃者によって選別されることなく)観測され、弱点を見つけるため解析され得る(例えば、バースデー攻撃、又は区別の付く興味ある入力/出力のペアの探索によって)。既知平文攻撃は、選択平文攻撃よりも弱いタイプの攻撃である。なぜならば、攻撃者はデータフローしか観測できないからである。既知平文攻撃は、ロジックアナライザを、システムと認証チップの間の配線に接続することによって実行し得る。
選択平文攻撃
選択平文攻撃は、暗号解読者が任意の選択されたメッセージを暗号システムへ送信し、その応答を観測できる能力を備えている場合である。暗号解読者がアルゴリズムを知っているならば、特定の出力を別の関数の入力へ供給することによって利用可能な入力と出力の間の関係があるであろう。内蔵型認証チップを使用するシステムでは、選択平文攻撃を防止することは難しい。なぜならば、暗号解読者は、論理的に自分がシステムであるふりをして、任意の選択されたビットパターンストリームを認証チップへ送信できるからである。
適応的選択平文攻撃
このタイプの攻撃は選択平文攻撃と類似しているが、攻撃者が先行の試験の結果に基づいて後続の選択された平文テキストを変更し得る点で異なる。上述のシステム/認証チップのシナリオがコピー機及びトナーカートリッジのような消耗品のために利用されるときは、確実にこのケースである。なぜならば、特に、システムと消耗品の両方は誰でも入手できるようにされているからである。
ブルートフォース攻撃
鍵ベースの暗号システムアルゴリズムを破るための保証付きの方法は、単純に全ての鍵を試してみることである。最終的に正しい鍵が見つけられるであろう。これは、ブルートフォース攻撃として知られている。しかし、鍵候補の数が増加すると、より多くの鍵を試してみる必要があり、正しい鍵を見つけるために(平均的に)要する時間が長くなる。N個の鍵がある場合、最大でN回の試行が必要である。鍵の長さがNビットであるならば、最大で2N回の試行が必要であり、半分だけの試行(2N−1)後に鍵を見つけるチャンスは50%である。Nが長くなればなるほど、鍵を見つけるために要する時間が長くなるので、鍵の安全性が高まる。勿論、攻撃が最初の試行で鍵を当てる可能性はあるが、この可能性は鍵が長くなると共に低下する。ここで、56ビットの鍵長さを考える。最悪ケースでは、鍵を見つけるために全部で256回のテスト(7.2×1016回のテスト)を行わなければならない。1977年に、DiffieとHellmanは、100万個のプロセッサにより構成され、各プロセッサが毎秒100万回のテストを実行刷る能力を備えたDES解読専用機械を発表した。このような機械は任意のDESコードを破るためには20時間を要する。鍵長さが128ビットの場合を考える。最悪ケースでは、鍵を見つけるために全部で2128回のテスト(3.4×1038回のテスト)を行わなければならない。これは、各々が毎秒10億回のテストを実行する1兆個のプロセッサ上で10億年を要する。鍵長さが十分に長い場合、ブルースフォース攻撃は非常に長い時間を要するので、攻撃者の努力に値しない。
推測攻撃
このタイプの攻撃は、攻撃者が単に鍵を「推測」しようとする場合である。攻撃としては、ブルースフォース攻撃と同じであり、成功の確率は鍵の長さにかかっている。
量子コンピュータ攻撃
nビット鍵を解読するため、適切なアルゴリズムに埋め込まれたnキュビットを有する量子コンピュータ(NMR、オプティカル、又はケージドアトム)を構築しなければならない。量子コンピュータは、実効的に、2n個の同時コヒーレント状態に存在する。デコヒーレントを生じることなく正しいコヒーレント状態を抽出することが要領である。今までのところ、これは、2キュビットのシステム(4コヒーレント状態で存在する)によって達成されている。数年の間に、これを6キュビット(64の同時コヒーレント状態をもつ)まで拡張することは可能であると思われる。
残念なことに、キュビットを付加する毎に、鍵を表現する信号の相対強度が半分になる。これは、特に、暗号方式的に安全なシステムで使用される長い鍵の場合に、直ぐに鍵取り出しの重大な障害になる。その結果として、量子コンピュータを使用した、暗号方式的に安全な鍵(例えば、160ビット)に対する攻撃は、おそらく実施される可能性はなく、量子コンピュータが、認証チップの商業的な耐用年限中に50キュビット以上のキュビット数を達成する可能性は非常に低い。たとえ、50キュビットの量子コンピュータを使用しても、160ビット鍵を解読するために、2110回のテストが必要である。
意図的なエラー攻撃
一部のアルゴリズムの場合、攻撃者は悪い入力の結果から有用な情報を収集することができる。有用な情報の範囲は、エラーメッセージ文から、エラーを発生させるために要した時間までに亘る。簡単な一例は、ユーザID/パスワードのスキームである。エラーメッセージが通常「間違ったユーザID」であるならば、攻撃者が「間違ったパスワード」というメッセージを取得したとき、ユーザIDが正しいことを知る。メッセージが常に「間違ったユーザID/パスワード」であるならば、攻撃者に与えられる情報は遙かに少ない。より複雑な例は、最近発表された、安全なウェブサイトから暗号コードを解読する方法である。この攻撃には、特定のメッセージをサーバーへ送信することと、エラーメッセージ応答を観測することとが含まれる。応答は、鍵を学習するために十分な情報を与え、応答が無くても何らかの情報が得られる。アルゴリズムの一例として、時間は、誤りのあるビットが入力メッセージ中に検出されたときに直ちにエラーを返すアルゴリズムの場合に知ることができる。ハードウェア実装形態に依存して、攻撃者が、応答の時間を計り、エラー応答に要した時間に基づいて1ビットずつ変更し、このようにして鍵を獲得することは、簡単な方法である。チップ実装形態の場合、必要な時間がインターネット経由の場合よりもかなり高い精度で観測できることは確実である。
バースデー攻撃
この攻撃は、有名な「バースデーパラドックス」(実際には全くパラドックスではない)にちなんで命名された。ある人が他の人と同じ誕生日である確率は365分の1である(閏年は考えない)。したがって、室内の183人のうちの一人があなたと同じ誕生日である確率は50%よりも高い筈である。しかし、室内に23人の人がいれば、何れか二人の誕生日が同じである確率は50%を超える。その理由は、23人によって253通りのペアが生じるからである。バースデー攻撃は、ハッシングアルゴリズム、特に、ハッシングとデジタル署名を組み合わせるアルゴリズムに対する一般的な攻撃である。メッセージが生成され、既に署名されている場合、攻撃者は、同じ値にハッシュする衝突メッセージを探す必要がある(あなたと同じ誕生日の人を見つけることと類似している)。しかし、攻撃者がメッセージを生成可能であるならば、バースデー攻撃が作用し始める。攻撃者は、同じハッシュ値をもつ二つのメッセージを探し(何れか二人が同じ誕生日である場合と類似している)、一方のメッセージだけがそれに署名をした人に受け入れられ、もう一方は攻撃者の役に立つ。その人が元のメッセージに署名をし終えたならば、攻撃者は、その人は別のメッセージに署名をしたことを主張するだけでよく、数学的にどちらのメッセージが原本であるかを示す方法は無い。なぜならば、両方のメッセージは同じ値にハッシュするからである。ブルートフォース攻撃が一致を判定するための唯一の方法であるとすると、バースデー攻撃によるnビット鍵の脆弱化は2n/2である。バースデー攻撃を受ける可能性のある128ビットの長さの鍵は、事実上64ビットの長さしかない。
連鎖攻撃
これらの攻撃は、ハッシュ関数の連鎖性に対して行われる攻撃である。連鎖攻撃は、ハッシュ関数の圧縮関数に的を絞る。このアイデアは、ハッシュ関数が一般的に任意の長さの入力をとり、入力nビットを同時に処理することによって、一定の長さの出力を生成する点に基づいている。1ブロックからの出力は次のブロックへの連鎖変数セットとして使用される。入力全体に対する衝突を見つけるのではなく、このアイデアは、入力連鎖変数セットが与えられた場合に、本来のメッセージと同じ出力連鎖変数を生じる代用ブロックを見つけることである。特定のブロックの選択数は、ブロックの長さに基づいている。連鎖変数がcビットであり、ハッシング関数はランダムマッピングのように挙動し、ブロック長さがbビットであるならば、このようなbビットブロックの個数は、約2b/2c個である。代用ブロックを見つけるためのチャレンジは、このようなブロックが考えられる全てのブロックのうちの疎部分集合であることである。SHA−1の場合、512ビットブロックの個数は、約2512/2160、即ち、2352個である。ブルートフォース検索によってブロックを見つける見込みは2160分の1である。
完全ルックアップテーブルによる代用
チップへ送信された可能性のあるメッセージの数が少ない場合、鍵を解読するために複製品製造者は不要である。その代わりに、複製品製造者は、システムによって送信されたコードに対する純正チップからのレスポンスの全てを記録したROMをチップに組み込むことが可能である。鍵が長くなり、レスポンスが長くなると共に、このようなルックアップテーブルに必要な空間が大きくなる。
疎ルックアップテーブルによる代用
チップへ送られたメッセージが、実効的にランダムではなく、ある程度予測可能であるならば、複製品製造者は完全ルックアップテーブルを提供しなくてもよい。例えば:
メッセージが単なるシリアル番号であるならば、複製品製造者は、過去及び未来の予測シリアル番号を格納するルックアップテーブルを提供すればよい。これらのシリアル番号が1019個を超える可能性は低い;
テストコードが単なる日付であるならば、複製品製造者はアドレスとして日付を使用してルックアップテーブルを生成することができる;
テストコードが、シリアル番号又は日付をシードとして用いる疑似乱数であるならば、複製品製造者は、まさに、システム内の疑似乱数生成器を解読する必要がある。これは、おそらく難しくはないであろう。なぜならば、複製品製造者はシステムのオブジェクトコードを入手できるからである。複製品製造者は、蓄積された認証コードへアクセスするためこれらのコードを使用して、内容アドレス可能メモリ(又は、その他の疎配列ルックアップ)を生成するであろう。
差分暗号解読
差分暗号解読は、入力ストリームのペアが既知差分を用いて生成され、符号化ストリームの差分が解析される攻撃を表す。既知差分攻撃は、DES及びその他の同様のアルゴリズムで使用されるようなSボックスの構造にかなり依存している。HMAC−SHA1のような他のアルゴリズムはSボックスを持たないが、攻撃者は、
最小差分入力及びそれに対応した出力
最小差分出力及びそれに対応した入力
の統計的解析を行うことによって差分的な攻撃を実行し得る。
殆どのアルゴリズムは、差分暗号解読のプロセスが記載された後、差分暗号解読に対して補強された。これは、各暗号化方式に専用のセクションで対称とされている。しかし、一部の密かに開発された近年のアルゴリズムは破られている。なぜならば、開発者がある種のスタイルの差分攻撃を考慮せず、自分のアルゴリズムを公開の精査の対象としなかったからである。
メッセージ置換攻撃
ある種のプロトコルでは、媒介物はメッセージの一部又は全部を置換可能である。これは、真の認証チップが消耗品内の再使用可能な複製チップにプラグインされる場合である。複製チップは、システムと認証チップの間の全てのメッセージを盗み取り、多数の置換攻撃を実行し得る。ヘッダとその後に続く内容とを格納したメッセージを例として考える。攻撃者は有効ヘッダを生成し得ないが、特に、有効レスポンスが「はい、あなたのメッセージを受信しました。」のようなものであるならば、メッセージの固有の内容を置換することができる。たとえ、リターンメッセージが「はい、以下のメッセージを受信しました...」であったとしても、攻撃者は、肯定応答を本来の送信者へ返信する前に、元のメッセージを置換することができる。メッセージ認証コードは、殆どのメッセージ置換攻撃に対抗するために開発された。
鍵生成器のリバースエンジニアリング
疑似乱数生成器が鍵を生成するため使用される場合、複製品製造者は、生成器プログラムを取得するか、又は使用されたランダムシードを推測する可能性がある。これは、ネットスケープのセキュリティプログラムが最初に破られたときの方法である。
認証全体の回避
認証プロトコルには認証プロセス全体の回避を可能にする問題があり得る。この種の攻撃の場合、鍵は全く無関係であり、攻撃者は鍵を復元する、又は鍵を推定する必要がない。電源投入時に認証を行なうが、その他のときには認証しないシステムを例として考える。複製認証チップを含む再使用可能な消耗品は、真正認証チップを利用する場合もある。複製認証チップ53は、認証呼び出しのため真正チップを使用し、次に、その後の真正認証チップの状態データをシミュレーションする。認証を回避する別の例は、消耗品が使用された後に限りシステムが認証する場合である。複製認証チップは、消耗品の使用後で、認証プロトコルが完了する前に(或いは、開始される前に)コネクションの失敗をシミュレーションすることにより単純な認証回避を実行できる。「ケンタッキーフライドチップ」ハックと呼ばれる悪名の高い攻撃は、衛星テレビジョンシステム用のマイクロコントローラチップを置換する。加入者が受信料の支払いを停止したとき、システムは、「使用不能」メッセージを送出するであろう。しかし、新しいマイクロコントローラは、このメッセージを検出するだけで、それを消費者の衛星テレビジョンシステムへ渡さない。
強盗/賄賂攻撃
鍵を知っている人は、それを他の誰かに教える可能性がある。この秘密の暴露は、強制(賄賂、強盗等)、報復(例えば、不満を抱いている従業員)、又は単に信条のために行われる。これらの攻撃は、通常、鍵を推測する他の試みよりも安価かつ容易である。一例として、Divx規格の開発に関わることを要求した多数の人々は、近年(1998年5/6月)、Divx仕様解読解読装置の開発に参加したいという趣旨で、即ち、信条によって、多種多様なDVDニュースグループで主張している。
物理的攻撃
以下の攻撃は、攻撃者が物理的にアクセスできるシリコンチップに認証機構が実装されていることを前提としている。最初の攻撃であるROM読み出しは、鍵がROMに保存されているときの攻撃を表し、残りの攻撃は秘密鍵がフラッシュメモリに保存されることを前提としている。
ROM読み出し
鍵がROMに保存されている場合、鍵を直接読み出すことが可能である。ROMは、このように(非対称暗号方式で使用するための)公開鍵を保持するため安全に使用することができるが、秘密鍵を保持するためには使用できない。対称暗号方式では、ROMは全く当てにならない。著作権付きテキスト(例えば、俳句)を鍵として使用することは不十分である。なぜならば、鍵の複製は、知的所有権が遵守されない国で行われることが想定されるからである。
チップのリバースエンジニアリング
チップのリバースエンジニアリングでは、攻撃者は、チップを分解し、回路を解析する。回路が解析されてしまうと、チップのアルゴリズムの内部動作を復元することができる。ルーセント・テクノロジー社は、回路を映像化するため、TOBIC(ツー・フォトンOBICの略であり、OBICはOptical
Beam Induced Current光ビーム誘導電流の頭文字である。)と呼ばれるアクティブな方法を開発した。主としてスタティックRAM解析のために開発されたプロセスは、全ての裏材を取り除き、裏面を鏡面仕上げまで磨き、表面に光を集光させる。励起波長は、特にICに電流を誘導しないように選択される。19世紀にケルクホフスは、アルゴリズムの内部動作がスキームの単なる秘密であるならば、スキームは解読されたも同然である、という暗号解読に関する基本的な仮説を立てた。ケルクホフスは、秘密性は完全に鍵の中に存在しなければならない、ということを明記している。その結果として、チップのリバースエンジニアリングに対する最良の保護策は、内部動作を無関係にすることである。
認証プロセスの不当使用
あらゆる複製品製造者はシステムと消耗品の両方のデザインを入手していることを想定しなければならない。同じチャンネルが、システムと信頼できるシステム認証チップとの間、並びに、信頼できない消耗品認証チップとの間の通信のために使用されるならば、信頼できないチップが「正しい回答」を得るために信頼できるチップに問い合わせをする可能性がある。もしそうであるならば、複製品製造者は鍵を決定する必要がないであろう。彼らは、システム認証チップからの応答を使用してシステムをだますだけでよい。認証プロセスを不当使用する別の方法は、論理的攻撃「認証プロセスの回避」と同じ方法に従って、認証プロセスが行われるとき、システムとの接続の失敗をシミュレーションし、電源遮断等をシミュレーションする。
システムの変更
この種の攻撃は、システム自体が複製消耗品を受け入れるように変更される攻撃である。攻撃は、システムROMの変更、消耗品の配線し直し、又は極端なケースでは、完全な複製システムである。この種の攻撃は、各個のシステムが変更されることが必要であり、殆どの場合に所有者の承諾が必要であろう。通常は、消費者がこのような変更を行うために明らかな利益が必要である。なぜならば、このような変更は、典型的に、保証を無効にさせ、殆どの場合に費用が掛かるからである。消費者にとって明らかな利益のあるこのような変更の一例は、固定リージョン型DVDプレーヤーをリージョンフリー型DVDプレーヤーに変更するソフトウェアパッチである。
従来のプロービングによるチップ動作の直接視
チップ動作がSTM又は電子ビームを使用して直接監視できるならば、鍵は、内部不揮発性メモリから読み出され、作業レジスタへ取り込まれるときに記録できる。従来の3形態のプロービングは、ICの通電中にICの上面又は前面に直接アクセスすることが必要である。
不揮発性メモリの直接視
チップが、フラッシュメモリのフローティングゲートを放電させることなく露出するためにスライスされているならば、鍵は、おそらく、STM又はSKM(走査ケルビン顕微鏡)を使用して直接監視できる。しかし、ゲートを放電させることなくこのレベルでチップをスライスすることはおそらく実施不可能である。湿式エッチング、プラズマエッチング、イオンミリング(集光イオンビームエッチング)、又は化学機械研磨は、ほぼ確実にフローティングゲート上に存在する小さい電荷を放出する。
状態変化によって生じる光バーストの監視
ゲートの状態が変化するとき、少量の赤外線エネルギーが放出される。シリコンは赤外線透過性であるため、これらの変化はチップの下側から回路を注視することによって観測できる。放出プロセスは弱いが、天文学で使用するために開発された超高感度機器を用いて検出できる程度に輝いている。IBMによって開発されたこの技術は、PICA(ピコセコンド・イメージング・サーキット・アナライザ)と呼ばれる。レジスタの状態が時点tで既知であるならば、レジスタ切り替わり時間の監視によって、時点t+nにおける正確な値が明らかになり、データが鍵の一部分であるならば、その部分は解読される。
EMIの監視
電子回路が動作しているときには、かならず微弱な電磁信号が放出される。比較的低価格(数千ドル)装置はこれらの信号を監視できる。これは、攻撃者が鍵を推測するために十分な情報を与える。
Idd変動の監視
鍵を監視できないとしても、レジスタが状態を変化させるときにはかならず電流の変動が生じる。信号対雑音比が十分に高い場合、攻撃者は、ハイビット又はロービットをプログラミングするときに生じるIddの差を監視することができる。Iddの変化は鍵に関する情報を示し得る。このような攻撃は、スマートカードを解読するために既に使用されている。
差分故障解析
この攻撃は、イオン化、マイクロ波放射、又は環境ストレスによってビット誤りが取り込まれることを前提としている。殆どのケースでは、このような誤りは、鍵を明らかにするであろう役に立つ変更ではなく、チップに悪影響を与える(例えば、プログラムコードを破壊させる)可能性が高い。ROM上書き、ゲート破壊等のような目標としている故障は、有用な結果を生じる可能性が更に低い。
クロック誤作動攻撃
チップは、典型的に、一定のクロック速度レンジ内で適切に動作するように設計されている。一部の攻撃者は、チップを非常に高いクロック速度で動作させることによってロジックに故障を生じさせ、又は特定の間隔で特定の時間にクロック誤作動を生じさせることを試みる。このアイデアは、回路が適切に機能しない乱調状態を作ることである。一例として、ANDゲートは、(乱調状態のために)入力1と入力2の論理積ではなく、常に入力1をスルーする。攻撃者がチップの内部構造を知っているならば、攻撃者は、アルゴリズム実行中の正確な時点で乱調状態を取り入れ、これにより、鍵に関する情報を明らかにすることができる(或いは、最悪ケースでは、鍵自体を明らかにする)。
電源攻撃
クロック信号に誤動作を引き起こす代わりに、攻撃者は電源に誤動作を生じさせることができ、電力は動作電圧レンジを外れるように増加又は減少させられる。正味の効果はクロック誤動作の場合と同じであり、特定の命令の実行に誤りを生じさせる。このアイデアは、CPUが鍵をXOR演算することを停止させること、又はデータを1ビット位置だけシフトすることを停止させること等である。鍵に関する情報を明らかにするために、特定の命令が目標にされる。
ROMの上書き
ROMの単一ビットは、レーザーカッター顕微鏡を使用して、ロジックの向きに応じて、1又は0に書き換えることができる。あるオペコード/オペランドのセットがある場合、攻撃者が条件付きジャンプを無条件ジャンプへ書き換えること、又はたぶんレジスタ転送の宛先を変更することは簡単なことである。目標命令が慎重に選択されたならば、鍵が明らかにされるであろう。
EEPROM/フラッシュの変更
EEPROM/フラッシュ攻撃は、ROM攻撃と類似しているが、レーザーカッター顕微鏡技術が個別のビットのセットとリセットの両方に使用できる点で異なる。これは、アルゴリズムの変更の適用範囲を非常に拡大する。
ゲート破壊
AndersonとKuhnは、BihamとShamirがDESに関する攻撃を発表した高速ソフトウェア暗号化に関する1997年のワークショップのランプセッションで、ゲート破壊を説明している。この攻撃は、従来のブロック暗号(DES)のハードウェア実装内の個々のゲートを破壊するためレーザーカッターを使用するものであった。この攻撃の正味の効果は、レジスタの特定のビットを強制的に「無価値」にすることである。BihamとShamirは、特定のレジスタに強制的にこのような影響を与えることの効果−丸め関数からの出力の最下位ビットが0にセットされる、を説明している。左半分と右半分の最下位6ビットを比較することにより、鍵の数ビットを復元することができる。このようにして多数のチップにダメージを加えると、完全な鍵の復元を容易に行うために、鍵に関する十分な情報を明らかにすることができる。このように変更された暗号化チップは、暗号化と復号化はもはや逆の関係ではなくなるという性質をもつであろう。
上書き攻撃
フラッシュメモリを読み出す代わりに、攻撃者は、単に、レーザーカッター顕微鏡を用いて単一ビットをセットする。攻撃者が前の値を知らないとしても、新しい値がわかる。チップが動作し続けるならば、そのビットの元の状態は、新しい状態と同じであるはずである。チップが動作しなくなった場合、そのビットの元の状態は、現在の状態の論理否定NOTである。攻撃者は、鍵の各ビットに対してこの攻撃を実行し、最大でnチップを使用してnビット鍵を獲得することができる(新しいビットが古いビットと一致するならば、新しいビットは次のビットを決定するために必要ではない)。
テスト回路攻撃
殆どの回路は、製造上の欠陥を検査するために特に設計されたテスト回路を備えている。これは、BIST(ビルト・イン・セルフ・テスト)とスキャンパスとを含む。非常に頻繁に、スキャンパス及びテスト回路は、内蔵された全てのラッチへのアクセス及びリードアウト機構を含む。一部のケースでは、テスト回路は特定のレジスタの内容に関する情報を与えるために使用される可能性がある。テスト回路は、しばしば、チップが全ての製造上のテストに合格すると、一部のケースではチップ内の特定の配線を切ることによって、無効状態にされる。しかし、やる気のある攻撃者は、テスト回路を再接続して、動作可能状態にし得る。
残留メモリ
値は、電源が取り外された後、長期間RAMに残存するが、不揮発性とみなされるまで長期間残存することはない。攻撃者は、機密情報がRAM(例えば、作業用レジスタ)へ移された後、電源を取り外し、RAMから値を読み出そうとすることが可能である。この攻撃は、通常のRAMチップを有するセキュリティシステムに対して最も有効である。典型的な例として、セキュリティシステムは、コンピュータケースが開けられたときにトリガーされる自動電源遮断機能付きで設計されていた。攻撃者は、単にケースを開け、RAMチップを取り外し、メモリ残留を利用して鍵を取り出せばよかった。
チップ窃盗攻撃
認証チップの耐用期間に多数のステージが存在する場合、これらのステージの各々は、チップが盗み取られた場合のセキュリティ用の派生問題の観点で調べる必要がある。例えば、情報が複数のステージでチップにプログラミングされる場合、ステージ間でチップを窃盗したならば、攻撃者は鍵情報を入手できるか、又は攻撃のための労力が軽減される可能性がある。同様に、チップが、製造直後であり、プログラミングの前に盗み取られた場合、攻撃者に論理的利益又は物理的利益があるだろうか?
必要条件
消耗品を認証する問題に対する従来のソリューションは、典型的に、物理的なパッケージングについての特許に依存している。しかし、これは、家庭での詰め替え作業や産業財産権の保護の弱い国における複製品製造を止められない。その結果、より高レベルの保護が必要である。したがって、認証メカニズムは、システムが消耗品を安全かつ容易に認証できるようにする認証チップ53内に構築される。ここでは、消耗品を認証するシステムだけに限定すると(システムを認証する消耗品については考えない)、次の2レベルの保護を考えることができる:
プレゼンスオンリー認証
この場合、認証チップが存在することだけがテストされる。認証チップは、最プログラミングすることなく、別の消耗品で再使用することができる;
消耗品ライフタイム認証
この場合、認証チップの存在がテストされるだけではなく、認証チップ53は、消耗品の耐用期間に限り持続しなければならない。チップを再使用する場合、チップは、完全に消去され、再プログラミングされなければならない。これらの二つの保護レベルは、異なる必要条件を取り扱う。ここでは、主に、大量生産消耗品の複製品を防止するため、消耗品ライフタイム認証に関心がある。このケースでは、各チップは、認証対象である消耗品に関するセキュア状態情報を保持しなければならない。尚、消耗品ライフタイム認証チップは、プレゼンスオンリー認証チップを必要とするあらゆる状況で使用できることに注意する必要がある。認証の必要条件、データ記憶完全性の必要条件、及び製造の必要条件は、別々に検討すべきである。以下のセクションは各々の必要条件を簡単に説明する。
認証
プレゼンスオンリー認証と消耗品ライフタイム認証の両方に対する認証必要条件は、システムが消耗品を認証するケースに限定される。プレゼンスオンリー認証の場合、認証チップが物理的に存在することが保証されなければならない。消耗品ライフタイム認証の場合、状態データが実際に認証チップに由来すること、及び状態データが途中で改ざんされていないこと、が保証される必要がある。これらの問題は切り離すことができず、改ざんされたデータは新しい送信元からのものであり、送信元を判定できない場合、改ざんの問題を解決できない。機密性があり、セキュリティ専門家によって精査されていない自家製のセキュリティ法に基づく認証方法を提供するだけでは不十分である。したがって、主要な必要条件は、専門家の精査に耐えた手段による認証を提供することである。認証チップ53によって使用される認証スキームは、論理的手段による打破に抵抗できなければならない。論理的タイプの攻撃は費用が掛かり、次の三つの事柄:
認証プロセスを完全に回避する;
あらゆる質問に回答できるように、力ずく又は推論によって秘密鍵を取得する;
鍵を用いることなく各質問に正しい回答を与えるため、認証用の質問及び回答の性質を十分に検出する;
のうちの一つを実行しようとする。
データ記憶完全性
認証プロトコルは、通信されるメッセージ中のデータ完全性の保証に対押しているが、データ記憶完全性も必要である。次の2種類のデータ:
秘密鍵のような認証データ;
シリアル番号及びメディア残量等の消耗品状態データ;
を認証チップ内に記憶しなければならない。
これらの二つのデータタイプのアクセス必要条件は全く異なる。したがって、認証チップ53は、各タイプの完全性必要条件を考慮する記憶/アクセス制御メカニズムを必要とする。
認証データ
認証データは機密保持されなければならない。認証データは、チップの耐用期間の製造/プログラミングステージの間にチップに記憶される必要があるが、それ以降、チップから取り出されることは許可されるべきではない。認証データは、不揮発性メモリから読み出されることに対抗できなければならない。認証スキームは鍵が推論によって取得できないことを保証する役目があり、製造プロセスは鍵が物理的手段によって取得できないことを保証する役目がある。認証データ記憶エリアのサイズは、必要な鍵、及び認証プロトコルによって義務づけられるような秘密情報を保持するために十分な大きさでなければならない。
消耗品状態データ
各認証チップ53は、消耗品状態データのうちの256ビット(32バイト)を記憶できる。消耗品状態データは以下のタイプに分類される。アプリケーションに依存して、以下のタイプのデータ項目の各々の数は異なる。単一のデータ項目に対する最大数は32ビットであると仮定する:
リードオンリー;
リードライト;
デクリメントオンリー。
リードオンリーデータは、チップの耐用期間の製造/プログラミングステージの間にチップに保存できなければならないが、それ以降、変更を許されるべきではない。リードオンリーデータの例は、消耗品バッチ番号及びシリアル番号である。
リードライトデータは、変更可能な状態情報であり、例えば、特定の消耗品が使用された最後の時間である。リードライトデータ項目は、消耗品の耐用期間中、無制限の回数で読み書きをすることができる。それらは、消耗品に関するあらゆる状態情報を記憶するため使用できる。このデータに対する唯一の必要条件は、不揮発性メモリに保持されるべきである、ということである。攻撃者はシステムへのアクセス権を獲得し得るので(リードライトデータへの書き込みが可能であり)、攻撃者はこのタイプのデータフィールドを変更する可能性がある。このデータタイプは秘密情報のために使用されるべきではなく、不確かであると考えるべきである。
デクリメントオンリーデータは、消耗品リソースの利用可能度をカウントダウンするため使用される。例えば、コピー機のトナーカートリッジは、デクリメントオンリーデータ項目としてトナー残量を記憶する。カラープリンタ用のインクカートリッジは、各インク色の量をデクリメントオンリーデータ項目として記憶し、3個(シアン、マゼンタ及びイエローの各々に1個ずつ)、又は5から6個のデクリメントオンリーデータ項目を必要とする。この種のデータ項目の必要条件は、一旦、製造/プログラミングステージで初期値を用いてプログラミングされると、値を減少させることだけが可能である、ということである。それは、最小値に達すると、それ以上は減少し得ない。デクリメントオンリーデータ項目は、消耗品ライフタイム認証だけで必要になる。
製造
認証チップ53は、理想的には、低価格消耗品の認証メカニズムとして組み込むことができるように低製造コストであるべきである。認証チップ53は、フラッシュのような標準的な製造プロセスを使用すべきである。これは:
製造場所の非常に広範囲の選択を可能にさせること;
明確であり、且つ正常に動作するテクノロジーを使用すること;
コストを低減すること;
が必要である。
使用される認証スキームとは無関係に、チップの認証部の回路は物理的攻撃に対抗できなければならない。物理的な攻撃は、以下の4つの主要な形で現れるが、攻撃の形態は変化し得る:
認証チップを完全に回避する;
動作中にチップを物理的に検査する(破壊的及び非破壊的);
チップを物理的に分解する;
チップを物理的に改変する。
理想的には、チップは米国から持ち出せるべきであるので、認証チップ53をセキュア暗号化装置として使用可能であってはならない。これは優先度の低い必要条件である。なぜならば、他の国にも認証チップを製造し得る多数の企業が存在するからである。いずれにせよ、米国からの国外持ち出し規制は変わり得る。
認証
消耗品を認証する問題に対する従来のソリューションは、典型的に、物理的なパッケージングについての特許に依存している。しかし、これは、家庭での詰め替え作業や産業財産権の保護の弱い国における複製品製造を止められない。したがって、より高レベルの保護が必要である。機密性があり、セキュリティ専門家によって精査されていない自家製のセキュリティ法に基づく認証方法を提供するだけでは不十分である。ネットスケープの最初の独自に開発したシステム、及び携帯電話で私用されるGSM不正防止ネットワークは、設計秘密主義によって生じたセキュリティの脆弱性である。両方のセキュリティシステムは、それらの企業がオープン設計プロセスに従っていたならば検出できたであろう従来の手段によって破られた。ソリューションは、専門家の精査に耐えた手段による認証を提供することである。多数のプロトコルを消耗品認証のために使用することが可能である。ここでは、公表されたセキュリティ方法だけを使用し、この新しい方法によって知られた動作を使用する。全てのプロトコルにおいて、スキームの安全性は、秘密アルゴリズムではなく、秘密鍵に依拠する。プロトコルの全ては、時変性チャレンジ(即ち、毎回異なるチャレンジ)に依存し、レスポンスはチャレンジと秘密情報に依存する。チャレンジは乱数を含むので、観測者は後続のアイデンティフィケーションに関する有益な情報を集めることができない。プレゼンスオンリー認証と消耗品ライフタイム認証の各々のために二つのプロトコルが提案される。プロトコルは認証プロセスのために必要な認証チップの個数が異なるが、全てのケースで、システムは消耗品を認証する。ある種のプロトコルは、1個又は2個のチップで動作するが、他のプロトコルは2個のチップだけで動作する。使用される認証チップが1個であるか2個であるかとは無関係に、システムは認証判定を行う役割を担う。
シングルチップ認証
唯一の認証チップ53が認証プロトコルのために使用される場合、単一チップ(チップAと呼ぶ)は、システム(システムと呼ぶ)に対し、チップAが真正であることを伝える責任がある。プロトコルの開始時に、システムは、チップAの真正性を確信できない。システムは、チップAとチャレンジ−レスポンスプロトコルを実行し、チップの真正性を判定する。全てのプロトコルにおいて、消耗品の真正性は、チップの真正性に直接的に基づいている。即ち、チップAが真正であるとみなされるならば、消耗品も真正であるとみなされる。データフローは図167に示されている。シングルチップ認証プロトコルの場合、システムは、ソフトウェア、ハードウェア、又は両者の組み合わせのどれでもよい。重要なことは、システムは安全ではなく、攻撃者がROMを調べることによって、又は回路を調べることによって容易にリバースエンジニアリングをすることができる、ということである。システムは、それ自体で安全になるようには特に設計されていない。
ダブルチップ認証
別のプロトコルでは、2個の認証チップが図168に示されるように必要になる。単一のチップ(チップA)は、システム(システムと呼ぶ)に対し、チップAが真正であることを伝える責任がある。認証プロセスの一部として、システムは、信頼できる認証チップ(チップTと呼ぶ)を利用する。ダブルチップ認証プロトコルでは、システムは、ソフトウェア、ハードウェア、又は両者の組み合わせのどれでもよい。しかし、チップTは物理的な認証チップでなければならない。あるプロトコルでは、チップT及びチップAは同じ内部構造を備え、他のプロトコルでは、チップT及びチップAは異なる内部構造を備えている。
プレゼンスオンリー認証(不確かな状態データ)
このレベルの消耗品認証の場合、認証チップ53の存在を確認することだけに関心がある。認証チップは状態情報を格納し得るが、その状態情報の伝送は安全であるとは考えられない。二つのプロトコルが提案される。プロトコル1は2個の認証チップが必要であり、プロトコル2は1個又は2個の認証チップを使用して実現可能である。
プロトコル1
プロトコル1はダブルチッププロトコルである(2個の認証チップが必要になる)。各認証チップは以下の値を格納する:
K FK[X]用の鍵。秘密でなければならない;
R 現在の乱数。秘密でなくてもよいが、チップインスタンス毎に異なる初期値でシードされなければならない。Random関数の呼び出し毎に変化する。
各認証チップは以下の論理関数を格納する:
Random[] Rを返し、Rをシーケンス内で次へ進める;
F[X] 一方向関数Fを秘密鍵Kに基づいてXに適用した結果であるFK[X]を返す。
プロトコルは以下の通りである:
システムはチップTからのRandom[]を要求する;
チップTはRをシステムへ返す;
システムはチップT及びチップAの両方からのF[R]を要求する;
チップTはFKT[R]をシステムへ返す;
チップAはFKA[R]をシステムへ返す;
システムは、FKT[R]をFKA[R]と比較する。それらが一致しているならば、チップAは有効であるとみなされる。一致しないならば、チップAは無効であるとみなされる。
データフローは図169に示されている。システムは、FK[R]メッセージを理解する必要がない。システムは、チップAからの応答とチップTからの応答が同じであることをチェックするだけでよい。したがって、システムは鍵を必要としない。プロトコル1の安全性は以下の2カ所にある:
F[X]の安全性。認証チップだけが秘密鍵を格納するので、
信頼できる認証チップ53(チップT)によって生成されたF[X]と一致するF[X]をXから生成し得るチップは真正に違いない;
全ての認証チップによって生成されたRのドメインは大きく、非決定論的である筈である。全ての認証チップによって生成されたRのドメインが小さいならば、複製品製造者は鍵を解読しなくてもよい。その代わりに、複製品製造者は、システムによって送信されたコードに対する純正チップからのレスポンスの全てが記録されたROMを自分のチップに組み込むことができる。Random関数は厳密に認証チップ内に収容しなくてもよい。なぜならば、システムは、同じ乱数シーケンスを生成する可能性を秘めているからである。しかし、それは、システムの設計を簡単化し、乱数生成器の安全性が認証チップを使用する全ての実装形態に対して同一であり、システム実装においてエラーが起こる可能性を減少させる。
プロトコル1には複数の利点がある:
Kは認証プロセス中に明らかにされることがない;
Xが与えられたとき、複製チップは、Kを用いないで、又は実際の認証チップへアクセスしないで、FK[X]を生成できない;
システムは、特に、インクジェットプリンタのような低価格システムにおいて容易に設計できる。なぜならば、暗号化又は復号化がシステム自体によって要求されないからである;
広範囲の鍵付き一方向関数が存在し、対称暗号化、乱数シーケンス、及びメッセージ認証コードが含まれる;
一方向関数は必要なゲート数が少なく、非対称アルゴリズムよりも簡単に検証することができる;
鍵付き一方向関数のための安全な鍵サイズは、非対称(公開鍵)アルゴリズムの場合と同程度に大きくする必要がない;
F[X]が対称暗号化関数であるならば、最小限の128ビットは、適切な安全性を提供することができる。
しかし、このプロトコルには問題がある:
これは選択テキスト攻撃の対象になりやすい。攻撃者は、チップを自分専用のシステムにプラグインし、選択されたRを生成、出力を観測することができる。鍵を見つけるため、攻撃者は、特定のF[M]を生成するRを探索することも可能である。なぜならば、多数の認証チップを並列にテストできるからである;
選択された一方向関数に応じて、鍵生成は複雑化し得る。よい鍵を選択する方法は、使用されるアルゴリズムに依存する。ある種の鍵は一定のアルゴリズムに対して弱い;
鍵付き一方向関数の選択自体は重要ではない。特許保護に由来するライセンスを必要とする場合もある。
媒介物は、平文メッセージMをチップAへ渡す前に平文メッセージMに作用することが可能であり、これは、チップAがMを見るまで媒介物がMを見ない場合には好ましい。媒介物がMを全く見ない場合にはより好ましい。
Fが対称暗号化である場合、適切なセキュリティのために必要な鍵サイズのため、チップは米国から国外へ持ち出せない。なぜならば、チップは強い暗号化装置として使用できるからである。
プロトコルが非対称暗号アルゴリズムとしてFを用いて実現されるならば、対称の場合を上回る利点は無く、鍵をより長くする必要があり、シリコン内の暗号化アルゴリズムがより高価になる。プロトコル1は、鍵の安全性を維持するため、2個の認証チップを用いて実現しなければならない。すなわち、各システムは認証チップが必要であり、各消耗品は認証チップが必要である。
プロトコル2
あるケースでは、システムは大規模の処理能力を備えている。或いは、例えば、大量に製造されたシステムの場合、チップTをシステムに統合することは望ましい。非対称暗号アルゴリズムの使用によって、システムのチップT部を不確かにすることが許容される。したがって、プロトコル2は非対称暗号方式を使用する。このプロトコルの場合、各チップは以下の値を格納する:
K EK[X]及びDK[X]用の鍵である。チップA内で秘密にされるべきである。チップT内で秘密にする必要がない;
R 現在の乱数。秘密でなくてもよいが、チップインスタンス毎に異なる初期値でシードされなければならない。Random関数の呼び出し毎に変化する。
以下の関数が定義される:
E[X] チップTだけ。EK[X]を返す。但し、Eは非対称暗号化関数Eである;
D[X] チップAだけ。DK[X]を返す。但し、Dは非対称暗号化関数Dである;
Random[] チップTだけ。R|EK[R]を返す。RはシードSに基づく乱数である。乱数シーケンス内でRを次へ進める。
公開鍵KTはチップT内にあり、一方、秘密鍵KAはチップAにある。KTがチップTにあることは、チップTをソフトウェア又はハードウェアで実現できるという利点がある(但し、Rのシードはチップ又はシステム毎に異なる)。したがっって、プロトコル2は、シングルチッププロトコルとしてもダブルチッププロトコルとしても実現できる。認証のためのプロトコルは以下の通りである:
システムはチップTのRandom関数を呼び出す;
チップTはR|EKT[R]をシステムへ返す;
システムはチップAの関数Dを呼び出し、EKT[R]を渡す;
チップAは、DKA[EKT[R]]によって獲得されたRを返す;
システムは、チップAからのRとチップTによって生成された元のRを比較する。それらが一致しているならば、チップAは有効であるとみなされる。一致しないならば、チップAは無効であるとみなされる。
データフローは図170に示されている。プロトコル2には次の利点がある:
KA(秘密鍵)は認証プロセス中に明らかにされることがない;
EKT[X]が与えられたとき、複製チップは、KAを用いないで、又は実際のチップAへアクセスすることなく、Xを生成できない;
KT≠KAであるため、チップTは、完全にソフトウェアで、不確かなハードウェアで、又はシステムの一部として実現できる。チップA(消耗品内)だけが安全な認証チップであることを要求される;
チップTが物理的なチップであるならば、システムは容易に設計できる;
多数の十分に文書化され暗号解読された非対称アルゴリズムの中から、特許が開放されライセンスフリーであるソリューションを含む、インプリメンテーション用のアルゴリズムを選択することができる。
しかし、プロトコル2には多数の固有の問題がある:
十分な安全性のため、各鍵は2048ビットにする必要がある(これに対して、プロトコル1の対称暗号方式の場合、最小値は128ビットである)。暗号化及び復号化アルゴリズムによって使用される関連した中間メモリは、相応に大きくなる;
鍵生成は重要である。乱数は優れた鍵ではない;
チップTがコアとして実装された場合、チップTを所与のシステムASICに連結することが難しい;
チップTがソフトウェアとして実装された場合、システムの実装がプログラミングエラー及び厳密ではないテストに対して無防備であるだけではなく、コンパイラ及び数学的プリミティブの完全性をシステムのインプリメンテーション毎に厳密にチェックしなければならない。これは、単純に十分にテストされたチップを使用する場合よりも複雑であり、且つコスト高である;
多数の対称アルゴリズムが特に差分暗号解読(選択テキスト攻撃に基づいている)に対抗するため強化されているにもかかわらず、秘密鍵KAは選択テキスト攻撃の対象になりやすい;
チップA及びチップTが同じ認証チップのインスタンスである場合、各チップは、非対称暗号化及び復号化の両方の機能を備える必要がある。その結果として、各チップは、プロトコル1のために必要なチップよりも大型化し、複雑化し、高価になる;
認証チップが、コストを節約し、設計/テストの複雑さを低減するため2個のチップに分割された場合、2個のチップを依然として製造する必要があり、スケールメリットが減少する。これは、システムの消耗品に対する相対的な個数によって相殺されるが、依然として考慮することが必要である;
プロトコル2の認証チップは、米国から国外へ持ち出すことができない。なぜならば、それらは、強力な暗号化装置であるとみなされるからである。
たとえ、プロトコル2用の鍵を選択するプロセスが簡単であるとしても、プロトコル2は、(鍵サイズ及び機能的実装の両方の)シリコン実装のコストが高いため、現時点では実際的ではない。したがって、プロトコル1がプレゼンスオンリー認証のためのプロトコルとして選択される。
本物の認証チップを使用する複製消耗品
プロトコル1及び2は、チップAが本物の認証チップであるかどうかをチェックするだけである。それらは、消耗品自体が有効であるかどうかを調べるためのチェックを行わない。認証に関する基本的な前提として、チップAが有効であるならば、消耗品は有効である。したがって、複製品製造者は本物の認証チップを複製消耗品に挿入することが可能である。以下の二つのケースを検討する:
状態データが認証チップに書き込まれないケースでは、チップは完全に再使用可能である。したがって、複製品製造者は、有効な消耗品を複製消耗品にリサイクルすることができる。これは、認証チップを消耗品の物理的パッケージングに融合することによって困難になるが、詰め替え作業者を止められないであろう;
状態データが認証チップに書き込まれるケースでは、チップは、新品か、部分的に使用されているか、又は完全に使い切られている。しかし、これは、複製品製造者によるピギーバック攻撃の使用を止められず、複製品製造者はピギーバックとして本物の認証チップを具備したチップを構築する。攻撃者のチップ(チップE)は、媒介物である。電源投入時、チップEは、本物の認証チップ53から固有のメモリへ全ての記憶状態値を読み込む。チップEは、次に、システムからの要求を検査し、要求に応じて様々な動作をとる。認証要求は、本物の認証チップ53へそのまま渡すことができ、一方、リード/ライト要求は、本物の認証チップの動作と似ているメモリによってシミュレーションされ得る。このようにして、認証チップ53は、常に、電源投入時に新品であるかのように見える。チップEがこれを行うことができるのは、データアクセスは認証されないからである。
システムを欺いて、システムのデータアクセスが成功したと思わせるために、チップEは、依然として本物の認証チップを必要とし、第2のケースでは、複製チップが本物のチップの他に必要になる。その結果として、プロトコル1及び2が有効になるのは、複製品製造者が本物の認証チップ53を消耗品に埋め込むことの費用対効果がよくない場合である。消耗品をリサイクルできない、又は簡単に詰め替えできないならば、プロトコル1又はプロトコル2の使用によって十分な保護が得られる。複製動作を成功させるためには、各複製消耗品は、有効な認証チップを具備しなければならない。そのチップは、まとめて盗み取るか、又は古い消耗品から取り出さなければならない。これらの再生チップの量は(それらを再生する労力と共に)ビジネスの基盤とするためには不十分であり、セキュアデータ転送(プロトコル3及び4を参照)の保護を追加する実益はない。
鍵の寿命
上記の二つのプロトコルの一般的な問題は、一旦、認証鍵が選択されると、それを変更することが容易ではない点である。ある種の状況では、鍵が危険にさらされることは問題ではないが、他の場合には、鍵を危うくすることは致命的である。例えば、車/車キーシステム/消耗品のシナリオでは、消費者は、1組の車/車キーだけを保有する。各車は異なる認証鍵を有する。その結果として、車キーの損失は個々の車を危うくするだけである。所有者がこのことを問題であると考えるならば、所有者は、車のエレクトロニクス内のシステムチップを交換することによって、新しい「車キー」を入手しなければならない。所有者の鍵は、新しい「車のシステム認証チップ」と連動するように再プログラミング/交換する必要がある。これに対して、大量消耗品市場(例えば、プリンタのインクカートリッジ)の鍵が危うくなることは、複製インクカートリッジ製造者が自分専用の認証チップを製造可能にさせる。既存のシステムに対する唯一のソリューションはシステム認証チップを更新することであり、これは、コストが掛かり、物流的に困難な課題である。いずれにしても、消費者のシステムは既に正常に機能し、既存の機器を妨害しようとする動機がない。
消耗品ライフタイム認証
この消耗品認証のレベルでは、認証チップの存在を確認すること、並びに、認証チップが消耗品と同じ期間だけ確実に存続することに関心がある。認証チップが存在することを確認することに加えて、認証チップのメモリ空間の書き込み及び読み出しも同様に認証されなければならない。このセクションでは、認証チップのデータ記憶完全性は安全であると仮定し、メモリの一部はリードオンリーであり、他の一部はリード/ライトであり、その他はデクリメントオンリーである(より詳しくは、データ記憶完全性というタイトルの章を参照のこと)。二つのプロトコルが存在する。プロトコル3は2個の認証チップを必要とし、プロトコル4は1個又は2個の認証チップを使用して実現することができる。
プロトコル3
このプロトコルはダブルチッププロトコルである(2個の認証チップが必要になる)。このプロトコルの場合、各認証チップは以下の値を格納する:
K1 FK1[X]を計算するための鍵。秘密にしなければならない;
K2 FK2[X]を計算するための鍵。秘密にしなければならない;
R 現在の乱数。秘密でなくてもよいが、チップインスタンス毎に異なる初期値でシードされなければならない。Test関数によって定義されるように認証が成功する毎に変化する;
M 認証チップ53のメモリベクトル。この空間の一部はチップ毎に異なるべきである(乱数でなくてもよい)。
各認証チップは以下の論理関数を格納する:
F[X] 内部関数専用。一方向関数Fを鍵K1又は鍵K2の何れかに基づいてXに適用した結果であるFK[X]を返す;
Random[] R|FK1[R]を返す;
Test[X,Y] FK2[R|X]=Yであるならば、1を返しRを進める。そうでなければ、0を返す。0を返すために要する時間は、全ての不良な入力に対して同じでなければならない;
Read[X.Y] FK1[X]=Yであるならば、M|FK2[X|M]を返す。そうでなければ、0を返す。0を返すために要する時間は、全ての不良な入力に対して同じでなければならない;
Write[X] Mのうち正当に書き換え可能な部分にXを書き込む。
チップAを認証し、チップAのメモリMを読み出すためには、
システムはチップTのRandom関数を呼び出し、
チップTはR|FK[R]を生成し、これをシステムへ返し、
システムはチップAのRead関数を呼び出し、R、FK[R]を渡し、
チップAはM及びFK[R|M]を返し、
システムはチップTのTest関数を呼び出し、M及びFK[R|M]を渡し、
システムはチップTからのレスポンスをチェックする。レスポンスが1であるならば、チップAは真正であるとみなされる。0であるならば、チップAは無効であるとみなされる。
チップAのメモリMへのMnewの書き込みを認証するためには、
システムはチップAのWrite関数を呼び出し、Mnewを渡し、
読み出しのための認証手続きが実行され、
チップAが真正であり、Mnew=Mであるならば、書き込みは成功である。そうでなければ、書き込みは失敗した。
読み出し認証のデータフローは図171に示されている。プロトコル3に関して最初に注意しなければならないことは、FK[X]を直接呼び出せないことである。その代わりに、FK[X]は、Random、Test及びReadによって間接的に呼び出される:
Random[]はFK1[X]を呼び出す。Xは呼び出し元によって選択されない。XはRandom関数によって選択される。攻撃者は、希望のX、FK1[X]のペアを獲得するためには、Random、Read、及びTestの複数回の呼び出しを使用してブルートフォース検索を実行しなければならない;
Test[X,Y]はFK2[X]を呼び出す。結果をそのまま返すのではなく、結果をYと比較し、1又は0を返す。所定のXに対してFK2[R|X]の様々な値を試して、Testを複数回呼び出すことによってK2を推論しようとする試みは、Rが攻撃者によって選択できないブルートフォース検索まで軽減される;
Read[X,Y]はFK1[X]を呼び出す。X及びFK1[X]は、呼び出し元によって供給されなければならないので、呼び出し元は、前もってX、FK1[X]ペアが分かっていなければならない;
この呼び出しは、Y≠FK1[X]であるならば0を返すので、呼び出し元は、K1に対するブルートフォース攻撃のためRead関数を使用することができる;
Read[X,Y]はFK2[X|M]を呼び出す。Xは呼び出し元によって供給されるが、XはRandom関数によって既に与えられた値だけをとり得る(なぜならば、X及びYはK1によって検証されている)。このため、選択テキスト攻撃は、最初に、Randomからペアを収集しなければならない(事実上、ブルートフォース攻撃である)。その上、Mの一部だけが選択テキスト攻撃で使用される。なぜならば、Mの一部は一定であり(リードオンリー)、Mのデクリメントオンリー部分は、消耗品毎に1回ずつ使用できる。次の消耗品で、Mのリードオンリー部分は異なる。
FK[X]が間接的に呼び出されることは、認証チップへの選択テキスト攻撃を阻止する。攻撃者は、望ましいRが現れるまで、Random、Read、及びTestを複数回呼び出すことによって選択されたR、FK1[R]ペアしか獲得できないので、K1へのブルートフォース攻撃は、K2への制限選択テキスト攻撃を実行するために必要である。K2への選択テキスト攻撃における試みは制限されるであろう。なぜならば、テキストを完全に選択できないからであり、Mの一部はリードオンリーであり、依然として各認証チップに対して異なる。2番目に注意すべきことは、2個の鍵が使用されることである。小さいサイズのMが与えられた場合、2種類の鍵K1及びK2は、F[R]とF[R|M]の間に相関が無いことを保証するため使用される。したがって、K1は、差分攻撃からK2を保護するために使用される。1個のより長い鍵を使用することは不十分である。なぜならば、Mは256ビットだけであり、Mの一部分しか消耗品の耐用期間中に変化しないからである。そうでなければ、攻撃者は、ある種の未発見の技術によって、限定されたMの変化が、特定のRのビット組み合わせに与える影響を判定し、FK1[X]に基づいてFK2[X|M]を計算できる可能性がある。付加的な事前計算として、チップAのRandom関数及びTest関数は無効にされるべきであり、その結果、R、FK[R]のペアを生成するため、攻撃者は、チップTのインスタンスを使用する必要があり、その各々はチップAよりも高価である(なぜならば、システムは各チップTに対して獲得されなければならないからである)。同様に、Random、Read及びTestの呼び出しの間の遅れは最小限にされるべきであり、その結果として、攻撃者はこれらの関数を高速で呼び出すことができない。このようにして、各チップは、ある時間に、特定の個数のX、FK[X]のペアだけを明らかにする。プロトコル3の唯一の特有のタイミング必要条件は、返り値0(不良な入力を示す)が、誤りが入力のどこに存在するかとは無関係に、同じ時間で生成されるべきである、ということである。したがって、攻撃者は、入力値に関する誤りが何であるかに関して学習できない。これは、RD関数とTST関数の両方に対しても成り立つ。
プロトコル3に関して注意すべき別の事項は、チップAからのデータ読みだしにもチップAの認証が必要になる、ということである。システムは、FK2[R|M]が正しく返された場合に、メモリ(M)の内容はチップAが主張している内容そのものであることを確認できる。複製チップは、Mがある値であると偽る(例えば、消耗品が一杯詰まっているように見せかける)かもしれないが、複製チップは、システムによって渡された任意のRに対して、FK2[R|M]を返すことができない。このように、事実上の署名、FK2[R|M]は、認証チップAがMを送信したことだけではなく、MがチップAとシステムの間で改ざんされていないことをシステムに保証する。最後に、上述のWrite関数は書き込みを認証しない。書き込みを認証するため、システムは、各書き込みの後に読み出しを実行しなければならない。プロトコル3には幾つかの基本的な利点がある:
K1及びK2は認証プロセス中に明らかにされることがない;
Xが与えられたとき、複製チップは、Kを用いないで、又は本物のチップAへアクセスすることなく、FK2[X|M]を生成できない;
システム自体によって暗号化又は復号化が必要ではないため、特に、インクジェットプリンタのような低コストシステムにおいて、システムは簡単に設計できる;
対称暗号方式、乱数シーケンス、及びメッセージ認証コードを含む広範囲の鍵ベースの一方向関数が存在する;
鍵付き一方向関数は必要なゲート数が少なく、非対称アルゴリズムよりも簡単に検証することができる。);
鍵付き一方向関数のための安全な鍵サイズは、非対称(公開鍵)アルゴリズムの場合と同程度に大きくする必要がない。F[X]が対称暗号化関数であるならば、最小限の128ビットで適切な安全性を提供することができる。
したがって、プロトコル3の場合、チップAを認証する唯一の方法は、チップAのメモリの内容を読み出すことである。このプロトコルの安全性は、基本となるFK[X]スキームと、すべてのシステムの組に亘るRのドメインと、に依存する。FK[X]は鍵付き一方向関数であればよいが、それを非対称暗号として実現することに利点はない。鍵はより長くすることが必要であり、暗号化アルゴリズムはシリコン内でより高価になる。このため、非対称アルゴリズムと共に使用するための第2のプロトコル、即ち、プロトコル4が生じる。プロトコル3は、鍵を秘密のまま保つために2個の認証チップで実現する必要がある。即ち、各システムは認証チップを必要とし、各消耗品は認証チップを必要とする。
プロトコル4
あるケースでは、システムは大規模の処理能力を備えている。或いは、例えば、大量に製造されたシステムの場合、チップTをシステムに統合することは望ましい。非対称暗号アルゴリズムの使用によって、システムのチップT部を不確かにすることが許容される。したがって、プロトコル4は非対称暗号方式を使用する。このプロトコルの場合、各チップは以下の値を格納する:
K EK[X]及びDK[X]用の鍵である。チップA内で秘密にされるべきである。チップT内で秘密にする必要がない;
R 現在の乱数。秘密でなくてもよいが、チップインスタンス毎に異なる初期値でシードされなければならない。Test関数によって定義されるように認証が成功する毎に変化する;
M 認証チップ53のメモリベクトル。この空間の一部はチップ毎に異なるべきである(乱数でなくてもよい)。
Read関数で何かを検証する意味はない。なぜならば、誰でも公開鍵を使用して暗号化できるからである。したがって、以下の関数が定義される:
E[X] 内部関数だけ。EK[X]を返す。但し、Eは非対称暗号化関数Eである;
D[X] 内部関数だけ。DK[X]を返す。但し、Dは非対称暗号化関数Dである;
Random[] チップTだけ。EK[R]を返す;
Test[X,Y] DK[R|X]=Yであるならば、1を返しRを進める。そうでなければ、0を返す。0を返すために要する時間は、全ての不良な入力に対して同じでなければならない;
Read[X] M|EK[R|M]を返す。但し、R=DK[X]である(入力をテストしない);
Write[X] Mのうち正当に書き換え可能な部分にXを書き込む。
公開鍵KTはチップT内にあり、一方、秘密鍵KAはチップAにある。KTがチップTにあることは、チップTをソフトウェア又はハードウェアで実現できるという利点がある(但し、Rはシステム毎に異なる乱数でシードされる)。チップAを認証し、チップAのメモリMを読み出すためには、
システムはチップTのRandom関数を呼び出し、
チップTはEKT[R]を生成し、これをシステムへ返し、
システムはチップAのRead関数を呼び出し、EKT[R]を渡し、
チップAはM|EKA[R|M]を返し、最初にDKA[EKT[R]]によってRを獲得し、
システムはチップTのTest関数を呼び出し、M及びEKA[R|M]を渡し、
チップTはDKT[EKA[R|M]]を計算し、それをR|Mと比較し、
システムはチップTからのレスポンスをチェックする。レスポンスが1であるならば、チップAは真正であるとみなされる。0であるならば、チップAは無効であるとみなされる。
チップAのメモリMへのMnewの書き込みを認証するためには、
システムはチップAのWrite関数を呼び出し、Mnewを渡し、
読み出しのための認証手続きが実行され、
チップAが真正であり、Mnew=Mであるならば、書き込みは成功である。そうでなければ、書き込みは失敗した。
読み出し認証のデータフローは図172に示されている。有効なチップAだけにRの値がわかる。なぜならば、Rは認証関数に渡されないからである(それは暗号化された値として渡される)。RはE[R]を復号化することによって獲得しなければならず、これは、秘密鍵KAを使用することによってのみ行える。Rが獲得されると、RはMに付加され、結果が再符号化される。チップTは、復号化された形式のEKA[R|M]=R|Mを検証することができ、これにより、チップAは有効である。KT≠KAであるため、EKT[R]≠EKA[R]である。プロトコル4には以下の利点がある:
KA(秘密鍵)は認証プロセス中に明らかにされることがない;
EKT[X]が与えられたとき、複製チップは、KAを用いないで、又は実際のチップAへアクセスすることなく、Xを生成できない;
KT≠KAであるため、チップTは、完全にソフトウェアで、不確かなハードウェアで、又はシステムの一部として実現できる。チップAだけが安全な認証チップであることを要求される;
チップT及びチップAは異なる鍵を格納するので、チップTの激しいテストによってもKAに関して何も明らかにならない;
チップTが物理的なチップであるならば、システムは容易に設計できる;
多数の十分に文書化され暗号解読された非対称アルゴリズムの中から、特許が開放されライセンスフリーであるソリューションを含む、インプリメンテーション用のアルゴリズムを選択することができる;
チップAの要求がチップTへ向けられるようにシステムを再配線できるとしても、KT≠KAであるため、チップTはチップAに対して回答できない。攻撃は、認証プロトコルを回避するため、システムROM自体へ向けられるべきであろう。
しかし、プロトコル4には多数の問題がある:
全ての認証チップは、非対称暗号化及び復号化の両方の機能を収容する必要がある。その結果として、各チップは、プロトコル3のために必要なチップよりも大型化し、複雑化し、高価格化する;
十分な安全性のため、各鍵は2048ビットにする必要がある(これに対して、プロトコル1の対称暗号方式の場合、最小値は128ビットである)。暗号化及び復号化アルゴリズムによって使用される関連した中間メモリは、相応に大きくなる;
鍵生成は重要である。乱数は優れた鍵ではない;
チップTがコアとして実装された場合、チップTを所与のシステムASICに連結することが難しい;
チップTがソフトウェアとして実装された場合、システムの実装がプログラミングエラー及び厳密ではないテストに対して無防備であるだけではなく、コンパイラ及び数学的プリミティブの完全性をシステムのインプリメンテーション毎に厳密にチェックしなければならない。これは、単純に十分にテストされたチップを使用する場合よりも複雑であり、且つコスト高である;
多数の対称アルゴリズムが特に差分暗号解読(選択テキスト攻撃に基づいている)に対抗するため強化されているにもかかわらず、秘密鍵KAは選択テキスト攻撃の対象になりやすい。
プロトコル4の認証チップは、米国から国外へ持ち出すことができない。なぜならば、それらは、強力な暗号化装置であるとみなされるからである。
プロトコル3の場合と同様に、プロトコル4の唯一の特有のタイミング必要条件は、返り値0(不良な入力を示す)が、誤りが入力のどこに存在するかとは無関係に、同じ時間で生成されるべきである、ということである。したがって、攻撃者は、入力値に関する誤りが何であるかに関して学習できない。これは、RD関数とTST関数の両方に対しても成り立つ。
TST呼び出しの変化
2個の認証チップが使用される場合、理論的には、複製品製造者はシステム認証チップを、TSTの各呼び出しに1(成功)を返すもので置換することが可能である。システムは、多数回、間違ったハッシュ値を用いてN回に亘ってTSTを呼び出すことによってこれをテストし、その結果が0であることを予測することができる。TSTが最後に呼び出されたとき、チップAからの真の戻り値が渡され、その戻り値は信頼できる。TSTを呼び出す回数が問題になる。呼び出しの回数はランダムでなければならない。これにより、複製チップ製造者は前もって回数を知り得ない。システムがクロックを持っているならば、クロックからのビットは、間違ったTST呼び出しを何回行わなければならないかを決めるために使用される。それ以外の場合、チップAからの戻り値を使用できる。後者のケースでは、攻撃者は、依然として、複製チップTがチップAからの戻り値を監視できるようにするため、システムを書き換えることができ、これにより、正しいハッシュ値を知ることができる。最悪のケースは、勿論、システムが、認証された消耗品を必要としない複製システムによって完全に置き換えられた場合であり、これは、システムを書き換え、変更する限界のケースである。このため、TST呼び出しの変化はオプションであり、システム、消耗品、及び変更が行われる可能性に依存する。このようなロジックをシステムに追加することは、システムがより複雑になるので、(例えば、小型デスクトッププリンタの場合)それだけの価値があるとは考えられない。これに対して、このようなロジックをカメラに追加することは、それだけの価値があると考えられる。
本物の認証チップを使用する複製消耗品
消耗品部分を使用する前に消耗品残量をデクリメントすることは重要である。消耗品が先に使用されると、複製消耗品は、特別の既知アドレスへの書き込みの間に、接触の不備のふりをして、新しい消耗品のように見えるからである。この攻撃は、依然として、各消耗品に本物の認証チップが必要であることが重要である。
鍵の寿命
上記の二つのプロトコルの一般的な問題は、一旦、認証鍵が選択されると、それを変更することが容易ではない点である。ある種の状況では、鍵が危険にさらされることは問題ではないが、他の場合には、鍵を危うくすることは致命的である。
プロトコルの選択
プロトコル2及び4の鍵の選択が簡単であるとしても、両方のプロトコルは、(鍵サイズと機能的な実装の両面で)シリコン実装のコストが高いため、現時点では実際的ではない。したがって、選択されるプロトコルは、プロトコル1及び3である。しかし、プロトコル1及び3は、多数の同じコンポーメントを含み、
どちらも書き込み及び読み出しアクセスが必要であり、
どちらも鍵付き一方向関数の実装が必要であり、
どちらも乱数生成機能が必要である。
プロトコル3は付加的な鍵(K2)が必要であると共に、ある種の最小限の状態機械の変化:
Random中にFK1[X]を呼び出せるような状態機械の変更と、
FK2[X]を呼び出すTest関数と、
FK1[X]及びFK2[X]を呼び出すために状態機械のRead関数への変更と、が必要である。
プロトコル3はプロトコル1に対して最小限の変更だけが必要である。プロトコル3の方が安全性が高く、プレゼンスオンリー認証(プロトコル1)が要求されるような全ての状況で使用可能である。したがって、それは特に優れたプロトコルである。プロトコル1及び3の両方が鍵付き一方向関数を使用する場合に、一方向関数の選択をより詳細に説明する。以下の表は、適用可能な選択肢の属性の概要を示している。属性は、その属性が利点であることが分かるように表されている。
この表を検討することによって、事実上、3種類のHMAC構造とランダムシーケンスとの間で選択されることがわかる。鍵サイズ及び鍵生成の問題は、ランダムシーケンスを除外する。多数の攻撃が既にMD5に対して実行されていることを考えると、ハッシュ結果は128ビットに過ぎないので、HMAC−MD5も除外される。したがって、HMAC−SHA1とHMAC−RIPEMD160の間で選択を行うことになる。RIPEMD−160は比較的新しく、SHA1のようには大規模に暗号解読されていない。しかし、SHA−1はNSAによって設計されているので、これは、否定的な属性として見られることもある。
両者の間に大差がないのであれば、SHA−1がHMAC構造用に使用されるであろう。
乱数生成器の選択
上述の各プロトコル(1−4)は、乱数生成器を必要とする。生成器は、全てのシステムの耐用期間に亘って生成される乱数が予測不能であるという意味で「優良」でなければならない。乱数が各システムに対して同一であるならば、攻撃者は、簡単に、本物の認証チップからの正しいレスポンスを記録し、そのレスポンスを複製チップ用のROMルックアップに収容することが可能である。このような攻撃の場合、K1又はK2を獲得しなくてもよい。したがって、各システムからの乱数は、予測不能であるために、即ち、非決定論的であるために十分に異なることが必要である。このようにして、R(ランダムシード)の初期値は、特定のビットが1であるか、又は0であるかに関する情報が存在しない物理的にランダムな現象から収集された物理的に生成された乱数を用いてプログラミングされるべきである。Rのシードは、決して、コンピュータ上で実行される乱数生成器で生成してはならない。そうでなければ、生成器アルゴリズム及びシードが解読され、攻撃者は、全てのシステムの全てのRの組を生成し、知ることができるようになる。
各認証チップのRシードが異なることは、最初のRはランダムであり、且つあらゆるチップで予測不能であるということである。したがって、各チップで後続のRをどのようにして生成するかが問題になってくる。
基本的なケースでは、Rは全く変更されない。その結果としてR及びFK1[R]は、Random[]の各呼び出しに対して同じである。それらが同一である場合、FK1[R]は、計算されるのではなく、定数にすることができる。攻撃者は、有効なルックアップテーブルを生成するために、単一の有効認証チップを使用し、そのシステムのために特にプログラミングされた複製チップ内でそのルックアップテーブルを使用することが可能である。定数Rは安全ではない。
Rを変化させる最も簡単な概念的な方法は、Rを1ずつインクリメントすることである。Rは乱数から始められるので、種々のシステムにおけるその値はランダムである可能性が高い。しかし、初期Rを与えると、後続の全てのR値は直接的に決定できる(10000回繰り返すまでもなく、RはR0からR0+10000までの値をとる)。Rをインクリメントすることは、定数Rに対する上記の攻撃を受ける心配はない。Rは常に異なるので、代用される複製チップと同数の認証チップを無駄にすること無しに、特定のシステムに対するルックアップテーブルを構築する方法がない。
アダーを使用するインクリメントの他に、Rを変化させる別の方法は、それをLFSR(線形フィードバックシフトレジスタ)として実現することである。これは、アダーよりもシリコンが少ないという利点があり、また、LFSRの値ドメインは順次アクセスによって決定されるので、攻撃者が特定のシステムに対するRのレンジを直接的に決定できないという利点もある。所定の初期Rが生成する値を決定するためには、攻撃者は、可能性を反復し、それらを列挙しなければならない。Rを変化させることの利点は、LFSRソリューションの場合にも明白である。Rは常に相違するので、(特定のシステムに専用の)複製チップが置換する認証チップと同数の認証チップを使い果たすこと無しに、特定のシステムに対するルックアップテーブルを構築する方法がない。したがって、Rを変更するために、これ以上複雑な関数を導入する利点はない。関数とは無関係に、攻撃者は、常に、シミュレーションによって値の組を、耐用期間を通じて繰り返すことが可能である。本来の安全性は、Rの初期ランダム性にある。Rを変更するためLFSRを使用することは、(アダーよりもシリコン使用量が少ない点を別にして)連続した数値レンジに限定されないという利点があるだけである(即ち、R、RNを計算によって直接知ることができないので、攻撃者はLFSRをN回繰り返さなければならない)。
したがって、認証チップ内の乱数生成器は、160ビットのLFSRである。最大周期LFSR用の160ビットのタップ選択(即ち、LFSRは、0が有効な状態ではないので、全部で2160−1状態を循環する)によって、図173にしめされるようなビット159、4、2及び1が得られる。LFSRは疎構造であり、多数のビットがフィードバックに使用されるわけではない(160ビットの中から4ビットだけが使用される)。これは、暗号アプリケーションの場合に問題であるが、非順次数生成のアプリケーションの場合には問題ではない。Rの160ビットシード値は0以外の任意の乱数をとり得る。なぜならば、0が詰められたLFSRは0の際限のないストリームを生成するからである。上述のLFSRは最大周期LFSRであるため、全ての160ビットをそのままRとして使用することができる。出力ビットb0から順番に数を構築する必要がない。TSTの呼び出しが成功する毎に、乱数(R)はビット1、2、4及び159をXOR論理演算し、その結果を上位ビットへシフトすることによって進められる。新しいR及び対応したFK1[R]は、次のRandomへの呼び出しの際に取り出すことができる。
論理的攻撃への対抗
プロトコル3は認証チップによって使用される認証スキームである。このため、論理的手段による無効化に対し耐性であるべきである。プロトコル3に対する様々なタイプの攻撃の効果を説明したが、このセクションでは、プロトコル3の観点から攻撃の各タイプを詳述する。
ブルートフォース攻撃
ブルートフォース攻撃はプロトコル3を破ることが保証されている。しかし、鍵の長さは、攻撃者がブルートフォース攻撃を実行するために要する時間が非常に長いので労力に値しない、ということを意味する。攻撃者は、複製認証チップを構築するためK2を破るだけでよい。K1は、その他の形態の攻撃に対してK2を強化するために設けられているだけである。K2へのブルートフォース攻撃は、したがって、160ビット鍵を破らなければならない。K2に対する攻撃は、最大で2160回の試行が必要であり、2159回の試行後に鍵を検出する確率は50%である。1兆個のプロセッサのアレイを想定すると、各々が毎秒100万回のテストを実行すると、2159回(7.3×1047)のテストには2.3×1023年を要し、これは宇宙の寿命よりも長い。世界には1億台のパーソナルコンピュータしか存在しない。それらが攻撃の際に(例えば、インターネットを介して)接続されたとしても、その数は、上述の1兆個のプロセッサの攻撃よりも10000倍少ない。更に、1兆個のプロセッサの製造がナノコンピュータの時代に可能になったとしても、鍵を獲得するために要する時間は宇宙の寿命よりも長い。
推測攻撃
攻撃者が単に「鍵を推測」することは理論的に可能である。実際上、十分な時間があり、あらゆる数を試すならば、攻撃者は鍵を獲得するであろう。これは、上述のブルートフォース攻撃と同じであり、50%の成功率を達成する前に、2159回の試行をしなければならない。ある人が最初の試行で単に鍵を推測する機会みは2160である。これに対して、ある人が米国宝くじで一等賞を獲得し、同じ日に稲光によって死亡する確率は、226分の1に過ぎない。ある人が最初の試行で鍵を推測する確率は、2160分の1であり、これは、地球上の全ての原子の中から二人が全く同一の原子を選択することに匹敵することであり、即ち、非常に可能性が低い。
量子コンピュータ攻撃
K2を破るため、適切なアルゴリズムに組み込まれた160キュビットを含む量子コンピュータを構築することが必要である。160ビット鍵に対する攻撃は実施不可能である。量子コンピュータの可能性のぎりぎりの見込みは、50年以内に50キュビットを達成することである。50キュビット量子コンピュータを使用したとしても、160ビット鍵を解読するためには、2110回のテストが必要になる。1億台の50キュビット量子コンピュータのアレイを想定し、各量子コンピュータが1マイクロ秒に250回の鍵(現時点での最も乱暴な推定を超えている)を試すことができるとするならば、鍵を見つけるために平均で180億年を要する。
暗号文だけの攻撃
攻撃者は、RND及びRDへの呼び出しを呼び出し監視することによってK1に対する暗号文だけの攻撃に出ること、及びRD及びTSTへの呼び出しを監視することによってK2に対する暗号文だけの攻撃に出ることが可能である。しかし、これらの全ての呼び出しが、平文と、平文のハッシュ形式を明らかにするならば、攻撃は、より強力な攻撃の形態、即ち、既知平文攻撃に変わるであろう。
既知平文攻撃
ロジックアナライザを、システムと認証チップの間の配線に接続し、これにより、データのフローを監視することは容易である。このデータのフローは、既知平文と、平文のハッシュ形式とを生じ、K1とK2の両方に対する既知平文攻撃に出るため使用できる。K1に対する攻撃に出るため、RND及びTSTへの多数の呼び出しを行うことが必要である(TSTへの呼び出しが成功し、有効チップ上のRDへの呼び出しが必要になる)。これは簡単であり、攻撃者は、システム認証チップと消耗品認証チップの両方をもつことが必要である。K1、X、HK1[X]の各ペアが明らかになると、K2、Y、HK2[X]のペアも明らかになる。攻撃者は更なる解析のためこれらのペアを収集しなければならない。このデータを用いて意味のある攻撃に出るためには何個のペアを収集すべきであるかという問題が生じる。統計的解析のためのデータの収集を必要とする攻撃の一例は差分暗号解読である。しかし、SHA−1又はHMAC−SHA1に対する攻撃は知られていないので、現時点では、収集されたデータの使い道はない。
選択平文攻撃
暗号解読者が先行の調査の結果に基づいて後続の選択平文を変更する能力を備えているならば、K2は、単純な選択平文攻撃よりも強い攻撃の形式である適応的選択平文攻撃の一部の形式に無防備である。選択平文攻撃はK1に対しては起こり得ない。なぜならば、呼び出し元には、RND関数への入力として使用されるRを変更する方法がないからである(RNDはK1によるハッシュ化の結果を与える唯一の関数である)。Rをクリアすることは、鍵をクリアする効果があるので有用ではなく、SSIコマンドは新しいR値を格納する前にCLRを呼び出す。
適応的選択平文攻撃
このタイプの攻撃はK1に対して起こり得ない。なぜならば、K1は選択平文攻撃を許さないからである。しかし、この攻撃の一部の形式はK2に対して起こる可能性があり、特に、システムと消耗品の両方は、典型的に、攻撃者が入手可能であるからである(システムは、特定の車のようなある種の場合には攻撃者からアクセスできない)。HMAC構造は、選択平文攻撃のあらゆる形式に対して安全性を提供する。その理由は主として、HMAC構造が2個の秘密入力変数(元のハッシュの結果と秘密鍵)を有するからである。このようにして、入力変数が秘密であるときに、ハッシュ関数自体の衝突を検出することは、平文ハッシュ関数の衝突を見つけることよりも難しい。その理由は、前者は、SHA−1から入力/出力のペアを生成するため、SHA−1への直接アクセス(プロトコル3では許可されない)を必要とするからである。攻撃者によって収集できる唯一の値は、HMAC[R]及びHMAC[R|M]である。これらは、SHA−1ハッシュ関数自体への攻撃ではなく、収集されたデータ間の統計的差分を調べる差分暗号解読攻撃まで攻撃を低減させる。SHA−1又はHMACに対して知られている差分暗号解読攻撃がないとすれば、プロトコル3は適応的選択平文攻撃に対抗する。
意図的なエラー攻撃
攻撃者は、TST関数及びRD関数に対しては意図的なエラー攻撃しか出すことができない。なぜならば、これらは、鍵に対する入力を検証する唯一の関数であるからである。TSTとRDの両方の関数の場合、0値は、入力にエラーが見つかったときに生成され、それ以上の情報は与えられない。その上、0結果を生成するために要する時間は入力に依存せず、攻撃者はどのビットにエラーが存在するかに関する情報を得られない。したがって、意図的なエラー攻撃は効果がない。
連鎖攻撃
全ての形式の連鎖攻撃は、ハッシュされるべきメッセージが数ブロックに広がっているか、又は入力変数を何らかの方法でセットできることを前提としている。プロトコル3で使用されるHMAC−SHA1アルゴリズムは、同時に単一の512ビットのブロックしかハッシュできない。その結果として、連鎖攻撃はプロトコル3に対してはあり得ない。
バースデー攻撃
HMACに対して知られている最強の攻撃は、ハッシュ関数の衝突の頻度に基づくバースデー攻撃である。しかし、これは、SHA−1のような必要最小限度で合理的なハッシュ関数には全く実際的でない。また、バースデー攻撃は、攻撃者が署名付きのメッセージを管理するときに限り実現可能である。プロトコル3は、デジタル署名の形式としてハッシングを使用する。システムは、有効人種チップからのレスポンスに組み込まれるべき数を送信する。認証チップはH[R|M]を用いて応答しなければならないが、入力値Rをコントロールできないので、バースデー攻撃は実現不能である。なぜならば、メッセージは、事実上、既に生成され、署名されているからである。その代わりに、攻撃者は、同じ値にハッシュした衝突メッセージを探索しなければならない(あなたと同じ誕生日の人を見つける場合と類似している)。したがって、複製チップは、R2のハッシュと選択されたM2がH[R|M]と同じハッシュ値を生ずるような新しい値R2を見つけようとしなければならない。しかし、システム認証チップは正しいハッシュ値を明らかにしない(TST関数はハッシュ値が正しいかどうかに依存して1又は0を返すだけである)。したがって、(衝突を見つけるために)正しいハッシュ値を見つける唯一の方法は、本物の認証チップに問い合わせることである。しかし、正しい値を見つけることは、Mを更新することを意味し、Mのデクリメントオンリー部分、及びMのリードオンリー部分は変更できないので、複製消耗品は、衝突を見つけようとする前に、本物の消耗品を更新しなければならない。代案は、成功を見つけるためのTST関数へのブルートフォース攻撃探索である(各複製消耗品はシステム消耗品へアクセスできることが必要である)。ブルートフォース検索は、上述の通り、この例では認証毎に、宇宙の寿命よりも長い時間を要する。ハッシュ値を適時に収集することは本物の消耗品をデクリメントしなければならないことを意味するので、複製消耗品がこの種の攻撃を仕掛ける意味がない。
完全ルックアップテーブルによる代用
各システムの乱数シードは160ビットである。認証チップの最悪ケースの状況では、状態データが変更されない。その結果、一定値がMとして戻される。しかし、複製チップは、160ビット値であるFK2[R|M]を返し続けなければならない。結果が160ビットの160ビットルックアップテーブルを想定すると、これは、7.3×1048バイト、即ち、6.6×1036テラバイトを必要とし、近い将来に実施可能である空間よりも間違いなく大きい。これは、勿論、ROMのための値を収集する方法さえを考慮していない。したがって、完全なルックアップテーブルは完全に実現不可能である。
疎ルックアップテーブルによる代用
疎ルックアップテーブルは、認証チップへ送信されたメッセージが、実効的にランダムではなく、ある程度予測可能である場合に限り実施可能である。乱数Rは、自然界のランダム事象から収集された未知乱数でシードされる。複製品製造者は全てのしすてむに対して考えられるRのレンジを知る可能性はない。なぜならば、各ビットが1であるか、又は0である確率は50%であるからである。全てのシステムにおけるRのレンジは未知であるため、全てのシステムで使用可能な疎ルックアップテーブルを構築することは不可能である。したがって、一般的な疎ルックアップテーブルによる攻撃は考えられない。しかし、複製品製造者は、ある特定のシステムに対するRのレンジを知ることは可能である。これは、LFSRに、特定のシステム認証チップのRND関数への呼び出しからの現在の結果をロードし、将来に向けて数回繰り返すことによって実現できる。これが行われた場合、特定のRのレンジに対するレスポンスだけを格納した特別なROM、即ち、その特定のシステムの消耗品に専用のROMを構築できる。しかし、攻撃者は、正しい情報をROMに収容し続けなければならない。したがって、攻撃者は、有効認証チップを検出し、Rの値毎にそれを呼び出すことが必要である。
複製認証チップが完全な消耗品をリポートし、接続のロスと新しい完全な消耗品の挿入をシミュレーションする前に1回だけ使用できる場合を想定する。複製消耗品は、完全な消耗品の認証に対するレスポンス、及び部分的に使用された消耗費にに対するレスポンスを格納しなければならない。最悪ケースで、ROMは、システムの耐用期間に亘るRに関して、完全な消耗品及び部分的に使用された消耗品のエントリーを格納する。しかし、有効認証チップは、情報を生成するために使用され、部分的にそのプロセスで使用されるべきである。所定のシステムがn個のR値だけを生成するならば、必要な疎ルックアップROMは、Mに対する異なる値の個数によって乗算された10nバイトである。ROMを構築するために要する時間は、RD呼び出しの間に課された時間に依存する。
それにもかかわらず、複製品製造者は、詰め替えのため返品される消耗品に頼らざるを得ない。なぜならば、最初の場所にROMを構築するコストは1個の消耗品を消費するからである。このような状況における複製品製造者のビジネスは、結果的に詰め替えにある。時間及びコストは、Rのサイズと、ルックアップに組み込まれるべきMの値の種類の数と、に依存する。その上、カスタム複製ROMは、一つ一つのシステムに適合する必要があり、(完全なデータ及び部分的に使用されたデータを提供するため)異なる有効認証チップがシステム毎に使用されなければならない。システム内の認証チップの使用は、したがって、この種の攻撃が複製品製造者にとって価値があるかどうかを判定するために検査しなければならない。一例は、耐用期間に約10000プリントを有するカメラシステムである。単一のデクリメントオンリー値(残りプリント数)と、RDの呼び出しの間に1秒の遅延がある場合を想定する。このようなシステムにおいて、疎テーブルは、構築に約3時間を要し、100Kを消費する。ROMを構成するためには、有効認証チップを消費することが必要であるので、料金は、1個の消耗品と複製消耗品の合計よりも高くしなければならないことに注意すべきである。このようにして、1個の消耗品に対してこの機能を実行することは(複製消耗品が同等の多数の認証消耗品に何とかして収容されない限り)費用対効果がよくない。複製品製造者がシステムの所有者毎にカスタムROMを構築する労力を惜しまないのであれば、より簡単なアプローチは、認証チップを完全に無視するようにシステムを更新することであろう、したがって、この攻撃は、システム毎の攻撃として実現可能であり、所定のシステム/消耗品の組み合わせに対してこのようなことが起こる可能性を判定しなければならない。その可能性は、消耗品及び認証チップのコストと、消耗品の寿命と、消耗品の利益幅と、ROMを生成するために要する時間と、得られるROMのサイズと、顧客が同じ複製チップ等を使用する詰め替えのために複製品製造者へ戻ってくるかどうかと、に依存する。
差分暗号解読
既知差分攻撃は、DES及びその他の同様のアルゴリズムで使用されるようなSボックスの構造にかなり依存している。プロトコル3で使用されるHMAC−SHA1のような他のアルゴリズムはSボックスを持たないが、攻撃者は、
最小差分入力及びそれに対応した出力
最小差分出力及びそれに対応した入力
の統計的解析を行うことによって差分的な攻撃を実行し得る。
この性質の攻撃に出るため、入力/出力ペアの組が収集される。プロトコル3からの収集は、既知平文攻撃、又は部分適応的選択平文攻撃による。明らかに、後者が選ばれる方が有用である。一般的にハッシュ化アルゴリズムは差分解析に対抗するように設計されている。特に、SHA−1は、特に80語の拡張によって、強化されているので、入力における最小限の差は、(128ビットハッシュ関数と比較して)多数のビット位置が変わる出力を生成するであろう。その上、収集される情報は、HMACアルゴリズムの性質により、直接的なSHA−1入力/出力ではない。HMACアルゴリズムは、既知の値を、未知の値(鍵)でハッシュし、このハッシュの結果が次に別個の未知の値で再ハッシュされる。攻撃者は、秘密値も、最初のハッシュの結果もわからないので、SHA−1からの入力及び出力は不明であり、あらゆる差分攻撃を極めて難しくさせる。以下では、認証チップからの最小限度の差の入力及び出力をより詳細に説明する。
最小限度の差の入力
この場合、攻撃者は、X値、FK[X]値の組を取得し、X値が最小限度の差であり、出力FK[X]の間の統計的な差を検査する。攻撃は、最小限度のビット数だけの差があるX値に依存する。FK[X]値を比較するために最小限度の差のX値をどのようにして獲得するかが問題である。
K1:K1の場合、攻撃者は、最小限度の差X、FK1[X]ペアを統計的に検査しなければならない。しかし、攻撃者は、X値を選択できず、関連したFK1[X]値を獲得できない。X、FK1[X]ペアは、システム認証チップ上のRND関数を呼び出すことによってのみ生成することができるので、攻撃者はRNDを複数回呼び出し、観測された各ペアをテーブルに記録する。次に、FK1[X]の統計的解析を行うため、観測された値の中で十分に最小限度の差X値を探索しなければならない。
K2:K2の場合、攻撃者は、最小限度の差X、FK2[X]ペアを統計的に検査しなければならない。X、FK2[X]ペアを生成する唯一の方法は、RD関数によるものであり、所定のY、FK1[Y]ペアに対してFK2[X]を生成し、ここで、X=Y|Mである。これは、Yと、Mの変更可能部分が攻撃者によって限られた範囲で選択され得ることを意味する。選択の量は、したがって、できる限り多くされるべきである。
攻撃者の選択を制限する第1の方法はYを制限することである。なぜならば、RDはフォーマットY、FK1[Y]の入力を要求するからである。有効なペアはRND関数から容易に獲得できるが、それは、RNDの選択によるペアである。攻撃者は、RNDから適切なペアを獲得した場合に限り、又はK1を知っている場合に限り、固有のYを提供することが可能である。RNDから適切なペアを獲得するためには、ブルースフォース探索が必要になる。K1を知ることは、RND関数から獲得されたペアへの暗号解読を実行することによってのみ、即ち、事実上の既知テキスト攻撃によってのみ論理的に実現可能である。RNDは1秒当たりに呼び出せる回数は決まっているが、K1はシステムのチップで共通である。したがって、既知ペアは並列に生成できる。攻撃者の選択を制限する第2の方法は、Mを制限すること、又は少なくとも攻撃者のM選択能力を制限することである。Mの制限は、Mの一部をリードオンリーにさせ、認証チップ毎に相違させ、Mの他の部分をデクリメントオンリーにすることで実現される。Mのリードオンリー部分は、理想的には、認証チップ毎に異なるべきであるので、シリアル番号、バッチ番号、又は乱数のような情報でもよい。Mのデクリメントオンリー部分は、攻撃者が異なるMを試すとき、その回数だけMのその部分だけをデクリメントすることができ、Mのデクリメントオンリー部分が0まで低下した後、その部分は再度変更し得ない、ということを意味する。新しい認証チップ53を獲得すると、新しいMを与えるが、リードオンリー部分は、前の認証チップのリードオンリー部分とは異なり、したがって、攻撃者のMを選択する能力が更に低下する。その結果として、攻撃者は、Y及びMに対する値を選択するチャンスが少ししか高めることができない。
最小限度の差の出力
この場合、攻撃者は、X値、FK[X]値の組を取得し、FK[X]値が最小限度の差を表し、X値の間の統計的な差を検査する。攻撃は、最小限度のビット数だけの差があるFK[X]値に依存する。K1とK2の両方に対し、攻撃者は所与のFK[X]に対するX値を生成する方法がない。そうするためには、Fは一方向関数であるという事実に違反するであろう。その結果として、攻撃者がこの性質をもつ攻撃を組み込む唯一の方法は、全ての観測されたX、FK[X]ペアをテーブルに記録することである。検索は、X値の統計的解析を行うため十分に最小限度の差FK[X]値を見つけるため観測値の中で行われる。これが(Mに関する制限及びRの選択に関する制限のために非常に限定されている)最小限度の差の入力攻撃よりも多くの作業を必要とするならば、この攻撃は無益である。
メッセージ置換攻撃
この種の攻撃を実行するためには、複製物製造者は本物の認証チップ53を格納する必要があるが、それは減少しないので、事実上、再使用可能である。複製認証チップは、メッセージを盗み取り、それを自分のメッセージで置き換える。しかし、この攻撃は攻撃者にとって成功しない。複製認証チップは、WRコマンドを本物の認証チップへ渡さないように選択するかもしれない。しかし、後続のRDコマンドは(WRが成功したかのうよう)正しいレスポンスを戻さなければならない。正しいレスポンスを返すためには、特定のR及びMについてのハッシュ値がわかっていなければならない。バースデー攻撃のセクションで説明したように、攻撃者は、本物のチップ内のMを実際に更新しなければハッシュ値を決定できないが、攻撃者はこれを行うことを望まない。システムによって送信されたRを変更することさえ役に立たない。なぜならば、システム認証チップは引き続くTSTの間にRをマッチさせなければならないからである。したがって、メッセージ置換攻撃は成功しない。これは、システムが消耗品を使用する前に消耗品残量を更新する場合に限り成り立つ。
鍵生成器のリバースエンジニアリング
疑似乱数生成器が鍵を生成するため使用される場合、複製品製造者は、生成器プログラムを取得するか、又は使用されたランダムシードを推測する可能性がある。これは、ネットスケープのセキュリティプログラムが最初に破られたときの方法である。
認証全体の回避
プロトコル3は、システムが消耗品の使用前に消耗品状態データを更新し、(書き込みを認証するため)全ての書き込みの後に読み出しを続けることを要求する。このように、消耗品の使用毎に認証を要求する。システムがこれらの二つの簡単なルールに固執するならば、複製品製造者は(疎ROMルックアップのような)上述の方法により認証をシミュレーションしなければならない。
認証チップの再使用
上述のように、プロトコル3は、システムが消耗品の使用前に消耗品状態データを更新し、(書き込みを認証するため)全ての書き込みの後に読み出しを続けることを要求する。このように、消耗品の使用毎に認証を要求する。消耗品が使い切られた場合、その認証チップの適切な状態データ値は0まで減少している。したがって、チップは別の消耗品で使用できない。このことが成り立つのは、デクリメントオンリーデータ項目を保持する認証チップの場合だけであることに注意する必要がある。使用される毎にデクリメントさせられる状態データが無い場合、チップの再使用を阻止するものはない。これは、プレゼンスオンリー認証と消耗品ライフタイム認証との間の基本的な差異である。プロトコル3はその両方を可能にさせる。結論として、消耗品がシステムによって使用されるデクリメントオンリーデータ項目を備えている場合、認証チップは、秘密鍵を知っている有効なプログラミングステーションによって完全に再プログラミングされない限り、再使用不能である。
コスト節約のため認証を省略する経営上の判断
外部攻撃には限られないが、コストを節約するため将来のシステムでは認証を省略する判断は、様々なマーケットに種々の影響を与えるであろう。大量生産消耗品の場合、販売開始後に認証を導入することは極めて困難であるということに留意しなければならない。なぜならば、認証された消耗品を要求するシステムは、流通中の旧式の消耗品と連携しないからである。同様に、ある段階で認証を打ち切ることも非現実的である。なぜならば、旧式のシステムは、新しい認証されていない消耗品と連携しないからである。第2のケースでは、旧式のシステムは、システム認証チップを、同じプログラミングインタフェースを具備しているが、そのTST関数が常に成功する単純なチップで置換することによって、個別に改造することが可能である。勿論、そのシステムは、常に成功するTST関数をテストし、停止するようにプログラミングしてもよい。車/車キー、又は扉/扉の鍵、又はその他の類似した状況のような特殊化したペアの場合、将来のシステムで認証を省くことは重要ではなく影響もない。なぜならば、消費者は、システムと消耗品認証チップの組全体を同時に購入しているからである。
強盗/賄賂攻撃
この形態の攻撃は、以下の二つの環境の何れかでしか成功しない:
K1、K2、及びRはチッププログラマによって既に記録されているか、又は
攻撃者は、将来のK1、K2、及びRの値を強制的に記録させることができる。
プログラミングステーションの外部の人間又はコンピュータシステムが鍵を知らないとき、暴力や賄賂をもってしてもそれらを明らかにできない。この種の攻撃に対する安全性のレベルは、究極的に、システム/消耗品所有者が望ましいサービスのレベルに応じて行う判断である。例えば、自動車会社は、製造した全てのキーの記録を保存しようとするので、その車のため新しいキーの作成を要求することができる。しかし、これは、キーデータベースの全体が危険にさらされる可能性があり、攻撃者は製造者の既存の車に対するキーを作成できるようになる。これは、攻撃者が新しい車キーを作成することを可能にさせない。勿論、キーデータベース自体は、別の鍵で暗号化され、キーデータベースにアクセスするためには、一定の人数の人のそれぞれの鍵部分を一つに組み合わせることが必要である。特定の車にどのキーが使用されているかについての記録が保存されていないならば、キーを紛失した場合に補助キーを作成する方法はない。この場合、所有者は自分の車の認証チップと自分の車キーの全てを交換しなければないであろう。これは、必ずしも困った状況ではない。これに対して、プリンタのインクカートリッジのような消耗品の場合、一つの鍵の組み合わせが全てのシステム及び全ての消耗品に対して使用される。勿論、鍵のバックアップが保存されていないならば、誰もその鍵がわからず、攻撃はあり得ない。しかし、バックアップの無い状況は、インクカートリッジのような消耗品の場合に望ましくない。なぜならば、鍵が失われた場合、それ以上消耗品を製造できないからである。したがって、製造者は鍵情報のバックアップを幾つかの部分に保存すべきであり、何人かの人は、鍵全体の情報を明らかにするため、それぞれの部分を一つに結合することが必要である。これは、チッププログラミングステーションに再ロードしなければならない場合に要求される。いずれにしても、これらの攻撃はプロトコル3自体に対する攻撃ではない。なぜならば、人が認証プロセスに関与していないからである。そのかわりに、これは、チップのプログラミングステージに対する攻撃である。
HMAC−SHA1
認証のためのメカニズムは、HMAC−SHA1アルゴリズムであり、
HMAC−SHA1(R1,K1)又は
HMAC−SHA1(R|M,K2)
の一方に従って動作する。
次に、HMAC−SHA1アルゴリズムをここまでの説明よりも詳しく検討し、本来の定義よりもメモリリソース必要量が少なくなるアルゴリズムの最適化を説明する。
HMAC
HMACアルゴリズムは、以下の定義を前提として進む:
H=ハッシュ関数(例えば、MD5又はSHA−1);
n=Hから出力されるビット数(例えば、SHA−1の場合に160ビット、MD5の場合に128ビット);
M=MAC関数が適用されるデータ;
K=両当事者で共有される秘密鍵;
ipad=0x36の64回の繰り返し;
opad=0x5Cの64回の繰り返し。
HMACアルゴリズムは次の通りである:
0x00バイトをKの最後に追加することによりKを64バイトに拡張する;
(1)で作成された64バイト文字列をipadでXOR論理演算する;
(2)で作成された64バイト文字列にデータストリームMを追加する;
(3)で生成されたストリームにHを適用する;
(1)で作成された64バイト文字列をopadでXOR論理演算する;
(4)からの結果Hを(5)から得られた64バイト文字列に追加する;
(6)の出力にHを追加し、その結果を出力する。
これにより、
HMAC[M]=H[(KAopad)|H[(KAipad)|M]]
である;
HMAC−SHA1アルゴリズムは、単にH=SHA−1となるHMACである。
SHA−1
SHA−1ハッシングアルゴリズムは以下で要約するアルゴリズムに規定される。
9個の32ビット定数が定義される。5個の定数は連鎖変数を初期化するため使用され、4個の付加的定数がある。
最適化されていないSHA−1は、全部で2912ビットのデータ記憶を必要とする:
5個の32ビット連鎖変数:H
1、H
2、H
3、H
4及びH
5が定義される;
5個の32ビット作業変数:A、B、C、D及びEが定義される;
1個の32ビット一時変数:tが定義される;
80個の32ビット一時レジスタ:X
0−79が定義される。
以下の関数はSHA−1のために定義される。
ハッシングアルゴリズムは、最初に、512ビットの倍数になるまで入力メッセージをパディングし、連鎖変数H
1−5をh
1−5で初期化する。パッドされたメッセージは、次に、512ビットチャンクで処理され、出力ハッシュ値は、連鎖変数:H
1|H
2|H
3|H
4|H
5の連結によって与えられる最後の160ビット値である。次に、SHA−1アルゴリズムのステップを詳細に説明する。
ステップ1 処理
SHA−1の第1ステップは、以下のように入力メッセージを512ビットの倍数になるまで詰め込み、連鎖変数を初期化する。
ステップ2 処理
詰め込まれた入力メッセージが処理可能である。512ビットのブロック内でメッセージを処理する。各512ビットのブロックは、16×32ビット語の形であり、InputWord
0−15として表される。
ステップ3 終了
詰め込まれた入力メッセージの全ての512ビットのブロックが処理された後、出力ハッシュ値は、H
1|H
2|H
3|H
4|H
5によって与えられる最後の160ビット値である。
ハードウェア実装用の最適化
SHA−1のステップ2の手続は、ハードウェアのために最適化されていない。特に、80個の一時的な32ビットレジスタは、ハードウェア実装上の貴重なシリコンを使い果たす。このセクションは、16個の一時レジスタだけを使用するSHA−1アルゴリズムへの最適化を説明する。シリコンの削減は、2560ビットから512ビットまでへの減少であり、2000ビット以上の節約になる。これは、一部のアプリケーションでは重要でないが、認証チップの場合、記憶スペースはできるだけ縮小されるべきである。最適化の基礎は、元の16ワードメッセージブロックが80ワードメッセージブロックに拡張されるが、80ワードはアルゴリズムの間に更新されないことにある。その上、ワードは、前の16ワードだけに依存しているので、拡張されたワードは、16ワードが後方参照のため保持される限り、処理中にオンザフライ方式で計算可能である。どのレジスタを使おうとしているかを追跡するために循環カウンタが必要になるが、その効果は大量の記憶量を節約することである。単一の値jでXをインデックス付けするのではなく、繰り返しを通してカウントするため5ビットのカウンタを使用する。これは、5ビットレジスタを16又は20で初期化し、0に達するまでそれをデクリメントすることによって実現される。16個の一時変数を80個であるかのようにして更新するため、4個のインデックスが必要であり、各インデックスは4ビットレジスタである。4個の全てのインデックスはアルゴリズムの途中(ラップアラウンド付きで)インクリメントされる。
ラウンド0及び1Aの間のN
1、N
2及びN
3のインクリメントは随意的である。ソフトウェア実装は、時間を要するので、それらをインクリメントせずに、16巡のループの最後に、全4個のカウンタは元の値になる。ハードウェアの設計者は、制御ロジックを節約するため、全4個のカウンタを同時にインクリメントしようとする。呼び出し元が512ビットのX
0−15をロードするならば、ラウンド0は完全に省くことができる。
HMAC−SHA1
認証チップ実装の場合、HMAC−SHA1ユニットは、二つのタイプの入力:K1を使用するR、及びK2を使用するR|Mにハッシングを実行するだけである。入力は2個の一定長さであるため、HMACとSHA−1をチップ上に別個のエンティティとして設けるのではなく、それらを合成し、ハードウェアを最適化することができる。SHA−1のステップ1におけるメッセージのパディング(1ビット、0ビットの文字列、及びメッセージの長さ)は、異なるメッセージがパディング後に同じように見えないことを保証するために必要である。2タイプのメッセージしか取り扱わないので、パディングは定数0でもよい。その上、SHA−1アルゴリズムの最適化バージョンが使用され、16個の32ビットワードだけが一時記憶のために使用される。これらの16個のレジスタは、最適化されたHMAC−SHA1ハードウェアによって直接ロードされる。9個の32ビット定数h−1−5及びy1−4は依然として必要であるが、それらが定数であることは、ハードウェア実装に有利である。ハードウェアの最適化されたHMAC−SHA−1は、全部で、以下の1024ビットのデータ記憶を必要とする:
5個の32ビット連鎖変数:H1、H2、H3、H4及びH5が定義される;
5個の32ビット作業変数:A、B、C、D及びEが定義される;
一時記憶及び最終結果のための5個の32ビット変数:Buff1601−5が定義される;
1個の32ビット一時変数:tが定義される;
16個の32ビット一時レジスタ:X0−15が定義される。
以下の2セクションは、HMAC−SHA1への2タイプの呼び出しのためのステップを説明する。
H[R,K1]
K1を使用してRの鍵付きハッシュを生成するケースでは、元の入力メッセージRは、160ビットの一定長さである。したがって、処理中にこのことを有利に活用することができる。SHA−1アルゴリズムの最初の部分の間にX0−15をロードするのではなく、X0−15を直接ロードし、これにより、SHA−1の最適化プロセスブロック(ステップ2)のラウンド0を省く。擬似コードは次のステップを行う。
H[R|M,K
2]
K
2を使用してR|Mの鍵付きハッシュを生成するケースでは、元の入力メッセージは、416(256+160)ビットの一定長さである。したがって、処理中にこのことを有利に活用することができる。SHA−1アルゴリズムの最初の部分の間にX
0−15をロードするのではなく、X
0−15を直接ロードし、これにより、SHA−1の最適化プロセスブロック(ステップ2)のラウンド0を省く。擬似コードは次のステップを行う。
データ記憶完全性
確認証チップは、認証プロトコル3によって要求される変数を保持するため、不揮発性メモリを含む。以下の不揮発変数が定義される。
これらの変数がフラッシュメモリにあるならば、古い値を置き換えるため新しい値を書き込むことは簡単ではないことに注意する必要がある。メモリは、最初に消去され、次に、適切なビットをセットされる。これは、フラッシュメモリベースの変数を変更するため使用されるアルゴリズムに影響を与える。例えば、フラッシュメモリはシフトレジスタとして簡単に使用できない。汎用演算でフラッシュメモリ変数を更新するためには、以下のステップが必要になる:
Nビット値全体を汎用レジスタに読み込む;
汎用レジスタに演算を実行する;
変数に対応したフラッシュメモリを消去する;
汎用レジスタにセットされたビットに基づいてフラッシュメモリロケーションのビットをセットする。
認証チップのリセットはこれらの不揮発性変数に影響を与えない。
Mとアクセスモード
変数M[0]からM[15]は、シリアル番号、バッチ番号、及び消耗品残量のような消耗品状態データを保持するため使用される。各M[n]レジスタは16ビットであり、Mベクトル全体で256ビット(32バイト)になる。クライアントは個々のM[n]変数を読み書きできない。その代わりに、Mで表されるベクトル全体が単一論理アクセスによって読み出し、又は書き込みをされる。MはRD(リード)コマンドを使用して読み出され、WR(ライト)コマンドを使用して書き込まれる。これらのコマンドは、K1とK2の両方が確定し(SIWritten=1)、認証チップが消耗品の信頼できないチップ(IsTrusted=0)である場合に限り成功する。Mは多数の異なるデータタイプを格納するが、それらは書き込み許可が異なるだけである。各データタイプは常に読み出すことができる。一旦クライアントメモリに入ると、256ビットはクライアントによって選択された何らかの方法で解釈できる。Mの256ビット全体は、認証の章で説明したようにセキュリティの理由から少量ずつ読み出すのではなく、同時に読み出される。様々な書き込み許可が以下の表に列挙されている。
書き込みに要求される保護を実現するため、2ビットアクセスモード値がM[n]毎に定められる。以下の表は、2ビットアクセスモードビットパターンの解釈を定義する。
16個のM[n]レジスタのための16組のアクセスモードビットは、単一のアクセスモードAccessModeレジスタにまとめられる。32ビットのAccessModeレジスタは、以下のように、n付きのM[n]に対応する。
各2ビット値は、上位/下位のフォーマットで記憶される。したがって、M[0−5]がアクセスモードMSRであり、M[6−15]がアクセスモードROであるならば、32ビットAccessModeレジスタは、
11−11−11−11−11−11−11−11−11−11−01−01−01−01−01−01
である。
WR(ライト)コマンドの実行中に、AccessMode[n]は各M[n]について調べられ、新しいM[n]値が古い方を置き換えるかどうかを判断する。AccessModeレジスタは認証チップのSAM(セットアクセスモード)コマンドを使用してセットされる。デクリメントオンリー比較は符号無しであり、負のレンジを要求するデクリメントオンリー値は、正のレンジにシフトさせなければならない。例えば、−50から50のレンジのデクリメントオンリーデータ項目を含む消耗品は、そのレンジが0から100へシフトされる。システムは、そのレンジ0から100を−50から50として解釈する。尚、殆どの場合に、デクリメントオンリーレンジはNから0であり、レンジシフトは必要ない。デクリメントオンリーデータ項目の場合、データは、最上位16ビット量から最下位16ビット量の順にM[n]から前方へ並べられる。最上位16ビット(M[n]に記憶されている)に対するアクセスモードは、MSRにセットされるべきである。残りのレジスタ(M[n+1]、M[n+2]等)は、それらのアクセモードがNMSRにセットされるべきである。誤ってNMSRにセットされ、関連したMSR領域が無い場合、各NMSR領域は、倍精度比較ではなく、独立であるとみなされる。
K1
K1は認証プロトコル中にRを変換するため使用される160ビット秘密鍵である。K1は、SSI(秘密情報セット)コマンドでK2及びRと共にプログラミングされる。K1は秘密にされなければならないので、クライアントはK1を直接読み出し得ない。K1を利用するコマンドはRND及びRDである。RNDは、R、FK1[R]のペアを返し、Rは乱数であり、一方、RDは入力としてX、FK2[R]のペアを要求する。K1は鍵付き一方向ハッシュ関数HMAC−SHA1で使用される。したがって、K1は、物理的にランダムな現象から収集された、物理的に生成された乱数でプログラミングされるべきである。K1は、決して、コンピュータ上で実行される乱数生成器で生成してはならない。認証チップの安全性は、決定論的では無い方法で生成されたK1、K2及びRに依存する。例えば、K1をセットするため、ある人は公正なコインを160回トスし、表を1として記録し、裏を0として記録する。K1は、CLRコマンドの実行時に自動的に0にクリアされる。それは、SSIコマンドだけによって非零値にセットすることができる。
K2
K2は認証プロトコル中にM|Rを変換するため使用される160ビット秘密鍵である。K2は、SSI(秘密情報セット)コマンドでK1及びRと共にプログラミングされる。K2は秘密にされなければならないので、クライアントはK2を直接読み出し得ない。K2を利用するコマンドはRD及びTSTである。RDは、M、FK2[M|X]のペアを返し、Xはパラメータのうちの一つとしてRD関数へ渡される。TSTは入力としてM、FK2[M|R]のペアを要求し、Rは認証チップのRND関数から獲得された。K2は鍵付き一方向ハッシュ関数HMAC−SHA1で使用される。したがって、K2は、物理的にランダムな現象から収集された、物理的に生成された乱数でプログラミングされるべきである。K2は、決して、コンピュータ上で実行される乱数生成器で生成してはならない。認証チップの安全性は、決定論的では無い方法で生成されたK1、K2及びRに依存する。例えば、K2をセットするため、ある人は公正なコインを160回トスし、表を1として記録し、裏を0として記録する。K2は、CLRコマンドの実行時に自動的に0にクリアされる。それは、SSIコマンドだけによって非零値にセットすることができる。
RとIsTrusted
Rは、SSI(秘密情報セット)コマンドでK1及びRと共にプログラミングされる160ビットの乱数シードである。Rは秘密にする必要がない。なぜならば、それは、RNDコマンドによって自由に呼び出し元へ与えられるからである。しかし、Rを変更できるのは認証チップだけであり、呼び出し元によって任意の選択した値にセットできない。Rは、TSTコマンド中に使用され、前のRND呼び出しからのRが、信頼できない認証チップ(チップA)においてFK2[M|R]を生成するために使用されたことを保証する。RND及びTSTの両方は、信頼されている認証チップ(チップT)だけで使用される。
IsTrustedは1ビットフラグレジスタであり、認証チップが信頼されているチップ(チップT)であるかどうかを決定する:
IsTrustedビットがセットされているならば、チップは信頼されているチップであるとみなされるので、クライアントはRND関数及びTST関数を呼び出すことができる(RD又はWRではない);
IsTrustedビットがクリアされているならば、チップは信頼されているチップであるとみなされない。したがって、RND関数及びTST関数を呼び出すことができない(その代わり、RDとWRを呼び出しても構わない)。システムは、消耗品上のRND又はTSTを決して呼び出す必要がない(なぜならば、複製チップはTSTのような関数に1を返すだけであり、RNDに対して一定値を返すだけである)。
IsTrustedビットは、攻撃者によって獲得できる利用可能なR、FK1[R]の個数を減少させる付加的な利点があり、しかも認証プロトコルの完全性を維持する。有効なR、FK1[R]のペアを獲得するため、攻撃者は、システム認証チップが必要であり、これは、消耗品よりも高価であり入手が困難である。R及びIsTrustedビットの両方はCLRコマンドによって0にクリアされる。これらは共に、SSTコマンドの発行によって書き込まれる。IsTrustedビットは、SSIコマンドによって、非零シード値をRに格納することによってのみセットすることができる(Rは有効なLFSR状態であるために非零であり、これは全く合理的である)。Rは、ビット1、2、4及び159にタップが付いた160ビットの最大限の周期のLFSRによって変更され、TSTへの呼び出しが成功したときだけに(1が返された場合)変更される。
システムで信頼されているチップ(チップT)になることが予定されている認証チップは、プログラミング中にそのIsTrustedビットがセットされるべきであり、消耗品で使用される認証チップ(チップA)は(プログラミング中にSSIコマンドでRに0を格納することにより)そのIsTrustedビットがクリアのままにされるべきである。IsTrustedビットを直接読み書きするためのコマンドは存在しない。認証チップの安全性は、K1及びK2のランダム性、並びに、HMAC−SHA1アルゴリズムの強度だけに依存するわけではない。攻撃者が疎ルックアップテーブルを構築することを妨げるため、認証チップの安全性は、全てのシステムの耐用期間に亘るRのレンジにも依存する。したがって、Rは、物理的にランダムな現象から収集された、物理的に生成された乱数でプログラミングされるべきである。Rは、決して、コンピュータ上で実行される乱数生成器で生成してはならない。Rの生成は決定論的であってはならない。例えば、信頼できるシステムチップで使用するためのRを生成するため、ある人は公正なコインを160回トスし、表を1として記録し、裏を0として記録する。0は信頼できるRに対する唯一の有効でない初期値である(又は、IsTrustedビットはセットされない)。
SIWritten
SIWritten(秘密情報書き込み(Secret Information Written)1ビットレジスタは、認証チップ内に記憶された秘密情報の状態を保持する。秘密情報はK1、K2及びRである。クライアントはSIWrittenビットに直接アクセスできない。その代わりに、SIWrittenビットはCLRコマンドによってクリアされる(このコマンドは、K1、K2及びRもクリアする)。認証チップが、SSIコマンド(書き込まれる値とは無関係に)を使用して秘密鍵及び乱数シードでプログラミングされたとき、SIWrittenビットは自動的にセットされる。Rは厳密には秘密ではないが、攻撃者が選択されたR、FK1[R]のペアを獲得するために自分の固有の乱数シードを生成し得ないことを保証するため、RはK1及びK2と一緒に書き込まなければならない。SIWritten状態ビットは、K1、K2又はRにアクセスする全ての関数によって使用される。SIWrittenビットがクリアされている場合、RD、WR、RND及びTSTの呼び出しはCLRの呼び出しとして解釈される。
MINTICKS
攻撃者が短時間の間にTST及びRD関数への多数の呼び出しを生成できないようにする二つのメカニズムが存在する。第1のメカニズムは、内部クロックが特定の最大値(例えば、10MHz)を超える速度で動作することを妨げるクロック制限ハードウェアコンポーネントである。第2のメカニズムは32ビットのMinTicks(最小チック)レジスタであり、これは、鍵付き関数への呼び出しの間に経過しなければならない最小のクロックチック回数を指定するため使用される。MinTicks変数はCLRコマンドによって0にクリアされる。ビットは、SMT(MinTicksセット)コマンドによってセットされる。SMTへの入力パラメータは、MinTicksのどのビットをセットすべきであるかを表現するビットパターンを含む。実際の効果は、攻撃者がMinTicksの単位でしか値を増加し得ないことである(なぜならば、SMT関数はビットをセットするだけである)。その上、呼び出し元がこのレジスタの現在の値を読み出すことができる関数は設けられていない。MinTicksの値は、動作クロック速度と、鍵付き関数呼び出しの間の合理的な時間の定め方(アプリケーションに固有)と、に依存する。1チックの間隔は動作クロック速度に依存する。これは、入力クロック速度と認証チップのクロック制限ハードウェアの最大値である。例えば、認証チップのクロック制限ハードウェアは10MHzにセットされるが(これは変更できない)、入力クロックは1MHzである。このケースでは、1チックの値は10MHzではなく、1MHzが基準になる。入力クロックが1MHzではなく20MHzであるならば、1チックの値は10MHzが基準になる(なぜならば、クロック速度は10MHzで制限されている)。
1チックの間隔がわかると、MinTicks値をセットすることができる。MinTicksの値は、鍵付きRD及びTST関数への呼び出しの間に経過することが要求されるMinTicks数である。この値は、リアルタイム数であり、動作チックの長さで除算される。入力クロック速度が10MHzの最大クロック速度と一致する場合を想定する。鍵付き関数の呼び出しの間に1秒の最小値を求めるならば、MinTicksの値は10000000にセットされる。攻撃者がRND、RD及びTSTを何回も呼び出すことによってX、FK1[X]のペアを収集しようとしている場合を考える。TSTへの呼び出しの間の時間が1秒になるようにMinTicks値がセットされているならば、各ペアを生成するために1秒が必要になる。225個のペア(1.25Gbの記憶量しか必要にならない)を生成するため、攻撃者は1年以上を必要とする。264個のペアが必要になる攻撃は、1個のチップを使用すると、5.84×1011年が必要になり、10億個のチップが使用されるならば、584年が必要になり、このような攻撃は時間的に全く非現実的になる(記憶必要量については言うまでもない!)。
K1に関しては、MinTicks変数は攻撃者を遅くさせ、攻撃のコストを高くするだけである。なぜならば、MinTicksは攻撃者が多数のシステムチップを並列に使用することを止めるものではないからである。しかし、MinTicksは、本当にK2への攻撃をより困難にさせる。なぜならば、各消耗品は異なるMを有するからである(Mの一部はランダムなリードオンリーデータである)。差分攻撃に出るためには、最小限度の差の入力が必要であり、これは、単一の消耗品(Mの実効的に定数部を含む)によって実現できる。最小限度の差の入力は、攻撃者が単一チップを使用することを要求し、MinTicksは、単一チップの使用をスローダウンさせる。差分攻撃を始めるために値の検索を開始するためのデータを取得するだけに1年を要するのであれば、これは攻撃のコストを上昇させ、複製消耗品の実効的な販売期間を短縮する。
認証チップコマンド
システムは簡単なオペレーションコマンドセットによって認証チップと通信する。このセクションは、プロトコル3の実装のために必要な実際のコマンド及びパラメータを詳述する。認証チップは、最低限の実装としてシリアルインタフェースによってシステムと通信するものとして定義される。より幅広いインタフェース(例えば、8、16又は32ビット)によって動作する等価的なチップを定義することは慣用的なことである。オペコードの解釈は、IsTrustedビットの現在の値と、IsWrittenビットの現在の値と、に依存し得る。以下のオペレーションが定義される。
Op=オペコード、T=IsTrusted値、W=IsWrtten値、
Mn=ニューモニック、[n]=パラメータに必要なビット数。
この表に定義されていないコマンドは、NOP(ノーオペレーション)として解釈される。その例には、(IsTrusted値又はIsWritten値とは無関係である)オペコード110及び111と、IsWritten=0のときのSSI以外のオペコードと、が含まれる。RD及びRNDのオペコードは同じであり、WR及びTSTのオペコードも同じであることに注意する必要がある。オペコードの受け取り後に動かされる実際のコマンドは、(IsWrittenが1である限り)IsTrustedビットの現在値に依存する。IsTrustedビットがクリアされているところでは、RD及びWR関数が呼び出される。IsTrustedビットがセットされると、RND及びTST関数が呼び出される。2組のコマンドは、信頼されている認証チップと信頼されていない認証チップとの間で相互に排他的であり、同じオペコードはこの関係を強いる。各コマンドは引き続くセクションで詳細に検討される。一部のアルゴリズムは具体的に設計される。なぜならば、フラッシュメモリが不揮発変数の実現形態として想定されるからである。
CLR(クリア)コマンドは、全ての認証チップメモリの内容を完全に消去するため設計される。これは、全ての鍵及び秘密情報と、アクセスモードビットと、状態データと、を含む。CLRコマンドの実行後、認証チップは、新しく製造されたときと丁度同じように、プログラマブル状態になる。それは、新しい鍵として再プログラムして、再使用することができる。CLRコマンドは、CLRコマンドオペコードだけにより構成される。認証チップはシリアルであるため、これは同時に1ビットずつ転送される。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、CLRコマンドは、CLRオペコードのビット0から2として送られる。全部で3ビットが転送される。CLRコマンドはいつでも直ちに呼び出すことができる。消去の順序は重要である。SIWrittenbit値は、(RND、TST、RD及びWRのような)鍵アクセス関数への更なる呼び出しを禁止するため、最初に消去されなければならない。AccessModeビットがSIWrittenの前にクリアされると、攻撃者は、それらがクリアされた後のある時点で電源を取り外し、Mを操作し、これにより、部分選択テキスト攻撃で秘密情報を取り出すよい機会を得る。CLRコマンドは以下のステップで実現される。
チップがクリアされると、チップは再プログラミングと再使用の準備が完了する。ブランクチップは攻撃者にとって無用である。なぜならば、Mに対して任意の値を作成することが可能であるとしても(Mは読み出し及び書き込みが可能である)、K
1及びK
2が間違っているので鍵付き関数は全く情報を提供しないからである。CLRがCLR以外の任意のオペコードのために要求されるならば、入力パラメータビットを費やす必要がない。攻撃者はチップをリセットするだけでよい。CLRを呼び出す理由は、全ての秘密情報が破壊され、チップが攻撃者にとって無用になることを保証するためである。
SSI−秘密情報セット(SET SECRET INFORMATION)
入力:K1、K2、R=[160ビット,160ビット,160ビット]
出力:無し
変更内容:K1、K2、R、SIWritten、IsTrusted。
SSI(秘密情報セット(Set Secret
Information))コマンドは、K1、K2及びR変数にロードし、RND、TST、RD及びWRコマンドを後で呼び出すためSIWritten及びIsTrustedフラグをセットするため使用される。SSIコマンドは、SSIコマンドオペコードと、その後に続く、K1、K2及びRレジスタに格納されるべき秘密情報と、を含む。認証チップはシリアルであるため、これは同時に1ビットずつ転送されるべきである。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、SSIコマンドは、SSIオペコードのビット0−2と、その後に続く、K1に対する新しい値のビット0−159と、K2に対する新しい値のビット0−159と、最後に、Rに対するシード値のビット0−159として送られる。全部で483ビットが転送される。K1、K2、R、SIWritten、及びIsTrustedレジスタはCLRコマンドによって全て0にクリアされる。それらは、SSIコマンドを使用することによってのみセットすることができる。
SSIコマンドは、データがK1、K2及びRにロードされた事実を格納するためフラグSIWrittenを使用する。SIWrittenフラグ及びIsTrustedフラグをクリアされているならば(これは、CLR命令後のケースである)、K1、K2及びRに新しい値がロードされる。何れかのフラグがセットされているならば、SSIの呼び出しの試みによって、CLRコマンドが実行される。なぜならば、攻撃者又は間違ったクライアントだけが、CLRを先に呼び出すことなく、鍵又はランダムシードを変更しようとするからである。また、SSIコマンドは、Rに対する値に依存してIsTrustedフラグをセットする。R=0であるならば、チップは信用できないとみなされ、したがって、IsTrustedは0のまま維持される。R≠0であるならば、チップは信用できるとみなされ、IsTrustedは1にセットされる。IsTrustedビットの設定は、SSIコマンドの間だけで行われることに注意する必要がある。認証チップが再使用されるならば、CLRコマンドは最初に呼び出されなければならない。その後、鍵は、SSIコマンドで安全にプログラムされ、新たな状態情報がSAM及びWRコマンドを用いてMへロードされる。SSIコマンドは以下のステップで実行される。
RD−読み出し
入力:X、F
K1[X]=[160ビット、160ビット、160ビット]
出力:M、F
K2[X|M]=[256ビット、160ビット]
変更内容:R。
RD(リード)コマンドは、信頼されない認証チップから状態データ(M)の256ビット全体を安全に読み出すために使用される。有効認証チップだけがRD要求に正しく応答する。RDコマンドからの出力ビットは、入力ビットとして、検証用の信頼された認証チップ上のTSTコマンドへ供給でき、最初の256ビット(M)は、TSTが(期待通りに)1を戻す場合に後で使用するため保存される。認証チップはシリアルであるため、コマンド及び入力パラメータは同時に1ビットずつ転送されるはずである。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、RDコマンドは、RDオペコードのビット0−2と、その後に続く、Xのビット0−159と、FK1[x]のビット0−159である。全部で320ビットが転送される。X及びFK1[X]は信頼された認証チップのRNDコマンドを呼び出すことによって獲得される。信頼されたチップのRNDコマンドから出力された320ビットは、したがって、信頼されないチップのRDコマンドへそのまま供給することが可能であり、それらのビットをシステムによって保存しなくてもよい。RDコマンドは、以下の条件が充たされたときに限り使用できる:
SIWritten=1 K1、K2、RがSSIコマンドによってセットアップされたことを示す;
IsTrusted=0 乱数シーケンスを生成することが許可されないのでチップは信頼されないことを示す。
加えて、RDの呼び出しは、MinTicksRemainingレジスタが0に達するまで待たなければならない。そうなった後、レジスタには、MinTicksが再ロードされ、RDへの呼び出しの間に最小限度の時間が確実に経過する。MinTicksRemainingにMinTicksが再ロードされると、RDコマンドは入力パラメータが有効であることを検証する。これは、入力Xに対するFK1[X]を内部的に生成し、次に、得られた結果を入力FK1[X]と比較することによって行われる。この生成及び比較は、入力パラメータが正しいかどうかとは無関係に同じ時間を使用しなければならない。時間が同一ではない場合、攻撃者は、FK1[X]のどのビットが間違っているかに関する情報を得ることができる。入力パラメータが無効になるのは、間違ったシステム(誤ったビットを渡す)、間違ったシステムに間違った消耗品がある場合、不良の信頼されるチップ(不良なペアを生成する)、又は認証チップへの攻撃に限られる。一定値0は入力パラメータが間違っている場合に返される。0が返されるまでに要する時間は、あらゆる不良な入力に対して同じでなければならないので、攻撃者は何が無効であるかに関する情報を全く学習できない。入力パラメータが検証されると、出力値が計算される。Mの256ビットの内容は、M[0]のビット0−15、M[1]のビット0−15から、M[15]のビット0−15の順番に転送される。FK2[X|M]は計算され、ビット0−159として出力される。Rレジスタは、X、FK1[X]ペアの検証中に、値を格納するため使用される。その理由は、RNDとRDが相互に排他的であるためである。RDコマンドは以下のステップで実施される。
RND−ランダム
入力:無し
出力:R、F
K1[R]=[160ビット、160ビット]
変更内容:無し。
RND(ランダム)コマンドは、RD及びTSTコマンドによって、後続の認証で使用するための有効R、FK1[R]ペアを獲得するためクライアントによって使用される。入力パラメータが無いので、RNDコマンドは単にRNDオペコードのビット0−2である。RNDコマンドは以下の条件が充たされた場合に限り使用できる:
SIWritten=1 K1およびRがSSIコマンドによってセットアップされたことを示す;
IsTrusted=1 チップは乱数シーケンスを生成することが許可されていることを示す。
RNDは、RとFK1[R]の両方を呼び出し元へ返す。RNDコマンドの288ビット出力は、信頼されないチップのRDコマンドに入力パラメータとして供給することが可能である。クライアントはそれらを全く格納する必要が無い。なぜならば、それらは再度要求されないからである。しかし、TSTコマンドは、RDコマンドに渡された乱数が最初にRNDコマンドから取得されたものである場合に限り成功する。呼び出し元がRNDだけを複数回呼び出すならば、同じR、FK1[R]のペアが毎回返されるであろう。Rは、TSTへの呼び出しが成功であった後、シーケンス内の次の乱数へ進む。より詳しくはTSTの説明を参照せよ。RNDコマンドは以下のステップで実施される。
TST−テスト(TEST)
入力:X、F
K2[R|X]=[256ビット、160ビット]
出力:1又は0=[1ビット]
変更内容:M、R及びMinTicksRemaining(又は攻撃が検出されたならば全てのレジスタ)。
TST(テスト(Test))コマンドは、信頼されない認証チップからのMの読み出しを認証するため使用される。TST(テスト)コマンドは、TSTコマンドオペコードと、その後に続く入力パラメータ:X及びFK2[R|X]と、により構成される。認証チップはシリアルであるため、これは同時に1ビットずつ転送されなければならない。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、TSTコマンドは、TSTオペコードのビット0−2と、その後に続く、Mのビット0−255と、FK2[R|M]のビット0−159である。全部で419ビットが転送される。最後の416入力ビットは、RDコマンドから信頼されない認証チップへの出力ビットとして獲得されるので、データ全体をクライアントが保存する必要はない。その代わりに、ビットは、信頼された認証チップのTSTコマンドへそのまま渡すことができる。Mのうちの256ビットだけがRDコマンドに秘密にされるべきである。TSTコマンドは、以下の条件が充たされたときに限り使用できる:
SIWritten=1 K2およびRがSSIコマンドによってセットアップされたことを示す;
IsTrusted=1 チップは乱数シーケンスを生成することが許可されていることを示す。
加えて、TSTの呼び出しは、MinTicksRemainingレジスタが0に達するまで待たなければならない。そうなった後、レジスタには、MinTicksが再ロードされ、TSTへの呼び出しの間に最小限度の時間が確実に経過する。TSTは、内部M値を入力M値によって置き換えさせる。次に、FK2[M|R]が計算され、160ビット入力ハッシュ値と比較される。生成される単一出力ビットは、両者が同じであるならば1であり、両者が異なるならば0である。内部M値を使用することは、チップ上のスペースを節約し、RD及びTSTが相互に排他的なコマンドであることの理由である。出力ビットが1であるならば、Rはシーケンス内の次の乱数になるように更新される。これは、RD及びTSTテストが呼び出される毎に、呼び出し元に強制的に新しい乱数を使用させる。結果の出力ビットは、入力文字列全体が比較されるまでは出力されないので、TST関数内の比較を評価するために要する時間は常に同じである。このようにして、攻撃者は、実行時間、又は出力が与えられる前に処理されたビット数を比較できない。
次の乱数は、160ビットの最大周期のLFSR(タップはビット159、4、2及び1で選択)を使用してRから生成される。Rの初期160ビット値はSSIコマンドによってセットアップされ、0以外のいかなる乱数でもよい(0で満たされたLFSRは際限のない0のストリームを生成する)。Rはビット1、2、4及び159をまとめてXOR論理演算し、XOR論理演算の結果をb159への入力として用いて160ビット全部を右へ1ビットシフトすることにより変換される。新しいRは次のRND呼び出しの際に返される。TSTから0を返すために要する時間は、全ての不良な入力に対して同じであり、攻撃者は無効な入力に関して何も学習し得ないことに注意する必要がある。
TSTコマンドは以下のステップで実施される。
尚、ステップ7では、単純にそのままRを進めることができない。なぜならば、Rはフラッシュメモリであり、セットされたビットが0になるためには消去しなければならないからである。電源が、古いRの値を消去した後で新しいRの値が書き込まれる前に、ステップ7の間に認証チップから取り外された場合、Rは消去されるが再プログラミングされない。したがって、IsTrusted=1でありながら、R=0であるという状況が生まれ、この状況が起こり得るのは攻撃者が原因となる場合だけである。ステップ4はこの事象を検出し、攻撃が検出された場合に動作する。この問題は、Rのための第2の160ビットフラッシュレジスタと有効性ビットとを設け、新しい値がロードされた後にトグル切替することで防ぐことができる。これは、スペースの理由で本実施形態には組み込まれていないが、チップ空間がそれを許容するならば、補助的な160ビットフラッシュレジスタがこの目的のために有用であろう。
WR−書き込み(WRITE)
入力:Mnew=[256ビット]
出力:無し
変更内容:M。
WR(書き込み(Write))コマンドは、認証チップ状態データを格納するMの書き込み可能な部分を更新するため使用される。WRコマンド自体は安全ではない。WRコマンドの後には、(RDコマンドによる)認証されたMの読み出しが続き、指定されたとおりに変更がなされたことを保証する。WRコマンドは、WRコマンドオペコードと、その後に続くMへ書き込まれるべき新しい256ビットのデータと、を渡すことによって呼び出される。認証チップはシリアルであるため、Mの新しい値は同時に1ビットずつ転送されなければならない。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、WRコマンドは、WRオペコードのビット0−2と、その後に続く、M[0]のビット0−15と、M[1]のビット0−15からM[15]のビット0−15まである。全部で259ビットが転送される。WRコマンドは、SIWritten=1のとき、即ち、K1、K2、RがSSIコマンドによってセットアップされたことを示すときに限り使用できる(SIWrittenが0であるならば、K1、K2、Rは未だセットアップされていないので、代わりにCLRコマンドが呼び出される)。特定のM[n]への書き込みの可能性は、AccesssModeレジスタに格納されているような対応したアクセスモードビットにより支配される。AccessModeビットはSAMコマンドを用いてセットできる。新しい値をM[n]へ書き込みとき、M[n]はフラッシュメモリであるということを考慮しなければならない。M[n]の全てのビットを消去した後、適切なビットをセットしなければならない。二つのステップが別々のサイクルで行われるので、攻撃の可能性は無防備のままである。攻撃者は、消去後、しかし、新しい値をプログラミングする前に、電源を取り外すことが可能である。しかしながら、攻撃者はこれを行っても利益がない:
この手段によってリード/ライトM[n]が0に変更されることは全く利益がない。なぜならば、攻撃者はWRコマンドを使用して任意の値を書き込めるからである;
この手段によってリードオンリーM[n]が0に変更されることによって、付加的なテキストペアを知ることができる(ここで、M[n]は元の値ではなく0である)。将来M[n]値を使用する場合、それらは既に0であるため、全く情報が与えられない;
デクリメントオンリーM[n]が0に変更されると、消耗品が使い切られる時間が早まるだけである。これは、消耗品を使用することによって得られるような何ら新しい情報を攻撃者に与えることはない。
WRコマンドは以下のステップで実施される。
SAM−アクセスモードセット(SET ACCESS MODE)
入力:AccessMode
new=[32ビット]
出力:AccessMode=[32ビット]
変更内容:AccessMode。
SAM(アクセスモードセット(Set Access Mode))コマンドは、AccessModeレジスタの32ビットをセットするため使用され、消耗品認証チップでの使用だけが有効である(IsTrustedフラグ=0の場合)。SAMコマンドは、SAMコマンドオペコードと、その後に続く、AccessModeレジスタにビットをセットするために使用される32ビット値と、を渡すことによって呼び出される。認証チップはシリアルであるため、データは同時に1ビットずつ転送されなければならない。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、SAMコマンドは、SAMオペコードのビット0−2と、その後に続く、AccessModeにセットされるビットのビット0−31と、である。全部で35ビットが転送される。AccessModeレジスタはCLRコマンドの実行時に限り0にクリアされる。00というアクセスモードはRW(リード/ライト)のアクセスモードを示すので、CLR後にAccessModeビットをセットしないことは、全てのMが読み書きできることを意味する。SAMコマンドだけがAccessModeレジスタのビットをセットする。したがって、クライアントは、32ビット語に適当なビットをセットし、入力パラメータとしての32ビット値を用いてSAMを呼び出すことにより、M[n]に対するアクセスモードビットをRWからRO(リードオンリー)へ変更可能である。これは、様々な時点での、おそらく製造プロセスの種々のステージにおけるアクセスモードビットのプログラミングを可能にさせる。例えば、リードオンリーランダムデータは、初期鍵プログラミングステージ中に書き込むことが可能であり、一方、消耗品シリアル番号のような項目のための第2のプログラミングステージが許可される。
SAMコマンドはビットをセットするだけであるので、その効果は、M[n]に対応するアクセスモードビットをRWからMSR、NMSR又はROの何れかへ進行させ得ることである。尚、MSRのアクセスモードはROへ変更可能であるが、これは、攻撃者には役立たないことに注意する必要がある。なぜならば、不正に加工された認証チップへの書き込み後のMの認証は、書き込みが不成功であったことを検出し、オペレーションを中止するからである。ビットの設定は、フラッシュメモリが最も巧く機能する方法に対応する。AccessModeレジスタ内のビットをクリアする唯一の方法は、例えば、デクリメントオンリーM[n]をリード/ライトに変更するための唯一の方法は、CLRコマンドを使用することである。CLRコマンドは、AccessModeレジスタを消去(クリア)するだけではなく、鍵及び全てのMをクリアする。このようにして、M[n]に対応するAccessMode[n]ビットは、CLRコマンドの間で1回だけ有効に変更することができる。SAMコマンドは(適切なビットが入力パラメータによってセットされた後)AccessModeレジスタの新しい値を返す。入力パラメータを0としてSAMを呼び出すことにより、AccessModeは変更されず、したがって、AccessModeの現在値が呼び出し元へ返される。
SAMコマンドは以下のステップで実施される。
GIT−IsTrustedを取得(GET ISTRUSTED)
入力:無し
出力:IsTrusted=[1ビット]
変更内容:無し。
GIT(IsTrusted取得(Get IsTrusted)コマンドは、認証チップ上のIsTrustedビットの現在値を読むため使用される。戻されるビットが1であるならば、認証チップは信頼できるシステム認証チップである。戻されるビットが0であるならば、認証チップは消耗品認証チップである。GITコマンドは、GITコマンドオペコードだけを含む。認証チップはシリアルであるため、これは同時に1ビットずつ転送されなければならない。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、SAMコマンドは、SAMオペコードのビット0−2として送信される。全部で3ビットが転送される。GITコマンドは以下のステップで実施される。
SMT−MinTicksセット(SET MINTICKS)
入力:MinTicks
new=[32ビット]
出力:無し
変更内容:MinTicks。
SMT(MinTicksセット(Set MinTicks))コマンドは、MinTicksレジスタのビットをセットし、TST及びRDへの呼び出しの間に経過すべきMinTicks数を定めるため使用される。SMTコマンドは、SMTコマンドオペコードと、その後に続く、MinTicksレジスタにビットをセットするために使用される32ビット値と、を渡すことによって呼び出される。認証チップはシリアルであるため、データは同時に1ビットずつ転送されなければならない。ビット順序は、各コマンドコンポーネントのLSBからMSBである。したがって、SMTコマンドは、SMTオペコードのビット0−2と、その後に続く、MinTicksにセットされるビットのビット0−31と、である。全部で35ビットが転送される。MinTicksレジスタはCLRコマンドの実行時に限り0にクリアされる。0という値は、鍵付き関数の呼び出しの間にチックを経過させなくてもよいことを示す。したがって、この関数は、クロック速度制限ハードウェアがチップに動作を許可する頻度で呼び出される。
SMTコマンドはビットをセットするだけなので、その効果は、クライアントが値をセットできるようにさせ、更なる呼び出しが行われた場合に時間遅延を増大させるだけである。既にセットされたビットをセットすることは効果がなく、クリアされているビットをセットすることだけが、チップを更に遅くさせるために作用する。ビットの設定はフラッシュメモリが最も巧く機能する方法に対応する。MinTicksレジスタ内のビットをクリアする唯一の方法は、例えば、10チックの値を4チックの値に変更するための唯一の方法は、CLRコマンドを使用することである。しかし、CLRコマンドは、MinTicksレジスタを0にクリアするだけではなく、全ての鍵及びMをクリアする。したがって、それは攻撃者にとっては役に立たない。このようにして、MinTicksレジスタは、CLRコマンドの間で1回だけ有効に変更することができる。
SMTコマンドは以下のステップで実施される。
認証チップのプログラミング
認証チップは物理的に安全な環境内で論理的に安全な情報でプログラミングしなければならない。その結果として、プログラミング手続は論理的セキュリティと物理的セキュリティの両方を取り扱う。論理的セキュリティは、K
1、K
2、R及び乱数M[n]の値が、コンピュータではなく、物理的にランダムなプロセスによって生成されることを保証するプロセスである。また、それは、チップの部品のプログラミングされる順序が最も論理的に安全であることを保証するプロセスでもある。物理的セキュリティは、プログラミングステーションが物理的に安全であり、したがって、鍵生成ステージ期間と鍵の記憶の耐用期間の両方で、K
1及びK
2が秘匿されることを保証するプロセスである。その上、プログラミングステーションは、鍵を獲得又は破壊する物理的攻撃に対抗しなければならない。認証チップは、K
1及びK
2が秘匿されることを保証するための固有のセキュリティメカニズムを備えているが、プログラミングステーションはK
1及びK
2を安全に保持しなければならない。
概要
製造後、認証チップは使用可能にされる前にプログラミングする必要がある。全てのチップにおいて、K1及びK2の値を確定しなければならない。チップがシステム認証チップを目的としているならば、Rの初期値を決めなければならない。チップが消耗品認証チップを目的としているならば、Rは0にセットし、M及びAccessModeの初期値も設定しなければならない。したがって、以下のステージが確認される:
システムと消耗品の間の繰り返しを決定する;
システム及び消耗品用の鍵を決定する;
システム及び消耗品用のMinTicksを決定する;
鍵、ランダムシート、MinTicks及び未使用Mをプログラムする;
状態データ及びアクセスモードをプログラムする。
消耗品又はシステムが必要でなくなると、取り付けられた認証チップは再使用可能である。これは、もう一度ステージ4から始めて、チップを再プログラミングすることによって簡単に実現できる。各ステージは以下のセクションで説明する。
ステージ0:製造
認証チップの製造は特別なセキュリティを必要としない。製造ステージでは、チップにプログラミングされている秘密情報はない。アルゴリズム及びチッププロセスは特別ではない。標準的なフラッシュプロセスが使用される。チップ製造者とプログラミングステーションの間での認証チップの盗難は、複製品製造者にブランクチップを与えることになるだけである。これは、認証チップの販売を危うくすることは殆どなく、認証チップによって何も認証されない。プログラミングステーションは、消耗品及びシステムのプロダクト鍵を含む唯一のメカニズムであるため、複製品製造者は、正しい鍵を用いてチップをプログラムできない。複製品製造者は、自分専用のシステム及び消耗品用にブランクチップをプログラミングすることは可能であるが、それらの品を見破られずに販売することは困難であろう。その上、1回の盗みではビジネスの基礎を置くことは難しいであろう。
ステージ1:システムと消耗品の間の相互作用の決定
システムとは何か、及び消耗品とは何か、の判断は、認証チップのプログラミングが可能になる前に決定されるべきである。どの消耗品がどのシステムで使用可能であるかに関する判断をする必要がある。なぜならば、接続されるシステムと消耗品だけが同じ鍵情報を共有しなければならないからである。また、それらは、状態データの一部の解釈が未決定であっても、状態データ使用メカニズムを共有すべきである。簡単な例は、車と、車キーの場合である。車自体はシステムであり、車キーは消耗品である。各車には数個の車キーがあり、各キーは特定の車と同じ鍵情報を格納する。しかし、各車(システム)は(その車キーと共有される)異なる鍵をもつであろう。なぜならば、ある車の車キーが別の車で機能することが求められないからである。別の例は、特定のトナーカートリッジを必要とするコピー機の場合である。簡単に言えば、コピー機はシステムであり、トナーカットリッジは消耗品である。しかし、カートリッジとコピー機の間にどのような互換性があるかを判断する必要がある。この判断は、従来、トナーカートリッジの物理的パッケージングによって行われ、ある種のカートリッジは、新しいモデルのコピー機の設計判断に基づいて、その新しいモデルのコピー機に適合し、或いは、適合しない。認証チップが使用されるとき、連動すべきコンポーネントは同じ鍵情報を共有しなければならない。
更に、消耗品はタイプ毎に、M(状態データ)の異なる分割方法が必要になる。Mの使用法は、アプリケーション毎に変化するものであり、M[n]及びAccessMode[n]の割付方法も同様である:
特定用途の消耗品状態データを定義する;
将来の使用のため(必要に応じて)一部のM[n]レジスタを確保する。それらを0にセットし、リードオンリーにセットする。値は互換性を保つためにシステムでテストすることができる;
残りのM[n]レジスタ(少なくとも1個、しかし、M[15]であってはならない)をリードオンリーにセットし、各M[n]の内容を完全にランダムにする。これによって、複製品製造者は認証鍵への攻撃がより困難になる;
以下の例は、状態データが編成される方法を示す。
例1
車キーが付随した車を想定する。16ビット鍵番号は、所定の車の車キーを一意に識別するために十分足りる。Mの256ビットは以下の通り分割される。
車製造者が全ての車の全ての論理的鍵を保持するならば、車キーを紛失したときに、新しい物理的な車キーを製造することは些細な問題である。新しい車キーは、M[0]に新しい鍵番号を格納するが、その車の認証チップと同じK
1及びK
2を含む。車システムは、特定の鍵番号を無効にすることができる(例えば、鍵を紛失したとき)。このようなシステムは、鍵0(マスター鍵)を最初に挿入し、次に全ての有効な鍵を挿入し、次に、鍵0をもう一度挿入することを要求するかもしれない。これらの有効な鍵だけが車と連動するようになる。最悪のケースでは、例えば、全ての車キーを紛失すると、その車に対する新しい論理的な鍵の組を生成し、必要に応じて、関連した物理的な車キーを生成することができる。カーエンジン番号は、その鍵を特定の車に結びつけるために使用される。将来用データは、レンタル情報、例えば、ドライバ/貸出者の詳細情報のような事項を格納する。
例2
100000回のコピー毎に交換しなければならないコピー機画像ユニットの例を想定する。残りページ数を記憶するため32ビットが必要になる。Mの256ビットは次の通り分割される。
10000回のコピー毎に交換しなければならない低品質画像ユニットが製作されたとき、32ビットのページカウントは、既存コピー機との互換性のためにそのまま使用される。これにより、数タイプの消耗品を同じシステムで使用できるようになる。
例3
25枚の写真を格納するポラロイド型カメラの例を考える。残り写真数を記憶するためには16ビットのカウントダウンだけあればよい。Mの256ビットは次の通り分割される。
M[2]の残り写真数は、同じカメラシステムと使用するための多数の消耗品タイプの構築を可能にさせる。例えば、写真数36の新しい消耗品は簡単にプログラムできる。カメラの発表後、2年が経過した場合を考えると、新しいタイプのカメラが発表されている。それは、古い消耗品を使用することが可能であるが、新しいフィルムタイプも処理できる。M[3]はフィルムタイプを定義するため使用できる。古いフィルムタイプは0であり、新しいフィルムタイプは他の新しい値である。新しいシステムはこれを利用することができる。元のシステムはM[3]に非零値を検出し、新しいフィルムタイプとの非互換性を認識する。新しいシステムは、M[3]の値を理解し、適切に応じる。古い消耗品との互換性を保つため、新しい消耗品及びシステムは、古いものと同じ鍵情報をもつことが必要である。新しいシステム及びその専用消耗品と完全に断ち切るためには、新しい鍵セットが必要になるであろう。
例4
シアン、マゼンタ、及びイエローの三つのインクを格納するプリンタ消耗品の例を考える。各インク量は別々にデクリメントされるべきである。Mの256ビットは次の通り分割される。
ステージ2:システム及び消耗品の鍵の決定
どのシステムとどの消耗品が同じ鍵を共有すべきであるかに関する決定がなされると、それらの鍵を定義しなければならない。したがって、K
1及びK
2の値が決定される。殆どのケースでは、K
1及びK
2は全体で1回だけ生成される。連動すべき(現在及び将来の)全てのシステム及び消耗品は、同じ鍵K
1及びK
2の値をもつ。したがって、K
1及びK
2は秘匿されなければならない。なぜならば、システム/消耗品の組み合わせに対するセキュリティメカニズム全体は、鍵が見られてしまうと、役に立たなくなるからである。鍵が暴露されると、その損害は、システム及び消耗品の数、並びに、それらを新たな暴露されていない鍵で再プログラミングすることの容易さに依存する。トナーカートリッジを用いるコピー機の場合、最悪のケースでは、複製品製造者は固有の認証チップを製造し(又は、さらに悪い場合には、それらを購入し)、判明した鍵でチップをプログラムし、固有の消耗品に挿入する。車キー付きの車のケースでは、各車は、異なる鍵の組をもつ。このことにより、2通りの一般的なシナリオが生まれる。第1のシナリオでは、車及び車キーがそれらの鍵を用いてプログラムされた後、K
1及びK
2が削除され、それらの値の記録が保持されず、即ち、K
1及びK
2を暴露する方法がない。しかし、その車のための予備の車キーは、車の認証チップを再プログラミングしない限り製作できない。第2のシナリオでは、車製造者はK
1及びK
2を保持し、その車のための新しいキーを製作可能である。K
1及びK
2の暴露は、ある者が特定の車専用の車キーを製作できることを意味する。
したがって、認証チップで使用される鍵及びランダムデータは、非決定論的な手段によって生成されるべきである(完全にコンピュータで生成された疑似乱数は使用できない。なぜならば、それは、生成器のシードを知ることによって将来の全ての数が得られるという点で決定論的であるからである)。K1及びK2は、コンピュータではなく、物理的にランダムなプロセスによって生成されるべきである。しかし、ランダム性の自然発生源に基づくランダムビット生成器は、外因の影響を受けやすく、故障し易い。そのような装置は、統計的なランダム性を定期的にテストすべきであることが避けられない。
簡単ではあるが、有用な乱数発生源は、SGIからのLavarand(登録商標)システムである。この生成器は、数分間隔で6個のラバランプを撮影するデジタルカメラを使用する。ラバランプは無秩序なタービュラント系を含む。得られたデジタル画像はSHA−1実装部に供給され、SHA−1実装部は、7方向のハッシュを生成し、デジタル化された画像から7バイト毎に160ビット値を生じる。7組の160ビットの合計は140バイトになる。この140バイトの値がBBS生成器に供給され、出力ビットストリームのスタート位置を決める。BBSからの出力160ビットは、鍵、又は認証チップ53である。
非決定論的なランダムプロセスの極端な例は、クリーンルーム内で、K1のためにコインを160回トスし、K2のためにコインを160回トスすることである。それぞれの表又は裏に応じて、1又は0が鍵プログラマ装置のパネルに入力される。このプロセスは、(検証のための)数人の観測者が沈黙した状態(誰かが隠しマイクを持っているかもしれない)で行われる。重要なことは、安全なデータ入力及び記憶は、それほど簡単ではないということである。鍵プログラマ装置及び付随するプログラミングステーションの物理的セキュリティは、その固有の完全なドキュメントが必要である。鍵K1及びK2が決定された後、それらは、認証チップがその鍵を使用する必要のある限り保持されなければならない。最初の車/車キーのシナリオでは、K1及びK2は、単一のシステムチップ及び数個の消耗品チップがプログラムされた後に破壊されている。コピー機/トナーカートリッジのケースでは、K1及びK2は、トナーカートリッジがコピー機の役に立っている間に限り保持されなければならない。それらは秘匿されるべきである。
ステージ3:システム及び消耗品のMinTicksの決定
MinTicksの値は、認証チップの動作クロック速度(システム固有)と、RD又はTST関数呼び出しの間の妥当な時間の根拠(アプリケーション固有)と、に依存する。単一チックの間隔は動作クロック速度に依存する。これは、入力クロック速度と認証チップのクロック制限ハードウェアの最大値である。例えば、認証チップのクロック制限ハードウェアは10MHzにセットされるが(これは変更できない)、入力クロックは1MHzである。このケースでは、1チックの値は10MHzではなく、1MHzが基準になる。入力クロックが1MHzではなく20MHzであるならば、1チックの値は10MHzが基準になる(なぜならば、クロック速度は10MHzで制限されている)。1チックの間隔がわかると、MinTicks値をセットすることができる。MinTicksの値は、鍵付きRD又はST関数への呼び出しの間に経過することが要求されるMinTicks数である。入力クロック速度が10MHzの最大クロック速度と一致する場合を想定する。TSTの呼び出しの間に1秒の最小値を求めるならば、MinTicksの値は10000000にセットされる。2秒のような値は、(1ページ当たりに1回の認証で、1ページが2から3秒毎に生成される)プリンタのようなシステムの場合には全く妥当な値である。
ステージ4:鍵、ランダムシード、最終チック及び未使用Mのプログラム
認証チップは、製造後、状態が不明である。或いは、認証チップは、ある消耗品で既に使用済みであり、別の消耗品で使用するために再プログラムしなければならない。確認証チップの各々は、クリアされ、新しい鍵及び新しい状態データでプログラムされる。認証チップのクリア処理及びその後のプログラミングは、安全なプログラミングステーション環境で行われる。
信頼されたシステム認証チップのプログラミング
チップが信頼されたシステムチップであるならば、Rのシード値が生成される。それは、物理的にランダムなプロセスから抽出された乱数であり、0ではない。以下のタスクは、以下の順に、安全なプログラミング環境で行われる:
リセット チップをリセット
CLR[]
Load R
R(160ビットレジスタ)に物理的ランダムデータをロード
SSI[K1,K2,R]
SMT[MinTicksSystem]。
ここで、認証チップはシステムへ挿入するための準備が完了している。認証チップは完全にプログラムされている。システム認証チップがこの時点で盗まれたならば、複製品製造者は、K1への既知テキスト攻撃に出るために、又はK2への部分選択テキスト攻撃に出るために、R、FK1[R]のペアを生成すべくそれらを使用できる。これは、各々が信頼された認証チップを含む多数のシステムの購入と差がない。セキュリティは、認証プロトコルの強度と、K1及びK2のランダム性と、に依存する。
信頼されない消耗品認証チップのプログラミング
チップが信頼されない消耗品認証チップである場合、プログラミングは信頼されたシステム認証チップのプログラミングとは少し異なる。最初に、Rのシード値は0である。それは、M及びAccessModeの値用の付加的なプログラミングを行う。未使用M[n]は0でプログラムされ、ランダムM[n]はランダムデータでプログラムされる。以下のタスクは、以下の順に、安全なプログラミング環境で行われる:
リセット チップをリセット
CLR[]
Load R
R(160ビットレジスタ)に0をロード
SSI[K1,K2,R]
Load X
X(256ビットレジスタ)に0をロード
Set 適当なM[n]に対応したXに物理的ランダムデータをセット
WR[X]
Load Y
Y(32ビットレジスタ)に0をロード
Set 適当なM[n]に対応したYにリードオンリーアクセスモードをセット
SAM[Y]
SMT[MinTicksConsumable]。
ここで、信頼されない消耗品チップは一般的な状態データでプログラムする準備が完了している。認証チップがこの時点で盗まれたならば、攻撃者は、制限選択テキスト攻撃を実行できる。最もよい状況では、Mの一部分はリードオンリー(0及びランダムデータ)であり、Mの残りは攻撃者によって(WRコマンドを用いて)完全に選択される。攻撃者による多数のRD呼び出しは、限定されたMに対するFK2[M|R]を獲得する。最悪の状況では、Mは攻撃者によって完全に選択される(なぜならば、256ビットの全てが状態データに使用されるためである)。しかし、どちらの場合でも、攻撃者はRの値を選択できない。なぜならば、RはRNDへの呼び出しによってシステム認証チップから供給されるためである。選択されたRを獲得する唯一の方法は、ブルートフォース攻撃である。ステージ4及び5が同じプログラミングステーションで実行された場合(好ましく、且つ理想的な状況)、認証チップはステージ間で取り外せないことに注意すべきである。この場合、認証チップがこの時点で盗まれる可能性はない。認証チップを1回でプログラムするか、又は2回でプログラムするかの決定は、システム/消耗品製造者の要求次第である。
ステージ5:状態データ及びアクセスモードのプログラム
このステージは、消耗品認証チップの場合だけに必要である。なぜならば、M及びAccessModeレジスタはシステム認証チップ上では変更できないからである。M[n]の未使用及びランダム値は既にステージ4でプログラムされている。残りの状態データをプログラムする必要があり、関連したAccessMode値をセットする。このステージの速度は、MinTicksレジスタに格納された値によって制限されることに注意する必要がある。このステージは、ステージ4とステージ5が実行される場所/時間の物理的場所の違い又は時間の違いを考慮して、ステージ4から分離されている。理想的には、ステージ4及び5は同時に同じプログラミングステーションで実行される。ステージ4は有効認証チップを生成するが、それらに初期状態値(0以外)をロードしない。これは、チップのプログラミングを消耗品の生産ラインの運行と一致させることができる。ステージ5は何回も実行し、毎回、異なる状態データ値及びアクセスモード値を設定することが可能であるが、1回だけ実行され、残りの全ての状態データ値をセットし、残りの全てのアクセスモード値をセットする可能性の方が高い。例えば、生産ラインがセットアップされ、認証チップのバッチ番号及びシリアル番号が生産される物理的な消耗品に応じて生成される。これを一致させることは、状態データが物理的に異なる工場でロードされる場合にはかなり難しくなる。
ステージ5のプロセスは、最初に、チップが有効消耗品チップであることを保証するために検査を行い、ここでは、認証チップからデータを収集するRDが含まれ、次に、初期データ値のWRが行われ、更に、新しいデータ値を永久的にセットするためSAMが行われる。これらのステップの概要を次に記載する:
IsTrusted=GIT[];
IsTrustedがセットされているならば、エラー(間違った種類のチップ!)で終了する;
有効な入力ペアを取得するため有効システムチップのRNDを呼び出し;
有効な入力ペアを渡して、プログラムされるべきチップのRDを呼び出し;
認証チップのRDからの結果をX(256ビットレジスタ)にロードする;
X及び消耗品チップが有効であることを保証するため有効システムチップのTSTを呼び出し;
TSTが0を返したならば、エラー(システムに対し間違った消耗品チップ)で終了する。
Xのビットに初期状態値をセット;
WR[X];
Y(32ビットレジスタ)に0をロード;
新しい状態値のためのアクセスモードに対応したYのビットをセット;
SAM[Y]。
勿論、検証(ステージ1から7)は、ステージ4及び5が同じプログラミングステーションで次々と行われる場合には行わなくてもよい。しかし、この検証は、ステージ5がステージ4とは別個のプログラミングプロセスとして実行される他の全ての状況では行われるべきである。これらの認証チップがここで盗まれた場合には、それらは既に特定の消耗品で使用するためにプログラムされている。攻撃者は、盗んだチップを複製消耗品に取り付けることができる。このような盗難は、複製された製品の個数を盗難されたチップの個数に制限する。1回の盗難では、複製品製造者が費用対効果に優れたビジネスを行うために十分な供給数が得られない。このチップの別の用途は、攻撃者が部分選択テキスト攻撃又はブルートフォース攻撃に出るために、認証チップ付きの同数の消耗品を購入しなくても済むことである。このような攻撃が行われても、鍵の特別な安全性の欠陥はない。
製造
認証チップの回路は物理的攻撃に対抗できなければならない。製造インプリメンテーションガイドラインの概要を説明し、その後に、チップの物理的防御の仕様を(攻撃の順に)説明する。
製造のガイドライン
製造に関する認証チップの実装用の一般的なガイドラインを以下に列挙する:
標準プロセス
最小サイズ(なるべく)
クロックフィルタ
雑音発生器
タンパー防止及び検出回路
タンパー検出付き保護メモリ
プログラムコードのローディング用ブート回路
鍵データパス用のFETの特殊実装
可能な場所でのポリシリコン層内のデータコネクション
過小過多電力検出ユニット
テスト回路無し。
標準プロセス
認証チップは(フラッシュのような)標準的な製造プロセスで実装できる。これは、製造場所の非常に広範囲の選択を可能にさせること
明確であり、且つ正常に動作するテクノロジーを使用すること
コストを低減すること
を充たすために必要である。標準プロセスは物理的な保護メカニズムを可能にさせることに注意する必要がある。
最小サイズ
認証チップ53は、低コスト消耗品のための認証メカニズムとして組み込むことができるように製造コストを低くしなければならない。したがって、チップサイズはできるだけ小さいままにすることが望ましい。各認証チップは、802ビットの不揮発性メモリが必要である。その上、最適化されたHMAC−SHA1に必要な記憶容量は1024ビットである。チップの残りの部分(状態機械、プロセッサ、CPU、又はプロトコル3を実施するために選択されたもの)は、トランジスタの個数が最小限に抑えられ、チップ当たりのコストが最小限になるように最低限に維持される。秘密鍵情報を保有する回路面積、また亜h、鍵に関する情報が漏れる虞のある回路面積も最小限に抑えられるべきである(特殊データパスのための以下のノンフラッシングCMOSを参照せよ)。
クロックフィルタ
認証チップ回路は特定のクロック速度レンジで動作するように設計される。ユーザはクロック信号を直接供給するので、攻撃者は、処理中の特定の時点で回路に乱調状態を生じさせ用とする可能性がある。この一例は、高いクロック速度(回路が設計対象とした速度よりも高い)は、XORが適切に動作することを妨げ、2個の入力のうちの最初の入力がそのまま返される場合である。このようなスタイルの過渡現象障害攻撃は、秘密鍵情報を復元する際に非常に有効である。ここらか学ぶべきことは、入力クロック信号は信頼できないということである。入力クロック信号は信頼できないので、最大周波数までで動作するように制限されるべきである。これはいろいろな方法で実現できる。クロック信号をフィルタ処理する一つの方法は、「エッジオン」を遅延器へ渡すエッジ検出ユニットを使用することであり、次に、遅延によって入力クロック信号の通過を許可する。図174は、クロックフィルタ内のクロック信号フローの説明図である。遅延は、最大クロック速度が特定の周波数(例えば、4MHz)になるようにセットされる。この遅延はプログラマブルではなく、固定であることに注意すべきである。フィルタ処理されたクロック信号は、必要に応じて内部で更に分周される。
雑音発生器
各認証チップは連続した回路雑音を発生する雑音発生器を含む。雑音は、チップの通常の動作からの他の電磁放射と干渉し、雑音をIdd信号に加える。雑音発生器の設置は、放射波長の長さのために認証チップに問題を起こさない。雑音発生器は、電子雑音、クロックサイクル毎の複数状態変化を発生し、タンパー防止及び検出回路用の疑似ランダムビットソースとして使用される。雑音発生器の簡単な実装は、非零の数でシードされた64ビットLFSRである。雑音発生器で使用されるクロックは、できるだけ多くの雑音を発生させるため、チップの最大クロックレートで動く。
タンパー防止及び検出回路
1組の回路が認証チップへの物理的攻撃のテスト及び防止のために必要である。しかし、実際に攻撃として検出される者は、意図的な物理的攻撃ではないかもしれない。したがって、認証チップ内で以下の2タイプの攻撃、即ち、
物理的攻撃の出現を確信できる場合
物理的攻撃の出現を確信できない場合
を区別することが重要である。
この2タイプの検出は、検出の結果として実行されることが違う。第1のケース、即ち、物理的攻撃の出現を確信できる場合、フラッシュメモリ鍵情報の消去が目的にかなった動作である。第2のケース、即ち、物理的攻撃の出現を確信できない場合、何かの間違いがあるかもしれない。動作を行うべきではあるが、秘密鍵情報を消去する動作ではない。第2のケースでとるべき適切な動作は、チップリセットである。検出されたものがチップに永久的な損傷を加える攻撃であるならば、次にも同じ状態が出現し、チップは再度リセットする。これに対して、検出されたものがチップの通常の動作環境の一部であるならば、このリセットは鍵を損ねない。
回路が状況を理解できない事象の良い例は、電源誤動作である。この誤動作は、鍵に関する情報を暴こうとする意図的な攻撃かもしれない。しかし、それは、接続間違い、又は単に、電源遮断シーケンスの開始かもしれない。したがって、チップをリセットだけすることが最良であり、鍵を消去しない。チップが電源遮断中であれば、何も失われない。システムが故障している場合、リセットの繰り返しによって、消費者はシステムを修理する。両方のケースで、消耗品は損なわれていない。回路が状況を理解できる事象の良い例は、チップ内のデータラインの切断である。この攻撃が何らかの方法で検出された場合、これは、チップの故障(製造欠陥)、又は攻撃の結果に限られる。何れのケースでも、秘密情報の消去は、目的にかなった選択すべきステップである。
この結果として、各認証チップは図示されるように2本のタンパー検出ラインを含む。一方は明確な攻撃用であり、もう一方は攻撃可能性のためのものである。これらのタンパー検出ラインには、多数のタンパー検出テストユニットが接続され、各ユニットは様々な形態のタンパーリングをテストする。その上、タンパー検出ライン及び回路自体は不正に手を加えられないことを保証したい。
タンパー検出ラインの一方の端は、(一般的な動作回路よりも高速でクロッキングする)疑似ランダムビットのソースである。上記の雑音発生器回路は適当なソースである。生成されたビットは、2種類のパスを通り、一方のパスは原データを搬送し、他方は原データの反転を搬送する。これらのビットを搬送する配線は、一般的なチップ回路(例えば、メモリ、鍵操作回路等)よりも上の層にある。配線はランダムビット発生器もカバーする。ビットは、XORゲートによって多数の場所で再結合される。ビットが異なる場合(そうあるべきである)、1が出力され、特定のユニットによって使用される(例えば、メモリ読み出しからの各出力ビットはこのビット値とAND演算される)。ラインは、最終的に、フラッシュメモリ消去回路に集まり、そこで、XORからの0によって完全な消去がトリガーされる。ラインには多数のトリガーが取り付けられ、各々はチップ上の物理的攻撃を検出する。各トリガーは、GNDへ繋がれた大型nMOSトランジスタを有する。タンパー検出ラインは、このnMOSトランジスタを物理的に通る。テストが失敗したとき、トリガーはタンパー検出ラインを0にする。XORテストは、このクロックサイクル、又は次のクロックサイクル(平均的に)の何れかで失敗し、チップをリセット又は消去する。図175は、テストと、消去回路又はリセット回路の何れかに接続されたXORと、を用いるタンパー検出回路の基本原理の説明図である。
タンパー検出ラインは、図176の大型nMOSトランジスタのレイアウトに示されているように、各Testの出力トランジスタのドレインを通る。タンパー検出ラインは切断できない。なぜならば、これは、ランダムソースからの1と0の流れを止めるからである。それにより、XORテストは失敗する。タンパー検出ラインは、各テストを物理的に通るので、タンパー検出ラインを切断することなく、特定のテストを除去することは不可能である。重要なことは、XORは、攻撃の機会を減らすため、タンパー検出ラインに沿って様々な場所からの値を取ることである。図177は、チップの様々な部分で使用されるタンパー検出ラインから多数のXORをとる状況を示している。これらのXORの各々は、各ユニット又はサブユニットで使用されるチップ正常ビットChipOKを生成しているとみなすことができる。
サンプル用途としては、各ユニットにOKビットを設け、これを各サイクルで与えられたChipOKビットとAND演算することがある。OKビットはリセットで1がロードされる。OKビットが0であるならば、ユニットは次のリセットまで失敗(フェイル)である。タンパー検出ラインが正しく機能するならば、チップは、リセットを行うか、又は全ての鍵情報を消去する。リセット回路又は消去回路が破壊されているならば、このユニットは機能しないので、攻撃者を阻止する。リセットライン及び消去ライン、並びに、関連した回路の行き先は、非常に状況に敏感である。それは、個別のタンパーテストと非常に類似した方法で保護されるべきである。攻撃者がリセット回路に繋がる配線を簡単に切断できるのであれば、リセットパルスを生成しても意味がない。実際の実装形態は、リセットでクリアされるべき項目と、それらの項目をクリアする方法と、に依存する部分が大きい。
最後に、図178は、タンパーラインがチップの雑音発生器回路を保護する様子を示す図である。発生器及びNOTゲートは同じ高さにあり、一方、タンパー検出ラインは発生器よりも高いところを通る。
タンパー検出付き保護メモリ
秘密情報又はプログラムコードはフラッシュメモリに記憶するだけでは不十分である。フラッシュメモリ及びRAMは、プログラムコード又は鍵情報の特定のビットを変更(又はセット)使用とする攻撃者から保護されなければならない。使用されるメカニズムは、(上述の)タンパー検出回路で使用されているメカニズムに準拠する。ソリューションの第1の部分は、タンパー検出ラインが各フラッシュ又はRAMビットの直ぐ上を確実に通ることである。これは、攻撃者がフラッシュ又はRAMの内容をプローブできないことを保証する。配線の保護部の破損はタンパー検出ラインの切断である。この破損は、消去信号をセットするので、メモリの内容が消去される。タンパー検出ライン上の高周波雑音も受動的な観測の妨げになる。
フラッシュに対するソリューションの第2の部分は、多重レベルデータ記憶装置を使用し、しかも、それらの多重レベルのうちのサブセットだけを有効ビット表現のために使用することである。一般的に、多重レベルフラッシュ記憶装置が使用されるとき、単一のフローティングゲートが2ビット以上を保持する。例えば、4電圧状態トランジスタは、2ビットを表現できる。最小電圧及び最大電圧がそれぞれ00及び11で表すことにすると、2個の中間電圧は01及び10を表す。認証チップの場合、単一ビットを表現するために2個の中間電圧を使用し、両端の2個は無効状態であるとみなす。攻撃者がゲートの回路を閉じる、又は切断することにより、ビットの状態を強制的にある方向又は別の方向にさせようとした場合に、無効電圧(従って、無効状態)が現れる。
RAMに対するソリューションの第2の部分は、パリティビットを使用することである。レジスタのデータ部分は(攻撃後には一致しなくなる)パリティビットを使って検査できる。フラッシュ及びRAMから到来するビットは、共通タンパー検出ラインに接続された(1ビットに一つずつの)多数のテストユニットによって確認される。タンパー検出回路は、データが通過する最初の回路である(したがって、攻撃者によるデータラインの切断を阻止する)。
プログラムコードのローディング用ブート回路
プログラムコードは、ROMではなく、多重レベルフラッシュに保持されるべきである。なぜならば、ROMはテストできない方法で変更されやすいからである。したがって、ブートメカニズムは、プログラムをフラッシュメモリに取り込むために必要である(フラッシュメモリは製造後中間状態になっている)。ブート回路はROM内には置かれず、小型の状態機械で十分である。そうでなければ、ブートコードは検出できない方法によって変更される。ブート回路は、全てのフラッシュメモリを消去し、消去が正しく動作したことを確認し、次に、プログラムコードをロードする。フラッシュメモリは、プログラムをローディングする前に消去しなければならない。そうでなければ、攻撃者はチップをブート状態に置き、既存の鍵を抽出しただけのプログラムをロードすることができる。状態機械は、新しいプログラムコードをロードする前に、全てのフラッシュメモリがクリアされていることを保証するため(攻撃者が消去ラインを切断していないことを保証するため)検査を行う。プログラムコードのローディングは、(鍵のような)秘密情報がロードされる前に、安全なプログラミングステーションによって行われる。
鍵データパス用の特殊なFETの実装
CMOSインバータ(nMOSトランジスタと組み合わされたpMOSトランジスタを含む)場合の通常のFET実装の状況が図179に示されている。遷移中に、nMOSトランジスタとpMOSトランジスタの両方が中間的な抵抗値をもつ短い期間が存在する。その結果としての電源−グラウンド短絡回路は、電流を一時的に増大させ、実際上、CMOS装置によって消費される電流の大部分を占める。少量の赤外線光が短絡回路の期間に放出され、シリコン基板を介して観測することができる(シリコンは赤外線を透過する)。また、少量の光がトランジスタゲート容量と伝送ライン容量の充電中及び放電中に放出される。
秘密鍵情報を操作する回路の場合、このような情報は秘匿されなければならない。代替的なノンフラッシングCMOS実装が、鍵、又はその鍵に基づいて部分的に計算された値を操作する全てのデータパスのため使用される。二つの重なり合わないクロックφ1及びφ2の使用によって、フラッシュしないメカニズムが得られる。φ1は全てのnMOSトランジスタの第2ゲートに接続され、φ2は全てのpMOSトランジスタの第2ゲートに接続される。遷移は、クロックと組み合わされた場合に発生する。φ1及びφ2は重なり合わないので、pMOS及びnMOSトランジスタは、同時に中間的な抵抗値をとることがない。その構成は図180に示されている。
最後に、通常のCMOSインバータは、重要なノンフラッシングCMOSコンポーネントの近傍に配置することができる。これらのインバータは上記のタンパー検出ラインからそれらの入力信号を取り出す。タンパー検出ラインは通常の動作回路の何倍も高速に動作するので、正味の影響は、ノンフラッシングCMOSコンポーネントの各々の場所付近に高いレートで生じる光バーストである。明るい光は、付近の弱い光の観測を邪魔するので、観測者は、チップそのものでどのようなスイッチング動作が行われているかを検出し得ない。これらの通常のCMOSインバータは、回路雑音の量を効果的に増加させ、SN比を低下させ、役に立つEMIを覆い隠す。
ノンフラッシングCMOSの使用によって多数の副作用が現れる:
チップの実効速度は、1クロックサイクル当たりのクロック立ち上がり時間の2倍だけ減少する。これは、認証チップの場合、問題にならない;
ノンフラッシングCMOSによって引き出される電流量が減少する(なぜならば、短絡回路が現れないからである)。しかし、これは、通常のCMOSインバータの使用によって相殺される;
クロックの配線によってチップ面積が増加し、特に、φ1及びφ2の多数のバージョンが様々な伝搬のレベルを考慮に入れるために要求されるからである。チップ面積の推定量は通常の実装の2倍である;
認証チップのフラッシュしないエリアの設計は、通常のCMOS設計を用いた場合よりも多少複雑になる。特に、標準的なセルコンポーネントが使用できず、そのエリアがフルカスタム化されるからである。これは、認証チップのように小さいものの場合、特に、チップ全体をこの方法で保護しなくても構わないときには、問題にならない。
可能な場所でのポリシリコン層内の配線
どこでも可能であれば、鍵又は秘密データが流れる配線は、ポリシリコン層内に作られるべきである。必要であれば、メタル1に設けられるが、決して(タンパー検出ラインを含む)最上部のメタル層に設けるべきではない。
過小過多電力検出ユニット
各認証チップは、電源攻撃を妨げるため、過小過多電力検出ユニットが必要である。過小過多電力検出ユニットは、電源誤動作を検出し、電源レベルがある許容範囲に収まることを保証するため、電圧基準に対して電源レベルをテストする。このユニットは、単一の電圧基準と、2個のコンパレータを含む。過小過多電力検出ユニットは、リセットタンパー検出ラインに接続してもよく、これにより、トリガーされたときにリセットを引き起こす。過小過多電力検出ユニットの副作用は、電源遮断中に電圧が降下したとき、リセットがトリガーされ、作業レジスタを消去することである。
テスト回路無し
認証チップ上のテストハードウェアは簡単に脆弱性を持ち込み得る。その結果として、認証チップは、BIST又はスキャンパスを含むべきではない。したがって、認証チップは外部テストベクトルを用いてテスト可能にされる。これは、認証チップが複雑ではないので実現可能である。
ROM読み出し
この攻撃は、鍵がアドレス指定可能なROMに記憶されていることに依存する。各認証チップはその認証鍵を、アドレス指定可能なROMではなく内部フラッシュメモリに記憶しているので、この攻撃は無関係である。
チップのリバースエンジニアリング
チップのリバースエンジニアリングは、認証の安全性がアルゴリズムに由来している場合に限り有用である。しかし、本発明の認証チップは、アルゴリズムの秘密性ではなく、秘密鍵に依存している。これに対して、本発明の認証アルゴリズムは公開されていて、いずれにしても、大量生産消耗品の攻撃者は、チップの内部の詳細な設計図を獲得する可能性があったと考えられる。これらの要因から見て、チップ自体のリバースエンジニアリングは、記憶されたデータとは対照的に、脅威ではない。
認証プロセスの不当使用
この攻撃がとり得る形態は幾つかあり、各々の形態は成功の程度に違いがある。全てのケースにおいて、複製品製造者はシステム設計と消耗品設計の両方を入手できると考えられる。ある攻撃者は、認証コードを生成するのではなく、システムを騙して有効なコードを返すチップを構築しようとする。この攻撃は以下の二つの理由から実現不可能である。第1の理由は、システム認証チップ及び消耗品認証チップは、物理的には同じであるとしても、別々にプログラムされている点にある。特に、RDオペコード及びRNDオペコードは同一であり、WRオペコードとTSTオペコードも同様である。システム認証チップはRDコマンドを実行できない。なぜならば、全ての呼び出しは、RDではなく、RNDへの呼び出しとして解釈されるからである。この攻撃が失敗する第2の理由は、別々のシリアルデータラインがシステムからシステム認証チップ及び消耗品認証チップへ設けられるからである。その結果として、どちらのチップも、もう一方へ送信される内容、或いは、もう一方から受信される内容を見ることができないからである。攻撃者が、(消耗品残量をデクリメントする)WRコマンドを無視する複製チップを構築した場合、プロトコル3は、その後のRDがWRは出現しなかったことを検出することを保証する。システムは、したがって、消耗品を使用しなくなり、攻撃者を阻止する。これは、攻撃者が認証前に接触の欠損をシミュレートした場合にも成り立ち、認証が行われないので、消耗品の使用は発生しない。したがって、攻撃者は、複製消耗品が受け付けられるように各システムを変更する範囲に制限される。
システムの変更
変更の最も簡単な方法は、システムの認証チップを、TSTへの呼び出し毎に成功だけを通知するチップと置き換えることである。これは、認証毎に何回もTSTを呼び出し、最初の数回は偽の値を与え、TSTからの失敗の通知を要求するシステムによって妨げられる。TSTへの最後の呼び出しは成功することが予想される。TSTの偽の呼び出しの回数は、RD、又はシステムクロックから戻された結果の一部分から決定してもよい。残念ながら、攻撃者は、単に、システムを書き換えることができるので、新しいシステム複製認証チップ53は、消耗品チップ又はクロックから返された結果を監視できる。複製システム認証チップは、監視された値がそのTST関数へ与えられたときに、成功しか返さない。複製消耗品はRDのハッシュ結果として任意の値を返すことができ、複製システムチップはその値を有効であることを明らかにする。したがって、システムがシステム認証チップを何回も呼び出しても意味がない。なぜならば、書き換え攻撃は、全てのシステムに対してではなく、再配線されたシステムだけに対して正しく動作するからである。システムに対する類似した攻撃の形態は、システムROMの取り替えである。ROMプログラムコードは、認証が行われることの無いように変更可能である。これに関しては何もできない。なぜならば、システムは消費者の手にあるからである。勿論、これはあらゆる保証を無効にするが、消費者は、複製消耗品が非常に安価であり、且つ本物の品物よりも簡単に入手できるのであれば、変更する価値があると考えるであろう。
システム/消耗品製造者は、したがって、この種類の攻撃がどの程度起こり得るかを判断しなければならない。このような調査は、システム及び消耗品の価格構成、システムサービスの頻度、物理的な変更を加えたときの消費者の利益、消費者がその変更を実行するために出向く場所を当然に含む。システムを変更する限界のケースは、複製品製造者が、複製消耗品を必要とする完全な複製システムを提供する場合である。これは、単なる競合、又は特許権の侵害である。いずれにしても、これは認証チップの目的の範囲外であり、複製される技術やサービスに依存する。
従来のプロービングによるチップ動作の直接視
チップ動作を視察するためには、チップは動作していなければならない。しかし、タンパー防止及び検出回路は、鍵を処理又は保持するチップの区域を覆う。これらの区域を、タンパー防止ラインを通して見ることは不可能である。攻撃者は、単にタンパー防止層を通してチップをスライスできない。なぜならば、そうすることによって、タンパー検出ラインが破断し、電源投入時に全ての鍵を消去するからである。単に消去回路を破壊するだけでは不十分である。なぜならば、認証チップ内の多数のユニットに供給される多数のChipOKビット(このとき全て0)は、チップの通常の動作回路の機能を停止させるからである。攻撃のためにチップをセットアップするためには、攻撃者は、タンパー検出ラインを削除し、フラッシュメモリの消去を停止し、ChipOKラインを信頼していたコンポーネントを何とかして書き換えることが必要である。たとえ、この全てを実行できたとしても、チップをこのレベルまでスライスする動作は、鍵を保持する不揮発性メモリ内の電荷パターンを殆ど破壊し、プロセスを無益にするであろう。
不揮発性メモリの直接視
認証チップがフラッシュメモリのフローティングゲートを露出させるようにスライスされ、それらを放電させない場合、鍵は、おそらくSTM又はSKMを用いて直接視できるであろう。しかし、ゲートを放電させずにチップをこのレベルまでスライスすることは、おそらく不可能である。湿式エッチング、プラズマエッチング、イオンミリング、又は化学機械研磨は、ほぼ確実にフローティングゲート上に存在する小さい電荷を放出する。これは、通常のフラッシュメモリの場合に成り立つが、多重レベルフラッシュメモリの場合にはより確かである。
状態変化によって生じる光バーストの監視
秘密鍵情報を操作する回路の全ての区域は、上記のノンフラッシングCMOSに実現される。これは、大部分の光バーストの放出を阻止する。ノンフラッシングCMOSの直ぐ近くに配置された通常のCMOSインバータは、キャパシタの充電及び放電によって生じる僅かな放射を見えなくする。インバータはタンパー検出回路に接続されるので、インバータは、ノンフラッシングCMOSの状態変化毎に何回も(高いクロックレートで)状態を変化する。
EMIの監視
上記の雑音発生器は回路雑音を誘起する。雑音は、チップの通常の動作からの他の電磁放射を妨害し、内部データ転送の有意な読み出しが曖昧になる。
Idd変動の監視
この種の攻撃に対するソリューションは、Idd信号におけるSN比を減少させることである。これは、回路の雑音量を増大させ、信号量を減少させることにより実現される。雑音発生器回路(これは、EMI攻撃に対する防御としても機能する)は、Idd中の重要な情報を目立たなくするため、サイクル毎に十分な状態変化を引き起こす。その上、チップの鍵を伝搬するデータパスの特別なノンフラッシングCMOS実装は、状態変化が生じたときに電流が流れることを阻止する。これは、信号量を減少させる利点がある。
差分故障解析
差分故障ビット誤りは、イオン化、マイクロ波放射、又は環境ストレスによって、目標とした形ではなく、取り込まれる。この種の攻撃の最も起こりやすい影響は、フラッシュメモリの変更(無効な状態を引き起こす)又はRAMの変更(不良パリティ)である。無効な状態及び不良なパリティは、タンパー検出回路によって検出され、鍵の消去を生じさせる。タンパー検出ラインは鍵操作回路を覆うので、鍵操作回路に取り込まれたあらゆる誤りは、タンパー検出ラインの誤りによって反映される。タンパー検出ラインが影響されるならば、チップは、継続的にリセットをするか、又は単にパワーアップ時に鍵を消去し、攻撃を無益にする。目標としていない攻撃に頼り、「チップのちょうど良い部分がちょうど良い方法で影響を受ける」ことを望むのではなく、攻撃者は、(上書き攻撃、ゲート破壊等の)目標とした故障を持ち込むことをやってみる方がよい。
クロック誤作動攻撃
(上記の)クロックフィルタはクロック誤動作攻撃の実現性を除外する。
電源攻撃
(上記の)過小過大電力検出ユニットは電源攻撃の実現性を除外する。
ROMの上書き
認証チップは、プログラムコード、鍵、及び秘密情報を、ROMではなく、フラッシュメモリに格納する。したがって、この攻撃は可能性がない。
EEPROM/フラッシュの変更
認証チップは、プログラムコード、鍵、及び秘密情報をフラッシュメモリに格納する。しかし、フラッシュメモリは、2本のタンパー防止及び検出ラインによって覆われている。これらのラインの何れか一方が(ゲートを破壊するプロセスにおいて)破断されると、攻撃はパワーアップ時に検出され、各チップは、(連続的に)リセットするか、又はフラッシュメモリから鍵を消去する。しかし、たとえ、攻撃者が何とかしてフラッシュメモリのビットへアクセスし、特定のビットを保持しているゲートを破壊するか、若しくは、省くことができるとしても、これは、そのビットを強制的に無充電、又はフル充電の状態にする。これらはどちらも、認証チップの多重レベルフラッシュメモリの使用法では無効状態である(二つの中間状態だけが有効である)。データ値がフラッシュから転送されたとき、検出回路は、消去タンパー検出ラインをトリガーさせ、これにより、フラッシュメモリの残りの部分を消去し、チップをリセットする。したがって、EEPROM/フラッシュメモリの変更攻撃は無益である。
ゲート破壊攻撃
ゲート破壊攻撃は、単一ゲートを変更し、動作中にチップに情報を暴露させる攻撃者の能力に依存している。しかし、秘密情報を操作する回路は、2本のタンパー防止及び検出ラインの一方によって覆われている。これらのラインの何れか一方が(ゲートを破壊するプロセスにおいて)破断されると、攻撃はパワーアップ時に検出され、各チップは、(連続的に)リセットするか、又はフラッシュメモリから鍵を消去する。この種の攻撃に出るためには、攻撃者は、最初に、どのゲートを目標にすべきかを決定するためにチップをリバースエンジニアリングしなければならない。目標ゲートの場所が決定された後、攻撃者は、保護しているタンパー検出ラインを破断し、フラッシュメモリの消去を停止し、ChipOKラインを信頼していたコンポーネントを何とかして書き換えることが必要である。回路の書き換えはチップをスライスすることなく実行できず、たとえ、実行できたとしても、チップをこのレベルまでスライスする動作は、鍵を保持する不揮発性メモリ内の電荷パターンを殆ど破壊し、プロセスを無益にするであろう。
上書き攻撃
上書き攻撃は、鍵の個々のビットを、その前の値を知ることなく、セットし得ることに依存している。それは、従来のプロービング攻撃と同じようにチップをプロービングし、ゲート破壊攻撃と同じようにゲートを破壊することに依存する。これらの両方の攻撃は(それぞれのセクションで説明したように)タンパー防止及び検出回路とChipOKラインを使用しているので成功しない。しかし、たとえ、攻撃者が何とかしてフラッシュメモリのビットへアクセスし、特定のビットを保持しているゲートを破壊するか、若しくは、省くことができるとしても、これは、そのビットを強制的に無充電、又はフル充電の状態にする。これらはどちらも、認証チップの多重レベルフラッシュメモリの使用法では無効状態である(二つの中間状態だけが有効である)。データ値がフラッシュから転送されたとき、検出回路は、消去タンパー検出ラインをトリガーさせ、これにより、フラッシュメモリの残りの部分を消去し、チップをリセットする。同じように、RAMから読み出された改ざんされている値のパリティチェックによって、消去タンパー検出ラインがトリガーされる。したがって、上書き攻撃は無益である。
残留メモリ攻撃
認証チップ内の作業用レジスタ又はRAMは、電源が取り外されたとき、認証鍵の一部を保持している。作業用レジスタ及びRAMは、電源の取り外し後、ある時間その情報を保持し続ける。チップがスライスされ、レジスタ/RAMのゲートが、それらを放電させることなく露出されたとき、データは、STMを使用して、おそらく直接視できるであろう。第1の防御は、上述の電源誤動作攻撃に対する防御の説明からわかる。電源が取り外されると、リセット状態がメモリのクリアを引き起こすのとちょうど同じように、全てのレジスタ及びRAMがクリアされる。この攻撃が成功する見込みは、フラッシュメモリの読み出しの見込みよりもひくり。RAM電荷は(本質的に)フラッシュメモリよりも簡単に失われる。RAMを明らかにするためのチップのスライス化は、(電荷が、単に、メモリがリフレッシュされていないこと、及びスライス化を実行するために要する時間を原因として失われていないとしても)確実に電荷を失わせる。したがって、この攻撃は無益である。
チップ窃盗攻撃
認証チップの耐用期間には、区別可能なフェーズが存在する。チップは、以下のステージの何れかのときに盗まれる可能性がある:
製造後、鍵をプログラミングする前;
鍵のプログラミング後、状態データをプログラミングする前;
状態データのプログラミング後、消耗品又はシステムに挿入する前;
システム又は消耗品に挿入された後。
チップ製造とプログラミングステーションの間の盗難は、複製品製造者にブランクチップを与えるだけである。これは、認証チップの販売を危うくするだけであり、認証チップによって認証されるものはない。プログラミングステーションは、消耗品及びシステム製品鍵をもつ唯一のメカニズムであり、複製品製造者はチップを正しい鍵でプログラミングできない。複製品製造者は、自分専用のシステム及び消耗品用にブランクチップをプログラミングすることは可能であるが、それらの品を見破られずに販売することは困難であろう。盗難の第2の形態は、認証チップが2以上の別個のプログラミングフェーズを通るような状況だけで起こり得る。これは起こり得るが、可能性は低い。いずれにしても、最悪の状況は、状態データがプログラミングされておらず、全てのMがリード/ライトになっている場合である。このケースでは、攻撃者はチップに対して適応的選択テキスト攻撃に出ることが可能である。HMAC−SHA1アルゴリズムはこの攻撃に対抗できる。盗難の第3の形態は、プログラミングステーションと取付工場との間で行われる。認証チップは、既に特定のシステム用、又は特定の消耗品用にプログラムされている。これらのチップの唯一の用途として、泥棒はこれらを複製システム又は複製消耗品に収容する。複製システムは見当違いであり、複製システムは認証チップ53を必要とさえしないであろう。複製消耗品の場合、このような盗難は、複製品の数を盗み取られたチップの数に制限する。1回の窃盗は、複製品製造者が費用対効果に優れたビジネスを行うために十分な供給数が得られない。盗難の最後の形態は、システム又は消耗品自体の盗難である。盗難が製造者側で発生した場合、物理的セキュリティプロトコルを強化しなければならない。盗難が他の場所で行われた場合、それは、その品の所有者、及び警察又は保険会社だけの問題である。認証チップが使用するセキュリティメカニズムは、消耗品及びシステムが一般の人の支配下にあることを前提としている。その結果として、それらが盗まれても、鍵の安全性に重大な影響はない。
認証チップ設計
認証チップは、物理的及び論理的外部インタフェースをもつ。物理的インタフェースは認証チップをどのように物理的システムに接続できるかを規定し、論理的インタフェースはシステムがどのように認証チップと通信できるかを規定する。
物理的インタフェース
認証チップは、小型の4ピンCMOSパッケージである(実際の内部サイズは、0.25μmフラッシュプロセスを使用する約0.30mm2である)。4ピンは、グランド(GND)、クロック(CLK)、パワー(Power)、及びデータ(Data)である。パワーは公称電圧である。電圧が公称電圧からある量以上変動すると、チップはリセットする。推奨されるクロック速度は4から10MHzである。内部回路は、クロック信号をフィルタ処理し、安全最大クロック速度を超えないことを保証する。データは、シリアルデータラインに沿って、同時に1ビットずつ送受信される。チップは、パワーアップ時、パワーダウン時にリセットを実行する。その上、チップ内のタンパー検出及び防止回路は、攻撃が検出された場合、(検出された攻撃に応じて)チップをリセットさせるか、又はフラッシュメモリを消去させる。特殊プログラミングモードは、CLK電圧を特定レベルに保持することによってイネーブル状態にされる。これは次のセクションで更に説明される。
論理的インタフェース
認証チップは、ノーマルモードとプログラミングモードの二つの動作モードを有する。二つのモードが必要になる理由は、動作プログラムコードは、(安全性の理由から)ROMではなくフラッシュメモリに記憶されるからである。プログラミングモードは、製造後にテスト目的のため使用され、動作プログラムコードを詰め込み、一方、ノーマルモードは、その後のチップの使用のために用いられる。
プログラミングモード
プログラミングモードはCLKライン上に特定電圧を所定の時間だけ維持することによって有効にされる。チップがプログラミングモードに入るとき、全てのフラッシュメモリは消去される(全ての秘密鍵情報及びプログラムコードを含む)。認証チップは、次に、消去を検証する。消去が成功であるならば、認証チップは、新しいプログラムコードに対応した384バイトのデータを受け取る。バイトは、バイト0からバイト383の順に転送される。ビットは、ビット0からビット7の順に転送される。384バイト全部のプログラムコードがロードされると、認証チップはハングする。消去が成功しなかった場合、認証チップは全くデータをフラッシュメモリにロードすることなくハングする。チップがプログラムされた後、チップを再スタートすることができる。チップがCLKライン上の通常電圧でリセットされたとき、ノーマルモードに入る。
ノーマルモード
認証チップは、プログラミングモードではないときには、ノーマルモードである。認証チップがノーマルモードでスタートアップしたとき(例えば、パワーアップリセット)、認証チップは、そのときフラッシュメモリのプログラムコード領域に格納されているプログラムを実行する。プログラムコードは、システムと認証チップの間に通信メカニズムを組み込み、システムからのコマンド及びデータを受け取り、出力値を生成する。認証チップはシリアル通信をするので、ビットは同時に1ビットずつ転送される。システムは、簡単なオペレーションコマンドセットによって認証チップと通信する。各コマンドは3ビットオペコードによって定義される。オペコードの解釈は、IsTrustedビット及びIsWrittenビットの現在値に依存する。
以下のオペレーションが定義される。
Op=オペコード、T=IsTrusted値、W=IsWritten値、
Mn=ニューモニック、[n]=パラメータに必要なビット数。
この表に定義されていないコマンドは、NOP(ノーオペレーション)として解釈される。その例には、(IsTrusted値又はIsWritten値とは無関係である)オペコード110及び111と、IsWritten=0のときのSSI以外のオペコードと、が含まれる。RD及びRNDのオペコードは同じであり、WR及びTSTのオペコードも同じであることに注意する必要がある。オペコードの受け取り後に動かされる実際のコマンドは、(IsWrittenが1である限り)IsTrustedビットの現在値に依存する。IsTrustedビットがクリアされているところでは、RD及びWR関数が呼び出される。IsTrustedビットがセットされると、RND及びTST関数が呼び出される。2組のコマンドは、信頼されている認証チップと信頼されていない認証チップとの間で相互に排他的である。認証チップ上でコマンドを実行するため、(システムのような)クライアントは、コマンドオペコードと、その後に続く、そのオペコードに必要な入力パラメータと、を送る。オペコードは、最下位ビットから最上位ビットまで送られる。例えば、SSIコマンドを送るため、ビット1、0及び0がこの順に送られる。各入力パラメータも同じ方法で送られ、最初に最下位ビットから送られ、最後に最上位ビットまでが送られる。戻り値はこの方法で読み出され、最初に最下位ビットが読まれ、最後に最上位ビットが読まれる。クライアントは獲得するビット数がわかっていなければならない。
一部のケースでは、あるチップのコマンドからの出力ビットは、別のチップのコマンドへの入力ビットとしてそのまま供給される。この一例は、RNDコマンドとRDコマンドである。信頼された認証チップ上のRNDへの呼び出しからの出力ビットはシステムによって保持されなくてもよい。その代わりに、システムは、その出力ビットをそのまま信頼されない認証チップのRDコマンドの入力へ転送することができる。各コマンドの説明は、それがその場合であるかを示している。各コマンドは後続のセクションで詳細に検討される。一部のアルゴリズムは、常駐レジスタがフラッシュメモリに保持されているので、特別に設計されている。
レジスタ
認証チップ内のメモリは認証プロトコルによって要求される変数を記憶するため不揮発性メモリを含む。以下の不揮発性メモリ(フラッシュ)変数が定義される。
アーキテクチャ概要
このセクション・章は、認証チップの必要な機能を実装することができる専用CPUの上位定義を与える。このCPUは汎用CPUではないことに注意する必要がある。認証ロジックを実装するためオーダーメードされている。WRITE、TST、RND等のような認証チップのユーザが目にする認証コマンドは、CPU命令セットでかかれた小型プログラムとして全て実装される。CPUは、32ビットのアキュムレータ(殆どのオペレーションで使用される)と、多数のレジスタと、を含む。CPUは、認証ロジックを実装するため専用に仕立てられた8ビット命令を含む。各8ビット命令は、典型的に、4ビットのオペコードと、4ビットのオペランドと、により構成される。
動作速度
内部クロック周波数リミッタユニットは、チップが所定の周波数よりも速い速度で動作することを防止する。この周波数は、製造中にチップに組み込まれ、変更不可である。この周波数は約4から10MHzであることが推奨される。
コンポジション及びブロック図
認証チップは以下のコンポーネントを含む。
図181は認証チップの概略ブロック図である。タンパー防止及び検出回路は図示されない。雑音発生器、過小過大電力検出ユニット、及びプログラミングモード検出ユニットは、タンパー防止及び検出回路に接続され、残りのユニットへは接続されない。
メモリマップ
図182はメモリマップの一例を示す図である。認証チップは外部メモリを持たないが、内部メモリを有する。内部メモリは9ビットによってアドレス指定され、32ビット幅又は8ビット幅である(アドレスに依存する)。32ビット幅メモリは不揮発性データ、HAMC−SHA1のため使用される変数、及び定数を保持するため使用される。8ビット幅メモリは、プログラムと、プログラムによって使用される様々なジャンプテーブルと、を保持するため使用される。アドレス分割(予備メモリレンジを含む)はアドレス生成及び復号化を最適化するため設計される。
定数
図183は定数メモリマップの一例の説明図である。定数領域は32ビット定数により構成される。これらは、(32ビットの全部が0、及び32ビットの全部が1のような)単純な定数、HAMCアルゴリズムによって使用される定数、並びに、SHA−1アルゴリズムで使用するため必要な定数y0−3及びh0−4である。これらの値はリセットによって影響を受けない。定数を利用する唯一のオペコードはLDKである。このケースでは、オペランド及びメモリ配置は、アドレス生成及び復号化を最小限に抑えるため、密接に関連付けられている。
RAM
図184はRAMメモリマップの一例の説明図である。RAM領域は、認証チップの汎用機能のために必要な32個のパリティチェック付き32ビットレジスタを含むが、チップの動作中だけである。RAMは揮発性メモリであり、一旦電源が取り外されると、値は失われる。実際上、メモリは、(メモリ残留のために)その値をパワーダウン後のある時間は維持するが、パワーアップ後に利用可能であるとは考えられない。これは、この文書の他のセクションで記載されているセキュリティの問題である。RAMは、HMAC−SHA1アルゴリズムで使用される変数、即ち、A−E、一時変数T、160ビット作業用ハッシュ値のためのスペースH、(HMACによって要求される)ハッシュ結果の一時記憶のためのスペースB160、及び拡張ハッシングメモリの512ビット用のスペースXを含む。全てのRAM変数は、リセット後に0にクリアされるが、プログラムコードはこれを当てにしてはならない。RAMアドレスを利用するオペコードは、LD、ST、ADD、LOG、XOR及びPRLである。全てのケースで、オペランド及びメモリ配置は、アドレス生成及び復号化を最小限に抑えるため、密接に関連付けられている(マルチワード変数は最上位ワードが先に格納される)。
フラッシュメモリ−変数
図185はフラッシュメモリ変数メモリマップの一例の説明図である。フラッシュメモリ領域は、認証チップ内の不揮発性情報を格納する。フラッシュメモリは、電源の取り外し後もその値を維持し、次に電源が入れられたとき、変化していないことが期待できる。マルチステートフラッシュメモリに保持された不揮発性情報は、2個の160ビット鍵(K1及びK2)と、現在ランダム値(R)と、状態データ(M)と、MinTicks値(MT)と、AccessMode値(AM)と、IsWritten(ISW)フラグと、IsTrusted(IST)フラグと、を含む。フラッシュ値は、リセットによって変わらないが、プログラミングモードに入ったときに(0に)クリアされる。フラッシュアドレスを利用するオペレーションは、LD、ST、ADD、PRL、ROR、CLR及びSETである。全てのケースで、オペランド及びメモリ配置は、アドレス生成及び復号化を最小限に抑えるため、密接に関連付けられている。マルチワード変数K1、K2及びMは、アドレッシングの必要条件のため、最上位ワードから先に格納される。使用されるアドレッシングスキームは、Nで始まり、0で終わるインデックスによるベースアドレスオフセットである。このようにして、MNは最初にアクセスされるワードであり、M0は、ループ処理でアクセスされる最後の32ビットワードである。マルチワード変数Rは、同じインデキシングスキームを使用するLFSR生成を簡単にするため、最下位ワードから先に格納される。
フラッシュメモリ−プログラム
図186はフラッシュメモリのプログラムメモリマップの一例の説明図である。第2のマルチステートフラッシュメモリ領域は、384×8ビットである。この領域は、JSR、JSI及びTBR命令のためのアドレステーブルと、DBRコマンド用のオフセットと、定数と、プログラム自体と、を格納する。フラッシュメモリは、リセットによって変わらないが、プログラミングモードに入ったときに(0に)クリアされる。一旦、プログラミングモードに入ると、8ビットフラッシュメモリに、新しい384バイトの組をロードすることができる。これが終了すると、チップはリセットされ、通常のチップ動作が行われる。
レジスタ
多数のレジスタが認証チップに定義される。それらは、関数実行中に一時記憶として使用される。一部は算術関数用であり、他の一部はカウンティング及びインデキシングに使用され、その他はシリアルI/Oのため使用される。これらのレジスタは不揮発性(フラッシュ)メモリに保持しなくてもよい。それらは、(フラッシュメモリとは異なり)消去サイクル無しで読み出し又は書き込みをすることができる。秘密情報を格納する一時記憶レジスタは、タンパー防止及び検出回路並びにパリティチェックによって、物理的攻撃から保護されなければならない。全てのレジスタはリセット後に0にクリアされる。しかし、プログラムコードは特定の状態を前提とすべきではなく、レジスタ値を適切に設定すべきである。これらのレジスタは、タンパー防止及び検出回路のために定義された様々なOKビットを含まなくてもよいことに注意する必要がある。OKビットは種々のユニットに散在され、リセット後に1にセットされる。
サイクル
1ビットサイクル値は、CPUがフェッチサイクル(0)であるか、実行サイクル(1)であるかを決める。サイクルは、実際には、前のサイクル値を保持する1ビットレジスタから得られる。サイクルは命令セットから直接アクセスできない。それは内部レジスタ専用である。
プログラムカウンタ
6レベルの深さの9ビットプログラムカウンタアレイ(PCA)が定義される。それは、3ビットスタックポインタ(SP)によってインデキシングされる。現在プログラムカウンタ(PC)は、現在実行中命令のアドレスを格納し、事実上、PCA[SP]である。更に、9ビットAdrレジスタが定義され、(インデックス付きアクセス、又は間接メモリアクセスのための)現在メモリ基準の分解アドレスを格納する。PCA、SP及びAdrレジスタは、命令セットから直接アクセスできない。これらは内部レジスタ専用である。
CMD
8ビットCMDレジスタは、現在実行中のコマンドを保持するため使用される。CMDレジスタレジスタは命令セットから直接アクセス不可であるが、内部レジスタ専用である。
アキュムレータ及びZフラグ
アキュムレータは32ビット汎用レジスタである。これは、算術演算への入力の一つとして使用され、メモリレジスタ間で情報を転送するため使用されるレジスタである。Zレジスタは1ビットフラグであり、アキュムレータが書き込まれるときに更新される。Zレジスタはアキュムレータの零性を格納する。アキュムレータに最後に書き込まれた値が0であるならば、Z=1であり、最後に書き込まれた値が非0であるならば、Z=0である。アキュムレータとZレジスタの両方は命令セットから直接アクセス可能である。
カウンタ
多数の専用カウンタ/インデックスレジスタが定義される。
これらの全てのカウンタ・レジスタは、命令セットから直接アクセス可能である。これらに特定の値をロードするための専用命令が存在し、別の命令は、それらをデクリメント又はインクリメントし、或いは、特定のカウンタが零であるかどうかに応じて分岐する。2個の専用フラグ(レジスタではない)がC1及びC2に関連付けられ、これらのフラグはC1又はC2の零性を保持する。これらのフラグは、ループ制御のために使用され、以下に列挙される。これれのフラグはレジスタではないが、レジスタと同様にテストできる。
フラグ
CPU動作モードに対応する多数の1ビットフラグが定義される。
これらの全ての1ビットフラグは命令セットから直接アクセス可能である。専用命令がこれらのフラグをセット及びクリアするため設けられる。
書き込み完全性のため使用されるレジスタ
I/Oのため使用されるレジスタ
4個の1ビットレジスタがクライアント(システム)と認証チップの間の通信のため定義される。これらのレジスタは、InBit(入力ビット)、InBitValid(入力ビット有効)、OutBit(出力ビット)、及びOutBitValid(出力ビット有効)である。InBit及びInBitValidは、クライアントがコマンド及びデータを認証チップへ送るための手段を提供する。OutBit及びOutBitValidはクライアントが認証チップから情報を受けるための手段を提供する。クライアントは、コマンド及びパラメータビットを、同時に1ビットずつ認証チップへ送る。認証チップはスレーブ装置であるため、認証チップの観点では:
InBitからの読み出しは、InBitValidがクリアされている間はハングする。InBitValidは、クライアントが次の入力ビットをInBitに書き込むまでクリアされたままである。InBitの読み出しはInBitValidビットをクリアし、次のInBitをクライアントから読み出せるようになる。クライアントは、InBitValidビットがクリアされるまでビットを認証チップに書き込めない;
OutBitへの書き込みは、OutBitValidがセットされている間はハングする。OutBitValidは、クライアントがOutBitからビットを読み出すまでセットされたままである。OutBitの書き込みはOutBitValidビットをセットし、次のOutBitをクライアントが読み出せるようにする。クライアントは、OutBitValidビットがセットされるまで認証チップからビットを読み出せない。
タイミングアクセスのため使用されるレジスタ
1個の32ビットレジスタがタイマーとして使用するため定義される。MTR(MinTicksRemaining)レジスタは、命令が実行されると、その都度デクリメントする。MTRレジスタが0になると、それは零に留まる。MTRは1ビットフラグMTRZに関連付けられ、MTRZはMTRの零性を格納する。MTRZが1であるならば、MTRレジスタは零である。MTRZが0であるならば、MTRレジスタは未だ零ではない。MTRは(リセット後、又は特定の鍵アクセス関数後)常にMinTicks値から始まり、最終的に0まで減少する。MTRをセットし、MTRZを専用命令でテストすることができるが、MTRの値は命令によって直接読み出せない。
レジスタの要約
以下のテーブルは(レジスタ名の順に)全ての一時レジスタを要約する。そのテーブルは、レジスタ名と、サイズ(ビット単位)と、その指定されたレジスタがどこにあるかを列挙する。
命令セット
CPUは、認証ロジックを実現するため特別に用意された8ビット命令で動作する。8ビット命令の大半は、4ビットオペコードと、4ビットオペランドと、により構成される。上位4ビットはオペコードを含み、下位4ビットがオペランドを含む。
オペコード及びオペランド(要約)
オペコードは以下の表に要約されている。
以下の表は、どのオペランドがどのオペコードと共に使用できるかを要約した表である。この表は、オペコードのニューモニックによってアルファベット順に並べられている。各オペランドのバイナリ値は、その次の表に示されている。
以下のオペランド表は、4ビットオペランドの解釈を示し、全ての4ビットが直接解釈のため使用されている。
以下の命令は、オペランドの最上位ビットに基づいて選択を行う。
オペランドの下位3ビットは、オフセット(DBR,TBR)か、専用テーブル(SC)からの値であるか、LOGの場合のように、それらは論理演算のための第2の入力を選択する。解釈は、ADD、LD、及びSTオペコードの解釈と一致する。
ADD−アキュムレータへの加算
ニューモニック: ADD
オペコード: 1000
用法: ADD
値。
ADD命令は、指定されたオペランドを、モジュロー232の加法でアキュムレータに加算する。オペランドは、A、B、C、D、E、T、AM、MT、AE[C1]、H[C1]、B160[C1]、R[C1]、K[C1]、M[C1]、又はX[N4]のうちの一つである。また、Zフラグはこの演算中に、ロードされた値が零か非零かに応じてセットされる。
CLR−ビットをクリア
ニューモニック: CLR
オペコード: 0110
用法: CLR
フラグ/レジスタ。
CLR命令は、指定された内部フラグ、又はフラッシュメモリレジスタをクリアさせる。フラッシュメモリのケースでは、CLR命令はある時間を要するが、次の命令は、フラッシュメモリの消去が終了するまで引き延ばされる。クリアできるレジスタは、WE及びK2MXである。クリアできるフラッシュメモリは、R、M[C1]、Group1、及びGroup2である。Group1は、IST及びISWフラグである。それらがクリアされると、唯一の有効な上位レベルコマンドはSSI命令である。Group2は、MT、AM、K1及びK2レジスタである。Rは別個に消去される。なぜならば、RはTSTへの呼び出し毎に更新されるからである。また、Mは、インデックスメカニズムによって消去され、Mの個々の部分を更新することができる。また、対応したSET命令がある。
DBR−デクリメント及びブランチ
ニューモニック: DBR
オペコード: 0001
用法: DBR
カウンタ、オフセット。
この命令は、簡単なループを構築するメカニズムを提供する。オペランドのハイビットは、C1のテストか、C2のテスト(2個のカウンタ)を選択する。指定されたカウンタが非零であるならば、カウンタはデクリメントされ、所定のオフセットの値(符号拡張)がPCに加算される。指定されたカウンタが零であるならば、カウンタはデクリメントされ、処理はPC+1で継続する。8エントリーのオフセットテーブルがアドレス011000000(プログラムメモリの64番目のエントリー)に格納される。オフセットの8ビットは符号付き数として取り扱われる。このようにして、0xFFは−1として扱われ、0x01は+1として取り扱われる。典型的に、その値はループで使用するため負である。
JSI−サブルーチン間接ジャンプ
ニューモニック: JSI
オペコード: 01001
用法: JSI(Acc)。
JSI命令は、アキュムレータの現在値に依存したサブルーチンへのジャンプを可能にさせる。この命令は、現在PCをスタックへプッシュし、PCに新しい値をロードする。新しいPCの上位8ビットはジャンプテーブル2からロードされ(オフセットはアキュムレータの下位5ビットによって与えられる。)、PCの最下位ビットは0にクリアされる。このようにして、全てのサブルーチンは偶数アドレスでスタートしなければならない。スタックは、6個の実行レベル(5回のサブルーチン深さ)を提供する。プログラマは、この深さを超えないこと、又は戻り値が上書きされること(スタックがラップするため)を保証する責任がある。
JSR−サブルーチンジャンプ
ニューモニック: JSR
オペコード: 001
用法: JSR
オフセット。
JSR命令は、最も一般的なサブルーチン構造の用法を提供する。この命令は、現在PCをスタックへプッシュし、PCに新しい値をロードする。新しいPCの上位8ビットはアドレステーブル1から与えられ、テーブルへのオフセットは5ビットオペランド(32通りのアドレスを実現できる)によって与えられる。PCの最下位ビットは0にクリアされる。このようにして、全てのサブルーチンは偶数アドレスでスタートしなければならない。スタックは、6個の実行レベル(5回のサブルーチン深さ)を提供する。プログラマは、この深さを超えないこと、又は戻り値が上書きされること(スタックがラップするため)を保証する責任がある。
LD−アキュムレータへのロード
ニューモニック: LD
オペコード: 1011
用法: LD
値。
LD命令は、指定されたオペランドからアキュムレータにロードする。オペランドは、A、B、C、D、E、T、AM、MT、AE[C1]、H[C1]、B160[C1]、R[C1]、K[C1]、M[C1]、又はX[N4]のうちの一つである。また、Zフラグはこの演算中に、ロードされた値が零か非零かに応じてセットされる。
LDK−定数のロード
ニューモニック: LDK
オペコード: 1110
用法: LDK
定数。
LDK命令は、アキュムレータに指定された定数をロードする。定数は、HMAC−SHA1のために必要な32ビット値と、汎用処理のために最も有用な全て0及び全て1と、である。したがって、
0x00000000
0x36363636
0x5C5C5C5C
0xFFFFFFFF
又は、C1でインデックス付けされたh及びy定数テーブルからの選択肢がある。hとyの定数テーブルは、HMAC−SHA1に必要な32ビットの表形式の定数を保持する。また、Zフラグはこの演算中に、ロードされた値が零か非零かに応じてセットされる。
LOG−論理演算
ニューモニック: LOG
オペコード: 1001
用法: LOG
演算 値。
LOG命令は、アキュムレータと指定された値に対して、32ビットのビット論理演算を実行する。LOG命令によってサポートされる2個の演算は、AND及びORである。ビットNOT及びXOR演算は、XOR命令によってサポートされる。アキュムレータとAND演算又はOR演算される32ビット値は、A、B、C、D、E、T、MT及びAMのうちの一つである。また、Zフラグはこの演算中に、(アキュムレータにロードされる)得られた32ビット値が零か非零かに応じてセットされる。
ROR−右回転
ニューモニック: ROR
オペコード: 1100
用法: ROR
値。
ROR命令は、アキュムレータを設定されたビット数だけ右へ回転する方法を提供する。アキュムレータの最上部に現れるビット(ビット31になる)は、アキュムレータの前のビット0の値でもよく、又は(フラグ、又はシリアル入力コネクションのような)外部1ビットフラグからでもよい。回転して溢れたビットはシリアルコネクションから出力してもよく、又は外部フラグと結合してもよい。許容されるオペランドは、InBit、OutBit、LFSR、RLFSR、IST、ISW、MTRZ、1、2、27、及び31である。また、Zフラグはこの演算中に、(アキュムレータにロードされる)得られた32ビット値が零か非零かに応じてセットされる。最も簡単な形式では、ROR命令用のオペランドは、アキュムレータを回転させるビット位置数を示す1、2,27、31のうちの一つである。これらのオペランドの場合、外部入力又は出力はなく、アキュムレータのビットが単に右へ回転させられる。オペランドがIST、ISW及びMTRZの場合、適切なフラグがアキュムレータの最上位ビットへ転送される。アキュムレータの残りの部分は、1ビット位置だけ右へシフトされ(ビット31がビット30になる等)、アキュムレータの最下位ビットはシフトされて溢れる。オペランドがInBitである場合、次のシリアル入力ビットがアキュムレータの最上位ビットへ転送される。次に、InBitValidビットはクリアされる。クライアントから入力ビットが得られない場合、実行は入力ビットが現れるまで一時停止される。アキュムレータの残りの部分は、1ビット位置だけ右へシフトされ(ビット31がビット30になる等)、アキュムレータの最下位ビットはシフトされて溢れる。
オペランドがOutBitである場合、アキュムレータは右へ1ビット位置だけシフトされる。ビット0からシフトで送り出されたビットはOutBitフラグに格納され、OutBitValidフラグがセットされる。したがって、それは、クライアントによる読み出しの準備が完了する。OutBitValidフラグが既にセットされている場合、命令の実行は、OutBitがクライアントによって読み出される(そして、OutBitValidフラグがクリアされる)まで引き延ばされる。ビット31へシフトされた新しいビットはガーベッジ(実際には、現在のInBitレジスタの値)であると考えられる。最後に、RB及びXBRオペランドは、LFSRと倍精度シフトレジスタの実装を可能にさせる。RBの場合、シフトで送り出されたビット(形式的にビット0)は、RTMPレジスタに書き込まれる。RTMPレジスタの現在のレジスタはアキュムレータの新しいビット31になる。数個の32ビット値に複数のROR
RBコマンドを実行すると、倍精度の右回転/シフトが実現される。XRBは、RBと同様に動作し、RTMPレジスタの現在値がアキュムレータオン新しいビット31になる。しかし、XRB命令の場合、形式的にビット0であることが分かっているビットは、(RB命令の用に)単純にRTMPを置き換えない。その代わりに、そのビットはXORとRTMP演算され、その結果がRTMPに格納される。これにより、認証プロトコルによって要求される長いLFSRを実現できる。
RPL−ビット置換
ニューモニック: RPL
オペランド: 1101
用法: ROR
値。
RPL命令は、上位レベルWRITEコマンドを認証チップに組み込むため設計された。この命令は、アキュムレータの上位16ビットを、(アクセスモード値に依存して)最終的にMアレイに書き込まれた値で置き換えることを予定している。この命令は、3個のオペランド:Init、MHI及びMLOをとる。Initオペランドは、全ての内部フラグをセットし、後続の処理のためALU内のRPLユニットを準備する。アキュムレータは内部AccessModeレジスタへ転送される。アキュムレータは、WRITEコマンドを実行する場合には、RPL
Initへの呼び出しの前に、AMフラッシュメモリ場所からロードされるべきであり、TSTコマンドを実行する場合には、0でロードされるべきである。アキュムレータはそのまま変化しない。MHI及びMLOオペランドは、M[C1]の上位16ビット又は下位16ビットが(常に)アキュムレータの上位16ビットとの比較に使用されるかどうかを参照する。実行されるMHI及びMLO命令の各々は、初期化されたAccessMode値からの引き続く2ビットを使用する。最初のMHI又はMLOの実行は最下位2ビットを使用し、次の実行はその次の2ビットを使用し、以下同様である。
RTS−サブルーチンからのリターン
ニューモニック: RTS
オペコード: 01000
用法: RTS。
RTS命令は、直前に実行されたJSR又はJSI命令の後の命令で実行を再開させる。したがって、サブルーチンからの復帰と呼ばれる。実際には、この命令は、セーブされたPCをスタックからプルし、1を加え、得られたアドレスから実行を再開する。6個の実行レベル(5回のサブルーチン)が提供されるが、JSR及びJSI命令の各々と、RTSを合わせることはプログラマの責任である。先行するJSR無しに実行されたRTSは、スタックからプルされたアドレスから実行を開始させる。
SC−カウンタセット
ニューモニック: SC
オペコード: 0101
用法: SC
カウンタ 値。
SC命令はカウンタに特定の値をロードするため使用される。オペランドは、カウンタC1とC2のうちのどちらにロードするかを決める。ロードされるべき値は、2、3、4、7、10、15、19及び31のうちの一つである。カウンタ値は、ループ処理及びインデックス処理のため使用される。C1とC2の両方は、(DBR命令と組み合わされたとき)ループ構造のため使用されるが、一方、C1だけが倍精度変数の32ビット部分をインデックス付けするため使用できる。
SET−ビットセット
ニューモニック: SET
オペコード: 0111
用法: SET
フラグ/レジスタ。
SET命令は、特定のフラグ又はフラッシュメモリの設定を可能にさせる。また、対応したCLR命令がある。WEオペランド及びK2MXオペランドの各々は、後の処理のため指定されたフラグをセットする。ISTオペランド及びISWオペランドの各々は、フラッシュメモリの適切なビットをセットし、一方、MTRオペランドはアキュムレータの現在値をMTRレジスタへ転送する。SET
Nxコマンドは、N1からN4に以下の定数をロードする。
参照される各初期X[N
n]は、最適化されたSHA−1アルゴリズムのインデックスN1からN4に対する初期状態と一致することに注意すべきである。各インデックス値Nnがデクリメントするとき、有効なX[N]がインクリメントする。なぜならば、X個のワードは、最上位ビットの方からメモリに格納されるからである。
ST−アキュムレータを保存
ニューモニック: ST
オペコード: 1111
用法: ST
ロケーション。
ST命令は、アキュムレータの現在値を指定されたロケーションに格納する。ロケーションは、A、B、C、D、E、T、AM、MT、AE[C1]、H[C1]、B160[C1]、R[C1]、K[C1]、M[C1]、又はX[N4]のうちの一つである。X[N4]オペランドはN4インデックスを進める副作用がある。格納が行われた後、N4はXアレイの次の要素を指示する。N4は1ずつデクリメントされるが、Xアレイはハイからローへ並べられているので、インデックスをデクリメントすると、アレイ内の次の要素へ進む。格納先がフラッシュメモリである場合、ST命令の効果は、アキュムレータ内のビットに対応したフラッシュメモリのビットがセットされることである。アキュムレータからの正確な値が格納されることを保証するために、適切なメモリロケーションを先に消去するCLR命令を確実に使用すべきである。
TBR−テスト及びブランチ
ニューモニック: TBR
オペコード: 0000
用法: TBR
値 インデックス。
テスト及びブランチ命令は、アキュムレータが零か非零かをテストし、アキュムレータの現在状態がテスト相手の状態と一致しているならば、所与のアドレスへ分岐する。ZフラグがTRBテストと一致するならば、PCを9ビット値で置き換え、ここで、bit0=0であり、上位8ビットはMUから与えられる。そうでなければ、PCを1だけインクリメントする。値オペランドは0又は1である。0は、アキュムレータが零であることについてのテストであることを示す。1は、アキュムレータが非零であることについてのテストであることを示す。インデックスオペランドは、テストが成功したときに実行をジャンプさせる場所を示す。オペランドインデックスの残りの3ビットはジャンプテーブル1の最下位8エントリーをインデックス付けする。上位8ビットはテーブルから取り出され、最下位ビット(ビット0)は0にクリアされる。CMDはリセット時に0にクリアされる。0はTBR0として翻訳され、これは、アキュムレータ=0である場合に、アドレスオフセット0に格納されたアドレスへ分岐することを意味する。アキュムレータ及びZフラグもリセット時にクリアされるので、テストが真であり、正味の効果はジャンプテーブルの0番目のエントリーに格納されたアドレスへのジャンプである。
XOR−排他的論理和
ニューモニック: XOR
オペコード: 1010
用法: XOR
値。
XOR演算は、アキュムレータとの32ビットのビットXORを実行し、結果をアキュムレータに格納する。オペランドは、A、B、C、D、E、T、AM、MT、X[N1]、X[N2]、X[N3]又はX[N4]のうちの一つである。また、Zフラグは、結果に応じて(即ち、アキュムレータにロードされた値に応じて)、この演算中にセットされる。ビットNOT演算は、(LDK命令を用いて)アキュムレータを0xFFFFFFFFとXOR演算することによって実行される。X[N]オペランドは、(演算後に)適切なインデックスを次の値へ進める副作用がある。XORが行われた後、インデックスはXアレイの次の要素を指示する。N4は、ST
X[N4]命令によって進められる。インデックスは1ずつデクリメントされるが、Xアレイはハイからローへ並べられているので、インデックスをデクリメントすると、アレイ内の次の要素へ進む。
プログラミングモード検出ユニット
プログラミングモード検出ユニットは入力クロック電圧を監視する。クロック電圧が特定の値であるならば、消去タンパー検出ラインはトリガーされ、全ての鍵、プログラムコード、秘密情報等を消去し、プログラムモードに入る。プログラミングモード検出ユニットは通常のCMOSを用いて実装可能である。なぜならば、鍵はこのユニットを通過しないからである。このユニットはノンフラッシングCMOSで実現しなくてもよい。プログラミングモード検出ユニットをタンパー検出ラインで覆うべき特別の必要性はない。なぜならば、攻撃者は、CLR入力によってチップをプログラミングモードに移すことができるからである。プログラミングモードへ入るための信号として、消去タンパー検出ラインを使用することは、攻撃者が攻撃の一部としてプログラミングモードを使用したい場合に、消去タンパー検出ラインをアクティブにし、且つ機能させなければならないことを意味する。これは、認証チップへの攻撃を非常に困難にさせる。
雑音発生器
雑音発生器は通常のCMOSで実現できる。なぜならば、鍵はこのユニットを通らないからである。このユニットはノンフラッシングCMOSで実現しなくてもよい。しかし、雑音発生器は、両方のタンパー検出及び保護ラインで保護されるべきであり、この結果として、攻撃者がこのユニットを改ざん使用とする場合、チップは、リセットするか、又は全ての秘密情報をクリアする。その上、LFSRのビットは、それらが改ざんされていないことを保証するため検証されるべきである(即ち、パリティチェック)。パリティチェックが失敗した場合、消去タンパー検出ラインがトリガーされる。最後に、雑音発生器の64ビット全部が単一ビットにOR演算される。このビットが0であるならば、消去タンパー検出ラインがトリガーされる。なぜならば、0はLFSRの無効状態だからである。OKビットセットアップを使用することは意味がない。なぜならば、雑音発生器はタンパー検出及び防止回路だけによって使用されるからである。
状態機械
状態機械は、CPUの二つの動作サイクルを生成し、長いコマンドオペレーション中に引き延ばしを行い、オペレーティングサイクル中にオペコード及びオペランドを記憶する。状態機械は通常のCMOSで実現可能であり、その理由は、鍵がこのユニットを通らないからである。このユニットはノンフラッシングCMOSで実現しなくてもよい。しかし、オペコード/オペランドのラッチは、パリティチェックされるべきである。状態機械に格納されるロジック及びレジスタは、両方のタンパー検出ラインによって覆われるべきである。これは、実行される命令が攻撃者によって変更されないことを保証する。
認証チップは、汎用CPUの高速性及びスループットを要求しない。それは、認証プロトコルを実行できる速さで動作すればよく、それ以上に高速である必要はない。分岐制御を最適化し、又は次のオペコードをフェッチしている間にオペコードを実行する専用回路(及び、それに関連した全ての複雑さ)を具備するよりは、状態機械は、単純化した考え方を採用する。これは、設計時間を最小限に抑え、実装にエラーが起こる可能性を低減することに役立つ。
状態機械の一般的な動作は、以下のサイクルの組を生成することである:
サイクル0:フェッチサイクル。これは、オペコードがプログラムメモリからフェッチされ、フェッチされたオペコードから実効アドレスが生成されるサイクルである;
サイクル1:実行サイクルこれは、オペランドが(サイクル0で)生成された実効アドレスによってルックアップされ(かもしれない)、オペレーション自体が実行されるサイクルである。
正常な条件下で、状態機械は、サイクル:0、1、0、1、0、1...を生成する。しかし、あるケースでは、状態機械は、引き延ばしを行い、引き延ばし条件が終了するまで、各クロックチックでサイクル0を生成する。引き延ばし条件には、フラッシュサイクルの消去サイクル待ち、クライアントのシリアルデータの読み書きの待機、又は(タンパーリングによる)無効オペコード等が含まれる。フラッシュメモリがそのとき消去中であるならば、次の命令は、フラッシュメモリが消去され尽くすまで実行できない。これは、メモリユニットから送られるWait信号によって判定される。Wait=1であるならば、状態機械はサイクル0だけを生成する。シリアルI/O動作を原因とする引き延ばしには、2通りのケースがある:
オペコードがROR
OutBitであり、既にOutBitValid=1であるケース。これは、現在オペレーションは、ビットをクライアントへ出力することを要求するが、クライアントは最後のビットを未だ読み出していないケースである;
オペレーションがROR
InBitであり、InBitValid=0であるケース。これは、現在オペレーションがクライアントからのビットの読み出しを要求するが、クライアントが未だそのビットを供給していないケースである。
両方のケースで、状態機械は、引き延ばし条件が終了するまで引き延ばしをしなければならない。したがって、次の「サイクル」は、古いサイクル又は前のサイクルと、CMD、Wait、OutBitValid、及びInBitValidの現在値と、に依存する。WaitはMUに由来し、OutBitValid及びInBitValidはI/Oユニットに由来する。サイクルが0であるとき、8ビットオペコードはメモリユニットからフェッチされ、8ビットCMDレジスタに収容される。CMDレジスタの書き込みイネーブルは、−サイクルである。このユニットからの二つの出力は、サイクルとCMDである。両方の値は、認証チップ内の他の全ての処理ユニットへ渡される。1ビットのサイクル値は、各ユニットにフェッチ又は実行サイクルが行われているかどうかを報せ、一方、8ビットのCMDは、各ユニットが特定のユニットに関連したコマンドのための適切な動作を行えるようにする。
図187は、状態機械のコンポーネント間のデータフロー及び関係を示す図であり、同図では、
Old及びCMDは、共にリセットで0にクリアされる。この結果によって第1のサイクルは1であり、これは、0CMDを実行させる。0はTBR
0として翻訳され、即ち、Accmulator=0ならば、アドレスオフセット0に格納されたアドレスへ分岐する。アキュムレータもリセットで0にクリアされるので、テストは真であり、正味の効果はジャンプテーブルの0番目のエントリーに格納されたアドレスへのジャンプである。2個のVALユニットがそれらを通過する値を検証するため設計される。各VALは、両方のタンパー防止及び検出ラインに接続されたOKビットを含む。OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー防止及び検出ラインからのChipOK値とOR演算される。OKビットはそのユニットを通過する各データビットとAND演算される。VAL1の場合、チップが改ざんされたならば、実効サイクルは常に0である。このようにして、決してサイクル1にならないので、プログラムコードは実行されない。Oldが改ざんされたかどうかを検査する必要はない。なぜならば、攻撃者がOld状態を止めるならば、チップはそれ以上命令を実行しないからである。VAL2の場合、実効8ビットCMD値は、チップ改ざんされたならば、常に0であり、これは、TBR
0命令である。これは、あらゆるプログラムコードの実効を停止する。VAL2は、CMDが改ざんされていないことを保証するため、CMDからのビットにパリティチェックを行う。パリティチェックが失敗したならば、消去タンパー検出ラインがトリガーされる。
I/Oユニット
I/Oユニットは外界とシリアル通信する。認証チップは、スレーブシリアル装置として動作し、クライアントからのシリアルデータを受け取り、コマンドを処理し、得られたデータをクライアントへシリアル送信する。I/Oユニットは通常のCMOSで実現できる。なぜならば、鍵がこのユニットを通らないからである。このユニットはノンフラッシングCMOSで実現しなくてもよい。更に、ラッチはパリティチェックしなくてもよい。なぜならば、攻撃者にとってそれらを破壊又は変更する利益がないからである。I/Oユニットは、タンパー検出ラインの何れかが破断された場合、0を出力し0を入力する。これは、攻撃者がリセット及び/又は消去回路を動作禁止状態にした場合に限り有効になる。なぜならば、タンパー検出ラインの何れかを破断することは、リセット又は全フラッシュメモリの消去を生じるからである。
InBit、InBitValid、OutBit、及びOutBitValidの1ビットレジスタは、クライアント(システム)と認証チップとの間の通信のため使用される。InBit及びInBitValidは、クライアントがコマンド及びデータを認証チップへ送る手段を提供する。OutBit及びOutBitValidは、クライアントが認証チップから情報を得る手段を提供する。チップがリセットされたとき、InBitValid及びOutBitValidは共にクリアされる。クライアントは、同時に1ビットずつ、コマンド及びパラメータビットを認証チップへ送る。認証チップの観点では:
InBitからの読み出しは、InBitValidがクリアされている間はハングする。InBitValidは、クライアントが次の入力ビットをInBitに書き込むまでクリアされたままである。InBitの読み出しはInBitValidビットをクリアし、次のInBitをクライアントから読み出せるようになる。クライアントは、InBitValidビットがクリアされるまでビットを認証チップに書き込めない;
OutBitへの書き込みは、OutBitValidがセットされている間はハングする。OutBitValidは、クライアントがOutBitからビットを読み出すまでセットされたままである。OutBitの書き込みはOutBitValidビットをセットし、次のOutBitをクライアントが読み出せるようにする。クライアントは、OutBitValidビットがセットされるまで認証チップからビットを読み出せない。
実際のコマンドの引き延ばしは、状態機械によって管理されるが、種々の通信レジスタ及び通信回路がI/Oユニットに存在する。
図188はI/Oユニットのコンポーネント間のデータフロー及び関係を示す図である。
シリアルI/Oユニットは、データピンを使って外界と外部的に通信する回路を含む。InBitUsed制御信号は、所定のクロックサイクル中にInBitを使用する何れかのユニットによってセットされるべきである(サイクルのあらゆる状態になり得る)。2個のVALユニットは、タンパー防止及び検出回路に接続された検証ユニットであり、各VALはOKビットを含む。OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー防止及び検出ラインからのChipOK値とOR演算される。OKビットはそのユニットを通過する各データビットとAND演算される。
VAL1の場合、チップが改ざんされたならば、チップからの実効ビット出力は常に0である。このようにして、攻撃者は有用な出力を生成できない。VAL2の場合、チップ改ざんされたならば、チップへの実効ビット入力は常に0である。このようにして、攻撃者は有用な入力を選択できない。I/Oユニットのレジスタを検証する必要はない。なぜならば、攻撃者はそれらを破壊又は変更することによる利益がないからである。
ALU
図189は、算術論理ユニットの概略ブロック図である。算術論理ユニット(ALU)は、32ビットAcc(アキュムレータ)レジスタと、簡単な算術及び論理演算用の回路を含む。ALU及び全てのサブユニットは、ノンフラッシングCMOSで実現されるべきである。なぜならば、鍵がその中を通るからである。その上、アキュムレータはパリティチェックされる。ALUに収容されたロジック及びレジスタは、両方のタンパー検出ラインによってカバーされる。これは、鍵及び中間計算値が攻撃者によって変更されないことを保証する。1ビットのZレジスタは、アキュムレータの零性を格納する。Z及びアキュムレータレジスタの両方は、リセット後にクリアされる。Zレジスタはアキュムレータが更新されたときに更新され、アキュムレータは、LD、LDK、LOG、XOR、ROR、RPL及びADDの何れかのコマンドに対して更新される。各算術及び論理ブロックは、二つの32ビット入力、即ち、アキュムレータの現在値と、MUの現在32ビット出力と、に基づいて動作する。ここで、
Acc及びZのWriteEnablesは、(Logic1により)CMD7及びサイクルを考慮するので、これらの2ビットは、出力を選択するためにマルチプレクサMX1により要求されない。MX1の出力選択は、CMDのビット6−3だけを要求するので、結果としてより簡単である。
2個のVALユニットは、タンパー防止及び検出ラインに接続された検証ユニットであり、各VALはOKビットを含む。OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー防止及び検出ラインからのChipOK値とOR演算される。OKビットはそのユニットを通過する各データビットとAND演算される。VAL
1の場合、チップが改ざんされたならば、アキュムレータから出力された実効ビットは常に0である。これは、攻撃者がアキュムレータに関する何かを処理することを妨げる。VAL
1はアキュムレータに対するパリティチェックを実行し、チェックが失敗したならば、消去タンパー検出ラインをセットする。VAL
2の場合、アキュムレータの実効Z状態は、チップ改ざんされたならば、常に真である。このようにして、攻撃者はループ構造を作成できない。ALUの残りの機能ブロックは後述する。すべてがフラッシュしないCMOSで実現されるべきである。
RPL
図190はRPLユニットの概略ブロック図である。RPLユニットはALU内のコンポーネントである。これは、認証チップのRPL
CMP機能を実現するため設計されている。RPL CMPコマンドは、AccessModeの値に基づいて、フラッシュメモリMへの安全な書き込みに使用するため特に設計された。RPLユニットは、シフトパルス毎に2ビット右シフトを実行するAMT(AccessModeTemp)と呼ばれる32ビットシフトレジスタと、WR擬似コードのEqEncounteredフラグ及びDecEncounteredフラグに直接基づいているEE及びDEと呼ばれる1ビットレジスタと、を含む。全てのレジスタはリセット後に0にクリアされる。AMTは、PRL
INITコマンドを用いて(アキュムレータを介して)32ビットAM値がロードされ、EE及びDEは、RPL
MHIへの呼び出し及びRPL
MLOへの呼び出しを用いて汎用書き込みアルゴリズムに従ってセットされる。EQブロック及びLTブロックはWRコマンド擬似コードに記載されている通りの機能を備えている。EQブロックは、2個の16ビット入力がビット一致であるならば、1を出力し、ビット一致でなければ、0を出力する。LTブロックは、アキュムレータから入力された上位16ビットがMX
2によってMUから選択された16ビット値よりも小さい場合に、1を出力する。比較は符号無しである。オペランドのビットパターンは組み合わせロジックがより簡単化されるように特に選択される。オペランドのビットパターンを利用するので、そのパターンをもう一度列挙する。
MHI及びMLOは、ハイビットがセットされているので、Initのビットパターンと簡単に区別することができ、最下位ビットはMHIとMLOを区別するために使用できる。EEフラグ及びDEフラグは、RPLコマンドが発行されるたびに更新される。Initステージのため、2個の値を設定し、MHI及びMLOのため、EE及びDEの値を適切に更新する。したがって、EE及びDEのためのWriteEnableは以下の通りである。
32ビットのAMTレジスタに関して、このレジスタには、RPL Initコマンドのときに、(MUから読み出された)AMの内容をロードし、RPL MLOコマンド及びRPL
MHIコマンドのためにAMTレジスタを右へ2ビット位置シフトさせる。これは、RPLオペランドの最上位ビット(CMD
3)に対して簡単にテストできる。したがって、AMTレジスタのためのWriteEnable及びShiftEnableは、以下の通りである。
Logic
3からの出力は、マルチプレクサMX
1への入力としても有用である。なぜならば、それは、現在の2個のアクセスモードビット、又は00(これは、アクセスモードRWを表すので、DE及びEEレジスタをリセットさせる)の何れかを通すために使用されるからである。したがって、MX
1は次の通りである。
RPLロジックは、アキュムレータの上位16ビットだけを置換する。下位16ビットはそのまま通過する。しかし、(M[0−15]のうちの一つに対応する)MUからの32ビットのうちの、上位又は下位16ビットだけが使用される。したがって、MX
2はMHIとMLOを区別するためにCMD
0をテストする。
DEレジスタ及びEEレジスタを更新するロジックは、WRコマンドの擬似コードと一致する。AccessMode値が00(=RW、これはRPL
INIT中に出現する)である入力は、DEとEEの両方に0(正しい初期値)をロードさせることに注意する必要がある。EEはLogic
4からの結果がロードされ、DEはLogic
5からの結果がロードされる。
アキュムレータの上位16ビットはMへ書き込まれるべき値によって置き換えられる。したがって、Logic
6はWRコマンド擬似コードからのWEフラグと一致する。
Logic
6からの出力は、マルチプレクサMX
3による、アキュムレータからの元の16ビットと、M[0−15]からの値との間の選択を駆動するためそのまま使用される。アキュムレータからの16ビットが選択された場合(アキュムレータは変更されないで残される場合)、これは、アキュムレータ値がM[n]に書き込まれることを意味する。Mからの16ビット値が選択された場合(アキュムレータの上位16ビットを変更する場合)、これは、Mの16ビット値が変更されないことを意味する。したがって、MX
3は以下の形式をとる。
AMTをパリティチェックする意味はない。なぜならば、攻撃者はMX
3への入力を強制的に0にする方がよいからである(これにより、攻撃者は任意の値をMに書き込めるようになる)。しかし、攻撃者がチップ(全てタンパー検出テスト及び回路を含む)をレーザー切断する手間を選ぶならば、MX
3の入力を固定することにより制限選択テキスト攻撃を可能にさせるよりも優れたターゲットがある。
ROR
図191は、ALUのRORブロックの概略ブロック図である。RORユニットは、ALU内のコンポーネントである。RORユニットは、認証チップのROR機能を実現するため設計される。RTMPという名前の1ビットレジスタは、RORユニットに格納される。RTMPはリセットで0にクリアされ、ROR
RBコマンド及びROR XRBコマンド中にセットされる。RTMPレジスタは、任意のタップ構造をもつ線形フィードバックシフトレジスタの実装を可能にさせる。XORブロックは、2個の1ビット入力、1ビット出力のXORである。RORnは、ブロックが便宜上示されているが、実際には、マルチプレクサMX3に配線接続される。なぜならば、各ブロックは、単に、右へNビットシフトされた、32ビットの書き換えである。3個全てのマルチプレクサ(MX1、MX2及びMX3)は8ビットのCMD値に依存する。しかし、RORオペコードのビットパターンはロジック最適化の目的のために並べられる。オペランドのビットパターンを利用するので、このパターンを再度列挙する。
Logic
1は、RTMPにWriteEnable信号を与えるために使用される。RTMPレジスタは、ROR
RB及びROR XORコマンドの間だけ書き込まれるべきである。Logic
2は、InBitが使われたときならいつでも、制御信号を与えるために使用される。2個の組み合わせロジックブロックは次の通りである。
マルチプレクサMX
1を用いて、RTMPに格納されるビットを選択する。Logic
1は、予めRBとXRBの一方へのCMD入力の範囲を限定する。したがって、これらの二つを区別するため、CMD
0をテストするだけでよい。以下の表は、CMD
0とMX
1から出力される値との間の関係を表現する。
マルチプレクサMX
2を用いて、アキュムレータ入力のビット0を置換する予定の入力ビットを選択する。ここでは、少しの量の最適化を行う。なぜならば、個別の入力ビットは、典型的に、特定のオペランドに関係するからである。以下御表は、CMD
3−0とMX
2から出力される値との間の関係を表現する。
最後のマルチプレクサMX
3は32ビット値の最終的な回転を行う。再度、CMDオペランドのビットパターンが利用される。
MinTicksユニット
図192は、MinTicksユニットのコンポーネント間のデータフロー及び関係を示す図である。MinTicksユニットは、認証チップ内の鍵付きオペレーションの間のプログラマブル最小遅延(カウントダウンを利用)の役目を担う。MinTicksユニットに収容されるロジック及びレジスタは、両方のタンパー検出ラインによってカバーする必要がある。これは、攻撃者が鍵付きの関数への呼び出しの間の時間を変更できないことを保証する。殆ど全てのMinTicksユニットは通常のCMOSで実現可能である。なぜならば、鍵は、殆どのこのユニットを通らないからである。しかし、アキュムレータは、SET
MTR命令で使用される。その結果として、この回路のこの小さい区域は、ノンフラッシングCMOSで実現しなければならない。MinTicksユニットの残りの部分はノンフラッシングCMOSで実現しなくてもよい。しかし、MTRZラッチ(以下を参照)はパリティチェックしなければならない。
MinTicksユニットは、MTR(MinTicks残量(MinTicksRemaining))という名前の32ビットレジスタを含む。MTRレジスタは、次の鍵付き関数を読み出せるまでの残りクロックチック数を格納する。各サイクルに、MTRの値は、その値が0になるまで1ずつ減少させられる。MTRが0に達すると、それ以上減少しない。MTRZ(MinTicks残量レジスタ零MinTicksRegisterZero)という名前の補助的な1ビットレジスタは、MTRレジスタの現在の零性を反映する。MTRZレジスタが0である場合、MTRZは1であり、MTRZレジスタが0ではない場合、MTRZは0である。MTRレジスタはリセットによってクリアされ、SET
MTRコマンドを用いて新しいカウントにセットされ、アキュムレータの現在値をMTRレジスタへ転送する。
ここで、
サイクルはMTR及びMTRZのWriteEnableに接続されるので、これらのレジスタは実行サイクル中に、即ち、サイクル=1であるときに限り更新される。2個のVALユニットは、タンパー防止及び検出ラインに接続された検証ユニットであり、各VALはOKビットを含む。OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー検出ラインからのChipOK値とOR演算される。OKビットはそのユニットを通過する各データビットとAND演算される。VAL1の場合、MTRからの実効出力は0であり、これは、デクリメンターユニットからの出力が全て1であることを示し、これにより、MTRZは0のままであり、攻撃者が鍵付き関数を使用することは阻止される。また、VAL1は、MTRレジスタのパリティを検証する。パリティチェックが失敗した場合、消去タンパー検出ラインがトリガーされる。VAL2の場合、チップ改ざんされたならば、MTRZからの実効出力は0であり、MinTicksRemainingレジスタは未だ0に到達していないことを示し、これにより、攻撃者が鍵付き関数を使用することは阻止される。
プログラムカウントユニット
図192は、プログラムカウントユニットのブロック図である。プログラムカウントユニット(PCU)は、9ビットのPC(プログラムカウンタ)と、分岐及びサブルーチン制御用のロジックと、を含む。プログラムカウントユニットは、通常のCMOSで実現できる。なぜならば、鍵はこのユニットを通らないからである。このユニットはノンフラッシングCMOSで実現しなくてもよい。しかし、ラッチはパリティチェックされる。その上、メモリユニットに収容されたロジック及びレジスタは、PCが攻撃者によって変更できないことを保証するため、両方のタンパー検出ラインで覆う必要がある。PCは実際には6レベル×9ビットのPCA(PCアレイ)として実装され、3ビットのSP(スタックポインタ)レジスタによってインデックス付けされる。PC及びSPレジスタはリセットで全てクリアされ、オペコードに従ってプログラム制御のフロー中に更新される。PCの現在値は、サイクル0(フェッチサイクル)の間にMUへ出力される。PCは、実行されるコマンドに基づいてサイクル1(実行サイクル)の間に更新される。殆どのケースで、PCは単に1ずつ増加する。しかし、(サブルーチン、又はその他のジャンプの形式により)分岐が現れたとき、PCはあ多らしい値で置き換えられる。新しいPC値を計算するメカニズムは、処理されるオペコードに依存する。
ADDブロックはモジュロー29の単純なアダーである。入力は、PC値と、1(PCを1ずつ増加するため)、又は9ビットオフセット(ハイビットがセットされ、下位8ビットはMUから)の何れか一方である。“+1”ブロックは、3ビット入力を使用し、1ずつ増加する(ラップ付き)。“−1”ブロックは、3ビット入力を使用し、1ずつ減少する(ラップ付き)。種々のPC制御の形式は以下の通りである。
JSRとJSI(ACC)に対して同じ動作がとられるので、Logic
1でそのケースを具体的に検出する。同じ考え方によって、Logic
2でJSI
RTSを具体的にテストする。
PCを更新するとき、PCが完全に新しい項目によって置き換えられるべきか、又はアダーの結果によって置き換えられるべきかを決定しなければならない。これは、JSR及びJSI(ACC)の場合に成り立つが、テストビットがアキュムレータの状態と一致する限り、TBRにも成り立つ。TBR以外の全ては、Logic
1によってテストされるので、Logic
3はLogic
1の出力を入力として含む。Logic
3からの出力は、次に、新しいPC値を得るため、マルチプレクサMX
2によって使用される。
9ビットアダーへの入力は、1ずつ増加するか(普通のケース)、又はMUから読み出されたオフセットを加算するか(DBRコマンド)に依存する。Logic
4はtestを生成する。Logic
4からの出力は、これに応じてマルチプレクサMX
3によってそのまま使用される。
最後に、どのPCエントリーを使用するかについての選択は、SPの現在値に依存する。サブルーチンに入るとき、SPインデックス値はインクリメントされ、サブルーチンから戻るとき、SPインデックス値はデクリメントされる。全てのケースで、且つコマンドをフェッチしたいとき(サイクル0)、SPの現在値を使用する。Logic
1は、サブルーチンに入るときを通知し、Logic
2はサブルーチンから戻るときを通知する。マルチプレクサ選択は、したがって、以下のように定義される。
2個のVALユニットは、タンパー防止及び検出ラインに接続された検証ユニットであり、各VALはOKビットを含む。OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー検出ラインからのChipOK値とOR演算される。OKビットはそのユニットを通過する各データビットとAND演算される。両方のVALユニットは、データビットをパリティチェックし、それらが有効であることを保証する。パリティチェックが失敗した場合、消去タンパー検出ラインがトリガーされる。VAL
1の場合、SPレジスタからの実効出力は、チップが改ざんされたならば、常に0である。これにより、攻撃者がサブルーチンを実行することは阻止される。VAL
2の場合、実効PC出力は、チップが改ざんされたならば、常に0である。これにより、攻撃者がプログラムコードを実行することは阻止される。
メモリユニット
メモリユニット(MU)は、認証チップの内部メモリを含む。内部メモリは、9ビットのアドレスによってアドレス指定され、9ビットのアドレスはアドレス生成器ユニットから渡される。メモリユニットは、アドレスに応じて、適切な32ビット及び8ビット値を出力する。また、メモリユニットは、特殊なプログラミングモードを担い、これにより、プログラムがフラッシュメモリに入力される。メモリユニット全体の内容は、タンパーリングから保護されるべきである。したがって、メモリユニットに収容されたロジック及びレジスタは、両方のタンパー検出ラインによって覆われるべきである。これは、プログラムコード、鍵、及び中間データ値が攻撃者によって変更できないことを保証する。全てのフラッシュメモリは、マルチステートであり、無効電圧で読み出されたときにチェックしなければならない。32ビットRAMもパリティチェックされるべきである。メモリユニットを通る32ビットデータパスは、ノンフラッシングCMOSで実現できる。なぜならば、鍵はそのデータパスに沿って送られるからである。8ビットデータパスは、通常のCMOSで実現できる。なぜならば、鍵はそのデータパスに沿って送られないからである。
定数
定数メモリ領域のアドレスレンジは、000000000−000001111である。したがって、レンジは00000xxxxである。しかし、次の48アドレスが予備であるならば、これは復号化中に利用できる。定数メモリ領域は、アドレスの上位3ビット(Adr8−6=000)によって選択され、下位4ビットは組み合わせロジックへ供給され、その4ビットは、以下の通り、32ビット出力値にマッピングされる。
RAM
32エントリーの32ビットRAMのアドレス空間は、001000000−001011111である。したがって、レンジは0010xxxxxである。RAMメモリ領域は、したがって、アドレスの上位4ビット(Adr
8−5=0010)によって選択され、下位5ビットはアドレス指定する値を選択する。連続的な32エントリーのアドレス空間が与えられた場合、RAMは、単純な32×32ビットRAMとして簡単に実現できる。CPUは、特殊な方法でレンジ00000−11111からの各アドレスを取り扱うが、RAMアドレスデコーダ自体は、アドレスを特別に取り扱うわけではない。全てのRAM値はリセットで0にクリアされるが、プログラムコードはこのことを当てにしてはならない。
フラッシュメモリ−変数
32ビット幅フラッシュメモリのアドレス空間は、001100000−001111111である。したがって、レンジは0011xxxxxである。フラッシュメモリ領域は、したがって、アドレスの上位4ビット(Adr8−5=0111)によって選択され、下位5ビットはアドレス指定する値を選択する。フラッシュメモリは特別な消去が必要である。フラッシュメモリの消去を完了するためにはかなり長い時間を要する。したがって、Wait信号は、CLRコマンドの受信時にフラッシュコントローラの内部にセットされ、要求されたメモリが消去されたときに限りクリアされる。内部的に、特定のメモリレンジの消去ラインは一つに結合され、その結果として、以下の表に示されるように、2ビットだけが要求される。
フラッシュ値はリセットによって変更されないが、プログラムコードは、ガーベッジ以外では、(製造後に)フラッシュの初期値をとるべきではない。フラッシュアドレスを利用するオペレーションは、LD、ST、ADD、RPL、ROR、CLR及びSETである。全てのケースで、オペランド及びメモリ配置は、アドレス生成及び復号化を最小限に抑えるため、密接に連結される。フラッシュメモリの全変数区域は、プログラミングモードへ入ったとき、及び明確な物理的攻撃を検出したときに消去される。
フラッシュメモリ−プログラム
384エントリーの8ビット幅プログラムフラッシュメモリのアドレスレンジは、010000000−111111111である。したがって、レンジは01xxxxxxx−11xxxxxxxである。ROMスタートアドレスとアドレスレンジが与えられるならば、復号化は簡単である。CPUはアドレスレンジの一部を特殊は方法で取り扱うが、アドレスデコーダ自体はアドレスを特別に取り扱うわけではない。フラッシュ値はリセットによって変わらず、プログラムモードへ入ることによってのみクリアされる。製造後、フラッシュ内容はガーベッジであると見なされるべきである。384バイトは、プログラミングモードにあるときに限り、状態機械によってロードされる。
MUのブロック図
図193は、メモリユニットのブロック図である。図示されたロジックは、32ビットデータ及び8ビットデータが別々のコマンドによって要求され、その結果として、復号化のために必要なビットが少なくなるということを利用する。図示されるように、32ビット出力及び8ビット出力は常に生成される。認証チップの残りの適切なコンポーネントは、単に、実行されるコマンドに依存して、32ビット値又は8ビット値を使用する。マルチプレクサMX1は、真理表定数、RAM、及びフラッシュメモリの選択から出力された32ビットを選択する。3出力の間で選択するためには、2ビットだけが、即ち、Adr6及びAdr5が要求される。このようにして、MX2の形式は以下の通りである。
32ビットフラッシュメモリの特定の部分を消去するロジックはLogic
1によって満たされる。消去部分制御信号は、サイクル=1の間に、メモリの正しい部分へのCLRコマンド中に限りセットされるべきである。単一のCLRコマンドがあるレンジのフラッシュメモリをクリアすることに注意する必要がある。Adr
6はCLRのためのアドレスレンジとして十分である。なぜならば、レンジは、有効オペランドに対して常にフラッシュの範囲内に治まり、有効ではないオペランドに対して0である。32ビット幅フラッシュメモリのレンジ全体は、(攻撃者によって、又は意図的にプログラミングモードに入ることによって)消去検出ラインがトリガーされたときに消去される。
フラッシュメモリの特定の部分に書き込むためのロジックは、Logic
2によって満たされる。WriteEnable制御信号は、サイクル=1の間に、フラッシュメモリレンジへの適切なSTコマンド中に限りセットされるべきである。Adr
6−5だけのテストが許容される。なぜならば、STコマンドだけがフラッシュまたはRAMへ有効に書き込むからである(Adr
6−5が00であるならば、K2MXは0でなければならない。)。
WE(WriteEnable)フラグは、SET WEコマンドとCLR
WEコマンドの実行中にセットされる。Logic
3はこれらの二つのケースをテストする。WEに書き込まれる実際のビットはCMD
4である。
メモリのRAM領域へ書き込むためのロジックは、Logic
4によって満たされる。WriteEnable制御信号は、サイクル=1の間に、RAMメモリレンジへの適切なSTコマンド中に限りセットされる。しかし、これは、X[N]への書き込みが許可されるかどうかを管理するWEフラグによって改ざんされる。X[N]レンジはRAMの上位半分であり、これは、Adr
4を使用してテストできる。RAMのフルアドレスレンジとしてAdr
6−5だけをテストすることが容認できる。なぜならば、STコマンドはフラッシュ又はRAMだけに書き込むからである。
3個のVALユニットは、タンパー防止及び検出ラインに接続された検証ユニットであり、各VALはOKビットを含む。OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー防止及び検出ラインからのChipOK値とOR演算される。OKビットはそのユニットを通過する各データビットとAND演算される。VALユニットは、データビットをパリティチェックし、それらが有効であることを保証する。VAL
1及びVAL
2は、各データビットの状態をチェックすることにより検証し、VAL
3はパリティチェックを実行する。妥当性テストが失敗したとき、消去タンパー検出ラインがトリガーされる。VAL
1の場合、プログラムフラッシュからの実効出力は、チップが改ざんされているならば、常に0である(TBR
0として解釈される)。これは攻撃者が有用な命令を実行することを阻止する。VAL
2の場合、実効32ビットは、チップが改ざんされたならば、常に0である。これにより、攻撃者は、鍵、又は中間記憶値を入手できない。8ビットフラッシュメモリは、プログラムコード、ジャンプテーブル、及びその他のプログラム情報を保持するため使用される。384バイトのプログラムフラッシュメモリは、(アドレスレンジ01xxxxxxx−11xxxxxxxを使用して)完全な9ビットのアドレスにより選択される。プログラムフラッシュメモリは、(攻撃者によって、又はプログラミングモード検出ユニットが原因でプログラミングモードに入ることによって)消去検出ラインがトリガーされたときに限り消去される。消去検出ラインがトリガーされたとき、プログラムフラッシュメモリユニット内の小型状態機械は、8ビットフラッシュメモリを消去し、消去を検証し、シリアル入力から新しい内容(384バイト)にロードする。以下の擬似コードは、消去検出ラインがトリガーされたときに実効される状態機械ロジックを説明する:
プログラミングモード状態機械実行中に、0が8ビット出力にセットされる。0コマンドは、認証チップの残りの部分に、コマンドをTBR
0として解釈させる。チップが全部で384バイトをプログラムフラッシュメモリへ読み込んだとき、チップはハングする(無限ループに入る)。次に、認証チップはリセットされ、プログラムは正常に使用される。消去は、8ビットプログラムフラッシュメモリの新しい内容をロードするために使用される8ビットレジスタによって検証されることに注意すべきである。これは、攻撃が成功する見込みを低下させるために役立つ。なぜならば、プログラムコードは、消去を認証するため使用されるレジスタが攻撃者によって破壊された場合に、適切にロードされ得ないからである。更に、状態機械全体は、両方のタンパー検出ラインによって保護される。
アドレス生成器ユニット
アドレス生成器ユニットは、メモリユニット(MU)へアクセスするための実効アドレスを生成する。サイクル0において、PCは次のオペコードをフェッチするためMUへ渡される。アドレス生成器は、サイクル1の実効アドレスを生成するため、戻されたオペコードを解釈する。サイクル1において、生成されるアドレスはMUへ渡される。アドレス生成器ユニットに格納されたロジック及びレジスタは、両方のタンパー検出ラインによってカバーされる。これは、攻撃者が生成されたアドレスを変更し得ないことを保証する。殆ど全部のアドレス生成器ユニットは通常のCMOSで実現できる。なぜならば、鍵が殆どのこのユニットを通らないからである。しかし、アキュムレータの5ビットはJSIアドレス生成で使用される。この結果として、回路のこの小さい区域は、ノンフラッシングCMOSで実現される。アドレス生成器ユニットの残りの部分は、ノンフラッシングCMOSで実現しなくてもよい。しかし、カウンタ及び計算されたアドレスのラッチはパリティチェックされるべきである。タンパー検出ラインの何れかが破断しているならば、アドレス生成器ユニットは、各サイクルでアドレス0を生成し、全てのカウンタは0に確定される。これは、攻撃者がリセットを禁止状態にするか、及び/又は、消去回路を禁止状態にした場合に始めて効果がある。なぜならば、正常な状況下では、タンパー検出ラインの破断は、リセット又は全てのフラッシュメモリの消去を生じさせるからである。
アドレス生成の背景
アドレス生成用ロジックは、種々のオペコードとオペランドの組み合わせを調べることが必要である。オペコード/オペランドと、アドレスとの関係はこのセクションで検討され、アドレス生成器ユニットの基礎として使用される。
定数
下位4エントリーは、汎用用途、並びに、HMACアルゴリズムのための簡単な定数である。LDKオペランドの下位4ビットは、これらの4個の値、即ち、0000、0001、0010及び0011のメモリ内アドレスの下位3ビットにそのまま対応する。y定数及びh定数もLDKコマンドによってアドレス指定される。しかし、アドレスは、オペランドの下位3ビットをC1カウンタ値のインバースでOR演算し、そのままのオペランドの第4ビットを保持することによって生成される。このようにして、LDK
yの場合、yオペランドは0100であり、LDK hの場合、hオペランドは1000である。反転したC1値は、yに対して000−011の範囲にあり、hに対して、000−100の範囲にあり、OR演算結果は正確なアドレスを与える。全ての定数に対して、最終アドレスの上位5ビットは常に00000である。
RAM
変数A−Tは、それらのオペランド値の下位3ビットに直接関係したアドレスをもつ。即ち、LD、ST、ADD、LOG、及びXORコマンドのオペランド値0000−0101の場合、並びに、LOGコマンドのオペランド値1000−1101の場合、下位3ビットのオペランドアドレスビットは、最終アドレスを生成するため、001000の一定上位6ビットアドレスと共に使用される。残りのレジスタ値は、インデックス付きメカニズムによってアクセスできる。変数A−E、B160及びHは、C1カウンタ値によるインデックス付きとしてのみアクセス可能であり、Xは、N1、N2、N3及びN4によってインデックス付けされる。LD、ST及びADDコマンドの場合、C1によってインデックス付けされたAEのアドレスは、オペランドの下位3ビット(000)を取り、C1カウンタ値とOR演算することにより生成される。しかし、H及びB160のアドレスは、同じ方法では生成できない(そうでなければ、RAMアドレス空間は不連続になるであろう)。したがって、簡単な組み合わせロジックは、AEを0000に、Hを0110に、B160を1011に変換する。最終アドレスは、C1を4ビット値に加算し(4ビット値が得られる)、00100の一定上位5ビットアドレスを前に付加することによって得られる。最後に、レジスタのXレンジは、N1、N2、N3及びN4によるインデックス付きとしてのみアクセス可能である。XORコマンドの場合、インデックス付けのため任意のN1−4を使用可能であり、一方、LD、ST及びADDの場合、N4だけが使用可能である。LD、ST及びADDにおけるXのオペランドは、XN4オペランドと同じであるため、オペランドの下位2ビットは、使用すべきNを選択する。アドレスは、このようにして、00101の一定上位5ビット値と、選択されたNカウンタに由来する下位4ビットとして生成される。
フラッシュメモリ−変数
変数MT及びAMのアドレスは、関連したコマンドのオペランドから生成される。オペランドの4ビットはそのまま使用され(0110及び0111)、00110の一定上位5ビットアドレスが前に付加される。変数R1−5、K11−5、K21−5、及びM0−7は、C1カウンタ値のインバースによるインデックス付きとしてのみアクセス可能である(付加的には、Rの場合には実際のC1値による)。簡単な組み合わせロジックは、R及びRFを00000に、K1又はK2がアドレス指定されているかどうかに応じてKを01000又は11000に、M(MHI及びMLOを含む)を10000に変換する。最終アドレスは、C1を5ビット値とOR演算(又は加算)し(RFの場合には、C1をそのまま使用し)、0011の一定上位4ビットを前に付加することによって獲得される。変数IST及びISWは各々が1ビット値に過ぎないが、任意のビット数によって実装できる。データは、0x00000000又は0xFFFFFFFFの何れかとして読み書きされる。それらは、ROR、CLR及びSETコマンドだけによってアドレス指定される。RORの場合、オペランドの下位ビットは、00111111の一定上位8ビット値と合成され、IST及びISWに対して、それぞれ、0011111110及び001111111が得られる。なぜならば、他のRORオペランドはメモリを使用せず、IST及びISW以外の場合には、返された値は無視できるからである。SET及びCLRの場合、IST及びISWは、0011の一定上位4ビットをIST(0100)から11110へのマッピング、及びISW(0101)から11111へのマッピングと組み合わせることによりアドレス指定される。IST及びISWは、RAMからのE及びTと同じオペランド値を共有するので、同じ復号化ロジックを下位5ビットのため使用することが可能である。最終アドレスは、ビット4、3及び1がセットされることを要求する(これは、オペランド値010xのテストの結果にOR演算することより行われる)。
フラッシュメモリ−プログラム
プログラムフラッシュメモリ内でルックアップするためのアドレスは9ビットPC(サイクル0の場合)又は9ビットAdrレジスタ(サイクル1の場合)から直接もたらされる。TBR、DBR、JSR及びJSIのようなコマンドは、プログラムメモリ内の特定のアドレスでテーブルに記憶されたデータにしたがってPCを変更する。その結果として、アドレス生成は、一部の定数アドレスコンポーネントを利用し、コマンドオペランド(又はアキュムレータ)は実効アドレスの下位ビットを形成する。
アドレス生成器ユニットのブロック図
図194はアドレス生成器ユニットの概略ブロック図である。アドレス生成器ユニットからの一次出力は、以下の表に示されるように、マルチプレクサMX
1によって選択される。
CMDデータとMUからの8ビットを区別することが重要である:
サイクル0では、8ビットデータラインは、後のサイクル1で実行されるべき次の命令を保持する。この8ビットコマンド値は実効アドレスをデコードするため使用される。これに対して、CMDの8ビットデータは前の命令を保持するので、無視されるべきである;
サイクル1では、CMDラインは現在実行中の命令(サイクル0中に8ビットデータラインに保持されていた命令)を保持し、一方、8ビットデータラインは命令からの実効アドレスのデータを保持する。CMDデータはサイクル1中に実行されなければならない。
したがって、MU又はCMDからの9ビットデータの選択は、以下の表に示されるようにマルチプレクサMX3によって行われる。
9ビットAdrレジスタはサイクル0毎に更新されるので、AdrのWriteEnableは〜サイクルに接続される。カウンタユニットはカウンタC1、C2(内部的に使用される)と、選択されたNインデックスを生成する。その上、カウンタユニットは、プログラムカウンタユニットによって使用されるフラグC1Z及びC2Zを出力する。様々な*GENユニットは、サイクル0中に、特有のコマンドタイプのアドレスを生成し、マルチプレクサMX
2は、PC(即ち、8ビットデータライン)によってプログラムメモリから読み出されるようなコマンドに基づいてそれらの間で選択を行う。生成された値は以下の通りである。
マルチプレクサMX
2は以下の選択規準をもっている。
VAL
1ユニットは、タンパー防止及び検出回路に接続された検証ユニットである。それはOKビットを含み、OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー防止及び検出ラインからのChipOK値とOR演算される。OKビットは、使用可能前の9ビットの実効アドレスとAND演算される。チップが改ざんされているならば、アドレス出力は常に0であり、これにより、攻撃者はメモリの他の部分へのアクセスが妨げられる。VAL
1ユニットは、実効アドレスビットにパリティチェックを実行し、それらが改ざんされていないことを保証する。パリティチェックが失敗であるならば、消去タンパー検出ラインがトリガーされる。
JSIGEN
図195はJSIGENユニットの概略ブロック図である。JSIGENユニットはJSI
ACC命令のためのアドレスを生成する。実効アドレスは、単に、
JSIテーブル(0101)用のアドレスの4ビット上位部分と、
アキュムレータ値の下位5ビットと、
の連結である。
アキュムレータは他の時点(ジャンプアドレスが生成されないとき)で鍵を保持することがあるので、その値は秘匿されなければならない。その結果として、このユニットはノンフラッシングCMOSで実現される。マルチプレクサMX1は、単に、コマンドがJSIGENであるかどうかに基づいて、アキュムレータからの下位5ビット又は0の間で選択を行う。マルチプレクサMX1は以下の選択規準をもっている。
JSRGEN
図196はJSRGENユニットの概略ブロック図である。JSRGENユニットはJSR及びTBR命令のためのアドレスを生成する。実効アドレスは、単に、
JSRテーブル(0100)用のアドレスの4ビット上位部分と、
オペランドからのテーブル内のオフセット(JSRコマンド用の3ビットと、TBR用の3ビット+定数0ビット)と、
の連結からもたらされる。ここで、Logic
1は実効アドレスのビット3を生成する。このビットはJSRの場合にはビット3であり、TBRの場合には0である。
JSR命令はビット5に1があるので(これに対して、TBRはこのビットが0である)、これをビット3とAND演算することにより、JSRの場合にはビット3を生成し、TBRの場合には0を生成する。
DBRGEN
図197は、DBRGENユニットの概略ブロック図である。DBRGENユニットはDBR命令のためのアドレスを生成する。実効アドレスは、
DBRテーブル(011000)用のアドレスの6ビット上位部分と、
オペランドの下位3ビットと、
の連結からもたらされる。
LDKGEN
図198は、LDKGENユニットの概略ブロック図である。LDKGENユニットはLDK命令のためのアドレスを生成する。実効アドレスは、
LDKテーブル(00000)用のアドレスの5ビット上位部分と、
オペランドのハイビットと、
オペランドの下位3ビット(下位が定数の場合)、又はC1とOR演算されたオペランドの下位3ビット(インデックス付き定数の場合)と
の連結からもたらされる。
OR2ブロックは、C1の3ビットを、MUからの8ビットデータ出力からの下位3ビットとOR演算するだけである。マルチプレクサMX1は、オペランドの上位ビットがセットされているか、又はセットされていないかに基づいて、実際のデータビットと、C1がOR演算されたデータビットとの間で選択を行うだけである。マルチプレクサへのセレクタ入力は、簡単なORゲートであり、bit2をbit3とOR演算する。マルチプレクサMX1は以下の選択規準をもっている。
RPLGEN
図199は、RPLGENユニットの概略ブロック図である。RPLGENユニットはRPL命令のためのアドレスを生成する。K2MXが0であるとき、実効アドレスは定数000000000である。K2MXが1であるとき(Mからの読み出しが有効な値を返すことを示す)、実効アドレスは、
M(001110)用のアドレスの6ビット上位部分と、
C1の現在値の3ビットと、
の連結からもたらされる。
マルチプレクサMX1は、K2MXの現在値に基づいて、2個のアドレスの間で選択を行う。したがって、マルチプレクサMX1は以下の選択規準をもっている。
VARGEN
図200は、VARGENユニットの概略ブロック図である。VARGENユニットはLD、ST、ADD、LOG及びXOR命令のためのアドレスを生成する。K2MX
1ビットフラグは、Mからの読み出しが定数0アドレス(0を返すが、書き込み不可である)にマッピングされるか、オペランドがKを指定したとき、K1とK2のどちらがアクセスされるか、を決定するため使用される。4ビットアダーブロックは2組の4ビット入力をとり、モジュロー2
4の加法で、4ビットの出力を生成する。シングルビットレジスタK2MXは、CLR
K2MX命令、又はSET K2MX命令の実行中だけに書き込まれる。Logic
1は、これらの条件に基づいてK2MX
WriteEnableをセットする。
SET命令中にK2MX変数に書き込まれるビットは1であり、CLR命令中は0である。入力ビットのソースとして、オペコードの下位ビット(bit
4)を使用するのが好都合である。アドレス生成中に、組み合わせロジックとして実装された真理表は、以下の通り、ベースアドレスの一部を決定する。
真理表は5ビットの出力を生成するが、下位4ビットは4ビットアダーへ送られ、そこで、下位4ビットはインデックス値(C1、N又はオペランド自体の下位3ビット)に加算される。最上位ビットはアダーへ送られ、5ビット結果を生成するために、アダー結果からの4ビット結果の前に付加される。アダーへの第2の入力はマルチプレクサMX
1に由来し、マルチプレクサMX
1は、C1、N、及びオペランド自体の下位3ビットからインデックス値を選択する。C1は3ビットしかないが、4番目のビットは定数0である。マルチプレクサMX
1は以下の選択規準をもっている。
実効アドレスの第6ビット(bit
5)は、RAMアドレスの場合に0であり、フラッシュメモリアドレスの場合に1である。フラッシュメモリアドレスは、MT、AM、R、K、及びMである。bit
5の計算はLogic
2によって与えられる。
定数1ビットが表現され、実効アドレスは全部で7ビットになる。これらのビットは、K2MXが0でなく、命令がLD、ADD又はST
M[C1]ではない限り、実効アドレスを形成する。後者では、実効アドレスは定数アドレス0000000である。両方のケースで、2個の0ビットが最終的な9ビットアドレスを形成するため前に追加される。この計算は、以下に示され、Logic
3及びマルチプレクサMX
2によって行われる。
CLRGEN
図201は、CLRGENユニットの概略ブロック図である。CLRGENユニットはCLR命令のためのアドレスを生成する。実効アドレスは常に、有効メモリアクセスオペランド用のフラッシュメモリにあり、無効オペランドに対して0である。CLR
M[C1]命令は、(VARGENユニットに保持された)K2MXフラグの状態とは無関係に、常に、M[C1]を消去する。真理表は、単純な組み合わせロジックであり、以下の関係を実現する。
真理表に必要なロジックを削減することは簡単である。なぜならば、全部で4種類の主要なケースにおいて、実効アドレスの最初の6ビットは00であり、その後にオペランド(bit
3−0)が続く。
BITGEN
図202は、BITGENユニットの概略ブロック図である。BITGENユニットはROR及びSET命令のためのアドレスを生成する。実効アドレスは常に、有効メモリアクセスオペランド用のフラッシュメモリにあり、無効オペランドに対して0である。ROR及びSET命令は、IST及びISWフラッシュメモリアドレスだけにアクセスし(オペランドの残りはレジスタにアクセスする)、簡単な組み合わせロジック真理表はアドレス生成に十分である。
カウンタユニット
図Y37は、カウンタユニットの概略ブロック図である。カウンタユニットは、カウンタC1、C2(内部で使用)と、選択されたNインデックスと、を生成する。更に、カウンタユニットは、外部で使用するための出力フラグC1Z及びC2Zを出力する。レジスタC1及びC2は、DBR命令又はSC命令のターゲットであるときに更新される。オペランドのハイビット(実効コマンドのbit
3)は、C1とC2の間で選択を行う。Logic
1及びLogic
2は、それぞれ、C1及びC2のためのWriteEnableを判定する。
シングルビットフラグC1Z及びC2Zは、それらのマルチビットC1及びC2の対応した部分のNOR演算によって生成される。このようにして、C1Zは、C1=0のときに1であり、C2Zは、C2=0のときに1である。DBR命令中に、C1又はC2の何れかの値が1ずつデクリメントされる(ラップ付き)。デクリメンターユニットへの入力は、以下の通り、マルチプレクサMX
2によって選択される。
C1又はC2に書き込まれた実際の値は、DBR命令又はSC命令が実行されたかどうかに依存する。マルチプレクサMX
1は、デクリメンターからの出力(DBR命令用)と、真理表からの出力(SC命令用)との間で選択を行う。5ビット出力のうちの最下位3ビットだけがC1に書き込まれることに注意する必要がある。マルチプレクサMX
1は、したがって、以下の選択規準をもっている。
真理表は、SC命令を用いて、C1及びC2へロードされるべき値を保持する。真理表は、以下の関係を実現する簡単な組み合わせロジックである。
レジスタN1、N2、N3及びN4は、XOR命令によって参照されたとき、次の値−1(ラップ付き)によって更新される。レジスタN4は、ST
X[N4]命令が実行されるときにも更新される。LD及びADD命令はN4を更新しない。その上、全部で4個のレジスタはSET
Nxコマンド中に更新される。Logic
4−7は、レジスタN1からN4のWriteEnableを生成する。どれもがLogic
3を使用し、Logic
3は、コマンドがSET
Nxである場合に1を生成し、そうでなければ0を生成する。
送出された、又はデクリメンターへの入力として使用された実際のインデックス値は、マルチプレクサMX
4がオペランドの下位2ビットを使用して簡単に選択する。
インクリメンターは、(マルチプレクサMX
4によって選択された)入力値のうちの4ビットを取得し、1を加え、4ビット結果を生成する(モジュロー2
4の加法による)。最後に、マルチプレクサMX
3は4時点で、(N毎に異なり、SET
Nxコマンド中にロードされる)定数値と、(XOR又はST命令中の)デクリメンターの結果と、の間で選択を行う。その値は、適当なWriteEnableフラグがセットされている場合に限り書き込まれ(Logic
4−Logic
7を参照せよ)、Logic
3はマルチプレクサのために安全に使用できる。
SET Nxコマンドは、N1からN4に以下の定数をロードする。
参照される各初期X[Nn]は、最適化されたSHA−1アルゴリズムのインデックスN1からN4の初期状態と一致する。各インデックス値Nnがデクリメントするとき、実効X[N]はインクリメントする。その理由は、Xワードは最上位ワードから先にメモリに格納されているからである。3個のVALユニットは、タンパー防止及び検出回路に接続された検証ユニットであり、各VALはOKビットを含む。OKビットはリセットで1にセットされ、サイクル毎に両方のタンパー防止及び検出ラインからのChipOK値とOR演算される。OKビットはそのユニットを通過する各データビットとAND演算される。全てのVALユニットは、データビットをパリティチェックし、カウンタが改ざんされていないことを保証する。パリティチェックが失敗であるならば、消去タンパー検出ラインがトリガーされる。VAL
1の場合、カウンタC1からの実効出力は、チップが改ざんされているならば、常に0である。これは、攻撃者が鍵の最初から最後までインデックス付けをするループ構造を実行することを阻止する。VAL
2の場合、カウンタC2からの実効出力は、チップが改ざんされたならば、常に0である。これは、攻撃者がループ構造を実行することを阻止する。VAL
3の場合、Nカウンタ(N1−N14)からの実効出力は、チップが改ざんされているならば、常に0である。これは、攻撃者がXの最初から最後までインデックス付けをするループ構造を実行することを阻止する。
次に、図203を参照すると、フラッシュメモリ記憶装置701に格納された情報705が示されている。このデータには以下のものが含まれる。
工場コード
工場コードは、プリントロールが製造された工場を示す16ビットコードである。これは、プリントロールテクノロジーの所有者に属する工場、又は許可を得てプリントロールを製造する工場を識別する。この数値の目的は、品質の問題がある場合に、プリントロールの由来する工場を追跡できるようにすることである。
バッチ番号
バッチ番号は、プリントロールの製造バッチを示す32ビット番号である。この数値の目的は、品質の問題がある場合に、プリントロールの由来するバッチを追跡することである。
シリアル番号
48ビットシリアル番号は、最大で28兆個まで各プリントロールを一意に識別できるようにするため設けられる。
製造日
16ビット製造日は、有効期限が制限されている場合に、プリントロールの経年を追跡するため組み込まれる。
メディア長さ
ロール上に残っているプリントメディアの長さはこの数値によって表される。この長さは、ミリメータ、又はプリントロールを使用するプリンタ装置の最小ドットピッチのような小さい単位で表現され、周知のC、H及びPの各フォーマット、並びに、印刷されるその他のフォーマットで残り写真数の計算を可能にさせる。この小さい単位を使用することによって、プレ印刷されたメディアとの同期を保つために高解像度が使用できることを保証する。
メディアタイプ
メディアタイプデータはプリントロールに格納されているメディアを列挙する:
(1)透明
(2)乳白色
(3)不透明着色
(4)3次元レンチキュラー
(5)プレ印刷:長さ限定
(6)プレ印刷:非長さ限定
(7)金属箔
(8)ホログラフィック/光学的可変デバイス箔。
プレ印刷メディア長さ
例えば、プリントロールの裏面に収容されているプレ印刷メディアの繰り返しパターンの長さがここに保存される。
インク粘性
各インクカラーの粘性が8ビット数値として格納される。インク粘性数は、粘性を補償するためプリントヘッドアクチュエータ特性を調節する際に使用される(典型的に、粘性が高くなると、同じドロップボリュームを実現するためにはより長いアクチュエータパルスが必要になる)。
1200dpi用の推奨ドロップボリューム
各インクカラーの推奨ドロップボリュームは8ビット数値として格納される。最も適切なドロップボリュームは、インク及び印刷メディア特性に依存する。例えば、要求されるドロップボリュームは、色素濃度又は吸収性が増加すると減少する。また、透明メディアは乳白色メディアの約2倍のドロップボリュームを必要とする。なぜならば、光は、透明メディアの場合、色素層を1回しか通過しないからである。
プリントロールは、インクとメディアの両方を収容するので、顧客適合を実現することができる。ドロップボリュームは、推奨ドロップマッチに過ぎない。なぜならば、プリンタは1200dpiではないかもしれないし、また、プリンタは、印刷の明暗について調節されるかもしれないからである。
インクカラー
染料色の各々のカラーが格納され、印刷前に画像に適用されるデジタル中間調を精細調整するために使用できる。
残りメディア長さインジケータ
ロールに残っている印刷メディアの長さが数値によって表現され、カメラ装置によって更新される。長さは、C、H及びPの各フォーマット、並びに、印刷されるその他のフォーマットで残り写真数を計算できるように、小さい単位(例えば、1200dpiピクセル)で表現される。プレ印刷メディアとの同期を保つために高解像度を使用してもよい。
著作権又はビットパターン
この512ビットパターンは、保存されたフラッシュメモリの内容を著作権保護可能にするために十分なASCII文字列を表現する。
図204を参照すると、Artcam認証チップの記憶テーブル730が示されている。テーブルは、製造コード、バッチ番号、シリアル番号、及び日付を含み、上述のフォーマットと同じである。テーブル730は、更に、Artcam装置内のプリントエンジン上の情報731を含む。蓄積された情報は、プリンタエンジンタイプ、プリンタのDPI解像度、及びプリンタ装置によって作成されたプリント数のプリンタカウントを含む。
更に、認証テスト鍵710が設けられ、これは、チップとチップの間でランダムに変化し、上述のアルゴリズムにおけるArtcamランダム識別コードとしても利用される。128ビットのプリントロール認証鍵713も設けられ、これはプリントロール内に保存されたキーと同等である。次に、512ビットパターンが保存され、その後に、Artcamの利用に適した120ビットの予備エリアが続く。
上述のように、Artcamは、好ましくは、液晶ディスプレイ15を含み、液晶ディスプレイは、Artcamに格納されているプリントロールに残されたプリント数を示す。更に、Artcamは、3状態スイッチ17を含み、これにより、ユーザは、3種類の標準的なフォーマットC、H及びP(クラシック、HDTV及びパノラマ)を切り換えることが可能である。三つの状態間の切替後、液晶ディスプレイ15は、選択された特定のフォーマットが使用されるならば、プリントロールに残っている画像の枚数を反映するため更新される。
液晶ディスプレイを正しく動作させるため、Artcamプロセッサは、プリントロールを挿入し、認証テストに合格した後、プリントロールチップ53のフラッシュメモリ記憶装置から読み出し、用紙残量を判定する。次に、出力フォーマット選択スイッチ17の値がArtcamプロセッサによって判定される。プリント長さを、選択された出力フォーマットの対応した長さで除算することにより、Artcamプロセッサは、プリント可能数を判定し、残りプリント数で液晶ディスプレイ15を更新する。ユーザが出力フォーマット選択スイッチ17を変更すると、Artcamプロセッサ31は、そのフォーマットに応じて出力ピクチャーの数を再計算し、再度、LCDディスプレイ15を更新する。
プロセス情報をプリントロールテーブル705(図165)に保存することによって、Artcam装置はプロセスの変化、及びプリントロールのプリント特性の変化を利用することができる。
特に、プリントヘッド内の各ノズルに加えられたパルス特性は、プロセス特性の変化を考慮するために変更可能である。図205を参照すると、Artcamプロセッサは、補助メモリROMチップに記憶されたソフトウェアプログラムを動かすために適合し得る。ソフトウェアプログラムであるパルスプロファイルキャラクタライザ771は、プリントロールから多数の変数を読み出すことができる。これらの変数には、プリントロール772上の残りロールメディア、プリンタメディアタイプ773、インクカラー粘性774、インクカラードロップボリューム775、及びインクカラー776が含まれる。これらの変数の各々は、パルスプロファイルキャラクタライザによって読み出され、対応した最も適しているパルスプロファイルは、従来の試行錯誤法によって決定される。パラメータは、インク出力の安定性を高めるために、各プリンタノズルで受け取られるプリンタパルスを変更する。
明らかなように、認証チップは、重要かつ価値ある情報がプリンタロールと一体のプリンタチップに格納されている点で著しく進歩している。この情報は、対象となっているプリントロールのプロセス特性を、プリントロールのタイプ及びプリントロールに残っている用紙量と共に含む。
更に、プリントロールインタフェースチップは、貴重な認証情報を提供し、耐タンパー性の形で構築することが可能である。また、このチップを利用する耐タンパー性のある方法が提供される。プリントロールチップの利用は、Artcam装置の迅速な出力フォームのために便利かつ効率的なユーザインタフェースを提供することができ、多数の写真フォーマットを出力でき、同時に、印刷装置に残っている写真の数のインジケータを提供することができる。
プリントヘッドユニット
図206には、図162のプリントヘッドユニット615の分解斜視部分断面図が示されている。
プリントヘッドユニット615は、像を形成するように要求に応じてインクドロップをプリントメディア611へ噴射するプリントヘッド44が中心に置かれる。プリントメディア611は、第1セット618及び616と、第2セット617及び619からなる2組のローラーの間に挟まれている。
プリントヘッド44は電源、グランド、及び信号線810の制御下で動作し、電源、グランド、及び信号線810は、プリントヘッド44用の電源及び制御を提供し、テープ自動ボンディング(TAB)によってプリントヘッド44の表面に接合されている。
重要なことは、適当に分離されたシリコンウェハー装置から構築することができるプリントヘッド44は、一連の異方性エッチ812に依拠し、ウェハーを介して、ほぼ垂直な側壁を有する。ウェハーを貫通するエッチ812は、後で取り出すためウェハーの裏側からインクをプリントヘッド表面に直接供給することができる。
インクは、インクヘッド供給ユニット814を用いてインクジェットプリントヘッド44の裏側に供給される。インクジェットプリントヘッド44は、その表面に沿って、別々の色のインクを供給するため3つの別個の行をもつ。インクヘッド供給ユニット814は、インクチャンネルをシールする蓋815を含む。
図207から図210には、インクヘッド供給ユニット814の多数の斜視図が示されている。図207から図210の各々は、長さに制限のないインクヘッド供給ユニットの一部だけを示し、図示された部分は典型的な細部を示す。図207には、底側斜視図が示され、図148は上側斜視図を示し、図209は拡大斜視部分断面図を示し、図210はインクチャンネルの詳細を示す上側斜視図であり、図211は上側斜視図であり、図212も同様である。
インクヘッド供給ユニット814は、例えば、マイクロマシーン加工されたシリコンからではなく、射出成形プラスチックから形成する方がコスト的にかなり有利である。プラスチックインクチャンネルの製造コストは非常に低く、製造は十分に容易である。添付図面に示された設計は、所定の長さの1600dpiの3色モノリシックプリントヘッドを想定している。与えられた流速計算は、100mmフォトプリンタに対するものである。
インクヘッド供給ユニット814は、必要な精細部の全てを含んでいる。蓋815(図206)は、インクヘッド供給ユニット814に永久的に接着されるか、又は超音波溶接され、インクチャンネルのシールを提供する。
図209を参照すると、シアン、マゼンタ、イエローのインクが、インクインレット820−822に流入し、マゼンタインクはスルーホール824,825の中を流れ、マゼンタメインチャンネル826,827(図141)に沿って流れる。シアンインクは、シアンメインチャンネル830に沿って流れ、イエローインクはイエローメインチャンネル831に沿って流れる。図209に最もよく示されているように、シアンインクメインチャンネル内のシアンインクは、シアンサブチャンネル833に流れ込む。イエローサブチャンネル834は、同様に、イエローメインチャンネル831からイエローインクを受け取る。
図210の最もよく示されているように、マゼンタインクもマゼンタメインチャンネル826,827からマゼンタスルーホール836,837へ流れる。図209に戻ると、マゼンタインクはスルーホール836,837から流出する。マゼンタインクは、マゼンタサブチャンネル、例えば、838に沿って流れ、次に、第2のマゼンタサブチャンネル、例えば、839に沿って流れ、その後、マゼンタトラフ840に流入する。マゼンタインクは、次に、マゼンタバイア、例えば、842を流れ、マゼンタバイアは、対応したインクジェットヘッドスルーホール(例えば、図166の812)と整列させられ、それらは、次に、インクをプリントアウト用のインクジェットノズルへ供給する。
同様に、シアンサブチャンネル833内のシアンインクはシアンピットエリア849に流入し、それは、インクを二つのシアンバイア843,844に供給する。同様に、イエローサブチャンネル834は、イエローピットエリア46へ供給し、イエローピットエリアはイエローバイア847,848へ供給する。
図210に示されるように、プリントヘッドは、プリントヘッドスロット850に収容できるように設計され、種々のバイア、例えば、851は、プリントヘッドウェハー内で対応したスルーホール、例えば、851と揃えられる。
図206に戻ると、適切なインクがプリントヘッドチップ44の全体へ流れ、同時に、射出成形プロセスの制約を満たすように注意すべきである。プリントヘッドチップの裏側にあるインクスルーウェハーホール812のサイズは、約100μm×50μmであり、異なる色のインクを運ぶスルーホールの隙間は約170μmである。このサイズの形状は容易にプラスチック成形でき(コンパクトディスクはミクロンサイズの形状である)、理想的には壁の高さは、適当なスティフネスを維持するため、壁の厚さの数倍を超えてはならない。好適な実施形態は、少しずつ小さくなるインクチャンネルの階層構造を使用することによってこの問題を解決している。
図211には、プリントヘッド44の表面の小部分870が示されている。表面は、シアン系列871、マゼンタ系列872、及びイエロー系列873からなる3系列のノズルに分割される。ノズルの各系列は、更に、2列、例えば、875、876に分割され、プリントヘッド44は、電源及び制御信号を接合する接合パッド878の系列を含む。
プリントヘッドは、好ましくは、Artcam装置を含む用途のため創作された非常に多数のインクジェットの異なる形態に応じて構築される。これらのインクジェット装置は以下で詳述される。
プリントヘッドノズルは、図206の異方性エッチホール812と同等のインク供給チャンネル880を含む。インクは、ウェハーの裏側から、供給チャンネル881を通り、次に、フィルタグリル882を通り、インクノズルチャンバー、例えば、883へ流れる。ノズルチャンバー883及びプリントヘッド44(図1)の動作は、既に説明した通りであり、上述の特許明細書に記載されている。
インクチャンネル流体フロー解析
次に、インクフローの解析を説明すると、メインインクチャンネル826、827、830、831(図207、図141)は、約1mm×1mmであり、1色の全てのノズルに供給する。サブチャンネル833、834、838、839(図209)は約200μm×100μmであり、一つが約25のインクジェットノズルへ供給する。プリントヘッドスルーホール843、844、847、848及びウェハースルーホール、例えば、881(図221)は、100μm×50μmであり、プリントヘッドスルーホールのそれぞれの側で3個のノズルに供給する。各ノズルフィルタ882は8スリットを有し、各スリットは20μm×2μmの面積を有し、一つのノズルに供給する。
上記のように構成されたインクジェットプリンタの圧力必要条件の解析を行った。解析は、写真印刷用の1600dpiの3色プロセスプリントヘッドに対するものである。プリント幅は100mmであり、1色毎に6250のノズルがあり、全部で18750のノズルがある。
フルブラック印刷の場合に種々のチャンネルで必要な最大インク流速が重要である。これは、インクチャンネルに沿った圧力降下を決定し、したがって、プリントヘッドが表面張力だけで充満した状態を保つかどうか、保てない場合に、プリントヘッドを充満した状態に保つために必要なインク圧を決定する。
圧力降下を計算するため、1600dpi動作に対して2.5pIのドロップボリュームを利用した。ノズルはもっと高速に動作する能力を備えているが、選択されたドロップ繰り返しレートは5kHzであり、これは、150mm長さの写真を2秒以内に印刷するために適当である。このようにして、極端なケースでは、プリントヘッドは、18750ノズルを有し、すべてが毎秒最大5000ドロップで印刷をする。このインクフローは、インクチャンネルの階層構造全体に広がる。各インクチャンネルは、全てのノズルが印刷をしているとき、事実上、一定数のノズルに供給する。
圧力降下Δρは、Darcy−Weisbach式に従って計算した:
Δρ=ρU2fL/2D
ここで、ρはインクの密度であり、Uは平均流速であり、Lは長さであり、Dは水力直径であり、fは無次元摩擦係数であり、以下の式で計算した:
f=κ/Re
ここで、Reはレイノルズ数であり、κは、チャンネルの断面積に依存する無次元摩擦係数であり、以下の式で計算した:
Re=UD/ν
ここで、νはインクの運動学的粘性である。
矩形断面の場合、κは、
κ=64/(2/3+(11b/24a)(11b/24a)(2−b/a))
によって近似できる。
式中、aは矩形断面の長辺であり、bは短辺である。矩形断面に対する水力直径Dは、
D=2ab/(a+b)
によって与えられる。
インクは、チャンネルの長手方向の250点でメインインクチャンネルから抜かれた。インク粘性はチャンネルの先端から線形に降下し、チャンネルの終端で0まで降下するので、平均流速Uは最大流速の半分である。したがって、メインインクチャンネルに沿った圧力降下は、最大流速を用いて計算した圧力降下の半分である。
これらの式を利用して、圧力降下を計算することにより、次の表が得られた。
インクチャンネル寸法と圧力降下の表
インクインレットからノズルまでの総圧力降下は、したがって、シアン及びイエローに関して約701Paであり、マゼンタに関して845Paである。これは、大気圧の1%未満である。勿論、印刷された画像がフルブラック未満の場合、インクフロー(したがって、圧力降下)はこれらの値よりも低下するであろう。
インクヘッド供給ユニット用の金型製作
インクヘッド供給ユニット14(図1)は50μの外形と106mmの長さがある。射出成形ツールを従来の方法で加工することは実施不可能である。しかし、全体的な形状が複雑であるとしても、複雑な曲線は不要である。射出成形ツールは、メインインクチャンネル及びその他のミリメートルスケールの形状については従来のミリングを使用して製作可能であり、精細な形状はリソグラフ的に製作されたインセットを用いる。LIGAプロセスをインセットのために使用できる。
単一の射出成形ツールは、簡単に50以上のキャビティを含む。ツールの複雑さの殆どはインセットにある。
図206を参照すると、印刷システムはインク供給ユニット814及び蓋815を一体的に成形し、上述のようにそれらを一体的にシーリングする。次に、プリントヘッド44が対応したスロット850に設置される。粘着性シーリングストリップ852、853がマゼンタメインチャンネル上に置かれ、それらが適切にシールされることを保証する。テープ自動ボンディング(TAB)ストリップ810がインクジェットプリントヘッド44に接続され、タブボンディングワイヤはキャビティ855内に通る。図206、図207及び図212からよく分かるように、アパーチャスロット855から862は、ローラーの挿入の際のスナップのために設けられる。スロットは、ある程度の遊びをもってローラーを「クリッピングイン」し、次に、ローラーを容易に回転させる。
図213から図217には、最終的に組み立てられたArtcam装置の内部の様々な斜視図が示され、装置には適当な番号が付されている:
・図213は、Artcamカメラの内部の上面側の斜視図であり、平らにされた部品が示されている;
・図214は、Artcamカメラの内部の底面側の斜視図であり、平らにされた部品が示されている;
・図215は、Artcamカメラの内部の第1の上面側の斜視図であり、Artcamに収容された部品が示されている;
・図216は、Artcamカメラの内部の第2の上面側の斜視図であり、Artcamに収容された部品が示されている;
・図217は、Artcamカメラの内部の第2の上面側の斜視図であり、Artcamに収容された部品が示されている。
ポストカードプリントロール
図218を参照すると、好適な実施形態の一形態として、出力プリンタ用紙11は、画像が印刷されない面に、多数のプレ印刷された「ポストカード」型裏書き部分885を含む。ポストカード型セクション885は、プリペイド式郵便料金「スタンプ」886を含み、この「スタンプ」886は、関連した郵便当局からの印刷された認証により構成され、その当局の管轄区域内で、そのプリントロールが販売若しくは利用される。関連した管轄区域の郵便当局との合意によって、プリントロールは様々な郵便料金を利用できる。これは、特に、外国からの旅行者が国内の管轄内にいて、自国へ多数のポストカードを送る場合に便利である。更に、住所書式部分887が設けられ、通常のポストカードの形式で宛先発送の詳細を記入できる。最後に、メッセージ領域887が設けられ、私信を記入することができる。
図218及び図219を参照して、カメラ装置の動作を説明すると、一連の画像890から892がプリントロールの第1面に印刷されたときの、対応した裏書き面が図218に示されている。したがって、各画像、例えば、891がカメラによって印刷されると、画像の裏面は、既にポストカード885になっているので、直ちに、管轄区域内の最も近い郵便ポストへ投函することができる。このように、パーソナル化されたポストカードを作成することができる。
図219及び図220に示されるようなポストカードシステムを利用するとき、予め定められた画像サイズだけが可能であることは明白である。なぜならば、裏面のポストカード部分885と、表面の画像891との対応関係を維持しなければならないからである。これは、各ポストカードの裏書き書式シート885の長さの詳細を記憶するためプリントロール内に収容された認証チップのメモリ部分を利用することによって実現される。これは、各ポストカードのサイズを同じサイズにすること、又はそれぞれのサイズをプリントロールのオンボードプリントチップメモリに格納することによっても実現される。
Artcamカメラ制御システムは、予め書式化されたポストカードを利用するとき、プリントロールは、各画像がポストカードの境界に収まるように画像を印刷するためだけに使用されることを保証することができる。勿論、多少の位置合わせ誤差を考慮できるように境界領域を各写真のエッジに設けることによってある程度の「遊び」が与えられる。
図220から明らかであるように、ポストカードロールは、それを利用可能な特定の管轄区域内に旅行するとき、カメラユーザが事前に購入できる。ポストカードロールは、その外面に、購入国、各ポストカードの郵便料金、各ポストカードのフォーマット(例えば、C、H、P、又はこれらの画像モードの組み合わせ)、使用するのに適した国名、及びその日以降に郵便料金が不足になるかもしれない郵便料金期限を含む情報が印刷されている。
したがって、カメラ装置のユーザは、関連したシーンに向けられた自分のハンドヘルドカメラを利用して、写真を撮影して、その画像が一方の面に掲載され、もう一方の面にはプリペイド式ポストカードの詳細が記載されている郵便で発送するためのポストカードを製作することが可能である。次に、このポストカードに宛先を指定し、短いメッセージを記入し、その後、直ぐに郵便で発送することができる。
Artcam装置のソフトウェア動作に関して、種々のソフトウェア設計が可能であるが、ある設計では、各Artcam装置は、1組の緩く結合した機能モジュールにより構成され、これらの機能モジュールは、一つの埋め込み型アプリケーションによって連係した形で利用できるようにされ、装置の中心目的のために機能する。機能モジュールは、様々なクラスのArtcam装置において、異なる組み合わせで再使用され、アプリケーションはArtcamのクラスに特有である。
殆どの機能モジュールは、ソフトウェアとハードウェアの両方のコンポーネントを含む。ソフトウェアは、ハードウェア抽象化レイヤによって、ハードウェアの細部からシールドされ、一方、モジュールのユーザは、抽象化ソフトウェアインタフェースによってソフトウェアインプリメンテーションからシールドされている。システムは、全体として、ユーザ始動、及びハードウェア始動のイベントによって駆動されるので、殆どのモジュールは、一つ以上の同期的なイベント駆動型プロセスを動かすことができる。
一般的なArtcam装置を構成する殆どの重要なモジュールが図221に示されている。同図及びその後の図には、ソフトウェアコンポーネントが左側にsめされ、垂直点線901によって右側のハードウェアコンポーネントから分離されている。これらのモジュールのソフトウェアの面を次に説明する。
ソフトウェアモジュール−Artcamアプリケーション902
ArtcamアプリケーションはArtcam装置の上位レベル機能を実現する。これは、通常、像の撮影、像に対する芸術的効果の適用、及び像の印刷を含む。カメラ指向のArtcam装置の場合、画像は、カメラマネージャ903によって捕捉される。プリンタ指向のArtcam装置の場合、画像は、ネットワークマネージャ904によって捕捉され、おそらく、この画像は他の装置によって送出された結果物である。
芸術的効果は、ファイルマネージャ905によって管理される統合ファイルシステム内で行われる。芸術的効果は、スクリプトファイルとリソースのセット途により構成される。スクリプトは、画像処理マネージャ906によって翻訳され、画像に適用される。スクリプトは、通常、Artcardとして知られているArtCardsで出荷される。デフォルトとして、システムは、現在搭載されているArtcardに格納されているスクリプトを使用する。
画像はプリントマネージャ908によって印刷される。
Artcam装置がスタートアップしたとき、ブートストラッププロセスが、アプリケーションを開始する前に種々のマネージャプロセスを始動する。これにより、アプリケーションは、スタートしたときに、直ちに様々なマネージャからのサービスを要求できる。
初期化後、アプリケーション902は、それ自体を以下に列挙されたイベントのハンドラーとして登録する。アプリケーションはイベントを受け取ったとき、表に記載された動作を実行する。
カメラがディスプレイを含むとき、アプリケーションはユーザインタフェースマネージャ910によってグラフィカルユーザインタフェースを構築し、ユーザは現在日時、及びその他の編集可能なカメラパラメータを編集できるようになる。アプリケーションは、全ての常駐パラメータをフラッシュメモリに保存する。
リアルタイムマイクロカーネル911
リアルタイムマイクロカーネルは、割込とプロセス優先順位に基づいて、予めプロセスをスケジューリングする。それは、プロセススケジューリングに非常に密接している統合プロセス間通信及びタイマーサービスを提供する。全ての他のオペレーティングシステム機能はマイクロカーネルの外部で行われる。
カメラマネージャ903
カメラマネージャは、画像捕捉(撮像)サービスを提供する。それは、Artcamに組み込まれたカメラハードウェアを制御する。それは、抽象的カメラ制御インタフェースを提供し、カメラパラメータの問い合わせ及び設定、画像捕捉を可能にさせる。この抽象的インタフェースは、アプリケーションを他のカメラインプリメンテーションの細部から切り離す。カメラマネージャは以下の入力/出力パラメータ及びコマンドを利用する。
カメラマネージャは、非同期イベント駆動型プロセスとして動く。それは、連結された状態機械の組を含み、各状態機械は一つの非同期オペレーションに対応する。それらは、オートフォーカス、フラッシュ充電、セルフタイマのカウントダウン、及び像の撮影を含む。初期化時、カメラマネージャはカメラハードウェアを既知状態にセットする。これは、通常の焦点距離の設定、及びズームの戻しを含む。カメラマネージャのソフトウェア構造は、図222に示されている。ソフトウェアコンポーネントは以下のサブセクションに記載されている。
フォーカス固定913
ロックフォーカスは、フォーカス制御モード、露出制御モード、及びフラッシュモードに応じて、現在シーンに対して自動的にフォーカスと露出を調整し、必要に応じてフラッシュを動作可能状態にする。ロックフォーカスは、通常、ユーザが撮影ボタンを半押しすることによって始動される。これは、正常な像撮影シーケンスの一部であるが、ユーザが撮影ボタンを半押しのままにした場合、時間的に、実際の像の撮影からは分離される。これは、ユーザがスポットフォーかシング及びスポット測距をできるようにする。
撮影914
撮影(像捕捉)は、現在シーンの像を撮影する。フラッシュモードがレッドアイ除去を含む場合、レッドアイランプを点灯し、シャッターを制御し、動作可能状態であれば、フラッシュをトリガーし、イメージセンサによって像を検知する。それは、カメラの向き、即ち、撮影像の向きを判定し、これにより、後の画像処理で、像は適切に向きを決められる。また、それは、後の画像処理中にブラーを取り除くため、撮像中にカメラの動きの有無を検出する。
セルフタイム撮影915
セルフタイム撮影は、20秒タイマーのカウントダウン後に、現在シーンの像を撮影する。これは、カウントダウン中に、セルフタイマーLEDを用いて、ユーザにフィードバックを与える。最初の15秒間に、それは、LEDを点灯できる。最後の5秒間にLEDは点滅する。
ビューシーン917
ビューシーンは、周期的に、イメージセンサを通して現在シーンを検知し、そのシーンをカラーLCDに表示させ、ユーザにLCDベースのビューファインダーを提供する。
オートフォーカス918
オードフォーカスは、像の選択された領域が焦点が合っていると言えるまで十分に鮮明になるまで、焦点距離を変化させる。それは、イメージセンサの指定された領域から抽出された画像鮮明さメトリックが固定の閾値を超えた場合に領域の焦点が合うということを前提とする。それは、鮮明さの微分に関する勾配降下法を実行し、必要に応じて方向及びステップサイズを変えることによって、最適焦点距離を見つける。焦点制御モードがマルチポイントオートであるならば、視野全体に水平に配置された3個の領域が使用される。焦点制御モードがシングルポイントオートであるならば、視野の中心にある一つの領域が使用される。オートフォーカスは、フォーカスコントローラによって指定された有効焦点距離の範囲内で機能する。固定焦点装置の場合、これは、事実上、無効にされる。
オートフラッシュ919
オートフラッシュは、シーンの照度がフラッシュを必要とする程度に薄暗いかどうかを判定する。これは、シーンの照度が所定の閾値以下であるならば、照度が十分に薄暗いとみなす。シーンの照度は、照度センサから獲得され、照度センサはイメージセンサの中央領域から照度メトリックを抽出する。フラッシュが必要であれば、フラッシュを充電する。
自動露出920
シーン照度、絞り、および、シャッター速度は、撮影像の露出を決定する。望ましい露出は固定値である。露出制御モードがオートであるならば、自動露出は、所定のシーン照度に対して望ましい露出を生じる絞りとシャッター速度の組み合わせを決定する。露出制御モードが絞り優先であるならば、自動露出は、所定のシーン照度及び現在の絞りに対して望ましい露出を生じるシャッター速度を決める。露出制御モードがシャッター優先であるならば、自動露出は、所定のシーン照度及び現在のシャッター速度に対して望ましい露出を生じる絞りを決める。シーン照度は照度センサから取得され、照度センサはイメージセンサの中央領域から照度メトリックを抽出する。
自動露出は、絞りコントローラ及びシャッター速度コントローラによって指定された有効絞り及びシャッター速度の範囲内で機能する。シャッター速度コントローラ及びシャッターコントローラは、殆どのArtcam装置では機械的シャッターの無いことを隠す。
フラッシュが、マニュアル又はオートで有効にされている場合、実効的なシャッター速度はフラッシュの間隔であり、これは、典型的に、1/1000秒から1/10000秒である。
画像処理マネージャ906(図221)
画像処理マネージャは、画像処理と芸術的効果サービスを提供する。これは、高速画像処理を実行するためArtcamに組み込まれたVLIWベクトルプロセッサを利用する。画像処理マネージャは、Vark画像処理言語で記述されたスクリプト用のインタープリタを具備する。したがって、芸術的効果は、Varkスクリプトファイルと、フォント、クリップ画像のような関連したリソースと、を含む。画像処理マネージャのソフトウェア構造は図223により詳細に示され、以下のモジュールを含む。
画像の変換及び強調921
画像処理マネージャは、装置に依存しないCIE LAB色空間において、Artcamプリンタハードウェアの生成能力に適した解像度で、画像処理を実行する。撮影された像は、最初に、ノイズをフィルタ処理して強調される。それは、オプションとして、動きによって生じたブラー効果を取り除くために行われる。画像は、次に、装置に依存したRGB色空間から、CIE
LAB色空間へ変換される。像は、撮影時のカメラ回転の影響を相殺するため回転させられ、作業用画像解像度へスケール変換される。画像は、そのダイナミックレンジを利用可能なダイナミックレンジへスケーリングすることによって強調される。
顔検出923
顔は、色相及び局部的特徴解析に基づいて撮影された像内で検出される。検出された顔領域のリストは、ワーピング及び吹き出しの配置のような顔専用効果を適用するためVarkスクリプトによって使用される。
Vark画像処理言語インタープリタ924
Varkは、豊富な画像処理のセットで拡張された汎用プログラミング言語を含む。それは、プリミティブデータタイプの範囲(整数、実数、ブール、文字)、より複雑なタイプを構築するための集合データタイプの範囲(配列、文字列、レコード)、算術演算及び論理演算の豊富な組、条件付き及び反復制御フロー(if−then−else、while−do)、及び再帰的関数及び手続を提供する。また、それは、画像処理データタイプの範囲(画像、クリップ画像、マット、カラー、カラールックアップテーブル、パレット、ディザ行列、コンボリューションカーネル、等)、グラフィックデータタイプ(フォント、テキスト、パス)、画像処理関数の組(カラー変換、コンポジット処理、フィルタ処理、空間変換及びワーピング、イルミネーション、テキスト設定及びレンダリング)、及び上位レベルの芸術的関数の組(タイリング、ペインティング、及びストローキング)を提供する。
Varkプログラムは二つの意味でポータブルである。それは、インタープリットされるので、CPU及びホストの画像処理エンジンに依存しない。装置に依存しないモデル空間及び装置に依存しない色空間を使用するので、それは、入力色特性、ホスト入力装置の解像度、出力色特性、及びホスト出力装置の解像度に依存しない。
Varkインタープリタ924は、Varkスクリプトを構成するソースステートメントを解析し、そのスクリプトの意味を表現するパースツリーを生成する。パースツリーのノードは、プログラムのステートメント、エクスプレッション、サブエクスプレッション、変数、及び定数に対応する。ルートノードはメインプロシジャーステートメントリストに対応する。このインタープリタは、パースツリーのルートステートメントを実行することにより、プログラムを実行する。パースツリーの各ノードはその子にそれ自体を適切に評価又は実行するように要求する。例えば、ifステートメントノードは、条件表現ノードと、thenステートメントノードと、elseステートメントノードの三つの子を持つ。ifステートメントは、条件表現ノードに、それ自体を評価し、返されたブール値に基づいて、thenステートメント又はelseステートメントにそれ自体を実行させる。それは、実際の条件表現又は実際のステートメントは知らない。
殆どのデータタイプの演算はパースツリーの実行中に行われるが、画像データタイプの演算は、パースツリーの実行後まで、延期される。これにより、画像演算が最適化され、最終的な画像に寄与する中間画素だけが計算される。これは、最終画像を、空間細分によって多数のパスで計算することを可能にさせ、これにより、必要なメモリ量を減少させる。
パースツリーの実行中に、各画像関数は画像グラフを返すだけであり、この画像グラフは、ノードが画像オペレータを表し、リーフが画像を表すものであり、対応した画像オペレータをルートとし、その画像パラメータをルートの子とすることによって構築される。画像パラメータは勿論それ自体が画像グラフである。このようにして、それぞれの逐次的な画像関数は、より深い画像グラフを返す。
パースツリーの実行後、最終画像に対応した画像グラフが得られる。この画像グラフは、次に、(任意の表現ツリーと同じように)深さ優先方式で実行され、以下の2点で最適化される。(1)最終画像に寄与する画素だけが所定のノードで計算される。(2)ノードの子は、メモリ必要量を最小限に抑える順番で実行される。画像グラフ中の画像オペレータは、最終画像を生成するために最適化された順序で実行される。計算集約的な画像オペレータは、Artcam装置に組み込まれたVLIWプロセッサを使用して加速される。画像グラフを実行するために必要なメモリ量が利用可能なメモリを超えたとき、最終画像領域は、必要なメモリが利用可能なメモリを超えなくなるまで細分される。
巧く構築されたVarkプログラムの場合、最初の最適化は特に大きな効果があるとは思えない。しかし、最終画像領域が細分された場合、最適化はかなりの効果を生ずる可能性がある。細分化がメモリ必要量を減少させる効果的な技術として使用することができることが、まさにこの最適化である。画像オペレーションの実行を遅らせることの結果の一つは、プログラム制御フローを画像内容に依存させられないことである。なぜならば、画像内容はパースツリー実行中には分からないからである。実際上、これはそれほど制約にはならないが、それにもかかわらず、言語設計中には注意しなければならない。
画像オペレーションの延期実行(又は遅延評価)の考え方については、Guibas
and Stolfiによって記載されている(Guibas,
L.J,., and J.Stolfi, ''A Language for Bitmap Manupulation'',ACM Transactions
on Graphics,Vol.1,
No.3,July 1982,
pp.191−214)。彼らは、プログラムの実行中に同様に画像グラフを構築し、後続のグラフ評価中に、最終画像に寄与しない画素の計算を回避するため、結果領域を逆伝搬させる。Shantzisは、更に、利用可能な画素を画像グラフ評価中に前方へ伝搬させる(Shantzis,
M.A.,''A Model for Efficient and
Flexible
Image Computing'', Computer Graphics Proceedings, Annual
Conference
Series, 1994,pp.147−154)。Varkインタープリタは、Cameronによって提案された、より洗練されたマルチパス型ビットディレクショナル領域伝搬スキームを使用する(Cameron,
S.,''Efficient
Bounds in
Constructive
Solid Geometry'', IEEE Computer Graphics & Appkications,
Vol.11, No.3,
May
1991, pp.68−74)。メモリ使用量を最小限に押させるため実行順序を最適化する方法は、Shantzisに由来するが、標準的なコンパイラ理論に基づいている(Aho,
A. V.,
R. Sehi,
and J.D.
Ullman,
''GeneratingCode from DAGs'', in Compilers: Principles, Techniques,
and Tools,
Addison−Wesley, 1986, pp.557−567)。Varkインタープリタは、Shantzisよりも洗練されたスキームを使用するが、可変サイズ画像バッファをサポートする。メモリ使用量を減少させるため、領域伝搬と組み合わせて結果領域を細分することは、Shantzisに由来している。
プリンタマネージャ908(図221)
プリンタマネージャは画像プリンティングサービスを提供する。それは、Artcamに組み込まれたインクジェットプリンタハードウェアを制御する。それは、抽象的プリンタ制御インタフェースを提供し、プリンタパラメータの問い合わせと設定を可能にさせ、画像を印刷される。この抽象的インタフェースは、アプリケーションをプリンタインプリメンテーションの詳細から切り離し、以下の変数を含む。
プリンタマネージャは非同期イベント駆動型プロセスとして実行される。それは、連結された状態機械の組を含み、各状態機械は一つの非同期オペレーションに対応している。これらは、画像を印刷し、プリントロールを自動マウントする。プリンタマネージャのソフトウェア構造は図224に示されている。ソフトウェアコマンドは後述される。
プリントイメージ930
プリントイメージは供給された画像を印刷する。これは、印刷用の画像を準備するためVLIWプロセッサ回路を使用する。VLIWプロセッサ回路は、画像色空間を装置固有CMYに変換し、プリントヘッドで期待されるフォーマットで中間調バイレベルデータを生成する。
プリントの間に、プリントロールを取り外すことができるように、用紙はプリントロールのリップに引き込まれ、ノズルはインク漏れ及び乾燥を防ぐためにキャップを被せることができる。実際の印刷がスタートする前に、従って、ノズルはキャップを取り外され、きれいにされ、用紙はプリントヘッドへ進められる。印刷自体は、画像が完全に印刷されるまで、VLIWプロセッサからラインデータを転送し、ラインデータを印刷し、用紙を進める。印刷の終了後、用紙は裁断機で切断され、プリントロールに引き込まれ、ノズルにキャップが被せられる。残りメディア長さはプリントロールで更新される。
プリントロール自動マウント131
プリントロール自動マウントは、プリントロールの装着と取り外しに応答する。それは、プリントロールの装着と取り外しのイベントを生成し、このイベントは、アプリケーションによって処理され、状態表示を更新するため使用される。プリントロールは、プリントロールに組み込まれた認証チップと、Artcamに組み込まれた認証チップとの間でプロトコルに従って認証される。プリントロールが認証を失敗した場合、プリントロールは拒絶される。種々の情報がプリントロールから抽出される。用紙及びインク特性は、印刷プロセス中に使用される。残りメディア長さ及びメディアの固定ページサイズは、いずれにしても、プリントマネージャにより公表され、アプリケーションによって使用される。
ユーザインタフェースマネージャ910(図221)
ユーザインタフェースマネージャは図225により詳細に示され、ユーザインタフェース管理サービスを提供する。それは、状態表示及び入力ハードウェアを制御し物理的ユーザインタフェースマネージャ911と、カラーディスプレイ上の仮想グラフィカルユーザインタフェースを管理するグラフィカルユーザインタフェースマネージャ912と、を含む。ユーザインタフェースマネージャは、仮想及び物理的入力をイベントに翻訳する。各イベントはそのイベントのために登録されたプロセスのイベントキュー入れられる。
ファイルマネージャ905(図222)
ファイルマネージャは、ファイルマネージメントサービスを提供する。それは、統合階層ファイルシステムを提供し、その中では、全てのマウントされたボリュームのファイルシステムが現れる。Artcamで使用される一次着脱式記憶媒体はArtCardである。Artcardは、2値のドットのブロックによって高解像度で印刷され、2値のドットのブロックは、誤差を許容するリード・ソロモン符号化2値データを直接表現する。ブロック構造は、(Artcamで初期には使用されていない)適当なリード−ライトArtCard装置における追記及び追記−書き換えをサポートする。より高いレベルでは、ArtCardは、拡張型追記−書き換え可能ISO9660準拠CD−ROMファイルシステムを含み得る。ファイルマネージャのソフトウェア構造、及び特に、ArtCard装置コントローラは、図226に示されている。
ネットワークマネージャ904(図222)
ネットワークマネージャは、赤外線(IrDA)及び汎用シリアルバス(USB)を含む様々なインタフェース上での家電製品ネットワーキングサービスを提供する。これは、Artcamシステムが撮影された画像を共有し、印刷のための画像を受信できる。
クロックマネージャ907(図222)
クロックマネージャは日付及び時刻のクロックサービスを提供する。それは、Artcamに組み込まれたバッテリバックアップ型リアルタイムクロックを利用し、ユーザが時刻をセットしたときに実行される自動キャリブレーションに基づいて、クロック変動を自動的に調節する程度までそれを制御する。
パワーマネージメント
システムが使用されていないとき、システムは、入力イベントの周期的走査が行われる休止電力状態に入る。入力イベントは、ボタンの押下、又はArtCardの挿入を含む。入力イベントが検出されると直ぐに、Artcam装置は、動作電力状態に戻る。その後、システムは入力イベントをいつもの通りに取り扱う。
システムが動作電力状態であるときでさえ、個々のモジュールに関連したハードウェアは、典型的に窮し電力状態にある。これは、全体的な電力消費を削減し、プリンタの用紙切断機のような特に浪費のもとになるハードウェアコンポーネントが動作中に電源を独占できるようする。カメラ指向のArtcam装置は、デフォルトで、画像撮影モードである。即ち、カメラは動作状態であり、プリンタのような他のモジュールは休止状態である。つまり、カメラ以外の機能が始動されたとき、アプリケーションはカメラモジュールを明白に一時停止させなければならない。他のモジュールは、待機状態になると、自発的に一時停止する。
ウォッチドッグタイマー
システムは、周期的な優先度の高いウォッチドッグタイマー割込を生成する。割込ハンドラーは、システムが最後の割込以降、進んでいない、即ち、システムが故障していると判断した場合、システムをリセットする。
代替プリントロール
他の一実施形態では、適切に簡単に一つにはめ込まれた射出成形プラスチック部品によって大部分を構築することができる改良された形態のプリントロールが提供される。改良された形態のプリントロールは、多少構造が単純化されると共に、インク貯蔵容量が増加している。画像が印刷されるべきプリントメディアは、構造を簡単化するため、プラスチック製スリーブフォーマーの周りに巻き付けられる。インク媒体リザーバは、インクが流れ出る可能性ができるだけ少なくなる構造にされた一連の通気孔を有する。更に、ラバーシールがインク出口孔に設けられ、ラバーシールはプリントロールをカメラシステムに挿入する際に穿刺される。更に、プリントロールは、プリントメディア排出スロットを含み、排出スロットは周囲に成形された表面を有し、その表面は、プリントメディア放出スロットが、印刷又はカメラシステム内のプリントヘッドに対して正確な位置に置かれるように補助する。
次に、図227から図231を参照すると、図227には、組み付けられた形式のシングルポイントロールユニット1001が示され、部分的に切断されてプリントロールの内部が表されている。図228及び図229は、それぞれ、左側及び右側の分解斜視図である。図230及び図231は図227から図229の内部コア部1007の拡大斜視図である。
プリントロール1001は、内部インク補充部を含む内部コア部1007の周りに構築される。コア部1007の外側にはフォーマー1008が設けられ、フォーマーの周りに、用紙又はフィルム補給品1009が巻き付けられる。用紙補給品の周りには、二つのカバー部品1010、1011が設けられ、プリントロールの周りで一体としてスナップ式に留まり、図227に示されるようにカバーユニットを形成する。下側カバー部品1011はスロット1012を含み、そのスロットを通って、プリントメディア1004の出力がカメラシステムと相互連結する。
二つのピンチローラー1038、1039が用紙を駆動ピンチローラー1040に圧迫するため設けられるので、それらは、一体として、ローラー1040の周りで用紙のカールを取り去る。このカールの取り除きは、長期間に亘ってプリントロールの形で蓄えられている用紙に加わる強いカールを打ち消すように作用する。ローラー1038、1039は、カバーベース部1077の端部及びローラーとスナップ式にフィットするため設けられ、ローラー1040は、駆動用の歯車付きの端部1043を含み、上側カバー部品1010とスナップ式にフィットし、用紙1004を間でしっかりと締め付ける。
カバー部品1011は、端部隆起又はリップ1042を含む。端部リップ1042は用紙の出口孔を、カメラシステム内の対応した印刷熱プラテン構造体と正確にアライメントするため設けられる。このようにして、既存の用紙は、近傍のプリントヘッドに対して、正確にアライメント又は位置決めされ、用紙をプリントヘッドへ完全に案内する。
図230及び図231を参照すると、射出成形部品から形成可能である内部コア部の分解斜視図が示され、このコア部は、内部スポンジ部分1034から1036を有する3個のコアインクシリンダが中心に置かれている。
コア部の一端には、一連の通気チャンネル、例えば、1014から1016が設けられる。各通気チャンネル1014から1016は、第1の孔、例えば、1018を外部接点1019と相互連結し、外部接点は雰囲気に相互連結される。通気チャンネル、例えば、1014が後に続く通路は、好ましくは、曲がりくねった性質があり、あちこちに曲がりくねっている。通気チャンネルは、シーリングテープ1020の一部分によってシールされ、シーリングテープはコア部の端に被せられる。シーリングテープ1020の表面は、好ましくは、疎水性を高めるため、疎水性的に処理されているので、流体部分が通気チャンネルに進入することを防ぐ。
コア部1007の第2の端には、3個の厚くなった部分1024、1025及び1026を含むラバーシーリングキャップ1023が設けられ、厚くなった各部分は一連の疎らな孔が存在する。例えば、部分1024は、疎らな孔1029、1030及び1031を含む。疎らな孔は、別個の厚くなった部分の各々からの1個の孔は1本の直線に並ぶように配置される。例えば、疎らな孔1031、1032及び1033(図230)は、全てが1本の線に並び、各孔は別個の厚くなった部分に由来する。厚くなった部分の各々は、対応したインク供給リザーバと対になり、3個の孔が穿刺されたとき、対応したリザーバと流体連通する。
端部キャップユニット1044は、コア部1007に取り付けられる。端部キャップ1044は、認証チップ1033を挿入するためのアパーチャ1046を含み、その上、3個の突起を含む延長されたアダプタ(図示せず)を含み、3個の突起は、対応した孔(例えば、1048)を貫通し、シール1023の厚くなった部分(例えば、1033)を穿刺し、対応したインクチャンバー(例えば、1035)と相互連結する。
更に、端部1044には、認証チップ1033が挿入され、認証チップは、プリントロールのカメラシステムへのアクセスを認証するため設けられる。したがって、このコア部は、3個の別個のチャンバーに分割され、各チャンバーは、別の色のインクと、内部スポンジと、を収容する。各チャンバーは、第1の端にインク出口を含み、第2の端に通気孔を含む。シーリングテープ1020のカバーは通気チャンネルを覆うために設けられ、ラバーシール1023はインクチャンバーの第2の端をシールするため設けられる。
内部インクチャンバースポンジ、及び疎水性チャンネルは、プリントロールを移動可能な環境、多種多様な向きでも利用できるようにさせる。更に、スポンジは、それ自体に疎水化処理をすることができるので、インクをコア部から順序正しく追い出すことができる。
一連のリブ(例えば、1027)は、コア部1007とプリントロールフォーマー1008との間の摩擦的接触を最低限にさせるため、コア部の表面に設けることができる。
プリントロールの殆どの部分は、射出成形プラスチックから構成することが可能であり、プリントロールは、大きい内部インク貯蔵容量をもつ。簡単化された構造は、用紙のカールを取り除くメカニズムと、漏れを最小限に抑えるインクチャンバー通気孔と、を含む。ラバーシールは、インク供給チャンバーとの間に効率的な通路を設けるので、動作的能力が高まる。
Artcardは、勿論、それ以外の様々な環境で使用される。例えば、Artcardは、組み込み型及びパーソナルコンピュータ(PC)アプリケーションの両方で使用可能であり、大量のデータ又はコンフィギュレーション情報への使い勝手のよいインタフェースを提供する。
この結果として、多数のアプリケーションが見込まれる。例えば、ArtCardリーダーはPCに取り付けてもよい。PCのアプリケーションは多種多様である。最も簡単なアプリケーションは、低コスト読み出し専用配布媒体である。ArtCardは印刷されるので、社内のデータ配布のため使用されるならば、監査の証跡を与える。
更に、PCは、しばしば、クローズドシステムのベースとして使用されるが、多数のコンフィギュレーション上のオプションが存在する。複雑なオペレーティングシステムのユーザ用インタフェースに頼るのではなく、ArtCardをArtCardリーダーに単に挿入するだけで、あらゆるコンフィギュレーション上の必要条件を満たすことができる。
ArtCardの裏面は、アプリケーションとは無関係に、同一の視覚的外観を備えているが(なぜならば、データを格納しているからである)、ArtCarの表面はアプリケーションに依存している。表面は、アプリケーションの状況においてユーザに理解される。
したがって、図Z35の装置は、本、新聞、雑誌、技術マニュアル等の形で情報の効率的な配信を行う。
更なるアプリケーションでは、図Z36に示されるように、Artcard80の表面は、サンプル画像に適用される芸術的な効果を含む画像を表示する。カード80の裏面にプログラムされたデータを読み出すカードリーダー82を含むカメラシステム81を準備し、アルゴリズム的なデータをサンプル画像83に適用して出力画像84を生成することが可能である。カメラユニット81は、オンボードインクジェットプリンタと、サンプル画像データを処理するために十分な処理手段と、を含む。ArtCardの構想の更なるアプリケーションは、BizCardと呼ぶものであり、会社情報を名刺に記憶させる。BizCardは、会社情報の新しいコンセプトである。bizCardの表面は、図Z37に示されるように、外観と機能の点で現在の普通の名刺と全く同じである。それは、写真と連絡先情報とを含み、名刺と同じように多種多様なカードスタイルがある。しかし、各biZCardの裏面は、黒色ドットと白色ドットの印刷された配列を含み、会社に関する1から2メガバイトの情報を保持する。その結果は、3.5インチ形ディスケットの記憶装置が各名刺に取り付けられていることと同じである。
情報は、会社情報、特定製品シート、ウェブサイトポインタ、電子メールアドレス、経歴等、bizCardの所有者が望む情報であれば何でも構わない。BizCardは、USBポートを用いて標準的なPCに接続可能なPC付属型カードリーダーのような如何なるArtCardリーダーでも読むことが可能である。BizCardは、ドキュメントとして専用組み込み装置に表示させてもよい。PCの場合、ユーザはそのbizCardをリーダーに挿入するだけでよい。bizCarは、好ましくは、ウェブサイトと全く同様に、通常のウェブブラウザを使用してナビゲートされる。
所有者の写真及びデジタル署名を、会社の公開鍵へのポインタと共に収容することによって、各biZCardは、その人が、本当にその人本人であり、且つ指定の会社のために実際に働いている人であることを電子的に検証するために使用できる。その上、会社の公開鍵を指すことにより、biZCardは、安全な通信を簡単に開始させることができる。
TourCardと呼ばれる更なるアプリケーションは、ある都市への旅行者及び訪問者のための情報を格納したArtCardのアプリケーションである。tourCardがArtcardブックリーダーに挿入されると、情報は次の形式をとり得る:
*地図
*公共輸送機関時刻表
*名所
*郷土史
*行事及び催事
*レストラン案内
*ショッピングセンター
TourCardは、観光客用パンフレット、ガイドブック、及び街角案内の低コスト代替物である。製造コストがカード1枚当たりわずか1セントであれば、tourCardは、観光客案内所、ホテル、及び観光地で、最低限のコスト、又は広告による資金援助があれば無料で配布可能である。ブックリーダーの携帯性は、これを旅行者にとって完璧なソリューションにする。TourCardは、ArtCardリーダーを備わっているコンピュータが任意のウェブブラウザ上でtourCardに符号化された情報を復号化することができる情報キオスクでも使用可能である。
ブックリーダーの双方向性は、tourCardを非常に多用途化する。例えば、地図に格納されたハイパーテキストリンクは、呼び物ビルディングの歴史的物語を表示するために選択可能である。このように、旅行者は、その都市のガイド付きツアーに出かけることが可能であり、関連した交通機関の路線図及び時刻表は何時でも利用可能である。tourCardは、地図と、ガイドブックと、時刻表と、レストラン案内と、を別々にする必要性を無くし、各個の旅行者に対する簡単なソリューションを作成する。勿論、データカードにはこの他にも多くの利用可能性がある。例えば、新聞、学習案内、ポップグループカード、ベースボールカード、時刻表、音楽データファイル、製品パーツ、広告、テレビガイド、映画ガイド、見本市情報、雑誌のクーポンカード、レシピ、求人広告、医療情報、プログラム及びソフトウェア、競馬新聞、電子新聞、年次報告書、レストランガイド、ホテルガイド、バケーションガイド、翻訳プログラム、ゴルフコース情報、ニュース放送、コミック、気象詳細等がある。
例えば、ArtCardは、本の内容、又は新聞の内容を含み得る。このようなシステムの一例は図Z35に示され、ArtCard70は、一方の面に本のタイトルを含み、もう一方の面には本の符号化された内容が印刷されている。カード70はリーダー72に挿入され、リーダー72には、カードリーダー72の折り畳みを可能にさせるフレキシブルディスプレイ73が含まれ得る。カードリーダー72は表示制御部74を含み、表示制御部は、前ページへの移動、次ページへの移動、及びカードリーダー72のその他の制御を可能にさせる。
アートカードの特別の使用
技術説明
技術04の説明
さらなる改善では、アートカム装置は、マイクロフォン装置や関連の録音技術を装備するように適当に変更される。写真が撮られる時、周囲の音環境か、その画像に関係するメッセージのいずれかを録音する機会が与えられる。そして、録音された音声は、エンコード形式により出力写真の裏面に印刷される。そのエンコード化は高い復元性を有することが望ましい。その録音された音声は写真に関係する、永久的な音声録音を提供する。次に、再生装置は、エンコードされた音声をスキャンし、この情報を復号化するために提供される。
ここで、図233を参照すると、アートカム配列のさらなる改善1601が概略形式で示されており、該配列では、画像1602がCCDセンサー1603により検知され、重要な計算リソースを有するアートカム中央プロセッサ1604に転送されるようになっている。該アートカム中央プロセッサ1604は、メモリー1605に画像を格納でき、該メモリ1605は、好ましくは、メモリーに結合された高速RAMBUS(登録商標)を備える。アートカム中央プロセッサ1604は、また、要求に応じてインスタント写真を提供するため、フルカラー写真、例えば1607の印刷のためにプリントヘッド1606の駆動を制御するようになっている。
さらなる改善では、そのカメラ編成1601はサウンドチップ1610も備えており、該サウンドチップ1610は、ACPプロセッサ1604の制御下で、RAMBUS1611を介してメモリー1605に接続されている。そのサウンドチップ1610は、標準的又は専用形式であることができ、例えばサウンドマイクロフォン1613からアナログ入力1612を取り込むDSPプロセッサを備えることができる。或いは、チップの複雑度が増大するのに従い(ムーアの法則)、サウンドチップ1610の機能はACPチップ1604内に組込まれることができ、ACPチップ1604は、最先端のCMOS型集積回路チップを備えるのが好ましい。本発明の範囲内に該当する他の多くの種類の編成を提供できることは容易に明白であろう。
サウンドチップ1610は、アナログ入力1612を対応するデジタル形式へ変換し、それをメモリー1605に格納するために転送する。録音プロセスは、カメラ装置上のボタン(図示せず)を押すことによって作動させることができ、そうでなければ、ボタンがACPプロセッサ1604の制御下にあって、録音プロセスは写真を撮るときに実質的に自動化されることができる。録音されたデータは、メモリ1605に格納される。
図234を参照すると、カメラ編成は、好ましくは、2つのプリントヘッド1615,1616からなるプリンター装置1606を有し、第1のプリントヘッド1615はプリントメディア1617に画像を印刷するのに使用され、第2のプリントヘッド1616はプリントメディアの裏面に情報を印刷するのに使用される。
図235を参照すると、写真メディア1617の裏面への見本の出力が示されている。該出力は図234のプリントヘッド1616にて印刷されたものである。その情報は、場所や日付や時間のデータ1620を含むことができる。そして、場所のデータは、キーボード入力により、或いは、GPSや同様のもののような、付属の位置決めシステムの利用によって与えられる。それらの情報1620は、印刷された画像の記録をユーザが整備するために、視認可能な形式で呈示される。重要なことは、画像1617の裏面には、エンコード形式の音声情報1622も印刷されているということである。エンコード形式は多種多様であることができるが、擦り傷、汚れ、書き込み、磨耗、回転、退色などを許容するよう、エンコード化は高い障害許容力を有する方法で行われるのが好ましい。図236には、データ1625の一部分が概略形式で示され、そのデータは、図234のプリントヘッド1616により印刷されるドット列を有する。その開示された手法は写真の裏面に約2.5メガバイトの任意のデータを保管し、この特別な場合には、音声データを含めることができる。符号化フォーマットは、データのリード・ソロモン符号化の利用に強く依存し、高い障害許容力を提供する。さらに、画像の検知を補助するよう、図236に示されるように、高周波“チェッカーボード状”模様がデータに追加されるように記載される。図234のプリントヘッドにより印刷されるドット列をデータが含むようなデータ部1625が図236に概略形式で示される。
録音された音声を“再生”したいときは、読み取り装置1626を通り抜けるように写真1617を移動させる。その読み取り装置1626はピンチローラーを有しており、該ピンチローラーは写真を挟んだ状態で回転し、CCDリニアセンサー装置1627を該写真が通過するようにする。
図238を参照すると、図237の音声読み取り装置1626の操作を示す概略形式が示されている。前記CCDリニアセンサー1627は第2のアートカム中央プロセッサ1628に接続されており、該プロセッサ1628は、写真の裏面に格納されているデータを読み取り復号化するよう適切に適合化されている。復号化された音声情報は、サウンド処理チップ1633を介してスピーカー1629で再生するためにメモリー1632に格納される。そのサウンド処理チップ1633はACPデコーダ1628の制御下で動作でき、ACPデコーダ1628は、音量制御、巻戻し、再生および早送り制御などを含むことのできる、種々のユーザ入力制御1633の下で動作する。
重要なことには、上述の通り、アートカードの裏面にあたかも情報が印刷されているかのように、CCDリニアセンサー1627及びACPデコーダ1628は読み取りプロセスを実行する。
好適な実施の形態の上記の説明から分るように、写真と関係する音声録音を提供するように、出力画像と関係する音声の自動録音のためのシステムが提供される。写真の裏面の画像出力を読み取るための音声読み取りシステムも開示される。
技術06の説明
さらなる改善では、先述したアートカムは、後のデジタル画像の生成に利用されるカメラの向きを自動的に決定するための装置を含む。そして、そのアートカムは、画像生成に向きの情報を利用することを適切にプログラムされている。
ところで、向きの情報を使用する多くの例が添付図面を参照して説明される。図239を参照すると、第1のポートレート写真1801が示されており、該写真1801には、カメラシステムに入力された日付けや撮影場所情報のような、ポートレート1801に関連した情報を配置するために領域1802が用意されている。さらに、そのポートレート1801は、顔などのような、画像の特定の目に見える部分を変形させる画像処理技術により処理されるかも知れないと予想される。これらの変形は、写真1801を撮影するカメラの向き決定に依存する。また、図239には、カメラが回転されたポートレートモードで使用された第2のポートレートモード画像1803が示されている。残念なことに、横向きモードの画像1801の画像データ1802が同じ位置にあるならば、該データは、最後の画像における望まれない領域1805に現われる。理想的には、ポートレートモードで写真が撮影されるとき、画像の特定の情報は場所1806に現われるべきであろう。なお、直角で、異方性で、画像内容の特定の方法で画像に与えられる画像処理効果は、画像が回転されるときに無駄になってしまうだろう。
前記向きセンサー1846は向きを検知し、該検知された向きはACP1831によって、対応するデジタル向き角度に変換される。前記エリアイメージセンサー1802はカメラにより撮影される画像を検知し、該画像はACP1831に転送され、メモリー記憶装置1833に保存される。次に、検知された向きは、撮影された画像がポートレートモードか風景モードであるかを決定するために使用される。該検知された画像はメモリー記憶装置1833から読み取られ、再びメモリー記憶装置1833に出力される前に回転される。最後の結果が回転された画像1808である。また、検知された向きの情報を利用するための他の技術を挙げることができる。例えば、メモリー記憶装置1833に保存されている検知画像は、向き情報と関連付けて保存されることができ、該向き情報は、従来の回転マトリクスマッピング、世界座標系及び局所座標系マッピングに利用される。続いて、その情報の処理を行うコンピュータ・グラフィック・アルゴリズムは、回転向きに画像を操作するように処理している最中にその座標系を使用することができる。位置検知情報(例えば、図239の符号1806)が画像に組み入れられる場合には、このテキストは正しい向きに配置されることができる。さらに、カメラの向きは、顔検出のような、画像に適用される画像を特定するアルゴリズム技術に使用されることができる。顔の位置は大体分るので、向きの情報の利用は顔検出アルゴリズムを大幅に単純化する。
向きセンサーは、例えばマーキュリーセンサのような、単純で安価な重力スイッチを含むことができ、或いは、マイクロマシンシリコン加速度計のような、より複雑な小規模の装置にすることができる。
技術07の説明
さらに、プリントローラーの他の形態が構成されることができる。図241を参照すると、前述した装置の修正版に利用されるようなプリントロールの他の配列が概略的に示されている。重要なことには、使い捨てのプリントロール(例えば、1910)は、インクを集めることを許容するスポンジ部1912を有する“延長されたリーフ部分1911”を備える。従って、プリントヘッドを横切るように搬送されるフィルムや紙の端縁部へのプリントヘッドによる印刷を許容するため、運転中、前記スポンジ部1912はプリントヘッドの下方に配置される。
そのスポンジ部1912は、使い捨てのプリントロール1910の一部を形成するので、プリントロールを使い切ったときにカメラの外に取り出され、それによって、余分の不用なインクがプリントヘッドから取り除かれる。
技術08の説明
さらなる実施例では、最大のコントラストを確保するCCDデータストリームの処理によりオートフォーカスが実行される。CCDデータストリームに基づき焦点位置を決定する技術は公知である。例えば、Butterworth−Heinemannによって1993年に出版され、Leslie StroebelとRichard Zakiaにより編集された“The Encyclopedia of Photograpy”や、“Applied Photographic Optics(ロンドン及びボストン、フォーカルプレス、1988年)”にて言及されている。これらの技術は、第一に、入力画像の一部を覆う隣接画素間のコントラスト測定を行う。その画像は、正確なオートフォーカス設定を決定するためにACPにより処理される。
このオートフォーカスの情報は、特定のモード、例えば、画像の中に顔の位置を見つけようとする場合にACPによって使用され、画像における顔の大体のサイズを案内することによって顔位置検知プロセスを簡素化している。
図242を参照すると、顔検出アルゴリズムによる調査のために大体の画像の特徴を決定すべく使用される方法の見本2001が示されている。
例えば、2002,2003,2004のような様々な画像がカメラ装置により取得される。焦点設定の詳細は、オートフォーカスの操作の副産物としてACPに保存される。加えて、ズーム・モータの現在位置もまた使用される(2006)。これらの設定のいずれもがACPにより決定される。次に、大体の奥行き位置(depth location)に応じた大きさとなる、画像中のオブジェクト(興味のあるオブジェクト)を含む画像を出力する前に、ACPは、検知した値に分析技術2008を適用する。
次に、画像におけるオブジェクトの位置を見つけるため、該奥行きの値(depth value)が、入力された検知画像2011に加えてACP2031の顔検出アルゴリズム2010に利用される。近距離値2009はポートレート画像の高い可能性を示し、中距離値はグループ写真の高い可能性を示し、遠距離値は風景画像の高い可能性を示す。この可能性の情報は顔検出の目的としても使用されることができ、オブジェクトまでの距離に依存して適用される他の技術やクリップアートと共に、画像中に“描いた”ような効果を生成したり、画像を描いたりする場合に、様々なパラメータを選択するために使用されることができる。
技術09の説明
さらなる実施例では、アートカム装置は、そのときのアイポジションを検知するアイポジションセンサーを有するように変更されることができる。その検知されたアイポジション情報は、その検知されたアイポジションに従った修正や変形等を行うため、カメラにより撮影されたデジタル画像を処理するために使用される。
アイポジションセンサーの構成は当業者に知られており、多くの製品のカメラ(特に、キヤノン社のカメラ)にて使用されている。アイポジションセンサーは、ビューファインダから視聴者の目への赤外線の照射と、大体のアイポジションを決定するために検出され使用される反射とに依存している。
図243を参照すると、アイポジション情報2110と画像2111とはアートカムのメモリーに格納されており、ACPによって処理が行われ(2112)、その処理画像は、プリントヘッドにより写真として印刷するために出力される。画像処理2112の形態は、アイポジション情報2110に依存してかなり変化されることができる。例えば、画像処理の第1の形態においては、画像中の顔の位置を検出して、様々なグラフィック・オブジェクト(例えば、顔との関係で一般的にオフセットしている吹き出し)を適用するために、顔検出アルゴリズムが画像2111に適用される。そのようなプロセスの一例が図244に示されており、第1の画像2115は3人の人間を示している。前記顔検出アルゴリズムの適用により、3つの顔2116,2117,2118が検出される。そして、アイポジション情報は、フレーム中に推定された目に最も近い顔選択するために使用される。第1の例においては、吹き出しは頭2116に対して配置される。第2の例2120においては、吹き出しは頭2117に対して配置され、第3の例2121においては、吹き出しは頭2118に対して配置されている。したがって、画像中の所定の顔の上方に吹き出し文字を配置するために、アートカードは、吹き出し適用アルゴリズムのコード化された形態と、処理された画像とを含むように提供される。
アイポジション情報は多くの異なる方法で画像2111を処理するために使用することができるということは容易に理解される。局所的な、或いは特定の方法で焦点合わせの効果を適用し、顔やオブジェクトに特定の変形を与えることができる。さらに、行われた画像処理は、画像の芸術的な演出を含み、該演出は、芸術的な絵筆技術を適用することを含む。その芸術的なブラッシング方法は、アイポジション情報2110に従って特定の方法で適用され得る。最終的な処理画像2113は、要求に応じて印刷され得る。さらなる画像が撮影され、異なる出力画像の生成のため、異なるアイポジションが検出され使用される。
技術10の説明
さらなる改善では、アートカムは、撮影画像の明るさのレベルを決定するために自動露出センサーを有するように構成変更されている。この自動露出センサーは、画像の一部分を引き立たせるため、設定された露光量に従って画像を処理するために使用される。
望ましくは、前記エリアイメージセンサーは、画像を撮影するときの光の状態を決定するための装置を有する。該エリアイメージセンサーは、検出したレベルに従って、CCDにより取得されたダイナミックレンジの値を調整する。取得した画像はアートカム中央プロセッサに送られ、メモリーストアに格納される。前記エリアイメージセンサーにより測定された強度情報は、また、ACPに転送される。この情報は、保存されている画像に特定の効果を与えるため、ACPによって使用される。
図245を参照すると、ACPによって画像を処理するため、自動露出設定情報2201が、保存されている画像2202に関連して使用される。処理された画像は、後でプリンターで印刷2204するためにメモリーに戻される。
所定の光の状態に従って多数の処理ステップが実施されることができる。暗い場所で画像が撮影されたことを自動露出設定情報2201が示す場合には、画像の色をより強く、より深く、より鮮やかにするために、画像の画素の色が選択的にリマップされる。
写真が撮影されるときが明るい状態であると自動露出情報が示す場合には、より明るく、よりサチュレートするように画像の色が処理される。画像の再配色は、色相・彩度・明度(HSV)フォーマットに画像を変換し、要求に従ってピクセル値を変更することにより行うことができる。該ピクセル値は、印刷の出力色フォーマットに変換して出力することができる。
もちろん、数多くの異なる再配色技術が使用されるかも知れない。それらの技術は、好ましくは、読み出し装置に挿入されるアートカードに明確に示されている。他の方法としては、ある状態での使用のため、画像処理アルゴリズムが自動的に適用され、カメラの中に組み込まれることができる。
他の方法としては、挿入されたアートカードは、画像に適用される、自動露出設定に限定された、多くの取扱いを有することができる。例えば、暗い画像には、蝋燭等を含むクリップ・アートが挿入されることができ、明るい画像には大きな太陽が挿入されることができる。
技術11の説明
フラッシュを使用した結果、取得画像に生じる“赤目”の影響を除去することは、重要な処理の1つである。図246を参照すると、さらなる改善において、CCD装置により取得された画像は、フラッシュが使用されていた場合には、印刷のために処理された出力画像を形成するため、処理ステップ3を受けさせる。図247を参照すると、CCD装置による画像の取得の際にフラッシュが使用されていた場合に使用されることのできる、1つの特別な画像処理アルゴリズム2310が、より詳細に示されている。そのアルゴリズムは、好ましくは、CCDにより画像を取得するためにフラッシュが使用されたときにのみ使用される(2311)。そのアルゴリズムの目的は、フラッシュの利用による画像への影響を低減することである。そのような画像の影響は、写真画像において個々の眼が赤く見えるという、周知の“赤目”影響を含むことができる。また、フラッシュ光の反射面からの反射などのような他の影響は、別途、他のアルゴリズムを使用して処理することができる。画像における赤目の影響を排除するための第1ステップは、画像中における顔を決定することである(2312)。何らかの他の画質増強や色修正を行った後、通常光の下で人間の顔の色についてのHSVの値の地図で近接する範囲を決定することにより、顔検出プロセスが実行される。検出された範囲については、目や口や全体形状や重なりの決定を含む、様々な簡単なテストがなされる。その簡単なテストは、顔の可能性についての結果を生じさせることができ、閾値以上の場合には、画像での顔の位置を決定することができる。
画像の中で顔が決定されると(2312)、その顔の中で眼の位置が見つけられる(2313)。そして、赤目除去処理が必要かどうかを決定するため、特別な範囲の色を判断する処理がそれぞれの眼に個別に行われる。もし、赤目除去処理が必要とされるならば、出力画像において、如何なる不連続さや起こり得る不自然さを生じないようにさせながら、赤色を減少させるようにすべく、目のエリアに対して修正アルゴリズムが適用される。もちろん、眼の中心点の周りのガウシアン・デグリーの形式を含む多くの異なる技術が使用される。最後に、メモリーストア2333の裏にアップデートされた形式で画像が書き込まれる(2316)。
望ましくは、この時点で、フラッシュ光のスペクトル特性の影響を受けた色をリマップすることを含む、他の修正アルゴリズムが使用される。代わりに、挿入されるアートカードが、画像に適用される多くの処理(フラッシュの設定を特定する処理)を行うようにしても良い。例えば、蝋燭や光の球体(light globe)等のクリップアートが、如何なる閃光も無い画像中に閃光や大きな太陽が挿入されても良い。
技術12の説明
さらなる改善においては、第2のインクジェットが写真の裏面への印刷のために用意されている。図248には、標準的な配列の概略図が示されている。ローラー(例えば、2404)に挟まれる紙2403に写真を印刷するためにプリントヘッド2402が用意されている。2つのインクジェット・プリントヘッド2402,2411を備えるという実施例に従い、図249には代替案2410が示されている。プリントヘッド2411は、写真に関連のある重要な情報を写真2403の裏面に印刷するために用意されている。例えば、その写真を撮った時間や日付が、そのインクジェット・プリントヘッド2411によってその裏面に印刷されることができる。加えて、そのアートカム装置はグローバル・ポジショニング・センサーを備えるかも知れない。該センサーは、アートカム中央プロセッサによってデータ取り出しが行われ、その写真が撮られた場所を確定するために利用されるかも知れない。この付加情報は、また、写真出力2403の裏面に印刷されるかも知れない。
技術13の説明
プリントロールは堅く巻かれた形態で提供される。残念なことに、プリントロールを堅く巻いた結果として、プリントメディアの特性が、アートカムシステムにより出力される写真には過量のカールがもたらされるというようになるかも知れない。
図250を参照すると、3個のローラー配列2511−2513を有するシステムを提供する、プリントロールの別の配列が示されている。そのローラー配列は、プリントロールを抜け出たプリントメディア2514に、しっかりとしたアンチカールを与える。それらの3つのローラー2511−2513はメディア2514を挟み込み、ピンチローラー(例えば、2517)によってプリントヘッド2516へ搬送される前にその紙にアンチカールを与える。それらの3つのローラー2511−2513は、プリントロールケース、或いはアートカム装置の内部に配置されることができる。
技術15の説明
図251を参照すると、さらなる改善では、観察者2703に、立体的、或いは疑似三次元的な効果で見せるような写真画像を作ることが望まれる。これらの効果は、2つの画像をすぐ近くに同時に記録し、1つ目の画像を観察者の右眼2704に与え、2つ目の画像を観察者の左眼2705に与えることにより得ることができる。左眼と右眼のために画像を記録し、そして左眼には左の立体的画像を見せ、右眼には右の立体的画像を見せることにより、3次元の立体効果を作り出すことができる。
さらなる改善では、左右の眼の画像を取得する、一連のレンズ状の透明な柱によって、写真や立体画像2702は、以下のように、よりはっきりとなるように、構成されるだろう。
図252を参照すると、写真紙2702の表面部分の断面図が示されている。断面図2710に明らかなように、写真紙は、左右の立体視が可能となるようにデザインされた、一連のレンズ状の列を有する。画像は、透明な写真紙2710の底面2712に印刷される。
1つの画素のピッチ2713は80μmで、ドットの配列ピッチ2714は20μmである。それ故に、1つの画素につき4つのドット2714−2717が配置される。2つのドット2714−2715は左側の立体視のために用意され、2つのドット2716−2717は右側の立体視のために用意される。その写真紙を見る右眼は右側の画素ドット2716,2717の像を取得し(2720,2721)、左眼は左側のドット2725,2726の像を取得する(2723,2724)。それ故、2つの画像がそれぞれの眼に別々に示され、実体写真効果が生じる。主として、2711のような各列(column)のレンズ状の外形に起因する実体写真効果。
ここで、図253を参照すると、紙2710の下面部の斜視図が示されている。図253の説明図は、4つのドット2731−2734を有する画素のピッチに加えて、各ドット2730のドットピッチを示すために作図線を含む。図253に明らかなように、右側立体視のために用意された2つのドット2731−2732、及び、左側立体視のために用意された2つのドット2733−2734の4つのドットにより各画素が構成される。そのドット、例えば、2730はプリントメディア2710に配置されているので、該メディアが裏返された時に、正しい立体視が行われる。
ここで、図254を参照すると、立体画像を撮像する1つの方法が論じられるだろう。望ましくは、携帯用カメラ装置に配置されたCCDカプラー2740,2741により2つの画像が撮像される。各CCD装置2740,2741は別々の画像を取得し、それら別々の画像は、図235に示されるような左右交互の方法で、立体処理ユニット2742にて結合されるべきである。画像が立体処理ユニット2742にて正しく交互配置されると、その画像は、プリントエンジン2743、及び、写真紙2710の表面2746にその画像をプリントするプリントヘッド2744に送られる。
写真紙2710の現在位置が位置合わせユニット2750により検知され、その現在位置が、プリントヘッド2744の制御のためにプリントエンジン2743によりフィードバックされる。その位置は、LEDタイプの装置2780がプリントメディア2710のレンズ状面を照らすと共に、プリントメディア2710の反対側の光導電体2781が周期的な明るさの変化を測定することにより決定される。
図255を参照すると、破線2750により示される位置合わせユニットの動作がここでさらに説明される。写真紙2710はローラー2751,2752に挟まれ、ローラー2752は、写真紙(プリントメディア)2710のレンズ状面2754に一致する面を有するように構成されている。その写真紙2710のレンズの周期が2780mmのオーダーなので、ローラー2752の表面は、写真紙2710のレンズ状面のように、誇張して示される。レンズ状写真紙の緻密な周期は、ローラー2752がプリントメディアの他の形態にも同様に使用できることを意味している。
ローラー2752の表面は、ローラー2752との一定の空間的関係をプリントメディア2710が維持することを保証する。従って、要求に応じてローラー2752を回転し、それによってプリントヘッド2744を通過するようにプリントメディア2710を搬送するように、プリントローラー2751,2752はプリントエンジン2743の制御下で位置合わせユニット2750によりモニターされながら駆動される。結果として、プリントヘッド2744により印刷されるドットとレンズ状列との位置の合致が維持される。
プリントメディア2710がプリントヘッドを通過するように搬送される際に、プリントヘッド2744により立体画像をプリントすることができる。プリントヘッド2744としては、フルページ幅のプリントヘッドが望ましい。
もちろん、プリントヘッド2744に関連する、プリントメディア2710の現在位置を他の装置により決定することも可能である。
図256を参照すると、好適な形状のレンズ状紙2761と、対応するインク供給(不図示)とを有するプリンターロール2760を結合することにより、カメラ装置が、提案された実施例の原則に従って提供され得る。その紙2761は、プリントローラー2760からピンチローラー2763,2763によってプリント装置2764に取り出される。該プリント装置2764は、さらに、ピンチローラー2765,2766、カッター2767、プラテン2769、ピンチローラー2751,2752、及びプリントヘッド2744を有する。立体画像はプリントヘッド2744によってプリントされ、その紙2761がカッター2767により切断された後に取り出される。その出力2770は透明な形態である。
図257を参照すると、画像の排出物2770の上に、平坦な白の面2771を付着することができる。これは、透明2770を貼り付ける粘着面の使用により成し遂げられる。続いて、左右のステレオ画像を生成して、撮影画像に三次元効果を与えるように、図251に示されるように、レンズシステムを通して画像が視認される。図256に描かれたカメラシステムは、理想的には、写真を撮影して直ぐに立体写真を得たい場所に運ぶことができるような携帯用である。
技術17の説明
技術21の説明
さらなる改善では、堅くロール状に巻かれて格納される画像メディアは、異方性のリブ構造を持つように処理され、ロール状で運ぶのに好適で、該プリントメディアに印刷された画像を見るときには該プリントメディアのカール度合いが減少されるようになっている。
ここで図259を参照すると、この改善の本質に従って取り扱われるプリントメディア3311が示されている(3310)。該プリントメディア3311は、他の形態が好適だけれども、プラスチックの平面的なフィルムにて構成される。該プリントメディア3311は、図259の拡大図に示されるように、ポリマーのリブ状構造3312を有するように前処理されており、実際の列のピッチが約200mである。したがって、該プリントメディア331の一方の表面は、該プリントメディア331の全長を上下に走行する一連の列3312を有するように処理されている。該列3312の断面は図に拡大図で示されている。
一連の列3312を使用することのメリットは、プリントメディア3311の表面部分に力3313が加えられた場合に明らかである。その列3312は、プリントメディア3311が堅く巻かれることを許容する一方で、3316の向きにプリントメディア3311が巻かれることに抵抗する。従って、加えられた如何なる力3313も、3315及び3316の両向きに伝達しそうである。そのメディア3311の異方性の性質は、3315及び3316の両向きに支持を与えるように機能するリブ3312によってもたらされ、それによってメディア3311のカールを制限する。また、その材料の異方性の強度は、ロールの中心軸に沿った強度で格納されることが許容される。
図260を参照すると、ユーザの手3320,3321の中で画像3311を単に保持して、ポイント3324,3325に僅かな圧力を与えることによって、カーリングによる効果を減少させて、メディア3310上の画像を見ることができる。
もちろん、異方性のメディアは、該メディアがプラスチック材料を含んでいる場合には多くの技術を利用して製造されることができる。例えば、それは、押し出し成形法により製造されることができる。或いは、他の技術が利用され得る。例えば、1つの製造方法が図261に模式的に示される(3340)。該方法では、ローラー3342,3343の間でメディア3341がプレスされるようになっている。図261(a)に示すように、ローラー3343はフラットな面を有し、ローラー3342はギザギザのある面3345を有している。説明のため、鋸状の外形は図261に拡大されている。
メディアがそのようなプロセス3340での利用に適していない場合、異方性メディアは、互いに貼り合わされた2枚のフィルムの面を利用することによってもたらされる。そのようなプロセス3350は図262に示される。画像の印刷が望まれる第1面3351は、接着剤や熱融合等の方法によって要求通りに第2面3352に貼り付けられる。
さらに、プリントメディアの製造の他の方法が可能である。例えば、図263及び図264を参照すると、プリントメディア3360の構造が断面図で示される。該プリントメディア3360の構造は、繊維型の中に引かれる、軟ポリエチレン・ナフタレートにより形成された繊維からなる強化ポリマーを含む第1繊維材料3361から形成される。ポリエチレン等を含む第2の熱流動ポリマー(heat−flowable−polymer)3362は、インク/画像の化学薬品のキャリッジのための“紙”の基材を提供するために使用される。繊維3361と印刷ベース3362とが、図264に示すように一体ユニットを形成するように、メディア・ポリマー3362は粘着力が残っている間(例えば、加熱後)繊維材料3361に押し付けられる。図263及び図264のメディアの配列は、多くの技術に従って作られることができる。次に、図265を参照すると、繊維状材料の成型スプール3380を使用する、第1のそのような技術が示されている。その技術では、多くのスプールと、対応する繊維3381とが、所望のプリントロール長に相当している。それらのスプール3380は、対応する繊維3381が第1ローラー3382に供給されるように配列されている。そして、それらの繊維3381は、加熱された粘着性のあるプリントメディアの層を該繊維に供給するプリントメディア塗布ユニット3384を通過するように引かれる。その後、ローラー3385,3386が、繊維とプリントメディアとが一つに融合するように必要な圧力を供給すると共に、最後に異方性面3388を形成するようにプリントメディアの面を平らにする。その後、該面3388は裁断され、上述のように異方性プリントメディアを形成するように巻かれる。
もちろん、要望に応じて繊維状材料の形成を他の形態で行うことが可能である。例えば、図266には、タンク3390からファイバ3391を引く方法により繊維状材料を押し出して生成する1つの形態が示されている。図266の装置は図265のスプール3380に置き換えることができる。
技術24の説明
さらなる改良版では、前記アートカムシステムに利用されるアルゴリズムが説明される。該アルゴリズムは、入力画像中における一群の画素を、出力画像では“ブラッシュストローク”で置き換えることにより、写真画像を“描いた”ような演出に自動変換するものである。該アルゴリズムは、ブラッシュストロークをヴァン・ゴッホ・スタイルに近付けるように、画像中のフラットな部分での主要なエッジを自動検出し、該エッジの方向の情報を増殖させる(propagate)ように働く。該アルゴリズムは、前述のアートカム装置にて履行するのに好適である。
まず、図267を参照すると、そのアルゴリズムは多くのステップ3601を含む。これらのステップは、エッジを検出するために画像のフィルタリングをする第1ステップ(3602)を含む。次に、それらのエッジは、最終的なエッジを決定する処理(3605)の前に、閾値処理、或いは“スケルトン処理(3604)”される。そして、それらのエッジにベジエ曲線が適合(fit)される。次に、該曲線はオフセットされ(3607)、最終的な画像にブラッシュストロークが描かれる(3608)。それらの処理3607,3608は、画像がブラッシュストロークにより十分に覆われるようになるまで繰り返される。その後、画像への最後の“修正”が実行される(3609)。
次にそれぞれのステップをより詳細に説明する。エッジを検出するためにフィルタリングをする第1のステップ(3602)では、図268に示すような係数の集合3612,3613を持つソーベル(Sobel)の3×3のフィルターが前記画像に適用される。ソーベルフィルターはデジタル画像処理にて使用される、良く知られたフィルターであり、その特性は、マサチューセッツのAddison−Wesley出版社により1992年に出版された、規範となる教科書“デジタル画像処理”にてGonzalez及びWoodsにより197−201頁に完全に討論されている。ソーベル微分フィルターは、フィルタリング前に画像をグレースケールに変換するか、或いは、画像を各カラーチャネルにフィルタリングして最大値を取ることにより適用されることができる。ソーベルフィルタリングにより、画像の画素単位のエッジ強度を示すグレースケール画像が作成される。
次に、対応する二値画像を作成するために閾値処理が行われる(3603)。その閾値を変化させることができるが、最大強度値の50%の値が適切である。エッジを強化した画像(edge strength image)中の各画素が該閾値と比較され、もし閾値よりも大きければ“1”が出力され、閾値よりも小さければ“0”が出力される。この処理の結果、閾値エッジマップ(threshold edge map)が作成される。
次に、図267のステップ3604では前記閾値エッジマップが“スケルトン処理”される。画像をスケルトンする処理は、上述参考教科書の491〜494頁や、他の標準的な教科書に完全に明確に記載されている。そのスケルトン処理は、前記閾値エッジマップにおける相当数の特徴を維持しつつ、“薄く”スケルトン化されたエッジマップを作成する。
次のステップでは、画像におけるポイントのリストを含むデータ構造を生じさせる、スケルトン化されたエッジマップにおけるエッジが決定される。好ましくは、予め決められた最小値よりも長いエッジのみがリストに加えられる。
前記スケルトン化された画像は、多重分岐が可能な1画素幅のエッジのみを有するので、C++コード片(code fragment)で表された次のアルゴリズムは、スケルトン化された画像において切れ目のないエッジに属するポイントを決定したり同定したりする1つの方法を提示する。それは、分岐したエッジを別々のエッジに分解し、各分岐の湾曲を最小限にする方向にエッジに沿って伸びることを選択する。例えば、分岐ポイントにて、最小の湾曲を生じさせる分岐を助ける。そのコードは以下の通りである。:
スケルトン化されたエッジマップにこのアルゴリズムを使用することにより、少なくとも所定のサイズを有するエッジのリストが生成される。好適なサイズは、20画素長であることが分っている。
図267の次のステップ3606では、ステップ3605にて得られた各エッジリストのそれぞれにベジエ曲線が適合される。エッジリストのそれぞれのため、区分的なベジエ曲線がポイントのリストに適合される。区分的ベジエ曲線を適合させる好適なアルゴリズムは、“デジタル化された曲線を自動的に適合させるためのアルゴリズム”シュナイダー,P.J.著、Glassner,A.S.編集、Graphics Gems、Academic出版、1990年にて説明されるようなシュナイダー曲線適合アルゴリズムである。このアルゴリズムは、パラメトリックの連続性ではなく幾何学的な連続性のみを目的とし、素早く収束するようにしている。シュナイダーアルゴリズムは機能的であり、もし適合度が乏しければ、最大エラー部で曲線を再分割し、該分割されたものに曲線を適合させる。次に、その分割部分での接線の推定は、分割点のいずれかのみを使用してなされる。密集した点集合のために、ローカルノイズが増幅される傾向がある。曲線を適合することの、改良された品質は、接線の基礎とした分割点から遠ざかる点を使用することで得られる。
図267の次のステップ3607では、所望の“ブラッシュストローク幅”の半分だけ初期のカーブリストから曲線がオフセットされる。そのオフセットは、最初の主曲線の両側に平行となるように、互いにほぼ1ストローク幅だけ離れる2つの曲線を生じさせる。
特定の区分的ベジエ曲線にほぼ平行な区分的ベジエ曲線を生成するため、次のステップを含むアルゴリズムが使用される。
i. 空のポイントリストの作成
ii. 空の接線(ベクトル)リストの作成
iii. 区分的ベジエ曲線を形成する曲線部分のそれぞれに選択されたポイントを評価し、特定のオフセット値によりそれらをオフセットさせる。前記ポイントリストにオフセットポイントを付け足し、対応する接線を前記接線リストに付け足す。
iv. 得られたポイントリストに区分的ベジエ曲線を適合させる。曲線を適合させるプロセスにおいて接線を予測するのではなく、オフセットポイントに関連した正確な接線を使用する。
各曲線の区分は次のようにオフセットさせる:
i. 曲線値と、標準化された接線と、標準化された法線とを求める。その法線は、0.0以上1.0以下の、等間隔に配置されるパラメータ値(例えば、0.25の間隔)で画像のサイズが標準化される。
ii. 前記特定のオフセット値により法線をscaleする。
iii. 前記曲線のポイントと縮小された法線とを使用して線分を組み立てる。
iv. もし、2本の線分が交差するならば、1本の線分に関連するポイントを削除する。
v. 存続するポイント(surviving point)をポイントリストに付け足し、それらに対応する接線を接線リストに付け足す。もし、問題の線分が区分的曲線の最後のものであったなら、パラメータ値1.0に関連するポイントのみを付け足し、次の線分のパラメータ値0.0に関連するポイントは複写する。
各曲線部分をオフセットさせるプロセスは次のように行われる。すなわち、
1. 初めに、0.0以上1.0以下の、ベジエ曲線上に等間隔に配置されるパラメータ値のため、各パラメータ値Pn(図269)のため、曲線値3630と、標準化された接線3631と、標準化された法線3632とが計算される。
2. 次に、特定のオフセット値により前記法線3632がscaleされる。
3. 次に、ポイント3630からポイント3636(scaleされた法線3634の端のポイント)までの線分が計算される。
4. 次に、その線分3630−3639は、曲線上の他の全てのポイント(例えば、3638,3639)がチェックされる。もし、いずれか2つの線分が交差しているならば、ポイントの1つ3636は廃棄される。存続するポイント(surviving point)をポイントリストに付け足し、それらに対応する接線を接線リストに付け足す。もし、問題の線分が区分的曲線の最後のものであったなら、パラメータ値1.0に関連するポイントのみを付け足し、次の線分のパラメータ値0.0に関連するポイントは複写する。
図270を参照すると、一連のベジエ曲線区分(例えば、C1,C2等)を作成するため、図267のステップ3607に従った曲線のオフセットの最終結果が示されている。最初に、一定間隔で配置された一連のパラメータポイントP1−P5。次に、各ポイントP1−P5に対して、法線のポイントN1−N5(図269のポイント3636に対応する)が作成される。次に、それらのポイントN1−N5を利用して、区分的ベジエ曲線3640が作成される。このプロセスは、ポイントN6−N10を含む反対側の曲線3641にも適用される。このプロセスは、続く区分的曲線C2等にも適用される。この結果、互いに平行で、ほぼ1ブラッシュストロークの幅だけ離れて配置される2本の曲線3640,3641が得られる。
次に、一連のブラッシュストロークが、前記曲線に沿って、出力画像中に配置される。それらのストロークは、曲線の接線方向に方向付けられる。各ブラッシュストロークは、他のブラッシュストロークと重ならない場所を規定するフットプリントによって規定される。そのフットプリントが出力画像中に既に表示されているフットプリントと重ならない場合には、ブラッシュストロークはその曲線に沿うようにのみ配置される。ブラッシュストロークが配置されていない曲線は廃棄され、ステップ3607と3608のプロセスが、曲線がなくなるまで(若干の修正を加えられながら)繰り返される。ステップ3607における若干の修正は、図270の曲線C1から曲線をオフセットさせる場合に必要な、半分のブラッシュストロークよりも大きく曲線をオフセットさせることである。
上述の方法は、画像中の興味のあるオブジェクトから一連のブラッシュストロークが放射されるようにすることにも利用できる。
与えられたサイズのブラッシュストロークで画像が覆われるのに続いて、より小さなブラッシュストロークでさらなる処理がなされ、画像においてブラッシュストロークの重要な特徴をさらに正しくするように、閾値レベルが高められる。そのようなテクニックは、細かさが要求される特定の部分にゴッホが使用するテクニックに近似している。
技術26の説明
何らかの画像(例えば、写真)のために、該写真等の中の興味を引く領域(例えば、顔等の位置)を割り出せることが望まれる。一旦、画像中における顔の位置が特定されると、図271に示されるように、顔領域に対して吹き出しを配置するような、多くの奇抜な効果を実行する画像処理を単純にできる。顔領域が一旦検出されると、眼鏡のような顔に関連する物を配置する等、顔を変形させるというような他の効果を履行することができる。
前述したように、画像における領域の検出は、領域に限定して芸術的効果を適用するというような、領域特異的処理に適用できる。例えば、背景の空の領域は幅広のブラッシュストロークで描き、最前面の顔の領域は細かいブラッシュストロークで描くと言った処理である。また、画像における特徴の決定等である。色を基準にした領域の検出は、検出される色が肌の自然な色合いであって、画像における人の顔の検出を行う時に極めて役に立つ。
照明を変化させると、特定のスペクトルの色のオブジェクトが、輝度や彩度が変化されて画像中に現われるかも知れない。色相はオブジェクトの優位周波数(卓越周波数、dominant frequency)を評価するので、オブジェクトの色は、色相よりも輝度や彩度においての方が大きく異なる傾向がある。図272に示されるように、さらなる改善の方法3801は、輝度や彩度から色相を区別する色空間に、取得した画像をまず変換するという第1のステップを有する。そのようなもので、良く知られている2つの色空間としてはHLS色空間とHSV色空間がある。これらの色空間を含む様々な色空間は、フォーリー,J.D.、ヴァン・ダム、A.、フェイナー、S.K.、ヒューズ、J.F.、コンピュータグラフィックス、原理と実行、第二版、アディソンウェスレー、1990年、584―599ページのような標準的なテキストで十分に説明されている。
次のステップは、多数の入力カラーシード(color seed)を入力することである(3804)。各シード3805は次のように定義される。:
(1)色値のシードカラー範囲
(2)局部的な色の差の制限(a
local color difference limit)
(3)全体的な差の制限(a
global color difference limit)
次のステップ3808はビットマップを構築するためにシードを処理することである。
図271の方法における最後のステップ3807は、入力画像と同じ容量であって、入力画像中の画素が、シードのリスト3805により定義される色域に属することを示すビットマップを出力することである。この方法3801は、別々のパス3808の各シードの処理と、各パスの出力ビットマップと全体の出力ビットマップの結合を含む。個々のビットマップのどんなセット・ビットも全体のビットマップに書かれている。
図273を参照すると、図272のステップ3808がより詳細に示されている。第1のステップ3820では、問題になっているシードが定義されるシードカラーレンジにシードがある全ての色について、シードビットマップが割り出される。次のステップ3821では、該シードビットマップにおける各シードのため、シード位置に連結される入力画像中の4コネクト又は8コネクトの領域を検出する“シード充填”アルゴリズムのためのシード位置として利用される。そのシード充填アルゴリズムは、シード出力ビットマップの領域に属する画素にフラッグを立てる。ステップ3821にてシード出力ビットマップ中でフラッグが立てられたシードは、それらが次のシード充填のためのスタートポイントとして使用されないように、ステップ3820で作成されたシードビットマップから消去される。
全てのシードがシード充填処理のために使用されると、シードの全てのリストのために、シード出力ビットマップは全体的な出力ビットマップと結合される。
上述の参考文献の979頁〜986頁に開示されているように、シード充填アルゴリズムは標準タイプである。しかしながら、該シード充填アルゴリズムは特定の画素関係テストを有する。
もし、色が、前述の画素の色と局部的色差制限と同程度までに異なり、シードカラーと全体的色差制限と同程度までに異なるならば、画素は現在の領域の一部となる。その色差制限は各色成分毎に別々に決められる。スパンは検出されるか、左右から処理されるので、前述の画素は現在の画素の左の画素である。新しいスパンの初めの部分で、前述の画素の色は、もとのスパンの平均色となるようにされる。シードカラーは、シードカラー範囲の中間色となるようにされる。
区別できる色の特徴であるが良く知られた顔のような領域を同定するために、1つのシードを使用するのではなく、シードのリストが使用される。
局部的色差制限及び全体的色差制限の使用は、画像中の不連続を横切らずに、可能な限り領域を検出するために使用される。領域は様々な色を含むかも知れないが、これらは、その領域にわたって穏やかに変化する。領域における全体の色の変化は、局部的な色の変化よりも一般的に大きい。局部的色差制限の使用(imposing)は、画像の不連続部を横切るというリスクを減少させる。また、それは、全体的色差制限が控えめにならないことを許容する。その領域の検出は、例えば、徐々に明るく或いは暗くなる領域においてでさえより完全にできる。
入力画像の色空間が色相を基準としている場合、低輝度又は低飽和のため、色相は少々当てにならないので、色相差制限は好ましくは輝度(又は輝度値)及び飽和によって縮小される。したがって、領域中の暗いエリアや飽和していないエリアにおいて色相が当てにならない場合には、検出された領域にそれらのエリアが含まれるようにその効果は縮小される。これは、もちろん、輝度及び飽和に関しての差制限が前提となっている。
また、色相六角形の円の特性に一致して、色相差は正確に計算される。
画像中のオブジェクトを検出する上記アルゴリズムを使用した場合に、非常に適切な結果がしばしば得られることは分っている。例えば、上記の方法は、多くの固体を有する画像であって、カラーシードが標準的な皮膚の色調にセットされた画像に利用された。その結果は、画像中の個々の顔の位置を正確に探すことができる。
技術27の説明
さらなる改善では、図274に示すように、ソースとなる画像3901が、対応する“タイル状”のカラー画像3902に変換される。その変換処理については後述する。第1の実施例では、各タイル3094は、出力画像3902において標準的配列を取る。さらに、各タイル3904の色は、入力画像3901における対応画素3905の色から引き出したものである。出力画像におけるタイル化処理は、入力画像3901よりも高解像度で行われ、よって、そのタイル化処理は実際において低解像度画像にするために使用される。
もちろん、タイルの形状としては、多くの異なるものが可能である。画像をタイル化するタイルの形状は、好ましくは、全体の画像をタイル化して複製する場合に“パターンユニット”に結合されると良い。例えば、図276に示すように、タイル3908と3909は、複製される際に画像をタイル状にして、パターンユニット3907として結合される。
さらなる実施例においては、一つ一つのタイルは2つのチャンネルを持つ画像により規定される。第1のチャンネル3970は、図276に示すように、タイルの形状と不透明とを規定する。零でない不透明な領域3971は、タイルの一部である画素を規定する。各画素3971の値はその画素の不透明度を示す。図277及び図278を参照すると、第2のチャンネル3980は、高さ(height field)として、タイルにおける画素表面テクスチャを定義する。図278では、図277のA−A’線に沿った断面図が示されており、強度やピーク3991や傾斜3992,3993が示されている。
そのアルゴリズムへの入力は以下の通りである。すなわち、
タイルとして再生されるべきカラー画像
上述したようなタイルのパターン
出力解像度
付加される光学上の入力パラメータは下記のものである。
該アルゴリズムからの出力は、入力画像にタイル状の演出を行うことである。
繰り返しのタイル“パターンユニット”は次のように規定できる:
(1) パターンユニットのサイズ(行の数、列の数)
(2) 画像の第1画素のため、パターンユニットにおけるスタートポイントへのオフセット(行及び列のオフセット)
(3) 連続するパターンユニットの配置についての、垂直方向のオフセット
(4) パターンユニットを構成するタイルのリスト
(5) 1つのパターンユニットにおける、水平方向の連続的なタイルの配置のオフセット
(6) 該パターンの解像度(例えば、該パターンのタイル画像の解像度)
該パターンの幅は、水平方向に連続的に配置されるタイルの列オフセットの合計により定義される。
全てのオフセットは、連続する画素の組み合わせ(例えば、実数値の行及び列のオフセット)の中にある。このことは、タイルがサブ画素の正確さで配置されることを許容する。このことは、入力画像や出力画像や独立するタイルパターンの解像度を許容する。
基本的なタイリング・アルゴリズムは、次のC++コードフラグメントにより実施される。すなわち、:
上述の通り、一つ一つのタイルは、その形状/不透明性チェンネルにより特徴付けられる形態を有している。そのタイルの形状並びにタイルの画像中における配置は、一緒になって、そのタイルによって覆われるところの、入力画像中の一連の画素を決定する。出力画像における、そのタイルの色は、その一連の画素に基づく。色を付与するという機能は、限定するものではないが、入力される色を1画素ずつコピーしたり、入力される色の平均を取ったり、入力される色の中央を取ったりすること等を含むようにしても良い。
このように色が付されたタイルは、不透明度を無視して出力画像に直接描かれるかも知れないし、或いは、タイルの不透明度に従って出力画像に合成されるかも知れない。後者のケースでは、出力画像は最初に何らかの明度(例えば、黒)や何らかの任意の画像(例えば、入力画像自体)に初期化されなければならない。不透明なマスクやチャンネルを使用した合成画像は、例えばTomas Porter and Tom Duff(1984)“合成デジタル画像”SIGGRAPH会報1984年、253ページから259ページのような一般的な記事に開示されている標準的な合成技術を使用することができる。
それぞれのタイルは、テクスチャチャンネルにより定義される表面テクスチャマップを有している。そのテクスチャチャンネルは、タイル中における各画素の相対的な表面高さを規定する。この高さ(height field)は、模擬的な入射光の反射角決定に使用される表面法線を決定するために後で使用される。タイルや、そのタイルが配置される部分の画像に模擬的な光が与えられる場合、表面テクスチャは視覚的により明白になる。
タイルが出力画像に直接描かれるか、出力画像に合成されるか、いずれにせよ、最も単純なケースでは、タイルのテクスチャは出力画像のテクスチャチャンネルに直接書かれる。
各タイルの不透明チャンネルは、タイルの背景への合成を制御する。加えて、画像サイズの不透明チャンネルは、タイル全体の背景への合成を制御するかも知れない。最も単純なケースでは、タイルの不透明度は、タイルの合成に使用される不透明度を生じさせる、大域的な不透明度(global opacity)によって測られる。図279を参照すると、大域的な不透明度を使用するプロセスの一例が示されている。第1のプロット4000では、折り返された不透明度プロフィール(例えば、4001,4002等)の単純な形状を持つ各タイルの、断面の輪郭の例が示されている。次に、不透明度4005の段階的増加からなる、好ましい大域的不透明度チャンネル4004が示されている。上述した単純なケースでは、増加している不透明度のエリア(例えば、4007)を有する不透明度4006を生じさせるため、大域的不透明プロフィール4004でタイル不透明プロフィール4001が測られる。
もちろん、大域不透明チャンネルを伴った局所タイル不透明度の組み合わせのスキームは可能である。例えば、最初に、各タイルについて、画素の不透明度が平均化され、画素毎の不透明度は、画素毎の大域的不透明度ではなく、この平均化された不透明度によって測られる。
上述したタイリング・アルゴリズムが、僅かな簡単な修正を行うことによって、描いたような効果を簡単に生じさせる上で役立つということは、驚きを持って発見されている。パターンユニットをブラッシュストロークの堆積として取扱い、各タイル画像がブラッシュストローク(例えば、ブラッシュヘアーの層や、ストローク端部で厚みを有するもの)に見えるようにすることにより、ストロークがオーバーラップされて、描いたような効果がタイル内やパターンユニット内に実行される。次に、このアルゴリズムは、連続的にパターン内でタイルを反復するよりもむしろ、無作為にストロークコレクションからストロークを選択するために修正される。さらに、下に描かれた、多くののテクスチュアリング、配置、彩色効果は代替的付加的に供給され得る。
第一に、入力イメージ内に一般的には様々なレベルの細部がある。入力イメージは、タイリング又は彩色アルゴリズムを介して再現されたとき異なったレベルの細部を要求する。これは、多様な変化内でイメージの加工、それぞれの変化内の異なった程度のストロークコレクションの利用、それぞれの変化と(累積的な)バックグラウンドの合成によって達成され得る。画素単位の詳細な寸法で構成された、イメージサイズにされた細部マップは、それぞれの変化過程のイメージ部分を制御するために利用され得る。それぞれの変化は、その上でイメージの対応部分が処理される“細部境界”が与えられる。継続的な変化に、細部のレベルの増加とストロークコレクション割合の減少が与えられる。最初の変化はこのように、例えば全体のイメージを加工処理し、第2の変化は細部の確定したレベルを加え、第3の変化はなお多くの細部を加える、などである。これは、画家がどんどん細部を加えていくことによって絵画を精密にしていくのにいくらか類似している。この細部マップ自体は、イメージ内にエッジを配置すること、言い換えると派生したフィルターの間をイメージが通過することによって、簡単かつ自動的に生成され得る。
タイルは概念上は柔軟性の無いもの(rigid)である。その表面のテクスチャは、背景の表面テクスチャや、重なり合う他のタイル(通常は如何なる他のタイルとも重なり合わないが)の表面テクスチャからの影響を受けることはない。他方では、ブラッシュストロークは概念的には柔軟である。その厚さや表面テクスチャは、背景の表面テクスチャや、重なり合う他のブラッシュストロークの表面ストラクチャの影響を受ける。特に、そのブラッシュストロークは、背景の凹部に充填される傾向があるが、背景の頂点(peak)では薄くなる傾向がある。(背景は、そのストロークに先行するブラッシュストロークの影響を含んでいる。)
別の実施例においては、ブラッシュストロークが描かれる場合、幾つかの方法の内の一つによって、そのテクスチャは背景のテクスチャと結合される。まず、新しい背景高さを生じさせるために、ストローク高さは背景高さの一定割り合い(例えば、25%)だけ付加されるが、その高さは減少しないようにされる。このテクスチャの効果は図280(a) から(c) を参照して説明される。図280(a) においては、シングルタイルのブラッシュの断面輪郭の例が示されている。図280(b) においては、図280(a) のブラッシュパターン4010を覆う、画像部分の断面が一例として示されている。図280(c) においては、上述したルールを使用した結合処理の結果が示されている。線分4013,4014,4016,4017は、画像値4011が対応するブラッシュ値4010を超えるように、画像4011から直接取られたものである。しかしながら、4015の部分は、画像4011の対応部分の25%に、スト録4010のストローク高さを加えて計算されたものである。ストロークの下の背景が計算される。個々の画素において、背景の高さがもし平均よりも低ければ、ストローク高さは単に背景高さに加えられる。このようにして、背景の凹部にストロークが“充填”されるような擬態が行われる。もし、背景高さが平均に等しいか、平均よりも高ければ、ストローク高さはその平均に加えられる。このようにして、背景のピークによってストロークは薄くなる。背景がストロークを実質的に打ち破らない(例えば、ゼロまで薄くならない)ようにするため、その高さは、最小量(もちろん、ゼロを含む、最小ストローク厚さ)に応じて増加するようにされている。
さらに、テクスチャー結合アルゴリズムの結果である、ストロークの正味の薄さを計算するため、ストロークの不透明度が計られるかも知れない。このようにして、背景のピークによりストロークが薄くなる場所は、より透明になる。
タイル/ストロークの位置が決定されると、さらに、多くの方法によって処理がされるかも知れない。例えば、手によるタイルやストロークのポジショニングにおける自然なバリエーションを真似るため、タイル/ストロークの位置は、特定の範囲や特定の速度で任意にジッターされるかも知れない。ストロークよりもタイルを真似た場合、通常は、タイルが重ならないように、タイルのジッターの範囲が限定される。例えば、“内部タイルのギャップ”の幅のみが変化される。ブラッシュストロークを真似る場合、ブラッシュストロークは通常は重なるので、ストロークジッター範囲は通常はより狭く限定される。
さらに、タイルやストロークの位置についてのより標準的なバリエーションを真似るため、置換マップに従って各タイルの位置が置換される。その置換マップは2つのチャンネルからなる。第1は行の置換を含み、第2は列の置換を含む。
タイル/ストロークの色自体は、芸術的な効果のためにさらに処理されるかも知れない。例えば、
(1) 制限されたタイルや制限されたペイントパレットを真似るため、その色は、任意のパレットにマッピングされるかも知れない。
(2) タイルカラーの不完全性や、絵の具を混合するバリエーションを真似るため、その色は、特定の範囲及び特定の速度で任意にジッターされるかも知れない。
(3) その色のクロミナンスは、特定の速度で任意に変換されて、反対色を使用した印象派のスタイルを真似るかも知れない。
タイル/ストロークの平均大域不透明度が決定されると、芸術的効果のためにさらに処理されるかも知れない。例えば、平均化された不透明度が、ゼロの不透明度や100%の不透明度に二値化されるかも知れない。このことは、タイルの不存在や存在を作り出す。もし、平均化された不透明度が二値化されたなら、大域的不透明度の再生は、入力画像に部分的に誤差拡散を行うことによって改良されるかも知れない。これは、画像中に重要な効果を生成するために見出されている。
さらなる実施例が、アートカム装置の適切なプログラミングにより実行される。キャンバスに画像を“描く”ときの画家は、通常は、絵の具の色が限定されたパレットと、制約されたセットのものであって特徴的な筆遣いを形成するブラシとを用いて仕事をし、そして、独特の色や質感のキャンバスに描いている。そのことに気付くことにより、さらなる実施例が構築される。描くシーンをより真実に近付けたり真実から遠ざけたりするため、そのシーンについての画家のビジョンを描くため、画家は、異なる色の筆遣いを行う。いくつかの絵のスタイルが、シーンの特徴や色を再生するために試みられる。他のスタイルが、シーンの特徴や色についてのより多くの印象を取得するために試みられ、より単純で一様なブラッシュストロークや絵の具を混合したり重ね塗りしないことによって特徴づけられる。これらの印象派のスタイルは、写実派のスタイルに比べると より明るくより鮮明な色を達成するが、詳細な描写は犠牲にされる。
“描かれた”演出となるように写真画像を自動的に変換するコンピュータシステムが、一般的には、入力画像中の画素から何らかの方法で取得した色のブラッシュストロークを出力画像中に入れる。そのようなシステムの課題は、上述したような、人が描くという行為の態様を取り入れることにある。印象派の演出を作り出す部分的解決法は、実際の芸術家の絵の具の色に基づくカラーパレットの構築と、入力画像に可能な限り一致させるような該パレットからのブラッシュストローク色の選択と、入力画像と整合する全体的な色を維持するための色の誤差拡散とにある。
さらなる実施例においては、生の色だけを基準とするのではなく、ブラッシュストロークの最終的な色を基準とした画像を誤差拡散させるアルゴリズムが構築されている。この最終的な色は、絵の具の色や、ブラッシュの構成や、キャンバスの色や生地によって決定される。
該アルゴリズムの入力は以下の通りである。すなわち、
* 絵の具の色が限定されたパレット
* それぞれが不透明マップ(opacity
map)やバンプマップ(bump
map)にて定義された一連のブラッシュストローク。バンプマップの使用は三次元グラフィック演出の当業者に良く知られていて、例えば、Graphic Gemsの4巻433−437ページに記載されている。
* 色画像やバンプマップにより規定されるキャンバス
* 絵画として再生されるカラー画像
前記アルゴリズムの出力は、入力された画像の演出、つまり、ペイントパレットによって着色されたブラッシュストロークでキャンバスに“描く”ことである。該キャンバスやブラッシュストロークはテクスチャーされていると共に、これらのテクスチャーはペインティング工程の間は結合されているので、最終的なペインティングは一方向的に照らされるかも知れない。
描かれたような効果を成し遂げるため、出力画像と入力画像との間で、より優れた色整合を成し遂げるための基本タイリングアルゴリズム(tiling algorithm)が使用される。最初のプロセスは、ブラッシュストロークのパレットフィードバックアルゴリズムである。このプロセスは、ストロークのカラーパレットの表を作成して実行される。図281に示す表4025は、ブラッシュストロークB1,B2,B3等により区分けされている。ブラッシュストロークセット中の各ブラッシュストロークBnのため、そして、ペイントパレットセット中の各ペイントカラーC1−CNのため、ストロークカラーS1−S4は、図282のフローチャートを参照して説明される通り、次のように決定される。すなわち、
1. ステップ4021にて、対応するブラッシュストロークB1を色付けるためにペイントカラーC1が使用される。
2. そして、不透明マップとバンプマップとを使用して、色つきのブラッシュストロークが空のキャンバスに合成される。
3. ステップ4023にて、描かれたストロークの平均色が計算される。この平均色が、図281のストロークカラーS1である。そして、ポインター(不図示)が、ストロークカラーパレット入力S1から、対応するペイントカラーパレット入力C1にポイントするためにセットされる。
4. そして、ストローク・カラー・テーブルが色によりソートされる。
画像を描く場合、図283に示されるように、各ブラッシュストロークが通常の方法で選択される。そして、各ブラッシュストロークの所望の色が入力画像から通常の方法で決定される。しかしながら、ペイントカラーパレット中で最も近いペイントカラーCnは使用されない。その替わり、そのブラッシュストロークのため、ストロークカラーパレットの中で最も近いストロークカラーSnが使用される。次に、そのブラッシュストロークのためのペイントカラーとして、対応するペイントカラーCnが絵の具の色として使用される。
該ペイントパレット中で利用できる色の範囲は制限されているため、通常は、所望の色と選択できる色Cnとの間にはいくらかの違いがある。この違い、或いは誤差は、誤差拡散を行う通常の方法で、入力画像の近接した部分に誤差拡散されることができる。所望の色とペイントカラーCnの違いの誤差は使用されない。代わりに、所望の色とストロークカラーSnとの違いである誤差が、この目的のため、ストロークを横断する平均色として使用される。実際のブラッシュストロークは他のストロークと重なるのに対して、ストロークパレット中のストロークは空のキャンバスに描かれるので、この平均色Snがストロークパレットにおける平均色と異なるかも知れないことに気付く。
この方法は、他のペインティング・パラメータの効果が同じ方法で取り入れられるように拡張することができる。これは、ペインティング・メディウムの種類(パイン油、チョーク、チャコール等)や、キャンバスの種類(テクスチャー紙、グラス等)などを含む。各パラメータは、ストロークカラーパレットの多次元表に次元を加えるが、本質的なアルゴリズムは変化しない。
芸術家は、時折、1つのブラッシュストロークに2色又はそれ以上を混合させる。印象派のスタイルでは、これらの色はしばしば十分には混合されず、また、混合されない色がストロークの分離された成分として視認される。
上述したアルゴリズムにおいて、多数色のブラッシュストロークは1色のブラッシュストロークの一般化にすることができる。それは、多数の不透明度マップにより適宜されることができる。これらの不透明度マップは、ブラッシュストロークの共通の排他的領域のため、ゼロでない不透明度を定義する。それらは、全体的なブラッシュストロークの形状を規定する。そのアルゴリズムに次の修正を導入することにより、多数色のブラッシュストロークが提供される。
一つ一つのブラッシュストロークのためにストロークカラーパレットが構築される場合、ペイントカラーパレットからのペンチカラーの可能な組み合わせでブラッシュストロークに色が塗られる。このことは、小さなペイントカラーパレットのため明らかに役立つ。各ストロークカラーパレットの入力は通常の方法で構築し、各ストロークカラーパレットは対応する多数のペイントカラーパレット入呂気宇。画像を描く場合、通常の方法で、ストロークカラーパレット中で最も近いストロークカラーを見つける。しかし、ストロークは、多数のペイントカラーで色づけされる。
技術30の説明
図284を参照すると、アートカム装置のプログラムのさらなる改善のステップが示されている。標準的な技法の通り、ブラッシュストロークが区分的ベジエ曲線として特徴付けられると想定される。ブラッシュストロークは所定の厚みを持つと想定される。そのブラッシュストロークは一連のベジエ曲線からなる。第1のステップ4211は各区分的ベジエ曲線を処理することである。それぞれのベジエ曲線は、標準的な技術を使用して、最初に折れ線に変換される(4212)。次に、“最も速い”エッジ(その意味は以下で明らかになる)が、所定のインクリメントにおける最も速いエッジを“出発する(step along)ために使用される。その位置は、ブラッシュストローク4214を合成するために使用される。
図285を参照すると、ブラッシュストローク4221の基礎を形成する第1のベジエ曲線4220が示されている。そのベジエ曲線4220を対応する一連の線分(例えば、4222)に変換するプロセス。折れ線の区分に線形近似するプロセスは標準的で良く知られており、普通の教科書に取り上げられている。その線形近似プロセスの一環として、各線の端点の法線(例えば、4224)がまた決定される。それらの法線は、必要ならば、線の傾きを補間する方法によって、点(例えば、4225)に隣接される線から決定されることができる。
図286を参照すると、2本の線分4233,4234の拡大図が示されている。各点(例えば、4232)のために、法線(例えば、4233,4234)は、それぞれの側にブラッシュストロークの幅の距離だけ突き出ている。点4236は突き出た法線4237,4238を有している。次に、法線4233と法線4237との間の距離4239が測定され、法線4234と法線4238との間の距離4240が測定される。エッジ4239に沿って移動するbodyが、エッジ4240に沿うよりも早く移動しなければならないという意味で、最も長い距離を有する側に“最も速い”エッジが定義される。したがって、最も速いエッジは曲線の凸状のエッジである。
最も速いエッジは、等しい量だけ離れたパラメータとしての所定数のポイントを定義するために使用される。図286の例は、線4239に沿って等間隔に規定された3つのポイント4243−4245が示されている。ほとんどの間隔は図286に示されたものよりも長い。
次に、各ポイントのパレメータ位置が決定され、線4230に沿ったパラメータポイントを決定するために使用される。その位置は、ブラッシュストロークが配置される位置である。
図287を参照すると、一連のブラシスタンプ4246,4247,4248が示されている。2つのスタンプ4246,4248は線の端の部分に使用され、部分4247は線の中央部分に沿って連続的に使用される。
該ブラシスタンプは、マットチャネル、バンプマップチャネル及びフットプリントチャネルの3つの別々のチャネルにより定義される。図287の例では、ブラッシュのマットチャネルが示されている。“最大”テクニックとして知られている、第1のテクニックにおいては、マットチャネルやバンプマップチャネルは、分離されたブラッシングバッファにおいてブラッシュストロークを構築するために使用される。この合成技術においては、ブラッシュは最大不透明度を取ることにより構築される。そのバッファにて新しい不透明度が古い不透明度を超える場合、その不透明度は新しい不透明度に置き換えられる。生成された結果は、フォトショップにおけるエアーブラシやペインティングに近似したものとなる。
第2の合成技術においては、“フットプリント”技術として知られる。現在のラインのための前述したブラッシュスタンプが画素のためのブラッシュバッファに書き込まれなかった場合にのみマット値が変更されるように、フットプリントチャネルが使用される。第3の技術においては、マットチャネルやバンプマップチャネルが使用されるが、このとき、マットチャネルやバンプマップチャネは最小である。
上記の技術は、特に水彩画の効果を真似る場合に良い結果をもたらすことが分っている。次のコードセグメントは、さらに改良された実施例の処理を示す。:
技術31の説明
図288を参照すると、アートカム装置4302を含む、さらなる改善の配列(4310)が示されており、該アートカム装置4302は、適切な文字認識のできるタッチパッドLCDからなる文章入力装置4303に接続されている。代わりに、キーボード入力装置(例えば、4304)を文章入力装置とすることができる。文章入力装置の好適な形態は、前記アートカム装置4302に接続されるように適応されプログラムされたアップルのニュートン(登録商標)装置にて構成され得る。また、文章入力装置4303の他の形態が利用されることもできる。さらに、アートカム装置4302に挿入されるアートカード装置4305が提供され、該アートカードの表面に描かれている図に従って検知画像を(予め十分に検討されたように)処理するようになっている。
図289を参照すると、さらなる改良版の操作に関しての好ましい形態が示されている。この操作の形態においては、アートカード4305は、ローマ字で規定されるフォントと、該フォントで特別の文字を作成する方法の説明とを含むVarkスクリプトで符号化されている。例えば、その説明は、そのフォントで新しい文字を作成するために外形を処理する方法を含む。
入力装置4303,4304は入力装置フォントを有する。その入力装置フォントは、情報を表示するためにテキスト入力装置4303,4304によって使用される。特に、非ローマ字が使用される。したがって、入力装置4303,4304は、アートカード4305によって要求されるテキストの入力のために使用される。入力に基づき、フォントのアウトラインが、特別の文字の作成のためにアートカード4305に符号化された指示に従ってアウトラインを処理するアートカムユニット4302にダウンロードされる。それらの文字はアートカム装置4302によって作成され、印刷される出力画像の一部として表示される。
この操作方法を使用することで、アートカム装置4302やアートカード装置4305にフォントの配列を保存することになしにアートカム装置4302の柔軟性が拡張される。この方法によれば、非ローマ字言語形式でアートカム装置4302を操作するために利用されるモデルの複雑さを減少すべく、テキスト入力装置(例えば、4303,4304)が各国ごとであることのみが必要である。
技術33の説明
さらなる改善では、デジタル画像カメラで撮影し、前述の特許出願にて開示されているような所定のdpi(例えば、1600dpi)を持つインクジェットプリンターのようなプリント装置で印刷するという、カメラ画像の再生が望まれることが前提である。
図290を参照すると、そのようなデジタル画像カメラ装置4501が、標準的な出力解像度の画像4502をプリントアウトするように設計されている。その画像4502は、マルチカラー出力(シアン、マゼンタ、イエロー)であって、入力画像の各色成分のためのドットの配列からなるインクジェットプリンター装置によって印刷される。出力された写真4502のコピーを希望する場合には、まず画像がスキャンされ、適切な色成分が抽出される。
さらに改良された方法が図291に示されている。この方法では、写真画像4502がリニアCCD4510によって各色成分にスキャンされる。適切なリニアCCDは技術的に知られている。リニアCCD装置の構成及び操作の説明のために、「“CCDアレイ、カメラ、ディスプレイ”Gerald
C Holst著、1996年発行、SPIE
オプティカルエンジニアリング出版」のような標準的な文献が参考とされる。さらに、適切なセンサー装置は、家電についての電気電子技術者協会報告書で定期的に述べられている。
CCDアレイ4510は、CCDヘッドの下を通過する画像をスキャンして信号を生成し、アナログ信号をデジタル信号に変換する。CCDアレイ4510は、写真のドット解像度の3倍である、1インチ当たり4800ドットにする。該CCDアレイ4510は、各色に対して一つずつ三原色、フィルター、CCDを有する。4800dpiは一連の千鳥配列CCDアレイを使用することにより達成される。
前記データ値はフレームバッファコントローラ4512に転送され、色成分毎にフレームバッファ4513に保存される。保存された画像は、写真の上にプリントされ、前述したように、印刷時の約3倍の解像度であるCCDスキャニング解像度にてCCDによりスキャンされるとき、本来のドットの位置に配置されるように処理される。残念ながら、スキャンされた画像には多くの欠陥が存在するかも知れない。これらの欠陥は、写真4502がCCDスキャナー4510に送られるときの写真4502の微々たる回転に加えて、写真4502の傷や歪みの影響を含む、スキャニング工程に関連した欠陥を含む。
パターンやドットを決めるための手順は、写真4502の回転を抽出するプロセスの使用に依存する。そのような回転を割り出す(determine)ため、多くの方法を利用することができる。
例えば、インクドットのスキャンされたパターンは前記回転に基づく基本的特徴周波数(fundamental characteristic frequencies)を有する。写真には、ドットの一般的な配列でインクが印刷されるので、その画像のフーリエ変換が、起こり得る回転を割り出すために使用される。その代案としては、写真の境界(abrupt boundary)やCCDの下方のスキャニング面(the underneath scanning surface of the CCD)からカードのエッジを割り出すことができる。さらに、画素の所望のドットピッチが決定(determine)される(1600dpi)。
写真のスキャン画像の一端縁から、ドットがそれぞれの出力ドット位置に配置されているかどうかを判断するための処理がなされる。重要なことは、出力ドットの判定を行うように、カードを横切る同期を維持するという方法が使用される。1つのカラムから次のカラムへの間隙についての局部的な変化は極めて小さく、多くの変化は画像の長さを超えることは明らかである。
回転や、隣接するドットの間隔を割り出す処理の1形態は、ドット中心(“重心”として知られたもの)の列を記録し(keep)、カラム中の重心をカラム方法によって書き換える(update)ことである。図292を参照すると、重心処理の一形態が示されており、画像領域4520は、カードの表面部分にて見本のインクドット4521を有している。各画素における各インクドットのサイズは、対応する画素サンプリングレートの約3倍である。一連の重心のマーク(例えば、4522)は、各カラムに保持(keep)されている。カラムCn+1の重心マークにおいて初期の重心の回転を割り出すために、前に計算されていた重心マークや、隣接するカラムCnの重心マークが利用される。例えば、重心マーク4523の初期位置を割り出すために、重心マーク4522,4524,4525が利用される。初期位置が割り出されると、さらなる調整が必要かどうかの判断のため、重心マーク4523の周りの画素値が調べられる。
期待される位置から重心4523が動いているとの判定は、該ポイント4523の周りの画素値を調べることにより導き出される。その調査はX及びY方向で別々に行われ、その移動は、それらの方向で別々に行われる。
多くの異なる方法が使用され得る。重心4523の微小な修正が必要かどうかを判断するための1つの方法は、図293に従って述べられる。この方法によれば、限定された数のインクドット配列のみが可能であることに気付く。これらの可能な配列は、図293に4530で示される通りのものであって、現在の画素(current pixel)4531と、隣接する2つの画素4532,4533を示す。それぞれのインクドット4531−4533は、CCDセンサーにて検知されるところの、ほぼ3つの画素値を有する。図293における各画素パターン4530のため、デジタル変換された後のCCD出力値4535の例を示す。CCDのサンプリング効果や、他の機械的及び明るさの効果のため、ドットパターンのCCD値4535は、AD変換されたガウス曲線(或いは、その一部)と同等なものをしばしば含む。したがって、切り立ったエッジは通常は与えられない。しかしながら、期待された断面は、最も近い断面を割り出すために得られたものを調べることができ、誤差はそれほど大きくはなく、よりフィットするために制限内に調整される。この方法によれば、新しい重心位置は第1のディメンジョン内にて得られる。もちろん、重心を調整するという課題は2つの方向において対称的であり、同じ処理ステップが他のディメンジョンにおいても適用される。多数の他の技術が、見本画像からトレーニングされたニューラル・ネットワークのような、より発展した技術が使用されるかも知れない。
調整した位置が割り出されると、重心4523(図292)が僅かに調整され、重心割り出しの処理が続行される。その新しい重心位置から、特定の重心位置のためにオン又はオフのインクドットの値が記録されるべきかどうかを判断するために周囲の見本の値が調べられる。
図291に戻ると、記録されたインクドット値はインクドット配列4516に保存され、同じ解像度(1600dpi)か異なる解像度でプリンター(例えば、4517に示すものであって、オリジナル写真4502に等しいインクドットの写真4518をコピーするためのもの)にて印刷するために利用される。この方法によれば、ネガの使用や、画像をデジタルで分割して保存することをしなくても、オリジナル写真からのコピーである高品質写真のコピーが得られる。
もちろん、処理のスピードアップと、大容量のデータのセットをフレームバッファ等に保存する必要を排除するため、カスタマイズされたリアルタイムのパイプラインの基本設計概念の利用を含む、多くの改善が可能かも知れない。
技術34の説明
さらなる改善では、アートカム装置は、2Dモーションセンサーを含むように変更さる。そのモーションセンサーは、2軸での動きを検出する小さな微小電気機械システム(MEMS)装置や、他の好適な装置を備えることができる。そのモーションセンサーはカメラ装置に取り付けることができ、その出力はアートカム中央プロセッサによりモニターされる。
図294を参照すると、さらなる改善の好ましい配列の概略図が示されている。加速度計4601は、CCD装置から不鮮明な検知画像を受け取るアートカム中央プロセッサ4602に出力する。そのアートカム中央プロセッサ4602は、写真が撮影されたときのカメラの角速度を決定するために、前記加速時計の測定値を使用する。そして、その測定値(速度因子)は、好適にプログラムされたアートカードプロセッサー4602によって利用され、不鮮明な検知画像4603に対してボケ修正が行われ、ボケの無い出力画像4604が出力される。アートカードプロセッサ4602におけるボケ修正プログラムとしては、コンピュータプログラミングやデジタル画像修復の当業者により知られている標準的なアルゴリズムが使用される。例えば、“Selected Papers on Digital Image Restoration”、M.Ibrahim Sezan編集、SPIE Milestoneシリーズ、74巻、特に再版の167−175ページが参照される。更に、簡易化された技術は“Image Processing Handbook” 第2版、John C.Russ著、CRC出版発行、336−341ページで明らかにされている。
技術38の説明
図295を参照すると、さらなる改善の方向に従った構成として、付属のプリンター5010の形態が示されている。該プリンター5010は、空洞5012の中に挿入されるプリントロール5011を有するように設計されている。該プリントロール5011は空洞5012に挿入されると共に、ローラー(例えば、5013,5014)を有している。該ローラーは、内部の紙を挟むと共に、画像の印刷のため、要求に応じて該紙をプリントヘッド5015に搬送する。理想的には、該プリントロール5011は、消耗されるインクを供給する装置に加え、プリントメディアを備えている。インクは、画像の印刷の際にプリントヘッド5015により消耗される。
プリンター5010は、アートカムの実施例の適切な再加工により構築されることができる。プリンターは、USBポートを介してコンピュータ5024と通信する。プリンターユニット5018はプラスチック成形のケースであり、画像を印刷するための内部プリントヘッド5015を有する。
そのプリントヘッド5015は、自動ボンディング技術によりプリントヘッドチップ5020に接続されている。プリンターユニット5018のサイズを減少させるため、該プリントヘッドチップ5020はフレキシブルな回路基板に取り付けられている。USB通信ケーブル5022を介してプリンターユニット5018に転送される描写(description)から画像を生成するため、該プリントヘッドチップは、最新の半導体製造技術により作られ、関連したメモリー等を有している。もちろん、他の多くのインターフェースの形式が利用され得る。プリンタヘッドチップは、予め説明され得る。
従って、画像の印刷が望まれるとき、プリンターユニット5018に接続されているコンピュータシステム5024は、ケーブル5022を介してプリントユニット5018にページ記述言語(page description )を転送する。プリントチップ5020は、後でプリンタヘッド5015で印刷される画像を準備する。プリントロール5011は、消耗されるプリントメディアやインクを、使いやすい形態で供給し、プリンターユニット5018により使用されると、そのプリントロールは新しいプリントロールに置き換えられる。
技術40の説明
さらなる適応では、カメラシステム及び印刷システムは免除され、大きなスクリーンの読み取り装置(large screen reader)に置き換えられる。アートカードは、裏面に情報が書き込まれ、その情報の表示が他の面に印刷されるように設定されている。例えば、アートカードは本のコンテンツや新聞のコンテンツを含むことができる。そのようなシステムの一例が図296に示されるものであって、アートカード5210はその一面に本のタイトルを有し、他の面には、印刷されたコード化されたデータを有する。カード5210は読み取り装置5212に挿入される。この読み取り装置5212は、折り畳むことができるようにフレキシブルなディスプレイ5213を備える。カードの読み取り装置5212は、前や後ろにページをめくったり、他の制御を行ったりするためのディスプレイ制御装置5214を有する。
したがって、図296の構成のものは、本や新聞や雑誌や技術マニュアル等の形式で情報を効率良く配布できることが分る。
数多くの変更及び/又は修正が、大まかに説明された本発明の精神または範囲から逸脱することなく、特定の実施の形態に示されるような本発明へなされてもよいことは、当業者によって理解されよう。したがって、本実施例は、図示されていてもされていなくても、あらゆる点で考慮されるべきである。
技術47の説明
さらなる改良は、擬似的なブラッシュストロークを使用してキャンバスの上に画像を“描く”という処理について論じられる。バンプマップ技術が使用されることが前提であり、特に、使用される各画像が、画像表面のテクスチャーを規定するバンプマップを有することが前提である。
図297には、見本としてのラウンドブラッシュ・バンプマップ5901が示されている。図298では、図297のA−A’線の断面が示され、該断面は、一般的なラウンドブラッシュストローク5901の表面の一般的外形5903を有する。図297のバンプマップを有するブラッシュストロークを一般的なへシアン形の“キャンバス”画像(バンプマップは図299に示され、B−B’線の高さは図300に示されたもの)に塗ることが前提である。その高さは、波状のピーク(例えば、5906)からなる。
さらなる改善では、最終的なバンプマップの形成のために、図298のバンプマップと図300のバンプマップとが、供給された剛性因子に従って種々の方法で結合される。その剛性因子は、“剛性”のペイント、又は“フレキシブル”のペイントを使った効果を生じるように設計される。図301では、図298と図300の2つのバンプマップが低い剛性のブラッシュペイントのために結合された例が示されている。図302では、図298と図300の2つのバンプマップが高い剛性のブラッシュペイントのために結合された例が示されている。
さらなる改善では、絵の具からなるブラッシュストロークが一定の可塑性を有していて背景の凹部に満たされるので、バンプマップの結合に際して、バンプマップは単純に付加されはしない。したがって、図301や図302の効果を成し遂げるためには、ブラッシュストロークのバンプマップは、背景のバンプマップであってローパスフィルターされたものに付加される。そのフォーパスフィルターは、絵の具の剛性因子によって決まる範囲(radius)を有している。該剛性因子が高ければ高いほど、フィルターの範囲は広くなり、透かして見える背景の表面テクスチャは少なくなる。ブラッシュストロークが薄かったり、何も無かったりする場所(ほとんどが縁部に沿っている)ではフィルターがかけられた背景の表面テクスチャが、実際の背景の表面テクスチャに収斂するように、ローパスフィルターの範囲はブラッシュストローク厚さに応じて変動される。
図303及び図304を参照すると、初期の背景バンプマップを示す図303を用いた処理の例が示されている。バンプマップ5911の、ローパスフィルターがかけられたものを覆う状態の、剛性の高いペイント5912を図304は示し、ローパスフィルターがかけられたバンプマップ5913を覆う状態の、剛性の低いペイント5914を図305は示している。
技術48の説明
さらなる改善では、入力画像の色域(color gamut)は出力画像の色域(color
gamut)に“モーフ(morphed)”される。この出力画像の色域は、異なる複数の色域の試行という方法によって独断的に決定されたものである。さらなる改善では、理想的には、特定のスタイルのブラッシュストロークで画像を置き換えるというような、さらなる芸術的な処理にプレ処理ステップが使用される。そのブラッシュストロークは、画像から色を抽出し、該ブラッシュストロークは所望色域に関連する色を有する。
最終的な出力画像を作成するステップは、図306に符号6010で示されたものである。第1のステップ6011は、望ましくはアートカム装置により検知された任意の入力画像を入力することである。その入力画像の色域は、所定範囲の色域の出力画像を作成するために“モーフ(Morphed)”又は“ワープ(Warped)”される(6012)。モーフィング処理については後述する。出力の色域が作成されると、次のステップでは、適正なブラッシュストローク技術が適用される。ブラッシュストローク技術は、大いなる変化をもたらすことのできる処理である。使用されるブラッシュストロークの実際の形態では、前述した技術が本発明に絶対必要である訳ではない。入力画像に対して、色域を制限した演出を行って出力画像を形成するためにそのブラッシュストローク技術が適用される。
図307を参照すると、ガモットマッピングとモーフィングの問題の一例が示されている。L*a*b*色空間であるユニバーサル色空間6021で多くの可能な色値が定義されてシングルの色空間が使用されることが前提である。この色空間の内部で、入力センサーは、ある範囲の明度6022を検知することができる。さらに、出力プリント装置は、プリンター色域6023における特定の範囲の色を出力できるものと仮定する。該プリンター色域は入力センサーの色域6022よりも小さいかも知れないし大きいかも知れない。芸術的色域6024は特定のスタイルに従って規定される。その芸術的色域6024は、様々な技術の使用を通じて慎重に構築することができる。例えば、所望の出力画像がスキャンされ、所望の出力画像は、L*a*b*色空間の内部の特定の範囲を含むように、色のヒストグラムが構築される。所定の明度の3次元のL*a*b*色空間のように図307が解釈できることは、コンピュータグラフィック関係の当業者によれば理解され得る。
したがって、入力センサー色域6022の中の色を芸術的色域6024に移す(map)ことが必要である。さらに、残念ながら、芸術的色域6024は、特定の出力プリンター色域6023にとって“はみ出る色域”の色を含んでいる。そのようなケースでは、出力の色がプリンター色域6023内にあるために、芸術的な色域6024を移す(map)必要があるだろう。
図308を参照すると、主要な要求は、L*a*b*値6031をL*a*b*出力値6032に移すための3次元ルックアップテーブル(例えば、6030)をアートカードが有するということである。好ましくは、その3次元ルックアップテーブル6030は、3次元マッピングのために定義される特定のポイントと、定義されたポイント間の中間値のマッピングのために利用される3次補間とを有するコンパクトな形式で提供される。
図309を参照すると、1つの実質的に任意の入力ガモットスペース6040から第2の所望の出力ガモットターゲットスペース6041へのガモット・モーフィングを適用するための処理についての極めて一般的な例が示されている。潜在的には、入力ガモットスペース6040の内側であって出力ガモットターゲットスペース6041の外側にあるポイント(例えば、6042)をガモットマッピング処理は処理しなければならない。前記3次元カラールックアップテーブル6030は(2n+1)3のサイズを有する。nは、1から、最大色コンポーネント・プレシジョン(例えば、通常は8ビット)までの範囲である。任意のワープがルックアップテーブル内で符号化される。該テーブルの使用は、また、別々に準備された符号化ワープファンクションを独立させるアルゴリズムを生じさせる。そのアルゴリズムは、任意のワープ関数のための予測できる性能を有している。ワープ関数が連続することは要求されない。したがって、そのアルゴリズムにおいては、任意のワープ関数にとって強固である。
そのルックアップテーブルは、整数の3D配列であり、実数の出力色コーディネートは入力コーディネートの順で配列される。このようにして、前方ワープ関数が符号化される。
要求された画像のカラー・ワープが、1画素毎、出力画像の順に計算される。そのアルゴリズムは3Dカラールックアップテーブルへのランダムなアクセスを必要とするが、入力色は空間中では滑らかに変化するので、ランダムなアクセスは一般的には統一性(coherent)がある。入力及び出力画像へのシーケンシャルなアクセスが要求される。
不可欠なトリリニア・ワープ・アルゴリズムは次の疑似C++コードで実施される。
前記ガモット圧縮プロセスは、ソースガモットにおける色の違いを維持しつつ、認知できる色の変化を最小限にするという方法で、ソースガモットの色を、より小さなターゲットガモットの色にマップさせようとする。ガモット圧縮の計算は色のワーピングから分断されるので、効果的なガモット圧縮は上述したルックアップテーブルで駆動されるプロセスを用いて実施される。
ガモット圧縮アルゴリズムは3次元ルックアップテーブルの構築を含み、図309を参照して述べたような次の疑似コードで実施される。
ソースガモット又はターゲットガモットのいずれかがパレットフォームにて知られているならば、ガモット多面体はパレットポイントの凸包から計算される。
図310を参照すると、芸術的効果の創造において一般的に活用される処理であって、後述の如くガモット・モーフィングと称される処理を使用して、何らかのソース・ガモット6050をターゲット・ガモット6051にマップさせるために上記処理が使用され得る。ガモット・モーフィングは、ソース・ガモット中の色をターゲット・ガモット中の色へのマッピングを直接コントロールするために使用される。
ガモット圧縮と同様に、ガモット・モーフィングは、画像の色域(ガモット)を特定の芸術的スタイルに似させるために使用されるかも知れない。ガモット・モーフの計算はカラーワーピング処理から分断されるので、ガモット圧縮と同様に、効果的なガモット・モーフィングは、ルックアップテーブルを駆動するアルゴリズムによって実施されることができる。
ガモット・モーフィングと共に、多くのソース・ガモット色(例えば、6053)が、同数の対応するターゲットガモット色(例えば、6054)に直接マップされる。ルックアップテーブル中のマップされたターゲットの残存しているターゲット色は、特定のターゲット色(例えば、6054)の加重和として計算される。そのターゲット色は好ましくは、各ルックアップテーブルのポイントから対応するソースカラーまでの距離の二乗の逆数により重み付けされる。
ガモット・モーフィング・アルゴリズムが次の疑似コードにより具現化される。
前述の技術が最初に画像のガモットを所定のエリアに限定するために使用できることは、コンピュータグラフィックスにおける当業者には明白であろう。続いて、例えば、“点描画法”技術によって与えられると同様の効果を生じさせるため、制限されたガモット画像にブラッシュストロークフィルターが適用される。
技術53の説明
前述のアートカムシステムの基本が図311に符号6501で示されている。そのアートカムシステム6501は、入力としてアートカード6503を必要とするアートカム6502に依存している。該アートカード6503は、出力写真6505の作成のため、画像のシーン(image scene)6504を処理するためのコード化された情報(指示情報)を有し、出力写真は、そのアートカード6503の指示情報に従って大幅に画像処理される。該アートカード6503は極度に高価とはならないようにされており、一面にはコード化された情報を含み、他の面には、アートカム6502に挿入された場合に生成されるであろう効果の描写を含んでいる。
さらなる改善の方法に従って、図312に示すように、多数のアートカード6510が用意され、パックで販売される。各パックは、特定のサイズの衣服の着用に関連しており、カメラにより撮影された画像がマッピングされて衣服6512を着用したモデルの画像(例えば、6511)を有する。そのマッピングは、異なるアートカード6510でha
異なる衣服アイテムとすることも可能である。マッピングアルゴリズムの1つの形態が図313の6520に示される。該アルゴリズムでは、魅力的なワーピングの効果を生成する反復タイリングパターンに画像をマップするというワープマップを使用して、入力画像が最初にワープされる(6521)。もちろん、アートカード6503(図311)により与えられる、多くの他の形式のアルゴリズムが、材料の魅力的な形式を生成するために準備される。
次に、第2のワープ6522は、第1のワープマップ6521の出力を、アートカード中の特定のモデルの画像にワープするために用意される。したがって、ワープ6522はアートカード特有である。その結果は、アートカム写真6505として印刷されるために出力される(6523)。したがって、ユーザは、望みの画像6504をアートカム6502に示すことができ、流行の衣服のモデルを有する画像の処理バージョンを有するアートカム写真6505を作成することができる。この処理は、希望の結果が得られるまで続けることができる。
次に、布についての最終的な選択がなされた場合には、図314に示されるように、インクジェット布プリンタや関連の駆動制御電子機器等を有する布プリンター6534にUSBポートを介してアートカム6502が接続される(6503)。アートカム6502又はインクジェットプリンタ6534のどちらかが、布6535にガーメントピース(例えば、6536)を印刷するようにプログラムされている。ガーメントピースは、アートカードのモデルにより伝えられるのと同じ衣類を作成するため、オリジナルのワープ画像をその表面に有している。
出力された布は、ガーメントピースを繋ぎ合わせるための指示6540に加えて、位置合わせと境界領域(例えば、6539)のためのタブ部(例えば、6538)を有している。好ましくは、その出力プログラムは、衣服の交差した継ぎ目上に連続して発生させるために縁取り部分のワープマッチングへの提供を含む。
さらに、ユーザーインターフェースは、異なった形のボディーを考慮に入れるため、多くの異なった出力サイズを有する同じカードの利用に備えられる。アートカム技術の利用に基づいて、アートカム機構6502の利用によって、カスタムされた衣類の生産と適当な結果の迅速な描写のためにシステムを提供することが出来る。
技術54の説明**
技術56の説明
さらなる改善では、画像の効果を転送するために、先述したようなアートカム装置が複数、USBポートを介して接続されている。各アートカムの内部のコンピュータ部の適切なプログラムにより、画像効果の転送が成し遂げられる。
好ましい配列は、図315に示されているように、一連のアートカム(例えば、6802,6803,6804)がそれらのUSBポートを介して接続されているというものである(6805)。それぞれのアートカム6802,6803,6804には、好適な画像処理プログラムが格納されたアートカード6807,6808,6809が備えられている。さらに、ネットワーク環境を利用するという指示をアートカード6807,6808,6809により与えることができる。そして、アートカム6802により検知された画像6810は、アートカード6807上の処理プログラムによって処理される。アートカード6808によって画像処理機能が適用されるアートカム装置(一連のアートカム装置の内の次のアートカム装置)6803に、その結果が転送される(6805)。このような目的のため、各アートカム装置は2つのUSBポートを持つように修正されている。最後のアートカム装置6804は、前述した画像処理の集積である出力6812を作成するため、アートカード6809に格納された処理を適用する。
したがって、図315の構成6801は、1つの検知画像に対して多様な効果を与えることができる。もちろん、多くのさらなる改良は可能である。例えば、それぞれのアートカムは、次のアートカムへ画像を転送することに加えて、自身が処理した画像を印刷することもあり得る。加えて、経路を分離して、1つのアートカムを2つの異なった下流側アートカムに出力し、異なる最終画像を出力するようにする。加えて、ループ等も利用される。
技術57の説明
さらなる改善では、開示されている技術は、双眼鏡セットに組み込まれるように適合されていて、双眼鏡のユーザからの要求により画像を印刷できるようになっている。まず、図316を参照すると、双眼鏡システムの一例が開示されている。該双眼鏡6901は、公知のタイプのものであり、本発明の原理に従って変形される。該双眼鏡は、レンズ入力を有する通常の光学レンズシステム6902,6902を有する。2つのレンズシステムは、コネクタープレート6906にヒンジシステム6904,6905を介して取り付けられている。その配列は大体従来的である。
第1の光学レンズシステム6902はビーム・スプリッタ装置6908を有しており、該装置は、光学システム6902に入射された光の光路6909を2つの光路に分割する。第1の光路6910は、CCDシステム6914が取り付けられた側に向けられる。第2の光路6911は、接眼部6915の方向へ向けられる。該ビーム・スプリッタ装置6908は、光線6911の出力強度を弱くさせることとなる。したがって、光学レンズシステム6902の中のビーム・スプリッタ装置6908による減衰と一致させるようにするため、減衰フィルター6918を配置しても良い。
したがって、CCD撮影装置6914は、光学レンズシステム6902で見るのと同じシーンを撮影することとなる。該CCD装置6914は、アートカム中央プロセッサやメモリー装置を有するプリント基板6920に取り付けられた処理システムに接続されている。そのアートカム中央プロセッサ装置は、重要な画像処理機能を有しており、画像をキャプチャーするように前記CCD装置を制御し、プリントヘッド装置6923を使用して画像を印刷するようにする。プリンターには、プリントメディアにインクを吐出するインクジェットプリント装置を使用する。該プリントメディアは、プリントメディアと印刷用インクとを含む着脱可能な使い捨て型プリントロール6925から供給される“紙”フィルム(実際には、適切なポリマー)からなる。該プリントロール6925はハウジング6925に収容されており、該ハウジングにはバッテリー6927が着脱可能に配置されている。
ユーザがボタン6919を押し下げると、アートカム中央処理装置は、シーンを撮影するためにCCD6914を作動させる。CCD装置6914によってキャプチャーされた画像はACPプロセッサによって処理され、撮影したシーンを即座に永久的に記録すべく、プリントヘッドに転送されて即座に印刷される。プリントヘッドは再び上述のようになる。
多くの改良が、さらなる改善を成し遂げることができる。例えば、アートカム中央プロセッサーに接続されるUSBポートが提供されて、画像処理アルゴリズムを双眼鏡6901にプレロードできるようにしても良い。そのルーチンを作動させるための一連のボタンを配置するようにしても良い。そのルーチンは様々な画像強調操作等を含む。加えて、画像の特徴を強調するため、多くの異なる方法で出力画像を修正するようにしても良い。日時や場所についての関連情報を画像に自動的に掲載することにより画像をさらに特徴付けるようにしても良い。加えて、観察者の座標もまた出力画像に即座に印刷されるように、該双眼鏡をGPSに接続しておいても良い。加えて、被写体の場所を特定するための距離測定装置の提供や、該被写体に関する情報の前記出力画像への表示のような他のオプションが行われるようにしても良い。
技術58の説明
技術59の説明
さらなる改善では、開示された技術が、カード表面にフォールト・トレラント・データ配列を与えるために利用される。該データは、他のフォールト・トレラント配列に書き換えることによりアップデートされる。
まず、図317を参照すると、カード表面にデータ(例えば、7102)が書き込まれて、完全にデータ配列が書き込まれた後のカード1701が示されている。各データ配列(例えば、7102)は、カード表面に示されている64個のデータブロックの配列で、約20KBの情報が符号化される。もちろん、他の配列は、各データブロック(例えば、7102)の中に書き込まれるデータ量をより少なくすることも、より多くすることも可能である。初期状態では、該カード7101はデータブロックは有していない。代わりに、多分、1つの利用データブロックがそのカードの表面に書き込まれている。
図318を参照すると第2のカード7105が示されており、該カードでは、書き込まれた最後のデータブロックであるところの最新のデータブロック7106で12回“アップデート”されている。したがって、各カード(例えば、7105)は、該カードに与えられたデータブロック数に従ってアップデートされ、何回も使用される。
図319を参照すると、1つのデータブロック(例えば、7108)の構成が示されている。該ブロックは、“アートカム”技術の縮小バージョンである。そのデータブロック7108はデータエリア7109からなり、該エリアは、印刷されたドット配列を有し、該ドットは、縁に沿った一連のクロック・マークに加えて、1画素幅のボーダーを有する。そのデータエリア7109のエッジに沿ってターゲット7110が配置され、該データエリア7109の位置決め及び読み取りをアシストするようになっている。各ターゲット7110の構成は図320に示される通りであって、たった一つの白のドットを囲む、大きな黒エリアからなる。もちろん、他の構成も可能である。該ターゲット7110はデータエリア7109を正確に位置決めするために提供される。さらに、それらのターゲット7110は、さらに、正確に検知され、正確な位置情報を導き出すために提供される。
図321を参照すると、カード読み取り及び書き込み装置7120が示されている。図321の要点部分の拡大は図322に示されている。該装置7120は、情報が印刷されるカード7122を挿入するための細長い隙間7121を有している。多くのピンチローラー(例えば、7123,7124)が、プリントヘッド7125やリニアCCDスキャナー7126を横切るようにカードの移動を制御する。該スキャナー7126は、下を通過するデータをスキャンする。図322には、挿入されたカード722のためのプリントヘッド7125及びCCDスキャナー7126の配列の拡大図が示されている。
図323を参照すると、CCDスキャナー7126へカード7122が挿入される様子が概略的に示されている。CCDスキャナー7126は、該スキャナーを通過するようにカード7122を搬送し、カード7122に保存されている情報が、CCDスキャナー7126に取り付けられているアートカム中央プロセッサユニットによってデコードされる。カードリーダーからカード7122を取り出したい場合、新たなブロックのカードへの書き込みが必要か否かの決定がなされる。新たなブロックの位置は前にスキャンされたCCDデータから分る。カードの取り出しは、カードをプリントヘッド7125及びCCDスキャナー7126を通過するように、図324に示されるようにして行われる。スキャナー7126はカード7122の現在位置をモニターしており、図325に示すように、四角の領域7128を新しいデータでアップデートすることが望まれる場合は、プリントヘッド7125によりインク滴を吐出する。そして、フロッピーディスクなどと似たような方法でカードは装置(図321)から取り出される。そして、そのカードは、全てのデータスペースが埋め尽くされて新たなカードが作成されるまで、継続的に使用される。
それゆえ、カードを安価に作成し、情報配置のため弾力的な方法で利用可能であるという点で、前述のカードシステムの利用は、情報配置の効果的で安価な形式を提供するということが明白だろう。
図326を参照すると、アートカード読み取り装置に利用される異なる機能のブロック図が示されている。プリントヘッド7125やリニアCCD7126は、適切にプログラムされたアートカム中央プロセッサー(ACP)チップ(ACP)7130の制御により操作される。ACP7130は、スキャンされたデータや他のデータ及びプログラムを保管するメモリー7131を備えている。さらに、ACPは、ピンチローラーを作動させる種々のモータ7132を制御する。もちろん、要求に応じて他の制御ボタン等も配置され得る。そのような編成の利用は、カード表面に格納された情報のモニタリングやアップデートのためのシステムを提供する。
技術60の説明
さらなる改善では、ユーザの要求に応じて自身のアートカードを作成できるアートカード写真自動販売機が提供される。該自動販売機は通常の写真自動販売機と同様の方法で構成されるが、与えられた時間内にアートカードを自動作成するように構成されたコンピューテイショナル・リソースの要求のみが本質的要素ではない。
まず、図327を参照すると、さらなる改善7201の機能要素が図解的に示されている。さらなる改善7201は、ユーザーの見本写真7203をスキャンするための高解像度スキャナー7202を有している。また一方、そのスキャナー7202をオプションとして、付加された度合いのリアリズムをアートカード作成システムに与えるため、ユーザが彼らの写真を処理することを許容しても良い。スキャナー7202によってスキャンされた写真7203は、適正なオペレーティングシステムとプログラムを有するハイエンドのPCタイプのコンピュータである基幹コンピュータシステム7204に転送される。該コンピュータ7204は、スキャンされた写真のストレージ、並びに写真プリンター及びアートカードプリンター7205のコントロールをする。写真プリンター及びアートカードプリンター7205は、好ましくは出力されたプリントメディアの両面に印刷することができ、前に開示したような印刷技術を使用することができる。該プリンター7205は、アートカード7207に加えてユーザの写真7206の処理されたものを出力する。アートカードは両面が印刷される。写真7206を生成するため、写真7203の画像処理のための符号化された指示を含む。該符号化された指示はアートカードフォーマットに出力される。
該コンピュータシステム7204は、また、標準的なタッチ・スクリーン・タイプのようなユーザ・インターフェース7209を有している。該コンピュータシステム7204は、また、支払いシステム7210をコントロール又は内蔵している。該支払いシステム7210は、標準的なコイン又は紙幣の支払いシステム、或いは、取引の承認のためのクレジットカードのサービスプロバイダと適切なネットワーク接続をするクレジット支払いシステムより成る。加えて、エフトポス(EFTPOS)設備が提供されるかも知れない。
ユーザが彼らの写真7203をスキャナースロット7202に挿入すると、写真はスキャンされ、保管され、続いて排出される。次に、“フォト・ブース”内に位置するユーザ・インターフェース7209をユーザが操作する。該ユーザ・インターフェース7209は支払いシステム7210に金を支払うための指示を最初に行う。しかしながら、該ユーザ・インターフェース7209の中核は、タッチスクリーンによる様々なアートカードの創作である。
好適なユーザ・インターフェースの一例は、図328に示される。該ユーザ・インターフェースの中核は、後に述べる方法で処理される多くの見本サムネイル画像7213をユーザに示すことで構成される。最初に、例えば、会社のイベントや、誕生日のイベントや、季節のイベントや、処理のタイプ等のような画像の処理7213がサブジェクトエリアに配置される。ユーザは、タッチスクリーンによって好みの画像(例えば、7213)を選択する。好みの画像が存在しない場合、ユーザは矢印ボタン7214を押して、他の処理を表示させることができる。ユーザが画像7213を選択したとき、その画像に似た“テーマ”を有して、一連の処理を提示する代替物の生成にその画像が使用される。そのユーザは、選択された種類から画像を選択することを継続できる。
好みの画像はセーブボタン7217の使用によりセーブすることができる。そして、そのユーザ・インターフェースは、セーブされている選択7218を示す。ナビゲーション・ボタン7215は前画面に戻るためのものであり、ナビゲーション・ボタン7216hは上位に戻るためのものである。この方法によれば、ユーザは、彼ら自身の特有のカスタマイズした要求を作るため、様々なアートカードを検索することができる。この方法によれば、独特の芸術的創作活動が、独特のアートカードの作成を促す。
そのような様々なアートカードの作成は、作成プロセスにおける創作者の役割をユーザに与える遺伝的アルゴリズム技術に依存している。ここで、図329を参照すると、図327のコンピュータシステムにて実行されるアプリケーションのソフトウェア・レイアウトの例が示されている。該ソフトウェア・レイアウト7220は、実行できる画像処理の遺伝的プール7221と、特定の画像に適合させるテーマ処理とを備えている。この遺伝的プールは、新たな種類(属)の生成のための遺伝的アルゴリズム・コアによって利用される。遺伝的アルゴリズムの標準的なテキストを紹介すると、例えば、この分野において最新の処理が加えられている“遺伝的アルゴリズム”Golberg著がある。或いは、遺伝子のプログラミングの分野は利用され得、そして、この点で、“遺伝子プログラミング”と題名づけられたKozaによる一般的な研究を参照する。
前記遺伝的アルゴリズムのコアは、また、新たで好適な画像を作成する際に、ユーザの選択7223を使用することができる。該遺伝的アルゴリズムのコアの出力は、タッチスクリーンディスプレイに表示するためにユーザインターフェースモジュール7225に転送される、適切な新しい画像を含む。
再び図328に戻ると、ユーザが好みの選択を発見すると、受け付けボタン7219を押すことができる。これにより、ユーザによる支払いが要求されるとともに受け付けられる。また、アートカード7207を受け入れる他の装置(例えば、上述したアートカム装置)でユーザが利用できるように、アートカード7207には、一連の画像処理に加えてプリンタ7205に画像を出力させる指示がコンピュータシステム7204(図327)によりなされる。
したがって、ユーザが別々に利用することのできる、複雑な、自分の名前を記入するようにカスタマイズされた画像を作成するシステムがさらなる改善によって提供されることは、当業者には明らかだろう。多くの画像の利用は、同様に重要な個性化に導くことのできるアートカードの重要な結合の急変動をもたらす。
もちろん、多くの他のタイプの中核技術が画像の構築に使用されることができる。例えば、他の非遺伝的技術が適するかも知れない。最悪の場合、各画像の選択は手動で用意される。さらに、他のユーザーインターフェース機構が提供され得る。加えて、本発明は、標準のコンピュータシステムのような、自動販売機で無い環境で実行されることもできる。
更なる改良の操作は、個人の創造性の重要な表現に備える。そして、芸術家による個々の創造が個々の芸術家等のアートカード“シリーズ”を提供する際に重要な価値を呈するかもしれないと考えられる。
技術61の説明
技術62の説明
上述したアートカム配列の基本は、概略図の形態で図330に示されている。この配列は、画像やシーンを検知するためのCCDセンサー7402を有する。加えて、検知画像を処理するための画像処理アルゴリズムであってコード化されたものについての、アートカード7408の読み取りを行うために、アートカード読み込みセンサー7403が提供される。該CCDセンサー7402と該アートカード読み込みセンサー7403の両方は、検知した画像の処理のために複雑な計算能力を与えるアートカード中央処理ユニット(ACP)7404に接続されている。加えて、メモリーユニット7405が、画像や、検知したデータや、プログラムなどを保存しておくために用意されている。ACP7404に接続されているのは、内部のプリントロールから供給されるプリントメディアに最終的な写真7404を印刷するためのプリントヘッド7406である。
さらなる改善では、独特な一連のアートカード7408がアートカード・リーダー7403に挿入されることにより、アートカム中央プロセッサー7404の独特のコントロールがなされる。第1の例は、図X2や図332に示されるものであって、重ね合わせた、或いは増大する画像の効果を与えるためのマルティプル・アートカードの使用を提供する。適切な複製アートカードは、図332に7410で示されたものであって、効果を生じさせるためにどのようにカメラ装置を操作するかに関しての指示が一側面に設けられている。他側の面には、その効果を生じさせるためのアートカム装置の操作の指示が設けられている。図331を参照すると、組み合わせた効果を生じさせるためのリピティションカードの操作の例が示されている。アートカムシステムは、あるシーンの検知画像又は保存画像を有している。第1のステップは、リピティション・モードにするため、アートカムシステムの操作を変更するコードを有するリピティションカード7413を挿入することである。続いて、第1のアートカード7414がアートカード読み込みセンサー7403に挿入され、そのカード7414の指示に従って画像に第1の効果が与えられる(符号7415参照)。続いて、リピティションカードが再び挿入され(符号7416)、次に、第2のアートカード7417が挿入され、例えば、画像にテキストメッセージを配置するという第2の効果が与えられる(符号7418)。次に、再びリピティションカード7419が挿入され、その後、第3のアートカード7420が挿入されて、さらなる効果が画像7421に与えられる。図331のプロセスは、所望の出力画像の形成のため、要求に従って繰り返し行われる。この方法によれば、1つの効果だけを有するアートカードから組み合わせの効果を作成するため、柔軟性を持って上述した装置が使用される。さらに、提供されるユーザ・インターフェースは、組み合わせの効果を作成する上において、シンプルで効果的である。もちろん、多くの変更を行うことができる。例えば、別の実施例においては、リピティションカードは1回だけ挿入され、一連のアートカードがそのリピティションカードに続いて挿入される。
図333を参照すると、アートカムシステムの内部テストのための、別のアートカード7430が示されている。一つ一つのアートカムシステムには多くの内部テストルーチンが内部ROMに用意されている。そのテストは、アートカム中央プロセッサーに用意された翻訳言語での、特別な関数呼出しによりアクセスされる。そのルーチンは、アートカム装置の仕様であり、例えば、
プリントヘッドの動作状態を判断するためのテストパターンのプリントアウトと;
ノズルのクリーニングのため、及びプリントヘッドの操作が改良されるようなノズル配列のため、プリントヘッドの操作処理を行うテストパターンのプリントアウト(例えば、全てが黒のプリント)と;
プリントヘッドの操作の有効性を示すため、後の分析のためにテストパターンがプリントされること;
が含まれる。
図334を参照すると、テストパターン7437のプリントアウトに加え、参考になる様々な内部データを有するテスト・アウトプット7435の見本が示されている。そのテストパターン7437は、そのカメラシステムに存在しているかも知れない何らかの問題を割り出す自動的又は主導的な方法によって後で調査することができる。さらなる改善は、アートカム装置にプログラムされ、ROMメモリーに格納されているソフトウェア・ルーチンの使用を通じて実行される。
もちろん、前記ルーチンがアップデートされたり、変更されたりすることで、多くの改善が予想され得る。多くのテストは実際には制限されない。この方法によれば、カメラ装置の操作は、挿入されるカードに従って変更され得る。
技術63の説明
技術64の説明
さらなる改善では、出力写真の裏面に音声メッセージを記録するために磁気感受性プリントメディア材料が使用される。アートカム装置は、写真の全面を覆う磁気レコーダの配列や、或いは、例えば、磁気的感受性のある写真中央部のような、磁気帯からなる磁気記録装置を含むように改変される。該アートカム装置にはさらに後で再生するための音声メッセージを録音できる能力が与えられる。
さらなる改善では、アートカム装置は、マイクロフォン装置や関連の録音技術を装備するように適当に変更される。写真を撮影するとき、周囲の音環境か、その画像に関係するメッセージのいずれかを録音する機会が与えられる。そのプリントメディア又はフィルムは、テープメディアと同じように、磁気感受性を有するように前処理されている。出力写真の裏面全体、或いは磁気感受性帯に録音がなされる。録音された音声は、コード化された形式で出力写真の裏面に保持される。そのコード化は、好ましくは、高度なデジタル再現性のある形式である。その録音された音声は写真に関係する、永久的な音声録音を提供する。次に、再生装置は、コード化された音声をスキャンし、この情報を復号化するために提供される。
図335を参照すると、上述した構成、つまり、画像7602がCCDセンサー7603により検知されアートカム中央プロセッサ7604に転送されるという構成を含むさらなる改善7601が、概略形式にて示されている。該アートカム中央プロセッサ7604は、好ましくは高速RAMBUS(登録商標)インターフェースのメモリーからなるメモリー7605に画像を格納する。また、アートカム中央プロセッサ7604は、写真の裏に記録をするための磁気記録ヘッド7616に加え、プリントヘッド7606(要求に応じてインスタント画像を提供するため、フルカラー写真7607を印刷するためのもの)の操作をコントロールするようになっている。
さらなる改善では、カメラ編成7601は、ACPプロセッサ7604の制御下でRAMBUSバス7611経由でメモリー7605にインターフェース接続されているサウンドチップ7610を備えている。該サウンドチップ7610は、標準的形式とすることも、或いは専用形式とすることもでき、例えば、サウンドマイクロフォン7613からのアナログ入力7612を取得するDSPプロセッサを備えることができる。もう一つの方法として、チップの複雑さに伴って(ムーアの法則)、サウンドチップ7610の機能を、好ましくは最先端のCMOS型集積回路チップを備えるACPチップ7604に組み込むことができる。本発明の範囲内に該当する他の多くの種類の編成を提供できることは容易に明白であろう。
サウンドチップ7610は、アナログ入力7612を対応するデジタル形式へ変換し、それをメモリー7605に格納するために転送する。そのような記録プロセスは、カメラ装置上のボタン(図示せず)を押すことによって作動させることができる。該ボタンはACPプロセッサ7604の制御下にあるか、そうでなければ、写真を撮るときに実質的に自動化されることができる。記録されたデータは、メモリー7605に格納される。
図336を参照すると、カメラ編成は、好ましくは、プリンター装置7606(プリントメディア7617に画像を印刷するのに使用されるプリントヘッドを有する)と磁気記録プリントヘッド7616(プリントメディア7617の裏面に情報を印刷するのに使用される)とを備えている。図337を参照すると、フォトメディア7617の裏面に形成された磁気帯7618の出力例が示されている。その磁気帯は図336の記録ヘッド7616によって記録される。記録された情報は、場所や日付や時間のデータを含み、場所のデータはキーボード入力により、或いは、GPSや同様のもののような、付属の位置決めシステムの利用によって与えられる。重要なことには、画像7617の裏面に、コード化された音声情報が記録される。コード化の方法には多くの様々なものとすることができるが、好ましくは、エラーを許容するように、高度なフォールトトレラント方法でコード化される。その高度化の形式は、高度なフォールトトレラントを提供するため、データのリード・ソロモン符号化を利用するようにしても良い。
図338を参照すると、録音された音声を“再生”したいときは読み取り装置7626を用い、ピンチローラーにて写真7617を挟み込みながら磁気センサー装置7627を通過させる。
図339を参照すると、図338の音声読み取り装置7626の操作が概略形式で示されている。前記磁気センサー7627は第2のアートカム中央プロセッサ7628に接続されていて、写真の裏面に格納されているデータを読み取って復号化するようになっている。その復号化された音声情報はメモリー7632に格納され、サウンド処理チップ7633を介してスピーカー7629で再生される。そのサウンド処理チップ7633はACPデコーダー7628の制御下で操作され、ボリュームコントロールや巻き戻しや再生や早送り等の、ユーザの様々な入力制御7633に基づき順に操作される。
さらなる改善についての上記説明から理解できるように、出力画像に関係する音声の自動録音のためのシステムが提供され、写真に関係する音声録音が行われる。また、写真の裏面に記録された画像を読み取るための音声読み取りシステムも開示される。数多くの変更及び/又は修正が、大まかに説明された本発明の精神または範囲から逸脱することなく、特定の実施の形態に示されるような本発明へなされてもよいことは、当業者によって理解されよう。例えば、ステレオおよびBフォーマット技術等のような、より複雑な音声録音再生技術への利用である。
技術65の説明
さらなる改善では、プリントヘッドを使用して“ネガ”を印刷するよう、上述したアートカム装置が適正にプログラムされる。該ネガは、アートカード・センサー装置に挿入されて利用できるよう、標準的なアートカード形式に適合している。アートカード・センサー装置は“ネガ”アートカードに格納された情報を検知し、写真を印刷する。
まず、図340を参照すると、要求に応じて画像を検知するセンサー装置7702と、アートカード情報を検知するためのカード読み取りセンサー7703とを備えた標準的なアートカム装置7701が、概略形式で示されている。それらのセンサー7702,7703は、アートカム装置の操作のための重要な計算手段であるアートカム中央プロセッサ7704の制御下で操作される。そのアートカム中央プロセッサ7704は、完全にベクトル化されたVLIW(very long instruction word)中央プロセッサに加えて、オンボードCPUを含むことができる。ACP7704は、取得した画像7702の処理に加えて、アートカード読み取り装置7703にて読み取ったアートカード(情報)の処理及び復号化を行う。内部プリントロールにより供給されるプリントメディアにプリントヘッド7706により印刷する処理画像を形成し、写真7707を出力するため、ACP7704はメモリー7705との間での処理を行う(interact)。該アートカムシステム7701は、完全なポータブルカメラシステムを構築するように設計されており、プリントヘッド7706(該プリントヘッドは、ACPプロセッサ7704の制御下において要求により写真7707の印刷を行うためのものである)に接続されたプリントロール(内蔵型で使い捨てできるものであって、印刷メディア及びインクを供給するためのものである)を備えている。
図341を参照すると、図340のアートカムシステムの操作のステップであって、さらなる改善に従ったもの7710が示されている。さらなる改善では、まず、第1のアートカム装置を使って所望の画像が撮影される(7710)。次に、高度なフォールトトレラントであって、回復される出力データ形式を提供すべく、該撮影画像が処理される。その処理は、画像、複製されたデータ、データ値の配列にデータを疑似ランダムに展開するのに加えてリード−ソロモン符号化データの圧縮を含むことができる。その出力形式は、必要なら、画像の圧縮に加え、上述したような“アートカード”装置により提供されるのと同じにできる。アートカードの出力データに加え、検知画像のサムネイル画像がその符号化されたデータに沿って印刷される。
そのアートカード編成は、図342に示されるように、CCDセンサー7702によって画像7720を取得すると共に、アートカムの“ネガ”のもの7721を出力するアートカム装置7701を備えている。該“ネガ”形式のものは、入力画像のサムネイル7724と、検知画像を高度に符号化したもの7722とを含む。図342には示されていないけれども、その出力されたものは、アートカム装置7701内の裁断装置によって線7725に沿って通常は切り取られる。
データエリア7722は、該エリア7722の側縁に沿った一連の印(例えば、7727,7728)と共に印刷される。それらの印7727,7728は、スキャンされるときにデータエリア7722の正確な位置を与える。“ネガ”7721を印刷することにより、画像の半永久的な記録が得られる。この“ネガ”7721は、写真のネガを保存するのと同様の方法により保存される。取得した画像の、さらなる、高品質なコピーを必要とする場合には、前記アートカード“ネガ”が、図342のアートカム装置のアートカード読み取り装置7703の中へ挿入され(図341の7713)、アートカードデータは通常の方法で復号化され、オリジナル画像が得られる。符号化されているデータは、オリジナルな画像と、該画像をアートカム装置により印刷するために必要な指示を含むことができる。検知されたカードは復号化され(図341の7714)、要求に応じて何度も印刷され(7715)、オリジナル画像が得られる。つまり、検知された画像が出力される。よって、検知された画像を高解像度と高い回復力でコピーするシステムが得られる。
他の実施例も構成することができる。例えば、前記“ネガ”データを、写真面の裏面に自動印刷する編成を利用しても良い。そのような編成は図343に示される。該図に示されるものは、写真7730の裏面であり、サムネイル部分7732に加えて、データ符号化エリア7731が印刷されている。したがって、該データエリア7731は、該カード7730の表面において、画像に関しての、半永久的で、高い精度の記録を提供することができる。
技術66の説明
さらなる改善では、ランダムな出力の要求に応じて多数のアートカードを出力できるアートカード・プリンターが提供される。その製品のプリンターは、ネットワークを介して他の製品のプリンターと接続され、総合コンピュータシステムが、所定の要求に従ってアートカードを分配するためにネットワークを制御する。このような方法で、高い柔軟性を与えるため、アートカードの製造がコントロールされる。
図344を参照すると、たった一つのアートカードプリンター7801が概略図の形式で示されている。該プリンターは、アートカードの上面に画像を印刷するためのプリントヘッド7802、及びアートカードの下面に画像取扱説明書(符号化されたもの)を印刷するためのプリントヘッド7803の2つのプリントヘッド7802,7803を備えている。該プリントヘッド7802はインク供給部7806を有する3色のプリントヘッドにすることができる。下面プリンター7803は1つのインク供給部7807を有する単色プリントヘッドにすることができる。プリンター7801は、要求に応じてアートカードをプリントアウトすべくコンピュータシステムの制御にて操作される。印刷した後、ベースプレート7810(流通目的のために多数のアートカードが配置されたもの)からアートカードを打ち出すためにパンチ装置7809が配置されている。所定の区域の要求に従った分配。
図345を参照すると、アートカード交付システムの制御ネットワーク7820の一般的な配列が示されている。一連のプリンターコンピュータ装置(例えば、7821)が配置され、要求に応じて様々な形態を取ることのできるネットワーク7822に一緒に接続されている。中央統合コンピュータ7823がネットワーク7822及びプリンターコンピュータ(例えば、7821)を制御して、プリンターコンピュータ(例えば、7821)によってアートカードの組み合わせたものを印刷する指示を送るようになっている。プリンターコンピュータ(例えば、7821)は、要求に応じて地方に配置することができる。或いは、それらのプリンターコンピュータを中心(centrally)に配置しても良いが、様々な地方に送られ、或いは、様々な要求を満足するために命令されるかも知れない。それぞれのプリンターコンピュータは、アートカードの大きなキャッシュを有することができる。そのキャッシュは、メモリーや、ディスクや、各プリンターコンピュータに適宜配布されるCD−ROMに設けることができる。中央統合コンピュータは、プリンターコンピュータによって印刷されるべきアートカードのリストを配布する。加えて、新しいアートカードが該中央統合コンピュータ7832に読み込まれ、要求に応じ、関連するプリンターコンピュータ(例えば、7821)に送られる。その配布は、キャッシュされた配布配列の形式である。
図346を参照すると、プリンターコンピュータの好適な編成7830の1つの形態が示されている。その編成7830は基幹コンピュータシステム7831を備え、該コンピュータシステム7831は、大きなメモリやディスクキャパシティを持つ、ハイエンドのPCタイプのコンピュータである。そのコンピュータシステムは7831は、図344の編成に従って配列されたアートカードプリンター7832に接続されている。該コンピュータシステム7831は、ネットワーク7834に加えて、キャッシュされるアートカード7833の大きなストアを備えている。よって、プリントアウトされるべきアートカードのリストは前記中央コンピュータから各プリンターコンピュータへ、アートカードの印刷のために転送される。
図345の編成では、大きな組み合わせの複雑な配布の問題が打開され、配布のシステムの改良された形態であることが分る。
インクジェット技術
本発明の実施例はインクジェットプリンタ型装置を使用している。もちろん、多くの異なる装置を使用することができる。しかしながら、現在ポピュラーなインクジェットプリント技術は適していそうにも無い。
サーマルインクジェットでの最も重要な問題は電力消費である。インク滴の射出のエネルギー効率が悪いことに起因し、高速のために必要な電力は約100倍である。インクを吐出させる蒸気泡を生成するために、水の迅速な沸騰を必要とするからである。水は大変高い熱容量を有していて、サーマルインクジェットの利用において過熱される。これは、電気の入力を運動の出力に変換するため、約0.02%の効率を必要とする。
ピエゾエレクトリックインクジェットでの最も重要な問題はサイズとコストである。ピエゾエレクトリッククリスタルは適当な駆動電圧にて非常に小さなデフレクション(deflection)を有していて、それ故、各ノズルのために大きなエリアが必要となる。また、各ピエゾエレクトリックのアクチュエータは、分離した基板の駆動回路に接続されなければならない。このことは、300程度のノズルの電流制限においては重要な問題ではないが、19,200のノズルを有するページ幅プリントヘッドの製造には大きな障害となる。
理想としては、使用されたインクジェット技術は、非公開のデジタルカラープリンティングや、他のハイクォリティでハイスピードでローコストのプリント利用が要求される。デジタル写真の要求に合わせるため、新たなインクジェット技術が創出されてきた。目的の特徴は次のものである。:すなわち、
低電力(10ワット未満)
高解像度性能(1,600dpi又はそれ以上)
写真クォリティの出力
低製造コスト
小サイズ(横切り幅が最小となるようにページ幅を調整する)
ハイスピード(<1頁当たり2秒)
これらの特徴の全ては、後述するインクジェットシステムにより、異なるレベルの困難さで突破されることが可能である。45個の異なるインクジェット技術は、高ボリュームの製造のために幅広い選択を与えるよう、受け継ぐ者によって発展されてきた。これらの技術は、後に記載する表に示すように、本出願人に指定された分離された応用を形成する。
ここに示されるインクジェットの設計(デザイン)は、電池で駆動される1回使用のデジタルカメラから、卓上のネットワークプリンタや業務用のプリントシステムまで、幅の広いデジタルプリントシステムに適している。
標準の装置を使用して簡単に製造するために、前記プリントヘッドは、MEMS後処理法によって、モノリシックの0.5ミクロンのCMOSチップに設計される。カラー写真の応用のため、前記プリントヘッドは100mmの長さで、インクジェットのタイプに応じた幅を有する。最小のプリントヘッドはIJ38であり、幅は0.35mmで、35mm2のチップ面積を有する。そのプリントヘッドは19,200個のノズルとデータ及び制御回路を有している。
インクは、射出成形されたプラスチック製のインク通路を経由して、プリントヘッドの背面に供給される。そのモールディングは50ミクロの特徴(features)が必要とされる。その特徴は、標準的な射出成型工具の中にリソグラフィでマイクロマシン加工されたインサートを使用して形成されることができる。インクは、ウエハの正面に形成されたノズル・チャンバーへ、ウエハを貫通するように形成された孔を通って流れる。そのプリントヘッドはTABによりカメラ回路に接続されている。
相互参照付きのアプリケーション
次表は、最近出願された米国特許出願のガイドである。それらの出願は、これと共に一斉に提出され、特別なケースに言及するときに、その後の表で使用される参考を用いて検討されている。これらの出願は、また、対応する参考番号を有するオーストラリア仮特許出願(前述の表にて示されたような)のように出願されている。
ドロップ・オン・デマンド方式のインクジェット
個々のインクジェットノズルの基本動作に関する11個の重要な特徴が特定されてきている。これらの特徴は大体は直角(orthogonal)であり、したがって、11次元のマトリクスとして解明されることができる。このマトリクスの11軸のほとんどは、本出願人により発展された記入事項を含む。
次の表は、インクジェットタイプの11次元の表の軸を形成する。
アクチュエータ・メカニズム(18タイプ)
基本動作モード(7タイプ)
補助のアクチュエータ(8タイプ)
アクチュエータの増幅及び改良方法(17タイプ)
アクチュエータの動き(19タイプ)
ノズル補給方法(4タイプ)
吸入口への逆流を制限する方法(10タイプ)
ノズルの掃除方法(9タイプ)
ノズルプレート構造(9タイプ)
滴の噴出方向(5タイプ)
インクタイプ(7タイプ)
これらの軸により表示された完全な11次元の表は、インクジェットノズルに関し、369億の可能な形態を含む。様々なインクジェット技術においてそれらの全てが実現可能ではないけれども、数百万は実行可能である。可能な形態の全てを説明することは、明らかに非現実的である。その代わり、いくつかのインクジェットタイプが詳細に吟味されてきた。それらが、上述の、指名されたIJ01からIJ45である。
他のインクジェットの形態は、11軸の1又はそれ以上に沿って代替となる形態に置き換えることにより、これらの45の例から直ちに導き出すことができる。IJ01からIJ45のほとんどは、何らかの現在利用できるインクジェット技術より上位である特徴を、インクジェットプリントヘッドに作り込むことができる。
発明者に知られている先行技術例がある場合には、これらの1又はそれ以上が、下記の表の例の欄に示される。該IJ01からIJ45のシリーズはまた、例の欄にも示されている。幾つかのケースでは、プリンタが、1つ以上の特徴を共有する場合には、1つの表に1回以上示されるかも知れない。
好適な応用は以下のものを含む。すなわち、家庭用プリンタ、オフィス用ネットワークプリンタ、短期用デジタルプリンタ、業務用プリントシステム、布用プリンタ、ポケットプリンタ、インターネットwwwプリンタ、ビデオプリンタ、医療用画像、大判プリンタ、ノート型パソコン用プリンタ、ファックス機、工業用プリントシステム、写真コピー機、写真現像店等。
前述した11次元のマトリクスで関連付けられた情報が以下の表に示される。
相当数の新型のインクジェットプリンタが、好適な実施形態として、インクジェット技術に取って代わるために発展してきている。インクジェットデバイスの様々な組み合わせが、本発明の一部として開示されているプリンタデバイスの中に含めることができる。相互参照表により特別に示される、これらのインクジェットに関連するオーストラリアの仮特許の明細書がある。すなわち、
インクジェットの生産
さらに、本出願は、多数のインクジェットプリンタの構築に、高度な半導体製造技術が使用されるかも知れない。好適な製造技術は、次の相互参照表に示されているオーストラリア仮特許の明細書中に開示されている。
流体の供給
さらに、本実施例は、インクジェットヘッドへのインク配送システムを利用しても良い。一連のインクジェットノズルにインクを供給するための配送システムは、次の相互参照表に示されているオーストラリア仮特許の明細書中に開示されている。
MEMS技術
さらに、本願は、インクジェットプリンタの配列を行う際に高度な半導体マイクロエレクトロメカニカル技術(MEMS技術)を利用しても良い。好適なマイクロエレクトロメカニカル技術は、次の相互参照表に示されているオーストラリア仮特許の明細書中に開示されている。
IR技術
さらに、本願は、次の相互参照表に示されているオーストラリア仮特許の明細書中に開示されているような使い捨てカメラシステムを利用するようにしても良い。
ドットカード技術
さらに、本願は、次の相互参照表に示されているオーストラリア仮特許の明細書中に開示されているようなデータ配信システムを使用するようにしても良い。
アートカム技術
さらに、本願は、次の相互参照表に示されているオーストラリア仮特許の明細書中に開示されているアートカム型装置のようなカメラとデータ処理技術を使用するようにしても良い。
当業者にとって、特定の実施例に示された本発明に対して、広範に述べられた発明の範囲及び精神から離脱することなく多様な変形や変更を加えることが可能である。本実施例は、従って例外的なものであり、制限的なものではないものとあらゆる面で考慮すべきである。
好適な実施例によって構成されたアートカム装置の説明図である。
主要なアートカム電子コンポーネントの概略ブロック図である。
アートカム中央プロセッサの概略ブロック図である。
VLIWベクトルプロセッサの詳細図である。
処理ユニットの詳細図である。
ALU188の詳細図である。
入力ブロックの詳細図である。
出力ブロックの詳細図である。
レジスタブロックの詳細図である。
クロスバー1の詳細図である。
クロスバー2の詳細図である。
読み出しプロセスブロックの詳細図である。
読み出しプロセスブロックの詳細図である。
バレルシフタブロックの詳細図である。
アダー/ロジックブロックの詳細図である。
乗算ブロックの詳細図である。
I/Oアドレス生成器の詳細図である。
画素蓄積フォーマットの説明図である。
順次読み出しイタレータプロセスの説明図である。
ボックス読み出しイタレータプロセスの説明図である。
ボックス書き込みイタレータプロセスの説明図である。
垂直ストリップ読み出し/書き込みイタレータプロセスの説明図である。
垂直ストリップ読み出し/書き込みイタレータプロセスの説明図である。
シーケンシャル生成プロセスの説明図である。
シーケンシャル生成プロセスの説明図である。
垂直ストリップ生成プロセスの説明図である。
垂直ストリップ生成プロセスの説明図である。
画素データ構造の説明図である。
画素処理プロセスの説明図である。
表示コントローラの概略ブロック図である。
CCD像編成の説明図である。
論理的画像用の蓄積フォーマットの説明図である。
内部画像メモリー蓄積フォーマットの説明図である。
画像ピラミッド蓄積フォーマットの説明図である。
アートカードをサンプリングするプロセスの時系列の説明図である。
スーパーサンプリングプロセスの説明図である。
回転したアートカードを読み取るプロセスの説明図である。
アートカードを復号化するために必要なステップのフローチャートである。
単一のアートカードの左隅の拡大図である。
検出用の単一ターゲットである。
ターゲットを検出するため使用される方法の説明図である。
二つのターゲット間の距離を計算する方法の説明図である。
重心ドリフトのプロセスの説明図である。
重心ルックアップテーブルの一形態を示す図である。
重心更新プロセスの説明図である。
好適な実施例において利用されるデルタ処理用ルックアップテーブルの説明図である。
アートカードのスクランブルを解除するプロセスの説明図である。
ドットの系列の拡大図である。
ドットカードのデータ面の説明図である。
単一データブロックの概略説明図である。
単一データブロックの説明図である。
図50のデータブロックの部分拡大図である。
図50のデータブロックの部分拡大図である。
単一ターゲット構造の説明図である。
データブロックのターゲット構造の説明図である。
データ領域のボーダークロック用領域に対するターゲットの位置関係の説明図である。
データブロックのオリエンテーションカラムの説明図である。
データブロックのドットのアレイの説明図である。
リード・ソロモン符号化のデータの構造の概略説明図である。
例示的なリード・ソロモン符号化プロセスの説明図である。
リード・ソロモン符号化プロセスの説明図である。
データブロック内の符号化されたデータのレイアウトの説明図である。
代替的なアートカードをサンプリングする際のサンプリングプロセスの説明図である。
回転した代替的なアートカードをサンプリングする一例の拡大図である。
スキャニングプロセスの説明図である。
スキャニングプロセスの起こり得るスキャニング分布の説明図である。
シンボル誤りとリード・ソロモンブロック誤りの確率の間の関係を示す図である。
復号化プロセスのフローチャートである。
復号化プロセスのプロセス稼働図である。
復号化におけるデータフローステップの説明図である。
読み出しプロセスの詳細図である。
代替的なアートカードの開始を検出するプロセスの詳細図である。
ビットデータ抽出プロセスの詳細図である。
復号化プロセスで利用されるセグメンテーションプロセスの説明図である。
ターゲットを見つける復号化プロセスの詳細図である。
ターゲットを見つける際に利用されるデータ構造の説明図である。
Lancos3関数構造の説明図である。
クロックマーク及びボーダー領域を示すデータブロックの部分拡大図である。
ビットイメージを復号化する際の処理ステップの説明図である。
ビットイメージを復号化する際のデータフローステップの説明図である。
好適な実施例のスクランブル解除プロセスの説明図である。
コンボルバの一実施形態の説明図である。
コンボルブプロセスの説明図である。
コンポジットプロセスの説明図である。
通常のコンポジットプロセスの詳細図である。
ワープマップを使用するワーププロセスの説明図である。
ワープバイリニア補間プロセスの説明図である。
スパン計算のプロセスの説明図である。
基本スパン計算プロセスの説明図である。
スパン計算プロセスの詳細な一実施形態の説明図である。
画像ピラミッドレベルを読み取るプロセスの説明図である。
バイリニア補間のためピラミッドテーブルを使用する方法の説明図である。
ヒストグラム収集プロセスの説明図である。
色変換プロセスの説明図である。
色変換プロセスの説明図である。
色空間変換プロセスの詳細図である。
入力座標を計算するプロセスの説明図である。
フィードバック付きコンポジット処理するプロセスの説明図である。
汎用スケーリングプロセスの説明図である。
Xスケーリングプロセスにおけるスケールの説明図である。
Yスケーリングプロセスにおけるスケールの説明図である。
モザイクプロセスの説明図である。
サブピクセル移動プロセスの説明図である。
コンポジットプロセスの説明図である。
フィードバック付きでコンポジットするプロセスの説明図である。
入力画像からの色でタイル貼りするプロセスの説明図である。
フィードバック付きでタイル貼りするプロセスの説明図である。
テクスチャ置換でタイル貼りするプロセスの説明図である。
入力画像からの色でタイル貼りするプロセスの説明図である。
入力画像からの色でタイル貼りするプロセスの説明図である。
フィードバック無しでテクスチャを与えるプロセスの説明図である。
フィードバック付きでテクスチャを与えるプロセスの説明図である。
CCD画素の回転のプロセスの説明図である。
緑色サブピクセルの補間のプロセスの説明図である。
青色サブピクセルの補間のプロセスの説明図である。
赤色サブピクセルの補間のプロセスの説明図である。
奇数画素行に対し0度回転のCCD画素補間のプロセスの説明図である。
偶数画素行に対し0度回転のCCD画素補間のプロセスの説明図である。
Lab色空間への色変換のプロセスの説明図である。
1/√Xの計算のプロセスの説明図である。
1/√Xの計算の実施例の詳細説明図である。
バンプマップによる法線計算のプロセスの説明図である。
バンプマップによる照度計算のプロセスの説明図である。
バンプマップによる照度計算のプロセスの詳細説明図である。
指向性ライトを使用するLの計算のプロセスの説明図である。
オムニライト及びスポットライトを使用するLの計算のプロセスの説明図である。
オムニライト及びスポットライトを使用するLの計算の一実施形態の説明図である。
N.L内積を計算するプロセスの説明図である。
N.L内積を計算するプロセスの詳細説明図である。
R.V内積を計算するプロセスの説明図である。
R.V内積を計算するプロセスの詳細説明図である。
減衰計算の入力及び出力の説明図である。
減衰計算の実際の実施形態の説明図である。
円錐ファクタのグラフの説明図である。
半影計算のプロセスの説明図である。
半影計算に利用される角の説明図である。
半影計算への入力及び出力の説明図である。
半影計算の実際の実施形態の説明図である。
周辺光計算への入力及び出力の説明図である。
周辺光計算の実際の実施形態の説明図である。
散光計算の実際の実施形態の説明図である。
散光計算への入力及び出力の説明図である。
散光計算の実際の実施形態の説明図である。
反射計算への入力及び出力の説明図である。
反射計算の実際の実施形態の説明図である。
反射計算への入力及び出力の説明図である。
反射計算の実際の実施形態の説明図である。
周辺光だけの独計算の実際の実施形態の説明図である。
光計算のプロセス概要の説明図である。
単一無限光源用の照明計算の一例の説明図である。
バンプマップを用いないオムニ光源用の照明計算の一例の説明図である。
バンプマップを用いるオムニ光源用の照明計算の一例の説明図である。
バンプマップを用いないスポットライト光源用の照明計算の一例の説明図である。
関連したバンプマップを用いて画像に単一スポットライトを当てるプロセスの説明図である。
単一プリントヘッドの論理的レイアウトの説明図である。
プリントヘッドインタフェースの構造の説明図である。
Lab画像の回転のプロセスの説明図である。
印刷画像の画素のフォーマットの説明図である。
ディザリングプロセスの説明図である。
8ビットドット出力を生成するプロセスの説明図である。
カードリーダーの斜視図である。
カードリーダーの展開斜視図である。
アートカードリーダーのクローズアップ図である。
プリントロール及びプリントヘッドの斜視図である。
プリントロールの第1の展開斜視図である。
プリントロールの第2の展開斜視図である。
プリントロール認証チップの説明図である。
プリントロール認証チップの拡大図である。
一段階認証チップデータプロトコルの説明図である。
二段階認証チップデータプロトコルの説明図である。
第1のプレゼンスオンリープロトコルの説明図である。
第2のプレゼンスオンリープロトコルの説明図である。
第3のデータプロトコルの説明図である。
第4のデータプロトコルの説明図である。
最長期間LFSRの概略ブロック図である。
クロック制限フィルターの概略ブロック図である。
タンパー検出ラインの概略ブロック図である。
特大のnMOSトランジスタの概略ブロック図である。
タンパー検出ラインからの多数のXORの取り出しを説明する図である。
タンパーラインがノイズ発生回路を覆う状態の説明図である。
通常のFETの実施形態の説明図である。
好適な実施例の修正されたFETの実施形態の説明図である。
認証チップの略ブロックである。
メモリマップの一例の説明図である。
定数メモリマップの一例の説明図である。
RAMメモリマップの一例の説明図である。
フラッシュメモリ変数メモリマップの一例の説明図である。
フラッシュメモリプログラムメモリマップの一例の説明図である。
状態機械のコンポーネント間のデータフロー及び関係を示す図である。
I/Oユニットのコンポーネント間のデータフロー及び関係を示す図である。
算術論理ユニット(ALU)の概略ブロック図である。
RPLユニットの概略ブロック図である。
ALUのRORブロックの概略ブロック図である。
プログラムカウンタユニットのブロック図である。
メモリーユニットの概略ブロック図である。
アドレス生成ユニットの概略ブロック図である。
JSIGENユニットの概略ブロック図である。
JSRGENユニットの概略ブロック図である。
DBRGENユニットの概略ブロック図である。
LDKGENユニットの概略ブロック図である。
RPLGENユニットの概略ブロック図である。
VARGENユニットの概略ブロック図である。
CLRGENユニットの概略ブロック図である。
BITGENユニットの概略ブロック図である。
プリントロール認証チップに記憶された情報を示す図である。
アートカム認証チップ内に記憶されたデータの説明図である。
プリントヘッドパルス特徴付けプロセスの説明図である。
プリントヘッドインク供給機構の拡大断面斜視図である。
インクヘッド供給ユニットの底面斜視図である。
インクヘッド供給ユニットの底面側の断面図である。
インクヘッド供給ユニットの上面斜視図である。
インクヘッド供給ユニットの上面側の断面図である。
プリントヘッドの一部分の斜視図である。
プリントヘッドユニットの拡大斜視図である。
アートカムカメラの内部の上面側の斜視図であり、平らにされた部品が示されている。
アートカムカメラの内部の底面側の斜視図であり、平らにされた部品が示されている。
アートカムカメラの内部の第1の上面側の斜視図であり、アートカムに収容された部品が示されている。
アートカムカメラの内部の第2の上面側の斜視図であり、アートカムに収容された部品が示されている。
アートカムカメラの内部の第2の上面側の斜視図であり、アートカムに収容された部品が示されている。
葉書プリントロールの裏書き部分の説明図である。
画像印刷後の葉書プリントロールの対応した表画像の説明図である。
顧客が購入できる状態のプリントロールの形態の説明図である。
アートカムアプリケーション全体のソフトウェア/ハードウェアモジュールのレイアウトの説明図である。
カメラマネージャのソフトウェア/ハードウェアモジュールのレイアウトの説明図である。
画像処理マネージャのソフトウェア/ハードウェアモジュールのレイアウトの説明図である。
プリンタマネージャのソフトウェア/ハードウェアモジュールのレイアウトの説明図である。
画像処理マネージャのソフトウェア/ハードウェアモジュールのレイアウトの説明図である。
ファイルマネージャのソフトウェア/ハードウェアモジュールのレイアウトの説明図である。
代替的な形態のプリントロールの部分断面斜視図である。
図227のプリントロールの左側の拡大斜視図である。
単一プリントロールの右側の拡大斜視図である。
プリントロールのコア部分の部分断面拡大斜視図である。
プリントロールのコア部分の第2の拡大斜視図である。
‘Bizcard’の正面図である。
さらなる改良に従って構成されたカメラシステムを概略的に示す。
出力メディアの表面と裏面に印刷をするためのプリンター装置を概略的に示す。
写真の裏面における出力データの形式を示す。
出力メディアの拡大された部分を示す。
写真の裏面からデータを読み込むために使用される読み取り装置を示す。
さらなる改良の装置の利用を示す。
画像の向きの具体的な処理の概略的な例を示す。
さらなる改良に従って構成されたカメラを使用した場合の画像の特有の効果を作る方法を示す。
さらなる改良に従ったプリントロールを示す。
さらに改良された実施例の方法を示す。
さらなる改良の操作方法を示す。
さらなる改良に従った画像処理の一形態を示す。
さらなる改良の操作方法を示す。
画像のキャプチャー及び出力のプロセスを示す。
赤目除去のプロセスを示す。
標準的なアートカム装置に従って構成された写真印刷編成を示す。
さらなる改良に従って構成されたデュアルプリントヘッド編成を示す。
さらなる改良のカール除去装置を示す。
立体写真画像を見るプロセスを示す。
立体写真効果を作成するために設計された、さらなる改善のレンズシステムを示す。
立体写真画像の創造を示す部分斜視図である。
さらなる改良に従って立体写真画像を作るための装置を示す。
図254の位置決めユニットをさらに詳細に示す。
立体写真画像の作成に好適なカメラ装置を示す。
立体写真効果を改良すべく、不透明な裏当てを使用するプロセスを示す。
プリントメディアに画像を生成する方法を概略的に示す。
本発明に従って構成されたプリントメディアの構造を示す。
さらなる改良に従って構成されたプリントメディアの利用を示す。
さらなる改良に従ったプリントメディアの構造の第1形態を示す。
本発明に従ったプリントメディアの構造のさらなる形態を示す。
本発明に従ったプリントメディアの構造のさらなる形態の概略的な断面図を示す。
本発明に従ったプリントメディアの構造のさらなる形態の概略的な断面図を示す。
図263及び7に従ったプリントメディア構成の製造の一形態を示す。
図265の編成を利用するために繊維材料を押し出すことによる製造の別の形態を示す。
さらなる改良の主要ステップを示す。
さらなる改良にて使用されるSobelフィルターの効果を示す。
さらなる改良にて使用される曲線のオフセット方法を示す。
さらなる改良にて使用される曲線のオフセット方法を示す。
認識された顔を含む標準的な画像を示す。
興味の領域を決定するための第1のフローチャートを示す。
興味の領域を決定するための第2のフローチャートを示す。
画像をタイリングする最初の工程を示す。
画像のタイリングのための別のタイルパターンを示す。
タイルの不透明なマスクを示す。
図276のタイルのための、対応する表面テクスチャ高さを示す。
図276のタイルのための、対応する表面テクスチャ高さを示す。
画像を修正するためにglobalopacigtyを使用する工程を示す。
実際のペイントを混合させる効果を真似るための、ストローキング効果を修正する方法を示す。
ブラッシュストロークのテーブルを作成する工程を示す。
ストロークカラーパレットを作成する工程を示す。
結果として起こるペインティング工程を示す。
ブラッシュストロークを合成するさらなる実施例におけるステップのフローチャートを示す。
ベジエ曲線の区分的線分への変換方法を示す。
ブラッシュストロークプロセスを示す。
さらなる実施例で使用される、好適なブラッシュスタンプを示す。
さらなる改良の第1の編成を示す。
さらなる改良の操作のフローチャートを示す。
高解像度で印刷された画像の構成を示す。
コピーを作成するための、図290の画像を処理するための装置を示す。
centroidの処理ステップを示す。
一連の検知したパターンを示す。
さらなる改良の実施の図を示す。
さらなる改良を示す。
さらなる実施例のカード読み取り装置を示す。
ブラシ・バンプマップを示す。
ブラシ・バンプマップを示す。
背景キャンバスのバンプマップを示す。
背景キャンバスのバンプマップを示す。
バンプマップを結合するプロセスを示す。
バンプマップを結合するプロセスを示す。
マップの背景を示す。
さらなる改良に従ってバンプマップを結合するプロセスを示す。
さらなる改良に従ってバンプマップを結合するプロセスを示す。
芸術的な画像の生成のさらなる改良の方法におけるステップを示す。
一つのガモットを第2のガモットにマッピングするプロセスを示す。
さらなる改良の一実施形態を示す。
ガモットリマッピングの好ましい形態を示す。
さらなる改善にて使用されるガモット・モーフィングを示す。
アートカム装置の基本操作を示す。
さらなる改良で使用される一連のアートカードを示す。
さらなる改良で使用されるアルゴリズムのフローチャート図である。
本発明に従って作成される、印刷された布の出力の概略図である。
さらなる改良の接続方式を示す。
部分的に断面が描かれた、さらなる改良の斜視図を示す。
書き込みデータエリア配列を有するカードを示す。
限定された数の書き込みデータ領域のみを有するカードを示す。
データ領域の構成を示す。
ターゲット構成を示す。
さらなる改良の装置を示す。
図321を近づいて見た状態を示す。
読み取り装置の中にカードを挿入するプロセスを示す。
カードを取り出すプロセスを示す。
カードにデータ領域を書くプロセスを示す。
カードリーダーの構造の概略図である。
さらなる改善の概略的な配列を示す。
さらなる改善のインターフェースの例を示す。
さらなる改善のソフトウェアモジュールの構成の一形態を示す。
アートカムシステムの操作の概略図である。
アートカムシステムの変形された操作の第1の例が示されている。
アートカムの操作を変更するリピティションカードが示されている。
アートカムの操作を変更するためのアートカードテストカードが示されている。
アートカム装置の出力テスト結果を示す。
さらなる改良に従って構成されたカメラシステムを概略的に示す。
さらなる改良のプリンター装置及び録音装置を概略的に示す。
写真の裏面の磁気帯の構成を示す。
写真の裏面に録音されたデータを読むために使用される読み取り装置を示す。
さらなる改良の装置の使用を示す。
アートカム装置の機能部分の概略図を示す。
さらなる改良を使用するステップを示す。
さらなる改良に従ったアートカム装置の操作を示す。
出力された“写真”の裏面に印刷された他の実施例を示す。
さらなる実施例に従って構成されたプリンター装置の内部を示す。
さらなる実施例に従って構成されたネットワーク配布システムを示す。
図345のプリンターコンピュータの操作を概略的に示す。