JP2009282986A - デジタル画像内の数字を検知する方法 - Google Patents
デジタル画像内の数字を検知する方法 Download PDFInfo
- Publication number
- JP2009282986A JP2009282986A JP2009123421A JP2009123421A JP2009282986A JP 2009282986 A JP2009282986 A JP 2009282986A JP 2009123421 A JP2009123421 A JP 2009123421A JP 2009123421 A JP2009123421 A JP 2009123421A JP 2009282986 A JP2009282986 A JP 2009282986A
- Authority
- JP
- Japan
- Prior art keywords
- character string
- connected components
- aspect ratio
- value
- threshold
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images













Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V20/00—Scenes; Scene-specific elements
- G06V20/60—Type of objects
- G06V20/62—Text, e.g. of license plates, overlay texts or captions on TV images
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Image Analysis (AREA)
- Character Input (AREA)
- Character Discrimination (AREA)
Abstract
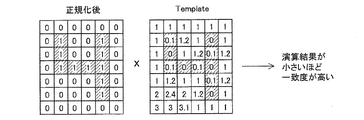
【解決手段】画像データから、文字列を抽出し(332)、当該文字列に含まれる非背景画素の連結成分の各々について外接矩形枠を決定する(334)。そして、文字列に含まれる複数の連結成分について、外接矩形枠の各辺の座標の変動量として、平均値からの誤差量の平均を求める(336,338,340)。そして、当該誤差量の平均に基づいて、文字列がアラビア数字からなる数字列の候補であるか否かを判定する(344)。
【選択図】図21
Description
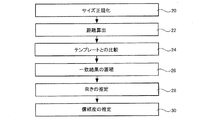
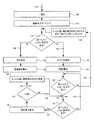
本発明に係る一実施形態について、図2を参照しながら説明する。本実施形態では、まず、原稿要素のサイズが正規化される(10)。ここで、原稿要素とは、2値化された電子原稿画像データにおいて、非背景画素が連結したひとまとまりの連結成分である。なお、ここでは説明を省略するが、数字部分と推定される連結成分が選択され、当該連結成分に対してのみ、符号10以降の処理が実行される。次に、サイズ正規化された原稿要素において、各画素の画素値を文字画素からの距離を示す値に変換する距離算出処理が実行される(12)。その後、距離算出処理がされた原稿要素は、参照テンプレートに対して照合される(14)。そして、照合結果が累積され(16)、累積された照合結果に基づいて、推定向きが求められる(18)。ここで、推定向きとは、照合結果から推定される電子原稿画像データの向きのことである。本実施形態において、参照テンプレートは向きを特定した数字テンプレートを含んでいる。この数字テンプレートの詳細については後述する。
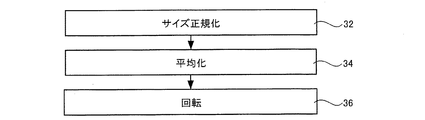
また、本発明に係る別の実施形態について、図3を参照しながら説明する。本実施形態でも、原稿要素は、サイズが正規化され(20)、距離算出処理が実行され(22)、参照テンプレートに対して照合される(24)。なお、本実施形態でも、原稿要素とは、2値化された電子原稿画像データにおいて、黒画素が連結したひとまとまりの連結成分である。また、ここでは説明を省略するが、数字部分と推定される連結成分が選択され、当該連結成分に対してのみ、符号10以降の処理が実行される。そして、照合結果が累積され(26)、累積された照合結果に基づいて、推定向きが求められる(28)。また、この実施形態では、推定向きの信頼性を示す信頼度が求められる(30)。本実施形態でも、参照テンプレートとしては、向きを特定した数字テンプレートがある。
上記の実施形態1・2では、連結成分オブジェクトの候補を原稿要素として4つの基本方向の数字テンプレートと照合し、原稿画像の向きを推測する。数字テンプレートは、トレーニングデータ(training data)を用いて作り出してもよい。また、数字テンプレートは、共通の、サイズ及びフォント不変の数字の代表例(representation)であってもよい。

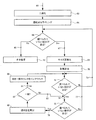
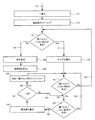
上述した実施形態1の具体的な処理例の一つを、図6を参照しつつ説明する。この具体例においては、原稿画像60は、向き推定の処理を行う前に、前処理がされている。この前処理として、まず、原稿画像60の2値化処理を行う(62)。次に、2値化された原稿画像に連結成分ラベリング処理を行う(64)。
次に、上述した実施形態2の具体的な処理例の一つを、図7を参照しつつ説明する。図7に示されるように、本具体例では、図6に示した具体例の処理に加えて、推定向きが決定されたあと(92)、当該推定向きに関する信頼度(確実性度)を求める(94)。
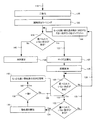
上記の(実施形態1の具体的処理例1−1)では、図6を参照して述べるように、ある向きに対応する一致カウンタは、当該向きに関連付けられた少なくとも一つのテンプレートが、連結成分を含む部分画像と一致しているに、カウンタ数が増やされる。しかしながら、本発明はこれに限定されず、部分画像ごとに、全ての数字および向きに対応する数字テンプレートとの一致度を求め、最も一致度が高かった向きに対応する向き一致カウンタのカウンタ数を増やすようにしてもよい。本具体例は、このような方式の例である。本具体例について、図9を参照しつつ述べる。
次に、上述した実施形態2の具体的な別の処理例の一つを、図10を参照しつつ説明する。図10に示されるように、本具体例では、図9に示した具体例の処理に加えて、推定向きが決定されたあと(148)、当該推定向きに関する信頼度(確実性度)を求める(150)。
以下、別の実施形態における数字テンプレートの作成方法について説明する。本実施形態においても、連結成分オブジェクトの候補は、4つの基本の向きの数字テンプレートと照合され、原稿画像の向きを推測する。数字テンプレートは、トレーニングデータ(training data)を用いて作り出してもよい。また、数字テンプレートは、共通の、サイズ及びフォント不変の数字の代表例(representation)であってもよい。
まず、トレーニングデータを作成する。このトレーニングデータの作成方法は、以下のとおりである。すなわち、様々な種類のフォント、サイズのサンプル原稿を準備し、当該サンプル原稿をスキャンする。そして、当該スキャンにより得られたスキャンデータを2値化する。そして、2値化されたスキャンデータの中から、数字を含み、当該数字の外接矩形の部分画像を切り取ることでトレーニングデータを作成することができる。ここで、外接矩形は、原稿画像の縦方向および横方向に平行な辺を有し、連結成分に外接する矩形である。なお、このスキャンデータでは、読むのに適した向きになるように数字が配置されているようにしている。このように、様々な種類のフォント、サイズのサンプル原稿から得られた複数のトレーニングデータをまとめたものをトレーニングセットという。
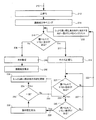
上記(別の実施形態における数字テンプレートの作成方法)で記載された数字テンプレートを用いた一実施形態を、図12を参照しつつ説明する。この実施形態においては、原稿画像170、向き推定の処理を行う前に、前処理がされている。この前処理として、まず、原稿画像170の2値化処理を行う(172)。次に、2値化された原稿画像に連結成分ラベリング処理を行う(174)。
次に、上記(別の実施形態における数字テンプレートの作成方法)で記載された数字テンプレートを用いた別の実施形態の具体的な処理例の一つを、図13を参照しつつ説明する。図13に示されるように、本実施形態では、図12に示した具体例の処理に加えて、推定向きが決定されたあと(198)、当該推定向きに関する信頼度(確実性度)を求める(200)。
上記の実施形態3では、図12を参照して述べるように、ある向きに対応する一致カウンタは、当該向きに関連付けられた少なくとも一つのテンプレートが、連結成分を含む部分画像と一致しているに、カウンタ数が増やされる。しかしながら、本発明はこれに限定されず、部分画像ごとに、全ての数字および向きに対応する数字テンプレートとの一致度を求め、最も一致度が高かった向きに対応する向き一致カウンタのカウンタ数を増やすようにしてもよい。本実施形態は、このような方式の例である。本実施形態について、図14を参照しつつ述べる。
次に、上記(別の実施形態における数字テンプレートの作成方法)で記載された数字テンプレートを用いた別の実施形態の具体的な処理例の一つを、図15を参照しつつ説明する。図15に示されるように、本実施形態では、図14に示した具体例の処理に加えて、
推定向きが決定されたあと(240)、当該推定向きに関する信頼度(確実性度)が判定される(242)。
上記の実施形態1−6は、これに限定されるものではなく、種々の変更が可能である。以下、この変形例について説明する。
以下、上記の実施形態1−6で説明を省略した数字文字の検出について説明する。すなわち、上記の実施形態1−6では、原稿画像から抽出した全ての連結成分の中から、数字部分と推定される連結成分を選択し、当該連結成分に対してのみ数字テンプレートとの比較処理を行う。
下記式に従って計算される平均絶対誤差(Mean Absolute Error (MAE))
下記式に従って計算される平均絶対誤差(Mean Absolute Error (MAE))
条件1.etop≦Tvかつebottom≦Tv
条件2.μAR>TARμ
条件3.σ2 AR<TARσ
条件4.N<Tlength
あるいは、条件2および条件3のみが満たされた場合に、数字列だと見なしても良い。あるいは、条件2、条件3および条件4のみが満たされた場合に、数字列だと見なしても良い。あるいは、条件1、条件2および条件3のみが満たされた場合に、数字列だと見なしても良い。あるいは、条件1および条件4のみが見たされた場合に、数字列だと見なしても良い。あるいは、条件2、条件3および条件4のみが満たされた場合に、数字列だと見なしても良い。あるいは、条件2のみが満たされた場合に、数字列だと見なしても良い。あるいは、条件3のみが満たされた場合に、数字列だと見なしても良い。あるいは、条件1および条件2のみが満たされた場合に、数字列だと見なしても良い。あるいは、条件1および条件3のみが満たされた場合に、数字列だと見なしても良い。
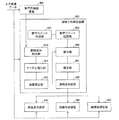
次に本発明の適用例について説明する。図25は、本発明に係る画像の向きの判定方法を適用した原稿方向判定装置500および周辺装置を含む原稿方向判定システムの構成を示すブロック図である。
条件1.etop≦Tvかつebottom≦Tv
条件2.μAR>TARμ
条件3.σ2 AR<TARσ
条件4.N<Tlength
そして、数字列抽出装置400は、抽出した数字列の位置を特定する情報を、原稿方向判定装置500に出力する。なお、数字列抽出装置400の具体的な処理方法は、上記(数字文字の検出について)で述べたとおりである。
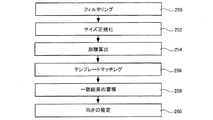
400 数字列抽出装置
500 原稿方向判定装置
501 数字テンプレート作成部
502 数字テンプレート記憶部
503 連結成分抽出部
504 サイズ正規化部
505 距離算出部
506 照合部
507 推定部
508 信頼度判定部
600 画像表示装置
700 画像形成装置
800 画像処理装置
Claims (14)
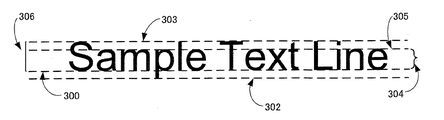
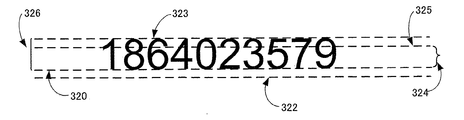
- デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
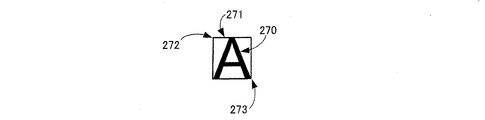
b)上記文字列要素に含まれる非背景画素の連結成分の各々について、所定の第1軸に平行な第1辺および第2辺と当該第1軸に垂直な第2軸に平行な第3辺および第4辺とを有する外接矩形枠を決定する工程と、
c)上記連結成分の各々について、上記第1辺の上記第2軸上の座標である第1辺座標と、上記第2辺の上記第2軸上の座標である第2辺座標と、上記第3辺の上記第1軸上の座標である第3辺座標と、上記第4辺の上記第1軸上の座標である第4辺座標とを求める工程と、
d)上記文字列要素に含まれる複数の上記連結成分について、上記第1辺座標の変動量を示す第1変動量と、上記第2辺座標の変動量を示す第2変動量と、上記第3辺座標の変動量を示す第3変動量と、上記第4辺座標の変動量を示す第4変動量とを求める変動量算出工程と、
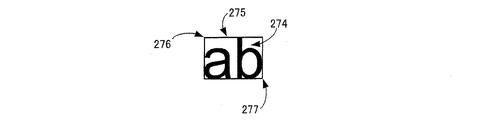
e)上記第1変動量と上記第2変動量との和が上記第3変動量と上記第4変動量との和よりも小さい場合、上記第1変動量が所定の第1閾値よりも小さく、かつ、上記第2変動量が所定の第2閾値よりも小さいときに、上記文字列要素をアラビア数字からなる文字列の候補である数字列候補として分類し、上記第1変動量が上記第1閾値以上であるか、または、上記第2変動量が上記第2閾値以上であるときに、上記文字列要素をアルファベットの大文字と小文字との混合文字列として分類し、
上記第1変動量と上記第2変動量との和が上記第3変動量と上記第4変動量との和よりも大きい場合、上記第3変動量が所定の第3閾値よりも小さく、かつ、上記第4変動量が所定の第4閾値よりも小さいときに、上記文字列要素をアラビア数字からなる文字列の候補である数字列候補として分類し、上記第3変動量が上記第3閾値以上であるか、または、上記第4変動量が上記第4閾値以上であるときに、上記文字列要素をアルファベットの大文字と小文字との混合文字列として分類する数字列候補分類工程と、
を含む方法。 - 上記変動量算出工程は、
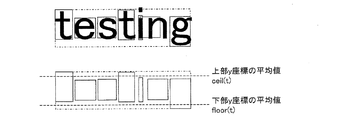
上記文字列要素に含まれる複数の連結成分の第1辺座標の代表値である第1代表値と、当該複数の連結成分の第2辺座標の代表値である第2代表値と、当該複数の連結成分の第3辺座標の代表値である第3代表値と、当該複数の連結成分の第4辺座標の代表値である第4代表値とを求める工程と、
上記第1変動量として、上記複数の連結成分の各々の第1辺座標と上記第1代表値との誤差量の平均値を算出し、上記第2変動量として、上記複数の連結成分の各々の第2辺座標と上記第2代表値との誤差量の平均値を算出し、上記第3変動量として、上記複数の連結成分の各々の第3辺座標と上記第3代表値との誤差量の平均値を算出し、上記第4変動量として、上記複数の連結成分の各々の第4辺座標と上記第4代表値との誤差量の平均値を算出する工程とを含む、
請求項1に記載のデジタル画像内の数字連結成分を検知する方法。 - 上記第1代表値は、上記複数の連結成分の第1辺座標の平均値であり、
上記第2代表値は、上記複数の連結成分の第2辺座標の平均値であり、
上記第3代表値は、上記複数の連結成分の第3辺座標の平均値であり、
上記第4代表値は、上記複数の連結成分の第4辺座標の平均値である、
請求項2に記載のデジタル画像内の数字連結成分を検知する方法。 - 上記誤差量は、平均絶対誤差、二乗平均誤差、二乗平均平方根誤差から選ばれる誤差量である、請求項2または3に記載のデジタル画像内の数字連結成分を検知する方法。
- 上記数字列候補分類工程にて分類された数字列候補に含まれる複数の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
上記複数の連結成分の上記縦横比の平均値を算出する工程と、
上記複数の連結成分の上記縦横比の分散値または標準偏差を算出する工程と、
上記縦横比の平均値が所定の第5閾値よりも大きく、かつ、上記縦横比の分散値または標準偏差が所定の第6閾値よりも小さい場合に、上記数字列候補を、アラビア数字からなる数字列として決定し、上記縦横比の平均値が上記第5閾値以下である、もしくは、上記縦横比の分散値または標準偏差が上記第6閾値以上である場合に、上記数字列候補を、非数字文字を含む文字列として決定する工程と、をさらに含む、請求項1から4のいずれか1項に記載のデジタル画像内の数字連結成分を検知する方法。 - 上記数字列候補分類工程にて分類された数字列候補に含まれる複数の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
上記複数の連結成分の上記縦横比の平均値を算出する工程と、
上記複数の連結成分の上記縦横比の分散値または標準偏差を算出する工程と、
上記縦横比の平均値が所定の第5閾値よりも大きく、かつ、上記縦横比の分散値または標準偏差が所定の第6閾値よりも小さく、かつ、上記数字列候補に含まれる連結成分の個数が所定の第7閾値より小さい場合に、上記数字列候補を、アラビア数字からなる数字列として決定し、上記縦横比の平均値が上記第5閾値以下である、もしくは、上記縦横比の分散値または標準偏差が上記第6閾値以上である、もしくは、上記数字列候補に含まれる連結成分の個数が上記第7閾値以上である場合に、上記数字列候補を、非数字文字を含む文字列として決定する工程と、をさらに含む、請求項1から4のいずれか1項に記載のデジタル画像内の数字連結成分を検知する方法。 - 上記数字列候補分類工程にて分類された数字列候補に含まれる連結成分の個数が所定の第7閾値より小さい場合に、上記数字列候補をアラビア数字からなる数字列として決定し、上記数字列候補に含まれる連結成分の個数が上記第7閾値以上である場合に、上記数字列候補を、非数字文字を含む文字列として決定する工程、をさらに含む、請求項1から4のいずれか1項に記載のデジタル画像内の数字連結成分を検知する方法。
- デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
b)上記文字列要素に含まれる非背景画素の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
c)上記複数の連結成分の上記縦横比の平均値を算出する工程と、
d)上記縦横比の平均値が所定の第1閾値よりも大きい場合に、上記文字列要素を、アラビア数字からなる数字列として決定し、上記縦横比の平均値が上記第1閾値以下である場合に、上記文字列要素を、非数字文字を含む文字列として決定する工程と、
を含むデジタル画像内の数字連結成分を検知する方法。 - デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
b)上記文字列要素に含まれる非背景画素の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
c)上記複数の連結成分の上記縦横比の分散値または標準偏差を算出する工程と、
d)上記縦横比の分散値または標準偏差が所定の第2閾値よりも小さい場合に、上記文字列要素を、アラビア数字からなる数字列として決定し、上記縦横比の分散値または標準偏差が上記第2閾値以上である場合に、上記文字列要素を、非数字文字を含む文字列として決定する工程と、
を含むデジタル画像内の数字連結成分を検知する方法。 - デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
b)上記文字列要素に含まれる非背景画素の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
c)上記複数の連結成分の上記縦横比の平均値を算出する工程と、
d)上記複数の連結成分の上記縦横比の分散値または標準偏差を算出する工程と、
e)上記縦横比の平均値が所定の第1閾値よりも大きく、かつ、上記縦横比の分散値または標準偏差が所定の第2閾値よりも小さい場合に、上記文字列要素を、アラビア数字からなる数字列として決定し、上記縦横比の平均値が上記第1閾値以下である、もしくは、上記縦横比の分散値または標準偏差が上記第2閾値以上である場合に、上記文字列要素を、非数字文字を含む文字列として決定する工程と、
を含むデジタル画像内の数字連結成分を検知する方法。 - デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
b)上記文字列要素に含まれる非背景画素の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
c)上記複数の連結成分の上記縦横比の平均値を算出する工程と、
d)上記縦横比の平均値が所定の第1閾値よりも大きく、かつ、上記文字列要素に含まれる連結成分の個数が所定の第3閾値より小さい場合に、上記文字列要素を、アラビア数字からなる数字列として決定し、上記縦横比の平均値が上記第1閾値以下である、もしくは、上記文字列要素に含まれる連結成分の個数が上記第3閾値以上である場合に、上記文字列要素を、非数字文字を含む文字列として決定する工程と、
を含むデジタル画像内の数字連結成分を検知する方法。 - デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
b)上記文字列要素に含まれる非背景画素の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
c)上記複数の連結成分の上記縦横比の分散値または標準偏差を算出する工程と、
d)上記縦横比の分散値または標準偏差が所定の第2閾値よりも小さく、かつ、上記文字列要素に含まれる連結成分の個数が所定の第3閾値より小さい場合に、上記文字列要素を、アラビア数字からなる数字列として決定し、上記縦横比の分散値または標準偏差が上記第2閾値以上である、もしくは、上記文字列要素に含まれる連結成分の個数が上記第3閾値以上である場合に、上記文字列要素を、非数字文字を含む文字列として決定する工程と、
を含むデジタル画像内の数字連結成分を検知する方法。 - デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
b)上記文字列要素に含まれる非背景画素の連結成分の各々について、当該連結成分の上記外接矩形枠の縦横比を算出する工程と、
c)上記複数の連結成分の上記縦横比の平均値を算出する工程と、
d)上記複数の連結成分の上記縦横比の分散値または標準偏差を算出する工程と、
e)上記縦横比の平均値が所定の第1閾値よりも大きく、かつ、上記縦横比の分散値または標準偏差が所定の第2閾値よりも小さく、かつ、上記文字列要素に含まれる連結成分の個数が所定の第3閾値より小さい場合に、上記文字列要素を、アラビア数字からなる数字列として決定し、上記縦横比の平均値が上記第1閾値以下である、もしくは、上記縦横比の分散値または標準偏差が上記第2閾値以上である、もしくは、上記文字列要素に含まれる連結成分の個数が上記第3閾値以上である場合に、上記文字列要素を、非数字文字を含む文字列として決定する工程と、
を含むデジタル画像内の数字連結成分を検知する方法。 - デジタル画像内の数字連結成分を検知する方法であって、
a)デジタル画像内の文字列の候補である文字列要素を取得する工程と、
b)上記文字列要素に含まれる非背景画素の連結成分の個数が所定の第1閾値より小さい場合に、上記文字列要素を、アラビア数字からなる数字列として決定し、上記文字列要素に含まれる連結成分の個数が上記第1閾値以上である場合に、上記文字列要素を、非数字文字を含む文字列として決定する工程と、
を含むデジタル画像内の数字連結成分を検知する方法。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/126,561 | 2008-05-23 | ||
| US12/126,561 US8023741B2 (en) | 2008-05-23 | 2008-05-23 | Methods and systems for detecting numerals in a digital image |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2009282986A true JP2009282986A (ja) | 2009-12-03 |
| JP5015195B2 JP5015195B2 (ja) | 2012-08-29 |
Family
ID=41342142
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2009123421A Active JP5015195B2 (ja) | 2008-05-23 | 2009-05-21 | デジタル画像内の数字を検知する方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (2) | US8023741B2 (ja) |
| JP (1) | JP5015195B2 (ja) |
Families Citing this family (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20050097046A1 (en) | 2003-10-30 | 2005-05-05 | Singfield Joy S. | Wireless electronic check deposit scanning and cashing machine with web-based online account cash management computer application system |
| US8799147B1 (en) | 2006-10-31 | 2014-08-05 | United Services Automobile Association (Usaa) | Systems and methods for remote deposit of negotiable instruments with non-payee institutions |
| US7873200B1 (en) | 2006-10-31 | 2011-01-18 | United Services Automobile Association (Usaa) | Systems and methods for remote deposit of checks |
| US8708227B1 (en) | 2006-10-31 | 2014-04-29 | United Services Automobile Association (Usaa) | Systems and methods for remote deposit of checks |
| US10380559B1 (en) | 2007-03-15 | 2019-08-13 | United Services Automobile Association (Usaa) | Systems and methods for check representment prevention |
| US9058512B1 (en) | 2007-09-28 | 2015-06-16 | United Services Automobile Association (Usaa) | Systems and methods for digital signature detection |
| US9892454B1 (en) | 2007-10-23 | 2018-02-13 | United Services Automobile Association (Usaa) | Systems and methods for obtaining an image of a check to be deposited |
| US9898778B1 (en) | 2007-10-23 | 2018-02-20 | United Services Automobile Association (Usaa) | Systems and methods for obtaining an image of a check to be deposited |
| US9159101B1 (en) | 2007-10-23 | 2015-10-13 | United Services Automobile Association (Usaa) | Image processing |
| US10380562B1 (en) | 2008-02-07 | 2019-08-13 | United Services Automobile Association (Usaa) | Systems and methods for mobile deposit of negotiable instruments |
| US8023770B2 (en) * | 2008-05-23 | 2011-09-20 | Sharp Laboratories Of America, Inc. | Methods and systems for identifying the orientation of a digital image |
| JP4572248B2 (ja) | 2008-06-23 | 2010-11-04 | シャープ株式会社 | 画像処理装置、画像形成装置、画像処理方法、制御プログラム、記録媒体 |
| US10504185B1 (en) | 2008-09-08 | 2019-12-10 | United Services Automobile Association (Usaa) | Systems and methods for live video financial deposit |
| US8620080B2 (en) * | 2008-09-26 | 2013-12-31 | Sharp Laboratories Of America, Inc. | Methods and systems for locating text in a digital image |
| JP4625861B2 (ja) * | 2008-11-17 | 2011-02-02 | シャープ株式会社 | 画像処理装置、画像読取装置、画像形成装置、画像処理方法、制御プログラム、および記録媒体 |
| US8452689B1 (en) | 2009-02-18 | 2013-05-28 | United Services Automobile Association (Usaa) | Systems and methods of check detection |
| US10956728B1 (en) | 2009-03-04 | 2021-03-23 | United Services Automobile Association (Usaa) | Systems and methods of check processing with background removal |
| JP4927122B2 (ja) * | 2009-06-15 | 2012-05-09 | シャープ株式会社 | 画像処理方法、画像処理装置、画像形成装置、プログラムおよび記録媒体 |
| US9779392B1 (en) | 2009-08-19 | 2017-10-03 | United Services Automobile Association (Usaa) | Apparatuses, methods and systems for a publishing and subscribing platform of depositing negotiable instruments |
| US8699779B1 (en) | 2009-08-28 | 2014-04-15 | United Services Automobile Association (Usaa) | Systems and methods for alignment of check during mobile deposit |
| US9129340B1 (en) | 2010-06-08 | 2015-09-08 | United Services Automobile Association (Usaa) | Apparatuses, methods and systems for remote deposit capture with enhanced image detection |
| US10380565B1 (en) | 2012-01-05 | 2019-08-13 | United Services Automobile Association (Usaa) | System and method for storefront bank deposits |
| US10552810B1 (en) | 2012-12-19 | 2020-02-04 | United Services Automobile Association (Usaa) | System and method for remote deposit of financial instruments |
| US9152930B2 (en) | 2013-03-15 | 2015-10-06 | United Airlines, Inc. | Expedited international flight online check-in |
| JP2014215752A (ja) * | 2013-04-24 | 2014-11-17 | 株式会社東芝 | 電子機器および手書きデータ処理方法 |
| KR102107395B1 (ko) * | 2013-08-28 | 2020-05-07 | 삼성전자주식회사 | 모바일 단말기 및 그의 코드 인식 방법 |
| US11138578B1 (en) | 2013-09-09 | 2021-10-05 | United Services Automobile Association (Usaa) | Systems and methods for remote deposit of currency |
| US9286514B1 (en) | 2013-10-17 | 2016-03-15 | United Services Automobile Association (Usaa) | Character count determination for a digital image |
| US9355313B2 (en) * | 2014-03-11 | 2016-05-31 | Microsoft Technology Licensing, Llc | Detecting and extracting image document components to create flow document |
| US20150286862A1 (en) * | 2014-04-07 | 2015-10-08 | Basware Corporation | Method for Statistically Aided Decision Making |
| US9652690B2 (en) * | 2015-02-27 | 2017-05-16 | Lexmark International, Inc. | Automatically capturing and cropping image of check from video sequence for banking or other computing application |
| US10402790B1 (en) | 2015-05-28 | 2019-09-03 | United Services Automobile Association (Usaa) | Composing a focused document image from multiple image captures or portions of multiple image captures |
| CN106845473B (zh) * | 2015-12-03 | 2020-06-02 | 富士通株式会社 | 用于确定图像是否为带地址信息的图像的方法和装置 |
| CN109753953B (zh) * | 2017-11-03 | 2022-10-11 | 腾讯科技(深圳)有限公司 | 图像中定位文本的方法、装置、电子设备和存储介质 |
| CN108052937B (zh) | 2017-12-28 | 2019-05-31 | 百度在线网络技术(北京)有限公司 | 基于弱监督的字符检测器训练方法、装置、系统及介质 |
| CN108304835B (zh) * | 2018-01-30 | 2019-12-06 | 百度在线网络技术(北京)有限公司 | 文字检测方法和装置 |
| US11030752B1 (en) | 2018-04-27 | 2021-06-08 | United Services Automobile Association (Usaa) | System, computing device, and method for document detection |
| CN110414497A (zh) * | 2019-06-14 | 2019-11-05 | 拉扎斯网络科技(上海)有限公司 | 对象电子化的方法、装置、服务器及存储介质 |
| US11900755B1 (en) | 2020-11-30 | 2024-02-13 | United Services Automobile Association (Usaa) | System, computing device, and method for document detection and deposit processing |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS62224870A (ja) * | 1986-03-26 | 1987-10-02 | Hitachi Ltd | 文書画像処理方法 |
| JPH0210480A (ja) * | 1988-06-29 | 1990-01-16 | Fuji Electric Co Ltd | 文字判別方法 |
| JPH0496882A (ja) * | 1990-08-14 | 1992-03-30 | Ricoh Co Ltd | 全角/半角判定方法 |
| JPH10214308A (ja) * | 1997-01-29 | 1998-08-11 | Ricoh Co Ltd | 文字判別方法 |
Family Cites Families (76)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US598717A (en) * | 1898-02-08 | Office | ||
| JPS57155673A (en) | 1981-03-20 | 1982-09-25 | Agency Of Ind Science & Technol | Pattern recognizing system |
| US5031225A (en) * | 1987-12-09 | 1991-07-09 | Ricoh Company, Ltd. | Character recognition method for recognizing character in an arbitrary rotation position |
| DE68916978T2 (de) * | 1988-01-18 | 1994-11-17 | Toshiba Kawasaki Kk | Zeichenkettenerkennungssystem. |
| US5101448A (en) * | 1988-08-24 | 1992-03-31 | Hitachi, Ltd. | Method and apparatus for processing a document by utilizing an image |
| US5060276A (en) * | 1989-05-31 | 1991-10-22 | At&T Bell Laboratories | Technique for object orientation detection using a feed-forward neural network |
| JP2940960B2 (ja) * | 1989-10-31 | 1999-08-25 | 株式会社日立製作所 | 画像の傾き検出方法および補正方法ならびに画像情報処理装置 |
| US5191438A (en) * | 1989-12-12 | 1993-03-02 | Sharp Kabushiki Kaisha | Facsimile device with skew correction and text line direction detection |
| US5054098A (en) * | 1990-05-21 | 1991-10-01 | Eastman Kodak Company | Method of detecting the skew angle of a printed business form |
| US5077811A (en) * | 1990-10-10 | 1991-12-31 | Fuji Xerox Co., Ltd. | Character and picture image data processing system |
| JPH04195485A (ja) * | 1990-11-28 | 1992-07-15 | Hitachi Ltd | 画像情報入力装置 |
| US5235651A (en) | 1991-08-06 | 1993-08-10 | Caere Corporation | Rotation of images for optical character recognition |
| US5251268A (en) * | 1991-08-09 | 1993-10-05 | Electric Power Research Institute, Inc. | Integrated method and apparatus for character and symbol recognition |
| JP3251959B2 (ja) * | 1991-10-17 | 2002-01-28 | 株式会社リコー | 画像形成装置 |
| US5276742A (en) * | 1991-11-19 | 1994-01-04 | Xerox Corporation | Rapid detection of page orientation |
| US5236651A (en) * | 1991-12-02 | 1993-08-17 | Akzo N.V. | Extrusion, collection, and drying of ceramic precursor gel to form dried gel particles |
| US6574375B1 (en) * | 1992-04-06 | 2003-06-03 | Ricoh Company, Ltd. | Method for detecting inverted text images on a digital scanning device |
| US5680479A (en) * | 1992-04-24 | 1997-10-21 | Canon Kabushiki Kaisha | Method and apparatus for character recognition |
| JP2723118B2 (ja) * | 1992-08-31 | 1998-03-09 | インターナショナル・ビジネス・マシーンズ・コーポレイション | 2次元オブジェクトの認識に用いるためのニューラル・ネットワーク及び光学式文字認識装置 |
| EP0587450B1 (en) * | 1992-09-11 | 2004-11-17 | Canon Kabushiki Kaisha | Image processing method and apparatus |
| US5319722A (en) * | 1992-10-01 | 1994-06-07 | Sony Electronics, Inc. | Neural network for character recognition of rotated characters |
| CA2116600C (en) * | 1993-04-10 | 1996-11-05 | David Jack Ittner | Methods and apparatus for inferring orientation of lines of text |
| JP3050007B2 (ja) * | 1993-08-26 | 2000-06-05 | ミノルタ株式会社 | 画像読取装置およびこれを備えた画像形成装置 |
| US5588072A (en) * | 1993-12-22 | 1996-12-24 | Canon Kabushiki Kaisha | Method and apparatus for selecting blocks of image data from image data having both horizontally- and vertically-oriented blocks |
| EP0677818B1 (en) * | 1994-04-15 | 2000-05-10 | Canon Kabushiki Kaisha | Image pre-processor for character recognition system |
| EP0710003B1 (en) * | 1994-10-25 | 2001-08-16 | Canon Kabushiki Kaisha | Copier apparatus capable of rotating an image |
| US5987171A (en) | 1994-11-10 | 1999-11-16 | Canon Kabushiki Kaisha | Page analysis system |
| JPH08249422A (ja) * | 1995-03-08 | 1996-09-27 | Canon Inc | 文字処理装置及び方法 |
| US5889884A (en) * | 1995-05-23 | 1999-03-30 | Minolta Co., Ltd. | Image forming apparatus capable of recognizing top and bottom of document image |
| JP3088019B2 (ja) * | 1995-07-31 | 2000-09-18 | 富士通株式会社 | 媒体処理装置及び媒体処理方法 |
| US6137905A (en) * | 1995-08-31 | 2000-10-24 | Canon Kabushiki Kaisha | System for discriminating document orientation |
| JPH1021336A (ja) | 1996-07-03 | 1998-01-23 | Canon Inc | 文字列種別判定方法及び装置 |
| US6473196B2 (en) * | 1996-09-19 | 2002-10-29 | Canon Kabushiki Kaisha | Image forming apparatus and method |
| US6304681B1 (en) * | 1996-09-26 | 2001-10-16 | Canon Kabushiki Kaisha | Image processing apparatus for executing image processing in correspondence with portrait and landscape types |
| US6173088B1 (en) * | 1996-10-01 | 2001-01-09 | Canon Kabushiki Kaisha | Image forming method and apparatus |
| US6512848B2 (en) * | 1996-11-18 | 2003-01-28 | Canon Kabushiki Kaisha | Page analysis system |
| JP3728040B2 (ja) * | 1996-12-27 | 2005-12-21 | キヤノン株式会社 | 画像形成装置及び方法 |
| KR100247970B1 (ko) * | 1997-07-15 | 2000-03-15 | 윤종용 | 문서 영상의 방향 교정방법 |
| US6151423A (en) * | 1998-03-04 | 2000-11-21 | Canon Kabushiki Kaisha | Character recognition with document orientation determination |
| JP3422924B2 (ja) * | 1998-03-27 | 2003-07-07 | 富士通株式会社 | 文字認識装置、文字認識方法およびその方法をコンピュータに実行させるプログラムを記録したコンピュータ読み取り可能な記録媒体 |
| US6804414B1 (en) * | 1998-05-01 | 2004-10-12 | Fujitsu Limited | Image status detecting apparatus and document image correcting apparatus |
| JPH11338974A (ja) | 1998-05-28 | 1999-12-10 | Canon Inc | 文書処理方法及び装置、記憶媒体 |
| US6798905B1 (en) * | 1998-07-10 | 2004-09-28 | Minolta Co., Ltd. | Document orientation recognizing device which recognizes orientation of document image |
| US6624905B1 (en) * | 1998-09-29 | 2003-09-23 | Canon Kabushiki Kaisha | Image formation apparatus having image direction discrimination function |
| JP2001043310A (ja) * | 1999-07-30 | 2001-02-16 | Fujitsu Ltd | 文書画像補正装置および補正方法 |
| US6473517B1 (en) | 1999-09-15 | 2002-10-29 | Siemens Corporate Research, Inc. | Character segmentation method for vehicle license plate recognition |
| JP3854024B2 (ja) * | 1999-11-30 | 2006-12-06 | 株式会社Pfu | 文字認識前処理装置及び方法並びにプログラム記録媒体 |
| JP4228530B2 (ja) * | 2000-02-09 | 2009-02-25 | 富士通株式会社 | 画像処理方法及び画像処理装置 |
| US6993205B1 (en) * | 2000-04-12 | 2006-01-31 | International Business Machines Corporation | Automatic method of detection of incorrectly oriented text blocks using results from character recognition |
| US7031553B2 (en) * | 2000-09-22 | 2006-04-18 | Sri International | Method and apparatus for recognizing text in an image sequence of scene imagery |
| JP2002169233A (ja) * | 2000-11-30 | 2002-06-14 | Fuji Photo Film Co Ltd | 画像形成方法およびシステム |
| KR100411894B1 (ko) * | 2000-12-28 | 2003-12-24 | 한국전자통신연구원 | 문서영상 영역해석 방법 |
| US6546215B2 (en) | 2001-09-10 | 2003-04-08 | Toshiba Tec Kabushiki Kaisha | Image forming apparatus and method having document orientation control |
| JP2006502421A (ja) * | 2001-11-06 | 2006-01-19 | キーオティ | 画像投影装置 |
| US6567628B1 (en) | 2001-11-07 | 2003-05-20 | Hewlett-Packard Development Company L.P. | Methods and apparatus to determine page orientation for post imaging finishing |
| US7215828B2 (en) * | 2002-02-13 | 2007-05-08 | Eastman Kodak Company | Method and system for determining image orientation |
| CN1183436C (zh) | 2002-04-03 | 2005-01-05 | 摩托罗拉公司 | 用于手写字符的方向确定及其识别 |
| US7020338B1 (en) * | 2002-04-08 | 2006-03-28 | The United States Of America As Represented By The National Security Agency | Method of identifying script of line of text |
| US7167279B2 (en) * | 2002-05-08 | 2007-01-23 | Kabushiki Kaisha Toshiba | Image forming apparatus |
| US20040001606A1 (en) | 2002-06-28 | 2004-01-01 | Levy Kenneth L. | Watermark fonts |
| JP2004272798A (ja) * | 2003-03-11 | 2004-09-30 | Pfu Ltd | 画像読み取り装置 |
| JP4350414B2 (ja) * | 2003-04-30 | 2009-10-21 | キヤノン株式会社 | 情報処理装置及び情報処理方法ならびに記憶媒体、プログラム |
| US7565030B2 (en) * | 2003-06-26 | 2009-07-21 | Fotonation Vision Limited | Detecting orientation of digital images using face detection information |
| WO2005022077A2 (en) * | 2003-08-28 | 2005-03-10 | Sarnoff Corporation | Method and apparatus for differentiating pedestrians, vehicles, and other objects |
| US7454045B2 (en) * | 2003-10-10 | 2008-11-18 | The United States Of America As Represented By The Department Of Health And Human Services | Determination of feature boundaries in a digital representation of an anatomical structure |
| US7286718B2 (en) * | 2004-01-26 | 2007-10-23 | Sri International | Method and apparatus for determination of text orientation |
| JP4553241B2 (ja) * | 2004-07-20 | 2010-09-29 | 株式会社リコー | 文字方向識別装置、文書処理装置及びプログラム並びに記憶媒体 |
| ATE388449T1 (de) * | 2004-08-10 | 2008-03-15 | Oce Tech Bv | Detektion abweichender seiten während des scannens |
| JP4366318B2 (ja) * | 2005-01-11 | 2009-11-18 | キヤノン株式会社 | 画像処理装置及びその方法、プログラム |
| CN100369049C (zh) * | 2005-02-18 | 2008-02-13 | 富士通株式会社 | 灰度字符的精确分割装置及方法 |
| JP4607633B2 (ja) * | 2005-03-17 | 2011-01-05 | 株式会社リコー | 文字方向識別装置、画像形成装置、プログラム、記憶媒体および文字方向識別方法 |
| US7545529B2 (en) * | 2005-03-24 | 2009-06-09 | Kofax, Inc. | Systems and methods of accessing random access cache for rescanning |
| US7330604B2 (en) * | 2006-03-02 | 2008-02-12 | Compulink Management Center, Inc. | Model-based dewarping method and apparatus |
| US7636478B2 (en) | 2006-07-31 | 2009-12-22 | Mitutoyo Corporation | Fast multiple template matching using a shared correlation map |
| US7953268B2 (en) * | 2008-01-18 | 2011-05-31 | Mitek Systems, Inc. | Methods for mobile image capture and processing of documents |
| US8023770B2 (en) * | 2008-05-23 | 2011-09-20 | Sharp Laboratories Of America, Inc. | Methods and systems for identifying the orientation of a digital image |
-
2008
- 2008-05-23 US US12/126,561 patent/US8023741B2/en not_active Expired - Fee Related
-
2009
- 2009-05-21 JP JP2009123421A patent/JP5015195B2/ja active Active
-
2011
- 2011-08-18 US US13/212,241 patent/US8406530B2/en not_active Expired - Fee Related
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS62224870A (ja) * | 1986-03-26 | 1987-10-02 | Hitachi Ltd | 文書画像処理方法 |
| JPH0210480A (ja) * | 1988-06-29 | 1990-01-16 | Fuji Electric Co Ltd | 文字判別方法 |
| JPH0496882A (ja) * | 1990-08-14 | 1992-03-30 | Ricoh Co Ltd | 全角/半角判定方法 |
| JPH10214308A (ja) * | 1997-01-29 | 1998-08-11 | Ricoh Co Ltd | 文字判別方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP5015195B2 (ja) | 2012-08-29 |
| US8406530B2 (en) | 2013-03-26 |
| US20090290751A1 (en) | 2009-11-26 |
| US20110299779A1 (en) | 2011-12-08 |
| US8023741B2 (en) | 2011-09-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5015195B2 (ja) | デジタル画像内の数字を検知する方法 | |
| JP4796169B2 (ja) | デジタル画像の向きの判定方法 | |
| US6249604B1 (en) | Method for determining boundaries of words in text | |
| EP0543590B1 (en) | Method for comparing word shapes | |
| US8442319B2 (en) | System and method for classifying connected groups of foreground pixels in scanned document images according to the type of marking | |
| US5390259A (en) | Methods and apparatus for selecting semantically significant images in a document image without decoding image content | |
| US9020248B2 (en) | Window dependent feature regions and strict spatial layout for object detection | |
| EP0543594A2 (en) | A method for deriving wordshapes for subsequent comparison | |
| US9042601B2 (en) | Selective max-pooling for object detection | |
| US8351700B2 (en) | Variable glyph system and method | |
| US11170265B2 (en) | Image processing method and an image processing system | |
| CN109635796B (zh) | 调查问卷的识别方法、装置和设备 | |
| US9020198B2 (en) | Dimension-wise spatial layout importance selection: an alternative way to handle object deformation | |
| JP2009020884A (ja) | 画像データの特徴を特定する方法及びシステム | |
| JP2010217996A (ja) | 文字認識装置、文字認識プログラム、および文字認識方法 | |
| CN111008635A (zh) | 一种基于ocr的多票据自动识别方法及识别系统 | |
| US20020154818A1 (en) | Automatic table locating technique for documents | |
| CN104899551B (zh) | 一种表单图像分类方法 | |
| US6694059B1 (en) | Robustness enhancement and evaluation of image information extraction | |
| CN113723508A (zh) | 票据图像分类方法、装置、计算设备和存储介质 | |
| JP2000306045A (ja) | 単語認識装置 | |
| Raj et al. | Handwriting detection using object detection models | |
| JP2004046723A (ja) | 文字認識方法、該方法の実行に用いるプログラム及び文字認識装置 | |
| Worch et al. | Glyph spotting for mediaeval handwritings by template matching | |
| Srihari et al. | Content-based information retrieval from handwritten documents |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20120113 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120124 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120321 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20120508 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20120606 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20150615 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5015195 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |