JP2010146430A - 情報処理装置 - Google Patents
情報処理装置 Download PDFInfo
- Publication number
- JP2010146430A JP2010146430A JP2008324988A JP2008324988A JP2010146430A JP 2010146430 A JP2010146430 A JP 2010146430A JP 2008324988 A JP2008324988 A JP 2008324988A JP 2008324988 A JP2008324988 A JP 2008324988A JP 2010146430 A JP2010146430 A JP 2010146430A
- Authority
- JP
- Japan
- Prior art keywords
- keyword
- data
- virtual directory
- hierarchical structure
- combined
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 238000000547 structure data Methods 0.000 claims abstract description 107
- 230000010365 information processing Effects 0.000 claims description 112
- 238000012544 monitoring process Methods 0.000 claims description 71
- 238000002910 structure generation Methods 0.000 claims description 50
- 238000000605 extraction Methods 0.000 claims description 34
- 238000000034 method Methods 0.000 claims description 19
- 238000003672 processing method Methods 0.000 claims description 16
- 230000008569 process Effects 0.000 claims description 12
- 238000004519 manufacturing process Methods 0.000 claims description 11
- 238000011161 development Methods 0.000 description 71
- 238000010586 diagram Methods 0.000 description 9
- 238000004458 analytical method Methods 0.000 description 7
- 239000000284 extract Substances 0.000 description 6
- 238000012545 processing Methods 0.000 description 6
- 230000000877 morphologic effect Effects 0.000 description 5
- 230000004913 activation Effects 0.000 description 2
- 238000004891 communication Methods 0.000 description 2
- 238000010276 construction Methods 0.000 description 2
- 238000005516 engineering process Methods 0.000 description 2
- 230000008859 change Effects 0.000 description 1
- 238000013075 data extraction Methods 0.000 description 1
- 238000003066 decision tree Methods 0.000 description 1
- 230000007717 exclusion Effects 0.000 description 1
- 239000000203 mixture Substances 0.000 description 1
- 230000008520 organization Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
Images

































Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
【課題】利用者によるデータの利用状況に応じて適切な分類階層構造を生成し、当該利用者の利便性の向上を図る。
【解決手段】所定のテキストデータを取得するテキスト取得手段と、上記テキスト取得手段にて取得した上記テキストデータに含まれるキーワードを抽出して、当該キーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶する階層構造生成手段と、を備え、上記階層構造生成手段は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する。
【選択図】図1
【解決手段】所定のテキストデータを取得するテキスト取得手段と、上記テキスト取得手段にて取得した上記テキストデータに含まれるキーワードを抽出して、当該キーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶する階層構造生成手段と、を備え、上記階層構造生成手段は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する。
【選択図】図1
Description
本発明は、情報処理装置にかかり、特に、階層構造を生成する情報処理装置に関する。
近年、コンピュータ技術の発達に伴い、あらゆる情報を電子データにて管理することが一般的になっている。このため、電子データを効率よく管理する技術が必要となっている。そして、電子データを分類して管理する技術が、特許文献1乃至2に開示されている。
特許文献1に開示の文書分類装置では、当該文献の図1に示すように、文書が保存されている文書データベースと、文書データベース中の文書から作者、タイトル、キーワード等の属性情報を抽出する属性抽出部と、この抽出された属性情報をもとに文書を分類する文書分類部と、を備えている。また、この分類された文書を木構造である話題構造として表現し格納するフォルダを備えている。そして、このシステムでは、文書の分類時に、話題構造から上位ノードをつなげて付けて表わした話題構造リストを得て、この話題構造リストの個々の要素と文書に付随した属性情報との一致量を計算し、この一致量に基づいて文書を分類する。なお、話題構造は、特許文献1の図2に示すような構造で、ユーザがあらかじめ用意しておく。
また、特許文献2に開示の文書データ分類装置では、当該文献の図1に示すように、ノードの木構造により構成され、かつ、葉ノードには、分類クラスが割り付けられるよう構成される分類決定木を用意し、これを辿ることで文書データの属する分類クラスを特定する。また、特許文献2では、上記文書データ分類装置を構築する文書分類機能構築装置を開示している。この文書分類機能構築装置では、予め文書データと当該文書データの属する分類クラスとの組の集合データからなるサンプルデータを参照して、分類決定木を作成している。
しかしながら、上述した特許文献に開示の技術では、いずれも事前に分類に必要なデータを用意しておく必要がある。例えば、特許文献1では、文書データを分類する構造、つまり、キーワードの階層リストを、あらかじめ矛盾のなく適切に作っておく必要がある。また、特許文献2では、サンプルデータに文書データと文書データの属する分類クラスとを関連付けておく必要がある。従って、事前に分類クラスを把握したうえで、サンプルデータを作成することになるため、これによって作成される分類構造は限られたものとなる。
以上のように、特許文献に開示の技術では、分類を行うために必要であり適切な情報が事前に用意されていない場合には、適切な分類階層構造データを生成することができない。また、分類を追加・変更する場合には、分類構造を再定義すべくデータを変更する作業が必要となり、手間が生じうる。従って、利用者にとって利便性に欠ける、という問題が生じる。
このため、本発明の目的は、上述した課題である、利用者によるデータの利用状況に応じて適切な分類階層構造を生成し、当該利用者の利便性の向上を図る、ことにある。
かかる目的を達成するため本発明の一形態である情報処理装置は、
所定のテキストデータを取得するテキスト取得手段と、
上記テキスト取得手段にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成手段と、を備え、
上記階層構造生成手段は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する、
という構成を採っている。
所定のテキストデータを取得するテキスト取得手段と、
上記テキスト取得手段にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成手段と、を備え、
上記階層構造生成手段は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する、
という構成を採っている。
また、本発明の他の形態であるプログラムは、
情報処理装置に、
所定のテキストデータを取得するテキスト取得手段と、
上記テキスト取得手段にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成手段と、
を実現させ、
上記階層構造生成手段は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する機能を有する、
という構成を採っている。
情報処理装置に、
所定のテキストデータを取得するテキスト取得手段と、
上記テキスト取得手段にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成手段と、
を実現させ、
上記階層構造生成手段は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する機能を有する、
という構成を採っている。
また、本発明の他の形態である階層構造データは、
取得した所定のテキストデータに含まれるキーワード及び当該キーワードを結合した結合キーワードにそれぞれ対応して生成された仮想ディレクトリが階層化されて構成されており、
上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて構成されている。
取得した所定のテキストデータに含まれるキーワード及び当該キーワードを結合した結合キーワードにそれぞれ対応して生成された仮想ディレクトリが階層化されて構成されており、
上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて構成されている。
また、本発明の他の形態である情報処理方法は、
所定のテキストデータを取得するテキスト取得工程と、
上記テキスト取得工程にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成工程と、を有し、
上記階層構造生成工程は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する、
という構成を採っている。
所定のテキストデータを取得するテキスト取得工程と、
上記テキスト取得工程にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成工程と、を有し、
上記階層構造生成工程は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する、
という構成を採っている。
本発明は、以上のように構成されることにより、利用者は、生成された階層構造を利用して、データ分類やデータ検索を行うことが容易となり、また、適切かつ効率よく、データ分類やデータ検索を実行することができる。その結果、利用者の利便性の向上を図ることができる。
<実施形態1>
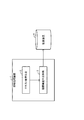
本発明の第1の実施形態を、図1を参照して説明する。図1は、本発明の一形態である情報処理装置の構成を示す機能ブロックである。なお、本実施形態では、本発明である情報処理装置の概略を説明する。
本発明の第1の実施形態を、図1を参照して説明する。図1は、本発明の一形態である情報処理装置の構成を示す機能ブロックである。なお、本実施形態では、本発明である情報処理装置の概略を説明する。
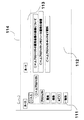
図1に示すように、本発明の一形態である情報処理装置1は、所定のテキストデータを取得するテキスト取得手段2と、上記テキスト取得手段2にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段4に記憶する階層構造生成手段3と、を備えている。
そして、上記階層構造生成手段3は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する、という構成を採っている。
上記構成の情報処理装置によると、まず、情報処理装置は、テキストデータを取得し、このテキストデータに含まれるキーワードを抽出する。続いて、情報処理装置は、抽出したキーワードに基づいて仮想ディレクトリを生成する。具体的には、単一のキーワードに対応する仮想ディレクトリと、単一のキーワードを結合した結合キーワードに対応するディレクトリを生成する。そして、情報処理装置は、生成した仮想ディレクトリを階層化した階層構造データを生成する。具体的には、単一のキーワードに対応するディレクトリの下位階層に、当該単一のキーワードを含む結合キーワードに対応するディレクトリを配置し、さらに、この結合キーワードに対応するディレクトリの下位階層に、当該結合キーワードを含む別の結合キーワードに対応するディレクトリを配置して、各ディレクトリを関連付け、階層構造データを生成する。
これにより、例えば利用者が利用しているなどのテキストデータから、当該テキストデータに含まれるキーワードに基づいて自動的に階層構造を生成することができる。特に、単一キーワードと結合キーワードとに含まれるキーワードの包含関係に基づいて、適切に階層化された階層構造を生成することができる。従って、利用者は、生成された階層構造を利用して、データ分類やデータ検索を行うことが容易となり、また、適切かつ効率よく、データ分類やデータ検索を実行することができる。その結果、利用者の利便性の向上を図ることができる。
また、上記情報処理装置1では、上記階層構造生成手段3は、単一の上記キーワードにそれぞれ対応する上記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の上記キーワードを結合した上記結合キーワードに対応する上記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに他の単一の上記キーワードを結合した他の上記結合キーワードに対応する上記仮想ディレクトリを関連付けて、上記階層構造データを生成する、という構成を採る。
また、上記情報処理装置1では、上記階層構造生成手段3は、上記テキスト取得手段2にて取得した上記テキストデータにおける上記キーワードの出現順序に従って、当該キーワードを結合して上記結合キーワードを生成する、という構成を採る。
また、上記情報処理装置1では、上記階層構造生成手段3は、上記テキスト取得手段にて取得した上記テキストデータにおける上記キーワード間の隣接度合に応じて、当該キーワードを結合して上記結合キーワードを生成する、という構成を採る。
また、上記情報処理装置1では、上記階層構造生成手段3は、所定の単一の上記キーワードあるいは所定の上記結合キーワードに対応する上記仮想ディレクトリの下位階層に、他の上記仮想ディレクトリに既に関連付けられている上記仮想ディレクトリであって上記所定の単一のキーワードあるいは上記所定の結合キーワードを含む上記結合キーワードに対応する上記仮想ディレクトリを関連付ける、という構成を採る。
これにより、所定の結合キーワードに含まれる単一のキーワードや他の結合キーワードに対応する仮想ディレクトリが既に存在している場合には、この既存の仮想ディレクトリの下位階層に、上記所定の結合キーワードに対応する仮想ディレクトリを関連付ける。従って、仮想ディレクトリが重複して生成されることを抑制することができる。
また、上記情報処理装置1では、上記階層構造生成手段3は、上記仮想ディレクトリに、当該仮想ディレクトリが対応する単一の上記キーワードあるいは上記結合キーワードに含まれる上記キーワードを関連付けて記憶する、という構成を採る。
また、上記情報処理装置1では、上記階層構造生成手段3は、上記仮想ディレクトリに、当該仮想ディレクトリが対応する単一の上記キーワードあるいは上記結合キーワードを抽出した上記テキストデータが関連付けられたデータファイルを関連付けて記憶する、という構成を採る。
これにより、仮想ディレクトリに関連付けたキーワードを用いることで、当該仮想ディレクトリに対応させるテキストデータ、つまり、当該テキストデータを含むデータファイルを容易に特定することができる。従って、データファイルを、当該データファイルのテキストデータに含まれるキーワードに基づいて、容易に階層構造に従って分類することができる。
また、上記情報処理装置1では、図示しないが、所定のデータへのアクセスを監視するデータアクセス監視手段と、上記データアクセス監視手段にてアクセスされたことを検出した上記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出し、当該アクセス対象キーワードが上記階層構造データに含まれる上記仮想ディレクトリに対応する上記キーワードあるいは上記結合キーワードと同一である場合に、当該仮想ディレクトリに、当該アクセス対象キーワードが検出された上記所定のデータを表すデータファイルを関連付けるデータ関連付け手段と、を備える。
また、上記情報処理装置1は、図示しないが、所定のデータへのアクセスを監視するデータアクセス監視手段と、上記データアクセス監視手段にてアクセスされたことを検出した上記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出すると共に、当該アクセス対象キーワードが上記階層構造データに含まれる上記仮想ディレクトリに対応する上記キーワードあるいは上記結合キーワードと同一ではないものをキーワード候補データとして抽出するキーワード候補抽出手段と、を備える。そして、上記キーワード候補抽出手段は、上記キーワード候補データの抽出回数をカウントして、この抽出回数に基づいて当該キーワード候補データを上記キーワードとして設定し、上記階層構造生成手段3は、上記キーワード候補抽出手段にて設定された上記キーワードに基づいて上記仮想ディレクトリを生成し、既存の上記階層構造データに追加する、という構成を採る。
これにより、アクセスされたデータに含まれるキーワードを抽出することで、上述同様に、当該データを容易に階層構造に従って分類することができる。また、アクセスされたデータに含まれるキーワードをキーワード候補として、その抽出回数をカウントして、その回数が多くなったときに当該キーワード候補に対応する仮想ディレクトリを生成し、上述同様に階層構造データに追加する。従って、利用者の利用状況に応じて適切な階層構造データを生成することができる。
また、上記情報処理装置1では、図示しないが、上記階層構造データを表示手段に表示出力する表示制御手段を備えている。そして、当該表示制御手段は、上記階層構造データを構成する上記仮想ディレクトリの選択を受け付けて、当該選択された上記仮想ディレクトリに関連付けられた上記データファイルを上記表示手段に表示するよう制御する、という構成を採る
また、上記情報処理装置1では、図示しないが、上記階層構造データを表示手段に表示出力する表示制御手段を備えている。そして、上記表示制御手段は、上記階層構造データを構成する上記仮想ディレクトリの選択を受け付けて、当該選択された上記仮想ディレクトリの上位階層及び/又は下位階層に関連付けられた他の上記仮想ディレクトリに関連付けられた上記データファイルを上記表示手段に表示するよう制御する、という構成を採る。
さらに、上記情報処理装置では、上記表示制御手段は、上記階層構造データに基づいて上記選択された仮想ディレクトリの上位階層及び/又は下位階層に関連付けられた上記仮想ディレクトリを選択可能なよう上記表示手段に表示する、という構成を採る。
これにより、利用者にて所定の仮想ディレクトリが選択されると、当該仮想ディレクトリに関連付けられたデータファイル、あるいは、当該仮想ディレクトリよりも下位階層の他の仮想ディレクトリに関連付けられたデータファイルを表示する。従って、利用者は容易にデータファイルを検索することが可能である。
また、上記構成の情報処理装置は、当該情報処理装置に階層構造生成用プログラムが組み込まれることにより実現できる。具体的に、本発明の他の形態である階層構造性生成用プログラムは、情報処理装置に、所定のテキストデータを取得するテキスト取得手段と、上記テキスト取得手段にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成手段と、を実現させるためのプログラムである。そして、上記階層構造生成手段は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する機能を有する。
また、上記プログラムでは、上記階層構造生成手段は、単一の上記キーワードにそれぞれ対応する上記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の上記キーワードを結合した上記結合キーワードに対応する上記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに単一の上記キーワードを結合した他の上記結合キーワードに対応する上記仮想ディレクトリを関連付けて、上記階層構造データを生成する、という構成を採る。
そして、上記情報処理装置によって構成される階層構造データは、取得した所定のテキストデータに含まれるキーワード及び当該キーワードを結合した結合キーワードにそれぞれ対応して生成された仮想ディレクトリが階層化されて構成されており、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて構成されている。
また、上記階層構造データは、単一の上記キーワードにそれぞれ対応する上記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の上記キーワードを結合した上記結合キーワードに対応する上記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに単一の上記キーワードを結合した他の上記結合キーワードに対応する上記仮想ディレクトリを関連付けて構成されている。
さらに、上記階層構造データは、所定の単一の上記キーワードあるいは所定の上記結合キーワードに対応する上記仮想ディレクトリの下位階層に、他の上記仮想ディレクトリに既に関連付けられている上記仮想ディレクトリであって上記所定の単一のキーワードあるいは上記所定の結合キーワードを含む上記結合キーワードに対応する上記仮想ディレクトリを関連付けて構成されている。
また、上述した情報処理装置が作動することにより実行される動画像処理方法は、所定のテキストデータを取得するテキスト取得工程と、上記テキスト取得工程にて取得した上記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成工程と、を有している。
そして、上記階層構造生成工程は、上記キーワードを結合した結合キーワードを生成すると共に、上記キーワード及び上記結合キーワードにそれぞれ対応する上記仮想ディレクトリを生成して、上記結合キーワードに対応する上記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の上記仮想ディレクトリの下位階層に関連付けて、上記階層構造データを生成する、という構成を採る。
また、上記情報処理方法では、上記階層構造生成工程は、単一の上記キーワードにそれぞれ対応する上記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の上記キーワードを結合した上記結合キーワードに対応する上記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに他の単一の上記キーワードを結合した他の上記結合キーワードに対応する上記仮想ディレクトリを関連付けて、上記階層構造データを生成する、という構成を採る。
また、上記情報処理方法では、上記階層構造生成工程は、所定の単一の上記キーワードあるいは所定の上記結合キーワードに対応する上記仮想ディレクトリの下位階層に、他の上記仮想ディレクトリに既に関連付けられている上記仮想ディレクトリであって上記所定の単一のキーワードあるいは上記所定の結合キーワードを含む上記結合キーワードに対応する上記仮想ディレクトリを関連付ける、という構成を採る。
さらに、上記情報処理方法では、上記階層構造生成工程の後に、所定のデータへのアクセスを監視するデータアクセス監視工程と、上記データアクセス監視工程にてアクセスされたことを検出した上記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出し、当該アクセス対象キーワードが上記階層構造データに含まれる上記仮想ディレクトリに対応する上記キーワードあるいは上記結合キーワードと同一である場合に、当該仮想ディレクトリに、当該アクセス対象キーワードが検出された上記所定のデータを表すデータファイルを関連付けるデータ関連付け工程と、を有する、という構成を採る。
また、上記情報処理方法では、上記階層構造生成工程の後に、所定のデータへのアクセスを監視するデータアクセス監視工程と、上記データアクセス監視工程にてアクセスされたことを検出した上記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出すると共に、当該アクセス対象キーワードが上記階層構造データに含まれる上記仮想ディレクトリに対応する上記キーワードあるいは上記結合キーワードと同一ではないものをキーワード候補データとして抽出するキーワード候補抽出工程と、を有する。そして、上記キーワード候補抽出工程は、上記キーワード候補データの抽出回数をカウントして、この抽出回数に基づいて当該キーワード候補データを上記キーワードとして設定し、その後、上記階層構造生成工程を再度実行し、上記キーワード候補抽出手段にて設定された上記キーワードに基づいて上記仮想ディレクトリを生成し、既存の上記分類階層構造データに追加する、という構成を採る。
上述した構成を有する、プログラム、階層構造データ、又は、情報処理方法、の発明であっても、上記情報処理装置と同様の作用を有するために、上述した本発明の目的を達成することができる。
<実施形態2>
本発明の第2の実施形態を、図2乃至図20を参照して説明する。図2は、情報処理装置の構成を示す機能ブロック図である。図3乃至図5は、情報処理装置に格納されるデータの一例を示す図である。図6乃至図12は、情報処理装置の動作を示すフローチャートである。図13乃至図19は、情報処理装置による分類階層構造データの生成処理の様子を示す説明図である。図20は、分類階層構造データを表示したときの様子を示す図である。
本発明の第2の実施形態を、図2乃至図20を参照して説明する。図2は、情報処理装置の構成を示す機能ブロック図である。図3乃至図5は、情報処理装置に格納されるデータの一例を示す図である。図6乃至図12は、情報処理装置の動作を示すフローチャートである。図13乃至図19は、情報処理装置による分類階層構造データの生成処理の様子を示す説明図である。図20は、分類階層構造データを表示したときの様子を示す図である。
ここで、本実施形態は、上述した実施形態1にて開示した情報処理装置の具体的な一例を示すものである。なお、本実施形態では、1台の情報処理装置にて分類階層構造を生成する場合を説明するが、以下に説明する情報処理装置は、複数台の情報処理装置にて構成されていてもよい。
[構成]
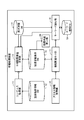
図1に示す情報処理装置10は、図示しないが、演算処理を行うCPU(Central Processing Unit)といった演算装置と、情報を記憶するHDD(Hard disk drive)などの記憶装置と、を備えた一般的なコンピュータである。また、情報処理装置10は、図示しないが、入力装置や表示装置なども備えている。
図1に示す情報処理装置10は、図示しないが、演算処理を行うCPU(Central Processing Unit)といった演算装置と、情報を記憶するHDD(Hard disk drive)などの記憶装置と、を備えた一般的なコンピュータである。また、情報処理装置10は、図示しないが、入力装置や表示装置なども備えている。
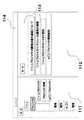
そして、情報処理装置10は、演算装置に階層構造生成用プログラムが組み込まれることによって構築された、ユーザ入力監視部11と、分類構造生成部13と、アクセス情報監視部16と、情報関連付け部17と、キーワード抽出部18と、階層構造表示部20と、を備えている。また、記憶装置は、監視場所情報DB(データベース)12と、除外単語DB(データベース)14と、関連付け情報保存DB(データベース)15と、キーワード候補DB(データベース)19と、を備えている。以下、各構成について詳述する。
上記ユーザ入力監視部11(テキスト取得手段)は、予め監視場所情報DB12に設定された場所への、ユーザによるテキスト入力を監視する。そして、ユーザ入力監視部11は、ユーザが監視場所にテキストを入力したら、そのテキストを収集し、収集したテキストデータを分類階層構造生成部13に送信する。
上記監視場所情報DB12は、図3(A)に示すユーザ入力監視場所設定テーブルを記憶している。このユーザ入力監視場所設定テーブルは、上記ユーザ入力監視部11が監視する場所を指定する情報が保存されている。例えば、図3(A)に示すユーザ入力監視場所設定テーブルは、監視するアプリケーションの存在場所を示す「監視アプリケーション」と、この「監視アプリケーション」で指定されたアプリケーションにある監視するテキスト入力エリアを示す「監視テキスト入力エリア」と、からなる。なお、このユーザ入力監視場所設定テーブルは、ユーザによって設定変更可能である。
上記分類階層構造生成部13(階層構造生成手段)は、ユーザ入力監視部11から受信したテキスト情報や、後述するキーワード抽出部18から受信したキーワード情報に基づいて、階層化された仮想ディレクトリから成る分類階層構造データを生成し、それを関連情報保存DB15に保存する。なお、分類階層構造部13が有する具体的な機能については、後述する動作説明時に説明する。
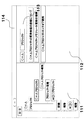
ここで、上記関連付け保存DB15に保存されている情報を説明する。関連情報保存DB15は、図3(B)に示す情報管理テーブルと、図3(C)に示す関連管理テーブルと、を有する。そして、図3(B)に示す情報管理テーブルは、情報を一意に識別するために関連付け保存DB15が自動的に割り振る1つ情報に対して固有のIDである「ID」と、キーワードのキーワード名や、ファイルのファイル名など、情報のタイトルを保存する「情報の名前」と、「ファイル」、「Webページ」、「キーワード」など情報の種類を保存する「情報の種類」と、その情報の存在場所を示す「存在場所」と、からなる。また、図3(C)に示す関連管理テーブルは、関連する2つの情報間のIDを保存する「関連元ID」及び「関連先ID」と、情報間の関係の種類を示す「関係」と、からなる。
また、上記アクセス情報監視部16(データアクセス監視手段)は、ユーザがアクセスした情報を監視し、そのアクセス情報に関連するアクセス関連情報を情報関連付け部17に送る。ここで、図4(A)、にアクセス情報監視部16が情報関連付け部17に送るアクセス関連情報を示す。この図に示すように、アクセス関連情報は、アクセスした情報のタイトルやファイル名などの重要な場所のテキストを示す「アクセス情報の重要な場所のテキスト」と、ファイル、Webサイト等のアクセス情報の種類を示す「アクセス情報の種類」と、ファイルパスやURLなどのアクセス情報が存在する場所を示す「アクセス情報の存在場所」と、から構成される。
また、上記情報関連付け部17(データ関連付け手段)は、アクセス情報監視部16から上述したアクセス関連情報を受信し、関連情報保存DB15に既に保存されている分類階層構造に、アクセス情報を関連付ける。また、アクセス情報に含まれる情報と、そのアクセス情報が関連付けされた分類階層構造の場所を表す情報と、をキーワード抽出部18に送る。図4(B)に、情報関連付け部18からキーワード抽出部18に送信される情報を示す。この情報は、アクセス情報監視部16から情報関連付け部17に送られたアクセス情報中の「アクセス情報の重要な場所のテキスト」と同じテキストである「アクセス情報の重要な場所のテキスト」と、そのアクセス情報が情報関連付け部17で関連付けられた分類階層構造中の仮想ディレクトリのIDを示す「関連付けられた仮想ディレクトリのID」と、からなる。なお、情報関連付け部17が有する具体的な情報関連付けに関する機能については、後述する動作説明時に説明する。
また、上記キーワード抽出部18(キーワード候補抽出手段)は、情報関連付け部17から送信された情報を受信し、「アクセス情報の重要な場所のテキスト」からキーワード候補(アクセス対象キーワード)を生成する。そして、キーワード候補DB19のキーワード候補テーブルに、生成したキーワード候補と、そのキーワード候補を生成の元となった「アクセス情報の重要な場所のテキスト」の「関連付けられた仮想ディレクトリのID」と、を保存する。このとき、キーワード候補DB19に保存する際に、既に同じ情報が保存されていた場合は、その情報のカウント数を増加させる。そして、カウント数が閾値に達したら、そのキーワード候補を上述した分類階層構造生成部13に送信し、当該キーワード候補に基づく仮想ディレクトリを生成する。
ここで、図5(C)に、キーワード候補DB19に格納されるキーワード候補テーブルの構成を示す。このキーワード候補テーブルは、アクセス情報から抽出した単語を保存する「キーワード候補」と、アクセス情報の「関連付けられた仮想ディレクトリのID」と同じ情報を保存する「仮想ディレクトリのID」と、カウント数を示す「カウント数」と、からなる。また、図5(D)に、キーワード抽出部18から分類階層構造生成部13に送られるキーワード情報を示す。この送信されるキーワード情報は、閾値に達したキーワード候補を示す「キーワード」と、そのキーワード候補の仮想ディレクトリのIDを示す「仮想ディレクトリのID」と、からなる。
次に、関連情報保存DB15に保存されている分類階層構造データのデータ構造について説明する。図5に、分類階層構造データの構造の一例を示す。この図に示すように、分類階層構造データは、「仮想ディレクトリ」、「キーワード」、「アクセス情報」、それらを結ぶ線、で構成されている。
そして、仮想ディレクトリ、キーワード、アクセス情報に関する情報は、関連情報保存DB15に格納されている図3(B)に示す情報管理テーブルに保存される。具体的に、「仮想ディレクトリ」の場合は、情報管理テーブルの「情報の名前」に「仮想ディレクトリの名前」が、「情報の種類」には「仮想ディレクトリ」が、保存される。そして、「存在場所」には情報は保存されない。また、「キーワード」の場合は、情報管理テーブルの「情報の名前」に「キーワード名」が、「情報の種類」に「キーワード」が、保存され、存在場所には情報は保存されない。また、「アクセス情報」の場合は、「情報の名前」に「アクセス情報のタイトルやファイル名」が、「情報の種類」に「ファイル」や「Webサイト」などの「情報の種類」が、「存在場所」にはそのアクセス情報が存在する「物理フォルダのパス」や「URL」が保存される。さらに、「仮想ディレクトリ」、「キーワード」、「アクセス情報」の全てにおいて、関連情報保存DB15により一意となるID番号が割り振られる。また、情報管理テーブルには、最初から「ID」に「0」が、「情報の名前」に「ルート」が、「情報の種類」に「仮想ディレクトリ」が、保存されており、これは仮想ディレクトリのルートディレクトリである。
また、「仮想ディレクトリ」、「キーワード」、「アクセス情報」を結ぶ線は、これら相互間の関連付け状態を表しており、これに関する情報は関連管理テーブルに保存される。具体的に、関連管理テーブルは、上述した図3(C)に示す構成であり、関連する情報間のIDを、「関連元ID」と「関連先ID」とに保存し、「関係」にはどのような関係か、つまり関連付け状態を保存する。そして、関連の方向つまり関連付けの親子(主従)関係については、「関係」に保存した情報で表現する。例えば、仮想ディレクトリ間において階層の上位(親)下位(子)関係がある場合には、関連元IDに親仮想ディレクトリのIDを、関連先IDに子仮想ディレクトリIDを、関係に「親子ディレクトリ」を、保存する。これにより、関係「親子ディレクトリ」において、関連元が親で、関連先が子である、という方向性を示している。また、仮想ディレクトリとキーワード間であれば、「関連元ID」に仮想ディレクトリのID、「関連先ID」にキーワードのID、「関係」に「キーワード」を保存する。さらに、仮想ディレクトリとアクセス情報間であれば、「関連元ID」に仮想ディレクトリのID、「関連先ID」にアクセス情報のID、「関係」に「所属」を保存する。
また、上記除外単語DB14は、上述した分類階層構造生成部13とキーワード抽出部18が階層構造を生成したり、キーワードを抽出するときに除外する単語の一覧が保存されている。
また、上記階層構造表示部20(表示制御手段)は、関連情報保存DB15の情報に基づいて、分類階層構造画面を生成し表示する。なお、階層構造表示部20の具体的な分類階層構造データの表示制御に関する機能については、後述する動作説明時に説明する。
[動作]
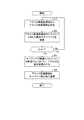
次に、上記構成の情報処理装置10の動作を、図6乃至図20を参照して説明する。はじめに、図6のフローチャートを参照して、ユーザ入力監視部11の動作について説明する。
次に、上記構成の情報処理装置10の動作を、図6乃至図20を参照して説明する。はじめに、図6のフローチャートを参照して、ユーザ入力監視部11の動作について説明する。
まず、ユーザ入力監視部11は、起動時に監視場所情報DB12から監視場所情報を読み出す(ステップA1)。そして、監視場所にテキストが入力されていないか監視する(ステップA2)。その後、監視場所へのテキストの入力を検出すると(ステップA3)、そのテキストデータを収集し(テキスト取得工程)、文単位に分割する(ステップA4)。そして、文単位に分割したテキストデータを、分類階層構造生成部13に送信する(ステップA5)。
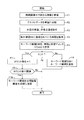
次に、図7のフローチャートを参照して、分類階層構造生成部13の動作について説明する。分類階層構造生成部13は、ユーザ入力監視部11から送信されたテキストデータを受信すると(ステップB1)、受信したテキストデータを形態素解析して単語に分解する(ステップB2)。続いて、分解した単語から、動詞、名詞、形容詞以外の単語と、動詞、名詞、形容詞の非自立語を除外する(ステップB3)。続いて、除外単語DB14に保存されている単語を除外する(ステップB4)。そして、残った単語(キーワード)に基づいて、分類階層構造データを生成し(ステップB5、分類階層構造生成工程)、当該分類階層構造データを関連情報保存DB15に保存する(ステップB6)。
ここで、上述した分類階層構造生成部13による分類階層構造データの生成方法を、図8のフローチャート、及び、図13〜図18の説明図を参照して説明する。なお、ここでは、上述した処理にて抽出された単語(キーワード)の数が、a個であるとする。
まず、分類階層構造生成部13は、すべての単語(キーワード)において、その単語を名前とする仮想ディレクトリをそれぞれ生成する(図13(A)参照)。このとき、関連情報保存DB15の情報管理テーブルの「情報の名前」に単語を、「情報の種類」に「仮想ディレクトリ」を、保存する(ステップC1)。続いて、ステップC1で生成した全ての仮想ディレクトリを、既存の仮想ディレクトリである「ルート」の下位階層に関連付ける(図13(B)参照)。このとき、関連情報保存DB15の関連管理テーブルの「関連元ID」に「ルート」のIDを、「関連先ID」に「仮想ディレクトリ」のIDを、「関係」に「親子ディレクトリ」を、保存する(ステップC2)。これにより、単一の各単語に対応する「仮想ディレクトリ」が、ルートの下位ではあるが、分類としては最上位階層に配置される。
続いて、全ての単語において、その単語をキーワード名とする「キーワード」を生成する(図13(C)参照)。このとき、関連情報保存DB15の情報管理テーブルの「情報の名前」に「単語」を、「情報の種類」に「キーワード」を、保存する(ステップC3)。そして、ステップC3で生成した「キーワード」と、当該キーワードと同じ単語が名前となっている「仮想ディレクトリ」とを関連付ける(図13(D)参照)。具体的には、関連情報保存DB15の関連管理テーブルの「関連元ID」に仮想ディレクトリのIDを、「関連先ID」にキーワードのIDを、「関係」に「キーワード」を、保存する(ステップC4)。
続いて、元のテキストデータ内における単語の並び順(出現順序)に従って、1番目と2番目の単語、1番目から3番目の単語、・・・、1番目からn番目の単語、をそれぞれ連結し、連結して生成された連結単語(結合キーワード)を名前とする仮想ディレクトリ生成する(図14(A)参照)。このとき、関連情報保存DB15の情報管理テーブルの「情報の名前」に「連結した単語」を、「情報の種類」に「仮想ディレクトリ」を、保存する(ステップC5)。例えば、図14(A)に示すように、連結単語に基づく仮想ディレクトリとして、「word1word2」、「word1word2word3」などを生成する。
そして、ステップC5で生成した仮想ディレクトリに、その仮想ディレクトリの名前を生成した連結前の各単語を、それぞれキーワードとして関連付ける(図14(B)参照)。このとき、関連情報保存DB15の関連管理テーブルの「関連元ID」に仮想ディレクトリのIDを、「関連先ID」にキーワードのIDを、「関係」に「キーワード」を、保存する(ステップC6)。例えば、「word1」と「word2」とを連結した「word1word2」の仮想ディレクトリに対して、キーワード「word1」と「word2」とを関連付ける。
なお、上述した単語の連結は、元となったテキストデータ内における単語相互間の隣接度合に基づいて行われる。例えば、単語間を連結する場合には、上述した処理で除去された助詞などを挟んで隣同士に位置する単語同士を連結する。そして、隣同士にはない単語同士は連結しない。但し、上述した単語の連結方法は一例であって、他の方法にて単語を連結してもよい。
続いて、元のテキストデータ内における単語の並び順に、1番目から(n−1)番目までを連結した名前を持つ仮想ディレクトリと、1番目からn番目(n=2〜a)までを連結した名前を持つ仮想ディレクトリとを、親子ディレクトリとして関連付ける(図15参照)。つまり、連結単語の名前を持つ仮想ディレクトリを、この連結単語に含まれる単一の単語あるいは他の連結単語の名前を持つ仮想ディレクトリの下位階層に関連付ける。そして、関連情報保存DB15の関連管理テーブルの「関連元ID」に1番目から(n−1)番目までを連結した名前を持つ仮想ディレクトリのIDを、「関連先ID」に1番目からn番目までを連結した名前を持つ仮想ディレクトリのIDを、「関係」に「親子ディレクトリ」を、保存する(ステップC7)。
上述したステップC7の処理を、図15を参照して具体的に説明する。まず、単一の単語(word1)に対応する仮想ディレクトリ「word1」を最上位階層に配置し、この下位階層に当該単一の単語(word1)に他の単一の単語(word2)を連結した連結単語(word1word2)に対応する仮想ディレクトリ「word1word2」を関連付ける。さらに、この下位階層には、上記連結単語(word1word2)に他の単一の単語(word3)を連結した他の連結単語(word1word2word3)に対応する仮想ディレクトリ「word1word2word3」を関連付ける。そして、さらに下位の階層まで、仮想ディレクトリを関連付ける。
続いて、出現順番が2番目以下であるm番目の単語に対応する仮想ディレクトリの下位階層を構築する。具体的には、m番目と(m+1)番目、m番目から(m+2)番目、・・・、m番目からn番目(m=2〜(a−1)、n=3〜a、m<n)の単語を連結し、連結した単語を名前とする仮想ディレクトリを生成する(図16(A)参照)。そして、関連情報保存DB15の情報管理テーブルの「情報の名前」に連結した単語を、「情報の種類」に「仮想ディレクトリ」を、保存する(ステップC8)。
なお、このときも、元のテキストデータ内における単語の並び順(出現順序)や相互に隣接する単語同士を連結する。例えば、図16(A)に示すように、仮想ディレクトリとして、「word2word3」、「word2word3word4」などを生成する。
次に、ステップC8で生成した仮想ディレクトリに、その仮想ディレクトリの名前を生成した連結前の各単語をそれぞれキーワードとして関連付ける(図16(B)参照)。そして、関連情報保存DB15の関連管理テーブルの「関連元ID」に仮想ディレクトリのIDを、「関連先ID」にキーワードのIDを、「関係」に「キーワード」を、保存する(ステップC9)。
次に、元のテキストデータ内における単語の並び順となるよう、m番目から(n−1)番目までを連結した名前を持つ仮想ディレクトリと、m番目からn番目(n=2〜(a−1、n=3〜a、m<n)までを連結した名前を持つ仮想ディレクトリとを、親子ディレクトリとして関連付ける(図17参照)。つまり、連結単語の名前を持つ仮想ディレクトリを、この連結単語に含まれる単一の単語あるいは他の連結単語結合の名前を持つ仮想ディレクトリの下位階層に関連付ける。そして、関連情報保存DB15の関連管理テーブルの「関連元ID」にm番目から(n−1)番目までを連結した名前を持つ仮想ディレクトリのIDを、「関連先ID」にm番目からn番目までを連結した名前を持つ仮想ディレクトリのIDを、「関係」に「親子ディレクトリ」を、保存する(ステップC10)。
ここで、上述したステップC10の処理を、図17を参照して具体的に説明する。まず、単一の単語(word2)に対応する仮想ディレクトリ「word2」が最上位階層に配置されており、この下位階層に当該単一の単語(word2)に他の単一の単語(word3)を連結した連結単語(word2word3)に対応する仮想ディレクトリ「word2word3」を関連付ける。さらに、この下位階層には、上記連結単語(word1word2)に他の単一の単語(word3)を連結した他の連結単語(word1word2word3)に対応する仮想ディレクトリ「word1word2word3」を関連付ける。そして、さらに下位の階層まで、仮想ディレクトリを関連付ける。
次に、m番目からn番目までの単語を連結した名前を持つ仮想ディレクトリと、(m−1)番目からn番目(m=2〜(a−1)、n=2〜(a−1)、m≦n)までの単語を連結した名前を持つ仮想ディレクトリを、親子ディレクトリとして関連付ける(図18参照)。そして、関連情報保存DB15の関連管理テーブルの「関連元ID」にm番目からn番目までを連結した名前を持つ仮想ディレクトリのIDを、「関連先ID」に(m−1)番目からn番目までを連結した名前を持つ仮想ディレクトリのIDを、「関係」に「親子ディレクトリ」を、保存する(ステップC11)。
上記処理を、図18を参照してさらに説明する。まず、所定の単一の単語(例えば、word2)に対応する仮想ディレクトリ(例えば、仮想ディレクトリ「word2」)の下位階層に、他の仮想ディレクトリ(例えば、仮想ディレクトリ「word1」)に既に関連付けられている仮想ディレクトリであって上記所定の単一の単語(word2)を含む連結単語(例えば、word1word2)に対応する仮想ディレクトリ(例えば、仮想ディレクトリ「word1word2」)を関連付ける。また、他の例としては、所定の連結単語(例えば、word2word3)に対応する仮想ディレクトリ(例えば、仮想ディレクトリ「word2word3」)の下位階層に、他の仮想ディレクトリ(例えば、仮想ディレクトリ「word1word2」)に既に関連付けられている仮想ディレクトリであって上記所定の連結単語(word2word3)を含む連結単語(例えば、word1word2word3)に対応する仮想ディレクトリ(例えば、仮想ディレクトリ「word1word2word3」)を関連付ける。
また、上記分類階層構造生成部13は、上述したユーザ入力監視部11にて収集したテキストデータが関連付けられた所定の情報(データファイル)を、上述したように生成した分類階層構造データの仮想ディレクトリに関連付けて記憶する。つまり、分類階層構造を生成するために用いたテキストデータが入力される情報自体を、当該テキストデータから抽出されたキーワードと同一のキーワードが関連付けられた各仮想ディレクトリに関連付ける。これにより、上記情報へは、後述するように、関連付けられたすべての仮想ディレクトリから参照することができる。
次に、図9のフローチャートを参照して、アクセス情報監視部16の動作について説明する。アクセス情報監視部16は、ユーザのファイル、Webページなどの情報へのアクセスを監視する(ステップD1、データアクセス監視工程)。そして、ユーザの情報へのアクセスを検出すると(ステップD2)、ユーザのアクセスした情報のファイル名やタイトルなどのテキストデータを抽出し、アクセス関連情報を生成する(ステップD3)。続いて、この生成したアクセス関連情報を、情報関連付け部17に送信する(ステップD4)。
次に、図10を参照して、情報関連付け部17の動作について説明する。まず、アクセス情報監視部16からアクセス関連情報を受信する(ステップE1)。すると、関連情報保存DB15の情報管理テーブルから、「関係」が「キーワード」であるものの「情報の名前」を抽出し、この「情報の名前」がアクセス関連情報内の「アクセス情報の重要な場所のテキスト」にあるかどうか検索する(ステップE2)。つまり、アクセスした情報に含まれるテキストデータに、既に分類階層構造データに含まれるキーワードと同一の情報が存在するか否かを調べる。
そして、上記検索によりヒットし(ステップE3:Yes)、既に分類階層構造データにキーワードとして登録されている情報がアクセスした情報に含まれている場合には、関連情報保存DB15の情報管理テーブルの「情報の名前」に、アクセス関連情報の「アクセス情報の重要な場所のテキスト」を、「情報の種類」にアクセス関連情報の「アクセス情報の種類」を、「存在場所」にアクセス情報の「アクセス情報の存在場所」を、保存する。
続いて、上記ヒットしたキーワードが関連付いている全ての仮想ディレクトリを関連情報保存DB15の関連管理テーブルから検索し、その仮想ディレクトリとアクセス情報(データファイル)とを関連付ける(ステップE4、データ関連付け工程)。具体的には、関連情報保存DB15の関連管理テーブルの「関連元ID」に仮想ディレクトリのIDを、「関連先ID」にアクセス情報のIDを、「関係」に「所属」を、保存する(ステップE4)。
続いて、キーワード情報として、アクセス関連情報の「アクセス情報の重要な場所のテキスト」と、そのアクセス情報が関連付いた「仮想ディレクトリのID」とを、キーワード抽出部18に送信する(ステップE5)。
なお、上記では、ヒットした全てのキーワードが関連付いている仮想ディレクトリにアクセス情報を関連付けたが、階層構造を考慮し、階層構造の一番浅い部分のみに関連付ける、または、一番深い部分に関連付けるなどしてもよい。
次に、図11を参照して、キーワード抽出部18の動作について説明する。まず、情報関連付け部17から情報を受信する(ステップF1)。続いて、受信した情報の「アクセス情報の重要な場所のテキスト」を形態素解析して単語に分割する(ステップF2)。続いて、抽出した単語のうち、動詞、名詞、および形容詞以外の品詞の単語と、動詞、名詞、および形容詞で非自立語に分類される単語を除外する(ステップF3)。続いて、除外単語DB14に保存されている単語を除外する(ステップF4)。これにより、ユーザがアクセスした情報に含まれるテキストデータ内の単語(アクセス対象キーワード)を、キーワード候補データとして抽出する(キーワード候補抽出工程)。このとき、特に、上述した情報関連付け部17にて関連情報保存DB15内にキーワードとして登録されていない単語を、キーワード候補とする。
続いて、キーワード候補DB19のキーワード候補テーブルを、上述したように抽出した単語であるキーワード候補と仮想ディレクトリIDで検索する(ステップF5)。この検索により、キーワード候補がキーワード候補DB19に存在するとヒットした場合には(ステップF6:Yes)、ヒットしたキーワード候補に関連付けられたカウント数を「1」だけ加算する(ステップF7)。一方、ヒットしなかった場合には、キーワード候補テーブルの「仮想ディレクトリID」に検索した仮想ディレクトリIDを、「キーワード候補」に検索した単語であるキーワード候補を、「カウント数」に「1」を保存する(ステップF8)。続いて、上述したようにヒットした場合には(ステップF7以降)、カウント数を「1」だけ加算した結果、当該カウント数が閾値に達したかどうかチェックする(ステップF9)。そして、閾値に達していた場合には(ステップF9:Yes)、達した「仮想ディレクトリID」と「キーワード候補」を、キーワード情報として分類構造生成部13に送信する(ステップF10)。そして、全ての単語に関してステップF5を繰り返す。
次に、図12のフローチャートを参照して、分類階層構造生成部13がキーワード抽出部18からキーワード候補を含むキーワード情報を受信したときの動作について説明する。
まず、キーワード抽出部18からキーワード情報を受信する(ステップG1)。続いて、キーワード情報の「キーワード候補」を名前にした仮想ディレクトリを生成する。そして、関連情報保存DB15の情報管理テーブルの「情報の名前」にキーワード情報の「キーワード候補」を、「情報の種類」に「仮想ディレクトリ」を、保存する(ステップG2)。
続いて、キーワード候補を名前にしてキーワードを生成する。そして、関連情報保存DB15の情報管理テーブルの「情報の名前」にキーワード候補を、「情報の種類」に「キーワード」を、保存する(ステップG3)。続いて、生成した仮想ディレクトリとキーワードとを関連付ける。そして、関連情報保存DB15の関連管理テーブルの「関連元ID」に仮想ディレクトリのIDを、「関連先ID」にキーワードのIDを、「関係」に「キーワード」を、保存する(ステップG4)。
続いて、キーワード候補情報の仮想ディレクトリIDの仮想ディレクトリを親ディレクトリにして、生成した仮想ディレクトリを関連付ける。そして、関連管理テーブルの「関連元ID」にキーワード候補情報の仮想ディレクトリIDを、「関連先ID」に仮想ディレクトリのIDを、「関係」に「親子ディレクトリ」を、保存する(ステップG5)。このとき、親ディレクトリに関連付いているキーワードを子ディレクトリにも関連付けるため、関連管理テーブルの「関連元ID」を親ディレクトリのIDで、「関係」を「キーワード」で検索し、関連管理テーブルの「関連元ID」に生成した仮想ディレクトリのIDを、「関連先ID」に検索結果のキーワードのIDを「関係」に「キーワード」を、保存する(ステップG6)。そして、生成した仮想ディレクトリに、親ディレクトリに関連付いている情報のうちキーワードを含むものを関連付ける。このとき、関連管理テーブルの「関連元ID」に仮想ディレクトリIDを、「関連先ID」にキーワードを含む親ディレクトリに所属している情報のIDを、「関係」に「所属」を、保存する(ステップG7)。
ここで、図19に、仮想ディレクトリに新たな情報が関連づき、この情報に含まれるキーワード候補のカウント値が閾値に達して、仮想ディレクトリが分類階層構造データに追加された場合を示す。この図の例では、まず、「wordd」を含む情報が既存の仮想ディレクトリ「wordc」に関連付き、その後、単語「word」のカウント値が閾値に達すると、仮想ディレクトリ「wordc」の下位に、新たな仮想ディレクトリ「wordcwordd」が追加される。
次に、図20を参照して、階層構造表示部20が生成して表示制御する階層構造表示画面について説明する。階層好評画面は、領域101、領域102、領域103、領域104からなる。領域101には、分類階層構造データがルートを頂点としたツリー状で表示される。そして、表示されている仮想ディレクトリがクリックされるなど選択されると、ツリーが展開され、クリックした仮想ディレクトリの子ディレクトリ(下位階層)が表示される。同様に、子ディレクトリが選択されると、このディレクトリに関連付いているさらに下位の子ディレクトリが表示される。
また、領域102には、領域101で選択されている仮想ディレクトリに関連付いている情報(データファイル)が表示される。例えば、図20の例では、「仮想ディレクトリAB」が選択された状態を示しており、領域102には、「仮想ディレクトリAB」に関連付けられている「キーワードA」と「キーワードB」に基づいて関連付けられた「情報A」と「情報AB」とが表示されている。
また、領域103には、現在領域101で選択されている仮想ディレクトリの親ディレクトリが表示される。図20の例では、「仮想ディレクトリAB」の親ディレクトリとなる「仮想ディレクトリA」と「仮想ディレクトリB」とが、選択可能なよう表示されている。これにより、現在の「仮想ディレクトリ」から、上位階層や下位階層に進むことができる。なお、領域104には、ツールバー領域でユーザがたどった階層を戻ったり、進んだりするための機能が割り当てられたボタンが表示される。
以上のように、本実施形態によると、例えばユーザが利用しているなどのテキストデータから、当該テキストデータに含まれるキーワードに基づいて自動的に分類階層構造を生成することができる。特に、単一の単語と連結単語とに含まれる単語の包含関係に基づいて、適切に階層化された階層構造を生成することができる。従って、ユーザは、生成された階層構造を利用して、データ分類やデータ検索を行うことが容易となり、また、適切かつ効率よく、データ分類やデータ検索を実行することができる。その結果、ユーザの利便性の向上を図ることができる。
なお、上記では、1台の情報処理装置にて、テキストデータの抽出から解析、分類階層構造データの生成、当該分類階層構造データを用いたアクセス情報の分類、情報の検索などの処理を行うこととして説明したが、必ずしも1台の情報処理装置で実現されていなくてもよい。例えば、分類階層構造データの生成のみ、他の情報処理装置で実行されるなど、上述した情報処理装置が有する各機能が、複数の各情報処理装置に分散して装備されていてもよい。つまり、上述した情報処理装置による機能が、複数台の情報処理装置から成るシステムで構成されていてもよい。
<実施形態3>
次に、本発明の第3の実施形態を、図21乃至図41を参照して説明する。本実施形態は、上述した実施形態2における情報処理装置10におけるさらなる具体的な動作例を示すものである。
次に、本発明の第3の実施形態を、図21乃至図41を参照して説明する。本実施形態は、上述した実施形態2における情報処理装置10におけるさらなる具体的な動作例を示すものである。
まず、監視場所情報DB12のユーザ入力監視場所設定テーブルには、図21のような情報が保存されている。すると、ユーザ入力監視部11は、監視場所情報DB12の入力監視場所設定テーブルから、例えば、起動時に監視場所情報を読み込み、その場所の入力を監視する。
一例として、ユーザがメーラーを起動し、新規にメールを作成し、サブジェクトに”Re:○×△プロジェクトの開発会議の連絡について”を入力し(図22(A)参照)、送信したとする。すると、ユーザ入力監視部11は、メーラーのサブジェクト入力欄が監視場所にあるため、このテキストデータを収集し、分類階層構造生成部13に送信する。
次に、分類階層構造生成部13は、このテキストデータを受信すると、形態素解析を行って単語に分解する。すると、図22(B)に示すように、単語に分解された結果、”Re”、”:”、○×△”、プロジェクト、”の”、”開発”、”会議”、”の”、”連絡”、”について”の10個の単語に分割される。このうち”:”と、”の”と、および”について”は品詞が名詞、動詞、形容詞以外のため除外する。なお、除外単語DB14には、図21(B)のような除外単語一覧が保存されていたとする。この場合には、”Re”が除外単語一覧に登録されているため、除外する。これにより、図22(C)に示すように、残った単語”○×△”、”プロジェクト”、”開発”、”会議”、”連絡”を使って、分類階層構造データを生成する。
次に、”○×△”、”プロジェクト、”開発”、”会議”、”連絡”を名前とする仮想ディレクトリを生成する。このとき、関連情報保存DB15の情報管理テーブルに、図23に示すように、順番にIDを付番し、「情報の名前」にそれぞれの「単語」を、「情報の種類」に「仮想ディレクトリ」を、保存する。
続いて、「ルート」と生成した「仮想ディレクトリ」とを関連付ける。このとき、関連情報保存DB15の関連管理テーブルに、図24に示すように、「関連元ID」にルートのID”0”を、「関連先ID」にそれぞれ生成した仮想ディレクトリのID”1”、”2”、”3”、”4”、”5”を、「関係」に「親子ディレクトリ」を、それぞれ保存する。
次に、全ての単語において、その単語をキーワード名とするキーワードを生成する。このとき、関連情報保存DB15の情報管理テーブルに、図23に示すように、順番にIDを付番して、「情報の名前」に「単語」を、「情報の種類」に「キーワード」を、保存する。
次に、生成したキーワードと同じ単語が名前である仮想ディレクトリとを関連付ける。このとき、関連情報保存DB15の関連管理テーブルに、図24に示すようにそれぞれ「関連元ID」に”1”、「関連先ID」に”6”、「関係」に「キーワード」を、「関連元ID」に”2”、「関連先ID」に”7”、「関係」に「キーワード」を、「関連元ID」に”3”、「関連先ID」に”8”、「関係」に「キーワード」を、「関連元ID」に”4”、「関連先ID」に”9”、「関係」に「キーワード」を、「関連元ID」に”5”、「関連先ID」に”10”、「関係」に「キーワード」を保存する。
次に”○×△”と”プロジェクト”を連結した”○×△プロジェクト”を、”○×△”、”プロジェクト”、”開発”を連結した”○×△プロジェクト開発”を、”○×△”、”プロジェクト”、”開発”、”会議”を連結した”○×△プロジェクト開発会議”を、”○×△”、”プロジェクト、”開発”、”会議”、”連絡”を連結した”○×△プロジェクト開発会議連絡”を名前とする仮想ディレクトリを生成する。このとき、関連情報保存DB15の情報管理テーブルに、図23に示すように、順番にIDを付与して、「情報の名前」に「連結した単語」を、「情報の種類」に「仮想ディレクトリ」を保存する。
次に、仮想ディレクトリ”○×△プロジェクト”にキーワード”○×△”と”プロジェクト”を、仮想ディレクトリ”○×△プロジェクト開発”にキーワード”○×△”と”プロジェクト”と”開発”を、仮想ディレクトリ”○×△プロジェクト開発会議”にキーワード”○×△”と”プロジェクト”と”開発”と”会議”を、仮想ディレクトリ”○×△プロジェクト開発会議連絡”にキーワード”○×△”と”プロジェクト”と”開発”と”会議”と”連絡”を関連付ける。このとき、上述同様に、図24に示すように、関連管理テーブルに関連情報を保存する。
次に、仮想ディレクトリ”○×△”と仮想ディレクトリ”○×△プロジェクト”を親子ディレクトリとして、仮想ディレクトリ”○×△プロジェクト”と仮想ディレクトリ”○×△プロジェクト開発”を親子ディレクトリとして、仮想ディレクトリ”○×△プロジェクト開発”と仮想ディレクトリ”○×△プロジェクト開発会議”を親子ディレクトリとして、仮想ディレクトリ”○×△プロジェクト開発会議”と仮想ディレクトリ”○×△プロジェクト開発会議連絡”を親子ディレクトリとして関連付ける。このとき、上述同様に図24に示すように、関連管理テーブルに関連情報を保存する。
次に、仮想ディレクトリ”プロジェクト開発”、”プロジェクト開発会議”、”プロジェクト開発会議連絡”、”開発会議”、”開発会議連絡”、”会議連絡”を生成する。このとき、上述同様に図23に示すように、情報管理テーブルに保存する。
次に、仮想ディレクトリ”プロジェクト開発”にキーワード”プロジェクト”と”開発”を、”プロジェクト開発会議”にキーワード”プロジェクト”と”開発”と”会議”を、”プロジェクト開発会議連絡”にキーワード”プロジェクト”と”開発”と”会議”と”連絡”を、仮想ディレクトリ”開発会議”にキーワード”開発”と”会議”を、仮想ディレクトリ”開発会議連絡”にキーワード”開発”と”会議”と”連絡”を、仮想ディレクトリ”会議連絡”にキーワード”会議”と”連絡”を、それぞれ関連付ける。このとき、上述同様に、図25に示すように、関連管理テーブルに保存する。なお、図25は、上述した図24の続きを示しており、当該図24と図25で関連管理テーブルを構成している。
次に、仮想ディレクトリ”プロジェクト”と仮想ディレクトリ”プロジェクト開発”を、仮想ディレクトリ”プロジェクト開発”と仮想ディレクトリ”プロジェクト開発会議”を、仮想ディレクトリ”プロジェクト開発会議”と仮想ディレクトリ”プロジェクト開発会議連絡”を親子ディレクトリとして関連付ける。このとき、関連管理テーブルに、上述同様に図25に示すように保存する。
次に、仮想ディレクトリ”開発”と仮想ディレクトリ”開発会議”を、仮想ディレクトリ”開発会議”と仮想ディレクトリ”開発会議連絡”を、仮想ディレクトリ”会議”と仮想ディレクトリ”会議連絡”を親子ディレクトリとして関連付ける。このとき、関連管理テーブルに、上述同様に図25に示すように保存する。
次に、仮想ディレクトリ”プロジェクト”と仮想ディレクトリ”○×△プロジェクト”を、仮想ディレクトリ”プロジェクト開発”と仮想ディレクトリ”○×△プロジェクト開発”を、仮想ディレクトリ開発会議”プロジェクト”と仮想ディレクトリ”○×△プロジェクト開発会議”を、仮想ディレクトリ”プロジェクト開発会議連絡”と仮想ディレクトリ”○×△プロジェクト開発会議連絡”を、仮想ディレクトリ”開発”と仮想ディレクトリ”プロジェクト開発”を、仮想ディレクトリ”会議連絡”と仮想ディレクトリ”開発会議連絡”を、仮想ディレクトリ”連絡”と仮想ディレクトリ”会議連絡”を関連付ける。このとき、関連管理テーブルに、上述同様に図25に示すように保存する。
以上のようにすることで、図26に示すような分類階層構造データを生成することができる。
次に、ユーザがファイラーを起動し、新規にファイルを作成し、ファイル名に”★□○プロジェクト開発報告”を入力した場合を説明する。ユーザ入力監視部10は、ファイラーのファイル名入力欄が監視場所にあるため、このテキストデータを収集し、分類階層構造生成部13に送信する。
そして、分類階層構造生成部13は、このテキストデータを受信すると、形態素解析で単語に分解する。すると、単語に分解された結果、”★□○”、”プロジェクト”、”開発”、”報告”の4個の単語に分割される。続いて、”★□○”、”プロジェクト”、”開発”、”報告”の単語を用いて、分類階層構造データを生成する。この分類階層構造データの生成手順は、上述と同様である。つまり、関連情報保存DB15の情報管理テーブルと関連管理テーブルに、図27及び図28に示す情報を記憶して、生成する。但し、このとき、”★□○”、”プロジェクト”、”開発”、”報告”を名前とする仮想ディレクトリを生成するが、既に”プロジェクト”と”開発”を名前とする仮想ディレクトリは生成済みなので、新たに生成しない。そして、新たに生成された仮想ディレクトリやキーワードは、上述した図26に示す分類階層構造データに追加され、図29に示すような新たな分類階層構造データが生成される。
次に、ユーザが”C:\ドキュメント”フォルダにあるファイル名”○×△プロジェクトUIモジュール開発仕様書”というドキュメントを、テキストエディタで開いたとする。このとき、図30(A)に示すように、アクセス情報監視場所設定テーブルにはテキストエディタで開いたファイルはファイル名を収集するように設定されている。従って、アクセス情報監視部16は、ユーザによるファイルへのアクセスを検出し、ファイル名”○×△プロジェクトUIモジュール開発仕様書”を収集する。そして、このファイルに基づいて、図30(B)に示すアクセス関連情報を生成し、情報関連付け部17に送信する。
次に、情報関連付け部17は、アクセス関連情報を受信すると、関連情報保存DB15の情報管理テーブルを検索し、情報の種類が「キーワード」であるものを抽出する。このとき、関連情報保存DB15の情報管理テーブルは、図23に示す状態であるとすると、”○×△”、”プロジェクト”、”開発”、”会議”、”連絡”が抽出される。このキーワードで”○×△プロジェクトUIモジュール開発仕様書”を検索すると、”○×△”、”プロジェクト”、”開発”がヒットする。続いて、情報管理テーブルからこの3つキーワードのIDを抽出すると、”6”、”7”、”8”が抽出される。続いて、関連管理テーブルの関連先IDをこのIDで、関係を「キーワード」で検索し、この3つキーワードが1つでも関連付いている仮想ディレクトリを抽出する。このとき、関連管理テーブルは、図24及び図25のような状態のため、関連元IDとして”1”、”2”、”3”、”11”、”12”、”13”、”14”、”25”、”26”、”27”、”28”、”29”が抽出される。
次に、情報管理テーブルにアクセス関連情報を保存する。このとき、情報管理テーブルの「情報の名前」に”○×△プロジェクトUIモジュール開発仕様書”を、「情報の種類」に「ファイル」を、「存在場所」に”C:\ドキュメント”を、保存すると、IDに”30”が自動的に割り当てられる。
次に、アクセス関連情報を仮想ディレクトリに関連付ける。このとき、関連管理テーブルの関連元IDにそれぞれ先ほど抽出された”1”、”2”、”3”、”11”、”12”、”13”、”14”、”25”、”26”、”27”、”28”、”29”を、関連先IDにアクセス情報のIDである”30”を、「関係」に「所属」を、保存する。その結果、図31に示すデータが、図24及び図25に示した関連管理テーブルに追加される。
次に、情報関連付け部17は、図32に示すようなキーワード候補情報を生成し、キーワード抽出部18に送信する。そして、キーワード抽出部18は、キーワード候補情報を受信すると、形態素解析で単語に分解する。すると、”○×△”、”プロジェクト”、”UI”、”モジュール”、”開発”、”仕様書”の6つの単語が抽出される。ここで、キーワード候補テーブルが図33(A)の状態であったとすると、キーワード候補”UI”で仮想ディレクトリのIDが”11”のカウント数が「1」加算され、閾値である10に到達する。すると、キーワード抽出部18は、図33(B)に示すようなキーワード情報を生成し、分類階層構造生成部13に送信する。
次に、分類階層構造生成部13は、上述したようにキーワード抽出部18から図33(B)に示すようなキーワード情報を受信すると、仮想ディレクトリ”UI”を生成し、情報管理テーブルの「情報の名前」に”UI”を、「情報の種類」に「仮想ディレクトリ」を設定する。このとき、関連情報保存DB15により、「ID」には”31”が自動的に割り振られる。
次に、分類階層構造生成部13は、キーワードを生成し、仮想ディレクトリ”UI”に関連付け、情報管理テーブルの「情報名前」に”UI”を、「情報の種類」に「キーワード」を、保存する。このとき、関連情報保存DB15により「ID」には、”32”自動的に割り振られる。そして、生成した仮想ディレクトリとキーワードを関連付け、関連管理テーブルの「関連元ID」に”31”を、「関連先ID」に”32”を、「関係」にキーワードを、それぞれ保存する。
次に、生成した仮想ディレクトリを、「ID」が”11”の仮想ディレクトリに関連付け、関連管理テーブルの「関連元ID」に”11”を、「関連先ID」に”31”を「関係」に「親子ディレクトリ」を、保存する。続いて、親ディレクトリである仮想ディレクトリIDが”11”の仮想ディレクトリに関連付いているキーワードを検索し、生成した仮想ディレクトリに関連付ける。
次に、ユーザが上述したように生成された分類階層構造データを表示したとする。すると、まず、図34に示すように、領域111に、分類階層構造データがルートを頂点としたツリー状で表示される。ここでは、ルートの一段下位の階層が表示された状態である。続いて、図35に示すように、仮想ディレクトリ「○×△」が選択されると、ツリーが展開され、領域111には、クリックした仮想ディレクトリ「○×△」の下位階層に関連付けられた子ディレクトリである仮想ディレクトリ「○×△プロジェクト」が表示される。同様に、子ディレクトリが選択されると、このディレクトリに関連付いているさらに下位の子ディレクトリが表示される。
また、領域112には、仮想ディレクトリ「○×△」に関連付けられている情報であるデータファイルが表示される。ここでは、ファイル名に「○×△」を含むファイルが関連付けられているため、表示される。従って、ユーザが特定のキーワードを有するファイルにアクセスすることが容易となる。
また、このとき、領域113には、現在、領域111で選択されている仮想ディレクトリの親ディレクトリが表示される。ここでは、「ルート」が表示される。なお、これを選択することで、「ルート」に移動することができる。なお、領域114には、左右の矢印ボタンが表示されており、ユーザがたどった階層を戻ったり、進んだりすることができる。
そして、図35の画面からさらに下位の仮想ディレクトリ「○×△プロジェクト」を選択したときの表示画面を、図36に示す。まず、領域111には、ツリーがさらに展開され、クリックした仮想ディレクトリ「○×△プロジェクト」の下位階層に関連付けられた子ディレクトリである仮想ディレクトリ「○×△プロジェクト開発」が表示される。また、領域112には、仮想ディレクトリ「○×△プロジェクト」に関連付けられている情報であるデータファイルが表示される。ここでは、ファイル名に「○×△」を含むファイルが関連付けられているため、表示される。
また、このとき、領域113には、現在、領域111で選択されている仮想ディレクトリの親ディレクトリが表示されるが、ここでは、「○×△」と「プロジェクト」が表示される。従って、例えば、「プロジェクト」を選択することで、仮想ディレクトリ「プロジェクト」に移動することができる。そして、仮想ディレクトリ「プロジェクト」に移動したときの表示画面を、図37に示す。
図37に示すように、仮想ディレクトリ「プロジェクト」を選択すると、まず、領域111には、当該仮想ディレクトリの下位階層に関連付けられた仮想ディレクトリ「○×△プロジェクト」、「プロジェクト開発」などが表示される。そして、領域112には、仮想ディレクトリ「プロジェクト」に関連付けられている情報として、キーワードが「プロジェクト」である情報が表示される。また、領域113には、上位階層である「ルート」が表示される。
そして、図37の画面からさらに下位の仮想ディレクトリ「○×△プロジェクト」を選択したときの表示画面を、図38に示す。すると、上述した図35と同様の表示となる。つまり、仮想ディレクトリ「○×△プロジェクト」に、上位階層に位置する仮想ディレクトリ「○×△」あるいは「プロジェクト」のいずれからきても、同じ情報にたどり着くことができる。
そして、図37の画面の領域111にて、仮想ディレクトリ「★□○プロジェクト」を選択したときの表示画面を、図39に示す。この画面では、領域113に、仮想ディレクトリ「★□○プロジェクト」の上位階層に位置する仮想ディレクトリ「★□○」と「プロジェクト」が表示される。従って、上位階層である仮想ディレクトリ「★□○」にも移動することができる。
また、図40は、仮想ディレクトリ「開発」を選択した時の様子を示している。さらに、図41は、その下位階層である仮想ディレクトリ「プロジェクト開発」を選択したときの様子を示している。
以上のように、本実施形態では、ユーザが利用しているなどのテキストデータから、当該テキストデータに含まれるキーワードに基づいて、当該ユーザに適した階層構造を自動的に生成することができる。このため、ユーザは、生成された階層構造を利用して、データ分類やデータ検索を行うことが容易となり、また、適切かつ効率よく、データ分類やデータ検索を実行することができる。その結果、ユーザの利便性の向上を図ることができる。
本発明は、ユーザがパーソナルコンピュータなどの情報処理装置を用いて作業を行う場合に、ユーザの作業を情報の整理や検索を支援する用途に適用することができ、産業上の利用可能性を有する。
1 情報処理装置
2 テキスト取得手段
3 階層構造生成手段
4 記憶装置
10 情報処理装置
11 ユーザ入力監視部
12 監視場所情報DB
13 分類階層構造生成部
14 除外単語DB
15 関連情報保存DB
16 アクセス情報監視部
17 情報関連付け部
18 キーワード抽出部
19 キーワード候補DB
20 階層構造表示部
2 テキスト取得手段
3 階層構造生成手段
4 記憶装置
10 情報処理装置
11 ユーザ入力監視部
12 監視場所情報DB
13 分類階層構造生成部
14 除外単語DB
15 関連情報保存DB
16 アクセス情報監視部
17 情報関連付け部
18 キーワード抽出部
19 キーワード候補DB
20 階層構造表示部
Claims (22)
- 所定のテキストデータを取得するテキスト取得手段と、
前記テキスト取得手段にて取得した前記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成手段と、を備え、
前記階層構造生成手段は、前記キーワードを結合した結合キーワードを生成すると共に、前記キーワード及び前記結合キーワードにそれぞれ対応する前記仮想ディレクトリを生成して、前記結合キーワードに対応する前記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の前記仮想ディレクトリの下位階層に関連付けて、前記階層構造データを生成する、
情報処理装置。 - 請求項1記載の情報処理装置であって、
前記階層構造生成手段は、単一の前記キーワードにそれぞれ対応する前記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の前記キーワードを結合した前記結合キーワードに対応する前記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに他の単一の前記キーワードを結合した他の前記結合キーワードに対応する前記仮想ディレクトリを関連付けて、前記階層構造データを生成する、
情報処理装置。 - 請求項1又は2記載の情報処理装置であって、
前記階層構造生成手段は、前記テキスト取得手段にて取得した前記テキストデータにおける前記キーワードの出現順序に従って、当該キーワードを結合して前記結合キーワードを生成する、
情報処理装置。 - 請求項1乃至3のいずれか一項に記載の情報処理装置であって、
前記階層構造生成手段は、前記テキスト取得手段にて取得した前記テキストデータにおける前記キーワード間の隣接度合に応じて、当該キーワードを結合して前記結合キーワードを生成する、
情報処理装置。 - 請求項1乃至4のいずれか一項に記載の情報処理装置であって、
前記階層構造生成手段は、所定の単一の前記キーワードあるいは所定の前記結合キーワードに対応する前記仮想ディレクトリの下位階層に、他の前記仮想ディレクトリに既に関連付けられている前記仮想ディレクトリであって前記所定の単一のキーワードあるいは前記所定の結合キーワードを含む前記結合キーワードに対応する前記仮想ディレクトリを関連付ける、
情報処理装置。 - 請求項1乃至5のいずれか一項に記載の情報処理装置であって、
前記階層構造生成手段は、前記仮想ディレクトリに、当該仮想ディレクトリが対応する単一の前記キーワードあるいは前記結合キーワードに含まれる前記キーワードを関連付けて記憶する、
情報処理装置。 - 請求項1乃至5のいずれか一項に記載の情報処理装置であって、
前記階層構造生成手段は、前記仮想ディレクトリに、当該仮想ディレクトリが対応する単一の前記キーワードあるいは前記結合キーワードを抽出した前記テキストデータが関連付けられたデータファイルを関連付けて記憶する、
情報処理装置。 - 請求項1乃至7のいずれか一項に記載の情報処理装置であって、
所定のデータへのアクセスを監視するデータアクセス監視手段と、
前記データアクセス監視手段にてアクセスされたことを検出した前記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出し、当該アクセス対象キーワードが前記階層構造データに含まれる前記仮想ディレクトリに対応する前記キーワードあるいは前記結合キーワードと同一である場合に、当該仮想ディレクトリに、当該アクセス対象キーワードが検出された前記所定のデータを表すデータファイルを関連付けるデータ関連付け手段と、
を備えた情報処理装置。 - 請求項1乃至8のいずれか一項に記載の情報処理装置であって、
所定のデータへのアクセスを監視するデータアクセス監視手段と、
前記データアクセス監視手段にてアクセスされたことを検出した前記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出すると共に、当該アクセス対象キーワードが前記階層構造データに含まれる前記仮想ディレクトリに対応する前記キーワードあるいは前記結合キーワードと同一ではないものをキーワード候補データとして抽出するキーワード候補抽出手段と、を備え、
前記キーワード候補抽出手段は、前記キーワード候補データの抽出回数をカウントして、この抽出回数に基づいて当該キーワード候補データを前記キーワードとして設定し、
前記階層構造生成手段は、前記キーワード候補抽出手段にて設定された前記キーワードに基づいて前記仮想ディレクトリを生成し、既存の前記階層構造データに追加する、
情報処理装置。 - 請求項7又は8記載の情報処理装置であって、
前記階層構造データを表示手段に表示出力する表示制御手段を備え、
前記表示制御手段は、前記階層構造データを構成する前記仮想ディレクトリの選択を受け付けて、当該選択された前記仮想ディレクトリに関連付けられた前記データファイルを前記表示手段に表示するよう制御する、
情報処理装置。 - 請求項7又は8記載の情報処理装置であって、
前記階層構造データを表示手段に表示出力する表示制御手段を備え、
前記表示制御手段は、前記階層構造データを構成する前記仮想ディレクトリの選択を受け付けて、当該選択された前記仮想ディレクトリの上位階層及び/又は下位階層に関連付けられた他の前記仮想ディレクトリに関連付けられた前記データファイルを前記表示手段に表示するよう制御する、
情報処理装置。 - 請求項10又は11記載の情報処理装置であって、
前記表示制御手段は、前記階層構造データに基づいて前記選択された仮想ディレクトリの上位階層及び/又は下位階層に関連付けられた前記仮想ディレクトリを選択可能なよう前記表示手段に表示する、
情報処理装置。 - 情報処理装置に、
所定のテキストデータを取得するテキスト取得手段と、
前記テキスト取得手段にて取得した前記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成手段と、
を実現させ、
前記階層構造生成手段は、前記キーワードを結合した結合キーワードを生成すると共に、前記キーワード及び前記結合キーワードにそれぞれ対応する前記仮想ディレクトリを生成して、前記結合キーワードに対応する前記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の前記仮想ディレクトリの下位階層に関連付けて、前記階層構造データを生成する機能を有する、
プログラム。 - 請求項13記載のプログラムであって、
前記階層構造生成手段は、単一の前記キーワードにそれぞれ対応する前記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の前記キーワードを結合した前記結合キーワードに対応する前記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに単一の前記キーワードを結合した他の前記結合キーワードに対応する前記仮想ディレクトリを関連付けて、前記階層構造データを生成する、
プログラム。 - 取得した所定のテキストデータに含まれるキーワード及び当該キーワードを結合した結合キーワードにそれぞれ対応して生成された仮想ディレクトリが階層化されて構成されており、
前記結合キーワードに対応する前記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の前記仮想ディレクトリの下位階層に関連付けて構成された、
階層構造データ。 - 請求項15記載の階層構造データであって、
単一の前記キーワードにそれぞれ対応する前記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の前記キーワードを結合した前記結合キーワードに対応する前記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに単一の前記キーワードを結合した他の前記結合キーワードに対応する前記仮想ディレクトリを関連付けて構成された、
階層構造データ。 - 請求項15又は16記載の階層構造データであって、
所定の単一の前記キーワードあるいは所定の前記結合キーワードに対応する前記仮想ディレクトリの下位階層に、他の前記仮想ディレクトリに既に関連付けられている前記仮想ディレクトリであって前記所定の単一のキーワードあるいは前記所定の結合キーワードを含む前記結合キーワードに対応する前記仮想ディレクトリを関連付けて構成された、
階層構造データ。 - 所定のテキストデータを取得するテキスト取得工程と、
前記テキスト取得工程にて取得した前記テキストデータに含まれるキーワードを抽出して、当該抽出したキーワードに基づいて階層化された仮想ディレクトリから成る階層構造データを生成して、記憶手段に記憶する階層構造生成工程と、を有し、
前記階層構造生成工程は、前記キーワードを結合した結合キーワードを生成すると共に、前記キーワード及び前記結合キーワードにそれぞれ対応する前記仮想ディレクトリを生成して、前記結合キーワードに対応する前記仮想ディレクトリを、この結合キーワードに含まれるキーワードあるいは他の結合キーワードに対応する他の前記仮想ディレクトリの下位階層に関連付けて、前記階層構造データを生成する、
情報処理方法。 - 請求項18記載の情報処理方法であって、
前記階層構造生成工程は、単一の前記キーワードにそれぞれ対応する前記仮想ディレクトリを最上位階層に配置し、この下位階層に当該単一のキーワードに他の単一の前記キーワードを結合した前記結合キーワードに対応する前記仮想ディレクトリを関連付け、この下位階層に、当該結合キーワードに他の単一の前記キーワードを結合した他の前記結合キーワードに対応する前記仮想ディレクトリを関連付けて、前記階層構造データを生成する、
情報処理方法。 - 請求項18又は19記載の情報処理方法であって、
前記階層構造生成工程は、所定の単一の前記キーワードあるいは所定の前記結合キーワードに対応する前記仮想ディレクトリの下位階層に、他の前記仮想ディレクトリに既に関連付けられている前記仮想ディレクトリであって前記所定の単一のキーワードあるいは前記所定の結合キーワードを含む前記結合キーワードに対応する前記仮想ディレクトリを関連付ける、
情報処理方法。 - 請求項18乃至20のいずれか一項に記載の情報処理方法であって、
前記階層構造生成工程の後に、
所定のデータへのアクセスを監視するデータアクセス監視工程と、
前記データアクセス監視工程にてアクセスされたことを検出した前記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出し、当該アクセス対象キーワードが前記階層構造データに含まれる前記仮想ディレクトリに対応する前記キーワードあるいは前記結合キーワードと同一である場合に、当該仮想ディレクトリに、当該アクセス対象キーワードが検出された前記所定のデータを表すデータファイルを関連付けるデータ関連付け工程と、
を有する情報処理方法。 - 請求項18乃至21のいずれか一項に記載の情報処理方法であって、
前記階層構造生成工程の後に、
所定のデータへのアクセスを監視するデータアクセス監視工程と、
前記データアクセス監視工程にてアクセスされたことを検出した前記所定のデータに含まれるテキストデータに含まれるキーワードをアクセス対象キーワードとして抽出すると共に、当該アクセス対象キーワードが前記階層構造データに含まれる前記仮想ディレクトリに対応する前記キーワードあるいは前記結合キーワードと同一ではないものをキーワード候補データとして抽出するキーワード候補抽出工程と、を有し、
前記キーワード候補抽出工程は、前記キーワード候補データの抽出回数をカウントして、この抽出回数に基づいて当該キーワード候補データを前記キーワードとして設定し、
その後、前記階層構造生成工程を再度実行し、前記キーワード候補抽出手段にて設定された前記キーワードに基づいて前記仮想ディレクトリを生成し、既存の前記分類階層構造データに追加する、
情報処理方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008324988A JP2010146430A (ja) | 2008-12-22 | 2008-12-22 | 情報処理装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008324988A JP2010146430A (ja) | 2008-12-22 | 2008-12-22 | 情報処理装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2010146430A true JP2010146430A (ja) | 2010-07-01 |
Family
ID=42566782
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008324988A Withdrawn JP2010146430A (ja) | 2008-12-22 | 2008-12-22 | 情報処理装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2010146430A (ja) |
Cited By (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012083929A (ja) * | 2010-10-12 | 2012-04-26 | Hitachi Solutions Ltd | ファイル検索装置およびファイル検索プログラム |
| WO2012088706A1 (zh) * | 2010-12-31 | 2012-07-05 | Xiao Yan | 一种检索的方法和系统 |
| JP2013016090A (ja) * | 2011-07-06 | 2013-01-24 | Obic Business Consultants Ltd | 識別子生成装置、識別子生成方法、及びプログラム |
| JP2016162054A (ja) * | 2015-02-27 | 2016-09-05 | 日本放送協会 | オントロジー生成装置、メタデータ出力装置、コンテンツ取得装置、オントロジー生成方法及びオントロジー生成プログラム |
| KR20160112248A (ko) * | 2015-03-18 | 2016-09-28 | 성균관대학교산학협력단 | 잠재 키워드 생성 방법 및 장치 |
| CN119848170A (zh) * | 2025-03-17 | 2025-04-18 | 中信联合云科技有限责任公司 | 一种基于人工智能的图书数据结构的索引目录生成方法 |
-
2008
- 2008-12-22 JP JP2008324988A patent/JP2010146430A/ja not_active Withdrawn
Cited By (10)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2012083929A (ja) * | 2010-10-12 | 2012-04-26 | Hitachi Solutions Ltd | ファイル検索装置およびファイル検索プログラム |
| WO2012088706A1 (zh) * | 2010-12-31 | 2012-07-05 | Xiao Yan | 一种检索的方法和系统 |
| CN103314371A (zh) * | 2010-12-31 | 2013-09-18 | 肖岩 | 一种检索的方法和系统 |
| US9870392B2 (en) | 2010-12-31 | 2018-01-16 | Yan Xiao | Retrieval method and system |
| JP2013016090A (ja) * | 2011-07-06 | 2013-01-24 | Obic Business Consultants Ltd | 識別子生成装置、識別子生成方法、及びプログラム |
| JP2016162054A (ja) * | 2015-02-27 | 2016-09-05 | 日本放送協会 | オントロジー生成装置、メタデータ出力装置、コンテンツ取得装置、オントロジー生成方法及びオントロジー生成プログラム |
| KR20160112248A (ko) * | 2015-03-18 | 2016-09-28 | 성균관대학교산학협력단 | 잠재 키워드 생성 방법 및 장치 |
| KR101668725B1 (ko) * | 2015-03-18 | 2016-10-24 | 성균관대학교산학협력단 | 잠재 키워드 생성 방법 및 장치 |
| US11132389B2 (en) | 2015-03-18 | 2021-09-28 | Research & Business Foundation Sungkyunkwan University | Method and apparatus with latent keyword generation |
| CN119848170A (zh) * | 2025-03-17 | 2025-04-18 | 中信联合云科技有限责任公司 | 一种基于人工智能的图书数据结构的索引目录生成方法 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP4241934B2 (ja) | テキスト処理及び検索システム及び方法 | |
| JP6759308B2 (ja) | 保守装置 | |
| US10698964B2 (en) | System and method for automatically detecting and interactively displaying information about entities, activities, and events from multiple-modality natural language sources | |
| RU2501078C2 (ru) | Ранжирование результатов поиска с использованием расстояния редактирования и информации о документе | |
| JP5229226B2 (ja) | 情報共有システム、情報共有方法、および情報共有プログラム | |
| US20130305149A1 (en) | Document reader and system for extraction of structural and semantic information from documents | |
| US20140195884A1 (en) | System and method for automatically detecting and interactively displaying information about entities, activities, and events from multiple-modality natural language sources | |
| JP6165913B1 (ja) | 情報処理装置、情報処理方法およびプログラム | |
| US20130205236A1 (en) | Web application for debate maps | |
| JPWO2008149843A1 (ja) | 情報提示システム、情報提示方法及び情報提示用プログラム | |
| JP2010146430A (ja) | 情報処理装置 | |
| KR101441219B1 (ko) | 정보 엔터티들의 자동 연관 | |
| US20110307497A1 (en) | Synthewiser (TM): Document-synthesizing search method | |
| JP5221664B2 (ja) | 情報マップ管理システムおよび情報マップ管理方法 | |
| JP5494493B2 (ja) | 情報検索装置、情報検索方法、及びプログラム | |
| Hoeber et al. | Visualization support for interactive query refinement | |
| Spitz et al. | Entity-centric topic extraction and exploration: A network-based approach | |
| CN102479219B (zh) | 一种交互式搜索的处理方法 | |
| JP5911839B2 (ja) | 情報検索システム、情報検索装置、情報検索方法、及びプログラム | |
| JP5112027B2 (ja) | 文書群提示装置および文書群提示プログラム | |
| Hoeber et al. | VisiQ: Supporting visual and interactive query refinement | |
| JP6290805B2 (ja) | ファイル管理装置、ファイル管理方法、ユーザインタフェース提供方法及びファイル管理プログラム | |
| JP2014146076A (ja) | 文字列抽出方法、文字列抽出装置、および文字列抽出プログラム | |
| CN120144017A (zh) | 文本生成方法、装置、电子设备及存储介质 | |
| JP2005063366A (ja) | 情報管理装置および情報管理方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| RD03 | Notification of appointment of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7423 Effective date: 20100702 |
|
| A300 | Application deemed to be withdrawn because no request for examination was validly filed |
Free format text: JAPANESE INTERMEDIATE CODE: A300 Effective date: 20120306 |