JP2012164031A - Data processor, data storage device, data processing method, data storage method and program - Google Patents
Data processor, data storage device, data processing method, data storage method and program Download PDFInfo
- Publication number
- JP2012164031A JP2012164031A JP2011022147A JP2011022147A JP2012164031A JP 2012164031 A JP2012164031 A JP 2012164031A JP 2011022147 A JP2011022147 A JP 2011022147A JP 2011022147 A JP2011022147 A JP 2011022147A JP 2012164031 A JP2012164031 A JP 2012164031A
- Authority
- JP
- Japan
- Prior art keywords
- data
- storage
- tag
- index
- keyword
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images







Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Storage Device Security (AREA)
Abstract
【課題】確率的暗号を利用した秘匿検索を安全に高速化する。
【解決手段】利用者端末装置201は、保管対象の文書情報に対して指定された保管キーワードから一意に得られる乱数値をエントロピー符号化して、保管対象の文書情報に対応付けられるタグがデータセンター装置301で保管される際にタグに付される保管索引値を生成し、保管対象の文書情報とタグと保管索引値をデータセンター装置301に送信する。データセンター装置301では、保管索引値を用いてタグを分類、索引化することができ、確率的暗号を利用した秘匿検索を安全に高速化することができる。
【選択図】図1Secure search using probabilistic encryption is speeded up safely.
A user terminal device 201 entropy-encodes a random value obtained uniquely from a storage keyword specified for document information to be stored, and a tag associated with the document information to be stored is a data center. A storage index value attached to the tag when stored in the apparatus 301 is generated, and the document information to be stored, the tag, and the storage index value are transmitted to the data center apparatus 301. In the data center device 301, tags can be classified and indexed using the storage index value, and the confidential search using probabilistic encryption can be safely accelerated.
[Selection] Figure 1
Description
本発明は、秘匿検索技術に関する。 The present invention relates to a secret search technique.
秘匿検索とは、暗号化データを暗号化したまま検索する技術である。
近年は、クラウドサービスなどのインターネット上でデータを管理する際に、盗聴などの脅威から守るためのセキュリティ技術として注目されている。
The secret search is a technique for searching encrypted data while encrypting it.
In recent years, when managing data on the Internet such as a cloud service, it is attracting attention as a security technology for protecting against threats such as eavesdropping.
暗号化したデータを検索する手法は、確定的暗号を利用する方法と、確率的暗号を利用する方法の2種類がある。
確定的暗号を利用する方法は、同一のキーワードを暗号化した際に、同一の暗号文が得られるため、暗号化しないデータベース検索システムと同様の高速化手法を利用することができる(例えば、同一キーワードのタグのグルーピング)。
一方、確率的暗号を利用した方式は、同一のキーワードを暗号化する場合でも、異なる暗号文となる。
したがって、単純に(バイナリデータとして)同一の暗号文をグルーピングする方法などを利用することはできない。
特に、確率的暗号を利用した方法では、安全性証明が付加される場合が多く、暗号文から一切の情報を得られないことが、数学的に証明されている。
そのため、キーワードの(部分)情報を利用する索引化は困難である。
There are two methods for retrieving encrypted data: a method using deterministic encryption and a method using probabilistic encryption.
In the method using deterministic encryption, the same ciphertext can be obtained when the same keyword is encrypted. Therefore, the same speed-up method as the database search system without encryption can be used (for example, the same keyword) Keyword tag grouping).
On the other hand, a method using probabilistic encryption results in different ciphertexts even when the same keyword is encrypted.
Therefore, a method of simply grouping the same ciphertext (as binary data) cannot be used.
In particular, in a method using probabilistic encryption, a security proof is often added, and it is mathematically proved that no information can be obtained from the ciphertext.
For this reason, indexing using (partial) information of keywords is difficult.
次に、確率的暗号を利用したキーワード検索システムを説明する。 Next, a keyword search system using probabilistic encryption will be described.
確率的暗号を利用した秘匿検索は、ユーザ(検索者、登録者)とデータセンター(データ管理者)の間で、以下のようにしてデータ検索を行うことが一般的である。
データ登録者は、文書情報と、それを検索するためのキーワードを鍵として無意味な平文を暗号化したタグデータ(以下、タグという)を登録する。
データセンターは、タグと文書情報を組にして保存する。
検索時には、検索者は検索したいキーワードで作成した検索クエリをデータセンターに送信する。
データセンターは、検索クエリを用いて、保存しているタグとの一致検査を行う。
一致すれば、組で保存されている文書情報を検索者に返却する。
なお、上記において、文書情報とは、検索システムとは別の暗号で暗号化された文書そのものや、文書名、文書を保管しているデータベースの位置情報などである。
また、上記において、検索クエリとは、検索語に対応するキーワードで暗号化されたタグを復号するための復号鍵である。また、検索クエリから検索キーワードを読み取ることはできない。
In secret search using probabilistic encryption, data search is generally performed between a user (searcher, registrant) and a data center (data manager) as follows.
A data registrant registers document data and tag data (hereinafter referred to as a tag) obtained by encrypting meaningless plaintext using a keyword for searching for the document information as a key.
The data center stores tags and document information in pairs.
At the time of search, the searcher sends a search query created with a keyword to be searched to the data center.
The data center uses the search query to perform a matching check with the stored tag.
If they match, the document information stored in the group is returned to the searcher.
In the above description, the document information includes a document itself encrypted with a different encryption from the search system, a document name, location information of a database storing the document, and the like.
In the above, the search query is a decryption key for decrypting a tag encrypted with a keyword corresponding to the search term. Further, the search keyword cannot be read from the search query.
なお、単純な秘匿検索方式としては、例えば非特許文献1に記載されている方式がある。
これは、単一のキーワードにおける秘匿検索を実現したものである。
As a simple confidential search method, for example, there is a method described in
This realizes a secret search for a single keyword.
秘匿検索において、データセンターはタグ、検索クエリ、一致検査のいずれにおいても一切の情報も得ることができないため、高いセキュリティが提供される。
しかし、データセンターで行われる一致検査時に、保存されたすべてのタグを検査しなければないため、検索速度が低速であるという課題がある。
この解決法として、特許文献1では、検索履歴を利用して高速化する手法を提案している。また、特許文献2では、ブルームフィルタによって索引木を構成する方法を提案している。
なお、ブルームフィルタとは、フィルタに登録された集合に対して、ある要素が集合に含まれているかを判定するためのフィルタである。
In the secret search, the data center cannot obtain any information in any of the tag, the search query, and the matching check, so that high security is provided.
However, there is a problem that the search speed is low because all the stored tags must be inspected at the time of a matching check performed in the data center.
As a solution to this problem,
The Bloom filter is a filter for determining whether a certain element is included in the set with respect to the set registered in the filter.
秘匿検索の最も基本的な方式は非特許文献1である。
この方式はIDベース暗号(以下、IBE:Identity−Based Encryption)を用いた秘匿検索方式である。
IBEは、IDを鍵としてデータの暗号化を行う。
IDはEメールアドレスや住所、名前など、ユーザを一意に識別できるものある。
IDを鍵とするため、誰でもデータの暗号化を行うことができる。
暗号化データは、IDに対応する復号鍵を持つ者(一般的には暗号化に使用したIDの所有者)だけが復号できる。
データ登録者はまず、文書情報に設定するキーワードを、IBEの暗号化機能を利用して、キーワードを鍵(ID)として無意味な平文を暗号化し、文書情報のタグとして文書情報と共にデータセンターに保存する。
タグは暗号化されているため、キーワードに関する情報は漏洩しない。
次に、検索者は検索したいキーワードと、自身の秘密鍵(ユーザ鍵)から検索クエリを生成し、データセンターに送信する。
第三者は検索クエリからも、キーワード情報を知ることはできない。
検索クエリを受信したデータセンターは、保存されているタグに対し、検索クエリを用いてIBEの復号処理を実行する。
無意味な平文が正しく復号できた場合、暗号化に用いたキーワード(文書情報に設定したキーワード)と検索クエリを生成する際に用いたID(検索キーワード)が対応していることを意味するため、「一致」という検索結果のみをデータセンターは知ることができる。
This method is a secret search method using ID-based encryption (hereinafter referred to as IBE: Identity-Based Encryption).
IBE encrypts data using an ID as a key.
An ID such as an e-mail address, an address, or a name can uniquely identify a user.
Since ID is used as a key, anyone can encrypt data.
Only the person who has the decryption key corresponding to the ID (generally the owner of the ID used for encryption) can decrypt the encrypted data.
First, the data registrant uses the IBE encryption function to encrypt the meaningless plaintext using the keyword as a key (ID) and sets the keyword to be set in the document information as a document information tag to the data center along with the document information. save.
Since the tag is encrypted, no information about keywords is leaked.
Next, the searcher generates a search query from the keyword to be searched and its own secret key (user key), and transmits it to the data center.
A third party cannot obtain keyword information from a search query.
The data center that has received the search query executes IBE decryption processing on the stored tag using the search query.
When a meaningless plaintext can be correctly decrypted, it means that the keyword (keyword set in the document information) used for encryption corresponds to the ID (search keyword) used when generating the search query. The data center can know only the search result “match”.
特許文献1は、ある検索キーワードで検索した結果をインデックスに保存し、次回以降に同一のキーワードが検索された場合に、高速に検索結果を応答する仕組みである。
特許文献1の方法は、一度検索したキーワードに対しては高速に検索結果を検索者に返却することが可能であるが、一度も検索したことのないキーワードに対しては、データセンターに保存された全てのタグを検索する必要がある。
そのため、膨大なタグを保存するデータベースで、初めて検索されるキーワードに対する検索結果を得るのに、多大な時間を要するという課題がある。
The method of
Therefore, there is a problem that it takes a lot of time to obtain a search result for a keyword searched for the first time in a database storing a huge number of tags.
特許文献2の方法は、確定的暗号で暗号化したキーワードからブルームフィルタを作成し、索引木を構築する方法である。
この方法は、データセンターに保存されたブルームフィルタ同士のハミング距離を計算する必要があるため、保存されたブルームフィルタ数が増加すると、索引木生成のための計算量が急激に増加するという課題がある。
また、ブルームフィルタの大きさにより、ブルームフィルタに含まれるキーワードの識別には限度がある。
特に偽陽性の問題から、ブルームフィルタに登録される可能性のあるキーワード種類数を考慮して、十分に大きなフィルタを用意する必要がある。
また、ブルームフィルタ1つに対して1つのキーワードが対応している場合(ブルームフィルタに単一のキーワードしか入力しなかった場合)、ブルームフィルタに対応するデータ数を分析することにより、データセンターにキーワード分布に関する情報が漏洩するという課題がある。
The method of Patent Document 2 is a method for creating a Bloom filter from a keyword encrypted with deterministic encryption and constructing an index tree.
In this method, it is necessary to calculate the Hamming distance between Bloom filters stored in the data center. Therefore, when the number of stored Bloom filters increases, the calculation amount for generating the index tree increases rapidly. is there.
Further, there is a limit to identification of keywords included in the Bloom filter due to the size of the Bloom filter.
In particular, because of the false positive problem, it is necessary to prepare a sufficiently large filter in consideration of the number of keyword types that may be registered in the Bloom filter.
In addition, when one keyword corresponds to one Bloom filter (when only a single keyword is input to the Bloom filter), the data center corresponding to the Bloom filter is analyzed to analyze the data center. There is a problem that information on keyword distribution leaks.
また、他の類似する索引方式でも、単一のキーワードに対して対応するデータ群を管理するものがほとんどである。
そのため、データセンターはキーワード分布を知ることができ、経験上知られている分布と照合することで、キーワードを推測する「頻度解析」が実施できるという課題がある。
Most other similar index methods manage data groups corresponding to a single keyword.
Therefore, the data center can know the keyword distribution, and there is a problem that “frequency analysis” for estimating the keyword can be performed by collating with the distribution known from experience.
本発明では、上記のような課題を解決することを主な目的としており、確率的暗号を利用した秘匿検索を安全に高速化することを目的とする。 The main object of the present invention is to solve the above-described problems, and it is an object of the present invention to speed up a secure search using probabilistic encryption safely.
本発明に係るデータ処理装置は、
複数の暗号化データと、各暗号化データに対応付けられている、暗号化データの検索の際に照合されるタグデータとを保管するデータ保管装置に接続され、
前記データ保管装置での保管の対象となる保管対象データのキーワードを保管キーワードとして指定するキーワード指定部と、
前記保管キーワードから一意に得られる乱数値をエントロピー符号化して、前記保管対象データの暗号化データに対応付けられるタグデータが前記データ保管装置で保管される際に前記タグデータに付される索引値を生成する索引生成部と、
前記保管対象データの暗号化データと前記タグデータと前記索引値とが含まれる保管要求を、前記データ保管装置に対して送信する通信部とを有することを特徴とする。
The data processing apparatus according to the present invention
Connected to a data storage device that stores a plurality of encrypted data and tag data that is associated with each encrypted data and that is collated when searching for the encrypted data;
A keyword designating unit for designating a keyword of data to be stored to be stored in the data storage device as a storage keyword;
An index value assigned to the tag data when the tag data associated with the encrypted data of the storage target data is stored in the data storage device by entropy encoding a random value uniquely obtained from the storage keyword An index generation unit for generating
A communication unit that transmits a storage request including encrypted data of the storage target data, the tag data, and the index value to the data storage device.
本発明によれば、データ処理装置において、保管キーワードから一意に得られる乱数値をエントロピー符号化して、保管対象データの暗号化データに対応付けられるタグデータがデータ保管装置で保管される際にタグデータに付与される索引値を生成するため、データ保管装置において、索引値を用いてタグデータを分類、索引化することができ、確率的暗号を利用した秘匿検索を安全に高速化することができる。 According to the present invention, in a data processing apparatus, a random number value uniquely obtained from a storage keyword is entropy-encoded, and tag data associated with encrypted data of storage target data is stored in the data storage apparatus. In order to generate an index value to be assigned to data, tag data can be classified and indexed by using the index value in the data storage device, and secure search using probabilistic encryption can be safely accelerated. it can.
実施の形態1.
本実施の形態では、エントロピー符号を用いてキーワードタグを分類、索引化することで、確率的暗号を利用した秘匿検索を安全に高速化する構成を説明する。
なお、本実施の形態では、エントロピー符号の例として、ハフマン符号を用いて説明を行う。
また、本実施の形態では、ユーザ(検索者、登録者)とデータセンター(データ管理者)の間で、キーワードの鍵付ハッシュ値をハフマン符号化した符号値を索引値とする例を説明する。
In the present embodiment, a configuration for speeding up a secure search using probabilistic encryption by classifying and indexing keyword tags using entropy codes will be described.
In the present embodiment, a description will be given using a Huffman code as an example of the entropy code.
Further, in this embodiment, an example will be described in which a code value obtained by Huffman coding a keyed hash value of a keyword between a user (searcher, registrant) and a data center (data manager) is used as an index value. .
本実施の形態における大まかな流れは、次の通りである。
まず、データ登録者は、保存したい文書に関する「文書情報」と文書に関連するキーワードから生成した「タグデータ(以下、タグと表記する)」およびキーワードの鍵付ハッシュ値をハフマン符号で符号化した値(索引値)をデータセンターに保存する。
ここで、文書情報とは、検索システムとは別の暗号で暗号化された文書そのものや、文書名、文書を保管しているデータベースの位置情報などである。
文書情報から文書そのものを閲覧することはできない。
タグは文書情報を検索する際に用いる、キーワードを暗号鍵にして無意味な平文(乱数)を暗号化した値である。
データセンターは、タグと文書情報を組にして保存し、索引値を利用してインデックスを構築する。
検索時には、検索者は検索したいキーワードで作成した検索クエリと、登録時と同様の手順で検索キーワードから生成した索引値をデータセンターに送信する。
データセンターは、受信した索引値から検索対象のタグを限定し、検索クエリを用いて、それらのタグと一致検査を行う。
一致すれば、組で保存されている文書情報を検索者に返却する。
なお、以下では、文書情報をデータセンターに保管する際に、保管対象の文書情報に対して指定するキーワードを保管キーワードとも表記し、検索時に指定するキーワードを検索キーワードとも表記する。
また、文書情報及びタグとともにデータセンターで保管される索引値を保管索引値とも表記し、検索時に検索クエリとともにデータセンターに送信する索引値を検索索引値とも表記する。
The general flow in the present embodiment is as follows.
First, the data registrant encodes the “document information” related to the document to be stored and the “tag data (hereinafter referred to as a tag)” generated from the keyword related to the document and the keyed hash value of the keyword with a Huffman code Store the value (index value) in the data center.
Here, the document information includes a document itself encrypted with a different encryption from the search system, a document name, location information of a database storing the document, and the like.
The document itself cannot be viewed from the document information.
The tag is a value obtained by encrypting meaningless plaintext (random number) using a keyword as an encryption key and used when searching for document information.
The data center stores tags and document information in pairs, and builds an index using index values.
At the time of search, the searcher transmits a search query created with the keyword to be searched and an index value generated from the search keyword in the same procedure as at the time of registration to the data center.
The data center limits the tags to be searched from the received index values, and performs a matching check with these tags using a search query.
If they match, the document information stored in the group is returned to the searcher.
In the following, when document information is stored in a data center, a keyword specified for the document information to be stored is also expressed as a storage keyword, and a keyword specified at the time of search is also expressed as a search keyword.
An index value stored in the data center together with the document information and the tag is also referred to as a storage index value, and an index value transmitted to the data center together with the search query at the time of search is also referred to as a search index value.
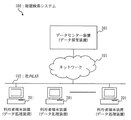
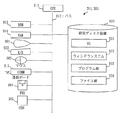
次に、本実施の形態に係る秘匿検索システムの構成を説明する。
図1は、本実施の形態に係る秘匿検索システムの構成例を示す図である。
Next, the configuration of the secret search system according to the present embodiment will be described.
FIG. 1 is a diagram illustrating a configuration example of a secret search system according to the present embodiment.
図1において、秘匿検索システム100は、利用者端末装置201、データセンター装置301を備える。
利用者端末装置201は社内LAN(Local Area Network)102に接続されている。
社内LAN102はネットワーク101を介してデータセンター装置301と接続されている。
In FIG. 1, the confidential search system 100 includes a
A
The in-house LAN 102 is connected to the
利用者端末装置201は、企業のユーザが利用するPC(Personal Computer)である。
利用者端末装置201は、文書情報とそれを検索するためのタグをデータセンター装置301に保管するとともに、データセンター装置301に蓄積したタグを検索し、データセンター装置301から文書情報を取り出す。
なお、利用者端末装置201は、データ処理装置の例である。
The
The
The
データセンター装置301は、企業内で作成された文書情報およびタグを保管する大容量の記憶装置を持つサーバ装置である。
また、利用者端末装置201から送信されるキーワードの暗号文(またはハッシュ値)をエントロピー符号化した値を利用した索引値を持ち、保存されたタグを効率的に検索する機能を備える。
タグは暗号化された状態で保存されるため、データセンター装置301はタグからキーワードを知ることはできない。
なお、データセンター装置301は、データ保管装置の例である。
The
In addition, it has an index value using an entropy-encoded value of a keyword ciphertext (or hash value) transmitted from the
Since the tag is stored in an encrypted state, the
The
ネットワーク101は、社内LAN102とデータセンター装置301を接続する通信路である。
代表的なネットワーク101の例はインターネットがある。
The
An example of a
社内LAN102は、企業内に施設された通信路であり、企業内で利用される様々なサーバ装置やPCが接続される。
なお、通信路は専用線や無線、ルータなどで構成される複雑な通信路となる。
The in-house LAN 102 is a communication path established in the company, and is connected to various server devices and PCs used in the company.
The communication path is a complicated communication path composed of a dedicated line, a radio, a router, and the like.
図2は、利用者端末装置201の構成例を示すブロック図である。
利用者端末装置201は、文書・鍵格納領域202、文書情報管理部203、利用者I/F(Interface)部204、検索クエリ生成部205、タグ生成部206、通信部207、索引生成部208を備える。
FIG. 2 is a block diagram illustrating a configuration example of the
A
文書・鍵格納領域202は、データセンター装置301に保存する文書情報を生成するためのオリジナルの文書と、検索クエリの生成のためのユーザ秘密鍵、およびタグ生成のための公開鍵を保存する。
文書情報として、文書を暗号化したデータを利用する場合、文書情報を暗号化するための鍵も保存する。
また、索引生成部208において、利用者I/F204から得られたキーワードを暗号化(またはハッシュ化)するための鍵を保存する。
The document /
When using data obtained by encrypting a document as document information, a key for encrypting the document information is also stored.
The
文書情報管理部203は、文書・鍵格納領域202に保存されている文書をもとに、文書情報を生成する。
文書情報からは、文書を閲覧することはできない。
文書情報の例としては、検索システムとは別の暗号で暗号化された文書そのものや、文書名、文書を保管しているデータベースの位置情報などがある。
つまり、文書情報管理部203は、データセンター装置301での保管の対象となる文書(保管対象データ)の暗号化を行って文書情報(保管対象データの暗号化データ)を生成する。
The document
Documents cannot be viewed from document information.
Examples of document information include a document itself encrypted with a different encryption from the search system, a document name, and location information of a database storing the document.
That is, the document
利用者I/F部204は、秘匿検索システム100を操作するためのインタフェースである。
検索クエリ生成部205や、タグ生成部206のためのキーワードをユーザから入力する機能を備える。
つまり、利用者I/F部204は、ユーザからの指示に従って、保管キーワードや検索キーワードを指定する。
利用者I/F部204は、キーワード指定部の例である。
The user I /
A function for inputting keywords for the search
That is, the user I /
The user I /
検索クエリ生成部205は、ユーザが利用者I/F部204を介して入力した検索したいキーワードと、文書・鍵格納領域202に保存されたユーザ鍵から検索クエリを生成する。
つまり、検索クエリ生成部205は、検索クエリとして検索キーワードに対応するタグを復号するための復号鍵を生成する。
検索クエリ生成部205は、検索キーワード秘匿化部の例である。
The search
That is, the search
The search
タグ生成部206は、ユーザが利用者I/F部204を介して入力した文書に設定したいキーワードと、文書・鍵格納領域202に保存された公開鍵からタグデータを生成する。
The
通信部207は、データセンター装置301に対して検索を実行するための検索要求(検索クエリと検索索引値)や、データセンター装置301に対して新規に文書情報とタグを保存するための登録データ(文書情報、タグ、保管索引値)を、データセンター装置301に送信するために、社内LAN102に接続するものである。
なお、登録データは、保管要求ともいう。
The
The registration data is also called a storage request.
索引生成部208は、利用者I/F部204から受信したキーワードを、文書・鍵格納領域202に保存してある共通鍵(データ登録者と検索者との間の共通鍵)を用いてハッシュ値を計算する(以下、鍵付ハッシュ値という)。
さらに鍵付ハッシュ値に対して、ハフマン符号化を実施して得られた値を索引値として出力する。
つまり、索引生成部208は、保管キーワードから一意に得られる乱数値をハフマン符号化して、タグがデータセンター装置301で保管される際にタグに付される索引値(保管索引値)を生成する。
また、索引生成部208は、検索キーワードから一意に得られる乱数値をハフマン符号化して、データセンター装置301において、検索クエリ(秘匿化された検索キーワード)との照合の対象となるタグを選出するために、データセンター装置301に保管されている保管索引値と比較される索引値(検索索引値)を生成する。
The
Further, a value obtained by performing Huffman coding on the keyed hash value is output as an index value.
That is, the
Further, the
図3は、データセンター装置301の構成例を示すブロック図である。
データセンター装置301は、検索要求受信部302、検索処理部303、インデックス記憶部304、データ保管部305、索引分類部306、検索要求回答部307、登録データ受信部308を備える。
FIG. 3 is a block diagram illustrating a configuration example of the
The
登録データ受信部308は、利用者端末装置201から登録データ(保管要求)を受信すると、受信した登録データに含まれるタグにタグID(Identification)を付与し、索引分類部306に保管索引値とタグIDを、データ保管部305にタグと文書情報をそれぞれ転送する。
タグIDは、タグを一意に特定することができる識別子である。
なお、登録データ受信部308は、保管要求受信部の例である。
When the registration
The tag ID is an identifier that can uniquely identify the tag.
The registration
索引分類部306は、登録データ受信部308から登録データとして保管索引値とタグIDを受信し、インデックス記憶部304にインデックス情報を追加する機能を持つ。
つまり、索引分類部306は、タグIDと保管索引値とを対応付けるインデックス情報を生成する。
索引分類部306は、インデックス情報生成部の例である。
また、索引分類部306は、後述する検索処理部303から受信した検索索引値から、対応するタグID群をインデックス記憶部304から取り出す機能を持つ。
The
That is, the
The
The
インデックス記憶部304は、保管索引値とタグIDとの対応付けが示されるインデックス情報を保存する機能を持つ。
なお、インデックス記憶部304に保存するインデックス情報では、一つの保管索引値に1つ又は複数のタグIDが対応する。
The
In the index information stored in the
データ保管部305は、登録データ受信部308から受信した文書情報とタグとを対応付けて保存する。
The
検索要求受信部302は、利用者端末装置201から送信された検索要求を受信し、検索処理部303へ転送する。
The search
検索処理部303は、検索要求受信部302から検索要求を受信し、検索要求に含まれる検索索引値を索引分類部306に送信し、検索索引値と一致する保管索引値がインデックス記憶部304に存在する場合は、保管索引値から得られた検索対象タグをデータ保管部305から取り出し、検索クエリとの一致検査を行う。
そして、検索処理部303は、一致検査の結果より得られた文書情報を検索要求回答部307を介して利用者端末装置201に送信する。
つまり、検索処理部303は、インデックス記憶部304に記憶されているインデックス情報を参照して、検索要求に含まれる検索索引値と一致する保管索引値と対応付けられているタグIDを1つ以上選出する。
更に、検索処理部303は、選出したタグIDに対応するタグをデータ保管部305から抽出し、抽出したタグごとに、検索要求に含まれる検索クエリ(秘匿化された検索キーワード)との照合を行い、検索キーワードと一致する保管キーワードから生成されているタグを特定し、特定したタグと対応付けられている文書情報をデータ保管部305から抽出する。
検索処理部303は、タグID選出部及びデータ抽出部の例に相当する。
The
Then, the
That is, the
Further, the
The
検索要求回答部307は、検索処理部303によって検索された文書情報を検索要求元の利用者端末装置201に送信する。
The search
図4は、本実施の形態に係る検索要求2001のデータ構造の一例を示す。
FIG. 4 shows an example of the data structure of the
ここでは、この構成例を検索要求Aとする。
検索要求Aは検索クエリ2002と索引値2004から構成される。
検索クエリ2002は、文書・鍵格納領域202に保存されたユーザ秘密鍵と検索キーワード2003を用いて生成する。
生成された検索クエリ2002からは、検索キーワード2003を知ることはできない。
データセンター装置301は、検索クエリ2002を用いてタグとの一致検査を行い、検索キーワード2003と同じ保管キーワードから生成されたタグを抽出する。
索引値2004は、検索キーワード2003から図8の手順で得られるエントロピー符号値である。
Here, this configuration example is referred to as a search request A.
The search request A includes a
The
The
The
The
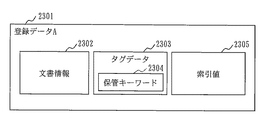
図5は、本実施の形態に係る登録データ2301のデータ構造の一例を示す。
FIG. 5 shows an example of the data structure of the
ここでは、この構成例を登録データAとする。
登録データAは文書情報2302、タグ2303、索引値2305から構成される。
文書情報2302は、例えば、検索システムとは別の暗号で暗号化された文書そのものや、文書名、文書を保管しているデータベースの位置情報などであり、文書情報から文書そのものを閲覧することはできない。
タグ2303は、ユーザによって付与された、文書情報2302に対する保管キーワード2304と文書・鍵格納領域202に保存された公開鍵を鍵として無意味な平文を暗号化したデータである。
索引値2305は、保管キーワード2304から図8の手順で得られるエントロピー符号値である。
Here, this configuration example is registered data A.
The registration data A includes
The
A
The
本実施の形態における索引値は2進数のビット列である。
インデックス情報の構造は索引値から検索対象のタグIDが得られればよい。
本実施の形態では、インデックス情報は、最も単純な転置インデックスの形式を例とするが、2分木やB木を用いた索引木を構成してもよい。
The index value in the present embodiment is a binary bit string.
As for the structure of the index information, the tag ID to be searched may be obtained from the index value.
In the present embodiment, the index information uses the simplest form of an inverted index as an example, but an index tree using a binary tree or a B-tree may be configured.
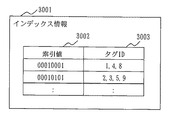
図6は、インデックス記憶部304に記憶されるインデックス情報3001のデータ構造の一例を示す。
インデックス情報3001は、索引値3002とタグID3003から構成される。
索引値3002は、文書情報に設定されたキーワードの鍵付ハッシュ値をエントロピー符号化した値(保管索引値)である。
タグID3003は、索引値3002を生成するために用いた保管キーワードのタグに対応するIDである。
検索の際には、検索者が指定した検索索引値と同じ保管索引値と対応付けられているタグID群から得られるタグを一致検査対象とする。
FIG. 6 shows an example of the data structure of the
The
The
The
In the search, a tag obtained from a tag ID group associated with the same storage index value as the search index value designated by the searcher is set as a matching check target.
図7のようにデータ保管部305は、タグID3051、タグ3052、文書情報3053を列に持つような表の形式でデータを保存する。
タグID3051は、登録データ受信部308によって付与され、インデックス記憶部304に保存されるタグIDと一致する。
As shown in FIG. 7, the
The
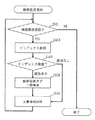
図8は、本実施の形態における索引値の計算方法を説明するためのフローチャートである。 FIG. 8 is a flowchart for explaining an index value calculation method according to the present embodiment.
まず、ステップS3061において、索引生成部208は、利用者I/F部204から入力されたキーワードを文書・鍵格納領域202に保存してある鍵を利用してハッシュ値を計算する(本実施の形態ではハッシュ値だが、共通鍵暗号化した値としてもよい)。
このとき、キーワードのハッシュ値を計算する際に用いるハッシュ関数は、同一のキーワードからは同じ値が計算される必要がある。
また、データセンターがキーワードのハッシュ値を計算できないように、データ登録者と、検索者のみ暗号化の鍵を保持することが望ましい。
例えば、暗号化データベースとは無関係の確定的暗号や鍵付ハッシュ関数を利用する。
本実施の形態では、用語の混乱を避け、説明を簡単にするため、キーワードの鍵付ハッシュ値を利用するものとする。
First, in step S3061, the
At this time, the hash function used when calculating the hash value of the keyword needs to be calculated from the same keyword.
Also, it is desirable that only the data registrant and the searcher hold the encryption key so that the data center cannot calculate the hash value of the keyword.
For example, a deterministic encryption unrelated to the encryption database or a hash function with a key is used.
In the present embodiment, a keyed hash value of a keyword is used to avoid confusion of terms and simplify the explanation.
次に、ステップS3062において、索引生成部208は、ステップS3061で生成した値に対し、エントロピー符号化を実施する。
本実施の形態では、エントロピー符号としてハフマン符号を用いることとする。
Next, in step S3062, the
In this embodiment, a Huffman code is used as the entropy code.
次に、ステップS3063において、索引生成部208は、ステップS3062で出力された符号値を、索引値として通信部207に送信する。
エントロピー符号として、ハフマン符号を利用した例を次に示す。
Next, in step S3063, the
An example using a Huffman code as an entropy code is shown below.
キーワードとして、「original」「confirm」「share」を持つ文書情報をそれぞれD(“original”)、D(“confirm”)、D(“share”)とする。
また、それぞれの文書情報に付加されるタグをtag(“original”)、tag(“confirm”)、tag(“share”)とし、そのタグに付与されるタグIDをそれぞれ1、2、3とする。
(タグ、タグID)として表すと、(tag(“original”)、1)、(tag(“confirm”)、2)、(tag(“share”)、3)となる。
Document information having “original”, “confirm”, and “share” as keywords are D (“original”), D (“confirm”), and D (“share”), respectively.
Further, the tag added to each document information is tag (“original”), tag (“confirm”), tag (“share”), and tag IDs assigned to the tags are 1, 2, 3, respectively. To do.
When expressed as (tag, tag ID), they are (tag ("original"), 1), (tag ("confirm"), 2), (tag ("share"), 3).
次に、キーワード「original」「confirm」「share」のハッシュ値を計算する。
例えば、ハッシュアルゴリズムであるSHA256でそれぞれのハッシュ値を取ると、図11(a)に示すような16進数(0〜9、a〜f)64桁の数値が得られる。
SHA256の性質から、このハッシュ値からキーワードを求めることはできない。
Next, hash values of the keywords “original”, “confirm”, and “share” are calculated.
For example, when each hash value is taken with the hash algorithm SHA256, a hexadecimal number (0-9, af) as shown in FIG. 11A is obtained.
Due to the nature of SHA256, keywords cannot be obtained from this hash value.
次に、得られたハッシュ値をハフマン符号化する。
ハフマン符号化を実施すると、図11(b)に示すよう2進数の数値を得ることができる。
このキーワードのハッシュ値をハフマン符号化した2進数を索引値とする。
Next, the obtained hash value is Huffman encoded.
When Huffman coding is performed, binary numerical values can be obtained as shown in FIG.
A binary number obtained by Huffman coding the hash value of this keyword is used as an index value.
上記ハフマン符号値は、符号化時の変換表がなければハッシュ値を復元することはできない。
本実施の形態では、ハフマン符号の変換表を破棄するため、符号値からハッシュ値を復元することはできない。
また、「original」と「confirm」の索引値が同じであるため、tag(“original”)とtag(“confirm”)はデータセンター装置301のインデックス情報において同一のエントリに保存されることになる。
そのため、単純な索引技術のように、索引値からタグの分布を読み取ることができなくなるため、キーワードの頻度解析を防止することが可能であり、より安全である。
The Huffman code value cannot be restored without a conversion table at the time of encoding.
In this embodiment, since the Huffman code conversion table is discarded, the hash value cannot be restored from the code value.
Further, since the index values of “original” and “confirm” are the same, tag (“original”) and tag (“confirm”) are stored in the same entry in the index information of the
For this reason, the tag distribution cannot be read from the index value as in a simple index technique, so that it is possible to prevent keyword frequency analysis and it is safer.
次に、秘匿検索システム100の動作について説明する。
図9は、本実施の形態のデータ登録処理の例を説明するフローチャートである。
この処理はデータセンター装置301で実施される処理である。
Next, the operation of the confidential search system 100 will be described.
FIG. 9 is a flowchart illustrating an example of data registration processing according to the present embodiment.
This processing is performed by the
まず、ステップS401において、データセンター装置301は、利用者端末装置201からネットワーク101を経由して送信される登録データAを、登録データ受信部308で受信する。
登録データAは、図5の登録データ2301のようになっている。
登録データ受信部308は、受信したタグ2303にタグIDを付与する。
そして、タグIDと文書情報2302とタグ2303をデータ保管部305に送信し、タグIDと索引値2305を索引分類部306に送信する。
First, in
The registration data A is as the
The registration
The tag ID,
次に、ステップS402において、索引分類部306は、登録データ受信部308から受信した索引値が、既にインデックス情報に存在するかを検査するためにインデックス記憶部304を参照する。
In step S402, the
次に、ステップS403において、索引分類部306は、登録データ受信部308から受信した索引値がインデックス記憶部304に保存されたインデックス情報3001のエントリに含まれるかどうかを検査する。
既に該当するエントリがある場合(該当あり)、ステップS404に進む。
該当するエントリがない場合(該当なし)は、ステップS406に進む。
In step S <b> 403, the
If there is a corresponding entry already (corresponding), the process proceeds to step S404.
If there is no corresponding entry (not applicable), the process proceeds to step S406.
次に、ステップS404において、索引分類部306は、該当するインデックス情報3001のエントリのタグID3003に、登録データ受信部308から受信したタグIDを追加する。
Next, in step S404, the
次に、ステップS405おいて、データ保管部305が、登録データ受信部308から受信したタグIDと文書情報2302とタグ2303を保存する。
In step S 405, the
次に、ステップS403で、インデックス記憶部304に保存されたインデックス情報3001に登録データ受信部308から受信した索引値が存在しない場合について説明する。
Next, a case where the index value received from the registered
ステップS406において、索引分類部306は、登録データ受信部308から受信した索引値と対応するタグIDから新たにエントリを作成し、インデックス情報3001に新しいエントリを追加する。
その後ステップS405を実行する。
In step S <b> 406, the
Thereafter, step S405 is executed.
以上がデータ登録処理の動作の説明である。
次にデータ検索処理の説明をする。
図10は、本実施の形態のデータ検索処理の例を説明するフローチャートである。
The above is the description of the operation of the data registration process.
Next, the data search process will be described.
FIG. 10 is a flowchart for explaining an example of data search processing according to the present embodiment.
まず、ステップS501において、データセンター装置301は、利用者端末装置201からネットワーク101を経由して送信される検索要求Aを、検索要求受信部302で受信する。
First, in step S <b> 501, the
次に、ステップS502において、検索要求受信部302は、検索要求Aを検索処理部303に転送する。
検索処理部303はインデックス情報を参照するために、索引分類部306に検索要求Aに含まれる索引値2004を転送する。
Next, in step S <b> 502, the search
The
次に、ステップS503において、索引分類部306は、インデックス記憶部304に保存されているインデックス情報3001に、検索処理部303から受信した索引値2004が含まれているかどうか検査する。
In step S <b> 503, the
次に、S503の検査で検索要求Aの索引値2004がインデックス記憶部304に存在しなかった場合(該当なし)は、ステップS504において、索引分類部306は検索処理部303に対して検索要求Aに含まれる検索キーワード2003がデータ保管部305に存在しないと通知する。
検索処理部303は、データ保管部305を検索せずに、検索要求回答部307を介して、検索要求のあった利用者端末装置201へ該当データが存在しない旨を回答する。
Next, when the
The
次に、S503の検査の結果、受信した検索要求Aの索引値2004がインデックス記憶部304に存在した場合は(該当あり)、ステップS505において、索引分類部306によってインデックス情報3001から索引値2004に対応するタグID群が返却される。
検索処理部303は、索引値2004に対応するタグID群を用いて、該当するタグをデータ保管部305から参照し、検索要求Aに含まれる検索クエリ2002を用いてキーワード一致検査を行う。
Next, if the
The
次に、S505の検索の結果、検索要求Aに一致するタグがある場合に、検索処理部303は、ステップS504において、該当するタグに対応する文書情報をデータ保管部305から読み出し、検索要求回答部307を介して、検索要求のあった利用者端末装置201へ回答する。
データ保管部305に、検索要求に該当するデータが存在しない場合は、検索処理部303は、検索要求回答部307を介して、検索要求のあった利用者端末装置201へ該当データが存在しない旨を回答する。
Next, if there is a tag that matches the search request A as a result of the search in S505, the
If the data corresponding to the search request does not exist in the
以上の手順により、暗号化データベースにおいて、暗号化したままデータを検索する方法を安全かつ高速に実施することができる。 According to the above procedure, the method for searching data in the encrypted database while being encrypted can be safely and rapidly performed.
以上の実施の形態によれば、検索キーワードのハッシュ値のエントロピー符号を利用することで、検索キーワードに関する情報を漏らすことなく、索引を構成することが可能となり、高速な検索を実施できるという効果がある。 According to the above embodiment, by using the entropy code of the hash value of the search keyword, it is possible to configure an index without leaking information related to the search keyword, and an effect that a high-speed search can be performed is achieved. is there.
また、本実施の形態で構成する索引は1つ以上のキーワードに対応する検索タグをグルーピングすることが可能であり、索引からキーワードに対応するデータの分布を秘匿するという効果がある。 Further, the index configured in this embodiment can group search tags corresponding to one or more keywords, and has an effect of concealing the distribution of data corresponding to the keywords from the index.
また、保存されるキーワードの種類の増加に対して、索引を再構成する必要がなく、索引の維持のための計算量を低減するという効果がある。 Further, it is not necessary to reconstruct the index with respect to an increase in the number of saved keywords, and there is an effect that the amount of calculation for maintaining the index is reduced.
本実施の形態ではキーワードの鍵付ハッシュ値をハフマン符号化した値を索引値として利用する例を開示したが、キーワードから一意に得られる値であればよく、ハッシュ関数や共通鍵暗号(確定的暗号)を利用してもよい。 In the present embodiment, an example is disclosed in which a value obtained by encoding a keyed hash value of a keyword using a Huffman code is used as an index value. (Encryption) may be used.
また、本実施の形態では、エントロピー符号としてハフマン符号を利用したが、エントロピー符号であればよく、例えば算術符号であっても良い。 In this embodiment, the Huffman code is used as the entropy code. However, any entropy code may be used, and for example, an arithmetic code may be used.
また、本実施の形態では、最も単純な転置インデックスの形式を例としたが、索引値から検索対象のタグIDが得られればよく、2分木やB木を用いた索引木を構成しても良い。 In this embodiment, the simplest inverted index format is used as an example, but it is sufficient that the tag ID to be searched can be obtained from the index value, and an index tree using a binary tree or a B-tree is constructed. Also good.
以上、秘匿検索におけるエントロピー符号を利用した索引手法を開示したが、これは、文書情報のキーワード検索に限らず、任意のデータに対応した検索のためのキーデータ(検索キー)であれば、応用可能なことは明らかである。
つまり、本実施の形態で説明したキーワードとは、単語やセンテンスに限らず、あらゆる形式のキーデータを意味する。
このように、本実施の形態によれば、データを暗号化したままで複数の検索キーを用いた検索を高速に実施することができる。
したがって、画像検索、動画検索、音声検索などへの応用が可能である。
As mentioned above, although the index method using the entropy code in the secret search has been disclosed, this is not limited to the keyword search of the document information, but can be applied to any key data (search key) for search corresponding to arbitrary data. Clearly it is possible.
In other words, the keyword described in the present embodiment means not only words and sentences but also all types of key data.
Thus, according to the present embodiment, it is possible to perform a search using a plurality of search keys at a high speed while the data is encrypted.
Therefore, application to image search, video search, voice search, etc. is possible.
以上、本実施の形態では、
検索キーワードおよび、文書情報に設定するキーワードから索引値を生成する索引生成部と、
新規登録対象のキーワードタグと文書情報を受信する登録データ受信部と、
前記登録データ受信部から受信した全てのキーワードタグと文書情報を保存するデータ保管部と、
キーワードから一意に得られる乱数値(暗号文やハッシュ値)をエントロピー符号化した値(索引値)と、その索引値に対応するキーワードタグを示すタグIDとからなるエントリを複数保持するインデックスを記憶するインデックス記憶部と、
検索要求に含まれる索引値が前記インデックス記憶部に存在する場合に、検索対象となるタグIDから該当するタグをデータ保管部から取り出し、キーワードが一致するタグかどうかを検査する検索処理部と、
データ検索時には、索引処理部から受信した索引値から、対応するタグIDをインデックス記憶部から取り出し、データ登録時には登録データ受信部から受信した索引値とタグを用いてインデックス記憶部に索引情報を追加する索引分類部とを備える秘匿検索システムを説明した。
As described above, in the present embodiment,
An index generation unit that generates an index value from a search keyword and a keyword set in document information;
A registration data receiving unit for receiving a keyword tag and document information of a new registration target;
A data storage unit for storing all keyword tags and document information received from the registered data receiving unit;
Stores an index that holds a plurality of entries consisting of a value (index value) obtained by entropy encoding a random value (ciphertext or hash value) uniquely obtained from a keyword and a tag ID indicating a keyword tag corresponding to the index value. An index storage unit,
When an index value included in a search request exists in the index storage unit, a search processing unit that takes out a corresponding tag from the tag ID to be searched from the data storage unit and checks whether the keyword matches a tag,
At the time of data retrieval, the corresponding tag ID is extracted from the index storage unit from the index value received from the index processing unit, and at the time of data registration, index information is added to the index storage unit using the index value and tag received from the registered data reception unit A secret search system including an index classification unit to perform was described.
また、本実施の形態では、
前記索引生成部は、データ登録時の文書情報に設定するキーワードやデータ検索時の検索キーワードからエントロピー符号値を計算して索引値として出力し、
前記索引分類部は、前記索引生成部によって出力された索引値と、索引値に対応するタグを示すタグIDを保存および参照することを説明した。
In the present embodiment,
The index generation unit calculates an entropy code value from a keyword set in document information at the time of data registration and a search keyword at the time of data search, and outputs it as an index value.
It has been described that the index classification unit stores and refers to the index value output by the index generation unit and the tag ID indicating the tag corresponding to the index value.
また、本実施の形態では、
前記索引分類部は、前記索引生成部によって出力された索引値と、索引値に対応するタグを示すタグIDを表形式でインデックス記憶部に保存および参照することを説明した。
In the present embodiment,
It has been described that the index classification unit stores and refers to the index value output by the index generation unit and the tag ID indicating the tag corresponding to the index value in the index storage unit in a tabular format.
また、本実施の形態では、
前記索引分類部は、前記索引生成部によって出力された索引値と、索引値に対応するタグを示すタグIDを木形式(2分木、B木など)でインデックス記憶部に保存および参照することを説明した。
In the present embodiment,
The index classification unit stores and references the index value output by the index generation unit and the tag ID indicating the tag corresponding to the index value in the index storage unit in a tree format (binary tree, B-tree, etc.). Explained.
最後に、本実施の形態に示した利用者端末装置201及びデータセンター装置301のハードウェア構成例について説明する。
図12は、本実施の形態に示す利用者端末装置201及びデータセンター装置301のハードウェア資源の一例を示す図である。
なお、図12の構成は、あくまでも利用者端末装置201及びデータセンター装置301のハードウェア構成の一例を示すものであり、利用者端末装置201及びデータセンター装置301のハードウェア構成は図12に記載の構成に限らず、他の構成であってもよい。
Finally, a hardware configuration example of the
FIG. 12 is a diagram illustrating an example of hardware resources of the
The configuration of FIG. 12 is merely an example of the hardware configuration of the
図12において、利用者端末装置201及びデータセンター装置301は、プログラムを実行するCPU911(Central Processing Unit、中央処理装置、処理装置、演算装置、マイクロプロセッサ、マイクロコンピュータ、プロセッサともいう)を備えている。
CPU911は、バス912を介して、例えば、ROM(Read Only Memory)913、RAM(Random Access Memory)914、通信ボード915、表示装置901、キーボード902、マウス903、磁気ディスク装置920と接続され、これらのハードウェアデバイスを制御する。
更に、CPU911は、FDD904(Flexible Disk Drive)、コンパクトディスク装置905(CDD)と接続していてもよい。また、磁気ディスク装置920の代わりに、SSD(Solid State Drive)、光ディスク装置、メモリカード(登録商標)読み書き装置などの記憶装置でもよい。
RAM914は、揮発性メモリの一例である。ROM913、FDD904、CDD905、磁気ディスク装置920の記憶媒体は、不揮発性メモリの一例である。これらは、記憶装置の一例である。
本実施の形態で説明した文書・鍵格納領域202、インデックス記憶部304及びデータ保管部305は、RAM914、磁気ディスク装置920等により実現される。
通信ボード915、キーボード902、マウス903、FDD904などは、入力装置の一例である。
また、通信ボード915、表示装置901などは、出力装置の一例である。
In FIG. 12, the
The
Further, the
The
The document /
The communication board 915, the
The communication board 915, the
通信ボード915は、図1に示すように、ネットワークに接続されている。
例えば、通信ボード915は、LAN、インターネットの他、WAN(ワイドエリアネットワーク)、SAN(ストレージエリアネットワーク)などに接続されていても構わない。
As shown in FIG. 1, the communication board 915 is connected to a network.
For example, the communication board 915 may be connected to a WAN (wide area network), a SAN (storage area network), or the like in addition to the LAN and the Internet.
磁気ディスク装置920には、オペレーティングシステム921(OS)、ウィンドウシステム922、プログラム群923、ファイル群924が記憶されている。
プログラム群923のプログラムは、CPU911がオペレーティングシステム921、ウィンドウシステム922を利用しながら実行する。
The
The programs in the
また、RAM914には、CPU911に実行させるオペレーティングシステム921のプログラムやアプリケーションプログラムの少なくとも一部が一時的に格納される。
また、RAM914には、CPU911による処理に必要な各種データが格納される。
The
The
また、ROM913には、BIOS(Basic Input Output System)プログラムが格納され、磁気ディスク装置920にはブートプログラムが格納されている。
利用者端末装置201及びデータセンター装置301の起動時には、ROM913のBIOSプログラム及び磁気ディスク装置920のブートプログラムが実行され、BIOSプログラム及びブートプログラムによりオペレーティングシステム921が起動される。
The
When the
上記プログラム群923には、本実施の形態の説明において「〜部」(「インデックス記憶部304及びデータ保管部305」以外、以下同様)として説明している機能を実行するプログラムが記憶されている。プログラムは、CPU911により読み出され実行される。
The
ファイル群924には、本実施の形態の説明において、「〜の判断」、「〜の計算」、「〜の暗号化」、「〜の符号化」、「〜の比較」、「〜の照合」、「〜の参照」、「〜の検索」、「〜の抽出」、「〜の検査」、「〜の生成」、「〜の設定」、「〜の登録」、「〜の選択」、「〜の入力」、「〜の受信」等として説明している処理の結果を示す情報やデータや信号値や変数値やパラメータが、「〜ファイル」や「〜データベース」の各項目として記憶されている。
「〜ファイル」や「〜データベース」は、ディスクやメモリなどの記録媒体に記憶される。
ディスクやメモリなどの記憶媒体に記憶された情報やデータや信号値や変数値やパラメータは、読み書き回路を介してCPU911によりメインメモリやキャッシュメモリに読み出される。
そして、読み出された情報やデータや信号値や変数値やパラメータは、抽出・検索・参照・比較・演算・計算・処理・編集・出力・印刷・表示などのCPUの動作に用いられる。
抽出・検索・参照・比較・演算・計算・処理・編集・出力・印刷・表示のCPUの動作の間、情報やデータや信号値や変数値やパラメータは、メインメモリ、レジスタ、キャッシュメモリ、バッファメモリ等に一時的に記憶される。
また、本実施の形態で説明しているフローチャートの矢印の部分は主としてデータや信号の入出力を示す。
データや信号値は、RAM914のメモリ、FDD904のフレキシブルディスク、CDD905のコンパクトディスク、磁気ディスク装置920の磁気ディスク、その他光ディスク、ミニディスク、DVD等の記録媒体に記録される。
また、データや信号は、バス912や信号線やケーブルその他の伝送媒体によりオンライン伝送される。
In the description of the present embodiment, the
The “˜file” and “˜database” are stored in a recording medium such as a disk or a memory.
Information, data, signal values, variable values, and parameters stored in a storage medium such as a disk or memory are read out to the main memory or cache memory by the
The read information, data, signal value, variable value, and parameter are used for CPU operations such as extraction, search, reference, comparison, calculation, calculation, processing, editing, output, printing, and display.
Information, data, signal values, variable values, and parameters are stored in the main memory, registers, cache memory, and buffers during the CPU operations of extraction, search, reference, comparison, calculation, processing, editing, output, printing, and display. It is temporarily stored in a memory or the like.
In addition, the arrows in the flowchart described in this embodiment mainly indicate input / output of data and signals.
Data and signal values are recorded on a recording medium such as a memory of the
Data and signals are transmitted online via a bus 912, signal lines, cables, or other transmission media.
また、本実施の形態の説明において「〜部」として説明しているものは、「〜回路」、「〜装置」、「〜機器」であってもよく、また、「〜ステップ」、「〜手順」、「〜処理」であってもよい。
すなわち、本実施の形態で説明したフローチャートに示すステップ、手順、処理により、本発明に係るデータ処理方法及びデータ保管方法を実現することができる。
また、「〜部」として説明しているものは、ROM913に記憶されたファームウェアで実現されていても構わない。
或いは、ソフトウェアのみ、或いは、素子・デバイス・基板・配線などのハードウェアのみ、或いは、ソフトウェアとハードウェアとの組み合わせ、さらには、ファームウェアとの組み合わせで実施されても構わない。
ファームウェアとソフトウェアは、プログラムとして、磁気ディスク、フレキシブルディスク、光ディスク、コンパクトディスク、ミニディスク、DVD等の記録媒体に記憶される。
プログラムはCPU911により読み出され、CPU911により実行される。
すなわち、プログラムは、本実施の形態の「〜部」としてコンピュータを機能させるものである。あるいは、本実施の形態の「〜部」の手順や方法をコンピュータに実行させるものである。
In addition, what is described as “˜unit” in the description of the present embodiment may be “˜circuit”, “˜device”, “˜device”, and “˜step”, “˜”. “Procedure” and “˜Process” may be used.
That is, the data processing method and the data storage method according to the present invention can be realized by the steps, procedures, and processes shown in the flowchart described in the present embodiment.
Further, what is described as “˜unit” may be realized by firmware stored in the
Alternatively, it may be implemented only by software, or only by hardware such as elements, devices, substrates, and wirings, by a combination of software and hardware, or by a combination of firmware.
Firmware and software are stored as programs in a recording medium such as a magnetic disk, a flexible disk, an optical disk, a compact disk, a mini disk, and a DVD.
The program is read by the
In other words, the program causes the computer to function as “to part” of the present embodiment. Alternatively, the procedure or method of “˜unit” in the present embodiment is executed by a computer.
このように、本実施の形態に示す利用者端末装置201及びデータセンター装置301は、処理装置たるCPU、記憶装置たるメモリ、磁気ディスク等、入力装置たるキーボード、マウス、通信ボード等、出力装置たる表示装置、通信ボード等を備えるコンピュータである。
そして、上記したように「〜部」として示された機能をこれら処理装置、記憶装置、入力装置、出力装置を用いて実現するものである。
As described above, the
Then, as described above, the functions indicated as “˜units” are realized using these processing devices, storage devices, input devices, and output devices.
100 秘匿検索システム、101 ネットワーク、102 社内LAN、201 利用者端末装置、202 文書・鍵格納領域、203 文書情報管理部、204 利用者I/F部、205 検索クエリ生成部、206 タグ生成部、207 通信部、208 索引生成部、301 データセンター装置、302 検索要求受信部、303 検索処理部、304 インデックス記憶部、305 データ保管部、306 索引分類部、307 検索要求回答部、308 登録データ受信部。 DESCRIPTION OF SYMBOLS 100 Secret search system, 101 Network, 102 Internal LAN, 201 User terminal device, 202 Document / key storage area, 203 Document information management part, 204 User I / F part, 205 Search query generation part, 206 Tag generation part, 207 Communication unit, 208 Index generation unit, 301 Data center device, 302 Search request reception unit, 303 Search processing unit, 304 Index storage unit, 305 Data storage unit, 306 Index classification unit, 307 Search request response unit, 308 Registration data reception Department.
Claims (13)
前記データ保管装置での保管の対象となる保管対象データのキーワードを保管キーワードとして指定するキーワード指定部と、
前記保管キーワードから一意に得られる乱数値をエントロピー符号化して、前記保管対象データの暗号化データに対応付けられるタグデータが前記データ保管装置で保管される際に前記タグデータに付される索引値を生成する索引生成部と、
前記保管対象データの暗号化データと前記タグデータと前記索引値とが含まれる保管要求を、前記データ保管装置に対して送信する通信部とを有することを特徴とするデータ処理装置。 Connected to a data storage device that stores a plurality of encrypted data and tag data that is associated with each encrypted data and that is collated when searching for the encrypted data;
A keyword designating unit for designating a keyword of data to be stored to be stored in the data storage device as a storage keyword;
An index value assigned to the tag data when the tag data associated with the encrypted data of the storage target data is stored in the data storage device by entropy encoding a random value uniquely obtained from the storage keyword An index generation unit for generating
A data processing apparatus comprising: a communication unit that transmits a storage request including encrypted data of the storage target data, the tag data, and the index value to the data storage apparatus.
秘匿化された検索キーワードと、前記秘匿化された検索キーワードとの照合の対象となるタグデータの索引値とが含まれる検索要求を受信した際に、前記検索要求に含まれる索引値と一致する索引値と対応付けられているタグデータを抽出し、抽出したタグデータと前記秘匿化された検索キーワードとを照合して暗号化データを検索するデータ保管装置に接続され、
前記索引生成部は、
前記データ保管装置において前記検索要求に含まれる索引値と比較される索引値を生成することを特徴とする請求項1に記載のデータ処理装置。 The data processing device includes:
When a search request including a search keyword that is concealed and an index value of tag data that is a target of collation with the concealed search keyword is received, it matches the index value included in the search request The tag data associated with the index value is extracted, connected to the data storage device that searches the encrypted data by comparing the extracted tag data with the concealed search keyword,
The index generation unit
The data processing apparatus according to claim 1, wherein an index value to be compared with an index value included in the search request is generated in the data storage apparatus.
暗号化データとタグデータと索引値とを対応付けて保管するデータ保管装置に接続され、
前記キーワード指定部は、
前記データ保管装置に暗号化データの検索を行わせる検索キーワードを指定し、
前記データ処理装置は、更に、
前記検索キーワードを秘匿化する検索キーワード秘匿化部を有し、
前記索引生成部は、
前記検索キーワードから一意に得られる乱数値をエントロピー符号化して、前記データ保管装置において、秘匿化された検索キーワードとの照合の対象となるタグデータを選出するために、前記データ保管装置に保管されている索引値と比較される索引値を生成し、
前記通信部は、
前記秘匿化された検索キーワードと前記索引値とが含まれる検索要求を、前記データ保管装置に対して送信することを特徴とする請求項1又は2に記載のデータ処理装置。 The data processing device includes:
Connected to a data storage device that stores encrypted data, tag data, and index values in association with each other,
The keyword designating part is
Specify a search keyword that causes the data storage device to search for encrypted data;
The data processing device further includes:
A search keyword concealment unit that conceals the search keyword;
The index generation unit
A random number value uniquely obtained from the search keyword is entropy-encoded and stored in the data storage device to select tag data to be collated with a concealed search keyword in the data storage device. Generate an index value that is compared with the index value
The communication unit is
The data processing apparatus according to claim 1, wherein a search request including the concealed search keyword and the index value is transmitted to the data storage apparatus.
前記保管キーワードのハッシュ値を算出し、算出したハッシュ値をハフマン符号化して、前記保管対象データの暗号化データに対応付けられるタグデータが前記データ保管装置で保管される際に前記タグデータに付される索引値を生成し、
前記検索キーワードのハッシュ値を算出し、算出したハッシュ値をハフマン符号化して、前記データ保管装置において、前記秘匿化された検索キーワードとの照合の対象となるタグデータを選出するために、前記データ保管装置に保管されている索引値と比較される索引値を生成することを特徴とする請求項3に記載のデータ処理装置。 The index generation unit
A hash value of the storage keyword is calculated, the calculated hash value is Huffman-encoded, and tag data associated with the encrypted data of the storage target data is attached to the tag data when stored in the data storage device. Index value to be generated,
The data for calculating the hash value of the search keyword, Huffman encoding the calculated hash value, and selecting tag data to be collated with the concealed search keyword in the data storage device 4. The data processing apparatus according to claim 3, wherein an index value to be compared with an index value stored in the storage apparatus is generated.
前記データ処理装置から、保管対象の暗号化データと、暗号化データの検索の際に照合されるタグデータと、前記保管対象の暗号化データに指定された保管キーワードから一意に得られる乱数値をエントロピー符号化して得られた保管索引値とが含まれる保管要求を受信し、受信した前記保管要求に含まれるタグデータのID(Identification)をタグIDとして設定する保管要求受信部と、
前記保管要求受信部により設定されたタグIDと前記保管要求に含まれる保管索引値とを対応付けるインデックス情報を生成するインデックス情報生成部と、
前記インデックス情報生成部により生成されたインデックス情報を記憶するインデックス記憶部と、
前記保管要求に含まれる保管対象の暗号化データと、前記保管要求に含まれるタグデータとを対応付けて保管するデータ保管部とを有することを特徴とするデータ保管装置。 A data storage device connected to a data processing device and storing encrypted data transmitted from the data processing device,
From the data processing device, the encrypted data to be stored, the tag data that is collated when searching for the encrypted data, and a random value that is uniquely obtained from the storage keyword specified in the encrypted data to be stored A storage request receiving unit that receives a storage request including a storage index value obtained by entropy encoding, and sets an ID (Identification) of tag data included in the received storage request as a tag ID;
An index information generating unit that generates index information that associates a tag ID set by the storage request receiving unit with a storage index value included in the storage request;
An index storage unit for storing the index information generated by the index information generation unit;
A data storage device, comprising: a data storage unit that stores encrypted data to be stored included in the storage request and tag data included in the storage request in association with each other.
前記保管要求に含まれる保管索引値と同じ保管索引値が記述されている既存のインデックス情報が前記インデックス記憶部に記憶されている場合に、既存のインデックス情報において同じ保管検索値と対応付けられている他のタグIDとともに、前記保管要求に含まれるタグデータのタグIDを既存のインデックス情報において前記保管索引値と対応付けることを特徴とする請求項5に記載のデータ保管装置。 The index information generation unit
When existing index information describing the same storage index value as the storage index value included in the storage request is stored in the index storage unit, the existing index information is associated with the same storage search value. 6. The data storage device according to claim 5, wherein the tag ID of the tag data included in the storage request is associated with the storage index value in the existing index information together with the other tag IDs.
複数のデータ処理装置に接続されており、
前記データ保管装置は、更に、
前記複数のデータ処理装置のうち暗号化データの検索を要求するデータ処理装置から、秘匿化された検索キーワードと、秘匿化前の検索キーワードから一意に得られる乱数値をエントロピー符号化して得られた検索索引値とが含まれる検索要求を受信する検索要求受信部と、
前記インデックス記憶部に記憶されているインデックス情報を参照して、前記検索要求に含まれる検索索引値と一致する保管索引値と対応付けられているタグIDを1つ以上選出するタグID選出部と、
前記タグID選出部により選出されたタグIDに対応するタグデータを前記データ保管部から抽出し、抽出したタグデータごとに、前記検索要求に含まれる秘匿化された検索キーワードとの照合を行い、検索キーワードと一致する保管キーワードから生成されているタグデータを特定し、特定したタグデータと対応付けられている暗号化データを前記データ保管部から抽出するデータ抽出部とを有することを特徴とする請求項5又は6に記載のデータ保管装置。 The data storage device is:
Connected to multiple data processing devices,
The data storage device further includes:
Obtained by entropy encoding a concealed search keyword and a random value uniquely obtained from the concealed search keyword from a data processing device that requests retrieval of encrypted data among the plurality of data processing devices A search request receiver for receiving a search request including a search index value;
A tag ID selection unit that selects one or more tag IDs associated with a storage index value that matches a search index value included in the search request with reference to the index information stored in the index storage unit; ,
Tag data corresponding to the tag ID selected by the tag ID selection unit is extracted from the data storage unit, and each extracted tag data is compared with a concealed search keyword included in the search request, A data extraction unit that identifies tag data generated from a storage keyword that matches a search keyword and extracts encrypted data associated with the identified tag data from the data storage unit; The data storage device according to claim 5 or 6.
タグIDと保管索引値とを表形式で対応付けるインデックス情報を生成することを特徴とする請求項5〜7のいずれかに記載のデータ保管装置。 The index information generation unit
8. The data storage device according to claim 5, wherein index information that associates the tag ID with the storage index value in a table format is generated.
タグIDと保管索引値とを木形式で対応付けるインデックス情報を生成することを特徴とする請求項5〜8のいずれかに記載のデータ保管装置。 The index information generation unit
9. The data storage device according to claim 5, wherein index information that associates the tag ID with the storage index value in a tree format is generated.
前記コンピュータが、前記データ保管装置での保管の対象となる保管対象データのキーワードを保管キーワードとして指定するキーワード指定ステップと、
前記コンピュータが、前記保管キーワードから一意に得られる乱数値をエントロピー符号化して、前記保管対象データの暗号化データに対応付けられるタグデータが前記データ保管装置で保管される際に前記タグデータに付される索引値を生成する索引生成ステップと、
前記コンピュータが、前記保管対象データの暗号化データと前記タグデータと前記索引値とが含まれる保管要求を、前記データ保管装置に対して送信する通信ステップとを有することを特徴とするデータ処理方法。 A data processing method performed by a computer connected to a data storage device that stores a plurality of encrypted data and tag data that is associated with each encrypted data and that is collated when searching for encrypted data There,
A keyword specifying step in which the computer specifies a keyword of storage target data to be stored in the data storage device as a storage keyword;
The computer entropy-encodes a random value uniquely obtained from the storage keyword, and is attached to the tag data when tag data associated with the encrypted data of the storage target data is stored in the data storage device. Generating an index value to be generated; and
A data processing method comprising: a communication step in which the computer transmits a storage request including encrypted data of the storage target data, the tag data, and the index value to the data storage device. .
前記コンピュータが、前記データ処理装置から、保管対象の暗号化データと、暗号化データの検索の際に照合されるタグデータと、前記保管対象の暗号化データに指定された保管キーワードから一意に得られる乱数値をエントロピー符号化して得られた保管索引値とが含まれる保管要求を受信し、受信した前記保管要求に含まれるタグデータのID(Identification)をタグIDとして設定する保管要求受信ステップと、
前記コンピュータが、前記保管要求受信ステップにより設定されたタグIDと前記保管要求に含まれる保管索引値とを対応付けるインデックス情報を生成するインデックス情報生成ステップと、
前記コンピュータが、前記インデックス情報生成ステップにより生成されたインデックス情報を記憶するインデックス記憶ステップと、
前記コンピュータが、前記保管要求に含まれる保管対象の暗号化データと、前記保管要求に含まれるタグデータとを対応付けて保管するデータ保管ステップとを有することを特徴とするデータ保管方法。 A data storage method performed by a computer connected to a data processing device and storing encrypted data transmitted from the data processing device,
The computer uniquely obtains from the data processing device from the encrypted data to be stored, the tag data that is collated when searching for the encrypted data, and the storage keyword specified in the encrypted data to be stored. A storage request receiving step for receiving a storage request including a storage index value obtained by entropy encoding a random value to be obtained, and setting an ID (Identification) of tag data included in the received storage request as a tag ID; ,
An index information generating step for generating index information in which the computer associates the tag ID set in the storage request receiving step with a storage index value included in the storage request;
An index storing step in which the computer stores the index information generated by the index information generating step;
A data storage method, comprising: a data storage step in which the computer stores the encrypted data to be stored included in the storage request in association with the tag data included in the storage request.
前記データ保管装置での保管の対象となる保管対象データのキーワードを保管キーワードとして指定するキーワード指定ステップと、
前記保管キーワードから一意に得られる乱数値をエントロピー符号化して、前記保管対象データの暗号化データに対応付けられるタグデータが前記データ保管装置で保管される際に前記タグデータに付される索引値を生成する索引生成ステップと、
前記保管対象データの暗号化データと前記タグデータと前記索引値とが含まれる保管要求を、前記データ保管装置に対して送信する通信ステップとを実行させることを特徴とするプログラム。 To a computer connected to a data storage device that stores a plurality of encrypted data and tag data that is associated with each encrypted data and that is collated when searching for encrypted data,
A keyword designating step of designating as a storage keyword a keyword of data to be stored to be stored in the data storage device;
An index value assigned to the tag data when the tag data associated with the encrypted data of the storage target data is stored in the data storage device by entropy encoding a random value uniquely obtained from the storage keyword An index generation step for generating
A program for executing a communication step of transmitting a storage request including encrypted data of the storage target data, the tag data, and the index value to the data storage device.
前記データ処理装置から、保管対象の暗号化データと、暗号化データの検索の際に照合されるタグデータと、前記保管対象の暗号化データに指定された保管キーワードから一意に得られる乱数値をエントロピー符号化して得られた保管索引値とが含まれる保管要求を受信し、受信した前記保管要求に含まれるタグデータのID(Identification)をタグIDとして設定する保管要求受信ステップと、
前記保管要求受信ステップにより設定されたタグIDと前記保管要求に含まれる保管索引値とを対応付けるインデックス情報を生成するインデックス情報生成ステップと、
前記インデックス情報生成ステップにより生成されたインデックス情報を記憶するインデックス記憶ステップと、
前記保管要求に含まれる保管対象の暗号化データと、前記保管要求に含まれるタグデータとを対応付けて保管するデータ保管ステップとを実行させることを特徴とするプログラム。 A computer connected to a data processing device and storing encrypted data transmitted from the data processing device,
From the data processing device, the encrypted data to be stored, the tag data that is collated when searching for the encrypted data, and a random value that is uniquely obtained from the storage keyword specified in the encrypted data to be stored A storage request reception step of receiving a storage request including a storage index value obtained by entropy encoding, and setting an ID (Identification) of tag data included in the received storage request as a tag ID;
An index information generating step for generating index information for associating the tag ID set by the storage request receiving step with the storage index value included in the storage request;
An index storage step for storing the index information generated by the index information generation step;
A program for executing a data storage step of storing encrypted data to be stored included in the storage request and tag data included in the storage request in association with each other.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011022147A JP2012164031A (en) | 2011-02-03 | 2011-02-03 | Data processor, data storage device, data processing method, data storage method and program |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011022147A JP2012164031A (en) | 2011-02-03 | 2011-02-03 | Data processor, data storage device, data processing method, data storage method and program |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2012164031A true JP2012164031A (en) | 2012-08-30 |
Family
ID=46843378
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011022147A Withdrawn JP2012164031A (en) | 2011-02-03 | 2011-02-03 | Data processor, data storage device, data processing method, data storage method and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2012164031A (en) |
Cited By (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014098990A (en) * | 2012-11-13 | 2014-05-29 | Fujitsu Ltd | Retrieval processing method, data generation method, and information processor |
| WO2014128958A1 (en) * | 2013-02-25 | 2014-08-28 | 三菱電機株式会社 | Server device, private search program, recording medium, and private search system |
| JP2015118603A (en) * | 2013-12-19 | 2015-06-25 | 日本電信電話株式会社 | Database search system and search method |
| JP2016206555A (en) * | 2015-04-27 | 2016-12-08 | 株式会社東芝 | Concealment device, decryption device, concealment method and decryption method |
| WO2017122696A1 (en) | 2016-01-14 | 2017-07-20 | 三菱電機株式会社 | Anonymous search system, anonymous search method, and anonymous search program |
| CN108919695A (en) * | 2018-05-28 | 2018-11-30 | 深圳创维-Rgb电子有限公司 | A kind of coding method, device, equipment and the storage medium of electrical equipment module |
| USRE48146E1 (en) | 2012-01-25 | 2020-08-04 | Mitsubishi Electric Corporation | Data search device, data search method, computer readable medium storing data search program, data registration device, data registration method, computer readable medium storing data registration program, and information processing device |
| US11005645B2 (en) | 2016-01-15 | 2021-05-11 | Mitsubishi Electric Corporation | Encryption device, encryption method, computer readable medium, and storage device |
| US11106740B2 (en) | 2017-04-25 | 2021-08-31 | Mitsubishi Electric Corporation | Search device, search system, search method, and computer readable medium |
| JP2021170056A (en) * | 2020-04-14 | 2021-10-28 | 富士通株式会社 | Search methods, search programs, and confidential information search systems |
| US11170123B2 (en) | 2017-09-12 | 2021-11-09 | Mitsubishi Electric Corporation | Registration terminal, key server, search system, and computer readable medium |
| CN113836187A (en) * | 2020-06-08 | 2021-12-24 | 腾讯科技(深圳)有限公司 | Data processing method, device, server and computer readable storage medium |
| US11360978B2 (en) | 2017-05-18 | 2022-06-14 | Mitsubishi Electric Corporation | Search device, tag generation device, query generation device, searchable encryption system and computer readable medium |
| CN116451263A (en) * | 2023-06-16 | 2023-07-18 | 深圳市彦胜科技有限公司 | Hard disk data storage method, device, equipment and storage medium |
| WO2025130630A1 (en) * | 2023-12-20 | 2025-06-26 | 杭州拓数派科技发展有限公司 | Metadata storage method and apparatus, metadata query method and apparatus, and computer device and storage medium |
-
2011
- 2011-02-03 JP JP2011022147A patent/JP2012164031A/en not_active Withdrawn
Cited By (20)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| USRE48146E1 (en) | 2012-01-25 | 2020-08-04 | Mitsubishi Electric Corporation | Data search device, data search method, computer readable medium storing data search program, data registration device, data registration method, computer readable medium storing data registration program, and information processing device |
| JP2014098990A (en) * | 2012-11-13 | 2014-05-29 | Fujitsu Ltd | Retrieval processing method, data generation method, and information processor |
| WO2014128958A1 (en) * | 2013-02-25 | 2014-08-28 | 三菱電機株式会社 | Server device, private search program, recording medium, and private search system |
| JP5963936B2 (en) * | 2013-02-25 | 2016-08-03 | 三菱電機株式会社 | Server device, secret search program, recording medium, and secret search system |
| US10235539B2 (en) | 2013-02-25 | 2019-03-19 | Mitsubishi Electric Corporation | Server device, recording medium, and concealed search system |
| JP2015118603A (en) * | 2013-12-19 | 2015-06-25 | 日本電信電話株式会社 | Database search system and search method |
| JP2016206555A (en) * | 2015-04-27 | 2016-12-08 | 株式会社東芝 | Concealment device, decryption device, concealment method and decryption method |
| US10872158B2 (en) | 2016-01-14 | 2020-12-22 | Mitsubishi Electric Corporation | Secret search system, secret search method, and computer readable medium |
| WO2017122696A1 (en) | 2016-01-14 | 2017-07-20 | 三菱電機株式会社 | Anonymous search system, anonymous search method, and anonymous search program |
| US11005645B2 (en) | 2016-01-15 | 2021-05-11 | Mitsubishi Electric Corporation | Encryption device, encryption method, computer readable medium, and storage device |
| US11106740B2 (en) | 2017-04-25 | 2021-08-31 | Mitsubishi Electric Corporation | Search device, search system, search method, and computer readable medium |
| US11360978B2 (en) | 2017-05-18 | 2022-06-14 | Mitsubishi Electric Corporation | Search device, tag generation device, query generation device, searchable encryption system and computer readable medium |
| US11170123B2 (en) | 2017-09-12 | 2021-11-09 | Mitsubishi Electric Corporation | Registration terminal, key server, search system, and computer readable medium |
| CN108919695A (en) * | 2018-05-28 | 2018-11-30 | 深圳创维-Rgb电子有限公司 | A kind of coding method, device, equipment and the storage medium of electrical equipment module |
| JP2021170056A (en) * | 2020-04-14 | 2021-10-28 | 富士通株式会社 | Search methods, search programs, and confidential information search systems |
| JP7381893B2 (en) | 2020-04-14 | 2023-11-16 | 富士通株式会社 | Search method, search program, and secret information retrieval system |
| CN113836187A (en) * | 2020-06-08 | 2021-12-24 | 腾讯科技(深圳)有限公司 | Data processing method, device, server and computer readable storage medium |
| CN116451263A (en) * | 2023-06-16 | 2023-07-18 | 深圳市彦胜科技有限公司 | Hard disk data storage method, device, equipment and storage medium |
| CN116451263B (en) * | 2023-06-16 | 2023-08-22 | 深圳市彦胜科技有限公司 | Hard disk data storage method, device, equipment and storage medium |
| WO2025130630A1 (en) * | 2023-12-20 | 2025-06-26 | 杭州拓数派科技发展有限公司 | Metadata storage method and apparatus, metadata query method and apparatus, and computer device and storage medium |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2012164031A (en) | Data processor, data storage device, data processing method, data storage method and program | |
| US12212666B2 (en) | Cryptographic key generation for logically sharded data stores | |
| CN103329184B (en) | Data processing equipment and data storing device | |
| US9197613B2 (en) | Document processing method and system | |
| US10586057B2 (en) | Processing data queries in a logically sharded data store | |
| CN103119594B (en) | Retrievable Cryptographic Processing System | |
| US10235539B2 (en) | Server device, recording medium, and concealed search system | |
| JP4958246B2 (en) | Method, apparatus and system for fast searchable encryption | |
| JP5084817B2 (en) | Ciphertext indexing and retrieval method and apparatus | |
| US10872158B2 (en) | Secret search system, secret search method, and computer readable medium | |
| US8819408B2 (en) | Document processing method and system | |
| Awad et al. | Chaotic searchable encryption for mobile cloud storage | |
| US20140331338A1 (en) | Device and method for preventing confidential data leaks | |
| CN112042150A (en) | Registration device, server device, hidden retrieval system, hidden retrieval method, registration program and server program | |
| CA3065767C (en) | Cryptographic key generation for logically sharded data stores | |
| US20190260583A1 (en) | Encryption device, search device, computer readable medium, encryption method, and search method | |
| CN111753312B (en) | Data processing method, device, equipment and system | |
| CN104283930B (en) | Keyword search system for security index and method for establishing the system | |
| US11902418B2 (en) | Registration device, search operation device, and data management device | |
| US11106740B2 (en) | Search device, search system, search method, and computer readable medium | |
| WO2015107561A1 (en) | Search system, search method, and search program | |
| Poon et al. | A combined solution for conjunctive keyword search, phrase search and Auditing for encrypted cloud storage | |
| TWI519978B (en) | Secure indexed keyword search system | |
| Sankar et al. | A Survey on Efficient Privacy-Preserving Ranked Keyword Search Method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A300 | Application deemed to be withdrawn because no request for examination was validly filed |
Free format text: JAPANESE INTERMEDIATE CODE: A300 Effective date: 20140513 |