JP2012190377A - コンテンツ分散保管システム - Google Patents
コンテンツ分散保管システム Download PDFInfo
- Publication number
- JP2012190377A JP2012190377A JP2011055016A JP2011055016A JP2012190377A JP 2012190377 A JP2012190377 A JP 2012190377A JP 2011055016 A JP2011055016 A JP 2011055016A JP 2011055016 A JP2011055016 A JP 2011055016A JP 2012190377 A JP2012190377 A JP 2012190377A
- Authority
- JP
- Japan
- Prior art keywords
- content
- file
- server
- distributed
- pieces
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images







Landscapes
- Information Transfer Between Computers (AREA)
- Computer And Data Communications (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
【課題】分散ファイルシステムにおいて、コンテンツ片をユーザ端末へ配信するコンテンツ配信サーバが、配信前に複数のコンテンツ片をまとめて読込むに際して、特定のファイルサーバに負荷を集中させることなく読込みを可能とするシステムを得る。
【解決手段】各コンテンツ片を格納する複数のファイルサーバを含む分散ファイルシステムと、ユーザ端末からの配信要求に応じて各ファイルサーバから各コンテンツ片をN個まとめて読込みユーザ端末への配信を行うコンテンツ配信サーバとを備えたコンテンツ分散保管システムにおいて、分散ファイルシステムは、複数のファイルサーバから各コンテンツ片の書込み先となるN個以上のファイルサーバを決定する分散ファイルシステムクライアント21を有し、分散ファイルシステムクライアントは、前記各コンテンツ片が時系列順に分散するように書込み先のファイルサーバ22を決定する書込み先決定部52を備える。
【選択図】図4
【解決手段】各コンテンツ片を格納する複数のファイルサーバを含む分散ファイルシステムと、ユーザ端末からの配信要求に応じて各ファイルサーバから各コンテンツ片をN個まとめて読込みユーザ端末への配信を行うコンテンツ配信サーバとを備えたコンテンツ分散保管システムにおいて、分散ファイルシステムは、複数のファイルサーバから各コンテンツ片の書込み先となるN個以上のファイルサーバを決定する分散ファイルシステムクライアント21を有し、分散ファイルシステムクライアントは、前記各コンテンツ片が時系列順に分散するように書込み先のファイルサーバ22を決定する書込み先決定部52を備える。
【選択図】図4
Description
本発明は、ビデオ・オン・デマンド(VoD)配信サーバにおいて、ネットワークを介して散在する複数コンピュータのストレージを仮想的に統合して提供可能な分散ファイルシステムを利用し、一つのコンテンツを断片化(コンテンツ片を作成)し、一連のファイルセットを別々のファイルサーバに保管するコンテンツ分散保管システムに関する。
この種の技術としては、非特許文献1や非特許文献2で示されるように、複数のマシンのディスクを組み合わせて1つの分散ファイルシステムとして機能する分散プラットフォームが提案されている。
非特許文献1に示されたGfarmは、広域ネットワーク上で、大容量、大規模データ処理の要求に応えるスケーラブルな分散ファイルシステムプラットフォームであり、広域なネットワーク上での効率的なファイル共有に適した分散プラットフォームである。
一方、非特許文献2に示されたHadoopは、1つのディスクで保存できない大量のデータを並列化することで高速かつ効率良く処理できるものであり、比較的大きなサイズかつ基本的に更新されることのないファイルのI/Oに適した分散プラットフォームである。
非特許文献1に示されたGfarmは、広域ネットワーク上で、大容量、大規模データ処理の要求に応えるスケーラブルな分散ファイルシステムプラットフォームであり、広域なネットワーク上での効率的なファイル共有に適した分散プラットフォームである。
一方、非特許文献2に示されたHadoopは、1つのディスクで保存できない大量のデータを並列化することで高速かつ効率良く処理できるものであり、比較的大きなサイズかつ基本的に更新されることのないファイルのI/Oに適した分散プラットフォームである。
従来、複数のサーバで構成された分散ファイルシステムにおける監視システムは、各サーバの状態を定期的に収集し、統合的に分析することが行われている。収集される情報としては、CPU使用率、メモリ使用量、ディスク使用量、CPU温度、ネットワーク接続状態などが存在する。統合的な分析例としては、CPU使用率が80%以上のファイルサーバの台数を把握することでファイルサーバの混雑度が分かる。これにより、システムの使用状況に対して、ファイルサーバの台数が十分かどうかなどの指標を得ることができる。
URL:http://datafarm.apgrid.org/indeX.ja.html
URL:http://hadoop.apache.org/
上述した分散ファイルシステムにおいて、断片化されたコンテンツ片をそれぞれ保管する場合のファイルサーバの選択は、各ファイルサーバのCPU利用率やディスク空き容量などのリソース情報をもとに選択することが行われている。
例えば図7に示すように、コンテンツ配信サーバは、エンドユーザからの再生要求に従い、コンテンツ片を時系列順に配信する。ただし、各コンテンツ片の配信開始時刻に対象コンテンツ片の読込みを開始するのではなく、配信ストリーム(映像、音声)が途切れない様、先のコンテンツ片をN個配信時刻前に読込み、メモリ上に予めロードしておき、配信開始時刻に備えるようになっている。
例えば図7に示すように、コンテンツ配信サーバは、エンドユーザからの再生要求に従い、コンテンツ片を時系列順に配信する。ただし、各コンテンツ片の配信開始時刻に対象コンテンツ片の読込みを開始するのではなく、配信ストリーム(映像、音声)が途切れない様、先のコンテンツ片をN個配信時刻前に読込み、メモリ上に予めロードしておき、配信開始時刻に備えるようになっている。
しかしながら、上述のような方式であると、時系列的に隣接するコンテンツ片をN個まとめて読込む場合(図7の例であれば、コンテンツ片1,2,3をまとめて読込む場合、あるいはコンテンツ片4,5,6をまとめて読込む場合)、まとめて読込むコンテンツ片が、図8に示すように同一のファイルサーバ(2010srv)内に保管されている場合には、コンテンツ片1,2,3をまとめて読込むに際して、同一のファイルサーバ(2010srv)にてコンテンツ片1及びコンテンツ片3の読込み処理が輻輳するため、対象ファイルサーバ(2010srv)においてデータ入出力負荷が高騰し、コンテンツ配信サーバに対する応答速度等の読込み性能が低下するという問題があった。
本発明は上記実情に鑑みて提案されたもので、コンテンツ片が格納される複数のファイルサーバを備えた分散ファイルシステムにおいて、コンテンツ片をユーザ端末へ配信するコンテンツ配信サーバが、配信前に複数のコンテンツ片をまとめて読込むに際して、特定のファイルサーバに負荷を集中させることなく読込みが可能なコンテンツ分散保管システムを提供することを目的としている。
上記目的を達成するため本発明(請求項1)は、コンテンツを断片化して複数のコンテンツ片を生成するコンテンツ生成サーバと、前記各コンテンツ片を格納するため物理的に分散した複数のファイルサーバを含んで構成される分散ファイルシステムと、ユーザ端末からの配信要求に応じて前記各ファイルサーバから各コンテンツ片をN個まとめて読込み前記ユーザ端末への配信を行うコンテンツ配信サーバとを備えたシステムにおいて、次の構成を含むことを特徴としている。
前記分散ファイルシステムは、前記複数のファイルサーバから各コンテンツ片の書込み先となるN個以上のファイルサーバを決定する分散ファイルシステムクライアントを有している。
前記分散ファイルシステムクライアントは、前記各コンテンツ片が時系列順に分散するように書込み先のファイルサーバを決定する書込み先決定部を備える。
前記分散ファイルシステムは、前記複数のファイルサーバから各コンテンツ片の書込み先となるN個以上のファイルサーバを決定する分散ファイルシステムクライアントを有している。
前記分散ファイルシステムクライアントは、前記各コンテンツ片が時系列順に分散するように書込み先のファイルサーバを決定する書込み先決定部を備える。
請求項2は、請求項1のコンテンツ分散保管システムにおいて、前記分散ファイルシステムは、CPU利用率やディスク空き容量などのリソース情報が所定の閾値以上あるファイルサーバのリストを作成するためのメタデータサーバを有し、前記書込み先決定部は、前記メタデータサーバから取得した前記リストに基づいて複数のファイルサーバの中からコンテンツ片の書込み先のファイルサーバを選択することを特徴としている。
請求項3は、請求項2のコンテンツ分散保管システムにおいて、前記リストは、ファイルサーバを一意に識別可能な値の順に並べて作成されることを特徴としている。
請求項4は、請求項3のコンテンツ分散保管システムにおいて、前記リストにおけるファイルサーバを一意に識別可能な値の順は、各ファイルサーバのホスト名順又はIPアドレス順又はMACアドレス順であることを特徴としている。
請求項5は、請求項2のコンテンツ分散保管システムにおいて、前記リストは、ファイルサーバを運用者が指定した任意の順に並べて作成されることを特徴としている。
請求項6は、請求項1または請求項2のコンテンツ分散保管システムにおいて、前記コンテンツ配信サーバからの同時読込み数とファイルサーバでの書込み総数との乗数以上の台数のファイルサーバを設置した環境で、前記リストにおいて、コンテンツ片を保管したファイルサーバの順位に同時読込み数を加えた順位のファイルサーバにコンテンツ片の複製を保管することを特徴としている。
本発明によれば、分散ファイルシステムクライアントは、書込み先決定部により各コンテンツ片が時系列順に分散するように書込み先のファイルサーバを決定するので、コンテンツ配信サーバがユーザ端末からの配信要求に応じて各ファイルサーバから各コンテンツ片をN個まとめて読み込む場合、読み込まれる各コンテンツ片は、N個以上のファイルサーバに時系列順に分散するように格納されているので、読込み先のファイルサーバが重複することなく、特定のファイルサーバに負荷を集中させることなく読み込みを行うことができる。
また、書込み先決定部は、CPU利用率やディスク空き容量などのリソース情報が所定の閾値以上あるファイルサーバのリストに基づいて複数のファイルサーバの中からコンテンツ片の書込み先を決定するので、選択されたファイルサーバにコンテンツ片を確実に格納させることができる。
本発明のコンテンツ分散保管システムの実施形態の一例について、図面を参照しながら説明する。図1は、コンテンツ分散保管システムの全体構成図である。
コンテンツ分散保管システムは、コンテンツ生成サーバ10と、分散ファイルシステム20と、コンテンツ配信サーバ30と、ユーザ端末40とを備え、それぞれネットワークを介して接続して構成されている。
コンテンツ分散保管システムは、コンテンツ生成サーバ10と、分散ファイルシステム20と、コンテンツ配信サーバ30と、ユーザ端末40とを備え、それぞれネットワークを介して接続して構成されている。
コンテンツ生成サーバ10は、コンテンツを提供する外部ストレージ11に接続され、運用者に指定される時間単位に外部ストレージ11から提供されたコンテンツを断片化して複数のコンテンツ片15を生成し、このコンテンツ片15を分散ファイルシステム20内に分割書込みする処理が行われる。
分散ファイルシステム20は、コンテンツ片15の書込み及び読込みを行う分散ファイルシステムクライアント21と、各コンテンツ片が時系列的に格納される複数のファイルサーバ22と、各コンテンツ片の格納先情報(メタ情報)を記録するメタデータサーバ23を備えている。分散ファイルシステムクライアント21は、コンテンツ片15の書込みを行う場合、各コンテンツ片の格納先となるファイルサーバ22を選択する。
メタデータサーバ23は、各コンテンツ片がどのファイルサーバ22に格納されたかのメタ情報を記録する。
メタデータサーバ23は、各コンテンツ片がどのファイルサーバ22に格納されたかのメタ情報を記録する。
ファイルサーバ22は、各コンテンツ片15を時系列的に格納するため物理的に分散して配置されている。
コンテンツ配信サーバ30は、ユーザ端末40からの配信要求に応じて各ファイルサーバ22から各コンテンツ片をN個ずつまとめて読込み、ネットワークを介してユーザ端末40へ順次配信を行う。そして、前記したファイルサーバ22は、N個の各コンテンツ片15を時系列的に物理的に分散して格納するため、少なくとも書込み先として選択可能なファイルサーバ22がN個以上存在する個数を備えている。
コンテンツ配信サーバ30は、ユーザ端末40からの配信要求に応じて各ファイルサーバ22から各コンテンツ片をN個ずつまとめて読込み、ネットワークを介してユーザ端末40へ順次配信を行う。そして、前記したファイルサーバ22は、N個の各コンテンツ片15を時系列的に物理的に分散して格納するため、少なくとも書込み先として選択可能なファイルサーバ22がN個以上存在する個数を備えている。
次に、コンテンツ分散保管システムでのコンテンツ片の書込み及び配信処理について、図2及び図3を参照しながら説明する。
先ず、コンテンツ片の書込みを行う場合について説明する。
コンテンツ生成サーバ10は、運用者に指定される時間単位に提供されたコンテンツを断片化して複数のコンテンツ片15を生成し、各コンテンツ片15を分散ファイルシステム20内に分割書込みする処理が行われる(図3におけるA)。
先ず、コンテンツ片の書込みを行う場合について説明する。
コンテンツ生成サーバ10は、運用者に指定される時間単位に提供されたコンテンツを断片化して複数のコンテンツ片15を生成し、各コンテンツ片15を分散ファイルシステム20内に分割書込みする処理が行われる(図3におけるA)。
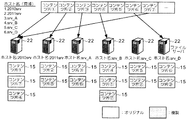
分散ファイルシステム20内では、分散ファイルシステムクライアント21が、コンテンツ生成サーバ10からのコンテンツ片15の書込み要求を受け、コンテンツ生成サーバ10から時系列順に順次渡されるコンテンツ片15を書き込むファイルサーバ22を選択する。ファイルサーバ22の選択は、メタデータサーバ23に対して書込み先のリスト問い合わせを行い、CPU利用率やディスク空き容量などのリソース情報に余裕がある複数のファイルサーバ22を抽出(応答)し、例えば各ファイルサーバ22のホスト名順(図2に示す例の場合、ホスト名が2010srv,srv_A,srv_B,workhostの順)に並べたリストを作成し、リストにおける各ファイルサーバ22の昇順に書込み先を決定しコンテンツ片15が書き込まれる。
分散ファイルシステムクライアント21において、リストに抽出される複数のファイルサーバ22は、リソース情報が予め設定された閾値より大きいものが選択される。なお、N個のコンテンツ片15を物理的に別々のファイルサーバ22に分散させて保管するためには、リストに抽出される複数のファイルサーバ22(リソース情報に余裕があるもの)がN個以上必要である。
これにより、一つのコンテンツの一連のファイルセットの中で、時系列的に近いN個のコンテンツ片15は、物理的に別々のファイルサーバ22に分散して保管される。従って、これらのコンテンツ片15を読込むコンテンツ配信サーバ30にとっては、読込むファイルが物理的に分散して保管されているため、ファイルサーバ22の負荷を分散しつつ各々を並列に読み込むことができ、高速にメモリ上にデータをロードして配信を開始することができる。
尚、図2の例では、各ファイルサーバ22のホスト名順(昇順)にコンテンツ片の書込み先を決定するようにしたが、ホスト名順(降順)、IPアドレス順、各サーバのMACアドレス順など、ファイルサーバ22を一意に識別可能な値の順、あるいは運用者が設定ファイルに指定した任意の順で書込み先を決定してもよい。
次に、コンテンツの配信を行う場合について説明する。
コンテンツ配信サーバ30がユーザ端末40から所望コンテンツの配信要求を受けた場合、コンテンツ配信サーバ30は、分散ファイルシステム20に対して所望コンテンツを構成するN個のコンテンツ片15の内の第1コンテンツ片の読込み命令を発する(図3におけるB)。
コンテンツ片の読込み命令を受けた分散ファイルシステムクライアント21は、メタデータサーバ23に対して読込み先の問い合わせを行い、メタデータサーバ23からの応答から該当するファイルサーバ22に対して読込み要求を行い、読込み要求を受けたファイルサーバ22が分散ファイルシステムクライアント21に第1コンテンツ片15のデータを送付(応答)し、これを受けた分散ファイルシステムクライアント21がコンテンツ配信サーバ30に対して読込応答を行う。
コンテンツ配信サーバ30がユーザ端末40から所望コンテンツの配信要求を受けた場合、コンテンツ配信サーバ30は、分散ファイルシステム20に対して所望コンテンツを構成するN個のコンテンツ片15の内の第1コンテンツ片の読込み命令を発する(図3におけるB)。
コンテンツ片の読込み命令を受けた分散ファイルシステムクライアント21は、メタデータサーバ23に対して読込み先の問い合わせを行い、メタデータサーバ23からの応答から該当するファイルサーバ22に対して読込み要求を行い、読込み要求を受けたファイルサーバ22が分散ファイルシステムクライアント21に第1コンテンツ片15のデータを送付(応答)し、これを受けた分散ファイルシステムクライアント21がコンテンツ配信サーバ30に対して読込応答を行う。
同様の処理が順次行われることで、分散ファイルシステムクライアント21は、コンテンツ配信サーバ30に対して第2コンテンツ片〜第Nコンテンツ片を読込み(各ファイルサーバ22から各コンテンツ片をN個まとめて読込み)、ユーザ端末40への第1〜第Nコンテンツ片を順次配信する。
そして、第1〜第Nコンテンツ片の配信時において、コンテンツ配信サーバ30は、分散ファイルシステム20に対して、第(N+1)コンテンツ片の読込み命令を発し、この命令に基づいて分散ファイルシステム20からコンテンツ配信サーバ30へ読込応答が順次行われる。
そして、第1〜第Nコンテンツ片の配信時において、コンテンツ配信サーバ30は、分散ファイルシステム20に対して、第(N+1)コンテンツ片の読込み命令を発し、この命令に基づいて分散ファイルシステム20からコンテンツ配信サーバ30へ読込応答が順次行われる。
次に、分散ファイルシステムクライアント21の構成について、図4を参照しながら説明する。分散ファイルシステムクライアント21は、ユーザアクセス制御部51、書込み先決定部52、書込み先情報収集部53、ファイルシステムアクセス部54の各モジュールを備えて構成されている。
ユーザアクセス制御部51は、外部アプリケーション(コンテンツ生成サーバ)から、コンテンツ片の書込み要求を順次受信し、書込み先決定部52に要求を伝える。また、書込み結果を外部アプリケーションに応答する。
書込み先決定部52は、書込み対象として選択可能なファイルサーバリストの中から、ファイルサーバ22のホスト名順、IPアドレス順、各サーバのMACアドレス順など、ファイルサーバ22を一意に識別可能な値の順で書込み先を決定する(従って、前回書込み対象としたファイルサーバ22を記憶しておき、その次のファイルサーバ22を選択する)。決定した書込み先ファイルサーバ22をファイルシステムアクセス部54に伝える。
書込み先決定部52は、書込み対象として選択可能なファイルサーバリストの中から、ファイルサーバ22のホスト名順、IPアドレス順、各サーバのMACアドレス順など、ファイルサーバ22を一意に識別可能な値の順で書込み先を決定する(従って、前回書込み対象としたファイルサーバ22を記憶しておき、その次のファイルサーバ22を選択する)。決定した書込み先ファイルサーバ22をファイルシステムアクセス部54に伝える。
書込み先情報収集部53は、メタデータサーバ23がファイルサーバ22から定期的に収集した各ファイルサーバ22のディスク空き容量、CPU使用率などのリソース情報を基に作成した書込み可能なファイルサーバ22のファイルサーバリストを取得し、書込み先決定部52に渡す。
ファイルシステムアクセス部54は、書込み先決定部52から渡される書込み先ファイルサーバ情報に従い、対象となるファイルサーバ22に書込みデータを転送し、応答を受け取る。
ファイルシステムアクセス部54は、書込み先決定部52から渡される書込み先ファイルサーバ情報に従い、対象となるファイルサーバ22に書込みデータを転送し、応答を受け取る。
続いて、分散ファイルシステムクライアント21の書込み先決定部52における処理手順について、図5のフローチャートを参照しながら説明する。
先ず、書込み先決定部52は、ユーザアクセス制御部51からの書込み要求を受け付ける(ステップ61)。
次に、ユーザアクセス制御部51から受け取った書込み要求から、ファイル名、ファイルオープンオプション(どのようなモードでファイルを開くか)、ファイル作成時のアクセスモード(書込み許可、読込み許可、書き込みと読み出し許可いずれか)の要求パラメータを抽出する(ステップ62)。
書込み先決定部52は、作成されたファイルサーバリストをメタデータサーバ23から取得する(ステップ63)。
次に、ユーザアクセス制御部51から受け取った書込み要求から、ファイル名、ファイルオープンオプション(どのようなモードでファイルを開くか)、ファイル作成時のアクセスモード(書込み許可、読込み許可、書き込みと読み出し許可いずれか)の要求パラメータを抽出する(ステップ62)。
書込み先決定部52は、作成されたファイルサーバリストをメタデータサーバ23から取得する(ステップ63)。
ファイルサーバリストの取得が成功した場合は(ステップ64)、前回書込み先の有無をチェックする(ステップ65)。前回書込み先の有無は、書込み先決定部52のメモリ上に保管しておいた前回書込み先ファイルサーバが、メタデータサーバ23から受け取ったファイルサーバリスト中に存在しているかのチェックを行う。
前回書込み先ファイルサーバが有る場合(ステップ66)、今回の書込み先(前回書込み先に対してリスト順において+1を加えた書込み先)となる次のホスト名を選定する(ステップ67)。
前回書込み先ファイルサーバが有る場合(ステップ66)、今回の書込み先(前回書込み先に対してリスト順において+1を加えた書込み先)となる次のホスト名を選定する(ステップ67)。
選定された書込み先のファイルサーバに対して書込み要求を発行する(ステップ68)。
書込み先のファイルサーバからファイル書込み応答を受信する(ステップ69)。
書込み先をメモリに記録する(ステップ70)。
書込み先のファイルサーバからファイル書込み応答を受信する(ステップ69)。
書込み先をメモリに記録する(ステップ70)。
前回書込み先ファイルサーバが無い場合(ステップ66)、書込み1回目であるかを判断し(ステップ71)、1回目である場合はファイルサーバリストの先頭のホストに決定する(ステップ72)。1回目の書込みであるので、ホスト名でソートしたファイルサーバリストの先頭を選定する。
前回書込み先がない場合で書込みが1回目でない場合(ステップ71)とは、前回書込み先となったファイルサーバを削除した場合や、前回書込み先のファイルサーバが故障している場合を想定している。この場合には、前回書込み先に近いファイルサーバを検索する(ステップ73)。
すなわち、ファイルサーバリストの中から辞書順に、前回書込み先ホスト名の次のファイルサーバ名を今回の書込み先に決定する。書込み先の決定後は、ファイル書込み要求の発行(ステップ68)、ファイル書込み応答の受信(ステップ69)、書込み先の記録(ステップ70)が順次行われる。
すなわち、ファイルサーバリストの中から辞書順に、前回書込み先ホスト名の次のファイルサーバ名を今回の書込み先に決定する。書込み先の決定後は、ファイル書込み要求の発行(ステップ68)、ファイル書込み応答の受信(ステップ69)、書込み先の記録(ステップ70)が順次行われる。
図6は、コンテンツ分散保管システムでのコンテンツ片の書込み及び配信処理の他の実施形態を示すもので、図2と同一の構成をとる部分については同一の符号を付している。
この例のコンテンツ分散保管システムでは、図1と同様に、コンテンツ生成サーバ、コンテンツ配信サーバ、分散ファイルシステム(分散ファイルシステムクライアント、メタデータサーバ、複数のファイルサーバ)が稼働されている。また、コンテンツ配信サーバからの同時読込み数は「3」とする。
この例のコンテンツ分散保管システムでは、図1と同様に、コンテンツ生成サーバ、コンテンツ配信サーバ、分散ファイルシステム(分散ファイルシステムクライアント、メタデータサーバ、複数のファイルサーバ)が稼働されている。また、コンテンツ配信サーバからの同時読込み数は「3」とする。
そして、コンテンツ生成サーバからのコンテンツ片書込み要求を受けた分散ファイルシステムクライアントは、図2の例と同様に、コンテンツ生成サーバから時系列順に順次渡されるコンテンツ片を書き込むファイルサーバを、各ファイルサーバのCPU利用率やディスク空き容量などのリソース情報に余裕があること(ある程度の閾値より上のものの中から)に加え、各ファイルサーバを一意に識別可能な値の順に選択する。
本例のコンテンツ分散保管システムの分散ファイルシステム内においては、最初にファイルサーバに書き込まれたコンテンツ片(オリジナル)の複製を別のファルサーバに作成する機能を有している。すなわち、コンテンツ配信サーバからの同時読込み数(例えば「3」)と複製数(例えば、オリジナルを含む複製数が「2」)との乗数(この場合、6台)以上の台数のファイルサーバを設置した環境で、コンテンツ片15(オリジナル)を保管したファイルサーバの順位(ソートした中での順位)に同時読込み数(図6の例では「3」)を加えた順位のファイルサーバに複製を保管する。図6の例によれば、ファイルサーバ(2010srv)に保管された第1コンテンツ片15(オリジナル)の複製は、昇順では3番後(順位4)のファイルサーバ(srv_B)に複製として書き込まれる。
このアルゴリズムにより、コンテンツ配信サーバ30が時系列的に隣接した3つのコンテンツ片15を同時に読込む際、オリジナルあるいは複製いずれの読込みを行っても、読込み先ファイルサーバが重複することは無い。
また、一旦コンテンツ片15が書き込まれたファイルサーバ22に障害が発生した場合は、運用者が代替機を用意することにより、分散ファイルシステム20内のメタデータサーバ23が保持するコンテンツ片15のメタ情報から、用意された代替機にコンテンツ片を再配置すれば、障害に対処することができる。
上述した各実施形態によれば、コンテンツ配信サーバ30が各コンテンツ片15をN個まとめて読込みに際して、時系列的に近いN個のコンテンツ片15は物理的に別々のファイルサーバ22に保管されているため、コンテンツ片15を順次読込む処理において、複数のコンテンツ片が一つのファイルサーバに格納される状態を防止し、ファイルサーバへの負荷を集中させることなく並列に読み込みことができるので、低負荷でシームレスな配信を行うことが可能となる。
10…コンテンツ生成サーバ、 11…外部ストレージ、 15…コンテンツ片 20…分散ファイルシステム、 21…分散ファイルシステムクライアント、 22…ファイルサーバ、 23…メタデータサーバ、 30…コンテンツ配信サーバ、 40…ユーザ端末。
Claims (6)
- コンテンツを断片化して複数のコンテンツ片を生成するコンテンツ生成サーバと、前記各コンテンツ片を格納するため物理的に分散した複数のファイルサーバを含んで構成される分散ファイルシステムと、ユーザ端末からの配信要求に応じて前記各ファイルサーバから各コンテンツ片をN個まとめて読込み前記ユーザ端末への配信を行うコンテンツ配信サーバとを備えたシステムにおいて、
前記分散ファイルシステムは、前記複数のファイルサーバから各コンテンツ片の書込み先となるN個以上のファイルサーバを決定する分散ファイルシステムクライアントを有し、
前記分散ファイルシステムクライアントは、前記各コンテンツ片が時系列順に分散するように書込み先のファイルサーバを決定する書込み先決定部を備える
ことを特徴とするコンテンツ分散保管システム。 - 前記分散ファイルシステムは、CPU利用率やディスク空き容量などのリソース情報が所定の閾値以上あるファイルサーバのリストを作成するためのメタデータサーバを有し、
前記書込み先決定部は、前記メタデータサーバから取得した前記リストに基づいて複数のファイルサーバの中からコンテンツ片の書込み先のファイルサーバを選択する
請求項1に記載のコンテンツ分散保管システム。 - 前記リストは、ファイルサーバを一意に識別可能な値の順に並べて作成される請求項2に記載のコンテンツ分散保管システム。
- 前記リストにおけるファイルサーバを一意に識別可能な値の順は、各ファイルサーバのホスト名順又はIPアドレス順又はMACアドレス順である請求項3に記載のコンテンツ分散保管システム。
- 前記リストは、ファイルサーバを運用者が指定した任意の順に並べて作成される請求項2に記載のコンテンツ分散保管システム。
- 前記コンテンツ配信サーバからの同時読込み数とファイルサーバでの書込み総数(オリジナルを含めた複製数)との乗数以上の台数のファイルサーバを設置した環境で、前記リストにおいて、コンテンツ片を保管したファイルサーバの順位に同時読込み数を加えた順位のファイルサーバにコンテンツ片の複製を保管する請求項1または請求項2に記載のコンテンツ分散保管システム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011055016A JP2012190377A (ja) | 2011-03-14 | 2011-03-14 | コンテンツ分散保管システム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2011055016A JP2012190377A (ja) | 2011-03-14 | 2011-03-14 | コンテンツ分散保管システム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2012190377A true JP2012190377A (ja) | 2012-10-04 |
Family
ID=47083428
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2011055016A Withdrawn JP2012190377A (ja) | 2011-03-14 | 2011-03-14 | コンテンツ分散保管システム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2012190377A (ja) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014164473A (ja) * | 2013-02-25 | 2014-09-08 | Nippon Telegr & Teleph Corp <Ntt> | ブートイメージ配信システム及びブートイメージ配信方法 |
| JP2014174597A (ja) * | 2013-03-06 | 2014-09-22 | Kddi Corp | インメモリ型分散データベース、データ分散方法及びプログラム |
| JP2014175004A (ja) * | 2013-03-12 | 2014-09-22 | Hon Hai Precision Industry Co Ltd | 記憶スペース拡張システム及びその方法 |
| JP2016162193A (ja) * | 2015-03-02 | 2016-09-05 | 富士通株式会社 | ストレージ装置、読出記憶装置決定方法、読出記憶装置決定プログラム、およびストレージシステム |
-
2011
- 2011-03-14 JP JP2011055016A patent/JP2012190377A/ja not_active Withdrawn
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2014164473A (ja) * | 2013-02-25 | 2014-09-08 | Nippon Telegr & Teleph Corp <Ntt> | ブートイメージ配信システム及びブートイメージ配信方法 |
| JP2014174597A (ja) * | 2013-03-06 | 2014-09-22 | Kddi Corp | インメモリ型分散データベース、データ分散方法及びプログラム |
| JP2014175004A (ja) * | 2013-03-12 | 2014-09-22 | Hon Hai Precision Industry Co Ltd | 記憶スペース拡張システム及びその方法 |
| JP2016162193A (ja) * | 2015-03-02 | 2016-09-05 | 富士通株式会社 | ストレージ装置、読出記憶装置決定方法、読出記憶装置決定プログラム、およびストレージシステム |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10776396B2 (en) | Computer implemented method for dynamic sharding | |
| US9342529B2 (en) | Directory-level referral method for parallel NFS with multiple metadata servers | |
| US9614912B2 (en) | System and method of implementing an object storage infrastructure for cloud-based services | |
| US8793373B2 (en) | Network system and method for operating the same | |
| US20130018855A1 (en) | Data deduplication | |
| Noghabi et al. | Ambry: Linkedin's scalable geo-distributed object store | |
| JP2010079549A (ja) | 管理装置及び計算機システム | |
| EP2393009A1 (en) | Storage system | |
| US20150201016A1 (en) | Methods and system for incorporating a direct attached storage to a network attached storage | |
| CN111782134A (zh) | 数据处理方法、装置、系统和计算机可读存储介质 | |
| US8683121B2 (en) | Storage system | |
| JP2012190377A (ja) | コンテンツ分散保管システム | |
| KR101531564B1 (ko) | 네트워크 분산 파일 시스템 기반 iSCSI 스토리지 시스템에서의 부하 분산 방법 및 시스템 | |
| US20120324182A1 (en) | Storage device | |
| JP2009193271A (ja) | ストレージシステム | |
| US10083121B2 (en) | Storage system and storage method | |
| KR101589122B1 (ko) | 네트워크 분산 파일 시스템 기반 iSCSI 스토리지 시스템에서의 장애 복구 방법 및 시스템 | |
| JP6260088B2 (ja) | 仮想ファイルアクセスシステム、仮想ファイルアクセス方法、及び、仮想ファイルアクセスプログラム | |
| KR101470857B1 (ko) | iSCSI 스토리지 시스템을 이용한 네트워크 분산 파일 시스템 및 방법 | |
| KR20160050745A (ko) | 실시간 또는 일괄 처리 기반의 데이터 처리방법 및 장치 | |
| Meng et al. | A Network Load Sensitive Block Placement Strategy of HDFS. | |
| US10275300B2 (en) | Systems and methods for prioritizing a support bundle | |
| JP2015088109A (ja) | ストレージシステム、ストレージ制御方法、およびストレージ制御プログラム | |
| JP6330824B2 (ja) | ストレージシステム、アクセス装置、クライアント装置、方法およびプログラム | |
| WO2010116539A1 (en) | File detection device and method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A300 | Application deemed to be withdrawn because no request for examination was validly filed |
Free format text: JAPANESE INTERMEDIATE CODE: A300 Effective date: 20140603 |