JP2017102247A - 音声対話システム、音声対話制御法およびプログラム - Google Patents
音声対話システム、音声対話制御法およびプログラム Download PDFInfo
- Publication number
- JP2017102247A JP2017102247A JP2015234835A JP2015234835A JP2017102247A JP 2017102247 A JP2017102247 A JP 2017102247A JP 2015234835 A JP2015234835 A JP 2015234835A JP 2015234835 A JP2015234835 A JP 2015234835A JP 2017102247 A JP2017102247 A JP 2017102247A
- Authority
- JP
- Japan
- Prior art keywords
- voice
- sequence
- gram
- feature
- utterance
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images



Landscapes
- Machine Translation (AREA)
Abstract
【課題】談話行為識別精度の向上を図る。【解決手段】音声入力部P1と、声道特徴系列を計算する声道特徴抽出部P2と、エネルギー系列を計算するエネルギー抽出部P3と、基本周波数系列を計算する基本周波数抽出部P4と、声道特徴系列とエネルギー系列に基づいてタイムスタンプ付きの単語列を出力する音声認識部P5と、タイムスタンプ付きの単語列とタイムスタンプ付きの前記エネルギー系列と前記基本周波数系列から韻律特徴が付加された拡張単語N−gramを生成する言語・韻律特徴合成部P6と、拡張単語N−gramと該発話のコンテキスト情報から談話行為タグを推定する意図推定部P7と、談話行為タグが表す発話意図と対話文脈を考慮してシステム発話を生成する対話制御部P8と、該生成されたシステム発話を音声信号に変換する音声合成部P9と、該変換された音声信号を音声出力装置で再生する音声出力部P10とからなる。【選択図】図1
Description
本発明は、音声対話を利用してユーザと情報のやりとりを行う、音声対話システム、音声対話制御手法、プログラムに関する。
従来、機器やシステムのインタフェースとして、ユーザが日常的に用いているコミュニケーション手段である音声対話を用いたインタフェースが利用されてきた。
音声対話インタフェースにおいては、ユーザの発話からユーザの意図を抽出し適切な応答を生成する対話制御技術が必要になる。
音声対話インタフェースにおいては、ユーザの発話からユーザの意図を抽出し適切な応答を生成する対話制御技術が必要になる。
ユーザの意図の中でも、対話文脈における発話の機能、例えば、相手の発言に対して、肯定しているのか、否定しているのか、あるいは疑問を発しているか等を判定する問題は、談話行為識別と呼ばれている。
例えば、非特許文献1では、発話意図を表す談話行為タグを予測するための確率モデルを、発話に談話行為タグが付与された音声対話データから、統計的に機械学習させ、学習されたモデルを用いて、音声対話中の発話に談話行為タグを付与する技術が開示されている。
例えば、非特許文献1では、発話意図を表す談話行為タグを予測するための確率モデルを、発話に談話行為タグが付与された音声対話データから、統計的に機械学習させ、学習されたモデルを用いて、音声対話中の発話に談話行為タグを付与する技術が開示されている。
ところで、これまでの発話意図推定技術においては、音声に含まれる言語特徴が意図を推定するための重要な手がかりとして用いられてきた。
また、表情や韻律(音声のリズム、抑揚、速度、強勢など)等の非言語特徴も、発話者の意図を反映することが良く知られている。
また、表情や韻律(音声のリズム、抑揚、速度、強勢など)等の非言語特徴も、発話者の意図を反映することが良く知られている。
例えば、特許文献1では、表情と韻律を用いたユーザの感情の推定技術が開示されている他、特許文献2では、システムの間違いをユーザが指摘した箇所を同定する技術が開示されている。
また、非特許文献1および非特許文献2では、韻律に関する発話の統計量を言語情報に付加して、談話行為識別精度を向上させる技術が開示されている。
また、非特許文献1および非特許文献2では、韻律に関する発話の統計量を言語情報に付加して、談話行為識別精度を向上させる技術が開示されている。
さらに、特許文献3および非特許文献3においては、ピッチの変化等、韻律特徴の軌跡を離散符号化した系列を言語特徴とともに利用して談話行為識別精度を向上させる技術が開示されている。
いずれも、言語特徴に付加する形で、言語特徴とは独立な、発話文の音響的な特徴として韻律特徴が用いられている。
いずれも、言語特徴に付加する形で、言語特徴とは独立な、発話文の音響的な特徴として韻律特徴が用いられている。
A. Stolcke et al. : "Dialogue act modeling for automatic tagging and recognition of conversational speech", Computational Linguistics, Vol.26, No.3, pp.339-373, 2000.
E. Shriberg et al. : "Can prosody aid the automatic classification of dialog acts in conversational speech?", Language and speech, Vol.41, No.3-4, pp.443-492,1998.
V.K.R. Sridhar et al. : "Combining lexical, syntactic and prosodic cues for improved online dialog act tagging", Computer Speech and Language, Vol.23, No.4, pp.407-422, 2009.
A. Black et al. : "Predicting the intonation of discourse segments from examples in dialogue speech. ", Computing Prosody, pp.117-128, 1997.
K.Sadohara et al. : "Sub-lexical dialogue act classification in a spoken dialogue system support for the elderly with cognitive disabilities". In Proceedings of the Workshop on Speech and Language Processing for Assistive Technologies. pp.93-98, 2013.
鹿野清宏他:"音声認識システム",オーム社,2001.
河原達也,荒木雅弘:"音声対話システム",オーム社,2006.
P.Taylor: "The tilt intonation model",In Proceedings of the International Conference on Spoken Language Processing, Vol.4,pp.1383-1386,1998.
S.Ananthakrishnan: "Categorical prosody models for spoken language applications",PhD Thesis,University of Southern California,2008.
しかしながら、談話行為識別精度の向上のために用いられる、韻律特徴の従来の利用法は以下の理由で十分ではない。
まず、韻律特徴を発話文の特徴として抽出するためには、ユーザの一連の発話の中から、各発話文を正しく抜き出す必要がある。
しかし、文法や話し方のスタイルに制約のない自由発話においては、そもそも文の境界は不明瞭になりがちであり、しかも音声認識の間違いを含んだ発話を文の単位に正しく分節することは一般に難しい。
まず、韻律特徴を発話文の特徴として抽出するためには、ユーザの一連の発話の中から、各発話文を正しく抜き出す必要がある。
しかし、文法や話し方のスタイルに制約のない自由発話においては、そもそも文の境界は不明瞭になりがちであり、しかも音声認識の間違いを含んだ発話を文の単位に正しく分節することは一般に難しい。
例えば、「もう一回言ってくれない」は文の最後にかけてピッチを上げながら話せば依頼を意味するが、十分な長さの無音区間を置かずに直後に「もう一回」と念を押した場合、この発話のピッチは文末にかけて上昇するとは限らない。
もしも、両者を別個の文として分離できない場合は、依頼の発話であっても文末のピッチ上昇は観測できなくなってしまう。
もしも、両者を別個の文として分離できない場合は、依頼の発話であっても文末のピッチ上昇は観測できなくなってしまう。
また、談話行為識別において、ある種の談話行為タグは、特定のフレーズに特定の韻律の変化を伴うことがしばしば観察される。
例えば、システムの発話をもう一度聞きたいという意図に対応する「言い直し要求」では、「言ってくれる?」、「言ってください?」のような特定のフレーズと同時にピッチの上昇が観察される場合が多い。
その場合、特徴の共起関係をより確実な識別の手がかりとすることで、より頑健かつ高精度な識別が期待できる。
例えば、システムの発話をもう一度聞きたいという意図に対応する「言い直し要求」では、「言ってくれる?」、「言ってください?」のような特定のフレーズと同時にピッチの上昇が観察される場合が多い。
その場合、特徴の共起関係をより確実な識別の手がかりとすることで、より頑健かつ高精度な識別が期待できる。
ところが、韻律特徴を言語特徴とは独立に発話の特徴としてモデル化する従来の技術では、言語特徴と韻律特徴の共起関係を捉えることができない。
このような問題点に鑑み、本発明は、言語特徴と韻律特徴の相関を直接モデル化し、もって談話行為識別精度の向上を図る技術を提案する。
このような問題点に鑑み、本発明は、言語特徴と韻律特徴の相関を直接モデル化し、もって談話行為識別精度の向上を図る技術を提案する。
まず、入力されたユーザの音声から、音声認識に用いられる声道特徴量系列を抽出すると同時に、エネルギーや基本周波数など韻律に関する特徴量の時系列を抽出する。
次に、得られた音声認識結果と韻律特徴時系列から、談話行為識別に用いる特徴系列を合成する。
この合成特徴は、音声認識によって得られた単語N−gramに対して、その時区間に対応する離散的な韻律特徴を付与して得られる拡張単語N−gramとなっている。
こうして得られた拡張単語N−gramを入力として、言語特徴を利用した談話行為識別技術を適用し、識別モデルの学習やタグの予測を行う。
このように、言語特徴と韻律特徴を合成した特徴を用いることで、両者の相関を考慮した談話行為識別が可能になるだけでなく、韻律特徴が、発話文ではなく、単語N−gramに付与されていることで、発話文の正確な分節が得られない場合でも、韻律特徴を効果的に用いた談話行為識別が可能になる。
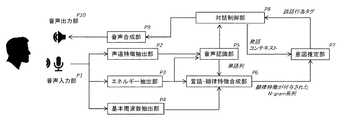
次に、図1を参照して、本発明の音声対話装置の全体構成例を説明する。
音声入力部(P1)において、発話はマイクロホン等を用いてアナログ信号として取得された後、ただちにデジタル信号に変換される。
声道特徴抽出部(P2)において、音声認識において用いられる、Mel Frequency Cepstral Coefficient(MFCC)等の声道特徴量が計算される。
また、エネルギー抽出部(P3)において、フレーム毎のエネルギーが計算され、声道特徴系列と併せてエネルギー特徴系列が音声認識部(P5)に送られ、音声認識が行われ単語列に変換される。
この時、各単語の発話における時区間を表すタイムスタンプを同時に計算しておく。
また、ここで音声認識部の出力を単語列としているが、正確には当該音声認識システム(P5)の使用する辞書に登録されている認識ユニットの列を意味しており、言語学的単語の列に限定されるものではない。
日本語のように単語に分かち書きされない言語の場合には、形態素解析のエラー等により、認識結果が正しく単語に分かち書きされない場合もあり、そのような場合には、音素やモーラのようなサブワードを認識ユニットとして用いて、サブワードユニットのN−gramを使って談話行為識別を行った方が良い場合もある。
また、識別に特徴的なフレーズ(単語列)がある場合は、フレーズを認識ユニットとして用いた方が良い場合もある。
本明細書では、典型的な認識ユニットである単語を用いて説明を行うが、認識ユニットは言語学的単語に限定されるわけではなく、単語N−gramは、認識ユニットのN−gramと読み替えることができる。
この時、各単語の発話における時区間を表すタイムスタンプを同時に計算しておく。
また、ここで音声認識部の出力を単語列としているが、正確には当該音声認識システム(P5)の使用する辞書に登録されている認識ユニットの列を意味しており、言語学的単語の列に限定されるものではない。
日本語のように単語に分かち書きされない言語の場合には、形態素解析のエラー等により、認識結果が正しく単語に分かち書きされない場合もあり、そのような場合には、音素やモーラのようなサブワードを認識ユニットとして用いて、サブワードユニットのN−gramを使って談話行為識別を行った方が良い場合もある。
また、識別に特徴的なフレーズ(単語列)がある場合は、フレーズを認識ユニットとして用いた方が良い場合もある。
本明細書では、典型的な認識ユニットである単語を用いて説明を行うが、認識ユニットは言語学的単語に限定されるわけではなく、単語N−gramは、認識ユニットのN−gramと読み替えることができる。
声道特徴やエネルギーと並行して、基本周波数抽出部(P4)では、フレーム毎に基本周波数が計算される。
次に、音声認識部(P5)で計算されたタイムスタンプ付きの単語列、およびタイムスタンプが付与されたエネルギー系列と基本周波数系列が言語・韻律特徴合成部(P6)に送られ、韻律特徴が付加された拡張単語N−gramが生成される。
この拡張単語N−gramと、対話制御部(P8)が提供する発話のコンテキスト情報から、意図推定部(P7)において、発話の談話行為タグが推定される。
引き続いて、対話制御部(P8)では、談話行為タグが表す発話意図と対話文脈を考慮して、システム発話が生成され、引き続く音声合成部(P9)で音声信号に変換された後、スピーカー等の音声出力部(P10)を通して音声が再生される。
ここで、音声入力部(P1)、声道特徴抽出部(P2)、エネルギー抽出部(P3)、基本周波数抽出部(P4)、音声認識部(P5)、対話制御部(P8)、音声合成部(P9)、音声出力部(P10)には公知の技術を用いることができる(非特許文献6、非特許文献7)。
以下では、言語・韻律特徴合成部(P6)および意図推定部(P7)についてのみ詳細に説明する。
本発明の1つの実施形態で用いられる、談話行為識別のための基本的な原理は、談話行為タグを表す確率変数Iの事後確率の最大化である。

音響信号Aが、声道成分Asと韻律成分Apに分離できると仮定すると、Aの尤度は以下のように書ける。
声道成分と韻律成分が条件付き独立であると仮定すると、
さらに、声道成分は、単語列のみに依存すると仮定すると、
非特許文献1では、ここからさらに、韻律成分は単語列に依存しないと仮定し、
非特許文献2および非特許文献3においても、モデル化手法は異なるが、基本的に、韻律成分が単語列に依存せず、発話意図のみに依存するとしてモデル化を行っている。
本発明では、このような仮定(非特許文献1乃至非特許文献3)を置かず、数式(4)を、
本発明では、このような仮定(非特許文献1乃至非特許文献3)を置かず、数式(4)を、
そのために、離散化された韻律特徴が付与された拡張単語列Wfを導入し、
離散化された韻律特徴fとしては、例えば、Wに対応するフレーム列において、基本周波数の変化量が平均+標準偏差よりも大きい場合は+を、変化量が平均−標準偏差よりも小さい場合は−を、あるいは変化量が平均±標準偏差の範囲内であれば0を付与する3値の離散化を用いることができる。
あるいは、強勢であれば、エネルギーが平均+標準偏差よりも大きい場合はs+を、平均−標準偏差よりも小さい場合はs−を、あるいは平均±標準偏差の範囲内であればs0を付与する3値に離散化を用いることができる。
例えば、「もう1回言って」という単語列に、強勢とピッチの上昇が観察されれば、「もう1回言って+,s+」と単語列が拡張されることになる。
もちろん、離散化のやり方は、これ以外の方法を考えることもでき、離散化の粒度も3値に限るものではない。
もちろん、離散化のやり方は、これ以外の方法を考えることもでき、離散化の粒度も3値に限るものではない。
このような韻律特徴の離散化は、非特許文献8記載の、tilt特徴と基本的な考え方は同じであり、このような特徴を非特許文献4では音声合成に、非特許文献9では音声認識に用いているが、本発明では談話行為識別に用いる。
また、非特許文献3では、韻律特徴量の軌跡を離散符号化し、符号のN−gramを談話行為識別に利用しているが、単語列との相関は考慮されていない。
ところで、このような韻律特徴の離散化の際には、話者間の変動や発話環境の変動に対処するため、話者毎また発話環境毎に特徴量の正規化を行うことが望ましい。
例えば、同一話者の直近複数の発話を用いて、平均値や標準偏差を計算することができる。
例えば、同一話者の直近複数の発話を用いて、平均値や標準偏差を計算することができる。
以上述べたような離散化を適用することで、言語・韻律特徴合成部(P6)において、音声認識により得られた単語列W=w1,…,wnは離散韻律特徴が付与されたN−gram列に拡張される。
その過程をより詳細に述べる。まず、WからN−gram(N≧1)を抽出する。
例えば、N=2であれば、
例えば、N=2であれば、
ここで、<s>,</s>はそれぞれ文頭、文末を表す記号である。
このとき、単語の一種として、短い無音区間を表すwi=<sp>を含めれば、別種の韻律特徴を拡張N−gramの中に取り込むことができる。
次に、各単語に付与されたタイムスタンプに基づいて、各N−gram毎に、対応する時区間におけるエネルギー系列と基本周波数系列の部分区間を抽出し韻律特徴を計算する。
その際、欠損値があれば線形補完等で補い、当該時区間の平均や変化量等の統計量を計算し、前述の正規化を施した後に離散化し各N−gramに付与される。
その際、欠損値があれば線形補完等で補い、当該時区間の平均や変化量等の統計量を計算し、前述の正規化を施した後に離散化し各N−gramに付与される。
次に、意図推定部(P7)を説明する。
音声信号Aが所与のとき、数式1を最大化する談話行為タグIを計算する。
音声信号Aが所与のとき、数式1を最大化する談話行為タグIを計算する。
事前確率P(I)は、訓練データから予め計算した値を利用することができる。
このとき、発話のコンテキストを用いることでタグの識別精度が向上することが広く知られている。
例えば、非特許文献5では、直前のシステム発話の談話行為タグCが所与であることを利用して、P(I)の代わりにP(I|C)を用いることでタグの識別精度を向上させている。
このとき、発話のコンテキストを用いることでタグの識別精度が向上することが広く知られている。
例えば、非特許文献5では、直前のシステム発話の談話行為タグCが所与であることを利用して、P(I)の代わりにP(I|C)を用いることでタグの識別精度を向上させている。
数式1の尤度P(A|I)の計算には数式7を用いる。
数式7においてP(As|W)は、音声認識で用いている音響モデルから計算される音響尤度を用いることができる。
つまり、音声認識部から出力される尤度上位n個の単語列を正しい認識の候補と考える場合、各候補Wi(1≦i≦n)の音響尤度P(As|Wi)を重みとするP(Wi f|I)の重みづけ和としてP(A|I)が計算される。
数式7においてP(As|W)は、音声認識で用いている音響モデルから計算される音響尤度を用いることができる。
つまり、音声認識部から出力される尤度上位n個の単語列を正しい認識の候補と考える場合、各候補Wi(1≦i≦n)の音響尤度P(As|Wi)を重みとするP(Wi f|I)の重みづけ和としてP(A|I)が計算される。
この重みづけ和を計算する際、一般に音響尤度は非常に小さな値になるので、桁落ちを防ぐために、非特許文献5では、音響尤度を尤度の最大値Mで正規化して用いており、本発明でも有効な計算方法である。
尤度P(Wf|I)は、N−gramでモデル化される。つまり、Wに含まれるN−gram、W1,…,Wmに対して離散韻律特徴を付与した、拡張N−gram列Wf 1,…,Wf mが条件付き独立であると仮定し、
ここで用いる、拡張N−gramの尤度P(Wf i|I)は、予め訓練データから推定しておく。
ただし、離散韻律特徴で拡張されているので、訓練データが十分に多くない場合は、必ずしも拡張N−gram Wi fが訓練データに含まれない場合が想定される。
そのような場合は、以下のような平滑化を行うことが望ましい。
そのような場合は、以下のような平滑化を行うことが望ましい。
特に、j=0は、離散韻律特徴が付与されていないN−gramの生起確率であり、これ自身、ゼロ頻度問題に対処するために、Good−Turing法など公知の方法(非特許文献6)を用いて平滑化されているものとする。
図2は、基本周波数(F0)の変化量を韻律特徴として用いた場合の、本発明による談話行為タグ識別率の向上を示している。
図2で「F0なし」として示されているのは、言語特徴のみを用いて識別した場合の識別精度を示している。
また、「F0変化(発話単位)」として示されているものは、一つの発話における基本周波数の勾配を3値に離散化した韻律特徴を、言語特徴とは独立に用いた場合の識別精度を示している。「F0変化(2gram)」として示されているのは、単語2−gram毎に、3値の離散韻律特徴を付与した拡張2−gram特徴を用いた場合の識別精度を示している。
また、「F0変化(発話単位)」として示されているものは、一つの発話における基本周波数の勾配を3値に離散化した韻律特徴を、言語特徴とは独立に用いた場合の識別精度を示している。「F0変化(2gram)」として示されているのは、単語2−gram毎に、3値の離散韻律特徴を付与した拡張2−gram特徴を用いた場合の識別精度を示している。
この結果から分かるように、韻律特徴を言語特徴と独立に付与しても、必ずしも識別精度は向上しない一方で、言語特徴と韻律特徴の相関を考慮する本発明によれば、識別率がおよそ1%向上していることが分かる。
図3と図4は、韻律特徴が寄与すると予想される「情報要求」と「言い直し要求」の2つの談話行為タグの適合率、すなわち、それぞれのタグを予測した発話の中で、正しい予測の割合を示している。
タグ個別にみると、「情報要求」でおよそ5%、「言い直し要求」で2%適合率が向上していることが分かる。
タグ個別にみると、「情報要求」でおよそ5%、「言い直し要求」で2%適合率が向上していることが分かる。
本発明のシステムは、マイクロホンとスピーカーとパーソナルコンピュータを用い、図1に示した各処理部を実行するプログラムをCおよびPerl言語で作成し、実行して確認した。
作成したプログラムは、上で述べたように、汎用計算機を用いた汎用的なプログラムであってもよいし、各種音声対話システム・装置・機器にのみ適合する固有のプログラムであってもよい。
また、プログラムは、内蔵式、埋め込み式(Imbedded)、読み込み式、ダウンロード方式、分散型、あるいはクラウドコンピューティングであってもよい。
作成したプログラムは、上で述べたように、汎用計算機を用いた汎用的なプログラムであってもよいし、各種音声対話システム・装置・機器にのみ適合する固有のプログラムであってもよい。
また、プログラムは、内蔵式、埋め込み式(Imbedded)、読み込み式、ダウンロード方式、分散型、あるいはクラウドコンピューティングであってもよい。
音声入力に使用したマイクロホンは、機器の一部として備わるマイクロホンであってもよいし、その設置場所は近接地・遠隔地を問わず、音声入力装置であれば足りる。
音声出力に使用したスピーカーは、機器の一部として備わるスピーカーや、イヤホンであってもよいし、その設置場所は近接地・遠隔地を問わず、音声出力装置であれば足りる。
音声入力信号はアナログ音響信号だけでなく、本発明の内部処理に適してデジタル化された音響信号のいずれであってもよい。
音声出力に使用したスピーカーは、機器の一部として備わるスピーカーや、イヤホンであってもよいし、その設置場所は近接地・遠隔地を問わず、音声出力装置であれば足りる。
音声入力信号はアナログ音響信号だけでなく、本発明の内部処理に適してデジタル化された音響信号のいずれであってもよい。
Claims (7)
- 人との音声対話インタフェースを含む音声対話システムであって、
音声入力装置からの音声入力を処理して音響信号に変換する音声入力部(P1)と、
その音響信号を処理して声道特徴系列を計算する声道特徴抽出部(P2)と、
その音響信号を処理してエネルギー系列を計算するエネルギー抽出部(P3)と、
その音響信号を処理して基本周波数系列を計算する基本周波数抽出部(P4)と、
該計算された声道特徴系列とエネルギー系列に基づいてタイムスタンプ付きの単語列を出力する音声認識部(P5)と、
該出力されたタイムスタンプ付きの単語列とタイムスタンプ付きの前記エネルギー系列と前記基本周波数系列から韻律特徴が付加された拡張単語N−gramを生成する言語・韻律特徴合成部(P6)と、
該生成された拡張単語N−gramと該発話のコンテキスト情報から該発話の談話行為タグを推定する意図推定部(P7)と、
前記該発話のコンテキスト情報を提供し該推定された談話行為タグが表す発話意図と対話文脈を考慮してシステム発話を生成する対話制御部(P8)と、
該生成されたシステム発話を音声信号に変換する音声合成部(P9)と、
該変換された音声信号を音声出力装置で再生する音声出力部(P10)とからなることを特徴とする音声対話システム。 - 言語・韻律特徴合成部(P6)において、前記拡張単語N−gramに付加された韻律特徴は離散化された韻律特徴であることを特徴とする請求項1に記載する音声対話システム。
- 意図推定部(P7)において、前記該発話の談話行為タグを推定は、次の談話行為タグを表す確率変数Iの事後確率の最大化により行うことを特徴とする請求項2に記載の音声対話システム。
ただし、Aは音響信号、ASはその声道成分、Wは単語列、Wfは前記離散化された韻律特徴が付与された拡張単語列とする。
- 言語・韻律特徴合成部(P6)において、前記離散化を、Wに対応するフレーム列において、当該基本周波数の変化量が平均+標準偏差よりも大きい場合は+を、変化量が平均−標準偏差よりも小さい場合は−を、変化量が平均±標準偏差の範囲内であれば0を付与する3値の離散化であることを特徴とする請求項3に記載の音声対話システム。
- 意図推定部(P7)において、前記尤度P(Wf|I)は、次式により計算されることを特徴とする請求項4に記載の音声対話システム。
ただしWi fはWに含まれるN−gram、W1,…,Wmに前記離散韻律特徴を付与した、拡張N−gram列Wf 1,…,Wf mの1つとする。
- 意図推定部(P7)において、前記尤度P(Wi f|I)は、次式により計算されることを特徴とする請求項5に記載の音声対話システム。
ただし、jは自然数、j>0の場合は、基本周波数の勾配、強勢等、fで用いられている離散韻律特徴が付与されたN−gramを表し、特に、j=0の場合は、韻律特徴を用いないN−gramを表す。
- 人との音声対話インタフェースを含む音声対話プログラムであって、請求項1乃至請求項5のいずれか1項に記載される音声対話システムの各処理を実行することを特徴とする音声対話プログラム、および当該プログラムを記憶したプログラム媒体。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015234835A JP2017102247A (ja) | 2015-12-01 | 2015-12-01 | 音声対話システム、音声対話制御法およびプログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2015234835A JP2017102247A (ja) | 2015-12-01 | 2015-12-01 | 音声対話システム、音声対話制御法およびプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2017102247A true JP2017102247A (ja) | 2017-06-08 |
Family
ID=59015339
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015234835A Pending JP2017102247A (ja) | 2015-12-01 | 2015-12-01 | 音声対話システム、音声対話制御法およびプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2017102247A (ja) |
Cited By (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107704447A (zh) * | 2017-08-23 | 2018-02-16 | 海信集团有限公司 | 一种中文分词方法、中文分词装置和终端 |
| JP2020067585A (ja) * | 2018-10-25 | 2020-04-30 | トヨタ自動車株式会社 | コミュニケーション装置およびコミュニケーション装置の制御プログラム |
| CN111210822A (zh) * | 2020-02-12 | 2020-05-29 | 支付宝(杭州)信息技术有限公司 | 语音识别方法及其装置 |
| CN111261189A (zh) * | 2020-04-02 | 2020-06-09 | 中国科学院上海微系统与信息技术研究所 | 一种车辆声音信号特征提取方法 |
| US10971149B2 (en) | 2018-05-11 | 2021-04-06 | Toyota Jidosha Kabushiki Kaisha | Voice interaction system for interaction with a user by voice, voice interaction method, and program |
| CN114171004A (zh) * | 2021-11-15 | 2022-03-11 | 科大讯飞股份有限公司 | 语音交互方法、装置、电子设备及存储介质 |
| WO2025020877A1 (zh) * | 2023-07-26 | 2025-01-30 | 阿里巴巴(中国)有限公司 | 语音数据的处理方法、电子设备和存储介质 |
-
2015
- 2015-12-01 JP JP2015234835A patent/JP2017102247A/ja active Pending
Cited By (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN107704447A (zh) * | 2017-08-23 | 2018-02-16 | 海信集团有限公司 | 一种中文分词方法、中文分词装置和终端 |
| US10971149B2 (en) | 2018-05-11 | 2021-04-06 | Toyota Jidosha Kabushiki Kaisha | Voice interaction system for interaction with a user by voice, voice interaction method, and program |
| JP2020067585A (ja) * | 2018-10-25 | 2020-04-30 | トヨタ自動車株式会社 | コミュニケーション装置およびコミュニケーション装置の制御プログラム |
| CN111192577A (zh) * | 2018-10-25 | 2020-05-22 | 丰田自动车株式会社 | 交流装置及交流装置的控制程序 |
| US11222638B2 (en) | 2018-10-25 | 2022-01-11 | Toyota Jidosha Kabushiki Kaisha | Communication device and control program for communication device |
| JP7063230B2 (ja) | 2018-10-25 | 2022-05-09 | トヨタ自動車株式会社 | コミュニケーション装置およびコミュニケーション装置の制御プログラム |
| CN111192577B (zh) * | 2018-10-25 | 2023-10-13 | 丰田自动车株式会社 | 交流装置及交流装置的控制程序 |
| CN111210822A (zh) * | 2020-02-12 | 2020-05-29 | 支付宝(杭州)信息技术有限公司 | 语音识别方法及其装置 |
| CN111261189A (zh) * | 2020-04-02 | 2020-06-09 | 中国科学院上海微系统与信息技术研究所 | 一种车辆声音信号特征提取方法 |
| CN111261189B (zh) * | 2020-04-02 | 2023-01-31 | 中国科学院上海微系统与信息技术研究所 | 一种车辆声音信号特征提取方法 |
| CN114171004A (zh) * | 2021-11-15 | 2022-03-11 | 科大讯飞股份有限公司 | 语音交互方法、装置、电子设备及存储介质 |
| WO2025020877A1 (zh) * | 2023-07-26 | 2025-01-30 | 阿里巴巴(中国)有限公司 | 语音数据的处理方法、电子设备和存储介质 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US10176809B1 (en) | Customized compression and decompression of audio data | |
| EP3114679B1 (en) | Predicting pronunciation in speech recognition | |
| JP6052814B2 (ja) | 音声認識モデルの構築方法、音声認識方法、コンピュータ・システム、音声認識装置、プログラムおよび記録媒体 | |
| JP2017102247A (ja) | 音声対話システム、音声対話制御法およびプログラム | |
| US20180137109A1 (en) | Methodology for automatic multilingual speech recognition | |
| CN106935239A (zh) | 一种发音词典的构建方法及装置 | |
| JPWO2009078256A1 (ja) | 発音変動規則抽出装置、発音変動規則抽出方法、および発音変動規則抽出用プログラム | |
| KR101153078B1 (ko) | 음성 분류 및 음성 인식을 위한 은닉 조건부 랜덤 필드모델 | |
| JP7295839B2 (ja) | 音節に基づく自動音声認識 | |
| JP2013205842A (ja) | プロミネンスを使用した音声対話システム | |
| CN111243599A (zh) | 语音识别模型构建方法、装置、介质及电子设备 | |
| JP2019012095A (ja) | 音素認識辞書生成装置および音素認識装置ならびにそれらのプログラム | |
| CN110853669B (zh) | 音频识别方法、装置及设备 | |
| JP6712754B2 (ja) | 談話機能推定装置及びそのためのコンピュータプログラム | |
| Fadel et al. | Which French speech recognition system for assistant robots? | |
| US20040006469A1 (en) | Apparatus and method for updating lexicon | |
| CN116052655A (zh) | 音频处理方法、装置、电子设备和可读存储介质 | |
| EP3718107B1 (en) | Speech signal processing and evaluation | |
| Nga et al. | A Survey of Vietnamese Automatic Speech Recognition | |
| JP7814276B2 (ja) | 音声認識装置、音声認識方法、およびプログラム | |
| Rudzionis et al. | Web services based hybrid recognizer of Lithuanian voice commands | |
| Aboelela et al. | A review of speech recognition and application to arabic speech recognition | |
| Mansikkaniemi | Acoustic model and language model adaptation for a mobile dictation service | |
| Akther et al. | Automated speech-to-text conversion systems in Bangla language: A systematic literature review | |
| Wottawa et al. | Towards interactive annotation for hesitation in conversational speech |