JP2017107228A - 歌声合成装置および歌声合成方法 - Google Patents
歌声合成装置および歌声合成方法 Download PDFInfo
- Publication number
- JP2017107228A JP2017107228A JP2017028630A JP2017028630A JP2017107228A JP 2017107228 A JP2017107228 A JP 2017107228A JP 2017028630 A JP2017028630 A JP 2017028630A JP 2017028630 A JP2017028630 A JP 2017028630A JP 2017107228 A JP2017107228 A JP 2017107228A
- Authority
- JP
- Japan
- Prior art keywords
- singing
- acoustic
- singing voice
- styles
- voice
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images









Landscapes
- Electrophonic Musical Instruments (AREA)
Abstract
Description
(A)状態継続長モデル:歌声の中に含まれる各音素の長さは、歌唱スタイルなどによって変動することから、音声の時間的な構造(どれだけその音素が継続するか)をより精度良くモデル化するために、明示的な状態継続長分布を用いている。こうした状態継続長モデルを付加したHMMを、隠れセミマルコフモデルと呼ぶ。
(B)コンテキスト依存モデル:基本周波数や継続長は、歌詞に含まれる言語的な情報の影響を受けやすい。このため、歌詞の言語情報と、更に楽譜から得られる音高、テンポ、調性、拍子などのコンテキストを考慮してモデル化している。
(C)多空間確率分布HMM:歌声を含む音声には無声区間があって、そこでは基本周波数の時系列データそのものが存在しない。本実施形態では、こうした特殊な時系列を扱うために、多空間確率分布HMM(MSD−HMM)を用いる。
(1)タイミング:実際の歌声は、楽譜から計算される音符の時間軸上の位置から意図せずもしくは意図的にずれることがある。例えば、子音はその音符の開始タイミングより少し前で発声されることが多い。また「前ノリ」「後ノリ」「タメ」など、発声のタイミングを意図的にずらす歌唱表現が存在する。このため、楽譜から計算される絶対的な時間を基準とした実際の発声との時間的なズレを、音素単位でモデル化している。
(2)ビブラート:ビブラートは、音高および音量の少なくとも一方を周期的に揺らす歌唱表現である。歌声においてビブラートがかかるタイミングやその周期、振幅の変化は、歌唱スタイル毎に異なるため、歌唱スタイル毎の音響モデルの学習に用いられる。ビブラートは、更にその周期と振幅の2つのパラメータとして扱われ、音響モデルに組み込まれる。
(3)その他の歌唱表現:上記のビブラート以外にも様々な歌唱表現が存在する。例えば、「こぶし」「しゃくり上げ」「しゃくり下げ」「アタック・リリース」などがある。こうした歌唱表現は、周期と振幅のパラメータや、基本周波数の音素途中で変動量として扱うことができ、音響モデルに組み込まれる。
本明細書では、上述した各モデルを含めて、HMM(隠れマルコフモデル)と称する。
20…音声入力部
30…サーバ
31…ハードディスク
33…楽譜解析部
40…学習部
41…F0抽出部
43…SP抽出部
44…歌唱P抽出部
45…HMM学習部
50…音響モデル記憶部
51…キーボード
52…ポインティングデバイス
53…表示部
55…パラメータ調整部
57…楽譜解析部
60…音声合成部
61…音声パラメータ生成部
63…音源生成部
65…合成フィルタ
100…歌声処理装置
Claims (19)
- 歌声を合成する歌声合成装置であって、
複数の歌唱スタイルの歌声の少なくとも1つについて、複数の歌唱スタイルの歌声の少なくとも1つについて、前記歌声の少なくとも歌唱表現が反映されるパラメータを含む音響パラメータを学習して得られた音響モデルを当該歌唱スタイルについてのベースモデルとして記憶する記憶部と、
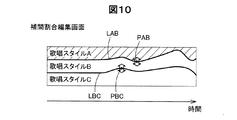
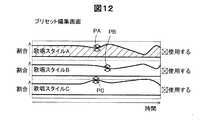
前記複数の歌唱スタイルの中から選択された少なくとも2つの歌唱スタイルに含まれる前記歌唱表現の組合せの程度を調整するインタフェース部と、
歌唱スタイルに含まれる歌唱表現を再現可能な音響パラメータの集まりの中から、前記記憶されたベースモデルを用いて得られた音響パラメータの集まりを少なくとも一つを含む、少なくとも2つの音響パラメータの集まりを選択し、前記選択された少なくとも2つの前記歌唱表現に影響する音響パラメータを、前記インタフェース部により調整された組合せの程度で補間して、合成用音響パラメータを決定するパラメータ決定部と、
前記合成用音響パラメータを用いて歌声を合成する合成部と
を備えた歌声合成装置。 - 前記音響パラメータの集まりには、少なくとも基本周波数、音量、歌唱表現に対応したパラメータのうちの少なくとも一つを含む請求項1記載の歌声合成装置。
- 前記音響パラメータの集まりには、更にスペクトルパラメータを含む請求項2記載の歌声合成装置。
- 前記選択される少なくとも2つの音響パラメータの集まりは、いずれも前記記憶されたベースモデルを用いて得られた音響パラメータの集まりである請求項1から請求項3のいずれか一項に記載の歌声合成装置。
- 前記選択される少なくとも2つの音響パラメータの集まりのうちの一つは、ルールベースの手法で生成された音響パラメータの集まりである請求項1から請求項3のいずれか一項に記載の歌声合成装置。
- 歌声を合成する歌声合成装置であって、
複数の歌唱スタイルの歌声のそれぞれに含まれる少なくとも歌唱表現が反映されるパラメータを含む音響パラメータを統計的な手法を用いて学習して得られた音響モデルを、前記歌唱スタイル毎のベースモデルとして記憶した記憶部と、
前記複数の歌唱スタイルの中から選択された少なくとも2つの歌唱スタイルに含まれる前記歌唱表現の組合せの程度を調整するインタフェース部と、
前記記憶部に記憶された前記複数のベースモデルから、前記複数の歌唱スタイルのうちから選択された少なくとも2つの歌唱スタイルに対応したベースモデルに基づき、前記インタフェース部により調整された組合せの程度で前記歌唱表現を補間した合成用音響パラメータを抽出する補間抽出部と
前記合成用音響パラメータを用いて歌声を合成する合成部と
を備えた歌声合成装置。 - 前記歌唱表現が反映されるパラメータには、少なくともビブラート、しゃくり、アタック・リリース、こぶしのうちの1つに対応したパラメータが含まれる請求項1から請求項6のいずれか一項に記載の歌声合成装置。
- 前記歌唱表現が反映されるパラメータには、少なくとも発声開始タイミング、発声終了タイミングのいずれか1つに対応したパラメータが含まれる請求項1から請求項6のいずれか一項に記載の歌声合成装置。
- 請求項1から請求項5のいずれか一項に記載の歌声合成装置であって、
前記歌唱表現の組合せの程度の調整は、前記各音響パラメータの値を補間することにより行なわれる歌声合成装置。 - 前記補間は、前記音響パラメータを線形結合または非線形結合することにより行なわれる請求項9記載の歌声合成装置。
- 前記補間は、音符単位、音素単位、音節単位、フレーズ単位、曲単位、所定の時間単位のいずれか1つにより行なう請求項9または請求項10に記載の歌声合成装置。
- 請求項6に記載の歌声合成装置であって、
前記歌唱表現の組合せの程度の調整は、前記ベースモデルの内部パラメータを補間することにより行なわれる歌声合成装置。 - 前記補間は、前記前記ベースモデルの内部パラメータを線形結合または非線形結合することにより行なわれる請求項12記載の歌声合成装置。
- 前記補間は、ベースモデルの状態単位で行なう請求項12また請求項13に記載の歌声合成装置。
- 前記補間は、内挿補間または外挿補間である請求項9から請求項14のいずれか一項に記載の歌声合成装置。
- 前記記憶されたベースモデルの1つは、予め用意された標準的な音響パラメータからなるベースモデルである請求項1から請求項15のいずれか一項に記載の歌声合成装置。
- 請求項1から請求項16のいずれか一項に記載の歌声合成装置であって、
更に、画像表示装置とポインティングデバイスとを備え、
前記インタフェース部は、
前記画像表示装置上に描画されるグラフィカルユーザインタフェースであり、
前記グラフィカルユーザインタフェースとして前記画像表示装置上に描画された画面を前記ポインティングデバイスにより操作することにより、前記組合せの程度が変更される
歌声合成装置。 - 歌声を合成する歌声合成方法であって、
複数の歌唱スタイルの歌声の少なくとも1つについて、複数の歌唱スタイルの歌声の少なくとも1つについて、前記歌声の少なくとも歌唱表現が反映されるパラメータを含む音響パラメータを学習して得られた音響モデルを当該歌唱スタイルについてのベースモデルとして記憶し、
前記複数の歌唱スタイルの中から選択された少なくとも2つの歌唱スタイルに含まれる前記歌唱表現の組合せの程度を調整し、
歌唱スタイルに含まれる歌唱表現を再現可能な音響パラメータの集まりの中から、前記記憶されたベースモデルを用いて得られた音響パラメータの集まりを少なくとも一つを含む、少なくとも2つの音響パラメータの集まりを選択し、前記選択された少なくとも2つの前記歌唱表現に影響する音響パラメータを、前記調整された組合せの程度で補間して、合成用音響パラメータを決定し、
前記合成用音響パラメータを用いて歌声を合成する
歌声合成方法。 - 歌声を合成する歌声合成方法であって、
複数の歌唱スタイルの歌声のそれぞれに含まれる少なくとも歌唱表現が反映されるパラメータを含む音響パラメータを統計的な手法を用いて学習して得られた音響モデルを、前記歌唱スタイル毎のベースモデルとして記憶部に記憶し、
前記複数の歌唱スタイルの中から選択された少なくとも2つの歌唱スタイルに含まれる前記歌唱表現の組合せの程度を調整し、
前記記憶部に記憶された前記複数のベースモデルから、前記複数の歌唱スタイルのうちから選択された少なくとも2つの歌唱スタイルに対応したベースモデルに基づき、前記調整された組合せの程度で前記歌唱表現を補間した合成用音響パラメータを抽出し、
前記合成用音響パラメータを用いて歌声を合成する
歌声合成方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017028630A JP2017107228A (ja) | 2017-02-20 | 2017-02-20 | 歌声合成装置および歌声合成方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017028630A JP2017107228A (ja) | 2017-02-20 | 2017-02-20 | 歌声合成装置および歌声合成方法 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015238285 Division | 2015-12-07 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2017107228A true JP2017107228A (ja) | 2017-06-15 |
| JP2017107228A5 JP2017107228A5 (ja) | 2018-12-27 |
Family
ID=59059550
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017028630A Pending JP2017107228A (ja) | 2017-02-20 | 2017-02-20 | 歌声合成装置および歌声合成方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2017107228A (ja) |
Cited By (23)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN109036377A (zh) * | 2018-07-26 | 2018-12-18 | 中国银联股份有限公司 | 一种语音合成方法及装置 |
| EP3462442A1 (en) * | 2017-09-29 | 2019-04-03 | Yamaha Corporation | Singing voice edit assistant method and singing voice edit assistant device |
| CN109817191A (zh) * | 2019-01-04 | 2019-05-28 | 平安科技(深圳)有限公司 | 颤音建模方法、装置、计算机设备及存储介质 |
| WO2019239971A1 (ja) * | 2018-06-15 | 2019-12-19 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| WO2019239972A1 (ja) * | 2018-06-15 | 2019-12-19 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| US20190392798A1 (en) * | 2018-06-21 | 2019-12-26 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| CN110634464A (zh) * | 2018-06-21 | 2019-12-31 | 卡西欧计算机株式会社 | 电子乐器、电子乐器的控制方法以及存储介质 |
| CN110634460A (zh) * | 2018-06-21 | 2019-12-31 | 卡西欧计算机株式会社 | 电子乐器、电子乐器的控制方法以及存储介质 |
| JP2020024456A (ja) * | 2019-10-30 | 2020-02-13 | カシオ計算機株式会社 | 電子楽器、電子楽器の制御方法、及びプログラム |
| JP2020042056A (ja) * | 2018-09-06 | 2020-03-19 | 株式会社テクノスピーチ | 音声合成装置、および音声合成方法 |
| WO2020095950A1 (ja) * | 2018-11-06 | 2020-05-14 | ヤマハ株式会社 | 情報処理方法および情報処理システム |
| WO2020095951A1 (ja) * | 2018-11-06 | 2020-05-14 | ヤマハ株式会社 | 音響処理方法および音響処理システム |
| CN111418006A (zh) * | 2017-11-29 | 2020-07-14 | 雅马哈株式会社 | 声音合成方法、声音合成装置及程序 |
| CN113257222A (zh) * | 2021-04-13 | 2021-08-13 | 腾讯音乐娱乐科技(深圳)有限公司 | 合成歌曲音频的方法、终端及存储介质 |
| CN113421544A (zh) * | 2021-06-30 | 2021-09-21 | 平安科技(深圳)有限公司 | 歌声合成方法、装置、计算机设备及存储介质 |
| WO2021218324A1 (zh) * | 2020-04-27 | 2021-11-04 | 北京字节跳动网络技术有限公司 | 歌曲合成方法、装置、可读介质及电子设备 |
| WO2022054496A1 (ja) * | 2020-09-11 | 2022-03-17 | カシオ計算機株式会社 | 電子楽器、電子楽器の制御方法、及びプログラム |
| US11417312B2 (en) | 2019-03-14 | 2022-08-16 | Casio Computer Co., Ltd. | Keyboard instrument and method performed by computer of keyboard instrument |
| WO2022202415A1 (ja) * | 2021-03-25 | 2022-09-29 | ヤマハ株式会社 | 機械学習モデルを用いた信号処理方法、信号処理装置および音生成方法 |
| JP2022159784A (ja) * | 2021-04-05 | 2022-10-18 | 日野自動車株式会社 | 注意喚起システム |
| WO2022244818A1 (ja) * | 2021-05-18 | 2022-11-24 | ヤマハ株式会社 | 機械学習モデルを用いた音生成方法および音生成装置 |
| CN117238273A (zh) * | 2023-09-28 | 2023-12-15 | 腾讯音乐娱乐科技(深圳)有限公司 | 歌声合成方法、计算机设备和存储介质 |
| US12254854B2 (en) | 2019-05-23 | 2025-03-18 | Casio Computer Co., Ltd. | Electronic musical instrument, control method for electronic musical instrument, and storage medium |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001242882A (ja) * | 2000-02-29 | 2001-09-07 | Toshiba Corp | 音声合成方法及び音声合成装置 |
| JP2006227589A (ja) * | 2005-01-20 | 2006-08-31 | Matsushita Electric Ind Co Ltd | 音声合成装置および音声合成方法 |
| JP2013137520A (ja) * | 2011-11-29 | 2013-07-11 | Yamaha Corp | 音楽データ編集装置 |
| JP2015034920A (ja) * | 2013-08-09 | 2015-02-19 | ヤマハ株式会社 | 音声解析装置 |
| JP2015049253A (ja) * | 2013-08-29 | 2015-03-16 | ヤマハ株式会社 | 音声合成管理装置 |
-
2017
- 2017-02-20 JP JP2017028630A patent/JP2017107228A/ja active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2001242882A (ja) * | 2000-02-29 | 2001-09-07 | Toshiba Corp | 音声合成方法及び音声合成装置 |
| JP2006227589A (ja) * | 2005-01-20 | 2006-08-31 | Matsushita Electric Ind Co Ltd | 音声合成装置および音声合成方法 |
| JP2013137520A (ja) * | 2011-11-29 | 2013-07-11 | Yamaha Corp | 音楽データ編集装置 |
| JP2015034920A (ja) * | 2013-08-09 | 2015-02-19 | ヤマハ株式会社 | 音声解析装置 |
| JP2015049253A (ja) * | 2013-08-29 | 2015-03-16 | ヤマハ株式会社 | 音声合成管理装置 |
Cited By (58)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| EP3462442A1 (en) * | 2017-09-29 | 2019-04-03 | Yamaha Corporation | Singing voice edit assistant method and singing voice edit assistant device |
| JP2019066648A (ja) * | 2017-09-29 | 2019-04-25 | ヤマハ株式会社 | 歌唱音声の編集支援方法、および歌唱音声の編集支援装置 |
| US10497347B2 (en) | 2017-09-29 | 2019-12-03 | Yamaha Corporation | Singing voice edit assistant method and singing voice edit assistant device |
| JP7000782B2 (ja) | 2017-09-29 | 2022-01-19 | ヤマハ株式会社 | 歌唱音声の編集支援方法、および歌唱音声の編集支援装置 |
| CN111418006A (zh) * | 2017-11-29 | 2020-07-14 | 雅马哈株式会社 | 声音合成方法、声音合成装置及程序 |
| CN111418006B (zh) * | 2017-11-29 | 2023-09-12 | 雅马哈株式会社 | 声音合成方法、声音合成装置及记录介质 |
| WO2019239972A1 (ja) * | 2018-06-15 | 2019-12-19 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| US12014723B2 (en) | 2018-06-15 | 2024-06-18 | Yamaha Corporation | Information processing method, information processing device, and program |
| US11437016B2 (en) | 2018-06-15 | 2022-09-06 | Yamaha Corporation | Information processing method, information processing device, and program |
| JP7127682B2 (ja) | 2018-06-15 | 2022-08-30 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| JP7124870B2 (ja) | 2018-06-15 | 2022-08-24 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| WO2019239971A1 (ja) * | 2018-06-15 | 2019-12-19 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| JPWO2019239971A1 (ja) * | 2018-06-15 | 2021-07-08 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| JPWO2019239972A1 (ja) * | 2018-06-15 | 2021-06-17 | ヤマハ株式会社 | 情報処理方法、情報処理装置およびプログラム |
| EP3588484A1 (en) * | 2018-06-21 | 2020-01-01 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| EP3588486A1 (en) * | 2018-06-21 | 2020-01-01 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| US10629179B2 (en) | 2018-06-21 | 2020-04-21 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| US11545121B2 (en) | 2018-06-21 | 2023-01-03 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| US20190392798A1 (en) * | 2018-06-21 | 2019-12-26 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| US11468870B2 (en) | 2018-06-21 | 2022-10-11 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| CN110634464A (zh) * | 2018-06-21 | 2019-12-31 | 卡西欧计算机株式会社 | 电子乐器、电子乐器的控制方法以及存储介质 |
| CN110634461A (zh) * | 2018-06-21 | 2019-12-31 | 卡西欧计算机株式会社 | 电子乐器、电子乐器的控制方法以及存储介质 |
| US10810981B2 (en) | 2018-06-21 | 2020-10-20 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| US10825433B2 (en) | 2018-06-21 | 2020-11-03 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| EP3588485A1 (en) * | 2018-06-21 | 2020-01-01 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| CN110634460A (zh) * | 2018-06-21 | 2019-12-31 | 卡西欧计算机株式会社 | 电子乐器、电子乐器的控制方法以及存储介质 |
| US11854518B2 (en) | 2018-06-21 | 2023-12-26 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method, and storage medium |
| EP3886084A1 (en) * | 2018-06-21 | 2021-09-29 | Casio Computer Co., Ltd. | Electronic musical instrument, electronic musical instrument control method |
| CN109036377A (zh) * | 2018-07-26 | 2018-12-18 | 中国银联股份有限公司 | 一种语音合成方法及装置 |
| JP2020042056A (ja) * | 2018-09-06 | 2020-03-19 | 株式会社テクノスピーチ | 音声合成装置、および音声合成方法 |
| WO2020095951A1 (ja) * | 2018-11-06 | 2020-05-14 | ヤマハ株式会社 | 音響処理方法および音響処理システム |
| WO2020095950A1 (ja) * | 2018-11-06 | 2020-05-14 | ヤマハ株式会社 | 情報処理方法および情報処理システム |
| US11942071B2 (en) | 2018-11-06 | 2024-03-26 | Yamaha Corporation | Information processing method and information processing system for sound synthesis utilizing identification data associated with sound source and performance styles |
| US11842720B2 (en) | 2018-11-06 | 2023-12-12 | Yamaha Corporation | Audio processing method and audio processing system |
| EP3879521A4 (en) * | 2018-11-06 | 2022-08-03 | Yamaha Corporation | ACOUSTIC TREATMENT METHOD AND ACOUSTIC TREATMENT SYSTEM |
| CN113016028A (zh) * | 2018-11-06 | 2021-06-22 | 雅马哈株式会社 | 音响处理方法及音响处理系统 |
| JP2020076843A (ja) * | 2018-11-06 | 2020-05-21 | ヤマハ株式会社 | 情報処理方法および情報処理装置 |
| JP2020076844A (ja) * | 2018-11-06 | 2020-05-21 | ヤマハ株式会社 | 音響処理方法および音響処理装置 |
| CN109817191A (zh) * | 2019-01-04 | 2019-05-28 | 平安科技(深圳)有限公司 | 颤音建模方法、装置、计算机设备及存储介质 |
| CN109817191B (zh) * | 2019-01-04 | 2023-06-06 | 平安科技(深圳)有限公司 | 颤音建模方法、装置、计算机设备及存储介质 |
| US11417312B2 (en) | 2019-03-14 | 2022-08-16 | Casio Computer Co., Ltd. | Keyboard instrument and method performed by computer of keyboard instrument |
| US12254854B2 (en) | 2019-05-23 | 2025-03-18 | Casio Computer Co., Ltd. | Electronic musical instrument, control method for electronic musical instrument, and storage medium |
| JP2020024456A (ja) * | 2019-10-30 | 2020-02-13 | カシオ計算機株式会社 | 電子楽器、電子楽器の制御方法、及びプログラム |
| WO2021218324A1 (zh) * | 2020-04-27 | 2021-11-04 | 北京字节跳动网络技术有限公司 | 歌曲合成方法、装置、可读介质及电子设备 |
| JP7578156B2 (ja) | 2020-09-11 | 2024-11-06 | カシオ計算機株式会社 | 電子楽器、電子楽器の制御方法、及びプログラム |
| JP7276292B2 (ja) | 2020-09-11 | 2023-05-18 | カシオ計算機株式会社 | 電子楽器、電子楽器の制御方法、及びプログラム |
| JP2022047167A (ja) * | 2020-09-11 | 2022-03-24 | カシオ計算機株式会社 | 電子楽器、電子楽器の制御方法、及びプログラム |
| WO2022054496A1 (ja) * | 2020-09-11 | 2022-03-17 | カシオ計算機株式会社 | 電子楽器、電子楽器の制御方法、及びプログラム |
| WO2022202415A1 (ja) * | 2021-03-25 | 2022-09-29 | ヤマハ株式会社 | 機械学習モデルを用いた信号処理方法、信号処理装置および音生成方法 |
| JP2022159784A (ja) * | 2021-04-05 | 2022-10-18 | 日野自動車株式会社 | 注意喚起システム |
| CN113257222A (zh) * | 2021-04-13 | 2021-08-13 | 腾讯音乐娱乐科技(深圳)有限公司 | 合成歌曲音频的方法、终端及存储介质 |
| CN113257222B (zh) * | 2021-04-13 | 2024-06-11 | 腾讯音乐娱乐科技(深圳)有限公司 | 合成歌曲音频的方法、终端及存储介质 |
| JPWO2022244818A1 (ja) * | 2021-05-18 | 2022-11-24 | ||
| JP7578192B2 (ja) | 2021-05-18 | 2024-11-06 | ヤマハ株式会社 | 機械学習モデルを用いた音生成方法および音生成装置 |
| WO2022244818A1 (ja) * | 2021-05-18 | 2022-11-24 | ヤマハ株式会社 | 機械学習モデルを用いた音生成方法および音生成装置 |
| CN113421544B (zh) * | 2021-06-30 | 2024-05-10 | 平安科技(深圳)有限公司 | 歌声合成方法、装置、计算机设备及存储介质 |
| CN113421544A (zh) * | 2021-06-30 | 2021-09-21 | 平安科技(深圳)有限公司 | 歌声合成方法、装置、计算机设备及存储介质 |
| CN117238273A (zh) * | 2023-09-28 | 2023-12-15 | 腾讯音乐娱乐科技(深圳)有限公司 | 歌声合成方法、计算机设备和存储介质 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP2017107228A (ja) | 歌声合成装置および歌声合成方法 | |
| US9818396B2 (en) | Method and device for editing singing voice synthesis data, and method for analyzing singing | |
| US11468870B2 (en) | Electronic musical instrument, electronic musical instrument control method, and storage medium | |
| JP6004358B1 (ja) | 音声合成装置および音声合成方法 | |
| CN101308652B (zh) | 一种个性化歌唱语音的合成方法 | |
| JP5024711B2 (ja) | 歌声合成パラメータデータ推定システム | |
| JP5293460B2 (ja) | 歌唱合成用データベース生成装置、およびピッチカーブ生成装置 | |
| JP5471858B2 (ja) | 歌唱合成用データベース生成装置、およびピッチカーブ生成装置 | |
| JP3823930B2 (ja) | 歌唱合成装置、歌唱合成プログラム | |
| Umbert et al. | Expression control in singing voice synthesis: Features, approaches, evaluation, and challenges | |
| CN109952609B (zh) | 声音合成方法 | |
| JP3838039B2 (ja) | 音声合成装置 | |
| JP2018537727A (ja) | 言語および/またはグラフィカルアイコンベースの音楽体験記述子を採用する自動化音楽作曲および生成機械、システムおよびプロセス | |
| EP3975167A1 (en) | Electronic musical instrument, control method for electronic musical instrument, and storage medium | |
| JP2014170146A (ja) | 日本語歌詞からの多重唱の自動作曲方法及び装置 | |
| Umbert et al. | Generating singing voice expression contours based on unit selection | |
| Angelini et al. | Singing synthesis: With a little help from my attention | |
| JP4839891B2 (ja) | 歌唱合成装置および歌唱合成プログラム | |
| CN115273806A (zh) | 歌曲合成模型的训练方法和装置、歌曲合成方法和装置 | |
| JP6756151B2 (ja) | 歌唱合成データ編集の方法および装置、ならびに歌唱解析方法 | |
| Ardaillon et al. | Expressive control of singing voice synthesis using musical contexts and a parametric f0 model | |
| JP6578544B1 (ja) | 音声処理装置、および音声処理方法 | |
| JP2017097332A (ja) | 音声合成装置および音声合成方法 | |
| JP6587308B1 (ja) | 音声処理装置、および音声処理方法 | |
| Wada et al. | Sequential generation of singing f0 contours from musical note sequences based on wavenet |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20181115 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20181115 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20190227 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20190301 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20190416 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20191015 |