JP2017135613A - 画像処理装置およびコンピュータプログラム - Google Patents
画像処理装置およびコンピュータプログラム Download PDFInfo
- Publication number
- JP2017135613A JP2017135613A JP2016014861A JP2016014861A JP2017135613A JP 2017135613 A JP2017135613 A JP 2017135613A JP 2016014861 A JP2016014861 A JP 2016014861A JP 2016014861 A JP2016014861 A JP 2016014861A JP 2017135613 A JP2017135613 A JP 2017135613A
- Authority
- JP
- Japan
- Prior art keywords
- character
- pixels
- extraction condition
- image
- extraction
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images







Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/14—Image acquisition
- G06V30/148—Segmentation of character regions
- G06V30/153—Segmentation of character regions using recognition of characters or words
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
- G06V30/18—Extraction of features or characteristics of the image
- G06V30/18086—Extraction of features or characteristics of the image by performing operations within image blocks or by using histograms
- G06V30/18095—Summing image-intensity values; Projection and histogram analysis
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/40—Document-oriented image-based pattern recognition
- G06V30/41—Analysis of document content
- G06V30/414—Extracting the geometrical structure, e.g. layout tree; Block segmentation, e.g. bounding boxes for graphics or text
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V30/00—Character recognition; Recognising digital ink; Document-oriented image-based pattern recognition
- G06V30/10—Character recognition
Landscapes
- Engineering & Computer Science (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Multimedia (AREA)
- Theoretical Computer Science (AREA)
- Computer Graphics (AREA)
- Geometry (AREA)
- Artificial Intelligence (AREA)
- Facsimile Image Signal Circuits (AREA)
- Character Input (AREA)
Abstract
【課題】 対象画像内の文字画素を精度良く抽出する。
【解決手段】画像処理装置は、複数個の画素にて構成され、文字を含む対象画像を表す対象画像データを取得する画像取得部と、対象画像内の文字に対応する文字コードを取得するコード取得部と、対象画像内の文字に対応する文字コードを用いて、対象画像内の文字を構成する複数個の文字画素の個数に関する指標値を取得する指標値取得部と、指標値を用いて、第1の抽出条件を決定する決定部と、対象画像内の複数個の画素の中から、第1の抽出条件を満たす複数個の文字画素を抽出する抽出部と、を備える。
【選択図】 図2
Description
本明細書は、文字を含む画像を表す画像データを用いる画像処理に関する。
文字を含む対象画像を表す対象画像データを用いて、文字を構成する文字画素を適切に抽出する技術が求められている。例えば、抽出済みの文字画素を示す二値データは、対象画像データの圧縮、具体的には、いわゆる高圧縮PDFファイルの生成のために、有効に利用することができる(例えば、特許文献1)。この技術では、対象画像において、文字色値と背景色値と文字の鮮鋭度に関する特徴値とを用いて、文字画素を示す二値データが生成される。
しかしながら、上記技術では、文字画素を抽出するために考慮される情報が十分でないために、文字画素を高い精度で抽出できない可能性があった。
本明細書は、対象画像データを用いて対象画像内の文字画素を精度良く抽出することができる新たな技術を開示する。
本明細書に開示された技術は、上述の課題の少なくとも一部を解決するためになされたものであり、以下の適用例として実現することが可能である。
[適用例1]画像処理装置であって、複数個の画素にて構成され、文字を含む対象画像を表す対象画像データを取得する画像取得部と、前記対象画像内の文字に対応する文字コードを取得するコード取得部と、前記対象画像内の文字に対応する前記文字コードを用いて、前記対象画像内の文字を構成する複数個の文字画素の個数に関する指標値を取得する指標値取得部と、前記指標値を用いて、第1の抽出条件を決定する決定部と、前記対象画像内の複数個の画素の中から、前記第1の抽出条件を満たす前記複数個の文字画素を抽出する抽出部と、を備える、画像処理装置。
上記構成によれば、対象画像内の文字に対応する文字コードを用いて、文字を構成する文字画素の個数に関する指標値が取得され、該指標値を用いて、第1の抽出条件が決定されるので、対象画像内の複数個の文字画素を精度良く抽出することができる。
なお、本明細書に開示された技術は、種々の形態で実現可能であり、例えば、上記の画像処理装置、画像読取装置、複合機、これらの制御方法、これらの装置や方法の機能を実現するためのコンピュータプログラム、そのコンピュータプログラムを記録した記録媒体、等の形態で実現することができる。
A.実施例:
A−1.画像処理装置の構成:
次に、本発明の実施の形態を実施例に基づき説明する。図1は、実施例における画像処理装置としての計算機200の構成を示すブロック図である。
A−1.画像処理装置の構成:
次に、本発明の実施の形態を実施例に基づき説明する。図1は、実施例における画像処理装置としての計算機200の構成を示すブロック図である。
計算機200は、例えば、パーソナルコンピュータやスマートフォンなどの端末装置である。計算機200は、計算機200のコントローラとしてのCPU210と、RAMなどの揮発性記憶装置220と、ハードディスクドライブなどの不揮発性記憶装置230と、液晶ディスプレイなどの表示部260と、マウスやキーボードなどの操作部270と、通信部280と、を備えている。計算機200は、通信部280を介して、スキャナ300や複合機400などの外部装置と通信可能に接続される。
揮発性記憶装置220は、CPU210が処理を行う際に生成される種々の中間データを一時的に格納するバッファ領域221を提供する。不揮発性記憶装置230には、アプリケーションプログラムPG1と、スキャナドライバプログラムPG2と、が格納されている。アプリケーションプログラムPG1は、デバイス、例えば、複合機400やスキャナ300の管理や利用のためのアプリケーションを実現するためのコンピュータプログラムであり、例えば、アプリケーションの一部として後述する画像処理を実現する。スキャナドライバプログラムPG2は、複合機400のスキャン機能やスキャナ300を制御するためのスキャナドライバを実現するためのコンピュータプログラムである。これらのコンピュータプログラムPG1、PG2は、例えば、サーバからダウンロードされる形態で提供される。これに代えて、コンピュータプログラムPG1、PG2は、DVD−ROMなどに格納される形態で提供されてもよい。
計算機200は、通信部280を介して、外部のデバイスであるスキャナ300と複合機400と通信可能に接続されている。スキャナ300は、光学的に原稿を読み取ることによってスキャンデータを生成する画像読取装置である。複合機400は、光学的に原稿を読み取ることによってスキャンデータを生成する画像読取部(図示省略)と、所定の方式(例えば、インクジェット、レーザー)によって用紙などの印刷媒体に画像を印刷する印刷実行部(図示省略)と、を備えている。
CPU210は、アプリケーションプログラムPG1を実行することにより、後述する画像処理を実行する。
A−2.画像処理:
図2は、画像処理のフローチャートである。この画像処理は、原稿を光学的に読み取ることによってスキャン画像を示すスキャンデータを生成し、該スキャンデータを用いて、スキャン画像を示す高圧縮PDFファイルを生成する処理である。この画像処理は、保存形式として高圧縮PDFファイルが指定された原稿の読み取り指示が、ユーザから操作部270を介して計算機200に入力された場合に実行される。高圧縮PDFファイルは、文字画像を表す圧縮済の文字画像データと、背景画像を表す圧縮済の背景画像データと、を含み、これらの複数個の画像データによって1個の画像を表すPDF形式の画像ファイルである。
図2は、画像処理のフローチャートである。この画像処理は、原稿を光学的に読み取ることによってスキャン画像を示すスキャンデータを生成し、該スキャンデータを用いて、スキャン画像を示す高圧縮PDFファイルを生成する処理である。この画像処理は、保存形式として高圧縮PDFファイルが指定された原稿の読み取り指示が、ユーザから操作部270を介して計算機200に入力された場合に実行される。高圧縮PDFファイルは、文字画像を表す圧縮済の文字画像データと、背景画像を表す圧縮済の背景画像データと、を含み、これらの複数個の画像データによって1個の画像を表すPDF形式の画像ファイルである。
S10では、CPU210は、対象画像データとしてのスキャンデータを取得する。具体的には、CPU210は、スキャナドライバプログラムPG2を起動して、スキャナドライバとしての機能を実行する。これによって、CPU210は、スキャナ300または複合機400の画像読取部を制御して、ユーザが準備した原稿を光学的に読み取ることによってスキャンデータを取得する。スキャンデータは、複数個の画素にて構成されるビットマップデータ、具体的には、画素ごとの色をRGB値で表すRGB画像データである。1個の画素のRGB値は、赤(R)と緑(G)と青(B)との3個の色成分の階調値(以下、成分値とも呼ぶ)を含んでいる。本実施例では、各成分値の階調数は、256階調である。
なお、変形例では、CPU210は、予め生成されて不揮発性記憶装置230などの記憶装置に格納済みのスキャンデータを、当該記憶装置から取得しても良い。
図3は、画像処理で用いられる画像の一例を示す図である。図3(A)には、スキャンデータによって表されるスキャン画像SI、すなわち、本実施例の対象画像としてのスキャン画像SIの一例が示されている。スキャン画像SIには、図示しない複数の画素が、横方向と縦方向とに沿って、マトリクス状に配置されている。
スキャン画像SIは、背景Bg1と、複数個のオブジェクトOb1〜Ob4と、を含んでいる。オブジェクトOb1、Ob2は、文字である。オブジェクトOb3は、写真であり、オブジェクトOb4は、描画である。描画は、イラスト、表、線図、模様などを表すオブジェクトである。
S15では、CPU210は、スキャン画像SI内の文字Ob1、Ob2に対応する文字情報Tx1、Tx2(図3(A))を取得する。具体的には、CPU210は、スキャンデータに対して、公知のOCR(Optical Character Recognition)技術で利用される文字認識処理を実行することによって、文字情報Tx1、Tx2を生成する。
文字情報Tx1は、対応する文字Ob1を示す文字コードを少なくとも含む。文字コードは、文字や記号をコンピュータで扱うために、文字や記号に割り当てられた識別情報(具体的には、数値)であり、例えば、「Unicode」である。なお、本実施例では、文字情報Tx1は、さらに、文字コード以外の文字に関する情報、例えば、対応する文字Ob1のサイズを示すサイズ情報と、対応する文字Ob1のフォントを示すフォント情報と、を含んでいる。また、文字情報Tx1は、文字Ob1が配置された文字領域TA1のスキャン画像SI内の位置を示す座標情報を含んでいる。この座標情報によって、文字情報Tx1は、スキャン画像SI内の文字Ob1と対応付けられている。文字Ob2(文字領域TA2)に対応する文字情報Tx2についても同様である。
S20では、CPU210は、文字情報Tx1、Tx2を用いて、文字画像(参照画像RIとも呼ぶ)を示す参照画像データを生成する。具体的には、生成される参照画像RIに含まれる文字は、文字情報Tx1、Tx2に含まれる文字コードによって示される文字であり、文字情報Tx1、Tx2に含まれるサイズ情報によって示されるサイズを有する。また、参照画像RIに含まれる文字は、文字情報Tx1、Tx2に含まれるフォント情報によって示されるフォントの文字であり、文字情報Tx1、Tx2に含まれる座標情報によって示される参照画像RI内の位置に配置される。参照画像データは、文字情報Tx1、Tx2をラスタライズすることによって得られるビットマップデータ、と言うこともできる。なお、参照画像データは、文字情報Tx1、Tx2を用いて、スキャンデータを用いずに、生成される。
図3(B)には、参照画像データによって示される参照画像RIの一例が示されている。参照画像RIは、スキャン画像SIと同じサイズの画像、すなわち、スキャン画像SIと同一の横方向および縦方向の画素数分の画素にて構成される画像である。参照画像RIは、スキャン画像SI内の文字Ob1、Ob2に対応する文字画像である。すなわち、参照画像RIは、スキャン画像SI内の文字Ob1に対応する文字情報Tx1を用いて生成される文字To1と、スキャン画像SI内の文字Ob2に対応する文字情報Tx2を用いて生成される文字To2と、背景Bo1と、を含んでいる。参照画像RIは、文字To1、To2を構成する複数個の文字画素と、背景Bo1を構成する複数個の背景画素と、を含む二値画像である。
S25では、CPU210は、スキャンデータを用いて、スキャン画像SI内の文字を含む1個以上の文字領域を特定するための文字領域特定処理を実行する。具体的には、CPU210は、sobelフィルタなどのエッジ検出フィルタをスキャンデータに適用して、エッジ画像EI(図3(C))を表すエッジ画像データを生成する。CPU210は、エッジ画像EI内の、エッジ強度が基準値より大きい領域を特定し、当該領域に対応するスキャン画像SI内の領域をオブジェクト領域として特定する。図3(B)の例では、スキャン画像SIの4つのオブジェクトOb1〜Ob4にそれぞれ対応する4つのオブジェクト領域OA1〜OA4が、エッジ画像EI内に特定されている。エッジ画像EI内に4つのオブジェクト領域OA1〜OA4が特定されることは、スキャン画像SI内に、4つのオブジェクト領域が特定されることに等しい。CPU210は、スキャン画像SI内の各オブジェクト領域の色分布に応じて、各オブジェクト領域が、文字領域であるか否かを判定する。具体的には、CPU210は、オブジェクト領域の輝度のヒストグラムを用いて、当該領域内に含まれる輝度値の種類数C(色数C)を算出する。CPU210は、オブジェクト領域に含まれる複数の画素を、オブジェクト領域の周囲の色(下地の色)に近似する色を有する非オブジェクト画素と、非オブジェクト画素以外のオブジェクト画素とに分類し、背景画素の数に対するオブジェクト画素の比率D(画素密度D)を算出する。文字は、文字以外のオブジェクトと比較して、色数C、および、画素密度Dが小さい傾向がある。CPU210は、例えば、判定対象のオブジェクト領域の色数Cが第1の閾値より小さく、かつ、画素密度Dが第2の閾値より小さい場合に、当該オブジェクト領域は、文字領域であると判定する。
なお、文字領域を特定する手法は、様々な公知の手法を採用することができ、公知の手法は、例えば、特開平5−225378号公報、特開2002−288589号公報に開示されている。
図3(A)の例では、文字Ob1、Ob2にそれぞれ対応する文字領域TA1、TA2が、スキャン画像SI内に特定されている。
S30〜S85では、CPU210は、特定済みの文字領域ごとに、文字を構成する複数個の文字画素を抽出するための一連の処理を実行する。
S30では、CPU210は、スキャン画像SI内に特定済みの複数個の文字領域の中から、処理対象の1個の文字領域を選択する。図3(A)の例では、特定済みの文字領域TA1、TA2の中から、1つの文字領域が1個ずつ選択される。
S35では、CPU210は、処理対象の文字領域内の複数個の文字画素を抽出するための抽出条件を設定する。具体的には、CPU210は、抽出すべき文字画素のRGB値の範囲(以下、抽出範囲とも呼ぶ)を設定する。
図4は、抽出範囲の設定について説明する図である。CPU210は、処理対象の文字領域のRGBの各成分値のヒストグラムを生成する。例えば、文字領域TA1、TA2のうち、S30で選択された処理対象の1個の文字領域のR成分のヒストグラム(図4(A))は、当該文字領域内の各画素を、各画素が有するR成分の値に応じて、複数のクラスに分類することによって生成される。本実施例では、R成分の値が取り得る256階調の階調値のそれぞれを、1個のクラスとして、ヒストグラムが生成される。図4(B)、(C)に示すG、B成分のヒストグラムについても同様である。
各成分のヒストグラムは、背景に対応するピークと、文字に対応するピークと、を含む。背景に対応するピークは、例えば、その成分の最頻値に対応するピーク、すなわち、ヒストグラムにおいて最も高いピークである。文字に対応するピークは、例えば、2番目に高いピークである。図4(A)〜(C)のR、G、Bの各成分のヒストグラムでは、背景に対応するピークは、それぞれ、値Rbg、Gbg、Bbgの位置にあるピークであり、文字に対応するピークは、それぞれ、値Rtx、Gtx、Btxの位置にあるピークである。文字に対応するピークに対応するRGB値(Rtx、Gtx、Btx)は、文字の色を示す文字色値であり、背景に対応するピークに対応するRGB値(Rbg、Gbg、Bbg)は、背景の色を示す背景色値である。
CPU210は、ヒストグラムを用いて、文字色値(Rtx、Gtx、Btx)を特定し、該文字色値(Rtx、Gtx、Btx)に基づいて、抽出範囲を設定する。具体的には、文字色値の各成分の値を中心とする予め定められたデフォルトの幅を有する範囲が、各成分の抽出範囲として設定される。例えば、図4(A)〜(C)の例では、R成分の範囲SRd、G成分の範囲SGd、B成分の範囲SBdが設定される。なお、範囲SRd、SGb、SBdを設定することは、これらの範囲の上限と下限を示す閾値を設定することであるので、文字画素を抽出するための閾値を設定すること、とも言うことができる。
抽出範囲が設定されることによって、抽出範囲に含まれる値を有する画素であることが、文字画素の抽出条件として設定される。より詳しくは、範囲SRd、SGb、SBdが設定されることによって、R成分の範囲SRd内のR成分の値と、G成分の範囲SGd内のG成分の値と、B成分の範囲SBd内のB成分の値と、を含むRGB値を有する画素であることが、文字画素の抽出条件として設定される。なお、S35にて設定される抽出条件をデフォルトの抽出条件とも呼ぶ。
S40では、CPU210は、デフォルトの抽出条件を満たす文字画素を抽出する。具体的には、CPU210は、処理対象の文字領域内の複数個の画素のうち、S35にて設定済みの抽出条件を満たす画素を文字画素に分類し、該抽出条件を満たさない画素を背景画素に分類する二値化処理を実行する。
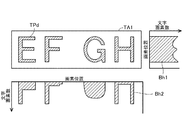
図5は、文字画素の抽出結果の一例を示す図である。図5(A)には、図3(A)の文字領域TA1が処理対象の文字領域である場合に、文字領域TA1内においてデフォルトの抽出条件を用いて抽出される文字画素TPdが示されている。
S42では、CPU210は、処理対象の文字領域内にて抽出済みの文字画素の個数NT1を算出する。
S44では、CPU210は、処理対象の文字領域に対応する参照画像RI内の対応領域を特定する。ここで、文字領域に対応する対応領域は、互いに同じサイズのスキャン画像SIと参照画像RIとを、4辺が互いに重なるように重ねた場合に、スキャン画像SI内の文字領域と重なる参照画像RI内の領域である。例えば、図3(A)の文字領域TA1が処理対象の文字領域である場合には、図3(B)の領域CA1が、対応領域として特定される。スキャン画像SI内の文字領域と、該文字領域に対応する参照画像RI内の対応領域とは、互いに同一の画素数を有する互いに同一のサイズの領域である。
S46では、CPU210は、参照画像RI内の対応領域内の文字画素の個数NT2を算出する。
S50では、CPU210は、2個の領域間の文字画素の個数の差分ΔT、すなわち、処理対象の文字領域内の文字画素の個数NT1と、対応領域内の文字画素の個数NT2と、の差分ΔTを算出する(ΔT=(NT1−NT2))。
S55では、CPU210は、差分ΔTの絶対値が、第1の基準値TH1より大きいか否かを判断する。第1の基準値TH1には、例えば、処理対象の文字領域内の画素の総数の第1の割合分の個数が用いられる。第1の割合は、本実施例では、10%である。
差分ΔTの絶対値が、第1の基準値TH1より大きい場合には(S55:YES)、S60にて、CPU210は、差分ΔTの絶対値が第2の基準値TH2以下であるか否かを判断する。第2の基準値TH2には、例えば、処理対象の文字領域内の画素の総数の第2の割合分の個数が用いられる。第2の割合は、上述した第1の割合より大きな値であり、本実施例では、30%である。
差分ΔTの絶対値が、第2の基準値TH2以下である場合には(S60:YES)、S65〜S75にて、文字画素のデフォルトの抽出条件の調整が行われる。デフォルトの抽出条件の調整は、抽出条件を満たす文字画素の個数NT1が、対応領域内の文字画素の個数NT2に近づくように行われる。
S65では、CPU210は、対応領域内の文字画素の個数NT2は、処理対象の文字領域内の文字の個数NT1より大きいか否かを判断する。
対応領域内の文字画素の個数NT2が、処理対象の文字領域内の文字画素の個数NT1より多い場合には(S65:YES)、処理対象の文字領域内の文字画素の個数NT1は、抽出すべき適切な文字画素の個数より過度に少ないと考えられる。このために、この場合には、抽出条件を満たす文字画素の個数NT1が増加するように、デフォルトの抽出条件が調整される。具体的には、S70にて、CPU210は、S35にて設定された抽出範囲を広げる。より具体的には、抽出範囲は、図4(A)〜(C)のR、G、B成分の範囲SRd、SGd、SBdから、より広い範囲SRb、SGb、SBbに変更される。図4(A)〜(C)に示すように、変更後の範囲SRb、SGb、SBbは、文字色値(Rtx、Gtx、Btx)の各成分の値を中心とし、かつ、デフォルトの幅より広い幅を有する範囲である。
対応領域内の文字画素の個数NT2が、処理対象の文字領域内の文字画素の個数NT1以下である場合には(S65:NO)、処理対象の文字領域内の文字画素の個数NT1は、抽出すべき適切な文字画素の個数より過度に多いと考えられる。このために、この場合には、抽出条件を満たす文字画素の個数NT1が減少するように、デフォルトの抽出条件が調整される。具体的には、S75にて、CPU210は、S35にて設定された抽出範囲を狭くする。より具体的には、抽出範囲は、図4(A)〜(C)のR、G、B成分の範囲SRd、SGd、SBdから、より狭い範囲SRs、SGs、SBsに変更される。図4(A)〜(C)に示すように、変更後の範囲SRs、SGs、SBsは、文字色値(Rtx、Gtx、Btx)の各成分の値を中心とし、かつ、デフォルトの幅より狭い幅を有する範囲である。
S80では、CPU210は、調整済みの抽出条件を満たす文字画素を抽出する。具体的には、CPU210は、処理対象の文字領域内の複数個の画素のうち、S70またはS75にて調整済みの抽出条件を満たす画素を文字画素に分類し、該調整済みの抽出条件を満たさない画素を背景画素に分類する二値化処理を実行する。調整済みの抽出条件を用いて抽出された文字画素が、処理対象の文字領域内で最終的に抽出される文字画素となる。
図5(B)には、抽出範囲を広げることによって、デフォルトの抽出条件が調整された場合に、文字領域TA1内において調整済みの抽出条件を用いて抽出される文字画素TPbが示されている。図5(C)には、抽出範囲を狭くすることによって、デフォルトの抽出条件が調整された場合に、文字領域TA1内において調整済みの抽出条件を用いて抽出される文字画素TPsが示されている。図5(B)、(C)には、比較のために、デフォルトの抽出条件を用いて抽出される文字画素TPd(図5(A))が波線で示されている。
図5(B)では、調整済みの抽出条件を用いて抽出される文字画素TPbによって表現される文字の太さが、デフォルトの抽出条件を用いて抽出される文字画素TPdより太くなっている。このように、図5(B)では、文字画素TPbの個数は、文字画素TPdの個数より増加していることが解る。図5(C)では、調整済みの抽出条件を用いて抽出される文字画素TPsによって表現される文字の太さが、デフォルトの抽出条件を用いて抽出される文字画素TPdより細くなっている。このように、図5(C)では、文字画素TPsの個数は、文字画素TPdの個数より減少していることが解る。
差分ΔTの絶対値が、第1の基準値TH1以下である場合には(S55:NO)、S70〜S80の処理は、スキップされる。すなわち、この場合には、S40にてデフォルトの抽出条件を用いて抽出された文字画素が、そのまま、最終的に抽出される文字画素になる。この場合には、差分ΔTの絶対値が比較的小さいので、デフォルトの抽出条件を用いて抽出された文字画素の個数NT1は、適切な個数である、と考えられるからである。
差分ΔTの絶対値が、第2の基準値TH2より大きい場合にも(S60:NO)、S70〜S80の処理は、スキップされ、S40にてデフォルトの抽出条件を用いて抽出された文字画素が、そのまま、最終的に抽出される文字画素になる。このように、差分ΔTの絶対値が過度に大きい場合には、例えば、S15での文字認識の誤りによって、取得した文字コードが実際の文字を示していないことなどに起因して、参照画像RI内の対応領域内の文字画素の個数NT2が異常な値となっている可能性が高い。対応領域内の文字画素の個数NT2が異常な値となっている場合には、抽出条件の調整を行うことによって、抽出される文字画素の個数を適切な値に調整することはできないと考えられる。このために、S70〜S80の処理をスキップすることが適切であると考えられるからである。
このように、1個の文字領域を処理対象として、S35〜S80の処理が行われた結果、処理対象の文字領域において抽出された文字画素を示す文字二値データが生成される。文字二値データは、例えば、文字画素を「ON」の画素とし、背景画素を「OFF」の画素とする二値データである。図3(D)には、スキャン画像SIの文字領域TA1、TA2(図3(A))に対応する文字二値データによって示される二値画像TIA、TIBが示されている。
S85では、CPU210は、S25にて特定済みの全ての文字領域を処理したか否かを判断する。未処理の文字領域がある場合には(S85:NO)、CPU210は、S30に戻る。全ての文字領域を処理した場合には(S85:YES)、CPU210は、S90に処理を進める。
S90では、CPU210は、スキャン画像SIを示す画像ファイルとして、高圧縮PDFファイルを生成する圧縮画像生成処理を実行する。図6は、圧縮画像生成処理のフローチャートである。
S110では、CPU210は、文字二値データと、スキャンデータとを用いて、背景画像データを生成する。具体的には、CPU210は、スキャンデータによって示されるスキャン画像SIに含まれる複数の画素のうち、文字二値データによって特定される文字画素の値(RGB値)を背景色値に置き換える。背景色値は、スキャン画像SIの背景Bg1の色を表す値であり、例えば、上述した背景Bg1に対応するピークに対応するRGB値(Rbg、Gbg、Bbg)である(図4)。この結果、スキャン画像SIから文字が消去された背景画像BIを表す背景画像データが生成される。図3(E)には、図3(A)のスキャン画像SIに対応する背景画像BIが図示されている。背景画像BIは、消去された文字Ob1、Ob2を含まず、文字以外のオブジェクト、すなわち、写真Ob3と、描画Ob4とを含んでいる。
S120では、CPU210は、生成された背景画像データを圧縮する。背景画像BIは、文字を含んでおらず、写真や描画を含み得る多階調(例えば、256階調)の画像である。CPU210は、このような多階調の画像の圧縮に適した圧縮方式、具体的には、JPEG(Joint Photographic Experts Group)圧縮を用いて、背景画像データを圧縮する。背景画像BIは、文字を含んでいないので、高周波数成分が比較的少ない。この結果、背景画像データをJPEG圧縮によって圧縮した際の圧縮率は、元データ(スキャンデータ)を圧縮した際の圧縮率より高くなる。
ステップS130では、CPU210は、文字二値データを圧縮する。例えば、図3(D)に示す二値画像TIA、TIBをそれぞれ示す2個の文字二値データが圧縮される。文字を示す二値画像は、解像度を落とすとエッジのがたつきが目立ち、視認性が悪化しやすい。CPU210は、二値データに適した圧縮方式、具体的には、高い圧縮率で、かつ、解像度を落とすことなく二値データを圧縮できる可逆圧縮方式、例えば、FAXG3やMMR(Modified Modified Read)圧縮を用いて、文字二値データを圧縮する。このように、背景画像データと、文字二値データとは、それぞれ異なる方法で圧縮される。
ステップS140では、CPU210は、圧縮済みの背景画像データと、圧縮済みの文字二値データと、文字色値と、座標情報と、文字コードと、を用いて、高圧縮PDFファイルIFを生成する。文字色値は、各文字二値データによって示される二値画像内の文字の色を表す色値であり、例えば、上述した文字に対応するピークに対応するRGB値(Rtx、Gtx、Btx)である(図4)。座標情報は、文字二値データによって示される二値画像の背景画像内の位置を示す情報である。文字コードは、文字二値データによって示される二値画像内の各文字を示す識別情報であり、図2のS15にて取得済みである。PDFでは、複数の異なる形式の画像データを1つのファイルに格納し、当該ファイルを再現する際には、これらの画像データを重畳して1つの画像として再現可能なように、規格が定められている。CPU210は、規格に従って、高圧縮PDFファイルIFを生成する。この結果、文字を含むスキャン画像SIを、文字がシャープで読みやすく、かつ、データ量が比較的小さい形で保存することができる。また、文字に、対応する文字コードが関連付けられていることで、例えば、高圧縮PDFファイルIFを、端末装置において、ビューアプログラムを用いて表示した場合に、表示された画像内の特定の文字の位置を検索することができる。
図7は、高圧縮PDFファイルIFを概念的に示す図である。この高圧縮PDFファイルIFは、図3(A)のスキャン画像SIを示す高圧縮PDFファイルIFである。図7に示すように、1個の高圧縮PDFファイルIFには、図3(E)の背景画像BIを示す圧縮済みの背景画像データと、図3(D)の二値画像TIA、TIBをそれぞれ示す圧縮済みの文字二値データと、が格納されている。高圧縮PDFファイルIFには、さらに、二値画像TIA、TIB内の文字の色を示す文字色値と、二値画像TIA、TIBの背景画像BI内での位置を示す座標情報と、二値画像TIA、TIBの背景画像BI内の各文字を示す文字コードとが、圧縮済みの文字二値データと関連付けて格納されている。
図2のS90の圧縮画像データ生成処理が終了すると、図2の画像処理は終了される。生成済みの高圧縮PDFファイルIFは、例えば、様々な形で出力される。例えば、高圧縮PDFファイルIFは、不揮発性記憶装置230に格納される。これに代えて、高圧縮PDFファイルIFは、ユーザの他の端末装置に送信されても良い。また、高圧縮PDFファイルIFは、高圧縮PDFファイルIFを用いて表示部260にスキャン画像SIを表示させる形態で、出力されても良いし、高圧縮PDFファイルIFをプリンタに送信して、プリンタにスキャン画像SIを印刷させる形態で、出力されても良い。
以上説明した本実施例によれば、CPU210は、スキャン画像SI内の文字Ob1、Ob2に対応する文字コードを含む文字情報Tx1、Tx2を用いて、スキャン画像SI内の複数個の文字画素の個数に関する指標値を取得する。具体的には、スキャン画像SI内の文字領域TA1、TA2に対応する参照画像RI内の対応領域CA1、CA2内の文字画素の個数NT2が、指標値として取得される(図2のS20、S44、S46)。そして、CPU210は、当該指標値を用いて、文字画素の抽出条件を決定する(図2のS35、S50〜S75)。この結果、スキャン画像SI内の複数個の文字画素を精度良く抽出することができる。
仮に、文字コード等を用いない場合には、考慮すべき情報が不十分であるために、適切な抽出条件を決定できない可能性がある。例えば、スキャン画像SI内の文字の色のばらつきの程度や、文字のエッジ強度などは、画像によって異なり得るので、上述した抽出範囲などの抽出条件を、適切に決定することは比較的困難である。例えば、抽出範囲が過度に狭い場合には、抽出される文字画素の個数が過度に少なくなり、抽出される文字画素によって表現される文字がかすれてしまう場合がある。また、抽出範囲が過度に広い場合には、抽出される文字画素の個数が過度に多くなり、抽出される文字画素によって表現される文字が潰れてしまう場合がある。いずれの場合でも抽出される文字画素によって表現される文字の判読性や見栄えが低下する不具合が発生し得る。本実施例では、文字コードを用いて取得される指標値を用いて、文字画素の抽出条件が決定されるので、複数個の文字画素を精度良く抽出できる。その結果、例えば、上記不具合を抑制できる。
また、上記実施例では、CPU210は、上記の指標値と、スキャンデータと、を用いて、文字画素の抽出条件を決定するので、スキャン画像SI内の文字画素をより精度良く抽出することができる。
より具体的には、CPU210は、スキャンデータを用いて、上記の指標値を用いずに、デフォルトの抽出条件を満たす複数個の文字画素を抽出する(図2のS35、S40)。そして、CPU210は、デフォルトの抽出条件を満たす複数個の文字画素の抽出結果(具体的には、抽出された文字画素の個数NT1)と、上記の指標値(具体的には、対応領域内の文字画素の個数NT2)と、を用いて、最終的な文字画素の抽出条件を決定する(S50〜S75)。この結果、より適切な文字画素の抽出条件を決定することができる。例えば、デフォルトの抽出条件が適切ではない場合であっても、適切な文字画素の抽出条件を決定することができる。
さらに、詳しく説明すれば、上記の指標値、具体的には、対応領域内の文字画素の個数NT2は、処理対象の文字領域内に抽出すべき文字画素の個数NT2を示していると、言うことができる。上記実施例では、文字領域内のデフォルトの抽出条件を満たす文字画素の個数NT1が、指標値によって示される文字領域内に抽出すべき文字画素の個数NT2に近づくように、デフォルトの抽出条件が調整されることによって、最終的な文字画素の抽出条件が決定される(図2のS55〜S75)。この結果、より適切な抽出条件を決定することができる。例えば、デフォルトの抽出条件を満たす文字画素の個数が、指標値から見て過度に多いと考えられる場合には、抽出すべき文字画素の個数が減少するように、デフォルトの抽出条件が調整される(図2のS64:NO、S75)。これによって、適切に最終的な文字画素の抽出条件が決定される。逆に、デフォルトの抽出条件を満たす文字画素の個数が、指標値から見て過度に少ないと考えられる場合には、抽出すべき文字画素の個数が増加するように、デフォルトの抽出条件が調整される(図2のS64:YES、S70)。これによって、適切に最終的な文字画素の抽出条件が決定される。
さらに、上述したように、デフォルトの抽出条件や、最終的な抽出条件は、抽出範囲内に判定対象の画素の値が含まれるか否かに基づく条件である。すなわち、最終的な抽出条件は、抽出範囲の上限や下限を定義する第1の閾値と、判定対象の画素の値と、の比較に基づく条件である。また、デフォルトの抽出条件は、抽出範囲の上限や下限を定義する第2の閾値と、判定対象の画素の値と、の比較に基づく条件である。したがって、上記実施例における抽出範囲の調整(S70、S75)は、最終的な抽出条件を満たす文字画素の個数が、デフォルトの抽出条件を満たす文字画素の個数NT1よりも、指標値によって示される抽出すべき前記複数個の文字画素の個数NT2に近づくように、第2の閾値を基準として、第1の閾値を決定するものである、と言うことができる。このように、デフォルトの抽出条件における第2の閾値を基準として、最終的な抽出条件の第1の閾値が決定されるので、最終的な抽出条件を容易に適切な値に決定することができる。
また、指標値(具体的には、対応領域内の文字画素の個数NT2)は、スキャンデータを用いずに、取得される(図2のS20、S44、S46)。この結果、スキャンデータを用いずに取得される文字領域内の文字画素の個数に関する指標値を用いて、精度良く文字画素を抽出できる抽出条件を決定することができる。
より詳しくは、CPU210は、文字コードを用いて、スキャンデータを用いずに、文字領域に対応する文字画像(具体的には、図3(B)内の対応領域CA1、CA2内の画像)を含む参照画像RIを示す参照画像データを生成する(図2のS20)。そして、CPU210は、参照画像データを用いて、文字領域内の指標値を取得する(図2のS44、S46)。この結果、参照画像データを用いて、適切な指標値を取得することができる。
さらに、CPU210は、差分ΔTの絶対値が第2の基準値TH2より大きい場合、すなわち、デフォルトの抽出条件を満たす文字画素の個数NT1が、指標値によって示される抽出すべき文字画素の個数NT2から第2の基準値TH2を超えて離れている場合には(図2のS60:NO)、S70やS75の抽出条件の調整を行わない。そして、CPU210は、デフォルトの抽出条件を満たす文字画素を、最終的な文字画素として抽出する。この結果、指標値が適切でない場合に、デフォルトの抽出条件が不適切に調整されることを抑制できる。したがって、不適切な複数個の文字画素が抽出されることを抑制することができる。
また、CPU210は、差分ΔTの絶対値が第1の基準値TH1以下である場合、すなわち、デフォルトの抽出条件を満たす文字画素の個数NT1が、指標値によって示される抽出すべき文字画素の個数NT2から第1の基準値TH1を超えるほど離れていない場合には(図2のS55:NO)、S70やS75の抽出条件の調整を行わない。そして、CPU210は、デフォルトの抽出条件を満たす文字画素を、最終的な文字画素として抽出する。この結果、デフォルトの抽出条件を用いることが妥当である場合に、デフォルトの抽出条件が調整されないので、適切な複数個の文字画素を抽出することができる。
さらに、CPU210は、スキャン画像SI内の1個以上の文字領域を特定し(図2のS25)、特定済みの文字領域ごとに、S35〜S80の処理を行う。すなわち、特定済みの文字領域ごとに、指標値の算出(S46)や、最終的な抽出条件の決定(S65〜S75)や、文字画素の抽出(S80)が実行される。この結果、文字領域ごとに、適切に文字画を抽出できるので、文字画素の抽出精度をさらに向上することができる。
以上の説明から解るように、上記実施例のS40で用いられるデフォルトの抽出条件は、第2の抽出条件の例であり、S80で用いられる抽出条件は、第1の抽出条件の例である。また、S40にて抽出される複数個の文字画素は、第2の抽出条件を満たす複数個の抽出画素の例であり、S80にて抽出される複数個の文字画素は、第1の抽出条件を満たす複数個の文字画素の例である。また、上記実施例のスキャン画像SI内の文字領域TA1、TA2は、対象画像内の特定領域の例である。
B.変形例:
(1)上記実施例では、指標値は、参照画像RI内の対応領域内の文字画素の個数NT2である。指標値は、これに限られず、スキャン画像SI内の文字画素の個数に関する値であれば良い。例えば、指標値は、例えば、対応領域の面積に対する対応領域内の文字画素の個数のレベルを、複数段階(例えば、3段階)で示す値であっても良い。この場合には、例えば、CPU210は、文字コードによって示される文字が数字やアルファベットである場合には、文字画素の個数が比較的少ないことを示す指標値を取得し、文字コードによって示される文字がひらがなやカタカナである場合には、文字画素の個数が標準的であることを示す指標値を取得し、文字コードによって示される文字が漢字である場合には、文字画素の個数が比較的多いことを示す指標値を取得しても良い。そして、CPU210は、指標値が文字画素の個数が比較的多いことを示すにも関わらず、デフォルトの抽出条件を満たす文字画素の個数NT1が、基準値より少ない場合には、抽出条件を満たす文字画素の個数が増加するように、抽出条件を調整しても良い。また、CPU210は、指標値が文字画素の個数が比較的少ないことを示すにも関わらず、デフォルトの抽出条件を満たす文字画素の個数NT1が、基準値より多い場合には、抽出条件を満たす文字画素の個数が減少するように、抽出条件を調整しても良い。
(1)上記実施例では、指標値は、参照画像RI内の対応領域内の文字画素の個数NT2である。指標値は、これに限られず、スキャン画像SI内の文字画素の個数に関する値であれば良い。例えば、指標値は、例えば、対応領域の面積に対する対応領域内の文字画素の個数のレベルを、複数段階(例えば、3段階)で示す値であっても良い。この場合には、例えば、CPU210は、文字コードによって示される文字が数字やアルファベットである場合には、文字画素の個数が比較的少ないことを示す指標値を取得し、文字コードによって示される文字がひらがなやカタカナである場合には、文字画素の個数が標準的であることを示す指標値を取得し、文字コードによって示される文字が漢字である場合には、文字画素の個数が比較的多いことを示す指標値を取得しても良い。そして、CPU210は、指標値が文字画素の個数が比較的多いことを示すにも関わらず、デフォルトの抽出条件を満たす文字画素の個数NT1が、基準値より少ない場合には、抽出条件を満たす文字画素の個数が増加するように、抽出条件を調整しても良い。また、CPU210は、指標値が文字画素の個数が比較的少ないことを示すにも関わらず、デフォルトの抽出条件を満たす文字画素の個数NT1が、基準値より多い場合には、抽出条件を満たす文字画素の個数が減少するように、抽出条件を調整しても良い。
(2)上記実施例では、文字情報は、文字コードと、サイズ情報と、フォント情報と、を含んでいるが、少なくとも文字コードを含んでいれば良く、サイズ情報やフォント情報は省略されても良い。例えば、上記変形例(1)に示す例では、指標値を取得するために、サイズ情報やフォント情報は、必要ないことがわかる。
(3)上記実施例では、文字情報を用いて、参照画像データを生成し、該参照画像データを用いて、指標値(具体的には、対応領域内の文字画素の個数NT2)を決定している。これに代えて、参照画像データを生成することなく、文字情報を用いて、指標値を決定しても良い。例えば、例えば、上記変形例(1)に示す例では、指標値を取得するために、参照画像データを生成する必要はないことがわかる。
また、各文字コードによって示される文字の画像における画素数を、例えば、文字のサイズごとに予め算出し、当該画素数を記憶したデータベースを予め準備しておいても良い。この場合には、CPU210は、参照画像データを生成することなく、該データベースを参照して、文字コードと文字のサイズに対応する文字画素の個数NT2を決定しても良い。該データベースは、計算機200の不揮発性記憶装置230に格納されていても良く、計算機200と通信可能に接続された他の計算機、例えば、サーバに格納されていても良い。
(4)また、指標値は、例えば、いわゆる射影ヒストグラムを用いて算出される値であっても良い。図8は、文字領域TA1の射影ヒストグラムの一例を示す図である。CPU210は、例えば、処理対象の文字領域の射影ヒストグラムを、デフォルトの抽出条件を満たす文字画素について生成する。例えば、文字領域TA1の複数個の画素を、縦方向の位置に基づいて、複数個のクラスに分類する。本実施例では、縦方向の位置が等しい複数個の画素、すなわち、横方向に延びる1本の画素のライン上の複数個の画素が、1個のクラスに分類される。例えば、文字領域TA1のサイズが、縦P画素×横Q画素である場合には、文字領域TA1内の複数個の画素は、P個のクラスに分類され、1個のクラスに属する画素数は、Q個である。そして、CPU210は、P個のクラスのそれぞれについて、各クラスに属するQ個の画素のうち、文字画素の個数をカウントすることによって、縦方向の射影ヒストグラムBh1(図8)を作成する。同様に、CPU210は、横方向の射影ヒストグラムBh2(図8)を生成する。
そして、CPU210は、同様に、参照画像RIの対応領域について、それぞれ、縦方向および横方向の射影ヒストグラムを生成する(図示省略)。CPU210は、これらの射影ヒストグラムの形状に関する特徴値(例えば、ヒストグラムの面積など)を、指標値として算出する。そして、これらの射影ヒストグラムの形状に関する特徴値に基づいて、参照画像RIの対応領域の射影ヒストグラムと、文字領域TA1の射影ヒストグラムと、が類似しているか否かを判断する。そして、CPU210は、類似している場合には、デフォルトの抽出条件の調整を行わない。そして、類似していない場合には、参照画像RIの対応領域の射影ヒストグラムと、文字領域TA1の射影ヒストグラムとが、類似するように、デフォルトの抽出条件の調整を行うことによって、最終的な抽出条件を決定しても良い。
(5)上記実施例では、デフォルトの抽出条件を設定し、指標値を用いて、デフォルトの抽出条件を調整することによって、最終的な抽出条件を決定している。これに代えて、デフォルトの抽出条件を設定することなく、指標値を用いて、最終的な抽出条件を決定しても良い。例えば、文字画素は、一般的に、明度が比較的低い画素であり、背景画素は、明度が比較的高い画素であることが多い。このために、CPU210は、指標値として、対応領域内の文字画素の個数NT2を取得した場合には、処理対象の文字領域内の複数固の画素のうち、明度が低い順に、1番目からNT2番目までの画素を、文字画素として抽出するように、文字画素の最終的な抽出条件を決定しても良い。
(6)上記実施例では、スキャンデータと、指標値と、を用いて、最終的な抽出条件を決定している。これに代えて、指標値だけを用いて、最終的な抽出条件を決定してもよい。例えば、CPU210は、文字コードを用いて、文字コードによって示される文字の平均の画数を指標値として、算出する。そして、CPU210は、画数が比較的多い場合には、文字が潰れて見栄えが低下しやすいために、文字が潰れないように、比較的狭い抽出範囲を用いる抽出条件を、最終的な抽出条件として決定し、画数が比較的少ない場合には、文字が潰れる可能性は低いために、文字がかすれないように、比較的広い抽出範囲を用いる抽出条件を、最終的な抽出条件として決定しても良い。
(7)なお、上記実施例では、文字領域ごとに、指標値の取得や、抽出条件の決定を行っているが、スキャン画像SIの全体で1個の指標値を取得しても良く、スキャン画像SIの全体で1個の抽出条件を決定しても良い。
(8)上記実施例では、文字画素の抽出条件では、1個の色成分について、上限と下限との2個の閾値を有する抽出範囲が用いられているが、1個の閾値のみを有する抽出範囲が用いられても良い。例えば、1個の色成分について、1個の閾値未満の範囲を抽出範囲とし、1個の閾値以上の範囲を非抽出範囲としても良い。
(9)上記実施例では、デフォルトの抽出条件の抽出範囲を変更して、最終的な抽出条件を決定している。例えば、抽出範囲を広げることに代えて、デフォルトの抽出条件を満たす複数個の文字画素を含む二値画像に対して、二値画像内の文字を太らせるいわゆる太らせフィルタを適用することによって、抽出すべき文字画素の個数を増加させても良い。この場合には、デフォルトの抽出条件を満たす複数個の画素を含む二値画像に対して、太らせフィルタして得られる画素であることが、最終的な文字画素の抽出条件である、と言うことができる。同様に、抽出範囲を狭くすることに代えて、デフォルトの抽出条件を満たす複数個の文字画素を含む二値画像に対して、二値画像内の文字を細らせるいわゆる細らせフィルタを適用することによって、抽出すべき文字画素の個数を減少させても良い。
(10)上記実施例では、文字画素の抽出結果を用いて、高圧縮PDFファイルが生成されている。これに代えて、例えば、CPU210は、XPS形式などの他の形式の画像ファイルを生成しても良い。また、CPU210は、文字画素の抽出結果を用いて、抽出された文字画素によって特定された文字に対して所定の補正処理を行った補正済み画像を示す画像ファイルを生成してもよい。所定の補正処理は、例えば、文字の色を見やすい色に補正する処理や、文字のエッジを強調する処理などが含まれる。
(11)上記実施例では、対象画像データは、スキャンデータであるが、これに限られない。対象画像データは、例えば、ワープロソフトなどの文書作成アプリケーションによって生成された画像ファイル(例えば、PDFファイル)であっても良い。この場合等において、PDFファイルに予め文字情報が付加されている場合には、図2の画像処理において、文字認識処理を行う必要はなく、図2のS15では、CPU210は、PDFファイルに予め付加されている文字情報を取得すればよい。
(12)上記各実施例において、計算機200が実行する図2の画像処理は、複合機400やスキャナ300などの画像読取部を有する装置、あるいは、デジタルカメラなどの光学的な画像データ生成部を有する装置、あるいは、計算機200と通信可能な図示しないサーバによって実行されても良い。例えば、当該画像処理機能を備える複合機やスキャナは、自身が有する画像読取部を用いて生成したスキャンデータに対して画像処理を行って、処理済み画像データ(例えば、高圧縮PDFデータ)を生成し、当該処理済み画像データを、通信可能に接続された計算機200に出力しても良い。また、当該画像処理機能を備えるサーバは、計算機200や複合機400やスキャナ300からネットワークを介して取得したスキャンデータに対して画像処理を行って、処理済み画像データを生成し、当該処理済み画像データを、ネットワークを介して計算機200に出力しても良い。
一般的に言えば、画像処理機能を実現する装置は、計算機200に限らず、複合機、デジタルカメラ、スキャナ、サーバなどによって実現されても良い。また、当該画像処理機能は、1つの装置で実現されても良いし、ネットワークを介して接続された複数の装置によって、実現されても良い。この場合には、当該画像処理機能を実現する複数の装置を備えるシステムが、画像処理装置に相当する。
(13)上記実施例において、ハードウェアによって実現されていた構成の一部をソフトウェアに置き換えるようにしてもよく、逆に、ソフトウェアによって実現されていた構成の一部をハードウェアに置き換えるようにしてもよい。
以上、実施例、変形例に基づき本発明について説明してきたが、上記した発明の実施の形態は、本発明の理解を容易にするためのものであり、本発明を限定するものではない。本発明は、その趣旨並びに特許請求の範囲を逸脱することなく、変更、改良され得ると共に、本発明にはその等価物が含まれる。
200...計算機、210...CPU、220...揮発性記憶装置、221...バッファ領域、230...不揮発性記憶装置、260...表示部、270...操作部、280...通信部、300...スキャナ、400...複合機、PG1...アプリケーションプログラム、PG2...スキャナドライバプログラム
Claims (11)
- 画像処理装置であって、
複数個の画素にて構成され、文字を含む対象画像を表す対象画像データを取得する画像取得部と、
前記対象画像内の文字に対応する文字コードを取得するコード取得部と、
前記対象画像内の文字に対応する前記文字コードを用いて、前記対象画像内の文字を構成する複数個の文字画素の個数に関する指標値を取得する指標値取得部と、
前記指標値を用いて、第1の抽出条件を決定する決定部と、
前記対象画像内の複数個の画素の中から、前記第1の抽出条件を満たす前記複数個の文字画素を抽出する抽出部と、
を備える、画像処理装置。 - 請求項1に記載の画像処理装置であって、
前記決定部は、前記対象画像データと、前記指標値と、を用いて、前記第1の抽出条件を決定する、画像処理装置。 - 請求項2に記載の画像処理装置であって、
前記決定部は、
前記対象画像データを用いて、前記指標値を用いずに、第2の抽出条件を満たす複数個の抽出画素を抽出し、
前記第2の抽出条件を満たす前記複数個の抽出画素の抽出結果と、前記指標値と、を用いて、前記第1の抽出条件を決定する、画像処理装置。 - 請求項1〜3のいずれかに記載の画像処理装置であって、
前記指標値取得部は、前記対象画像データを用いずに、前記対象画像内の特定領域内の前記複数個の文字画素の個数に関する前記指標値を取得する、画像処理装置。 - 請求項4に記載の画像処理装置であって、
前記決定部は、
前記対象画像データを用いて、前記指標値を用いずに、第2の抽出条件を満たす複数個の抽出画素を抽出し、
前記特定領域内の前記第2の抽出条件を満たす前記複数個の抽出画素の個数が、前記指標値によって示される前記特定領域内に抽出すべき前記複数個の文字画素の個数に近づくように、前記第2の抽出条件を調整することによって、前記第1の抽出条件を決定する、画像処理装置。 - 請求項5に記載の画像処理装置であって、
前記第1の抽出条件は、第1の閾値と、判定対象の画素の値と、の比較に基づく条件であり、
前記第2の抽出条件は、第2の閾値と、判定対象の画素の値と、の比較に基づく条件であり、
前記決定部は、前記特定領域内の前記第1の抽出条件を満たす前記複数個の文字画素の個数が、前記特定領域内の前記第2の抽出条件を満たす前記複数個の抽出画素の個数よりも、前記指標値によって示される前記特定領域内に抽出すべき前記複数個の文字画素の個数に近づくように、前記第2の閾値を基準として、前記第1の閾値を決定する、画像処理装置。 - 請求項5または6に記載の画像処理装置であって、
前記決定部は、
前記特定領域内の前記第2の抽出条件を満たす前記複数個の抽出画素の個数が、前記指標値によって示される前記特定領域内に抽出すべき前記複数個の文字画素の個数から基準値を超えて離れている場合には、前記第2の抽出条件の調整を行わず、
前記抽出部は、前記第2の抽出条件を満たす前記複数個の抽出画素を、前記複数個の文字画素として抽出する、画像処理装置。 - 請求項4〜7のいずれかに記載の画像処理装置であって、
前記指標値取得部は、
前記文字コードを用いて、前記対象画像データを用いずに、前記特定領域に対応する文字画像を示す参照画像データを生成し、
前記参照画像データを用いて、前記特定領域内の前記指標値を取得する、画像処理装置。 - 請求項1〜8のいずれかに記載の画像処理装置であって、さらに、
前記対象画像内の1個以上の文字領域を特定する特定部を備え、
前記決定部は、特定済みの前記文字領域ごとに、前記文字領域に対応する前記指標値を用いて、前記第1の抽出条件を決定し、
前記抽出部は、特定済みの前記文字領域ごとに、前記第1の抽出条件を満たす前記複数個の文字画素を抽出する、画像処理装置。 - 請求項1〜9のいずれかに記載の画像処理装置であって、さらに、
抽出済みの前記複数個の文字画素を示す文字画像データと、前記対象画像データと、を用いて、背景画像データを生成する背景画像生成部と、
前記文字データと前記背景画像データとを用いて、前記対象画像を示す画像ファイルであって、それぞれ異なる方法で圧縮された前記文字データと前記背景画像データとを含む前記画像ファイルを生成するファイル生成部と、
を備える、画像処理装置。 - コンピュータプログラムであって、
複数個の画素にて構成され、文字を含む対象画像を表す対象画像データを取得する画像取得機能と、
前記対象画像内の文字に対応する文字コードを取得するコード取得機能と、
前記対象画像内の文字に対応する前記文字コードを用いて、前記対象画像内の文字を構成する複数個の文字画素の個数に関する指標値を取得する指標値取得機能と、
前記指標値を用いて、第1の抽出条件を決定する決定機能と、
前記対象画像内の複数個の画素の中から、前記第1の抽出条件を満たす前記複数個の文字画素を抽出する抽出機能と、
をコンピュータに実現させる、コンピュータプログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016014861A JP2017135613A (ja) | 2016-01-28 | 2016-01-28 | 画像処理装置およびコンピュータプログラム |
| US15/418,089 US10521686B2 (en) | 2016-01-28 | 2017-01-27 | Image processing apparatus, information processing method and storage medium for generating an image file by extracting character pixels of a target image |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016014861A JP2017135613A (ja) | 2016-01-28 | 2016-01-28 | 画像処理装置およびコンピュータプログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2017135613A true JP2017135613A (ja) | 2017-08-03 |
Family
ID=59386898
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016014861A Pending JP2017135613A (ja) | 2016-01-28 | 2016-01-28 | 画像処理装置およびコンピュータプログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10521686B2 (ja) |
| JP (1) | JP2017135613A (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113191346A (zh) * | 2021-05-20 | 2021-07-30 | 努比亚技术有限公司 | 一种图像区域提取结果识别方法、设备及计算机可读存储介质 |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| FR3104360B1 (fr) * | 2019-12-10 | 2021-12-03 | Zodiac Data Systems | Procédé de compression d’une séquence d’images montrant des éléments graphiques synthétiques d’origine non photographique |
Family Cites Families (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH05225378A (ja) | 1991-06-03 | 1993-09-03 | Fujitsu Ltd | 文書画像の領域分割システム |
| US5999647A (en) * | 1995-04-21 | 1999-12-07 | Matsushita Electric Industrial Co., Ltd. | Character extraction apparatus for extracting character data from a text image |
| JPH09330378A (ja) | 1996-06-10 | 1997-12-22 | Ricoh Co Ltd | パターン辞書比較方法 |
| JPH10116317A (ja) | 1996-10-14 | 1998-05-06 | Ricoh Co Ltd | 文字認識方法および記録媒体 |
| US7472348B2 (en) | 1998-11-05 | 2008-12-30 | Canon Kabushiki Kaisha | Image processing apparatus, image processing method and storage medium using character size and width for magnification |
| JP2001134026A (ja) | 1999-11-02 | 2001-05-18 | Canon Inc | 画像処理装置及び方法、並びにコンピュータにより読み取り可能な記憶媒体 |
| JP4558232B2 (ja) | 2001-03-26 | 2010-10-06 | 株式会社リコー | 画像処理方法、画像処理装置および画像処理方法をコンピュータに実行させるプログラムを記録したコンピュータ読み取り可能な記録媒体 |
| US7925098B2 (en) * | 2006-03-02 | 2011-04-12 | Canon Kabushiki Kaisha | Image encoding apparatus and method with both lossy and lossless means |
| JP4280939B2 (ja) | 2007-07-30 | 2009-06-17 | 義尚 神山 | 位置面システム画像認識コンピューターソフトウェア |
| JP5036844B2 (ja) * | 2010-04-15 | 2012-09-26 | シャープ株式会社 | 画像圧縮装置、画像出力装置、画像読取装置、画像圧縮方法、コンピュータプログラム及び記録媒体 |
| JP5862259B2 (ja) * | 2011-12-09 | 2016-02-16 | ブラザー工業株式会社 | 表示制御装置、および、コンピュータプログラム |
| JP5984439B2 (ja) * | 2012-03-12 | 2016-09-06 | キヤノン株式会社 | 画像表示装置、画像表示方法 |
| JP5935454B2 (ja) | 2012-03-30 | 2016-06-15 | ブラザー工業株式会社 | 画像処理装置および画像処理プログラム |
| US9046996B2 (en) * | 2013-10-17 | 2015-06-02 | Google Inc. | Techniques for navigation among multiple images |
| JP6531398B2 (ja) * | 2015-01-19 | 2019-06-19 | 富士通株式会社 | プログラム |
-
2016
- 2016-01-28 JP JP2016014861A patent/JP2017135613A/ja active Pending
-
2017
- 2017-01-27 US US15/418,089 patent/US10521686B2/en active Active
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113191346A (zh) * | 2021-05-20 | 2021-07-30 | 努比亚技术有限公司 | 一种图像区域提取结果识别方法、设备及计算机可读存储介质 |
Also Published As
| Publication number | Publication date |
|---|---|
| US20170220888A1 (en) | 2017-08-03 |
| US10521686B2 (en) | 2019-12-31 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US7567708B2 (en) | Apparatus and method for image processing | |
| US11341733B2 (en) | Method and system for training and using a neural network for image-processing | |
| US9386187B2 (en) | Image processing apparatus and operations of selecting compression scheme to generate compressed file | |
| US9253368B2 (en) | Image processing device setting binary value without using dither matrix when prescribed condition is satisfied | |
| US10706340B2 (en) | Image processing apparatus and method for controlling the same with character attribute indicating that pixel is pixel of a character | |
| US7412108B2 (en) | Image enhancement employing partial template matching | |
| US10592766B2 (en) | Image processing apparatus and medium storing program executable by image processing apparatus | |
| US20160086063A1 (en) | Image forming device and method and non-transitory computer readable medium | |
| US9888147B2 (en) | Image processing apparatus, electronic file generating method, and recording medium | |
| CN103716506B (zh) | 图像处理装置及图像处理方法 | |
| US10044906B2 (en) | Image processing apparatus, medium storing program executable by image processing apparatus, and system | |
| US9338310B2 (en) | Image processing apparatus and computer-readable medium for determining pixel value of a target area and converting the pixel value to a specified value of a target image data | |
| US10521686B2 (en) | Image processing apparatus, information processing method and storage medium for generating an image file by extracting character pixels of a target image | |
| US10360446B2 (en) | Data processing apparatus, storage medium storing program, and data processing method | |
| US10872216B2 (en) | Image output device, image output method, and output image data production method | |
| JP4189654B2 (ja) | 画像処理装置 | |
| US20240020997A1 (en) | Methods and systems for adjusting text colors in scanned documents | |
| JP7654375B2 (ja) | 画像処理装置、画像処理装置の制御方法、及びプログラム | |
| JP6736299B2 (ja) | 印刷装置、印刷方法、および、プログラム | |
| US11080573B2 (en) | Image processing apparatus, control method thereof and storage medium for performing thickening processing | |
| JP2018182464A (ja) | 画像処理装置及びプログラム | |
| JP2016048879A (ja) | 画像形成装置、画像形成装置の制御方法およびプログラム | |
| US20200211270A1 (en) | Image processing apparatus, image processing method, and storage medium | |
| JP6957912B2 (ja) | 画像処理装置、および、コンピュータプログラム | |
| JP2015049794A (ja) | 画像処理装置、および、コンピュータプログラム |