JP2017181667A - 音声認識装置および音声認識方法 - Google Patents
音声認識装置および音声認識方法 Download PDFInfo
- Publication number
- JP2017181667A JP2017181667A JP2016066312A JP2016066312A JP2017181667A JP 2017181667 A JP2017181667 A JP 2017181667A JP 2016066312 A JP2016066312 A JP 2016066312A JP 2016066312 A JP2016066312 A JP 2016066312A JP 2017181667 A JP2017181667 A JP 2017181667A
- Authority
- JP
- Japan
- Prior art keywords
- recognition
- voice
- recognition result
- result
- speech
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


Landscapes
- Telephonic Communication Services (AREA)
- Navigation (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
【課題】認識精度と速度を両立させた音声認識装置を提供する。【解決手段】ユーザから取得した音声を認識する音声認識装置であって、前記ユーザから音声を取得する音声取得手段と、前記音声を認識し、第一の認識結果と、前記第一の認識結果に対応する確度を取得する認識手段と、前記音声を、自装置とは異なる第二の音声認識装置に認識させた結果である第二の認識結果を取得する情報取得手段と、前記認識手段が音声を認識した際の確度が所定の値以上である場合に、前記第一の認識結果を採用し、確度が所定の値を下回る場合に、前記ユーザに問い合わせを行い、当該問い合わせに対する回答に基づいて、前記第一の認識結果または前記第二の認識結果のどちらを採用するかを決定する決定手段と、を有する。【選択図】図1
Description
本発明は、入力された音声を認識する音声認識装置に関する。
ユーザが発した音声を認識し、当該認識結果を用いてコンピュータが処理を行う音声認識技術が普及している。音声認識技術を用いることで、コンピュータを非接触で操作することが可能になり、特に自動車などの移動体に搭載されたコンピュータの利便性が大きく向上する。
音声認識を行う際の認識精度は、認識に用いる辞書の規模によって異なる。例えば、音声認識に特化されたワークステーションと、音声認識に特化されていないパーソナルコンピュータとでは、認識精度に大きな差があることがある。
そこで、規模の小さいコンピュータにおいて音声認識を利用したい場合、通信回線を通して規模の大きいコンピュータに音声データを転送し、認識結果を取得するという手法が利用されている。
そこで、規模の小さいコンピュータにおいて音声認識を利用したい場合、通信回線を通して規模の大きいコンピュータに音声データを転送し、認識結果を取得するという手法が利用されている。
しかし、ネットワークを介して音声認識を行う場合、全体的なレスポンスが遅くなるという問題がある。すなわち、認識精度とレスポンスの両立という点において課題があった。
これに対応するため、音声の認識をローカルで行うか、サーバ上で行うかを動的に切り替える技術が提案されている。例えば、特許文献1には、ローカルで行った音声認識結果の信頼度を算出し、信頼度が低い場合に、サーバによる音声認識結果を採用するシステムが記載されている。
これに対応するため、音声の認識をローカルで行うか、サーバ上で行うかを動的に切り替える技術が提案されている。例えば、特許文献1には、ローカルで行った音声認識結果の信頼度を算出し、信頼度が低い場合に、サーバによる音声認識結果を採用するシステムが記載されている。
特許文献1に記載のシステムでは、ローカルで行った音声認識結果の信頼度を閾値と比較し、比較結果に基づいて、ローカルで音声認識を行った結果を利用するか、サーバで音声認識を行うかを決定している。しかし、当該判断をローカルで保持している閾値のみに依存して行うと、適切な判断が行えなくなるケースが発生する。
例えば、辞書の規模に対して閾値が高すぎる場合、音声認識が常にサーバで行われることになってしまい、全体的なレスポンスが低下してしまう。また、閾値が低すぎる場合、応答は高速になるが、質の高い認識結果を得ることができない。
また、信頼度が閾値を下回っていた場合、仮にローカルで行った音声認識の結果が正しい場合であっても、無条件でサーバが行った音声認識の結果を採用してしまう。
すなわち、認識精度と速度の両立という点において課題があった。
また、信頼度が閾値を下回っていた場合、仮にローカルで行った音声認識の結果が正しい場合であっても、無条件でサーバが行った音声認識の結果を採用してしまう。
すなわち、認識精度と速度の両立という点において課題があった。
本発明は上記の課題を考慮してなされたものであり、認識精度と速度を両立させた音声認識装置を提供することを目的とする。
本発明に係る音声認識装置は、
ユーザから取得した音声を認識する音声認識装置であって、前記ユーザから音声を取得する音声取得手段と、前記音声を認識し、第一の認識結果と、前記第一の認識結果に対応する確度を取得する認識手段と、前記音声を、自装置とは異なる第二の音声認識装置に認識させた結果である第二の認識結果を取得する情報取得手段と、前記認識手段が音声を認識した際の確度が所定の値以上である場合に、前記第一の認識結果を採用し、確度が所定の値を下回る場合に、前記ユーザに問い合わせを行い、当該問い合わせに対する回答に基づいて、前記第一の認識結果または前記第二の認識結果のどちらを採用するかを決定する決定手段と、を有することを特徴とする。
ユーザから取得した音声を認識する音声認識装置であって、前記ユーザから音声を取得する音声取得手段と、前記音声を認識し、第一の認識結果と、前記第一の認識結果に対応する確度を取得する認識手段と、前記音声を、自装置とは異なる第二の音声認識装置に認識させた結果である第二の認識結果を取得する情報取得手段と、前記認識手段が音声を認識した際の確度が所定の値以上である場合に、前記第一の認識結果を採用し、確度が所定の値を下回る場合に、前記ユーザに問い合わせを行い、当該問い合わせに対する回答に基づいて、前記第一の認識結果または前記第二の認識結果のどちらを採用するかを決定する決定手段と、を有することを特徴とする。
第一の認識結果は、ローカルで音声認識を行った結果であり、第二の認識結果は、自装置とは異なる(すなわち外部にある)音声認識装置を利用して音声認識を行った結果である。
音声認識は、一定の認識精度が得られるのであればローカルで行ったほうが応答時間の観点で好ましく、一定の認識精度が得られないのであれば外部装置を用いて行ったほうが正確性の観点で好ましい。すなわち、ローカルにおける音声認識結果の確度を用いて、第一の認識結果を採用するか、第二の認識結果を採用するかを決定することができる。しかし、どちらを採用するかを確度のみに基づいて決定すると、例えば、結果的に第一の認識結果が正しいにもかかわらず、第二の認識結果を採用しようとして、余分な通信が発生したり、応答時間が長くなるといった問題が発生する。
そこで、本発明に係る音声認識装置は、第一の認識結果の確度が所定値以上である場合に、無条件に第一の認識結果を採用し、確度が所定値を下回っていた場合、ユーザに問い合わせを行い、当該問い合わせに対する回答内容に基づいて、第一の認識結果と第二の認識結果のどちらを採用するかを決定する。
ユーザに対する問い合わせの内容は、典型的には、第一の認識結果の正誤に関するものであるが、これに限られない。かかる構成によると、ローカルでの認識結果に疑義がある場合に限ってユーザに問い合わせを行い、この結果、明確な誤りがあると認められる場合にのみ外部ソースを利用して音声認識を行うため、ローカルで音声認識を行うことによる応答性を活かしつつ、不正確な認識結果を採用してしまう確率を下げることができる。
ユーザに対する問い合わせの内容は、典型的には、第一の認識結果の正誤に関するものであるが、これに限られない。かかる構成によると、ローカルでの認識結果に疑義がある場合に限ってユーザに問い合わせを行い、この結果、明確な誤りがあると認められる場合にのみ外部ソースを利用して音声認識を行うため、ローカルで音声認識を行うことによる応答性を活かしつつ、不正確な認識結果を採用してしまう確率を下げることができる。
また、前記決定手段は、前記確度が所定の値を下回る場合に、前記第一の認識結果が正しいかを前記ユーザに問い合わせ、回答が肯定的であった場合に前記第一の認識結果を採用することを特徴としてもよい。
確度が所定値を下回る場合、ユーザに対して問い合わせを行い、肯定的、すなわち第一の認識結果が正しいという回答があった場合に、第一の認識結果を採用する。このようにすることで、確度は比較的低いが、結果的にローカルで行った音声認識の結果が正しいというケースにおいて、応答速度を確保することができる。
また、前記決定手段は、前記回答が否定的であり、かつ、前記第一の認識結果と第二の認識結果が異なる場合に、前記第二の認識結果を採用することを特徴としてもよい。
ユーザの回答が否定的なものであった場合であって、かつ、第一の認識結果と第二の認識結果が異なる場合、第二の認識結果が正しい可能性が高いためである。
また、前記決定手段は、前記回答が否定的であり、かつ、前記第一の認識結果と第二の認識結果が異なる場合に、前記第二の認識結果が正しいかを前記ユーザに問い合わせ、回答が肯定的であった場合に前記第二の認識結果を採用することを特徴としてもよい。
かかる構成によると、第二の認識結果を採用するか、認識自体をやり直させるかを決定することができる。
また、前記情報取得手段は、前記音声取得手段が取得した音声を前記第二の音声認識装置に送信し、前記回答が否定的であった場合に前記第二の認識結果を取得することを特徴としてもよい。
第二の認識結果は、必ずしも第一の認識結果と同時に取得する必要はない。例えば、問い合わせに対して否定的な回答が得られるまで第二の認識結果を取得しないことで、応答を高速化することができる。
なお、第二の音声認識装置にデータを送信するタイミングは、第一の認識結果を取得するタイミングであってもよいし、第一の認識結果を採用しないと決定した後であってもよい。また、第二の音声認識装置に対する問い合わせを並列に実行してもよい。
なお、第二の音声認識装置にデータを送信するタイミングは、第一の認識結果を取得するタイミングであってもよいし、第一の認識結果を採用しないと決定した後であってもよい。また、第二の音声認識装置に対する問い合わせを並列に実行してもよい。
また、前記第二の音声認識装置は、前記決定手段と無線ネットワーク経由で通信を行う装置であり、自装置よりも音声認識の精度が高い装置であることを特徴としてもよい。
このような構成においては、認識精度とレスポンスとのトレードオフ問題が発生するため、本発明を好適に適用することができる。
また、本発明に係る音声認識装置は、前記決定手段が採用した音声認識結果に基づいて、前記ユーザに情報を提供する情報提供手段をさらに有することを特徴としてもよい。
情報提供手段は、音声を認識した結果に基づいて、ユーザに対して情報を提供する手段である。提供される情報は、例えば、目的地までの経路情報、経路に関連付いた情報、ウェブ検索結果、データベースに対する検索結果、他のサーバに対する検索結果などであるが、これに限られない。また、音声認識結果に応じてコンピュータに処理を行わせ、当該処理の結果を情報として提供してもよい。
なお、本発明は、上記手段の少なくとも一部を含む音声認識装置として特定することができる。また、前記音声認識装置が行う音声認識方法として特定することもできる。上記処理や手段は、技術的な矛盾が生じない限りにおいて、自由に組み合わせて実施することができる。
本発明によれば、認識精度と速度を両立させた音声認識装置を提供することができる。
以下、本発明の好ましい実施形態について図面を参照しながら説明する。
本実施形態に係る情報提供システムは、車両に搭乗している乗員(例えば運転者)から音声コマンドを取得して音声認識を行い、認識結果に基づいて、対応する情報を収集して乗員に提供するシステムである。
本実施形態に係る情報提供システムは、車両に搭乗している乗員(例えば運転者)から音声コマンドを取得して音声認識を行い、認識結果に基づいて、対応する情報を収集して乗員に提供するシステムである。
<システム構成>
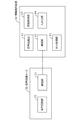
図1は、本実施形態に係る情報提供システムのシステム構成図である。
本実施形態に係る情報提供システムは、情報提供装置10と情報提供サーバ20から構成される。
図1は、本実施形態に係る情報提供システムのシステム構成図である。
本実施形態に係る情報提供システムは、情報提供装置10と情報提供サーバ20から構成される。
まず、情報提供装置10について説明する。情報提供装置10は、車両の乗員から音声を取得して音声認識を行う機能と、音声認識の結果に基づいて情報を取得し、取得した情報を車両の乗員に提供する機能を有する装置である。情報提供装置10は、例えば、車載されたカーナビゲーション装置であってもよいし、汎用のコンピュータであってもよい。また、他の車載端末であってもよい。
また、情報提供装置10は、音声認識処理を、自装置ではなく、外部の音声認識装置(音声認識サーバ20)を利用して行う機能を有している。音声認識サーバ20の詳細については後述する。
また、情報提供装置10は、音声認識処理を、自装置ではなく、外部の音声認識装置(音声認識サーバ20)を利用して行う機能を有している。音声認識サーバ20の詳細については後述する。
情報提供装置10は、音声取得部11、音声認識部12、情報取得部13、入出力部14、通信部15から構成される。
音声取得部11は、車両の乗員から音声を取得する手段である。具体的には、不図示のマイクを用いて、音声を電気信号(以下、音声データ)に変換する。取得した音声データは、音声認識部12へ送信される。
音声取得部11は、車両の乗員から音声を取得する手段である。具体的には、不図示のマイクを用いて、音声を電気信号(以下、音声データ)に変換する。取得した音声データは、音声認識部12へ送信される。
音声認識部12は、取得した音声データに対して音声認識を行い、テキストに変換する手段である。音声認識は、既知の技術によって行うことができる。例えば、音声認識部12には、音響モデルと認識辞書が記憶されており、取得した音声データと音響モデルとを比較して特徴を抽出し、抽出した特徴を認識辞書とをマッチングさせることで音声認識を行う。また、音声認識部12は、認識結果(テキスト)とともに、当該認識結果の尤度(すなわち確度)を取得可能な構成となっている。
情報取得部13は、音声認識結果に基づいて乗員に提供する情報を取得する手段である。
提供する情報は、例えば、出発地と目的地を結ぶ経路を表す情報であってもよいし、経路に関連付いた情報や、車両の移動に関連付いた情報であってもよい。また、ウェブ検索結果など、車両の走行と直接関連しない情報であってもよい。例えば、経路情報を提供する場合、「○○(目的地)までの経路」という音声コマンドに応答して経路探索を行い、結果を提示してもよい。また、経路に関連付いた情報を提供する場合、例えば、「○○(目的地)までの所要時間」という音声コマンドに応答して所要時間の推定を行い、結果を提示してもよい。この他にも、自然言語処理によって情報を提供できるものであれば、音声コマンドの内容と提供する情報はどのようなものであってもよい。
提供する情報は、例えば、出発地と目的地を結ぶ経路を表す情報であってもよいし、経路に関連付いた情報や、車両の移動に関連付いた情報であってもよい。また、ウェブ検索結果など、車両の走行と直接関連しない情報であってもよい。例えば、経路情報を提供する場合、「○○(目的地)までの経路」という音声コマンドに応答して経路探索を行い、結果を提示してもよい。また、経路に関連付いた情報を提供する場合、例えば、「○○(目的地)までの所要時間」という音声コマンドに応答して所要時間の推定を行い、結果を提示してもよい。この他にも、自然言語処理によって情報を提供できるものであれば、音声コマンドの内容と提供する情報はどのようなものであってもよい。
入出力部14は、利用者が行った入力操作を受け付け、利用者に対して情報を提示する手段である。本実施形態では一つのタッチパネルディスプレイからなる。すなわち、液晶ディスプレイとその制御手段、タッチパネルとその制御手段から構成される。
通信部15は、通信回線(例えば携帯電話網)を介してネットワークにアクセスすることで、音声認識サーバ20との通信を行う手段である。
通信部15は、通信回線(例えば携帯電話網)を介してネットワークにアクセスすることで、音声認識サーバ20との通信を行う手段である。
音声認識サーバ20は、音声の認識に特化したサーバ装置であり、通信部21および音声認識部22からなる。
通信部21が有する機能は、前述した通信部15と同様であるため、詳細な説明は省略する。また、音声認識部22は、前述した音声認識部12と同様の機能を有するが、有している認識辞書の規模が音声認識部12よりも大きいという点において異なる。すなわち、音声認識部22は、音声認識部12よりも高い精度で音声認識を行うことが可能な構成となっている。
通信部21が有する機能は、前述した通信部15と同様であるため、詳細な説明は省略する。また、音声認識部22は、前述した音声認識部12と同様の機能を有するが、有している認識辞書の規模が音声認識部12よりも大きいという点において異なる。すなわち、音声認識部22は、音声認識部12よりも高い精度で音声認識を行うことが可能な構成となっている。
情報提供装置10および音声認識サーバ20は、いずれもCPU、主記憶装置、補助記憶装置を有する情報処理装置として構成することができる。補助記憶装置に記憶されたプログラムが主記憶装置にロードされ、CPUによって実行されることで、図1に図示した各手段が機能する。なお、図示した機能の全部または一部は、専用に設計された回路を用いて実行されてもよい。
<処理フローチャート>
次に、情報提供装置10が行う具体的な処理の内容について説明する。図2は、情報提供装置10が実行する処理を示したフローチャートである。
まず、ステップS11で、音声取得部11が不図示のマイクを通して車両の乗員から音声を取得する。取得した音声は音声データに変換され、音声認識部12および通信部15へ送信される。
次に、ステップS12で、音声認識部12が、取得した音声データに対して音声認識を行い、音声をテキストに変換する。変換結果のテキストは、尤度とともに情報取得部13へ送信される。
次に、情報提供装置10が行う具体的な処理の内容について説明する。図2は、情報提供装置10が実行する処理を示したフローチャートである。
まず、ステップS11で、音声取得部11が不図示のマイクを通して車両の乗員から音声を取得する。取得した音声は音声データに変換され、音声認識部12および通信部15へ送信される。
次に、ステップS12で、音声認識部12が、取得した音声データに対して音声認識を行い、音声をテキストに変換する。変換結果のテキストは、尤度とともに情報取得部13へ送信される。
次に、ステップS13で、通信部15が、音声認識サーバ20に対して、取得した音声データの送信を開始する。また、情報提供装置10は、音声データの送信と平行してステップS14の処理を行う。送信された音声データは、音声認識部22によってテキストに変換され、変換が完了次第、通信部21および通信部15を介して情報取得部13へ送信される。
ステップS14では、情報取得部13が、ローカルでの音声認識の成否(すなわち、音声認識結果が得られたか否か)を判定する。この結果、音声認識結果が得られた場合、処理はステップS15へ遷移する。
ステップS15では、情報取得部13が、音声認識部12が音声認識を行った際の尤度(以下、ローカル尤度)が予め定められた閾値以上であるか否かを判定する。この結果、ローカル尤度が、閾値を上回っていた場合、ローカルでの音声認識結果を採用し、提供する情報を生成する(ステップS16)。
ローカル尤度が閾値を下回っていた場合、入出力部14を通して、音声認識部12が音声認識を行った結果をユーザに提示し、正しいか否かの確認を求める(ステップS17)。問い合わせは、画面を通して行ってもよいし、音声で行ってもよい。ここで行う確認は、認識結果をそのまま提示するものであってもよいし、認識結果に基づいて文脈の解釈を行い、その結果を提示するものであってもよい。
例えば、問い合わせの内容は、「入力されたコマンドは『○○駅周辺のレストランを教えて』でよろしいですか?」といったものであってもよいし、「○○駅周辺のレストランを検索してよろしいですか?」といったものであってもよい。
例えば、問い合わせの内容は、「入力されたコマンドは『○○駅周辺のレストランを教えて』でよろしいですか?」といったものであってもよいし、「○○駅周辺のレストランを検索してよろしいですか?」といったものであってもよい。
この結果、回答が肯定的であった場合、すなわち、認識結果が正しい旨の回答が得られた場合、ローカルでの音声認識結果を採用し、提供する情報を生成する(ステップS16)。
一方、ステップS17において否定的な回答が得られた場合、すなわち、認識結果が誤っている旨の回答が得られた場合、情報提供装置10は、音声認識サーバ20が音声認識を行った結果を取得し、採用を試みる。
当該処理について、図3(A)を参照しながら説明する。図3(A)に示した処理は、情報取得部13が行う処理である。
まず、ステップS21で、音声認識サーバ20から取得した認識結果があるか否かを判定する。ここで、認識結果が取得できていない場合、ステップS25へ遷移し、音声の再取得を行う。なお、認識結果が取得できていないとは、認識ができなかった旨の応答を受信した場合や、タイムアウト時間を経過しても応答が得られなかった場合を含む。
まず、ステップS21で、音声認識サーバ20から取得した認識結果があるか否かを判定する。ここで、認識結果が取得できていない場合、ステップS25へ遷移し、音声の再取得を行う。なお、認識結果が取得できていないとは、認識ができなかった旨の応答を受信した場合や、タイムアウト時間を経過しても応答が得られなかった場合を含む。
音声認識サーバ20から送信された認識結果がある場合、当該認識結果が、ローカルでの認識結果と同一であるか否かを判定する(ステップS22)。この結果、同一であった場合、ローカルとサーバのどちらの認識結果も誤りであるため、ステップS25へ遷移し、音声の再取得を行う。
ローカルでの認識結果とサーバでの認識結果が異なる場合、ステップS23へ遷移し、サーバが音声認識を行った結果をユーザに提示し、確認を求める。確認方法は、ステップS17で行ったものと同様のものであってもよい。
この結果、回答が肯定的であった場合(すなわち、認識結果が正しい旨の回答が得られた場合)、ステップS24へ遷移し、サーバにおける音声認識結果を採用する。また、否定的な回答が得られた場合(すなわち、認識結果が誤っている旨の回答が得られた場合)、ステップS25へ遷移し、音声の再取得を行う。
この結果、回答が肯定的であった場合(すなわち、認識結果が正しい旨の回答が得られた場合)、ステップS24へ遷移し、サーバにおける音声認識結果を採用する。また、否定的な回答が得られた場合(すなわち、認識結果が誤っている旨の回答が得られた場合)、ステップS25へ遷移し、音声の再取得を行う。
一方、ステップS14において、ローカルでの音声認識が失敗していた場合、情報提供装置10は、音声認識サーバ20が音声認識を行った結果を取得し、採用を試みる。
当該処理について、図3(B)を参照しながら説明する。図3(B)に示した処理は、情報取得部13が行う処理である。
まず、ステップS21で、音声認識サーバ20から取得した認識結果があるか否かを判定する。ここで、認識結果が取得できていない場合、ステップS25へ遷移し、音声の再取得を行う。一方、音声認識サーバ20から送信された認識結果がある場合、ステップS24へ遷移し、サーバにおける音声認識結果を採用する。
すなわち、図3(B)の処理は、サーバにおける認識結果をユーザに提示する処理を省略するという点において、図3(A)の処理と相違する。
当該処理について、図3(B)を参照しながら説明する。図3(B)に示した処理は、情報取得部13が行う処理である。
まず、ステップS21で、音声認識サーバ20から取得した認識結果があるか否かを判定する。ここで、認識結果が取得できていない場合、ステップS25へ遷移し、音声の再取得を行う。一方、音声認識サーバ20から送信された認識結果がある場合、ステップS24へ遷移し、サーバにおける音声認識結果を採用する。
すなわち、図3(B)の処理は、サーバにおける認識結果をユーザに提示する処理を省略するという点において、図3(A)の処理と相違する。
以上説明したように、本実施形態に係る情報提供装置は、ローカルにおける音声認識結果の尤度が閾値を下回っていた場合に、認識結果をユーザに確認させ、回答が否定的であった場合に限って、サーバにおける音声認識結果を採用する処理を実行する。
かかる構成によると、ローカルでの認識結果に疑義がある場合に、サーバにおける認識結果を無条件に採用するのではなく、ユーザへの問い合わせを挟んだうえで、どちらを採用するか判断するため、応答性を高めつつ、認識精度を確保することができる。
かかる構成によると、ローカルでの認識結果に疑義がある場合に、サーバにおける認識結果を無条件に採用するのではなく、ユーザへの問い合わせを挟んだうえで、どちらを採用するか判断するため、応答性を高めつつ、認識精度を確保することができる。
(変形例)
上記の実施形態はあくまでも一例であって、本発明はその要旨を逸脱しない範囲内で適宜変更して実施しうる。
例えば、ステップS15における閾値は、固定値でなくてもよい。例えば、学習結果に基づいて設定された動的な値であってもよい。
また、音声認識を行った結果、結果が二つ以上得られた場合、ステップS17またはS23の処理において、順番に内容を提示して問い合わせを行ってもよい。
上記の実施形態はあくまでも一例であって、本発明はその要旨を逸脱しない範囲内で適宜変更して実施しうる。
例えば、ステップS15における閾値は、固定値でなくてもよい。例えば、学習結果に基づいて設定された動的な値であってもよい。
また、音声認識を行った結果、結果が二つ以上得られた場合、ステップS17またはS23の処理において、順番に内容を提示して問い合わせを行ってもよい。
また、音声認識サーバから音声認識の尤度(以下、サーバ尤度)を取得できる場合、サーバ尤度に基づいて、ステップS23を実行するか省略するかを決定してもよい。例えば、サーバ尤度が所定の閾値を上回る場合、ステップS23を省略してステップS24を実行するようにしてもよい。
また、実施形態の説明では、ステップS13で音声認識サーバに対する音声の送信を開
始したが、音声認識サーバに対する音声の送信は、ステップS21以降で行ってもよい。このようにすることで、通信量を削減することができる。
始したが、音声認識サーバに対する音声の送信は、ステップS21以降で行ってもよい。このようにすることで、通信量を削減することができる。
10・・・情報提供装置
20・・・音声認識サーバ
11・・・音声取得部
12,22・・・音声認識部
13・・・情報取得部
14・・・入出力部
15,21・・・通信部
20・・・音声認識サーバ
11・・・音声取得部
12,22・・・音声認識部
13・・・情報取得部
14・・・入出力部
15,21・・・通信部
Claims (8)
- ユーザから取得した音声を認識する音声認識装置であって、
前記ユーザから音声を取得する音声取得手段と、
前記音声を認識し、第一の認識結果と、前記第一の認識結果に対応する確度を取得する認識手段と、
前記音声を、自装置とは異なる第二の音声認識装置に認識させた結果である第二の認識結果を取得する情報取得手段と、
前記認識手段が音声を認識した際の確度が所定の値以上である場合に、前記第一の認識結果を採用し、確度が所定の値を下回る場合に、前記ユーザに問い合わせを行い、当該問い合わせに対する回答に基づいて、前記第一の認識結果または前記第二の認識結果のどちらを採用するかを決定する決定手段と、を有する、
音声認識装置。 - 前記決定手段は、前記確度が所定の値を下回る場合に、前記第一の認識結果が正しいかを前記ユーザに問い合わせ、回答が肯定的であった場合に前記第一の認識結果を採用する、
請求項1に記載の音声認識装置。 - 前記決定手段は、前記回答が否定的であり、かつ、前記第一の認識結果と第二の認識結果が異なる場合に、前記第二の認識結果を採用する、
請求項2に記載の音声認識装置。 - 前記決定手段は、前記回答が否定的であり、かつ、前記第一の認識結果と第二の認識結果が異なる場合に、前記第二の認識結果が正しいかを前記ユーザに問い合わせ、回答が肯定的であった場合に前記第二の認識結果を採用する、
請求項2に記載の音声認識装置。 - 前記情報取得手段は、前記音声取得手段が取得した音声を前記第二の音声認識装置に送信し、前記回答が否定的であった場合に前記第二の認識結果を取得する、
請求項2から4のいずれかに記載の音声認識装置。 - 前記第二の音声認識装置は、前記決定手段と無線ネットワーク経由で通信を行う装置であり、自装置よりも音声認識の精度が高い装置である、
請求項1から5のいずれかに記載の音声認識装置。 - 前記決定手段が採用した音声認識結果に基づいて、前記ユーザに情報を提供する情報提供手段をさらに有する、
請求項1から6のいずれかに記載の音声認識装置。 - ユーザから取得した音声を認識する音声認識装置が行う音声認識方法であって、
前記ユーザから音声を取得する音声取得ステップと、
前記音声を認識し、第一の認識結果と、前記第一の認識結果に対応する確度を取得する認識ステップと、
前記認識ステップにおいて音声を認識した際の確度が所定の値以上である場合に、前記第一の認識結果を採用し、確度が所定の値を下回る場合に、前記ユーザに問い合わせを行い、当該問い合わせに対する回答に基づいて、前記第一の認識結果か、または、前記音声を、前記音声認識装置とは異なる第二の音声認識装置に認識させた結果である第二の認識結果のどちらを採用するかを決定する、
音声認識方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016066312A JP2017181667A (ja) | 2016-03-29 | 2016-03-29 | 音声認識装置および音声認識方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016066312A JP2017181667A (ja) | 2016-03-29 | 2016-03-29 | 音声認識装置および音声認識方法 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2017181667A true JP2017181667A (ja) | 2017-10-05 |
Family
ID=60005329
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016066312A Pending JP2017181667A (ja) | 2016-03-29 | 2016-03-29 | 音声認識装置および音声認識方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2017181667A (ja) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019139211A (ja) * | 2018-02-09 | 2019-08-22 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | 音声ウェイクアップ方法及び装置 |
| CN114639395A (zh) * | 2020-12-16 | 2022-06-17 | 观致汽车有限公司 | 车载虚拟人物的语音控制方法、装置及具有其的车辆 |
-
2016
- 2016-03-29 JP JP2016066312A patent/JP2017181667A/ja active Pending
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019139211A (ja) * | 2018-02-09 | 2019-08-22 | バイドゥ オンライン ネットワーク テクノロジー (ベイジン) カンパニー リミテッド | 音声ウェイクアップ方法及び装置 |
| US11322138B2 (en) | 2018-02-09 | 2022-05-03 | Baidu Online Network Technology (Beijing) Co., Ltd. | Voice awakening method and device |
| CN114639395A (zh) * | 2020-12-16 | 2022-06-17 | 观致汽车有限公司 | 车载虚拟人物的语音控制方法、装置及具有其的车辆 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9583100B2 (en) | Centralized speech logger analysis | |
| US9564132B2 (en) | Communication system and method between an on-vehicle voice recognition system and an off-vehicle voice recognition system | |
| US8903651B2 (en) | Information terminal, server device, searching system, and searching method thereof | |
| US10679620B2 (en) | Speech recognition arbitration logic | |
| JP5958475B2 (ja) | 音声認識端末装置、音声認識システム、音声認識方法 | |
| US9159322B2 (en) | Services identification and initiation for a speech-based interface to a mobile device | |
| US8909153B2 (en) | Vehicle communications using a mobile device | |
| US9183835B2 (en) | Speech-based user interface for a mobile device | |
| CN109285541B (zh) | 语音识别系统及语音识别方法 | |
| EP2518447A1 (en) | System and method for fixing user input mistakes in an in-vehicle electronic device | |
| US20140066053A1 (en) | Automatically managing a wireless connection at a mobile device | |
| US20130103404A1 (en) | Mobile voice platform architecture | |
| JP2008256659A (ja) | 車両用ナビゲーション装置 | |
| JP2009300537A (ja) | 音声作動システム、音声作動方法および車載装置 | |
| JP6281202B2 (ja) | 応答制御システム、およびセンター | |
| JP2003241788A (ja) | 音声認識装置及び音声認識システム | |
| JP2017181667A (ja) | 音声認識装置および音声認識方法 | |
| US11195535B2 (en) | Voice recognition device, voice recognition method, and voice recognition program | |
| JP2014062944A (ja) | 情報処理装置 | |
| JPWO2010073406A1 (ja) | 情報提供装置、通信端末、情報提供システム、情報提供方法、情報出力方法、情報提供プログラム、情報出力プログラムおよび記録媒体 | |
| JP2020112728A (ja) | 情報処理装置および情報処理方法 | |
| JP2018194849A (ja) | 情報処理装置 |