JP2019012477A - 診断プログラム、診断方法及び診断装置 - Google Patents
診断プログラム、診断方法及び診断装置 Download PDFInfo
- Publication number
- JP2019012477A JP2019012477A JP2017129803A JP2017129803A JP2019012477A JP 2019012477 A JP2019012477 A JP 2019012477A JP 2017129803 A JP2017129803 A JP 2017129803A JP 2017129803 A JP2017129803 A JP 2017129803A JP 2019012477 A JP2019012477 A JP 2019012477A
- Authority
- JP
- Japan
- Prior art keywords
- delay
- correlation
- resource
- degree
- data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images


































Landscapes
- Debugging And Monitoring (AREA)
Abstract
【課題】アプリの性能低下がクラウド基盤に原因があるのかアプリに原因があるのかを特定すること。【解決手段】遅延判定部41が遅延度合情報を遅延情報作成装置2から取得してアプリに遅延が発生したか否かを判定し、第1相関分析部42と第2相関分析部44が遅延が発生したアプリに関係するリソースデータと遅延度合との相関分析を行う。そして、遅延原因診断部46が、第1相関分析部42と第2相関分析部44の相関分析結果に基づいて遅延原因を特定する。【選択図】図2
Description
本発明は、診断プログラム、診断方法及び診断装置に関する。
顧客にリソース(Resource)を提供するシステムでは、提供するリソースの状況を監視してリソースに問題がないかを確認することが重要となる。例えば、仮想マシンを提供するクラウドシステムでは、仮想マシン上で動作するアプリケーションの応答時間や負荷を監視してアプリケーションの性能に問題がないかを確認することが重要である。
ここで、仮想マシンとは、物理マシン(コンピュータ)上で動作する仮想的なコンピュータである。また、クラウドシステムとは、ネットワークを介して利用者にコンピュータのハードウェアやソフトウェアを提供するシステムである。
アプリケーションの性能に関するデータの収集にはエージェントが用いられる。図38は、エージェントによる監視を説明するための図である。図38に示すように、物理マシン9では仮想マシン9aが動作し、仮想マシン9aによりアプリとエージェントが実行される。ここで、アプリは、アプリケーションである。エージェントは、アプリから性能に関するデータを収集してアプリの性能を監視する。
なお、論理的サーバ構成である複数のインスタンスに割り当てられたリソースの性能劣化を検出するとともに、性能劣化を呈するリソースを共有するインスタンスを抽出し、抽出したインスタンスの性能傾向と、性能パターンを比較する技術がある。ここで、性能パターンは、ボトルネック要因と関連付けてリソースの性能情報から抽出した特徴量を示す。この技術によれば、インスタンスの性能傾向との類似度が最大となる性能パターンからボトルネック要因を推定することができる。
また、連携してサービスを提供する複数のリソース各々に関する複数の情報を異なる管理装置から取得し、取得した複数の情報間の相関関係と所定の相関関係との差に基づいて、異常を発生させる原因となった異常原因リソースを特定する技術がある。この技術は、複数の情報間の相関関係と所定の相関関係との差が許容値よりも大きくなったリソースを異常リソース候補として抽出し、サービスにおける複数のリソース構成を示す構成情報に基づいて、異常リソース候補の中から異常原因リソースを特定する。この技術によれば、異常原因リソースを適切に特定することができる。
図38に示した性能監視には、各アプリケーションの性能を監視することはできるが、アプリケーションの性能低下がクラウド基盤に原因があるのかアプリケーションに原因があるのかを特定することができないという問題がある。ここで、クラウド基盤とは、サーバ、ネットワーク、ストレージ等のICT(Information and Communication Technology)インフラを仮想化技術を利用して提供する基盤である。クラウド基盤は、仮想マシン管理、ストレージ管理、ネットワーク管理等の機能を備える。
本発明は、一つの側面では、アプリケーションの性能低下がクラウド基盤に原因があるのかアプリケーションに原因があるのかを特定することを目的とする。
1つの態様では、診断プログラムは、コンピュータに、アプリケーション毎に実行の遅延を示す遅延度合を取得して遅延度合が所定の閾値以上であるか否かを判定する処理を実行させる。そして、診断プログラムは、コンピュータに、遅延度合が所定の閾値以上であると判定した場合に、アプリケーションに関係するリソースに関する情報と遅延度合との相関関係に基づいて遅延の原因を特定する処理を実行させる。
1つの側面では、本発明は、アプリケーションの性能低下がクラウド基盤に原因があるのかアプリケーションに原因があるのかを特定することができる。
以下に、本願の開示する診断プログラム、診断方法及び診断装置の実施例を図面に基づいて詳細に説明する。なお、実施例は開示の技術を限定するものではない。
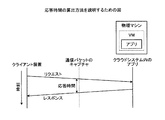
まず、実施例1に係る診断装置による遅延原因診断について説明する。図1は、実施例1に係る診断装置による遅延原因診断を説明するための図である。図1に示すように、実施例1に係る診断装置は、アプリに関係するVM(Virtual Machine:仮想マシン)のリソースデータと遅延度合との相関分析を行う(t1)。
ここで、アプリに関係するVMは、アプリが利用するVMであり、複数ある場合がある。例えば、Webサーバ、アプリサーバ、DB(Database)サーバから成る3階層システムでは、1つのアプリに関係するVMは3つある。遅延度合は、アプリの遅延の度合である。
リソースデータには、VMのリソース毎にリソース負荷量を表すデータとリソース性能低下の影響を受けるデータの2種類のデータがある。例えば、リソースがCPU(Central Processing Unit)の場合には、リソース負荷量を表すデータにはCPU使用率があり、リソース性能低下の影響を受けるデータにはCPUの割り当て待ち時間の割合がある。図1は、リソースがCPUの場合を示す。
また、リソースがディスク装置の場合には、リソース負荷量を表すデータにはRead発行数、読み込み量、Write発行数、書き込み量等があり、リソース性能低下の影響を受けるデータには平均Read時間、平均Write時間等がある。また、リソースがネットワークの場合には、リソース負荷量を表すデータにはパケット数、通信量等があり、リソース性能低下の影響を受けるデータにはラウンドトリップ時間、パケットのドロップ率等がある。
実施例1に係る診断装置は、アプリに関係するVMのリソース毎に、リソース負荷量を表すデータと遅延度合との相関分析、リソース性能低下の影響を受けるデータと遅延度合との相関分析を行う。
そして、遅延度合が、あるVMのCPUのリソースデータと相関がない場合には、実施例1に係る診断装置は、遅延とこのVMのCPUとは関係ないと診断する(t2)。また、遅延度合がCPU使用率と相関がある場合には、実施例1に係る診断装置は、アプリ要因による遅延と診断する(t3)。
また、遅延度合がCPUの割り当て待ち時間の割合と相関がある場合には、実施例1に係る診断装置は、遅延度合がCPUの割り当て待ち時間の割合と相関があったVMとCPUを共有している全VMについてCPU使用率と遅延度合との相関分析を行う(t4)。ここで、遅延度合がCPUの割り当て待ち時間の割合と相関があったVMとCPUを共有している全VMには、遅延度合がCPUの割り当て待ち時間の割合と相関のあったVMも含まれる。
そして、遅延度合が他VMのCPU使用率と相関があった場合には、他VMがCPUを大量に使うことによりCPU負荷が上昇し、遅延が発生しているため、実施例1に係る診断装置は、CPU要因すなわちクラウド基盤要因による遅延と診断する(t5)。また、遅延度合がいずれのVMのCPU使用率とも相関がない場合には、実施例1に係る診断装置は、CPU負荷上昇の原因不明と診断する(t6)。また、遅延度合がCPU負荷の影響を受けているVM自体のCPU使用率と相関がある場合には、遅延しているアプリのVM自身がCPUの負荷を上昇させ遅延が発生してるため、実施例1に係る診断装置は、アプリ要因による遅延と診断する(t3)。
このように、実施例1に係る診断装置は、アプリに関係するVMのリソース毎に、リソース負荷量を表すデータと遅延度合との相関分析、リソース性能低下の影響を受けるデータと遅延度合との相関分析を行う。そして、遅延度合がリソース性能低下の影響を受けるデータとの相関がある場合には、実施例1に係る診断装置は、遅延度合がリソース性能低下の影響を受けるデータと相関があったVMとリソースを共有している全VMについてリソース負荷量を表すデータとの相関分析を行う。そして、実施例1に係る診断装置は、これらの相関分析の結果に基づいて、アプリの遅延原因を診断する。したがって、実施例1に係る診断装置は、アプリの性能低下がクラウド基盤に原因があるのかアプリに原因があるのかを特定することができる。
次に、実施例1に係るクラウドシステムの構成について説明する。図2は、実施例1に係るクラウドシステムの構成を示す図である。図2に示すように、実施例1に係るクラウドシステム1は、遅延情報作成装置2と、診断装置4と、VM情報記憶部31と、リソースデータ記憶部32と、構成情報記憶部33と、リソース34とを有する。リソース34には、CPU、ディスク装置、ネットワークスイッチが含まれる。
遅延情報作成装置2は、アプリの遅延度合情報を作成し、作成した遅延度合情報を遅延度合情報記憶部30に記憶する。図3は、遅延情報作成装置2の構成を示す図である。図3に示すように、遅延情報作成装置2は、キャプチャ部21と、パケット情報記憶部22と、種別判定用データ記憶部23と、種別判定部24と、種別情報記憶部25と、応答時間算出部26と、応答時間情報記憶部27とを有する。また、遅延情報作成装置2は、正規化部28と、代表情報記憶部29と、遅延度合情報記憶部30とを有する。
キャプチャ部21は、ネットワークスイッチ3cを通過する通信パケットをポートミラーリングによりキャプチャし、キャプチャした通信パケットの情報をパケット情報記憶部22に格納する。パケット情報記憶部22は、ネットワークスイッチ3cを通過する通信パケットの情報を記憶する。
種別判定用データ記憶部23は、アプリの種別を判定するためのデータを記憶する。アプリの種別には、応答時間が性能面で重要となるアプリとその他のアプリとがある。遅延情報作成装置2は、応答時間が性能面で重要となるアプリを遅延度合情報作成の対象とする。
種別判定部24は、種別判定用データ記憶部23が記憶するデータを用いて通信コネクション毎にアプリの種別を判定する。図4は、種別判定用データ記憶部23の一例を示す図である。図4(a)は、アプリの種別を判定するためのデータとしてポート番号のリストであるポートリストを記憶する場合を示す。図4(a)において、種別判定用データ記憶部23が記憶するポート番号は、応答時間が性能面で重要となるアプリが使用するポート番号である。例えば、種別判定用データ記憶部23は、応答時間が性能面で重要となるアプリが使用するポート番号として、「80」、「443」等を記憶する。
種別判定部24は、パケット情報記憶部22に記憶された通信パケットの情報を解析し、サーバ側のポート番号を抽出する。ここで、サーバとは、仮想マシンである。そして、種別判定部24は、抽出したポート番号が種別判定用データ記憶部23が記憶するポートリストに含まれる場合に、解析した通信パケットに送信又は受信するアプリを応答時間が性能面で重要となるアプリとして判定する。そして、種別判定部24は、判定結果を種別情報記憶部25に格納する。
また、種別判定部24は、ポート番号からアプリの種別が判定できないアプリについては、通信パターンを入力として機械学習によってアプリの種別を判定する。
具体的には、種別判定部24は、あらかじめ、応答時間が性能面で重要となるアプリ及びその他のアプリについて、通信パケットを収集しておく。そして、種別判定部24は、収集した通信パケットを解析して一定時間間隔(例えば1分)の平均応答時間、サーバの平均通信量、サーバの平均通信回数、クライアント装置の平均通信量、及びクライアント装置の平均通信回数を計算する。
そして、種別判定部24は、計算した値を学習データとして、学習器を構築する。学習器としては、SVM(Support Vector Machine)、ランダムフォレスト等が利用可能である。図4(b)は、種別判定用データ記憶部23がアプリの種別を判定するためのデータとして学習データを記憶する場合を示す。図4(b)に示すように、種別判定用データ記憶部23は、アプリの種別、平均応答時間、サーバの平均通信量、サーバの平均通信回数、クライアント装置の平均通信量、及びクライアント装置の平均通信回数を一つの学習データとして記憶する。平均応答時間の単位はマイクロ秒であり、サーバの平均通信量及びクライアント装置の平均通信量の単位はバイトである。
図4(b)では、アプリの種別が「応答時間が性能面で重要となるアプリ」について二つの学習データが示され、アプリの種別が「その他のアプリ」について一つの学習データが示されている。アプリの種別が「応答時間が性能面で重要となるアプリ」の学習データの一つでは、平均応答時間が「600」であり、サーバの平均通信量は「100」であり、サーバの平均通信回数は「1」である。また、その学習データでは、クライアント装置の平均通信量は「100」であり、クライアント装置の平均通信回数は「1」である。
そして、種別判定部24は、キャプチャされた通信パケットから通信コネクション毎に学習データと同じ時間間隔の平均応答時間、サーバの平均通信量、サーバの平均通信回数、クライアント装置の平均通信量、及びクライアント装置の平均通信回数を計算する。そして、種別判定部24は、計算した値から、学習器を利用して通信コネクションに対応するアプリの種別を判定する。そして、種別判定部24は、判定結果を種別情報記憶部25に格納する。
種別情報記憶部25は、アプリの種別の判定結果を記憶する。図5は、種別情報記憶部25の一例を示す図である。図5に示すように、種別情報記憶部25は、IPアドレス、ポート番号及び種別をアプリ毎に記憶する。IPアドレスは、アプリが稼働しているVMのIPアドレスである。ポート番号は、アプリが使用するポート番号である。種別は、アプリの種別である。例えば、IPアドレスが「10.20.30.40」であるVMで稼働するアプリは、使用するポート番号は「80」であり、「応答時間が性能面で重要となるアプリ」である。
応答時間算出部26は、応答時間が性能面で重要となるアプリに関して、通信パケットを解析して応答時間を算出し、算出した応答時間を応答時間情報記憶部27に格納する。応答時間算出部26は、通信パケットが暗号化されていない場合には、プロトコルメッセージを再構築し、リクエストの時刻とレスポンスの時刻より応答時間を算出する。
すなわち、応答時間算出部26は、通信パケットからプロトコルメッセージを再構成して、どの通信パケットがリクエストメッセージであり、どの通信パケットがレスポンスメッセージなのかを判定する。そして、応答時間算出部26は、リクエストメッセージが送信されてからレスポンスメッセージが返ってくるまでの時間を応答時間として算出する。
図6は、応答時間の算出方法を説明するための図である。図6に示すように、クライアント装置が送信したリクエストメッセージがクラウドシステム1内のVMで稼働するアプリにより処理され、レスポンスメッセージがアプリからクライアント装置に送信される。応答時間算出部26は、リクエストメッセージがキャプチャされた時刻とレスポンスメッセージがキャプチャされた時刻の間の時間を応答時間とする。
応答時間算出部26は、通信パケットが暗号化されている場合には、通信パケットの送受のフローを解析することによって、アプリの応答時間を推定する。通信パケットが暗号化されている場合、応答時間算出部26は、通信パケットの内部が見られないためにプロトコルの解析ができないので、リクエストメッセージやレスポンスメッセージを再構成することができない。そこで、応答時間算出部26は、アプリ側から一方的にデータをリアルタイムに送信するための技術である「ロングポーリング」を考慮し、クライアント装置とクラウドシステム1上のアプリの通信パケットの時間間隔から応答時間を推定する。
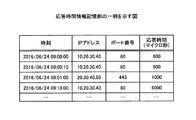
応答時間情報記憶部27は、応答時間算出部26によりアプリ毎に算出された応答時間を記憶する。図7は、応答時間情報記憶部27の一例を示す図である。図7に示すように、応答時間情報記憶部27は、時刻と、IPアドレスと、ポート番号と、応答時間とを対応付けて記憶する。
時刻は、応答時間が算出された時刻である。IPアドレスは、アプリが稼働しているVMのIPアドレスである。ポート番号は、アプリが使用するポート番号である。応答時間は、応答時間算出部26により算出された応答時間である。応答時間の単位はマイクロ秒である。例えば、IPアドレスが「10.20.30.40」であるVMで稼働し、使用するポート番号が「80」であるアプリの「2016/06/24 09:00:00」の応答時間は、「600」である。
正規化部28は、応答時間算出部26により算出された応答時間を応答時間情報記憶部27から読み出し、アプリ毎の平均応答時間を算出する。そして、正規化部28は、代表情報記憶部29に記憶された情報を用いて平均応答時間の正規化を行い、正規化した平均応答時間を遅延度合情報として遅延度合情報記憶部30に格納する。
図8は、平均応答時間の正規化を説明するための図である。応答時間は、アプリによって、正常時にとりうる値や、遅延とみなす基準が異なる。このため、アプリの応答時間をそのまま用いただけでは、アプリに遅延があるのか判断することは困難である。そこで、遅延情報作成装置2は、平均応答時間を正規化して、アプリ間で比較可能な尺度に変換する。図8では、正常時にとりうる値が異なるアプリ#1とアプリ#2について、平均応答時間を正規化することによって、応答時間の比較が可能となっている。
正規化部28は、平均応答時間tの基本統計量trを代表応答時間として、正規化された平均応答時間tnをtn=t/trにより計算する。基本統計量には、平均、中央値、最頻値等がある。
代表情報記憶部29は、代表応答時間をアプリ毎に記憶する。図9は、代表情報記憶部29の一例を示す図である。図9に示すように、代表情報記憶部29は、時刻と、IPアドレスと、ポート番号と、応答時間をアプリ毎に記憶する。
時刻は、代表応答時間が計算された時刻である。IPアドレスは、アプリが稼働しているVMのIPアドレスである。ポート番号は、アプリが使用するポート番号である。応答時間は、代表応答時間である。代表応答時間の単位はマイクロ秒である。例えば、IPアドレスが「10.20.30.40」であるVMで稼働し、使用するポート番号が「80」であるアプリの「2016/06/23 00:00:00」に計算された代表応答時間は、「600」である。
正規化部28は、アプリ毎に一定時間間隔(例えば1分)毎の平均応答時間tを計算し、平均応答時間tの基本統計量trを計算する。基本統計量を計算するためのデータとしては前日の1日分のデータ等が用いられる。一定時間間隔が1分の場合は、1日分のデータから60*24=1440のサンプルデータが得られる。
また、正規化部28は、基本統計量trの代わりに、平均応答時間の分布をex−Gaussian分布でフィッティングさせたときのμを代表応答時間としてもよい。図10は、ex−Gaussian分布を説明するための図である。ex−Gaussian分布は、確率分布の一つであり、図10(a)に示すように、ガウス分布(正規分布)と指数分布を畳込み積分したものである。ex−Gaussian分布は、正規分布の平均μ及び標準偏差σと、指数分布の平均及び標準偏差τの3つのパラメータにより決定される。ex−Gaussian分布では、μは、図10(b)に示すように、分布のピークの部分の値になる。
正規化部28は、アプリ毎に一定時間間隔(例えば1分)毎の平均応答時間tを計算し、平均応答時間の分布をex−Gaussian分布でフィッティングする。ex−Gaussian分布へのフィッティングのためのデータとしては前日の1日分のデータ等が用いられる。一定時間間隔が1分の場合は、1日分のデータから60*24=1440のサンプルデータが得られる。
そして、正規化部28は、フィッティングの確からしさを一標本コルモゴロフ−スミルノフ検定で判定する。一標本コルモゴロフ−スミルノフ検定の入力は、平均応答時間の分布と、フィッティング結果の分布曲線との二つである。正規化部28は、有意水準を例えば0.05で検定し、検定した結果、平均応答時間の分布がex−Gaussian分布であった場合、ex−Gaussian分布のμを代表平均応答時間とする。
なお、正規化部28は、平均応答時間の分布をex−Gaussian分布でフィッティングする前に外れ値除去を行ってもよい。図11は、外れ値を説明するための図である。図11に示すように、外れ値は、他の値から大きく外れた値である。平均応答時間に外れ値がある場合、ex−Gaussian分布でうまくフィッティングできない場合がある。このため、正規化部28は、フィッティングの前に外れ値除去を行う。外れ値除去の方法にはTukeyの外れ値除去等がある。
遅延度合情報記憶部30は、正規化部28により正規化された平均応答時間を遅延度合情報としてアプリ毎に記憶する。図12は、遅延度合情報記憶部30の一例を示す図である。図12に示すように、遅延度合情報記憶部30は、時刻と、IPアドレスと、ポート番号と、正規化平均応答時間と、リクエスト数とをアプリ毎に記憶する。
時刻は、応答時間が算出された時刻である。IPアドレスは、アプリが稼働しているVMのIPアドレスである。ポート番号は、アプリが使用するポート番号である。正規化平均応答時間は、正規化された平均応答時間である。リクエスト数は、正規化された平均応答時間の計算に用いられたリクエストの数である。
例えば、IPアドレスが「10.20.30.40」であるVMで稼働し、使用するポート番号が「80」のアプリの「2016/06/24 09:00:00」に算出された応答時間に関して正規化された平均応答時間は「1.0」である。正規化された平均応答時間の計算に用いられたリクエストの数は「2」である。
図2に戻って、診断装置4は、遅延判定部41と、第1相関分析部42と、第1分析結果記憶部43と、第2相関分析部44と、第2分析結果記憶部45と、遅延原因診断部46と、診断結果記憶部47とを有する。
遅延判定部41は、遅延情報作成装置2から正規化応答時間を遅延度合情報として取得し、アプリに遅延が発生しているか否かを判定する。図13は、アプリの遅延判定を説明するための図である。図13に示すように、遅延判定部41は、アプリ毎に、診断対象期間のデータにおいて、遅延度合が閾値Trt以上になった回数を定期的にカウントし、回数が閾値Tdr以上の場合に、アプリが遅延していると判定する。
判定を実行する間隔は、例えば1日である。あるいは、遅延判定部41は、クラウド運用管理者の指示に基づいて遅延判定を行ってもよい。図13では、Trt=10、Tdr=5として、アプリ#2の遅延度合がTrt以上の回数が「5」であるので、アプリ#2に遅延が発生していると判定される。
第1相関分析部42は、遅延判定部41により遅延が発生していると判定された各アプリについて、アプリに関係するVMのリソースデータと遅延度合との相関分析を行うことによって、遅延と関係するリソースデータを絞り込む。第1相関分析部42は、VM情報記憶部31を参照してアプリに関係するVMを特定する。
図14は、VM情報記憶部31の一例を示す図である。図14に示すように、VM情報記憶部31は、変更日時、VMのIPアドレス、ポート番号、関係するVMリストを対応付けてアプリ毎に記憶する。変更日時は、対応する情報が変更された日時である。VMのIPアドレスは、アプリが動作するVMのIPアドレスである。ポート番号は、アプリが使用するポートの番号である。VMのIPアドレスとポート番号の組合せで1つのアプリが特定される。
関係するVMリストは、VMのIPアドレスとポート番号で特定されるアプリに関係するVMのリストである。例えば、IPアドレス「10.20.30.40」とポート番号「80」で特定されるアプリが関係するVMは、「VM#1」と「VM#2」と「VM#3」である。
第1相関分析部42は、リソースデータ記憶部32からVMのリソースデータを取得する。図15は、リソースデータ記憶部32の一例を示す図である。図15に示すように、リソースデータ記憶部32は、時刻、VM名、リソースデータ名、値を対応付けてリソースデータ毎に記憶する。
時刻は、値が取得された時刻である。VM名は、リソースデータがどのVMのものであるか示す。リソースデータ名は、リソースデータを識別する名前である。値は、リソースデータの値である。例えば、「2016/06/24 09:00:00」において、「VM#1」の「CPU使用率」は「10.0」%である。
なお、リソースデータ記憶部32には、リソース34から取得されたデータが記憶される。また、第1相関分析部42は、アプリが関係するVMの情報が得られない場合には、アプリのユーザが利用する全VMのリソースデータとの相関分析を行う。
第1相関分析部42は、相関係数を利用して相関分析を行う。すなわち、第1相関分析部42は、遅延度合とリソースデータとの相関係数を計算し、遅延度合とリソースデータとの間で正の相関があるかを検定する。図16は、リソースデータと遅延度合の関係の例を示す図である。図16では、1つの時刻のリソースデータの値と遅延度合の値の組が点で表される。第1相関分析部42は、図16に示す複数の点の値を用いて相関係数を計算する。
第1相関分析部42は、相関係数として例えばピアソンの相関係数、スピアマンの順位相関係数を用いる。そして、第1相関分析部42は、無相関検定のp−valueを計算する。
第1相関分析部42は、アプリに関係するVMのリソースデータ数の回数の検定を行う。このように、複数回の検定が実行されると、本来相関がないにもかかわらず相関があると判定されるケースの数が増加する。例えば、有意水準が0.05の場合、1回の検定で、相関がないにもかかわらず、相関があると間違えて判定される確率は5%となる。この検定を3回繰り返すと、1度でも間違える可能性は1−(1−0.05)3=14%にまで増加する。
そこで、第1相関分析部42は、誤った判定を減らすために、計算したp−valueを多重検定補正によって補正する。補正方法には、例えば、Benjamini-Hochberg法がある。第1相関分析部42は、補正したp−valueが閾値以下であるリソースデータを遅延度合と相関があると判定する。閾値としては、例えば0.05が用いられる。
なお、第1相関分析部42は、相関係数を用いる相関分析の代わりに、遅延しているときと遅延していないときのリソースデータの傾向に差があるか否かを判定することによって相関分析を行ってもよい。相関係数を用いる場合には、全てのデータが等価に扱われる。このため、相関しているかどうかは数が多い方のデータすなわち遅延していないデータで決まってしまう場合がある。この結果、遅延しているときにリソースデータの値が大きいものを見逃す場合がある。そこで、遅延しているときのリソースデータを分けて扱うことで、第1相関分析部42は、データ数の影響を抑えて、相関しているか否かを判断することができる。
図17は、遅延しているときと遅延していないときのリソースデータの傾向に差があるか否かの判定による相関分析を説明するための図である。図17に示すように、第1相関分析部42は、遅延度合が閾値Trt以上のとき遅延しているとして、遅延しているときと遅延していないときで、リソースデータを分ける。そして、第1相関分析部42は、遅延しているときのリソースデータのほうが、遅延していないときよりも大きくなる傾向にあるかの検定(二群比較検定)のp−valueを計算する。検定方法には、t−検定、Wilcoxonの順位和検定、Mann-WhitneyのU検定等がある。
そして、第1相関分析部42は、計算したp−valueを多重検定補正によって補正する。補正方法には、例えば、Benjamini-Hochberg法がある。第1相関分析部42は、補正したp−valueが閾値以下であるリソースデータを遅延度合と相関があると判定する。閾値としては、例えば0.05が用いられる。
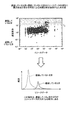
相関分析により相関があると検定された場合でも、相関の強さはデータ毎に異なる。図18Aは、相関が弱い場合と強い場合を示す図である。図18Aに示すように、リソースデータ#1は遅延度合との相関が弱いが、リソースデータ#2は遅延度合との相関が強い。そこで、第1相関分析部42は、アプリの遅延原因のリソース候補を減らすために、相関があるリソースデータのうち、遅延度合とよく相関のあるリソースデータだけを抽出する。
図18Bは、遅延度合とよく相関のあるリソースデータの抽出を説明するための図である。図18Bに示すように、第1相関分析部42は、遅延しているときのデータを利用し、遅延しているときのリソースデータの値を推定する。そして、第1相関分析部42は、推定値よりもリソースデータが大きいときの遅延度合の分布を2つのリソースデータについて比較し、リソースデータが大きいときによく遅延しているリソースデータを特定する。図18Bでは、リソースデータ#2が遅延度合とよく相関のあるリソースデータとして抽出される。
具体的には、第1相関分析部42は、遅延度合と相関のあったリソースデータ毎に以下の手順(1)、(2)を実行する。
(1)第1相関分析部42は、遅延度合が閾値Trt以上のリソースデータの中央値を計算し、Trとする(左斜線網掛けのデータを利用)。
(2)そして、第1相関分析部42は、リソースデータがTr以上の時の遅延度合のデータを抽出する(右斜線網掛けのデータを抽出)。
(1)第1相関分析部42は、遅延度合が閾値Trt以上のリソースデータの中央値を計算し、Trとする(左斜線網掛けのデータを利用)。
(2)そして、第1相関分析部42は、リソースデータがTr以上の時の遅延度合のデータを抽出する(右斜線網掛けのデータを抽出)。
そして、第1相関分析部42は、抽出された遅延度合のデータをSteel Dwass法で検定し、2つのリソースデータの遅延度合の分布に差があると出た回数の最も多いリソースデータを特定する。検定の有意水準には、例えば0.05が用いられる。そして、第1相関分析部42は、差があるとされた回数が最も多いリソースデータと、そのリソースデータとの差がないとされるリソースデータを遅延度合とよく相関があるリソースデータとする。
第1相関分析部42は、相関分析の結果を第1分析結果記憶部43に格納する。図19は、第1分析結果記憶部43の一例を示す図である。図19に示すように、第1分析結果記憶部43は、診断日時、開始時間、終了時間、VMのIPアドレス、ポート番号、VM名、リソース種類、リソースデータ名を対応付けて記憶する。
診断日時は、診断を行った日時である。開始時間は、診断対象期間の開始時間である。終了時間は、診断対象期間の終了時間である。VMのIPアドレスは、アプリが動作するVMのIPアドレスである。ポート番号は、アプリが使用するポートの番号である。VM名は、リソースデータがどのVMのものであるか示す。リソース種類は、遅延に関係のあるリソース34の種類であり、「CPU」、「ディスク装置」、「ネットワーク」等がある。リソースデータ名は、遅延度合と相関のあったリソースデータを識別する名前である。
例えば、「2016/05/24 00:00:00」〜「2016/06/24 00:00:00」を診断対象期間として「2016/06/24 00:00:00」に行った診断において、アプリの遅延度合と相関のあるリソースデータがあった。アプリは、VMのIPアドレス「10.20.30.40」とポート番号「80」で特定され、「VM#3」の「CPUの割り当て待ち時間の割合」とアプリの遅延度合との間に相関があった。
第2相関分析部44は、リソース性能低下の影響を受けるデータと遅延度合の相関があった場合に、リソース性能低下の影響を受けるデータの相関があったVMとリソース34を共有している全VMについてリソース負荷量を表すデータと遅延度合との相関分析を行う。
第2相関分析部44は、リソースデータ記憶部32と、クラウドシステム1の構成情報を記憶する構成情報記憶部33とを参照して相関分析を行う。図20は、構成情報記憶部33の一例を示す図である。図20に示すように、構成情報記憶部33は、変更日時、物理マシン、利用ユーザ、VM名、VMのIPアドレス、利用ディスク名を対応付けてVM毎に記憶する。
変更日時は、対応する情報が変更された日時である。物理マシンは、VMが動作する物理マシンである。利用ユーザは、VMを利用するユーザである。VM名は、VMを識別する名前である。VMのIPアドレスは、VMに付与されたIPアドレスである。利用ディスク名は、VMが利用するディスク装置の名前である。例えば、「VM#1」は「PM#1」で動作して「ディスク#1」を利用し、「VM#1」のユーザは「ユーザ#1」であり、「VM#1」のIPアドレスは「10.20.30.40」である。「VM#1」の情報は「2016/06/24 00:00:00」に変更された。
図21は、第2相関分析部44による相関分析を説明するための図である。リソース性能低下の影響を受けるデータと遅延度合の相関があった場合、リソース34の性能低下の影響を受けてアプリが遅延したと考えられる。このため、第2相関分析部44は、リソース性能低下の影響を受けるデータの相関があったVMとリソース34を共有する全VM(リソース性能低下の影響を受けるデータの相関があったVM自体を含む)を構成情報記憶部33を参照して特定する。図21では、ユーザ#1のVMがリソース性能低下の影響を受けるデータの相関がアプリ#1の遅延度合とあったVMである。また、リソース性能低下の影響を受けるデータの相関があったVMとリソース34を共有する他のVMとしてユーザ#2のVMが特定される。
そして、第2相関分析部44は、特定した各VMのリソース負荷量を表すデータと遅延度合との相関分析をリソースデータ記憶部32を参照して行うことで、特定したVMの中から負荷をかけているVMを特定する。リソース負荷量を表すデータと遅延度合との相関があるVMが負荷をかけているVMである。図21では、ユーザ#2のVMのCPU使用率とアプリ#1の遅延度合との相関が分析される。
そして、第2相関分析部44は、相関分析により相関のあったリソースデータのうち、遅延度合とよく相関のあるリソースデータを抽出する。そして、第2相関分析部44は、抽出したリソースデータについて、相関分析の結果を第2分析結果記憶部45に格納する。
図22は、第2分析結果記憶部45の一例を示す図である。図22に示すように、第2分析結果記憶部45は、診断日時、開始時間、終了時間、VMのIPアドレス、ポート番号、アプリVM、リソース種類、相関VM、リソース負荷量データを対応付けて記憶する。
診断日時は、診断を行った日時である。開始時間は、診断対象期間の開始時間である。終了時間は、診断対象期間の終了時間である。VMのIPアドレスは、アプリが動作するVMのIPアドレスである。ポート番号は、アプリが使用するポートの番号である。アプリVMは、リソース性能低下の影響を受けているデータと遅延度合の相関があったアプリが動作するVMである。リソース種類は、遅延に関係のあるリソース34の種類である。相関VMは、リソース負荷量を表すデータと遅延度合との相関があったVMである。リソース負荷量データは、遅延度合と相関のあったリソース負荷量を表すデータである。
例えば、「2016/05/24 00:00:00」〜「2016/06/24 00:00:00」を診断対象期間として「2016/06/24 00:00:00」に診断が行われた。遅延が発生したアプリは、VMのIPアドレス「10.20.30.40」とポート番号「80」で特定され、「VM#3」で動作する。影響を受けているリソース34の種類は「CPU」であり、「VM#3」と「CPU」を共有する「VM#4」の「CPU使用率」が遅延度合と相関があった。
遅延原因診断部46は、第1分析結果記憶部43と第2分析結果記憶部45を参照してVMのリソースデータの種類毎にアプリの遅延原因を判定する。具体的には、遅延原因診断部46は、アプリに関係するVMのリソース負荷量を表すデータとの相関があった場合は、常に時間のかかるリクエストを処理したことにより、平均応答時間が増加し、遅延しているので、「アプリの要因による遅延」と判定する。
また、遅延原因診断部46は、アプリに関係するVMのリソース性能低下の影響を受けるデータとの相関があった場合は、以下の3つの場合に分けて判定する。第1に、同じVMのリソース負荷量を表すデータとも相関がある場合は、遅延しているアプリのVM自身がリソース34への負荷が上昇させ、遅延が発生しているので、遅延原因診断部46は、「アプリの要因による遅延」と判定する。第2に、リソース34を共有している他VMのリソース負荷量を表すデータと相関がある場合は、他VMがリソース34を大量に使ったことによりリソース負荷が上昇し、遅延が発生しているので、遅延原因診断部46は、「クラウド基盤要因による遅延」と判定する。第3に、リソース34を共有しているVMのリソース負荷量を表すデータと相関がなかった場合は、遅延原因診断部46は、「リソース負荷上昇の原因不明」と判定する。
相関のあったリソース34が複数ある場合は、遅延原因診断部46は、遅延原因を複数出力する。また、遅延原因診断部46は、全てのVMで相関のあったリソースデータがない場合、もしくは逆に多い場合(遅延原因の数が閾値Td以上の場合)、原因を特定できなかったと判定する。
そして、遅延原因診断部46は、判定結果を診断結果記憶部47に格納する。図23は、診断結果記憶部47の一例を示す図である。図23に示すように、診断結果記憶部47は、診断日時、開始時間、終了時間、VMのIPアドレス、ポート番号、遅延割合、アプリVM、リソース種類、リソースデータ、負荷VM、リソース負荷量データ、診断結果を対応付けて記憶する。
診断日時は、診断を行った日時である。開始時間は、診断対象期間の開始時間である。終了時間は、診断対象期間の終了時間である。VMのIPアドレスは、アプリが動作するVMのIPアドレスである。ポート番号は、アプリが使用するポートの番号である。遅延割合は、遅延が発生している合計時間の割合である。アプリVMは、相関のあったアプリが動作するVMである。リソース種類は、遅延に関係のあるリソース34の種類である。リソースデータは、相関のあったアプリのVMのリソースデータである。負荷VMは、リソース34を共有していて負荷をかけているVMである。リソース負荷量データは、リソース34を共有していて負荷をかけているVMの相関のあったリソース負荷量データである。診断結果は、遅延原因診断部46による判定結果である。
例えば、「2016/05/24 00:00:00」〜「2016/06/24 00:00:00」を診断対象期間として「2016/06/24 00:00:00」に診断が行われた。合計時間で「0.10」の割合で遅延が発生したアプリは、VMのIPアドレス「10.20.30.40」とポート番号「80」で特定され、「VM#3」で動作する。遅延に関係のあるリソース34の種類は「CPU」である。「CPUの割り当て待ち時間の割合」が遅延度合と相関があり、「VM#3」と「CPU」を共有する「VM#4」の「CPU使用率」が遅延度合と相関のあったリソース負荷量データであり、遅延原因は「クラウド基盤要因」である。
また、遅延原因診断部46は、アプリの遅延要因として「クラウド基盤要因」が含まれている場合、遅延していたアプリ、アプリの遅延要因、遅延と関係するVMのリソース34等をクラウド運用管理者に通知する。図24は、クラウド運用管理者への通知例を示す図である。図24では、Webサーバ、アプリサーバ、DBサーバから成る3階層システムのDBサーバが他アプリのVMのCPU負荷の影響を受けている場合を示す。
図24に示すように、アプリケーション、診断対象期間、遅延が発生している合計時間の割合、遅延原因、リソース負荷の影響を受けているアプリケーションのVMとリソース34、リソース負荷を与えているVMとリソース34がクラウド運用管理者に通知される。
次に、診断装置4による処理のフローについて図25〜図31を用いて説明する。図25は、診断装置4による処理のフローを示すフローチャートである。図25に示すように、診断装置4は、アプリ数だけステップS1〜ステップS5の処理を繰り返す。すなわち、診断装置4は、アプリの診断対象期間の遅延度合情報を取得する(ステップS1)。
そして、診断装置4は、遅延度合が閾値Trt以上の回数がTdr以上か否かを判定し(ステップS2)、Tdr以上でない場合には、次のアプリを処理する。一方、Tdr以上である場合には、診断装置4は、第1相関分析処理を行う(ステップS3)。ここで、第1相関分析処理は、第1相関分析部42が行う処理である。
そして、診断装置4は、第2相関分析処理を行う(ステップS4)。ここで、第2相関分析処理は、第2相関分析部44が行う処理である。なお、ステップS4の処理は、リソース性能低下の影響を受けるデータと遅延度合との相関があった場合に行われる。そして、診断装置4は、遅延原因診断処理を行う(ステップS5)。ここで、遅延原因診断処理は、遅延原因診断部46が行う処理である。
そして、アプリ数だけステップS1〜ステップS5の処理を繰り返すと、診断装置4は、クラウド基盤要因により応答遅延が発生と診断されたアプリがあるか否かを判定し(ステップS6)、ある場合には、クラウド運用管理者に通知する(ステップS7)。
このように、クラウド基盤要因により応答遅延が発生と診断されたアプリがある場合に診断装置4がクラウド運用管理者に通知することで、クラウド運用管理者はクラウド基盤に関して対策を検討することができる。
図26は、第1相関分析処理のフローを示すフローチャ−トである。図26に示すように、第1相関分析部42は、VM情報記憶部31からアプリに関係するVMの情報を取得し(ステップS11)、リソースデータ記憶部32からアプリに関係する全VMのリソースデータを取得する(ステップS12)。
そして、第1相関分析部42は、アプリの遅延度合とリソースデータとの無相関検定のp−valueを計算する(ステップS13)処理をリソースデータ数だけ繰り返す。そして、第1相関分析部42は、多重検定補正を実行し(ステップS14)、多重検定補正により補正したp−valueが閾値以下のリソースデータのみを抽出する(ステップS15)。
そして、第1相関分析部42は、抽出したリソースデータから、遅延度合とよく相関しているリソースデータを抽出するリソースデータ抽出処理を行う(ステップS16)。そして、第1相関分析部42は、第1分析結果記憶部43に相関分析結果を保存する(ステップS17)。
このように、第1相関分析部42は、アプリの遅延度合とリソースデータとの無相関検定のp−valueを計算し、多重検定補正によりp−valueを補正し、補正したp−valueが閾値以下のリソースデータのみを抽出する。そして、第1相関分析部42は、抽出したリソースデータから、さらに、遅延度合とよく相関しているリソースデータを抽出する。したがって、遅延度合と相関のあるリソースデータを正確に抽出することができる。
図27は、リソースデータ抽出処理のフローを示すフローチャ−トである。図27に示すように、第1相関分析部42は、相関のあるリソースデータ数だけステップS21〜ステップS22の処理を繰り返す。すなわち、第1相関分析部42は、遅延度合が閾値Trt以上のときのリソースデータの中央値を計算し閾値Trとし(ステップS21)、リソースデータが閾値Tr以上のときの遅延度合のデータを抽出する(ステップS22)。
そして、第1相関分析部42は、リソースデータ毎に抽出された遅延度合を入力として多重比較検定を行う(ステップS23)。そして、第1相関分析部42は、検定の結果、他のリソースデータの遅延度合の分布よりも大きくなる傾向にあるとなった回数が最も多いリソースデータを特定する(ステップS24)。
そして、第1相関分析部42は、抽出された遅延度合の分布において、特定されたリソースデータのものと差がないと判定されたリソースデータと、特定されたリソースデータを遅延度合とよく相関があるリソースデータとして出力する(ステップS25)。
このように、リソースデータ抽出処理により遅延度合とよく相関があるリソースデータを抽出することで、第1相関分析部42は、遅延度合と相関が強いリソースデータだけを抽出することができる。なお、リソースデータ抽出処理は、後述するように第2相関分析部44により呼び出された場合には、第2相関分析部44が行う。
図28は、第2相関分析処理のフローを示すフローチャ−トである。図28に示すように、第2相関分析部44は、リソース性能低下の影響を受けるデータの相関のあったリソース数だけステップS31〜ステップS37の処理を繰り返す。
すなわち、第2相関分析部44は、注目リソースを共有しているVMの情報を取得する(ステップS31)。ここで、注目リソースとは、ステップS31〜ステップS37の1回の処理の対象となるリソース34である。そして、第2相関分析部44は、注目リソースを共有している全VMのリソース負荷量を表すデータを取得する(ステップS32)。全VMには、注目リソースのVMも含まれる。
そして、第2相関分析部44は、アプリの遅延度合とリソース負荷量を表すデータとの無相関検定のp−valueを計算する処理(ステップS33)をリソース34を共有している全VMのリソース負荷量を表すデータ数だけ繰り返す。そして、第2相関分析部44は、多重検定補正を実行し(ステップS34)、多重検定補正により補正したp−valueが閾値以下のリソースデータのみを抽出する(ステップS35)。そして、第2相関分析部44は、リソースデータ抽出処理を行い(ステップS36)、第2分析結果記憶部45に相関分析結果を保存する(ステップS37)。
このように、第2相関分析部44は、リソース性能低下の影響を受けるデータの相関のあった各リソース34について、リソース34を共有する全VMのリソース負荷量を表すデータとの無相関検定のp−valueを計算する。そして、第2相関分析部44は、多重検定補正によりp−valueを補正し、補正したp−valueが閾値以下のリソースデータのみを抽出する。そして、第2相関分析部44は、抽出したリソースデータから、さらに、遅延度合とよく相関しているリソースデータを抽出する。したがって、第2相関分析部44は、リソース性能低下の影響を受けるデータの相関のあった各リソース34について、リソース34を共有する全VMのリソース負荷量を表すデータの遅延度合との相関分析を正確に行うことができる。
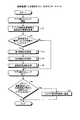
図29は、遅延原因診断処理のフローを示すフローチャ−トである。図29に示すように、遅延原因診断部46は、遅延度合が閾値Trt以上の回数から遅延していた合計時間の割合を計算する(ステップS41)。そして、遅延原因診断部46は、相関のあるリソースデータを持つアプリのVM数だけステップS42〜ステップS49の処理を繰り返す。
すなわち、遅延原因診断部46は、注目VMのリソース負荷量を表すデータとの相関があるか否かを判定する(ステップS42)。ここで、注目VMとは、ステップS42〜ステップS49の1回の処理の対象となるVMである。そして、遅延原因診断部46は、注目VMのリソース負荷量を表すデータとの相関がある場合には、アプリ要因による遅延と判定し(ステップS43)、次のVMの処理に進む。
一方、注目VMのリソース負荷量を表すデータとの相関がない場合には、遅延原因診断部46は、注目VMのリソース性能低下の影響を受けるデータとの相関があるか否かを判定し(ステップS44)、否の場合には次のVMの処理に進む。一方、注目VMのリソース性能低下の影響を受けるデータとの相関がある場合には、遅延原因診断部46は、リソース34を共有している全VMについてリソース負荷量を表すデータとの相関があるか否かを判定する(ステップS45)。そして、遅延原因診断部46は、リソース負荷量を表すデータと遅延度合との相関があるVMが1つもない場合には、リソース負荷上昇の原因不明と判定し(ステップS46)、次のVMの処理に進む。
また、遅延原因診断部46は、リソース負荷量を表すデータと遅延度合との相関がある各VMについて、ステップS47〜ステップS49の処理を行う。すなわち、遅延原因診断部46は、相関のあるリソース性能低下の影響を受けるデータとリソース負荷量を表すデータが同じVMのものか否かを判定する(ステップS47)。
そして、相関のあるリソース性能低下の影響を受けるデータとリソース負荷量を表すデータが同じVMのものである場合には、遅延原因診断部46は、アプリ要因による遅延と判定し(ステップS48)、次のVMの処理に進む。一方、相関のあるリソース性能低下の影響を受けるデータとリソース負荷量を表すデータが同じVMのものでない場合には、遅延原因診断部46は、クラウド基盤要因による遅延と判定し(ステップS49)、次のVMの処理に進む。
そして、ステップS42〜ステップS49の繰り返し処理を完了すると、遅延原因診断部46は、判定結果の数が1以上かつ閾値Td以下か否かを判定する(ステップS50)。そして、判定結果の数が1以上かつ閾値Td以下である場合には、遅延原因診断部46は、遅延と関係するリソース34を特定できたとして判定結果を出力する(ステップS51)。一方、判定結果の数が1以上かつ閾値Td以下ではない場合には、遅延原因診断部46は、遅延と関係するリソース34を特定できなかったとする(ステップS52)。
そして、遅延原因診断部46は、遅延診断結果を保存する(ステップS53)。このように、遅延原因診断部46が、第1相関分析部42及び第2相関分析部44による分析結果に基づいて遅延の原因を特定することで、診断装置4は、クラウド基盤に問題がある場合に、問題のあるリソース34を特定することができる。
次に、二群比較検定を用いて相関分析を行う場合の第1相関分析処理及び第2相関分析処理のフローについて図30及び図31を用いて説明する。図30は、二群比較検定を用いる第1相関分析処理のフローを示すフローチャートである。
図30に示すように、第1相関分析部42は、VM情報記憶部31からアプリに関係するVMの情報を取得し(ステップS61)、リソースデータ記憶部32からアプリに関係する全VMのリソースデータを取得する(ステップS62)。
そして、第1相関分析部42は、遅延度合が閾値Trt未満のときのリソースデータと閾値Trt以上のリソースデータに分け(ステップS63)、二群比較検定によりp−valueを計算する(ステップS64)処理をリソースデータ数だけ繰り返す。そして、第1相関分析部42は、多重検定補正を実行し(ステップS65)、多重検定補正により補正したp−valueが閾値以下のリソースデータのみを抽出する(ステップS66)。
そして、第1相関分析部42は、リソースデータ抽出処理を行い(ステップS67)、第1分析結果記憶部43に相関分析結果を保存する(ステップS68)。
図31は、二群比較検定を用いる第2相関分析処理のフローを示すフローチャ−トである。図31に示すように、第2相関分析部44は、リソース性能低下の影響を受けるデータの相関のあったリソース数だけステップS71〜ステップS78の処理を繰り返す。
すなわち、第2相関分析部44は、注目リソースを共有しているVMの情報を取得し(ステップS71)、注目リソースを共有している全VMのリソース負荷量を表すデータを取得する(ステップS72)。
そして、第2相関分析部44は、リソース34を共有している全VMのリソース負荷量を表すデータ数だけステップS73とステップS74の処理を繰り返す。すなわち、第2相関分析部44は、遅延度合が閾値Trt未満のときのリソースデータと閾値Trt以上のリソースデータに分け(ステップS73)、二群比較検定によりp−valueを計算する(ステップS74)。
そして、第2相関分析部44は、多重検定補正を実行し(ステップS75)、多重検定補正により補正したp−valueが閾値以下のリソースデータのみを抽出する(ステップS76)。そして、第2相関分析部44は、リソースデータ抽出処理を行い(ステップS77)、第2分析結果記憶部45に相関分析結果を保存する(ステップS78)。
このように、第1相関分析部42及び第2相関分析部44は、遅延度合が閾値Trt未満のときのリソースデータと閾値Trt以上のリソースデータに分け、二群比較検定によりp−valueを計算することで、遅延していないデータの影響を抑えて相関分析を行うことができる。
上述してきたように、実施例1では、遅延判定部41が遅延度合情報を遅延情報作成装置2から取得してアプリに遅延が発生したか否かを判定し、第1相関分析部42が遅延が発生したアプリに関係するVMのリソースデータと遅延度合との相関分析を行う。そして、リソース性能低下の影響を受けるデータと遅延度合との相関がある場合に、第2相関分析部44がリソース34を共有している全VMについて、リソース負荷量を表すデータと遅延度合との相関関係を分析する。そして、遅延原因診断部46が、第1相関分析部42と第2相関分析部44の相関分析結果に基づいて遅延原因を特定する。
したがって、診断装置4は、アプリの性能低下がクラウド基盤に原因があるのかアプリに原因があるのかを特定することができる。また、診断装置4は、クラウド基盤に原因がある場合に、どのリソース34に原因があるかを特定することができる。
また、実施例では、第1相関分析部42は、遅延しているときと遅延していないときのリソースデータの傾向に差があるか否かを判定することで相関分析を行う場合には、遅延していないデータの影響を抑えて相関分析を行うことができる。
また、実施例では、第1相関分析部42は、遅延度合との相関係数を計算し、無相関検定を行ってp−valueを計算し、計算したp−valueを多重検定補正によって補正し、補正したp−valueに基づいて遅延度合と相関があるか否かを判定する。したがって、第1相関分析部42は、遅延度合とリソースデータの相関分析を正確に行うことができる。
ところで、リクエスト数が少ない場合には、平均応答時間が不安定になり、遅延度合が不安定になる。遅延度合が不安定な部分があると、遅延と関係するリソース34を見つけられない場合がある。そこで、実施例2では、遅延度合が不安定な部分のデータを取り除いた場合と全データを使った場合の両方で遅延原因診断を行う診断装置について説明する。
図32は、遅延度合が不安定なデータの除去を説明するための図である。図32の横軸はリクエスト数を示し、縦軸は遅延度合を示す。図32に示すように、リクエスト数が少ない場合には、遅延度合が不安定になる。このため、実施例2に係る診断装置は、実線の四角で囲まれた全データを使った場合と、破線の四角で囲まれたデータだけを使った場合の両方で遅延原因診断を行う。
図33は、実施例2に係るクラウドシステムの構成を示す図である。なお、ここでは説明の便宜上、図2に示した各部と同様の役割を果たす機能部については同一符号を付すこととしてその詳細な説明を省略する。
図33に示すように、実施例2に係るクラウドシステム1aは、図2に示したクラウドシステム1と比較して、診断装置4の代わりに診断装置4aを有する。診断装置4aは、診断装置4にはないデータ除去部40を有し、遅延判定部41の代わりに遅延判定部41aを有する。
データ除去部40は、遅延度合が不安定なデータを取り除く。遅延判定部41aは、データ除去部40により遅延度合が不安定な部分のデータが取り除かれたデータと、遅延情報作成装置2が作成した全データと両方でアプリに遅延が発生しているか否かを判定する。
遅延度合を計算するために用いられる平均応答時間は、リクエスト数が増加すると安定するため、リクエスト数が大きくなると遅延度合の分散が小さくなる。そこで、データ除去部40は、リクエスト数を基準にデータを分割し、遅延度合の分散が減少から増加に変わるリクエスト数を閾値とし、閾値以下のデータを遅延度合が不安定なデータとして取り除く。
図34は、遅延度合が不安定なデータの除去方法を説明するための図である。図34(a)は、データの分割を示す。横軸はリクエスト数であり、縦軸は遅延度合である。図34(a)に示すように、データはリクエスト数に応じて分割される。分割されたデータには、リクエスト数が少ない方から順に0、1、2、3のIDが付加される。
図34(b)は、分割されたデータの遅延度合の分散を示す。横軸はデータのIDであり、縦軸は遅延度合の分散である。図34(b)に示すように、IDが0であるデータについての遅延度合の分散は約3.3であり、IDが1であるデータについての遅延度合の分散は約2.0であり、IDが2であるデータについての遅延度の分散は約4.9である。すなわち、遅延度合の分散は、ID=1までは減少し、ID=2で増加する。
したがって、データ除去部40は、ID=1とID=2の境界のリクエスト数を閾値として、リクエスト数が閾値以下のデータを遅延度合が不安定なデータとして取り除く。図34(b)では、閾値は約1600であり、ID=0とID=1のデータが取り除かれる。
具体的には、データ除去部40は、以下の手順でデータを取り除く。
(1)データ除去部40は、遅延度合が閾値Trt以上のデータのうち、最小と最大のリクエスト数をそれぞれCmin、Cmaxとする。
(2)そして、データ除去部40は、リクエスト数がCmin以上、Cmax以下のデータ数をnとし、分割数kをSturgesの公式を利用してk=1+log2nにより計算する。
(3)そして、データ除去部40は、リクエスト数がCmin以上、Cmax以下のデータを、リクエスト数順にk個に分割し、分割されたそれぞれのデータで遅延度合の分散を計算する。
(4)そして、データ除去部40は、リクエスト数が低いデータから順に分散を見ていき、分散が減少から増加に変わる分割の最小のリクエスト数をTcとする。
(5)そして、データ除去部40は、リクエスト数が閾値Tc以下のデータを取り除く。
(1)データ除去部40は、遅延度合が閾値Trt以上のデータのうち、最小と最大のリクエスト数をそれぞれCmin、Cmaxとする。
(2)そして、データ除去部40は、リクエスト数がCmin以上、Cmax以下のデータ数をnとし、分割数kをSturgesの公式を利用してk=1+log2nにより計算する。
(3)そして、データ除去部40は、リクエスト数がCmin以上、Cmax以下のデータを、リクエスト数順にk個に分割し、分割されたそれぞれのデータで遅延度合の分散を計算する。
(4)そして、データ除去部40は、リクエスト数が低いデータから順に分散を見ていき、分散が減少から増加に変わる分割の最小のリクエスト数をTcとする。
(5)そして、データ除去部40は、リクエスト数が閾値Tc以下のデータを取り除く。
図35は、診断装置4aによる処理のフローを示すフローチャートである。図35に示すように、診断装置4aは、アプリ数だけステップS81〜ステップS91の処理を繰り返す。すなわち、診断装置4aは、アプリの診断対象期間の遅延度合情報を取得する(ステップS81)。そして、診断装置4aは、リクエスト数の閾値Tcを計算する閾値計算処理を行う(ステップS82)。
そして、診断装置4aは、リクエスト数が閾値Tcより大きくかつ遅延度合が閾値Trt以上の回数がTdr以上か否かを判定し(ステップS83)、ステップS83の判定結果がNoの場合には、ステップS88へ進む。一方、ステップS83の判定結果がYesである場合には、診断装置4aは、リクエスト数が閾値Tcより大きいデータを抽出し(ステップS84)、第1相関分析処理を行う(ステップS85)。
そして、診断装置4aは、第2相関分析処理を行う(ステップS86)、なお、ステップS86の処理は、リソース性能低下の影響を受けるデータの相関があった場合に行われる。そして、診断装置4aは、遅延原因診断処理を行う(ステップS87)。
そして、診断装置4aは、遅延度合が閾値Trt以上の回数がTdr以上か否かを判定し(ステップS88)、遅延度合が閾値Trt以上の回数がTdr以上でない場合には、次のアプリの処理を行う。一方、遅延度合が閾値Trt以上の回数がTdr以上である場合には、診断装置4aは、第1相関分析処理を行う(ステップS89)。
そして、診断装置4aは、第2相関分析処理を行う(ステップS90)、なお、ステップS90の処理は、リソース性能低下の影響を受けるデータの相関があった場合に行われる。そして、診断装置4aは、遅延原因診断処理を行う(ステップS91)。
そして、アプリ数だけステップS81〜ステップS91の処理を繰り返すと、診断装置4aは、クラウド基盤要因により応答遅延が発生と診断されたアプリがあるかを判定し(ステップS92)、ある場合には、クラウド運用管理者に通知する(ステップS93)。
図36は、閾値計算処理のフローを示すフローチャートである。図36に示すように、データ除去部40は、遅延度合が閾値Trt以上のデータのうち、最小のリクエスト数と最大のリクエスト数をそれぞれCmin、Cmaxとする(ステップS101)。そして、データ除去部40は、リクエスト数がCmin以上、Cmax以下のデータ数をnとし、分割数kを計算する(ステップS102)。
そして、データ除去部40は、リクエスト数がCmin以上、Cmax以下のデータを、リクエスト数順に並び替え、k個に分割する(ステップS103)。そして、データ除去部40は、分割されたデータの遅延度合の分散を計算する(ステップS104)処理を分割数分だけ繰り返す。そして、データ除去部40は、分散が減少から増加に変わる分割データの最小のリクエスト数をTcとする(ステップS105)。
上述してきたように、実施例2では、診断装置4aは、リクエスト数がTc以下のデータが取り除かれたデータと、全データとの両方でアプリに遅延が発生しているか否かを判定してアプリ遅延原因の診断を行う。したがって、診断装置4aは、遅延度合が不安定なデータに影響されることなくアプリ遅延原因の診断を行うことができる。
なお、実施例1及び2では、診断装置4及び4aについて説明したが、診断装置4及び4aが有する構成をソフトウェアによって実現することで、同様の機能を有する診断プログラムを得ることができる。そこで、診断プログラムを実行するコンピュータについて説明する。
図37は、実施例1及び2に係る診断プログラムを実行するコンピュータのハードウェア構成を示す図である。図37に示すように、コンピュータ50は、メインメモリ51と、CPU52と、LAN(Local Area Network)インタフェース53と、HDD(Hard Disk Drive)54とを有する。また、コンピュータ50は、スーパーIO(Input Output)55と、DVI(Digital Visual Interface)56と、ODD(Optical Disk Drive)57とを有する。
メインメモリ51は、プログラムやプログラムの実行途中結果などを記憶するメモリである。CPU52は、メインメモリ51からプログラムを読み出して実行する中央処理装置である。CPU52は、メモリコントローラを有するチップセットを含む。
LANインタフェース53は、コンピュータ50をLAN経由で他のコンピュータに接続するためのインタフェースである。HDD54は、プログラムやデータを格納するディスク装置であり、スーパーIO55は、マウスやキーボードなどの入力装置を接続するためのインタフェースである。DVI56は、液晶表示装置を接続するインタフェースであり、ODD57は、DVDの読み書きを行う装置である。
LANインタフェース53は、PCIエクスプレス(PCIe)によりCPU52に接続され、HDD54及びODD57は、SATA(Serial Advanced Technology Attachment)によりCPU52に接続される。スーパーIO55は、LPC(Low Pin Count)によりCPU52に接続される。
そして、コンピュータ50において実行される診断プログラムは、コンピュータ50により読み出し可能な記録媒体の一例であるDVDに記憶され、ODD57によってDVDから読み出されてコンピュータ50にインストールされる。あるいは、診断プログラムは、LANインタフェース53を介して接続された他のコンピュータシステムのデータベースなどに記憶され、これらのデータベースから読み出されてコンピュータ50にインストールされる。そして、インストールされた診断プログラムは、HDD54に記憶され、メインメモリ51に読み出されてCPU52によって実行される。
また、実施例1及び2では、正規化平均応答時間を遅延度合として用いる場合について説明したが、本発明はこれに限定されるものではなく、他の値を遅延度合として用いる場合にも同様に適用することができる。
また、実施例1及び2では、遅延情報作成装置2が、診断装置4及び4aと異なる装置である場合について説明したが、本発明はこれに限定されるものではなく、遅延情報作成装置2の機能が、診断装置4及び4aに含まれる場合にも同様に適用することができる。
1,1a クラウドシステム
2 遅延情報作成装置
3c ネットワークスイッチ
4,4a 診断装置
9 物理マシン
9a 仮想マシン
21 キャプチャ部
22 パケット情報記憶部
23 種別判定用データ記憶部
24 種別判定部
25 種別情報記憶部
26 応答時間算出部
27 応答時間情報記憶部
28 正規化部
29 代表情報記憶部
30 遅延度合情報記憶部
31 VM情報記憶部
32 リソースデータ記憶部
33 構成情報記憶部
40 データ除去部
41,41a 遅延判定部
42 第1相関分析部
43 第1分析結果記憶部
44 第2相関分析部
45 第2分析結果記憶部
46 遅延原因診断部
47 診断結果記憶部
50 コンピュータ
51 メインメモリ
52 CPU
53 LANインタフェース
54 HDD
55 スーパーIO
56 DVI
57 ODD
2 遅延情報作成装置
3c ネットワークスイッチ
4,4a 診断装置
9 物理マシン
9a 仮想マシン
21 キャプチャ部
22 パケット情報記憶部
23 種別判定用データ記憶部
24 種別判定部
25 種別情報記憶部
26 応答時間算出部
27 応答時間情報記憶部
28 正規化部
29 代表情報記憶部
30 遅延度合情報記憶部
31 VM情報記憶部
32 リソースデータ記憶部
33 構成情報記憶部
40 データ除去部
41,41a 遅延判定部
42 第1相関分析部
43 第1分析結果記憶部
44 第2相関分析部
45 第2分析結果記憶部
46 遅延原因診断部
47 診断結果記憶部
50 コンピュータ
51 メインメモリ
52 CPU
53 LANインタフェース
54 HDD
55 スーパーIO
56 DVI
57 ODD
Claims (10)
- コンピュータに、
アプリケーション毎に実行の遅延を示す遅延度合を取得して前記遅延度合が所定の閾値以上であるか否かを判定し、
前記遅延度合が所定の閾値以上であると判定した場合に、前記アプリケーションに関係するリソースに関する情報と前記遅延度合との相関関係に基づいて前記遅延の原因を特定する
診断プログラム。 - 前記特定する処理は、前記アプリケーションが実行される仮想マシンが利用するリソースに関する情報と前記遅延度合との相関関係である第1相関関係、及び、前記リソースを共有している全仮想マシンのリソース負荷量を表すデータと前記遅延度合との相関関係である第2相関関係に基づいて前記遅延の原因を特定することを特徴とする請求項1に記載の診断プログラム。
- 前記第1相関関係は、前記仮想マシンのリソース負荷量を表すデータと前記遅延度合との相関関係、及び、前記仮想マシンのリソース性能低下の影響を受けるデータと前記遅延度合との相関関係であることを特徴とする請求項2に記載の診断プログラム。
- 前記第1相関関係は、前記仮想マシンのCPU使用率と前記遅延度合との相関関係、及び、前記仮想マシンのCPU割り当て待ち時間の割合と前記遅延度合との相関関係であることを特徴とする請求項3に記載の診断プログラム。
- 前記特定する処理は、前記仮想マシンのCPU割り当て待ち時間の割合と前記遅延度合との間に相関関係があり、かつ、前記仮想マシンが利用するCPUを共有している他の仮想マシンのCPU使用率と前記遅延度合との相関関係がある場合に、前記遅延の原因としてクラウド基盤を特定することを特徴とする請求項4に記載の診断プログラム。
- 前記遅延の原因を特定する処理は、前記遅延度合が所定の閾値以上のときの前記リソースに関する情報と前記遅延度合が所定の閾値以上でないときの前記リソースに関する情報との間に差がある場合に、前記相関関係があると判定することを特徴とする請求項1〜5のいずれか1つに記載の診断プログラム。
- 前記遅延度合は、リクエストに対する応答時間の一定時間毎の平均値を正規化した正規化平均応答時間であり、
複数の正規化平均応答時間のうち、平均値の算出に用いられたリクエストの数が少ない場合の正規化平均応答時間を不安定な正規化平均応答時間として除く処理をさらに前記コンピュータに実行させ、
前記特定する処理は、前記不安定な正規化平均応答時間が除かれた正規化応答時間のうち第1閾値以上の個数が一定期間に第2閾値以上であるとき、又は、前記不安定な正規化平均応答時間を含む正規化応答時間のうち第1閾値以上の個数が一定期間に第2閾値以上であるときに、前記遅延の原因を特定することを特徴とする請求項1〜6のいずれか1つに記載の診断プログラム。 - 前記特定する処理は、前記遅延度合との相関係数を計算し、無相関検定を行ってp−valueを計算し、計算したp−valueを多重検定補正によって補正し、補正したp−valueに基づいて前記遅延度合と相関があるか否かを判定して前記第1相関関係を分析することを特徴とする請求項2〜5のいずれか1つに記載の診断プログラム。
- コンピュータが、
アプリケーション毎に実行の遅延を示す遅延度合を取得して前記遅延度合が所定の閾値以上であるか否かを判定し、
前記遅延度合が所定の閾値以上であると判定した場合に、前記アプリケーションに関係するリソースに関する情報と前記遅延度合との相関関係に基づいて前記遅延の原因を特定する
処理を実行することを特徴とする診断方法。 - アプリケーション毎に実行の遅延を示す遅延度合を取得して前記遅延度合が所定の閾値以上であるか否かを判定する遅延判定部と、
前記遅延判定部により遅延度合が所定の閾値以上であると判定された場合に、前記アプリケーションに関係するリソースに関する情報と前記遅延度合との相関関係に基づいて前記遅延の原因を特定する特定部と
を有することを特徴とする診断装置。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017129803A JP2019012477A (ja) | 2017-06-30 | 2017-06-30 | 診断プログラム、診断方法及び診断装置 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017129803A JP2019012477A (ja) | 2017-06-30 | 2017-06-30 | 診断プログラム、診断方法及び診断装置 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2019012477A true JP2019012477A (ja) | 2019-01-24 |
Family
ID=65226891
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017129803A Pending JP2019012477A (ja) | 2017-06-30 | 2017-06-30 | 診断プログラム、診断方法及び診断装置 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP2019012477A (ja) |
Cited By (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2024142180A1 (ja) * | 2022-12-26 | 2024-07-04 | ||
| JPWO2024142181A1 (ja) * | 2022-12-26 | 2024-07-04 | ||
| WO2024142179A1 (ja) * | 2022-12-26 | 2024-07-04 | 楽天モバイル株式会社 | アプリケーションが不安定である原因の推定 |
| WO2024158199A1 (ko) * | 2023-01-26 | 2024-08-02 | 삼성전자 주식회사 | 전자 장치 및 전자 장치의 성능 변화 감지 방법 |
-
2017
- 2017-06-30 JP JP2017129803A patent/JP2019012477A/ja active Pending
Cited By (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2024142180A1 (ja) * | 2022-12-26 | 2024-07-04 | ||
| JPWO2024142181A1 (ja) * | 2022-12-26 | 2024-07-04 | ||
| WO2024142181A1 (ja) * | 2022-12-26 | 2024-07-04 | 楽天モバイル株式会社 | 通信システムに含まれるプロセスが不安定であるか否かの判定 |
| WO2024142179A1 (ja) * | 2022-12-26 | 2024-07-04 | 楽天モバイル株式会社 | アプリケーションが不安定である原因の推定 |
| WO2024142180A1 (ja) * | 2022-12-26 | 2024-07-04 | 楽天モバイル株式会社 | 不安定なアプリケーションのリプレース |
| JPWO2024142179A1 (ja) * | 2022-12-26 | 2024-07-04 | ||
| JP7812467B2 (ja) | 2022-12-26 | 2026-02-09 | 楽天モバイル株式会社 | 不安定なアプリケーションのリプレース |
| JP7814556B2 (ja) | 2022-12-26 | 2026-02-16 | 楽天モバイル株式会社 | アプリケーションが不安定である原因の推定 |
| JP7838123B2 (ja) | 2022-12-26 | 2026-03-31 | 楽天モバイル株式会社 | 通信システムに含まれるプロセスが不安定であるか否かの判定 |
| WO2024158199A1 (ko) * | 2023-01-26 | 2024-08-02 | 삼성전자 주식회사 | 전자 장치 및 전자 장치의 성능 변화 감지 방법 |
| EP4443303A4 (en) * | 2023-01-26 | 2025-12-03 | Samsung Electronics Co Ltd | ELECTRONIC DEVICE AND METHOD FOR DETECTING CHANGES IN PERFORMANCE IN AN ELECTRONIC DEVICE |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11500757B2 (en) | Method and system for automatic real-time causality analysis of end user impacting system anomalies using causality rules and topological understanding of the system to effectively filter relevant monitoring data | |
| EP4182796B1 (en) | Machine learning-based techniques for providing focus to problematic compute resources represented via a dependency graph | |
| EP3745272B1 (en) | An application performance analyzer and corresponding method | |
| CN108039964B (zh) | 基于网络功能虚拟化的故障处理方法及装置、系统 | |
| CN108989136B (zh) | 业务端到端性能监控方法及装置 | |
| US10275301B2 (en) | Detecting and analyzing performance anomalies of client-server based applications | |
| US11106562B2 (en) | System and method for detecting anomalies based on feature signature of task workflows | |
| US9015006B2 (en) | Automated enablement of performance data collection | |
| US9015362B2 (en) | Monitoring network performance and detecting network faults using round trip transmission times | |
| US8631280B2 (en) | Method of measuring and diagnosing misbehaviors of software components and resources | |
| US9600523B2 (en) | Efficient data collection mechanism in middleware runtime environment | |
| US9027025B2 (en) | Real-time database exception monitoring tool using instance eviction data | |
| CN110865867A (zh) | 应用拓扑关系发现的方法、装置和系统 | |
| CN110716842A (zh) | 集群故障检测方法和装置 | |
| JP2019507454A (ja) | アプリケーションの実行中に観察される問題の根本原因を特定する方法 | |
| CN111181800A (zh) | 测试数据处理方法、装置、电子设备及存储介质 | |
| JP2018028783A (ja) | システム状態可視化プログラム、システム状態可視化方法及びシステム状態可視化装置 | |
| JP2019012477A (ja) | 診断プログラム、診断方法及び診断装置 | |
| CN120358147A (zh) | 监控指标依赖关系分析与拓扑建立方法、装置及计算机设备 | |
| CN114741218A (zh) | 操作系统的异常指标提取方法、装置、设备、系统及介质 | |
| JP2011113122A (ja) | 障害影響分析装置及び業務システム及び障害影響分析方法 | |
| US20070086350A1 (en) | Method, system, and computer program product for providing failure detection with minimal bandwidth usage | |
| JP2023039385A (ja) | 仮想機能性能分析システムおよびその分析方法 | |
| CN120104452A (zh) | 自动化微服务健康监测的方法、装置和电子设备 | |
| US20180285238A1 (en) | Intelligent deinstrumentation of instrumented applications |