JP2019509015A - 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 - Google Patents
二本鎖配列決定のための改善されたアダプター、方法、及び組成物 Download PDFInfo
- Publication number
- JP2019509015A JP2019509015A JP2018530698A JP2018530698A JP2019509015A JP 2019509015 A JP2019509015 A JP 2019509015A JP 2018530698 A JP2018530698 A JP 2018530698A JP 2018530698 A JP2018530698 A JP 2018530698A JP 2019509015 A JP2019509015 A JP 2019509015A
- Authority
- JP
- Japan
- Prior art keywords
- nucleic acid
- adapter
- adapter nucleic
- pair
- acid sequence
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
- RHJITQJBHCWZLJ-UHFFFAOYSA-N CC(C1)C1NC Chemical compound CC(C1)C1NC RHJITQJBHCWZLJ-UHFFFAOYSA-N 0.000 description 1
Images






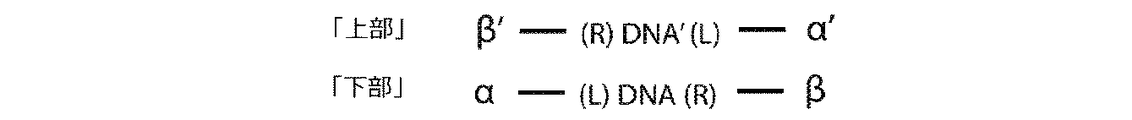




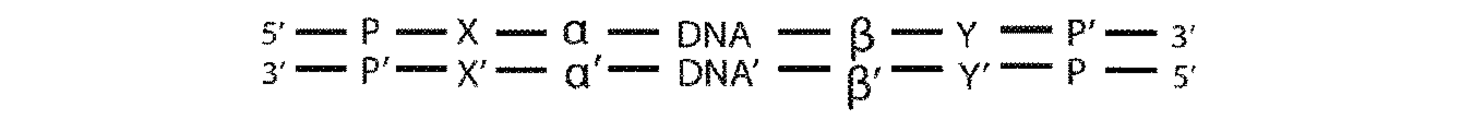











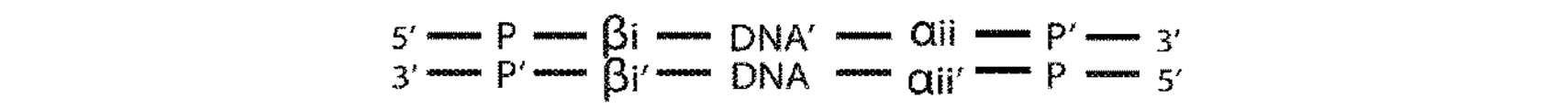






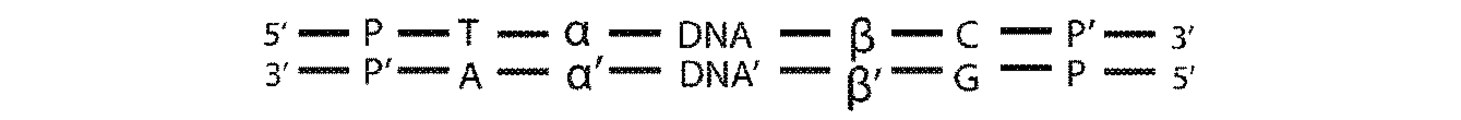








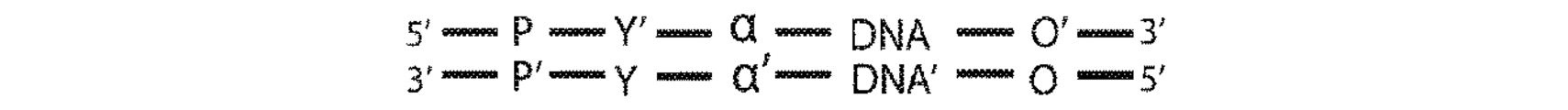










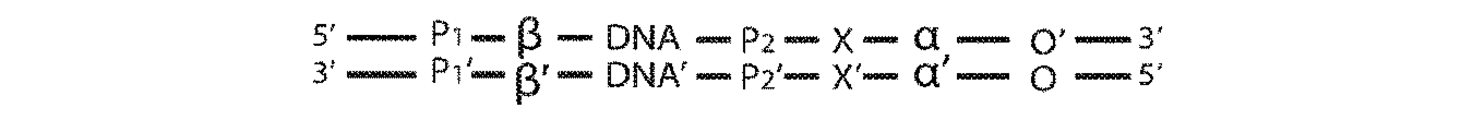










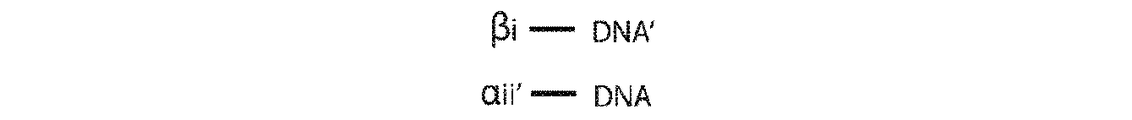







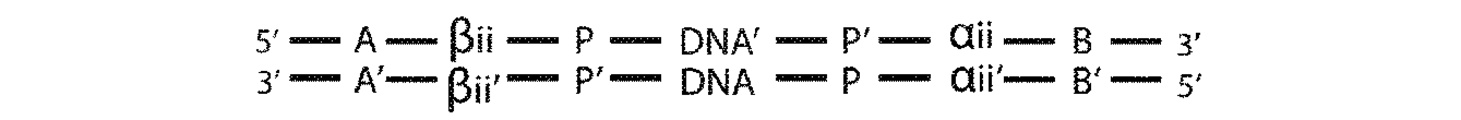







































Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
- C12Q1/6853—Nucleic acid amplification reactions using modified primers or templates
- C12Q1/6855—Ligating adaptors
Landscapes
- Chemical & Material Sciences (AREA)
- Life Sciences & Earth Sciences (AREA)
- Organic Chemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Health & Medical Sciences (AREA)
- Zoology (AREA)
- Wood Science & Technology (AREA)
- Engineering & Computer Science (AREA)
- Molecular Biology (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Immunology (AREA)
- Biotechnology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Analytical Chemistry (AREA)
- Physics & Mathematics (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Measuring Or Testing Involving Enzymes Or Micro-Organisms (AREA)
Abstract
Description
本出願は、2015年12月8日出願の米国特許仮出願第62/264,822号及び2016年1月22日出願の米国特許仮出願第62/281,917号に対する優先権及びそれらの利益を主張する。上述の出願の各々は、その全体が参照により本明細書に組み込まれる。
本出願は、EFS−Webを介してASCII形式で提出されている配列表を含み、その全体がこれにより参照により組み込まれる。2016年12月8日作製の該ASCIIのコピーは、TWIN−001_ST25.txtと称され、サイズは11,778バイトである。
たは第2のアダプター核酸配列は、一本鎖であり得る。第1のアダプター核酸配列及び第2のアダプター核酸配列は、一本鎖であり得る。

二本鎖配列決定にY形アダプターを使用することによる不利益
Y形アダプターによる二本鎖配列決定は、元来記載されているように(WO2013/142389A1及びSchmitt et al,PNAS2012、これらの各々は、その全体が参照により本明細書に組み込まれる)、ペアードエンド配列決定読み取りによって最も容易に実行される。しかしながら、全ての配列決定プラットフォームが、ペアードエンド配列決定読み取りと適合するわけではない。以前に記載されているY形またはループ形アダプター(非対称プライマー部位がアダプターの連結可能な末端の反対の一本鎖領域内に位置する)を使用する場合、シングルエンド配列決定読み取りによる二本鎖配列決定は、DNA分子を通した配列決定読み取りの完全な延長を必要とする。これは、配列決定読み取りを二本の誘導体鎖から区別するために必要とされる、分子の両末端のSMIタグ配列を捕捉するために必要である。この必要性は、以下の通り説明される。
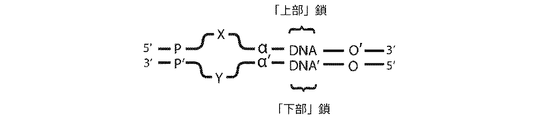
「上部」鎖に由来する二本鎖PCR生成物が、図1Dに示される。
非ペアードエンド配列決定(すなわち、「バブルアダプター」)による二本鎖配列決定を可能にする(本発明の)非Y形アダプターの一例示的な設計が、図2Aに開示される。2つのプライマー部位を有する、以前に記載されているY形アダプターとは異なり、逆相補体(P’)を有する単一プライマー部位(P)のみが存在する。α及び相補体α’は、縮重または半縮重単一分子識別子(SMI)配列を表し、X及びYは、アダプター内の隣接する相補的配列の中間に非対合の「バブル」を形成する非相補的配列のセグメントである、鎖定義要素(SDE)の2つの半分を表す。最後に、アダプターは、連結可能な配列を有する。SDEによってこのアダプター設計内に導入される非対称は、図2B〜図2Gに説明されるような各鎖から得られる配列決定読み取りを区別する。
アダプターP1
アダプターA
アスタリスク「*」は、ホスホロチオエート結合を表す。
アダプター1:
アダプター2:
アダプター3:
アダプター4:
図2A〜2Kに示されるアダプター設計は、タグに基づく二本鎖配列決定を可能にする2つの重要な特徴を含有する。一方は、特有な分子識別子(すなわち、SMI)であり、他方は、二本のDNA鎖内への非対称の導入手段(すなわち、SDE)である。二本鎖配列決定の初期の記述において、Y形アダプター及びペアードエンド配列決定読み取りが利用された。二本のDNA鎖内への非対称の導入は、非対称尾部自体のために達成された。図3Aに示されるように、別個かつ優れた二本鎖配列決定アダプター設計は、共同で分子識別子及び非対称導入SDEとしての役割を果たす非相補的「バブル」形SMIを含む。
二本鎖配列決定アダプターに鎖非対称が導入され得る別の方法は、最初は対合した鎖DNAを形成するが、その後、更なる生化学的ステップ後にDNAミスマッチをもたらす、ヌクレオチドまたはヌクレオチド類似体による。この一例が、DNAポリメラーゼ誤組み込みである。誤組み込みは、増幅中に本質的に、または化学的もしくは酵素的ステップを介したミスマッチ領域への変換後のいずれかで生じ得る。
非Y形アダプターの前述の実施例は、DNA分子の両末端への、同一の種類のアダプターの対称連結を示す。現在、ほとんどの配列決定プラットフォームは、例えば、表面またはビーズのいずれかの上でのクラスター増幅を可能にするために、適応したDNA分子がいずれかの末端上に異なるプライマー部位を有することを必要とする。これらの異なるプライマー部位を作製するためにY形アダプターを通例使用しない配列決定プラットフォーム(例えば、Ion Torrent(商標)(Thermo(登録商標)Inc)、SOLiD(Applied Biosystems(登録商標)Inc.、及び454(Roche(登録商標)Inc.))では、2つの異なるアダプターの混合物が連結され、その後、最も一般的にはビーズに基づくエマルジョンPCRプロセスを通して、各プライマー部位のうちの1つを含有する分子が選択される。
Illumina(登録商標)機器で実行されるものなどのペアードエンド配列決定は一般に、配列決定プラットフォームが、アダプターDNA分子の一方の末端上のプライマー部位からの一方の鎖を配列決定することができ、その後、異なるプライマー部位からのその分子の他方の末端を配列決定する前に逆相補体鎖を生成することを必要とする。この技術的な課題としては、相補的鎖生成のプロセスが挙げられ、これが、全てのプラットフォームがこのペアードエンド配列決定とは容易には適合しない理由である。
上記に開示される形態の二重読み取りの使用から生じる潜在的な利点は、読み取り長さの単純な保存を超えて拡張する。Y形アダプターによるタグに基づく二本鎖配列決定についての初期の記述において、1つのSMI配列が、適応したDNA分子の各末端に付加された。この設計は、多様なSMI含有アダプターの十分に大きな集団を効率的に生成して、全てのDNA分子が特有に標識され得ることを確実にするために、特定の状況において、実用的利点を有する。
いくつかの現在入手可能な配列決定プラットフォームは、クラスター増幅及び配列決定を可能にするために、DNA分子の反対の末端上に異なるプライマー部位を必要とする。これは、非対称プライマー結合部位を有するY形またはバブル形アダプターによって、または直前の3つの実施形態において説明される2つのアダプターの連結法を通して達成することができる。Illumina(登録商標)によって製造されているものなどのY形アダプターが、ペアードエンド配列決定適合プラットフォーム上では最も一般的に使用されているが、それらは、他のプラットフォーム上でも使用することができる。
Y形またはループ形アダプターにおける非対合のSMIの概念の別の変異形は、PCRプライマー部位と相補的ステムとの間の遊離一本鎖尾部領域内に位置するこれらの非対合のSMIを含む。この設計の1つの利点は、それが、選ばれたIllumina(登録商標)配列決定システム上で利用可能であるように、「二重インデックス」読み取りの一部としてSMIが完全に配列決定されることを可能にすることである(Kircher et al(2012)Nucleic Acid Res.Vol.40,No.1,e3)。長い読み取りが特に好ましい用途では、主要配列決定読み取りにSMIが含まれないことによって、DNA挿入物の読み取り長さが最大化されるだろう。一例を続ける。
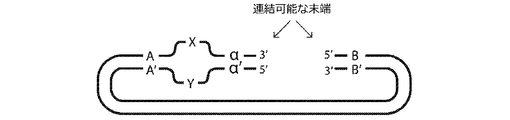
二本鎖配列決定に必要な全ての要素を、2つの対合したアダプターではなく、単一分子内に導入する代替的な構造が、図10に説明される。
上記に論じられるように、二本鎖配列決定は基本的に、DNA二本鎖の両方の鎖の区別が可能であるような、それらの配列決定に依存する。二本鎖配列決定の元来記載されている一実施形態(WO2013/142389A1)において、両方の鎖をヘアピン配列でともに結合して、対合した鎖をともに配列決定することができる。開示に開示される実施形態においてだけでなく、WO2013/142389A1も、特有なDNA二本鎖の二本の鎖が、DNAタグ付けを使用して区別され得る方法を記載する。この後者のアプローチは、特有なDNA配列(DNA断片の一末端もしくは両末端の座標を含む内在性SMI、または縮重もしくは半縮重配列を含む外来性SMI)で各DNA分子を標識付けし、少なくとも1つの形態のSDE(例えば、ペアードエンド読み取りによる非対称プライマー部位、「バブル」配列、非相補的SMI配列、及び天然または化学的のいずれかでミスマッチへと変換される非標準ヌクレオチド)を通して鎖定義非対称を導入することを伴う。
Ion Torrent(商標)プラットフォームのアダプター連結に使用される市販のキットにおけるものなどのいくつかの状況において、二本鎖アダプターは、配列決定される二本鎖標的DNA分子に連結される。しかしながら、ここでは標的DNA分子の二本の鎖のうちの一方のみが、アダプターに連結される。この一般的な実施形態は、連結ドメインの5’鎖がリン酸化されていない場合である。その後、鎖置換活性を有するポリメラーゼを使用して、一般的に「ニック翻訳」として知られるプロセスにおいて、連結された鎖からの配列を未連結の鎖にコピーする。本明細書に開示されるアダプター設計が、この方法で、かつ修飾なしで使用されるとき、多くの場合、SDEはニック翻訳ステップ中に失われ、それにより二本鎖配列決定を防止するだろう。これを以下に例証する。
アダプターP1
アダプターA
アスタリスク「*」は、ホスホロチオエート結合を表す。
(上:配列番号23及び下:配列番号24)
(上:配列番号25、中間:配列番号26、及び下:配列番号27)
上記に対する代替的なアプローチは、存在する4つ全てのヌクレオチドについてニック翻訳を完了し、その後、鋳型鎖内の塩基を異なる塩基に変化させることだろう。
「ニック翻訳中のSDEの導入」と題する実施形態は、アダプター配列内でニック翻訳中に非対称SDEがいかに導入され得るかを示した。可能性としてはアダプターが添加される前にすら、非対称部位(SDE)がライブラリ分子内に組み込まれるように、同一の原理がDNA分子ライブラリ自体に適用され得る。これは、様々な方法で達成することができる。以下は単なる一例に過ぎない。
上記に開示される実施形態は、二本鎖配列決定のための改善された方法を説明し、組み立てられる最終分子は、少なくとも1つの鎖定義要素(SDE)及び少なくとも1つの単一分子識別子(SMI)配列を含み、SDE及びSMIの両方は、配列決定されるDNAの二本鎖または部分二本鎖分子に結合する。しかしながら、SMI及びSDEは単一アダプター内に含まれている必要はなく、それらは単純に、理想的には任意の増幅及び/もしくは配列決定ステップ前またはステップ中に、最終分子内に存在する必要がある。
二本鎖配列決定は、2つの個々のDNA鎖の各々から生じる増幅された重複の「コンセンサス」を得て、2つの一本鎖コンセンサス配列を得、その後、結果として得られる一本鎖コンセンサスを比較して、二本鎖コンセンサス配列を得ることによって実行することができる。単一分子の増幅された重複の配列を位置毎に「平均化」するこのアプローチは、いくつかの設定(例えば、重度に損傷したDNA内の所与の位置で反復増幅エラーが生じ得る場合)においては望ましくない可能性があり、故に異なるデータ処理キームを有するいくつかの設定において、より信頼できる結果を得ることができる。
1.実験からの全ての配列決定読み取りを含有するファイルを準備する。
2.このファイルを2つのファイル(GCGCと標識される読み取りを含有する1つのファイルは「GCGC」と呼ばれ、TATAと標識される読み取りを含有する第2のファイルは「TATA」と呼ばれる)に分ける。
3.「GCGC」ファイル内の任意の読み取りを選び、そのSMIタグを読み取り、「TATA」ファイル内でマッチするSMIタグを検索する。
4.マッチが見出される場合、これらの2つの配列から新たな配列を作製する。新たな配列内では、一致する読み取り内の全ての配列位置は維持し、2つの読み取り内の全ての一致しない位置を未定義としてマークする。この新たな配列を、「二本鎖」と呼ばれるファイルに書き込み、「GCGC」ファイル及び「TATA」ファイルからの2つの配列を除去する。
マッチが見出されない場合、「GCGC」ファイルからの配列を除去し、それを「非対応」と呼ばれるファイルに書き込む。
5.「GCGC」ファイルから別の任意の読み取りを選び、ステップ3〜4を再度実行する。
6.「GCGC」ファイル内にいかなる読み取りも残らなくなるまで続ける。
本発明が、その発明を実施するための形態と組み合わせて記載されている一方で、上述の記述は、説明が意図され、本発明の範囲の限定は意図されず、本発明の範囲は、添付の特許請求の範囲によって定義される。他の態様、利点、及び修飾が、以下の特許請求の範囲内である。
Claims (238)
- 第1のアダプター核酸配列及び第2のアダプター核酸配列を含む、二本鎖標的核酸分子の配列決定において使用するためのアダプター核酸配列の対であって、各アダプター核酸配列が、
プライマー結合ドメインと、
鎖定義要素(SDE)と、
単一分子識別子(SMI)ドメインと、
連結ドメインと、を含み、
前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEと少なくとも部分的に非相補的である、前記アダプター核酸配列の対。 - 前記2つのアダプター配列が、少なくとも部分的にともにアニールされている2つの別個のDNA分子からなる、請求項1に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列及び前記第2のアダプター核酸配列が、リンカードメインを介して結合される、請求項1に記載のアダプター核酸配列の対。
- 前記リンカードメインが、ヌクレオチドで構成される、請求項3に記載のアダプター核酸配列の対。
- 前記リンカードメインが、1つ以上の修飾ヌクレオチドまたは非ヌクレオチド分子を含有する、請求項3に記載のアダプター核酸配列の対。
- 前記1つ以上の修飾ヌクレオチドまたは非ヌクレオチド分子が、脱塩基部位;ウラシル;テトラヒドロフラン;8−オキソ−7,8−ジヒドロ−2’−デオキシアデノシン(8−オキソ−A);8−オキソ−7,8−ジヒドロ−2’−デオキシグアノシン(8−オキソ−G);デオキシイノシン、5’−ニトロインドール;5−ヒドロキシメチル−2’−デオキシシチジン;イソ−シトシン;5’−メチル−イソシトシン;またはイソ−グアノシンから選択される、請求項4に記載のアダプター核酸配列の対。
- 前記リンカードメインが、ループを形成する、請求項3〜5のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEと非相補的である、請求項1〜7のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、前記第2のアダプター核酸配列の前記プライマー結合ドメインと少なくとも部分的に相補的である、請求項1〜7のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、前記第2のアダプター核酸配列の前記プライマー結合ドメインと相補的である、請求項1〜9のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、前記第2のアダプター核酸配列の前記プライマー結合ドメインと少なくとも部分的に非相補的である、請求項1〜7のいずれか1項に記載のアダプター核酸配列の対。
- 少なくとも1つのSMIドメインが、内在性SMIである、請求項1〜7のいずれか1項に記載のアダプター核酸配列の対。
- 前記内在性SMIが、剪断点に関連付けられる、請求項12に記載のアダプター核酸配列の対。
- 前記SMIドメインが、少なくとも1つの縮重または半縮重核酸を含む、請求項1〜11のいずれか1項に記載のアダプター核酸配列の対。
- 前記SMIドメインが、非縮重である、請求項1〜11のいずれか1項に記載のアダプター核酸配列の対。
- 単一DNA分子を互いに区別することができるSMI配列を得るために、前記SMIドメインの前記配列が、連結されたDNAのランダムまたは半ランダムに剪断された末端に対応する前記配列と組み合わせて考慮される、請求項1〜15のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと少なくとも部分的に相補的である、請求項1〜16のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと相補的である、請求項1〜17のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと少なくとも部分的に非相補的である、請求項1〜15のいずれか1項に記載のアダプター核酸配列の対。
- 各SMIドメインが、プライマー結合部位を含む、請求項19に記載のアダプター核酸配列の対。
- 各SMIドメインが、その連結ドメインに対して遠位に位置する、請求項20に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと非相補的である、請求項19に記載のアダプター核酸配列の対。
- 各SMIドメインが、約1〜約30個の縮重または半縮重核酸を含む、請求項1〜22のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記連結ドメインが、前記第2のアダプター核酸配列の前記連結ドメインと少なくとも部分的に相補的である、請求項1〜23のいずれか1項に記載のアダプター核酸配列の対。
- 各連結ドメインが、二本鎖標的核酸配列の一方の鎖に連結されることができる、請求項1〜24のいずれか1項に記載のアダプター核酸配列の対。
- 前記連結ドメインの一方が、T−オーバーハング、A−オーバーハング、CG−オーバーハング、平滑末端、または別の連結可能な核酸配列を含む、請求項1〜25のいずれか1項に記載のアダプター核酸配列の対。
- 両方の連結ドメインが、平滑末端を含む、請求項1〜26のいずれか1項に記載のアダプター核酸配列の対。
- 前記連結ドメインの少なくとも一方が、修飾核酸を含む、請求項1〜26のいずれかに記載のアダプター核酸配列の対。
- 前記修飾ヌクレオチドが、脱塩基部位;ウラシル;テトラヒドロフラン;8−オキソ−7,8−ジヒドロ−2’−デオキシアデノシン(8−オキソ−A);8−オキソ−7,8−ジヒドロ−2’−デオキシグアノシン(8−オキソ−G);デオキシイノシン、5’−ニトロインドール;5−ヒドロキシメチル−2’−デオキシシチジン;イソ−シトシン;5’−メチル−イソシトシン;またはイソ−グアノシンから選択される、請求項28に記載のアダプター核酸配列の対。
- 前記連結ドメインの少なくとも一方が、脱リン酸化塩基を含む、請求項1〜26のいずれかに記載のアダプター核酸配列の対。
- 前記連結ドメインの少なくとも一方が、脱ヒドロキシル化塩基を含む、請求項1〜26のいずれかに記載のアダプター核酸配列の対。
- 前記連結ドメインの少なくとも一方が、それを連結不能にするように化学的に修飾されている、請求項1〜26のいずれかに記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEと少なくとも1つのヌクレオチドだけ異なる、かつ/またはそこで非相補的である、請求項1〜27のいずれか1項に記載のアダプター核酸配列の対。
- 少なくとも1つのヌクレオチドが、前記第1のアダプター核酸配列の前記SDEまたは前記第2のアダプター核酸の前記SDEのいずれかから酵素反応によって取り除かれる、請求項1〜27のいずれか1項に記載のアダプター核酸配列の対。
- 前記酵素反応が、ポリメラーゼ、エンドヌクレアーゼ、グリコシラーゼ、またはリアーゼを含む、請求項34に記載のアダプター核酸配列の対。
- 前記少なくとも1つのヌクレオチドが、修飾ヌクレオチドまたは標識を含むヌクレオチドである、請求項33に記載のアダプター核酸配列の対。
- 前記修飾ヌクレオチドまたは標識を含むヌクレオチドが、脱塩基部位;ウラシル;テトラヒドロフラン;8−オキソ−7,8−ジヒドロ−2’−デオキシアデノシン(8−オキソ−A);8−オキソ−7,8−ジヒドロ−2’−デオキシグアノシン(8−オキソ−G);デオキシイノシン、5’−ニトロインドール;5−ヒドロキシメチル−2’−デオキシシチジン;イソ−シトシン;5’−メチル−イソシトシン;またはイソ−グアノシンから選択される、請求項37に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、ヘアピンループを形成することができる自己相補的ドメインを含む、請求項35に記載のアダプター核酸配列の対。
- その連結ドメインに対して遠位の第1のアダプター核酸配列の前記末端が、その連結ドメインに対して遠位である前記第2のアダプター核酸配列の前記末端に連結され、それによりループを形成する、請求項1〜38のいずれか1項に記載のアダプター核酸配列の対。
- 前記ループが、制限酵素認識部位を含む、請求項39に記載のアダプター核酸配列の対。
- 少なくとも前記第1のアダプター核酸配列が、第2のSDEを更に含む、請求項1〜35のいずれか1項に記載のアダプター核酸配列の対。
- 前記第2のSDEが、前記第1のアダプター核酸配列の終端に位置する、請求項41に記載のアダプター核酸配列の対。
- 前記第2のアダプター核酸配列が、第2のSDEを更に含む、請求項41または請求項42に記載のアダプター核酸配列の対。
- 前記第2のSDEが、前記第2のアダプター核酸配列の終端に位置する、請求項41〜43のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記第2のSDEが、前記第2のアダプター核酸配列の前記第2のSDEと少なくとも部分的に非相補的である、請求項41〜44のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記第2のSDEが、前記第2のアダプター核酸配列の前記第2のSDEと少なくとも1つのヌクレオチドだけ異なる、かつ/またはそこで非相補的である、請求項45に記載のアダプター核酸配列の対。
- 少なくとも1つのヌクレオチドが、前記第1のアダプター核酸配列の前記第2のSDEまたは前記第2のアダプター核酸の前記第2のSDEのいずれかから酵素反応によって取り除かれる、請求項46に記載のアダプター核酸配列の対。
- 前記酵素反応が、ポリメラーゼ、エンドヌクレアーゼ、グリコシラーゼ、またはリアーゼを含む、請求項47に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記第2のSDEが、前記第2のアダプター核酸配列の前記第2のSDEと非相補的である、請求項45または請求項46に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記第2のSDEに直接結合する、請求項41〜45のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、第1のSDEに対して5’に位置する、請求項1〜50のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記第1のSDEが、前記SMIドメインに対して5’に位置する、請求項1〜51のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記第1のSDEが、前記SMIドメインに対して3’に位置する、請求項1〜51のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記第1のSDEが、前記SMIドメインに対して5’に位置し、前記プライマー結合ドメインに対して3’に位置する、請求項1〜53のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記第1のSDEが、前記プライマー結合ドメインに対して3’に位置する前記SMIドメインに対して3’に位置する、請求項1〜53のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記連結ドメインに対して5’に位置する、請求項1〜54のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記3’終端が、前記連結ドメインを含む、請求項1〜56のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列が、5’から3’まで、前記プライマー結合ドメイン、前記第1のSDE、前記SMIドメイン、及び前記連結ドメインを含む、請求項1〜57のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列が、5’から3’まで、前記プライマー結合ドメイン、前記SMIドメイン、前記第1のSDE、及び前記連結ドメインを含む、請求項1〜57のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列のいずれかが、修飾ヌクレオチドまたは非ヌクレオチド分子を含む、請求項1〜59のいずれか1項に記載のアダプター核酸配列の対。
- 前記修飾ヌクレオチドまたは非ヌクレオチド分子が、コリシンE2、Im2、グルチチオン(Glutithione)、グルタチオン−s−トランスフェラーゼ(GST)、ニッケル、ポリ−ヒスチジン、FLAG−タグ、myc−タグ、またはビオチンである、請求項60に記載のアダプター核酸配列の対。
- 前記ビオチンが、ビオチン−16−アミノアリル−2’−デオキシウリジン−5’−トリホスフェート、ビオチン−16−アミノアリル−2’−デオキシシチジン−5’−トリホスフェート、ビオチン−16−アミノアリルシチジン−5’−トリホスフェート、N4−ビオチン−OBEA−2’−デオキシシチジン−5’−トリホスフェート、ビオチン−16−アミノアリルウリジン−5’−トリホスフェート、ビオチン−16−7−デアザ−7−アミノアリル−2’−デオキシグアノシン−5’−トリホスフェート、デスチオビオチン−6−アミノアリル−2’−デオキシシチジン−5’−トリホスフェート、5’−ビオチン−G−モノホスフェート、5’−ビオチン−A−モノホスフェート、5’−ビオチン−dG−モノホスフェート、または5’−ビオチン−dA−モノホスフェートである、請求項61に記載のアダプター核酸配列の対。
- 前記ビオチンが、基質に結合したストレプトアビジンに結合することができる、請求項61または請求項62に記載のアダプター核酸配列の対。
- 前記ビオチンが、基質に結合したストレプトアビジンに結合するとき、前記第1のアダプター核酸配列が、前記第2のアダプター核酸配列から分離することができる、請求項63に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列のいずれかが、小分子、核酸、ペプチド、及び親和性パートナーによって結合されることができる特有に結合可能な部分から選択される、親和性標識を含む、請求項1〜59のいずれか1項に記載のアダプター核酸配列の対。
- 前記親和性パートナーが、固体基質に結合し、前記親和性標識に結合するとき、前記親和性標識を含む前記アダプター核酸配列が、前記親和性標識を含まない前記アダプター核酸配列から分離されることができる、請求項65に記載のアダプター核酸配列の対。
- 前記固体基質が、固体表面、ビーズ、または別の固定された構造である、請求項66に記載のアダプター核酸配列の対。
- 前記核酸が、DNA、RNA、またはこれらの組み合わせであり、任意で、ペプチド−核酸またはロックド核酸を含む、請求項65〜67のいずれか1項に記載のアダプター核酸配列の対。
- 前記親和性標識が、前記第2のアダプター核酸配列内の対向するドメインと完全には相補的ではない前記第1のアダプター核酸配列内の、アダプターの終端またはドメイン内に位置する、請求項65〜68のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列のいずれかが、磁気特性、電荷特性、または不溶性特性を有する物理的基を含む、請求項1〜59のいずれか1項に記載のアダプター核酸配列の対。
- 前記物理的基が磁気特性を有し、磁場が適用されるとき、前記物理的基を含む前記アダプター核酸配列が、前記物理的基を含まない前記アダプター核酸配列から分離される、請求項70に記載のアダプター核酸配列の対。
- 前記物理的基が電荷特性を有し、電場が適用されるとき、前記物理的基を含む前記アダプター核酸配列が、前記物理的基を含まない前記アダプター核酸配列から分離される、請求項70に記載のアダプター核酸配列の対。
- 前記物理的基が不溶性特性を有し、前記アダプター核酸配列の対が前記物理的基が不溶性である溶液中に含有されるとき、前記物理的基を含む前記アダプター核酸配列が、溶液中に残る前記物理的基を含まない前記アダプター核酸配列から離れて沈殿する、請求項70に記載のアダプター核酸配列の対。
- 前記物理的基が、前記第2のアダプター核酸配列内の対向するドメインと完全には相補的ではない前記第1のアダプター核酸配列内の、アダプターの終端またはドメイン内に位置する、請求項70〜73のいずれか1項に記載のアダプター核酸配列の対。
- 前記第2のアダプター核酸配列が、少なくとも1つのホスホロチオエート結合を含む、請求項1〜64のいずれか1項に記載のアダプター核酸配列の対。
- 前記二本鎖標的核酸配列が、DNAまたはRNAである、請求項1〜75のいずれか1項に記載のアダプター核酸配列の対。
- 各アダプター核酸配列が、その終端の各々に連結ドメインを含む、請求項1〜76のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列が、少なくとも部分的に一本鎖である、請求項1〜77のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列が、一本鎖である、請求項78に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列及び前記第2のアダプター核酸配列が、一本鎖である、請求項79に記載のアダプター核酸配列の対。
- 請求項1〜80のいずれかに記載のアダプター核酸配列の少なくとも1つの対及びアダプター核酸配列の第2の対を含む組成物であって、アダプター核酸配列の前記第2の対の各鎖が、少なくともプライマー結合部位及び連結ドメインを含む、前記組成物。
- アダプター核酸配列の前記第2の対の各鎖内にSMIドメインを更に含む、請求項81に記載の組成物。
- アダプター核酸配列の前記第2の対の各鎖内にプライマー結合部位を更に含む、請求項81または請求項82に記載の組成物。
- 請求項1〜83のいずれかに記載のアダプター核酸配列の少なくとも2つの対を含む組成物であって、アダプター核酸配列の第1の対からの第1のアダプター核酸配列の前記SDEが、アダプター核酸配列の少なくとも第2の対からの第1のアダプター核酸配列の前記SDEとは異なる、前記組成物。
- 請求項1〜80のいずれか1項のいずれかに記載のアダプター核酸配列の少なくとも2つの対を含む組成物であって、アダプター核酸分子の第1の対からの第1のアダプター核酸分子の前記SMIドメインが、アダプター核酸分子の少なくとも第2の対からの第1のアダプター核酸分子の前記SMIドメインとは異なる、前記組成物。
- 一本鎖アダプター核酸分子の前記第1の対からの前記第1のアダプター核酸分子の前記SMIドメインが、一本鎖アダプター核酸分子の前記少なくとも第2の対からの前記第1の一本鎖アダプター核酸分子の前記SMIドメインと同一の長さである、請求項85に記載の組成物。
- 一本鎖アダプター核酸分子の前記第1の対からの前記第1のアダプター核酸分子の前記SMIドメインが、一本鎖アダプター核酸分子の前記少なくとも第2の対からの前記第1の一本鎖アダプター核酸分子の前記SMIドメインとは異なる長さを有する、請求項85に記載の組成物。
- 各SMIドメインが、前記SMI内またはそれに隣接する部位に1つ以上の固定された塩基を含む、請求項85〜87のいずれか1項に記載の組成物。
- 二本鎖標的核酸分子の第1の終端に連結された請求項1〜88のいずれか1項に記載のアダプター核酸分子の第1の対と、前記二本鎖標的核酸分子の第2の終端に連結された請求項1〜50のいずれか1項に記載のアダプター核酸分子の第2の対と、を含む、少なくとも第1の二本鎖複合化核酸を含む、組成物。
- アダプター核酸分子の前記第1の対が、アダプター核酸分子の前記第2の対とは異なる、請求項89に記載の組成物。
- アダプター核酸分子の前記第1の対の前記第1の鎖アダプター−標的核酸分子が、第1のSMIドメインを含み、アダプター核酸分子の前記第2の対の前記第1の鎖アダプター−標的核酸分子が、第2のSMIドメインを含む、請求項90に記載の組成物。
- 少なくとも第2の二本鎖複合化核酸を含む、請求項89〜91のいずれか1項に記載の組成物。
- 第1のアダプター核酸配列及び第2のアダプター核酸配列を含む、二本鎖標的核酸分子の配列決定において使用するためのアダプター核酸配列の対であって、各アダプター核酸配列が、
プライマー結合ドメインと、
単一分子識別子(SMI)ドメインと、を含む、前記アダプター核酸配列の対。 - 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列の少なくとも一方が、少なくとも1つの修飾ヌクレオチドを含むドメインを更に含む、請求項93に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列及び前記第2のアダプター核酸配列が、少なくとも1つの修飾ヌクレオチドを含むドメインを更に含む、請求項93または請求項94に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列の少なくとも一方が、連結ドメインを更に含む、請求項93〜95のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列及び前記第2のアダプター核酸配列が、連結ドメインを含む、請求項93〜95のいずれか1項に記載のアダプター核酸配列の対。
- 前記少なくとも1つの修飾ヌクレオチドが、脱塩基部位;ウラシル;テトラヒドロフラン;8−オキソ−7,8−ジヒドロ−2’−デオキシアデノシン(8−オキソ−A);8−オキソ−7,8−ジヒドロ−2’−デオキシグアノシン(8−オキソ−G);デオキシイノシン、5’−ニトロインドール;5−ヒドロキシメチル−2’−デオキシシチジン;イソ−シトシン;5’−メチル−イソシトシン;またはイソ−グアノシンから選択される、請求項94〜97に記載のアダプター核酸配列の対。
- 前記2つのアダプター配列が、少なくとも部分的にともにアニールされている2つの別個のDNA分子からなる、請求項97〜請求項98のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列及び前記第2のアダプター核酸配列が、リンカードメインを介して結合される、請求項97に記載のアダプター核酸配列の対。
- 前記リンカードメインが、ヌクレオチドで構成される、請求項100に記載のアダプター核酸配列の対。
- 前記リンカードメインが、1つ以上の修飾ヌクレオチドまたは非ヌクレオチド分子を含有する、請求項100に記載のアダプター核酸配列の対。
- 前記少なくとも1つの修飾ヌクレオチドまたは非ヌクレオチド分子が、脱塩基部位;ウラシル;テトラヒドロフラン;8−オキソ−7,8−ジヒドロ−2’−デオキシアデノシン(8−オキソ−A);8−オキソ−7,8−ジヒドロ−2’−デオキシグアノシン(8−オキソ−G);デオキシイノシン、5’−ニトロインドール;5−ヒドロキシメチル−2’−デオキシシチジン;イソ−シトシン;5’−メチル−イソシトシン;またはイソ−グアノシンから選択される、請求項102に記載のアダプター核酸配列の対。
- 前記リンカードメインが、ループを形成する、請求項58〜61のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、前記第2のアダプター核酸配列の前記プライマー結合ドメインと少なくとも部分的に相補的である、請求項97〜104のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、前記第2のアダプター核酸配列の前記プライマー結合ドメインと相補的である、請求項97〜104のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、前記第2のアダプター核酸配列の前記プライマー結合ドメインと非相補的である、請求項97〜104のいずれか1項に記載のアダプター核酸配列の対。
- 少なくとも1つのSMIドメインが、内在性SMIである、請求項97〜107のいずれか1項に記載のアダプター核酸配列の対。
- 前記内在性SMIが、剪断点に関連付けられる、請求項108に記載のアダプター核酸配列の対。
- 前記SMIドメインが、少なくとも1つの縮重または半縮重核酸を含む、請求項97〜109のいずれか1項に記載のアダプター核酸配列の対。
- 前記SMIドメインが、非縮重である、請求項97〜110のいずれか1項に記載のアダプター核酸配列の対。
- 単一DNA分子を互いに区別することができるSMI配列を得るために、前記SMIドメインの前記配列が、連結されたDNAのランダムまたは半ランダムに剪断された末端に対応する前記配列と組み合わせて考慮される、請求項97〜111のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと少なくとも部分的に相補的である、請求項97〜112のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと相補的である、請求項97〜113のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと少なくとも部分的に非相補的である、請求項97〜113のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記第2のアダプター核酸配列の前記SMIドメインと非相補的である、請求項97〜113のいずれか1項に記載のアダプター核酸配列の対。
- 各SMIドメインが、約1〜約30個の縮重または半縮重核酸を含む、請求項97〜116のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記連結ドメインが、前記第2のアダプター核酸配列の前記連結ドメインと少なくとも部分的に相補的である、請求項97〜117のいずれか1項に記載のアダプター核酸配列の対。
- 各連結ドメインが、二本鎖標的核酸配列の一方の鎖に連結されることができる、請求項97〜118のいずれか1項に記載のアダプター核酸配列の対。
- 前記連結ドメインの一方が、T−オーバーハング、A−オーバーハング、CG−オーバーハング、平滑末端、または別の連結可能な核酸配列を含む、請求項97〜119のいずれか1項に記載のアダプター核酸配列の対。
- 両方の連結ドメインが、平滑末端を含む、請求項97〜120のいずれか1項に記載のアダプター核酸配列の対。
- 各SMIドメインが、プライマー結合部位を含む、請求項97〜121のいずれか1項に記載のアダプター核酸配列の対。
- 少なくとも前記第1のアダプター核酸配列が、SDEを更に含む、請求項97〜122のいずれか1項に記載のアダプター核酸配列の対。
- 前記SDEが、前記第1のアダプター核酸配列の終端に位置する、請求項123に記載のアダプター核酸配列の対。
- 前記第2のアダプター核酸配列が、SDEを更に含む、請求項123または請求項124に記載のアダプター核酸配列の対。
- 前記SDEが、前記第2のアダプター核酸配列の終端に位置する、請求項123〜124のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEと少なくとも部分的に非相補的である、請求項123〜126のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEと非相補的である、請求項127に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEに直接結合する、請求項123〜128のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEと少なくとも1つのヌクレオチドだけ異なる、かつ/またはそこで非相補的である、請求項123〜129のいずれか1項に記載のアダプター核酸配列の対。
- 前記少なくとも1つのヌクレオチドが、前記第1のアダプター核酸配列の前記SDEまたは前記第2のアダプター核酸の前記SDEのいずれかから酵素反応によって取り除かれる、請求項130に記載のアダプター核酸配列の対。
- 前記酵素反応が、ポリメラーゼまたはエンドヌクレアーゼを含む、請求項131に記載のアダプター核酸配列の対。
- 前記少なくとも1つのヌクレオチドが、修飾ヌクレオチドまたは標識を含むヌクレオチドである、請求項132に記載のアダプター核酸配列の対。
- 前記修飾ヌクレオチドまたは標識を含むヌクレオチドが、脱塩基部位;ウラシル;テトラヒドロフラン;8−オキソ−7,8−ジヒドロ−2’−デオキシアデノシン(8−オキソ−A);8−オキソ−7,8−ジヒドロ−2’−デオキシグアノシン(8−オキソ−G);デオキシイノシン、5’−ニトロインドール;5−ヒドロキシメチル−2’−デオキシシチジン;イソ−シトシン;5’−メチル−イソシトシン;またはイソ−グアノシンから選択される、請求項134に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SDEが、ヘアピンループを形成することができる自己相補的ドメインを含む、請求項123〜135のいずれか1項に記載のアダプター核酸配列の対。
- その連結ドメインに対して遠位の第1のアダプター核酸配列の前記末端が、その連結ドメインに対して遠位である前記第2のアダプター核酸配列の前記末端に連結され、それによりループを形成する、請求項123〜135のいずれか1項に記載のアダプター核酸配列の対。
- 前記ループが、制限酵素認識部位を含む、請求項136に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記プライマー結合ドメインが、前記SMIドメインに対して5’に位置する、請求項93〜129のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の少なくとも1つの修飾ヌクレオチドを含む前記ドメインが、前記SMIドメインに対して5’に位置する、請求項93〜138のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の少なくとも1つの修飾ヌクレオチドを含む前記ドメインが、前記SMIドメインに対して3’に位置する、請求項93〜138のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の少なくとも1つの修飾ヌクレオチドを含む前記ドメインが、前記SMIドメインに対して5’に位置し、前記プライマー結合ドメインに対して3’に位置する、請求項93〜139のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の少なくとも1つの修飾ヌクレオチドを含む前記ドメインが、前記プライマー結合ドメインに対して3’に位置する前記SMIドメインに対して3’に位置する、請求項93〜138のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記SMIドメインが、前記連結ドメインに対して5’に位置する、請求項93〜141のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列の前記3’終端が、前記連結ドメインを含む、請求項93〜143のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列が、5’から3’まで、前記プライマー結合ドメイン、少なくとも1つの修飾ヌクレオチドを含む前記ドメイン、前記SMIドメイン、及び前記連結ドメインを含む、請求項93〜143のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列が、5’から3’まで、前記プライマー結合ドメイン、前記SMIドメイン、少なくとも1つの修飾ヌクレオチドを含む前記ドメイン、及び前記連結ドメインを含む、請求項93〜138のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列のいずれかが、修飾ヌクレオチドまたは非ヌクレオチド分子を含む、請求項93〜146のいずれか1項に記載のアダプター核酸配列の対。
- 前記修飾ヌクレオチドまたは非ヌクレオチド分子が、コリシンE2、Im2、グルチチオン、グルタチオン−s−トランスフェラーゼ(GST)、ニッケル、ポリ−ヒスチジン、FLAG−タグ、myc−タグ、またはビオチンである、請求項147に記載のアダプター核酸配列の対。
- 前記ビオチンが、ビオチン−16−アミノアリル−2’−デオキシウリジン−5’−トリホスフェート、ビオチン−16−アミノアリル−2’−デオキシシチジン−5’−トリホスフェート、ビオチン−16−アミノアリルシチジン−5’−トリホスフェート、N4−ビオチン−OBEA−2’−デオキシシチジン−5’−トリホスフェート、ビオチン−16−アミノアリルウリジン−5’−トリホスフェート、ビオチン−16−7−デアザ−7−アミノアリル−2’−デオキシグアノシン−5’−トリホスフェート、デスチオビオチン−6−アミノアリル−2’−デオキシシチジン−5’−トリホスフェート、5’−ビオチン−G−モノホスフェート、5’−ビオチン−A−モノホスフェート、5’−ビオチン−dG−モノホスフェート、または5’−ビオチン−dA−モノホスフェートである、請求項148に記載のアダプター核酸配列の対。
- 前記ビオチンが、基質に結合したストレプトアビジンに結合することができる、請求項148または請求項149に記載のアダプター核酸配列の対。
- 前記ビオチンが、基質に結合したストレプトアビジンに結合するとき、前記第1のアダプター核酸配列が、前記第2のアダプター核酸配列から分離することができる、請求項150に記載のアダプター核酸配列の対。
- 前記第2のアダプター核酸配列が、少なくとも1つのホスホロチオエート結合を含む、請求項93〜148のいずれか1項に記載のアダプター核酸配列の対。
- 前記二本鎖標的核酸配列が、DNAまたはRNAである、請求項93〜152のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列のいずれかが、小分子、核酸、ペプチド、及び親和性パートナーによって結合されることができる特有に結合可能な部分から選択される、親和性標識を含む、請求項93〜153のいずれか1項に記載のアダプター核酸配列の対。
- 前記親和性パートナーが、固体基質に結合し、前記親和性標識に結合するとき、前記親和性標識を含む前記アダプター核酸配列が、前記親和性標識を含まない前記アダプター核酸配列から分離されることができる、請求項154に記載のアダプター核酸配列の対。
- 前記固体基質が、固体表面、ビーズ、または別の固定された構造である、請求項155に記載のアダプター核酸配列の対。
- 前記核酸が、DNA、RNA、またはこれらの組み合わせであり、任意で、ペプチド−核酸またはロックド核酸を含む、請求項154〜156のいずれか1項に記載のアダプター核酸配列の対。
- 前記親和性標識が、前記第2のアダプター核酸配列内の対向するドメインと完全には相補的ではない前記第1のアダプター核酸配列内の、アダプターの終端またはドメイン内に位置する、請求項154〜157のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列のいずれかが、磁気特性、電荷特性、または不溶性特性を有する物理的基を含む、請求項93〜158のいずれか1項に記載のアダプター核酸配列の対。
- 前記物理的基が磁気特性を有し、磁場が適用されるとき、前記物理的基を含む前記アダプター核酸配列が、前記物理的基を含まない前記アダプター核酸配列から分離される、請求項159に記載のアダプター核酸配列の対。
- 前記物理的基が電荷特性を有し、電場が適用されるとき、前記物理的基を含む前記アダプター核酸配列が、前記物理的基を含まない前記アダプター核酸配列から分離される、請求項159に記載のアダプター核酸配列の対。
- 前記物理的基が不溶性特性を有し、前記アダプター核酸配列の対が前記物理的基が不溶性である溶液中に含有されるとき、前記物理的基を含む前記アダプター核酸配列が、溶液中に残る前記物理的基を含まない前記アダプター核酸配列から離れて沈殿する、請求項157に記載のアダプター核酸配列の対。
- 前記物理的基が、前記第2のアダプター核酸配列内の対向するドメインと完全には相補的ではない前記第1のアダプター核酸配列内の、アダプターの終端またはドメイン内に位置する、請求項157〜162のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列が、少なくとも部分的に一本鎖である、請求項93〜163のいずれか1項に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列または前記第2のアダプター核酸配列が、一本鎖である、請求項163に記載のアダプター核酸配列の対。
- 前記第1のアダプター核酸配列及び前記第2のアダプター核酸配列が、一本鎖である、請求項165に記載のアダプター核酸配列の対。
- 前記連結ドメインの少なくとも一方が、脱ヒドロキシル化塩基を含む、請求項96〜166のいずれか1項に記載のアダプター核酸配列の対。
- 前記連結ドメインの少なくとも一方が、それを連結不能にするように化学的に修飾されている、請求項96〜166のいずれか1項に記載のアダプター核酸配列の対。
- 請求項93〜168のいずれか1項のいずれかに記載のアダプター核酸配列の少なくとも2つの対を含む組成物であって、アダプター核酸分子の第1の対からの第1のアダプター核酸分子の前記SMIドメインが、アダプター核酸分子の少なくとも第2の対からの第1のアダプター核酸分子の前記SMIドメインとは異なる、前記組成物。
- 一本鎖アダプター核酸分子の前記第1の対からの前記第1のアダプター核酸分子の前記SMIドメインが、一本鎖アダプター核酸分子の前記少なくとも第2の対からの前記第1の一本鎖アダプター核酸分子の前記SMIドメインと同一の長さである、請求項169に記載の組成物。
- 一本鎖アダプター核酸分子の前記第1の対からの前記第1のアダプター核酸分子の前記SMIドメインが、一本鎖アダプター核酸分子の前記少なくとも第2の対からの前記第1の一本鎖アダプター核酸分子の前記SMIドメインとは異なる長さを有する、請求項169に記載の組成物。
- 各SMIドメインが、前記SMI内またはそれに隣接する部位に1つ以上の固定された塩基を含む、請求項169〜171のいずれか1項に記載の組成物。
- 二本鎖標的核酸分子の第1の終端に連結された請求項93〜168のいずれか1項に記載のアダプター核酸分子の第1の対と、前記二本鎖標的核酸分子の第2の終端に連結された請求項93〜168のいずれか1項に記載のアダプター核酸分子の第2の対とを含む、少なくとも第1の二本鎖複合化核酸を含む、組成物。
- アダプター核酸分子の前記第1の対が、アダプター核酸分子の前記第2の対とは異なる、請求項173に記載の組成物。
- アダプター核酸分子の前記第1の対の前記第1の鎖アダプター−標的核酸分子が、第1のSMIドメインを含み、アダプター核酸分子の前記第2の対の前記第1の鎖アダプター−標的核酸分子が、第2のSMIドメインを含む、請求項174に記載の組成物。
- アダプター核酸分子の前記第1の対の前記第1の鎖アダプター−標的核酸分子が、第1のSMIドメインを含み、アダプター核酸分子の前記第2の対の前記第1の鎖アダプター−標的核酸分子が、第2のSMIドメインを含む、請求項175に記載の組成物。
- 少なくとも第2の二本鎖複合化核酸を含む、請求項173〜176のいずれか1項に記載の組成物。
- 請求項1〜80のいずれか1項のいずれかに記載のアダプター核酸分子の少なくとも1つの対と、請求項93〜168のいずれか1項のいずれかに記載のアダプター核酸分子の少なくとも1つの対と、を含む、組成物。
- 二本鎖標的核酸分子の第1の終端に連結された請求項1〜80のいずれか1項に記載のアダプター核酸分子の第1の対と、前記二本鎖標的核酸分子の第2の終端に連結された請求項93〜168のいずれか1項に記載のアダプター核酸分子の第2の対と、を含む、少なくとも第1の二本鎖複合化核酸を含む、組成物。
- 二本鎖標的核酸を配列決定する方法であって、
(1)請求項1〜80のいずれか1項に記載のアダプター核酸配列の対を、二本鎖標的核酸分子の少なくとも1つの終端に連結し、それにより第1の鎖アダプター−標的核酸配列及び第2の鎖アダプター−標的核酸配列を含む二本鎖核酸分子を形成するステップと、
(2)前記第1の鎖アダプター−標的核酸配列を増幅し、それにより複数の第1の鎖アダプター−標的核酸配列及び複数のその相補的分子を含む、増幅された生成物の第1の組を生成するステップと、
(3)前記第2の鎖アダプター−標的核酸配列を増幅し、それにより複数の第2の鎖アダプター−標的核酸配列及び複数のその相補的分子を含む増幅された生成物の第2の組を生成するステップであって、増幅された生成物の前記第2の組が、増幅された生成物の前記第1の組から区別可能である、生成するステップと、
(4)増幅された生成物の前記第1の組を配列決定するステップと、
(5)増幅された生成物の前記第2の組を配列決定するステップと、を含む、前記方法。 - 前記少なくとも1つの終端が、2つの終端である、請求項180に記載の方法。
- 増幅が、PCRによって実行される、請求項180または請求項181に記載の方法。
- 増幅が、多置換増幅によって実行される、請求項180に記載の方法。
- 増幅が、等温増幅によって実行される、請求項180に記載の方法。
- 前記二本鎖標的核酸配列の第1の終端に連結されたアダプター核酸配列の前記対が、前記二本鎖標的核酸配列の第2の終端に連結されたアダプター核酸配列の前記対と同一の構造を有する、請求項180〜184に記載の方法。
- 前記第1の鎖アダプター−標的核酸配列が、5’から3’の順で、
(a)第1のアダプター核酸配列と、
(b)前記二本鎖標的核酸の第1の鎖と、
(c)第2のアダプター核酸配列と、を含む、請求項180または請求項185に記載の方法。 - 前記第2の鎖アダプター−標的核酸配列が、3’から5’の順で、
(a)第1のアダプター核酸配列と、
(b)前記二本鎖標的核酸の第2の鎖と、
(c)第2のアダプター核酸配列と、を含む、請求項180〜186のいずれか1項に記載の方法。 - 前記二本鎖標的核酸配列の第1の終端に連結されたアダプター核酸配列の前記対が、前記二本鎖標的核酸配列の第2の終端に連結されたアダプター核酸配列の前記対とは異なる、請求項180に記載の方法。
- 前記二本鎖標的核酸配列の第1の終端に連結されたアダプター核酸配列の前記対が、第1のSMIドメインを有し、前記二本鎖標的核酸配列の第2の終端に連結されたアダプター核酸配列の前記対が、第2のSMIドメインを有し、
前記第1のSMIドメインが、前記第2のSMIドメインとは異なってもよい、請求項188に記載の方法。 - 前記第1の鎖アダプター−標的核酸配列が、5’から3’の順で、
(a)前記第1のSDEを含む第1のアダプター核酸配列と、
(b)第1のSMIドメインと、
(c)前記二本鎖標的核酸の第1の鎖と、
(d)第2のアダプター核酸配列と、を含む、請求項188または請求項189に記載の方法。 - 前記第2の鎖アダプター−標的核酸配列が、5’から3’の順で、
(a)前記第1のSDEを含む第1のアダプター核酸配列と、
(b)第2のSMIドメインと、
(c)前記二本鎖標的核酸の第2の鎖と、
(d)第2のアダプター核酸配列と、を含む、請求項188〜190のいずれか1項に記載の方法。 - 増幅された生成物の前記第1の組のコンセンサス配列が、増幅された生成物の前記第2の組のコンセンサス配列と比較され、前記2つのコンセンサス配列間の差異が、人為産物であると見なされる、請求項180〜191のいずれか1項に記載の方法。
- 二本鎖標的核酸を配列決定する方法であって、
(1)請求項93〜168のいずれか1項に記載のアダプター核酸配列の対を、二本鎖標的核酸分子の少なくとも1つの終端に連結し、それにより第1の鎖アダプター−標的核酸配列及び第2の鎖アダプター−標的核酸配列を含む二本鎖核酸分子を形成するステップと、
(2)前記第1の鎖アダプター−標的核酸分子を増幅し、それにより複数の第1の鎖アダプター−標的核酸分子及び複数のその相補的分子を含む、増幅された生成物の第1の組を生成するステップと、
(3)前記第2の鎖アダプター−標的核酸分子を増幅し、それにより複数の第2の鎖アダプター−標的核酸分子及び複数のその相補的分子を含む、増幅された生成物の第2の組を生成するステップと、
(4)増幅された生成物の前記第1の組を配列決定し、それにより増幅された生成物の前記第1の組のコンセンサス配列を得るステップと、
(5)増幅された生成物の前記第2の組を配列決定し、それにより増幅された生成物の前記第2の組のコンセンサス配列を得るステップと、を含む、前記方法。 - 増幅された生成物の前記第2の組が、増幅された生成物の前記第1の組から区別可能である、請求項193に記載の方法。
- 増幅が、PCRによって実行される、請求項193または請求項194に記載の方法。
- 増幅が、多置換増幅によって実行される、請求項193または請求項194に記載の方法。
- 増幅が、等温増幅によって実行される、請求項193または請求項194に記載の方法。
- ステップ(1)の後に、前記二本鎖核酸分子を、前記少なくとも1つの修飾ヌクレオチドを別の化学構造に変化させる少なくとも1つの酵素と接触させるステップを更に含む、請求項193または請求項194に記載の方法。
- 前記酵素が、グリコシラーゼである、請求項198に記載の方法。
- 前記二本鎖標的核酸分子の第1の終端に連結されたアダプター核酸配列の前記対が、前記二本鎖標的核酸分子の第2の終端に連結されたアダプター核酸配列の前記対と同一である、請求項193〜199に記載の方法。
- 前記二本鎖標的核酸分子の第1の終端に連結されたアダプター核酸配列の前記対が、前記二本鎖標的核酸分子の第2の終端に連結されたアダプター核酸配列の前記対とは異なる、請求項193〜199に記載の方法。
- アダプター核酸配列の対が、二本鎖標的核酸分子の第1の終端に連結され、前記標的DNA分子の前記DNA配列の一部分に対応するプライマーが、前記DNA分子を増幅するために利用される、請求項193〜199に記載の方法。
- 前記第1の鎖アダプター−標的核酸配列が、5’から3’の順で、
(a)前記少なくとも1つの修飾ヌクレオチドまたは前記少なくとも1つの脱塩基部位を含む第1のアダプター核酸配列と、
(b)前記二本鎖標的核酸の第1の鎖と、
(c)第2のアダプター核酸配列と、を含む、請求項193〜200のいずれか1項に記載の方法。 - 前記第2の鎖アダプター−標的核酸配列が、3’から5’の順で、
(a)第1のアダプター核酸配列と、
(b)前記二本鎖標的核酸の第2の鎖と、
(c)第2のアダプター核酸配列と、を含む、請求項193〜203のいずれか1項に記載の方法。 - 前記二本鎖標的核酸分子の第1の終端に連結されたアダプター核酸配列の前記対が、前記二本鎖標的核酸分子の第2の終端に連結されたアダプター核酸配列の前記対とは異なる、請求項193に記載の方法。
- 前記二本鎖標的核酸分子の第1の終端に連結されたアダプター核酸配列の前記対が、第1のSMIドメインを有し、前記二本鎖標的核酸配列の第2の終端に連結されたアダプター核酸配列の前記対が、第2のSMIドメインを有し、
前記第1のSMIドメインが、前記第2のSMIドメインとは異なる、請求項205に記載の方法。 - 前記第1の鎖アダプター−標的核酸配列が、5’から3’の順で、
(a)前記少なくとも1つの修飾ヌクレオチドまたは前記少なくとも1つの脱塩基部位、及び前記第1のSMIドメインを含む第1のアダプター核酸配列と、
(b)前記二本鎖標的核酸の第1の鎖と、
(c)前記第2のSMIドメインを含む第2のアダプター核酸配列と、を含む、請求項205または請求項206に記載の方法。 - 前記少なくとも1つの修飾ヌクレオチドが、8−オキソ−Gであるとき、前記第2のアダプター核酸配列が、前記8−オキソ−Gに対応する位置にシトシンを含む、請求項207に記載の方法。
- 前記第2の鎖アダプター−標的核酸配列が、3’から5’の順で、
(a)前記第1のSMIドメインを含む第1のアダプター核酸配列と、
(b)前記二本鎖標的核酸の第2の鎖と、
(c)前記第2のSMIドメインを含む第2のアダプター核酸配列と、を含む、請求項205〜208のいずれか1項に記載の方法。 - 前記少なくとも1つの修飾ヌクレオチドが、8−オキソ−Gであるとき、前記第2のアダプター核酸配列が、前記8−オキソ−Gに対応する位置にシチジンを含む、請求項209に記載の方法。
- 区別可能な増幅生成物が、個々のDNA分子の前記二本の鎖の各々から得られ、増幅された生成物の前記第1の組の前記コンセンサス配列が、増幅された生成物の前記第2の組の前記コンセンサス配列と比較され、2つのコンセンサス配列間の差異が、人為産物と見なされ得る、方法。
- 増幅された生成物が、同一のSMI配列を共有しているために、同一の初期DNA分子から生じていることが決定される、請求項211に記載の方法。
- 増幅された生成物が、SMIアダプターライブラリ合成の時点で、かつそれと組み合わせて生成されたデータベースに基づいて、互いに対応することが既知である、別個のSMI配列を担持しているために、同一の初期DNA分子から生じていることが決定される、請求項211に記載の方法。
- 増幅された生成物が、SDEによって導入された配列差異の少なくとも1つのヌクレオチドを介して、同一の初期二本鎖DNA配列の別個の鎖から生じていることが決定される、請求項211〜213のいずれか1項に記載の方法。
- 区別可能な増幅生成物が、個々のDNA分子の前記二本の鎖の各々から得られ、単一DNA分子の前記二本の初期DNA鎖のうちの一本に対応する増幅された生成物から得られる前記配列が、前記二本の初期DNA鎖のうちの二本目に対応する増幅された生成物と比較され、2つの配列間の差異が、人為産物と見なされる、方法。
- 単一DNA分子の前記二本の初期DNA鎖のうちの一本に対応する増幅された生成物から得られる前記配列が、前記二本の初期DNA鎖のうちの二本目に対応する増幅された生成物と比較され、前記2つの配列間にいかなる差異も特定されないとき、区別不可能な増幅生成物が、個々のDNA分子の前記二本の鎖から得られる、方法。
- 増幅された生成物が、SMIアダプターライブラリ合成の時点で、かつそれと組み合わせて生成されたデータベースに基づいて、同一のSMI配列を共有しているために、同一の初期二本鎖DNA分子から生じていることが決定される、請求項215または請求項216に記載の方法。
- 増幅された生成物が、SDEによって導入された配列差異の少なくとも1つのヌクレオチドを介して、同一の初期二本鎖DNA配列の別個の鎖から生じていることが決定される、請求項214〜217に記載の方法。
- DNA二本鎖のそれらの構成要素の一本鎖への熱融解または化学融解後に、単一分子希釈のステップを更に含む、請求項214〜218に記載の方法。
- 前記二本の元々対合した鎖が同一の容器を共有する可能性が小さいように、前記一本鎖が、複数の物理的に分離された反応チャンバ内へと希釈される、請求項219に記載の方法。
- 前記物理的に分離された反応チャンバが、容器、管、ウェル、及び少なくとも1対の非連通液滴から選択される、請求項220に記載の方法。
- PCR増幅が、好ましくは異なるタグ配列を担持する各チャンバのためのプライマーを使用して、物理的に分離された各反応チャンバに実行される、請求項220に記載の方法。
- 各タグ配列が、SDEとして動作する、請求項222に記載の方法。
- 同一の初期DNAの前記二本の鎖に対応する一連の対合した配列が、互いに比較され、前記一連の生成物からの少なくとも1つの配列が、前記初期DNA分子の正確な配列を表す可能性が最も高いものとして選択される、請求項216〜223に記載の方法。
- 前記初期DNA分子の正確な配列を表す可能性が最も高いものとして選択される前記生成物が、少なくとも一部には、前記二本のDNA鎖から得られる前記生成物間に最小数のミスマッチを有するために選択される、請求項224に記載の方法。
- 前記初期DNA分子の正確な配列を表す可能性が最も高いものとしてとして選択される前記生成物が、少なくとも一部には、前記参照配列と比較して最小数のミスマッチを有するために選択される、請求項224または請求項225に記載の方法。
- ステップ(2)またはステップ(3)の前記増幅中に、前記少なくとも1つの脱塩基部位が、前記対応する増幅された生成物中のチミジンへの増幅時に変換され、SDEの導入をもたらす、請求項203〜210のいずれか1項に記載の方法。
- ステップ(2)またはステップ(3)の前記増幅中に、前記少なくとも1つの修飾ヌクレオチド部位が、前記対応する増幅された生成物中のアデノシンをコードする、請求項193に記載の方法。
- 少なくとも2対のアダプター核酸配列を含む組成物であって、アダプター核酸配列の第1の対が、
プライマー結合ドメインと、
鎖定義要素(SDE)と、
連結ドメインと、を含み、
アダプター核酸配列の第2の対が、
プライマー結合ドメインと、
単一分子識別子(SMI)ドメインと、
連結ドメインと、を含む、前記組成物。 - 二本鎖複合化核酸であって、
(1)プライマー結合ドメインと、
SDEと、を含む、アダプター核酸配列の第1の対と、
(2)二本鎖標的核酸と、
(3)プライマー結合ドメインと、
単一分子識別子(SMI)ドメインと、を含む、アダプター核酸配列の第2の対と、を含み、
アダプター核酸分子の前記第1の対が、前記二本鎖標的核酸分子の第1の終端に連結され、アダプター核酸分子の前記第2の対が、前記二本鎖標的核酸分子の第2の終端に連結される、前記二本鎖複合化核酸。 - アダプター核酸分子の前記第1の対及び/またはアダプター核酸分子の前記第2の対が、連結ドメインを更に含む、請求項230に記載の二本鎖複合化核酸。
- 第1のアダプター核酸配列及び第2のアダプター核酸配列を含む、二本鎖標的核酸分子の配列決定において使用するためのアダプター核酸配列の対であって、各アダプター核酸配列が、
プライマー結合ドメインと、
SDEと、
連結ドメインと、を含み、
前記第1のアダプター核酸配列の前記SDEが、前記第2のアダプター核酸配列の前記SDEと少なくとも部分的に非相補的である、前記アダプター核酸配列の対。 - 二本鎖標的核酸分子の第1の終端に連結され、前記二本鎖標的核酸分子の第2の第2の終端に連結された、請求項1〜80のいずれか1項に記載のアダプター核酸分子の対を含む、二本鎖環状核酸。
- 二本鎖標的核酸分子の第1の終端に連結され、前記二本鎖標的核酸分子の第2の第2の終端に連結された、請求項93〜168のいずれか1項に記載のアダプター核酸分子の対を含む、二本鎖環状核酸。
- 二本鎖標的核酸分子の第1の終端に連結された請求項1〜80のいずれか1項に記載のアダプター核酸分子の対と、前記二本鎖標的核酸分子の第2の終端に連結されたプライマー結合ドメインのアニールされた対と、を含み、
プライマー結合ドメインの前記アニールされた対が、アダプター核酸分子の前記対に連結される、二本鎖環状核酸。 - 二本鎖標的核酸分子の第1の終端に連結された請求項93〜168のいずれか1項に記載のアダプター核酸分子の対と、前記二本鎖標的核酸分子の第2の終端に連結されたプライマー結合ドメインのアニールされた対と、を含み、
プライマー結合ドメインの前記アニールされた対が、アダプター核酸分子の前記対に連結される、二本鎖環状核酸。 - 二本鎖複合化核酸であって、
(1)プライマー結合ドメインと、
鎖定義要素(SDE)と、
単一分子識別子(SMI)ドメインと、を含む、アダプター核酸配列の対と、
(2)二本鎖標的核酸と、
(3)アニールされた対プライマー結合ドメインと、を含み、
アダプター核酸分子の前記対が、前記二本鎖標的核酸分子の第1の終端に連結され、前記アニールされた対プライマー結合ドメインが、前記二本鎖標的核酸分子の第2の終端に連結される、前記二本鎖複合化核酸。 - アダプター核酸分子の前記対及び/または前記アニールされた対プライマー結合ドメインが、連結ドメインを更に含む、請求項237に記載の二本鎖複合化核酸。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2021179334A JP7548579B2 (ja) | 2015-12-08 | 2021-11-02 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
| JP2023184524A JP2024010122A (ja) | 2015-12-08 | 2023-10-27 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201562264822P | 2015-12-08 | 2015-12-08 | |
| US62/264,822 | 2015-12-08 | ||
| US201662281917P | 2016-01-22 | 2016-01-22 | |
| US62/281,917 | 2016-01-22 | ||
| PCT/US2016/065605 WO2017100441A1 (en) | 2015-12-08 | 2016-12-08 | Improved adapters, methods, and compositions for duplex sequencing |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021179334A Division JP7548579B2 (ja) | 2015-12-08 | 2021-11-02 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2019509015A true JP2019509015A (ja) | 2019-04-04 |
| JP2019509015A5 JP2019509015A5 (ja) | 2020-01-23 |
| JP6975507B2 JP6975507B2 (ja) | 2021-12-01 |
Family
ID=57750605
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018530698A Active JP6975507B2 (ja) | 2015-12-08 | 2016-12-08 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
| JP2021179334A Active JP7548579B2 (ja) | 2015-12-08 | 2021-11-02 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
| JP2023184524A Pending JP2024010122A (ja) | 2015-12-08 | 2023-10-27 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
Family Applications After (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2021179334A Active JP7548579B2 (ja) | 2015-12-08 | 2021-11-02 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
| JP2023184524A Pending JP2024010122A (ja) | 2015-12-08 | 2023-10-27 | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 |
Country Status (11)
| Country | Link |
|---|---|
| US (3) | US11332784B2 (ja) |
| EP (2) | EP4043584A1 (ja) |
| JP (3) | JP6975507B2 (ja) |
| CN (1) | CN109072294A (ja) |
| AU (1) | AU2016366231B2 (ja) |
| CA (1) | CA3006792A1 (ja) |
| ES (1) | ES2911421T3 (ja) |
| IL (1) | IL259788B2 (ja) |
| PL (1) | PL3387152T3 (ja) |
| PT (1) | PT3387152T (ja) |
| WO (1) | WO2017100441A1 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022551688A (ja) * | 2019-10-16 | 2022-12-13 | 中国医学科学院腫瘤医院 | ctDNA中の腫瘍特異的遺伝子の変異及びメチル化の検出方法 |
Families Citing this family (66)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2012129363A2 (en) | 2011-03-24 | 2012-09-27 | President And Fellows Of Harvard College | Single cell nucleic acid detection and analysis |
| WO2013123442A1 (en) | 2012-02-17 | 2013-08-22 | Fred Hutchinson Cancer Research Center | Compositions and methods for accurately identifying mutations |
| PT2828218T (pt) | 2012-03-20 | 2020-11-11 | Univ Washington Through Its Center For Commercialization | Métodos para baixar a taxa de erro da sequenciação paralela massiva de adn utilizando sequenciação duplex de consensus |
| US20160040229A1 (en) | 2013-08-16 | 2016-02-11 | Guardant Health, Inc. | Systems and methods to detect rare mutations and copy number variation |
| US11913065B2 (en) | 2012-09-04 | 2024-02-27 | Guardent Health, Inc. | Systems and methods to detect rare mutations and copy number variation |
| CN104781421B (zh) | 2012-09-04 | 2020-06-05 | 夸登特健康公司 | 检测稀有突变和拷贝数变异的系统和方法 |
| US10876152B2 (en) | 2012-09-04 | 2020-12-29 | Guardant Health, Inc. | Systems and methods to detect rare mutations and copy number variation |
| SG11201600853UA (en) | 2013-08-05 | 2016-03-30 | Twist Bioscience Corp | De novo synthesized gene libraries |
| ES2660989T3 (es) | 2013-12-28 | 2018-03-27 | Guardant Health, Inc. | Métodos y sistemas para detectar variantes genéticas |
| WO2016078095A1 (zh) * | 2014-11-21 | 2016-05-26 | 深圳华大基因科技有限公司 | 鼓泡状接头元件和使用其构建测序文库的方法 |
| US10669304B2 (en) | 2015-02-04 | 2020-06-02 | Twist Bioscience Corporation | Methods and devices for de novo oligonucleic acid assembly |
| US9981239B2 (en) | 2015-04-21 | 2018-05-29 | Twist Bioscience Corporation | Devices and methods for oligonucleic acid library synthesis |
| US10844428B2 (en) | 2015-04-28 | 2020-11-24 | Illumina, Inc. | Error suppression in sequenced DNA fragments using redundant reads with unique molecular indices (UMIS) |
| EP3350314A4 (en) | 2015-09-18 | 2019-02-06 | Twist Bioscience Corporation | OLIGONUCLEIC ACID VARIANT LIBRARIES VARIANT AND SYNTHESIS THEREOF |
| KR102794025B1 (ko) | 2015-09-22 | 2025-04-09 | 트위스트 바이오사이언스 코포레이션 | 핵산 합성을 위한 가요성 기판 |
| CN115920796A (zh) | 2015-12-01 | 2023-04-07 | 特韦斯特生物科学公司 | 功能化表面及其制备 |
| CA3006792A1 (en) | 2015-12-08 | 2017-06-15 | Twinstrand Biosciences, Inc. | Improved adapters, methods, and compositions for duplex sequencing |
| SG11201805119QA (en) | 2015-12-17 | 2018-07-30 | Guardant Health Inc | Methods to determine tumor gene copy number by analysis of cell-free dna |
| US11384382B2 (en) | 2016-04-14 | 2022-07-12 | Guardant Health, Inc. | Methods of attaching adapters to sample nucleic acids |
| ES3002715T3 (en) | 2016-04-14 | 2025-03-07 | Guardant Health Inc | Methods for early detection of cancer |
| US11821028B2 (en) | 2016-07-12 | 2023-11-21 | QIAGEN Sciences, LLP | Single end duplex DNA sequencing |
| CN109312391B (zh) | 2016-07-18 | 2022-06-03 | 豪夫迈·罗氏有限公司 | 生成用于单分子测序的单链环状dna文库的方法 |
| WO2018031588A1 (en) * | 2016-08-09 | 2018-02-15 | Takara Bio Usa, Inc. | Nucleic acid adaptors with molecular identification sequences and use thereof |
| EP3500672A4 (en) | 2016-08-22 | 2020-05-20 | Twist Bioscience Corporation | DE NOVO SYNTHETIZED NUCLEIC ACID LIBRARIES |
| US10417457B2 (en) | 2016-09-21 | 2019-09-17 | Twist Bioscience Corporation | Nucleic acid based data storage |
| GB2573069A (en) | 2016-12-16 | 2019-10-23 | Twist Bioscience Corp | Variant libraries of the immunological synapse and synthesis thereof |
| BR112019013391A2 (pt) | 2016-12-28 | 2020-03-03 | Quest Diagnostics Investments Llc | Adaptador de ácido nucleico, e, método para detecção de uma mutação em uma molécula de dna circulante tumoral (ctdna) de fita dupla. |
| SG11201906428SA (en) | 2017-01-18 | 2019-08-27 | Illumina Inc | Methods and systems for generation and error-correction of unique molecular index sets with heterogeneous molecular lengths |
| EP4556433A3 (en) | 2017-02-22 | 2025-08-06 | Twist Bioscience Corporation | Nucleic acid based data storage |
| WO2018170169A1 (en) | 2017-03-15 | 2018-09-20 | Twist Bioscience Corporation | Variant libraries of the immunological synapse and synthesis thereof |
| IL269431B2 (en) | 2017-03-23 | 2025-05-01 | Univ Washington | Methods for targeted nucleic acid sequence enrichment with applications to error corrected nucleic acid sequencing |
| WO2018183942A1 (en) * | 2017-03-31 | 2018-10-04 | Grail, Inc. | Improved library preparation and use thereof for sequencing-based error correction and/or variant identification |
| AU2018261332B2 (en) | 2017-05-01 | 2024-12-05 | Illumina, Inc. | Optimal index sequences for multiplex massively parallel sequencing |
| EP3622089B1 (en) | 2017-05-08 | 2024-07-17 | Illumina, Inc. | Method for sequencing using universal short adapters for indexing of polynucleotide samples |
| WO2018231872A1 (en) | 2017-06-12 | 2018-12-20 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| WO2018231864A1 (en) | 2017-06-12 | 2018-12-20 | Twist Bioscience Corporation | Methods for seamless nucleic acid assembly |
| US11407837B2 (en) | 2017-09-11 | 2022-08-09 | Twist Bioscience Corporation | GPCR binding proteins and synthesis thereof |
| US11447818B2 (en) * | 2017-09-15 | 2022-09-20 | Illumina, Inc. | Universal short adapters with variable length non-random unique molecular identifiers |
| CN111565834B (zh) | 2017-10-20 | 2022-08-26 | 特韦斯特生物科学公司 | 用于多核苷酸合成的加热的纳米孔 |
| CN118126816A (zh) | 2017-11-06 | 2024-06-04 | 伊鲁米那股份有限公司 | 核酸索引化技术 |
| AU2018366213B2 (en) | 2017-11-08 | 2025-05-15 | Twinstrand Biosciences, Inc. | Reagents and adapters for nucleic acid sequencing and methods for making such reagents and adapters |
| KR102804057B1 (ko) | 2018-01-04 | 2025-05-07 | 트위스트 바이오사이언스 코포레이션 | Dna 기반 디지털 정보 저장 |
| CN108300716B (zh) * | 2018-01-05 | 2020-06-30 | 武汉康测科技有限公司 | 接头元件、其应用和基于不对称多重pcr进行靶向测序文库构建的方法 |
| CA3093846A1 (en) | 2018-03-15 | 2019-09-19 | Twinstrand Biosciences, Inc. | Methods and reagents for enrichment of nucleic acid material for sequencing applications and other nucleic acid material interrogations |
| GB201804641D0 (en) | 2018-03-22 | 2018-05-09 | Inivata Ltd | Methods of sequencing nucleic acids and error correction of sequence reads |
| EP3768853A4 (en) | 2018-03-23 | 2021-04-28 | Board Of Regents The University Of Texas System | EFFICIENT SEQUENCING OF DSDNA WITH EXTREMELY LOW ERROR RATE |
| WO2019222560A1 (en) * | 2018-05-16 | 2019-11-21 | Twinstrand Biosciences, Inc. | Methods and reagents for resolving nucleic acid mixtures and mixed cell populations and associated applications |
| CA3100739A1 (en) | 2018-05-18 | 2019-11-21 | Twist Bioscience Corporation | Polynucleotides, reagents, and methods for nucleic acid hybridization |
| BR112021000409A2 (pt) | 2018-07-12 | 2021-04-06 | Twinstrand Biosciences, Inc. | Métodos e reagentes para caracterizar edição genômica, expansão clonal e aplicações associadas |
| WO2020043803A1 (en) * | 2018-08-28 | 2020-03-05 | Sophia Genetics S.A. | Methods for asymmetric dna library generation and optionally integrated duplex sequencing |
| JP7152599B2 (ja) * | 2018-09-21 | 2022-10-12 | エフ.ホフマン-ラ ロシュ アーゲー | 塩基配列決定のためのモジュール式およびコンビナトリアル核酸試料調製のためのシステムおよび方法 |
| JP7541363B2 (ja) | 2018-10-16 | 2024-08-28 | ツインストランド・バイオサイエンシズ・インコーポレイテッド | プーリングを介した多数の試料の効率的な遺伝子型決定のための方法および試薬 |
| TWI725686B (zh) | 2018-12-26 | 2021-04-21 | 財團法人工業技術研究院 | 用於產生液珠的管狀結構及液珠產生方法 |
| WO2020139871A1 (en) | 2018-12-26 | 2020-07-02 | Twist Bioscience Corporation | Highly accurate de novo polynucleotide synthesis |
| CA3131514A1 (en) * | 2019-02-25 | 2020-09-03 | Twist Bioscience Corporation | Compositions and methods for next generation sequencing |
| JP2022522668A (ja) | 2019-02-26 | 2022-04-20 | ツイスト バイオサイエンス コーポレーション | 抗体を最適化するための変異体核酸ライブラリ |
| CN113766930B (zh) | 2019-02-26 | 2025-07-22 | 特韦斯特生物科学公司 | Glp1受体的变异核酸文库 |
| US11332738B2 (en) | 2019-06-21 | 2022-05-17 | Twist Bioscience Corporation | Barcode-based nucleic acid sequence assembly |
| WO2021022237A1 (en) * | 2019-08-01 | 2021-02-04 | Twinstrand Biosciences, Inc. | Methods and reagents for nucleic acid sequencing and associated applications |
| EP4034566A4 (en) | 2019-09-23 | 2024-01-24 | Twist Bioscience Corporation | VARIANT NUCLEIC ACID BANKS FOR CRTH2 |
| JP2022548783A (ja) | 2019-09-23 | 2022-11-21 | ツイスト バイオサイエンス コーポレーション | 単一ドメイン抗体のバリアント核酸ライブラリー |
| GB2627085B (en) | 2019-11-06 | 2024-11-13 | Univ Leland Stanford Junior | Methods and systems for analysing nucleic acid molecules |
| BR112022011235A2 (pt) | 2019-12-09 | 2022-12-13 | Twist Bioscience Corp | Bibliotecas de variantes de ácido nucleico para receptores de adenosina |
| US11783912B2 (en) | 2021-05-05 | 2023-10-10 | The Board Of Trustees Of The Leland Stanford Junior University | Methods and systems for analyzing nucleic acid molecules |
| WO2024015869A2 (en) * | 2022-07-12 | 2024-01-18 | University Of Washington | Systems and methods for variant detection in cells |
| WO2024022207A1 (en) * | 2022-07-25 | 2024-02-01 | Mgi Tech Co., Ltd. | Methods of in-solution positional co-barcoding for sequencing long dna molecules |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013142389A1 (en) * | 2012-03-20 | 2013-09-26 | University Of Washington Through Its Center For Commercialization | Methods of lowering the error rate of massively parallel dna sequencing using duplex consensus sequencing |
| WO2015100427A1 (en) * | 2013-12-28 | 2015-07-02 | Guardant Health, Inc. | Methods and systems for detecting genetic variants |
Family Cites Families (95)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6582908B2 (en) | 1990-12-06 | 2003-06-24 | Affymetrix, Inc. | Oligonucleotides |
| US5308751A (en) | 1992-03-23 | 1994-05-03 | General Atomics | Method for sequencing double-stranded DNA |
| JP2002503954A (ja) * | 1997-04-01 | 2002-02-05 | グラクソ、グループ、リミテッド | 核酸増幅法 |
| US6087099A (en) | 1997-09-08 | 2000-07-11 | Myriad Genetics, Inc. | Method for sequencing both strands of a double stranded DNA in a single sequencing reaction |
| CA2345441A1 (en) | 1998-10-27 | 2000-05-04 | Affymetrix, Inc. | Complexity management and analysis of genomic dna |
| US6958225B2 (en) | 1999-10-27 | 2005-10-25 | Affymetrix, Inc. | Complexity management of genomic DNA |
| US7300751B2 (en) | 2000-06-30 | 2007-11-27 | Syngenta Participations Ag | Method for identification of genetic markers |
| US6632611B2 (en) | 2001-07-20 | 2003-10-14 | Affymetrix, Inc. | Method of target enrichment and amplification |
| US7297778B2 (en) | 2001-07-25 | 2007-11-20 | Affymetrix, Inc. | Complexity management of genomic DNA |
| CA2497740C (en) | 2001-10-15 | 2011-06-21 | Bioarray Solutions, Ltd. | Multiplexed analysis of polymorphic loci by probe elongation-mediated detection |
| US7406385B2 (en) | 2001-10-25 | 2008-07-29 | Applera Corporation | System and method for consensus-calling with per-base quality values for sample assemblies |
| US7459273B2 (en) | 2002-10-04 | 2008-12-02 | Affymetrix, Inc. | Methods for genotyping selected polymorphism |
| US7452699B2 (en) | 2003-01-15 | 2008-11-18 | Dana-Farber Cancer Institute, Inc. | Amplification of DNA in a hairpin structure, and applications |
| US20040209299A1 (en) | 2003-03-07 | 2004-10-21 | Rubicon Genomics, Inc. | In vitro DNA immortalization and whole genome amplification using libraries generated from randomly fragmented DNA |
| WO2005071110A2 (en) | 2004-01-23 | 2005-08-04 | Lingvitae As | Improving polynucleotide ligation reactions |
| US7393665B2 (en) | 2005-02-10 | 2008-07-01 | Population Genetics Technologies Ltd | Methods and compositions for tagging and identifying polynucleotides |
| US8796441B2 (en) | 2005-04-13 | 2014-08-05 | The United States Of America As Represented By The Secretary Of The Department Of Health And Human Services | Human sweet and umami taste receptor variants |
| DK2302070T3 (da) | 2005-06-23 | 2012-11-26 | Keygene Nv | Strategier til identifikation og detektion af polymorfismer med højt gennemløb |
| WO2007037678A2 (en) | 2005-09-29 | 2007-04-05 | Keygene N.V. | High throughput screening of mutagenized populations |
| GB0522310D0 (en) | 2005-11-01 | 2005-12-07 | Solexa Ltd | Methods of preparing libraries of template polynucleotides |
| WO2007087312A2 (en) | 2006-01-23 | 2007-08-02 | Population Genetics Technologies Ltd. | Molecular counting |
| US20070172839A1 (en) | 2006-01-24 | 2007-07-26 | Smith Douglas R | Asymmetrical adapters and methods of use thereof |
| EP3239304B1 (en) | 2006-04-04 | 2020-08-19 | Keygene N.V. | High throughput detection of molecular markers based on aflp and high troughput sequencing |
| WO2008093098A2 (en) | 2007-02-02 | 2008-08-07 | Illumina Cambridge Limited | Methods for indexing samples and sequencing multiple nucleotide templates |
| EP2201143B2 (en) | 2007-09-21 | 2016-08-24 | Katholieke Universiteit Leuven | Tools and methods for genetic tests using next generation sequencing |
| EP4230747A3 (en) | 2008-03-28 | 2023-11-15 | Pacific Biosciences Of California, Inc. | Compositions and methods for nucleic acid sequencing |
| US8029993B2 (en) | 2008-04-30 | 2011-10-04 | Population Genetics Technologies Ltd. | Asymmetric adapter library construction |
| US8383345B2 (en) | 2008-09-12 | 2013-02-26 | University Of Washington | Sequence tag directed subassembly of short sequencing reads into long sequencing reads |
| WO2010056728A1 (en) | 2008-11-11 | 2010-05-20 | Helicos Biosciences Corporation | Nucleic acid encoding for multiplex analysis |
| EP2391732B1 (en) | 2009-01-30 | 2015-05-27 | Oxford Nanopore Technologies Limited | Methods using adaptors for nucleic acid constructs in transmembrane sequencing |
| US20100331204A1 (en) | 2009-02-13 | 2010-12-30 | Jeff Jeddeloh | Methods and systems for enrichment of target genomic sequences |
| US20120165202A1 (en) | 2009-04-30 | 2012-06-28 | Good Start Genetics, Inc. | Methods and compositions for evaluating genetic markers |
| US9085798B2 (en) | 2009-04-30 | 2015-07-21 | Prognosys Biosciences, Inc. | Nucleic acid constructs and methods of use |
| EP2248914A1 (en) | 2009-05-05 | 2010-11-10 | Max-Planck-Gesellschaft zur Förderung der Wissenschaften e.V. | The use of class IIB restriction endonucleases in 2nd generation sequencing applications |
| EP3029141A1 (en) | 2009-08-20 | 2016-06-08 | Population Genetics Technologies Ltd. | Compositions and methods for intramolecular nucleic acid rearrangement |
| US8835358B2 (en) | 2009-12-15 | 2014-09-16 | Cellular Research, Inc. | Digital counting of individual molecules by stochastic attachment of diverse labels |
| US9080210B2 (en) | 2010-06-09 | 2015-07-14 | Keygene N.V. | High throughput screening using combinatorial sequence barcodes |
| US20120244525A1 (en) * | 2010-07-19 | 2012-09-27 | New England Biolabs, Inc. | Oligonucleotide Adapters: Compositions and Methods of Use |
| WO2012012037A1 (en) | 2010-07-19 | 2012-01-26 | New England Biolabs, Inc. | Oligonucleotide adaptors: compositions and methods of use |
| ES2523140T3 (es) | 2010-09-21 | 2014-11-21 | Population Genetics Technologies Ltd. | Aumento de la confianza en las identificaciones de alelos con el recuento molecular |
| WO2012042374A2 (en) | 2010-10-01 | 2012-04-05 | Anssi Jussi Nikolai Taipale | Method of determining number or concentration of molecules |
| WO2012061832A1 (en) | 2010-11-05 | 2012-05-10 | Illumina, Inc. | Linking sequence reads using paired code tags |
| US9074251B2 (en) * | 2011-02-10 | 2015-07-07 | Illumina, Inc. | Linking sequence reads using paired code tags |
| WO2012083225A2 (en) | 2010-12-16 | 2012-06-21 | Gigagen, Inc. | System and methods for massively parallel analysis of nycleic acids in single cells |
| WO2012112804A1 (en) | 2011-02-18 | 2012-08-23 | Raindance Technoligies, Inc. | Compositions and methods for molecular labeling |
| WO2012129363A2 (en) | 2011-03-24 | 2012-09-27 | President And Fellows Of Harvard College | Single cell nucleic acid detection and analysis |
| ES2986436T3 (es) | 2011-04-15 | 2024-11-11 | Univ Johns Hopkins | Sistema de secuenciación segura |
| DK2729580T3 (en) | 2011-07-08 | 2015-12-14 | Keygene Nv | SEQUENCE BASED genotyping BASED ON OLIGONUKLEOTIDLIGERINGSASSAYS |
| EP3620533B1 (en) | 2011-09-06 | 2023-01-18 | Gen-Probe Incorporated | Closed nucleic acid structures |
| AU2012304328B2 (en) | 2011-09-09 | 2017-07-20 | The Board Of Trustees Of The Leland Stanford Junior University | Methods for obtaining a sequence |
| JP5418579B2 (ja) | 2011-12-06 | 2014-02-19 | 株式会社デンソー | 開閉眼検出装置 |
| US20160153039A1 (en) | 2012-01-26 | 2016-06-02 | Nugen Technologies, Inc. | Compositions and methods for targeted nucleic acid sequence enrichment and high efficiency library generation |
| EP2807292B1 (en) | 2012-01-26 | 2019-05-22 | Tecan Genomics, Inc. | Compositions and methods for targeted nucleic acid sequence enrichment and high efficiency library generation |
| WO2013123442A1 (en) | 2012-02-17 | 2013-08-22 | Fred Hutchinson Cancer Research Center | Compositions and methods for accurately identifying mutations |
| EP2820174B1 (en) | 2012-02-27 | 2019-12-25 | The University of North Carolina at Chapel Hill | Methods and uses for molecular tags |
| WO2013128281A1 (en) | 2012-02-28 | 2013-09-06 | Population Genetics Technologies Ltd | Method for attaching a counter sequence to a nucleic acid sample |
| NO2694769T3 (ja) * | 2012-03-06 | 2018-03-03 | ||
| WO2013138510A1 (en) | 2012-03-13 | 2013-09-19 | Patel Abhijit Ajit | Measurement of nucleic acid variants using highly-multiplexed error-suppressed deep sequencing |
| EP2847353B1 (en) | 2012-05-10 | 2022-01-19 | The General Hospital Corporation | Methods for determining a nucleotide sequence |
| AU2013267609C1 (en) | 2012-05-31 | 2019-01-03 | Board Of Regents, The University Of Texas System | Method for accurate sequencing of DNA |
| US20160040229A1 (en) | 2013-08-16 | 2016-02-11 | Guardant Health, Inc. | Systems and methods to detect rare mutations and copy number variation |
| CN104781421B (zh) | 2012-09-04 | 2020-06-05 | 夸登特健康公司 | 检测稀有突变和拷贝数变异的系统和方法 |
| CN102877136B (zh) * | 2012-09-24 | 2014-03-12 | 上海交通大学 | 基于基因组简化与二代测序dna文库构建方法及试剂盒 |
| WO2014071070A1 (en) * | 2012-11-01 | 2014-05-08 | Pacific Biosciences Of California, Inc. | Compositions and methods for selection of nucleic acids |
| DK2970951T3 (da) * | 2013-03-13 | 2019-05-13 | Illumina Inc | Fremgangsmåder til nukleinsyresekventering |
| US9290800B2 (en) * | 2013-03-15 | 2016-03-22 | Pacific Biosciences Of California, Inc. | Targeted rolling circle amplification |
| US10087481B2 (en) * | 2013-03-19 | 2018-10-02 | New England Biolabs, Inc. | Enrichment of target sequences |
| US9873907B2 (en) | 2013-05-29 | 2018-01-23 | Agilent Technologies, Inc. | Method for fragmenting genomic DNA using CAS9 |
| KR102348283B1 (ko) * | 2013-09-24 | 2022-01-10 | 소마로직, 인크. | 멀티앱타머 표적 검출 |
| EP3363904B1 (en) | 2014-01-31 | 2019-10-23 | Swift Biosciences, Inc. | Improved methods for processing dna substrates |
| CN107075730A (zh) | 2014-09-12 | 2017-08-18 | 利兰·斯坦福青年大学托管委员会 | 循环核酸的鉴定及用途 |
| US11149305B2 (en) | 2015-01-23 | 2021-10-19 | Washington University | Detection of rare sequence variants, methods and compositions therefor |
| WO2016133044A1 (ja) | 2015-02-20 | 2016-08-25 | 日本電気株式会社 | 受信装置、受信方法 |
| US10844428B2 (en) | 2015-04-28 | 2020-11-24 | Illumina, Inc. | Error suppression in sequenced DNA fragments using redundant reads with unique molecular indices (UMIS) |
| EP3307908B1 (en) | 2015-06-09 | 2019-09-11 | Life Technologies Corporation | Methods for molecular tagging |
| US10465241B2 (en) | 2015-06-15 | 2019-11-05 | The Board Of Trustees Of The Leleand Stanford Junior University | High resolution STR analysis using next generation sequencing |
| GB201515557D0 (en) | 2015-09-02 | 2015-10-14 | 14M Genomics Ltd | Method of sequencing |
| EP3377656B1 (en) | 2015-11-18 | 2025-07-02 | Pacific Biosciences of California, Inc. | Loading nucleic acids onto substrates |
| CA3006792A1 (en) | 2015-12-08 | 2017-06-15 | Twinstrand Biosciences, Inc. | Improved adapters, methods, and compositions for duplex sequencing |
| EP3405574A4 (en) | 2016-01-22 | 2019-10-02 | Grail, Inc. | VARIANTS-BASED SICKNESS DIAGNOSTICS AND PURSUIT |
| WO2017127741A1 (en) | 2016-01-22 | 2017-07-27 | Grail, Inc. | Methods and systems for high fidelity sequencing |
| US11821028B2 (en) | 2016-07-12 | 2023-11-21 | QIAGEN Sciences, LLP | Single end duplex DNA sequencing |
| EP3276328B1 (en) | 2016-07-29 | 2020-12-02 | Sysmex Corporation | Smear transporting apparatus, smear image capture system, and smear analysis system |
| WO2018031588A1 (en) | 2016-08-09 | 2018-02-15 | Takara Bio Usa, Inc. | Nucleic acid adaptors with molecular identification sequences and use thereof |
| WO2018057928A1 (en) | 2016-09-23 | 2018-03-29 | Grail, Inc. | Methods of preparing and analyzing cell-free nucleic acid sequencing libraries |
| WO2018119399A1 (en) | 2016-12-23 | 2018-06-28 | Grail, Inc. | Methods for high efficiency library preparation using double-stranded adapters |
| IL269431B2 (en) | 2017-03-23 | 2025-05-01 | Univ Washington | Methods for targeted nucleic acid sequence enrichment with applications to error corrected nucleic acid sequencing |
| WO2018183942A1 (en) | 2017-03-31 | 2018-10-04 | Grail, Inc. | Improved library preparation and use thereof for sequencing-based error correction and/or variant identification |
| AU2018366213B2 (en) | 2017-11-08 | 2025-05-15 | Twinstrand Biosciences, Inc. | Reagents and adapters for nucleic acid sequencing and methods for making such reagents and adapters |
| BR112020016516A2 (pt) | 2018-02-13 | 2020-12-15 | Twinstrand Biosciences, Inc. | Métodos e reagentes para detectar e avaliar a genotoxicidade |
| CA3093846A1 (en) | 2018-03-15 | 2019-09-19 | Twinstrand Biosciences, Inc. | Methods and reagents for enrichment of nucleic acid material for sequencing applications and other nucleic acid material interrogations |
| EP3768853A4 (en) | 2018-03-23 | 2021-04-28 | Board Of Regents The University Of Texas System | EFFICIENT SEQUENCING OF DSDNA WITH EXTREMELY LOW ERROR RATE |
| WO2019222560A1 (en) | 2018-05-16 | 2019-11-21 | Twinstrand Biosciences, Inc. | Methods and reagents for resolving nucleic acid mixtures and mixed cell populations and associated applications |
| BR112021000409A2 (pt) | 2018-07-12 | 2021-04-06 | Twinstrand Biosciences, Inc. | Métodos e reagentes para caracterizar edição genômica, expansão clonal e aplicações associadas |
| KR102662200B1 (ko) | 2019-07-15 | 2024-04-29 | 엘지디스플레이 주식회사 | 유기발광표시장치 |
-
2016
- 2016-12-08 CA CA3006792A patent/CA3006792A1/en active Pending
- 2016-12-08 WO PCT/US2016/065605 patent/WO2017100441A1/en not_active Ceased
- 2016-12-08 PT PT168228328T patent/PT3387152T/pt unknown
- 2016-12-08 AU AU2016366231A patent/AU2016366231B2/en active Active
- 2016-12-08 JP JP2018530698A patent/JP6975507B2/ja active Active
- 2016-12-08 ES ES16822832T patent/ES2911421T3/es active Active
- 2016-12-08 EP EP21217292.8A patent/EP4043584A1/en active Pending
- 2016-12-08 PL PL16822832T patent/PL3387152T3/pl unknown
- 2016-12-08 EP EP16822832.8A patent/EP3387152B1/en active Active
- 2016-12-08 US US15/372,761 patent/US11332784B2/en active Active
- 2016-12-08 CN CN201680080120.4A patent/CN109072294A/zh active Pending
-
2018
- 2018-06-03 IL IL259788A patent/IL259788B2/en unknown
-
2021
- 2021-11-02 JP JP2021179334A patent/JP7548579B2/ja active Active
-
2022
- 2022-04-12 US US17/719,147 patent/US20220267841A1/en not_active Abandoned
-
2023
- 2023-10-27 JP JP2023184524A patent/JP2024010122A/ja active Pending
-
2025
- 2025-03-21 US US19/087,128 patent/US20250313888A1/en active Pending
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2013142389A1 (en) * | 2012-03-20 | 2013-09-26 | University Of Washington Through Its Center For Commercialization | Methods of lowering the error rate of massively parallel dna sequencing using duplex consensus sequencing |
| WO2015100427A1 (en) * | 2013-12-28 | 2015-07-02 | Guardant Health, Inc. | Methods and systems for detecting genetic variants |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2022551688A (ja) * | 2019-10-16 | 2022-12-13 | 中国医学科学院腫瘤医院 | ctDNA中の腫瘍特異的遺伝子の変異及びメチル化の検出方法 |
| JP7614192B2 (ja) | 2019-10-16 | 2025-01-15 | 中国医学科学院腫瘤医院 | ctDNA中の腫瘍特異的遺伝子の変異及びメチル化の検出方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CA3006792A1 (en) | 2017-06-15 |
| AU2016366231A1 (en) | 2018-06-14 |
| WO2017100441A1 (en) | 2017-06-15 |
| IL259788B1 (en) | 2023-01-01 |
| JP7548579B2 (ja) | 2024-09-10 |
| US11332784B2 (en) | 2022-05-17 |
| US20250313888A1 (en) | 2025-10-09 |
| PT3387152T (pt) | 2022-04-19 |
| JP2024010122A (ja) | 2024-01-23 |
| AU2016366231B2 (en) | 2022-12-15 |
| EP4043584A1 (en) | 2022-08-17 |
| JP6975507B2 (ja) | 2021-12-01 |
| US20170211140A1 (en) | 2017-07-27 |
| EP3387152A1 (en) | 2018-10-17 |
| PL3387152T3 (pl) | 2022-05-09 |
| EP3387152B1 (en) | 2022-01-26 |
| ES2911421T3 (es) | 2022-05-19 |
| IL259788B2 (en) | 2023-05-01 |
| CN109072294A (zh) | 2018-12-21 |
| IL259788A (en) | 2018-07-31 |
| JP2022017453A (ja) | 2022-01-25 |
| US20220267841A1 (en) | 2022-08-25 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7548579B2 (ja) | 二本鎖配列決定のための改善されたアダプター、方法、及び組成物 | |
| US20240141426A1 (en) | Compositions and methods for identification of a duplicate sequencing read | |
| ES2724824T3 (es) | Métodos para la secuenciación de ácidos nucleicos | |
| CN114045282B (zh) | 接近性保留性转座 | |
| US20170226580A1 (en) | Method of making a paired tag library for nucleic acid sequencing | |
| CN108138228B (zh) | 用于下一代测序的高分子量dna样品追踪标签 | |
| CN104093890A (zh) | 用于靶向核酸序列富集和高效文库产生的组合物和方法 | |
| EP3408406B1 (en) | A novel y-shaped adaptor for nucleic acid sequencing and method of use | |
| JP2025522572A (ja) | 核酸配列決定のための方法及び組成物 | |
| CN112805373B (zh) | 用于跨非连续模板的有序和连续的互补DNA(cDNA)合成的组合物和方法 | |
| US20240052339A1 (en) | Rna probe for mutation profiling and use thereof | |
| HK1227923A1 (en) | Compositions and methods for identification of a duplicate sequencing read |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A711 Effective date: 20181221 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20181221 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20191206 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20191206 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20210112 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20210409 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20210609 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20210709 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20211005 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20211102 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6975507 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |