JP2020009400A - Data processing device, data processing system and program - Google Patents
Data processing device, data processing system and program Download PDFInfo
- Publication number
- JP2020009400A JP2020009400A JP2018227556A JP2018227556A JP2020009400A JP 2020009400 A JP2020009400 A JP 2020009400A JP 2018227556 A JP2018227556 A JP 2018227556A JP 2018227556 A JP2018227556 A JP 2018227556A JP 2020009400 A JP2020009400 A JP 2020009400A
- Authority
- JP
- Japan
- Prior art keywords
- data
- input data
- input
- learning
- output
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images





Landscapes
- Testing And Monitoring For Control Systems (AREA)
- Feedback Control In General (AREA)
Abstract
【課題】比較的簡易な構成で、準備工程を簡略化でき、環境に適合した判定を行うことのできるデータ処理装置、データ処理システム及びプログラムを提供する。【解決手段】繰り返し入力されるデータに基づく所定の判定処理を行うデータ処理装置であって、入力データと教師データとを受け入れて、逆数演算により機械学習可能な推定器を用い、入力されたデータを入力データ及び教師データとして、前記推定器を機械学習し、当該推定器の出力と、入力されたデータとの比較に基づいて判定処理を行い、当該判定処理の結果を出力するデータ処理装置である。【選択図】図1A data processing device, a data processing system, and a program capable of simplifying the preparation process with a relatively simple configuration and making judgments suitable for the environment are provided. A data processing device that performs predetermined determination processing based on data that is repeatedly input, receives input data and teacher data, uses an estimator capable of machine learning by reciprocal arithmetic, and processes the input data. is used as input data and teacher data, the estimator is machine-learned, the output of the estimator is compared with the input data, and judgment processing is performed, and the result of the judgment processing is output. be. [Selection drawing] Fig. 1
Description
本発明は、データ処理装置、データ処理システム及びプログラムに関する。 The present invention relates to a data processing device, a data processing system, and a program.
近年では、製品製造の現場等の種々の場所に適用可能な異常検知のシステムとして、機械学習を用いたシステムが開発されている。 In recent years, a system using machine learning has been developed as an abnormality detection system applicable to various places such as a product manufacturing site.
例えば特許文献1には、予め現場で収集可能なログデータを記録しておき、当該ログデータを参照しつつ、ログデータの各記録時点での異常発生の有無を教師データとして学習処理を行い、異常判定を行う装置が開示されている。
For example, in
しかしながら、例えば製品製造の現場では、振動等の情報を収集するセンサが出力するデータは、周辺のノイズの状況により、現場ごとに異なっているのが実情である。具体的には隣接して別の振動を生じる製造機械が動作している現場と、そうでない現場とでは出力は大きく異なっている。また、別の振動を生じる製造機械が停止している間と動作している間でも出力が異なるため、同じ現場であっても時間帯など種々の要因によって異常判断を行うための基礎となるデータに相当の相違があるのが一般的である。 However, for example, in a product manufacturing site, the data output from a sensor that collects information such as vibrations differs from site to site depending on the surrounding noise situation. Specifically, the output differs greatly between a site where a manufacturing machine that generates another vibration adjacent thereto is operating and a site where it is not. In addition, since the output is different even when the manufacturing machine that generates another vibration is stopped and while it is operating, even if it is the same site, it is the data that is the basis for making an abnormality judgment due to various factors such as time zone. There is generally a considerable difference between
このような状況のため、事前にログデータを収集して学習する装置では、現場ごとにログデータを収集する必要があり、装置構成が複雑となり、また、動作させるまでに多くの準備工程を要していた。またそうして学習処理を行っても、上述のように時間帯によって環境が異なる場合があるため、必ずしも適切な判定が行えない場合があった。 Under such circumstances, a device that collects and learns log data in advance needs to collect log data for each site, which complicates the device configuration and requires many preparation steps before operation. Was. Further, even if the learning process is performed in such a manner, the environment may differ depending on the time zone as described above, so that an appropriate determination may not always be performed.
本発明は上記実情に鑑みて為されたもので、比較的簡易な構成で、準備工程を簡略化でき、環境に適合した判定を行うことのできるデータ処理装置、データ処理システム及びプログラムを提供することを、その目的の一つとする。 The present invention has been made in view of the above circumstances, and provides a data processing apparatus, a data processing system, and a program which can simplify a preparation process with a relatively simple configuration, and can perform determination suitable for an environment. That is one of its purposes.
上記従来例の問題点を解決する本発明の一態様は、繰り返し入力されるデータに基づく所定の判定処理を行うデータ処理装置であって、入力データと教師データとを受け入れて、逆数演算により機械学習可能な推測手段と、前記入力されたデータを入力データ及び教師データとして、前記推測手段を機械学習する学習処理手段と、前記推測手段の出力と、前記入力されたデータとの比較に基づいて、前記所定の判定処理を行い、当該判定処理の結果を出力する出力手段と、を含むこととしたものである。 One aspect of the present invention that solves the above-described problems of the conventional example is a data processing device that performs a predetermined determination process based on repeatedly input data. Learning estimating means, learning processing means for machine-learning the estimating means using the input data as input data and teacher data, and comparing the output of the estimating means with the input data. And an output unit that performs the predetermined determination process and outputs a result of the determination process.
本発明によると、入力データを用いて機械学習を行いつつ判定を行い、また、逆数演算により機械学習を可能な推測手段を用いることで、比較的簡易な構成で、準備工程を簡略化でき、環境に適合した判定を行うことが可能となる。 According to the present invention, determination is performed while performing machine learning using input data, and by using estimating means capable of performing machine learning by reciprocal operation, the preparation process can be simplified with a relatively simple configuration, It is possible to make a determination that is suitable for the environment.
本発明の実施の形態について図面を参照しながら説明する。本発明の実施の形態に係るデータ処理装置1の例は、図1に示すように、制御部11と、記憶部12と、入力部13と、出力部14とを含んで構成されている。
An embodiment of the present invention will be described with reference to the drawings. As shown in FIG. 1, the example of the
ここで制御部11は、CPU等のプログラム制御デバイス、あるいはFPGA(Field Programmable Gate Array)等のロジックデバイス、あるいはASIC(Application Specific Integrated Circuit)であり、本発明の推測手段、学習処理手段、及び出力手段を実現する。制御部11として、CPU等のプログラム制御デバイスを用いる場合は、この制御部11は、記憶部12に格納されたプログラムを実行することで、上記各部の動作を実現する。
Here, the
また制御部11としてFPGA等のロジックデバイスを用いる場合は、プログラムされた論理に従って動作し、上記各部の動作を実現する。
When a logic device such as an FPGA is used as the
すなわち本実施の形態ではこの制御部11が、繰り返し入力されるデータを受け入れ、入力されたデータを入力データ及び教師データとして、逆数演算により機械学習可能な機械学習モデルの機械学習処理を実行する。また、この制御部11は、当該入力されたデータを入力データとして、当該機械学習モデルが表す推定器に入力したときの、当該推定器の出力を得る。そして制御部11は、当該得られた推定器の出力と、入力されたデータとの比較に基づいて、予め定めた判定処理を行い、当該判定処理の結果を出力する。この制御部11の詳しい動作の例については後に述べる。
That is, in the present embodiment, the
記憶部12は、メモリデバイスやディスクデバイスを含んで構成される。この記憶部12は、制御部11がCPU等のプログラム制御デバイスである場合は、制御部11によって実行されるプログラムを保持する。このプログラムは、コンピュータ可読、かつ非一時的な記録媒体に格納されて提供され、この記憶部12に格納されたものであってもよい。
The
またこの記憶部12は、推定器を機械学習する際の機械学習モデルのモデルパラメータ等、制御部11の処理において必要となる情報を保持する、ワークメモリとしても動作する。
The
入力部13は、外部のセンサ等から入力されるデータをディジタルデータに変換し、また予め定められた次元のベクトル情報に変換して制御部11に出力する。出力部14は、制御部11から入力される指示に従って情報を出力する。この出力部14は例えばディスプレイ等であり、制御部11から入力される情報を表示出力する。
The
本実施の形態では制御部11は、機能的には、図2に例示するように、データ受入部21と、推定器22と、学習処理部23と、判定処理部24と、出力処理部25とを含んで構成される。
In the present embodiment, the
データ受入部21は、入力部13からデータの入力を受け入れる。本実施の形態の例では、データ処理装置1は、例えば製品製造の現場等に配され、当該製品製造に用いる装置に取り付けられ、当該装置の振動や、温度等の種々の情報を検出して出力するセンサに接続される。そして入力部13は、これらのセンサの出力を所定のタイミングごと(例えば定期的なタイミングごと)に、繰り返しディジタル値に変換して制御部11に対して出力する。また、入力部13は複数のセンサの出力を変換して得たディジタル値を所定の順に配列したベクトル値をデータとして制御部11に出力する。データ受入部21は、この入力部13が所定のタイミングごとに出力するデータを受け入れて、学習処理部23に出力する。
The
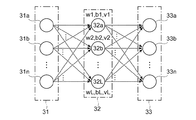
推定器22は、推測手段を実現するもので、機能的には図3に例示するように、入力層31と、中間層(隠れ層)32と、出力層33とを含む、3層の全結合型のニューラルネットワークである。また、本実施の形態においてこの推定器22は入力層31のノードの数(入力データのベクトルの次元)と、出力層33のノードの数(出力するデータのベクトルの次元)とが一致しているものとする。
The
すなわちこの推定器22では、入力データとなったベクトル値の各成分に対応する入力層31のノード31a,31b,…,31nと中間層32のノード32a,32b,…32Lとの間の結合重みをW(w1,w2,…,wL)(ここでwiは入力層31のノード数nに等しい次元のベクトル)、バイアスをb(b1,b2,…bL)とし、中間層32のノード32a,32b,…32Lと出力層33のノード33a,33b,…,33nとの間の結合重みをV(v1,v2,…,vL)(ここでviは出力層33のノード数nに等しい次元のベクトル)とするとき、これらの結合重みの値W,V及びバイアスbが推定器22の機械学習モデルのパラメータとなる。
That is, in the
推定器22は、入力データが入力されると、当該入力データを入力層31に入力し、この入力層31に入力された入力データの各成分に、それぞれ対応する結合重みWを乗じて総和するなど、入力層31に入力された入力データの各成分と結合重みWとに基づく所定の演算を行うことで中間層32の各ノードの値を求める。また、中間層32の各ノードの値h1,h2…,hLに、所定の非線形関数fを適用して求められる値f(hi)(i=1,2,…L)に対し、対応する結合重みVを乗じて出力層33の各ノードの値を求める。この演算は、一般的なニューラルネットワークにおける演算と同様であるので、ここでの詳しい説明を省略する。
When the input data is input, the
ここでの非線形関数は、シグモイド関数、ReLU等広く知られたものを採用してもよい。推定器22は、出力層33の各ノードの値を成分とするベクトルを、出力データとして出力する。
As the nonlinear function here, a widely known function such as a sigmoid function or ReLU may be adopted. The
本実施の形態では、この推定器22は、少なくとも学習処理の条件によっては、逆数演算により上記機械学習モデルのパラメータの機械学習が可能なものとなっている。このような推定器22の例については後に詳しく説明する。
In the present embodiment, the
学習処理部23は、データ受入部21が受け入れたデータを入力データ及び教師データとして、推定器22の機械学習処理を行う。具体的にこの学習処理部23は、データ受入部21が受け入れた直近所定回数分(バッチサイズ分)のデータを、推定器22に対して入力データとして入力する。ここでバッチサイズを1とする場合は、学習処理部23は、データ受入部21が受け入れたデータを、推定器22に対してそのまま入力データとして入力する。
The learning processing unit 23 performs a machine learning process of the
学習処理部23は、当該入力データを入力したときに推定器22が出力した出力データと、データ受入部21が受け入れたデータ(教師データ)とを比較し、その差(絶対誤差や二乗平均誤差等)を損失(ロス)として演算する。そして学習処理部23は、当該損失が小さくなるよう、推定器22のパラメータ(結合重みの値)を更新する。
The learning processing unit 23 compares the output data output by the
つまり、本実施の形態の例では、学習処理部23は、推定器22をオートエンコーダとして機械学習することとなる。
That is, in the example of the present embodiment, the learning processing unit 23 performs machine learning using the
判定処理部24は、学習処理部23が推定器22に対し、入力データを入力したときに、推定器22が出力する出力データに基づいて所定の判定処理を実行する。
The
具体的な例として、この判定処理部24は、学習処理部23が演算した損失を参照し、当該損失の大きさが予め定めたしきい値を超える場合に入力データが異常である旨(つまり、製造装置等に異常が生じている旨)を表す判定の結果を出力処理部25に出力させる。また判定処理部24は、損失の大きさが予め定めたしきい値を超えていないときには、入力データが正常である旨(つまり、製造装置等に異常がない旨)を表す判定の結果を出力処理部25に出力させてもよい。
As a specific example, the
なお、この判定処理部24は、学習処理部23により推定器22のパラメータが十分に学習されるまでは、判定の処理を行わないよう制御されてもよい。具体的には、判定処理部24は、推定器22が機械学習をしていない状態(リセットされた状態)から、推定器22に入力データを入力した回数(学習処理部23によりパラメータの更新が行われた回数)が予め定めた初期化しきい値を超えたか否かを比較し、当該初期化しきい値を超えている場合に、推定器22のパラメータが十分に学習されたと判断してもよい。ここで初期化しきい値は例えば、中間層32のノードの数L以上の数として予め定めておく。
Note that the
この場合、判定処理部24は、当該初期化しきい値として定められた回数だけ学習処理を実行するまでは(推定器22が初期化しきい値の回数だけ入力データを受け入れてパラメータの更新を受けるまでは)判定の処理を行わない。
In this case, the
出力処理部25は、判定処理部24から入力される指示に従い、判定の結果を出力部14に出力する。
The
ここで本実施の形態の例に係る推定器22の具体的な機械学習モデルについて説明する。本実施の形態では、この推定器22は、学習処理部23の動作により、入力層31と中間層32との結合重みW、及びバイアスbをランダムに決定し、中間層32と出力層33との間の結合重みVを機械学習するニューラルネットワークとする。具体的にここでは推定器22と学習処理部23とにより、OS-ELM(Online Sequential - Extreme Learning Machine)を実現して用いる。このOS-ELMは、N.Y. Liang, G.B. Huang, P.Saratchandran, and N.Sundararajan,”A Fast and Accurate Online Sequential Learning Algorithm for Feedforward Networks,” IEEE Transactions on Neural Networks, Vol. 17, No.6, pp. 1411-1423, Nov. 2006等の文献に開示され、広く知られているので、ここでの詳細な説明は省略する。
Here, a specific machine learning model of the
このOS-ELMとする場合、学習処理部23は、当初は推定器22をリセットするため、入力層31と中間層32との結合重みWとバイアスbとをランダムに決定する(なお、このとき、結合重みVもランダムに定めておいてもよい)。そして学習処理部23は、データ受入部21が受け入れたデータを推定器22に対し、入力データとして入力する。学習処理部23は、当該入力データを入力したときに推定器22が出力した出力データと、データ受入部21が受け入れたデータ(教師データ)とを比較し、その差(例えば二乗平均誤差とする)を損失として演算する。そして学習処理部23は、当該損失が小さくなるよう、推定器22の、中間層32と出力層33との間の結合重みVを更新する。
In the case of the OS-ELM, the learning processing unit 23 randomly determines the connection weight W and the bias b between the
OS-ELMでは学習処理は次のようにして行われる。学習処理部23は、入力データを、ni(i=1,2…)個ずつに分けてバッチとし、各バッチを順次、訓練データとする。ここでi番目のバッチに含まれる入力データをxi(i=1,2,…,)とし、入力層31と中間層32との間の結合重みをWk(Wk=w1,w2,…,wL)、バイアスをbk(bk=b1,b2,…bL)とするとき、このi番目のバッチに対する出力層33の出力は、次の行列で表される。

なお、Gは、出力層33の各ノードの出力を表し、xi(j)は、i番目のバッチに含まれるj番目の入力データであることを表す。なお、niは、i番目のバッチにおけるバッチサイズである。
In the OS-ELM, the learning process is performed as follows. The learning processing unit 23 divides the input data into n i (i = 1, 2,...) Batches, and sets each batch as training data. Here, the input data included in the i-th batch is x i (i = 1, 2,...), And the connection weight between the
G represents the output of each node of the
また、ここで教師データは入力データに同じであるので、この教師データTは、
となる。なお、右肩のTは転置を意味する(以下同じ)。
Since the teacher data is the same as the input data, the teacher data T
It becomes. Note that T on the right shoulder means transposition (the same applies hereinafter).
学習処理部23は、i番目のバッチが入力された時点では、損失の大きさ
を最小とする結合重みβを求めて、これを推定器22の中間層32と出力層33との間の結合重みVとすることで、推定器22を最適化することとなる。このとき、
を用い、i=2の場合を考慮すると、(1)式は、
と変形できる。なお、A-1は、Aの疑似逆行列を意味する。
When the i-th batch is input, the learning processing unit 23 determines the magnitude of the loss.
Is determined, and this is used as the connection weight V between the
And considering the case of i = 2, equation (1) becomes
And can be transformed. Note that A -1 means a pseudo inverse matrix of A.
これを一般化して、i番目のバッチまでの学習が終了し、その時点での推定器22の中間層32と出力層33との間の結合重みVがV=βiとなっているとすると、i+1番目のバッチに基づく機械学習の結果である結合重みβi+1を、
とすることができる(逐次更新式)。ただし、
である。
Assuming that this is generalized, the learning up to the i-th batch is completed, and the connection weight V between the
(Sequential updating type). However,
It is.
ここで、
とすると、これらの逐次更新式は、
として(ただしIは単位行列)、
と表現できる。
here,
Then, these successive updating formulas are
(Where I is an identity matrix),
Can be expressed as
従って学習処理部23は、i番目のバッチが入力されたときに、中間層32の出力Hiを得て、その時点で最適化された中間層32と出力層33との結合重みV=βiと、中間結果としてのPiとを得ておく。そしてi+1番目のバッチが入力されると、(2)式により次の中間結果Pi+1を得て、中間層32と出力層33との結合重みVを(3)式で演算されるβi+1に更新する。なお、逆行列を求める演算については、特異値分解を用いるのが一般的であるが、各バッチにおけるバッチサイズNiをNi=1とする(バッチサイズを1とする)と、疑似逆行列を求めるべき行列である(2)式の
は、スカラ値となり((4)式は、Ni×Niの行列であるため)、従ってこの疑似逆行列は、単なる逆数演算により求められることとなる。
Thus the learning processing unit 23, when the i-th batch is input, with the output H i of the
Is a scalar value (because equation (4) is a matrix of N i × N i ), and therefore, this pseudo inverse matrix is obtained by simple reciprocal operation.
すなわち、本実施の形態において逆数演算により機械学習可能な推測手段は、推定器22及び学習処理部23として、中間層と出力層との間の結合重みを疑似逆行列演算によって機械学習するニューラルネットワークを用い、その機械学習のバッチサイズを1とすることで(データを受け入れるごとに機械学習をすることで)実現される。このようなニューラルネットワークは、具体的には入力層と中間層との結合重みをランダムに決定するELM(Extreme Learning Machine)及び、それから派生するニューラルネットワーク(FP(Forgetting Parameters)-ELM、OS(On-Line Sequential)-ELM、EOS(Ensemble of OS)-ELM、FOS-ELM(OS-ELM with forgetting mechanism))等が相当する。もっともこれら推定器22と学習処理部23とによって、逆数演算により機械学習可能な推測手段を実現するニューラルネットワークは、これらの例に限られるものではない。
That is, in the present embodiment, the estimating means capable of machine learning by reciprocal operation is a neural network that performs machine learning on the connection weight between the intermediate layer and the output layer by pseudo-inverse matrix operation as the
[動作]
本実施の形態のデータ処理装置1は以上の構成を備えており、次のように動作する。以下の例では、制御部11を、FPGAを用いて実装するものとし、推定器22として、バッチサイズを1とした、OS-ELMを用いるものとする。
[motion]
The
またここではデータ処理装置1は、製品を製造する装置の近傍に配した複数の振動センサからの信号を受け入れるものとする。振動センサは、取り付けられた部位の振動の大きさを表すアナログの電気信号を出力する。
Here, it is assumed that the
データ処理装置1は、当初は、推定器22であるOS-ELMの入力層31と中間層32との結合重みW及びバイアスbをランダムに決定する。そしてデータ処理装置1は、各センサが出力した電気信号をディジタル値に変換し、制御部11に入力する。制御部11はデータ受入部21として機能して、複数のセンサの出力を変換して得たディジタル値を所定の順に配列したベクトル値を、学習処理部23に出力する。
Initially, the
学習処理部23は、データの入力を受け入れるごとに、つまりバッチサイズが1の入力データを受け入れるごとに、推定器22に当該入力データを入力する。学習処理部23は、推定器22の出力データHと、教師データとしての入力データTと、その段階での推定器22の中間層32と出力層33との結合重みV=βiと、前回演算した中間結果としてのPi(β,Pとも、初回の値は予め設定しておく)を得る。
The learning processing unit 23 inputs the input data to the
そして学習処理部23は、(2),(3)式により推定器22の中間層32と出力層33との結合重みVを更新する。また学習処理部23は、推定器22の出力と、入力データ(教師データ)との二乗平均誤差を損失として演算し、判定処理部24に出力する。
Then, the learning processing unit 23 updates the connection weight V between the
判定処理部24は、推定器22のパラメータが十分に機械学習されたか否かを判断する。この判断は、データ処理装置1が推定器22を初期化してから入力データを入力した回数が予め定めた初期化しきい値を超えたか否かにより判断する。判定処理部24は、推定器22のパラメータが十分に機械学習された状態にないと判断すると、判定処理部24は、判定処理を行わない。
The
一方、推定器22のパラメータが十分に機械学習された状態となっていると判断すると、判定処理部24は、学習処理部23から入力された損失の値の大きさが、予め定めたしきい値を超えたか否かを調べ、損失の値の大きさが当該予め定めたしきい値を超えている場合に、入力データが異常であり、製造装置等に異常が生じていると推定される旨を表す判定の結果を、出力部14であるディスプレイに出力するよう制御する等の処理を行う。
On the other hand, when determining that the parameters of the
このように本実施の形態のデータ処理装置1によると、実際の異常検知を行う現場に設置してから推定器の逐次的な機械学習をオートエンコーダとして(つまり別途、教師データを用意することなく)行い、当該機械学習の結果に基づいて異常検知を行うので、準備工程を簡略化でき、環境に適合した判定を行うことが可能となる。
As described above, according to the
また、機械学習の過程の演算を比較的簡素な逆数演算により行うことが可能な推定器を用いることで、比較的簡易な構成とすることができる。 In addition, a relatively simple configuration can be achieved by using an estimator capable of performing the operation of the machine learning process by a relatively simple reciprocal operation.
なお、ここでは製品を製造する装置の異常検知を行う例について述べたが、本実施の形態はこの例に限られるものではなく、発熱する装置の温度データを入力データとして発熱に係る異常検知を行うこととしてもよいし、配線上の電流を入力データとした電流量に関する異常検知や、ある製品の熱分布(サーモグラフィー)のデータを入力データとした熱分布の異常検知、人の行動や装置の操作履歴を入力データとした異常検知、無人航空機(ドローン等)の動作に係る異常検知等、種々の例に適用可能である。 Here, an example in which an abnormality is detected in an apparatus that manufactures a product has been described. However, the present embodiment is not limited to this example. It is also possible to detect abnormalities in the amount of current using the current on the wiring as input data, to detect abnormalities in the heat distribution using the data of heat distribution (thermography) of a certain product as input data, The present invention can be applied to various examples such as abnormality detection using an operation history as input data, abnormality detection relating to the operation of an unmanned aerial vehicle (drone, etc.).
[忘却]
また、本実施の形態の例において、忘却処理を含めるべき場合は、忘却率をαとして、(3)式のPi+1に1/α2を乗じることとすればよい。これによって簡易な方法で忘却効果を得ることが可能となる。
[Forgetting]
Further, in the example of the present embodiment, when the forgetting process is to be included, the forgetting rate may be set to α, and P i + 1 in Expression (3) may be multiplied by 1 / α 2 . This makes it possible to obtain a forgetting effect by a simple method.
[学習結果の部分破棄]
また本実施の形態において、バッチサイズが1であるなど、比較的少数のバッチサイズの入力データ群により学習処理を行う場合は、異常なデータが連続することで生じる、異常なデータへの適合を防止するため、次のような学習結果の部分破棄の処理を行ってもよい。
[Partial discard of learning result]
Further, in the present embodiment, when learning processing is performed using a relatively small number of batch size input data groups, such as a batch size of 1, the adaptation to abnormal data caused by continuous abnormal data is considered. To prevent this, the following process of partially discarding the learning result may be performed.
本実施の形態の一例では、学習処理部23はデータ受入部21が受け入れたデータを、推定器22に対してそのまま入力データとして入力する(バッチサイズを1として逐次的な学習処理を実行する)。具体的にこの推定器22としては、OS-ELM のニューラルネットワークを用いることとすればよい。この場合、推定器22と学習処理部23とにより、バッチサイズを「1」とした、逐次的な学習処理を行うOS-ELMが実現される。
In one example of the present embodiment, the learning processing unit 23 inputs the data received by the
この例において学習処理部23は、入力データXを推定器22に入力し、当該推定器22が出力する出力データと入力データXとを用いて機械学習処理を行うごとに、つまり推定器22の中間層32と出力層33との結合重みVを更新するごとに、推定器22に入力した入力データXと、更新のために求めた結合重みβ、及び機械学習処理で必要となるデータ(例えば上述のP)を互いに関連付けて記憶部12に格納する。
In this example, the learning processing unit 23 inputs the input data X to the
またこのとき学習処理部23は、過去M回より前に格納した、入力データX,結合重みβ及び中間結果Pを互いに関連付けた情報が記憶部12に格納されていれば、当該情報を削除してもよい。
Further, at this time, the learning processing unit 23 deletes the information stored in the
これにより記憶部12には、最大で直近のM回分の推定器22の機械学習結果である中間層32と出力層33との結合重みβjと、中間結果としてのPjと、それぞれの結合重みを求めたときの入力データXjとを互いに関連付けた情報Rj(j=1,2,…)が記憶されている状態となる(図4)。
Thus, the
学習処理部23は、予め定めた方法で決定した複数回(ここではM回とする)の機械学習処理を行うごとに、記憶部12に記憶したM回前の中間層32と出力層33との結合重みβ、中間結果P、及び入力データXを読み出す。学習処理部23は、ここで読み出した入力データXを、推定器22に入力する。
Each time the learning processing unit 23 performs a plurality of (here, M) machine learning processes determined by a predetermined method, the
学習処理部23は、推定器22の出力を参照し、当該出力が予め定めた条件を満足するか否かを判断する。ここでは学習処理部23は、当該推定器22の出力と、入力データX(教師データに相当する)との差に基づく値(例えば二乗平均誤差)を損失として演算し、この損失の大きさが予め定めたしきい値を超えるか否かを調べる。ここで演算される損失の大きさが予め定めたしきい値を超えるとの条件が、例えば上記の予め定めた条件の一例に相当する。
The learning processing unit 23 refers to the output of the
学習処理部23は、ここで損失の大きさが予め定めたしきい値を超えていたとき、つまり、上記予め定めた条件が満足されるときには、ここで入力した入力データに関連付けて記憶されている機械学習結果であるM回前の中間層32と出力層33との結合重みβを用いて、推定器22の機械学習状態を補正する。具体的には、推定器22の中間層32と出力層33との結合重みVを、ここで読み出した結合重みβに設定する(この動作は、直近の機械学習の結果を部分的に破棄することに相当する)。
When the magnitude of the loss exceeds a predetermined threshold value, that is, when the predetermined condition is satisfied, the learning processing unit 23 stores the loss value in association with the input data input here. The machine learning state of the
またこのときには、学習処理部23は、この時点で記憶している中間結果を、ここで読み出した中間結果Pに設定し直す。 Further, at this time, the learning processing unit 23 resets the intermediate result stored at this time to the intermediate result P read here.
なお、学習処理部23は、損失の大きさが予め定めたしきい値を超えていなかった場合は、推定器22の機械学習状態を補正することなく、機械学習処理を続ける。
If the magnitude of the loss does not exceed the predetermined threshold, the learning processing unit 23 continues the machine learning process without correcting the machine learning state of the
本実施の形態のこの例によると、予め定めた方法で決定した回数(例えば実験的に定めてもよい)だけの機械学習を行うごとに、過去の所定の時点での入力データを現在の推定器22に入力して損失の大きさが大きくなっていないかを確認する。そして損失が大きくなっていれば、直近の機械学習の内容を破棄して、推定器22のパラメータを、上記過去の所定の時点での推定器22のパラメータに戻すこととなる。
According to this example of the present embodiment, each time machine learning is performed for the number of times determined by a predetermined method (for example, may be determined experimentally), input data at a predetermined time in the past is estimated by the current estimation. To determine whether the magnitude of the loss is large. If the loss is large, the latest machine learning contents are discarded, and the parameters of the
これにより、バッチサイズが比較的大きい値となっている場合と同様に、時間的に平均化した機械学習が行われることとなる。 As a result, similarly to the case where the batch size has a relatively large value, time-averaged machine learning is performed.
[遅延学習]
また本実施の形態の一例では、学習データを部分破棄する代わりに、学習を遅延して行ってもよい。この例では、学習処理部23はデータ受入部21が受け入れたデータを、推定器22に対してそのまま入力データとして入力する(バッチサイズを1として逐次的な学習処理を実行する)。この推定器22は、既に述べた例と同様にOS-ELM のニューラルネットワークを用いることとすればよい。すなわち、ここでも推定器22と学習処理部23とにより、バッチサイズを「1」とした、逐次的な学習処理を行うOS-ELMが実現されるものとする。
[Delayed learning]
Further, in an example of the present embodiment, learning may be performed with delay, instead of partially discarding the learning data. In this example, the learning processing unit 23 inputs the data received by the
学習処理部23は、入力データXを受け入れて推定器22に入力し、当該推定器22が出力する出力データを得て、当該出力データと入力データXとの差に基づく値(例えば二乗平均誤差)を損失として演算し、入力データXと演算した損失とを関連付けて記憶部12に格納する。この段階では学習処理部23は、推定器22の機械学習処理を行わない。
The learning processing unit 23 receives the input data X and inputs the data to the
学習処理部23は、予め定められた回数M(Mは2以上の自然数とする)だけ、上記の処理を繰り返して、過去M回分の入力データXとそれに基づく推定結果の損失の値とを、記憶部12に保持している状態となると、M回前の入力データXを用いた機械学習処理を行うか否かを判断する。
The learning processing unit 23 repeats the above process a predetermined number of times M (M is a natural number of 2 or more), and calculates the input data X for the past M times and the value of the loss of the estimation result based on the data. When the state is held in the
具体的にこの判断は、次のようにして行うことができる。すなわち学習処理部23は、保持している情報を参照して、直近M回分の損失の値に基づく統計値(例えばここでは平均Eavとする)を求める。そして学習処理部23は、M回前の(機械学習処理を行うか否かを判断する対象となったM回前の入力データXに対する)損失の値Eを参照し、この値Eが、上記統計値である平均Eavを用いた条件
E<a・Eav
を満足するか否かを判断する。このaは予め定めた定数であり、例えばa=3.0などとしておく。なお、ここでは統計値として平均を用いたが、平均だけでなく、中間値としてもよい。またaは定数ではなく直近M回分の損失の値の分散や標準偏差に基づいて定められてもよい。
Specifically, this determination can be made as follows. That is, the learning processing unit 23 refers to the stored information and obtains a statistical value (for example, an average Eav in this case) based on the values of the losses for the most recent M times. Then, the learning processing unit 23 refers to the value E of the loss M times before (with respect to the input data X M times before the machine learning process is performed or not), and this value E is Condition E <a · Eav using average Eav which is a statistical value
Is determined. This “a” is a predetermined constant, for example, a = 3.0. Although the average is used as the statistical value here, the average value may be used instead of the average. Also, a may be determined based on the variance or the standard deviation of the loss values of the latest M times, instead of the constant.
学習処理部23は、上記の値Eが、E<a・Eavを満足するときには、M回前の入力データXを用いて機械学習処理を実行する。つまり、当該M回前の入力データXと、対応する損失Eとを用いて、推定器22の中間層32と出力層33との結合重みVを更新する。
When the value E satisfies E <a · Eav, the learning processing unit 23 executes a machine learning process using the input data X M times earlier. That is, the connection weight V between the
学習処理部23は、そして当該M回前に格納した、入力データXと損失の情報とを削除してもよい。 The learning processing unit 23 may delete the input data X and the loss information stored M times before.
なお、学習処理部23は、上記の判断において、値Eが、E<a・Eavを満足しない場合は、M回前の入力データXを用いた機械学習処理を実行することなく、当該M回前に格納した入力データXと損失の情報とを削除する。 If the value E does not satisfy E <a · Eav in the above determination, the learning processing unit 23 performs the M learning without executing the machine learning process using the input data X M times before. The previously stored input data X and loss information are deleted.
本実施の形態のこの例によると、予め定めた方法で決定した回数(例えば実験的に定めてもよい)だけ遅延して機械学習を行うか否かを判断し、大きく外れた入力データに基づく機械学習を行わないよう制御するので、条件に応じて直近の学習内容を破棄する上述の例と同様の効果を得ることができ、時間的に平均化した機械学習が行われることとなる。 According to this example of the present embodiment, it is determined whether or not to perform machine learning with a delay determined by a predetermined method (for example, may be determined experimentally) based on input data that largely deviates. Since control is performed so that machine learning is not performed, it is possible to obtain the same effect as in the above-described example in which the latest learning content is discarded according to conditions, and time-averaged machine learning is performed.
[並列化]
さらに本実施の形態によると、推定器22は複数あっても構わない。この例に係るデータ処理装置1の制御部11は、機能的には、図5に例示するように、データ受入部21と、複数の推定器42-1,42-2…と、各推定器42に対応して設けられる複数の学習処理部43-1,43-2…と、判定処理部44と、出力処理部25とを含んで構成される。なお、図2に例示したものと同様の構成となるものについては、同じ符号を付して繰り返しての説明を省略する。
[Parallelization]
Further, according to the present embodiment, there may be a plurality of
本実施の形態のこの例に係る推定器42(ここで各推定器を区別する必要がない場合は、それぞれの推定器をまとめて推定器42と表記する。また学習処理部についても同様とする)のそれぞれは、図2に例示した推定器22と同じもので構わない。つまり、各推定器42は、それぞれOS-ELMに対応するニューラルネットワークでよい。
また学習処理部43は、対応する推定器42のパラメータを、既に説明した学習処理部23と同様にして機械学習処理により逐次的に更新する。学習処理部43は、また推定器42の出力データと、入力データ(教師データに相当する)との差に係る値(二乗平均誤差等)を損失として演算して出力する。さらに本実施の形態のこの例では、学習処理部43は、損失の値を出力するとともに、対応する推定器42をリセットしてからのパラメータの更新回数(入力データを入力した回数)を、学習状況情報として出力する。なお、ここでの例でも、それぞれの学習処理部43は、学習結果の部分破棄の処理を実行してもよい。
Further, the
本実施の形態のこの例において学習処理部43-i(i=1,2,…)は、対応する推定器42-i(i=1,2,…)を、学習処理部43-iごとに定められる所定のタイミングTiごとにリセットする。すなわち学習処理部43-iは、前回推定器42-iをリセット(入力層31と中間層32との結合重みW及びバイアスbをランダムに決定)してから、タイミングTiだけの時間が経過するごとに、推定器42-iを再度リセットする。
In this example of the present embodiment, the learning processing unit 43-i (i = 1, 2,...) Sets a corresponding estimator 42-i (i = 1, 2,...) For each learning processing unit 43-i. Is reset at every predetermined timing T i defined in the above. That learning processing unit 43-i is (connection weights W and bias b of the
ここでタイミングTiは、入力データの入力回数により定めてもよい(例えばタイミングTiは入力データがqi回入力されるごととしてもよい)し、図示しない時計部(現在時刻を計時ないし取得する回路部)から時刻の情報を取得し、当該時刻の情報に基づいて判断される、実際の時間経過により定めてもよい。 Here, the timing T i may be determined by the number of times of input of the input data (for example, the timing T i may be each time the input data is input q i times), or a clock unit (not shown) Information may be determined from the actual elapsed time, which is determined based on the time information obtained from the circuit unit performing the time.
またこのタイミングTiは、すべての推定器42が(少なくとも異常検知の処理に必要な時間の間は)一斉にリセットされないタイミングとしておくこととしてもよい。例えばタイミングTiを入力データの入力回数により定める場合は、各タイミングTiに係る入力回数を素数とする。一例として推定器42を2つ用いる場合に、それぞれのリセットのタイミングを、T1=27437,T2=27449(いずれも素数)としておくと、7.5億回までは同じタイミングでリセットすることがなくなる。
Further, the timing Ti may be a timing at which all the
またタイミングTiを現実の時刻により定める場合は、T1を毎日午前0時0分0秒に、T2を毎週月曜日の午前1時0分0秒に…というように定めれば、同じタイミングでリセットされることがなくなる。 The cases specified by the reality of the time the timing T i is, the T 1 to the daily morning 0 hours, 0 minutes, 0 seconds, be determined so that the T 2 every Monday morning to 1 hours, 0 minutes, 0 seconds of ..., same timing Will not be reset.
このように本実施の形態の一例では、学習処理部43は、各推定器42を、例えばそれぞれ互いに異なるタイミングでリセットすることで、すべての推定器42が(少なくとも異常検知の処理に必要な時間の間は)一斉にリセットされないようにしておく。
As described above, in the example of the present embodiment, the
また、この例の判定処理部44は、複数の学習処理部43から、それぞれ対応する推定器42が出力した出力データに係る損失の演算結果と、学習状況情報(ここでは対応する推定器42をリセットしてからのパラメータの更新回数)とを受け入れる。
In addition, the
そして判定処理部44は、学習状況情報を参照して、パラメータが十分に学習されている推定器42に対応する学習処理部43が出力した損失を参照し、当該損失の大きさが予め定めたしきい値を超えるか否かを調べる。ここでパラメータが十分に学習されているか否かは、例えば学習状況情報が表すパラメータの更新回数が予め定めた初期化しきい値を超えているか否かにより判断すればよい。つまり判定処理部44は、学習状況情報が表すパラメータの更新回数が予め定めた初期化しきい値を超えていればパラメータが十分に学習されていると判断する。
Then, the
判定処理部44は、パラメータが十分に学習されていると判断された推定器42の数Qにより、パラメータが十分に学習されていると判断された推定器42に対応する学習処理部43のうち、出力した損失の大きさが予め定めたしきい値を超えるものの数qを除して、この値q/Qが所定の値、例えば1/2を超えるか否かを調べる。そしてこの値q/Qが例えば1/2を超える場合(この所定の値が1/2であるときには、過半数の推定器42が異常を検知したと判断される場合)に、入力データが異常である旨(つまり、製造装置等に異常が生じている旨)を表す判定の結果を出力処理部25に出力させる。
Based on the number Q of the
[クラスタリング]
また、このように推定器22を複数設けて並列化するときには、次のように機械学習処理を行ってもよい。本実施の形態のここでの例に係るデータ処理装置1の制御部11は、機能的には、図6に例示するように、図5に示した例と同様、データ受入部21と、複数の推定器42-1,42-2…と、学習処理部43′と、判定処理部44′と、出力処理部25と、第2学習処理部45とを含んで構成される。なお、図5に例示したものと同様の構成となるものについては、同じ符号を付して繰り返しての説明を省略する。
[Clustering]
When a plurality of
本実施の形態のこの例に係る推定器42(ここでも各推定器を区別する必要がない場合は、それぞれの推定器をまとめて推定器42と表記する)のそれぞれは、図2に例示した推定器22と同じもので構わない。つまり各推定器42は、それぞれOS-ELMに対応するニューラルネットワークでよい。
Each of the
学習処理部43′は、データ受入部21が受け入れた入力データXを各推定器42に入力する。そして学習処理部43′は、各推定器42の出力データと、入力データXとの二乗平均誤差を損失として演算し、判定処理部44′に出力する。学習処理部43′は、入力データXを記憶部12に蓄積して保持する。
The
また学習処理部43′は、推定器42のうち、その出力データに係る損失に基づく判断の結果が、入力データXが「正常」であることを表すものとなっている推定器42を特定する情報を判定処理部44′から受け入れ、当該情報で特定される推定器42のパラメータを、既に説明した学習処理部23と同様にして機械学習処理により更新する。
In addition, the
判定処理部44′は、学習処理部43′から各推定器42の損失に係る情報の入力を受けて、当該損失に基づいて、各推定器42による入力データXの正常/異常判定の結果を出力する。具体的に、判定処理部44′は、対応する損失の大きさが予め定めたしきい値を超える推定器42については、当該推定器42が入力データXを異常と判定したとする。また、対応する損失の大きさが予め定めたしきい値を超えていない推定器42については、当該推定器42が入力データXを正常と判定したものとする。判定処理部44′は、すべての推定器42が入力データXを異常と判定した場合に、入力データXが異常であったと判定して、その旨を出力するよう、出力処理部25に指示する。
The
また判定処理部44′は、少なくとも一つの推定器42が入力データを正常と判定しているときには、入力データXは正常であるとして、その旨を出力するよう、出力処理部25に指示する。
When at least one of the
さらに判定処理部44′は、入力データXを正常であると判断した推定器42を特定する情報を、学習処理部43′に出力する。
Further, the
第2学習処理部45は、予め定められたタイミングで起動し、推定器42の機械学習処理を実行する。ここで予め定められたタイミングは、データ処理装置1の起動時点、あるいは所定の時間に1度、入力データXが所定の回数だけ入力されるごと、異常と判断された入力データが所定の回数を超えて入力された時点、入力データの傾向に基づいて定めたクラスタ数mの値が妥当でないと判断した時点、利用者の指示による時点など、として定めておけばよい。クラスタ数の値が妥当であるか否かの判断は、クラスタ数を異ならせて試験的なクラスタリングを行い、その結果を参照して、クラスタ数を変更するか否かを判断する処理を予め定めた判断のタイミングごとに繰り返して実行することによって行う。ここでクラスタ数を変更するか否かの具体的な判断は、上記判断の処理の時点におけるクラスタ数でのクラスタリングの結果と、上記の試験的なクラスタリングの結果とにおける、同じクラスタに属する入力データ同士の距離(凝集性)や、互いに異なるクラスタに属する入力データ同士の距離(クラスタ間離散性)とに基づいて行うことができる。
The second
この第2学習処理部45による機械学習処理は、次のようにして行われる。第2学習処理部45は、学習処理部43′が記憶部12に蓄積して記録した入力データをクラスタリングする。ここでのクラスタリングの方法は、教師なしのクラスタリングであれば、どのような方法であってもよく、例えばDBScan、SUBCLU、k-meansなど、種々の処理のいずれかを採用できる。
The machine learning processing by the second
第2学習処理部45は、推定器42の数と同じ、またはより少ない数のクラスタに分類を行う。つまり推定器42の数がnであるとすると、クラスタの数をm≦nなるmとする。あるいは、ここで得られるクラスタの数より多い推定器42を予め用意しておくこととしてもよい(その場合は、入力データとなるべきデータを予め蓄積し、クラスタリング処理を行ってクラスタ数を決定する)。
The second
第2学習処理部45は、各推定器42を、いずれかのクラスタに係る入力データを機械学習する推定器であるとして、各推定器42をいずれかのクラスタに割り当てる。なお、以前に割り当てを行っている場合には、第2学習処理部45は改めて割り当てを変更することなく、以前の割り当ての結果をそのまま利用する。
The second
そして第2学習処理部45は、記憶部12に蓄積されている入力データを順次取り出し、取り出した入力データのクラスタリングの結果(属するクラスタを表す情報)を参照する。第2学習処理部45は、当該情報で表されるクラスタに割り当てられている推定器42に対して、当該入力データを入力し、その出力データを得て、既に述べた方法と同様の方法で、当該推定器42を機械学習処理する。このとき、参照した情報で表されるクラスタに割り当てられていない推定器42については、機械学習処理を行わない。
Then, the second
第2学習処理部45は、記憶部12に蓄積されている入力データのすべてについて上記の処理を終了すると、記憶部12に蓄積している入力データを削除する(次回の学習には利用しないよう制御する)こととしてもよい。
When the above processing is completed for all of the input data stored in the
そして第2学習処理部45による機械学習処理後、学習処理部43′と、判定処理部44′と出力処理部25とによる動作を継続する。
After the machine learning processing by the second
つまりこの例では、入力データをクラスタに分類し、分類されたクラスタごとに、対応する推定器42を用意して、当該推定器42を、対応するクラスタに属する入力データで機械学習する。
That is, in this example, the input data is classified into clusters, a corresponding
本実施の形態のこの例によると、各推定器42が第2学習処理部45の動作により、入力データの種類に特化した機械学習を行うこととなる。これにより、例えば製造装置の異常判定を行う例においては、製造装置が一時停止しているときの振動、動作中の振動、…といったように、複数の異なるタイプの振動をそれぞれ機械学習するようになる。
According to this example of the present embodiment, each
なお、本実施の形態のこの例においては、各クラスタに対して利用者が任意にラベルを付してもよい。この例では制御部11は当該ラベルの情報を記憶する。
In this example of the present embodiment, the user may arbitrarily label each cluster. In this example, the
そして判定処理部44′は、少なくとも一つの推定器42が入力データを正常と判定しているときには、当該推定器42が割り当てられているクラスタに係るラベルの情報を、出力処理部25に出力し、当該ラベルの情報を出力させる。これによると、利用者は、入力データの異常・正常の判断に加え、当該入力データがどのような状態に対応するものであるか(例えば上述の例であれば、「装置停止中」などといった状態)を識別可能となる。
Then, when at least one of the
また、判定処理部44′は、すべての推定器42の判定結果を総合的に判断することで、当該入力データに対応するラベル(当該入力データがどのような状態に対応するものであるか)の確信度を出力してもよい。例えば、一つの推定器42が正常と判定し、それ以外の推定器42がすべて異常と判定したときは正常と判断した推定器42が割り当てられているクラスタに係るラベルの情報に対する確信度(当該クラスタ分類に対する信頼度)は高くなる。一方、一つの入力データに対して、複数の推定器42が一斉に正常と判定したときには、当該複数の推定器42のそれぞれが割り当てられているクラスタに係るラベルの情報に対する確信度は低くなる。
Further, the
そこで判定処理部44′は、複数の入力データのそれぞれに対して推定器42ごとに、単独で正常と判断した(他の推定器42が異常と判断しているときに、当該推定器42のみが正常と判断した)割合、つまり単独で正常と判断した回数を、正常と判断した回数(他の推定器42も正常と判断したときを含む回数)で除した値を、当該推定器42に割り当てられているクラスタに係るラベルの確信度として出力してもよい。
Accordingly, the
[行動異常の検出]
また既に述べたように、本実施の形態のデータ処理装置1は、被験者の行動の正常・異常を判断することにも用いることができる。
[Detection of abnormal behavior]
As described above, the
この行動異常の検出を行う場合、被験者の行動(例えば車両を運転中の被験者であればハンドルを左に切る、右に切る、アクセルを踏む、などの行動であり、コンピュータ操作を行う被験者を対象とする場合は、入力したコマンドの種類等)を表す符号(例えばアルファベット一文字)を予め規定しておき、被験者の一連の行動を符号列(A,C,E,B…といった列)として表現する。 When detecting this behavioral abnormality, the behavior of the subject (for example, turning the steering wheel to the left, turning to the right, stepping on the accelerator, etc. if the subject is driving a vehicle) In this case, a code (for example, one letter of the alphabet) representing the type of the input command is defined in advance, and a series of actions of the subject is expressed as a code sequence (a sequence such as A, C, E, B...). .
データ処理装置1のデータ受入部21は、一定の期間ごとの被験者の一連の行動を表す符号列の入力を入力部13から複数回受け入れる。そしてデータ受入部21は、各期間に対応する符号列に基づいて各期間ごとの状態遷移表を生成する。具体的にデータ受入部21は、N個の符号からなる符号列からi番目(iは、0<i<Nの各整数)の符号Ciと、i+1番目の符号Ci+1とを取り出て順列(Ci,Ci+1)を作成し、この順列ごとの出現確率を演算する。
The
データ受入部21は、あり得るすべての順列について、その出現確率を関連付けたベクトル情報(符号列から取り出されなかった順列についての出現確率は0とする)を生成して状態遷移表とする。そしてデータ受入部21は、この状態遷移表のベクトル情報を入力データとして学習処理部23(あるいは学習処理部43や学習処理部43′)に出力し、正常・異常を判別する推定器を得る。
For all possible permutations, the
もっとも、このようにして生成した状態遷移表は、スパース(ほとんどの要素が「0」)なベクトル情報となっていることが想定される。 However, it is assumed that the state transition table generated in this manner is sparse (most elements are “0”) vector information.
そこで本実施の形態のここでの例では、データ受入部21は、複数の期間のそれぞれについて求められた状態遷移表について、広く知られた圧縮(複数の要素を統合して要素数を減少させる)処理を行った後、圧縮処理後のベクトル情報を入力データとすることとしてもよい。この処理としては、Candes-Taoの理論に基づく方法など、広く知られた方法を採用できるので、ここでの詳しい説明は省略する。
Therefore, in this example of the present embodiment, the
あるいは、データ受入部21は、第j番目の期間に対応する状態遷移表Vjを求める際、第j−1番目の期間に対応する状態遷移表Vj-1があれば、第j番目の期間に対応して上記の方法で求めた状態遷移表V′jを用い、求める状態遷移表Vjを、
Vj=V′j+α・Vj-1
として求めてもよい。ここでαは任意の定数であり、例えばα=0.8などとする。
Alternatively, when obtaining the state transition table V j corresponding to the j-th period, the
V j = V ' j + α · V j-1
May be obtained as Here, α is an arbitrary constant, for example, α = 0.8.
この例のデータ処理装置1は、図6に例示した構成を有するものであってもよい。この図6の構成を有するものとした場合は、車両を運転する被験者の行動の異常・正常を検出するときには、各推定器42は、走行中に対応するもの、停車中に対応するもの…といったように分化して機械学習されることが期待される。そしてこの場合のデータ処理装置1は、どの推定器42においても異常であると判断されたときに、行動の異常が検出されたことを表す情報を出力することとなる。
The
[前処理]
さらに本実施の形態のデータ処理装置1のデータ受入部21は、入力部13が出力するデータに対して前処理を行ってもよい。この前処理は、処理の対象とするベクトルデータx(要素が(x0,x1,x2…,xn)とする)に対して所定の変換を行うもので、変換後のベクトルy(要素が(y0,y1,y2…,yn)とする)を、
yi=Σαj・xj
(ただしΣは、jについての総和を求めることを意味する)などとして求めることを意味する。ここでαは、フィルタ関数(カーネル)であり、例えば、
αj=0(j<i−1,またはj>i+1のとき)
αj=1/3(i−1≦j≦i+1のとき)
としてもよい。
[Preprocessing]
Further,
y i = Σα j · x j
(However, Σ means obtaining the sum of j). Here, α is a filter function (kernel), for example,
α j = 0 (when j <i−1 or j> i + 1)
α j = 1/3 (when i−1 ≦ j ≦ i + 1)
It may be.
また、
αj=0(j<i−1,またはj>i+1のとき)
αj=1/4(j=i−1,またはj=i+1のとき)
αj=1/2(j=iのとき)
としてもよい。
Also,
α j = 0 (when j <i−1 or j> i + 1)
α j = 1/4 (when j = i−1 or j = i + 1)
α j = 1/2 (when j = i)
It may be.
データ受入部21は、入力部13が出力するデータを受け入れて、当該データに対して上述のフィルタ関数を用いて変換処理を行ってから、変換処理後のデータを入力データとして学習処理部23(あるいは学習処理部43や学習処理部43′)に出力することとしてもよい。
The
このようにすると、例えば時系列に値を配列したベクトルデータを入力データとする場合に、時間変化に対する変動に対してロバストな判定を行うことが可能となる。 In this way, for example, when vector data in which values are arranged in a time series is used as input data, it is possible to make a robust determination against a change with time.
また、上述のように、フィルタ関数の定め方は複数あるため、図5に例示した構成を用いることとしてもよい。この場合、各フィルタ関数に対応する推定器42を定めておく。そしてこの場合のデータ受入部21は複数のフィルタ関数をそれぞれ適用して変換したデータを複数得て、各フィルタ関数に対応する推定器42を、対応するフィルタ関数で変換したデータを用いて機械学習させるよう、各学習処理部43にそれぞれ対応する変換したデータを出力することとしてもよい。
Further, as described above, since there are a plurality of ways of determining the filter function, the configuration illustrated in FIG. 5 may be used. In this case, an
また変換処理の方法として、HOG特徴量を用いる方法を採用してもよい。具体的には、ベクトルデータxの各要素を所定サイズ(例えばw×h)のマトリクス状に配列した上で、当該配列後のマトリクス内で予め定めたウインドウサイズWw×Hw(Ww<w、Hw<h)の領域を設定し、当該領域(局所データとなる)の勾配方向と勾配強度とを演算して、それらのヒストグラムを変換後のベクトルyとして、当該変換処理後のデータを入力データとして学習処理部23(あるいは学習処理部43や学習処理部43′)に出力することとしてもよい。
Further, as a method of the conversion processing, a method using a HOG feature amount may be adopted. Specifically, after arranging each element of the vector data x in a matrix of a predetermined size (for example, w × h), a predetermined window size Ww × Hw (Ww <w, Hw <H) is set, the gradient direction and the gradient strength of the region (local data) are calculated, and the histogram is used as a converted vector y, and the converted data is used as input data. It may be output to the learning processing unit 23 (or the
この処理は、ベクトルデータxがもともと上記所定サイズ(w×h)の画像データである場合に有効である。この場合、ベクトルデータxの各成分は当該画像データの各画素の輝度値となる。またそのHOG特徴量をベクトルyとして表現する方法は、広く知られているため、ここでの詳しい説明は省略する。 This process is effective when the vector data x is originally the image data of the predetermined size (w × h). In this case, each component of the vector data x is a luminance value of each pixel of the image data. Also, since a method of expressing the HOG feature amount as a vector y is widely known, a detailed description thereof will be omitted.
[多層化]
また、本実施の形態のデータ処理装置1を複数用い、各データ処理装置1を互いに、FATツリー等の木構造ネットワーク状に接続して用いてもよい。
[Multilayer]
Further, a plurality of
この場合、データ処理装置1を、木構造ネットワークの各ノードに配する。そして親となるノードのないノード(ルートノード)に対応するデータ処理装置1を最上位とする。子のあるノードに対応するデータ処理装置1pは、子となっているノードに対応するデータ処理装置1fが出力する判定の結果(当該データ処理装置1fに入力された入力データが正常であるか否かを表す情報)を受け入れ、この判定の結果の情報を入力部13から受け入れて、機械学習の対象(入力データ及び教師データ)として、OS-ELM等で構成した推定器をオートエンコーダとして学習処理し、入力データが正常であるか異常であるかの判定を行う。
In this case, the
この例によると、より下位側(製品の製造機械の振動などの情報を入力とする)データ処理装置1において、異常検知の対象となったシステムの細部における異常を検知するとともに、例えば一つの作業室において、個々の製造機械の振動についての異常検知を行う複数のデータ処理装置1からの入力を受け入れる(親となっているノードに相当する)データ処理装置1は、この作業室全体(システムのより広域な部分)における集約的な異常検知を行うこととなる。
According to this example, in the
このように本実施の形態のデータ処理装置1を多層的に接続することで、システムの種々のスケールで異常検知を行うことが可能となる。
As described above, by connecting the
[要因推定]
また、本実施の形態のデータ処理装置1は、異常と判断された入力データと、その前後にデータ処理装置1に入力されていた複数の入力データとを入力とし、異常の原因を表す情報を正解として機械学習処理した、ディープラーニングのニューラルネットワークを用いた要因推定装置に接続されてもよい。
[Factor estimation]
Further, the
この場合、データ処理装置1は、最近入力した入力データを少なくともN個蓄積して保持する。そして異常と判断される入力データが入力されると、その後、m個(m<N,m=N−nとする)の入力データが入力されるまで待機し、異常と判断された入力データが入力された後、m個の入力データが入力されたときに、保持しているN個の入力データ(異常発生前にn−1個、異常と判断された入力データが1個、異常と判断された後の入力データm個の合計N個)を、要因推定装置に送出する。
In this case, the
なお、上述のような要因推定装置の構成は、広く知られたものを採用できるので、ここでの詳しい説明は省略する。 The configuration of the factor estimating apparatus as described above can employ widely known ones, and a detailed description thereof will be omitted.
1 データ処理装置、11 制御部、12 記憶部、13 入力部、14 出力部、21 データ受入部、22 推定器、23 学習処理部、24 判定処理部、25 出力処理部、31 入力層、32 中間層、33 出力層、42 推定器、43,43′ 学習処理部、44,44′ 判定処理部、45 第2学習処理部。
DESCRIPTION OF
Claims (9)
入力データと教師データとを受け入れて、逆数演算により機械学習可能な推測手段と、
前記入力されたデータを入力データ及び教師データとして、前記推測手段を機械学習する学習処理手段と、
前記推測手段の出力と、前記入力されたデータとの比較に基づいて、前記所定の判定処理を行い、当該判定処理の結果を出力する出力手段と、
を含むデータ処理装置。 A data processing device that performs a predetermined determination process based on repeatedly input data,
Estimating means that can accept input data and teacher data and perform machine learning by reciprocal operation;
Learning processing means for machine learning the inference means, using the input data as input data and teacher data,
Output means for performing the predetermined determination processing based on a comparison between the output of the estimation means and the input data, and outputting a result of the determination processing;
A data processing device including:
前記推測手段は、入力層と中間層との結合重みをランダムに決定し、中間層と出力層との間の結合重みを機械学習するニューラルネットワークを含んで構成されるデータ処理装置。 The data processing device according to claim 1, wherein
A data processing apparatus comprising a neural network that randomly determines a connection weight between an input layer and a hidden layer and machine-learns a connection weight between the hidden layer and an output layer.
前記学習処理手段は、前記データの入力を受け入れるごとに、前記推測手段の機械学習処理を行うデータ処理装置。 The data processing device according to claim 1 or 2,
The data processing device, wherein the learning processing means performs a machine learning process of the estimating means each time the data input is received.
前記学習処理手段は、機械学習処理を行うごとに、前記推測手段の機械学習結果と、入力データとを関連付けて記録し、
予め定めた方法で決定した複数回の機械学習処理が行われるごとに、前記記録している入力データをその時点での推測手段に入力したときの推測手段の出力を参照し、当該出力が予め定めた条件を満足するときには、当該入力データに関連付けて記録している機械学習結果により、前記推測手段の機械学習状態を補正するデータ処理装置。 The data processing device according to claim 3, wherein
Each time the learning processing unit performs the machine learning process, records the machine learning result of the estimating unit and the input data in association with each other,
Each time a plurality of machine learning processes determined by a predetermined method are performed, reference is made to the output of the estimating means when the recorded input data is input to the estimating means at that time, and the output is determined in advance. A data processing device for correcting a machine learning state of the estimating means based on a machine learning result recorded in association with the input data when a predetermined condition is satisfied.
前記推測手段を複数備え、
前記学習処理手段は、前記複数の推測手段を、すべての推測手段が一斉にリセットされることのないタイミングでそれぞれリセットし、
前記出力手段は、当該複数の推測手段のそれぞれの出力と、前記入力されたデータとの比較に基づいて、前記所定の判定処理を行い、当該判定処理の結果を出力するデータ処理装置。 The data processing device according to claim 1, wherein:
Comprising a plurality of said estimating means,
The learning processing means resets the plurality of estimating means at a timing at which all the estimating means are not reset at the same time,
A data processing device that performs the predetermined determination process based on a comparison between each output of the plurality of estimation units and the input data, and outputs a result of the determination process.
前記データ処理装置がそれぞれ、
繰り返し入力されるデータに基づく所定の判定処理を行うデータ処理装置であって、
入力データと教師データとを受け入れて、逆数演算により機械学習可能な推測手段と、
前記入力されたデータを入力データ及び教師データとして、前記推測手段を機械学習する学習処理手段と、
前記推測手段の出力と、前記入力されたデータとの比較に基づいて、前記所定の判定処理を行い、当該判定処理の結果を出力する出力手段と、
を備える、データ処理システム。 Including a plurality of data processing devices connected to each other in a tree structure network,
Each of the data processing devices,
A data processing device that performs a predetermined determination process based on repeatedly input data,
Estimating means capable of receiving input data and teacher data and performing machine learning by reciprocal operation;
Learning processing means for machine learning the inference means, using the input data as input data and teacher data,
Output means for performing the predetermined determination processing based on a comparison between the output of the estimation means and the input data, and outputting a result of the determination processing;
A data processing system comprising:
繰り返し入力されるデータに基づく所定の判定処理を行うデータ処理装置として機能させるためのプログラムであって、
入力データと教師データとを受け入れて、逆数演算により機械学習可能な推測手段、
前記入力されたデータを入力データ及び教師データとして、前記推測手段を機械学習する学習処理手段、及び
前記推測手段の出力と、前記入力されたデータとの比較に基づいて、前記所定の判定処理を行い、当該判定処理の結果を出力する出力手段、として、コンピュータを機能させるプログラム。 Computer
A program for functioning as a data processing device that performs a predetermined determination process based on repeatedly input data,
Estimation means that accepts input data and teacher data and can perform machine learning by reciprocal operation,
Learning processing means for machine-learning the estimating means using the input data as input data and teacher data, and performing the predetermined determination processing based on a comparison between the output of the estimating means and the input data. A program that causes a computer to function as an output unit that performs the determination process and outputs the result of the determination process.
前記推測手段は、入力データを入力したときの出力と、教師データとの間の差に基づく損失の情報を用いて機械学習するニューラルネットワークを含んで構成され、
前記学習処理手段は、予め定めたM回数分(Mは自然数)の直近の入力データに対する前記損失を記録し、当該記録した損失に基づいて演算される統計値と、M回前の入力データを前記推測手段に入力したときの損失との比較に基づいて、当該M回前の入力データに基づく機械学習処理を行うか否かを判断し、機械学習処理を行うと判断したときに、当該M回前の入力データを、入力データかつ教師データとして、前記推測手段を機械学習するデータ処理装置。 The data processing device according to claim 1 or 2,
The estimating means is configured to include a neural network that performs machine learning using an output when input data is input and loss information based on a difference between teacher data,
The learning processing means records the loss with respect to the most recent input data for a predetermined number of M times (M is a natural number), and calculates a statistical value calculated based on the recorded loss and the input data M times before. Based on a comparison with the loss at the time of input to the estimating means, it is determined whether or not to perform a machine learning process based on the input data M times before. A data processing device that machine-learns the estimating means by using input data from a previous session as input data and teacher data.
前記推測手段を複数備えるとともに、前記入力データをクラスタに分類する手段をさらに備え、
前記学習処理手段は、前記複数の推測手段のそれぞれを、前記分類されたクラスタごとに対応づけて、入力データごとに属するクラスタを決定し、当該決定したクラスタに対応する推測手段を、当該入力データを用いて機械学習するデータ処理装置。
The data processing device according to claim 1 or 2,
A plurality of the inference means, and further comprising means for classifying the input data into clusters,
The learning processing means associates each of the plurality of estimating means with each of the classified clusters, determines a cluster belonging to each input data, and outputs the estimating means corresponding to the determined cluster to the input data. A data processing device that performs machine learning using.
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018125151 | 2018-06-29 | ||
| JP2018125151 | 2018-06-29 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2020009400A true JP2020009400A (en) | 2020-01-16 |
| JP7272575B2 JP7272575B2 (en) | 2023-05-12 |
Family
ID=69151848
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018227556A Active JP7272575B2 (en) | 2018-06-29 | 2018-12-04 | Data processing device, data processing system and program |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7272575B2 (en) |
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113723517A (en) * | 2021-08-31 | 2021-11-30 | 北京理工大学 | Image classification method based on state transition extreme learning machine |
| JP2023047003A (en) * | 2021-09-24 | 2023-04-05 | トヨタ自動車株式会社 | Machine learning system, learning data collection method and learning data collection program |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1182137A (en) * | 1998-02-09 | 1999-03-26 | Matsushita Electric Ind Co Ltd | Parameter estimation device |
| JP2015082259A (en) * | 2013-10-23 | 2015-04-27 | 本田技研工業株式会社 | Time series data prediction device, time series data prediction method, and program |
| WO2016132468A1 (en) * | 2015-02-18 | 2016-08-25 | 株式会社日立製作所 | Data evaluation method and device, and breakdown diagnosis method and device |
| JP2017168057A (en) * | 2016-03-18 | 2017-09-21 | 株式会社Spectee | Device, system, and method for sorting images |
-
2018
- 2018-12-04 JP JP2018227556A patent/JP7272575B2/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1182137A (en) * | 1998-02-09 | 1999-03-26 | Matsushita Electric Ind Co Ltd | Parameter estimation device |
| JP2015082259A (en) * | 2013-10-23 | 2015-04-27 | 本田技研工業株式会社 | Time series data prediction device, time series data prediction method, and program |
| WO2016132468A1 (en) * | 2015-02-18 | 2016-08-25 | 株式会社日立製作所 | Data evaluation method and device, and breakdown diagnosis method and device |
| JP2017168057A (en) * | 2016-03-18 | 2017-09-21 | 株式会社Spectee | Device, system, and method for sorting images |
Non-Patent Citations (2)
| Title |
|---|
| LIANG, N ET AL.: ""A Fast and Accurate Online Sequential Learning Algorithm for Feedforward Networks"", IEEE TRANSACTIONS ON NEURAL NETWORKS [ONLINE], vol. 17, no. 6, JPN6022039904, 2006, pages 1411 - 1423, ISSN: 0004881089 * |
| 岩本恵太 ほか: ""Extreme Learning Machineによる特徴抽出を用いた決定木とセマンティックセグメンテーションへの応用"", IN: SSII2015 第21回 画像センシングシンポジウム 講演論文集 [CD-ROM], JPN6022039903, 2015, JP, pages 2 - 18, ISSN: 0004881090 * |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN113723517A (en) * | 2021-08-31 | 2021-11-30 | 北京理工大学 | Image classification method based on state transition extreme learning machine |
| JP2023047003A (en) * | 2021-09-24 | 2023-04-05 | トヨタ自動車株式会社 | Machine learning system, learning data collection method and learning data collection program |
| JP7666266B2 (en) | 2021-09-24 | 2025-04-22 | トヨタ自動車株式会社 | Machine learning system, learning data collection method, and learning data collection program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7272575B2 (en) | 2023-05-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102486699B1 (en) | Method and apparatus for recognizing and verifying image, and method and apparatus for learning image recognizing and verifying | |
| CN108509970B (en) | Learning method, corresponding system, device and computer program product | |
| KR20190118387A (en) | Convolutional neural network based image processing system and method | |
| CN106897404B (en) | Recommendation method and system based on multi-GRU layer neural network | |
| CN111989696A (en) | Neural network for scalable continuous learning in domains with sequential learning tasks | |
| WO2017103917A1 (en) | Methods and systems for data traffic analysis | |
| CN110659742A (en) | Method and device for acquiring sequence representation vector of user behavior sequence | |
| CN113825978B (en) | Method and device for defining path and storage device | |
| WO2018151765A1 (en) | Unsupervised learning techniques for temporal difference models | |
| US20220230067A1 (en) | Learning device, learning method, and learning program | |
| CN112948155A (en) | Model training method, state prediction method, device, equipment and storage medium | |
| JP2019125319A (en) | Learning program, learning method and learning device | |
| JP2023554336A5 (en) | ||
| US11943277B2 (en) | Conversion system, method and program | |
| JP7272575B2 (en) | Data processing device, data processing system and program | |
| JP6900576B2 (en) | Movement situational awareness model learning device, movement situational awareness device, method, and program | |
| JP7466702B2 (en) | Interpretable Imitation Learning by Discovering Prototype Options | |
| KR20190059033A (en) | Input vector generating apparatus and method using singular vaule decomposition for deep neural network speech recognition system | |
| KR20220091161A (en) | Method and device for predicting the next event to occur | |
| JP7752278B1 (en) | Abnormality management device and abnormality management method | |
| JP7047665B2 (en) | Learning equipment, learning methods and learning programs | |
| CN108090266B (en) | A Method for Calculating Correlation Reliability of Mechanical Parts with Multiple Failure Modes | |
| CN114511099B (en) | Data prediction method, device and equipment based on factor decomposition machine and partial order relationship | |
| KR101893290B1 (en) | System for instructional video learning and evaluation using deep learning | |
| EP4414900A1 (en) | Learning device, learning method, sensing device, and data collection method |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20211203 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20220914 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20220927 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20221125 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230328 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230419 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7272575 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |