JP2022062876A - 音信号処理方法および音信号処理装置 - Google Patents
音信号処理方法および音信号処理装置 Download PDFInfo
- Publication number
- JP2022062876A JP2022062876A JP2020171052A JP2020171052A JP2022062876A JP 2022062876 A JP2022062876 A JP 2022062876A JP 2020171052 A JP2020171052 A JP 2020171052A JP 2020171052 A JP2020171052 A JP 2020171052A JP 2022062876 A JP2022062876 A JP 2022062876A
- Authority
- JP
- Japan
- Prior art keywords
- sound signal
- speaker
- signal processing
- filter
- correction filter
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images












Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R3/00—Circuits for transducers
- H04R3/04—Circuits for transducers for correcting frequency response
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V10/00—Arrangements for image or video recognition or understanding
- G06V10/70—Arrangements for image or video recognition or understanding using pattern recognition or machine learning
- G06V10/82—Arrangements for image or video recognition or understanding using pattern recognition or machine learning using neural networks
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06V—IMAGE OR VIDEO RECOGNITION OR UNDERSTANDING
- G06V40/00—Recognition of biometric, human-related or animal-related patterns in image or video data
- G06V40/10—Human or animal bodies, e.g. vehicle occupants or pedestrians; Body parts, e.g. hands
- G06V40/16—Human faces, e.g. facial parts, sketches or expressions
- G06V40/161—Detection; Localisation; Normalisation
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0316—Speech enhancement, e.g. noise reduction or echo cancellation by changing the amplitude
- G10L21/0324—Details of processing therefor
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/02—Speech enhancement, e.g. noise reduction or echo cancellation
- G10L21/0208—Noise filtering
- G10L21/0216—Noise filtering characterised by the method used for estimating noise
- G10L2021/02161—Number of inputs available containing the signal or the noise to be suppressed
- G10L2021/02166—Microphone arrays; Beamforming
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R2430/00—Signal processing covered by H04R, not provided for in its groups
- H04R2430/01—Aspects of volume control, not necessarily automatic, in sound systems
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Health & Medical Sciences (AREA)
- Multimedia (AREA)
- Human Computer Interaction (AREA)
- Signal Processing (AREA)
- Acoustics & Sound (AREA)
- Theoretical Computer Science (AREA)
- Computational Linguistics (AREA)
- Quality & Reliability (AREA)
- Audiology, Speech & Language Pathology (AREA)
- General Health & Medical Sciences (AREA)
- General Physics & Mathematics (AREA)
- Oral & Maxillofacial Surgery (AREA)
- Evolutionary Computation (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Computing Systems (AREA)
- Databases & Information Systems (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Circuit For Audible Band Transducer (AREA)
Abstract

【解決手段】音信号処理方法は、話者の音声に係る音信号を入力し、話者画像を取得し、前記話者画像から前記話者の姿勢情報を推定し、推定した前記姿勢情報に応じた補正フィルタを生成し、前記補正フィルタに係るフィルタ処理を前記音信号に施し、前記フィルタ処理を施した後の音信号を出力する。
【選択図】図10
Description
図1は、音信号処理装置1の構成を示すブロック図である。図2は、音信号処理方法の動作を示すフローチャートである。
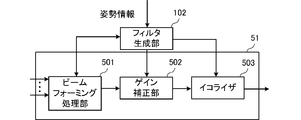
次に、図9は、姿勢情報に基づいて補正フィルタを生成する場合の、音信号処理方法の動作を示すフローチャートである。図10は、姿勢情報に基づいて補正フィルタを生成する場合の、音信号処理装置1の機能的構成を示すブロック図である。この例の音信号処理装置1は、位置推定部101に代えて、姿勢推定部201を備える。ハードウェア構成は、図1に示した構成と同一である。
11…カメラ
12…CPU
13…DSP
14…フラッシュメモリ
15…RAM
16…ユーザI/F
17…スピーカ
18A~18F…マイク
19…通信部
50…音信号入力部
51…音信号処理部
52…出力部
100…画像取得部
101…位置推定部
102…フィルタ生成部
201…姿勢推定部
501…ビームフォーミング処理部
502…ゲイン補正部
503…イコライザ
701…AEC
Claims (14)
- 話者の音声に係る音信号を入力し、
話者画像を取得し、
前記話者画像から前記話者の姿勢情報を推定し、
推定した前記姿勢情報に応じた補正フィルタを生成し、
前記補正フィルタに係るフィルタ処理を前記音信号に施し、
前記フィルタ処理を施した後の音信号を出力する、
音信号処理方法。 - 前記姿勢情報は、前記話者の顔の向きを含み、
前記補正フィルタは、前記顔の向きに応じて減衰するレベルを補償する処理を含む、
請求項1に記載の音信号処理方法。 - 前記補正フィルタは、イコライザを含む、
請求項1または請求項2に記載の音信号処理方法。 - 前記姿勢情報は、顔の左右の向きを示す情報を含み、
前記顔の左右の向きに応じて前記補正フィルタを生成する、
請求項1乃至請求項3のいずれか1項に記載の音信号処理方法。 - 前記補正フィルタは、前記顔の左右の向きが大きいほど高域のレベルを高くする、または低域のレベルを低くする処理を含む、
請求項4に記載の音信号処理方法。 - 前記姿勢情報は、後ろ向きの姿勢の情報を含む、
請求項1乃至請求項5のいずれか1項に記載の音信号処理方法。 - 前記話者画像から前記話者の位置情報を推定し、
前記位置情報に基づいて前記補正フィルタを生成し、
前記位置情報の推定速度は、前記姿勢情報の推定速度よりも速く、
前記補正フィルタは、前記位置情報を推定した時、および前記姿勢情報を推定した時、のそれぞれのタイミングで生成される、
請求項1乃至請求項6のいずれか1項に記載の音信号処理方法。 - 話者の音声に係る音信号を入力する音信号入力部と、
話者画像を取得する画像取得部と、
前記話者画像から前記話者の姿勢情報を推定する位置推定部と、
推定した前記姿勢情報に応じた補正フィルタを生成するフィルタ生成部と、
前記補正フィルタに係るフィルタ処理を前記音信号に施す音信号処理部と、
前記フィルタ処理を施した後の音信号を出力する出力部と、
備えた音信号処理装置。 - 前記姿勢情報は、前記話者の顔の向きを含み、
前記補正フィルタは、前記顔の向きに応じて減衰するレベルを補償する処理を含む、
請求項8に記載の音信号処理装置。 - 前記補正フィルタは、イコライザを含む、
請求項8または請求項9に記載の音信号処理装置。 - 前記姿勢情報は、顔の左右の向きを示す情報を含み、
前記フィルタ生成部は、前記顔の左右の向きに応じて前記補正フィルタを生成する、
請求項8乃至請求項10のいずれか1項に記載の音信号処理装置。 - 前記補正フィルタは、前記顔の左右の向きが大きいほど高域のレベルを高くする、または低域のレベルを低くする処理を含む、
請求項11に記載の音信号処理装置。 - 前記姿勢情報は、後ろ向きの姿勢の情報を含む、
請求項8乃至請求項12のいずれか1項に記載の音信号処理装置。 - 前記話者画像から前記話者の位置情報を推定する位置推定部を備え、
前記フィルタ生成部は、前記位置情報に基づいて前記補正フィルタを生成し、
前記位置情報の推定速度は、前記姿勢情報の推定速度よりも速く、
前記補正フィルタは、前記位置情報を推定した時、および前記姿勢情報を推定した時、のそれぞれのタイミングで生成される、
請求項8乃至請求項13のいずれか1項に記載の音信号処理装置。
Priority Applications (4)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020171052A JP7567345B2 (ja) | 2020-10-09 | 2020-10-09 | 音信号処理方法および音信号処理装置 |
| CN202111133047.1A CN114420144B (zh) | 2020-10-09 | 2021-09-27 | 声音信号处理方法及声音信号处理装置 |
| US17/492,914 US11956606B2 (en) | 2020-10-09 | 2021-10-04 | Audio signal processing method and audio signal processing apparatus that process an audio signal based on posture information |
| EP21201420.3A EP3982363B1 (en) | 2020-10-09 | 2021-10-07 | Audio signal processing method and audio signal processing apparatus |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020171052A JP7567345B2 (ja) | 2020-10-09 | 2020-10-09 | 音信号処理方法および音信号処理装置 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022062876A true JP2022062876A (ja) | 2022-04-21 |
| JP7567345B2 JP7567345B2 (ja) | 2024-10-16 |
Family
ID=78085846
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020171052A Active JP7567345B2 (ja) | 2020-10-09 | 2020-10-09 | 音信号処理方法および音信号処理装置 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US11956606B2 (ja) |
| EP (1) | EP3982363B1 (ja) |
| JP (1) | JP7567345B2 (ja) |
| CN (1) | CN114420144B (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7567344B2 (ja) | 2020-10-09 | 2024-10-16 | ヤマハ株式会社 | 音信号処理方法および音信号処理装置 |
Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009156888A (ja) * | 2007-12-25 | 2009-07-16 | Sanyo Electric Co Ltd | 音声補正装置及びそれを備えた撮像装置並びに音声補正方法 |
| WO2010146857A1 (ja) * | 2009-06-17 | 2010-12-23 | パナソニック株式会社 | 補聴装置 |
| JP2014216787A (ja) * | 2013-04-24 | 2014-11-17 | パナソニック株式会社 | 会議端末装置及び増幅率登録方法 |
| JP2015082734A (ja) * | 2013-10-22 | 2015-04-27 | パナソニックIpマネジメント株式会社 | 音声処理装置、音声処理システム、及び音声処理方法 |
| JP2019103009A (ja) * | 2017-12-05 | 2019-06-24 | パナソニックIpマネジメント株式会社 | 指向性制御装置と収音システムおよび指向性制御方法、指向性制御プログラム |
| JP2020092358A (ja) * | 2018-12-06 | 2020-06-11 | パナソニックIpマネジメント株式会社 | 信号処理装置及び信号処理方法 |
Family Cites Families (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20010055399A1 (en) * | 1998-10-30 | 2001-12-27 | Kenneth A. Ullrich | Assistive listening system and method for television, radio and music systems |
| US5940118A (en) | 1997-12-22 | 1999-08-17 | Nortel Networks Corporation | System and method for steering directional microphones |
| US7130705B2 (en) * | 2001-01-08 | 2006-10-31 | International Business Machines Corporation | System and method for microphone gain adjust based on speaker orientation |
| US9445193B2 (en) | 2008-07-31 | 2016-09-13 | Nokia Technologies Oy | Electronic device directional audio capture |
| JP2010206451A (ja) * | 2009-03-03 | 2010-09-16 | Panasonic Corp | カメラ付きスピーカ、信号処理装置、およびavシステム |
| JP2012029209A (ja) * | 2010-07-27 | 2012-02-09 | Hitachi Ltd | 音処理システム |
| WO2013058728A1 (en) * | 2011-10-17 | 2013-04-25 | Nuance Communications, Inc. | Speech signal enhancement using visual information |
| US8185387B1 (en) * | 2011-11-14 | 2012-05-22 | Google Inc. | Automatic gain control |
| DE102012214081A1 (de) * | 2012-06-06 | 2013-12-12 | Siemens Medical Instruments Pte. Ltd. | Verfahren zum Fokussieren eines Hörinstruments-Beamformers |
| US9338551B2 (en) | 2013-03-15 | 2016-05-10 | Broadcom Corporation | Multi-microphone source tracking and noise suppression |
| US9124990B2 (en) | 2013-07-10 | 2015-09-01 | Starkey Laboratories, Inc. | Method and apparatus for hearing assistance in multiple-talker settings |
| JP6464449B2 (ja) * | 2014-08-29 | 2019-02-06 | 本田技研工業株式会社 | 音源分離装置、及び音源分離方法 |
| EP3147898A1 (en) | 2015-09-23 | 2017-03-29 | Politechnika Gdanska | Method and system for improving the quality of speech signals in speech recognition systems |
| US10387108B2 (en) | 2016-09-12 | 2019-08-20 | Nureva, Inc. | Method, apparatus and computer-readable media utilizing positional information to derive AGC output parameters |
| CN107993671A (zh) * | 2017-12-04 | 2018-05-04 | 南京地平线机器人技术有限公司 | 声音处理方法、装置和电子设备 |
| EP3901740A1 (en) | 2018-10-15 | 2021-10-27 | Orcam Technologies Ltd. | Hearing aid systems and methods |
| JP7567344B2 (ja) | 2020-10-09 | 2024-10-16 | ヤマハ株式会社 | 音信号処理方法および音信号処理装置 |
-
2020
- 2020-10-09 JP JP2020171052A patent/JP7567345B2/ja active Active
-
2021
- 2021-09-27 CN CN202111133047.1A patent/CN114420144B/zh active Active
- 2021-10-04 US US17/492,914 patent/US11956606B2/en active Active
- 2021-10-07 EP EP21201420.3A patent/EP3982363B1/en active Active
Patent Citations (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2009156888A (ja) * | 2007-12-25 | 2009-07-16 | Sanyo Electric Co Ltd | 音声補正装置及びそれを備えた撮像装置並びに音声補正方法 |
| WO2010146857A1 (ja) * | 2009-06-17 | 2010-12-23 | パナソニック株式会社 | 補聴装置 |
| JP2014216787A (ja) * | 2013-04-24 | 2014-11-17 | パナソニック株式会社 | 会議端末装置及び増幅率登録方法 |
| JP2015082734A (ja) * | 2013-10-22 | 2015-04-27 | パナソニックIpマネジメント株式会社 | 音声処理装置、音声処理システム、及び音声処理方法 |
| JP2019103009A (ja) * | 2017-12-05 | 2019-06-24 | パナソニックIpマネジメント株式会社 | 指向性制御装置と収音システムおよび指向性制御方法、指向性制御プログラム |
| JP2020092358A (ja) * | 2018-12-06 | 2020-06-11 | パナソニックIpマネジメント株式会社 | 信号処理装置及び信号処理方法 |
Also Published As
| Publication number | Publication date |
|---|---|
| CN114420144A (zh) | 2022-04-29 |
| EP3982363A1 (en) | 2022-04-13 |
| JP7567345B2 (ja) | 2024-10-16 |
| US20220116703A1 (en) | 2022-04-14 |
| CN114420144B (zh) | 2025-10-17 |
| US11956606B2 (en) | 2024-04-09 |
| EP3982363B1 (en) | 2025-09-03 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN114333873B (zh) | 声音信号处理方法及声音信号处理装置 | |
| US10582117B1 (en) | Automatic camera control in a video conference system | |
| CN107534725B (zh) | 一种语音信号处理方法及装置 | |
| US9197974B1 (en) | Directional audio capture adaptation based on alternative sensory input | |
| US10939202B2 (en) | Controlling the direction of a microphone array beam in a video conferencing system | |
| CN108091344A (zh) | 一种降噪方法、装置及系统 | |
| US11398220B2 (en) | Speech processing device, teleconferencing device, speech processing system, and speech processing method | |
| CN111078185A (zh) | 录制声音的方法及设备 | |
| JP7577960B2 (ja) | 話者予測方法、話者予測装置、およびコミュニケーションシステム | |
| US12039993B2 (en) | Speech processing device and speech processing method | |
| US11683634B1 (en) | Joint suppression of interferences in audio signal | |
| CN114420144B (zh) | 声音信号处理方法及声音信号处理装置 | |
| CN115482828A (zh) | 声音信号处理方法及装置、计算机可读存储介质 | |
| US12309557B2 (en) | Selective sound modification for video communication | |
| WO2023149254A1 (ja) | 音声信号処理装置、音声信号処理方法及び音声信号処理プログラム | |
| WO2023054047A1 (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| US12581038B2 (en) | Audio processing in video conferencing system using multimodal features | |
| EP4187926B1 (en) | Method and system for providing hearing assistance | |
| JP2021135311A (ja) | 音声処理装置および音声処理方法 | |
| Fu | Visually-guided beamforming for a circular microphone array | |
| EP4462769A1 (en) | Generation of an audiovisual signal | |
| EP4475560A1 (en) | Microphone assembly and method for providing hearing assistance |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230824 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240418 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240528 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20240725 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240903 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240916 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7567345 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |