JP2024091702A - 情報提供装置 - Google Patents
情報提供装置 Download PDFInfo
- Publication number
- JP2024091702A JP2024091702A JP2024062673A JP2024062673A JP2024091702A JP 2024091702 A JP2024091702 A JP 2024091702A JP 2024062673 A JP2024062673 A JP 2024062673A JP 2024062673 A JP2024062673 A JP 2024062673A JP 2024091702 A JP2024091702 A JP 2024091702A
- Authority
- JP
- Japan
- Prior art keywords
- information
- unit
- concentrated
- occupant
- vehicle
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Pending
Links
Images












Landscapes
- Navigation (AREA)
- Image Analysis (AREA)
- Instructional Devices (AREA)
Abstract

【課題】利便性を向上させること。
【解決手段】情報提供装置3は、移動体の周囲を撮影した撮影画像を取得する画像取得部323と、乗員から所定の要求があった場合に、移動体の位置情報を取得する情報取得部324と、位置情報を用いて、統計的に視線が集中する物体を特定する特定部325と、特定部325によって視線が集中する物体を特定できない場合には、撮影画像に基づいて、撮影画像内における視線が集中する注目領域を抽出する領域抽出部326と、撮影画像内における前記注目領域に含まれる物体を認識する物体認識部327と、特定部325によって特定された物体に関する物体情報、または、注目領域に含まれる物体に関する物体情報を提供する情報提供部328とを備える。
【選択図】図3
【解決手段】情報提供装置3は、移動体の周囲を撮影した撮影画像を取得する画像取得部323と、乗員から所定の要求があった場合に、移動体の位置情報を取得する情報取得部324と、位置情報を用いて、統計的に視線が集中する物体を特定する特定部325と、特定部325によって視線が集中する物体を特定できない場合には、撮影画像に基づいて、撮影画像内における視線が集中する注目領域を抽出する領域抽出部326と、撮影画像内における前記注目領域に含まれる物体を認識する物体認識部327と、特定部325によって特定された物体に関する物体情報、または、注目領域に含まれる物体に関する物体情報を提供する情報提供部328とを備える。
【選択図】図3
Description
本発明は、情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体に関する。
従来、車両の周囲に存在する対象物を特定し、当該対象物に関する名称等の情報を音声にて読み上げる対象物特定装置が知られている(例えば、特許文献1参照)。特許文献1に記載の対象物特定装置では、車両の乗員が手や指で指し示している指示方向に存在する地図上の施設等を対象物として特定している。
しかしながら、特許文献1に記載の技術では、対象物に関する情報を得ることを望む車両の乗員に対して、当該対象物を手や指で指し示すという作業を行わせる必要があり、利便性を向上させることができない、という問題が一例として挙げられる。
本発明は、上記に鑑みてなされたものであって、例えば利便性を向上させることができる情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体を提供することを目的とする。
請求項1に記載の情報提供装置は、移動体の周囲を撮影した撮影画像を取得する画像取得部と、乗員から所定の要求があった場合に、前記移動体の位置情報を取得する情報取得部と、前記位置情報を用いて、統計的に視線が集中する物体を特定する特定部と、前記特定部によって前記視線が集中する物体を特定できない場合には、前記撮影画像に基づいて、前記撮影画像内における視線が集中する注目領域を抽出する領域抽出部と、前記撮影画像内における前記注目領域に含まれる物体を認識する物体認識部と、前記特定部によって特定された物体に関する物体情報、または、前記注目領域に含まれる物体に関する物体情報を提供する情報提供部とを備えることを特徴とする。
以下に、図面を参照しつつ、本発明を実施するための形態(以下、実施の形態)について説明する。なお、以下に説明する実施の形態によって本発明が限定されるものではない。さらに、図面の記載において、同一の部分には同一の符号を付している。
(実施の形態1)
〔情報提供システムの概略構成〕
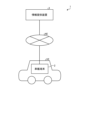
図1は、実施の形態1に係る情報提供システム1の構成を示すブロック図である。情報提供システム1は、移動体である車両VE(図1)の乗員PA(図7参照)に対して、当該車両VEの周囲に存在する建物等の物体に関する物体情報(例えば当該物体の名称等)を提供するシステムである。この情報提供システム1は、図1に示すように、車載端末2と、情報提供装置3とを備える。そして、これら車載端末2及び情報提供装置3は、無線通信網であるネットワークNE(図1)を介して、通信を行う。
〔情報提供システムの概略構成〕
図1は、実施の形態1に係る情報提供システム1の構成を示すブロック図である。情報提供システム1は、移動体である車両VE(図1)の乗員PA(図7参照)に対して、当該車両VEの周囲に存在する建物等の物体に関する物体情報(例えば当該物体の名称等)を提供するシステムである。この情報提供システム1は、図1に示すように、車載端末2と、情報提供装置3とを備える。そして、これら車載端末2及び情報提供装置3は、無線通信網であるネットワークNE(図1)を介して、通信を行う。
なお、情報提供装置3と通信を行う車載端末2としては、図1では1台である場合を例示しているが、複数の車両にそれぞれ搭載された複数台であっても構わない。また、1台の車両に乗車している複数の乗員に対してそれぞれ物体情報を提供するために、1台の車両に車載端末2が複数台、搭載されていても構わない。
〔車載端末の構成〕
図2は、車載端末2の構成を示すブロック図である。車載端末2は、例えば、車両VEに設置される据え置き型のナビゲーション装置またはドライブレコーダーである。なお、車載端末2としては、ナビゲーション装置またはドライブレコーダーに限らず、車両VEの乗員PAが利用するスマートフォン等の携帯型端末を採用しても構わない。この車載端末2は、図2に示すように、音声入力部21と、音声出力部22と、撮像部23と、入力部24と、端末本体25と、センサ部26と、表示部27とを備える。
図2は、車載端末2の構成を示すブロック図である。車載端末2は、例えば、車両VEに設置される据え置き型のナビゲーション装置またはドライブレコーダーである。なお、車載端末2としては、ナビゲーション装置またはドライブレコーダーに限らず、車両VEの乗員PAが利用するスマートフォン等の携帯型端末を採用しても構わない。この車載端末2は、図2に示すように、音声入力部21と、音声出力部22と、撮像部23と、入力部24と、端末本体25と、センサ部26と、表示部27とを備える。
音声入力部21は、音声を入力して電気信号に変換するマイクロフォン211(図7参照)を含み、当該電気信号にA/D(Analog/Digital)変換等を行うことにより音声情報を生成する。本実施の形態1において、音声入力部21にて生成された音声情報は、デジタル信号である。そして、音声入力部21は、当該音声情報を端末本体25に出力する。
音声出力部22は、スピーカ221(図7参照)を含み、端末本体25から入力したデジタルの音声信号をD/A(Digital/Analog)変換によってアナログの音声信号に変換し、当該スピーカ221から当該アナログの音声信号に応じた音声を出力する。
撮像部23は、端末本体25による制御の下、車両VEの周囲を撮影して撮影画像を生成する。そして、撮像部23は、生成した撮影画像を端末本体25に出力する。
入力部24は、タッチパネル、キーボードやマウス等の入力デバイスを含み、乗員PAの操作に応じて各種データの入力を受け付ける。そして、入力部24は、入力を受け付けた各種データを端末本体25に出力する。表示部27は、液晶または有機EL(Electro Luminescence)等を用いた表示ディスプレイで構成され、端末本体25による制御の下、各種の画像を表示する。
センサ部26は、GPS(Global Positioning System)センサ、ジャイロセンサ、加速度センサや方位センサ等のセンサ装置を含み、端末本体25における処理に用いられる情報をセンシングする機能を有する。GPSセンサは、GPS衛星からのGPS信号を受信することで、対象の緯度、経度及び高度を示す情報を測定する。GPSセンサ109により取得される情報は、以下では、「位置情報」とも称される。
端末本体25は、図2に示すように、通信部251と、制御部252と、記憶部253とを備える。通信部251は、制御部252による制御の下、ネットワークNEを介して情報提供装置3との間で情報の送受信を行う。
制御部252は、CPU(Central Processing Unit)やMPU(Micro Processing Unit)等のコントローラによって、記憶部253に記憶された各種のプログラムが実行されることにより実現され、車載端末2全体の動作を制御する。なお、制御部252は、CPUやMPUに限らず、ASIC(Application Specific Integrated Circuit)やFPGA(Field Programmable Gate Array)等の集積回路によって構成されても構わない。
記憶部253は、制御部252が実行する各種のプログラムや、当該制御部252が処理を行うときに必要なデータ等を記憶する。
〔情報提供装置の構成〕
図3は、情報提供装置3の構成を示すブロック図である。情報提供装置3は、例えば、サーバ装置である。この情報提供装置3は、図3に示すように、通信部31と、制御部32と、記憶部33とを備える。
図3は、情報提供装置3の構成を示すブロック図である。情報提供装置3は、例えば、サーバ装置である。この情報提供装置3は、図3に示すように、通信部31と、制御部32と、記憶部33とを備える。
通信部31は、制御部32による制御の下、ネットワークNEを介して車載端末2(通信部251)との間で情報の送受信を行う。
制御部32は、CPUやMPU等のコントローラによって、記憶部33に記憶された各種のプログラム(本実施の形態に係る情報提供プログラムを含む)が実行されることにより実現され、情報提供装置3全体の動作を制御する。なお、制御部32は、CPUやMPUに限らず、ASICやFPGA等の集積回路によって構成されても構わない。この制御部32は、図3に示すように、要求情報取得部321と、音声解析部322と、画像取得部323と、情報取得部324と、特定部325と、領域抽出部326と、物体認識部327と、情報提供部328と、反映部329とを備える。
要求情報取得部321は、車両VEの乗員PAからの物体情報の提供を要求する要求情報を取得する。本実施の形態1では、当該要求情報は、車両VEの乗員PAが発した言葉(音声)を音声入力部21が取り込み、当該音声に基づいて当該音声入力部21にて生成された音声情報である。すなわち、要求情報取得部321は、通信部31を介して車載端末2から当該要求情報(音声情報)を取得する。音声解析部322は、要求情報取得部321が取得した要求情報(音声情報)を解析する。
画像取得部323は、撮像部23にて生成された撮影画像を、通信部31を介して車載端末2から取得する。情報取得部324は、乗員PAから所定の要求があった場合に、移動体の位置情報を取得する。本実施形態では、情報取得部324は、音声解析部322が要求情報(音声情報)を解析した結果、当該要求情報(音声情報)に特定のキーワードが含まれている場合に、移動体の位置情報を車載端末2から取得する。ここで、当該特定のキーワードとしては、車両VEの乗員PAが物体情報の提供を要求する言葉であり、「なに」、「なんですか」、「なんだろう」、「おしえて」等の言葉を例示することができる。また、情報取得部324は、移動体の位置情報とともに、乗員の所定の要求内容から、乗員PAが着目している物体を特定するための特定のキーワードをさらに取得するようにしてもよい。例えば、情報取得部324は、乗員PAが発した言葉に、「建物」、「お寺」、「お店」などの特定のキーワードが含まれている場合には、該特定のキーワードを取得する。
特定部325は、位置情報を用いて、統計的に視線が集中する物体を特定する。本実施の形態1では、特定部325は、位置情報を入力データとして、統計的に視線が集中する物体を特定する第3の学習モデルを用いて、視線が集中する物体を特定する。つまり、特定部325は、第3の学習モデルに位置情報を入力し、第3の学習モデルからの出力結果として、視線が集中する物体の情報を取得する。なお、ここで統計的に視線が集中する物体とは、乗員PAの視線が集中する物体と予測される物体、言い換えると、特定部325が乗員PAの視線が集中する物体であろうと判定した物体のことを意味するものである。また、特定部325は、位置情報およびキーワードを用いて、位置情報およびキーワードに応じて統計的に視線が集中する物体を特定するようにしてもよい。例えば、特定部325は、乗員PAが「あの建物は何?」、「あそこのお寺について教えて」、「あのお店は何?」などと言葉を発した場合に、言葉を発した際の車両VEの位置情報の他に、「建物」、「お寺」、「お店」などの乗員PAが着目している物体を特定するためのキーワードも用いて、統計的に視線が集中する物体を特定するようにしてもよい。この場合には、例えば、特定部325は、位置情報およびキーワードを入力データとして、統計的に視線が集中する物体を特定する第3の学習モデルを用いて、視線が集中する物体を特定する。つまり、特定部325は、位置情報とともに、乗員PAが着目している物体を特定するためのキーワードを第3の学習モデルに入力し、第3の学習モデルからの出力結果として、視線が集中する物体の情報を取得するようにしてもよい。
第3の学習モデルは、例えば、アイトラッカを用いて被験者の視線が集中する領域を判別し、当該領域が予めラベリングされた位置情報とキーワードを教師データとし、当該教データ像を利用して当該領域を機械学習(例えば深層学習等)することにより得られたモデルである。なお、本実施形態では、第3の学習モデルは、後述する反映部329により更新される。
領域抽出部326は、特定部325によって視線が集中する物体を特定できない場合には、画像取得部323にて取得された撮影画像に基づいて、当該撮影画像内における視線が集中する(視線が集中し易い)注目領域を抽出(予測)する。本実施の形態1では、領域抽出部326は、所謂、視覚的顕著性技術を利用して撮影画像内における注目領域を抽出する。より具体的に、領域抽出部326は、以下に示す第1の学習モデルを用いた画像認識(AI(Artificial Intelligence)を用いた画像認識)により、撮影画像内における注目領域を抽出する。
なお、ここで特定部325によって視線が集中する物体を特定できない場合とは、特定部325が実際に特定できなかった場合のみならず、例えば、第3の学習モデルの学習不足により十分な精度で視線が集中する物体を特定できない場合を含むものとする。当該第1の学習モデルは、アイトラッカを用いて被験者の視線が集中する領域を判別し、当該領域が予めラベリングされた画像を教師画像とし、当該教師画像を利用して当該領域を機械学習(例えば深層学習等)することにより得られたモデルである。
物体認識部327は、撮影画像内において、領域抽出部326にて抽出された注目領域に含まれる物体を認識する。本実施の形態1では、物体認識部327は、以下に示す第2の学習モデルを用いた画像認識(AIを用いた画像認識)により、撮影画像内における注目領域に含まれる物体を認識する。
当該第2の学習モデルは、動物、山、川、湖、及び施設等の各種の物体が撮影された撮影画像を教師画像とし、当該教師画像に基づいて当該物体の特徴を機械学習(例えば深層学習等)することにより得られたモデルである。
情報提供部328は、特定部325によって特定された物体に関する物体情報、または、物体認識部327にて認識された物体に関する物体情報を提供する。より具体的に、情報提供部328は、記憶部33における物体情報DB(Data Base:データベース)333から特定部325にて特定された物体に対応する物体情報、または、物体認識部327にて認識された物体に対応する物体情報を読み出す。そして、情報提供部328は、通信部31を介して車載端末2に当該物体情報を送信する。
反映部329は、情報提供部328によって物体情報を提供した結果を学習モデルに反映する。例えば、反映部329は、情報提供部328によって物体情報を提供した結果として、情報提供部328によって提供された物体情報がユーザの希望に沿う情報であったか否かを判定する。この結果、反映部329は、ユーザの希望に沿う情報であった場合には、情報提供部328によって物体情報を提供した結果を正解データとして学習モデルに反映し、ユーザの希望に沿う情報でなかった場合には、情報提供部328によって物体情報を提供した結果を不正解データとして学習モデルに反映する。なお、ユーザの希望に沿う情報であったか否かを判定する手法については、ユーザの手動による入力を受け付けることで判定してもよいし、物体情報を提供した後のユーザの行動等から自動で判定してもよい。なお、反映部329は、位置情報とともに、乗員PAが着目している物体を特定するためのキーワードを第3の学習モデルに入力して物体情報を提供した場合には、キーワードについても学習モデルに反映する。
記憶部33は、制御部32が実行する各種のプログラム(本実施の形態に係る情報提供プログラム)の他、制御部32が処理を行うときに必要なデータ等を記憶する。この記憶部33は、図3に示すように、第1の学習モデルDB331と、第2の学習モデルDB332と、物体情報DB333と、第3の学習モデルDB334を備える。第1の学習モデルDB331は、上述した第1の学習モデルを記憶する。第2の学習モデルDB332は、上述した第2の学習モデルを記憶する。第3の学習モデルDB334は、上述した第3の学習モデルを記憶する。
物体情報DB333は、上述した物体情報を記憶する。ここで、物体情報DB333には、各種の物体に関連付けられた複数の物体情報が記憶されている。当該物体情報としては、物体の名称等の当該物体を説明する情報であって、文字データ、音声データ、あるいは、画像データによって構成されている。
ここで、図4および図5を用いて、情報提供装置3による情報提供方法の一例を説明する。図4および図5は、情報提供方法を説明する図である。図4を用いて、位置情報を考慮した第3の学習モデルを用いて統計的に視線が集中する物体を特定できた場合の情報提供方法について説明する。
図4の例では車両VEの乗員PAが建物に注目して「あれは何?」と発話した場合を例に説明する。図4に例示するように、車両VEの乗員PAから物体情報の提供を要求する言葉として「あれは何?」というが言葉が発話された場合には、車両VEの車載端末2は、位置情報を情報提供装置3に通知する。そして、情報提供装置3は、位置情報を考慮して学習された第3の学習モデルを用いて、車両VEの現在位置で統計的に乗員の視線が集中するであろうと予測される物体を特定する。そして、情報提供装置3は、特定した物体に対応する物体情報(建物名称、詳細説明、画像など)を、通信部31を介して車載端末2に送信する。
このように、情報提供装置3では、位置情報を考慮した第3の学習モデルを用いて統計的に視線が集中する物体を特定して、該物体に対応する物体情報を乗員PAに提供することができるので、視覚顕著性技術を用いる場合と比較して、処理負荷を軽減することが可能である。
ここで、情報提供装置3が第3の学習モデルを用いて統計的に視線が集中する物体を特定できなかった場合に、視覚顕著性技術と物体認識により視線が集中する物体を特定する情報提供方法について図5を用いて説明する。なお、図5の例では車両VEの乗員PAがライオンに注目して「あれ何?」と発話した場合を例に説明する。
情報提供装置3は、第3の学習モデルを用いて統計的に視線が集中する物体を特定できなかった場合には、第1の学習モデルを用いた画像認識により、撮影画像内における注目領域を抽出する。続いて、情報提供装置3は、第2の学習モデルを用いた画像認識により、撮影画像内における注目領域に含まれるライオンを認識する。そして、情報提供装置3は、認識したライオンに対応する物体情報を、通信部31を介して車載端末2に送信する。
このように、情報提供装置3は、第3の学習モデルを用いて統計的に視線が集中する物体を特定できなかった場合であっても、視覚顕著性技術を用いてリアルタイムに乗員PAの要求に応じた物体情報を提供することが可能である。
〔情報提供方法〕
次に、情報提供装置3(制御部32)が実行する情報提供方法について説明する。図6は、情報提供方法を示すフローチャートである。図7は、情報提供方法を説明する図である。具体的に、図7は、撮像部23にて生成され、ステップS106にて取得される撮影画像IMを示す図である。ここで、図7では、車両VE内からフロントガラスを介して当該車両VEの前方が撮影されるように当該車両VE内に撮像部23を設置した場合を例示している。また、図7では、撮影画像IM内に車両VEの助手席に座った乗員PAが被写体として含まれる場合を例示している。さらに、図7では、当該乗員PAが「あれ何?」という言葉を発している場合を例示している。
次に、情報提供装置3(制御部32)が実行する情報提供方法について説明する。図6は、情報提供方法を示すフローチャートである。図7は、情報提供方法を説明する図である。具体的に、図7は、撮像部23にて生成され、ステップS106にて取得される撮影画像IMを示す図である。ここで、図7では、車両VE内からフロントガラスを介して当該車両VEの前方が撮影されるように当該車両VE内に撮像部23を設置した場合を例示している。また、図7では、撮影画像IM内に車両VEの助手席に座った乗員PAが被写体として含まれる場合を例示している。さらに、図7では、当該乗員PAが「あれ何?」という言葉を発している場合を例示している。
なお、撮像部23の設置位置としては、上述した設置位置に限らない。例えば、車両VE内から当該車両VEの左側方や右側方、あるいは、後方が撮影されるように当該車両VE内に撮像部23を設置してもよく、車両VEの周囲が撮影されるように当該車両VE外に撮像部23を設置しても構わない。また、本実施の形態に係る車両の乗員としては、車両VEの助手席に座った乗員に限らず、運転席や後部座席に座った乗員等を含むものである。また、撮像部23の数としては、一つに限らず、複数としても構わない。
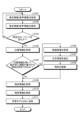
先ず、要求情報取得部321は、通信部31を介して車載端末2から要求情報(音声情報)を取得する(ステップS101)。ステップS101の後、音声解析部322は、当該ステップS101にて取得された要求情報(音声情報)を解析する(ステップS102)。ステップS102の後、音声解析部322は、当該ステップS102にて要求情報(音声情報)を解析した結果、当該要求情報(音声情報)に特定のキーワードが含まれているか否かを判定する(ステップS103)。ここで、当該特定のキーワードとしては、車両VEの乗員PAが物体情報の提供を要求する言葉であり、「なに」、「なんですか」、「なんだろう」、「おしえて」等の言葉を例示することができる。
特定のキーワードが含まれていないと判定された場合(ステップS103:No)には、制御部32は、ステップS101に戻る。一方、特定のキーワードが含まれていると判定された場合(ステップS103:Yes)には、情報取得部324は、乗員PAから所定の要求があった場合に、車両VEの位置情報を取得する(ステップS104)。そして、特定部325は、位置情報を用いて統計的に視線が集中する物体を特定した結果、視線が集中する物体を特定できるかを判定する(ステップS105)。
この結果、特定部325が、視線が集中する物体を特定できないと判定した場合には(ステップS105:No)、画像取得部323は、通信部31を介して車載端末2から撮像部23にて生成された撮影画像IMを取得する(ステップS106)。
なお、図6及び図7では、車両VEの乗員PAが「あれ何?」との言葉を発したタイミング(ステップS103:Yes)で画像取得部323が通信部31を介して車載端末2から撮像部23にて生成された撮影画像IMを取得する構成としているが、これに限らない。例えば、情報提供装置3は、通信部31を介して車載端末2から撮像部23にて生成された撮影画像を順次、取得する。そして、画像取得部323は、当該順次、取得された撮影画像のうち、車両VEの乗員PAが「あれ何?」との言葉を発したタイミング(ステップS103:Yes)で取得された撮影画像をステップS104以降の処理に用いる撮影画像として取得する構成としても構わない。
ステップS106の後、領域抽出部326は、第1の学習モデルDB331に記憶された第1の学習モデルを用いた画像認識により、撮影画像IM内における視線が集中する注目領域Ar1(図7参照)を抽出する(ステップS107)。
ステップS107の後、物体認識部327は、第2の学習モデルDB332に記憶された第2の学習モデルを用いた画像認識により、撮影画像IM内において、当該ステップS5にて抽出された注目領域Ar1に含まれる物体OB1を認識する(ステップS108)。
ステップS108の後、情報提供部328は、物体情報DB333から、特定部325によって特定された物体OB1、または、物体認識部327によって認識された物体OB1に対応する物体情報を取得し(ステップS109)、通信部31を介して車載端末2に当該物体情報を送信する(ステップS110)。そして、制御部252は、音声出力部22及び表示部27の少なくともいずれかの動作を制御し、情報提供装置3から送信された物体情報を音声、文字、及び画像の少なくともいずれかによって、車両VEの乗員PAに対して報知する。例えば、物体OB1が「ムーラン・ルージュ」である場合には、物体情報として「あれはムーラン・ルージュです。華やかなダンスショーを夜にやっています。」等の音声が車両VEの乗員PAに対して報知される。また、例えば、物体OB1が建物ではなく動物のバッファローである場合には、物体情報として「あれはバッファローです。バッファローは群れで行動します。」等の音声が車両VEの乗員PAに対して報知される。その後、反映部329は、物体情報を提供した結果を学習モデルに反映する(ステップS111)。
以上説明した本実施の形態1によれば、以下の効果を奏する。本実施の形態1に係る情報提供装置3は、車両VEの周囲を撮影した撮影画像を取得し、乗員PAから所定の要求があった場合に、車両VEの位置情報を取得する。そして、情報提供装置3は、位置情報を用いて、統計的に視線が集中する物体を特定する。また、情報提供装置3は、視線が集中する物体を特定できない場合には、撮影画像に基づいて、撮影画像内における視線が集中する注目領域を抽出し、撮影画像内における注目領域に含まれる物体を認識する。その後、情報提供装置3は、特定した物体に関する物体情報、または、注目領域に含まれる物体に関する物体情報を提供する。
したがって、物体に関する物体情報を得ることを望む車両VEの乗員PAに対して、従来のように当該物体を手や指で指し示すという作業を行わせる必要がなく、利便性を向上させることができる。
また、情報提供装置3は、位置情報を考慮した第3の学習モデルを用いて統計的に視線が集中する物体を特定して、該物体に対応する物体情報を乗員PAに提供することができるので、視覚顕著性技術を用いる場合と比較して、処理負荷を軽減することが可能である。
また、情報提供装置3は、統計的に視線が集中する物体を特定できなかった場合であっても、視覚的顕著性技術を利用して、撮影画像IM内における視線が集中する注目領域Ar1を抽出することができる。このため、車両VEの乗員PAが物体OB1を手や指で指し示さなくても、当該物体OB1を含む領域を注目領域Ar1として精度良く抽出することができる。
また、情報提供装置3は、車両VEの乗員PAからの物体情報の提供を要求する要求情報に応じて、当該物体情報を提供する。このため、当該要求情報によらず、常時、物体情報を提供する構成と比較して、情報提供装置3の処理負荷を軽減することができる。
(実施の形態2)
次に、本実施の形態2について説明する。以下の説明では、上述した実施の形態1と同様の構成には同一符号を付し、その詳細な説明は省略または簡略化する。図8は、実施の形態2に係る情報提供装置3Aの構成を示すブロック図である。本実施の形態2に係る情報提供装置3Aでは、情報取得部324および特定部325の機能が変更されている。以下では、説明の便宜上、本実施の形態2に係る情報取得部を情報取得部324A、本実施の形態2に係る特定部を特定部325Aと記載する(図8参照)。さらに、情報提供装置3Aでは、記憶部33に第4の学習モデルDB335(図8参照)が追加されている。
次に、本実施の形態2について説明する。以下の説明では、上述した実施の形態1と同様の構成には同一符号を付し、その詳細な説明は省略または簡略化する。図8は、実施の形態2に係る情報提供装置3Aの構成を示すブロック図である。本実施の形態2に係る情報提供装置3Aでは、情報取得部324および特定部325の機能が変更されている。以下では、説明の便宜上、本実施の形態2に係る情報取得部を情報取得部324A、本実施の形態2に係る特定部を特定部325Aと記載する(図8参照)。さらに、情報提供装置3Aでは、記憶部33に第4の学習モデルDB335(図8参照)が追加されている。
第4の学習モデルは、例えば、アイトラッカを用いて被験者の視線が集中する領域を判別し、当該領域が予めラベリングされた位置情報とキーワードと属性情報を教師データとし、当該教師データを利用して当該領域を機械学習(例えば深層学習等)することにより得られたモデルである。なお、本実施形態では、第4の学習モデルは、反映部329により更新される。そして、第4の学習モデルDB335は、当該第4の学習モデルを記憶する。
情報取得部324Aは、車両VEの位置情報とともに、乗員PAの属性情報をさらに取得する。例えば、情報取得部324Aは、属性情報として、乗員PAの年齢、乗員PAの性別、乗員PAの国籍、乗員PAの外観、乗員PAの嗜好(例えば、コーヒーが好き、旅行が好き等)、および、乗員PAの言語のうち、いずれか一つまたは複数の情報を車載端末2から取得する。なお、車載端末2は、どのような手法で属性情報を取得してもよい。例えば、車載端末2は、入力部24を介して乗員PAの手動による属性情報の入力を受け付けてもよし、音声入力部21や撮像部23により入力された音声や画像を解析して乗員の属性情報を自動で取得してもよい。また、車載端末2は、属性情報を事前に記憶していてもよいし、外部のDBから属性情報を取得するようにしてもよい。
特定部325Aは、位置情報および属性情報を用いて、位置情報および属性情報に応じて統計的に視線が集中する物体を特定する。例えば、特定部325Aは、位置情報および属性情報を入力データとして、統計的に視線が集中する物体を特定する学習モデルを用いて、視線が集中する物体を特定する。
ここで、図9を用いて、情報提供装置3Aによる情報提供方法の一例を説明する。図9は、情報提供方法を説明する図である。図9を用いて、位置情報および属性情報を考慮した第4の学習モデルを用いて統計的に視線が集中する物体を特定できた場合の情報提供方法について説明する。
図9の例では車両VEの乗員PAが建物に注目して「あれは何?」と発話した場合を例に説明する。図9に例示するように、車両VEの乗員PAから物体情報の提供を要求する言葉として「あれは何?」というが言葉が発話された場合には、車両VEの車載端末2は、位置情報および属性情報を情報提供装置3Aに通知する。そして、情報提供装置3Aは、位置情報および属性情報を考慮して学習された第4の学習モデルを用いて、統計的に視線が集中するであろうと予測される物体を特定する。具体的な例を挙げて図9について説明すると、例えば、カフェについて「あれは何?」と発話した乗員PAの属性情報が、性別「女性」、嗜好「コーヒーが好き」であるものとする。この場合に、情報提供装置3Aは、言葉を発した際の車両VEの位置情報とともに属性情報を考慮して学習された第4の学習モデルに対して、位置情報とともに、属性情報として、性別「女性」、嗜好「コーヒーが好き」という情報を入力することで、現在位置において同一または類似の属性情報を有する者が統計的に視線を集中させるであろう物体として「カフェ○○」を特定する。言い換えると、情報提供装置3Aは、当該場所に置いて、コーヒー好きな女性が統計的に注目しやすい物体として「カフェ○○」を特定する。そして、図9の例では、情報提供装置3Aは、カフェ○○の情報に対応する物体情報として、カフェ○○の情報とともにカフェ○○のメニューや予約情報を取得して車両VEの車載端末2に送信する。
このように、情報提供装置3Aでは、位置情報および属性情報を考慮した第4の学習モデルを用いて統計的に視線が集中する物体を特定して、該物体に対応する物体情報を乗員PAに提供することができるので、視覚顕著性技術を用いる場合と比較して、処理負荷を軽減することが可能である。なお、情報提供装置3Aは、第4の学習モデルを用いて統計的に視線が集中する物体を特定できなかった場合には、実施の形態1と同様に、視覚顕著性技術と物体認識により視線が集中する物体を特定する。
次に、情報提供装置3Aが実行する情報提供方法について説明する。図10は、情報提供方法を示すフローチャートである。本実施の形態2に係る情報提供方法では、図10に示すように、上述した実施の形態1で説明した情報提供方法(図6参照)に対して、ステップS205の処理が追加されている。図10のステップS201~204は、図6のステップS101~S104と同様の処理であり、ステップS207~S211は、図6のステップS106~110で同様の処理である。このため、以下では、ステップS205~S206のみを主に説明する。
ステップS206は、ステップS205の後に実行される。ステップS205において、情報取得部324Aは、乗員PAの属性情報を取得する(ステップS205)。そして、特定部325Aは、位置情報および属性情報を用いて、位置情報および属性情報に応じて統計的に視線が集中する物体を特定した結果、視線が集中する物体を特定できるかを判定する(ステップS206)。
この結果、特定部325Aが、視線が集中する物体を特定できないと判定した場合には(ステップS206:No)、ステップS207の処理に進む。また、特定部325Aは、視線が集中する物体を特定できると判定した場合には(ステップS206:Yes)、ステップS210の処理に進む。
なお、情報提供装置10Aは、ステップS204において、位置情報を取得した後、位置情報のみを用いて、位置情報に応じて統計的に視線が集中する物体を特定し、その結果、視線が集中する物体を特定できるかを判定し、視線が集中する物体を特定できないと判定した場合にのみ、ステップS205の処理に進むようにしてもよい。
以上説明した本実施の形態2によれば、上述した実施の形態1と同様の効果の他、以下の効果を奏する。本実施の形態2に係る情報提供装置3Aは、位置情報および属性情報に応じて統計的に視線が集中する物体を特定した結果、視線が集中する物体を特定できるかを判定するので、車両VEの乗員PAが物体情報を得ることを望む物体を含む領域を注目領域として精度良く特定することができる。したがって、車両VEの乗員PAに対して、適切な物体情報を提供することができる。
(実施の形態3)
次に、本実施の形態3について説明する。以下の説明では、上述した実施の形態1、実施の形態2と同様の構成には同一符号を付し、その詳細な説明は省略または簡略化する。
次に、本実施の形態3について説明する。以下の説明では、上述した実施の形態1、実施の形態2と同様の構成には同一符号を付し、その詳細な説明は省略または簡略化する。
図11は、実施の形態3に係る情報提供装置3Bの構成を示すブロック図である。また、本実施の形態3に係る情報提供装置3Bでは、上述した実施の形態2で説明した情報提供装置3A(図8参照)と比べて、画像取得部323、領域抽出部326および物体認識部327を有していない点が変更されている。
情報取得部324Aは、実施の形態2と同様に、車両VEの位置情報とともに、乗員PAの属性情報をさらに取得する。例えば、情報取得部324Aは、属性情報として、乗員PAの年齢、乗員PAの性別、乗員PAの国籍、乗員PAの外観、および、乗員PAの言語のうち、いずれか一つまたは複数の情報を車載端末2から取得する。
特定部325Aは、位置情報および属性情報を用いて、位置情報および属性情報に応じて統計的に視線が集中する物体を特定する。例えば、特定部325Aは、位置情報および属性情報を入力データとして、統計的に視線が集中する物体を特定する学習モデルを用いて、視線が集中する物体を特定する。
反映部329は、情報提供部328によって物体情報を提供した結果を学習モデルに反映する。例えば、反映部329は、情報提供部328によって物体情報を提供した結果として、情報提供部328によって提供された物体情報がユーザの希望に沿う情報であったか否かを判定する。この結果、反映部329は、ユーザの希望に沿う情報であった場合には、情報提供部328によって物体情報を提供した結果を正解データとして学習モデルに反映し、ユーザの希望に沿う情報でなかった場合には、情報提供部328によって物体情報を提供した結果を不正解データとして学習モデルに反映する。なお、ユーザの希望に沿う情報であったか否かを判定する手法については、ユーザの手動による入力を受け付けることで判定してもよいし、物体情報を提供した後のユーザの行動等から自動で判定してもよい。
次に、情報提供装置3Bが実行する情報提供方法について説明する。図12は、情報提供方法を示すフローチャートである。先ず、要求情報取得部321は、通信部31を介して車載端末2から要求情報(音声情報)を取得する(ステップS301)。ステップS301の後、音声解析部322は、当該ステップS301にて取得された要求情報(音声情報)を解析する(ステップS302)。ステップS302の後、音声解析部322は、当該ステップS302にて要求情報(音声情報)を解析した結果、当該要求情報(音声情報)に特定のキーワードが含まれているか否かを判定する(ステップS303)。ここで、当該特定のキーワードとしては、車両VEの乗員PAが物体情報の提供を要求する言葉であり、「なに」、「なんですか」、「なんだろう」、「おしえて」等の言葉を例示することができる。
特定のキーワードが含まれていないと判定された場合(ステップS303:No)には、制御部32は、ステップS301に戻る。一方、特定のキーワードが含まれていると判定された場合(ステップS303:Yes)には、情報取得部324は、乗員PAから所定の要求があった場合に、車両VEの位置情報を取得する(ステップS304)。
そして、情報取得部324Aは、乗員PAの属性情報を取得する(ステップS305)。そして、特定部325Aは、位置情報および属性情報を用いて、位置情報および属性情報に応じて統計的に視線が集中する物体を特定した結果、視線が集中する物体を特定できるかを判定する(ステップS306)。
この結果、特定部325Aが、視線が集中する物体を特定できないと判定した場合には(ステップS306:No)、そのまま処理を終了する。また、特定部325Aは、視線が集中する物体を特定できると判定した場合には(ステップS306:Yes)、ステップS307の処理に進む。その後、情報提供部328は、物体情報DB333から当該ステップS306にて特定された物体に対応する物体情報を取得し(ステップS307)、通信部31を介して車載端末2に当該物体情報を送信する(ステップS308)。
そして、制御部252は、音声出力部22及び表示部27の少なくともいずれかの動作を制御し、情報提供装置3から送信された物体情報を音声、文字、及び画像の少なくともいずれかによって、車両VEの乗員PAに対して報知する。例えば、物体OB1が「ムーラン・ルージュ」である場合には、物体情報として「あれはムーラン・ルージュです。華やかなダンスショーを夜にやっています。」等の音声が車両VEの乗員PAに対して報知される。また、例えば、物体OB1が建物ではなく動物のバッファローである場合には、物体情報として(あれはバッファローです。バッファローは群れで行動します。」等の音声が車両VEの乗員PAに対して報知される。その後、反映部329は、物体情報を提供した結果を学習モデルに反映する(ステップS309)。
以上説明した本実施の形態3によれば、上述した実施の形態1、2と同様の効果の他、以下の効果を奏する。本実施の形態3に係る情報提供装置3Bは、乗員PAから所定の要求があった場合に、車両VEの位置情報と乗員PAの属性を示す属性情報を取得し、位置情報および属性情報を用いて、統計的に視線が集中する物体を特定し、特定した物体に関する物体情報を提供する。このため、上述した実施の形態1、2で説明した画像取得部323、領域抽出部326および物体認識部327で説明した第2の学習モデルDB332を設ける必要がなく、情報提供装置3Bの構成の簡素化を図ることができる。
(その他の実施形態)
ここまで、本発明を実施するための形態を説明してきたが、本発明は上述した実施の形態1~3によってのみ限定されるべきものではない。上述した実施の形態1~3に係る情報提供装置3、3A、3Bは、位置情報とキーワードを考慮した第3の学習モデル、または、位置情報、キーワードおよび属性情報を考慮した第4の学習モデルを用いて、統計的に視線が集中する物体を特定した。しかしながら、学習モデルを用いずとも、テーブルを用いて統計的に視線が集中する物体を特定するようにしてもよい。
ここまで、本発明を実施するための形態を説明してきたが、本発明は上述した実施の形態1~3によってのみ限定されるべきものではない。上述した実施の形態1~3に係る情報提供装置3、3A、3Bは、位置情報とキーワードを考慮した第3の学習モデル、または、位置情報、キーワードおよび属性情報を考慮した第4の学習モデルを用いて、統計的に視線が集中する物体を特定した。しかしながら、学習モデルを用いずとも、テーブルを用いて統計的に視線が集中する物体を特定するようにしてもよい。
例えば、特定部325Aは、第3の学習モデルを用いずに、図13に例示するテーブルを用いて統計的に視線が集中する物体を特定するようにしてもよい。図13に例示するテーブルでは、「位置情報」と「キーワード」と統計的に視線が集中する「物体」とが対応付けられている。
また、例えば、特定部325Aは、第4の学習モデルを用いずに、図14に例示するテーブルを用いて統計的に視線が集中する物体を特定するようにしてもよい。図14に例示するテーブルでは、「位置情報」と「キーワード」と「属性情報」と統計的に視線が集中する「物体」とが対応付けられている。これらのテーブルは、予め記憶部33に記憶されていてもよいし、適宜追加や変更されるようになっていてもよい。
上述した実施の形態1~3において、情報提供装置3、3A、3Bは、特定のキーワードを含む要求情報(音声情報)を取得したことをトリガとして、各処理を実行していた。しかしながら、本実施の形態に係る情報提供装置としては、特定のキーワードを含む要求情報(音声情報)を取得しなくても、常時、当該各処理を実行する構成としても構わない。また、本実施の形態に係る要求情報としては、音声情報に限らず、車両VEの乗員PAによる車載端末2に設けられたスイッチ等の操作部への操作に応じた操作情報であっても構わない。
上述した実施の形態1~3において、情報提供装置3、3A、3Bの全ての構成を車載端末2に設けても構わない。この場合には、当該車載端末2は、本実施の形態に係る情報提供装置に相当する。また、情報提供装置3、3A、3Bにおける制御部32の一部の機能、及び記憶部33の一部を車載端末2に設けても構わない。この場合には、情報提供システム1全体が本実施の形態に係る情報提供装置に相当する。
3、3A、3B 情報提供装置
321 要求情報取得部
322 音声解析部
323 画像取得部
324、324A 情報取得部
325、325A 特定部
326 領域抽出部
327 物体認識部
328 情報提供部
329 反映部
321 要求情報取得部
322 音声解析部
323 画像取得部
324、324A 情報取得部
325、325A 特定部
326 領域抽出部
327 物体認識部
328 情報提供部
329 反映部
Claims (1)
- 移動体の周囲を撮影した撮影画像を取得する画像取得部と、
乗員から所定の要求があった場合に、前記移動体の位置情報を取得する情報取得部と、
前記位置情報を用いて、統計的に視線が集中する物体を特定する特定部と、
前記特定部によって前記視線が集中する物体を特定できない場合には、前記撮影画像に基づいて、前記撮影画像内における視線が集中する注目領域を抽出する領域抽出部と、
前記撮影画像内における前記注目領域に含まれる物体を認識する物体認識部と、
前記特定部によって特定された物体に関する物体情報、または、前記注目領域に含まれる物体に関する物体情報を提供する情報提供部とを備える
ことを特徴とする情報提供装置。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024062673A JP2024091702A (ja) | 2020-03-31 | 2024-04-09 | 情報提供装置 |
| JP2025119166A JP2025133991A (ja) | 2020-03-31 | 2025-07-15 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020062289A JP2021162398A (ja) | 2020-03-31 | 2020-03-31 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
| JP2024062673A JP2024091702A (ja) | 2020-03-31 | 2024-04-09 | 情報提供装置 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020062289A Division JP2021162398A (ja) | 2020-03-31 | 2020-03-31 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2025119166A Division JP2025133991A (ja) | 2020-03-31 | 2025-07-15 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP2024091702A true JP2024091702A (ja) | 2024-07-05 |
Family
ID=78003187
Family Applications (3)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020062289A Ceased JP2021162398A (ja) | 2020-03-31 | 2020-03-31 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
| JP2024062673A Pending JP2024091702A (ja) | 2020-03-31 | 2024-04-09 | 情報提供装置 |
| JP2025119166A Pending JP2025133991A (ja) | 2020-03-31 | 2025-07-15 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020062289A Ceased JP2021162398A (ja) | 2020-03-31 | 2020-03-31 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2025119166A Pending JP2025133991A (ja) | 2020-03-31 | 2025-07-15 | 情報提供装置、情報提供方法、情報提供プログラム及び記憶媒体 |
Country Status (1)
| Country | Link |
|---|---|
| JP (3) | JP2021162398A (ja) |
Families Citing this family (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6717758B2 (ja) | 2017-01-10 | 2020-07-01 | ファナック株式会社 | 複合加工方法及び複合加工プログラム |
| JP7844257B2 (ja) * | 2022-05-20 | 2026-04-13 | Lineヤフー株式会社 | 端末装置、情報処理方法、および情報処理プログラム |
| JP2025054143A (ja) * | 2023-09-26 | 2025-04-07 | トヨタ自動車株式会社 | 乗員支援システム、及び乗員支援方法 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003329463A (ja) * | 2002-05-10 | 2003-11-19 | Matsushita Electric Ind Co Ltd | 対象物案内装置およびその方法 |
| JP2007080060A (ja) * | 2005-09-15 | 2007-03-29 | Matsushita Electric Ind Co Ltd | 対象物特定装置 |
| JP2008082822A (ja) * | 2006-09-27 | 2008-04-10 | Denso It Laboratory Inc | 注視対象物検出装置および注視対象物検出方法 |
| JP2009031065A (ja) * | 2007-07-25 | 2009-02-12 | Aisin Aw Co Ltd | 車両用情報案内装置、車両用情報案内方法及びコンピュータプログラム |
| JP2017122640A (ja) * | 2016-01-07 | 2017-07-13 | トヨタ自動車株式会社 | 情報制御装置 |
-
2020
- 2020-03-31 JP JP2020062289A patent/JP2021162398A/ja not_active Ceased
-
2024
- 2024-04-09 JP JP2024062673A patent/JP2024091702A/ja active Pending
-
2025
- 2025-07-15 JP JP2025119166A patent/JP2025133991A/ja active Pending
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2003329463A (ja) * | 2002-05-10 | 2003-11-19 | Matsushita Electric Ind Co Ltd | 対象物案内装置およびその方法 |
| JP2007080060A (ja) * | 2005-09-15 | 2007-03-29 | Matsushita Electric Ind Co Ltd | 対象物特定装置 |
| JP2008082822A (ja) * | 2006-09-27 | 2008-04-10 | Denso It Laboratory Inc | 注視対象物検出装置および注視対象物検出方法 |
| JP2009031065A (ja) * | 2007-07-25 | 2009-02-12 | Aisin Aw Co Ltd | 車両用情報案内装置、車両用情報案内方法及びコンピュータプログラム |
| JP2017122640A (ja) * | 2016-01-07 | 2017-07-13 | トヨタ自動車株式会社 | 情報制御装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2021162398A (ja) | 2021-10-11 |
| JP2025133991A (ja) | 2025-09-11 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US12406661B2 (en) | Digital assistant control of applications | |
| JP2024091702A (ja) | 情報提供装置 | |
| KR102225411B1 (ko) | 다중모드 신호 분석을 이용한 명령 프로세싱 | |
| US11176948B2 (en) | Agent device, agent presentation method, and storage medium | |
| US20170148436A1 (en) | Speech processing system and terminal | |
| US20070136222A1 (en) | Question and answer architecture for reasoning and clarifying intentions, goals, and needs from contextual clues and content | |
| US11380325B2 (en) | Agent device, system, control method of agent device, and storage medium | |
| US11450316B2 (en) | Agent device, agent presenting method, and storage medium | |
| EP4095490B1 (en) | Information provision device, information provision method, information provision program, and recording medium | |
| CN111661068A (zh) | 智能体装置、智能体装置的控制方法及存储介质 | |
| KR20150058286A (ko) | 사람-대-사람 교류들을 가능하게 하기 위한 헤드 마운티드 디스플레이들의 레버리징 | |
| US20200286479A1 (en) | Agent device, method for controlling agent device, and storage medium | |
| JPWO2021149594A5 (ja) | ||
| CN118782044A (zh) | 多模态交互方法、装置、电子设备和存储介质 | |
| US20220208187A1 (en) | Information processing device, information processing method, and storage medium | |
| US11709065B2 (en) | Information providing device, information providing method, and storage medium | |
| JP6387287B2 (ja) | 不明事項解消処理システム | |
| CN113409770B (zh) | 发音特征处理方法、装置、服务器及介质 | |
| JP2007272534A (ja) | 省略語補完装置、省略語補完方法、及びプログラム | |
| CN113270101A (zh) | 一种虚拟人物自动讲解的方法、系统、装置和介质 | |
| JP2022103553A (ja) | 情報提供装置、情報提供方法、およびプログラム | |
| JP2022103472A (ja) | 情報処理装置、情報処理方法、及びプログラム | |
| CN116802601A (zh) | 应用程序的数字助理控件 | |
| US20230134103A1 (en) | Information processing apparatus and information processing method | |
| US20230162514A1 (en) | Intelligent recommendation method, vehicle-mounted device, and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240409 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20241126 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20250415 |