【0001】
【産業上の利用分野】
本発明は、手話を入力手段とする手話通訳や情報検索等を行なう装置における手話認識装置に関する。
【0002】
【従来の技術】
従来、手話の認識は例えば、特願平4−247285号や特願平4−235633号記載のように、カメラや手の動作データを取り込むセンサから、あらかじめ単語単位の手話を登録しておき(これを以下標準パタンと呼ぶ)、認識時には、同様にカメラやセンサから入力された手話パタン(これを以下入力パタンと呼ぶ)と各単語の標準パタンとのパタンマッチングを行い、入力パタン中に含まれる手話単語列を求めていた。このパタンマッチングにおいては、例えば、特開昭55−2205号記載のパタンマッチング法(連続DPマッチング法)を用いることにより、標準パタンに対して時間的に伸び縮みした入力パタンからでも正しく含まれる手話単語列を求めることが可能である。この出力としては、図2のように、正解の単語以外も単語の候補として求まる。この中から、例えば、文法的、意味的に正しく、最も類似した単語列を正解として出力する。
【0003】
【発明が解決しようとする課題】
上記従来技術では、入力パタン中の手話単語列の認識は、パタンのマッチング結果からボトムアップに求めていた。このため、図2のように、正解の単語列のほかに、候補となる単語列が多く求まってしまう。この候補から文法や意味の知識などを用いて正解を求めるが、候補が多過ぎると非常に多くの時間がかかるほか、正解でない単語の組合せでも、尤もらしい解釈ができる場合もあり、解を1つに絞れない場合もある。
【0004】
本発明の目的は、上記候補数を削減することにより、認識の処理時間を短縮するとともに認識性能を向上させることにある。
【0005】
【課題を解決するための手段】
あらかじめ単語などのパタンを登録、格納し、認識は登録されたパタンと入力とのパタンマッチングを行うことにより実現する手話認識装置において、入力を単語や文節などの意味あるまとまりに分割し、分割点にまたがって検出されるパタンにはペナルティをつけて認識する。
【0006】
手話における手の動作から、手の動作速度とその極小点、手の形の変化、および手の動作速度が極小点となる位置間の空間上の距離を特徴として検出する。
【0007】
そして、手の動作速度の極小点および、手の動作速度がある一定値以下の区間の始点と終点をそれぞれ境界候補とし、更に境界候補のうち繰返し動作により生じる極小点や他の同一動作中に生じる極小点を除いたものを境界として検出する。
【0008】
また、手の形状の変化や繰返し動作の有無により、分割された区間の動作の特徴付けを行う。
【0009】
手話単語を表現位置により分類し登録する手段と、パタンマッチングに際して現在マッチングの入力パタンの空間位置には表現されない手話単語は、パタンマッチングの対象から外す。
【0010】
【作用】
単語の境界が検出されるため、その境界にまたがって検出される単語は正解でない単語と判定でき、候補の可能性が低いと判定可能となる。また、境界にまたがる単語はパタンマッチングの際にペナルティが課せられるのみで、切り捨てられることはないため、単語境界の誤検出で正しい候補がなくなることはない。
【0011】
また、分割区間の動作の特徴付けを行うことにより、その区間に存在可能な手話単語を限定することができ、候補を絞り込むことが可能となる。
【0012】
【実施例】
以下、本発明の一実施例を図1を用いて説明する。
図1は、本発明を手話認識装置に適用した場合の一実施例の構成図である。図において、1は、例えば1/30秒毎に、手の位置や指の曲がりを検出するためのセンサ、2は、手の動作速度、手の形の変化などの特徴を計算するための特徴抽出部、3は、手話入力から単語の境界を検出する単語境界検出部、6は、認識したい手話単語の標準パタンを登録するための標準パタンメモリ、4は、入力と登録された標準パタンとの距離を計算する距離計算部、5は、距離計算部4の結果に基づいて、入力中の標準パタンの存在位置やその類似度をもとめるためのマッチング部である。そして、7はマッチング部の結果から、文法規則や意味に関する知識を用いて、実際に表現された手話の単語列を求める手話単語列検出部である。特徴抽出部2は、距離計算部4や標準パタンメモリ6にはセンサ1からの入力をそのまま送る。ここで、センサ1としては、例えば、データグローブ(VPL Research社製)を用いることにより実現可能である。
【0013】
以下、まず認識の基本的な処理について説明する。認識に先立って、まず装置に認識したい手話の単語を標準パタンメモリ6に登録する。登録時には、特徴抽出部2はセンサ1の出力を、そのまま標準パタンメモリ6に送り、格納する。この1/30秒毎に求められる特徴パラメータは、次のように表すことができる。
【0014】
【数1】
Y=(y1,y2,y3,...yn)
ここで、y1,y2,y3は、例えば、手のX座標、Y座標、Z座標である。他に、特徴量yとしては、各指の第1、2関節の曲がり角度なども含まれる。以下、この1/30秒単位をフレームと呼ぶ。ここで、Jフレームから成る(1秒の単語は30フレームと成る)単語標準パタンの特徴パラメータは、1フレームの特徴ベクトルの時系列として、次式のように表せる。
【0015】
【数2】
Y=Y1,Y2,Y3,...,YJ
さて、距離計算部4は、入力パタンと各標準単語パタンの各フレーム間の距離を計算する。すなわち、特徴抽出部2より、入力パタンの1フレームの特徴ベクトルXiが送られてくる度に、この特徴ベクトルXiと全ての標準単語パタンの全てのフレームの特徴ベクトルとの間の距離(例えばユークリッド距離)を計算する。この距離の小さい標準パタンが良く似たパタンとなる。例えば、入力パタンのtフレーム目の特徴ベクトルXtとある標準単語パタンのτフレーム目の特徴ベクトルYτとの間の距離d(t,τ)は次のように計算する。
【0016】
【数3】
【0017】
次に、マッチング部5は、入力中の標準パタンの存在位置ならびにその類似度を求める。本処理は、次のようにして実現可能である。すなわち、距離d(t,τ)が計算され、送られてくると、次の距離の累和を計算する。
【0018】
【数4】
D(t,τ)=d(t,τ)+D(t−1,τ−1)
ここで、D(t,τ)は、その時点(t,τ)までの距離の累和の中間結果である。ただし、標準パタンの1フレーム目の中間結果は、次の式により求められる。
【0019】
【数5】
D(t,1)=d(t,1)
標準パタンとの類似度(距離)Sは、標準パタンの最終フレームにおける距離の累和の中間結果をD(t,SFN)とおくと、
【0020】
【数6】
S(t)=D(t,SFN)/SFN
となる。ここで、SFNは、マッチング対象の標準パタンのフレーム長である。この距離の累和Sの時系列が極小を示す位置が、標準パタンの単語が入力パタン中に存在する終点の位置の候補の点となる。そして、その時の類似度がSである。その単語の始点位置は、その終点位置から標準パタンのフレーム長SFNだけさかのぼった位置である。このようにして、マッチング部6は、入力パタンの認識を行う。この標準パタンとのマッチングは線形マッチングであるが、時間の伸縮を整合しながら行う方式に連続DPマッチングと呼ばれる方式がある。このマッチング法を用いることにより、より柔軟な認識が可能となるが、マッチング法の違いが本発明に直接関係しないため、以下では上記の線形マッチング法に基づいて説明する。
【0021】
さて、特徴抽出部2では、手の動作速度、手の形の変化を求める。手の動作速度v(t)は、センサ1から送られてくるtフレーム目の手のX座標、Y座標、Z座標位置をそれぞれy1(t),y2(t),y3(t)とすると、
【0022】
【数7】
v2(t) =(y1(t)−y1(t−1))2+(y2(t)−y2(t−1))2+(y3(t)−y3(t−1))2
により求まる。ここでy1(t−1)は、t−1フレーム目における手のX座標位置である。また、手の形の変化に関しては、各指の第1、2関節の曲がり角度の特徴量yについて、上式によりフレーム間での変化量を求める。ここで、変化量は、1フレーム前との変化量dh1のみでなく、2フレーム前との変化量dh2、3フレーム前との変化量dh3も求める。また、手の動作速度v(t)の極小点が検出されると、図3のように、それ以前の極小点の手の位置との距離を上式により求める。ここでも、1つ前の極小点との位置の距離dist1のほか、2つ前の極小点との位置の距離dist2も求める。
【0023】
さて、単語境界検出部3は、図4の手順で単語境界を検出する。まず、ステップ31では、手の動作速度の極小点および、手の動作速度がある一定値以下の区間の始点と終点をそれぞれ境界候補として検出する。動作速度の極小点は、繰返し動作や手の変動でも生じる。手話の単語では、例えば手話単語「何」は、人差指を立てた手を左右に振る。このため、単語内で動作速度の極小点が生じてしまう。このため、ステップ32で繰返し動作などにより生じる極小点を検出し、候補から外す(図5)。さらに、ステップ33では分割された区間の手話の特徴付けを行う(図6)。
【0024】
ステップ32における、同一動作中に生じる極小点は次のようにもとめる。手話では、単語内では手の形状を一定に保つ手話が多い。このため、
(ルール1)前後の極小点と手の形状が一定である極小点は、単語内とする。
【0025】
次に、繰返し動作は、前後、上下、左右の反復動作となる。このため、
(ルール2)1つ前の極小点との位置の距離dist1、2つ前の極小点との位置の距離dist2に、dist2<dist1の関係があり、dist2が一定閾値以下の場合、反復動作と判断し、距離dist1の極小点は、単語内とする。特に、極小点で手の形状が一定のものは、単語内の信頼度を高くする。
【0026】
ステップ33では、次のように手話を特徴付ける。
ステップ32のルール2で反復動作が抽出できる。このため、
(ルール1)反復動作の極小点を有する区間は、繰返し動作区間とする。
(ルール2)区間内で手の形状が一定であれば、手形状一定の手話区間とする。
【0027】
手の動作速度がある一定値以下の区間は、動きの少ない手話単語であるか、ポーズのどちらかである。ポーズの場合は、動作速度が一定値以下の区間(以下、この区間を徐行区間と呼ぶ)の後に手話単語が開始し、それ以外の場合は、単語間の移動(渡り)の部分となる。このため、
(ルール3)徐行区間の後に生じる極小点において、手の形状が徐行区間と同一であれば、徐行区間はポーズである。
ここで、手の形状が一定の検出は、例えば、手形状の変化量dh1からdh3が全て閾値以下の場合のみ一定とし、その3フレームは一定と判定する。
【0028】
このように、単語境界が検出される。このため、マッチング部5において認識される手話単語のうち、単語境界にまたがって検出されるものは、候補から外すことが可能である。さらに、単語境界間の区間の特徴が抽出されるため、候補を削減することが可能である。例えば、ある区間が繰返し動作区間と特徴付けされたら、繰返し動作をする手話がそこに存在することが分かるため、他の候補は削除可能である。
【0029】
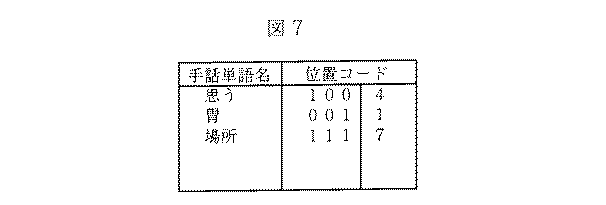
次に、標準パタンメモリ6に登録する単語は、その表現される位置の情報を与えておく。例えば、首より上、胸と首の間、胸より下である。そして、例えば、各位置により図7のようにビット割当てを行う。例えば、手話「思う」のように、常に首より上で表現される手話は4、「胃」のように常に胸より下で表現される手話は1、「場所」のようにどこでも表現される手話は7である。次に、特徴抽出部2は、1フレームの入力があると、その手の位置を上記と同様にコード化する。例えば、手が胸と首の間にあれば、位置コードを2にする。距離計算部4とマッチング部5は、入力フレームの位置コードに該当しない標準パタンとの計算は行わない。これにより、パタンマッチングの処理量を削減可能である。この判定は、標準パタンに付けられた位置コードと入力フレームの位置コードの論理積をとることにより容易に実現可能である。上記例では、手話「場所」のみが対象となる。
【0030】
【発明の効果】
本発明によれば、入力される手話の単語境界や境界間の区間の特徴付けができるため、パタンマッチングで検出されるパタンを限定できる。このため、認識処理量を削減でき、かつ認識性能の向上が図れる。
【図面の簡単な説明】
【図1】本発明の一実施例の手話認識装置の構成を示す図である。
【図2】パタンマッチングによる単語のマッチング結果の例を示す図である。
【図3】手話の動作速度の変化と極小点の特徴抽出を説明する図である。
【図4】単語境界検出部の処理を示す図である。
【図5】単語境界検出部の単語内極小点の検出規則の例を示す図である。
【図6】単語境界検出部の分割区間の特徴付け規則の例を示す図である。
【図7】手話の位置コードを示す図である。
【符号の説明】
1‥センサ、2‥特徴抽出部、3‥単語境界検出部、4‥距離計算部、5‥マッチング部、6‥標準パタンメモリ、7‥手話単語列検出部。[0001]
[Industrial applications]
The present invention relates to a sign language recognition device in a device that performs sign language interpretation, information retrieval, and the like using sign language as input means.
[0002]
[Prior art]
2. Description of the Related Art Conventionally, sign language recognition is performed by registering a sign language in word units in advance from a camera or a sensor that captures hand movement data, as described in Japanese Patent Application Nos. 4-247285 and 4-235633. At the time of recognition, pattern matching between a sign language pattern (hereinafter, referred to as an input pattern) similarly input from a camera or a sensor and a standard pattern of each word is performed and included in the input pattern. Wanted a sign language word string. In this pattern matching, for example, by using a pattern matching method (continuous DP matching method) described in Japanese Patent Application Laid-Open No. 55-2205, a sign language that is correctly included even from an input pattern that is temporally expanded and contracted with respect to a standard pattern is used. It is possible to find word strings. As this output, as shown in FIG. 2, words other than the correct word are obtained as word candidates. From these, for example, a word string that is grammatically and semantically correct and most similar is output as a correct answer.
[0003]
[Problems to be solved by the invention]
In the above-described related art, the recognition of the sign language word string in the input pattern is obtained from the pattern matching result from the bottom up. Therefore, as shown in FIG. 2, many candidate word strings are obtained in addition to the correct word strings. A correct answer is obtained from these candidates using knowledge of grammar and semantics. However, if the number of candidates is too large, it takes a very long time. There are times when you can't focus on just one.
[0004]
An object of the present invention is to reduce the number of candidates, thereby shortening the processing time of recognition and improving the recognition performance.
[0005]
[Means for Solving the Problems]
In a sign language recognition device that registers and stores patterns such as words in advance and performs recognition by performing pattern matching between the registered patterns and the input, the input is divided into meaningful units such as words and phrases, and the division points A penalty is attached to the pattern detected over the, and the pattern is recognized.
[0006]
From the hand motion in the sign language, the hand motion speed and its minimum point, a change in the hand shape, and the spatial distance between positions where the hand motion speed is a minimum point are detected as features.
[0007]
Then, the minimum point of the movement speed of the hand and the start point and the end point of the section where the hand movement speed is below a certain value are set as boundary candidates, respectively. A boundary excluding the generated minimum point is detected as a boundary.
[0008]
In addition, the movement of the divided section is characterized based on the change in the shape of the hand and the presence or absence of the repeated movement.
[0009]
Means for classifying and registering sign language words according to their expression positions, and sign language words that are not represented in the spatial position of the current matching input pattern during pattern matching are excluded from pattern matching targets.
[0010]
[Action]
Since a word boundary is detected, a word detected over the boundary can be determined as an incorrect word, and can be determined as having a low possibility of a candidate. In addition, words that straddle the boundary are only penalized in pattern matching and are not truncated, so that no incorrect candidates are lost due to erroneous detection of the word boundary.
[0011]
Further, by characterizing the operation of the divided section, the sign language words that can exist in the section can be limited, and the candidates can be narrowed down.
[0012]
【Example】
Hereinafter, an embodiment of the present invention will be described with reference to FIG.
FIG. 1 is a configuration diagram of an embodiment when the present invention is applied to a sign language recognition device. In the figure, 1 is a sensor for detecting the position of the hand and bending of the finger every 1/30 seconds, for example, and 2 is a feature for calculating characteristics such as a movement speed of the hand and a change in the shape of the hand. An extraction unit 3 is a word boundary detection unit that detects a word boundary from a sign language input. 6 is a standard pattern memory for registering a standard pattern of a sign language word to be recognized. The distance calculation unit 5 for calculating the distance is a matching unit for obtaining the location of the standard pattern being input and the similarity thereof based on the result of the distance calculation unit 4. Reference numeral 7 denotes a sign language word sequence detecting unit that obtains a word sequence of a sign language that is actually expressed, based on the result of the matching unit, using knowledge about grammar rules and meanings. The feature extraction unit 2 sends the input from the sensor 1 to the distance calculation unit 4 and the standard pattern memory 6 as they are. Here, the sensor 1 can be realized by using, for example, a data glove (manufactured by VPL Research).
[0013]
Hereinafter, first, basic processing of recognition will be described. Prior to recognition, first, a sign language word to be recognized by the device is registered in the standard pattern memory 6. At the time of registration, the feature extraction unit 2 sends the output of the sensor 1 to the standard pattern memory 6 as it is and stores it. The characteristic parameters obtained every 1/30 second can be expressed as follows.
[0014]
(Equation 1)
Y = (y1, y2, y3,... Yn)
Here, y1, y2, and y3 are, for example, the X, Y, and Z coordinates of the hand. In addition, the feature amount y includes the bending angles of the first and second joints of each finger. Hereinafter, this 1/30 second unit is called a frame. Here, a feature parameter of a word standard pattern composed of J frames (a word of one second is composed of 30 frames) can be expressed as a time series of a feature vector of one frame as follows.
[0015]
(Equation 2)
Y = Y1, Y2, Y3,. . . , YJ
The distance calculator 4 calculates the distance between the input pattern and each frame of each standard word pattern. That is, each time a feature vector Xi of one frame of the input pattern is sent from the feature extraction unit 2, the distance between this feature vector Xi and the feature vectors of all frames of all standard word patterns (for example, Euclidean Distance). Small standard pattern of this distance is very similar pattern. For example, the distance d (t, τ) between the feature vector Xt of the t-th frame of the input pattern and the feature vector Yτ of the τ-th frame of a certain standard word pattern is calculated as follows.
[0016]
(Equation 3)
[0017]
Next, the matching unit 5 obtains the existing position of the standard pattern being input and the similarity thereof. This processing can be realized as follows. That is, when the distance d (t, τ) is calculated and sent, the sum of the next distance is calculated.
[0018]
(Equation 4)
D (t, τ) = d (t, τ) + D (t−1, τ−1)
Here, D (t, τ) is an intermediate result of the sum of distances up to the time (t, τ). However, the intermediate result of the first frame of the standard pattern is obtained by the following equation.
[0019]
(Equation 5)
D (t, 1) = d (t, 1)
The similarity (distance) S to the standard pattern is obtained by defining the intermediate result of the sum of distances in the final frame of the standard pattern as D (t, SFN).
[0020]
(Equation 6)
S (t) = D (t, SFN) / SFN
It becomes. Here, SFN is the frame length of the reference pattern to be matched. The position at which the time series of the sum S of the distances shows the minimum is a candidate point of the position of the end point where the word of the standard pattern exists in the input pattern. Then, the similarity at that time is S. The start position of the word is a position which is retroactive from the end position by the frame length SFN of the standard pattern. In this way, the matching unit 6 performs recognition of input patterns. The matching with the standard pattern is a linear matching, but there is a method called continuous DP matching as a method of performing matching while expanding and contracting time. The use of this matching method enables more flexible recognition, but since the difference in the matching method is not directly related to the present invention, the following description will be made based on the above-described linear matching method.
[0021]
The feature extraction unit 2 obtains the movement speed of the hand and the change in the shape of the hand. Assuming that the X, Y, and Z coordinate positions of the hand in the t-th frame sent from the sensor 1 are y1 (t), y2 (t), and y3 (t), respectively, ,
[0022]
(Equation 7)
v 2 (t) = (y1 (t) -y1 (t-1)) 2 + (y2 (t) -y2 (t-1)) 2 + (y3 (t) -y3 (t-1)) 2
Is determined by Here, y1 (t-1) is the X coordinate position of the hand in the t-1 frame. Regarding the change in the shape of the hand, the amount of change between the frames for the characteristic amount y of the bending angles of the first and second joints of each finger is obtained by the above equation. Here, as the change amount, not only the change amount dh1 with respect to one frame before, but also the change amount dh2 with respect to two frames before, and the change amount dh3 with respect to three frames before. Further, when the minimum point of the movement speed v (t) of the hand is detected, as shown in FIG. 3, the distance between the previous minimum point and the position of the hand is obtained by the above equation. Here, in addition to the distance dist1 from the position of the immediately preceding minimum point, the distance dist2 of the position from the immediately preceding minimum point is also obtained.
[0023]
Now, the word boundary detection unit 3 detects a word boundary according to the procedure of FIG. First, in step 31, the minimum point of the hand movement speed and the start point and end point of the section where the hand movement speed is below a certain value are detected as boundary candidates. Minimum point of the operating speed occurs in variation of repetitive operations and hand. In the sign language word, for example, the sign language word "what" shakes the hand with the index finger raised left and right. Therefore, minimum point of the operating speed in the word occurs. For this reason, the minimum point generated by the repetitive operation or the like is detected in step 32 and is excluded from the candidates (FIG. 5). Further, in step 33, the sign language of the divided section is characterized (FIG. 6).
[0024]
The minimum point occurring during the same operation in step 32 is determined as follows. In sign language, there are many sign languages that keep the shape of a hand constant within a word. For this reason,
(Rule 1) The minimum point before and after and the minimum point whose hand shape is constant are within a word.
[0025]
Next, the repetitive operation is a forward / backward, up / down, left / right repetitive operation. For this reason,
(Rule 2) The distance dist1 from the position to the previous minimum point and the distance dist2 from the position to the previous minimum point have a relationship of dist2 <dist1, and when dist2 is equal to or smaller than a certain threshold value, the repetition operation is performed. determined, the minimum point of the distance dist1 is, and in a word. In particular, when the minimum point has a fixed hand shape, the reliability in the word is increased.
[0026]
In step 33, the sign language is characterized as follows.
The repetitive operation can be extracted by the rule 2 of step 32. For this reason,
(Rule 1) The section having the minimum point of the repetitive operation is a repetitive operation section.
(Rule 2) If the shape of the hand is constant in the section, the sign language section having the constant hand shape is set.
[0027]
A section in which the movement speed of the hand is below a certain value is either a sign language word with little movement or a pause. In the case of the pause, the sign language word starts after a section in which the operation speed is equal to or lower than a certain value (hereinafter, this section is referred to as a slow section). In other cases, the sign language word moves (crossover). For this reason,
(Rule 3) At the minimum point generated after the slow-motion section, if the hand shape is the same as the slow-motion section, the slow-motion section is a pause.
Here, the detection of the constant hand shape is made constant only when, for example, all the hand change amounts dh1 to dh3 are equal to or smaller than the threshold value, and the three frames are determined to be constant.
[0028]
Thus, word boundaries are detected. For this reason, among the sign language words recognized by the matching unit 5, those detected over the word boundaries can be excluded from the candidates. Furthermore, since the feature of the section between word boundaries is extracted, it is possible to reduce the number of candidates. For example, if a certain section is characterized as a repetitive operation section, it is known that the sign language performing the repetitive operation exists there, and other candidates can be deleted.
[0029]
Next, the word registered in the standard pattern memory 6 is given information on the position where the word is expressed. For example, above the neck, between the chest and neck, below the chest. Then, for example, performs a bit allocation as shown in FIG. 7 by the respective positions. For example, sign language always expressed above the neck, like sign language "I think," is 4, sign language always expressed below the chest, such as "stomach," is 1, and it is expressed everywhere, such as "place." Sign language is 7. Next, when one frame is input, the feature extraction unit 2 codes the position of the hand in the same manner as described above. For example, if the hand is between the chest and the neck, the position code is set to 2. The distance calculation unit 4 and the matching unit 5 do not calculate a standard pattern that does not correspond to the position code of the input frame. This allows reducing the amount of processing pattern matching. This determination can be easily realized by taking the logical product of the position code assigned to the standard pattern and the position code of the input frame. In the above example, only sign language "place" is the subject.
[0030]
【The invention's effect】
According to the present invention, it is possible to characterize a word boundary of an input sign language and a section between boundaries, so that patterns detected by pattern matching can be limited. Therefore, it is possible to reduce a recognition processing amount, and improvement of recognition performance can be achieved.
[Brief description of the drawings]
FIG. 1 is a diagram showing a configuration of a sign language recognition device according to one embodiment of the present invention.
FIG. 2 is a diagram illustrating an example of a result of word matching by pattern matching.
FIG. 3 is a diagram illustrating a change in the operation speed of sign language and extraction of a feature at a minimum point.
FIG. 4 is a diagram illustrating processing of a word boundary detection unit.
FIG. 5 is a diagram showing an example of a rule for detecting a minimum point in a word by the word boundary detection unit.
FIG. 6 is a diagram illustrating an example of a characterization rule for a divided section of a word boundary detection unit.
FIG. 7 is a diagram showing a position code of a sign language.
[Explanation of symbols]
1 sensor, 2 feature extraction unit, 3 word boundary detection unit, 4 distance calculation unit, 5 matching unit, 6 standard pattern memory, 7 sign language word string detection unit.