JP4370873B2 - 文書分類装置、プログラムおよび文書分類方法 - Google Patents
文書分類装置、プログラムおよび文書分類方法 Download PDFInfo
- Publication number
- JP4370873B2 JP4370873B2 JP2003358081A JP2003358081A JP4370873B2 JP 4370873 B2 JP4370873 B2 JP 4370873B2 JP 2003358081 A JP2003358081 A JP 2003358081A JP 2003358081 A JP2003358081 A JP 2003358081A JP 4370873 B2 JP4370873 B2 JP 4370873B2
- Authority
- JP
- Japan
- Prior art keywords
- document
- page
- sentence
- area
- hierarchy
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images






Landscapes
- Character Input (AREA)
- Character Discrimination (AREA)
- Machine Translation (AREA)
- Document Processing Apparatus (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
特許文献1に記載の技術では、予め文書フォームとそれに対応する文書の種類が登録されており、入力された文書のフォームを識別し、そのフォームに対応する文書の種類を表す情報と当該文書画像とを対応付けて格納する。入力された文書のフォームに該当するフォームが登録されていない場合には、新たにそのフォームを登録する。これによって、予め登録されていないフォームを有する文書が入力された場合でも、その文書を分類してファイリングすることが可能になるとしている。
特許文献2に記載の技術では、入力された文書の画像から文章、図、表などの領域を抽出し、各領域のレイアウトを表す情報と当該文書画像とを対応付けて格納する。これによって、非定型、すなわちフォームによって識別できない文書であっても、そのレイアウトを表す情報によって分類してファイリングすることが可能になるとしている。
本発明は、上述した背景のもとになされたものであり、厳密な定型フォームではない文書を適切に分類することのできる技術の提供を目的とする。
[構成]
図1は、文書分類装置10のハードウェア構成を示す図である。ROM(Read Only Memory)102には、プログラム10Pが書き込まれている。CPU(Central Processing Unit)101は、文書分類装置10に電源(図示省略)が投入されると、ROM102に書き込まれているプログラム10Pを読み出し、RAM(Random Access Memory)103をワークエリアとしてプログラム10Pを実行する。CPU101がプログラム10Pを実行することによって、文書分類装置10には、図8に示すモジュール群が仮想的に形成される。なお、外部の装置にプログラム10Pを記憶させておき、通信網(図示省略)を介してプログラム10PをダウンロードしてROM102に記憶させることとしてもよい。
表示部105は、CRT(Cathode Ray Tube)あるいは液晶パネルである。操作部107は、ポインティングデバイス(マウスあるいはデジタイザ)およびキーボードである。スキャナ109は、原稿を光学的に読み取り、画像信号を出力する。プリンタ111は、電子写真方式あるいはインクジェット方式のプリンタである。表示部105、操作部107、スキャナ109およびプリンタ111はそれぞれインターフェイス106,108,110,112を介してバス116に接続されており、バス116とバス115とはバスブリッジ104によって接続されている。バス116は、インターフェイス114を介してネットワーク113に接続されており、これによって文書分類装置10と外部の装置との通信が可能となっている。
画像取得手段21は、文書の画像を表す画像データを取得する手段である。文書の画像を表す画像データとは、スキャナ109等の画像入力装置を用いて文書を走査することによって生成された画像データである。なお、画像データは、予め画像蓄積部117に格納されていてもよいし、外部の装置からネットワーク113を介して文書分類装置10が受信することとしてもよい。
レイアウト解析手段22はこのようにして文書のレイアウト情報を取得し、各ページを文章領域、図領域および表領域の集合として認識する。
キーワード抽出手段24は、文字認識手段により認識された文字列から視覚的に強調された文字列を抽出し、抽出された文字列をキーワードとする手段である。キーワードの抽出は、例えば特開平9−297765号公報に記載されている方法を用いて行う。ここで、キーワードとは、何らかの方法により視覚的に強調されている文字列である。例えば、予め文字サイズの閾値を定めておき、この閾値を超える大きさの文字列を抽出する。あるいは、太字、斜体など、通常と異なるフォントを用いた文字列、枠で囲まれた文字列、下線を引かれた文字列などを抽出してもよい。
分類手段27は、論理構造抽出手段26で抽出された論理構造を用いて文書を分類して記憶する手段である。
なお、論理構造抽出手段26および分類手段27によって行われる処理については、動作の説明において詳述する。
上記の構成からなる文書分類装置10の動作について説明する。ただし、文書分類装置10は、ハードウェアがソフトウェアを用いることによって動作する装置であるから、これ以降の説明においては、動作の主体を、仮想的に形成されるモジュールではなく、ハードウェアとする。
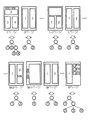
ここで、文書の例について説明する。図3は、文書分類装置10による処理の対象とされる文書の例を示す図である。この例は、横書き2段組を基本とする書式に従って作成された文書(例えば、論文)の例である。
最初に、文書分類装置10は画像データを取得する(ステップS01)。ここでは、まず、スキャナ109によって文書が読み取られ、文書の画像を表す画像信号が文書分類装置10に送信される。文書分類装置10は、スキャナ109から送信された画像信号を受信する。すると、CPU101が、受信された画像信号に基づいて画像データを生成し、画像蓄積部117に格納する。そして、CPU101は、画像蓄積部117に格納された画像データをRAM103上に展開する。
次に、CPU101は、文章領域に含まれる文字を認識するための処理を行い(ステップS03)、認識された文字列からキーワードとなり得る文字列を抽出する(ステップS04)。ここでは、特定の文字サイズ、特定のフォント、枠で囲まれた文字列、下線の引いてある文字列などを抽出する。
まず、構造データの生成(ステップS05)について説明する。図4に示すように、構造データは、ページの各々を根とする木構造を有している。木構造の階層は、以下のようにして決定される。1ページ目の例では、まず水平方向に3つの領域に分割された後、最も下の領域が垂直方向に2分割されたとみなされる。これを木構造で表すと、根の1つ下の階層には2つの葉と1つの中間接点が存在し、2つの葉は領域1と領域2に対応付けられる。中間接点の1つ下の階層にはさらに2つの葉が存在し、2つの葉は領域3と領域4に対応付けられる。
一方、Mページ目とNページ目の例では、Mページ目の領域2がNページ目の領域2、3および4を包含している(1対多の包含)。従って、Nページ目の領域2、3および4は、Mページ目の領域2よりも下の階層に位置付けられることとなる。よって、図5に示すように、Nページ目の領域2、3および4は、Mページ目の領域1および2の1つ下の階層(Level_3)に位置付けられる。
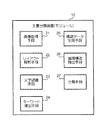
ステップS08では、特定の階層のキーワードを用いて、文書の論理構造を抽出する。図6は、文書の論理構造を抽出した例を示す図である。この例では、文書Aおよび文書Bはともに公開特許公報である。図6には、「要約」。「特許請求の範囲」、「技術分野」、…と続く特許公報の記載項目の見出しが出現順に示されている。公開特許公報は、帳票のように全ページにおいて文字枠が厳密に既定されているものではなく、ページ数やレイアウトが1件1件異なるものである。また、数式や表が記載された公報と記載されていない公報が存在する。また、各項目毎の文章の分量も1件毎に異なる。このような違いを含んだ文書の場合、従来知られているような厳密なフォーム認識では異なる種類の文書とみなされることになる。しかしながら、文書Aと文書Bの論理構造に着目すれば、両者は明らかに同じ種類の文書である。このように、文書の論理構造を比較することによって、フォームが厳密には一致していない文書や、ページ数が1件毎に異なる文書であっても、同種の文書として分類することができる。ステップS09では、このようにして分類された文書のカテゴリーを表す情報と当該文書の画像データとを対応付けて画像蓄積部117に格納する。
以上説明した形態に限らず、本発明は種々の形態で実施可能である。例えば、上述の実施形態を以下のように変形した形態でも実施可能である。
スキャナが接続された1または複数のパーソナルコンピュータをネットワークを介して文書分類装置10に接続し、スキャナで読み込まれた文書の画像データを文書分類装置10に送信し、文書分類装置10において文書の分類および格納を行うようにしてもよい。このようにすれば、例えば、オフィス内の別々の場所に分散して保管されている文書を文書分類装置10で集中管理することが可能となる。
文書の論理構造は、特定の階層のキーワードではなく、すべての階層のキーワードをその階層を表す情報とともに表したものであってもよい。
21…画像取得手段、22…レイアウト解析手段、23…文字認識手段、24…キーワード抽出手段、25…構造データ生成手段、26…論理構造抽出手段、27…分類手段。
Claims (6)
- 文書の画像を表す画像データを取得する画像取得手段と、
前記画像データで表される画像を解析することによって、前記文書の各ページを構成する構成要素のレイアウトを表すレイアウト情報を取得し、前記構成要素のうち、各ページ内で文章が空間的に連続している領域である構成要素を、文章領域として抽出するレイアウト解析手段と、
前記文章領域に含まれる文字列を認識する文字認識手段と、
前記文字認識手段により認識された文字列から視覚的に強調された文字列を抽出し、抽出された文字列をキーワードとするキーワード抽出手段と、
前記レイアウト解析手段で抽出された複数の文章領域間の境界で各ページを分割し、各ページを根とし各文章領域を葉とし、前記境界の方向を基準とした木構造を用いて、各ページにおける複数の文章領域を階層的に表す構造データをページ毎に生成し、各文章領域に対応する特徴量をページ間で比較することで文章領域毎の包含関係を求め、前記包含関係に基づいて前記構造データにおける各文章領域の階層をページ間で調整する構造データ生成手段と、
前記構造データ生成手段で各文章領域の階層が調整された構造データに基づいて前記各キーワードの階層を求め、前記各キーワードの階層及び出現順を前記文書の論理構造として抽出する論理構造抽出手段と、
前記論理構造抽出手段で抽出された各文書の論理構造に含まれるキーワードの階層及び出現順を比較することで前記各文書を分類して記憶する分類手段と
を有する文書分類装置。 - 前記特徴量が、文章領域の位置、文章領域の大きさ、文字の大きさ、段組みの向き、1行あたりの平均的な文字数のうち少なくとも一つを含むことを特徴とする請求項1に記載の文書分類装置。
- 前記構造データ生成手段が、垂直方向又は水平方向の少なくとも一方の境界で各ページを分割することを特徴とする請求項1に記載の文書分類装置。
- 前記特徴量が、前記レイアウト解析手段により取得されたレイアウト情報を基に各文章領域に対応付けられる情報であることを特徴とする請求項1に記載の文書分類装置。
- コンピュータ装置を、
文書の画像を表す画像データを取得する画像取得手段と、
前記画像データで表される画像を解析することによって、前記文書の各ページを構成する構成要素のレイアウトを表すレイアウト情報を取得し、前記構成要素のうち、各ページ内で文章が空間的に連続している領域である構成要素を、文章領域として抽出するレイアウト解析手段と、
前記文章領域に含まれる文字列を認識する文字認識手段と、
前記文字認識手段により認識された文字列から視覚的に強調された文字列を抽出し、抽出された文字列をキーワードとするキーワード抽出手段と、
前記レイアウト解析手段で抽出された複数の文章領域間の境界で各ページを分割し、各ページを根とし各文章領域を葉とし、前記境界の方向を基準とした木構造を用いて、各ページにおける複数の文章領域を階層的に表す構造データをページ毎に生成し、各文章領域に対応する特徴量をページ間で比較することで文章領域毎の包含関係を求め、前記包含関係に基づいて前記構造データにおける各文章領域の階層をページ間で調整する構造データ生成手段と、
前記構造データ生成手段で各文章領域の階層が調整された構造データに基づいて前記各キーワードの階層を求め、前記各キーワードの階層及び出現順を前記文書の論理構造として抽出する論理構造抽出手段と、
前記論理構造抽出手段で抽出された各文書の論理構造に含まれるキーワードの階層及び出現順を比較することで前記各文書を分類して記憶する分類手段
として機能させるためのプログラム。 - CPUが文書の画像を表す画像データを取得する画像取得ステップと、
CPUが前記画像データで表される画像を解析することによって、前記文書の各ページを構成する構成要素のレイアウトを表すレイアウト情報を取得し、前記構成要素のうち、各ページ内で文章が空間的に連続している領域である構成要素を、文章領域として抽出するレイアウト解析ステップと、
CPUが前記文章領域に含まれる文字列を認識する文字認識ステップと、
CPUが前記文字認識ステップにより認識された文字列から視覚的に強調された文字列を抽出し、抽出された文字列をキーワードとするキーワード抽出ステップと、
CPUが前記レイアウト解析ステップで抽出された複数の文章領域間の境界で各ページを分割し、各ページを根とし各文章領域を葉とし、前記境界の方向を基準とした木構造を用いて、各ページにおける複数の文章領域を階層的に表す構造データをページ毎に生成し、各文章領域に対応する特徴量をページ間で比較することで文章領域毎の包含関係を求め、前記包含関係に基づいて前記構造データにおける各文章領域の階層をページ間で調整する構造データ生成ステップと、
CPUが前記構造データ生成ステップで各文章領域の階層が調整された構造データに基づいて前記各キーワードの階層を求め、前記各キーワードの階層及び出現順を前記文書の論理構造として抽出する論理構造抽出ステップと、
CPUが前記論理構造抽出ステップで抽出された各文書の論理構造に含まれるキーワードの階層及び出現順を比較することで前記各文書を分類して画像蓄積部に記憶する分類ステップと
を有する文書分類方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003358081A JP4370873B2 (ja) | 2003-10-17 | 2003-10-17 | 文書分類装置、プログラムおよび文書分類方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2003358081A JP4370873B2 (ja) | 2003-10-17 | 2003-10-17 | 文書分類装置、プログラムおよび文書分類方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2005122550A JP2005122550A (ja) | 2005-05-12 |
| JP4370873B2 true JP4370873B2 (ja) | 2009-11-25 |
Family
ID=34614777
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2003358081A Expired - Fee Related JP4370873B2 (ja) | 2003-10-17 | 2003-10-17 | 文書分類装置、プログラムおよび文書分類方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4370873B2 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106599155A (zh) * | 2016-12-07 | 2017-04-26 | 北京亚鸿世纪科技发展有限公司 | 一种网页分类方法及系统 |
Families Citing this family (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5233213B2 (ja) * | 2007-09-11 | 2013-07-10 | コニカミノルタビジネステクノロジーズ株式会社 | 画像処理装置、画像処理方法および画像処理プログラム |
| WO2018031628A1 (en) | 2016-08-09 | 2018-02-15 | Ripcord, Inc. | Systems and methods for electronic records tagging |
| CN113485615B (zh) * | 2021-06-30 | 2024-02-02 | 福州大学 | 基于计算机视觉的典型应用智能图文教程制作的方法及系统 |
| WO2023062799A1 (ja) * | 2021-10-14 | 2023-04-20 | 株式会社Pfu | 情報処理システム、原稿種識別方法、モデル生成方法及びプログラム |
| KR102947713B1 (ko) * | 2022-08-19 | 2026-04-01 | 동의대학교 산학협력단 | 표 구조를 포함하는 문서 인식 방법 및 그 시스템 |
| KR20260001919A (ko) * | 2024-06-28 | 2026-01-06 | 주식회사 올빅뎃 | 컨텐츠 영역 간 연관성 추론을 통한 문서 분석 장치 및 방법 |
| KR20260001918A (ko) * | 2024-06-28 | 2026-01-06 | 주식회사 올빅뎃 | 컨텐츠 영역 추출을 통한 문서 유형 분류 장치 및 방법 |
-
2003
- 2003-10-17 JP JP2003358081A patent/JP4370873B2/ja not_active Expired - Fee Related
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN106599155A (zh) * | 2016-12-07 | 2017-04-26 | 北京亚鸿世纪科技发展有限公司 | 一种网页分类方法及系统 |
| CN106599155B (zh) * | 2016-12-07 | 2020-05-26 | 北京亚鸿世纪科技发展有限公司 | 一种网页分类方法及系统 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2005122550A (ja) | 2005-05-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6838209B1 (ja) | 文書画像解析装置、文書画像解析方法およびプログラム | |
| JP5663866B2 (ja) | 情報処理装置及び情報処理プログラム | |
| US7913191B2 (en) | Common input/output interface for application programs | |
| US20090074303A1 (en) | Method and System for Creating a Form Template for a Form | |
| US11475688B2 (en) | Information processing apparatus and information processing method for extracting information from document image | |
| JPH0798765A (ja) | 方向検出方法および画像解析装置 | |
| JP4443443B2 (ja) | 文書画像レイアウト解析プログラム、文書画像レイアウト解析装置、および文書画像レイアウト解析方法 | |
| JPH11120293A (ja) | 文字認識/修正方式 | |
| US20230004706A1 (en) | Device Dependent Rendering of PDF Content Including Multiple Articles and a Table of Contents | |
| US20100131841A1 (en) | Document image layout apparatus | |
| JP4370873B2 (ja) | 文書分類装置、プログラムおよび文書分類方法 | |
| US20230039280A1 (en) | Device dependent rendering of pdf content | |
| JP4232679B2 (ja) | 画像形成装置およびプログラム | |
| WO2021140682A1 (ja) | 情報処理装置、情報処理方法及び情報処理プログラム | |
| KR20230062251A (ko) | 텍스트 기반의 문서분류 방법 및 문서분류 장치 | |
| Baloun et al. | ChronSeg: Novel Dataset for Segmentation of Handwritten Historical Chronicles. | |
| Lin | Header and footer extraction by page association | |
| JP5794154B2 (ja) | 画像処理プログラム、画像処理方法、及び画像処理装置 | |
| JP2011070529A (ja) | 文書処理装置 | |
| JP7430219B2 (ja) | 文書情報構造化装置、文書情報構造化方法およびプログラム | |
| JP2006318219A (ja) | 類似スライド検索プログラム及び検索方法 | |
| JP7651962B2 (ja) | 情報処理装置、情報処理システム、情報処理方法、及びプログラム | |
| JP2008108114A (ja) | 文書処理装置および文書処理方法 | |
| JP2000090194A (ja) | 画像処理方法および画像処理装置 | |
| Bataineh et al. | Generating an arabic calligraphy text blocks for global texture analysis |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20060921 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20090507 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20090519 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090717 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090811 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090824 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120911 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4370873 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20120911 Year of fee payment: 3 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20130911 Year of fee payment: 4 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| LAPS | Cancellation because of no payment of annual fees |