JP4382808B2 - 基本周波数情報を分析する方法、ならびに、この分析方法を実装した音声変換方法及びシステム - Google Patents
基本周波数情報を分析する方法、ならびに、この分析方法を実装した音声変換方法及びシステム Download PDFInfo
- Publication number
- JP4382808B2 JP4382808B2 JP2006505682A JP2006505682A JP4382808B2 JP 4382808 B2 JP4382808 B2 JP 4382808B2 JP 2006505682 A JP2006505682 A JP 2006505682A JP 2006505682 A JP2006505682 A JP 2006505682A JP 4382808 B2 JP4382808 B2 JP 4382808B2
- Authority
- JP
- Japan
- Prior art keywords
- fundamental frequency
- spectral
- information
- function
- speech
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
- 238000000034 method Methods 0.000 title claims abstract description 51
- 238000004458 analytical method Methods 0.000 title claims abstract description 44
- 238000006243 chemical reaction Methods 0.000 title claims description 34
- 238000001228 spectrum Methods 0.000 claims abstract description 29
- 230000015572 biosynthetic process Effects 0.000 claims abstract description 7
- 230000003595 spectral effect Effects 0.000 claims description 78
- 230000005236 sound signal Effects 0.000 claims description 13
- 230000009466 transformation Effects 0.000 claims description 11
- 239000000203 mixture Substances 0.000 claims description 7
- 238000003786 synthesis reaction Methods 0.000 claims description 6
- 238000004364 calculation method Methods 0.000 claims description 3
- 230000001131 transforming effect Effects 0.000 claims description 3
- 239000000523 sample Substances 0.000 claims 17
- 239000013598 vector Substances 0.000 description 7
- 238000004422 calculation algorithm Methods 0.000 description 4
- 230000004048 modification Effects 0.000 description 4
- 238000012986 modification Methods 0.000 description 4
- 230000015556 catabolic process Effects 0.000 description 2
- 238000010586 diagram Methods 0.000 description 2
- 238000010606 normalization Methods 0.000 description 2
- 230000000737 periodic effect Effects 0.000 description 2
- 238000013139 quantization Methods 0.000 description 2
- 238000009877 rendering Methods 0.000 description 2
- 210000001260 vocal cord Anatomy 0.000 description 2
- 230000001755 vocal effect Effects 0.000 description 2
- 238000004590 computer program Methods 0.000 description 1
- 230000005284 excitation Effects 0.000 description 1
- 239000003550 marker Substances 0.000 description 1
- 239000011159 matrix material Substances 0.000 description 1
- 230000001360 synchronised effect Effects 0.000 description 1
- 238000011426 transformation method Methods 0.000 description 1
Images



Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/90—Pitch determination of speech signals
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L21/00—Speech or voice signal processing techniques to produce another audible or non-audible signal, e.g. visual or tactile, in order to modify its quality or its intelligibility
- G10L21/003—Changing voice quality, e.g. pitch or formants
- G10L21/007—Changing voice quality, e.g. pitch or formants characterised by the process used
- G10L21/013—Adapting to target pitch
- G10L2021/0135—Voice conversion or morphing
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L25/00—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00
- G10L25/03—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters
- G10L25/24—Speech or voice analysis techniques not restricted to a single one of groups G10L15/00 - G10L21/00 characterised by the type of extracted parameters the extracted parameters being the cepstrum
Landscapes
- Engineering & Computer Science (AREA)
- Computational Linguistics (AREA)
- Signal Processing (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Machine Translation (AREA)
Description
それぞれのサンプルフレームごとに、スペクトル関連情報および基本周波数関連情報を取得するべくフレームとして1つにグループ化された音声サンプルを分析するステップと、
すべてのサンプルのスペクトルおよび基本周波数の共通特性を表すモデルを判定するステップと、
このモデルおよび音声サンプルに基づいて、スペクトル関連情報のみに従って基本周波数予測関数を判定するステップと、
を少なくとも備えることを特徴としている。
前述の音声サンプルを分析するステップは、スペクトル関連情報をケプストラム係数の形態で供給するべく適合されており、
この分析ステップは、高調波信号と雑音信号との合計に従って音声サンプルをモデル化するサブステップと、
音声サンプルの周波数パラメータおよび少なくとも基本周波数を推定するサブステップと、
それぞれのサンプルフレームの基本周波数を同期分析するサブステップと、
各サンプルフレームのスペクトルパラメータを推定するサブステップと、
を備え、
かつ、この分析方法は、分析対象のサンプルの基本周波数の平均値との関係において、それぞれのサンプルフレームの基本周波数を正規化する段階をさらに備え、
モデルを判定するステップは、ガウス密度の混合によるモデルの判定に対応しており、
このモデルを判定するステップは、
ガウス密度の混合に対応するモデルを判定するサブステップと、
サンプルおよびモデルのスペクトル情報とサンプルおよびモデルの基本周波数情報との間における最大類似性の推定に基づいて、ガウス密度の混合のパラメータを推定するサブステップと、
を備え、
予測関数を判定するステップは、サンプルのスペクトル情報を知ることによって基本周波数を実現する推定値に基づいて実現されており、
基本周波数予測関数を判定するステップは、モデルに基づいてスペクトル情報が得られる事後確率に基づいて、スペクトル情報を知ることによって基本周波数を実現する条件付きの期待値を判定するサブステップを備えており、この条件付きの期待値が推定値を形成している。
ソース発話者およびターゲット発話者の音声サンプルに基づいて実現され、ソース発話者のスペクトル特性をターゲット発話者のスペクトル特性に変換する関数を判定するステップと、
この変換関数を使用して、変換対象のソース発話者の音声信号のスペクトル情報を変換するステップと、
を少なくとも備える方法であって、
ターゲット発話者のスペクトル関連情報にのみ従って基本周波数予測関数を判定するステップ(この予測関数は、上記で定義した分析方法を使用して得られるものである)と、
この基本周波数予測関数をソース発話者の音声信号の変換済みのスペクトル情報に適用することにより、変換対象の音声信号の基本周波数を予測するステップと、
をさらに備えることを特徴とする。
変換関数を判定するステップは、ソーススペクトル特性を知ることによってターゲットスペクトル特性を実現する推定値に基づいて実現されており、
この変換関数を判定するステップは、
高調波信号と雑音信号の合計モデルに従ってソースおよびターゲット音声サンプルをモデル化するサブステップと、
ソースおよびターゲットサンプルをアライメントするサブステップと、
ソーススペクトル特性の実現を知ることによってターゲットスペクトル特性を実現する条件付き期待値の算出値に基づいて変換関数を判定するサブステップ(この条件付き期待値が推定値を形成している)と、を備え、
この変換関数は、スペクトルエンベロープ変換関数であり、
この方法は、スペクトル関連情報および基本周波数関連情報を供給するべく適合された変換対象の音声信号を分析するステップをさらに備え、
この方法は、変換済みのスペクトル情報と予測基本周波数情報に少なくとも基づいて変換済みの音声信号を形成可能な合成段階をさらに備える。
ソース発話者およびターゲット発話者の音声サンプルを入力として受信し、ソース発話者のスペクトル特性をターゲット発話者のスペクトル特性に変換する関数を判定する手段と、
この手段によって供給される変換関数を適用することにより、変換対象であるソース発話者の音声信号のスペクトル情報を変換する手段と、
を少なくとも備えるシステムであって、
ターゲット発話者の音声サンプルに基づいた分析方法を実現するべく適合され、ターゲット発話者のスペクトル関連情報にのみ従って基本周波数予測関数を判定する手段と、
この予測関数を判定する手段によって判定される予測関数を、スペクトル情報を変換する手段によって供給される変換済みのスペクトル情報に適用することにより、変換対象の音声信号の基本周波数を予測する手段と、
をさらに備えることを特徴とする。
このシステムは、変換対象の音声信号のスペクトル関連情報および基本周波数関連情報を出力として供給するべく適合された変換対象の音声信号を分析する手段と、
前述の手段によって供給される変換済みのスペクトル情報と前述の手段によって供給される予測基本周波数情報とに少なくとも基づいて変換済みの音声信号を形成可能な合成手段と、を更に備え、
変換関数を判定する手段は、スペクトルエンベロープ変換関数を供給するべく適合されており、これは、上記で定義した音声変換方法を実現するべく適合されている。
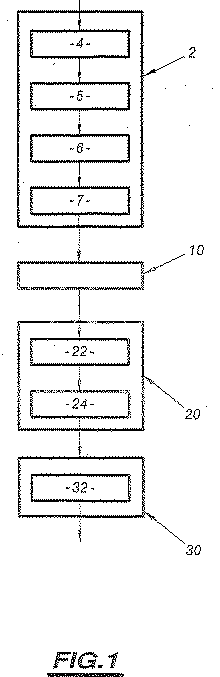
Claims (16)
- 音声サンプル内に含まれている基本周波数の情報を分析する分析方法であって、
それぞれのサンプルフレームごとに、スペクトル関連情報および前記基本周波数を取得するべく、前記サンプルフレームとして1つにグループ化された前記音声サンプルを分析するステップ(2)と、
前記音声サンプルを分析するステップ(2)において分析されたすべての前記音声サンプルの前記スペクトル関連情報および前記基本周波数を表現する同時密度確率モデルを決定するステップ(20)と、
前記モデルを決定するステップ(20)において得られた前記同時密度確率モデルの関数として、および前記分析された音声サンプルから取得された前記スペクトル関連情報および基本周波数を適用することによって、前記基本周波数を予測する予測関数を決定するステップ(30)であって、前記予測関数は、前記スペクトル関連情報が与えられた場合の前記基本周波数の条件付き期待値を決定することによって、或る音声信号の前記基本周波数の生成を、該音声信号のスペクトル関連情報にのみ従って推定するものである、ステップ(30)と、
を少なくとも備えることを特徴とする分析方法。 - 前記音声サンプルを分析するステップ(2)は、ケプストラム係数の形態で前記スペクトル関連情報を提供するべく適合されていることを特徴とする請求項1に記載の分析方法。
- 前記音声サンプルを分析するステップ(2)は、
高調波および雑音信号の合計に従って音声サンプルをモデル化するサブステップ(4)と、
前記音声サンプルの周波数パラメータおよび少なくとも前記基本周波数を推定するサブステップ(5)と、
それぞれのサンプルフレームの前記基本周波数を同期分析するサブステップ(6)と、
それぞれのサンプルフレームの前記スペクトルパラメータを推定するサブステップ(7)と、
を備えることを特徴とする請求項1または2に記載の分析方法。 - 分析された前記音声サンプルの前記基本周波数の平均値との関係において、それぞれのサンプルフレームの前記基本周波数を正規化するステップ(10)をさらに備えることを特徴とする請求項1〜3のいずれか一項に記載の分析方法。
- 前記モデルを決定するステップ(20)は、混合ガウス密度によるモデルの判定に対応していることを特徴とする請求項1〜4のいずれか一項に記載の分析方法。
- 前記モデルを決定するステップ(20)は、
前記取得されたスペクトル関連情報および基本周波数情報のガウス密度の混合に対応するガウス混合モデルを決定するサブステップ(22)と、
前記音声サンプルの前記スペクトル情報および前記基本周波数情報と、前記モデルの前記スペクトル情報および前記基本周波数情報との間における最大類似性の推定に基づいて前記ガウス密度の混合のパラメータを推定するサブステップ(24)と、
を備えることを特徴とする請求項5に記載の分析方法。 - 前記基本周波数を予測する予測関数を決定するステップ(30)は、前記スペクトル情報を知ることで、前記スペクトル情報が前記確率モデルのi次成分によって生成される事後確率Piの関数として、前記基本周波数を生成する条件付き期待値を決定するサブステップ(32)を備え、前記条件付き期待値が前記推定を形成していることを特徴とする請求項1に記載の分析方法。
- ソース発話者が発音した音声信号を、特性がターゲット発話者のものに類似している変換済みの音声信号に変換する方法であって、
前記ソース発話者の音声サンプルおよび前記ターゲット発話者の音声サンプルに基づいて実現され、前記ソース発話者のスペクトル特性を前記ターゲット発話者のスペクトル特性に変換する関数を判定するステップ(50)と、
前記変換関数を使用し、前記変換対象の前記ソース発話者の音声信号のスペクトル情報を変換するステップ(70)と、
を少なくとも備える方法において、
前記ターゲット発話者のスペクトル関連情報にのみ従って基本周波数を予測する推定関数を判定するステップ(60)であって、前記推定関数は、請求項1に記載の分析方法を使用して取得される、ステップと、
前記基本周波数を予測する推定関数を、前記ソース発話者の前記音声信号の前記変換済みのスペクトル情報に適用することにより、前記変換対象の音声信号の前記基本周波数を予測するステップ(80)と、
をさらに備えることを特徴とする方法。 - 前記変換する関数を判定するステップ(50)は、前記ソース発話者の前記スペクトル特性に従って前記ターゲットスペクトル特性の生成の推定値に基づいて実行されることを特徴とする請求項8に記載の方法。
- 前記変換関数を判定するステップ(50)は、
高調波信号および雑音信号の合計モデルに従って前記ソース発話者の音声サンプルおよび前記ターゲットの音声サンプルをモデル化するサブステップ(52)と、
前記ソースおよびターゲットのサンプルをアライメントするサブステップ(54)と、
前記ソーススペクトル特性の実現を知ることによって前記ターゲットスペクトル特性を実現する条件付き期待値の計算に基づいて前記変換関数を判定するサブステップ(56)であって、前記条件付き期待値が前記推定値を形成している、ステップと、
を備えることを特徴とする請求項9に記載の方法。 - 前記変換関数は、スペクトルエンベロープ変換関数であることを特徴とする請求項8〜10のいずれか一項に記載の方法。
- 前記スペクトル関連情報および前記基本周波数関連情報を供給するべく適合された前記変換対象の音声信号を分析するステップ(65)をさらに備えることを特徴とする請求項8〜11の一項に記載の方法。
- 前記変換済みのスペクトル情報および予測された前記基本周波数情報に少なくとも基づいて変換済みの音声信号を形成可能な合成ステップ(90)をさらに備えることを特徴とする請求項8〜12のいずれか一項に記載の方法。
- ソース発話者によって発音された音声信号(110)を、特性がターゲット発話者のものと類似している変換済みの音声信号(120)に変換するシステムであって、
前記ソース発話者の音声信号(100)と前記ターゲット発話者の音声信号(102)とを入力として受信し、前記ソース発話者のスペクトル特性を前記ターゲット発話者のスペクトル特性に変換する関数を判定する手段(104)と、
前記手段(104)によって供給される前記変換関数を適用することにより、変換対象の前記ソース発話者の前記音声信号(110)のスペクトル情報を変換する手段(114)と、
を少なくとも備えるシステムにおいて、
前記ターゲット発話者の音声サンプル(102)に基づいて、請求項1に記載の分析方法を実現するべく適合されており、前記ターゲット発話者のスペクトル情報にのみ従って基本周波数を予測する推定関数を判定する手段(106)と、
前記推定関数を判定する手段(106)によって判定された前記推定関数を前記変換手段(114)によって供給される前記変換済みのスペクトル情報に適用することにより、前記変換対象の音声信号の前記基準周波数を予測する手段(116)と、
をさらに備えることを特徴とするシステム。 - 前記変換対象の音声信号(110)を分析し、前記変換対象の音声信号のスペクトル関連情報と前記基本周波数関連情報とを出力として供給するべく適合された手段(112)と、
前記手段(114)によって供給される前記変換済みのスペクトル情報と前記手段(116)によって供給される予測された前記基本周波数情報とに少なくとも基づいて変換済みの音声信号を形成可能な合成手段(118)と、
をさらに備えることを特徴とする請求項14に記載のシステム。 - 前記変換関数を判定する手段(104)は、スペクトルエンベロープ変換関数を供給するべく適合されていることを特徴とする請求項14または15に記載のシステム。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| FR0303790A FR2853125A1 (fr) | 2003-03-27 | 2003-03-27 | Procede d'analyse d'informations de frequence fondamentale et procede et systeme de conversion de voix mettant en oeuvre un tel procede d'analyse. |
| PCT/FR2004/000483 WO2004088633A1 (fr) | 2003-03-27 | 2004-03-02 | Procede d'analyse d'informations de frequence fondamentale et procede et systeme de conversion de voix mettant en oeuvre un tel procede d'analyse |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2006521576A JP2006521576A (ja) | 2006-09-21 |
| JP2006521576A5 JP2006521576A5 (ja) | 2007-04-19 |
| JP4382808B2 true JP4382808B2 (ja) | 2009-12-16 |
Family
ID=32947218
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006505682A Expired - Fee Related JP4382808B2 (ja) | 2003-03-27 | 2004-03-02 | 基本周波数情報を分析する方法、ならびに、この分析方法を実装した音声変換方法及びシステム |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US7643988B2 (ja) |
| EP (1) | EP1606792B1 (ja) |
| JP (1) | JP4382808B2 (ja) |
| CN (1) | CN100583235C (ja) |
| AT (1) | ATE395684T1 (ja) |
| DE (1) | DE602004013747D1 (ja) |
| FR (1) | FR2853125A1 (ja) |
| WO (1) | WO2004088633A1 (ja) |
Families Citing this family (17)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4241736B2 (ja) * | 2006-01-19 | 2009-03-18 | 株式会社東芝 | 音声処理装置及びその方法 |
| CN101064104B (zh) * | 2006-04-24 | 2011-02-02 | 中国科学院自动化研究所 | 基于语音转换的情感语音生成方法 |
| US20080167862A1 (en) * | 2007-01-09 | 2008-07-10 | Melodis Corporation | Pitch Dependent Speech Recognition Engine |
| JP4966048B2 (ja) * | 2007-02-20 | 2012-07-04 | 株式会社東芝 | 声質変換装置及び音声合成装置 |
| US8131550B2 (en) * | 2007-10-04 | 2012-03-06 | Nokia Corporation | Method, apparatus and computer program product for providing improved voice conversion |
| JP4577409B2 (ja) * | 2008-06-10 | 2010-11-10 | ソニー株式会社 | 再生装置、再生方法、プログラム、及び、データ構造 |
| CN102063899B (zh) * | 2010-10-27 | 2012-05-23 | 南京邮电大学 | 一种非平行文本条件下的语音转换方法 |
| CN102664003B (zh) * | 2012-04-24 | 2013-12-04 | 南京邮电大学 | 基于谐波加噪声模型的残差激励信号合成及语音转换方法 |
| ES2432480B2 (es) * | 2012-06-01 | 2015-02-10 | Universidad De Las Palmas De Gran Canaria | Método para la evaluación clínica del sistema fonador de pacientes con patologías laríngeas a través de una evaluación acústica de la calidad de la voz |
| US9570087B2 (en) * | 2013-03-15 | 2017-02-14 | Broadcom Corporation | Single channel suppression of interfering sources |
| CN109410980A (zh) * | 2016-01-22 | 2019-03-01 | 大连民族大学 | 一种基频估计算法在各类具有谐波结构的信号的基频估计中的应用 |
| WO2018138543A1 (en) * | 2017-01-24 | 2018-08-02 | Hua Kanru | Probabilistic method for fundamental frequency estimation |
| CN108766450B (zh) * | 2018-04-16 | 2023-02-17 | 杭州电子科技大学 | 一种基于谐波冲激分解的语音转换方法 |
| CN108922516B (zh) * | 2018-06-29 | 2020-11-06 | 北京语言大学 | 检测调域值的方法和装置 |
| CN111179902B (zh) * | 2020-01-06 | 2022-10-28 | 厦门快商通科技股份有限公司 | 基于高斯模型模拟共鸣腔的语音合成方法、设备及介质 |
| CN112750446B (zh) * | 2020-12-30 | 2024-05-24 | 标贝(青岛)科技有限公司 | 语音转换方法、装置和系统及存储介质 |
| CN115148225B (zh) * | 2021-03-30 | 2024-09-03 | 北京猿力未来科技有限公司 | 语调评分方法、语调评分系统、计算设备及存储介质 |
Family Cites Families (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO1993018505A1 (en) * | 1992-03-02 | 1993-09-16 | The Walt Disney Company | Voice transformation system |
| EP0970466B1 (en) * | 1997-01-27 | 2004-09-22 | Microsoft Corporation | Voice conversion |
| JP2001500284A (ja) * | 1997-07-11 | 2001-01-09 | コーニンクレッカ フィリップス エレクトロニクス エヌ ヴィ | 改良した調波音声符号器を備えた送信機 |
| CN1151490C (zh) * | 2000-09-13 | 2004-05-26 | 中国科学院自动化研究所 | 用于语音识别的高精度高分辨率基频提取方法 |
-
2003
- 2003-03-27 FR FR0303790A patent/FR2853125A1/fr active Pending
-
2004
- 2004-03-02 CN CN200480014488.8A patent/CN100583235C/zh not_active Expired - Fee Related
- 2004-03-02 US US10/551,224 patent/US7643988B2/en not_active Expired - Fee Related
- 2004-03-02 EP EP04716265A patent/EP1606792B1/fr not_active Expired - Lifetime
- 2004-03-02 WO PCT/FR2004/000483 patent/WO2004088633A1/fr not_active Ceased
- 2004-03-02 DE DE602004013747T patent/DE602004013747D1/de not_active Expired - Lifetime
- 2004-03-02 AT AT04716265T patent/ATE395684T1/de not_active IP Right Cessation
- 2004-03-02 JP JP2006505682A patent/JP4382808B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| EP1606792A1 (fr) | 2005-12-21 |
| CN100583235C (zh) | 2010-01-20 |
| US7643988B2 (en) | 2010-01-05 |
| FR2853125A1 (fr) | 2004-10-01 |
| US20060178874A1 (en) | 2006-08-10 |
| DE602004013747D1 (de) | 2008-06-26 |
| EP1606792B1 (fr) | 2008-05-14 |
| ATE395684T1 (de) | 2008-05-15 |
| CN1795491A (zh) | 2006-06-28 |
| JP2006521576A (ja) | 2006-09-21 |
| WO2004088633A1 (fr) | 2004-10-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Hayashi et al. | An investigation of multi-speaker training for WaveNet vocoder | |
| JP4382808B2 (ja) | 基本周波数情報を分析する方法、ならびに、この分析方法を実装した音声変換方法及びシステム | |
| EP1252621B1 (en) | System and method for modifying speech signals | |
| US7765101B2 (en) | Voice signal conversation method and system | |
| JP5961950B2 (ja) | 音声処理装置 | |
| CN110648684B (zh) | 一种基于WaveNet的骨导语音增强波形生成方法 | |
| US20060064301A1 (en) | Parametric speech codec for representing synthetic speech in the presence of background noise | |
| US7792672B2 (en) | Method and system for the quick conversion of a voice signal | |
| NZ243731A (en) | Synthesising human speech | |
| JP6783475B2 (ja) | 声質変換装置、声質変換方法およびプログラム | |
| US20100217584A1 (en) | Speech analysis device, speech analysis and synthesis device, correction rule information generation device, speech analysis system, speech analysis method, correction rule information generation method, and program | |
| EP1995723B1 (en) | Neuroevolution training system | |
| WO2019163848A1 (ja) | 音声変換学習装置、音声変換装置、方法、及びプログラム | |
| JP3973492B2 (ja) | 音声合成方法及びそれらの装置、並びにプログラム及びそのプログラムを記録した記録媒体 | |
| JP2898568B2 (ja) | 声質変換音声合成装置 | |
| JP2002123298A (ja) | 信号符号化方法、装置及び信号符号化プログラムを記録した記録媒体 | |
| JP2798003B2 (ja) | 音声帯域拡大装置および音声帯域拡大方法 | |
| JP4766559B2 (ja) | 音楽信号の帯域拡張方式 | |
| JP2008519308A5 (ja) | ||
| JP2000235400A (ja) | 音響信号符号化装置、復号化装置、これらの方法、及びプログラム記録媒体 | |
| KR100484666B1 (ko) | 성도특성 변환을 이용한 음색변환장치 및 방법 | |
| Orphanidou et al. | Voice morphing using the generative topographic mapping | |
| JP2003323200A (ja) | 音声符号化のための線形予測係数の勾配降下最適化 | |
| Söderberg | Optimization of the FARGAN Model for Speech Compression: Exploring Different Frame Partitions | |
| En-Najjary et al. | Fast GMM-based voice conversion for text-to-speech synthesis systems. |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20070227 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20070227 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20080708 |
|
| A601 | Written request for extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A601 Effective date: 20081007 |
|
| A602 | Written permission of extension of time |
Free format text: JAPANESE INTERMEDIATE CODE: A602 Effective date: 20081015 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20081225 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20090303 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090701 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20090619 |
|
| A911 | Transfer to examiner for re-examination before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20090722 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20090818 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20090917 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20121002 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20131002 Year of fee payment: 4 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |