JP4804836B2 - データ生成装置及びデータ生成プログラム - Google Patents
データ生成装置及びデータ生成プログラム Download PDFInfo
- Publication number
- JP4804836B2 JP4804836B2 JP2005251400A JP2005251400A JP4804836B2 JP 4804836 B2 JP4804836 B2 JP 4804836B2 JP 2005251400 A JP2005251400 A JP 2005251400A JP 2005251400 A JP2005251400 A JP 2005251400A JP 4804836 B2 JP4804836 B2 JP 4804836B2
- Authority
- JP
- Japan
- Prior art keywords
- data
- pattern
- algorithm
- output data
- rule
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images






















Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
入力データから前記入力データに対応する出力データを生成するデータ生成装置において、
前記入力データを受け付けるデータ入力部と、
前記出力データの生成に使用可能な複数のルールをメモリに記憶して格納するルール格納部と、
前記ルール格納部が前記メモリに記憶して格納した前記複数のルールのうち前記出力データの生成に使用するルールを選択して前記メモリから読み出し、選択して読み出した前記ルールに基づいて、前記入力データから前記出力データを生成可能な互いに異なる複数の出力データ生成経路を構築する経路構築部と、
前記経路構築部が構築したそれぞれの前記出力データ生成経路によって、前記出力データ生成経路ごとに前記出力データである経路別出力データを生成する出力データ生成部と
を備えたことを特徴とする。
図1〜図10を用いて、実施の形態1を説明する。実施の形態1は、後述の実施1〜実施例3に共通する最適アルゴリズム判定装置の基本構成と、基本動作とを説明する。そして、後述の実施例1〜実施例3では、最適アルゴリズム判定装置をファイル圧縮に適用した場合(実施例1)、差分データ更新に適用した場合(実施例2)、及び音楽ファイル変換に適用した場合(実施例3)について説明する。
以下において、
(1)「ルール」とは、入力データからその入力データに対応する出力データの生成処理に使用可能なアルゴリズム、あるいは「パラメータ組合せ設定」等の方式、手段をいう。
(2)「実行パターン」とは、原則として、一つの処理において独立して適用可能なルールをいう。
(3)「組合せパターン」(出力データ生成経路)とは、「ルール」に基づいて構築された、入力データから出力データを生成することができる一連の処理工程をいう。なお、「組合せパターン」は少なくとも一つのルールを含めばよい。また、「組合せパターン」を「探索パターン」と呼ぶ場合がある。
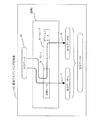
(1)入力データ201から、出力データAを生成する場合を想定する。同一の入力データ201から、「ルール1−1」と「ルール1−2」とのいずれかを使用して出力データが生成されるとする。処理1の「実行パターン」は、「ルール1−1」と「ルール1−2」である。この場合、同一の入力データ201であっても「ルール1−1」を適用する場合と、「ルール1−2」を適用する場合とでは、出力結果である出力データa1と出力データa2とについて、その性能値(ファイルサイズ、画質など)に差異が生じる場合を想定する。すなわち、出力データa1と出力データa2とは、ともに出力データAとなるべき出力データであるが、適用するアルゴリズムが異なるため、性能値が異なる。本実施の形態1、実施例1〜実施例3ではこのような場合を想定している。
(2)最適アルゴリズム判定装置100(図8で後述する探索パターン抽出部104)は、処理1に適用することができる「ルール1−1」と「ルール1−2」とを選択する。そして、選択したこれらのルールから、「組合せパターン11」(出力データ生成経路)と、「組合せパターン12」(出力データ生成経路)とを抽出する。最適アルゴリズム判定装置100(図8で後述する探索パターン実行部105)は、抽出された「組合せパターン11」、「組合せパターン12」を順次実行し、それぞれの出力データa1(経路別出力データ),出力データa2(経路別出力データ)を生成する。最適アルゴリズム判定装置100(図8で後述する最適パターン判定部107)は、出力データa1と出力データaとのうちいずれかを最適データとして特定して出力データAとし、また最適データを生成した「組合せパターン」を「最適組合せパターン」として特定する。
(3)このように、最適アルゴリズム判定装置100は、出力データAを生成するあらゆる「組合せパターン」(この場合「組合せパターン11」、「組合せパターン12」)を網羅的に実行し、最適な出力データA(出力データa1,a2のいずれか)と、最適な出力データAを生成した「組合せパターン」である「最適組合せパターン」とを特定する。
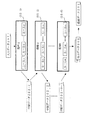
(1)最適アルゴリズム判定装置100(探索パターン抽出部104)は、入力データ201から出力データBの生成に使用するルール(アルゴリズム、あるいはパラメータの組合せ設定)を選択する。図3は、最適アルゴリズム判定装置100(探索パターン抽出部104)が、「ルール1−1」、「ルール1−2」、「ルール2−1」、「ルール2−2」の4つを選択した場合を示している。すなわち最適アルゴリズム判定装置100が、処理1について「ルール1−1」、「ルール1−2」を選択し、処理2について「ルール2−1」、「ルール2−2」を選択した状態を示している。この場合、処理1の実行パターンは「ルール1−1」と「ルール1−2」であり、処理2の実行パターンは「ルール2−1」と「ルール2−2」である。
(2)最適アルゴリズム判定装置100(探索パターン抽出部104)は、選択した「ルール1−1」等に基づいて、「組合せパターン」を抽出(構築)する。図3においては、最適アルゴリズム判定装置100(探索パターン抽出部104)は、「ルール1−1」等に基づいて、
「ルール1−1」と「ルール2−1」から成る組合せパターン13、
「ルール1−1」と「ルール2−2」から成る組合せパターン15、
「ルール1−2」と「ルール2−1」から成る組合せパターン14、
「ルール1−2」と「ルール2−2」から成る組合せパターン16の
互いに異なる4通りの組合せパターンを抽出(構築)する。
(3)そして、最適アルゴリズム判定装置100(探索パターン実行部105)は、組合せパターン13等の互いに異なる4通りの組合せパターンを実行し、
組合せパターン13(出力データ生成経路)から出力データb1(経路別出力データ)を生成し、
組合せパターン14(出力データ生成経路)から出力データb2(経路別出力データ)を生成し、
組合せパターン15(出力データ生成経路)から出力データb3(経路別出力データ)を生成し、
組合せパターン16(出力データ生成経路)から出力データb4(経路別出力データ)を生成する。
(4)最適アルゴリズム判定装置100(最適パターン判定部107)は各出力データb1等のなかから、いずれかを最適データとして選び、選んだ最適データを出力データBとする。
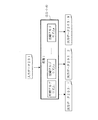
(1)アルゴリズム登録部101(ルール受付部)は、データ処理に使用する各種アルゴリズム、あるいは「各種パラメータ組み合わせルール」の追加、削除を行う。アルゴリズム登録部101は、アルゴリズム格納部108に格納するためのルールの登録を受け付け、登録を受け付けたルールをアルゴリズム格納部108に格納する。また、アルゴリズム格納部108に格納したルールの削除を受け付け、受け付けたルールをアルゴリズム格納部108から削除する。
(2)最適パターン判定条件指定部102(目標値受付部)は、最適パターン判定部107による「最適組合せパターン」の判定において、判定条件となる目標性能値の入力を受け付けて設定する。ここで「目標性能値」とは、出力データに要求される目標性能を示す値である。例えば、最適アルゴリズム判定装置100により出力データとして圧縮ファイルを生成する場合は、「目標性能値」は、「ファイルサイズ」である。
(3)アルゴリズム指定部103(選択条件受付部)は、前記探索パターン抽出部104がルールを選択する場合の「選択条件」をユーザから受け付ける。探索パターン抽出部104は、アルゴリズム指定部103が受け付けた選択条件に基づいて、ルールを選択する。例えば、選択条件として、ユーザは、アルゴリズム指定部103により、「組合せパターン」の抽出に使用するアルゴリズムを指定する。この場合、探索パターン抽出部104は、ユーザが指定したアルゴリズムに限定して選択する。
(4)探索パターン抽出部104(経路構築部)は、アルゴリズム格納部108がメモリに記憶して格納した複数のルールのうち出力データの生成に使用するルールを選択してメモリから読み出す。そして、選択して読み出したルールを使用して、入力データから出力データを生成可能な互いに異なる複数の「組合せパターン」(出力データ生成経路)を抽出(構築)する。
(5)探索パターン実行部105(出力データ生成部)は、探索パターン抽出部104の抽出した各探索パターンの順次実行を行う。探索パターン実行部105は、探索パターン抽出部104が抽出した複数の「組合せパターン」を順次実行し、各「組合せパターン」のそれぞれから、各「組合せパターン」ごとの出力データ(経路別出力データ)を生成する。
(6)データ入力部106は、処理対象となるデータを入力データとして受け付ける。
(7)最適パターン判定部107(出力データ特定部)は、探索パターン実行部105の実行結果から、最適パターン判定条件指定部102で指定された判定条件(目標性能値)に従い、最適な出力データの特定、及び最適な「組合せパターン」の特定等を行う。最適パターン判定部107は、最適パターン判定条件指定部102が受け付けた「目標性能値」に従い、探索パターン実行部105がそれぞれの「組合せパターン」によって生成した出力データのなかから「目標性能値」に最も適合する出力データを「最適データ」として特定する。特定結果は、出力部に出力する。また、最適パターン判定部107は、「最適データ」を生成した「組合せパターン」を「最適組合せパターン」(最適経路)として特定し出力部に出力する。
(8)アルゴリズム格納部108(ルール格納部)は、入力データに関するデータ処理に使用するアルゴリズムや「パラメータ組み合わせルール」等の「ルール」をメモリに記憶する。ここで「メモリ」とは、半導体素子やフラッシュメモリや磁気ディスクなどである。
(9)特定情報格納部109は、最適パターン判定部107が特定した最適データや、「最適組合せパターン」を格納する。
処理1には、「ルール11」〜「ルール1N」までのN個のルールがある。
処理2には、「ルール21」〜「ルール2N」までのN個のルールがある。
以下同様にして、
処理Nには、「ルールN1」〜「ルールNN」までのN個のルールがある。
以下、探索パターン実行部105は入力データ201に対して、複数の「組合せパターン」を抽出し、各「組合せパターン」ごとに(S5−1)〜(S5−N)の過程を実行し、「組合せパターン」ごとに出力データ203を生成する。
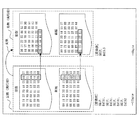
P1では1〜10の10種類、
P2では1,2,3の3種類、
P3では0から8の9種類の値の設定が可能とする。すなわち、
(P1、P2、P3)=(1、1、0)〜(10、3、8)
この場合、設定可能な値は、
P1が10通り、
P2が3通り、
P3が9通りである。
(P1、P2、P3)の値の設定は必須であり、あるパラメータ設定値によっては他のパラメータが影響をうけて設定値不可の値が生じる、といった制約は一切ないものとした場合、「実行パターン」の総数は、
(P1、P2、P3)=10×3×9=270通りとなる。
つまり、この場合は「処理1のルール数=270」と考える。このような場合、探索パターン抽出部104は、ルール数270と判断して「組合せパターン」を抽出する。これは、図5で説明したとおりである。なお、このようなケースにおいては、各パラメータの値はある程度、相関関係あり、設定して効果の得られる値の範囲が大体決まっている場合もある。そのような場合は、アルゴリズム指定部103により、ユーザが各パラメータで設定する値を予め指定しておくことができるようにしてもよい。ユーザからこの指定がされた場合、探索パターン抽出部104は、その設定値の範囲から可能な組み合わせの数を決定し、「組合せパターン」を抽出する。
図11、図12を用いて実施例1を説明する。以上では最適アルゴリズム判定装置100の基本構成について説明した。この基本構成に基づく第1の実施例として、最適アルゴリズム判定装置100で行う処理を、「ファイル圧縮」とした場合について述べる。実施例1のシステム構成は、図1と同様である。
「入力データ201→圧縮アルゴリズム1」、
「入力データ201→圧縮アルゴリズム2」、
「入力データ201→圧縮アルゴリズム3」
という3つの「組合せパターン」を抽出する。
具体的には、
(1)前記探索パターン抽出部104は、複数(例えば4つ)の「組合せパターン」を抽出する。
(2)探索パターン実行部105は、「組合せパターン」ごとに、順次、出力データ203−1、出力データ203−2、出力データ203−3、出力データ203−4を生成する。
(3)最適パターン判定部107は、探索パターン実行部105により1番目に生成された出力データ203−1(第1経路別出力データの一例)を図8に示す特定情報格納部109(例えば図7の磁気ディスク装置830を想定)に最適データの候補を示す「候補データ」として保存する。
(4)次に探索パターン実行部105によって2番目の出力データ203−2(第2経路別出力データの一例)が生成された場合、最適パターン判定部107は、候補データとして保存されている出力データ203−1と出力データ203−2とのうち、どちらが判定条件に適合するかを判断する。そして、より適合しないと判断した方を削除し、より適合していると判断した方を特定情報格納部109に「候補データ」として保存する。候補データとして出力データ203−1を維持し保存したとする。
(5)次に探索パターン実行部105によって3番目の出力データ203−3(第3経路別出力データの一例)が生成された場合、最適パターン判定部107は、候補データとして保存している出力データ203−1と、出力データ203−3とのうち、どちらが判定条件に適合するかを判断する。そして、より適合しないと判断した方を削除し、より適合していると判断した方を特定情報格納部109に最適データの候補である候補データとして保存する。この場合、候補データである出力データ203−1の方がより適合していると判断した場合、出力データ203−1を候補データとして維持し保存する。
(6)次に探索パターン実行部105によって4番目の出力データ203−4(第4経路別出力データの一例)が生成された場合、最適パターン判定部107は、候補データとして保存している出力データ203−1と、出力データ203−4とのうち、どちらが判定条件に適合するかを判断する。そして、より適合しないと判断した方を削除し、より適合していると判断した方を特定情報格納部109に最適データの候補である候補データとして保存する。この場合、候補データである出力データ203−4の方がより適合していると判断した場合、出力データ203−1を削除し、出力データ203−4を新たな候補データとして特定情報格納部109に保存する。
(7)最適パターン判定部107は、最終的に候補データとして保存されている出力データ203−4を「最適データ」として特定する。
(8)以上の(1)から(7)により、最適アルゴリズム判定装置100に「組合せパターン」ごとのファイル出力を行えるだけの十分なディスクの空き領域がないような場合でも、2つの出力データを格納できるディスク容量(記憶容量)があれば、登録した全アルゴリズムからファイルサイズが最小となる圧縮ファイル、及びファイル圧縮アルゴリズムの探索・判定を行うことができる。
図13〜図21を用いて実施例2を説明する。実施例2は、最適アルゴリズム判定装置100で行う処理を、「差分更新向けの差分データ作成」とした場合である。
差分更新では、新旧のデータの差分データを作成し、これを旧版に適用することで、新版への書き換え、バージョンアップを行う。通常、バージョンアップは、新版全体データを配布、置き換える方式の方が簡易で良いが、差分更新は、携帯電話などの組み込み機器のように、新版データを配布する通信回線やバージョンを行う端末のディスク容量などに制約があり、新版全体データを配布する方式を使えない場合に適用されることが多い。そのため、配布する差分データも極力サイズを小さくすることが要求される。しかし、差分データサイズは、その作成過程で使用するアルゴリズムによって異なり、差分データの作成過程も2過程以上あり、それぞれに有効なアルゴリズムがある。このため、差分量を最小とするには、最終的には、これらアルゴリズムの組み合わせを選択する必要がある。アルゴリズムの組み合わせ全てを網羅するように差分データを作成し、差分量が最小となる組み合わせの確認を手動で行うには作業負荷が大きい。自動実行による作業効率化、精度の高い最適な「組合せパターン」の発見を支援する環境が必要であり、最適アルゴリズム判定装置100の適用による効果が大きい。
図14は、本実施例2において、最適アルゴリズム判定装置100が、図9に示したS5に相当する「組合せパターン」を実行する場合の詳細処理、およびその処理で使用するアルゴリズム(ルール)と、データフローを示す図である。図14は、実施の形態1で説明した図10と同様に、探索パターン抽出部104が、すでにルールを選択し、選択したルールに基づいて複数の「組合せパターン」を抽出した状態を示している。
差分データ作成の場合、入力データ201は、差分データを作成したい「新版データ」と「旧版データ」の2つのファイルを対にしたファイルとなる。また、出力結果である各「組合せパターン」ごとの出力データ203は、「差分データ」である。「差分データ」を得るためは、図14に示す処理1〜処理3を順次実行する必要がある。なお、後述のように処理1は、「差分データ」を得るために必須ではない処理(後述のオプション処理)であり、処理1を実行しない場合もあり得る。
図14に示す様に処理は、処理1〜処理3の3種類ある。
処理1は、フォーマット変換(S5−1―B)である。
処理2は、バイナリ比較(差分抽出ともいう)(S5−2―B)である。
処理3は、差分表現(差分データ出力ともいう)(S5−3―B)である。
(2)処理2は、入力データを入力データ201(処理1を実行しない場合)、もしくは処理1を実行した場合は中間データ202−1とし、中間データ202−2(一致/更新領域情報)を出力する。
(3)処理3は、入力データを中間データ202−2とし、各「組合せパターン」ごとに出力データ203(差分データ)を出力する。中間データ202−1、中間データ202−2、出力データ203は、それぞれの処理で適用するルールの組み合わせ別(組合せパターン別)に出力される。即ち、例えば図3に示したのと同様に、それぞれの処理において、探索パターン抽出部104が抽出した「組合せパターン」ごとに出力され、複数の出力があり得る。
一般的に、差分データ作成のプロセスは、差分抽出、差分表現の2段階からなる。これらには、図14の処理2(差分抽出)と処理3(差分表現)が相当する。図14の処理2、処理3は必須の処理である。一方、図14の処理1はオプション的な処理である。処理1は差分サイズ削減上の効果はあるものの、「実行しなくても差分データの作成自体は可能」といった位置づけの処理である。
なお、上記<5.差分データ作成プロセス概要説明>で述べたようなことは、図10に示した一般的な場合にもあり得ることであり、処理1〜処理Nの中には、出力データ203を得るために必須な処理と、必須とはいえない処理の2種類あるものとする。以下、出力データ203を得るために必須な処理を「必須処理」と呼び、必須でない処理を「オプション処理」と呼ぶこととする。以下、「必須処理」である差分抽出(処理2)と差分表現(処理3)とについて一般的な処理概要をまず説明し、続いてこの2つの処理でそれぞれ差分サイズ削減に有効なアルゴリズム(ルール)の例について説明する。その後に、「オプション処理」であるフォーマット変換(処理1)について説明する。
処理2の差分抽出(S5−2−B)では、新版データを旧版とバイナリ比較を行うことにより、一致箇所と、不一致箇所(更新箇所)とをバイト単位で検出する処理を行う。バイナリ比較の一般的なアルゴリズムとしては、rsyncやLCS(Longest Common Subsequence:最長一致箇所)探索などのアルゴリズムがある。本実施例2では、処理2の差分抽出は、rsyncとLCSとを組み合わせて行なう。
(1)まず、rsyncによるブロック単位での新版データを分割し、旧版からの一致するブロック探索を行う。
(2)一致するブロックがない場合は、LCSにより、ブロックデータをより小さなバイト列データとして、一致するバイト列を探する。一致した場合は、一致しなくなるまで探索するバイト長を1バイトずつ延長して最長の一致領域(=LCS)を探す、という方式で差分抽出を行う。出力として一致個所と不一致個所の情報(一致/更新領域情報、中間データ202−2)を出力することとする。なおrsyncやLCSは差分抽出の一般的アルゴリズムであるので、詳しい説明はここではこれ以上は行わない。
なお、上記方式での差分抽出では、出力する「一致/更新領域の構成比(差分量相当)」は、上記アルゴリズムで使用する「パラメータ情報の設定値」により違いが生じる。上記パラメータの具体的な例としては、rsyncアルゴリズムで使用する比較用分割ブロックサイズや、LCSとして一致比較を行う最小連続バイト数、バイト列一致時の延長バイト数などがある。よって差分抽出処理は、これらのパラメータ値の設定は必須であるが、設定値の「組合せパターン」がいくつかあるので、パターン毎に「一致/更新領域の構成比(差分サイズ)」が異なる。よって処理2では、「設定値の組み合わせ1つ1つ」をルールとみなし、扱うこととする。ただし、これらのパラメータの値設定は必須であるため、デフォルトとしてそれぞれのデフォルト値を決めたデフォルトパターンを設定しておく。探索パターン抽出部104による「組合せパターン」の抽出(構築)では、デフォルト値以外も含めあらゆる組み合わせを抽出する。また、処理2のルールの性格上、処理2ではルールは同時に1つしか使用できないものとする。
処理2の差分抽出に関わらず、図10に示した一般的な場合においても、処理1〜処理Nの各処理のルールには、2種類あるものとする。
第1に、同時に使用できないルール(必須パラメータ値の組み合わせなど)である。
第2に、同時に使用可能なルールである。
言い換えると、ルールは、以下の2種類があるといえる。
(1)第1に、必ず使用しなければならないルール(以下「必須ルール」という。)である。上記設定必須パラメータは「必須ルール」に該当する。ただし、上記パラメータのように1通りではなく、組み合わせが複数ある場合である。1通りしかない場合は、必ず実行し出力も1通りなので、「基本処理」と呼び、ルールとは区別することとする。
(2)第2に、使用しなくてもよいルール(以下「オプションルール」という。)である。例えば、使用しなくても出力データ203は得られるが、出力データ203の性能(ファイルサイズ等)に効果を期待できるルールを意味する。なお「オプション処理」のルールは、全て「オプションルール」となる。
次に処理3について説明する。処理3(S5−3−B)の差分表現は、差分抽出(S5−2−B)で得た「一致箇所・不一致箇所情報」を元に、これをバイナリで表現した差分データの出力を行う。処理2の差分抽出で出力した中間データ202−2(一致/更新領域情報)は、新版と旧版との一致、不一致(更新)の領域情報(各領域の開始、終了番地などの情報)である。しかし、差分データとして配布するには好ましい形式ではい。このため、中間データ202−2(一致/更新領域情報)に対して処理を行う。処理3の差分表現は、中間データ202−2(一致/更新領域情報)について、より少ないバイト数で更新状況(後述のCOPY,SKIP,DATAなどの種別と、サイズなどの情報がわかる形で)を効率よく表現した「差分コマンドの形式」で表現する。この処理3は、処理2の差分抽出と同様に「必須処理」である。処理3の差分表現には、実行必須の「必須ルール」と「オプションルール」とが含まれるものとする。以下、それぞれ説明する。
差分データサイズを小さくするには、差分表現は極力少ないバイト数で、差分の情報を効率的に表現できることが要求される。バイナリ差分の表現方式としては、W3CのGdiffなどが一般的に使用されている。本実施例2では、このGdiffを一部拡張した方式での差分表現を、差分表現の基本方式(必須ルール)とする。図15により、本実施例2で使用する主要な3種類の差分表現について説明する。基本方式では、上記中間データ202−2(一致/更新領域情報)のうち、「一致箇所」はCOPYコマンドとSKIPコマンドで表現し,「不一致箇所」はDATAコマンドとして表現する。一致領域には、位置ずれのある場合、ない場合の2種類があるので、それぞれCOPY(位置ずれあり)、SKIP(位置ずれなし)と区別している。
図16に、図15の差分表現の基本方式に従った本実施例2で使用する差分コマンド体系を示す。まず、コマンド種別は常に1バイトで表現し、0〜255まで256種類のコマンドを定義可能とする。
(1)0は、差分データの終端を意味する。
(2)次に、1〜242までが、DATAコマンド(不一致領域=更新領域)とし、コマンド種別に1バイトで、値は更新データのバイト数を示すものとする。243バイト以上の更新領域の場合は、2つ以上のDATAコマンドを使って表現するものとする。
(3)次に、243〜245をCOPY領域とし、2つのパラメータ(コピー元の旧版アドレスと、領域サイズ)を記述する。領域サイズのバイト数を1〜3までとし、243が1バイト、244が2バイト、245を3バイトとするため、COPYコマンドは3種類としている。コピー元アドレスは、新旧データのデータサイズやアドレス空間(差分更新対象がプログラムの場合)より使用するアドレスバイト数が異なるので、この影響を受けてコピー元アドレスに必要なバイト数は異なる。
(4)次に、246〜248をSKIP領域とし、1つのパラメータ(領域サイズ)を記述する。これも、COPYコマンド同様、領域サイズのバイト数を1〜3までとし、246が1バイト、247が2バイト、248を3バイトとするため、SKIPコマンドは3種類としている。
(5)次に、249〜254までが、拡張用予約コマンド(未使用)、255が、書き換え時のイメージ書き出しを行うFLUSHコマンドとしている。
(6)差分適用は、直接旧版データに適用・書き換えではなく、新版を分割したより小さな単位で、ワークメモリ上に
「旧版コピー」→「差分適用での新版イメージ作成」→「旧版該当領域への新版イメージ上書き」
を行っている。書き換え失敗発生時のダメージを小さくする目的でこのような方式を取っている。この「旧版該当領域への新版イメージ上書き」を実行するのがFLUSHコマンドである。これは差分表現としては不要だが、差分適用時に必要なため、コマンドとして定義している。
また差分表現効率化として、COPYコマンドは領域サイズが小さい場合、DATAコマンドで表現した方が使用バイト数を少なく出来る場合があり、このような場合はDATAコマンドに変換する処理を行う。(COPYコマンドで、コピー元アドレスを4バイト使用する場合、4バイトのCOPY領域はCOPYコマンドでは、1+4+1=6バイト、DATAコマンドでは 1+4=5 でDATAコマンドのほうが使用バイト数は少ない)
続いて、差分表現の「オプションルール」を説明する。差分表現の「オプションルール」は、必須ではないが「必須ルール」で作成した差分データをもとに、更なるサイズ削減効果を持つ「オプションルール」について説明する。これらは、「必須ルール」で作成した差分データに適用し、差分コマンドの変換処理を行うものである。ここでは、例として、「INSERT/DELETEコマンド」を挙げる。なお、「必須ルール」と「オプションルール」との関係は図4で示したような関係である。
図17は、差分表現の効率化のルール(オプションルール)の1つであるマクロコピーの概要を示す図である。従来の差分表現方式では、新版の先頭アドレスから順に差分を表現する方式を取っている。この方式では、図17に示すように、COPY領域とDATA領域とが交互に繰り返し出てくるような場合、データ内容の不変領域が多く、変更領域が少ない場合であるにもかかわらず、差分コマンドとして表現すると差分量が大きくなるという問題がある。これは、COPYコマンドはSKIPコマンドと比較すると、処理サイズの他にコピー元アドレス分を余分に要するためである。しかし、各COPY領域の位置ずれのサイズ(オフセット)が同一である場合、1コマンド毎に、このアドレス指定バイト数分は冗長であり、差分表現として非効率である。この対策として、「COPYコマンドのオフセットが同一である領域はこの領域全体を1つのCOPY領域として表現してから、その後に相違部分の情報をDATAコマンドとSKIPコマンドで表現する差分表現方法(マクロコピー)」が有効である。この方法を用いると、アドレス指定を必要とするCOPYコマンドは最初の1つで良く、それ以外のCOPYコマンドはアドレス指定の不要なSKIPコマンドに変換出来るため、差分データサイズの削減が可能である。
図18、図19は、差分表現効率化のルール(オプションルール)の1つである「INSERTコマンド」,「DELETEコマンド」の概要を示す図である。たとえばデータ更新で、データテーブルのレコード相当が多数追加(図18)、あるいは削除(図19)したような場合、その前後の領域(レコード)の内容は不変だが位置ずれが生じるので、COPYコマンドが多くなる傾向がある。COPYコマンドが多くなると、マクロコピー同様、不変領域が多く変更領域が少ない場合にもかかわらず、差分コマンドとして表現すると差分量が大きくなるという問題がある。そこで更新を表現するコマンドとして、置換(上書き)の意味しか持たないDATAコマンドのほかに、追加、削除を意味するINSERT,DELETEの各コマンドを追加すれば、新旧のオフセットが自動調整され、位置ずれ領域はSKIPコマンド、あるいはコマンドなしで表現することが可能になる。以下、詳細について図18、図19に従い説明する。
以上、差分データ作成の「必須処理」である、差分抽出・差分表現について説明した。次に「オプション処理」である、フォーマット変換処理(処理1)について説明する。
処理1の「フォーマット変換」とは、入力データ201である新旧データを、更新の発生する位置に注目し、分散して発生している更新箇所を1箇所に集約するよう変換することである。これにより、変換新旧データ(中間データ202−1)に対して差分抽出(処理2)を行えば、変換しない場合(入力データ201、新旧データ)に比べ、更新箇所の数が削減される。このため、より少ない差分コマンドでの表現が可能となり差分データサイズを小さくする効果が得られる。以下、具体的なルールの例としてバイト列変換を示す。
図20は、フォーマット変換の例を示す図である。図の左側が、フォーマット変換の「実施前」の新旧データを示す。また、右側が、フォーマット変換の「実施後」の新旧データを示す。両側とも、上側が旧版、下側が新版の各データである。図20の変換実施前は、1レコードが8byteであり7byte目の要素が頻繁に変更となっている例を示しており、新版と旧版でアドレス(先頭からのオフセット)は異なっているものとしている。従来の差分表現ではSKIPとDATAの繰り返しとなり、合計で17byteの差分データが必要となる(SKIP領域がCOPY領域の場合は、32byteである)。ここで、「7byte目の要素が変更になりやすい」ことを前提条件とすることで、差分データサイズをより小さくすることができる。7byte目の要素のみをデータから抽出し、データの最後方に移動させる形式にフォーマット変換を行う。この変換データに対して差分を取ると「DATAコマンド」が1箇所に集まるため、差分データサイズが8byteとなり、変換しない場合に比べバイト数を約50%削減できる(COPYコマンドの場合は、12byteで約60%の削減である)。このようなケースを、フォーマット変換の1つの「ルール」として使用するには、新旧データのフォーマットを解析し、どの要素の更新が発生しているかの規則性を確認の上、アルゴリズム登録部101により、「ルール」として最適アルゴリズム判定装置100に登録しておく。
上記のように、特定のバイト列で更新が見られるケースは、プログラムデータで機械語の命令サイズが固定バイト数の場合に多く見られる。これは、特定関数を改修してサイズに増減が生じた結果、以後の関数も位置ずれが生じたような場合、これら関数の参照先(アドレス直接参照や、オフセットを使用している)も影響受けて位置ずれが発生する。このような差分では、関数参照(ジャンプ命令)の命令コードのパラメータ部の値が変更になり、これが特例バイト列の更新発生となる。しかし、CPUによっては機械語の命令コード体系が固定バイトではなく、可変バイトの場合もある。そのような場合、この固定バイトのフォーマット変換は適用しても差分サイズ削減の効果は期待できない。しかし、あらかじめ「ルール」として、アルゴリズム登録部101により、そのCPUのプログラムデータの構造を解析する情報を与えておき、新旧データをこれに従い解析可能にすれば、上記と同様、関数の改修による位置ずれの影響で発生したバイト位置を特定できる。よって、上記と同様、更新の発生するバイト列のみ一箇所に集めるようなフォーマット変換を行うことが可能となる。
以下、これまでの説明をもとに、図14について補足する。処理1〜処理3の登録ルールの具体例としては、以下のとおりである。
(1)図14において、処理1のフォーマット変換は、先に述べた「オプション処理」に相当する。先に述べた「バイト列変換のルール」が、データ種別毎(プログラム用にCPU別、データ用にデータフォーマット別)に、アルゴリズム登録部101により事前登録されているものとする。
(2)処理2のバイナリ比較(差分抽出)は、先に述べた「必須処理」である。先に述べたパラメータ設定値の組み合わせの各パターンが、ユーザによりアルゴリズム登録部101を介して、ルール(必須ルール)として事前登録されている。あるいは、探索パターン実行部105が、実行時に各パラメータの設定値の指定範囲を受け取り、これらから可能な組み合わせをそれぞれルールとして動的に生成し使用する方式でも良い。
(3)処理3の差分表現は、先に述べた「必須処理」である。この処理3は「必須ルール」の他に、先に述べた「マクロコピー」、「INSERT/DELETEコマンド変換」を「オプションルール」として登録している。
図21を参照して実施例2における最適アルゴリズム判定装置100の動作を説明する。図21は、実施例2における最適アルゴリズム判定装置100の動作を説明するフローチャートであり、実施の形態1の図9に対応する。図21により、ユーザがある入力ファイル201から、図21のS201〜S208の手順に従い、最適データ204として、最小差分データ(差分ファイル)の出力を行う処理フローについて説明する。
なお、S203に関して、本実施例2の場合、入力データ201のデータ種別により有効なアルゴリズムが異なるため、あらかじめ効果が期待できないアルゴリズム(入力データ201のデータ種別には有効でないアルゴリズム)がわかっている場合は、アルゴリズム指定部103により、効果が期待できないアルゴリズムを適用除外対象として指定すればよい。これにより、S205、S206で無駄なルール実行(アルゴリズム実行)を行う必要がなくなり、実行時間を短縮できる。また、入力データ201のデータ種別により、効果の期待できるルールとそうでないルールを判別できる場合がある。このため、ユーザは、アルゴリズム指定部103により、入力データ201のデータ種別について使用するアルゴリズムを指定(選択条件の一例)することが可能である。
(1)(処理1の実行パターン数Aについて)
図14に示した処理1(S5−1−B)のフォーマット変換では、登録ルールはバイト列変換ルールがある。これは、データ種別毎に使用可能なルールは1つであり、したがって、処理1として適用可能なルール数は、「1」となる。ただし、処理1は「オプション処理」であり、実行しない場合もありうる。よって、処理1のフォーマット変換としての「実行パターン数(Aとおく)」は、最大2である。データ種別の指定は、アルゴリズム指定部103により、S203の使用アルゴリズム指定の過程で行う。
(2)(処理2の実行パターン数Bについて)
処理2(S5−2−B)のバイナリ比較(差分抽出)では、登録ルールは「パラメータ組み合わせルール」である。「パラメータ組み合わせルール」は、複数の組み合わせがある。設定可能なパラメータがP1、P2、P3の3種類とし、それぞれの設定値がP1が2種類、P2が3種類、P3が4種類とすれば、パラメータ(P1、P2、P3)の組み合わせ数は、2×3×4=24(通り)となる。差分抽出処理は「必須処理」なので、差分抽出処理(処理2)としての実行パターン数(Bとおく)の最大は、上記の組み合わせ数=24(通り)である。なお、アルゴリズム指定部103により、S203における使用アルゴリズム指定の過程で、上記パラメータの設定値で使用する値を限定することも可能であり、そうすれば、上記組み合わせ数も設定に応じ全組み合わせの場合よりも少なくなる。
(3)(処理3の実行パターン数Cについて)
処理3(S5−3−B)の差分表現では、「必須ルール」の他に、「オプションルール」として登録ルールは「マクロコピー」と、「INSERT/DELETE」との2種類である。よって、差分表現の「実行パターン」として、まずは次の(a)〜(d)の4通りがある。
(a)「マクロコピー」と「INSERT/DELETE」とのいずれも実行しない(必須ルールのみ実行する)。
(b)「マクロコピー」だけ実行する(必須ルール+「マクロコピー」)。
(c)「INSERT/DELETE」だけ実行する(必須ルール+「INSERT/DELETE」)。
(d)「マクロコピー」と「INSERT/DELETE」とも両方実行する(必須ルール+「マクロコピー」、「INSERT/DELETE」)。
よって、差分表現としての実行パターン数(Cとおく)は、最大4(通り)となる。さらに、「マクロコピー」については、マクロコピーの検出ルールを複数あるとした場合は、「マクロコピー」の実行パターンが増え、Cも増える。なお、アルゴリズム指定部103により、S203の使用アルゴリズム指定の過程で、差分表現で上記4種類の実行パターンを指定したり、「マクロコピー」の検出ルールが複数ある場合、使用するものを限定することも可能であり、そうすれば、上記組み合わせ数も設定に応じ全組み合わせの場合よりも少なくなる。
A×B×C=2×24×4=192
となる。探索パターン抽出部104は、処理1〜処理3で使用可能なアルゴリズム(ルール)をアルゴリズム格納部108から選択し、選択したアルゴリズムにもとづいて、最大で互いに異なる「A×B×C=192(通り)」の「組合せパターン」を抽出(構築)する。そして、探索パターン実行部105が、192(通り)の「組合せパターン」を実行して、192個の出力データ203を生成する。
以上より、手動で「最適組合せパターン」を判定するには、上記の例では最大192(通り)の差分データを作成する必要がある。しかし、本実施例2の最適アルゴリズム判定装置100を使用すれば、各処理に必なルールのみを登録しておけば、出力結果(出力データ)を1つ1つ手動で作成する必要ない。最適アルゴリズム判定装置100は、簡易な操作で全ての「組合せパターン」を自動実行し、正確に最適データ(本実施例2の場合は最小差分データ)を特定し、また最適データを生成する「最適組合せパターン」を特定することができる。よって、作業負担の大幅な軽減、より的確なアルゴリズム選択を行うことができる。
また、本実施例2においても、実施例1と同様に実行時間やディスク容量節約を考慮した処理が可能である。また、S204における「組合せパターン」の抽出において、差分データ作成の場合、処理1(フォーマット変換)はオプション処理である。よって探索パターン抽出部104は、処理1を実行せず、処理2から開始する「組合せパターン」を構築してもよいのはもちろんである。また、処理3(差分表現)に関しても、更新内容が登録されたマクロコピーやINSERT/DELETEのルールでは効果のあるケースを含んでいないことが明らかである場合は、「必須ルール」のみ行い、これらの「オプションルール」の適用を除外するようにアルゴリズム指定部103により指定し、「組合せパターン」の抽出を行うようにしても良い。
また、S208では、ユーザへの参考情報として、最適パターン判定部107は、各「組合せパターン」により生成された出力データ203についての情報、例えば出力データサイズなどを「実行結果情報」として、一緒に出力部に出力しても良い。
また、各処理の新たなルールの発見、あるいはルール適用効果の個別確認を支援するため、各処理の適用結果である中間データを分析する分析手段、あるいは中間データ分析部を追加し、各処理の実行結果の分析情報を人間がわかりやすい形で提供することを行っても良い。特に差分データ作成の場合、最初に処理2の差分抽出のみデフォルトのルールで実行し、一致・更新領域情報を出力し、これを人間が理解しやすい形式に出力すれば、さらには更新発生個所の分布や、更新内容などの統計情報を出力することで、更新傾向の確認や、バイナリ比較で効果のあるパラメータ値の組み合わせを確認したり、フォーマット変換や差分表現の新たなルール発見を支援する効果が得られる。
次に図22〜図24を用いて実施例3を説明する。実施例3として、最適アルゴリズム判定装置100で行う処理を、携帯音楽プレーヤー820への音楽コンテンツ登録とした場合について述べる。
(1)さらに、音楽ファイル変換の場合、各音楽ファイル変換アルゴリズム毎にパラメータ情報としてビットレートやサンプリングレートなどが設定できるので、ユーザは、これらの値の範囲などもアルゴリズム指定部103により設定することができる。音質を一定以上に保ちたい場合などに指定する。
(2)また、複数ある曲のうち、特にお気に入りの曲だけは、高品質を確保したい、といった場合、ユーザは、アルゴリズム指定部103により、曲や曲のグループを定義し、これらの単位で、アルゴリズムやパラメータなどの条件を設定することも可能とする。
(3)また、事前に登録済音楽ファイルから削除してよい曲を最適アルゴリズム判定装置100に記憶しておき、「最適組合せパターン」の判定の結果、空き容量が不足する場合は、最適パターン判定部107が、これらのファイル(削除してもよい曲)を削除した場合に登録可能かどうかも含めて判定を行うようにすれば、ユーザの希望に沿うディスク領域(記憶媒体の記憶領域)の有効利用を図ることが出来る。
実施の形態2は、実施の形態1の最適アルゴリズム判定装置100の動作を、方法、プログラム、及びプログラムを記録した記録媒体により実施する実施形態である。
(1)データ入力部106の動作、
(2)アルゴリズム格納部108がアルゴリズムを複数のアルゴリズム(ルール)をメモリに格納する動作、
(3)探索パターン抽出部104が、「組合せパターン」を抽出(構築)する動作、
(4)探索パターン実行部105が、「組合せパターン」ごとに出力データを生成する動作
という一連の動作をステップに置き換えてデータ生成方法の実施形態としたフローチャートを示す。
(1)データ作成のための各過程で使用可能なアルゴリズムを登録するアルゴリズム登録手段
(2)複数の登録アルゴリズムからこれらの可能な「組合せパターン」を抽出する探索パターン抽出手段
(3)探索パターン抽出手段で検出した各パターンを順次実行してそれぞれの出力データを出力する探索パターン実行手段
(4)探索パターン実行手段の各種出力データに対し、ユーザが目標とする性能値の指定が可能な最適パターン判定条件指定手段
(5)探索パターン実行手段の各種出力データの中から、最適パターン判定条件指定手段で指定した条件に最も近似するパターンを特定、そのパターンのアルゴリズムの組み合わせを通知する最適パターン判定手段
Claims (4)
- 入力データを受け付けるデータ入力部と、
前記入力データに対応する出力データを生成するために実行される一連のN個(Nは2以上の整数)の処理の各々で使用可能な方式を示すルールを格納するルール格納部であって、前記N個の処理のうちの少なくとも二つの前記処理には、前記出力データを生成するに際して独立に使用可能な複数個の前記ルールが存在する、前記N個の処理ごとの前記複数のルールを格納するルール格納部と、
前記ルール格納部が格納する前記処理ごとの前記複数のルールを使用することによって、前記入力データから前記出力データを生成することができる一連のN個の処理からなる処理工程を示す組合せパターンであって、前記複数のルールが存在するそれぞれの前記処理から一つの前記ルールを選択することで得られ、かつ、前記複数のルールが存在するそれぞれの前記処理の前記複数のルールの個数どうしを乗じて得られる組合せの数だけ存在するそれぞれの組合せパターンを抽出するパターン抽出部と、
前記パターン抽出部によって抽出されたそれぞれの組合せパターンのすべてを網羅して実行し、前記入力データから前記出力データを生成するパターン実行部と、
前記パターン実行部によって実行された前記組合せパターンのうち、予め設定された条件を満足する前記組合せパターンを格納する特定情報格納部と
を備えたことを特徴とするデータ生成装置。 - 前記ルール格納部は、
前記複数のルールとして、複数のアルゴリズムと、複数のパラメータ設定値との少なくともいずれかを格納することを特徴とする請求項1記載のデータ生成装置。 - 前記データ入力部は、
前記入力データとして、前記出力データである差分データの作成に使用する旧版データと、前記旧版データから更新された新版データとを受け付け、
前記ルール格納部は、
前記複数のルールとして、複数の差分アルゴリズムと、前記差分データの生成に使用される複数のパラメータ設定値との少なくともいずれかを格納することを特徴とする請求項2記載のデータ生成装置。 - コンピュータを、
入力データを受け付けるデータ入力部、
前記入力データに対応する出力データを生成するために実行される一連のN個(Nは2以上の整数)の処理の各々で使用可能な方式を示すルールを格納するルール格納部であって、前記N個の処理のうちの少なくとも二つの前記処理には、前記出力データを生成するに際して独立に使用可能な複数個の前記ルールが存在する、前記N個の処理ごとの前記複数のルールを格納するルール格納部、
前記ルール格納部が格納する前記処理ごとの前記複数のルールを使用することによって、前記入力データから前記出力データを生成することができる一連のN個の処理からなる処理工程を示す組合せパターンであって、前記複数のルールが存在するそれぞれの前記処理から一つの前記ルールを選択することで得られ、かつ、前記複数のルールが存在するそれぞれの前記処理の前記複数のルールの個数どうしを乗じて得られる組合せの数だけ存在するそれぞれの組合せパターンを抽出するパターン抽出部、
前記パターン抽出部によって抽出されたそれぞれの組合せパターンのすべてを網羅して実行し、前記入力データから前記出力データを生成するパターン実行部、
前記パターン実行部によって実行された前記組合せパターンのうち、予め設定された条件を満足する前記組合せパターンを格納する特定情報格納部、
として機能させるためのデータ生成プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005251400A JP4804836B2 (ja) | 2005-08-31 | 2005-08-31 | データ生成装置及びデータ生成プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2005251400A JP4804836B2 (ja) | 2005-08-31 | 2005-08-31 | データ生成装置及びデータ生成プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2007066007A JP2007066007A (ja) | 2007-03-15 |
| JP4804836B2 true JP4804836B2 (ja) | 2011-11-02 |
Family
ID=37928138
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2005251400A Expired - Fee Related JP4804836B2 (ja) | 2005-08-31 | 2005-08-31 | データ生成装置及びデータ生成プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP4804836B2 (ja) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8359293B2 (en) | 2010-04-19 | 2013-01-22 | Nec Corporation | Processing procedure management device, processing procedure management method, processing procedure management system, and processing procedure management program |
Families Citing this family (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP5636635B2 (ja) * | 2009-03-12 | 2014-12-10 | 日本電気株式会社 | バックアップ装置、バックアップシステム、バックアップ方法、及びプログラム |
| JP2012093997A (ja) * | 2010-10-27 | 2012-05-17 | Toshiba Tec Corp | 予約受付装置およびプログラム |
| WO2012060098A1 (ja) * | 2010-11-05 | 2012-05-10 | 日本電気株式会社 | 情報処理装置 |
| WO2016046878A1 (ja) * | 2014-09-22 | 2016-03-31 | 株式会社日立製作所 | データ処理方法、及びデータ処理システム |
| WO2020144842A1 (ja) * | 2019-01-11 | 2020-07-16 | 富士通株式会社 | 探索制御プログラム、探索制御方法および探索制御装置 |
| US11487940B1 (en) * | 2021-06-21 | 2022-11-01 | International Business Machines Corporation | Controlling abstraction of rule generation based on linguistic context |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH04359315A (ja) * | 1991-06-05 | 1992-12-11 | Matsushita Electric Ind Co Ltd | データ圧縮制御装置及びデータ復元制御装置 |
| JPH05265819A (ja) * | 1992-03-19 | 1993-10-15 | Nec Ic Microcomput Syst Ltd | データ圧縮方式 |
| JPH05274198A (ja) * | 1992-03-27 | 1993-10-22 | Hitachi Ltd | 情報処理装置 |
| JPH08191427A (ja) * | 1995-01-09 | 1996-07-23 | Hitachi Ltd | 情報記録再生装置 |
| JP2000076077A (ja) * | 1998-09-03 | 2000-03-14 | Ricoh Co Ltd | 光ディスクドライブ制御システム |
| JP4167359B2 (ja) * | 1999-09-30 | 2008-10-15 | 株式会社東芝 | データ管理システム及びデータ管理方法 |
| JP2001177830A (ja) * | 1999-12-20 | 2001-06-29 | Mega Chips Corp | 画像圧縮装置及び圧縮画像データ伝送システム |
| EP1259883B1 (en) * | 2000-03-01 | 2005-12-07 | Computer Associates Think, Inc. | Method and system for updating an archive of a computer file |
| US6804401B2 (en) * | 2000-05-12 | 2004-10-12 | Xerox Corporation | Method for compressing digital documents with control of image quality subject to multiple compression rate constraints |
| JP2003044874A (ja) * | 2001-08-02 | 2003-02-14 | Ricoh Co Ltd | 3次元形状処理システム間データ交換方法 |
| JP2003337822A (ja) * | 2002-05-21 | 2003-11-28 | Fujitsu Ltd | 圧縮検索アーカイブ処理方法,圧縮検索アーカイブ処理プログラムおよびそのプログラムの記録媒体 |
-
2005
- 2005-08-31 JP JP2005251400A patent/JP4804836B2/ja not_active Expired - Fee Related
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8359293B2 (en) | 2010-04-19 | 2013-01-22 | Nec Corporation | Processing procedure management device, processing procedure management method, processing procedure management system, and processing procedure management program |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2007066007A (ja) | 2007-03-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP3174819U (ja) | 標準化プレーリストの作成および統一の維持 | |
| US7631022B2 (en) | Information processing apparatus and recording medium | |
| US7949938B2 (en) | Comparing and merging multiple documents | |
| US20050146995A1 (en) | Information processing apparatus and method | |
| CN101082930A (zh) | 管理数据的设备和方法 | |
| US20080147791A1 (en) | Communication system, communication apparatus, communication method, recording medium and program | |
| JPWO2008084738A1 (ja) | 符号化装置、復号化装置、それらの方法、その方法のプログラム及びそのプログラムを記録した記録媒体 | |
| JP4804836B2 (ja) | データ生成装置及びデータ生成プログラム | |
| WO2005059775A1 (ja) | 情報処理装置、および情報処理方法、並びにコンピュータ・プログラム | |
| JP4356257B2 (ja) | オーディオ再生装置 | |
| JPWO2005062184A1 (ja) | データ処理装置およびデータ処理方法 | |
| JP4539115B2 (ja) | 情報処理装置、および情報処理方法、並びにコンピュータ・プログラム | |
| US20140108356A1 (en) | Information processing apparatus | |
| CN100429642C (zh) | 信息处理方法、装置、程序和记录介质 | |
| CN107025212A (zh) | 编码方法、编码装置、解码方法和解码装置 | |
| JP7059516B2 (ja) | 符号化プログラム、符号化装置および符号化方法 | |
| JP4944033B2 (ja) | 情報処理システム、情報処理方法、実行バイナリイメージ作成装置、実行バイナリイメージ作成方法、実行バイナリイメージ作成プログラム、実行バイナリイメージ作成プログラムを記録したコンピュータ読み取り可能な記録媒体、実行バイナリイメージ実行装置、実行バイナリイメージ実行方法、実行バイナリイメージ実行プログラム及び実行バイナリイメージ実行プログラムを記録したコンピュータ読み取り可能な記録媒体 | |
| JP5217155B2 (ja) | ファイル圧縮自動判定方式および方法、並びに、プログラム | |
| JP2004227285A (ja) | オーディオ再生装置 | |
| CN102622430A (zh) | 基于usb接口的单机点播系统设备扩容管理的方法 | |
| JP4978306B2 (ja) | コンテンツファイル処理装置、コンテンツファイル処理方法及びコンテンツファイル処理プログラム | |
| US9081776B2 (en) | Method and apparatus for directly writing multimedia data on digital device | |
| JP5076621B2 (ja) | 特許分析プログラム、特許分析方法および特許分析装置 | |
| JP5855989B2 (ja) | データ処理装置及びデータ処理方法及びデータ処理プログラム | |
| JP2008102883A (ja) | ホスト装置、データベース管理システム、データベース管理方法及びプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20080426 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20101207 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20101214 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110207 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20110412 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20110509 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20110809 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20110810 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 4804836 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20140819 Year of fee payment: 3 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |