JP5126541B2 - 情報分類装置、情報分類方法、及び情報分類プログラム - Google Patents
情報分類装置、情報分類方法、及び情報分類プログラム Download PDFInfo
- Publication number
- JP5126541B2 JP5126541B2 JP2008517918A JP2008517918A JP5126541B2 JP 5126541 B2 JP5126541 B2 JP 5126541B2 JP 2008517918 A JP2008517918 A JP 2008517918A JP 2008517918 A JP2008517918 A JP 2008517918A JP 5126541 B2 JP5126541 B2 JP 5126541B2
- Authority
- JP
- Japan
- Prior art keywords
- classification
- information
- label
- character
- character string
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images



















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/30—Information retrieval; Database structures therefor; File system structures therefor of unstructured textual data
- G06F16/35—Clustering; Classification
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Databases & Information Systems (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Document Processing Apparatus (AREA)
Description
技術分野
本発明は、潜在的に表形式となりうるキーワード列から個々のレコードを推定する情報分類装置、情報分類方法、及び情報分類プログラムに関する。
しかし、表形式を用いた文書を構成する表データの記述方法は、文書ファイルのフォーマットや表の構成の仕方によって千差万別である。例えば、ある文書はマイクロソフト社のExcelというソフトウェアが用いられることによって、Excelブック形式という専用の表形式で表データが記述される。一方、別のある文書はWebブラウザで閲覧するためにHTML(Hyper Text Markup Language)形式という表形式で記述されるため、HTML専用のタグを使って表データが記述される。このように、文書中の表データはそれぞれのファイル形式専用の構造情報を用いて記述され、さらに個々の表データによっても要素の構成が異なる。
このため、様々な形式で記述された表データやレコードを文書から検出する従来の手法は、例えば特許文献1(特開2003−150624号公報)に開示されている。特許文献1には、HTML文書を対象とした場合はTABLEタグやTRタグなどを手掛かりに表データの構造を解析し、同様に前述のExcelなどによる文書を対象とした場合はそのExcelなどのソフトウェア専用の構造解析方法を用いて表データを抽出する手法が開示されている。また、明確な表としての区切り線がなくテキストエディタで要素を列挙したような表データの記述方法もあるが、これは例えば特許文献2(特開平9−282208号公報)に開示されている。特許文献2には、表データを構成するレコードの先頭や末尾を識別するためのテキストデータのパタンを予め与えておくことで、個々のレコードを識別して表データの要素を抽出する手法が開示されている。
しかし、上記従来の手法は以下に示すような問題点を有する。
第1の問題点は、様々なファイル形式に対応する表構造解析方法を予め個別に用意しておくことは、ファイル形式の詳細な仕様が公開されていない場合もあるため、一般に容易ではないことである。
第2の問題点は、ファイルの拡張子が同じであっても文書を作成するソフトウェアやファイル形式自体のバージョンが異なると、表データなどの構造記述方法が異なってくる場合があるということであり、さらに、将来の新たなファイル形式への対応をその都度行う必要があるということである。
第3の問題点は、ファイル形式ではなくテキストデータの記述パタンを使ってレコードを検出する従来の方法は、ファイル形式には依存しないものの、予め個々の表データにおけるレコードの記述パタンを全て知っておく必要があるため、多くの人やシステムによって記述された多種多様な表データを含む文書に当該従来の方法を適用することは困難であるということである。
本発明の例示的な目的は、データのファイル形式や表データを構成するレコードの識別パタンが予め分からない場合でも、精度良く表データを構成する個々のレコードを推定する情報分類装置、情報分類方法、及び情報分類プログラムを提供することにある。
なお、上記の情報分類装置と、該情報分類装置と通信ネットワークを介して接続され、該通信ネットワークを通じて取得したデータを格納する少なくとも1つのデータ蓄積部を含む情報分類システムを提供することができる。この場合、前記情報分類装置における前記文字情報抽出部は、前記データ蓄積部に格納された前記データの文字情報から所定の文字列を抽出する。
本発明によればまた、文字情報を含むデータの構成を解析する情報分類方法が提供される。この情報分類方法は、データの文字情報から所定の文字列を抽出し、抽出した各文字列を、文字列の分類を表すラベルに置き換えることによって、文字列を一連のラベル列に変換し、ラベル列内に繰り返し出現するラベルの出現パタンを推定する。
本発明によれば更に、コンピュータに、文字情報を含むデータの構成の解析を実行させるための情報分類プログラムが提供される。この情報分類プログラムは、コンピュータに、データの文字情報から所定の文字列を抽出する文字情報抽出処理と、抽出した各文字列を、文字列の分類を表すラベルに置き換えることによって、文字列を一連のラベル列に変換するラベル化処理と、ラベル列内に繰り返し出現するラベルの出現パタンを推定するラベル出現パタン推定処理とを実行させる。
以上のような本発明によれば、ラベルの出現パタンに基づいて、文字情報を含むデータの構成を推定できる。つまり、本発明による情報分類装置について言えば、データの文字情報から所定の文字列を抽出する文字情報抽出部と、抽出した各文字列を、文字列の分類を表すラベルに置き換えることによって、文字列を一連のラベル列に変換するラベル化部と、ラベル列内に繰り返し出現するラベルの出現パタンを推定するラベル出現パタン推定部とを含む。これにより、データのファイル形式や表を構成するレコードの識別パタンが予め分からない場合や、個々のレコードの要素が部分的に欠損している不完全な表を対象とする場合や、1レコードが複数行から構成されている場合においても、ラベルの出現パタンからデータの分類に基づいた構成を精度良く推定することができる。
図2は、図1に示された表レコード推定装置のハードウェア構成を示すブロック図である。
図3は、図1に示された表レコード推定装置の動作を示すフローチャートである。
図4は、図1に示された表レコード推定装置の第1の例において入力されるテキストデータに含まれる表データの例を示す説明図である。
図5は、第1の例におけるキーワードの種類別ラベルの例を示す説明図である。
図6は、第1の例において表データを構成するキーワード列から置き換えたラベル列から表データのレコード構成を表すラベル列を推定する一連の流れを示した説明図である。
図7は、第1の例において最終的なレコード推定結果の出力情報を説明する図である。
図8は、図1に示された表レコード推定装置の第2の例において表データを構成するキーワード列から置き換えたラベル列から表データのレコード構成を表すラベル列を推定する一連の流れを示した説明図である。
図9は、図1に示された表レコード推定装置の第3の例において入力されるテキストデータに含まれる表データの例を示す説明図である。
図10は、第3の例におけるキーワードの種類別ラベルの例を示す説明図である。
図11は、本発明の第2の例示的な実施例において入力されるテキストデータの例を示す説明図である。
図12は、本発明による情報分類装置の第2の例示的な実施例である、情報解析装置の構成を示すブロック図である。
図13は、第2の例示的な実施例におけるキーワード辞書の例を示す説明図である。
図14は、第2の例示的な実施例における分類ルールの例を示す説明図である。
図15は、第2の例示的な実施例において入力されたテキストデータから抽出されたキーワード列の例を示す説明図である。
図16は、第2の例示的な実施例において表データを構成するキーワード列から置き換えたラベル列から表データのレコード構成を表すラベル列を推定する一連の流れを示した説明図である。
図17は、第2の例示的な実施例における出力データの例を示す説明図である。
図18は、本発明による情報分類装置の第3の例示的な実施例を示し、本発明による情報分類装置を用いて情報分類システムを構成した場合の構成例を示すブロック図である。
図19は、第2の例示的な実施例における表レコード推定部及びデータ分類部の別の動作例を示すフローチャートである。
図20は、第2の例示的な実施例における分類ルールの他の例を示す説明図である。
図21は、第2の例示的な実施例において入力されるテキストデータの例を示す説明図である。
図22は、第2の例示的な実施例による分類結果の例を示す説明図である。
例示的な実施例の説明
[第1の例示的な実施例]
本発明の第1の例示的な実施例を、図面を参照して説明する。
(第1の例示的な実施例の構成)
図1は、本発明による情報分類装置の第1の例示的な実施例である、表レコード推定装置の機能構成を示すブロック図である。
図1を参照すると、表レコード推定装置10は、表要素列抽出部(表要素列抽出手段)1と、表要素ラベル化部(表要素ラベル化手段)2と、ラベル出現パタン推定部(ラベル出現パタン推定手段)3と、分類ルール格納部(分類ルール格納手段)4と、分割基準格納部(分割基準格納手段)5とを備える。
ここで、表要素列抽出部1は、データを入力してテキストデータを抽出する機能と、抽出したテキストデータから表(表データ)の要素となる一連のキーワードを取得する機能を有する。なお、表要素列抽出部1によってテキストデータを抽出されるデータは、例えば、表形式の文書や実行プログラムファイル等を対象として含んでいてもよく、データの種類に特に制限はない。
すなわち、表要素列抽出部1は、入力されたデータから抽出したテキストデータを参照することによって、表(表データ)を構成しうる要素集合を当該テキストデータから抽出する機能を有する。
表要素列抽出部1においてデータからテキストデータを抽出する方法としては、データからレイアウト情報や表データの罫線情報などの表示制御用情報(例えばHTML文書におけるタグ情報)を取り除くことによってテキストデータを抽出する方法や、ASCIIやJISなど特定種類の文字コードに合致するバイナリデータを抽出する方法などがある。後者の方法では、対象とするデータはワードプロセッサやテキストエディタなどで作成された文書ファイルに限らず、テキストデータを内部に含みうる実行プログラムファイルなども対象とすることができる。
また、表要素列抽出部1は、分割基準格納部5に格納された分割基準に基づいて、抽出したキーワードが同じ表データを構成するキーワードであるか否かを判断する。表要素列抽出部1は上述した文字情報抽出処理を実行するものであり、文字情報抽出手段と呼ばれても良い。
表要素ラベル化部2は、表要素列抽出部1によって取得した個々のキーワードを分類ルール格納部4に格納された対応情報に基づいてその種類別にラベル付けする機能を有する。
すなわち、表要素ラベル化部2は、テキストデータから抽出された1つの要素集合について、分類ルール格納部4に格納された対応情報に基づいて各要素を種類別のラベルに置き換えることにより、当該要素集合を一連のラベル列に変換する機能を有する。表要素ラベル化部2は上述したラベル化処理を実行するものであり、ラベル化手段と呼ばれても良い。
ラベル出現パタン推定部3は上述したラベル出現パタン推定処理を実行するものであり、表要素ラベル化部2によって種類別に付されたラベルの列から1単位レコードを構成するラベル順列を推定し、当該ラベル順列をレコード推定結果として出力する機能を有する。
すなわち、ラベル出現パタン推定部3は、得られたラベル列から同一種類のラベルが出現する繰り返しパタンを検出し、1回の繰り返しパタン分の単位ラベル列を1単位の情報を表すレコードと判定する機能を有する。
分類ルール格納部4は、各種のキーワードとラベルとの対応関係を示す対応情報(分類ルール)を格納する機能を有する。分類ルール格納部4は上述した対応情報格納処理を実行するものであり、対応情報格納手段と呼ばれても良い。
分割基準格納部5は、抽出したキーワードが同じ表データに属するか否かの基準を示す分割基準を格納する機能を有する。
図2は、表レコード推定装置10のハードウェア構成を示すブロック図である。
図2を参照すると、表レコード推定装置10は、一般的なコンピュータと同様のハードウェア構成によって実現することができる。表レコード推定装置10は、CPU(Central Processing Unit)11、RAM(Random Access Memory)等のメインメモリであり、データの作業領域やデータの一時退避領域に用いられる主記憶部12を含む。表レコード推定装置10はまた、液晶ディスプレイ、プリンタやスピーカ等の出力手段(まとめて提示部13と呼ぶ)、キーボードやマウス、スキャナ等の入力手段(まとめて入力部14と呼ぶ)を含む。表レコード推定装置10は更に、周辺機器と接続してデータの送受信を行うインタフェース部15、ROM(Read Only Memory)、磁気ディスク、半導体メモリ等の不揮発性メモリから構成されるハードディスク装置である補助記憶部16、上記各構成要素を相互に接続するシステムバス17を備えている。
表レコード推定装置10は、後述される動作を含む上記各機能を実現するプログラムを組み込んだ、LSI(Large Scale Integration)等のハードウェア部品からなる回路部品を実装して上記機能をハードウェア的に実現することは勿論として、上記した各構成要素の各機能を提供するプログラムを、コンピュータ上のCPU11で実行することにより、ソフトウェア的に実現することができる。
すなわち、CPU11は、補助記憶部16に格納されているプログラムを、主記憶部12にロードして実行し、表レコード推定装置10の動作を制御することにより、上述した各機能をソフトウェア的に実現する。なお、プログラムは、CPU11で読み出し可能な可搬型の記憶媒体に記憶されても良い。
後述される第2の例示的な実施例や第3の例示的な実施例における情報解析装置も、表レコード推定装置10と同様のハードウェア構成を備えることによって、所定の機能をハードウェア的又はソフトウェア的に実現することができる。
(第1の例示的な実施例の動作)
図3は、表レコード推定装置10の動作を説明するためのフローチャートである。
表レコード推定装置10は、図3に示すような手順で表のレコードを推定する。まず、表要素列抽出部1が、入力されたデータからテキストデータを抽出し(ステップS101)、抽出したテキストデータから1つの表データを構成する一連のキーワード列を、キーワード集合(部分文字列集合)として取得する(ステップS102)。
ステップS102におけるキーワード列の取得方法としては、例えば表要素列抽出部1内の記憶部に予め用意した辞書に含まれるキーワードと合致する文字列がテキストデータ中に見つかれば、その文字列を抽出する方法や、または、テキストデータの形態素解析を行ない、固有名詞のうち氏名や地名など文字情報の種類が特定できるものを全て抽出する方法がある。これらの方法の他にも、正規表現などで定義した一定のパタンに合致する文字列を抽出することで、電話番号やメールアドレス、会社名、学校名、特定の形式を持つ製品名などを取得する方法などがある。
また、1つの表データを構成する範囲の上記キーワード列の区切りは、例えば、隣り合うキーワード間の距離で判断することができる。すなわち、分割基準として同じ表データに含まれるキーワード間の最大許容距離(容量)を100バイトとすると、テキストデータから抽出されたあるキーワードとその次の抽出された別のキーワードとの間の距離がデータ長で100バイト以内であれば、表要素列抽出部1は、分割基準に基づいて、それら2つのキーワードが同じ表データを構成する1つのキーワード集合(1つの部分文字列集合)であると判断する。
次に、表要素ラベル化部2が、ステップS102で得られた1つの表データを構成するキーワード列を分類ルール格納部4に格納された対応情報に基づいてそれぞれ種類別のラベルに置き換える(ステップS103)。
分類ルール格納部4において、例えば、キーワードの内、氏名はA、住所はBというように予めキーワードの種類と対応するラベルを定義しておくと、表要素ラベル化部2によって山田や鈴木といった名前はAというラベルに、京都府や名古屋市といった地名はBというラベルに置き換えられる。このような置換処理を全てのキーワードに適用すると、一連のキーワード列はステップS103においてラベル列となる。
次に、表要素ラベル化部2が、ステップS103で得られたラベル列の中で、隣り合うラベルが同じ種類のラベルであった場合、それらを1つのラベルにまとめる(ステップS104)。例えば、AABBBCというラベル列はまとめられてABCというラベル列になる。
ここで、ステップS103で各キーワードをラベルに置き換える際、あるキーワードを置き換えた場合のラベルが、当該キーワードの直前のキーワードの置き換え後のラベルと同じであれば、その当該キーワードの置き換えた場合のラベルを削除することによって、表要素ラベル化部2がステップS103とステップS104を同時に処理できる。
以上のようにして、ステップS104によって2つ以上同じ種類のラベルが連続しないラベル列ができると、ラベル出現パタン推定部3が、そのラベル列の先頭からラベルを読み込んで(検出して)いき、既に検出したラベルと同一の種類のラベルを2度目に検出したとき、その直前までの一連のラベルを候補レコードとして記憶する(ステップS105)。例えば、「ABCABDCA・・・」というラベル列があった場合、先頭からA、B、Cと読み込み、次にまたAを検出した時点で、その直前までのラベル列「ABC」を最初の候補レコードとする。
その後、ラベル出現パタン推定部3は、2度目のAから再びA、Bと読み込むが、ここからはステップS105で記憶した候補レコード「ABC」と比較しながら読み込む。例えば、ABの次に新たなラベルDを検出すると、候補レコード上でもABの次にラベルDを挿入し、新たな候補レコードを「ABDC」として記憶する(ステップS106)。
その後、ラベル出現パタン推定部3は、例えば、Dの次にCを検出し、さらに3度目のAを検出すると、ステップS106で記憶した新たな候補レコード「ABDC」との差異は無いことを理由として、当該新たな候補レコード「ABDC」を上記のようにそのまま後段のステップで利用する。
以降、ラベル出現パタン推定部3は、同様に最新の候補レコードとステップS104によって得られたラベル列中のラベルを順に比較しながら、候補レコードを更新していき、ステップS104によって得られたラベル列の最後まで読み込んだ結果得られた最新の候補レコードを、その表データのレコード構成を表すラベル列と推定(判定)する(ステップS107)。
(第1の例示的な実施例の効果)
第1の例示的な実施例によれば、データのファイル形式や表データを構成するレコードの識別パタンが予め分からない場合でも、表データを構成する個々のレコードについての種類及び構成順序を精度良く推定することができるため、データ中から顧客情報や財務情報などの所定の情報を正しく検出することができる。その理由は、以下の通りである。表レコード推定装置10が、入力されたデータからテキストデータを抽出し、抽出したテキストデータから一連のキーワードを抽出する。この場合、様々なファイル形式に影響されず、しかも、予め個々の表データにおけるレコードの記述パタンを全て知っておくことを必要としない。そして、多くの人やシステムによって記述された多種多様な表データを含むデータから抽出した一連のキーワードを、キーワードの種類に対応付けられたラベルに置き換える。続いて、隣接する同一種類のラベルをまとめることによって生成したラベル列についての同一種類のラベルが繰り返し出現する繰り返しパタンに基づいて、1回の繰り返しパタン分の単位ラベル列を1単位の情報を表すレコードと判定する。
(第1の例示的な実施例の第1の例)
第1の例示的な実施例の第1の例を、図面を参照して説明する。第1の例は、本発明を上記第1の例示的な実施例に適用したものであり、第1の例示的な実施例をより具体的な例によって説明するものである。なお、第1の例の構成及び動作の概略は上記第1の例示的な実施例の構成及び動作の概略と同様であるため、重複する部分については適宜省略して説明する。
(第1の例の動作)
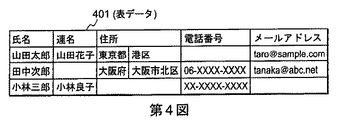
第1の例において、あるデータ中に図4に示すような表データ401が記述されていたとする。前述の表要素列抽出部1を用いて、この表データ401を構成する文字列をテキストデータとして抽出し、さらに、図5に示した氏名や地名などいずれかの種類に合致するキーワードを当該テキストデータから抽出する(図3のステップS101〜S102参照)。
さらに、図5に示した各種のキーワードとラベルとの対応関係を示す対応情報501が、例えば氏名であれば、ラベルAを適用することで、抽出したキーワード列を前述の表要素ラベル化部2によりラベル列に置き換える(図3のステップS103参照)。
すなわち、図4の表データ401からは、表要素列抽出部1によって、2行目から、氏名(山田太郎)、氏名(山田花子)、地名(東京都)、地名(港区)、メールアドレス(taro@sample.com)というキーワード列が抽出され、3行目から、氏名(田中次郎)、地名(大阪府)、地名(大阪市)、地名(北区)、電話番号(06−XXXX−XXXX)、メールアドレス(tanaka@abc.net)というキーワード列が抽出され、4行目から、氏名(小林三郎)、氏名(小林良子)、電話番号(XX−XXXX−XXXX)というキーワード列が抽出される(図3のステップS102参照)。続いて、図5に示した対応情報501に基づいて、表要素ラベル化部2によって、これがラベル列{AABBCABBBDCAAD}に置換される(図3のステップS103参照)。
図6は、図3に示したフローチャートに対応させ、表データを構成するキーワード列から置き換えたラベル列から表データのレコード構成を表すラベル列を推定する一連の流れを示した説明図である。
まず、図4の表データから表要素列抽出部1によって抽出されたキーワード列(図3のステップS102参照)が図5に示した対応関係に基づいて表要素ラベル化部2によって初期ラベル列(ステップS601)に置き換えられる(図3のステップS103参照)。得られた初期ラベル列について、隣り合うラベルで同じ種類のラベルを1つにまとめると(図3のステップS104参照)、ラベル列{ABCABDCAD}が得られる(ステップS602)。
ラベル出現パタン推定部3がこのステップS602で得られたラベル列{ABCABDCAD}を、上記第1の例示的な実施例で説明した通り、先頭から順に読み込んでゆくと(図3のステップS105参照)、最初の候補レコード「ABC」が得られる(ステップS603)。さらに、上記第1の例示的な実施例と同様にして(図3のステップS106参照)2つめの候補レコード「ABDC」が得られる(ステップS604)。図6のステップS604では、最初の候補レコード「ABC」に対して、2つめの候補レコード「ABDC」にはあって最初の候補レコード「ABC」には無いラベルDに対応する位置にNULL値を示すアスタリスク「*」を配置している。以降、アスタリスク「*」表記のラベルは実際には存在しないが候補レコードとの対応上要素が抜けているラベルを表すものとする。
次いで、図6において、上記第1の例示的な実施例と同様に、ステップS602で得られたラベル列の左端を先頭として3度目のラベルAから順にラベルを読み込むと、Aの次にはDが検出される。この時の最新の候補レコードは「ABDC」であるため(ステップS604参照)、ラベル出現パタン推定部3は、3つめのレコードにラベルB相当の要素が欠如しているものと判断し、そのまま次のラベルDをラベル列から検出されたDと対応付ける。なお、欠如していると判断されたラベルBは、図6において、前述の方針に従いアスタリスク「*」が仮のラベルとして記載されている。また、この例のラベル列は2度目に検出されたDで終了しているため、ラベル出現パタン推定部3が、最新の候補レコード「ABDC」の最後のラベルCも3つめのレコードから欠如しているものと推定(判定)することから、前述の方針に従い図6においてアスタリスク「*」で表現されている(ステップS605)。
以上のステップにより、ラベル出現パタン推定部3は、候補レコード「ABDC」を最終的なレコード推定結果とする{ステップS606(図3ステップS107参照)}。
なお、推定結果のレコードは、ラベル出現パタン推定部3によって、元のラベル列からその要素となるラベルを1つも漏らすことなく、当該ラベル列を1つ以上のレコードに分割する。
図7は、最終的なレコード推定結果の出力情報を説明する図である。
図7は、ステップS606において最終的なレコード推定結果とされた「ABDC」を、図5に示した対応情報501に基づきキーワードの種類に対応付けて示した出力情報701を説明する図である。図7を参照すると、出力情報701に基づいて表データのレコード構成を推定することができる。
(第1の例の効果)
第1の例による表レコード推定装置10の動作にかかる一連の表レコード推定方法においては、テキストデータ上のキーワード列を、対応関係を示す対応情報に基づいてラベル列に1対1に置き換えることによって、1次元のラベル列のみからレコードを推定する。このため、見かけ上の表データがどのような構造になっているかには依存することなく、また、キーワード列内において各種類のキーワードが出現することもあれば出現しないこともあるような場合であっても、レコードを推定することができる。
第1の例によれば、例えば、図4に示した表データが1行目に{氏名、連名、住所}を、2行目に{電話番号、メールアドレス}をそれぞれ記載した2行1組のレコード構成であったとしても、そこから得られるラベル列は図6のステップS601で得られるラベル列と同じであるため、表データの構造が相違してもレコード推定結果に影響しないという効果を奏する。
(第1の例示的な実施例の第2の例)
次に、第1の例示的な実施例の第2の例について説明する。第2の例は、上記第1の例の変形例であり、構成及び動作の概略が上記第1の例示的な実施例の構成及び動作の概略と同様であるため、第1の例と相違する点を中心に説明する。
(第2の例の動作)
図8は、図6の変形例を示し、図3に示したフローチャートに対応させ、表データを構成するキーワード列から置き換えたラベル列から表データのレコード構成を表すラベル列を推定する一連の流れを示した説明図である。
まず、表要素列抽出部1によって抽出されたキーワード列が図5に示した対応関係に基づいて表要素ラベル化部2によって初期ラベル列に置き換えられ(ステップS801)、得られた初期ラベル列について、隣り合うラベルで同じ種類のラベルを1つにまとめると、ラベル列{ABCBDCBD}が得られたとする(ステップS802)。
ラベル出現パタン推定部3は、ステップS802で得られたラベル列{ABCBDCBD}を、上記第1の例示的な実施例と同様に、先頭から順に読み込んでゆく。この場合、「A→B→C→B」と検出した時点で、「B」のラベルが「C」のラベルの後、「A」のラベルが検出されることなく再度出現しているため、既に検出したラベルと同一の種類のラベルを2度目に検出したこととなる。この場合、ラベル出現パタン推定部3は、その直前までの一連のラベル「ABC」を候補レコードとして記憶する(ステップS105参照)。すなわち、ラベル出現パタン推定部3は、「ABCB」は「ABC」と「B」で異なるレコードに属すると判断し、最初の候補レコードを「ABC」と推定する(ステップS803)。
この場合、図6を参照し、ステップS803と同様にすると、ラベル出現パタン推定部3は、候補レコード「ABDC」を最終的なレコード推定結果とする(ステップS804〜ステップS806)。
(第2の例の効果)
第2の例による表レコード推定装置10の動作にかかる一連の表レコード推定方法によれば、例えば、先頭の「A」のような、ラベル列を読み込む際に基準とするラベルがラベル列内の各レコードに常には出現しない場合であっても、第1の実施例と同様の効果を達成することができる。
(第1の例示的な実施例の第3の例)
第1の例示的な実施例の第3の例を、図面を参照して説明する。第3の例は、第1の例や第2の例の変形例であり、入力する表データの構成をより上位の構成又はより下位の構成によって分類するものである。なお、第3の例は、構成及び動作の概略が上記第1の例示的な実施例の構成及び動作の概略と同様であるため、第1の例や第2の例と相違する点を中心に説明する。
(第3の例の構成)
図9は、図4の変形例を示し、図9に示す表データ901は、「住所」について、「住所」のより下位の概念を示す分類として「都道府県」及び「市区町村」を対応付け、「メールアドレス」及び「電話番号」について、「メールアドレス」及び「電話番号」のより上位の概念としての分類である「連絡先」を対応付けたものである。また、図10は、図5の変形例を示し、図10に示す対応情報1001は、「電話番号」(ラベルD)及び「メールアドレス」(ラベルC)について、「電話番号」(ラベルD)及び「メールアドレス」(ラベルC)のより上位の概念としての分類である「連絡先」を示すラベルXを対応付けたものである。このことは、「連絡先」(ラベルX)について、「連絡先」(ラベルX)のより下位の概念を示す分類として「電話番号」(ラベルD)及び「メールアドレス」(ラベルC)を対応付けているともいえる。
(第3の例の動作)
第3の例において、図6のステップS606や図8のステップS806で示される推定結果「ABDC」は、図9で示される表データ901及び図10で示される対応情報1001に基づいて、「ABX」が最終的なレコード推定結果となる。
(第3の例の効果)
第3の例によれば、抽出したキーワードの種類について、抽出した複数のキーワードの種類をまとめたより上位の概念を示す種類、又は抽出したキーワードの種類を詳細に分類したより下位の概念を示す種類に階層的に任意に対応付けることができるため、入力したデータの構成を任意の階層によって推定することができる。
[第2の例示的な実施例]
本発明の第2の例示的な実施例は、様々なファイル形式に対応する表構造解析方法を予め個別に用意しておく必要や、厳密に表データに対応するレコードの記述パタン等の体裁を持つ必要などがない。つまり、第2の例示的な実施例は、図11に示したような自然言語文や語句のリストのみからなるテキストデータ1101からでも、上記第1の例と同様にレコードを推定できる。これを、以下に説明する。なお、第2の例示的な実施例のうち、上記第1の例示的な実施例や第1の例と重複する部分については適宜省略して説明する。
(第2の例示的な実施例の構成)
図12は、本発明による情報分類装置の第2の例示的な実施例である、情報解析装置の構成を示すブロック図である。
図12を参照すると、情報解析装置20は、第1の例示的な実施例で説明した表要素列抽出部1と同様の機能を有する表要素列抽出部(文字情報抽出手段)1aと、第1の例示的な実施例で説明した表要素ラベル化部2及びラベル出現パタン推定部3から構成される表レコード推定部23とを含む。情報解析装置20はまた、表レコード推定部23によって推定されたレコードから得たキーワードの種類の列を分類ルール格納部(対応情報格納手段)4aに格納されている分類ルールと照合してキーワード列を分類する機能を有するデータ分類部24とを含む。情報解析装置20は更に、データ分類部24によって分類された前記キーワード列が示す所定の結果を表示する機能を有する結果表示部(結果出力手段)26と、分類ルールを格納する機能を有する分類ルール格納部4aと、第1の例示的な実施例で説明した分割基準格納部5とを備える。
表要素列抽出部1aは、データ格納部(データ格納手段)25に格納されている文書等のデータを参照し、参照したデータからテキストデータを抽出する機能を有するテキストデータ抽出部(テキストデータ抽出手段)21を含む。表要素列抽出部1aはまた、テキストデータ抽出部21によって抽出されたテキストデータからキーワード辞書27に格納されているキーワード情報に基づいてキーワードを抽出してキーワード列を生成する機能を有するキーワード抽出部(キーワード抽出手段)22を含む。表要素列抽出部1aは更に、文書等のデータを格納する機能を有するデータ格納部25と、抽出するキーワードを種類毎に定義付けたキーワード情報を格納する機能を有するキーワード辞書27とを備える。キーワード辞書27は抽出情報格納手段と呼ばれても良く、キーワード情報は抽出情報と呼ばれても良い。
キーワード辞書27は、例えば、図13に示すような構成で実現される。すなわち、キーワードの種類別に、氏名であれば“上田”や“加藤”といった名字及び“太郎”や“花子”といった名前(図示せず)がキーワード辞書27に記載され、これらのキーワードに該当したテキスト文字列がキーワード抽出部22によってテキストデータから抽出される。
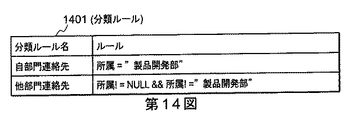
また、分類ルール格納部4aは、第1の例示的な実施例における分類ルール格納部4に格納されている分類ルールに加えて、例えば、図14に示したような構成を有する分類ルール1401を格納することによって実現される。
図14を参照すると、「自部門連絡先」という分類ルールは、所属に該当するキーワードが“製品開発部”であったレコードのみに合致する。一方、「他部門連絡先」という分類ルールは、何らかの所属を含む(前述の例ではラベルEを含む)ことを示す“所属!=“NULL””という条件に加えて、所属に該当するキーワードが“製品開発部”ではないことを示す“所属!=“製品開発部””という条件を共に満たした場合のみに合致する。
情報解析装置20は、図14に示したような分類ルール1401に基づいて、抽出されたキーワードをラベルに置き換えることによって、後述する図17に示すような、抽出したキーワードのより詳細な分類を示す分類付きのレコード件数を表示することができる。
(第2の例示的な実施例の動作)
情報解析装置20は、まず、データ格納部25に格納されているデータを、テキストデータ抽出部21を用いて参照し、各データからテキストデータを抽出する。テキストデータ抽出部21におけるテキストデータの抽出方法としては、上述したように、データからレイアウト情報や表データの罫線情報などの表示制御用情報(例えばHTML文書におけるタグ情報)を取り除くことによってテキストデータを抽出する方法や、ASCIIやJISなど特定種類の文字コードに合致するバイナリデータを抽出する方法などがある。後者の方法では、対象とするデータはワードプロセッサやテキストエディタなどで作成された文書ファイルに限らず、テキストデータを内部に含みうる実行プログラムファイルなども対象とすることができる。
次いで、キーワード抽出部22が、テキストデータ抽出部21によって抽出されたテキストデータから、キーワード辞書27に定義した特定種類のキーワードを抽出し、キーワード列を生成する。次いで、表レコード推定部23が、第1の例示的な実施例における図3などで説明した手順で各キーワードのラベル化とレコード推定を行う。データ分類部24は、表レコード推定部23によって推定されたレコードから得たキーワードの種類の列を分類ルール格納部4aの分類ルールと照合して所定の組み合わせに適合するものを適合文字情報として選択することによって前記キーワード列の分類を行い、その結果を結果表示部26で表示する。データ分類部24は上述した文字情報分類処理を実行するものであり、文字情報分類手段と呼ばれても良い。
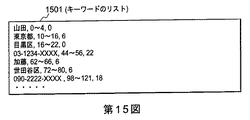
第2の例示的な実施例によれば、図11に示したテキストデータ1101から、図5に示したキーワードの種類と対応するラベルの定義(対応関係を示す対応情報501)に基づいて表要素列抽出部1aによってキーワードを抽出すると、図15に示すようなキーワードのリスト1501が得られる。
図15に示すキーワードのリスト1501では、各行に、テキストデータから抽出したキーワード、当該キーワードの検出位置、当該キーワードと直前のキーワード間の距離をそれぞれこの順で記載している。なお、キーワードの抽出位置は、テキストデータの先頭からのバイト数及びキーワードの末尾のバイト数によって表している。ただし、日本語文字1文字は2バイト、英数字記号1文字は1バイトとする。
ここで、分割基準を100バイトとすると、図11に示したテキストデータ1101及び図15に示すキーワードのリスト1501では、全てのキーワード間の距離が100バイト以下である。このため、表要素列抽出部1aは、「山田さん」に関する当該キーワードから「高橋さん」に関する当該キーワードの全てが同じ表データを構成するものとして判断する。
抽出したキーワード列を図5に示した対応情報501に基づいて表レコード推定部23内の表要素ラベル化部2によってラベル列に置き換えた結果は、図16のステップS1601に示されるようになる。ここから、先の例と同様に連続した同じラベルを1つにまとめ(ステップS1602)、ラベル列の先頭から候補レコードの推定を開始し(ステップS1603)、ラベル列の最後まで到達すると(ステップS1604)、最終的なレコード推定結果としてラベル列{ABD}が得られる(ステップS1605)。
ここで、表レコード推定部23内のラベル出現パタン推定部3は、推定した1レコード分のラベル列がステップS1604に示したような全ラベル列の中に幾つ含まれているかを数えることによって、当該表データが何レコード分の情報を持っているかを計算できる。
情報解析装置20は、レコード推定結果に基づいて各レコードに実際に含まれているキーワードのラベル(図16のステップS1604の中で大文字のアルファベットで示したラベル)を分類すると、例えば、図17に示したような分類結果1701を出力することができる。
情報解析装置20は、入力されたテキストデータが図11のようなものであった場合、図17の分類結果1701の2行目に示したabc.docのように、合計6件の連絡先が検出されたという分類結果を出力することができる。
また、図5に示した対応情報501のキーワードの種類別ラベルには所属を示すラベルEを定義している。第2の例示的な実施例において、図11に示すテキストデータ1101とは別に入力されたテキストデータから氏名や地名などを示すラベルに加えて所属を示すラベルを含むラベル列(例えば「ABEC」)が得られた場合、情報解析装置20は、図17に示す分類結果1701の3行目や4行目のように、各レコード別に「自部門連絡先」や「他部門連絡先」、及び所属を示すラベルを含まない「その他連絡先」などの件数を表示することもできる。
なお、上記第3の例で説明したのと同様に、「自部門連絡先」及び「他部門連絡先」について、「自部門連絡先」及び「他部門連絡先」のより上位の概念としての分類である「連絡先」を対応付けてもよい。すなわち、例えば、「自部門連絡先」にラベル「Y」、「他部門連絡先」にラベル「Z」を対応付け、「自部門連絡先」(ラベルY)及び「他部門連絡先」(ラベルZ)について、「自部門連絡先」(ラベルY)及び「他部門連絡先」(ラベルZ)のより上位の概念としての分類である「連絡先」を示すラベルXを対応付けてもよい。このことは、上記第3の例で説明したのと同様に、「連絡先」(ラベルX)について、「連絡先」(ラベルX)のより下位の概念を示す分類として「自部門連絡先」(ラベルY)及び「他部門連絡先」(ラベルZ)を対応付けているともいえる。
また、例えば、分割基準を40バイトとした場合や、テキストデータ内の構成が変化する箇所とした場合などは、図11に示したテキストデータ1101及び図15に示すキーワードのリスト1501は、表要素列抽出部1aによって、山田さんに関する当該キーワードから中川さんに関する当該キーワードによって構成される表データと、藤井さんに関する当該キーワードから高橋さんに関する当該キーワードによって構成される表データとに分割される。
(第2の例示的な実施例の別の動作)
図19を参照して、本発明の第2の例示的な実施例における、さらに別の動作について説明する。
図19は、図12に示された第2の例示的な実施例における表レコード推定部23およびデータ分類部24の動作を示すフローチャートである。
図19のフローチャートによれば、図1、図3に示した第1の例示的な実施例における表レコード推定装置10の動作と同様に、まず、入力されたデータからテキストデータを抽出する(ステップS101)。続いて、抽出したテキストデータから1つの表データを構成する一連のキーワード列を取得する(ステップ102)。
次に、表要素ラベル化部2が、ステップS102で得られた1つの表データを構成するキーワード列を分類ルール格納部4aに格納された対応情報に基づいてそれぞれ種類別のラベルに置き換える(ステップS103)。
ステップS103の後、ここでは図3のフローチャートとは異なり、分類ルール格納部4aの分類ルールを参照して1種類のラベルのみで成立するルールがあれば、そのルールに適合するラベルをラベル列から検出し、当該ラベルを当該ルールが示す分類の1件とする(ステップS1901)。
例えば、分類ルール格納部4aの分類ルールが図20に示したような3種類のルール集合からなる分類ルール2001で構成されていたとする。分類ルールのうち、「その他連絡先」のルールは“連絡先!=NULL”と記載されている。これは「連絡先」に該当するラベルが1つでも存在すれば、当該ラベルは「その他連絡先」に分類されることを意味する。このような「その他連絡先」のルールは、「連絡先」が図10に示した対応情報1001のように定義されている場合、メールアドレスまたは電話番号のいずれか1種類のみに相当するラベルのみで当該ルールを評価でき、それらのうちいずれか1つでもあれば「その他連絡先」と判定される。ただし、メールアドレスまたは電話番号が他の分類ルールの判定条件にも含まれる場合は、判定条件により多くのラベルを必要とする分類ルールを優先することで、分類ルール2001における「他部門連絡先」や「自部門連絡先」に該当する情報も適切に抽出することができる。
ここで、ステップS101によって図21に示すようなテキストデータ2101が抽出された場合、図20の分類ルール2001により、末尾の4つの連続したメールアドレスが「その他連絡先」のルールに適合するため、ステップS1901によって当該ルールによる分類が行なわれる。
ステップS1901の処理を終えると、図3のステップS104と同様に、表要素ラベル化部2が、ラベル列の中で隣り合うラベルが同じ種類のラベルであった場合、それらを1つのラベルにまとめる(ステップS1902)。ステップS1902の後で行なわれるステップS105、S106、S107は図3のフローチャートの説明と同じであるため省略する。
ステップS107までの処理によって1つの表を構成するキーワード列から一連のレコードの列が判定できると、全ラベル列を、判定した個々のレコードに対応する1つ以上の部分ラベル列に分割する(ステップS1903)。
ステップS1903の処理を終えると、データ分類部24が、分割した各部分ラベル列を分類ルール格納部4aの各ルールと照合し、適合したルールのうち最も多くのラベルが対応付いたルールによって当該部分ラベル列をそれぞれ分類する(ステップS1904)。
図10に示した対応情報1001及び図20に示した分類ルール2001を利用して、図21に示したテキストデータ2101をステップS1904までの処理により分類すると、図22に示した表のようになる。図22において、所属が「製品開発部」で氏名(田中)とその連絡先である電話番号及びメールアドレスを含んだ「自部門連絡先」1件、所属が「製品開発部」ではなく「企画部」で氏名(山田)とその連絡先である電話番号を含んだ「他部門連絡先」1件がそれぞれ検出できるほか、メールアドレスの上位の分類である連絡先のみがあれば成立する「その他連絡先」が計4件検出できる。
(第2の例示的な実施例の効果)
第2の例示的な実施例によれば、自然言語文や語句の羅列からなるテキストデータから、特定種類のキーワードの組合せを含んだ任意の情報をその件数と共に検出することが可能になる。すなわち、特定種類のキーワードの組合せについて、例えば、「自部門連絡先」や「他部門連絡先」など同一階層の複数の組合せを同時に検出することができる。また、「地名」が「東京都港区」及び「連絡先」が「自部門連絡先」としての「製品開発部」など異なる種類、異なる階層のキーワードの組合せに適合するものを同時に検出することができる。更に、分類ルール1401における「他部門連絡先」という分類ルールに関し、上記“所属!=“NULL””及び上記“所属!=“製品開発部””という条件に加え、所属に該当するキーワードが“「大阪府」”であることを示す“所属=“大阪府””という条件を同時に満たす組合せを検出することができる。
以上のような情報解析装置20を利用することにより、例えば、個人情報や商品情報の特徴をキーワードの種類として定義した辞書を用意することにより、組織内の様々な文書(データ)から個人情報や商品情報を抽出し、その件数を洗い出すことで管理を容易にすることができる。従って、第2の例示的な実施例による表レコード推定方法とこれを用いた情報解析装置は、企業などの組織内の資産管理や情報セキュリティ管理に有用である。また、様々な分割基準に基づいて、入力したテキストデータ1101から作成したキーワードのリスト1501から単一又は複数の表データを生成することができる。
[第3の例示的な実施例]
本発明の第3の例示的な実施例を以下に説明する。なお、第3の例示的な実施例のうち、上記第1、第2の例示的な実施例や第1の例と重複する部分については適宜省略して説明する。
図18は、本発明による情報分類装置を用いて情報分類システムを構成した第3の例示的な実施例を示すブロック図である。ここでは情報分類装置として情報解析装置100を備えるほか、データ蓄積装置300を備える。
図18を参照すると、情報解析装置100は、メインメモリ101と、CPU102と、データ記憶装置103と、通信装置104と、入力装置106と、出力装置107とを少なくとも備え、第2の例示的な実施例における情報解析装置20と同様の機能を有する。情報解析装置100は、通信ネットワーク200を介してデータ蓄積装置(データ蓄積手段)300と接続される。データ蓄積装置300は通信ネットワーク200を通じて取得したデータを格納するものであって、情報解析の対象として個人情報や商品情報を含みうるデータを蓄積することにより、図12に示したデータ格納部25と同様の機能を実現する。
図18ではデータ蓄積装置300を1台のみ示したが、情報解析装置100は2台以上のデータ蓄積装置300に接続されていても良い。すなわち、データは2台以上のデータ蓄積装置に分散して蓄積されていても良い。さらには、情報解析の対象となるデータの一部または全てが情報解析装置100のデータ記憶装置103に蓄積されていてもよい。
加えて、情報解析の対象となるデータは必ずしもワードプロセッサやテキストエディタなどで作成されたファイルのみに限らず、テキストデータを内部に含みうるあらゆるファイルであってもよく、例えば、実行プログラムファイルであっても良い。
また、データ蓄積装置300は、必ずしも各データを長期間保持するものでなくともよく、例えば、Eメール送信サーバとして機能する装置であってもよい。例えば、データ蓄積装置300がEメール送信サーバの一部として機能する場合、通信ネットワーク200を介して1つ以上の端末装置(図示せず)から送られてきたEメールデータを他の端末装置やEメール受信サーバ(図示せず)に送る前に、第3の例示的な実施例における情報解析装置100によって特定種類の情報が当該Eメールデータに含まれているか否かを確認してもよい。
次に、第3の例示的な実施例における情報解析装置100の構成要素について説明する。CPU102は、メインメモリ101の記憶するプログラム105に従って処理を実行する。プログラム105は、図12に示したテキストデータ抽出部21、キーワード抽出部22、表レコード推定部23、データ分類部24、及び結果表示部26の処理を実行させる情報解析プログラムである。従って、これらの各部の動作は、CPU102によって実現される。なお、プログラム105は、CPU102で読み出し可能な可搬型の記憶媒体に記憶されても良い。
データ記憶装置103は、少なくとも図12に示したキーワード辞書27、分類ルール格納部4aの対応情報501及び分割基準を記憶する。また、前述したように情報解析の対象となるデータを記憶していても良く、その場合はCPU102がデータ記憶装置103に蓄積されたデータを参照する。
通信装置104は、CPU102通信ネットワーク200との間のインタフェースである。通信ネットワーク200を介して通信装置104がデータ蓄積装置300にアクセスすることで、CPU102はデータ蓄積装置300に蓄積されているデータを参照する。
入力装置106は、例えばキーボードやマウスなどの情報入力装置であり、CPU102に対して処理の実行や停止、処理結果の表示を指示する。CPU102は、処理結果を出力装置107に表示出力させる。また、情報解析装置100がプリンタ(図示せず)を備える場合、CPU102はプリンタによって処理結果をプリント用紙に出力してもよい。
第3の例示的な実施例は、情報解析装置100を、図1、図2に示した表レコード推定装置10と置き換えて情報分類システムを実現するようにしても良い。
(第3の例示的な実施例の効果)
第3の例示的な実施例によれば、情報解析装置100が、通信ネットワーク200を介してデータ蓄積装置300と接続されるため、情報解析装置100においてデータ蓄積装置を有する必要がない。また、情報解析装置100が、通信ネットワーク200を介して複数のデータ蓄積装置300と接続できるため、災害や障害等に対し、可用性等が向上する。さらに、通信ネットワーク200を介して端末装置から送られてきたEメールデータを他の端末装置やEメール受信サーバに送る前に、情報解析装置100によって特定種類の情報が当該Eメールデータに含まれているか否かを確認できる等、ネットワークを介して送信又は受信される情報内に所定の情報が含まれているか否かを確認することができる。
以上説明してきたように、本発明によれば、文書等のデータのファイル形式や表データを構成するレコードの識別パタンが予め分からない場合でも、精度良く表データを構成する個々のレコードを推定できる。このことから、本発明は、組織内のWebサーバやファイルサーバ、端末装置などに蓄積された様々な記述形式の大量のファイルから、個人情報や財務情報などを示すキーワードの組を含んだファイルとそこに含まれる個人情報や財務情報の種類や件数を明らかにする組織内情報管理システムに適用でき、情報セキュリティ監査や情報資産管理の支援に有効である。本発明はまた、製品名、日付、価格、置き場所などのキーワードの組が多数含まれているデータを検出することによって、設備品情報を含んだ棚卸し用の文書を精度良く発見できるなど、データの内容に基づくデータ検索システムへの適用も可能である。
以下に、本発明にかかる情報分類装置、情報分類方法、情報分類プログラムの実施の態様を列挙する。
本発明の情報分類装置におけるラベル化部は、同一種類の隣り合う2つ以上の文字列を1つのラベルに置き換える。
本発明の情報分類装置は、更に、抽出した文字列の種類と文字列を置き換えるラベルとの対応関係を定義した対応情報を格納する対応情報格納部を含んでも良い。この場合、ラベル化部は、対応情報に基づいて、抽出した文字列を種類別にラベルに置き換える。
本発明の情報分類装置におけるラベル出現パタン推定部は、前後の出現パタン間で欠落したラベルを補足しながら逐次的に当該出現パタンの推定を行なう。
本発明の情報分類装置における文字情報抽出部は、データの文字情報から文字列を抽出するための抽出情報を格納する抽出情報格納部を含み、抽出情報に基づいて、データの文字情報から文字列を抽出する。
本発明の情報分類装置は、更に、予め定めた分割基準を格納する分割基準格納部を含んでも良い。この場合、文字情報抽出部は、抽出情報に基づいて抽出した文字列の集合を、予め定めた分割基準に基づいて複数の部分文字列集合に分割し、ラベル化部は、部分文字列集合に含まれる文字列を種類別にラベルに置き換え、ラベル出現パタン推定部は、部分文字列集合からラベル化部により置き換えられたラベル列を入力としてラベルの出現パタンを推定する。
本発明の情報分類装置においては、予め定めた分割基準として、データ内での隣接する文字列間の距離が規定値以上であるか否かを設定し、分割基準を満たすか否かに基づいて、各文字列を異なる部分文字列集合に含ませるか、又は、各文字列を同一の部分文字列集合に含ませるようにしても良い。
本発明の情報分類装置においては、対応情報は、抽出した文字列について、分類した文字列の種類より上位の分類又はより下位の分類に関しても対応関係を定義されても良い。この場合、情報分類装置は更に、文字情報分類部を含んでも良い。文字情報分類部は、推定した出現パタンで表される各ラベルを、対応情報に基づいて置き換え前の各文字列の任意の分類又は該任意の分類より上位の分類あるいは該任意の分類より下位の分類に対応付け、所定の組合せに適合する適合文字情報を選択することによって、データから抽出した文字列を分類する。
本発明の情報分類装置における文字情報分類部は、単一種類の文字列で成立する分類条件があれば、ラベル化部において同一種類の隣り合う2つ以上の文字列を1つのラベルに置き換える処理の前に、ラベル列を当該分類条件と照合し、当該分類条件による分類を行なうようにしても良い。
本発明の情報分類装置における文字情報抽出部は、文字列として抽出するキーワードを種類毎に定義付けたキーワード情報を格納するキーワード辞書を、前記抽出情報格納部として含んでも良い。この場合、文字情報抽出部は更に、文書等のデータを格納するデータ格納部と、データ格納部に格納されているデータを参照し、参照したデータからテキストデータを抽出するテキストデータ抽出部と、抽出されたテキストデータからキーワード辞書に格納されているキーワード情報に基づいてキーワードを抽出してキーワード列を文字列として生成するキーワード抽出部とを含んでも良い。
本発明の情報分類装置は、更に、分類の結果を出力する結果出力部を備えても良い。
本発明の情報分類方法におけるラベル化処理においては、抽出した文字列の集合に含まれる同一種類の隣り合う2つ以上の文字列を1つのラベルに置き換えることによって文字列を一連のラベル列に変換する。
本発明の情報分類方法は、更に、抽出した文字列の種類と文字列を置き換えるラベルとの対応関係を定義した対応情報を格納する対応情報格納処理を含んでも良い。この場合、ラベル化処理においては、対応情報に基づいて、抽出した文字列を種類別にラベルに置き換える。
本発明の情報分類方法におけるラベル出現パタン推定処理においては、前後の出現パタン間で欠落したラベルを補足しながら逐次的に当該出現パタンの推定を行なうようにしても良い。
本発明の情報分類方法においては、対応情報は、抽出した文字列について、分類した文字列の種類より上位の分類又はより下位の分類に関しても対応関係を定義されても良い。この場合、情報分類方法は更に、文字情報分類処理を含んでも良い。文字情報分類処理は、推定した出現パタンで表される各ラベルを、置き換え前の各文字列の任意の分類又は該任意の分類より上位の分類又は該任意の分類より下位の分類に対応付け、所定の組合せに適合する適合文字情報を選択することによって、データから抽出した文字列を分類する。
本発明の情報分類方法における文字情報分類処理においては、単一種類の文字列で成立する分類条件があれば、ラベル化処理において同一種類の隣り合う2つ以上の文字列を1つのラベルに置き換える処理の前に、ラベル列を当該分類条件と照合し、当該分類条件による分類を行なうようにしても良い。
本発明の情報分類方法は更に、分類の結果を出力する処理を含んでも良い。
本発明による情報分類プログラムは、ラベル化処理において、抽出した文字列の集合に含まれる同一種類の隣り合う2つ以上の文字列を1つのラベルに置き換えることによって文字列を一連のラベル列に変換する処理を実行させるようにしても良い。
本発明による情報分類プログラムは更に、抽出した文字列の種類と文字列を置き換えるラベルとの対応関係を定義した対応情報を格納する対応情報格納処理を実行させても良い。この場合、ラベル化処理においては、対応情報に基づいて、抽出した文字列を種類別にラベルに置き換える処理を実行させる。
本発明による情報分類プログラムは、ラベル出現パタン推定処理において、前後の出現パタン間で欠落したラベルを補足しながら逐次的に当該出現パタンの推定を実行させるようにしても良い。
本発明による情報分類プログラムにおいては、対応情報は、抽出した文字列について、分類した文字列の種類より上位の分類又はより下位の分類に関しても対応関係を定義されても良い。この場合、情報分類プログラムは更に、文字情報分類処理を実行させても良い。文字情報分類処理においては、推定した出現パタンで表される各ラベルを、置き換え前の各文字列の任意の分類又は該任意の分類より上位の分類又は該任意の分類より下位の分類に対応付け、所定の組合せに適合する適合文字情報を選択することによって、データから抽出した文字列を分類する処理を実行させる。
本発明による情報分類プログラムは、文字情報分類処理において、単一種類の文字列で成立する分類条件があれば、ラベル化処理において同一種類の隣り合う2つ以上の文字列を1つのラベルに置き換える処理の前に、ラベル列を当該分類条件と照合し、当該分類条件による分類を行わせるようにしても良い。
本発明による情報分類プログラムは更に、分類の結果を出力する処理を実行させるようにしても良い。
以上、幾つかの例示的な実施例、例をあげて本発明を説明したが、本発明は必ずしも、上記の例示的な実施例、例に限定されるものでなく、その技術的思想の範囲内において様々に変形して実施することができる。
Claims (24)
- 文字情報を含むデータの構成を解析する情報分類装置において、
前記データの文字情報から所定の文字列を抽出する文字情報抽出手段と、
抽出した各文字列を、文字列の分類を表すラベルに置き換えることによって、前記文字列を一連のラベル列に変換するラベル化手段と、
前記ラベル列内に繰り返し出現する前記ラベルの出現パタンを推定するラベル出現パタン推定手段と、
を含み、
前記ラベル化手段は、前記抽出した文字列の集合に含まれる同一分類の隣り合う2つ以上の前記文字列を1つの前記ラベルに置き換えることによって前記文字列を前記一連のラベル列に変換することを特徴とする情報分類装置。 - 前記文字情報抽出手段は、出現順序が定められた前記文字列を含む前記データから前記所定の文字列を抽出し、
前記ラベル化手段は、抽出した各文字列を前記出現順序で分類別に前記ラベルに置き換えることによって、抽出した文字列を前記一連のラベル列に変換することを特徴とする請求項1に記載の情報分類装置。 - 更に、抽出した文字列の分類と前記文字列を置き換える前記ラベルとの対応関係を定義した対応情報を格納する対応情報格納手段を含み、
前記ラベル化手段は、前記対応情報に基づいて、抽出した文字列を分類別に前記ラベルに置き換えることを特徴とする請求項1又は2に記載の情報分類装置。 - 前記ラベル出現パタン推定手段は、前後の出現パタン間で欠落したラベルを補足しながら逐次的に当該出現パタンの推定を行なうことを特徴とする請求項1〜3のいずれか1項に記載の情報分類装置。
- 前記文字情報抽出手段は、前記データの文字情報から前記文字列を抽出するための抽出情報を格納する抽出情報格納手段を含み、前記抽出情報に基づいて、前記データの文字情報から前記文字列を抽出することを特徴とする請求項1〜4のいずれか1項に記載の情報分類装置。
- 更に、予め定めた分割基準を格納する分割基準格納手段を含み、
前記文字情報抽出手段は、前記抽出情報に基づいて抽出した前記文字列の集合を、前記予め定めた分割基準に基づいて複数の部分文字列集合に分割し、
前記ラベル化手段は、前記部分文字列集合に含まれる前記文字列を分類別に前記ラベルに置き換え、
前記ラベル出現パタン推定手段は、前記部分文字列集合から前記ラベル化手段により置き換えられたラベル列を入力としてラベルの出現パタンを推定することを特徴とする請求項5に記載の情報分類装置。 - 前記予め定めた分割基準として、前記データ内での隣接する前記文字列間の距離が規定値以上であるか否かを設定し、
前記分割基準を満たすか否かに基づいて、各文字列を異なる部分文字列集合に含ませるか、又は、各文字列を同一の部分文字列集合に含ませることを特徴とする請求項6に記載の情報分類装置。 - 前記対応情報は、抽出した前記文字列について、分類した文字列の分類より上位の分類又はより下位の分類に関しても対応関係を定義され、
更に、文字情報分類手段を含み、該文字情報分類手段は、推定した前記出現パタンで表される前記各ラベルを、前記対応情報に基づいて前記置き換え前の前記各文字列の任意の分類又は該任意の分類より上位の分類あるいは該任意の分類より下位の分類に対応付け、所定の組合せに適合する適合文字情報を選択することによって、前記データから抽出した前記文字列を分類することを特徴とする請求項3に記載の情報分類装置。 - 前記文字情報分類手段は、同一分類の前記文字列で成立する分類条件があれば、前記ラベル化手段において同一分類の隣り合う2つ以上の前記文字列を1つの前記ラベルに置き換える処理の前に、前記ラベル列を当該分類条件と照合し、当該分類条件による分類を行なうことを特徴とする請求項8に記載の情報分類装置。
- 前記文字情報抽出手段は、前記文字列として抽出するキーワードを分類毎に定義付けたキーワード情報を格納するキーワード辞書を、前記抽出情報格納手段として含み、
前記文字情報抽出手段は更に、文書等のデータを格納するデータ格納手段と、前記データ格納手段に格納されているデータを参照し、参照したデータからテキストデータを抽出するテキストデータ抽出手段と、抽出されたテキストデータから前記キーワード辞書に格納されているキーワード情報に基づいてキーワードを抽出してキーワード列を前記文字列として生成するキーワード抽出手段と含むことを特徴とする請求項5に記載の情報分類装置。 - 更に、前記分類の結果を出力する結果出力手段を含むことを特徴とする請求項8又は9に記載の情報分類装置。
- 請求項1〜11のいずれか1項に記載の情報分類装置と、
前記情報分類装置と通信ネットワークを介して接続され、該通信ネットワークを通じて取得したデータを格納する少なくとも1つのデータ蓄積手段を含む情報分類システムであって、
前記情報分類装置における前記文字情報抽出手段は、前記データ蓄積手段に格納された前記データの文字情報から所定の文字列を抽出することを特徴とする情報分類システム。 - 文字情報を含むデータの構成を解析する情報分類方法であって、
前記データの文字情報から所定の文字列を抽出する文字情報抽出処理と、
抽出した各文字列を、前記文字列の分類を表すラベルに置き換えることによって、前記文字列を一連のラベル列に変換するラベル化処理と、
前記ラベル列内に繰り返し出現する前記ラベルの出現パタンを推定するラベル出現パタン推定処理と、
を含み、
前記ラベル化処理においては、前記抽出した文字列の集合に含まれる同一分類の隣り合う2つ以上の前記文字列を1つの前記ラベルに置き換えることによって前記文字列を前記一連のラベル列に変換することを特徴とする情報分類方法。 - 更に、抽出した文字列の分類と前記文字列を置き換える前記ラベルとの対応関係を定義した対応情報を格納する対応情報格納処理を含み、
前記ラベル化処理においては、前記対応情報に基づいて、抽出した文字列を分類別に前記ラベルに置き換えることを特徴とする請求項13に記載の情報分類方法。 - 前記ラベル出現パタン推定処理においては、前後の出現パタン間で欠落したラベルを補足しながら逐次的に当該出現パタンの推定を行なうことを特徴とする請求項13又は14に記載の情報分類方法。
- 前記対応情報は、抽出した前記文字列について、分類した文字列の分類より上位の分類又はより下位の分類に関しても対応関係を定義され、
更に、文字情報分類処理を含み、該文字情報分類処理は、推定した前記出現パタンで表される前記各ラベルを、前記置き換え前の前記各文字列の任意の分類又は該任意の分類より上位の分類又は該任意の分類より下位の分類に対応付け、所定の組合せに適合する適合文字情報を選択することによって、前記データから抽出した前記文字列を分類することを特徴とする請求項14に記載の情報分類方法。 - 前記文字情報分類処理においては、同一分類の前記文字列で成立する分類条件があれば、前記ラベル化処理において同一分類の隣り合う2つ以上の前記文字列を1つの前記ラベルに置き換える処理の前に、前記ラベル列を当該分類条件と照合し、当該分類条件による分類を行なうことを特徴とする請求項16に記載の情報分類方法。
- 更に、前記分類の結果を出力する処理を含むことを特徴とする請求項16又は17に記載の情報分類方法。
- コンピュータに、文字情報を含むデータの構成の解析を実行させるための情報分類プログラムであって、
前記データの文字情報から所定の文字列を抽出する文字情報抽出処理と、
抽出した前記各文字列を、前記文字列の分類を表すラベルに置き換えることによって、前記文字列を一連のラベル列に変換するラベル化処理と、
前記ラベル列内に繰り返し出現する前記ラベルの出現パタンを推定するラベル出現パタン推定処理と、
を実行させ、
前記ラベル化処理においては、前記抽出した文字列の集合に含まれる同一分類の隣り合う2つ以上の前記文字列を1つの前記ラベルに置き換えることによって前記文字列を一連のラベル列に変換する処理を実行させるための情報分類プログラム。 - 更に、抽出した文字列の分類と前記文字列を置き換える前記ラベルとの対応関係を定義した対応情報を格納する対応情報格納処理を実行させ、
前記ラベル化処理においては、前記対応情報に基づいて、抽出した文字列を分類別に前記ラベルに置き換える処理を実行させることを特徴とする請求項19に記載の情報分類プログラム。 - 前記ラベル出現パタン推定処理においては、前後の出現パタン間で欠落したラベルを補足しながら逐次的に当該出現パタンの推定を実行させることを特徴とする請求項19又は20に記載の情報分類プログラム。
- 前記対応情報は、抽出した前記文字列について、分類した文字列の分類より上位の分類又はより下位の分類に関しても対応関係を定義され、
更に、文字情報分類処理を実行させ、該文字情報分類処理においては、推定した前記出現パタンで表される前記各ラベルを、前記置き換え前の前記各文字列の任意の分類又は該任意の分類より上位の分類又は該任意の分類より下位の分類に対応付け、所定の組合せに適合する適合文字情報を選択することによって、前記データから抽出した前記文字列を分類する処理を実行させることを特徴とする請求項19〜21のいずれか1項に記載の情報分類プログラム。 - 前記文字情報分類処理においては、同一分類の前記文字列で成立する分類条件があれば、前記ラベル化処理において同一分類の隣り合う2つ以上の前記文字列を1つの前記ラベルに置き換える処理の前に、前記ラベル列を当該分類条件と照合し、当該分類条件による分類を行わせることを特徴とする請求項22に記載の情報分類プログラム。
- 更に、前記分類の結果を出力する処理を実行させることを特徴とする請求項22又は23に記載の情報分類プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2008517918A JP5126541B2 (ja) | 2006-05-26 | 2007-05-21 | 情報分類装置、情報分類方法、及び情報分類プログラム |
Applications Claiming Priority (6)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2006146148 | 2006-05-26 | ||
| JP2006146148 | 2006-05-26 | ||
| JP2007125612 | 2007-05-10 | ||
| JP2007125612 | 2007-05-10 | ||
| JP2008517918A JP5126541B2 (ja) | 2006-05-26 | 2007-05-21 | 情報分類装置、情報分類方法、及び情報分類プログラム |
| PCT/JP2007/060741 WO2007139039A1 (ja) | 2006-05-26 | 2007-05-21 | 情報分類装置、情報分類方法、及び情報分類プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2007139039A1 JPWO2007139039A1 (ja) | 2009-10-08 |
| JP5126541B2 true JP5126541B2 (ja) | 2013-01-23 |
Family
ID=38778560
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2008517918A Expired - Fee Related JP5126541B2 (ja) | 2006-05-26 | 2007-05-21 | 情報分類装置、情報分類方法、及び情報分類プログラム |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US9025890B2 (ja) |
| EP (1) | EP2028598A4 (ja) |
| JP (1) | JP5126541B2 (ja) |
| WO (1) | WO2007139039A1 (ja) |
Families Citing this family (15)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR100714393B1 (ko) * | 2005-09-16 | 2007-05-07 | 삼성전자주식회사 | 텍스트 추출 기능을 갖는 호스트 장치 및 그의 텍스트 추출방법 |
| JP5402099B2 (ja) * | 2008-03-06 | 2014-01-29 | 株式会社リコー | 情報処理システム、情報処理装置、情報処理方法およびプログラム |
| US8131720B2 (en) * | 2008-07-25 | 2012-03-06 | Microsoft Corporation | Using an ID domain to improve searching |
| JP5299619B2 (ja) * | 2008-12-18 | 2013-09-25 | 日本電気株式会社 | データ検査装置、データ検査方法、及びデータ検査プログラム |
| US8255416B2 (en) * | 2009-02-11 | 2012-08-28 | Execware, LLC | System and method for contextual data modeling utilizing tags |
| US9405821B1 (en) | 2012-08-03 | 2016-08-02 | tinyclues SAS | Systems and methods for data mining automation |
| US9396179B2 (en) * | 2012-08-30 | 2016-07-19 | Xerox Corporation | Methods and systems for acquiring user related information using natural language processing techniques |
| US8813242B1 (en) * | 2013-02-25 | 2014-08-19 | Mobile Iron, Inc. | Auto-insertion of information classification |
| US9495347B2 (en) * | 2013-07-16 | 2016-11-15 | Recommind, Inc. | Systems and methods for extracting table information from documents |
| US10762142B2 (en) | 2018-03-16 | 2020-09-01 | Open Text Holdings, Inc. | User-defined automated document feature extraction and optimization |
| US11048762B2 (en) | 2018-03-16 | 2021-06-29 | Open Text Holdings, Inc. | User-defined automated document feature modeling, extraction and optimization |
| US11610277B2 (en) | 2019-01-25 | 2023-03-21 | Open Text Holdings, Inc. | Seamless electronic discovery system with an enterprise data portal |
| WO2020257973A1 (en) * | 2019-06-24 | 2020-12-30 | Citrix Systems, Inc. | Detecting hard-coded strings in source code |
| US11861693B2 (en) * | 2021-07-30 | 2024-01-02 | Ramp Business Corporation | User interface for recurring transaction management |
| US20250148039A1 (en) * | 2023-11-02 | 2025-05-08 | Sap Se | Generic web page extraction and data comparison framework |
Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6052693A (en) * | 1996-07-02 | 2000-04-18 | Harlequin Group Plc | System for assembling large databases through information extracted from text sources |
| JP2000268033A (ja) * | 1999-03-12 | 2000-09-29 | Nippon Telegr & Teleph Corp <Ntt> | 情報列に対してタグ情報を付与するための方法および装置ならびに同方法が記録される記録媒体 |
| US20030046078A1 (en) * | 2001-09-04 | 2003-03-06 | Abrego Gustavo Hernandez | Supervised automatic text generation based on word classes for language modeling |
| US20040123233A1 (en) * | 2002-12-23 | 2004-06-24 | Cleary Daniel Joseph | System and method for automatic tagging of ducuments |
| JP2004240517A (ja) * | 2003-02-03 | 2004-08-26 | Toshiba Corp | テキスト分類ルール作成装置、テキスト分類ルール作成方法およびテキスト分類ルール作成プログラム |
| US20050022115A1 (en) * | 2001-05-31 | 2005-01-27 | Roberts Baumgartner | Visual and interactive wrapper generation, automated information extraction from web pages, and translation into xml |
| JP3705439B1 (ja) * | 2004-11-08 | 2005-10-12 | クオリティ株式会社 | 個人情報探索プログラム,個人情報管理システムおよび個人情報管理機能付き情報処理装置 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3489326B2 (ja) | 1996-04-10 | 2004-01-19 | 株式会社日立製作所 | テーブル生成方法 |
| TW421764B (en) * | 1996-05-21 | 2001-02-11 | Hitachi Ltd | Input character string estimation and identification apparatus |
| US6178396B1 (en) * | 1996-08-02 | 2001-01-23 | Fujitsu Limited | Word/phrase classification processing method and apparatus |
| JP3639126B2 (ja) * | 1998-01-22 | 2005-04-20 | 富士通株式会社 | 住所認識装置及び住所認識方法 |
| US7233891B2 (en) * | 1999-08-24 | 2007-06-19 | Virtural Research Associates, Inc. | Natural language sentence parser |
| JP2003150624A (ja) | 2001-11-12 | 2003-05-23 | Mitsubishi Electric Corp | 情報抽出装置および情報抽出方法 |
| JP2003167914A (ja) * | 2001-11-30 | 2003-06-13 | Fujitsu Ltd | マルチメディア情報検索方法、プログラム、記録媒体及びシステム |
| US7072880B2 (en) * | 2002-08-13 | 2006-07-04 | Xerox Corporation | Information retrieval and encoding via substring-number mapping |
| AU2003271083A1 (en) * | 2002-10-08 | 2004-05-04 | Matsushita Electric Industrial Co., Ltd. | Language model creation/accumulation device, speech recognition device, language model creation method, and speech recognition method |
| JP2006099236A (ja) * | 2004-09-28 | 2006-04-13 | Toshiba Corp | 分類支援装置、分類支援方法及び分類支援プログラム |
| KR20060056820A (ko) | 2004-11-22 | 2006-05-25 | 엘지전자 주식회사 | 플라즈마 디스플레이 패널 구동장치 및 구동방법 |
| JP4780296B2 (ja) | 2005-10-03 | 2011-09-28 | トヨタ自動車株式会社 | 半溶融成形装置 |
-
2007
- 2007-05-21 EP EP07744175A patent/EP2028598A4/en not_active Ceased
- 2007-05-21 US US12/302,483 patent/US9025890B2/en active Active
- 2007-05-21 WO PCT/JP2007/060741 patent/WO2007139039A1/ja not_active Ceased
- 2007-05-21 JP JP2008517918A patent/JP5126541B2/ja not_active Expired - Fee Related
Patent Citations (7)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6052693A (en) * | 1996-07-02 | 2000-04-18 | Harlequin Group Plc | System for assembling large databases through information extracted from text sources |
| JP2000268033A (ja) * | 1999-03-12 | 2000-09-29 | Nippon Telegr & Teleph Corp <Ntt> | 情報列に対してタグ情報を付与するための方法および装置ならびに同方法が記録される記録媒体 |
| US20050022115A1 (en) * | 2001-05-31 | 2005-01-27 | Roberts Baumgartner | Visual and interactive wrapper generation, automated information extraction from web pages, and translation into xml |
| US20030046078A1 (en) * | 2001-09-04 | 2003-03-06 | Abrego Gustavo Hernandez | Supervised automatic text generation based on word classes for language modeling |
| US20040123233A1 (en) * | 2002-12-23 | 2004-06-24 | Cleary Daniel Joseph | System and method for automatic tagging of ducuments |
| JP2004240517A (ja) * | 2003-02-03 | 2004-08-26 | Toshiba Corp | テキスト分類ルール作成装置、テキスト分類ルール作成方法およびテキスト分類ルール作成プログラム |
| JP3705439B1 (ja) * | 2004-11-08 | 2005-10-12 | クオリティ株式会社 | 個人情報探索プログラム,個人情報管理システムおよび個人情報管理機能付き情報処理装置 |
Non-Patent Citations (8)
| Title |
|---|
| CSNG199800747024; 土井美和子、外4名: '文書構造抽出技法の開発' 電子情報通信学会論文誌 第J76-D-II巻,第9号, 19930925, p.2042-2052, 社団法人電子情報通信学会 * |
| CSNG200501237002; 相澤彰子、外3名: 'レコード同定問題に関する研究の課題と現状' 電子情報通信学会論文誌 第J88-D-I巻,第3号, 20050301, p.576-589, 社団法人電子情報通信学会 * |
| CSNG200600955008; 細見格: '情報資産管理と個人情報保護のための機密文書検出手法' 情報処理学会研究報告(2006-DD-57) 第2006巻,第104号, 20060929, p.53-60, 社団法人情報処理学会 * |
| CSNJ200610049018; 細見格、外2名: '文書内容解析と設定検証に基づく情報漏洩脅威分析方式 (2)文書内容と構造解析を用いた機密情報分類' 第67回(平成17年)全国大会講演論文集(3) データベースとメディア ネットワーク , 20050302, p.3-35〜3-36, 社団法人情報処理学会 * |
| JPN6012035733; 相澤彰子、外3名: 'レコード同定問題に関する研究の課題と現状' 電子情報通信学会論文誌 第J88-D-I巻,第3号, 20050301, p.576-589, 社団法人電子情報通信学会 * |
| JPN6012035734; 土井美和子、外4名: '文書構造抽出技法の開発' 電子情報通信学会論文誌 第J76-D-II巻,第9号, 19930925, p.2042-2052, 社団法人電子情報通信学会 * |
| JPN6012035736; 細見格、外2名: '文書内容解析と設定検証に基づく情報漏洩脅威分析方式 (2)文書内容と構造解析を用いた機密情報分類' 第67回(平成17年)全国大会講演論文集(3) データベースとメディア ネットワーク , 20050302, p.3-35〜3-36, 社団法人情報処理学会 * |
| JPN6012035738; 細見格: '情報資産管理と個人情報保護のための機密文書検出手法' 情報処理学会研究報告(2006-DD-57) 第2006巻,第104号, 20060929, p.53-60, 社団法人情報処理学会 * |
Also Published As
| Publication number | Publication date |
|---|---|
| EP2028598A1 (en) | 2009-02-25 |
| US20090148048A1 (en) | 2009-06-11 |
| WO2007139039A1 (ja) | 2007-12-06 |
| JPWO2007139039A1 (ja) | 2009-10-08 |
| US9025890B2 (en) | 2015-05-05 |
| EP2028598A4 (en) | 2011-06-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5126541B2 (ja) | 情報分類装置、情報分類方法、及び情報分類プログラム | |
| EP2527991B1 (en) | Analysis method, analysis device, and analysis program | |
| US8983962B2 (en) | Question and answer data editing device, question and answer data editing method and question answer data editing program | |
| US8140468B2 (en) | Systems and methods to extract data automatically from a composite electronic document | |
| US8954839B2 (en) | Contract authoring system and method | |
| Kiefer | Assessing the Quality of Unstructured Data: An Initial Overview. | |
| JP5013081B2 (ja) | 情報解析装置、情報解析方法、及び情報解析プログラム | |
| US7359896B2 (en) | Information retrieving system, information retrieving method, and information retrieving program | |
| CN111026961A (zh) | 标引多重数据元素内的感兴趣的数据的方法及系统 | |
| CN112463737A (zh) | 针对多格式数据智能匹配模板快速采集数据的系统及方法 | |
| US7493323B2 (en) | Document group analyzing apparatus, a document group analyzing method, a document group analyzing system, a program, and a recording medium | |
| JP5676522B2 (ja) | 文字列変換方法及びプログラム | |
| JP2006099249A (ja) | 障害管理装置および障害管理方法 | |
| CN114676245A (zh) | 上位政策提取方法、装置及电子设备 | |
| US20200226162A1 (en) | Automated Reporting System | |
| CN117112598A (zh) | 处理文本数据的方法和系统、非暂时性计算机可读介质 | |
| JP5238105B2 (ja) | プログラム、及びデータ抽出方法 | |
| JP2020101898A (ja) | 設計図作成支援方法、設計図作成支援装置、及び設計図作成支援プログラム | |
| JP2003058559A (ja) | 文書分類方法、検索方法、分類システム及び検索システム | |
| JP4700637B2 (ja) | Web文書分割方法、システム及びプログラム | |
| KR102183815B1 (ko) | 데이터 관리 시스템 및 데이터 관리 방법 | |
| KR100544375B1 (ko) | 문서파일로부터 명함정보를 추출하기 위한 장치와 방법,및 상기 방법을 기록한 기록매체 | |
| JP2011008811A (ja) | プログラム、及びデータ抽出方法 | |
| WO2024236614A1 (ja) | 文書処理装置、文書処理方法、及び、記録媒体 | |
| JP2022082746A (ja) | 文章処理装置および文章処理方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20100413 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20120711 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20120829 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20121003 |
|
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20121016 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5126541 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20151109 Year of fee payment: 3 |
|
| LAPS | Cancellation because of no payment of annual fees |