JP5245004B2 - 高性能ビデオプロセッサ用の低電力メモリ階層 - Google Patents
高性能ビデオプロセッサ用の低電力メモリ階層 Download PDFInfo
- Publication number
- JP5245004B2 JP5245004B2 JP2012273316A JP2012273316A JP5245004B2 JP 5245004 B2 JP5245004 B2 JP 5245004B2 JP 2012273316 A JP2012273316 A JP 2012273316A JP 2012273316 A JP2012273316 A JP 2012273316A JP 5245004 B2 JP5245004 B2 JP 5245004B2
- Authority
- JP
- Japan
- Prior art keywords
- buffer
- memory
- client
- transfer
- external
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Lifetime
Links
Images


Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/42—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals characterised by implementation details or hardware specially adapted for video compression or decompression, e.g. dedicated software implementation
- H04N19/43—Hardware specially adapted for motion estimation or compensation
- H04N19/433—Hardware specially adapted for motion estimation or compensation characterised by techniques for memory access
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N19/00—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals
- H04N19/60—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using transform coding
- H04N19/61—Methods or arrangements for coding, decoding, compressing or decompressing digital video signals using transform coding in combination with predictive coding
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Picture Signal Circuits (AREA)
- Compression Or Coding Systems Of Tv Signals (AREA)
- Image Input (AREA)
- Dram (AREA)
Description
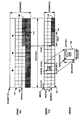
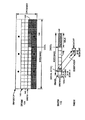
102 ビデオチップ
104 外部メモリ・チップ
106 インタフェース
108 インタフェース
110 ダイレクトメモリアクセス(DMA)ユニット
112 共有メモリ回路
114 動き予測(ME)エンジン
116 クライアント・エンジン
118 処理エンジン
120 ウインドウ・バッファ
122 小バッファ
124 外部DMA回路
126 クライアントDMA回路
140 画像
148 ターゲット・ブロック
152a−152n ローカルメモリ
152 ローカルメモリ
160a クライアントDMAレジスタ
160b 外部DMAレジスタ
RMEM 基準メモリ
TMEM ターゲットメモリ
Claims (20)
- チップ上に配置されるとともに、(i)動き補償を適用し(ii)前記チップ外の外部メモリに格納された少なくとも1つの基準フレームのサブセットを格納するための少なくとも1つの第1のバッファを含む、内部メモリであって、前記少なくとも1つの第1のバッファの大きさが前記基準フレームのブロックの1行より大きい内部メモリと、
前記チップ上に配置されるとともに、(i)前記サブセットを前記外部メモリから前記内部メモリへ転送し(ii)前記第1のバッファにおける前記ブロックの古いセットの処理が完了したとき、前記ブロックの新しいセットを前記外部メモリから前記第1のバッファに転送するように構成された外部転送回路と、
を備え、
(1)前記新しいセットのサイズが(a)前記古いセットのサイズと一致し(b)前記第1のバッファの一部分を占め、(2)ターゲットフレームと前記基準フレームとの間の複数個の動き予測を容易にするように、前記基準フレーム内の前記ブロックのそれぞれが1ターゲットフレームごとに一回だけ前記外部メモリから前記第1のバッファへ転送されることを特徴とする装置。 - 前記チップ上に配置されるとともに、画像データを前記内部メモリから処理エンジンへ転送するように構成されたクライアント転送回路を更に含む請求項1に記載の装置。
- 前記クライアント転送回路が、前記内部メモリと前記処理エンジン間で前記ブロックを転送するように使用される前記少なくとも1つの第1のバッファ内において、複数個の内部オフセットを指定する複数個のクライアント・オフセット・メモリを使用する請求項2に記載の装置。
- 前記クライアント転送回路は更に、クライアントからのインクリメント要求に応答して前記内部オフセットの少なくとも1つをプログラム可能な量だけインクリメントするように構成される請求項3に記載の装置。
- 前記クライアント転送回路への転送要求内の少なくとも1つのベクトルオフセットが、前記クライアント・オフセット・メモリ内に格納された前記内部オフセットの少なくとも1つに加算される請求項3に記載の装置。
- 前記処理エンジンがダブルバッファ・ローカルメモリを含み、前記ダブルバッファ・ローカルメモリの第1の部分は前記処理エンジンと前記内部メモリ間でのデータ転送用に構成可能であり、前記ダブルバッファ・ローカルメモリの第2の部分は前記処理エンジンによる前記データに対する演算用に構成可能である請求項2に記載の装置。
- 前記転送と前記演算の両方が完了すると、前記第1の部分と前記第2の部分が交換される請求項6に記載の装置。
- 前記内部メモリと前記外部メモリ間でデータを転送するために使用される前記基準フレーム内において、前記外部転送回路が、複数個の外部オフセットを指定する複数個の外部オフセット・メモリを使用する請求項2に記載の装置。
- (i)前記外部オフセット・メモリの少なくとも1つが、複数個のクライアント・オフセット・メモリの少なくとも1つに接続され、
(ii)前記外部メモリと前記内部メモリ間の転送は、前記内部メモリと前記処理エンジン間で転送を行うための前記少なくとも1つのクライアント・オフセット・メモリへの信号に基づいて開始される請求項8に記載の装置。 - 前記クライアント転送回路は更に、前記外部メモリと前記内部メモリ間の少なくとも特定数のメモリ処理が完了するまでの間、前記内部メモリと前記処理エンジン間のクライアント転送を遮断するように構成される請求項9に記載の装置。
- 前記内部メモリが前記ブロックの行より小さい、少なくとも1つの第2のバッファを含む請求項1から10の何れかに記載の装置。
- チップ上に配置されるとともに、(i)動き補償を適用し(ii)前記チップ外の外部メモリに格納された少なくとも1つの基準フレームのサブセットを格納する第1のバッファを含む、内部メモリであって、(a)前記第1のバッファの幅が前記基準フレームの幅に一致し、前記第1のバッファの高さが1ブロック行より高く、(b)複数個のブロックの新しいセットが、前記第1のバッファにおける前記ブロックの古いセットの処理が完了したとき、前記外部メモリから受信され、(c)前記新しいセットのサイズが(1)前記古いセットのサイズと一致し(2)前記第1のバッファの一部分を占める内部メモリと、
前記チップ上に配置されるとともに、前記内部メモリからの前記サブセットの少なくとも一部分に作用するように構成された第1の処理エンジンと、
を備え、
ターゲットフレームと前記基準フレームとの間の複数個の動き予測を容易にするように、前記基準フレーム内の前記ブロックのそれぞれが1ターゲットフレームごとに一回だけ前記外部メモリから前記第1のバッファへ転送されることを特徴とする装置。 - 前記チップ上に配置されるとともに、(i)前記サブセットの第1の部分を前記外部メモリから前記内部メモリへ転送し、(ii)前記サブセットの第2の部分を前記内部メモリから前記第1の処理エンジンへ転送するように構成された転送回路を更に含む請求項12に記載の装置。
- (i)前記第1の処理エンジンが、前記転送回路へ水平オフセット及び垂直オフセットの両方を与えるように構成され、前記転送回路が、前記水平オフセット及び前記垂直オフセットで前記第1の部分を前記第1のバッファから読み込むことによって動き補償を行う請求項13に記載の装置。
- 前記第1の処理エンジンが動き予測エンジンを備える請求項12から14の何れかに記載の装置。
- 前記内部メモリが、前記基準フレームのブロックの1行より狭い幅を有する第2のバッファを含む請求項12から15の何れかに記載の装置。
- 前記第2のバッファと前記外部メモリ間でデータを転送するように構成された外部転送回路を更に含む請求項16に記載の装置。
- 前記チップ上に配置されるとともに、画像データを前記内部メモリから受信するように構成された第2の処理エンジンを更に含む請求項12から17の何れかに記載の装置。
- 前記内部メモリの一部分を中間記憶領域として使用することにより、データを前記第1の処理エンジンと前記第2の処理エンジン間で転送するように構成された転送回路を更に備える請求項18に記載の装置。
- 前記チップ上に配置され、前記内部メモリと通信するとともに、(i)入力ビット・ストリームを処理すること、(ii)出力ビット・ストリームを生成することのうち少なくとも1つを行うように構成されたクライアント・エンジンを更に備える請求項12から19の何れかに記載の装置。
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/078,779 US7536487B1 (en) | 2005-03-11 | 2005-03-11 | Low power memory hierarchy for high performance video processor |
| US11/078,779 | 2005-03-11 |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006057833A Division JP5300176B2 (ja) | 2005-03-11 | 2006-03-03 | 高性能ビデオプロセッサ用の低電力メモリ階層 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013055703A JP2013055703A (ja) | 2013-03-21 |
| JP5245004B2 true JP5245004B2 (ja) | 2013-07-24 |
Family
ID=36609333
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006057833A Expired - Lifetime JP5300176B2 (ja) | 2005-03-11 | 2006-03-03 | 高性能ビデオプロセッサ用の低電力メモリ階層 |
| JP2012273316A Expired - Lifetime JP5245004B2 (ja) | 2005-03-11 | 2012-12-14 | 高性能ビデオプロセッサ用の低電力メモリ階層 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2006057833A Expired - Lifetime JP5300176B2 (ja) | 2005-03-11 | 2006-03-03 | 高性能ビデオプロセッサ用の低電力メモリ階層 |
Country Status (3)
| Country | Link |
|---|---|
| US (1) | US7536487B1 (ja) |
| EP (1) | EP1701550A3 (ja) |
| JP (2) | JP5300176B2 (ja) |
Families Citing this family (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP4922839B2 (ja) * | 2007-06-04 | 2012-04-25 | 三洋電機株式会社 | 信号処理装置、映像表示装置及び信号処理方法 |
| US8547445B1 (en) | 2010-02-17 | 2013-10-01 | Ambarella, Inc. | Camera using combined color processing in lookup |
| US8531549B1 (en) | 2010-02-25 | 2013-09-10 | Ambarella, Inc. | Camera that uses YUV to YUV table-based color correction for processing digital images |
| US8508624B1 (en) | 2010-03-19 | 2013-08-13 | Ambarella, Inc. | Camera with color correction after luminance and chrominance separation |
| US8675086B1 (en) | 2010-03-26 | 2014-03-18 | Ambarella, Inc. | Architecture for video, fast still and high quality still picture processing |
| US8659683B1 (en) | 2010-03-25 | 2014-02-25 | Ambarella, Inc. | Digital picture noise reduction by combining high-noise and low-noise processed pictures |
| PL2617186T3 (pl) | 2010-09-13 | 2022-05-09 | Contour Ip Holding, Llc | Przenośna cyfrowa kamera wideo przystosowana do zdalnego sterowania pozyskiwaniem obrazu i podglądu |
| TW201215149A (en) * | 2010-09-17 | 2012-04-01 | Alpha Imaging Technology Corp | Notebook computer for processing original high resolution images and image processing device thereof |
| US8447134B1 (en) | 2010-12-20 | 2013-05-21 | Ambarella, Inc. | Image warp caching |
| KR101996641B1 (ko) | 2012-02-06 | 2019-07-04 | 삼성전자주식회사 | 메모리 오버레이 장치 및 방법 |
| US10558599B2 (en) * | 2017-09-12 | 2020-02-11 | Nxp Usa, Inc. | Method and apparatus for loading a matrix into an accelerator |
| US11234017B1 (en) * | 2019-12-13 | 2022-01-25 | Meta Platforms, Inc. | Hierarchical motion search processing |
Family Cites Families (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPS61251967A (ja) * | 1985-04-30 | 1986-11-08 | Fanuc Ltd | 画像処理装置 |
| JPH02190968A (ja) * | 1989-01-19 | 1990-07-26 | Nec Corp | ベクトル処理装置 |
| JP3605891B2 (ja) * | 1995-06-29 | 2004-12-22 | セイコーエプソン株式会社 | コンピュータシステム |
| US6335950B1 (en) * | 1997-10-14 | 2002-01-01 | Lsi Logic Corporation | Motion estimation engine |
| US6563549B1 (en) * | 1998-04-03 | 2003-05-13 | Sarnoff Corporation | Method and apparatus for adaptively encoding an information stream |
| JP2000010856A (ja) * | 1998-06-19 | 2000-01-14 | Asahi Chem Ind Co Ltd | メモリ制御装置 |
| JP2000287214A (ja) * | 1999-03-31 | 2000-10-13 | Toshiba Corp | 動き検出方法および装置 |
| JP2001101396A (ja) * | 1999-09-30 | 2001-04-13 | Toshiba Corp | 画像歪み補正処理装置および方法、並びに画像歪み補正処理を行うプログラムを格納した媒体 |
| US6859494B2 (en) * | 2001-07-27 | 2005-02-22 | General Instrument Corporation | Methods and apparatus for sub-pixel motion estimation |
| JP2003070000A (ja) * | 2001-08-23 | 2003-03-07 | Matsushita Electric Ind Co Ltd | 画像符号化装置 |
| US20030103567A1 (en) * | 2001-12-03 | 2003-06-05 | Riemens Abraham Karel | Motion compensation and/or estimation |
| US6683614B2 (en) * | 2001-12-21 | 2004-01-27 | Hewlett-Packard Development Company, L.P. | System and method for automatically configuring graphics pipelines by tracking a region of interest in a computer graphical display system |
| JP2004005287A (ja) * | 2002-06-03 | 2004-01-08 | Hitachi Ltd | コプロセッサを搭載したプロセッサシステム |
| JP2004013389A (ja) * | 2002-06-05 | 2004-01-15 | Sony Corp | データ転送システム、データ転送方法 |
| JP4195969B2 (ja) * | 2002-08-05 | 2008-12-17 | パナソニック株式会社 | 動きベクトル検出装置 |
| JP2004126873A (ja) * | 2002-10-01 | 2004-04-22 | Sony Corp | 情報処理装置および方法、記録媒体、並びにプログラム |
| MY134659A (en) * | 2002-11-06 | 2007-12-31 | Nokia Corp | Picture buffering for prediction references and display |
| JP2004356673A (ja) * | 2003-05-26 | 2004-12-16 | Sony Corp | 動きベクトル検出方法及び同方法を用いた画像処理装置 |
| US20040258147A1 (en) * | 2003-06-23 | 2004-12-23 | Tsu-Chang Lee | Memory and array processor structure for multiple-dimensional signal processing |
| US20050129121A1 (en) * | 2003-12-01 | 2005-06-16 | Chih-Ta Star Sung | On-chip image buffer compression method and apparatus for digital image compression |
| US20060050976A1 (en) * | 2004-09-09 | 2006-03-09 | Stephen Molloy | Caching method and apparatus for video motion compensation |
| US8311088B2 (en) * | 2005-02-07 | 2012-11-13 | Broadcom Corporation | Method and system for image processing in a microprocessor for portable video communication devices |
-
2005
- 2005-03-11 US US11/078,779 patent/US7536487B1/en active Active
- 2005-11-12 EP EP05256994.4A patent/EP1701550A3/en not_active Ceased
-
2006
- 2006-03-03 JP JP2006057833A patent/JP5300176B2/ja not_active Expired - Lifetime
-
2012
- 2012-12-14 JP JP2012273316A patent/JP5245004B2/ja not_active Expired - Lifetime
Also Published As
| Publication number | Publication date |
|---|---|
| JP2006254437A (ja) | 2006-09-21 |
| US7536487B1 (en) | 2009-05-19 |
| JP5300176B2 (ja) | 2013-09-25 |
| JP2013055703A (ja) | 2013-03-21 |
| EP1701550A2 (en) | 2006-09-13 |
| EP1701550A3 (en) | 2014-10-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5245004B2 (ja) | 高性能ビデオプロセッサ用の低電力メモリ階層 | |
| KR100606812B1 (ko) | 비디오 디코딩 시스템 | |
| US8175157B2 (en) | Apparatus and method for controlling data write/read in image processing system | |
| US20110013696A1 (en) | Moving image processor and processing method for moving image | |
| US9530387B2 (en) | Adjusting direct memory access transfers used in video decoding | |
| KR100881539B1 (ko) | 메모리 직접 접근 방식의 이미지 데이터 구조 | |
| EP0602642B1 (en) | Moving picture decoding system | |
| JPH06225292A (ja) | イメージデコーデングシステムのためのモジュールメモリ | |
| Li et al. | Architecture and bus-arbitration schemes for MPEG-2 video decoder | |
| US20070071099A1 (en) | External memory device, method of storing image data for the same, and image processor using the method | |
| JPWO1999067742A1 (ja) | 画像処理装置 | |
| US7330595B2 (en) | System and method for video data compression | |
| US20030123555A1 (en) | Video decoding system and memory interface apparatus | |
| US8045021B2 (en) | Memory organizational scheme and controller architecture for image and video processing | |
| JP2008136177A (ja) | 動き検出装置、MOS(metal−oxidesemiconductor)集積回路および映像システム | |
| KR100708183B1 (ko) | 움직임 추정을 위한 영상 데이터 저장 장치 및 그 데이터저장 방법 | |
| Li et al. | Design of memory sub-system with constant-rate bumping process for H. 264/AVC decoder | |
| KR100504507B1 (ko) | 비디오 디코딩 시스템 | |
| US20090310683A1 (en) | Video coding device and video coding method | |
| US20130322551A1 (en) | Memory Look Ahead Engine for Video Analytics | |
| Wang et al. | SDRAM bus schedule of HDTV video decoder | |
| KR20000045011A (ko) | 엠펙 비디오 인코더의 메모리 접속 장치 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20121214 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20121214 |
|
| A975 | Report on accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A971005 Effective date: 20130107 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20130312 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20130408 |
|
| FPAY | Renewal fee payment (event date is renewal date of database) |
Free format text: PAYMENT UNTIL: 20160412 Year of fee payment: 3 |
|
| R150 | Certificate of patent or registration of utility model |
Free format text: JAPANESE INTERMEDIATE CODE: R150 Ref document number: 5245004 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313113 |
|
| S531 | Written request for registration of change of domicile |
Free format text: JAPANESE INTERMEDIATE CODE: R313531 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |