従来のパスワードベースのセキュリティシステム
従来のパスワードに基づくセキュリティシステムは、典型的に2つのフェイズ(段階)を含む。具体的には、登録段階の間、ユーザはパスワードを選択し、それらのパスワードはサーバなどの認証デバイスに格納(記憶)される。認証段階の間、リソースやデータへのアクセスを得るために、ユーザは彼らのパスワードを入力し、それらのパスワードは該パスワードの格納されたバージョンに対して検証される。パスワードがプレーンテキストとして格納されるなら、システムへのアクセスを得る敵対者は、あらゆるパスワードを得ることができるかもしれない。このようにして、単一の成功している攻撃でさえも、全体システムのセキュリティを危険に曝しうる。
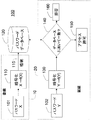
図1に示されているように、従来のパスワードに基づくセキュリティシステム100は、登録段階10の間に、コード化110されたパスワード101をパスワードデータベース120に格納(記憶)1115する。具体的には、Xが格納115されるパスワード101であるならば、システム100は実際にf(X)を格納し、ここでf(.)は或る暗号化すなわちハッシュ関数110である。認証段階20の間、ユーザは候補パスワードY102を入力し、システムはf(Y)を判別130して、f(Y)が格納されたパスワードf(X)に一致するとき、システムへのアクセス150を許可し、そうでなければ、アクセスは否定160される。
利点としては、暗号化されたパスワードは、通常、インバート(逆転、逆行)させることが非常に難しいので、暗号化関数なしでは、敵対者には役に立たない。
従来のバイオメトリックに基づくセキュリティシステム
バイオメトリックセキュリティシステムは、しばしば観測と呼ばれるバイオメトリックパラメータを得るため、肉体的なバイオメトリック特徴を計測する。従来のバイオメトリックセキュリティシステムには、暗号化されていないパスワードを格納する、パスワードに基づくシステムと同じような脆弱性がある。具体的には、データベースが暗号化されていないバイオメトリックパラメータを格納するならば、それらのパラメータは攻撃と誤用を被りやすい。
たとえば、顔認識システムまたは音声認識を使用するセキュリティシステムでは、敵対者は、該敵対者と同様のバイオメトリックパラメータを捜し求めることができるかもしれない。適当なバイオメトリックパラメータが見つけ出された後に、敵対者は、不正アクセスを得るために、該パラメータを変更して該敵対者の外観または声と一致するようにすることができるかもしれない。同様に、指紋或いは虹彩認識を使用するセキュリティシステムでは、敵対者は、不正アクセスを得るために、一致する指紋または虹彩を模造するデバイスを制作することができるかもしれない。たとえば、そのようなデバイスは、偽造の指または偽造の目である。
基本的なバイオメトリック特徴の変動可能性ばかりでなく、それらの特徴が測定される方法における変動可能性によっても、バイオメトリックパラメータを暗号化することが常に可能であるというわけではない。この変動可能性すなわち差を「ノイズ」と呼ぶことができる。
具体的には、バイオメトリックパラメータXは登録段階の間に入力される。たとえば、パラメータXが暗号化すなわちハッシュ化関数f(X)を使用して暗号化されて、格納されるとする。認証段階の間に、同じユーザから得られたバイオメトリックパラメータは異なる場合がある。たとえば、顔認証を使用するセキュリティシステムでは、登録および認証のために使用されるカメラは、異なる方向、感度および分解能を持つことができる。通常、照明はかなり異なる。肌の色合い、ヘアスタイル、およびその他の顔の特徴は簡単に変えることができる。このようにして、認証の間に、新たに観測されたパラメータYが同じ暗号化関数fに通されるならば、その結果f(Y)はf(X)と一致せず、拒否を引き起こすであろう。同様の問題は、虹彩および指紋パターンなどの他のバイオメトリックに基づくユーザ認証でも存在する。
誤り訂正符号(コード)
アルファベットQ上の、(N、K)誤り訂正符号(ECC)Cは長さNのQKベクトルを含む。リニア(N、K)ECCは、N行K列の生成行列Gを使用するか、またはN−K行N列のパリティチェックマトリクスHを使用することによって、説明できる。名称「生成行列」は、ベクトルwとして表される符号語が、ベクトルvにマトリクスGを後から(右から)掛けることにより、すなわちw=vGにより、どんな長さKの入力行ベクトルvからも生成され得るという事実に基づいている。同様に、ベクトルwが符号語であるかどうかをチェックするために、HwT=0であるか否かチェックしてもよく、ここで、列ベクトルwTは行wの転置である。
誤り訂正符号の標準的用法では、入力ベクトルvはベクトルwにコード化(符号化)されて、格納されるか、或いは伝送される。ベクトルwの崩壊した(間違いのある)バージョンが受信されるならば、デコーダは、エラーを修正するために、コードに冗長性を使用する。直観的に、コードのエラー修正能力はコードの冗長性の量に依存する。
スレピアンーウォルフ、ウイナージブ、およびシンドロームコード
ある意味で、スレピアンーウォルフ(SW)コードは誤り訂正符号の逆(反意語)である。誤り訂正符号は冗長性を加えてデータを拡大するが、SWコードは冗長性を取り除いてデータを圧縮する。具体的に、ベクトルxおよびyは関連付けられたデータを表している。エンコーダが既にベクトルyを持っているデコーダにベクトルxを伝えることを望むならば、該エンコーダは、デコーダにはベクトルyがあるという事実を考慮に入れて、データを圧縮することができる。
極端な例として、ベクトルxおよびyが1ビットだけ異なるならば、エンコーダは、単にベクトルxおよび相違の位置を記載することにより、データの圧縮を実現することができる。勿論、より現実的な相関モデルに対しては、より高度なコードが要求される。
SWコーディングおよび関連するウイナージブ(WZ)コーディングの基本理論は、IEEE Transactions on Information Theory(情報理論に関するIEEEトランザクション)、Vol.19、ページ471〜480、1973年7月発行の「Noiseless coding of correlated information sources(相関情報ソースの無雑音符号化)」において、スレピアンおよびヴォルフによって記載されているとともに、IEEE Transactions on Information Theory、Vol.22、ページ1〜10、1976年1月発行の「The rate−distortion function for source coding with side information at the decoder(デコーダでの副情報を有するソースコーディングに対する速度−歪み関数」において、WynerおよびZivによっても記載されている。より最近、プラダン(Pradhan)およびラムチャンドラン(Ramchandran)が、IEEE Transactions on Information Theory、Vol.49、ページ626〜643、2003年3月発行の「Distributed Source Coding Using Syndromes (DISCUS):Design and Construction(シンドロームを使用する分散型ソースコーディング:設計と構成)」において、そのようなコードの実用的な実用化について記載している。
本質的には、シンドロームコードは、N−K行N列を有するパリティチェックマトリクスHを使用することによって、動作する。長さNのバイナリ(2進)ベクトルxを長さKのシンドロームベクトルに圧縮するために、S=Hxを判定する。復号化は、しばしば、使用された特定のシンドロームコードの詳細に依存する。たとえば、シンドロームコードがトレリス(trellis)に基づくならば、パラダン(Pradhan)外により記述されているように、シンドロームベクトルSに対応する最も有望なソースシーケンスXおよび副情報のシーケンスを見つけるために、周知のヴィテルビ(Viterbi)アルゴリズムなどの様々なダイナミックプログラミングに基づく検索アルゴリズムを使用できる。
或いはまた、低密度のパリティチェックシンドロームコードが用いられるならば、2004年3月発行のData Compression Conference(データ圧縮カコンファレンス)の予稿集、ページ282〜291、「On some new approaches to practical Slepian−Wolf compression inspired by channel coding(チャネル符号化で鼓舞された実用的なスレピアンーウォルフ圧縮への幾つかの新アプローチ)」に、コールマン外により記載されているように、確率伝搬復号化を適用できる。
ファクター(要素)グラフ
従来技術では、上述したようなコードは、しばしば「ファクターグラフ」と呼ばれる2部グラフによって表される。F.R.Kschischang、B.J.FreyおよびH.A.Loeliger、「Factor Graphs and the Sum−Product Algorithm(ファクターグラフと加算値積のアルゴリズム)」、IEEE Transactions on Information Theory、vol.47、ページ498〜519、2001年2月、およびG.D.Forney,Jr.、「Codes on Graphs:Normal Realizations(グラフに関するコード:通常の実現」、IEEE Transactions on Information Theory、vol.47、ページ520〜549、2001年2月、およびR.M.Tanner、「A Recursive Approach to Low−Complexity Codes(低複雑さコードへの反復アプローチ)」、IEEE Transactions on Information Theory、vol.27、ページ533〜547、1981年9月、を参照。また、これらはすべて本明細書中に引用して援用される。
一般に、ファクター(要素)グラフは2部グラフであり、「可変ノード」および「ファクター(要素)ノード」と呼ばれる2つのタイプのノードを含んでいる。可変ノードはファクターノードに接続されるだけであり、また、逆も同様である。ファクターノードは慣習的に四角形を使用して描かれ、また、可変ノードは慣習的に円を使用して描かれ、また、可変ノードおよびファクターノードの間の接続は対応する円および四角形を接続する線によって表される。時々、符号(シンボル)、すなわち「+」は、それが実行する制約条件の種類を表すために、ファクターノードの中に描かれる。
可変ノードはコードで使用される符号を表しており、またファクターノードはそれらの符号に対する制約条件を表している。可変ノードは該当する制約条件を受ける場合にだけ、ファクターノードに接続される。
バイオメトリックパラメータをコーディングする従来技術
この発明に関連する従来技術は3つのカテゴリになる。まず最初に、そのようなバイオメトリックパラメータの安全な格納に関係ない、特徴抽出、記録およびバイオメトリックパラメータの使用について記述している多くの従来技術がある。この発明は安全な格納に関係しており、主に、バイオメトリックパラメータをどのように取得するかに関する詳細には関わらないので、従来技術のこのカテゴリの詳細は省略される。
この発明に関連する2番目のクラスの従来技術は、安全な格納とバイオメトリックス(生物測定学)の認証のために設計された以下のシステムを含む。「Method and system for normalizing biometric variations to authenticate users from a public database and that ensures individual biometric data privacy(公開データベースからユーザを認証するためにバイオメトリックなバラツキを正規化して、個々のバイオメトリックデータのプライバシーを保障する方法およびシステム)」、米国特許6,038,315;Proceedings of the IEEE Symposium on Security and Privacy,May 1998における、Davida,G.I.,Frankel,Y.,Matt,B.J.による「On enabling secure applications through off−line biometric identification(オフラインバイオメトリック認証で安全な応用を可能にすることについて)」;Proceedings of the 2002 IEEE International Symposium on Information Theory,June 2002における、Juels,A.,Sudan,M.,による「A Fuzzy Vault Scheme(ファジィボールトスキーム)」;2001年11月26日に出願された米国特許出願第09/994,476、「Order invariant fuzzy commitment system(順序不変ファジィコミットメントシステム」;Proc. 5th ACM Conf. on Comp. and Commun. Security,New York,NY,pgs.28−36,1999における、Juels and Wattenbergの「A fuzzy commitment scheme(ファジィコミットメントスキーム)」;Asilomar Conf. on Signals,Systems,and Comp.,vol.1,pp.577−581,November 2004における、S.Yang and I.M.Verbauwhedeの「Secure fuzzy vault based fingerprint verification system(安全なファジィボールトに基づく指紋照合システム」;Proc. Workshop:Biometrics:Challenges arising from theory to practice,pp.13−16,August 2004における、U.Uludag and A.Jainの「Fuzzy fingerprint vault(ファジィ指紋ボールト」。
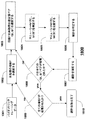
図2は、米国特許6,038,315に記載されている基本的方法の詳細の幾つかを示す。登録フェーズ(段階)210では、バイオメトリックパラメータが、Eで表されたビットのシーケンスの形式で取得201される。次に、ランダムな符号語W202が2進の誤り訂正符号から選択され、エクスクルーシブOR(排他的論理和)関数220を使用してパラメータEに加算的に結合されて、リファレンス(基準)Rを生成221する。任意ではあるが、リファレンスRはさらにコード化230されうる。何れの場合でも、リファレンスRはパスワードデータベース240に格納される。
認証段階220では、バイオメトリックパラメータE’205が認証のために提示される。その方法は、E’でRのXOR(排他的論理和)を判定250し、これらの2つを減算してZ=R−E=W+E−E’を得る251。次に、この結果が誤り訂正符号で復号260されて、W’を生成261する。ステップ270で、W’がWと一致するならば、アクセスが許可271され、そうでなければ、アクセスが拒否272される。
その方法は、本質的には、ハミング距離、すなわち登録されたバイオメトリックE201と認証バイオメトリックE’205との間で異なるビット数を測定する。その差が或る所定の閾値より小さいならば、アクセスが許可される。この方法は実際のバイオメトリックパラメータEではなく、リファレンスRだけを格納するので、安全である。
ダビダ外(Davida et al.)およびジュエルス外(Juels et al.)は、図2に示される方法の変形例を記述する。具体的には、両者とも、結果として得られる符号語を安全にする操作が後に続く登録段階の間、誤り訂正符号でバイオメトリックデータをコード化する。ダビダ外は、チェックビットを送るだけで符号語を隠し、他方、ジュエルス外は「チャフ」と呼ばれる幾らかの量のノイズを加算する。
「多因子のバイオメトリック認証デバイスおよび方法」という名称の米国特許6,363,485は、秘密鍵を生成するために、バイオメトリックデータと誤り訂正符号およびパスワードや個人識別番号(PIN)などの或る秘密情報を結合するための方法について記載している。ゴッパコードやBCHコードなどの誤り訂正符号が様々な排他的論理和操作で使われる。
図2に図示した固定データベースアクセス制御システムに加えて、3番目のクラスの従来技術は、データ保護、具体的には、ラップトップ、PDA、携帯電話、およびデジタルカメラなどの、メモリを含むモバイル機器ためのデータ保護のための生体認証を使用することを含む。モバイル機器は容易に紛失したり、盗まれたりし易いので、モバイル機器に格納されたデータを保護することが必要になる。
従来技術に関する問題
図4は、データDを格納するための現存する手法での問題を図示する。コード化プロセス410では、データDを暗号化440して暗号文Cを生成441するために、バイオメトリックパラメータP402がユーザから得られ、キーとして使用される。バイオメトリックパラメータPおよび暗号文Cの両方ともストリッジ450にセーブ(保存)される。ユーザがデータDを解読420したがっているとき、バイオメトリックパラメータP’460がユーザから得られて、格納されたバイオメトリックパラメータP402と比較される。P’がPと一致470するならば、システムはアクセスを許して、格納された暗号文Cを解読してデータDを生成401するためにPを使用し、さもなければ、データは解読されない471。
記憶媒体が危険にさらされていない限りでのみ、そのような従来のシステムは有効である。しかし、敵対者がそのようなメディア(媒体)へアクセスすることができるならば、敵対者はPを得て、データを復号する。
第1に、ビットベースの従来の方法は疑わしいセキュリティ(安全性)しか提供しない。さらに、バイオメトリックパラメータは、バイナリ(2進)値の代わりに、しばしば実数或いは整数である。一般に、従来技術は、バイオメトリックパラメータが一様に分布しているランダムな(無作為の)ビットで構成され、格納されたバイオメトリックからこれらのビットを正確に判別するのが難しいと仮定する。実際には、バイオメトリックパラメータはしばしばバイアスをかけられており、これがセキュリティにネガティブに影響する。また、敵対者が格納されたバイオメトリックの大体(近似)のバージョンだけを再生したとしても、敵対者の攻撃により重要な害が引き起こされる場合がある。従来の方法は、敵対者がコード化されたバージョンから実際のバイオメトリックを推定するのを防止するように設計されていない。
たとえば、米国特許6,038,315は、ランダムな符号語Wを加算することによって、基準値R=W+Eが効果的にバイオメトリックEを暗号化するという事実に頼る。ところで、その方法は劣悪なセキュリティを実現する。EをRから再生する多くの方法がある。たとえば、ベクトルEが1と等しいほんの数ビットを有するならば、RとWの間のハミング距離は小さい。このようにして、誤り訂正デコーダは容易にWをRから再生することができるかもしれないし、したがってEを再生することができるかもしれない。或いはまた、たとえば、符号語の分布が悪く、すなわちコードの重さスペクトルが小さくて、多くの符号語がすべてゼロベクトルの回りに群がるならば、敵対者はRからEの良い近似を得ることができるかもしれない。
第2に、疑わしいセキュリティに加えて、従来の方法は、格納されるデータ量を増大させるという実用的な不都合を有する。バイオメトリックデータベースがしばしば多数の個々のユーザのためのデータを格納するので、追加のストリッジ(記憶装置)によりシステムの費用と複雑さがかなり増大される。
第3に、多くの従来の方法は、高い計算量(複雑さ)を有する誤り訂正符号またはアルゴリズムを必要とする。たとえば、従来技術のリード−ソロモン(Reed−Solomon)およびリード−ミューラー(Reed−Muller)復号アルゴリズムは一般に、2次関数的な大きな計算量(複雑さ)を有し、また、しばしばコード化されたバイオメトリックの長さにおいて、より高位に(大きく)なる。
第4に、従来技術では既知のモバイルセキュリティシステム用の基本アーキテクチャに基本的な問題がある。図4に示されているようなモバイルセキュリティシステムは、それ自体が危険にさらされない場合にだけ、有効であり得る。ラップトップ上のモバイルセキュリティシステムの例に戻ると、敵対者がPとCが格納された媒体へ物理的にアクセスすることができない場合にだけ、セキュリティは有効であり得る。敵対者が、たとえばラップトップからハードディスクを取り外すことによって、そのようなメディアへアクセスすることができるならば、敵対者は、直ちに、Cを生成するのに使用された暗号化キーであったPを得て、Cを解読できる。
従来のモバイルセキュリティシステムにおける主な困難は、ユーザのバイオメトリックパラメータに対応する暗号キーが、デバイスに格納されているということである。このようにして、デバイスが盗まれるならば、格納されたパラメータを使用することでデータを復号できる。
第5に、バイオメトリックス(生体認証)に特有のノイズ構造に対する、誤り訂正符号化またはシンドロームコード復号化を行うための良い方法がないので、或いは、該ノイズ構造をモデル化するまでの多くの考察も行われていないので、安全なバイオメトリック(生体測定認証)システムに関する殆どの従来技術は、無記憶な雑音モデルや、ノイズの本質を単純化しすぎて実際の運用条件を反映しない、他のモデルを使用している。すなわち、従来のモデルは、バイオメトリック特徴の時間とともに変動するダイナミックス(動力学)および取得と測定のプロセスを正確に表していない。その代わりに、それらのモデルは、ノイズが無記憶であり、空間的或いは時間的な構造も持っていないと仮定する。
しばしば、バイオメトリック特徴は、1つの計測から別の計測まで変動する。たとえば、指紋生体認証では、「マニューシャ(特徴;minutiae)」点が設定された特徴集合(feature set)としてしばしば使用される。マニューシャ点の相対的な位置と方向は、登録および認証の間、かなり異なる場合がある。これにより、認証過程が複雑になる。この問題を解決するためのほとんどの簡単な試みは、非常に高次元であるために、実用化のためには非実用的であるモデルを使用する。
したがって、構造化されたノイズを含むバイオメトリックデータのためのモデルを提供することが望ましい。さらに、チャネルコードを使用してバイオメトリックパラメータを前処理し、前処理されたパラメータが符号化および復号化のために最適な形式を有するようにすることが望ましい。
実施の形態1.
この発明の実施の形態は以下の構成部を含む:
バイオメトリックパラメータを安全に格納するためのシンドロームエンコーダとハッシュ化方法、バイオメトリックキーで暗号化されたデータを安全に格納するためのシンドロームコードに基づく暗号化方法、および前の2つの方法などの安全なバイオメトリック応用のために使用されるシンドロームコードを最適化する方法。
安全なバイオメトリックパラメータのためのシンドロームおよびハッシュ化方法
図3は、この発明によるシンドロームとハッシング(ハッシュ化)に基づくバイオメトリックセキュリティシステム300を示している。ユーザのバイオメトリック特徴が、バイオメトリックパラメータ(データまたは観測)を得るために、測定される。この発明による方法は、圧縮されたシンドロームベクトルに生成するために、シンドロームコードでバイオメトリックパラメータを圧縮する。
従来の圧縮とは違って、シンドロームコードによって生成されたシンドロームベクトルのみから、元のバイオメトリックデータを再構成或いは近似することはできない。シンドロームベクトルおよび元のバイオメトリックパラメータのハッシュはバイオメトリックデータベースに格納される。
ユーザを認証するために、バイオメトリックパラメータが再び測定される。そのバイオメトリックパラメータは、元のバイオメトリックパラメータを復号するために、格納されたシンドロームベクトルに結合される。シンドローム復号化が失敗するならば、元のバイオメトリックパラメータが再生されず、また復号されたパラメータのハッシュは格納されたハッシュと一致しない。したがって、ユーザはアクセスを拒否される。シンドローム復号化が成功するならば、元のバイオメトリックパラメータのハッシュは復号されたパラメータのハッシュと一致し、それはユーザの真正性を証明する。ハッシュの役割は、ユーザエントリ制御を提供し、ユーザによって提供されたバイオメトリックパラメータが、元のバイオメトリックパラメータを正確に再構成することができるくらいに、充分に良いことを確認することである。シンドロームエンコーダとハッシュの両方とも多対1マッピングであるが、シンドロームコードは、元のバイオメトリックパラメータを再構成するのに有用な構造を有する。他方、ハッシュ関数は、たとえば、暗号のハッシュでもよいが、それは元のバイオメトリックを推定するのに役に立つ情報を提供しない。
登録フェーズ(段階)
登録段階310では、ユーザの肉体的(身体的)な特徴についてのバイオメトリックデータを取得する。たとえば、バイオメトリックデータは、顔の画像、スピーチ(音声)の録音、指紋の画像、または虹彩のスキャンから得られる。
以下、バイオメトリックデータとは、ユーザの身体的な特徴から感知され、測定され、または別の方法で取得された生のバイオメトリック信号のことを言及する。特徴はバイオメトリックデータから抽出される。特徴はd次元の特徴ベクトルに配設される。特徴ベクトルは登録バイオメトリックパラメータ301を形成する。様々な形式のバイオメトリックデータから特徴を抽出するための方法は、上述したように、当技術分野では周知である。特徴ベクトルのバイオメトリックパラメータへの変換および最適なシンドロームコードは以下に詳述する。
バイオメトリックパラメータE301は、登録シンドロームベクトルがS331を生成するために、シンドロームエンコーダ330を使用してコード化される。次に、登録ハッシュH341を生成するために、メッセージ認証符号すなわちハッシュ関数がバイオメトリックパラメータEに適用340される。ハッシュ関数は、RFC1321、1992年4月の「The MD5 Message Digest Algorithm(MD5メッセージダイジェストアルゴリズム)」において、ロン リベスト(Ron Rivest)により記述された周知のMD5暗号ハッシュ関数でもよい。登録シンドロームベクトル−ハッシュペア(S、H)331、341はバイオメトリックデータベース350に格納される。
如何なるタイプのシンドロームコード、たとえば、上述したSWコードやWZコード、でも使用できる。この発明の好適な実施の形態では、いわゆる「反復−累積(repeat−accumulate)コード」から得られたコード、すなわち「積−累積(product−accumulate)コード」および我々が「拡張ハミング−累積(extended Hamming−accumulate)コード」と呼ぶコードを使用する。
我々は一般に、これらを直列に連結された累積(SCA)コードと言及する。一般的な意味における、これらのクラスのコードに関する詳しい情報ためには、以下を参照。J. Li,K.R.Narayanan,and C.N.Georghiades、「Product Accumulate Codes:A Class of Codes With Near−Capacity Performance and Low Decoding Complexity(積累積コード:能力に近いパフォーマンスおよび低い復号化複雑さのクラスのコード)」、IEEE Transactions on Information Theory,Vol.50,pp.31−46,January 2004;M.Isaka and M.Fossorier、「High Rate Serially Concatenated Coding with Extended Hamming Codes(拡張ハミングコードを有する高速直列連鎖コーディング)」、submitted to IEEE Communications Letters, 2004;D.Divsalar and S.Dolinar、「Concatenation of Hamming Codes and Accumulator Codes with High Order Modulation for High Speed Decoding(高速デコーディングための上位変調によるハミングコードと累算器コードとの連結)」、IPN Progress Report 42−156,Jet Propulsion Laboratory,Feb.15,2004。
Yedidia,et al.により2004年8月27日に出願された、「Compressing Signals Using Serially−Concatenated Accumulate Codes(直列連鎖累積コードを使用して信号を圧縮する)」という発明の名称の米国特許出願第10/928,448が、引用によりここに援用されるが、これには、この発明によって使用されるようなSCAコードに基づく、我々の好適なシンドロームエンコーダの動作が記載されている。
バイオメトリックパラメータ301ための我々のシンドロームエンコーダ330には、多くの利点がある。そのシンドロームエンコーダ330は整数値入力で作動することができる。対照的に、従来のエンコーダは一般的に2進値入力で作動する。シンドロームエンコーダは、バイオメトリックデータベース350のストリッジ(格納)要求条件を最小にするために、非常に高い圧縮率を有する。シンドロームエンコーダは、レート(rate)適応型になるように設計できて、増加形式(漸増的)に作動することができる。
認証フェーズ(段階)
認証段階320では、ユーザからバイオメトリックデータを再び取得する。認証バイオメトリックパラメータE’360を得るために、特徴が抽出される。マッチ(一致)する登録シンドロームベクトルS331および登録ハッシュH341を見つけるために、データベース350が検索される。
この検索によりデータベース350のあらゆるエントリ(S−Hペア)をチェックすることができ、或いはまたヒューリスティック(発見的)に順序付けられた検索を使用して、マッチするエントリを見つけるプロセスを加速することができる。具体的には、データベースのi番目のシンドロームベクトル−ハッシュペアを(Si、Hi)と表すならば、全数探索により最初に、シンドローム復号化をE’およびS1に適用して、シンドロームデコーダ出力のハッシュをH1と比較する。アクセスが拒否されるならば、同じプロセスが(S2、H2)で試みられ、次に(S3、H3)など、すべてのエントリが試みられるまで、或いはまた、アクセスが許可されるまで、実行される。
登録ユーザ名などのその他の情報が利用可能であれば、検索を加速できる。たとえば、登録ユーザ名のハッシュ(バイオメトリックパラメータのハッシュHと混同すべきではない)は、登録段階の間、ペアSおよびHとともに格納される。次に、認証段階では、ユーザは認証ユーザ名を提供し、またシステムはその認証ユーザ名のハッシュを判別して、マッチ(一致)するハッシュ化登録ユーザ名でS−Hペアに対してデータベースを検索し、その結果得られたS−Hペアを有するE’を認証するよう試みる。
具体的には、シンドロームデコーダ370が登録シンドロームベクトルSに適用され、この際、認証パラメータE’360は「副」情報として働く。シンドロームデコーダは、当技術分野では一般的に知られている。典型的には、確率伝播すなわちターボ符号を使用するデコーダは、低い複雑さで素晴らしいエラー復元力を持っている。シンドロームデコーダ370の出力は復号された登録パラメータE”371である。復号された値E”371は、シンドロームベクトルS331を生成するのに使用された元のバイオメトリックパラメータE301の推定値である。ハッシュ関数340は、認証ハッシュH’381を生成するために、E”371に適用される。
登録値および認証値H341およびH’381が互いに比較390される。それらの値が一致しないならば、アクセスは拒否392される。そうでなければ、値E”381は元のバイオメトリックE301にほぼ(実質的に)一致する。この場合、ユーザはアクセス391を許可されることができる。
また、ユーザを認証するため、復号されたパラメータE”381と認証バイオメトリックパラメータE’360とを直接比較してもよい。たとえば、E’およびE”が顔認識システムでバイオメトリックパラメータに対応するならば、顔の間の類似性を比較するための在来型アルゴリズムをパラメータE’およびE”に適用してもよい。
シンドロームに基づくデータ暗号化
図5は、データ501をコード化(符号化)510および復号化520するための方法500を示している。コード化プロセス510では、第1のユーザから最初のバイオメトリックパラメータP502を得る。パラメータは、暗号文C541を生成するために、入力データD501を暗号化540するのに使用される。ところで、従来技術と対比して、第1のバイオメトリックパラメータPはメ決してモリに格納されない。その代わりに、シンドロームエンコーダ530は、シンドロームベクトルS531を生成するために、第1のバイオメトリックパラメータPをコード化し、また、ペア(S、C)が互いに関連付けられてメモリ550に格納される。この発明の実施の形態1では、入力データは、登録プロセスの間にユーザから取得された生のバイオメトリックデータである。
人が暗号文541を解読520したいと思うとき、第2のユーザからバイオメトリックパラメータP’560を取得する。格納されたシンドロームベクトルC531は、第2のバイオメトリックパラメータを使用してシンドローム復号化され、第3のバイオメトリックパラメータP”571を生成する。そして、第3のバイオメトリックパラメータP”は、出力データD’509を生成するために、暗号文541を解読580するのに使用される。明らかに、第2または第3のバイオメトリックパラメータが第1のバイオメトリックパラメータと一致しないならば、出力データD’509は入力データD501と一致しない。出力データは、第1のユーザと第2のユーザが正確に同一人である場合にだけ、入力データと一致するであろう。
この発明の実施の形態1では、前述と同様に、バイオメトリックパラメータのハッシュHもまた格納できる。ハッシュ同士が一致するのをチェックすることにより、復号化が成功したことを確認する。ハッシュがなければ、セキュリティは維持されるが、デコーダは、復号化が成功したことを確認できない。多くの形式のソースデータには、不正確な復号化に起因するファイルは有用なものは何ら対応しないので、ハッシュは必要でない。
本方法には、以下の利点がある。敵対者がシンドロームベクトルおよび暗号文(S、C)へのアクセスを得たとしても、データを解読することができない。これは、シンドロームベクトルから暗号キー、すなわち第1のバイオメトリックパラメータPを再生できないからである。また、シンドロームコードの誤り訂正特性により、第2のバイオメトリックパラメータP’が第1のバイオメトリックパラメータPと若干異なっても、適切に設計されたシンドロームデコーダは、暗号キーP502として使用された第1のバイオメトリックパラメータと正確に同じ第3のバイオメトリックパラメータP”を成功裏に生成することができる。
シンドロームコード化は、バイオメトリックパラメータを安全に格納する効果的な方法を提供し、また、バイオメトリックな情報を安全に格納する他の方法にも適用できる。なお、バイオメトリックデータから特徴ベクトルを抽出できることに注意するべきである。したがって、上述したバイオメトリックパラメータのいずれも、対応する特徴ベクトルで代替することができる。
暗号化された形式でバイオメトリックパラメータを格納することの追加の利点は、これが、安全なバイオメトリックストリッジアプリケーション(バイオメトリック格納への適用)がバイオメトリック認識アプリケーション(バイオメトリック認識への適用)で使用されたものと異なる特徴ベクトルで作動するのを可能にすることである。たとえば、指紋認識システムは、しばしば指紋の画像から抽出された、いわゆる「マニューシャ(特徴:minutiae)」に基づく特徴ベクトルを使用する。同様に、虹彩認識システムは、虹彩画像を1列のガボール(Gabor)フィルタに通過させることにより抽出された特徴を使用することもある。
多くの場合、バイオメトリック認識(たとえば、顔認証や指紋による本人確認)用の理想的な特徴ベクトルは、シンドロームコード化/復号化のための理想的な特徴ベクトルと異なる場合がある。多くの場合、これは、認識(recognition)または確認(identification)システムのための分類子、たとえば、ガウス混合モデル(GMM)、或いはニューラルネットワーク、或いは隠れマルコフ(Markov)モデルに基づく分類子、を訓練するためのプロセスは、シンドロームエンコーダやデコーダの確率伝搬デコーダとともに用いられるヒストグラムを訓練するために使用されるプロセスとは異なる特徴ベクトルを生成することによる。
図6は、入力バイオメトリックデータ601の暗号化されたバージョンを格納するための方法600を示している。上述したように、バイオメトリックデータは、ユーザのバイオメトリック特性を測定或いは検知するのに使用される生の信号から得る。
アクセス制御システムの登録段階610では、たとえば、ユーザから最初のバイオメトリックデータB601を取得する。次に、最初のバイオメトリックデータB601から第1のバイオメトリックパラメータP602の特徴ベクトルを得る。第1のバイオメトリックデータBは、暗号キーとして第1のバイオメトリックパラメータPを使用して暗号化640され、暗号文C641を生成する。さらに、第1のバイオメトリックパラメータは、シンドロームコード化されて、シンドロームベクトルS631を生成する。そして、関連付けられたペア(S、C)がバイオメトリックデータベース650に格納される。
認証段階620では、ユーザから認証用の第2のバイオメトリックデータB’660を得る。この第2のデータは、第2のバイオメトリックパラメータP’661の特徴ベクトルを生成するのに使用される。そして、シンドロームデコーダ670は、第1のバイオメトリックパラメータを復号して、第3のバイオメトリックパラメータP”671を生成する。次に、第3のバイオメトリックパラメータをキーとして使用して暗号文Cを解読680して、第3のバイオメトリックデータB”681を生成する。その後、認証バイオメトリックデータB’および復号されたバイオメトリックデータB”をバイオメトリック認識法690のより比較して、特有の関数へのアクセスが許可されるか拒否されるかを判別する692。前述したように、第1および第3バイオメトリックデータが正確に同じである場合、すなわち最初および次のユーザが同じ人間である場合にだけ、アクセスが許可される。
別の変形例では、比較ステップは、バイオメトリックデータから抽出された特徴ベクトルを使用できる。それらの特徴ベクトルは、バイオメトリックパラメータと同じである必要はない。さらに、検証ステップは完全に異なるプロセスを使用できるので、比較されるそれら2つの特徴ベクトルは、ほぼ(実質的に)同じであればよい。このようにして、特徴ベクトルは、時間経過とともに特定のユーザを特徴付けるバイオメトリックデータの変動(バラツキ)における、より広い範囲を許容することができる。
我々は、図6に示されるプロセスの幾つかの利点を列挙する。認証システムは、ステップ690で従来の認識システムを使用できる。また、シンドロームエンコーダ/デコーダによって使用されるバイオメトリックパラメータPおよびP’は、バイオメトリックな検証ステップ690によって使用されるパラメータまたは特徴ベクトルの如何にかかわらず選択できる。その上、シンドロームコード化はバイオメトリックパラメータを安全に格納する効果的な方法である。ところで、図6に示される方法は、バイオメトリックパラメータを安全に格納する他の方法にも適用できる。
安全なバイオメトリックパラメータのための最適のシンドロームコードの設計
一般に、バイオメトリックパラメータとバイオメトリック特徴とを保護するためにシンドロームコードを使用する際のセキュリティと精度との間には、トレードオフがある。具体的には、如何なるシンドロームコードのキーパラメタも、シンドロームベクトルにおけるビットの数である。多くのビットを有するシンドロームベクトルは、バイオメトリックデータに関するより多くの情報を伝達して、バイオメトリックデータにおけるノイズと変動を許容することをより容易にする。対照的に、より小さなシンドロームベクトルは、より少ない情報を敵対者に与えるが、エラーをより生じやすい傾向がある。
或る極端な場合、シンドロームベクトルの長さがその基礎となるバイオメトリックデータの長さとほぼ同じであるとき、元のバイオメトリックデータはシンドロームベクトルのみから正確に再生できるので、如何なる量のノイズも許容できる。勿論、この場合、シンドロームベクトルを得る敵対者はまたバイオメトリックデータを再生することができるので、システムのセキュリティを危険にさらすことになる。
それとは正反対に、非常に少ないビット数のシンドロームベクトルは、敵対者がそのシンドロームベクトルからバイオメトリックデータを再生できないという意味で、非常に良いセキュリティを提供する。しかし、この場合、登録バイオメトリックデータと認証バイオメトリックデータとの間の許容できる変動(バラツキ)は限定的である(小さい)。
明らかに、シンドロームに基づくエンコーダおよびデコーダは、セキュリティとバイオメトリック変動(バラツキ)に対する許容度とをバランスさせるシンドロームベクトルのための長さを選択するべきである。ところで、入念に設計されたシンドロームコードはエラー復元力を改善できる。
図12に示されるように、以下の用語でシンドロームコードのデザインと動作について記述する。バイオメトリックデータ1201は、たとえば、顔や指紋の画像でよい。完全な特徴ベクトル1202はトレーニングバイオメトリックデータから抽出される。完全な特徴ベクトル1202はシンドローム特徴ベクトル1203まで減少される。シンドローム特徴ベクトルは、デザイナーがシンドロームコード化および復号化のために適切であると判断する、完全な特徴ベクトルの部分をキャプチャする。シンドローム特徴ベクトルからシンドロームベクトル1204をコード化するのに、シンドロームコードが使用される。シンドローム特徴ベクトル1203は図3においてバイオメトリックパラメータE310の役割を担い、一方、シンドロームベクトルはS331である。
バイオメトリック統計モデル
図13は、この発明の実施の形態によるシンドロームコード1204および対応するデコーダ1205(すなわちエンコーダおよびデコーダ)を構成するためのプロセス1300を示している。トレーニングバイオメトリックデータ1301を取得する。選択された特徴モデル1304のパラメータ1302を、トレーニングデータから決定1310する。コーデックに関して、特徴モデルは本質的には「ソース」モデルである。同様に、選択された測定モデル1305のパラメータ1303を1320決定する。測定モデルは、実質的には、「チャンネル」モデルである。そして、パラメータ1302−1303およびモデル1304−1305は、シンドロームコードおよび対応デコーダを構成するのに使用される。なお、チャネルモデルは計測プロセスにおける構造化ノイズに対処するように設計されていることに注意するべきである。このノイズはたとえば、異なる計測インスタンスで観測されるようなバイオメトリックデータの特徴における変化や、インスタンス間の特徴の挿入および削除によって引き起こされ得る。
機械学習の多くのツールは上記の設計プロセス(工程)で役立ち得るが、結果として得られるモデルがシンドロームコード化のために適切な「ハード」特徴ベクトルを有するので、この問題は、機械学習における多くのモデル化問題とは可成り異なる。「ハード」および「ソフト」特徴ベクトル間の相異について、以下で詳細に議論する。
図12に示されるように、シンドローム特徴ベクトル1203は、シンドローム復号化を取り扱い易くするために、典型的には、減少されたサイズ(大きさ)である。シンドロームコードを構成するために、デンシティエボリューション(density evolution)を度数分布(degree distribution)に適用できる。シンドロームコードは、シンドロームベクトル1204をユーザ間に亘るバイオメトリック特徴における変動(バラツキ)に一致させるために、シンドローム特徴ベクトル1203の有限ブロック長などの特徴、或いは可変レートコードを使用する必要性、を考慮に入れるためにさらに洗練される。
シンドロームコードが構成されて選択された後に、以下に述べるように、繰り返しの確率伝搬デコーダを構成する。
量子化
図7に示されるプロセス1300のインスタンス700を詳しく述べる前に、先ず、認証のときに登録中および認証中のバイオメトリックデータの使用を区別する以下の用語を定義する。特徴ベクトルの量子化バージョンに言及するために「ハード」特徴ベクトルという用語を使用し、非量子化特徴ベクトル、または細かく量子化された特徴ベクトルのバージョンに言及するために「ソフト」特徴ベクトルという用語を使用する。
幾つかのバイオメトリックパラメータは、比較的大きな数値範囲に亘って、整数および実数を含むことができるため、量子化が使用されている。暗号化、キー発行、および他の認証プロセス(過程)は小さな範囲に亘って整数でベストに働く。
「ハード」特徴ベクトルと「ソフト」特徴ベクトルとを区分けする理由は、シンドロームベクトルが「ハードな」特徴ベクトルから得られるためである。したがって、「ハード」特徴ベクトルは通常、量子化される。対照的に、認証段階の間、シンドロームデコーダは、「ハード」特徴ベクトルを復号するために、シンドロームベクトルに「ソフト」特徴ベクトルを結合してもよい。したがって、「ソフト」特徴ベクトルは、量子化される必要がないか、またはシステムにおけるエラーを小さくするために異なるように量子化され得る。たとえば、ソフト特徴ベクトルの使用により、シンドロームデコーダは各特徴の最も可能性のありそうな選択の困難な決断より、むしろ各特徴の尤度(likelihoods)を入力として取ることが可能になる。
一般に、バイオメトリックデータから完全な特徴ベクトルに抽出する複数の方法があり、また、完全な特徴ベクトルから「ハード」および「ソフト」特徴ベクトルを抽出する複数の方法がある。したがって、図13のプロセスを各可能性に適用して、トレーニングの間、最も良い総合的な結果をもたらすシンドローム特徴ベクトル1304を選択する。
図7は、最適のシンドロームを構成するためのプロセス1300のインスタンスの詳細を示しており、ここで、バイオメトリック特徴1304に対する統計モデルはバイオメトリック特徴の間のマルコフ関係を表す。トレーニングバイオメトリックデータを取得800する。バイオメトリックデータは、エラーヒストグラム890を生成するのに使用される。エラーヒストグラムはシンドローム特徴ベクトルを選択900するのに使用される。このような関係において、すべてのバイオメトリックパラメータを表すのに「完全な特徴ベクトル」1202(図12を参照)という用語を使用し、また、完全な特徴ベクトルの部分集合を表すのに「シンドローム特徴ベクトル」1203という用語を使用する。シンドローム特徴ベクトルを任意の特徴空間に変形することができる。
シンドローム特徴ベクトル1203が選択された後に、私たちはシンドローム特徴ベクトルの異なる係数の間の相関関係を測定1000する。次に、シンドローム特徴ベクトルと係数間相関関係に対するエラー統計を使用することによって、デンシティエボリューション740を適用して、所与の長さの最適のシンドロームコード1204をもたらす度数分布を検索する。シンドローム特徴ベクトルおよびシンドロームコードが選択された後に、係数間相関関係を利用する確率伝搬デコーダを構成1100する。
エラーヒストグラムを構成する
図8は、エラーヒストグラム890を生成するためのプロセス800を示している。最初に、異なる機会に採られた特定のユーザのためのトレーニングバイオメトリックデータを取得810する。次に、一対のバイオメトリックパラメータBおよびB’を選択820して、完全な「ソフト」特徴ベクトルVS(B)830および完全な「ハード」特徴ベクトルVH(B’)840を決定する。そして、完全な特徴ベクトルの中の各特徴または寸法(dimension)iに対して、位置iのVS(B)から対応する特徴iにおけるVH(B’)の値を推定845し、その推定値が正しいか否かを判定850する。その推定値が正しくなければ、エラーヒストグラム890における特徴iでのVH(B’)およびVS(B)の対応する値に対する階級(bin)をインクリメントする。各特徴iに対してこの過程を完了した後に、すべてのペアのバイオメトリクス(生体認証)BおよびB’が処理されたか否かをチェック860する。そうでなければ、ステップ820に戻って、別のペアのバイオメトリックパラメータを選択する。すべてのペアが既に処理されていれば、エラーヒストグラムが完了し、本プロセスは終了880する。
シンドローム特徴ベクトルの選択
図9は、図8のエラーヒストグラムの支援によりシンドローム特徴ベクトルを選択するためのプロセス900を示している。まず最初に、エラーヒストグラムは信頼性の最も高い特徴から最も低い特徴920へソート(並べ替え)される。具体的には、E(i)がVS(B)の特徴iからVH(B’)の特徴iを予測するさいの平均誤差であるならば、特徴iは、E(i)<E(j)のときに、特徴jよりも信頼できると考えられる。エラーヒストグラムがソートされた後に、エラーヒストグラムから次に最も信頼できる特徴をシンドローム特徴ベクトルに含めて930、現在のシンドローム特徴ベクトルに対する最も良いシンドロームコードを構成し940、最新の特徴を含めることがセキュリティすなわちエラー復元力を増大させるか否かをテスト950する。セキュリティすなわちエラー復元力が増大するならば、シンドローム特徴ベクトルに付加的な特徴を追加し続ける。さもなければ、特徴ベクトルから最も最近に加算された特徴を取り除き960、そして、本プロセスを終了970する。
セキュリティのレベルを特定して、エラー復元力を最適化することを望むならば、ステップ940および950に対して以下のステップを使用できる。まず最初に、ステップ940で、kシンドロームを有する低密度パリティチェック(LDPC)コードを固定度数分布から生成することによって、特徴ベクトルの中の現在の特徴の数に対応する長さNの新しいシンドロームコードが構成される。この場合、セキュリティのレベルは、数量N−kを固定して、且つ本プロセス中それを一定に保っことによって一定に保たれる。そして、バイオメトリックデータのランダムなバイオメトリックサンプルがデータベースから選択され、LDPCコードのパリティチェックマトリクスを適用することによって、シンドロームベクトルへマッピングされ、この結果得られたシンドロームベクトルは、同じユーザからの別のランダムなバイオメトリックサンプルに適用された確率伝搬を使用して復号される。これを何回も繰り返すことにより、与えられた特徴ベクトルに対するシンドロームコードのエラー復元力の推定値を生成する。或いはまた、計算上の更なる複雑さが設計プロセス(工程)で許容できるならば、そのコードに対する度数分布を最適化して、より精度よく誤り確率を推定するためにデンシティエボリューションプロセスを使用できる。これに関して、T.J.Richardson,M.A.Shokrollahi,and R.L.Urbanke,discussed,「Design of capacity−approaching irregular low−density parity−check codes」、IEEE Transactions on Information Theory,Volume 47,Issue 2,pp.619−637,February 2001を参照。なお、この文献は引用によりここに援用される。
エラー復元力のレベルを特定して、最高のセキュリティを得ることを望むならば、ステップ940および950に対して以下のステップを使用できる。まず最初に、ステップ940では、特徴ベクトルの中で現在の特徴の数に対応する長さNの新しいシンドロームコードが、デンシティエボリューションを使用して、設計される。具体的には、デンシティエボリューションによって評価されるように、エラー復元力の特定のレベルを満たす最も高いレートコードが見つかるまで、デンシティエボリューションを使用して、一連の異なるレートコードが構成される。
このプロセスによって選択された特徴ベクトルは、そのシンドロームコードのために特別に設計された特徴ベクトルであるため、「シンドローム特徴ベクトル」として言及される。なお、この特徴ベクトルは、顔或いは物体の認識などのバイオメトリック認識のために構成された他のタイプの特徴ベクトルとは異なる特性を持つことができることに注意すべきである。
係数間相関関係を測定する
シンドローム特徴ベクトルが選択された後、次のステップは、データが互いに相関すると信じられるならば、その係数間相関関係を測定することである。図7によりエラーヒストグラムは完全な特徴ベクトル1202に対して生成されたものなので、そのエラーヒストグラムからこの情報を抽出することはできない。ステップ900は、シンドローム特徴ベクトル1203を生成するために、完全な特徴ベクトルの中の特徴の部分集合だけを選択する。
図10は、バイナリ(2進の)シンドローム特徴ベクトルにおける一次相関関係を測定するためのプロセス1000を示している。このプロセスはまた、非バイナリ特徴ベクトルまたは高次相関に適用できる。まず最初に、バイオメトリックトレーニングデータセットから要素が選択され、そして、シンドローム特徴ベクトルがその要素から抽出される。それから、カウンタ変数iがゼロに初期化1010される。次に、特徴iが0であるか1であるかを検査して、前者(すなわち0)の場合にはステップ1030へ進み、後者(すなわち1)の場合にはステップ1040へ進む。その後、特徴i−1、すなわち1つ前の特徴、が0であったか1であったかを検査して、ヒストグラム中の適切な階級(bin)をインクリメント(増分)1035する。直観的には、階級p00はa0が後続するa0の出現を計数し、また、階級p01はa1が後続するa0の出現を計数する、などである。次に、カウンタiを増分1050し、更なる(処理されていない)特徴がシンドローム特徴ベクトルに残っていないか検査1060して、次の特徴に対して本プロセスを繰り返す。そうでなければ、すなわち各特徴を既に処理していれば、本プロセスを終了1070する。
図10のプロセスがバイオメトリックトレーニングセット(生体認証訓練集合)の各要素に対して実行された後、シンドローム特徴ベクトルの一次相関関係を測定するために、階級p00、p01、p10、およびp11の値を該バイオメトリックトレーニングセットのサイズ(大きさ)で除算する。
最適のシンドロームコードを構成するためにデンシティエボリューションを使用する
シンドローム特徴ベクトル1203が選択されて、係数間相関関係が測定された後、デンシティエボリューションを使用してシンドロームコード1204を設計する。具体的には、LDPCシンドロームコードに対して、シンドロームコード用の度数分布を設計する。
実際に最適度分布を構成するために、デンシティエボリューション技術を適用して幾つかの候補度数分布を生成する。
ところで、当技術分野で知られているような従来のデンシティエボリューションプロセスは係数間相関関係を考慮していない。したがって、デンシティエボリューションによって生成された候補度数分布は、係数間相関関係がないケースに対して適切であるかもしれないが、係数間相関関係が存在するときには、一般的には、異なった振る舞い方をする。
シンドロームコードに対して最も良い度数分布を得るために、バイオメトリックトレーニングデータセットでデンシティエボリューションによって得られた候補度数分布同士を比較して、最善に振る舞う度数分布を選択する。代わりの実施の形態では、係数間相関関係を考慮に入れるように、従来のデンシティエボリューションアルゴリズムを変更する。
シンドロームコードに対する確率伝搬デコーダを構成する
シンドロームコードを設計する際の最終的なステップは、関連付けられた確率伝搬シンドロームデコーダ1205を構成することである。
図11Aは登録段階のハイレベル構造を示しており、ここで、エンコーダ330は、シンドロームコード1102を使用して、シンドローム特徴ベクトル1203からシンドロームベクトル1204を生成する。
図11Bは、認証段階の間に使用される相補型(complementary)デコーダ1107に対する構造を示している。再び、認証を試みるユーザについてバイオメトリックデータ1104のノイズの入った観測が取得される。元のシンドローム特徴ベクトル1203の推定値1108を復号1107して生成するために、バイオメトリックデータ1104は、その測定モデル1305(および測定モデルパラメータ1303)とともに、反復確率伝搬ネットワーク(ファクタ(要素)グラフ)におけるシンドロームベクトル1204および特徴モデル1304(およびその特徴モデルのパラメータ1302)とともに使用される。復号化が成功するならば、推定されたシンドローム特徴ベクトル1108と元のシンドローム特徴ベクトル1203とは一致する。
図11Cに示されるように、我々の確率伝搬ファクターグラフの構成1100は、シンドロームコード1102および可変ノード(=)1120を特定するチェックノード(+)1110に加えて、特徴モデル1304(およびモデルパラメータ1302)を特定する相関関係ノード(C)1130を含む。具体的には、相関関係ノードは各ペアの連続した可変ノードの間に加えられる。可変ノードから隣接するチェックノードまでメッセージを流通させる方法は、他のメッセージで乗算される、各隣接相関ファクターノードからの追加メッセージを含むように変更される。
具体的には、Kschischang外の表記を使用して、μy→f(x)がチェックfから可変ノードyへの状態xに対する入力メッセージであり、L(x)が左の相関関係ノードからの入力メッセージであるならば、可変ノードから右の相関関係ノードへの出力メッセージは、次式で表される。
L(x)・Πμy→f(x),
一方、左の相関関係ノードへの出力メッセージは次式で表される。
R(x)・Πμy→f(x),
ここで、R(x)は右の相関関係ノードからの入力メッセージである。
また、この発明の実施の形態による、メッセージを相関関係ノードに対して流通(入出力)する方法についても記述する。具体的には、メッセージL(x)およびR(x)を判別するための処理手順について記述する。μ(0)が左の相関関係ノードへの入力メッセージであるならば、その相関関係ノードの右側への出力メッセージ、すなわちその相関関係ノードの右側の可変ノードへの入力メッセージ、は次式で表される。
L(0)=p00・μ(0)+p10・μ(1) and L(1)=p10・μ(0)+p11・μ(1),
ここで、p00、p01、p10、およびp11の項は、図10に示されるように、測定された一次相関関係値である。
同様に、その相関関係ノードの左側の出力メッセージ、すなわちその相関関係ノードの左の可変ノードへの入力メッセージ、は次式で表される。
R(0)=p00・μ(0)+p01・μ(1) and R(1)=p01・μ(0)+p11・μ(1).
虹彩バイオメトリックパラメータに対するシンドロームコード設計
次に、処理手順700の虹彩バイオメトリックパラメータの特定のケースへの適用について記述する。完全な「ハード」特徴ベクトルは、「How iris recognition works」,by J.Daugman in IEEE Transactions on Circuits and Systems for Video Technology,Volume 14,Issue 1,Jan.2004 pages 21−30に記述されるように、1組のガボールフィルタから抽出されたビットのシーケンスであるように選択される。この文献は引用によりここに援用される。
完全な「ハード」特徴ベクトルはバイナリ(2元)であるが、完全な「ソフト」特徴ベクトルはクオターナリ(4元)であるように選択される。具体的には、特徴iの完全な「ソフト」特徴ベクトルの値は、その特徴が「ハード」特徴ベクトルにおいて最良の推測であるように選択され、また信頼レベル(信頼度)を示すビットが追加される。詳細には、その特徴に対する判定に自信があるか、または自信が無いかを示すビットが追加された。
たとえば、「ハード」特徴ベクトルの幾つかの特徴は、予測するのが難しいかもしれない。その理由は、たとえば、それらの特徴が、瞼或いは睫毛よって覆われて、「自信が無い」という信頼度数値を受けるべきであるからである。
次に、図8について上述したように、エラーヒストグラムを作成するために、バイオメトリックトレーニングデータを使用し、それから図9の特徴ベクトル設計方法を適用する。完全な特徴ベクトルは約1万の長さを有するが、我々は、多くの特徴1202が信頼できないことを発見した。たとえば、目の上端に対応する特徴ベクトルの構成要素はしばしば瞼または睫毛で覆われる。最も信頼の低い特徴が図9の処理手順によって捨てられた後、シンドローム特徴ベクトル中のおよそ2,000の最も信頼できる特徴が残される。
図7におけるステップ900で処理を止めると、結果として得られるシンドロームベクトルは、単一ユーザに対する虹彩バイオメトリックパラメータにおける自然な変動(バラツキ)を許容しうるようなエラー復元力を有さないであろう。具体的には、或る日に採られたユーザの虹彩の計測が異なる日に採られ同じ虹彩からの計測に結合された状態でコード化されたシンドロームベクトルは、その時の約12%の復号に失敗する。これは、図7における残りのステップに対する必要性を正当化する。
図10の手続きを使用して一次相関関係を測定した後、我々は、「ハード」シンドローム特徴ベクトルにおける或るビットが隣接ビットと同じ値を取る見込み(可能性)が、該隣接ビットの反対の値を取る見込み(可能性)の約2倍であることを検出した。そして、我々は、高い相関関係を利用するために、図7のステップ740を続けて、デンシティエボリューションを使用して最適化されたシンドロームコードを構成した。最終的に、高い一次相関関係を考慮に入れるために、ステップ1100にしたがって確率伝搬デコーダを構成した。
これらのステップに従うことにより、我々の初期のコードより1桁以上も信頼できるシンドロームコードを生成でき、したがって、図7の全体の手続きに従う利点を実証することができる。
指紋特徴に対するシンドロームコード
手続き1300を指紋に適用する。指紋に基づくシステムは、一般に、パターンに基づくか、或いはマニューシャ(特徴)に基づく。ここでは、後者を使用する。指紋マニューシャから特徴ベクトルを抽出する。一般的な手順1300を殆どのバイオメトリックデータに適用できるが、我々は、指紋のマニューシャに対する手続きの詳細について記述する。指紋マニューシャは、その特性として、時間経過とともに変動することがあり、また、計測プロセスは構造化ノイズを受け易い。
図14は、一例の指紋1401および抽出された特徴ベクトル1402を示している。抽出された特徴ベクトル1402はシンドローム特徴ベクトル1203の一例である。特徴は計測フィールド(観測窓)1403で測定されるのみである。便宜上、マニューシャは格子状の四角形で示される。各マニューシャはトリプレットにマッピングされ、たとえば、(a、b、c)は空間的な位置座標(a、b)とマニューシャの角度(c)を表す。以下に述べるように、1つのマニューシャはアラインメント(位置合わせ、整列)の目的のための「コア」として指定することができる。
指紋1401が測定される平面はピクセルのアレーを有するディジタルセンサによって量子化されるので、特徴はマトリクスとして格納される。各センサーピクセルはマトリクス1402における特定のエントリに対応している。マニューシャの存在(有ること)は「1」により表されるが、検知されたマニューシャの欠如(無いこと)はマトリクス1402において「0」で表される。より一般的な表示では、マニューシャの存在を意味する「1」の代わりに、マトリクスにおけるエントリはマニューシャの角度cであろう。
マニューシャの数、位置、および角度は指紋の或る計測から次の計測までに変化する。たとえば、或る計測で(74、52、36o)にマニューシャが存在すれば、別の計測では、それは(80、45、63o)として現れるかも知れないし、或いは全く現れないかも知れない。
様々な理由により、或る計測から次の計測までのマニューシャのこの変動性は、指紋を処理するための多くの従来の方法に対して問題を生じさせる。
明白なバイオメトリックデータの変動性
図に15A−15Cに示されているように、我々のモデルはバイオメトリックデータにおける変動性に対処することができる。これらの図では、破線1500はローカル(局所的)な近傍を示す。図15Aはマニューシャの運動1501(pi、j)を示している。図15Bは削除pe1502を示しており、また、図15Cは挿入psを示している。
図16Aおよび16Bは、この発明の実施の形態による確率伝搬復号化1107を実施するために使用されるファクターグラフ1600の高レベルおよび低レベルの詳細をそれぞれ示す。
高レベルでは、バイオメトリックデータ1201は、シンドロームベクトル1204を生成するために使用されるシンドローム特徴ベクトル1203を生成するために使用される。しかし、シンドローム特徴ベクトル1203はデコーダにより知られていないが、シンドロームベクトル1204は知られている。シンドロームベクトル1204とシンドローム特徴ベクトル1203とは、コード構造1623によって関連付けられる。また、デコーダはバイオメトリックデータ1104のノイズの入った計測を得る。雑音構造は統計モデル1305により記述される。シンドロームベクトル1203とともに、コード構造1623、観測1104および測定モデル1305は、復号1107を行って、元のシンドローム特徴ベクトル1203の推定値1108を生成するために使用される。
図16Bはシンドローム特徴ベクトル、シンドロームベクトルおよびノイズの入った観測の統計モデルを記述するファクターグラフ1600の低レベル構造を示している。
特徴ベクトルグリッド(格子)1402の各位置tは、ファクターグラフ1600における対応するバイナリ確率変数x[t]ノード1609を有する。この確率変数は登録の間、位置tに存在し、それ以外はゼロである、1つのマニューシャである。
特徴ベクトルの格子位置とラベルtとの関連付けは任意であり得る、たとえば、ラスタス−キャン順序でもよい。特徴集合の2次元的性質は、我々のモデルでも考慮に入れられる。
各格子位置に対して、マニューシャが登録の間存在しているという事前確率がある。この事前確率、Pr[x[t]=1]、はファクターノード1608により表される。
その登録格子に対する可変ノード1609の各位置に対して、対応する認証格子に対する対応位置ノード1601がある。認証の間の格子位置tにおけるマニューシャの存在はバイナリ(2進)確率変数y[t]によって表される。マニューシャがプローブに存在していれば、この変数は1と等しく、そうでなければ、ゼロに等しい。ファクターグラフの目標は、登録時の指紋の最初の計測と認証時の2番目の計測との同時分布を表すことである。
我々のモデルでは、各登録位置は、x[t]=1の場合、位置tのマニューシャがプローブ内の位置tの近傍の位置へ移動する確率を持っているか、或いはまた、削除の場合には、測定されない。
変数1604は登録マニューシャの位置の相対変化を表し、また、ファクターノード1603は挿入されたマニューシャの移動および確率に関する事前確率分布を表す。特に、図16Bに示された1次元の移動モデルに対して、z[t]=iは、登録時の位置x[t+i]のマニューシャが認証時に位置z[t]へ移動することを表す。より一般には、そして我々の実施では、2次元移動モデルを使用する。
このような変位(移動){i}のドメインまたは近域(neighborhood)は、破線1500で表す設計パラメータである。変数z[t]=sであれば、偽マニューシャが認証時に位置tに挿入され、また、z[t]=*は、認証時にマニューシャが位置t存在しないことを示す。z[t]=*などのような変数z[t]とy[t]=0などのような変数y[t]との間には、正確な対応がある。
位置tの登録マニューシャ、すなわちx[t]=1、は、tの近傍におけるたかだか1つの観測されたマニューシャについて説明できるだけであるという制約条件を表すために、我々はファクターノード1607を含める。これらのノードに接続される確率変数h[t]1606は、x[t]の削除を表すバイナリ変数である。削除は、検知されなかった或いは抽出されなかったマニューシャ、または登録時に検知された偽のマニューシャ、または大きな移動から生じ得る。ノード1605は各h[t]に対する事前分布を表す。
各ノードy[t]をその対応ノードz[t]に接続するファクターノード1602は、該対応ノードz[t]が*でない場合にのみ、各認証マニューシャy[t]がノンゼロでなければならないという概念を表す。
このモデルに、シンドロームコード1102から生じる制約条件を加える。各シンドロームノードs[i]1611はローカルコード制約条件1610を満し、その制約条件1610は、シンドロームの値が特徴ベクトルx1、x2、…に適合する場合には1に等しく、そうでなければ、ゼロに等しい特性関数である。
それらのマニューシャの方位をファクターグラフに加えることができる。方位情報を加えるために、登録ノード1609はマニューシャについて位置tと方位の両方を示す。また、この情報は事前確率ノード1608に反映される。登録時の方位をシンドロームコード化に必要なハード特徴ベクトルに適合させるために、該登録時の方位は量子化される。
シンドロームビット1611のベクトルは、以上と同様にコード化されるが、今度は、マニューシャの存在の有無およびもし存在すれば、その方位を表す登録変数1609のベクトルからである。削除1605の事前確率は、移動に関する制約条件1607と同様に、変化しないままである。移動と挿入1604の事前確率も変化しないままである。認証ノード1602上の制約条件ノードは、登録ノード1609と認証ノード1601との間の方位の変化がより少なるであろうという概念を反映するように変更される。
メッセージ通過規則と最適化
ファクターグラフ1600によって表される計測および移動モデルを考えると、従来からの技術を使用することによりメッセージ通過規則を導き出すことができる。以下、複雑さの減少を実現するために、メッセージを通過させるための幾つかの簡素化について記述する。
第1の簡素化は制約条件ノード1602からのメッセージに関連する。私たちは、観測されないマニューシャを取り除くためにファクターグラフから「余分なものを取り除く」。具体的には、制約条件1602の形式にしたがって、y[t]=0であるなら、ノード1602からz[t]可変ノード1604への唯一のノンゼロメッセージは状態z[t]=*に対するものである。
その結果、隣接するノード1607に送られる唯一のノンゼロメッセージz[t]は、*状態に対するものである。我々は、この一定のメッセージが1に正規化されると仮定することができる。たとえば、y[t]=y[t+2]=y[t+4]=y[t+5]=*であれば、図16Bの完全なファクターグラフを使用する代わりに、必要なメッセージ通過作用を導き出すために、図17に示すように、余分なものを取り除いたグラフ1700を使用する。これは、ノード1607に対するメッセージ計算の複雑さを大幅に減少させることに通じる。
ファクターノード1607に出入りするメッセージを演算することによって、第2の簡素化が得られる。z[t]可変ノードからの完全なメッセージを使用する必要はない。代わりに、これらのメッセージを、x[t’]におけるマニューシャが位置z[t]に対応する位置へ移動するか否かを示すバイナリメッセージに減少させることができる。ノードz[t]に対するバイナリ情報を使用することによって、可成り演算量を削減することができる。
最初に1組の中間的数量を計算して、その後これらの中間的数量を再利用することにより、様々な規則に対する第3の簡素化を図ることができる。たとえば、可変ノードz[t]からの出力メッセージは他のすべてのノードからの入力メッセージの積である。可変ノードz[t]へのK個の接続があれば、この規則の簡単な実施は、他のK−1個の接続からのメッセージを結合しなければならないので、K2に比例する演算を必要とする。これをより効率的に行うためには、ノードz[t]に対する限界確率(marginal belief)を計算するプロセスにおいて、一度、ノードz[t]に入ってくるすべてのメッセージを結合する。そして、特定の接続に対する出力メッセージを得るために、対数尤度ドメインにおいて、その接続からの入力メッセージにより全メッセージを割り算或いは減算する。
また、三角形ノードからの出力メッセージを計算する際に、中間的数量の同様の再利用を適用できる。特に、z’[t]が、可変ノードz[t]から位置t’のノード1607へのバイナリメッセージを表すものとする。数量z’[t]は、マニューシャが認証の間、位置t’から位置tまで移動するか否かを示す。これらのバイナリメッセージに関するノード1607に対する簡単な合計積(sum−product)の規則は、1604が位置t’でノード1607に接続される可変ノードのすべての可能な組合せに亘って積算することを必要とする。たとえば、位置t’におけるノード1607がノードz[1]、z[2]、z[3]およびz[4]に接続されるならば、z’[1]へのメッセージを演算することは、z’[2]、z’[3]およびz’[4]のすべての可能な組合せに亘って積算することを必要とする。この方法は、各三角形ノードに接続された可変ノードの数で指数関数的な計算の複雑さを有する。
制約条件ノード1607が、高々z’[t]ノードの1つがノンゼロであることを許容することを実現することによって、この指数関数的な複雑さを解消することができる。このようにして、ノードz’[t]に対する各出力メッセージは、他のすべてのノードz’[t]がゼロであることに対応する項と、1つのノードがゼロであることを除いて他のすべてのノードz’[t]に対応する項とを含む。これらの項をあらかじめ計算することによって、ファクターノード1607に対するメッセージ通過規則を、接続の数における指数関数的複雑さから接続の数における1次関数的複雑さへ減少させることができる。
バイオメトリックパラメータの統計を収集する
図18は、ファクターグラフ1600、すなわちこの発明によるモデル、のパラメータ1303を設定するためのプロセス1800を示す。バイオメトリックトレーニングデータ1301を取得する。未処理の指紋Fが選択1802される。指紋Fの測定値BおよびB’の未処理のペアが選択1803される。それらのそれぞれのマニューシャM(B)およびM(B’)が判別1804される。マニューシャを比較1805して、移動、回転、挿入および削除の統計を判別1806する。統計はファクターグラフにおける統計を改訂(revise)1807するのに使用される。まだ処理1808されていない指紋Fの一対の測定値があれば、ステップ1803へ戻る。そうでなければ、まだ処理1809されていない指紋があれば、ステップ1802に戻る。すべての指紋とそれらのマニューシャペアが処理済になった後、統計収集はステップ1810で完了する。
データアラインメント
生体測定システムでは、登録バイオメトリックデータはしばしば認証データに対して位置がずれる。同じバイオメトリックデータの異なる測定値は、平行移動、回転、拡大縮小などのグローバル(大域的)変換(global transformations)によりしばしば変動する。そのような変動は、パターンに基づくバイオメトリック認証、すなわちシンドロームコーディングを使用しない認証方式ではそれほど問題ではない。
対照的に、我々のシステムでは、登録バイオメトリックパラメータのシンドロームベクトル331だけが比較のために利用できる。したがって、異なるアラインメント(配列、配置)に亘る検索は、各可能なアラインメントに対する復号化を伴う。マニューシャ移動モデルは細かいミスアラインメント(位置ずれ)に対応できるが、復号化の演算費用を最小にするために、探索空間を最小にすることが望まれる。
図19は、この発明の実施の形態による、登録或いは認証時の指紋のアラインメントプロセス(整合処理)の各々のステップを示している。指紋が取得1901され、マニューシャパラメータが、そのコア(中心)点の位置および方位とともに、抽出1902される。そのコア点と方位は指紋に対する慣性基準フレームを定義し、ここで、コア点の位置は原点であり、その方位はY軸として機能する。そのコア点に関連する慣性基準フレームに対するマニューシャの位置と方位が再計算1903される。その結果1904、指紋に対する基準フレームで測定された1組のマニューシャが得られる。
利点としては、この手続きにより、平行移動および回転の効果の大部分またはすべてを取り除くことができる。典型的には、そのような前処理は、復号化がより少ない組の平行移動および回転で実行される、計算上より強力(集中的)なローカルサーチ(局所検索)と結合される。この前処理手続きは、マニューシャ抽出ルーチンの一部として使用できる。
パラメータ設定に関するアラインメント後のリビジョン(改訂)
登録および認証バイオメトリック特徴が復号化前にお互いに対して変位する毎に、ファクターグラフのパラメータはこの変位を反映するように変更される。このような例は、登録および認証機能がアラインメント手続き1900により、或いはローカルサーチに対応する多数の小変位により移行する時である。
変位、および登録と認証観測窓1403(図14を参照)の相対的大きさによっては、認証の間、幾つかの登録特徴位置を全く観測できないかも知れない。したがって、これらの観測されない位置に対して、マニューシャ消去の確率を1に設定することによって、これを反映するようにファクターグラフを変更する。これは、ファクターノード1605における消去確率を1に等しく設定することによって、図16Bに反映される。観測される多少の尤度および観測されない多少の尤度を持っている窓1403のエッジ(縁部)の近くのマニューシャに対して、その事前確率1605がそれに応じて変更される。
シンドローム前処理
図3のバイオメトリックセキュリティシステム300では、登録段階の間、バイオメトリックパラメータ301はシンドロームエンコーダ330に直接入力される。同様に、認証段階では、バイオメトリックパラメータ360はシンドロームデコーダ370に直接入力される。
図14はマニューシャ点位置を表示しており、マニューシャ点位置は指紋に対するバイオメトリックパラメータとしてしばしば使用される。図3、5および6に記載したようなバイオメトリックセキュリティシステム用のシンドロームに基づくフレームワークにおいて、この表示を使用することに関して幾つかの問題がある。
第1に、その表示は、まばら(sparse)であり、モデル化するのは難しい。図15に示されるモデルは、マニューシャに固有の移動、挿入および削除をモデル化することを試みる。しかしながら、それらのモデルは複雑である。
第2に、その表示は従来のシンドロームコードに余り適していない。その表示はバイナリデータの形式であっても、データは、偏っており、従来のチャネルコードおよび対応する復号方法がデータに適用されるとき高性能をもたらすような固有の統計的性質を持っていない。
その性能は、ソースの偏った性質および計測チャンネルの非対称性を説明する新しいシンドロームコードを設計することによって、改善できる。これは興味深く且つ複雑なプロセスである。
図20はこの発明の実施の形態によるバイオメトリックパラメータをシンドロームコード化する方法を表している。第1のバイオメトリックパラメータ2010が、たとえば登録段階10の間に(図1を参照)、ユーザから取得される。第1のバイオメトリックパラメータ2010は、バイオメトリックパラメータ2030のバイナリ表示を生成するために、シンドローム前処理2020される。前処理2020は、1組(1以上)のバイナリロジック条件2022を、取得されたバイオメトリックパラメータ2010に適用する。1組のバイナリロジック条件2022は、そのバイナリ表示2030に1組(1以上)の望ましい所定の統計的性質2025を持たせるように、強制或いは試みる。その1組の所定の統計的性質2025について、以下でさらに記述する。バイオメトリックパラメータ2030のバイナリ表示はシンドロームコード化2040されて、第1のシンドローム2050を生成する。ここで、ロジック条件が目標統計的性質を達成しようとすることができることに注意するべきである。また、その処理の間、その統計的性質をダイナミックに調整できることに注意するべきである。
次に、ハッシュ関数を適用することによって、第1のシンドロームをさらに処理して登録ハッシュを生成することができ、生成された登録ハッシュは、後でユーザを認証する際に使用するために、シンドロームベクトルとともに格納されることができる。
我々は、バイナリ表示2030および望ましい統計的性質2025と互換性があるように、我々のエンコーダ2040を明確に設計する。我々は、コード化をバイナリ表示および望ましい統計的性質に適合させることにより、我々のシステムの性能と信頼性が改善されると信じる。
図21は、この発明の実施の形態にしたがってシンドローム復号化する方法の詳細を示す。バイオメトリックパラメータは、たとえば認証段階20の間に、再び獲得される。第2のバイオメトリックパラメータ2110は、シンドローム前処理2020されて、バイオメトリックパラメータ2130のバイナリ表示を生成する。上述したように、バイナリ表示2130は、登録時に課されるのと同じ組の望ましい所定の統計的性質2025を有する。そして、前処理されたバイナリ表示2130は、シンドローム復号化2140への入力として使用されて、再構成されたバイオメトリックパラメータが2145を生成する。上述したように、デコーダは望ましい統計的性質を持っているバイナリ表示と互換性がある。コード化および復号化をバイナリ表示および望ましい統計的性質に適合させることにより、我々のシステムの性能と信頼性とを改善する。
第1および第2のバイオメトリックパラメータが同じ人から来ているならば、譬え第1および第2のパラメータからのバイオメトリックパラメータが詳細では異なっていたとしても、再構成されたバイオメトリックパラメータは、第1のバイオメトリックパラメータと同じでなければならない。
本明細書に記載されたシンドローム前処理は、図3、5および6に示された方法に適用できる。
望ましい目標統計的性質
シンドローム前処理2020は、バイオメトリックパラメータを、望ましい統計的性質2025を有するバイナリ表示すなわちバイナリストリング(文字列)に変形するのに使用される。それらの性質は、いつも得られるわけではないかも知れないので、目標性質であると考えられる。
統計的性質は、シンドロームコードが最適性能を実現できることを保証する。我々の前処理2020により、バイオメトリックパラメータ間の複雑な関係をモデル化するのに関わる複雑さは大きく減少される。
バイナリ表示2030/2130の望ましい1組の統計的性質2025は以下の通り概括される:バイナリ表示における各ビットには、ゼロまたは1のどちらかであるという等しい確率がある;同じバイナリ表示における異なるビットはお互いに独立している;異なるユーザからのバイナリ表示はお互いに独立している;同じユーザの異なる読取りに対するバイナリ表示はお互いに統計的に依存している。
この発明のこれらの実施の形態に具現された手法は図13の実施の形態に対比することができる。図13に示された実施の形態では、特徴モデル1304および測定モデル1305は、トレーニング(訓練)集合におけるバイオメトリックデータの基底構造をモデル化するとともに、バイオメトリックデータが、単一ユーザに対するおよび複数のユーザに亘る、複数の読取りの中でどう変動するかをモデル化する。コード化および復号化をそれらのモデルに適合させるために、何も行わない。
対照的に、図20に示されるようなシンドローム前処理手法は、図13のように、バイオメトリックデータから直接取得された特徴集合を使用しない。その代わりに、図20−21の特徴集合、すなわちバイナリ表示、は、シンドロームコード化および復号化手続きと互換性があるように設計される。
我々は、特徴集合を、既存の、コード設計、シンドロームコード化およびシンドローム復号化手続きと互換性があるように明確に設計する。本明細書に記述した所定の統計的性質を有する特定の組の特徴に対して、設計された特徴集合に適合するバイナリ(2進)対称チャネルに対するチャネルコードを利用できる。そのようなチャネルコードの構造およびそれらに関連するシンドロームコード化および復号化手続きは、よく理解され且つ深く探究されたトピックである。
図22A−22Cはそれぞれ200ビットを有する1組のバイナリ表示のビットストリング(列)に対応する1組の統計的性質を示す。
図22Aはその組のバイナリストリングにおける平均数のヒストグラムを示す。理想的な分布は100を中心しており、それはビットの半分が1であることを含意する。
図22Bは各ストリングにおける、ビットのペア平均情報量(pair−wise entropy)を示す。理想的には、各対のビットが独立していれば、平均情報量はすべての対に対して2である。しかしながら、ビットの中に幾らか依存性があれば、平均情報量の値は2未満となる。最悪の場合には、プロセスバイオメトリックパラメータにおける特定のビットがいつも別のビットから予測できて、その他のビットが等しい確率でゼロまたは1であるなら、ペア平均情報量は1である。
図22Cは、イントラユーザ(ユーザ内)変動(intra−user variations)2210とインターユーザ(ユーザ間)変動(inter−user variations)2220を示す。イントラユーザ変動2210は、同じユーザの複数のサンプルに対応するビットストリング(ビット列)の間の正規化されたハミング距離を表す。インターユーザ変動2220は、異なるユーザのサンプルに対応するビットストリングの間の正規化されたハミング距離を表す。理想的には、イントラユーザ変動とインターユーザ変動は重ね合わせるべきでなく、また、それぞれが狭い範囲に亘って分布するべきである。その上、イントラユーザ変動2210はできるだけ低く(小さく)なるべきであり、たとえば、図示されるように、分布約0.1は、同じユーザの各ビットには10%のエラー確率があることを示す。他方、インターユーザ変動に対する分布は0.5を中心にするべきであり、これは、異なるユーザからのビットストリングがお互いに独立していることを示す。
シンドローム前処理の実行
図23は、我々のシンドローム前処理方法を示す。シンドローム前処理は1組(1以上)のバイナリロジック条件を適用する、すなわち、バイナリ表示すなわちバイナリストリング「00111000101110001…..」をもたらすバイオメトリックパラメータに関してイエス(yes)/ノー(no)応答を有する条件を適用する。
図24に示される我々の方法では、1組のバイナリロジック条件2022がバイオメトリックパラメータに適用される。その適用結果の出力が非バイナリ2430であるならば、その出力は、必要なバイナリ表示をもたらすために2値化4202される。
たとえば、バイオメトリックパラメータは指紋に対するマニューシャ点の位置である。1つのバイナリ(2値)条件は、与えられた2次元(2D)領域のマニューシャの数が閾値Mより大きいか否かを判別する。
バイナリロジック条件
図25A−25Cに示されるように、幾つかのタイプのバイナリロジック条件がバイオメトリックパラメータに適用できる。図25A−25Cのドットは指紋マニューシャの座標(サンプル位置)を表す。図25Aおよび25Bにおいて(x−位置、y−位置)座標、或いはまた図25Cにおいて(x−位置、y−位置、方位)座標(z)。
図25Aでは、各条件はサンプルを通して描かれた線2501に基づいている。バイナリロジック条件はy−mx−n=0である。線はランダムな傾きとy切片値を持つことができる。この発明の実施の形態1では、線より上の(すなわち、条件y−mx−n>0を満たす領域に位置する)マニューシャ点の数と線より下の(すなわち、条件y−mx−n<0を満たす領域に位置する)マニューシャ点の数の差が得られる。これは範囲[−M、M]の値のベクトルをもたらし、ここで、Mは指紋のマニューシャ点の最大数である。必要ならば、ベクトルを2値化することができる。
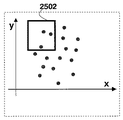
図25Bでは、条件は1組の長方形2502である。各長方形は、幅と高さとともに、該長方形の左上隅を表す原点で生成される。1組の長方形は、これらの点のランダムな値で、または所定の配置により生成できる。この発明の実施の形態1では、条件は与えられた長方形の中のマニューシャ点の数である。
この発明の実施の形態1では、条件は、特定の閾値よりも大きな、与えられた長方形内のマニューシャ点の数であり、ここで、その閾値は、各長方形に対して、その位置および領域、および/又はユーザデータサンプルのグローバルな統計に基づいて変動してもよい。
この発明の別の実施の形態では、条件は1つの長方形内のマニューシャの数と2番目の長方形内のマニューシャの数の差である。
マニューシャ方位などの指紋に関する追加データを含めるために、長方形条件を立方体や直方体2503に拡張でき、ここで、最初の2つの寸法(dimensions)は、上述したように、マニューシャ点位置を表し、また、3番目の寸法(dimension)(z)はマニューシャ方位を表す。図25Cでは、条件は1組の直方体を含んでいる。各直方体は、幅、高さおよび深さとともに、該直方体の左上隅を示す原点で生成される。1組の直方体は、これらの点のランダムな値で、または所定の配置により生成できる。この発明の実施の形態1では、条件は与えられた直方体内のマニューシャ点の数である。この発明の実施の形態1では、条件は、特定の閾値よりも大きな、与えられた長方体内のマニューシャ点の数であり、ここで、その閾値は、各直方体に対して、その位置および体積、および/又はユーザデータサンプルのグローバルな統計に基づいて変動してもよい。この発明の更に別の実施の形態では、条件は1つの直方体内のマニューシャの数と2番目の直方体内のマニューシャの数の差である。
この発明は本明細書に記述した特定のロジック条件に限定されない。バイオメトリックの特性によって、円形、球形、および多角形に基づく他の様々な条件もまた使用できる。
さらに、これらの方法は、マニューシャに基づく特徴集合の変換および2値化に制限されない。その目的は、シンドロームコード化および復号化に適合する、統計情報を有するバイナリ表示を生成するために、バイナリロジック条件をバイオメトリックデータに適用することである。たとえば、この発明は、とりわけ他のタイプの指紋データの中で、パターンに基づくデータや周波数領域データに適用できる。
一般的に言えば、条件の間のオーバラップは、結果として得られるバイナリ表示における相関関係に影響する。条件は、この影響を考えて設計され得る。たとえば、2つの長方形の間の許容できるオーバラップの量に関して制限を課すことができるであろう。また、シンドロームコード化および復号化手続きも、そのような相関関係を考えて設計され得る。しかしながら、この発明の目的は、市販のコード設計やコード化および復号化手続きに対するそのような調整の必要性を最小にすることである。
2値化
図26は2値化の幾つかのタイプを示す。図26Aでは、閾値2601が、バイナリベクトル2603を生成ために、ベクトル2602のすべての値に適用される。この閾値は、すべてのビット位置に対して同じでもよいし、或いは各ビット位置に対して変化してもよい。
図26Bでは、正規直交基底へのランダム投影2604が最初に非バイナリのベクトル2602に適用され、ここで、このランダム投影はすべてのユーザに対して同じである。そして、この投影の結果は、バイナリベクトル2603を生成するために、閾値化プロセスを加えられる。ランダム投影の代わりに、本物のユーザと詐欺師(偽者)とから取得されたサンプルの分離を改善するために、たとえば、主成分分析(principal component analysis)や線形判別分析(linear discriminant analysis)などの他の線形(リニア)或いは非線(ノンリニア)変換を使用することができる。
図26Cでは、非バイナリ(非2値)ベクトル2602が最初に正規化2605され、次に、1組のランダム投影(RP)2604が各ユーザに対して適用され、それに続いて、各ランダム投影に対する閾値化2601が行われる。この閾値化は各投影に対して同じでもよいし、それらの投影の中で変動してもよい。そして、バイナリベクトル2603を生成するため、連結(concatenation)2607がこの後に続いて行われる。
統計的分析
望ましい目標統計的性質が達成されることを保証、確認するために、シンドローム前処理の設計の一部として、統計的分析をバイナリ表示に対して実行することができる。このように、統計的分析が、シンドローム前処理の最終的な結果に対して実行され、シンドローム前処理の動作に対してフィードバックは行われない。
或いは、シンドローム前処理の動作を導くために、シンドローム前処理の間、統計的分析はまた中間的バイナリストリングに対しても実行することができる。このようにして、シンドローム前処理の間、統計的性質の明確なフィードバックが提供される。
シンドローム前処理に対するセキュリティの考察
バイナリ表示におけるビット数および同じユーザの異なるサンプル間の相関関係により、セキュリティのレベルが判別される。たとえば、バイナリストリングが400ビットであり、相関関係が十分に強いためユーザの復号に成功するために300ビットのシンドロームを必要とするだけであるならば、セキュリティのレベルは100ビットである。
セキュリティがシンドロームコード化段階から得られる。事実、シンドローム前処理の結果、所定の統計的相関を有するバイナリストリングが生成される。この場合、本システムによって提供されるセキュリティの推定値は、シンドロームコード化および復号化がモデル化の難しい相関関係を有するバイナリストリングを使用して実行される場合と比較して、より正確であると考えられる。
発明の効果
この発明はバイオメトリックパラメータに基づく安全なユーザ認証を実現する。シンドロームベクトルが元のバイオメトリックデータ或いは如何なる特徴ベクトルの代わりに格納されるので、この発明は安全である。これにより、基礎となるバイオメトリックデータを学習することによりデータベースへのアクセスを得る敵対者を防ぐことができる。
多重記述(multiple descriptions)の周知の問題から従来のツールを使用することにより、敵対者がシンドロームベクトルSだけを使用することで作り出すことができる元のバイオメトリックパラメータEの可能な限り良い推定値を制限することが可能である。たとえば、V.K.Goyal,Multiple description coding:compression meets the network」,IEEE Signal Processing Magazine,Volume:18,pages 74−93,September 2001を参照。その上、推定値の品質が絶対誤差、2乗誤差、重み付け誤差方法、或いは如何なる任意の誤差関数により測定されるか否かに関係なく、これらの制限(限界)を策定することが可能である。対照的に、すべての従来技術の方法はバイナリ値に基づいている。そこでは、セキュリティはハミング距離に依存する。
本質的には、シンドロームベクトルSのセキュリティは、それが元のバイオメトリックパラメータEの圧縮されたバージョンであるという事実による。その上、この圧縮表現はEの「最下位ビット」に対応している。データ圧縮理論から周知のツールを使用して、「高圧縮のシンドロームコードが使用されるならば、これらの最下位ビットはせいぜい元のパラメータEの劣悪な(不十分な)推定値しか生成することができない」ことを立証することが可能である。たとえば、Effros、「Distortion−rate bounds for fixed− and variable−rate multi−resolution source codes」、IEEE Transactions on Information Theory,volume 45,pages1887−1910,September 1999、および「Steinberg and Merhav,「On successive refinement for the Wyner−Ziv problem」、IEEE Transactions on Information Theory,volume 50,pages 1636−1654,August 2004を参照。
第2に、偽造は基礎となるハッシュ関数340における衝突を見つけるのと少なくとも同じくらい難しいので、この発明は安全である。特に、復号されたバイオメトリックE”のハッシュH’が元のハッシュHと一致する場合にだけ、本システムは認証段階390におけるシンドロームペア(S、H)を受け付ける。MD5などの暗号化ハッシュ関数にとって、Eと異なっているがEのハッシュと一致するハッシュを持つ要素E”を見つけ出すことは、一般的に、不可能であると考えられている。而して、シンドローム復号化が、適切なハッシュでE”を復号するのに成功するならば、本システムは事実上、E”がEと同じであると確信することができ、すべての認証決定が元のバイオメトリックパラメータで行われる。
第3に、この発明は、シンドロームベクトルSを生成する際に、元のバイオメトリックパラメータEを圧縮する。特にバイオメトリックデータの質問がたとえば顔画像或いは音声信号などの多量のデータを必要とする場合には、多くのユーザに対するバイオメトリックデータベースは大容量ストレージを必要とすることがある。したがって、必要とされるストリッジ容量を小さくすることにより、費用とエラー復元力の両方で劇的な改良をもたらすことができる。対照的に、バイオメトリックデータの安全な格納に対する殆どの従来技術の方法は、暗号化や誤り訂正のオーバヘッドにより実際に記憶データのサイズ(大きさ)を増大させ、したがって安全でない(セキュリティ保護されていない)システムよりも多くのストリッジ容量を必要とする。
第4に、この発明は、シンドロームコードの理論で作られるので、精巧なコード構造と復号アルゴリズムを適用することができる。特に、この発明によるシンドロームコーディングは、バイナリおよびマルチレベル両方の符号化構造に対して、周知のビタビ(Viterbi)アルゴリズム、確率伝搬、およびターボデコーディングを用いたソフトデコーディングの使用を容易にする。対照的に、殆どの従来技術の方法はバイナリコード、リード−ソロモンコード、および代数的復号化に基づいているので、バイオメトリックデータが、バイナリ値とは反対に、実際の値(real values)をとるとき、ソフトデコーディングを効果的に適用することができない。たとえば、幾つかの方法は、リファレンス(基準)を生成するために、登録段階におけるランダムな符号語でバイオメトリックデータの排他的論理和(XOR)を計算することを特に要求し、また、認証段階におけるバイオメトリックデータでそのリファレンスの排他的論理和を計算することを要求する
第5に、安全なバイオメトリックスに関する殆どの従来技術は誤り訂正符号化を使用するが、この発明はシンドローム符号化を使用する。通常、誤り訂正符号化の計算の複雑さは、入力サイズ(大きさ)において超線形(super linear)である。対照的に、様々なタイプの低密度パリティチェックに基づくシンドロームコードを使用することによって、シンドローム符号化の計算の複雑さ(量)が入力サイズ(大きさ)においてリニアのみであるシンドロームエンコーダを構成することが容易になる。
第6に、シンドロームコーディングフレームワークを使用することによって、「直列連鎖累積コードを使用して信号を圧縮する」という発明の名称の米国特許出願第10/928,448(引用によりここに援用される)にYedidia外によって記載されたSCAコードのような強力な新しい埋め込まれたシンドロームコードを使用することが可能である。これらのコードは、シンドロームエンコーダが、登録の間、バイオメトリックデータの固有の変動性を推定して、シンドローム復号化に成功するのを許容するのに丁度充分なだけのシンドロームビットを符号化することを許容する。
第7に、データを暗号化するために、上述したようなシンドロームコードを使用できる。その上、所与のレベルの性能とエラー復元力とを有する最適のシンドロームコードのための設計を可能にする方法が記述される。
第8に、計測チャンネルが構造化ノイズを受けることがあっても、シンドローム特徴ベクトルを正しく復号できる。
第9に、符号化および復号化は、バイナリロジック条件によって課される望ましい統計的性質と互換性があるように設計することができる。
この発明は好適な実施の形態を例に挙げて説明したが、この発明の精神および範囲内で種々の他の改変および変更を行うことができることを理解すべきである。したがって、この発明の精神および範囲内に入るすべての変更例および変形例をカバーすることが、付加されたクレームの目的である。