JP5592015B2 - ハードウェア制限に基づく調整可能なトランザクション・サイズを利用してコードを動的に最適化する装置、方法およびシステム - Google Patents
ハードウェア制限に基づく調整可能なトランザクション・サイズを利用してコードを動的に最適化する装置、方法およびシステム Download PDFInfo
- Publication number
- JP5592015B2 JP5592015B2 JP2013528405A JP2013528405A JP5592015B2 JP 5592015 B2 JP5592015 B2 JP 5592015B2 JP 2013528405 A JP2013528405 A JP 2013528405A JP 2013528405 A JP2013528405 A JP 2013528405A JP 5592015 B2 JP5592015 B2 JP 5592015B2
- Authority
- JP
- Japan
- Prior art keywords
- speculative
- code
- checkpoint
- execution
- instruction
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images












Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3836—Instruction issuing, e.g. dynamic instruction scheduling or out of order instruction execution
- G06F9/3842—Speculative instruction execution
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F8/00—Arrangements for software engineering
- G06F8/40—Transformation of program code
- G06F8/52—Binary to binary
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/3004—Arrangements for executing specific machine instructions to perform operations on memory
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30072—Arrangements for executing specific machine instructions to perform conditional operations, e.g. using predicates or guards
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30003—Arrangements for executing specific machine instructions
- G06F9/30076—Arrangements for executing specific machine instructions to perform miscellaneous control operations, e.g. NOP
- G06F9/30087—Synchronisation or serialisation instructions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/30098—Register arrangements
- G06F9/30105—Register structure
- G06F9/30116—Shadow registers, e.g. coupled registers, not forming part of the register space
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3854—Instruction completion, e.g. retiring, committing or graduating
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/30—Arrangements for executing machine instructions, e.g. instruction decode
- G06F9/38—Concurrent instruction execution, e.g. pipeline or look ahead
- G06F9/3854—Instruction completion, e.g. retiring, committing or graduating
- G06F9/3858—Result writeback, i.e. updating the architectural state or memory
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Software Systems (AREA)
- General Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Memory System Of A Hierarchy Structure (AREA)
- Advance Control (AREA)
- Retry When Errors Occur (AREA)
- Executing Machine-Instructions (AREA)
- Devices For Executing Special Programs (AREA)
Description

Claims (46)
- コードを含む機械可読媒体であって、前記コードは、前記機械によって実行されたときに、前記機械に:
最適化されるべきプログラム・コードのセクションを同定する動作と;
前記プログラム・コードの前記セクション内の条件付きコミット点を決定する動作と;
前記条件付きコミット点を決定することに応答して前記条件付きコミット点において条件付きコミット命令を挿入する動作と;
最適化されるべきプログラム・コードの前記セクションを同定することに応答してプログラム・コードの前記セクションを最適化する動作とを実行させる、
機械可読媒体。 - 最適化されるべきプログラム・コードのセクションを同定する動作が、前記プログラム・コードの動的プロファイリングに基づき、条件付きコミット点を決定する動作が、前記プログラム・コードの前記セクション内のループの先頭に前記条件付きコミット点を割り当てる、動的プロファイリングに基づいてある実行経路に前記条件付きコミット点を割り当てる、およびハードウェア資源を独占すると知られている実行経路に前記条件付きコミット点を割り当てる、からなる群より選択される割り当てアルゴリズムに基づく、請求項1記載の機械可読媒体。
- 前記条件付きコミット命令が、実行されたときに、第一の分枝として、プログラム・コードの前記セクションの実行を継続する、または、第二の分枝として、条件付きコミット・コード位置にジャンプする条件付き分岐命令を含む、請求項1記載の機械可読媒体。
- 前記コードが、前記機械によって実行されたときに、前記機械にさらに:
プログラム・コードの前記セクションの先頭に第一の領域開始命令を挿入する動作と;
プログラム・コードの前記セクションの末尾に第一のコミット命令を挿入する動作と;
前記条件付きコミット・コード位置に第二のコミット命令を挿入する動作と;
前記第二のコミット命令後に、前記条件付きコミット・コード位置における第二の領域開始命令を挿入する動作とを実行させる、
請求項3記載の機械可読媒体。 - プログラム・コードの前記セクションを最適化する動作が、前記第一および第二の領域開始命令より上にメモリ順序付けを破るロードを持ち上げることなく、かつ前記第一および第二のコミット命令より下にメモリ順序付けを破るストアを押し出すこともなく、コードの前記セクションを動的に最適化することを含む、請求項4記載の機械可読媒体。
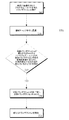
- ランタイムの間にコードを動的に最適化する方法であって:
最適化されるべきプログラム・コードのセクションを同定する段階と;
最適化されるべきプログラム・コードの前記セクションを同定することに応答して、プログラム・コードの前記セクションの少なくとも一部を原子的領域として画定する段階と;
前記原子的領域内の条件付きコミット点を決定する段階と;
前記条件付きコミット点を決定することに応答して前記条件付きコミット点において領域チェック命令を挿入する段階と;
最適化されるべきプログラム・コードの前記セクションを同定することに応答してプログラム・コードの前記セクションを最適化する段階とを含む、
方法。 - プログラム・コードの前記セクションの少なくとも一部を原子的領域として画定する段階が、コードの前記セクションの前記一部の先頭に開始トランザクション命令を、コードの前記セクションの前記一部の末尾に終了トランザクション命令を挿入することを含む、請求項6記載の方法。
- プログラム・コードの前記セクションを最適化する段階が、部分冗長性ロード消去(PRLE)、部分デッド・ストア消去(PDSE)、ループ最適化、データ・フロー最適化、コード生成最適化、境界チェック消去、分岐オフセット最適化、デッド・コード消去およびジャンプ接続からなる群より選択される最適化技法を利用してコードの前記セクションを最適化することを含む、請求項6記載の方法。
- 前記領域チェック命令が、実行されたときにハードウェアに問い合わせする条件付き分岐命令を含み、前記条件付き分岐命令は、前記ハードウェアの前記問い合わせへのあらかじめ定義された応答に応答して、早発(premature)領域コミット命令および領域再開命令に分岐するものである、請求項6記載の方法。
- 前記領域チェック命令を挿入する段階が、前記プログラム・コードの前記セクションの前記一部の中のループの先頭において行われ、前記領域チェック命令は前記ループの反復工程毎に実行される、請求項6記載の方法。
- コードを含む機械可読媒体であって、前記コードは、前記機械によって実行されたときに、前記機械に:
動的に最適化されたプログラム・コードを含むトランザクションを実行する動作と;
前記トランザクションの終わりより前の領域チェック点において、前記トランザクションの実行をサポートするハードウェア・ユニットが前記トランザクションのある領域を完遂するための利用可能な十分な資源を含んでいるかどうかを判定する動作と;
前記トランザクションの実行をサポートするハードウェア・ユニットの資源が少ないと判定することに応答して前記領域チェック点において前記トランザクションをコミットする動作とを実行させる、
機械可読媒体。 - 前記領域チェック点において前記トランザクションをコミットしたあと新たなトランザクションを開始することをさらに含む、請求項11記載の機械可読媒体。
- 前記ハードウェア・ユニットが、ストア・バッファ、ロード・バッファ、キャッシュ・メモリおよびレジスタ・ファイルからなる群より選択されるユニットを含む、請求項11記載の機械可読媒体。
- 前記ハードウェア・ユニットがキャッシュ・メモリを含む請求項11記載の機械可読媒体であって、前記トランザクションの実行をサポートするハードウェア・ユニットが前記トランザクションの前記領域を完遂するための利用可能な十分な資源を含んでいるかどうかを判定する動作が:前記トランザクションの前記領域を完遂することにおいてタッチされると期待されるキャッシュ・ラインの数を決定し;前記キャッシュ・メモリ中の利用可能なエントリーの数を決定し;期待されるキャッシュ・ラインの数を利用可能なキャッシュ・ラインの数と比較し;前記トランザクションの実行をサポートする前記キャッシュ・メモリが前記トランザクションの前記領域を完遂するための利用可能な十分な資源を含むかどうかを、期待されるキャッシュ・ラインの数と利用可能なキャッシュ・ラインの数との前記比較に基づいて、判定することを含む、機械可読媒体。
- 前記領域を完遂することにおいてタッチされると期待されるキャッシュ・ラインの数を決定することが、前記トランザクションに挿入されたコンパイラ・ヒントに基づき、前記コンパイラ・ヒントは、前記トランザクションの前記領域の以前の実行の動的プロファイリングに基づく、請求項14記載の機械可読媒体。
- コードを含む機械可読媒体であって、前記コードは、前記機械によって実行されたときに、前記機械に:
最適化されるべきプログラム・コードのセクションを同定する段階と;
前記プログラム・コードの前記セクション内の投機的チェックポイントを決定する段階と;
前記投機的チェックポイントを決定することに応答して前記投機的チェックポイントにおいて投機的チェックポイント・コードを挿入する動作と;
最適化されるべきプログラム・コードの前記セクションを同定することに応答してプログラム・コードの前記セクションを最適化する動作とを実行させる、
機械可読媒体。 - 最適化されるべきプログラム・コードのセクションを同定する動作が、前記プログラム・コードの動的プロファイリングに基づき、投機的チェックポイントを決定する動作が、前記プログラム・コードの前記セクション内のループの先頭に、前記プログラム・コードの前記セクション内のループのループバック端に前記投機的チェックポイントを割り当てる、動的プロファイリングに基づいてある実行経路に前記投機的チェックポイントを割り当てる、ハードウェア資源を独占すると知られている実行経路に前記投機的チェックポイントを割り当てる、および、投機的ハードウェア資源の枯渇を回避するよう実行経路に前記投機的チェックポイントを割り当てる、からなる群より選択される割り当てアルゴリズムに基づく、請求項16記載の機械可読媒体。
- 前記コードが、前記機械によって実行されたときに、前記機械にさらに:
プログラム・コードの前記セクションに原子的領域開始命令を挿入する動作と;
プログラム・コードの前記セクションに原子的領域終了命令を挿入する動作とをさらに実行させる、
請求項16記載の機械可読媒体。 - 前記投機的チェックポイント・コードが投機的チェックポイント動作を含み、前記投機的チェックポイント動作は、実行されたときに、前記機械に、投機的レジスタ・ファイルおよびストア・バッファをチェックポイント記憶構造においてチェックポイント化させ、前記コードは、前記機械によって実行されたとき、前記機械に、コードの前記セクションの実行中に前記ストア・バッファの資源が尽きることに応答して前記投機的レジスタ・ファイルの前記チェックポイントにロールバックするフィックスアップ・コードを挿入する動作をさらに実行させる、請求項16記載の機械可読媒体。
- プログラム・コードの前記セクションを最適化する動作が、部分冗長性ロード消去(PRLE)、部分デッド・ストア消去(PDSE)、ループ最適化、データ・フロー最適化、コード生成最適化、境界チェック消去、分岐オフセット最適化、デッド・コード消去およびジャンプ接続からなる群より選択される最適化技法を利用してコードの前記セクションを最適化することを含む、請求項16記載の機械可読媒体。
- 最適化されるべきプログラム・コードのセクションを同定する段階と;
最適化されるべきプログラム・コードの前記セクションを同定することに応答して、プログラム・コードの前記セクションの少なくとも一部を原子的領域として画定する段階と;
前記原子的領域内の投機的チェックポイントを決定する段階と;
前記投機的チェックポイントを決定することに応答して前記投機的チェックポイントにおいて投機的チェックポイント・コードを挿入する段階と;
最適化されるべきプログラム・コードの前記セクションを同定することに応答してプログラム・コードの前記セクションを最適化する段階とを含む、
方法。 - プログラム・コードの前記セクションの少なくとも一部を原子的領域として画定する段階が、コードの前記セクションの前記一部の先頭に開始トランザクション命令を、コードの前記セクションの前記一部の末尾に終了トランザクション命令を挿入することを含む、請求項21記載の方法。
- 投機的チェックポイント動作を実行する段階と;
前記投機的チェックポイント動作の実行に応答して、投機的レジスタ・ファイルを投機的チェックポイント・レジスタ・ファイルにおいてチェックポイント化する段階と;
前記投機的チェックポイント動作の実行に応答して、ストア・バッファを投機的キャッシュにおいてチェックポイント化する段階と;
コードの前記セクションの前記一部の実行中に前記投機的キャッシュまたは前記ストア・バッファの資源が尽きることに応答して前記投機的チェックポイント・レジスタ・ファイルに保持されている前記投機的レジスタ・ファイルの前記チェックポイントにロールバックするフィックスアップ・コードを挿入する段階とをさらに含む、
請求項21記載の方法。 - コードの前記セクションの前記一部の実行中に前記ストア・バッファの資源が尽きることに応答して前記フィックスアップ・コードを挿入することは:前記ストア・バッファがコードの前記セクションの前記一部の実行の間に利用可能なエントリーを全く含まないことに応答して前記フィックスアップ・コードを挿入することを含み、
コードの前記セクションの前記一部の実行中に前記投機的キャッシュの資源が尽きることに応答して前記フィックスアップ・コードを挿入することは:前記投機的キャッシュが、前記投機的チェックポイント動作の実行の際に前記ストア・バッファからのエントリーを保持するための十分な利用可能なエントリーを含まないことに応答して前記フィックスアップ・コードを挿入することを含む、
請求項23記載の方法。 - プログラム・コードの前記セクションを最適化する動作が、部分冗長性ロード消去(PRLE)、部分デッド・ストア消去(PDSE)、ループ最適化、データ・フロー最適化、コード生成最適化、境界チェック消去、分岐オフセット最適化、デッド・コード消去およびジャンプ接続からなる群より選択される最適化技法によりコードの前記セクションを最適化することを含む、請求項21記載の方法。
- コードを含む機械可読媒体であって、前記コードは、前記機械によって実行されたときに、前記機械に:
動的に最適化されたプログラム・コードを含むトランザクションを実行する動作と;
前記トランザクション内のチェックポイントにおいて、投機的レジスタ・ファイルをチェックポイント・レジスタ・ファイル中にチェックポイント化する動作と;
前記トランザクションの実行をサポートするハードウェア・ユニットの資源が少ないことを判別する動作と;
前記ハードウェア・ユニットの資源が少ないことを判別することに応答して前記チェックポイント・レジスタ・ファイルを前記投機的レジスタ・ファイル中に復元し、ストア・バッファをフラッシュする動作とを実行させる、
機械可読媒体。 - 前記トランザクション内のチェックポイントにおいて、投機的レジスタ・ファイルをチェックポイント・レジスタ・ファイル中にチェックポイント化する動作が、投機的チェックポイント命令の実行に応答して行われ、前記コードは、前記機械によって実行されたとき、前記機械に、やはり投機的チェックポイント命令の実行に応答して、前記トランザクション内の前記チェックポイントにおいて、ストア・バッファを投機的キャッシュ中にチェックポイント化する動作をさらに実行させる、請求項26記載の機械可読媒体。
- 前記ハードウェア・ユニットが前記ストア・バッファを含み、前記トランザクションの実行をサポートするハードウェア・ユニットの資源が少ないことを判別する動作が、前記トランザクションからのストアに遭遇する際に前記ストア・バッファの資源が少なく、前記ストア・バッファが利用可能なストア・バッファ・エントリーを含まないことを判別することを含む、請求項27記載の機械可読媒体。
- 前記ハードウェア・ユニットが投機的キャッシュをも含み、前記トランザクションの実行をサポートするハードウェア・ユニットの資源が少ないことを判別する動作が、
やはり投機的チェックポイント命令の実行に応答して、前記トランザクション内の前記チェックポイントにおいて、前記ストア・バッファを前記投機的キャッシュ中にチェックポイント化する際に、
前記ストア・バッファからのエントリーを保持するために十分な利用可能なエントリーを前記投機的キャッシュが含まないことに応答して、
前記投機的キャッシュの資源が少ないことを判別することを含む、請求項28記載の機械可読媒体。 - 前記コードが、前記機械によって実行されたとき、前記機械に、前記ハードウェア・ユニットの資源が少ないことを判別することに応答して前記チェックポイント・レジスタ・ファイルを前記投機的レジスタ・ファイル中に復元し、前記ストア・バッファをフラッシュすることに応答して、前記トランザクションの一部の領域コミットを実行する動作を実行させる、請求項26記載の機械可読媒体。
- 前記ハードウェア・ユニットの資源が少ないことを判別することに応答して前記チェックポイント・レジスタ・ファイルを前記投機的レジスタ・ファイル中に復元し、前記ストア・バッファをフラッシュする動作が:前記ハードウェア・ユニットの資源が少ないことを判別し、前記ハードウェア・ユニットに関連する因子に基づいて、前記復元が、最も最近のコミットされた点ではなく前記チェックポイント・レジスタ・ファイルに関連するチェックポイントまでであることを判別するコードを実行し、前記復元が前記チェックポイント・レジスタ・ファイルに関連する前記チェックポイントまでであることを判別するのに応答して、前記チェックポイント・レジスタ・ファイルを前記投機的レジスタ・ファイル中に復元し、前記ストア・バッファをフラッシュすることを含む、請求項26記載の機械可読媒体。
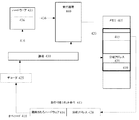
- 投機的チェックポイント命令をデコードしてデコードされた投機的チェックポイント命令を得るよう適応されたデコード論理と;
デコードされた投機的チェックポイント命令を実行するよう適応された実行論理と;
最適化されたコードを含むことになるソフトウェア・スレッドの原子的領域の開始前から前記ソフトウェア・スレッドに関連付けられた非投機的な値を保持するよう適応された第一のメモリと;
前記原子的領域の実行中および前記デコードされた投機的チェックポイント命令が前記実行論理によって実行されたあとに、前記ソフトウェア・スレッドに関連付けられた投機的な値を保持するよう適応された第二のメモリと;
前記実行論理が前記デコードされた投機的チェックポイント命令を実行するのに応答して前記第二のメモリからの投機的チェックポイント値を保持するよう適応された第三のメモリとを有する、
装置。 - 前記第一のメモリが非投機的レジスタ・ファイルを含み、前記第二のメモリが投機的レジスタ・ファイルを含み、前記第三のメモリが投機的チェックポイント・レジスタ・ファイルを含む、請求項32記載の装置。
- 前記投機的レジスタ・ファイルが前記原子的領域の実行中および前記デコードされた投機的チェックポイント命令が前記実行論理によって実行されたあとに、前記ソフトウェア・スレッドに関連付けられた投機的な値を保持するよう適応されていることが、前記投機的レジスタ・ファイルが、前記原子的領域の実行中および前記デコードされた投機的チェックポイント命令が前記実行論理によって実行されたあとに、前記ソフトウェア・スレッドに関連付けられた投機的アーキテクチャ状態値を保持するよう適応されていることを含み、
前記投機的チェックポイント・レジスタ・ファイルが前記実行論理が前記デコードされた投機的チェックポイント命令を実行するのに応答して前記投機的レジスタ・ファイルからの投機的チェックポイント値を保持するよう適応されていることが、前記投機的チェックポイント・レジスタ・ファイルが、前記実行論理が前記投機的レジスタ・ファイルからの前記投機的チェックポイント命令を実行する際に、前記ソフトウェア・スレッドに関連付けられたアーキテクチャ状態値を、投機的チェックポイント・アーキテクチャ状態値として前記投機的チェックポイント・レジスタ・ファイル中にロードするよう適応されていることを含む、
請求項33記載の装置。 - 不十分なハードウェア資源に基づく、前記投機的チェックポイント命令に関連付けられたチェックポイントへのロールバックに応答して、前記投機的チェックポイント・レジスタ・ファイル中に保持される前記投機的チェックポイント・アーキテクチャ状態値が前記投機的レジスタ・ファイル中に再ロードされ;
前記原子的領域のコミットに応答して、前記投機的レジスタ・ファイル中に保持される前記投機的アーキテクチャ状態値が前記非投機的レジスタ・ファイル中にロードされ;
前記原子的領域の始まりへのロールバックに応答して、前記非投機的レジスタ・ファイル中に保持される前記非投機的な値が、前記投機的レジスタ・ファイル中にロードされる、
請求項34記載の装置。 - 前記第一のメモリがキャッシュ・メモリを含み、前記第二のメモリがバッファを含み、前記第三のメモリが投機的キャッシュ・メモリを含む、請求項32記載の装置。
- 前記バッファが前記原子的領域の実行中および前記デコードされた投機的チェックポイント命令が前記実行論理によって実行されたあとに、前記ソフトウェア・スレッドに関連付けられた投機的な値を保持するよう適応されていることが、前記バッファが、前記原子的領域の実行中および前記デコードされた投機的チェックポイント命令が前記実行論理によって実行されたあとに、前記ソフトウェア・スレッドに関連付けられた投機的なメモリ値を保持するよう適応されていることを含み、
前記投機的キャッシュ・メモリが前記実行論理が前記デコードされた投機的チェックポイント命令を実行するのに応答して前記バッファからの投機的チェックポイント値を保持するよう適応されていることが、前記投機的キャッシュ・メモリが、前記実行論理が前記バッファからの前記投機的チェックポイント命令を実行する際に、前記ソフトウェア・スレッドに関連付けられた投機的なメモリ値を、投機的チェックポイント・メモリ値として前記投機的キャッシュ・メモリ中にロードするよう適応されていることを含む、
請求項36記載の装置。 - 前記原子的領域のコミットに応答して、前記バッファおよび前記投機的キャッシュ・メモリが、前記投機的なメモリ値および前記投機的チェックポイント・メモリ値を前記キャッシュ・メモリ中にロードするよう適応されており;
前記投機的チェックポイント命令に関連付けられたチェックポイントへのロールバックに応答して、前記バッファがフラッシュされるよう適応されており;
前記原子的領域より前の点へのロールバックに応答して、前記バッファおよび前記投機的キャッシュ・メモリがフラッシュされるよう適応されている、
請求項37記載の装置。 - 前記デコード論理、実行論理、第一のメモリ、第二のメモリおよび第三のメモリが複数処理要素のマイクロプロセッサ内に含まれており、前記複数処理要素のマイクロプロセッサは、同期的動的ランダム・アクセス・メモリ(SDRAM:Synchronous Dynamic Random Access Memory)、読み出し専用メモリ(ROM)およびフラッシュメモリからなる群より選択されるシステム・メモリを含むコンピュータ・システム内に結合されるよう適応されている、請求項32記載の装置。
- 投機的チェックポイント命令をデコードしてデコードされた投機的チェックポイント命令を得るよう適応されたデコード論理と;
デコードされた投機的チェックポイント命令を実行するよう適応された実行論理と;
原子的領域の実行中の投機的更新を保持するよう適応されたストア・バッファと;
前記実行論理が前記デコードされた投機的チェックポイント命令を実行するのに応答して前記ストア・バッファからの前記投機的更新をチェックポイント化するよう適応された投機的キャッシュと;
前記原子的領域の始まりより前からの非投機的な値を保持するよう適応された非投機的キャッシュとを有しており、
前記原子的領域のコミットに応答して、前記投機的キャッシュからの前記投機的更新が前記非投機的キャッシュ中にロードされる、
装置。 - 前記投機的キャッシュおよび前記ストア・バッファが、前記原子的領域のコミットに応答して、投機的更新をもって前記非投機的キャッシュを更新するようさらに適応されている、請求項40記載の装置。
- 前記ストア・バッファがさらに、前記投機的チェックポイント命令に関連付けられたチェックポイントへのロールバックまたは前記原子的領域の始まりへのロールバックに応答してフラッシュされるよう適応されている、請求項40記載の装置。
- 前記投機的キャッシュがさらに、前記原子的領域の始まりへのロールバックに応答してフラッシュされるよう適応されている、請求項42記載の装置。
- 前記投機的キャッシュがさらに、前記投機的キャッシュが前記ストア・バッファからの前記投機的更新を保持するための十分なエントリーを含まないことに応答して、前記ストア・バッファからの前記投機的更新の前記チェックポイントを完遂するために十分な投機的キャッシュ・エントリーが利用可能でないことを示すよう適応されており;
前記ストア・バッファがさらに、前記原子的領域からのストアに遭遇する際にストア・バッファ・エントリーが利用可能でないことに応答して、ストア・バッファ・エントリーが利用可能でないことを示すよう適応されており;
前記原子的領域内のチェックポイントへのロールバックは、前記投機的キャッシュが、前記ストア・バッファからの前記投機的更新の前記チェックポイントを完遂するために十分な投機的キャッシュ・エントリーが利用可能でないことを示すこと、または、前記ストア・バッファが、前記原子的領域からのストアに遭遇する際にストア・バッファ・エントリーが利用可能でないことに応答して、ストア・バッファ・エントリーが利用可能でないことを示すことに応答して開始される、
請求項43記載の装置。 - 前記非投機的キャッシュがさらに、前記原子的領域からの投機的読み出しに応答してロード・バッファにエントリーを与えるよう適応されている、請求項42記載の装置。
- 前記非投機的キャッシュがより上位レベルのメモリからのラインをキャッシュするよう適応されており、前記より上位レベルのメモリは:同期的動的ランダム・アクセス・メモリ(SDRAM:Synchronous Dynamic Random Access Memory)、読み出し専用メモリ(ROM)およびフラッシュメモリからなる群より選択される、請求項42記載の装置。
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US12/890,638 US20120079245A1 (en) | 2010-09-25 | 2010-09-25 | Dynamic optimization for conditional commit |
| US12/890,638 | 2010-09-25 | ||
| PCT/US2011/053337 WO2012040742A2 (en) | 2010-09-25 | 2011-09-26 | Apparatus, method, and system for dynamically optimizing code utilizing adjustable transaction sizes based on hardware limitations |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2013537334A JP2013537334A (ja) | 2013-09-30 |
| JP5592015B2 true JP5592015B2 (ja) | 2014-09-17 |
Family
ID=45871871
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013528405A Expired - Fee Related JP5592015B2 (ja) | 2010-09-25 | 2011-09-26 | ハードウェア制限に基づく調整可能なトランザクション・サイズを利用してコードを動的に最適化する装置、方法およびシステム |
Country Status (8)
| Country | Link |
|---|---|
| US (1) | US20120079245A1 (ja) |
| EP (1) | EP2619655B1 (ja) |
| JP (1) | JP5592015B2 (ja) |
| KR (1) | KR101524446B1 (ja) |
| CN (1) | CN103140828B (ja) |
| AU (1) | AU2011305091B2 (ja) |
| TW (1) | TWI571799B (ja) |
| WO (1) | WO2012040742A2 (ja) |
Families Citing this family (76)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| GB2480285A (en) * | 2010-05-11 | 2011-11-16 | Advanced Risc Mach Ltd | Conditional compare instruction which sets a condition code when it is not executed |
| US8549504B2 (en) * | 2010-09-25 | 2013-10-01 | Intel Corporation | Apparatus, method, and system for providing a decision mechanism for conditional commits in an atomic region |
| US20130159673A1 (en) * | 2011-12-15 | 2013-06-20 | Advanced Micro Devices, Inc. | Providing capacity guarantees for hardware transactional memory systems using fences |
| US8893094B2 (en) | 2011-12-30 | 2014-11-18 | Intel Corporation | Hardware compilation and/or translation with fault detection and roll back functionality |
| US9075727B2 (en) | 2012-06-14 | 2015-07-07 | International Business Machines Corporation | Reducing penalties for cache accessing operations |
| US9015423B2 (en) | 2012-06-14 | 2015-04-21 | International Business Machines Corporation | Reducing store operation busy times |
| US9244846B2 (en) * | 2012-07-06 | 2016-01-26 | International Business Machines Corporation | Ensuring causality of transactional storage accesses interacting with non-transactional storage accesses |
| US9262170B2 (en) * | 2012-07-26 | 2016-02-16 | International Business Machines Corporation | Out-of-order checkpoint reclamation in a checkpoint processing and recovery core microarchitecture |
| CN106170761B (zh) * | 2012-09-27 | 2019-05-10 | 英特尔公司 | 用于在二进制转换中横跨多个原子区调度存储指令的方法和装置 |
| US9612834B2 (en) * | 2012-09-27 | 2017-04-04 | Texas Instruments Deutschland Gmbh | Processor with variable instruction atomicity |
| US9384002B2 (en) * | 2012-11-16 | 2016-07-05 | International Business Machines Corporation | Speculative finish of instruction execution in a processor core |
| US9189433B2 (en) * | 2012-12-18 | 2015-11-17 | International Business Machines Corporation | Tracking a relative arrival order of events being stored in multiple queues using a counter |
| US9047092B2 (en) * | 2012-12-21 | 2015-06-02 | Arm Limited | Resource management within a load store unit |
| US9135177B2 (en) | 2013-02-26 | 2015-09-15 | Apple Inc. | Scheme to escalate requests with address conflicts |
| US9448799B2 (en) | 2013-03-14 | 2016-09-20 | Samsung Electronics Co., Ltd. | Reorder-buffer-based dynamic checkpointing for rename table rebuilding |
| US9304863B2 (en) | 2013-03-15 | 2016-04-05 | International Business Machines Corporation | Transactions for checkpointing and reverse execution |
| US9547594B2 (en) * | 2013-03-15 | 2017-01-17 | Intel Corporation | Instructions to mark beginning and end of non transactional code region requiring write back to persistent storage |
| US9116719B2 (en) * | 2013-06-27 | 2015-08-25 | Intel Corporation | Partial commits in dynamic binary translation based systems |
| EP3039554A1 (en) | 2013-08-30 | 2016-07-06 | Hewlett Packard Enterprise Development LP | Completion packet return |
| CA2830605A1 (en) | 2013-10-22 | 2015-04-22 | Ibm Canada Limited - Ibm Canada Limitee | Code versioning for enabling transactional memory region promotion |
| US9459849B2 (en) | 2014-01-17 | 2016-10-04 | International Business Machines Corporation | Adaptive cloud aware just-in-time (JIT) compilation |
| US9317379B2 (en) * | 2014-01-24 | 2016-04-19 | International Business Machines Corporation | Using transactional execution for reliability and recovery of transient failures |
| US20150242216A1 (en) * | 2014-02-27 | 2015-08-27 | International Business Machines Corporation | Committing hardware transactions that are about to run out of resource |
| US10120681B2 (en) | 2014-03-14 | 2018-11-06 | International Business Machines Corporation | Compare and delay instructions |
| US9558032B2 (en) | 2014-03-14 | 2017-01-31 | International Business Machines Corporation | Conditional instruction end operation |
| US9454370B2 (en) | 2014-03-14 | 2016-09-27 | International Business Machines Corporation | Conditional transaction end instruction |
| US20150278123A1 (en) * | 2014-03-28 | 2015-10-01 | Alex Nayshtut | Low-overhead detection of unauthorized memory modification using transactional memory |
| US9569212B2 (en) * | 2014-03-28 | 2017-02-14 | Intel Corporation | Instruction and logic for a memory ordering buffer |
| US9678773B1 (en) | 2014-09-30 | 2017-06-13 | Amazon Technologies, Inc. | Low latency computational capacity provisioning |
| US10303525B2 (en) | 2014-12-24 | 2019-05-28 | Intel Corporation | Systems, apparatuses, and methods for data speculation execution |
| US10387156B2 (en) | 2014-12-24 | 2019-08-20 | Intel Corporation | Systems, apparatuses, and methods for data speculation execution |
| US9785442B2 (en) | 2014-12-24 | 2017-10-10 | Intel Corporation | Systems, apparatuses, and methods for data speculation execution |
| US10061583B2 (en) | 2014-12-24 | 2018-08-28 | Intel Corporation | Systems, apparatuses, and methods for data speculation execution |
| US10387158B2 (en) | 2014-12-24 | 2019-08-20 | Intel Corporation | Systems, apparatuses, and methods for data speculation execution |
| US10942744B2 (en) | 2014-12-24 | 2021-03-09 | Intel Corporation | Systems, apparatuses, and methods for data speculation execution |
| US10061589B2 (en) | 2014-12-24 | 2018-08-28 | Intel Corporation | Systems, apparatuses, and methods for data speculation execution |
| US10540524B2 (en) * | 2014-12-31 | 2020-01-21 | Mcafee, Llc | Memory access protection using processor transactional memory support |
| KR101533042B1 (ko) * | 2015-02-11 | 2015-07-09 | 성균관대학교산학협력단 | 데이터 일관성을 보장하기 위한 컴퓨팅 장치 및 방법 |
| US9792124B2 (en) | 2015-02-13 | 2017-10-17 | International Business Machines Corporation | Speculative branch handling for transaction abort |
| US9858074B2 (en) * | 2015-06-26 | 2018-01-02 | International Business Machines Corporation | Non-default instruction handling within transaction |
| US9703537B2 (en) | 2015-11-02 | 2017-07-11 | International Business Machines Corporation | Method for defining alias sets |
| US10459727B2 (en) * | 2015-12-31 | 2019-10-29 | Microsoft Technology Licensing, Llc | Loop code processor optimizations |
| US9542290B1 (en) | 2016-01-29 | 2017-01-10 | International Business Machines Corporation | Replicating test case data into a cache with non-naturally aligned data boundaries |
| US10901940B2 (en) * | 2016-04-02 | 2021-01-26 | Intel Corporation | Processors, methods, systems, and instructions to atomically store to memory data wider than a natively supported data width |
| US10169180B2 (en) | 2016-05-11 | 2019-01-01 | International Business Machines Corporation | Replicating test code and test data into a cache with non-naturally aligned data boundaries |
| CN109564525B (zh) * | 2016-06-28 | 2023-05-02 | 亚马逊技术有限公司 | 按需网络代码执行环境中的异步任务管理 |
| US10055320B2 (en) | 2016-07-12 | 2018-08-21 | International Business Machines Corporation | Replicating test case data into a cache and cache inhibited memory |
| GB2555628B (en) * | 2016-11-04 | 2019-02-20 | Advanced Risc Mach Ltd | Main processor error detection using checker processors |
| US10223225B2 (en) | 2016-11-07 | 2019-03-05 | International Business Machines Corporation | Testing speculative instruction execution with test cases placed in memory segments with non-naturally aligned data boundaries |
| US10261878B2 (en) | 2017-03-14 | 2019-04-16 | International Business Machines Corporation | Stress testing a processor memory with a link stack |
| US10296343B2 (en) * | 2017-03-30 | 2019-05-21 | Intel Corporation | Hybrid atomicity support for a binary translation based microprocessor |
| GB2563588B (en) | 2017-06-16 | 2019-06-26 | Imagination Tech Ltd | Scheduling tasks |
| GB2563587B (en) | 2017-06-16 | 2021-01-06 | Imagination Tech Ltd | Scheduling tasks |
| GB2563589B (en) | 2017-06-16 | 2019-06-12 | Imagination Tech Ltd | Scheduling tasks |
| GB2560059B (en) | 2017-06-16 | 2019-03-06 | Imagination Tech Ltd | Scheduling tasks |
| GB2570110B (en) | 2018-01-10 | 2020-04-15 | Advanced Risc Mach Ltd | Speculative cache storage region |
| US10853115B2 (en) | 2018-06-25 | 2020-12-01 | Amazon Technologies, Inc. | Execution of auxiliary functions in an on-demand network code execution system |
| US11099870B1 (en) | 2018-07-25 | 2021-08-24 | Amazon Technologies, Inc. | Reducing execution times in an on-demand network code execution system using saved machine states |
| US11119673B2 (en) | 2018-08-12 | 2021-09-14 | International Business Machines Corporation | Optimizing synchronous I/O for zHyperLink |
| US11943093B1 (en) | 2018-11-20 | 2024-03-26 | Amazon Technologies, Inc. | Network connection recovery after virtual machine transition in an on-demand network code execution system |
| US12327133B1 (en) | 2019-03-22 | 2025-06-10 | Amazon Technologies, Inc. | Application gateways in an on-demand network code execution system |
| US11861386B1 (en) | 2019-03-22 | 2024-01-02 | Amazon Technologies, Inc. | Application gateways in an on-demand network code execution system |
| US12147353B2 (en) | 2019-05-24 | 2024-11-19 | Texas Instruments Incorporated | Methods and apparatus for read-modify-write support in multi-banked data RAM cache for bank arbitration |
| US11119809B1 (en) | 2019-06-20 | 2021-09-14 | Amazon Technologies, Inc. | Virtualization-based transaction handling in an on-demand network code execution system |
| WO2021050066A1 (en) * | 2019-09-12 | 2021-03-18 | Hewlett-Packard Development Company, L.P. | Self-adaptive circuit breakers for applications that include execution location markers |
| US11714682B1 (en) | 2020-03-03 | 2023-08-01 | Amazon Technologies, Inc. | Reclaiming computing resources in an on-demand code execution system |
| CN112231246A (zh) * | 2020-10-31 | 2021-01-15 | 王志平 | 一种处理器缓存结构的实现方法 |
| US11593270B1 (en) | 2020-11-25 | 2023-02-28 | Amazon Technologies, Inc. | Fast distributed caching using erasure coded object parts |
| US11789829B2 (en) * | 2021-04-27 | 2023-10-17 | Capital One Services, Llc | Interprocess communication for asynchronous tasks |
| US11968280B1 (en) | 2021-11-24 | 2024-04-23 | Amazon Technologies, Inc. | Controlling ingestion of streaming data to serverless function executions |
| US12015603B2 (en) | 2021-12-10 | 2024-06-18 | Amazon Technologies, Inc. | Multi-tenant mode for serverless code execution |
| US12026379B2 (en) * | 2022-03-14 | 2024-07-02 | Western Digital Technologies, Inc. | Data storage device and method for host-initiated transactional handling for large data set atomicity across multiple memory commands |
| CN116244203A (zh) * | 2023-03-15 | 2023-06-09 | 吉林大学 | 一种检查点设置方法、装置、设备及存储介质 |
| US12381878B1 (en) | 2023-06-27 | 2025-08-05 | Amazon Technologies, Inc. | Architecture for selective use of private paths between cloud services |
| US12288045B2 (en) | 2023-07-25 | 2025-04-29 | Bank Of America Corporation | Methods and systems for self-optimizing library functions |
| US12476978B2 (en) | 2023-09-29 | 2025-11-18 | Amazon Technologies, Inc. | Management of computing services for applications composed of service virtual computing components |
Family Cites Families (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US6658656B1 (en) * | 2000-10-31 | 2003-12-02 | Hewlett-Packard Development Company, L.P. | Method and apparatus for creating alternative versions of code segments and dynamically substituting execution of the alternative code versions |
| US7131119B2 (en) * | 2001-05-30 | 2006-10-31 | International Business Machines Corporation | Code optimization |
| US6862664B2 (en) * | 2003-02-13 | 2005-03-01 | Sun Microsystems, Inc. | Method and apparatus for avoiding locks by speculatively executing critical sections |
| US20050071438A1 (en) * | 2003-09-30 | 2005-03-31 | Shih-Wei Liao | Methods and apparatuses for compiler-creating helper threads for multi-threading |
| WO2009076324A2 (en) * | 2007-12-10 | 2009-06-18 | Strandera Corporation | Strand-based computing hardware and dynamically optimizing strandware for a high performance microprocessor system |
| US7496735B2 (en) * | 2004-11-22 | 2009-02-24 | Strandera Corporation | Method and apparatus for incremental commitment to architectural state in a microprocessor |
| US7984248B2 (en) * | 2004-12-29 | 2011-07-19 | Intel Corporation | Transaction based shared data operations in a multiprocessor environment |
| US7882339B2 (en) * | 2005-06-23 | 2011-02-01 | Intel Corporation | Primitives to enhance thread-level speculation |
| WO2007015925A1 (en) * | 2005-08-01 | 2007-02-08 | Sun Microsystems, Inc. | Avoiding locks by transactionally executing critical sections |
| US20080005332A1 (en) * | 2006-06-08 | 2008-01-03 | Georgia Tech Research Corporation | Method for Opportunistic Computing |
| US7802136B2 (en) * | 2006-12-28 | 2010-09-21 | Intel Corporation | Compiler technique for efficient register checkpointing to support transaction roll-back |
| US8060728B2 (en) * | 2007-05-14 | 2011-11-15 | Apple Inc. | Generating stop indicators during vector processing |
| US7966459B2 (en) * | 2007-12-31 | 2011-06-21 | Oracle America, Inc. | System and method for supporting phased transactional memory modes |
| US20100199269A1 (en) * | 2008-02-05 | 2010-08-05 | Panasonic Corporation | Program optimization device and program optimization method |
| CN101266549B (zh) * | 2008-03-19 | 2010-10-20 | 华为技术有限公司 | 插入代码的方法、装置 |
| EP2332043B1 (en) * | 2008-07-28 | 2018-06-13 | Advanced Micro Devices, Inc. | Virtualizable advanced synchronization facility |
| US8166481B2 (en) * | 2008-10-20 | 2012-04-24 | Microsoft Corporation | Transaction processing in transactional memory |
| JP5547208B2 (ja) * | 2008-11-24 | 2014-07-09 | インテル コーポレイション | シーケンシャル・プログラムを複数スレッドに分解し、スレッドを実行し、シーケンシャルな実行を再構成するシステム、方法および装置 |
| US20110208921A1 (en) * | 2010-02-19 | 2011-08-25 | Pohlack Martin T | Inverted default semantics for in-speculative-region memory accesses |
| US8688963B2 (en) * | 2010-04-22 | 2014-04-01 | Oracle International Corporation | Checkpoint allocation in a speculative processor |
| US9880848B2 (en) * | 2010-06-11 | 2018-01-30 | Advanced Micro Devices, Inc. | Processor support for hardware transactional memory |
| US8560816B2 (en) * | 2010-06-30 | 2013-10-15 | Oracle International Corporation | System and method for performing incremental register checkpointing in transactional memory |
-
2010
- 2010-09-25 US US12/890,638 patent/US20120079245A1/en not_active Abandoned
-
2011
- 2011-09-23 TW TW100134348A patent/TWI571799B/zh not_active IP Right Cessation
- 2011-09-26 WO PCT/US2011/053337 patent/WO2012040742A2/en not_active Ceased
- 2011-09-26 KR KR1020137007502A patent/KR101524446B1/ko not_active Expired - Fee Related
- 2011-09-26 AU AU2011305091A patent/AU2011305091B2/en not_active Ceased
- 2011-09-26 EP EP11827755.7A patent/EP2619655B1/en not_active Not-in-force
- 2011-09-26 CN CN201180045933.7A patent/CN103140828B/zh not_active Expired - Fee Related
- 2011-09-26 JP JP2013528405A patent/JP5592015B2/ja not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| WO2012040742A2 (en) | 2012-03-29 |
| US20120079245A1 (en) | 2012-03-29 |
| EP2619655B1 (en) | 2017-11-08 |
| CN103140828B (zh) | 2015-09-09 |
| EP2619655A2 (en) | 2013-07-31 |
| AU2011305091B2 (en) | 2014-09-25 |
| TW201218080A (en) | 2012-05-01 |
| KR101524446B1 (ko) | 2015-06-01 |
| JP2013537334A (ja) | 2013-09-30 |
| EP2619655A4 (en) | 2015-03-04 |
| TWI571799B (zh) | 2017-02-21 |
| WO2012040742A3 (en) | 2012-06-14 |
| KR20130063004A (ko) | 2013-06-13 |
| AU2011305091A1 (en) | 2013-03-14 |
| CN103140828A (zh) | 2013-06-05 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP5592015B2 (ja) | ハードウェア制限に基づく調整可能なトランザクション・サイズを利用してコードを動的に最適化する装置、方法およびシステム | |
| EP2619654B1 (en) | Apparatus, method, and system for providing a decision mechanism for conditional commits in an atomic region | |
| JP6095670B2 (ja) | コンピュータ・システム内のオペランド活性情報の維持 | |
| KR101617975B1 (ko) | 트랜잭셔널 메모리 시스템에서의 적응성 스레드 스케줄링을 위한 방법, 장치 및 시스템 | |
| JP2013541094A5 (ja) | ||
| US20140047219A1 (en) | Managing A Register Cache Based on an Architected Computer Instruction Set having Operand Last-User Information | |
| US20140108772A1 (en) | Exploiting an Architected Last-Use Operand Indication in a System Operand Resource Pool | |
| US10289414B2 (en) | Suppressing branch prediction on a repeated execution of an aborted transaction | |
| Zacharopoulos | Employing hardware transactional memory in prefetching for energy efficiency |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20140225 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20140311 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20140609 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20140701 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20140730 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 5592015 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| R250 | Receipt of annual fees |
Free format text: JAPANESE INTERMEDIATE CODE: R250 |
|
| LAPS | Cancellation because of no payment of annual fees |