JP6231623B2 - File server, information system, and information system control method - Google Patents
File server, information system, and information system control method Download PDFInfo
- Publication number
- JP6231623B2 JP6231623B2 JP2016141758A JP2016141758A JP6231623B2 JP 6231623 B2 JP6231623 B2 JP 6231623B2 JP 2016141758 A JP2016141758 A JP 2016141758A JP 2016141758 A JP2016141758 A JP 2016141758A JP 6231623 B2 JP6231623 B2 JP 6231623B2
- Authority
- JP
- Japan
- Prior art keywords
- user
- storage device
- file
- data
- request
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images

































Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
本発明は、通信ネットワークに接続されるファイルサーバを含む情報システム、及び情報システムの制御方法に関し、ファイルサーバのファイルを管理する技術に関する。 The present invention relates to an information system including a file server connected to a communication network, a method for controlling the information system, and a technique for managing files of the file server.
従来、企業や個人が自費でサーバやソフトウェアを購入し、これを利用する形態が主流であったが、TCO(Total Cost of Ownership)を削減するため、インターネット経由でサーバやソフトウェアを利用するクラウドコンピューティングが広まる傾向にある。 In the past, companies and individuals purchased servers and software at their own expense and used them, but in order to reduce TCO (Total Cost of Ownership), cloud computers that use servers and software via the Internet Tend to spread.
特許文献1には、複数の拠点(Edgeという)のストレージ装置(ローカルストレージ装置、ローカルファイルサーバ)と、データセンタ(Coreという)のストレージ装置(リモートストレージ装置、リモートファイルサーバ)とを接続したシステムにおいて、拠点のファイルがデータセンタへコピーされ、このコピーされたファイルは、拠点においてスタブ化されて管理され、また、拠点においてスタブ化されているファイルに対してアクセスが発生すると、データセンタ側からこのファイルを読み出す技術が開示されている。
特許文献1におけるシステムにおいては、ローカルストレージ装置に対して、ユーザからファイルシステムにファイルの書き込みがあると、ローカルストレージ装置は、定期的にコア側へファイルのレプリケーションを行う。このレプリケーションの処理は、レプリケーション処理が実行できる時間や時間帯、送信できるデータ量等が制限される場合がある。
In the system disclosed in
ローカルストレージ装置においては、レプリケーション後においても、そのファイルを削除せずに、キャッシュファイルとして管理する。 In the local storage device, even after replication, the file is managed as a cache file without being deleted.
その後、Edge側のファイルシステム容量が或る閾値に達した場合には、アクセス日時の古いキャッシュファイルをスタブファイルにする(スタブ化する)。ここで、スタブファイルとは、Edgeにおける実データへの参照を有しておらず、Coreにおける実データへの参照を保持しているファイルである。 Thereafter, when the file system capacity on the Edge side reaches a certain threshold value, the cache file having the old access date and time is converted into a stub file (stubbing). Here, the stub file is a file that does not have a reference to actual data in Edge but holds a reference to actual data in Core.
このような状態において、ローカルストレージ装置に対して、ユーザからスタブファイルに対するアクセスが発生した場合には、Edge側にファイルの実データがないために、Core側から実データをEdge側にダウンロードする処理(リコール処理)が実行される。 In such a state, when the user accesses the stub file to the local storage device, there is no actual data of the file on the Edge side, so the process of downloading the actual data from the Core side to the Edge side (Recall processing) is executed.
特許文献1に記載のシステムでは、ユーザがEdge間を移動し、移動先の他のEdgeから当該ユーザのデータにアクセスすることは考慮されていない。このようなシステムにおいては、例えば、ユーザが他のEdgeに移動して、そのEdgeにおいて、そのユーザの専用のディレクトリ(ホームディレクトリ)内のデータへアクセスする場合、移動元のEdgeで更新されたファイルがCore側にレプリケーションされるまで、移動先のEdgeでは、移動元のEdgeで更新されたファイルを参照できないという問題がある。この問題は特に、レプリケーションが行える時間、時間帯、データ量が制限される場合に、一度のレプリケーション処理で更新のあったデータを送りきれなかったときに生じやすい。
In the system described in
そこで、本発明は、一の拠点のファイルサーバで管理されていたファイルを、他の拠点のファイルサーバで適切に参照することのできる技術を提供することを目的とする。 Therefore, an object of the present invention is to provide a technique that can appropriately refer to a file managed by a file server at one site by using a file server at another site.
本発明の一観点に係るローカルのファイルサーバは、複数のユーザ端末とリモートのファイルサーバとに接続され、複数のユーザ端末から受信するファイルのデータを記憶デバイスに格納し、当該ファイルをリモートのファイルサーバにレプリケーションし、記憶デバイスに格納されたファイルをスタブ化し、ユーザ端末からのアクセス要求に基づいて、アクセス要求に係るファイルがスタブ化されていない場合は、記憶デバイスからそのファイルのデータを読み出して要求元のユーザ端末に送信し、そのアクセス要求に係るファイルがスタブ化されている場合は、ファイルのデータをリモートのファイルサーバから取得し、要求元のユーザ端末に当該ファイルのデータを送信する処理を制御する。そして、所定時間内にローカルのファイルサーバに対してセッション切断要求を行ったユーザのデータを優先してリモートのファイルサーバにレプリケーションする。 A local file server according to an aspect of the present invention is connected to a plurality of user terminals and a remote file server, stores file data received from the plurality of user terminals in a storage device, and the file is a remote file Replicate to the server, stubb the file stored in the storage device, and if the file related to the access request is not stubbed based on the access request from the user terminal, read the file data from the storage device Processing to send to the requesting user terminal, if the file related to the access request is stubbed, obtain the file data from the remote file server, and send the file data to the requesting user terminal To control. Then, the data of the user who made a session disconnection request to the local file server within a predetermined time is preferentially replicated to the remote file server.
本発明によると、ローカルのファイルサーバで更新されたファイルを、リモートのファイルサーバに適切に格納させることができる。このため、例えば、リモートのファイルサーバに接続された他のローカルのファイルサーバから、或るローカルのファイルサーバで更新されたファイルを適切に参照することができる。 According to the present invention, a file updated in a local file server can be appropriately stored in a remote file server. Therefore, for example, a file updated in a certain local file server can be appropriately referred from another local file server connected to the remote file server.
いくつかの実施例について、図面を参照して説明する。なお、以下に説明する実施例は特許請求の範囲にかかる発明を限定するものではなく、また実施例の中で説明されている諸要素及びその組み合わせの全てが発明の解決手段に必須であるとは限らない。 Several embodiments will be described with reference to the drawings. The embodiments described below do not limit the invention according to the claims, and all the elements and combinations described in the embodiments are essential for the solution of the invention. Is not limited.
なお、以後の説明では「aaaテーブル」等の表現にて本発明の情報を説明する場合があるが、これら情報は、テーブル等のデータ構造以外で表現されていてもよい。そのため、データ構造に依存しないことを示すために「aaaテーブル」等について「aaa情報」と呼ぶことがある。また、「bbb名」等の表現にて本発明の「bbb」を識別するための情報を説明する場合があるが、これらの識別するための情報は、名前に限られず、識別子や識別番号、アドレスなど、「bbb」が特定できる情報であればよい。 In the following description, the information of the present invention may be described using an expression such as “aaa table”, but the information may be expressed in a form other than a data structure such as a table. Therefore, the “aaa table” or the like may be referred to as “aaa information” to indicate that it does not depend on the data structure. In addition, information for identifying “bbb” of the present invention may be described by an expression such as “bbb name”. However, the information for identifying these is not limited to a name, but an identifier, an identification number, Any information that can identify “bbb” such as an address may be used.
また、以後の説明では「プログラム」を主語として説明を行う場合があるが、プログラムはプロセッサ(典型的にはCPU(Central Processing Unit))によって実行されることで定められた処理をメモリ及びI/F(インタフェース)を用いながら行うため、プロセッサを主語とした説明としてもよい。また、プログラムを主語として開示された処理は、ファイルサーバ(例えば、後述のファイルストレージ装置、アーカイブストレージ装置)が行う処理としてもよい。また、プログラムの一部または全ては専用ハードウェアによって実現されてもよい。また、各種プログラムはプログラム配布サーバや、計算機が読み取り可能な記憶メディアによって各計算機にインストールされてもよい。記憶メディアとしては、例えば、ICカード、SDカード、DVD等であってもよい。 In the following description, “program” may be used as the subject, but the program executes processing determined by being executed by a processor (typically a CPU (Central Processing Unit)) in the memory and I / O. Since it is performed while using F (interface), the description may be made with the processor as the subject. Further, the processing disclosed with the program as the subject may be processing performed by a file server (for example, a file storage device or archive storage device described later). Further, part or all of the program may be realized by dedicated hardware. Various programs may be installed in each computer by a program distribution server or a computer-readable storage medium. As the storage medium, for example, an IC card, an SD card, a DVD, or the like may be used.
ここで、各種用語について説明する。「Core」とは、リモートの計算機システムを含んだ拠点(集約拠点)であり、例えば、サーバやストレージ装置を一括管理する拠点やクラウドサービスを提供する拠点である。「Edge」とは、ローカルの計算機システムを含んだ拠点であり、例えば、支店、営業所、リモートオフィスなどユーザが実際に業務を行う拠点である。「スタブ」とは、ファイルの格納先情報(リンク先を表す情報)が関連付けられたオブジェクト(メタデータ)である。「スタブ化」とは、Edge(Edgeの計算機システム)のファイルについて、実際のデータ(実データ)を削除し、管理情報のみを保持した状態にすることをいう。スタブ化されたファイルは、実際のデータを保持していないため、アクセスされるとCoreの計算機システムから実データを取得する必要がある。このため、スタブ化されたファイルへのアクセスは、通常のファイルに比べてアクセス性能が低下する。 Here, various terms will be described. “Core” is a base (aggregation base) including a remote computer system, for example, a base that collectively manages servers and storage devices or a base that provides cloud services. “Edge” is a base including a local computer system, for example, a base where a user actually performs business such as a branch office, a sales office, or a remote office. A “stub” is an object (metadata) associated with file storage location information (information indicating a link destination). “Stubbing” refers to deleting actual data (actual data) from an Edge (Edge computer system) file and maintaining only management information. Since a stubbed file does not hold actual data, it is necessary to obtain actual data from the Core computer system when accessed. For this reason, access performance to a stubbed file is lower than that of a normal file.
「レプリケーション」とは、EdgeにあるファイルをCoreにコピーすることをいう。「マイグレーション」とは、EdgeにあるファイルをCoreにレプリケーションし、Edgeのファイルをスタブ化することをいう。「アーカイブ」とは、マイグレーションとレプリケーションとの総称である。「リコール」とは、スタブ化されたファイルについて、Coreから実データを取得し、Edgeのファイルに保持させることをいう。「キャッシュ」とは、EdgeからCoreへレプリケーションした後に、Edgeに残っているファイルのこと又は、そのようにEdgeにファイルを残すことをいう。キャッシュへのアクセスは、通常のファイルと同等なアクセス性能である。「ホームディレクトリ」とは、ファイルシステムにおいて、ユーザ毎に割り当てられるユーザ専用のディレクトリのことをいい、配下に当該ユーザのディレクトリ及びファイルを含む。 “Replication” means copying a file in Edge to Core. “Migration” means that a file in Edge is replicated to Core and a file in Edge is stubbed. “Archive” is a general term for migration and replication. “Recall” refers to acquiring actual data from the Core for a stubbed file and holding it in an Edge file. “Cache” means a file remaining in Edge after replication from Edge to Core, or leaving a file in Edge as such. Access to the cache has access performance equivalent to that of a normal file. The “home directory” refers to a user-specific directory assigned to each user in the file system, and includes the directory and file of the user under the subordinate.
まず、実施例1に係る情報システムを説明する。 First, an information system according to the first embodiment will be described.
図1は、実施例1に係る情報システムの概要を示す図である。 FIG. 1 is a diagram illustrating an overview of the information system according to the first embodiment.
情報システムのEdge10A(拠点Aともいう)において、ユーザAによりファイルストレージ装置30のファイルシステム36のファイルAが更新される(図中(A))と、ファイルストレージ装置30は、所定の時点、例えば、ユーザAがファイルストレージ装置30に対するセッションを切断した時、又は定期的に、ファイルシステム36のファイル(ファイルA等)についてアーカイブストレージ装置120へのレプリケーション、及びファイルのスタブ化を実行する(図中(B))。
When the file A of the
この後、ユーザAが拠点Aから拠点B(Edge10B)に移動して(図中(C))、ユーザAが拠点Bのファイルストレージ装置30に対するセッションを接続すると、拠点Bのファイルストレージ装置30は、Core100のアーカイブストレージ装置120のファイルシステム126からファイルAをリコールして、ファイルAをファイルシステム36に格納する(図中(D))。ここで、拠点BにおいてファイルAをリコールする場合には、既に、Core100のファイルシステム126にファイルAがレプリケーションされているので、適切にファイルAのリコールを行うことができる。
Thereafter, when the user A moves from the site A to the site B (
図2は、実施例1に係る情報システムのハードウェア構成を示す図である。 FIG. 2 is a diagram illustrating a hardware configuration of the information system according to the first embodiment.
情報システムのハードウェアは、Edge10とCore100とに配置される。図2に示す例では、Edge10は複数、Core100が単数であるが、Edge10が単数、及び/又は、Core100が複数でもよい。
The hardware of the information system is arranged in
Edge10の計算機システムは、RAID(Redundant Array of Independent (or Inexpensive ) Disks)システム20と、1以上のファイルストレージ装置30と、1以上のクライアント(例えば、パーソナルコンピュータ)/ホスト(例えば、サーバ)40と、を備える。ファイルストレージ装置30は、ローカルのファイルサーバの一例である。ファイルストレージ装置30は、例えば、通信ネットワーク50(例えばLAN(Local Area Network))経由で、クライアント/ホスト40に接続されている。また、ファイルストレージ装置30は、例えば、通信ネットワーク(例えばSAN(Storage Area Network))経由で、RAIDシステム20に接続されている。
The computer system of
RAIDシステム20は、CHA(Channel Adaptor)21と、DKC(DisK Controller)22と、DISK23とを備える。DKC22に、CHA21及びDISK23が接続されている。CHA21は、ファイルストレージ装置30に接続される通信インタフェース装置である。DKC22は、コントローラである。DISK23は、ディスク型の物理記憶デバイス(例えば、HDD(Hard Disk Drive))である。物理記憶デバイスとして、他種の物理記憶デバイス(例えば、フラッシュメモリデバイス)が採用されてもよい。また、DISK23は、図2では単数であるが、実際は、複数である(図示通り、単数でも良い)。複数のDISK23で、1以上のRAIDグループが構成されてよい。また、図示されていないが、RAIDシステム20は、RAIDシステム20内で実行されるプログラムを格納するメモリ、及び当該プログラムを実行するCPU(Central Processing Unit)とを有する。
The
RAIDシステム20は、ファイルストレージ装置30から送信されたブロックレベルのI/O要求をCHA21で受信し、DKC22の制御に基づいて、適切なDISK23へのI/Oを実行する。
The
ファイルストレージ装置30は、メモリ31と、CPU32と、NIC(Network Interface Card)33と、HBA(Host Bus Adaptor)34と、を備える。メモリ31、NIC33及びHBA34に、CPU32が接続されている。
The
NIC33は、アーカイブストレージ装置120及びクライアント/ホスト40と通信する通信インタフェース装置である。
The
HBA34は、RAIDシステム20と通信する通信インタフェース装置である。
The
メモリ31は、CPU32が直接読み書きできる記憶領域(例えば、RAM(Random Access Memory)やROM(Read Only Memory))である。ファイルストレージ装置30では、メモリ31上にファイルストレージ装置30を制御するプログラム(例えばOS(Operating System))を読み込み、CPU32がそのプログラムを実行する。ファイルストレージ装置30は、メモリ31に加えて又は代えて、別種の記憶資源を有してもよい。メモリ31は、記憶デバイスの一例である。
The
ファイルストレージ装置30は、NIC33経由で、クライアント/ホスト40からファイルレベルのI/O要求を受信する。ファイルストレージ装置30は、そのI/O要求で指定されているファイルを構成するデータブロックのI/OのためのI/O要求(ブロックレベルのI/O要求)を作成する。ファイルストレージ装置30は、ブロックレベルのI/O要求を、HBA34経由で、RAIDシステム20に送信する。
The
クライアント/ホスト40は、メモリ41と、CPU42と、NIC43と、DISK44と、を備える。クライアント/ホスト40は、メモリ41及び/又はDISK44に加えて又は代えて、別種の記憶資源を有してもよい。
The client /
クライアント/ホスト40では、DISK44に格納されているプログラム(クライアント/ホスト40を制御するプログラム(例えばOS))をメモリ41上に読み込み、CPU42がプログラムを実行する。また、クライアント/ホスト40は、NIC43経由で、ファイルレベルのI/O要求をファイルストレージ装置30に送信する。
In the client /
Core100の計算機システムは、RAIDシステム110と、アーカイブストレージ装置120と、を備える。アーカイブストレージ装置120は、リモートのファイルサーバの一例である。アーカイブストレージ装置120に、RAIDシステム110が接続されている。
The
RAIDシステム110は、CHA111と、DKC112と、DISK113と、を備える。図2では、RAIDシステム110の構成とRAIDシステム20の構成とは、同一である。従って、RAIDシステム110も、アーカイブストレージ装置120から送信されたブロックレベルのI/O要求をCHA111で受信し、DKC112の制御に基づいて、適切なDISK113へのI/Oを実行する。なお、RAIDシステム110の構成とRAIDシステム20の構成は、異なっていてもよい。
The
アーカイブストレージ装置120は、メモリ121と、CPU122と、NIC123と、HBA124と、を備える。メモリ121に代えて又は加えて、別種の記憶資源が備えられてもよい。アーカイブストレージ装置120では、メモリ121上にアーカイブストレージ装置120を制御するプログラム(例えばOS)を読み込み、CPU122がそのプログラムを実行する。また、アーカイブストレージ装置120は、NIC123及び通信ネットワーク80経由で、ファイルストレージ装置30と通信する。アーカイブストレージ装置120は、HBA124経由で、RAIDシステム110に対してブロック単位のアクセスを行う。
The
図3は、実施例1に係る情報システムのソフトウェア構成図である。 FIG. 3 is a software configuration diagram of the information system according to the first embodiment.
RAIDシステム20(110)は、複数のLU(Logical Unit)24(114)と、OS LU(OS用 Logical Unit)25(115)とを有する。LU24(114)は、ファイルストレージ装置30(アーカイブストレージ装置120)等の上位装置に対して提供される論理的な記憶デバイスであり、DISK23(113)の記憶領域に基づいて作成される。LU24(114)は、1以上のDISK23(113)に基づく実体的なLUであってもよいし、Thin Provisioningに従う仮想的なLUであってもよい。LU24(114)は、複数のブロック(記憶領域)で構成されている。LU24(114)に、ファイルが記憶される。 The RAID system 20 (110) includes a plurality of LU (Logical Unit) 24 (114) and an OS LU (Logical Unit for OS) 25 (115). The LU 24 (114) is a logical storage device provided to a host device such as the file storage device 30 (archive storage device 120), and is created based on the storage area of the DISK 23 (113). The LU 24 (114) may be a substantial LU based on one or more DISKs 23 (113), or may be a virtual LU according to Thin Provisioning. The LU 24 (114) is composed of a plurality of blocks (storage areas). The file is stored in the LU 24 (114).
OS LU25(115)は、論理的な記憶デバイスである。OS LU25(115)は、1以上のDISK23(113)に基づく実体的なLUであってもよい。OS LU25(115)は、ファイルストレージ装置30又はアーカイブストレージ装置120を制御するプログラム等や、後述のファイルシステム構成情報200の全部又は一部が、記憶されてよい。
The OS LU 25 (115) is a logical storage device. The OS LU 25 (115) may be a substantial LU based on one or more DISKs 23 (113). The OS LU 25 (115) may store a program or the like for controlling the
ファイルストレージ装置30のメモリ31(アーカイブストレージ装置120のメモリ121)には、データムーバプログラム37(125)と、ファイルシステム36(126)と、カーネル/ドライバ38(127)と、が記憶されている。ファイルストレージ装置30のメモリ31には、更に、ファイル共有プログラム35が記憶されている。以下、ファイルストレージ装置30内のデータムーバプログラム37を、「ローカルムーバ」と言い、アーカイブストレージ装置120内のデータムーバプログラム125を、「リモートムーバ」と言い、それらを特に区別しない場合に、「データムーバプログラム」と言う。ファイルストレージ装置30とアーカイブストレージ装置120との間では、ローカルムーバ37及びリモートムーバ125を介して、ファイルのやり取りが行われる。
A data mover program 37 (125), a file system 36 (126), and a kernel / driver 38 (127) are stored in the
ローカルムーバ37は、RAIDシステム20のLU24から、レプリケーション対象のファイル(ファイルの実データ及びファイルのメタデータ)を読み出し、そのファイルをアーカイブストレージ装置120に転送する。リモートムーバ125は、レプリケーション対象のファイルをファイルストレージ装置30から受信し、そのファイルを、RAIDシステム110のLU114に書き込む。
The
また、ローカルムーバ37は、LU24内のレプリケーション済みファイル(厳密にはそのファイルの実データ)を、ある所定の条件が満たされた場合に、削除し、それにより、レプリケーション済みファイルの実質的なマイグレーションを実現する。その後、ローカルムーバ37は、実データが削除されたファイルのスタブ(メタデータ)に対してクライアント/ホスト40からリード要求を受けた場合、リモートムーバ125を経由して、スタブにリンクしているファイル(ファイルの実データ)を取得し、取得したファイルをクライアント/ホスト40に送信する。なお、本実施例において、「スタブ」とは、ファイルの格納先情報(リンク先を表す情報)が関連付けられたオブジェクト(メタデータ)である。クライアント/ホスト40からは、ファイルがスタブであるかは分からない。
In addition, the
カーネル/ドライバ38(127)は、ファイルストレージ装置30(アーカイブストレージ装置120)上で動作する複数のプログラム(プロセス)のスケジュール制御やハードウェアからの割り込みをハンドリングするなど、全般的な制御及びハードウェア固有の制御を行う。 The kernel / driver 38 (127) performs general control and hardware such as schedule control of a plurality of programs (processes) operating on the file storage device 30 (archive storage device 120) and handling interrupts from hardware. Perform inherent control.
ファイル共有プログラム35は、CIFS(Common Internet File System)、NFS(Network File System)といった通信プロトコルを使用して、クライアント/ホスト40との間で、ファイル共有サービスを提供するプログラムである。
The
クライアント/ホスト40のメモリ41には、アプリケーション45と、ファイルシステム46と、カーネル/ドライバ47とが記憶されている。
In the memory 41 of the client /
アプリケーション45は、クライアント/ホスト40が、作業の目的に応じて使うソフトウェア(アプリケーションプログラム)である。ファイルシステム46及びカーネル/ドライバ47は、上述のファイルシステム36(126)、カーネル/ドライバ38(127)とほぼ同様である。
The
ファイルシステム36(126)は、ファイルシステムプログラムであり、ファイルシステム構成情報200を管理する。ファイルシステム構成情報200は、各ファイル、ディレクトリに関する情報(例えば、ファイルのサイズや場所などを表す情報等)を含み、例えばOS LU25(115)やメモリ31(121)に格納される。
The file system 36 (126) is a file system program and manages the file
図4は、実施例1に係るファイルシステム構成情報の構成図である。 FIG. 4 is a configuration diagram of file system configuration information according to the first embodiment.
ファイルシステム構成情報200は、スーパーブロック210と、inode管理テーブル220と、データブロック群230とを含む。スーパーブロック210は、ファイルシステムの情報を一括保持するブロックであり、例えば、ファイルシステムの大きさ、ファイルシステムの空き容量等の情報を格納する。inode管理テーブル220は、ファイル管理情報の一例であるinodeを管理するテーブルである。ファイルシステム36(126)では、1つのディレクトリや、1つのファイルのそれぞれに対して1つのinodeを対応させている。ここで、ディレクトリに対応するinodeをディレクトリエントリと呼ぶ。複数のディレクトリエントリを用いて、ファイルパスを辿ることにより、ファイルに対応するinodeにアクセスすることができる。
The file
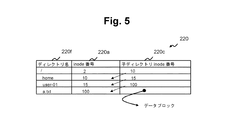
図5は、実施例1に係るディレクトリエントリの構成図である。図5は、「/home/use-01/a.txt」で示されるファイルにアクセスする際に利用するinode管理テーブル220のディレクトリエントリを示している。 FIG. 5 is a configuration diagram of a directory entry according to the first embodiment. FIG. 5 shows a directory entry of the inode management table 220 used when accessing the file indicated by “/home/use-01/a.txt”.
「/home/use-01/a.txt」で示されるファイルにアクセスする際には、ファイルのパス名に従って、inode番号「2」、「10」、「15」に対応するinodeを辿って行き、ファイルに対応するinode番号「100」のinodeを特定する。そして、ファイルに対応するinode番号「100」のinodeに基づいて、ファイルの実データが格納されているデータブロックを特定し、このデータブロックにアクセスすることとなる。 When accessing the file indicated by “/home/use-01/a.txt”, the inode corresponding to the inode numbers “2”, “10”, “15” is traced according to the path name of the file. The inode of the inode number “100” corresponding to the file is specified. Then, based on the inode of the inode number “100” corresponding to the file, the data block storing the actual data of the file is specified, and this data block is accessed.
図6は、実施例1に係るファイルに対応するinodeの構成図である。 FIG. 6 is a configuration diagram of an inode corresponding to a file according to the first embodiment.
ファイルに対応するinode201は、複数のメタデータで構成される。メタデータの種類としては、ファイルの所有者、ファイルのアクセス権、ファイルサイズ、ファイルの格納位置(データブロックアドレス1、2、3、…)などがある。例えば、inode番号「100」を含む行(inode番号「100」のinode)によれば、ファイルは、図6に示すように、下記のデータブロック(LU内のデータブロック)が記憶するデータ(実データ)で構成されていることがわかる。
(*)アドレス100のデータブロックを先頭とした所定数(ここでは、2つ)の連続したデータブロック内のデータ。
(*)アドレス200のデータブロックを先頭とした所定数(ここでは、2つ)の連続したデータブロック内のデータ。
(*)アドレス250のデータブロックを先頭とした所定数(ここでは、2つ)の連続したデータブロック内のデータ。
The
(*) Data in a predetermined number (in this case, two) consecutive data blocks starting from the data block at
(*) Data in a predetermined number (two in this case) of consecutive data blocks starting from the data block at
(*) Data in a predetermined number (two in this case) of consecutive data blocks starting from the data block at
次に、inode管理テーブルの詳細な構成について説明する。 Next, a detailed configuration of the inode management table will be described.
図7は、実施例1に係るinode管理テーブルの構成図である。 FIG. 7 is a configuration diagram of an inode management table according to the first embodiment.
inode管理情報テーブル220は、ディレクトリに対応するinode202と、ファイルに対応するinode201との2種類のエントリを管理する。
The inode management information table 220 manages two types of entries, an
ディレクトリに対応するinode202は、inode番号220aと、所有者220bと、アクセス権220cと、サイズ220dと、最終アクセス日時220eと、ディレクトリ名220fと、子ディレクトリinode番号220gとのフィールドを有する。
The
inode番号220aには、このエントリに対応するinode番号が格納される。所有者220bには、このエントリに対応するディレクトリの所有者の識別情報が格納される。アクセス権220cには、このエントリに対応するディレクトリに対するアクセス権が格納される。サイズ220dには、このエントリに対応するディレクトリのサイズが格納される。最終アクセス日時220eには、このエントリに対応するディレクトリに対する最終アクセス日時が格納される。ディレクトリ名220fには、このエントリに対応するディレクトリの名前(ディレクトリ名)が格納される。子ディレクトリinode番号220gには、このエントリに対応するディレクトリの子となる(直下の)ディレクトリ(ファイル)に対応するinode番号が格納される。
The
ファイルに対応するinode201は、inode番号220aと、所有者220bと、アクセス権220cと、サイズ220dと、最終アクセス日時220eと、ファイル名220hと、データブロックアドレス1 220lと、データブロックアドレス2 220mと、データブロックアドレス3 220nとのフィールドを有する。なお、ディレクトリに対応するinode202と同一の符号で示しているフィールドについては、同様な情報が格納される。ファイル名220hには、このエントリに対応するファイルのファイル名が格納される。データブロックアドレス1 220l、データブロックアドレス2 220m、及びデータブロックアドレス3 220nには、このエントリに対応するファイルの実データが格納されているデータブロックのアドレスが格納される。
The
本実施例では、inode管理テーブル220には、新たな種類のメタデータが管理されている。 In this embodiment, a new type of metadata is managed in the inode management table 220.
図8は、実施例1に係るinode管理テーブルの詳細構成図である。 FIG. 8 is a detailed configuration diagram of an inode management table according to the first embodiment.
ファイルに対応するinode201は、スタブ化フラグ220iと、レプリケーション済みフラグ220jと、リンク先220kとのフィールドを更に有する。
The
スタブ化フラグ220iには、このエントリに対応するファイル(図8の説明で対象ファイルという)がスタブ化されているか否かを表すスタブ化フラグが格納される。スタブ化フラグは、例えば、対象ファイルがスタブ化されている場合には、「ON」であり、対象ファイルがスタブ化されていない場合、「OFF」である。 The stubification flag 220i stores a stubification flag indicating whether or not the file corresponding to this entry (referred to as the target file in the description of FIG. 8) is stubbed. The stubbing flag is, for example, “ON” when the target file is stubbed, and “OFF” when the target file is not stubbed.
レプリケーション済みフラグ220jには、対象ファイルがレプリケーション済みであるか否かを表すレプリケーション済みフラグが格納される。レプリケーション済みフラグは、対象ファイルがレプリケーション済みの場合に「ON」であり、対象ファイルがレプリケーションされていない場合は「OFF」である。
The replicated
リンク先220kには、対象ファイルの実データのCore100における格納先(リンク先)を表す情報(例えば、URL(Uniform Resource Locator))が格納される。
The
本実施例では、ファイルストレージ装置30に接続可能なユーザを管理するとともに、セッション接続をしたユーザを管理するためにセッション接続管理用のユーザ管理テーブル240を用いている。セッション接続管理用のユーザ管理テーブル240は、例えば、ファイルストレージ装置30のメモリ31に格納されている。また、セッション切断をしたユーザを管理するためにも同様な構成のセッション切断管理用のユーザ管理テーブルを用いている。このセッション切断管理用のユーザ管理テーブルについてもメモリ31に格納されている。
In this embodiment, a user who can connect to the
図9は、実施例1に係るユーザ管理テーブル及びユーザ管理テーブルの管理方法を説明する図である。図9は、セッション接続したユーザを管理するセッション接続管理用のユーザ管理テーブル240であるが、セッション切断したユーザを管理するセッション切断管理用のユーザ管理テーブルも同様な構成であり、その構成及びその管理方法は、図9におけるセッション接続したユーザを、セッション切断したユーザと読み替えればよい。 FIG. 9 is a diagram illustrating a user management table and a user management table management method according to the first embodiment. FIG. 9 shows a user management table 240 for session connection management for managing users connected to a session. The user management table for session disconnection management for managing users disconnected from a session has the same configuration. In the management method, the user connected to the session in FIG. 9 may be read as the user who disconnected the session.
セッション接続管理用のユーザ管理テーブル240は、図9の上図に示すように、ポインタ240aと、ユーザ240bとのフィールドを含むエントリを格納する。ポインタ240aには、ユーザ管理テーブル240におけるエントリの番号が格納される。ユーザ240bには、エントリに対応するユーザのユーザ名(ユーザID等、ユーザを識別できるユーザ特定情報)が格納される。
As shown in the upper diagram of FIG. 9, the user management table 240 for session connection management stores entries including fields of a
本実施例では、図9の下図に示すように、接続管理用のポインタ250によって示される番号に対応するエントリ以降であるか否かにより、エントリに対応するユーザが所定の時点以降にセッション接続したことがあるユーザであるか否かを管理している。すなわち、接続管理用のポインタによって示されるエントリよりも前のエントリに対応するユーザは、所定の時点以降にセッション接続したことがあるユーザであり、ポインタによって示されるエントリ以降のエントリに対応するユーザは、所定の時点以降にセッション接続したことがないユーザであることを意味している。接続管理用のポインタ250は、例えば、メモリ31に格納されている。
In the present embodiment, as shown in the lower diagram of FIG. 9, the user corresponding to the entry connected to the session after a predetermined time depending on whether or not the entry corresponds to the number indicated by the
このセッション接続管理用のユーザ管理テーブル240を用いたセッション接続したユーザの管理は、次のように行われる。まず、ユーザがセッション接続した際には、そのユーザのユーザ名が格納されているエントリが、ポインタが示すエントリ以降であるか否かを判定し、ポインタが示すエントリ以降であれば、そのエントリのユーザ名と、ポインタが示すエントリのユーザ名とをスワップし、ポインタ250を1つインクリメントする。これにより、ポインタ250が示すエントリよりも前に、所定時点以降にセッション接続したユーザのユーザ名を含むエントリを集約することができる。
Management of users connected to a session using the user management table 240 for session connection management is performed as follows. First, when a user connects to a session, it is determined whether or not the entry storing the user name of the user is after the entry indicated by the pointer. The user name and the user name of the entry indicated by the pointer are swapped, and the
例えば、図9の上図のような状態であり、だれもセッション接続していない場合において、UserA及びUserEがセッション接続をすると、ポインタが初期値0であるので、UserAについては、ポインタ以降のエントリであるので、ポインタの位置のユーザ名とのスワップをすることとなるが、ポインタの位置なのでユーザ名は移動しないで、ポインタが1となる。次に、UesrEについては、ポインタが示すエントリ以降のエントリであるので、図9の下図に示すように、ポインタの位置のユーザ名であるUserBとUesrEとをスワップし、UserEを2番目のエントリに格納するとともに、ポインタに1を加算して、ポインタを2とする。したがって、ポインタが示すエントリよりも前のエントリに、セッション接続したユーザのユーザ名、すなわち、UserA及びUserEを集約して管理することができる。
For example, in the state shown in the upper diagram of FIG. 9 and when no user is connected to the session, when User A and User E make a session connection, the pointer is the
次に、実施例1で行われる処理を説明する。 Next, processing performed in the first embodiment will be described.
図10は、実施例1に係るアクセス処理のフローチャートである。アクセス処理は、クライアント/ホスト40からファイルストレージ装置30に対してユーザによるアクセス処理が来た場合に実行される。
FIG. 10 is a flowchart of an access process according to the first embodiment. The access process is executed when an access process is performed by the user from the client /
ファイルストレージ装置30は、アクセス処理を受け取ると、アクセス処理の種類がいずれであるかを判定する(ステップS11)。
When the
ステップS11で、アクセス処理の種類がファイルストレージ装置30に対するセッション接続であると判定した場合(ステップS11:セッション接続)には、ファイルストレージ装置30は、アクセス処理を要求したユーザのホームディレクトリのロック要求を実行する(ステップS12)。ロック要求に起因して実行される処理は、図11を参照して後述する。
If it is determined in step S11 that the type of access processing is session connection to the file storage device 30 (step S11: session connection), the
ファイルストレージ装置30は、ロックが成功したか否かを判定する(ステップS13)。この結果、ロック成功していない場合(ステップS13:No)には、ファイルストレージ装置30は、処理をステップS12に進める。
The
一方、ロック成功した場合(ステップS13:Yes)には、ファイルストレージ装置30は、ユーザのホームディレクトリの配下のディレクトリ及びファイルに対応するスタブ情報の取得要求を行う(ステップS14)。ここで、スタブ情報とは、アーカイブストレージ装置120のファイルシステム126において管理されているinode(エントリ)である。スタブ情報の取得要求に起因して実行される処理は、図16を参照して後述する。
On the other hand, if the lock is successful (step S13: Yes), the
その後、ファイルストレージ装置30は、取得したスタブ情報に基づいて、ホームディレクトリを作成し(ステップS15)、データ同期処理(図13及び図14参照)を実行し(ステップS16)、アクセス処理を終了する。
Thereafter, the
また、ステップS11で、アクセス処理の種類がファイルストレージ装置30に対するセッション切断であると判定した場合(ステップS11:セッション切断)には、ファイルストレージ装置30は、セッション切断時の処理を行う(ステップS17)。例えば、ファイルストレージ装置30は、アクセス処理を要求したユーザのホームディレクトリのレプリケーション、スタブ化等の処理を行う。セッション切断時の処理については、図17乃至図19を参照して後述する。
If it is determined in step S11 that the type of access processing is session disconnection for the file storage device 30 (step S11: session disconnection), the
次に、ファイルストレージ装置30は、ホームディレクトリのアンロック要求を実行する(ステップS18)。アンロック要求に起因して実行される処理は、図12を参照して後述する。その後、ファイルストレージ装置30は、アクセス処理を終了する。
Next, the
また、ステップS11で、アクセス処理の種類がファイルのRead処理であると判定した場合(ステップS11:Read処理)には、ファイルストレージ装置30は、ファイルシステム36のinode管理テーブル220のRead対象のファイルに対応するinode(エントリ)を参照し、このファイルがスタブ化されているか否かを判定する(ステップS19)。ここで、ファイルがスタブ化されているか否かは、inode201のスタブ化フラグ220iを参照することにより判定することができる。この結果、このファイルがスタブ化されている場合(ステップS19:Yes)には、ファイルストレージ装置30は、このファイルの実データをリコールする処理を実行し(ステップS20)、処理をステップS21に進める。ファイルをリコールする処理によると、ファイルの実データが、LU24のデータブロックに格納され、inode管理テーブル220のファイルに対応するinode201のデータブロックアドレスに実データが格納されたブロックアドレスが格納される。なお、ファイルの実データをリコールするリコール処理については、図15を参照して後述する。
If it is determined in step S11 that the type of access processing is file read processing (step S11: read processing), the
一方、このファイルがスタブ化されていない場合(ステップS19:No)、すなわち、ファイルの実データがLU24に格納されている場合には、ファイルストレージ装置30は、処理をステップS21に進める。
On the other hand, if this file is not stubbed (step S19: No), that is, if the actual data of the file is stored in the
ステップS21では、ファイルストレージ装置30は、ファイルのinode201に基づいて、ファイルの実体を読み出す、すなわち、inode201から実データが格納されているデータブロックを特定し、当該データブロックからデータを読み出す。その後、ファイルストレージ装置30は、アクセス処理を終了する。
In step S21, the
また、ステップS11で、アクセス処理の種類がファイルのWrite処理であると判定した場合(ステップS11:Write処理)には、ファイルストレージ装置30は、ファイルシステム36のinode管理テーブル220のWrite対象のファイルに対応するinode(エントリ)201を参照し、このファイルがスタブ化されているか否かを判定する(ステップS22)。この結果、このファイルがスタブ化されている場合(ステップS22:Yes)には、ファイルストレージ装置30は、このファイルの実データをリコールする処理を実行し(ステップS23)、処理をステップS24に進める。ファイルをリコールする処理によると、ファイルの実データが、LU24のデータブロックに格納され、inode管理テーブル240のファイルに対応するinode201のデータブロックアドレスに実データが格納されたブロックアドレスが格納される。ファイルの実データをリコールする処理については、図15を参照して後述する。
If it is determined in step S11 that the type of access process is a file write process (step S11: Write process), the
一方、このファイルがスタブ化されていない場合(ステップS22:No)には、ファイルストレージ装置30は、処理をステップS24に進める。
On the other hand, if this file is not stubbed (step S22: No), the
ステップS24では、ファイルストレージ装置30は、ファイルのinode201に基づいて、ファイルの実データを書き込む、すなわち、inode201から実データが格納されているデータブロックを特定し、当該データブロックに対して実データを書き込む。その後、ファイルストレージ装置30は、このファイルのinode201のレプリケーション済みフラグ220jのレプリケーション済みフラグを、このファイルがレプリケーションされていないことを示すレプリケーション済みフラグ(ここでは、「OFF」)に変更し(ステップS25)、アクセス処理を終了する。
In step S24, the
図11は、実施例1に係るロック処理のフローチャートである。 FIG. 11 is a flowchart of the lock process according to the first embodiment.
ロック処理は、図10に示すステップS12において、ファイルストレージ装置30によりロック要求が実行されることにより実行される。
The lock process is executed when a lock request is executed by the
Core100のアーカイブストレージ装置120は、ロック要求を受け取ると、ロック要求に含まれるEdge名称及びロック対象のホームディレクトリ名から、当該ホームディレクトリのロックを管理するためのロックファイルの名前(ロックファイル名)を特定し、同一のホームディレクトリのロックを管理するためのロックファイル、すなわち、同一のホームディレクトリ名を含むロックファイルを検索する(ステップS31)。ここで、ロックファイルとは、ロック状態の有無を識別するためにCORE100側に作成されるファイルであり、ホームディレクトリがロックされると当該ホームディレクトリについてのロックファイルが作成され、ホームディレクトリがアンロックされると当該ホームディレクトリについてのロックファイルが削除される。ファイル名をロック要求元(Edgeの識別情報)とホームディレクトリ名称とにすることにより、ファイル検索によって、誰がどのリソースをロックしているかを知ることができる。なお、ロックファイル名は、ロック要求を行ったユーザ名を含んでいてもよい。ロックファイルは、例えば、メモリ121に格納されている。
Upon receiving the lock request, the
次いで、アーカイブストレージ装置120は、同一のホームディレクトリ名を含むロックファイルを発見したか否かを判定する(ステップS32)。この結果、同一のホームディレクトリ名を含むロックファイルを発見した場合(ステップS32:Yes)には、そのホームディレクト名のホームディレクトリがロックされていることを意味しているので、アーカイブストレージ装置120は、ロック要求の結果を失敗と設定し(ステップS34)、ロック要求の結果をEdge10のファイルストレージ装置30に返し(ステップS35)、処理を終了する。
Next, the
一方、同一のホームディレクトリ名を含むロックファイルを発見しなかった場合(ステップS32:No)には、アーカイブストレージ装置120は、ステップS31で特定したロックファイル名のロックファイルを例えば、メモリ121に格納し、ロック要求の結果を成功と設定し(ステップS33)、ロック要求の結果をEdge10のファイルストレージ装置30に返す(ステップS35)。
On the other hand, when no lock file including the same home directory name is found (step S32: No), the
ステップS35で返されたロック要求の結果を受け取ったファイルストレージ装置30は、ステップS12を終了して、次のステップに処理を進める。このロック処理によると、適切にホームディレクトリを単位としたロック制御を行うことができる。
The
なお、ロック処理は、セッション接続時ではなくて、ファイルに対する最初のアクセス時に行ってもよい。 The lock process may be performed at the first access to the file, not at the time of session connection.
図12は、実施例1に係るアンロック処理のフローチャートである。 FIG. 12 is a flowchart of the unlocking process according to the first embodiment.
アンロック処理は、図10に示すステップS18において、ファイルストレージ装置30によりアンロック要求が実行されることにより実行される。
The unlock process is executed when an unlock request is executed by the
Core100のアーカイブストレージ装置120は、アンロック要求を受け取ると、アンロック要求に含まれるEdge名称及びロック対象のホームディレクトリ名から、このホームディレクトリのロックを管理するためのロックファイルの名前(ロックファイル名)を特定し、このロックファイル名のロックファイルを検索する(ステップS41)。
When receiving the unlock request, the
次いで、アーカイブストレージ装置120は、このロックファイル名のロックファイルを発見したか否かを判定する(ステップS42)。この結果、このロックファイル名のロックファイルを発見した場合(ステップS42:Yes)には、アーカイブストレージ装置120は、このロックファイルを削除し、アンロック要求の結果を成功と設定し(ステップS43)、アンロック要求の結果をEdge10のファイルストレージ装置30に返し(ステップS45)、処理を終了する。
Next, the
一方、このロックファイル名のロックファイルを発見しなかった場合(ステップS42:No)には、アーカイブストレージ装置120は、アンロック要求の結果を失敗と設定し(ステップS44)、アンロック要求の結果をEdge10のファイルストレージ装置30に返す(ステップS45)。
On the other hand, when the lock file having this lock file name is not found (step S42: No), the
ステップS45で返されたアンロック要求の結果を受け取ったファイルストレージ装置30は、ステップS18を終了して、次のステップに処理を進める。このアンロック処理によると、適切にホームディレクトリを単位としたロック制御を行うことができる。
The
なお、アンロック処理は、セッション切断時ではなくて、レプリケーション後に所定時間以上ファイルに対するアクセス(リード又はライト)がない場合に行ってもよい。 The unlock process may be performed not when the session is disconnected but when there is no access (read or write) to the file for a predetermined time or longer after replication.
図13は、実施例1に係る接続ユーザ管理処理のフローチャートである。 FIG. 13 is a flowchart of connected user management processing according to the first embodiment.
接続ユーザ管理処理は、図10に示すステップS16のデータ同期処理の一部の処理に対応する。 The connected user management process corresponds to a part of the data synchronization process in step S16 shown in FIG.
まず、ファイルストレージ装置30は、セッション接続管理用のユーザ管理テーブル240におけるセッション接続したユーザのユーザ名の位置の値(エントリの順番)が接続管理用のポインタの値以上であるか否か判定する。
First, the
この結果、セッション接続したユーザのユーザ名の位置の値がポインタの値以上の場合(ステップS51:Yes)には、ファイルストレージ装置30は、ユーザ管理テーブル240におけるポインタの値が示すエントリのユーザ名と、セッション接続したユーザのユーザ名が格納されているエントリのユーザ名とをswap(交換)し(ステップS52)、ポインタの値に1を加算し(ステップS53)、処理を終了する。
As a result, when the value of the position of the user name of the user connected to the session is equal to or greater than the value of the pointer (step S51: Yes), the
一方、セッション接続したユーザのユーザ名の位置の値がポインタの値より小さい場合(ステップS51:No)、ファイルストレージ装置30は、処理を終了する。
On the other hand, when the value of the position of the user name of the user connected to the session is smaller than the value of the pointer (step S51: No), the
この処理により、セッション接続したユーザのユーザ名をユーザ管理テーブル240のポインタが示すエントリよりも前のエントリに集約して管理することができる。 With this process, the user names of the users connected in the session can be collected and managed in an entry before the entry indicated by the pointer in the user management table 240.
図14は、実施例1に係るキャッシュ上書き処理のフローチャートである。 FIG. 14 is a flowchart of the cache overwriting process according to the first embodiment.
キャッシュ上書き処理は、図10に示すステップS16のデータ同期処理の一部の処理に対応する。このキャッシュ上書き処理は、例えば、所定の時間毎に実行される。なお、キャッシュ上書き処理を、接続ユーザ管理処理の終了直後に実行するようにしてもよい。 The cache overwriting process corresponds to a part of the data synchronization process in step S16 shown in FIG. This cache overwriting process is executed, for example, every predetermined time. Note that the cache overwriting process may be executed immediately after the connected user management process ends.
ファイルストレージ装置30は、変数Nを0に設定し(ステップS61)、変数NがEdge10のファイルストレージ装置30に接続可能なユーザ数より小さいか否かを判定する(ステップS62)。この結果、変数NがEdge10のファイルストレージ装置30に接続可能なユーザ数より小さい場合(ステップS62:Yes)には、ファイルストレージ装置30は、ユーザ管理テーブル240の変数Nの位置のユーザ名に対応するユーザのホームディレクトリ情報を、アーカイブストレージ装置120に要求し(ステップS63)、処理をステップS64に進める。ここで、ホームディレクトリ情報とは、ユーザのホームディレクトリの配下にあるファイル及びディレクトリのinodeを含む情報である。また、ホームディレクトリ情報の要求には、例えば、ユーザのホームディレクトリの名称が含まれる。
The
これに対して、アーカイブストレージ装置120は、ホームディレクトリ情報の要求を受け取ると、要求の対象となるユーザのホームディレクトリ情報をメモリ121から取得し(ステップS71)、当該取得したホームディレクトリ情報をファイルストレージ装置30に転送する(ステップS72)。
On the other hand, when receiving the request for home directory information, the
ファイルストレージ装置30は、アーカイブストレージ装置120から転送されたホームディレクトリ情報を取得し、ホームディレクトリを設定し、当該ホームディレクトリ情報に基づいて、メモリ31にキャッシュされているデータ、例えば、ユーザのホームディレクトリのディレクトリ及びファイルのinode等を上書きする(ステップS64)。
The
次いで、ファイルストレージ装置30は、変数Nに1を加算して(ステップS65)、処理をステップS62に進める。
Next, the
一方、変数NがEdge10のファイルストレージ装置30に接続可能なユーザ数より小さくない場合(ステップS62:No)には、このファイルストレージ装置30に接続可能な全てのユーザのキャッシュされているデータを上書きしたことを意味しているので、ファイルストレージ装置30は、ポインタを0に設定して、接続したことがあるユーザをリセットし(ステップS66)、処理を終了する。
On the other hand, if the variable N is not smaller than the number of users connectable to the
ここで、図13に示す接続ユーザ管理処理により、所定の時点以降でセッション接続したユーザのユーザ名がユーザ管理テーブル240の先頭から順に並んで管理されているので、図14に示すキャッシュ上書き処理においては、セッション接続したユーザのキャッシュが優先して上書きされることとなる。すなわち、例えば、切断中のユーザが格納した大きいサイズのファイルを上書きするために、セッション接続しているユーザのデータの上書き処理が遅れることを適切に防止できる。なお、セッション接続したユーザとしては、例えば、他のEdge10から移動してきたユーザが含まれる。
Here, in the connected user management process shown in FIG. 13, the user names of users who connected to the session after a predetermined time are managed in order from the top of the user management table 240, so in the cache overwriting process shown in FIG. 14. In this case, the cache of the user connected to the session is preferentially overwritten. That is, for example, in order to overwrite a large-sized file stored by the disconnected user, it is possible to appropriately prevent a delay in overwriting the data of the user connected to the session. Note that the user connected to the session includes, for example, a user who has moved from another
図15は、実施例1に係るリコール処理のフローチャートである。 FIG. 15 is a flowchart of the recall process according to the first embodiment.
リコール処理は、図10に示すステップS20、又はS23におけるファイルストレージ装置30の処理に応じて実行される。
The recall process is executed according to the process of the
ファイルストレージ装置30は、スタブ化されているファイルの実データの取得要求(ファイル取得要求)をCore100のアーカイブストレージ装置120に送信する(ステップS81)。ファイル取得要求には、取得対象の実データが格納されている格納先(リンク先)の情報が含まれている。このリンク先は、スタブ化されているファイルのinode201のリンク先220kから取得することができる。
The
アーカイブストレージ装置120は、ファイル取得要求を受信すると、ファイル取得要求の格納先に基づいて、対応する格納先から取得対象のファイルの実データを取得し(ステップS91)、このファイルの実データをファイルストレージ装置30に転送し(ステップS92)、処理を終了する。
Upon receiving the file acquisition request, the
ファイルストレージ装置30は、ファイルの実データを取得すると、取得したファイルの実データの呼び出し元、すなわち、図10のステップS20、又はS23の処理ステップに返し(ステップS82)、リコール処理を終了する。なお、図10のステップS20、又はS23では、返されたファイルの実データが、LU24のデータブロックに格納され、inode管理テーブル220のファイルに対応するinode201のデータブロックアドレス(220l等)に実データが格納されたブロックアドレスが格納され、スタブ化フラグ220iがOFFにされる。
When the
図16は、実施例1に係るスタブ情報取得処理のフローチャートである。 FIG. 16 is a flowchart of stub information acquisition processing according to the first embodiment.
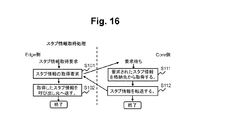
スタブ情報取得処理は、図10に示すステップS14において、ファイルストレージ装置30によりスタブ情報の取得要求が実行されることにより実行される。
The stub information acquisition process is executed when a request for acquiring stub information is executed by the
ファイルストレージ装置30は、スタブ情報の取得要求(スタブ情報取得要求)をCore100のアーカイブストレージ装置120に送信する(ステップS101)。スタブ情報取得要求には、スタブ情報を取得する対象のホームディレクトリを特定する情報(例えば、ホームディレクトリ名)が含まれている。
The
アーカイブストレージ装置120は、スタブ情報取得要求を受信すると、ホームディレクトリを特定する情報に基づいて、ホームディレクトリ配下の全てのディレクトリのinode202及びファイルのinode201(スタブ情報)を取得し(ステップS111)、このinode201及び202をファイルストレージ装置30に転送し(ステップS112)、処理を終了する。ここで、ファイルストレージ装置30に転送されるinode201のレプリケーション済みフラグ220jには、レプリケーション済みであることを示すONが設定され、リンク先220kには、実データが格納されているリンク先が格納されている。
Upon receiving the stub information acquisition request, the
ファイルストレージ装置30は、inode201及び202を取得すると、取得したスタブ情報取得要求の呼び出し元、すなわち、図10のステップS14の処理ステップに返し(ステップS102)、スタブ情報取得処理を終了する。これにより、ファイルストレージ装置30は、ホームディレクトリ配下のディレクトリ及びファイルのinode201及び202を受け取ることとなる。
When the
なお、スタブ情報取得処理は、例えば、セッション接続時だけでなく、例えば、定期的に実行するようにしてもよい。 Note that the stub information acquisition process may be executed not only when the session is connected, but also periodically, for example.
また、スタブ情報取得処理におけるステップS101を実行する前において、以下の(1)〜(4)に示すようなファイルのリネーム処理、キャッシュしたファイルの無効化処理等を実行してもよい。
(1)ファイルストレージ装置30は、ファイルシステム36が管理しているファイルのinode番号、ファイルパス名、及び最終更新日時をアーカイブストレージ装置120に送信する。
(2)アーカイブストレージ装置120は、ファイルシステム126が管理しているファイルのinode番号及びファイルパス名と、ファイルストレージ装置30から送信されたinode番号及びファイルパス名とを参照し、inode番号が同じで、ファイルパス名が異なる場合には、ファイルパス名を変更(リネーム)する。
(3)アーカイブストレージ装置120は、ファイルシステム126が管理しているファイルのinode番号及び最終更新日時と、ファイルストレージ装置30から送信されたinode番号及び最終更新日時とを参照し、inode番号が同じであり且つファイルストレージ装置30から送信された最終更新日時がアーカイブストレージ装置120の最終更新日時よりも古い場合、すなわち、ファイルストレージ装置30のファイルが古いデータである場合には、そのinode番号をファイルストレージ装置30に送信する。
(4)ファイルストレージ装置30は、アーカイブストレージ装置120から送信されたinode番号に対応するファイルの実データを削除して、当該ファイルをスタブ化する。
In addition, before executing step S101 in the stub information acquisition process, a file renaming process, a cached file invalidation process, and the like as shown in (1) to (4) below may be executed.
(1) The
(2) The
(3) The
(4) The
図17は、実施例1に係る切断ユーザ管理処理のフローチャートである。 FIG. 17 is a flowchart of disconnected user management processing according to the first embodiment.
切断ユーザ管理処理は、図10に示すステップS17において実行されるセッション切断時の処理の一部の処理である。 The disconnected user management process is a part of the session disconnection process executed in step S17 shown in FIG.
まず、ファイルストレージ装置30は、セッション切断管理用のユーザ管理テーブルにおけるセッション切断したユーザのユーザ名の位置の値(エントリの順番)が切断管理用のポインタの値以上であるか否か判定する。切断管理用のポインタは、例えば、メモリ31に格納されている。
First, the
この結果、セッション切断したユーザのユーザ名の位置の値がポインタの値以上である場合(ステップS121:Yes)には、ファイルストレージ装置30は、ユーザ管理テーブル240におけるポインタの値が示すエントリのユーザ名と、セッション切断したユーザのユーザ名が格納されているエントリのユーザ名とをswap(交換)し(ステップS122)、ポインタの値に1を加算し(ステップS123)、処理を終了する。
As a result, if the value of the position of the user name of the user who disconnected the session is equal to or greater than the value of the pointer (step S121: Yes), the
一方、セッション切断したユーザのユーザ名の位置の値がポインタの値より小さい場合(ステップS121:No)、ファイルストレージ装置30は、処理を終了する。
On the other hand, when the value of the position of the user name of the user who disconnected the session is smaller than the value of the pointer (step S121: No), the
この処理により、セッション切断したユーザのユーザ名をセッション切断管理用のユーザ管理テーブルの切断管理用のポインタが示すエントリよりも前のエントリに集約して管理することができる。すなわち、所定期間の間にセッション切断したユーザをセッション切断した時刻が早いものから順に並べることができる。 By this processing, the user name of the user who disconnected the session can be managed by collecting the entry before the entry indicated by the disconnection management pointer in the user management table for session disconnection management. That is, it is possible to arrange the users who disconnected their sessions during a predetermined period in order from the earliest time when the sessions were disconnected.
図18は、実施例1に係るレプリケーション処理(方式A)のフローチャートである。 FIG. 18 is a flowchart of the replication process (scheme A) according to the first embodiment.
レプリケーション処理(方式A)は、図10に示すステップS17において実行されるセッション切断時の処理の一部の処理であり、図17に示す切断ユーザ管理処理と併せて実行される方式Aに従う処理である。このレプリケーション処理(方式A)は、例えば、所定の時間毎または、所定の時間帯に実行される。また、一度のレプリケーションで送信されるデータ量を制限してもよい。 The replication process (method A) is a part of the process at the time of session disconnection executed in step S17 shown in FIG. 10, and is a process according to method A executed in conjunction with the disconnection user management process shown in FIG. is there. This replication process (method A) is executed, for example, at predetermined time intervals or at predetermined time zones. Further, the amount of data transmitted by one replication may be limited.
ファイルストレージ装置30は、変数Nを0に設定し(ステップS131)、変数NがEdge10のファイルストレージ装置30に接続可能なユーザ数より小さいか否かを判定する(ステップS132)。この結果、変数NがEdge10のファイルストレージ装置30に接続可能なユーザ数より小さい場合(ステップS132:Yes)には、ファイルストレージ装置30は、ユーザ管理テーブル240の変数Nの位置のユーザ名に対応するユーザのホームディレクトリの配下に属するファイルのレプリケーションを実行する(ステップS133)。具体的には、ファイルストレージ装置30は、ユーザのホームディレクトリの配下のファイルの中のレプリケーションが必要なファイルに対応するinode(レプリケーション済みフラグ220jのレプリケーション済みフラグがOFFのinode)201及び実データをアーカイブストレージ装置120に送信する。
The
これに対して、アーカイブストレージ装置120は、ファイルストレージ装置30から送信されるファイルのinodeを取得するとともに、ファイルの実データを取得する(ステップS141)。次いで、アーカイブストレージ装置120は、取得したinode及びファイルの実データをファイルシステム126のinode管理テーブル220に格納するとともに、ファイル実体をLU114に格納し、取得したinodeのリンク先220kに、ファイル実体を格納した格納位置を示すURLを格納し(ステップS142)、データの格納を終了した旨の通知をファイルストレージ装置30に送信し、処理を終了する。ここで、inode201のリンク先220kには、格納位置を示すURLが格納されるので、以降において、いずれかのファイルストレージ装置30がこのinode201を取得することにより、リンク先220kを用いて、当該ファイルの実データを適切にリコールすることができる。
In response to this, the
ファイルストレージ装置30は、アーカイブストレージ装置120からデータの格納を終了した旨の通知を受け取ると、ファイルストレージ装置30は、レプリケーションを行ったファイルに対応するinode201のレプリケーション済みフラグ220jにレプリケーション済みを示すONを設定し、リンク先220kにアーカイブストレージ装置120がファイルの実データを格納する格納位置を示すURLを格納し、変数Nに1を加算して(ステップS134)、処理をステップS132に進める。なお、アーカイブストレージ装置120がファイルの実データを格納する格納位置を示すURLについては、ステップS133の前に、アーカイブストレージ装置120から取得するようにしてもよいし、アーカイブストレージ装置120からデータの格納を終了した旨の通知として受け取るようにしてもよい。
When the
一方、変数NがEdgeのファイルストレージ装置30に接続可能なユーザ数より小さくない場合(ステップS132:No)には、このファイルストレージ装置30に接続可能な全てのユーザのホームディレクトリの配下のレプリケーションをしていない全てのファイルについてレプリケーションを実行したことを意味しているので、ファイルストレージ装置30は、ポインタを0に設定して、全てのユーザを切断したユーザから外し(ステップS135)、処理を終了する。
On the other hand, when the variable N is not smaller than the number of users connectable to the Edge file storage device 30 (step S132: No), replication under the home directories of all users connectable to the
ここで、図17に示す接続ユーザ管理処理により、セッション切断したユーザのユーザIDがユーザ管理テーブル240の先頭から順に並んで管理されているので、図18示す処理においては、セッション切断しているユーザのファイルが優先してレプリケーションされることとなる。すなわち、自身のファイルがレプリケーションされていないユーザのうち、セッション切断をしているユーザのファイルが、セッション切断をしていいないユーザ(セッション接続中のユーザ、またはセッションの接続も切断も行っていないユーザ)のファイルより先に(優先的に)レプリケーションされる。さらに、図17及び図18に示す処理によって、セッション切断した時刻が早いユーザのファイルから順にレプリケーションされることとなる。ここで、セッション切断しているユーザのうちセッション切断した時刻が早いユーザほど他のEdge10に移動する可能性が高いユーザであると考えられる。よって、以降において、このユーザが他のedge10でセッション接続する場合において、このユーザのホームディレクトリのファイルが適切にCore100に存在するようにすることができる。また、上記処理によると、例えば、接続中のユーザが格納した大きいサイズのファイルをレプリケーションするために、セッション切断したユーザのデータが一定時間以内にレプリケーションされないということを適切に防止できる。また、図17に示す接続ユーザ管理処理によらず、任意の順番、例えば任意に定められたユーザ毎の優先順位の順に、各ユーザのデータをレプリケーションをしてもよい。
Here, in the connected user management process shown in FIG. 17, the user IDs of the users who disconnected the session are managed side by side from the top of the user management table 240. Therefore, in the process shown in FIG. Will be replicated preferentially. That is, among the users whose files are not replicated, the file of the user who has disconnected the session is the user who has not disconnected the session (the user who is connected to the session, or the user who has not connected or disconnected the session) ) Is replicated prior to (priority) files. Furthermore, by the processing shown in FIGS. 17 and 18, replication is performed in order from the file of the user whose session is disconnected earlier. Here, it is considered that a user whose session is disconnected earlier among users who are disconnected from the session is more likely to move to another
図19は、実施例1に係るレプリケーション処理(方式B)のフローチャートである。 FIG. 19 is a flowchart of the replication processing (method B) according to the first embodiment.
レプリケーション処理(方式B)は、図10に示すステップS17において実行されるセッション切断時の処理の一部の処理の他の例であり、図17に示す切断ユーザ管理処理と図18に示すレプリケーション処理(方式A)とを併せた処理に代えて実行するようにしてもよい処理である。このレプリケーション処理(方式B)は、例えば、セッション切断時に実行される。 The replication process (method B) is another example of a part of the process at the time of session disconnection executed in step S17 shown in FIG. 10, and the disconnected user management process shown in FIG. 17 and the replication process shown in FIG. This is a process that may be executed instead of the process combined with (Method A). This replication process (method B) is executed, for example, when the session is disconnected.
ファイルストレージ装置30は、セッション切断を行ったユーザのホームディレクトリの配下に属するファイルのレプリケーションを実行する(ステップS151)。具体的には、ファイルストレージ装置30は、ユーザのホームディレクトリの配下のファイルの中のレプリケーションが必要なファイルに対応するinode(レプリケーション済みフラグ220jのアプリケーション済みフラグがOFFのinode)201と、そのファイルの実データとをアーカイブストレージ装置120に送信する。
The
これに対して、アーカイブストレージ装置120は、ファイルストレージ装置30から送信されるファイルのinodeを取得するとともに、ファイルの実データを取得する(ステップS161)。次いで、アーカイブストレージ装置120は、取得したinode及びファイルの実データをファイルシステム126のinode管理テーブル220に格納するとともに、ファイル実体をLU114に格納し(ステップS162)、データの格納を終了した旨の通知をファイルストレージ装置30に送信し、処理を終了する。ここで、inode201のリンク先220kには、格納位置を示すURLが格納されるので、以降において、いずれかのファイルストレージ装置30がこのinode201を取得することにより、リンク先220kを用いて、当該ファイルの実データを適切にリコールすることができる。
In response to this, the
ファイルストレージ装置30は、アーカイブストレージ装置120からデータの格納を終了した旨の通知を受け取ると、レプリケーションを行ったファイルに対応するinode201のレプリケーション済みフラグ220jにレプリケーション済みを示すONを設定し、リンク先220kにアーカイブストレージ装置120がファイルの実データを格納する格納位置を示すURLを格納し、ステップS151を終了し、レプリケーション処理(方式B)を終了する。なお、アーカイブストレージ装置120がファイルの実データを格納する格納位置を示すURLについては、ステップS151の前に、アーカイブストレージ装置120から取得するようにしてもよいし、アーカイブストレージ装置120からデータの格納を終了した旨の通知として受け取るようにしてもよい。
When the
このレプリケーション処理(方式B)によると、セッション切断したユーザ、すなわち、他のEdge10に移動して、ファイルにアクセスする可能性のあるユーザのホームディレクトリの配下のファイルを適切にCore100側に格納させることができる。
According to this replication process (method B), the user who has disconnected the session, that is, moved to another
図20は、実施例1に係るレプリケーション処理(配下以外)のフローチャートである。 FIG. 20 is a flowchart of replication processing (other than subordinates) according to the first embodiment.
このレプリケーション処理(配下以外)は、ユーザのホームディレクトリ配下のファイル以外のファイルについてのレプリケーションを行う処理である。このレプリケーション処理(配下以外)は、例えば、所定時間毎、又は、ユーザから要求があった場合に実行される。 This replication process (other than subordinates) is a process of performing replication for files other than files under the user's home directory. This replication process (other than subordinates) is executed, for example, every predetermined time or when a user requests it.
ファイルストレージ装置30は、各ユーザのホームディレクトリ以外のディレクトリの中からレプリケーションが必要なファイルを検索する(ステップS171)。次いで、ファイルストレージ装置30は、検索によって得られたファイルのレプリケーションを実行する(ステップS172)。具体的には、ファイルストレージ装置30は、ユーザのホームディレクトリ以外のディレクトリのファイルの中のレプリケーションが必要なファイルに対応するinode(レプリケーション済みフラグ220jのレプリケーション済みフラグがOFFのinode)をアーカイブストレージ装置120に送信するとともに、ファイルの実データを送信する。
The
これに対して、アーカイブストレージ装置120は、ファイルストレージ装置30から送信されるファイルのinodeを取得するとともに、ファイルの実データを取得する。次いで、アーカイブストレージ装置120は、取得したinode及びファイルの実データをファイルシステム126のinode管理テーブル220に格納するとともに、ファイル実体をLU114に格納し、データの格納を終了した旨の通知をファイルストレージ装置30に送信し、処理を終了する。
On the other hand, the
ファイルストレージ装置30は、アーカイブストレージ装置120からデータの格納を終了した旨の通知を受け取ると、レプリケーションを行ったファイルに対応するinodeのレプリケーション済みフラグ220jをレプリケーション済であることを示す「Yes」に変更しレプリケーションを行ったファイルに対応するinode201のレプリケーション済みフラグ220jにレプリケーション済みを示すONを設定し、リンク先220kにアーカイブストレージ装置120がファイルの実データを格納する格納位置を示すURLを格納し(ステップS173)、処理を終了する。
When the
図21は、実施例1に係るスタブ化処理のフローチャートである。 FIG. 21 is a flowchart of the stubbing process according to the first embodiment.
スタブ化処理は、図10に示すステップS17において実行されるセッション切断時の処理の一部の処理である。なお、スタブ化処理は、所定の時間毎に実行するようにしてもよい。 The stubbing process is a part of the process at the time of session disconnection executed in step S17 shown in FIG. Note that the stubbing process may be executed every predetermined time.
ファイルストレージ装置30は、ファイルシステム36の容量が所定の閾値より大きいか否かを判定する(ステップS181)。この結果、ファイルシステム36の容量が所定の閾値より大きい場合(ステップS181:Yes)には、LU24の空き容量が少ないことを意味しているので、ファイルストレージ装置30は、レプリケーション済みフラグ220jのレプリケーション済みフラグがレプリケーション済みを示し、且つ最終アクセス日時220eの最終アクセス日時が古いinode201に対応するファイルから順にスタブ化を実行する(ステップS182)。具体的には、ファイルストレージ装置30は、対象のファイルの実データをデータブロックから削除するとともに、inode201のスタブ化フラグ220iにスタブ化したことを示すONを設定する。これにより、LU24の空き容量を増加させることができる。
The
次に、実施例2に係る情報システムを説明する。 Next, an information system according to the second embodiment will be described.
まず、課題について説明する。 First, the problem will be described.
図22は、課題を説明する図である。 FIG. 22 is a diagram illustrating the problem.
ここで、例えば、拠点X(Edge10X)で大規模な会議が開催され、他の拠点から多数のユーザが拠点Xに集合し、拠点Xにおいて多数のユーザがファイルにアクセスする場合を想定する。
Here, for example, it is assumed that a large-scale meeting is held at the base X (
この場合においては、拠点Xのファイルストレージ装置30に対して、ユーザがクライアント/ホスト40を用いて接続し、ファイルに対するアクセスを行うと、ファイルストレージ装置30には、inode201(スタブ情報)しか格納されていない場合が多いので、ファイルストレージ装置30は、アーカイブストレージ装置120に対して、ファイルの実データを取得するためのリコール要求を実行することとなる。ここで、多数のユーザがファイルに対するアクセスを行うと、多数のリコール要求がアーカイブストレージ装置120に送信されるとともに、そのリコール要求に対する応答であるファイルの実データの送信が行われることとなり、ネットワークに対する負荷や、アーカイブストレージ装置120に対する負荷が大きくなってしまう。
In this case, when the user connects to the
実施例2に係る情報システムでは、図22に示す課題を、以下に示す実現方法1乃至実現方法3によって解決している。
In the information system according to the second embodiment, the problem shown in FIG. 22 is solved by
まず、実現方法1の概要について説明する。実現方法1は、ユーザによって設定された移動先の拠点に対して予めファイルを格納しておく方法である。
First, an outline of the
実施例2の実現方法1に係る情報システムは、図2及び図3に示す実施例1の情報システムと同様な構成に対して、新たな構成及び新たな処理が追加されている。以下、実施例1と異なる点について説明する。
In the information system according to the
実現方法1に係る情報システムでは、アーカイブストレージ装置120が設定ファイル131を新たに格納している。
In the information system according to the realizing
図23は、実施例2に係る設定ファイルの構成図である。 FIG. 23 is a configuration diagram of a setting file according to the second embodiment.
設定ファイル131は、ユーザが移動する移動先の拠点に関する情報を格納する。設定ファイル131は、例えば、ユーザがクライアント/ホスト40を利用することにより、予め設定される。設定ファイル131は、移動先の拠点(Edge)を示す移動先拠点情報131aと、移動先の拠点で利用する時間を特定する時間情報131bとを含む。移動先拠点情報131aは、例えば、移動先拠点のファイルストレージ装置30のIPアドレスである。時間情報131bは、例えば、ユーザがいる移動元の拠点から移動先の拠点への移動時間である。なお、複数の移動先についての移動先拠点情報131a及び時間情報131bを設定していてもよい。
The
図24は、実施例2に係る実現方法1の概要を示す図である。
FIG. 24 is a diagram illustrating an overview of the realizing
ユーザが移動元拠点(ここでは、例えば、拠点A)で作業をし、セッション切断を行うと、ファイルストレージ装置30からアーカイブストレージ装置120にファイルのレプリケーションが実行され、セッション切断要求がアーカイブストレージ装置120に送信される(図24の(1))。
When the user works at the source site (here, for example, site A) and disconnects the session, file replication is performed from the
アーカイブストレージ装置120は、セッション切断要求を行ったユーザのホームディレクトリ内の設定ファイル131を参照して、移動先拠点情報を取得する(図24の(2−A))。図24の例では、移動先が拠点Cであるとする。
The
次いで、アーカイブストレージ装置120は、セッション切断要求を行ったユーザのホームディレクトリ内のファイル(実データを含む)を移動先の拠点Cのファイルストレージ装置30に送信する(図24の(2−B))。
Next, the
その後、ユーザが移動元の拠点Aから移動先の拠点Cに移動し(図24(3))、拠点Cのファイルストレージ装置30に対してユーザがセッション接続し、ファイルの参照を行うと、拠点Cに対してファイルの実データがリコール済みであるので、そのファイルを迅速にユーザが参照することができる(図24の(4))。
Thereafter, when the user moves from the source base A to the destination base C (FIG. 24 (3)), the user makes a session connection to the
次に、実現方法2の概要について説明する。実現方法2は、ユーザの移動履歴に基づいて、移動先の拠点を特定し、その拠点に予めファイルを格納しておく方法である。
Next, an outline of the
実現方法2に係る情報システムでは、アーカイブストレージ装置120が拠点リスト132を新たに格納している。拠点リスト132は、ユーザの各拠点に対する移動の履歴を管理する。
In the information system according to the
図25は、実施例2に係る拠点リストの構成図である。 FIG. 25 is a configuration diagram of a base list according to the second embodiment.
拠点リスト132は、ユーザ名132aと、移動先拠点132bと、ユーザIP132cと、移動回数132dと、平均移動時間132eと、データ転送速度132fとのフィールドを含むエントリを有している。
The
ユーザ名132aには、ユーザ名が格納される。移動先拠点132bには、移動先の拠点を特定する情報(例えば、その拠点のファイルストレージ装置30のIPアドレス)が格納される。ユーザIP132cには、ユーザが所属している拠点のファイルストレージ装置30のIPアドレス(ユーザIP)が格納される。本実施例では、例えば、ユーザは、複数の拠点のいずれか1つに所属しているものとしている。移動回数132dには、ユーザIP132cのユーザIPが示す移動元の拠点から、移動先拠点132bの情報が示す移動先の拠点への移動回数が格納される。平均移動時間132eには、ユーザIP132cのユーザIPが示す移動元の拠点から、移動先拠点132bの情報が示す移動先の拠点への移動時間の平均(平均移動時間)が格納される。データ転送速度132fには、移動先拠点132bのIPアドレスが示す拠点に対してデータを転送する際の速度(データ転送速度)が格納される。
A user name is stored in the
図26は、実施例2に係る実現方法2の概要を示す図である。
FIG. 26 is a diagram illustrating an overview of the
ユーザが移動元拠点(ここでは、例えば、拠点A)で作業をし、セッション切断を行うと、ファイルストレージ装置30からアーカイブストレージ装置120にファイルのレプリケーションが実行され、セッション切断要求がアーカイブストレージ装置120に送信される(図26の(1))。
When the user works at the source site (here, for example, site A) and disconnects the session, file replication is performed from the
アーカイブストレージ装置120は、拠点リスト132を参照して、セッション切断要求を行ったユーザの移動回数132dの移動回数が最大のエントリの移動先拠点132bのIPアドレスが示す拠点(ここでは、拠点Cであるとする。)を選択する(図26の(2−A))。
The
次いで、アーカイブストレージ装置120は、選択した1以上のファイルの転送データ量が以下の式1を満たすように、セッション切断要求を行ったユーザのホームディレクトリ内のファイル(実データを含む)の中の最終アクセス日時が新しいファイルから順に1以上のファイルを選択する(図26(2−B))。
(式1)転送データ量 < 拠点リスト132のデータ転送速度132fのデータ転送速度×拠点リスト132の平均移動時間132eの平均移動時間
Next, the
(Expression 1) Transfer data amount <Data transfer speed of the
次いで、アーカイブストレージ装置120は、選択した1以上のファイルを、選択した拠点(ここでは、拠点C)のファイルストレージ装置30に送信する(図26の(2−C))。
Next, the
その後、ユーザが移動元の拠点Aから移動先の拠点Cに移動した場合(図26(3))には、拠点Cのファイルストレージ装置30に対してユーザがセッション接続し、ファイルの参照を行うと、拠点Cに対して1以上のファイルの実データがリコール済みであるので、そのファイルを迅速にユーザが参照することができる(図26の(4))。
Thereafter, when the user moves from the source base A to the destination base C (FIG. 26 (3)), the user connects to the
実現方法2によると、ユーザが移動する可能性が高い拠点に対して、予めファイルが移動されることとなるので、移動先の拠点において、ファイルを迅速に参照できる可能性が高い。また、実現方法2によると、ユーザが設定ファイル131等の設定を予め行わなくてもよい。
According to the
次に、実現方法3の概要について説明する。
Next, an outline of the realizing
実現方法2では、ユーザの移動履歴に基づいて、移動先の拠点を特定し、その拠点に予めファイルを格納するようにしていた。しかしながら、ユーザの拠点への移動回数の分布は、特定の拠点への移動に集中している場合や、各拠点への移動が略均一である場合等のいろいろな場合が考えられる。このため、特定の移動先の拠点にファイルを格納するだけでは、好ましくない場合が発生する虞がある。
In the
そこで、実現方法3においては、各ユーザの移動の履歴に基づいて、ユーザの拠点の移動に関する傾向を分析し、その移動の傾向に基づいて、ファイルストレージ装置30へのファイルの転送を制御するようにしている。
Therefore, in the
各ユーザの拠点への移動の傾向を判定するために、各拠点を、その拠点へのユーザの移動回数に基づいて、グループ分けを行う。 In order to determine the tendency of each user to move to a base, each base is grouped based on the number of times the user has moved to that base.
図27は、実施例2に係る拠点のグループ分けを説明する図である。 FIG. 27 is a diagram illustrating grouping of bases according to the second embodiment.
本実施例では、例えば、各拠点を2つのグループ(グループA、グループB)に分ける。グループに分ける方法としては、例えば、図27に示すように、移動回数が上位の所定数(例えば、3つ)の拠点をグループAとし、それ以外の拠点をグループBとする。なお、グループ分けは、これに限られず、例えば、最も多い移動回数の50%以上の移動回数がある1以上の拠点をグループAとし、それ以外の拠点をグループBとしてもよい。 In this embodiment, for example, each base is divided into two groups (group A and group B). As a method of dividing into groups, for example, as shown in FIG. 27, a predetermined number (for example, three) bases with the highest number of movements are set as group A, and other bases are set as group B. The grouping is not limited to this. For example, one or more bases having 50% or more of the most frequent movements may be group A, and the other bases may be group B.
そして、実施方法3においては、グループAに属する拠点への総移動回数(グループA総移動回数)と、グループBに属する拠点への総移動回数(グループB総移動回数)とを比較し、その比較結果によって、ファイルストレージ装置30へのファイルの転送方式を異ならせている。
And in the
例えば、グループA総移動回数がグループB総移動回数以上である場合には、グループAの拠点への移動の傾向が高いと考えられるので、グループAの拠点のファイルストレージ装置30にファイルを転送する転送方式(転送方式A)とし、グループA総移動回数がグループB総移動回数未満である場合には、各拠点への移動の傾向が比較的均一であると考えられるので、各拠点のファイルストレージ装置30にファイルを転送する転送方式(転送方式B)とする。
For example, if the total number of movements of group A is equal to or greater than the total number of movements of group B, it is considered that there is a high tendency to move to the base of group A, so the file is transferred to the
実現方法3においては、各ユーザの移動傾向に応じた転送方式を管理するために、ユーザリスト133をアーカイブストレージ装置120に格納するようにしている。
In the
図28は、実施例2に係るユーザリストの構成図である。 FIG. 28 is a configuration diagram of a user list according to the second embodiment.
ユーザリスト133は、ユーザ名133aと、ユーザIP133bと、セッション切断時刻133cと、転送方式133dと、帯域速度133eとのフィールドを含むレコード(エントリ)を格納する。
The
ユーザ名133aには、ファイルストレージ装置30に接続するユーザのユーザ名が格納される。ユーザIP133bには、ユーザが所属している拠点のファイルストレージ装置30のIPアドレス(ユーザIP)が格納される。セッション切断時刻133cには、セッションを切断した時刻(セッション切断時刻)が格納される。このセッション切断時刻を用いると、他の拠点への移動時間を計算することができる。転送方式133dには、このエントリのユーザの拠点への移動傾向に対応するファイルの転送方式が格納される。本実施例では、転送方式133dには、転送方式A又は転送方式Bのいずれかが格納される。帯域速度133eには、アーカイブストレージ装置120からのデータ転送に対して、このエントリに対応するユーザに対して許容された帯域速度が格納される。
The
図29は、実施例2に係る実現方法3の転送方式Aの概要を示す図である。この転送方式Aは、ユーザがグループAの拠点に移動する傾向が高い場合に実行される。
FIG. 29 is a diagram illustrating an outline of the transfer method A of the realizing
ユーザが移動元拠点(ここでは、例えば、拠点A)で作業をし、セッション切断を行うと、ファイルストレージ装置30からアーカイブストレージ装置120にファイルのレプリケーションが実行され、セッション切断要求がアーカイブストレージ装置120に送信される(図29の(1))。
When the user works at the source site (here, for example, site A) and disconnects the session, file replication is performed from the
アーカイブストレージ装置120は、ユーザリスト133を参照して、セッション切断要求を行ったユーザの転送方式133dを参照し、転送方式(ここでは、転送方式Aであるとする。)を特定する(図29の(2−A))。
The
次いで、アーカイブストレージ装置120は、セッション切断要求を行ったユーザのホームディレクトリ内の1以上のファイル(実データを含む)を最終アクセス日時が新しいファイルを優先して選択し、選択したファイルをグループAに属する各拠点(ここでは、拠点B及び拠点C)のファイルストレージ装置30に送信する(図29の(2−B))。
Next, the
その後、ユーザが移動元の拠点AからグループAに属する拠点Cに移動した場合(図29の(3))には、拠点Cのファイルストレージ装置30に対してユーザがセッション接続し、ファイルの参照を行うと、拠点Cに対して1以上のファイルの実データがリコール済みであるので、そのファイルを迅速にユーザが参照することができる(図29の(4))。
Thereafter, when the user moves from the source base A to the base C belonging to the group A ((3) in FIG. 29), the user makes a session connection to the
これにより、ユーザがグループAの拠点に移動する傾向が高い場合には、グループAの拠点に対して、ファイルが格納されることとなるので、移動先の拠点において、ファイルを迅速に参照できる可能性が高い。 As a result, when the user has a high tendency to move to the base of group A, the file is stored in the base of group A. Therefore, the file can be referred to quickly at the base of the destination. High nature.
図30は、実施例2に係る実現方法3の転送方式Bの概要を示す図である。この転送方式Bは、ユーザが各拠点に比較的均一して移動する傾向が高い場合に実行される。
FIG. 30 is a diagram illustrating an outline of the transfer method B of the realizing
ユーザが移動元拠点(ここでは、例えば、拠点A)で作業をし、セッション切断を行うと、ファイルストレージ装置30からアーカイブストレージ装置120にファイルのレプリケーションが実行され、セッション切断要求がアーカイブストレージ装置120に送信される(図30の(1))。
When the user works at the source site (here, for example, site A) and disconnects the session, file replication is performed from the
アーカイブストレージ装置120は、ユーザリスト133を参照して、セッション切断要求を行ったユーザの転送方式133dを参照し、転送方式(ここでは、転送方式Bであるとする。)を特定する(図30の(2−A))。
The
次いで、アーカイブストレージ装置120は、セッション切断要求を行ったユーザのホームディレクトリ内の1以上のファイル(実データを含む)を最終アクセス日時が新しいファイルを優先して選択し、選択したファイルを全ての拠点のファイルストレージ装置30に送信する(図30の(2−B))。なお、全ての拠点にファイルを送信するので、転送方式Aのデータ量よりは少ないデータ量分のファイルが選択される。
Next, the
その後、ユーザが移動元の拠点Aから移動先の拠点Cに移動した場合(図30(3))には、拠点Cのファイルストレージ装置30に対してユーザがセッション接続し、ファイルの参照を行うと、拠点Cに対して1以上のファイルの実データがリコール済みであるので、そのファイルを迅速にユーザが参照することができる(図30の(4))。なお、いずれの拠点にユーザが移動しても同様に、ファイルを迅速に参照できる可能性が高い。
Thereafter, when the user moves from the source base A to the destination base C (FIG. 30 (3)), the user makes a session connection to the
これにより、ユーザが各拠点に比較的均一に移動する傾向がある場合には、各拠点に対して、ファイルが格納されることとなるので、移動先の拠点において、ファイルを迅速に参照できる可能性が高い。 As a result, if the user has a tendency to move to each base relatively uniformly, the file is stored in each base, so the file can be referred to quickly at the destination base. High nature.
次に、実施例2で行われる処理を説明する。 Next, processing performed in the second embodiment will be described.
図31は、実施例2に係るEdge側のセッション切断処理のフローチャートである。 FIG. 31 is a flowchart of Edge-side session disconnection processing according to the second embodiment.
Edge側のセッション切断処理は、ファイルストレージ装置30がクライアント/ホスト40からセッション切断要求を受け取った場合に実行される。
Edge side session disconnection processing is executed when the
ファイルストレージ装置30は、クライアント/ホスト40とファイルストレージ装置30との間のセッション切断処理を実行する(ステップS191)。次いで、ファイルストレージ装置30は、セッション切断を要求したユーザのホームディレクトリのレプリケーションとスタブ化を実行する(ステップS192)。この処理は、実施例1に係る図10のステップS17と同様な処理である。
The
次いで、ファイルストレージ装置30は、セッション切断したEdge10が切断要求したユーザが所属するEdge10であるか否かを判定する(ステップS193)。
Next, the
この結果、セッション切断したEdge10が、ユーザが所属するEdge10である場合(ステップS193:Yes)には、ファイルストレージ装置30は、Core100のアーカイブストレージ装置120にセッション切断時処理の要求を行い(ステップS194)、セッション切断処理を終了する。一方、セッション切断したEdge10が自分のEdge10でない場合(ステップS193:No)には、ファイルストレージ装置30は、セッション切断処理を終了する。
As a result, if
図32は、実施例2に係るCore側のセッション切断時の処理のフローチャートである。なお、図32のフローチャートは、便宜的に、実現方式1乃至実現方式3における処理をまとめて記載しているが、実際には、アーカイブストレージ装置120が採用しているいずれかの実現方式に対応する部分の処理が実行される。
FIG. 32 is a flowchart of processing when a session on the Core side is disconnected according to the second embodiment. Note that the flowchart in FIG. 32 collectively describes the processes in the
Core側のセッション切断時処理は、アーカイブストレージ装置120がファイルストレージ装置30から図31のステップS194のセッション切断時処理の要求を受け取った場合に実行される。
The session disconnection process on the Core side is executed when the
アーカイブストレージ装置120が実現方式1を採用している場合には、アーカイブストレージ装置120は、セッション切断時処理要求を受け取ると、設定ファイル131から移動先拠点のIPアドレスと、移動時間を取得し(ステップS201)、取得した移動時間を変数「移動時間合計」に設定し(ステップS209)、処理をステップS210に進める。
When the
また、アーカイブストレージ装置120が実現方式2を採用している場合には、アーカイブストレージ装置120は、セッション切断時処理要求を受け取ると、拠点リスト132から切断するユーザ名に対応するレコードの中の移動回数132dの移動回数が最大であるレコードを取得し(ステップS202)、当該レコードの平均移動時間132eの移動平均時間を変数「移動時間合計」に設定し(ステップS209)、処理をステップS210に進める。
In addition, when the
また、アーカイブストレージ装置120が実現方式3を採用している場合には、アーカイブストレージ装置120は、セッション切断時処理要求を受け取ると、ユーザリスト133から、切断要求したユーザのユーザIPが設定されているレコードを選択する(ステップS203)。次いで、アーカイブストレージ装置120は、選択したレコードのセッション切断時刻133cに、セッション切断時処理要求に含まれているセッション切断時刻を記録する(ステップS204)。次いで、アーカイブストレージ装置120は、選択したレコードの転送方式133dを参照して転送方式を特定し(ステップS205)、転送方式が転送方式Aであるか、又は転送方式Bであるかを判定する(ステップS206)。
Further, when the
この結果、転送方式が転送方式Aである場合(ステップS206:転送方式A)には、拠点リスト132からユーザに対応するグレープAに属する拠点のレコードを取得し(ステップS207)、取得した全てのレコードの平均移動時間132eの平均移動時間の和を変数「移動時間合計」に設定し(ステップS209)、処理をステップS210に進める。
As a result, when the transfer method is transfer method A (step S206: transfer method A), records of locations belonging to grape A corresponding to the user are acquired from the location list 132 (step S207), and all acquired The sum of the average movement time of the
一方、転送方式が転送方式Bである場合(ステップS206:転送方式B)には、拠点リスト132から切断要求したユーザに対応する全てのレコードを取得し(ステップS208)、取得した全てのレコードの平均移動時間132eの平均移動時間の和を変数「移動時間合計」に設定し(ステップS209)、処理をステップS210に進める。
On the other hand, when the transfer method is transfer method B (step S206: transfer method B), all records corresponding to the user who requested disconnection are acquired from the site list 132 (step S208), and all the acquired records are recorded. The sum of the average travel times of the
ステップS210では、アーカイブストレージ装置120は、変数「転送データ量_TMP」に0を設定する。次いで、アーカイブストレージ装置120は、(式2)変数「転送データ量_TMP」<帯域速度×変数「移動時間合計」を満たすか否かを判定する(ステップS211)。ここで、帯域速度は、実現方式3では、ユーザリスト133の切断要求したユーザのレコードの帯域速度133eの値であり、実現方式2又は実現方式1では、予め設定されている帯域速度である。
In step S210, the
この結果、(式2)を満たしている場合(ステップS211:満たす)には、アーカイブストレージ装置120は、変数「転送データ量」に変数「転送データ量_TMP」の値を設定する(ステップS212)。次いで、アーカイブストレージ装置120は、切断要求したユーザのホームディレクトリに属するファイルの中で、最終アクセス日時220eの最終アクセス日時が、転送データ量に反映させたファイルの次に新しいファイルを取得する(ステップS213)。なお、転送データ量に反映させたファイルが存在しない場合には、切断要求したユーザのホームディレクトリに属するファイルの中で、最終アクセス日時220eの最終アクセス日時が最も新しいファイルを取得する。
As a result, when (Formula 2) is satisfied (step S211: Satisfaction), the
次いで、アーカイブストレージ装置120は、変数「転送データ量」に、ステップS213で取得したファイルのサイズを反映させた(加算した)値を変数「転送データ量_TMP」に設定し(ステップS214)、処理をステップS211に進める。
Next, the
ステップS211で、(式2)を満たしていない場合(ステップS211:満たさない)には、転送データ量_TMPに反映させたファイルについて、移動時間合計が示す時間内にデータ転送できないことを意味しているので、アーカイブストレージ装置120は、現在の変数「転送データ量」に反映させたファイル(前回のステップS211の判定において(式2)を満たすと判定された際に反映させていたファイル)を送信対象のファイルとして選択する(ステップS215)。
If (Equation 2) is not satisfied in step S211, (step S211: not satisfied), it means that the data reflected in the transfer data amount_TMP cannot be transferred within the time indicated by the total movement time. Therefore, the
次いで、アーカイブストレージ装置120は、データ転送速度を決定する(ステップS216)。例えば、データ転送速度は、変数「転送データ量」の値を、拠点リスト132の移動先の拠点に対応するレコードの平均移動時間132eの平均移動時間で除算して得られる。
Next, the
次いで、アーカイブストレージ装置120は、決定したデータ転送速度と、実際の転送速度とを比較して、送信対象のファイルを送信対象のファイルストレージ装置30に転送するデータ量を制御する(ステップS217)。なお、アーカイブストレージ装置120の動作を起因として、アーカイブストレージ装置120からファイルストレージ装置30へデータを転送できない場合には、以下に示すようなファイルストレージ装置30によるポーリングを利用して、ファイルストレージ装置30へデータを転送してもよい。
Next, the
次に、ファイルストレージ装置30がポーリングによりファイルのデータをアーカイブストレージ装置120から取得する例を説明する。
Next, an example in which the
図33は、実施例2に係るポーリングによるデータ取得処理の概要を示す図である。 FIG. 33 is a diagram illustrating an overview of data acquisition processing by polling according to the second embodiment.
ユーザが移動元拠点(ここでは、例えば、拠点A)で作業をし、セッション切断を行うと、ファイルストレージ装置30からアーカイブストレージ装置120にファイルのレプリケーションが実行され、セッション切断要求がアーカイブストレージ装置120に送信される(図33の(1))。
When the user works at the source site (here, for example, site A) and disconnects the session, file replication is performed from the
アーカイブストレージ装置120は、ファイルの転送先の拠点と、転送するファイルを決定する(図33の(2))。ここで、ファイルの転送先としては、例えば、拠点B、拠点C、及び拠点Dに決定したとする。
The
次いで、アーカイブストレージ装置120は、決定した転送するファイルを、送信データキュー140のファイルの転送先の拠点用のキューにセットする(図33の(3))。この例では、拠点B、拠点C、及び拠点D用のキューに、転送するファイルのデータがセットされる。
Next, the
その後、各拠点のファイルストレージ装置30がポーリングを行って、アーカイブストレージ装置120の中の自身用のキューにセットされたファイルのデータを取得し(図33の(4))、LU24に取得したデータを格納する。
Thereafter, the
このデータ取得処理により、アーカイブストレージ装置120の動作を起因としてデータを転送できないファイルストレージ装置30に対して、ファイルのデータを適切に送信することができる。
By this data acquisition processing, file data can be appropriately transmitted to the
図34は、実施例2に係るポーリングによるデータ取得処理のフローチャートである。 FIG. 34 is a flowchart of data acquisition processing by polling according to the second embodiment.
Edge10のファイルストレージ装置30は、ポーリングを行うタイミングになった際に、自拠点用のキューにデータがあるか否かの確認要求をアーカイブストレージ装置120に送信する(ステップS221)。
The
アーカイブストレージ装置120は、キューにデータがあるか否かの確認要求を受け取ると、この確認要求に対応するキュー、すなわち、このファイルストレージ装置30の拠点用(自分用)のキューにデータがあるか否かをチェックし(ステップS231)、チェック結果をファイルストレージ装置30に転送する(ステップS232)。
When the
ファイルストレージ装置30は、チェック結果を受け取ると、チェック結果に基づいて、自分用のキューにデータがあるか否かを判定する(ステップS222)。この結果、自分用のキューにデータがある場合(ステップS222:Yes)には、ファイルストレージ装置30は、キューにあるファイルのデータをリコールする(ステップS223)。
Upon receiving the check result, the
すなわち、ファイルストレージ装置30は、ファイルの転送要求をアーカイブストレージ装置120に送信する。アーカイブストレージ装置120は、ファイルの転送要求を受信すると、転送要求に対応するファイルのデータをキューから取得し(ステップS233)、ファイルのデータをファイルストレージ装置30に転送する(ステップS234)。ファイルストレージ装置30は、ファイルのデータを取得すると、このデータをLU24に格納し、データ取得処理を終了する。
That is, the
一方、自分用のキューにデータがない場合(ステップS222:No)には、ファイルストレージ装置30は、データ取得処理を終了する。
On the other hand, when there is no data in its own queue (step S222: No), the
図35は、実施例2に係るEdge側のセッション接続処理のフローチャートである。 FIG. 35 is a flowchart of Edge-side session connection processing according to the second embodiment.
Edge側のセッション接続処理は、クライアント/ホスト40からファイルストレージ装置30に対してユーザによるセッション接続要求が来た場合に実行される。
The session connection processing on the Edge side is executed when a session connection request is received from the client /
ファイルストレージ装置30は、クライアント/ホスト40とのセッション接続を行う(ステップS251)。次いで、ファイルストレージ装置30は、アーカイブストレージ装置120に対してユーザのホームディレクトリのスタブ情報の取得要求を行う(ステップS252)。これにより、アーカイブストレージ装置120からホームディレクトリのスタブ情報が取得できることとなる。次いで、ファイルストレージ装置30は、取得したスタブ情報に基づいて、ホームディレクトリを作成する(ステップS253)。
The
ファイルストレージ装置30は、セッション接続したEdge10(セッション接続したファイルストレージ装置30が属するEdge10)が、接続したユーザの所属するEdge10であるか否かを判定する(ステップS254)。この結果、セッション接続したEdge10が、接続したユーザが所属するEdge10である場合(ステップS254:Yes)には、ファイルストレージ装置30は、処理を終了する。
The
一方、セッション接続したEdge10が、接続したユーザが所属するEdge10でない場合(ステップS254:No)には、ファイルストレージ装置30は、アーカイブストレージ装置120にセッション接続処理要求を送信し(ステップS255)、処理を終了する。アーカイブストレージ装置120は、セッション接続処理要求を受け取ると、図36に示すCore側のセッション接続処理を実行する。
On the other hand, when
図36は、実施例2に係るCore側のセッション接続処理のフローチャートである。 FIG. 36 is a flowchart of the session connection processing on the Core side according to the second embodiment.
Core側のセッション接続処理は、アーカイブストレージ装置120が、ファイルストレージ装置30からセッション接続処理要求を受け取った場合に実行される。セッション接続処理要求には、セッション接続を要求したユーザのユーザ名、接続した拠点のIPアドレス、及びセッション接続時刻等が含まれている。
The session connection processing on the Core side is executed when the
アーカイブストレージ装置120は、ユーザリスト133を参照し、セッション接続要求を行ったユーザ名に対応するレコードを選択する(ステップS261)。次いで、アーカイブストレージ装置120は、拠点リスト132を参照し、移動先拠点132bの移動先拠点がセッション接続処理要求に含まれている接続した拠点のIPアドレスであり、且つユーザ名132aのユーザ名及びユーザIP132cのユーザIPが、ステップS261で取得したレコードのユーザ名133aのユーザ名及びユーザIP133bのユーザIPであるレコードを特定する(ステップS262)。
The
次いで、アーカイブストレージ装置120は、以下の(式3)により平均移動時間を算出し、特定したレコードの平均移動時間132dの平均移動時間を更新する(ステップS263)。(式3)平均移動時間 =((セッション接続処理要求中のセッション接続時刻−ステップS261で選択したレコードのセッション切断時刻133cのセッション切断時刻)+ステップS262で特定したレコードの平均移動時間132eの平均移動時間)/2
Next, the
次いで、アーカイブストレージ装置120は、特定したレコードの移動回数132dの移動回数に1を加算する(ステップS264)。これにより、実際のユーザの拠点の移動に応じた平均移動時間及び移動回数がユーザリスト132に反映されることとなる。
Next, the
ステップS264の後の処理は、採用している実現方式に応じて異なっている。ここで、実現方式1又は実現方式2においては、アーカイブストレージ装置120は、セッション接続処理を終了する。一方、実現方式3の場合には、アーカイブストレージ装置120は、処理をステップS266に進める。
The processing after step S264 differs depending on the implementation method employed. Here, in the
ステップS266では、アーカイブストレージ装置120は、拠点リスト132のセッション接続したユーザ名に対応するレコードに基づいて、各移動先拠点132bの移動先拠点を、グループAと、グループBとに分ける。
In step S266, the
更に、アーカイブストレージ装置120は、これらレコードに基づいて、グループAに分けられた移動先拠点に対応するレコードの移動回数132dの移動回数の合計(グループA移動回数合計)と、グループBに分けられた移動先拠点に対応するレコードの移動回数132dの移動回数の合計(グループB移動回数合計)とを算出し、グループA移動回数合計が、Bグループ移動回数合計よりも大きいか否かを判定する(ステップS267)。
Further, based on these records, the
この結果、グループA移動回数合計が、Bグループ移動回数合計よりも大きい場合(ステップS267:Yes)には、アーカイブストレージ装置120は、ステップS261で選択したレコードの転送方式133dに転送方式Aを設定し(ステップS268)、処理を終了する。
As a result, when the total number of group A movements is larger than the total number of group B movements (step S267: Yes), the
一方、グループA移動回数合計が、Bグループ移動回数合計よりも大きくない場合(ステップS267:No)には、アーカイブストレージ装置120は、ステップS261で選択したレコードの転送方式133dに転送方式Bを設定し(ステップS269)、処理を終了する。この処理により、ユーザの拠点の移動傾向に応じて、転送方式A又は転送方式Bのいずれとするかを適切に決定することができる。
On the other hand, when the total number of group A movements is not larger than the total number of group B movements (step S267: No), the
以上、いくつかの実施例を説明したが、これは、本発明の説明のための例示であって、本発明の範囲をこれらの実施例にのみ限定する趣旨ではない。すなわち、本発明は、他の種々の形態でも実施する事が可能である。 Although several embodiments have been described above, these are examples for explaining the present invention, and are not intended to limit the scope of the present invention only to these embodiments. That is, the present invention can be implemented in various other forms.
10 Edge、30 ファイルストレージ装置、100 Core、120 アーカイブストレージ装置。 10 Edge, 30 File storage device, 100 Core, 120 Archive storage device.
Claims (12)
ユーザ端末から受信するデータを格納する記憶デバイスと、
前記記憶デバイスに対するデータの読み出しと書き込みを制御するプロセッサと
を備え、
前記プロセッサは、
前記複数のユーザ端末から受信するファイルのデータを記憶デバイスに格納し、
当該データを前記リモートストレージ装置にレプリケーションし、
前記記憶デバイスに格納されたデータをスタブ化し、
前記ユーザ端末からのアクセス要求を受信すると、
当該アクセス要求に係るデータがスタブ化されていない場合は、前記記憶デバイスから当該データを読み出して前記ユーザ端末に送信し、
当該アクセス要求に係るデータがスタブ化されている場合は、前記データを前記リモートストレージ装置から取得し、前記ユーザ端末に当該データを送信し、
あるユーザからのセッション接続要求を受信すると、当該ユーザのホームディレクトリに対するロック要求を前記リモートストレージ装置に送信し、
当該ユーザからのセッション切断要求を受信すると、前記リモートストレージ装置へのデータのレプリケーションを実行して、当該ユーザのホームディレクトリに対するアンロック要求を前記リモートストレージ装置に送信し、
前記プロセッサは、所定時間内にストレージ装置に対して前記セッション切断要求を早く行ったユーザのデータから順に前記リモートストレージ装置にレプリケーションする
ことを特徴とするストレージ装置。 A storage device connected to a plurality of users and a remote storage device,
A storage device for storing data received from the User chromatography The terminal,
A processor for controlling reading and writing of data to the storage device,
The processor is
Storing file data received from the plurality of user terminals in a storage device;
Replicate the data to the remote storage device,
Stub the data stored in the storage device;
When receiving an access request from the user terminal,
If the data related to the access request is not stubbed, the data is read from the storage device and transmitted to the user terminal,
If the data related to the access request is stubbed, the data is acquired from the remote storage device, the data is transmitted to the user terminal,
Upon receiving a session connection request from a user, a lock request for the user's home directory is sent to the remote storage device,
Upon receiving a session disconnection request from the user, execute replication of data to the remote storage device, and send an unlock request for the user's home directory to the remote storage device ,
The processor replicates to the remote storage device in order from the data of the user who made the session disconnection request to the storage device early within a predetermined time.
A storage device.
ことを特徴とする請求項1に記載のストレージ装置。 The storage apparatus according to claim 1, wherein when the processor receives a session connection request from a user, the processor acquires the home directory information of the user from the remote storage apparatus.
ユーザ端末から受信するデータを格納する記憶デバイスと、
前記記憶デバイスに対するデータの読み出しと書き込みを制御するプロセッサと
を備え、
前記プロセッサは、
前記複数のユーザ端末から受信するファイルのデータを記憶デバイスに格納し、
当該データを前記リモートストレージ装置にレプリケーションし、
前記記憶デバイスに格納されたデータをスタブ化し、
前記ユーザ端末からのアクセス要求を受信すると、
当該アクセス要求に係るデータがスタブ化されていない場合は、前記記憶デバイスから当該データを読み出して前記ユーザ端末に送信し、
当該アクセス要求に係るデータがスタブ化されている場合は、前記データを前記リモートストレージ装置から取得し、前記ユーザ端末に当該データを送信し、
あるユーザからのセッション接続要求を受信すると、当該ユーザのホームディレクトリに対するロック要求を前記リモートストレージ装置に送信し、
当該ユーザからのセッション切断要求を受信すると、前記リモートストレージ装置へのデータのレプリケーションを実行して、当該ユーザのホームディレクトリに対するアンロック要求を前記リモートストレージ装置に送信し、
前記プロセッサは、
前記ストレージ装置に接続可能なユーザの識別子と、所定時間内にセッション切断要求を送信したユーザを示すポインタとを有するユーザ管理情報を管理し、
ユーザからセッション切断要求を受信すると、そのセッション切断要求を送信したユーザの識別子が前記ポインタが示すユーザの識別子よりも下位の場合、前記ポインタが示すユーザの識別子と当該セッション切断要求を送信したユーザを示す識別子とをスワップし、前記ポインタの位置を1つ下げる
ことを特徴とするストレージ装置。 A storage device connected to a plurality of users and a remote storage device,
A storage device for storing data received from the User chromatography The terminal,
A processor for controlling reading and writing of data to the storage device,
The processor is
Storing file data received from the plurality of user terminals in a storage device;
Replicate the data to the remote storage device,
Stub the data stored in the storage device;
When receiving an access request from the user terminal,
If the data related to the access request is not stubbed, the data is read from the storage device and transmitted to the user terminal,
If the data related to the access request is stubbed, the data is acquired from the remote storage device, the data is transmitted to the user terminal,
Upon receiving a session connection request from a user, a lock request for the user's home directory is sent to the remote storage device,
Upon receiving a session disconnection request from the user, execute replication of data to the remote storage device, and send an unlock request for the user's home directory to the remote storage device ,
The processor is
Managing user management information having an identifier of a user connectable to the storage device and a pointer indicating a user who has transmitted a session disconnection request within a predetermined time;
When the session disconnection request is received from the user, if the identifier of the user who transmitted the session disconnection request is lower than the identifier of the user indicated by the pointer, the user identifier indicated by the pointer and the user who transmitted the session disconnection request are A storage apparatus , wherein the identifier is swapped and the position of the pointer is lowered by one .
ことを特徴とする請求項3に記載のストレージ装置。 The storage apparatus according to claim 3 , wherein when the processor receives a session connection request from a user, the processor acquires information on the home directory of the user from the remote storage apparatus.
ことを特徴とする請求項3又は4に記載のストレージ装置。 5. The storage apparatus according to claim 3 , wherein the processor replicates to the remote storage apparatus in order from data of a user who has made the session disconnection request to the storage apparatus early within a predetermined time.
ことを特徴とする請求項3乃至5のうちのいずれか一項に記載のストレージ装置。 Wherein the processor, when executing the replication of data of a user, wherein the user management information, any one of claims 3 to 5, characterized in that removing the user from the user who has a session disconnection request The storage device according to item .
前記複数のユーザ端末から受信するデータを記憶し、
当該データを前記リモートストレージ装置にレプリケーションし、
記憶デバイスに格納されたデータをスタブ化し、
前記ユーザ端末からのアクセス要求を受信すると、当該アクセス要求に係るデータがスタブ化されていない場合は、前記記憶デバイスから当該データのデータを読み出して前記ユーザ端末に送信し、当該アクセス要求に係るデータがスタブ化されている場合は、前記データを前記リモートストレージ装置から取得し、前記ユーザ端末に当該データを送信し、
あるユーザからのセッション接続要求を受信すると、当該ユーザのホームディレクトリに対するロック要求を前記リモートストレージ装置に送信し、
当該ユーザからのセッション切断要求を受信すると、前記リモートストレージ装置へのデータのレプリケーションを実行して、当該ユーザのホームディレクトリに対するアンロック要求を前記リモートストレージ装置に送信し、
所定時間内にストレージ装置に対して前記セッション切断要求を早く行ったユーザのデータから順に前記リモートストレージ装置にレプリケーションする
ことを特徴とする情報システムの制御方法。 A control method for an information processing system having a storage device connected to a plurality of user terminals and a remote storage device via a communication network,
Storing data received from the plurality of user terminals;
Replicate the data to the remote storage device,
The stored in remembers device data stubs,
When the access request from the user terminal is received, if the data related to the access request is not stubbed, the data of the data is read from the storage device and transmitted to the user terminal. Is stubbed, the data is acquired from the remote storage device, the data is transmitted to the user terminal,
Upon receiving a session connection request from a user, a lock request for the user's home directory is sent to the remote storage device,
Upon receiving a session disconnection request from the user, execute replication of data to the remote storage device, and send an unlock request for the user's home directory to the remote storage device ,
The information system control method , wherein data is replicated to the remote storage device in order from the data of a user who made the session disconnection request to the storage device early within a predetermined time .
ことを特徴とする請求項7に記載の情報システムの制御方法。 8. The information system control method according to claim 7 , wherein when a session connection request is received from a user, information on the home directory of the user is acquired from the remote storage device.
前記複数のユーザ端末から受信するデータを記憶し、
当該データを前記リモートストレージ装置にレプリケーションし、
記憶デバイスに格納されたデータをスタブ化し、
前記ユーザ端末からのアクセス要求を受信すると、当該アクセス要求に係るデータがスタブ化されていない場合は、前記記憶デバイスから当該データのデータを読み出して前記ユーザ端末に送信し、当該アクセス要求に係るデータがスタブ化されている場合は、前記データを前記リモートストレージ装置から取得し、前記ユーザ端末に当該データを送信し、
あるユーザからのセッション接続要求を受信すると、当該ユーザのホームディレクトリに対するロック要求を前記リモートストレージ装置に送信し、
当該ユーザからのセッション切断要求を受信すると、前記リモートストレージ装置へのデータのレプリケーションを実行して、当該ユーザのホームディレクトリに対するアンロック要求を前記リモートストレージ装置に送信し、
前記ストレージ装置に接続可能なユーザの識別子と、所定時間内にセッション切断要求を送信したユーザを示すポインタとを有するユーザ管理情報を管理し、
ユーザからセッション切断要求を受信すると、そのセッション切断要求を送信したユーザの識別子が前記ポインタが示すユーザの識別子よりも下位の場合、前記ポインタが示すユーザの識別子と当該セッション切断要求を送信したユーザを示す識別子とをスワップし、前記ポインタの位置を1つ下げる
ことを特徴とする情報システムの制御方法。 A control method for an information processing system having a storage device connected to a plurality of user terminals and a remote storage device via a communication network,
Storing data received from the plurality of user terminals;
Replicate the data to the remote storage device,
The stored in remembers device data stubs,
When the access request from the user terminal is received, if the data related to the access request is not stubbed, the data of the data is read from the storage device and transmitted to the user terminal. Is stubbed, the data is acquired from the remote storage device, the data is transmitted to the user terminal,
Upon receiving a session connection request from a user, a lock request for the user's home directory is sent to the remote storage device,
Upon receiving a session disconnection request from the user, execute replication of data to the remote storage device, and send an unlock request for the user's home directory to the remote storage device ,
Managing user management information having an identifier of a user connectable to the storage device and a pointer indicating a user who has transmitted a session disconnection request within a predetermined time;
When the session disconnection request is received from the user, if the identifier of the user who transmitted the session disconnection request is lower than the identifier of the user indicated by the pointer, the user identifier indicated by the pointer and the user who transmitted the session disconnection request are Swaps the indicated identifier and lowers the pointer position by one
An information system control method characterized by the above.
ことを特徴とする請求項9に記載の情報システムの制御方法。 10. The information system control method according to claim 9 , wherein when a session connection request is received from a user, information on the home directory of the user is acquired from the remote storage device.
ことを特徴とする請求項9又は10に記載の情報システムの制御方法。 11. The information system control method according to claim 9 or 10 , wherein replication is performed to the remote storage device in order from data of a user who has made the session disconnection request to the storage device early within a predetermined time.
ことを特徴とする請求項9乃至11のうちのいずれか一項に記載の情報システムの制御方法。 When you perform a user data replication, in the user management information, according to the user, in any one of claims 9 to 11, wherein the removing the user who made the session disconnection request Information system control method.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016141758A JP6231623B2 (en) | 2016-07-19 | 2016-07-19 | File server, information system, and information system control method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2016141758A JP6231623B2 (en) | 2016-07-19 | 2016-07-19 | File server, information system, and information system control method |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2015511536A Division JP2015526772A (en) | 2012-12-17 | 2012-12-17 | File server, information system, and information system control method |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2016212902A JP2016212902A (en) | 2016-12-15 |
| JP6231623B2 true JP6231623B2 (en) | 2017-11-15 |
Family
ID=57551893
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2016141758A Expired - Fee Related JP6231623B2 (en) | 2016-07-19 | 2016-07-19 | File server, information system, and information system control method |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP6231623B2 (en) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7061635B2 (en) * | 2020-03-10 | 2022-04-28 | 株式会社日立製作所 | Computer system, file storage, and data transfer method |
| JP7465301B2 (en) * | 2022-05-20 | 2024-04-10 | 株式会社日立製作所 | DATA MANAGEMENT SYSTEM, DATA MANAGEMENT METHOD, AND PROGRAM |
Family Cites Families (6)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP3124664B2 (en) * | 1993-11-12 | 2001-01-15 | 松下電器産業株式会社 | Remote file lock system |
| JPH11249948A (en) * | 1998-02-27 | 1999-09-17 | Toshiba Corp | Computer system, file resource switching method used in the system, and recording medium |
| JP4199021B2 (en) * | 2003-02-19 | 2008-12-17 | 株式会社エヌ・ティ・ティ・ドコモ | Server apparatus and program |
| JP4349301B2 (en) * | 2004-11-12 | 2009-10-21 | 日本電気株式会社 | Storage management system, method and program |
| US8209307B2 (en) * | 2009-03-31 | 2012-06-26 | Commvault Systems, Inc. | Systems and methods for data migration in a clustered file system |
| CN102870098B (en) * | 2010-05-27 | 2015-09-30 | 株式会社日立制作所 | Via communication network to the local file server of remote file server transmission file and the storage system with this file server |
-
2016
- 2016-07-19 JP JP2016141758A patent/JP6231623B2/en not_active Expired - Fee Related
Also Published As
| Publication number | Publication date |
|---|---|
| JP2016212902A (en) | 2016-12-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN104641369B (en) | File server, information system and control method thereof | |
| US12229082B2 (en) | Flexible tiering of snapshots to archival storage in remote object stores | |
| US12608283B2 (en) | Data connector component for implementing data requests | |
| JP5343166B2 (en) | Local file server for transferring files to remote file server via communication network, and storage system having these file servers | |
| US7836017B1 (en) | File replication in a distributed segmented file system | |
| CN107885758B (en) | Data migration method of virtual node and virtual node | |
| US8538924B2 (en) | Computer system and data access control method for recalling the stubbed file on snapshot | |
| JP2015530629A (en) | Destination file server and file system migration method | |
| JP2015503780A (en) | Hierarchical storage system management apparatus and management method | |
| EP4241159A1 (en) | Data connector component for implementing management requests | |
| CN104679665A (en) | Method and system for achieving block storage of distributed file system | |
| WO2014064740A1 (en) | Computer system and file server migration method | |
| CN109302448A (en) | A data processing method and device | |
| WO2014054065A1 (en) | Backup and restore system for a deduplicated file system and corresponding server and method | |
| US12130798B1 (en) | Variable reclamation of data copies | |
| JP6231623B2 (en) | File server, information system, and information system control method | |
| US9135116B1 (en) | Cloud enabled filesystems provided by an agent which interfaces with a file system on a data source device | |
| WO2017145214A1 (en) | Computer system for transferring data from center node to edge node | |
| US20160259808A1 (en) | Information System | |
| WO2018051429A1 (en) | File server and information system | |
| WO2017109862A1 (en) | Data file management method, data file management system, and archive server | |
| Pye et al. | MASTER OF SCIENCE in COMPUTER SCIENCE | |
| WO2015166529A1 (en) | Storage system, storage control method, and storage management device |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20170724 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20170801 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170911 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171010 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171019 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6231623 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |