JP6234060B2 - ターゲットドメインの学習用音声データの生成方法、生成装置、および生成プログラム - Google Patents
ターゲットドメインの学習用音声データの生成方法、生成装置、および生成プログラム Download PDFInfo
- Publication number
- JP6234060B2 JP6234060B2 JP2013099645A JP2013099645A JP6234060B2 JP 6234060 B2 JP6234060 B2 JP 6234060B2 JP 2013099645 A JP2013099645 A JP 2013099645A JP 2013099645 A JP2013099645 A JP 2013099645A JP 6234060 B2 JP6234060 B2 JP 6234060B2
- Authority
- JP
- Japan
- Prior art keywords
- target domain
- domain
- data
- audio data
- channel
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/063—Training
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/06—Creation of reference templates; Training of speech recognition systems, e.g. adaptation to the characteristics of the speaker's voice
- G10L15/065—Adaptation
- G10L15/07—Adaptation to the speaker
- G10L15/075—Adaptation to the speaker supervised, i.e. under machine guidance
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L15/00—Speech recognition
- G10L15/08—Speech classification or search
- G10L15/14—Speech classification or search using statistical models, e.g. Hidden Markov Models [HMMs]
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Computational Linguistics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Acoustics & Sound (AREA)
- Multimedia (AREA)
- Artificial Intelligence (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Compression, Expansion, Code Conversion, And Decoders (AREA)
- Probability & Statistics with Applications (AREA)
Description
1.再利用法
2.モデル適応法
3.特徴量変換法
4.正規化法
1.の再利用法は、ターゲットドメインの音響モデルを構築するために、ソースドメインの音声データを用いてターゲットドメインの音声データをシミュレートする手法である(例えば、非特許文献1〜2を参照)。
2.のモデル適応法は、ソースドメインの音響モデルのパラメータを変更してテスト音声に合わせる手法であり、最大事後確率推定法(MaximumA Posteriori Estimation : MAP)や、最尤線形回帰法(Maximum LikelihoodLinear Regression : MLLR)がこれに該当する(例えば、特許文献1、非特許文献3〜非特許文献5を参照)。なお、該手法とは異なるが、同様にモデルを適応させる技術として特許文献2〜3、非特許文献6が存在する。
3.の特徴量変換法は、デコード時にテスト音声の特徴量をソースドメインの音響モデルに合わせるように変換する手法であり、特徴量空間最尤線形回帰法(Feature space Maximum Likelihood Linear Regression : fMLLR)や、特徴量空間相互情報量最小化法(Feature speace Minimum Mutual Information : fMMI)がこれに該当する(例えば、非特許文献3〜5、非特許文献7を参照)。
4.の正規化法は、テスト音声の特徴量の分布を正規化してソースドメインの音響モデルに合わせる手法であり、ケプストラム平均正規化法(Cepstral MeanNormalization: CMN)、分散平均正規化法(Mean and Variance Normalization: MVN)がこの手法に該当する(例えば、非特許文献8を参照)。
ここではマッピング・パラメータによってソースドメインの音声データをターゲットドメインの音声データにマッピングする生成モデル式において、チャネルバイアスのみを考慮する場合について説明する。時間領域におけるソースドメインの観測音声の特徴量ベクトルYsは、チャネルの特徴量ベクトルHs、クリーン音声の特徴量ベクトルX、ノイズの特徴量ベクトルNを用いて下記式(1)のように表すことができる(添え字sはソースドメインであることを示す)。なおNは、マイクロフォンに音声以外の音源から混入し波形に加法的な変形を与える雑音であり、Hは伝送系により加えられる乗法性の歪みである。

同様に、時間領域におけるターゲットドメインの観測音声の特徴量ベクトルYtは、チャネルの特徴量ベクトルHt、クリーン音声の特徴量ベクトルXを用いて下記式(2)のように表すことができる(添え字tはターゲットドメインであることを示す)。
同様に上記式(2)をケプストラム領域に書き直すと下記式(5)になり、これを更に上記式(3)を用いて変形すると、最終的に下記式(8)、(9)が得られる。ここで式(9)より定義されるcが求めるべきチャネルバイアスである。ここで、行列Cは、Discrete Cosine Transform(DCT)行列を、C-1はその逆行列を表す。
上述したように、本発明では、チャネルバイアスcをVTS近似とEMアルゴリズムを用いて推定する。具体的には、上記式(10)で表される生成モデル式を参照し、混合ガウスモデル格納部224に事前に用意したターゲットドメインのGMMから変換したソースドメインのGMMに含まれるチャネルバイアスcを、EMアルゴリズムを用いて推定する。即ち、ターゲットドメインのGMMから変換したソースドメインのGMMにソースドメインの観測音声の特徴ベクトルyを入力して得られる音響尤度を求めるステップと、求めた音響尤度に基づいた目的関数を最小化するチャネルバイアスcを求めるステップとを交互に繰り返す。以下、数式を用いてこの繰り返しステップを説明する。
ここで、事後確率ρは下記式(16)より定義される。
なお、式(18)に表される共分散対角行列は、さらなる近似を用いて簡略化してもかまわない。例えば、ターゲットドメインの共分散行列と同一にしても、精度の劣化は少量にとどまる。逆に、対角近似の条件を外して精密な共分散行列としても良い。上記式(17)に現れるベクトルG、及び、上記式(18)に現れるヤコビ行列Fは、それぞれ下記式(19)、(20)により定式化される雑音成分である。ここで、行列Cは、Discrete CosineTransform(DCT)行列を、C−1はその逆行列を表す。
なお、式(23)では、ソースドメインのノイズ除去とチャネル特性の補正を同時に行っている。ソースドメインのノイズを無視できる場合には、下記式(24)のように、ノイズ除去を省略しても良い。
ここではマッピング・パラメータによってソースドメインの音声データをターゲットドメインの音声データにマッピングする生成モデル式において、チャネルバイアスcに加えて、チャネル振幅aを新たに導入する場合について説明する。この場合、上記式(10)の生成モデル式は、下記式(25)のように拡張される。式中記号*は、ベクトル要素ごとの内積を表す。
上述したように、本発明では、チャネルバイアスcとチャネル振幅aをVTS近似とEMアルゴリズムを用いて推定する。具体的には、上記式(25)で表される生成モデル式を参照し、混合ガウスモデル格納部224に事前に用意したターゲットドメインのGMMから変換したソースドメインのGMMに含まれるチャネルバイアスcとチャネル振幅aを、EMアルゴリズムを用いて推定する。即ち、ターゲットドメインのGMMから変換したソースドメインのGMMにソースドメインの観測音声の特徴ベクトルyを入力して得られる音響尤度を求めるステップと、求めた音響尤度に基づいた目的関数を最小化するチャネルバイアスcとチャネル振幅aを求めるステップとを交互に繰り返す。以下、数式を用いて説明する。
式(28)では、ソースドメインのノイズ除去とチャネル特性の補正を同時に行っている。ソースドメインのノイズを無視できる場合には、下記式(29)のように、ノイズ除去を省略しても良い。
上記説明した2つのケースでは、混合ガウスモデル格納部224に事前に用意したターゲットドメインのGMMは1つであり、性別の区別なく多少の話者バリエーションを含んでいた。ここでは、ターゲットドメインのGMMは、話者の性別ごとに用意するものとする。そして、入力として受け取るソースドメインの音声データの1発話ごとに男性らしさ及び女性らしさを求めながら、ターゲットドメインの音声データにマッピングするものとする。すると目的関数Φは下記式(30)のように表される。
ここでgはgenderインデックスであり、女性(female)又は男性(male)のいずれかを示す。また、事後gender確率λgは、ガウス分布の尤度を事後確率とみたてて合計を1になるように正規化したものである。また、ρは上記式(16)により定義される事後確率である。
オプションとして、下記式(33)に示す事後gender確率λgを用いてもよい。
但しβの値は定数である。なお、ここまで、ケプストラム領域を前提に定式化をしてきたが、よく行われるように対数メルスペクトル領域や対数スペクトル領域でも同様に定式化できることは当業者に明らかである(ケプストラム領域とは、対数メルスペクトル領域を離散コサイン変換したものである。)。
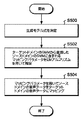
事前に用意したターゲットドメインのGMMとステップ500で決定した生成モデル式とから、VTS近似により算出される。
本実験は、自動車内音声認識の評価用データベースCENSREC-3を用いて行った。評価条件は、学習データと評価データの双方に遠隔マイクロフォンを使用するミスマッチのない場合(A)と、学習データに接話マイクロフォンを使用し、評価データに遠隔マイクロフォンを使用するミスマッチのある場合(B〜E)とした。更に、ミスマッチのある場合(B〜E)は、本発明の適用の無い場合(B)と、本発明の適用のある場合(C〜E)とし、本発明の適用のある場合は以下の3つの条件について検討した。学習データに対しチャネルバイアスのみを考慮したチャネルマッピングを適用した場合(C)。学習データに対し、チャネルバイアスのみを考慮し、話者の性別を区別したチャネルマッピングを適用した場合(D)。学習データに対し、チャネルバイアスとチャネル振幅を考慮し、話者の性別を区別したチャネルマッピングを適用した場合(E)。
図6は、上述したA〜Eの6つの条件下それぞれでのCMNオンとCMNオフでの単語正解精度(%)を示す。条件Aはミスマッチの無い場合の単語正解精度であるため、その値は上限を示す。条件Bはミスマッチのある場合であって、本発明によるチャネルマッピングがなされていないため、その値はベースラインとなる。条件C〜条件Eは、ミスマッチのある場合であって、本発明によるチャネルマッピングが適用されている場合である。いずれの場合も単語正解精度はベースラインよりも高くなっている。また、条件Dでの単語正解精度の値は条件Cのそれよりも改善されているため、本発明によるチャネルマッピング手法は、チャネル特性と話者特性の両方に有効であるといえる。また、条件C〜条件EのすべてにおいてCMNオンの場合の単語正解精度の値はベースラインのそれよりも高くなっているため、本発明によるチャネルマッピング手法はCMNと相性がよいといえる。
Claims (12)
- コンピュータの演算処理により、ソースドメインの音声データを利用してターゲットドメインの学習用の音声データを生成する方法であって、
ターゲットドメインのクリーンな音声データを用いて学習された前記ターゲットドメインの混合ガウスモデル(Gaussian mixture model :GMM)を読み出すステップと、
前記ターゲットドメインのGMMを参照して、入力として受け取ったソースドメインの音声データの補正量を求めることにより、前記ソースドメインの音声データを、前記ターゲットドメインの音声データに、該ターゲットドメインの音声データのチャネル特性に基づきマッピングするステップと、
マッピングした前記ソースドメインの音声データに、前記ターゲットドメインのノイズを加えて、擬似的なターゲットドメインの音声データを出力するステップとを含み、
前記マッピングするステップは、前記ソースドメインの音声データを前記ターゲットドメインの音声データにチャネルマッピング・パラメータによってマッピングする生成モデル式を決定するステップと、前記生成モデル式を参照して前記ターゲットドメインのGMMから変換したソースドメインのGMMに含まれるチャネルマッピング・パラメータを、Expectation Maximization(EM)アルゴリズムを用いて推定するステップとを含む、
学習データ生成方法。 - 前記チャネルマッピング・パラメータは、前記擬似的なターゲットドメインの音声データを求めるために前記ソースドメインの音声データから差し引くチャネルバイアスを含む、請求項1に記載の学習データ生成方法。
- 前記チャネルマッピング・パラメータは、前記擬似的なターゲットドメインの音声データを求めるために前記ソースドメインの音声データに乗算するチャネル振幅を更に含む、請求項2に記載の学習データ生成方法。
- 前記EMアルゴリズムを用いて推定するステップは、変換した前記ソースドメインのGMMにソースドメインの観測値を入力して得られる音響尤度を求めるステップと、求めた音響尤度に基づいた目的関数を最小化する前記チャネルマッピング・パラメータを求めるステップとを交互に繰り返すステップを含む、請求項1に記載の学習データ生成方法。
- 前記音響尤度を求めるステップにおいて、現在の推定されている前記チャネルマッピング・パラメータに基づき算出した雑音成分を参照する、請求項4に記載の学習データ生成方法。
- 前記生成モデル式を参照して前記ターゲットドメインのGMMから変換したソースドメインのGMMを求める際にVector Taylor Series(VTS)近似を用いる、請求項5に記載の学習データ生成方法。
- 学習された前記ターゲットドメインの混合ガウスモデル(GMM)は話者の性別ごと用意されており、入力として受け取ったソースドメインの音声データの1発話ごとに男性らしさ及び女性らしさを求めながら、前記ターゲットドメインの音声データにマッピングする、請求項1に記載の学習データ生成方法。
- 前記マッピングするステップは、ソースドメインの各音声データについて、前記ターゲットドメインのGMMのガウス分布コンポーネントのうち、該音声データとの音響空間における距離が近いガウス分布コンポーネントの平均との差を求め、該差を、ガウス分布コンポーネントごとの尤度で重みづけした上で、時間方向の平均として求めて前記ソースドメインの音声データに足し合わせるステップを含む、請求項1に記載の学習データ生成方法。
- コンピュータに、請求項1乃至8のいずれか一項に記載の学習データ生成方法の各ステップを実行させるための学習データ生成プログラム。
- 請求項1乃至8のいずれか一項に記載の学習データ生成方法の各ステップを実行するように適合された手段を備える、学習データ生成システム。
- ソースドメインの音声データを利用してターゲットドメインの学習用の音声データを生成するシステムであって、
ターゲットドメインの少量のクリーンな音声データを用いて学習された前記ターゲットドメインの混合ガウスモデル(Gaussian mixture model :GMM)を格納する混合ガウスモデル格納部と、
前記ターゲットドメインのGMMを参照して、入力として受け取ったソースドメインの音声データの補正量を求めることにより、前記ソースドメインの音声データを、前記ターゲットドメインの音声データに、該ターゲットドメインの音声データのチャネル特性に基づきマッピングするチャネルマッピング部と、
マッピングした前記ソースドメインの音声データに、前記ターゲットドメインのノイズを加えて、擬似的なターゲットドメインの音声データを出力するノイズ付加部と、
を含み、
前記チャネルマッピング部は、前記ソースドメインの音声データを前記ターゲットドメインの音声データにチャネルマッピング・パラメータによってマッピングする生成モデル式を決定し、該生成モデル式を参照して前記ターゲットドメインのGMMから変換したソースドメインのGMMに含まれるチャネルマッピング・パラメータを、Expectation Maximization(EM)アルゴリズムを用いて推定する、
学習データ生成システム。 - 前記チャネルマッピング・パラメータは、前記擬似的なターゲットドメインの音声データを求めるために前記ソースドメインの音声データから差し引くチャネルバイアスと、前記ソースドメインの音声データに乗算するチャネル振幅を含む、請求項11に記載の学習データ生成システム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013099645A JP6234060B2 (ja) | 2013-05-09 | 2013-05-09 | ターゲットドメインの学習用音声データの生成方法、生成装置、および生成プログラム |
| US14/251,772 US10217456B2 (en) | 2013-05-09 | 2014-04-14 | Method, apparatus, and program for generating training speech data for target domain |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2013099645A JP6234060B2 (ja) | 2013-05-09 | 2013-05-09 | ターゲットドメインの学習用音声データの生成方法、生成装置、および生成プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2014219605A JP2014219605A (ja) | 2014-11-20 |
| JP6234060B2 true JP6234060B2 (ja) | 2017-11-22 |
Family
ID=51865433
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2013099645A Active JP6234060B2 (ja) | 2013-05-09 | 2013-05-09 | ターゲットドメインの学習用音声データの生成方法、生成装置、および生成プログラム |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10217456B2 (ja) |
| JP (1) | JP6234060B2 (ja) |
Families Citing this family (22)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP6189818B2 (ja) * | 2014-11-21 | 2017-08-30 | 日本電信電話株式会社 | 音響特徴量変換装置、音響モデル適応装置、音響特徴量変換方法、音響モデル適応方法、およびプログラム |
| US10540957B2 (en) * | 2014-12-15 | 2020-01-21 | Baidu Usa Llc | Systems and methods for speech transcription |
| US11062228B2 (en) | 2015-07-06 | 2021-07-13 | Microsoft Technoiogy Licensing, LLC | Transfer learning techniques for disparate label sets |
| US11443169B2 (en) * | 2016-02-19 | 2022-09-13 | International Business Machines Corporation | Adaptation of model for recognition processing |
| US9922664B2 (en) * | 2016-03-28 | 2018-03-20 | Nuance Communications, Inc. | Characterizing, selecting and adapting audio and acoustic training data for automatic speech recognition systems |
| JP6199461B1 (ja) * | 2016-09-13 | 2017-09-20 | ヤフー株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| CN108305619B (zh) * | 2017-03-10 | 2020-08-04 | 腾讯科技(深圳)有限公司 | 语音数据集训练方法和装置 |
| US10885900B2 (en) | 2017-08-11 | 2021-01-05 | Microsoft Technology Licensing, Llc | Domain adaptation in speech recognition via teacher-student learning |
| US10783882B2 (en) * | 2018-01-03 | 2020-09-22 | International Business Machines Corporation | Acoustic change detection for robust automatic speech recognition based on a variance between distance dependent GMM models |
| JP6452061B1 (ja) * | 2018-08-10 | 2019-01-16 | クリスタルメソッド株式会社 | 学習データ生成方法、学習方法、及び評価装置 |
| CN111210809B (zh) * | 2018-11-22 | 2024-03-19 | 阿里巴巴集团控股有限公司 | 语音训练数据适配方法和装置、语音数据转换方法以及电子设备 |
| JP7073286B2 (ja) * | 2019-01-10 | 2022-05-23 | 株式会社日立製作所 | データ生成装置、予測器学習装置、データ生成方法、及び学習方法 |
| US11790263B2 (en) | 2019-02-25 | 2023-10-17 | International Business Machines Corporation | Program synthesis using annotations based on enumeration patterns |
| CN110414845B (zh) * | 2019-07-31 | 2023-09-19 | 创新先进技术有限公司 | 针对目标交易的风险评估方法及装置 |
| US11335329B2 (en) * | 2019-08-28 | 2022-05-17 | Tata Consultancy Services Limited | Method and system for generating synthetic multi-conditioned data sets for robust automatic speech recognition |
| CN111210811B (zh) * | 2019-12-31 | 2022-10-04 | 深圳市瑞讯云技术有限公司 | 一种基音混合方法及装置 |
| US11803758B2 (en) * | 2020-04-17 | 2023-10-31 | Microsoft Technology Licensing, Llc | Adversarial pretraining of machine learning models |
| CN111785300B (zh) * | 2020-06-12 | 2021-05-25 | 北京快鱼电子股份公司 | 一种基于深度神经网络的哭声检测方法和系统 |
| KR102557810B1 (ko) * | 2021-05-11 | 2023-07-24 | 고려대학교 산학협력단 | 학습 데이터 생성 방법 및 이를 이용한 음성 인식 후처리 방법 |
| US12112767B2 (en) | 2021-05-21 | 2024-10-08 | International Business Machines Corporation | Acoustic data augmentation with mixed normalization factors |
| JP7804603B2 (ja) * | 2023-03-03 | 2026-01-22 | 株式会社日立製作所 | 合成学習データ生成装置、合成学習データ生成方法 |
| CN117975208A (zh) * | 2024-04-01 | 2024-05-03 | 泉州装备制造研究所 | 一种基于无监督领域适应算法的输电线检测方法及装置 |
Family Cites Families (12)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH0573088A (ja) * | 1991-09-13 | 1993-03-26 | Toshiba Corp | 認識辞書の作成方法、認識辞書作成装置及び音声認識装置 |
| JP3587966B2 (ja) | 1996-09-20 | 2004-11-10 | 日本電信電話株式会社 | 音声認識方法、装置そよびその記憶媒体 |
| US6324510B1 (en) | 1998-11-06 | 2001-11-27 | Lernout & Hauspie Speech Products N.V. | Method and apparatus of hierarchically organizing an acoustic model for speech recognition and adaptation of the model to unseen domains |
| EP1564721A1 (en) * | 2002-11-21 | 2005-08-17 | Matsushita Electric Industrial Co., Ltd. | Standard model creating device and standard model creating method |
| JP2005196020A (ja) * | 2004-01-09 | 2005-07-21 | Nec Corp | 音声処理装置と方法並びにプログラム |
| US20070239441A1 (en) * | 2006-03-29 | 2007-10-11 | Jiri Navratil | System and method for addressing channel mismatch through class specific transforms |
| US7480641B2 (en) * | 2006-04-07 | 2009-01-20 | Nokia Corporation | Method, apparatus, mobile terminal and computer program product for providing efficient evaluation of feature transformation |
| JP4996156B2 (ja) * | 2006-07-19 | 2012-08-08 | 旭化成株式会社 | 音声信号変換装置 |
| ES2678415T3 (es) * | 2008-08-05 | 2018-08-10 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Aparato y procedimiento para procesamiento y señal de audio para mejora de habla mediante el uso de una extracción de característica |
| US9009039B2 (en) * | 2009-06-12 | 2015-04-14 | Microsoft Technology Licensing, Llc | Noise adaptive training for speech recognition |
| US8433567B2 (en) * | 2010-04-08 | 2013-04-30 | International Business Machines Corporation | Compensation of intra-speaker variability in speaker diarization |
| GB2482874B (en) * | 2010-08-16 | 2013-06-12 | Toshiba Res Europ Ltd | A speech processing system and method |
-
2013
- 2013-05-09 JP JP2013099645A patent/JP6234060B2/ja active Active
-
2014
- 2014-04-14 US US14/251,772 patent/US10217456B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| JP2014219605A (ja) | 2014-11-20 |
| US20140337026A1 (en) | 2014-11-13 |
| US10217456B2 (en) | 2019-02-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6234060B2 (ja) | ターゲットドメインの学習用音声データの生成方法、生成装置、および生成プログラム | |
| CN111161752A (zh) | 回声消除方法和装置 | |
| JP4245617B2 (ja) | 特徴量補正装置、特徴量補正方法および特徴量補正プログラム | |
| JP6723120B2 (ja) | 音響処理装置および音響処理方法 | |
| JP5242782B2 (ja) | 音声認識方法 | |
| US20110040561A1 (en) | Intersession variability compensation for automatic extraction of information from voice | |
| CN110998723B (zh) | 使用神经网络的信号处理装置及信号处理方法、记录介质 | |
| JP4316583B2 (ja) | 特徴量補正装置、特徴量補正方法および特徴量補正プログラム | |
| Kim et al. | Feature compensation in the cepstral domain employing model combination | |
| JP6499095B2 (ja) | 信号処理方法、信号処理装置及び信号処理プログラム | |
| JP2007286377A (ja) | 応対評価装置、その方法、プログラムおよびその記録媒体 | |
| JP2019090930A (ja) | 音源強調装置、音源強調学習装置、音源強調方法、プログラム | |
| JP5997114B2 (ja) | 雑音抑圧装置、雑音抑圧方法、およびプログラム | |
| JP5670298B2 (ja) | 雑音抑圧装置、方法及びプログラム | |
| JP5881454B2 (ja) | 音源ごとに信号のスペクトル形状特徴量を推定する装置、方法、目的信号のスペクトル特徴量を推定する装置、方法、プログラム | |
| JP6721165B2 (ja) | 入力音マスク処理学習装置、入力データ処理関数学習装置、入力音マスク処理学習方法、入力データ処理関数学習方法、プログラム | |
| JP2008158035A (ja) | 多音源有音区間判定装置、方法、プログラム及びその記録媒体 | |
| JP4705414B2 (ja) | 音声認識装置、音声認識方法、音声認識プログラムおよび記録媒体 | |
| JPH10149191A (ja) | モデル適応方法、装置およびその記憶媒体 | |
| Han et al. | Reverberation and noise robust feature compensation based on IMM | |
| JP6000094B2 (ja) | 話者適応化装置、話者適応化方法、プログラム | |
| JP5457999B2 (ja) | 雑音抑圧装置とその方法とプログラム | |
| JP2010049102A (ja) | 残響除去装置、残響除去方法、コンピュータプログラムおよび記録媒体 | |
| JP2008064849A (ja) | 音響モデル作成装置、その装置を用いた音声認識装置、これらの方法、これらのプログラム、およびこれらの記録媒体 | |
| JP2019193073A (ja) | 音源分離装置、その方法、およびプログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20151127 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20161128 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20161206 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170303 |
|
| A02 | Decision of refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A02 Effective date: 20170516 |
|
| A521 | Written amendment |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20170830 |
|
| A911 | Transfer of reconsideration by examiner before appeal (zenchi) |
Free format text: JAPANESE INTERMEDIATE CODE: A911 Effective date: 20170907 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20171003 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20171024 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6234060 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |