JP6836065B2 - 情報処理装置、pld管理プログラム及びpld管理方法 - Google Patents
情報処理装置、pld管理プログラム及びpld管理方法 Download PDFInfo
- Publication number
- JP6836065B2 JP6836065B2 JP2017034302A JP2017034302A JP6836065B2 JP 6836065 B2 JP6836065 B2 JP 6836065B2 JP 2017034302 A JP2017034302 A JP 2017034302A JP 2017034302 A JP2017034302 A JP 2017034302A JP 6836065 B2 JP6836065 B2 JP 6836065B2
- Authority
- JP
- Japan
- Prior art keywords
- parallelism
- circuit
- degree
- execution time
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Expired - Fee Related
Links
Images















Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F9/00—Arrangements for program control, e.g. control units
- G06F9/06—Arrangements for program control, e.g. control units using stored programs, i.e. using an internal store of processing equipment to receive or retain programs
- G06F9/44—Arrangements for executing specific programs
- G06F9/445—Program loading or initiating
- G06F9/44505—Configuring for program initiating, e.g. using registry, configuration files
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/34—Circuit design for reconfigurable circuits, e.g. field programmable gate arrays [FPGA] or programmable logic devices [PLD]
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F15/00—Digital computers in general; Data processing equipment in general
- G06F15/76—Architectures of general purpose stored program computers
- G06F15/78—Architectures of general purpose stored program computers comprising a single central processing unit
- G06F15/7867—Architectures of general purpose stored program computers comprising a single central processing unit with reconfigurable architecture
- G06F15/7871—Reconfiguration support, e.g. configuration loading, configuration switching, or hardware OS
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/32—Circuit design at the digital level
- G06F30/327—Logic synthesis; Behaviour synthesis, e.g. mapping logic, HDL to netlist, high-level language to RTL or netlist
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F30/00—Computer-aided design [CAD]
- G06F30/30—Circuit design
- G06F30/34—Circuit design for reconfigurable circuits, e.g. field programmable gate arrays [FPGA] or programmable logic devices [PLD]
- G06F30/343—Logical level
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Computer Hardware Design (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Software Systems (AREA)
- Evolutionary Computation (AREA)
- Geometry (AREA)
- Stored Programmes (AREA)
- Logic Circuits (AREA)
Description
前記プロセッサからのコンフィグレーション要求に応じて、前記コンフィグレーション要求が要求する論理回路をコンフィグレーションするリコンフィグレーション領域を有するプログラマブルロジック回路装置(以下PLD)を有し、
前記プロセッサは、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のうち、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った場合の前記複数の論理回路の第1の実行時間と、前記並列度調整を行わない場合の前記複数の論理回路の第2の実行時間とを比較し、
前記第1の実行時間が前記第2の実行時間より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、情報処理装置である。
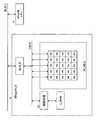
図6は、FPGAにおけるバス帯域のボトルネックを説明する図である。FPGA内にコンフィグレーションされた論理回路は、FPGAバスBUS_3を介して図1、2に示したFPGA用メモリ16にアクセスする。FPGA用メモリ16には、リコンフィグレーションされる論理回路のコンフィグレーションデータと、コンフィグレーションされた論理回路がアクセスするデータとが格納される。したがって、FPGA管理プログラムを実行するプロセッサが、FPGAにある論理回路のコンフィグレーションを要求したとき、FPGA内の制御回路がFPGA用メモリにアクセスし、論理回路のコンフィグレーションデータをダウンロードする。さらに、FPGA内にコンフィグレーションされた論理回路がそれぞれのジョブを実行すると、各論理回路がFPGA用メモリ内に格納されているデータにアクセスする。したがって、PFGA内にコンフィグレーションされた論理回路は、FPGAバスBUS_3が提供可能な帯域のうち、それぞれのデータ転送量に対応する帯域を使用する。
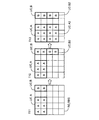
図7は、第1の実施の形態におけるFPGA管理方法による並列度の制御例を示す図である。このFPGA管理方法では、ユーザの論理回路に、1つのジョブを実行するのに要する実行時間を測定する実行時間測定回路と、FPGAバスへのアクセスを監視しバスアクセスの単位時間当たりのデータ転送量の平均値を測定するデータ転送量測定回路とが含まれる。これらの測定回路は、FPGAのコンフィグレーションデータによりコンフィグレーション可能である。そして、FPGAの制御回路は、ユーザの論理回路をコンフィグレーションデータでコンフィグレーションするときに同時に測定回路もコンフィグレーションデータでコンフィグレーションする。または、測定回路を予め部分リコンフィグレーションブロックに形成しておき、部分リコンフィグレーションブロックにコンフィグレーションされる論理回路の測定回路として使用してもよい。
図7の時間T23でユーザ回路UC_1の並列度を増やした場合、ユーザ回路UC_1のデータ処理パターンによって、実行時間の短縮度が異なる。例えば、データ処理パターンには、データ・インテンシブ(DI:Data Intensive)と、コンピュテーション・インテンシブ(CI:Computation Intensive)とがある。一般に、DI処理回路の場合は、並列度を増やすと実行時間がそれに比例して短くなるが、CI処理回路の場合は、並列度を増やしても実行時間の短縮は少ない場合がある。
Ti=TLD+Δi+TCOMP_SINGLE+TST 式1
ここで、Δiは、TIIの(S-1)倍であるので、次のとおりである。
Δi=TII * (S-1)
Δi=TII * {(S/Pi)-1}

Ttotal_before=TDI_total_before+TCI_total_before
Ttotal_after=TDI_total_after+TCI_total_after
図10は、第1の実施の形態におけるFPGA管理プログラムのフローチャート図である。例えば、OS(Operating System)のジョブ管理プログラムは、プロセッサが実行するユーザのアプリケーションプログラムのジョブを監視し、ジョブの処理がFPGA内の論理回路で実行可能な場合、プロセッサに新ユーザ回路のコンフィグレーション要求の割込みを発生する。
並列度調整処理S8の説明をする前に、まず、プロセッサが管理するユーザ回路の各種パラメータの例について説明する。
そして、プロセッサは、FPGAバスの帯域上限BD_Lからユーザ回路の測定使用帯域の合計値を減じた値が、FPGA内にコンフィグレーション中のユーザ回路のいずれかの並列度を増加するために必要な最小帯域より大きいか否かを判定する(S12)。工程S12の判定がYESであれば、プロセッサは、以下に示す式1、式2を満たす範囲で、ユーザ回路の並列度を増加する(S13A)。
Σ(BD_Mj/Pj)*PXj < BD_L 式1
Σ (Aj*PXj) ≦ A_L 式2
ここで、Σは全ユーザ回路j=1〜nの合計である。また、式1、式2のPXjは、j=iならPXj=Pj + 1、j≠iならPXj=Pjとなり、処理対象のi番目のユーザ回路だけ並列度Pjを+1増加し、i番目ではない他のユーザ回路は増加しない並列度Pjのままである。
(BD_M1/P1)*P1 + (BD_M2/P2)*PX2 + (BD_M3/P3)*P3 + (BD_M4/P4)*P4 < BD_L
上記の左辺の第1項は(BD_M1/P1)*P1=BD_M1であり、第3,4項も同様であるから、よって、
BD_M1 + (BD_M2/P2)*PX2 + BD_M3 + BD_M4 < BD_L
A1*P1 + A2*PX2 +A3*P3 + A4*P4 ≦ A_L
図12に戻り、工程S12での判定がNOの場合、プロセッサは、測定使用帯域の合計がFPGAバスの帯域上限に達しているか否か判定する(S14)。この工程S14の判定がYESの場合、FPGAバスの帯域にボトルネックが発生していることを意味する。
図12に戻り、プロセッサは、一定時間待機中(S10のNO)、ユーザ回路のジョブ実行完了通知を受信すると(S16のYES)、式1、式2を満たす範囲で、ユーザ回路UC_MAXの並列度を増加する制御を行う(S17)。一定時間待機中にジョブ実行完了通知を受信しない場合、プロセッサは、ユーザ回路の並列度調整処理S8を終了する。
(BD_M2/P2)*PX2 + BD_M4 < BD_L 式1
A2*PX2 + A4*P4 ≦ A_L 式2
図16は、第1の具体例を示す図である。横軸が時間TIMEであり、縦方向に(1)バスボトルネックが発生しない場合の予測実行時間、(2)バスボトルネックが発生し並列度調整しない場合の予測実行時間、(3)バスボトルネックが発生し並列度調整した場合の予測実行時間をそれぞれ示す。第1の具体例は、FPAG内にユーザ回路UC-AとUC-Bがコンフィグレーションされ、ユーザ回路UC-AがDI処理回路、ユーザ回路UC-BがCI処理回路という、最も単純化した例である。
プログラムを実行するプロセッサと、
前記プロセッサからのコンフィグレーション要求に応じて、前記コンフィグレーション要求が要求する論理回路をコンフィグレーションするリコンフィグレーション領域を有するプログラマブルロジック回路装置(以下PLD)を有し、
前記プロセッサは、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のうち、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った場合の前記複数の論理回路の第1の実行時間と、前記並列度調整を行わない場合の前記複数の論理回路の第2の実行時間とを比較し、
前記第1の実行時間が前記第2の実行時間より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、情報処理装置。
前記プロセッサは、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のデータ転送量の測定値を取得し、
前記データ転送量の合計が前記PLDのバスのデータ転送量の上限値に達した場合、前記比較を実行する、付記1に記載の情報処理装置。
前記比較では、前記複数の論理回路の前記第1の実行時間の合計と、前記第2の実行時間の合計とを比較し、
前記第1の実行時間の合計値が前記第2の実行時間の合計値より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、付記1に記載の情報処理装置。
前記プロセッサは、さらに、
前記複数の論理回路の前記第1の実行時間と、前記第2の実行時間とを計算する、付記1に記載の情報処理装置。
前記プロセッサは、
前記複数の論理回路の前記第1の実行時間として、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った後、前記第2の論理回路の実行が完了後に前記第1の論理回路の並列度を上げる場合に予測される前記複数の論理回路の実行時間を計算する、付記4に記載の情報処理装置。
前記複数の論理回路は、データ処理中にメモリアクセスが発生するデータ・インテンシブ処理回路と、データ処理の最初と最後にメモリアクセスが発生するコンピュテーション・インテンシブ処理回路のいずれか一方または両方を含み、
前記プロセッサは、
前記データ・インテンシブ処理回路の並列度をN倍にした場合、前記実行時間を1/N倍になるよう前記第1の実行時間を算出し、
前記コンピュテーション・インテンション処理回路の並列度をN倍にした場合、前記実行時間を、前記コンピュテーション・インテンション処理回路のパイプライン処理におけるイニシエーション・インターバル時間が1/N倍になるよう前記第1の実行時間を算出する、付記4に記載の情報処理装置。
前記複数の論理回路は、データ処理中にメモリアクセスが発生するデータ・インテンシブ処理回路と、データ処理の最初と最後にメモリアクセスが発生するコンピュテーション・インテンシブ処理回路の両方を含み、
前記プロセッサは、
前記第1の論理回路を前記データ・インテンシブ処理回路から選択し、前記第2の論理回路を前記コンピュテーション・インテンシブ処理回路から選択する、付記1に記載の情報処理装置。
前記プロセッサは、
前記第1の実行時間が前記第2の実行時間より短くない場合、前記第2の論理回路を変更して、前記比較を再度行う、付記7に記載の情報処理装置。
前記プロセッサは、
前記第2の論理回路の変更を、前記第2の論理回路のうち前記並列度を増やした場合の実行時間の短縮の程度が少ないコンピュテーション・インテンシブ処理回路に代えて、前記データ・インテンシブ処理回路を選択する、付記8に記載の情報処理装置。
プロセッサからのコンフィグレーション要求に応じて、前記コンフィグレーション要求が要求する論理回路をコンフィグレーションするリコンフィグレーション領域を有するプログラマブルロジック回路装置(以下PLD)管理処理をプロセッサに実行させるPLD管理プログラムであって、
前記管理処理は、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のうち、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った場合の前記複数の論理回路の第1の実行時間と、前記並列度調整を行わない場合の前記複数の論理回路の第2の実行時間とを比較し、
前記第1の実行時間が前記第2の実行時間より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、処理を有するPLD管理プログラム。
プログラムを実行するプロセッサと、
前記プロセッサからのコンフィグレーション要求に応じて、前記コンフィグレーション要求が要求する論理回路をコンフィグレーションするリコンフィグレーション領域を有するプログラマブルロジック回路装置(以下PLD)を有する情報処理装置の前記PLD管理方法であって、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のうち、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った場合の前記複数の論理回路の第1の実行時間と、前記並列度調整を行わない場合の前記複数の論理回路の第2の実行時間とを比較し、
前記第1の実行時間が前記第2の実行時間より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、PLD管理方法。
11:CPU、プロセッサ
12:メインメモリ
15:FPGA、PLD
16:補助記憶装置
17:FPGA用のデータメモリ
BUS_1:CPUバス
BUS_2:PCIバス
BUS_3:FPGAバス
I_BUS:FPGA内部バス
RC_REG:リコンフィグレーション領域
OC:FPGAの運用回路
PB:部分リコンフィグレーションブロック
UC_A, UC_B:ユーザ回路
151:C_DATA書き込み制御回路
C_RAM:コンフィグレーションデータメモリ
P:並列度
ET_E:予測実行時間
BD_E:予測帯域
ET_M:測定実行時間
BD_M:測定帯域、使用帯域
A1、A2:ユーザ回路面積
BD_L:上限帯域
A_L:総回路面積
Ttotal_after:第1の実行時間、第1の合計実行時間、並列度調整後の合計実行時間
Ttotal_before:第2の実行時間、第2の合計実行時間、並列度調整前の合計実行時間
CI:コンピュテーション・インテンシブ処理回路
DI:データ・インテンシブ処理回路
Claims (10)
- プログラムを実行するプロセッサと、
前記プロセッサからのコンフィグレーション要求に応じて、前記コンフィグレーション要求が要求する論理回路をコンフィグレーションするリコンフィグレーション領域を有するプログラマブルロジック回路装置(以下PLD)を有し、
前記プロセッサは、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のうち、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った場合の前記複数の論理回路の第1の実行時間と、前記並列度調整を行わない場合の前記複数の論理回路の第2の実行時間とを比較し、
前記第1の実行時間が前記第2の実行時間より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、情報処理装置。 - 前記プロセッサは、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のデータ転送量の測定値を取得し、
前記データ転送量の合計が前記PLDのバスのデータ転送量の上限値に達した場合、前記比較を実行する、請求項1に記載の情報処理装置。 - 前記比較では、前記複数の論理回路の前記第1の実行時間の合計と、前記第2の実行時間の合計とを比較し、
前記第1の実行時間の合計値が前記第2の実行時間の合計値より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、請求項1に記載の情報処理装置。 - 前記プロセッサは、さらに、
前記複数の論理回路の前記第1の実行時間と、前記第2の実行時間とを計算する、請求項1に記載の情報処理装置。 - 前記プロセッサは、
前記複数の論理回路の前記第1の実行時間として、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った後、前記第2の論理回路の実行が完了後に前記第1の論理回路の並列度を上げる場合に予測される前記複数の論理回路の実行時間を計算する、請求項4に記載の情報処理装置。 - 前記複数の論理回路は、データ処理中にメモリアクセスが発生するデータ・インテンシブ処理回路と、データ処理の最初と最後にメモリアクセスが発生するコンピュテーション・インテンシブ処理回路のいずれか一方または両方を含み、
前記プロセッサは、
前記データ・インテンシブ処理回路の並列度をN倍にした場合、前記実行時間を1/N倍になるよう前記第1の実行時間を算出し、
前記コンピュテーション・インテンシブ処理回路の並列度をN倍にした場合、前記実行時間を、前記コンピュテーション・インテンシブ処理回路のパイプライン処理におけるイニシエーション・インターバル時間が1/N倍になるよう前記第1の実行時間を算出する、請求項4に記載の情報処理装置。 - 前記複数の論理回路は、データ処理中にメモリアクセスが発生するデータ・インテンシブ処理回路と、データ処理の最初と最後にメモリアクセスが発生するコンピュテーション・インテンシブ処理回路の両方を含み、
前記プロセッサは、
前記第1の論理回路を前記データ・インテンシブ処理回路から選択し、前記第2の論理回路を前記コンピュテーション・インテンシブ処理回路から選択する、請求項1に記載の情報処理装置。 - 前記プロセッサは、
前記第1の実行時間が前記第2の実行時間より短くない場合、前記第2の論理回路を変更して、前記比較を再度行う、請求項7に記載の情報処理装置。 - プロセッサからのコンフィグレーション要求に応じて、前記コンフィグレーション要求が要求する論理回路をコンフィグレーションするリコンフィグレーション領域を有するプログラマブルロジック回路装置(以下PLD)管理処理をプロセッサに実行させるPLD管理プログラムであって、
前記管理処理は、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のうち、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った場合の前記複数の論理回路の第1の実行時間と、前記並列度調整を行わない場合の前記複数の論理回路の第2の実行時間とを比較し、
前記第1の実行時間が前記第2の実行時間より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、処理を有するPLD管理プログラム。 - プログラムを実行するプロセッサと、
前記プロセッサからのコンフィグレーション要求に応じて、前記コンフィグレーション要求が要求する論理回路をコンフィグレーションするリコンフィグレーション領域を有するプログラマブルロジック回路装置(以下PLD)を有する情報処理装置の前記PLD管理方法であって、
前記リコンフィグレーション領域内にコンフィグレーションされ動作中の複数の論理回路のうち、第1の論理回路の並列度を下げて第2の論理回路の並列度を上げる並列度調整を行った場合の前記複数の論理回路の第1の実行時間と、前記並列度調整を行わない場合の前記複数の論理回路の第2の実行時間とを比較し、
前記第1の実行時間が前記第2の実行時間より短い場合、前記PLDに前記並列度調整の要求を行い、短くない場合、前記PLDに前記並列度調整の要求を行わない、PLD管理方法。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017034302A JP6836065B2 (ja) | 2017-02-27 | 2017-02-27 | 情報処理装置、pld管理プログラム及びpld管理方法 |
| US15/901,931 US10534621B2 (en) | 2017-02-27 | 2018-02-22 | Information processing apparatus, PLD management program and PLD management method |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2017034302A JP6836065B2 (ja) | 2017-02-27 | 2017-02-27 | 情報処理装置、pld管理プログラム及びpld管理方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2018142046A JP2018142046A (ja) | 2018-09-13 |
| JP6836065B2 true JP6836065B2 (ja) | 2021-02-24 |
Family
ID=63246208
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2017034302A Expired - Fee Related JP6836065B2 (ja) | 2017-02-27 | 2017-02-27 | 情報処理装置、pld管理プログラム及びpld管理方法 |
Country Status (2)
| Country | Link |
|---|---|
| US (1) | US10534621B2 (ja) |
| JP (1) | JP6836065B2 (ja) |
Families Citing this family (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2020181105A (ja) * | 2019-04-25 | 2020-11-05 | キヤノン株式会社 | 投影装置およびその制御方法 |
| CN112306574B (zh) * | 2020-10-30 | 2022-05-31 | 联想(北京)有限公司 | 一种配置方法及装置 |
Family Cites Families (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2004032043A (ja) | 2002-06-21 | 2004-01-29 | Matsushita Electric Ind Co Ltd | 半導体集積回路およびコンパイラ |
| JP4909588B2 (ja) * | 2005-12-28 | 2012-04-04 | 日本電気株式会社 | 情報処理装置及び再構成デバイスの利用方法 |
| JP5589479B2 (ja) * | 2010-03-25 | 2014-09-17 | 富士ゼロックス株式会社 | データ処理装置 |
| WO2014120157A1 (en) * | 2013-01-30 | 2014-08-07 | Empire Technology Development Llc | Dynamic reconfiguration of programmable hardware |
| KR102110812B1 (ko) * | 2013-05-30 | 2020-05-14 | 삼성전자 주식회사 | 멀티 코어 시스템 및 멀티 코어 시스템의 작업 스케줄링 방법 |
| US9286084B2 (en) * | 2013-12-30 | 2016-03-15 | Qualcomm Incorporated | Adaptive hardware reconfiguration of configurable co-processor cores for hardware optimization of functionality blocks based on use case prediction, and related methods, circuits, and computer-readable media |
| JP6282482B2 (ja) | 2014-02-18 | 2018-02-21 | 株式会社日立製作所 | プログラマブル回路装置、コンフィギュレーション情報修復方法 |
| JP2015231205A (ja) | 2014-06-06 | 2015-12-21 | 国立大学法人静岡大学 | フィールドプログラマブルゲートアレイ、フィールドプログラマブルゲートアレイ開発ツール、及び、フィールドプログラマブルゲートアレイ開発方法 |
| JP2016076867A (ja) | 2014-10-08 | 2016-05-12 | キヤノン株式会社 | 情報処理装置、情報処理装置の制御方法、及びプログラム |
| JP6435826B2 (ja) * | 2014-12-09 | 2018-12-12 | 株式会社リコー | データ処理装置およびデータ処理方法 |
| WO2017029743A1 (ja) * | 2015-08-20 | 2017-02-23 | 株式会社日立製作所 | 情報処理装置および情報処理システム |
-
2017
- 2017-02-27 JP JP2017034302A patent/JP6836065B2/ja not_active Expired - Fee Related
-
2018
- 2018-02-22 US US15/901,931 patent/US10534621B2/en active Active
Also Published As
| Publication number | Publication date |
|---|---|
| US20180246735A1 (en) | 2018-08-30 |
| JP2018142046A (ja) | 2018-09-13 |
| US10534621B2 (en) | 2020-01-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US20220414503A1 (en) | Slo-aware artificial intelligence inference scheduler for heterogeneous processors in edge platforms | |
| JP7313381B2 (ja) | ハードウェアアクセラレーションのためのハードウェアリソースの埋込みスケジューリング | |
| US8782657B2 (en) | Dynamic creation and destruction of IO resources based on actual load and resource availability | |
| US11093352B2 (en) | Fault management in NVMe systems | |
| US9342365B2 (en) | Multi-core system for balancing tasks by simultaneously comparing at least three core loads in parallel | |
| US9477532B1 (en) | Graph-data partitioning for workload-balanced distributed computation with cost estimation functions | |
| US11119932B2 (en) | Operation of a multi-slice processor implementing adaptive prefetch control | |
| USRE50734E1 (en) | Apparatus for managing disaggregated memory and method thereof | |
| CN111177984B (zh) | 电子设计自动化中异构计算单元的资源利用 | |
| WO2013111022A1 (en) | Branch prediction logic | |
| KR102469927B1 (ko) | 분할 메모리 관리장치 및 방법 | |
| JP2010009160A (ja) | 性能値算出装置 | |
| CN113326140A (zh) | 一种进程迁移方法、装置、计算设备以及存储介质 | |
| US20100057967A1 (en) | Recording medium with load distribution program recorded therein and load distribution apparatus | |
| US8756371B2 (en) | Methods and apparatus for improved raid parity computation in a storage controller | |
| JP6836065B2 (ja) | 情報処理装置、pld管理プログラム及びpld管理方法 | |
| JP6849908B2 (ja) | 情報処理装置、pld管理プログラム及びpld管理方法 | |
| US9740618B2 (en) | Memory nest efficiency with cache demand generation | |
| WO2018179873A1 (ja) | アクセラレータを有する計算機のためのライブラリ、およびアクセラレータ | |
| US20140013142A1 (en) | Processing unit power management | |
| US11954527B2 (en) | Machine learning system and resource allocation method thereof | |
| JP5704176B2 (ja) | プロセッサ処理方法、およびプロセッサシステム | |
| US11899551B1 (en) | On-chip software-based activity monitor to configure throttling at a hardware-based activity monitor | |
| US8024738B2 (en) | Method and system for distributing unused processor cycles within a dispatch window | |
| JP2024528421A (ja) | ストールされたデータを処理するためのデータ処理装置及び方法 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20191112 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20201030 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20201117 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20201130 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20210105 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20210118 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 6836065 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| LAPS | Cancellation because of no payment of annual fees |