JP7362976B2 - 音声合成装置及びプログラム - Google Patents
音声合成装置及びプログラム Download PDFInfo
- Publication number
- JP7362976B2 JP7362976B2 JP2022049374A JP2022049374A JP7362976B2 JP 7362976 B2 JP7362976 B2 JP 7362976B2 JP 2022049374 A JP2022049374 A JP 2022049374A JP 2022049374 A JP2022049374 A JP 2022049374A JP 7362976 B2 JP7362976 B2 JP 7362976B2
- Authority
- JP
- Japan
- Prior art keywords
- adjustment
- unit
- learning
- data
- acoustic
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images
















Landscapes
- Electrically Operated Instructional Devices (AREA)
- Machine Translation (AREA)
Description
〔学習装置〕
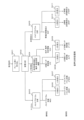
まず、本発明の実施形態による学習装置について説明する。図1は、学習装置の構成例を示すブロック図であり、図2は、学習装置による事前学習処理例を示すフローチャートである。
磯健一、渡辺隆夫、桑原尚夫、「音声データベース用文セットの設計」、音講論(春)、 pp.89-90(1988.3)
“MeCab:Yet Another Part-of-Speech and Morphological Analyzer”,インターネット<URL:http://taku910.github.io/mecab/>
また、言語分析処理としては、例えば以下に記載された係り受け解析処理が用いられる。
“CaboCha/南瓜:Yet Another Japanese Dependency Structure Analyzer”,インターネット<URL:https://taku910.github.io/cabocha/>
“A high-quality speech analysis, manipulation and synthesis system”,インターネット<URL:https://github.com/mmorise/World>
また、音響分析処理としては、例えば以下に記載された音声信号処理が用いられる。
“Speech Signal Processing Toolkit(SPTK) Version 3.11 December 25, 2017”,インターネット<URL:http://sp-tk.sourceforge.net/>
“REFERENCE MANUAL for Speech Signal Processing Toolkit Ver. 3.9”
“The Hidden Markov Model Toolkit(HTK)”,インターネット<URL:http://htk.eng.cam.ac.uk>
“Speech Signal Processing Toolkit(SPTK) Version 3.11 December 25, 2017”
(遅い)0.5<=RST<=4.0(速い)
これは、話速RSTは0.5から4.0までの範囲において、0.5に近いほど遅く、4.0に近いほど速いことを意味する。
(小さい)1.0E-5<=RPW<=2.0(大きい)
これは、パワーRPWは1.0E-5から2.0までの範囲において、1.0E-5に近いほど小さく、2.0に近いほど大きいことを意味する。
(低い)0.5<=RPT<=2.0(高い)
これは、ピッチRPTは0.5から2.0までの範囲において、0.5に近いほど低く、2.0に近いほど高いことを意味する。
(小さい)1.0E-5<=RPD<=2.0(大きい)
これは、抑揚RPDは1.0E-5から2.0までの範囲において、1.0E-5に近いほど小さく、2.0に近いほど大きいことを意味する。話速RST、パワーRPW、ピッチRPT及び抑揚RPDの標準値は、いずれも1.0とする。
[数1]

[数2]
DUR’= int(DUR×1/RST) ・・・(2)
対応付け部13から入力した時間長をDUR、調整後の時間長をDUR’とする。
[数3]
MGC[0]’= max(0,MGC[0]+logRPW) ・・・(3)
対応付け部13から入力した音響特徴量に含まれる静特性のメルケプストラム係数MGCにおける0次元目の値をMGC[0]、調整後の値をMGC[0]’とする。
[数4]
LF0[0]’= max(0,LF0[0]+logRPT) ・・・(4)
対応付け部13から入力した音響特徴量に含まれる静特性の対数ピッチ周波数LF0における0次元目の値をLF0[0]、調整後の値をLF0[0]’とする。
[数5]


[数7]
LF0’= max(0,((LF0-μLF0)/ΣLF0)×max(0,ΣLF0+logRPD)+μLF0)
・・・(7)
対応付け部13から入力した音響特徴量に含まれる静特性の対数ピッチ周波数をLF0、その平均値をμLF0、その標準偏差をΣLF0、調整後の静特性の対数ピッチ周波数をLF0’とする。
次に、学習部16による時間長モデルの学習処理について説明する。図8は、時間長モデルの学習処理例を説明する図である。学習部16は、調整量追加部14から入力した音素毎の言語特徴量に基づいて、言語特徴を表す312次元のバイナリ値及び13次元の数値データ、並びに1次元の調整データを生成する。1次元の調整データは話速データであり、言語特徴量の次元数は326である。
“CSTR-Edinburgh/merlin”,インターネット<URL:https://github.com/CSTR-Edinburgh/merlin>
後述する図9のステップS905における音響モデルの学習の場合も同様である。
次に、学習部16による音響モデルの学習処理について説明する。図9は、音響モデルの学習処理例を説明する図である。学習部16は、調整量追加部14から入力した音素毎の言語特徴量に基づいて、言語特徴を表す312次元のバイナリ値、13次元の数値データ、4次元の時間データ及び3次元の調整データを生成する。
学習係数の最適化方法として確率的勾配降下法、開始学習率を0.001、10エポックを過ぎてからエポック毎に学習率を指数減衰させ、誤差逆伝播法にて学習するものとする。尚、15エポックを過ぎてから、5エポック連続して評価誤差が減少しない場合は学習を早期終了するものとする。
次に、本発明の実施形態による音声合成装置について説明する。図10は、音声合成装置の構成例を示すブロック図であり、図11は、音声合成装置による音声合成処理例を示すフローチャートである。
次に、音響特徴量推定部22による時間長モデルを用いた時間長の推定処理について説明する。図12は、時間長モデルを用いた時間長推定処理例を説明する図である。音響特徴量推定部22は、調整量追加部21から入力した音素毎の言語特徴量に基づいて、言語特徴を表す312次元のバイナリ値及び13次元の数値データ、並びに1次元の調整データ(話速データ)を生成する。言語特徴量の次元数は326である。
次に、音響特徴量推定部22による音響モデルを用いた音響特徴量の推定処理について説明する。図13は、音響モデルを用いた音響特徴量推定処理例を説明する図である。音響特徴量推定部22は、ステップS1205にて求めた音素毎の時間長の1次元のデータに基づいて、図9のステップS901と同様に、音素に対応する複数フレームのそれぞれについて、時間データの4次元のデータを生成する(ステップS1301)。
2 音声合成装置
10,17 記憶部
11,20 言語分析部
12 音声分析部
13 対応付け部
14,21 調整量追加部
15 音響特徴量調整部
16 学習部
22 音響特徴量推定部
23 音声生成部
Claims (6)
- 音声合成対象のテキストを言語分析し、言語特徴量を求める言語分析部と、
前記言語分析部により求めた前記言語特徴量に、音響の特徴を調整するための調整パラメータの調整量情報を追加する調整量追加部と、
前記調整量追加部により前記調整量情報が追加された前記言語特徴量に基づき、予め学習された統計モデルを用いて、音響特徴量を推定する音響特徴量推定部と、
前記音響特徴量推定部により推定された前記音響特徴量に基づいて、音声信号を合成し、前記テキストに対して前記調整パラメータによる調整が加えられた音声信号を出力する音声生成部と、を備えた音声合成装置であって、
前記音響特徴量推定部が用いる統計モデルは、
予め設定されたテキストを言語分析し、学習言語特徴量を求める学習言語分析部と、
前記テキストに対応する音声信号を音響分析し、学習音響特徴量を求める音声分析部と、
前記学習言語分析部により求めた前記学習言語特徴量及び前記音声分析部により求めた前記学習音響特徴量を時間的に対応付ける対応付け部と、
前記対応付け部により対応付けられた前記学習言語特徴量に、音響の特徴を調整するための調整パラメータの調整量情報を追加する学習調整量追加部と、
前記対応付け部により対応付けられた前記学習音響特徴量を、前記調整パラメータの前記調整量情報に従って調整する学習音響特徴量調整部と、
前記学習調整量追加部により前記調整量情報が追加された前記学習言語特徴量及び前記学習音響特徴量調整部により調整された前記学習音響特徴量を用いて、統計モデルを学習する学習部と、
を備えた学習装置によって、予め学習された統計モデルである
ことを特徴とする音声合成装置。 - 請求項1に記載の音声合成装置において、
前記統計モデルは、ニューラルネットワークで構成された時間長モデル及び音響モデルからなり、
前記音響特徴量推定部は、
前記時間長モデルを用いて、音素毎の前記言語特徴量を前記時間長モデルの入力データとして、前記時間長モデルの出力データである音素毎の時間長を推定し、
音素毎の前記時間長からフレーム毎の時間長を生成し、
前記音響モデルを用いて、フレーム毎の前記言語特徴量及びフレーム毎の前記時間長を入力データとし、前記音響モデルの出力データであるフレーム毎の前記音響特徴量を推定する、ことを特徴とする音声合成装置。 - 請求項1または2に記載の音声合成装置において、
前記調整パラメータを、話速または時間長、パワー、ピッチ、及び抑揚の4つのパラメータのうちのいずれか1つまたは2つ以上の組み合わせとする、ことを特徴とする音声合成装置。 - 請求項1または2に記載の音声合成装置において、
前記調整パラメータを、話速または時間長、パワー、ピッチ、及び抑揚の4つのパラメータとし、
当該4つのパラメータのうちのいずれか1つのパラメータの調整量は、所定範囲内の任意の値が指定され、他の3つのパラメータの調整量は、固定値が用いられる、ことを特徴とする音声合成装置。 - 請求項1または2に記載の音声合成装置において、
前記調整パラメータを、話速または時間長、パワー、ピッチ、及び抑揚の4つのパラメータとし、
当該4つのパラメータにおけるそれぞれの調整量は、それぞれの所定範囲内の任意の値が指定される、ことを特徴とする音声合成装置。 - コンピュータを、請求項1から5までのいずれか一項に記載の音声合成装置として機能させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022049374A JP7362976B2 (ja) | 2018-06-14 | 2022-03-25 | 音声合成装置及びプログラム |
Applications Claiming Priority (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2018113433A JP7126384B2 (ja) | 2018-06-14 | 2018-06-14 | 学習装置及びプログラム |
| JP2022049374A JP7362976B2 (ja) | 2018-06-14 | 2022-03-25 | 音声合成装置及びプログラム |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018113433A Division JP7126384B2 (ja) | 2018-06-14 | 2018-06-14 | 学習装置及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022081691A JP2022081691A (ja) | 2022-05-31 |
| JP7362976B2 true JP7362976B2 (ja) | 2023-10-18 |
Family
ID=68919387
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018113433A Active JP7126384B2 (ja) | 2018-06-14 | 2018-06-14 | 学習装置及びプログラム |
| JP2022049374A Active JP7362976B2 (ja) | 2018-06-14 | 2022-03-25 | 音声合成装置及びプログラム |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2018113433A Active JP7126384B2 (ja) | 2018-06-14 | 2018-06-14 | 学習装置及びプログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (2) | JP7126384B2 (ja) |
Families Citing this family (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US11302301B2 (en) * | 2020-03-03 | 2022-04-12 | Tencent America LLC | Learnable speed control for speech synthesis |
| CN111402855B (zh) * | 2020-03-06 | 2021-08-27 | 北京字节跳动网络技术有限公司 | 语音合成方法、装置、存储介质和电子设备 |
| JP7611744B2 (ja) * | 2021-03-23 | 2025-01-10 | 日本放送協会 | 信号処理装置およびプログラム |
| EP4293660A4 (en) | 2021-06-22 | 2024-07-17 | Samsung Electronics Co., Ltd. | Electronic device and method for controlling same |
| CN113450758B (zh) * | 2021-08-27 | 2021-11-16 | 北京世纪好未来教育科技有限公司 | 语音合成方法、装置、设备及介质 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017032839A (ja) | 2015-08-04 | 2017-02-09 | 日本電信電話株式会社 | 音響モデル学習装置、音声合成装置、音響モデル学習方法、音声合成方法、プログラム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPWO2009107441A1 (ja) * | 2008-02-27 | 2011-06-30 | 日本電気株式会社 | 音声合成装置、テキスト生成装置およびその方法並びにプログラム |
| JP6594251B2 (ja) * | 2016-04-18 | 2019-10-23 | 日本電信電話株式会社 | 音響モデル学習装置、音声合成装置、これらの方法及びプログラム |
-
2018
- 2018-06-14 JP JP2018113433A patent/JP7126384B2/ja active Active
-
2022
- 2022-03-25 JP JP2022049374A patent/JP7362976B2/ja active Active
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2017032839A (ja) | 2015-08-04 | 2017-02-09 | 日本電信電話株式会社 | 音響モデル学習装置、音声合成装置、音響モデル学習方法、音声合成方法、プログラム |
Non-Patent Citations (1)
| Title |
|---|
| 山田 修平 Shuhei YAMADA,テーラーメイド音声合成のための差分特徴量を用いたDNNに基づくF0制御,日本音響学会 2017年 春季研究発表会講演論文集CD-ROM [CD-ROM],日本,2023年02月17日,PP271-274 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2019215468A (ja) | 2019-12-19 |
| JP2022081691A (ja) | 2022-05-31 |
| JP7126384B2 (ja) | 2022-08-26 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7362976B2 (ja) | 音声合成装置及びプログラム | |
| EP4292078B1 (en) | Methods and systems for modifying speech generated by a text-to-speech synthesiser | |
| US20220059076A1 (en) | Speech Processing System And A Method Of Processing A Speech Signal | |
| EP4266306A1 (en) | A speech processing system and a method of processing a speech signal | |
| Van Den Oord et al. | Wavenet: A generative model for raw audio | |
| Oord et al. | Wavenet: A generative model for raw audio | |
| EP2846327B1 (en) | Acoustic model training method and system | |
| US12027165B2 (en) | Computer program, server, terminal, and speech signal processing method | |
| CN107924686B (zh) | 语音处理装置、语音处理方法以及存储介质 | |
| US10706837B1 (en) | Text-to-speech (TTS) processing | |
| JP4738057B2 (ja) | ピッチパターン生成方法及びその装置 | |
| Laskar et al. | Comparing ANN and GMM in a voice conversion framework | |
| US10157608B2 (en) | Device for predicting voice conversion model, method of predicting voice conversion model, and computer program product | |
| KR20210035042A (ko) | 감정 간의 강도 조절이 가능한 감정 음성 생성 방법 및 장치 | |
| CN118506761A (zh) | 语音克隆模型训练及语音克隆方法、装置、设备、介质 | |
| CN120599999A (zh) | 语音生成方法、装置、介质、电子设备及程序产品 | |
| JP7088796B2 (ja) | 音声合成に用いる統計モデルを学習する学習装置及びプログラム | |
| US10446133B2 (en) | Multi-stream spectral representation for statistical parametric speech synthesis | |
| Nandi et al. | Implicit excitation source features for robust language identification | |
| JP7133998B2 (ja) | 音声合成装置及びプログラム | |
| Kammili et al. | Handling emotional speech: a prosody based data augmentation technique for improving neutral speech trained ASR systems | |
| US9230536B2 (en) | Voice synthesizer | |
| Sulír et al. | Hidden Markov Model based speech synthesis system in Slovak language with speaker interpolation | |
| Singh et al. | Straight-based emotion conversion using quadratic multivariate polynomial | |
| Jayasinghe | Machine Singing Generation Through Deep Learning |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20220325 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20230228 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20230303 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230413 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20230728 |
|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20230823 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20230824 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7362976 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |