JP7537700B2 - 学習装置、学習データの作成方法、学習方法、及び学習プログラム - Google Patents
学習装置、学習データの作成方法、学習方法、及び学習プログラム Download PDFInfo
- Publication number
- JP7537700B2 JP7537700B2 JP2020203258A JP2020203258A JP7537700B2 JP 7537700 B2 JP7537700 B2 JP 7537700B2 JP 2020203258 A JP2020203258 A JP 2020203258A JP 2020203258 A JP2020203258 A JP 2020203258A JP 7537700 B2 JP7537700 B2 JP 7537700B2
- Authority
- JP
- Japan
- Prior art keywords
- walking
- learning
- learning data
- occlusion
- complete
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images













Landscapes
- Image Analysis (AREA)
- Closed-Circuit Television Systems (AREA)
Description
例えば、特許文献1の技術では、外観による特徴や座標、及び歩行の方向などを手がかりにして複数のカメラで撮影した人物を追跡しつつ、アバターに変換している。
このような集団で歩行するようなシーンで歩行者を追跡する場合、外見の似た他者が近くを同じ方向に歩いていたり、歩行者の身体の一部が他の歩行者の陰に隠れたり、あるいは、服装のデザインの影響で角度によって歩行者の外見の見え方が変化したり、など、同様な情報が取得できるため、個々の歩行者を分離して追跡することが困難な場合があった。
そこで、特許文献2では、カメラによる対象物の骨格から歩行者を認識する場合に、遮蔽のない学習データから人工的に骨格の一部を欠損させたデータを用いて補間器を作成し、補間器と推定器を用いて対象物の骨格を認識する技術が提案されている。
また、データを欠損させる際に現実空間でありえないような欠損を行うことは、逆にノイズとなる可能性がある。
(2)請求項2に記載の発明では、前記歩行状態sは、前記被写体の周期的な歩行動作における歩行段階と、前記被写体の歩行する方向を構成要素としている、ことを特徴とする請求項1に記載の学習装置を提供する。
(3)請求項3に記載の発明では、前記遮蔽学習データ作成手段は、鼻、首、及び、腰部中心に設定されたジョイントを前記主要ジョイントとして削除対象から除外する、ことを特徴とする請求項1、又は請求項2に記載の学習装置を提供する。
(4)請求項4に記載の発明では、前記遮蔽学習データ作成手段は、前記被写体の右手、左手、右足、左足に対応する少なくとも1つの先端側から前記主要ジョイントに向けて繋がるジョイントを削除対象とする、ことを特徴とする請求項1、請求項2、又は請求項3に記載の学習装置を提供する。
(5)請求項5に記載の発明では、前記遮蔽学習データ作成手段は、前記被写体に対して設定された全てのジョイントの80%以下のジョイントを削除対象とする、ことを特徴とする請求項1~請求項4のうちの1の請求項に記載の学習装置を提供する。
(6)請求項6に記載の発明では、前記遮蔽学習データ作成手段は、前記主要ジョイントに加え、前記主要ジョイントに直結している1次ジョイントの少なくとも2以上を残して削除する、ことを特徴とする請求項1~請求項4のうちの1の請求項に記載の学習装置を提供する。
(7)請求項7に記載の発明では、前記遮蔽学習データ作成手段は、全ての完全学習データに対する遮蔽学習データを予め作成し、前記学習手段は、完全学習データと予め作成した遮蔽学習データを使用して学習を行う、ことを特徴とする請求項1から請求項6のうちのいずれか1の請求項に記載の学習装置を提供する。
(8)請求項8に記載の発明では、前記遮蔽学習データ作成手段は、1の完全学習データに対する複数の遮蔽学習データを作成し、当該1の完全学習データと作成した複数の遮蔽学習データによる学習の後に、次の完全学習データに対する遮蔽学習データを作成する、ことを特徴とする請求項1から請求項6のうちのいずれか1の請求項に記載の学習装置を提供する。
(9)請求項9に記載の発明では、歩行している被写体を撮影した動画のフレーム画像から取得した前記被写体の骨格情報を入力し、当該被写体の歩行状態を出力するニューラルネットワークにおける学習データの作成方法であって、前記被写体に骨格情報として設定されている複数のジョイントの位置情報が全て揃った完全骨格情報jと、当該完全骨格情報jによる歩行状態sとからなる複数の完全学習データ(j、s)を取得する完全学習データ取得ステップと、前記取得した各完全学習データに対して、その完全骨格情報jから前記被写体の中心線に沿って設定された主要ジョイントを除くジョイントの位置情報を削除した遮蔽骨格情報cjと歩行状態sとからなる複数の遮蔽学習データ(cj、s)を作成する遮蔽学習データ作成ステップと、を具備することを特徴とする学習データの作成方法を提供する。
(10)請求項10に記載の発明では、歩行している被写体を撮影した動画のフレーム画像から取得した前記被写体の骨格情報を入力し、当該被写体の歩行状態を出力するニューラルネットワークの学習方法であって、前記被写体に骨格情報として設定されている複数のジョイントの位置情報が全て揃った完全骨格情報jと、当該完全骨格情報jによる歩行状態sとからなる複数の完全学習データ(j、s)を取得する完全学習データ取得ステップと、前記取得した各完全学習データに対して、その完全骨格情報jから前記被写体の中心線に沿って設定された主要ジョイントを除くジョイントの位置情報を削除した遮蔽骨格情報cjと歩行状態sとからなる複数の遮蔽学習データ(cj、s)を作成する遮蔽学習データ作成ステップと、前記取得した複数の完全学習データ(j、s)と前記作成した複数の遮蔽学習データ(cj、s)を使用して前記ニューラルネットワークの学習を行う学習ステップと、を具備することを特徴とする学習方法を提供する。
(11)請求項11に記載の発明では、歩行している被写体を撮影した動画のフレーム画像から取得した前記被写体の骨格情報を入力し、当該被写体の歩行状態を出力するニューラルネットワークの学習プログラムであって、前記被写体に骨格情報として設定されている複数のジョイントの位置情報が全て揃った完全骨格情報jと、当該完全骨格情報jによる歩行状態sとからなる複数の完全学習データ(j、s)を取得する完全学習データ取得機能と、前記取得した各完全学習データに対して、その完全骨格情報jから前記被写体の中心線に沿って設定された主要ジョイントを除くジョイントの位置情報を削除した遮蔽骨格情報cjと歩行状態sとからなる複数の遮蔽学習データ(cj、s)を作成する遮蔽学習データ作成機能と、前記取得した複数の完全学習データ(j、s)と前記作成した複数の遮蔽学習データ(cj、s)を使用して前記ニューラルネットワークの学習を行う学習機能と、をコンピュータに実現させることを特徴とする学習プログラムを提供する。
歩行追跡装置1(図1)は、動画の異なるフレーム画像に写った歩行者9が同一人物であることを同定して追跡する。
同定は、歩行者9の外見情報による同定と歩行状態による同定を相補的に組み合わせて行い、これによって頑健性を高めている。外見情報による同定は、一般的に利用されている技術を用いる。
歩行者は、歩行する際に周期2πの周期的な歩行動作を行うが、この歩行動作の各歩行段階を位相角φで表し、更に、歩行方向をθで表し、θとφの組み合わせによって歩行状態を定義する。
また、歩行状態自体も、歩行方向θと歩行段階φを相補的に組み合わせてあるため、多少歩行方向がぶれたり、歩調が乱れたりしても、頑健に歩行者9の歩行状態を検出することができる。
本実施形態のMLP16に対しては、フレーム画像から抽出した骨格情報15が遮蔽などによって一部欠損してても、より高い精度で歩行状態を推定することが可能な学習を済ませてある。
すなわち、歩行状態の学習の際に、歩行者と判断するために重要な骨格(顔の中心や胴など)は保持し、遮蔽が発生しやすい手やつま先等の骨格の末端から一定の割合で削除した学習データを使用してMLP16の学習を行う。
学習データは、全てを備えた骨格情報15とその歩行状態s(教師信号)からなる完全学習データと、当該骨格情報15から末端側のジョイントの位置情報を欠如(削除)した遮蔽骨格情報と同一の歩行情報s(教師信号)とからなる遮蔽学習データ、を使用する。遮蔽骨格情報と教師信号については、予め作成しておく場合と、学習の際に作成する場合のいずれでもよい。
カメラで歩行者を動画撮影し、2つのフレーム画像に写った歩行者を対応させて同一人物であると同定する場合、同じ動画データの時間的に前後するフレーム画像間で歩行者を対応させて同定する場合と、複数台のカメラで撮影した異なる動画データのフレーム画像間で歩行者を対応させて同定する場合がある。
以下、第1~第3実施形態で前者について説明し、第4実施形態で後者について説明するが、歩行状態を用いて2つのフレーム画像に写っている歩行者を同定する技術は共通である。
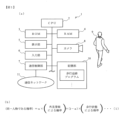
図1(a)は、第1実施形態に係る歩行追跡装置1のハードウェア的な構成を示した図である。
歩行追跡装置1は、CPU(Central Processing Unit)2、ROM(Read Only Memory)3、RAM(Random Access Memory)4、表示部5、入力部6、通信制御部7、カメラ8、記憶部10などから構成されている。
歩行追跡装置1は、歩行者ごとにばらばらである歩行状態を用いて個々の歩行者9を識別するため、集団的な歩行で特に顕著な頑健性を示す。
歩行追跡装置1は、例えば、自律走行ロボットに搭載されて省人化を行ったり、監視カメラ映像を用いて防犯対策やマーケティング分析などを行うのに用いられる。
本実施形態では、歩行追跡プログラムに従って情報処理することにより、動画データを構成する2つのフレーム画像に写った歩行者9を同定し、この同定処理を繰り返すことによって歩行者9を動画内で追跡する。
RAM4は、読み書きが可能なメモリであって、CPU2が動作する際のワーキングメモリを提供する。
本実施形態では、動画を構成するフレーム画像(1コマの静止画像)の画像データを展開して記憶したり、計算結果を記憶したりすることにより、CPU2が、歩行者9を追跡するのを支援する。
入力部6は、キーボードやマウスなどの入力デバイスを用いて構成されており、操作画面への入力などを受け付ける。
本実施形態では、例えば、遠隔地のイベント会場などの外部のカメラで撮影した動画データを通信ネットワーク11経由で受信して、この動画について歩行追跡処理を行うことができる。
カメラ8は、歩行者9が歩行している場所を所定のフレームレートで撮影し、これら連続するフレーム画像で構成された動画をRGB信号などの所定の画像信号によって出力する。
このように歩行追跡装置1は、歩行している被写体(歩行者9)を撮影した動画をカメラ8や通信ネットワーク11経由で外部の装置などから取得する動画取得手段を備えている。
式(1)は、2つのフレーム画像に写っている歩行者9を対応させて同定するのに用いる式であって、第1実施形態~第3実施形態では、単一のカメラ8で撮影した時間的に前後するフレーム画像間で歩行者9を同定するのに用い、第4実施形態では、複数台のカメラ8、8、・・・で同時刻に撮影した2つのフレーム画像間で歩行者9を同定するのに用いる。
このように、動画撮影したカメラ8の異同にかかわらず、式(1)を用いて2つのフレーム画像間で歩行者9を同定することができる。
歩行追跡装置1は、外見情報と歩行状態を併せて判定した同一人物である確率が所定の閾値以上である場合に、歩行者9を同一人物であると同定する。閾値は、実験により求める。
このように、歩行追跡装置1は、被写体の外見情報を取得する外見情報取得手段を備え、歩行状態と、当該外見情報と、を用いて被写体を同定する。
外見情報を用いて同定する技術には、色分布によるカラーヒストグラム特徴を用いるもの、輝度勾配分布によるHOG特徴量を用いるもの、及び、深層学習で構築した距離空間に基づくもの(同一人物同士を近づけ、異なる人物同士を遠ざける距離空間を学習したもの)などがある。
これらは、何れも外見(Appearance)に基づくものであり、例えば、服の色や種類が類似している場合や、照明が変化する場合、あるいは、カメラ設置位置による見え方が違う場合に誤同定することがある。
近接する時刻であれば、カメラ位置によらず同一人物は同じ姿勢をとるため、姿勢に基づいて人物同定を行うことが可能となる。
そのため、式(1)に示したように、外見情報による同定と、歩行状態による同定と、を相補的に組み合わせることによって、外見情報で生じる誤同定の原因に対しても頑健となり、人物同定判断の精度を大幅に高めることができる。
以下では、今回新たに導入した歩行状態の検出について説明する。
まず、歩行追跡装置1は、フレーム画像から歩行者9を矩形により人物検出する。そして、検出した歩行者9の姿勢情報を骨格情報15によって抽出する。
骨格情報15の抽出には、例えば、OpenPoseやPoseNetといったソフトウェアで一般的に利用されている技術を用いることができる。
このように、歩行追跡装置1は、被写体の骨格情報を取得する骨格情報取得手段を備えている。
このように、歩行追跡装置1は、各種の歩行状態を骨格情報によって学習したニューラルネットワークを備えている。
なお、ベクトルのsは、図では太字で表しているが、文字コードの誤変換を防ぐために、明細書中では通常の英文字sで表す。他のベクトル量についても同様とする。
このように、歩行追跡装置1は、ニューラルネットワークを用いて被写体の周期的な歩行動作の連続性に基づく歩行状態を取得する。
歩行状態が近いほどユーグリッド距離Uは小さくなるため、これによって2つの歩行状態の類似度を定量的に比較することができる。そのため、ユーグリッド距離Uが近いほど同一人物である確率が高くなるように同定判断を行うことができる。なお、これは一例であって、他の計量を用いてもよい。
そして、歩行追跡装置1は、フレーム画像での同定処理を逐次行うことにより、歩行者9を動画内で追跡することができる。
このように、歩行追跡装置1は、動画で同定した被写体を追跡する追跡手段を備えている。
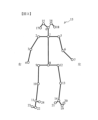
本実施形態では、骨格情報をジョイント番号0~24の合計25個のジョイントで定義した。以下、ジョイント番号0のジョイントをJ0などと略記する。ジョイントは、骨格情報において関節として機能する部位であって、ジョイントを中心としてこれらを結ぶ線分を回転させることにより姿勢を変化させることができる。本実施形態で用いたジョイントと人体部位との対応関係は次の通りである。
座標を取得する元となる画像は、フレーム画像から人物検出で切り出した矩形の画像における座標でもよいし、フレーム画像上での座標でもよい。
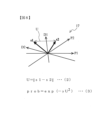
図4(a)は、撮影エリアを上から見たところを示しており、歩行者9の歩行方向dを、歩行面に平行な平面上の単位ベクトルで表す。
図の例では、撮影方向のD1軸と、これに垂直なD2軸で張られるD平面を設定し、歩行者9を中心として回転する単位ベクトルによって歩行方向dを定義した。
図5(a)に示したように、歩行動作(足や手を運動させて体の重心を移動させる全身の連続動作)を歩行方向に垂直な方向から観察すると、歩行者9は、同じ周期的な動作を連続的に繰り返している。
このように歩行動作は周期的な動作であるため、歩行段階は1歩行周期の位相で表すことができる。
位相角の起点は、どこでもよいが、図の例では、歩行者9aの段階を位相角φの起点とし、歩行者9b~9eの段階に進むに従って反時計回りに増大するようにφを定義した。
なお、図5(b)では、歩行者9eを省略し、P1、P2軸による単位円上に歩行者9a~9dを順に表示した概念図であって、P1、P2軸と、歩行者9a~9dの正確な対応関係を示すものではない。
図6(a)に示したように、歩行方向dと歩行段階pを合わせた4次元ベクトルで歩行状態s=(d1、d2、p1、p2)を定義する。
図示すると、歩行状態sは、図6(b)で示したようなD1、D2、P1、P2軸で張られる4次元の歩行状態空間17内のベクトルsで表される。
4次元空間は図示することはできないため、図では、模式的にD1~P2軸を示してある。
歩行状態は、同一時刻(多少前後してもよい)の歩行方向θと歩行段階の位相角φの組み合わせで規定されるため、直交するθ軸とφ軸からなる平面での点(θ、φ)(0≦θ、φ<2π)で表したり、単位球からなる球座標(θ、φ)で表すこともできる。これらのうち、理論計算や実装など、それぞれの場面で便利な座標系を用いればよい。
また、更に他の要素を加えて更に高次元のベクトルとすることもできる。
歩行追跡装置1が備える同定手段は、歩行方向と歩行段階から歩行状態を生成することにより、歩行動作に加えて、被写体の歩行する方向を歩行状態に含めて同定を行うことができる。
歩行追跡装置1は、MLP(多層パーセプトロン:ニューラルネットワークの一種)による深層学習によって歩行状態sを計算した。
MLP16は、入力層、中間層、及び出力層を備えている。中間層の層数は3、各中間層のノード数は64とした。
出力層は、歩行状態s=(d1、d2、p1、p2)の各成分を出力する4個のノードを備えている。
エポック数は、学習回数であり、バッチサイズは、学習データをバッチに分けて学習させる際の各バッチに含まれる学習データ数である。
つまり、学習データ(j、s)のjを入力すると、MLP16はsを出力するが、これを正解であるところの学習データ(j、s)のsと比較し、その誤差が小さくなるように中間層などのパラメータを調節した。
このようにパラメータが調整されたMLP16を用いると、あるフレーム画像から抽出た骨格情報15のジョイント座標値を入力するだけで、歩行状態s、即ち、歩行方向dと歩行段階pを同時に算出することができる。
人物同定は、先に述べたように歩行状態空間17でのユーグリッド距離Uを用いて行う。
例えば、歩行状態s1、s2を、それぞれ、最新のフレーム画像の歩行者9から抽出した歩行状態と、これより1つ前のフレーム画像の歩行者9から抽出した歩行状態とする。
なお、第4実施形態で、複数台のカメラ8a、8bからの動画で歩行者9を同定する場合は、カメラ8aで撮影したフレーム画像aから抽出した歩行状態と、カメラ8bで同一時刻に撮影したフレーム画像bから抽出した歩行状態とする。
このように同一時刻の概念は、追跡対象の動く早さと、フレーム画像の撮影間隔の対比により規定され、撮影間隔での歩行状態sの変化が同定処理に実質的に影響を与えない範囲内である時間差は、同一時刻と考えられる。
式(2)で示したユーグリッド距離Uが小さいほど歩行状態s1、s2の差が小さく、両フレーム画像での歩行者9の姿勢が近くなり、同一人物である可能性が高くなる。
そして、式(3)によれば、ユーグリッド距離Uが小さいほど確率が1に近づいて同一人物である確率が高まり、その近づき方を定数γによって調節することができる。
両人物が同一であると同定判断するための確率の閾値と定数γは、実験により適当な値を設定する。
例えば、歩行状態s1、s2の大きさが、それぞれ1となるように規格化して内積を計算すると、歩行状態s1、s2の距離を内積によって-1から1までの値で測量することができる。内積計算は、計算機で容易に計算できるため、これを用いることも考えられる。
これらは、一例であって、他の計算式によって人物同定を行ってもよい。
このように、歩行追跡装置1は、実質的に同一時刻での歩行状態sを抽出して比較するため、歩行者9が方向を変えたり歩調を変化させたりしても、これに追随して追跡することができる。
図9(a)の左図は、歩行方向dの実験結果を表したグラフである。
横軸は実線31で示したグランドトゥルースを表しており、縦軸は、実際に動画から計算した歩行者の歩行方向dの予測値(MLP16が出力した値)の分布(縦線)を表している。
グランドトゥルースとは、機械学習の精度を評価するための比較用のデータである。
図に示したように、予測値は、グランドトゥルース上に分布しており、高い精度で歩行方向dを予測することができている。
同様に、実線32でグランドトゥルースを表し、縦線で予測値の分布を表している。歩行方向dに比べると、予測値のばらつきが若干広がるものの、予測値は、概ねグランドトゥルース上に分布しており、高い精度で歩行段階pを予測することができている。
RMSE(Root Mean Square Error:二乗平均平方根誤差)は、式(4)で表され、グランドトゥルース(yobs、i)と予測値(ypred、i)とのずれの二乗の総和の平均の平方根である。この値が小さいほどMLP16の性能が良く、予測精度が高いことを意味している。
なお、表では、歩行方向dと歩行段階pについて、平均誤差をベクトルの角度に換算した値も併記してあり、それぞれ、6.3°、13.1°である。
以下の処理は、記憶部10に記憶した歩行追跡プログラムに従ってCPU2が行うものである。
まず、CPU2は、カメラ8が撮影した動画のフレーム画像を取得してRAM4に記憶する(ステップ5)。
人物検出で複数の歩行者9、9、・・・が検出された場合は、これら全員を追跡対象としてもよいし、これから選択した単数、又は複数の歩行者9、9、・・・を追跡対象としてもよい。複数の歩行者9、9、・・・を追跡対象とする場合は、個々の歩行者9の追跡を並列処理にて同時に行う。
また、追跡対象とする歩行者9を選択する場合は、何らかのアルゴリズムに従って自動的に選択してもよいし、手動で選択してもよい。
複数の歩行者9、9、・・・を追跡対象として設定した場合は、それぞれの歩行者9について外見情報を取得する。以下同様に、複数の歩行者9、9、・・・を追跡する場合は、歩行者ごとに処理する。
以上の外見情報と歩行状態が、追跡に用いる初期値となり、以降の動作で外見情報と歩行状態を連続的に追跡していく際の起点となる。
次に、CPU2は、外見情報計算処理を行って、式(1)右辺第1項の外見情報による確率を計算してRAM4に記憶する(ステップ30)。
まず、CPU2は、ステップ25でRAM4に記憶したフレーム画像から歩行者9を人物検出し、その外見情報を取得してRAM4に記憶する。
そして、CPU2は、ステップ15でRAM4に記憶した1つ前のフレーム画像から取得した外見情報を読み取り、それを今回記憶した外見情報と比較して、その類似度によって同一人物である確率を計算する。
この計算は、一例であって、外見情報を用いて一般的に行われている他の方法を用いてもよい。
次に、CPU2は、ステップ30で記憶した外見情報による確率とステップ35で記憶した歩行状態による確率をRAM4から読み出し、これらを式(1)に代入して、歩行者9が同一人物である確率を計算してRAM4に記憶する。
同定により、ステップ25でRAM4に記憶したフレーム画像での追跡が成功したことになる。
一方、追跡を続行しない場合(ステップ45;N)、CPU2は、処理を終了する。
まず、CPU2は、矩形領域によって人物検出した歩行者9から骨格情報15を抽出してRAM4に記憶する(ステップ60)。
CPU2は、例えば、矩形領域によって切り出した画像におけるJ0~J24の座標値によって骨格情報15を構成する。
次に、CPU2は、前のフレーム画像で取得した歩行状態s2をRAM4から読み出して取得する(ステップ75)。
第1実施形態では、例えば、OpenPoseやPoseNetなどで用いられている骨格検出可能な手法を利用して歩行者9の姿勢を算出した。
しかし、障害物の存在や人とのすれ違いなど、環境によっては歩行者9の一部が隠れによって観測できず、骨格座標が部分的にしか検出できない場合があり、このようなときは歩行状態の推定が困難となる場合がある。
これにより、隠れによって未検出のジョイントがあっても頑健な歩行状態の推定を実施することができる。
本実施形態では、骨格情報15の一部の領域に含まれるジョイントを未検出に設定することにより、隠れによって未検出となったジョイントを含む学習データ(遮蔽学習データ)を用意した。
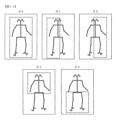
例えば、図に示した領域35を隠すと右頭部が未検出となった骨格情報15が得られ、領域36を隠すと左手が未検出となった骨格情報15が得られ、領域37を隠すと右足が未検出となった骨格情報15が得られる。
骨格の先端から骨格の中心に向けて領域が隠れるようにしたのは、歩行中には手足などの四肢や片半身が隠れる場合が多いためである。
完全学習データ(j、s)は、第1実施形態で説明した学習データと同じで、全ジョイント座標値jが揃った骨格情報(完全骨格情報j)と歩行状態s(教師信号)からなる学習データである。
遮蔽学習データ(cj、s)は、完全学習データの完全骨格情報jから、末端側のジョイントから優先的に位置情報を削除(欠如)して作成した遮蔽骨格情報cjと、完全骨格情報jに対する歩行状態s(教師信号)からなる学習データである。
遮蔽学習データの遮蔽骨格情報cjは、完全骨格情報jから、図12に示すように、末端側のジョイントを削除することで作成する。
一方、遮蔽が発生しやすい手やつま先等の骨格の末端側から優先して一定の割合で削除する。
主要ジョイントに直結しているジョイントを1次ジョイントとした場合、この1次ジョイントについては、隠れ領域の全面積(削除するジョイントの割合)が最大80%以下、好ましくは60%以下となる数の範囲まで削除する。
全ジョイント数が25で、主要ジョイント数が3なので、6つの1次ジョイントのうち、少なくとも2つ以上のジョイントは削除対象から除外することで、隠れ領域の全面積を80%以下としている。
このように、主要ジョイントと、それに直結する1次ジョイントの一部を保持することで、歩行状態sの推定が可能になる。
なお、上述のように、遮蔽学習データは完全学習データから作成するが、次の何れの方法によることも可能である。
すなわち、第1の方法では、予め全学習データから対応する全ての遮蔽学習データを作成しておき、両学習データを使用してMLP16の学習を行う。
一方、第2の方法では、完全学習データにおける個々の学習データを使用してMLP16の学習を行う際に、対応する個々の個別学習データを作成しながらMLP16の学習を行う。
この隠れ学習処理については、上記第2の方法によるMPL16の学習方法である。
なお、本実施形態としては、MPL16の学習を、歩行追跡装置1のCPU2が行う場合について説明する。但し、取得したフレーム画像から歩行者9の歩行状態sを推定する場合、歩行追跡装置1は学習済みのMPL16を使用することになるので、歩行追跡装置1以外のコンピュータシステムによりMPL16の学習を行うことも可能である。
そして、CPU2は、RAM4から1つの完全学習データ(j、s)を取得する(ステップ200)。
すなわち、CPU2は、取得した完全学習データ(j、s)の完全骨格情報jのジョイント座標値j=[x0、y0、・・・、x24、y24]から、図12で説明したように、骨格の末端側の座標値を一定の割合で削除することで、遮蔽骨格情報cjを作成する。
なお、遮蔽骨格情報cjにおいて、削除したジョイントの座標値は(xn、yn)は存在しない。このため、MLP16の層入力(図7参照)における50個のノードのうち、削除した1ジョイント当たり対応する2か所のノードの入力はされない。
そしてCPU2は、作成した遮蔽骨格情報cjと、完全学習データの歩行情報sとから写生学習データ(cj、s)を作成しRAM4に記憶する。
CPU2は、1の完全学習データ(j、s)に対して作成する遮蔽学習データ(cj、s)は1つではなく、異なる割合いでジョイントを削除した複数の遮蔽データ(cj1、s)、(cj2、s)、…、を作成する。
この遮蔽学習データ(cj、s)のパターンとしては、手足の4つの組み合わせのパターン(13通り)×それぞれの欠如範囲を変えたパターン(任意通り)の組み合わせが可能である。
この場合にも、上述したように、主要ジョイントである、鼻(j0)、首(j1)、腰部中心(j8)と、この主要ジョイントに直結している1次ジョイントj2、j5、j9、j12、j15、j16のうちの少なくとも2つの1次ジョイントとを残すことで、隠れ領域の全面積80%以下の条件を満たす必要がある。
すなわち、CPU2は、取得した完全学習データ(j、s)と、作成した複数の遮蔽学習データ(cj、s)を使用し、MLP16に対する学習を行う。
一方、CPU2は、他の完全学習データが存在しなければ(ステップ230;N)、隠れ学習処理を終了する。
このように骨格の先端領域から中心領域に向けて骨格情報が欠如するように、全身の骨格情報の少なくとも一部の領域から構成された学習データを用いて学習したMLP16を用いて実験したところ、全身の骨格情報15がある場合に加えて、隠れがある場合でも歩行状態を高い精度で予測することができた。
実験結果は、第3実施形態において、第1~第3実施形態での実験結果を比較する形で説明する。
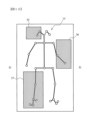
本実施形態では、骨格情報15を上半身・下半身などの部分領域に分割して、それぞれの部分領域を個別に学習したMLP16を用意し、これらによる結果を統合して歩行状態を推定する。
本実施形態では、図の破線で示したように、骨格情報15を、全身(R0)、右半身(R1)、左半身(R2)、上半身(R3)、下半身(R4)の5領域に分類し、領域R0~領域R4の各領域について隠れありの学習を行った。以下、領域R1の骨格情報15を骨格情報(R1)などと記すことにする。
なお、この領域分割例は一例であって、更に多数の領域、あるいは少数の領域に分割してもよい。
本実施形態ではMLPを6個用いるが、これらをMLP(R0)、MLP(R1)、MLP(R2)、MLP(R3)、MLP(R4)、MLP(重み)とする。
第2実施形態では、全身の骨格情報15や、ジョイントの一部が欠如し、未検出となった骨格情報15を多数用いてMLP16を学習させたが、本実施形態でも同じく、全身や隠れのある骨格情報15を用いて学習を行った。
同様に、MLP(R1)~MLP(R4)は、それぞれ骨格情報(R1)~骨格情報(R4)を用いて学習しており、骨格情報15を入力すると、それぞれ、領域R1~R4に含まれるジョイントの座標値を用いて領域別歩行状態を出力する。
このように、本実施形態では、隠れを含めた骨格情報15で領域ごとに歩行状態推定の学習を行った複数のMLPを並列に配置して使用する。
例えば、主に右半身のジョイントが検出された骨格情報15に関しては、右半身用のMLP(R1)での推定値の精度が高く、左半身用のMLP(R2)での推定値は、精度が高くないと予想される。また、下半身用の領域R4など、他の領域での推定値も、MLP(R1)ほどではないものの、MLP(R2)よりは、ある程度確かであると思われる。
MLP(重み)は、骨格情報15の隠れのパターンに対して、このようなMLP(R0)~MLP(R4)による領域別歩行状態の適切な重み付けを学習している。
主に右半身のジョイントが検出された骨格情報15に関しては、その領域あたりのフラグが主に1になるなど、ジョイントの検出/未検出のパターンを検出フラグで表すことができる。
上述したように、ニューラルネットワーク(MLP(R0)~MLP(R4)、MLP(重み))は、骨格の領域ごとに学習した複数の領域ネットワーク(MLP(R0)~MLP(R4))と、当該領域ネットワークのそれぞれの出力を、骨格情報の欠如に応じて重み付けする重み付けネットワーク(MLP(重み))と、によって歩行状態を出力している。
図11と同じステップには同じ番号を付して説明を簡略化する。
まず、CPU2は、矩形領域によって検出した歩行者9から骨格情報15を抽出してRAM4に記憶する(ステップ60)。
次に、CPU2は、当該記憶した骨格情報15で、ジョイントの検出/未検出を調べてて検出フラグを生成し、これをRAM4に記憶する(ステップ105)。
次に、CPU2は、ステップ110でRAM4に記憶した領域別の骨格情報を、それぞれ対応する領域別のMLP(R0)~MLP(R4)に入力する(ステップ115)。
次に、CPU2は、MLP(R0)~MLP(R4)が出力した領域別歩行状態を取得してRAM4に記憶する(ステップ120)。
そしてCPU2は、MLP(重み)によって計算した歩行状態s1を取得してRAM4に記憶する(ステップ70)。
そして、CPU2は、ステップ70で記憶した歩行状態s1とステップ75で読み出した歩行状態s2を用いて歩行状態による確率を計算し、これをRAM4に記憶する(ステップ80)。
以上のように、第3実施形態では、各領域の学習モデルにより歩行状態を推定し、各ジョイントの検出/未検出により、動的に各領域の推定結果に重み付けを付与して歩行状態を算出することができる。
第1実施形態、第2実施形態、第3実施形態で行った処理形態を、それぞれ、隠れ未学習モデル、隠れ学習モデル、領域分割モデルと呼ぶことにする。
実験では、テストデータの未検出ジョイントの割合rを変化させることにより、隠れに対する頑健性を評価した。
縦軸はRMSEを表し、横軸は未検出ジョイントの割合rを示している。ジョイントの未検出(隠れ)割合は、最大80%とし、20%間隔で測定を行った。RMSEが小さいほど精度が高いことを示している。具体的な数値は、図16(b)の表に示した通りである。
グラフから分かるように、隠れがない場合(r=0)は、どのモデルも高い精度を示しており、隠れ未学習モデルが他のモデルよりも若干よい精度を示している。
しかし、隠れ未学習モデルは、隠れが生じた場合(0<r≦0.8)、精度が大幅に低下し、r=0.8では、RMSEが1.0近くまで達している。
特に、r=0.8においては、領域分割モデルは、隠れ学習モデルよりも10%近く高い精度を示した。
このように、隠れ学習モデルと領域分割モデルは、隠れに対して頑健な状態推定を行うことができ、領域分割モデルは特に効果が高いことがわかった。
本実施形態では、複数のカメラの映像に写った歩行者9をカメラ間で対応づけて追跡する場合について説明する。
この例では、例えば、イベント会場などに設置した複数台のカメラ8、8、・・・の動画データを通信ネットワーク11経由で歩行追跡装置1に送信する。
このように、歩行追跡装置1の有する動画取得手段は、複数のカメラで撮影した被写体の複数の動画を取得する。
そして、これらカメラ8、8、・・・の映像の重なったエリアにおいて、複数のカメラによる同一時刻のフレーム画像で歩行者9を同定する。
これにより、複数のカメラ映像を連携させて歩行者9を追跡することができる。
この場合、ロボットは、右フレーム画像と左フレーム画像で歩行者9を対応させて歩行者9を立体視しながら、これによって得られる3次元情報を用いて歩行者9を追跡する。
そのため、固定カメラの設置が容易であるほか、複数のドローンに搭載したカメラを配置、移動させながら歩行者9を追跡することも可能である。
ここで、カメラ8aとカメラ8bは、異なる位置から歩行者9を撮影するため、カメラ8a、8bから見た歩行方向の角度θが異なる。そのため、例えば、カメラ8bによるD平面の座標軸がカメラ8aによる座標軸に対してΔθの角度を成すとき、カメラ8bによる歩行方向からΔθを減算して歩行状態を補正するなどして、両カメラ8の歩行方向を揃えて比較する。
なお、歩行段階の位相角φは、両カメラ8に共通である。また、歩行状態を歩行段階から成る2次元ベクトルで定義し、θによらない歩行状態を定義することもできる。
図11と同じステップには、a、bを付して処理対象となるフレーム画像のa、bを区別しながら説明を簡略化する。
まず、CPU2は、フレーム画像aから骨格情報15を抽出して(ステップ60a)、MLP16に入力し(ステップ65a)、MLP16が出力した歩行状態s1を取得してRAM4に記憶する(ステップ70a)。
このように、歩行追跡装置1が有する同定手段は、複数の動画のフレーム画像間で被写体を対応させることにより被写体を同定している。
この場合、カメラ8aによる時間的に隣接するフレーム画像a1、a2で歩行者9を同定し、カメラ8bによる時間的に隣接するフレーム画像b1、b2で歩行者9を同定すると共に、更に、同一時刻のフレーム画像a1、b1間(あるいは、フレーム画像a2、b2間、撮影時刻が近ければフレーム画像a1、b2などの組み合わせも可能)で歩行者9を同定して対応づける。
ここで、2台のカメラ8a、8bで歩行者9を同定する場合について説明したが、3台以上のカメラ8で撮影する場合も同様にして歩行者9の同定を行うことができる。
歩行追跡装置1を自律走行ロボットに搭載する場合、例えば、ホテルで顧客を追尾しながら顧客の荷物を運んだり、イベント会場の入り口で入場者を追跡して検温したり、あるいは、工場で資材を積載した状態で担当者の後についていったり、といった用途に用いることができる。
また、歩行追跡装置1は、未来に向かって歩行者9を追跡するほか、撮影した動画を逆に辿ることにより(即ち、動画を逆に再生して)、歩行者9が歩行してきた経路を過去に向かって追跡することもできる。
これにより、ある店で商品を購入した顧客の歩行経路を過去に向かって追跡し、どのような動線を経て当該店にやってきたかを調べる、といったマーケティング分析に用いることもできる。
例えば、リハビリで歩行訓練している患者の歩行を撮影して歩行状態の時間的推移を計測し、歩行方向や歩行周期のばらつきなどを統計学的手法を用いて解析して訓練の進捗状況を把握する、といった歩行診断装置としての利用方法が考えられる。
このように、歩行追跡装置1は、ニューラルネットワークが出力した歩行状態の時間変化を提示する提示手段を備えている。
更に、スマートフォンなどを用いて患者に自宅で歩行するところを動画撮影してもらい、これを病院に設置した歩行追跡装置1に送信して、病院で歩行状態を解析するといったような、遠隔診断も可能である。
そこで、歩行追跡装置1は、異常歩行検出装置として用いることが可能である。
例えば、ホテルのロビーで異常歩行を検出した場合、顧客が重い荷物を運んでいる場合や気分が悪くなった場合などが考えられ、これを異常歩行検出装置で検出して早期の支援を行うことができる。
あるいは、重い荷物を運んでいる顧客の歩行状態を学習させておき、事務所に設置した異常歩行検出装置でこれを検出した場合は、歩行追跡装置1を搭載した自律走行ロボットが顧客の場所に急行して荷物を受け取り、顧客の歩行を追跡しながら顧客の荷物を搬送する、といった運用も考えられる。
これは、例えば、同じ制服を着用した高校生などの集団が団体旅行している場合に適用できる。
また、同じ外見の集団が同一の歩行状態である場合は行進を行っている、とか、人々の歩行状態が一斉に変化して一方向に急激に移動を始めた場合は、何らかの緊急の事象が起こって人々が避難行動を始めた、などと歩行が行われているシーンを推論することも可能である。
例えば、近年、農業分野や牧畜分野のIT化が急速に進んでおり、牧羊の数理解析モデルの研究に基づく牧羊ロボットの開発が行われている。
これにより、例えば、複数の羊オーナーから集めた羊の群れを牧畜しているところを複数のドローンで撮影し、オーナーごとに個別の羊を追跡して動画配信したり、あるいは、各羊を追跡しながら画像解析することにより食べた牧草の量を羊ごとに推定し、その代金をオーナーに課金する、といった新たなビジネスを生む可能性を秘めている。
これらは一例であって、歩行状態を用いた観察対象の同定は要素的な技術であるため、裾野の広い応用分野を有している。
(1)構成1では、歩行している被写体を撮影した動画を取得する動画取得手段と、前記被写体の周期的な歩行動作に基づく歩行状態を用いて、前記取得した動画を構成するフレーム画像間での前記被写体を同定する同定手段と、前記取得した動画で前記同定した被写体を追跡する追跡手段と、を具備したことを特徴とする歩行追跡装置を提供する。
(2)構成2では、前記同定手段が、前記歩行動作に加えて、前記被写体の歩行する方向を前記歩行状態に含めて前記同定を行うことを特徴とする構成1に記載の歩行追跡装置を提供する。
(3)構成3では、前記同定手段が、前記歩行動作の連続性に基づく歩行状態を用いることを特徴とする構成1、又は構成2に記載の歩行追跡装置を提供する。
(4)構成4では、前記被写体の外見情報を取得する外見情報取得手段を具備し、前記同定手段は、前記歩行状態と、前記取得した外見情報と、を用いて前記被写体を同定することを特徴とする構成1、構成2、又は構成3に記載の歩行追跡装置を提供する。
(5)構成5では、前記被写体の骨格情報を取得する骨格情報取得手段と、各種の歩行状態を骨格情報によって学習したニューラルネットワークと、を具備し、前記同定手段は、前記取得した骨格情報を前記ニューラルネットワークに入力して、当該ニューラルネットワークが出力する歩行状態を取得する、ことを特徴とする構成1から構成4までのうちの何れか1の構成に記載の歩行追跡装置を提供する。
(6)構成6では、前記ニューラルネットワークが、全身の骨格情報の少なくとも一部の領域から構成された学習データを用いて学習した、ことを特徴とする構成5に記載の歩行追跡装置を提供する。
(7)構成7では、前記ニューラルネットワークが、骨格の先端領域から中心領域に向けて骨格情報が欠如するように構成された学習データで学習した、ことを特徴とする構成6に記載の歩行追跡装置を提供する。
(8)構成8では、前記ニューラルネットワークが、骨格の領域ごとに学習した複数の領域ネットワークと、当該領域ネットワークのそれぞれの出力を、骨格情報の欠如に応じて重み付けする重み付けネットワークと、によって前記歩行状態を出力する、ことを特徴とする構成6、又は構成7に記載の歩行追跡装置を提供する。
(9)構成9では、前記動画取得手段が、複数の前記カメラで撮影した前記被写体の複数の動画を取得し、前記同定手段は、前記取得した複数の動画のフレーム画像間で前記被写体を対応させることにより前記被写体を同定する、ことを特徴とする構成1から構成8までのうちの何れか1の構成に記載の歩行追跡装置を提供する。
(10)構成10では、前記ニューラルネットワークが出力した歩行状態の時間変化を提示する提示手段を具備したことを特徴とする構成5から構成9までのうちの何れか1の構成に記載の歩行追跡装置を提供する。
(11)構成11では、歩行している被写体を撮影した動画を取得する動画取得機能と、前記被写体の周期的な歩行動作に基づく歩行状態を用いて、前記取得した動画を構成するフレーム画像間での前記被写体を同定する同定機能と、前記取得した動画で前記同定した被写体を追跡する追跡機能と、をコンピュータで実現する歩行追跡プログラムを提供する。
2 CPU
3 ROM
4 RAM
5 表示部
6 入力部
7 通信制御部
8 カメラ
9 歩行者
10 記憶部
11 通信ネットワーク
15 骨格情報
16 MLP
17 歩行状態空間
31、32、41、42、43 実線
35、36、37 領域
Claims (11)
- 歩行している被写体を撮影した動画のフレーム画像から取得した前記被写体の骨格情報を入力し、当該被写体の歩行状態を出力するニューラルネットワークの学習装置であって、
前記被写体に骨格情報として設定されている複数のジョイントの位置情報が全て揃った完全骨格情報jと、当該完全骨格情報jによる歩行状態sとからなる複数の完全学習データ(j、s)を取得する完全学習データ取得手段と、
前記取得した各完全学習データに対して、その完全骨格情報jから前記被写体の中心線に沿って設定された主要ジョイントを除くジョイントの位置情報を削除した遮蔽骨格情報cjと歩行状態sとからなる複数の遮蔽学習データ(cj、s)を作成する遮蔽学習データ作成手段と、
前記取得した複数の完全学習データ(j、s)と前記作成した複数の遮蔽学習データ(cj、s)を使用して前記ニューラルネットワークの学習を行う学習手段と、
を具備することを特徴とする学習装置。 - 前記歩行状態sは、前記被写体の周期的な歩行動作における歩行段階と、前記被写体の歩行する方向を構成要素としている、
ことを特徴とする請求項1に記載の学習装置。 - 前記遮蔽学習データ作成手段は、鼻、首、及び、腰部中心に設定されたジョイントを前記主要ジョイントとして削除対象から除外する、
ことを特徴とする請求項1、又は請求項2に記載の学習装置。 - 前記遮蔽学習データ作成手段は、前記被写体の右手、左手、右足、左足に対応する少なくとも1つの先端側から前記主要ジョイントに向けて繋がるジョイントを削除対象とする、ことを特徴とする請求項1、請求項2、又は請求項3に記載の学習装置。
- 前記遮蔽学習データ作成手段は、前記被写体に対して設定された全てのジョイントの80%以下のジョイントを削除対象とする、
ことを特徴とする請求項1~請求項4のうちの1の請求項に記載の学習装置。 - 前記遮蔽学習データ作成手段は、前記主要ジョイントに加え、前記主要ジョイントに直結している1次ジョイントの少なくとも2以上を残して削除する、
ことを特徴とする請求項1~請求項4のうちの1の請求項に記載の学習装置。 - 前記遮蔽学習データ作成手段は、全ての完全学習データに対する遮蔽学習データを予め作成し、
前記学習手段は、完全学習データと予め作成した遮蔽学習データを使用して学習を行う、
ことを特徴とする請求項1から請求項6のうちのいずれか1の請求項に記載の学習装置。 - 前記遮蔽学習データ作成手段は、1の完全学習データに対する複数の遮蔽学習データを作成し、当該1の完全学習データと作成した複数の遮蔽学習データによる学習の後に、次の完全学習データに対する遮蔽学習データを作成する、
ことを特徴とする請求項1から請求項6のうちのいずれか1の請求項に記載の学習装置。 - 歩行している被写体を撮影した動画のフレーム画像から取得した前記被写体の骨格情報を入力し、当該被写体の歩行状態を出力するニューラルネットワークにおける学習データの作成方法であって、
前記被写体に骨格情報として設定されている複数のジョイントの位置情報が全て揃った完全骨格情報jと、当該完全骨格情報jによる歩行状態sとからなる複数の完全学習データ(j、s)を取得する完全学習データ取得ステップと、
前記取得した各完全学習データに対して、その完全骨格情報jから前記被写体の中心線に沿って設定された主要ジョイントを除くジョイントの位置情報を削除した遮蔽骨格情報cjと歩行状態sとからなる複数の遮蔽学習データ(cj、s)を作成する遮蔽学習データ作成ステップと、
を具備することを特徴とする学習データの作成方法。 - 歩行している被写体を撮影した動画のフレーム画像から取得した前記被写体の骨格情報を入力し、当該被写体の歩行状態を出力するニューラルネットワークの学習方法であって、
前記被写体に骨格情報として設定されている複数のジョイントの位置情報が全て揃った完全骨格情報jと、当該完全骨格情報jによる歩行状態sとからなる複数の完全学習データ(j、s)を取得する完全学習データ取得ステップと、
前記取得した各完全学習データに対して、その完全骨格情報jから前記被写体の中心線に沿って設定された主要ジョイントを除くジョイントの位置情報を削除した遮蔽骨格情報cjと歩行状態sとからなる複数の遮蔽学習データ(cj、s)を作成する遮蔽学習データ作成ステップと、
前記取得した複数の完全学習データ(j、s)と前記作成した複数の遮蔽学習データ(cj、s)を使用して前記ニューラルネットワークの学習を行う学習ステップと、
を具備することを特徴とする学習方法。 - 歩行している被写体を撮影した動画のフレーム画像から取得した前記被写体の骨格情報を入力し、当該被写体の歩行状態を出力するニューラルネットワークの学習プログラムであって、
前記被写体に骨格情報として設定されている複数のジョイントの位置情報が全て揃った完全骨格情報jと、当該完全骨格情報jによる歩行状態sとからなる複数の完全学習データ(j、s)を取得する完全学習データ取得機能と、
前記取得した各完全学習データに対して、その完全骨格情報jから前記被写体の中心線に沿って設定された主要ジョイントを除くジョイントの位置情報を削除した遮蔽骨格情報cjと歩行状態sとからなる複数の遮蔽学習データ(cj、s)を作成する遮蔽学習データ作成機能と、
前記取得した複数の完全学習データ(j、s)と前記作成した複数の遮蔽学習データ(cj、s)を使用して前記ニューラルネットワークの学習を行う学習機能と、
をコンピュータに実現させることを特徴とする学習プログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020203258A JP7537700B2 (ja) | 2020-12-08 | 2020-12-08 | 学習装置、学習データの作成方法、学習方法、及び学習プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020203258A JP7537700B2 (ja) | 2020-12-08 | 2020-12-08 | 学習装置、学習データの作成方法、学習方法、及び学習プログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022090760A JP2022090760A (ja) | 2022-06-20 |
| JP7537700B2 true JP7537700B2 (ja) | 2024-08-21 |
Family
ID=82060680
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020203258A Active JP7537700B2 (ja) | 2020-12-08 | 2020-12-08 | 学習装置、学習データの作成方法、学習方法、及び学習プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7537700B2 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN117555489B (zh) * | 2024-01-11 | 2024-06-07 | 烟台大学 | 物联网数据存储交易异常检测方法、系统、设备和介质 |
Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104463118A (zh) | 2014-12-04 | 2015-03-25 | 龙岩学院 | 一种基于Kinect的多视角步态识别方法 |
| JP2019012304A (ja) | 2017-06-29 | 2019-01-24 | 株式会社デンソー | 移動物認識装置、移動物認識方法およびプログラム |
| JP2019025134A (ja) | 2017-08-01 | 2019-02-21 | 株式会社大武ルート工業 | 動作推定装置及び動作推定プログラム |
| CN109766868A (zh) | 2019-01-23 | 2019-05-17 | 哈尔滨工业大学 | 一种基于身体关键点检测的真实场景遮挡行人检测网络及其检测方法 |
| JP2020123105A (ja) | 2019-01-30 | 2020-08-13 | セコム株式会社 | 学習装置、学習方法、学習プログラム、及び対象物認識装置 |
-
2020
- 2020-12-08 JP JP2020203258A patent/JP7537700B2/ja active Active
Patent Citations (5)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104463118A (zh) | 2014-12-04 | 2015-03-25 | 龙岩学院 | 一种基于Kinect的多视角步态识别方法 |
| JP2019012304A (ja) | 2017-06-29 | 2019-01-24 | 株式会社デンソー | 移動物認識装置、移動物認識方法およびプログラム |
| JP2019025134A (ja) | 2017-08-01 | 2019-02-21 | 株式会社大武ルート工業 | 動作推定装置及び動作推定プログラム |
| CN109766868A (zh) | 2019-01-23 | 2019-05-17 | 哈尔滨工业大学 | 一种基于身体关键点检测的真实场景遮挡行人检测网络及其检测方法 |
| JP2020123105A (ja) | 2019-01-30 | 2020-08-13 | セコム株式会社 | 学習装置、学習方法、学習プログラム、及び対象物認識装置 |
Non-Patent Citations (1)
| Title |
|---|
| 岩下友美 外1名,人影に着目した個人認証手法の提案と開発,画像ラボ,日本工業出版株式会社 ,2018年03月10日,第29巻 第3号,pp.9~13 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022090760A (ja) | 2022-06-20 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR102933193B1 (ko) | 실세계 환경의 4d 시공간 모델을 생성하기 위한 실시간 시스템 | |
| Yuan et al. | 3d ego-pose estimation via imitation learning | |
| CN113168521B (zh) | 关节体姿态检测系统和方法 | |
| Yoo et al. | Automated markerless analysis of human gait motion for recognition and classification | |
| Hasan et al. | Robust pose-based human fall detection using recurrent neural network | |
| JP7422456B2 (ja) | 画像処理装置、画像処理方法及びプログラム | |
| Ohashi et al. | Synergetic reconstruction from 2D pose and 3D motion for wide-space multi-person video motion capture in the wild | |
| Wang et al. | Multi-sensor fusion federated learning method of human posture recognition for dual-arm nursing robots | |
| CN111079481A (zh) | 一种基于二维骨架信息的攻击性行为识别方法 | |
| Chen et al. | Camera networks for healthcare, teleimmersion, and surveillance | |
| Hori et al. | Silhouette-based 3d human pose estimation using a single wrist-mounted 360 camera | |
| Krzeszowski et al. | Gait recognition based on marker-less 3D motion capture | |
| Seredin et al. | The study of skeleton description reduction in the human fall-detection task | |
| JP7537700B2 (ja) | 学習装置、学習データの作成方法、学習方法、及び学習プログラム | |
| CN113196283A (zh) | 使用射频信号的姿态估计 | |
| Saboune et al. | Markerless human motion capture for gait analysis | |
| Brieva et al. | An intelligent human fall detection system using a vision-based strategy | |
| Liu et al. | Heuristic weakly supervised 3d human pose estimation | |
| Muller et al. | Foothold selection during locomotion in uneven terrain: Results from the integration of eye tracking, motion capture, and photogrammetry | |
| Saboune et al. | Using interval particle filtering for marker less 3D human motion capture | |
| Stone et al. | Silhouette classification using pixel and voxel features for improved elder monitoring in dynamic environments | |
| Bejinariu et al. | Image processing for the rehabilitation assessment of locomotion injuries and post stroke disabilities | |
| JP2022086610A (ja) | 歩行追跡装置、及び歩行追跡プログラム | |
| US20230050992A1 (en) | Multi-view multi-target action recognition | |
| Song et al. | Real-time abnormal behavior recognition for patient monitoring in hospitals |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A711 | Notification of change in applicant |
Free format text: JAPANESE INTERMEDIATE CODE: A712 Effective date: 20210728 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230928 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20230929 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20230929 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A821 Effective date: 20230929 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20231020 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240613 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20240701 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20240730 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7537700 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |