JP7577700B2 - Program, terminal and method for assisting users who cannot speak during online meetings - Google Patents
Program, terminal and method for assisting users who cannot speak during online meetings Download PDFInfo
- Publication number
- JP7577700B2 JP7577700B2 JP2022014504A JP2022014504A JP7577700B2 JP 7577700 B2 JP7577700 B2 JP 7577700B2 JP 2022014504 A JP2022014504 A JP 2022014504A JP 2022014504 A JP2022014504 A JP 2022014504A JP 7577700 B2 JP7577700 B2 JP 7577700B2
- Authority
- JP
- Japan
- Prior art keywords
- chat
- voice data
- text
- speech
- user
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Landscapes
- User Interface Of Digital Computer (AREA)
- Telephonic Communication Services (AREA)
- Two-Way Televisions, Distribution Of Moving Picture Or The Like (AREA)
Description
本発明は、複数のユーザが、端末を用いて参加するオンライン会議システムの技術に関する。 The present invention relates to technology for an online conference system in which multiple users participate using terminals.
スマートフォンやパーソナルコンピュータのような端末を用いて、複数のユーザが同時に会議可能なオンライン会議システムが、広く普及している。端末のディスプレイには、複数のユーザの映像が表示され、端末のスピーカから会議の音声が出力され、端末のマイクからユーザの発話音声が収音される。また、オンライン会議システムには、一般的に、テキストチャットを投稿可能な機能もある。 Online conference systems that allow multiple users to hold conferences simultaneously using terminals such as smartphones and personal computers are now in widespread use. Videos of multiple users are displayed on the terminal's display, the audio of the conference is output from the terminal's speaker, and the users' speech is picked up by the terminal's microphone. Online conference systems also generally have a function that allows users to post text chat.
従来、人と対話する対話システムが自ら発話する際に、円滑なコミュニケーションを図るための技術がある。
例えば、対話システムが、ユーザの発話内容の音響的特徴及び言語的特徴を分析し、発話の終了状態と、発話権限の有無とを判断する技術がある(例えば特許文献1参照)。この技術によれば、対話システムは、ユーザに対して発話する適切なタイミングを検知することができる。
また、対話システムが、自ら発話をする際に呼吸音を発し、自ら発話しようするタイミングを周辺にほのめかすように、発話意思を表現する技術もある(例えば特許文献2参照)。
2. Description of the Related Art Conventionally, there are techniques for achieving smooth communication when a dialogue system that converses with a person speaks by itself.
For example, there is a technique in which a dialogue system analyzes the acoustic and linguistic features of the content of a user's utterance to determine the end state of the utterance and whether or not the user has the authority to speak (see, for example, Patent Document 1). This technique allows the dialogue system to detect the appropriate timing to speak to the user.
There is also a technique in which a dialogue system expresses its intention to speak by making breathing sounds when it speaks, thereby hinting to those around it when it is about to speak (see, for example, Patent Document 2).
オンライン会議システムの場合、会議に参加しているメンバは、自由に発話して議論し合うことができる。但し、メンバの一部には、発話できない環境に居る場合もある。そのメンバは、通常、他のメンバが発話する議論を聞くだけとなってしまう。自らの意見を周知するためには、例えばテキストチャットに投稿しなければならない。 In an online conference system, members participating in the conference can freely speak and discuss. However, some members may be in an environment where they cannot speak. These members usually end up only listening to the discussions that other members are speaking. In order to make their own opinions known, they must post them in a text chat, for example.
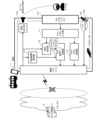
図1は、従来技術におけるオンライン会議システムの概要図である。
図1によれば、オンライン会議の際に、ユーザ@b及び@cは、発話可能な環境に居るが、ユーザ@aは、発話できない環境に居る場合を想定している。ユーザ@aは、例えば電車で移動中であるかもしれない。そのような環境に居るユーザ@aは、オンライン会議の議論を聞くことはできても、自ら発話することは難しい。
FIG. 1 is a schematic diagram of an online conference system in the prior art.
According to Fig. 1, during an online conference, it is assumed that users @b and @c are in an environment where they can speak, but user @a is in an environment where he cannot speak. User @a may be traveling by train, for example. User @a in such an environment can hear the discussion of the online conference, but it is difficult for him to speak himself.
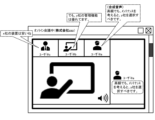
図2は、図1に対するオンライン会議システムの画面図である。
図2によれば、以下のように、オンライン会議中に発話が交換されている。「」は発話された音声データである。
ユーザ@c「x社の装置は、安いね」
ユーザ@b「でも、y社の管理機能は優れています」
ユーザ@a「・・・・・」
このとき、ユーザ@aは、オンライン会議中であっても、テキストチャット欄に、自らの意見を書き込むことはできる。{}は入力されたチャットテキストである。
ユーザ@c{高額でも、メンテナンスを考えると、y社を選択すべきです}
FIG. 2 is a screen diagram of the online conference system shown in FIG.
According to Fig. 2, speech is exchanged during an online conference as follows: "" is spoken voice data.
User @c: "X company's equipment is cheap."
User @b: "But company Y's management functions are excellent."
User @a "..."
At this time, user @a can write his/her own opinion in the text chat field even during the online conference. {} is the entered chat text.
User @c {Even though it is expensive, considering the maintenance, we should choose company y.}
しかしながら、オンライン会議中であっても、全ての参加者がテキストチャット欄に常に注目しておらず、気付いてもらえないだけでなく、直ぐに話題が変わった場合には完全にタイミングを逸してしまうこととなる。 However, even during online meetings, not all participants are always paying attention to the text chat, so not only will your message go unnoticed, but if the topic quickly changes, you will miss the timing entirely.
これに対し、本願の発明者らは、オンライン会議中に発話できないユーザを補助することができないか、と考えた。特に、発話できない環境に居るユーザの意見を、できる限り適切なタイミングで、メンバ全員に周知することができないか、と考えた。 In response to this, the inventors of this application wondered if it would be possible to assist users who are unable to speak during online meetings. In particular, they wondered if it would be possible to communicate the opinions of users who are in an environment where they cannot speak to all members as timely as possible.
そこで、本発明は、オンライン会議中に発話できないユーザを補助することができるプログラム、端末及び方法を提供することを目的とする。 The present invention aims to provide a program, terminal, and method that can assist users who cannot speak during online conferences.
本発明によれば、オンライン会議サーバを介して、リアルタイムに音声データを交換する端末に搭載されたコンピュータを機能させるプログラムであって、
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と
してコンピュータを機能させ、
チャットテキスト入力手段に対してユーザがチャットテキストの入力中に、所定タイミングとなった際に、
チャット音声データ送信手段は、既に入力されたチャットテキストのみについて音声合成されたチャット音声データを、オンライン会議サーバへ送信すると共に、
音声合成手段は、後に続いて入力されるであろうテキストチャットを考慮して、音声合成の発話テンポが遅くなるように制御する
ようにコンピュータを機能させることを特徴とする。
また、本発明によれば、オンライン会議サーバを介して、リアルタイムに音声データを交換する端末に搭載されたコンピュータを機能させるプログラムであって、
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と、
オンライン会議サーバから受信した会議の発話音声データを、発話音声テキストに変換する音声認識手段と、
発話音声テキストとチャットテキストとの会話内容の一致度として、出現単語列の類似度を算出する類似度算出手段と、
チャット音声データ送信手段がチャット音声データを送信する前に、類似度に応じて異なるフィラー音声データを送信するフィラー音声データ送信手段と
してコンピュータを機能させ
フィラー音声データ送信手段は、
類似度が所定閾値以上となる真と判定した際に、現在の話題に沿った発言を希望するフィラーワードに基づく第1のフィラー音声データを送信し、
偽と判定した際に、先の話題に戻った発言を希望するフィラーワードに基づく第2のフィラー音声データを送信する
ようにコンピュータを更に機能させることを特徴とする。
According to the present invention, there is provided a program for causing a computer installed in a terminal that exchanges voice data in real time via an online conference server to function, the program comprising:
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
causing the computer to function as chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing ;
When a predetermined timing occurs while the user is inputting chat text to the chat text input means,
The chat voice data transmission means transmits chat voice data generated by voice synthesis only for the chat text that has already been input to the online conference server, and
The speech synthesis means controls the speech synthesis speech tempo to be slowed down in consideration of the text chat that will be input subsequently.
The present invention is characterized in that the computer is made to function in such a manner .
According to the present invention, there is also provided a program for causing a computer installed in a terminal that exchanges voice data in real time via an online conference server to function, the program comprising:
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
a chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing;
A speech recognition means for converting conference speech data received from an online conference server into speech text;
a similarity calculation means for calculating a similarity between appearing word strings as a degree of agreement between the contents of the conversation between the spoken voice text and the chat text;
a filler voice data transmitting means for transmitting different filler voice data according to the similarity before the chat voice data transmitting means transmits the chat voice data;
to make the computer function
The filler audio data transmitting means includes:
When the similarity is determined to be equal to or greater than a predetermined threshold, a first filler voice data based on a filler word that is desired to be spoken in accordance with the current topic is transmitted;
When the answer is false, a second filler voice data based on a filler word indicating a desire to return to the previous topic is transmitted.
The present invention is characterized in that the computer further functions as follows.
本発明のプログラムにおける他の実施形態によれば、
オンライン会議サーバから受信した会議の発話音声データが、所定時間以上受信されていない会話間隙を検知する会話間隙検知手段を更に有し、
チャット音声データ送信手段は、所定タイミングとして会話間隙が検知された際に、チャット音声データを、オンライン会議サーバへ送信する
ようにコンピュータを機能させることも好ましい。
According to another embodiment of the program of the present invention,
The method further comprises: detecting a conversation gap during which the speech voice data of the conference received from the online conference server is not received for a predetermined period of time or longer;
It is also preferable that the chat voice data transmitting means causes the computer to function so as to transmit the chat voice data to the online conference server when a conversation gap is detected as the predetermined timing.
本発明のプログラムにおける他の実施形態によれば、
端末は、ユーザの発話音声データの収音を、ユーザの操作によってオン/オフするマイクを更に搭載しており、
マイクがオフになっている際に、音声合成手段及びチャット音声データ送信手段が機能する
ようにコンピュータを機能させることも好ましい。
According to another embodiment of the program of the present invention,
The terminal further includes a microphone that can be turned on/off by a user's operation to collect the user's speech data;
It is also preferable to make the computer function so that the voice synthesis means and the chat voice data transmission means function when the microphone is turned off.
本発明のプログラムにおける他の実施形態によれば、
当該端末に、移動検知センサを更に搭載しており、
移動検知センサによって移動中と判定された際に、音声合成手段及びチャット音声データ送信手段が機能する
ようにコンピュータを更に機能させることも好ましい。
According to another embodiment of the program of the present invention,
The terminal is further equipped with a motion detection sensor,
It is also preferable that the computer further functions so that, when it is determined by the movement detection sensor that the user is moving, the voice synthesis means and the chat voice data transmission means function.
本発明のプログラムにおける他の実施形態によれば、
オンライン会議サーバから受信した会議の発話音声データを、発話音声テキストに変換する音声認識手段と、
発話音声テキストに、当該端末のユーザに対する発言を求める所定キーワードが含まれているか否かを判定する発言要請判定手段と
してコンピュータを更に機能させることも好ましい。
According to another embodiment of the program of the present invention,
A speech recognition means for converting conference speech data received from an online conference server into speech text;
It is also preferable that the computer further functions as a statement request determination means for determining whether or not the spoken voice text contains a predetermined keyword that requests a statement from the user of the terminal.
本発明によれば、オンライン会議サーバを介して、リアルタイムに音声データを交換する端末であって、
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と
を有し、
チャットテキスト入力手段に対してユーザがチャットテキストの入力中に、所定タイミングとなった際に、
チャット音声データ送信手段は、既に入力されたチャットテキストのみについて音声合成されたチャット音声データを、オンライン会議サーバへ送信すると共に、
音声合成手段は、後に続いて入力されるであろうテキストチャットを考慮して、音声合成の発話テンポが遅くなるように制御する
ことを特徴とする。
また、本発明によれば、オンライン会議サーバを介して、リアルタイムに音声データを交換する端末であって、
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と、
オンライン会議サーバから受信した会議の発話音声データを、発話音声テキストに変換する音声認識手段と、
発話音声テキストとチャットテキストとの会話内容の一致度として、出現単語列の類似度を算出する類似度算出手段と、
チャット音声データ送信手段がチャット音声データを送信する前に、類似度に応じて異なるフィラー音声データを送信するフィラー音声データ送信手段と
を有し、
フィラー音声データ送信手段は、
類似度が所定閾値以上となる真と判定した際に、現在の話題に沿った発言を希望するフィラーワードに基づく第1のフィラー音声データを送信し、
偽と判定した際に、先の話題に戻った発言を希望するフィラーワードに基づく第2のフィラー音声データを送信する
ことを特徴とする。
According to the present invention, there is provided a terminal for exchanging voice data in real time via an online conference server, comprising:
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
a chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing ;
When a predetermined timing occurs while the user is inputting chat text to the chat text input means,
The chat voice data transmission means transmits chat voice data generated by voice synthesis only for the chat text that has already been input to the online conference server, and
The speech synthesis means controls the speech synthesis speech tempo to be slowed down in consideration of the text chat that will be input subsequently.
It is characterized by:
According to the present invention, there is also provided a terminal for exchanging voice data in real time via an online conference server, comprising:
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
a chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing;
A speech recognition means for converting conference speech data received from an online conference server into speech text;
a similarity calculation means for calculating a similarity between appearing word strings as a degree of agreement between the contents of the conversation between the spoken voice text and the chat text;
a filler voice data transmitting means for transmitting different filler voice data according to the similarity before the chat voice data transmitting means transmits the chat voice data;
having
The filler audio data transmitting means includes:
When the similarity is determined to be equal to or greater than a predetermined threshold, a first filler voice data based on a filler word that is desired to be spoken in accordance with the current topic is transmitted;
When the answer is false, a second filler voice data based on a filler word indicating a desire to return to the previous topic is transmitted.
It is characterized by:
本発明によれば、オンライン会議サーバを介して、リアルタイムに音声データを交換する端末のチャット音声データ送信方法であって、
端末は、
ユーザの操作によって、チャットテキストの入力を受け付ける第1のステップと、
チャットテキストを、チャット音声データに音声合成する第2のステップと、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信する第3のステップと
を実行し、
第1のステップについて、ユーザがチャットテキストの入力中に、所定タイミングとなった際に、
第3のステップについて、既に入力されたチャットテキストのみについて音声合成されたチャット音声データを、オンライン会議サーバへ送信すると共に、
第2のステップについて、後に続いて入力されるであろうテキストチャットを考慮して、音声合成の発話テンポが遅くなるように制御する
ことを特徴とする。
また、本発明によれば、オンライン会議サーバを介して、リアルタイムに音声データを交換する端末のチャット音声データ送信方法であって、
端末は、
ユーザの操作によって、チャットテキストの入力を受け付ける第1のステップと、
チャットテキストを、チャット音声データに音声合成する第2のステップと、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信する第3のステップと、
オンライン会議サーバから受信した会議の発話音声データを、発話音声テキストに変換する第4のステップと、
発話音声テキストとチャットテキストとの会話内容の一致度として、出現単語列の類似度を算出する第5のステップと、
第3のステップについてチャット音声データを送信する前に、類似度に応じて異なるフィラー音声データを送信する第6のステップと
を実行し、
第6のステップについて、
類似度が所定閾値以上となる真と判定した際に、現在の話題に沿った発言を希望するフィラーワードに基づく第1のフィラー音声データを送信し、
偽と判定した際に、先の話題に戻った発言を希望するフィラーワードに基づく第2のフィラー音声データを送信する
ことを特徴とする。
According to the present invention, there is provided a chat voice data transmission method for terminals exchanging voice data in real time via an online conference server, comprising the steps of:
The terminal is
A first step of accepting input of chat text by a user operation;
a second step of synthesizing the chat text into chat voice data;
and a third step of transmitting chat voice data to an online conference server at a predetermined timing .
In the first step, when a predetermined timing occurs while the user is inputting chat text,
In the third step, chat voice data generated by voice synthesis only for the chat text already input is transmitted to the online conference server,
In the second step, the speech synthesis tempo is controlled to be slower, taking into account the text chat that will follow.
It is characterized by:
According to the present invention, there is also provided a chat voice data transmission method for terminals exchanging voice data in real time via an online conference server, comprising the steps of:
The terminal is
A first step of accepting input of chat text by a user operation;
a second step of synthesizing the chat text into chat voice data;
a third step of transmitting chat voice data to an online conference server at a predetermined timing;
A fourth step of converting the conference speech voice data received from the online conference server into speech voice text;
a fifth step of calculating a similarity between appearing word strings as a degree of agreement between the conversation contents of the spoken voice text and the chat text;
A sixth step of transmitting different filler voice data according to the similarity before transmitting the chat voice data for the third step;
Run
Regarding the sixth step,
When the similarity is determined to be equal to or greater than a predetermined threshold, a first filler voice data based on a filler word that is desired to be spoken in accordance with the current topic is transmitted;
When the answer is false, a second filler voice data based on a filler word indicating a desire to return to the previous topic is transmitted.
It is characterized by:
本発明のプログラム、端末及び方法によれば、オンライン会議中に発話できないユーザを補助することができる。 The program, terminal, and method of the present invention can assist users who cannot speak during online conferences.
以下、本発明の実施の形態について、図面を用いて詳細に説明する。 The following describes in detail the embodiments of the present invention with reference to the drawings.
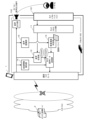
図3は、本発明における端末の第1の機能構成図である。
図4は、本発明におけるオンライン会議システムの画面図である。
FIG. 3 is a first functional configuration diagram of a terminal according to the present invention.
FIG. 4 is a diagram showing a screen of the online conference system according to the present invention.
図3によれば、端末1は、オンライン会議の参加メンバとなるユーザによって操作される。端末1には、オンライン会議システムのアプリケーションが予めインストールされている。端末1のアプリケーションは、オンライン会議のユーザインタフェースとして機能すると共に、オンライン会議サーバ2と通信し、会議の他のメンバとの間でリアルタイムに音声データを交換する。
As shown in FIG. 3,
端末1は、ユーザインタフェースとして、タッチパネルディスプレイ101と、音声出力部(スピーカや音声出力端子)102と、マイク103とを有する。
タッチパネルディスプレイ101は、アプリケーションによって、オンライン会議の参加メンバの映像を表示すると共に、ユーザ自ら入力可能なチャットテキストの入力インタフェースも表示する(例えば図4参照)。
音声出力部102は、アプリケーションによって、オンライン会議の参加メンバ同士で発話される音声データを、音声信号としてユーザに出力する。例えば図1のように、ユーザが電車内で移動中であるような、発話することができない環境では、ユーザは、イヤフォンを用いて、オンライン会議のメンバ同士の議論を聞くことができる。勿論、ユーザが発話可能な環境に居る際には、スピーカからオンライン会議の音声を聞くこともできる。
マイク103は、端末1を操作するユーザ自ら発話した音声データを収音する。ここで、マイク103は、ユーザによってオン/オフに操作することができる。例えばユーザが発話することができない環境では、マイク103はオフにされる。
The
The
The
The
図3によれば、端末1は、チャットテキスト入力部11と、音声合成部12と、チャット音声データ送信部13と、会話間隙検知部14と、チャットテキスト送信部15とを有する。これら機能構成部は、端末に搭載されたコンピュータを機能させるプログラムを実行することによって実現される。また、これら機能構成部の処理の流れは、端末の音声データ送信方法としても理解できる。
As shown in FIG. 3, the
[チャットテキスト入力部11]
チャットテキスト入力部11は、ユーザの操作によって、チャットテキストの入力を受け付ける。図4によれば、右欄に、ユーザ自ら、チャットテキストを入力することができる。入力されたチャットテキストは、音声合成部12へ出力される。
[Chat text input unit 11]
The chat
[音声合成部12]
音声合成部12は、チャットテキストを、チャット音声データに音声合成する。これは、例えばText to Speechと称される既存技術であって、テキストをリアルな音声に変換する。特に、声の品質を、人間が話しているような自然に聞こえる音声に変換する。このとき、ユーザ@aの声の特徴(男性/女性や高音/低音など)に近い合成音声を生成することが好ましい。音声合成されたチャット音声データは、チャット音声データ送信部13へ出力される。
[Speech synthesis unit 12]
The
[チャット音声データ送信部13]
チャット音声データ送信部13は、所定タイミングで、チャット音声データを、オンライン会議サーバ2へ送信する。ここで、「所定タイミング」とは、従来技術として前述した特許文献1及び2のような技術を用いて、自ら発話する適切なタイミングを図ったものであってもよい。
[Chat voice data transmission unit 13]
The chat voice
図4におけるオンライン会議の表示画面によれば、右欄にユーザ@aが入力したチャットテキストが表示されると共に、所定タイミングで、ユーザ@aに似せた合成音声が発話される。オンライン会議の中で発話された合成音声は、他のメンバからみて、ユーザ@aが発話したように聞き取ることができる。 According to the display screen of the online conference in FIG. 4, chat text entered by user @a is displayed in the right column, and a synthetic voice that sounds like user @a is spoken at a specified timing. The synthetic voice spoken during the online conference can be heard by other members as if it were spoken by user @a.
尚、図3によれば、マイクがオフになっている際にのみ、音声合成部12及びチャット音声データ送信部13が機能することが好ましい。マイクがオフになっているということは、ユーザ@aは、オンライン会議に参加しているにも拘わらず、発話できないような環境に居ると判断することができる。
Note that, according to FIG. 3, it is preferable that the
[会話間隙検知部14]
会話間隙検知部14は、オンライン会議サーバ2から受信した会議の発話音声データが、所定時間以上受信されていない「会話間隙」を検知する。即ち、会議の中で、複数のメンバの議論が一瞬途絶えた時(切れ目)を検知する。その時、ユーザの発話に適したタイミングとする。そのタイミングを、所定タイミングとして、チャット音声データ送信部13へ通知する。
これによって、チャット音声データ送信部13は、所定タイミングとして会話間隙が検知された際に、チャット音声データを、オンライン会議サーバ2へ送信する。
[Conversation Gap Detection Unit 14]
The conversation
Thereby, the chat voice
[チャットテキスト送信部15]
チャットテキスト送信部15は、チャットテキストを、オンライン会議サーバ2へ送信する。チャットテキスト送信部15は、マイクがオフのときのみ機能するものであってもよいし、マイクがオンでもオフでも通常どおり機能するものであってもよい。
[Chat text transmission unit 15]
The chat
図3における他の実施形態として、ユーザが、チャットテキストの入力中に、所定タイミングとなる場合もある。そのような場合、チャット音声データ送信部13は、既に入力されたチャットテキストのみについて音声合成されたチャット音声データを、オンライン会議サーバ2へ送信するものであってもよい。チャットテキストの入力中か否かの判定は、文字入力インタフェースが起動しているか否かによって判断することもできる。例えばチャットテキストの入力画面がトップにある際に、文字入力インタフェースも起動している場合である。
As another embodiment of FIG. 3, the predetermined timing may occur while the user is inputting chat text. In such a case, the chat voice
図4によれば、例えば以下のように、オンライン会議中に発話させることができる。「」は発話された音声データであり、{}は入力されたチャットテキストである。
ユーザ@c「x社の装置は、安いね」
ユーザ@b「でも、y社の管理機能は優れています」
ユーザ@a{高額でも、メンテナンスを考えると、}・・・
<会話間隙の検知>
ユーザ@a「高額でも、メンテナンスを考えると、」・・・
このように、例えば会話間隙時(所定タイミング)に、素早く、ユーザがチャットテキストで入力した意見を、会議で発話することができる。
4, for example, the following can be spoken during an online conference: "" is spoken voice data, and { } is input chat text.
User @c: "X company's equipment is cheap."
User @b: "But company Y's management functions are excellent."
User @a {Even though it's expensive, considering the maintenance}...
Conversation Gaps Detection
User @a: "Even though it's expensive, when you consider the maintenance..."
In this way, for example, during a gap in conversation (predetermined timing), the user can quickly speak out the opinion that he or she inputted in the chat text during the conference.
このとき、音声合成部12は、後に続いて入力されるであろうテキストチャットを考慮して、音声合成の発話テンポが遅くなるように制御することも好ましい。
ユーザ@a{高額でも、メンテナンスを考えると、}
<会話間隙の検知>
ユーザ@a「高額でも、メンテナンスを考えると、」
ユーザ@a{y社を選択}
ユーザ@a「y・・社・・を・・選・・択・・」※発話テンポが遅い
ユーザ@a{すべきです}
ユーザ@a「すべきです」
このように、例えば音声合成の発話テンポを遅くすることによって、ユーザのチャットテキストの遅さを、アシストすることができる。即ち、発話の間合いが延びても、ユーザがチャットテキストで入力中の意見を、できる限り会議で発話することができる。例えば、音声合成部12は、入力されたチャットテキストを一時的にバッファして、合成音声に変換するものであるが、このバッファの空き容量を検出するものであってもよい。バッファが空に近いほど、ユーザのチャットテキストの入力が遅れているために、発話テンポが遅くなるように音声合成を実行する。
At this time, it is also preferable that the
User @a {Even though it's expensive, considering the maintenance,}
Conversation Gaps Detection
User @a: "It may be expensive, but considering the maintenance..."
User@a{select company y}
User @a: "Choose company Y..." *Slow speech tempo User @a {Should}
User @a: "Yes, you should."
In this way, for example, by slowing down the speech tempo of the voice synthesis, it is possible to assist in the slowness of the user's chat text. In other words, even if the pauses in speech are extended, the user can speak the opinions he is inputting in the chat text as much as possible in the conference. For example, the
図5は、本発明における端末の第2の機能構成図である。 Figure 5 is a diagram showing the second functional configuration of a terminal according to the present invention.
図5によれば、図3と比較して、端末1に、移動検知センサ104が更に搭載されている。移動検知センサ104は、加速度センサであってもよいし、GPS(Global Positioning System)のような測位センサであってもよい。これによって、ユーザが会議で発話することができない環境に居ると判定する。
音声合成部12及びチャット音声データ送信部13は、移動検知センサ104によって移動中と判定された際に機能する。
5, compared to FIG. 3, the
The
図6は、本発明における端末の第3の機能構成図である。 Figure 6 is a diagram showing the third functional configuration of a terminal according to the present invention.
図6によれば、図3と比較して、音声認識部16と、類似度算出部17と、フィラー音声データ送信部18とを更に有する。
As compared to FIG. 3, FIG. 6 further includes a
[音声認識部16]
音声認識部16は、オンライン会議サーバ2から受信した会議の発話音声データを、発話音声テキストに変換する。変換された発話音声テキストは、類似度算出部17へ出力される。
[Speech recognition unit 16]
The
[類似度算出部17]
類似度算出部17は、発話音声テキスト(会議の中で他のメンバが発話したテキスト)と、チャットテキスト(発話できない環境に居るユーザが入力したテキスト)との会話内容の一致度として、出現単語列の類似度を算出する。
これは、一般的な言語処理の技術であって、テキストを形態素解析によって複数の単語に分解した上で、それぞれのテキストをベクトル化する。そして、それらの間の類似度が所定閾値以上であるか否かを判定する。
[Similarity calculation unit 17]
The
This is a common language processing technique that breaks down text into multiple words using morphological analysis, and then converts each text into a vector. If the similarity between the words is equal to or greater than a certain threshold, It is determined whether or not
例えば各個性語をWord2vec(登録商標)によってベクトル化することができる。「Word2vec」とは、単語の意味や文法を捉えるために単語をベクトル表現化して次元を圧縮する技術をいう。また、Bag of Wordsを用いて、文に含まれる各単語の出現頻度のみをベクトルとして表現したものであってもよい。勿論、個性語同士の一致率ではなく、テキスト全体(個性語群)同士の類似度によって比較することが好ましい。 For example, each unique word can be vectorized using Word2vec (registered trademark). "Word2vec" refers to a technology that compresses the dimension by expressing words as vectors in order to capture the meaning and grammar of the words. Alternatively, a bag of words may be used to express only the frequency of occurrence of each word contained in a sentence as a vector. Of course, it is preferable to compare the similarity between the entire text (groups of unique words) rather than the match rate between unique words.
Word2vecやBag of Wordsに限ることなく、各単語の品詞又は意味を解析した特徴ベクトルに変換することができればよい。尚、発話音声テキストについては、例えばTextTilingによって、話題のセグメンテーションをし、分割されたテキストをベクトル化するものであってもよい。
S(a,b)=cosθ=(Va・Vb)/(|Va||Vb|)
S(a,b):コサイン類似度
Va:会議の他のメンバによる発話音声テキスト
Vb:ユーザが入力したチャットテキスト
コサイン類似度S(a,b)は、0~1の値となり、類似性が高いほど1に近づく。
It is not limited to Word2vec or Bag of Words, but may be converted into a feature vector obtained by analyzing the part of speech or meaning of each word. For spoken voice text, topic segmentation may be performed by, for example, TextTiling, and the segmented text may be vectorized.
S(a,b)=cosθ=(Va・Vb)/(|Va||Vb|)
S(a,b): Cosine similarity
Va: Text of speech by other members of the meeting
Vb: Chat text entered by the user. The cosine similarity S(a, b) is a value between 0 and 1, and the closer to 1 the similarity is, the higher it is.
[フィラー音声データ送信部18]
フィラー音声データ送信部18は、チャット音声データ送信部13がチャット音声データを送信する前に、類似度に応じて異なるフィラー音声データを送信する。
ここで、「フィラー(filler)」とは、「埋めるもの、詰めもの」という意味であって、言語の分野では、会話の合間に半ば無意識に挟み込まれる「えーと」「あー」「うーん」といった言葉や言い回しをいう。本発明におけるフィラーとしては、会議で自ら発言する前に、発話するような言葉となる。
[Filler audio data transmission unit 18]
A filler voice data transmitting unit transmits different filler voice data according to the degree of similarity before the chat voice data transmitting unit transmits the chat voice data.
Here, "filler" means something that fills in or fills something up, and in the field of language, it refers to words and phrases such as "um,""ah," and "hmm" that are inserted semi-unconsciously between gaps in a conversation. In the present invention, fillers are words that are spoken before speaking in a meeting.
フィラー音声データ送信部18は、類似度が所定閾値以上となる(真)か否か(偽)の判定に応じて、以下のようにフィラーを使い分ける。
真:類似度が所定閾値以上であるということは、会議中の他のメンバの発話音声テキストと、ユーザが入力したチャットテキストとの話題が同じであることを意味する。その場合、現在の話題に沿った発言を希望するフィラーワードに基づく第1のフィラー音声データを送信する。例えば「発言してもよろしいでしょうか」「ちょっといいですか」・・・などがある。
偽:類似度が所定閾値以上でないということは、会議中の他のメンバの発話音声テキストよりも、ユーザが入力したチャットテキストとの話題が遅れていることを意味する。その場合、先の話題に戻った発言を希望するフィラーワードに基づく第2のフィラー音声データを送信する。例えば「先ほどの件で発言してもよろしいでしょうか」「戻ってしまうのですが」・・・などがある。
The filler audio
True: The similarity is equal to or greater than a predetermined threshold, which means that the topic of the speech text of other members in the conference is the same as the chat text entered by the user. In this case, the first filler speech data is sent based on a filler word that is desired to be spoken along with the current topic. For example, "May I make a comment?", "Can I just say something?", etc.
False: If the similarity is not equal to or greater than the predetermined threshold, it means that the topic of the chat text entered by the user is behind the speech text of other members in the conference. In this case, a second filler voice data based on a filler word that indicates a desire to return to the previous topic is sent. For example, "May I make a comment about the previous matter?", "I'm going back," etc.
勿論、フィラー音声データを送信しているにも拘わらず、ユーザのチャットテキストの入力が完了していない場合、ユーザのテキスト入力画面に、一旦、入力完了を促すことも好ましい。これによって、ユーザの意見をできる限り素早く、会議の中で発話させることができる。 Of course, if the user has not finished inputting chat text even though filler audio data has been sent, it is preferable to prompt the user to complete input on the text input screen. This allows the user to speak their opinion in the conference as quickly as possible.
図7は、本発明におけるフィラー音声データの送信を表す説明図である。 Figure 7 is an explanatory diagram showing the transmission of filler audio data in the present invention.
図7(a)によれば、例えば以下のように、フィラー音声データが送信される。「」は発話された音声データであり、{}は入力されたチャットテキストである。
ユーザ@c「高額でも、メンテナンスを考えると、」
ユーザ@b「y社の管理機能は優れています」
ユーザ@a{高額でも、メンテナンスを考えると、y社を選択すべきです}
※会議中の他のメンバの発話音声テキストと、ユーザ@aのチャットテキストとは、類似度が高い(所定閾値以上)と判定する。
ユーザ@a(フィラー音声データ)
「発言してもよろしいでしょうか」
ユーザ@a「高額でも、メンテナンスを考えると、y社を選択すべきです」
According to Fig. 7(a), filler voice data is transmitted, for example, as follows: "" is spoken voice data, and { } is input chat text.
User @c: "It's expensive, but considering the maintenance..."
User @b: "Company Y's management functions are excellent."
User @a {Even though it is expensive, considering the maintenance, we should choose company y.}
*The speech text of other members in the conference and the chat text of user @a are determined to have a high degree of similarity (above a predetermined threshold).
User @a (filler audio data)
"May I speak?"
User @a: "Even though it's expensive, if you consider the maintenance, you should choose company Y."
図7(b)によれば、例えば以下のように、フィラー音声データが送信される。
ユーザ@c「高額でも、メンテナンスを考えると、」
ユーザ@b「y社の管理機能は優れています」
ユーザ@c「そう言えば、w社の件はどうなってる?」
ユーザ@b「w社には連絡済みです」
ユーザ@a{高額でも、メンテナンスを考えると、y社を選択すべきです}
※会議中の他のメンバの発話音声テキストと、ユーザ@aのチャットテキストとは、類似度が低い(所定閾値未満)と判定する。
ユーザ@a(フィラー音声データ)
「先ほどの件で発言してもよろしいでしょうか」
ユーザ@a「高額でも、メンテナンスを考えると、y社を選択すべきです」
According to FIG. 7B, for example, filler audio data is transmitted as follows:
User @c: "It's expensive, but considering the maintenance..."
User @b: "Company Y's management functions are excellent."
User @c: "By the way, how's the situation with Company W going?"
User @b: "I've already contacted W company."
User @a {Even though it is expensive, considering the maintenance, we should choose company y.}
*The speech text of other members in the conference and the chat text of user @a are determined to have a low similarity (less than a predetermined threshold).
User @a (filler audio data)
"May I speak about what we discussed earlier?"
User @a: "Even though it's expensive, if you consider the maintenance, you should choose company Y."
図8は、本発明における端末の第4の機能構成図である。 Figure 8 is a fourth functional configuration diagram of a terminal according to the present invention.
図8によれば、図3と比較して、音声認識部16と、発言要請判定部19とを更に有する。音声認識部16は、前述したものと同様のものである。
As compared to FIG. 3, FIG. 8 further includes a
[発言要請判定部19]
発言要請判定部19は、発話音声テキストに、当該端末のユーザに対する発言を求める所定キーワードが含まれているか否かを判定する。所定キーワードは、ユーザ毎に予め登録されたものであってもよい。
[Speech request determination unit 19]
The speech
図9は、本発明における発言要請の検出を表す説明図である。 Figure 9 is an explanatory diagram showing the detection of a request to speak in the present invention.
図9によれば、発言要請判定部19に、例えばユーザの名前[a]が登録されたものである。例えば、以下のように、発話音声テキストが検出されたとする。「」は発話された音声データであり、{}は入力されたチャットテキストである。
ユーザ@c「x社の装置は、安いね」
ユーザ@b「でも、y社の管理機能は優れています」
ユーザ@a{高額でも、メンテナンスを考えると、y社を選択すべきです}
ユーザ@c「a君はどう思う?」
このとき、発言要請判定部19は、[a]を検出し、会議でユーザ@aに発言要請があったと判定する。そして、発言要請判定部19は、チャット音声データ送信部13へ、チャット音声データを送信するように指示する。
そうすると、以下のような、合成音声のチャット音声データが、会議で発話される。
ユーザ@c「高額でも、メンテナンスを考えると、y社を選択すべきです」
9, for example, a user's name [a] is registered in the speech
User @c: "X company's equipment is cheap."
User @b: "But company Y's management functions are excellent."
User @a {Even though it is expensive, considering the maintenance, we should choose company y.}
User @c: "What do you think, A?"
At this time, the speech
Then, chat voice data in the form of synthetic voice like the following will be spoken in the conference.
User @c: "Even though it's expensive, if you consider the maintenance, you should choose company y."
以上、詳細に説明したように、本発明のプログラム、端末及び方法によれば、オンライン会議中に発話できないユーザを補助することができる。特に、発話できない環境に居るユーザの意見を、できる限り適切なタイミングで、メンバ全員に周知することができる。 As described above in detail, the program, terminal, and method of the present invention can assist users who are unable to speak during an online conference. In particular, the opinions of users who are in an environment where they cannot speak can be communicated to all members at the most appropriate time possible.
尚、これにより、例えば「ユーザの滞在場所に関係無く、オンライン会議を提供することができる」ことから、国連が主導する持続可能な開発目標(SDGs)の目標8「すべての人々のための包摂的かつ持続可能な経済成長、雇用およびディーセント・ワークを推進する」に貢献することが可能となる。 As a result, for example, it will be possible to "provide online meetings regardless of the user's location," which will contribute to Goal 8 of the United Nations' Sustainable Development Goals (SDGs), which is to "promote inclusive and sustainable economic growth, employment and decent work for all."
前述した本発明の種々の実施形態について、本発明の技術思想及び見地の範囲の種々の変更、修正及び省略は、当業者によれば容易に行うことができる。前述の説明はあくまで例であって、何ら制約しようとするものではない。本発明は、特許請求の範囲及びその均等物として限定するものにのみ制約される。 With respect to the various embodiments of the present invention described above, various changes, modifications, and omissions within the scope of the technical ideas and viewpoints of the present invention can be easily made by a person skilled in the art. The above description is merely an example and is not intended to be restrictive in any way. The present invention is limited only by the scope of the claims and their equivalents.
1 端末
101 タッチパネルディスプレイ
102 音声出力部
103 マイク
104 移動検知センサ
11 チャットテキスト入力部
12 音声合成部
13 チャット音声データ送信部
14 会話間隙検知部
15 チャットテキスト送信部
16 音声認識部
17 類似度算出部
18 フィラー音声データ送信部
19 発言要請判定部
2 オンライン会議サーバ
REFERENCE SIGNS
Claims (10)
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と
してコンピュータを機能させ、
チャットテキスト入力手段に対してユーザがチャットテキストの入力中に、所定タイミングとなった際に、
チャット音声データ送信手段は、既に入力されたチャットテキストのみについて音声合成されたチャット音声データを、オンライン会議サーバへ送信すると共に、
音声合成手段は、後に続いて入力されるであろうテキストチャットを考慮して、音声合成の発話テンポが遅くなるように制御する
ようにコンピュータを機能させることを特徴とするプログラム。 A program for causing a computer installed in a terminal that exchanges voice data in real time via an online conference server to function,
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
causing the computer to function as chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing ;
When a predetermined timing occurs while the user is inputting chat text to the chat text input means,
The chat voice data transmission means transmits chat voice data generated by voice synthesis only for the chat text that has already been input to the online conference server, and
The speech synthesis means controls the speech synthesis speech tempo to be slowed down in consideration of the text chat that will be input subsequently.
A program that causes a computer to function in such a manner .
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と、
オンライン会議サーバから受信した会議の発話音声データを、発話音声テキストに変換する音声認識手段と、
発話音声テキストとチャットテキストとの会話内容の一致度として、出現単語列の類似度を算出する類似度算出手段と、
チャット音声データ送信手段がチャット音声データを送信する前に、類似度に応じて異なるフィラー音声データを送信するフィラー音声データ送信手段と
してコンピュータを機能させ
フィラー音声データ送信手段は、
類似度が所定閾値以上となる真と判定した際に、現在の話題に沿った発言を希望するフィラーワードに基づく第1のフィラー音声データを送信し、
偽と判定した際に、先の話題に戻った発言を希望するフィラーワードに基づく第2のフィラー音声データを送信する
ようにコンピュータを更に機能させることを特徴とするプログラム。 A program for causing a computer installed in a terminal that exchanges voice data in real time via an online conference server to function,
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
a chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing;
A speech recognition means for converting conference speech data received from an online conference server into speech text;
a similarity calculation means for calculating a similarity between appearing word strings as a degree of agreement between the contents of the conversation between the spoken voice text and the chat text;
a filler voice data transmitting means for transmitting different filler voice data according to the similarity before the chat voice data transmitting means transmits the chat voice data;
to make the computer function
The filler audio data transmitting means includes:
When the similarity is determined to be equal to or greater than a predetermined threshold, a first filler voice data based on a filler word that is desired to be spoken in accordance with the current topic is transmitted;
When the answer is false, a second filler voice data based on a filler word indicating a desire to return to the previous topic is transmitted.
A program for causing a computer to further function as described above.
チャット音声データ送信手段は、所定タイミングとして会話間隙が検知された際に、チャット音声データを、オンライン会議サーバへ送信する
ようにコンピュータを機能させることを特徴とする請求項1又は2に記載のプログラム。 The method further comprises: detecting a conversation gap during which the speech voice data of the conference received from the online conference server is not received for a predetermined period of time or longer;
3. The program according to claim 1, wherein the chat voice data transmission means causes the computer to function so as to transmit chat voice data to the online conference server when a conversation gap is detected as the predetermined timing.
マイクがオフになっている際に、音声合成手段及びチャット音声データ送信手段が機能する
ようにコンピュータを機能させることを特徴とする請求項1から3のいずれか1項に記載のプログラム。 The terminal further includes a microphone that can be turned on/off by a user's operation to collect the user's speech data;
4. The program according to claim 1, further comprising: causing a computer to function so that a voice synthesis unit and a chat voice data transmission unit function when a microphone is turned off.
移動検知センサによって移動中と判定された際に、音声合成手段及びチャット音声データ送信手段が機能する
ようにコンピュータを更に機能させることを特徴とする請求項1から3のいずれか1項に記載のプログラム。 The terminal is further equipped with a motion detection sensor,
4. The program according to claim 1, further causing the computer to function so that a voice synthesis unit and a chat voice data transmission unit function when the movement detection sensor determines that the user is moving.
発話音声テキストに、当該端末のユーザに対する発言を求める所定キーワードが含まれているか否かを判定する発言要請判定手段と
してコンピュータを更に機能させることを特徴とする請求項1から5のいずれか1項に記載のプログラム。 A speech recognition means for converting conference speech data received from an online conference server into speech text;
The program according to any one of claims 1 to 5 , further causing the computer to function as a speech request determination means for determining whether or not the spoken voice text contains a predetermined keyword that requests a statement from the user of the terminal.
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と
を有し、
チャットテキスト入力手段に対してユーザがチャットテキストの入力中に、所定タイミングとなった際に、
チャット音声データ送信手段は、既に入力されたチャットテキストのみについて音声合成されたチャット音声データを、オンライン会議サーバへ送信すると共に、
音声合成手段は、後に続いて入力されるであろうテキストチャットを考慮して、音声合成の発話テンポが遅くなるように制御する
ことを特徴とする端末。 A terminal for exchanging voice data in real time via an online conference server,
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
a chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing ;
When a predetermined timing occurs while the user is inputting chat text to the chat text input means,
The chat voice data transmission means transmits chat voice data generated by voice synthesis only for the chat text that has already been input to the online conference server, and
The speech synthesis means controls the speech synthesis speech tempo to be slowed down in consideration of the text chat that will be input subsequently.
A terminal characterized by:
ユーザの操作によって、チャットテキストの入力を受け付けるチャットテキスト入力手段と、
チャットテキストを、チャット音声データに音声合成する音声合成手段と、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信するチャット音声データ送信手段と、
オンライン会議サーバから受信した会議の発話音声データを、発話音声テキストに変換する音声認識手段と、
発話音声テキストとチャットテキストとの会話内容の一致度として、出現単語列の類似度を算出する類似度算出手段と、
チャット音声データ送信手段がチャット音声データを送信する前に、類似度に応じて異なるフィラー音声データを送信するフィラー音声データ送信手段と
を有し、
フィラー音声データ送信手段は、
類似度が所定閾値以上となる真と判定した際に、現在の話題に沿った発言を希望するフィラーワードに基づく第1のフィラー音声データを送信し、
偽と判定した際に、先の話題に戻った発言を希望するフィラーワードに基づく第2のフィラー音声データを送信する
ことを特徴とする端末。 A terminal for exchanging voice data in real time via an online conference server,
a chat text input means for accepting input of a chat text by a user's operation;
A voice synthesis means for synthesizing chat text into chat voice data;
a chat voice data transmission means for transmitting chat voice data to an online conference server at a predetermined timing;
A speech recognition means for converting conference speech data received from an online conference server into speech text;
a similarity calculation means for calculating a similarity between appearing word strings as a degree of agreement between the contents of the conversation between the spoken voice text and the chat text;
a filler voice data transmitting means for transmitting different filler voice data according to the similarity before the chat voice data transmitting means transmits the chat voice data;
having
The filler audio data transmitting means includes:
When the similarity is determined to be equal to or greater than a predetermined threshold, a first filler voice data based on a filler word that is desired to be spoken in accordance with the current topic is transmitted;
When the answer is false, a second filler voice data based on a filler word indicating a desire to return to the previous topic is transmitted.
A terminal characterized by:
端末は、
ユーザの操作によって、チャットテキストの入力を受け付ける第1のステップと、
チャットテキストを、チャット音声データに音声合成する第2のステップと、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信する第3のステップと
を実行し、
第1のステップについて、ユーザがチャットテキストの入力中に、所定タイミングとなった際に、
第3のステップについて、既に入力されたチャットテキストのみについて音声合成されたチャット音声データを、オンライン会議サーバへ送信すると共に、
第2のステップについて、後に続いて入力されるであろうテキストチャットを考慮して、音声合成の発話テンポが遅くなるように制御する
ことを特徴とする端末のチャット音声データ送信方法。 A chat voice data transmission method for terminals exchanging voice data in real time via an online conference server, comprising:
The terminal is
A first step of accepting input of chat text by a user operation;
a second step of synthesizing the chat text into chat voice data;
and a third step of transmitting chat voice data to an online conference server at a predetermined timing .
In the first step, when a predetermined timing occurs while the user is inputting chat text,
In the third step, chat voice data generated by voice synthesis only for the chat text already input is transmitted to the online conference server,
In the second step, the speech synthesis tempo is controlled to be slower, taking into account the text chat that will follow.
A chat voice data transmission method for a terminal, comprising:
端末は、
ユーザの操作によって、チャットテキストの入力を受け付ける第1のステップと、
チャットテキストを、チャット音声データに音声合成する第2のステップと、
所定タイミングで、チャット音声データを、オンライン会議サーバへ送信する第3のステップと、
オンライン会議サーバから受信した会議の発話音声データを、発話音声テキストに変換する第4のステップと、
発話音声テキストとチャットテキストとの会話内容の一致度として、出現単語列の類似度を算出する第5のステップと、
第3のステップについてチャット音声データを送信する前に、類似度に応じて異なるフィラー音声データを送信する第6のステップと
を実行し、
第6のステップについて、
類似度が所定閾値以上となる真と判定した際に、現在の話題に沿った発言を希望するフィラーワードに基づく第1のフィラー音声データを送信し、
偽と判定した際に、先の話題に戻った発言を希望するフィラーワードに基づく第2のフィラー音声データを送信する
ことを特徴とする端末のチャット音声データ送信方法。 A chat voice data transmission method for terminals exchanging voice data in real time via an online conference server, comprising:
The terminal is
A first step of accepting input of chat text by a user operation;
a second step of synthesizing the chat text into chat voice data;
a third step of transmitting chat voice data to the online conference server at a predetermined timing ;
A fourth step of converting the conference speech voice data received from the online conference server into speech voice text;
a fifth step of calculating a similarity between appearing word strings as a degree of agreement between the conversation contents of the spoken voice text and the chat text;
A sixth step of transmitting different filler voice data according to the similarity before transmitting the chat voice data for the third step;
Run
Regarding the sixth step,
When the similarity is determined to be equal to or greater than a predetermined threshold, a first filler voice data based on a filler word that is desired to be spoken in accordance with the current topic is transmitted;
When the answer is false, a second filler voice data based on a filler word indicating a desire to return to the previous topic is transmitted.
A chat voice data transmission method for a terminal, comprising:
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022014504A JP7577700B2 (en) | 2022-02-01 | 2022-02-01 | Program, terminal and method for assisting users who cannot speak during online meetings |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2022014504A JP7577700B2 (en) | 2022-02-01 | 2022-02-01 | Program, terminal and method for assisting users who cannot speak during online meetings |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2023112602A JP2023112602A (en) | 2023-08-14 |
| JP7577700B2 true JP7577700B2 (en) | 2024-11-05 |
Family
ID=87562166
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2022014504A Active JP7577700B2 (en) | 2022-02-01 | 2022-02-01 | Program, terminal and method for assisting users who cannot speak during online meetings |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7577700B2 (en) |
Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000023132A (en) | 1998-07-06 | 2000-01-21 | Canon Inc | Data communication control device, control method therefor, and data communication system |
| JP2004336292A (en) | 2003-05-06 | 2004-11-25 | Namco Ltd | Voice processing system, apparatus and method |
| JP2007243392A (en) | 2006-03-07 | 2007-09-20 | Nec Corp | Call terminal, multi-user call system, multi-user call method, and program |
| CN101515455A (en) | 2008-02-20 | 2009-08-26 | 株式会社Ntt都科摩 | Communication system for building speech database for speech synthesis, relay device therefor, and relay method therefor |
| US20110093272A1 (en) | 2008-04-08 | 2011-04-21 | Ntt Docomo, Inc | Media process server apparatus and media process method therefor |
| JP2015231083A (en) | 2014-06-04 | 2015-12-21 | 日本電信電話株式会社 | Voice synthesis call system, communication terminal, and voice synthesis call method |
| JP2017054193A (en) | 2015-09-07 | 2017-03-16 | 富士ゼロックス株式会社 | Information processing device, information processing system, program, and recording medium |
| WO2017200072A1 (en) | 2016-05-20 | 2017-11-23 | 日本電信電話株式会社 | Dialog method, dialog system, dialog device, and program |
| JP2019110451A (en) | 2017-12-19 | 2019-07-04 | 日本電気株式会社 | Information processing system, information processing method, and program |
| JP2020113217A (en) | 2019-01-16 | 2020-07-27 | 株式会社SR factory | Emotion assessment terminal, emotion assessment program, and emotion assessment method |
| JP2021081838A (en) | 2019-11-15 | 2021-05-27 | レノボ・シンガポール・プライベート・リミテッド | Information processing apparatus and control method |
-
2022
- 2022-02-01 JP JP2022014504A patent/JP7577700B2/en active Active
Patent Citations (11)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2000023132A (en) | 1998-07-06 | 2000-01-21 | Canon Inc | Data communication control device, control method therefor, and data communication system |
| JP2004336292A (en) | 2003-05-06 | 2004-11-25 | Namco Ltd | Voice processing system, apparatus and method |
| JP2007243392A (en) | 2006-03-07 | 2007-09-20 | Nec Corp | Call terminal, multi-user call system, multi-user call method, and program |
| CN101515455A (en) | 2008-02-20 | 2009-08-26 | 株式会社Ntt都科摩 | Communication system for building speech database for speech synthesis, relay device therefor, and relay method therefor |
| US20110093272A1 (en) | 2008-04-08 | 2011-04-21 | Ntt Docomo, Inc | Media process server apparatus and media process method therefor |
| JP2015231083A (en) | 2014-06-04 | 2015-12-21 | 日本電信電話株式会社 | Voice synthesis call system, communication terminal, and voice synthesis call method |
| JP2017054193A (en) | 2015-09-07 | 2017-03-16 | 富士ゼロックス株式会社 | Information processing device, information processing system, program, and recording medium |
| WO2017200072A1 (en) | 2016-05-20 | 2017-11-23 | 日本電信電話株式会社 | Dialog method, dialog system, dialog device, and program |
| JP2019110451A (en) | 2017-12-19 | 2019-07-04 | 日本電気株式会社 | Information processing system, information processing method, and program |
| JP2020113217A (en) | 2019-01-16 | 2020-07-27 | 株式会社SR factory | Emotion assessment terminal, emotion assessment program, and emotion assessment method |
| JP2021081838A (en) | 2019-11-15 | 2021-05-27 | レノボ・シンガポール・プライベート・リミテッド | Information processing apparatus and control method |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2023112602A (en) | 2023-08-14 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US9293133B2 (en) | Improving voice communication over a network | |
| US12159643B2 (en) | Systems and methods for filtering unwanted sounds from a conference call using voice synthesis | |
| US7617094B2 (en) | Methods, apparatus, and products for identifying a conversation | |
| US20240388659A1 (en) | Methods and systems for automatic queuing in conference calls | |
| US20200012724A1 (en) | Bidirectional speech translation system, bidirectional speech translation method and program | |
| JP2023524088A (en) | End-to-end multi-speaker overlapping speech recognition | |
| US11501768B2 (en) | Dialogue method, dialogue system, dialogue apparatus and program | |
| JPWO2017200074A1 (en) | Dialogue method, dialogue system, dialogue apparatus, and program | |
| US12073849B2 (en) | Systems and methods for filtering unwanted sounds from a conference call | |
| KR20210124050A (en) | Automatic interpretation server and method thereof | |
| CN111936964A (en) | Non-disruptive NUI commands | |
| WO2024055299A1 (en) | Real-time speech translation method, system, device, and storage medium | |
| US20220230622A1 (en) | Electronic collaboration and communication method and system to facilitate communication with hearing or speech impaired participants | |
| WO2018198791A1 (en) | Signal processing device, method, and program | |
| WO2025043996A1 (en) | Human-computer interaction method and apparatus, computer readable storage medium and terminal device | |
| JP7577700B2 (en) | Program, terminal and method for assisting users who cannot speak during online meetings | |
| US20250218440A1 (en) | Context-based speech assistance | |
| US20210082427A1 (en) | Information processing apparatus and information processing method | |
| JP7070402B2 (en) | Information processing equipment | |
| JP2023135870A (en) | Auxiliary device | |
| JPWO2017200077A1 (en) | Dialogue method, dialogue system, dialogue apparatus, and program | |
| EP1453287A1 (en) | Automatic management of conversational groups | |
| CN121303151A (en) | Voice translation methods, devices, readable storage media, and software products | |
| KR20250161150A (en) | Multilateral Real-Time Voice Recognition Method using TCP-based Multi-IDL Generation Technology | |
| WO2026090508A1 (en) | Systems and methods of deep reinforcement learning within an audiovisual environment |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240117 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240828 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240902 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20241003 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20241021 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20241023 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7577700 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |