JP7614475B2 - 演算装置、及び演算方法 - Google Patents
演算装置、及び演算方法 Download PDFInfo
- Publication number
- JP7614475B2 JP7614475B2 JP2020193718A JP2020193718A JP7614475B2 JP 7614475 B2 JP7614475 B2 JP 7614475B2 JP 2020193718 A JP2020193718 A JP 2020193718A JP 2020193718 A JP2020193718 A JP 2020193718A JP 7614475 B2 JP7614475 B2 JP 7614475B2
- Authority
- JP
- Japan
- Prior art keywords
- decimal point
- output
- shift
- amount
- input
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images











Landscapes
- Complex Calculations (AREA)
Description
通常、DNNの内部では、32ビット演算精度の浮動小数点が演算で使われる。積和演算時の桁あふれ検出やAIチップでの動作検証のため、量子化ではその精度を8ビットなど、より少ないビット幅へ変換し、演算を行うことで重みを軽量化する。
また、CNN(Convolutional neural network)に対して重みを量子化し、実行する技術が知られている(例えば、特許文献2参照)。
また、浮動小数点で学習されたモデルの重みを固定小数点に変換する技術が知られている(例えば、特許文献3参照)。この技術では、統計に基づいてビット幅、シフト量などのパラメータの決定、CNNのチャンネルごとにパラメータの設定が可能である。
本発明の一実施形態は、前述の演算装置において、前記パラメータには、複数の層の各々のパラメータが含まれる。
本発明の一実施形態は、前述の演算装置において、前記パラメータには、ウエイトおよび出力が含まれる。
本発明の一実施形態は、前述の演算装置において、前記パラメータには、バイアスがさらに含まれる。
本発明の一実施形態は、前述の演算装置において、前記パラメータは、固定小数点の形式である。
本発明の一実施形態は、前述の演算装置において、前記学習モデルは、ディープニューラルネットワーク形式の学習済モデルに基づいて、パラメータを固定小数点の形式に変換することによって作成されたものである。
本発明の一実施形態は、前述の演算装置において、前記演算部は、前記パラメータに基づいて、入力値に対して、MAC(multiply-accumulate)演算を行う。
なお、実施形態を説明するための全図において、同一の機能を有するものは同一符号を用い、繰り返しの説明は省略する。
また、本願でいう「XXに基づく」とは、「少なくともXXに基づく」ことを意味し、XXに加えて別の要素に基づく場合も含む。また、「XXに基づく」とは、XXを直接に用いる場合に限定されず、XXに対して演算や加工が行われたものに基づく場合も含む。「XX」は、任意の要素(例えば、任意の情報)である。
[全体構成]
図1は、本発明の実施形態に係る演算装置の構成図である。
演算装置100に、入力値が入力される。入力値の一例は、浮動小数点の形式である。以下、入力値が、浮動小数点の形式である場合について説明を続ける。
演算装置100は、入力された入力値を受け付ける。演算装置100は、受け付けた入力値を浮動小数点の形式から固定小数点の形式へ変換する。固定小数点の形式へ変換するときの桁数(ビット幅)nは、予め設定されている。
演算装置100は、固定小数点の形式へ変換後の入力値およびパラメータの小数点のシフト量を特定する情報に基づいて、入力値に対する学習モデルの出力値を演算する。
演算装置100は、学習モデルの出力値の演算結果を導出する際に、出力値の小数点のシフト量osfに基づいて、積和演算の結果の小数点をシフトさせることによって最終出力値を導出する。演算装置100は、導出した最終出力値を出力する。
以下、演算装置100について説明する。
演算装置100は、スマートフォン、携帯端末、又はパーソナルコンピュータ、タブレット端末装置、あるいはその他の情報処理機器として実現される。演算装置100は、例えば、入力部110と、受付部120と、取得部125と、演算部130と、出力部140と、記憶部150とを備える。
学習モデル152の一例は、ディープニューラルネットワーク形式の学習モデルである。この学習モデル152は、量子化されている。学習モデルを量子化する方法については、後述する。以下、学習モデル152が、ディープニューラルネットワーク形式の量子化された学習モデルである場合について説明を続ける。
学習モデル152は、入力層151-1と、中間層151-2と、出力層151-3とを備える。入力層151-1は一または複数のユニットを有し、中間層151-2は一または複数のユニットを有し、出力層151-3は一または複数のユニットを有する。入力層151-1に含まれる一または複数のユニットの各々は、中間層151-2に含まれる一または複数のユニットの各々と、一または複数のリンクによって接続される。中間層151-2に含まれる一または複数のユニットの各々は、出力層151-3に含まれる一または複数のユニットの各々と、一または複数のリンクによって接続される。
さらに、パラメータには、バイアスが含まれてもよい。一例として、パラメータには、ウエイトとバイアスとが含まれる場合について説明を続ける。一または複数のユニットの各々は、一または複数の入力値と一または複数のウエイトとをそれぞれ乗算した結果の和とバイアスとを加算する。
つまり、パラメータの小数点のシフト量を特定する情報には、ウエイトの小数点のシフト量wsfを特定する情報とバイアスの小数点のシフト量を特定する情報とが含まれる。入力層151-1と中間層151-2と出力層151-3との各々の入力値の小数点のシフト量を特定する情報と、パラメータの小数点のシフト量と、入力層151-1と中間層151-2と出力層151-3との各々の出力の小数点のシフト量とを導出する方法については、後述する。
取得部125は、受付部120が入力値を特定する情報を受け付けた場合に、記憶部150のシフト量情報154に記憶されている入力層と中間層と出力層との各々の入力値の小数点のシフト量を特定する情報と、パラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とを取得する。取得部125が取得した入力層と中間層と出力層との各々の入力値の小数点のシフト量を特定する情報と、パラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とは、演算部130へ出力される。

例えば、演算部130は、ビット幅nを8とした場合には、32ビットの浮動小数点の形式の入力値を、8ビットの固定小数点の形式に変換する。
図3に示すように、浮動小数点形式の入力値200は、符号ビット210、指数部220および仮数部230を含む。浮動小数点は、1つの数を、小数点部分を示す部分と小数点位置を示す部分とに分けて表現する表記法である。仮数部230は、小数点部分を示す部分であり、指数部220は小数点位置を示す部分である。符号ビット210は、入力値200の符号を決定する部分である。
図4に示すように、固定小数点形式の入力値205は、符号ビット215、整数部225、小数部235および小数点245を含む。固定小数点は、小数点を使用して固定された桁数の小数を示す表記法を意味する。符号ビット215は入力値205の符号を決定し、整数部225は入力値205の整数を示す部分に対応し、小数部235は入力値205の小数を示す部分に対応する。小数点245は、入力値205の整数部225および小数部235を区分する基準になる点を示す。
演算部130は、取得した入力層と中間層と出力層との各々の入力値の小数点のシフト量を特定する情報と、パラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とに基づいて、入力値に対する学習モデル152の出力値を演算する。
演算部130は、乗算器10と加算器20と加算器30とを備え、積和演算を行う。演算部130は、入力値inとパラメータの小数点のシフト量を特定する情報とを取得する。ここで、入力値inは、入力値の小数点のシフト量isfを特定する情報に基づいて、固定小数点の形式に変換されたものである。
演算部130は、パラメータの小数点のシフト量を特定する情報に基づいて、ウエイトWEの小数点をシフトさせる。
演算部130において、乗算器10は、入力値inと小数点をシフトさせたウエイトWEとを乗算する。加算器20は、入力値inと小数点をシフトさせたウエイトWEとを乗算した結果とを加算する。加算器30は、加算器20の出力値OUと出力の小数点のシフト量osfとに基づいて、出力値OUの小数点をシフトさせることによって、最終出力を導出する。具体的には、加算器30は、出力値OUに0.5を加算する。出力値OUの小数点をシフトさせることによって、出力値OUの精度を向上させることができる。
入力値の小数点のシフト量を特定する情報と、パラメータの小数点のシフト量との導出は、端末装置によって実行される。
端末装置は、記憶している学習モデルから入力層を取得し、取得した入力層に含まれるウエイトとバイアスとに基づいて、入力層のウエイトの小数点のシフト量とバイアスの小数点のシフト量とを導出する。端末装置は、導出した入力層のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とを記憶する。
端末装置は、ウエイトとバイアスとを固定小数点の形式に変換する。端末装置は、固定小数点の形式に変換したウエイトとバイアスとを含む入力層を新たに作成する。端末装置は、記憶している学習モデルの入力層を、新たに作成した入力層に交換する。
端末装置は、ウエイトとバイアスとを固定小数点の形式に変換する。端末装置は、固定小数点の形式に変換したウエイトとバイアスとを含む中間層を新たに作成する。端末装置は、記憶している学習モデルの中間層を、新たに作成した中間層に交換する。
端末装置は、ウエイトとバイアスとを固定小数点の形式に変換する。端末装置は、固定小数点の形式に変換したウエイトとバイアスとを含む出力層を新たに作成する。端末装置は、記憶している学習モデルの出力層を、新たに作成した出力層に交換する。以上で、量子化した学習モデルが完成する。
ただし、このままでは、学習モデルの演算結果の精度が低下する。この学習モデルの演算結果の精度の低下は、演算精度の減少だけが原因ではない。浮動小数点の形式の学習モデルでは、出力部分で(式1)の演算を行っている。
しかし、量子化された学習モデルの出力部分では(式1)と同等の処理をしてない。そのため、すべての層において、入力値、ウエイト、出力のシフト量から、整数でも実行できるようにすることによって、量子化された学習モデルの各層において、出力OUに、出力の小数点のシフト量を適用する。このように構成することによって、演算結果の精度の低下を防止できる。
端末装置は、取得した入力層のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報に基づいて、固定小数点の形式に変換した入力値に対する量子化した学習モデルの入力層の出力を導出する。端末装置は、導出した入力層の出力に基づいて、入力層の出力の小数点のシフト量を導出する。このように構成することによって、仮に入力層の出力が量子化されていない場合でも、量子化を行うことができる。端末装置は、導出した入力層の出力の小数点のシフト量、換言すれば中間層の入力値の小数点のシフト量を特定する情報を記憶する。
このように構成することによって、仮に中間層の出力が量子化されていない場合でも、量子化を行うことができる。端末装置は、導出した中間層の出力の小数点のシフト量、換言すれば出力層の入力値の小数点のシフト量を特定する情報を記憶する。
端末装置は、導出した出力層の出力に基づいて、分散などの演算を行うことによって、出力層の出力の小数点のシフト量を導出する。このように構成することによって、仮に出力層の出力が量子化されていない場合でも、量子化を行うことができる。端末装置は、導出した出力層の出力の小数点のシフト量を特定する情報を記憶する。
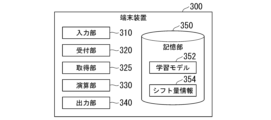
以下、端末装置300について説明する。
図6は、本実施形態に係る端末装置のパラメータの小数点のシフト量の導出を説明するための図である。
端末装置300は、パーソナルコンピュータ、サーバー、タブレットコンピュータ又は産業用コンピュータ等の装置によって実現される。端末装置300は、例えば、入力部310と、受付部320と、取得部325と、演算部330と、出力部340と、記憶部350とを備える。
学習モデル352の一例は、ディープニューラルネットワーク形式の学習済の学習モデルである。以下、学習モデル352が、ディープニューラルネットワーク形式の学習済の学習モデルである場合について説明を続ける。
学習モデル352は、入力層351-1と、中間層351-2と、出力層351-3とを備える。入力層351-1は一または複数のユニットを有し、中間層351-2は一または複数のユニットを有し、出力層351-3は一または複数のユニットを有する。
入力層351-1に含まれる一または複数のユニットの各々は、中間層351-2に含まれる一または複数のユニットの各々と、一または複数のリンクによって接続される。中間層351-2に含まれる一または複数のユニットの各々は、出力層351-3に含まれる一または複数のユニットの各々と、一または複数のリンクによって接続される。
演算部330は、ウエイトとバイアスとを固定小数点の形式に変換する。演算部330は、固定小数点の形式に変換したウエイトとバイアスとを含む入力層351a-1を作成する(2)。演算部330は、記憶部350の学習モデル352の入力層351-1を、作成した入力層351a-1に交換する(3)。
演算部330は、ウエイトとバイアスとを固定小数点の形式に変換する。演算部130は、固定小数点の形式に変換したウエイトとバイアスとを含む中間層351a-2を作成する。演算部330は、学習モデル352の中間層351-2を、作成した中間層351a-2に交換する。
演算部330は、導出した出力層351-3のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とを、記憶部350のシフト量情報354に記憶させる。
演算部330は、ウエイトとバイアスとを固定小数点の形式に変換する。演算部330は、固定小数点の形式に変換したウエイトとバイアスとを含む出力層351a-3を作成する。演算部330は、学習モデル352の出力層351-3を、作成した出力層351a-3に交換する(4)。
前述した処理を行うことによって、演算部330は、学習モデル352から、量子化した学習モデル352aを作成する。
演算部330は、入力層351-1のウエイトの小数点のシフト量とバイアスの小数点のシフト量と、中間層351-2のウエイトの小数点のシフト量とバイアスの小数点のシフト量と、出力層351-3のウエイトの小数点のシフト量wsfとバイアスの小数点のシフト量とを導出できる。
演算部330は、取得部325から入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報を取得する。演算部330は、取得した入力層351-1のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報に基づいて、固定小数点の形式に変換した入力値に対する量子化した学習モデル352aの入力層351a-1の出力を導出する。
演算部330は、導出した入力層351a-1の出力に基づいて、分散などの演算を行うことによって、入力層351a-1の出力の小数点のシフト量を導出する。このように構成することによって、仮に入力層351a-1の出力が量子化されていない場合でも、量子化を行うことができる。演算部330は、導出した入力層351a-1の出力の小数点のシフト量、換言すれば中間層351a-2の入力の小数点のシフト量を特定する情報を記憶部350のシフト量情報354に記憶させる。
演算部330は、導出した中間層351a-2の出力に基づいて、分散などの演算を行うことによって、中間層351a-2の出力の小数点のシフト量を導出する。このように構成することによって、仮に中間層351a-2の出力が量子化されていない場合でも、量子化を行うことができる。演算部330は、導出した中間層351a-2の出力の小数点のシフト量、換言すれば出力層351a-3の入力の小数点のシフト量を特定する情報を記憶部350のシフト量情報354に記憶させる。
演算部330は、取得した出力層351a-3のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報に基づいて、学習モデル352aの中間層351a-2の出力値に対する量子化した学習モデル352aの出力層351a-3の出力を導出する。
前述した処理を行うことによって、演算部330は、入力層351a-1の出力の小数点のシフト量、換言すれば中間層351a-2の入力の小数点のシフト量と、中間層351a-2の出力の小数点のシフト量、換言すれば出力層351a-3の入力の小数点のシフト量と、出力層351a-3の出力の小数点のシフト量とを導出する。
端末装置300によって作成された量子化した学習モデル352aが、演算装置100において学習モデル152として使用される。端末装置300によって作成されたシフト量情報354が、演算装置100においてシフト量情報154として使用される。
図8は、本実施形態に係る演算装置の動作の一例を示すフローチャートである。
(ステップS1-1)
演算装置100において、受付部120は、入力部110に入力された入力値を特定する情報を取得し、取得した入力値を特定する情報を受け付ける。
(ステップS2-1)
演算装置100において、取得部125は、記憶部150のシフト量情報154に記憶されている入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とを取得する。入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報には、入力層の入力値の小数点のシフト量を特定する情報と、中間層の入力値の小数点のシフト量を特定する情報と、出力層の入力値の小数点のシフト量を特定する情報とが含まれる。
演算装置100において、演算部130は、受付部120が受け付けた入力値を特定する情報を取得する。演算部130は、取得した入力値を特定する情報と、入力値の小数点のシフト量を特定する情報とに基づいて、入力値を固定小数点の形式へ変換する。
(ステップS4-1)
演算装置100において、演算部130は、取得部125が取得した入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とを取得する。演算部130は、取得した入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とに基づいて、入力値に対する出力値OUを演算する。
(ステップS5-1)
演算装置100において、演算部130は、出力値OUと出力の小数点のシフト量osfとに基づいて、出力値OUの小数点をシフトさせることによって、最終出力を導出する。
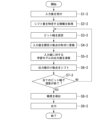
図9は、本実施形態に係る端末装置の動作の一例を示すフローチャートである。
(ステップS1-2)
端末装置300において、演算部330は、記憶部350の学習モデル352から入力層351-1を取得する。演算部330は、取得した入力層351-1に含まれるウエイトとバイアスとに基づいて、入力層351-1のウエイトの小数点のシフト量とバイアスの小数点のシフト量とを導出する。
演算部330は、導出した入力層351-1のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とを記憶部350のシフト量情報354に記憶させる。
(ステップS2-2)
端末装置300において、演算部330は、入力層351-1のウエイトとバイアスとを固定小数点の形式に変換する。
端末装置300において、演算部330は、固定小数点の形式に変換したウエイトとバイアスとを含む入力層351a-1を作成する。演算部330は、記憶部350の学習モデル352の入力層351-1を、作成した入力層351a-1に交換する。
(ステップS4-2)
端末装置300において、演算部330は、記憶部350の学習モデル352から中間層351-2を取得する。演算部330は、取得した中間層351-2に含まれるウエイトとバイアスとに基づいて、中間層351-2のウエイトの小数点のシフト量とバイアスの小数点のシフト量とを導出する。演算部330は、導出した中間層351-2のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とを記憶部350のシフト量情報354に記憶させる。
(ステップS5-2)
端末装置300において、演算部330は、中間層351-2のウエイトとバイアスとを固定小数点の形式に変換する。
端末装置300において、演算部130は、固定小数点の形式に変換したウエイトとバイアスとを含む中間層351a-2を作成する。演算部330は、学習モデル352の中間層351-2を、作成した中間層351a-2に交換する。
(ステップS7-2)
端末装置300において、演算部330は、記憶部350の学習モデル352から出力層351-3を取得する。演算部330は、取得した出力層351-3に含まれるウエイトとバイアスとに基づいて、出力層351-3のウエイトの小数点のシフト量を導出する。演算部330は、導出した出力層351-3のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とを記憶部350のシフト量情報354に記憶させる。
端末装置300において、演算部330は、出力層351-3のウエイトとバイアスとを固定小数点の形式に変換する。
(ステップS9-2)
端末装置300において、演算部330は、固定小数点の形式に変換したウエイトとバイアスとを含む出力層351a-3を作成する。演算部330は、学習モデル352の出力層351-3を、作成した出力層351a-3に交換する。
(ステップS10-2)
端末装置300において、受付部320は、入力部310に入力された入力値を特定する情報を取得し、取得した入力値を特定する情報を受け付ける。
端末装置300において、取得部325は、記憶部350のシフト量情報354に記憶されている入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報を取得する。
(ステップS12-2)
端末装置300において、演算部330は、受付部320が受け付けた入力値を特定する情報を取得する。演算部330は、取得した入力値を特定する情報と、入力値の小数点のシフト量を特定する情報とに基づいて、入力値を固定小数点の形式に変換する。
(ステップS13-2)
端末装置300において、演算部330は、取得部325から入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報を取得する。演算部330は、取得した入力層351-1のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とに基づいて、固定小数点の形式に変換した入力値に対する量子化した学習モデル352aの入力層351a-1の出力を導出する。
演算部330は、導出した入力層351a-1の出力に基づいて、入力層351a-1の出力の小数点のシフト量を導出する。演算部330は、導出した入力層351a-1の出力の小数点のシフト量、換言すれば中間層351a-2の入力値の小数点のシフト量を特定する情報を記憶部350のシフト量情報354に記憶させる。
端末装置300において、演算部330は、取得した中間層351a-2のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とに基づいて、学習モデル352aの入力層351a-1の出力値に対する量子化した学習モデル352aの中間層351a-2の出力を導出する。
演算部330は、導出した中間層351a-2の出力に基づいて、中間層351a-2の出力の小数点のシフト量を導出する。演算部330は、導出した中間層351a-2の出力の小数点のシフト量、換言すれば出力層351a-3の入力値の小数点のシフト量を特定する情報を記憶部350のシフト量情報354に記憶させる。
(ステップS15-2)
端末装置300において、演算部330は、取得した出力層351a-3のウエイトの小数点のシフト量を特定する情報とバイアスの小数点のシフト量を特定する情報とに基づいて、学習モデル352aの中間層351a-2の出力値に対する量子化した学習モデル352aの出力層351a-3の出力を導出する。
演算部330は、導出した出力層351a-3の出力に基づいて、分散などの演算を行うことによって、出力層351a-3の出力の小数点のシフト量を導出する。演算部330は、導出した出力層351a-3の出力の小数点のシフト量を特定する情報を記憶部350のシフト量情報354に記憶させる。
図10は、本実施形態に係る演算装置100の精度の一例を説明するための図である。図10は、入力値を固定小数点の形式へ変換するときの桁数(ビット幅)nを2から8とした場合の各々について、出力値OUの小数点をシフトさせたものを最終出力値とした場合と、出力値OUを最終出力値とした場合について、最終出力値の精度の一例を示す。
図10によれば、ビット幅が6桁までは、出力値OUの小数点をシフトさせたか否かにかかわらず、小数点第二位まで等しい精度が得られているのが分かる。ビット幅が5桁では、出力値OUの小数点をシフトさせない場合と小数点をシフトさせた場合とでは、小数点第二位に差が生じている。ビット幅が4桁以下では、小数点をシフトさせない場合は、出力値OUの小数点をシフトさせた場合と比較して、精度が大きく低下する。
前述した実施形態では、学習モデルの一例が、Pytonで記述されている場合について説明したが、この例に限られない。例えば、学習モデルの一例が、Pytorch、Tensorflowなどのライブラリーで記述されていてもよい。
前述した実施形態では、入力値の一例として、32ビットの浮動小数点の形式の数である場合について説明したが、この例に限られない。例えば、入力値として、16ビットの浮動小数点の形式の数などの32ビット以外の浮動小数点の形式の数を使用してもよい。
前述した実施形態において、学習モデル152と学習モデル352との各々は、複数の中間層を備えてもよい。複数の中間層を備える場合に、複数の中間層の各々について、ウエイトの小数点のシフト量とバイアスの小数点のシフト量と出力の小数点のシフト量(入力の小数点のシフト量)が導出される。
前述した実施形態において、演算装置100は、出力値OUと出力の小数点のシフト量osfとに基づいて、出力値OUの小数点をシフトさせるか否かを選択できるようにしてもよい。例えば、図10に示すように、ビット幅nが6から8では、出力値OUの小数点をシフトさせたものを最終出力値とした場合と、出力値OUを最終出力値とした場合との間で精度の差が小さいため、出力値OUの小数点をシフトさせる必要がないためである。このように構成することによって、出力値OUの小数点をシフトさせるハードウェアを削減できる。
このように構成することによって、演算装置100は、学習モデル152のパラメータの小数点のシフト量を特定する情報に基づいて、固定小数点の形式の入力値に対する学習モデル152の出力値を演算し、出力値と出力値の小数点のシフト量とに基づいて、出力値の小数点をシフトさせ、小数点をシフトさせた出力値を出力する。
出力値と出力値の小数点のシフト量とに基づいて、出力値の小数点をシフトさせることができるため、入力値を固定小数点の形式に変換した場合に演算精度を向上できる。このため、ハードウェアに実装する前に正確な精度を求めることができる。ハードウェアと同等のエミュレーションができるため、ハードウェアのデバッグに使用できる。エミュレーションの段階で、桁あふれをチェックできる。通常使用されているディープニューラルネットワークフレームワークと併用して使用できる。
また、パラメータには、ウエイトおよび出力が含まれる。このように構成することによって、演算装置100は、学習モデル152の複数のウエイトの各々の小数点のシフト量と複数の層の各々の出力の小数点のシフト量とを特定する情報に基づいて、入力値に対する学習モデル152の出力値を演算できるため、入力値を固定小数点の形式に変換した場合に、演算精度を向上できる。
また、パラメータには、バイアスがさらに含まれる。このように構成することによって、演算装置100は、学習モデル152の複数のバイアスの各々の小数点のシフト量を特定する情報にさらに基づいて、入力値に対する学習モデル152の出力値を演算できるため、入力値を固定小数点の形式に変換した場合に、演算精度を向上できる。
また、学習モデルは、ディープニューラルネットワーク形式の学習済モデルに基づいて、パラメータを固定小数点の形式に変換することによって作成されたものである。このように構成することによって、学習済モデルから学習モデルを用意できる。
また、演算部130は、パラメータに基づいて、入力値に対して、MAC(multiply-accumulate)演算を行う。このように構成することによって、入力値に対してMAC演算を行うことによって、入力値に対する学習モデル152の出力値を演算できる。
[全体構成]
図11は、実施形態の変形例に係る演算装置の構成図である。
ユーザーUは、演算装置100aに、入力値を入力する操作を行う。入力値の一例は、浮動小数点の形式である。以下、入力値が、浮動小数点の形式である場合について説明を続ける。
演算装置100aは、ユーザーUが入力した入力値を受け付ける。演算装置100aは、受け付けた入力値を浮動小数点の形式から固定小数点の形式へ変換する。固定小数点の形式へ変換するときの桁数(ビット幅)nは、予め設定されている。ここで、本実施形態の変形例に係る演算装置100aでは、複数のビット幅nが設定されている。具体的には、n=6、7、8、9、10、16などである。
演算装置100aは、複数の最終出力値の各々について、最終出力値の精度を導出する。演算装置100aは、入力値を固定小数点の形式へ変換するときの複数のビット幅nの各々について、ビット幅と精度とを関連付けて出力する。
以下、演算装置100aについて説明する。
演算装置100aは、スマートフォン、携帯端末、又はパーソナルコンピュータ、タブレット端末装置、あるいはその他の情報処理機器として実現される。演算装置100aは、例えば、入力部110と、受付部120と、取得部125と、演算部130aと、導出部135と、出力部140aと、記憶部150とを備える。
演算部130aは、パラメータの小数点のシフト量を特定する情報に基づいて、ウエイトWEの小数点をシフトさせる。演算部130aにおいて、乗算器10は、入力値inと小数点をシフトさせたウエイトWEとを乗算する。加算器20は、入力値inと小数点をシフトさせたウエイトWEとを乗算した結果とを加算する。
導出部135は、演算部130aから、複数のビット幅nの各々について、最終出力を取得する。導出部135は、取得した複数の最終出力に基づいて、最終出力の精度を導出する。
出力部140aは、導出部135から、入力値を固定小数点の形式に変換したときの複数のビット幅の各々と、最終出力の精度とを関連付けた情報を取得する。出力部140aは、取得した複数のビット幅の各々と、最終出力の精度とを関連付けた情報を出力する。
図12は、実施形態の変形例に係る演算装置の動作の一例を示すフローチャートである。
(ステップS1-3)
演算装置100aにおいて、受付部120は、入力部110に入力された入力値を特定する情報を取得し、取得した入力値を特定する情報を受け付ける。
(ステップS2-3)
演算装置100aにおいて、取得部125は、記憶部150のシフト量情報154に記憶されている入力値の小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とを取得する。
(ステップS3-3)
演算装置100aにおいて、演算部130aは、ビット幅を設定する。
演算装置100aにおいて、演算部130aは、受付部120が受け付けた入力値を特定する情報を取得する。演算部130aは、取得した入力値を特定する情報と設定したビット幅とに基づいて、入力値を固定小数点の形式へ変換する。
(ステップS5-3)
演算装置100aにおいて、演算部130aは、取得部125が取得した入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とを取得する。演算部130aは、取得した入力層と中間層と出力層との各々のパラメータの小数点のシフト量を特定する情報と、入力層と中間層と出力層との各々の出力の小数点のシフト量を特定する情報とに基づいて、入力値に対する学習モデル152の出力値を演算する。
演算装置100aにおいて、演算部130aは、出力値と出力の小数点のシフト量osfとに基づいて、出力値OUの小数点をシフトさせることによって、最終出力を導出する。
(ステップS7-3)
演算装置100aにおいて、演算部130aは、全てのビット幅で最終出力を導出したか否かを判定する。最終出力を導出していないビット幅がある場合には、ステップS3-3へ戻る。
(ステップS8-3)
演算装置100aにおいて、導出部135は、演算部130aが全てのビット幅で最終出力を導出したと判定した場合に、演算部130aから、複数のビット幅nの各々について、最終出力を取得する。導出部135は、取得した複数の最終出力に基づいて、最終出力の精度を導出する。
演算装置100aにおいて、出力部140aは、導出部135から、入力値を固定小数点の形式に変換したときの複数のビット幅の各々と、最終出力の精度とを関連付けた情報を取得する。出力部140aは、取得した複数のビット幅の各々と、最終出力の精度とを関連付けた情報を出力する。
図12では、全てのビット幅で最終出力を導出した後に、最終出力の精度が導出される場合について説明したが、この例に限られない。例えば、最終出力が導出されるたびに、最終出力の精度が導出されるようにしてもよい。
このように構成することによって、演算装置100aは、複数のビット幅の各々について、学習モデルの出力値の小数点をシフトさせた結果の精度を導出できる。このため、仮に学習モデルに要求される精度が設定された場合に、その要求される精度を満足するビット幅を求めることができる。つまり、複数の学習モデルが用意された場合に、許容できるビット幅を求めることができる。また、エミュレーションの時点で、量子化によってどの程度精度が低下するかが分かる。
「FP32」は浮動小数点形式の32ビットであり、「FP16」は浮動小数点形式の16ビットである。「INT16」は固定小数点形式の16ビットであり、「INT10」は固定小数点形式の10ビットであり、「INT9」は固定小数点形式の9ビットである。「INT8」は固定小数点形式の8ビットであり、「INT7」は固定小数点形式の7ビットであり、「INT6」は固定小数点形式の6ビットである。
ImageNetとCIFAR100とで学習された学習モデルを使用して、精度の評価を行った。ここでは、学習モデルの一例として、AlexNetと、VGG16と、MobileNet-v2とについて示す。
ImageNetで学習されたVGG16(Innet_VGG16)の場合には、FP32、FP16、INT16、INT10、INT9、INT8に比べて、INT7、INT6については精度が低下することが分かる。
ImageNetで学習されたMobileNet-v2(Innet_MobileNet-v2)の場合には、FP32、FP16、INT16、INT10に比べて、INT9、INT8、INT7、INT6については精度が低下することが分かる。
CIFAR100で学習されたVGG16(C100_VGG16)の場合には、FP32、FP16、INT16、INT10、INT9、INT8に比べて、INT7、INT6については精度が低下することが分かる。
CIFAR100で学習されたMobileNet-v2(C100_MobileNet-v2)の場合には、FP32、FP16、INT16、INT10、INT9に比べて、INT8、INT7、INT6については精度が低下することが分かる。
さらに、図13によれば、CIFAR100で学習されたAlexNetにGAP(Global average Pooling)を適用(C100_AlexNet_GAP)の場合には、FP32、FP16、INT16、INT10、INT9に比べて、INT8、INT7、INT6については精度が低下することが分かる。
CIFAR100で学習されたVGG16にGAPを適用(C100_VGG16_GAP)の場合には、FP32、FP16、INT16、INT10、INT9、INT8に比べて、INT7、INT6については精度が低下することが分かる。
図13によれば、学習モデルが用意された場合に、許容される精度に基づいて、何ビットまで許容できるか求めることができる。
なお、前述の演算装置100、端末装置300、演算装置100aは内部にコンピュータを有している。そして、前述した各装置の各処理の過程は、プログラムの形式でコンピュータ読み取り可能な記録媒体に記憶されており、このプログラムをコンピュータが読み出して実行することによって、上記処理が行われる。ここでコンピュータ読み取り可能な記録媒体とは、磁気ディスク、光磁気ディスク、CD-ROM、DVD-ROM、半導体メモリなどをいう。また、このコンピュータプログラムを通信回線によってコンピュータに配信し、この配信を受けたコンピュータが当該プログラムを実行するようにしてもよい。
また、上記プログラムは、前述した機能の一部を実現するためのものであってもよい。
さらに、前述した機能をコンピュータシステムにすでに記録されているプログラムとの組み合わせで実現できるもの、いわゆる差分ファイル(差分プログラム)であってもよい。
Claims (8)
- ニューラルネットワーク形式の学習モデルのパラメータの小数点のシフト量を特定する情報を取得する取得部と、
前記取得部が取得したパラメータの小数点のシフト量を特定する情報に基づいて、異なるビット幅で固定小数点の形式へ変換された複数の入力値に対する前記学習モデルの出力値を求め、求めた複数の前記出力値の各々と出力値の小数点のシフト量とに基づいて、求めた複数の前記出力値の各々の小数点をシフトさせる演算部と、
複数の前記出力値の各々の小数点をシフトさせた結果の精度を導出する導出部と、
を備え、
前記入力値は、固定小数点の形式である、演算装置。 - 前記パラメータには、複数の層の各々のパラメータが含まれる、請求項1に記載の演算装置。
- 前記パラメータには、ウエイトおよび出力が含まれる、請求項2に記載の演算装置。
- 前記パラメータには、バイアスがさらに含まれる、請求項3に記載の演算装置。
- 前記パラメータは、固定小数点の形式である、請求項1から請求項4のいずれか一項に記載の演算装置。
- 前記学習モデルは、ディープニューラルネットワーク形式の学習済モデルに基づいて、パラメータを固定小数点の形式に変換することによって作成されたものである、請求項1から請求項5のいずれか一項に記載の演算装置。
- 前記演算部は、前記パラメータに基づいて、入力値に対して、MAC(multiply-accumulate)演算を行う、請求項1から請求項6のいずれか一項に記載の演算装置。
- ニューラルネットワーク形式の学習モデルのパラメータの小数点のシフト量を特定する情報を取得するステップと、
取得する前記ステップで取得したパラメータの小数点のシフト量を特定する情報に基づいて、異なるビット幅で固定小数点の形式へ変換された複数の入力値に対する前記学習モデルの出力値を求め、求めた複数の前記出力値の各々と出力値の小数点のシフト量とに基づいて、求めた複数の前記出力値の各々の小数点をシフトさせるステップと、
複数の前記出力値の各々の小数点をシフトさせた結果の精度を導出するステップと、
を有し、
前記入力値は、固定小数点の形式である、コンピュータが実行する演算方法。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020193718A JP7614475B2 (ja) | 2020-11-20 | 2020-11-20 | 演算装置、及び演算方法 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020193718A JP7614475B2 (ja) | 2020-11-20 | 2020-11-20 | 演算装置、及び演算方法 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JP2022082257A JP2022082257A (ja) | 2022-06-01 |
| JP7614475B2 true JP7614475B2 (ja) | 2025-01-16 |
Family
ID=81810679
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020193718A Active JP7614475B2 (ja) | 2020-11-20 | 2020-11-20 | 演算装置、及び演算方法 |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7614475B2 (ja) |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019139338A (ja) | 2018-02-07 | 2019-08-22 | 富士通株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| JP2020009444A (ja) | 2018-07-04 | 2020-01-16 | 三星電子株式会社Samsung Electronics Co.,Ltd. | ニューラルネットワークにおいてパラメータを処理する方法及び装置 |
-
2020
- 2020-11-20 JP JP2020193718A patent/JP7614475B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019139338A (ja) | 2018-02-07 | 2019-08-22 | 富士通株式会社 | 情報処理装置、情報処理方法、およびプログラム |
| JP2020009444A (ja) | 2018-07-04 | 2020-01-16 | 三星電子株式会社Samsung Electronics Co.,Ltd. | ニューラルネットワークにおいてパラメータを処理する方法及び装置 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022082257A (ja) | 2022-06-01 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11169778B2 (en) | Converting floating point numbers to reduce the precision | |
| CN113011425B (zh) | 图像分割方法、装置、电子设备及计算机可读存储介质 | |
| Mandelli et al. | Adaptive sampling using support vector machines | |
| US20080219352A1 (en) | Motion vector searching apparatus, motion vector searching method and storage medium for storing motion vector searching program | |
| US10628124B2 (en) | Stochastic rounding logic | |
| US11106431B2 (en) | Apparatus and method of fast floating-point adder tree for neural networks | |
| EP3796233A1 (en) | Information processing device and method, and program | |
| US20240404262A1 (en) | Method and machine learning system to perform quantization of neural network | |
| EP3798929A1 (en) | Information processing apparatus, information processing method, and information processing program | |
| CN114556373A (zh) | 用于大规模并行神经推理引擎的多模式低精度内积计算电路 | |
| WO2022247368A1 (en) | Methods, systems, and mediafor low-bit neural networks using bit shift operations | |
| JP4500358B2 (ja) | 演算処理装置および演算処理方法 | |
| JP7614475B2 (ja) | 演算装置、及び演算方法 | |
| CN118424201A (zh) | 一种特征筛选下多核tcn网络的边坡形变预测方法 | |
| Santos | Deep and Physics-Informed Neural Networks as a Substitute for Finite Element Analysis | |
| CN112182729A (zh) | 一种基于朴素贝叶斯的隧道掌子面稳定性快速判定方法 | |
| JP7188237B2 (ja) | 情報処理装置、情報処理方法、情報処理プログラム | |
| CN110337636A (zh) | 数据转换方法和装置 | |
| CN118070551A (zh) | 不确定性系统可靠性分析的鞍点近似线抽样方法 | |
| US20080071852A1 (en) | Method to perform a subtraction of two operands in a binary arithmetic unit plus arithmetic unit to perform such a method | |
| JP2023031296A (ja) | 演算方法及び装置 | |
| CN112236749B (zh) | 一种浮点精度检测方法与装置 | |
| CN120431283B (zh) | 基于gpu加速的隐式地质建模方法、系统和设备 | |
| CN120911144B (zh) | 一种基于浮点分解重构的单精度硬件实现双精度模拟方法 | |
| CN119494414B (zh) | 脏量子常量比较器、脏量子变量比较器及量子计算机 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20201208 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20231102 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240830 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20240903 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20241031 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20241119 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20241127 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7614475 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |