JP7620164B2 - ネットワークの異常の原因推定 - Google Patents
ネットワークの異常の原因推定 Download PDFInfo
- Publication number
- JP7620164B2 JP7620164B2 JP2024524532A JP2024524532A JP7620164B2 JP 7620164 B2 JP7620164 B2 JP 7620164B2 JP 2024524532 A JP2024524532 A JP 2024524532A JP 2024524532 A JP2024524532 A JP 2024524532A JP 7620164 B2 JP7620164 B2 JP 7620164B2
- Authority
- JP
- Japan
- Prior art keywords
- network
- cause
- cause estimation
- unit
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images











Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/08—Monitoring or testing based on specific metrics, e.g. QoS, energy consumption or environmental parameters
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0631—Management of faults, events, alarms or notifications using root cause analysis; using analysis of correlation between notifications, alarms or events based on decision criteria, e.g. hierarchy, tree or time analysis
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/06—Management of faults, events, alarms or notifications
- H04L41/0654—Management of faults, events, alarms or notifications using network fault recovery
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L41/00—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks
- H04L41/16—Arrangements for maintenance, administration or management of data switching networks, e.g. of packet switching networks using machine learning or artificial intelligence
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04L—TRANSMISSION OF DIGITAL INFORMATION, e.g. TELEGRAPHIC COMMUNICATION
- H04L43/00—Arrangements for monitoring or testing data switching networks
- H04L43/02—Capturing of monitoring data
Landscapes
- Engineering & Computer Science (AREA)
- Computer Networks & Wireless Communication (AREA)
- Signal Processing (AREA)
- Environmental & Geological Engineering (AREA)
- Artificial Intelligence (AREA)
- Computer Vision & Pattern Recognition (AREA)
- Databases & Information Systems (AREA)
- Evolutionary Computation (AREA)
- Medical Informatics (AREA)
- Software Systems (AREA)
- Data Exchanges In Wide-Area Networks (AREA)
Description
本開示は、ネットワークシステムおよびネットワーク異常の対応方法に関する。
機器やソフトウェアから取得される監視情報に基づいてルールベースでネットワークの状態を監視することが行われている。
ネットワークに生じる異常には様々なタイプがある。障害のメカニズムが複雑な場合には、監視情報から異常の原因を判定するルールを作成することが難しい。
発明者らは、機械学習モデルを用いて異常の原因を判定することを検討している。しかしながら、ネットワークに生じる異常は非常に複雑であるため、単に機械学習モデルを用いてその異常の原因を判定しようとした場合、その判定の精度が確保できなかった。
本開示は上記実情に鑑みてなされたものであって、その目的の一つは、ネットワークに生じた異常の原因を精度よく推定することを可能にする技術を提供することにある。
上記課題を解決するために、本開示にかかるネットワークシステムは、1以上のプロセッサを備え、前記1以上のプロセッサのうち少なくとも一つによって、取得処理、選択処理、出力取得処理、対応処理が実行される。取得処理では、ネットワークの状態を示す第1の情報を取得する。選択処理では、前記ネットワークに生じる障害の原因の種類ごとに設けられ、それぞれモデル選択条件に対応付けられる複数の原因推定モデルであって、前記第1の情報とは異なる時間帯における前記ネットワークの状態を示す第2の情報を含む入力データと、対応する原因の種類に属する前記ネットワークに生じた異常の原因を示す正解データとを含む訓練データにより学習される複数の原因推定モデルから、前記取得された第1の情報が満たすモデル選択条件に対応する原因推定モデルを選択する。出力取得処理では、前記選択された原因推定モデルに前記ネットワークの状態を示す第1の情報が入力された際の出力を取得する。対応処理では、前記選択された前記原因推定モデルの前記取得された出力に基づいて前記ネットワークに生じた異常に対処する処理を開始させる。
また、本開示にかかるネットワークの異常の対応方法は、1以上のプロセッサを備え、前記1以上のプロセッサのうち少なくとも一つによって、取得処理、選択処理、出力取得処理、対応処理が実行される。選択処理では、前記ネットワークに生じる障害の原因の種類ごとに設けられ、それぞれモデル選択条件に対応付けられる複数の原因推定モデルであって、前記第1の情報とは異なる時間帯における前記ネットワークの状態を示す第2の情報を含む入力データと、対応する原因の種類に属する前記ネットワークに生じた異常の原因を示す正解データとを含む訓練データにより学習される複数の原因推定モデルから、前記取得された第1の情報が満たすモデル選択条件に対応する原因推定モデルを選択する。出力取得処理では、前記選択された原因推定モデルに前記ネットワークの状態を示す第1の情報が入力された際の出力を取得する。対応処理では、前記選択された前記原因推定モデルの前記取得された出力に基づいて前記ネットワークに生じた異常に対処する処理を開始させる。
以下、本開示における実施形態について図面に基づき詳細に説明する。
図1および図2は、本開示の実施形態に係る通信システム1の一例を示す図である。図1は、通信システム1に含まれるデータセンタ群のロケーションに着目した図となっている。図2は、通信システム1に含まれるデータセンタ群で実装されている各種のコンピュータシステムに着目した図となっている。
図1に示すように、通信システム1に含まれるデータセンタ群は、セントラルデータセンタ10、リージョナルデータセンタ12、エッジデータセンタ14に分類される。
セントラルデータセンタ10は、例えば、通信システム1がカバーするエリア内(例えば、日本国内)に分散して数個配置されている。
リージョナルデータセンタ12は、例えば、通信システム1がカバーするエリア内に分散して数十個配置されている。例えば、通信システム1がカバーするエリアが日本国内全域である場合に、リージョナルデータセンタ12が、各都道府県に1から2個ずつ配置されてもよい。
エッジデータセンタ14は、例えば、通信システム1がカバーするエリア内に分散して数千個配置される。また、エッジデータセンタ14のそれぞれは、アンテナ16を備えた通信設備18と通信可能となっている。図1に示すように、1つのエッジデータセンタ14が数個の通信設備18と通信可能になっていてもよい。通信設備18は、サーバコンピュータなどのコンピュータを含んでいてもよい。本実施形態に係る通信設備18は、アンテナ16を介してUE(User Equipment)20との間で無線通信を行う。アンテナ16を備えた通信設備18には、例えば、後述のRU(Radio Unit)が設けられている。
本実施形態に係るセントラルデータセンタ10、リージョナルデータセンタ12、エッジデータセンタ14には、それぞれ、複数のサーバが配置されている。
本実施形態では例えば、セントラルデータセンタ10、リージョナルデータセンタ12、エッジデータセンタ14は、互いに通信可能となっている。また、セントラルデータセンタ10同士、リージョナルデータセンタ12同士、エッジデータセンタ14同士も互いに通信可能になっている。
図2に示すように、本実施形態に係る通信システム1には、プラットフォームシステム30、複数の無線アクセスネットワーク(RAN)32、複数のコアネットワークシステム34、複数のUE20が含まれている。コアネットワークシステム34、RAN32、UE20は、互いに連携して、移動通信ネットワークを実現する。
RAN32は、第4世代移動通信システム(以下、4Gと呼ぶ。)におけるeNB(eNodeB)や、第5世代移動通信システム(以下、5Gと呼ぶ。)におけるgNB(NR基地局)に相当する、アンテナ16を備えたコンピュータシステムである。本実施形態に係るRAN32は、主に、エッジデータセンタ14に配置されているサーバ群および通信設備18によって実装される。なお、RAN32の一部(例えば、DU(Distributed Unit)、CU(Central Unit)、vDU(virtual Distributed Unit)、vCU(virtual Central Unit))は、エッジデータセンタ14ではなく、セントラルデータセンタ10やリージョナルデータセンタ12で実装されてもよい。
コアネットワークシステム34は、4GにおけるEPC(Evolved Packet Core)や、5Gにおける5Gコア(5GC)に相当するシステムである。本実施形態に係るコアネットワークシステム34は、主に、セントラルデータセンタ10やリージョナルデータセンタ12に配置されているサーバ群によって実装される。
本実施形態に係るプラットフォームシステム30は、例えば、クラウド基盤上に構成されており、図2に示すように、1または複数のプロセッサ30a、記憶部30b、通信部30c、が含まれる。プロセッサ30aは、プラットフォームシステム30にインストールされるプログラムに従って動作するマイクロプロセッサ等のプログラム制御デバイスである。記憶部30bは、例えばROMやRAM等の記憶素子や、ソリッドステートドライブ(SSD)、ハードディスクドライブ(HDD)などである。記憶部30bには、プロセッサ30aによって実行されるプログラムなどが記憶される。通信部30cは、例えば、NIC(Network Interface Controller)や無線LAN(Local Area Network)モジュールなどといった通信インタフェースである。通信部30cは、RAN32、コアネットワークシステム34、との間でデータを授受する。通信部30cは、SDN(Software-Defined Networking)の一部を構成してもよい。
本実施形態では、プラットフォームシステム30は、セントラルデータセンタ10に配置されているサーバ群によって実装されている。なお、プラットフォームシステム30が、リージョナルデータセンタ12に配置されているサーバ群によって実装されていてもよい。プロセッサ30a、記憶部30b、通信部30cは、実際にはサーバに含まれるものであってもよい。RAN32およびコアネットワークシステム34は、プラットフォームシステム30と同様にプロセッサ30a、記憶部30b、通信部30cを含んでよい。
本実施形態では例えば、購入者によるネットワークサービス(NS)の購入要求に応じて、購入要求がされたネットワークサービスがRAN32やコアネットワークシステム34に構築される。そして、構築されたネットワークサービスが購入者に提供される。
例えば、MVNO(Mobile Virtual Network Operator)である購入者に、音声通信サービスやデータ通信サービス等のネットワークサービスが提供される。本実施形態によって提供される音声通信サービスやデータ通信サービスは、図1および図2に示すUE20を利用する、購入者(上述の例ではMVNO)にとっての顧客(エンドユーザ)に対して最終的に提供されることとなる。当該エンドユーザは、RAN32やコアネットワークシステム34を介して他のユーザとの間で音声通信やデータ通信を行うことが可能である。また、当該エンドユーザのUE20は、RAN32やコアネットワークシステム34を介してインターネット等のデータネットワークにアクセスできるようになっている。
また、本実施形態において、ロボットアームやコネクテッドカーなどを利用するエンドユーザに対して、IoT(Internet of Things)サービスが提供されてよい。そして、この場合において、例えば、ロボットアームやコネクテッドカーなどを利用するエンドユーザが本実施形態に係るネットワークサービスの購入者となってもよい。
本実施形態では、セントラルデータセンタ10、リージョナルデータセンタ12、および、エッジデータセンタ14に配置されているサーバには、ドッカー(Docker(登録商標))などのコンテナ型の仮想化アプリケーション実行環境がインストールされており、これらのサーバにコンテナをデプロイして稼働させることができるようになっている。これらのサーバにおいて、このような仮想化技術によって生成される1以上のコンテナから構成されるクラスタが構築されてもよい。例えば、クバネテス(Kubernetes(登録商標))等のコンテナ管理ツールによって管理されるクバネテスクラスタが構築されていてもよい。そして、構築されたクラスタ上のプロセッサがコンテナ型のアプリケーションを実行してもよい。
そして本実施形態におけるネットワークサービスは、1または複数の機能ユニット(例えば、ネットワークファンクション(NF))から構成される。本実施形態では、当該機能ユニットは、仮想化技術によって実現されたNFで実装される。仮想化技術によって実現されたNFは、VNF(Virtualized Network Function)と称される。なお、どのような仮想化技術によって仮想化されたかは問わない。例えば、コンテナ型の仮想化技術によって実現されたCNF(Containerized Network Function)も、本説明においてVNFに含まれる。本実施形態では、ネットワークサービスが1または複数のCNFによって実装されるものとして説明する。また、本実施形態に係る機能ユニットは、ネットワークノードに相当するものであってもよい。
図3は、稼働中のネットワークサービスの一例を模式的に示す図である。図3は、ネットワークサービスのうちの1つの、エンド・ツー・エンドのネットワークスライスに関する構成の一例を示している。ネットワークスライスは、物理的な通信ネットワークが仮想的に分割されたものである。
図3に示すネットワークサービスには、複数のRU40、複数のDU42、複数のCU44、複数のUPF(User Plane Function)46、1または複数のAMF(Access and Mobility Management Function)、1または複数のSMF(Session Management Function)といったなどのNFがソフトウェア要素として含まれている。
また、CU44とAMFおよびUPFとの間は、それぞれSDN36によりネットワークの経路が設けられる。SDN36は、専用のネットワーク機器および複数のサーバを含む機器により実装されている。ネットワークの経路は一種のトンネルに相当し、SDN36ではソフトウェア的な設定により、新たな経路を設定することや既存の経路において物理的に経由する機器を変更することが可能である。
そして、本実施形態では例えば、図3に示すネットワークサービスによって、あるエリアにおける通信サービスが提供される。なお、当該ネットワークサービスには、他のソフトウェア要素も含まれるが、これらの要素については記載を省略する。また、ネットワークサービスは、複数のサーバ等のコンピュータリソース(ハードウェア要素)上に実装されている。
図4は、本実施形態において通信システム1に構築される要素間の関連付けの一例を模式的に示す図である。なお、図4に示された記号MおよびNは1以上の任意の整数を表し、リンクで接続された要素同士の個数の関係を示す。リンクの両端がMとNの組み合わせの場合は、当該リンクで接続された要素同士は多対多の関係であり、リンクの両端が1とNの組み合わせまたは1とMの組み合わせの場合は、当該リンクで接続された要素同士は1対多の関係である。
図4に示すように、ネットワークサービス(NS)、ネットワークファンクション(NF)、CNFC(Containerized Network Function Component)、pod、および、コンテナは、階層構成となっている。
NSは、例えば、複数のNFから構成されるネットワークサービスに相当する。ここで、NSが、例えば、5GC、EPC、5GのRAN(gNB)、4GのRAN(eNB)、などの粒度の要素に相当するものであってもよい。
NFは、5Gでは、例えば、DU42、CU44、UPF46、などの粒度の要素に相当する。また、NFは、AMF、SMFなどの粒度の要素に相当する。また、NFは、4Gでは、例えば、MME(Mobility Management Entity)、HSS(Home Subscriber Server)、S-GW(Serving Gateway)、vDU、vCUなどの粒度の要素に相当する。本実施形態では例えば、1つのNSには、1または複数のNFが含まれる。すなわち、1または複数のNFが、1つのNSの配下にあることとなる。
CNFCは、例えば、DU mgmtやDU Processingなどの粒度の要素に相当する。CNFCは、1つ以上のコンテナとしてサーバにデプロイされるマイクロサービスであってもよい。例えば、あるCNFCは、DU42、CU44等の機能のうち一部の機能を提供するマイクロサービスであってもよい。また、あるCNFCは、UPF46、AMF、SMF等の機能のうちの一部の機能を提供するマイクロサービスであってもよい。本実施形態では例えば、1つのNFには、1または複数のCNFCが含まれる。すなわち、1または複数のCNFCが、1つのNFの配下にあることとなる。
podは、例えば、クバネテスでドッカーコンテナを管理するための最小単位を指す。本実施形態では例えば、1つのCNFCには、1または複数のpodが含まれる。すなわち、1または複数のpodが、1つのCNFCの配下にあることとなる。
そして、本実施形態では例えば、1つのpodには、1または複数のコンテナが含まれる。すなわち、1または複数のコンテナが、1つのpodの配下にあることとなる。
また、図4に示すように、ネットワークスライス(NSI)とネットワークスライスサブネットインスタンス(NSSI)とは階層構成となっている。
NSIは、複数ドメイン(例えばRAN32からコアネットワークシステム34)に跨るエンド・ツー・エンドの仮想回線とも言える。NSIは、高速大容量通信用のスライス(例えば、eMBB:enhanced Mobile Broadband用)、高信頼度かつ低遅延通信用のスライス(例えば、URLLC:Ultra-Reliable and Low Latency Communications用)、または、大量端末の接続用のスライス(例えば、mMTC:massive Machine Type Communication用)であってもよい。NSSIは、NSIを分割した単一ドメインの仮想回線とも言える。NSSIは、RANドメインのスライス、MBH(Mobile Back Haul)ドメインのスライス、または、コアネットワークドメインのスライスであってもよい。
本実施形態では例えば、1つのNSIには、1または複数のNSSIが含まれる。すなわち、1または複数のNSSIが、1つのNSIの配下にあることとなる。なお、本実施形態において、複数のNSIが同じNSSIを共有してもよい。
また、図4に示すように、NSSIとNSとは、一般的には、多対多の関係となる。
また、本実施形態では例えば、1つのNFは、1または複数のネットワークスライスに所属できるようになっている。具体的には例えば、1つのNFには、1または複数のS-NSSAI(Sub Network Slice Selection Assist Information)を含むNSSAI(Network Slice Selection Assistance Information)を設定できるようになっている。ここで、S-NSSAIは、ネットワークスライスに対応付けられる情報である。なお、NFが、ネットワークスライスに所属していなくてもよい。
複数のネットワークスライスは、互いに、対象とするエリアやNFの構成、対象とするUE20の種類、などが異なっていてよい。図5は、ネットワークスライスの属性の一例を示す図である。図5では、ネットワークスライスの属性として、スライスID、タイプ、構成、グループが示されている。スライスIDはネットワークスライスを識別する情報である。タイプはネットワークの特性の種類を示し、空白の場合は一般的なUE20との通信向けの特性、IoTの場合はIoT端末との通信に特化した特性を有することを示す。構成はネットワークスライスを実現するNF(AMF、SMF、UPF)の数、およびカバーするエリアを示す。グループは、ネットワークスライスが属するグループを示す。
本実施形態では、複数のネットワークスライスは、そのタイプや構成、ネットワークの利用特性(例えば都市部中心の利用特性か郊外中心の利用特性か)に応じて複数のグループに分類される。グループの分類においては、AMF、SMF、UPFの数とRANの数とから求められるネットワーク経路の数、またそのネットワーク経路の種類、RAN(例えばgNB)の数も用いられてよい。この分類は、いわゆるクラスタリング技術により行われてよい。複数のグループのそれぞれには、1または複数のネットワークスライスが属する。
本実施形態にかかるプラットフォームシステム30は、複数のネットワークスライスのそれぞれを監視し、それらに生じた異常を検出し、その異常に応じた対応処理を実行する。以下ではそれらの処理にについてより詳細に説明する。
図6は、本実施形態にかかるプラットフォームシステム30に実装される機能の一例を示す機能ブロック図である。なお、本実施形態にかかるプラットフォームシステム30に対して、図5に示す機能のすべてが実装される必要はなく、また、図6に示す機能以外の機能が実装されていても構わない。
図6に示すように、本実施形態に係るプラットフォームシステム30は、機能的には、インベントリデータベース50、オーケストレーション(E2EO:End-to-End-Orchestration)部52、チケット管理部54、AI・ビッグデータ処理部56、性能算出部57、監視機能部58、SDNコントローラ60、構成管理部62、を含む。E2EO部52は、機能的に、ポリシーマネージャ部80、スライスマネージャ部82を含む。AI・ビッグデータ処理部56は、機能的に、ビッグデータ格納部70、正常判定部72、原因推定部74、API部76を含む。正常判定部72は複数の正常判定モデル73を含み、原因推定部74は、複数の原因推定モデル75を含む。これらの要素は、主に、プロセッサ30a、記憶部30b、および、通信部30cにより実装される。
本実施形態に記載される機能および処理は、プロセッサ30a、記憶部30b(例えばメモリ)などを備えた1または複数の情報処理装置(例えばサーバ)にソフトウェア(プログラムの実行命令)が記録された記憶媒体を読み込ませ、プロセッサ30aがそのソフトウェアにかかる処理を実行することによって実現される。この記憶媒体は、例えば、光ディスク、磁気ディスク、磁気テープ、光磁気ディスク、フラッシュメモリ等のコンピュータ読み取り可能な、非揮発性の情報記憶媒体であってよい。また、プラットフォームシステム30の記憶部30bに含まれる外部記憶装置(例えばハードディスクドライブやソリッドステートドライブ)に、このソフトウェアが格納されてよい。また、図6に示す機能が、回路ブロック、メモリ、その他の集積回路により実装されてもよい。また、図6に示す機能が、ハードウェアのみ、ソフトウェアのみ、またはそれらの組合せといった様々な形態で実現できることは、当業者には容易に理解される。
インベントリデータベース50は、インベントリ情報が格納されたデータベースである。当該インベントリ情報には、例えば、RAN32やコアネットワークシステム34に配置され、プラットフォームシステム30で管理されているサーバについての情報が含まれる。
また本実施形態では、インベントリデータベース50には、インベントリデータが記憶されている。インベントリデータには、通信システム1に含まれる要素群の構成や要素間の関連付け(例えばトポロジーデータ)の現況が示されている。要素は、ハードウェア的な要素と、ソフトウェア的な要素とを含む。ハードウェア的な要素は、例えば、サーバ、ラック、建物、ネットワーク機器を含む。ソフトウェア的な要素は、例えば、ネットワークスライスやNF、稼働するコンテナを含む。また、インベントリデータには、プラットフォームシステム30で管理されているリソースの状況(例えば、リソースの使用状況)が示されている。
要素間の関連付けの現況を示すトポロジーデータは、例えば、あるNSの識別子と当該NSの配下にある1または複数のNFの識別子とを含み、また例えば、あるネットワークスライスの識別子と当該ネットワークスライスに所属する1または複数のNFの識別子とを含む。
図6に示されるE2EO部52、チケット管理部54、AI・ビッグデータ処理部56、性能算出部57、監視機能部58、SDNコントローラ60、構成管理部62の各機能は、その処理においてインベントリデータベース50に格納されるインベントリデータを参照し、必要に応じてインベントリデータを追加または更新する。例えば、通信システム1に含まれる新規要素の構築、通信システム1に含まれる要素の構成変更、通信システム1に含まれる要素のスケーリング、通信システム1に含まれる要素のリプレース、などのアクションが実行されることに応じて、インベントリデータベース50に記憶されているインベントリデータが更新される。
スライスマネージャ部82は、本実施形態では例えば、スライステンプレートが示すロジックを実行することで、ネットワークスライスのインスタンス化を実行する。ここで、スライスマネージャ部82は、ネットワークスライスのインスタンス化に関係する構成管理指示を構成管理部62に出力してよい。そして、構成管理部62が、当該構成管理指示に従った設定等の構成管理を実行してよい。
スライスマネージャ部82は、SDNコントローラ60に、NF間(CU44とUPF46およびAMFとの間)の通信経路の作成指示を出力してよい。SDNコントローラ60は、SDN36に対して、より具体的な通信経路の作成指示を出力してよい。具体的な通信経路の作成指示は、互いに通信するCU44と、UPF46またはAMFとを特定する情報として、2つのSRV6のIPアドレスを含む。
ここで、スライスマネージャ部82は、ポリシーマネージャ部80からの指示に応じて、ネットワークスライスにおける通信経路と、コアネットワークシステム34等におけるNFとのうち少なくとも一方を増強する処理を実行する。例えばスライスマネージャ部82は、ネットワークスライスに関連付けられるUPF46、AMF、SMFのうちいずれかをスケールアウトする構成管理指示を構成管理部62に出力し、スケールアウトされたUPF46またはAMFと各RAN32のCU44との新たな通信経路を作成する作成指示をSDNコントローラ60に出力してよい。またスライスマネージャ部82は、既存のUPF46またはAMFと各RAN32のCU44との通信経路の帯域幅の上限を変更する、または通信経路を再作成する(言い換えれば、使用する通信経路を変更する)変更指示をSDNコントローラ60に出力してよい。
スライスマネージャ部82は、例えば、3GPP(Third Generation Partnership Project)(登録商標)の仕様書「TS28 533」に記載される、NSMF(Network Slice Management Function)と、NSSMF(Network Slice Sub-network Management Function)の機能を含んで構成される。NSMFは、ネットワークスライスを生成して管理する機能であり、NSIのマネジメントサービスを提供する。NSSMFは、ネットワークスライスの一部を構成するネットワークスライスサブネットを生成し管理する機能であり、NSSIのマネジメントサービスを提供する。
構成管理部62は、本実施形態では例えば、スライスマネージャ部82から受け付ける構成管理指示に従って、NF等の要素群の設定等の構成管理を実行する。
SDNコントローラ60は、本実施形態では例えば、スライスマネージャ部82から受け付けた通信経路の作成指示に従って、当該作成指示に関連付けられているNF間の通信経路を作成する。またSDNコントローラ60は、スライスマネージャ部82から受け付けた変更指示に従って、NF間の通信経路の帯域幅の上限を変更する、またはNF間の通信経路を再作成する。
ここで、SDNコントローラ60は、セグメントルーティング技術(例えばSRv6(セグメントルーティングIPv6))を用いて、通信経路間に存在するアグリゲーションルータや、サーバなどに対して、NSIやNSSIを構築してもよい。また、SDNコントローラ60は、複数の設定対象のNFに対して、共通のVLAN(Virtual Local Area Network)を設定するコマンド、および、当該VLANに設定情報が示す帯域幅や優先度を割り当てるコマンドを発行することにより、それら複数の設定対象のNFにわたるNSIおよびNSSIを生成してもよい。
監視機能部58は、ネットワークの状態を示す監視情報を取得する。監視機能部58は、ネットワークスライスごとに、その状態を示す監視情報を取得してよい。監視情報は例えばメトリックデータおよびアラートの通知である。なお、監視機能部58は、NSのレベル、NFのレベル、CNFCのレベル、サーバ等のハードウェアのレベル、などといった、様々なレベルについて監視情報を取得してよい。
監視機能部58は、例えば、メトリックデータを出力するモジュールから監視情報を取得してよい。メトリックデータを出力するモジュールは、サーバ等のハードウェアや、通信システム1に含まれるソフトウェア要素に設定されてよい。また、NFが、当該NFにおいて測定可能(特定可能)なメトリックを示すメトリックデータを監視機能部58に出力するように構成されてもよい。また、サーバが、当該サーバにおいて測定可能(特定可能)なハードウェアに関するメトリックを示すメトリックデータを監視機能部58に出力するように構成されてもよい。
また、例えば、監視機能部58は、サーバにデプロイされるサイドカーコンテナからメトリックデータを取得してもよい。サイドカーコンテナは、複数のコンテナから出力されたメトリックを示すメトリックデータをCNFC(マイクロサービス)単位に集計する。このサイドカーコンテナは、エクスポーターと呼ばれるエージェントを含んでもよい。監視機能部58は、クバネテス等のコンテナ管理ツールを監視可能なプロメテウス(Prometheus)などのモニタリングツールの仕組みを利用して、マイクロサービス単位に集計されたメトリックデータをサイドカーコンテナから取得する処理を、所与の監視間隔で繰り返し実行してもよい。
監視機能部58は、メトリックデータとして、ネットワークの性能を示す性能指標値およびその性能指標値が取得された時刻を取得してよい。監視機能部58は、例えば、「TS 28.552, Management and orchestration; 5G performance measurements」または「TS 28.554, Management and orchestration; 5G end to end Key Performance Indicators (KPI)」に記載された性能指標についての性能指標値を示すメトリックデータを監視情報として取得してよい。
そして、監視機能部58は、例えば、上述の監視情報を取得すると、当該監視情報をAI・ビッグデータ処理部56に向けて出力してよい。AI・ビッグデータ処理部56は出力された監視情報をビッグデータ格納部70に格納する。
また、通信システム1に含まれるネットワークスライス、NS、NF、CNFC等の要素や、サーバ等のハードウェアは、監視機能部58に、各種のアラートの通知(例えば、ハードウェアまたはソフトウェアに生じた何らかの異常の発生をトリガとしたアラートの通知)を行う。
そして、監視機能部58は、例えば、上述のアラートの通知を監視情報として取得すると、当該通知をAI・ビッグデータ処理部56に出力する。AI・ビッグデータ処理部56は、その監視情報をビッグデータ格納部70に格納する。格納されたアラートの通知は、ポリシーマネージャ部80により利用される。ポリシーマネージャ部80の処理については後述する。
性能算出部57は、ビッグデータ格納部70に格納された複数のメトリックデータに基づいて、これらのメトリックデータが示すメトリックに基づく性能指標値(例えば、一種のKPI)を算出する。性能算出部57は、単一のメトリックデータからは算出できない、複数の種類のメトリックの総合評価である性能指標値(例えば、エンド・ツー・エンドのネットワークスライスに係る性能指標値)を算出してよい。性能算出部57は、算出された性能指標値を示す性能指標データをAI・ビッグデータ処理部56に出力し、その性能指標値データをビッグデータ格納部70に格納させてよい。性能指標データも、ネットワークスライスの状態を示す監視情報の一種である。
なお、性能算出部57は、メトリックデータを監視機能部58から直接的に取得してそのメトリックデータに基づいて性能指標値を算出してもよい。
AI・ビッグデータ処理部56は、メトリックデータ、アラートの通知、性能指標値などの監視情報を蓄積し、またその蓄積された監視情報に基づいてネットワークに生じる異常の原因を推定する。
AI・ビッグデータ処理部56に含まれるビッグデータ格納部70は、サーバ等のハードウェアやNFのようなソフトウェア要素から取得された、メトリックデータおよびアラートを含む監視情報を、対応するネットワークスライスおよび時刻と関連付けて格納する。ビッグデータ格納部70には過去の監視情報が蓄積される。
AI・ビッグデータ処理部56に含まれる正常判定部72は、複数のネットワークスライスにそれぞれ対応する複数の正常判定モデル73を含む。正常判定部72は、対象となるネットワークスライスに対応する正常判定モデル73に対象となるネットワークスライスから取得される指標を含む入力データを入力した際の出力を取得することにより、対象となるネットワークスライスの状態が正常であるか否かを判定する。複数の正常判定モデル73は、複数のネットワークスライスと1対1で対応してよい。
正常判定モデル73は、対応するネットワークスライスにおける、正常時のある時刻またはその直近の一定の期間に取得されたメトリックの指標と、その指標が取得された時間帯を示す情報とを含む正常訓練データにより学習されている。正常時とは、障害が発生していない期間である。正常時の指標は、所定期間の通信量を示すデータ、所定期間のネットワークの性能を示す指標、所定期間の代表時刻、所定期間の曜日、所定期間が休日か否かを示す休日フラグのうち少なくとも一部を含んでよい。正常判定モデル73は、例えばk-近傍法、密度準拠クラスタリング、アイソレーションフォレストのような、データから外れ値を検出可能な公知の教師なし機械学習モデルに基づく異常検知モデルであってよい。
正常判定モデル73には、あるネットワークスライスにおける、現在または直近の一定の時間の指標と、現在の時間帯を示す情報を含む入力データが入力される。入力データは、ビッグデータ格納部70に格納されたデータからネットワークスライスおよび時刻に応じて選択されたデータであってよい。正常判定モデル73は、ネットワークの状態が正常であるか否かの推定結果を示す情報を出力する。正常判定モデル73は、例えば、訓練データのいずれかとの差異が小さい入力データに対しては正常を示す情報を出力し、どの訓練データとも差異が大きい入力データに対しては異常を示す情報を出力してよい。
AI・ビッグデータ処理部56に含まれる原因推定部74は、複数のグループにそれぞれ対応する複数の原因推定モデル75を含む。複数のグループに、複数のネットワークスライスが分類されている。また原因推定部74は、複数の原因の種類にそれぞれ対応する複数の原因推定モデル75を含んでよい。原因推定モデル75は、機械学習モデルである。原因の種類は、例えば、異常が発見されるトリガとなる事象の種類(以下では単にトリガの種類と記載する)であってよい。原因推定モデル75は、ネットワークに異常が生じた際の過去の監視情報を含む入力データと、前記異常の原因を示す正解データとを含む訓練データによって学習されている。
また原因推定モデル75のそれぞれは、原因の種類と対応づけられており、原因推定モデル75は、異常の原因が、対応づけられた原因の種類に含まれる複数の原因のうちいずれであるかを推定する。原因推定モデル75はグループおよび原因の種類の組み合わせごとに設けられ、互いに異なる訓練データにより学習されてよい。複数の原因推定モデル75から原因の種類に応じたものに原因を推定させるために、複数の原因の種類にそれぞれ対応し互いに異なる複数のモデル決定条件が存在する。このモデル決定条件により、用いられる原因推定モデル75が決定される。なお、複数の原因推定モデル75から用いられるものを選択するための条件とも言えるので、モデル決定条件はモデル選択条件とも称される。
なお、原因推定モデル75のインスタンスは、ネットワークインスタンスと原因の種類の組み合わせごとに設けられてよい。この場合、同じグループに属する複数のネットワークスライスを含むある原因の種類についての原因推定モデル75のインスタンスは、同じ訓練データにより学習された同じ種類のものである。なお、原因推定モデル75は原因の種類に応じて分かれていなくてもよく、全てのネットワークスライスで共通の内部パラメータを有してもよい。
原因推定モデル75は、例えばTransformerモデルのように時系列の情報からネットワークに生じた異常の原因を推定するモデルであってよい。原因推定モデル75に入力される入力データは、直近の3ブロック(例えば1h間隔であれば3h)のそれぞれのスナップショットにおける代表的な指標であってよい。その代表的な指標は、監視情報に含まれる、トラフィック、KPIの推移、代表時刻、曜日、休日フラグのうち少なくとも一部の項目を含んでよい。学習用のデータセットは、連続する3ブロックのそれぞれのスナップショットにおける代表的な指標のデータを含んでよい。原因推定モデル75の学習用の入力データに含まれる複数の指標は、対応するグループに属するネットワークスライスについてビッグデータ格納部70に格納される監視情報のログから取得されてよい。
ある原因の種類について、正常判定モデル73および原因推定モデル75が組み合わせて用いられてよい。またある原因の種類について、複数の原因推定モデル75の出力を組み合わせた情報が原因の推定に用いられてもよい。
AI・ビッグデータ処理部56に含まれるAPI部76は、ポリシーマネージャ部80から呼び出されるAPIを提供する。API部76は、ポリシーマネージャ部80から呼び出されるAPIに応じて、原因推定部74によるネットワークに生じた異常の原因の推定結果(原因推定部74の出力)を取得し、さらに、原因推定部74の原因推定モデル75の出力を呼び出し元へ返す。
API部76は、原因の種類(トリガの種類)に応じて異なるAPIを提供してよいし、ネットワークスライスに応じて異なるAPIを提供してもよい。API部76は、単にAPIを呼び出す際のパラメータとして原因の種類およびネットワークスライスを取得し、そのパラメータに応じた原因推定モデル75の出力を返してもよい。
ポリシーマネージャ部80は、本実施形態では例えば、上述のメトリックデータ、上述のアラートの通知、上述の原因推定モデル75の出力、上述の性能指標値データ、のうちの少なくともいずれかに基づいて、所定の判定処理を実行する。
そして、ポリシーマネージャ部80は、判定処理の結果に応じたアクションを実行する。例えば、ポリシーマネージャ部80は、スライスマネージャ部82に、ネットワークスライスにおける通信経路と、コアネットワークシステム34等におけるNFとのうち少なくとも一方を増強させる指示を送信する。また例えば、ポリシーマネージャ部80は、チケット管理部54へ、発生した異常の内容(例えば検知された自称およびその推定された原因)を送信する。また例えば、ポリシーマネージャ部80は、判定処理の結果に応じて、要素のスケーリングやリプレースの指示を図示しないライフサイクル管理部に出力する。
チケット管理部54は、本実施形態では例えば、通信システム1の管理者に通知すべき内容が示されたチケットを生成する。チケット管理部54は、発生した異常(障害)の内容を示すチケットを生成してもよい。また、チケット管理部54は、性能指標値データやメトリックデータの値を示すチケットを生成してもよい。また、チケット管理部54は、ポリシーマネージャ部80による判定結果を示すチケットを生成してもよい。
そして、チケット管理部54は、生成されたチケットを、通信システム1の管理者に通知する。チケット管理部54は、例えば、生成されたチケットが添付された電子メールを、通信システム1の管理者の電子メールアドレスに宛てて送信してもよい。
以下では、通信システム1における、ネットワークに異常が生じた際のその異常の原因の推定およびその原因に応じた対応の処理についてより詳細に説明する。これらの推定および対応の処理は、ポリシーマネージャ部80およびAI・ビッグデータ処理部56により実装される。
本実施形態では、原因の推定に用いる原因推定モデル75は、原因の種類(トリガの種類)および対象のネットワークスライスが属するグループに応じて定まる。複数のモデル決定条件は、原因推定モデル75を決定するための条件であり、原因の種類に対応している。
図7は、ポリシーマネージャ部80の処理の概要を示すフロー図である。図7に示される処理フローは、ポリシーマネージャ部80の機能のうち、ネットワークに生じた異常の原因を取得し、その原因に対応する機能に関する処理の概要を示している。
はじめにポリシーマネージャ部80は、ビッグデータ格納部70から監視情報を取得する(S101)。そして、ポリシーマネージャ部80は、取得された監視情報が満たすモデル決定条件に応じて、API部76の呼び出し手法を決定する(S102)。そしてポリシーマネージャ部80はその呼び出し手法によりAPI部76を介してモデル決定条件に応じた原因推定モデル75の出力を取得する(S103)。原因推定モデル75にはビッグデータ格納部70から取得された監視情報を含む入力データが入力されてよい。S102においてポリシーマネージャ部80は監視情報のうち一部を用いてモデル決定条件を満たすか判定してよい。原因推定モデル75に入力される監視情報は、S102において用いられる監視情報と異なる項目を含んでもよい。
複数のモデル決定条件は第1および第2のモデル決定条件を含む。第1のモデル決定条件はネットワークスライスにおけるトラフィックの異常(スループット等の性能指標の異常)を示す条件である。第2のモデル決定条件は端末の登録に関する異常を示す条件である。第1のモデル決定条件および第2のモデル決定条件に関する処理の詳細については、図10、図12を用いて後述する。
呼び出されたAPI部76の処理について説明する。図8は、AI・ビッグデータ処理部56の処理の一例を示すフロー図である。図8は、S103によりAI・ビッグデータ処理部56に含まれるAPI部76が呼び出された際の処理の一例を示す。
API部76は、APIの種類および対象となるネットワークスライスが属するグループに基づいて原因推定モデル75を決定する(S201)。厳密には、API部76は、グループに基づいて原因推定モデル75の種類を決定する。APIの種類は、APIの呼び出し手法の一例である。本図の例では、APIの種類は、原因の種類や、異常が発見されるトリガとなる事象の種類に対応している。APIは、原因の種類とネットワークスライスの組み合わせごとに設けられてもよい。
API部76は、原因推定モデル75の決定において、呼び出されたAPIの種類とネットワークスライスとの組み合わせに対応する原因推定モデル75のインスタンスを決定してよい。原因推定モデル75のインスタンスに応じた原因推定モデル75の種類はグループに応じて決まっているため、ネットワークスライスに応じた原因推定モデル75のインスタンスの決定は、グループに応じた原因推定モデル75の決定に相当する。なお、API部76は、S201において、出力の取得の対象となる2以上の原因推定モデル75の組み合わせを決定してもよい。
用いられる原因推定モデル75が決定されると、API部76は、決定された原因推定モデル75(厳密にはそのインスタンス)にそのネットワークスライスについてのネットワークの状態を示す監視情報が入力された際の出力を取得する(S202)。ここで、API部76は、S201の処理の後に、入力データの取得と、決定された原因推定モデル75への入力データとして監視情報の入力と、その原因推定モデル75の出力の取得とを順に行ってよい。API部76は、入力データとしてビッグデータ格納部70から決定された原因推定モデル75に入力する現在または直近の監視情報を取得してよい。
一方、複数の原因推定モデル75のいずれかには、API部76による原因推定モデル75の決定と関係なく、入力データとして監視情報が入力されてもよい。この場合、原因推定モデル75には定期的に、ビッグデータ格納部70から現在または直近の監視情報が入力データとして入力されてよい。この場合、ポリシーマネージャによるモデル決定条件に関する判定や、API部76による原因推定モデル75の決定より前に、原因推定モデル75に監視情報が入力されてよい。この場合、API部76は、S202において、既に出力された原因推定モデルの結果を取得してもよいし、最新の入力データに対する結果がまだ出力されていない場合には、その結果の出力まで待機してもよい。原因推定モデル75の推定が早く開始されるため、より早く異常に対応することができる。
そして、API部76は、その決定された原因推定モデル75の出力を呼び出し元へ送信する(S203)。
なお、決定された原因推定モデルによっては、原因推定モデルと正常判定モデルの判定とが組み合わされてもよい。この詳細については後述する。
ポリシーマネージャ部80は、API部76から出力を受け付けると、原因推定モデル75の出力に応じた対応の処理を実行する(S104)。この対応の処理によりネットワークに生じた異常が解消または抑制される。例えば、原因推定モデル75の出力が第1のラベルを示す場合(言い換えれば、当該出力の値が、第1のラベルに相当する値と一致する、第1のラベルに相当する範囲内にある、または、出力のうち第1のラベルに対応する項目の値が閾値を超える)には、ポリシーマネージャ部80はCU44とUPF46との間の通信経路を増強する、より具体的にはその通信経路の帯域幅を増加させてよい。原因推定モデル75の出力が第2のラベルを示す場合には、その通信経路を再作成させてよい。原因推定モデル75の出力が第3のラベルを示す場合には、データ通信にかかるUPF46の数を増加させ(スケールアウト)、その増加されたUPF46と既存のCU44との間の通信経路を追加させてよい。また例えば原因推定モデルの出力が第4のラベルを示す場合には、SMFの数を増加させ(スケールアウト)、第5のラベルを示す場合には、AMFおよびSMFの数を増加させ、第6のラベルを示す場合にはUEの接続に制限をかけてよい。また、前述の対応の処理として、ポリシーマネージャ部80は、チケット管理部54へ障害の発生の通知を送ってもよい。
図7の処理は実際にはこの順番通りにされなくてもよい。例えば、モデル決定条件ごとにS102からS104に相当する処理が行われてよい。例えば、モデル決定条件ごとに記憶部30bにプログラムが格納され、それぞれのプログラムを実行するプロセッサ30aが、そのプログラムに含まれるモデル決定条件を満たすか否かを判定し(S102に相当)、その判定結果に応じてAPI部76を呼び出し(S103に相当)、原因分析モデルの出力に応じた対応の処理を実行してよい(S104に相当)。
以下では、モデル決定条件ごとにより詳細に処理を説明していく。図10は、ポリシーマネージャ部80が原因推定モデル75を用いて対応する処理の一例を示すフロー図である。図10には、モデル決定条件として性能に関する条件が用いられる場合における、図7のS102からS104に相当する処理をより詳細に記載している。図10に示される処理は定期的に繰り返し実行される。
図10の処理において、はじめにポリシーマネージャ部80は、最新の取得された性能指標値(例えばスループット)が閾値未満であり、かつ前回取得された性能指標値が閾値未満であるか判定する(S301)。
S301において最新および前回の性能指標値が閾値以上である場合には(S301のN)、図10の処理を終了する。一方、性能指標値が閾値未満である場合には(S301のY)、ポリシーマネージャ部80は、API部76のAPI-Aを介して原因推定モデル75に原因を問合せ、その原因推定モデル75の出力を取得する(S302)。ここで、原因推定モデル75の出力は、予め定められた複数のラベルのうちいずれかを指す、または、どのラベルも該当しないことを示すものとする。
最新および前回の性能指標値が閾値未満であることは、モデル決定条件の一種である。API-Aを介して呼び出される原因推定モデル75は限定されているため、API-Aを選択する条件は、原因推定モデル75を選択する条件でもあるからである。
取得された出力がラベルA1を指し示す場合には(S303のY)、ポリシーマネージャ部80はSDNコントローラ60に対して、UPF46とRAN32との既存の通信経路における帯域幅を増加させる指示を送信し(S304)、SDNコントローラ60にその帯域幅を増加させる。またS304の処理がされると図10に示される処理は終了する。
取得された出力がラベルA2を指し示す場合には(S305のY)、ポリシーマネージャ部80はSDNコントローラ60に対して、UPF46とRAN32との通信経路を再作成させる指示を送信し(S306)、SDNコントローラ60にその通信経路を再作成する。またS306の処理がされると図10に示される処理は終了する。
取得された出力がラベルBを指し示す場合には(S307のY)、ポリシーマネージャ部80は構成管理部62に対して、UPF46をスケールアウトさせる指示を送信し、SDNコントローラ60に、UPF46とRAN32との通信経路をスケールアウトさせる指示を送信する(S308)。UPF46をスケールアウトさせる指示は、UPF46の処理能力を増強するための処理を実行させる指示であり、例えば対象のネットワークスライスにUPF46を追加する指示でもよい。また、UPF46が使用可能なCNFのリソースの上限を増やしてもよい。通信経路をスケールアウトさせる指示は、追加されたUPF46とRAN32との間の通信を増強するための処理を実行させる指示であり、例えば、UPF46とRAN32との通信に使用する仮想の通信経路を新規に作成させる指示でもよい。また、UPF46とRAN32との通信に使用されている通信経路の帯域幅を増加させてもよい。指示を受け付けた構成管理部62はUPF46を追加し、指示を受け付けたSDNコントローラ60はその通信経路を新規作成する。またS308の処理がされると図10に示される処理は終了する。
S303からS308の処理は、図7のS104に示される、原因分析モデルの出力に応じた対応の処理に相当する。なお、例えば後述の図11の処理においてネットワークの状態が正常であると判定されたことを示す情報が返ってきた場合には、この対応の処理が行われなくてよい。
ここで、S302においてAPI部76が呼び出されると、図8に示される処理により、呼び出されたAPIの種類およびネットワークスライスに応じて原因推定モデル75が選択され、選択された原因推定モデル75の出力がポリシーマネージャ部80に返される。ここで、API部76を含むAI・ビッグデータ処理部56は、正常判定モデル73の判定結果も用いて原因を推定してもよい。
図11は、AI・ビッグデータ処理部56の処理の他の一例を示すフロー図である。図11の例では、複数の種類がある原因推定モデル75のうち一部の種類についてネットワークスライスに対応する正常判定モデル73と組み合わせて処理をする場合の処理を示している。予め、原因推定モデル75のそれぞれについて、正常判定モデル73と組み合わせるか否かを示す正常判定情報が記憶部30bに格納されているものとする。
はじめにAPI部76は、呼び出されたAPIの種類とネットワークスライスが属するグループとに応じて原因推定モデル75を決定する(S401)。
そしてAPI部76は、決定された原因推定モデル75が、正常判定モデル73と組み合わせるか否か判定する(S402)。この判定は、API部76が決定された原因推定モデル75と関連付けて記憶される正常判定情報により行われてよい。例えば、API部76は、例えば図10の性能指標値のような、トラフィック量と関係するトリガの場合には正常判定モデル73と原因推定モデル75とを組み合わせ、トラフィック量と関係のないトリガの場合には正常判定モデル73を用いなくてよい。
そして正常判定モデルと組み合わせると判定された場合には(S402のY)、API部76は該当するネットワークスライスに対応する正常判定モデル73の出力を取得する(S403)。またAPI部76はその取得された出力が、ネットワークスライスの状態が異常でないことを示す場合には(S404のN)、API部76は異常が生じていないことを示す情報を呼び出し元へ送信し処理を終了する。正常判定モデル73の出力はネットワークスライスの状態が正常であるか異常であるかの2値の情報であってもよいし、異常である蓋然性を示す値であってもよい。後者の場合には、正常判定モデル73の出力が閾値を超えるか否かに基づいてネットワークスライスの状態が正常であるか異常であるか判定されてよい。
一方、ネットワークスライスの状態が異常であることを示す場合には(S404のY)、API部76は決定された原因推定モデル75の出力を取得する(S405)。そして取得された原因推定モデル75の出力を、APIを介して呼び出し元へ送る(S406)。S405、S406の処理の詳細は、図8におけるS202、S203の処理と同様である。
S402の判定において、正常判定モデルと組み合わせないと判定された場合には(S402のN)、S405以降の処理を実行する。この場合に実質的に行われる処理は、図8と同様となる。
図11に示されるように、正常判定モデル73によってネットワークスライスの状態に異常があると判定された場合に原因推定モデル75の出力が呼び出し元に送信されると、ポリシーマネージャ部80は、正常判定モデル73によってネットワークに異常があると判定された場合にのみその異常に対応する処理が実行される。
なお、図8、図11の例と異なり、APIに応じて異なるプログラムが実行されてよい。この場合、APIが原因の種類(またはトリガの種類)ごとに設けられている場合には、API部76はネットワークスライスに基づいて原因推定モデル75の種類(およびインスタンス)を決定してよい。APIが原因の種類(またはトリガの種類)とネットワークスライスとの組み合わせごとに設けられている場合には、API部76はS201およびS401の処理を経ずに、呼び出されたAPIにより特定される原因推定モデル75の出力を取得してよい。
次に、図10と異なるモデル決定条件についてのポリシーマネージャ部80の処理の例について説明する。図12は、ポリシーマネージャ部80が原因推定モデル75を用いて対応する処理の他の一例を示すフロー図である。図12には、モデル決定条件として特定のNF(具体的にはAMF、SMF)からアラートが上がった場合における、図7のS102からS104に相当する処理をより詳細に記載している。図12に示される処理も定期的に繰り返し実行される。
図12の処理において、はじめにポリシーマネージャ部80は、最新の監視情報がAMFまたはSMFからのアラートが上がっていることを示し、また前回の監視情報も同じアラートが上がっていることを示すか判定する(S501)。
最新および前回の監視情報が、ともにAMFまたはSMFからの同一のアラートが上がっていることを示さない場合には(S501のN)、図12の処理を終了する。一方、最新および前回の監視情報が、ともにAMFまたはSMFからの同一のアラートが上がっていることを示す場合には(S501のY)、ポリシーマネージャ部80は、API部76のAPI-Bを介して原因推定モデル75に原因を問合せ、その原因推定モデル75の出力を取得する(S502)。
最新および前回の監視情報が、ともにAMFまたはSMFからの同一のアラートが上がっていることを示すことは、モデル決定条件の一種である。API-Bと原因推定モデル75とは対応関係を有するため、API-Bを選択する条件は、原因推定モデル75を選択する条件でもあるからである。
取得された出力がラベルC1を指し示す場合には(S503のY)、ポリシーマネージャ部80は構成管理部62に対して、SMFをスケールアウトさせる指示を送信する(S504)。またS504の処理がされると図12に示される処理は終了する。
取得された出力がラベルC2を指し示す場合には(S505のY)、ポリシーマネージャ部80は構成管理部62に対して、AMFおよびSMFをスケールアウトさせる指示を送信する(S506)。またS506の処理がされると図12に示される処理は終了する。
取得された出力がラベルDを指し示す場合には(S507のY)、ポリシーマネージャ部80はRAN32に対してUE20の接続に制限をかける指示を送信する(S508)。UEの接続の制限は、公知の手法で行われてよい。例えば、指示を受信したRAN32が、UE20からの接続要求を所定の割合で拒否してもよい。これにより、時間とともにUE20の接続数を減らすことができる。なお、所定の割合は、適宜に定めてよい。またS508の処理がされると図12に示される処理は終了する。
S503からS508の処理は、図7のS104に示される、原因推定モデル75の出力に応じた対応の処理に相当する。
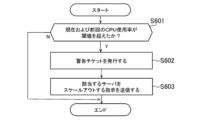
なお、取得された監視情報が所定の対応条件を満たす場合には、原因推定モデル75の出力を用いずに、所定の対応の処理が行われてもよい。図13はポリシーマネージャ部80が原因推定モデル75を用いずに対応する処理の一例を示すフロー図である。図13に示される処理は、原因の推定が比較的容易な異常に対応するために用いられる。
図13の処理において、はじめにポリシーマネージャ部80は、最新および前回に取得された、いずれかのサーバのCPU使用率の両方が閾値を超えているか否か判定する(S601)。複数のサーバのそれぞれのCPU使用率は監視情報に含まれる。
いずれのサーバについても、最新および前回に取得された2つのCPU使用率の両方が閾値を超えていない場合には(S601のN)、図13の処理を終了する。一方、いずれかのサーバについて最新および前回に取得されたCPU使用率の両方が閾値を超えている場合には(S601のY)、ポリシーマネージャ部80はチケット管理部54へ警告チケットを発行し(S602)、チケット管理部54は管理者へ警告チケットに基づくメッセージを出力する。またポリシーマネージャ部80は、構成管理部62に対して該当するサーバをスケールアウトする指示を送信する(S603)。より具体的にはポリシーマネージャ部80は、構成管理部62に、該当するサーバにデプロイされている機能を他の新たなサーバと分割して配置する指示を送信する。このように、CPU使用率などの所定の対応条件を満たした場合に、警告チケットの発行、サーバのスケールアウトといった所定の対応が実行されてもよい。
S602、S603の処理もネットワークの異常に対応する処理に対応する処理の一種である。
本実施形態では、機械学習モデルである原因推定モデル75を用いてネットワークスライスに生じた異常の原因を推定している。ここで、一般的にネットワークに実際に異常が生じるケースは少なく、異常の原因に関する訓練データを大量に取得することは容易でない。
本実施形態では、ネットワークスライスのグループごとに原因推定モデル75が学習されている。またネットワークスライスが属するグループに応じた原因推定モデル75の出力に応じて対応処理が実行される。これらにより、ネットワークに生じる異常を適切に判定することができる。
より具体的には、ネットワークスライスごとに学習する場合に比べ、より多くの異常に関する訓練データを確保することができ推定の精度が向上する。また仮に原因推定モデル75をすべてのネットワークスライスで共通にした場合、ネットワークの構成に応じて生じる異常が異なるようなケースにおいて原因を推定することが難しい。ネットワーク構成に応じて分類されたグループを用いることで、ネットワークの構成に応じた原因の推定が可能になり、推定精度を向上させることができる。
また、図10、図11に示されるように、正常判定モデル73によってネットワークに異常があると判定された場合に原因推定モデル75の原因推定の結果に応じた対応処理が行われている。
前述のように異常の原因に関する訓練データを大量に取得することは容易でない一方で、ネットワークスライスの状態が正常である場合の訓練データを確保することは容易である。そのため、予めネットワークスライスの状態が正常であるか否かを正常判定モデル73により精緻に推定し、その後原因推定モデル75で異常の原因を推定することにより、異常の原因の推定の精度を向上させることが可能になる。また正常判定モデル73をネットワークスライスごとに学習させることにより、さらに精度を向上させることが可能になる。
また本実施形態では、異常が検出されるトリガにそれぞれ対応する複数の原因推定モデル75が設けられ、原因の推定に用いる原因推定モデル75は、異常が検出されるトリガに対応するモデル決定条件に応じて特定されている。このトリガは異常の原因の種類に対応している。これにより、個々の原因推定モデル75が推定すべき異常の原因の範囲を効率的に限定することができ、原因推定の精度を向上させることが可能になる。
なお、本開示は上述の実施形態に限定されるものではない。実施形態において開示された構成を様々に組み合わせることが可能である。また本開示の技術的思想の範囲内において、本実施形態に記載される構成の一部が変更されてもよい。
例えば、本実施形態に係る実行基盤は、クバネテスクラスタであってもよい。また、本実施形態に係る実行基盤は、サーバであってもよい。
また、本実施形態に係る機能ユニットは、5GにおけるNFである必要はない。例えば、本実施形態に係る機能ユニットが、eNodeB、vDU、vCU、P-GW(Packet Data Network Gateway)、S-GW(Serving Gateway)、MME(Mobility Management Entity)、HSS(Home Subscriber Server)などといった、4Gにおけるネットワークノードであっても構わない。
また、本実施形態に係る機能ユニットが、コンテナ型の仮想化技術でなく、ハイパーバイザ型やホスト型の仮想化技術を用いて実現されてもよい。また、本実施形態に係る機能ユニットがソフトウェアによって実装されている必要はなく、電子回路等のハードウェアによって実装されていてもよい。また、本実施形態に係る機能ユニットが、電子回路とソフトウェアとの組合せによって実装されていてもよい。
なお、上記の実施形態では実際の運用を想定して説明したため、過去の監視情報に基づいて学習されたモデルと、現在または直近の監視情報と、を用いて、現在のネットワークの状態を判定すると述べた。しかし、判定されるネットワークの状態は、必ずしも現在の状態でなくてもよい。すなわち、第1の時間帯に得られた監視情報と、第1の時間帯とは異なる第2の時間帯に得られた監視情報に基づいて学習されたモデルとを用いて、第1の時間帯におけるネットワークの状態を判定してもよい。
以上に説明した実施形態についての記載から把握されるように、本明細書では以下の開示を含む多様な技術的思想が開示されている。
(1)1以上のプロセッサを備え、前記1以上のプロセッサのうち少なくとも一つによって、ネットワークの状態を示す第1の情報を取得する取得処理と、前記ネットワークに生じる障害の原因の種類ごとに設けられ、それぞれモデル選択条件に対応付けられる複数の原因推定モデルであって、前記第1の情報とは異なる時間帯における前記ネットワークの状態を示す第2の情報を含む入力データと、対応する原因の種類に属する前記ネットワークに生じた異常の原因を示す正解データとを含む訓練データにより学習される複数の原因推定モデルから、前記取得された第1の情報が満たすモデル選択条件に対応する原因推定モデルを選択する選択処理と、前記選択された原因推定モデルに前記ネットワークの状態を示す第1の情報が入力された際の出力を取得する出力取得処理と、前記選択された前記原因推定モデルの前記取得された出力に基づいて前記ネットワークに生じた異常に対処する処理を実行する対応処理と、が実行されるネットワークシステム。
(2)(1)に記載のネットワークシステムにおいて、前記対応処理では、前記取得された第1の情報が所定の対応条件を満たす場合には、前記複数の原因推定モデルのいずれからの出力も用いずに前記ネットワークに生じた異常に対処する処理を開始させる、ネットワークシステム。
(3)(1)または(2)に記載のネットワークシステムにおいて、前記複数の原因推定モデルのいずれかには、前記選択処理において前記原因推定モデルが選択される前に、当該原因推定モデルに前記第1の情報が入力される、ネットワークシステム。
(4)1以上のプロセッサのうち少なくとも一つによって、ネットワークの状態を示す第1の情報を取得し、前記ネットワークに生じる障害の原因の種類ごとに設けられ、それぞれモデル選択条件に対応付けられる複数の原因推定モデルであって、前記第1の情報とは異なる時間帯における前記ネットワークの状態を示す第2の情報を含む入力データと、対応する原因の種類に属する前記ネットワークに生じた異常の原因を示す正解データとを含む訓練データにより学習される複数の原因推定モデルから、前記取得された第1の情報が満たすモデル選択条件に対応する原因推定モデルを選択し、前記選択された原因推定モデルに前記ネットワークの状態を示す第1の情報が入力された際の出力を取得し、前記選択された前記原因推定モデルの前記取得された出力に基づいて前記ネットワークに生じた異常に対処する処理を実行する、ネットワーク異常に対する対応方法。
Claims (4)
- 1以上のプロセッサを備え、前記1以上のプロセッサのうち少なくとも一つによって、
ネットワークの状態を示す第1の情報を取得する取得処理と、
前記ネットワークに生じる障害の原因の種類ごとに設けられ、それぞれモデル選択条件に対応付けられる複数の原因推定モデルであって、前記第1の情報とは異なる時間帯における前記ネットワークの状態を示す第2の情報を含む入力データと、対応する原因の種類に属する前記ネットワークに生じた異常の原因を示す正解データとを含む訓練データにより学習される複数の原因推定モデルから、前記取得された第1の情報が満たすモデル選択条件に対応する原因推定モデルを選択する選択処理と、
前記選択された原因推定モデルに前記ネットワークの状態を示す第1の情報が入力された際の出力を取得する出力取得処理と、
前記選択された前記原因推定モデルの前記取得された出力に基づいて前記ネットワークに生じた異常に対処する処理を実行する対応処理と、
が実行されるネットワークシステム。 - 請求項1に記載のネットワークシステムにおいて、
前記対応処理では、前記取得された第1の情報が所定の対応条件を満たす場合には、前記複数の原因推定モデルのいずれからの出力も用いずに前記ネットワークに生じた異常に対処する処理を開始させる、
ネットワークシステム。 - 請求項1に記載のネットワークシステムにおいて、
前記複数の原因推定モデルのいずれかには、前記選択処理において前記原因推定モデルが選択される前に、当該原因推定モデルに前記第1の情報が入力される、
ネットワークシステム。 - 1以上のプロセッサのうち少なくとも一つによって、
ネットワークの状態を示す第1の情報を取得し、
前記ネットワークに生じる障害の原因の種類ごとに設けられ、それぞれモデル選択条件に対応付けられる複数の原因推定モデルであって、前記第1の情報とは異なる時間帯における前記ネットワークの状態を示す第2の情報を含む入力データと、対応する原因の種類に属する前記ネットワークに生じた異常の原因を示す正解データとを含む訓練データにより学習される複数の原因推定モデルから、前記取得された第1の情報が満たすモデル選択条件に対応する原因推定モデルを選択し、
前記選択された原因推定モデルに前記ネットワークの状態を示す第1の情報が入力された際の出力を取得し、
前記選択された前記原因推定モデルの前記取得された出力に基づいて前記ネットワークに生じた異常に対処する処理を実行する、
ネットワーク異常に対する対応方法。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2022/021959 WO2023233471A1 (ja) | 2022-05-30 | 2022-05-30 | ネットワークの異常の原因推定 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2023233471A1 JPWO2023233471A1 (ja) | 2023-12-07 |
| JP7620164B2 true JP7620164B2 (ja) | 2025-01-22 |
Family
ID=89025949
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024524532A Active JP7620164B2 (ja) | 2022-05-30 | 2022-05-30 | ネットワークの異常の原因推定 |
Country Status (4)
| Country | Link |
|---|---|
| US (1) | US12289222B2 (ja) |
| EP (1) | EP4535749A4 (ja) |
| JP (1) | JP7620164B2 (ja) |
| WO (1) | WO2023233471A1 (ja) |
Families Citing this family (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20250106096A1 (en) * | 2023-03-31 | 2025-03-27 | Rakuten Mobile, Inc. | Estimation of router that is cause of silent failures |
Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019145107A (ja) | 2018-02-20 | 2019-08-29 | ダークトレース リミテッドDarktrace Limited | 機械学習モデルを用いてeメールネットワークを保護するサイバー脅威防御システム |
| JP2021083058A (ja) | 2019-11-22 | 2021-05-27 | 株式会社Kddi総合研究所 | 制御装置、制御方法、及びプログラム |
Family Cites Families (19)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2009090939A1 (ja) * | 2008-01-15 | 2009-07-23 | Nec Corporation | ネットワーク異常検出装置及び方法 |
| AU2011265563B2 (en) * | 2010-12-24 | 2016-09-22 | Commonwealth Scientific And Industrial Research Organisation | System and method for detecting and/or diagnosing faults in multi-variable systems |
| CN109600246B (zh) | 2017-09-30 | 2021-09-21 | 华为技术有限公司 | 网络切片管理方法及其装置 |
| US20190166024A1 (en) * | 2017-11-24 | 2019-05-30 | Institute For Information Industry | Network anomaly analysis apparatus, method, and non-transitory computer readable storage medium thereof |
| US11128578B2 (en) * | 2018-05-21 | 2021-09-21 | Pure Storage, Inc. | Switching between mediator services for a storage system |
| US11429192B2 (en) * | 2018-06-05 | 2022-08-30 | Google Llc | Confidence-based application-specific user interactions |
| US11050793B2 (en) * | 2018-12-19 | 2021-06-29 | Abnormal Security Corporation | Retrospective learning of communication patterns by machine learning models for discovering abnormal behavior |
| US11694804B2 (en) * | 2019-05-06 | 2023-07-04 | Medtronic, Inc. | Reduced power machine learning system for arrhythmia detection |
| KR102075293B1 (ko) * | 2019-05-22 | 2020-02-07 | 주식회사 루닛 | 의료 영상의 메타데이터 예측 장치 및 방법 |
| CN112887119B (zh) * | 2019-11-30 | 2022-09-16 | 华为技术有限公司 | 故障根因确定方法及装置、计算机存储介质 |
| US11620481B2 (en) * | 2020-02-26 | 2023-04-04 | International Business Machines Corporation | Dynamic machine learning model selection |
| EP3889777A1 (en) * | 2020-03-31 | 2021-10-06 | Accenture Global Solutions Limited | System and method for automating fault detection in multi-tenant environments |
| US11640401B2 (en) * | 2020-06-02 | 2023-05-02 | Microsoft Technology Licensing, Llc | Alert rule evaluation for monitoring of late arriving data |
| US11595282B2 (en) * | 2020-07-21 | 2023-02-28 | Google Llc | Network anomaly detection |
| US11601830B2 (en) * | 2020-11-23 | 2023-03-07 | Verizon Patent And Licensing Inc. | Systems and methods for autonomous network management using deep reinforcement learning |
| US11757736B2 (en) * | 2021-01-08 | 2023-09-12 | Vmware , Inc. | Prescriptive analytics for network services |
| US20220358375A1 (en) * | 2021-05-04 | 2022-11-10 | International Business Machines Corporation | Inference of machine learning models |
| US20240056462A1 (en) * | 2022-08-15 | 2024-02-15 | Virtual Connect Technologies, Inc. | Computerized system for temporal, volume, and velocity analysis of an electronic communication system |
| US12395881B2 (en) * | 2023-01-27 | 2025-08-19 | Qualcomm Incorporated | Interference prediction with network configuration information |
-
2022
- 2022-05-30 EP EP22944760.2A patent/EP4535749A4/en active Pending
- 2022-05-30 US US18/044,784 patent/US12289222B2/en active Active
- 2022-05-30 WO PCT/JP2022/021959 patent/WO2023233471A1/ja not_active Ceased
- 2022-05-30 JP JP2024524532A patent/JP7620164B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2019145107A (ja) | 2018-02-20 | 2019-08-29 | ダークトレース リミテッドDarktrace Limited | 機械学習モデルを用いてeメールネットワークを保護するサイバー脅威防御システム |
| JP2021083058A (ja) | 2019-11-22 | 2021-05-27 | 株式会社Kddi総合研究所 | 制御装置、制御方法、及びプログラム |
Also Published As
| Publication number | Publication date |
|---|---|
| EP4535749A4 (en) | 2025-07-23 |
| EP4535749A1 (en) | 2025-04-09 |
| US20240291740A1 (en) | 2024-08-29 |
| WO2023233471A1 (ja) | 2023-12-07 |
| US12289222B2 (en) | 2025-04-29 |
| JPWO2023233471A1 (ja) | 2023-12-07 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7689627B2 (ja) | 通信経路決定システム及び通信経路決定方法 | |
| US12531791B2 (en) | Validation system and validation method | |
| US12615204B2 (en) | Switching control of communication route | |
| JP7769135B2 (ja) | 通信システムに係る所与の予測目的で用いられる機械学習モデルの決定 | |
| WO2024189911A1 (ja) | サイレント障害の原因であるルータの推定 | |
| US20240248763A1 (en) | Arrangement system and arrangement method | |
| WO2024111027A1 (ja) | 通信システムに含まれる要素の性能指標値が示された監視画面の表示制御 | |
| JP7620164B2 (ja) | ネットワークの異常の原因推定 | |
| JP7620163B2 (ja) | ネットワークの異常の原因推定 | |
| JP7716598B2 (ja) | 通信システムに係る所与の予測目的で用いられる機械学習モデルの決定 | |
| US20240281301A1 (en) | Execution platform determination system and execution platform determination method | |
| JP7814556B2 (ja) | アプリケーションが不安定である原因の推定 | |
| JP7852146B2 (ja) | サイレント障害の原因であるルータの推定 | |
| US12368633B2 (en) | Estimation of router that is cause of silent failures | |
| JP7801534B2 (ja) | サイレント障害の原因であるルータの推定 | |
| JP7812467B2 (ja) | 不安定なアプリケーションのリプレース | |
| US20250103376A1 (en) | Determining whether process included in communication system is unstable | |
| WO2024069948A1 (ja) | 通信システムに含まれるハードウェアリソースの管理 |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20240522 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20241217 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250109 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7620164 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |