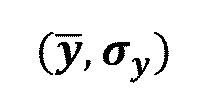様々な例において、本開示は、デバイスのジェスチャベースの制御を可能にする方法及びシステムを説明する。例えばジェスチャ制御デバイスは、他の可能性の中でも特に、テレビ(例えばスマートTV)、モバイル通信デバイス(例えばスマートフォン)、タブレットデバイス、デスクトップデバイス、車両ベースのデバイス(例えばダッシュボードデバイス)又はスマートスピーカ等であり得る。本明細書で説明されるジェスチャベースの制御は、ディスプレイ出力を伴う又は伴わないユーザインタフェースを含む、ジェスチャ制御デバイスによって提供される任意のユーザインタフェースとのユーザ対話を可能にするために使用され得る。本開示の例はまた、他の可能性の中でも特に、拡張現実(AR)、仮想現実(VR)又はビデオゲームアプリケーションのために実装され得る。
簡潔性のために、本開示は、ディスプレイ出力(例えばスマートTV、スマートフォン又はタブレット)を有するジェスチャ制御デバイスのコンテキストにおける例を説明し、ビデオの再生と対話するためのジェスチャベースの制御を説明する。しかしながら、本出願は、そのような実施形態に限定されず、様々な用途における様々なデバイスのジェスチャベースの制御に使用され得ることを理解されたい。
図1は、ジェスチャ制御デバイス100と対話するユーザ10の例を示す。この簡略化された図において、ジェスチャ制御デバイス100は、フレームのシーケンスがジェスチャ入力を含む視野(FOV:field-of-view)20内でフレーム(例えばデジタル画像)のシーケンスをキャプチャする、カメラ102を含む。FOV20は、以下で更に説明されるように、ユーザ10の少なくとも一部、特に、ユーザ10の顔と手を含み得る。注目すべきことに、実際の使用における(例えば実験室環境の外部で)FOV20が含むのは、典型的に、ユーザ10だけではない。例えばFOV20は、他の物体、背景シーン又は可能性のある他の人間も含み得る。ジェスチャ制御デバイス100は、カメラ102の代わりに、ユーザ10からのジェスチャ入力を感知することができる別のセンサ、例えば画像キャプチャデバイス/センサのFOV20内のジェスチャ入力を含むフレーム(例えば赤外線画像)のシーケンスをキャプチャする任意の画像キャプチャデバイス/センサ(例えば赤外線画像センサ)を有してもよい。ジェスチャ制御デバイス100はまた、ビデオのような出力を提供するディスプレイ104も含む。ジェスチャ制御デバイス100は、図1に示される実施形態ではカメラ102を含むが、他の実施形態では、カメラ102は、ジェスチャ制御デバイス100と通信する周辺デバイスであってもよい。
図2は、ジェスチャ制御デバイス100のいくつかの構成要素を示すブロック図である。ジェスチャ制御デバイス100の例示的な実施形態が以下に示され、説明されるが、他の実施形態を使用して本明細書で開示される実施例を実装してもよく、これは、図示されたものとは異なる構成要素を含んでもよい。図2は、各構成要素の単一のインスタンスを示しているが、図示される各構成要素の複数のインスタンスが存在してもよい。
ジェスチャ制御デバイス100は、プロセッサ、マイクロプロセッサ、特定用途向け集積回路(ASIC)、フィールドプログラマブルゲートアレイ(FPGA)、専用論理回路、専用人工知能プロセッサユニット又はそれらの組合せのような1つ以上の処理デバイス202を含む。ジェスチャ制御デバイス100はまた、1つ以上の入力/出力(I/O)インタフェース204も含み、これは、カメラ102のような入力デバイスとディスプレイ104のような出力デバイスをインタフェースする。ジェスチャ制御デバイス100は、他の入力デバイス(例えばボタン、マイクロホン、タッチスクリーン、キーボード等)及び他の出力デバイス(例えばスピーカ、振動ユニット等)を含み得る。カメラ102(又は他の入力デバイス)は、ジェスチャ入力を含むフレームのシーケンスをキャプチャする能力を有し得る。キャプチャされたフレームは、I/Oインタフェース204によって、記憶(例えばその中へのバッファリング)のためにメモリ208に提供され、リアルタイム又はほぼリアルタイム(例えば10ms以内)で処理されるように処理デバイス202に提供され得る。
ジェスチャ制御デバイス100は、ネットワーク(例えばイントラネット、インターネット、P2Pネットワーク、WAN及び/又はLAN)又は他のノードとの有線又は無線通信のための1つ以上のオプションのネットワークインタフェース206を含み得る。ネットワークインタフェース206は、イントラネットワーク及び/又はインターネットワーク通信のための有線リンク(例えばイーサネット(登録商標)ケーブル)及び/又は無線リンク(例えば1つ以上のアンテナ)を含み得る。
ジェスチャ制御デバイス100は、1つ以上のメモリ208を含み、これは、揮発性又は不揮発性メモリ(例えばフラッシュメモリ、ランダムアクセスメモリ(RAM)及び/又は読取専用メモリ(ROM))を含み得る、。非一時的なメモリ208は、本開示で説明される実施例を実行するように、処理デバイス202による実行のための命令を記憶し得る。例えばメモリ208は、適応ジェスチャ感知システム300を実行するための命令を含み得る。メモリ208は、オペレーティングシステム及び他のアプリケーション/機能を実装するためのような他のソフトウェア命令を含み得る。メモリ208はまた、ディスプレイ104を介して出力として提供され得るビデオコンテンツファイルのようなデータ210も含み得る。
いくつかの例では、ジェスチャ制御デバイス100は、ソリッドステートドライブ、ハードディスクドライブ、磁気ディスクドライブ及び/又は光ディスクドライブのような、1つ以上の電子記憶ユニット(図示せず)も含み得る。いくつかの例において、1つ以上のデータセット及び/又はモジュールは、外部メモリ(例えばジェスチャ制御デバイス100と有線又は無線通信する外部ドライブ)によって提供され得るか、あるいは一時的又は非一時的なコンピュータ読取可能媒体によって提供され得る。非一時的なコンピュータ読取可能媒体の例は、RAM、ROM、消去可能プログラマブルROM(EPROM)、電気的消去可能プログラマブルROM(EEPROM)、フラッシュメモリ、CD-ROM又は他のポータブルメモリストレージを含む。ジェスチャ制御デバイス100の構成要素は、例えばバスを介して互いに通信し得る。
本開示の理解を助けるために、ジェスチャの議論を最初に提供する。本開示において、ハンドジェスチャは、一般に、ジェスチャ制御デバイス100によって特定のコマンド入力として認識され得る明確な手の形状として定義される。ハンドジェスチャは、異なる形状と動きを有し得る。例えばハンドジェスチャは、図3A~図3Hに示されるクラスのうちの1つに属するものとしてジェスチャ制御デバイス100によって認識され得る。カメラ102によってキャプチャされるフレーム(例えば画像)のシーケンスに存在する、図3A~図3Hに示されるようなハンドジェスチャは、ジェスチャ入力と呼ばれる。
図3Aは「オープンハンド」ジェスチャ30を示し、図3Bは「握りこぶし」(又は「クローズドハンド」)ジェスチャ32を示し、図3Cは「ピンチオープン」ジェスチャ34を示し、図3Dは「ピンチクローズド」ジェスチャ36を示し、図3Eは「ミュート」(又は「静かに」)のジェスチャ38を示し、図3Fは「いいね」(又は「賛成(approve)」)のジェスチャ40を示し、図3Gは「他のもの」(又は「次」)のジェスチャ42を示し、図3Hは「タッチ」(又は「選択」)のジェスチャ44を示す。他のジェスチャクラスが、ジェスチャ制御デバイス100によって認識されてもよい。
このようなジェスチャクラスに基づいて、ハンドジェスチャは静的又は動的ジェスチャに分類され得る。静的ジェスチャは、単一のジェスチャクラスによって定義され、カメラ102によってキャプチャされるフレームのシーケンスにおいて、少なくとも定義された期間(例えば1秒)又は少なくとも定義された数の連続フレーム(例えば100フレーム)の間、一般的に固定された位置(例えば何らかの誤差のマージンを許容する定義された領域内)に保持される。例えば静的なオープンハンドジェスチャ30は、ジェスチャ制御デバイス100(例えば適応ジェスチャ感知システム300)によって認識され得、ビデオ再生のコンテキストでは、一時停止コマンド入力として解釈され得る。静的な握りこぶしジェスチャ32は、ジェスチャ制御デバイス100によって認識され得、ビデオ再生のコンテキストでは、停止コマンド入力として解釈され得る。
動的ジェスチャは、1つ以上のジェスチャクラス、位置及び/又は動きの組合せによって定義される。例えば動的ジェスチャは、経時的に位置が変化する単一のジェスチャクラスであり得る(例えばカメラ102によってキャプチャされるフレームのシーケンスにわたる異なる位置で検出される)。位置が変化するオープンハンドジェスチャ30は、ジェスチャ制御デバイス100(例えば適応ジェスチャ感知システム300)によって認識され得、表示されたアイコンのようなインタフェースオブジェクトをドラッグ又は移動するためのコマンドとして解釈され得る。
図4Aは、ジェスチャクラスの組合せであり得る別のタイプの動的ジェスチャを示す。図4Aでは、動的ジェスチャは、タッチジェスチャ44と、それに続く握りこぶしジェスチャ32との組合せを含む。この動的ジェスチャは、ジェスチャ制御デバイス100(例えばジェスチャ制御デバイス100において動作する適応ジェスチャ感知システム300)によって認識され得、マウスデバイスを使用してインタフェースオブジェクトを選択してその後クリックするのと同等のコマンド入力として解釈され得る。別の例では、ピンチクローズドジェスチャ36に続くピンチオープンジェスチャ34は一緒に、「ピンチング」動的ジェスチャとして認識され得、これは、ジェスチャ制御デバイス100によって認識され得、ズームアウトコマンド入力として解釈され得る。
より複雑な動的ジェスチャは、ジェスチャクラスの組合せと位置の変化の両方を含み得る。例えば図4Aでは、タッチジェスチャ44が、経時的に位置の変化として検出され(例えばカメラデバイス102によってキャプチャされるフレームのシーケンス内の異なる位置で検出され)、その後に握りこぶしジェスチャ32が続く場合、ジェスチャ制御デバイス100(例えばジェスチャ制御デバイス100において動作する適応ジェスチャ感知システム300)は、握りこぶしジェスチャ32が検出されると、表示されたカーソルを、その後にクリックコマンドが続くタッチジェスチャ44の位置の変化をミラーリングするような方法で動かすためのコマンド入力として、その複雑な動的なジェスチャを解釈し得る。
別の例では、ピンチオープンジェスチャ34、それに続くピンチクローズドジェスチャ36、それに続くピンチクローズドジェスチャ36の位置の変化及びそれに続くピンチオープンジェスチャ34は、ジェスチャ制御デバイス100(例えばジェスチャ制御デバイス100上で動作する適応ジェスチャ感知システム300)によって、動的な「ピンチドラッグ解放」ジェスチャとして、やはり一緒に認識され得る。位置の変化を含む動的なジェスチャは、位置の特定の変化に依存して異なる入力として解釈され得ることに留意されたい。例えば図4Bに示されるように、ピンチクローズドジェスチャ36の位置の垂直変化46(又は垂直「ドラッグ」)を伴うピンチドラッグ解放ジェスチャは、ビデオ再生のコンテキストでは、音量を変更するためのコマンド入力として解釈され得る。対照的に、図4Cに示されるように、ピンチクローズドジェスチャ36の位置の水平変化48を伴うピンチドラッグ解放ジェスチャは、ビデオ再生のコンテキストでは、ビデオ内を前方又は後方に動かすためのコマンド入力として解釈され得る。このようなピンチドラッグ解放の動的ジェスチャは、ユーザがジェスチャ制御デバイス100と対話するための直感的かつ便利な方法を提供することができ、ジェスチャ入力が、ジェスチャ制御デバイス100(例えばジェスチャ制御デバイス100上で動作する適応ジェスチャ感知システム300)によって比較的高い精度で検出及び認識されることを可能にすることもできる。特に、ピンチドラッグ解放の動的ジェスチャは、該動的ジェスチャを、その静的ジェスチャ構成要素(例えばピンチオープンジェスチャ34、それに続くピンチクローズドジェスチャ36、それに続く別のピンチオープンジェスチャ34)に分割することによって検出され、認識され得る。
ハンドジェスチャ認識のためのいくつかの従来的な既存のコンピュータビジョン技術は、カメラ102によってキャプチャされるフレーム(例えばデジタル画像)のシーケンスにおける手の形状及び位置に基づいて、手検出、手の形状分類及びジェスチャ認識を実行する。ジェスチャ・セグメンテーション及び認識は、一般に、計算コストが高い。さらに、フレームのシーケンスが、制御されていない潜在的に複雑な環境(例えば散らかった背景で、ユーザがデバイスから遠い距離にあるとき、低光環境において又はFOV内に複数の人間がいる環境のとき)においてジェスチャ制御デバイス100のカメラ102によってキャプチャされるときに、カメラ102によってキャプチャされるフレームのシーケンスを処理して、ハンドジェスチャ(静的であっても又は動的であっても)を検出及び認識することは、しばしば困難である。
様々な例において、本開示は、ジェスチャ制御デバイスのカメラによってキャプチャされるフレームのシーケンスにおいて、より正確で効率的なジェスチャ検出及び認識を可能にする解決策を説明する。いくつかの例において、本開示は、ジェスチャ検出のために処理されるべき、カメラによってキャプチャされるフレームのシーケンスの各フレーム内の領域を低減するために、仮想ジェスチャ空間を利用する適応ジェスチャ検出システムを説明する。いくつかの例において、本開示はまた、動的ジェスチャを認識するための(動きベースの代わりに)状態ベースのアプローチを説明する。本開示は追加の態様及び特徴を含むことが理解されよう。
本開示は、フレームのシーケンス内のハンドジェスチャを検出するために、カメラによってキャプチャされるフレームのシーケンスの各フレームを処理するために、少なくとも最初はユーザの顔を囲む空間として定義される仮想ジェスチャ空間の使用を説明する。仮想ジェスチャ空間は、カメラ102によってキャプチャされるFOV20よりも小さくなければならない。仮想ジェスチャ空間内で検出及び認識されたハンドジェスチャ(例えばジェスチャ入力)のみが、有効なハンドジェスチャ(例えばジェスチャ入力)とみなされ得る。仮想ジェスチャ空間の使用は、フレームのシーケンス内のハンドジェスチャの検出における(例えば特に、複雑な背景における)偽陽性の低減を可能にすることができ、ハンドジェスチャを特定のユーザに関連付けることをより容易にすることができ、ハンドジェスチャ(例えばジェスチャ入力)を検出及び認識するためにフレームのシーケンスのより効率的な処理を可能にすることができる。
図5は、適応ジェスチャ感知システム300のいくつかの例示的なサブシステムを示すブロック図である。この例では、適応ジェスチャ感知システム300は、仮想ジェスチャ空間サブシステム310及びジェスチャ解析サブシステム320を使用して実装され得る。以下の例では、適応ジェスチャ感知システム300は、両方のサブシステム310、320を含むものとして又は両方のサブシステム310、320の機能を提供するものとして説明されることになる。しかしながら、他の例では、適応ジェスチャ感知システム300は、サブシステム310、320のうちの1つのみを含む(又はその機能を提供する)ことがある。例えば適応ジェスチャ感知システム300は、(例えば仮想ジェスチャ空間サブシステム310を使用して)仮想ジェスチャ空間の適応的生成と、仮想ジェスチャ空間内にあるジェスチャ制御デバイス100のカメラ102によってキャプチャされたフレームのシーケンスにおけるハンドジェスチャの検出のみを提供するだけでよく、ジェスチャ認識及び解析は、ジェスチャ制御デバイス100の別の構成要素によって(例えば任意の適切な既存のジェスチャ認識技術を使用して)実行されてよい。別の例では、適応ジェスチャ感知システム300は、(例えばジェスチャ解析サブシステム320を使用して)複数のユーザのジェスチャ認識及び管理のみを提供してよく、ジェスチャ検出は、ジェスチャ制御デバイス100の別の構成要素によって(例えば任意の適切な既存のジェスチャ検出技術を使用して)実行されてもよい。
いくつかの例では、適応ジェスチャ感知システム300は、別個のサブシステム310、320を含まなくてもよい。代わりに、サブシステム310、320のサブブロックが、適応ジェスチャ感知システム300自体のサブブロックとみなされてもよい。したがって、別個のサブシステム310、320を使用する適応ジェスチャ感知システム300の実装は任意である。
適応ジェスチャ感知システム300は、顔検出及び追跡サブシステム312と、仮想ジェスチャ空間生成サブシステム314と、手検出及び追跡サブシステム316と、ジェスチャ認識サブシステム322と、ユーザリスト324を含む。顔検出及び追跡サブシステム312と、仮想ジェスチャ空間生成サブシステム314と、手検出及び追跡サブシステム316は、仮想ジェスチャ空間サブシステム310の一部であってよく、ジェスチャ認識サブシステム322とユーザリスト324は、ジェスチャ解析サブシステム320の一部であってよい。
いくつかの例において、顔検出及び追跡サブシステム312の代わりに又はこれに加えて、別のサブシステム(図示せず)が、カメラ102によってキャプチャされるフレームのシーケンスにおける異なる解剖学的特徴(例えば人間の身体全体又は人間の胴)の検出及び追跡のために使用されてもよい。以下で更に議論されるように、仮想ジェスチャ空間を生成するための基礎として、人間の顔の代わりに又はこれに加えて、異なる解剖学的特徴が使用され得る。簡潔性のために、本開示は、カメラ102によってキャプチャされたフレームのシーケンスにおける顔検出及び追跡の使用に焦点を当てるが、これは限定することを意図していないことを理解されたい。
カメラ102によってキャプチャされるフレームのシーケンスのフレームは、適応ジェスチャ感知システム300への入力フレームとして受信される。顔検出及び追跡サブシステム312は、入力フレームに対して顔検出を実行する。顔検出及び追跡サブシステム312は、任意の適切な顔検出技術を使用して、入力フレーム内の顔を検出し、検出した顔についてバウンディングボックスを生成し得る。バウンディングボックスは、入力フレーム内で検出された顔を中心にして顔を囲む二次元(2D)又は三次元(3D)ボックスであり得る。
入力フレーム内で検出された顔について生成されるバウンディングボックスは、仮想ジェスチャ空間生成サブシステム314によって、仮想ジェスチャ空間を定義するために使用される。本開示において、仮想ジェスチャ空間(又は単にジェスチャ空間)は、入力フレーム内において定義され、かつユーザ10の実生活環境内の仮想空間にマップする、2D又は3D空間を指し、その中で、ハンドジェスチャ(例えばジェスチャ入力)が検出され得る。換言すれば、ユーザ10は、ジェスチャ制御デバイス100にコマンド入力を提供するために、仮想的に定義された2D又は3D仮想ジェスチャ空間内でハンドジェスチャを成し得る。仮想ジェスチャ空間の外部で実行されるジェスチャは検出されない可能性があり、ジェスチャ制御デバイス100によってコマンド入力として認識されない可能性がある。仮想ジェスチャ空間の次元は、顔のバウンディングボックスの次元と一致しても一致しなくてもよい(例えば顔のバウンディングボックスは2Dであってよく、仮想ジェスチャ空間は3Dであってもよい)。
仮想ジェスチャ空間生成サブシステム314によって定義される仮想ジェスチャ空間は、手検出及び追跡サブシステム316によって、カメラによってキャプチャされたフレームのシーケンスにおいて手検出及び追跡を実行するために使用される。特に、手検出及び追跡サブシステム316は、入力フレーム内の定義された仮想ジェスチャ空間と、フレームのシーケンス内の各後続フレームのみを分析して、フレームのシーケンス内の手を検出して手を追跡し得る。手検出及び追跡サブシステム316は、任意の適切な手検出技術を使用して、入力フレーム内の手を検出し、検出した手についての2D又は3Dバウンディングボックスを定義し得る。
いくつかの例では、顔検出及び追跡サブシステム312は、顔検出を実行するために構成される、トレーニングされたニューラルネットワークを含み得る。同様に、手検出及び追跡サブシステム316は、手検出を実行するために構成される、別のトレーニングされたニューラルネットワークを含み得る。例えば顔又は手検出のために構成される適切なトレーニングされたニューラルネットワークは、(例えばHe,Kaiming等著、"Deep residual learning for image recognition" Proceedings of the IEEE conference on computer vision and pattern recognition. 2016 において記載される)ResNet34のような残差ニューラルネットワーク(ResNet:residual neural network)アーキテクチャに基づく、(例えばRedmon等著、"Yolov3: An incremental improvement"、arXiv preprint arXiv:1804.02767, 2018 において記載される)YoloV3を使用するようなトレーニングされたオブジェクト検出器であり得る。顔又は手検出のために構成される適切なトレーニングされたニューラルネットワークの別の例は、(例えばSandler等著、"Mobilenetv2: Inverted residuals and linear bottlenecks" Proceedings of the IEEE Conference on Computer Vision and Pattern Recognition. 2018 において記載される)MobileNetV2のような畳み込みニューラルネットワーク(CNN)アーキテクチャに基づく、(例えばLiu等著、"Ssd: Single shot multibox detector" European conference on computer vision. Springer, Cham, 2016 において記載される)マルチボックスSSDのようなトレーニングされたシングルショット検出器(SSD:single shot detector)であり得る。顔及び手追跡は、それぞれ顔検出及び追跡サブシステム312と手検出及び追跡サブシステム316によって(Lucas等著、“An iterative image registration technique with an application to stereo vision.” Proceedings of Imaging Understanding Workshop, 1981 において記載される)、Lucas-Kanade光学フロー技術を使用して実行され得る。
検出された手について定義されるバウンディングボックスは、ジェスチャ認識サブシステム322によって使用され、ジェスチャクラスとして、検出された手の形状の識別及び分類を実行する。ジェスチャ認識サブシステム322は、任意の適切な分類技術を使用して、検出された手の形状を特定のジェスチャクラスとして分類し得る。例えばジェスチャ認識サブシステム322は、所定のジェスチャクラスのセットに従ってジェスチャを分類するようにトレーニングされたニューラルネットワーク(例えばCNN)を含み得る。ニューラルネットワークは、ニューラルネットワークのパラメータ(例えば重み)を学習するために、既知の機械学習アルゴリズムを使用してトレーニングされている。トレーニングされたニューラルネットワークは、検出されたハンドジェスチャについてのバウンディングボックスを受け取り、所定のジェスチャクラスのセットから、バウンディングボックスに対応する特定のジェスチャクラスを予測する。ジェスチャ認識サブシステム322によって予測されるジェスチャクラスは、適応ジェスチャ感知システム300から(例えばラベルとして)出力され得る。
ジェスチャ制御デバイス100のソフトウェアアプリケーション(例えばオペレーティングシステム)は、適応ジェスチャ感知システム300によって出力されるジェスチャクラスをコマンド入力に変換し得る。コマンド入力へのジェスチャクラスの変換は、アプリケーション依存であり得る。例えば所与のジェスチャクラスは、第1アプリケーションがアクティブであるときには第1コマンド入力に変換され得るが、第2アプリケーションがアクティブであるときには第2コマンド入力に変換され得る(又は無効とみなされ得る)。
いくつかの例では、適応ジェスチャ感知システム300は、プライマリユーザの追跡を続けるためにユーザリスト324を記憶して維持する。例えばカメラ102のFOV20内に複数の人間が存在し得る。したがって、顔検出及び追跡サブシステム312は、カメラ102によってFOV20内でキャプチャされるフレームのシーケンス内の複数の人間の顔を検出及び追跡し得る。各々の検出された顔は、ジェスチャ制御デバイス100に入力を提供することができる潜在的にユーザである人間に属し得る。したがって、各々の検出された人間は、たとえ当該検出された人間が、認識されたハンドジェスチャ(例えばジェスチャ入力)を現在提供していない場合であっても、ユーザ(又は潜在的なユーザ)とみなされ得る。ユーザリスト324は、検出されたすべてのユーザの追跡を続け、何らかの所定の基準に従って、検出されたユーザをランク付けする(例えばユーザのサイズ、ジェスチャ制御デバイス100からのユーザの距離、ユーザの注視がジェスチャ制御デバイス100に向けられるかどうか等に基づいて)。ユーザリスト324内の最も高いランキングのユーザは、プライマリユーザとみなされてよい。プライマリユーザに関連付けられるフレームのシーケンス内のハンドジェスチャ(例えばジェスチャ入力)は、他の検出されたユーザに関連付けられるフレームのシーケンス内で検出されたいずれの他のハンドジェスチャ(例えばジェスチャ入力)よりも優先され得る。いくつかの例では、許可又は事前登録されたユーザのみがユーザリスト324に含まれ得る。例えばユーザプロファイルは、許可又は事前登録されたユーザと関連付けられてよく、ユーザプロファイルは、許可又は事前登録されたユーザがジェスチャ制御デバイス100によって(例えば適切な顔認識技術を使用して)識別されることを可能にするデータ(例えば生体データ)を含み得る。許可又は事前登録されたユーザのこのような顔認識は、適応ジェスチャ感知システム300によって又はジェスチャ制御デバイス100の別個の顔認識システムによって実行され得る。許可又は事前登録されたユーザのみを含むようにユーザリスト324を制限することによって、デバイス100の許可されていないジェスチャベースの制御が回避され得る。加えて、ジェスチャ入力の偽陽性検出が低減され得る。
適応ジェスチャ感知システム300は、異なるサブブロック(又はサブシステム)を有するものとして図示されているが、これは、限定することを意図していないことを理解されたい。例えば適応ジェスチャ感知システム300は、より多くの又はより少ない数のサブブロック(又はサブシステム)を使用して実装され得るか又はいずれのサブブロック(又はサブシステム)も必要としないことがある。さらに、特定のサブブロック(又はサブシステム)によって実行されるものとして本明細書に記載される機能は、代わりに、別のサブブロック(又はサブシステム)によって実行されてもよい。
一般に、適応ジェスチャ感知システム300の機能は、様々な適切な方法で実装されてよく、本開示の範囲内にある。
適応ジェスチャ感知システム300の動作の例を次に説明する。
図6は、例えば仮想ジェスチャ空間サブシステム310(及びサブシステム312、314、316)を使用して、適応ジェスチャ感知システム300によって実行され得る、例示的な方法600を示すフローチャートである。方法600は、ジェスチャ制御デバイス100の処理デバイス202によって実行されるソフトウェアのルーチン又はサブルーチンによって実行されてもよい。このようなルーチン又はサブルーチンを実行するためのソフトウェアのコーディングは、本開示を考慮して十分に当業者の範囲内にある。方法600は、図示及び説明されるものの追加のステップ又はより少ないステップ又は動作を含んでよく、異なる順序で実行されてもよい。例えば処理デバイス202によって実行可能なコンピュータ読取可能なコードが、コンピュータ読取可能媒体に記憶されてもよい。
602において、フレームのシーケンス内の入力フレームを受信する。一般に、入力フレームと、フレームのシーケンスの入力フレームに対する各後続フレームは、一度に1つずつ、リアルタイムで又はほぼリアルタイムで受信される。入力フレーム(及び各後続フレーム)は、カメラ102によってキャプチャされた生の未処理のデジタル画像であり得るか又は最小限処理された(例えば正規化された)デジタル画像であり得る。
604において、適応ジェスチャ感知システム300は、入力フレーム内の区別的な解剖学的特徴(distinguishing anatomical feature)を検出する。入力フレーム全体が、ステップ604で処理され得る。区別的な解剖学的特徴は、背景から容易に検出及び区別され得る、ユーザの身体の任意の部分であり得る。一例は、(例えば顔検出及び追跡サブシステム312を使用する)人の顔の検出である。状況によっては、顔を検出することが難しいことがあり、その場合、異なる解剖学的特徴(例えば人間の身体全体又は人間の胴)が代わりに検出され得る。上述のように、解剖学的特徴は、任意の適切なコンピュータビジョン技術を使用することを含め、任意の適切なアプローチを使用して検出され得る。区別的な解剖学的特徴を検出することは、解剖学的特徴の位置(例えばバウンディングボックス又は座標によって表される)を決定することを含んでもよい。
606において、検出された区別的な解剖学的特徴(例えば検出された顔)に基づいて、(例えば仮想ジェスチャ空間生成サブシステム314を使用して)仮想ジェスチャ空間が生成される。いくつかの例では、区別的な解剖学的特徴の複数のインスタンスが検出されることがあり(例えばカメラ102によってFOV20内でキャプチャされた入力フレーム内に複数の人間が存在する場合、複数の顔が検出され得る)、その場合、区別的な解剖学的特徴のそれぞれの検出されたインスタンスごとに1つの仮想ジェスチャ空間が生成され得る。以下で更に議論されるように、いくつかの例では、区別的な解剖学的特徴の複数のインスタンスが検出されるとき、生成される仮想ジェスチャ空間は1つのみであってよく、あるいは仮想ジェスチャ空間の生成は、区別的な解剖学的特徴の検出されたインスタンスのランク付け又は優先順位付けに基づいてもよい。
仮想ジェスチャ空間は、入力フレーム内で検出されたそれぞれの解剖学的特徴の位置に関連する所定の方程式を使用して生成され得る。例えば仮想ジェスチャ空間は、検出された顔のバウンディングボックスに対する矩形空間を計算することによって生成され得る。いくつかの例示的な方程式は、以下で更に提供される。
任意に、608において、ジェスチャ制御デバイス100が、生成された仮想ジェスチャ空間に関するフィードバックをユーザ10に提供することを可能にするために、生成された仮想ジェスチャ空間に関する情報が適応ジェスチャ感知システム300によって提供され得る。例えば適応ジェスチャ感知システム300は、ジェスチャ制御デバイス100がユーザ10に対する仮想ジェスチャ空間の表現をディスプレイ104上に(例えばライブカメラ画像の上部にオーバーレイとして)レンダリングすることを可能にするために、仮想ジェスチャ空間の座標又は他のパラメータを示す情報を提供し得る。別の例では、仮想ジェスチャ空間は、該仮想ジェスチャ空間に対応するFOVのみを示すために、ジェスチャ制御デバイス100によってディスプレイ104上にレンダリングされる差込みウィンドウ又は補助ウィンドウを有することによって、ユーザ10に対して表現されてもよい。ユーザ10にフィードバックを提供する他の方法もまた適切であり得る。
610において、手が、入力フレーム内で、生成された仮想ジェスチャ空間において(例えば手検出及び追跡サブシステム316を使用して)検出される。検出された手は、該手が入力フレーム内で検出されたそれぞれの仮想ジェスチャ空間に関連付けられ得る(例えばラベル付けされる)。生成された複数の仮想ジェスチャ空間がある場合、入力フレーム内の各生成された仮想ジェスチャ空間内の手を検出しようという試みが行われ得る。手が入力フレーム内の所与の仮想ジェスチャ空間で検出されない場合、その所与の仮想ジェスチャ空間は無視されるか破棄されてよい。
入力フレーム内の生成された仮想ジェスチャ空間のいずれにおいても手が検出されない場合、入力フレーム内で発見されるハンドジェスチャ(例えばジェスチャ入力)はないと決定されてよく、方法600はステップ602に戻って、フレームのシーケンス内の次の入力フレームを受信し得る。少なくとも1つの手が少なくとも1つの仮想ジェスチャ空間で検出されると仮定すると、方法600は任意のステップ612に進む。
任意に、612において、入力フレーム内の所与の仮想ジェスチャ空間において2つ以上の手が検出される場合、所与の仮想ジェスチャ空間において1つのプライマリハンドが識別され得る。プライマリハンドは、他の可能性の中でも特に、例えば入力フレーム内の所与の仮想ジェスチャ空間において最も大きい手;入力フレーム内の所与の仮想ジェスチャ空間において、検出された区別的な解剖学的特徴(例えば顔)に最も近い、検出された手;又は入力フレーム内の所与の仮想ジェスチャ空間において、検出された区別的な解剖学的特徴(例えば顔)に照明及び/又は色相が最も近い、検出された手;に基づいて識別され得る。入力フレーム内の所与の仮想ジェスチャ空間において検出された手が片手のみである場合、当該片手がプライマリハンドであると仮定されてもよい。
614において、検出された手(又はプライマリハンド)は、フレームのシーケンスの入力フレームに対する後続フレーム内のそれぞれの仮想ジェスチャ空間において(例えば手検出及び追跡サブシステム316を使用して)追跡される。検出された手(又はプライマリハンド)の追跡は、各後続フレームを処理することによって実行される。各後続フレームにおける手(又はプライマリハンド)の検出及び追跡からの情報は、更なる分析及び解析のために提供される。例えば後続フレームにおいて検出された手を追跡するために、バウンディングボックス及び任意の識別子を生成し得る。次いで、バウンディングボックス(及び任意の識別子)は、分析及び解析のために(例えばジェスチャ認識サブシステム322に)提供され得る。
いくつかの例では、方法600は、適応ジェスチャ感知システム300によって、仮想ジェスチャ空間サブシステム310のみを使用して実装され得る。(図5に示すように)ジェスチャクラスを出力する代わりに、適応ジェスチャ感知システム300は、追跡された手に関する情報(例えばバウンディングボックス)を従来のジェスチャ認識システムに出力してもよく、従来のジェスチャ認識システムは、その情報(例えばバウンディングボックス)に対して手の分類及びジェスチャ認識を実行してよい。
ユーザの手を直接検出する代わりに、上述の例は、まず、入力フレーム内の区別的な解剖学的特徴(例えばユーザの顔)を検出し、検出された特徴に基づいて仮想ジェスチャ空間(入力フレーム内のFOVよりも小さい)を生成する。次いで、手検出が、仮想ジェスチャ空間内のみにおいて入力フレームに対して実行される。ユーザの顔は、仮想ジェスチャ空間を生成するための区別的な解剖学的特徴として使用され得る。なぜなら、顔検出は典型的に、手検出よりも正確かつ信頼性が高いからである。手検出を仮想ジェスチャ空間に制限することによって、手検出のために後続フレームを処理するために必要な処理を簡略化することができ、偽陽性を低減することができ、ジェスチャ入力のための後続フレーム内のプライマリハンドを識別することをより容易にすることができる。
いくつかの例では、方法600を使用して、カメラ102によってキャプチャされるすべてのフレームを処理し得る。他の例では、方法600は、ジェスチャ入力が期待されるときにのみ使用され得る。例えば方法600は、入力の受信(例えばキーボード入力、マウス入力又は音声入力を介して)に応答して開始され得る。いくつかの例では、方法600は、人間の注意の検出に基づいて開始され得る。例えばジェスチャ制御デバイス100は、注意検出技術(例えばアイトラッキングソフトウェアを実行し得る)を使用して、人間がジェスチャ制御デバイス100を直接見ているかどうかを判断してよく、方法600は、ジェスチャ制御デバイス100で直接的な人間注視が検出されるときにのみ開始され得る。検出された人間の注意に応答して方法600を開始することは、ジェスチャ入力の偽陽性又は誤った解釈を回避するために有用であり得る。
図7は、検出された顔に基づいて仮想ジェスチャ空間が生成される、方法600の例示的な実装を示す。この例では、プライマリユーザの顔12が604において検出され、顔12が、606において仮想ジェスチャ空間を生成するためのベースとして、区別的な解剖学的特徴として使用されると仮定される。
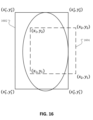
バウンディングボックス702は、上述のようなコンピュータビジョンベースの技術を含む任意の適切な顔検出技術を使用して、顔12について生成され得る。この例では、バウンディングボックス702は、値{xf,yf,wf,hf}のセットによって定義され、ここで、xf及びyfは、それぞれ、バウンディングボックス702のアンカーポイント(例えば中心)の(適応ジェスチャ感知システム300によって定義される基準のフレーム内の)x座標及びy座標を定義し、wf及びhfは、それぞれ、バウンディングボックス702の幅及び高さを定義する。バウンディングボックス702に基づいて、仮想ジェスチャ空間704が(例えばステップ606において)生成され、値{xg,yg,wg,hg}のセットによって定義され、ここで、xg及びygは、それぞれ、仮想ジェスチャ空間704のアンカーポイント(例えば中心)の(適応ジェスチャ感知システム300に定義される基準のフレーム内の)x座標及びy座標を定義し、wg及びhgは、それぞれ、仮想ジェスチャ空間704の幅及び高さを定義する。例えば以下の方程式を使用して、仮想ジェスチャ空間704を生成し得る:
hg=β・hf
ここで、(Δ
x,Δ
y)は、所定の相対位置パラメータであり、
(外1)
は、所定のスケールパラメータである。パラメータ(Δ
x,Δ
y)及び
(外2)
は、それに従う結果として仮想ジェスチャ空間704の所望のサイズ及び仮想ジェスチャ空間704内のバウンディングボックス702の所望のポジショニングをもたらすように、(例えばユーザ10によって又はジェスチャ制御デバイス100の製造者によって)予め定義され得る。いくつかの例において、仮想ジェスチャ空間704は、顔12のバウンディングボックス702が部分的又は全体的に仮想ジェスチャ空間704の外部にあるように生成されてもよいことに留意されたい。すなわち、仮想ジェスチャ空間704を生成するための基礎として顔12が使用され得るが、必ずしも仮想ジェスチャ空間704が顔12を含む必要はない。
図7の例では、仮想ジェスチャ空間704は、矩形形状を有する2D空間として生成される。しかしながら、仮想ジェスチャ空間704は、2D空間又は3D空間として生成さてよく、任意の幾何学的形状(例えば正方形、長方形、円等)、規則的な形状又は不規則な形状を有するように生成されてよいことを理解されたい。
いくつかの例において、仮想ジェスチャ空間704は、1つ以上の部分空間706、708を更に定義してよく、該部分空間は、特定の入力機能を実装するために使用され得る。部分空間706、708は、検出された顔12の特徴に基づいて(例えば仮想ジェスチャ空間生成サブシステム314によって)定義され得る。例えば左部分空間706及び右部分空間708は、顔12の検出された目及び鼻の位置に基づいて、検出された顔12の左下部分及び右下部分に対応して仮想ジェスチャ空間内において定義され得る。左部分空間706におけるタッチ(又はポイント)ジェスチャの検出は、左マウスボタンクリック入力として解釈され得る。同様に、右部分空間708におけるタッチ(又はポイント)ジェスチャの検出は、右マウスボタンクリック入力として解釈され得る。このようにして、定義された部分空間706、708を有する仮想ジェスチャ空間704を使用して、仮想マウスを実装し得る。いくつかの例において、図4Aに図示される動的ジェスチャは、仮想カーソルを実装するようにジェスチャ入力として検出され得る。仮想カーソルは、タッチ(又はポイント)ジェスチャ44が追跡されるにつれて移動されてよく(及びユーザ10に表示される視覚的オーバーレイを介して表現されてよい)、マウスクリック入力は、クローズドハンドジェスチャ32が検出されるときに検出され得る。このようにして、仮想マウスが実装され得る。
図8A及び図8Bは、カメラ102によってキャプチャされたフレームのシーケンス内の入力フレームにおいて検出されたユーザ10の顔12に基づいて生成される、仮想ジェスチャ空間704の別の例を示す。図8Aにおいて、仮想ジェスチャ空間704は、2D空間であり、ユーザ10の顔12と手14の両方を含む矩形形状を有する(例えば図7の例と同様)。図8Bにおいて、仮想ジェスチャ空間704は、ユーザ10の顔12と手14の両方を含む3D空間である。仮想ジェスチャ空間704は、深度情報が利用可能であるとき、3D空間として生成され得る。例えば深度情報は、ビデオ分析技術を使用してフレームのシーケンスから計算され得る。例えばジェスチャ制御デバイス100は、2つのカメラ102を使用して(例えばコンピュータステレオビジョン技術を使用して)深度情報を計算してもよく、あるいはカメラ102は、(従来のRGB画像情報に加えて)深度情報を生成することができるRGB深度(RGBD)カメラであってよく、あるいはジェスチャ制御デバイス100は、従来のカメラ102に加えて、RGB画像情報及び追加の対応する深度情報を取得するための飛行時間(ToF)カメラを含んでもよい。いくつかの例では、深度情報は、カメラ102に加えて、深度情報をキャプチャすることができるセンサ(例えば赤外線センサ)を使用してキャプチャされ得る。3D仮想ジェスチャ空間704の使用は、(例えば手をジェスチャ制御デバイス100により近くに又はより遠くに動かす)深度ベースジェスチャ入力を検出して、コマンド入力として認識することを可能にするために有用であり得る。
いくつかの例において、仮想ジェスチャ空間は最初に、フレームのシーケンス内の入力フレームにおいて検出された区別的な解剖学的特徴(例えば顔)に基づいて生成され、その後、フレームのシーケンス内の入力フレームに対する後続フレームにおいて検出された手に基づいて再定義又は更新され得る。このように、仮想ジェスチャ空間は、たとえ手が区別的な解剖学的特徴から遠くへ動く場合であっても、検出された手の位置に従うことができる。
図9は、例えば仮想ジェスチャ空間サブシステム310(及びサブシステム312、314、316)を使用して、適応ジェスチャ感知システム300によって実行され得る、例示的な方法900を示すフローチャートである。方法900は、ジェスチャ制御デバイス100の処理デバイス202によって実行されるソフトウェアのルーチン又はサブルーチンによって実行され得る。このようなルーチン又はサブルーチンを実行するためのソフトウェアのコーディングは、本開示を考慮して十分に当業者の範囲内にある。方法900は、図示及び説明されるものの追加のステップ又はより少ないステップ又は動作を含んでよく、異なる順序で実行されてもよい。例えば処理デバイス202によって実行可能なコンピュータ読取可能なコードは、コンピュータ読取可能媒体に記憶されてもよい。方法900は、上記方法600について説明されたものと同様のステップを含んでもよく、その場合、同様のステップは、再度詳細には説明されないことがある。
902において、フレームのシーケンスの入力フレームを受信する。このステップは、上述のステップ602と同様であり得る。
904において、適応ジェスチャ感知システム300は、入力フレーム内の区別的な解剖学的特徴を検出する。このステップは、上述のステップ604と同様であり得る。
906において、入力フレーム内の検出された区別的な解剖学的特徴(例えば検出された顔)に基づいて、(例えば仮想ジェスチャ空間生成サブシステム314を使用して)仮想ジェスチャ空間が生成される。このステップは、上述のステップ606と同様であり得る。任意に、仮想ジェスチャ空間を表す情報が提供され得る(例えばその結果、フィードバックがユーザ10に提供され得る)。簡潔性のために、方法900の以下の説明では、1つの仮想ジェスチャ空間のみが生成されると仮定する。しかしながら、方法900は、(例えば入力フレーム内の区別的な解剖学的特徴の複数の検出されたインスタンスに基づいて)複数の仮想ジェスチャ空間が生成される場合に適合され得ることを理解されたい。
908において、手が、入力フレーム内の仮想ジェスチャ空間において(例えば手検出及び追跡サブシステム316を使用して)検出され、該手が検出された仮想ジェスチャ空間に関連付けられる。このステップは、上述のステップ610と同様であり得る。任意に、プライマリハンドが識別されて、仮想ジェスチャ空間に関連付けられ得る。
910において、検出された手に基づいて、仮想ジェスチャ空間が再定義される。仮想ジェスチャ空間を再定義することは、(検出された解剖学的特徴に関連するのではなく)検出された手に関連する所定の方程式を使用して、入力フレームに対する後続フレーム内で仮想ジェスチャ空間の位置及び/又は寸法を再計算することを含み得る。例えば仮想ジェスチャ空間は、該仮想ジェスチャ空間が、検出された手のバウンディングボックスを中心とするように再定義され得る。いくつかの例示的な方程式は、以下で更に説明される。
912において、再定義された仮想ジェスチャ空間が記憶される。これは、(検出された手に基づいて再定義された)再定義された仮想ジェスチャ空間を、(検出された顔のような、入力フレーム内の検出された区別的な解剖学的特徴に基づいて最初に生成された)最初に生成された仮想ジェスチャ空間の代わりに、入力フレームに対する後続フレームにおける手の検出及び追跡のための基礎として使用することを可能にする。
914において、入力フレーム内で検出された手(又はプライマリハンド)は、(例えば手検出及び追跡サブシステム316を使用して)再定義された仮想ジェスチャ空間内の入力フレームに対する後続フレームにおいて追跡される。このステップは、上述のステップ614と同様であり得る。バウンディングボックス(及び任意の識別子)は、ジェスチャ入力を分析及び解析するために(例えばジェスチャ認識サブシステム322又は他の手分類器に)提供され得る。
方法900は、仮想ジェスチャ空間が、入力フレーム内で検出された手に基づいて再定義されることを可能にし、その結果、たとえ手が区別的な解剖学的特徴から更に遠くに動かされる場合であっても、手を追跡し続けて、入力フレームに対する各後続フレーム内で検出し得る。検出された手に基づいて仮想ジェスチャ空間が再定義された後、後続フレームは、再定義された仮想ジェスチャ空間を使用して処理され得る。再定義された仮想ジェスチャ空間は、手が動くにつれて、仮想ジェスチャ空間が、検出される手を中心とし続けるように、手が空間内の位置を変えるにつれて、各後続フレームにおいて連続的に再定義され得る。例えばフレームのシーケンス内の入力フレームに対する後続フレームは、ステップ904及びステップ906が省略される方法900の変形を使用して処理され得る。
いくつかの例において、後続フレーム内の再定義された仮想ジェスチャ空間において、手がもはや検出されない場合、仮想ジェスチャ空間は、入力フレーム内の検出された区別的な解剖学的特徴に基づいて再生成され得る。換言すれば、区別的な解剖学的特徴は、仮想ジェスチャ空間を定義するためのアンカー又はデフォルトの基礎として使用され得る。いくつかの例において、仮想ジェスチャ空間のデフォルトの基礎として区別的な解剖学的特徴を使用することへのこの復帰は、所定の数より多くの後続フレーム(例えば入力フレームに後続する少なくとも10のフレーム)についての再定義された仮想ジェスチャ空間内で手を検出することができない場合にのみ実行され得る。
図10A及び図10Bは、仮想ジェスチャ空間704が、フレームのシーケンス内の入力フレーム内で検出されたユーザ10の顔12に基づいて最初に生成され、その後、入力フレーム内で検出されたユーザ10の手14に基づいて再定義される、方法900の例示的な実装を示す。図10Aでは、仮想ジェスチャ空間704は、入力フレーム内で検出される顔12のバウンディングボックス702に基づいて生成される、矩形形状を有する2D空間である(例えば図7の例と同様)。手14は、入力フレーム内の仮想ジェスチャ空間704において検出され、手14についてのバウンディングボックス706が定義される。図10Bにおいて、仮想ジェスチャ空間704bは、手14のバウンディングボックス706に基づいて再定義される。
例えば手14のバウンディングボックス706は、値{xh,yh,wh,hh}のセットによって定義されてよく、ここで、xh及びyhは、それぞれ、バウンディングボックス706のアンカーポイント(例えば中心)の(適応ジェスチャ感知システム300によって定義される基準のフレーム内の)x座標及びy座標を定義し、wh及びhhは、それぞれ、バウンディングボックス706の幅及び高さを定義する。バウンディングボックス706に基づいて、仮想ジェスチャ空間704bが(例えばステップ910において)再定義される。例えば以下の方程式を使用して、仮想ジェスチャ空間704bを再定義し得る:
hg=βh・hf
ここで、{x
h,y
h,w
h,h
h}は、前述のように、仮想ジェスチャ空間704bを定義するパラメータであり、(Δ
xh、Δ
yh)は、所定の相対位置パラメータであり、
(外3)
は、検出された手に関する所定のスケールパラメータである。パラメータ(Δ
xh、Δ
yh)及び
(外4)
は、それに従う結果として、再定義された仮想ジェスチャ空間704bの所望のサイズ及び再定義された仮想ジェスチャ空間704b内のバウンディングボックス706の所望のポジショニングをもたらすように、(例えばユーザ10によって又はジェスチャ制御デバイス100の製造者によって)予め定義され得る。注目すべきことに、図10Bの例に示されるように、顔12は、再定義された仮想ジェスチャ空間704bから部分的又は全体的に除外され得る。
いくつかの例において、複数の人間が入力フレーム内で検出される(例えば複数の顔が顔検出及び追跡サブシステム312によって検出される)とき、適応ジェスチャ感知システム300は、検出された人間をランク付けして1人の人間をプライマリユーザ(又はプライマリコントローラ)として識別するために、ユーザリスト324を実装し得る。仮想ジェスチャ空間は、プライマリユーザに対してのみ生成され得る。
図11は、例えば仮想ジェスチャ空間サブシステム310及びジェスチャ解析サブシステム320(及びサブシステム312、314、316、322、324)を使用して、適応ジェスチャ感知システム300によって実行され得る、例示的な方法1100を示すフローチャートである。方法1100は、ジェスチャ制御デバイス100の処理デバイス202によって実行されるソフトウェアのルーチン又はサブルーチンによって実行され得る。このようなルーチン又はサブルーチンを実行するためのソフトウェアのコーディングは、本開示を考慮して十分に当業者の範囲内にある。方法1100は、図示及び説明されるものの追加のステップ又はより少ないステップ又は動作を含んでもよく、異なる順序で実行されてもよい。例えば処理デバイス202によって実行可能なコンピュータ読取可能なコードは、コンピュータ読取可能媒体に記憶され得る。方法1100は、上記で方法600について説明されたものと同様のステップを含んでよく、その場合、同様のステップは、再度詳細に説明されないことがある。
1102において、フレームのシーケンス内の入力フレームを受信する。このステップは、上述のステップ602と同様であり得る。
1104において、プライマリユーザがすでに識別されて選択されているかどうかが判断される。例えばプライマリユーザは、フレームのシーケンス内の前の入力フレームを分析することから識別され、選択されたものであり得る。プライマリユーザがすでに選択されている場合、方法1100は、ステップ1106に進み、そうでない場合、方法1100は、ステップ1108に進む。
1106において、プライマリユーザの区別的な解剖学的特徴(例えば顔)が、(例えば顔検出及び追跡サブシステム312を使用して)入力フレーム内で検出され、フレームのシーケンス内の入力フレームに対する後続フレームにおいて追跡される。プライマリユーザが前の入力フレーム内で識別された場合、仮想ジェスチャ空間がプライマリユーザについてすでに定義されている可能性がある。このような場合、入力フレームと、入力フレームの後続フレームにおける解剖学的特徴の検出及び追跡は、すでに定義された仮想ジェスチャ空間内のみにおいて各後続フレームを処理することによって実行され得る。解剖学的特徴の追跡は、すべての後続フレームを処理することによって実行されるが、検出は、より低い頻度で(例えば1つ以上の後続フレームをスキップして)実行され得る。解剖学的特徴の検出は、追跡誤差を補正するために実行され得る(例えば追跡誤差は、多数の後続フレームにわたって追跡するときに累積され得る)。この議論は、プライマリユーザの区別的な解剖学的特徴(例えば顔)を検出及び追跡するコンテキストにおけるものであるが、(例えば図10A及び図10Bに関して上述したように)入力フレーム内で検出された手に基づいて仮想ジェスチャ空間が再定義される場合、入力フレーム及び後続フレームを処理してプライマリユーザの手を検出及び追跡するために、ステップ1106の修正が行われてもよいことに留意されたい。
1108において、プライマリユーザが以前に選択されていない場合、例えば顔検出及び追跡サブシステム312を使用して、入力フレーム全体が、区別的な解剖学的特徴のインスタンス(例えば人間の顔のすべてのインスタンス)を検出するため処理され得る。バウンディングボックス及び識別子が、各々の検出された解剖学的特徴について生成され得る。区別的な解剖学的特徴のインスタンスが入力フレーム内で検出されない場合、方法1100は、フレームのシーケンス内の次の入力フレームを処理するために1102に戻ってよい。
1110において、ランク付けされたユーザリスト324が、解剖学的特徴の検出されたインスタンスに基づいて生成される。各々の検出されたインスタンスは、それぞれの検出されたユーザに関連付けられ得る。ユーザリスト324は、所定のランク付け基準に従って、(例えば任意のアイトラッキング技術のような任意の適切な顔分析技術を使用して)検出された解剖学的特徴を更に分析することによってランク付けされ得る。例えば解剖学的特徴が顔である場合、ランク付け基準は、より大きな顔(ジェスチャ制御デバイス100により近いと仮定される)が小さな顔よりも上位にランク付けされること;ジェスチャ制御デバイス100の方に向けられる顔が、ジェスチャ制御デバイス100から離れる方に向いている顔よりも上位にランク付けされること;あるいは目がジェスチャ制御デバイス100を注視している顔が、目がジェスチャ制御デバイス100から離れたところを見ている顔よりも上位にランク付けされ得ることを指定し得る。他のランク付け基準が使用されてもよい。検出された区別的な解剖学的特徴のインスタンスが1つのみの場合、その1つのインスタンスは、デフォルトでリストの最上位にランク付けされ得る。
1112において、ランク付けされたユーザリスト324内の最も高いランキングのユーザが、プライマリユーザとして選択される。ユーザリスト324内に1人のユーザしか存在しない場合、そのユーザはデフォルトでプライマリユーザとして選択され得る。次いで、方法1100は、ステップ1106に進み、カメラ102によってキャプチャされたフレームのシーケンス内のプライマリユーザの解剖学的特徴を追跡する。
1114において、プライマリユーザについて仮想ジェスチャ空間が生成される。仮想ジェスチャ空間が(カメラ102によってキャプチャされた前のフレームの分析に基づいて)以前に定義されている場合、仮想ジェスチャ空間を生成する代わりに、すでに定義された仮想ジェスチャ空間が使用され得る。そうでなければ、仮想ジェスチャ空間は、(例えば前述のステップ606と同様に)フレームのシーケンスの入力フレーム内で検出されたプライマリユーザの区別的な解剖学的特徴(例えば顔)に基づいて生成される。任意に、仮想ジェスチャ空間を表す情報が提供され得る(例えばその結果、フィードバックがプライマリユーザに提供され得る)。
1116において、手が、フレームのシーケンス内の入力フレーム内の仮想ジェスチャ空間において(例えば手検出及び追跡サブシステム316を使用して)検出される。このステップは、上述のステップ610と同様であり得る。任意に、入力フレーム内の仮想ジェスチャ空間において2つ以上の手が検出される場合、プライマリハンドが(例えば手のサイズのような何らかの所定の基準に基づいて)識別され、仮想ジェスチャ空間に関連付けられ得る。任意に、仮想ジェスチャ空間は、(図9について上述したものと同様に)入力フレーム内で検出された手に基づいて再定義され得る。仮想ジェスチャ空間が、入力フレーム内で検出された手に基づいて、入力フレームに対する後続フレームにおいて再定義された場合、検出及び追跡は、ステップ1106においてすでに実行されていることがあり、このステップは必要とされないことがある。
1118において、ジェスチャ認識は、入力フレームに対するフレームのシーケンス内で(例えばバウンディングボックスによって定義されるように)検出及び追跡される手について(例えばジェスチャ認識サブシステム322を使用して)実行され、検出された手についてのジェスチャクラスを予測する。予測されたジェスチャクラス(有効なジェスチャが識別される場合)は、例えばソフトウェアアプリケーションのためのコマンド入力に変換されるために出力される。ユーザリスト324内のすべての非プライマリユーザは破棄され(すなわち、プライマリユーザのみを維持する)、方法1100は1102に戻り、カメラ102によってキャプチャされたフレームのシーケンス内の次の入力フレームを受信して処理する。
ジェスチャ認識が、有効なジェスチャを予測できない(例えば手の形状を、いずれの所定のジェスチャクラスにも分類することができない)場合又はジェスチャが現在アクティブなソフトウェアアプリケーションにとって有効なジェスチャでない(例えばソフトウェアアプリケーションが、無効な入力を適応ジェスチャ感知システム300に報告する)場合、方法1100はステップ1120に進む。
1120において、現在選択されているプライマリユーザは、ユーザリスト324から破棄される。
1122において、ユーザリスト324内にいずれか他のユーザが存在するかどうかが判断される。ユーザリスト324に少なくとも1人の残りのユーザが存在する場合、ステップ1112において、ユーザリスト324内で最も高くランク付けされた残りのユーザがプライマリユーザとして選択され、方法1100は、上述のようにステップ1106に進む。ユーザリスト324内に残りのユーザが存在しない場合、方法1100は、ステップ1102に戻り、フレームのシーケンス内の次の入力フレームを受信して処理する。
ユーザリスト324は、カメラ102のFOV20内に複数の人間が存在するときであっても、適応ジェスチャ感知システム300が、減少した偽陽性で、ジェスチャ入力を分析して処理することを可能にする。ユーザリスト324は、複数の人間の存在に適応するよう比較的効率的な方法であり得るが、上述のように、ユーザリスト324の代わりに又はそれに加えて、他の技術が使用されてもよい。
上述のいくつかの例において、区別的な解剖学的特徴(例えば人間の顔)の検出は、入力フレーム全体を処理することによって実行され得る。他の例では、以下に説明するように、区別的な解剖学的特徴の検出は、入力フレーム内の関心領域(ROI)のみを処理することによって実行され得る。例えば上述のステップ1108において、適応ROIアプローチが使用され得る(例えば顔検出及び追跡サブシステム312によって、顔検出のために実装し得る)。
適応ROIは、本開示において、ROIのサイズ及び/又は位置が、例えば顔検出器(例えば顔検出及び追跡システムサブ312)の要件、入力フレームの解像度又は処理効率に基づいて調整され得るという意味で、「適応的」とみなされ得る。例えば機械学習ベース(例えばコンピュータビジョンベース)の顔及び手検出器は、典型的に、正方形入力画像を処理するようにトレーニングされる。したがって、顔と手の検出における改善された性能のために、検出を行うためのROIは正方形であるべきである。同様の理由で、手検出のための仮想ジェスチャ空間は正方形として定義され得る。
図12は、カメラ102によってキャプチャされるフレームのシーケンス内の入力フレームにおいて区別的な解剖学的特徴を検出するために適応ROIを使用する例示的な方法1200を示すフローチャートである。方法1200は、上述のステップ1108の一部として使用され得る。例えば方法1200は、顔検出及び追跡サブシステム312によって実装され得る。方法1100は、ステップ1108のための他の技術を使用して実装されてよく、適応ROIが使用されても使用されなくてもよいことを理解されたい。
1202において、解剖学的特徴が、前の入力フレーム内で検出されたかどうかが検出される。検出された場合、1204において、前の入力フレーム内の解剖学的特徴(例えば顔)の検出に使用されたROIが、現在の入力フレーム内で再び使用されるように選択される。一般に、解剖学的特徴の検出のためのROIは、入力フレーム全体よりも小さくあるべきであり、(検出アルゴリズムがトレーニング又は設計された方法に基づいて)正方形であり得る。
解剖学的特徴が前の入力フレームで検出されなかった(又は前の入力フレームがない)場合、1206において、ROIが、ROIシーケンスから選択される。ROIシーケンスからのあるROIが前の入力フレームで使用された場合、ROIシーケンス内の次のROIが、現在の入力フレームで使用するために選択され得る。ROIシーケンスは、予め定義され得る(例えば顔検出及び追跡サブシステム312において予め定義され得る)。ROIシーケンスは、逐次的入力フレームを処理するために使用されるべき異なるROIのシーケンスを定義する。例えばROIシーケンスが8つの異なるROI(例えば異なる位置及び/又はサイズを有する)のシーケンスである場合、シーケンス内の各ROIは、8つの入力フレームのシーケンス内の解剖学的特徴の検出を実行するために順番に選択される。次いで、ROIシーケンスは、シーケンス内の最初のROIに戻るようサイクルし得る。
図13は、8つの異なるROI 1302、1304、1306、1308、1310、1312、1314、1316を有する例示的なROIシーケンスを示す。8つのROI 1302~1316は、8つの異なる入力フレームのシーケンスにわたってサイクルされ得、異なる解像度の入力フレームに適用され得る。例えば6つのROI 1302~1312は、入力フレームの元の解像度1300に適用されてよく、(例えばユーザ10が、ジェスチャ制御デバイス100からより離れている場合)より小さな解剖学的特徴の検出を可能にするように設計され得る。2つのROI 1314、1316は、(より低い解像度を有する)入力フレームの小型化されたバージョン1350に適用されてよく、(例えばユーザ10が、ジェスチャ制御デバイス100により近い場合)より大きな解剖学的特徴の検出を可能にするように設計され得る。いくつかのROI 1314、1316のための入力フレームの小型化されたバージョンを使用することは、入力フレームのより大きな領域のより低計算コストの処理を可能にするために有用であり得る。
ROIのシーケンスは、(2つ以上のROIを使用して同じ入力フレームを処理する代わりに)各入力フレームが、1つの選択されたROIのみを使用して処理されるように、カメラ102によってキャプチャされるフレームのシーケンスにわたってサイクルされることに留意されたい。カメラ102によってキャプチャされる入力フレームは、典型的には高頻度でキャプチャされるので、隣接するフレーム間の時間差は、このようにして、ROIのシーケンスを用いてフレームを処理することによって失われる情報がない(又は非常に少ない)ように十分小さい可能性がある。
予め定義された(例えば顔検出及び追跡サブシステム312内に記憶された)異なるROIシーケンスが存在してもよい。使用されるROIシーケンスは、ユーザ10によって選択されてもよく、あるいは異なるROIシーケンスを通してサイクルするための所定の順序が存在してもよい(すなわち、使用すべきROIシーケンスの所定のシーケンスが存在しもよい)。さらに、図13の例は、シーケンス内で一度に使用されているROIシーケンス内の各ROIを示すが、いくつかの例では、ROIシーケンスは、該ROIシーケンス内で所与のROIを2回以上使用するよう定義され得る。他のそのようなバリエーションも可能であり得る。
1208において、選択されたROI(ステップ1204において前の入力フレーム内で選択されたROI又はステップ1206においてROIシーケンスから選択されたROIのいずれか)で、区別的な解剖学的特徴の検出が、選択されたROIを使用して実行される。
区別的な解剖学的特徴(例えば顔)の検出を実行するための適応ROIの使用は、計算コストの低減及び/又はトレーニングされた検出器の改善された性能を可能にし得る。
いくつかの例において、適応ROI技術は、ジェスチャ検出が活性化されるとき(又はジェスチャ検出がデフォルトで使用されるとき)、カメラ102によってキャプチャされるすべてのフレームを処理するために使用され得る。他の例では、適応ROI技術は、すべてのN(ここで、N>1)フレームを処理するために使用され得る。
前述したように、いくつかの例では、手検出及び追跡サブシステム316は、ジェスチャ認識のためにジェスチャ認識サブシステム322によって使用されるべきバウンディングボックスを出力し得る。いくつかの実施形態では、ジェスチャ認識サブシステム322は、機械学習アルゴリズムを使用して構築されるモデルを実装し得る。いくつかの実施形態では、ジェスチャ認識サブシステム322は、ジェスチャ分類を実行するために構成される、トレーニングされたニューラルネットワーク(以下、トレーニングされたジェスチャ分類ネットワークと称する)を含み得る。トレーニングされたジェスチャ分類ネットワークは、ニューラルネットワークのパラメータ(例えば重み)を学習するために既知の機械学習アルゴリズムを用いてトレーニングされている。トレーニングされたジェスチャ分類は、検出されたハンドジェスチャのためのバウンディングボックスを受け取り、バウンディングボックスに対応するジェスチャクラスの所定のセットから特定のジェスチャクラスを予測する。
典型的には、ジェスチャ分類を実行するように構成される、トレーニングされたニューラルネットワークによって達成されるジェスチャ分類の精度は、手画像が切り取られる(cropped)につれて(例えばバウンディングボックスがグラウンドトゥルースから大きなオフセットを有するとき)低下する。バウンディングボックスの調整の例は、2019年3月15日に出願された米国特許出願第16/355,665号、「ADAPTIVE IMAGE CROPPING FOR FACE RECOGNITION」に記載されており、その全体が参照によって本明細書に組み込まれる。ここでは、ジェスチャ認識を改善するのに役立つバウンディングボックス調整のための同様のアプローチについて説明する。
図14は、ジェスチャ認識サブシステム322に使用され得るジェスチャ分類ネットワークの例示的な実装を示すブロック図である。ジェスチャ分類ネットワーク1400は、バウンディングボックス精緻化ネットワーク(bounding box refinement network)1450への側枝とともに実装され得る。ジェスチャ分類ネットワーク1400は、入力フレーム内のバウンディングボックスによって定義された手画像に対してジェスチャ分類を実行し、バウンディングボックス精緻化ネットワーク1450は、ジェスチャ分類ネットワーク1400によって使用されるバウンディングボックスの精緻化(refinement)を実行する。
入力フレームは、ジェスチャ分類ネットワーク1400への入力データとして受信される。入力データは、(例えば手のための定義されたバウンディングボックスに基づいて)入力フレームの切り取られたバージョンであり得る。いくつかの実施形態において、入力データは、ネットワーク1400、1450のバッチベースのトレーニングのための、あるいはフレームのシーケンスに基づくジェスチャ分類を可能にするような、画像のバッチであり得る。ジェスチャ分類ネットワーク1400は、一連の畳み込みブロック1402(例えばResNet設計を使用して実装される)を含む。簡潔性のために、3つのそのような畳み込みブロック1402が示されているが、ジェスチャ分類ネットワーク1400内には、より大きい又はより少ない畳み込みブロック1402が存在し得る。一連の畳み込みブロック1402は、決定されたジェスチャクラスを出力するジェスチャ分類完全接続ネットワーク(FCN:fully connected network)1404に出力する。ジェスチャ分類FCN1404は、入力として、一連の畳み込みブロック1402内の最後の畳み込みブロック1402からのベクトル出力を受信する。ジェスチャ分類FCN1404は、バウンディングボックスによって定義される手についてのジェスチャクラスを決定するために特徴埋め込み(feature embedding)を使用し、決定されたジェスチャクラスをラベルとして出力する。いくつかの例では、ジェスチャ分類FCN1404は、可能なジェスチャクラスに対する確率分布を含むベクトルを出力する。すなわち、ジェスチャ分類ネットワーク1400の出力は、1つの最終的な決定されるジェスチャクラスの代わりに、異なるジェスチャクラスについての確率であってよい。いくつかの例では、ジェスチャ分類FCN1404は、最後の出力層内にソフトマックス関数を含み、これは、可能なジェスチャクラスについて、出力された確率分布を正規化する働きをする。
各畳み込みブロック1402は、バウンディングボックス精緻化ネットワーク1450に属する側枝1452にも出力する。各側枝1452は、バウンディングボックス精緻化FCN1454に出力する。各側枝1452は、独立に、任意の最大プーリング層、任意のリサイズresizing)層及び畳み込みブロックを含み得る。側枝1452の出力は、組合せ出力ベクトル(combined output vector)に連結され、該組合せ出力ベクトルは、バウンディングボックス精緻化FCN1454に入力される前に、1×1畳み込みブロック(図示せず)によって平坦化され得る。バウンディングボックス精緻化FCN1454の出力は、入力フレーム内の手を定義するバウンディングボックスのサイズ及び位置を調整又は精緻化する情報(例えばバウンディングボックスについての座標情報の形式の)である。
共同ネットワーク1400、1450のトレーニングを以下で議論する。上述のように、ジェスチャ分類FCN1404は、ソフトマックス層を含み得る。ジェスチャ分類FCN1404は更に、クロスエントロピー損失を計算して出力することができ、これは、出力された確率分布とモデルにおける元の確率分布との間の差の尺度として考えられ得る。このクロスエントロピー損失は、ソフトマックス層の損失関数として使用されてよく、したがって、ソフトマックス損失と呼ばれることもある。同様に、バウンディングボックス損失が、バウンディングボックス精緻化FCN1454から出力され得る。ソフトマックス損失とバウンディングボックス損失は、共同ネットワーク1400、1450のトレーニング1456に使用され得る全損失関数(total loss function)のために組み合わされ得る。ソフトマックス損失、バウンディングボックス損失及び全損失関数を使用するトレーニング1456は、ネットワーク1400、1450のトレーニング中にのみ使用され得、推論中には必要とされないことがある。
ネットワーク1400、1450のトレーニング中に、トレーニングデータサンプルは、グラウンドトゥルース・ハンドバウンディングボックスの周囲に基づいてランダムに切り取られた手画像で生成され得る。
いくつかの例が図15に示されており、ここでは、グラウンドトゥルース1502は、手画像のための最適化されたバウンディングボックスを定義し、他のランダムに切り取られた手画像は、トレーニングデータサンプル1504として生成される。トレーニングデータサンプル1504は、バウンディングボックスの位置をシフトし得るだけでなく、(バウンディングボックス内の手画像がより大きく又はより小さく表れ得るように)バウンディングボックスのサイズも変更し得ることに留意されたい。グラウンドトゥルース1502に対する各トレーニングデータサンプル1504のバウンディングボックスのオフセットは、バウンディングボックス精緻化をトレーニングするためのラベルとして使用される。
共同ネットワーク1400、1450は、全損失関数を最小化することによってトレーニングされ、該全損失関数は、この例では、分類損失関数(ソフトマックス損失)とバウンディングボックス損失関数の線形結合である。次に、バウンディングボックス損失関数の例を議論する。
図16の簡略化された例を考慮して、オブジェクトの周囲に定義されたグラウンドトゥルース・バウンディングボックス1602と、切り取られたトレーニングデータサンプル・バウンディングボックス1604とを例示する。{(x
1,y
1),(x
1,y
2),(x
2,y
1),(x
2,y
2)}は、トレーニングデータサンプル・バウンディングボックス1604の位置(この例では、四隅)を定義する座標であり、
は、対応するグラウンドトゥルース・バウンディングボックス1602の位置を定義する座標であるとする。バウンディングボックス精緻化ネットワーク1450は、トレーニングデータサンプル・バウンディングボックス1604とグラウンドトゥルース・バウンディングボックス1602との間の相対的回転θ及び相対的変位{z
1,z
2,z
3,z
4}を推定し、ここで、
である。
バウンディングボックス損失関数を、以下のように定義することができる:
ここで、λは、正規化パラメータである。
推論中、入力フレーム内の手画像を定義しているバウンディングボックスを、バウンディングボックス精緻化ネットワーク1450によって予測されるオフセットがゼロに近くなるまで、反復的に補正することができる。最終的なジェスチャ分類スコアは、各反復で取得されるすべての個々のジェスチャ分類スコアを以下のように組み合わせることによって、計算されることができる:
ここで、s
mは、m回目の反復の分類スコア(例えばソフトマックス出力)であり、
(外5)
は、m回目のバウンディングボックス及び最終的な精緻化バウンディングボックスの対応する重み(例えばIoU(intersection over union))である。
推論中、ジェスチャ分類ネットワーク1400を使用して、反復分類が(入力画像に適用されるバウンディングボックスによって定義される)入力の手画像に適用される。各反復において、ジェスチャ分類ネットワーク1400への入力画像は、前の反復の出力されたバウンディングボックス精緻化パラメータによって補正された前の入力画像に基づいて、取得される。
したがって、バウンディングボックス精緻化ネットワーク1450及びジェスチャ分類ネットワーク1400は、ジェスチャ分類ネットワーク1400の性能を改善するのを助けるために、入力フレーム内の手画像を定義するバウンディングボックスを精緻化するためのフィードバックを提供するように一緒に動作する。
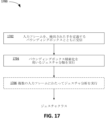
図17は、ジェスチャ認識を実行するためのバウンディングボックス精緻化を使用する(例えば上述の共同ネットワーク1400、1450を使用する)例示的な方法1700を示すフローチャートである。方法1700は、上述のステップ1118の一部として使用され得る。例えば方法1700は、ジェスチャ認識サブシステム322によって実装され得る。方法1100は、ステップ1118のための他の技術を使用して実装されてもよく、バウンディングボックス微細化が使用されても使用されなくてもよいことを理解されたい。
1702において、入力フレーム並びに(例えば手検出及び追跡サブシステム316によって出力される)検出された手を定義するバウンディングボックスを受信する。
1704において、(上述の)共同バウンディングボックス精緻化ネットワークを有するジェスチャ分類ネットワークが、バウンディングボックス精緻化を用いるジェスチャ分類を実行するために使用され得る。
任意に、1706において、ジェスチャ分析が、複数の入力フレームにわたって実行され得る。例えばジェスチャ認識サブシステム322は、前の入力フレームのバッファを記憶し、前の入力フレームを考慮することによってジェスチャ分析を実行し得る。
バッファ(例えば適応ジェスチャ感知システム300内で実装される)は、所定の数の前の入力フレームを記憶するために使用されてもよい。バッファに記憶される前の入力フレームの数は、メモリリソースのより効率的な使用のために、比較的少ない可能性がある(例えば10~30の前の入力フレーム)。いくつかの例では、バッファは追加又は代替的に、より少ない数の前の入力フレームに対して実行されたジェスチャ分析の結果を記憶し得る。
認識されるべき単一の静的ジェスチャについて、ジェスチャ認識サブシステム322は、同じジェスチャクラスが、所定の数の前の入力フレーム(N)にわたって所定の最小回数(K)検出されることを要求することがあり、ここで、K≧1及びK≦Nである。この要件は、検出精度を改善させて偽陽性を減少させるのに役立つ可能性がある。いくつかの例では、同じジェスチャクラスが、N個の前の入力フレームにわたってK個の連続する入力フレームにわたって検出される必要があり得る。所定の最小数Kは、より良好な検出を可能にし、依然としてほぼリアルタイムのジェスチャ認識を達成するために、比較的少ない数(例えば10)であるように選択され得る。このアプローチを使用して検出され得る静的ジェスチャは、例えばミュートジェスチャ(例えばミュート又は非ミュートコマンド)又はオープンハンドジェスチャ(例えば再生又は一時停止コマンド)を含み得る。N個の前の入力フレームは、バッファに記憶されてよく、偽陽性を減らすのを助けるために、ジェスチャを検出するためのスライディングウィンドウ(sliding window)として使用されてもよい。
動的ジェスチャは、2つ以上の静的ジェスチャの組合せに基づいて、ジェスチャ認識サブシステム322によって認識され得る。例えば完全な動的ジェスチャは、異なる状態に分離されてもよく、この場合、状態間の遷移は、静的ジェスチャの検出の結果である。ジェスチャ認識サブシステム322は、動的ジェスチャの状態ベースの認識のために、所定の状態遷移ルールのセットを実装してもよい。
図18は、ジェスチャ認識サブシステム322によって実装され得る、動的ジェスチャの状態ベースの認識の例を示す状態図である。中立状態1802は、ジェスチャ入力が最初に活性化されるとき又は現在の有効なジェスチャが検出されないときのデフォルトによる初期状態であり得る。
スワイプの動的なジェスチャは、握りこぶしジェスチャが最初に検出されてスワイプ準備(swipe ready)状態1804に遷移し、その後、オープンハンドジェスチャの検出が続いてスワイプド(swiped)状態1806に遷移するときに、検出され得る。スワイプド状態1806に到達すると、ジェスチャ認識サブシステム322は、ジェスチャ入力を動的なスワイプジェスチャとして認識する。したがって、静的な握りこぶしジェスチャとそれに続く静的なオープンハンドジェスチャの(適切な順序での)認識は、動的なスワイプジェスチャの認識という結果をもたらす。さらに、検出された握りこぶしジェスチャと検出されたオープンハンドのジェスチャとの間の位置の変化は、動的なスワイプジェスチャを積極的に検出するために必要とされ得る(例えばスワイプジェスチャを、位置の変化を伴わない別の動的なジェスチャと区別するために)。検出されたジェスチャの位置の変化は、手のバウンディングボックスの座標の変化に基づいて計算され得る。スワイプド状態1806に到達すると、ジェスチャ認識サブシステム322は、認識されたジェスチャを示す出力(例えばジェスチャクラスラベル)を生成してもよく、スワイプ準備状態1804とスワイプド状態1806の検出の間の位置の変化を示す出力を更に提供してもよい。
垂直又は水平の動的ドラッグジェスチャは、ピンチオープン、ピンチクローズド及びピンチオープン静的ジェスチャの組合せとして検出され得る。例えば中立状態1802から、ピンチオープン静的ジェスチャの検出後に、ピンチ準備状態1808への遷移が生じる。ピンチ準備状態1808から、ピンチクローズドの静的ジェスチャの検出は、ピンチ活性化(pinch activated)状態1810への遷移を引き起こす。ピンチ活性化状態1810から、ピンチクローズド静的ジェスチャに留まると、垂直位置の変化(例えば所定の閾値を超える変化)は、垂直ドラッグ状態1812への遷移を引き起こす。同様に、ピンチ活性化状態1810から、ピンチクローズド静的ジェスチャに留まると、水平位置の変化(例えば所定の閾値を超える変化)は、水平ドラッグ状態1814への遷移を引き起こす。位置の変化が、垂直及び水平変化の組合せ(例えば位置の斜めの変化)である場合、規模がより大きい変化が、状態遷移を決定するために使用され得る。あるいは、位置の変化が垂直と水平変化の組合せである場合、状態遷移が認識されないことがある。垂直ドラッグ状態1812又は水平ドラッグ状態1814に到達すると、ジェスチャ認識サブシステム322は、認識されたジェスチャを示す出力(例えばジェスチャクラスラベル)を生成してもよく、垂直又は水平位置の変化を示す出力を更に提供してもよい。例えばジェスチャ認識サブシステム322は、(例えば入力フレームで定義された座標に基づいて)距離を計算し、この値を出力し得る。距離値は、動的ドラッグジェスチャをドラッグコマンド入力にマッピングするために使用され得る。垂直ドラッグ状態1812又は水平ドラッグ状態1814から、ピンチオープン静的ジェスチャの検出は、ピンチ準備状態1808への遷移を引き起こす。ピンチ準備状態1808に戻ることは、動的ドラッグジェスチャの終了として認識され得る。
位置の変化を伴う動的ジェスチャについて、ジェスチャ認識サブシステム322は、可能性のある偽陽性を更に排除するために、物理的及び/又は期待される人間の動きの法則に基づいて所定のルールを実装し得る。例えば所定のルールは、検出された手は、連続する入力フレームの間の所定の閾値より大きい位置の変化(例えば100ピクセルを超える変化)を示すべきでないというものであり得る。
状態ベースのジェスチャ認識を使用することは、動きベースのジェスチャ・セグメンテーション及び認識よりも有利であり得る。例えば静的ジェスチャを検出することと比較して、ジェスチャの動きを検出して処理するためには、非常に高い処理リソースが必要とされ得る。さらに、状態ベースのジェスチャ認識は、偽陽性の傾向がより少ない可能性がある。
いくつかの例において、本開示は、画像品質を改善するのを助けるために画像調整を実行することを含む、カメラ102によってキャプチャされたフレームのシーケンス内の入力フレームにおける手検出のための方法を説明する。一般に、ジェスチャ認識の性能は、低光シナリオで劣化する傾向がある。例えばジェスチャ制御デバイス100が、暗い部屋で視聴されているスマートTVである場合、フレームのシーケンスがジェスチャ制御デバイス100のカメラ102によってキャプチャされるとき、スマートTVの画面が唯一の重要な照明源であり得る。本発明では、この問題を解決するための3つの方法を提案する。画像調整のためのいくつかの例示的な技術が以下に説明され、これらの技術の各々は、例えば手検出及び追跡サブシステム316によって実装されてよく、組み合わせて使用されてもよい。
図19は、カメラ102によってキャプチャされるフレームのシーケンスにおいて画像調整を実行することを含む、手の検出及び追跡を実行するための例示的な方法1900を示すフローチャートである。方法1900は、上述のステップ1116の一部として使用され得る。例えば方法1900は、手検出及び追跡サブシステム316によって実装され得る。方法1900は、ステップ1116のための他の技術を使用して実装されてもよく、以下に説明されるような画像調整が使用されても使用されなくてもよい。
方法1900は、(例えばステップ1114において、仮想ジェスチャ空間生成サブシステム314によって)仮想ジェスチャ空間が定義された後に開始する。
1902において、カメラ102によってキャプチャされたフレームのシーケンス内の前の入力フレームにおいて、手がすでに検出されているかどうかが判断される。手がすでに検出された場合、方法1900はステップ1908に進み得る。例えば手が前の入力フレームですでに成功裏に検出された場合、前の入力フレームにおける手の成功裏の検出から生成されたバウンディングボックスは、フレームのシーケンス内の現在の入力フレームにおいて手を追跡するための開始点として使用され得る(例えば連続するフレーム間の時間は、手がまだ少なくとも部分的に前のバウンディングボックス内にあるのに十分短いという仮定に基づく)。さらに、フレームのシーケンス内の前の入力フレームにおいて手が成功裏に検出された場合、環境内の照明は十分であるとみなされてよく(例えば環境内の光レベルは連続するフレーム間の短時間では大きく変化しないという仮定に基づく)、画像調整は必要とされない。
カメラ102によってキャプチャされたフレームのシーケンス内の前の入力フレームにおいて手がまだ検出されていない場合、方法1900はステップ1904に進む。
任意に、1904において、画像調整が実行される。いくつかの例において、画像調整は、画像調整が必要であると判断される場合にのみ実行され得る。例えばジェスチャ制御デバイス100の光センサを使用して、周囲光レベルを検出し、光レベルが画像調整を必要とするほど十分に低いかどうかを判断してよい。いくつかの例において、入力画像の少なくとも一部(例えば入力画像全体にわたる、仮想ジェスチャ空間のみにわたる又は手のバウンディングボックスのみにわたる)の分析が、画像調整が必要とされるかどうかを決定する(例えば全体的な画素強度レベルを決定する)ために実行され得る。
いくつかの例では、画像調整は、画像調整が必要とされるかどうかを最初に判断することなく、デフォルトで実行されてもよい。そのような場合、画像調整(例えばガンマ補正)を実行することは、画像がすでに十分に照明されている場合には、画像に対してほとんど又は全く変化をもたらさないことがある。
特に低光条件(low-light conditions)に対して補正するために、画像調整のための様々な技術が使用され得る。
いくつかの例では、画像調整は、(人の顔が区別的な解剖学的特徴である場合には)フレームのシーケンスにおける前のフレーム内で検出された顔を基準として使用して、画像の照明を調整することを含み得る。顔が前のフレームで検出されたと仮定すると(例えば顔検出及び追跡サブシステム312を使用して)、検出された顔は、入力フレームにおいて照明調整を実行するための基準として使用され得る。
(外6)
及び
(外7)
は、それぞれ、低光及び好ましい照明条件下でキャプチャされた顔画像について、所定の(例えば較正を介して経験的に決定された又は事前コード化された)平均値及びピクセル強度の標準偏差を示すものとする。
図20は、顔を含む画像が低光でキャプチャされるときのピクセル強度値の代表的なヒストグラム2002と、顔を含む画像が好ましい照明条件でキャプチャされるときのピクセル強度値の代表的なヒストグラム2004とを示すグラフである。
低光ピクセルから好ましい照明ピクセルへのマッピングは、以下の方程式を使用して計算されることができる:
この方程式を使用して、入力フレーム内で定義される仮想ジェスチャ空間内のすべてのピクセルxiは、より良好な手検出のために上記のマッピング式を使用することによって、調整されたピクセルyiに変換され得る。上記の説明は、低光条件を補正するための照明調整を議論しているが、同様の照明調整が過剰光状態を補正するために使用されてもよいことを理解されたい。
いくつかの例では、画像調整は、(照明補正の形態と考えられ得る)ガンマ補正を実行することを含み得る。様々なガンマ補正技術が使用され得る。例えばxiは、入力フレームの単一チャネルのピクセル値とする。次に、ガンマ変換は、次のように計算され得る:
ここで、yiは、調整されたピクセル値であり、γは、ガンマ変換の標準パラメータである。
いくつかの例では、画像調整は、ジェスチャ制御デバイス100の表示を変更することを含み得る。このアプローチは、ジェスチャ制御デバイス100の画面が環境内の照明源である(例えばジェスチャ制御デバイス100が、テレビ、スマートフォン又はタブレットである)状況において有用であり得る。このようなアプローチでは、低光条件は、任意の適切な技術を使用して最初に検出され得る。例えば低光条件は、ジェスチャ制御デバイス100の一部であり得る光センサを使用して検出され得る。また、低光条件は、入力フレームのピクセル強度を分析することによって検出されてもよく、ピクセルの大部分が所定の強度閾値を下回る場合、低光条件が決定され得る。
低光条件が検出された後、ジェスチャ制御デバイス100の画面の表示コンテンツ及び/又は明るさは、より良好な品質の画像をキャプチャするために画面がより強い光源となるように制御され得る。適応ジェスチャ感知システム300からの出力は、入力フレームが不十分な照明を有するよう分析されたことを示すために通信され、処理デバイス202は、それに応じて画面の表示コンテンツ及び/又は明るさを変更するようにディスプレイ104を制御し得る。いくつかの例では、低光条件の検出が、(例えばジェスチャ制御デバイス100の光センサを使用する)画像分析に基づいていない場合、処理デバイス202は、それに応じて、適応ジェスチャ感知システム300からのいずれの情報もなしにディスプレイ104を制御し得る。
いくつかの例において、このようにして表示コンテンツ及び/又は明るさを制御することは、低光条件が検出された後であって、ジェスチャ入力が開始された(例えばユーザ10がジェスチャベースのコマンド入力を活性化するための入力を手動で提供したか又は認識されたハンドジェスチャが最初に検出された)後に実行され得る。いくつかの例では、ジェスチャ制御デバイス100の画面は、画面背景照明をより明るくするように変更するように制御され得る。いくつかの例では、ジェスチャ制御デバイス100の画面は、表示されたコンテンツに照明セクションを追加するように制御され得る。照明セクションは、ディスプレイのより明るいセクション(例えばすべて白のセクション)であり得る。
例えば図21Aは、通常の光条件下で、あるいはテレビやスマートフォンのようなジェスチャ制御デバイスのディスプレイ104上でジェスチャ入力が開始されていないときに表示され得る、正常な画像2102を示す。低光条件が検出され、ジェスチャ入力が開始された後、表示されるコンテンツは、図21Bのものへと調整され得る。図21Bでは、画像2102はサイズが縮小されており、照明セクション2104が追加されている。この例では、照明セクション2104は、ディスプレイの4つの側面すべてに沿った縁である。他のセクションでは、照明セクション2104は、1つの側面、2つの側面又は3つの側面のみに沿っていてもよく、あるいはディスプレイの1つ以上の側面に沿った不連続なセクションを含んでもよい。照明セクション2104の明るさ、色相及び/又はサイズ(例えば厚さ及び長さ)は、検出された低光条件に基づいて自動的に調整され得る。例えば(例えば検出されたピクセル強度に基づいて又は光センサからの出力に基づいて)所定の閾値において異なる低照明レベルが存在することがあり、照明セクション2104のための異なるパラメータは、異なる低照明レベルにおいて予め定義され得る。一般に、より低い照明レベルは、より大きい及び/又はより明るい照明セクション2104を必要とし得る。
図19に戻ると、1906において、手検出は、(例えば手検出及び追跡サブシステム316を使用して)仮想ジェスチャ空間内で実行される。手検出及び追跡サブシステム316は、上述のように、画像2102内の手を検出するために使用されて構成され得るトレーニングされたニューラルネットワークを含み得る。トレーニングされたニューラルネットワークを使用する手検出及び追跡サブシステム316による成功した手検出は、仮想ジェスチャ空間で検出された手について定義されたバウンディングボックスを出力し得る。
1908において、手追跡は、検出された手について定義されたバウンディングボックスに基づいて、手検出及び追跡サブシステム316を使用して実行される。バウンディングボックスは、追跡に基づいて更新され得る。
次いで、手検出及び追跡からの情報(例えば手について定義されたバウンディングボックス)が、(例えばジェスチャ認識サブシステム322による)ジェスチャ認識のために提供され得る。
様々な例において、本開示は、ジェスチャ入力を検出及び認識するための精度及び効率を改善することを助けるためのシステム及び方法を説明する。本開示は、複雑な環境においてジェスチャ入力を検出及び認識するため及び/又はジェスチャの長距離検出のために有用であり得る。
上述の方法(例えば適応ROI技術、バウンディングボックス精緻化共同ネットワーク、仮想ジェスチャ空間、画像調整、状態ベースのジェスチャ認識)のうちの1つ以上を使用することは、複雑な実生活シナリオにおいてさえ、ジェスチャ入力のよりロバストな検出及び認識を可能にし得る。ジェスチャ検出の改善された精度は、キャプチャされた入力フレームのより効率的な処理を可能にし得る。いくつかの例において、入力フレームは、画像キャプチャの速度より低い頻度で処理され得る。例えばすべての入力フレームを処理する代わりに、すべてのN(N>1)のフレームが、顔(又は他の区別的な解剖学的特徴)及び手検出及び追跡のために処理される。Nは、ユーザ選択されたパラメータであってよく、予めプログラムされてよく、あるいはジェスチャ制御デバイス100によって自動的に選択されてもよい(例えば画像が所定の閾値を下回る速度でキャプチャされるとき、Nは1であってよく;画像が所定の閾値を上回ってキャプチャされるとき、Nは2以上であってよく;画像品質が悪いか又は低解像度のとき、Nは1であってよく;画像解像度が高いとき、Nは2以上であってよい)。すべてのN(N>1)フレームを処理することにより、ジェスチャ検出及び認識は依然として、良好な精度でほぼリアルタイムに実行されることができ、ジェスチャ制御デバイスから必要とされる処理リソースを低減することができる。
本開示は、顔及び手検出のためにニューラルネットワークを使用する例示的な実装を記載する。ジェスチャ分類及び認識の精度を改善することを助けるために、手のバウンディングボックスの精緻化を可能にする例示的な共同ニューラルネットワークを記載する。
いくつかの例において、仮想ジェスチャ空間が説明され、これは、検出された人間の顔(又は他の区別的な解剖学的特徴)に基づいて定義され得る。手の検出のために定義された仮想ジェスチャ空間を使用することによって、ハンドジェスチャのより正確及び/又は効率的な検出が達成され得る。いくつかの例では、仮想ジェスチャ空間は、特定の部分空間へのジェスチャ入力がマウス入力にマッピングされ得る部分空間で更に定義され得る。したがって、仮想ジェスチャ空間は仮想マウスとして使用され得る。
ディスプレイ及びカメラを有するジェスチャ制御デバイス(スマートTV、スマートフォン又はタブレットのような)のコンテキストで実施例を説明してきたが、本開示は、ディスプレイ及び/又はカメラを含むことも含まないこともある他のジェスチャ制御デバイスに関連してもよい。例えば本開示は、スマートスピーカ、スマートアプライアンス、モノのインターネット(IoT)デバイス、ダッシュボードデバイス(例えば車両に設置される)又は低計算リソースを有するデバイスに関連し得る。
本明細書に記載される例は、人工現実(AR)、仮想現実(VR)及び/又はビデオゲームアプリケーションに適用可能であり得る。
本開示は、特定の順序のステップを有する方法及びプロセスを説明するが、方法及びプロセスの1つ以上のステップは必要に応じて省略又は変更されてもよい。1つ以上のステップは、必要に応じてそれらが記載されている順序以外の順序で行われてよい。
本開示は、少なくとも部分的に、方法に関して説明されるが、当業者には、本開示が、ハードウェア構成要素、ソフトウェア又はこれら2つの任意の組合せによる方法である、説明される方法の態様及び特徴の少なくとも一部を実行するための様々な構成要素に向けられていることが理解されよう。したがって、本開示の技術的解決策は、ソフトウェア製品の形態で具体化され得る。適切なソフトウェア製品は、予め記録された記憶デバイス、あるいは例えばDVD、CD-ROM、USBフラッシュディスク、取り外し可能ハードディスク又は他の記憶媒体を含む、他の類似の不揮発性又は非一時的なコンピュータ読取可能媒体に記憶され得る。ソフトウェア製品は、処理デバイス(例えばパーソナルコンピュータ、サーバ又はネットワークデバイス)が本明細書に開示される方法の例を実行することを可能にする、その上に有形に記憶された命令を含む。
本開示は、特許請求の範囲の主題から逸脱することなく、他の特定の形態で具体化され得る。説明される例示的な実施形態は、すべての点において、単なる例示的なものであり、限定的なものではないと考えられるべきである。上述の実施形態の1つ以上からの選択された特徴を組み合わせて、明示的に説明されていない代替的な実施形態を作り出すことができ、そのような組合せに適した特徴は本開示の範囲内で理解される。
開示される範囲内のすべての値及び副次的範囲も開示される。また、本明細書において開示及び示されているシステム、デバイス及びプロセスは、特定の数の要素/構成要素を含み得るが、システム、デバイス及びアセンブリは、追加又はより少ない要素/構成要素を含むように修正される可能性がある。例えば開示される要素/構成要素のいずれかは、単数であるものとして参照され得るが、本明細書に開示される実施形態は、複数のそのような要素/構成要素を含むように修正される可能性がある。本明細書に記載される主題は、技術におけるすべての適切な変更をカバーし、包含するように意図している。