JP7658024B1 - 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム - Google Patents
学習データ生成装置、学習データ生成方法及び学習データ生成プログラム Download PDFInfo
- Publication number
- JP7658024B1 JP7658024B1 JP2024211898A JP2024211898A JP7658024B1 JP 7658024 B1 JP7658024 B1 JP 7658024B1 JP 2024211898 A JP2024211898 A JP 2024211898A JP 2024211898 A JP2024211898 A JP 2024211898A JP 7658024 B1 JP7658024 B1 JP 7658024B1
- Authority
- JP
- Japan
- Prior art keywords
- image
- model
- data
- converted
- image data
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images












Landscapes
- Image Analysis (AREA)
Abstract
Description
本開示は、人手によらず、検知精度を高めるために有効な画像データを生成可能にすることを目的とする。
画像データを変換する画像変換モデルに対して、物体検知モデルに学習させる学習データである画像データを入力して、前記画像変換モデルによって前記画像データが変換された変換後画像を取得する画像変換部と、
前記画像変換部によって取得された前記変換後画像を前記学習データに加える学習データ追加部と
を備える。
***構成の説明***
図1を参照して、実施の形態1に係る学習データ生成装置10の構成を説明する。
学習データ生成装置10は、コンピュータである。
学習データ生成装置10は、プロセッサ11と、メモリ12と、ストレージ13と、通信インタフェース14とのハードウェアを備える。プロセッサ11は、信号線を介して他のハードウェアと接続され、これら他のハードウェアを制御する。
ストレージ13には、学習データ生成装置10の各機能構成要素の機能を実現するプログラムが格納されている。このプログラムは、プロセッサ11によりメモリ12に読み込まれ、プロセッサ11によって実行される。これにより、学習データ生成装置10の各機能構成要素の機能が実現される。
ストレージ13には、学習データ31が記憶されている。学習データ31は、物体検知モデルに学習させるためのデータである。学習データ31は、複数の画像データを含む。物体検知モデルは、画像データから検知対象の属性の物体を検知する学習モデルである。物体検知モデルは、例えば、ディープラーニングを用いて構成されたモデルである。
画像変換モデル41は、画像を変換する、いわゆる生成AIである。AIは、Artificial Intelligenceの略である。画像変換モデル41は、具体例としては、BERT、GPT等のアルゴリズムを用いて構成されてもよい。BERTは、Bidirectional Encoder Representations from Transformersの略である。GPTは、Generative Pretrained Transformerの略である。学習モデル112は、これらのアルゴリズムを含む複数のアルゴリズムを組み合わせて構成されてもよい。
図2及び図3を参照して、実施の形態1に係る学習データ生成装置10の動作を説明する。
実施の形態1に係る学習データ生成装置10の動作手順は、実施の形態1に係る学習データ生成方法に相当する。また、実施の形態1に係る学習データ生成装置10の動作を実現するプログラムは、実施の形態1に係る学習データ生成プログラムに相当する。
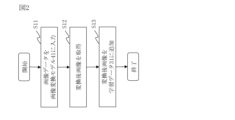
(ステップS11:入力処理)
画像変換部21は、学習データ31から1つの画像データを抽出する。画像変換部21は、画像変換モデル41に対して、抽出された画像データと、物体検知モデルの検知対象の属性である指定属性を示す属性情報とを入力する。物体検知モデルの検知対象の属性が複数存在する場合には、画像変換部21は、複数の属性のうち抽出した画像データに指定された属性情報を入力する。この際、画像変換部21は、画像データの変換規則を指示するプロンプトを画像変換モデル41に対して入力する。
ステップS11において抽出される1つの画像データは、物体検知モデルの学習前モデル評価段階において、特定の属性が検知できなかった画像あるいは、別の属性が検知された画像が望ましい。
ランダムに変更するものとしては、衣服の種類、性別、背景等が指定される。その他、光の当たり方、人数といった項目が状況に応じて指定されてもよい。
絶対に変更しないものとしては、属性情報に関する情報と、画角情報とが指定される。属性情報に関する情報とは、属性情報そのものだけでなく、属性情報に付随するものも含まれる。例えば、属性情報が白杖である場合には、属性情報に付随するものとは、白杖を右手で持っていること等である。図3のプロンプトでは、単に「${属性情報}に関する情報」と指定しているが、より具体的に「${属性情報}と、${属性情報}を持つ手」のように指定してもよい。ここで、${属性情報}は、入力情報で指定された属性情報(上記例では「白杖」)を表す。つまり、「${属性情報}と、${属性情報}を持つ手」は、「白杖と、白杖を持つ手」と読み替えられる。その他の${***}も同様に、入力情報における***として指定された情報に置き換えられる。
画像変換モデル41は、ステップS21で入力された画像データを変換した変換後画像を指定枚数だけ生成する。そして、画像変換モデル41は、指定枚数の変換後画像を出力する。指定枚数は、例えば、学習データ31の画像データの数の1割程度の数である。
この際、画像変換モデル41は、プロンプトでの指示に従い、ランダムに変更するものとして指定されたものについては、変換後画像毎にランダムに変更する。また、画像変換モデル41は、絶対に変更しないものとして指定されたものについては変更しない。つまり、指定属性については、変更されず維持された変換後画像が生成される。ランダムに変更するものと、絶対に変更しないものとのいずれにも指定されていないものについては、任意に変更可能である。
画像変換部21は、画像変換モデル41によって出力された指定枚数の変換後画像を取得する。
学習データ追加部22は、ステップS12で画像変換部21によって取得された指定枚数の変換後画像を学習データ31に追加する。
図2で示した学習データ追加処理は、学習データに追加が必要な属性情報ごとに処理が実行される。
以上のように、実施の形態1に係る学習データ生成装置10は、画像変換モデル41に対して学習データである画像データを入力して、画像変換モデル41によって画像データが変換された変換後画像を学習データ31に加える。これにより、背景の変更、周辺に存在する物体の変更、光の当たり方の変更といった様々な変更を加えた画像データを生成することが可能である。そのため、検知精度を高めるために有効な画像データを生成可能にすることが可能である。
実施の形態2は、画像データの説明文を生成させ、説明文を変換させ、変換された説明文から画像データを生成することにより、変換後画像を生成する点が実施の形態1と異なる。実施の形態2では、この異なる点を説明し、同一の点については説明を省略する。
図4を参照して、実施の形態2に係る学習データ生成装置10の構成を説明する。
画像変換モデル41は、文章生成モデル42と、文書変換モデル43と、画像生成モデル44とを含む。
文章生成モデル42は、画像データの説明文を生成するモデルである。文書変換モデル43は、説明文を変換するモデルである。画像生成モデル44は、説明文から画像データを生成するモデルである。
図5を参照して、実施の形態2に係る学習データ生成装置10の処理を説明する。
(ステップS21:画像入力処理)
画像変換部21は、学習データ31から1つの画像データを抽出する。画像変換部21は、文章生成モデル42に対して、抽出された画像データと、物体検知モデルの検知対象の属性である指定属性を示す属性情報とを入力する。物体検知モデルの検知対象の属性が複数存在する場合には、画像変換部21は、複数の属性のうち1つ以上の属性を示す属性情報を入力する。この際、画像変換部21は、説明文の生成規則を指示するプロンプトを文章生成モデル42に対して入力する。
文章生成モデル42は、ステップS21で入力された画像データを説明した説明文を生成して出力する。この際、図7に示すように、文章生成モデル42は、プロンプトでの指示に従い、画角の情報と属性情報とについての説明を含む画像データ全体の説明文を生成する。そして、画像変換部21は、文章生成モデル42によって出力された説明文を取得する。
画像変換部21は、文書変換モデル43に対して、ステップS22で取得された説明文と、物体検知モデルの検知対象の属性である指定属性を示す属性情報とを入力する。この際、画像変換部21は、説明文の変換規則を指示するプロンプトを画像変換モデル41に対して入力する。
例えば、画像変換部21は、図8に示すように、説明文及び属性情報とともに、説明文の変換規則を指示するプロンプトを文書変換モデル43に対して入力する。変換規則では、図3と同様に、ランダムに変更するものと、絶対に変更しない物とが指定される。また、図8では、説明文を英語に変換させている。これは、英語の説明文の方が、説明文から画像を生成する精度が高くなる傾向があるためである。
文書変換モデル43は、ステップS23で入力された説明文を変換した変換後文を生成して出力する。そして、画像変換部21は、文書変換モデル43によって出力された変換後文を取得する。
この際、文書変換モデル43は、プロンプトでの指示に従い、ランダムに変更するものとして指定されたものについては、変換後文毎にランダムに変更する。また、文書変換モデル43は、絶対に変更しないものとして指定されたものについては変更しない。ランダムに変更するものと、絶対に変更しないものとのいずれにも指定されていないものについては、任意に変更可能である。また、文書変換モデル43は、説明文を英文に変換する。なお、ここでは、変換後文が画像生成用プロンプトとして生成される。
画像変換部21は、画像生成モデル44に対して、ステップS24で取得された変換後文(画像生成用プロンプト)を入力する。この際、画像変換部21は、変換後文を表す画像データを指定枚数だけ生成するように指示するプロンプトを画像生成モデル44に対して入力する。
画像生成モデル44は、ステップS25で入力された変換後文を表す画像データを指定枚数だけ生成する。画像生成モデル44は、変換後文を表しつつ、画像データ毎にランダムに変更を加えて画像データを生成する。そして、画像生成モデル44は、指定枚数の変換後画像を出力する。
画像変換部21は、画像生成モデル44によって出力された指定枚数の変換後画像を取得する。
学習データ追加部22は、ステップS26で画像変換部21によって取得された指定枚数の変換後画像を学習データ31に追加する。
以上のように、実施の形態2に係る学習データ生成装置10は、画像データの説明文を生成させ、説明文を変換させ、変換された説明文から画像データを生成することにより、変換後画像を生成する。説明文を変換した変換後文を生成することで、変換した内容を明確化することができる。
<変形例1>
実施の形態2では、1個の変換後文が生成され、1個の変換後文から指定枚数の変換後画像が生成された。指定枚数の変換後文が生成され、1個の変換後文から1個の変換後画像が生成されてもよい。また、M個の変換後文が生成され、1つの変換後文からN個の変換後画像が生成されてもよい。このとき、M及びNは1以上の整数であり、M×N=指定枚数である。
実施の形態3は、変換後画像を学習データ31に追加するか否かを判断する点が実施の形態1,2と異なる。実施の形態3では、この異なる点を説明し、同一の点については説明を省略する。
図9を参照して、実施の形態3に係る学習データ生成装置10の構成を説明する。
学習データ生成装置10は、通信インタフェース14を介して、物体検知モデル45と、属性判定モデル46と接続されている。
物体検知モデル45は、画像データから検知対象の属性の物体を検知するモデルであり、学習データ31を学習するモデルである。
属性判定モデル46は、画像データに指定された属性の物体が含まれるか否か判定するモデルである。属性判定モデル46は、画像変換モデル41と同様に、いわゆる生成AIである。
図10を参照して、実施の形態3に係る学習データ追加処理(図2のステップS13、図5のステップS27)を説明する。
学習データ追加処理では、各変換後画像を対象として、以下の処理が実行される。
学習データ追加部22は、物体検知モデル45に対して、対象の変換後画像と、変換後画像を生成する際に入力とした属性情報とを入力する。変換後画像を生成する際に入力とした属性情報とは、図2のステップS11又は図5のステップS21で入力した属性情報である。
物体検知モデル45は、ステップS31で入力された対象の変換後画像から、ステップS31で入力された属性情報が示す属性の物体を検知する。物体検知モデル45は、検知結果と、検知の確信度とを出力する。
学習データ追加部22は、物体検知モデル45によって出力された検知結果及び確信度を取得する。
学習データ追加部22は、ステップS32で取得された確信度が閾値以上であるか否かを判定する。
学習データ追加部22は、確信度が閾値以上である場合には、対象の変換後画像を学習データ31に追加せず、対象の変換後画像についての処理を終了する。一方、学習データ追加部22は、確信度が閾値未満である場合には、処理をステップS34に進める。
学習データ追加部22は、属性判定モデル46に対して、対象の変換後画像と、変換後画像を生成する際に入力とした属性情報とを入力する。この際、図11に示すように、学習データ追加部22は、入力された変換後画像に、入力された属性情報が示す属性の物体が存在するか否かを判定するように指示するプロンプトを属性判定モデル46に入力する。
属性判定モデル46は、ステップS34で入力された対象の変換後画像に、ステップS31で入力された属性情報が示す属性の物体が存在するか否かを判定する。属性判定モデル46は、判定結果を出力する。
学習データ追加部22は、属性判定モデル46によって出力された判定結果を取得する。
学習データ追加部22は、ステップS35で取得された判定結果が、対象の変換後画像に物体が存在することを示す場合には、処理をステップS37に進める。一方、学習データ追加部22は、ステップS35で取得された判定結果が、対象の変換後画像に物体が存在しないことを示す場合には、対象の変換後画像を学習データ31に追加せず、対象の変換後画像についての処理を終了する。
学習データ追加部22は、対象の変換後画像を、学習データ31に追加する。
実施の形態3に係る学習データ生成装置10は、物体検知モデル45及び属性判定モデル46を用いて変換後画像を学習データ31に追加するか否かを判定する。これにより、検知精度を劣化させてしまうような変換後画像、あるいは、学習が不要な変換後画像を学習データ31に追加してしまうことを防止可能である。
具体的にはステップS33の判定では、現在の物体検知モデルで検知できるものを学習データ31に追加しないことで物体検知モデルの過学習を防いでいる。また、ステップS36の判定では、変換後画像で学習したい属性情報を有していないものを学習データ31に追加しないことで、関係ない画像を学習データ31に入れないようにしている。
<変形例2>
実施の形態3では、物体検知モデル45及び属性判定モデル46を用いて登録可能になった変換後画像だけが学習データ31に追加された。そのため、指定枚数の変換後画像が生成されても、指定枚数の変換後画像が学習データ31に追加されるとは限らなかった。
そこで、学習データ追加部22は、少なくとも一部の変換後画像が学習データ31に追加されなかった場合には、処理を画像変換部21に戻して、不足数の変換後画像を再生成させてもよい。不足数とは、指定枚数から学習データ31に追加された変換後画像の数を減算した値である。つまり、学習データ追加部22は、不足数を新たな指定枚数として、処理を図2のステップS11又は図5のステップS21からやり直させるようにしてもよい。
実施の形態4は、物体検知モデル45の学習まで行う点が実施の形態3と異なる。実施の形態4では、この異なる点を説明し、同一の点については説明を省略する。
図12を参照して、実施の形態4に係る学習データ生成装置10の構成を説明する。
学習データ生成装置10は、機能構成要素として、学習部23を備える点が、図9に示す学習データ生成装置10と異なる。学習部23は、画像変換部21及び学習データ追加部22と同様に、ソフトウェアによって実現される。
図13を参照して、実施の形態4に係る学習データ生成装置10の処理を説明する。
(ステップS41:生成追加処理)
画像変換部21及び学習データ追加部22は、実施の形態3で説明した処理により、学習データ31に変換後画像を追加する。
学習部23は、ステップS41で変換後画像が追加された学習データ31を用いて、物体検知モデル45に学習させる。
学習部23は、ステップS42で学習された物体検知モデル45の評価を行う。物体検知モデル45の評価は既存の技術を用いて行うことが可能である。
学習部23は、ステップS43で得られた評価が以前の評価よりも下がっている場合には、処理をステップS44に進める。学習部23は、ステップS43で得られた評価が以前の評価以上であるが、基準に達していない場合には、処理をステップS41に戻す。学習部23は、ステップS43で得られた評価が以前の評価以上であるが、基準に達している場合には、処理を終了する。
学習部23は、ステップS41で追加された変換後画像を学習データ31から削除する。また、学習部23は、物体検知モデル45を、ステップS42での学習前の状態に戻す。そして、学習部23は、処理をステップS41に戻す。
以上のように、実施の形態4に係る学習データ生成装置10は、学習データ31の追加と物体検知モデル45の学習とを繰り返す。これにより、人手によることなく物体検知モデル45の検知精度を高めることが可能である。
<変形例3>
以上の実施の形態では、各機能構成要素がソフトウェアで実現された。しかし、変形例3として、各機能構成要素はハードウェアで実現されてもよい。この変形例3について、以上の実施の形態と異なる点を説明する。
各機能構成要素を1つの電子回路で実現してもよいし、各機能構成要素を複数の電子回路に分散させて実現してもよい。
変形例4として、一部の各機能構成要素がハードウェアで実現され、他の各機能構成要素がソフトウェアで実現されてもよい。
(付記1)
画像データを変換する画像変換モデルに対して、物体検知モデルに学習させる学習データである画像データを入力して、前記画像変換モデルによって前記画像データが変換された変換後画像を取得する画像変換部と、
前記画像変換部によって取得された前記変換後画像を前記学習データに加える学習データ追加部と
を備える学習データ生成装置。
(付記2)
前記画像変換部は、前記画像データに指定属性が含まれる状態を維持するように前記画像変換モデルに対して指示して、前記画像データを変換させる
付記1に記載の学習データ生成装置。
(付記3)
前記画像変換部は、前記画像データにおける指定属性に関する部分については変更せず、他の部分を変更するように前記画像変換モデルに対して指示して、前記画像データを変換させる
付記1又は2に記載の学習データ生成装置。
(付記4)
前記画像変換モデルは、画像データの説明文を生成する文章生成モデルと、説明文を変換する文書変換モデルと、説明文から画像データを生成する画像生成モデルとを含み、
前記画像変換部は、前記文章生成モデルに対して前記画像データを入力して、前記文章生成モデルによって生成された前記画像データの説明文を取得し、前記文書変換モデルに対して取得された前記説明文を入力して、前記文書変換モデルによって変換された変換後文を取得し、前記画像生成モデルに対して変換された前記変換後文を入力して、前記画像生成モデルによって生成された画像データを前記変換後画像として取得する
付記1又は2に記載の学習データ生成装置。
(付記5)
前記画像変換部は、前記説明文における指定属性に関する部分については変更せず、他の部分を変更するように前記文書変換モデルに対して指示して、前記説明文を変換させる付記4に記載の学習データ生成装置。
(付記6)
前記学習データ生成装置は、さらに、
前記物体検知モデルに対して前記画像変換部によって取得された前記変換後画像を入力して、前記物体検知モデルで物体を検知した確信度が評価閾値以上であるか否かを判定するデータ判定部
を備え、
前記学習データ追加部は、前記データ判定部によって前記確信度が前記評価閾値未満であると判定された場合に、前記変換後画像を前記学習データに加える
付記1から5までのいずれか1項に記載の学習データ生成装置。
(付記7)
前記データ判定部は、前記確信度が前記評価閾値未満である場合に、画像データに特定の属性の物体が存在するか否かを判定する属性判定モデルに対して、前記変換後画像と指定属性とを入力して、前記変換後画像に前記指定属性の物体が存在するか否かの判定結果を取得し、
前記学習データ追加部は、前記データ判定部によって前記変換後画像に前記指定属性の物体が存在するという判定結果が取得された場合に、前記変換後画像を前記学習データに加える
付記6に記載の学習データ生成装置。
(付記8)
コンピュータが、画像データを変換する画像変換モデルに対して、物体検知モデルに学習させる学習データである画像データを入力して、前記画像変換モデルによって前記画像データが変換された変換後画像を取得し、
コンピュータが、前記変換後画像を前記学習データに加える学習データ生成方法。
(付記9)
画像データを変換する画像変換モデルに対して、物体検知モデルに学習させる学習データである画像データを入力して、前記画像変換モデルによって前記画像データが変換された変換後画像を取得する画像変換処理と、
前記画像変換処理によって取得された前記変換後画像を前記学習データに加える学習データ追加処理と
を行う学習データ生成装置としてコンピュータを機能させる学習データ生成プログラム。
Claims (5)
- 画像データを変換する画像変換モデルに対して、物体検知モデルに学習させる学習データである画像データを入力して、前記画像変換モデルによって前記画像データが変換された変換後画像を取得する画像変換部と、
前記画像変換部によって取得された前記変換後画像を前記学習データに加える学習データ追加部と
を備え、
前記画像変換モデルは、前記画像データの説明文を生成する文章生成モデルと、説明文を変換する文書変換モデルと、説明文から画像データを生成する画像生成モデルとを含み、
前記画像変換部は、前記文章生成モデルに対して前記画像データと指定属性を示す属性情報とを入力するとともに、前記画像データに含まれる前記属性情報が示す前記指定属性に関する説明と、前記画像データの画角についての説明とを含む説明文の生成を指示して、前記文章生成モデルによって生成された前記指定属性に関する説明と前記画角についての説明とを含む前記画像データの説明文を取得し、前記文書変換モデルに対して取得された前記説明文を入力するとともに、前記指定属性及び前記画角については変更せず、他の部分を変更するように指示して、前記文書変換モデルによって変換された変換後文を取得し、前記画像生成モデルに対して変換された前記変換後文を入力して、前記画像生成モデルによって生成された画像データを前記変換後画像として取得する学習データ生成装置。 - 前記学習データ生成装置は、さらに、
前記物体検知モデルに対して前記画像変換部によって取得された前記変換後画像を入力
して、前記物体検知モデルで物体を検知した確信度が評価閾値以上であるか否かを判定す
るデータ判定部
を備え、
前記学習データ追加部は、前記データ判定部によって前記確信度が前記評価閾値未満で
あると判定された場合に、前記変換後画像を前記学習データに加える
請求項1に記載の学習データ生成装置。 - 前記データ判定部は、前記確信度が前記評価閾値未満である場合に、画像データに特定の属性の物体が存在するか否かを判定する属性判定モデルに対して、前記変換後画像と指定属性とを入力して、前記変換後画像に前記指定属性の物体が存在するか否かの判定結果を取得し、
前記学習データ追加部は、前記データ判定部によって前記変換後画像に前記指定属性の物体が存在するという判定結果が取得された場合に、前記変換後画像を前記学習データに加える
請求項2に記載の学習データ生成装置。 - コンピュータが、画像データを変換する画像変換モデルに対して、物体検知モデルに学習させる学習データである画像データを入力して、前記画像変換モデルによって前記画像データが変換された変換後画像を取得し、
コンピュータが、前記変換後画像を前記学習データに加え、
前記画像変換モデルは、前記画像データの説明文を生成する文章生成モデルと、説明文を変換する文書変換モデルと、説明文から画像データを生成する画像生成モデルとを含み、
コンピュータが、前記文章生成モデルに対して前記画像データと指定属性を示す属性情報とを入力するとともに、前記画像データに含まれる前記属性情報が示す前記指定属性に関する説明と、前記画像データの画角についての説明とを含む説明文の生成を指示して、前記文章生成モデルによって生成された前記指定属性に関する説明と前記画角についての説明とを含む前記画像データの説明文を取得し、前記文書変換モデルに対して取得された前記説明文を入力するとともに、前記指定属性及び前記画角については変更せず、他の部分を変更するように指示して、前記文書変換モデルによって変換された変換後文を取得し、前記画像生成モデルに対して変換された前記変換後文を入力して、前記画像生成モデルによって生成された画像データを前記変換後画像として取得する学習データ生成方法。 - 画像データを変換する画像変換モデルに対して、物体検知モデルに学習させる学習データである画像データを入力して、前記画像変換モデルによって前記画像データが変換された変換後画像を取得する画像変換処理と、
前記画像変換処理によって取得された前記変換後画像を前記学習データに加える学習データ追加処理と
を行う学習データ生成装置としてコンピュータを機能させ、
前記画像変換モデルは、前記画像データの説明文を生成する文章生成モデルと、説明文を変換する文書変換モデルと、説明文から画像データを生成する画像生成モデルとを含み、
前記画像変換処理では、前記文章生成モデルに対して前記画像データと指定属性を示す属性情報とを入力するとともに、前記画像データに含まれる前記属性情報が示す前記指定属性に関する説明と、前記画像データの画角についての説明とを含む説明文の生成を指示して、前記文章生成モデルによって生成された前記指定属性に関する説明と前記画角についての説明とを含む前記画像データの説明文を取得し、前記文書変換モデルに対して取得された前記説明文を入力するとともに、前記指定属性及び前記画角については変更せず、他の部分を変更するように指示して、前記文書変換モデルによって変換された変換後文を取得し、前記画像生成モデルに対して変換された前記変換後文を入力して、前記画像生成モデルによって生成された画像データを前記変換後画像として取得する学習データ生成プログラム。
Priority Applications (2)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024211898A JP7658024B1 (ja) | 2024-12-05 | 2024-12-05 | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム |
| JP2025051056A JP7799879B1 (ja) | 2024-12-05 | 2025-03-26 | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2024211898A JP7658024B1 (ja) | 2024-12-05 | 2024-12-05 | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム |
Related Child Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2025051056A Division JP7799879B1 (ja) | 2024-12-05 | 2025-03-26 | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| JP7658024B1 true JP7658024B1 (ja) | 2025-04-07 |
Family
ID=95282057
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2024211898A Active JP7658024B1 (ja) | 2024-12-05 | 2024-12-05 | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム |
| JP2025051056A Active JP7799879B1 (ja) | 2024-12-05 | 2025-03-26 | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム |
Family Applications After (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2025051056A Active JP7799879B1 (ja) | 2024-12-05 | 2025-03-26 | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (2) | JP7658024B1 (ja) |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016076073A (ja) * | 2014-10-06 | 2016-05-12 | 日本電気株式会社 | データ処理装置、データ処理方法、及び、コンピュータ・プログラム |
| JP2018181157A (ja) * | 2017-04-19 | 2018-11-15 | 株式会社日立製作所 | 人物認証装置 |
| JP2019212073A (ja) * | 2018-06-06 | 2019-12-12 | アズビル株式会社 | 画像判別装置および方法 |
| JP2023044190A (ja) * | 2021-09-17 | 2023-03-30 | 日本無線株式会社 | 機械学習支援方法、プログラム及び機械学習支援システム |
Family Cites Families (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7380019B2 (ja) * | 2019-09-27 | 2023-11-15 | オムロン株式会社 | データ生成システム、学習装置、データ生成装置、データ生成方法及びデータ生成プログラム |
| JP7681863B2 (ja) * | 2021-03-31 | 2025-05-23 | 成典 田中 | 画像に基づく対象物推定装置 |
-
2024
- 2024-12-05 JP JP2024211898A patent/JP7658024B1/ja active Active
-
2025
- 2025-03-26 JP JP2025051056A patent/JP7799879B1/ja active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP2016076073A (ja) * | 2014-10-06 | 2016-05-12 | 日本電気株式会社 | データ処理装置、データ処理方法、及び、コンピュータ・プログラム |
| JP2018181157A (ja) * | 2017-04-19 | 2018-11-15 | 株式会社日立製作所 | 人物認証装置 |
| JP2019212073A (ja) * | 2018-06-06 | 2019-12-12 | アズビル株式会社 | 画像判別装置および方法 |
| JP2023044190A (ja) * | 2021-09-17 | 2023-03-30 | 日本無線株式会社 | 機械学習支援方法、プログラム及び機械学習支援システム |
Non-Patent Citations (6)
| Title |
|---|
| Bolong Liu et al.,"ACIGS: An automated large-scale crops image generation system based on large visual language multi-modal models",2023 20th Annual IEEE International Conference on Sensing, Communication, and Networking (SECON),米国,IEEE,2023年10月23日,pp.7-13 |
| BOLONG LIU ET AL.: ""ACIGS: An automated large-scale crops image generation system based on large visual language multi-", 2023 20TH ANNUAL IEEE INTERNATIONAL CONFERENCE ON SENSING, COMMUNICATION, AND NETWORKING (SECON), JPN6024052462, 23 October 2023 (2023-10-23), US, pages 7 - 13, ISSN: 0005522331 * |
| Qiufeng Wu et al.,"DCGAN-Based Data Augmentation for Tomato Leaf Disease Identification",IEEE Access,米国,IEEE,2020年05月25日,Vol.8,pp.98716-98728 |
| QIUFENG WU ET AL.: ""DCGAN-Based Data Augmentation for Tomato Leaf Disease Identification"", IEEE ACCESS, vol. 8, JPN6024052460, 25 May 2020 (2020-05-25), US, pages 98716 - 98728, ISSN: 0005548316 * |
| Yutong Xie et al.,"PairAug: What Can Augmented Image-Text Pairs Do for Radiology?",2024 IEEE/CVF Conference on Computer Vision and Pattern Recognition (CVPR),米国,IEEE,2024年06月16日,pp.11652-11661 |
| YUTONG XIE ET AL.: ""PairAug: What Can Augmented Image-Text Pairs Do for Radiology?"", 2024 IEEE/CVF CONFERENCE ON COMPUTER VISION AND PATTERN RECOGNITION (CVPR), JPN6024052461, 16 June 2024 (2024-06-16), US, pages 11652 - 11661, ISSN: 0005548315 * |
Also Published As
| Publication number | Publication date |
|---|---|
| JP7799879B1 (ja) | 2026-01-15 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| CN111754596B (zh) | 编辑模型生成、人脸图像编辑方法、装置、设备及介质 | |
| JP2022137145A (ja) | マルチモーダルデータ連合学習モデルトレーニング方法及び装置 | |
| CN116611496B (zh) | 文本到图像的生成模型优化方法、装置、设备及存储介质 | |
| JP6601470B2 (ja) | 自然言語の生成方法、自然言語の生成装置及び電子機器 | |
| CN112685582B (zh) | 自动生成故事板 | |
| Lee et al. | Crossing you in style: Cross-modal style transfer from music to visual arts | |
| CN117689745A (zh) | 基于提示从文本生成图像 | |
| US12248759B2 (en) | Method and system for automatic augmentation of sign language translation in gloss units | |
| CN116977903A (zh) | 一种通过文本智能生成短视频的aigc方法 | |
| CN117034133A (zh) | 一种数据处理方法、装置、设备和介质 | |
| JP7658024B1 (ja) | 学習データ生成装置、学習データ生成方法及び学習データ生成プログラム | |
| KR102281298B1 (ko) | 인공지능 기반 동영상 합성을 위한 시스템 및 방법 | |
| CN119293204B (zh) | 一种改进的上下文感知自适应对比解码方法 | |
| Vadhil et al. | The powerful AI: An exploration of generative Artificial Intelligence taxonomy and applications | |
| CN117372405A (zh) | 人脸图像质量评估方法、装置、存储介质及设备 | |
| JP2010529542A (ja) | テキスト・トゥ・アニメーションシステムに対する時系列テンプレート | |
| JP7681181B1 (ja) | 物体検知装置、物体検知方法及び物体検知プログラム | |
| JP7696528B1 (ja) | 実行時間見積装置、実行時間見積方法及び実行時間見積プログラム | |
| US12613894B2 (en) | Information processing apparatus, computer program product, and information processing method | |
| Hossain et al. | Hierarchical Region-Context Attention for image captioning | |
| KR102577734B1 (ko) | 라이브 공연의 자막 동기화를 위한 인공지능 학습 방법 | |
| WO2024171395A1 (ja) | 生成装置、生成方法および生成プログラム | |
| JP7003343B2 (ja) | ベクトル計算装置、分類装置及び出力プログラム | |
| CN119597954B (zh) | 图像搜索方法、装置、智能体、电子设备及存储介质 | |
| US20240193363A1 (en) | Information processing apparatus, information processing method, and storage medium |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20241205 |
|
| A871 | Explanation of circumstances concerning accelerated examination |
Free format text: JAPANESE INTERMEDIATE CODE: A871 Effective date: 20241205 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20241224 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20250129 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20250204 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20250225 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20250311 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250326 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7658024 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S111 | Request for change of ownership or part of ownership |
Free format text: JAPANESE INTERMEDIATE CODE: R313111 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |