JP7670951B2 - 情報処理装置、情報処理方法、プログラム - Google Patents
情報処理装置、情報処理方法、プログラム Download PDFInfo
- Publication number
- JP7670951B2 JP7670951B2 JP2020178643A JP2020178643A JP7670951B2 JP 7670951 B2 JP7670951 B2 JP 7670951B2 JP 2020178643 A JP2020178643 A JP 2020178643A JP 2020178643 A JP2020178643 A JP 2020178643A JP 7670951 B2 JP7670951 B2 JP 7670951B2
- Authority
- JP
- Japan
- Prior art keywords
- field
- document
- search
- searched
- information processing
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
- 230000010365 information processing Effects 0.000 title claims description 28
- 238000003672 processing method Methods 0.000 title claims description 7
- 238000000605 extraction Methods 0.000 claims description 109
- 238000000034 method Methods 0.000 claims description 58
- 238000004364 calculation method Methods 0.000 claims description 17
- 238000004458 analytical method Methods 0.000 claims description 15
- 230000000877 morphologic effect Effects 0.000 claims description 15
- 239000000284 extract Substances 0.000 claims 2
- 238000012545 processing Methods 0.000 description 41
- 238000010276 construction Methods 0.000 description 11
- 230000006870 function Effects 0.000 description 11
- 238000010586 diagram Methods 0.000 description 10
- 238000004891 communication Methods 0.000 description 4
- 238000005516 engineering process Methods 0.000 description 4
- 230000007704 transition Effects 0.000 description 4
- 230000000694 effects Effects 0.000 description 3
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical compound [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 1
- 230000001174 ascending effect Effects 0.000 description 1
- 238000012217 deletion Methods 0.000 description 1
- 230000037430 deletion Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- 230000003287 optical effect Effects 0.000 description 1
- 229910052710 silicon Inorganic materials 0.000 description 1
- 239000010703 silicon Substances 0.000 description 1
- 238000012876 topography Methods 0.000 description 1
Images
















Landscapes
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Description
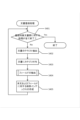
ステップS508では、抽出されたフィールドを該文書のフィールドとして記録しておく。このとき、該抽出定義情報のフィールド名と関連付けて記録する。
文書ID1401には、検索でヒットした文書を特定するための項目であり、ヒットした文書のIDが登録される。
100 情報処理装置
101 文書登録処理部
102 文書検索処理部
103 形態素解析辞書
104 登録文書インデックス
105 抽出定義DB
106 検索セッション統計情報
107 文書DB
108 クライアントPC
Claims (11)
- 文書のカテゴリ毎に、文書のフィールドと、当該フィールドから抽出する文字列と、当該フィールドの重みと、を定義した定義情報を受け付ける定義情報受付手段と、
複数の検索対象の文書のそれぞれについて、当該検索対象の文書に係るカテゴリに対応する前記定義情報に基づき、当該検索対象の文書から当該検索対象の文書のフィールド毎に前記文字列を抽出する抽出手段と、
ユーザから前記検索対象の文書を検索するための検索語を受け付ける検索語受付手段と、
複数の検索対象の文書のそれぞれについて、前記検索語受付手段により受け付けた検索語と、前記抽出手段により当該検索対象の文書から抽出された文字列と、前記定義情報により定義された当該文字列に係るフィールドの重みと、に基づき、当該検索対象の文書のフィールド毎に算出された検索スコアに基づく当該検索対象の文書の検索スコアを算出するスコア算出手段と、
を備えることを特徴とする情報処理システム。 - 前記スコア算出手段は、前記フィールド毎に算出された検索スコアの合計値を当該検索対象の文書の検索スコアとして算出することを特徴とする請求項1に記載の情報処理システム。
- 前記スコア算出手段は、前記フィールド毎の検索スコアを、当該フィールドにおける前記検索語と一致する前記抽出された文字列の数と、当該フィールドの重みとに基づき算出することを特徴とする請求項1または2に記載の情報処理システム。
- 前記スコア算出手段は、前記フィールド毎の検索スコアを、当該フィールドにおける前記検索語と一致する前記抽出された文字列の数に、当該フィールドの重みを掛け合わせることで算出することを特徴とする請求項1乃至3のいずれか1項に記載の情報処理システム。
- 前記定義情報は、前記フィールドから抽出する文字列の抽出方法として、前記フィールド毎に、形態素解析、キーワードマッチ、正規表現パターンのいずれかの方法が定義されていることを特徴とし、
前記抽出手段は、前記定義情報に定義された抽出方法に基づき、当該検索対象の文書のフィールド毎に前記文字列を抽出することを特徴とする請求項1乃至4のいずれか1項に記載の情報処理システム。 - 前記スコア算出手段により算出された検索スコアに基づき、前記検索語による検索結果を表示するよう制御する表示制御手段をさらに備えることを特徴とする請求項1乃至5のいずれか1項に記載の情報処理システム。
- 前記検索語により検索された文書の閲覧実績に基づき、当該検索された文書に係るカテゴリに対応する定義情報での前記フィールドの重みを更新する更新手段をさらに備えることを特徴とする請求項1乃至6のいずれか1項に記載の情報処理システム。
- 前記更新手段は、閲覧された文書に係るカテゴリに対応する定義情報での前記フィールドの重みを高くすることを特徴とする請求項7に記載の情報処理システム。
- 前記更新手段は、閲覧されなかった文書に係るカテゴリに対応する定義情報での前記フィールドの重みを低くすることを特徴とする請求項7または8に記載の情報処理システム。
- 情報処理システムの定義情報受付手段が、文書のカテゴリ毎に、フィールドと、当該フィールドから抽出する文字列と、当該フィールドの重みと、を定義した定義情報を受け付ける定義情報受付工程と、
前記情報処理システムの抽出手段が、複数の検索対象の文書のそれぞれについて、当該検索対象の文書に係るカテゴリに対応する前記定義情報に基づき、当該検索対象の文書から当該検索対象の文書のフィールド毎に前記文字列を抽出する抽出工程と、
前記情報処理システムの検索語受付手段が、ユーザから前記検索対象の文書を検索するための検索語を受け付ける検索語受付工程と、
前記情報処理システムのスコア算出手段が、複数の検索対象の文書のそれぞれについて、前記検索語受付工程により受け付けた検索語と、前記抽出工程により抽出された文字列と、前記定義情報により定義された当該文字列に係るフィールドの重みと、に基づき、当該検索対象の文書のフィールド毎に算出された検索スコアに基づく当該検索対象の文書の検索スコアを算出するスコア算出工程と、
を備えることを特徴とする情報処理方法。 - コンピュータを請求項1乃至9のいずれか1項に記載の各手段として機能させるためのプログラム。
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020178643A JP7670951B2 (ja) | 2020-10-26 | 2020-10-26 | 情報処理装置、情報処理方法、プログラム |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| JP2020178643A JP7670951B2 (ja) | 2020-10-26 | 2020-10-26 | 情報処理装置、情報処理方法、プログラム |
Publications (3)
| Publication Number | Publication Date |
|---|---|
| JP2022069790A JP2022069790A (ja) | 2022-05-12 |
| JP2022069790A5 JP2022069790A5 (ja) | 2023-11-06 |
| JP7670951B2 true JP7670951B2 (ja) | 2025-05-01 |
Family
ID=81534223
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2020178643A Active JP7670951B2 (ja) | 2020-10-26 | 2020-10-26 | 情報処理装置、情報処理方法、プログラム |
Country Status (1)
| Country | Link |
|---|---|
| JP (1) | JP7670951B2 (ja) |
Families Citing this family (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JP7298722B2 (ja) * | 2020-06-30 | 2023-06-27 | 株式会社三洋物産 | 遊技機 |
| JP7298721B2 (ja) * | 2020-06-30 | 2023-06-27 | 株式会社三洋物産 | 遊技機 |
| JP7298723B2 (ja) * | 2020-06-30 | 2023-06-27 | 株式会社三洋物産 | 遊技機 |
| JP7298724B2 (ja) * | 2020-08-07 | 2023-06-27 | 株式会社三洋物産 | 遊技機 |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190325212A1 (en) | 2018-04-20 | 2019-10-24 | EMC IP Holding Company LLC | Method, electronic device and computer program product for categorization for document |
Family Cites Families (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| JPH1049549A (ja) * | 1996-05-29 | 1998-02-20 | Matsushita Electric Ind Co Ltd | 文書検索装置 |
-
2020
- 2020-10-26 JP JP2020178643A patent/JP7670951B2/ja active Active
Patent Citations (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US20190325212A1 (en) | 2018-04-20 | 2019-10-24 | EMC IP Holding Company LLC | Method, electronic device and computer program product for categorization for document |
| CN110390094A (zh) | 2018-04-20 | 2019-10-29 | 伊姆西Ip控股有限责任公司 | 对文档进行分类的方法、电子设备和计算机程序产品 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2022069790A (ja) | 2022-05-12 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP7670951B2 (ja) | 情報処理装置、情報処理方法、プログラム | |
| KR101465769B1 (ko) | 사전 단어 및 어구 판정 | |
| JP2809341B2 (ja) | 情報要約方法、情報要約装置、重み付け方法、および文字放送受信装置。 | |
| US8280902B2 (en) | High precision search system and method | |
| US11573989B2 (en) | Corpus specific generative query completion assistant | |
| US9639518B1 (en) | Identifying entities in a digital work | |
| WO2019009995A1 (en) | SYSTEM AND METHOD FOR RESEARCHING MUSIC IN NATURAL LANGUAGE | |
| JP2669601B2 (ja) | 情報検索方法及びシステム | |
| JP2011134334A (ja) | ショートテキスト通信のトピックを識別するためのシステムおよび方法 | |
| US7440938B2 (en) | Method and apparatus for calculating similarity among documents | |
| TW200805095A (en) | Data product search using related concepts | |
| JP2872706B2 (ja) | 情報検索装置 | |
| CN103198059B (zh) | 电子设备以及词典数据显示方法 | |
| US20130036354A1 (en) | Music interface | |
| JP6287192B2 (ja) | 情報処理装置、情報処理方法、プログラム | |
| JP2005122665A (ja) | 電子機器装置、関連語データベースの更新方法、プログラム | |
| JP7626924B2 (ja) | 情報処理システム、情報処理方法、プログラム | |
| JP5112416B2 (ja) | 用語抽出装置、方法及び用語辞書のデータ構造 | |
| JP6571053B2 (ja) | 施設検索装置、施設検索方法、コンピュータプログラム及びコンピュータプログラムを記録した記録媒体 | |
| JP7614705B2 (ja) | 情報処理システム、情報処理方法、プログラム | |
| JP7545061B2 (ja) | 情報処理システム、情報処理方法、プログラム | |
| JP2018156552A (ja) | 計算機システム及び文章データの検索方法 | |
| JP4331177B2 (ja) | 情報検索システム、情報検索方法及び情報検索プログラム | |
| JP2008059392A (ja) | 辞書検索装置および辞書検索処理プログラム | |
| JP7587171B2 (ja) | 情報処理装置、制御方法、プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20231025 |
|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20231025 |
|
| A977 | Report on retrieval |
Free format text: JAPANESE INTERMEDIATE CODE: A971007 Effective date: 20240918 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20241008 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20241206 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20250107 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20250307 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20250318 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250331 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7670951 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |