前記課題を解決するためになされた第1の発明は、利用者の発声を収音して骨導音信号を生成する骨導マイクと、前記利用者を含む複数の人物の発声を収音して気導音信号を生成する気導マイクと、前記気導音信号に基づく前記複数の人物の前記発声から前記骨導音信号に基づく前記利用者の前記発声を分離するための処理を実行することにより、分離音信号を生成する音声分離部と、前記骨導音信号に基づき生成された前記利用者の前記発声を含む骨導音データ、及び前記分離音信号に基づき生成された前記利用者以外の前記人物の前記発声を含む分離音データをそれぞれ記憶する記憶部と、備えた構成とする。
これによると、骨導マイクおよび気導マイクを用いて利用者を含む複数の人物の発声が収音される場合に、利用者の発声を含む骨導音データと、利用者以外の人物の発声を含む分離音データとがそれぞれ記憶されるため、利用者の発声とその周囲の人物の発声とを分離して利用することが可能となる。
また、第2の発明は、前記骨導音信号が伝送される骨導音伝送路と、前記気導音信号が伝送される気導音伝送路と、を更に備え、前記音声分離部は、前記気導音伝送路を伝送される前記気導音信号から前記骨導音伝送路を伝送される前記骨導音信号を減算することにより、前記分離音信号を生成する構成とする。
これによると、簡易な構成によって利用者以外の人物の発声を含む分離音信号を生成することができる。
また、第3の発明は、前記骨導音伝送路において、前記分離音信号の生成に用いられる前記骨導音信号から前記利用者の前記発声に基づく音声信号を抽出するローパスフィルタを更に備えた構成とする。
これによると、ローパスフィルタによって抽出された利用者の発声に基づく音声信号によって、利用者を含む複数の人物の発声から利用者の発声のみをより精度良く分離することができる。
また、第4の発明は、前記骨導音伝送路において、前記分離音信号の生成に用いられる前記骨導音信号におけるノイズ成分を除去または低減するノイズキャンセラを更に備えた構成とする。
これによると、ノイズキャンセラによってノイズ成分が除去または低減された音声信号によって、利用者を含む複数の人物の発声から利用者の発声のみをより精度良く分離することができる。
また、第5の発明は、前記骨導音データに基づく音声と前記分離音データに基づく音声とを選択的に再生可能な音声再生部を更に備えた構成とする。
これによると、利用者の発声とその周囲の人物の発声とを分離して再生することができる。
また、第6の発明は、前記骨導音データに基づく音声と前記分離音データに基づく音声との音声認識処理を選択的に実行することにより、テキスト変換処理を実行可能な音声認識部を更に備えた構成とする。
これによると、利用者の発声とその周囲の人物の発声とを分離してテキスト化することができる。
また、第7の発明は、複数の利用者における各利用者によってそれぞれ使用されるマイクセットと、前記各マイクセットからの音声信号をそれぞれ取得するサーバとを備え、前記各マイクセットは、前記各利用者の発声を収音して骨導音信号を生成する骨導マイクと、前記各利用者を含む複数の人物の発声を収音して気導音信号を生成する気導マイクと、を有し、前記サーバは、前記骨導音信号に基づく骨導音データと、前記気導音信号に基づく気導音データとを、前記各マイクセットからそれぞれ取得する音声データ取得部と、前記音声データ取得部によって取得された複数の前記気導音データを合成することにより、合成気導音データを生成する気導音データ合成部と、前記合成気導音データに基づく合成音声から、少なくとも1つの前記マイクセットに対応する前記骨導音データに基づく前記利用者の前記発声を分離するための処理を実行することにより分離音データを生成する音声データ分離部と、前記骨導音データと、前記分離音データとをそれぞれ記憶する記憶部と、を有する構成とする。
これによると、骨導マイクおよび気導マイクを有するマイクセットをそれぞれ用いて複数の利用者の発声が収音される場合に、各利用者の発声を含む骨導音データと、特定の利用者(すなわち、複数の利用者の中から選択された利用者)の発声を含む分離音データとがそれぞれ記憶されるため、特定の利用者の発声とそれ以外の利用者の発声とを分離して利用することが可能となる。
また、第8の発明は、前記複数の利用者のいずれかにより使用される入力装置を更に備え、前記サーバは、前記入力装置への入力操作によって選択された少なくとも1つの前記マイクセットの情報を取得し、前記音声データ分離部は、選択された少なくとも1つの前記マイクセット以外の前記マイクセットに対応する前記骨導音データに基づき、前記分離音データを生成する構成とする。
これによると、利用者は、自ら選択した特定の利用者(自身を含む)の発声とそれ以外の利用者の発声とを分離して利用することが可能となる。
また、第9の発明は、録音装置の録音方法であって、前記録音装置は、利用者の発声を収音して骨導音信号を生成する骨導マイクと、前記利用者を含む複数の人物の発声を収音して気導音信号を生成する気導マイクと、を備え、前記気導音信号に基づく前記複数の人物の前記発声から前記骨導音信号に基づく前記利用者の前記発声を分離するための処理を実行することにより分離音信号を生成し、前記骨導音信号に基づき前記利用者の前記発声を含む骨導音データを生成し、かつ前記分離音信号に基づき前記利用者以外の前記人物の前記発声を含む分離音データを生成し、前記骨導音データおよび前記分離音データをそれぞれ記憶する構成とする。
これによると、骨導マイクおよび気導マイクを用いて利用者を含む複数の人物の発声が収音される場合に、利用者の発声を含む骨導音データと、利用者以外の人物の発声を含む分離音データとがそれぞれ記憶されるため、利用者の発声とその周囲の人物の発声とを分離して利用することが可能となる。
また、第10の発明は、録音システムの録音方法であって、前記録音システムは、複数の利用者における各利用者によってそれぞれ使用されるマイクセットと、前記各マイクセットからの音声信号をそれぞれ取得するサーバとを備え、前記各マイクセットは、前記各利用者の発声を収音して骨導音信号を生成する骨導マイクと、前記各利用者を含む複数の人物の発声を収音して気導音信号を生成する気導マイクと、を有し、前記サーバは、前記骨導音信号に基づく骨導音データと、前記気導音信号に基づく気導音データとを、前記各マイクセットからそれぞれ取得し、取得された複数の前記気導音データを合成することにより、合成気導音データを生成し、前記合成気導音データに基づく合成音声から、少なくとも1つの前記マイクセットに対応する前記骨導音データに基づく前記利用者の前記発声を分離するための処理を実行することにより分離音データを生成し、前記骨導音データと、前記分離音データとをそれぞれ記憶する構成とする。
これによると、骨導マイクおよび気導マイクを有するマイクセットをそれぞれ用いて複数の利用者の発声が収音される場合に、各利用者の発声を含む骨導音データと、特定の利用者(すなわち、複数の利用者の中から選択された利用者)の発声を含む分離音データとがそれぞれ記憶されるため、特定の利用者の発声とそれ以外の利用者の発声とを分離して利用することが可能となる。
以下、本開示の実施の形態を、図面を参照しながら説明する。
(第1実施形態)
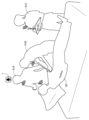
図1は、本開示の第1実施形態に係る録音装置1の使用状態を示す斜視図である。図2は、図1に示されたイヤホン2の分解斜視図である。
図1に示すように、録音装置1は、収音機能を有するイヤホン2と、イヤホン2によって収音された音声を録音するための信号処理を行う録音装置本体3(以下、「装置本体3」という。)とを含む。ここでは、イヤホン2が利用者(すなわち、録音装置1を所持する人物)の右側の耳5に挿入される場合の例が示されている。ただし、イヤホン2は利用者の左側の耳に挿入されて使用されてもよい。また、録音装置1は、左右一対のイヤホン2を備えていてもよい。
録音装置1において、装置本体3は、信号線4を介してイヤホン2に接続されている。ただし、イヤホン2と装置本体3とは、Wifi(登録商標)やBluetooth(登録商標)等に基づく無線信号を介して互いに通信可能に接続されてもよい。
また、イヤホン2は、装置本体3と同様の機能(または、その少なくとも一部の機能)を更に備えてもよい。つまり、録音装置1では、装置本体3(または、その少なくとも一部の構成要素)がイヤホン2の筐体内部に一体化された構成であってもよい。なお、装置本体3がイヤホン2の構成要素の一部(例えば、後述する気導マイク11)を備えてもよい。
図2に示すように、イヤホン2は、外装筐体9と、外装筐体9に収容された骨導マイク10および気導マイク11と、スピーカ12と、内部筐体13と、マイクラバー15とを備える。
外装筐体9は、イヤホン2の外殻を構成する。外装筐体9は、利用者の耳の内側部分(奥側部分)を構成するケース9Aと、利用者の耳の外側部分を構成するカバー9Bとを備えている。ケース9Aにカバー9Bが外側から重ね合わされることによって、外装筐体9が構成されている。外装筐体9には、信号線4を外部に導くためのケーブルキャップ18が設けられている。
骨導マイク(骨伝導マイク)11は、主に声帯振動伝達部位に伝達する声帯振動を収音できるように、利用者の耳に設けられるデバイスであって、イヤホン2を装着した利用者の発声を主として収音する。骨導マイク10は、音声振動を電気信号に変換するための素子(例えば、振動検出素子)を備えている。つまり、骨導マイク10は、利用者の発声等の音を収音して電気信号を生成することができる。骨導マイク10によって生成された電気信号は、信号線4を介して装置本体3に入力される。骨導マイク10は、音声振動として利用者の体内を伝搬する声帯振動を収音するため、利用者の発声以外の周囲音の影響を受け難いという性質を有する。
気導マイク11は、音声振動としての空気の振動を電気信号に変換するための素子(例えば、振動検出素子)を備えたマイクロフォンである。気導マイク11は、利用者の発声や、利用者の周囲で発生する周囲音(本実施形態では、利用者の周囲の人物の発声)などを収音する。気導マイク11によって生成された電気信号は、信号線4を介して装置本体3に入力される。ただし、骨導マイク10および気導マイク11は、信号線4を構成する互いに異なる伝送路を介して装置本体3にそれぞれ接続されている。
スピーカ12は、装置本体3から入力された電気信号を、利用者の発声等の音に変換して出力する。スピーカ12には、公知の構成を採用することができる。また、スピーカ12の代わりに骨導レシーバ(骨伝導レシーバ)が用いられてもよい。例えば、装置本体3が、予め録音された利用者の発声や周囲音に関する電気信号を出力したとき、スピーカ12はそれらの音(すなわち、再生音)を出力する。なお、スピーカ12から出力される音には、予め録音された音に限らず、装置本体3で生成された(または、装置本体3が外部から取得された)任意の音が含まれ得る。
内部筐体13は、スピーカ12の再生音を外耳道に導くための部材であり、スピーカ12の再生音を外耳道に導く通路13Aを備えている。スピーカ12は、内部筐体13の通路13Aの一端側に配置される。
通路13Aの他端側には、外装筐体9(詳細には、ケース9A)に設けられた開口9Cを介して、外装筐体9の外部にまで延びる筒状の筒部13Bが設けられている。本実施形態では、筒部13Bの延出端に、利用者の外耳道に全周に渡って当接する先端ラバー16が設けられている。先端ラバー16が外耳道に全周に渡って当接することによって、外耳道の気密性が確保されて、スピーカ12からの再生音が効果的に利用者に伝えられる。
マイクラバー15は、骨導マイク10を弾性的に保持する。マイクラバー15は、耳5の近傍の骨を介して声帯振動が伝わる部位(以下、声帯振動伝達部位という。)と骨導マイク10とを接続する。これにより、声帯振動伝達部位に伝わる声帯振動が骨導マイク10に伝わり、骨導マイク10は、マイクラバー15を介して耳周辺の骨及び皮膚に伝搬する声帯振動を検出することによって収音する。
気導マイク11は、外装筐体9とスピーカ12との間に配置されている。スピーカ12が発する音声振動が気導マイク11に伝わることを防止するため、気導マイク11とスピーカ12との間には樹脂部材17が設けられている。気導マイク11は主として、利用者の発声が空気を伝搬して耳近傍の気導マイク11にて収音する。
装置本体3は、イヤホン2によって収音された音(すなわち、生成された電気信号)に対して所定の処理を実行し、その処理された音を音声データとして記憶(すなわち、録音)する。また、装置本体3は、録音した音声を再生(すなわち、ボイスレコーダとして機能)したり、その音声をテキスト変換したりすることで利用者に利用させることができる。
装置本体3は、CPU等のプロセッサ、RAMやROM等のメモリ、SSDやHDD等のストレージ、タッチパネル等のディスプレイ、ネットワークインタフェース、及び音声入出力端子などを備えた端末(ここでは、スマートフォン)によって構成されている。ただし、装置本体3の構成は、スマートフォンには限定されず、例えば、音声入出力端子を備えたタブレットや各種コンピュータによっても構成され得る。さらに、装置本体3は、ロジックデバイスと、各種アナログデバイスとの組み合わせ等によっても実現され得る。
図3は、第1実施形態に係る録音装置1の構成を示す機能ブロック図である。図4は、図1に示された録音装置1の使用例を示す説明図である。図5は、録音装置1における設定画面の一例((A)ボイスレコーダ設定画面56、(B)文字起こし設定画面59)を示す説明図である。
図3に示すように、録音装置1において、装置本体3には骨導マイク10で生成された電気信号(以下、「骨導音信号」という。)が信号線4を介して入力される。同様に、装置本体3には気導マイク11で生成された電気信号(以下、「気導音信号」という。)が信号線4を介して入力される。骨導音信号は、主として利用者の発声に基づく信号である。また、気導音信号は、周囲音や複数の人物の発声(利用者の発声を含む)に基づく信号である。なお、図示は省略するが、装置本体3は、骨導マイク10および気導マイク11から入力されるアナログ信号をそれぞれディジタル信号に変換するADコンバータと、スピーカ12に出力されるディジタル信号をアナログ信号に関するDAコンバータとを備え得る。
装置本体3は、骨導マイク10から入力された骨導音信号を伝送する骨導音伝送路21を有する。また、装置本体3は、気導マイク11から入力された気導音信号を伝送する気導音伝送路22を有する。また、装置本体3は、骨導音伝送路21および気導音伝送路22との間を接続する接続路23を有する。
また、装置本体3は、骨導マイク10および気導マイク11によってそれぞれ収音された音を音声データとして録音するための処理を実行する録音処理部25を有する。また、装置本体3は、録音された音声データを再生する(すなわち、スピーカ12から出力させる)音声再生部26と、録音された音声データの音声認識を行う音声認識部27とを有する。さらに、装置本体3は、外部装置(例えば、外部のサーバ)と通信するための通信部29を有する。
骨導音伝送路21には、骨導マイク10で生成された骨導音信号を増幅する増幅部31が設けられている。増幅部31によって増幅された骨導音信号は、録音処理部25のチャンネルCH1に入力される。録音処理部25には、骨導音信号から利用者の発声のみを生成するための処理を行う第1分離処理部40が設けられている。第1分離処理部40は、増幅部31によって増幅された骨導音信号から利用者の発声に関する音声信号を抽出する(すなわち、周囲音やエコー成分を排除する)ためのLPF33(ローパスフィルタ)を含む。LPF33によって抽出された音声信号は、第2分離処理部41に送られる。なお、第1分離処理部40では、LPF33の代わりに、骨導音信号におけるノイズ成分を除去または低減するノイズキャンセラが用いられてもよい。
第2分離処理部41は、気導音信号に基づく複数の人物の発声から利用者の発声を取除いた分離音データを生成するための処理を行う。第2分離処理部41では、LPF33によって抽出された音声信号に基づき、骨導音データ45が生成される。生成された骨導音データ45は、録音処理部25に設けられた記憶部42に記憶される。また、第2分離処理部41では、LPF33によって抽出された音声信号が、接続路23を介して、分離音信号を生成する演算部36(音声分離部の一例)に入力される。
一方、気導音伝送路22には、気導マイク11で生成された気導音信号を増幅する増幅部35が設けられている。その増幅された音声信号は、録音処理部25のチャンネルCH2に入力される。第2分離処理部41では、その増幅された音声信号に基づき、気導音データ61が生成される。生成された気導音データ61は、記憶部42に記憶される。また、第2分離処理部41では、増幅部35によって増幅された音声信号が、接続路23を介して、演算部36に入力される。
演算部36は、増幅部35によって増幅された音声信号(すなわち、気導音信号)から、LPF33によって抽出された音声信号(すなわち、骨導音信号)を減算することにより、分離音信号を生成する。さらに、演算部36は、その分離音信号に基づき分離音データ46を生成する。生成された分離音データ46は、記憶部42に記憶される。
このように、装置本体3において、骨導音伝送路21からの骨導音信号および気導音伝送路22からの分離音信号は、それぞれ録音処理部25の異なるチャンネル(すなわち、チャンネルCH1、チャンネルCH2)に入力される。なお、各伝送路21-23、増幅部31、35、及び演算部36は、それぞれ電子素子や回路によって構成され得る。
録音処理部25は、異なるチャンネルCH1、CH2からそれぞれ入力される骨導音信号および分離音信号に対して録音処理を実行する。その録音処理により、骨導音信号、分離音信号、及び気導音信号からそれぞれ骨導音データ45、分離音データ46、及び気導音データ61が生成される。生成された骨導音データ45、分離音データ46、及び気導音データ61は、それぞれ記憶部42に記憶される。
録音処理部25による録音処理は、少なくとも1つのプロセッサが所定の制御プログラム(例えば、録音用ソフトウェア)を実行することにより実現可能である。なお、録音処理部25による電気信号(すなわち、音声信号)の処理については、公知の処理を採用することが可能であり、例えばサンプリングレート、ビット深度、及び録音のフォーマットなどが予め設定される。
記憶部42は、録音装置1の処理に必要なデータや情報を記憶するためのストレージ等の記憶装置を含む。
音声再生部26は、記憶部42に記憶された音声データ(ここでは、骨導音データ45および分離音データ46)を再生するための再生処理を実行する。その再生処理によって、対応する音声信号が生成される。生成された音声信号は、イヤホン2に送られ、スピーカ12から対応する音声が出力される。
音声再生部26による再生処理は、少なくとも1つのプロセッサが所定の制御プログラム(例えば、音声再生用ソフトウェア)を実行することにより実現可能である。なお、音声再生部26による音声データの処理については、公知の処理を採用することが可能である。
音声認識部27は、記憶部42に記憶された音声データに含まれる音声を認識するための音声認識処理(テキスト変換処理の一例)を実行する。その音声認識処理によって、音声認識された音声データがテキストに変換され、対応するテキストデータが生成される。生成されたテキストデータは、記憶部42に記憶される。
音声認識部27による音声認識処理は、少なくとも1つのプロセッサが所定の制御プログラム(例えば、音声認識用ソフトウェア)を実行することにより実現可能である。音声認識部27による音声認識処理には、予め生成された機械学習モデルを備えた音声認識エンジンが用いられてもよい。なお、音声認識部27による音声データの処理については、公知の処理を採用することが可能である。
通信部29は、公知の通信プロトコルにしたがって、図示しない通信ネットワークを介して他の装置と無線通信または有線通信を行う。通信部29は、アンテナや通信回路等を備えた通信装置を含み得る。
このように、録音装置1は、イヤホン2(すなわち、骨導マイク10および気導マイク11)を用いて利用者を含む複数の人物の発声が収音される場合に、利用者の発声(すなわち、骨導音データ45)とその周囲の人物の発声(すなわち、分離音データ46や気導音データ61)とを分離して利用することができる。
次に、図4に基づき(図3を併せて参照)、録音装置1について、利用者を含む複数の人物の発声の収音及び録音ならびにその録音された発声の利用方法について説明する。
図4に示すように、録音装置1は、例えば病室における複数の人物による会話を録音し、その録音データを利用するために用いることができる。図4に示す例では、第1から第3の医療従事者51A-51C(医師や看護師等を含む)の発声および患者52の発声が録音装置1によって録音される。第1の医療従事者51Aは、録音装置1(図中にアイコンで示す。)の利用者である。つまり、第1の医療従事者51Aのみが録音装置1(少なくとも骨導マイク10)を装着している。
第1の医療従事者51Aの発声は、骨導マイク10および気導マイク11によってそれぞれ収音される。また、第2及び第3の医療従事者51B、51Cの発声ならびに患者52の発声は、気導マイク11によって収音される。
収音された第1の医療従事者51Aの発声は、骨導マイク10から装置本体3に対して骨導音信号として入力される。また、第1から第3の医療従事者51A-51Cの発声および患者52の発声(以下、全員の発声という。)は、気導マイク11から装置本体3に対して気導音信号として入力される。
装置本体3では、第1の医療従事者51Aの発声を含む骨導音信号が、骨導音伝送路21から録音処理部25のチャンネルCH1に入力される。録音処理部25では、その骨導音信号に対して録音処理を実行することができる。これにより、主として第1の医療従事者51Aの発声を含む骨導音データ45が生成され、記憶部42に記憶される。
また、装置本体3では、第1から第3の医療従事者51A-51Cの発声を含む気導音信号が、骨導音伝送路21から録音処理部25のチャンネルCH2に入力される。録音処理部25では、その気導音信号に対して録音処理を実行することができる。これにより、主として第1から第3の医療従事者51A-51Cの発声を含む気導音データ61が生成され、記憶部42に記憶される。
さらに、録音処理部25では、演算部36により、第1の医療従事者51A以外の全員の発声を含む分離音信号が生成される。録音処理部25は、その分離音信号に対して録音処理を実行することができる。これにより、主として第2及び第3の医療従事者51B、51Cの発声(すなわち、利用者の発声以外の周囲音)を含む分離音データ46が生成され、記憶部42に記憶される。
その後、録音装置1において利用者が所望の再生対象を選択して再生を指示すると、音声再生部26は、その選択された再生対象に対応する音声データの再生処理を実行する。また、録音装置1において利用者が所望のテキスト変換対象を選択してテキスト変換を指示すると、音声認識部27は、その選択されたテキスト変換対象に対応する音声データの音声認識処理を実行する。
録音装置1は、記憶部42に記憶された音声データ(ここでは、骨導音データ45、分離音データ46、及び気導音データ61)を利用者が利用するための設定画面を、装置本体3のディスプレイに表示することができる。
例えば、録音装置1は、図5(A)に示すように、装置本体3のタッチパネルディスプレイ55(すなわち、表示装置および入力装置)に、ボイスレコーダ設定画面56を表示することができる。利用者は、ボイスレコーダ設定画面56において、音声データの再生処理に関する入力操作を行うことができる。ボイスレコーダ設定画面56では、利用者は、骨導音データ45(図中の「利用者」に対応)、分離音データ46(図中の「利用者以外(周囲)」に対応)、及び気導音データ61(図中の「全て(利用者+利用者以外)」に対応)の何れかを選択することが可能である。
なお、録音装置1は、表示装置としてタッチパネルディスプレイ55の代わりに入力機能を有していないディスプレイを備えてもよい。その場合、録音装置1は、入力装置として公知の装置(例えば、キーボードなど)を備えることができる。
図5(A)では、利用者が、利用者(すなわち、自身)の発声を再生対象として選択した例が示されている。そこで、利用者が実行ボタン57を押下する(すなわち、再生を指示する)と、音声再生部26が骨導音データ45の再生処理を実行する。これにより、利用者は、スピーカ12から出力される利用者(すなわち、自身)の発声を確認することができる。
同様に、利用者は、ボイスレコーダ設定画面56において、利用者以外の周囲の人物の音声や、全ての人物(すなわち、利用者および利用者以外の周囲の人物)の音声を選択することもできる。例えば、利用者が、利用者以外の周囲の人物の音声を選択した後に実行ボタン57を押下すると、音声再生部26が分離音データ46の再生処理を実行する。これにより、利用者は、スピーカ12から出力される利用者の発声以外の周囲音(すなわち、第2及び第3の医療従事者51B、51Cの発声ならびに患者52の発声)を確認することができる。
また例えば、録音装置1は、図5(B)に示すように、装置本体3のタッチパネルディスプレイ55に、文字起こし設定画面59を表示することができる。利用者は、文字起こし設定画面59において、音声データの音声認識処理に関する入力操作を行うことができる。
図5(B)では、利用者が、利用者の発声以外の周囲音(すなわち、第2及び第3の医療従事者51B、51Cの発声ならびに患者52の発声)の発声をテキスト変換対象として選択した例が示されている。そこで、利用者が実行ボタン57を押下する(すなわち、テキスト変換を指示する)と、音声認識部27が分離音データ46の音声認識処理を実行する。これにより、第2及び第3の医療従事者51B、51Cの発声ならびに患者52の発声がテキスト変換され、所定のフォーマットでテキストファイルが生成される。生成されたテキストファイルは記憶部42に記憶される。
なお、録音装置1では、音声データの生成および記憶に関する処理は、利用者の指示(すなわち、入力操作)に応じて開始または停止されてもよい。また、録音装置1では、利用者は、自身の音声のみを記憶するための入力操作を行うこともできる。その場合、録音装置1では、骨導音データ45のみが記憶部42に記憶される。一方、利用者は、自身以外の音声(すなわち、周囲の人物の音声)のみを記憶するための入力操作を行うこともできる。その場合、録音装置1では、分離音データ46のみが記憶部42に記憶される。
このように、録音装置1では、利用者の発声を含む骨導音データ45と、利用者以外の人物の発声を含む分離音データ46と、利用者の発声およびその周囲の人物の発声を含む気導音データ61とがそれぞれ記憶部42に記憶されるため、利用者の周囲の全ての人物(利用者を含む)の発声を利用することに加え、利用者の発声とその周囲の人物の発声とを分離して利用(ここでは、音声再生やテキスト変換)することが可能となる。
(第2実施形態)
上述の第1実施形態では、複数の人物の発声(または会話)を録音する場合において、利用者のみが録音装置1を使用する(すなわち、骨導マイク10を装着する)例を示した。一方、以下で説明する第2実施形態では、複数の録音装置1が準備され、複数の人物がそれぞれ対応する録音装置1の利用者となる(すなわち、複数の人物がそれぞれ骨導マイク10を装着する)場合について説明する。
図6は、第2実施形態に係る録音装置1を備えた録音システム100の構成を示す機能ブロック図である。図7は、図6に示された録音システム100の使用例を示す説明図である。図8は、第2実施形態に係る録音装置1における設定画面の一例((A)ボイスレコーダ設定画面156、(B)文字起こし設定画面159)を示す説明図である。図6~図8に示された録音装置1では、上述の第1実施形態に係る録音装置1と同様の構成要素については、同一の符号が付されている。また、第2実施形態に係る録音装置1に関し、以下で特に言及しない事項については、上述の第1実施形態に係る録音装置1と同様である。
録音システム100は、各利用者U1~UN(ただし、Nは、利用者の総数であって2以上の整数)がそれぞれ利用する録音装置1-1~1-Nと、録音装置1-1~1-Nによってそれぞれ生成された音声データを管理する管理サーバ101(サーバの一例)とを備える。図6では図示は省略されているが、録音装置1-2~1-Nは、録音装置1-1と同様の構成を有する。録音装置1-1~1-Nは、それぞれ通信ネットワーク103を介して管理サーバ101と通信可能に接続されている。以下では、録音装置1-1~1-Nを区別する必要がない場合には、録音装置1と総称する。
録音装置1の装置本体3において、気導音伝送路22では、上述の演算部36は省略されている。この場合、第2分離処理部41は、分離音データを生成するための処理を行うことなく、骨導音データ45および気導音データ61のみを生成するための処理を行う。
録音処理部25は、異なるチャンネルCH1、CH2からそれぞれ入力される骨導音信号および気導音信号に対して録音処理を実行する。その録音処理により、骨導音信号および気導音信号からそれぞれ骨導音データ45および気導音データ61が生成される。生成された骨導音データ45および気導音データ61は、それぞれ記憶部42に記憶される。記憶部42に記憶された音声データは、通信部29によって管理サーバ101に対して送信される。
録音処理部25による録音処理は、少なくとも1つのプロセッサが所定の制御プログラム(例えば、録音用ソフトウェア)を実行することにより実現可能である。なお、録音処理部25による電気信号(すなわち、音声信号)の処理については、公知の処理を採用することが可能であり、例えばサンプリングレート、ビット深度、及び録音のフォーマットなどが予め設定される。
管理サーバ101は、通信部105、制御部106、及び記憶部107を備える。
通信部105は、公知の通信プロトコルにしたがって、通信ネットワーク103を介して各録音装置1-1~1-Nとそれぞれ通信を行う。通信部105は、アンテナや通信回路等を備えた通信装置を含み得る。
制御部106は、音声データ取得部111、気導音データ合成部112、及び音声データ分離部113を有する。
音声データ取得部111は、各録音装置1-1~1-Nとの通信により、骨導音データ45および気導音データ61をそれぞれ取得する。それらの骨導音データ45および気導音データ61は、各録音装置1-1~1-Nにおける骨導マイク10および気導マイク11(以下、必要に応じて「マイクセット」という。)によりそれぞれ生成されたものである。
気導音データ合成部112は、音声データ取得部111によって取得された複数の気導音データ61を合成する処理を実行することにより、合成気導音データを生成する。本実施形態では、気導音データ合成部112は、各録音装置1-1~1-Nから取得された全ての気導音データを合成する。ただし、気導音データ合成部112は、それらの気導音データの一部(例えば、利用者によって選択されたデータ)を合成することにより、合成気導音データを生成することも可能である。生成された合成気導音データには、例えば、録音装置1-1~1-Nの全ての利用者U1~UNの音声が合成された合成音声が含まれる。
音声データ分離部113は、合成気導音データに基づく合成音声から、少なくとも1つの骨導マイク10に対応する骨導音データに基づく利用者の発声を分離するための処理を実行することにより分離音データを生成する。
例えば、利用者の総数N=3の場合(すなわち、利用者が3人の場合)、合成音声には、利用者U1~U3の音声が含まれる。例えば、音声データ分離部113は、その合成音声から、骨導音データ45に基づく利用者U3の発声を分離する処理を実行することができる。この場合、分離される利用者U3の発声は、利用者U3が利用する録音装置1-3の骨導マイク10で生成された骨導音信号に対応する音声に相当する。これにより、分離音データには、利用者U3の音声を除いた利用者U1、U2の音声が含まれる。利用者U1、U2の音声のデータは、利用者U1~U3の録音装置1-1~1-3のうちの少なくとも1つに送信され、その録音装置において利用(音声再生やテキスト変換)される。
なお、利用者の総数Nについては、3(人)に限らず種々の変更が可能である。また、音声データ分離部113によって合成音声から分離される利用者の発声(すなわち、分離対象の音声)についても、適宜変更することが可能である。
制御部106における各部111~113の機能の少なくとも一部は、少なくとも1つのプロセッサが所定の制御プログラムを実行することにより実現可能である。また、制御部106は、管理サーバ101の動作を統括的に制御可能である。
記憶部107は、管理サーバ101の処理に必要なデータや情報を記憶するためのストレージ等の記憶装置を含む。例えば、記憶部107には、各録音装置1-1~1-Nから取得した音声データや、管理サーバ101の処理によって生成された音声データ(合成気導音データおよび分離音データなど)が記憶される。
次に、図7に基づき(図6を併せて参照)、録音システム100について、複数の人物(ここでは、利用者U1~U8)の発声の収音およびその収音された発声の利用方法について説明する。
例えば、図7に示すように、各録音装置1-1~1-8は、集合した状態の複数の利用者U1~U8による発声(または会話)をそれぞれ録音し、その録音データを利用するために用いられる。図7では、利用者U1~U8の発声がそれぞれ対応する録音装置1-1~1-8(図中にアイコンで示す。)の骨導マイク10によって収音される。また、利用者U1~U8の発声は、全ての録音装置1-1~1-8の気導マイク11によって収音され得る。
各録音装置1-1~1-8によって生成された骨導音データ45および気導音データ61は、それぞれ管理サーバ101に送信される。管理サーバ101は、受信した全ての気導音データ61から合成気導音データを生成する。ただし、管理サーバ101は、受信した気導音データ61の一部(例えば、何れかの利用者によって選択されたデータ)から合成気導音データを生成してもよい。また、録音装置1-1~1-8のうちのいずれか1つによって生成された気導音データ61が全ての利用者U1~U8の明瞭な発声を含む場合には、管理サーバ101は、その1つの気導音データ61を合成気導音データの代わりに用いることもできる。
次に、管理サーバ101は、合成気導音データに基づく合成音声から、利用者(または録音システム100の管理者)によって選択された1以上の録音装置(すなわち、骨導マイク10)に対応する骨導音データに基づく利用者の発声を分離するための処理を実行する。これにより、管理サーバ101では、少なくとも一部の利用者の発声のみを含む(すなわち、それ以外の利用者の発声が取り除かれた)分離音データが生成される。
生成された分離音データや、各録音装置1-1~1-8から取得された骨導音データ45および気導音データ61は、記憶部107に記憶される。記憶部107に記憶されたそれらのデータは、利用者U1~U8からの要求に応じて録音装置1-1~1-8に送信される。
利用者U1~U8の何れかが、対応する録音装置1-1~1-8において所望の再生対象を選択して再生を指示すると、音声再生部26は、その選択された再生対象に対応する音声データの再生処理を実行する。また、利用者U1~U8の何れかが、所望のテキスト変換対象を選択してテキスト変換を指示すると、音声認識部27は、その選択されたテキスト変換対象に対応する音声データの音声認識処理を実行する。
第1実施形態の場合と同様に、録音装置1は、管理サーバ101の記憶部107に記憶された音声データ(ここでは、分離音データ)を利用者U1~U8が利用するための設定画面を、装置本体3のディスプレイに表示することができる。
例えば、録音装置1-1は、図8(A)に示すように、装置本体3のタッチパネルディスプレイ55に、ボイスレコーダ設定画面156を表示することができる。利用者U1は、ボイスレコーダ設定画面156において、音声データの再生処理に関する入力操作を行うことができる。
図8(A)では、利用者U1が、利用者U1(すなわち、自身)の発声を再生対象として選択した例(入力装置に対する入力操作の一例)が示されている。そこで、利用者U1が実行ボタン157を押下すると、利用者U1が選択した再生対象に関する情報(入力操作の情報の一例)が管理サーバ101に送信される。ここで、利用者U1が再生対象を選択することは、利用者U1が少なくとも1つのマイクセットを選択したことと同義である。管理サーバ101は、録音装置1-1から利用者U1が選択した再生対象に関する情報を取得することが可能である。音声データ分離部113は、利用者の発声を分離するための処理(すなわち、分離音データの生成)を、利用者U1によって選択された少なくとも1つのマイクセット(すなわち、再生対象)以外のマイクセットに含まれる骨導マイク10に対応する骨導音データに基づき実行する。その後、録音装置1-1は、管理サーバ101によって生成された分離音データを取得する。そこで、音声再生部26が、利用者U1の発声のみを含む(例えば、他の利用者U2~U8の発声が取り除かれた)分離音データの再生処理を実行する。これにより、利用者U1は、スピーカ12から出力される自身の発声を確認することができる。
同様に、利用者U1は、ボイスレコーダ設定画面156において、利用者U1以外の他の利用者U2-U8の音声を選択することができる。また、利用者U1は、例えば複数の利用者の間の会話を確認したい場合、ボイスレコーダ設定画面156においてそれら複数の利用者の音声を選択することもできる。その音声の選択後に利用者U1が実行ボタン57を押下すると、音声再生部26が分離音データ46の再生処理を実行する。これにより、利用者U1は、スピーカ12から出力される所望の利用者の発声を確認することができる。
また例えば、録音装置1-1は、図8(B)に示すように、装置本体3のタッチパネルディスプレイ55に、文字起こし設定画面159を表示することができる。利用者U1は、文字起こし設定画面159において、音声データの音声認識処理に関する入力操作を行うことができる。
図8(B)では、利用者U1が、利用者U1(すなわち、自身)の発声をテキスト変換対象として選択した例が示されている。そこで、利用者が実行ボタン57を押下すると、音声認識部27が上述のように管理サーバ101から取得された分離音データの音声認識処理を実行する。これにより、利用者U1の発声がテキスト変換され、所定のフォーマットでテキストファイルが生成される。生成されたテキストファイルは記憶部42に記憶される。
このように、第2実施形態に係る録音装置1を含む録音システム100によれば、各利用者の発声を含む骨導音データと、特定の利用者(すなわち、複数の利用者の中から選択された利用者)の発声を含む分離音データとがそれぞれ記憶部107に記憶されるため、特定の利用者の発声とそれ以外の利用者の発声とを分離して利用することが可能となる。
(第3実施形態)
第3実施形態では、第2実施形態の場合と同様に、複数の録音装置1が準備され、複数の人物がそれぞれ対応する録音装置1の利用者となる(すなわち、各人物が少なくとも骨導マイク10を装着する)場合について説明する。
図9は、第3実施形態に係る録音装置1を備えた録音システム100の構成を示す機能ブロック図である。図9に示した録音装置1および録音システム100では、上述の第1実施形態に係る録音装置1および第2実施形態に係る録音システム100と同様の構成要素については、同一の符号が付されている。また、第3実施形態に係る録音装置1および録音システム100に関し、以下で特に言及しない事項については、上述の第1実施形態に係る録音装置1および第2実施形態に係る録音システム100と同様である。
第3実施形態に係る録音装置1-1~1-Nは、上述の第1実施形態に係る録音装置1(図3参照)と同様の構成を有する。
各録音装置1-1~1-Nにおいて、録音処理部25により生成された骨導音データ45および分離音データ46は、それぞれ通信部29によって管理サーバ101に対して送信される。
管理サーバ101において、制御部106は、音声データ取得部111および 骨導音データ合成部115を有する。
音声データ取得部111は、骨導音データ45および分離音データ46を、各録音装置1-1~1-Nとの通信によってそれぞれ取得する。
骨導音データ合成部115は、2以上のマイクセットにおける骨導マイク10に対応する骨導音データを合成することにより、合成骨導音データを生成する。本実施形態では、そのような2以上のマイクセットは、利用者によって選択され得る。生成された合成骨導音データには、2以上の利用者の音声が合成された合成音声が含まれる。
生成された合成骨導音データや、各録音装置1-1~1-Nから取得された骨導音データ45および分離音データ46は、記憶部107に記憶され、利用者U1~UNからの要求に応じて録音装置1-1~1-Nに送信される。
第3実施形態に係る録音装置1-1では、例えば、上述の図8に示したボイスレコーダ設定画面156と同様の設定画面を装置本体3のディスプレイに表示することができる(録音装置1-2~1-Nも同様)。利用者U1は、その設定画面において2以上の利用者(すなわち、再生対象)を選択することができる。ここで、利用者U1が2以上の再生対象(または合成対象)を選択することは、利用者U1が2以上のマイクセットを選択したことと同義である。管理サーバ101は、録音装置1-1からの2以上の再生対象に関する情報を取得すると、骨導音データ合成部115は、利用者U1によって選択された2以上のマイクセットにおける各骨導マイク10に対応する骨導音データ(すなわち、選択された2以上の再生対象に関する骨導音データ)を合成することにより、合成骨導音データを生成する。
その後、録音装置1-1は、管理サーバ101によって生成された合成骨導音データを取得する。続いて、音声再生部26が、利用者U1によって選択された2以上の利用者の発声のみを含む(例えば、他の利用者U1と利用者U2との発声が合成された)合成骨導音データの再生処理を実行する。これにより、利用者U1は、スピーカ12から出力される2以上の利用者(すなわち、自らが選択した利用者)の発声を確認することができる。
このように、第3実施形態に係る録音装置1を含む録音システム100によれば、複数の特定の利用者の声を含む合成骨導音データと、複数の利用者の発声を含む気導音データを記憶部107に記憶することにより、特定の利用者の発声とその特定の利用者を含む複数の利用者の発声とを分離して利用することが可能となる。
以上のように、本出願において開示する技術の例示として、実施形態を説明した。しかしながら、本開示における技術は、これに限定されず、変更、置き換え、付加、省略などを行った実施形態にも適用できる。また、上記の実施形態で説明した各構成要素を組み合わせて、新たな実施形態とすることも可能である。