JP7700862B2 - 要約学習支援装置、要約学習支援方法及びプログラム - Google Patents
要約学習支援装置、要約学習支援方法及びプログラム Download PDFInfo
- Publication number
- JP7700862B2 JP7700862B2 JP2023543588A JP2023543588A JP7700862B2 JP 7700862 B2 JP7700862 B2 JP 7700862B2 JP 2023543588 A JP2023543588 A JP 2023543588A JP 2023543588 A JP2023543588 A JP 2023543588A JP 7700862 B2 JP7700862 B2 JP 7700862B2
- Authority
- JP
- Japan
- Prior art keywords
- document
- query
- learning
- character strings
- model
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Active
Links
Images






Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F40/00—Handling natural language data
- G06F40/20—Natural language analysis
- G06F40/279—Recognition of textual entities
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- General Engineering & Computer Science (AREA)
- General Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Computational Linguistics (AREA)
- General Health & Medical Sciences (AREA)
- Health & Medical Sciences (AREA)
- Artificial Intelligence (AREA)
- Data Mining & Analysis (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
- Machine Translation (AREA)
Description
(a)ソーステキストと要約テキストを結合した文書(ソーステキスト及び要約テキストの双方を含む文書)
(b)要約テキストのみ
(c)ソーステキストのみ
(d)(a)~(c)のいずれかと、その他の付属情報テキスト(例えば、ソーステキストのタイトルなど)を結合した文書
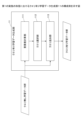
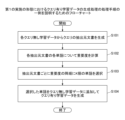
続いて、重要度計算部111は、所定のモデルに基づいて、各抽出元文書を構成する所定単位の各文字列(例えば、単語)について、文書の要約の際に用いるクエリ(追加される入力パラメータ)としての適切さを表すスコアの一例として、これらの抽出元文書群における重要度を算出する(S102)。例えば、重要度計算部111は、所定のモデルとして、TF-IDFの計算モデルを用いる。この場合、重要度計算部111は、各単語のTF-IDFを重要度として算出する。文書群に含まれる各単語のTF-IDFの算出は、公知の方法を用いて行うことができる。なお、本実施の形態において、入力パラメータにおける「パラメータ」とは、例えば、ニューラルネットワーク等のモデルの学習用パラメータとは明確に区別される。入力パラメータは、モデルに対する入力として与えられるデータであるのに対し、学習用パラメータは、モデルの学習に応じて値が変化するデータである。一般的な例としては、入力パラメータは、テキストデータ等で与えられるのに対し、学習用パラメータは、数値データの集合等で表現される。
メモリと、
前記メモリに接続された少なくとも1つのプロセッサと、
を含み、
前記プロセッサは、
複数の文字列について、所定のモデルに基づいて第1の文書の要約の際に追加される入力パラメータとしての適切さを表すスコアを計算し、
前記スコアに基づいて、前記複数の文字列の中から一部の文字列群を、文書の要約を生成する要約生成モデルの学習データを構成する前記入力パラメータとして選択する、
ことを特徴とする要約学習支援装置。
複数の文字列について、所定のモデルに基づいて第1の文書の要約の際に追加される入力パラメータとしての適切さを表すスコアを計算し、
前記スコアに基づいて、前記複数の文字列の中から一部の文字列群を、文書の要約を生成する要約生成モデルの学習データを構成する前記入力パラメータとして選択する、
処理をコンピュータに実行させるプログラムを記録した記録媒体。
11 クエリ有り学習データ生成部
12 要約学習部
13 要約部
100 ドライブ装置
101 記録媒体
102 補助記憶装置
103 メモリ装置
104 プロセッサ
105 インタフェース装置
111 重要度計算部
112 クエリ選択部
113 クエリ追加部
114 クエリ生成モデル学習部
115 クエリ候補生成部
131 内容選択部
132 エンコーダ
133 デコーダ
B バス
Claims (6)
- 複数の文字列について、所定のモデルに基づいて第1の文書の要約の際に追加される入力パラメータとしての適切さを表すスコアを計算する計算部と、
前記スコアに基づいて、前記複数の文字列の中から一部の文字列群を、文書の要約を生成する要約生成モデルの学習データを構成する前記入力パラメータとして選択する選択部と、
を有し、
前記スコアは、文書の本文と前記文書の標題を構成する文字列群との対応関係を学習済みのモデルに対して前記第1の文書の要約である第2の文書を入力した場合に当該モデルが出力候補の文字列の中から出力対象の文字列を選択するために前記出力候補の文字列ごとに計算するスコアである、
ことを特徴とする要約学習支援装置。 - 前記スコアは、前記第1の文書と前記第1の文書の要約である第2の文書とのうちのいずれか一方又は双方を含む第3の文書を構成する複数の文字列のそれぞれについての前記第3の文書における重要度である、
ことを特徴とする請求項1記載の要約学習支援装置。 - 前記第1の文書及び前記文字列群と、前記第1の文書の要約である第2の文書とを含む学習データを用いて、前記要約生成モデルを学習する学習部、
を有することを特徴とする請求項1又は2記載の要約学習支援装置。 - 前記学習部により学習された前記要約生成モデルに対して、或る文書と前記或る文書の要約に関する文字列とを入力して、前記或る文書の要約を生成する要約部、
を有することを特徴とする請求項3記載の要約学習支援装置。 - 複数の文字列について、所定のモデルに基づいて第1の文書の要約の際に追加される入力パラメータとしての適切さを表すスコアを計算する計算手順と、
前記スコアに基づいて、前記複数の文字列の中から一部の文字列群を、文書の要約を生成する要約生成モデルの学習データを構成する前記入力パラメータとして選択する選択手順と、
をコンピュータが実行し、
前記スコアは、文書の本文と前記文書の標題を構成する文字列群との対応関係を学習済みのモデルに対して前記第1の文書の要約である第2の文書を入力した場合に当該モデルが出力候補の文字列の中から出力対象の文字列を選択するために前記出力候補の文字列ごとに計算するスコアである、
ことを特徴とする要約学習支援方法。 - 請求項1乃至4いずれか一項記載の要約学習支援装置としてコンピュータを機能させることを特徴とするプログラム。
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| PCT/JP2021/031420 WO2023026444A1 (ja) | 2021-08-26 | 2021-08-26 | 要約学習支援装置、要約学習支援方法及びプログラム |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| JPWO2023026444A1 JPWO2023026444A1 (ja) | 2023-03-02 |
| JP7700862B2 true JP7700862B2 (ja) | 2025-07-01 |
Family
ID=85322940
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| JP2023543588A Active JP7700862B2 (ja) | 2021-08-26 | 2021-08-26 | 要約学習支援装置、要約学習支援方法及びプログラム |
Country Status (2)
| Country | Link |
|---|---|
| JP (1) | JP7700862B2 (ja) |
| WO (1) | WO2023026444A1 (ja) |
Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021124489A1 (ja) | 2019-12-18 | 2021-06-24 | 日本電信電話株式会社 | 要約学習方法、要約学習装置及びプログラム |
-
2021
- 2021-08-26 JP JP2023543588A patent/JP7700862B2/ja active Active
- 2021-08-26 WO PCT/JP2021/031420 patent/WO2023026444A1/ja not_active Ceased
Patent Citations (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2021124489A1 (ja) | 2019-12-18 | 2021-06-24 | 日本電信電話株式会社 | 要約学習方法、要約学習装置及びプログラム |
Non-Patent Citations (2)
| Title |
|---|
| 廣嶋伸章 他2名,Webページのヘッドライン生成のための統計的要約,自然言語処理,言語処理学会,2005年11月10日,第12巻第6号,113-128頁,ISSN 1340-7619 |
| 斉藤いつみ 他5名,クエリ・出力長を考慮可能な文書要約モデル,言語処理学会第25回年次大会 発表論文集,2019年03月04日,497-500頁 |
Also Published As
| Publication number | Publication date |
|---|---|
| JPWO2023026444A1 (ja) | 2023-03-02 |
| WO2023026444A1 (ja) | 2023-03-02 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| Lin et al. | Abstractive summarization: A survey of the state of the art | |
| KR102391466B1 (ko) | Ai 기반 질의응답 시스템 및 방법 | |
| US20140288915A1 (en) | Round-Trip Translation for Automated Grammatical Error Correction | |
| US11625544B2 (en) | Method and system for training document-level natural language processing models | |
| JP6955963B2 (ja) | 検索装置、類似度算出方法、およびプログラム | |
| JP7842236B2 (ja) | 言語モデルニューラルネットワークを使用したインライン証拠付き出力シーケンスの生成 | |
| JP2022111261A (ja) | 質問生成装置、質問生成方法及びプログラム | |
| Yan et al. | Response selection from unstructured documents for human-computer conversation systems | |
| CN119578411B (zh) | 一种结合句法信息和预训练语言模型的中文文本语法纠错方法 | |
| Xu et al. | Document-level relation extraction with entity mentions deep attention | |
| JP7550432B2 (ja) | モデル訓練装置、モデル訓練方法、及びコンピュータプログラム | |
| Han et al. | Bridging the gap between text-to-SQL research and real-world applications: A unified all-in-one framework for text-to-SQL | |
| Cremaschi et al. | steellm: An llm for generating semantic annotations of tabular data | |
| WO2026011262A1 (en) | Methods and systems for updating a retrieval-augmented generation framework | |
| JP7700862B2 (ja) | 要約学習支援装置、要約学習支援方法及びプログラム | |
| WO2020235024A1 (ja) | 情報学習装置、情報処理装置、情報学習方法、情報処理方法及びプログラム | |
| JP7384221B2 (ja) | 要約学習方法、要約学習装置及びプログラム | |
| Abdous et al. | PESTS: Persian_English cross lingual corpus for semantic textual similarity | |
| Trandafili et al. | Employing a SEQ2SEQ model for spelling correction in Albanian language | |
| JP2021135839A (ja) | 情報処理システム、文生成方法およびプログラム | |
| WO2023243273A1 (ja) | 発話データ生成装置、対話装置及び生成モデルの作成方法 | |
| CN114841289A (zh) | 一种基于深度学习和规则结合的论据匹配及论证生成方法、设备和介质 | |
| JP2006338261A (ja) | 翻訳装置、翻訳方法及び翻訳プログラム | |
| JP2023039785A (ja) | 出力プログラム、出力方法、および出力装置 | |
| De Kruijf et al. | Training a Dutch (+ English) BERT model applicable for the legal domain |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A621 | Written request for application examination |
Free format text: JAPANESE INTERMEDIATE CODE: A621 Effective date: 20231120 |
|
| RD02 | Notification of acceptance of power of attorney |
Free format text: JAPANESE INTERMEDIATE CODE: A7422 Effective date: 20240701 |
|
| A131 | Notification of reasons for refusal |
Free format text: JAPANESE INTERMEDIATE CODE: A131 Effective date: 20250121 |
|
| A521 | Request for written amendment filed |
Free format text: JAPANESE INTERMEDIATE CODE: A523 Effective date: 20250220 |
|
| TRDD | Decision of grant or rejection written | ||
| A01 | Written decision to grant a patent or to grant a registration (utility model) |
Free format text: JAPANESE INTERMEDIATE CODE: A01 Effective date: 20250520 |
|
| A61 | First payment of annual fees (during grant procedure) |
Free format text: JAPANESE INTERMEDIATE CODE: A61 Effective date: 20250602 |
|
| R150 | Certificate of patent or registration of utility model |
Ref document number: 7700862 Country of ref document: JP Free format text: JAPANESE INTERMEDIATE CODE: R150 |
|
| S533 | Written request for registration of change of name |
Free format text: JAPANESE INTERMEDIATE CODE: R313533 |
|
| R350 | Written notification of registration of transfer |
Free format text: JAPANESE INTERMEDIATE CODE: R350 |