KR20120072033A - 영상 컨텐츠의 자동 태깅 방법 및 장치 - Google Patents
영상 컨텐츠의 자동 태깅 방법 및 장치 Download PDFInfo
- Publication number
- KR20120072033A KR20120072033A KR1020100133797A KR20100133797A KR20120072033A KR 20120072033 A KR20120072033 A KR 20120072033A KR 1020100133797 A KR1020100133797 A KR 1020100133797A KR 20100133797 A KR20100133797 A KR 20100133797A KR 20120072033 A KR20120072033 A KR 20120072033A
- Authority
- KR
- South Korea
- Prior art keywords
- information
- tagging
- image
- augmented reality
- unit
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images



Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06T—IMAGE DATA PROCESSING OR GENERATION, IN GENERAL
- G06T19/00—Manipulating three-dimensional [3D] models or images for computer graphics
- G06T19/006—Mixed reality
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04N—PICTORIAL COMMUNICATION, e.g. TELEVISION
- H04N21/00—Selective content distribution, e.g. interactive television or video on demand [VOD]
- H04N21/80—Generation or processing of content or additional data by content creator independently of the distribution process; Content per se
- H04N21/81—Monomedia components thereof
- H04N21/8126—Monomedia components thereof involving additional data, e.g. news, sports, stocks, weather forecasts
- H04N21/8133—Monomedia components thereof involving additional data, e.g. news, sports, stocks, weather forecasts specifically related to the content, e.g. biography of the actors in a movie, detailed information about an article seen in a video programme
Landscapes
- Engineering & Computer Science (AREA)
- Multimedia (AREA)
- Signal Processing (AREA)
- Computer Graphics (AREA)
- Computer Hardware Design (AREA)
- General Engineering & Computer Science (AREA)
- Software Systems (AREA)
- Physics & Mathematics (AREA)
- General Physics & Mathematics (AREA)
- Theoretical Computer Science (AREA)
- Processing Or Creating Images (AREA)
Abstract
본 발명은 영상 컨텐츠 자동 태깅 장치로, 동영상 또는 정지 영상을 포함하는 영상 컨텐츠를 획득하는 영상 획득부와, 영상 컨텐츠의 생성 시간, 촬영 위치를 포함하는 센싱 정보를 획득하는 센서부와, 증강 현실 정보를 제공하는 증강 현실 서버와의 유무선 통신망을 통해 접속 처리하는 통신부와, 인물 사진을 포함하는 인물 정보를 저장하는 주소록 저장부와, 상기 획득된 영상 컨텐츠에 상기 센서부로부터 획득된 센싱 정보, 상기 통신부를 통해 획득된 증강 현실 정보 및 상기 주소록 저장부에서 검색한 인물 정보 중 하나 이상을 자동 태깅하는 자동 태깅 제어부를 포함한다.
Description
본 발명은 컨텐츠 제공 장치에 관한 것으로, 상세하게는 동영상 또는 사진과 같은 영상 컨텐츠에 대해 다양한 종류의 정보를 태깅하여 저장하는 장치 및 방법에 관한 것이다.
디지털 카메라, 스마트폰을 포함하는 디지털 영상 기기의 대중화로 개인이 생성할 수 있는 동영상 또는 정지 영상과 같은 영상 컨텐츠의 양이 증가되고 있다. 이에 따라 유튜브나 플리커와 같이 영상 컨텐츠를 공유하는 대규모 사이트가 인기를 얻고 있다.
이러한 영상 컨텐츠에 태깅된 정보는 매우 중요한 검색 정보로 활용되며, 태그 정보의 유무 및 정확성은 저장된 영상 컨텐츠의 활용도를 좌우하는 매우 중요한 요소가 되고 있다. 그런데, 소규모 영상 컨텐츠에 대해서는 수동 태깅이 가능하나, 대규모의 영상 컨텐츠에는 자동 태깅이 필수적이다.
대부분의 영상 기기에서는 기본적으로 내장된 타이머 정보를 이용한 시간 정보 태깅, 스마트폰과 같이 GPS가 내장된 기기에서는 지리적 위치 정보를 자동으로 태깅하기도 한다. 그러나, 시간과 위치 정보에 국한된 태깅 정보만으로는 추후 다양한 검색 조건으로 원하는 컨텐츠를 검색하고자 하는 사용자의 다양한 요구를 수용하는 데 한계가 있다.
본 발명은 영상 컨텐츠에 관련된 다양한 정보를 자동 태깅하는 장치 및 방법을 제공한다.
본 발명은 얼굴 인식 기술을 이용하여 영상 컨텐츠에 자동 태깅하는 장치 및 방법을 제공한다.
본 발명은 증강 현실 기술을 이용하여 영상 컨텐츠에 자동 태깅하는 장치 및 방법을 제공한다.
본 발명은 영상 컨텐츠 자동 태깅 장치로, 동영상 또는 정지 영상을 포함하는 영상 컨텐츠를 획득하는 영상 획득부와, 영상 컨텐츠의 생성 시간, 촬영 위치를 포함하는 센싱 정보를 획득하는 센서부와, 증강 현실 정보를 제공하는 증강 현실 서버와의 유무선 통신망을 통해 접속 처리하는 통신부와, 인물 사진을 포함하는 인물 정보를 저장하는 주소록 저장부와, 상기 획득된 영상 컨텐츠에 상기 센서부로부터 획득된 센싱 정보, 상기 통신부를 통해 획득된 증강 현실 정보 및 상기 주소록 저장부에서 검색한 인물 정보 중 하나 이상을 자동 태깅하는 자동 태깅 제어부를 포함한다.
본 발명은 얼굴 인식 기술과 증강 현실 서비스 기술을 영상 컨텐츠 태깅에 도입함으로써 보다 정확하고 다양한 종류의 정보를 자동 태깅할 수 있다는 이점 있다.
본 발명은 증강 현실 서비스를 이용하여 여러 사용자가 협동하여 일종의 집단 지성 형태로 각 장소에 대한 정보를 입력하게 됨으로써 개인에 의한 태깅보다 자세한 사항을 태깅할 수 있는 장점이 있다.
또한, 동영상의 태깅에 있어서는 비주기적 태깅 방식을 사용함으로써 주기적 태깅 방법에 비해 태깅 정보의 중복을 방지함과 동시에 태깅되어야 할 정보가 누락되는 일을 방지할 수 있다는 이점이 있다.
또한 인물 정보의 태깅에 있어서도 주소록의 사진 및 이름 정보를 기반으로 자동 태깅 작업을 수행하기 때문에 비교 대상 사진에 대해 사용자가 직접 태깅 작업을 수행할 필요가 없다는 장점이 있다.
결과적으로, 본 발명에 의해 태깅된 영상 컨텐츠는 각종 공유 사이트에 업로드될 경우, 태깅된 다양한 정보를 기반으로 검색을 용이하게 할 수 있게 된다. 이로써, 영상 켄텐츠의 공유 범위를 확대시킬 수 있다는 이점이 있다.
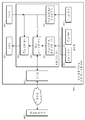
도 1은 본 발명의 바람직한 일 실시 예에 따른 영상 컨텐츠 자동 태깅 장치의 구성도이다.
도 2는 본 발명의 바람직한 일 실시 예에 따라 증강 현실을 이용한 영상 컨텐츠 자동 태깅 방법을 설명하기 위한 순서도이다.
도 3은 본 발명의 바람직한 다른 실시 예에 따른 영상 컨텐츠 자동 태깅 장치의 구성도이다.
도 4는 본 발명의 바람직한 다른 실시 예에 따른 주소록 정보를 이용한 영상 컨텐츠 자동 태깅 방법을 설명하기 위한 순서도이다.
도 2는 본 발명의 바람직한 일 실시 예에 따라 증강 현실을 이용한 영상 컨텐츠 자동 태깅 방법을 설명하기 위한 순서도이다.
도 3은 본 발명의 바람직한 다른 실시 예에 따른 영상 컨텐츠 자동 태깅 장치의 구성도이다.
도 4는 본 발명의 바람직한 다른 실시 예에 따른 주소록 정보를 이용한 영상 컨텐츠 자동 태깅 방법을 설명하기 위한 순서도이다.
이하, 첨부된 도면을 참조하여 기술되는 바람직한 실시 예를 통하여 본 발명을 당업자가 용이하게 이해하고 재현할 수 있도록 상세히 기술하기로 한다.
본 발명을 설명함에 있어 관련된 공지 기능 또는 구성에 대한 구체적인 설명이 본 발명 실시 예들의 요지를 불필요하게 흐릴 수 있다고 판단되는 경우에는 그 상세한 설명을 생략할 것이다.
본 발명은 영상 컨텐츠에 대해 사용자가 태그 정보를 직접 입력하지 않고, 각종 센싱 정보, 증강 현실 기술 및 얼굴 인식 기술을 이용하여 자동으로 다양한 종류의 정보를 영상 컨텐츠에 태깅할 수 있는 장치 및 방법을 제공한다.
또한, 본 발명에서 사용된 용어들은 본 발명 실시 예에서의 기능을 고려하여 사용된 용어들로서, 사용자 또는 운용자의 의도, 관례 등에 따라 충분히 변형될 수 있는 사항이므로, 이 용어들의 정의는 본 발명의 명세서 전반에 걸친 내용을 토대로 내려져야 할 것이다. 본 발명에서 사용되는 태그(tag)란 컨텐츠의 메타 데이터(meta data)로서 컨텐츠의 특징을 설명하는 일종의 키워드이다. 이러한 태그는 컨텐츠의 분류, 검색 등을 용이하게 함으로써 컨텐츠에 대한 보다 용이한 접근을 가능하게 해 준다.
또한, 본 발명의 영상 컨텐츠 자동 태깅 장치는 카메라 장치와, PDA(Personal digital assistants), 스마트 폰, 네비게이션 단말기 등의 이동 단말기뿐만 아니라, 데스크 탑 컴퓨터, 노트북 등과 같은 개인용 컴퓨터와 같이 영상 컨텐츠를 생성하는 모든 장치에 적용될 수 있는 것으로 해석된다.
도 1는 본 발명의 바람직한 일 실시 예에 따른 영상 컨텐츠 자동 태깅 장치의 개략적인 구성을 도시한 도면이다.
도 1을 참조하면, 본 발명의 바람직한 실시 예에 따른 영상 컨텐츠 자동 태깅 장치는 영상 획득부(110), 센서부(120), 저장부(130) 및 자동 태깅 제어부(140)가 포함된 구성을 갖는다. 또한, 본 발명의 바람직한 실시 예에 따라 통신부(150)을 구비하여, 증강 현실 서비스를 위한 정보를 제공하는 증강 현실 제공 서버 장치(200)가 유/무선 통신망 통해 접속 가능하도록 구성된다.
영상 획득부(110)는 현실 세계를 촬영한 영상을 획득하여 자동 태깅 제어부(140)에 출력하는 것으로, 예컨대 카메라 또는 이미지 센서가 될 수 있다. 또한, 영상 획득부(110)는 영상 촬영시 영상을 확대 또는 축소하거나, 자동 또는 수동으로 회전 가능한 카메라일 수 있다. 본 발명의 실시 예에 따라 영상 획득부(110)에 의해 획득된 사진이나 동영상은 자동 태깅 제어부(140)의 영상 획득 및 저장 판별 모듈(141)에 입력된다.
센서부(120)는 위치, 방향, 시간, 회전각 및 특정 객체까지의 거리값(p) 등을 감지하여 자동 태깅 제어부(140)에 출력한다. 이러한 센서부(120)는 예컨대, GPS 위성이 송신하는 위치 정보 신호 및 절대 시간 정보 등을 수신하는 GPS 수신기(121)와, 장치의 방위각, 경사각 및 회전 방향과 회전량을 측정하여 출력하는 지자기 센서(122)를 포함할 수 있다.
저장부(130)는 태깅된 영상 컨텐츠를 저장하는 것으로, 자동 태깅 제어부(140)에 의해 자동 태깅된 영상 컨텐츠가 저장될 수 있다. 저장부(130)는 태깅 정보에 따라 카테고리 분류되어 저장될 수도 있다.
자동 태깅 제어부(140)는 상술한 바와 같은 내부 구성 요소들을 제어하여 본 발명의 실시 예에 따른 영상 컨텐츠 자동 태깅 기능을 수행한다. 본 발명의 바람직한 일 실시 예에 따라 자동 태깅 제어부(140)는 영상 컨텐츠에 증강 현실 정보를 태깅할 수 있다. 이러한 자동 태깅 제어부(140)는 상세하게는 영상 획득 및 저장 판별 모듈(141), 센서 정보 수집 및 관리 모듈(142), 증강 현실 지원 모듈(143) 및 자동 태깅 모듈(144)을 포함한다.
영상 획득 및 저장 판별 모듈(141)은 영상 획득부(110)로부터 입력되는 영상 컨텐츠를 수신하여 저장 요청 여부를 판단하고, 저장 요청될 경우 이를 증강 현실 지원 모듈(143) 및 자동 태깅 모듈(144)로 전송한다. 센서 정보 수집 및 관리 모듈(120)은 상기 센서부(120)로부터 출력되는 센싱 정보를 취합하여 증강 현실 지원 모듈(143) 및 자동 태깅 모듈(144)에 전송한다. 증강 현실 지원 모듈(133)은 영상 획득 및 저장 판별 모듈(141)로부터 입력된 영상에 관련된 증강 현실 정보를 획득하는 기능을 수행한다. 증강 현실 정보를 획득하기 위해 본 발명의 바람직한 일 실시 예에 따른 영상 컨텐츠 자동 태깅 장치는 증강 현실 서버(200)와 통신 가능한 통신부(150)를 더 포함하는 구성을 갖는다.
통신부(150)는 유/무선 통신망을 통해 외부로부터 수신된 신호와 내부 출력 신호를 처리하는 것으로 주지된 구성이다. 본 발명의 일 실시 예에 따라, 상기 통신부(150)는 서버(200)로부터 증강 현실 정보를 수신/처리하여 자동 태깅 제어부(140)로 출력하고, 상기 자동 태깅 제어부(140)로부터의 증강 현실 정보 검출 요청 정보 신호를 처리하여 서버(200)에 전송한다. 증강 현실 서버(200)는 영상에 포함된 하나 이상의 객체에 관련된 보강 정보인 증강 현실 정보를 저장하는데, 예컨대, 루브르 박물관이 객체일 경우 루브르 박물관의 주소, 소장 미술품 정보 등이 증강 현실 정보에 해당될 수 있다.
증강 현실 지원 모듈(143)은 획득된 영상 정보 및 센싱 정보를 통신부(150)를 통해 증강 현실 서버(200)로 전송하여 관련된 증강 현실 정보를 요청한다. 이때, 증강 현실 서버(200)로 전송해야 하는 정보는 증강 현실 서비스에 따라 달라질 수 있으며, 증강 현실 지원 모듈(143)은 이를 고려하여 선별된 정보를 전송한다. 증강 현실 지원 모듈(143)이 증강 현실 서버(200)로부터 주소, 랜드마크, 피사체 정보 등의 증강 현실 정보를 수신하면 이를 자동 태깅 모듈(144)로 전달한다. 또한, 증강 현실 지원 모듈(143)은 사용자로부터 증강 현실 정보의 범위 설정 정보를 입력받아 태깅 정보로 사용될 증강 현실 정보의 검색 범위를 결정할 수 있다. 영상 컨텐츠 태깅에 있어서 컨텐츠의 생성 시간과 위치 뿐만 아니라 컨텐츠에 담긴 피사체 정보, 주소나 인근 랜드마크에 대한 정보 또한 컨텐츠 검색에 있어 중요한 단서로 사용될 수 있다. 태깅을 위해 생성 시간과 위치 정보는 영상 컨텐츠 자동 태깅 장치에 내장된 센서부를 이용해 용이하게 획득 가능하나, 그 외의 정보는 로컬 정보으로 검색하기가 어렵다. 예컨대, 영상 컨텐츠가 파리의 에펠탑에서 2 Km 떨어진 거리에서 촬영된 영상일 경우, 촬영 장소 정보만으로는 영상 컨텐츠의 검색이 용이하지 않다. 물론 위치 정보 태깅을 이용하여 에펠탑을 중심으로 반경 몇 미터 이내에서 촬영된 영상을 검색할 수는 있으나, 검색 반경이 너무 클 경우 검색되는 영상의 양도 너무 많아 검색할 필요가 없을 수도 있을 뿐만 아니라, 검색 반경이 너무 작은 경우 원거리에서 에펠탑을 배경으로 촬영한 영상은 검색되지 않는 경우가 발생할 수 있다.
이를 위해 본 발명의 영상 컨텐츠 자동 태깅 장치는 조작부(160)를 더 포함하는 구성을 갖는다. 조작부(160)는 사용자 정보를 입력받을 수 있는 인터페이스로, 예를 들어 키입력 패널, 터치 스크린, 마이크 등이 포함될 수 있다. 본 발명의 실시 예에 따라, 상기 조작부(160)를 통해 사용자로부터 저장 요청 정보, 태그 검색 범위 설정 정보 등을 입력받을 수 있다.
자동 태깅 모듈(144)은 영상 획득 및 저장 모듈(141)로부터 입력된 영상 컨텐츠에 상기 증강 현실 지원 모듈(143)로부터 입력된 증강 현실 정보를 태깅하여 저장부(130)에 저장한다. 그러면, 추후에 영상 컨텐츠 검색이 용이하게 된다.
도 2는 본 발명의 바람직한 일 실시 예에 따른 영상 컨텐츠 자동 태깅 방법을 설명하기 위한 순서도이다.
도 2를 참조하면, 자동 태깅 제어부(140)는 210 단계에서 영상 획득부(110)로부터 획득된 동영상 또는 정지 영상이 입력됨에 따라, 220 단계에서 저장 여부를 판단한다. 사용자로부터 영상 저장 요청이 입력되면 예컨대, 카메라의 사진 찍기 또는 녹화 버튼이 눌리는 경우, 영상 획득 및 저장 판별 모듈(141)은 이를 영상과 함께 자동 태깅 모듈(144)로 전달함과 동시에 영상 정보의 저장을 요청한다.
상기 220 단계의 판단 결과 저장 요청된 것으로 판단되면, 자동 태깅 제어부(140)는 230 단계에서 센싱 정보를 수집하여 영상 정보와 함께 통신부(150)를 통해 증강 현실 서버(200)로부터 증강 현실 정보를 획득한다. 이때, 증강 현실 지원 모듈(143)은 미리 설정된 범위의 증강 현실 정보만을 획득하게 되는데, 미리 설정된 범위는 사용자에 의해 미리 지정될 수 있다. 미리 설정된 범위는 지리적 설정 등이 포함될 수 있다. 예컨대, 태깅할 정보에 대한 지리적 설정(현재 위치에서 100m 이내의 정보만 선택)이나, 특정 장소에 대한 리뷰 정보의 포함 여부, 인근 랜드 마크 정보의 포함여부 등 제공되는 증강현실 서비스에서 제공하는 정보의 종류에 따라 다양한 선택을 할 수 있다.
자동 태깅 제어부(140)는 240 단계에서 획득된 증강 현실 정보를 영상 컨텐츠에 태깅 작업한다. 자동 태깅 모듈(144)이 영상 획득 및 저장 판별 모듈(141)로부터 영상 정보의 저장 요청을 받으면, 영상 정보에 증강 현실 지원 모듈(143)로부터 수신한 최근의 증강 현실 정보 중 사용자 설정에 의해 필요한 정보의 종류만 선택하고, 센서부(120)로부터 수신한 센싱 정보와 함께 태깅한다. 또한 증강 현실 서비스 자체에서 지원하는 기능을 이용하여 특정 위치나 장소에 대해 본인의 관심 포인트로 설정하여 이후 태깅에 활용하거나, 서비스에서 제공하지 않는 정보에 대한 새로운 정보를 입력함으로써 이를 태깅 정보에 반영할 수 있다. 그리고, 자동 태깅 제어부(140)는 260 단계에서 태깅 처리된 영상 컨텐츠를 저장한다.
그런데, 정지 영상의 경우에는 사용자에 의해 사진 찍기 버튼이 눌리는 것을 사진에 대한 태깅과 저장 요청이라고 판단하면 되나, 동영상의 경우에는 사진과는 달리 녹화 버튼이 눌리는 경우를 명시적인 태깅과 저장 요청이라고 판단할 수 없다. 즉, 동영상의 경우에는 녹화 버튼이 눌림과 동시에 태깅 및 저장 작업을 수행하고 이후 동영상에 대한 저장은 계속적으로 이루어지는 반면, 태깅 작업은 주기적 또는 비주기적으로 시간을 기준으로 수행되어 저장된다. 예를 들면, 동영상에 대한 자막 파일처럼 시간에 따른 태깅 정보를 저장할 수 있을 것이다. 또한 동영상에 대한 주기적인 태깅의 경우, 태깅 주기에 따라 중복된 정보가 태깅될 수도 있고, 반대로 반드시 필요한 정보가 태깅되지 않을 수도 있다. 따라서, 본 발명의 바람직한 실시 예에서는 화면의 전환을 판단하여 태깅하는 비주기적 태깅을 제안한다.
다시 도 2를 참조하면, 250 단계가 더 포함되는데 자동 태깅 제어부(140)는 250 단계의 판단 결과, 동영상이 아닐 경우에는 전술한 바와 같은 260 단계를 수행하나, 동영상일 경우에는 270 단계로 진행하여 동영상의 비주기적 태깅 동작을 수행한다.
본 발명의 바람직한 실시 예에 따라 동영상에 대한 화면 전환을 판단하기 위해 장착된 자동 태깅 제어부(140)는 센서부(120)로부터 입력되는 센싱값의 변화를 이용한다.
즉, 도 2를 참조하면, 자동 태깅 제어부(140)는 270 단계에서 센싱값들의 변화를 계산하고, 280 단계에서 상기 계산된 센싱값 변화량이 미리 정해진 소정 임계값보다 큰지를 판단한다. 자동 태깅 제어부(140)는 상기 280 단계의 판단 결과, 센싱값의 변화가 소정 임계값를 이상이면 화면이 전환된 것으로 판단하여 새로운 태깅 정보를 입력하는 작업을 수행하기 위해 230 단계로 진행한다. 예컨대, 센서부(120)로부터 입력되는 회전각 센싱값이 이전 태깅 때의 정보와 5도 이상 차이가 나면 새로운 화면으로의 전환으로 판단하여 새롭게 태깅 작업을 수행할 수 있다.
일반적인 화면 전환의 판단은 다음의 <수학식 1>을 기준으로 수행되나, 센서의 종류 및 경우에 따라 제 3의 기준이 사용될 수도 있다.
이때, 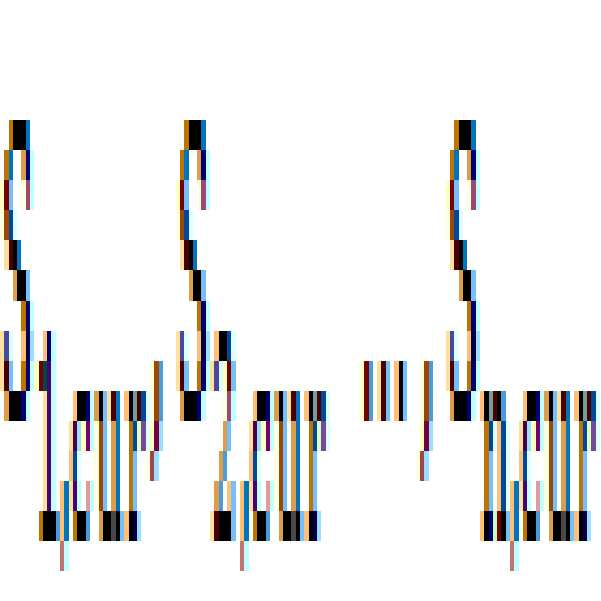
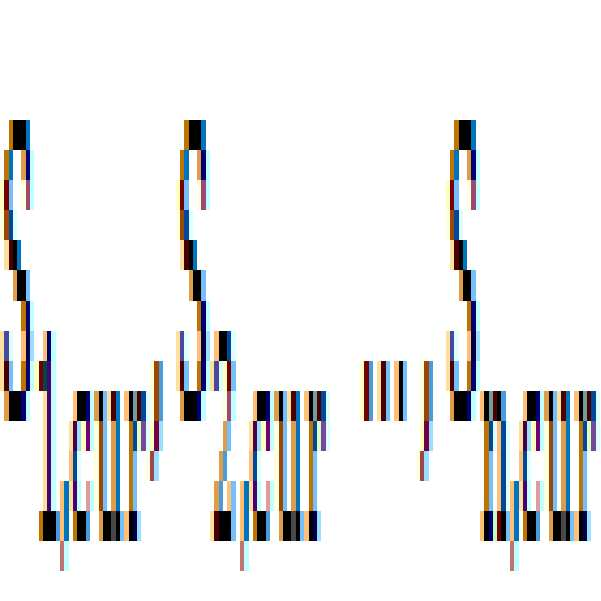 는 각각 센서 다수의 센서 S1 ~ Sn 에서 측정된 값이고,
는 각각 센서 다수의 센서 S1 ~ Sn 에서 측정된 값이고, 
 는 각각 이전에 다수의 센서 S1 ~ Sn 에서 측정한 값이다.
는 각각 이전에 다수의 센서 S1 ~ Sn 에서 측정한 값이다. 
 은 각 센서에 대한 가중치를 나타낸다. 즉, 각각의 센싱값에 대해 가중치가 주어지고 각 센싱값의 변화가 정해진 임계값 보다 크면 화면의 전환으로 판단하고 새로운 태깅 작업을 수행하게 되는 것이다.
은 각 센서에 대한 가중치를 나타낸다. 즉, 각각의 센싱값에 대해 가중치가 주어지고 각 센싱값의 변화가 정해진 임계값 보다 크면 화면의 전환으로 판단하고 새로운 태깅 작업을 수행하게 되는 것이다.
그런데, 상기 280 단계의 판단 결과, 센싱값의 변화량이 소정 임계값보다 크지 않을 경우, 자동 태깅 제어부(140)는 290 단계에서 동영상의 종료 여부를 판단한다. 상기 290 단계의 판단 결과 종료되는 것으로 판단될 경우, 자동 태깅 제어부(140)는 260 단계로 진행하여 태깅 영상을 저장한다. 그러나, 상기 290 단계의 판단 결과 종료되지 않는 것으로 판단될 경우, 자동 태깅 제어부(140)는 270 단계를 재수행하게 된다.
한편, 보다 다양한 종류의 정보를 태깅하기 위한 방법으로는 내용 기반 영상 검색 기법을 통해 이미 태깅된 영상들로부터 태깅을 원하는 영상과 유사한 영상을 검색하여, 검색된 영상의 태깅 정보를 복사해 사용하는 방법이 있다. 그러나, 이 방법은 유사한 영상의 검색 정확도 측면에서 불충분할 뿐만 아니라, 텍스트 매칭에 비해 매칭 영상의 검색을 위해 많은 시간 및 자원이 소요되는 단점이 있어 휴대 기기와 같은 소형 기기에는 적합하지 않다.
한편, 영상 전체를 비교하여 유사 영상을 검색하는 기술과는 달리, 영상 전체에서 인물의 얼굴과 같이 특징을 갖는 부문만을 추출하여 비교하는 기술은 최근 많은 발전이 있었다. 예를 들어, 얼굴 인식 및 매칭 기술의 경우 정확도가 매우 높아졌으며, 소니 에릭슨의 미디어 스케이프와 같이 스마트폰과 같은 장치에서 얼굴 인식을 지원하는 소프트웨어도 발표되고 있다. 특히 인물 사진의 경우 대상 인물과 사용자 간에 이미 소셜 네트워킹이 형성되어, 사용자 휴대폰의 주소록에 대상 인물이 이미 등록되어 있을 확률이 매우 높으며, 주소록에서 대상 인물의 사진, 이름 등의 정보를 얻을 수 있다. 즉, 주소록의 정보가 해당 사진에 대한 태깅 정보가 될 수 있는 것이다. 기존의 얼굴 인식 프로그램을 이용한 태깅은 각 인물들의 독사진에 대한 사용자의 직접적인 태깅이 최소 1번은 있어야만 이후의 사진들에 대한 태깅이 가능하다. 이는 각 인물의 사진에 대한 태그 정보를 바탕으로 나머지 사진들의 태깅이 결정되기 때문이며, 단체 사진에 대한 태그 정보의 경우, 여러 명에 대한 이름 정보가 한꺼번에 들어 있을 수 있기 때문에 특정 인물에 매칭 되는 태그가 어떤 것인지 용이하지 않다. 하지만, 주소록의 사진은 단체사진이 아니라 독사진일 확률이 매우 높고, 이미 주소록에 이름 정보가 함께 저장되어 있으므로, 이를 태깅을 위한 기본 정보로 사용한다면 인물 정보에 대해 사용자의 직접적인 태깅없이도 자동 태깅이 가능하다.
따라서, 본 발명은 이러한 주소록을 이용한 자동 태깅 방법을 제안한다.
도 3은 본 발명의 바람직한 다른 실시 예에 따른 영상 컨텐츠 자동 태깅 장치의 내부 구성도이다. 도 3에 도시된 영상 컨텐츠 자동 태깅 장치의 내부 구성 및 동작은 도 1에 도시된 구성 요소의 기능 및 동작과 유사하므로 하기에서는 차이점에 대해서만 설명하기로 한다.
도 3을 참조하면, 영상 컨텐츠 자동 태깅 장치는 도 2에 도시된 영상 컨텐츠 자동 태깅 장치에 비해 얼굴 인식 모듈(344) 및 주소록 저장부(360)를 그 구성 요소로 더 포함한다.
주소록 저장부(360)는 휴대폰과 같은 통신 장치의 전화 번호 저장을 위한 것으로, 최근에는 수신자의 이름, 전화 번호 외에 인물 사진 정보가 함께 저장되는 추세이다. 따라서, 주소록 저장부(360)에 저장된 사진 정보와 이름 정보를 이용하면 특정 인물에 대한 사용자의 명시적 태깅없이도 사진의 인물 정보에 대한 태깅이 가능해진다.
얼굴 인식 모듈(344)는 영상 획득 및 저장 판별 모듈(341)로부터 입력되는 영상 정보와 상기 주소록 저장부(360)에 저장된 인물 사진 정보를 비교하여 영상 정보에 포함된 인물 얼굴을 인식하여, 인식된 정보에 상응하는 사람의 주소록에 저장되어 있는 인물 정보를 검출하여 자동 태깅 모듈(344)에 전달한다. 그러면, 자동 태깅 모듈(344)은 상기 얼굴 인식 모듈(344)로부터 입력된 인물 정보를 영상에 태깅하여 저장부(330)에 저장한다.
또한, 얼굴 인식 모듈(344)는 인물 정보 태깅을 수행하기 위한 사전 작업으로, 매칭의 신속성을 위해 주소록 상의 사진들에 대해 얼굴 특징 정보를 추출하여, 얼굴로 인식되는 사진들만을 미리 저장해 둘 수 있다. 이를 통해 주소록 상의 사진 중 얼굴 사진이 아닌 경우는 필터링될 수 있다.
도 4는 본 발명의 바람직한 다른 실시 예에 따라 자동 태깅 방법을 설명하기 위한 순서도이다.
자동 태깅 제어부(340)는 410 단계에서 영상의 인물 정보에 대한 태깅 요청이 수신되면, 420 단계에서 수신된 영상에서 얼굴 정보를 추출한다. 자동 태깅 제어부(340)는 430 단계에서 얼굴 정보 추출 성공 여부를 판단한다. 상기 430 단계의 판단 결과 얼굴 정보가 추출된 것으로 판단되면, 자동 태깅 제어부(340)는 440 단계에서 추출된 얼굴 정보와 주소록 상의 사진들에 대한 얼굴 정보를 비교한다. 그리고, 자동 태깅 제어부(340)는 450 단계에서 상기 비교를 통해 매칭되는 사진이 검색되는지를 판단한다.
상기 450 단계의 판단 결과 얼굴 매칭이 성공한 것으로 판단되면, 자동 태깅 제어부(340)는 매칭된 사진에 대응되는 주소록 상의 정보 중 태깅에 사용할 인물 정보로 태깅 작업을 수행하게 한다.
반면, 450 단계의 판단 결과 얼굴 매칭에 성공하지 못한 것으로 판단되면, 자동 태깅 제어부(340)는 인물에 대한 태깅 정보가 없는 것으로 판단하고 작업을 종료한다. 또한, 상기 430 단계에서 얼굴 정보 추출 실패로 판단될 경우에도 인물에 대한 태깅 정보가 없는 것으로 판단하고 작업을 종료한다.
전술한 바와 같은 본 발명에 따라, 사진과 같은 영상 컨텐츠를 촬영한 시간 및 위치 정보는 촬영 장치에 내장된 각종 센서로부터 입력받고, 화면에 포함된 건물 정보, 거리 정보 및 각종 랜드마크와 관련된 정보는 증강 현실 기술을 통해 얻어 자동 태깅에 사용하며, 인물 정보에 대한 태깅은 얼굴 인식 기술과 주소록 내의 사진 및 이름 정보를 이용해 사용자가 직접 태깅 작업을 수행할 필요없이 자동 태깅을 지원할 수 있다는 이점이 있다.
Claims (1)
- 동영상 또는 정지 영상을 포함하는 영상 컨텐츠를 획득하는 영상 획득부와,
영상 컨텐츠의 생성 시간, 촬영 위치를 포함하는 센싱 정보를 획득하는 센서부와,
증강 현실 정보를 제공하는 증강 현실 서버와의 유무선 통신망을 통해 접속 처리하는 통신부와,
인물 사진을 포함하는 인물 정보를 저장하는 주소록 저장부와,
상기 획득된 영상 컨텐츠에 상기 센서부로부터 획득된 센싱 정보, 상기 통신부를 통해 획득된 증강 현실 정보 및 상기 주소록 저장부에서 검색한 인물 정보 중 하나 이상을 자동 태깅하는 자동 태깅 제어부를 포함하는 영상 컨텐츠 자동 태깅 장치.
Priority Applications (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020100133797A KR20120072033A (ko) | 2010-12-23 | 2010-12-23 | 영상 컨텐츠의 자동 태깅 방법 및 장치 |
Applications Claiming Priority (1)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| KR1020100133797A KR20120072033A (ko) | 2010-12-23 | 2010-12-23 | 영상 컨텐츠의 자동 태깅 방법 및 장치 |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20120072033A true KR20120072033A (ko) | 2012-07-03 |
Family
ID=46706867
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020100133797A Withdrawn KR20120072033A (ko) | 2010-12-23 | 2010-12-23 | 영상 컨텐츠의 자동 태깅 방법 및 장치 |
Country Status (1)
| Country | Link |
|---|---|
| KR (1) | KR20120072033A (ko) |
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20150126752A (ko) * | 2014-05-02 | 2015-11-13 | 동아대학교 산학협력단 | 위치 정보를 구비한 컨텐츠 제공 시스템 및 방법 그리고 그 위치 정보 제공 장치 |
| CN108255922A (zh) * | 2017-11-06 | 2018-07-06 | 优视科技有限公司 | 视频识别方法、设备、客户端装置、电子设备及服务器 |
| US12124753B2 (en) | 2020-08-11 | 2024-10-22 | Samsung Electronics Co., Ltd. | Electronic device for providing text associated with content, and operating method therefor |
-
2010
- 2010-12-23 KR KR1020100133797A patent/KR20120072033A/ko not_active Withdrawn
Cited By (3)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20150126752A (ko) * | 2014-05-02 | 2015-11-13 | 동아대학교 산학협력단 | 위치 정보를 구비한 컨텐츠 제공 시스템 및 방법 그리고 그 위치 정보 제공 장치 |
| CN108255922A (zh) * | 2017-11-06 | 2018-07-06 | 优视科技有限公司 | 视频识别方法、设备、客户端装置、电子设备及服务器 |
| US12124753B2 (en) | 2020-08-11 | 2024-10-22 | Samsung Electronics Co., Ltd. | Electronic device for providing text associated with content, and operating method therefor |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| US11647276B2 (en) | Portable information device having real-time display with relevant information | |
| JP5763075B2 (ja) | オブジェクト情報の提供方法及びそれを適用した撮影装置 | |
| US9852343B2 (en) | Imaging apparatus, display method, and storage medium | |
| CN105808542B (zh) | 信息处理方法以及信息处理装置 | |
| JP6591594B2 (ja) | 情報提供システム、サーバ装置、及び情報提供方法 | |
| KR20150145168A (ko) | 관심 지점 정보를 푸싱하기 위한 방법 및 시스템 | |
| KR100788605B1 (ko) | 컨텐츠 서비스 장치 및 방법 | |
| JP2010079788A (ja) | コンテンツ管理装置、システム、方法およびプログラム | |
| CN112989092A (zh) | 一种图像处理方法及相关装置 | |
| US9635234B2 (en) | Server, client terminal, system, and program | |
| CN105159976A (zh) | 图像文件的处理方法和系统 | |
| CN105159959A (zh) | 图像文件的处理方法和系统 | |
| CN107193820B (zh) | 位置信息获取方法、装置及设备 | |
| EP2975576A1 (en) | Method of determination of stable zones within an image stream, and portable device for implementing the method | |
| JP2019163998A (ja) | 情報提供システム、サーバ装置、及び情報提供方法 | |
| JP2010129032A (ja) | 画像検索装置および画像検索プログラム | |
| KR20120072033A (ko) | 영상 컨텐츠의 자동 태깅 방법 및 장치 | |
| KR100956114B1 (ko) | 촬상장치를 이용한 지역 정보 제공 장치 및 방법 | |
| JP2015056152A (ja) | 表示制御装置及び表示制御装置の制御方法 | |
| JP5272107B2 (ja) | 情報提供装置、情報提供処理プログラム、情報提供処理プログラムを記録した記録媒体、及び情報提供方法 | |
| CN105451175A (zh) | 一种记录照片定位信息的方法及装置 | |
| JP6168926B2 (ja) | 情報処理装置、表示システムおよび制御方法 | |
| JP5582453B2 (ja) | 画像管理装置、画像管理方法およびプログラム | |
| JP2016075992A (ja) | 撮像装置、情報処理装置およびそれらの情報処理方法、並びに、情報処理システム | |
| JP5920448B2 (ja) | 撮像装置、プログラム |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0109 | Patent application |
Patent event code: PA01091R01D Comment text: Patent Application Patent event date: 20101223 |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |