KR20130109977A - 개선된 항-혈청 알부민 결합 변이체 - Google Patents
개선된 항-혈청 알부민 결합 변이체 Download PDFInfo
- Publication number
- KR20130109977A KR20130109977A KR1020127033268A KR20127033268A KR20130109977A KR 20130109977 A KR20130109977 A KR 20130109977A KR 1020127033268 A KR1020127033268 A KR 1020127033268A KR 20127033268 A KR20127033268 A KR 20127033268A KR 20130109977 A KR20130109977 A KR 20130109977A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- gly
- leu
- val
- thr
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images








Classifications
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K39/395—Antibodies; Immunoglobulins; Immune serum, e.g. antilymphocytic serum
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K47/00—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient
- A61K47/50—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates
- A61K47/51—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent
- A61K47/68—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment
- A61K47/6835—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site
- A61K47/6843—Medicinal preparations characterised by the non-active ingredients used, e.g. carriers or inert additives; Targeting or modifying agents chemically bound to the active ingredient the non-active ingredient being chemically bound to the active ingredient, e.g. polymer-drug conjugates the non-active ingredient being a modifying agent the modifying agent being an antibody, an immunoglobulin or a fragment thereof, e.g. an Fc-fragment the modifying agent being an antibody or an immunoglobulin bearing at least one antigen-binding site the antibody targeting a material from animals or humans
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P3/00—Drugs for disorders of the metabolism
- A61P3/08—Drugs for disorders of the metabolism for glucose homeostasis
- A61P3/10—Drugs for disorders of the metabolism for glucose homeostasis for hyperglycaemia, e.g. antidiabetics
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/18—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans
- C07K16/28—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants
- C07K16/2878—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies against material from animals or humans against receptors, cell surface antigens or cell surface determinants against the NGF-receptor/TNF-receptor superfamily, e.g. CD27, CD30, CD40, CD95
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K16/00—Immunoglobulins [IG], e.g. monoclonal or polyclonal antibodies
- C07K16/46—Hybrid immunoglobulins
- C07K16/468—Immunoglobulins having two or more different antigen binding sites, e.g. multifunctional antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K19/00—Hybrid peptides, i.e. peptides covalently bound to nucleic acids, or non-covalently bound protein-protein complexes
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K39/00—Medicinal preparations containing antigens or antibodies
- A61K2039/505—Medicinal preparations containing antigens or antibodies comprising antibodies
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K14/00—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- C07K14/435—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- C07K14/76—Albumins
- C07K14/765—Serum albumin, e.g. HSA
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/20—Immunoglobulins specific features characterized by taxonomic origin
- C07K2317/21—Immunoglobulins specific features characterized by taxonomic origin from primates, e.g. man
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/30—Immunoglobulins specific features characterized by aspects of specificity or valency
- C07K2317/31—Immunoglobulins specific features characterized by aspects of specificity or valency multispecific
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/565—Complementarity determining region [CDR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/567—Framework region [FR]
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/50—Immunoglobulins specific features characterized by immunoglobulin fragments
- C07K2317/56—Immunoglobulins specific features characterized by immunoglobulin fragments variable (Fv) region, i.e. VH and/or VL
- C07K2317/569—Single domain, e.g. dAb, sdAb, VHH, VNAR or nanobody®
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/92—Affinity (KD), association rate (Ka), dissociation rate (Kd) or EC50 value
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2317/00—Immunoglobulins specific features
- C07K2317/90—Immunoglobulins specific features characterized by (pharmaco)kinetic aspects or by stability of the immunoglobulin
- C07K2317/94—Stability, e.g. half-life, pH, temperature or enzyme-resistance
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/31—Fusion polypeptide fusions, other than Fc, for prolonged plasma life, e.g. albumin
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/33—Fusion polypeptide fusions for targeting to specific cell types, e.g. tissue specific targeting, targeting of a bacterial subspecies
Landscapes
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Organic Chemistry (AREA)
- Life Sciences & Earth Sciences (AREA)
- Immunology (AREA)
- Medicinal Chemistry (AREA)
- General Health & Medical Sciences (AREA)
- Biochemistry (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Biophysics (AREA)
- Pharmacology & Pharmacy (AREA)
- Veterinary Medicine (AREA)
- Public Health (AREA)
- Animal Behavior & Ethology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Engineering & Computer Science (AREA)
- Epidemiology (AREA)
- Diabetes (AREA)
- Zoology (AREA)
- Hematology (AREA)
- Microbiology (AREA)
- Emergency Medicine (AREA)
- Obesity (AREA)
- Chemical Kinetics & Catalysis (AREA)
- General Chemical & Material Sciences (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
- Endocrinology (AREA)
- Mycology (AREA)
- Peptides Or Proteins (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
- Medicines Containing Antibodies Or Antigens For Use As Internal Diagnostic Agents (AREA)
- Medicines That Contain Protein Lipid Enzymes And Other Medicines (AREA)
Abstract
본 발명은 항-혈청 알부민 면역글로불린 단일 가변 도메인 DOM7h-11의 개선된 변이체, 뿐만 아니라 이러한 변이체를 포함하는 리간드 및 약물 컨쥬게이트, 조성물, 핵산, 벡터 및 숙주에 관한 것이다.
Description
본 발명은 항-혈청 알부민 면역글로불린 단일 가변 도메인 DOM7h-11의 개선된 변이체, 뿐만 아니라 이러한 변이체를 포함하는 리간드 및 약물 컨쥬게이트, 조성물, 핵산, 벡터 및 숙주에 관한 것이다.
발명의 배경
WO04003019호 및 WO2008/096158호에는 치료적으로 유용한 반감기를 갖는 항-SA 면역글로불린 단일 가변 도메인(dAb)과 같은 항-혈청 알부민(SA) 결합 모이어티(moiety)가 개시되어 있다. 이러한 문헌은 단량체 항-SA dAb 뿐만 아니라 상기 dAb를 포함하는 다중특이적 리간드, 예를 들어, 항-SA dAb 및 표적 항원, 예를 들어, TNFR1에 특이적으로 결합하는 dAb를 포함하는 리간드가 개시되어 있다. 하나 이상의 종으로부터의 혈청 알부민에 특이적으로 결합하는 결합 모이어티, 예를 들어, 인간/마우스 교차반응성 항-SA dAb가 개시되어 있다.
WO05118642호 및 WO2006/059106호에는 약물의 반감기를 증가시키기 위해 항-SA 결합 모이어티, 예를 들어, 항-SA 면역글로불린 단일 가변 도메인을 약물에 컨쥬게이션시키거나 회합시키는 개념이 개시되어 있다. 단백질, 펩티드 및 신규 화합물(NCE) 약물이 개시되고 예시되어 있다. WO2006/059106호에는 인슐린자극 작용제, 예를 들어, 인크레틴 호르몬, 예를 들어, 글루카곤-유사 펩티드(GLP)-1의 반감기를 증가시키는 상기 개념의 이용이 개시되어 있다. 문헌[Holt et al, "Anti-Serum albumin domain antibodies for extending the half-lives of short lived drugs", Protein Engineering, Design & Selection, vol 21, no 5, pp283-288, 2008]을 또한 참조하라. WO2008/096158호에는 우수한 항-SA dAb인 DOM7h-11이 개시되어 있다. 질병의 동물 모델 뿐만 아니라 인간 요법 및/또는 진단에서의 유용성을 제공하는, DOM7h-11의 변이체이고, 혈청 알부민, 바람직하게는 인간 및 비-인간 종으로부터의 알부민에 특이적으로 결합하는 개선된 dAb를 제공하는 것이 바람직할 것이다. 비교적 온건한-친화성 내지 높은-친화성의 항-SA 결합 모이어티(dAb)의 선택을 제공하는 것이 또한 바람직할 것이다. 이러한 모이어티는 약물에 연결될 수 있고, 항-SA 결합 모이어티는 고려되는 최종-적용에 따라 선택된다. 이는 항-SA 결합 모이어티의 선택에 따라 만성 또는 급성 적응증을 치료하고/하거나 예방하기 위해 약물이 맞춤화되도록 한다. 단량체이거나 실질적으로 용액 중에 존재하는 항-SA dAb를 제공하는 것이 또한 바람직할 것이다. 이는 수용체를 길항시키는 목적과 함께 항-SA dAb가 세포-표면 수용체, 예를 들어, TNFR1에 특이적으로 결합하는 결합 모이어티, 예를 들어, dAb에 연결되는 경우에 특히 유리할 것이다. 항-SA dAb의 단량체 상태는 수용체 가교의 기회를 감소시키는데 유용한데, 이는 세포 표면 상의 수용체(예를 들어, TNFR1)에 결합하고 이를 가교시켜, 이에 따라 수용체 효능작용 및 유해한 수용체 신호전달의 가능성을 증가시킬 수 있는 다합체가 형성될 가능성이 더 적기 때문이다.
다수의 개선된 dAb가 개시내용이 참조로서 포함되는 PCT/EP2010/052008호 및 PCT/EP2010/052007호에 개시되어 있다.
개선된 안정성을 갖는 개선된 dAb를 제공하는 것이 또한 바람직할 것이다. 이는 dAb가 적합한 안정성 프로파일 또는 저장 수명을 갖도록 하는데 유리할 것이다. 특히, 상승된 온도에 대한 노출 후에 언폴딩(unfolding)에 저항하는 개선된 능력, 즉, 개선된 열안정성을 갖는 dAb를 제공하는 것이 바람직할 것이다. 다중특이적 리간드와 같은 작제물로 포맷화되거나, 단백질, 펩티드 또는 NCE로 컨쥬게이션되는 경우 개선된 안정성을 갖는 dAb를 제공하는 것이 또한 바람직할 것이다.
발명의 개요
본 발명의 양태는 상기 문제점을 해소시킨다.
이를 위해, 본 발명자는 놀랍게도 DOM7h-11 계통의 면역글로불린 단일 가변 도메인 분자에 대해 돌연변이가 이루어져 모(parent) DOM7h-11 분자에 비한 개선된 열안정성에 의해 측정되는 바와 같은 안정성이 개선된 분자를 발생시킬 수 있는 것을 발견하였다.
일 양태에서, 적어도 54℃의 Tm을 갖는, DOM7h-11(도 1에 도시된 바와 같은 DOM7h-11)의 항-혈청 알부민(SA) 면역글로불린 단일 가변 도메인 변이체가 제공된다. 또 다른 양태에서, 54℃를 초과하는 Tm을 갖는, DOM7h-11(도 1에 도시된 바와 같은 DOM7h-11)의 항-혈청 알부민(SA) 면역글로불린 단일 가변 도메인 변이체가 제공된다. 전이 중간점(transition midpoint, Tm)은 단백질의 50%가 이의 자연 형태이고, 나머지 50%가 변성되는 온도이다. 적합하게는, 상기 Tm은 시차주사열용량분석에 의해 측정된다.
일 구체예에서, 상기 변이체는 DOM7h-11에 비해 위치 22, 42 또는 91(케이뱃(Kabat)에 따른 넘버링) 중 임의의 위치에 적어도 하나의 돌연변이를 포함한다. 적합하게는, 항-SA 면역글로불린 단일 가변 도메인 변이체는 DOM7h-11-15(도 1에 도시된 바와 같은 DOM7h-11-15)(SEQ ID NO:7)의 변이체이고, 이는 DOM7h-11-15에 비해 위치 22, 42 또는 91(케이뱃에 따른 넘버링) 중 임의의 위치에 적어도 하나의 돌연변이를 포함한다. 일 구체예에서, 변이체는 하기로부터 선택된 적어도 하나의 돌연변이를 포함한다:
위치 22 = Ser, Phe, Thr, Ala 또는 Cys;
위치 42 = Glu 또는 Asp;
위치 91 = Thr 또는 Ser.
다른 구체예에서, 위치 22가 Ser 또는 Phe인 항-SA 면역글로불린 단일 가변 도메인 변이체; 위치 42가 Glu이고, 위치 91이 Thr인 항-SA 면역글로불린 단일 가변 도메인 변이체; 위치 91이 Thr인 항-SA 면역글로불린 단일 가변 도메인 변이체; 위치 22가 Phe인 항-SA 면역글로불린 단일 가변 도메인 변이체가 제공된다. 일 구체예에서, 위치 108은 Trp이다.
추가 구체예는 DOM7h-11-56(SEQ ID NO:412), DOM7h-11-68(SEQ ID NO:416), DOM7h-11-79(SEQ ID NO:418) 및 DOM7h-11-80(SEQ ID NO:419)로부터 선택된 단일 가변 도메인의 아미노산 서열과 동일하거나 선택된 아미노산 서열에 비해 4개 이하의 변화를 갖는 아미노산 서열을 포함하는 변이체(또는 선택된 아미노산 서열의 아미노산 서열과 적어도 95, 96, 97, 98 또는 99% 동일한 아미노산을 갖는 변이체)를 제공한다.
특히, DOM7h-11의 FW3(위치 57 내지 88, 케이뱃에 따른 넘버링) 및 CDR3 영역(위치 89 내지 97, 케이뱃에 따른 넘버링)을 표적으로 하는 돌연변이가 개선된 안정성을 제공하는 것으로 밝혀졌다. 따라서, 또 다른 구체예에서, 본 발명의 양태에 따른 항-SA 면역글로불린 단일 가변 도메인 변이체가 제공되며, 이러한 변이체는 DOM7h-11에 비해 FW3 영역(위치 57 내지 88, 케이뱃에 따른 넘버링) 또는 CDR3 영역(위치 89 내지 97, 케이뱃에 따른 넘버링)에 적어도 하나의 돌연변이를 포함한다.
추가 구체예는 항-SA 면역글로불린 단일 가변 도메인을 제공하며, 상기 변이체는 DOM7h-11-15(도 1에 도시된 바와 같은 DOM7h-11-15)의 변이체이고, 이는 DOM7h-11-15에 비해 FW3 영역(위치 57 내지 88, 케이뱃에 따른 넘버링) 또는 CDR3 영역(위치 89 내지 97, 케이뱃에 따른 넘버링)에 적어도 하나의 돌연변이를 포함한다. 적합하게는, 상기 변이체는 위치 77, 83, 93 또는 95(케이뱃에 따른 넘버링) 중 임의의 위치에 적어도 하나의 돌연변이를 포함한다.
일 구체예에서, 변이체는 하기로부터 선택된 적어도 하나의 돌연변이를 포함한다:
위치 77 = Asn, Gln
위치 83 = Val, Ile, Met, Leu, Phe, Ala 또는 노르류신.
위치 93 = Val, Ile, Met, Leu, Phe, Ala 또는 노르류신.
위치 95 = His, Asn, Gln, Lys 또는 Arg.
또 다른 구체예에서, 본 발명에 따른 항-SA 면역글로불린 단일 가변 도메인은 위치 106 또는 108(케이뱃에 따른 넘버링)에 돌연변이를 추가로 포함한다. 적합하게는, 위치 106은 Asn 또는 Gln이다. 적합하게는, 위치 108은 Trp, Tyr 또는 Phe이다.
추가 구체예에서, 위치 77이 Asn인 항-SA 면역글로불린 단일 가변 도메인 변이체; 위치 83이 Val인 항-SA 단일 가변 도메인; 위치 95가 His인 항-SA 단일 가변 도메인; 위치 95가 His인 항-SA 단일 가변 도메인; 위치 93이 Val인 항-SA 단일 가변 도메인이 제공된다.
또 다른 추가 구체예에서, DOM7h-11-57(SEQ ID NO:413), DOM7h-11-65(SEQ ID NO:414) 또는 DOM7h-11-67(SEQ ID NO:415)로부터 선택된 단일 가변 도메인의 아미노산 서열과 동일하거나 선택된 아미노산 서열에 비해 4개 이하의 변화를 갖는 아미노산 서열을 포함하는 변이체(또는 선택된 아미노산 서열의 아미노산 서열과 적어도 95, 96, 97, 98 또는 99% 동일한 아미노산을 갖는 변이체)가 제공되나, 단, 이러한 변이체의 아미노산 서열은 FW3 또는 CDR3 영역에 적어도 하나의 돌연변이를 갖는다.
추가 구체예에서, DOM7h-11-69(SEQ ID NO:417), DOM 7h-11-90(SEQ ID NO:420), DOM 7h-11-86(SEQ ID NO:421), DOM 7h-11-87(SEQ ID NO:422), 또는 DOM 7h-11-88(SEQ ID NO:423)로부터 선택된 단일 가변 도메인의 아미노산 서열과 동일한 아미노산 서열을 포함하는 변이체(또는 선택된 아미노산 서열의 아미노산 서열과 적어도 95, 96, 97, 98 또는 99% 동일한 아미노산을 갖는 변이체)가 제공된다.
적합하게는, 변이체는 적어도 57℃의 Tm을 갖는다. 또 다른 구체예에서, 변이체는 57℃를 초과하는 Tm을 갖는다.
일 구체예에서, 본 발명의 임의의 구체예에 따른 변이체는 DOM7h-11에 비해 증가된 Tm 값을 갖는다. 또 다른 구체예에서, 상기 변이체는 DOM7h-11-15에 비해 증가된 Tm 값을 갖는다. 또 다른 구체예에서, 상기 나열된 돌연변이 중 임의의 돌연변이의 임의의 조합을 포함하는 변이체가 제공된다. 적합하게는, Tm은 본원에 기재된 방법에 따라 DSC에 의해 측정된다.
적합하게는, 본 발명에 따른 변이체는 표면 플라즈몬 공명에 의해 결정시 약 0.1 내지 약 10000 nM, 임의로, 약 1 내지 약 6000 nM의 해리상수(KD)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함한다. 상기 변이체는 표면 플라즈몬 공명에 의해 결정시 약 1.5 x 10-4 내지 약 0.1 초-1, 임의로 약 3 x 10-4 내지 약 0.1 초-1의 분리속도(off-rate) 상수(Kd)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함한다. 상기 변이체는 표면 플라즈몬 공명에 의해 결정시 약 2 x 106 내지 약 1 x 104 M-1초-1, 임의로 약 1 x 106 내지 약 2 x 104 M-1초-1의 결합속도(on-rate) 상수(Ka)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함한다.
유리하게는, 본 발명에 따른 변이체는 다수의 상이한 종, 예를 들어, 원숭이, 예를 들어, 시노몰구스(Cynomolgus) 원숭이, 순쿠스(뾰족뒤쥐(shrew)), 마모셋, 페렛, 래트, 마우스, 돼지 및 개 SA로부터의 혈청 알부민과 교차 반응성이다.
따라서, 일 구체예에서, 본 발명에 따른 변이체는 표면 플라즈몬 공명에 의해 결정시 약 0.1 내지 약 10000 nM, 임의로 약 1 내지 약 6000 nM의 해리상수(KD)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함한다. 상기 변이체는 표면 플라즈몬 공명에 의해 결정시 약 1.5 x 10-4 내지 약 0.1 초-1, 임의로 약 3 x 10-4 내지 약 0.1 초-1의 분리속도 상수(Kd)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함한다. 상기 변이체는 표면 플라즈몬 공명에 의해 결정시 약 2 x 106 내지 약 1 x 104 M-1초-1, 임의로 약 1 x 106 내지 약 5 x 103 M-1초-1의 결합속도 상수(Ka)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함한다. 또 다른 양태에서, 본 발명에 따른 항-SA 변이체 및 SA가 아닌 표적 항원에 특이적으로 결합하는 결합 모이어티를 포함하는 다중특이적 리간드가 제공된다. 적합한 표적 항원이 본원에 예시된다. 일 구체예에서, 표적 항원에 특이적으로 결합하는 결합 모이어티는 또 다른 단일 도메인 면역글로불린 분자일 수 있다. 또 다른 구체예에서, 표적 항원에 특이적으로 결합하는 결합 모이어티는 모노클로날 항체일 수 있다. 이중 특이적 분자, 예를 들어, mAbdAb 분자를 제조하기 위한 적합한 포맷 및 방법은, 예를 들어, WO2009/068649호에 기재되어 있다.
본 발명의 한 양태는 융합 생성물, 예를 들어, 융합 단백질 또는 펩티드 또는 NCE(신규 화합물) 약물과의 융합물, 예를 들어, 상기 기재된 임의의 변이체에 융합되거나 컨쥬게이션된 폴리펩티드, 단백질, 펩티드 또는 NCE 약물을 제공한다. 또 다른 양태에서, 본 발명에 따른 항-혈청 알부민 dAb 변이체에 융합된 폴리펩티드 또는 펩티드 약물을 포함하는 융합 단백질, 폴리펩티드 융합체 또는 컨쥬게이트가 제공되며, 임의로, 상기 선택된 변이체는 DOM7h-11-56(SEQ ID NO:412), DOM7h-11-57(SEQ ID NO:413), DOM7h-11-65(SEQ ID NO:414), DOM7h-11-67(SEQ ID NO:415), DOM7h-11-68(SEQ ID NO:416), DOM7h-11-69(SEQ ID NO:417), DOM7h-11-79(SEQ ID NO:418), DOM7h-11-80(SEQ ID NO:419), DOM 7h-11-90(SEQ ID NO:420), DOM 7h-11-86(SEQ ID NO:421), DOM 7h-11-87(SEQ ID NO:422), 또는 DOM 7h-11-88(SEQ ID NO:423)이다. 적합하게는, 상기 융합 단백질은 변이체와 약물 사이에 링커(예를 들어, 아미노산 서열 TVA, 임의로 TVAAPS(SEQ ID NO:437)를 포함하는 링커)를 포함한다.
일 구체예에서, 본원에 개시된 항-혈청 알부민 dAb 및 인크레틴 또는 인슐린분비자극 작용제(insulinotropic agent), 예를 들어, 엑센딘-4(exendin-4), GLP-1(7-37), GLP-1(6-36) 또는 WO06/059106호에 개시된 임의의 인크레틴 또는 인슐린분비자극 작용제를 포함하는 폴리펩티드 융합체 또는 컨쥬게이트가 제공되며, 상기 작용제는 본 발명 및 하기 청구항에서의 포함에 대해 본원에 기재되는 것과 같이 참조로서 본원에 명백히 포함된다.
또 다른 양태에서, 본 발명에 따른 항-SA 변이체 단일 가변 도메인이 제공되며, 상기 가변 도메인은 약물(임의로, NCE 약물)에 컨쥬게이션되고, 임의로, 상기 선택된 변이체는 DOM7h-11-56(SEQ ID NO:412), DOM7h-11-57(SEQ ID NO:413), DOM7h-11-65(SEQ ID NO:414), DOM7h-11-67(SEQ ID NO:415), DOM7h-11-68(SEQ ID NO:416), DOM7h-11-69(SEQ ID NO:417), DOM7h-11-79(SEQ ID NO:418), DOM7h-11-80(SEQ ID NO:419), DOM 7h-11-90(SEQ ID NO:420), DOM 7h-11-86(SEQ ID NO:421), DOM 7h-11-87(SEQ ID NO:422), 또는 DOM 7h-11-88(SEQ ID NO:423)이다.
또 다른 양태에서, 상기 기재된 변이체, 융합 단백질 또는 리간드 및 약학적으로 허용되는 희석제, 담체, 부형제 또는 비히클을 포함하는 조성물이 제공된다.
한 추가 양태에서, 본 발명에 따른 변이체 또는 본 발명에 따른 다중특이적 리간드 또는 융합 단백질을 엔코딩하는 누클레오티드 서열을 포함하는 핵산이 제공된다. 적합하게는, DOM7h-11-56(SEQ ID NO:425), DOM7h-11-57(SEQ ID NO:426), DOM7h-11-65(SEQ ID NO:427), DOM7h-11-67(SEQ ID NO:428), DOM7h-11-68(SEQ ID NO:429), DOM7h-11-69(SEQ ID NO:430), DOM7h-11-79(SEQ ID NO:431), DOM7h-11-80(SEQ ID NO:432), DOM 7h-11-90(SEQ ID NO:433), DOM 7h-11-86(SEQ ID NO:434), DOM 7h-11-87(SEQ ID NO:435), 또는 DOM 7h-11-88(SEQ ID NO:436)의 누클레오티드 서열로부터 선택된 DOM7h-11 변이체의 누클레오티드 서열 또는 상기 선택된 서열과 적어도 80% 동일한 누클레오티드 서열을 포함하는 핵산이 제공된다.
또 다른 양태는 본 발명에 따른 핵산을 포함하는 벡터를 제공한다. 추가 양태는 본 발명의 벡터를 포함하는 분리된 숙주 세포를 제공한다.
한 추가 양태에서, 본 발명의 임의의 양태 또는 구체예에 따른 적어도 1회 이상의 용량의 변이체를 환자에 투여하는 것을 포함하는 환자의 질병 또는 장애를 치료하거나 예방하는 방법이 제공된다.
도면의 간단한 설명
도 1: DOM7h-11 변이체 dAb에 대한 아미노산 서열 정렬. 특정 위치에서의 "."는 이러한 위치에서 DOM7h-11에서 발견된 것과 동일한 아미노산을 나타낸다. CDR은 밑줄과 굵은 글씨로 표시된다(첫번째 밑줄친 서열은 CDR1이고, 두번째 밑줄친 서열은 CDR2이고, 세번째 밑줄친 서열은 CDR3이다).
도 2: DOM7h-11 변이체의 동역학 파라미터. KD 단위 = nM; Kd 단위 = 초-1; Ka 단위 = M-1초-1. 기호법 A e-B는 A x 10-B를 의미하고, C e D는 C x 10D를 의미한다. 하기 실시예에 의해 뒷받침되는 다양한 종에서의 전체 동역학 범위가 표시된다. 특정 치료 환경(급성 또는 만성 적응증, 질환 또는 질병, 및 만성 및 급성 환경 둘 모두에서 사용하기 위한 "중간")에서 사용하기 위한 임의의 범위가 또한 제공된다. 고 친화성 dAb 및 이를 포함하는 생성물은 만성 환경에 유용하다. 중간 친화성 dAb 및 이를 포함하는 생성물은 중간 환경에서 유용하다. 저 친화성 dAb 및 이를 포함하는 생성물은 급성 환경에 유용하다. 상기와 관련된 친화성은 혈청 알부민에 대한 친화성이다. 다양한 예시적 항-혈청 dAb 및 융합 단백질이 나열되며, 이들은 개시된 범위를 뒷받침한다. 실시예 중 많은 실시예는 인간 및 하나 이상의 비-인간 동물(예를 들어, 인간 및 시노몰구스 원숭이 및/또는 마우스)에서 바람직한 동역학을 갖는다. dAb 및 이를 포함하는 생성물의 선택은 치료적으로 치료되는 환경(예를 들어, 만성 또는 급성)에 따라 본 발명에 따라 맞춤화될 수 있다.
도 3: DOM7h-11-15 변이체 dAb에 대한 아미노산(A) 및 핵산(B) 서열 정렬. 특정 위치에서의 "."는 이러한 위치에서 DOM7h-11-15에서 발견된 것과 동일한 아미노산을 나타낸다.
발명의 상세한 설명
본 명세서 내에서, 본 발명은 명세서가 명백하고 간결하게 기재되는 것을 가능케 하는 방식으로 구체예를 참조로 하여 기재된다. 구체예는 본 발명으로부터 벗어남이 없이 다양하게 조합되거나 분리될 수 있으며, 이는 인지되어야 한다.
달리 정의되지 않는 한, 본원에 사용되는 모든 기술 및 과학 용어는 당 분야(예를 들어, 세포 배양, 분자 유전학, 핵산 화학, 하이브리드화 기술 및 생화학)의 당업자에 의해 통상적으로 이해되는 것과 동일한 의미를 갖는다. 표준 기술은 분자적, 유전적 및 생화학 방법(일반적으로, 참조로서 본원에 포함되는 문헌[Sambrook et al ., Molecular Cloning: A Laboratory Manual, 2d ed. (1989) Cold Spring Harbor Laboratory Press, Cold Spring Harbor, N.Y. and Ausubel et al., Short Protocols in Molecular Biology (1999) 4th Ed, John Wiley & Sons, Inc] 참조) 및 화학적 방법에 사용된다.
본원에서 사용되는 용어 "종양 괴사 인자 수용체 1(TNFR1)의 길항제" 또는 "항-TNFR1 길항제" 등은 TNFR1에 결합하고, TNFR1의 기능(즉, 하나 이상의 기능)을 억제할 수 있는 작용제(예를 들어, 분자, 화합물)를 의미한다. 예를 들어, TNFR1의 길항제는 TNFR1에 대한 TNFα의 결합을 억제하고/하거나 TNFR1을 통해 매개되는 신호전달을 억제할 수 있다. 따라서, TNFR1-매개 과정 및 세포 반응(예를 들어, 표준 L929 세포독성 검정에서의 TNFα-유도 세포 사멸)이 TNFR1의 길항제로 억제될 수 있다.
"환자"는 임의의 동물, 예를 들어, 포유동물, 예를 들어, 비-인간 영장류(예를 들어, 비비, 레수스(rhesus) 원숭이 또는 시노몰구스 원숭이), 마우스, 인간, 토끼, 래트, 개, 고양이 또는 돼지이다. 일 구체예에서, 환자는 인간이다.
본원에서 사용되는 "펩티드"는 펩티드 결합을 통해 함께 연결되는 약 2 내지 약 50개의 아미노산을 의미한다.
본원에서 사용되는 "폴리펩티드"는 펩티드 결합에 의해 함께 연결되는 적어도 약 50개의 아미노산을 의미한다. 폴리펩티드는 일반적으로 3차 구조를 포함하며, 기능성 도메인으로 폴딩된다.
본원에서 사용되는 항체는 항체를 자연적으로 생성하는 임의의 종으로부터 유래되거나 재조합 DNA 기술에 의해 생성되거나, 혈청, B-세포, 하이브리도마, 트랜스펙토마(transfectoma), 효모 또는 박테리아로부터 분리되건 간에 IgG, IgM, IgA, IgD 또는 IgE 또는 단편(예를 들어, Fab , Fab', F(ab')2, Fv, 이황화 결합된 Fv, scFv, 폐쇄된 형태의 다중특이적 항체, 이황화 결합된 scFv, 디아바디(diabody))을 의미한다.
본원에서 사용되는 "항체 포맷"은 하나 이상의 항체 가변 도메인이 항원에 대한 결합 특이성을 제공하기 위해 구조 상에 통합될 수 있는 임의의 적합한 폴리펩티드 구조를 의미한다. 다양한 적합한 항체 포맷, 예를 들어, 키메라 항체, 인간화된 항체, 인간 항체, 단쇄 항체, 이특이적 항체, 항체 중쇄, 항체 경쇄, 항체 중쇄 및/또는 경쇄의 동종이합체 및 이종이합체, 상기 중 임의의 것의 항원-결합 단편(예를 들어, Fv 단편(예를 들어, 단쇄 Fv (scFv), 이황화 결합된 Fv), Fab 단편, Fab' 단편, F(ab')2 단편), 단일 항체 가변 도메인(예를 들어, dAb, VH, VHH, VL), 및 상기 중 임의의 것의 변형된 형태(예를 들어, 폴리에틸렌 글리콜 또는 다른 적합한 중합체 또는 인간화된 VHH의 공유 부착에 의해 변형됨)가 당 분야에 공지되어 있다.
구 "면역글로불린 단일 가변 도메인"은 상이한 V 영역 또는 도메인과 독립적으로 항원 또는 에피토프에 특이적으로 결합하는 항체 가변 도메인(VH, VHH, VL)을 의미한다. 면역글로불린 단일 가변 도메인은 다른 가변 영역 또는 가변 도메인을 갖는 포맷(예를 들어, 동종중합체 또는 이종중합체)으로 제공될 수 있으며, 여기서 상기 다른 영역 또는 도메인은 단일 면역글로불린 가변 도메인에 의한 항원 결합에 필요하지 않다(즉, 면역글로불린 단일 가변 도메인은 추가 가변 도메인과는 독립적으로 항원에 결합함). "도메인 항체" 또는 "dAb"는 본원에서 사용되는 용어 "면역글로불린 단일 가변 도메인"과 동일하다. "단일 면역글로불린 가변 도메인"은 본원에서 사용되는 용어 "면역글로불린 단일 가변 도메인"과 동일하다. "단일 항체 가변 도메인" 또는 "항체 단일 가변 도메인"은 본원에서 사용되는 용어 "면역글로불린 단일 가변 도메인"과 동일하다. 면역글로불린 단일 가변 도메인은 일 구체예에서 인간 항체 가변 도메인이나, 이는 또한, 다른 종, 예를 들어, 설치류로부터의 단일 항체 가변 도메인(예를 들어, 전체내용이 참조로서 본원에 포함되는 WO00/29004호에 개시된 바와 같은 단일 항체 가변 도메인), 너스 상어(nurse shark) 및 카멜리드 VHH dAb를 포함한다. 카멜리드 VHH는 경쇄가 자연적으로 결여된 중쇄 항체를 생성하는 낙타, 라마, 알파카, 단봉낙타, 및 과나코를 포함하는 종으로부터 유래되는 면역글로불린 단일 가변 도메인 폴리펩티드이다. VHH는 인간화될 수 있다.
"도메인"은 단백질의 나머지와 독립적인 3차 구조를 갖는 폴딩된 단백질 구조이다. 일반적으로, 도메인은 단백질의 별개의 기능적 특성을 담당하며, 많은 경우에, 단백질 및/또는 도메인의 나머지의 기능의 손실 없이 첨가되거나, 제거되거나, 다른 단백질로 옮겨질 수 있다. "단일 항체 가변 도메인"은 항체 가변 도메인의 서열 특징을 포함하는 폴딩된 폴리펩티드 도메인이다. 따라서, 이는 완전한 항체 가변 도메인, 및, 예를 들어, 하나 이상의 루프가 항체 가변 도메인의 특징이 아닌 서열에 의해 대체된 변형된 가변 도메인, 또는 트렁케이션되거나 N-말단 신장 또는 C-말단 신장을 포함하는 항체 가변 도메인 뿐만 아니라 적어도 완전한 길이의 도메인의 결합 활성 및 특이성을 보유하는 가변 도메인의 폴딩된 단편을 포함한다.
"계통"은 동일한 "모(parental)" 클론으로부터 유래되는 일련의 면역글로불린 단일 가변 도메인을 의미한다. 예를 들어, 다수의 변이체 클론을 포함하는 계통이 다양화, 부위 특이적 돌연변이유발, 오류 유발(error prone) 또는 도핑(dopping)된 라이브러리의 생성에 의해 모 또는 시작 면역글로불린 단일 가변 도메인으로부터 생성될 수 있다. 적합하게는, 결합 분자는 친화성 성숙 과정에서 생성된다. 본 발명에서, PCT/EP2010/052008호 및 PCT/EP2010/052007호에 기재된 항-SA 면역글로불린 단일 가변 도메인인 "DOM7h-11"이 참조된다. DOM7h-11-15는 본원에 기재된 바와 같은 DOM7h-11 모 클론으로부터 유래된 DOM7h-11 계통 중 하나이다.
본 출원에서, 용어 "예방" 및 "예방하는"은 질병 또는 질환의 유도 전의 보호 조성물의 투여를 포함한다. "치료" 및 "치료하는"은 질병 또는 질환 증상이 나타난 후의 보호 조성물의 투여를 포함한다. "억제" 또는 "억제하는"은 유도 사건 후이지만 질병 또는 질환의 임상적 출현 전의 조성물의 투여를 의미한다.
본원에서 사용되는 용어 "용량"은 한번에 모두(단위 용량) 또는 규정된 시간 간격에 걸쳐 2회 이상의 투여로 피검체에 투여되는 리간드의 양을 의미한다. 예를 들어, 용량은 1일(24시간)(매일 용량), 2일, 1주, 2주, 3주 또는 1개월 이상의 과정에 걸쳐 피검체에 투여(예를 들어, 단일 투여 또는 2회 이상의 투여에 의함)되는 리간드(예를 들어, 표적 항원에 결합하는 면역글로불린 단일 가변 도메인을 포함하는 리간드)의 양을 의미할 수 있다. 투여 사이의 간격은 임의의 요망되는 시간의 양일 수 있다. 용량에 대해 언급되는 경우 용어 "약학적으로 효과적인"은 요망되는 효과를 제공하는 리간드, 도메인 또는 약학적 활성제의 충분한 양을 의미한다. "효과적인" 양은 개체의 연령 및 전반적 상태, 특정 약물 또는 약학적 활성제 등에 따라 피검체마다 다양할 것이다. 따라서, 모든 환자에게 적용가능한 정확한 "효과적인" 양을 상술하는 것이 항상 가능한 것은 아니다. 그러나, 임의의 개별적 환자에서의 적절한 "효과적인" 용량은 통상적인 실험을 이용하여 당업자에 의해 결정될 수 있다.
약동학 분석 방법 및 리간드(예를 들어, 단일 가변 도메인, 융합 단백질 또는 다중특이적 리간드) 반감기의 결정은 당업자에게 친숙할 것이다. 세부사항은 문헌[Kenneth , A et al: Chemical Stability of Pharmaceuticals: A Handbook for Pharmacists and in Peters et al, Pharmacokinetc analysis: A Practical Approach (1996)]에서 발견될 수 있다. t 알파 및 t 베타 반감기 및 곡선하영역(AUC)과 같은 약동학 파라미터를 기재하는 문헌["Pharmacokinetics", M Gibaldi & D Perron, published by Marcel Dekker, 2nd Rev. ex edition (1982)]가 또한 언급될 수 있다. 임의로, 본원에 인용된 모든 약동학 파라미터 및 값은 인간에서의 값인 것으로 판독되어야 한다. 임의로, 본원에 인용된 모든 약동학 파라미터 및 값은 마우스 또는 래트 또는 시노몰구스 원숭이에서의 값인 것으로 판독되어야 한다.
반감기(t½ 알파 및 t½ 베타) 및 AUC는 시간에 대한 리간드의 혈청 농도의 곡선으로부터 결정될 수 있다. WinNonlin 분석 패키지, 예를 들어, 버전 5.1(Pharsight Corp., Mountain View, CA94040, USA로부터 이용가능함)가, 예를 들어, 곡선을 모델링하기 위해 사용될 수 있다. 2-구획 모델링이 사용되는 경우, 첫번째 단계(알파 단계)에서, 리간드는 약간의 제거와 함께 주로 환자 내의 분포를 겪는다. 두번째 단계(베타 단계)는 리간드가 분포되고, 리간드가 환자로부터 청소됨에 따라 혈청 농도가 감소되는 단계이다. t 알파 반감기는 첫번째 단계의 반감기이고, t 베타 반감기는 두번째 단계의 반감기이다. 따라서, 일 구체예에서, 본 발명의 상황에서, 가변 도메인, 융합 단백질 또는 리간드는 15분(또는 약 15분) 또는 이 초과의 범위의 tα 반감기를 갖는다. 일 구체예에서, 상기 범위의 하한은 30분, 45분, 1시간, 2시간, 3시간, 4시간, 5시간, 6시간, 7시간, 10시간, 11시간 또는 12시간(또는 약 30분, 약 45분, 약 1시간, 약 2시간, 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 10시간, 약 11시간 또는 약 12시간)이다. 또한, 또는 대안적으로, 본 발명에 따른 가변 도메인, 융합 단백질 또는 리간드는 12시간(또는 약 12시간) 이하의 범위의 tα 반감기를 가질 것이다. 일 구체예에서, 상기 범위의 상한은 11, 10, 9, 8, 7, 6 또는 5시간(또는 약 11, 약 10, 약 9, 약 8, 약 7, 약 6 또는 약 5시간)이다. 적합한 범위의 예는 1 내지 6시간, 2 내지 5시간 또는 3 내지 4시간(또는 약 1 내지 약 6시간, 약 2 내지 약 5시간 또는 약 3 내지 약 4시간)이다.
일 구체예에서, 본 발명은 2.5시간(또는 약 2.5시간) 또는 그 초과의 범위의 tβ 반감기를 갖는 본 발명에 따른 가변 도메인, 융합 단백질 또는 리간드를 제공한다. 일 구체예에서, 상기 범위의 하한은 3시간, 4시간, 5시간, 6시간, 7시간, 10시간, 11시간, 또는 12시간(또는 약 3시간, 약 4시간, 약 5시간, 약 6시간, 약 7시간, 약 10시간, 약 11시간, 또는 약 12시간)이다. 또한, 또는 대안적으로, tβ 반감기는 21 또는 25일(또는 약 21 또는 약 25일) 이하이다. 일 구체예에서, 상기 범위의 상한은 12시간, 24시간, 2일, 3일, 5일, 10일, 15일, 19일, 20일, 21일 또는 22일(약 12시간, 약 24시간, 약 2일, 약 3일, 약 5일, 약 10일, 약 15일, 약 19일, 약 20일, 약 21일 또는 약 22일)이다. 예를 들어, 본 발명에 따른 가변 도메인, 융합 단백질 또는 리간드는 12 내지 60시간(또는 약 12 내지 약 60시간) 범위의 tβ 반감기를 가질 것이다. 한 추가 구체예에서, 이는 12 내지 48시간(또는 약 12 내지 약 48시간) 범위일 것이다. 한 추가 구체예에서, 이는 12 내지 26시간(또는 약 12 내지 약 26시간) 범위일 것이다.
2-구획 모델링을 이용하는 것에 대한 대안으로서, 당업자는 비-구획 모델링의 사용에 친숙할 것이며, 이는 말기 반감기(이와 관련하여, 본원에서 사용되는 용어 "말기 반감기"는 비-구획 모델링을 이용하여 결정된 말기 반감기를 의미함)를 결정하는데 사용될 수 있다. WinNonlin 분석 패키지, 예를 들어, 버전 5.1(Pharsight Corp., Mountain View, CA94040, USA로부터 이용가능함)이, 예를 들어, 상기 방식으로 곡선을 모델링하는데 이용될 수 있다. 이러한 예에서, 한 구체예에서, 단일 가변 도메인, 융합 단백질 또는 리간드는 적어도 8시간, 10시간, 12시간, 15시간, 28시간, 20시간, 1일, 2일, 3일, 7일, 14일, 15일, 16일, 17일, 18일, 19일, 20일, 21일, 22일, 23일, 24일 또는 25일(또는 적어도 약 8시간, 약 10시간, 약 12시간, 약 15시간, 약 28시간, 약 20시간, 약 1일, 약 2일, 약 3일, 약 7일, 약 14일, 약 15일, 약 16일, 약 17일, 약 18일, 약 19일, 약 20일, 약 21일, 약 22일, 약 23일, 약 24일 또는 약 25일)의 말단 반감기를 갖는다. 일 구체예에서, 상기 범위의 상한은 24시간, 48시간, 60시간 또는 72시간 또는 120시간(또는 약 24시간, 약 48시간, 약 60시간 또는 약 72시간 또는 약 120시간)이다. 예를 들어, 말단 반감기는, 예를 들어, 인간에서 8 시간 내지 60시간, 또는 8시간 내지 48시간 또는 12시간 내지 120시간(또는 약 8 시간 내지 약 60시간, 또는 약 8시간 내지 약 48시간 또는 약 12시간 내지 약 120시간)이다.
상기 기준에 더하여, 또는 상기 기준에 대안적으로, 본 발명에 따른 가변 도메인, 융합 단백질 또는 리간드는 1 mg.분/ml(또는 약 1 mg.분/ml) 또는 그 초과의 범위의 AUC 값(곡선하영역)을 갖는다. 일 구체예에서, 상기 범위의 하한은 5, 10, 15, 20, 30, 100, 200 또는 300 mg.분/ml(또는 약 5, 약 10, 약 15, 약 20, 약 30, 약 100, 약 200 또는 약 300 mg.분/ml)이다. 또한, 또는 대안적으로, 본 발명에 따른 가변 도메인, 융합 단백질 또는 리간드는 600 mg.분/ml(또는 약 600 mg.분/ml) 이하의 범위의 AUC를 갖는다. 일 구체예에서, 상기 범위의 상한은 500, 400, 300, 200, 150, 100, 75 또는 50 mg.분/ml(또는 약 500, 약 400, 약 300, 약 200, 약 150, 약 100, 약 75 또는 약 50 mg.분/ml)이다. 유리하게는, 가변 도메인, 융합 단백질 또는 리간드는 15 내지 150 mg.분/ml, 15 내지 100 mg.분/ml, 15 내지 75 mg.분/ml, 및 15 내지 50mg.분/ml으로 구성되는 군으로부터 선택된 범위(또는 이의 대략의 범위)의 AUC를 가질 것이다.
"표면 플라즈몬 공명": 특정 항원 또는 에피토프, 예를 들어, 인간 혈청 알부민이 본원에 기재된 혈청 알부민 결합 리간드, 예를 들어, 특이적 dAb에 대한 결합에 대해 또 다른 항원 또는 에피토프, 예를 들어, 시노몰구스 혈청 알부민과 경쟁하는지 결정하기 위해 경쟁 검정이 이용될 수 있다. 유사하게, 첫번째 리간드, 예를 들어, dAb가 표적 항원 또는 에피토프에 대한 결합에 대해 두번째 리간드, 예를 들어, dAb와 경쟁하는지 결정하기 위해 경쟁 검정이 이용될 수 있다. 본원에서 사용되는 용어 "경쟁하다"는 2개 이상의 분자 사이의 특이적 결합 상호작용을 어느 정도까지 방해할 수 있는 물질, 예를 들어, 분자, 화합물, 바람직하게는 단백질을 의미한다. 구 "경쟁적으로 억제하지 않는"은 2개 이상의 분자 사이의 특정 결합 상호작용을 임의의 측정가능하거나 유의한 정도까지 방해하지 않는 물질, 예를 들어, 분자, 화합물, 바람직하게는 단백질을 의미한다. 2개 이상의 분자 사이의 특정 결합 상호작용은 바람직하게는 단일 가변 도메인과 이의 인지체 파트너 또는 표적 사이의 특정 결합 상호작용을 포함한다. 방해 또는 경쟁 분자는 또 다른 단일 가변 도메인일 수 있거나, 이는 인지체 파트너 또는 표적과 구조적 및/또는 기능적으로 유사한 분자일 수 있다.
용어 "결합 모이어티"는 상이한 에피토프 또는 항원 결합 도메인과 독립적으로 항원 또는 에피토프에 특이적으로 결합하는 도메인을 의미한다. 결합 모이어티는 도메인 항체(dAb)일 수 있거나, 이는 자연 리간드가 아닌 리간드(본 발명의 경우, 모이어티는 혈청 알부민에 결합됨)에 결합하는 CTLA-4, 리포칼린(lipocalin), SpA, 애드넥틴(adnectin), 어피바디(affibody), 아비머(avimer), GroE1, 트랜스페린(transferrin), GroES 및 피브로넥틴(fibronectin)으로 구성된 군으로부터 선택된 스캐폴드와 같은 비-면역글로불린 단백질 스캐폴드의 유도체인 도메인일 수 있다. 단백질 스캐폴드의 예 및 레퍼토리로부터 항원 또는 에피토프-특이적 결합 도메인을 선택하기 위한 방법이 개시된 WO2008/096158호를 참조하라(실시예 17 내지 25 참조). WO2008/096158호의 상기 특정 개시는 본 발명과 함께 사용하기 위해 본원에 명백히 기재되는 것과 같이 참조로서 본원에 명백히 포함되고, 상기 개시의 임의의 부분이 본원의 하나 이상의 청구항에 포함될 수 있는 것이 고려된다.
일 양태에서, 본 발명은 DOM7h-11의 항-혈청 알부민(SA) 면역글로불린 단일 가변 도메인 변이체를 제공하며, 이러한 변이체는 DOM7h-11에 비해 위치 22, 42 또는 91(케이뱃에 따른 넘버링)에서 적어도 하나의 돌연변이를 포함한다. 일 구체예에서, 변이체는 DOM7h-11-15에 비해 위치 22, 42 또는 91(케이뱃에 따른 넘버링)에서 적어도 하나의 돌연변이를 포함한다. 적합하게는, 본 발명에 따른 변이체는 DOM7h-11 또는 DOM7h-11-15의 아미노산 서열에 비해 1, 2, 3 또는 8개 이하의 변화를 갖는다.
또 다른 양태에서, 본 발명은 DOM7h-11의 항-혈청 알부민(SA) 면역글로불린 단일 가변 도메인 변이체를 제공하며, 이러한 변이체는 DOM7h-11에 비해 프레임워크 영역 3(FW3)(아미노산 57-88) 또는 상보성 결정 영역 3(CDR3)(아미노산 89-97)에 적어도 하나의 돌연변이를 포함하고, 상기 변이체는 DOM7h-11의 아미노산 서열에 비해 1, 2, 3 또는 8개 이하의 변화를 갖는다. 일 구체예에서, 변이체는 DOM7h 11-15에 비해 상기 위치에서 적어도 하나의 돌연변이를 포함한다.
일 구체예에서, 상기 위치 중 임의의 위치에서의 돌연변이는 본원의 실시예 섹션에 예시된 바와 같은 잔기에 대한 돌연변이이다. 또 다른 구체예에서, 돌연변이는 예시된 잔기의 보존성 아미노산 치환이다.
보존성 아미노산 치환은 당업자에게 널리 공지되어 있고, 이는 하기 표에 의해 예시된다:
아미노산 치환
본래의 잔기 예시적 치환 바람직한 치환
Ala Val, Leu, Ile Val
Arg Lys, Gln, Asn Lys
Asn Gln Gln
Asp Glu Glu
Cys Ser, Ala Ser
Gln Asn Asn
Glu Asp Asp
Gly Pro, Ala Ala
His Asn, Gln, Lys, Arg Arg
Ile Leu, Val, Met, Ala, Phe, Leu
노르류신
Leu 노르류신, Ile, Val, Met, Ile
Ala, Phe
Lys Arg, 1,4 디아미노부티르산, Arg
Gln, Asn
Met Leu, Phe, Ile Leu
Phe Leu, Val, Ile, Ala, Tyr Leu
Pro Ala Gly
Ser Thr, Ala, Cys Thr
Thr Ser Ser
Trp Tyr, Phe Tyr
Tyr Trp, Phe, Thr, Ser Phe
Val Ile, Met, Leu, Phe, Ala, Leu
노르류신
보존성 아미노산 치환은 또한 비-자연 발생 아미노산 잔기, 예를 들어, 펩티도미메틱(peptidomimetic), 및 화학적 펩티드 합성에 의해 통합될 수 있는 아미노산 모이어티의 다른 역전되거나 반전된 형태와 관련될 수 있다.
열안정성 또는 열역학적 안정성은 상승된 온도에 대한 노출 후의 가역적(비가역적) 언폴딩(unfolding)에 저항하는 물질/단백질의 특성이다.
열안정성/열역학적 안정성의 측정은 시차주사열용량분석(DSC)을 이용하여 이루어질 수 있다. DSC는 샘플 및 참조의 온도를 증가시키는데 필요한 에너지 또는 열의 양에서의 차이가 온도의 함수로 측정되는 열분석 기술이다. 이는 단백질에서의 광범위한 열 전이를 연구하는데 이용될 수 있고, 용융 온도 및 열역학 파라미터를 결정하는데 유용하다. 간단히, 단백질은 180℃/시간(PBS 중 통상적으로 1mg/mL)의 일정한 속도로 가열되고, 열 변성과 관련된 검출가능한 열용량 변화가 측정된다. 단백질의 50%가 이의 자연 형태로 존재하고, 나머지 50%가 변성되는 온도로 기재되는 전이 중간점(Tm)이 결정된다. 여기서, DSC는 시험된 대부분의 단백질이 완전히 재폴딩되지 않음에 따라 겉보기 전이 중간점(appTm)을 결정한다. Tm 또는 appTm이 높을수록, 분자는 더욱 안정적이다. Tm 값을 생성시키기 위해 소프트웨어 패키지, 예를 들어, OriginR v7.0383(Origin Lab)이 이용될 수 있다.
본 발명의 일 구체예에서, 개선된 열안정성은 모 분자에 비해 증가되거나 높은 Tm을 의미한다. 적합하게는, 모 분자는 DOM7h-11 또는 DOM7h-11-15이다. 적합하게는, "개선된" 열안정성은 모 분자의 Tm 값보다 높은 Tm 값을 의미한다. 적합하게는, "개선된 열안정성"은 적어도 54℃ 또는 적어도 55℃를 의미한다. 일 구체예에서, "개선된 열안정성"은 적어도 57℃를 의미한다. 또 다른 구체예에서, "개선된 열안정성"은 55℃ 초과 또는 57℃ 초과를 의미한다. 적합하게는, Tm은 본원에 기재된 바와 같은 DSC를 이용하여 측정된다.
면역글로불린 단일 가변 도메인에서의 개선된 열안정성은 면역글로불린 단일 가변 도메인 또는 단백질의 향상된 안정성을 제공함에 따라 바람직하다. 중요하게는, 향상된 열안정성은 단백질이 발달할 가능성의 척도를 제공하며, 개선된 면역글로불린 단일 가변 도메인을 포함하는 생성물은 생성 과정 전체에 걸친 우수한 안정성 및/또는 적합한 안정성/저장 수명을 가질 것이다. 개선된 열안정성 및 이를 측정하기 위한 예시적 방법, 예를 들어, 원형 2색성 분광법(circular dichroism spectroscopy)이, 예를 들어, 문헌[van der Sloot et al. Protein Engineering, Design and Selection, 2004, vol.17, no. 9, p.673-680 and Demarest et al. J. Mol. Biol. 2004, 335, 41-48]에 기재되어 있다.
개선되거나 높은 열안정성에 대한 분자 기초는 열안정적이지 않거나 덜 열안정적인 변이체에서 발견되는 것보다 높은 특정 수의 분자내 수소 상호작용 및 이온성 상호작용일 수 있다.
개선된 열안정성을 갖는 것으로 제시된 면역글로불린 단일 가변 도메인은 또한 직접적 결과로서 숙주 세포 발현 시스템으로부터 보다 높은 최초 발현 수율을 발생시킬 수 있다. 이는 이후에 낮은 수준의 미스폴딩 및/또는 번역 또는 막운반 동안의 보다 빠른 폴딩의 동역학을 초래할 수 있는 보다 높은 수의 분자내 상호작용이 존재하는 것으로부터 개선된 열안정성이 발생할 수 있기 때문이다.
또한, 단백질, 예를 들어, 개선된 열안정성을 갖는 면역글로불린 단일 가변 도메인은, 이러한 단백질이 보다 낮은 열안정성을 갖는 면역글로불린 단일 가변 도메인과 비교하는 경우에 증가된 온도 및 압력 뿐만 아니라 극한의 pH 및 염 농도와 같은 다운스트림 과정에 대해 더욱 내성이 될 가능성이 높음에 따라 보다 나은 전반적 발달가능성(developability)을 나타낼 수 있다.
일 구체예에서, 이중 또는 다중 특이적 조성물 또는 융합 폴리펩티드를 생성시키기 위해 본 발명에 따른 면역글로불린 단일 가변 도메인이 사용될 수 있다. 따라서, 본 발명에 따른 면역글로불린 단일 가변 도메인은 보다 큰 작제물에서 사용될 수 있다. 적합한 작제물은 항-SA 면역글로불린 단일 가변 도메인(dAb)과 모노클로날 항체, NCE, 단백질 또는 폴리펩티드 등 사이에 융합 단백질을 포함한다. 따라서, 본 발명에 따른 항-SA 면역글로불린 단일 가변 도메인은 다중특이적 분자, 예를 들어, 이중특이적 분자, 예를 들어, dAb-dAb(즉, 하나가 항-SA dAb인 2개의 연결된 면역글로불린 단일 가변 도메인), mAb-dAb 또는 폴리펩티드-dAb 작제물을 작제하는데 사용될 수 있다. 이러한 작제물에서, 항-SA dAb(AlbudAb™) 성분은 혈청 알부민(SA)에 대한 결합을 통해 반감기 연장을 제공한다. 적합한 mAb-dAb 및 이러한 작제물을 생성시키는 방법은, 예를 들어, WO2009/068649호에 기재되어 있다.
향상되거나, 개선되거나, 증가된 열안정성을 갖는 항-SA 면역글로불린 단일 가변 도메인을 선택하는 것은, 단일 분자가 이중특이적 작제물에 연결된 후에 이러한 단일 분자가 열안정성 특성을 손실할 수 있음에 따라, 융합 단백질로 제조되어야 하는 분자에 대한 시작점으로서 바람직할 수 있다. 따라서, 보다 높은 열안정성을 갖는 모이어티를 이용하여 시작하는 것은, 열안정성에서의 임의의 손실이 고려되어, 이중 (또는 다중) 특이적 작제물이 생성된 후에 전반적으로 유용한 열안정성이 유지되도록 하는 것을 가능케 할 것이다.
일 구체예에서, 변이체는 하기 동역학 특징 중 하나 이상을 포함한다:
(a) 변이체는 표면 플라즈몬 공명에 의해 결정시 0.1(또는 약 0.1) 내지 10000 nM(또는 약 10000 nM), 임의로 1(또는 약 1) 내지 6000 nM(또는 약 6000 nM)의 해리상수(KD)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(b) 변이체는 표면 플라즈몬 공명에 의해 결정시 1.5 x 10-4(또는 약 1.5 x 10-4) 내지 0.1 초-1(또는 약 0.1 초-1), 임의로 3 x 10-4(또는 약 3 x 10-4) 내지 0.1 초-1(또는 0.1 초-1)의 분리속도 상수(Kd)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(c) 변이체는 표면 플라즈몬 공명에 의해 결정시 2 x 106(또는 약 2 x 106) 내지 1 x 104 M-1초-1(또는 약 1 x 104 M-1초-1), 임의로 1 x 106(또는 약 1 x 106) 내지 2 x 104 M-1초-1(또는 2 x 104 M-1초-1)의 결합속도 상수(Ka)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(d) 변이체는 표면 플라즈몬 공명에 의해 결정시 0.1(또는 약 0.1) 내지 10000 nM(또는 약 10000 nM), 임의로 1(또는 약 1) 내지 6000 nM(또는 약 6000 nM)의 해리상수(KD)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(e) 변이체는 표면 플라즈몬 공명에 의해 결정시 1.5 x 10-4(또는 약 1.5 x 10-4) 내지 0.1 초-1(또는 약 0.1 초-1), 임의로 3 x 10-4(또는 약 3 x 10-4) 내지 0.1 초-1(또는 약 0.1 초-1)의 분리속도 상수(Kd)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(f) 변이체는 표면 플라즈몬 공명에 의해 결정시 2 x 106(또는 2 x 106) 내지 1 x 104 M-1초-1(또는 약 1 x 104 M-1초-1), 임의로 1 x 106(또는 약 1 x 106) 내지 5 x 103 M-1초-1(또는 약 5 x 103 M-1초-1)의 결합속도 상수(Ka)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(g) 변이체는 표면 플라즈몬 공명에 의해 결정시 1(또는 약 1) 내지 10000 nM(또는 약 10000 nM), 임의로 20(또는 약 20) 내지 6000 nM(또는 약 6000 nM)의 해리상수(KD)로 래트 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(h) 변이체는 표면 플라즈몬 공명에 의해 결정시 2 x 10-3(또는 약 2 x 10-3) 내지 0.15 초-1(또는 약 0.15 초-1), 임의로 9 x 10-3(또는 약 9 x 10-3) 내지 0.14 초-1(또는 약 0.14 초-1)의 분리속도 상수(Kd)로 래트 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(i) 변이체는 표면 플라즈몬 공명에 의해 결정시 2 x 106(또는 약 2 x 106) 내지 1 x 104 M-1초-1(또는 약 1 x 104 M-1초-1), 임의로 1 x 106(또는 약 1 x 106) 내지 3 x 104 M-1초-1(또는 약 3 x 104 M-1초-1)의 결합속도 상수(Ka)로 래트 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(j) 변이체는 표면 플라즈몬 공명에 의해 결정시 1(또는 약 1) 내지 10000 nM(또는 약 10000 nM)의 해리상수(KD)로 마우스 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(k) 변이체는 표면 플라즈몬 공명에 의해 결정시 2 x 10-3(또는 약 2 x 10-3) 내지 0.15 초-1(또는 약 0.15 초-1)의 분리속도 상수(Kd)로 마우스 SA에 특이적으로 결합하는 결합 부위를 포함하고/하거나;
(l) 변이체는 표면 플라즈몬 공명에 의해 결정시 2 x 106(또는 약 2 x 106) 내지 1 x 104 M-1초-1(또는 약 1 x 104 M-1초-1), 임의로 2 x 106(또는 약 2 x 106) 내지 1.5 x 104 M-1초-1(또는 약 1.5 x 104 M-1초-1)의 결합속도 상수(Ka)로 마우스 SA에 특이적으로 결합하는 결합 부위를 포함한다.
임의로, 변이체는 하기를 갖는다:
I: (a) 및 (d)에 따른 KD, (b) 및 (e)에 따른 Kd, 및 (c) 및 (f)에 따른 Ka; 또는
II: (a) 및 (g)에 따른 KD, (b) 및 (h)에 따른 Kd, 및 (c) 및 (i)에 따른 Ka; 또는
III: (a) 및 (j)에 따른 KD, (b) 및 (k)에 따른 Kd, 및 (c) 및 (l)에 따른 Ka; 또는
IV: I 및 II에 따른 동역학; 또는
V: I 및 III에 따른 동역학; 또는
VI: I, II 및 III에 따른 동역학.
본 발명은 또한 본 발명의 상기 임의의 양태 또는 구체예의 변이체를 포함하는 리간드를 제공한다. 예를 들어, 리간드는 이중 특이적 리간드(이중 특이적 리간드의 예에 대해 WO04003019호 참조)일 수 있다. 일 양태에서, 본 발명은 본 발명의 상기 임의의 양태 또는 구체예의 항-SA 변이체 및 SA가 아닌 표적 항원에 특이적으로 결합하는 결합 모이어티를 포함하는 다중특이적 리간드를 제공한다. 결합 모이어티는 표적에 특이적으로 결합하는 임의의 결합 모이어티일 수 있으며, 예를 들어, 모이어티는 항체, 항체 단편, scFv, Fab, dAb 또는 비-면역글로불린 단백질 스캐폴드를 포함하는 결합 모이어티이다. 이러한 모이어티는 WO2008/096158호(개시내용이 참조로서 본원에 포함되는 실시예 17 내지 25 참조)에 상세히 개시되어 있다. 비-면역글로불린 스캐폴드의 예는 CTLA-4, 리포칼린, 스태필로코쿠스 단백질 A(spA), 어피바디™, 아비머™, 애드넥틴, GroEL 및 피브로넥틴이다.
일 구체예에서, 항-표적 결합 모이어티와 항-SA 단일 변이체 사이에 링커가 제공되며, 이러한 링커는 아미노산 서열 AST, 임의로 ASTSGPS를 포함한다. 대안적 링커는 WO2007085814호(참조로서 본원에 포함됨) 및 WO2008/096158호(페이지 135의 12행 내지 페이지 140의 14행 참조, 이의 개시내용 및 링커의 모든 서열은 본 발명과 함께 사용하기 위해 본원에 명백히 기재되는 것과 같이 참조로서 본원에 명백히 포함되고, 상기 개시의 임의의 부분이 본원의 하나 이상의 청구항에 포함될 수 있는 것이 고려된다)에 기재되어 있다.
다중특이적 리간드의 일 구체예에서, 표적 항원은 자연 발생이거나 합성일 수 있는 폴리펩티드, 단백질 또는 핵산일 수 있거나, 이의 일부일 수 있다. 이러한 양태에서, 본 발명의 리간드는 표적 항원에 결합할 수 있고, 길항제 또는 효능제(예를 들어, EPO 수용체 효능제)로 작용한다. 당업자는 선택의 폭이 크고 다양한 것을 인지할 것이다. 이는, 예를 들어, 인간 또는 동물 단백질, 사이토카인, 사이토카인 수용체일 수 있고, 상기 사이토카인 수용체는 사이토카인, 효소, 효소 또는 DNA 결합 단백질에 대한 보조인자에 대한 수용체를 포함한다. 적합한 사이토카인 및 성장인자는 ApoE, Apo-SAA, BDNF, 카디오트로핀-1(Cardiotrophin-1), EGF, EGF 수용체, ENA-78, 에오탁신(Eotaxin), 에오탁신-2, 엑소두스-2(Exodus-2), EpoR, FGF-산성(acidic), FGF-염기성(basic), 섬유모세포 성장 인자-10, FLT3 리간드, 프랙탈카인(Fractalkine)(CX3C), GDNF, G-CSF, GM-CSF, GF-β1, 인슐린, IFN-γ, IGF-I, IGF-II, IL-1α, IL-1β, IL-2, IL-3, IL-4, IL-5, IL-6, IL-7, IL-8(72 a.a.), IL-8(77 a.a.), IL-9, IL-10, IL-11, IL-12, IL-13, IL-15, IL-16, IL-17, IL-18(IGIF), 인히빈 α(Inhibin α), 인히빈 β, IP-10, 각질세포 성장인자-2(KGF-2), KGF, 렙틴(Leptin), LIF, 림포탁틴(Lymphotactin), 뮐러관 억제물질(Mullerian inhibitory substance), 단핵구 집락 억제 인자, 단핵구 유인물질 단백질, M-CSF, MDC(67 a.a.), MDC(69 a.a.), MCP-1(MCAF), MCP-2, MCP-3, MCP-4, MDC(67 a.a.), MDC(69 a.a.), MIG, MIP-1α, MIP-1β, MIP-3α, MIP-3β, MIP-4, 골수모양 프로제니터 억제 인자-1(MPIF-1), NAP-2, 뉴투린(Neurturin), 신경 성장인자, β-NGF, NT-3, NT-4, 온코스타틴 M(Oncostatin M), PDGF-AA, PDGF-AB, PDGF-BB, PF-4, RANTES, SDF1α, SDF1β, SCF, SCGF, 줄기세포 인자(SCF), TARC, TGF-α, TGF-β, TGF-β2, TGF-β3, 종양 괴사인자(TNF), TNF-α, TNF-β, TNF 수용체 I, TNF 수용체 II, TNIL-1, TPO, VEGF, VEGF 수용체 1, VEGF 수용체 2, VEGF 수용체 3, GCP-2, GRO/MGSA, GRO-β, GRO-γ, HCC1, 1-309, HER 1, HER 2, HER 3 및 HER 4, CD4, 인간 케모카인 수용체 CXCR4 또는 CCR5, C형 간염 바이러스로부터의 비-구조 단백질 유형 3(NS3), TNF-알파, IgE, IFN-감마, MMP-12, CEA, H. 파이로리(H. pylori), TB, 인플루엔자, E형 간염, MMP-12, 특정 세포에서 과다발현되는 내재화 수용체, 예를 들어, 표피성장인자 수용체(EGFR), 종양 세포 상의 ErBb2 수용체, 내재화 세포 수용체, LDL 수용체, FGF2 수용체, ErbB2 수용체, 트랜스페린 수용체, PDGF 수용체, VEGF 수용체, PsmAr, 세포외 기질 단백질, 엘라스틴(elastin), 피브로넥틴(fibronectin), 라미닌(laminin), α1-항트립신, 조직 인자 프로테아제 억제제, PDK1, GSK1, Bad, 카스파제-9(caspase-9), Forkhead, 헬리코박터 파이로리(Helicobacter pylori)의 항원, 미코박테리움 튜버쿨로시스(Mycobacterium tuberculosis)의 항원, 및 인플루엔자 바이러스의 항원을 포함하나, 바람직하게는 이에 제한되지 않는다. 상기 목록은 총망라된 것이 아님이 인지될 것이다.
일 구체예에서, 다중특이적 리간드는 본 발명의 항-SA dAb 변이체 및 항-TNFR1 결합 모이어티, 예를 들어, 항-TNFR1 dAb를 포함한다. 임의로, 리간드는 수용체 가교의 기회를 감소시키기 위해 단지 하나의 항-TNFR1 결합 모이어티(예를 들어, dAb)를 갖는다.
일 구체예에서, 항-TNFR1 결합 모이어티는 WO2008149148호에 개시된 DOM1h-131-206이다(이러한 PCT 출원에 개시된 바와 같은 아미노산 서열 및 누클레오티드 서열은 본 발명과 함께 사용하기 위해 본원에 명백히 기재되는 것과 같이 참조로서 본원에 명백히 포함되고, 상기 개시의 임의의 부분이 본원의 하나 이상의 청구항에 포함될 수 있는 것이 고려된다).
일 구체예에서, 항-TNFR1 결합 모이어티 또는 dAb는 공동 계류 중인 출원 PCT/EP2010/052005호에 개시된 임의의 상기 모이어티 또는 dAb이며, 상기 출원의 개시내용은 참조로서 본원에 포함된다. 일 구체예에서, 항-TNFR1 결합 모이어티는 DOM1h-574-156, DOM1h-574-72, DOM1h-574-109, DOM1h-574-138, DOM1h-574-162 또는 DOM1h-574-180의 아미노산 서열과 적어도 95% 동일한 아미노산 서열, 또는 표 3에 개시된 임의의 항-TNFR1 dAb의 아미노산 서열을 포함한다.
일 구체예에서, 본 발명의 리간드는 하나 이상의 폴리펩티드에 직접적 또는 간접적으로 융합된 본 발명의 변이체를 포함하는 융합 단백질이다. 예를 들어, 융합 단백질은 WO2005/118642호(이의 개시내용은 참조로서 본원에 포함됨)에 개시된 바와 같은 "약물 융합체"일 수 있으며, 이는 본 발명의 변이체 및 상기 PCT 출원에 정의된 바와 같은 폴리펩티드 약물을 포함한다.
본원에서 사용되는 바와 같은 "약물"은 개체의 생물학적 표적 분자에 대한 결합을 통해 유리하거나, 치료적이거나, 진단적인 효과를 발생시키고/시키거나 개체의 생물학적 표적 분자의 기능을 변경시키기 위해 개체에 투여될 수 있는 임의의 화합물(예를 들어, 작은 유기 분자, 핵산, 폴리펩티드)을 의미한다. 표적 분자는 개체의 유전체에 의해 엔코딩되는 내인성 표적 분자(예를 들어, 개체의 유전체에 의해 엔코딩되는 효소, 수용체, 성장인자, 사이토카인) 또는 병원체의 유전체에 의해 엔코딩되는 외인성 표적 분자(예를 들어, 바이러스, 박테리아, 진균, 선충 또는 다른 병원체의 유전체에 의해 엔코딩되는 효소)일 수 있다. 본 발명의 항-SA dAb 변이체를 포함하는 융합 단백질 및 컨쥬게이트에서 사용하기에 적합한 약물은 WO2005/118642호 및 WO2006/059106호에 개시되어 있다(상기 출원의 전체 개시내용은 참조로서 본원에 포함되고, 이러한 출원의 특정 약물의 전체 목록은 이러한 목록이 본원에 명백히 기재되는 것과 같이 포함되며, 상기 포함이 본원의 청구항 내의 포함을 위해 특정 약물의 개시내용을 제공하는 것이 고려된다). 예를 들어, 약물은 글루카곤-유사 펩티드 1(GLP-1) 또는 변이체, 인터페론 알파 2b 또는 변이체 또는 엑센딘-4(exendin-4) 또는 변이체일 수 있다.
일 구체예에서, 본 발명은 WO2005/118642호 및 WO2006/059106호에 정의되고 개시된 약물 컨쥬게이트를 제공하며, 이러한 컨쥬게이트는 본 발명의 변이체를 포함한다. 일 예에서, 약물이 상기 변이체에 공유적으로 연결된다(예를 들어, 변이체 및 약물은 단일 폴리펩티드의 부분으로 발현된다). 대안적으로, 일 예에서, 약물은 변이체에 비공유적으로 결합되거나 회합된다. 약물은 직접 또는 간접적으로 변이체에 공유적 또는 비공유적으로 결합(예를 들어, 적합한 링커 및/또는 상보적 결합 파트너(예를 들어, 비오틴 및 아비딘)의 비공유적 결합을 통함)될 수 있다. 상보적 결합 파트너가 이용되는 경우, 결합 파트너 중 하나는 직접적 또는 적합한 링커 모이어티를 통해 약물에 공유적으로 결합될 수 있고, 상보적 결합 파트너는 직접적 또는 적합한 링커 모이어티를 통해 변이체에 공유적으로 결합될 수 있다. 약물이 폴리펩티드 또는 펩티드인 경우, 약물 조성물은 융합 단백질일 수 있고, 상기 폴리펩티드 또는 펩티드, 약물 및 폴리펩티드 결합 모이어티는 연속적 폴리펩티드 사슬의 별개의 부분(모이어티)이다. 본원에 기재된 바와 같은 폴리펩티드 결합 모이어티 및 폴리펩티드 약물 모이어티는 펩티드 결합을 통해 서로 직접 결합될 수 있거나, 적합한 아미노산, 또는 펩티드 또는 폴리펩티드 링커를 통해 연결될 수 있다.
혈청 알부민에 특이적으로 결합하는 본 발명의 하나의 단일한 가변 도메인(단량체) 변이체 또는 하나 이상의 단일한 가변 도메인(본원에 정의된 바와 같은 다합체, 융합 단백질, 컨쥬게이트, 및 이중 특이적 리간드)을 함유하는 리간드는 표지, 태그, 추가 단일 가변 도메인, dAb, 항체, 항체 단편, 마커 및 약물로부터 선택되나 바람직하게는 이에 제한되지는 않는 하나 이상의 존재물(entity)을 추가로 포함할 수 있다. 상기 존재물 중 하나 이상은 단일 가변 도메인(면역글로불린 또는 비-면역글로불린 단일 가변 도메인)을 포함하는 리간드의 COOH 말단 또는 N 말단 또는 N 말단과 COOH 말단 둘 모두에 위치될 수 있다. 상기 존재물 중 하나 이상은 하나의 단일 가변 도메인(단량체) 또는 하나 이상의 단일 가변 도메인(본원에 정의된 바와 같은 다합체, 융합 단백질, 컨쥬게이트, 및 이중 특이적 리간드)을 함유하는 리간드의 혈청 알부민에 특이적으로 결합하는 단일 가변 도메인의 COOH 말단, 또는 N 말단, 또는 N 말단과 COOH 말단 둘 모두에 위치될 수 있다. 상기 말단 중 하나 또는 둘 모두에 위치될 수 있는 태그의 비제한적 예는 HA, his 또는 myc 태그를 포함한다. 하나 이상의 태그, 표지 및 약물을 포함하는 존재물은 직접적 또는 상기 기재된 바와 같은 링커를 통해 혈청 알부민에 결합하는 하나의 단일 가변 도메인(단량체) 또는 하나 이상의 단일 가변 도메인(본원에 정의된 바와 같은 다합체, 융합 단백질, 컨쥬게이트, 및 이중 특이적 리간드)을 함유하는 리간드에 결합될 수 있다.
본 발명의 양태는 융합 생성물, 예를 들어, 본 발명에 따른 상기 기재된 바와 같은 임의의 변이체에 융합되거나 컨쥬게이션(NCE에 대해)된 폴리펩티드 약물을 포함하는 펩티드와의 융합 단백질 또는 융합체 또는 NCE(신규 화합물) 약물과의 컨쥬게이트를 제공한다.
본 발명은 본 발명의 임의의 양태의 변이체, 융합 단백질, 컨쥬게이트 또는 리간드 및 약학적으로 허용되는 희석제, 담체, 부형제 또는 비히클을 포함하는 조성물을 제공한다.
본원에 기재된 변이체, 융합 단백질, 컨쥬게이트 또는 리간드, 예를 들어, 혈청 알부민에 특이적으로 결합하거나, 인간 혈청 알부민 및 적어도 하나의 비-인간 혈청 알부민 둘 모두에 특이적으로 결합하는 본 발명의 하나의 단일 가변 도메인(단량체) 변이체 또는 하나 이상의 단일 가변 도메인(예를 들어, 본원에 정의된 바와 같은 다합체, 융합 단백질, 컨쥬게이트, 및 이중 특이적 리간드) 변이체를 함유하는 리간드 또는 이의 기능적으로 활성인 단편 중 임의의 것을 엔코딩하는 분리된 핵산이 본원에 또한 포함된다. 벡터 및/또는 발현 벡터, 벡터를 포함하는 숙주 세포, 예를 들어, 벡터로 형질전환된 식물 또는 동물 세포 및/또는 세포주, 일부 예에서 하나 이상의 변이체, 융합 단백질 또는 리간드 또는 이의 단편이 발현되도록 숙주 세포를 배양하고, 임의로, 숙주 세포 배양 배지로부터 혈청 알부민에 특이적으로 결합하는 하나의 단일 가변 도메인(단량체) 또는 하나 이상의 단일 가변 도메인(예를 들어, 본원에 정의된 바와 같은 다합체, 융합 단백질, 컨쥬게이트, 및 이중 특이적 리간드)을 함유하는 리간드를 회수하는 것을 포함하는, 혈청 알부민에 특이적으로 결합하는 하나의 단일 가변 도메인(단량체) 변이체 또는 하나 이상의 단일 가변 도메인 변이체(예를 들어, 본원에 정의된 바와 같은 다합체, 융합 단백질, 컨쥬게이트, 및 이중 특이적 리간드)를 함유하는 상기 벡터에 의해 엔코딩되는 하나 이상의 변이체, 융합 단백질 또는 리간드 또는 이의 단편(들)을 발현시키고/시키거나 생성시키는 방법이 본원에 또한 포함된다. 본원에 기재된 리간드와, 혈청 알부민 및/또는 비-인간 혈청 알부민(들)을 포함하는 혈청 알부민, 및/또는 혈청 알부민이 아닌 하나 이상의 표적을 접촉시키는 방법으로서, 상기 표적이 생물학적으로 활성인 분자, 동물 단백질, 상기 나열된 바와 같은 사이토카인을 포함하고, 접촉이 시험관내에서 이루어질 뿐만 아니라 본원에 기재된 변이체, 융합 단백질 또는 리간드 중 임의의 것을 생체내 및/또는 생체외에서 개별적 숙주 동물 또는 세포에 투여하는 것을 포함하는 방법이 또한 포함된다. 바람직하게는, 혈청 알부민 및/또는 비-인간 혈청 알부민(들)에 특이적인 단일 가변 도메인(면역글로불린 또는 비-면역글로불린), 및 혈청 알부민이 아닌 하나 이상의 표적에 특이적인 하나 이상의 도메인을 포함하는 본원에 기재된 리간드를 투여하는 것은 항-표적 리간드의 T 베타 및/또는 말단 반감기를 포함하는 반감기를 증가시킬 것이다. 변이체, 융합 단백질 또는 리간드 또는 이의 단편을 함유하는 단일 도메인, 예를 들어, 이의 기능성 단편을 엔코딩하는 핵산 분자가 본원에서 고려된다. 발현 벡터를 포함하나, 바람직하게는 이에 제한되지는 않는 핵산 분자를 엔코딩하는 벡터, 및 상기 발현 벡터 중 하나 이상을 함유하는 세포주 또는 유기체로부터의 숙주 세포가 또한 본원에서 고려된다. 상기 언급된 핵산, 벡터 및 숙주 세포 중 임의의 것을 포함하나 바람직하게는 이에 제한되지는 않는 임의의 변이체, 융합 단백질 또는 리간드를 생성시키는 방법이 또한 고려된다.
본 발명의 양태는 본 발명에 따른 변이체 또는 본 발명의 다중특이적 리간드 또는 본 발명의 융합 단백질을 엔코딩하는 누클레오티드 서열을 포함하는 핵산을 제공한다.
본 발명의 일 양태는 DOM7h-11-56, DOM7h-11-57, DOM7h-11-65, DOM7h-11-67, DOM7h-11-68, DOM7h-11-69, DOM7h-11-79 및 DOM7h-11-80으로부터 선택된 DOM7h-11 변이체의 누클레오티드 서열, 또는 상기 선택된 서열과 적어도 70, 75, 80, 85, 90, 95, 96, 97, 98 또는 99% 동일한 누클레오티드 서열을 포함하는 핵산을 제공한다.
본 발명의 일 양태는 본 발명의 핵산을 포함하는 벡터를 제공한다. 본 발명의 일 양태는 상기 벡터를 포함하는 분리된 숙주 세포를 제공한다.
라이브러리 벡터 시스템, 단일 가변 도메인의 조합, 이중 특이적 리간드의 특징, 이중 특이적 리간드의 구조, 이중 특이적 리간드를 작제하는데 사용하기 위한 스캐폴드, 항-혈청 알부민 dAb 및 다중특이적 리간드 및 반감기 향상 리간드의 용도, 및 항-혈청 알부민 dAb를 포함하는 조성물 및 제형의 세부사항에 대해서는 WO2008/096158호를 참조하라. 상기 개시는 본 발명의 변이체, 리간드, 융합 단백질, 컨쥬게이트, 핵산, 벡터, 숙주 및 조성물에 대한 것을 포함하는 본 발명과 함께 사용하기 위한 지침을 제공하기 위해 참조로서 본원에 포함된다.
본 발명은 DOM7h-11 변이체를 참조로 하여 기재되었으나, 다른 항-SA 면역글로불린 단일 가변 도메인 계통으로의 유사한 돌연변이가 예견될 수 있음이 인지될 것이다.
서열
표 1: DOM7h-11 변이체 dAb의 아미노산 서열


표 2:
DOM7h
-11
변이체
dAb
의
누클레오티드
서열


표 3: 항-TNFR1 dAb의 아미노산 서열

















표 4: 항-
TNFR1
dAb
의
누클레오티드
서열






























표 5: 항-혈청 알부민
dAb
(
DOM7h
)
융합체
(래트 연구에서 사용됨):-
DOM7h
-14/
엑센딘
-4
융합체
DMS
번호 7138
아미노산 서열(SEQ ID NO:307)
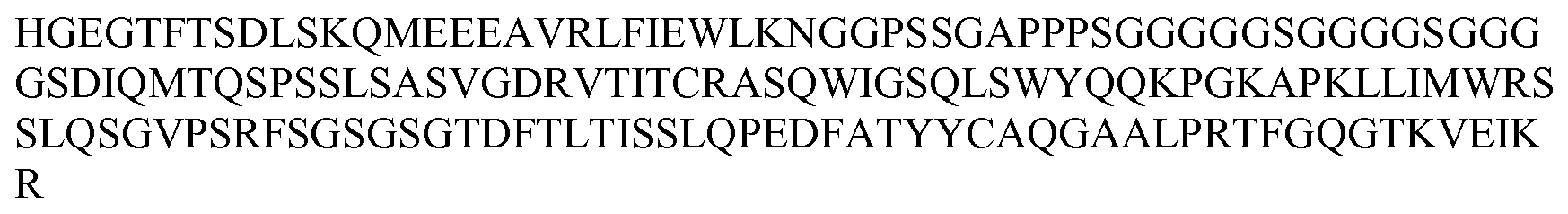
누클레오티드 서열(SEQ ID NO:308)
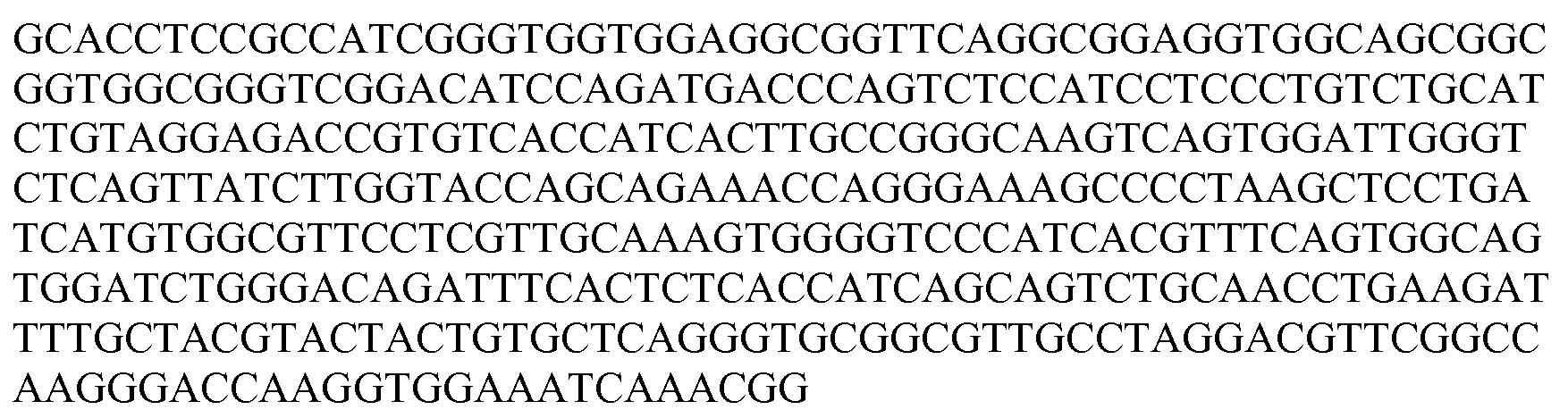
DOM7h
-14-10/
엑센딘
-4
융합체
DMS
번호 7139
아미노산 서열(SEQ ID NO:309)

누클레오티드 서열(SEQ ID NO:310)

DOM7h
-14-18/
엑센딘
-4
융합체
DMS
번호 7140
아미노산 서열(SEQ ID NO:311)

누클레오티드 서열(SEQ ID NO:312)

DOM7h
-14-19/
엑센딘
-4
융합체
DMS
번호 7141
아미노산 서열(SEQ ID NO:313)
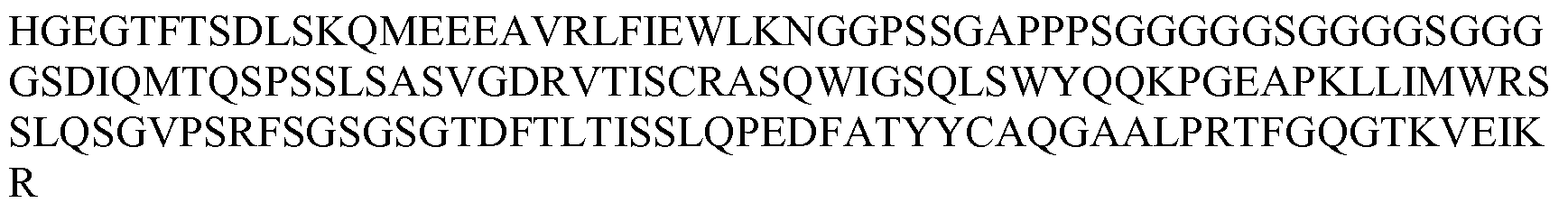
누클레오티드 서열(SEQ ID NO:314)

DOM7h
-11/
엑센딘
-4
융합체
DMS
번호 7142
아미노산 서열(SEQ ID NO:315)

누클레오티드 서열(SEQ ID NO:316)

DOM7h
-11-12/
엑센딘
-4
융합체
DMS
번호 7147
아미노산 서열(SEQ ID NO:317)

누클레오티드 서열(SEQ ID NO:318)

DOM7h
-11-15/
엑센딘
-4
융합체
DMS
번호 7143
아미노산 서열(SEQ ID NO:319)

누클레오티드 서열(SEQ ID NO:320)


DOM7h14
-10/
G4SC
-
NCE
융합체
DOM7h14-10/G4SC를 엔코딩하는 아미노산 서열(SEQ ID NO:321)
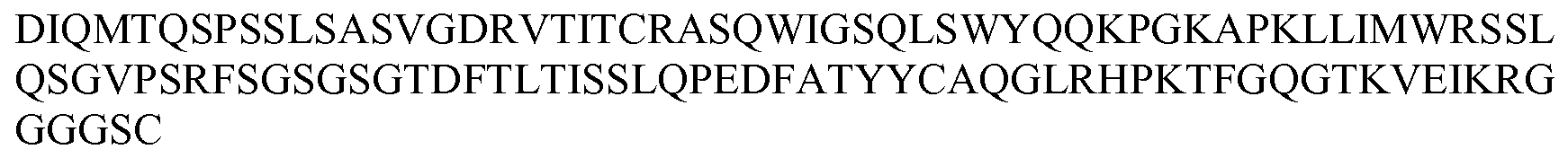
C-말단 시스테인은, 예를 들어, 말레이미드 결합을 이용하여 신규 화합물(약학적 화합물, NCE)에 연결될 수 있다.
DOM7h14-10/G4SC를 엔코딩하는 누클레오티드 서열(SEQ ID NO:322)

DOM7h14
-10/
TVAAPSC
융합체
아미노산 서열(SEQ ID NO:323)

C-말단 시스테인은, 예를 들어, 말레이미드 결합을 이용하여 신규 화합물(약학적 화합물, NCE)에 연결될 수 있다.
누클레오티드 서열(SEQ ID NO:324)

(마우스 연구에서 사용됨):-
DOM7h
-11/
DOM1m
-21-23
융합체
DMS
번호 5515
아미노산 서열(SEQ ID NO:325)

아미노산 + 누클레오티드 + myc 태그 서열(SEQ ID NO:326)

누클레오티드 서열(SEQ ID NO:327)

누클레오티드 + myc 태그 서열(SEQ ID NO:328)

DOM7h
-11-12/
DOM1m
-21-23
융합체
DMS
번호 5516
아미노산 서열(SEQ ID NO:329)

아미노산 + 누클레오티드 + myc 태그 서열(SEQ ID NO:330)

누클레오티드 서열(SEQ ID NO:331)


누클레오티드 + myc 태그 서열(SEQ ID NO:332)

DOM7h
-11-15/
DOM1m
-21-23
융합체
DMS
번호 5517
아미노산 서열(SEQ ID NO:333)

아미노산 + 누클레오티드 + myc 태그 서열(SEQ ID NO:334)

누클레오티드 서열(SEQ ID NO:335)
누클레오티드 + myc 태그 서열(SEQ ID NO:336)

myc-태깅된 분자가 상기 표에 표시되는 경우, 이는 실시예의 PK 연구에서 사용된 형태였다. myc-태깅된 서열이 제공되지 않는 경우, 실시예의 PK 연구는 myc-태깅된 물질로 수행되지 않았고, 즉, 연구는 제시된 태깅되지 않은 작제물로 수행되었다.
예시
실험 섹션에서의 모든 넘버링은 케이뱃(Kabat)(Kabat, E.A. National Institutes of Health (US) & Columbia University. Sequences of proteins of immunological interest, edn 5 (US Dept. Of Health and Human Services Public Health Service, National Institutes of Health, Bethesda, MD, 1991))에 따른다.
DOM7h-11 변이체의 유도가 기재된다.
실시예 1:
Vk
친화성 성숙
선택:
HSA(인간 혈청 알부민) 및 RSA(래트 혈청 알부민) 항원을 Sigma로부터 구입하였다(본질적으로 지방산 비함유, ~99%(아가로스 겔 전기영동), 각각 동결건조된 분말 Cat. No. A3782 및 A6414).
상기 2개의 항원의 비오티닐화된 생성물을 EZ Link Sulfo-NHS-SS-Biotin(Pierce, Cat. No.21331)을 이용하여 제조하였다. PD10 탈염 컬럼을 통해 샘플을 2회 통과시킨 후 4℃에서 PBS의 1000x 과량 부피에 대한 밤새의 투석에 의해 자유 비오틴 시약을 제거하였다. 생성된 생성물을 질량 분광법으로 시험하고, 분자당 1-2개의 비오틴을 관찰하였다.
친화성 성숙 라이브러리:
오류-유발 및 CDR 라이브러리를 DOM7h-11 및 DOM7h-14 모(parental) dAb(DOM7h-11 및 DOM7h-14의 서열에 대해 WO2008/096158호 참조)를 이용하여 생성시켰다. CDR 라이브러리를 pDOM4 벡터에서 생성시키고, 오류 유발 라이브러리를 pDOM33 벡터에서 생성시켰다(프로테아제 처리를 이용하거나 이용하지 않은 선택을 가능케 함). 벡터 pDOM4는 유전자 III 신호 펩티드 서열이 효모 당지질 부착된 표면 단백질(GAS) 신호 펩티드로 대체된 Fd 파지 벡터의 유도체이다. 이는 또한 선도 서열과 유전자 III 사이에 c-myc 태그를 함유하며, 이는 유전자 III 뒤에 프레임(frame)으로 놓여있다. 이러한 선도 서열은 파지 디스플레이 벡터 뿐만 아니라 다른 원핵생물 발현 벡터에 둘 모두에서 잘 작용하고, 이는 보편적으로 사용될 수 있다. pDOM33은 dAb-파지 융합체가 프로테아제 트립신에 대해 내성이 되도록 하는 c-myc 태그가 제거된 pDOM4 벡터의 변형된 형태이다. 이는 더욱 프로테아제 안정적인 dAb에 대해 선택하기 위해 파지 선택 내에서 트립신의 사용을 가능케 한다(WO2008149143호 참조).
오류-유발 돌연변이 라이브러리에 대해, 성숙되는 dAb를 엔코딩하는 플라스미드 DNA를 GENEMORPH® II RANDOM MUTAGENESIS KIT(무작위, 독특한 돌연변이유발 키트, Stratagene)를 이용한 PCR에 의해 증폭시켰다. 생성물을 SalI 및 NotI으로 절단하고, 절단된 파지 벡터 pDOM33과의 라이게이션 반응에 사용하였다. CDR 라이브러리에 대해, 친화성 성숙되는 dAb 내의 필요한 위치를 다양화시키기 위해 NNK 또는 NNS 코돈을 함유하는 축퇴성 올리고누클레오티드를 이용하여 PCR 반응을 수행하였다. 이후, 전장의 다양화된 삽입물을 생성시키기 위해 어셈블리 PCR을 사용하였다. 삽입물을 SalI 및 NotI로 절단시키고, 다수의 잔기의 돌연변이유발에 대해 pDOM4 및 단일 잔기의 돌연변이유발에 대해 pDOM5과의 라이게이션 반응에 사용하였다. pDOM5 벡터는 단백질 발현이 LacZ 프로모터에 의해 유도되는 pUC119-기반 발현 벡터이다. GAS1 선도 서열(WO2005/093074호 참조)은 분리된 가용성 dAb의 원형질막 주위공간 및 E. 콜리(E. coli)의 배양 상층액으로의 분비를 보장한다. dAb는 dAb의 C-말단에 myc 태그를 부착시키는 상기 벡터 내의 클로닝된 SalI/NotI이다. SalI 및 NotI을 이용하는 상기 프로토콜은 N-말단에 ST 아미노산 서열의 포함을 발생시킨다.
상기 어느 한 방법에 의해 생성된 라이게이션은 이후 전기천공에 의해 E. 콜리 균주 TB1을 형질전환시키는데 사용하였고, 형질전환된 세포를 15 μg/ml 테트라사이클린을 함유하는 2xTY 아가에 플레이팅시켜, >5x107 클론의 라이브러리 크기를 생성시켰다.
오류-유발 라이브러리는 하기 평균 돌연변이 비율 및 크기를 가졌다: DOM7h-11(dAb 당 2.5 돌연변이), 크기:6.1 x 108, DOM7h-14(dAb 당 2.9 돌연변이), 크기: 5.4 x 108.
각각의 CDR 라이브러리는 4개의 아미노산 다양성을 갖는다. CDR1 및 3 각각에 대해 2개의 라이브러리를 생성시키고, CDR2에 대해 1개의 라이브러리를 생성시켰다. 각각의 라이브러리 내에서 다양화된 위치는 하기와 같다(VK 더미(dummy) DPK9 서열을 기초로 한 아미노산):
라이브러리 크기
DOM7h-11 DOM7h-14
1 - Q27, S28, S30, S31 (CDR1) 8.8 x 107 5.8 x 107
2 - S30, S31, Y32, N34 (CDR1) 4.6 x 108 4.2 x 108
3 - Y49, A50, A51, S53 (CDR2) 3.9 x 108 2.4 x 108
4 - Q89, S91, Y92, S93 (CDR3) 1.8 x 108 2.5 x 108
5 - Y92, Y93, T94, N96 (CDR3) 4.0 x 108 3.3 x 108
실시예 2: 선택 방법:
1) Vκ AlbudAb™(항-혈청 알부민 dAb) 친화성 성숙을 위해 3개의 파지 선택 방법을 채택하였다: HSA 단독에 대한 선택:
HSA에 대한 3 라운드의 선택을 수행하였다. 오류 유발 라이브러리 및 각각의 CDR 라이브러리를 모든 라운드에서 개별적 푸울(pool)로 선택하였다. 첫번째 라운드의 선택을 1mg/ml로 면역튜브에 수동적으로 코팅된 HSA에 대해 수행하였다. 라운드 2를 100nM HSA에 대해 수행하고, 라운드 3를 10nM(CDR 선택) 또는 20 또는 100nM(오류 유발 선택) HSA에 대해 수행하였고, 상기 라운드 2 및 라운드 3 둘 모두는 가용성 선택으로 수행하였으며, 이후 네번째 라운드의 선택을 가용성 선택으로서 1.5 nM HSA에 대해 오류 유발 라이브러리로 수행하였다. 오류 유발 라이브러리를 1M Tris pH 8.0을 이용한 중화 전에 0.1M 글리신 pH 2.0로 용리시키고, CDR 라이브러리를 log 단계 TG1 세포로의 감염 전에 1mg/ml 트립신으로 용리시켰다. 세번째 라운드의 각각의 선택을 스크리닝을 위해 pDOM5로 서브클로닝시켰다. 가용성 선택은 비오티닐화된 HSA를 이용하였다.
2) HSA에 대한 트립신 선택:
모 클론에 비해 증가된 프로테아제 내성 및 잠재적으로 개선된 생물리학적 특성을 갖는 dAb를 선택하기 위해, 트립신을 파지 선택에서 사용하였다(WO2008149143호 참조). 4 라운드의 선택을 HSA에 대해 수행하였다. 오류 유발 라이브러리의 첫번째 라운드의 선택을 트립신 없이 1mg/ml로 수동적으로 코팅된 HSA에 대해 수행하였고; 두번째 라운드를 37℃에서 1시간 동안 20μg/ml 트립신과 함께 1mg/ml로 수동적으로 코팅된 HSA에 대해 수행하였고; 세번째 라운드 선택을 37℃에서 1시간 동안 20μg/ml 또는 100μg/ml 트립신과 함께 100nM HSA에 대해 비오티닐화된 HSA를 이용한 가용선 선택에 의해 수행하였다. 최종 라운드의 선택을 37℃에서 밤새 100μg/ml 트립신과 함께 100nM HSA에 대해 비오티닐화된 HSA를 이용한 가용성 선택에 의해 수행하였다.
3) HSA(라운드 1) 및 RSA(라운드 2-4)에 대한 교차 선택:
첫번째 라운드 선택을 1mg/ml의 수동적으로 코팅된 HSA 또는 1μM HSA(가용성 선택)에 대해 수행한 후, 라운드 1에 대해 1μM, 라운드 2에 대해 100nm 및 라운드 3에 대해 20nM, 10nM 또는 1nM의 농도의 비오티닐화된 RSA에 대한 추가 3 라운드의 가용성 선택을 수행하였다.
스크리닝 방법 및 친화성 결정:
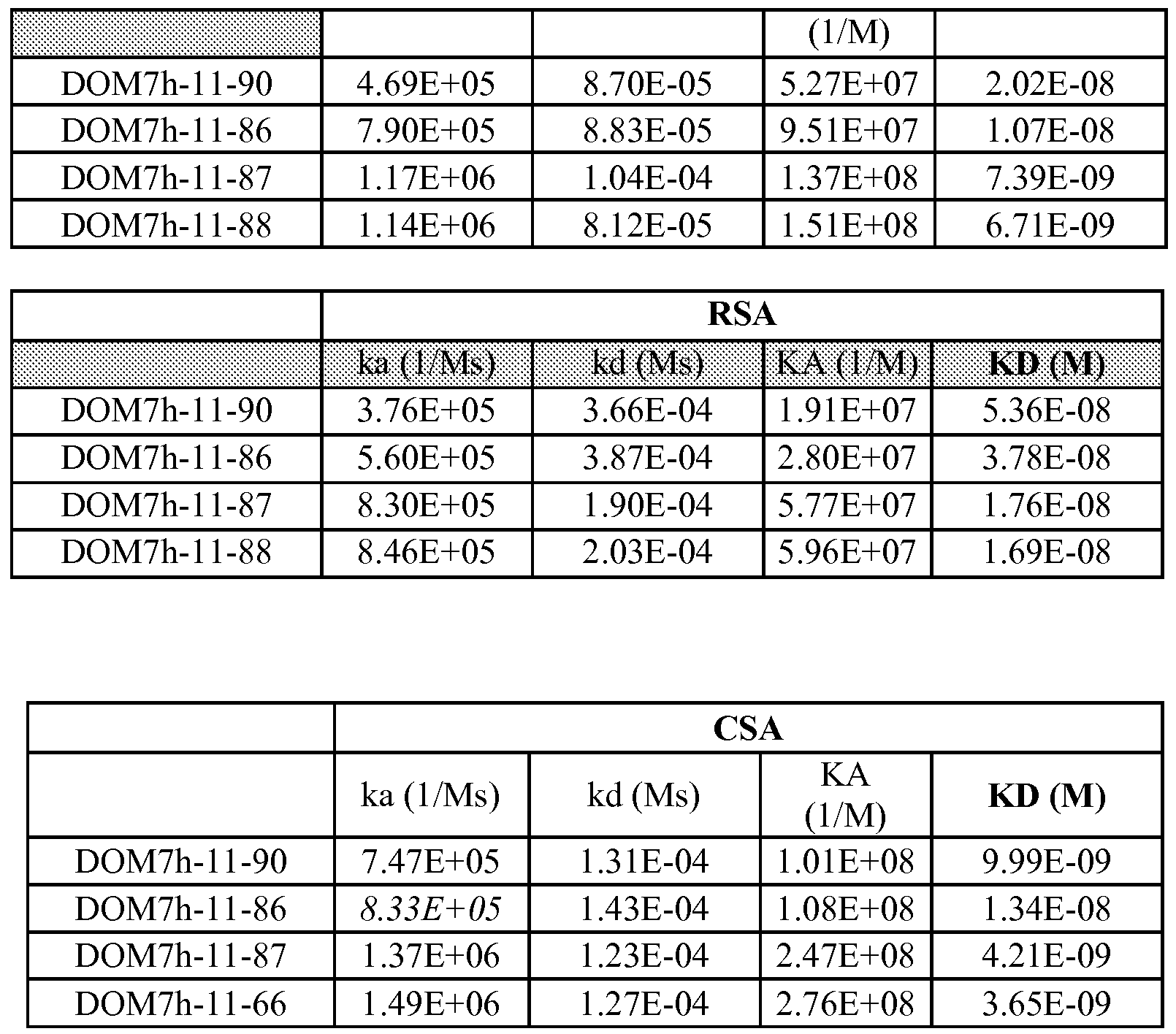
각각의 경우에서, 선택 후, 적절한 라운드의 선택으로부터의 파지 DNA의 푸울이 QIAfilter midiprep kit(Qiagen)를 이용하여 제조되며, DNA는 제한 효소 SalI 및 NotI을 이용하여 절단되고, 부화된 V 유전자는 myc 태그와 함께 dAb를 발현하는 가용성 발현 벡터인 pDOM5 내의 해당 부위에 라이게이션된다(PCT/EP2008/067789호 참조). 항생제 카르베니실린을 함유하는 아가 플레이트 상에서 이후에 밤새 성장되는 E. 콜리 HB 2151 세포를 전기 형질전환시키는데 라이게이션된 DNA가 사용된다. 생성된 집락이 항원 결합에 대해 개별적으로 평가된다. 각각의 경우에, 적어도 96개의 클론을 BIAcore™(표면 플라즈몬 공명)에 의해 HSA, CSA(시노몰구스 원숭이 혈청 알부민), MSA(마우스 혈청 알부민)에 대한 결합에 대해 시험하였다. MSA 항원을 Sigma(본질적으로 지방산 비함유, ~99%(아가로스 겔 전기영동), 동결건조된 분말 Cat. No. A3559)로부터 구입하였고, CSA를 프로메틱 블루(prometic blue) 수지(Amersham)를 이용하여 시노몰구스 혈청 알부민으로부터 정제하였다. 가용성 dAb 단편을 96 웰 플레이트에서 37℃에서 밤새 ONEX 배양 배지(Novagen)에서의 박테리아 배양에서 생성시켰다. 가용성 dAb를 함유하는 배양 상층액을 원심분리시키고, 고밀도 HSA, CSA, MSA 및 RSA CM5 칩에 대한 결합에 대해 BIAcore에 의해 분석하였다. 클론은 분리속도 스크리닝에 의해 혈청 알부민의 상기 모든 종에 결합하는 것으로 밝혀졌다. 클론을 서열분석하였고, 이는 독특한 dAb 서열을 나타내었다. 선택된 클론의 모(parent)에 대한 최소 동일성(아미노산 수준)은 97.2%(DOM7h-11-3:97.2%, DOM7h-11-12:98.2%, DOM7h11-15:96.3%, DOM7h-11-18:98.2%, DOM7h-11-19:97.2%)였다.
선택된 클론의 모에 대한 최소 동일성(아미노산 수준)은 96.3%(DOM7h-14-10:96.3%, DOM7h-14-18:96.3%, DOM7h-14-19:98.2%, DOM7h-14-28:99.1%, DOM7h-14-36:97.2%)였다.
독특한 dAb를 250rpm에서 48시간 동안 2.5L 진탕(shake) 플라스크 내에서 Onex 배지 중의 박테리아 상층액으로 발현시켰다. 단백질 L 아가로스로의 흡수 후 10mM 글리신 pH2.0을 이용한 용리에 의해 배양 배지로부터 dAb를 정제시켰다. BIAcore에 의한 HSA, CSA, MSA 및 RSA로의 결합을 1μM, 500nM 및 50nM의 3 농도의 정제된 단백질을 이용하여 확인하였다. 각각의 혈청 알부민에 대한 AlbudAb의 결합 친화성(KD)을 결정하기 위해, 정제된 dAb를 5000nM 내지 39nM(5000nM, 2500nM, 1250nM, 625nM, 312nM, 156nM, 78nM, 39nM)의 알부민 농도 범위에 걸쳐 BIAcore에 의해 분석하였다.
표 6




*: 괄호 내의 값은 두번째의 독립적인 SPR 실험으로부터 유도되었다.
모든 DOM7h-14 유래 변이체는 마우스, 래트, 인간 및 시노몰구스 혈청 알부민에 교차 반응적이다. DOM7h-14-10은 모에 비해 래트, 시노몰구스 및 인간 혈청 알부민에 대해 개선된 친화성을 갖는다. DOM7h-14-28은 RSA에 대해 개선된 친화성을 갖는다. DOM7h-14-36은 RSA, CSA 및 MSA에 대해 개선된 친화성을 갖는다.
DOM7h-11-3은 CSA 및 HSA에 대해 개선된 친화성을 갖는다. DOM7h-11-12는 RSA, MSA 및 HSA에 대해 개선된 친화성을 갖는다. DOM7h-11-15는 RSA, MSA, CSA 및 HSA에 대해 개선된 친화성을 갖는다. DOM7h-11-18 및 DOM7h-11-19는 RSA, MSA 및 HSA에 대해 개선된 친화성을 갖는다.
실시예
3: 중요
DOM7h
-11 계통 클론의 기원:
DOM7h-11-3: CDR2 라이브러리(Y49, A50, A51, S53), 라운드 3 결과 10nM HSA를 이용하여 HSA에 대해 수행된 친화성 성숙으로부터 기원.
DOM7h-11-12: 오류 유발 라이브러리, 100ug/ml 트립신과 함께 라운드 3 결과(100nM, HSA)를 이용하여 HSA에 대해 수행된 친화성 성숙으로부터 기원.
DOM7h-11-15: 라운드 1로서 HSA에 대해 수행된 후, 1nM의 RSA와 함께 라운드 3 선택에서 CDR2 라이브러리(Y49, A50, A51, S53)를 이용하여 RSA에 대해 추가 3 라운드의 선택으로 수행된 교차 선택으로부터 기원.
DOM7h-11-18: 라운드 1로서 HSA에 대해 수행된 후, 오류 유발 라이브러리, 20nM의 RSA의 라운드 3 결과를 이용하여 RSA에 대해 추가 3 라운드의 선택으로 수행된 교차 선택으로부터 기원.
DOM7h-11-19: 라운드 1로서 HSA에 대해 수행된 후, 오류 유발 라이브러리, 5nM의 RSA의 라운드 3 결과를 이용하여 RSA에 대해 추가 3 라운드의 선택으로 수행된 교차 선택으로부터 기원.
표 7:
CDR
서열(
케이뱃에
따름; 상기 참조)

실시예
4: 중요
DOM7h
-14 계통 클론의 기원
:
DOM7h-14-19: 오류 유발 라이브러리, 100ug/ml 트립신과 함께 라운드 3 결과(100nM, HSA)를 이용하여 HSA에 대해 수행된 친화성 성숙으로부터 기원.
DOM7h-14-10, DOM7h-14-18, DOM7h-14-28, DOM7h-14-36: CDR3 라이브러리(Y92, Y93, T94, N96), 라운드 3 결과를 이용하여 HSA에 대해 수행된 친화성 성숙으로부터 기원.
표 8:
CDR
서열(
케이뱃에
따름; 상기 참조)

실시예
5: 발현 및
생물리학적
특성규명
:
2.5L 진탕 플라스크 내의 통상적인 박테리아 발현 수준을 250rpm에서 48시간 동안 30℃에서 Onex 배지 중에서의 배양 후에 결정하였다. 생물리학적 특성규명을 SEC MALLS 및 DSC에 의해 결정하였다.
SEC MALLS(다각-레이저-광-분산을 이용한 크기 배제 크로마토그래피)는 용액 내의 거대분자의 특성규명을 위한 비-침입성 기술이다. 간단히, 단백질(완충액 둘베코(Dulbecco) PBS 중 1mg/mL의 농도)이 크기 배제 크로마토그래피(컬럼: TOSOH Biosciences로부터 TSK3000; Pharmacia로부터 S200)에 의해 유체역학 특성에 따라 0.5 ml/분으로 분리된다. 분리 후, 분산광에 대한 단백질의 편향이 다각-레이저-광-분산(MALLS) 검출기를 이용하여 측정된다. 검출기를 통해 단백질이 통과하는 동안의 분산광의 강도가 각의 함수에 따라 측정된다. 굴절 지수(RI) 검출기를 이용하여 결정된 단백질 농도와 함께 상기 측정은 적절한 식(분석 소프트웨어 Astra v.5.3.4.12의 필수 구성 부분)을 이용하여 몰 질량의 계산을 가능케 한다.
DSC(시차주사열용량분석): 간단히, 단백질(PBS 중 1mg/mL)은 180℃/시의 일정한 속도로 가열되고, 열 변성과 관련된 검출가능한 열 변화가 측정된다. 전이 중간점(appTm)이 결정되며, 이는 단백질의 50%가 이의 자연 형태로 존재하고, 나머지 50%가 변성되는 온도로 기재된다. 여기서, 시험된 단백질의 대부분이 완전히 재폴딩되지 않음에 따라, DSC는 겉보기 전이 중간점(appTm)을 결정하였다. Tm이 높을수록, 분자가 더욱 안정적이다. 비-2-상태 식에 의해 언폴딩 곡선을 분석하였다. 사용된 소프트웨어 패키지는 OriginR v7.0383이었다.
표 9

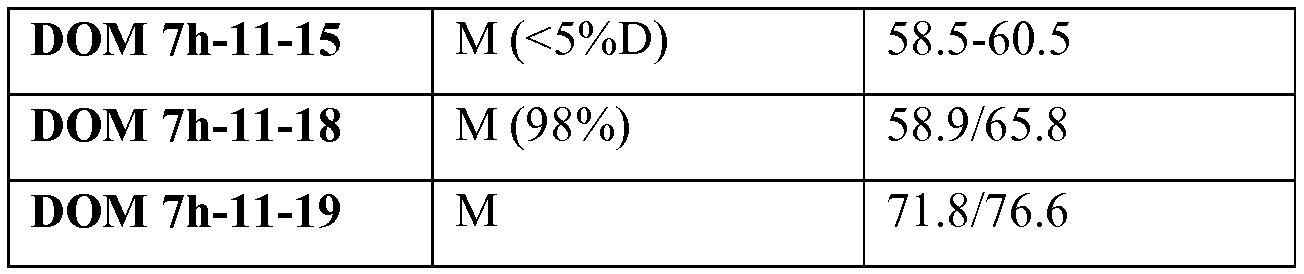
* 다른 한 시험에서, 비록 95%보다 낮았지만, SEC MALLS에 의해 주로 단량체가 관찰되었다.
표 9의 모든 클론에 대한 발현 수준은 E. 콜리에서 15 내지 119mg/L 범위 내로 관찰되었다.
DOM7h-14 및 DOM7h-11 변이체에 대해, 바람직한 생물리학적 파라미터(SEC MALLS에 의해 결정시 용액 중 단량체, 및 DSC에 의해 결정시 >55℃의 appTm) 및 발현 수준이 친화성 성숙 동안 유지되었다. 단량체 상태가 유리한데, 이는 이러한 상태가 이합체화를 피하고, 생성물이 표적, 예를 들어, 세포 표면 수용체를 가교시킬 수 있는 위험을 피하기 때문이다.
실시예
6:
래트
, 마우스 및
시노몰구스
원숭이에서의
혈청 반감기의 결정
AlbudAb DOM7h-14-10, DOM7h-14-18, DOM7h-14-19, DOM7h-11, DOM7h11-12 및 DOM7h-11-15를 pDOM5 벡터에 클로닝시켰다. 각각의 AlbudAb™에 대해, 20-50mg의 양을 E. 콜리에서 발현시키고, 단백질 L 친화성 수지를 이용하여 박테리아 배양 상층액으로부터 정제시키고, 100mM 글리신 pH2로 용리시켰다. 단백질을 1mg/ml 초과로 농축시키고, PBS로 완충액 교환하고, Q 회전 컬럼(Vivascience)을 이용하여 내독소를 고갈시켰다. 래트 약동학(PK) 분석을 위해, AlbudAb를 화합물 당 3마리의 래트를 이용하여 2.5mg/kg의 단일 정맥내 주사로 투여하였다. 혈청 샘플을 0.16, 1, 4, 12, 24, 48, 72, 120, 168시간에 채취하였다. 혈청 수준의 분석을 하기 기재되는 방법에 따라 항-myc ELISA에 의해 수행하였다.
마우스 PK에 대해, DOM7h-11, DOM7h11-12 및 DOM7h-11-15를 3 피검체의 투여 군 당 2.5mg/kg으로 단일한 정맥내 주사로 투여하고, 혈청 샘플을 10분; 1시간; 8시간; 24시간; 48시간; 72시간; 96시간에서 채취하였다. 혈청 수준의 분석을 하기 기재되는 방법에 따라 항-myc ELISA에 의해 수행하였다.
시노몰구스 원숭이 PK에 대해, DOM7h-14-10 및 DOM7h-11-15를 투여 군 당 3마리의 암컷 시노몰구스 원숭이로 2.5mg/kg의 단일 정맥내 주사로 투여하고, 혈청 샘플을 0.083, 0.25, 0.5, 1, 2, 4, 8, 24, 48, 96, 144, 192, 288, 336, 504시간에 채취하였다. 혈청 수준의 분석을 하기 기재되는 방법에 따라 항-myc ELISA에 의해 수행하였다.
항-myc ELISA 방법
혈청에서의 AlbudAb 농도를 항-myc ELISA에 의해 측정하였다. 간단히, 염소 항-myc 폴리클로날 항체(1:500; Abcam, catalogue number ab9132)를 밤새 Nunc 96-웰 Maxisorp 플레이트 상에 코팅시키고, 5% BSA/PBS + 1% tween으로 블로킹시켰다. 혈청 샘플을 공지된 농도의 표준과 함께 일정 범위의 희석액으로 첨가하였다. 이후, 결합된 myc-태깅된 AlbudAb를 토끼 폴리클로날 항-Vk(1:1000; 사내(in-house) 시약, 혈액이 풀링되고, 사용 전에 단백질 A 정제됨), 및 이후 항-토끼 IgG HRP 항체(1:10,000; Sigma, catalogue number A2074)를 이용하여 검출하였다. 플레이트를 3 x PBS+0.1% Tween20, 및 이후 3 x PBS를 이용하여 검정의 각각의 단계 사이에 세척하였다. 마지막 세척 후 TMB(SureBlue TMB1-Component Microwell Peroxidase Substrate, KPL, catalogue number 52-00-00)를 첨가하고, 발달되도록 두었다. 이를 1M HCl을 이용하여 중지시킨 후, 신호를 450nm에서의 흡광도를 이용하여 측정하였다.
미가공 ELISA 데이터로부터, 공지되지 않은 샘플의 농도를 희석 인자를 고려한 표준 곡선에 대한 보간법(interpolation)에 의해 확립하였다. 각각의 시점으로부터의 평균 농도 결과를 복제 값으로부터 결정하고, 이를 WinNonLin 분석 패키지(예를 들어, 버전 5.1)(Pharsight Corp., Mountain View, CA94040, USA로부터 이용가능함)에 입력시켰다. PK 파라미터가 말단 반감기를 제공하는 소프트웨어에 의해 평가되는 비-구획 모델을 이용하여 데이터를 적합화시켰다. 각각의 PK 프로파일의 말단 단계를 반영하는 투여 정보 및 시점을 선택하였다.
표 10: 단일
AlbudAb
™
PK

*역사적 데이터
래트, 마우스 및 시노몰구스 원숭이 연구로부터 유도된 약동학 파라미터를 비-구획 모델을 이용하여 적합화시켰다. 기호표: AUC: 무한대로 외삽된 투여 시간으로부터의 곡선하영역; CL: 청소; t1/2: 혈중 농도가 반감되는 기간; Vz: 말단 단계를 기초로 한 분포량.
DOM7h-11 12 및 DOM7h-11-15는 모(parent)에 비해 래트 및 마우스에서 개선된 AUC 및 t1/2를 갖는다. DOM7h-11-15는 또한 모에 비해 시노몰구스에서 개선된 AUC 및 t1/2를 갖는다. AUC/t1/2에서의 상기 개선은 혈청 알부민에 대한 개선된 시험관내 KD와 관련이 있다.
실시예
7:
AlbudAb
™
IFN
융합체
클로닝 및 발현
AlbudAb의 유용한 PK가 융합 단백질로서 유지되었는지의 여부를 결정하기 위해, 단일한 AlbudAb 뿐만 아니라, 친화성 성숙된 Vk AlbudAb를 인터페론 알파 2b(IFNα2b)에 연결시켰다.
인터페론 알파 2b 아미노산 서열:

인터페론 알파 2b 누클레오티드 서열:


IFNα2b를 TVAAPS 링커 영역을 통해 AlbudAb에 연결시켰다(WO2007085814호 참조). 작제물을 SOE-PCR(문헌[Horton et al. Gene, 77, p61(1989)]의 방법에 따른 단일 중첩 신장)에 의해 클로닝시켰다. AlbudAb 및 IFN 서열의 PCR 증폭을 TVAAPS 링커 영역에서 ~15 염기쌍 중첩을 갖는 프라이머를 이용하여 별개로 수행하였다. 사용된 프라이머는 하기와 같다:

단편을 별개로 정제시킨 후, 플랭킹(flanking) 프라이머만을 이용하여 SOE(단일 중첩 신장 PCR 신장) 반응에서 어셈블리시켰다.

어셈블리된 PCR 생성물을 제한 효소 BamHI 및 HindIII를 이용하여 절단시키고, 유전자를 세포 배지로의 발현을 촉진시키는 N-말단 V-J2-C 마우스 IgG 분비 선도 서열을 갖는 pTT5 유도체인 포유동물 발현 벡터인 pDOM50 내의 해당 부위에 라이게이션시켰다.
선도 서열(아미노산):
선도 서열(누클레오티드):
플라스미드 DNA를 QIAfilter megaprep(Qiagen)을 이용하여 제조하였다. 1 μg DNA/ml을 293-Fectin과 함께 HEK293E 세포로 트랜스펙션시키고, 혈청 비함유 배지에서 성장시켰다. 단백질을 5일 동안 배양하에 발현시키고, 단백질 L 친화성 수지를 이용하여 배양 상층액으로부터 정제시키고, 100mM 글리신 pH2로 용리시켰다. 단백질을 1mg/ml 초과로 농축시키고, PBS로 완충액 교환하고, Q 회전 컬럼(Vivascience)을 이용하여 내독소를 고갈시켰다.
친화성 결정 및
생물리학적
특성규명:
각각의 혈청 알부민에 대한 AlbudAb-IFNα2b 융합 단백질의 결합 친화성(KD)을 결정하기 위해, HBS-EP BIAcore 완충액 중 5000nM 내지 39nM(5000nM, 2500nM, 1250nM, 625nM, 312nM, 156nM, 78nM, 39nM)로부터의 융합 단백질 농도를 이용한 알부민(CM5 칩 상으로의 일차-아민 커플링에 의해 고정됨; BIAcore) 상에서의 BIAcore에 의해 정제된 융합 단백질을 분석하였다.
표 12:
SA
에 대한 친화성


IFNα2b가 AlbudAb 변이체에 연결되는 경우, 모든 경우에, 혈청 알부민에 대한 AlbudAb 결합의 친화성이 감소된다. DOM7h-14-10 및 DOM7-11-15는 모에 비해 종을 교차하여 혈청 알부민에 대한 개선된 결합 친화성을 보유한다. DOM7h-11-12는 또한 모에 비해 종을 교차하여 혈청 알부민에 대한 개선된 결합 친화성을 갖는다.
표 13:
생물리학적
특성규명
생물리학적 특성규명을 단일 AlbudAb에 대해 상기 기재된 바와 같이 SEC MALLS 및 DSC에 의해 수행하였다.


M/D는 SEC MALLS에 의해 검출된 단량체/이합체 평형을 나타낸다.
표 13의 모든 클론에 대한 발현은 HEK293 중 17.5 내지 54 mg/L 범위 내로 관찰되었다.
IFNα2b-DOM7h-14 및 IFNα2b-DOM7h-11 변이체에 대해, 바람직한 생물리학적 파라미터 및 발현 수준이 친화성 성숙 동안 유지되었다.
AlbudAb
-
IFN
α2b
융합체에
대한
PK
결정
AlbudAb IFNα2b 융합체 DMS7321(IFNα2b-DOM7h-14), DMS7322(IFNα2b-DOM7h-14-10), DMS7323(IFNα2b-DOM7h-14-18), DMS7324(IFNα2b-DOM7h-14-19), DMS7325(IFNα2b-DOM7h-11), DMS7326(IFNα2b-DOM7h-11-12), DMS7327(IFNα2b-DOM7h-11-15)을 HEK293 세포에서 20-50mg 양으로 myc 태그와 함께 발현시키고, 단백질 L 친화성 수지를 이용하여 배양 상층액으로부터 정제시키고, 100mM 글리신 pH2로 용리시켰다. 단백질을 1mg/ml 초과로 농축시키고, 둘베코 PBS로 완충액 교환하고, Q 회전 컬럼(Vivascience)을 이용하여 내독소를 고갈시켰다.
래트 PK에 대해, IFN-AlbudAb를 화합물 당 3마리의 래트를 이용하여 2.0mg/kg의 단일 정맥내 주사로 투여하였다. 혈청 샘플을 0.16, 1, 4, 8, 24, 48, 72, 120, 168시간에 채취하였다. 혈청 수준의 분석을 제조업체의 설명서(GE Healthcare, catalogue number RPN5960)에 따라 EASY ELISA에 의해 수행하였다.
마우스 PK에 대해, 모두 myc 태그를 갖는 DMS7322(IFN2b-DOM7h-14-10), DMS7325(IFN2b-DOM7h-11), DMS7326(IFN2b-DOM7h-11-12), DMS7327(IFN2b-DOM7h-11-15)을 3 피검체의 투여군 당 2.0mg/kg의 단일 정맥내 주사로 투여하고, 혈청 샘플을 10분; 1시간; 8시간; 24시간; 48시간; 72시간; 96시간에 채취하였다. 혈청 수준의 분석을 제조업체의 설명서(GE Healthcare, catalogue number RPN5960)에 따라 EASY ELISA에 의해 수행하였다.
표 14:

래트 및 마우스 연구로부터 유도된 약동학 파라미터를 비-구획 모델을 이용하여 적합화시켰다. 기호표: AUC: 무한대로 외삽된 투여 시간으로부터의 곡선하영역; CL: 청소; t1/2: 혈중 농도가 반감되는 기간; Vz: 말단 단계를 기초로 한 분포량.
IFNα2b-AlbudAb를 래트 및 마우스에서 시험하였다. 래트 및 마우스 둘 모두에서의 모든 IFNα2b-DOM7h-11 변이체 융합 단백질에 대해, t1/2는 모에 비해 개선된다. t1/2에서의 개선은 혈청 알부민에 대한 개선된 시험관내 KD와 관련이 있다. IFNα2b-DOM7h-14-10 변이체에 대해, 혈청 알부민에 대한 시험관내 KD에서의 개선은 또한 래트에서의 t1/2의 개선과 관련이 있다.
모든 IFNα2b-AlbudAb 융합 단백질은 단일 AlbudAb에 비해 RSA에 대한 결합에서 5 내지 10배의 감소를 나타낸다. 이러한 효과는 DOM7h-11 시리즈(단지 5배 감소)보다 DOM7h-14 시리즈에 대해 더욱 현저(즉, 10배)하다.
실시예
8: 단백질, 펩티드 및
NCE
와의 추가
AlbudAb
융합체
.
다른 화학 존재물, 즉, 도메인 항체(dAb), 펩티드 및 NCE에 융합된 다양한 AlbudAb를 시험하였다. 결과는 표 15에 제시된다.
표 15:


기호표: DOM1m-21-23은 항-TNFR1 dAb이고, 엑센딘-4는 39개의 아미노산 길이의 펩티드(GLP-1 효능제)이다. NCE, NCE-GGGGSC 및 NCE-TVAAPSC는 하기 기재된다.
이전에, 생체내에서 항-TNFR1 dAb의 PK 반감기를 연장시키기 위한 알부민-결합 dAb(AlbudAb)와의 유전적 융합체의 사용이 기재되었다(예를 들어, WO04003019호, WO2006038027호, WO2008149148호 참조). 상기 PCR 출원에서의 프로토콜이 참조된다. 상기 표에서, DOM1m-21-23은 항-마우스 TNFR1 dAb이다.
엑센딘-4 또는 혈청 알부민에 결합하는 DOM7h-14(또는 다른 AlbudAb)와의 유전적 융합체를 생성시키기 위해, 엑센딘-4-링커-AlbudAb 서열을 pTT-5 벡터(CNRC, Canada로부터 구입가능함)로 클로닝시켰다. 각각의 경우, 엑센딘-4는 작제물의 5' 말단에 존재하였고, dAb는 3' 말단에 존재하였다. 링커는 (G4S)3 링커였다. 내독소 비함유 DNA를 알칼리성 용해(Qiagen CA로부터 구입가능한 내독소 비함유 플라스미드 Giga 키트를 이용함)를 이용하여 E. 콜리에서 제조하고, HEK293E 세포(CNRC, Canada로부터 구입가능함)를 트랜스펙션시키는데 사용하였다. 플라스크 당 333ul의 293fectin(Invitrogen) 및 250ug의 DNA를 이용하여 250ml/플라스크의 HEK293E 세포로 1.75x106 세포/ml로 트랜스펙션시키고, 5일 동안 30℃에서 발현시켰다. 상층액을 원심분리에 의해 수거하고, 단백질 L 상에서의 친화성 정제에 의해 정제하였다. 단백질을 수지에 배치(batch) 결합시키고, 컬럼 상에 패킹시키고, 10 컬럼 부피의 PBS로 세척하였다. 단백질을 50ml의 0.1M 글리신 pH2로 용리시키고, Tris pH8로 중화시켰다. 예상 크기의 단백질을 SDS-PAGE 겔에서 확인하였다.
NCE Albudab 융합체:
신규 화합물(NCE) AlbudAb 융합체를 시험하였다. NCE, 소분자 ADAMTS-4 억제제를 PEG 링커(PEG 4 링커(즉, 말레이미드 앞의 4 PEG 분자)) 및 AlbudAb로의 컨쥬게이션을 위한 말레이미드기를 이용하여 합성하였다. AlbudAb로의 NCE의 컨쥬게이션은 아미노산 위치 R108C, 또는 AlbudAb의 말단에서 조작된 5개의 아미노산(GGGGSC) 또는 6개의 아미노산(TVAAPSC) 스페이서 뒤의 조작된 시스틴 잔기를 통해 이루어진다. 간단히, AlbudAb를 TCEP(Pierce, Catalogue Number 77720)를 이용하여 환원시키고, PD10 컬럼(GE healthcare)을 이용하여 25mM Bis-Tris, 5mM EDTA, 10%(v/v) 글리세롤 pH6.5로 탈염시켰다. 5배 몰과량의 말레이미드 활성화 NCE를 10%(V/V)의 최종 농도를 초과하지 않게 DMSO에 첨가하였다. 반응물을 실온에서 밤새 인큐베이션시키고, 20mM Tris pH7.4로 광범위하게 투석시켰다.
PEG 링커:
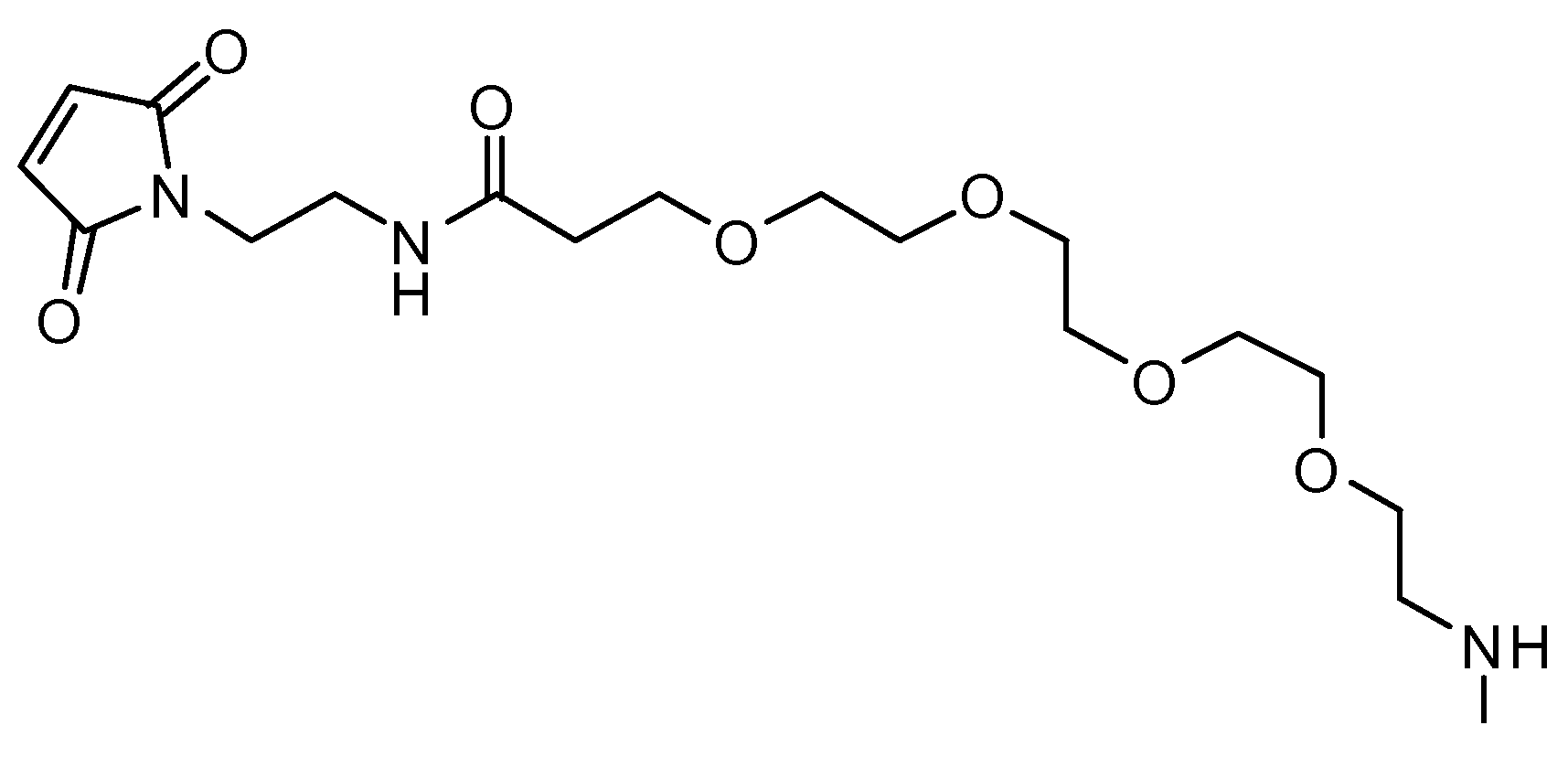
서열:
DOM7h-14 R108C:

누클레오티드:

DOM7h-14-10/TVAAPSC 및 DOM7h-14-10/GGGGSC(즉, DOM7h-14-10/G4SC)의 서열에 대해 표 5를 참조하라.
NCE-AlbudAb DOM7h-14-10 GGGGSC 및 DOM7h14-10 TVAAPSC는 화합물에 융합되는 경우에 BIAcore에 의해 결정시 RSA에 대한 시험관내 친화성(KD)에서 5 내지 10배 감소를 나타낸다. PK 데이터는 상기 분자에 대해 아직 이용가능하지 않다.
dAb-Albudab 융합체: RSA에 대해 가장 높은 친화성을 갖는 2 DOM7h-11 AlbudAb는 융합되지 않은 AlbudAb에 비해 치료 도메인 항체(DOM1m-21-23)에 융합되는 경우에 BIAcore에서 RSA에 대한 친화성에서 2배 감소를 경험한다. DOM7h-11 클론은 융합(2.8uM)되거나 융합되지 않는 경우(~5uM)에 마이크로몰 KD를 나타낸다.
엑센딘 4-AlbudAb 융합체: RSA로의 결합 능력에서 펩티드에 AlbudAb를 융합시키는 것의 효과는 결합에서 단지 4배 감소를 나타낸 DOM7h-14-10은 별개로 하고 약 10배이다. 그러나, 상기 효과는 DOM7h-11 시리즈에 대해 존재하는 것으로 보이는 것보다 DOM7h-14 시리즈(DOM7h-14-10 제외)에 대해 더욱 현저하다.
상기 데이터 모두에 대해, 상기 종의 SA에 대한 개선된 친화성과 함께 융합체의 T1/2가 증가하였다.
일반적으로, Albudab-치료는, AlbudAb-약물 융합체가 혈청 알부민 결합에 대해 0.1 nM 내지 10 mM의 친화성 범위(KD)를 나타내는 경우에 치료적으로 수용(질병, 질환 또는 적응증의 치료 및/또는 예방용)될 수 있는 것으로 분류된다.
AlbudAb 및 AlbudAb 융합체(단백질-AlbudAb, 예를 들어, IFNα2b-DOM7h-14-10; 펩티드-AlbudAb, 예를 들어, 엑센딘-4-DOM7h-14-10; dAb-AlbudAb, 예를 들어, DOM1m21-23-DOM7h11-15; NCE-AlbudAb, 예를 들어, ADAMTS-4-DOM7h-14-10)의 치료 범위는 다음과 같이 기재된다: 만성 또는 급성 질환, 질병 또는 적응증의 치료에 유용한 친화성(KD) 범위가 제시된다. "중간"으로 표시된 친화성 범위가 또한 제시된다. 상기 범위에서의 AlbudAb 및 융합체는 만성 또는 급성 질병, 질환 또는 적응증에 대해 유용성을 갖는다. 이러한 방식에서, 혈청 알부민에 대한 AlbudAb 또는 융합체의 친화성은 취급되는 질병, 질환 또는 적응증에 따라 맞춤화되거나 선택될 수 있다. 상기 기재된 바와 같이, 본 발명은 각각의 AlbudAb가 "높은 친화성", "중간 친화성" 또는 "낮은 친화성"으로 분류되는 것을 가능케 하는 친화성을 갖는 AlbudAb를 제공함으로써, 당업자가 직접 치료에 따라 본 발명의 적절한 AlbudAb를 선택하는 것을 가능케 한다. 도 2를 참조하라.
실시예
9:
DOM7h
-11-15
S12P
서열
DOM7h-11-15S12P의 아미노산 서열

본 발명의 일 양태는 DOM7h-11-15S12P의 누클레오티드 서열 또는 상기 선택된 서열과 적어도 80% 동일한 누클레오티드 서열을 포함하는 핵산을 제공한다. DOM7h-11-15S12P를 하기 핵산 서열(밑줄친 C는 위치 12에서 프롤린을 발생시키는 변화(DOM7h-11-15를 엔코딩하는 핵산에 비함)를 나타냄)을 이용하여 생성시켰다:-

DOM7h-11-15S12P를, 프라이머가 S12P 돌연변이를 도입시키기 위해 사용된 PCR에서 주형으로서 DOM7h-11-15를 이용하여 작제하였다. 프라이머 서열은 하기와 같다:-
본 발명의 대안적 양태는 SEQ ID NO:389의 누클레오티드 서열 또는 상기 선택된 서열과 적어도 80% 동일한 누클레오티드 서열을 포함하는 핵산을 제공한다. 일 구체예에서, DOM7h-11-15S12P는 링커 영역 및 단백질 또는 펩티드 약물 또는 단일 가변 도메인 또는 다른 항체 단편을 엔코딩하는 C-말단 서열을 함유하는 벡터에 의해 엔코딩되고, 이로부터 발현되어, 인-라인(in-line) 단백질 융합 생성물이 제조된다. 일 구체예에서, 링커는 아미노산 서열 TVA, 예를 들어, TVAAPS를 포함한다. 본 발명의 다른 양태는 핵산을 포함하는 벡터 및 벡터를 포함하는 분리된 숙주 세포이다. 본 발명은 또한 DOM7h-11-15S12P의 적어도 1회 용량을 환자에게 투여하는 것을 포함하는, 상기 환자의 질병 또는 장애를 치료하거나 예방하는 방법을 제공한다.
실시예
10:
DOM
7h-11-15
변이체
i)
Vk
친화성
성슥
선택:
HSA(인간 혈청 알부민) 및 RSA(래트 혈청 알부민) 항원 및 비오티닐화된 생성물을 실시예 1에 기재된 바와 같이 수득하였다.
친화성 성숙 라이브러리:
오류 유발 및 도핑(doping)된 라이브러리 둘 모두를 주형으로서 파지 선택을 위해 트립신의 이용을 가능케 하는 위치 108의 아르기닌이 트립토판으로 돌연변이(DOM7h-11-15 R108W(DOM7h-11-55))된 DOM7h-11-15 모 dAb(SEQ ID NO:2 참조)를 이용하여 생성시켰다. 라이브러리를 pDOM33 벡터에서 생성시켰다.
도핑된 CDR 라이브러리에 대해, dAb 내의 필요한 위치를 다양화시키기 위해 편향된 축퇴성 코돈을 함유하는 도핑된 올리고누클레오티드를 이용하여 일차 PCR 반응을 수행하였다. 도핑된 라이브러리의 생성은, 예를 들어, 문헌[Balint and Larrick, Gene, 137, 109-118 (1993)]에 기재되어 있다. 각각의 축퇴성 코돈으로부터 처음 2개의 누클레오티드만 변화시켜, 모 누클레오티드가 케이스(case)의 85%에 존재하고, 케이스의 5%에서 모든 다른 가능한 누클레오티드가 존재하도록 프라이머를 설계하였다. CDR 당 6개의 코돈을, 코돈 내의 누클레오티드 당 15% 가능성으로 모 누클레오티드와 상이하게 존재하도록 동시에 돌연변이되도록 표적화시켰다. 이후, 어셈블리 PCR을 사용하여 전장의 다양화된 삽입물을 생성시켰다. 삽입물을 SalI 및 NotI으로 절단시키고, pDOM33과의 라이게이션 반응에 사용하였다. 이후, 라이브러리의 라이게이션을 전기천공에 의한 E. 콜리 균주 TB1을 형질전환시키는데 사용하였고, 형질전환된 세포를 15μg/ml 테트라사이클린을 함유하는 2xTY 아가에 플레이팅시켰다.
각각의 CDR 당 하나의 3개의 도핑된 라이브러리가 존재하였고, 돌연변이 비율 및 라이브러리 크기는 다음과 같다:
CDR1 라이브러리 - 1.4 x 108의 라이브러리 크기를 갖는 dAb 당 1.6개의 아미노산 돌연변이
CDR2 라이브러리 - 2 x 108의 라이브러리 크기를 갖는 dAb 당 1.7개의 아미노산 돌연변이
CDR3 라이브러리 - 1.1 x 108의 라이브러리 크기를 갖는 dAb 당 2개의 아미노산 돌연변이
ii
) 선택 방법
:
HSA 에 대한 선택 HSA에 대한 2 라운드의 선택을 수행하였다. 각각의 CDR 라이브러리를 모든 라운드에서 개별적 푸울로 선택하였다. 둘 모두의 라운드의 선택을 10nM 농도의 비오티닐화된 HSA에 대해 용액 중에서 수행하였다. 라이브러리를 0.1M 글리신 pH 2.0으로 용리시키고, 1M Tris pH 8.0으로 중화시키고, log 단계 TG1 세포로 감염시켰다. 두번째 라운드의 각각의 선택을 스크리닝을 위해 pDOM5로 서브클로닝시켰다.
교차 선택 용액 중의 비오티닐화된 SA에 대한 2 라운드의 선택을 수행하였다. 첫번째 라운드를 10nM 농도의 HSA에 대해 수행하였고, 두번째 라운드를 100nm 농도의 RSA에 대해 수행하였다. 각각의 CDR 라이브러리를 모든 라운드에서 개별적 푸울로 선택하였다. 라이브러리를 0.1M 글리신 pH 2.0으로 용리시키고, 1M Tris pH 8.0으로 중화시키고, log 단계 TG1 세포로 감염시켰다. 두번째 라운드의 각각의 선택을 스크리닝을 위해 pDOM5로 서브클로닝시켰다.
ii
) 스크리닝 방법 및 친화성 결정
각각의 경우, 선택 후, 적절한 라운드의 선택으로부터의 파지 DNA의 푸울을 QIAfilter midiprep kit(Qiagen)를 이용하여 제조하고, DNA를 제한 효소 SalI 및 NotI을 이용하여 절단하고, 부화된 V 유전자를 myc 태그를 갖는 dAb를 발현하는 pDOM5 가용성 발현 벡터 내의 해당 부위로 라이게이션시켰다(PCT/EP2008/067789호 참조). 라이게이션된 DNA는 항생제 카르베니실린을 함유하는 아가 배지 상에서 이후 밤새 성장되는 화학 적격 E. 콜리 HB 2151 세포를 형질전환시키는데 사용된다. 생성된 집락이 항원 결합에 대해 개별적으로 평가된다. 각각의 선택 결과에 대해, 93개의 클론을 BIAcore™(표면 플라즈몬 공명)에 의해 HSA, 및 RSA로의 결합에 대해 시험하였다. 가용성 dAb 단편을 96 웰 플레이트에서 37℃에서 밤새 ONEX 배양 배지(Novagen)에서 박테리아 생성물로 생성시켰다. 가용성 dAb를 함유하는 배양 상층액을 원심분리시키고, 고밀도 HSA, 및 RSA CM5 칩으로의 결합에 대해 BIAcore에 의해 분석하였다. 분리속도 스크리닝에 의한 둘 모두의 상기 종의 혈청 알부민에 대해 모 클론과 동등하거나 이보다 낫게 결합하는 것으로 밝혀진 클론을 서열분석하였고, 이는 독특한 dAb 서열을 나타내었다.
독특한 dAb를 250rpm에서 48시간 동안 30℃에서 0.5L 진탕 플라스크에서 Onex 배지 중의 박테리아 상층액으로 발현시켰다. dAb를 단백질 L 스트림라인으로의 흡수 후, 0.1M 글리신 pH2.0를 이용한 용리에 의해 배양 배지로부터 정제시켰다. 인간, 래트, 마우스 및 시노몰구스 혈청 알부민에 대한 AlbudAb의 결합 친화성(KD)을 결정하기 위해, 500nM 내지 3.9nM(500nM, 250nM, 125nM, 31.25nM, 15.625nM, 7.8125nM, 3.90625nM) 범위의 알부민 농도에 걸쳐 BIAcore에 의해 정제된 dAb를 분석하였다.
MSA 항원을 Sigma(본질적으로 지방산 비함유, ~99%(아가로스 겔 전기영동), 동결건조된 분말 Cat. No. A3559)로부터 구입하고, CSA를 프로메틱 블루 수지(Amersham)를 이용하여 시노몰구스 혈청 알부민으로부터 정제하였다. 중요 클론의 모든 시험된 혈청 알부민 종에 대한 친화성이 표 16에 제시된다.
상기 검정에서, myc-태깅된 분자를 PK 연구에 사용하였다.
표 16 A 내지 D
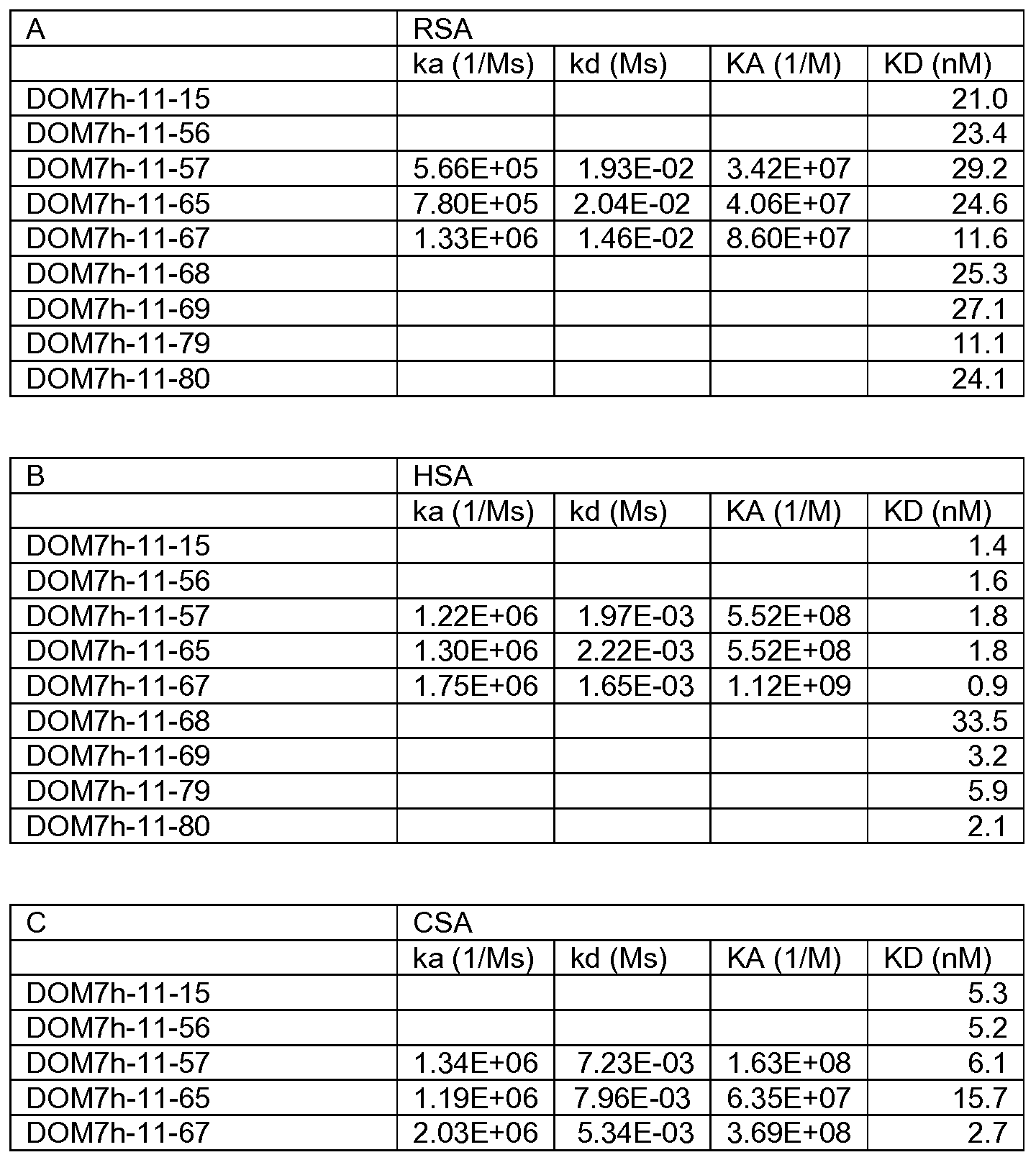

모든 D0M7h-11-15 변이체는 래트, 인간, 시노몰구스 및 마우스 혈청 알부민과 교차 반응적이다(해리 상수(KD); 분리속도 상수(Kd); 결합속도 상수(Ka)).
iv
) 발현 및
생물리학적
특성규명
:
박테리아 발현 및 SECMALLS 및 DSC에 의한 발현을 상기 실시예 5에 기재된 바와 같이 수행하였다.
표 17.

T/D 및 D/M은 SEC-MALLS에 의해 검출시 삼합체와 이합체 또는 이합체와 단량체 사이의 평형을 각각 나타낸다.
표 2에 제시된 모든 DOM7h-11-15 변이체는 바람직한 생물리학적 파라미터(SEC MALLs에 의해 결정되는 용액 중 단량체 및 DSC에 의해 결정되는 >55℃의 appTm)를 가지며, 발현 수준은 친화성 성숙 동안 대부분 유지되었다. 열안정성이 유리한데, 이는 낮은 Tm을 갖는 Albudab와 비교하는 경우 높은 용해 온도를 갖는 AlbudAb에 융합된 약물의 저장 수명을 개선시킬 수 있기 때문이다.
v) 대부분의
열안정성
클론의
CDR3
및
프레임워크
3 서열
대부분의 열안정성 AlbudAb(>57℃의 appTm)의 특성에서의 본질적 차이는 모 클론 DOM7h-11-15와 비교하는 경우 상기 클론의 CDR3 또는 프레임워크 3에서의 단일한 아미노산 돌연변이(중합효소 오류로 인한 돌연변이)로 인한 것이다. 바람직한 돌연변이를 함유하는 프레임워크 3 또는 CDR3의 서열이 표 18 및 19에 제시된다. 모로부터 열안정성 AlbudAb를 구별짓는 아미노산은 굵은 글씨로 제시된다.
모 및 DOM7h-11-15의 모든 열안정성 변이체(>55℃의 Tm)의 완전한 아미노산 및 누클레오티드 서열이 서열 섹션(서열 1-18)에 나열된다. 대부분의 클론은 위치 108의 아르기닌이 트립토판으로 돌연변이되었으며, 이는 필요시 트립신 유도 선택을 가능케 수행되었다(트립신 인지 부위 노킹 아웃(knocking out)). DOM7h-11-67의 위치 106에서의 이소류신으로부터 아스파라긴으로의 돌연변이가 또한 포함되었다.
위치 108이 아르기닌으로 역 돌연변이(W108R)되고, 임의로, 위치 106이 이소류신으로 역 돌연변이된 다른 클론(DOM 7h-11-87, DOM 7h-11-90, DOM 7h-11-86 참조)이 유도되었다. 상기 클론의 서열은 하기에 나열된다.
SA에 대한 결합은 하기 표에 요약되어 있다:

생물리학적 특성을 나타내는 표
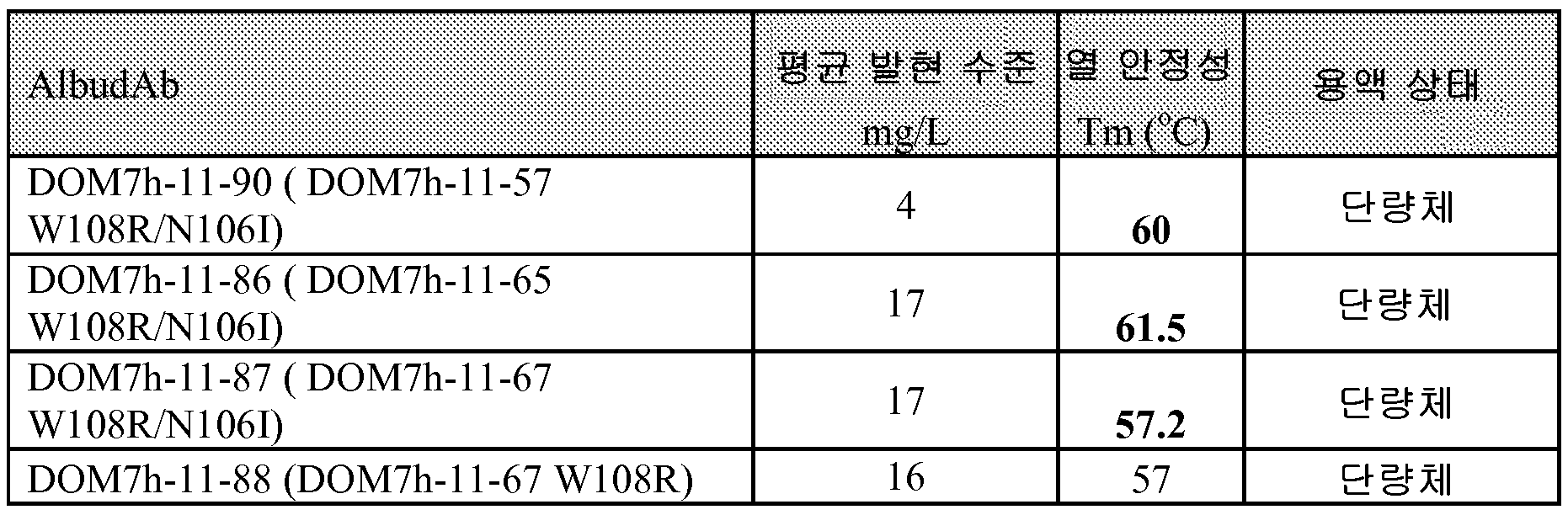
표 18
모로부터 열안정성 AlbudAb를 구별짓는 아미노산이 굵은 글씨로 제시된다. 모든 넘버링은 케이뱃을 참조로 하였다.

표 19


확인된 DOM 7h-11-15로의 돌연변이는 하기와 같다:

DOM7h
-11-15
변이체의
서열
아미노산 서열



누클레오티드
서열





서열표


SEQUENCE LISTING
<110> DE ANGELIS, Elena
ENEVER, Carolyn
LIU, Haiqun
SCHON, Oliver
PUPECKA, Malgorzata
<120> IMPROVED ANTI-SERUM ALBUMIN BINDING
VARIANTS
<130> DB64132
<150> 61/346,519
<151> 2010-05-20
<150> PCT/EP2011/058298
<151> 2011-05-20
<160> 438
<170> FastSEQ for Windows Version 4.0
<210> 1
<211> 108
<212> PRT
<213> Homo sapien
<400> 1
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 2
<211> 108
<212> PRT
<213> Homo sapien
<400> 2
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 3
<211> 108
<212> PRT
<213> Homo sapien
<400> 3
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Trp Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr His Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 4
<211> 108
<212> PRT
<213> Homo sapien
<400> 4
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Thr Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 5
<211> 108
<212> PRT
<213> Homo sapien
<400> 5
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Thr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Trp Asn Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 6
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 6
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatcttgttt ggttcccggt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 7
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 7
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgcgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 8
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 8
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatcttgttt ggttcccggt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacggat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag actgggacgc atcccacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 9
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 9
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgacgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatcctttgg aattcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 10
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 10
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgacgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatcctttgg aattcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 11
<211> 120
<212> PRT
<213> Homo sapien
<400> 11
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Gln Tyr
20 25 30
Arg Met His Trp Val Arg Gln Ala Pro Gly Lys Ser Leu Glu Trp Val
35 40 45
Ser Ser Ile Asp Thr Arg Gly Ser Ser Thr Tyr Tyr Ala Asp Pro Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ala Val Thr Met Phe Ser Pro Phe Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 12
<211> 123
<212> PRT
<213> Homo sapien
<400> 12
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ala Asp Tyr
20 25 30
Gly Met Arg Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Thr Arg Thr Gly Arg Val Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Trp Arg Asn Arg His Gly Glu Tyr Leu Ala Asp Phe Asp Tyr
100 105 110
Trp Gly Gln Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 13
<211> 120
<212> PRT
<213> Homo sapien
<400> 13
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Met Arg Tyr
20 25 30
Arg Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Asp Ser Asn Gly Ser Ser Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Asp Arg Thr Glu Arg Ser Pro Val Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Leu Val Thr Val Ser Ser
115 120
<210> 14
<211> 119
<212> PRT
<213> Homo sapien
<400> 14
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Asp Tyr
20 25 30
Glu Met His Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Ser Ile Ser Glu Ser Gly Thr Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Arg Arg Phe Ser Ala Ser Thr Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 15
<211> 119
<212> PRT
<213> Homo sapien
<400> 15
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Thr Gly His Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 16
<211> 119
<212> PRT
<213> Homo sapien
<400> 16
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Thr Gly Arg Trp Glu Pro Tyr Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 17
<211> 119
<212> PRT
<213> Homo sapien
<400> 17
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 18
<211> 119
<212> PRT
<213> Homo sapien
<400> 18
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 19
<211> 119
<212> PRT
<213> Homo sapien
<400> 19
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 20
<211> 119
<212> PRT
<213> Homo sapien
<400> 20
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Met Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 21
<211> 119
<212> PRT
<213> Homo sapien
<400> 21
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Asp Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 22
<211> 119
<212> PRT
<213> Homo sapien
<400> 22
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Asp Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 23
<211> 119
<212> PRT
<213> Homo sapien
<400> 23
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 24
<211> 119
<212> PRT
<213> Homo sapien
<400> 24
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 25
<211> 119
<212> PRT
<213> Homo sapien
<400> 25
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 26
<211> 119
<212> PRT
<213> Homo sapien
<400> 26
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 27
<211> 119
<212> PRT
<213> Homo sapien
<400> 27
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 28
<211> 119
<212> PRT
<213> Homo sapien
<400> 28
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 29
<211> 119
<212> PRT
<213> Homo sapien
<400> 29
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Asp Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 30
<211> 119
<212> PRT
<213> Homo sapien
<400> 30
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Asp Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 31
<211> 119
<212> PRT
<213> Homo sapien
<400> 31
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 32
<211> 119
<212> PRT
<213> Homo sapien
<400> 32
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 33
<211> 119
<212> PRT
<213> Homo sapien
<400> 33
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Lys Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 34
<211> 119
<212> PRT
<213> Homo sapien
<400> 34
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 35
<211> 119
<212> PRT
<213> Homo sapien
<400> 35
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 36
<211> 119
<212> PRT
<213> Homo sapien
<400> 36
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Ala Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 37
<211> 119
<212> PRT
<213> Homo sapien
<400> 37
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asn Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 38
<211> 119
<212> PRT
<213> Homo sapien
<400> 38
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 39
<211> 119
<212> PRT
<213> Homo sapien
<400> 39
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Ser Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Asp Asn Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 40
<211> 119
<212> PRT
<213> Homo sapien
<400> 40
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ile Thr Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Gln Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 41
<211> 119
<212> PRT
<213> Homo sapien
<400> 41
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Gly Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 42
<211> 119
<212> PRT
<213> Homo sapien
<400> 42
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 43
<211> 119
<212> PRT
<213> Homo sapien
<400> 43
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 44
<211> 119
<212> PRT
<213> Homo sapien
<400> 44
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 45
<211> 119
<212> PRT
<213> Homo sapien
<400> 45
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Lys Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 46
<211> 119
<212> PRT
<213> Homo sapien
<400> 46
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Ser Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Glu Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Pro Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 47
<211> 119
<212> PRT
<213> Homo sapien
<400> 47
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Asn Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Tyr Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Thr Ser
115
<210> 48
<211> 119
<212> PRT
<213> Homo sapien
<400> 48
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 49
<211> 119
<212> PRT
<213> Homo sapien
<400> 49
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Lys Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 50
<211> 119
<212> PRT
<213> Homo sapien
<400> 50
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 51
<211> 119
<212> PRT
<213> Homo sapien
<400> 51
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 52
<211> 119
<212> PRT
<213> Homo sapien
<400> 52
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 53
<211> 119
<212> PRT
<213> Homo sapien
<400> 53
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Val Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 54
<211> 119
<212> PRT
<213> Homo sapien
<400> 54
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Lys Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 55
<211> 119
<212> PRT
<213> Homo sapien
<400> 55
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 56
<211> 119
<212> PRT
<213> Homo sapien
<400> 56
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 57
<211> 119
<212> PRT
<213> Homo sapien
<400> 57
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 58
<211> 119
<212> PRT
<213> Homo sapien
<400> 58
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 59
<211> 119
<212> PRT
<213> Homo sapien
<400> 59
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Lys Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 60
<211> 119
<212> PRT
<213> Homo sapien
<400> 60
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 61
<211> 119
<212> PRT
<213> Homo sapien
<400> 61
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 62
<211> 119
<212> PRT
<213> Homo sapien
<400> 62
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 63
<211> 119
<212> PRT
<213> Homo sapien
<400> 63
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 64
<211> 119
<212> PRT
<213> Homo sapien
<400> 64
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Lys Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 65
<211> 119
<212> PRT
<213> Homo sapien
<400> 65
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 66
<211> 119
<212> PRT
<213> Homo sapien
<400> 66
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 67
<211> 119
<212> PRT
<213> Homo sapien
<400> 67
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 68
<211> 119
<212> PRT
<213> Homo sapien
<400> 68
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Phe
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 69
<211> 119
<212> PRT
<213> Homo sapien
<400> 69
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 70
<211> 119
<212> PRT
<213> Homo sapien
<400> 70
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 71
<211> 119
<212> PRT
<213> Homo sapien
<400> 71
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 72
<211> 119
<212> PRT
<213> Homo sapien
<400> 72
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Ala Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Pro Asp Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 73
<211> 119
<212> PRT
<213> Homo sapien
<400> 73
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Ala Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Pro Asp Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 74
<211> 119
<212> PRT
<213> Homo sapien
<400> 74
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Pro Asp Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 75
<211> 119
<212> PRT
<213> Homo sapien
<400> 75
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Pro Asp Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 76
<211> 119
<212> PRT
<213> Homo sapien
<400> 76
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Pro Asp Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 77
<211> 119
<212> PRT
<213> Homo sapien
<400> 77
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Pro Asp Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 78
<211> 119
<212> PRT
<213> Homo sapien
<400> 78
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Ala Trp Gly Asp Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 79
<211> 119
<212> PRT
<213> Homo sapien
<400> 79
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Gly Gly Gln Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 80
<211> 119
<212> PRT
<213> Homo sapien
<400> 80
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Ser Gly Tyr Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 81
<211> 119
<212> PRT
<213> Homo sapien
<400> 81
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Gly Gly Thr Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 82
<211> 119
<212> PRT
<213> Homo sapien
<400> 82
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Lys Gly Thr Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 83
<211> 119
<212> PRT
<213> Homo sapien
<400> 83
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Glu Thr Gly Arg Arg Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 84
<211> 119
<212> PRT
<213> Homo sapien
<400> 84
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Asn Asn Thr Gly Ser Thr Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Asp Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 85
<211> 119
<212> PRT
<213> Homo sapien
<400> 85
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 86
<211> 119
<212> PRT
<213> Homo sapien
<400> 86
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Pro Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 87
<211> 119
<212> PRT
<213> Homo sapien
<400> 87
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 88
<211> 119
<212> PRT
<213> Homo sapien
<400> 88
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 89
<211> 119
<212> PRT
<213> Homo sapien
<400> 89
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 90
<211> 119
<212> PRT
<213> Homo sapien
<400> 90
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Thr His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 91
<211> 119
<212> PRT
<213> Homo sapien
<400> 91
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Arg Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 92
<211> 119
<212> PRT
<213> Homo sapien
<400> 92
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Leu Asn Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 93
<211> 119
<212> PRT
<213> Homo sapien
<400> 93
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 94
<211> 119
<212> PRT
<213> Homo sapien
<400> 94
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Arg Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 95
<211> 119
<212> PRT
<213> Homo sapien
<400> 95
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Arg Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 96
<211> 119
<212> PRT
<213> Homo sapien
<400> 96
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Val Tyr Thr Gly Arg Trp Val Ser Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 97
<211> 119
<212> PRT
<213> Homo sapien
<400> 97
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Tyr Thr Gly Arg Trp Val Ser Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 98
<211> 119
<212> PRT
<213> Homo sapien
<400> 98
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Val Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 99
<211> 119
<212> PRT
<213> Homo sapien
<400> 99
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Leu Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 100
<211> 119
<212> PRT
<213> Homo sapien
<400> 100
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Ala Asp Arg Arg Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 101
<211> 119
<212> PRT
<213> Homo sapien
<400> 101
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 102
<211> 119
<212> PRT
<213> Homo sapien
<400> 102
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Asp Arg Arg Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 103
<211> 119
<212> PRT
<213> Homo sapien
<400> 103
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Ala Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 104
<211> 119
<212> PRT
<213> Homo sapien
<400> 104
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 105
<211> 119
<212> PRT
<213> Homo sapien
<400> 105
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Ala Asp Arg Arg Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 106
<211> 119
<212> PRT
<213> Homo sapien
<400> 106
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Ala Asp Arg Arg Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 107
<211> 119
<212> PRT
<213> Homo sapien
<400> 107
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Val Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 108
<211> 119
<212> PRT
<213> Homo sapien
<400> 108
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asn Thr Gly Asp Arg Arg Tyr Tyr Ala Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 109
<211> 119
<212> PRT
<213> Homo sapien
<400> 109
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 110
<211> 119
<212> PRT
<213> Homo sapien
<400> 110
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 111
<211> 119
<212> PRT
<213> Homo sapien
<400> 111
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 112
<211> 119
<212> PRT
<213> Homo sapien
<400> 112
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ser His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 113
<211> 119
<212> PRT
<213> Homo sapien
<400> 113
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Thr His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 114
<211> 119
<212> PRT
<213> Homo sapien
<400> 114
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Thr Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 115
<211> 119
<212> PRT
<213> Homo sapien
<400> 115
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 116
<211> 119
<212> PRT
<213> Homo sapien
<400> 116
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 117
<211> 119
<212> PRT
<213> Homo sapien
<400> 117
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 118
<211> 119
<212> PRT
<213> Homo sapien
<400> 118
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 119
<211> 119
<212> PRT
<213> Homo sapien
<400> 119
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 120
<211> 119
<212> PRT
<213> Homo sapien
<400> 120
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 121
<211> 119
<212> PRT
<213> Homo sapien
<400> 121
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Arg Tyr Tyr Asp Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 122
<211> 119
<212> PRT
<213> Homo sapien
<400> 122
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Gly Asp Arg Arg Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 123
<211> 119
<212> PRT
<213> Homo sapien
<400> 123
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Gly Asp Arg Arg Tyr Tyr Asp Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 124
<211> 119
<212> PRT
<213> Homo sapien
<400> 124
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Gly Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 125
<211> 119
<212> PRT
<213> Homo sapien
<400> 125
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Ala Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 126
<211> 119
<212> PRT
<213> Homo sapien
<400> 126
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Gly Pro Phe Gln Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 127
<211> 119
<212> PRT
<213> Homo sapien
<400> 127
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Gln Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 128
<211> 119
<212> PRT
<213> Homo sapien
<400> 128
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 129
<211> 119
<212> PRT
<213> Homo sapien
<400> 129
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Gln Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 130
<211> 119
<212> PRT
<213> Homo sapien
<400> 130
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Gln Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 131
<211> 119
<212> PRT
<213> Homo sapien
<400> 131
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 132
<211> 119
<212> PRT
<213> Homo sapien
<400> 132
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 133
<211> 119
<212> PRT
<213> Homo sapien
<400> 133
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 134
<211> 119
<212> PRT
<213> Homo sapien
<400> 134
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 135
<211> 119
<212> PRT
<213> Homo sapien
<400> 135
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Arg Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 136
<211> 119
<212> PRT
<213> Homo sapien
<400> 136
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 137
<211> 119
<212> PRT
<213> Homo sapien
<400> 137
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 138
<211> 119
<212> PRT
<213> Homo sapien
<400> 138
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ser His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 139
<211> 119
<212> PRT
<213> Homo sapien
<400> 139
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ser His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 140
<211> 119
<212> PRT
<213> Homo sapien
<400> 140
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Thr His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 141
<211> 119
<212> PRT
<213> Homo sapien
<400> 141
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Thr His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 142
<211> 119
<212> PRT
<213> Homo sapien
<400> 142
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 143
<211> 119
<212> PRT
<213> Homo sapien
<400> 143
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 144
<211> 119
<212> PRT
<213> Homo sapien
<400> 144
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Leu Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 145
<211> 119
<212> PRT
<213> Homo sapien
<400> 145
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 146
<211> 119
<212> PRT
<213> Homo sapien
<400> 146
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 147
<211> 119
<212> PRT
<213> Homo sapien
<400> 147
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 148
<211> 119
<212> PRT
<213> Homo sapien
<400> 148
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Thr Tyr Tyr Asp His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 149
<211> 119
<212> PRT
<213> Homo sapien
<400> 149
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Arg Tyr Tyr Ala His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 150
<211> 119
<212> PRT
<213> Homo sapien
<400> 150
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Arg Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 151
<211> 119
<212> PRT
<213> Homo sapien
<400> 151
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Arg Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 152
<211> 119
<212> PRT
<213> Homo sapien
<400> 152
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Arg Tyr Tyr Asp His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 153
<211> 119
<212> PRT
<213> Homo sapien
<400> 153
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Arg Tyr Tyr Asp His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 154
<211> 119
<212> PRT
<213> Homo sapien
<400> 154
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ala Asp Thr Ala Asp Arg Arg Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 155
<211> 119
<212> PRT
<213> Homo sapien
<400> 155
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Arg Tyr Tyr Asp Asp Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Thr Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Glu Pro Phe Val Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 156
<211> 119
<212> PRT
<213> Homo sapien
<400> 156
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Ala Asp Arg Thr Tyr Tyr Ala His Ala Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Val Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 157
<211> 119
<212> PRT
<213> Homo sapien
<400> 157
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Val Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asn Thr Gly Gly His Thr Tyr Tyr Ala Asp Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Tyr Thr Gly Arg Trp Glu Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 158
<211> 119
<212> PRT
<213> Homo sapien
<400> 158
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Phe Lys Tyr
20 25 30
Ser Met Gly Trp Val Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Gln Ile Ser Asp Thr Gly Asp Arg Arg Tyr Tyr Asp His Ser Val
50 55 60
Lys Gly Arg Phe Thr Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Ile Tyr Thr Gly Arg Trp Ala Pro Phe Glu Tyr Trp Gly Gln Gly
100 105 110
Thr Leu Val Thr Val Ser Ser
115
<210> 159
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 159
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttagt cagtatagga tgcattgggt ccgccaggct 120
ccagggaaga gtctagagtg ggtctcaagt attgatacta ggggttcgtc tacatactac 180
gcagaccccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaagctgtg 300
acgatgtttt ctcctttttt tgactactgg ggtcagggaa ccctggtcac cgtctcgagc 360
<210> 160
<211> 369
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 160
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgct gattatggga tgcgttgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcatct attacgcgga ctggtcgtgt tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatggcgg 300
aatcggcatg gtgagtatct tgctgatttt gactactggg gtcagggaac cctggtcacc 360
gtctcgagc 369
<210> 161
<211> 360
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 161
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttatg aggtatagga tgcattgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcatcg attgattcta atggttctag tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaagatcgt 300
acggagcgtt cgccggtttt tgactactgg ggtcagggaa ccctggtcac cgtctcgagc 360
<210> 162
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 162
gaggtgcagc tgttggagtc tgggggaggc ttggtgcagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt gattatgaga tgcattgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcatct attagtgaga gtggtacgac gacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaacgtcgt 300
ttttctgctt ctacgtttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 163
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 163
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatatacg 300
ggtcattggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 164
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 164
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatatacg 300
ggtcgttggg agccttatga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 165
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 165
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 166
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 166
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatatacg 300
ggtcgttggg agccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 167
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 167
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 168
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 168
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 169
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 169
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tgggatgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcacagt ctcgagc 357
<210> 170
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 170
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccata tcccgcgaca attccaagaa cacgctgtat 240
atgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 171
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 171
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttggt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg atctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 172
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 172
gaggtgcagc tgttggagtc agggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtggtca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatatacg 300
ggtcgttggg agccttttga ccactggggt caggggaccc tggtcaccgt ctcgagc 357
<210> 173
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 173
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 174
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 174
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gaaatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 175
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 175
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 176
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 176
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 177
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 177
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tgggatgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcacagt ctcgagc 357
<210> 178
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 178
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tgggatgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcgaata cgggtgatca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcacagt ctcgagc 357
<210> 179
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 179
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttggt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg atctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 180
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 180
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttggt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg atctagagtg ggtctcacag atttcgaata cgggtgatca tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 181
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 181
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 182
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 182
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 183
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 183
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcggactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga agccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 184
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 184
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 185
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 185
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 186
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 186
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggcat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 187
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 187
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttaa ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 188
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 188
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 189
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 189
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa ctcgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg tgccttttga caactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 190
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 190
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttatt acgtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttca gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 191
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 191
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttggt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcggactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 192
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 192
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaagac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 193
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 193
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 194
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 194
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 195
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 195
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttaa gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 196
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 196
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttagt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgagcg tagatactac 180
gcagactcag tgaagggccg gttcaccatc tcccgcgaca atcccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg agccttttga atactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 197
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 197
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aactattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tacatactac 180
gcggactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttatga gtactggggt cagggaaccc tggtcaccgt cacgagc 357
<210> 198
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 198
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgata attccaagaa cacactgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 199
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 199
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga agccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 200
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 200
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 201
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 201
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 202
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 202
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 203
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 203
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc ggtatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 204
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 204
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga agccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 205
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 205
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 206
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 206
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 207
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 207
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 208
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 208
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 209
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 209
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggcc 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga agccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 210
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 210
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 211
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 211
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 212
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 212
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 213
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 213
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 214
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 214
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga agccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 215
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 215
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggcc 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaagac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 216
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 216
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 217
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 217
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 218
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 218
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagttttcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 219
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 219
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 220
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 220
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 221
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 221
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 222
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 222
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggcat attactgtgc gatatatacg 300
ggtcggtggc ccgactttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 223
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 223
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggcat attactgtgc gatatatacg 300
ggtcggtggc ccgactttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 224
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide sequences of anti-TNFR1 dAbs
<400> 224
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggc ccgactttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 225
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 225
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggc ccgactttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 226
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 226
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggc ccgactttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 227
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 227
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggc ccgactttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 228
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 228
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tgggatgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcggcct ggggtgacag gacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 229
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 229
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcggacg gcggtcagag gacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 230
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 230
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tgggatgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcggact ccggttaccg cacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 231
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 231
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtccagagtg ggtctcacag atttcggacg ggggtacgcg gacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 232
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 232
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tgggatgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcggaca agggtacgcg cacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 233
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 233
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tgggatgggt ccgccaggct 120
ccagggaaag gtccagagtg ggtctcacag atttcggaga ccggtcgcag gacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 234
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 234
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attaacaata cgggttcgac cacatactac 180
gcagactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttga ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 235
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide sequences of anti-TNFR1 dAbs
<400> 235
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtccagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 236
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 236
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtccagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 237
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 237
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 238
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 238
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 239
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 239
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 240
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 240
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
acacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 241
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 241
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg cagatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 242
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 242
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attttgaata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 243
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 243
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 244
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 244
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tagatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 245
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 245
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tagatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 246
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 246
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc ggtatatact 300
gggcgttggg tgtcttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 247
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 247
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gctatatact 300
gggcgttggg tgtcttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 248
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 248
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gtttaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc ggtatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 249
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 249
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gctatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 250
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 250
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata ctgctgatcg tagatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 251
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 251
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 252
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 252
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcgg cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata cgggcgatcg tagatactac 180
gcacacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 253
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 253
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata ctgctgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 254
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 254
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcacacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 255
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 255
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcgaata ctgctgatcg tagatactac 180
gcacacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 256
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 256
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cggctgatcg tagatactac 180
gcacacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 257
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 257
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgtgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 258
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 258
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcgaata cgggtgatcg tagatactac 180
gcagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 259
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 259
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 260
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 260
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 261
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 261
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 262
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 262
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
tcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 263
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 263
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
acacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 264
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 264
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
acagacgcgg tgaaggggcg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 265
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 265
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 266
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 266
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 267
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 267
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata cgggtgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 268
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 268
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 269
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide sequences of anti-TNFR1 dAbs
<400> 269
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgcctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatcactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg aaccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 270
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 270
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata cgggtgatcg tagatactac 180
gatgacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 271
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 271
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tagatactac 180
gatgactctg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 272
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 272
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata cgggtgatcg tagatactac 180
gatcactctg tgaagggccg gttcactatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 273
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 273
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata cgggtgatcg tagatactac 180
gatgacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 274
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 274
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg ggccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 275
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 275
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg tgccttttgc ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 276
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 276
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg gaccttttca gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 277
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 277
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttca gtactggggt cagggaactc tggtcaccgt ctcgagc 357
<210> 278
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 278
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 279
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 279
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg cgccttttca gtactggggt cagggaactc tggtcaccgt ctcgagc 357
<210> 280
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 280
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg tgccttttca gtactggggt cagggcaccc tggtcaccgt ctcgagc 357
<210> 281
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 281
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ccggtgatcg tagatactac 180
gatcactctg tgaagggccg gttcactatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 282
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 282
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 283
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 283
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 284
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 284
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 285
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 285
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttgga ggccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 286
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 286
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 287
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 287
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 288
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 288
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
tcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 289
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 289
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
tcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 290
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 290
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
acacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 291
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 291
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
acacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 292
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 292
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 293
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 293
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttg aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 294
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 294
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ccggtgatcg tagatactac 180
gatcactctg tgaagggccg gttcactatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 295
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 295
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tacatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgcgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 296
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 296
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 297
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 297
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tacatactac 180
gcacacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 298
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 298
gaggtgcagc tgttggagtc tgggggaggc ttggtgcagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tacatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 299
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 299
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tacatactac 180
gatcacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgctgaggac accgcggtat attactgtgc gatatatact 300
gggcgttggg tgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 300
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 300
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tagatactac 180
gcacactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 301
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 301
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tagatactac 180
gcacacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 302
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 302
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tagatactac 180
gcacacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 303
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 303
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tagatactac 180
gatcacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 304
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 304
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tagatactac 180
gatcacgcgg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt caggggaccc tggtcaccgt ctcgagc 357
<210> 305
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 305
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttgtt aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag attgcggata ctgctgatcg tagatactac 180
gatcactccg tgaagggccg gttcaccatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcggtggg cgccttttga gtactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 306
<211> 357
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 306
gaggtgcagc tgctggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttttc aagtattcga tggggtgggt ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacag atttcggata ctgctgatcg tagatactac 180
gatgacgcgg tgaagggccg gttcaccatc acccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgcggtat attactgtgc gatatatacg 300
ggtcgttggg agccttttgt ctactggggt cagggaaccc tggtcaccgt ctcgagc 357
<210> 307
<211> 163
<212> PRT
<213> Mouse
<400> 307
His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys Gln Met Glu Glu
1 5 10 15
Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn Gly Gly Pro Ser
20 25 30
Ser Gly Ala Pro Pro Pro Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
50 55 60
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
65 70 75 80
Ser Gln Trp Ile Gly Ser Gln Leu Ser Trp Tyr Gln Gln Lys Pro Gly
85 90 95
Lys Ala Pro Lys Leu Leu Ile Met Trp Arg Ser Ser Leu Gln Ser Gly
100 105 110
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Ala
130 135 140
Gln Gly Ala Ala Leu Pro Arg Thr Phe Gly Gln Gly Thr Lys Val Glu
145 150 155 160
Ile Lys Arg
<210> 308
<211> 489
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 308
catggtgaag gaacatttac cagtgacttg tcaaaacaga tggaagagga ggcagtgcgg 60
ttatttattg agtggcttaa gaacggagga ccaagtagcg gggcacctcc gccatcgggt 120
ggtggaggcg gttcaggcgg aggtggcagc ggcggtggcg ggtcggacat ccagatgacc 180
cagtctccat cctccctgtc tgcatctgta ggagaccgtg tcaccatcac ttgccgggca 240
agtcagtgga ttgggtctca gttatcttgg taccagcaga aaccagggaa agcccctaag 300
ctcctgatca tgtggcgttc ctcgttgcaa agtggggtcc catcacgttt cagtggcagt 360
ggatctggga cagatttcac tctcaccatc agcagtctgc aacctgaaga ttttgctacg 420
tactactgtg ctcagggtgc ggcgttgcct aggacgttcg gccaagggac caaggtggaa 480
atcaaacgg 489
<210> 309
<211> 163
<212> PRT
<213> Homo sapien
<400> 309
His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys Gln Met Glu Glu
1 5 10 15
Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn Gly Gly Pro Ser
20 25 30
Ser Gly Ala Pro Pro Pro Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
50 55 60
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
65 70 75 80
Ser Gln Trp Ile Gly Ser Gln Leu Ser Trp Tyr Gln Gln Lys Pro Gly
85 90 95
Lys Ala Pro Lys Leu Leu Ile Met Trp Arg Ser Ser Leu Gln Ser Gly
100 105 110
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Ala
130 135 140
Gln Gly Leu Arg His Pro Lys Thr Phe Gly Gln Gly Thr Lys Val Glu
145 150 155 160
Ile Lys Arg
<210> 310
<211> 489
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 310
catggtgaag gaacatttac cagtgacttg tcaaaacaga tggaagagga ggcagtgcgg 60
ttatttattg agtggcttaa gaacggagga ccaagtagcg gggcacctcc gccatcgggt 120
ggtggaggcg gttcaggcgg aggtggcagc ggcggtggcg ggtcggacat ccagatgacc 180
cagtctccat cctccctgtc tgcatctgta ggagaccgtg tcaccatcac ttgccgggca 240
agtcagtgga ttgggtctca gttatcttgg taccagcaga aaccagggaa agcccctaag 300
ctcctgatca tgtggcgttc ctcgttgcaa agtggggtcc catcacgttt cagtggcagt 360
ggatctggga cagatttcac tctcaccatc agcagtctgc aacctgaaga ttttgctacg 420
tactactgtg ctcagggttt gaggcatcct aagacgttcg gccaagggac caaggtggaa 480
atcaaacgg 489
<210> 311
<211> 163
<212> PRT
<213> Homo sapien
<400> 311
His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys Gln Met Glu Glu
1 5 10 15
Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn Gly Gly Pro Ser
20 25 30
Ser Gly Ala Pro Pro Pro Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
50 55 60
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
65 70 75 80
Ser Gln Trp Ile Gly Ser Gln Leu Ser Trp Tyr Gln Gln Lys Pro Gly
85 90 95
Lys Ala Pro Lys Leu Leu Ile Met Trp Arg Ser Ser Leu Gln Ser Gly
100 105 110
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Ala
130 135 140
Gln Gly Leu Met Lys Pro Met Thr Phe Gly Gln Gly Thr Lys Val Glu
145 150 155 160
Ile Lys Arg
<210> 312
<211> 489
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 312
catggtgaag gaacatttac cagtgacttg tcaaaacaga tggaagagga ggcagtgcgg 60
ttatttattg agtggcttaa gaacggagga ccaagtagcg gggcacctcc gccatcgggt 120
ggtggaggcg gttcaggcgg aggtggcagc ggcggtggcg ggtcggacat ccagatgacc 180
cagtctccat cctccctgtc tgcatctgta ggagaccgtg tcaccatcac ttgccgggca 240
agtcagtgga ttgggtctca gttatcttgg taccagcaga aaccagggaa agcccctaag 300
ctcctgatca tgtggcgttc ctcgttgcaa agtggggtcc catcacgttt cagtggcagt 360
ggatctggga cagatttcac tctcaccatc agcagtctgc aacctgaaga ttttgctacg 420
tactactgtg ctcagggtct tatgaagcct atgacgttcg gccaagggac caaggtggaa 480
atcaaacgg 489
<210> 313
<211> 163
<212> PRT
<213> Homo sapien
<400> 313
His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys Gln Met Glu Glu
1 5 10 15
Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn Gly Gly Pro Ser
20 25 30
Ser Gly Ala Pro Pro Pro Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
50 55 60
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Ser Cys Arg Ala
65 70 75 80
Ser Gln Trp Ile Gly Ser Gln Leu Ser Trp Tyr Gln Gln Lys Pro Gly
85 90 95
Glu Ala Pro Lys Leu Leu Ile Met Trp Arg Ser Ser Leu Gln Ser Gly
100 105 110
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Ala
130 135 140
Gln Gly Ala Ala Leu Pro Arg Thr Phe Gly Gln Gly Thr Lys Val Glu
145 150 155 160
Ile Lys Arg
<210> 314
<211> 489
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 314
catggtgaag gaacatttac cagtgacttg tcaaaacaga tggaagagga ggcagtgcgg 60
ttatttattg agtggcttaa gaacggagga ccaagtagcg gggcacctcc gccatcgggt 120
ggtggaggcg gttcaggcgg aggtggcagc ggcggtggcg ggtcggacat ccagatgacc 180
cagtctccat cctccctgtc tgcatctgta ggagaccgtg tcaccatctc ttgccgggca 240
agtcagtgga ttgggtctca gttatcttgg taccagcaga aaccagggga agcccctaag 300
ctcctgatca tgtggcgttc ctcgttgcaa agtggggtcc catcacgttt cagtggcagt 360
ggatctggga cagatttcac tctcaccatc agcagtctgc aacctgaaga ttttgctacg 420
tactactgtg ctcagggtgc ggcgttgcct aggacgttcg gccaagggac caaggtggaa 480
atcaaacgg 489
<210> 315
<211> 163
<212> PRT
<213> Homo sapien
<400> 315
His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys Gln Met Glu Glu
1 5 10 15
Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn Gly Gly Pro Ser
20 25 30
Ser Gly Ala Pro Pro Pro Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
50 55 60
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
65 70 75 80
Ser Arg Pro Ile Gly Thr Thr Leu Ser Trp Tyr Gln Gln Lys Pro Gly
85 90 95
Lys Ala Pro Lys Leu Leu Ile Trp Phe Gly Ser Arg Leu Gln Ser Gly
100 105 110
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Ala
130 135 140
Gln Ala Gly Thr His Pro Thr Thr Phe Gly Gln Gly Thr Lys Val Glu
145 150 155 160
Ile Lys Arg
<210> 316
<211> 489
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 316
catggtgaag gaacatttac cagtgacttg tcaaaacaga tggaagagga ggcagtgcgg 60
ttatttattg agtggcttaa gaacggagga ccaagtagcg gggcacctcc gccatcgggt 120
ggtggaggcg gttcaggcgg aggtggcagc ggcggtggcg ggtcggacat ccagatgacc 180
cagtctccat cctccctgtc tgcatctgta ggagaccgtg tcaccatcac ttgccgggca 240
agtcgtccga ttgggacgac gttaagttgg taccagcaga aaccagggaa agcccctaag 300
ctcctgatct ggtttggttc ccggttgcaa agtggggtcc catcacgttt cagtggcagt 360
ggatctggga cagatttcac tctcaccatc agcagtctgc aacctgaaga ttttgctacg 420
tactactgtg cgcaggctgg gacgcatcct acgacgttcg gccaagggac caaggtggaa 480
atcaaacgg 489
<210> 317
<211> 163
<212> PRT
<213> Homo sapien
<400> 317
His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys Gln Met Glu Glu
1 5 10 15
Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn Gly Gly Pro Ser
20 25 30
Ser Gly Ala Pro Pro Pro Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
50 55 60
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
65 70 75 80
Ser Arg Pro Ile Gly Thr Met Leu Ser Trp Tyr Gln Gln Lys Pro Gly
85 90 95
Lys Ala Pro Lys Leu Leu Ile Leu Phe Gly Ser Arg Leu Gln Ser Gly
100 105 110
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Ala
130 135 140
Gln Ala Gly Thr His Pro Thr Thr Phe Gly Gln Gly Thr Lys Val Glu
145 150 155 160
Ile Lys Arg
<210> 318
<211> 489
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 318
catggtgaag gaacatttac cagtgacttg tcaaaacaga tggaagagga ggcagtgcgg 60
ttatttattg agtggcttaa gaacggagga ccaagtagcg gggcacctcc gccatcgggt 120
ggtggaggcg gttcaggcgg aggtggcagc ggcggtggcg ggtcggacat ccagatgacc 180
cagtctccat cctccctgtc tgcatctgta ggagaccgtg tcaccatcac ttgccgggca 240
agtcgtccga ttgggacgat gttaagttgg taccagcaga aaccagggaa agcccctaag 300
ctcctgatct tgtttggttc ccggttgcaa agtggggtcc catcacgttt cagtggcagt 360
ggatctggga cagatttcac tctcaccatc agcagtctgc aacctgaaga ttttgctacg 420
tactactgtg cgcaggctgg gacgcatcct acgacgttcg gccaagggac caaggtggaa 480
atcaaacgg 489
<210> 319
<211> 163
<212> PRT
<213> Homo sapien
<400> 319
His Gly Glu Gly Thr Phe Thr Ser Asp Leu Ser Lys Gln Met Glu Glu
1 5 10 15
Glu Ala Val Arg Leu Phe Ile Glu Trp Leu Lys Asn Gly Gly Pro Ser
20 25 30
Ser Gly Ala Pro Pro Pro Ser Gly Gly Gly Gly Gly Ser Gly Gly Gly
35 40 45
Gly Ser Gly Gly Gly Gly Ser Asp Ile Gln Met Thr Gln Ser Pro Ser
50 55 60
Ser Leu Ser Ala Ser Val Gly Asp Arg Val Thr Ile Thr Cys Arg Ala
65 70 75 80
Ser Arg Pro Ile Gly Thr Met Leu Ser Trp Tyr Gln Gln Lys Pro Gly
85 90 95
Lys Ala Pro Lys Leu Leu Ile Leu Ala Phe Ser Arg Leu Gln Ser Gly
100 105 110
Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr Leu
115 120 125
Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys Ala
130 135 140
Gln Ala Gly Thr His Pro Thr Thr Phe Gly Gln Gly Thr Lys Val Glu
145 150 155 160
Ile Lys Arg
<210> 320
<211> 489
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 320
catggtgaag gaacatttac cagtgacttg tcaaaacaga tggaagagga ggcagtgcgg 60
ttatttattg agtggcttaa gaacggagga ccaagtagcg gggcacctcc gccatcgggt 120
ggtggaggcg gttcaggcgg aggtggcagc ggcggtggcg ggtcggacat ccagatgacc 180
cagtctccat cctccctgtc tgcatctgta ggagaccgtg tcaccatcac ttgccgggca 240
agtcgtccga ttgggacgat gttaagttgg taccagcaga aaccagggaa agcccctaag 300
ctcctgatcc ttgctttttc ccgtttgcaa agtggggtcc catcacgttt cagtggcagt 360
ggatctggga cagatttcac tctcaccatc agcagtctgc aacctgaaga ttttgctacg 420
tactactgcg cgcaggctgg gacgcatcct acgacgttcg gccaagggac caaggtggaa 480
atcaaacgg 489
<210> 321
<211> 114
<212> PRT
<213> Homo sapien
<400> 321
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Trp Ile Gly Ser Gln
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Met Trp Arg Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Gly Leu Arg His Pro Lys
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Gly Gly Gly Gly
100 105 110
Ser Cys
<210> 322
<211> 345
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 322
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtca gtggattggg tctcagttat cttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatcatgtgg cgttcctcgt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgctcag ggtttgaggc atcctaagac gttcggccaa 300
gggaccaagg tggaaatcaa acggggtggc ggagggggtt cctgt 345
<210> 323
<211> 115
<212> PRT
<213> Homo sapien
<400> 323
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Trp Ile Gly Ser Gln
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Met Trp Arg Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Gly Leu Arg His Pro Lys
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Thr Val Ala Ala
100 105 110
Pro Ser Cys
115
<210> 324
<211> 345
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 324
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtca gtggattggg tctcagttat cttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatcatgtgg cgttcctcgt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgctcag ggtttgaggc atcctaagac gttcggccaa 300
gggaccaagg tggaaatcaa acggaccgtc gctgctccat cttgt 345
<210> 325
<211> 235
<212> PRT
<213> Mouse
<400> 325
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Arg Tyr
20 25 30
Ser Met Gly Trp Leu Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Arg Ile Asp Ser Tyr Gly Arg Gly Thr Tyr Tyr Glu Asp Pro Val
50 55 60
Lys Gly Arg Phe Ser Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Ser Gln Phe Gly Ser Asn Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ser Ala Ser Thr Ser Gly Pro Ser Asp
115 120 125
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp
130 135 140
Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Thr Leu
145 150 155 160
Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Trp
165 170 175
Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
180 185 190
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
195 200 205
Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr Thr
210 215 220
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
225 230 235
<210> 326
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino acid plus nucleotide plus myc tag sequence
<400> 326
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Arg Tyr
20 25 30
Ser Met Gly Trp Leu Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Arg Ile Asp Ser Tyr Gly Arg Gly Thr Tyr Tyr Glu Asp Pro Val
50 55 60
Lys Gly Arg Phe Ser Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Ser Gln Phe Gly Ser Asn Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ser Ala Ser Thr Ser Gly Pro Ser Asp
115 120 125
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp
130 135 140
Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Thr Leu
145 150 155 160
Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Trp
165 170 175
Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
180 185 190
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
195 200 205
Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr Thr
210 215 220
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Ala Ala Ala Glu Gln
225 230 235 240
Lys Leu Ile Ser Glu Glu Asp Leu Asn
245
<210> 327
<211> 705
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 327
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttaat aggtatagta tggggtggct ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacgg attgattctt atggtcgtgg tacatactac 180
gaagaccccg tgaagggccg gttcagcatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgccgtat attactgtgc gaaaatttct 300
cagtttgggt caaatgcgtt tgactactgg ggtcagggaa cccaggtcac cgtctcgagc 360
gctagcacca gtggtccatc ggacatccag atgacccagt ctccatcctc cctgtctgca 420
tctgtaggag accgtgtcac catcacttgc cgggcaagtc gtccgattgg gacgacgtta 480
agttggtacc agcagaaacc agggaaagcc cctaagctcc tgatctggtt tggttcccgg 540
ttgcaaagtg gggtcccatc acgtttcagt ggcagtggat ctgggacaga tttcactctc 600
accatcagca gtctgcaacc tgaagatttt gctacgtact actgtgcgca ggctgggacg 660
catcctacga cgttcggcca agggaccaag gtggaaatca aacgg 705
<210> 328
<211> 750
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide plus myc tag sequence
<400> 328
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttaat aggtatagta tggggtggct ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacgg attgattctt atggtcgtgg tacatactac 180
gaagaccccg tgaagggccg gttcagcatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgccgtat attactgtgc gaaaatttct 300
cagtttgggt caaatgcgtt tgactactgg ggtcagggaa cccaggtcac cgtctcgagc 360
gctagcacca gtggtccatc ggacatccag atgacccagt ctccatcctc cctgtctgca 420
tctgtaggag accgtgtcac catcacttgc cgggcaagtc gtccgattgg gacgacgtta 480
agttggtacc agcagaaacc agggaaagcc cctaagctcc tgatctggtt tggttcccgg 540
ttgcaaagtg gggtcccatc acgtttcagt ggcagtggat ctgggacaga tttcactctc 600
accatcagca gtctgcaacc tgaagatttt gctacgtact actgtgcgca ggctgggacg 660
catcctacga cgttcggcca agggaccaag gtggaaatca aacgggcggc cgcagaacaa 720
aaactcatct cagaagagga tctgaattaa 750
<210> 329
<211> 235
<212> PRT
<213> Homo sapien
<400> 329
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Arg Tyr
20 25 30
Ser Met Gly Trp Leu Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Arg Ile Asp Ser Tyr Gly Arg Gly Thr Tyr Tyr Glu Asp Pro Val
50 55 60
Lys Gly Arg Phe Ser Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Ser Gln Phe Gly Ser Asn Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ser Ala Ser Thr Ser Gly Pro Ser Asp
115 120 125
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp
130 135 140
Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met Leu
145 150 155 160
Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Leu
165 170 175
Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
180 185 190
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
195 200 205
Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr Thr
210 215 220
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
225 230 235
<210> 330
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino acid plus nucleotide plus myc tag sequence
<400> 330
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Arg Tyr
20 25 30
Ser Met Gly Trp Leu Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Arg Ile Asp Ser Tyr Gly Arg Gly Thr Tyr Tyr Glu Asp Pro Val
50 55 60
Lys Gly Arg Phe Ser Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Ser Gln Phe Gly Ser Asn Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ser Ala Ser Thr Ser Gly Pro Ser Asp
115 120 125
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp
130 135 140
Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met Leu
145 150 155 160
Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Leu
165 170 175
Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
180 185 190
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
195 200 205
Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr Thr
210 215 220
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Ala Ala Ala Glu Gln
225 230 235 240
Lys Leu Ile Ser Glu Glu Asp Leu Asn
245
<210> 331
<211> 705
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide plus myc tag sequence
<400> 331
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttaat aggtatagta tggggtggct ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacgg attgattctt atggtcgtgg tacatactac 180
gaagaccccg tgaagggccg gttcagcatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgccgtat attactgtgc gaaaatttct 300
cagtttgggt caaatgcgtt tgactactgg ggtcagggaa cccaggtcac cgtctcgagc 360
gctagcacca gtggtccatc ggacatccag atgacccagt ctccatcctc cctgtctgca 420
tctgtaggag accgtgtcac catcacttgc cgggcaagtc gtccgattgg gacgatgtta 480
agttggtacc agcagaaacc agggaaagcc cctaagctcc tgatcttgtt tggttcccgg 540
ttgcaaagtg gggtcccatc acgtttcagt ggcagtggat ctgggacaga tttcactctc 600
accatcagca gtctgcaacc tgaagatttt gctacgtact actgtgcgca ggctgggacg 660
catcctacga cgttcggcca agggaccaag gtggaaatca aacgg 705
<210> 332
<211> 750
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide plus myc tag sequence
<400> 332
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttaat aggtatagta tggggtggct ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacgg attgattctt atggtcgtgg tacatactac 180
gaagaccccg tgaagggccg gttcagcatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgccgtat attactgtgc gaaaatttct 300
cagtttgggt caaatgcgtt tgactactgg ggtcagggaa cccaggtcac cgtctcgagc 360
gctagcacca gtggtccatc ggacatccag atgacccagt ctccatcctc cctgtctgca 420
tctgtaggag accgtgtcac catcacttgc cgggcaagtc gtccgattgg gacgatgtta 480
agttggtacc agcagaaacc agggaaagcc cctaagctcc tgatcttgtt tggttcccgg 540
ttgcaaagtg gggtcccatc acgtttcagt ggcagtggat ctgggacaga tttcactctc 600
accatcagca gtctgcaacc tgaagatttt gctacgtact actgtgcgca ggctgggacg 660
catcctacga cgttcggcca agggaccaag gtggaaatca aacgggcggc cgcagaacaa 720
aaactcatct cagaagagga tctgaattaa 750
<210> 333
<211> 235
<212> PRT
<213> Homo sapien
<400> 333
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Arg Tyr
20 25 30
Ser Met Gly Trp Leu Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Arg Ile Asp Ser Tyr Gly Arg Gly Thr Tyr Tyr Glu Asp Pro Val
50 55 60
Lys Gly Arg Phe Ser Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Ser Gln Phe Gly Ser Asn Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ser Ala Ser Thr Ser Gly Pro Ser Asp
115 120 125
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp
130 135 140
Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met Leu
145 150 155 160
Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Leu
165 170 175
Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
180 185 190
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
195 200 205
Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr Thr
210 215 220
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
225 230 235
<210> 334
<211> 249
<212> PRT
<213> Artificial Sequence
<220>
<223> Amino acid plus nucleotide plus myc tag sequence
<400> 334
Glu Val Gln Leu Leu Glu Ser Gly Gly Gly Leu Val Gln Pro Gly Gly
1 5 10 15
Ser Leu Arg Leu Ser Cys Ala Ala Ser Gly Phe Thr Phe Asn Arg Tyr
20 25 30
Ser Met Gly Trp Leu Arg Gln Ala Pro Gly Lys Gly Leu Glu Trp Val
35 40 45
Ser Arg Ile Asp Ser Tyr Gly Arg Gly Thr Tyr Tyr Glu Asp Pro Val
50 55 60
Lys Gly Arg Phe Ser Ile Ser Arg Asp Asn Ser Lys Asn Thr Leu Tyr
65 70 75 80
Leu Gln Met Asn Ser Leu Arg Ala Glu Asp Thr Ala Val Tyr Tyr Cys
85 90 95
Ala Lys Ile Ser Gln Phe Gly Ser Asn Ala Phe Asp Tyr Trp Gly Gln
100 105 110
Gly Thr Gln Val Thr Val Ser Ser Ala Ser Thr Ser Gly Pro Ser Asp
115 120 125
Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly Asp
130 135 140
Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met Leu
145 150 155 160
Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile Leu
165 170 175
Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly Ser
180 185 190
Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro Glu
195 200 205
Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr Thr
210 215 220
Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg Ala Ala Ala Glu Gln
225 230 235 240
Lys Leu Ile Ser Glu Glu Asp Leu Asn
245
<210> 335
<211> 705
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 335
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttaat aggtatagta tggggtggct ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacgg attgattctt atggtcgtgg tacatactac 180
gaagaccccg tgaagggccg gttcagcatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgccgtat attactgtgc gaaaatttct 300
cagtttgggt caaatgcgtt tgactactgg ggtcagggaa cccaggtcac cgtctcgagc 360
gctagcacca gtggtccatc ggacatccag atgacccagt ctccatcctc cctgtctgca 420
tctgtaggag accgtgtcac catcacttgc cgggcaagtc gtccgattgg gacgatgtta 480
agttggtacc agcagaaacc agggaaagcc cctaagctcc tgatccttgc tttttcccgt 540
ttgcaaagtg gggtcccatc acgtttcagt ggcagtggat ctgggacaga tttcactctc 600
accatcagca gtctgcaacc tgaagatttt gctacgtact actgcgcgca ggctgggacg 660
catcctacga cgttcggcca agggaccaag gtggaaatca aacgg 705
<210> 336
<211> 750
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide plus myc tag sequence
<400> 336
gaggtgcagc tgttggagtc tgggggaggc ttggtacagc ctggggggtc cctgcgtctc 60
tcctgtgcag cctccggatt cacctttaat aggtatagta tggggtggct ccgccaggct 120
ccagggaagg gtctagagtg ggtctcacgg attgattctt atggtcgtgg tacatactac 180
gaagaccccg tgaagggccg gttcagcatc tcccgcgaca attccaagaa cacgctgtat 240
ctgcaaatga acagcctgcg tgccgaggac accgccgtat attactgtgc gaaaatttct 300
cagtttgggt caaatgcgtt tgactactgg ggtcagggaa cccaggtcac cgtctcgagc 360
gctagcacca gtggtccatc ggacatccag atgacccagt ctccatcctc cctgtctgca 420
tctgtaggag accgtgtcac catcacttgc cgggcaagtc gtccgattgg gacgatgtta 480
agttggtacc agcagaaacc agggaaagcc cctaagctcc tgatccttgc tttttcccgt 540
ttgcaaagtg gggtcccatc acgtttcagt ggcagtggat ctgggacaga tttcactctc 600
accatcagca gtctgcaacc tgaagatttt gctacgtact actgcgcgca ggctgggacg 660
catcctacga cgttcggcca agggaccaag gtggaaatca aacgggcggc cgcagaacaa 720
aaactcatct cagaagagga tctgaattaa 750
<210> 337
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 337
Ser Gln Ser Ile Ser Ser Tyr Leu Asn
1 5
<210> 338
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 338
Tyr Ala Ala Ser Ser Leu Gln Ser
1 5
<210> 339
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 339
Gln Gln Ser Tyr Ser Thr Pro Asn Thr
1 5
<210> 340
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 340
Ser Arg Pro Ile Gly Thr Thr Leu Ser
1 5
<210> 341
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 341
Trp Phe Gly Ser Arg Leu Gln Ser
1 5
<210> 342
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 342
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 343
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 343
Ser Arg Pro Ile Gly Thr Met Leu Ser
1 5
<210> 344
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 344
Leu Phe Gly Ser Arg Leu Gln Ser
1 5
<210> 345
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 345
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 346
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 346
Ser Arg Pro Ile Gly Thr Met Leu Ser
1 5
<210> 347
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 347
Leu Ala Phe Ser Arg Leu Gln Ser
1 5
<210> 348
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 348
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 349
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 349
Ser Arg Pro Ile Gly Thr Met Leu Ser
1 5
<210> 350
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 350
Trp Phe Gly Ser Arg Leu Gln Ser
1 5
<210> 351
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 351
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 352
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 352
Ser Arg Pro Ile Gly Thr Met Leu Ser
1 5
<210> 353
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 353
Leu Phe Gly Ser Arg Leu Gln Ser
1 5
<210> 354
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 354
Ala Gln Thr Gly Thr His Pro Thr Thr
1 5
<210> 355
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 355
Ser Arg Pro Ile Gly Thr Thr Leu Ser
1 5
<210> 356
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 356
Leu Trp Phe Ser Arg Leu Gln Ser
1 5
<210> 357
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 357
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 358
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> AlbudAb
<400> 358
Ser Gln Trp Ile Gly Ser Gln Leu Ser
1 5
<210> 359
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 359
Met Trp Arg Ser Ser Leu Gln Ser
1 5
<210> 360
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 360
Ala Gln Gly Ala Ala Leu Pro Arg Thr
1 5
<210> 361
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 361
Ser Gln Trp Ile Gly Ser Gln Leu Ser
1 5
<210> 362
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 362
Met Trp Arg Ser Ser Leu Gln Ser
1 5
<210> 363
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 363
Ala Gln Gly Leu Arg His Pro Lys Thr
1 5
<210> 364
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 364
Ser Gln Trp Ile Gly Ser Gln Leu Ser
1 5
<210> 365
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 365
Met Trp Arg Ser Ser Leu Gln Ser
1 5
<210> 366
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 366
Ala Gln Gly Leu Met Lys Pro Met Thr
1 5
<210> 367
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 367
Ser Gln Trp Ile Gly Ser Gln Leu Ser
1 5
<210> 368
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 368
Met Trp Arg Ser Ser Leu Gln Ser
1 5
<210> 369
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 369
Ala Gln Gly Ala Ala Leu Pro Arg Thr
1 5
<210> 370
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 370
Ser Gln Trp Ile Gly Ser Gln Leu Ser
1 5
<210> 371
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 371
Met Trp Arg Ser Ser Leu Gln Ser
1 5
<210> 372
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 372
Ala Gln Gly Ala Ala Leu Pro Lys Thr
1 5
<210> 373
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 373
Ser Gln Trp Ile Gly Ser Gln Leu Ser
1 5
<210> 374
<211> 8
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 374
Met Trp Arg Ser Ser Leu Gln Ser
1 5
<210> 375
<211> 9
<212> PRT
<213> Artificial Sequence
<220>
<223> CDR
<400> 375
Ala Gln Gly Phe Lys Lys Pro Arg Thr
1 5
<210> 376
<211> 165
<212> PRT
<213> Homo sapien
<400> 376
Cys Asp Leu Pro Gln Thr His Ser Leu Gly Ser Arg Arg Thr Leu Met
1 5 10 15
Leu Leu Ala Gln Met Arg Arg Ile Ser Leu Phe Ser Cys Leu Lys Asp
20 25 30
Arg His Asp Phe Gly Phe Pro Gln Glu Glu Phe Gly Asn Gln Phe Gln
35 40 45
Lys Ala Glu Thr Ile Pro Val Leu His Glu Met Ile Gln Gln Ile Phe
50 55 60
Asn Leu Phe Ser Thr Lys Asp Ser Ser Ala Ala Trp Asp Glu Thr Leu
65 70 75 80
Leu Asp Lys Phe Tyr Thr Glu Leu Tyr Gln Gln Leu Asn Asp Leu Glu
85 90 95
Ala Cys Val Ile Gln Gly Val Gly Val Thr Glu Thr Pro Leu Met Lys
100 105 110
Glu Asp Ser Ile Leu Ala Val Arg Lys Tyr Phe Gln Arg Ile Thr Leu
115 120 125
Tyr Leu Lys Glu Lys Lys Tyr Ser Pro Cys Ala Trp Glu Val Val Arg
130 135 140
Ala Glu Ile Met Arg Ser Phe Ser Leu Ser Thr Asn Leu Gln Glu Ser
145 150 155 160
Leu Arg Ser Lys Glu
165
<210> 377
<211> 495
<212> DNA
<213> Artificial Sequence
<220>
<223> Interferon alpha 2b nucleotide
<400> 377
tgtgatctgc ctcaaaccca cagcctgggt agcaggagga ccttgatgct cctggcacag 60
atgaggagaa tctctctttt ctcctgcttg aaggacagac atgactttgg atttccccag 120
gaggagtttg gcaaccagtt ccaaaaggct gaaaccatcc ctgtcctcca tgagatgatc 180
cagcagatct tcaatctctt cagcacaaag gactcatctg ctgcttggga tgagaccctc 240
ctagacaaat tctacactga actctaccag cagctgaatg acctggaagc ctgtgtgata 300
cagggggtgg gggtgacaga gactcccctg atgaaggagg actccattct ggctgtgagg 360
aaatacttcc aaagaatcac tctctatctg aaagagaaga aatacagccc ttgtgcctgg 420
gaggttgtca gagcagaaat catgagatct ttttctttgt caacaaactt gcaagaaagt 480
ttaagaagta aggaa 495
<210> 378
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> IFN2b SOE fragment 5'
<400> 378
gcccggatcc accggctgtg atctg 25
<210> 379
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> IFN2b SOE fragment 3'
<400> 379
ggaggatgga gactgggtca tctggatgtc 30
<210> 380
<211> 30
<212> DNA
<213> Artificial Sequence
<220>
<223> Vk SOE fragment 5'
<400> 380
gacatccaga tgacccagtc tccatcctcc 30
<210> 381
<211> 82
<212> DNA
<213> Artificial Sequence
<220>
<223> Vk SOE fragment 3' to also introduce a myc tag
<400> 381
gcgcaagctt ttattaattc agatcctctt ctgagatgag tttttgttct gcggccgccc 60
gtttgatttc caccttggtc cc 82
<210> 382
<211> 25
<212> DNA
<213> Artificial Sequence
<220>
<223> IFN2b SOE fragment 5'
<400> 382
gcccggatcc accggctgtg atctg 25
<210> 383
<211> 82
<212> DNA
<213> Artificial Sequence
<220>
<223> NucleotideVk SOE fragment 3' to also introduce a
myc tag
<400> 383
gcgcaagctt ttattaattc agatcctctt ctgagatgag tttttgttct gcggccgccc 60
gtttgatttc caccttggtc cc 82
<210> 384
<211> 20
<212> PRT
<213> Mouse
<400> 384
Met Glu Thr Asp Thr Leu Leu Leu Trp Val Leu Leu Leu Trp Val Pro
1 5 10 15
Gly Ser Thr Gly
20
<210> 385
<211> 61
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 385
atggagaccg acaccctgct gctgtgggtg ctgctgctgt gggtgcccgg atccaccggg 60
c 61
<210> 386
<211> 108
<212> PRT
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 386
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Gln Trp Ile Gly Ser Gln
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Met Trp Arg Ser Ser Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Gly Leu Arg His Pro Lys
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Cys
100 105
<210> 387
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 387
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtca gtggattggg tctcagttat cttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatcatgtgg cgttcctcgt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgctcag ggtttgaggc atcctaagac gttcggccaa 300
gggaccaagg tggaaatcaa atgc 324
<210> 388
<211> 108
<212> PRT
<213> Homo sapien
<400> 388
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Pro Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 389
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> nucleic acid
<400> 389
gacatccaga tgacccagtc tccatcctcc ctgcctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgcgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 390
<211> 62
<212> DNA
<213> Primer
<400> 390
gcaacagcgt cgacggacat ccagatgacc cagtctccat cctccctgcc tgcatctgta 60
gg 62
<210> 391
<211> 32
<212> PRT
<213> Homo sapien
<400> 391
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 392
<211> 9
<212> PRT
<213> Homo sapien
<400> 392
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 393
<211> 32
<212> PRT
<213> Homo sapien
<400> 393
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Asn Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 394
<211> 9
<212> PRT
<213> Homo sapien
<400> 394
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 395
<211> 32
<212> PRT
<213> Homo sapien
<400> 395
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Val Ala Thr Tyr Tyr Cys
20 25 30
<210> 396
<211> 9
<212> PRT
<213> Homo sapien
<400> 396
Ala Gln Ala Gly Thr His Pro Thr Thr
1 5
<210> 397
<211> 32
<212> PRT
<213> Homo sapien
<400> 397
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 398
<211> 9
<212> PRT
<213> Homo sapien
<400> 398
Ala Gln Ala Gly Thr His His Thr Thr
1 5
<210> 399
<211> 32
<212> PRT
<213> Homo sapien
<400> 399
Gly Val Pro Ser Arg Phe Ser Gly Ser Gly Ser Gly Thr Asp Phe Thr
1 5 10 15
Leu Thr Ile Ser Ser Leu Gln Pro Glu Asp Phe Ala Thr Tyr Tyr Cys
20 25 30
<210> 400
<211> 9
<212> PRT
<213> Homo sapien
<400> 400
Ala Gln Ala Gly Val His Pro Thr Thr
1 5
<210> 401
<211> 96
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 401
ggggtcccat cacgtttcag tggcagtgga tctgggacag atttcactct caccatcagc 60
agtctgcaac ctgaagattt tgctacgtac tactgc 96
<210> 402
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 402
gcgcaggctg ggacgcatcc tacgacg 27
<210> 403
<211> 96
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 403
ggggtcccat cacgtttcag tggcagtgga tctgggacag atttcactct caccatcagc 60
aatctgcaac ctgaagattt tgctacgtac tactgc 96
<210> 404
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 404
gcgcaggctg ggacgcatcc tacgacg 27
<210> 405
<211> 96
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 405
ggggtcccat cacgtttcag tggcagtgga tctgggacag atttcactct caccatcagc 60
agtctgcaac ctgaagatgt tgctacgtac tactgt 96
<210> 406
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 406
gcgcaggctg ggacgcatcc tacgacg 27
<210> 407
<211> 96
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 407
ggggtcccat cacgtttcag tggcagtgga tctgggacag atttcactct caccatcagc 60
agtctgcaac ctgaagattt tgctacgtac tactgt 96
<210> 408
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 408
gcgcaggctg ggacgcatca tacgacg 27
<210> 409
<211> 20
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 409
attttgctac gtactactgt 20
<210> 410
<211> 27
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 410
gcgcaggctg gggtgcatcc tacgacg 27
<210> 411
<211> 108
<212> PRT
<213> Homo sapien
<400> 411
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Trp
100 105
<210> 412
<211> 108
<212> PRT
<213> Homo sapien
<400> 412
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Ser Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Trp
100 105
<210> 413
<211> 108
<212> PRT
<213> Homo sapien
<400> 413
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Trp
100 105
<210> 414
<211> 108
<212> PRT
<213> Homo sapien
<400> 414
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Trp
100 105
<210> 415
<211> 108
<212> PRT
<213> Homo sapien
<400> 415
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His His Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Asn Lys Trp
100 105
<210> 416
<211> 108
<212> PRT
<213> Homo sapien
<400> 416
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Glu Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Thr Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Trp
100 105
<210> 417
<211> 108
<212> PRT
<213> Homo sapien
<400> 417
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Val His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 418
<211> 108
<212> PRT
<213> Homo sapien
<400> 418
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Thr Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Trp
100 105
<210> 419
<211> 108
<212> PRT
<213> Homo sapien
<400> 419
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Phe Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Trp
100 105
<210> 420
<211> 108
<212> PRT
<213> Homo sapien
<400> 420
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Asn Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 421
<211> 108
<212> PRT
<213> Homo sapien
<400> 421
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Val Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 422
<211> 108
<212> PRT
<213> Homo sapien
<400> 422
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His His Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
<210> 423
<211> 108
<212> PRT
<213> Homo sapien
<400> 423
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Met
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Leu Ala Phe Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His His Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Asn Lys Arg
100 105
<210> 424
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 424
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgcgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa atgg 324
<210> 425
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 425
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atctcttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgcgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa atgg 324
<210> 426
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 426
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcaa tctgcaacct 240
gaagattttg ctacgtacta ctgcgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa atgg 324
<210> 427
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 427
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagatgttg ctacgtacta ctgtgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa atgg 324
<210> 428
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 428
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag gctgggacgc atcatacgac gttcggccaa 300
gggaccaagg tggaaaacaa atgg 324
<210> 429
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 429
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
ggggaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag actgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa atgg 324
<210> 430
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 430
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag gctggggtgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 431
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 431
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag actgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa atgg 324
<210> 432
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 432
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcttttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgcgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa atgg 324
<210> 433
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 433
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcaa tctgcaacct 240
gaagattttg ctacgtacta ctgcgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 434
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 434
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagatgttg ctacgtacta ctgtgcgcag gctgggacgc atcctacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 435
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 435
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag gctgggacgc atcatacgac gttcggccaa 300
gggaccaagg tggaaatcaa acgg 324
<210> 436
<211> 324
<212> DNA
<213> Artificial Sequence
<220>
<223> Nucleotide
<400> 436
gacatccaga tgacccagtc tccatcctcc ctgtctgcat ctgtaggaga ccgtgtcacc 60
atcacttgcc gggcaagtcg tccgattggg acgatgttaa gttggtacca gcagaaacca 120
gggaaagccc ctaagctcct gatccttgct ttttcccgtt tgcaaagtgg ggtcccatca 180
cgtttcagtg gcagtggatc tgggacagat ttcactctca ccatcagcag tctgcaacct 240
gaagattttg ctacgtacta ctgtgcgcag gctgggacgc atcatacgac gttcggccaa 300
gggaccaagg tggaaaacaa acgg 324
<210> 437
<211> 6
<212> PRT
<213> Artificial Sequence
<220>
<223> Linker
<400> 437
Thr Val Ala Ala Pro Ser
1 5
<210> 438
<211> 108
<212> PRT
<213> Homo sapien
<400> 438
Asp Ile Gln Met Thr Gln Ser Pro Ser Ser Leu Ser Ala Ser Val Gly
1 5 10 15
Asp Arg Val Thr Ile Thr Cys Arg Ala Ser Arg Pro Ile Gly Thr Thr
20 25 30
Leu Ser Trp Tyr Gln Gln Lys Pro Gly Lys Ala Pro Lys Leu Leu Ile
35 40 45
Trp Phe Gly Ser Arg Leu Gln Ser Gly Val Pro Ser Arg Phe Ser Gly
50 55 60
Ser Gly Ser Gly Thr Asp Phe Thr Leu Thr Ile Ser Ser Leu Gln Pro
65 70 75 80
Glu Asp Phe Ala Thr Tyr Tyr Cys Ala Gln Ala Gly Thr His Pro Thr
85 90 95
Thr Phe Gly Gln Gly Thr Lys Val Glu Ile Lys Arg
100 105
Claims (42)
- 적어도 54℃의 Tm을 갖는, DOM7h-11(DOM7h-11은 도 1에 도시됨(SEQ ID NO:438))의 항-혈청 알부민(SA) 면역글로불린 단일 가변 도메인 변이체.
- 제 1항에 있어서, 상기 변이체가 DOM7h-11에 비해 위치 22, 42 또는 91(케이뱃(Kabat)에 따른 넘버링) 중 임의의 위치에 적어도 하나의 돌연변이를 포함하는 항-SA 면역글로불린.
- 제 2항에 있어서, 상기 변이체가 DOM7h-11-15(DOM7h-11-15는 도 1에 도시됨(SEQ ID NO:2))의 변이체이고, DOM7h-11-15에 비해 위치 22, 42, 또는 91(케이뱃에 따른 넘버링) 중 임의의 위치에 적어도 하나의 돌연변이를 포함하는 항-SA 면역글로불린.
- 제 1항 내지 제 3항 중 어느 한 항에 있어서, 변이체가 하기로부터 선택된 적어도 하나의 돌연변이를 포함하는 변이체:
위치 22 = Ser, Phe, Thr, Ala 또는 Cys;
위치 42 = Glu 또는 Asp;
위치 91 = Thr 또는 Ser. - 제 4항에 있어서, 위치 22가 Ser 또는 Phe인 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 4항에 있어서, 위치 42가 Glu이고, 위치 91이 Thr인 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 4항에 있어서, 위치 91이 Thr인 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 4항에 있어서, 위치 22가 Phe인 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 1항 또는 제 2항에 있어서, 변이체가 DOM7h-11-56(SEQ ID NO:412), DOM7h-11-68(SEQ ID NO:416), DOM7h-11-79(SEQ ID NO:418) 및 DOM7h-11-80(SEQ ID NO:419)으로부터 선택된 단일 가변 도메인의 아미노산 서열과 동일하거나, 선택된 아미노산 서열에 비해 4개 이하의 변화를 갖는 아미노산 서열을 포함하는 변이체.
- 제 1항에 있어서, 변이체가 DOM7h-11에 비해 FW3 영역(위치 57 내지 88, 케이뱃에 따른 넘버링) 또는 CDR3 영역(위치 89 내지 97, 케이뱃에 따른 넘버링) 내에 적어도 하나의 돌연변이를 포함하는 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 7항에 있어서, 상기 변이체가 DOM7h-11-15(DOM7h-11-15는 도 1에 도시됨)의 변이체이고, DOM7h-11-15에 비해 FW3 영역(위치 57 내지 88, 케이뱃에 따른 넘버링) 또는 CDR3 영역(위치 89 내지 97, 케이뱃에 따른 넘버링) 내에 적어도 하나의 돌연변이를 포함하는 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 7항 또는 제 8항에 있어서, 상기 변이체가 위치 77, 83, 93 또는 95(케이뱃에 따른 넘버링) 중 임의의 위치에 적어도 하나의 돌연변이를 포함하는 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 7항 내지 제 9항 중 어느 한 항에 있어서, 변이체가 하기로부터 선택된 적어도 하나의 돌연변이를 포함하는 변이체:
위치 77 = Asn, Gln;
위치 83 = Val, Ile, Met, Leu, Phe, Ala 또는 노르류신;
위치 93 = Val, Ile, Met, Leu, Phe, Ala 또는 노르류신;
위치 95 = His, Asn, Gln, Lys 또는 Arg. - 제 1항 내지 제 13항 중 어느 한 항에 있어서, 위치 106 또는 108(케이뱃에 따른 넘버링)에 돌연변이를 추가로 포함하는 항-SA 면역글로불린 단일 가변 도메인.
- 제 14항에 있어서, 위치 106이 Asn 또는 Gln인 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 14항에 있어서, 위치 108이 Trp, Tyr 또는 Phe인 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 1항 내지 제 16항 중 어느 한 항에 있어서, 위치 77이 Asn인 항-SA 면역글로불린 단일 가변 도메인 변이체.
- 제 1항 내지 제 17항 중 어느 한 항에 있어서, 위치 83이 Val인 항-SA 단일 가변 도메인.
- 제 1항 내지 제 18항 중 어느 한 항에 있어서, 위치 95가 His인 항-SA 단일 가변 도메인.
- 제 1항 내지 제 19항 중 어느 한 항에 있어서, 위치 95가 His인 항-SA 단일 가변 도메인.
- 제 1항 내지 제 20항 중 어느 한 항에 있어서, 위치 93이 Val인 항-SA 단일 가변 도메인.
- 제 1항에 있어서, 변이체가 DOM7h-11-57(SEQ ID NO:413), DOM7h-11-65(SEQ ID NO:414), DOM7h-11-67(SEQ ID NO:415) 및 DOM7h-11-69(SEQ ID NO:417)로부터 선택된 단일 가변 도메인의 아미노산 서열과 동일한 아미노산 서열을 포함하거나, 선택된 아미노산 서열에 비해 4개 이하의 변화를 갖지만, 단, 변이체의 아미노산 서열이 제 1항 내지 제 12항 중 어느 한 항에 정의된 바와 같은 FW3 또는 CDR3 영역에 적어도 하나의 돌연변이를 갖는 변이체.
- 제 10항 내지 제 21항 중 어느 한 항에 있어서, 상기 변이체가 적어도 57℃의 Tm을 갖는 변이체.
- 제 1항 내지 제 23항 중 어느 한 항에 있어서, 상기 변이체가 DOM7h-11에 비해 증가된 Tm 값을 갖는 변이체.
- 제 1항 내지 제 24항 중 어느 한 항에 있어서, 상기 변이체가 DOM7h-11-15에 비해 증가된 Tm 값을 갖는 변이체.
- 제 4항 및 제 13항에 나열된 돌연변이 중 임의의 돌연변이의 임의의 조합을 포함하는 제 1항 내지 제 25항 중 어느 한 항에 따른 변이체.
- 제 1항 내지 제 26항 중 어느 한 항에 있어서, 변이체가 표면 플라즈몬 공명에 의해 결정시 약 0.1 내지 약 10000 nM, 임의로 약 1 내지 약 6000 nM의 해리상수(KD)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함하는 변이체.
- 제 1항 내지 제 27항 중 어느 한 항에 있어서, 변이체가 표면 플라즈몬 공명에 의해 결정시 약 1.5 x 10-4 내지 약 0.1 초-1, 임의로 약 3 x 10-4 내지 약 0.1 초-1의 분리속도(off-rate) 상수(Kd)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함하는 변이체.
- 제 1항 내지 제 28항 중 어느 한 항에 있어서, 변이체가 표면 플라즈몬 공명에 의해 결정시 약 2 x 106 내지 약 1 x 104 M-1초-1, 임의로 약 1 x 106 내지 약 2 x 104 M-1초-1의 결합속도(on-rate) 상수(Ka)로 인간 SA에 특이적으로 결합하는 결합 부위를 포함하는 변이체.
- 제 1항 내지 제 29항 중 어느 한 항에 있어서, 변이체가 표면 플라즈몬 공명에 의해 결정시 약 0.1 내지 약 10000 nM, 임의로 약 1 내지 약 6000 nM의 해리상수(KD)로 시노몰구스(Cynomolgus) 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함하는 변이체.
- 제 1항 내지 제 30항 중 어느 한 항에 있어서, 변이체가 표면 플라즈몬 공명에 의해 결정시 약 1.5 x 10-4 내지 약 0.1 초-1, 임의로 약 3 x 10-4 내지 약 0.1 초-1의 분리속도 상수(Kd)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함하는 변이체.
- 제 1항 내지 제 31항 중 어느 한 항에 있어서, 변이체가 표면 플라즈몬 공명에 의해 측정시 약 2 x 106 내지 약 1 x 104 M-1초-1, 임의로 약 1 x 106 내지 약 5 x 103 M-1초-1의 결합속도 상수(Ka)로 시노몰구스 원숭이 SA에 특이적으로 결합하는 결합 부위를 포함하는 변이체.
- 제 1항 내지 제 32항 중 어느 한 항의 항-SA 변이체 및 SA가 아닌 표적 항원에 특이적으로 결합하는 결합 모이어티(moiety)를 포함하는 다중특이적 리간드.
- 제 1항 내지 제 17항 중 어느 한 항에 있어서, 가변성 도메인이 약물(임의로, NCE 약물)에 컨쥬게이션되고, 임의로 선택된 변이체가 DOM7h-11-56(SEQ ID NO:412), DOM7h-11-57(SEQ ID NO:413), DOM7h-11-65(SEQ ID NO:414), DOM7h-11-67(SEQ ID NO:415), DOM7h-11-68(SEQ ID NO:416), DOM7h-11-69(SEQ ID NO:417), DOM7h-11-79(SEQ ID NO:418), DOM7h-11-80(SEQ ID NO:419), DOM7h-11-90(SEQ ID NO:420), DOM7h-11-86(SEQ ID NO:421), DOM7h-11-87(SEQ ID NO:422) 또는 DOM7h-11-88(SEQ ID NO:423)인 항-SA 변이체 단일 가변 도메인.
- 제 1항 내지 제 17항 중 어느 한 항에 따른 변이체에 융합된 폴리펩티드 또는 펩티드 약물을 포함하는 융합 단백질로서, 임의로, 선택된 변이체가 DOM7h-11-56(SEQ ID NO:412), DOM7h-11-57(SEQ ID NO:413), DOM7h-11-65(SEQ ID NO:414), DOM7h-11-67(SEQ ID NO:415), DOM7h-11-68(SEQ ID NO:416), DOM7h-11-69(SEQ ID NO:417), DOM7h-11-79(SEQ ID NO:418), DOM7h-11-80(SEQ ID NO:419), DOM7h-11-90(SEQ ID NO:420), DOM7h-11-86(SEQ ID NO:421), DOM7h-11-87(SEQ ID NO:422) 또는 DOM7h-11-88(SEQ ID NO:423)인 융합 단백질.
- 제 20항에 있어서, 융합 단백질이 변이체와 약물 사이에 링커(예를 들어, 아미노산 서열 TVA, 임의로 TVAAPS를 포함하는 링커)를 포함하는 융합 단백질.
- 제 1항 내지 제 36항 중 어느 한 항의 변이체, 융합 단백질 또는 리간드, 및 약학적으로 허용되는 희석제, 담체, 부형제 또는 비히클을 포함하는 조성물.
- 제 1항 내지 제 17항 중 어느 한 항에 따른 변이체 또는 제 18항의 다중특이적 리간드 또는 제 20항 또는 제 21항의 융합 단백질을 엔코딩하는 누클레오티드 서열을 포함하는 핵산.
- DOM7h-11-56(SEQ ID NO:425), DOM7h-11-57(SEQ ID NO:426), DOM7h-11-65(SEQ ID NO:427), DOM7h-11-67(SEQ ID NO:428), DOM7h-11-68(SEQ ID NO:429), DOM7h-11-69(SEQ ID NO:430), DOM7h-11-79(SEQ ID NO:431), DOM7h-11-80(SEQ ID NO:432), DOM7h-11-90(SEQ ID NO:433), DOM7h-11-86(SEQ ID NO:434), DOM7h-11-87(SEQ ID NO:435) 또는 DOM7h-11-88(SEQ ID NO:436)의 누클레오티드 서열 또는 상기 선택된 서열과 적어도 80% 동일한 누클레오티드 서열로부터 선택된 DOM7h-11 변이체의 누클레오티드 서열을 포함하는 핵산.
- 제 23항 내지 제 25항 중 어느 한 항의 핵산을 포함하는 벡터.
- 제 26항의 벡터를 포함하는 분리된 숙주 세포.
- 제 1항 내지 제 22항 중 어느 한 항에 따른 변이체의 적어도 1회의 용량을 환자에게 투여하는 것을 포함하는, 상기 환자의 질병 또는 장애를 치료하거나 예방하는 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US34651910P | 2010-05-20 | 2010-05-20 | |
| US61/346,519 | 2010-05-20 | ||
| PCT/EP2011/058298 WO2011144751A1 (en) | 2010-05-20 | 2011-05-20 | Improved anti-serum albumin binding variants |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20130109977A true KR20130109977A (ko) | 2013-10-08 |
Family
ID=44352234
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020127033268A Withdrawn KR20130109977A (ko) | 2010-05-20 | 2011-05-20 | 개선된 항-혈청 알부민 결합 변이체 |
Country Status (13)
| Country | Link |
|---|---|
| US (2) | US9040668B2 (ko) |
| EP (1) | EP2571900A1 (ko) |
| JP (1) | JP2013529080A (ko) |
| KR (1) | KR20130109977A (ko) |
| CN (1) | CN103003303A (ko) |
| AU (1) | AU2011254559B2 (ko) |
| BR (1) | BR112012029280A2 (ko) |
| CA (1) | CA2799633A1 (ko) |
| EA (1) | EA201291009A1 (ko) |
| IL (1) | IL222802A0 (ko) |
| MX (1) | MX2012013406A (ko) |
| SG (1) | SG185437A1 (ko) |
| WO (1) | WO2011144751A1 (ko) |
Families Citing this family (16)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| UA116217C2 (uk) | 2012-10-09 | 2018-02-26 | Санофі | Пептидна сполука як подвійний агоніст рецепторів glp1-1 та глюкагону |
| AU2013366692B2 (en) | 2012-12-21 | 2017-11-23 | Sanofi | Dual GLP1/GIP or trigonal GLP1/GIP/Glucagon agonists |
| WO2015086733A1 (en) | 2013-12-13 | 2015-06-18 | Sanofi | Dual glp-1/glucagon receptor agonists |
| EP3080152A1 (en) | 2013-12-13 | 2016-10-19 | Sanofi | Non-acylated exendin-4 peptide analogues |
| EP3080154B1 (en) | 2013-12-13 | 2018-02-07 | Sanofi | Dual glp-1/gip receptor agonists |
| WO2015086728A1 (en) | 2013-12-13 | 2015-06-18 | Sanofi | Exendin-4 peptide analogues as dual glp-1/gip receptor agonists |
| TW201625669A (zh) | 2014-04-07 | 2016-07-16 | 賽諾菲公司 | 衍生自艾塞那肽-4(Exendin-4)之肽類雙重GLP-1/升糖素受體促效劑 |
| TW201625670A (zh) | 2014-04-07 | 2016-07-16 | 賽諾菲公司 | 衍生自exendin-4之雙重glp-1/升糖素受體促效劑 |
| TW201625668A (zh) | 2014-04-07 | 2016-07-16 | 賽諾菲公司 | 作為胜肽性雙重glp-1/昇糖素受體激動劑之艾塞那肽-4衍生物 |
| US9932381B2 (en) | 2014-06-18 | 2018-04-03 | Sanofi | Exendin-4 derivatives as selective glucagon receptor agonists |
| AR105319A1 (es) | 2015-06-05 | 2017-09-27 | Sanofi Sa | Profármacos que comprenden un conjugado agonista dual de glp-1 / glucagón conector ácido hialurónico |
| TW201706291A (zh) | 2015-07-10 | 2017-02-16 | 賽諾菲公司 | 作為選擇性肽雙重glp-1/升糖素受體促效劑之新毒蜥外泌肽(exendin-4)衍生物 |
| LT3374392T (lt) * | 2015-11-13 | 2022-01-25 | Ablynx Nv | Patobulinti serumo albuminą surišantys imunoglobulino kintami domenai |
| IL263079B2 (en) | 2016-05-18 | 2024-05-01 | Modernatx Inc | Polynucleotides encoding relaxin |
| TW202448926A (zh) | 2023-02-17 | 2024-12-16 | 比利時商艾伯霖克斯公司 | 結合新生兒fc受體之多肽 |
| WO2025021183A1 (zh) * | 2023-07-27 | 2025-01-30 | 上海复宏汉霖生物医药有限公司 | 编码促肾上腺皮质激素的多核苷酸及其相关组合物和方法 |
Family Cites Families (18)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| IL127127A0 (en) | 1998-11-18 | 1999-09-22 | Peptor Ltd | Small functional units of antibody heavy chain variable regions |
| US20060002935A1 (en) | 2002-06-28 | 2006-01-05 | Domantis Limited | Tumor Necrosis Factor Receptor 1 antagonists and methods of use therefor |
| US9321832B2 (en) * | 2002-06-28 | 2016-04-26 | Domantis Limited | Ligand |
| AU2003244817B2 (en) | 2002-06-28 | 2010-08-26 | Domantis Limited | Antigen-binding immunoglobulin single variable domains and dual-specific constructs |
| ATE479760T1 (de) | 2004-03-24 | 2010-09-15 | Domantis Ltd | Universelles signalpeptid gas1 |
| TW200607523A (en) | 2004-06-01 | 2006-03-01 | Domantis Ltd | Drug compositions, fusions and conjugates |
| CN101128487B (zh) | 2004-12-02 | 2012-10-10 | 杜门蒂斯有限公司 | 靶向血清白蛋白和glp-1或pyy的双特异性结构域抗体 |
| US20100047171A1 (en) | 2006-01-24 | 2010-02-25 | Roland Beckmann | Fusion Proteins That Contain Natural Junctions |
| JP2010528647A (ja) | 2007-06-06 | 2010-08-26 | ドマンティス リミテッド | ポリペプチド、抗体可変ドメインおよびアンタゴニスト |
| GB0724331D0 (en) * | 2007-12-13 | 2008-01-23 | Domantis Ltd | Compositions for pulmonary delivery |
| CA2688433A1 (en) * | 2007-06-06 | 2008-12-11 | Domantis Limited | Methods for selecting protease resistant polypeptides |
| US20090148905A1 (en) | 2007-11-30 | 2009-06-11 | Claire Ashman | Antigen-binding constructs |
| AU2010215479B2 (en) | 2009-02-19 | 2015-01-22 | Glaxo Group Limited | Improved anti-TNFR1 polypeptides, antibody variable domains & antagonists |
| EP2398825B1 (en) * | 2009-02-19 | 2017-10-25 | Glaxo Group Limited | Single variable domain against serum albumin |
| EP3656788A3 (en) * | 2009-02-19 | 2020-07-29 | Glaxo Group Limited | Improved anti-serum albumin binding variants |
| CN104127880A (zh) * | 2009-03-27 | 2014-11-05 | 葛兰素集团有限公司 | 药用融合体和缀合物 |
| JP2012532619A (ja) * | 2009-07-16 | 2012-12-20 | グラクソ グループ リミテッド | Tnfr1を部分的に阻害するためのアンタゴニスト、用途および方法 |
| CN104147611A (zh) | 2009-09-30 | 2014-11-19 | 葛兰素集团有限公司 | 具有延长的半衰期的药物融合体和缀合物 |
-
2011
- 2011-05-20 EP EP11720310A patent/EP2571900A1/en not_active Withdrawn
- 2011-05-20 AU AU2011254559A patent/AU2011254559B2/en not_active Ceased
- 2011-05-20 KR KR1020127033268A patent/KR20130109977A/ko not_active Withdrawn
- 2011-05-20 JP JP2013510643A patent/JP2013529080A/ja active Pending
- 2011-05-20 EA EA201291009A patent/EA201291009A1/ru unknown
- 2011-05-20 US US13/698,794 patent/US9040668B2/en not_active Expired - Fee Related
- 2011-05-20 MX MX2012013406A patent/MX2012013406A/es not_active Application Discontinuation
- 2011-05-20 BR BR112012029280A patent/BR112012029280A2/pt not_active IP Right Cessation
- 2011-05-20 WO PCT/EP2011/058298 patent/WO2011144751A1/en not_active Ceased
- 2011-05-20 CA CA2799633A patent/CA2799633A1/en not_active Abandoned
- 2011-05-20 CN CN2011800351661A patent/CN103003303A/zh active Pending
- 2011-05-20 SG SG2012081683A patent/SG185437A1/en unknown
-
2012
- 2012-11-01 IL IL222802A patent/IL222802A0/en unknown
-
2015
- 2015-04-21 US US14/691,913 patent/US20150284454A1/en not_active Abandoned
Also Published As
| Publication number | Publication date |
|---|---|
| CN103003303A (zh) | 2013-03-27 |
| EA201291009A1 (ru) | 2013-05-30 |
| SG185437A1 (en) | 2012-12-28 |
| US20150284454A1 (en) | 2015-10-08 |
| CA2799633A1 (en) | 2011-11-24 |
| IL222802A0 (en) | 2012-12-31 |
| EP2571900A1 (en) | 2013-03-27 |
| WO2011144751A1 (en) | 2011-11-24 |
| MX2012013406A (es) | 2012-12-10 |
| AU2011254559A1 (en) | 2013-01-17 |
| US20130129746A1 (en) | 2013-05-23 |
| JP2013529080A (ja) | 2013-07-18 |
| BR112012029280A2 (pt) | 2016-11-29 |
| US9040668B2 (en) | 2015-05-26 |
| AU2011254559B2 (en) | 2014-09-04 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101820968B1 (ko) | 개선된 항-혈청 알부민 결합 변이체 | |
| KR20130109977A (ko) | 개선된 항-혈청 알부민 결합 변이체 | |
| KR101819754B1 (ko) | 개선된 항-혈청 알부민 결합 변이체 | |
| KR20130055663A (ko) | 개선된 항-혈청 알부민 결합 변이체 | |
| HK40023197A (en) | Improved anti-serum albumin binding variants |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20121220 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |