KR20130133242A - 다운믹스기를 이용한 입력 신호 분해 장치 및 방법 - Google Patents
다운믹스기를 이용한 입력 신호 분해 장치 및 방법 Download PDFInfo
- Publication number
- KR20130133242A KR20130133242A KR1020137017810A KR20137017810A KR20130133242A KR 20130133242 A KR20130133242 A KR 20130133242A KR 1020137017810 A KR1020137017810 A KR 1020137017810A KR 20137017810 A KR20137017810 A KR 20137017810A KR 20130133242 A KR20130133242 A KR 20130133242A
- Authority
- KR
- South Korea
- Prior art keywords
- signal
- input
- channels
- input signal
- frequency
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images












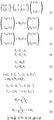

Classifications
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04R—LOUDSPEAKERS, MICROPHONES, GRAMOPHONE PICK-UPS OR LIKE ACOUSTIC ELECTROMECHANICAL TRANSDUCERS; ELECTRIC HEARING AIDS; PUBLIC ADDRESS SYSTEMS
- H04R5/00—Stereophonic arrangements
- H04R5/04—Circuit arrangements, e.g. for selective connection of amplifier inputs/outputs to loudspeakers, for loudspeaker detection, or for adaptation of settings to personal preferences or hearing impairments
-
- G—PHYSICS
- G10—MUSICAL INSTRUMENTS; ACOUSTICS
- G10L—SPEECH ANALYSIS TECHNIQUES OR SPEECH SYNTHESIS; SPEECH RECOGNITION; SPEECH OR VOICE PROCESSING TECHNIQUES; SPEECH OR AUDIO CODING OR DECODING
- G10L19/00—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis
- G10L19/02—Speech or audio signals analysis-synthesis techniques for redundancy reduction, e.g. in vocoders; Coding or decoding of speech or audio signals, using source filter models or psychoacoustic analysis using spectral analysis, e.g. transform vocoders or subband vocoders
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S3/00—Systems employing more than two channels, e.g. quadraphonic
- H04S3/008—Systems employing more than two channels, e.g. quadraphonic in which the audio signals are in digital form, i.e. employing more than two discrete digital channels
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/03—Aspects of down-mixing multi-channel audio to configurations with lower numbers of playback channels, e.g. 7.1 -> 5.1
-
- H—ELECTRICITY
- H04—ELECTRIC COMMUNICATION TECHNIQUE
- H04S—STEREOPHONIC SYSTEMS
- H04S2400/00—Details of stereophonic systems covered by H04S but not provided for in its groups
- H04S2400/15—Aspects of sound capture and related signal processing for recording or reproduction
Landscapes
- Engineering & Computer Science (AREA)
- Physics & Mathematics (AREA)
- Acoustics & Sound (AREA)
- Signal Processing (AREA)
- Multimedia (AREA)
- Computational Linguistics (AREA)
- Spectroscopy & Molecular Physics (AREA)
- Health & Medical Sciences (AREA)
- Audiology, Speech & Language Pathology (AREA)
- Human Computer Interaction (AREA)
- Stereophonic System (AREA)
- Measurement And Recording Of Electrical Phenomena And Electrical Characteristics Of The Living Body (AREA)
- Radar Systems Or Details Thereof (AREA)
- Amplifiers (AREA)
- Time-Division Multiplex Systems (AREA)
Abstract
Description
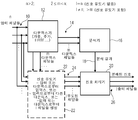
도 2는 본 발명의 추가 측면에 따른 미리-계산된 주파수 종속 상관 곡선을 가진 분석기를 사용하여, 적어도 세 개의 입력 채널들을 가진 신호를 분해하는 장치 구현을 나타내는 블록도이다.
도 3은 다운믹스, 분석 및 신호 처리에 대하여 주파수-도메인 처리하는 본 발명의 더 바람직한 구현 예를 나타낸다.
도 4는 도 1 또는 도 2에 표시된 분석을 위한 참조 곡선에 대한 미리-계산된 주파수 종속 상관 곡선의 예를 나타낸다.
도 5는 독립 요소들을 추출하기 위한 추가 처리를 나타내는 블록도이다.
도 6은 독립 확산, 독립 다이렉트 및 다이렉트 요소들이 추출되는 추가 처리에 대한 추가 구현을 나타내는 블록도이다.
도 7은 분석 신호 발생기로서 다운믹스기 구현을 나타내는 블록도이다.
도 8은 도 1 또는 도 2의 신호 분석기에서의 바람직한 처리 방식을 나타내는 흐름도를 나타낸다.
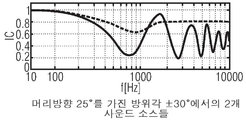
도 9a 내지 도 9e는 (라우드스피커들과 같은) 다른 개수 및 위치를 갖는 사운드 소스들의 여러 다른 설정들을 위한 참조 곡선들로서 사용될 수 있는 다른 미리-계산된 주파수 종속 상관 곡선들을 나타낸다.
도 10은 확산 요소들이 분해될 요소들인 확산 예측의 다른 실시예를 나타내는 블록도이다.
도 11a 및 도 11b는 주파수-종속 상관 곡선 없이, 위너(wiener) 필터링 접근법에 의존하는 신호 분석에 적용하는 수식 예이다.

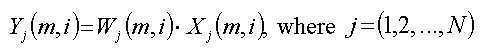






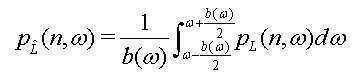










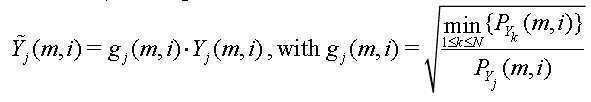





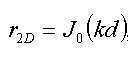




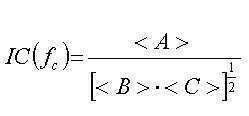


Claims (15)
- 적어도 세 개의 입력 채널들을 가지는 입력 신호(10)를 분해하는 장치로서,
다운믹스 신호를 획득하기 위한 입력 신호를 다운믹싱하며, 다운믹스된 신호(14)의 다수의 다운믹스 채널들이 적어도 2개이고 입력 채널들의 수보다 적도록 다운믹싱하도록 구성된, 다운믹스기(12);
분석 결과(18)를 유도하기 위해 상기 다운믹스된 신호를 분석하는 분석기(16); 및
상기 분석 결과(18)를 사용하여 상기 입력 신호(10) 또는 상기 입력 신호로부터 유도된 신호(24), 또는 상기 입력 신호가 유도된 신호를 처리하며, 분해된 신호(26)를 획득하기 위해 상기 분석 결과를 상기 입력 신호로부터 유도된 신호의 채널들 또는 상기 입력 신호의 상기 입력 채널들에 적용하도록 구성된, 신호 처리기(processor)(20)를 포함하는, 입력 신호를 분해하는 장치. - 청구항 1에 있어서,
상기 입력 채널들을 채널 주파수 표현들(representations)(각각의 입력 채널 주파수 표현은 다수의 서브밴드들(subbands)을 가짐)의 시간 시퀀스(sequence)로 변환하는 시간/주파수 변환기(32)를 더 포함하며, 또는 상기 다운믹스기(12)가 상기 다운믹스된 신호를 변환하기 위한 시간/주파수 변환기를 포함하며,
상기 분석기(16)는 개별의 서브밴드들을 위한 분석 결과(18)를 생성하도록 구성되고,
상기 신호 처리부(20)는 개별의 분석 결과들을 상기 입력 신호로부터 유도된 상기 신호 또는 상기 입력 신호의 상응하는 서브밴드들에 적용하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 1 또는 2에 있어서,
상기 분석기(16)는 상기 분석 결과로서 가중치 요소들을 생성하도록 구성되고,
상기 신호 처리기(20)는 상기 가중치 요소들을, 상기 가중치 요소들로 가중함에 의해 상기 입력 신호로부터 유도된 상기 신호 또는 상기 입력 신호에 적용하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 1 내지 3 중 어느 하나에 있어서,
상기 다운믹스기는 적어도 두 개의 다운믹스 채널들이 서로 다르도록 다운믹스 규칙에 따라 가중된 또는 가중되지 않은 입력 신호들을 추가하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 1 내지 4 중 어느 하나에 있어서,
상기 다운믹스기(12)는 실내 임펄스(impulse) 응답들-기반 필터들(filters), 바이노럴 실내 임펄스 응답들(binaural room impulse responses, BRIR)-기반 필터들 또는 머리-관련 전달 함수(head-related transfer function, HRTF)-기반 필터들을 사용하여 상기 입력 신호(10)를 필터링하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 1 내지 5 중 어느 하나에 있어서,
상기 처리기(20)는 위너(Wiener) 필터를 상기 입력 신호로부터 유도된 상기 신호 또는 상기 입력 신호에 적용하도록 구성되고,
상기 분석기(16)는 상기 다운믹스 채널들로부터 유도된 기대 값들을 사용하여 상기 위너 필터를 계산하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 1 내지 6 중 어느 하나에 있어서,
상기 입력 신호로부터 유도된 상기 신호가 상기 다운믹스 신호 또는 상기 입력 신호에 비해 다른 채널들의 수를 가지도록 상기 입력 신호로부터 상기 신호를 유도하는 신호 유도기(22)를 더 포함하는, 입력 신호를 분해하는 장치. - 청구항 1 내지 7 중 어느 하나에 있어서,
상기 분석기(20)는 미리 알려진 참조 신호들에 의해 생성 가능한 두 개의 신호들 간의 주파수-종속 유사도를 나타내는 미리-저장된 주파수-종속 유사도 곡선을 사용하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 1 내지 8 중 어느 하나에 있어서,
상기 분석기는, 신호들이 알려진 유사도 특성을 가지고 신호들이 알려진 라우드스피커(loudspeaker) 위치들에서 라우드스피커들에 의해 발생 가능하다는 가정하에서, 청취자 위치에서 둘 이상의 신호들 간의 주파수-종속 유사도를 나타내는 미리-저장된 주파수-종속 유사도 곡선을 사용하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 1 내지 7 중 어느 하나에 있어서,
상기 분석기는 상기 입력 채널들의 주파수-종속 짧은-시간 파워를 사용하여 단일-종속 주파수-종속 유사도 곡선을 계산하도록 구성되는, 입력 신호를 분해하는 장치. - 청구항 8 내지 10 중 어느 하나에 있어서,
상기 분석기(16)는, 주파수 서브밴드에서 상기 다운믹스된 채널의 유사도를 계산하고(80), 참조 곡선에 의해 표현된 유사도를 가지는 유사도 값을 비교하고(82, 83), 상기 분석결과로서 압축의 결과를 기반으로 가중치 요소를 생성하도록 구성되고,
또는 상기 동일한 주파수 서브밴드를 위한 상기 참조 곡선에 의해 표현된 유사도 및 상응하는 결과 간의 거리를 계산하고 상기 분석 결과로서 상기 거리를 기반으로 가중치 요소를 추가로 계산하도록 구성된, 입력 신호를 분해하는 장치. - 청구항 1 내지 11 중 어느 하나에 있어서,
상기 분석기(16)는 사람의 귀에 대한 주파수 해상도(resolustion)에 의해 결정된 서브밴드들에서 상기 다운믹스 채널들을 분석하도록 구성된, 입력 신호를 분해하는 장치. - 청구항 1 내지 12 중 어느 하나에 있어서,
상기 분석기(16)는 다이렉트(direct) 엠비언스(ambience) 분해를 허용하는 분석 결과를 생성하기 위해 상기 다운믹스된 신호를 분석하도록 구성되고,
상기 신호 처리기(20)는 상기 분석 결과를 사용하여 다이렉트 부분 또는 엠비언스 부분을 추출하도록 구성된, 입력 신호를 분해하는 장치. - 적어도 세 개의 입력 채널들(channels)을 가지는 입력 신호(10)를 분해하는 방법으로서,
다운믹스된(downmixed) 신호(14)에 대한 다수의 다운믹스 채널들이 적어도 2 및 입력 채널들의 수보다 적도록, 다운믹스 신호를 획득하기 위해 상기 입력 신호를 다운믹싱하는(12) 단계;
분석 결과(18)를 유도하기 위해 상기 다운믹스된 신호를 분석하는(16) 단계; 및
상기 분석 결과(18)를 사용하여, 상기 입력 신호(10) 또는 상기 입력 신호로부터 유도된 신호(24) 또는 상기 입력 신호가 유도된 신호를 처리하는(20) 단계를 포함하며,
상기 분석 결과는 분해된 신호(26)를 획득하기 위해 상기 입력 신호로부터 유도된 신호의 채널들 또는 상기 입력 신호의 상기 입력 채널들에 적용되는, 입력 신호를 분해하는 방법. - 컴퓨터(computer) 또는 프로세서(processor)에 의하여 실행될 때, 청구항 14의 방법을 수행하는 컴퓨터 프로그램.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US42192710P | 2010-12-10 | 2010-12-10 | |
| US61/421,927 | 2010-12-10 | ||
| EP11165742A EP2464145A1 (en) | 2010-12-10 | 2011-05-11 | Apparatus and method for decomposing an input signal using a downmixer |
| EP11165742.5 | 2011-05-11 | ||
| PCT/EP2011/070702 WO2012076332A1 (en) | 2010-12-10 | 2011-11-22 | Apparatus and method for decomposing an input signal using a downmixer |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20130133242A true KR20130133242A (ko) | 2013-12-06 |
| KR101471798B1 KR101471798B1 (ko) | 2014-12-10 |
Family
ID=44582056
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020137017699A Active KR101480258B1 (ko) | 2010-12-10 | 2011-11-22 | 미리 계산된 참조 곡선을 이용한 입력 신호 분해 장치 및 방법 |
| KR1020137017810A Active KR101471798B1 (ko) | 2010-12-10 | 2011-11-22 | 다운믹스기를 이용한 입력 신호 분해 장치 및 방법 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020137017699A Active KR101480258B1 (ko) | 2010-12-10 | 2011-11-22 | 미리 계산된 참조 곡선을 이용한 입력 신호 분해 장치 및 방법 |
Country Status (15)
| Country | Link |
|---|---|
| US (3) | US9241218B2 (ko) |
| EP (4) | EP2464145A1 (ko) |
| JP (2) | JP5654692B2 (ko) |
| KR (2) | KR101480258B1 (ko) |
| CN (2) | CN103355001B (ko) |
| AR (2) | AR084176A1 (ko) |
| AU (2) | AU2011340891B2 (ko) |
| BR (2) | BR112013014173B1 (ko) |
| CA (2) | CA2820376C (ko) |
| ES (2) | ES2530960T3 (ko) |
| MX (2) | MX2013006364A (ko) |
| PL (2) | PL2649815T3 (ko) |
| RU (2) | RU2554552C2 (ko) |
| TW (2) | TWI519178B (ko) |
| WO (2) | WO2012076332A1 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016024847A1 (ko) * | 2014-08-13 | 2016-02-18 | 삼성전자 주식회사 | 음향 신호를 생성하고 재생하는 방법 및 장치 |
Families Citing this family (43)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| TWI429165B (zh) | 2011-02-01 | 2014-03-01 | 富達通科技股份有限公司 | Method of data transmission in high power induction power supply |
| TWI472897B (zh) * | 2013-05-03 | 2015-02-11 | 富達通科技股份有限公司 | 自動調節電壓準位之方法、裝置及其感應式電源供應器 |
| US9600021B2 (en) | 2011-02-01 | 2017-03-21 | Fu Da Tong Technology Co., Ltd. | Operating clock synchronization adjusting method for induction type power supply system |
| US9671444B2 (en) | 2011-02-01 | 2017-06-06 | Fu Da Tong Technology Co., Ltd. | Current signal sensing method for supplying-end module of induction type power supply system |
| US9048881B2 (en) | 2011-06-07 | 2015-06-02 | Fu Da Tong Technology Co., Ltd. | Method of time-synchronized data transmission in induction type power supply system |
| US9831687B2 (en) | 2011-02-01 | 2017-11-28 | Fu Da Tong Technology Co., Ltd. | Supplying-end module for induction-type power supply system and signal analysis circuit therein |
| US10038338B2 (en) | 2011-02-01 | 2018-07-31 | Fu Da Tong Technology Co., Ltd. | Signal modulation method and signal rectification and modulation device |
| US8941267B2 (en) | 2011-06-07 | 2015-01-27 | Fu Da Tong Technology Co., Ltd. | High-power induction-type power supply system and its bi-phase decoding method |
| US9075587B2 (en) | 2012-07-03 | 2015-07-07 | Fu Da Tong Technology Co., Ltd. | Induction type power supply system with synchronous rectification control for data transmission |
| US10056944B2 (en) | 2011-02-01 | 2018-08-21 | Fu Da Tong Technology Co., Ltd. | Data determination method for supplying-end module of induction type power supply system and related supplying-end module |
| US9628147B2 (en) | 2011-02-01 | 2017-04-18 | Fu Da Tong Technology Co., Ltd. | Method of automatically adjusting determination voltage and voltage adjusting device thereof |
| KR20120132342A (ko) * | 2011-05-25 | 2012-12-05 | 삼성전자주식회사 | 보컬 신호 제거 장치 및 방법 |
| US9253574B2 (en) * | 2011-09-13 | 2016-02-02 | Dts, Inc. | Direct-diffuse decomposition |
| BR122021021487B1 (pt) | 2012-09-12 | 2022-11-22 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e. V | Aparelho e método para fornecer capacidades melhoradas de downmix guiado para áudio 3d |
| EP2976898B1 (en) | 2013-03-19 | 2017-03-08 | Koninklijke Philips N.V. | Method and apparatus for determining a position of a microphone |
| EP2790419A1 (en) * | 2013-04-12 | 2014-10-15 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for center signal scaling and stereophonic enhancement based on a signal-to-downmix ratio |
| WO2014171791A1 (ko) | 2013-04-19 | 2014-10-23 | 한국전자통신연구원 | 다채널 오디오 신호 처리 장치 및 방법 |
| KR102150955B1 (ko) | 2013-04-19 | 2020-09-02 | 한국전자통신연구원 | 다채널 오디오 신호 처리 장치 및 방법 |
| US20140355769A1 (en) * | 2013-05-29 | 2014-12-04 | Qualcomm Incorporated | Energy preservation for decomposed representations of a sound field |
| US9319819B2 (en) | 2013-07-25 | 2016-04-19 | Etri | Binaural rendering method and apparatus for decoding multi channel audio |
| KR102159990B1 (ko) | 2013-09-17 | 2020-09-25 | 주식회사 윌러스표준기술연구소 | 멀티미디어 신호 처리 방법 및 장치 |
| US10580417B2 (en) | 2013-10-22 | 2020-03-03 | Industry-Academic Cooperation Foundation, Yonsei University | Method and apparatus for binaural rendering audio signal using variable order filtering in frequency domain |
| KR101627657B1 (ko) | 2013-12-23 | 2016-06-07 | 주식회사 윌러스표준기술연구소 | 오디오 신호의 필터 생성 방법 및 이를 위한 파라메터화 장치 |
| CN104768121A (zh) | 2014-01-03 | 2015-07-08 | 杜比实验室特许公司 | 响应于多通道音频通过使用至少一个反馈延迟网络产生双耳音频 |
| CN107835483B (zh) | 2014-01-03 | 2020-07-28 | 杜比实验室特许公司 | 响应于多通道音频通过使用至少一个反馈延迟网络产生双耳音频 |
| KR101782917B1 (ko) | 2014-03-19 | 2017-09-28 | 주식회사 윌러스표준기술연구소 | 오디오 신호 처리 방법 및 장치 |
| KR101856540B1 (ko) | 2014-04-02 | 2018-05-11 | 주식회사 윌러스표준기술연구소 | 오디오 신호 처리 방법 및 장치 |
| EP2942981A1 (en) | 2014-05-05 | 2015-11-11 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | System, apparatus and method for consistent acoustic scene reproduction based on adaptive functions |
| EP3165007B1 (en) | 2014-07-03 | 2018-04-25 | Dolby Laboratories Licensing Corporation | Auxiliary augmentation of soundfields |
| CN105336332A (zh) * | 2014-07-17 | 2016-02-17 | 杜比实验室特许公司 | 分解音频信号 |
| US10559303B2 (en) * | 2015-05-26 | 2020-02-11 | Nuance Communications, Inc. | Methods and apparatus for reducing latency in speech recognition applications |
| US9666192B2 (en) | 2015-05-26 | 2017-05-30 | Nuance Communications, Inc. | Methods and apparatus for reducing latency in speech recognition applications |
| TWI596953B (zh) * | 2016-02-02 | 2017-08-21 | 美律實業股份有限公司 | 錄音模組 |
| EP3335218B1 (en) * | 2016-03-16 | 2019-06-05 | Huawei Technologies Co., Ltd. | An audio signal processing apparatus and method for processing an input audio signal |
| EP3232688A1 (en) | 2016-04-12 | 2017-10-18 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Apparatus and method for providing individual sound zones |
| US10659904B2 (en) * | 2016-09-23 | 2020-05-19 | Gaudio Lab, Inc. | Method and device for processing binaural audio signal |
| US10187740B2 (en) * | 2016-09-23 | 2019-01-22 | Apple Inc. | Producing headphone driver signals in a digital audio signal processing binaural rendering environment |
| JP6788272B2 (ja) * | 2017-02-21 | 2020-11-25 | オンフューチャー株式会社 | 音源の検出方法及びその検出装置 |
| CN110383700A (zh) * | 2017-03-10 | 2019-10-25 | 英特尔Ip公司 | 杂散降低电路和装置、无线电收发器、移动终端、用于杂散降低的方法和计算机程序 |
| IT201700040732A1 (it) * | 2017-04-12 | 2018-10-12 | Inst Rundfunktechnik Gmbh | Verfahren und vorrichtung zum mischen von n informationssignalen |
| PT3692523T (pt) | 2017-10-04 | 2022-03-02 | Fraunhofer Ges Forschung | Aparelho, método e programa de computador para codificação, descodificação, processamento de cena e outros procedimentos relacionados com codificação de áudio espacial com base em dirac |
| CN111107481B (zh) | 2018-10-26 | 2021-06-22 | 华为技术有限公司 | 一种音频渲染方法及装置 |
| CN120783782B (zh) * | 2025-09-09 | 2025-11-18 | 深圳市沃莱特电子有限公司 | 混音方法、音频设备及混音系统 |
Family Cites Families (33)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US9025A (en) * | 1852-06-15 | And chas | ||
| US7026A (en) * | 1850-01-15 | Door-lock | ||
| US5065759A (en) * | 1990-08-30 | 1991-11-19 | Vitatron Medical B.V. | Pacemaker with optimized rate responsiveness and method of rate control |
| US5912976A (en) | 1996-11-07 | 1999-06-15 | Srs Labs, Inc. | Multi-channel audio enhancement system for use in recording and playback and methods for providing same |
| TW358925B (en) * | 1997-12-31 | 1999-05-21 | Ind Tech Res Inst | Improvement of oscillation encoding of a low bit rate sine conversion language encoder |
| SE514862C2 (sv) | 1999-02-24 | 2001-05-07 | Akzo Nobel Nv | Användning av en kvartär ammoniumglykosidtensid som en effektförhöjande hjälpkemikalie för gödningsmedel eller pesticider samt kompositioner innehållande pesticider eller gödningsmedel |
| US6694027B1 (en) * | 1999-03-09 | 2004-02-17 | Smart Devices, Inc. | Discrete multi-channel/5-2-5 matrix system |
| BR0305434A (pt) | 2002-07-12 | 2004-09-28 | Koninkl Philips Electronics Nv | Métodos e arranjos para codificar e para decodificar um sinal de áudio multicanal, aparelhos para fornecer um sinal de áudio codificado e um sinal de áudio decodificado, sinal de áudio multicanal codificado, e, meio de armazenagem |
| PL378021A1 (pl) * | 2002-12-28 | 2006-02-20 | Samsung Electronics Co., Ltd. | Sposób i urządzenie do mieszania strumieni akustycznych i nośnik pamięciowy informacji |
| US7254500B2 (en) * | 2003-03-31 | 2007-08-07 | The Salk Institute For Biological Studies | Monitoring and representing complex signals |
| JP2004354589A (ja) * | 2003-05-28 | 2004-12-16 | Nippon Telegr & Teleph Corp <Ntt> | 音響信号判別方法、音響信号判別装置、音響信号判別プログラム |
| ATE390683T1 (de) | 2004-03-01 | 2008-04-15 | Dolby Lab Licensing Corp | Mehrkanalige audiocodierung |
| CN1930607B (zh) | 2004-03-05 | 2010-11-10 | 松下电器产业株式会社 | 差错隐藏装置以及差错隐藏方法 |
| US7392195B2 (en) * | 2004-03-25 | 2008-06-24 | Dts, Inc. | Lossless multi-channel audio codec |
| US8843378B2 (en) | 2004-06-30 | 2014-09-23 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung E.V. | Multi-channel synthesizer and method for generating a multi-channel output signal |
| US20070297519A1 (en) * | 2004-10-28 | 2007-12-27 | Jeffrey Thompson | Audio Spatial Environment Engine |
| US7961890B2 (en) * | 2005-04-15 | 2011-06-14 | Fraunhofer-Gesellschaft Zur Foerderung Der Angewandten Forschung, E.V. | Multi-channel hierarchical audio coding with compact side information |
| US7468763B2 (en) * | 2005-08-09 | 2008-12-23 | Texas Instruments Incorporated | Method and apparatus for digital MTS receiver |
| US7563975B2 (en) * | 2005-09-14 | 2009-07-21 | Mattel, Inc. | Music production system |
| KR100739798B1 (ko) * | 2005-12-22 | 2007-07-13 | 삼성전자주식회사 | 청취 위치를 고려한 2채널 입체음향 재생 방법 및 장치 |
| SG136836A1 (en) * | 2006-04-28 | 2007-11-29 | St Microelectronics Asia | Adaptive rate control algorithm for low complexity aac encoding |
| US8379868B2 (en) * | 2006-05-17 | 2013-02-19 | Creative Technology Ltd | Spatial audio coding based on universal spatial cues |
| US7877317B2 (en) * | 2006-11-21 | 2011-01-25 | Yahoo! Inc. | Method and system for finding similar charts for financial analysis |
| US8023707B2 (en) * | 2007-03-26 | 2011-09-20 | Siemens Aktiengesellschaft | Evaluation method for mapping the myocardium of a patient |
| DE102008009024A1 (de) | 2008-02-14 | 2009-08-27 | Fraunhofer-Gesellschaft zur Förderung der angewandten Forschung e.V. | Vorrichtung und Verfahren zum synchronisieren von Mehrkanalerweiterungsdaten mit einem Audiosignal und zum Verarbeiten des Audiosignals |
| EP2272169B1 (en) * | 2008-03-31 | 2017-09-06 | Creative Technology Ltd. | Adaptive primary-ambient decomposition of audio signals |
| KR101392546B1 (ko) | 2008-09-11 | 2014-05-08 | 프라운호퍼 게젤샤프트 쭈르 푀르데룽 데어 안겐반텐 포르슝 에. 베. | 마이크로폰 신호를 기반으로 공간 큐의 세트를 제공하는 장치, 방법 및 컴퓨터 프로그램과, 2채널 오디오 신호 및 공간 큐의 세트를 제공하는 장치 |
| WO2010092568A1 (en) * | 2009-02-09 | 2010-08-19 | Waves Audio Ltd. | Multiple microphone based directional sound filter |
| WO2010125228A1 (en) * | 2009-04-30 | 2010-11-04 | Nokia Corporation | Encoding of multiview audio signals |
| KR101566967B1 (ko) * | 2009-09-10 | 2015-11-06 | 삼성전자주식회사 | 디지털 방송 시스템에서 패킷 디코딩 방법 및 장치 |
| EP2323130A1 (en) * | 2009-11-12 | 2011-05-18 | Koninklijke Philips Electronics N.V. | Parametric encoding and decoding |
| CN102907120B (zh) | 2010-06-02 | 2016-05-25 | 皇家飞利浦电子股份有限公司 | 用于声音处理的系统和方法 |
| US9183849B2 (en) | 2012-12-21 | 2015-11-10 | The Nielsen Company (Us), Llc | Audio matching with semantic audio recognition and report generation |
-
2011
- 2011-05-11 EP EP11165742A patent/EP2464145A1/en not_active Withdrawn
- 2011-05-11 EP EP11165746A patent/EP2464146A1/en not_active Withdrawn
- 2011-11-22 AU AU2011340891A patent/AU2011340891B2/en active Active
- 2011-11-22 KR KR1020137017699A patent/KR101480258B1/ko active Active
- 2011-11-22 CN CN201180067280.2A patent/CN103355001B/zh active Active
- 2011-11-22 BR BR112013014173-5A patent/BR112013014173B1/pt active IP Right Grant
- 2011-11-22 WO PCT/EP2011/070702 patent/WO2012076332A1/en not_active Ceased
- 2011-11-22 KR KR1020137017810A patent/KR101471798B1/ko active Active
- 2011-11-22 CA CA2820376A patent/CA2820376C/en active Active
- 2011-11-22 MX MX2013006364A patent/MX2013006364A/es active IP Right Grant
- 2011-11-22 PL PL11793700T patent/PL2649815T3/pl unknown
- 2011-11-22 JP JP2013542452A patent/JP5654692B2/ja active Active
- 2011-11-22 CA CA2820351A patent/CA2820351C/en active Active
- 2011-11-22 JP JP2013542451A patent/JP5595602B2/ja active Active
- 2011-11-22 WO PCT/EP2011/070700 patent/WO2012076331A1/en not_active Ceased
- 2011-11-22 PL PL11787858T patent/PL2649814T3/pl unknown
- 2011-11-22 AU AU2011340890A patent/AU2011340890B2/en active Active
- 2011-11-22 CN CN201180067248.4A patent/CN103348703B/zh active Active
- 2011-11-22 MX MX2013006358A patent/MX2013006358A/es active IP Right Grant
- 2011-11-22 RU RU2013131775/08A patent/RU2554552C2/ru active
- 2011-11-22 RU RU2013131774/08A patent/RU2555237C2/ru active
- 2011-11-22 ES ES11787858T patent/ES2530960T3/es active Active
- 2011-11-22 EP EP11793700.3A patent/EP2649815B1/en active Active
- 2011-11-22 ES ES11793700.3T patent/ES2534180T3/es active Active
- 2011-11-22 EP EP11787858.7A patent/EP2649814B1/en active Active
- 2011-11-22 BR BR112013014172-7A patent/BR112013014172B1/pt active IP Right Grant
- 2011-11-28 TW TW100143542A patent/TWI519178B/zh active
- 2011-11-28 TW TW100143541A patent/TWI524786B/zh active
- 2011-12-06 AR ARP110104562A patent/AR084176A1/es active IP Right Grant
- 2011-12-06 AR ARP110104561A patent/AR084175A1/es active IP Right Grant
-
2013
- 2013-06-06 US US13/911,824 patent/US9241218B2/en active Active
- 2013-06-06 US US13/911,791 patent/US10187725B2/en active Active
-
2018
- 2018-12-04 US US16/209,638 patent/US10531198B2/en active Active
Cited By (2)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2016024847A1 (ko) * | 2014-08-13 | 2016-02-18 | 삼성전자 주식회사 | 음향 신호를 생성하고 재생하는 방법 및 장치 |
| US10349197B2 (en) | 2014-08-13 | 2019-07-09 | Samsung Electronics Co., Ltd. | Method and device for generating and playing back audio signal |
Also Published As
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101471798B1 (ko) | 다운믹스기를 이용한 입력 신호 분해 장치 및 방법 | |
| CA2835463C (en) | Apparatus and method for generating an output signal employing a decomposer | |
| AU2015255287B2 (en) | Apparatus and method for generating an output signal employing a decomposer | |
| HK1190552B (en) | Apparatus and method for decomposing an input signal using a pre-calculated reference curve | |
| HK1190553B (en) | Apparatus and method for decomposing an input signal using a downmixer |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A201 | Request for examination | ||
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| PA0105 | International application |
St.27 status event code: A-0-1-A10-A15-nap-PA0105 |
|
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
St.27 status event code: A-2-4-F10-F11-exm-PR0701 |
|
| PR1002 | Payment of registration fee |
St.27 status event code: A-2-2-U10-U12-oth-PR1002 Fee payment year number: 1 |
|
| PG1601 | Publication of registration |
St.27 status event code: A-4-4-Q10-Q13-nap-PG1601 |
|
| FPAY | Annual fee payment |
Payment date: 20171129 Year of fee payment: 4 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 4 |
|
| FPAY | Annual fee payment |
Payment date: 20181127 Year of fee payment: 5 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 5 |
|
| R18-X000 | Changes to party contact information recorded |
St.27 status event code: A-5-5-R10-R18-oth-X000 |
|
| FPAY | Annual fee payment |
Payment date: 20191126 Year of fee payment: 6 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 6 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 7 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 8 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 9 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 10 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 11 |
|
| PR1001 | Payment of annual fee |
St.27 status event code: A-4-4-U10-U11-oth-PR1001 Fee payment year number: 12 |
|
| U11 | Full renewal or maintenance fee paid |
Free format text: ST27 STATUS EVENT CODE: A-4-4-U10-U11-OTH-PR1001 (AS PROVIDED BY THE NATIONAL OFFICE) Year of fee payment: 12 |