KR20140000711A - 수크로스 이용에 있어서의 야로위아 리포라이티카에서의 사카로마이세스 세레비지애 suc2 유전자의 용도 - Google Patents
수크로스 이용에 있어서의 야로위아 리포라이티카에서의 사카로마이세스 세레비지애 suc2 유전자의 용도 Download PDFInfo
- Publication number
- KR20140000711A KR20140000711A KR1020137019892A KR20137019892A KR20140000711A KR 20140000711 A KR20140000711 A KR 20140000711A KR 1020137019892 A KR1020137019892 A KR 1020137019892A KR 20137019892 A KR20137019892 A KR 20137019892A KR 20140000711 A KR20140000711 A KR 20140000711A
- Authority
- KR
- South Korea
- Prior art keywords
- ser
- ala
- thr
- leu
- asn
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
Images







Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2408—Glucanases acting on alpha -1,4-glucosidic bonds
- C12N9/2431—Beta-fructofuranosidase (3.2.1.26), i.e. invertase
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N1/00—Microorganisms; Compositions thereof; Processes of propagating, maintaining or preserving microorganisms or compositions thereof; Processes of preparing or isolating a composition containing a microorganism; Culture media therefor
- C12N1/14—Fungi; Culture media therefor
- C12N1/16—Yeasts; Culture media therefor
- C12N1/18—Baker's yeast; Brewer's yeast
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N15/00—Mutation or genetic engineering; DNA or RNA concerning genetic engineering, vectors, e.g. plasmids, or their isolation, preparation or purification; Use of hosts therefor
- C12N15/09—Recombinant DNA-technology
- C12N15/11—DNA or RNA fragments; Modified forms thereof; Non-coding nucleic acids having a biological activity
- C12N15/62—DNA sequences coding for fusion proteins
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/24—Hydrolases (3) acting on glycosyl compounds (3.2)
- C12N9/2402—Hydrolases (3) acting on glycosyl compounds (3.2) hydrolysing O- and S- glycosyl compounds (3.2.1)
- C12N9/2405—Glucanases
- C12N9/2408—Glucanases acting on alpha -1,4-glucosidic bonds
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12N—MICROORGANISMS OR ENZYMES; COMPOSITIONS THEREOF; PROPAGATING, PRESERVING, OR MAINTAINING MICROORGANISMS; MUTATION OR GENETIC ENGINEERING; CULTURE MEDIA
- C12N9/00—Enzymes; Proenzymes; Compositions thereof; Processes for preparing, activating, inhibiting, separating or purifying enzymes
- C12N9/14—Hydrolases (3)
- C12N9/48—Hydrolases (3) acting on peptide bonds (3.4)
- C12N9/50—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25)
- C12N9/58—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from fungi
- C12N9/60—Proteinases, e.g. Endopeptidases (3.4.21-3.4.25) derived from fungi from yeast
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12P—FERMENTATION OR ENZYME-USING PROCESSES TO SYNTHESISE A DESIRED CHEMICAL COMPOUND OR COMPOSITION OR TO SEPARATE OPTICAL ISOMERS FROM A RACEMIC MIXTURE
- C12P7/00—Preparation of oxygen-containing organic compounds
- C12P7/64—Fats; Fatty oils; Ester-type waxes; Higher fatty acids, i.e. having at least seven carbon atoms in an unbroken chain bound to a carboxyl group; Oxidised oils or fats
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Y—ENZYMES
- C12Y302/00—Hydrolases acting on glycosyl compounds, i.e. glycosylases (3.2)
- C12Y302/01—Glycosidases, i.e. enzymes hydrolysing O- and S-glycosyl compounds (3.2.1)
- C12Y302/01026—Beta-fructofuranosidase (3.2.1.26), i.e. invertase
-
- C—CHEMISTRY; METALLURGY
- C07—ORGANIC CHEMISTRY
- C07K—PEPTIDES
- C07K2319/00—Fusion polypeptide
- C07K2319/01—Fusion polypeptide containing a localisation/targetting motif
- C07K2319/02—Fusion polypeptide containing a localisation/targetting motif containing a signal sequence
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Health & Medical Sciences (AREA)
- Organic Chemistry (AREA)
- Engineering & Computer Science (AREA)
- Genetics & Genomics (AREA)
- Wood Science & Technology (AREA)
- Zoology (AREA)
- Bioinformatics & Cheminformatics (AREA)
- General Engineering & Computer Science (AREA)
- General Health & Medical Sciences (AREA)
- Biotechnology (AREA)
- Biochemistry (AREA)
- Microbiology (AREA)
- Biomedical Technology (AREA)
- Mycology (AREA)
- Molecular Biology (AREA)
- Medicinal Chemistry (AREA)
- Oil, Petroleum & Natural Gas (AREA)
- General Chemical & Material Sciences (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Botany (AREA)
- Virology (AREA)
- Tropical Medicine & Parasitology (AREA)
- Physics & Mathematics (AREA)
- Biophysics (AREA)
- Plant Pathology (AREA)
- Micro-Organisms Or Cultivation Processes Thereof (AREA)
- Preparation Of Compounds By Using Micro-Organisms (AREA)
Abstract
수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 외인성 폴리뉴클레오티드를 포함하는 형질전환된 야로위아 리포라이티카(Yarrowia lipolytica)가 본 발명에서 개시된다. 형질전환된 와이. 리포라이티카의 사용 방법이 또한 개시된다.
Description
본 출원은 본 명세서에 전체적으로 참고로 포함되는, 2010년 12월 30일자로 출원된 미국 가특허 출원 제61/428,590의 이익을 청구한다.
본 발명은 생명 공학 분야이다. 더 구체적으로, 본 발명은 수크로스를 탄소 공급원으로 사용하는 능력을 갖는 형질전환된 야로위아 리포라이티카(Yarrowia lipolytica)에 관한 것이며, 여기서, 형질전환된 와이. 리포라이티카는 또한 관심대상의 비천연 생성물, 예를 들어 다중불포화 지방산(polyunsaturated fatty acid; "PUFA")을 생성하도록 선택적으로 엔지니어링될 수 있다.
유지성(oleaginous) 효모, 예를 들어 야로위아 리포라이티카는 글루코스를 그의 유일한 탄소 공급원으로 사용하는 천연적인 능력을 갖지만; 이 기질은 항상 가장 비용 효율적인 탄소 공급원인 것은 아니다. 글루코스 대신 탄소 공급원으로서 (단독으로든지 또는 다른 탄소 공급원과 조합해서든지 간에) 수크로스를 탄소 공급원으로 사용하는 것은 그의 비용으로 인하여 유리할 수 있다.
와이. 리포라이티카는 수크로스를 탄소 공급원으로 이용할 수 없으며, 그 이유는 이것이 인버타아제를 코딩하는 유전자를 갖지 않기 때문인데, 상기 인버타아제는 수크로스(이당류)가 단당류인 글루코스 및 프룩토스로 전환되는 것을 촉매한다. 이전의 몇몇 연구원들은 성숙 인버타아제 단백질을 주위 매질 내로 분비하도록 효모를 엔지니어링하기 위하여 시그널(signal) 서열을 인버타아제를 코딩하는 이종 유전자 (예를 들어, 사카로마이세스 세레비지애 SUC2 유전자)에 융합시켰는데, 상기 주위 매질에서 수크로스가 후에 가수분해될 수 있다.
와이. 리포라이티카로부터 단리된 하나의 잘 알려진 시그널 서열은 유도성 알칼리성 세포외 프로테아제(alkaline extracellular protease; "AEP")의 것이다 (유럽 특허 제0220864 B1호; 문헌[Davidow, et al., J. Bacteriol., 169:4621-4629 (1987)]; 문헌[Matoba, et al., Mol. Cell Biol., 8:4904-4916 (1988)]). AEP는 와이. 리포라이티카에서 XPR2 유전자에 의해 코딩된다. 더욱이, 대량이 자연적으로 세포외로 분비된다.
니코드(Nicaud) 등 (문헌[Current Genetics, 16:253-260 (1989)]; 유럽 특허 제0402226 A1호)은 와이. 리포라이티카 XPR2 프로모터 및 그의 시그널 서열을 포함하는 에스. 세레비지애 SUC2의 키메라 발현을 보고하였는데, 이는 와이. 리포라이티카에서 수크로스-이용(SUC + ) 표현형으로 이어졌다. 구체적으로, XPR2 유래의 23개 N-말단 아미노산은 절두형(truncated) SUC2 (여기서, 절두에 의해 전장 단백질의 처음 4개 아미노산이 제거됨)에 융합되었다. 인버타아제 활성 중 약 10%는 배양 브로쓰에서 관찰되며(즉, 세포외 분비를 통하여), 반면에 활성의 90%는 전세포를 사용하면 회복됨 (즉, 인버타아제는 주변세포질(periplasm) 내로 분비됨)이 보고되었다. 따라서, 세포외 수크로스 가수분해에서의 효율은 상대적으로 낮았다.
니코드 등에 의해 기재된 방법은 수크로스를 탄소 공급원으로 사용하는, 시트르산을 생성하는 형질전환 와이. 리포라이티카 주(strain)를 개발하려는 노력으로 다른 이들에 의해 이용되었다 (문헌[Wojtatowicz, M.,et al., Pol. J. Food Nutr. Sci ., 6/47(4): 49-54 (1997)]; 문헌[ , A. et al., Appl . Microbiol . Biotechnol., 75:1409-1417 (2007)]; 문헌[Lazar, Z. et al., Bioresour . Technol., 102:6982-6989 (2011)]). 상기 포스터(Foster) 등은 대다수(60-70%)의 인버타아제 활성이 세포 표면에서 발견되며(즉, 전세포에서 검출가능한 세포-결합된 활성), 반면에 인버타아제의 30-40%는 무세포 배양 배지에서 검출가능하고; 바이오매스(biomass)로부터의 최대 인버타아제 수율은 바이오매스의 건조 중량 1 g당 110 U임을 보고하였다. 가장 최근에는, 상기 라자르(Lazar) 등은 와이. 리포라이티카 XPR2 프로모터 및 그의 시그널 서열과, 에스. 세레비지애 SUC2를 포함하는 융합물의 두 카피(copy)를 함유하는 와이. 리포라이티카 주를 확인하였으며, 대부분의 인버타아제 활성이 세포와 결부된 반면 (세포 1 g당 2568 내지 3736 U), 약 232 내지 589 U/g은 세포외 활성임(즉, 활성의 단지 5-20%가 세포외 활성임)을 보여주었다.
, A. et al., Appl . Microbiol . Biotechnol., 75:1409-1417 (2007)]; 문헌[Lazar, Z. et al., Bioresour . Technol., 102:6982-6989 (2011)]). 상기 포스터(Foster) 등은 대다수(60-70%)의 인버타아제 활성이 세포 표면에서 발견되며(즉, 전세포에서 검출가능한 세포-결합된 활성), 반면에 인버타아제의 30-40%는 무세포 배양 배지에서 검출가능하고; 바이오매스(biomass)로부터의 최대 인버타아제 수율은 바이오매스의 건조 중량 1 g당 110 U임을 보고하였다. 가장 최근에는, 상기 라자르(Lazar) 등은 와이. 리포라이티카 XPR2 프로모터 및 그의 시그널 서열과, 에스. 세레비지애 SUC2를 포함하는 융합물의 두 카피(copy)를 함유하는 와이. 리포라이티카 주를 확인하였으며, 대부분의 인버타아제 활성이 세포와 결부된 반면 (세포 1 g당 2568 내지 3736 U), 약 232 내지 589 U/g은 세포외 활성임(즉, 활성의 단지 5-20%가 세포외 활성임)을 보여주었다.
따라서, 개선된 세포외 인버타아제 활성을 갖도록 와이. 리포라이티카를 엔지니어링하는 것이 바람직하며, 그 이유는 이것이 수크로스를 탄소 공급원으로 더욱 잘 이용하기 때문이다.
일 실시 형태에서, 본 발명은 수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 외인성 폴리뉴클레오티드를 포함하는 형질전환된 야로위아 리포라이티카에 관한 것이며, 여기서,
a) 상기 폴리펩티드는 성숙 수크로스 인버타아제를 코딩하는 폴리펩티드 서열에 융합된 시그널 서열을 포함하고;
b) 상기 시그널 서열은
(i) Xpr2 프리(pre)/프로(pro)-영역 및 N-말단 Xpr2 단편; 및
(ii) 제2 아미노산이 임의의 소수성 아미노산일 수 있는 수크로스 인버타아제 시그널 서열
로 이루어진 군으로부터 선택되며;
c) 성숙 수크로스 인버타아제를 코딩하는 상기 폴리펩티드 서열은, 서열 번호 4의 서열("m-ScSUC2")과 비교할 때, CLUSTALW 정렬법을 기반으로 할 경우 서열 동일성이 80% 이상이다.
바람직하게는, 상기에 기재된 수크로스 인버타아제 시그널 서열의 제2 아미노산은 류신, 페닐알라닌, 아이소류신, 발린 및 메티오닌으로 이루어진 군으로부터 선택된다.
제2 실시 형태에서, 성숙 수크로스 인버타아제를 코딩하는 폴리펩티드 서열은 서열 번호 4("m-ScSUC2")에 기술되어 있다.
제3 실시 형태에서, Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은 와이. 리포라이티카로부터 유래되고, 상기 수크로스 인버타아제 시그널 서열은 사카로마이세스 세레비지애로부터 유래된다. 바람직하게는, Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은 하기를 포함한다:
(i) 알칼리성 세포외 프로테아제 전구체의 N-말단의 157개 아미노산을 포함하는 Xpr2 프리/프로-영역; 및
(ii) 성숙 알칼리성 세포외 프로테아제의 N-말단의 13개 아미노산을 포함하는 N-말단 Xpr2 단편을 포함하는 형질전환된 야로위아 리포라이티카.
바람직하게는, Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은 서열 번호 10["XPR2PP+13"]에 기술되어 있다.
제4 실시 형태에서, 수크로스 인버타아제 시그널 서열은 서열 번호 8["Suc2SS"]에 기술되어 있다.
제5 실시 형태에서, 수크로스 인버타아제 코딩 서열에 융합된 시그널 서열을 포함하는 상기 폴리펩티드는 서열 번호 12["Suc2SS/m-ScSUC2"] 및 서열 번호 20["XPR2PP+13/m-ScSUC2"]의 서열로 이루어진 군으로부터 선택된다.
제6 실시 형태에서, 형질전환된 와이. 리포라이티카는 수크로스가 유일한 탄소 공급원인 조건 하에서 성장할 수 있다.
제7 실시 형태에서, 형질전환된 와이. 리포라이티카는 관심대상의 적어도 하나의 비천연 생성물을 생성할 수 있다. 바람직하게는, 관심대상의 상기 적어도 하나의 비천연 생성물은 다중불포화 지방산, 카로티노이드, 아미노산, 비타민, 스테롤, 플라보노이드, 유기 산, 폴리올 및 하이드록시에스테르, 퀴논-유도된 화합물 및 레스베라트롤로 이루어진 군으로부터 선택된다.
제8 실시 형태에서, 탄소 공급원으로서 적어도 수크로스를 갖는 배양 배지에서 성장된 본 발명의 임의의 형질전환된 와이. 리포라이티카는 80% 이상의 수크로스 인버타아제를 세포외로 분비할 수 있다.
제9 실시 형태에서, 본 발명은
a) 수크로스; 및
b) 글루코스
로 이루어진 군으로부터 선택되는 적어도 하나의 탄소 공급원을 갖는 배양 배지에서 본 발명의 형질전환된 야로위아 리포라이티카를 성장시키고,
이에 의해 관심대상의 적어도 하나의 비천연 생성물을 생성하는 단계와, 선택적으로, 관심대상의 상기 적어도 하나의 비천연 생성물을 회수하는 단계를 포함하는, 관심대상의 적어도 하나의 비천연 생성물을 생성하는 방법에 관한 것이다.
바람직하게는, 관심대상의 상기 적어도 하나의 비천연 생성물은 다중불포화 지방산, 카로티노이드, 아미노산, 비타민, 스테롤, 플라보노이드, 유기 산, 폴리올 및 하이드록시에스테르, 퀴논-유도된 화합물 및 레스베라트롤로 이루어진 군으로부터 선택된다.
제10 실시 형태에서, 형질전환된 와이. 리포라이티카는 80% 이상의 수크로스 인버타아제를 세포외로 분비할 수 있다.
도면의 간단한 설명 및 서열 설명
<도 1>
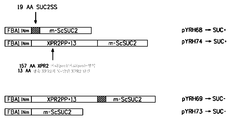
도 1은 세포외 인버타아제 발현 제작물 pYRH68 (서열 번호 13), pYRH74 (서열 번호 21), pYRH69 (서열 번호 18) 및 pYRH73 (서열 번호 15)과, 이들 제작물을 와이. 리포라이티카에서 발현시킬 때 생성된 표현형(즉, 수크로스-이용(SUC + ) 또는 수크로스-비이용(SUC - ))의 개략적인 요약을 제공한다.
<도 2a>
도 2a는 사카로마이세스 세레비지애 인버타아제("ScSUC2")의 N-말단 부분의 뉴클레오티드 및 번역 아미노산 서열을 제공한다. 더 구체적으로, 서열 번호 2의 아미노산 1-32가 예시되어 있으며; 처음 19개 아미노산은 본 명세서에서 Suc2SS (서열 번호 8)로 기술된 인버타아제 시그널 서열에 상응하는 반면, 윤곽이 그려진 박스 내에 예시된 나머지 아미노산은 본 명세서에서 m-ScSUC2 (서열 번호 4)로 표기된, 성숙 인버타아제 단백질의 N-말단을 나타낸다.
<도 2b>
도 2b는 XPR2 유전자에 의해 코딩되는 와이. 리포라이티카 알칼리성 세포외 프로테아제의 일부분의 뉴클레오티드 및 번역 아미노산 서열을 제공한다. 구체적으로, 알칼리성 세포외 프로테아제 전구체 (서열 번호 6)의 아미노산 145-192가 예시되어 있다. 이들 중, 점선 박스 내에 예시된 아미노산 145-157은 Xpr2 프리/프로-영역의 C-말단에 상응하는 반면, 아미노산 158-192는 성숙 단백질의 N-말단 Xpr2 단편에 상응한다. 밑줄이 그어진 아미노산은 본 명세서에서 XPR2PP+13 (서열 번호 10)으로 칭해지는 , Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편에 존재하는 N-말단 Xpr2 단편의 13개 아미노산에 상응한다.
<도 3>
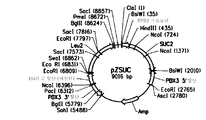
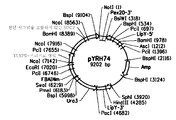
도 3은 pZSUC의 플라스미드 지도를 제공한다.
<도 4>
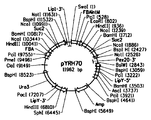
도 4는 하기: (도 4a) pYRH68 및 (도 4b) pYRH70의 플라스미드 지도를 제공한다.
<도 5>
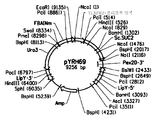
도 5는 하기: (도 5a) pYRH73 및 (도 5b) pYRH69의 플라스미드 지도를 제공한다.
<도 6>
도 6은 pYRH74의 플라스미드 지도이다.
<도 7>
도 7은 글루코스 및 수크로스 배지 둘 모두 상에서의 주 Y4184U + Suc2SS/m-ScSUC2 및 Y4184 (대조군)의 성장을 나타낸다.
<도 8>
도 8은 (도 8a) 글루코스; 및 (도 8b) 수크로스를 포함하는 배지 상에서의 주 Z1978U + Suc2SS/m-ScSUC2, Z1978U + 2_Suc2SS/m-ScSUC2, Z1978U + XPR2PP+13/m-ScSUC2, Z1978U + m-ScSUC2, Z1978U + XPR2PP+13/Suc2SS/m-ScSUC2 및 Z1978 (대조군)의 성장을 나타낸다.
<도 9>
도 9는 pZKL3-9DP9N의 플라스미드 지도이다.
하기의 서열들은 37 C.F.R. §§1.821-1.825("뉴클레오티드 서열 및/또는 아미노산 서열 개시를 포함하는 특허출원에 관한 요건 - 서열 규정")를 따르며 세계지적재산권기구(World Intellectual Property Organization, WIPO) 표준 ST.25(1998), 및 EPO 및 PCT의 서열 목록 요건(규정 5.2 및 49.5(a-bis), 및 시행세칙의 섹션 208 및 부칙 C)에 부합한다. 뉴클레오티드 및 아미노산 서열 데이터에 사용된 기호 및 체제는 37 C.F.R. §1.822에 제시된 규정을 준수한다.
서열 번호 1-41은 표 1에 확인된 바와 같이, 유전자를 코딩하는 ORF, 단백질(또는 그의 부분), 프라이머 또는 플라스미드이다.


본 명세서에 개시된 모든 특허, 특허 출원 및 간행물은 전체적으로 참고로 포함된다.
본 개시내용에서, 다수의 용어 및 약어가 사용된다. 하기의 정의가 제공된다.
"오픈 리딩 프레임(open reading frame)"은 "ORF"로 약칭된다.
"폴리머라아제 연쇄 반응"은 "PCR"로 약칭된다.
"아메리칸 타입 컬쳐 콜렉션(American Type Culture Collection)"은 "ATCC"로 약칭된다.
"다중불포화 지방산(들)"은 "PUFA(들)"로 약칭된다.
"트라이아실글리세롤"은 "TAG"로 약칭된다.
"전체 지방산"은 "TFA"로 약칭된다.
"지방산 메틸 에스테르"는 "FAME"로 약칭된다.
"건조 세포 중량"은 "DCW"로 약칭된다.
"중량 퍼센트"는 "wt%"로 약칭된다.
본 명세서 및 첨부된 특허청구범위에 사용되는 바와 같이, 문맥이 명백하게 달리 지시하지 않는 한, 단수형("a", "an" 및 "the")은 복수 언급(plural reference)을 포함한다. 따라서, 예를 들어, "세포"에 대한 언급은 하나 이상의 세포 및 당업자에게 공지된 그의 등가물 등을 포함한다.
용어 "분비 경로"는 세포가 분비 과정에서 단백질을 세포 외부로 수송하는 경로를 말한다. 일반적으로, 분비될 단백질은 조면 소포체["ER"] 내로 번역되고, 골지체(Golgi apparatus)를 통하여 수송되고, 그 후 소포(vesicle) 내로 혼입되고, 이는 궁극적으로 엑소사이토시스(exocytosis) 과정에서 원형질막과 융합되고 이럼으로써 상기 단백질을 방출한다. 분비는 구성적으로 또는 조절된 방식으로 일어날 수 있다.
"시그널 서열" (당업계에서 "프리-" 서열 영역, "시그널 펩티드", "표적화 시그널", "운반 펩티드(transit peptide)", 또는 "국재화 시그널"로도 칭해짐)은 일반적으로 세포 내에서 또는 세포외 환경으로 폴리펩티드의 나머지 부분의 수송 및 국재화를 지시하는 짧은 펩티드 서열(즉, 폴리펩티드의 가장 말단의 N-부분의, 길이가 약 3-60개인 아미노산)이다. 진핵생물에 있어서 평균 길이는 22.6개 아미노산이다. 일반적으로 시그널 서열은 막, 예를 들어 ER 막을 가로질러 전좌를 통하여 단백질을 그의 작용 부위로 표적화하는 규정된 펩티드 모티프를 포함한다. 전좌 후, 시그널 서열은 일반적으로 내인성 시그널 펩티다아제에 의해 후속적으로 절단된다. 시그널 서열을 포함하는 단백질은 "프리-단백질"로 칭해진다.
콘센서스(consensus) 서열은 없는 반면, 대부분의 모든 시그널 펩티드는 공통 구조, 즉 짧은, 양으로 하전된 아미노 영역(n-영역); 중심 소수성 영역(h-영역); 및 시그널 펩티다아제에 의해 절단되는 부위를 함유하는 더욱 극성인 영역(c-영역)을 보유한다 (문헌[Nielsen, et al., Protein Engineering , 10:1-6 (1997)]).
용어 "프로-단백질" 및 "단백질 전구체"는 본 명세서에서 상호교환가능하게 사용되며, N-말단 "프로-" 서열 영역의 절단에 의해 변형될 수 있는 폴리펩티드를 말한다. 일반적으로 엔도프로테아제에 의한 "프로-" 서열 영역의 제거는 "성숙 단백질"의 형성으로 이어진다. 이러한 "프로-" 서열 영역은 다양한 번역후 변형을 증강시키는 데 있어서 원인이 될 수 있거나, 성숙 단백질의 적당한 폴딩(folding)을 필요로 할 수 있거나, 또는 이것은 성숙 단백질의 활성을 그의 번역후 제거까지 저해하는 작용을 할 수 있다.
"프리/프로-단백질"은 프리/프로 영역이 제거될 때 성숙 단백질이 되는 것에 부착된 "프리/프로-" 영역을 갖는다. "프리/프로-단백질"은 "프리-" 서열 영역(즉, N-말단 시그널 서열) 및 "프로-" 서열 영역(즉, "프리-" 서열 영역과, 프리/프로 영역이 제거될 때 성숙 단백질이 되는 것 사이에 병치됨") 둘 모두를 포함한다.
용어 "인버타아제" 및 "베타-프룩토푸라노시다아제"는 가수분해 반응을 통하여 수크로스(즉, 알파-1,4-글리코시딕 결합에 의해 연결된 알파-D-글루코스 분자 및 베타-D-프룩토스 분자로 구성된 이당류)를 글루코스 및 프룩토스로 전환시키는 능력을 갖는 단백질(EC 3.2.1.26)을 말한다. 사카로마이세스 세레비지애에서, 인버타아제를 코딩하는 유전자는 Suc2 이다.
용어 "세포외 인버타아제"는 미생물 세포가 성장하는 배양 배지 내로 분비되는 인버타아제를 말한다. 따라서, 세포외 인버타아제 활성은 전형적으로 배양 배지 그 자체 내에서 측정된다. 이와는 대조적으로, "전세포 인버타아제"는 세포 외부로는 분비되지 않으며, 대신 세포 내의 주변 세포질 공간 내로 분비되는 인버타아제를 말한다. 전형적으로, 전세포 인버타아제 활성은 전세포 내에서 측정된다. 전세포 활성에 대한 세포외 인버타아제 활성의 상대적인 양(즉, 퍼센트)은 하기와 같이 결정된다: 100 * 배양 배지 중 인버타아제 활성/ [(전세포 중 인버타아제 활성) + (배양 배지 중 인버타아제 활성)].
용어 "알칼리성 세포외 프로테아제" 또는 "AEP"는 와이. 리포라이티카에서 XPR2 유전자에 의해 코딩되는 단백질(EC 3.4.21.-)을 말한다. AEP는 이 효모에 의해 분비되는 주요 세포외 단백질이며 (배양물 1 리터당 1 g 초과), 이때 상기 단백질의 99%는 무세포 배지 상청액에 존재한다. 전장 프로테아제의 N-말단은 "프리/프로-" 영역을 함유하며, 이는 성숙 단백질의 프로세싱 및 분비에 연루된다.
용어 "관심대상의 비천연 생성물"은 야생형 미생물에서 천연적으로는 생성되지 않는 임의의 생성물을 말한다. 전형적으로, 관심대상의 비천연 생성물은, 적절한 이종 유전자(들)가 숙주 미생물 내로 도입되어 관심대상의 생성물인 이종 단백질의 발현을 가능하게 하도록 재조합적 수단을 통하여 생성된다. 관심대상의 바람직한 비천연 생성물의 비제한적 예에는 다중불포화 지방산, 카로티노이드, 아미노산, 비타민, 스테롤, 플라보노이드, 유기 산, 폴리올 및 하이드록시에스테르, 퀴논-유도된 화합물 및 레스베라트롤이 포함되지만, 이에 한정되지 않는다.
용어 "관심대상의 비천연 생성물을 코딩하는 적어도 하나의 이종 유전자"는 그가 도입되는 숙주 미생물과는 상이한 기원으로부터 유래된 유전자(들)를 말한다. 이종 유전자는 숙주 미생물에서 관심대상의 비천연 생성물의 생성을 촉진한다. 일부의 경우, 단지 단일한 이종 유전자가 관심대상의 생성물의 생성을 가능하게 하는 데 필요할 수 있는데, 이는 어떠한 중간 단계 또는 경로의 중간체 없이 기질을 직접적으로 관심대상의 원하는 생성물로 전환시키는 것을 촉매한다. 대안적으로, 일련의 반응이 일어나 관심대상의 원하는 비천연 생성물을 생성하도록 신규한 생합성 경로를 코딩하는 일련의 유전자들을 미생물 내로 도입하는 것이 바람직할 수 있다.
일반적으로, 용어 "유지성"은 유기체의 에너지원을 오일의 형태로 저장하는 경향이 있는 유기체를 지칭한다(문헌[Weete, In: Fungal Lipid Biochemistry, 2nd Ed., Plenum, 1980]). 이러한 과정 동안, 유지성 미생물의 세포 오일 함량은 일반적으로 S자 모양의 곡선을 따르며, 여기서, 지질의 농도는 그것이 후기 대수 성장기 또는 초기 정지 성장기에서 최대에 도달할 때까지 증가하였다가 후기 정지기 및 사멸기 동안에 점차적으로 감소한다(문헌[Yongmanitchai and Ward, Appl. Environ. Microbiol., 57:419-25 (1991)]). 용어 "유지성"은 본 출원의 목적을 위해, 미생물의 건조 세포 중량["DCW"]의 적어도 약 25%를 오일로 축적할 수 있는 미생물을 말한다.
용어 "유지성 효모"는 오일을 만들 수 있는 효모로 분류되는 이러한 유지성 미생물을 말하며, 다시 말하면, 여기서, 효모의 DCW의 약 25%의 과량으로 오일이 축적될 수 있다. 유지성 효모의 예에는 하기의 속이 포함되나, 이에 제한되는 것을 의미하는 것은 아니다: 야로위아, 칸디다(Candida), 로도토룰라(Rhodotorula), 로도스포리듐(Rhodosporidium), 크립토코커스(Cryptococcus), 트리코스포론(Trichosporon) 및 리포마이세스(Lipomyces). 효모의 DCW의 약 25% 과량의 오일을 축적하는 능력은 재조합 엔지니어링(engineering)의 결과를 통하여 또는 유기체의 천연의 능력을 통하여 이루어질 수 있다.
용어 "탄소 공급원"은 미생물이 대사하여 에너지를 유도하는 탄소를 포함하는 영양소를 말한다. 예를 들어,
야생형 와이. 리포라이티카는 글루코스, 프룩토스, 글리세롤, 아세테이트, 알코올, 알칸, 지방산 및 트라이글리세라이드를 포함하는 다양한 탄소 공급원을 이용할 수 있지만; 이것은 수크로스를 유일한 탄소 공급원으로 사용할 수는 없다 (문헌[Barth, G. and C. Gaillardin, FEMS Microbiol. Rev., 19:219-237 (1997)]). 이와는 대조적으로, 본 발명의 재조합 와이. 리포라이티카는 수크로스를 유일한 발효성 탄소 공급원으로 또는 다른 적합한 탄소 공급원과 조합하여 사용할 수 있다.
용어 "미생물 숙주 세포" 및 "미생물 숙주 유기체"는 본 명세서에서 상호교환가능하게 사용되며, 외래 또는 이종 유전자를 받아들일 수 있으며 그 유전자를 발현할 수 있는 미생물을 말한다. "재조합 미생물 숙주 세포"는 (예를 들어, 미생물 숙주 세포가 외인성 폴리뉴클레오티드로 형질전환되도록) 재조합적으로 엔지니어링된 미생물 숙주 세포를 말한다.
본 명세서에 사용되는 바와 같이, "단리된 핵산 단편"은 선택적으로 합성, 비천연 또는 변경 뉴클레오티드 염기를 포함하는 단일 가닥 또는 이중 가닥인 RNA 또는 DNA의 중합체이다. DNA의 중합체 형태인 분리된 핵산 단편은 cDNA, 게놈 DNA 또는 합성 DNA의 하나 이상의 절편으로 이루어질 수 있다.
아미노산 또는 뉴클레오티드 서열의 "상당한 부분"은, 당업자에 의한 서열의 수동 평가에 의해, 또는 BLAST(기본 국소 정렬 검색 도구(Basic Local Alignment Search Tool); 문헌[Altschul, S. F., et al., J. Mol. Biol. 215:403-410 (1993)])와 같은 알고리즘을 사용한 컴퓨터-자동화 서열 비교 및 확인에 의해 그 폴리펩티드 또는 유전자를 추정적으로 확인하기에 충분한 폴리펩티드의 아미노산 서열 또는 유전자의 뉴클레오티드 서열을 포함하는 부분이다. 일반적으로, 폴리펩티드 또는 핵산 서열을 공지의 단백질 또는 유전자와 상동성인 것으로 추정적으로 확인하기 위해서는 10개 이상의 연접 아미노산 또는 30개 이상의 뉴클레오티드의 서열이 필요하다. 또한, 뉴클레오티드 서열에 있어서는, 서열-의존적인 유전자 확인(예를 들어, 서던 혼성화(Southern hybridization)) 및 단리(예를 들어, 박테리아 콜로니 또는 박테리오파지 플라크의 원위치 혼성화(in situ hybridization)) 방법에 20 내지 30개의 연접 뉴클레오티드를 포함하는 유전자-특이적 올리고뉴클레오티드 프로브가 사용될 수 있다. 게다가, 프라이머를 포함하는 특정 핵산 단편을 얻기 위하여, 12-15개 염기의 짧은 올리고뉴클레오티드가 폴리머라아제 연쇄 반응("PCR")에서 증폭 프라이머로 사용될 수 있다. 따라서, 뉴클레오티드 서열의 "실질적인 부분"은, 서열을 포함하는 핵산 단편을 특이적으로 확인 및/또는 단리하기에 충분한 서열을 포함한다.
용어 "상보적인"은, 역평행 배향으로 정렬될 때 왓슨-크릭(Watson-Crick) 염기쌍 형성이 가능한 2개 서열의 뉴클레오티드 염기 사이의 관계를 기술한다. 예를 들어, DNA에 있어서, 아데노신은 티민과 염기쌍 형성이 가능하고 시토신은 구아닌과 염기쌍 형성이 가능하다.
"코돈 축퇴성"은 코딩된 폴리펩티드의 아미노산 서열에 영향을 주지 않으면서 뉴클레오티드 서열의 변이를 허용하는 유전자 코드의 성질을 지칭한다. 주어진 아미노산을 특정하기 위한 뉴클레오티드 코돈의 사용에 있어서 특정 숙주 세포에서 나타나는 "코돈-바이어스(codon-bias)"가 당업자에게 주지되어 있다. 그러므로, 숙주 세포 내의 발현을 개선하기 위한 유전자를 합성할 경우에는, 그의 코돈 사용 빈도가 숙주 세포가 선호하는 코돈의 사용 빈도에 근접하도록 유전자를 디자인하는 것이 바람직하다.
"합성 유전자"는 당업자에게 공지되어 있는 절차를 사용하여 화학적으로 합성된 올리고뉴클레오티드 빌딩 블록(building block)으로부터 조립될 수 있다. 이들 빌딩 블록들을 라이게이션시키고 어닐링시켜 유전자 절편을 형성하며, 이어서, 효소적으로 조립하여 전체 유전자를 제작한다. 따라서, 유전자는 숙주 세포의 코돈 바이어스를 반영하기 위하여 뉴클레오티드 서열의 최적화에 기초하여 최적의 유전자 발현을 위해 맞춤화될 수 있다. 당업자는 코돈 사용이 숙주가 선호하는 코돈 쪽으로 편향된다면, 성공적인 유전자 발현이 가능함을 인식한다. 바람직한 코돈의 결정은 서열 정보를 이용할 수 있는 숙주 세포로부터 유래된 유전자의 조사에 기초할 수 있다. 예를 들어, 와이. 리포라이티카에 있어서 코돈 사용 프로파일이 본 명세서에 참고로 포함된 미국 특허 제7,125,672호에 제공되어 있다.
"유전자"는 특정 단백질을 발현시키는 핵산 단편을 지칭하며, 이는 코딩 영역만을 지칭하거나 코딩 서열 앞에 있는 조절 서열(5' 비-코딩 서열) 및 코딩 서열 뒤에 있는 조절 서열(3' 비-코딩 서열)을 포함할 수 있다. "천연 유전자"는 그 자신의 조절 서열과 함께 자연에서 발견되는 유전자를 지칭한다. "키메라 유전자"는 자연에서 함께 발견되지 않는 조절 및 코딩 서열을 포함하는, 천연 유전자가 아닌 임의의 유전자를 지칭한다. 따라서, 키메라 유전자는 상이한 공급원으로부터 유래된 조절 서열과 코딩 서열, 또는 동일한 공급원으로부터 유래되었지만, 자연에서 발견되는 것과 상이한 방식으로 배열된 조절 서열과 코딩 서열을 포함할 수 있다. "내인성 유전자"는 유기체의 게놈에서 그의 자연적 위치에 있는 천연 유전자를 지칭한다. "외래" 유전자 (또는 "외인성 유전자")는 유전자 전달에 의해 숙주 유기체 내로 도입된 유전자를 말한다. 외래 유전자는 비-천연 유기체에 삽입된 천연 유전자, 천연 숙주 내의 새로운 위치에 도입된 천연 유전자, 또는 키메라 유전자를 포함할 수 있다. "트랜스유전자(transgene)"는 형질전환 절차에 의해 게놈 내로 도입된 유전자이다. "코돈-최적화된 유전자"는 그의 코돈 사용 빈도가 숙주 세포의 선호하는 코돈 사용의 빈도를 모방하도록 디자인된 유전자이다.
"코딩 서열"은 특정 아미노산 서열을 코딩하는 DNA 서열을 말한다.
"적합한 조절 서열"은 코딩 서열의 상류(5' 비-코딩 서열), 그의 내부 또는 그의 하류(3' 비-코딩 서열)에 위치하고, 전사, RNA 프로세싱 또는 안정성 또는 결부된 코딩 서열의 번역에 영향을 미치는 뉴클레오티드 서열을 말한다. 조절 서열은 프로모터, 인핸서(enhancer), 사일런서(silencer), 5' 비번역 리더(untranslated leader) 서열(예를 들어, 전사 시작 부위와 번역 개시 코돈의 사이), 인트론, 폴리아데닐화 인식 서열, RNA 프로세싱 부위, 이펙터(effector) 결합 부위 및 스템-루프 구조를 포함할 수 있다.
"프로모터"는 코딩 서열 또는 기능성 RNA의 발현을 제어할 수 있는 DNA 서열을 말한다. 일반적으로, 코딩 서열은 프로모터 서열에 대해 3'에 위치한다. 프로모터는 천연 유전자로부터 그 전체가 유래될 수도 있거나, 자연에서 발견되는 상이한 프로모터로부터 유래된 상이한 요소로 구성될 수도 있거나, 또는 심지어 합성 DNA 절편을 포함할 수도 있다. 상이한 프로모터는 상이한 조직 또는 세포 유형에서, 또는 상이한 발생 단계에서, 또는 상이한 환경적 또는 생리학적 조건에 반응하여 유전자의 발현을 유도할 수 있음을 당업자는 이해할 것이다. 유전자가 대부분의 시점에 대부분의 세포 유형에서 발현되게 하는 프로모터는 통상 "구성적(constitutive) 프로모터"로 지칭된다. 대부분의 경우에, 조절 서열의 정확한 경계가 완벽하게 규정되어 있지 않기 때문에, 상이한 길이의 DNA 단편이 동일한 프로모터 활성을 가질 수 있다는 것이 추가로 인식된다.
용어 "3' 비-코딩 서열", "전사 종결자(terminator)" 및 "종결자"는 본 명세서에서 상호교환가능하게 사용되며, 코딩 서열의 3' 하류에 위치한 DNA 서열을 말한다. 이는 폴리아데닐화 인식 서열 및 mRNA 프로세싱 또는 유전자 발현에 영향을 미칠 수 있는 조절 신호를 코딩하는 다른 서열을 포함한다. 폴리아데닐화 신호는 통상적으로 mRNA 전구체의 3' 말단에 폴리아데닐산 트랙트(tract)를 부가하는 데에 영향을 미치는 것을 특징으로 한다. 3' 영역은 전사, RNA 프로세싱 또는 안정성, 또는 관련 코딩 서열의 번역에 영향을 미칠 수 있다.
용어 "작동가능하게 연결된"은 하나의 기능이 나머지에 의해 영향을 받도록 하는, 단일 핵산 단편 상에서의 핵산 서열의 결부를 말한다. 예를 들어, 프로모터는 그것이 코딩 서열의 발현을 초래할 수 있는 경우에 코딩 서열에 작동가능하게 연결된다. 다시 말하면, 코딩 서열은 프로모터의 전사적 조절 하에 있다. 코딩 서열은 센스(sense) 또는 안티센스(antisense) 배향으로 조절 서열에 작동가능하게 연결될 수 있다.
본 명세서에 사용되는 용어 "발현"은 센스(mRNA) 또는 안티센스 RNA의 전사 및 안정적인 축적을 지칭한다. 발현은 mRNA로부터의 폴리펩티드로의 번역을 지칭할 수도 있다.
"형질전환"은 핵산 분자의 숙주 유기체로의 전달을 지칭한다. 핵산 분자는 자가 복제되는 플라스미드일 수 있거나; 또는 이것은 숙주 유기체의 게놈 내로 통합될 수 있다. 형질전환된 핵산 단편을 함유하는 숙주 유기체는 "트랜스제닉" 또는 "재조합" 또는 "형질전환된" 유기체 또는 "형질전환체"로 지칭된다.
"안정적인 형질전환"은 핵산 단편을 핵 및 세포소기관 게놈 둘 모두를 포함하는 숙주 유기체의 게놈 내로 전달하여, 유전적으로 안정적인 유전을 야기하는 것을 말한다(즉, 핵산 단편은 "안정적으로 통합된다"). 반대로, "일시적 형질전환"은, 숙주 유기체의 핵, 또는 DNA-함유 소기관 내로 핵산 단편을 전달하여, 통합 또는 안정적인 유전성이 없는 유전자 발현을 유발하는 것을 지칭한다.
용어 "플라스미드" 및 "벡터"는 흔히 세포의 중추적 대사의 일부가 아닌 유전자를 운반하는 보통 원형의 이중 가닥 DNA 단편 형태의 염색체 외 요소를 지칭한다. 이러한 요소는 자가 복제되는 서열, 게놈 통합 서열, 파지 또는 뉴클레오티드 서열일 수 있으며, 임의의 공급원으로부터 유래되는 선형 또는 원형의 단일- 또는 이중-가닥 DNA 또는 RNA일 수 있고, 여기서, 다수의 뉴클레오티드 서열은 세포 내로 발현 카세트(들)를 도입할 수 있는 독특한 제작물 내로 연결되거나 재조합된다.
용어 "발현 카세트는", 선택된 유전자의 코딩 서열 및 선택된 유전자 생성물의 발현을 위해 필요한 코딩 서열에 선행하는 조절 서열(5' 비-코딩 서열) 및 후행하는 조절 서열(3' 비-코딩 서열)을 포함하는 DNA의 단편을 지칭한다. 따라서, 발현 카세트는 전형적으로 1) 프로모터 서열; 2) 코딩 서열(즉, 오픈 리딩 프레임("ORF")); 및 3) 진핵생물에서 대개 폴리아데닐화 부위를 함유하는 3' 비번역 영역(즉, 종결자)으로 구성된다. 발현 카세트(들)는 통상적으로 벡터 내에 포함되어, 클로닝 및 형질전환을 용이하게 한다. 정확한 조절 서열이 각각의 숙주에 대하여 사용되는 한, 상이한 발현 카세트로 박테리아, 효모, 식물 및 포유류 세포를 비롯한 상이한 유기체를 형질전환시킬 수 있다.
용어 "서열 분석 소프트웨어"는 뉴클레오티드 또는 아미노산 서열을 분석하는데 유용한 임의의 컴퓨터 알고리즘 또는 소프트웨어 프로그램을 말한다. "서열 분석 소프트웨어"는 상업적으로 입수할 수 있거나 독립적으로 개발할 수 있다. 전형적인 서열 분석 소프트웨어에는 하기의 것이 포함될 것이나, 이에 한정되지 않는다: 1) GCG 프로그램 모음(위스콘신 패키지 버전(Wisconsin Package Version) 9.0, 미국 위스콘신주 매디슨 소재의 제네틱스 컴퓨터 그룹(Genetics Computer Group, GCG)); 2) BLASTP, BLASTN, BLASTX(문헌[Altschul et al., J. Mol. Biol. 215:403-410 (1990)]); 3) DNASTAR(미국 위스콘신주 매디슨 소재의 디엔에이스타, 인코포레이티드); 4) 시퀀쳐(Sequencher)(미국 미시간주 앤 아버 소재의 진 코즈 코포레이션(Gene Codes Corporation)); 및 5) 스미스-워터만(Smith-Waterma) 알고리즘을 통합하는 FASTA 프로그램(문헌[W. R. Pearson, Comput. Methods Genome Res., [Proc. Int. Symp.] (1994), Meeting Date 1992, 111-20. Editor (s): Suhai, Sandor. Plenum: New York, NY])을 포함하는 FASTA 프로그램. 본 출원과 관련하여, 서열 분석 소프트웨어가 분석을 위해 사용된 경우에는, 그 분석 결과가 달리 명시되지 않는 한, 참조한 프로그램의 "디폴트 값"에 기초할 것임을 이해할 것이다. 본 명세서에 사용되는 바와 같이, "디폴트 값"은 최초 초기화할 때에 소프트웨어에 원래 로딩된 값 또는 파라미터의 임의의 세트를 의미할 것이다.
핵산 또는 폴리펩티드 서열과 관련하여 "서열 동일성" 또는 "동일성"은, 특정된 비교창 상에 최대 상응도로 정렬될 경우에 2개 서열 중의 동일한 핵산 염기 또는 아미노산 잔기를 말한다. 따라서, "서열 동일성의 백분율" 또는 "동일성 백분율"은 비교창에 걸쳐 최적으로 정렬된 2개의 서열을 비교함으로써 결정된 값을 지칭하며, 여기서 비교창 내의 폴리뉴클레오티드 또는 폴리펩티드 서열의 부분은 2개 서열의 최적 정렬을 위한 기준 서열(삽입 또는 결실을 포함하지 않음)과 비교하여 삽입 또는 결실(즉, 갭)을 포함할 수 있다. 양자 모두의 서열 내에서 동일한 핵산 염기 또는 아미노산 잔기가 나타나는 위치의 개수를 결정하여 일치하는 위치의 개수를 산출하고, 일치하는 위치의 개수를 비교창 내의 위치의 총 개수로 나누고, 그 결과에 100을 곱하여 서열 동일성의 백분율을 산출함으로써 백분율을 계산한다.
"동일성 백분율" 및 "유사성 백분율"의 결정 방법은 공중 이용가능한 컴퓨터 프로그램에 코드화되어 있다. 동일성 백분율 및 유사성 백분율은 하기의 문헌에 기재된 것을 포함하나 이에 한정되지 않는 공지의 방법에 의해 용이하게 계산될 수 있다: 1) 문헌[Computational Molecular Biology (Lesk, A. M., Ed.) Oxford University: NY (1988)]; 2) 문헌[Biocomputing: Informatics and Genome Projects (Smith, D. W., Ed.) Academic: NY (1993)]; 3) 문헌[Computer Analysis of Sequence Data, Part I (Griffin, A. M., and Griffin, H. G., Eds.) Humania: NJ (1994)]; 4) 문헌[Sequence Analysis in Molecular Biology (von Heinje, G., Ed.) Academic (1987)]; 및 5) 문헌[Sequence Analysis 프라이머 (Gribskov, M. and Devereux, J., Eds.) Stockton: NY (1991).
서열 정렬 및 퍼센트 동일성 또는 유사성 계산은 상동 서열을 검출하도록 디자인된 다양한 비교 방법을 사용하여 결정될 수 있다.
서열의 다중 정렬은 "ClustalV 정렬법" 및 "ClustalW 정렬법"(문헌[Higgins and Sharp, CABIOS, 5:151-153 (1989)]; 문헌[Higgins, D.G. et al., Comput . Appl. Biosci ., 8:189-191(1992)])을 포함하는 그리고 상기 멕얼라인(MegAlign™) (버전 8.0.2) 프로그램에서 발견되는 몇몇 다양한 알고리즘을 포함하는 "Clustal 정렬법"을 이용하여 수행될 수 있다. Clustal 프로그램 중 어느 하나를 사용한 서열의 정렬 후에, 프로그램 내의 "서열 거리" 표를 봄으로써 "동일성 백분율"을 수득할 수 있다.
본 발명에서 사용되는 표준 재조합 DNA 및 분자 클로닝 기술은 당업계에 잘 알려져 있으며, 문헌[Sambrook, J., Fritsch, E. F. and Maniatis, T., Molecular Cloning: A Laboratory Manual, 2nd ed., Cold Spring Harbor Laboratory: Cold Spring Harbor, NY (1989)] (이하, "Maniatis"); 문헌[Silhavy, T. J., Bennan, M. L. and Enquist, L. W., Experiments with Gene Fusions, Cold Spring Harbor Laboratory: Cold Spring Harbor, NY (1984)]; 및 문헌[Ausubel, F. M. et al., Current Protocols in Molecular Biology, published by Greene Publishing Assoc. and Wiley-Interscience, Hoboken, NJ (1987)]에 기재되어 있다.
와이. 리포라이티카는 수크로스를 탄소 공급원으로 사용하도록 재조합적으로 엔지니어링될 수 있다. 이는 상기 유기체가 인버타아제를 코딩하는 유전자를 발현하도록 엔지니어링하는 것을 포함하였는데, 상기 인버타아제는 수크로스의 글루코스 및 프룩토스로의 전환을 촉매한다. 그러나, 수크로스는 효모가 성장하는 배지에 존재하기 때문에, 수크로스는 세포내 인버타아제에 의한 그의 가수분해 이전에는 세포 내로 수송될 필요가 있거나 또는 인버타아제는 세포외에서 발현되어야 하며, 여기서 상기 인버타아제는 배지 중 수크로스를 글루코스 및 프룩토스로 가수분해할 수 있고 이것이 다시 세포 내로 수송될 수 있다. 바람직하게는, 시그널 서열이 이종 인버타아제 유전자에 융합되어서 인버타아제가 주위 매질 내로 세포외로 분비되게 한다.
사카로마이세스 세레비지애는 수크로스의 글루코스 및 프룩토스로의 전환을 촉매하는 기능성 인버타아제(EC 3.2.1.26; "β-프룩토푸라노시다아제"로도 칭해짐)의 발현에 의한 것 때문에 수크로스를 발효시킨다. 에스. 세레비지애 내의 동일 SUC2 대립유전자로부터 발현된 2가지 형태의 인버타아제, 즉 글루코스 억제에 의해 조절되는 분비형의 글리코실화된 형태 및 구성적으로 생성되는 세포내의 비글리코실화된 형태가 있다. 이들 두 형태 사이의 차이는 분비형의 글리코실화된 인버타아제의 합성에 필요한 5'-시그널 서열의 존재 또는 부재에 기인한다. 이 시그널 서열은 인버타아제 단백질의 처음 19개 아미노산으로 정의되었다 (문헌[Perlman, D., et al., Proc. Natl. Acad. Sci. U.S.A., 79:781-785 (1982)]; 문헌[Carlson and Botstein, Cell, 28(1):145-54 (1982)]; 문헌[Taussig and Carlson, Nucleic Acids Res., 11:1943-54 (1983)]).
따라서, 전장 에스. 세레비지애 SUC2["ScSUC2"] 유전자 (서열 번호 1)는 길이가 1599개 뉴클레오티드이며, 이는 글리코실화된 형태로 에스. 세레비지애의 주변세포질 내로 분비되는 532개 아미노산의 전장 인버타아제 (서열 번호 2)를 코딩한다. 이와는 대조적으로, "성숙" ScSUC2 유전자["m-ScSUC2"]는 서열 번호 1의 뉴클레오티드 1-57에 의해 코딩되는 19개 아미노산 길이의 5' 시그널 서열이 결여되어 있으며; 따라서, m-ScSUC2의 세포내 비글리코실화 형태는 서열 번호 3으로 기술된 1542 bp 뉴클레오티드 서열로 코딩되며 (이는 서열 번호 1의 뉴클레오티드 58-1599에 상응함), 이는 513개 아미노산의 절두형 m-ScSUC2 단백질 (서열 번호 4)을 생성하도록 번역된다.
세포의 막을 통하여 분비되는 단백질은 일반적으로 "프리"-단백질로서 세포내에서 생성된다. 이 형태에 있어서, 단백질은 아마도 그의 분비 및 국재화를 돕지만 분비 과정 동안 분비된 "성숙" 단백질로부터 궁극적으로 절단되는 추가의 "시그널" 펩티드 서열에 융합된다. 프리-단백질의 시그널 펩티드는 일부 유사성을 공유하지만, 그의 일차 구조는 상당히 상이하다. 이는 각각의 단백질이 세포막을 통하여 그 특정 단백질의 전좌에 특히 적합한 시그널 서열과 함께 진화되었음을 시사한다. 상기에 논의된 바와 같이, 와이. 리포라이티카는 다량의 AEP를 배양 배지 내로 천연적으로 분비한다. 서열 번호 6의 전장 와이. 리포라이티카 AEP (길이: 454개 아미노산)는 1365 bp XPR2 유전자 (서열 번호 5)에 의해 코딩된다. 상기 프로테아제의 N-말단 157개 아미노산 잔기는 성숙 단백질의 프로세싱 및 분비에 연루된 시그널 서열 및 프리/프로-영역을 함유한다.
상세한 연구에 의하면, AEP는 프리프로I-프로II-프로III N-말단 영역과 함께 합성됨이 밝혀졌으며, AEP의 4가지 상이한 전구체가 검출되었다. 아미노산 위치 1 내지 13은 분비성 시그널 서열, 이어서 전형적인 다이펩티딜 아미노펩티다아제 인식 부위들인 -Xaa-Ala- 및 -Xaa-Pro-의 런(run)을 포함하는 위치 14 내지 33을 함유한다. 아미노산 위치 54 또는 60은 프로I 영역과 프로II 영역 사이의 절단 부위인 것으로 생각되는 반면, 위치 129 또는 131은 프로II 영역과 프로III 영역 사이의 다른 절단 부위이다. 마지막으로, 서열 번호 6의 아미노산 위치 157은 프로 III과 성숙 AEP 사이의 절단 부위이다 (문헌[Matoba, S. et al., Mol. Cell Biol., 8(11):4904-4916 (1988)]; 또한 미국 특허 제4,937,189호 및 유럽 특허 제0220864 B1호 참조). 아미노산 1-157에 상응하는 프리/프로-영역은 단백질 폴딩, 효율적인 분비, 조기 활성화의 방지 등에 연루되며; 프리/프로-영역의 절단 없이는, AEP 단백질은 비기능성인 것으로 제안되었다.
Xpr2 프리프로-영역은 와이. 리포라이티카에서 다양한 이종 단백질의 분비에 이용되었지만; 단백질 분비에 있어서의 Xpr2 프리프로-영역의 사용은 혼합된 결과를 생성하였다 (문헌[Madzak, C.,et al., Microbiology, 145(1):75-87 (1999)]). 만족스럽지 못한 단백질 발현의 이유는 불완전 단백질 프로세싱 (문헌[Park, C. S., et al., J. Biol. Chem., 272:6876-6881 (1997)]; 문헌[Park, C. S., et al., Appl. Biochem. Biotechnol., 87:1-15 (2000)]; 문헌[Swennen, D., et al., Microbiology, 148:41-50 (2002)]) 및 세포외 발현의 결여 (문헌[Hamsa, P. V. and B. B. Chattoo, Gene, 143:165-70 (1994)]; 문헌[Tharaud, C., et al., Gene, 121:111-119 (1992)])를 포함한다. 따라서, 프로-서열은 이종 단백질 분비에 필요하지 않을 수 있거나 또는 심지어 해로울 수 있음이 제안되었다 (문헌[Madzak, C., et al., J. Biotechnol., 109:63-81 (2004)]; 문헌[Park, et al., J. Biol. Chem. (상기)]; 문헌[Tharaud, C., et al., 상기]). 이는 문헌[Tabuchi, M., et al., J. Bacteriol., 179:4179-4189 (1997)]에 나타나 있으며, 여기서, 카르복시펩티다아제 Y(CPY)의 프리프로-영역은 쉬조사카로마이세스 폼베(Schizosaccharomyces pombe) 유래의 Suc2의 분비에 효과가 없었다.
ScSuc2 시그널 서열 (서열 번호 1의 뉴클레오티드 1-57[즉, ScSUC2의 아미노산 1-19]에 상응함)을 발현하는 제작물을 아미노산 위치 2에서 돌연변이시켜 PciI 제한 효소 부위를 도입하였다. 그 결과, 야생형 Leu2 잔기는 다른 소수성 잔기인 Phe2로 돌연변이되었으며, 이럼으로써 ScSuc2의 분비 과정에 영향을 주지 않고서 시그널 서열의 소수성이 유지되었다 (문헌[Kaiser, C. A.,et al., Science, 235:312-317 (1987)]). 따라서, 본 발명의 하나의 적합한 ScSuc2 시그널 서열(즉, "Suc2SS")은 본 명세서에서 서열 번호 7 및 8로 기술된다.
Xpr2 프리/프로-영역을 포함하는 제작물은 서열 번호 10의 아미노산 1-170을 코딩하도록 디자인되었다. Xpr2 프리/프로-영역은 본 명세서에서 서열 번호 6의 아미노산 1-157만을 포함하는 것으로 기재되었지만, 프리/프로-영역(즉, N-말단 Xpr2 단편) 이후의 상기 프로테아제의 추가의 13개 아미노산을 "링커"로서 포함시켜 Xpr6 엔도펩티다아제가 Lys156-Arg157 절단 부위에 접근하는 것을 보장하였으며, 그 이유는 융합 접합부의 부정확한 프로세싱이 추정 2차 구조로 인하여 이전에 주목되었기 때문이었다 (문헌[Park, C. S., et al., J. Biol. Chem., 272:6876-6881 (1997)]). 따라서, 본 발명의 하나의 적합한 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편(즉, "XPR2PP+13")은 본 명세서에서 서열 번호 9 및 10으로 기술된다.
하기 표 2에 요약되고 도 1에 예시된 발현 카세트는 형질전환된 와이. 리포라이티카에서의 인버타아제 발현에 대하여 평가되었다. 더 구체적으로, 발현 플라스미드 pYRH68은 Suc2SS 시그널 서열이 성숙 SUC2(즉, 서열 번호 3; "m-ScSUC2")를 코딩하는 유전자에 융합된 것을 포함하며, 발현 플라스미드 pYRH70은 Suc2SS 시그널 서열이 서열 번호 3의 서열에 융합된 것의 2개의 카피를 포함하며, 발현 플라스미드 pYRH69는 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편 둘 모두와 Suc2SS 시그널 서열이 서열 번호 3에 융합된 것을 포함하며, 발현 플라스미드 pYRH73은 단지 서열 번호 3의 서열을 포함하며 (그리고 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편도 포함하지 않고 분비성 시그널 서열로서 Suc2SS 시그널 서열도 포함하지 않음), 발현 플라스미드 pYRH74는 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편이 서열 번호 3의 서열에 융합된 것을 포함하였다. "FBAINm 프로모터 영역"(즉, fba1 유전자에 의해 코딩되는 프룩토스-비스포스페이트 알돌라아제 효소(E.C. 4.1.2.13)의 'ATG' 번역 개시 코돈 앞의 5' 상류 비번역 영역으로부터 유래됨 [미국 특허 제7,202,356호])은 인버타아제 유전자 제작물에 작동가능하게 연결되었다.

상기 플라스미드 제작물들 각각을 발현하는 와이. 리포라이티카 형질전환체는 수크로스가 유일한 탄소 공급원인 배지 상에서 성장시켰다. Suc2SS 시그널 서열이 성숙 SUC2를 코딩하는 유전자(이는 ScSuc2[즉, 서열 번호 2]를 코딩하는 전장 유전자에 효과적으로 상응함)에 융합된 것을 발현하는 형질전환체(즉, pYRH68 및 pYRH70) 또는 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편이 성숙 SUC2를 코딩하는 유전자에 융합된 것을 발현하는 형질전환체(즉, pYRH74)만이 인버타아제, 즉, SUC+ 표현형을 발현하였다. 따라서, 이는 와이. 리포라이티카에서의 ScSUC2의 기능적 발현으로 이어지는 융합물들을 예시한다.
일 태양에서, 본 발명은 수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 외인성 폴리뉴클레오티드를 포함하는 형질전환된 와이. 리포라이티카에 관한 것이며, 여기서,
(a) 상기 폴리펩티드는 성숙 수크로스 인버타아제를 코딩하는 폴리펩티드 서열에 융합된 시그널 서열을 포함하고;
(b) 상기 시그널 서열은
(i) Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편; 및
(ii) 제2 아미노산이 임의의 소수성 아미노산일 수 있는 수크로스 인버타아제 시그널 서열로 이루어진 군으로부터 선택되며;
(c) 성숙 수크로스 인버타아제를 코딩하는 상기 폴리펩티드 서열은, 서열 번호 4의 서열("m-ScSUC2")과 비교할 때, CLUSTALW 정렬법을 기반으로 할 경우 서열 동일성이 80% 이상이다.
바람직한 실시 형태에서, 본 발명의 형질전환된 와이. 리포라이티카는, 적어도 수크로스를 탄소 공급원으로 갖는 배양 배지에서 배양될 때, 80% 이상의 수크로스 인버타아제를 세포외로 분비할 수 있을 것이다(한편, 세포내[또는 주변 세포질] 인버타아제 활성은 전체 인버타아제 활성의 20% 이하이다). 더 바람직하게는, 세포외 인버타아제 활성은 전체 인버타아제 활성의 적어도 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99% 또는 100%이다.
이전에 기재된 바와 같이, 본 명세서에서 서열 번호 4로 기술된 "성숙 ScSUC2 단백질["m-ScSUC2"]은 서열 번호 1의 뉴클레오티드 1-57에 의해 코딩되는 19개 아미노산 길이의 5' 시그널 서열이 결여되어 있다. 바람직하게는, 성숙 수크로스 인버타아제를 코딩하는 폴리펩티드 서열은 서열 번호 4("m-ScSUC2")에 기술되어 있다. 다른 실시 형태에서, 성숙 수크로스 인버타아제는 CLUSTALW 정렬법에 기초하면 서열 번호 4의 서열과 비교할 때 서열 동일성이 80% 이상이며, 즉, 상기 폴리펩티드는 서열 번호 4의 서열과 비교할 때 동일성이 적어도 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 또는 100%일 수 있다.
일 실시 형태에서, 서열 번호 4의 서열을 와이. 리포라이티카에서의 발현용으로 코돈-최적화하는 것이 바람직할 수 있다. 이는 이전의 와이. 리포라이티카 코돈 사용 프로파일의 결정, 바람직한 코돈의 확인, 및 'ATG' 개시 코돈 주위의 콘센서스 서열의 결정에 기초하면 가능하다 (미국 특허 제7,238,482호 참조).
다른 실시 형태에서, 표 14의 인버타아제 서열 (실시예 8) 또는 그 부분들이 본 발명에서 사용될 수 있다. 대안적으로, 이들 중 임의의 것은 서열 분석 소프트웨어를 사용하여 동일하거나 다른 종에서 인버타아제 상동체를 검색하는 데 사용될 수 있다. 일반적으로, 이러한 컴퓨터 소프트웨어는 상동성 정도를 다양한 치환, 결실 및 다른 변형에 할당함으로써 유사한 서열들을 매칭시킨다. 소프트웨어 알고리즘, 예를 들어 낮은 복잡성의 필터 및 하기 파라미터, 즉 기대 값 = 10, 매트릭스 = Blosum 62 (문헌[Altschul, et al., Nucleic Acids Res., 25:3389-3402 (1997)])를 이용한 BLASTP 정렬법의 사용은 표 14의 임의의 인버타아제 단백질을 핵산 또는 단백질 서열의 데이터베이스에 대하여 비교하고 이럼으로써 바람직한 유기체 내에서 유사한 공지된 서열들을 확인하기 위한 수단으로서 잘 알려져 있다.
공지된 서열의 데이터베이스를 통하여 찾기 위하여 소프트웨어 알고리즘을 사용하는 것은 표 14에 기재된 것과 같이, 공개적으로 입수가능한 인버타아제 서열에 대하여 상대적으로 낮은 퍼센트의 동일성을 갖는 상동체의 단리에 특히 적합하다. 단리는 공개적으로 입수가능한 인버타아제 서열에 대하여 적어도 약 80%-85%의 동일성의 인버타아제 상동체에 대하여 상대적으로 더욱 용이한 것으로 예측가능하다. 또한, 적어도 약 85%-90% 동일한 서열이 단리에 특히 적합할 것이며, 적어도 약 90%-95% 동일한 서열이 가장 용이하게 단리될 것이다.
일부 인버타아제 상동체는 또한 인버타아제 효소에 독특한 모티프의 사용에 의해 단리되었다. 모티프는 단백질 상동체들의 패밀리의 정렬된 서열들에 있어서 그의 높은 보존도에 의해 확인된다. 독특한 "시그너쳐(signature)"로서, 모티프는 새롭게 결정된 서열을 갖는 단백질이 이전에 확인된 단백질 패밀리에 속하는지를 결정할 수 있다. 이들 모티프는 신규한 인버타아제 유전자의 신속한 확인을 위한 진단 도구로서 유용하다.
본 명세서에 기재되거나 또는 공개 문헌에 기재된 인버타아제 핵산 단편들 중 임의의 것, 또는 임의의 확인된 상동체는 동일하거나 또는 다른 종으로부터 상동 단백질을 코딩하는 유전자를 단리하는 데 사용될 수 있다. 서열-의존성 프로토콜을 사용하는 상동 유전자의 분리는 당업계에 주지되어 있다. 서열-의존성 프로토콜의 예에는 1) 핵산 혼성화법; 2) 핵산 증폭 기술의 다양한 사용에 의해 예시되는 바와 같이 DNA 및 RNA 증폭법, 예를 들어 폴라머라아제 연쇄 반응["PCR"] (미국 특허 제4,683,202호); 리가아제 연쇄 반응(ligase chain reaction)["LCR"] (문헌[Tabor, S. et al., Proc. Natl. Acad. Sci. U.S.A., 82:1074 (1985)]); 또는 가닥 대체식 증폭법(strand displacement amplification)["SDA"] (문헌[Walker, et al., Proc. Natl. Acad. Sci. U.S.A., 89:392 (1992)]); 및 3) 상보성에 의한 스크리닝 및 라이브러리 제작 방법이 포함되지만, 이에 한정되지 않는다.
본 발명의 형질전환된 와이. 리포라이티카는 수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 외인성 폴리뉴클레오티드를 포함하며, 여기서, 폴리펩티드는 시그널 서열이 성숙 수크로스 인버타아제를 코딩하는 외인성 폴리펩티드에 융합된 것을 포함할 것이며, 상기 시그널 서열은 1) Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편; 및 2) 제2 아미노산이 임의의 소수성 아미노산일 수 있는 수크로스 인버타아제 시그널 서열로 이루어진 군으로부터 선택된다.
Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편을 포함하는 시그널 서열과 관련하여, 당업자라면 성숙 단백질을 코딩하는 서열에 대하여 프리/프로-영역을 코딩하는 서열을 확인하기 위하여 알칼리성 세포외 프로테아제(EC 3.4.21.-)를 코딩하는 적합한 XPR2 유전자를 분석할 수 있을 것이다. 예를 들어, SignalP 4.0 서버 (덴마크 DK-2800 링그비 소재의 테크니칼 유니버시티 오브 덴마크(Technical University of Denmark), 시스템 생물학과, 생물 서열 분석 센터(Center for Biological Sequence Analysis, Department of Systems Biology))는 상이한 유기체 유래의 아미노산 서열에 있어서 시그널 펩티드 절단 부위의 존재 및 위치를 예측하는 데 유용하다 (문헌[Nielsen, H., et al., Protein Engineering, 10:1-6 (1997)]; 문헌[Petersen, T. N., et al., Nature Methods, 8:785-786 (2011)]). 이 확인 후, 전장 Xpr2 프리/프로-영역, + 성숙 Xpr2 단백질(즉, AEP)의 추가의 N-말단 단편을 코딩하는 적절한 서열을 단리하는 것이 쉽게 가능해진다.
이러한 N-말단 Xpr2 단편은, (정확한 길이의 N-말단 단편이 이용되는 각각의 XPR2 유전자에 대하여 실험적으로 결정될 필요가 있을 것이지만) 프리/프로-영역과 성숙 단백질 사이의 절단 부위로의 Xpr6 엔도펩티다아제의 접근을 보장하기 위하여, 성숙 프로테아제의 대략 아미노산 1-10 이상, 그리고 성숙 프로테아제의 대략 아미노산 1-25 이하를 코딩한다.
더 바람직하게는, 성숙 프로테아제의 N-말단 Xpr2 단편은 성숙 프로테아제의 아미노산 1 내지 11, 아미노산 1 내지 12, 아미노산 1 내지 13, 아미노산 1 내지 14, 아미노산 1 내지 15, 아미노산 1 내지 16, 아미노산 1 내지 17, 아미노산 1 내지 18, 아미노산 1 내지 19, 아미노산 1 내지 20, 아미노산 1 내지 21, 아미노산 1 내지 22, 아미노산 1 내지 23 또는 성숙 프로테아제의 아미노산 1 내지 24를 코딩할 것이다.
와이. 리포라이티카 유래의 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은 Xpr2 프리/프로-영역의 적어도 157개 아미노산(서열 번호 6의 즉, 아미노산 1-157) 및 성숙 프로테아제를 코딩하는 추가의 N-말단 Xpr2 단편(즉, 서열 번호 6의 아미노산 158-167 또는 아미노산 158-168 또는 아미노산 158-169 또는 아미노산 158-170 또는 아미노산 158-171 또는 아미노산 158-172 또는 아미노산 158-173 또는 아미노산 158-174 또는 아미노산 158-175 또는 아미노산 158-176 또는 아미노산 158-177 또는 아미노산 158-178 또는 아미노산 158-179 또는 아미노산 158-180 또는 아미노산 158-181 또는 아미노산 158-182)을 포함할 것이다.
바람직한 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편(즉, "XPR2PP+13", 서열 번호 10에 기술되어 있는 바와 같음)은 서열 번호 6의 아미노산 1-170을 포함하였으며, 이는 Lys156-Arg157 절단 부위에 대한 Xpr6 엔도펩티다아제의 접근을 보장하기 위하여 Xpr2 프리/프로-영역 이후의 추가의 13개 아미노산(즉, 성숙 프로테아제의 아미노산 1 내지 13)에 부합되었다.) 따라서, Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은 하기를 포함한다:
(a) AEP 전구체의 N-말단의 157개 아미노산을 포함하는 Xpr2 프리/프로-영역; 및
(b) 성숙 AEP의 N-말단의 13개 아미노산을 포함하는 N-말단 Xpr2 단편.
와이. 리포라이티카를 형질전환시킬 수 있는, 수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 하나의 바람직한 외인성 폴리펩티드는 서열 번호 10의 N-말단 Xpr2 단편 및 Xpr2 프리/프로-영역의 시그널 서열이 서열 번호 4의 성숙 수크로스 인버타아제("m-ScSUC2")에 융합된 것을 포함하며, 이럼으로써 XPR2PP+13/m-ScSUC2 융합물을 생성하는데, 이는 서열 번호 19로 개시된 뉴클레오티드 서열을 갖고 서열 번호 20의 단백질을 코딩한다.
수크로스 인버타아제 활성을 갖는 폴리펩티드 - 여기서, 폴리펩티드는 시그널 서열이 성숙 수크로스를 코딩하는 폴리펩티드에 융합된 것을 포함함 - 를 코딩하는 외인성 폴리뉴클레오티드를 포함하는 형질전환된 와이. 리포라이티카는 대안적으로는 수크로스 인버타아제 시그널 서열을 이용할 수 있으며, 여기서, 수크로스 인버타아제 시그널 서열의 제2 아미노산은 임의의 소수성 아미노산일 수 있다.
당업자라면 성숙 인버타아제 단백질을 코딩하는 서열에 대하여 인버타아제 시그널 서열을 코딩하는 서열을 확인하기 위하여 상기에 기재된 유사한 방법을 이용할 수 있을 것이다. 일단 확인되면, 본 명세서에 기재된 바와 같이, 인버타아제 시그널 서열을 단리하여 수크로스 인버타아제 활성을 갖는 융합 폴리펩티드를 제작하는 것이 쉽게 가능해지며, 이는 본 명세서에 기재된 바와 같다. 명확함을 위하여, 수크로스 인버타아제 시그널 서열 및 성숙 수크로스 인버타아제는 단일 종으로부터 단리될 수 있거나 (이럼으로써 그 종의 전장 인버타아제 프리-단백질에 대하여 효과적으로 등가가 됨); 또는 수크로스 인버타아제 시그널 서열은 종 "A"로부터 단리될 수 있는 반면, 성숙 수크로스 인버타아제는 종 "B"로부터 단리될 수 있다. 수크로스 인버타아제 시그널 서열의 제2 아미노산은 임의의 소수성 아미노산, 예를 들어 류신, 페닐알라닌, 아이소류신, 발린 또는 메티오닌일 수 있다.
인버타아제 시그널 펩티드를 조사하는 몇몇 이전의 연구는 본질적으로 랜덤한 아미노산 서열들의 20% 이상이 적어도 부분적으로, 인버타아제를 위한 엑스포트(export) 시그널로서 작용할 수 있음을 보여주었다. 엑스포트 시그널의 기능은 시그널 펩티드의 규정된 구조 또는 길이라기보다는 오히려 소수성에 관련된다 (예를 들어, 문헌[Kaiser et al., Science, 235:312-317 (1987)]; 문헌[Kaiser and Botstein, Mol. Cell. Biol., 6:2382-2391(1986)] 참조). 또한, 천연 ScSUC2 시그널 서열과 성숙 ScSUC2 사이의 접합 서열은 시그널 펩티드의 적당한 절단에 중요한 것으로 공지되어 있다. 예를 들어, 서열 번호 2의 잔기 Ala19가 Val으로 돌연변이될 경우, ScSUC2는 결함을 갖게 된다 (문헌[Schauer et al., J. Cell Biol., 100:1664-1075 (1985)]). SUC2 시그널 서열의 변형에 대한 추가의 정보에 대해서는, 문헌[Ngsee et al. (Mol . Cell . Biol ., 9:3400-3410(1989)]을 참조하라.
일 실시 형태에서, 수크로스 인버타아제 시그널 서열은 사카로마이세스 속의 유기체로부터 유래될 수 있다. 더 바람직하게는, 수크로스 인버타아제 시그널 서열, 예를 들어 서열 번호 8에 기술되어 있는 수크로스 인버타아제 시그널 서열["Suc2SS"]은 사카로마이세스 세레비지애로부터 단리된다. 서열 번호 8의 제2 아미노산은 다른 소수성 아미노산으로 쉽게 치환될 수 있으며(즉, Phe2는 대안적으로 Leu2, Ile2, Val2 또는 Met2로 돌연변이될 수 있음), 이럼으로써 인버타아제의 분비 과정에 영향을 주지 않고서 시그널 서열의 소수성을 유지할 것으로 기대된다. 더 구체적으로, 본 발명에서 형질전환된 와이. 리포라이티카에서 사용되는 수크로스 인버타아제 시그널 서열은, 이것이 분비 활성을 사실상 유지하기만 한다면, 서열 번호 8의 서열과 비교할 때 동일성이 적어도 51%, 52%, 53%, 54%, 55%, 56%, 57%, 58%, 59%, 60%, 61%, 62%, 63%, 64%, 65%, 66%, 67%, 68%, 69%, 70%, 71%, 72%, 73%, 74%, 75%, 76%, 77%, 78%, 79%, 80%, 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 또는 100%일 수 있다 (예를 들어, 문헌[Kaiser and Botstein, Mol. Cell. Biol., 6:2382-2391(1986)] 참조).
와이. 리포라이티카의 형질전환을 위한, 수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 하나의 바람직한 외인성 폴리뉴클레오티드는 서열 번호 8의 수크로스 인버타아제 시그널 서열이 서열 번호 4의 성숙 수크로스 인버타아제("m-ScSUC2")에 융합된 것을 포함하고, 이럼으로써 Suc2SS/m-ScSUC2 융합물을 생성하는데, 이는 서열 번호 11로 기술된 뉴클레오티드 서열을 갖고 서열 번호 12의 단백질을 코딩한다.
서열 번호 12의 Suc2SS/m-ScSUC2 융합물은 예를 들어 (아미노산 2에서의 변화를 제외하고는) 서열 번호 2에 기술된 바와 같은 전장 인버타아제 프리-단백질에 대하여 효과적으로 등가가 되며, 그 이유는 Suc2SS 시그널 서열이 서열 번호 2의 아미노산 1-19에 상응하는 반면 m-ScSUC2가 서열 번호 2의 아미노산 20-532에 상응하기 때문임을 알아야 한다. 따라서, 예를 들어 수크로스 인버타아제 활성을 갖는 폴리펩티드는 서열 번호 2의 서열에 대한 서열 동일성이 80% 이상일 수 있지만 (CLUSTALW 정렬법에 기초함), 상기 폴리펩티드는 더 바람직하게는 서열 번호 2의 서열과 비교할 때 동일성이 적어도 81%, 82%, 83%, 84%, 85%, 86%, 87%, 88%, 89%, 90%, 91%, 92%, 93%, 94%, 95%, 96%, 97%, 98%, 99%, 또는 100%일 수 있다.
당업자라면 하기를 설명하는 표준 자원 재료를 알고 있다: 1) 거대분자, 예를 들어 DNA 분자, 플라스미드 등의 제작, 조작 및 단리를 위한 특정한 조건 및 절차; 2) 재조합 DNA 단편 및 재조합 발현 제작물의 생성; 및 3) 클론의 스크리닝 및 단리. 문헌[Maniatis, Silhavy, and Ausubel]을 참조하라.
일반적으로, 제작물에 포함되는 서열의 선택은 원하는 발현 생성물, 숙주 세포의 성질 및 형질전환되지 않은 세포에 대하여 형질전환된 세포를 분리하는 제안된 수단에 따라 달라진다. 전형적으로, 벡터는 적어도 하나의 발현 카세트, 선발가능한 마커 및 자가 복제 또는 염색체 통합을 허용하는 서열을 함유한다. 전형적으로, 적합한 발현 카세트는 프로모터, 선택된 유전자의 코딩 서열 및 종결자를 포함한다(즉, 키메라 유전자). 바람직하게는, 둘 모두의 제어 영역은 형질전환된 숙주 세포 유래의 유전자로부터 유래된다.
수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 ORF의 발현을 지시할 수 있는 사실상 임의의 프로모터(즉, 천연, 합성 또는 키메라 프로모터)가 적합하지만, 와이. 리포라이티카 유래의 전사 및 번역 영역이 특히 유용하다. 발현은 유도된 방식 또는 구성적 방식으로 달성될 수 있다. 유도된 발현은 대상 유전자에 작동가능하게 연결된 조절가능한 프로모터의 활성을 유도함으로써 달성될 수 있으며, 구성적 발현은 대상 유전자에 작동가능하게 연결된 구성적 프로모터의 사용에 의해 달성될 수 있다.
종결자는 프로모터가 수득되는 유전자의 3' 영역 또는 상이한 유전자로부터 유래될 수 있다. 매우 다수의 종결자가 공지되어 있으며, 그들이 유래된 것과 동일한 속과 종, 및 그와 상이한 속과 종에서 이용하는 경우 둘 모두에 다양한 숙주에서 만족스럽게 기능한다. 종결자는 통상 임의의 특정 특성 때문이 아니라, 편의성의 문제로 선택된다. 바람직하게는, 종결자는 효모 유전자 유래의 것이다. 또한, 종결자는 당업자가 종결자를 설계하고 합성하기 위하여 입수할 수 있는 정보를 이용할 수 있음에 따라, 합성일 수 있다. 종결자가 불필요할 수 있지만, 이는 매우 바람직하다.
한정하고자 하는 것은 아니지만, 재조합 와이. 리포라이티카에서 사용하기에 바람직한 프로모터 및 종결자는 미국 특허 공개 제2009-0093543-A1호, 미국 특허 공개 제2010-0068789-A1호, 미국 특허 공개 제2011-0059496-A1호, 미국 가특허 출원 제61/469,933호(대리인 문서 번호 CL4736USPRV(출원일: 2011년 3월 31일)), 미국 가특허 출원 제61/470,539호(대리인 문서 번호 CL5380USPRV(출원일: 2011년 4월 1일)), 미국 가특허 출원 제61/471,736호(대리인 문서 번호 CL5381USPRV(출원일: 2011년 4월 5일)) 및 미국 가특허 출원 제61/472,742호(대리인 문서 번호 CL5382USPRV(출원일: 2011년 4월 7일))에 교시된 것이며, 각각의 개시내용은 본 명세서에 참고로 포함된다. 더 구체적으로, 바람직한 프로모터는 GPD, GPDIN, GPM, GPM/FBAIN, FBA, FBAIN, FBAINm, GPAT, YAT1, EXP1, DGAT2, EL1, ALK2, 및 SPS19를 포함한다.
많은 특수 발현 벡터가 높은 발현율을 수득하기 위하여 생성되었다. 이러한 벡터는 전사, RNA 안정성, 번역, 단백질 안정성 및 위치, 및 숙주 세포로부터의 분비를 좌우하는 소정 특성들의 조정에 의해 만들어진다. 이들 특성은 관련 전사 프로모터 및 종결자 서열의 성질; 클로닝된 유전자의 카피수(여기서, 플라스미드 카피수를 증가시키거나, 클로닝된 유전자를 게놈 내로 다수 통합시킴으로써 추가의 카피가 단일의 발현 제작물 내에 클로닝될 수 있고/거나 추가의 카피가 숙주 세포에 도입될 수 있다); 유전자가 플라스미드-운반형(plasmid-borne)인지 숙주 세포 게놈 내로 통합된 것인지의 여부; 숙주 유기체에서의 단백질의 올바른 폴딩 및 번역의 효율; 숙주 세포 내의 클로닝된 유전자의 mRNA 및 단백질의 내재적 안정성; 및 클로닝된 유전자 내에서의 코돈 사용 - 그의 빈도가 숙주 세포의 바람직한 코돈 사용 빈도에 근접하도록 - 을 포함한다.
일단 와이. 리포라이티카에서의 발현에 적합한 DNA 카세트 (예를 들어, 프로모터, 수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 ORF 및 종결자를 포함하는 키메라 유전자를 포함함)가 수득되었으면, 이것은 숙주 세포 내에서 자율 복제가 가능한 플라스미드 내에 두어지거나, 또는 상기 키메라 유전자를 함유하는 DNA 단편은 게놈 내로 직접적으로 통합된다. 발현 카세트의 통합은 와이. 리포라이티카 게놈 내에서 랜덤하게 발생할 수 있거나, 또는 특정 유전자좌와의 재조합을 표적화하기에 충분한 게놈과의 상동성 영역을 함유하는 제작물의 사용을 통하여 표적화시킬 수 있다. 제작물이 내인성 유전자좌에 표적화될 경우, 전사 및 번역 조절 영역의 전부 또는 일부가 내인성 유전자좌에 의해 제공될 수 있다.
관심대상의 키메라 수크로스 인버타아제 유전자(들)를 포함하는 제작물은 임의의 표준 기술에 의해 와이. 리포라이티카 내로 도입될 수 있다. 이들 기술로는 형질전환(예컨대, 아세트산리튬 형질전환(문헌[Methods in Enzymology, 194:186-187 (1991)]), 바이올리스틱 충격, 전기천공, 미세주입, 또는 관심대상의 유전자(들)를 숙주 세포 내로 도입하는 임의의 다른 방법이 포함된다. 와이. 리포라이티카에 적용가능한 더욱 특정한 교시는 미국 특허 제4,880,741호 및 미국 특허 제5,071,764호와, 문헌[Chen, D. C. et al. (Appl. Microbiol. Biotechnol., 48(2):232-235 (1997))]을 포함한다. 바람직하게는, 숙주의 게놈 내로의 선형 DNA 단편의 통합이 와이. 리포라이티카 숙주 세포의 형질전환에서 선호된다. 높은 유전자 발현 수준이 바람직한 경우, 게놈 내의 다수의 위치로의 통합이 특히 유용할 수 있다. 바람직한 유전자좌는 미국 특허 공개 제2009-0093543-A1호의 표 3에 기재되어 있다.
용어 "형질전환된", "형질전환체" 또는 "재조합체"는 본 명세서에서 상호교환가능하게 사용된다. 형질전환된 숙주는 적어도 하나의 카피의 발현 제작물을 가질 것이며, 발현 카세트가 게놈 내로 통합되는지, 증폭되는지 아니면 다중 카피수를 갖는 염색체외 요소 상에 존재하는지에 따라 2개 이상을 가질 수 있다. 형질전환된 숙주 세포는 도입된 제작물에 함유되는 마커에 대한 선발에 의해 확인될 수 있다. 대안적으로, 별도의 마커 제작물은 많은 형질전환 기술에 의해 많은 DNA 분자가 숙주 세포 내로 도입됨에 따라 원하는 제작물과 함께 공동-형질전환시킬 수 있다. 전형적으로, 형질전환된 숙주는 항생제가 혼입되거나 또는 형질전환되지 않은 숙주의 성장에 필요한 인자, 예컨대 영양소 (예를 들어, 수크로스) 또는 성장 인자가 결여될 수 있는 선발 배지에서 그들이 성장하는 능력에 대하여 선발된다. 도입된 마커 유전자는 항생제 내성을 부여하거나 필수 성장 인자 또는 효소를 코딩하여, 형질전환된 숙주에서 발현되는 경우 선발 배지에서의 성장을 가능하게 할 수 있다. 또한, 형질전환된 숙주의 선발은 발현된 마커 단백질이 직접적으로 또는 간접적으로 검출될 수 있는 경우에 또한 발생할 수 있다. 추가의 선발 기술은 미국 특허 제7,238,482호, 미국 특허 제7,259,255호 및 국제특허 공개 WO 2006/052870호에 기재되어 있다.
와이. 리포라이티카에서의 통합된 DNA 단편의 안정성은 사용되는 개별 형질전환체, 수용 주 및 표적화 플랫폼에 의존적이다. 따라서, 특정 재조합 미생물 숙주의 다수의 형질전환체를 스크리닝하여, 원하는 발현 수준 및 패턴을 나타내는 주를 수득해야 한다. DNA 블롯의 서던 분석 (문헌[Southern, J. Mol. Biol., 98:503 (1975)]), mRNA 발현의 노던 분석(문헌[Kroczek, J. Chromatogr. Biomed. Appl., 618 (1-2):133-145 (1993)]), 단백질 발현의 웨스턴 분석, 표현형 분석 또는 GC 분석이 적합한 스크리닝 방법이다.
임의의 와이. 리포라이티카를 본 발명에 따른 성숙 수크로스 인버타아제를 코딩하는 적절한 폴리펩티드 서열로 형질전환시켜서, 수크로스를 탄소 공급원으로 이용할 수 있는 형질전환된 주를 생성할 수 있다. 아메리칸 타입 컬쳐 콜렉션["ATCC"]을 통하여 획득될 수 있는 쉽게 입수가능한 와이. 리포라이티카의 예에는 예를 들어 #8661, #8662, #9773, #15586, #16617, #16618, #18942, #18943, #18944, #18945, #20114, #20177, #20182, #20225, #20226, #20228, #20327, #20255, #20287, #20297, #20315, #20320, #20324, #20336, #20341, #20346, #20348, #20363, #20364, #20372, #20373, #20383, #20390, #20400, #20460, #20461, #20462, #20496, #20510, #20628, #20688, #20774, #20775, #20776, #20777, #20778, #20779, #20780, #20781, #20794, #20795, #20875, #20241, #20422, #20423, #32338, #32339, #32340, #32341, #34342, #32343, #32935, #34017, #34018, #34088, #34922, #38295, #42281, #44601, #46025, #46026, #46027, #46028, #46067, #46068, #46069, #46070, #46330, #46482, #46483, #46484, #46436, #60594, #62385, #64042, #74234, #76598, #76861, #76862, #76982, #90716, #90811, #90812, #90813, #90814, #90903, #90904, #90905, #96028, #201241, #201242, #201243, #201244, #201245, #201246, #201247, #201249, 또는 #201847이 포함된다. 이와 유사하게, 하기의 와이. 리포라이티카 주가 헤르만 제이. 파프 이스트 컬쳐 콜렉션, 유니버시티 오브 캘리포니아 데이비스 (Herman J. Phaff Yeast Culture Collection, University of California Davis; 미국 캘리포니아주 데이비스 소재)로부터 획득될 수 있었다: 와이. 리포라이티카 49-14, 와이. 리포라이티카 49-49, 와이. 리포라이티카 50-140, 와이. 리포라이티카 50-46, 와이. 리포라이티카 50-47, 와이. 리포라이티카 51-30, 와이. 리포라이티카 60-26, 와이. 리포라이티카 70-17, 와이. 리포라이티카 70-18, 와이. 리포라이티카 70-19, 와이. 리포라이티카 70-20, 와이. 리포라이티카 74-78, 와이. 리포라이티카 74-87, 와이. 리포라이티카 74-88, 와이. 리포라이티카 74-89, 와이. 리포라이티카 76-72, 와이. 리포라이티카 76-93, 와이. 리포라이티카 77-12T 및 와이. 리포라이티카 77-17. 또는, 주들은 프랑스 소재의, INRA 센터 드 그리뇽, 쟝-마끄 니코(Jean-Marc Nicaud) 박사의 래보러뜨와 드 마이크로바이올로지 엣 제네티크 몰레쿨레어(Laboratoire de Microbiologie et  )로부터 획득될 수 있으며, 이는 예를 들어 와이. 리포라이티카 JMY798 (문헌[
)로부터 획득될 수 있으며, 이는 예를 들어 와이. 리포라이티카 JMY798 (문헌[ , K. et al., Appl . Environ . Microbiol., 70(7):3918-24 (2004)]), 와이. 리포라이티카 JMY399 (문헌[Barth, G., and C. Gaillardin. In, Nonconventional Yeasts In Biotechnology; Wolf, W.K., Ed.; Springer-Verlag: Berlin, Germany, 1996; pp 313-388]) 및 와이. 리포라이티카 JMY154 (문헌[Wang, H.J., et al., J. Bacteriol., 181(17):5140-8 (1999)])를 포함한다.
, K. et al., Appl . Environ . Microbiol., 70(7):3918-24 (2004)]), 와이. 리포라이티카 JMY399 (문헌[Barth, G., and C. Gaillardin. In, Nonconventional Yeasts In Biotechnology; Wolf, W.K., Ed.; Springer-Verlag: Berlin, Germany, 1996; pp 313-388]) 및 와이. 리포라이티카 JMY154 (문헌[Wang, H.J., et al., J. Bacteriol., 181(17):5140-8 (1999)])를 포함한다.
바람직하게는, 와이. 리포라이티카 숙주 세포는 유지성이며, 즉, 오일 합성 및 축적이 가능하고, 여기서, 전체 오일 내용물은 건조 세포 중량(dry cell weight)["DCW"]의 약 25% 초과, 더 바람직하게는 DCW의 약 30% 초과, 그리고 가장 바람직하게는 DCW의 약 40% 초과로 포함될 수 있다. 일 실시 형태에서, ATCC #20362, ATCC #8862, ATCC #18944, ATCC #76982 및/또는 LGAM S(7)1 (문헌[Papanikolaou S., and Aggelis G., Bioresour. Technol., 82(1):43-9 (2002)])로 표기되는 와이. 리포라이티카 주가 특히 적합하다.
또한 본 발명은 수크로스 인버타아제 활성을 갖는 폴리펩티드를 코딩하는 외인성 폴리뉴클레오티드를 포함하는 형질전환된 와이. 리포라이티카에 관한 것이며 (여기서, 상기 폴리펩티드는 시그널 서열이 성숙 수크로스 인버타아제를 코딩하는 폴리펩티드 서열에 융합된 것을 포함함), 또한 여기서, 형질전환된 와이. 리포라이티카는 관심대상의 적어도 하나의 비천연 생성물을 생성할 수 있다. 관심대상의 이러한 적어도 하나의 비천연 생성물은 바람직하게는 형질전환된 와이. 리포라이티카를 탄소 공급원으로서 수크로스 (또는 그 혼합물)를 사용하여 성장시킬 때 생성된다. 와이. 리포라이티카가 이종 유전자들로 형질전환되는 순서는 중요하지 않다. 이러한 형질전환은 또한 동시적일 수 있다.
관심대상의 적합한 비천연 생성물의 예에는 예를 들어 다중불포화 지방산, 카로티노이드, 아미노산, 비타민, 스테롤, 플라보노이드, 유기 산, 폴리올 및 하이드록시에스테르, 퀴논-유도된 화합물 및 레스베라트롤이 포함되지만, 이것은 본 명세서에서 한정적인 것으로 의도되는 것은 아니다.
"다중불포화 지방산"(또는 "PUFA"), 특히 오메가-3 및 오메가-6 PUFA과 결부된 건강 상의 효과가 기록되어 왔다. 더 구체적으로, 본 명세서에서 PUFA는 18개 이상의 탄소 원자 및 2개 이상의 이중 결합을 갖는 지방산을 말한다. 용어 "지방산"은 약 C12 내지 C22의 다양한 쇄 길이의 장쇄 지방족 산(알칸산)을 지칭하지만, 더 긴 쇄 길이의 산과 더 짧은 쇄 길이의 산이 둘 모두 공지되어 있다. 주된 쇄 길이는 C16 내지 C22이다. 지방산의 구조는 "X:Y"의 단순한 표기 체계로 표현되며, 여기서, X는 특정 지방산에서의 전체 탄소 원자["C"]의 개수이고, Y는 이중 결합의 개수이다.
"포화 지방산" 대 "불포화 지방산", "단일불포화 지방산" 대 "다중불포화 지방산"["PUFA"] 및 "오메가-6 지방산"["n-6"] 대 "오메가-3 지방산"["n-3"] 간의 구별에 관한 추가의 상세사항은 본 명세서에 참고로 포함되는 미국 특허 제7,238,482호에 제공되어 있다. 미국 특허 공개 제2009-0093543-A1호의 표 3은 오메가-3 및 오메가-6 PUFA와 그 전구체의 화학명 및 일반명과, 일반적으로 사용되는 약어의 상세한 요약을 제공한다.
그러나, PUFA의 일부 예에는 리놀레산['LA", 18:2 ω-6], 감마-리놀렌산["GLA", 18:3 ω-6], 에이코사다이엔산["EDA", 20:2 ω-6], 다이호모-감마-리놀렌산["GLA", 20:3 ω-6], 아라키돈산["ARA", 20:4 ω-6], 도코사테트라엔산["DTA", 22:4 ω-6], 도코사펜타엔산["DPAn-6", 22:5 ω-6], 알파-리놀렌산["ALA", 18:3 ω-3], 스테아리돈산["STA", 18:4 ω-3], 에이코사트라이엔산["ETA", 20:3 ω-3], 에이코사테트라엔산["ETrA", 20:4 ω-3], 에이코사펜타엔산["EPA", 20:5 ω-3], 도코사펜타엔산["DPAn-3", 22:5 ω-3] 및 도코사헥사엔산["DHA", 22:6 ω-3]이 포함되지만, 이에 한정되지 않는다.
PUFA 생성을 위하여 와이. 리포라이티카 주를 엔지니어링하는 쪽으로 많은 노력이 투자되었다. 예를 들어, 미국 특허 제7,238,482호에서는 효모에서의 오메가-6 및 오메가-3 지방산의 생성 가능성이 입증되었다. 미국 특허 제7,932,077호에서는 전체 지방산의 28.1%의 EPA의 재조합적 생성이 입증되었으며; 미국 특허 제7,588,931호에서는 전체 지방산의 14%의 ARA의 재조합적 생성이 입증되었으며; 미국 특허 제7,550,286호에서는 전체 지방산의 5%의 DHA의 재조합적 생성이 입증되었으며; 미국 특허 공개 제2009-0093543-A1호에는 EPA 생성용으로 최적화된 재조합 주가 기재되어 있고 전체 지방산의 최대 55.6%의 EPA의 생성이 입증되었다. 미국 특허 공개 제2010-0317072-A1호에는 TFA의 최대 50%의 EPA를 포함하고, TFA의 중량%로 측정된 리놀레산에 대한, TFA의 중량%로 측정된 EPA의 비가 3.1 이상인 미생물 오일을 생성하는 최적화된 재조합 와이. 리포라이티카 주가 추가로 기재되어 있다. 형질전환 와이. 리포라이티카는 PUFA의 생성을 위하여 데새츄라아제(즉, 델타-12 데새츄라아제, 델타-6 데새츄라아제, 델타-8 데새츄라아제, 델타-5 데새츄라아제, 델타-17 데새츄라아제, 델타-15 데새츄라아제, 델타-9 데새츄라아제, 델타-4 데새츄라아제) 및 엘롱가아제(즉, C14/16 엘롱가아제, C16/18 엘롱가아제, C18/20 엘롱가아제, C20/22 엘롱가아제 및 델타-9 엘롱가아제) 유전자의 다양한 조합을 발현한다. 그러나, 이들 방법 전부에서, 글루코스를 탄소 공급원으로 사용하여 성장시킨 유지성 효모를 사용하여 PUFA의 생성을 입증하였다.
표 3은 상기에 인용된 참고 문헌에 기재된 특정 와이. 리포라이티카 주들 중 일부에 관한 정보를 제공하며, 여기서, 상기 주는 데새츄라아제 및 엘롱가아제의 다양한 조합을 보유하지만, 특정 주 및 생성된 특정 PUFA (또는 그 양)는 결코 본 발명을 한정하지 않음을 인식하여야 한다.


또한 카로티노이드가 관심대상의 적합한 비천연 생성물로서 고려되는데, 이는 수크로스를 탄소 공급원으로 이용하여 성장시킬 때 형질전환된 와이. 리포라이티카에서 생성될 수 있다. 본 명세서에 사용되는 바와 같이, 용어 "카로티노이드"는 공식적으로 아이소프렌으로부터 유도된 공액 폴리엔 탄소 골격을 갖는 탄화수소 부류를 말한다. 이 부류의 분자는 트라이테르펜["C30 다이아포카로티노이드"] 및 테트라테르펜["C40 카로티노이드"] 및 그의 산화된 유도체로 구성되며; 이들 분자는 전형적으로 강한 흡광 특성을 갖고, C200을 초과하는 길이의 범위일 수 있다. 다른 "카로티노이드 화합물"이 공지되어 있으며, 이는 예를 들어 길이가 C35, C50, C60, C70 및 C80 이다. 용어 "카로티노이드"는 카로틴 및 잔토필 둘 모두를 포함할 수 있다. "카로틴"은 탄화수소 카로티노이드 (예를 들어, 피토엔, β-카로틴 및 라이코펜)를 말한다. 이와는 대조적으로, 용어 "잔토필"은 하이드록시-, 메톡시-, 옥소-, 에폭시-, 카르복시- 또는 알데하이드 작용기의 형태의 하나 이상의 산소 원자를 함유하는 C40 카로티노이드를 말한다. 잔토필은 카로틴보다 극성이 더 크며, 이 특성은 유지류에서의 그의 용해도를 극적으로 감소시킨다. 따라서, 카로티노이드의 적합한 예에는 안테락산틴, 아도니루빈, 아도닉산틴, 아스탁산틴(즉, 3,3'-다이하이드록시-β,β-카로틴-4,4'-다이온), 칸탁산틴(즉, β,β-카로틴-4,4'-다이온), 캅소루브린, β-크립토잔틴, α-카로틴, β,ψ-카로틴, δ-카로틴, ε-카로틴, β-카로틴 케토-γ-카로틴, 에치네논, 3-하이드록시에치네논, 3'-하이드록시에치네논, γ-카로틴, ψ-카로틴, ζ-카로틴, 제아잔틴, 아도니루빈, 테트라하이드록시-β,β'-카로텐-4,4'-다이온, 테트라하이드록시-β,β'-카로텐-4-온, 칼로잔틴, 에리트로잔틴, 노스토잔틴, 플렉시잔틴, 3-하이드록시-γ-카로틴, 3-하이드록시-4-케토-γ-카로틴, 박테리오루비잔틴, 박테리오루비잔티날, 4-케토-γ-카로틴, α-크립토잔틴, 데옥시플렉시잔틴, 다이아토잔틴, 7,8-다이데하이드로아스타잔틴, 다이데하이드로라이코펜, 푸코잔틴, 푸코잔티놀, 아이소레니에라텐, β-아이소레니에라텐, 락투카잔틴, 루테인, 라이코펜, 믹소박톤, 네오잔틴, 뉴로스포렌, 하이드록시뉴로스포렌, 페리디닌, 피토엔, 피토플루엔, 로도핀, 로도핀 글루코시드, 4-케토-루비잔틴, 시포나잔틴, 스페로이덴, 스페로이데논, 스피릴로잔틴, 토룰렌, 4-케토-토룰렌, 3-하이드록시-4-케토-토룰렌, 우리올리드, 우리올리드 아세테이트, 비올라잔틴, 제아잔틴-β-다이글루코시드 및 그 조합이 포함된다.
야생형 와이. 리포라이티카는 보통은 카로티노이드 생성성(carotenogenic)이 아니다. 그러나, 국제특허 공개 WO 2008/073367호 및 국제특허 공개 WO 2009/126890호에는 카로티노이드 생합성 경로 유전자, 예를 들어 제라닐 제라닐 파이로포스페이트 신타아제를 코딩하는 crtE, 피토엔 신타아제를 코딩하는 crtB, 피토엔 데새츄라아제를 코딩하는 crtI, 라이코펜 사이클라아제를 코딩하는 crtY, 카로티노이드 하이드록실라아제를 코딩하는 crtZ 및/또는 카로티노이드 케톨라아제를 코딩하는 crtW의 도입을 통하여 재조합 와이. 리포라이티카에서 카로티노이드 모음을 생성하는 것이 기재되어 있다.
수크로스를 탄소 공급원으로 이용하여 성장시킬 때, 형질전환된 와이. 리포라이티카에서 생성될 수 있는 관심대상의 다른 비천연 생성물은 예를 들어 퀴닌-유도된 화합물, 스테롤 및 레스베라트롤을 포함한다. 용어 "적어도 하나의 퀴논 유도된 화합물"은 레독스-활성 퀴논 고리 구조를 갖는 화합물을 말하며, 하기로 이루어진 군으로부터 선택되는 화합물을 포함한다: CoQ 시리즈의 퀴논(즉, 이것은 Q6, Q7, Q8, Q9 및 Q10임), 비타민 K 화합물, 비타민 E 화합물, 및 그 조합. 예를 들어, 용어 조효소 Q10["CoQ10""]은 2,3-다이메톡시-다이메틸-6-데카프레닐-1,4-벤조퀴논을 말하며, 이는 유비퀴논-10 (CAS 등록 번호: 303-98-0)으로도 공지되어 있다. CoQ10의 벤조퀴논 부분은 타이로신으로부터 합성되며, 반면에 아이소프렌 측쇄는 메발로네이트 경로를 통하여 아세틸-CoA로부터 합성된다. 따라서, CoQ 화합물, 예를 들어 CoQ10의 생합성은 NADPH를 필요로 한다. "비타민 K 화합물"은 예를 들어 메나퀴논 또는 필로퀴논을 포함하는 반면, 비타민 E 화합물은 예를 들어 토코페롤, 토코트라이엔올 또는 α-토코페롤을 포함한다. 용어 "레스베라트롤"은 3,4',5-트라이하이드록시스틸벤을 말한다.
미국 특허 공개 제2009/0142322-A1호 및 국제특허 공개 WO 2007/120423호에는 이종 퀴논 생합성 경로 유전자, 예를 들어 조효소 Q10의 생성을 위한 데카프레닐 다이포스페이트 신타아제를 코딩하는 ddsA , 비타민 K 화합물의 생성을 위한 MenF, MenD, MenC, MenE, MenB, MenA, UbiE, 및/또는 MenG 폴리펩티드를 코딩하는 유전자, 및 비타민 E 화합물의 생성을 위한 tyrA, pdsl(hppd), VTEl, HPT1(VTE2), VTE3, VTE4, 및/또는 GGH 폴리펩티드를 코딩하는 유전자 등의 도입을 통하여 와이. 리포라이티카에서 다양한 퀴논 유도된 화합물을 생성하는 것이 기재되어 있다. 국제특허 공개 WO 2008/130372호에는 스쿠알렌 신타아제를 코딩하는 ERG9/SQS1 및 스쿠알렌 에폭시다아제를 코딩하는 ERGl의 도입을 통하여 와이. 리포라이티카에서 스테롤을 생성하는 것이 기재되어 있다. 그리고, 미국 특허 제7,772,444호에는 레스베라트롤 신타아제를 코딩하는 유전자의 도입을 통하여 와이. 리포라이티카에서 레스베라트롤을 생성하는 것이 기재되어 있다.
형질전환된 숙주 세포는 키메라 유전자 (예를 들어, 인버타아제를 코딩함, 관심대상의 비천연 생성물의 생합성을 가능하게 하는 유전자)의 발현을 최적화하는 조건 하에서 성장시킨다. 일반적으로, 최적화될 수 있는 배지 조건은 탄소 공급원의 유형 및 양, 질소 공급원의 유형 및 양, 탄소-대-질소 비, 상이한 미네랄 이온들의 양, 산소 수준, 성장 온도, pH, 바이오매스 생성기의 길이, 오일 축적기의 길이 및 세포 수확의 시간 및 방법을 포함한다. 유지성 효모는 흔히 성장에 필요한 성분이 결여되고 이럼으로써 원하는 발현 카세트의 선발을 강요하는 최소 규정 배지 (예를 들어, 이스트 니트로겐 베이스(Yeast Nitrogen Base; 미국 미시간주 디트로이트 소재의 디프코 래보러토리즈(DIFCO Laboratories)) 또는 복합 배지 (예를 들어, 효모 추출물-펩톤-덱스트로스 브로쓰["YPD"]에서 성장시킨다.
본 발명에서 발효 배지는 발효성 탄소 공급원을 포함한다. 발효성 탄소 공급원은 예를 들어 수크로스, 전화당(invert sucrose), 글루코스, 프룩토스 및 이들의 조합일 수 있다. 본 명세서에서 전화당은 수크로스의 가수분해에서 생기는, 대략 동일한 부의 프룩토스 및 글루코스를 포함하는 혼합물을 말한다. 전화당은 25 내지 50%의 글루코스 및 25 내지 50%의 프룩토스를 포함하는 혼합물일 수 있지만, 전화당은 수크로스를 또한 포함할 수 있으며, 그 양은 가수분해도에 따라 달라진다. 전화당은 수크로스의 가수분해에 의해 수득될 수 있으며, 상기 수크로스는 다양한 공급원, 예를 들어 사탕수수 또는 사탕무로부터 수득될 수 있다. 수크로스의 글루코스 및 프룩토스로의 가수분해는 산에 의해 (예를 들어, 시트르산 또는 아스코르브산의 첨가에 의해) 또는 효소에 의해 (예를 들어, 인버타아제 또는 β-프룩토푸라노시다아제에 의해) 촉매될 수 있으며, 이는 당업계에 공지된 바와 같다.
일부 실시 형태에서, 본 명세서에 개시된 와이. 리포라이티카는 다른 당류("혼합된 당류")의 존재 하에 수크로스를 함유하는 배지에서 성장시킨다. 혼합된 당류는 수크로스에 더하여 적어도 하나의 추가의 당을 포함한다. 와이. 리포라이티카 세포의 대사를 위한 에너지 공급원을 제공할 수 있는 임의의 당, 또는 수크로스를 함유하는 혼합물에 존재하는 임의의 당이 포함될 수 있다. 그러나, 야생형 와이. 리포라이티카 세포와 같이, 본 명세서에 개시된 수크로스-이용 와이. 리포라이티카는 여전히 글루코스를 유일한 탄소 공급원으로 사용할 수 있다.
부가적으로, 발효 배지는 적합한 질소 공급원을 포함한다. 질소는 무기 (예를 들어, (NH4)2SO4) 또는 유기 (예를 들어, 우레아, 글루타메이트 또는 효모 추출물) 공급원으로부터 공급될 수 있다. 수크로스 및 질소 공급원에 더하여, 발효 배지는 또한 적합한 미네랄, 염, 보조 인자, 완충제, 비타민 및 미생물의 성장에 적합한 당업자에게 공지된 다른 성분을 함유한다.
본 발명에서 바람직한 성장 배지로는 구매가능한 완제 배지(prepared media), 예를 들어 이스트 니트로겐 베이스 (미국 미시간주 디트로이트 소재의 디프코 래보러토리즈)가 있다. 다른 규정 또는 합성 성장 배지도 사용할 수 있으며, 특정 미생물의 성장에 적절한 배지는 미생물학 또는 발효과학 분야의 당업자에게 공지되어 있을 것이다. 전형적으로, 발효에 적합한 pH 범위는 약 pH 4.0 내지 pH 8.0이며, pH 5.5 내지 pH 7.5가 초기 성장 조건의 범위로서 바람직하다. 발효는 호기성 또는 혐기성 조건 하에 행해질 수 있으며, 미세호기성(microaerobic) 조건이 바람직하다.
전형적으로, 유지성 효모 세포에서의 높은 수준의 PUFA의 축적은 2단계 발효 공정을 필요로 하며, 이는 대사 상태가 성장과 지방의 합성/저장 간에 "균형을 이루어야" 하기 때문이다. 따라서, 가장 바람직하게는, 유지성 효모에서 PUFA를 생성하기 위해 2단계 발효 공정이 이용된다. 이러한 공정은 다양한 적합한 발효 공정 디자인(즉, 배치식, 유가식(fed-batch) 및 연속식) 및 성장 동안의 고려 사항이 그러한 바와 같이, 미국 특허 제7,238,482호에 기재되어 있다.
실시예
본 발명은 하기 실시예에서 추가로 정의된다. 이들 실시예는 본 발명의 바람직한 실시형태를 나타내면서도 단지 예로써만 주어지는 것으로 이해해야 할 것이다. 상기 논의 및 이러한 실시예로부터, 당업자는 본 발명의 본질적 특징을 확인할 수 있으며, 본 발명의 사상 및 범주를 벗어나지 않는 한 본 발명을 다양하게 변경하고 수정하여 다양한 용도 및 조건에 적합하게 할 수 있다.
약어의 의미는 다음과 같다: "sec"는 초를 의미하고, "min"은 분을 의미하며, "h"는 시간을 의미하고, "d"는 일을 의미하며, "㎕"은 마이크로리터를 의미하고, "mL"은 밀리리터를 의미하며, "L"은 리터를 의미하며, "μM"은 마이크로몰을 의미하고, "mM"은 밀리몰을 의미하며, "M"은 몰을 의미하고, "mmol"은 밀리몰을 의미하며, "μmole"는 마이크로몰을 의미하고, "g"는 그램을 의미하며, "μg"는 마이크로그램을 의미하고, "ng"는 나노그램을 의미하며, "U"는 유닛을 의미하고, "bp"는 염기쌍을 의미하며, "kB"는 킬로베이스를 의미한다.
발현 카세트에 대한 명명법
발현 카세트의 구조는 "X::Y::Z"의 간단한 표기 체계에 의해 나타내며, 여기서, X는 프로모터 단편을 말하며, Y는 유전자 단편을 말하고, Z는 종결자 단편을 말하며, 이들 모두는 서로 작동가능하게 연결된다.
야로위아
리포라이티카의
형질전환 및 배양
와이. 리포라이티카 주 ATCC #20362를 아메리칸 타입 컬쳐 콜렉션 (미국 메릴랜드주 록빌 소재)로부터 구매하였다. 야로위아 리포라이티카 주를 전형적으로 하기에 나타낸 방법에 따라 몇몇 배지에서 28 내지 30℃에서 성장시켰다.
고 글루코스 배지["HGM"](리터당): 80의 글루코스, 2.58 g의 KH2PO4 및 5.36 g의 K2HPO4, pH 7.5 (조정할 필요가 없음).
고 수크로스 배지 ["HSM"] (리터당): 80의 수크로스, 2.58 g의 KH2PO4 및 5.36 g의 K2HPO4, pH 7.5 (조정할 필요가 없음).
합성 덱스트로스 배지["SD"] (리터당): 황산암모늄을 포함하고 아미노산을 포함하지 않는 6.7 g의 효모 질소 베이스; 20 g의 글루코스.
합성 수크로스 배지 ["SS"] (리터당): 황산암모늄을 포함하고 아미노산을 포함하지 않는 6.7 g의 효모 질소 베이스; 20 g의 수크로스.
발효 배지["FM"](리터당): 아미노산을 포함하지 않는 6.7 g/L의 YNB; 6 g/L의 KH2PO4; 2 g/L의 K2HPO4; 1.5 g/L의 MgSO4-7수화물; 5 g/L의 효모 추출물; 2%의 탄소 공급원 (여기서, 탄소 공급원은 글루코스 또는 수크로스 중 어느 하나임).
야로위아 리포라이티카의 형질전환을 본 명세서에 참고로 포함되는 미국 특허 공개 제2009-0093543-A1호에 기재된 바와 같이 수행하였다.
야로위아
리포라이티카의
지방산 분석
지방산["FA"] 분석을 위하여, 세포를 원심분리에 의해 수집하고, 지질을 문헌[Bligh, E. G. & Dyer, W. J. (Can . J. Biochem . Physiol., 37:911-917 (1959))]에 기재된 바와 같이 추출하였다. 지방산 메틸 에스테르["FAME"]를 소듐 메톡시드를 사용한 지질 추출물의 에스테르 교환에 의해 제조하고(문헌[Roughan, G., and Nishida I., Arch Biochem Biophys., 276(1):38-46 (1990)]), 후속적으로 30-m X 0.25 mm(내경) HP-이노왁스(INNOWAX; 휴렛-패커드(Hewlett-Packard)) 컬럼을 갖춘 휴렛-패커드 6890 GC로 분석하였다. 오븐 온도는 3.5℃/분으로 170℃(25분 유지)로부터 185℃까지였다.
직접적인 염기 에스테르 교환을 위하여, 야로위아 세포(0.5 mL 배양물)를 수확하고, 증류수에 1회 세척하고, 스피드-백(Speed-Vac)에서 5 내지 10분 동안 진공 하에 건조시켰다. 소듐 메톡시드(1%의 100 μl) 및 공지된 양의 C15:0 트라이아실글리세롤(C15:0 TAG; 카탈로그 번호 T-145, 누-체크 프렙(Nu-Check Prep), 미국 미네소타주 엘라이시안 소재)을 샘플에 첨가하고, 그 후 샘플을 50℃에서 30분 동안 와동시키고 흔들었다. 3 드롭의 1 M NaCl 및 400 μl의 헥산의 첨가 후, 샘플을 와동시키고 스핀시켰다. 상층을 제거하고, GC로 분석하였다.
대안적으로, 문헌[Lipid Analysis, William W. Christie, 2003]에 기재된 염기-촉매작용된 에스테르 교환 방법의 변형법을 발효 또는 플라스크 샘플 중 어느 하나로부터의 브로쓰(broth) 샘플의 통상적인 분석을 위해 사용하였다. 구체적으로, 브로쓰 샘플을 실온의 물에서 빠르게 해동시킨 다음, 0.22 μm 코닝(Corning)(등록 상표) 코스타(Costar)(등록 상표) 스핀(Spin)-X(등록 상표) 원심분리용 튜브 필터(카탈로그 번호 8161)를 갖춘 타르를 칠한 2 mL 미량 원심분리용 튜브에 칭량해 넣었다(0.1 ㎎까지). 이전에 결정된 DCW에 따라 샘플(75 - 800 μl)을 사용하였다. 에펜도르프(Eppendorf) 5430 원심분리기를 사용하여, 샘플을 14,000 rpm에서 5 내지 7분 동안 또는 브로쓰를 제거하는데 필요한 만큼 오랫동안 원심분리하였다. 필터를 제거하고, 액체를 빼내고, 약 500 μl의 탈이온수를 필터에 첨가하여 샘플을 세척하였다. 물을 제거하기 위한 원심분리 후에, 필터를 다시 제거하고, 액체를 빼내고, 필터를 다시 삽입하였다. 그 다음, 튜브를 원심분리기에 다시 삽입하고, 이번에는 상측을 개방하여 약 3 내지 5분 동안 건조시켰다. 이어서, 필터를 튜브의 대략 절반에서 절단하고, 새로운 2 mL 둥근 바닥 에펜도르프 튜브(카탈로그 번호 22 36 335-2)에 삽입하였다.
필터를 오직 절단된 필터 용기의 가장자리와 접촉하며 샘플 또는 필터 물질과는 접촉하지 않는 적절한 도구를 사용하여 튜브의 바닥으로 프레스하였다. 톨루엔 중의 공지되어 있는 양의 C15:0 TAG(상기)를 첨가하고, 새로 제조한, 메탄올 중 1% 소듐 메톡시드의 용액 500 μl를 첨가하였다. 샘플 펠렛을 적절한 도구를 사용하여 철저히 부수고, 튜브를 닫고, 30분 동안 50℃ 히트 블록(heat block)(VWR 카탈로그 번호 12621-088) 내에 넣었다. 이어서, 튜브를 5분 이상 동안 냉각시켰다. 이어서, 헥산 400 μl 및 물 중의 1 M NaCl 용액 500 μl를 첨가하고, 튜브를 6초 동안 2회 와동시키고, 1분 동안 원심분리하였다. 대략 150 μl의 상부(유기)층을 인서트(insert)가 있는 GC 바이얼에 두고, GC로 분석하였다.
GC 분석을 통해 기록된 FAME 피크를 공지되어 있는 지방산의 피크와 비교시 그들의 체류 시간에 의해 확인하고, FAME 피크 면적을 공지되어 있는 양의 내부 표준물질(C15:0 TAG)의 피크 면적과 비교함으로써 정량화하였다. 따라서, 임의의 지방산 FAME의 근사량(㎍)["FAME ㎍"]은 식: (특정 지방산의 FAME 피크의 면적/표준물질 FAME 피크의 면적) * (표준물질 C15:0 TAG의 ㎍)에 따라 계산하는 반면, 임의의 지방산의 양(㎍)["FA ㎍"]은 식: (특정 지방산의 FAME 피크의 면적/표준물질 FAME 피크의 면적) * (표준물질 C15:0 TAG의 ㎍) * 0.9503에 따라 계산하는데, 이는 1 ㎍의 C15:0 TAG가 0.9503 ㎍의 지방산과 같기 때문이다. 0.9503의 변환 인자가 0.95 내지 0.96 범위인 대부분의 지방산에 대하여 결정된 값의 근사치임을 주목하라.
TFA의 wt%로서 각각의 개별 지방산의 양을 요약하는 지질 프로파일을 개별 FAME 피크 면적을 모든 FAME 피크 면적의 합으로 나누고 이에 100을 곱함으로써 결정하였다.
플라스크 분석법에 의한
야로위아
리포라이티카에서의
전체 지질 함량 및 조성의 분석
와이. 리포라이티카의 특정 주에서의 전체 지질 함량 및 조성의 상세한 분석을 위하여, 플라스크 분석법을 하기와 같이 행하였다. 구체적으로, 하나의 루프의 새로 스트리킹한 세포를 3 mL FM 배지에 접종하고, 250 rpm 및 30℃에서 하룻밤 성장시켰다. OD600 nm를 측정하고, 세포의 분취물을 125 mL 플라스크에서 25 mL FM 배지 중에 최종 0.3의 OD600 nm로 첨가하였다. 250 rpm 및 30℃의 진탕 인큐베이터에서 2일 후에, 6 mL의 배양물을 원심분리에 의해 수확하고, 125 mL 플라스크에서 25 mL HGM에 재현탁시켰다. 250 rpm 및 30℃의 진탕 인큐베이터에서 5일 후에, 1 mL 분취물을 지방산 분석(상기)을 위해 사용하고, 건조 세포 중량["DCW"] 결정을 위하여 10 mL을 건조시켰다.
DCW 결정을 위하여, 10 mL 배양물을 베크만(Beckman) GS-6R 원심분리기 내의 베크만 GH-3.8 로터에서 4000 rpm에서 5분 동안 원심분리함으로써 수확하였다. 펠렛을 25 mL의 물에 재현탁시키고, 상기와 같이 다시 수확하였다. 세척된 펠렛을 20 mL의 물에 재현탁시키고, 사전-칭량된 알루미늄 팬으로 옮겼다. 세포 현탁물을 80℃에서 진공 오븐에서 하룻밤 건조시켰다. 세포의 중량을 결정하였다.
세포의 전체 지질 함량["TFA % DCW"]을 계산하고, TFA의 중량%["% TFA"]로서의 각각의 지방산의 농도 및 건조 세포 중량의 퍼센트로서의 EPA 함량["EPA % DCW"]을 표로 만든 데이터와 함께 고려하였다.
실시예
1
야로위아
리포라이티카
세포외
인버타아제
발현 플라스미드
pZSUC
의 제작 및 발현
본 실시예는 문헌[Nicaud et al., Current Genetics (16:253-260 (1989))]에 보고된 것과 유사한 방식으로, 인버타아제를 코딩하는 사카로마이세스 세레비지애 SUC2의 절두형 변이체["m-ScSuc2"]의 유전자에 XPR2 프로모터 및 시그널 서열을 융합시킨 것을 포함하는 플라스미드 pZSUC (서열 번호 22)을 제작하는 것을 설명한다.
더 구체적으로, 니코드 등은, 와이. 리포라이티카 XPR2 유전자의 프로모터 및 N-말단 아미노산 시그널 서열의 제어 하에 에스. 세레비지애 SUC2 유전자를 발현시킬 때, 와이. 리포라이티카의 주변세포질 내로 인버타아제가 분비됨을 보고하였다. 상기 문헌(제257면) 내에는, "융합은 아미노산 11에서 시작하여 인버타아제의 앞에 XPR2 유전자 유래의 23개 N-말단 아미노산을 둔다" (즉, 이에 따라 전장 인버타아제의 처음 10개 아미노산은 절두된 반면, 시그널 서열의 아미노산 11-19는 발현되는 성숙 단백질과 함께 포함되었다)는 것이 기술되어 있다. 그러나, 니코드 등의 도 1b (제255면)에 따르면, 융합 제작물은 대신에 아미노산 5에서 시작하여 시그널 서열로서 XPR2 유전자 유래의 23개 N-말단 아미노산이 인버타아제에 융합된 것을 포함하는 것으로 보인다(즉, 이에 따라 전장 인버타아제의 처음 4개 아미노산은 절두된 반면, 시그널 서열의 아미노산 5-19는 발현되는 성숙 단백질과 함께 포함되었다). 융합에 관한 명확성의 결여에도 불구하고, 니코드 등은 인버타아제의 발현이 형질전환된 와이. 리포라이티카에서 수크로스-이용(Suc +) 표현형을 부여함을 보고하였다.
XPR2::SUC2 융합 제작물을 상기 니코드 등의 것과 유사한 방식으로 만들었다 ("pZSUC"; 도 2). 먼저, 369 bp XPR 프로모터 (-369 내지 -1) + 63 bp 코딩 영역 (+1 내지 +63)을 함유하는 432 bp DNA 단편을, 야로위아 게놈 DNA를 주형으로, 그리고 올리고뉴클레오티드 YL427 및 YL428 (서열 번호 36 및 37)을 프라이머로 사용하여 PCR에 의해 증폭시켰다. ClaI 부위를 디자인된 PCR 단편 (서열 번호 38)의 5' 말단에 부가하고, HindIII 부위를 3' 말단에 부가하였다. PCR 증폭은 하기를 포함하는 50 μl의 총 부피로 수행하였다: PCR 완충제 (10 mM KCl, 10 mM (NH4) 2SO4, 20 mM 트리스(Tris)-HCl (pH 8.75), 2 mM MgSO4, 0.1% 트리톤(Triton) X-100을 함유함), 100 ㎍/mL의 BSA (최종 농도), 200 μM의 각각의 데옥시리보뉴클레오티드 트라이포스페이트, 10 pmole의 각각의 프라이머, 50 ng의 와이. 리포라이티카 (ATCC #76982) 게놈 DNA 및 1 μl의 Taq DNA 폴리머라아제 (에피센터 테크놀로지즈(Epicentre Technologies)). 서모사이클러 조건을 35회 사이클의 경우 95℃, 1 min, 56℃, 30 sec, 및 72℃, 1 min, 이어서 72℃에서 10 min 동안의 최종 연장으로 설정하였다.
PCR 생성물을 퀴아젠(Qiagen) PCR 정제 키트 (미국 캘리포니아주 발렌시아 소재)를 사용하여 정제하고, 그 후 ClaI/HindIII로 절단하고; 절단된 생성물을 1% (w/v) 아가로스에서 겔 전기영동에 의해 분리하고, ClaI/HindIII 단편을 pZSUC (하기)의 제작에 사용하였다.
처음 10개 아미노산을 제외하고 에스. 세레비지애 SUC2 코딩 영역을 함유하는 1569 bp DNA 단편을, 에스. 세레비지애 게놈 DNA를 주형으로, 그리고 올리고뉴클레오티드 YL429 및 YL430 (서열 번호 39 및 40)을 프라이머로 사용하여 PCR에 의해 증폭시켰다. HindIII 부위를 SUC2 코딩 영역의 동일 리딩 프레임 내에서 5' 말단에 부가하고, BsiWI 부위를 SUC2 코딩 영역 (서열 번호 41)의 종결 코돈 이후에 부가하였다. 50 ng의 에스. 세레비지애의 게놈 DNA를 50 ng의 와이. 리포라이티카 (ATCC #76982) 게놈 DNA대신 사용한 것을 제외하고는, 상기에 기술한 성분들을 포함하는 50 μl의 총 부피로 PCR 증폭을 수행하였다. 서모사이클러 조건을 35회 사이클의 경우 95℃, 1 min, 56℃, 30 sec, 및 72℃, 2 min, 이어서 72℃에서 10 min 동안의 최종 연장으로 설정하였다.
PCR 생성물을 퀴아젠 PCR 정제 키트 (미국 캘리포니아주 발렌시아 소재)를 사용하여 정제하고, 그 후 HindIII/BsiWI로 절단하고; 절단된 생성물을 1% (w/v) 아가로스에서 겔 전기영동에 의해 분리하고, HindIII/BsiWI 단편을 pZSUC (하기)의 제작에 사용하였다.
따라서, 플라스미드 pZSUC2는 하기 성분을 함유한다.

그 후, 발현 플라스미드 pZSUC (서열 번호 22)로 와이. 리포라이티카 ATCC# 76982를 형질전환시켜 인버타아제 발현에 대하여 시험하였다. 형질전환체를 합성 수크로스 배지["SS"]에서 성장시켰다. 그러나, 형질전환된 와이. 리포라이티카 주는 수크로스 배지에서 성장할 수 없었다.
pZSUC 내의 XPR2::SUC2 융합 제작물에서, XPR2 코딩 서열의 처음 63 bp(즉, 프리/프로-영역)을 "시그널 서열"로 사용하였으며, SUC2 유전자에서는 처음 30개 뉴클레오티드가 결실되었다(즉, SUC2 시그널 서열의 처음 10개 아미노산을 제거함). 니코드 등에 의한 설명의 주의 깊은 연구 후, 이들이 엔지니어링된 주의 성장을 시험하기 위하여 오토클레이브된(autoclaved) 수크로스 배지를 사용하였음을 알아차렸다. 오토클레이브 공정은 일부 수크로스를 프룩토스 및 글루코스로 가수분해할 수 있었으며, 이는 와이. 리포라이티카에 의해 탄소 공급원으로 사용될 수 있었다 (데이터는 예시되어 있지 않음).
이 실시예에 제시된 데이터는, 니코드 등에 의해 기재된 바와 같이, ScSuc2의 절두형 변이체와 융합된 와이. 리포라이티카 XPR2 의 N-말단 21개 아미노산의 융합물을 발현하는 형질전환된 와이. 리포라이티카 주가 수크로스를 탄소 공급원으로 사용할 수 없음을 입증하였다. Suc2 시그널 서열의 소수성 코어는 적당한 분비 과정과 결부되며, 이의 파괴는 인버타아제의 세포내 축적에 이르게 됨이 보고되었다 (문헌[Kaiser and Botstein, Mol. Cell Biol., 6;2382-2391 (1986)]; 문헌[Perlman, et al., Proc. Natl. Acad. Sci. U.S.A., 83:5033-5037 (1986)]).
실시예
2
야로위아
리포라이티카
세포외
인버타아제
발현 플라스미드, 즉
pYRH68
,
pYRH69
, pYRH70,
pYRH73
및
pYRH74
의 제작
이 실시예는 인버타아제를 코딩하는 "성숙" 사카로마이세스 세레비지애 SUC2 ["m-ScSuc2"] 유전자에 융합된 XPR2 프리프로-영역 ["XPR2PP+13"] 및/또는 SUC2 시그널 서열 ["Suc2SS"]의 다양한 상이한 조합들을 포함하는 일련의 플라스미드의 제작을 설명한다. 각각의 제작물 내의 이종 유전자는 강한 와이. 리포라이티카 프로모터 (FBAINm; 미국 특허 제7,202,356호) 및 와이. 리포라이티카 Pex20 종결 서열이 측면에 존재하였다.
SucSS
/m-
ScSUC2
를 포함하는
pYRH68
의 제작
플라스미드 pYRH68은 Suc2 시그널 서열 ("SucSS"; 서열 번호 8)이 인버타아제를 코딩하는 "성숙" ScSUC2 유전자 ("m-ScSUC2"; 서열 번호 4)에 융합된 것을 과다발현하도록 제작하였다. 그러나, 실질적으로, SucSS/m-ScSUC2로 본 명세서에 기재된 이 인공 융합물은 5'-시그널 서열을 천연적으로 함유하는 야생형 전장 ScSUC2 유전자와 부합한다.
ScSUC2 ORF를 코딩하는 1.6 kB 단편을 프라이머 Sc.SUC2-5' (서열 번호 23) 및 Sc.SUC2-3' (서열 번호 24)를 사용하여 에스. 세레비지애 BY4743 (미국 앨라배마주 헌츠빌 소재의 오픈 바이오시스템즈(Open Biosystems))의 게놈 DNA로부터 증폭시켰다. 이들 프라이머는 아미노산 위치 2에 PciI 제한 효소 부위를 도입하도록 디자인하였다 (이럼으로써 야생형 Leu2 잔기를 Phe2로 변경하여 Suc2의 분비 과정에 영향을 주지 않고서 시그널 서열의 소수성을 유지함; 문헌[Kaiser, et al., Science, 235:312-317 (1987)]). 반응 혼합물은 1 μl의 게놈 DNA, 1 μl의 각각의 프라이머, 2 μl의 물 및 45 μl의 AccuPrime™ Pfx 수퍼믹스(SuperMix; 미국 캘리포니아주 칼스배드 소재의 인비트로겐(Invitrogen))를 함유하였다. 증폭을 하기와 같이 수행하였다: 94℃에서 5 min 동안 초기 변성, 이어서 94℃에서 15 sec 동안 변성, 55℃에서 30 sec 동안 어닐링 및 68℃에서 2 min 동안 신장의 35회 사이클. 68℃에서 7 min 동안 최종 신장 사이클을 수행하고, 4℃에서 반응을 종료하였다. 그 후, ScSUC2 ORF를 PciII/NotI 제한 효소로 절단하고, 이를 이용하여 플라스미드 pYRH68 (도 3a; 서열 번호 13)를 생성하였으며, 이는 하기 성분을 함유하였다 (NcoI 및 PciI는 아이소스키조머(isoschizomer)이다):

2개의 카피의 SucSS/m-ScSUC2를 포함하는 pYRH70의 제작
플라스미드 pYRH70은 2개의 카피의 SucSS/m-ScSUC2 (서열 번호 12)를 과다발현하도록 제작하였으며, 이는 5'-시그널 서열을 천연적으로 함유하는 야생형 전장 ScSUC2 유전자의 2개의 카피와 부합한다. 플라스미드 pYRH68 (서열 번호 13)을 SalI/SwaI로 절단하여 두 번째 카피의 1.6 kB PciII/NotI ScSUC2 단편을 삽입한다. 구체적으로, 하기를 포함하는 사원(four-way) 라이게이션을 제조하였다: 1) pYRH68 벡터 골격; 2) PciII/NotI 절단된 ScSUC2 단편; 3) 플라스미드 pZKLY-PP2 (서열 번호 25; 미국 특허 공개 제2011-0244512-A1호에 기재되어 있음)로부터 잘라낸 와이. 리포라이티카 FBA 프로모터 (미국 특허 제7,202,356호)를 포함하는 533 bp SalI/NcoI-단편; 및 4) 또한 pZKLY-PP2 (서열 번호 25)로부터 잘라낸, 야로위아 Lip1 유전자 (젠뱅크 등록 번호: Z50020) 유래의 Lip1 종결자 서열을 포함하는 322 bp NotI/SwaI-단편. 이는 pYRH70 (도 3b; 서열 번호 14)의 합성으로 이어졌다.
XPR2PP
+13 또는
SUC2SS
를 포함하지 않는 m-
ScSUC2
를 포함하는
pYRH73
의 제작
플라스미드 pYRH73은 인버타아제를 코딩하는 "성숙" ScSUC2 유전자("m-ScSUC2"; 서열 번호 4) - 이는 Suc2 시그널 서열 ("SucSS"; 서열 번호 8)이 결여됨 - 를 과다발현하도록 제작하였다. 따라서, SucSS의 5'- 시그널 서열 (서열 번호 2의 뉴클레오티드 1 내지 57에 상응함)을, 5'-시그널 서열을 천연적으로 함유하는 야생형 전장 ScSUC2 유전자로부터 절두시켰다. 성숙 ScSUC2 유전자를 스패닝하는 1.55 kB 단편을 프라이머 Sc.SUC2-5' (서열 번호 23) 및 nSc.SUC2-3' (서열 번호 26)를 사용하여 에스. 세레비지애 BY4743의 게놈 DNA로부터 증폭시켰다. 그 후, 이 단편을 상기에 기재한 것과 동일한 방식으로 PciII/NotI로 절단하여 와이. 리포라이티카 벡터 내로 클로닝하여 플라스미드 pYRH73 (도 4a; 서열 번호 15)을 생성하였다.
XPR2PP
+13/
SucSS
/m-
ScSUC2
를 포함하는
pYRH69
의 제작
플라스미드 pYRH69는 XPR2 프리프로-영역 ["XPR2PP+13"; 서열 번호 10]이 SUC2 시그널 서열 ["Suc2SS"; 서열 번호 8]에 융합된 것이 인버타아제를 코딩하는 "성숙" ScSUC2 유전자("m-ScSUC2"; 서열 번호 4)에 융합된 것을 과다발현하도록 제작하였다. 그러나, 이전에 pYRH68에서 설명한 바와 같이, SucSS/m-ScSUC2로 본 명세서에 기재된 인공 융합물은 5'-시그널 서열을 천연적으로 함유하는 야생형 전장 ScSUC2 유전자와 부합한다. 따라서, 본 명세서에서 XPR2PP+13/SucSS/m-ScSUC2로 기재되고 서열 번호 16 및 17로 기술된 이 특정 제작물은 XPR2PP+13을 전장 ScSUC2 유전자에 효과적으로 융합시킨다.
상기에 논의된 바와 같이, 서열 번호 10의 XPR2PP+13 영역은 서열 번호 6의 아미노산 1-170을 코딩하도록 디자인하였으며, 이럼으로써 프리프로-영역 이후에 Xpr2의 추가의 13개 아미노산을 코딩하게 되어서 Xpr6 엔도펩티다아제가 Lys156-Arg157 절단 부위에 접근하는 것을 보장하였다.
먼저, 전장 ScSUC2 ORF를 코딩하는 1.6 kB 단편은, 상기 플라스미드 pYRH68의 제작 동안 이용한 것과 동일한 방식으로 증폭시키고 PciI/NotI로 절단하였다. 그 후, 와이. 리포라이티카 XPR2 유전자의 N-말단 170개 아미노산을 코딩하는 단편(즉, 157개 아미노산 프리프로영역 + 성숙 AEP 단백질의 N-말단 13개 아미노산을 포함함)(즉, 서열 번호 9의 서열 + NcoI 및 PciI 제한 효소에 상응하는 측면 서열)을 프라이머 Yl.XPR2-5' (서열 번호 27) 및 Yl.XPR2-3' (서열 번호 28)를 사용하여 와이. 리포라이티카 ATCC #20362의 게놈 DNA로부터 증폭시켰다. 절단 후, PciI/ NcoI 절단된 513 bp XPR2PP+13 단편을 생성하였다.
PciI 및 NcoI 절단된 말단들은 양립가능하기 때문에, PciI/ NcoI 절단된 513 bp XPR2PP+13 단편 및 1.6 kB PciI/ NotI 절단된 ScSUC2 단편을 PciI/ NotI 절단된 pYRH68 골격 내로 삽입하여 pYRH69 (도 4b; 서열 번호 18)를 생성하였다. PciI/NcoI 절단된 513 bp XPR2PP+13 단편의 배향을 확인하였다. 프라이머 Yl.XPR2-5' (서열 번호 27) 및 Yl.XPR2-3' (서열 번호 28)를 이용한 pYRH69의 서열 결정에 의하면, 와이. 리포라이티카 ATCC #20362의 서열 번호 9에 기술되어 있는 XPR2PP+13 서열은 공개된 XPR2 서열 (문헌[Matoba, S. et al. , Mol. Cell Biol., 8:4904-4916 (1988)])에 대한 동일성이 100%임이 확증되었다.
XPR2PP
+13/m-
ScSUC2
를 포함하는
pYRH74
의 제작
플라스미드 pYRH74는 XPR2 프리프로-영역 ["XPR2PP+13"; 서열 번호 10]이 인버타아제를 코딩하는 "성숙" ScSUC2 유전자("m-ScSUC2"; 서열 번호 4)에 융합된 것을 과다발현하도록 제작하였다.
성숙 ScSUC2 유전자를 스패닝하는 1.55 kB 단편을 프라이머 Sc.SUC2-5' (서열 번호 23) 및 nSc.SUC2-3' (서열 번호 24)를 사용하여 에스. 세레비지애 BY4743의 게놈 DNA로부터 증폭시켰다.
구체적으로, 성숙 ScSUC2 유전자를 포함하는 1.55 kB PciI/NotI 단편 및 513 bp PciI/NcoI XPR2PP+13 단편을 각각 플라스미드 pYRH73 및 플라스미드 pYRH69에 대하여 상기에 설명한 바와 같이 제조하였다. 이들 단편을 함께 pYRH68 골격과 라이게이션시켜 플라스미드 pYRH74 (도 5; 서열 번호 21)를 생성하였다.
실시예
3
수크로스
또는
글루코스
중 어느 하나를 유일한 탄소 공급원으로 이용하여 성장시킨
야로위아
리포라이티카에서의
플라스미드
pYRH68
,
pYRH69
,
pYRH70
,
pYRH73
및
pYRH74
의 형질전환 및 발현
플라스미드 pYRH68, pYRH69, pYRH70, pYRH73, 및 pYRH74는 와이. 리포라이티카 주 Y4184U (실시예 5) 및 와이. 리포라이티카 주 Z1978U (실시예 6) - 이들 둘 모두는 유의한 양의 EPA % TFA를 생성하도록 유전적으로 엔지니어링됨 - 를 형질전환시키기 위하여 AscI/ SphI로 개별적으로 절단하였다. 수크로스 또는 글루코스 중 어느 하나를 유일한 탄소 공급원으로 포함하는 다양한 배지에서 형질전환체를 성장시켰다.
구체적으로, 먼저 우라실이 결여된 SD 배지 플레이트 상에서 형질전환체를 선발하였다 (일반 방법). 다양한 Y4184U 및 Z1978U 형질전환 주를 생성하였으며, 이는 하기 표 6에 기재된 바와 같았다.

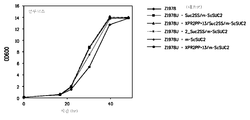
주 Y4184U+Suc2SS/m-ScSUC2 및 Y4184 (대조군)의 성장을 SD(즉, 글루코스) 및 SS(즉, 수크로스) 배지에서 비교하였다. 수크로스 가수분해를 피하기 위하여, 배지를 오토클레이브에 의한 것 대신 여과에 의해 살균하였다. 구체적으로, 세포를 0.03의 OD600으로 접종하고, 30℃에서 성장시켰다. 도 6에 예시된 바와 같이, Y4184U + Suc2SS/m-ScSUC2 주는 수크로스에서 매우 잘 성장한 반면, 대조 주 Y4184는 유일한 탄소 공급원으로서의 수크로스 상에서 성장하지 못하였다. 상기 둘 모두의 주는, 글루코스를 유일한 탄소 공급원으로 제공할 때 유사하게 성장하였다. 주 Y4184U + XPR2PP+13/Suc2SS/m-ScSUC2도 수크로스에서 성장하지 않았으며 (데이터는 예시되어 있지 않음); 2개의 상이한 시그널 서열은 서로를 간섭하고 분비 과정을 방지할 수 있다고 가정된다.
그 후, 주 Z1978U + Suc2SS/m-ScSUC2, Z1978U + 2_ Suc2SS/m-ScSUC2, Z1978U + m-ScSUC2, Z1978U + XPR2PP+13/Suc2SS/m-ScSUC2, Z1978 + XPR2PP+13/m-ScSUC2 및 Z1978 (대조군)의 성장을, 수크로스 또는 글루코스 중 어느 하나를 유일한 탄소 공급원으로 포함하는 FM에서 비교하였다. 수크로스 가수분해를 피하기 위하여, 배지를 오토클레이브에 의한 것 대신 여과에 의해 살균하였다. 세포를 0.03의 OD600으로 접종하고, 30℃에서 성장시켰다. 모든 주는 유일한 탄소 공급원으로서 글루코스를 포함하는 FM에서 비슷하게 성장하였다 (도 7a). 유일한 탄소 공급원으로 수크로스를 포함하는 FM에서 (도 7b), 주 Z1978U + Suc2SS/m-ScSUC2, Z1978U + 2_Suc2SS/m-ScSUC2 및 Z1978 + XPR2PP+13/m-ScSUC2는 매우 잘 성장하였지만, 주 Z1978U + m-ScSUC2, Z1978U + XPR2PP+13/Suc2SS/m-ScSUC2 및 Z1978 (대조군)은 매우 적게 성장하였으며; 사실상, 나머지 성장은 세포가 효모 추출물을 탄소 공급원으로 사용하는 능력으로 인한 것일 수 있었다.
따라서, 둘 모두의 Suc2SS/m-ScSUC2 (서열 번호 12) 및 XPR2PP+13/m-ScSUC2 (서열 번호 20)의 과다발현은 유일한 탄소 공급원으로 수크로스를 포함하는 배지에서 성장할 수 있는 형질전환된 와이. 리포라이티카 주로 이어졌다.
실시예
4
수크로스
또는
글루코스
중 어느 하나를 유일한 탄소 공급원으로 이용하여 성장시킨 형질전환
야로위아
리포라이티카에서의
지질 함량 및 조성
이 실시예에서는 수크로스를 유일한 탄소 공급원으로 함유하는 배지에서 성장시킬 때 에스. 세레비지애 세포외 인버타아제를 과다발현하는 Z1978 주(즉, 주 Z1978U + Suc2SS/m-ScSUC2, Z1978U + 2_Suc2SS/m-ScSUC2 및 Z1978 + XPR2PP+13/m-ScSUC2)에서의 지질 함량 및 조성을 조사한다. 이들 주에서의 축적된 지질의 수준 및 조성은 유일한 탄소 공급원으로서 글루코스에서 성장시킨 대조 주의 것과 비견되었다.
주 Z1978U + Suc2SS/m-ScSUC2에서의 전체 지질 함량 및 지방 조성에 대한 수크로스 이용의 영향을 평가하기 위하여, 상기 주의 이중 배양물을 HSM (유일한 탄소 공급원으로서 수크로스)에서 비견되는 유지성 조건 하에 성장시켰으며, 이는 일반 방법에서 설명한 바와 같았다. 따라서, Z1978U + Suc2SS/m-ScSUC2의 두 배양물 (각각 배양물 RHY243 및 RHY244로 표기함)을, HGM (유일한 탄소 공급원으로서 글루코스)에서 비견되는 유지성 조건 하에 성장시킨 대조 주 Z1978의 이중 샘플과 비교하였다. 더 구체적으로, 유지성 조건은 먼저 배양물을 25 mL의 SD 또는 SS 배지에서 30℃에서 48 h 동안 배양물을 호기적으로 성장시킴으로써 성취하였으며, 그 후 원심분리에 의해 수확하였다. 그 후, 펠렛을 25 mL의 HGM 또는 HSM에 재현탁시키고, 배양물을 250 rpm 및 30℃에서 진탕 인큐베이터에서 5일 동안 추가로 인큐베이션하였다.
주에 있어서 건조 세포 중량["DCW"], 세포의 전체 지질 함량["TFA % DCW"], TFA의 중량%로서의 각각의 지방산의 농도["% TFA"] 및 EPA 생산성(즉, 건조 세포 중량의 퍼센트로서의 EPA 함량["EPA % DCW"])을 하기 표 7에 예시하며, 이때 평균은 회색으로 하일라이트되어 있고 "Ave"로 나타내어져 있다. 지방산의 약어는 하기와 같다: 올레산 (18:1), 리놀레산 (18:2), 및 에이코사펜타엔산 ("EPA", 20:5).

표 7의 결과는 수크로스에서 성장시킨 주 Z1978U + Suc2SS/m-ScSUC2에 있어서의 TFA % DCW가 글루코스에서 성장시킨 주 Z1978의 것과 유사함을 나타냈다. 그러나, 수크로스가 유일한 탄소 공급원일 때 평균 EPA % DCW의 대략 10%의 감소가 관찰되었다.
주 Z1978U + Suc2SS/m-ScSUC2에 있어서 주의 능력의 임의의 변화가 있는지를 결정하기 위하여, 유일한 탄소 공급원으로서 글루코스 또는 수크로스 중 어느 하나에서 RHY243 (표 7)을 이중으로 성장시켰다. 표 8에는 표 7에서 사용한 것과 유사한 포맷으로, DCW, TFA % DCW, % TFA로서의 각각의 지방산의 농도, 및 EPA % DCW가 요약되어 있다.

표 8의 결과는 수크로스에서 성장시킨 주 Z1978U + Suc2SS/m-ScSUC2에 있어서의 TFA % DCW가 글루코스에서 상기 주를 성장시킬 때 상기 주의 지질 함량과 유사함을 나타냈다. 그러나, 수크로스가 유일한 탄소 공급원일 때 평균 EPA % DCW의 대략 10%의 감소가 관찰되었다.
또한 전체 지질 함량 및 지방산 조성은 일반 방법에서 설명한 바와 같이, 비견되는 유지성 조건 하에서 HSM (유일한 탄소 공급원으로서 수크로스)에서 성장시킬 때 Z1978U + Suc2SS/m-ScSUC2의 두 배양물 (즉, RHY243 및 RHY244), Z1978U + 2_Suc2SS/m-ScSUC2 (RHY248, RHY249 및 RHY250로 표기함)의 세 배양물 및 Z1978 + XPR2PP+13/m-ScSUC2의 세 배양물 (RHY257, RHY258 및 RHY259로 표기함)에서 비교하였다.) 이들 주는 HGM (유일한 탄소 공급원으로서 글루코스)에서 비견되는 유지성 조건 하에서 성장시킨 대조 주 Z1978의 이중 샘플과 비교하였다.
표 9에는 표 7에서 사용한 것과 유사한 포맷으로, DCW, TFA % DCW, % TFA로서의 각각의 지방산의 농도, 및 EPA % DCW가 요약되어 있다.

상기 결과는, 유일한 탄소 공급원으로서 수크로스에서 성장시킨 주 Z1978U + Suc2SS/m-ScSUC2, Z1978U + 2_Suc2SS/m-ScSUC2 및 Z1978 + XPR2PP+13/m-ScSUC2에 있어서 TFA % DCW 및 EPA % DCW가 글루코스에서 성장시킨 대조 주 Z1978의 TFA % DCW 및 EPA % DCW와 10% 미만만큼 다름을 나타냈다. 3개의 SUC2 엔지니어링된 주 중에서, 주 Z1978 + XPR2PP+13/m-ScSUC2가 최상의 EPA % DCW 성능을 가졌다. 모든 3가지의 SUC2 발현 주는 대조 주 Z1978보다 최대 14% 더 높은 최종 DCW (g/L)를 일관되게 나타냈다. 따라서, EPA 부피 생산성은 대조 주 Z1978과 엔지니어링된 수크로스-이용 주 사이에서 유사하다.
실시예 5
고
EPA
생성을 위한
야로위아
리포라이티카
주
Y4184
및
Y4184U
의 생성
와이. 리포라이티카 주 Y4184U를 상기 실시예 3에서 숙주로 사용하였다. 주 Y4184U는 와이. 리포라이티카 ATCC #20362로부터 유래되었으며, 이는 델타-9 엘롱가아제/델타-8 데새츄라아제 경로의 발현을 통하여 전체 지질에 비하여 높은 EPA를 생성할 수 있다. 상기 주는 Ura- 표현형을 가지며, 그 제작은 본 명세서에 참고로 포함된 국제특허 공개 WO 2008/073367호의 실시예 7에 기재되어 있다.
주 Y4184U의 개발은 주 Y2224, Y4001, Y4001U, Y4036, Y4036U, Y4069, Y4084, Y4084U1, Y4127 (기탁 번호 ATCC PTA-8802로, 2007년 11월 29일자로 아메리칸 타입 컬쳐 콜렉션에 기탁됨), Y4127U2, Y4158, Y4158U1 및 Y4184의 제작을 필요로 하였다.
야생형 와이. 리포라이티카 ATCC #20362에 대한 주 Y4184 (전체 지질의 30.7%의 EPA를 생성함)의 최종 유전형은 unknown 1-, unknown 2-, unknown 4-, unknown 5-, unknown 6-, unknown 7-, YAT1::ME3S::Pex16, EXP1::ME3S::Pex20 (2개의 카피), GPAT::EgD9e::Lip2, FBAINm::EgD9eS::Lip2, EXP1::EgD9eS::Lip1, FBA::EgD9eS::Pex20, YAT1::EgD9eS::Lip2, GPD::EgD9eS::Lip2, GPDIN::EgD8M::Lip1, YAT1::EgD8M::Aco, EXP1::EgD8M::Pex16, FBAINm::EgD8M::Pex20, FBAIN::EgD8M::Lip1 (2개의 카피), GPM/FBAIN::FmD12S::Oct, EXP1::FmD12S::Aco, YAT1::FmD12::Oct, GPD::FmD12::Pex20, EXP1::EgD5S::Pex20, YAT1::EgD5S::Aco, YAT1::Rd5S::Oct, FBAIN::EgD5::Aco, FBAINm::PaD17::Aco, EXP1::PaD17::Pex16, YAT1::PaD17S::Lip1, YAT1::YlCPT1::Aco, GPD::YlCPT1::Aco였다.
상기 약어는 하기와 같다: ME3S는 모르티에렐라 알피나(Mortierella alpina)로부터 유래된, 코돈-최적화된 C16 /18 엘롱가아제 유전자이고[미국 특허 제7,470,532호]; EgD9e는 유글레나 그라실리스(Euglena gracilis) 델타-9 엘롱가아제 유전자이고[미국 특허 제7,645,604호]; EgD9eS는 유글레나 그라실리스로부터 유래된, 코돈-최적화된 델타-9 엘롱가아제 유전자이고[미국 특허 제7,645,604호]; EgD8M은 유글레나 그라실리스[미국 특허 제7,256,033]로부터 유래된, 합성 돌연변이 델타-8 데새츄라아제이고 [미국 특허 제7,709,239호]; FmD12는 푸사리움 모닐리포르메(Fusarium moniliforme) 델타-12 데새츄라아제 유전자이고[미국 특허 제7,504,259호]; FmD12S는 푸사리움 모닐리포르메로부터 유래된 코돈-최적화된 델타-12 데새츄라아제 유전자이고[미국 특허 제7,504,259호]; EgD5는 유글레나 그라실리스 델타-5 데새츄라아제이고[미국 특허 제7,678,560호]; EgD5S는 유글레나 그라실리스로부터 유래된, 코돈-최적화된 델타-5 데새츄라아제 유전자이고 [미국 특허 제7,678,560호]; RD5S는 페리디늄(Peridinium) sp. CCMP626으로부터 유래된, 코돈-최적화된 델타-5 데새츄라아제이고 [미국 특허 제7,695,950호]; PaD17은 피티움 아파니더마툼(Pythium aphanidermatum) 델타-17 데새츄라아제이고 [미국 특허 제7,556,949호]; PaD17S는 피티움 아파니더마툼으로부터 유래된 코돈-최적화된 델타-17 데새츄라아제이고[미국 특허 제7,556,949호] YlCPT1은 야로위아 리폴리티카 다이아실글리세롤 콜린포스포트랜스퍼라아제 유전자이다[미국 특허 제7,932,077호].
마지막으로, 주 Y4184에서 Ura3 유전자를 파괴하기 위하여, 제작물 pZKUE3S (국제특허 공개 WO 2008/073367호, 그 안의 서열 번호 78)를 사용하여 EXP1::ME3S::Pex20 키메라 유전자를 주 Y4184의 Ura3 유전자내로 통합시켜 각각 주 Y4184U1 (전체 지질의 11.2%의 EPA), Y4184U2 (전체 지질의 10.6%의 EPA) 및 Y4184U4 (전체 지질의 15.5%의 EPA) (총괄적으로, Y4184U)를 생성하였다.
국제특허 공개 WO 2008/073367호에는 다른 성장 조건으로 인하여 Y4184U (평균 12.4%)에 대하여 Y4184에서 정량화된 EPA % TFA (30.7%)에 있어서의 차이가 기재되어 있음이 주목된다.
실시예 6
고 EPA 생성을 위한 야로위아 리포라이티카 주 Z1978 및 Z1978U의 생성
와이. 리포라이티카 주 Z1978U를 상기 실시예 3에서 숙주로 사용하였다. 주 Z1978U는 와이. 리포라이티카 ATCC #20362로부터 유래되었으며, 이는 델타-9 엘롱가아제/델타-8 데새츄라아제 경로의 발현을 통하여 전체 지질에 비하여 높은 EPA를 생성할 수 있다. 상기 주는 Ura- 표현형을 가지며, 그 제작은 본 명세서에 참고로 포함된 미국 특허 출원 제13/218,708호 (이.아이. 듀폰 디 네모아 앤드 컴퍼니, 인크.(E.I. duPont de Nemours & Co., Inc.), 대리인 문서 번호: CL5411USNA, 2011년 8월 26일자로 출원됨)의 실시예 2에 기재되어 있다.
주 Z1978U의 개발은 주 Y2224, Y4001, Y4001U, Y4036, Y4036U, L135, L135U9, Y8002, Y8006, Y8006U, Y8069, Y8069U, Y8154, Y8154U, Y8269, Y8269U, Y8412 (기탁 번호 ATCC PTA-10026으로 2009년 5월 14일자로 아메리칸 타입 컬쳐 콜렉션에 기탁됨) Y8412U, Y8647, Y8467U, Y9028, Y9028U, Y9502, Y9502U 및 Z1978의 제작을 필요로 하였다.
야로위아
리포라이티카
주
Y9502
의 유전형
주 Y9502의 생성은 미국 특허 공개 제2010-0317072-A1호에 기재되어 있다. 와이. 리포라이티카 ATCC #20362로부터 유래된 주 Y9502는 델타-9 엘롱가아제/델타-8 데새츄라아제 경로의 발현을 통하여 전체 지질과 비교하여 약 57.0%의 EPA를 생성할 수 있었다.
야생형 와이. 리포라이티카 ATCC #20362에 대한 주 Y9502의 최종 유전형은 Ura+, Pex3-, unknown 1-, unknown 2-, unknown 3-, unknown 4-, unknown 5-, unknown6-, unknown 7-, unknown 8-, unknown9-, unknown 10-, YAT1::ME3S::Pex16, GPD::ME3S::Pex20, YAT1::ME3S::Lip1, FBAINm::EgD9eS::Lip2, EXP1::EgD9eS::Lip1, GPAT::EgD9e::Lip2, YAT1::EgD9eS::Lip2, FBAINm::EgD8M::Pex20, EXP1::EgD8M::Pex16, FBAIN::EgD8M::Lip1, GPD::EaD8S::Pex16 (2개의 카피), YAT1::E389D9eS/EgD8M::Lip1, YAT1::EgD9eS/EgD8M::Aco, FBAINm::EaD9eS/EaD8S::Lip2, GPD::FmD12::Pex20, YAT1::FmD12::Oct, EXP1::FmD12S::Aco, GPDIN::FmD12::Pex16, EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, GPDIN::EgD5SM::Aco, GPM::EgD5SM::Oct, EXP1::EgD5SM::Lip1, YAT1::EaD5SM::Oct, FBAINm::PaD17::Aco, EXP1::PaD17::Pex16, YAT1::PaD17S::Lip1, YAT1::YlCPT1::Aco, YAT1::MCS::Lip1, FBA::MCS::Lip1, YAT1::MaLPAAT1S::Pex16이었다.
상기에서 사용한 그리고 실시예 5에 기술되어 있지 않은 약어는 하기와 같다: EaD8S는 유글레나 아나바에나(Euglena anabaena) 유래의 코돈-최적화된 델타-8 데새츄라아제 유전자이고[미국 특허 제7,790,156호]; E389D9eS/EgD8M은 유트렙티엘라Eutreptiella sp. CCMP389로부터 유래된 코돈-최적화된 델타-9 엘롱가아제 유전자("E389D9eS")(미국 특허 제7,645,604호)를 델타-8 데새츄라아제 "EgD8M" (상기) [미국 특허 공개 제2008-0254191-A1호]에 연결함으로써 생성되는 DGLA 신타아제이고; EgD9eS/EgD8M은 델타-9 엘롱가아제 "EgD9eS" (상기)를 델타-8 데새츄라아제 "EgD8M" (상기) [미국특허 공개 제2008-0254191-A1호]에 연결함으로써 생성되는 DGLA 신타아제이고; EaD9eS/EgD8M은 이. 아나바에나로부터 유래된 코돈-최적화된 델타-9 엘롱가아제 유전자 ("EaD9eS") [미국 특허 제7,794,701호]를 델타-8 데새츄라아제 "EgD8M" (상기) [미국 특허 공개 제2008-0254191-A1호]에 연결함으로써 생성되는 DGLA 신타아제이고; EgD5M 및 EgD5SM은 유글레나 그라실리스 [미국 특허 제7,678,560호]로부터 유래된, 돌연변이 HPG 모티프를 포함하는 합성 돌연변이 델타-5 데새츄라아제 유전자이고 [미국 특허 공개 제2010-0075386-A1호]; EaD5SM은 이. 아나바에나 [미국 특허 제7,943,365호]로부터 유래된, 돌연변이 HaGG 모티프를 포함하는 합성 돌연변이 델타-5 데새츄라아제 유전자이고 [미국 특허 공개 제2010-0075386-A1호]; MCS는 리조비움 레구미노사룸(Rhizobium leguminosarum) 생물변이형 비시애(bv. viciae) 3841로부터 유래된 코돈-최적화된 말로닐-CoA 신타아제 유전자이고 [미국 특허 공개 제2010-0159558-A1호]; MaLPAAT1S는 모르티에렐라 알피나(Mortierella alpina)로부터 유래된 코돈-최적화된 라이소포스파티드산 아실트랜스퍼라아제 유전자이다[미국 특허 제7,879,591호].
주 Y9502 내의 전체 지질 함량 및 조성의 상세한 분석을 위하여, 세포를 총 7일 동안 2단계로 성장시키는 플라스크 분석법을 행하였다. 분석에 기초하여, 주 Y9502는 3.8 g/L DCW, 37.1 TFA % DCW, 21.3 EPA % DCW를 생성하였으며, 지질 프로파일은 하기와 같았고, 여기서, 각 지방산의 농도는 TFA의 중량 백분율["% TFA"]로서의 것이다: 16:0(팔미테이트)-2.5, 16:1(팔미톨레산)-0.5, 18:0(스테아르산)-2.9, 18:1(올레산)-5.0, 18:2(LA)-12.7, ALA-0.9, EDA-3.5, DGLA-3.3, ARA-0.8, ETrA-0.7, ETA-2.4, EPA-57.0, 기타-7.5.
야로위아 리포라이티카 주 Z1978의 생성
주 Y9502로부터의 주 Z1978의 개발은 처음에 미국 가특허 출원 제61/377248호 (미국 특허 출원 제13/218,591호에 상응함) 및 미국 가특허 출원 제61/428,277호 (미국 특허 출원 제13/218,673호에 상응함)에 기재되었으며, 이는 본 명세서에 참고로 포함되었다.
구체적으로, 주 Y9502에서의 Ura3 유전자의 파괴를 위하여, SalI/PacI-절단된 제작물 pZKUM (미국 특허 공개 제2009-0093543-A1호, 그 안의 표 15, 서열 번호 133 및 도 8a 참조)을 사용하여 Ura3 돌연변이 유전자를 주 Y9502의 Ura3 유전자 내로 통합시켰으며, 이는 일반 방법에 따른 것이었다. 총 27개의 돌연변이체(8개의 형질전환체를 포함하는 제1군, 8개의 형질전환체를 포함하는 제2군 및 11개의 형질전환체를 포함하는 제3군으로부터 선택되는)를 최소 배지 + 5-플루오로오로트산["MM + 5-FOA"] 선발 플레이트에서 성장시키고, 30℃에서 2 내지 5일 동안 유지시켰다. MM+ 5-FOA는 (리터당) 하기를 포함한다: 20 g의 글루코스, 6.7 g의 효모 질소 베이스, 75 ㎎의 우라실, 75 ㎎의 우리딘 및 100 ㎎/L 내지 1000 ㎎/L의 농도 범위에 대하여 시험한 FOA 활성을 기준으로 하여 (이는, 공급자로부터 수령한 각각의 배치 내에서 변동이 일어나기 때문임) 적당량의 FOA (미국 캘리포니아주 오렌지 소재의 자이모 리서치 코포레이션(Zymo Research Corp.)).
추가의 실험에 의해, 오직 제3 형질전환체 군만이 실제 Ura- 표현형을 갖는 것으로 결정되었다.
Ura- 세포를 MM + 5-FOA 플레이트로부터 긁어내고, 일반 방법에 따라 지방산 분석을 가하였다. 이러한 방식으로, GC 분석에 의해, 각각 군 3의 MM + 5-FOA 플레이트 상에서 성장시킨 pZKUM-형질전환체 #1, #3, #6, #7, #8, #10 및 #11에서 TFA 중 28.5%, 28.5%, 27.4%, 28.6%, 29.2%, 30.3% 및 29.6%의 EPA가 있는 것으로 나타났다. 이들 7개의 주를 각각 주 Y9502U12, Y9502U14, Y9502U17, Y9502U18, Y9502U19, Y9502U21 및 Y9502U22 (총괄적으로, Y9502U)로 명명하였다.
이어서, 하나의 델타-9 데새츄라아제 유전자, 하나의 콜린-포스페이트 시티딜릴-트랜스퍼라아제 유전자 및 하나의 델타-9 엘롱가아제 돌연변이 유전자가 주 Y9502U의 야로위아 YALI0F32131p 유전자좌(젠뱅크 등록 번호: XM_506121) 내로 통합되도록 제작물 pZKL3-9DP9N(도 9; 서열 번호 29)을 생성하였다. 따라서, pZKL3-9DP9N 플라스미드는 하기의 성분을 포함하였다:

pZKL3-9DP9N 플라스미드를 AscI/SphI로 절단한 다음, 주 Y9502U17의 형질전환을 위해 사용하였다. 형질전환된 세포를 최소 배지["MM"] 플레이트 상에 도말하고, 30℃에서 3 내지 4일 동안 유지시켰다. MM 플레이트는 (리터당) 20 g의 글루코스, 아미노산을 포함하지 않는 1.7 g의 효모 질소 베이스, 1.0 g의 프롤린 및 pH 6.1 (조정할 필요가 없음)을 포함하였다. 단일의 콜로니를 MM 플레이트 상으로 다시 스트리킹한 다음, 30℃에서 액체 MM 내에 접종하고, 250 rpm/분으로 2일 동안 진탕시켰다. 세포를 원심분리에 의해 수집하고, HGM에 재현탁시킨 다음, 250 rpm/분에서 5일 동안 진탕시켰다. 세포는 상기 지방산 분석을 가하였다.
GC 분석에 의해, pZKL3-9DP9N을 갖는 선발된 96개의 Y9502U17 주의 대부분이 TFA 중 50 내지 56% EPA를 생성하는 것으로 나타났다. TFA 중 약 59.0%, 56.6%, 58.9%, 56.5% 및 57.6% EPA를 생성하였던 5개의 주(즉, #31, #32, #35, #70 및 #80)를 각각 주 Z1977, Z1978, Z1979, Z1980 및 Z1981로 명명하였다.
야생형 와이. 리포라이티카 ATCC #20362에 대한 이들 pZKL3-9DP9N 형질전환 주의 최종 유전형은 Ura +, Pex3 -, unknown 1-, unknown 2-, unknown 3-, unknown 4-, unknown 5-, unknown6 -, unknown 7-, unknown 8-, unknown9-, unknown 10-, unknown 11-, YAT1::ME3S::Pex16, GPD::ME3S::Pex20, YAT1::ME3S::Lip1, FBAINm::EgD9eS::Lip2, EXP1::EgD9eS::Lip1, GPAT::EgD9e::Lip2, YAT1::EgD9eS::Lip2, YAT1::EgD9eS-L35G::Pex20, FBAINm::EgD8M::Pex20, EXP1::EgD8M::Pex16, FBAIN::EgD8M::Lip1, GPD::EaD8S::Pex16 (2개의 카피), YAT1::E389D9eS/EgD8M::Lip1, YAT1::EgD9eS/EgD8M::Aco, FBAINm::EaD9eS/EaD8S::Lip2, GPDIN::YlD9::Lip1, GPD::FmD12::Pex20, YAT1::FmD12::Oct, EXP1::FmD12S::Aco, GPDIN::FmD12::Pex16, EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, GPDIN::EgD5SM::Aco, GPM::EgD5SM::Oct, EXP1::EgD5SM::Lip1, YAT1::EaD5SM::Oct, FBAINm::PaD17::Aco, EXP1::PaD17::Pex16, YAT1::PaD17S::Lip1, YAT1::YlCPT1::Aco, YAT1::MCS::Lip1, FBA::MCS::Lip1, YAT1::MaLPAAT1S::Pex16, EXP1::YlPCT::Pex16이었다.
주 Z1977, Z1978, Z1979, Z1980 및 Z1981에서의 YALI0F32131p 유전자좌(젠뱅크 등록 번호: XM_50612)의 넉아웃(Knockout)은 pZKL3-9DP9N을 이용한 형질전환에 의해 생성되는 이들 임의의 EPA 주에서 확인되지 않았다.
주 Z1977, Z1978, Z1979, Z1980 및 Z1981의 YPD 플레이트로부터의 세포를 성장시키고, 전체 지질 함량 및 조성에 대하여 분석하였다. 구체적으로, 플라스크 분석법을 일반 방법에 기재된 바와 같이 행하였다. 하기 표 11에는 이들 주 각각에서의 전체 지질 함량 및 조성이 요약되어 있다(즉, 총 DCW, TFA % DCW, TFA의 중량%로서의 각각의 지방산의 농도["% TFA"] 및 EPA % DCW). 지방산은 16:0(팔미테이트), 16:1(팔미톨레산), 18:0(스테아르산), 18:1(올레산), 18:2(리놀레산), ALA(알파-리놀렌산), EDA(에이코사다이엔산), DGLA(다이호모-감마-리놀렌산), ARA(아라키돈산), ETrA(에이코사트라이엔산), ETA(에이코사테트라엔산), EPA(에이코사펜타엔산) 등이 있다.

주 Z1978을 이후에 부분 게놈 서열 결정을 하였다. 미국 특허 출원 제13/218,673호에 기재된 바와 같이, 이 연구에 의하면, 야로위아 게놈 내로 통합된 6개의 델타-5 데새츄라아제 유전자(즉, 키메라 유전자 EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, GPDIN::EgD5SM::Aco, GPM::EgD5SM::Oct, EXP1::EgD5SM::Lip1, YAT1::EaD5SM::Oct) 대신에, 엔지니어링된 주는 실제로 단지 4개의 델타-5 데새츄라아제 유전자(즉, EXP1::EgD5M::Pex16, FBAIN::EgD5SM::Pex20, EXP1::EgD5SM::Lip1, 및 YAT1::EaD5SM::Oct)를 보유함이 결정되었다.
주 Z1978에서 Ura3 유전자를 파괴하기 위하여, 주 Y9502 (상기)의 pZKUM 형질전환에 대하여 설명한 것과 유사한 방식으로 제작물 pZKUM (미국 특허 공개 제2009-0093543-A1호, 그 안의 표 15, 서열 번호 133 및 도 8a 참조)을 사용하여 Ura3 돌연변이 유전자를 주 Z1978의 Ura3 유전자 내로 통합시켰다. 총 16개 형질전환체(8개의 형질전환체를 포함하는 제1 "B" 군 및 8개의 형질전환체를 포함하는 제2 "C" 군으로부터 선택)를 성장시켰으며, 이는 Ura- 표현형을 갖는 것으로 확인되었다.
GC 분석에 의해, MM + 5-FOA 플레이트 상에서 성장시킨, B 군 pZKUM-형질전환 주 #1, #2, #3 및 #4 각각에서 TFA의 30.8%, 31%, 30.9% 및 31.3%의 EPA의 존재가 나타났다. 이들 4개의 주를 각각 주 Z1978BU1, Z1978BU2, Z1978BU3 및 Z1978BU4로 명명하였다.
GC 분석에 의해, MM + 5-FOA 플레이트 상에서 성장시킨, C 군 pZKUM-형질전환 주 #1, #2, #5 및 #6 각각에서 TFA의 34.4%, 31.9%, 31.2% 및 31%의 EPA의 존재가 나타났다. 이들 4개의 주를 각각 주 Z1978CU1, Z1978CU2, Z1978CU3 및 Z1978CU4로 명명하였다.
주 Z1978BU1, Z1978BU2, Z1978BU3, Z1978BU4, Z1978CU1, Z1978CU2, Z1978CU3 및 Z1978CU4 주를 총괄적으로 주 Z1978U로 명명하였다.
실시예 7
야로위아
리포라이티카
형질전환체에서의 분비된
인버타아제의
국재화
플라스미드 pYRH68 (서열 번호 13, Suc2SS/m-ScSUC2 융합물을 포함함), pYRH73 (서열 번호 15, 단지 m-ScSUC2를 포함함), pYRH69 (서열 번호 18, XPR2PP+13/Suc2SS/
m-ScSUC2 융합물을 포함함) 및/또는 pYRH74 (서열 번호 21, XPR2PP+13/m-ScSUC2 융합물을 포함함)를, 와이. 리포라이티카 주 Y2224U (야생형 야로위아 주 ATCC #20362의 Ura3 유전자의 자율 돌연변이에 의한 5-플루오로오로트산["FOA"] 내성 돌연변이체) 또는 와이. 리포라이티카 주 Z1978U (실시예 6) 중 어느 하나의 형질전환을 위하여 BsiWI/ PacI로 개별적으로 절단하였다. 인버타아제 활성을 형질전환체의 전세포에서 그리고 그 배양 배지로부터 측정하였다.
인버타아제
활성 분석
생체내 인버타아제 활성은 문헌[Silveira, et al. (Anal . Biochem ., 238:26-28 (1996)])에 기재된 것을 약간 변경하여 전세포를 사용하여 측정하였다. 간략하게는, 40 ㎎ (건조 세포 중량)의 대수기 성장 세포 (1.4-1.8의 OD600) - SD 또는 SS 배지 중 - 를 4℃의 원심분리에 의해 수집하고, 냉 아세트산나트륨 완충제 (50 mM, pH 5.0)에서 3회 세척하였다. 세포를 교반하면서 30℃에서 15 min 동안 8 mL의 100 mM NaF에서 인큐베이션하였다. 50 mM 아세트산나트륨 완충제 - pH 5.0 - 중 300 mM 수크로스 용액 4 mL의 첨가 후, 최대 10 min의 상이한 시간 간격으로, 나노셉(Nanosep) MF 0.2μ (미국 뉴욕주 포트 워싱턴 소재의 폴 라이프 사이언시즈(Pall Life Sciences))를 사용한 여과 후 글루코스 분석기 (와이에스아이 라이프 사이언시즈(YSI Life Sciences))를 이용하여 측정하였다. 1 단위(U)의 효소 활성은 분당 생성되는 글루코스의 μmol로 정의하였으며, 수율을 계산하여 DCW의 그램당 인버타아제 활성의 단위를 제공하였다.
배양 배지로부터의 인버타아제 활성을 1.5 mL의 여과된 매질로부터 측정하였다. 샘플 중 임의의 잔류 당을 제거하기 위하여, 샘플을 0.1 M 아세트산염 완충제 (pH 5.0)에 대하여 4℃에서 하룻밤 투석시켰다. 투석시킨 샘플 (200 μl)을, 50 mM 아세트산나트륨 완충제 - pH 5.0 - 중 300 mM 수크로스 용액 100 μl를 이용하여 최대 30 min 동안 인큐베이션하였다. 50 μl의 1.0 M K2HPO4를 첨가하고, 즉각적으로 95℃ 히트 블록 내에 10 min 동안 둠으로써 반응을 중지시켰다. 인버타아제 활성을 글루코스 분석기 (와이에스아이 라이프 사이언시즈)를 이용하여 측정하였다. 단백질 농도는 소 혈청 알부민을 표준물질로 이용하여 쿠마시 플러스 브래드포드 분석 키트(Coomassie Plus Bradford Assay kit; 미국 일리노이주 록포드 소재의 서모 사이언티픽(Thermo Scientific))에 의해 측정하였다. 활성은 배양 배지 1 리터당 인버타아제 활성의 단위(U)로서, 그리고 비활성은 단백질 1 ㎎당 단위로서 계산하였다. 수율을 계산하여 배양물의 DCW 그램당 인버타아제 활성의 단위를 제공하였다.
형질전환 와이.
리포라이티카
Y2224U
SUC
+
주에서의
세포외
및
전세포
인버타아제
활성
세포외 및 전세포 인버타아제 활성은 각각 배양 상청액 및 전세포를 사용하여 대수기 성장 세포로부터 측정하였다. 두 독립 실험으로부터의 4회 이상의 분석을 행하였으며, 평균 값이 보고되어 있는데, 이는 하기 표 12에 예시한 바와 같다.
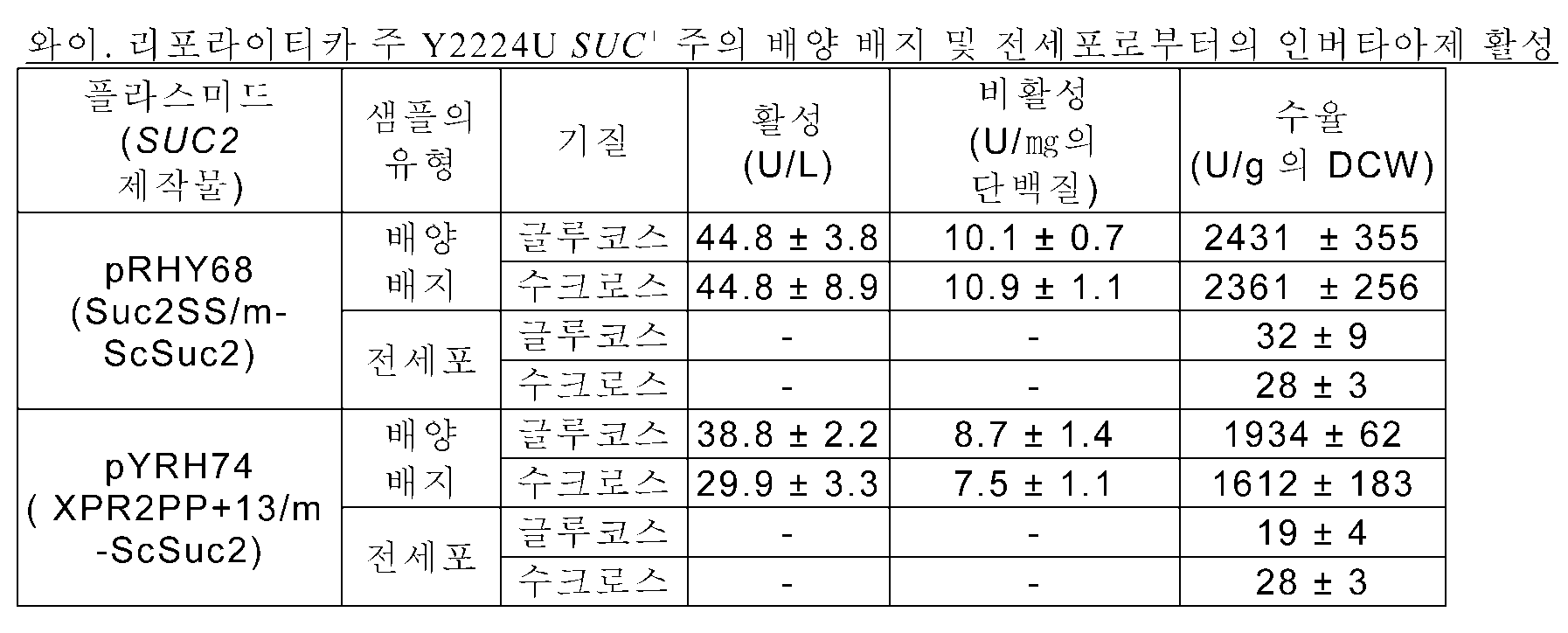
성장 연구의 결과와 일치하여, 인버타아제 활성이 pYRH68 또는 pYRH74로 형질전환된 와이. 리포라이티카 주에서 배양 상청액 및 전세포로부터 관찰되었다. pRH69 및 pRH73의 와이. 리포라이티카 형질전환체는 수크로스 배지 상에서 성장하지 않았으며, 글루코스 배지에서 성장시킨 세포 배양물로부터 어떠한 검출가능한 세포외 또는 전세포 인버타아제 활성도 없었다.
인버타아제 활성은 XPR2PP+13/m-ScSuc2에 대비하여 Suc2SS/m-ScSuc2의 형질전환체에서 약간 더 높았다. 심지어 성숙 Xpr2의 추가의 13개 아미노산에 의한 분비 시그널 프로세싱에 필요한 엔도펩티다아제에의 접근에 있어서 여전히 약간의 2차 구조 장해가 있었다는 것이 가능하다. 그러나, 98% 초과의 인버타아제 활성이 둘 모두의 SUC + 주의 배양 배지에서 검출되었으며, 배양 상청액 중 바이오매스당, 이전에 보고된 것보다 더 높은 세포외 인버타아제 활성이 관찰되었다.
형질전환 와이.
리포라이티카
주
Y1978U
SUC
+
주에서의
세포외
및
전세포
인버타아제
활성
인버타아제 활성을 형질전환체의 전세포에서 그리고 그 배양 배지로부터 측정하였다. 글루코스 또는 수크로스를 유일한 탄소 공급원으로 포함하는 YP (10 g/L의 박토(Bacto) 효모 추출물 및 20 g/L의 박토 펩톤) 배지에서 배양물을 성장시켰다. 2개의 상이한 형질전환체를 SUC2 제작물들 각각에 대하여 시험하였으며, 평균 값이 보고되어 있는데, 이는 하기 표 13에 예시된 바와 같다.

YP-기반 배양 배지 중 단백질 농도는 합성 기반 배양 배지의 것보다 유의하게 더 높았으며 (표 12), 이는 인버타아제 비활성(U/㎎의 단백질)을 감소시켰다. 이것에도 불구하고, pRHY68 형질전환체는 글루코스 배양물과 수크로스 배양물 사이에서 유사한 인버타아제 활성을 나타냈으며, 90% 초과의 인버타아제 활성이 배양 배지에서 검출되었다. pYRH74 형질전환체에 있어서, 하나의 형질전환체는 시험한 모든 조건에서 다른 형질전환체보다 훨씬 더 높은 인버타아제 활성을 나타냈다. 따라서, 평균 인버타아제 활성은 큰 표준 오차로 상승하였다. 그렇기는 하지만, 90% 초과의 인버타아제 활성이 글루코스 또는 수크로스 중 어느 하나를 유일한 탄소 공급원으로 포함하는 배양 배지에서 검출되었다.
실시예 8
공개적으로 입수가능한 인버타아제 코딩 유전자의 확인
사카로마이세스 세레비지애 인버타아제는 본 명세서에서 서열 번호 1로 기술된 SUC2 유전자에 의해 코딩된다. 이 1599 bp 유전자는 532개 아미노산의 전장 인버타아제 (서열 번호 2)를 코딩하며, 이는 글리코실화된 형태로 에스. 세레비지애의 주변세포질 내로 분비된다. 이와는 대조적으로, 19개 아미노산 길이의 5' 시그널 서열(즉, 서열 번호 1의 뉴클레오티드 1-57에 의해 코딩됨)이 결여된 "성숙" ScSUC2 유전자["m-ScSUC2"]는 서열 번호 3으로 기술되어 있으며, 서열 번호 4의 단백질을 코딩한다.
m-ScSUC2를 코딩하는 단백질 서열 (서열 번호 4)을 사용하여, 미국 국립 생물공학 정보 센터[National Center for Biotechnology Information; "NCBI"] BLASTP 2.2.26+ (문헌[Basic Local Alignment Search Tool; Altschul, S. F., et al., Nucleic Acids Res., 25:3389-3402 (1997)]; 문헌[Altschul, S. F., et al., FEBS J., 272:5101-5109 (2005)]) 검색을 행하여 BLAST "nr" 데이터베이스 (모든 비-잉여 젠뱅크 CDS 번역을 포함함), 단백질 데이터 은행[Protein Data Bank; "PDB"] 단백질 서열 데이터베이스, SWISS-PROT 단백질 서열 데이터베이스, 단백질 정보 리소스[Protein Information Resource; "PIR"] 단백질 서열 데이터베이스 및 단백질 연구 재단[Protein Research Foundation; "PRF"] 단백질 서열 데이터베이스 내에서 유사성을 갖는 서열을 확인하였으며, 전 게놈 샷건[whole genome shotgun; "WGS"] 프로젝트로부터 환경 샘플을 배제하였다).
서열 번호 4의 서열이 가장 큰 유사성을 갖는 서열을 요약한, BLASTP 비교 결과는 동일성 %, 유사성 % 및 기대값에 따라 보고될 수 있다. "동일성 %"는 두 단백질 사이에서 동일한 아미노산의 백분율로서 정의된다. "유사성 %"는 두 단백질 사이에서 동일하거나 또는 보존된 아미노산의 백분율로서 정의된다. "기대값"은 매치의 통계적 유의성을 개산한 것으로서, 이는 절대적으로 우연히 이 크기의 데이터베이스의 검색에서 기대되는 매치의 수를 주어진 스코어에 의해 특정한다.
다수의 단백질은 m-ScSUC2 (서열 번호 4)에 대하여 상당한 유사성을 공유하는 것으로 확인되었다. 표 14는 "4e-90" 이상의 기대값을 갖는 히트의 부분 요약 및 "인버타아제" 또는 "베타-프룩토푸라노시다아제" 중 어느 하나로서 당해 단백질을 특정적으로 확인해 주는 주석을 제공하지만, 이는 본 발명의 개시 내용을 한정하는 것으로 여겨져서는 안된다. 사카로마이세스 세레비지애에 대한 모든 히트는 하기에 보고된 결과에서 배제하였다. 표 14의 단백질은 91% 내지 99%의 질의 커버리지(query coverage)를 서열 번호 4의 서열과 공유하였다.

SEQUENCE LISTING
<110> E.I. du Pont de Nemours and Company
Hong, Raymond
Seip, John
Zhu, Quinn
<120> Use of Saccharomyces cerevisaie SUC2 gene in Yarrowia lipolytica
for sucrose utilization
<130> CL5174
<160> 41
<170> PatentIn version 3.5
<210> 1
<211> 1599
<212> DNA
<213> Saccharomyces cerevisiae
<220>
<221> CDS
<222> (1)..(1599)
<220>
<221> sig_peptide
<222> (1)..(57)
<400> 1
atg ctt ttg caa gct ttc ctt ttc ctt ttg gct ggt ttt gca gcc aaa 48
Met Leu Leu Gln Ala Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys
1 5 10 15
ata tct gca tca atg aca aac gaa act agc gat aga cct ttg gtc cac 96
Ile Ser Ala Ser Met Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His
20 25 30
ttc aca ccc aac aag ggc tgg atg aat gac cca aat ggg ttg tgg tac 144
Phe Thr Pro Asn Lys Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr
35 40 45
gat gaa aaa gat gcc aaa tgg cat ctg tac ttt caa tac aac cca aat 192
Asp Glu Lys Asp Ala Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn
50 55 60
gac acc gta tgg ggt acg cca ttg ttt tgg ggc cat gct act tcc gat 240
Asp Thr Val Trp Gly Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp
65 70 75 80
gat ttg act aat tgg gaa gat caa ccc att gct atc gct ccc aag cgt 288
Asp Leu Thr Asn Trp Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg
85 90 95
aac gat tca ggt gct ttc tct ggc tcc atg gtg gtt gat tac aac aac 336
Asn Asp Ser Gly Ala Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn
100 105 110
acg agt ggg ttt ttc aat gat act att gat cca aga caa aga tgc gtt 384
Thr Ser Gly Phe Phe Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val
115 120 125
gcg att tgg act tat aac act cct gaa agt gaa gag caa tac att agc 432
Ala Ile Trp Thr Tyr Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser
130 135 140
tat tct ctt gat ggt ggt tac act ttt act gaa tac caa aag aac cct 480
Tyr Ser Leu Asp Gly Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro
145 150 155 160
gtt tta gct gcc aac tcc act caa ttc aga gat cca aag gtg ttc tgg 528
Val Leu Ala Ala Asn Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp
165 170 175
tat gaa cct tct caa aaa tgg att atg acg gct gcc aaa tca caa gac 576
Tyr Glu Pro Ser Gln Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp
180 185 190
tac aaa att gaa att tac tcc tct gat gac ttg aag tcc tgg aag cta 624
Tyr Lys Ile Glu Ile Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu
195 200 205
gaa tct gca ttt gcc aat gaa ggt ttc tta ggc tac caa tac gaa tgt 672
Glu Ser Ala Phe Ala Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys
210 215 220
cca ggt ttg att gaa gtc cca act gag caa gat cct tcc aaa tct tat 720
Pro Gly Leu Ile Glu Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr
225 230 235 240
tgg gtc atg ttt att tct atc aac cca ggt gca cct gct ggc ggt tcc 768
Trp Val Met Phe Ile Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser
245 250 255
ttc aac caa tat ttt gtt gga tcc ttc aat ggt act cat ttt gaa gcg 816
Phe Asn Gln Tyr Phe Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala
260 265 270
ttt gac aat caa tct aga gtg gta gat ttt ggt aag gac tac tat gcc 864
Phe Asp Asn Gln Ser Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala
275 280 285
ttg caa act ttc ttc aac act gac cca acc tac ggt tca gca tta ggt 912
Leu Gln Thr Phe Phe Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly
290 295 300
att gcc tgg gct tca aac tgg gag tac agt gcc ttt gtc cca act aac 960
Ile Ala Trp Ala Ser Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn
305 310 315 320
cca tgg aga tca tcc atg tct ttg gtc cgc aag ttt tct ttg aac act 1008
Pro Trp Arg Ser Ser Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr
325 330 335
gaa tat caa gct aat cca gag act gaa ttg atc aat ttg aaa gcc gaa 1056
Glu Tyr Gln Ala Asn Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu
340 345 350
cca ata ttg aac att agt aat gct ggt ccc tgg tct cgt ttt gct act 1104
Pro Ile Leu Asn Ile Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr
355 360 365
aac aca act cta act aag gcc aat tct tac aat gtc gat ttg agc aac 1152
Asn Thr Thr Leu Thr Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn
370 375 380
tcg act ggt acc cta gag ttt gag ttg gtt tac gct gtt aac acc aca 1200
Ser Thr Gly Thr Leu Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr
385 390 395 400
caa acc ata tcc aaa tcc gtc ttt gcc gac tta tca ctt tgg ttc aag 1248
Gln Thr Ile Ser Lys Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys
405 410 415
ggt tta gaa gat cct gaa gaa tat ttg aga atg ggt ttt gaa gtc agt 1296
Gly Leu Glu Asp Pro Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser
420 425 430
gct tct tcc ttc ttt ttg gac cgt ggt aac tct aag gtc aag ttt gtc 1344
Ala Ser Ser Phe Phe Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val
435 440 445
aag gag aac cca tat ttc aca aac aga atg tct gtc aac aac caa cca 1392
Lys Glu Asn Pro Tyr Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro
450 455 460
ttc aag tct gag aac gac cta agt tac tat aaa gtg tac ggc cta ctg 1440
Phe Lys Ser Glu Asn Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu
465 470 475 480
gat caa aac atc ttg gaa ttg tac ttc aac gat gga gat gtg gtt tct 1488
Asp Gln Asn Ile Leu Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser
485 490 495
aca aat acc tac ttc atg acc acc ggt aac gct cta gga tct gtg aac 1536
Thr Asn Thr Tyr Phe Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn
500 505 510
atg acc act ggt gtc gat aat ttg ttc tac att gac aag ttc caa gta 1584
Met Thr Thr Gly Val Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val
515 520 525
agg gaa gta aaa tag 1599
Arg Glu Val Lys
530
<210> 2
<211> 532
<212> PRT
<213> Saccharomyces cerevisiae
<400> 2
Met Leu Leu Gln Ala Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys
1 5 10 15
Ile Ser Ala Ser Met Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His
20 25 30
Phe Thr Pro Asn Lys Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr
35 40 45
Asp Glu Lys Asp Ala Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn
50 55 60
Asp Thr Val Trp Gly Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp
65 70 75 80
Asp Leu Thr Asn Trp Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg
85 90 95
Asn Asp Ser Gly Ala Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn
100 105 110
Thr Ser Gly Phe Phe Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val
115 120 125
Ala Ile Trp Thr Tyr Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser
130 135 140
Tyr Ser Leu Asp Gly Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro
145 150 155 160
Val Leu Ala Ala Asn Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp
165 170 175
Tyr Glu Pro Ser Gln Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp
180 185 190
Tyr Lys Ile Glu Ile Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu
195 200 205
Glu Ser Ala Phe Ala Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys
210 215 220
Pro Gly Leu Ile Glu Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr
225 230 235 240
Trp Val Met Phe Ile Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser
245 250 255
Phe Asn Gln Tyr Phe Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala
260 265 270
Phe Asp Asn Gln Ser Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala
275 280 285
Leu Gln Thr Phe Phe Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly
290 295 300
Ile Ala Trp Ala Ser Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn
305 310 315 320
Pro Trp Arg Ser Ser Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr
325 330 335
Glu Tyr Gln Ala Asn Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu
340 345 350
Pro Ile Leu Asn Ile Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr
355 360 365
Asn Thr Thr Leu Thr Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn
370 375 380
Ser Thr Gly Thr Leu Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr
385 390 395 400
Gln Thr Ile Ser Lys Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys
405 410 415
Gly Leu Glu Asp Pro Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser
420 425 430
Ala Ser Ser Phe Phe Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val
435 440 445
Lys Glu Asn Pro Tyr Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro
450 455 460
Phe Lys Ser Glu Asn Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu
465 470 475 480
Asp Gln Asn Ile Leu Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser
485 490 495
Thr Asn Thr Tyr Phe Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn
500 505 510
Met Thr Thr Gly Val Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val
515 520 525
Arg Glu Val Lys
530
<210> 3
<211> 1542
<212> DNA
<213> Saccharomyces cerevisiae
<220>
<221> CDS
<222> (1)..(1542)
<400> 3
tca atg aca aac gaa act agc gat aga cct ttg gtc cac ttc aca ccc 48
Ser Met Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His Phe Thr Pro
1 5 10 15
aac aag ggc tgg atg aat gac cca aat ggg ttg tgg tac gat gaa aaa 96
Asn Lys Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr Asp Glu Lys
20 25 30
gat gcc aaa tgg cat ctg tac ttt caa tac aac cca aat gac acc gta 144
Asp Ala Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn Asp Thr Val
35 40 45
tgg ggt acg cca ttg ttt tgg ggc cat gct act tcc gat gat ttg act 192
Trp Gly Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp Asp Leu Thr
50 55 60
aat tgg gaa gat caa ccc att gct atc gct ccc aag cgt aac gat tca 240
Asn Trp Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg Asn Asp Ser
65 70 75 80
ggt gct ttc tct ggc tcc atg gtg gtt gat tac aac aac acg agt ggg 288
Gly Ala Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn Thr Ser Gly
85 90 95
ttt ttc aat gat act att gat cca aga caa aga tgc gtt gcg att tgg 336
Phe Phe Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val Ala Ile Trp
100 105 110
act tat aac act cct gaa agt gaa gag caa tac att agc tat tct ctt 384
Thr Tyr Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser Tyr Ser Leu
115 120 125
gat ggt ggt tac act ttt act gaa tac caa aag aac cct gtt tta gct 432
Asp Gly Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro Val Leu Ala
130 135 140
gcc aac tcc act caa ttc aga gat cca aag gtg ttc tgg tat gaa cct 480
Ala Asn Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp Tyr Glu Pro
145 150 155 160
tct caa aaa tgg att atg acg gct gcc aaa tca caa gac tac aaa att 528
Ser Gln Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp Tyr Lys Ile
165 170 175
gaa att tac tcc tct gat gac ttg aag tcc tgg aag cta gaa tct gca 576
Glu Ile Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu Glu Ser Ala
180 185 190
ttt gcc aat gaa ggt ttc tta ggc tac caa tac gaa tgt cca ggt ttg 624
Phe Ala Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys Pro Gly Leu
195 200 205
att gaa gtc cca act gag caa gat cct tcc aaa tct tat tgg gtc atg 672
Ile Glu Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr Trp Val Met
210 215 220
ttt att tct atc aac cca ggt gca cct gct ggc ggt tcc ttc aac caa 720
Phe Ile Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser Phe Asn Gln
225 230 235 240
tat ttt gtt gga tcc ttc aat ggt act cat ttt gaa gcg ttt gac aat 768
Tyr Phe Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala Phe Asp Asn
245 250 255
caa tct aga gtg gta gat ttt ggt aag gac tac tat gcc ttg caa act 816
Gln Ser Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala Leu Gln Thr
260 265 270
ttc ttc aac act gac cca acc tac ggt tca gca tta ggt att gcc tgg 864
Phe Phe Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly Ile Ala Trp
275 280 285
gct tca aac tgg gag tac agt gcc ttt gtc cca act aac cca tgg aga 912
Ala Ser Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn Pro Trp Arg
290 295 300
tca tcc atg tct ttg gtc cgc aag ttt tct ttg aac act gaa tat caa 960
Ser Ser Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr Glu Tyr Gln
305 310 315 320
gct aat cca gag act gaa ttg atc aat ttg aaa gcc gaa cca ata ttg 1008
Ala Asn Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu Pro Ile Leu
325 330 335
aac att agt aat gct ggt ccc tgg tct cgt ttt gct act aac aca act 1056
Asn Ile Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr Asn Thr Thr
340 345 350
cta act aag gcc aat tct tac aat gtc gat ttg agc aac tcg act ggt 1104
Leu Thr Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn Ser Thr Gly
355 360 365
acc cta gag ttt gag ttg gtt tac gct gtt aac acc aca caa acc ata 1152
Thr Leu Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr Gln Thr Ile
370 375 380
tcc aaa tcc gtc ttt gcc gac tta tca ctt tgg ttc aag ggt tta gaa 1200
Ser Lys Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys Gly Leu Glu
385 390 395 400
gat cct gaa gaa tat ttg aga atg ggt ttt gaa gtc agt gct tct tcc 1248
Asp Pro Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser Ala Ser Ser
405 410 415
ttc ttt ttg gac cgt ggt aac tct aag gtc aag ttt gtc aag gag aac 1296
Phe Phe Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val Lys Glu Asn
420 425 430
cca tat ttc aca aac aga atg tct gtc aac aac caa cca ttc aag tct 1344
Pro Tyr Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro Phe Lys Ser
435 440 445
gag aac gac cta agt tac tat aaa gtg tac ggc cta ctg gat caa aac 1392
Glu Asn Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu Asp Gln Asn
450 455 460
atc ttg gaa ttg tac ttc aac gat gga gat gtg gtt tct aca aat acc 1440
Ile Leu Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser Thr Asn Thr
465 470 475 480
tac ttc atg acc acc ggt aac gct cta gga tct gtg aac atg acc act 1488
Tyr Phe Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn Met Thr Thr
485 490 495
ggt gtc gat aat ttg ttc tac att gac aag ttc caa gta agg gaa gta 1536
Gly Val Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val Arg Glu Val
500 505 510
aaa tag 1542
Lys
<210> 4
<211> 513
<212> PRT
<213> Saccharomyces cerevisiae
<400> 4
Ser Met Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His Phe Thr Pro
1 5 10 15
Asn Lys Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr Asp Glu Lys
20 25 30
Asp Ala Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn Asp Thr Val
35 40 45
Trp Gly Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp Asp Leu Thr
50 55 60
Asn Trp Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg Asn Asp Ser
65 70 75 80
Gly Ala Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn Thr Ser Gly
85 90 95
Phe Phe Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val Ala Ile Trp
100 105 110
Thr Tyr Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser Tyr Ser Leu
115 120 125
Asp Gly Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro Val Leu Ala
130 135 140
Ala Asn Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp Tyr Glu Pro
145 150 155 160
Ser Gln Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp Tyr Lys Ile
165 170 175
Glu Ile Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu Glu Ser Ala
180 185 190
Phe Ala Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys Pro Gly Leu
195 200 205
Ile Glu Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr Trp Val Met
210 215 220
Phe Ile Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser Phe Asn Gln
225 230 235 240
Tyr Phe Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala Phe Asp Asn
245 250 255
Gln Ser Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala Leu Gln Thr
260 265 270
Phe Phe Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly Ile Ala Trp
275 280 285
Ala Ser Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn Pro Trp Arg
290 295 300
Ser Ser Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr Glu Tyr Gln
305 310 315 320
Ala Asn Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu Pro Ile Leu
325 330 335
Asn Ile Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr Asn Thr Thr
340 345 350
Leu Thr Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn Ser Thr Gly
355 360 365
Thr Leu Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr Gln Thr Ile
370 375 380
Ser Lys Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys Gly Leu Glu
385 390 395 400
Asp Pro Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser Ala Ser Ser
405 410 415
Phe Phe Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val Lys Glu Asn
420 425 430
Pro Tyr Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro Phe Lys Ser
435 440 445
Glu Asn Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu Asp Gln Asn
450 455 460
Ile Leu Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser Thr Asn Thr
465 470 475 480
Tyr Phe Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn Met Thr Thr
485 490 495
Gly Val Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val Arg Glu Val
500 505 510
Lys
<210> 5
<211> 1365
<212> DNA
<213> Yarrowia lipolytica
<220>
<221> CDS
<222> (1)..(1365)
<220>
<221> sig_peptide
<222> (1)..(471)
<400> 5
atg aag ctc gct acc gcc ttt act att ctc act gcc gtt ctg gcc gct 48
Met Lys Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
ccc ctg gcc gcc cct gcc cct gct cct gat gct gcc cct gct gct gtg 96
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
cct gag ggc cct gcc gcc gct gcc tac tca tct att ctg tcc gtg gtc 144
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
gct aag cag tcc aag aag ttt aag cac cac aag cga gat ctt gat gag 192
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
aag gat cag ttc atc gtt gtc ttt gac agt agc gct act gtt gac cag 240
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
atc gcc tcc gaa atc cag aag ctg gac tct ctg gtc gac gag gac tcg 288
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
tcc aac ggt atc acc tct gct ctt gat ctt cct gtc tac acg gat gga 336
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
tct ggc ttt ctc gga ttt gtt gga aag ttc aac tcc act atc gtt gac 384
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
aag ctc aag gag tcg tct gtt ctg acg gtc gag ccc gat acc att gtg 432
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
tct ctc ccc gag att cct gct tct tct aat gcc aag cga gct atc cag 480
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
act act ccc gtc act caa tgg ggc ctg tct aga atc tct cat aag aag 528
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser Arg Ile Ser His Lys Lys
165 170 175
gcc cag act gga aac tac gcc tac gtt cga gag aca gtt ggc aag cac 576
Ala Gln Thr Gly Asn Tyr Ala Tyr Val Arg Glu Thr Val Gly Lys His
180 185 190
ccc acc gtt tct tac gtt gtt gac tct ggt atc cga acc acc cac tcc 624
Pro Thr Val Ser Tyr Val Val Asp Ser Gly Ile Arg Thr Thr His Ser
195 200 205
gag ttc gga ggc cga gct gtc tgg gga gcc aac ttc gct gac aca cag 672
Glu Phe Gly Gly Arg Ala Val Trp Gly Ala Asn Phe Ala Asp Thr Gln
210 215 220
aac gct gat ctt ctc ggt cac ggc act cac gtt gca ggt acc gtg gga 720
Asn Ala Asp Leu Leu Gly His Gly Thr His Val Ala Gly Thr Val Gly
225 230 235 240
gga aag aca tac gga gtc gac gcc aac acc aag ctg gtg gcc gtc aag 768
Gly Lys Thr Tyr Gly Val Asp Ala Asn Thr Lys Leu Val Ala Val Lys
245 250 255
gtg ttt gca ggc cga tcc gca gct ctc tcc gtc atc aac cag ggc ttc 816
Val Phe Ala Gly Arg Ser Ala Ala Leu Ser Val Ile Asn Gln Gly Phe
260 265 270
acc tgg gct ctc aac gac tac atc tcc aag cga gac act ctg cct cga 864
Thr Trp Ala Leu Asn Asp Tyr Ile Ser Lys Arg Asp Thr Leu Pro Arg
275 280 285
gga gtg ctg aac ttc tct gga gga gga ccc aag tcc gct tcc cag gac 912
Gly Val Leu Asn Phe Ser Gly Gly Gly Pro Lys Ser Ala Ser Gln Asp
290 295 300
gcc cta tgg tct cga gct acc cag gag ggt ctg ctt gtc gcc atc gct 960
Ala Leu Trp Ser Arg Ala Thr Gln Glu Gly Leu Leu Val Ala Ile Ala
305 310 315 320
gcg gga aac gat gcc gtg gac gcc tgt aac gac tct ccc ggt aac att 1008
Ala Gly Asn Asp Ala Val Asp Ala Cys Asn Asp Ser Pro Gly Asn Ile
325 330 335
gga ggc tcc acc tct ggt atc atc act gtg ggt tcc att gac tct agc 1056
Gly Gly Ser Thr Ser Gly Ile Ile Thr Val Gly Ser Ile Asp Ser Ser
340 345 350
gat aag atc tcc gtc tgg tcc ggt gga cag gga tcc aac tac gga act 1104
Asp Lys Ile Ser Val Trp Ser Gly Gly Gln Gly Ser Asn Tyr Gly Thr
355 360 365
tgt gtt gat gtc ttt gcc ccc ggc tcc gat atc atc tct gcc tct tac 1152
Cys Val Asp Val Phe Ala Pro Gly Ser Asp Ile Ile Ser Ala Ser Tyr
370 375 380
cag tcc gac tct ggt act ttg gtc tac tcc ggt acc tcc atg gcc tgt 1200
Gln Ser Asp Ser Gly Thr Leu Val Tyr Ser Gly Thr Ser Met Ala Cys
385 390 395 400
ccc cac gtt gcc ggt ctt gcc tcc tac tac ctg tcc atc aat gac gag 1248
Pro His Val Ala Gly Leu Ala Ser Tyr Tyr Leu Ser Ile Asn Asp Glu
405 410 415
gtt ctc acc cct gcc cag gtc gag gct ctt att act gag tcc aac acc 1296
Val Leu Thr Pro Ala Gln Val Glu Ala Leu Ile Thr Glu Ser Asn Thr
420 425 430
ggt gtt ctt ccc acc acc aac ctc aag ggc tct ccc aac gct gtt gcc 1344
Gly Val Leu Pro Thr Thr Asn Leu Lys Gly Ser Pro Asn Ala Val Ala
435 440 445
tac aac ggt gtt ggc att tag 1365
Tyr Asn Gly Val Gly Ile
450
<210> 6
<211> 454
<212> PRT
<213> Yarrowia lipolytica
<400> 6
Met Lys Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser Arg Ile Ser His Lys Lys
165 170 175
Ala Gln Thr Gly Asn Tyr Ala Tyr Val Arg Glu Thr Val Gly Lys His
180 185 190
Pro Thr Val Ser Tyr Val Val Asp Ser Gly Ile Arg Thr Thr His Ser
195 200 205
Glu Phe Gly Gly Arg Ala Val Trp Gly Ala Asn Phe Ala Asp Thr Gln
210 215 220
Asn Ala Asp Leu Leu Gly His Gly Thr His Val Ala Gly Thr Val Gly
225 230 235 240
Gly Lys Thr Tyr Gly Val Asp Ala Asn Thr Lys Leu Val Ala Val Lys
245 250 255
Val Phe Ala Gly Arg Ser Ala Ala Leu Ser Val Ile Asn Gln Gly Phe
260 265 270
Thr Trp Ala Leu Asn Asp Tyr Ile Ser Lys Arg Asp Thr Leu Pro Arg
275 280 285
Gly Val Leu Asn Phe Ser Gly Gly Gly Pro Lys Ser Ala Ser Gln Asp
290 295 300
Ala Leu Trp Ser Arg Ala Thr Gln Glu Gly Leu Leu Val Ala Ile Ala
305 310 315 320
Ala Gly Asn Asp Ala Val Asp Ala Cys Asn Asp Ser Pro Gly Asn Ile
325 330 335
Gly Gly Ser Thr Ser Gly Ile Ile Thr Val Gly Ser Ile Asp Ser Ser
340 345 350
Asp Lys Ile Ser Val Trp Ser Gly Gly Gln Gly Ser Asn Tyr Gly Thr
355 360 365
Cys Val Asp Val Phe Ala Pro Gly Ser Asp Ile Ile Ser Ala Ser Tyr
370 375 380
Gln Ser Asp Ser Gly Thr Leu Val Tyr Ser Gly Thr Ser Met Ala Cys
385 390 395 400
Pro His Val Ala Gly Leu Ala Ser Tyr Tyr Leu Ser Ile Asn Asp Glu
405 410 415
Val Leu Thr Pro Ala Gln Val Glu Ala Leu Ile Thr Glu Ser Asn Thr
420 425 430
Gly Val Leu Pro Thr Thr Asn Leu Lys Gly Ser Pro Asn Ala Val Ala
435 440 445
Tyr Asn Gly Val Gly Ile
450
<210> 7
<211> 57
<212> DNA
<213> Saccharomyces cerevisiae
<220>
<221> CDS
<222> (1)..(57)
<223> SucSS
<400> 7
atg ttt ttg caa gct ttc ctt ttc ctt ttg gct ggt ttt gca gcc aaa 48
Met Phe Leu Gln Ala Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys
1 5 10 15
ata tct gca 57
Ile Ser Ala
<210> 8
<211> 19
<212> PRT
<213> Saccharomyces cerevisiae
<400> 8
Met Phe Leu Gln Ala Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys
1 5 10 15
Ile Ser Ala
<210> 9
<211> 510
<212> DNA
<213> Yarrowia lipolytica
<220>
<221> CDS
<222> (1)..(510)
<400> 9
atg aag ctc gct acc gcc ttt act att ctc act gcc gtt ctg gcc gct 48
Met Lys Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
ccc ctg gcc gcc cct gcc cct gct cct gat gct gcc cct gct gct gtg 96
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
cct gag ggc cct gcc gcc gct gcc tac tca tct att ctg tcc gtg gtc 144
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
gct aag cag tcc aag aag ttt aag cac cac aag cga gat ctt gat gag 192
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
aag gat cag ttc atc gtt gtc ttt gac agt agc gct act gtt gac cag 240
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
atc gcc tcc gaa atc cag aag ctg gac tct ctg gtc gac gag gac tcg 288
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
tcc aac ggt atc acc tct gct ctt gat ctt cct gtc tac acg gat gga 336
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
tct ggc ttt ctc gga ttt gtt gga aag ttc aac tcc act atc gtt gac 384
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
aag ctc aag gag tcg tct gtt ctg acg gtc gag ccc gat acc att gtg 432
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
tct ctc ccc gag att cct gct tct tct aat gcc aag cga gct atc cag 480
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
act act ccc gtc act caa tgg ggc ctg tct 510
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser
165 170
<210> 10
<211> 170
<212> PRT
<213> Yarrowia lipolytica
<400> 10
Met Lys Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser
165 170
<210> 11
<211> 1599
<212> DNA
<213> Saccharomyces cerevisiae
<220>
<221> CDS
<222> (1)..(1599)
<223> Suc2SS/m-ScSUC2
<400> 11
atg ttt ttg caa gct ttc ctt ttc ctt ttg gct ggt ttt gca gcc aaa 48
Met Phe Leu Gln Ala Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys
1 5 10 15
ata tct gca tca atg aca aac gaa act agc gat aga cct ttg gtc cac 96
Ile Ser Ala Ser Met Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His
20 25 30
ttc aca ccc aac aag ggc tgg atg aat gac cca aat ggg ttg tgg tac 144
Phe Thr Pro Asn Lys Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr
35 40 45
gat gaa aaa gat gcc aaa tgg cat ctg tac ttt caa tac aac cca aat 192
Asp Glu Lys Asp Ala Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn
50 55 60
gac acc gta tgg ggt acg cca ttg ttt tgg ggc cat gct act tcc gat 240
Asp Thr Val Trp Gly Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp
65 70 75 80
gat ttg act aat tgg gaa gat caa ccc att gct atc gct ccc aag cgt 288
Asp Leu Thr Asn Trp Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg
85 90 95
aac gat tca ggt gct ttc tct ggc tcc atg gtg gtt gat tac aac aac 336
Asn Asp Ser Gly Ala Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn
100 105 110
acg agt ggg ttt ttc aat gat act att gat cca aga caa aga tgc gtt 384
Thr Ser Gly Phe Phe Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val
115 120 125
gcg att tgg act tat aac act cct gaa agt gaa gag caa tac att agc 432
Ala Ile Trp Thr Tyr Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser
130 135 140
tat tct ctt gat ggt ggt tac act ttt act gaa tac caa aag aac cct 480
Tyr Ser Leu Asp Gly Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro
145 150 155 160
gtt tta gct gcc aac tcc act caa ttc aga gat cca aag gtg ttc tgg 528
Val Leu Ala Ala Asn Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp
165 170 175
tat gaa cct tct caa aaa tgg att atg acg gct gcc aaa tca caa gac 576
Tyr Glu Pro Ser Gln Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp
180 185 190
tac aaa att gaa att tac tcc tct gat gac ttg aag tcc tgg aag cta 624
Tyr Lys Ile Glu Ile Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu
195 200 205
gaa tct gca ttt gcc aat gaa ggt ttc tta ggc tac caa tac gaa tgt 672
Glu Ser Ala Phe Ala Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys
210 215 220
cca ggt ttg att gaa gtc cca act gag caa gat cct tcc aaa tct tat 720
Pro Gly Leu Ile Glu Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr
225 230 235 240
tgg gtc atg ttt att tct atc aac cca ggt gca cct gct ggc ggt tcc 768
Trp Val Met Phe Ile Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser
245 250 255
ttc aac caa tat ttt gtt gga tcc ttc aat ggt act cat ttt gaa gcg 816
Phe Asn Gln Tyr Phe Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala
260 265 270
ttt gac aat caa tct aga gtg gta gat ttt ggt aag gac tac tat gcc 864
Phe Asp Asn Gln Ser Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala
275 280 285
ttg caa act ttc ttc aac act gac cca acc tac ggt tca gca tta ggt 912
Leu Gln Thr Phe Phe Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly
290 295 300
att gcc tgg gct tca aac tgg gag tac agt gcc ttt gtc cca act aac 960
Ile Ala Trp Ala Ser Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn
305 310 315 320
cca tgg aga tca tcc atg tct ttg gtc cgc aag ttt tct ttg aac act 1008
Pro Trp Arg Ser Ser Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr
325 330 335
gaa tat caa gct aat cca gag act gaa ttg atc aat ttg aaa gcc gaa 1056
Glu Tyr Gln Ala Asn Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu
340 345 350
cca ata ttg aac att agt aat gct ggt ccc tgg tct cgt ttt gct act 1104
Pro Ile Leu Asn Ile Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr
355 360 365
aac aca act cta act aag gcc aat tct tac aat gtc gat ttg agc aac 1152
Asn Thr Thr Leu Thr Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn
370 375 380
tcg act ggt acc cta gag ttt gag ttg gtt tac gct gtt aac acc aca 1200
Ser Thr Gly Thr Leu Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr
385 390 395 400
caa acc ata tcc aaa tcc gtc ttt gcc gac tta tca ctt tgg ttc aag 1248
Gln Thr Ile Ser Lys Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys
405 410 415
ggt tta gaa gat cct gaa gaa tat ttg aga atg ggt ttt gaa gtc agt 1296
Gly Leu Glu Asp Pro Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser
420 425 430
gct tct tcc ttc ttt ttg gac cgt ggt aac tct aag gtc aag ttt gtc 1344
Ala Ser Ser Phe Phe Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val
435 440 445
aag gag aac cca tat ttc aca aac aga atg tct gtc aac aac caa cca 1392
Lys Glu Asn Pro Tyr Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro
450 455 460
ttc aag tct gag aac gac cta agt tac tat aaa gtg tac ggc cta ctg 1440
Phe Lys Ser Glu Asn Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu
465 470 475 480
gat caa aac atc ttg gaa ttg tac ttc aac gat gga gat gtg gtt tct 1488
Asp Gln Asn Ile Leu Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser
485 490 495
aca aat acc tac ttc atg acc acc ggt aac gct cta gga tct gtg aac 1536
Thr Asn Thr Tyr Phe Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn
500 505 510
atg acc act ggt gtc gat aat ttg ttc tac att gac aag ttc caa gta 1584
Met Thr Thr Gly Val Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val
515 520 525
agg gaa gta aaa tag 1599
Arg Glu Val Lys
530
<210> 12
<211> 532
<212> PRT
<213> Saccharomyces cerevisiae
<400> 12
Met Phe Leu Gln Ala Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys
1 5 10 15
Ile Ser Ala Ser Met Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His
20 25 30
Phe Thr Pro Asn Lys Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr
35 40 45
Asp Glu Lys Asp Ala Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn
50 55 60
Asp Thr Val Trp Gly Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp
65 70 75 80
Asp Leu Thr Asn Trp Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg
85 90 95
Asn Asp Ser Gly Ala Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn
100 105 110
Thr Ser Gly Phe Phe Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val
115 120 125
Ala Ile Trp Thr Tyr Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser
130 135 140
Tyr Ser Leu Asp Gly Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro
145 150 155 160
Val Leu Ala Ala Asn Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp
165 170 175
Tyr Glu Pro Ser Gln Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp
180 185 190
Tyr Lys Ile Glu Ile Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu
195 200 205
Glu Ser Ala Phe Ala Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys
210 215 220
Pro Gly Leu Ile Glu Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr
225 230 235 240
Trp Val Met Phe Ile Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser
245 250 255
Phe Asn Gln Tyr Phe Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala
260 265 270
Phe Asp Asn Gln Ser Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala
275 280 285
Leu Gln Thr Phe Phe Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly
290 295 300
Ile Ala Trp Ala Ser Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn
305 310 315 320
Pro Trp Arg Ser Ser Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr
325 330 335
Glu Tyr Gln Ala Asn Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu
340 345 350
Pro Ile Leu Asn Ile Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr
355 360 365
Asn Thr Thr Leu Thr Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn
370 375 380
Ser Thr Gly Thr Leu Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr
385 390 395 400
Gln Thr Ile Ser Lys Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys
405 410 415
Gly Leu Glu Asp Pro Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser
420 425 430
Ala Ser Ser Phe Phe Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val
435 440 445
Lys Glu Asn Pro Tyr Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro
450 455 460
Phe Lys Ser Glu Asn Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu
465 470 475 480
Asp Gln Asn Ile Leu Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser
485 490 495
Thr Asn Thr Tyr Phe Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn
500 505 510
Met Thr Thr Gly Val Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val
515 520 525
Arg Glu Val Lys
530
<210> 13
<211> 8743
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pYRH68
<400> 13
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgttgattga ggtggagcca gatgggctat tgtttcatat 360
atagactggc agccacctct ttggcccagc atgtttgtat acctggaagg gaaaactaaa 420
gaagctggct agtttagttt gattattata gtagatgtcc taatcactag agattagaat 480
gtcttggcga tgattagtcg tcgtcccctg tatcatgtct agaccaactg tgtcatgaag 540
ttggtgctgg tgttttacct gtgtactaca agtaggtgtc ctagatctag tgtacagagc 600
cgtttagacc catgtggact tcaccattaa cgatggaaaa tgttcattat atgacagtat 660
attacaatgg acttgctcca tttcttcctt gcatcacatg ttctccacct ccatagttga 720
tcaacacatc atagtagcta aggctgctgc tctcccacta cagtccacca caagttaagt 780
agcaccgtca gtacagctaa aagtacacgt ctagtacgtt tcataactag tcaagtagcc 840
cctattacag atatcagcac tatcacgcac gagtttttct ctgtgctatc taatcaactt 900
gccaagtatt cggagaagat acactttctt ggcatcaggt atacgaggga gcctatcaga 960
tgaaaaaggg tatattggat ccattcatat ccacctacac gttgtcataa tctcctcatt 1020
cacgtgattc atttcgtgac actagtttct cactttcccc cccgcaccta tagtcaactt 1080
ggcggacacg ctacttgtag ctgacgttga tttatagacc caatcaaagc gggttatcgg 1140
tcaggtagca cttatcattc atcgttcata ctacgatgag caatctcggg catgtccgga 1200
aaagtgtcgg gcgcgccagc tgcattaatg aatcggccaa cgcgcgggga gaggcggttt 1260
gcgtattggg cgctcttccg cttcctcgct cactgactcg ctgcgctcgg tcgttcggct 1320
gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg ttatccacag aatcagggga 1380
taacgcagga aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc gtaaaaaggc 1440
cgcgttgctg gcgtttttcc ataggctccg cccccctgac gagcatcaca aaaatcgacg 1500
ctcaagtcag aggtggcgaa acccgacagg actataaaga taccaggcgt ttccccctgg 1560
aagctccctc gtgcgctctc ctgttccgac cctgccgctt accggatacc tgtccgcctt 1620
tctcccttcg ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc tcagttcggt 1680
gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc ccgaccgctg 1740
cgccttatcc ggtaactatc gtcttgagtc caacccggta agacacgact tatcgccact 1800
ggcagcagcc actggtaaca ggattagcag agcgaggtat gtaggcggtg ctacagagtt 1860
cttgaagtgg tggcctaact acggctacac tagaagaaca gtatttggta tctgcgctct 1920
gctgaagcca gttaccttcg gaaaaagagt tggtagctct tgatccggca aacaaaccac 1980
cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa aaaaaggatc 2040
tcaagaagat cctttgatct tttctacggg gtctgacgct cagtggaacg aaaactcacg 2100
ttaagggatt ttggtcatga gattatcaaa aaggatcttc acctagatcc ttttaaatta 2160
aaaatgaagt tttaaatcaa tctaaagtat atatgagtaa acttggtctg acagttacca 2220
atgcttaatc agtgaggcac ctatctcagc gatctgtcta tttcgttcat ccatagttgc 2280
ctgactcccc gtcgtgtaga taactacgat acgggagggc ttaccatctg gccccagtgc 2340
tgcaatgata ccgcgagacc cacgctcacc ggctccagat ttatcagcaa taaaccagcc 2400
agccggaagg gccgagcgca gaagtggtcc tgcaacttta tccgcctcca tccagtctat 2460
taattgttgc cgggaagcta gagtaagtag ttcgccagtt aatagtttgc gcaacgttgt 2520
tgccattgct acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt cattcagctc 2580
cggttcccaa cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa aagcggttag 2640
ctccttcggt cctccgatcg ttgtcagaag taagttggcc gcagtgttat cactcatggt 2700
tatggcagca ctgcataatt ctcttactgt catgccatcc gtaagatgct tttctgtgac 2760
tggtgagtac tcaaccaagt cattctgaga atagtgtatg cggcgaccga gttgctcttg 2820
cccggcgtca atacgggata ataccgcgcc acatagcaga actttaaaag tgctcatcat 2880
tggaaaacgt tcttcggggc gaaaactctc aaggatctta ccgctgttga gatccagttc 2940
gatgtaaccc actcgtgcac ccaactgatc ttcagcatct tttactttca ccagcgtttc 3000
tgggtgagca aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg cgacacggaa 3060
atgttgaata ctcatactct tcctttttca atattattga agcatttatc agggttattg 3120
tctcatgagc ggatacatat ttgaatgtat ttagaaaaat aaacaaatag gggttccgcg 3180
cacatttccc cgaaaagtgc cacctgatgc ggtgtgaaat accgcacaga tgcgtaagga 3240
gaaaataccg catcaggaaa ttgtaagcgt taatattttg ttaaaattcg cgttaaattt 3300
ttgttaaatc agctcatttt ttaaccaata ggccgaaatc ggcaaaatcc cttataaatc 3360
aaaagaatag accgagatag ggttgagtgt tgttccagtt tggaacaaga gtccactatt 3420
aaagaacgtg gactccaacg tcaaagggcg aaaaaccgtc tatcagggcg atggcccact 3480
acgtgaacca tcaccctaat caagtttttt ggggtcgagg tgccgtaaag cactaaatcg 3540
gaaccctaaa gggagccccc gatttagagc ttgacgggga aagccggcga acgtggcgag 3600
aaaggaaggg aagaaagcga aaggagcggg cgctagggcg ctggcaagtg tagcggtcac 3660
gctgcgcgta accaccacac ccgccgcgct taatgcgccg ctacagggcg cgtccattcg 3720
ccattcaggc tgcgcaactg ttgggaaggg cgatcggtgc gggcctcttc gctattacgc 3780
cagctggcga aagggggatg tgctgcaagg cgattaagtt gggtaacgcc agggttttcc 3840
cagtcacgac gttgtaaaac gacggccagt gaattgtaat acgactcact atagggcgaa 3900
ttgggcccga cgtcgcatgc attccgacag cagcgactgg gcaccatgat caagcgaaac 3960
accttccccc agctgccctg gcaaaccatc aagaacccta ctttcatcaa gtgcaagaac 4020
ggttctactc ttctcacctc cggtgtctac ggctggtgcc gaaagcctaa ctacaccgct 4080
gatttcatca tgtgcctcac ctgggctctc atgtgcggtg ttgcttctcc cctgccttac 4140
ttctacccgg tcttcttctt cctggtgctc atccaccgag cttaccgaga ctttgagcga 4200
ctggagcgaa agtacggtga ggactaccag gagttcaagc gacaggtccc ttggatcttc 4260
atcccttatg ttttctaaac gataagctta gtgagcgaat ggtgaggtta cttaattgag 4320
tggccagcct atgggattgt ataacagaca gtcaatatat tactgaaaag actgaacagc 4380
cagacggagt gaggttgtga gtgaatcgta gagggcggct attacagcaa gtctactcta 4440
cagtgtacta acacagcaga gaacaaatac aggtgtgcat tcggctatct gagaattagt 4500
tggagagctc gagaccctcg gcgataaact gctcctcggt tttgtgtcca tacttgtacg 4560
gaccattgta atggggcaag tcgttgagtt ctcgtcgtcc gacgttcaga gcacagaaac 4620
caatgtaatc aatgtagcag agatggttct gcaaaagatt gatttgtgcg agcaggttaa 4680
ttaagtcata cacaagtcag ctttcttcga gcctcatata agtataagta gttcaacgta 4740
ttagcactgt acccagcatc tccgtatcga gaaacacaac aacatgcccc attggacaga 4800
tcatgcggat acacaggttg tgcagtatca tacatactcg atcagacagg tcgtctgacc 4860
atcatacaag ctgaacaagc gctccatact tgcacgctct ctatatacac agttaaatta 4920
catatccata gtctaacctc taacagttaa tcttctggta agcctcccag ccagccttct 4980
ggtatcgctt ggcctcctca ataggatctc ggttctggcc gtacagacct cggccgacaa 5040
ttatgatatc cgttccggta gacatgacat cctcaacagt tcggtactgc tgtccgagag 5100
cgtctccctt gtcgtcaaga cccaccccgg gggtcagaat aagccagtcc tcagagtcgc 5160
ccttaggtcg gttctgggca atgaagccaa ccacaaactc ggggtcggat cgggcaagct 5220
caatggtctg cttggagtac tcgccagtgg ccagagagcc cttgcaagac agctcggcca 5280
gcatgagcag acctctggcc agcttctcgt tgggagaggg gactaggaac tccttgtact 5340
gggagttctc gtagtcagag acgtcctcct tcttctgttc agagacagtt tcctcggcac 5400
cagctcgcag gccagcaatg attccggttc cgggtacacc gtgggcgttg gtgatatcgg 5460
accactcggc gattcggtga caccggtact ggtgcttgac agtgttgcca atatctgcga 5520
actttctgtc ctcgaacagg aagaaaccgt gcttaagagc aagttccttg agggggagca 5580
cagtgccggc gtaggtgaag tcgtcaatga tgtcgatatg ggttttgatc atgcacacat 5640
aaggtccgac cttatcggca agctcaatga gctccttggt ggtggtaaca tccagagaag 5700
cacacaggtt ggttttcttg gctgccacga gcttgagcac tcgagcggca aaggcggact 5760
tgtggacgtt agctcgagct tcgtaggagg gcattttggt ggtgaagagg agactgaaat 5820
aaatttagtc tgcagaactt tttatcggaa ccttatctgg ggcagtgaag tatatgttat 5880
ggtaatagtt acgagttagt tgaacttata gatagactgg actatacggc tatcggtcca 5940
aattagaaag aacgtcaatg gctctctggg cgtcgccttt gccgacaaaa atgtgatcat 6000
gatgaaagcc agcaatgacg ttgcagctga tattgttgtc ggccaaccgc gccgaaaacg 6060
cagctgtcag acccacagcc tccaacgaag aatgtatcgt caaagtgatc caagcacact 6120
catagttgga gtcgtactcc aaaggcggca atgacgagtc agacagatac tcgtcgacgt 6180
ttaaacagtg tacgcagatc tactatagag gaacatttaa attgccccgg agaagacggc 6240
caggccgcct agatgacaaa ttcaacaact cacagctgac tttctgccat tgccactagg 6300
ggggggcctt tttatatggc caagccaagc tctccacgtc ggttgggctg cacccaacaa 6360
taaatgggta gggttgcacc aacaaaggga tgggatgggg ggtagaagat acgaggataa 6420
cggggctcaa tggcacaaat aagaacgaat actgccatta agactcgtga tccagcgact 6480
gacaccattg catcatctaa gggcctcaaa actacctcgg aactgctgcg ctgatctgga 6540
caccacagag gttccgagca ctttaggttg caccaaatgt cccaccaggt gcaggcagaa 6600
aacgctggaa cagcgtgtac agtttgtctt aacaaaaagt gagggcgctg aggtcgagca 6660
gggtggtgtg acttgttata gcctttagag ctgcgaaagc gcgtatggat ttggctcatc 6720
aggccagatt gagggtctgt ggacacatgt catgttagtg tacttcaatc gccccctgga 6780
tatagccccg acaataggcc gtggcctcat ttttttgcct tccgcacatt tccattgctc 6840
gatacccaca ccttgcttct cctgcacttg ccaaccttaa tactggttta cattgaccaa 6900
catcttacaa gcggggggct tgtctagggt atatataaac agtggctctc ccaatcggtt 6960
gccagtctct tttttccttt ctttccccac agattcgaaa tctaaactac acatcacaga 7020
attccgagcc gtgagtatcc acgacaagat cagtgtcgag acgacgcgtt ttgtgtaatg 7080
acacaatccg aaagtcgcta gcaacacaca ctctctacac aaactaaccc agctctggta 7140
ccatgttttt gcaagctttc cttttccttt tggctggttt tgcagccaaa atatctgcat 7200
caatgacaaa cgaaactagc gatagacctt tggtccactt cacacccaac aagggctgga 7260
tgaatgaccc aaatgggttg tggtacgatg aaaaagatgc caaatggcat ctgtactttc 7320
aatacaaccc aaatgacacc gtatggggta cgccattgtt ttggggccat gctacttccg 7380
atgatttgac taattgggaa gatcaaccca ttgctatcgc tcccaagcgt aacgattcag 7440
gtgctttctc tggctccatg gtggttgatt acaacaacac gagtgggttt ttcaatgata 7500
ctattgatcc aagacaaaga tgcgttgcga tttggactta taacactcct gaaagtgaag 7560
agcaatacat tagctattct cttgatggtg gttacacttt tactgaatac caaaagaacc 7620
ctgttttagc tgccaactcc actcaattca gagatccaaa ggtgttctgg tatgaacctt 7680
ctcaaaaatg gattatgacg gctgccaaat cacaagacta caaaattgaa atttactcct 7740
ctgatgactt gaagtcctgg aagctagaat ctgcatttgc caatgaaggt ttcttaggct 7800
accaatacga atgtccaggt ttgattgaag tcccaactga gcaagatcct tccaaatctt 7860
attgggtcat gtttatttct atcaacccag gtgcacctgc tggcggttcc ttcaaccaat 7920
attttgttgg atccttcaat ggtactcatt ttgaagcgtt tgacaatcaa tctagagtgg 7980
tagattttgg taaggactac tatgccttgc aaactttctt caacactgac ccaacctacg 8040
gttcagcatt aggtattgcc tgggcttcaa actgggagta cagtgccttt gtcccaacta 8100
acccatggag atcatccatg tctttggtcc gcaagttttc tttgaacact gaatatcaag 8160
ctaatccaga gactgaattg atcaatttga aagccgaacc aatattgaac attagtaatg 8220
ctggtccctg gtctcgtttt gctactaaca caactctaac taaggccaat tcttacaatg 8280
tcgatttgag caactcgact ggtaccctag agtttgagtt ggtttacgct gttaacacca 8340
cacaaaccat atccaaatcc gtctttgccg acttatcact ttggttcaag ggtttagaag 8400
atcctgaaga atatttgaga atgggttttg aagtcagtgc ttcttccttc tttttggacc 8460
gtggtaactc taaggtcaag tttgtcaagg agaacccata tttcacaaac agaatgtctg 8520
tcaacaacca accattcaag tctgagaacg acctaagtta ctataaagtg tacggcctac 8580
tggatcaaaa catcttggaa ttgtacttca acgatggaga tgtggtttct acaaatacct 8640
acttcatgac caccggtaac gctctaggat ctgtgaacat gaccactggt gtcgataatt 8700
tgttctacat tgacaagttc caagtaaggg aagtaaaata ggc 8743
<210> 14
<211> 11962
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pYRH70
<400> 14
aaattgcccc ggagaagacg gccaggccgc ctagatgaca aattcaacaa ctcacagctg 60
actttctgcc attgccacta ggggggggcc tttttatatg gccaagccaa gctctccacg 120
tcggttgggc tgcacccaac aataaatggg tagggttgca ccaacaaagg gatgggatgg 180
ggggtagaag atacgaggat aacggggctc aatggcacaa ataagaacga atactgccat 240
taagactcgt gatccagcga ctgacaccat tgcatcatct aagggcctca aaactacctc 300
ggaactgctg cgctgatctg gacaccacag aggttccgag cactttaggt tgcaccaaat 360
gtcccaccag gtgcaggcag aaaacgctgg aacagcgtgt acagtttgtc ttaacaaaaa 420
gtgagggcgc tgaggtcgag cagggtggtg tgacttgtta tagcctttag agctgcgaaa 480
gcgcgtatgg atttggctca tcaggccaga ttgagggtct gtggacacat gtcatgttag 540
tgtacttcaa tcgccccctg gatatagccc cgacaatagg ccgtggcctc atttttttgc 600
cttccgcaca tttccattgc tcgataccca caccttgctt ctcctgcact tgccaacctt 660
aatactggtt tacattgacc aacatcttac aagcgggggg cttgtctagg gtatatataa 720
acagtggctc tcccaatcgg ttgccagtct cttttttcct ttctttcccc acagattcga 780
aatctaaact acacatcaca gaattccgag ccgtgagtat ccacgacaag atcagtgtcg 840
agacgacgcg ttttgtgtaa tgacacaatc cgaaagtcgc tagcaacaca cactctctac 900
acaaactaac ccagctctgg taccatgttt ttgcaagctt tccttttcct tttggctggt 960
tttgcagcca aaatatctgc atcaatgaca aacgaaacta gcgatagacc tttggtccac 1020
ttcacaccca acaagggctg gatgaatgac ccaaatgggt tgtggtacga tgaaaaagat 1080
gccaaatggc atctgtactt tcaatacaac ccaaatgaca ccgtatgggg tacgccattg 1140
ttttggggcc atgctacttc cgatgatttg actaattggg aagatcaacc cattgctatc 1200
gctcccaagc gtaacgattc aggtgctttc tctggctcca tggtggttga ttacaacaac 1260
acgagtgggt ttttcaatga tactattgat ccaagacaaa gatgcgttgc gatttggact 1320
tataacactc ctgaaagtga agagcaatac attagctatt ctcttgatgg tggttacact 1380
tttactgaat accaaaagaa ccctgtttta gctgccaact ccactcaatt cagagatcca 1440
aaggtgttct ggtatgaacc ttctcaaaaa tggattatga cggctgccaa atcacaagac 1500
tacaaaattg aaatttactc ctctgatgac ttgaagtcct ggaagctaga atctgcattt 1560
gccaatgaag gtttcttagg ctaccaatac gaatgtccag gtttgattga agtcccaact 1620
gagcaagatc cttccaaatc ttattgggtc atgtttattt ctatcaaccc aggtgcacct 1680
gctggcggtt ccttcaacca atattttgtt ggatccttca atggtactca ttttgaagcg 1740
tttgacaatc aatctagagt ggtagatttt ggtaaggact actatgcctt gcaaactttc 1800
ttcaacactg acccaaccta cggttcagca ttaggtattg cctgggcttc aaactgggag 1860
tacagtgcct ttgtcccaac taacccatgg agatcatcca tgtctttggt ccgcaagttt 1920
tctttgaaca ctgaatatca agctaatcca gagactgaat tgatcaattt gaaagccgaa 1980
ccaatattga acattagtaa tgctggtccc tggtctcgtt ttgctactaa cacaactcta 2040
actaaggcca attcttacaa tgtcgatttg agcaactcga ctggtaccct agagtttgag 2100
ttggtttacg ctgttaacac cacacaaacc atatccaaat ccgtctttgc cgacttatca 2160
ctttggttca agggtttaga agatcctgaa gaatatttga gaatgggttt tgaagtcagt 2220
gcttcttcct tctttttgga ccgtggtaac tctaaggtca agtttgtcaa ggagaaccca 2280
tatttcacaa acagaatgtc tgtcaacaac caaccattca agtctgagaa cgacctaagt 2340
tactataaag tgtacggcct actggatcaa aacatcttgg aattgtactt caacgatgga 2400
gatgtggttt ctacaaatac ctacttcatg accaccggta acgctctagg atctgtgaac 2460
atgaccactg gtgtcgataa tttgttctac attgacaagt tccaagtaag ggaagtaaaa 2520
taggcggccg caagtgtgga tggggaagtg agtgcccggt tctgtgtgca caattggcaa 2580
tccaagatgg atggattcaa cacagggata tagcgagcta cgtggtggtg cgaggatata 2640
gcaacggata tttatgtttg acacttgaga atgtacgata caagcactgt ccaagtacaa 2700
tactaaacat actgtacata ctcatactcg tacccgggca acggtttcac ttgagtgcag 2760
tggctagtgc tcttactcgt acagtgtgca atactgcgta tcatagtctt tgatgtatat 2820
cgtattcatt catgttagtt gcgtacgttg attgaggtgg agccagatgg gctattgttt 2880
catatataga ctggcagcca cctctttggc ccagcatgtt tgtatacctg gaagggaaaa 2940
ctaaagaagc tggctagttt agtttgatta ttatagtaga tgtcctaatc actagagatt 3000
agaatgtctt ggcgatgatt agtcgtcgtc ccctgtatca tgtctagacc aactgtgtca 3060
tgaagttggt gctggtgttt tacctgtgta ctacaagtag gtgtcctaga tctagtgtac 3120
agagccgttt agacccatgt ggacttcacc attaacgatg gaaaatgttc attatatgac 3180
agtatattac aatggacttg ctccatttct tccttgcatc acatgttctc cacctccata 3240
gttgatcaac acatcatagt agctaaggct gctgctctcc cactacagtc caccacaagt 3300
taagtagcac cgtcagtaca gctaaaagta cacgtctagt acgtttcata actagtcaag 3360
tagcccctat tacagatatc agcactatca cgcacgagtt tttctctgtg ctatctaatc 3420
aacttgccaa gtattcggag aagatacact ttcttggcat caggtatacg agggagccta 3480
tcagatgaaa aagggtatat tggatccatt catatccacc tacacgttgt cataatctcc 3540
tcattcacgt gattcatttc gtgacactag tttctcactt tcccccccgc acctatagtc 3600
aacttggcgg acacgctact tgtagctgac gttgatttat agacccaatc aaagcgggtt 3660
atcggtcagg tagcacttat cattcatcgt tcatactacg atgagcaatc tcgggcatgt 3720
ccggaaaagt gtcgggcgcg ccagctgcat taatgaatcg gccaacgcgc ggggagaggc 3780
ggtttgcgta ttgggcgctc ttccgcttcc tcgctcactg actcgctgcg ctcggtcgtt 3840
cggctgcggc gagcggtatc agctcactca aaggcggtaa tacggttatc cacagaatca 3900
ggggataacg caggaaagaa catgtgagca aaaggccagc aaaaggccag gaaccgtaaa 3960
aaggccgcgt tgctggcgtt tttccatagg ctccgccccc ctgacgagca tcacaaaaat 4020
cgacgctcaa gtcagaggtg gcgaaacccg acaggactat aaagatacca ggcgtttccc 4080
cctggaagct ccctcgtgcg ctctcctgtt ccgaccctgc cgcttaccgg atacctgtcc 4140
gcctttctcc cttcgggaag cgtggcgctt tctcatagct cacgctgtag gtatctcagt 4200
tcggtgtagg tcgttcgctc caagctgggc tgtgtgcacg aaccccccgt tcagcccgac 4260
cgctgcgcct tatccggtaa ctatcgtctt gagtccaacc cggtaagaca cgacttatcg 4320
ccactggcag cagccactgg taacaggatt agcagagcga ggtatgtagg cggtgctaca 4380
gagttcttga agtggtggcc taactacggc tacactagaa gaacagtatt tggtatctgc 4440
gctctgctga agccagttac cttcggaaaa agagttggta gctcttgatc cggcaaacaa 4500
accaccgctg gtagcggtgg tttttttgtt tgcaagcagc agattacgcg cagaaaaaaa 4560
ggatctcaag aagatccttt gatcttttct acggggtctg acgctcagtg gaacgaaaac 4620
tcacgttaag ggattttggt catgagatta tcaaaaagga tcttcaccta gatcctttta 4680
aattaaaaat gaagttttaa atcaatctaa agtatatatg agtaaacttg gtctgacagt 4740
taccaatgct taatcagtga ggcacctatc tcagcgatct gtctatttcg ttcatccata 4800
gttgcctgac tccccgtcgt gtagataact acgatacggg agggcttacc atctggcccc 4860
agtgctgcaa tgataccgcg agacccacgc tcaccggctc cagatttatc agcaataaac 4920
cagccagccg gaagggccga gcgcagaagt ggtcctgcaa ctttatccgc ctccatccag 4980
tctattaatt gttgccggga agctagagta agtagttcgc cagttaatag tttgcgcaac 5040
gttgttgcca ttgctacagg catcgtggtg tcacgctcgt cgtttggtat ggcttcattc 5100
agctccggtt cccaacgatc aaggcgagtt acatgatccc ccatgttgtg caaaaaagcg 5160
gttagctcct tcggtcctcc gatcgttgtc agaagtaagt tggccgcagt gttatcactc 5220
atggttatgg cagcactgca taattctctt actgtcatgc catccgtaag atgcttttct 5280
gtgactggtg agtactcaac caagtcattc tgagaatagt gtatgcggcg accgagttgc 5340
tcttgcccgg cgtcaatacg ggataatacc gcgccacata gcagaacttt aaaagtgctc 5400
atcattggaa aacgttcttc ggggcgaaaa ctctcaagga tcttaccgct gttgagatcc 5460
agttcgatgt aacccactcg tgcacccaac tgatcttcag catcttttac tttcaccagc 5520
gtttctgggt gagcaaaaac aggaaggcaa aatgccgcaa aaaagggaat aagggcgaca 5580
cggaaatgtt gaatactcat actcttcctt tttcaatatt attgaagcat ttatcagggt 5640
tattgtctca tgagcggata catatttgaa tgtatttaga aaaataaaca aataggggtt 5700
ccgcgcacat ttccccgaaa agtgccacct gatgcggtgt gaaataccgc acagatgcgt 5760
aaggagaaaa taccgcatca ggaaattgta agcgttaata ttttgttaaa attcgcgtta 5820
aatttttgtt aaatcagctc attttttaac caataggccg aaatcggcaa aatcccttat 5880
aaatcaaaag aatagaccga gatagggttg agtgttgttc cagtttggaa caagagtcca 5940
ctattaaaga acgtggactc caacgtcaaa gggcgaaaaa ccgtctatca gggcgatggc 6000
ccactacgtg aaccatcacc ctaatcaagt tttttggggt cgaggtgccg taaagcacta 6060
aatcggaacc ctaaagggag cccccgattt agagcttgac ggggaaagcc ggcgaacgtg 6120
gcgagaaagg aagggaagaa agcgaaagga gcgggcgcta gggcgctggc aagtgtagcg 6180
gtcacgctgc gcgtaaccac cacacccgcc gcgcttaatg cgccgctaca gggcgcgtcc 6240
attcgccatt caggctgcgc aactgttggg aagggcgatc ggtgcgggcc tcttcgctat 6300
tacgccagct ggcgaaaggg ggatgtgctg caaggcgatt aagttgggta acgccagggt 6360
tttcccagtc acgacgttgt aaaacgacgg ccagtgaatt gtaatacgac tcactatagg 6420
gcgaattggg cccgacgtcg catgcattcc gacagcagcg actgggcacc atgatcaagc 6480
gaaacacctt cccccagctg ccctggcaaa ccatcaagaa ccctactttc atcaagtgca 6540
agaacggttc tactcttctc acctccggtg tctacggctg gtgccgaaag cctaactaca 6600
ccgctgattt catcatgtgc ctcacctggg ctctcatgtg cggtgttgct tctcccctgc 6660
cttacttcta cccggtcttc ttcttcctgg tgctcatcca ccgagcttac cgagactttg 6720
agcgactgga gcgaaagtac ggtgaggact accaggagtt caagcgacag gtcccttgga 6780
tcttcatccc ttatgttttc taaacgataa gcttagtgag cgaatggtga ggttacttaa 6840
ttgagtggcc agcctatggg attgtataac agacagtcaa tatattactg aaaagactga 6900
acagccagac ggagtgaggt tgtgagtgaa tcgtagaggg cggctattac agcaagtcta 6960
ctctacagtg tactaacaca gcagagaaca aatacaggtg tgcattcggc tatctgagaa 7020
ttagttggag agctcgagac cctcggcgat aaactgctcc tcggttttgt gtccatactt 7080
gtacggacca ttgtaatggg gcaagtcgtt gagttctcgt cgtccgacgt tcagagcaca 7140
gaaaccaatg taatcaatgt agcagagatg gttctgcaaa agattgattt gtgcgagcag 7200
gttaattaag tcatacacaa gtcagctttc ttcgagcctc atataagtat aagtagttca 7260
acgtattagc actgtaccca gcatctccgt atcgagaaac acaacaacat gccccattgg 7320
acagatcatg cggatacaca ggttgtgcag tatcatacat actcgatcag acaggtcgtc 7380
tgaccatcat acaagctgaa caagcgctcc atacttgcac gctctctata tacacagtta 7440
aattacatat ccatagtcta acctctaaca gttaatcttc tggtaagcct cccagccagc 7500
cttctggtat cgcttggcct cctcaatagg atctcggttc tggccgtaca gacctcggcc 7560
gacaattatg atatccgttc cggtagacat gacatcctca acagttcggt actgctgtcc 7620
gagagcgtct cccttgtcgt caagacccac cccgggggtc agaataagcc agtcctcaga 7680
gtcgccctta ggtcggttct gggcaatgaa gccaaccaca aactcggggt cggatcgggc 7740
aagctcaatg gtctgcttgg agtactcgcc agtggccaga gagcccttgc aagacagctc 7800
ggccagcatg agcagacctc tggccagctt ctcgttggga gaggggacta ggaactcctt 7860
gtactgggag ttctcgtagt cagagacgtc ctccttcttc tgttcagaga cagtttcctc 7920
ggcaccagct cgcaggccag caatgattcc ggttccgggt acaccgtggg cgttggtgat 7980
atcggaccac tcggcgattc ggtgacaccg gtactggtgc ttgacagtgt tgccaatatc 8040
tgcgaacttt ctgtcctcga acaggaagaa accgtgctta agagcaagtt ccttgagggg 8100
gagcacagtg ccggcgtagg tgaagtcgtc aatgatgtcg atatgggttt tgatcatgca 8160
cacataaggt ccgaccttat cggcaagctc aatgagctcc ttggtggtgg taacatccag 8220
agaagcacac aggttggttt tcttggctgc cacgagcttg agcactcgag cggcaaaggc 8280
ggacttgtgg acgttagctc gagcttcgta ggagggcatt ttggtggtga agaggagact 8340
gaaataaatt tagtctgcag aactttttat cggaacctta tctggggcag tgaagtatat 8400
gttatggtaa tagttacgag ttagttgaac ttatagatag actggactat acggctatcg 8460
gtccaaatta gaaagaacgt caatggctct ctgggcgtcg cctttgccga caaaaatgtg 8520
atcatgatga aagccagcaa tgacgttgca gctgatattg ttgtcggcca accgcgccga 8580
aaacgcagct gtcagaccca cagcctccaa cgaagaatgt atcgtcaaag tgatccaagc 8640
acactcatag ttggagtcgt actccaaagg cggcaatgac gagtcagaca gatactcgtc 8700
gaccttttcc ttgggaacca ccaccgtcag cccttctgac tcacgtattg tagccaccga 8760
cacaggcaac agtccgtgga tagcagaata tgtcttgtcg gtccatttct caccaacttt 8820
aggcgtcaag tgaatgttgc agaagaagta tgtgccttca ttgagaatcg gtgttgctga 8880
tttcaataaa gtcttgagat cagtttggcc agtcatgttg tggggggtaa ttggattgag 8940
ttatcgccta cagtctgtac aggtatactc gctgcccact ttatactttt tgattccgct 9000
gcacttgaag caatgtcgtt taccaaaagt gagaatgctc cacagaacac accccagggt 9060
atggttgagc aaaaaataaa cactccgata cggggaatcg aaccccggtc tccacggttc 9120
tcaagaagta ttcttgatga gagcgtatcg atgagcctaa aatgaacccg agtatatctc 9180
ataaaattct cggtgagagg tctgtgactg tcagtacaag gtgccttcat tatgccctca 9240
accttaccat acctcactga atgtagtgta cctctaaaaa tgaaatacag tgccaaaagc 9300
caaggcactg agctcgtcta acggacttga tatacaacca attaaaacaa atgaaaagaa 9360
atacagttct ttgtatcatt tgtaacaatt accctgtaca aactaaggta ttgaaatccc 9420
acaatattcc caaagtccac ccctttccaa attgtcatgc ctacaactca tataccaagc 9480
actaacctac cgtttaaacc atcatctaag ggcctcaaaa ctacctcgga actgctgcgc 9540
tgatctggac accacagagg ttccgagcac tttaggttgc accaaatgtc ccaccaggtg 9600
caggcagaaa acgctggaac agcgtgtaca gtttgtctta acaaaaagtg agggcgctga 9660
ggtcgagcag ggtggtgtga cttgttatag cctttagagc tgcgaaagcg cgtatggatt 9720
tggctcatca ggccagattg agggtctgtg gacacatgtc atgttagtgt acttcaatcg 9780
ccccctggat atagccccga caataggccg tggcctcatt tttttgcctt ccgcacattt 9840
ccattgctcg gtacccacac cttgcttctc ctgcacttgc caaccttaat actggtttac 9900
attgaccaac atcttacaag cggggggctt gtctagggta tatataaaca gtggctctcc 9960
caatcggttg ccagtctctt ttttcctttc tttccccaca gattcgaaat ctaaactaca 10020
catcacacca tgtttttgca agctttcctt ttccttttgg ctggttttgc agccaaaata 10080
tctgcatcaa tgacaaacga aactagcgat agacctttgg tccacttcac acccaacaag 10140
ggctggatga atgacccaaa tgggttgtgg tacgatgaaa aagatgccaa atggcatctg 10200
tactttcaat acaacccaaa tgacaccgta tggggtacgc cattgttttg gggccatgct 10260
acttccgatg atttgactaa ttgggaagat caacccattg ctatcgctcc caagcgtaac 10320
gattcaggtg ctttctctgg ctccatggtg gttgattaca acaacacgag tgggtttttc 10380
aatgatacta ttgatccaag acaaagatgc gttgcgattt ggacttataa cactcctgaa 10440
agtgaagagc aatacattag ctattctctt gatggtggtt acacttttac tgaataccaa 10500
aagaaccctg ttttagctgc caactccact caattcagag atccaaaggt gttctggtat 10560
gaaccttctc aaaaatggat tatgacggct gccaaatcac aagactacaa aattgaaatt 10620
tactcctctg atgacttgaa gtcctggaag ctagaatctg catttgccaa tgaaggtttc 10680
ttaggctacc aatacgaatg tccaggtttg attgaagtcc caactgagca agatccttcc 10740
aaatcttatt gggtcatgtt tatttctatc aacccaggtg cacctgctgg cggttccttc 10800
aaccaatatt ttgttggatc cttcaatggt actcattttg aagcgtttga caatcaatct 10860
agagtggtag attttggtaa ggactactat gccttgcaaa ctttcttcaa cactgaccca 10920
acctacggtt cagcattagg tattgcctgg gcttcaaact gggagtacag tgcctttgtc 10980
ccaactaacc catggagatc atccatgtct ttggtccgca agttttcttt gaacactgaa 11040
tatcaagcta atccagagac tgaattgatc aatttgaaag ccgaaccaat attgaacatt 11100
agtaatgctg gtccctggtc tcgttttgct actaacacaa ctctaactaa ggccaattct 11160
tacaatgtcg atttgagcaa ctcgactggt accctagagt ttgagttggt ttacgctgtt 11220
aacaccacac aaaccatatc caaatccgtc tttgccgact tatcactttg gttcaagggt 11280
ttagaagatc ctgaagaata tttgagaatg ggttttgaag tcagtgcttc ttccttcttt 11340
ttggaccgtg gtaactctaa ggtcaagttt gtcaaggaga acccatattt cacaaacaga 11400
atgtctgtca acaaccaacc attcaagtct gagaacgacc taagttacta taaagtgtac 11460
ggcctactgg atcaaaacat cttggaattg tacttcaacg atggagatgt ggtttctaca 11520
aatacctact tcatgaccac cggtaacgct ctaggatctg tgaacatgac cactggtgtc 11580
gataatttgt tctacattga caagttccaa gtaagggaag taaaataggc ggccgcatga 11640
gaagataaat atataaatac attgagatat taaatgcgct agattagaga gcctcatact 11700
gctcggagag aagccaagac gagtactcaa aggggattac accatccata tccacagaca 11760
caagctgggg aaaggttcta tatacacttt ccggaatacc gtagtttccg atgttatcaa 11820
tgggggcagc caggatttca ggcacttcgg tgtctcgggg tgaaatggcg ttcttggcct 11880
ccatcaagtc gtaccatgtc ttcatttgcc tgtcaaagta aaacagaagc agatgaagaa 11940
tgaacttgaa gtgaaggaat tt 11962
<210> 15
<211> 8689
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pYRH73
<400> 15
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgttgattga ggtggagcca gatgggctat tgtttcatat 360
atagactggc agccacctct ttggcccagc atgtttgtat acctggaagg gaaaactaaa 420
gaagctggct agtttagttt gattattata gtagatgtcc taatcactag agattagaat 480
gtcttggcga tgattagtcg tcgtcccctg tatcatgtct agaccaactg tgtcatgaag 540
ttggtgctgg tgttttacct gtgtactaca agtaggtgtc ctagatctag tgtacagagc 600
cgtttagacc catgtggact tcaccattaa cgatggaaaa tgttcattat atgacagtat 660
attacaatgg acttgctcca tttcttcctt gcatcacatg ttctccacct ccatagttga 720
tcaacacatc atagtagcta aggctgctgc tctcccacta cagtccacca caagttaagt 780
agcaccgtca gtacagctaa aagtacacgt ctagtacgtt tcataactag tcaagtagcc 840
cctattacag atatcagcac tatcacgcac gagtttttct ctgtgctatc taatcaactt 900
gccaagtatt cggagaagat acactttctt ggcatcaggt atacgaggga gcctatcaga 960
tgaaaaaggg tatattggat ccattcatat ccacctacac gttgtcataa tctcctcatt 1020
cacgtgattc atttcgtgac actagtttct cactttcccc cccgcaccta tagtcaactt 1080
ggcggacacg ctacttgtag ctgacgttga tttatagacc caatcaaagc gggttatcgg 1140
tcaggtagca cttatcattc atcgttcata ctacgatgag caatctcggg catgtccgga 1200
aaagtgtcgg gcgcgccagc tgcattaatg aatcggccaa cgcgcgggga gaggcggttt 1260
gcgtattggg cgctcttccg cttcctcgct cactgactcg ctgcgctcgg tcgttcggct 1320
gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg ttatccacag aatcagggga 1380
taacgcagga aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc gtaaaaaggc 1440
cgcgttgctg gcgtttttcc ataggctccg cccccctgac gagcatcaca aaaatcgacg 1500
ctcaagtcag aggtggcgaa acccgacagg actataaaga taccaggcgt ttccccctgg 1560
aagctccctc gtgcgctctc ctgttccgac cctgccgctt accggatacc tgtccgcctt 1620
tctcccttcg ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc tcagttcggt 1680
gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc ccgaccgctg 1740
cgccttatcc ggtaactatc gtcttgagtc caacccggta agacacgact tatcgccact 1800
ggcagcagcc actggtaaca ggattagcag agcgaggtat gtaggcggtg ctacagagtt 1860
cttgaagtgg tggcctaact acggctacac tagaagaaca gtatttggta tctgcgctct 1920
gctgaagcca gttaccttcg gaaaaagagt tggtagctct tgatccggca aacaaaccac 1980
cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa aaaaaggatc 2040
tcaagaagat cctttgatct tttctacggg gtctgacgct cagtggaacg aaaactcacg 2100
ttaagggatt ttggtcatga gattatcaaa aaggatcttc acctagatcc ttttaaatta 2160
aaaatgaagt tttaaatcaa tctaaagtat atatgagtaa acttggtctg acagttacca 2220
atgcttaatc agtgaggcac ctatctcagc gatctgtcta tttcgttcat ccatagttgc 2280
ctgactcccc gtcgtgtaga taactacgat acgggagggc ttaccatctg gccccagtgc 2340
tgcaatgata ccgcgagacc cacgctcacc ggctccagat ttatcagcaa taaaccagcc 2400
agccggaagg gccgagcgca gaagtggtcc tgcaacttta tccgcctcca tccagtctat 2460
taattgttgc cgggaagcta gagtaagtag ttcgccagtt aatagtttgc gcaacgttgt 2520
tgccattgct acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt cattcagctc 2580
cggttcccaa cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa aagcggttag 2640
ctccttcggt cctccgatcg ttgtcagaag taagttggcc gcagtgttat cactcatggt 2700
tatggcagca ctgcataatt ctcttactgt catgccatcc gtaagatgct tttctgtgac 2760
tggtgagtac tcaaccaagt cattctgaga atagtgtatg cggcgaccga gttgctcttg 2820
cccggcgtca atacgggata ataccgcgcc acatagcaga actttaaaag tgctcatcat 2880
tggaaaacgt tcttcggggc gaaaactctc aaggatctta ccgctgttga gatccagttc 2940
gatgtaaccc actcgtgcac ccaactgatc ttcagcatct tttactttca ccagcgtttc 3000
tgggtgagca aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg cgacacggaa 3060
atgttgaata ctcatactct tcctttttca atattattga agcatttatc agggttattg 3120
tctcatgagc ggatacatat ttgaatgtat ttagaaaaat aaacaaatag gggttccgcg 3180
cacatttccc cgaaaagtgc cacctgatgc ggtgtgaaat accgcacaga tgcgtaagga 3240
gaaaataccg catcaggaaa ttgtaagcgt taatattttg ttaaaattcg cgttaaattt 3300
ttgttaaatc agctcatttt ttaaccaata ggccgaaatc ggcaaaatcc cttataaatc 3360
aaaagaatag accgagatag ggttgagtgt tgttccagtt tggaacaaga gtccactatt 3420
aaagaacgtg gactccaacg tcaaagggcg aaaaaccgtc tatcagggcg atggcccact 3480
acgtgaacca tcaccctaat caagtttttt ggggtcgagg tgccgtaaag cactaaatcg 3540
gaaccctaaa gggagccccc gatttagagc ttgacgggga aagccggcga acgtggcgag 3600
aaaggaaggg aagaaagcga aaggagcggg cgctagggcg ctggcaagtg tagcggtcac 3660
gctgcgcgta accaccacac ccgccgcgct taatgcgccg ctacagggcg cgtccattcg 3720
ccattcaggc tgcgcaactg ttgggaaggg cgatcggtgc gggcctcttc gctattacgc 3780
cagctggcga aagggggatg tgctgcaagg cgattaagtt gggtaacgcc agggttttcc 3840
cagtcacgac gttgtaaaac gacggccagt gaattgtaat acgactcact atagggcgaa 3900
ttgggcccga cgtcgcatgc attccgacag cagcgactgg gcaccatgat caagcgaaac 3960
accttccccc agctgccctg gcaaaccatc aagaacccta ctttcatcaa gtgcaagaac 4020
ggttctactc ttctcacctc cggtgtctac ggctggtgcc gaaagcctaa ctacaccgct 4080
gatttcatca tgtgcctcac ctgggctctc atgtgcggtg ttgcttctcc cctgccttac 4140
ttctacccgg tcttcttctt cctggtgctc atccaccgag cttaccgaga ctttgagcga 4200
ctggagcgaa agtacggtga ggactaccag gagttcaagc gacaggtccc ttggatcttc 4260
atcccttatg ttttctaaac gataagctta gtgagcgaat ggtgaggtta cttaattgag 4320
tggccagcct atgggattgt ataacagaca gtcaatatat tactgaaaag actgaacagc 4380
cagacggagt gaggttgtga gtgaatcgta gagggcggct attacagcaa gtctactcta 4440
cagtgtacta acacagcaga gaacaaatac aggtgtgcat tcggctatct gagaattagt 4500
tggagagctc gagaccctcg gcgataaact gctcctcggt tttgtgtcca tacttgtacg 4560
gaccattgta atggggcaag tcgttgagtt ctcgtcgtcc gacgttcaga gcacagaaac 4620
caatgtaatc aatgtagcag agatggttct gcaaaagatt gatttgtgcg agcaggttaa 4680
ttaagtcata cacaagtcag ctttcttcga gcctcatata agtataagta gttcaacgta 4740
ttagcactgt acccagcatc tccgtatcga gaaacacaac aacatgcccc attggacaga 4800
tcatgcggat acacaggttg tgcagtatca tacatactcg atcagacagg tcgtctgacc 4860
atcatacaag ctgaacaagc gctccatact tgcacgctct ctatatacac agttaaatta 4920
catatccata gtctaacctc taacagttaa tcttctggta agcctcccag ccagccttct 4980
ggtatcgctt ggcctcctca ataggatctc ggttctggcc gtacagacct cggccgacaa 5040
ttatgatatc cgttccggta gacatgacat cctcaacagt tcggtactgc tgtccgagag 5100
cgtctccctt gtcgtcaaga cccaccccgg gggtcagaat aagccagtcc tcagagtcgc 5160
ccttaggtcg gttctgggca atgaagccaa ccacaaactc ggggtcggat cgggcaagct 5220
caatggtctg cttggagtac tcgccagtgg ccagagagcc cttgcaagac agctcggcca 5280
gcatgagcag acctctggcc agcttctcgt tgggagaggg gactaggaac tccttgtact 5340
gggagttctc gtagtcagag acgtcctcct tcttctgttc agagacagtt tcctcggcac 5400
cagctcgcag gccagcaatg attccggttc cgggtacacc gtgggcgttg gtgatatcgg 5460
accactcggc gattcggtga caccggtact ggtgcttgac agtgttgcca atatctgcga 5520
actttctgtc ctcgaacagg aagaaaccgt gcttaagagc aagttccttg agggggagca 5580
cagtgccggc gtaggtgaag tcgtcaatga tgtcgatatg ggttttgatc atgcacacat 5640
aaggtccgac cttatcggca agctcaatga gctccttggt ggtggtaaca tccagagaag 5700
cacacaggtt ggttttcttg gctgccacga gcttgagcac tcgagcggca aaggcggact 5760
tgtggacgtt agctcgagct tcgtaggagg gcattttggt ggtgaagagg agactgaaat 5820
aaatttagtc tgcagaactt tttatcggaa ccttatctgg ggcagtgaag tatatgttat 5880
ggtaatagtt acgagttagt tgaacttata gatagactgg actatacggc tatcggtcca 5940
aattagaaag aacgtcaatg gctctctggg cgtcgccttt gccgacaaaa atgtgatcat 6000
gatgaaagcc agcaatgacg ttgcagctga tattgttgtc ggccaaccgc gccgaaaacg 6060
cagctgtcag acccacagcc tccaacgaag aatgtatcgt caaagtgatc caagcacact 6120
catagttgga gtcgtactcc aaaggcggca atgacgagtc agacagatac tcgtcgacgt 6180
ttaaacagtg tacgcagatc tactatagag gaacatttaa attgccccgg agaagacggc 6240
caggccgcct agatgacaaa ttcaacaact cacagctgac tttctgccat tgccactagg 6300
ggggggcctt tttatatggc caagccaagc tctccacgtc ggttgggctg cacccaacaa 6360
taaatgggta gggttgcacc aacaaaggga tgggatgggg ggtagaagat acgaggataa 6420
cggggctcaa tggcacaaat aagaacgaat actgccatta agactcgtga tccagcgact 6480
gacaccattg catcatctaa gggcctcaaa actacctcgg aactgctgcg ctgatctgga 6540
caccacagag gttccgagca ctttaggttg caccaaatgt cccaccaggt gcaggcagaa 6600
aacgctggaa cagcgtgtac agtttgtctt aacaaaaagt gagggcgctg aggtcgagca 6660
gggtggtgtg acttgttata gcctttagag ctgcgaaagc gcgtatggat ttggctcatc 6720
aggccagatt gagggtctgt ggacacatgt catgttagtg tacttcaatc gccccctgga 6780
tatagccccg acaataggcc gtggcctcat ttttttgcct tccgcacatt tccattgctc 6840
gatacccaca ccttgcttct cctgcacttg ccaaccttaa tactggttta cattgaccaa 6900
catcttacaa gcggggggct tgtctagggt atatataaac agtggctctc ccaatcggtt 6960
gccagtctct tttttccttt ctttccccac agattcgaaa tctaaactac acatcacaga 7020
attccgagcc gtgagtatcc acgacaagat cagtgtcgag acgacgcgtt ttgtgtaatg 7080
acacaatccg aaagtcgcta gcaacacaca ctctctacac aaactaaccc agctctggta 7140
ccatgtcaat gacaaacgaa actagcgata gacctttggt ccacttcaca cccaacaagg 7200
gctggatgaa tgacccaaat gggttgtggt acgatgaaaa agatgccaaa tggcatctgt 7260
actttcaata caacccaaat gacaccgtat ggggtacgcc attgttttgg ggccatgcta 7320
cttccgatga tttgactaat tgggaagatc aacccattgc tatcgctccc aagcgtaacg 7380
attcaggtgc tttctctggc tccatggtgg ttgattacaa caacacgagt gggtttttca 7440
atgatactat tgatccaaga caaagatgcg ttgcgatttg gacttataac actcctgaaa 7500
gtgaagagca atacattagc tattctcttg atggtggtta cacttttact gaataccaaa 7560
agaaccctgt tttagctgcc aactccactc aattcagaga tccaaaggtg ttctggtatg 7620
aaccttctca aaaatggatt atgacggctg ccaaatcaca agactacaaa attgaaattt 7680
actcctctga tgacttgaag tcctggaagc tagaatctgc atttgccaat gaaggtttct 7740
taggctacca atacgaatgt ccaggtttga ttgaagtccc aactgagcaa gatccttcca 7800
aatcttattg ggtcatgttt atttctatca acccaggtgc acctgctggc ggttccttca 7860
accaatattt tgttggatcc ttcaatggta ctcattttga agcgtttgac aatcaatcta 7920
gagtggtaga ttttggtaag gactactatg ccttgcaaac tttcttcaac actgacccaa 7980
cctacggttc agcattaggt attgcctggg cttcaaactg ggagtacagt gcctttgtcc 8040
caactaaccc atggagatca tccatgtctt tggtccgcaa gttttctttg aacactgaat 8100
atcaagctaa tccagagact gaattgatca atttgaaagc cgaaccaata ttgaacatta 8160
gtaatgctgg tccctggtct cgttttgcta ctaacacaac tctaactaag gccaattctt 8220
acaatgtcga tttgagcaac tcgactggta ccctagagtt tgagttggtt tacgctgtta 8280
acaccacaca aaccatatcc aaatccgtct ttgccgactt atcactttgg ttcaagggtt 8340
tagaagatcc tgaagaatat ttgagaatgg gttttgaagt cagtgcttct tccttctttt 8400
tggaccgtgg taactctaag gtcaagtttg tcaaggagaa cccatatttc acaaacagaa 8460
tgtctgtcaa caaccaacca ttcaagtctg agaacgacct aagttactat aaagtgtacg 8520
gcctactgga tcaaaacatc ttggaattgt acttcaacga tggagatgtg gtttctacaa 8580
atacctactt catgaccacc ggtaacgctc taggatctgt gaacatgacc actggtgtcg 8640
ataatttgtt ctacattgac aagttccaag taagggaagt aaaataggc 8689
<210> 16
<211> 2112
<212> DNA
<213> Artificial Sequence
<220>
<223> fusion
<220>
<221> CDS
<222> (1)..(2112)
<223> XPR2PP+13/Suc2SS/m-ScSUC2
<400> 16
atg gag ctc gct acc gcc ttt act att ctc act gcc gtt ctg gcc gct 48
Met Glu Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
ccc ctg gcc gcc cct gcc cct gct cct gat gct gcc cct gct gct gtg 96
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
cct gag ggc cct gcc gcc gct gcc tac tca tct att ctg tcc gtg gtc 144
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
gct aag cag tcc aag aag ttt aag cac cac aag cga gat ctt gat gag 192
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
aag gat cag ttc atc gtt gtc ttt gac agt agc gct act gtt gac cag 240
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
atc gcc tcc gaa atc cag aag ctg gac tct ctg gtc gac gag gac tcg 288
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
tcc aac ggt atc acc tct gct ctt gat ctt cct gtc tac acg gat gga 336
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
tct ggc ttt ctc gga ttt gtt gga aag ttc aac tcc act atc gtt gac 384
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
aag ctc aag gag tcg tct gtt ctg acg gtc gag ccc gat acc att gtg 432
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
tct ctc ccc gag att cct gct tct tct aat gcc aag cga gct atc cag 480
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
act act ccc gtc act caa tgg ggc ctg tct aac atg ttt ttg caa gct 528
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser Asn Met Phe Leu Gln Ala
165 170 175
ttc ctt ttc ctt ttg gct ggt ttt gca gcc aaa ata tct gca tca atg 576
Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys Ile Ser Ala Ser Met
180 185 190
aca aac gaa act agc gat aga cct ttg gtc cac ttc aca ccc aac aag 624
Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His Phe Thr Pro Asn Lys
195 200 205
ggc tgg atg aat gac cca aat ggg ttg tgg tac gat gaa aaa gat gcc 672
Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr Asp Glu Lys Asp Ala
210 215 220
aaa tgg cat ctg tac ttt caa tac aac cca aat gac acc gta tgg ggt 720
Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn Asp Thr Val Trp Gly
225 230 235 240
acg cca ttg ttt tgg ggc cat gct act tcc gat gat ttg act aat tgg 768
Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp Asp Leu Thr Asn Trp
245 250 255
gaa gat caa ccc att gct atc gct ccc aag cgt aac gat tca ggt gct 816
Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg Asn Asp Ser Gly Ala
260 265 270
ttc tct ggc tcc atg gtg gtt gat tac aac aac acg agt ggg ttt ttc 864
Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn Thr Ser Gly Phe Phe
275 280 285
aat gat act att gat cca aga caa aga tgc gtt gcg att tgg act tat 912
Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val Ala Ile Trp Thr Tyr
290 295 300
aac act cct gaa agt gaa gag caa tac att agc tat tct ctt gat ggt 960
Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser Tyr Ser Leu Asp Gly
305 310 315 320
ggt tac act ttt act gaa tac caa aag aac cct gtt tta gct gcc aac 1008
Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro Val Leu Ala Ala Asn
325 330 335
tcc act caa ttc aga gat cca aag gtg ttc tgg tat gaa cct tct caa 1056
Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp Tyr Glu Pro Ser Gln
340 345 350
aaa tgg att atg acg gct gcc aaa tca caa gac tac aaa att gaa att 1104
Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp Tyr Lys Ile Glu Ile
355 360 365
tac tcc tct gat gac ttg aag tcc tgg aag cta gaa tct gca ttt gcc 1152
Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu Glu Ser Ala Phe Ala
370 375 380
aat gaa ggt ttc tta ggc tac caa tac gaa tgt cca ggt ttg att gaa 1200
Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys Pro Gly Leu Ile Glu
385 390 395 400
gtc cca act gag caa gat cct tcc aaa tct tat tgg gtc atg ttt att 1248
Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr Trp Val Met Phe Ile
405 410 415
tct atc aac cca ggt gca cct gct ggc ggt tcc ttc aac caa tat ttt 1296
Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser Phe Asn Gln Tyr Phe
420 425 430
gtt gga tcc ttc aat ggt act cat ttt gaa gcg ttt gac aat caa tct 1344
Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala Phe Asp Asn Gln Ser
435 440 445
aga gtg gta gat ttt ggt aag gac tac tat gcc ttg caa act ttc ttc 1392
Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala Leu Gln Thr Phe Phe
450 455 460
aac act gac cca acc tac ggt tca gca tta ggt att gcc tgg gct tca 1440
Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly Ile Ala Trp Ala Ser
465 470 475 480
aac tgg gag tac agt gcc ttt gtc cca act aac cca tgg aga tca tcc 1488
Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn Pro Trp Arg Ser Ser
485 490 495
atg tct ttg gtc cgc aag ttt tct ttg aac act gaa tat caa gct aat 1536
Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr Glu Tyr Gln Ala Asn
500 505 510
cca gag act gaa ttg atc aat ttg aaa gcc gaa cca ata ttg aac att 1584
Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu Pro Ile Leu Asn Ile
515 520 525
agt aat gct ggt ccc tgg tct cgt ttt gct act aac aca act cta act 1632
Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr Asn Thr Thr Leu Thr
530 535 540
aag gcc aat tct tac aat gtc gat ttg agc aac tcg act ggt acc cta 1680
Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn Ser Thr Gly Thr Leu
545 550 555 560
gag ttt gag ttg gtt tac gct gtt aac acc aca caa acc ata tcc aaa 1728
Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr Gln Thr Ile Ser Lys
565 570 575
tcc gtc ttt gcc gac tta tca ctt tgg ttc aag ggt tta gaa gat cct 1776
Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys Gly Leu Glu Asp Pro
580 585 590
gaa gaa tat ttg aga atg ggt ttt gaa gtc agt gct tct tcc ttc ttt 1824
Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser Ala Ser Ser Phe Phe
595 600 605
ttg gac cgt ggt aac tct aag gtc aag ttt gtc aag gag aac cca tat 1872
Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val Lys Glu Asn Pro Tyr
610 615 620
ttc aca aac aga atg tct gtc aac aac caa cca ttc aag tct gag aac 1920
Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro Phe Lys Ser Glu Asn
625 630 635 640
gac cta agt tac tat aaa gtg tac ggc cta ctg gat caa aac atc ttg 1968
Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu Asp Gln Asn Ile Leu
645 650 655
gaa ttg tac ttc aac gat gga gat gtg gtt tct aca aat acc tac ttc 2016
Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser Thr Asn Thr Tyr Phe
660 665 670
atg acc acc ggt aac gct cta gga tct gtg aac atg acc act ggt gtc 2064
Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn Met Thr Thr Gly Val
675 680 685
gat aat ttg ttc tac att gac aag ttc caa gta agg gaa gta aaa tag 2112
Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val Arg Glu Val Lys
690 695 700
<210> 17
<211> 703
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 17
Met Glu Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser Asn Met Phe Leu Gln Ala
165 170 175
Phe Leu Phe Leu Leu Ala Gly Phe Ala Ala Lys Ile Ser Ala Ser Met
180 185 190
Thr Asn Glu Thr Ser Asp Arg Pro Leu Val His Phe Thr Pro Asn Lys
195 200 205
Gly Trp Met Asn Asp Pro Asn Gly Leu Trp Tyr Asp Glu Lys Asp Ala
210 215 220
Lys Trp His Leu Tyr Phe Gln Tyr Asn Pro Asn Asp Thr Val Trp Gly
225 230 235 240
Thr Pro Leu Phe Trp Gly His Ala Thr Ser Asp Asp Leu Thr Asn Trp
245 250 255
Glu Asp Gln Pro Ile Ala Ile Ala Pro Lys Arg Asn Asp Ser Gly Ala
260 265 270
Phe Ser Gly Ser Met Val Val Asp Tyr Asn Asn Thr Ser Gly Phe Phe
275 280 285
Asn Asp Thr Ile Asp Pro Arg Gln Arg Cys Val Ala Ile Trp Thr Tyr
290 295 300
Asn Thr Pro Glu Ser Glu Glu Gln Tyr Ile Ser Tyr Ser Leu Asp Gly
305 310 315 320
Gly Tyr Thr Phe Thr Glu Tyr Gln Lys Asn Pro Val Leu Ala Ala Asn
325 330 335
Ser Thr Gln Phe Arg Asp Pro Lys Val Phe Trp Tyr Glu Pro Ser Gln
340 345 350
Lys Trp Ile Met Thr Ala Ala Lys Ser Gln Asp Tyr Lys Ile Glu Ile
355 360 365
Tyr Ser Ser Asp Asp Leu Lys Ser Trp Lys Leu Glu Ser Ala Phe Ala
370 375 380
Asn Glu Gly Phe Leu Gly Tyr Gln Tyr Glu Cys Pro Gly Leu Ile Glu
385 390 395 400
Val Pro Thr Glu Gln Asp Pro Ser Lys Ser Tyr Trp Val Met Phe Ile
405 410 415
Ser Ile Asn Pro Gly Ala Pro Ala Gly Gly Ser Phe Asn Gln Tyr Phe
420 425 430
Val Gly Ser Phe Asn Gly Thr His Phe Glu Ala Phe Asp Asn Gln Ser
435 440 445
Arg Val Val Asp Phe Gly Lys Asp Tyr Tyr Ala Leu Gln Thr Phe Phe
450 455 460
Asn Thr Asp Pro Thr Tyr Gly Ser Ala Leu Gly Ile Ala Trp Ala Ser
465 470 475 480
Asn Trp Glu Tyr Ser Ala Phe Val Pro Thr Asn Pro Trp Arg Ser Ser
485 490 495
Met Ser Leu Val Arg Lys Phe Ser Leu Asn Thr Glu Tyr Gln Ala Asn
500 505 510
Pro Glu Thr Glu Leu Ile Asn Leu Lys Ala Glu Pro Ile Leu Asn Ile
515 520 525
Ser Asn Ala Gly Pro Trp Ser Arg Phe Ala Thr Asn Thr Thr Leu Thr
530 535 540
Lys Ala Asn Ser Tyr Asn Val Asp Leu Ser Asn Ser Thr Gly Thr Leu
545 550 555 560
Glu Phe Glu Leu Val Tyr Ala Val Asn Thr Thr Gln Thr Ile Ser Lys
565 570 575
Ser Val Phe Ala Asp Leu Ser Leu Trp Phe Lys Gly Leu Glu Asp Pro
580 585 590
Glu Glu Tyr Leu Arg Met Gly Phe Glu Val Ser Ala Ser Ser Phe Phe
595 600 605
Leu Asp Arg Gly Asn Ser Lys Val Lys Phe Val Lys Glu Asn Pro Tyr
610 615 620
Phe Thr Asn Arg Met Ser Val Asn Asn Gln Pro Phe Lys Ser Glu Asn
625 630 635 640
Asp Leu Ser Tyr Tyr Lys Val Tyr Gly Leu Leu Asp Gln Asn Ile Leu
645 650 655
Glu Leu Tyr Phe Asn Asp Gly Asp Val Val Ser Thr Asn Thr Tyr Phe
660 665 670
Met Thr Thr Gly Asn Ala Leu Gly Ser Val Asn Met Thr Thr Gly Val
675 680 685
Asp Asn Leu Phe Tyr Ile Asp Lys Phe Gln Val Arg Glu Val Lys
690 695 700
<210> 18
<211> 9256
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pYRH69
<400> 18
catggagctc gctaccgcct ttactattct cactgccgtt ctggccgctc ccctggccgc 60
ccctgcccct gctcctgatg ctgcccctgc tgctgtgcct gagggccctg ccgccgctgc 120
ctactcatct attctgtccg tggtcgctaa gcagtccaag aagtttaagc accacaagcg 180
agatcttgat gagaaggatc agttcatcgt tgtctttgac agtagcgcta ctgttgacca 240
gatcgcctcc gaaatccaga agctggactc tctggtcgac gaggactcgt ccaacggtat 300
cacctctgct cttgatcttc ctgtctacac ggatggatct ggctttctcg gatttgttgg 360
aaagttcaac tccactatcg ttgacaagct caaggagtcg tctgttctga cggtcgagcc 420
cgataccatt gtgtctctcc ccgagattcc tgcttcttct aatgccaagc gagctatcca 480
gactactccc gtcactcaat ggggcctgtc taacatgttt ttgcaagctt tccttttcct 540
tttggctggt tttgcagcca aaatatctgc atcaatgaca aacgaaacta gcgatagacc 600
tttggtccac ttcacaccca acaagggctg gatgaatgac ccaaatgggt tgtggtacga 660
tgaaaaagat gccaaatggc atctgtactt tcaatacaac ccaaatgaca ccgtatgggg 720
tacgccattg ttttggggcc atgctacttc cgatgatttg actaattggg aagatcaacc 780
cattgctatc gctcccaagc gtaacgattc aggtgctttc tctggctcca tggtggttga 840
ttacaacaac acgagtgggt ttttcaatga tactattgat ccaagacaaa gatgcgttgc 900
gatttggact tataacactc ctgaaagtga agagcaatac attagctatt ctcttgatgg 960
tggttacact tttactgaat accaaaagaa ccctgtttta gctgccaact ccactcaatt 1020
cagagatcca aaggtgttct ggtatgaacc ttctcaaaaa tggattatga cggctgccaa 1080
atcacaagac tacaaaattg aaatttactc ctctgatgac ttgaagtcct ggaagctaga 1140
atctgcattt gccaatgaag gtttcttagg ctaccaatac gaatgtccag gtttgattga 1200
agtcccaact gagcaagatc cttccaaatc ttattgggtc atgtttattt ctatcaaccc 1260
aggtgcacct gctggcggtt ccttcaacca atattttgtt ggatccttca atggtactca 1320
ttttgaagcg tttgacaatc aatctagagt ggtagatttt ggtaaggact actatgcctt 1380
gcaaactttc ttcaacactg acccaaccta cggttcagca ttaggtattg cctgggcttc 1440
aaactgggag tacagtgcct ttgtcccaac taacccatgg agatcatcca tgtctttggt 1500
ccgcaagttt tctttgaaca ctgaatatca agctaatcca gagactgaat tgatcaattt 1560
gaaagccgaa ccaatattga acattagtaa tgctggtccc tggtctcgtt ttgctactaa 1620
cacaactcta actaaggcca attcttacaa tgtcgatttg agcaactcga ctggtaccct 1680
agagtttgag ttggtttacg ctgttaacac cacacaaacc atatccaaat ccgtctttgc 1740
cgacttatca ctttggttca agggtttaga agatcctgaa gaatatttga gaatgggttt 1800
tgaagtcagt gcttcttcct tctttttgga ccgtggtaac tctaaggtca agtttgtcaa 1860
ggagaaccca tatttcacaa acagaatgtc tgtcaacaac caaccattca agtctgagaa 1920
cgacctaagt tactataaag tgtacggcct actggatcaa aacatcttgg aattgtactt 1980
caacgatgga gatgtggttt ctacaaatac ctacttcatg accaccggta acgctctagg 2040
atctgtgaac atgaccactg gtgtcgataa tttgttctac attgacaagt tccaagtaag 2100
ggaagtaaaa taggcggccg caagtgtgga tggggaagtg agtgcccggt tctgtgtgca 2160
caattggcaa tccaagatgg atggattcaa cacagggata tagcgagcta cgtggtggtg 2220
cgaggatata gcaacggata tttatgtttg acacttgaga atgtacgata caagcactgt 2280
ccaagtacaa tactaaacat actgtacata ctcatactcg tacccgggca acggtttcac 2340
ttgagtgcag tggctagtgc tcttactcgt acagtgtgca atactgcgta tcatagtctt 2400
tgatgtatat cgtattcatt catgttagtt gcgtacgttg attgaggtgg agccagatgg 2460
gctattgttt catatataga ctggcagcca cctctttggc ccagcatgtt tgtatacctg 2520
gaagggaaaa ctaaagaagc tggctagttt agtttgatta ttatagtaga tgtcctaatc 2580
actagagatt agaatgtctt ggcgatgatt agtcgtcgtc ccctgtatca tgtctagacc 2640
aactgtgtca tgaagttggt gctggtgttt tacctgtgta ctacaagtag gtgtcctaga 2700
tctagtgtac agagccgttt agacccatgt ggacttcacc attaacgatg gaaaatgttc 2760
attatatgac agtatattac aatggacttg ctccatttct tccttgcatc acatgttctc 2820
cacctccata gttgatcaac acatcatagt agctaaggct gctgctctcc cactacagtc 2880
caccacaagt taagtagcac cgtcagtaca gctaaaagta cacgtctagt acgtttcata 2940
actagtcaag tagcccctat tacagatatc agcactatca cgcacgagtt tttctctgtg 3000
ctatctaatc aacttgccaa gtattcggag aagatacact ttcttggcat caggtatacg 3060
agggagccta tcagatgaaa aagggtatat tggatccatt catatccacc tacacgttgt 3120
cataatctcc tcattcacgt gattcatttc gtgacactag tttctcactt tcccccccgc 3180
acctatagtc aacttggcgg acacgctact tgtagctgac gttgatttat agacccaatc 3240
aaagcgggtt atcggtcagg tagcacttat cattcatcgt tcatactacg atgagcaatc 3300
tcgggcatgt ccggaaaagt gtcgggcgcg ccagctgcat taatgaatcg gccaacgcgc 3360
ggggagaggc ggtttgcgta ttgggcgctc ttccgcttcc tcgctcactg actcgctgcg 3420
ctcggtcgtt cggctgcggc gagcggtatc agctcactca aaggcggtaa tacggttatc 3480
cacagaatca ggggataacg caggaaagaa catgtgagca aaaggccagc aaaaggccag 3540
gaaccgtaaa aaggccgcgt tgctggcgtt tttccatagg ctccgccccc ctgacgagca 3600
tcacaaaaat cgacgctcaa gtcagaggtg gcgaaacccg acaggactat aaagatacca 3660
ggcgtttccc cctggaagct ccctcgtgcg ctctcctgtt ccgaccctgc cgcttaccgg 3720
atacctgtcc gcctttctcc cttcgggaag cgtggcgctt tctcatagct cacgctgtag 3780
gtatctcagt tcggtgtagg tcgttcgctc caagctgggc tgtgtgcacg aaccccccgt 3840
tcagcccgac cgctgcgcct tatccggtaa ctatcgtctt gagtccaacc cggtaagaca 3900
cgacttatcg ccactggcag cagccactgg taacaggatt agcagagcga ggtatgtagg 3960
cggtgctaca gagttcttga agtggtggcc taactacggc tacactagaa gaacagtatt 4020
tggtatctgc gctctgctga agccagttac cttcggaaaa agagttggta gctcttgatc 4080
cggcaaacaa accaccgctg gtagcggtgg tttttttgtt tgcaagcagc agattacgcg 4140
cagaaaaaaa ggatctcaag aagatccttt gatcttttct acggggtctg acgctcagtg 4200
gaacgaaaac tcacgttaag ggattttggt catgagatta tcaaaaagga tcttcaccta 4260
gatcctttta aattaaaaat gaagttttaa atcaatctaa agtatatatg agtaaacttg 4320
gtctgacagt taccaatgct taatcagtga ggcacctatc tcagcgatct gtctatttcg 4380
ttcatccata gttgcctgac tccccgtcgt gtagataact acgatacggg agggcttacc 4440
atctggcccc agtgctgcaa tgataccgcg agacccacgc tcaccggctc cagatttatc 4500
agcaataaac cagccagccg gaagggccga gcgcagaagt ggtcctgcaa ctttatccgc 4560
ctccatccag tctattaatt gttgccggga agctagagta agtagttcgc cagttaatag 4620
tttgcgcaac gttgttgcca ttgctacagg catcgtggtg tcacgctcgt cgtttggtat 4680
ggcttcattc agctccggtt cccaacgatc aaggcgagtt acatgatccc ccatgttgtg 4740
caaaaaagcg gttagctcct tcggtcctcc gatcgttgtc agaagtaagt tggccgcagt 4800
gttatcactc atggttatgg cagcactgca taattctctt actgtcatgc catccgtaag 4860
atgcttttct gtgactggtg agtactcaac caagtcattc tgagaatagt gtatgcggcg 4920
accgagttgc tcttgcccgg cgtcaatacg ggataatacc gcgccacata gcagaacttt 4980
aaaagtgctc atcattggaa aacgttcttc ggggcgaaaa ctctcaagga tcttaccgct 5040
gttgagatcc agttcgatgt aacccactcg tgcacccaac tgatcttcag catcttttac 5100
tttcaccagc gtttctgggt gagcaaaaac aggaaggcaa aatgccgcaa aaaagggaat 5160
aagggcgaca cggaaatgtt gaatactcat actcttcctt tttcaatatt attgaagcat 5220
ttatcagggt tattgtctca tgagcggata catatttgaa tgtatttaga aaaataaaca 5280
aataggggtt ccgcgcacat ttccccgaaa agtgccacct gatgcggtgt gaaataccgc 5340
acagatgcgt aaggagaaaa taccgcatca ggaaattgta agcgttaata ttttgttaaa 5400
attcgcgtta aatttttgtt aaatcagctc attttttaac caataggccg aaatcggcaa 5460
aatcccttat aaatcaaaag aatagaccga gatagggttg agtgttgttc cagtttggaa 5520
caagagtcca ctattaaaga acgtggactc caacgtcaaa gggcgaaaaa ccgtctatca 5580
gggcgatggc ccactacgtg aaccatcacc ctaatcaagt tttttggggt cgaggtgccg 5640
taaagcacta aatcggaacc ctaaagggag cccccgattt agagcttgac ggggaaagcc 5700
ggcgaacgtg gcgagaaagg aagggaagaa agcgaaagga gcgggcgcta gggcgctggc 5760
aagtgtagcg gtcacgctgc gcgtaaccac cacacccgcc gcgcttaatg cgccgctaca 5820
gggcgcgtcc attcgccatt caggctgcgc aactgttggg aagggcgatc ggtgcgggcc 5880
tcttcgctat tacgccagct ggcgaaaggg ggatgtgctg caaggcgatt aagttgggta 5940
acgccagggt tttcccagtc acgacgttgt aaaacgacgg ccagtgaatt gtaatacgac 6000
tcactatagg gcgaattggg cccgacgtcg catgcattcc gacagcagcg actgggcacc 6060
atgatcaagc gaaacacctt cccccagctg ccctggcaaa ccatcaagaa ccctactttc 6120
atcaagtgca agaacggttc tactcttctc acctccggtg tctacggctg gtgccgaaag 6180
cctaactaca ccgctgattt catcatgtgc ctcacctggg ctctcatgtg cggtgttgct 6240
tctcccctgc cttacttcta cccggtcttc ttcttcctgg tgctcatcca ccgagcttac 6300
cgagactttg agcgactgga gcgaaagtac ggtgaggact accaggagtt caagcgacag 6360
gtcccttgga tcttcatccc ttatgttttc taaacgataa gcttagtgag cgaatggtga 6420
ggttacttaa ttgagtggcc agcctatggg attgtataac agacagtcaa tatattactg 6480
aaaagactga acagccagac ggagtgaggt tgtgagtgaa tcgtagaggg cggctattac 6540
agcaagtcta ctctacagtg tactaacaca gcagagaaca aatacaggtg tgcattcggc 6600
tatctgagaa ttagttggag agctcgagac cctcggcgat aaactgctcc tcggttttgt 6660
gtccatactt gtacggacca ttgtaatggg gcaagtcgtt gagttctcgt cgtccgacgt 6720
tcagagcaca gaaaccaatg taatcaatgt agcagagatg gttctgcaaa agattgattt 6780
gtgcgagcag gttaattaag tcatacacaa gtcagctttc ttcgagcctc atataagtat 6840
aagtagttca acgtattagc actgtaccca gcatctccgt atcgagaaac acaacaacat 6900
gccccattgg acagatcatg cggatacaca ggttgtgcag tatcatacat actcgatcag 6960
acaggtcgtc tgaccatcat acaagctgaa caagcgctcc atacttgcac gctctctata 7020
tacacagtta aattacatat ccatagtcta acctctaaca gttaatcttc tggtaagcct 7080
cccagccagc cttctggtat cgcttggcct cctcaatagg atctcggttc tggccgtaca 7140
gacctcggcc gacaattatg atatccgttc cggtagacat gacatcctca acagttcggt 7200
actgctgtcc gagagcgtct cccttgtcgt caagacccac cccgggggtc agaataagcc 7260
agtcctcaga gtcgccctta ggtcggttct gggcaatgaa gccaaccaca aactcggggt 7320
cggatcgggc aagctcaatg gtctgcttgg agtactcgcc agtggccaga gagcccttgc 7380
aagacagctc ggccagcatg agcagacctc tggccagctt ctcgttggga gaggggacta 7440
ggaactcctt gtactgggag ttctcgtagt cagagacgtc ctccttcttc tgttcagaga 7500
cagtttcctc ggcaccagct cgcaggccag caatgattcc ggttccgggt acaccgtggg 7560
cgttggtgat atcggaccac tcggcgattc ggtgacaccg gtactggtgc ttgacagtgt 7620
tgccaatatc tgcgaacttt ctgtcctcga acaggaagaa accgtgctta agagcaagtt 7680
ccttgagggg gagcacagtg ccggcgtagg tgaagtcgtc aatgatgtcg atatgggttt 7740
tgatcatgca cacataaggt ccgaccttat cggcaagctc aatgagctcc ttggtggtgg 7800
taacatccag agaagcacac aggttggttt tcttggctgc cacgagcttg agcactcgag 7860
cggcaaaggc ggacttgtgg acgttagctc gagcttcgta ggagggcatt ttggtggtga 7920
agaggagact gaaataaatt tagtctgcag aactttttat cggaacctta tctggggcag 7980
tgaagtatat gttatggtaa tagttacgag ttagttgaac ttatagatag actggactat 8040
acggctatcg gtccaaatta gaaagaacgt caatggctct ctgggcgtcg cctttgccga 8100
caaaaatgtg atcatgatga aagccagcaa tgacgttgca gctgatattg ttgtcggcca 8160
accgcgccga aaacgcagct gtcagaccca cagcctccaa cgaagaatgt atcgtcaaag 8220
tgatccaagc acactcatag ttggagtcgt actccaaagg cggcaatgac gagtcagaca 8280
gatactcgtc gacgtttaaa cagtgtacgc agatctacta tagaggaaca tttaaattgc 8340
cccggagaag acggccaggc cgcctagatg acaaattcaa caactcacag ctgactttct 8400
gccattgcca ctaggggggg gcctttttat atggccaagc caagctctcc acgtcggttg 8460
ggctgcaccc aacaataaat gggtagggtt gcaccaacaa agggatggga tggggggtag 8520
aagatacgag gataacgggg ctcaatggca caaataagaa cgaatactgc cattaagact 8580
cgtgatccag cgactgacac cattgcatca tctaagggcc tcaaaactac ctcggaactg 8640
ctgcgctgat ctggacacca cagaggttcc gagcacttta ggttgcacca aatgtcccac 8700
caggtgcagg cagaaaacgc tggaacagcg tgtacagttt gtcttaacaa aaagtgaggg 8760
cgctgaggtc gagcagggtg gtgtgacttg ttatagcctt tagagctgcg aaagcgcgta 8820
tggatttggc tcatcaggcc agattgaggg tctgtggaca catgtcatgt tagtgtactt 8880
caatcgcccc ctggatatag ccccgacaat aggccgtggc ctcatttttt tgccttccgc 8940
acatttccat tgctcgatac ccacaccttg cttctcctgc acttgccaac cttaatactg 9000
gtttacattg accaacatct tacaagcggg gggcttgtct agggtatata taaacagtgg 9060
ctctcccaat cggttgccag tctctttttt cctttctttc cccacagatt cgaaatctaa 9120
actacacatc acagaattcc gagccgtgag tatccacgac aagatcagtg tcgagacgac 9180
gcgttttgtg taatgacaca atccgaaagt cgctagcaac acacactctc tacacaaact 9240
aacccagctc tggtac 9256
<210> 19
<211> 2058
<212> DNA
<213> Artificial Sequence
<220>
<223> Fusion
<220>
<221> CDS
<222> (1)..(2058)
<223> XPR2PP+13/m-ScSUC2
<400> 19
atg gag ctc gct acc gcc ttt act att ctc act gcc gtt ctg gcc gct 48
Met Glu Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
ccc ctg gcc gcc cct gcc cct gct cct gat gct gcc cct gct gct gtg 96
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
cct gag ggc cct gcc gcc gct gcc tac tca tct att ctg tcc gtg gtc 144
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
gct aag cag tcc aag aag ttt aag cac cac aag cga gat ctt gat gag 192
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
aag gat cag ttc atc gtt gtc ttt gac agt agc gct act gtt gac cag 240
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
atc gcc tcc gaa atc cag aag ctg gac tct ctg gtc gac gag gac tcg 288
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
tcc aac ggt atc acc tct gct ctt gat ctt cct gtc tac acg gat gga 336
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
tct ggc ttt ctc gga ttt gtt gga aag ttc aac tcc act atc gtt gac 384
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
aag ctc aag gag tcg tct gtt ctg acg gtc gag ccc gat acc att gtg 432
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
tct ctc ccc gag att cct gct tct tct aat gcc aag cga gct atc cag 480
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
act act ccc gtc act caa tgg ggc ctg tct aac atg tca atg aca aac 528
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser Asn Met Ser Met Thr Asn
165 170 175
gaa act agc gat aga cct ttg gtc cac ttc aca ccc aac aag ggc tgg 576
Glu Thr Ser Asp Arg Pro Leu Val His Phe Thr Pro Asn Lys Gly Trp
180 185 190
atg aat gac cca aat ggg ttg tgg tac gat gaa aaa gat gcc aaa tgg 624
Met Asn Asp Pro Asn Gly Leu Trp Tyr Asp Glu Lys Asp Ala Lys Trp
195 200 205
cat ctg tac ttt caa tac aac cca aat gac acc gta tgg ggt acg cca 672
His Leu Tyr Phe Gln Tyr Asn Pro Asn Asp Thr Val Trp Gly Thr Pro
210 215 220
ttg ttt tgg ggc cat gct act tcc gat gat ttg act aat tgg gaa gat 720
Leu Phe Trp Gly His Ala Thr Ser Asp Asp Leu Thr Asn Trp Glu Asp
225 230 235 240
caa ccc att gct atc gct ccc aag cgt aac gat tca ggt gct ttc tct 768
Gln Pro Ile Ala Ile Ala Pro Lys Arg Asn Asp Ser Gly Ala Phe Ser
245 250 255
ggc tcc atg gtg gtt gat tac aac aac acg agt ggg ttt ttc aat gat 816
Gly Ser Met Val Val Asp Tyr Asn Asn Thr Ser Gly Phe Phe Asn Asp
260 265 270
act att gat cca aga caa aga tgc gtt gcg att tgg act tat aac act 864
Thr Ile Asp Pro Arg Gln Arg Cys Val Ala Ile Trp Thr Tyr Asn Thr
275 280 285
cct gaa agt gaa gag caa tac att agc tat tct ctt gat ggt ggt tac 912
Pro Glu Ser Glu Glu Gln Tyr Ile Ser Tyr Ser Leu Asp Gly Gly Tyr
290 295 300
act ttt act gaa tac caa aag aac cct gtt tta gct gcc aac tcc act 960
Thr Phe Thr Glu Tyr Gln Lys Asn Pro Val Leu Ala Ala Asn Ser Thr
305 310 315 320
caa ttc aga gat cca aag gtg ttc tgg tat gaa cct tct caa aaa tgg 1008
Gln Phe Arg Asp Pro Lys Val Phe Trp Tyr Glu Pro Ser Gln Lys Trp
325 330 335
att atg acg gct gcc aaa tca caa gac tac aaa att gaa att tac tcc 1056
Ile Met Thr Ala Ala Lys Ser Gln Asp Tyr Lys Ile Glu Ile Tyr Ser
340 345 350
tct gat gac ttg aag tcc tgg aag cta gaa tct gca ttt gcc aat gaa 1104
Ser Asp Asp Leu Lys Ser Trp Lys Leu Glu Ser Ala Phe Ala Asn Glu
355 360 365
ggt ttc tta ggc tac caa tac gaa tgt cca ggt ttg att gaa gtc cca 1152
Gly Phe Leu Gly Tyr Gln Tyr Glu Cys Pro Gly Leu Ile Glu Val Pro
370 375 380
act gag caa gat cct tcc aaa tct tat tgg gtc atg ttt att tct atc 1200
Thr Glu Gln Asp Pro Ser Lys Ser Tyr Trp Val Met Phe Ile Ser Ile
385 390 395 400
aac cca ggt gca cct gct ggc ggt tcc ttc aac caa tat ttt gtt gga 1248
Asn Pro Gly Ala Pro Ala Gly Gly Ser Phe Asn Gln Tyr Phe Val Gly
405 410 415
tcc ttc aat ggt act cat ttt gaa gcg ttt gac aat caa tct aga gtg 1296
Ser Phe Asn Gly Thr His Phe Glu Ala Phe Asp Asn Gln Ser Arg Val
420 425 430
gta gat ttt ggt aag gac tac tat gcc ttg caa act ttc ttc aac act 1344
Val Asp Phe Gly Lys Asp Tyr Tyr Ala Leu Gln Thr Phe Phe Asn Thr
435 440 445
gac cca acc tac ggt tca gca tta ggt att gcc tgg gct tca aac tgg 1392
Asp Pro Thr Tyr Gly Ser Ala Leu Gly Ile Ala Trp Ala Ser Asn Trp
450 455 460
gag tac agt gcc ttt gtc cca act aac cca tgg aga tca tcc atg tct 1440
Glu Tyr Ser Ala Phe Val Pro Thr Asn Pro Trp Arg Ser Ser Met Ser
465 470 475 480
ttg gtc cgc aag ttt tct ttg aac act gaa tat caa gct aat cca gag 1488
Leu Val Arg Lys Phe Ser Leu Asn Thr Glu Tyr Gln Ala Asn Pro Glu
485 490 495
act gaa ttg atc aat ttg aaa gcc gaa cca ata ttg aac att agt aat 1536
Thr Glu Leu Ile Asn Leu Lys Ala Glu Pro Ile Leu Asn Ile Ser Asn
500 505 510
gct ggt ccc tgg tct cgt ttt gct act aac aca act cta act aag gcc 1584
Ala Gly Pro Trp Ser Arg Phe Ala Thr Asn Thr Thr Leu Thr Lys Ala
515 520 525
aat tct tac aat gtc gat ttg agc aac tcg act ggt acc cta gag ttt 1632
Asn Ser Tyr Asn Val Asp Leu Ser Asn Ser Thr Gly Thr Leu Glu Phe
530 535 540
gag ttg gtt tac gct gtt aac acc aca caa acc ata tcc aaa tcc gtc 1680
Glu Leu Val Tyr Ala Val Asn Thr Thr Gln Thr Ile Ser Lys Ser Val
545 550 555 560
ttt gcc gac tta tca ctt tgg ttc aag ggt tta gaa gat cct gaa gaa 1728
Phe Ala Asp Leu Ser Leu Trp Phe Lys Gly Leu Glu Asp Pro Glu Glu
565 570 575
tat ttg aga atg ggt ttt gaa gtc agt gct tct tcc ttc ttt ttg gac 1776
Tyr Leu Arg Met Gly Phe Glu Val Ser Ala Ser Ser Phe Phe Leu Asp
580 585 590
cgt ggt aac tct aag gtc aag ttt gtc aag gag aac cca tat ttc aca 1824
Arg Gly Asn Ser Lys Val Lys Phe Val Lys Glu Asn Pro Tyr Phe Thr
595 600 605
aac aga atg tct gtc aac aac caa cca ttc aag tct gag aac gac cta 1872
Asn Arg Met Ser Val Asn Asn Gln Pro Phe Lys Ser Glu Asn Asp Leu
610 615 620
agt tac tat aaa gtg tac ggc cta ctg gat caa aac atc ttg gaa ttg 1920
Ser Tyr Tyr Lys Val Tyr Gly Leu Leu Asp Gln Asn Ile Leu Glu Leu
625 630 635 640
tac ttc aac gat gga gat gtg gtt tct aca aat acc tac ttc atg acc 1968
Tyr Phe Asn Asp Gly Asp Val Val Ser Thr Asn Thr Tyr Phe Met Thr
645 650 655
acc ggt aac gct cta gga tct gtg aac atg acc act ggt gtc gat aat 2016
Thr Gly Asn Ala Leu Gly Ser Val Asn Met Thr Thr Gly Val Asp Asn
660 665 670
ttg ttc tac att gac aag ttc caa gta agg gaa gta aaa tag 2058
Leu Phe Tyr Ile Asp Lys Phe Gln Val Arg Glu Val Lys
675 680 685
<210> 20
<211> 685
<212> PRT
<213> Artificial Sequence
<220>
<223> Synthetic Construct
<400> 20
Met Glu Leu Ala Thr Ala Phe Thr Ile Leu Thr Ala Val Leu Ala Ala
1 5 10 15
Pro Leu Ala Ala Pro Ala Pro Ala Pro Asp Ala Ala Pro Ala Ala Val
20 25 30
Pro Glu Gly Pro Ala Ala Ala Ala Tyr Ser Ser Ile Leu Ser Val Val
35 40 45
Ala Lys Gln Ser Lys Lys Phe Lys His His Lys Arg Asp Leu Asp Glu
50 55 60
Lys Asp Gln Phe Ile Val Val Phe Asp Ser Ser Ala Thr Val Asp Gln
65 70 75 80
Ile Ala Ser Glu Ile Gln Lys Leu Asp Ser Leu Val Asp Glu Asp Ser
85 90 95
Ser Asn Gly Ile Thr Ser Ala Leu Asp Leu Pro Val Tyr Thr Asp Gly
100 105 110
Ser Gly Phe Leu Gly Phe Val Gly Lys Phe Asn Ser Thr Ile Val Asp
115 120 125
Lys Leu Lys Glu Ser Ser Val Leu Thr Val Glu Pro Asp Thr Ile Val
130 135 140
Ser Leu Pro Glu Ile Pro Ala Ser Ser Asn Ala Lys Arg Ala Ile Gln
145 150 155 160
Thr Thr Pro Val Thr Gln Trp Gly Leu Ser Asn Met Ser Met Thr Asn
165 170 175
Glu Thr Ser Asp Arg Pro Leu Val His Phe Thr Pro Asn Lys Gly Trp
180 185 190
Met Asn Asp Pro Asn Gly Leu Trp Tyr Asp Glu Lys Asp Ala Lys Trp
195 200 205
His Leu Tyr Phe Gln Tyr Asn Pro Asn Asp Thr Val Trp Gly Thr Pro
210 215 220
Leu Phe Trp Gly His Ala Thr Ser Asp Asp Leu Thr Asn Trp Glu Asp
225 230 235 240
Gln Pro Ile Ala Ile Ala Pro Lys Arg Asn Asp Ser Gly Ala Phe Ser
245 250 255
Gly Ser Met Val Val Asp Tyr Asn Asn Thr Ser Gly Phe Phe Asn Asp
260 265 270
Thr Ile Asp Pro Arg Gln Arg Cys Val Ala Ile Trp Thr Tyr Asn Thr
275 280 285
Pro Glu Ser Glu Glu Gln Tyr Ile Ser Tyr Ser Leu Asp Gly Gly Tyr
290 295 300
Thr Phe Thr Glu Tyr Gln Lys Asn Pro Val Leu Ala Ala Asn Ser Thr
305 310 315 320
Gln Phe Arg Asp Pro Lys Val Phe Trp Tyr Glu Pro Ser Gln Lys Trp
325 330 335
Ile Met Thr Ala Ala Lys Ser Gln Asp Tyr Lys Ile Glu Ile Tyr Ser
340 345 350
Ser Asp Asp Leu Lys Ser Trp Lys Leu Glu Ser Ala Phe Ala Asn Glu
355 360 365
Gly Phe Leu Gly Tyr Gln Tyr Glu Cys Pro Gly Leu Ile Glu Val Pro
370 375 380
Thr Glu Gln Asp Pro Ser Lys Ser Tyr Trp Val Met Phe Ile Ser Ile
385 390 395 400
Asn Pro Gly Ala Pro Ala Gly Gly Ser Phe Asn Gln Tyr Phe Val Gly
405 410 415
Ser Phe Asn Gly Thr His Phe Glu Ala Phe Asp Asn Gln Ser Arg Val
420 425 430
Val Asp Phe Gly Lys Asp Tyr Tyr Ala Leu Gln Thr Phe Phe Asn Thr
435 440 445
Asp Pro Thr Tyr Gly Ser Ala Leu Gly Ile Ala Trp Ala Ser Asn Trp
450 455 460
Glu Tyr Ser Ala Phe Val Pro Thr Asn Pro Trp Arg Ser Ser Met Ser
465 470 475 480
Leu Val Arg Lys Phe Ser Leu Asn Thr Glu Tyr Gln Ala Asn Pro Glu
485 490 495
Thr Glu Leu Ile Asn Leu Lys Ala Glu Pro Ile Leu Asn Ile Ser Asn
500 505 510
Ala Gly Pro Trp Ser Arg Phe Ala Thr Asn Thr Thr Leu Thr Lys Ala
515 520 525
Asn Ser Tyr Asn Val Asp Leu Ser Asn Ser Thr Gly Thr Leu Glu Phe
530 535 540
Glu Leu Val Tyr Ala Val Asn Thr Thr Gln Thr Ile Ser Lys Ser Val
545 550 555 560
Phe Ala Asp Leu Ser Leu Trp Phe Lys Gly Leu Glu Asp Pro Glu Glu
565 570 575
Tyr Leu Arg Met Gly Phe Glu Val Ser Ala Ser Ser Phe Phe Leu Asp
580 585 590
Arg Gly Asn Ser Lys Val Lys Phe Val Lys Glu Asn Pro Tyr Phe Thr
595 600 605
Asn Arg Met Ser Val Asn Asn Gln Pro Phe Lys Ser Glu Asn Asp Leu
610 615 620
Ser Tyr Tyr Lys Val Tyr Gly Leu Leu Asp Gln Asn Ile Leu Glu Leu
625 630 635 640
Tyr Phe Asn Asp Gly Asp Val Val Ser Thr Asn Thr Tyr Phe Met Thr
645 650 655
Thr Gly Asn Ala Leu Gly Ser Val Asn Met Thr Thr Gly Val Asp Asn
660 665 670
Leu Phe Tyr Ile Asp Lys Phe Gln Val Arg Glu Val Lys
675 680 685
<210> 21
<211> 9202
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pYRH74
<400> 21
ggccgcaagt gtggatgggg aagtgagtgc ccggttctgt gtgcacaatt ggcaatccaa 60
gatggatgga ttcaacacag ggatatagcg agctacgtgg tggtgcgagg atatagcaac 120
ggatatttat gtttgacact tgagaatgta cgatacaagc actgtccaag tacaatacta 180
aacatactgt acatactcat actcgtaccc gggcaacggt ttcacttgag tgcagtggct 240
agtgctctta ctcgtacagt gtgcaatact gcgtatcata gtctttgatg tatatcgtat 300
tcattcatgt tagttgcgta cgttgattga ggtggagcca gatgggctat tgtttcatat 360
atagactggc agccacctct ttggcccagc atgtttgtat acctggaagg gaaaactaaa 420
gaagctggct agtttagttt gattattata gtagatgtcc taatcactag agattagaat 480
gtcttggcga tgattagtcg tcgtcccctg tatcatgtct agaccaactg tgtcatgaag 540
ttggtgctgg tgttttacct gtgtactaca agtaggtgtc ctagatctag tgtacagagc 600
cgtttagacc catgtggact tcaccattaa cgatggaaaa tgttcattat atgacagtat 660
attacaatgg acttgctcca tttcttcctt gcatcacatg ttctccacct ccatagttga 720
tcaacacatc atagtagcta aggctgctgc tctcccacta cagtccacca caagttaagt 780
agcaccgtca gtacagctaa aagtacacgt ctagtacgtt tcataactag tcaagtagcc 840
cctattacag atatcagcac tatcacgcac gagtttttct ctgtgctatc taatcaactt 900
gccaagtatt cggagaagat acactttctt ggcatcaggt atacgaggga gcctatcaga 960
tgaaaaaggg tatattggat ccattcatat ccacctacac gttgtcataa tctcctcatt 1020
cacgtgattc atttcgtgac actagtttct cactttcccc cccgcaccta tagtcaactt 1080
ggcggacacg ctacttgtag ctgacgttga tttatagacc caatcaaagc gggttatcgg 1140
tcaggtagca cttatcattc atcgttcata ctacgatgag caatctcggg catgtccgga 1200
aaagtgtcgg gcgcgccagc tgcattaatg aatcggccaa cgcgcgggga gaggcggttt 1260
gcgtattggg cgctcttccg cttcctcgct cactgactcg ctgcgctcgg tcgttcggct 1320
gcggcgagcg gtatcagctc actcaaaggc ggtaatacgg ttatccacag aatcagggga 1380
taacgcagga aagaacatgt gagcaaaagg ccagcaaaag gccaggaacc gtaaaaaggc 1440
cgcgttgctg gcgtttttcc ataggctccg cccccctgac gagcatcaca aaaatcgacg 1500
ctcaagtcag aggtggcgaa acccgacagg actataaaga taccaggcgt ttccccctgg 1560
aagctccctc gtgcgctctc ctgttccgac cctgccgctt accggatacc tgtccgcctt 1620
tctcccttcg ggaagcgtgg cgctttctca tagctcacgc tgtaggtatc tcagttcggt 1680
gtaggtcgtt cgctccaagc tgggctgtgt gcacgaaccc cccgttcagc ccgaccgctg 1740
cgccttatcc ggtaactatc gtcttgagtc caacccggta agacacgact tatcgccact 1800
ggcagcagcc actggtaaca ggattagcag agcgaggtat gtaggcggtg ctacagagtt 1860
cttgaagtgg tggcctaact acggctacac tagaagaaca gtatttggta tctgcgctct 1920
gctgaagcca gttaccttcg gaaaaagagt tggtagctct tgatccggca aacaaaccac 1980
cgctggtagc ggtggttttt ttgtttgcaa gcagcagatt acgcgcagaa aaaaaggatc 2040
tcaagaagat cctttgatct tttctacggg gtctgacgct cagtggaacg aaaactcacg 2100
ttaagggatt ttggtcatga gattatcaaa aaggatcttc acctagatcc ttttaaatta 2160
aaaatgaagt tttaaatcaa tctaaagtat atatgagtaa acttggtctg acagttacca 2220
atgcttaatc agtgaggcac ctatctcagc gatctgtcta tttcgttcat ccatagttgc 2280
ctgactcccc gtcgtgtaga taactacgat acgggagggc ttaccatctg gccccagtgc 2340
tgcaatgata ccgcgagacc cacgctcacc ggctccagat ttatcagcaa taaaccagcc 2400
agccggaagg gccgagcgca gaagtggtcc tgcaacttta tccgcctcca tccagtctat 2460
taattgttgc cgggaagcta gagtaagtag ttcgccagtt aatagtttgc gcaacgttgt 2520
tgccattgct acaggcatcg tggtgtcacg ctcgtcgttt ggtatggctt cattcagctc 2580
cggttcccaa cgatcaaggc gagttacatg atcccccatg ttgtgcaaaa aagcggttag 2640
ctccttcggt cctccgatcg ttgtcagaag taagttggcc gcagtgttat cactcatggt 2700
tatggcagca ctgcataatt ctcttactgt catgccatcc gtaagatgct tttctgtgac 2760
tggtgagtac tcaaccaagt cattctgaga atagtgtatg cggcgaccga gttgctcttg 2820
cccggcgtca atacgggata ataccgcgcc acatagcaga actttaaaag tgctcatcat 2880
tggaaaacgt tcttcggggc gaaaactctc aaggatctta ccgctgttga gatccagttc 2940
gatgtaaccc actcgtgcac ccaactgatc ttcagcatct tttactttca ccagcgtttc 3000
tgggtgagca aaaacaggaa ggcaaaatgc cgcaaaaaag ggaataaggg cgacacggaa 3060
atgttgaata ctcatactct tcctttttca atattattga agcatttatc agggttattg 3120
tctcatgagc ggatacatat ttgaatgtat ttagaaaaat aaacaaatag gggttccgcg 3180
cacatttccc cgaaaagtgc cacctgatgc ggtgtgaaat accgcacaga tgcgtaagga 3240
gaaaataccg catcaggaaa ttgtaagcgt taatattttg ttaaaattcg cgttaaattt 3300
ttgttaaatc agctcatttt ttaaccaata ggccgaaatc ggcaaaatcc cttataaatc 3360
aaaagaatag accgagatag ggttgagtgt tgttccagtt tggaacaaga gtccactatt 3420
aaagaacgtg gactccaacg tcaaagggcg aaaaaccgtc tatcagggcg atggcccact 3480
acgtgaacca tcaccctaat caagtttttt ggggtcgagg tgccgtaaag cactaaatcg 3540
gaaccctaaa gggagccccc gatttagagc ttgacgggga aagccggcga acgtggcgag 3600
aaaggaaggg aagaaagcga aaggagcggg cgctagggcg ctggcaagtg tagcggtcac 3660
gctgcgcgta accaccacac ccgccgcgct taatgcgccg ctacagggcg cgtccattcg 3720
ccattcaggc tgcgcaactg ttgggaaggg cgatcggtgc gggcctcttc gctattacgc 3780
cagctggcga aagggggatg tgctgcaagg cgattaagtt gggtaacgcc agggttttcc 3840
cagtcacgac gttgtaaaac gacggccagt gaattgtaat acgactcact atagggcgaa 3900
ttgggcccga cgtcgcatgc attccgacag cagcgactgg gcaccatgat caagcgaaac 3960
accttccccc agctgccctg gcaaaccatc aagaacccta ctttcatcaa gtgcaagaac 4020
ggttctactc ttctcacctc cggtgtctac ggctggtgcc gaaagcctaa ctacaccgct 4080
gatttcatca tgtgcctcac ctgggctctc atgtgcggtg ttgcttctcc cctgccttac 4140
ttctacccgg tcttcttctt cctggtgctc atccaccgag cttaccgaga ctttgagcga 4200
ctggagcgaa agtacggtga ggactaccag gagttcaagc gacaggtccc ttggatcttc 4260
atcccttatg ttttctaaac gataagctta gtgagcgaat ggtgaggtta cttaattgag 4320
tggccagcct atgggattgt ataacagaca gtcaatatat tactgaaaag actgaacagc 4380
cagacggagt gaggttgtga gtgaatcgta gagggcggct attacagcaa gtctactcta 4440
cagtgtacta acacagcaga gaacaaatac aggtgtgcat tcggctatct gagaattagt 4500
tggagagctc gagaccctcg gcgataaact gctcctcggt tttgtgtcca tacttgtacg 4560
gaccattgta atggggcaag tcgttgagtt ctcgtcgtcc gacgttcaga gcacagaaac 4620
caatgtaatc aatgtagcag agatggttct gcaaaagatt gatttgtgcg agcaggttaa 4680
ttaagtcata cacaagtcag ctttcttcga gcctcatata agtataagta gttcaacgta 4740
ttagcactgt acccagcatc tccgtatcga gaaacacaac aacatgcccc attggacaga 4800
tcatgcggat acacaggttg tgcagtatca tacatactcg atcagacagg tcgtctgacc 4860
atcatacaag ctgaacaagc gctccatact tgcacgctct ctatatacac agttaaatta 4920
catatccata gtctaacctc taacagttaa tcttctggta agcctcccag ccagccttct 4980
ggtatcgctt ggcctcctca ataggatctc ggttctggcc gtacagacct cggccgacaa 5040
ttatgatatc cgttccggta gacatgacat cctcaacagt tcggtactgc tgtccgagag 5100
cgtctccctt gtcgtcaaga cccaccccgg gggtcagaat aagccagtcc tcagagtcgc 5160
ccttaggtcg gttctgggca atgaagccaa ccacaaactc ggggtcggat cgggcaagct 5220
caatggtctg cttggagtac tcgccagtgg ccagagagcc cttgcaagac agctcggcca 5280
gcatgagcag acctctggcc agcttctcgt tgggagaggg gactaggaac tccttgtact 5340
gggagttctc gtagtcagag acgtcctcct tcttctgttc agagacagtt tcctcggcac 5400
cagctcgcag gccagcaatg attccggttc cgggtacacc gtgggcgttg gtgatatcgg 5460
accactcggc gattcggtga caccggtact ggtgcttgac agtgttgcca atatctgcga 5520
actttctgtc ctcgaacagg aagaaaccgt gcttaagagc aagttccttg agggggagca 5580
cagtgccggc gtaggtgaag tcgtcaatga tgtcgatatg ggttttgatc atgcacacat 5640
aaggtccgac cttatcggca agctcaatga gctccttggt ggtggtaaca tccagagaag 5700
cacacaggtt ggttttcttg gctgccacga gcttgagcac tcgagcggca aaggcggact 5760
tgtggacgtt agctcgagct tcgtaggagg gcattttggt ggtgaagagg agactgaaat 5820
aaatttagtc tgcagaactt tttatcggaa ccttatctgg ggcagtgaag tatatgttat 5880
ggtaatagtt acgagttagt tgaacttata gatagactgg actatacggc tatcggtcca 5940
aattagaaag aacgtcaatg gctctctggg cgtcgccttt gccgacaaaa atgtgatcat 6000
gatgaaagcc agcaatgacg ttgcagctga tattgttgtc ggccaaccgc gccgaaaacg 6060
cagctgtcag acccacagcc tccaacgaag aatgtatcgt caaagtgatc caagcacact 6120
catagttgga gtcgtactcc aaaggcggca atgacgagtc agacagatac tcgtcgacgt 6180
ttaaacagtg tacgcagatc tactatagag gaacatttaa attgccccgg agaagacggc 6240
caggccgcct agatgacaaa ttcaacaact cacagctgac tttctgccat tgccactagg 6300
ggggggcctt tttatatggc caagccaagc tctccacgtc ggttgggctg cacccaacaa 6360
taaatgggta gggttgcacc aacaaaggga tgggatgggg ggtagaagat acgaggataa 6420
cggggctcaa tggcacaaat aagaacgaat actgccatta agactcgtga tccagcgact 6480
gacaccattg catcatctaa gggcctcaaa actacctcgg aactgctgcg ctgatctgga 6540
caccacagag gttccgagca ctttaggttg caccaaatgt cccaccaggt gcaggcagaa 6600
aacgctggaa cagcgtgtac agtttgtctt aacaaaaagt gagggcgctg aggtcgagca 6660
gggtggtgtg acttgttata gcctttagag ctgcgaaagc gcgtatggat ttggctcatc 6720
aggccagatt gagggtctgt ggacacatgt catgttagtg tacttcaatc gccccctgga 6780
tatagccccg acaataggcc gtggcctcat ttttttgcct tccgcacatt tccattgctc 6840
gatacccaca ccttgcttct cctgcacttg ccaaccttaa tactggttta cattgaccaa 6900
catcttacaa gcggggggct tgtctagggt atatataaac agtggctctc ccaatcggtt 6960
gccagtctct tttttccttt ctttccccac agattcgaaa tctaaactac acatcacaga 7020
attccgagcc gtgagtatcc acgacaagat cagtgtcgag acgacgcgtt ttgtgtaatg 7080
acacaatccg aaagtcgcta gcaacacaca ctctctacac aaactaaccc agctctggta 7140
ccatggagct cgctaccgcc tttactattc tcactgccgt tctggccgct cccctggccg 7200
cccctgcccc tgctcctgat gctgcccctg ctgctgtgcc tgagggccct gccgccgctg 7260
cctactcatc tattctgtcc gtggtcgcta agcagtccaa gaagtttaag caccacaagc 7320
gagatcttga tgagaaggat cagttcatcg ttgtctttga cagtagcgct actgttgacc 7380
agatcgcctc cgaaatccag aagctggact ctctggtcga cgaggactcg tccaacggta 7440
tcacctctgc tcttgatctt cctgtctaca cggatggatc tggctttctc ggatttgttg 7500
gaaagttcaa ctccactatc gttgacaagc tcaaggagtc gtctgttctg acggtcgagc 7560
ccgataccat tgtgtctctc cccgagattc ctgcttcttc taatgccaag cgagctatcc 7620
agactactcc cgtcactcaa tggggcctgt ctaacatgtc aatgacaaac gaaactagcg 7680
atagaccttt ggtccacttc acacccaaca agggctggat gaatgaccca aatgggttgt 7740
ggtacgatga aaaagatgcc aaatggcatc tgtactttca atacaaccca aatgacaccg 7800
tatggggtac gccattgttt tggggccatg ctacttccga tgatttgact aattgggaag 7860
atcaacccat tgctatcgct cccaagcgta acgattcagg tgctttctct ggctccatgg 7920
tggttgatta caacaacacg agtgggtttt tcaatgatac tattgatcca agacaaagat 7980
gcgttgcgat ttggacttat aacactcctg aaagtgaaga gcaatacatt agctattctc 8040
ttgatggtgg ttacactttt actgaatacc aaaagaaccc tgttttagct gccaactcca 8100
ctcaattcag agatccaaag gtgttctggt atgaaccttc tcaaaaatgg attatgacgg 8160
ctgccaaatc acaagactac aaaattgaaa tttactcctc tgatgacttg aagtcctgga 8220
agctagaatc tgcatttgcc aatgaaggtt tcttaggcta ccaatacgaa tgtccaggtt 8280
tgattgaagt cccaactgag caagatcctt ccaaatctta ttgggtcatg tttatttcta 8340
tcaacccagg tgcacctgct ggcggttcct tcaaccaata ttttgttgga tccttcaatg 8400
gtactcattt tgaagcgttt gacaatcaat ctagagtggt agattttggt aaggactact 8460
atgccttgca aactttcttc aacactgacc caacctacgg ttcagcatta ggtattgcct 8520
gggcttcaaa ctgggagtac agtgcctttg tcccaactaa cccatggaga tcatccatgt 8580
ctttggtccg caagttttct ttgaacactg aatatcaagc taatccagag actgaattga 8640
tcaatttgaa agccgaacca atattgaaca ttagtaatgc tggtccctgg tctcgttttg 8700
ctactaacac aactctaact aaggccaatt cttacaatgt cgatttgagc aactcgactg 8760
gtaccctaga gtttgagttg gtttacgctg ttaacaccac acaaaccata tccaaatccg 8820
tctttgccga cttatcactt tggttcaagg gtttagaaga tcctgaagaa tatttgagaa 8880
tgggttttga agtcagtgct tcttccttct ttttggaccg tggtaactct aaggtcaagt 8940
ttgtcaagga gaacccatat ttcacaaaca gaatgtctgt caacaaccaa ccattcaagt 9000
ctgagaacga cctaagttac tataaagtgt acggcctact ggatcaaaac atcttggaat 9060
tgtacttcaa cgatggagat gtggtttcta caaataccta cttcatgacc accggtaacg 9120
ctctaggatc tgtgaacatg accactggtg tcgataattt gttctacatt gacaagttcc 9180
aagtaaggga agtaaaatag gc 9202
<210> 22
<211> 9016
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZSUC
<400> 22
cgatcccact acttgtagtc aggccatctt ttacgtacgc actgtaccat gatgtcaatg 60
gagtatgatg aaccgacttt gagagactca catctgcaca acaccatgtt tcagcggaat 120
ccgacttcca acccaaaccc aagcccctgt cagatatcgt gagaaggcac ggcaccaact 180
aatgcacaca ctccacctgt attgcaccaa gataatgagg gcatcgtctt ggcgcgtctt 240
ggcgagagcc gtgtttcgtg acgcaatcag agcagtttct ggatagtatc ttgtccagaa 300
acacgatata aaccccatcg acgggcccgt tgaagagcac caacccacta tccaatcctc 360
caatccaaca atgaagctcg ctaccgcctt tactattctc actgccgttc tggccgctcc 420
cctggccgcc cctaagcttg ctggttttgc agccaaaata tctgcatcaa tgacaaacga 480
aactagcgat agacctttgg tccacttcac acccaacaag ggctggatga atgacccaaa 540
tgggttgtgg tacgatgaaa aagatgccaa atggcatctg tactttcaat acaacccaaa 600
tgacaccgta tggggtacgc cattgttttg gggccatgct acttccgatg atttgactaa 660
ttgggaagat caacccattg ctatcgctcc caagcgtaac gattcaggtg ctttctctgg 720
ctccatggtg gttgattaca acaacacgag tgggtttttc aatgatacta ttgatccaag 780
acaaagatgc gttgcgattt ggacttataa cactcctgaa agtgaagagc aatacattag 840
ctattctctt gatggtggtt acacttttac tgaataccaa aagaaccctg ttttagctgc 900
caactccact caattcagag atccaaaggt gttctggtat gaaccttctc aaaaatggat 960
tatgacggct gccaaatcac aagactacaa aattgaaatt tactcctctg atgacttgaa 1020
gtcctggaag ctagaatctg catttgccaa cgaaggtttc ttaggctacc aatacgaatg 1080
tccaggtttg attgaagtcc caactgagca agatccttcc aaatcttatt gggtcatgtt 1140
tatttctatc aacccaggtg cacctgctgg cggttccttc aaccaatatt ttgttggatc 1200
cttcaatggt actcattttg aagcgtttga caatcaatct agagtggtag attttggtaa 1260
ggactactat gccttgcaaa ctttcttcaa cactgaccca acctacggtt cagcattagg 1320
tattgcctgg gcttcaaact gggagtacag tgcctttgtc ccaactaacc catggagatc 1380
atccatgtct ttggtccgca agttttcttt gaacactgaa tatcaagcta atccagagac 1440
tgaattgatc aatttgaaag ccgaaccaat attgaacatt agtaatgctg gtccctggtc 1500
tcgttttgct actaacacaa ctctaactaa ggccaattct tacaatgtcg atttgagcaa 1560
ctcgactggt accctagagt ttgagttggt ttacgctgtt aacaccacac aaaccatatc 1620
caaatccgtc tttgccgact tatcactttg gttcaagggt ttagaagatc ctgaagaata 1680
tttgagaatg ggttttgaag tcagtgcttc ttccttcttt ttggaccgtg gtaactctaa 1740
ggtcaagttt gtcaaggaga acccatattt cacaaacaga atgtctgtca acaaccaacc 1800
attcaagtct gagaacgacc taagttacta taaagtgtac ggcctactgg atcaaaacat 1860
cttggaattg tacttcaacg atggagatgt ggtttctaca aatacctact tcatgaccac 1920
cggtaacgct ctaggatctg tgaacatgac cactggtgtc gataatttgt tctacattga 1980
caagttccaa gtaagggaag taaaatagcg tacggtgtgt atcgtagagg tagtgacgtg 2040
ttgtccacag ggcgactgtg tccgtgtata tatatattcc tcggcccgag cttatttgtg 2100
tggggttgag gaaatcaaac caaatcggta gtcagagaaa taaaacaaaa agaaataaaa 2160
agaaatagag gacgcacaac gccatcaccg tcggagagac aggagaaggg aaaatgggca 2220
aaaatgccct tatcacaccc gcccgctttg tgctctcatt cggctcccac aagagcctct 2280
tgtcctggtt cccccccccc acattttaac accccacacg acgttgctgc acgtggaatt 2340
ttcggccgaa aacctgtggg gtacttactt ttggcactgg agagaagcat ctgggatttt 2400
gggaacctag gcagaagatg aggaaaaaaa taagaggaac cgttgtgagc ttgcttatca 2460
gtgtcatata ctcccccctc cttgcgtttt tgcgtctttt ccccctattt ttcaaatttt 2520
gcgatttttt ttctcttttt ttccgctttt ttccgctttt tttttggccg gcttttatcc 2580
atttctccaa gccgaggatc acatctatgc agcccagtcc gttggagcat atctgcggta 2640
gagtttcgga acggcgttaa gcactgtgtc cgggtcggtc tggaacgaga ttgagcggga 2700
aattcggggg aataagacca ccgttggact ccccgcaatg aggagatcaa gatgtgcttt 2760
tcagaattct gattggtggc gcgccagctg cattaatgaa tcggccaacg cgcggggaga 2820
ggcggtttgc gtattgggcg ctcttccgct tcctcgctca ctgactcgct gcgctcggtc 2880
gttcggctgc ggcgagcggt atcagctcac tcaaaggcgg taatacggtt atccacagaa 2940
tcaggggata acgcaggaaa gaacatgtga gcaaaaggcc agcaaaaggc caggaaccgt 3000
aaaaaggccg cgttgctggc gtttttccat aggctccgcc cccctgacga gcatcacaaa 3060
aatcgacgct caagtcagag gtggcgaaac ccgacaggac tataaagata ccaggcgttt 3120
ccccctggaa gctccctcgt gcgctctcct gttccgaccc tgccgcttac cggatacctg 3180
tccgcctttc tcccttcggg aagcgtggcg ctttctcata gctcacgctg taggtatctc 3240
agttcggtgt aggtcgttcg ctccaagctg ggctgtgtgc acgaaccccc cgttcagccc 3300
gaccgctgcg ccttatccgg taactatcgt cttgagtcca acccggtaag acacgactta 3360
tcgccactgg cagcagccac tggtaacagg attagcagag cgaggtatgt aggcggtgct 3420
acagagttct tgaagtggtg gcctaactac ggctacacta gaagaacagt atttggtatc 3480
tgcgctctgc tgaagccagt taccttcgga aaaagagttg gtagctcttg atccggcaaa 3540
caaaccaccg ctggtagcgg tggttttttt gtttgcaagc agcagattac gcgcagaaaa 3600
aaaggatctc aagaagatcc tttgatcttt tctacggggt ctgacgctca gtggaacgaa 3660
aactcacgtt aagggatttt ggtcatgaga ttatcaaaaa ggatcttcac ctagatcctt 3720
ttaaattaaa aatgaagttt taaatcaatc taaagtatat atgagtaaac ttggtctgac 3780
agttaccaat gcttaatcag tgaggcacct atctcagcga tctgtctatt tcgttcatcc 3840
atagttgcct gactccccgt cgtgtagata actacgatac gggagggctt accatctggc 3900
cccagtgctg caatgatacc gcgagaccca cgctcaccgg ctccagattt atcagcaata 3960
aaccagccag ccggaagggc cgagcgcaga agtggtcctg caactttatc cgcctccatc 4020
cagtctatta attgttgccg ggaagctaga gtaagtagtt cgccagttaa tagtttgcgc 4080
aacgttgttg ccattgctac aggcatcgtg gtgtcacgct cgtcgtttgg tatggcttca 4140
ttcagctccg gttcccaacg atcaaggcga gttacatgat cccccatgtt gtgcaaaaaa 4200
gcggttagct ccttcggtcc tccgatcgtt gtcagaagta agttggccgc agtgttatca 4260
ctcatggtta tggcagcact gcataattct cttactgtca tgccatccgt aagatgcttt 4320
tctgtgactg gtgagtactc aaccaagtca ttctgagaat agtgtatgcg gcgaccgagt 4380
tgctcttgcc cggcgtcaat acgggataat accgcgccac atagcagaac tttaaaagtg 4440
ctcatcattg gaaaacgttc ttcggggcga aaactctcaa ggatcttacc gctgttgaga 4500
tccagttcga tgtaacccac tcgtgcaccc aactgatctt cagcatcttt tactttcacc 4560
agcgtttctg ggtgagcaaa aacaggaagg caaaatgccg caaaaaaggg aataagggcg 4620
acacggaaat gttgaatact catactcttc ctttttcaat attattgaag catttatcag 4680
ggttattgtc tcatgagcgg atacatattt gaatgtattt agaaaaataa acaaataggg 4740
gttccgcgca catttccccg aaaagtgcca cctgatgcgg tgtgaaatac cgcacagatg 4800
cgtaaggaga aaataccgca tcaggaaatt gtaagcgtta atattttgtt aaaattcgcg 4860
ttaaattttt gttaaatcag ctcatttttt aaccaatagg ccgaaatcgg caaaatccct 4920
tataaatcaa aagaatagac cgagataggg ttgagtgttg ttccagtttg gaacaagagt 4980
ccactattaa agaacgtgga ctccaacgtc aaagggcgaa aaaccgtcta tcagggcgat 5040
ggcccactac gtgaaccatc accctaatca agttttttgg ggtcgaggtg ccgtaaagca 5100
ctaaatcgga accctaaagg gagcccccga tttagagctt gacggggaaa gccggcgaac 5160
gtggcgagaa aggaagggaa gaaagcgaaa ggagcgggcg ctagggcgct ggcaagtgta 5220
gcggtcacgc tgcgcgtaac caccacaccc gccgcgctta atgcgccgct acagggcgcg 5280
tccattcgcc attcaggctg cgcaactgtt gggaagggcg atcggtgcgg gcctcttcgc 5340
tattacgcca gctggcgaaa gggggatgtg ctgcaaggcg attaagttgg gtaacgccag 5400
ggttttccca gtcacgacgt tgtaaaacga cggccagtga attgtaatac gactcactat 5460
agggcgaatt gggcccgacg tcgcatgcgt cgagatatcg acattgttcc atctccagtt 5520
taaccccaac ttatcgagag tatttgtgag acacgcaata aatgaattta taccaatcaa 5580
atccatattc tacgctgtct acatatagat actttttgtc atctcttgcc ctactatttc 5640
gtcgatatat gaaggatacg ccaaccgaac ccatactcca cgctacacac gcgccttttc 5700
acgcatttct ggggaaaata gacacccttg gtgtcacctg aagaatatga aagaagatat 5760
tcattgtatt gagctgtaga tctgtgtatt tcttgacctc atcaatgact tctgggctct 5820
ttacctcgaa tcatggtggt actgtaccac atctcaacac cttgtagcac acctatggga 5880
aaattgagac tatgaatgga ttcccgtgcc cgtattactc tactaatttg atcttggaac 5940
gcgaaaatac gtttctagga ctccaaagaa tctcaactct tgtccttact aaatatacta 6000
cccatagttg atggtttact tgaacagaga ggacatgttc acttgaccca aagtttctcg 6060
catctcttgg atatttgaac aacggcgtcc actgaccgtc agttatccag tcacaaaacc 6120
cccacattca tacattccca tgtacgttta caaagttctc aattccatcg tgcaaatcaa 6180
aatcacatct attcattcat catatataaa cccatcatgt ctactaacac tcacaactcc 6240
atagaaaaca tcgactcaga acacacgctc catctattcc tcgtccagct cgcaaatgtc 6300
gtcatcttaa ttaagttgcg acacatgtct tgatagtatc ttggcttctc tctcttgagc 6360
ttttccataa caagttcttc tgcctccagg aagtccatgg tgaatgattc ttatactcag 6420
aaggaaatgc ttaacgattt cgggtgtgag ttgacaagga gagagagaaa agaagaggaa 6480
aggtaattcg gggacggtgg tcttttatac ccttggctaa agtcccaacc acaaagcaaa 6540
aaaattttca gtagtctatt ttgcgtccgg catgggttac ccggatggcc agacaaagaa 6600
actagtacaa agtctgaaca agcgtagatt ccagactgca gtaccctacg cccttaacgg 6660
caagtgtggg aaccggggga ggtttgatat gtggggtgaa gggggctctc gccggggttg 6720
ggcccgctac tgggtcaatt tggggtcaat tggggcaatt ggggctgttt tttgggacac 6780
aaatacgccg ccaacccggt ctctcctgaa ttctgcagat gggctgcagg aattccgtcg 6840
tcgcctgagt cgacatcatt taaataccag ttggccacaa acccttgacg atctcgtatg 6900
tcccctccga catactcccg gccggctggg gtacgttcga tagcgctatc ggcatcgaca 6960
aggtttgggt ccctagccga taccgcacta cctgagtcac aatcttcgga ggtttagtct 7020
tccacatagc acgggcaaaa gtgcgtatat atacaagagc gtttgccagc cacagatttt 7080
cactccacac accacatcac acatacaacc acacacatcc acaatggaac ccgaaactaa 7140
gaagaccaag actgactcca agaagattgt tcttctcggc ggcgacttct gtggccccga 7200
ggtgattgcc gaggccgtca aggtgctcaa gtctgttgct gaggcctccg gcaccgagtt 7260
tgtgtttgag gaccgactca ttggaggagc tgccattgag aaggagggcg agcccatcac 7320
cgacgctact ctcgacatct gccgaaaggc tgactctatt atgctcggtg ctgtcggagg 7380
cgctgccaac accgtatgga ccactcccga cggacgaacc gacgtgcgac ccgagcaggg 7440
tctcctcaag ctgcgaaagg acctgaacct gtacgccaac ctgcgaccct gccagctgct 7500
gtcgcccaag ctcgccgatc tctcccccat ccgaaacgtt gagggcaccg acttcatcat 7560
tgtccgagag ctcgtcggag gtatctactt tggagagcga aaggaggatg acggatctgg 7620
cgtcgcttcc gacaccgaga cctactccgt tcctgaggtt gagcgaattg cccgaatggc 7680
cgccttcctg gcccttcagc acaacccccc tcttcccgtg tggtctcttg acaaggccaa 7740
cgtgctggcc tcctctcgac tttggcgaaa gactgtcact cgagtcctca aggacgaatt 7800
cccccagctc gagctcaacc accagctgat cgactcggcc gccatgatcc tcatcaagca 7860
gccctccaag atgaatggta tcatcatcac caccaacatg tttggcgata tcatctccga 7920
cgaggcctcc gtcatccccg gttctctggg tctgctgccc tccgcctctc tggcttctct 7980
gcccgacacc aacgaggcgt tcggtctgta cgagccctgt cacggatctg cccccgatct 8040
cggcaagcag aaggtcaacc ccattgccac cattctgtct gccgccatga tgctcaagtt 8100
ctctcttaac atgaagcccg ccggtgacgc tgttgaggct gccgtcaagg agtccgtcga 8160
ggctggtatc actaccgccg atatcggagg ctcttcctcc acctccgagg tcggagactt 8220
gttgccaaca aggtcaagga gctgctcaag aaggagtaag tcgtttctac gacgcattga 8280
tggaaggagc aaactgacgc gcctgcgggt tggtctaccg gcagggtccg ctagtgtata 8340
agactctata aaaagggccc tgccctgcta atgaaatgat gatttataat ttaccggtgt 8400
agcaaccttg actagaagaa gcagattggg tgtgtttgta gtggaggaca gtggtacgtt 8460
ttggaaacag tcttcttgaa agtgtcttgt ctacagtata ttcactcata acctcaatag 8520
ccaagggtgt agtcggttta ttaaaggaag ggagttgtgg ctgatgtgga tagatatctt 8580
taagctggcg actgcaccca acgagtgtgg tggtagcttg ttagatctgt atattcggta 8640
agatatattt tgtggggttt tagtggtgtt taaacggtag gttagtgctt ggtatatgag 8700
ttgtaggcat gacaatttgg aaaggggtgg actttgggaa tattgtggga tttcaatacc 8760
ttagtttgta cagggtaatt gttacaaatg atacaaagaa ctgtatttct tttcatttgt 8820
tttaattggt tgtatatcaa gtccgttaga cgagctcagt gccttggctt ttggcactgt 8880
atttcatttt tagaggtaca ctacattcag tgaggtatgg taaggttgag ggcataatga 8940
aggcaccttg tactgacagt cacagacctc tcaccgagaa ttttatgaga tatactcggg 9000
ttcattttag gctcat 9016
<210> 23
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 23
gatcaaacat gtttttgcaa gctttccttt tccttttggc tgg 43
<210> 24
<211> 44
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 24
gatcaagcgg ccgcctattt tacttccctt acttggaact tgtc 44
<210> 25
<211> 11180
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZKLY-PP2
<400> 25
aaatgcgttt ggatagcact agtctatgag gagcgtttta tgttgcggtg agggcgattg 60
gtgctcatat gggttcaatt gaggtggcgg aacgagctta gtcttcaatt gaggtgcgag 120
cgacacaatt gggtgtcacg tggcctaatt gacctcgggt cgtggagtcc ccagttatac 180
agcaaccacg aggtgcatgg gtaggagacg tcaccagaca atagggtttt ttttggactg 240
gagagggttg ggcaaaagcg ctcaacgggc tgtttgggga gctgtggggg aggaattggc 300
gatatttgtg aggttaacgg ctccgatttg cgtgttttgt cgctcctgca tctccccata 360
cccatatctt ccctccccac ctctttccac gataatttta cggatcagca ataaggttcc 420
ttctcctagt ttccacgtcc atatatatct atgctgcgtc gtccttttcg tgacatcacc 480
aaaacacata caaccatggc tggcacctta cccaagttcg gcgacggaac caccattgtg 540
gttcttggag cctccggcga cctcgctaag aagaagaccg tgagtattga accagactga 600
ggtcaattga agagtaggag agtctgagaa cattcgacgg acctgattgt gctctggacc 660
actcaattga ctcgttgaga gccccaatgg gtcttggcta gccgagtcgt tgacttgttg 720
acttgttgag cccagaaccc ccaacttttg ccaccataca ccgccatcac catgacaccc 780
agatgtgcgt gcgtatgtga gagtcaattg ttccgtggca aggcacagct tattccaccg 840
tgttccttgc acaggtggtc tttacgctct cccactctat ccgagcaata aaagcggaaa 900
aacagcagca agtcccaaca gacttctgct ccgaataagg cgtctagcaa gtgtgcccaa 960
aactcaattc aaaaatgtca gaaacctgat atcaacccgt cttcaaaagc taaccccagt 1020
tccccgccct cttcggcctt taccgaaacg gcctgctgcc caaaaatgtt gaaatcatcg 1080
gctacgcacg gtcgaaaatg actcaggagg agtaccacga gcgaatcagc cactacttca 1140
agacccccga cgaccagtcc aaggagcagg ccaagaagtt ccttgagaac acctgctacg 1200
tccagggccc ttacgacggt gccgagggct accagcgact gaatgaaaag attgaggagt 1260
ttgagaagaa gaagcccgag ccccactacc gtcttttcta cctggctctg ccccccagcg 1320
tcttccttga ggctgccaac ggtctgaaga agtatgtcta ccccggcgag ggcaaggccc 1380
gaatcatcat cgagaagccc tttggccacg acctggcctc gtcacgagag ctccaggacg 1440
gccttgctcc tctctggaag gagtctgaga tcttccgaat cgaccactac ctcggaaagg 1500
agatggtcaa gaacctcaac attctgcgat ttggcaacca gttcctgtcc gccgtgtggg 1560
acaagaacac catttccaac gtccagatct ccttcaagga gccctttggc actgagggcc 1620
gaggtggata cttcaacgac attggaatca tccgagacgt tattcagaac catctgttgc 1680
aggttctgtc cattctagcc atggagcgac ccgtcacttt cggcgccgag gacattcgag 1740
atgagaaggt caaggtgctc cgatgtgtcg acattctcaa cattgacgac gtcattctcg 1800
gccagtacgg cccctctgaa gacggaaaga agcccggata caccgatgac gatggcgttc 1860
ccgatgactc ccgagctgtg acctttgctg ctctccatct ccagatccac aacgacagat 1920
gggagggtgt tcctttcatc ctccgagccg gtaaggctct ggacgagggc aaggtcgaga 1980
tccgagtgca gttccgagac gtgaccaagg gcgttgtgga ccatctgcct cgaaatgagc 2040
tcgtcatccg aatccagccc tccgagtcca tctacatgaa gatgaactcc aagctgcctg 2100
gccttactgc caagaacatt gtcaccgacc tggatctgac ctacaaccga cgatactcgg 2160
acgtgcgaat ccctgaggct tacgagtctc tcattctgga ctgcctcaag ggtgaccaca 2220
ccaactttgt gcgaaacgac gagctggaca tttcctggaa gattttcacc gatctgctgc 2280
acaagattga cgaggacaag agcattgtgc ccgagaagta cgcctacggc tctcgtggcc 2340
ccgagcgact caagcagtgg ctccgagacc gaggctacgt gcgaaacggc accgagctgt 2400
accaatggcc tgtcaccaag ggctcctcgt gagcggccgc aagtgtggat ggggaagtga 2460
gtgcccggtt ctgtgtgcac aattggcaat ccaagatgga tggattcaac acagggatat 2520
agcgagctac gtggtggtgc gaggatatag caacggatat ttatgtttga cacttgagaa 2580
tgtacgatac aagcactgtc caagtacaat actaaacata ctgtacatac tcatactcgt 2640
acccgggcaa cggtttcact tgagtgcagt ggctagtgct cttactcgta cagtgtgcaa 2700
tactgcgtat catagtcttt gatgtatatc gtattcattc atgttagttg cgtacgttga 2760
ttgaggtgga gccagatggg ctattgtttc atatatagac tggcagccac ctctttggcc 2820
cagcatgttt gtatacctgg aagggaaaac taaagaagct ggctagttta gtttgattat 2880
tatagtagat gtcctaatca ctagagatta gaatgtcttg gcgatgatta gtcgtcgtcc 2940
cctgtatcat gtctagacca actgtgtcat gaagttggtg ctggtgtttt acctgtgtac 3000
tacaagtagg tgtcctagat ctagtgtaca gagccgttta gacccatgtg gacttcacca 3060
ttaacgatgg aaaatgttca ttatatgaca gtatattaca atggacttgc tccatttctt 3120
ccttgcatca catgttctcc acctccatag ttgatcaaca catcatagta gctaaggctg 3180
ctgctctccc actacagtcc accacaagtt aagtagcacc gtcagtacag ctaaaagtac 3240
acgtctagta cgtttcataa ctagtcaagt agcccctatt acagatatca gcactatcac 3300
gcacgagttt ttctctgtgc tatctaatca acttgccaag tattcggaga agatacactt 3360
tcttggcatc aggtatacga gggagcctat cagatgaaaa agggtatatt ggatccattc 3420
atatccacct acacgttgtc ataatctcct cattcacgtg attcatttcg tgacactagt 3480
ttctcacttt cccccccgca cctatagtca acttggcgga cacgctactt gtagctgacg 3540
ttgatttata gacccaatca aagcgggtta tcggtcaggt agcacttatc attcatcgtt 3600
catactacga tgagcaatct cgggcatgtc cggaaaagtg tcgggcgcgc cagctgcatt 3660
aatgaatcgg ccaacgcgcg gggagaggcg gtttgcgtat tgggcgctct tccgcttcct 3720
cgctcactga ctcgctgcgc tcggtcgttc ggctgcggcg agcggtatca gctcactcaa 3780
aggcggtaat acggttatcc acagaatcag gggataacgc aggaaagaac atgtgagcaa 3840
aaggccagca aaaggccagg aaccgtaaaa aggccgcgtt gctggcgttt ttccataggc 3900
tccgcccccc tgacgagcat cacaaaaatc gacgctcaag tcagaggtgg cgaaacccga 3960
caggactata aagataccag gcgtttcccc ctggaagctc cctcgtgcgc tctcctgttc 4020
cgaccctgcc gcttaccgga tacctgtccg cctttctccc ttcgggaagc gtggcgcttt 4080
ctcatagctc acgctgtagg tatctcagtt cggtgtaggt cgttcgctcc aagctgggct 4140
gtgtgcacga accccccgtt cagcccgacc gctgcgcctt atccggtaac tatcgtcttg 4200
agtccaaccc ggtaagacac gacttatcgc cactggcagc agccactggt aacaggatta 4260
gcagagcgag gtatgtaggc ggtgctacag agttcttgaa gtggtggcct aactacggct 4320
acactagaag aacagtattt ggtatctgcg ctctgctgaa gccagttacc ttcggaaaaa 4380
gagttggtag ctcttgatcc ggcaaacaaa ccaccgctgg tagcggtggt ttttttgttt 4440
gcaagcagca gattacgcgc agaaaaaaag gatctcaaga agatcctttg atcttttcta 4500
cggggtctga cgctcagtgg aacgaaaact cacgttaagg gattttggtc atgagattat 4560
caaaaaggat cttcacctag atccttttaa attaaaaatg aagttttaaa tcaatctaaa 4620
gtatatatga gtaaacttgg tctgacagtt accaatgctt aatcagtgag gcacctatct 4680
cagcgatctg tctatttcgt tcatccatag ttgcctgact ccccgtcgtg tagataacta 4740
cgatacggga gggcttacca tctggcccca gtgctgcaat gataccgcga gacccacgct 4800
caccggctcc agatttatca gcaataaacc agccagccgg aagggccgag cgcagaagtg 4860
gtcctgcaac tttatccgcc tccatccagt ctattaattg ttgccgggaa gctagagtaa 4920
gtagttcgcc agttaatagt ttgcgcaacg ttgttgccat tgctacaggc atcgtggtgt 4980
cacgctcgtc gtttggtatg gcttcattca gctccggttc ccaacgatca aggcgagtta 5040
catgatcccc catgttgtgc aaaaaagcgg ttagctcctt cggtcctccg atcgttgtca 5100
gaagtaagtt ggccgcagtg ttatcactca tggttatggc agcactgcat aattctctta 5160
ctgtcatgcc atccgtaaga tgcttttctg tgactggtga gtactcaacc aagtcattct 5220
gagaatagtg tatgcggcga ccgagttgct cttgcccggc gtcaatacgg gataataccg 5280
cgccacatag cagaacttta aaagtgctca tcattggaaa acgttcttcg gggcgaaaac 5340
tctcaaggat cttaccgctg ttgagatcca gttcgatgta acccactcgt gcacccaact 5400
gatcttcagc atcttttact ttcaccagcg tttctgggtg agcaaaaaca ggaaggcaaa 5460
atgccgcaaa aaagggaata agggcgacac ggaaatgttg aatactcata ctcttccttt 5520
ttcaatatta ttgaagcatt tatcagggtt attgtctcat gagcggatac atatttgaat 5580
gtatttagaa aaataaacaa ataggggttc cgcgcacatt tccccgaaaa gtgccacctg 5640
atgcggtgtg aaataccgca cagatgcgta aggagaaaat accgcatcag gaaattgtaa 5700
gcgttaatat tttgttaaaa ttcgcgttaa atttttgtta aatcagctca ttttttaacc 5760
aataggccga aatcggcaaa atcccttata aatcaaaaga atagaccgag atagggttga 5820
gtgttgttcc agtttggaac aagagtccac tattaaagaa cgtggactcc aacgtcaaag 5880
ggcgaaaaac cgtctatcag ggcgatggcc cactacgtga accatcaccc taatcaagtt 5940
ttttggggtc gaggtgccgt aaagcactaa atcggaaccc taaagggagc ccccgattta 6000
gagcttgacg gggaaagccg gcgaacgtgg cgagaaagga agggaagaaa gcgaaaggag 6060
cgggcgctag ggcgctggca agtgtagcgg tcacgctgcg cgtaaccacc acacccgccg 6120
cgcttaatgc gccgctacag ggcgcgtcca ttcgccattc aggctgcgca actgttggga 6180
agggcgatcg gtgcgggcct cttcgctatt acgccagctg gcgaaagggg gatgtgctgc 6240
aaggcgatta agttgggtaa cgccagggtt ttcccagtca cgacgttgta aaacgacggc 6300
cagtgaattg taatacgact cactataggg cgaattgggc ccgacgtcgc atgcattccg 6360
acagcagcga ctgggcacca tgatcaagcg aaacaccttc ccccagctgc cctggcaaac 6420
catcaagaac cctactttca tcaagtgcaa gaacggttct actcttctca cctccggtgt 6480
ctacggctgg tgccgaaagc ctaactacac cgctgatttc atcatgtgcc tcacctgggc 6540
tctcatgtgc ggtgttgctt ctcccctgcc ttacttctac ccggtcttct tcttcctggt 6600
gctcatccac cgagcttacc gagactttga gcgactggag cgaaagtacg gtgaggacta 6660
ccaggagttc aagcgacagg tcccttggat cttcatccct tatgttttct aaacgataag 6720
cttagtgagc gaatggtgag gttacttaat tgagtggcca gcctatggga ttgtataaca 6780
gacagtcaat atattactga aaagactgaa cagccagacg gagtgaggtt gtgagtgaat 6840
cgtagagggc ggctattaca gcaagtctac tctacagtgt actaacacag cagagaacaa 6900
atacaggtgt gcattcggct atctgagaat tagttggaga gctcgagacc ctcggcgata 6960
aactgctcct cggttttgtg tccatacttg tacggaccat tgtaatgggg caagtcgttg 7020
agttctcgtc gtccgacgtt cagagcacag aaaccaatgt aatcaatgta gcagagatgg 7080
ttctgcaaaa gattgatttg tgcgagcagg ttaattaagt tgcgacacat gtcttgatag 7140
tatcttgaat tctctctctt gagcttttcc ataacaagtt cttctgcctc caggaagtcc 7200
atgggtggtt tgatcatggt tttggtgtag tggtagtgca gtggtggtat tgtgactggg 7260
gatgtagttg agaataagtc atacacaagt cagctttctt cgagcctcat ataagtataa 7320
gtagttcaac gtattagcac tgtacccagc atctccgtat cgagaaacac aacaacatgc 7380
cccattggac agatcatgcg gatacacagg ttgtgcagta tcatacatac tcgatcagac 7440
aggtcgtctg accatcatac aagctgaaca agcgctccat acttgcacgc tctctatata 7500
cacagttaaa ttacatatcc atagtctaac ctctaacagt taatcttctg gtaagcctcc 7560
cagccagcct tctggtatcg cttggcctcc tcaataggat ctcggttctg gccgtacaga 7620
cctcggccga caattatgat atccgttccg gtagacatga catcctcaac agttcggtac 7680
tgctgtccga gagcgtctcc cttgtcgtca agacccaccc cgggggtcag aataagccag 7740
tcctcagagt cgcccttagg tcggttctgg gcaatgaagc caaccacaaa ctcggggtcg 7800
gatcgggcaa gctcaatggt ctgcttggag tactcgccag tggccagaga gcccttgcaa 7860
gacagctcgg ccagcatgag cagacctctg gccagcttct cgttgggaga ggggactagg 7920
aactccttgt actgggagtt ctcgtagtca gagacgtcct ccttcttctg ttcagagaca 7980
gtttcctcgg caccagctcg caggccagca atgattccgg ttccgggtac accgtgggcg 8040
ttggtgatat cggaccactc ggcgattcgg tgacaccggt actggtgctt gacagtgttg 8100
ccaatatctg cgaactttct gtcctcgaac aggaagaaac cgtgcttaag agcaagttcc 8160
ttgaggggga gcacagtgcc ggcgtaggtg aagtcgtcaa tgatgtcgat atgggttttg 8220
atcatgcaca cataaggtcc gaccttatcg gcaagctcaa tgagctcctt ggtggtggta 8280
acatccagag aagcacacag gttggttttc ttggctgcca cgagcttgag cactcgagcg 8340
gcaaaggcgg acttgtggac gttagctcga gcttcgtagg agggcatttt ggtggtgaag 8400
aggagactga aataaattta gtctgcagaa ctttttatcg gaaccttatc tggggcagtg 8460
aagtatatgt tatggtaata gttacgagtt agttgaactt atagatagac tggactatac 8520
ggctatcggt ccaaattaga aagaacgtca atggctctct gggcgtcgcc tttgccgaca 8580
aaaatgtgat catgatgaaa gccagcaatg acgttgcagc tgatattgtt gtcggccaac 8640
cgcgccgaaa acgcagctgt cagacccaca gcctccaacg aagaatgtat cgtcaaagtg 8700
atccaagcac actcatagtt ggagtcgtac tccaaaggcg gcaatgacga gtcagacaga 8760
tactcgtcga ccttttcctt gggaaccacc accgtcagcc cttctgactc acgtattgta 8820
gccaccgaca caggcaacag tccgtggata gcagaatatg tcttgtcggt ccatttctca 8880
ccaactttag gcgtcaagtg aatgttgcag aagaagtatg tgccttcatt gagaatcggt 8940
gttgctgatt tcaataaagt cttgagatca gtttggccag tcatgttgtg gggggtaatt 9000
ggattgagtt atcgcctaca gtctgtacag gtatactcgc tgcccacttt atactttttg 9060
attccgctgc acttgaagca atgtcgttta ccaaaagtga gaatgctcca cagaacacac 9120
cccagggtat ggttgagcaa aaaataaaca ctccgatacg gggaatcgaa ccccggtctc 9180
cacggttctc aagaagtatt cttgatgaga gcgtatcgat gagcctaaaa tgaacccgag 9240
tatatctcat aaaattctcg gtgagaggtc tgtgactgtc agtacaaggt gccttcatta 9300
tgccctcaac cttaccatac ctcactgaat gtagtgtacc tctaaaaatg aaatacagtg 9360
ccaaaagcca aggcactgag ctcgtctaac ggacttgata tacaaccaat taaaacaaat 9420
gaaaagaaat acagttcttt gtatcatttg taacaattac cctgtacaaa ctaaggtatt 9480
gaaatcccac aatattccca aagtccaccc ctttccaaat tgtcatgcct acaactcata 9540
taccaagcac taacctaccg tttaaaccat catctaaggg cctcaaaact acctcggaac 9600
tgctgcgctg atctggacac cacagaggtt ccgagcactt taggttgcac caaatgtccc 9660
accaggtgca ggcagaaaac gctggaacag cgtgtacagt ttgtcttaac aaaaagtgag 9720
ggcgctgagg tcgagcaggg tggtgtgact tgttatagcc tttagagctg cgaaagcgcg 9780
tatggatttg gctcatcagg ccagattgag ggtctgtgga cacatgtcat gttagtgtac 9840
ttcaatcgcc ccctggatat agccccgaca ataggccgtg gcctcatttt tttgccttcc 9900
gcacatttcc attgctcggt acccacacct tgcttctcct gcacttgcca accttaatac 9960
tggtttacat tgaccaacat cttacaagcg gggggcttgt ctagggtata tataaacagt 10020
ggctctccca atcggttgcc agtctctttt ttcctttctt tccccacaga ttcgaaatct 10080
aaactacaca tcacaccatg gctcccaagg tcatctctaa gaacgaatcg caactggtcg 10140
ctgaggctgc tgccgctgag atcattcgac tccagaacga gtcaattgct gccactggag 10200
ctttccatgt tgccgtatct ggaggctctc tggtgtctgc tctccgaaag ggtctggtca 10260
acaactcgga gaccaagttc cccaagtgga agattttctt ctccgacgaa cggctggtca 10320
agctggacga tgccgactcc aactacggtc tcctcaagaa ggatctgctc gatcacatcc 10380
ccaaggatca gcaaccacag gtcttcaccg tcaaggagtc tcttctgaac gactctgatg 10440
ccgtctccaa ggactaccag gagcagattg tcaagaatgt gcctctcaac ggccagggag 10500
tgcctgtttt cgatctcatt ctgctcggat gcggtcctga tggccacact tgctcgctgt 10560
tccctggaca cgctctgctc aaggaggaga ccaagtttgt cgccaccatt gaggactctc 10620
ccaagcctcc tcctcgacga atcaccatca ctttccccgt tctcaaggct gccaaggcca 10680
tcgctttcgt cgccgaggga gccggaaagg cccctgtcct caagcagatc ttcgaggagc 10740
ccgagcccac tcttccctct gccattgtca acaaggtcgc taccggaccc gttttctggt 10800
ttgtttccga ctctgccgtt gagggcgtca acctctccaa gatctagcgg ccgcatgaga 10860
agataaatat ataaatacat tgagatatta aatgcgctag attagagagc ctcatactgc 10920
tcggagagaa gccaagacga gtactcaaag gggattacac catccatatc cacagacaca 10980
agctggggaa aggttctata tacactttcc ggaataccgt agtttccgat gttatcaatg 11040
ggggcagcca ggatttcagg cacttcggtg tctcggggtg aaatggcgtt cttggcctcc 11100
atcaagtcgt accatgtctt catttgcctg tcaaagtaaa acagaagcag atgaagaatg 11160
aacttgaagt gaaggaattt 11180
<210> 26
<211> 45
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 26
gatcaaacat gtcaatgaca aacgaaacta gcgatagacc tttgg 45
<210> 27
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 27
gatcaaccat ggagctcgct accgccttta ctattctcac tgc 43
<210> 28
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> primer
<400> 28
gatcaaacat gttagacagg ccccattgag tgacgggagt agt 43
<210> 29
<211> 13565
<212> DNA
<213> Artificial Sequence
<220>
<223> Plasmid pZKL3-9DP9N
<400> 29
gtacggattg tgtatgtccc tgtacctgca tcttgatgga gagagctccg gaaagcggat 60
caggagctgt ccaattttaa ttttataaca tggaaacgag tccttggagc tagaagacca 120
ttttttcaac tgccctatcg actatattta tctactccaa aaccgactgc ttcccaagaa 180
tcttcagcca aggcttccaa agtaacccct cgcttcccga cacttaattg aaaccttaga 240
tgcagtcact gcgagtgaag tggactctaa catctccaac atagcgacga tattgcgagg 300
gtttgaatat aactaagatg catgatccat tacatttgta gaaatatcat aaacaacgaa 360
gcacatagac agaatgctgt tggttgttac atctgaagcc gaggtaccga tgtcattttc 420
agctgtcact gcagagacag gggtatgtca catttgaaga tcatacaacc gacgtttatg 480
aaaaccagag atatagagaa tgtattgacg gttgtggcta tgtcataagt gcagtgaagt 540
gcagtgatta taggtatagt acacttactg tagctacaag tacatactgc tacagtaata 600
ctcatgtatg caaaccgtat tctgtgtcta cagaaggcga tacggaagag tcaatctctt 660
atgtagagcc atttctataa tcgaaggggc cttgtaattt ccaaacgagt aattgagtaa 720
ttgaagagca tcgtagacat tacttatcat gtattgtgag agggaggaga tgcagctgta 780
gctactgcac atactgtact cgcccatgca gggataatgc atagcgagac ttggcagtag 840
gtgacagttg ctagctgcta cttgtagtcg ggtgggtgat agcatggcgc gccagctgca 900
ttaatgaatc ggccaacgcg cggggagagg cggtttgcgt attgggcgct cttccgcttc 960
ctcgctcact gactcgctgc gctcggtcgt tcggctgcgg cgagcggtat cagctcactc 1020
aaaggcggta atacggttat ccacagaatc aggggataac gcaggaaaga acatgtgagc 1080
aaaaggccag caaaaggcca ggaaccgtaa aaaggccgcg ttgctggcgt ttttccatag 1140
gctccgcccc cctgacgagc atcacaaaaa tcgacgctca agtcagaggt ggcgaaaccc 1200
gacaggacta taaagatacc aggcgtttcc ccctggaagc tccctcgtgc gctctcctgt 1260
tccgaccctg ccgcttaccg gatacctgtc cgcctttctc ccttcgggaa gcgtggcgct 1320
ttctcatagc tcacgctgta ggtatctcag ttcggtgtag gtcgttcgct ccaagctggg 1380
ctgtgtgcac gaaccccccg ttcagcccga ccgctgcgcc ttatccggta actatcgtct 1440
tgagtccaac ccggtaagac acgacttatc gccactggca gcagccactg gtaacaggat 1500
tagcagagcg aggtatgtag gcggtgctac agagttcttg aagtggtggc ctaactacgg 1560
ctacactaga agaacagtat ttggtatctg cgctctgctg aagccagtta ccttcggaaa 1620
aagagttggt agctcttgat ccggcaaaca aaccaccgct ggtagcggtg gtttttttgt 1680
ttgcaagcag cagattacgc gcagaaaaaa aggatctcaa gaagatcctt tgatcttttc 1740
tacggggtct gacgctcagt ggaacgaaaa ctcacgttaa gggattttgg tcatgagatt 1800
atcaaaaagg atcttcacct agatcctttt aaattaaaaa tgaagtttta aatcaatcta 1860
aagtatatat gagtaaactt ggtctgacag ttaccaatgc ttaatcagtg aggcacctat 1920
ctcagcgatc tgtctatttc gttcatccat agttgcctga ctccccgtcg tgtagataac 1980
tacgatacgg gagggcttac catctggccc cagtgctgca atgataccgc gagacccacg 2040
ctcaccggct ccagatttat cagcaataaa ccagccagcc ggaagggccg agcgcagaag 2100
tggtcctgca actttatccg cctccatcca gtctattaat tgttgccggg aagctagagt 2160
aagtagttcg ccagttaata gtttgcgcaa cgttgttgcc attgctacag gcatcgtggt 2220
gtcacgctcg tcgtttggta tggcttcatt cagctccggt tcccaacgat caaggcgagt 2280
tacatgatcc cccatgttgt gcaaaaaagc ggttagctcc ttcggtcctc cgatcgttgt 2340
cagaagtaag ttggccgcag tgttatcact catggttatg gcagcactgc ataattctct 2400
tactgtcatg ccatccgtaa gatgcttttc tgtgactggt gagtactcaa ccaagtcatt 2460
ctgagaatag tgtatgcggc gaccgagttg ctcttgcccg gcgtcaatac gggataatac 2520
cgcgccacat agcagaactt taaaagtgct catcattgga aaacgttctt cggggcgaaa 2580
actctcaagg atcttaccgc tgttgagatc cagttcgatg taacccactc gtgcacccaa 2640
ctgatcttca gcatctttta ctttcaccag cgtttctggg tgagcaaaaa caggaaggca 2700
aaatgccgca aaaaagggaa taagggcgac acggaaatgt tgaatactca tactcttcct 2760
ttttcaatat tattgaagca tttatcaggg ttattgtctc atgagcggat acatatttga 2820
atgtatttag aaaaataaac aaataggggt tccgcgcaca tttccccgaa aagtgccacc 2880
tgatgcggtg tgaaataccg cacagatgcg taaggagaaa ataccgcatc aggaaattgt 2940
aagcgttaat attttgttaa aattcgcgtt aaatttttgt taaatcagct cattttttaa 3000
ccaataggcc gaaatcggca aaatccctta taaatcaaaa gaatagaccg agatagggtt 3060
gagtgttgtt ccagtttgga acaagagtcc actattaaag aacgtggact ccaacgtcaa 3120
agggcgaaaa accgtctatc agggcgatgg cccactacgt gaaccatcac cctaatcaag 3180
ttttttgggg tcgaggtgcc gtaaagcact aaatcggaac cctaaaggga gcccccgatt 3240
tagagcttga cggggaaagc cggcgaacgt ggcgagaaag gaagggaaga aagcgaaagg 3300
agcgggcgct agggcgctgg caagtgtagc ggtcacgctg cgcgtaacca ccacacccgc 3360
cgcgcttaat gcgccgctac agggcgcgtc cattcgccat tcaggctgcg caactgttgg 3420
gaagggcgat cggtgcgggc ctcttcgcta ttacgccagc tggcgaaagg gggatgtgct 3480
gcaaggcgat taagttgggt aacgccaggg ttttcccagt cacgacgttg taaaacgacg 3540
gccagtgaat tgtaatacga ctcactatag ggcgaattgg gcccgacgtc gcatgcagga 3600
atagacatct tcaataggag cattaatacc tgtgggatca ctgatgtaaa cttctcccag 3660
agtatgtgaa taaccagcgg gccatccaac aaagaagtcg ttccagtgag tgactcggta 3720
catccgtctt tcggggttga tggtaagtcc gtcgtctcct tgcttaaaga acagagcgtc 3780
cacgtagtct gcaaaagcct tgtttccaag tcgaggctgc ccatagttga ttagcgttgg 3840
atcatatcca agattcttca ggttgatgcc catgaataga gcagtgacag ctcctagaga 3900
gtggccagtt acgatcaatt tgtagtcagt gttgtttcca aggaagtcga ccagacgatc 3960
ctgtacgttc accatagtct ctctgtatgc cttctgaaag ccatcatgaa cttggcagcc 4020
aggacaattg atactggcag aagggtttgt ggagtttatg tcagtagtgt taagaggagg 4080
gatactggtc atgtagggtt gttggatcgt ttggatgtca gtaatagcgt ctgcaatgga 4140
gaaagtgcct cggaaaacaa tatacttttc ctttttggtg tgatcgtggg ccaaaaatcc 4200
agtaactgaa gtcgagaaga aatttcctcc aaactggtag tcaagagtca catcgggaaa 4260
atgagcgcaa gagtttccac aggtaaaatc gctctgcagg gcaaatgggc caggggctct 4320
gacacaatag gccacgttag atagccatcc gtacttgaga acaaagtcgt atgtctcctg 4380
ggtgatagga gccgttaatt aagttgcgac acatgtcttg atagtatctt gaattctctc 4440
tcttgagctt ttccataaca agttcttctg cctccaggaa gtccatgggt ggtttgatca 4500
tggttttggt gtagtggtag tgcagtggtg gtattgtgac tggggatgta gttgagaata 4560
agtcatacac aagtcagctt tcttcgagcc tcatataagt ataagtagtt caacgtatta 4620
gcactgtacc cagcatctcc gtatcgagaa acacaacaac atgccccatt ggacagatca 4680
tgcggataca caggttgtgc agtatcatac atactcgatc agacaggtcg tctgaccatc 4740
atacaagctg aacaagcgct ccatacttgc acgctctcta tatacacagt taaattacat 4800
atccatagtc taacctctaa cagttaatct tctggtaagc ctcccagcca gccttctggt 4860
atcgcttggc ctcctcaata ggatctcggt tctggccgta cagacctcgg ccgacaatta 4920
tgatatccgt tccggtagac atgacatcct caacagttcg gtactgctgt ccgagagcgt 4980
ctcccttgtc gtcaagaccc accccggggg tcagaataag ccagtcctca gagtcgccct 5040
taggtcggtt ctgggcaatg aagccaacca caaactcggg gtcggatcgg gcaagctcaa 5100
tggtctgctt ggagtactcg ccagtggcca gagagccctt gcaagacagc tcggccagca 5160
tgagcagacc tctggccagc ttctcgttgg gagaggggac taggaactcc ttgtactggg 5220
agttctcgta gtcagagacg tcctccttct tctgttcaga gacagtttcc tcggcaccag 5280
ctcgcaggcc agcaatgatt ccggttccgg gtacaccgtg ggcgttggtg atatcggacc 5340
actcggcgat tcggtgacac cggtactggt gcttgacagt gttgccaata tctgcgaact 5400
ttctgtcctc gaacaggaag aaaccgtgct taagagcaag ttccttgagg gggagcacag 5460
tgccggcgta ggtgaagtcg tcaatgatgt cgatatgggt tttgatcatg cacacataag 5520
gtccgacctt atcggcaagc tcaatgagct ccttggtggt ggtaacatcc agagaagcac 5580
acaggttggt tttcttggct gccacgagct tgagcactcg agcggcaaag gcggacttgt 5640
ggacgttagc tcgagcttcg taggagggca ttttggtggt gaagaggaga ctgaaataaa 5700
tttagtctgc agaacttttt atcggaacct tatctggggc agtgaagtat atgttatggt 5760
aatagttacg agttagttga acttatagat agactggact atacggctat cggtccaaat 5820
tagaaagaac gtcaatggct ctctgggcgt cgcctttgcc gacaaaaatg tgatcatgat 5880
gaaagccagc aatgacgttg cagctgatat tgttgtcggc caaccgcgcc gaaaacgcag 5940
ctgtcagacc cacagcctcc aacgaagaat gtatcgtcaa agtgatccaa gcacactcat 6000
agttggagtc gtactccaaa ggcggcaatg acgagtcaga cagatactcg tcgacctttt 6060
ccttgggaac caccaccgtc agcccttctg actcacgtat tgtagccacc gacacaggca 6120
acagtccgtg gatagcagaa tatgtcttgt cggtccattt ctcaccaact ttaggcgtca 6180
agtgaatgtt gcagaagaag tatgtgcctt cattgagaat cggtgttgct gatttcaata 6240
aagtcttgag atcagtttgg ccagtcatgt tgtggggggt aattggattg agttatcgcc 6300
tacagtctgt acaggtatac tcgctgccca ctttatactt tttgattccg ctgcacttga 6360
agcaatgtcg tttaccaaaa gtgagaatgc tccacagaac acaccccagg gtatggttga 6420
gcaaaaaata aacactccga tacggggaat cgaaccccgg tctccacggt tctcaagaag 6480
tattcttgat gagagcgtat cgatggttaa tgctgctgtg tgctgtgtgt gtgtgttgtt 6540
tggcgctcat tgttgcgtta tgcagcgtac accacaatat tggaagctta ttagcctttc 6600
tattttttcg tttgcaaggc ttaacaacat tgctgtggag agggatgggg atatggaggc 6660
cgctggaggg agtcggagag gcgttttgga gcggcttggc ctggcgccca gctcgcgaaa 6720
cgcacctagg accctttggc acgccgaaat gtgccacttt tcagtctagt aacgccttac 6780
ctacgtcatt ccatgcgtgc atgtttgcgc cttttttccc ttgcccttga tcgccacaca 6840
gtacagtgca ctgtacagtg gaggttttgg gggggtctta gatgggagct aaaagcggcc 6900
tagcggtaca ctagtgggat tgtatggagt ggcatggagc ctaggtggag cctgacagga 6960
cgcacgaccg gctagcccgt gacagacgat gggtggctcc tgttgtccac cgcgtacaaa 7020
tgtttgggcc aaagtcttgt cagccttgct tgcgaaccta attcccaatt ttgtcacttc 7080
gcacccccat tgatcgagcc ctaacccctg cccatcaggc aatccaatta agctcgcatt 7140
gtctgccttg tttagtttgg ctcctgcccg tttcggcgtc cacttgcaca aacacaaaca 7200
agcattatat ataaggctcg tctctccctc ccaaccacac tcactttttt gcccgtcttc 7260
ccttgctaac acaaaagtca agaacacaaa caaccacccc aaccccctta cacacaagac 7320
atatctacag caatggccat ggccaaaagc aaacgacggt cggaggctgt ggaagagcac 7380
gtgaccggct cggacgaggg cttgaccgat acttcgggtc acgtgagccc tgccgccaag 7440
aagcagaaga actcggagat tcatttcacc acccaggctg cccagcagtt ggatcgggag 7500
cgcaaggagg agtatctgga ctcgctgatc gacaacaagg actatctcaa gtaccgtcct 7560
cgaggctgga agctcaacaa cccgcctacc gaccgacctg tgcgaatcta cgccgatgga 7620
gtgtttgatt tgttccatct gggacacatg cgtcagctgg agcagtccaa gaaggccttc 7680
cccaacgcag tgttgattgt gggcattccc agcgacaagg agacccacaa gcggaaggga 7740
ttgaccgtgc tgagtgacgt ccagcggtac gagacggtgc gacactgcaa gtgggtggac 7800
gaggtggtgg aggatgctcc ctggtgtgtc accatggact ttctggaaaa acacaaaatc 7860
gactacgtgg cccatgacga tctgccctac gcttccggca acgacgatga tatctacaag 7920
cccatcaagg agaagggcat gtttctggcc acccagcgaa ccgagggcat ttccacctcg 7980
gacatcatca ccaagattat ccgagactac gacaagtatt taatgcgaaa ctttgcccgg 8040
ggtgctaacc gaaaggatct caacgtctcg tggctcaaga agaacgagct ggacttcaag 8100
cgtcatgtgg ccgagttccg aaactcgttc aagcgaaaga aggtcggtaa ggatctctac 8160
ggcgagattc gcggtctgct gcagaatgtg ctcatttgga acggcgacaa ctccggcact 8220
tccactcccc agcgaaagac gctgcagacc aacgccaaga agatgtacat gaacgtgctc 8280
aagactctgc aggctcctga cgctgttgac gtggactcct cggagaacgt gtctgagaac 8340
gtcactgatg aggaggagga agacgacgac gaggttgatg aggacgaaga agccgacgac 8400
gacgacgaag acgacgaaga cgaggaagac gacgagtagg cggccgcatt gatgattgga 8460
aacacacaca tgggttatat ctaggtgaga gttagttgga cagttatata ttaaatcagc 8520
tatgccaacg gtaacttcat tcatgtcaac gaggaaccag tgactgcaag taatatagaa 8580
tttgaccacc ttgccattct cttgcactcc tttactatat ctcatttatt tcttatatac 8640
aaatcacttc ttcttcccag catcgagctc ggaaacctca tgagcaataa catcgtggat 8700
ctcgtcaata gagggctttt tggactcctt gctgttggcc accttgtcct tgctgtttaa 8760
acacgcagta ggatgtcctg cacgggtctt tttgtggggt gtggagaaag gggtgcttgg 8820
agatggaagc cggtagaacc gggctgcttg tgcttggaga tggaagccgg tagaaccggg 8880
ctgcttgggg ggatttgggg ccgctgggct ccaaagaggg gtaggcattt cgttggggtt 8940
acgtaattgc ggcatttggg tcctgcgcgc atgtcccatt ggtcagaatt agtccggata 9000
ggagacttat cagccaatca cagcgccgga tccacctgta ggttgggttg ggtgggagca 9060
cccctccaca gagtagagtc aaacagcagc agcaacatga tagttggggg tgtgcgtgtt 9120
aaaggaaaaa aaagaagctt gggttatatt cccgctctat ttagaggttg cgggatagac 9180
gccgacggag ggcaatggcg ctatggaacc ttgcggatat ccatacgccg cggcggactg 9240
cgtccgaacc agctccagca gcgttttttc cgggccattg agccgactgc gaccccgcca 9300
acgtgtcttg gcccacgcac tcatgtcatg ttggtgttgg gaggccactt tttaagtagc 9360
acaaggcacc tagctcgcag caaggtgtcc gaaccaaaga agcggctgca gtggtgcaaa 9420
cggggcggaa acggcgggaa aaagccacgg gggcacgaat tgaggcacgc cctcgaattt 9480
gagacgagtc acggccccat tcgcccgcgc aatggctcgc caacgcccgg tcttttgcac 9540
cacatcaggt taccccaagc caaacctttg tgttaaaaag cttaacatat tataccgaac 9600
gtaggtttgg gcgggcttgc tccgtctgtc caaggcaaca tttatataag ggtctgcatc 9660
gccggctcaa ttgaatcttt tttcttcttc tcttctctat attcattctt gaattaaaca 9720
cacatcaaca tggccatcaa agtcggtatt aacggattcg ggcgaatcgg acgaattgtg 9780
agtaccatag aaggtgatgg aaacatgacc caacagaaac agatgacaag tgtcatcgac 9840
ccaccagagc ccaattgagc tcatactaac agtcgacaac ctgtcgaacc aattgatgac 9900
tccccgacaa tgtactaaca caggtcctgc ccatggtgaa aaacgtggac caagtggatc 9960
tctcgcaggt cgacaccatt gcctccggcc gagatgtcaa ctacaaggtc aagtacacct 10020
ccggcgttaa gatgagccag ggcgcctacg acgacaaggg ccgccacatt tccgagcagc 10080
ccttcacctg ggccaactgg caccagcaca tcaactggct caacttcatt ctggtgattg 10140
cgctgcctct gtcgtccttt gctgccgctc ccttcgtctc cttcaactgg aagaccgccg 10200
cgtttgctgt cggctattac atgtgcaccg gtctcggtat caccgccggc taccaccgaa 10260
tgtgggccca tcgagcctac aaggccgctc tgcccgttcg aatcatcctt gctctgtttg 10320
gaggaggagc tgtcgagggc tccatccgat ggtgggcctc gtctcaccga gtccaccacc 10380
gatggaccga ctccaacaag gacccttacg acgcccgaaa gggattctgg ttctcccact 10440
ttggctggat gctgcttgtg cccaacccca agaacaaggg ccgaactgac atttctgacc 10500
tcaacaacga ctgggttgtc cgactccagc acaagtacta cgtttacgtt ctcgtcttca 10560
tggccattgt tctgcccacc ctcgtctgtg gctttggctg gggcgactgg aagggaggtc 10620
ttgtctacgc cggtatcatg cgatacacct ttgtgcagca ggtgactttc tgtgtcaact 10680
cccttgccca ctggattgga gagcagccct tcgacgaccg acgaactccc cgagaccacg 10740
ctcttaccgc cctggtcacc tttggagagg gctaccacaa cttccaccac gagttcccct 10800
cggactaccg aaacgccctc atctggtacc agtacgaccc caccaagtgg ctcatctgga 10860
ccctcaagca ggttggtctc gcctgggacc tccagacctt ctcccagaac gccatcgagc 10920
agggtctcgt gcagcagcga cagaagaagc tggacaagtg gcgaaacaac ctcaactggg 10980
gtatccccat tgagcagctg cctgtcattg agtttgagga gttccaagag caggccaaga 11040
cccgagatct ggttctcatt tctggcattg tccacgacgt gtctgccttt gtcgagcacc 11100
accctggtgg aaaggccctc attatgagcg ccgtcggcaa ggacggtacc gctgtcttca 11160
acggaggtgt ctaccgacac tccaacgctg gccacaacct gcttgccacc atgcgagttt 11220
cggtcattcg aggcggcatg gaggttgagg tgtggaagac tgcccagaac gaaaagaagg 11280
accagaacat tgtctccgat gagagtggaa accgaatcca ccgagctggt ctccaggcca 11340
cccgggtcga gaaccccggt atgtctggca tggctgctta ggcggccgca tgagaagata 11400
aatatataaa tacattgaga tattaaatgc gctagattag agagcctcat actgctcgga 11460
gagaagccaa gacgagtact caaaggggat tacaccatcc atatccacag acacaagctg 11520
gggaaaggtt ctatatacac tttccggaat accgtagttt ccgatgttat caatgggggc 11580
agccaggatt tcaggcactt cggtgtctcg gggtgaaatg gcgttcttgg cctccatcaa 11640
gtcgtaccat gtcttcattt gcctgtcaaa gtaaaacaga agcagatgaa gaatgaactt 11700
gaagtgaagg aatttaaata gttggagcaa gggagaaatg tagagtgtga aagactcact 11760
atggtccggg cttatctcga ccaatagcca aagtctggag tttctgagag aaaaaggcaa 11820
gatacgtatg taacaaagcg acgcatggta caataatacc ggaggcatgt atcatagaga 11880
gttagtggtt cgatgatggc actggtgcct ggtatgactt tatacggctg actacatatt 11940
tgtcctcaga catacaatta cagtcaagca cttacccttg gacatctgta ggtacccccc 12000
ggccaagacg atctcagcgt gtcgtatgtc ggattggcgt agctccctcg ctcgtcaatt 12060
ggctcccatc tactttcttc tgcttggcta cacccagcat gtctgctatg gctcgttttc 12120
gtgccttatc tatcctccca gtattaccaa ctctaaatga catgatgtga ttgggtctac 12180
actttcatat cagagataag gagtagcaca gttgcataaa aagcccaact ctaatcagct 12240
tcttcctttc ttgtaattag tacaaaggtg attagcgaaa tctggaagct tagttggccc 12300
taaaaaaatc aaaaaaagca aaaaacgaaa aacgaaaaac cacagttttg agaacaggga 12360
ggtaacgaag gatcgtatat atatatatat atatatatac ccacggatcc cgagaccggc 12420
ctttgattct tccctacaac caaccattct caccacccta attcacaacc atggaggtcg 12480
tgaacgaaat cgtctccatt ggccaggagg ttcttcccaa ggtcgactat gctcagctct 12540
ggtctgatgc ctcgcactgc gaggtgctgt acctctccat cgccttcgtc atcctgaagt 12600
tcacccttgg tcctctcgga cccaagggtc agtctcgaat gaagtttgtg ttcaccaact 12660
acaacctgct catgtccatc tactcgctgg gctccttcct ctctatggcc tacgccatgt 12720
acaccattgg tgtcatgtcc gacaactgcg agaaggcttt cgacaacaat gtcttccgaa 12780
tcaccactca gctgttctac ctcagcaagt tcctcgagta cattgactcc ttctatctgc 12840
ccctcatggg caagcctctg acctggttgc agttctttca ccatctcgga gctcctatgg 12900
acatgtggct gttctacaac taccgaaacg aagccgtttg gatctttgtg ctgctcaacg 12960
gcttcattca ctggatcatg tacggctact attggacccg actgatcaag ctcaagttcc 13020
ctatgcccaa gtccctgatt acttctatgc agatcattca gttcaacgtt ggcttctaca 13080
tcgtctggaa gtaccggaac attccctgct accgacaaga tggaatgaga atgtttggct 13140
ggtttttcaa ctacttctac gttggtactg tcctgtgtct gttcctcaac ttctacgtgc 13200
agacctacat cgtccgaaag cacaagggag ccaaaaagat tcagtgagcg gccgcaagtg 13260
tggatgggga agtgagtgcc cggttctgtg tgcacaattg gcaatccaag atggatggat 13320
tcaacacagg gatatagcga gctacgtggt ggtgcgagga tatagcaacg gatatttatg 13380
tttgacactt gagaatgtac gatacaagca ctgtccaagt acaatactaa acatactgta 13440
catactcata ctcgtacccg gcaacggttt cacttgagtg cagtggctag tgctcttact 13500
cgtacagtgt gcaatactgc gtatcatagt ctttgatgta tatcgtattc attcatgtta 13560
gttgc 13565
<210> 30
<211> 777
<212> DNA
<213> Euglena gracilis
<220>
<221> CDS
<222> (1)..(777)
<223> mutant delta-9 elongase "EgD9eS-L35G"
<400> 30
atg gag gtc gtg aac gaa atc gtc tcc att ggc cag gag gtt ctt ccc 48
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
aag gtc gac tat gct cag ctc tgg tct gat gcc tcg cac tgc gag gtg 96
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
ctg tac ggg tcc atc gcc ttc gtc atc ctg aag ttc acc ctt ggt cct 144
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
ctc gga ccc aag ggt cag tct cga atg aag ttt gtg ttc acc aac tac 192
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
aac ctg ctc atg tcc atc tac tcg ctg ggc tcc ttc ctc tct atg gcc 240
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
tac gcc atg tac acc att ggt gtc atg tcc gac aac tgc gag aag gct 288
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
ttc gac aac aat gtc ttc cga atc acc act cag ctg ttc tac ctc agc 336
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
aag ttc ctc gag tac att gac tcc ttc tat ctg ccc ctc atg ggc aag 384
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
cct ctg acc tgg ttg cag ttc ttt cac cat ctc gga gct cct atg gac 432
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
atg tgg ctg ttc tac aac tac cga aac gaa gcc gtt tgg atc ttt gtg 480
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
ctg ctc aac ggc ttc att cac tgg atc atg tac ggc tac tat tgg acc 528
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
cga ctg atc aag ctc aag ttc cct atg ccc aag tcc ctg att act tct 576
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
atg cag atc att cag ttc aac gtt ggc ttc tac atc gtc tgg aag tac 624
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
cgg aac att ccc tgc tac cga caa gat gga atg aga atg ttt ggc tgg 672
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
ttt ttc aac tac ttc tac gtt ggt act gtc ctg tgt ctg ttc ctc aac 720
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
ttc tac gtg cag acc tac atc gtc cga aag cac aag gga gcc aaa aag 768
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
att cag tga 777
Ile Gln
<210> 31
<211> 258
<212> PRT
<213> Euglena gracilis
<400> 31
Met Glu Val Val Asn Glu Ile Val Ser Ile Gly Gln Glu Val Leu Pro
1 5 10 15
Lys Val Asp Tyr Ala Gln Leu Trp Ser Asp Ala Ser His Cys Glu Val
20 25 30
Leu Tyr Gly Ser Ile Ala Phe Val Ile Leu Lys Phe Thr Leu Gly Pro
35 40 45
Leu Gly Pro Lys Gly Gln Ser Arg Met Lys Phe Val Phe Thr Asn Tyr
50 55 60
Asn Leu Leu Met Ser Ile Tyr Ser Leu Gly Ser Phe Leu Ser Met Ala
65 70 75 80
Tyr Ala Met Tyr Thr Ile Gly Val Met Ser Asp Asn Cys Glu Lys Ala
85 90 95
Phe Asp Asn Asn Val Phe Arg Ile Thr Thr Gln Leu Phe Tyr Leu Ser
100 105 110
Lys Phe Leu Glu Tyr Ile Asp Ser Phe Tyr Leu Pro Leu Met Gly Lys
115 120 125
Pro Leu Thr Trp Leu Gln Phe Phe His His Leu Gly Ala Pro Met Asp
130 135 140
Met Trp Leu Phe Tyr Asn Tyr Arg Asn Glu Ala Val Trp Ile Phe Val
145 150 155 160
Leu Leu Asn Gly Phe Ile His Trp Ile Met Tyr Gly Tyr Tyr Trp Thr
165 170 175
Arg Leu Ile Lys Leu Lys Phe Pro Met Pro Lys Ser Leu Ile Thr Ser
180 185 190
Met Gln Ile Ile Gln Phe Asn Val Gly Phe Tyr Ile Val Trp Lys Tyr
195 200 205
Arg Asn Ile Pro Cys Tyr Arg Gln Asp Gly Met Arg Met Phe Gly Trp
210 215 220
Phe Phe Asn Tyr Phe Tyr Val Gly Thr Val Leu Cys Leu Phe Leu Asn
225 230 235 240
Phe Tyr Val Gln Thr Tyr Ile Val Arg Lys His Lys Gly Ala Lys Lys
245 250 255
Ile Gln
<210> 32
<211> 1449
<212> DNA
<213> Yarrowia lipolytica
<220>
<221> CDS
<222> (1)..(1449)
<223> delta-9 desaturase; GenBank Accession No. XM_501496
<400> 32
atg gtg aaa aac gtg gac caa gtg gat ctc tcg cag gtc gac acc att 48
Met Val Lys Asn Val Asp Gln Val Asp Leu Ser Gln Val Asp Thr Ile
1 5 10 15
gcc tcc ggc cga gat gtc aac tac aag gtc aag tac acc tcc ggc gtt 96
Ala Ser Gly Arg Asp Val Asn Tyr Lys Val Lys Tyr Thr Ser Gly Val
20 25 30
aag atg agc cag ggc gcc tac gac gac aag ggc cgc cac att tcc gag 144
Lys Met Ser Gln Gly Ala Tyr Asp Asp Lys Gly Arg His Ile Ser Glu
35 40 45
cag ccc ttc acc tgg gcc aac tgg cac cag cac atc aac tgg ctc aac 192
Gln Pro Phe Thr Trp Ala Asn Trp His Gln His Ile Asn Trp Leu Asn
50 55 60
ttc att ctg gtg att gcg ctg cct ctg tcg tcc ttt gct gcc gct ccc 240
Phe Ile Leu Val Ile Ala Leu Pro Leu Ser Ser Phe Ala Ala Ala Pro
65 70 75 80
ttc gtc tcc ttc aac tgg aag acc gcc gcg ttt gct gtc ggc tat tac 288
Phe Val Ser Phe Asn Trp Lys Thr Ala Ala Phe Ala Val Gly Tyr Tyr
85 90 95
atg tgc acc ggt ctc ggt atc acc gcc ggc tac cac cga atg tgg gcc 336
Met Cys Thr Gly Leu Gly Ile Thr Ala Gly Tyr His Arg Met Trp Ala
100 105 110
cat cga gcc tac aag gcc gct ctg ccc gtt cga atc atc ctt gct ctg 384
His Arg Ala Tyr Lys Ala Ala Leu Pro Val Arg Ile Ile Leu Ala Leu
115 120 125
ttt gga gga gga gct gtc gag ggc tcc atc cga tgg tgg gcc tcg tct 432
Phe Gly Gly Gly Ala Val Glu Gly Ser Ile Arg Trp Trp Ala Ser Ser
130 135 140
cac cga gtc cac cac cga tgg acc gac tcc aac aag gac cct tac gac 480
His Arg Val His His Arg Trp Thr Asp Ser Asn Lys Asp Pro Tyr Asp
145 150 155 160
gcc cga aag gga ttc tgg ttc tcc cac ttt ggc tgg atg ctg ctt gtg 528
Ala Arg Lys Gly Phe Trp Phe Ser His Phe Gly Trp Met Leu Leu Val
165 170 175
ccc aac ccc aag aac aag ggc cga act gac att tct gac ctc aac aac 576
Pro Asn Pro Lys Asn Lys Gly Arg Thr Asp Ile Ser Asp Leu Asn Asn
180 185 190
gac tgg gtt gtc cga ctc cag cac aag tac tac gtt tac gtt ctc gtc 624
Asp Trp Val Val Arg Leu Gln His Lys Tyr Tyr Val Tyr Val Leu Val
195 200 205
ttc atg gcc att gtt ctg ccc acc ctc gtc tgt ggc ttt ggc tgg ggc 672
Phe Met Ala Ile Val Leu Pro Thr Leu Val Cys Gly Phe Gly Trp Gly
210 215 220
gac tgg aag gga ggt ctt gtc tac gcc ggt atc atg cga tac acc ttt 720
Asp Trp Lys Gly Gly Leu Val Tyr Ala Gly Ile Met Arg Tyr Thr Phe
225 230 235 240
gtg cag cag gtg act ttc tgt gtc aac tcc ctt gcc cac tgg att gga 768
Val Gln Gln Val Thr Phe Cys Val Asn Ser Leu Ala His Trp Ile Gly
245 250 255
gag cag ccc ttc gac gac cga cga act ccc cga gac cac gct ctt acc 816
Glu Gln Pro Phe Asp Asp Arg Arg Thr Pro Arg Asp His Ala Leu Thr
260 265 270
gcc ctg gtc acc ttt gga gag ggc tac cac aac ttc cac cac gag ttc 864
Ala Leu Val Thr Phe Gly Glu Gly Tyr His Asn Phe His His Glu Phe
275 280 285
ccc tcg gac tac cga aac gcc ctc atc tgg tac cag tac gac ccc acc 912
Pro Ser Asp Tyr Arg Asn Ala Leu Ile Trp Tyr Gln Tyr Asp Pro Thr
290 295 300
aag tgg ctc atc tgg acc ctc aag cag gtt ggt ctc gcc tgg gac ctc 960
Lys Trp Leu Ile Trp Thr Leu Lys Gln Val Gly Leu Ala Trp Asp Leu
305 310 315 320
cag acc ttc tcc cag aac gcc atc gag cag ggt ctc gtg cag cag cga 1008
Gln Thr Phe Ser Gln Asn Ala Ile Glu Gln Gly Leu Val Gln Gln Arg
325 330 335
cag aag aag ctg gac aag tgg cga aac aac ctc aac tgg ggt atc ccc 1056
Gln Lys Lys Leu Asp Lys Trp Arg Asn Asn Leu Asn Trp Gly Ile Pro
340 345 350
att gag cag ctg cct gtc att gag ttt gag gag ttc caa gag cag gcc 1104
Ile Glu Gln Leu Pro Val Ile Glu Phe Glu Glu Phe Gln Glu Gln Ala
355 360 365
aag acc cga gat ctg gtt ctc att tct ggc att gtc cac gac gtg tct 1152
Lys Thr Arg Asp Leu Val Leu Ile Ser Gly Ile Val His Asp Val Ser
370 375 380
gcc ttt gtc gag cac cac cct ggt gga aag gcc ctc att atg agc gcc 1200
Ala Phe Val Glu His His Pro Gly Gly Lys Ala Leu Ile Met Ser Ala
385 390 395 400
gtc ggc aag gac ggt acc gct gtc ttc aac gga ggt gtc tac cga cac 1248
Val Gly Lys Asp Gly Thr Ala Val Phe Asn Gly Gly Val Tyr Arg His
405 410 415
tcc aac gct ggc cac aac ctg ctt gcc acc atg cga gtt tcg gtc att 1296
Ser Asn Ala Gly His Asn Leu Leu Ala Thr Met Arg Val Ser Val Ile
420 425 430
cga ggc ggc atg gag gtt gag gtg tgg aag act gcc cag aac gaa aag 1344
Arg Gly Gly Met Glu Val Glu Val Trp Lys Thr Ala Gln Asn Glu Lys
435 440 445
aag gac cag aac att gtc tcc gat gag agt gga aac cga atc cac cga 1392
Lys Asp Gln Asn Ile Val Ser Asp Glu Ser Gly Asn Arg Ile His Arg
450 455 460
gct ggt ctc cag gcc acc cgg gtc gag aac ccc ggt atg tct ggc atg 1440
Ala Gly Leu Gln Ala Thr Arg Val Glu Asn Pro Gly Met Ser Gly Met
465 470 475 480
gct gct tag 1449
Ala Ala
<210> 33
<211> 482
<212> PRT
<213> Yarrowia lipolytica
<400> 33
Met Val Lys Asn Val Asp Gln Val Asp Leu Ser Gln Val Asp Thr Ile
1 5 10 15
Ala Ser Gly Arg Asp Val Asn Tyr Lys Val Lys Tyr Thr Ser Gly Val
20 25 30
Lys Met Ser Gln Gly Ala Tyr Asp Asp Lys Gly Arg His Ile Ser Glu
35 40 45
Gln Pro Phe Thr Trp Ala Asn Trp His Gln His Ile Asn Trp Leu Asn
50 55 60
Phe Ile Leu Val Ile Ala Leu Pro Leu Ser Ser Phe Ala Ala Ala Pro
65 70 75 80
Phe Val Ser Phe Asn Trp Lys Thr Ala Ala Phe Ala Val Gly Tyr Tyr
85 90 95
Met Cys Thr Gly Leu Gly Ile Thr Ala Gly Tyr His Arg Met Trp Ala
100 105 110
His Arg Ala Tyr Lys Ala Ala Leu Pro Val Arg Ile Ile Leu Ala Leu
115 120 125
Phe Gly Gly Gly Ala Val Glu Gly Ser Ile Arg Trp Trp Ala Ser Ser
130 135 140
His Arg Val His His Arg Trp Thr Asp Ser Asn Lys Asp Pro Tyr Asp
145 150 155 160
Ala Arg Lys Gly Phe Trp Phe Ser His Phe Gly Trp Met Leu Leu Val
165 170 175
Pro Asn Pro Lys Asn Lys Gly Arg Thr Asp Ile Ser Asp Leu Asn Asn
180 185 190
Asp Trp Val Val Arg Leu Gln His Lys Tyr Tyr Val Tyr Val Leu Val
195 200 205
Phe Met Ala Ile Val Leu Pro Thr Leu Val Cys Gly Phe Gly Trp Gly
210 215 220
Asp Trp Lys Gly Gly Leu Val Tyr Ala Gly Ile Met Arg Tyr Thr Phe
225 230 235 240
Val Gln Gln Val Thr Phe Cys Val Asn Ser Leu Ala His Trp Ile Gly
245 250 255
Glu Gln Pro Phe Asp Asp Arg Arg Thr Pro Arg Asp His Ala Leu Thr
260 265 270
Ala Leu Val Thr Phe Gly Glu Gly Tyr His Asn Phe His His Glu Phe
275 280 285
Pro Ser Asp Tyr Arg Asn Ala Leu Ile Trp Tyr Gln Tyr Asp Pro Thr
290 295 300
Lys Trp Leu Ile Trp Thr Leu Lys Gln Val Gly Leu Ala Trp Asp Leu
305 310 315 320
Gln Thr Phe Ser Gln Asn Ala Ile Glu Gln Gly Leu Val Gln Gln Arg
325 330 335
Gln Lys Lys Leu Asp Lys Trp Arg Asn Asn Leu Asn Trp Gly Ile Pro
340 345 350
Ile Glu Gln Leu Pro Val Ile Glu Phe Glu Glu Phe Gln Glu Gln Ala
355 360 365
Lys Thr Arg Asp Leu Val Leu Ile Ser Gly Ile Val His Asp Val Ser
370 375 380
Ala Phe Val Glu His His Pro Gly Gly Lys Ala Leu Ile Met Ser Ala
385 390 395 400
Val Gly Lys Asp Gly Thr Ala Val Phe Asn Gly Gly Val Tyr Arg His
405 410 415
Ser Asn Ala Gly His Asn Leu Leu Ala Thr Met Arg Val Ser Val Ile
420 425 430
Arg Gly Gly Met Glu Val Glu Val Trp Lys Thr Ala Gln Asn Glu Lys
435 440 445
Lys Asp Gln Asn Ile Val Ser Asp Glu Ser Gly Asn Arg Ile His Arg
450 455 460
Ala Gly Leu Gln Ala Thr Arg Val Glu Asn Pro Gly Met Ser Gly Met
465 470 475 480
Ala Ala
<210> 34
<211> 1101
<212> DNA
<213> Yarrowia lipolytica
<220>
<221> CDS
<222> (1)..(1101)
<223> cholinephosphate cytidylyltransferase; GenBank Accession No.
XM_502978
<400> 34
atg gcc aaa agc aaa cga cgg tcg gag gct gtg gaa gag cac gtg acc 48
Met Ala Lys Ser Lys Arg Arg Ser Glu Ala Val Glu Glu His Val Thr
1 5 10 15
ggc tcg gac gag ggc ttg acc gat act tcg ggt cac gtg agc cct gcc 96
Gly Ser Asp Glu Gly Leu Thr Asp Thr Ser Gly His Val Ser Pro Ala
20 25 30
gcc aag aag cag aag aac tcg gag att cat ttc acc acc cag gct gcc 144
Ala Lys Lys Gln Lys Asn Ser Glu Ile His Phe Thr Thr Gln Ala Ala
35 40 45
cag cag ttg gat cgg gag cgc aag gag gag tat ctg gac tcg ctg atc 192
Gln Gln Leu Asp Arg Glu Arg Lys Glu Glu Tyr Leu Asp Ser Leu Ile
50 55 60
gac aac aag gac tat ctc aag tac cgt cct cga ggc tgg aag ctc aac 240
Asp Asn Lys Asp Tyr Leu Lys Tyr Arg Pro Arg Gly Trp Lys Leu Asn
65 70 75 80
aac ccg cct acc gac cga cct gtg cga atc tac gcc gat gga gtg ttt 288
Asn Pro Pro Thr Asp Arg Pro Val Arg Ile Tyr Ala Asp Gly Val Phe
85 90 95
gat ttg ttc cat ctg gga cac atg cgt cag ctg gag cag tcc aag aag 336
Asp Leu Phe His Leu Gly His Met Arg Gln Leu Glu Gln Ser Lys Lys
100 105 110
gcc ttc ccc aac gca gtg ttg att gtg ggc att ccc agc gac aag gag 384
Ala Phe Pro Asn Ala Val Leu Ile Val Gly Ile Pro Ser Asp Lys Glu
115 120 125
acc cac aag cgg aag gga ttg acc gtg ctg agt gac gtc cag cgg tac 432
Thr His Lys Arg Lys Gly Leu Thr Val Leu Ser Asp Val Gln Arg Tyr
130 135 140
gag acg gtg cga cac tgc aag tgg gtg gac gag gtg gtg gag gat gct 480
Glu Thr Val Arg His Cys Lys Trp Val Asp Glu Val Val Glu Asp Ala
145 150 155 160
ccc tgg tgt gtc acc atg gac ttt ctg gaa aaa cac aaa atc gac tac 528
Pro Trp Cys Val Thr Met Asp Phe Leu Glu Lys His Lys Ile Asp Tyr
165 170 175
gtg gcc cat gac gat ctg ccc tac gct tcc ggc aac gac gat gat atc 576
Val Ala His Asp Asp Leu Pro Tyr Ala Ser Gly Asn Asp Asp Asp Ile
180 185 190
tac aag ccc atc aag gag aag ggc atg ttt ctg gcc acc cag cga acc 624
Tyr Lys Pro Ile Lys Glu Lys Gly Met Phe Leu Ala Thr Gln Arg Thr
195 200 205
gag ggc att tcc acc tcg gac atc atc acc aag att atc cga gac tac 672
Glu Gly Ile Ser Thr Ser Asp Ile Ile Thr Lys Ile Ile Arg Asp Tyr
210 215 220
gac aag tat tta atg cga aac ttt gcc cgg ggt gct aac cga aag gat 720
Asp Lys Tyr Leu Met Arg Asn Phe Ala Arg Gly Ala Asn Arg Lys Asp
225 230 235 240
ctc aac gtc tcg tgg ctc aag aag aac gag ctg gac ttc aag cgt cat 768
Leu Asn Val Ser Trp Leu Lys Lys Asn Glu Leu Asp Phe Lys Arg His
245 250 255
gtg gcc gag ttc cga aac tcg ttc aag cga aag aag gtc ggt aag gat 816
Val Ala Glu Phe Arg Asn Ser Phe Lys Arg Lys Lys Val Gly Lys Asp
260 265 270
ctc tac ggc gag att cgc ggt ctg ctg cag aat gtg ctc att tgg aac 864
Leu Tyr Gly Glu Ile Arg Gly Leu Leu Gln Asn Val Leu Ile Trp Asn
275 280 285
ggc gac aac tcc ggc act tcc act ccc cag cga aag acg ctg cag acc 912
Gly Asp Asn Ser Gly Thr Ser Thr Pro Gln Arg Lys Thr Leu Gln Thr
290 295 300
aac gcc aag aag atg tac atg aac gtg ctc aag act ctg cag gct cct 960
Asn Ala Lys Lys Met Tyr Met Asn Val Leu Lys Thr Leu Gln Ala Pro
305 310 315 320
gac gct gtt gac gtg gac tcc tcg gag aac gtg tct gag aac gtc act 1008
Asp Ala Val Asp Val Asp Ser Ser Glu Asn Val Ser Glu Asn Val Thr
325 330 335
gat gag gag gag gaa gac gac gac gag gtt gat gag gac gaa gaa gcc 1056
Asp Glu Glu Glu Glu Asp Asp Asp Glu Val Asp Glu Asp Glu Glu Ala
340 345 350
gac gac gac gac gaa gac gac gaa gac gag gaa gac gac gag tag 1101
Asp Asp Asp Asp Glu Asp Asp Glu Asp Glu Glu Asp Asp Glu
355 360 365
<210> 35
<211> 366
<212> PRT
<213> Yarrowia lipolytica
<400> 35
Met Ala Lys Ser Lys Arg Arg Ser Glu Ala Val Glu Glu His Val Thr
1 5 10 15
Gly Ser Asp Glu Gly Leu Thr Asp Thr Ser Gly His Val Ser Pro Ala
20 25 30
Ala Lys Lys Gln Lys Asn Ser Glu Ile His Phe Thr Thr Gln Ala Ala
35 40 45
Gln Gln Leu Asp Arg Glu Arg Lys Glu Glu Tyr Leu Asp Ser Leu Ile
50 55 60
Asp Asn Lys Asp Tyr Leu Lys Tyr Arg Pro Arg Gly Trp Lys Leu Asn
65 70 75 80
Asn Pro Pro Thr Asp Arg Pro Val Arg Ile Tyr Ala Asp Gly Val Phe
85 90 95
Asp Leu Phe His Leu Gly His Met Arg Gln Leu Glu Gln Ser Lys Lys
100 105 110
Ala Phe Pro Asn Ala Val Leu Ile Val Gly Ile Pro Ser Asp Lys Glu
115 120 125
Thr His Lys Arg Lys Gly Leu Thr Val Leu Ser Asp Val Gln Arg Tyr
130 135 140
Glu Thr Val Arg His Cys Lys Trp Val Asp Glu Val Val Glu Asp Ala
145 150 155 160
Pro Trp Cys Val Thr Met Asp Phe Leu Glu Lys His Lys Ile Asp Tyr
165 170 175
Val Ala His Asp Asp Leu Pro Tyr Ala Ser Gly Asn Asp Asp Asp Ile
180 185 190
Tyr Lys Pro Ile Lys Glu Lys Gly Met Phe Leu Ala Thr Gln Arg Thr
195 200 205
Glu Gly Ile Ser Thr Ser Asp Ile Ile Thr Lys Ile Ile Arg Asp Tyr
210 215 220
Asp Lys Tyr Leu Met Arg Asn Phe Ala Arg Gly Ala Asn Arg Lys Asp
225 230 235 240
Leu Asn Val Ser Trp Leu Lys Lys Asn Glu Leu Asp Phe Lys Arg His
245 250 255
Val Ala Glu Phe Arg Asn Ser Phe Lys Arg Lys Lys Val Gly Lys Asp
260 265 270
Leu Tyr Gly Glu Ile Arg Gly Leu Leu Gln Asn Val Leu Ile Trp Asn
275 280 285
Gly Asp Asn Ser Gly Thr Ser Thr Pro Gln Arg Lys Thr Leu Gln Thr
290 295 300
Asn Ala Lys Lys Met Tyr Met Asn Val Leu Lys Thr Leu Gln Ala Pro
305 310 315 320
Asp Ala Val Asp Val Asp Ser Ser Glu Asn Val Ser Glu Asn Val Thr
325 330 335
Asp Glu Glu Glu Glu Asp Asp Asp Glu Val Asp Glu Asp Glu Glu Ala
340 345 350
Asp Asp Asp Asp Glu Asp Asp Glu Asp Glu Glu Asp Asp Glu
355 360 365
<210> 36
<211> 43
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer YL427
<400> 36
tttatcgatc ccactacttg tagtcaggcc atcttttacg tac 43
<210> 37
<211> 50
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer YL428
<400> 37
tttaagctta ggggcggcca ggggagcggc cagaacggca gtgagaatag 50
<210> 38
<211> 441
<212> DNA
<213> Yarrowia lipolytica
<400> 38
atcgatccca ctacttgtag tcaggccatc ttttacgtac gcactgtacc atgatgtcaa 60
tggagtatga tgaaccgact ttgagagact cacatctgca caacaccatg tttcagcgga 120
atccgacttc caacccaaac ccaagcccct gtcagatatc gtgagaaggc acggcaccaa 180
ctaatgcaca cactccacct gtattgcacc aagataatga gggcatcgtc ttggcgcgtc 240
ttggcgagag ccgtgtttcg tgacgcaatc agagcagttt ctggatagta tcttgtccag 300
aaacacgata taaaccccat cgacgggccc gttgaagagc accaacccac tatccaatcc 360
tccaatccaa caatgaagct cgctaccgcc tttactattc tcactgccgt tctggccgct 420
cccctggccg cccctaagct t 441
<210> 39
<211> 38
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer YL429
<400> 39
cccaagcttg ctggttttgc agccaaaata tctgcatc 38
<210> 40
<211> 37
<212> DNA
<213> Artificial Sequence
<220>
<223> Primer YL430
<400> 40
cttcgtacgc tattttactt cccttacttg gaacttg 37
<210> 41
<211> 1581
<212> DNA
<213> Saccharomyces cerevisiae
<400> 41
aagcttgctg gttttgcagc caaaatatct gcatcaatga caaacgaaac tagcgataga 60
cctttggtcc acttcacacc caacaagggc tggatgaatg acccaaatgg gttgtggtac 120
gatgaaaaag atgccaaatg gcatctgtac tttcaataca acccaaatga caccgtatgg 180
ggtacgccat tgttttgggg ccatgctact tccgatgatt tgactaattg ggaagatcaa 240
cccattgcta tcgctcccaa gcgtaacgat tcaggtgctt tctctggctc catggtggtt 300
gattacaaca acacgagtgg gtttttcaat gatactattg atccaagaca aagatgcgtt 360
gcgatttgga cttataacac tcctgaaagt gaagagcaat acattagcta ttctcttgat 420
ggtggttaca cttttactga ataccaaaag aaccctgttt tagctgccaa ctccactcaa 480
ttcagagatc caaaggtgtt ctggtatgaa ccttctcaaa aatggattat gacggctgcc 540
aaatcacaag actacaaaat tgaaatttac tcctctgatg acttgaagtc ctggaagcta 600
gaatctgcat ttgccaacga aggtttctta ggctaccaat acgaatgtcc aggtttgatt 660
gaagtcccaa ctgagcaaga tccttccaaa tcttattggg tcatgtttat ttctatcaac 720
ccaggtgcac ctgctggcgg ttccttcaac caatattttg ttggatcctt caatggtact 780
cattttgaag cgtttgacaa tcaatctaga gtggtagatt ttggtaagga ctactatgcc 840
ttgcaaactt tcttcaacac tgacccaacc tacggttcag cattaggtat tgcctgggct 900
tcaaactggg agtacagtgc ctttgtccca actaacccat ggagatcatc catgtctttg 960
gtccgcaagt tttctttgaa cactgaatat caagctaatc cagagactga attgatcaat 1020
ttgaaagccg aaccaatatt gaacattagt aatgctggtc cctggtctcg ttttgctact 1080
aacacaactc taactaaggc caattcttac aatgtcgatt tgagcaactc gactggtacc 1140
ctagagtttg agttggttta cgctgttaac accacacaaa ccatatccaa atccgtcttt 1200
gccgacttat cactttggtt caagggttta gaagatcctg aagaatattt gagaatgggt 1260
tttgaagtca gtgcttcttc cttctttttg gaccgtggta actctaaggt caagtttgtc 1320
aaggagaacc catatttcac aaacagaatg tctgtcaaca accaaccatt caagtctgag 1380
aacgacctaa gttactataa agtgtacggc ctactggatc aaaacatctt ggaattgtac 1440
ttcaacgatg gagatgtggt ttctacaaat acctacttca tgaccaccgg taacgctcta 1500
ggatctgtga acatgaccac tggtgtcgat aatttgttct acattgacaa gttccaagta 1560
agggaagtaa aatagcgtac g 1581
Claims (15)
- 수크로스 인버타아제(invertase) 활성을 갖는 폴리펩티드를 코딩하는 외인성 폴리뉴클레오티드를 포함하며,
(a) 상기 폴리펩티드는 성숙 수크로스 인버타아제를 코딩하는 폴리펩티드 서열에 융합된 시그널(signal) 서열을 포함하고;
(b) 상기 시그널 서열은
(i) Xpr2 프리(pre)/프로(pro)-영역 및 N-말단 Xpr2 단편; 및
(ii) 제2 아미노산이 임의의 소수성 아미노산일 수 있는 수크로스 인버타아제 시그널 서열
로 이루어진 군으로부터 선택되며;
(c) 성숙 수크로스 인버타아제를 코딩하는 상기 폴리펩티드 서열은, 서열 번호 4의 서열과 비교할 때, CLUSTALW 정렬법을 기반으로 할 경우 서열 동일성이 80% 이상인 형질전환된 야로위아 리포라이티카(Yarrowia lipolytica). - 제1항에 있어서, 수크로스 인버타아제 시그널 서열의 상기 제2 아미노산은 류신, 페닐알라닌, 아이소류신, 발린 및 메티오닌으로 이루어진 군으로부터 선택되는 형질전환된 야로위아 리포라이티카.
- 제1항에 있어서, 성숙 수크로스 인버타아제를 코딩하는 상기 폴리펩티드 서열은 서열 번호 4에 기술되어 있는 형질전환된 야로위아 리포라이티카.
- 제1항에 있어서, 상기 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은 야로위아 리포라이티카로부터 유래되고, 상기 수크로스 인버타아제 시그널 서열은 사카로마이세스 세레비지애(Saccharomyces cerevisiae )로부터 유래된 형질전환된 야로위아 리포라이티카.
- 제4항에 있어서, 상기 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은
(a) 알칼리성 세포외 프로테아제 전구체의 N-말단의 157개 아미노산을 포함하는 Xpr2 프리/프로-영역; 및
(b) 성숙 알칼리성 세포외 프로테아제의 N-말단의 13개 아미노산을 포함하는 N-말단 Xpr2 단편을 포함하는 형질전환된 야로위아 리포라이티카. - 제5항에 있어서, 상기 Xpr2 프리/프로-영역 및 N-말단 Xpr2 단편은 서열 번호 10에 기술되어 있는 형질전환된 야로위아 리포라이티카.
- 제4항에 있어서, 상기 수크로스 인버타아제 시그널 서열은 서열 번호 8에 기술되어 있는 형질전환된 야로위아 리포라이티카.
- 제1항에 있어서, 수크로스 인버타아제 코딩 서열에 융합된 시그널 서열을 포함하는 상기 폴리펩티드는 서열 번호 12의 서열 및 서열 번호 20의 서열로 이루어진 군으로부터 선택되는 형질전환된 야로위아 리포라이티카.
- 제1항에 있어서, 수크로스가 유일한 탄소 공급원인 조건 하에서 성장할 수 있는 형질전환된 야로위아 리포라이티카.
- 제1항에 있어서, 관심대상의 적어도 하나의 비천연 생성물을 생성할 수 있는 형질전환된 야로위아 리포라이티카.
- 제10항에 있어서, 관심대상의 상기 적어도 하나의 비천연 생성물은 다중불포화 지방산, 카로티노이드, 아미노산, 비타민, 스테롤, 플라보노이드, 유기 산, 폴리올 및 하이드록시에스테르, 퀴논-유도된 화합물 및 레스베라트롤로 이루어진 군으로부터 선택되는 형질전환된 야로위아 리포라이티카.
- 제1항 또는 제10항에 있어서, 80% 이상의 수크로스 인버타아제를 세포외로 분비할 수 있는, 탄소 공급원으로서 적어도 수크로스를 갖는 배양 배지에서 성장된 형질전환된 야로위아 리포라이티카.
- a) 수크로스; 및
b) 글루코스
로 이루어진 군으로부터 선택되는 적어도 하나의 탄소 공급원을 갖는 배양 배지에서 제10항의 형질전환된 야로위아 리포라이티카를 성장시키고,
이에 의해 관심대상의 적어도 하나의 비천연 생성물을 생성하는 단계와, 선택적으로, 관심대상의 상기 적어도 하나의 비천연 생성물을 회수하는 단계를 포함하는, 관심대상의 적어도 하나의 비천연 생성물을 생성하는 방법. - 제13항에 있어서, 관심대상의 상기 적어도 하나의 비천연 생성물은 다중불포화 지방산, 카로티노이드, 아미노산, 비타민, 스테롤, 플라보노이드, 유기 산, 폴리올 및 하이드록시에스테르, 퀴논-유도된 화합물 및 레스베라트롤로 이루어진 군으로부터 선택되는 방법.
- 제13항에 있어서, 상기 형질전환된 야로위아 리포라이티카는 80% 이상의 수크로스 인버타아제를 세포외로 분비할 수 있는 방법.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201061428590P | 2010-12-30 | 2010-12-30 | |
| US61/428,590 | 2010-12-30 | ||
| PCT/US2011/060788 WO2012091812A1 (en) | 2010-12-30 | 2011-11-15 | Use of saccharomyces cerevisiae suc2 gene in yarrowia lipolytica for sucrose utilization |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20140000711A true KR20140000711A (ko) | 2014-01-03 |
Family
ID=45063228
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020137019892A Withdrawn KR20140000711A (ko) | 2010-12-30 | 2011-11-15 | 수크로스 이용에 있어서의 야로위아 리포라이티카에서의 사카로마이세스 세레비지애 suc2 유전자의 용도 |
Country Status (10)
| Country | Link |
|---|---|
| US (1) | US8735137B2 (ko) |
| EP (1) | EP2658962A1 (ko) |
| JP (1) | JP2014503216A (ko) |
| KR (1) | KR20140000711A (ko) |
| CN (1) | CN103443266A (ko) |
| AU (1) | AU2011353002A1 (ko) |
| BR (1) | BR112013016769A2 (ko) |
| CA (1) | CA2824584A1 (ko) |
| CL (1) | CL2013001887A1 (ko) |
| WO (1) | WO2012091812A1 (ko) |
Families Citing this family (8)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| CN104178435A (zh) * | 2014-08-21 | 2014-12-03 | 天津科技大学 | 一种适合于高糖面团发酵的高活性干酵母 |
| CA3004177A1 (en) | 2015-11-24 | 2017-06-01 | Cargill, Incorporated | Genetically modified yeasts and fermentation processes using genetically modified yeasts |
| CN107022499A (zh) * | 2017-05-04 | 2017-08-08 | 北京化工大学 | 调控酿酒酵母社会行为提高生物乙醇发酵速率效率的方法 |
| CN108070579A (zh) * | 2017-12-21 | 2018-05-25 | 中诺生物科技发展江苏有限公司 | 一种蔗糖转化酶工业化生产方法 |
| CN111996132A (zh) * | 2020-07-21 | 2020-11-27 | 郑州大学 | 一种解脂耶氏酵母表面展示方法 |
| US20250320535A1 (en) | 2021-05-17 | 2025-10-16 | Dsm Ip Assets B.V. | Novel technology to enable sucrose utilization in strains for biosynthetic production |
| DK181442B1 (en) * | 2021-05-17 | 2024-01-17 | Dsm Ip Assets Bv | Cells capable of producing one or more human milk oligosaccharides (hmos) comprising expression of an invertase, method comprising said cells for biosynthetic production and use of said cells for biosynthetic production; use of an invertase in a biosynthetic production |
| CN119824045B (zh) * | 2025-03-19 | 2025-07-25 | 东晓生物科技股份有限公司 | Fads基因在调控解脂耶氏酵母发酵生产赤藓糖醇的产量中的应用 |
Family Cites Families (39)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4880741A (en) | 1983-10-06 | 1989-11-14 | Pfizer Inc. | Process for transformation of Yarrowia lipolytica |
| US5071764A (en) | 1983-10-06 | 1991-12-10 | Pfizer Inc. | Process for integrative transformation of yarrowia lipolytica |
| US4683202A (en) | 1985-03-28 | 1987-07-28 | Cetus Corporation | Process for amplifying nucleic acid sequences |
| US4937189A (en) | 1985-10-18 | 1990-06-26 | Pfizer Inc. | Expression and secretion of heterologous proteins by Yarrowia lipolytica transformants |
| FR2626584B1 (fr) | 1988-01-28 | 1990-07-13 | Agronomique Inst Nat Rech | Sequence ars efficace chez yarrowia lipolytica et procede pour sa preparation |
| EP0402226A1 (en) * | 1989-06-06 | 1990-12-12 | Institut National De La Recherche Agronomique | Transformation vectors for yeast yarrowia |
| US7125672B2 (en) | 2003-05-07 | 2006-10-24 | E. I. Du Pont De Nemours And Company | Codon-optimized genes for the production of polyunsaturated fatty acids in oleaginous yeasts |
| US7238482B2 (en) | 2003-05-07 | 2007-07-03 | E. I. Du Pont De Nemours And Company | Production of polyunsaturated fatty acids in oleaginous yeasts |
| US7259255B2 (en) | 2003-06-25 | 2007-08-21 | E. I. Du Pont De Nemours And Company | Glyceraldehyde-3-phosphate dehydrogenase and phosphoglycerate mutase promoters for gene expression in oleaginous yeast |
| US20110059496A1 (en) | 2003-06-25 | 2011-03-10 | E. I. Du Pont De Nemours And Company | Glyceraldehyde-3-phosphate dehydrogenase and phosphoglycerate mutase promoters for gene expression in oleaginous yeast |
| US7504259B2 (en) | 2003-11-12 | 2009-03-17 | E. I. Du Pont De Nemours And Company | Δ12 desaturases suitable for altering levels of polyunsaturated fatty acids in oleaginous yeast |
| WO2005049805A2 (en) | 2003-11-14 | 2005-06-02 | E.I. Dupont De Nemours And Company | Fructose-bisphosphate aldolase regulatory sequences for gene expression in oleaginous yeast |
| US7550651B2 (en) | 2004-06-25 | 2009-06-23 | E.I. Du Pont De Nemours And Company | Delta-8 desaturase and its use in making polyunsaturated fatty acids |
| US20060094102A1 (en) | 2004-11-04 | 2006-05-04 | Zhixiong Xue | Ammonium transporter promoter for gene expression in oleaginous yeast |
| US7879591B2 (en) | 2004-11-04 | 2011-02-01 | E.I. Du Pont De Nemours And Company | High eicosapentaenoic acid producing strains of Yarrowia lipolytica |
| US7550286B2 (en) | 2004-11-04 | 2009-06-23 | E. I. Du Pont De Nemours And Company | Docosahexaenoic acid producing strains of Yarrowia lipolytica |
| US7772444B2 (en) | 2005-05-19 | 2010-08-10 | E. I. Du Pont De Nemours And Company | Method for the production of resveratrol in a recombinant oleaginous microorganism |
| US7470532B2 (en) | 2005-10-19 | 2008-12-30 | E.I. Du Pont De Nemours And Company | Mortierella alpina C16/18 fatty acid elongase |
| DK1951866T3 (da) | 2005-11-23 | 2014-10-27 | Du Pont | Delta-9-elongaser og anvendelse heraf til fremstilling af flerumættede fedtsyrer |
| EP2004801A2 (en) | 2006-03-20 | 2008-12-24 | Microbia Precision Engineering | Production of quinone derived compounds in oleaginous yeast fungi |
| US7678560B2 (en) | 2006-05-17 | 2010-03-16 | E.I. Du Pont De Nemours And Company | Δ 5 desaturase and its use in making polyunsaturated fatty acids |
| US7695950B2 (en) | 2006-05-17 | 2010-04-13 | E. I. Du Pont De Nemours And Company | Δ5 desaturase and its use in making polyunsaturated fatty acids |
| EP2074214A2 (en) | 2006-09-28 | 2009-07-01 | Microbia, Inc. | Production of sterols in oleaginous yeast and fungi |
| DK2087105T3 (da) | 2006-10-30 | 2015-05-26 | Du Pont | Delta 17-desaturase og anvendelse heraf ved fremstilling af flerumættede fedtsyrer |
| US7709239B2 (en) | 2006-12-07 | 2010-05-04 | E.I. Du Pont De Nemours And Company | Mutant Δ8 desaturase genes engineered by targeted mutagenesis and their use in making polyunsaturated fatty acids |
| US8846374B2 (en) | 2006-12-12 | 2014-09-30 | E I Du Pont De Nemours And Company | Carotenoid production in a recombinant oleaginous yeast |
| ES2559312T3 (es) | 2007-04-03 | 2016-02-11 | E. I. Du Pont De Nemours And Company | Multienzimas y su uso en la fabricación de ácidos grasos poliinsaturados |
| US7790156B2 (en) | 2007-04-10 | 2010-09-07 | E. I. Du Pont De Nemours And Company | Δ-8 desaturases and their use in making polyunsaturated fatty acids |
| US7794701B2 (en) | 2007-04-16 | 2010-09-14 | E.I. Du Pont De Nemours And Company | Δ-9 elongases and their use in making polyunsaturated fatty acids |
| US8957280B2 (en) | 2007-05-03 | 2015-02-17 | E. I. Du Pont De Nemours And Company | Delta-5 desaturases and their use in making polyunsaturated fatty acids |
| US20090004715A1 (en) * | 2007-06-01 | 2009-01-01 | Solazyme, Inc. | Glycerol Feedstock Utilization for Oil-Based Fuel Manufacturing |
| US20090117253A1 (en) | 2007-10-03 | 2009-05-07 | E. I. Du Pont De Nemours And Company | Peroxisome biogenesis factor protein (pex) disruptions for altering polyunsaturated fatty acids and total lipid content in oleaginous eukaryotic organisms |
| US8815567B2 (en) | 2007-11-30 | 2014-08-26 | E I Du Pont De Nemours And Company | Coenzyme Q10 production in a recombinant oleaginous yeast |
| WO2009126890A2 (en) | 2008-04-10 | 2009-10-15 | Microbia, Inc. | Production of carotenoids in oleaginous yeast and fungi |
| AU2009293160B2 (en) | 2008-09-19 | 2013-11-21 | E. I. Du Pont De Nemours And Company | Mutant delta5 desaturases and their use in making polyunsaturated fatty acids |
| CN102257126B (zh) | 2008-12-18 | 2014-07-09 | 纳幕尔杜邦公司 | 减少发酵过程中的丙二酸副产物 |
| EP2442666B1 (en) * | 2009-06-16 | 2015-04-08 | E. I. du Pont de Nemours and Company | High eicosapentaenoic acid oils from improved optimized strains of yarrowia lipolytica |
| US8637298B2 (en) | 2009-06-16 | 2014-01-28 | E I Du Pont De Nemours And Company | Optimized strains of yarrowia lipolytica for high eicosapentaenoic acid production |
| CN103189513A (zh) | 2010-03-31 | 2013-07-03 | 纳幕尔杜邦公司 | 上调磷酸戊糖途径以提高转基因微生物中受关注的非天然产物的产量 |
-
2011
- 2011-11-15 JP JP2013547474A patent/JP2014503216A/ja active Pending
- 2011-11-15 EP EP11788953.5A patent/EP2658962A1/en not_active Withdrawn
- 2011-11-15 AU AU2011353002A patent/AU2011353002A1/en not_active Abandoned
- 2011-11-15 BR BR112013016769A patent/BR112013016769A2/pt not_active IP Right Cessation
- 2011-11-15 WO PCT/US2011/060788 patent/WO2012091812A1/en not_active Ceased
- 2011-11-15 CN CN2011800630477A patent/CN103443266A/zh active Pending
- 2011-11-15 KR KR1020137019892A patent/KR20140000711A/ko not_active Withdrawn
- 2011-11-15 US US13/296,524 patent/US8735137B2/en not_active Expired - Fee Related
- 2011-11-15 CA CA2824584A patent/CA2824584A1/en not_active Abandoned
-
2013
- 2013-06-26 CL CL2013001887A patent/CL2013001887A1/es unknown
Also Published As
| Publication number | Publication date |
|---|---|
| CL2013001887A1 (es) | 2014-01-31 |
| US20120171719A1 (en) | 2012-07-05 |
| EP2658962A1 (en) | 2013-11-06 |
| WO2012091812A1 (en) | 2012-07-05 |
| CA2824584A1 (en) | 2012-07-05 |
| CN103443266A (zh) | 2013-12-11 |
| BR112013016769A2 (pt) | 2016-10-11 |
| AU2011353002A1 (en) | 2013-05-30 |
| JP2014503216A (ja) | 2014-02-13 |
| US8735137B2 (en) | 2014-05-27 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| DK2087105T3 (da) | Delta 17-desaturase og anvendelse heraf ved fremstilling af flerumættede fedtsyrer | |
| CN101437953B (zh) | 用于改变含油生物的多不饱和脂肪酸和油含量的二酰基甘油酰基转移酶 | |
| CN101939434B (zh) | 用于在大豆中提高种子贮藏油脂的生成和改变脂肪酸谱的来自解脂耶氏酵母的dgat基因 | |
| CN101365788B (zh) | Δ-9延伸酶及其在制备多不饱和脂肪酸中的用途 | |
| KR102319845B1 (ko) | 조류 숙주 세포에 대한 crispr-cas 시스템 | |
| AU2017220789B2 (en) | Compositions and Methods for Modifying Genomes | |
| KR102711998B1 (ko) | 조작되고 완전-기능 맞춤 당단백질 | |
| CN101646766B (zh) | △17去饱和酶及其用于制备多不饱和脂肪酸的用途 | |
| AU2016358063B2 (en) | Functional expression of monooxygenases and methods of use | |
| KR20220012327A (ko) | 피토칸나비노이드 및 피토칸나비노이드 전구체의 생산을 위한 방법 및 세포 | |
| KR102147005B1 (ko) | Fad2 성능 유전자좌 및 표적화 파단을 유도할 수 있는 상응하는 표적 부위 특이적 결합 단백질 | |
| AU609783B2 (en) | Novel fusion proteins and their purification | |
| DK2443248T3 (en) | IMPROVEMENT OF LONG-CHAIN POLYUM Saturated OMEGA-3 AND OMEGA-6 FATTY ACID BIOS SYNTHESIS BY EXPRESSION OF ACYL-CoA LYSOPHOSPHOLIPID ACYL TRANSFERASES | |
| CN108138121B (zh) | 用微生物高水平生产长链二羧酸 | |
| DK2140006T3 (en) | DELTA-5 desaturases AND USE THEREOF FOR THE PRODUCTION OF polyunsaturated fatty acids | |
| KR20140000711A (ko) | 수크로스 이용에 있어서의 야로위아 리포라이티카에서의 사카로마이세스 세레비지애 suc2 유전자의 용도 | |
| CN107250163A (zh) | 修饰的葡糖淀粉酶和具有增强的生物产物产生的酵母菌株 | |
| CN111836825A (zh) | 优化的植物crispr/cpf1系统 | |
| KR20140092759A (ko) | 숙주 세포 및 아이소부탄올의 제조 방법 | |
| KR20130138760A (ko) | 고농도의 에이코사펜타엔산 생성을 위한 재조합 미생물 숙주 세포 | |
| KR20130032897A (ko) | 알코올 발효 시의 알코올 에스테르의 생성 및 원위치에서의 생성물 제거 | |
| CN109996874A (zh) | 10-甲基硬脂酸的异源性产生 | |
| CN101883843A (zh) | 破坏过氧化物酶体生物合成因子蛋白(pex)以改变含油真核生物中多不饱和脂肪酸和总脂质含量 | |
| AU2017233862B2 (en) | Methods and compositions for increased double stranded RNA production | |
| DK2475679T3 (da) | Forbedrede, optimerede stammer af yarrowia lipolytica til fremstilling af højkoncentreret eicosapentaensyre |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20130726 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |