KR20140089384A - 알츠하이머병의 치료, 진단 및 모니터링 방법 - Google Patents
알츠하이머병의 치료, 진단 및 모니터링 방법 Download PDFInfo
- Publication number
- KR20140089384A KR20140089384A KR1020147014033A KR20147014033A KR20140089384A KR 20140089384 A KR20140089384 A KR 20140089384A KR 1020147014033 A KR1020147014033 A KR 1020147014033A KR 20147014033 A KR20147014033 A KR 20147014033A KR 20140089384 A KR20140089384 A KR 20140089384A
- Authority
- KR
- South Korea
- Prior art keywords
- amino acid
- subject
- genetic
- allele
- snp
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Withdrawn
Links
- 208000024827 Alzheimer disease Diseases 0.000 title claims abstract description 336
- 238000000034 method Methods 0.000 title claims abstract description 290
- 238000012544 monitoring process Methods 0.000 title description 2
- 230000035772 mutation Effects 0.000 claims abstract description 109
- 239000003814 drug Substances 0.000 claims abstract description 55
- 229940124597 therapeutic agent Drugs 0.000 claims abstract description 45
- 238000003745 diagnosis Methods 0.000 claims abstract description 36
- 238000011282 treatment Methods 0.000 claims abstract description 29
- 230000004044 response Effects 0.000 claims abstract description 22
- 238000004393 prognosis Methods 0.000 claims abstract description 12
- 230000002250 progressing effect Effects 0.000 claims abstract description 8
- 125000003275 alpha amino acid group Chemical group 0.000 claims description 244
- 108700028369 Alleles Proteins 0.000 claims description 187
- 230000007614 genetic variation Effects 0.000 claims description 186
- 108090000623 proteins and genes Proteins 0.000 claims description 171
- 102100037792 Interleukin-6 receptor subunit alpha Human genes 0.000 claims description 146
- 238000006467 substitution reaction Methods 0.000 claims description 139
- 101000841744 Homo sapiens Netrin receptor UNC5C Proteins 0.000 claims description 114
- 102100029514 Netrin receptor UNC5C Human genes 0.000 claims description 114
- 239000000523 sample Substances 0.000 claims description 108
- 125000003729 nucleotide group Chemical group 0.000 claims description 66
- 230000002068 genetic effect Effects 0.000 claims description 63
- 150000007523 nucleic acids Chemical class 0.000 claims description 63
- 239000002773 nucleotide Substances 0.000 claims description 62
- 102000039446 nucleic acids Human genes 0.000 claims description 56
- 108020004707 nucleic acids Proteins 0.000 claims description 56
- 102200115791 rs121918427 Human genes 0.000 claims description 56
- 102200010335 rs2228145 Human genes 0.000 claims description 56
- 208000037265 diseases, disorders, signs and symptoms Diseases 0.000 claims description 55
- 238000004458 analytical method Methods 0.000 claims description 51
- 201000010099 disease Diseases 0.000 claims description 47
- 108091034117 Oligonucleotide Proteins 0.000 claims description 43
- 102000004169 proteins and genes Human genes 0.000 claims description 41
- 238000001514 detection method Methods 0.000 claims description 40
- 239000003153 chemical reaction reagent Substances 0.000 claims description 39
- 210000001519 tissue Anatomy 0.000 claims description 37
- 239000012472 biological sample Substances 0.000 claims description 36
- 102100033857 Neurotrophin-4 Human genes 0.000 claims description 33
- 101000599048 Homo sapiens Interleukin-6 receptor subunit alpha Proteins 0.000 claims description 32
- 238000003556 assay Methods 0.000 claims description 30
- FWMNVWWHGCHHJJ-SKKKGAJSSA-N 4-amino-1-[(2r)-6-amino-2-[[(2r)-2-[[(2r)-2-[[(2r)-2-amino-3-phenylpropanoyl]amino]-3-phenylpropanoyl]amino]-4-methylpentanoyl]amino]hexanoyl]piperidine-4-carboxylic acid Chemical compound C([C@H](C(=O)N[C@H](CC(C)C)C(=O)N[C@H](CCCCN)C(=O)N1CCC(N)(CC1)C(O)=O)NC(=O)[C@H](N)CC=1C=CC=CC=1)C1=CC=CC=C1 FWMNVWWHGCHHJJ-SKKKGAJSSA-N 0.000 claims description 29
- 238000012217 deletion Methods 0.000 claims description 29
- 230000037430 deletion Effects 0.000 claims description 29
- 101000996663 Homo sapiens Neurotrophin-4 Proteins 0.000 claims description 28
- 238000003780 insertion Methods 0.000 claims description 27
- 230000037431 insertion Effects 0.000 claims description 27
- 239000003550 marker Substances 0.000 claims description 27
- 108090000765 processed proteins & peptides Proteins 0.000 claims description 23
- 230000001225 therapeutic effect Effects 0.000 claims description 22
- 230000003321 amplification Effects 0.000 claims description 19
- 210000001175 cerebrospinal fluid Anatomy 0.000 claims description 19
- 238000003199 nucleic acid amplification method Methods 0.000 claims description 19
- 238000004949 mass spectrometry Methods 0.000 claims description 17
- 238000012216 screening Methods 0.000 claims description 17
- 101150056950 Ntrk2 gene Proteins 0.000 claims description 16
- 238000009396 hybridization Methods 0.000 claims description 16
- 238000012163 sequencing technique Methods 0.000 claims description 14
- 230000008685 targeting Effects 0.000 claims description 14
- 101710163270 Nuclease Proteins 0.000 claims description 13
- 102000004196 processed proteins & peptides Human genes 0.000 claims description 12
- 230000002829 reductive effect Effects 0.000 claims description 12
- 210000004369 blood Anatomy 0.000 claims description 11
- 239000008280 blood Substances 0.000 claims description 11
- 210000002966 serum Anatomy 0.000 claims description 11
- 206010036790 Productive cough Diseases 0.000 claims description 10
- 150000001413 amino acids Chemical class 0.000 claims description 10
- 230000009286 beneficial effect Effects 0.000 claims description 10
- 238000001574 biopsy Methods 0.000 claims description 10
- 238000001962 electrophoresis Methods 0.000 claims description 10
- 230000008569 process Effects 0.000 claims description 10
- 210000003296 saliva Anatomy 0.000 claims description 10
- 230000028327 secretion Effects 0.000 claims description 10
- 210000003802 sputum Anatomy 0.000 claims description 10
- 208000024794 sputum Diseases 0.000 claims description 10
- 108020004705 Codon Proteins 0.000 claims description 9
- 230000002939 deleterious effect Effects 0.000 claims description 9
- 210000000582 semen Anatomy 0.000 claims description 9
- 239000000758 substrate Substances 0.000 claims description 9
- 210000004243 sweat Anatomy 0.000 claims description 9
- 238000004587 chromatography analysis Methods 0.000 claims description 8
- 238000011161 development Methods 0.000 claims description 8
- 238000002405 diagnostic procedure Methods 0.000 claims description 8
- 230000000694 effects Effects 0.000 claims description 8
- 238000002493 microarray Methods 0.000 claims description 8
- 239000003607 modifier Substances 0.000 claims description 8
- 102000053642 Catalytic RNA Human genes 0.000 claims description 7
- 108090000994 Catalytic RNA Proteins 0.000 claims description 7
- 239000003298 DNA probe Substances 0.000 claims description 7
- JLCPHMBAVCMARE-UHFFFAOYSA-N [3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[3-[[3-[[3-[[3-[[3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-[[5-(2-amino-6-oxo-1H-purin-9-yl)-3-hydroxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxyoxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(5-methyl-2,4-dioxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(6-aminopurin-9-yl)oxolan-2-yl]methoxy-hydroxyphosphoryl]oxy-5-(4-amino-2-oxopyrimidin-1-yl)oxolan-2-yl]methyl [5-(6-aminopurin-9-yl)-2-(hydroxymethyl)oxolan-3-yl] hydrogen phosphate Polymers Cc1cn(C2CC(OP(O)(=O)OCC3OC(CC3OP(O)(=O)OCC3OC(CC3O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c3nc(N)[nH]c4=O)C(COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3COP(O)(=O)OC3CC(OC3CO)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3ccc(N)nc3=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cc(C)c(=O)[nH]c3=O)n3cc(C)c(=O)[nH]c3=O)n3ccc(N)nc3=O)n3cc(C)c(=O)[nH]c3=O)n3cnc4c3nc(N)[nH]c4=O)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)n3cnc4c(N)ncnc34)O2)c(=O)[nH]c1=O JLCPHMBAVCMARE-UHFFFAOYSA-N 0.000 claims description 7
- 230000015556 catabolic process Effects 0.000 claims description 7
- 238000006731 degradation reaction Methods 0.000 claims description 7
- 230000017854 proteolysis Effects 0.000 claims description 7
- 108091092562 ribozyme Proteins 0.000 claims description 7
- 239000003446 ligand Substances 0.000 claims description 6
- 210000004877 mucosa Anatomy 0.000 claims description 6
- 238000000734 protein sequencing Methods 0.000 claims description 6
- 108020004518 RNA Probes Proteins 0.000 claims description 5
- 239000003391 RNA probe Substances 0.000 claims description 5
- 230000004913 activation Effects 0.000 claims description 5
- 239000000556 agonist Substances 0.000 claims description 5
- 230000001640 apoptogenic effect Effects 0.000 claims description 5
- 230000003340 mental effect Effects 0.000 claims description 5
- 239000003068 molecular probe Substances 0.000 claims description 5
- 239000000126 substance Substances 0.000 claims description 5
- 101150037123 APOE gene Proteins 0.000 claims description 4
- 230000003247 decreasing effect Effects 0.000 claims description 4
- 238000003384 imaging method Methods 0.000 claims description 4
- 210000004400 mucous membrane Anatomy 0.000 claims description 4
- 102100029470 Apolipoprotein E Human genes 0.000 claims description 3
- 230000001627 detrimental effect Effects 0.000 claims description 3
- 230000029087 digestion Effects 0.000 claims description 3
- 108010038501 Interleukin-6 Receptors Proteins 0.000 description 112
- 210000004027 cell Anatomy 0.000 description 32
- 102000007592 Apolipoproteins Human genes 0.000 description 25
- 108010071619 Apolipoproteins Proteins 0.000 description 25
- 241000282414 Homo sapiens Species 0.000 description 19
- 108020004414 DNA Proteins 0.000 description 17
- 239000000203 mixture Substances 0.000 description 16
- 108091033319 polynucleotide Proteins 0.000 description 16
- 102000040430 polynucleotide Human genes 0.000 description 16
- 239000002157 polynucleotide Substances 0.000 description 16
- 239000000047 product Substances 0.000 description 16
- 210000000349 chromosome Anatomy 0.000 description 15
- 102000005962 receptors Human genes 0.000 description 15
- 108020003175 receptors Proteins 0.000 description 15
- 230000000875 corresponding effect Effects 0.000 description 14
- 108010008355 arginyl-glutamine Proteins 0.000 description 13
- UJWYPUUXIAKEES-CUJWVEQBSA-N His-Cys-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UJWYPUUXIAKEES-CUJWVEQBSA-N 0.000 description 12
- PMGDADKJMCOXHX-UHFFFAOYSA-N L-Arginyl-L-glutamin-acetat Natural products NC(=N)NCCCC(N)C(=O)NC(CCC(N)=O)C(O)=O PMGDADKJMCOXHX-UHFFFAOYSA-N 0.000 description 12
- 108010025020 Nerve Growth Factor Proteins 0.000 description 12
- 102000007072 Nerve Growth Factors Human genes 0.000 description 12
- KLYYKKGCPOGDPE-OEAJRASXSA-N Phe-Thr-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O KLYYKKGCPOGDPE-OEAJRASXSA-N 0.000 description 12
- VVZDBPBZHLQPPB-XVKPBYJWSA-N Val-Glu-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O VVZDBPBZHLQPPB-XVKPBYJWSA-N 0.000 description 12
- 239000012528 membrane Substances 0.000 description 12
- 210000004379 membrane Anatomy 0.000 description 12
- 208000022099 Alzheimer disease 2 Diseases 0.000 description 11
- 241000124008 Mammalia Species 0.000 description 11
- 108010087924 alanylproline Proteins 0.000 description 11
- 230000008499 blood brain barrier function Effects 0.000 description 11
- 210000001218 blood-brain barrier Anatomy 0.000 description 11
- 101710137189 Amyloid-beta A4 protein Proteins 0.000 description 10
- 102100022704 Amyloid-beta precursor protein Human genes 0.000 description 10
- 101710151993 Amyloid-beta precursor protein Proteins 0.000 description 10
- 108010002311 N-glycylglutamic acid Proteins 0.000 description 10
- 239000003795 chemical substances by application Substances 0.000 description 10
- 229920001184 polypeptide Polymers 0.000 description 10
- 108091032973 (ribonucleotides)n+m Proteins 0.000 description 9
- WRNAXCVRSBBKGS-BQBZGAKWSA-N Glu-Gly-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)NCC(=O)N[C@@H](CCC(N)=O)C(O)=O WRNAXCVRSBBKGS-BQBZGAKWSA-N 0.000 description 9
- VOCZPDONPURUHV-QEWYBTABSA-N Ile-Phe-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N VOCZPDONPURUHV-QEWYBTABSA-N 0.000 description 9
- BPANDPNDMJHFEV-CIUDSAMLSA-N Leu-Asp-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O BPANDPNDMJHFEV-CIUDSAMLSA-N 0.000 description 9
- JIODCDXKCJRMEH-NHCYSSNCSA-N Val-Arg-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N JIODCDXKCJRMEH-NHCYSSNCSA-N 0.000 description 9
- 238000003776 cleavage reaction Methods 0.000 description 9
- 230000000295 complement effect Effects 0.000 description 9
- 150000001875 compounds Chemical class 0.000 description 9
- 230000007017 scission Effects 0.000 description 9
- MMEDVBWCMGRKKC-GARJFASQSA-N Leu-Asp-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N MMEDVBWCMGRKKC-GARJFASQSA-N 0.000 description 8
- -1 NTF4 Proteins 0.000 description 8
- 108091028043 Nucleic acid sequence Proteins 0.000 description 8
- 210000001744 T-lymphocyte Anatomy 0.000 description 8
- 210000004556 brain Anatomy 0.000 description 8
- 230000008859 change Effects 0.000 description 8
- 208000035475 disorder Diseases 0.000 description 8
- 238000003752 polymerase chain reaction Methods 0.000 description 8
- 206010012289 Dementia Diseases 0.000 description 7
- KOSRFJWDECSPRO-UHFFFAOYSA-N alpha-L-glutamyl-L-glutamic acid Natural products OC(=O)CCC(N)C(=O)NC(CCC(O)=O)C(O)=O KOSRFJWDECSPRO-UHFFFAOYSA-N 0.000 description 7
- DZHSAHHDTRWUTF-SIQRNXPUSA-N amyloid-beta polypeptide 42 Chemical compound C([C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(=O)NCC(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)NCC(=O)N[C@@H](C)C(=O)N[C@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(=O)NCC(=O)NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](C)C(O)=O)[C@@H](C)CC)C(C)C)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@@H](NC(=O)[C@H](CC(C)C)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](CC=1C=CC(O)=CC=1)NC(=O)CNC(=O)[C@H](CO)NC(=O)[C@H](CC(O)=O)NC(=O)[C@H](CC=1N=CNC=1)NC(=O)[C@H](CCCNC(N)=N)NC(=O)[C@H](CC=1C=CC=CC=1)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(O)=O)C(C)C)C(C)C)C1=CC=CC=C1 DZHSAHHDTRWUTF-SIQRNXPUSA-N 0.000 description 7
- 239000000306 component Substances 0.000 description 7
- 238000003205 genotyping method Methods 0.000 description 7
- PHEDXBVPIONUQT-RGYGYFBISA-N phorbol 13-acetate 12-myristate Chemical compound C([C@]1(O)C(=O)C(C)=C[C@H]1[C@@]1(O)[C@H](C)[C@H]2OC(=O)CCCCCCCCCCCCC)C(CO)=C[C@H]1[C@H]1[C@]2(OC(C)=O)C1(C)C PHEDXBVPIONUQT-RGYGYFBISA-N 0.000 description 7
- 238000002560 therapeutic procedure Methods 0.000 description 7
- WEZNQZHACPSMEF-QEJZJMRPSA-N Ala-Phe-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 WEZNQZHACPSMEF-QEJZJMRPSA-N 0.000 description 6
- KUTPGXNAAOQSPD-LPEHRKFASA-N Glu-Glu-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CCC(=O)O)N)C(=O)O KUTPGXNAAOQSPD-LPEHRKFASA-N 0.000 description 6
- HAOUOFNNJJLVNS-BQBZGAKWSA-N Gly-Pro-Ser Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O HAOUOFNNJJLVNS-BQBZGAKWSA-N 0.000 description 6
- SITLTJHOQZFJGG-UHFFFAOYSA-N N-L-alpha-glutamyl-L-valine Natural products CC(C)C(C(O)=O)NC(=O)C(N)CCC(O)=O SITLTJHOQZFJGG-UHFFFAOYSA-N 0.000 description 6
- 108090000099 Neurotrophin-4 Proteins 0.000 description 6
- 238000013459 approach Methods 0.000 description 6
- 239000000872 buffer Substances 0.000 description 6
- 230000018109 developmental process Effects 0.000 description 6
- 208000025688 early-onset autosomal dominant Alzheimer disease Diseases 0.000 description 6
- 230000002255 enzymatic effect Effects 0.000 description 6
- 210000002569 neuron Anatomy 0.000 description 6
- 239000007787 solid Substances 0.000 description 6
- 208000024891 symptom Diseases 0.000 description 6
- YCRAFFCYWOUEOF-DLOVCJGASA-N Ala-Phe-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 YCRAFFCYWOUEOF-DLOVCJGASA-N 0.000 description 5
- YNJBLTDKTMKEET-ZLUOBGJFSA-N Cys-Ser-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O YNJBLTDKTMKEET-ZLUOBGJFSA-N 0.000 description 5
- FKXCBKCOSVIGCT-AVGNSLFASA-N Gln-Lys-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O FKXCBKCOSVIGCT-AVGNSLFASA-N 0.000 description 5
- IVXJIMGDOYRLQU-XUXIUFHCSA-N Ile-Pro-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O IVXJIMGDOYRLQU-XUXIUFHCSA-N 0.000 description 5
- 241000880493 Leptailurus serval Species 0.000 description 5
- BAJIJEGGUYXZGC-CIUDSAMLSA-N Leu-Asn-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CS)C(=O)O)N BAJIJEGGUYXZGC-CIUDSAMLSA-N 0.000 description 5
- TUIOUEWKFFVNLH-DCAQKATOSA-N Leu-Val-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O TUIOUEWKFFVNLH-DCAQKATOSA-N 0.000 description 5
- PINHPJWGVBKQII-SRVKXCTJSA-N Lys-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N PINHPJWGVBKQII-SRVKXCTJSA-N 0.000 description 5
- 108010021466 Mutant Proteins Proteins 0.000 description 5
- 102000008300 Mutant Proteins Human genes 0.000 description 5
- SOACYAXADBWDDT-CYDGBPFRSA-N Pro-Ile-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O SOACYAXADBWDDT-CYDGBPFRSA-N 0.000 description 5
- FUMGHWDRRFCKEP-CIUDSAMLSA-N Ser-Leu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O FUMGHWDRRFCKEP-CIUDSAMLSA-N 0.000 description 5
- KCNSGAMPBPYUAI-CIUDSAMLSA-N Ser-Leu-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O KCNSGAMPBPYUAI-CIUDSAMLSA-N 0.000 description 5
- IMULJHHGAUZZFE-MBLNEYKQSA-N Thr-Gly-Ile Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H]([C@@H](C)CC)C(O)=O IMULJHHGAUZZFE-MBLNEYKQSA-N 0.000 description 5
- 108010024078 alanyl-glycyl-serine Proteins 0.000 description 5
- 239000000499 gel Substances 0.000 description 5
- 108010055341 glutamyl-glutamic acid Proteins 0.000 description 5
- 230000003834 intracellular effect Effects 0.000 description 5
- 230000000069 prophylactic effect Effects 0.000 description 5
- 235000000346 sugar Nutrition 0.000 description 5
- YBJHBAHKTGYVGT-ZKWXMUAHSA-N (+)-Biotin Chemical compound N1C(=O)N[C@@H]2[C@H](CCCCC(=O)O)SC[C@@H]21 YBJHBAHKTGYVGT-ZKWXMUAHSA-N 0.000 description 4
- NBTGEURICRTMGL-WHFBIAKZSA-N Ala-Gly-Ser Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O NBTGEURICRTMGL-WHFBIAKZSA-N 0.000 description 4
- 208000037259 Amyloid Plaque Diseases 0.000 description 4
- 108010043324 Amyloid Precursor Protein Secretases Proteins 0.000 description 4
- 102000002659 Amyloid Precursor Protein Secretases Human genes 0.000 description 4
- 102000013455 Amyloid beta-Peptides Human genes 0.000 description 4
- 108010090849 Amyloid beta-Peptides Proteins 0.000 description 4
- 238000002965 ELISA Methods 0.000 description 4
- LURQDGKYBFWWJA-MNXVOIDGSA-N Gln-Lys-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CCC(=O)N)N LURQDGKYBFWWJA-MNXVOIDGSA-N 0.000 description 4
- CIJLNXXMDUOFPH-HJWJTTGWSA-N Ile-Pro-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 CIJLNXXMDUOFPH-HJWJTTGWSA-N 0.000 description 4
- NURNJECQNNCRBK-FLBSBUHZSA-N Ile-Thr-Thr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NURNJECQNNCRBK-FLBSBUHZSA-N 0.000 description 4
- 108010021625 Immunoglobulin Fragments Proteins 0.000 description 4
- 102000008394 Immunoglobulin Fragments Human genes 0.000 description 4
- FADYJNXDPBKVCA-UHFFFAOYSA-N L-Phenylalanyl-L-lysin Natural products NCCCCC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FADYJNXDPBKVCA-UHFFFAOYSA-N 0.000 description 4
- OHZIZVWQXJPBJS-IXOXFDKPSA-N Leu-His-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OHZIZVWQXJPBJS-IXOXFDKPSA-N 0.000 description 4
- XDPLZVNMYQOFQZ-BJDJZHNGSA-N Lys-Ile-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N XDPLZVNMYQOFQZ-BJDJZHNGSA-N 0.000 description 4
- 241000699660 Mus musculus Species 0.000 description 4
- KKKVOZNCLALMPV-XKBZYTNZSA-N Ser-Thr-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O KKKVOZNCLALMPV-XKBZYTNZSA-N 0.000 description 4
- MFMGPEKYBXFIRF-SUSMZKCASA-N Thr-Thr-Gln Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O MFMGPEKYBXFIRF-SUSMZKCASA-N 0.000 description 4
- KPMIQCXJDVKWKO-IFFSRLJSSA-N Thr-Val-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O KPMIQCXJDVKWKO-IFFSRLJSSA-N 0.000 description 4
- MNYNCKZAEIAONY-XGEHTFHBSA-N Thr-Val-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O MNYNCKZAEIAONY-XGEHTFHBSA-N 0.000 description 4
- 108010005233 alanylglutamic acid Proteins 0.000 description 4
- 239000005557 antagonist Substances 0.000 description 4
- 239000002249 anxiolytic agent Substances 0.000 description 4
- 239000013068 control sample Substances 0.000 description 4
- 238000003935 denaturing gradient gel electrophoresis Methods 0.000 description 4
- 230000001419 dependent effect Effects 0.000 description 4
- 229940079593 drug Drugs 0.000 description 4
- 238000000132 electrospray ionisation Methods 0.000 description 4
- 238000001943 fluorescence-activated cell sorting Methods 0.000 description 4
- 230000006870 function Effects 0.000 description 4
- 230000014509 gene expression Effects 0.000 description 4
- 108010049041 glutamylalanine Proteins 0.000 description 4
- 108010037850 glycylvaline Proteins 0.000 description 4
- 238000002347 injection Methods 0.000 description 4
- 239000007924 injection Substances 0.000 description 4
- 238000001840 matrix-assisted laser desorption--ionisation time-of-flight mass spectrometry Methods 0.000 description 4
- 108020004999 messenger RNA Proteins 0.000 description 4
- 108010051242 phenylalanylserine Proteins 0.000 description 4
- 230000002285 radioactive effect Effects 0.000 description 4
- 238000011160 research Methods 0.000 description 4
- 230000004083 survival effect Effects 0.000 description 4
- 238000012360 testing method Methods 0.000 description 4
- CCDFBRZVTDDJNM-GUBZILKMSA-N Ala-Leu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O CCDFBRZVTDDJNM-GUBZILKMSA-N 0.000 description 3
- 208000000044 Amnesia Diseases 0.000 description 3
- OBFTYSPXDRROQO-SRVKXCTJSA-N Arg-Gln-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CCCN=C(N)N OBFTYSPXDRROQO-SRVKXCTJSA-N 0.000 description 3
- CZUHPNLXLWMYMG-UBHSHLNASA-N Arg-Phe-Ala Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](C)C(O)=O)CC1=CC=CC=C1 CZUHPNLXLWMYMG-UBHSHLNASA-N 0.000 description 3
- IBLAOXSULLECQZ-IUKAMOBKSA-N Asn-Ile-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H]([C@@H](C)CC)NC(=O)[C@@H](N)CC(N)=O IBLAOXSULLECQZ-IUKAMOBKSA-N 0.000 description 3
- HAFCJCDJGIOYPW-WDSKDSINSA-N Asp-Gly-Gln Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(N)=O HAFCJCDJGIOYPW-WDSKDSINSA-N 0.000 description 3
- IVPNEDNYYYFAGI-GARJFASQSA-N Asp-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(=O)O)N IVPNEDNYYYFAGI-GARJFASQSA-N 0.000 description 3
- MGSVBZIBCCKGCY-ZLUOBGJFSA-N Asp-Ser-Ser Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O MGSVBZIBCCKGCY-ZLUOBGJFSA-N 0.000 description 3
- 102100021277 Beta-secretase 2 Human genes 0.000 description 3
- 101710150190 Beta-secretase 2 Proteins 0.000 description 3
- 102000010170 Death domains Human genes 0.000 description 3
- 108050001718 Death domains Proteins 0.000 description 3
- PBEQPAZRHDVJQI-SRVKXCTJSA-N Glu-Arg-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CCC(=O)O)N PBEQPAZRHDVJQI-SRVKXCTJSA-N 0.000 description 3
- LTUVYLVIZHJCOQ-KKUMJFAQSA-N Glu-Arg-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O LTUVYLVIZHJCOQ-KKUMJFAQSA-N 0.000 description 3
- GCYFUZJHAXJKKE-KKUMJFAQSA-N Glu-Arg-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O GCYFUZJHAXJKKE-KKUMJFAQSA-N 0.000 description 3
- DYFJZDDQPNIPAB-NHCYSSNCSA-N Glu-Arg-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(O)=O DYFJZDDQPNIPAB-NHCYSSNCSA-N 0.000 description 3
- UMZHHILWZBFPGL-LOKLDPHHSA-N Glu-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)O)N)O UMZHHILWZBFPGL-LOKLDPHHSA-N 0.000 description 3
- GWCJMBNBFYBQCV-XPUUQOCRSA-N Gly-Val-Ala Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O GWCJMBNBFYBQCV-XPUUQOCRSA-N 0.000 description 3
- ZZHGKECPZXPXJF-PCBIJLKTSA-N Ile-Asn-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 ZZHGKECPZXPXJF-PCBIJLKTSA-N 0.000 description 3
- KVRKAGGMEWNURO-CIUDSAMLSA-N Leu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N KVRKAGGMEWNURO-CIUDSAMLSA-N 0.000 description 3
- YFBBUHJJUXXZOF-UWVGGRQHSA-N Leu-Gly-Pro Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N1CCC[C@H]1C(O)=O YFBBUHJJUXXZOF-UWVGGRQHSA-N 0.000 description 3
- AVEGDIAXTDVBJS-XUXIUFHCSA-N Leu-Ile-Arg Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O AVEGDIAXTDVBJS-XUXIUFHCSA-N 0.000 description 3
- MVHXGBZUJLWZOH-BJDJZHNGSA-N Leu-Ser-Ile Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MVHXGBZUJLWZOH-BJDJZHNGSA-N 0.000 description 3
- KWUKZRFFKPLUPE-HJGDQZAQSA-N Lys-Asp-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KWUKZRFFKPLUPE-HJGDQZAQSA-N 0.000 description 3
- IZJGPPIGYTVXLB-FQUUOJAGSA-N Lys-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCCCN)N IZJGPPIGYTVXLB-FQUUOJAGSA-N 0.000 description 3
- KDXKERNSBIXSRK-UHFFFAOYSA-N Lysine Natural products NCCCCC(N)C(O)=O KDXKERNSBIXSRK-UHFFFAOYSA-N 0.000 description 3
- YBAFDPFAUTYYRW-UHFFFAOYSA-N N-L-alpha-glutamyl-L-leucine Natural products CC(C)CC(C(O)=O)NC(=O)C(N)CCC(O)=O YBAFDPFAUTYYRW-UHFFFAOYSA-N 0.000 description 3
- 101100068676 Neurospora crassa (strain ATCC 24698 / 74-OR23-1A / CBS 708.71 / DSM 1257 / FGSC 987) gln-1 gene Proteins 0.000 description 3
- 108020002230 Pancreatic Ribonuclease Proteins 0.000 description 3
- 102000005891 Pancreatic ribonuclease Human genes 0.000 description 3
- UNBFGVQVQGXXCK-KKUMJFAQSA-N Phe-Ser-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O UNBFGVQVQGXXCK-KKUMJFAQSA-N 0.000 description 3
- 241000700157 Rattus norvegicus Species 0.000 description 3
- YIUWWXVTYLANCJ-NAKRPEOUSA-N Ser-Ile-Arg Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O YIUWWXVTYLANCJ-NAKRPEOUSA-N 0.000 description 3
- NLOAIFSWUUFQFR-CIUDSAMLSA-N Ser-Leu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O NLOAIFSWUUFQFR-CIUDSAMLSA-N 0.000 description 3
- XNCUYZKGQOCOQH-YUMQZZPRSA-N Ser-Leu-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O XNCUYZKGQOCOQH-YUMQZZPRSA-N 0.000 description 3
- GDUZTEQRAOXYJS-SRVKXCTJSA-N Ser-Phe-Asn Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)O)NC(=O)[C@H](CO)N GDUZTEQRAOXYJS-SRVKXCTJSA-N 0.000 description 3
- BVOVIGCHYNFJBZ-JXUBOQSCSA-N Thr-Leu-Ala Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O BVOVIGCHYNFJBZ-JXUBOQSCSA-N 0.000 description 3
- JMBRNXUOLJFURW-BEAPCOKYSA-N Thr-Phe-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N2CCC[C@@H]2C(=O)O)N)O JMBRNXUOLJFURW-BEAPCOKYSA-N 0.000 description 3
- IVDFVBVIVLJJHR-LKXGYXEUSA-N Thr-Ser-Asp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O IVDFVBVIVLJJHR-LKXGYXEUSA-N 0.000 description 3
- XGEUYEOEZYFHRL-KKXDTOCCSA-N Tyr-Ala-Phe Chemical compound C([C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CC=1C=CC=CC=1)C(O)=O)C1=CC=C(O)C=C1 XGEUYEOEZYFHRL-KKXDTOCCSA-N 0.000 description 3
- 101150032479 UNC-5 gene Proteins 0.000 description 3
- NGXQOQNXSGOYOI-BQFCYCMXSA-N Val-Trp-Gln Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O)=CNC2=C1 NGXQOQNXSGOYOI-BQFCYCMXSA-N 0.000 description 3
- 241000251539 Vertebrata <Metazoa> Species 0.000 description 3
- 230000002159 abnormal effect Effects 0.000 description 3
- 108010076324 alanyl-glycyl-glycine Proteins 0.000 description 3
- 108010069020 alanyl-prolyl-glycine Proteins 0.000 description 3
- 108010060035 arginylproline Proteins 0.000 description 3
- 108010040443 aspartyl-aspartic acid Proteins 0.000 description 3
- 238000011888 autopsy Methods 0.000 description 3
- 230000003920 cognitive function Effects 0.000 description 3
- 108010016616 cysteinylglycine Proteins 0.000 description 3
- 239000003937 drug carrier Substances 0.000 description 3
- 238000002474 experimental method Methods 0.000 description 3
- 239000012634 fragment Substances 0.000 description 3
- 108010006664 gamma-glutamyl-glycyl-glycine Proteins 0.000 description 3
- 238000001502 gel electrophoresis Methods 0.000 description 3
- 108010072405 glycyl-aspartyl-glycine Proteins 0.000 description 3
- 108010010147 glycylglutamine Proteins 0.000 description 3
- 108010018006 histidylserine Proteins 0.000 description 3
- 210000003917 human chromosome Anatomy 0.000 description 3
- 238000001727 in vivo Methods 0.000 description 3
- 238000002372 labelling Methods 0.000 description 3
- 108010034529 leucyl-lysine Proteins 0.000 description 3
- 108010057821 leucylproline Proteins 0.000 description 3
- 238000004519 manufacturing process Methods 0.000 description 3
- 230000015654 memory Effects 0.000 description 3
- 229910052751 metal Inorganic materials 0.000 description 3
- 239000002184 metal Substances 0.000 description 3
- 150000002739 metals Chemical class 0.000 description 3
- 230000004048 modification Effects 0.000 description 3
- 238000012986 modification Methods 0.000 description 3
- 229940097998 neurotrophin 4 Drugs 0.000 description 3
- 230000001575 pathological effect Effects 0.000 description 3
- 210000003819 peripheral blood mononuclear cell Anatomy 0.000 description 3
- 108010073101 phenylalanylleucine Proteins 0.000 description 3
- 229920000642 polymer Polymers 0.000 description 3
- 238000012545 processing Methods 0.000 description 3
- 108010079317 prolyl-tyrosine Proteins 0.000 description 3
- 108010090894 prolylleucine Proteins 0.000 description 3
- 239000013074 reference sample Substances 0.000 description 3
- 102210052732 rs4129267 Human genes 0.000 description 3
- 108010026333 seryl-proline Proteins 0.000 description 3
- 239000000243 solution Substances 0.000 description 3
- 238000004885 tandem mass spectrometry Methods 0.000 description 3
- 102000039356 unc-5 family Human genes 0.000 description 3
- 108091030276 unc-5 family Proteins 0.000 description 3
- 238000012070 whole genome sequencing analysis Methods 0.000 description 3
- GHOKWGTUZJEAQD-ZETCQYMHSA-N (D)-(+)-Pantothenic acid Chemical compound OCC(C)(C)[C@@H](O)C(=O)NCCC(O)=O GHOKWGTUZJEAQD-ZETCQYMHSA-N 0.000 description 2
- GORKKVHIBWAQHM-GCJQMDKQSA-N Ala-Asn-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GORKKVHIBWAQHM-GCJQMDKQSA-N 0.000 description 2
- SFNFGFDRYJKZKN-XQXXSGGOSA-N Ala-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C)N)O SFNFGFDRYJKZKN-XQXXSGGOSA-N 0.000 description 2
- ZVFVBBGVOILKPO-WHFBIAKZSA-N Ala-Gly-Ala Chemical compound C[C@H](N)C(=O)NCC(=O)N[C@@H](C)C(O)=O ZVFVBBGVOILKPO-WHFBIAKZSA-N 0.000 description 2
- VGPWRRFOPXVGOH-BYPYZUCNSA-N Ala-Gly-Gly Chemical compound C[C@H](N)C(=O)NCC(=O)NCC(O)=O VGPWRRFOPXVGOH-BYPYZUCNSA-N 0.000 description 2
- WQKAQKZRDIZYNV-VZFHVOOUSA-N Ala-Ser-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WQKAQKZRDIZYNV-VZFHVOOUSA-N 0.000 description 2
- 108091093088 Amplicon Proteins 0.000 description 2
- NXDXECQFKHXHAM-HJGDQZAQSA-N Arg-Glu-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O NXDXECQFKHXHAM-HJGDQZAQSA-N 0.000 description 2
- COXMUHNBYCVVRG-DCAQKATOSA-N Arg-Leu-Ser Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O COXMUHNBYCVVRG-DCAQKATOSA-N 0.000 description 2
- XWGJDUSDTRPQRK-ZLUOBGJFSA-N Asn-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC(N)=O XWGJDUSDTRPQRK-ZLUOBGJFSA-N 0.000 description 2
- MNQMTYSEKZHIDF-GCJQMDKQSA-N Asp-Thr-Ala Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C)C(O)=O MNQMTYSEKZHIDF-GCJQMDKQSA-N 0.000 description 2
- YFXFOZPXVFPBDH-VZFHVOOUSA-N Cys-Ala-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)CS)C(O)=O YFXFOZPXVFPBDH-VZFHVOOUSA-N 0.000 description 2
- SRBFZHDQGSBBOR-IOVATXLUSA-N D-xylopyranose Chemical compound O[C@@H]1COC(O)[C@H](O)[C@H]1O SRBFZHDQGSBBOR-IOVATXLUSA-N 0.000 description 2
- 206010061818 Disease progression Diseases 0.000 description 2
- 102000004190 Enzymes Human genes 0.000 description 2
- 108090000790 Enzymes Proteins 0.000 description 2
- MWLYSLMKFXWZPW-ZPFDUUQYSA-N Gln-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@@H](N)CCC(N)=O MWLYSLMKFXWZPW-ZPFDUUQYSA-N 0.000 description 2
- KKCUFHUTMKQQCF-SRVKXCTJSA-N Glu-Arg-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O KKCUFHUTMKQQCF-SRVKXCTJSA-N 0.000 description 2
- JRCUFCXYZLPSDZ-ACZMJKKPSA-N Glu-Asp-Ser Chemical compound OC(=O)CC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O JRCUFCXYZLPSDZ-ACZMJKKPSA-N 0.000 description 2
- MWMJCGBSIORNCD-AVGNSLFASA-N Glu-Leu-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O MWMJCGBSIORNCD-AVGNSLFASA-N 0.000 description 2
- GMVCSRBOSIUTFC-FXQIFTODSA-N Glu-Ser-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMVCSRBOSIUTFC-FXQIFTODSA-N 0.000 description 2
- GAAHQHNCMIAYEX-UWVGGRQHSA-N Gly-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN GAAHQHNCMIAYEX-UWVGGRQHSA-N 0.000 description 2
- CSMYMGFCEJWALV-WDSKDSINSA-N Gly-Ser-Gln Chemical compound NCC(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(N)=O CSMYMGFCEJWALV-WDSKDSINSA-N 0.000 description 2
- QNILDNVBIARMRK-XVYDVKMFSA-N His-Cys-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CC1=CN=CN1)N QNILDNVBIARMRK-XVYDVKMFSA-N 0.000 description 2
- BQFGKVYHKCNEMF-DCAQKATOSA-N His-Glu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CN=CN1 BQFGKVYHKCNEMF-DCAQKATOSA-N 0.000 description 2
- 101150004586 IL6R gene Proteins 0.000 description 2
- ASCFJMSGKUIRDU-ZPFDUUQYSA-N Ile-Arg-Gln Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O ASCFJMSGKUIRDU-ZPFDUUQYSA-N 0.000 description 2
- FADXGVVLSPPEQY-GHCJXIJMSA-N Ile-Cys-Asn Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N FADXGVVLSPPEQY-GHCJXIJMSA-N 0.000 description 2
- DURWCDDDAWVPOP-JBDRJPRFSA-N Ile-Cys-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)O)N DURWCDDDAWVPOP-JBDRJPRFSA-N 0.000 description 2
- YGDWPQCLFJNMOL-MNXVOIDGSA-N Ile-Leu-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YGDWPQCLFJNMOL-MNXVOIDGSA-N 0.000 description 2
- XOZOSAUOGRPCES-STECZYCISA-N Ile-Pro-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 XOZOSAUOGRPCES-STECZYCISA-N 0.000 description 2
- WXLYNEHOGRYNFU-URLPEUOOSA-N Ile-Thr-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)O)N WXLYNEHOGRYNFU-URLPEUOOSA-N 0.000 description 2
- 102000004889 Interleukin-6 Human genes 0.000 description 2
- 108090001005 Interleukin-6 Proteins 0.000 description 2
- 101710185757 Interleukin-6 receptor subunit alpha Proteins 0.000 description 2
- UGTHTQWIQKEDEH-BQBZGAKWSA-N L-alanyl-L-prolylglycine zwitterion Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)NCC(O)=O UGTHTQWIQKEDEH-BQBZGAKWSA-N 0.000 description 2
- JNDYEOUZBLOVOF-AVGNSLFASA-N Leu-Leu-Gln Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JNDYEOUZBLOVOF-AVGNSLFASA-N 0.000 description 2
- QNBVTHNJGCOVFA-AVGNSLFASA-N Leu-Leu-Glu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCC(O)=O QNBVTHNJGCOVFA-AVGNSLFASA-N 0.000 description 2
- WXUOJXIGOPMDJM-SRVKXCTJSA-N Leu-Lys-Asn Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O WXUOJXIGOPMDJM-SRVKXCTJSA-N 0.000 description 2
- LVTJJOJKDCVZGP-QWRGUYRKSA-N Leu-Lys-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)NCC(O)=O LVTJJOJKDCVZGP-QWRGUYRKSA-N 0.000 description 2
- KIZIOFNVSOSKJI-CIUDSAMLSA-N Leu-Ser-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N KIZIOFNVSOSKJI-CIUDSAMLSA-N 0.000 description 2
- SBANPBVRHYIMRR-UHFFFAOYSA-N Leu-Ser-Pro Natural products CC(C)CC(N)C(=O)NC(CO)C(=O)N1CCCC1C(O)=O SBANPBVRHYIMRR-UHFFFAOYSA-N 0.000 description 2
- LINKCQUOMUDLKN-KATARQTJSA-N Leu-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC(C)C)N)O LINKCQUOMUDLKN-KATARQTJSA-N 0.000 description 2
- GZRABTMNWJXFMH-UVOCVTCTSA-N Leu-Thr-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O GZRABTMNWJXFMH-UVOCVTCTSA-N 0.000 description 2
- QFSYGUMEANRNJE-DCAQKATOSA-N Lys-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCCCN)N QFSYGUMEANRNJE-DCAQKATOSA-N 0.000 description 2
- XBAJINCXDBTJRH-WDSOQIARSA-N Lys-Val-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCCN)N XBAJINCXDBTJRH-WDSOQIARSA-N 0.000 description 2
- 208000026139 Memory disease Diseases 0.000 description 2
- AFFKUNVPPLQUGA-DCAQKATOSA-N Met-Leu-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O AFFKUNVPPLQUGA-DCAQKATOSA-N 0.000 description 2
- 241000699670 Mus sp. Species 0.000 description 2
- PESQCPHRXOFIPX-UHFFFAOYSA-N N-L-methionyl-L-tyrosine Natural products CSCCC(N)C(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 PESQCPHRXOFIPX-UHFFFAOYSA-N 0.000 description 2
- KZNQNBZMBZJQJO-UHFFFAOYSA-N N-glycyl-L-proline Natural products NCC(=O)N1CCCC1C(O)=O KZNQNBZMBZJQJO-UHFFFAOYSA-N 0.000 description 2
- AJOKKVTWEMXZHC-DRZSPHRISA-N Phe-Ala-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=CC=C1 AJOKKVTWEMXZHC-DRZSPHRISA-N 0.000 description 2
- SWZKMTDPQXLQRD-XVSYOHENSA-N Phe-Asp-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SWZKMTDPQXLQRD-XVSYOHENSA-N 0.000 description 2
- YDUGVDGFKNXFPL-IXOXFDKPSA-N Phe-Thr-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O YDUGVDGFKNXFPL-IXOXFDKPSA-N 0.000 description 2
- IWNOFCGBMSFTBC-CIUDSAMLSA-N Pro-Ala-Glu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O IWNOFCGBMSFTBC-CIUDSAMLSA-N 0.000 description 2
- NMELOOXSGDRBRU-YUMQZZPRSA-N Pro-Glu-Gly Chemical compound OC(=O)CNC(=O)[C@H](CCC(=O)O)NC(=O)[C@@H]1CCCN1 NMELOOXSGDRBRU-YUMQZZPRSA-N 0.000 description 2
- CLNJSLSHKJECME-BQBZGAKWSA-N Pro-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H]1CCCN1 CLNJSLSHKJECME-BQBZGAKWSA-N 0.000 description 2
- VZKBJNBZMZHKRC-XUXIUFHCSA-N Pro-Ile-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O VZKBJNBZMZHKRC-XUXIUFHCSA-N 0.000 description 2
- 238000002123 RNA extraction Methods 0.000 description 2
- 241000700159 Rattus Species 0.000 description 2
- BTKUIVBNGBFTTP-WHFBIAKZSA-N Ser-Ala-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C)C(=O)NCC(O)=O BTKUIVBNGBFTTP-WHFBIAKZSA-N 0.000 description 2
- YRBGKVIWMNEVCZ-WDSKDSINSA-N Ser-Glu-Gly Chemical compound OC[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)NCC(O)=O YRBGKVIWMNEVCZ-WDSKDSINSA-N 0.000 description 2
- BRIZMMZEYSAKJX-QEJZJMRPSA-N Ser-Glu-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CO)N BRIZMMZEYSAKJX-QEJZJMRPSA-N 0.000 description 2
- RIAKPZVSNBBNRE-BJDJZHNGSA-N Ser-Ile-Leu Chemical compound OC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O RIAKPZVSNBBNRE-BJDJZHNGSA-N 0.000 description 2
- CUXJENOFJXOSOZ-BIIVOSGPSA-N Ser-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CO)N)C(=O)O CUXJENOFJXOSOZ-BIIVOSGPSA-N 0.000 description 2
- XQJCEKXQUJQNNK-ZLUOBGJFSA-N Ser-Ser-Ser Chemical compound OC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O XQJCEKXQUJQNNK-ZLUOBGJFSA-N 0.000 description 2
- VLMIUSLQONKLDV-HEIBUPTGSA-N Ser-Thr-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O VLMIUSLQONKLDV-HEIBUPTGSA-N 0.000 description 2
- ANOQEBQWIAYIMV-AEJSXWLSSA-N Ser-Val-Pro Chemical compound CC(C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N ANOQEBQWIAYIMV-AEJSXWLSSA-N 0.000 description 2
- 238000012338 Therapeutic targeting Methods 0.000 description 2
- LVHHEVGYAZGXDE-KDXUFGMBSA-N Thr-Ala-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)N1CCC[C@@H]1C(=O)O)N)O LVHHEVGYAZGXDE-KDXUFGMBSA-N 0.000 description 2
- MEJHFIOYJHTWMK-VOAKCMCISA-N Thr-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)[C@@H](C)O MEJHFIOYJHTWMK-VOAKCMCISA-N 0.000 description 2
- GVMXJJAJLIEASL-ZJDVBMNYSA-N Thr-Pro-Thr Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O GVMXJJAJLIEASL-ZJDVBMNYSA-N 0.000 description 2
- YGCDFAJJCRVQKU-RCWTZXSCSA-N Thr-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)[C@@H](C)O YGCDFAJJCRVQKU-RCWTZXSCSA-N 0.000 description 2
- TVOGEPLDNYTAHD-CQDKDKBSSA-N Tyr-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 TVOGEPLDNYTAHD-CQDKDKBSSA-N 0.000 description 2
- NYTKXWLZSNRILS-IFFSRLJSSA-N Val-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](C(C)C)N)O NYTKXWLZSNRILS-IFFSRLJSSA-N 0.000 description 2
- OTJMMKPMLUNTQT-AVGNSLFASA-N Val-Leu-Arg Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](C(C)C)N OTJMMKPMLUNTQT-AVGNSLFASA-N 0.000 description 2
- VHIZXDZMTDVFGX-DCAQKATOSA-N Val-Ser-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](C(C)C)N VHIZXDZMTDVFGX-DCAQKATOSA-N 0.000 description 2
- DZBUGLKDJFMEHC-UHFFFAOYSA-N acridine Chemical compound C1=CC=CC2=CC3=CC=CC=C3N=C21 DZBUGLKDJFMEHC-UHFFFAOYSA-N 0.000 description 2
- 239000004480 active ingredient Substances 0.000 description 2
- 230000032683 aging Effects 0.000 description 2
- 238000007844 allele-specific PCR Methods 0.000 description 2
- VREFGVBLTWBCJP-UHFFFAOYSA-N alprazolam Chemical compound C12=CC(Cl)=CC=C2N2C(C)=NN=C2CN=C1C1=CC=CC=C1 VREFGVBLTWBCJP-UHFFFAOYSA-N 0.000 description 2
- 230000004075 alteration Effects 0.000 description 2
- 239000012491 analyte Substances 0.000 description 2
- 239000003242 anti bacterial agent Substances 0.000 description 2
- 230000001430 anti-depressive effect Effects 0.000 description 2
- 239000000935 antidepressant agent Substances 0.000 description 2
- 230000000949 anxiolytic effect Effects 0.000 description 2
- 230000006907 apoptotic process Effects 0.000 description 2
- PYMYPHUHKUWMLA-UHFFFAOYSA-N arabinose Natural products OCC(O)C(O)C(O)C=O PYMYPHUHKUWMLA-UHFFFAOYSA-N 0.000 description 2
- 108010029539 arginyl-prolyl-proline Proteins 0.000 description 2
- 108010062796 arginyllysine Proteins 0.000 description 2
- 230000008901 benefit Effects 0.000 description 2
- SRBFZHDQGSBBOR-UHFFFAOYSA-N beta-D-Pyranose-Lyxose Natural products OC1COC(O)C(O)C1O SRBFZHDQGSBBOR-UHFFFAOYSA-N 0.000 description 2
- 230000004071 biological effect Effects 0.000 description 2
- 229960002685 biotin Drugs 0.000 description 2
- 235000020958 biotin Nutrition 0.000 description 2
- 239000011616 biotin Substances 0.000 description 2
- 230000000903 blocking effect Effects 0.000 description 2
- 230000037396 body weight Effects 0.000 description 2
- 239000000969 carrier Substances 0.000 description 2
- 210000003169 central nervous system Anatomy 0.000 description 2
- 239000000544 cholinesterase inhibitor Substances 0.000 description 2
- 239000002299 complementary DNA Substances 0.000 description 2
- 230000021615 conjugation Effects 0.000 description 2
- 230000002596 correlated effect Effects 0.000 description 2
- 108010069495 cysteinyltyrosine Proteins 0.000 description 2
- 230000034994 death Effects 0.000 description 2
- 231100000517 death Toxicity 0.000 description 2
- 230000002950 deficient Effects 0.000 description 2
- 230000004069 differentiation Effects 0.000 description 2
- 239000003085 diluting agent Substances 0.000 description 2
- 108010054813 diprotin B Proteins 0.000 description 2
- 230000005750 disease progression Effects 0.000 description 2
- 229940088598 enzyme Drugs 0.000 description 2
- 238000009313 farming Methods 0.000 description 2
- 239000007850 fluorescent dye Substances 0.000 description 2
- 238000009472 formulation Methods 0.000 description 2
- 238000003633 gene expression assay Methods 0.000 description 2
- 239000011521 glass Substances 0.000 description 2
- 108010075431 glycyl-alanyl-phenylalanine Proteins 0.000 description 2
- 108010020688 glycylhistidine Proteins 0.000 description 2
- 239000011544 gradient gel Substances 0.000 description 2
- 210000004295 hippocampal neuron Anatomy 0.000 description 2
- 125000002887 hydroxy group Chemical group [H]O* 0.000 description 2
- 238000003018 immunoassay Methods 0.000 description 2
- 238000000338 in vitro Methods 0.000 description 2
- 238000010348 incorporation Methods 0.000 description 2
- 239000003999 initiator Substances 0.000 description 2
- 108010060857 isoleucyl-valyl-tyrosine Proteins 0.000 description 2
- 125000005647 linker group Chemical group 0.000 description 2
- 150000002632 lipids Chemical class 0.000 description 2
- 239000002502 liposome Substances 0.000 description 2
- 108010025153 lysyl-alanyl-alanine Proteins 0.000 description 2
- 239000000463 material Substances 0.000 description 2
- 239000011159 matrix material Substances 0.000 description 2
- 238000002844 melting Methods 0.000 description 2
- 230000008018 melting Effects 0.000 description 2
- BUGYDGFZZOZRHP-UHFFFAOYSA-N memantine Chemical compound C1C(C2)CC3(C)CC1(C)CC2(N)C3 BUGYDGFZZOZRHP-UHFFFAOYSA-N 0.000 description 2
- 229960004640 memantine Drugs 0.000 description 2
- 230000006984 memory degeneration Effects 0.000 description 2
- 208000023060 memory loss Diseases 0.000 description 2
- 230000000474 nursing effect Effects 0.000 description 2
- 210000000056 organ Anatomy 0.000 description 2
- 238000004806 packaging method and process Methods 0.000 description 2
- 239000008194 pharmaceutical composition Substances 0.000 description 2
- 108010024654 phenylalanyl-prolyl-alanine Proteins 0.000 description 2
- 108010073025 phenylalanylphenylalanine Proteins 0.000 description 2
- 229920002401 polyacrylamide Polymers 0.000 description 2
- 239000003755 preservative agent Substances 0.000 description 2
- 108010031719 prolyl-serine Proteins 0.000 description 2
- 108010015796 prolylisoleucine Proteins 0.000 description 2
- 125000006239 protecting group Chemical group 0.000 description 2
- 230000001681 protective effect Effects 0.000 description 2
- 238000000159 protein binding assay Methods 0.000 description 2
- ZCCUUQDIBDJBTK-UHFFFAOYSA-N psoralen Chemical compound C1=C2OC(=O)C=CC2=CC2=C1OC=C2 ZCCUUQDIBDJBTK-UHFFFAOYSA-N 0.000 description 2
- 238000003127 radioimmunoassay Methods 0.000 description 2
- 230000001105 regulatory effect Effects 0.000 description 2
- 238000007894 restriction fragment length polymorphism technique Methods 0.000 description 2
- 238000000926 separation method Methods 0.000 description 2
- 239000006228 supernatant Substances 0.000 description 2
- 108010061238 threonyl-glycine Proteins 0.000 description 2
- 238000011200 topical administration Methods 0.000 description 2
- 231100000331 toxic Toxicity 0.000 description 2
- 230000002588 toxic effect Effects 0.000 description 2
- 238000001890 transfection Methods 0.000 description 2
- 238000007482 whole exome sequencing Methods 0.000 description 2
- DGVVWUTYPXICAM-UHFFFAOYSA-N β‐Mercaptoethanol Chemical compound OCCS DGVVWUTYPXICAM-UHFFFAOYSA-N 0.000 description 2
- XVZCXCTYGHPNEM-IHRRRGAJSA-N (2s)-1-[(2s)-2-[[(2s)-2-amino-4-methylpentanoyl]amino]-4-methylpentanoyl]pyrrolidine-2-carboxylic acid Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(O)=O XVZCXCTYGHPNEM-IHRRRGAJSA-N 0.000 description 1
- NTUPOKHATNSWCY-PMPSAXMXSA-N (2s)-2-[[(2s)-1-[(2r)-2-amino-3-phenylpropanoyl]pyrrolidine-2-carbonyl]amino]-5-(diaminomethylideneamino)pentanoic acid Chemical compound C([C@@H](N)C(=O)N1[C@@H](CCC1)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)C1=CC=CC=C1 NTUPOKHATNSWCY-PMPSAXMXSA-N 0.000 description 1
- VGONTNSXDCQUGY-RRKCRQDMSA-N 2'-deoxyinosine Chemical compound C1[C@H](O)[C@@H](CO)O[C@H]1N1C(N=CNC2=O)=C2N=C1 VGONTNSXDCQUGY-RRKCRQDMSA-N 0.000 description 1
- QMOQBVOBWVNSNO-UHFFFAOYSA-N 2-[[2-[[2-[(2-azaniumylacetyl)amino]acetyl]amino]acetyl]amino]acetate Chemical compound NCC(=O)NCC(=O)NCC(=O)NCC(O)=O QMOQBVOBWVNSNO-UHFFFAOYSA-N 0.000 description 1
- ASJSAQIRZKANQN-CRCLSJGQSA-N 2-deoxy-D-ribose Chemical compound OC[C@@H](O)[C@@H](O)CC=O ASJSAQIRZKANQN-CRCLSJGQSA-N 0.000 description 1
- VXGRJERITKFWPL-UHFFFAOYSA-N 4',5'-Dihydropsoralen Natural products C1=C2OC(=O)C=CC2=CC2=C1OCC2 VXGRJERITKFWPL-UHFFFAOYSA-N 0.000 description 1
- 102100022464 5'-nucleotidase Human genes 0.000 description 1
- QTBSBXVTEAMEQO-UHFFFAOYSA-M Acetate Chemical compound CC([O-])=O QTBSBXVTEAMEQO-UHFFFAOYSA-M 0.000 description 1
- HHGYNJRJIINWAK-FXQIFTODSA-N Ala-Ala-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N HHGYNJRJIINWAK-FXQIFTODSA-N 0.000 description 1
- BUANFPRKJKJSRR-ACZMJKKPSA-N Ala-Ala-Gln Chemical compound C[C@H]([NH3+])C(=O)N[C@@H](C)C(=O)N[C@H](C([O-])=O)CCC(N)=O BUANFPRKJKJSRR-ACZMJKKPSA-N 0.000 description 1
- YLTKNGYYPIWKHZ-ACZMJKKPSA-N Ala-Ala-Glu Chemical compound C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CCC(O)=O YLTKNGYYPIWKHZ-ACZMJKKPSA-N 0.000 description 1
- VBDMWOKJZDCFJM-FXQIFTODSA-N Ala-Ala-Met Chemical compound CSCC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@H](C)N VBDMWOKJZDCFJM-FXQIFTODSA-N 0.000 description 1
- WRDANSJTFOHBPI-FXQIFTODSA-N Ala-Arg-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N WRDANSJTFOHBPI-FXQIFTODSA-N 0.000 description 1
- QDRGPQWIVZNJQD-CIUDSAMLSA-N Ala-Arg-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O QDRGPQWIVZNJQD-CIUDSAMLSA-N 0.000 description 1
- JBGSZRYCXBPWGX-BQBZGAKWSA-N Ala-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CCCN=C(N)N JBGSZRYCXBPWGX-BQBZGAKWSA-N 0.000 description 1
- YAXNATKKPOWVCP-ZLUOBGJFSA-N Ala-Asn-Ala Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O YAXNATKKPOWVCP-ZLUOBGJFSA-N 0.000 description 1
- STACJSVFHSEZJV-GHCJXIJMSA-N Ala-Asn-Ile Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O STACJSVFHSEZJV-GHCJXIJMSA-N 0.000 description 1
- YSMPVONNIWLJML-FXQIFTODSA-N Ala-Asp-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(O)=O YSMPVONNIWLJML-FXQIFTODSA-N 0.000 description 1
- CSAHOYQKNHGDHX-ACZMJKKPSA-N Ala-Gln-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O CSAHOYQKNHGDHX-ACZMJKKPSA-N 0.000 description 1
- NKJBKNVQHBZUIX-ACZMJKKPSA-N Ala-Gln-Asp Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O NKJBKNVQHBZUIX-ACZMJKKPSA-N 0.000 description 1
- IFTVANMRTIHKML-WDSKDSINSA-N Ala-Gln-Gly Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O IFTVANMRTIHKML-WDSKDSINSA-N 0.000 description 1
- NWVVKQZOVSTDBQ-CIUDSAMLSA-N Ala-Glu-Arg Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O NWVVKQZOVSTDBQ-CIUDSAMLSA-N 0.000 description 1
- NJPMYXWVWQWCSR-ACZMJKKPSA-N Ala-Glu-Asn Chemical compound C[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O NJPMYXWVWQWCSR-ACZMJKKPSA-N 0.000 description 1
- WKOBSJOZRJJVRZ-FXQIFTODSA-N Ala-Glu-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O WKOBSJOZRJJVRZ-FXQIFTODSA-N 0.000 description 1
- OBVSBEYOMDWLRJ-BFHQHQDPSA-N Ala-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@H](C)N OBVSBEYOMDWLRJ-BFHQHQDPSA-N 0.000 description 1
- QCTFKEJEIMPOLW-JURCDPSOSA-N Ala-Ile-Phe Chemical compound C[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 QCTFKEJEIMPOLW-JURCDPSOSA-N 0.000 description 1
- VNYMOTCMNHJGTG-JBDRJPRFSA-N Ala-Ile-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O VNYMOTCMNHJGTG-JBDRJPRFSA-N 0.000 description 1
- RUQBGIMJQUWXPP-CYDGBPFRSA-N Ala-Leu-Ala-Pro Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(=O)N1CCC[C@H]1C(O)=O RUQBGIMJQUWXPP-CYDGBPFRSA-N 0.000 description 1
- HHRAXZAYZFFRAM-CIUDSAMLSA-N Ala-Leu-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O HHRAXZAYZFFRAM-CIUDSAMLSA-N 0.000 description 1
- AWZKCUCQJNTBAD-SRVKXCTJSA-N Ala-Leu-Lys Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCCN AWZKCUCQJNTBAD-SRVKXCTJSA-N 0.000 description 1
- VHVVPYOJIIQCKS-QEJZJMRPSA-N Ala-Leu-Phe Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 VHVVPYOJIIQCKS-QEJZJMRPSA-N 0.000 description 1
- SOBIAADAMRHGKH-CIUDSAMLSA-N Ala-Leu-Ser Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O SOBIAADAMRHGKH-CIUDSAMLSA-N 0.000 description 1
- RGQCNKIDEQJEBT-CQDKDKBSSA-N Ala-Leu-Tyr Chemical compound C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 RGQCNKIDEQJEBT-CQDKDKBSSA-N 0.000 description 1
- LDLSENBXQNDTPB-DCAQKATOSA-N Ala-Lys-Arg Chemical compound NCCCC[C@H](NC(=O)[C@@H](N)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N LDLSENBXQNDTPB-DCAQKATOSA-N 0.000 description 1
- AJBVYEYZVYPFCF-CIUDSAMLSA-N Ala-Lys-Asn Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(O)=O AJBVYEYZVYPFCF-CIUDSAMLSA-N 0.000 description 1
- PIXQDIGKDNNOOV-GUBZILKMSA-N Ala-Lys-Gln Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(N)=O)C(O)=O PIXQDIGKDNNOOV-GUBZILKMSA-N 0.000 description 1
- OMDNCNKNEGFOMM-BQBZGAKWSA-N Ala-Met-Gly Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CCSC)C(=O)NCC(O)=O OMDNCNKNEGFOMM-BQBZGAKWSA-N 0.000 description 1
- DHBKYZYFEXXUAK-ONGXEEELSA-N Ala-Phe-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)[C@@H](N)C)CC1=CC=CC=C1 DHBKYZYFEXXUAK-ONGXEEELSA-N 0.000 description 1
- IPZQNYYAYVRKKK-FXQIFTODSA-N Ala-Pro-Ala Chemical compound C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IPZQNYYAYVRKKK-FXQIFTODSA-N 0.000 description 1
- VJVQKGYHIZPSNS-FXQIFTODSA-N Ala-Ser-Arg Chemical compound C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCN=C(N)N VJVQKGYHIZPSNS-FXQIFTODSA-N 0.000 description 1
- NZGRHTKZFSVPAN-BIIVOSGPSA-N Ala-Ser-Pro Chemical compound C[C@@H](C(=O)N[C@@H](CO)C(=O)N1CCC[C@@H]1C(=O)O)N NZGRHTKZFSVPAN-BIIVOSGPSA-N 0.000 description 1
- OEVCHROQUIVQFZ-YTLHQDLWSA-N Ala-Thr-Ala Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](C)C(O)=O OEVCHROQUIVQFZ-YTLHQDLWSA-N 0.000 description 1
- HCBKAOZYACJUEF-XQXXSGGOSA-N Ala-Thr-Gln Chemical compound N[C@@H](C)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(N)=O)C(=O)O HCBKAOZYACJUEF-XQXXSGGOSA-N 0.000 description 1
- LSMDIAAALJJLRO-XQXXSGGOSA-N Ala-Thr-Glu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(O)=O LSMDIAAALJJLRO-XQXXSGGOSA-N 0.000 description 1
- SAHQGRZIQVEJPF-JXUBOQSCSA-N Ala-Thr-Lys Chemical compound C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@H](C(O)=O)CCCCN SAHQGRZIQVEJPF-JXUBOQSCSA-N 0.000 description 1
- KUFVXLQLDHJVOG-SHGPDSBTSA-N Ala-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](C)N)O KUFVXLQLDHJVOG-SHGPDSBTSA-N 0.000 description 1
- IETUUAHKCHOQHP-KZVJFYERSA-N Ala-Thr-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H](NC(=O)[C@H](C)N)[C@@H](C)O)C(O)=O IETUUAHKCHOQHP-KZVJFYERSA-N 0.000 description 1
- ZJLORAAXDAJLDC-CQDKDKBSSA-N Ala-Tyr-Leu Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O ZJLORAAXDAJLDC-CQDKDKBSSA-N 0.000 description 1
- BVLPIIBTWIYOML-ZKWXMUAHSA-N Ala-Val-Asp Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BVLPIIBTWIYOML-ZKWXMUAHSA-N 0.000 description 1
- BOKLLPVAQDSLHC-FXQIFTODSA-N Ala-Val-Cys Chemical compound C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(=O)O)N BOKLLPVAQDSLHC-FXQIFTODSA-N 0.000 description 1
- OMSKGWFGWCQFBD-KZVJFYERSA-N Ala-Val-Thr Chemical compound [H]N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OMSKGWFGWCQFBD-KZVJFYERSA-N 0.000 description 1
- 208000031091 Amnestic disease Diseases 0.000 description 1
- 101710095339 Apolipoprotein E Proteins 0.000 description 1
- 102000008128 Apolipoprotein E3 Human genes 0.000 description 1
- 108010060215 Apolipoprotein E3 Proteins 0.000 description 1
- GXCSUJQOECMKPV-CIUDSAMLSA-N Arg-Ala-Gln Chemical compound C[C@H](NC(=O)[C@@H](N)CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O GXCSUJQOECMKPV-CIUDSAMLSA-N 0.000 description 1
- KJGNDQCYBNBXDA-GUBZILKMSA-N Arg-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)CN=C(N)N KJGNDQCYBNBXDA-GUBZILKMSA-N 0.000 description 1
- MUXONAMCEUBVGA-DCAQKATOSA-N Arg-Arg-Gln Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(N)=O)C(O)=O MUXONAMCEUBVGA-DCAQKATOSA-N 0.000 description 1
- UXJCMQFPDWCHKX-DCAQKATOSA-N Arg-Arg-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCC(O)=O)C(O)=O UXJCMQFPDWCHKX-DCAQKATOSA-N 0.000 description 1
- NABSCJGZKWSNHX-RCWTZXSCSA-N Arg-Arg-Thr Chemical compound NC(N)=NCCC[C@@H](C(=O)N[C@@H]([C@H](O)C)C(O)=O)NC(=O)[C@@H](N)CCCN=C(N)N NABSCJGZKWSNHX-RCWTZXSCSA-N 0.000 description 1
- BVBKBQRPOJFCQM-DCAQKATOSA-N Arg-Asn-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O BVBKBQRPOJFCQM-DCAQKATOSA-N 0.000 description 1
- KWTVWJPNHAOREN-IHRRRGAJSA-N Arg-Asn-Phe Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O KWTVWJPNHAOREN-IHRRRGAJSA-N 0.000 description 1
- MFAMTAVAFBPXDC-LPEHRKFASA-N Arg-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O MFAMTAVAFBPXDC-LPEHRKFASA-N 0.000 description 1
- HKRXJBBCQBAGIM-FXQIFTODSA-N Arg-Asp-Ser Chemical compound C(C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CO)C(=O)O)N)CN=C(N)N HKRXJBBCQBAGIM-FXQIFTODSA-N 0.000 description 1
- MTANSHNQTWPZKP-KKUMJFAQSA-N Arg-Gln-Tyr Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)N)NC(=O)[C@H](CCCN=C(N)N)N)O MTANSHNQTWPZKP-KKUMJFAQSA-N 0.000 description 1
- GOWZVQXTHUCNSQ-NHCYSSNCSA-N Arg-Glu-Val Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O GOWZVQXTHUCNSQ-NHCYSSNCSA-N 0.000 description 1
- AQPVUEJJARLJHB-BQBZGAKWSA-N Arg-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)[C@@H](N)CCCN=C(N)N AQPVUEJJARLJHB-BQBZGAKWSA-N 0.000 description 1
- AUFHLLPVPSMEOG-YUMQZZPRSA-N Arg-Gly-Glu Chemical compound NC(N)=NCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CCC(O)=O)C(O)=O AUFHLLPVPSMEOG-YUMQZZPRSA-N 0.000 description 1
- QKSAZKCRVQYYGS-UWVGGRQHSA-N Arg-Gly-His Chemical compound N[C@@H](CCCN=C(N)N)C(=O)NCC(=O)N[C@@H](Cc1cnc[nH]1)C(O)=O QKSAZKCRVQYYGS-UWVGGRQHSA-N 0.000 description 1
- LVMUGODRNHFGRA-AVGNSLFASA-N Arg-Leu-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O LVMUGODRNHFGRA-AVGNSLFASA-N 0.000 description 1
- JEXPNDORFYHJTM-IHRRRGAJSA-N Arg-Leu-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CCCN=C(N)N JEXPNDORFYHJTM-IHRRRGAJSA-N 0.000 description 1
- XUGATJVGQUGQKY-ULQDDVLXSA-N Arg-Lys-Phe Chemical compound NC(=N)NCCC[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XUGATJVGQUGQKY-ULQDDVLXSA-N 0.000 description 1
- RIQBRKVTFBWEDY-RHYQMDGZSA-N Arg-Lys-Thr Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O RIQBRKVTFBWEDY-RHYQMDGZSA-N 0.000 description 1
- FVBZXNSRIDVYJS-AVGNSLFASA-N Arg-Pro-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCCN=C(N)N FVBZXNSRIDVYJS-AVGNSLFASA-N 0.000 description 1
- ICRHGPYYXMWHIE-LPEHRKFASA-N Arg-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCN=C(N)N)N)C(=O)O ICRHGPYYXMWHIE-LPEHRKFASA-N 0.000 description 1
- AIFHRTPABBBHKU-RCWTZXSCSA-N Arg-Thr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O AIFHRTPABBBHKU-RCWTZXSCSA-N 0.000 description 1
- DRDWXKWUSIKKOB-PJODQICGSA-N Arg-Trp-Ala Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](C)C(O)=O DRDWXKWUSIKKOB-PJODQICGSA-N 0.000 description 1
- QMQZYILAWUOLPV-JYJNAYRXSA-N Arg-Tyr-Arg Chemical compound NC(N)=NCCC[C@H](N)C(=O)N[C@H](C(=O)N[C@@H](CCCN=C(N)N)C(O)=O)CC1=CC=C(O)C=C1 QMQZYILAWUOLPV-JYJNAYRXSA-N 0.000 description 1
- CGWVCWFQGXOUSJ-ULQDDVLXSA-N Arg-Tyr-Leu Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC(C)C)C(O)=O CGWVCWFQGXOUSJ-ULQDDVLXSA-N 0.000 description 1
- VYZBPPBKFCHCIS-WPRPVWTQSA-N Arg-Val-Gly Chemical compound OC(=O)CNC(=O)[C@H](C(C)C)NC(=O)[C@@H](N)CCCN=C(N)N VYZBPPBKFCHCIS-WPRPVWTQSA-N 0.000 description 1
- FMYQECOAIFGQGU-CYDGBPFRSA-N Arg-Val-Ile Chemical compound [H]N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O FMYQECOAIFGQGU-CYDGBPFRSA-N 0.000 description 1
- LEFKSBYHUGUWLP-ACZMJKKPSA-N Asn-Ala-Glu Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(O)=O)C(O)=O LEFKSBYHUGUWLP-ACZMJKKPSA-N 0.000 description 1
- CMLGVVWQQHUXOZ-GHCJXIJMSA-N Asn-Ala-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O CMLGVVWQQHUXOZ-GHCJXIJMSA-N 0.000 description 1
- IARGXWMWRFOQPG-GCJQMDKQSA-N Asn-Ala-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IARGXWMWRFOQPG-GCJQMDKQSA-N 0.000 description 1
- POOCJCRBHHMAOS-FXQIFTODSA-N Asn-Arg-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O POOCJCRBHHMAOS-FXQIFTODSA-N 0.000 description 1
- QRHYAUYXBVVDSB-LKXGYXEUSA-N Asn-Cys-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(O)=O QRHYAUYXBVVDSB-LKXGYXEUSA-N 0.000 description 1
- UBKOVSLDWIHYSY-ACZMJKKPSA-N Asn-Glu-Ser Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O UBKOVSLDWIHYSY-ACZMJKKPSA-N 0.000 description 1
- DMLSCRJBWUEALP-LAEOZQHASA-N Asn-Glu-Val Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O DMLSCRJBWUEALP-LAEOZQHASA-N 0.000 description 1
- ACKNRKFVYUVWAC-ZPFDUUQYSA-N Asn-Ile-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)N)N ACKNRKFVYUVWAC-ZPFDUUQYSA-N 0.000 description 1
- BXUHCIXDSWRSBS-CIUDSAMLSA-N Asn-Leu-Asp Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O BXUHCIXDSWRSBS-CIUDSAMLSA-N 0.000 description 1
- BZWRLDPIWKOVKB-ZPFDUUQYSA-N Asn-Leu-Ile Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O BZWRLDPIWKOVKB-ZPFDUUQYSA-N 0.000 description 1
- FTSAJSADJCMDHH-CIUDSAMLSA-N Asn-Lys-Asp Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@H](CC(=O)N)N FTSAJSADJCMDHH-CIUDSAMLSA-N 0.000 description 1
- GIQCDTKOIPUDSG-GARJFASQSA-N Asn-Lys-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCCN)NC(=O)[C@H](CC(=O)N)N)C(=O)O GIQCDTKOIPUDSG-GARJFASQSA-N 0.000 description 1
- PLTGTJAZQRGMPP-FXQIFTODSA-N Asn-Pro-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CC(N)=O PLTGTJAZQRGMPP-FXQIFTODSA-N 0.000 description 1
- QXOPPIDJKPEKCW-GUBZILKMSA-N Asn-Pro-Arg Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC(=O)N)N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O QXOPPIDJKPEKCW-GUBZILKMSA-N 0.000 description 1
- HPBNLFLSSQDFQW-WHFBIAKZSA-N Asn-Ser-Gly Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H](CO)C(=O)NCC(O)=O HPBNLFLSSQDFQW-WHFBIAKZSA-N 0.000 description 1
- ZUFPUBYQYWCMDB-NUMRIWBASA-N Asn-Thr-Glu Chemical compound NC(=O)C[C@H](N)C(=O)N[C@@H]([C@H](O)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZUFPUBYQYWCMDB-NUMRIWBASA-N 0.000 description 1
- QUCCLIXMVPIVOB-BZSNNMDCSA-N Asn-Tyr-Phe Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)O)NC(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC(=O)N)N QUCCLIXMVPIVOB-BZSNNMDCSA-N 0.000 description 1
- XEGZSHSPQNDNRH-JRQIVUDYSA-N Asn-Tyr-Thr Chemical compound [H]N[C@@H](CC(N)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XEGZSHSPQNDNRH-JRQIVUDYSA-N 0.000 description 1
- PBVLJOIPOGUQQP-CIUDSAMLSA-N Asp-Ala-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O PBVLJOIPOGUQQP-CIUDSAMLSA-N 0.000 description 1
- RGKKALNPOYURGE-ZKWXMUAHSA-N Asp-Ala-Val Chemical compound N[C@@H](CC(=O)O)C(=O)N[C@@H](C)C(=O)N[C@@H](C(C)C)C(=O)O RGKKALNPOYURGE-ZKWXMUAHSA-N 0.000 description 1
- QOVWVLLHMMCFFY-ZLUOBGJFSA-N Asp-Asp-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QOVWVLLHMMCFFY-ZLUOBGJFSA-N 0.000 description 1
- SVFOIXMRMLROHO-SRVKXCTJSA-N Asp-Asp-Phe Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 SVFOIXMRMLROHO-SRVKXCTJSA-N 0.000 description 1
- WLKVEEODTPQPLI-ACZMJKKPSA-N Asp-Gln-Asn Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O WLKVEEODTPQPLI-ACZMJKKPSA-N 0.000 description 1
- XDGBFDYXZCMYEX-NUMRIWBASA-N Asp-Glu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC(=O)O)N)O XDGBFDYXZCMYEX-NUMRIWBASA-N 0.000 description 1
- YNCHFVRXEQFPBY-BQBZGAKWSA-N Asp-Gly-Arg Chemical compound OC(=O)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCN=C(N)N YNCHFVRXEQFPBY-BQBZGAKWSA-N 0.000 description 1
- QCVXMEHGFUMKCO-YUMQZZPRSA-N Asp-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CC(O)=O QCVXMEHGFUMKCO-YUMQZZPRSA-N 0.000 description 1
- NHSDEZURHWEZPN-SXTJYALSSA-N Asp-Ile-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)NC(=O)[C@H](CC(=O)O)N NHSDEZURHWEZPN-SXTJYALSSA-N 0.000 description 1
- TZBJAXGYGSIUHQ-XUXIUFHCSA-N Asp-Leu-Leu-Ser Chemical compound OC(=O)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O TZBJAXGYGSIUHQ-XUXIUFHCSA-N 0.000 description 1
- UMHUHHJMEXNSIV-CIUDSAMLSA-N Asp-Leu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC(O)=O UMHUHHJMEXNSIV-CIUDSAMLSA-N 0.000 description 1
- YRZIYQGXTSBRLT-AVGNSLFASA-N Asp-Phe-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(O)=O YRZIYQGXTSBRLT-AVGNSLFASA-N 0.000 description 1
- GPPIDDWYKJPRES-YDHLFZDLSA-N Asp-Phe-Val Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](C(C)C)C(O)=O GPPIDDWYKJPRES-YDHLFZDLSA-N 0.000 description 1
- YFGUZQQCSDZRBN-DCAQKATOSA-N Asp-Pro-Leu Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O YFGUZQQCSDZRBN-DCAQKATOSA-N 0.000 description 1
- XUVTWGPERWIERB-IHRRRGAJSA-N Asp-Pro-Phe Chemical compound N[C@@H](CC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](Cc1ccccc1)C(O)=O XUVTWGPERWIERB-IHRRRGAJSA-N 0.000 description 1
- BKOIIURTQAJHAT-GUBZILKMSA-N Asp-Pro-Pro Chemical compound OC(=O)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 BKOIIURTQAJHAT-GUBZILKMSA-N 0.000 description 1
- CUQDCPXNZPDYFQ-ZLUOBGJFSA-N Asp-Ser-Asp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(O)=O CUQDCPXNZPDYFQ-ZLUOBGJFSA-N 0.000 description 1
- ZVGRHIRJLWBWGJ-ACZMJKKPSA-N Asp-Ser-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(N)=O)C(O)=O ZVGRHIRJLWBWGJ-ACZMJKKPSA-N 0.000 description 1
- QOCFFCUFZGDHTP-NUMRIWBASA-N Asp-Thr-Gln Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(N)=O)C(O)=O QOCFFCUFZGDHTP-NUMRIWBASA-N 0.000 description 1
- YODBPLSWNJMZOJ-BPUTZDHNSA-N Asp-Trp-Arg Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CC(=O)O)N YODBPLSWNJMZOJ-BPUTZDHNSA-N 0.000 description 1
- FIRWLDUOFOULCA-XIRDDKMYSA-N Asp-Trp-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(=O)O)N FIRWLDUOFOULCA-XIRDDKMYSA-N 0.000 description 1
- SQIARYGNVQWOSB-BZSNNMDCSA-N Asp-Tyr-Phe Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQIARYGNVQWOSB-BZSNNMDCSA-N 0.000 description 1
- VHUKCUHLFMRHOD-MELADBBJSA-N Asp-Tyr-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC2=CC=C(C=C2)O)NC(=O)[C@H](CC(=O)O)N)C(=O)O VHUKCUHLFMRHOD-MELADBBJSA-N 0.000 description 1
- HTSSXFASOUSJQG-IHPCNDPISA-N Asp-Tyr-Trp Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O HTSSXFASOUSJQG-IHPCNDPISA-N 0.000 description 1
- ALMIMUZAWTUNIO-BZSNNMDCSA-N Asp-Tyr-Tyr Chemical compound [H]N[C@@H](CC(O)=O)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ALMIMUZAWTUNIO-BZSNNMDCSA-N 0.000 description 1
- 108090001008 Avidin Proteins 0.000 description 1
- ZOXJGFHDIHLPTG-UHFFFAOYSA-N Boron Chemical compound [B] ZOXJGFHDIHLPTG-UHFFFAOYSA-N 0.000 description 1
- 101800004538 Bradykinin Proteins 0.000 description 1
- 102400000967 Bradykinin Human genes 0.000 description 1
- 241000244203 Caenorhabditis elegans Species 0.000 description 1
- 241000282836 Camelus dromedarius Species 0.000 description 1
- 241000282472 Canis lupus familiaris Species 0.000 description 1
- DLGOEMSEDOSKAD-UHFFFAOYSA-N Carmustine Chemical compound ClCCNC(=O)N(N=O)CCCl DLGOEMSEDOSKAD-UHFFFAOYSA-N 0.000 description 1
- 102000011727 Caspases Human genes 0.000 description 1
- 108010076667 Caspases Proteins 0.000 description 1
- GHOKWGTUZJEAQD-UHFFFAOYSA-N Chick antidermatitis factor Natural products OCC(C)(C)C(O)C(=O)NCCC(O)=O GHOKWGTUZJEAQD-UHFFFAOYSA-N 0.000 description 1
- 229940122041 Cholinesterase inhibitor Drugs 0.000 description 1
- 108091026890 Coding region Proteins 0.000 description 1
- 208000028698 Cognitive impairment Diseases 0.000 description 1
- 206010009944 Colon cancer Diseases 0.000 description 1
- 208000001333 Colorectal Neoplasms Diseases 0.000 description 1
- CEZSLNCYQUFOSL-BQBZGAKWSA-N Cys-Arg-Gly Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O CEZSLNCYQUFOSL-BQBZGAKWSA-N 0.000 description 1
- QLCPDGRAEJSYQM-LPEHRKFASA-N Cys-Arg-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](CS)N)C(=O)O QLCPDGRAEJSYQM-LPEHRKFASA-N 0.000 description 1
- CPTUXCUWQIBZIF-ZLUOBGJFSA-N Cys-Asn-Ser Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O CPTUXCUWQIBZIF-ZLUOBGJFSA-N 0.000 description 1
- VZKXOWRNJDEGLZ-WHFBIAKZSA-N Cys-Asp-Gly Chemical compound SC[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)NCC(O)=O VZKXOWRNJDEGLZ-WHFBIAKZSA-N 0.000 description 1
- ATPDEYTYWVMINF-ZLUOBGJFSA-N Cys-Cys-Ser Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O ATPDEYTYWVMINF-ZLUOBGJFSA-N 0.000 description 1
- YRKJQKATZOTUEN-ACZMJKKPSA-N Cys-Gln-Cys Chemical compound C(CC(=O)N)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N YRKJQKATZOTUEN-ACZMJKKPSA-N 0.000 description 1
- UPURLDIGQGTUPJ-ZKWXMUAHSA-N Cys-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CS)N UPURLDIGQGTUPJ-ZKWXMUAHSA-N 0.000 description 1
- OXOQBEVULIBOSH-ZDLURKLDSA-N Cys-Gly-Thr Chemical compound [H]N[C@@H](CS)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O OXOQBEVULIBOSH-ZDLURKLDSA-N 0.000 description 1
- PGBLJHDDKCVSTC-CIUDSAMLSA-N Cys-Met-Gln Chemical compound CSCC[C@H](NC(=O)[C@@H](N)CS)C(=O)N[C@@H](CCC(N)=O)C(O)=O PGBLJHDDKCVSTC-CIUDSAMLSA-N 0.000 description 1
- UDDITVWSXPEAIQ-IHRRRGAJSA-N Cys-Phe-Arg Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O UDDITVWSXPEAIQ-IHRRRGAJSA-N 0.000 description 1
- XBELMDARIGXDKY-GUBZILKMSA-N Cys-Pro-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@@H]1CCCN1C(=O)[C@H](CS)N XBELMDARIGXDKY-GUBZILKMSA-N 0.000 description 1
- ZGERHCJBLPQPGV-ACZMJKKPSA-N Cys-Ser-Gln Chemical compound C(CC(=O)N)[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CS)N ZGERHCJBLPQPGV-ACZMJKKPSA-N 0.000 description 1
- GGRDJANMZPGMNS-CIUDSAMLSA-N Cys-Ser-Leu Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O GGRDJANMZPGMNS-CIUDSAMLSA-N 0.000 description 1
- NRVQLLDIJJEIIZ-VZFHVOOUSA-N Cys-Thr-Ala Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](C)C(=O)O)NC(=O)[C@H](CS)N)O NRVQLLDIJJEIIZ-VZFHVOOUSA-N 0.000 description 1
- FCXJJTRGVAZDER-FXQIFTODSA-N Cys-Val-Ala Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(O)=O FCXJJTRGVAZDER-FXQIFTODSA-N 0.000 description 1
- MQQLYEHXSBJTRK-FXQIFTODSA-N Cys-Val-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CS)N MQQLYEHXSBJTRK-FXQIFTODSA-N 0.000 description 1
- NGOIQDYZMIKCOK-NAKRPEOUSA-N Cys-Val-Ile Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O NGOIQDYZMIKCOK-NAKRPEOUSA-N 0.000 description 1
- GQNZIAGMRXOFJX-GUBZILKMSA-N Cys-Val-Met Chemical compound [H]N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCSC)C(O)=O GQNZIAGMRXOFJX-GUBZILKMSA-N 0.000 description 1
- 102000004127 Cytokines Human genes 0.000 description 1
- 108090000695 Cytokines Proteins 0.000 description 1
- FBPFZTCFMRRESA-KVTDHHQDSA-N D-Mannitol Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)[C@H](O)CO FBPFZTCFMRRESA-KVTDHHQDSA-N 0.000 description 1
- HMFHBZSHGGEWLO-SOOFDHNKSA-N D-ribofuranose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H]1O HMFHBZSHGGEWLO-SOOFDHNKSA-N 0.000 description 1
- 108010090461 DFG peptide Proteins 0.000 description 1
- 102000053602 DNA Human genes 0.000 description 1
- 108020003215 DNA Probes Proteins 0.000 description 1
- 238000001712 DNA sequencing Methods 0.000 description 1
- 102000016928 DNA-directed DNA polymerase Human genes 0.000 description 1
- 108010014303 DNA-directed DNA polymerase Proteins 0.000 description 1
- 108090000626 DNA-directed RNA polymerases Proteins 0.000 description 1
- 102000004163 DNA-directed RNA polymerases Human genes 0.000 description 1
- 208000031124 Dementia Alzheimer type Diseases 0.000 description 1
- 102100022273 Disrupted in schizophrenia 1 protein Human genes 0.000 description 1
- 238000008157 ELISA kit Methods 0.000 description 1
- 241000287828 Gallus gallus Species 0.000 description 1
- 206010064571 Gene mutation Diseases 0.000 description 1
- 229930183217 Genin Natural products 0.000 description 1
- 208000010412 Glaucoma Diseases 0.000 description 1
- RMOCFPBLHAOTDU-ACZMJKKPSA-N Gln-Asn-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O RMOCFPBLHAOTDU-ACZMJKKPSA-N 0.000 description 1
- XEYMBRRKIFYQMF-GUBZILKMSA-N Gln-Asp-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O XEYMBRRKIFYQMF-GUBZILKMSA-N 0.000 description 1
- ZNZPKVQURDQFFS-FXQIFTODSA-N Gln-Glu-Ser Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ZNZPKVQURDQFFS-FXQIFTODSA-N 0.000 description 1
- XKBASPWPBXNVLQ-WDSKDSINSA-N Gln-Gly-Asn Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O XKBASPWPBXNVLQ-WDSKDSINSA-N 0.000 description 1
- GFLNKSQHOBOMNM-AVGNSLFASA-N Gln-His-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)NC(=O)[C@H](CCC(=O)N)N GFLNKSQHOBOMNM-AVGNSLFASA-N 0.000 description 1
- XFAUJGNLHIGXET-AVGNSLFASA-N Gln-Leu-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O XFAUJGNLHIGXET-AVGNSLFASA-N 0.000 description 1
- ZBKUIQNCRIYVGH-SDDRHHMPSA-N Gln-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCC(=O)N)N ZBKUIQNCRIYVGH-SDDRHHMPSA-N 0.000 description 1
- IOFDDSNZJDIGPB-GVXVVHGQSA-N Gln-Leu-Val Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O IOFDDSNZJDIGPB-GVXVVHGQSA-N 0.000 description 1
- ILKYYKRAULNYMS-JYJNAYRXSA-N Gln-Lys-Phe Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O ILKYYKRAULNYMS-JYJNAYRXSA-N 0.000 description 1
- WLRYGVYQFXRJDA-DCAQKATOSA-N Gln-Pro-Pro Chemical compound NC(=O)CC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 WLRYGVYQFXRJDA-DCAQKATOSA-N 0.000 description 1
- YPFFHGRJCUBXPX-NHCYSSNCSA-N Gln-Pro-Val Chemical compound CC(C)[C@H](NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CCC(N)=O)C(O)=O YPFFHGRJCUBXPX-NHCYSSNCSA-N 0.000 description 1
- LPIKVBWNNVFHCQ-GUBZILKMSA-N Gln-Ser-Leu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O LPIKVBWNNVFHCQ-GUBZILKMSA-N 0.000 description 1
- UBRQJXFDVZNYJP-AVGNSLFASA-N Gln-Tyr-Ser Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)N)N)O UBRQJXFDVZNYJP-AVGNSLFASA-N 0.000 description 1
- BBFCMGBMYIAGRS-AUTRQRHGSA-N Gln-Val-Glu Chemical compound [H]N[C@@H](CCC(N)=O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O BBFCMGBMYIAGRS-AUTRQRHGSA-N 0.000 description 1
- UTKICHUQEQBDGC-ACZMJKKPSA-N Glu-Ala-Cys Chemical compound C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CCC(=O)O)N UTKICHUQEQBDGC-ACZMJKKPSA-N 0.000 description 1
- KBKGRMNVKPSQIF-XDTLVQLUSA-N Glu-Ala-Tyr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O KBKGRMNVKPSQIF-XDTLVQLUSA-N 0.000 description 1
- RCCDHXSRMWCOOY-GUBZILKMSA-N Glu-Arg-Gln Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(N)=O)C(O)=O RCCDHXSRMWCOOY-GUBZILKMSA-N 0.000 description 1
- CGYDXNKRIMJMLV-GUBZILKMSA-N Glu-Arg-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O CGYDXNKRIMJMLV-GUBZILKMSA-N 0.000 description 1
- VTTSANCGJWLPNC-ZPFDUUQYSA-N Glu-Arg-Ile Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O VTTSANCGJWLPNC-ZPFDUUQYSA-N 0.000 description 1
- YYOBUPFZLKQUAX-FXQIFTODSA-N Glu-Asn-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O YYOBUPFZLKQUAX-FXQIFTODSA-N 0.000 description 1
- PCBBLFVHTYNQGG-LAEOZQHASA-N Glu-Asn-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](CCC(=O)O)N PCBBLFVHTYNQGG-LAEOZQHASA-N 0.000 description 1
- IESFZVCAVACGPH-PEFMBERDSA-N Glu-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CCC(O)=O IESFZVCAVACGPH-PEFMBERDSA-N 0.000 description 1
- WATXSTJXNBOHKD-LAEOZQHASA-N Glu-Asp-Val Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O WATXSTJXNBOHKD-LAEOZQHASA-N 0.000 description 1
- ISXJHXGYMJKXOI-GUBZILKMSA-N Glu-Cys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CCC(O)=O ISXJHXGYMJKXOI-GUBZILKMSA-N 0.000 description 1
- UENPHLAAKDPZQY-XKBZYTNZSA-N Glu-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CS)NC(=O)[C@H](CCC(=O)O)N)O UENPHLAAKDPZQY-XKBZYTNZSA-N 0.000 description 1
- XHUCVVHRLNPZSZ-CIUDSAMLSA-N Glu-Gln-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O XHUCVVHRLNPZSZ-CIUDSAMLSA-N 0.000 description 1
- QQLBPVKLJBAXBS-FXQIFTODSA-N Glu-Glu-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O QQLBPVKLJBAXBS-FXQIFTODSA-N 0.000 description 1
- YLJHCWNDBKKOEB-IHRRRGAJSA-N Glu-Glu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O YLJHCWNDBKKOEB-IHRRRGAJSA-N 0.000 description 1
- OAGVHWYIBZMWLA-YFKPBYRVSA-N Glu-Gly-Gly Chemical compound OC(=O)CC[C@H](N)C(=O)NCC(=O)NCC(O)=O OAGVHWYIBZMWLA-YFKPBYRVSA-N 0.000 description 1
- KRGZZKWSBGPLKL-IUCAKERBSA-N Glu-Gly-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CCC(=O)O)N KRGZZKWSBGPLKL-IUCAKERBSA-N 0.000 description 1
- CXRWMMRLEMVSEH-PEFMBERDSA-N Glu-Ile-Asn Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(N)=O)C(O)=O CXRWMMRLEMVSEH-PEFMBERDSA-N 0.000 description 1
- HVYWQYLBVXMXSV-GUBZILKMSA-N Glu-Leu-Ala Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O HVYWQYLBVXMXSV-GUBZILKMSA-N 0.000 description 1
- WNRZUESNGGDCJX-JYJNAYRXSA-N Glu-Leu-Phe Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O WNRZUESNGGDCJX-JYJNAYRXSA-N 0.000 description 1
- CBEUFCJRFNZMCU-SRVKXCTJSA-N Glu-Met-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O CBEUFCJRFNZMCU-SRVKXCTJSA-N 0.000 description 1
- KJBGAZSLZAQDPV-KKUMJFAQSA-N Glu-Phe-Arg Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)NC(=O)[C@H](CCC(=O)O)N KJBGAZSLZAQDPV-KKUMJFAQSA-N 0.000 description 1
- ITVBKCZZLJUUHI-HTUGSXCWSA-N Glu-Phe-Thr Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ITVBKCZZLJUUHI-HTUGSXCWSA-N 0.000 description 1
- HLYCMRDRWGSTPZ-CIUDSAMLSA-N Glu-Pro-Cys Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CS)C(=O)O HLYCMRDRWGSTPZ-CIUDSAMLSA-N 0.000 description 1
- AAJHGGDRKHYSDH-GUBZILKMSA-N Glu-Pro-Gln Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CCC(=O)O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O AAJHGGDRKHYSDH-GUBZILKMSA-N 0.000 description 1
- DXVOKNVIKORTHQ-GUBZILKMSA-N Glu-Pro-Glu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O DXVOKNVIKORTHQ-GUBZILKMSA-N 0.000 description 1
- SYWCGQOIIARSIX-SRVKXCTJSA-N Glu-Pro-Leu Chemical compound [H]N[C@@H](CCC(O)=O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(O)=O SYWCGQOIIARSIX-SRVKXCTJSA-N 0.000 description 1
- ZTNHPMZHAILHRB-JSGCOSHPSA-N Glu-Trp-Gly Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)N)C(=O)NCC(O)=O)=CNC2=C1 ZTNHPMZHAILHRB-JSGCOSHPSA-N 0.000 description 1
- DXMOIVCNJIJQSC-QEJZJMRPSA-N Glu-Trp-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CCC(=O)O)N DXMOIVCNJIJQSC-QEJZJMRPSA-N 0.000 description 1
- QXUPRMQJDWJDFR-NRPADANISA-N Glu-Val-Ser Chemical compound CC(C)[C@H](NC(=O)[C@@H](N)CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O QXUPRMQJDWJDFR-NRPADANISA-N 0.000 description 1
- WQZGKKKJIJFFOK-GASJEMHNSA-N Glucose Chemical compound OC[C@H]1OC(O)[C@H](O)[C@@H](O)[C@@H]1O WQZGKKKJIJFFOK-GASJEMHNSA-N 0.000 description 1
- VSVZIEVNUYDAFR-YUMQZZPRSA-N Gly-Ala-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)CN VSVZIEVNUYDAFR-YUMQZZPRSA-N 0.000 description 1
- JXYMPBCYRKWJEE-BQBZGAKWSA-N Gly-Arg-Ala Chemical compound [H]NCC(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O JXYMPBCYRKWJEE-BQBZGAKWSA-N 0.000 description 1
- RJIVPOXLQFJRTG-LURJTMIESA-N Gly-Arg-Gly Chemical compound OC(=O)CNC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N RJIVPOXLQFJRTG-LURJTMIESA-N 0.000 description 1
- VXKCPBPQEKKERH-IUCAKERBSA-N Gly-Arg-Pro Chemical compound NC(N)=NCCC[C@H](NC(=O)CN)C(=O)N1CCC[C@H]1C(O)=O VXKCPBPQEKKERH-IUCAKERBSA-N 0.000 description 1
- KKBWDNZXYLGJEY-UHFFFAOYSA-N Gly-Arg-Pro Natural products NCC(=O)NC(CCNC(=N)N)C(=O)N1CCCC1C(=O)O KKBWDNZXYLGJEY-UHFFFAOYSA-N 0.000 description 1
- WKJKBELXHCTHIJ-WPRPVWTQSA-N Gly-Arg-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CCCN=C(N)N WKJKBELXHCTHIJ-WPRPVWTQSA-N 0.000 description 1
- UXJHNZODTMHWRD-WHFBIAKZSA-N Gly-Asn-Ala Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](C)C(O)=O UXJHNZODTMHWRD-WHFBIAKZSA-N 0.000 description 1
- JVWPPCWUDRJGAE-YUMQZZPRSA-N Gly-Asn-Leu Chemical compound [H]NCC(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JVWPPCWUDRJGAE-YUMQZZPRSA-N 0.000 description 1
- LCNXZQROPKFGQK-WHFBIAKZSA-N Gly-Asp-Ser Chemical compound NCC(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CO)C(O)=O LCNXZQROPKFGQK-WHFBIAKZSA-N 0.000 description 1
- BYYNJRSNDARRBX-YFKPBYRVSA-N Gly-Gln-Gly Chemical compound NCC(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O BYYNJRSNDARRBX-YFKPBYRVSA-N 0.000 description 1
- GNPVTZJUUBPZKW-WDSKDSINSA-N Gly-Gln-Ser Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CO)C(O)=O GNPVTZJUUBPZKW-WDSKDSINSA-N 0.000 description 1
- LJXWZPHEMJSNRC-KBPBESRZSA-N Gly-Gln-Trp Chemical compound [H]NCC(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O LJXWZPHEMJSNRC-KBPBESRZSA-N 0.000 description 1
- JNGJGFMFXREJNF-KBPBESRZSA-N Gly-Glu-Trp Chemical compound [H]NCC(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O JNGJGFMFXREJNF-KBPBESRZSA-N 0.000 description 1
- CCQOOWAONKGYKQ-BYPYZUCNSA-N Gly-Gly-Ala Chemical compound OC(=O)[C@H](C)NC(=O)CNC(=O)CN CCQOOWAONKGYKQ-BYPYZUCNSA-N 0.000 description 1
- KAJAOGBVWCYGHZ-JTQLQIEISA-N Gly-Gly-Phe Chemical compound [NH3+]CC(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=CC=C1 KAJAOGBVWCYGHZ-JTQLQIEISA-N 0.000 description 1
- FSPVILZGHUJOHS-QWRGUYRKSA-N Gly-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)CN)CC1=CNC=N1 FSPVILZGHUJOHS-QWRGUYRKSA-N 0.000 description 1
- NSTUFLGQJCOCDL-UWVGGRQHSA-N Gly-Leu-Arg Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N NSTUFLGQJCOCDL-UWVGGRQHSA-N 0.000 description 1
- CCBIBMKQNXHNIN-ZETCQYMHSA-N Gly-Leu-Gly Chemical compound NCC(=O)N[C@@H](CC(C)C)C(=O)NCC(O)=O CCBIBMKQNXHNIN-ZETCQYMHSA-N 0.000 description 1
- LOEANKRDMMVOGZ-YUMQZZPRSA-N Gly-Lys-Asp Chemical compound NCCCC[C@H](NC(=O)CN)C(=O)N[C@@H](CC(O)=O)C(O)=O LOEANKRDMMVOGZ-YUMQZZPRSA-N 0.000 description 1
- GMTXWRIDLGTVFC-IUCAKERBSA-N Gly-Lys-Glu Chemical compound [H]NCC(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(O)=O GMTXWRIDLGTVFC-IUCAKERBSA-N 0.000 description 1
- HHRODZSXDXMUHS-LURJTMIESA-N Gly-Met-Gly Chemical compound CSCC[C@H](NC(=O)C[NH3+])C(=O)NCC([O-])=O HHRODZSXDXMUHS-LURJTMIESA-N 0.000 description 1
- SCJJPCQUJYPHRZ-BQBZGAKWSA-N Gly-Pro-Asn Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(N)=O)C(O)=O SCJJPCQUJYPHRZ-BQBZGAKWSA-N 0.000 description 1
- JJGBXTYGTKWGAT-YUMQZZPRSA-N Gly-Pro-Glu Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O JJGBXTYGTKWGAT-YUMQZZPRSA-N 0.000 description 1
- HFPVRZWORNJRRC-UWVGGRQHSA-N Gly-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN HFPVRZWORNJRRC-UWVGGRQHSA-N 0.000 description 1
- OOCFXNOVSLSHAB-IUCAKERBSA-N Gly-Pro-Pro Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 OOCFXNOVSLSHAB-IUCAKERBSA-N 0.000 description 1
- JNGHLWWFPGIJER-STQMWFEESA-N Gly-Pro-Tyr Chemical compound NCC(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 JNGHLWWFPGIJER-STQMWFEESA-N 0.000 description 1
- BMWFDYIYBAFROD-WPRPVWTQSA-N Gly-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)CN BMWFDYIYBAFROD-WPRPVWTQSA-N 0.000 description 1
- IRJWAYCXIYUHQE-WHFBIAKZSA-N Gly-Ser-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CO)NC(=O)CN IRJWAYCXIYUHQE-WHFBIAKZSA-N 0.000 description 1
- POJJAZJHBGXEGM-YUMQZZPRSA-N Gly-Ser-Lys Chemical compound C(CCN)C[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)CN POJJAZJHBGXEGM-YUMQZZPRSA-N 0.000 description 1
- LCRDMSSAKLTKBU-ZDLURKLDSA-N Gly-Ser-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)CN LCRDMSSAKLTKBU-ZDLURKLDSA-N 0.000 description 1
- TVTZEOHWHUVYCG-KYNKHSRBSA-N Gly-Thr-Thr Chemical compound [H]NCC(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O TVTZEOHWHUVYCG-KYNKHSRBSA-N 0.000 description 1
- ONSARSFSJHTMFJ-STQMWFEESA-N Gly-Trp-Ser Chemical compound [H]NCC(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CO)C(O)=O ONSARSFSJHTMFJ-STQMWFEESA-N 0.000 description 1
- SYOJVRNQCXYEOV-XVKPBYJWSA-N Gly-Val-Glu Chemical compound [H]NCC(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O SYOJVRNQCXYEOV-XVKPBYJWSA-N 0.000 description 1
- FNXSYBOHALPRHV-ONGXEEELSA-N Gly-Val-Lys Chemical compound NCC(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCCCN FNXSYBOHALPRHV-ONGXEEELSA-N 0.000 description 1
- 102000002068 Glycopeptides Human genes 0.000 description 1
- 108010015899 Glycopeptides Proteins 0.000 description 1
- QXZGBUJJYSLZLT-UHFFFAOYSA-N H-Arg-Pro-Pro-Gly-Phe-Ser-Pro-Phe-Arg-OH Natural products NC(N)=NCCCC(N)C(=O)N1CCCC1C(=O)N1C(C(=O)NCC(=O)NC(CC=2C=CC=CC=2)C(=O)NC(CO)C(=O)N2C(CCC2)C(=O)NC(CC=2C=CC=CC=2)C(=O)NC(CCCN=C(N)N)C(O)=O)CCC1 QXZGBUJJYSLZLT-UHFFFAOYSA-N 0.000 description 1
- RVKIPWVMZANZLI-UHFFFAOYSA-N H-Lys-Trp-OH Natural products C1=CC=C2C(CC(NC(=O)C(N)CCCCN)C(O)=O)=CNC2=C1 RVKIPWVMZANZLI-UHFFFAOYSA-N 0.000 description 1
- AWASVTXPTOLPPP-MBLNEYKQSA-N His-Ala-Thr Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O AWASVTXPTOLPPP-MBLNEYKQSA-N 0.000 description 1
- SVHKVHBPTOMLTO-DCAQKATOSA-N His-Arg-Asp Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(O)=O)C(O)=O SVHKVHBPTOMLTO-DCAQKATOSA-N 0.000 description 1
- QZAFGJNKLMNDEM-DCAQKATOSA-N His-Asn-Arg Chemical compound NC(N)=NCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(N)=O)NC(=O)[C@@H](N)CC1=CN=CN1 QZAFGJNKLMNDEM-DCAQKATOSA-N 0.000 description 1
- JWTKVPMQCCRPQY-SRVKXCTJSA-N His-Asn-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CC(C)C)C(O)=O JWTKVPMQCCRPQY-SRVKXCTJSA-N 0.000 description 1
- VOEGKUNRHYKYSU-XVYDVKMFSA-N His-Asp-Ala Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C)C(O)=O VOEGKUNRHYKYSU-XVYDVKMFSA-N 0.000 description 1
- JFFAPRNXXLRINI-NHCYSSNCSA-N His-Asp-Val Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O JFFAPRNXXLRINI-NHCYSSNCSA-N 0.000 description 1
- CYHWWHKRCKHYGQ-GUBZILKMSA-N His-Cys-Glu Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N CYHWWHKRCKHYGQ-GUBZILKMSA-N 0.000 description 1
- LBCAQRFTWMMWRR-CIUDSAMLSA-N His-Cys-Ser Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O LBCAQRFTWMMWRR-CIUDSAMLSA-N 0.000 description 1
- PQKCQZHAGILVIM-NKIYYHGXSA-N His-Glu-Thr Chemical compound C[C@@H](O)[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)Cc1cnc[nH]1)C(O)=O PQKCQZHAGILVIM-NKIYYHGXSA-N 0.000 description 1
- UVDDTHLDZBMBAV-SRVKXCTJSA-N His-His-Cys Chemical compound C1=C(NC=N1)C[C@@H](C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CS)C(=O)O)N UVDDTHLDZBMBAV-SRVKXCTJSA-N 0.000 description 1
- MPXGJGBXCRQQJE-MXAVVETBSA-N His-Ile-Leu Chemical compound [H]N[C@@H](CC1=CNC=N1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CC(C)C)C(O)=O MPXGJGBXCRQQJE-MXAVVETBSA-N 0.000 description 1
- UXSATKFPUVZVDK-KKUMJFAQSA-N His-Lys-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CCCCN)NC(=O)[C@H](CC1=CN=CN1)N UXSATKFPUVZVDK-KKUMJFAQSA-N 0.000 description 1
- ZFDKSLBEWYCOCS-BZSNNMDCSA-N His-Phe-Lys Chemical compound C([C@@H](C(=O)N[C@@H](CCCCN)C(O)=O)NC(=O)[C@@H](N)CC=1NC=NC=1)C1=CC=CC=C1 ZFDKSLBEWYCOCS-BZSNNMDCSA-N 0.000 description 1
- YEKYGQZUBCRNGH-DCAQKATOSA-N His-Pro-Ser Chemical compound C1C[C@H](N(C1)C(=O)[C@H](CC2=CN=CN2)N)C(=O)N[C@@H](CO)C(=O)O YEKYGQZUBCRNGH-DCAQKATOSA-N 0.000 description 1
- BFOGZWSSGMLYKV-DCAQKATOSA-N His-Ser-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CN=CN1)N BFOGZWSSGMLYKV-DCAQKATOSA-N 0.000 description 1
- 108010061805 His-Trp-Arg-Arg Proteins 0.000 description 1
- 108010033040 Histones Proteins 0.000 description 1
- 101000678236 Homo sapiens 5'-nucleotidase Proteins 0.000 description 1
- 101100005713 Homo sapiens CD4 gene Proteins 0.000 description 1
- 101000902072 Homo sapiens Disrupted in schizophrenia 1 protein Proteins 0.000 description 1
- 101000981675 Homo sapiens Leucine-rich repeat and immunoglobulin-like domain-containing nogo receptor-interacting protein 2 Proteins 0.000 description 1
- 101000990985 Homo sapiens Myosin regulatory light chain 12B Proteins 0.000 description 1
- 101000990929 Homo sapiens Myosin regulatory light chain 2, skeletal muscle isoform Proteins 0.000 description 1
- 101100134044 Homo sapiens NTF4 gene Proteins 0.000 description 1
- 101000672311 Homo sapiens Netrin receptor UNC5A Proteins 0.000 description 1
- 101000617536 Homo sapiens Presenilin-1 Proteins 0.000 description 1
- 101000617546 Homo sapiens Presenilin-2 Proteins 0.000 description 1
- 101000697580 Homo sapiens Putative STAG3-like protein 4 Proteins 0.000 description 1
- 101000962366 Homo sapiens Type II inositol 1,4,5-trisphosphate 5-phosphatase Proteins 0.000 description 1
- 101000772964 Homo sapiens Ubiquitin-protein ligase E3C Proteins 0.000 description 1
- 102000008100 Human Serum Albumin Human genes 0.000 description 1
- 108091006905 Human Serum Albumin Proteins 0.000 description 1
- CISBRYJZMFWOHJ-JBDRJPRFSA-N Ile-Ala-Cys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CS)C(=O)O)N CISBRYJZMFWOHJ-JBDRJPRFSA-N 0.000 description 1
- YPWHUFAAMNHMGS-QSFUFRPTSA-N Ile-Ala-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N YPWHUFAAMNHMGS-QSFUFRPTSA-N 0.000 description 1
- QICVAHODWHIWIS-HTFCKZLJSA-N Ile-Ala-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N QICVAHODWHIWIS-HTFCKZLJSA-N 0.000 description 1
- HDOYNXLPTRQLAD-JBDRJPRFSA-N Ile-Ala-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(=O)O)N HDOYNXLPTRQLAD-JBDRJPRFSA-N 0.000 description 1
- ATXGFMOBVKSOMK-PEDHHIEDSA-N Ile-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N ATXGFMOBVKSOMK-PEDHHIEDSA-N 0.000 description 1
- UMYZBHKAVTXWIW-GMOBBJLQSA-N Ile-Asp-Arg Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N UMYZBHKAVTXWIW-GMOBBJLQSA-N 0.000 description 1
- JQLFYZMEXFNRFS-DJFWLOJKSA-N Ile-Asp-His Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N JQLFYZMEXFNRFS-DJFWLOJKSA-N 0.000 description 1
- NPROWIBAWYMPAZ-GUDRVLHUSA-N Ile-Asp-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N NPROWIBAWYMPAZ-GUDRVLHUSA-N 0.000 description 1
- PFTFEWHJSAXGED-ZKWXMUAHSA-N Ile-Cys-Gly Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CS)C(=O)NCC(=O)O)N PFTFEWHJSAXGED-ZKWXMUAHSA-N 0.000 description 1
- UBHUJPVCJHPSEU-GRLWGSQLSA-N Ile-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)O)N UBHUJPVCJHPSEU-GRLWGSQLSA-N 0.000 description 1
- SPQWWEZBHXHUJN-KBIXCLLPSA-N Ile-Glu-Ser Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O SPQWWEZBHXHUJN-KBIXCLLPSA-N 0.000 description 1
- UQXADIGYEYBJEI-DJFWLOJKSA-N Ile-His-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC(=O)O)C(=O)O)N UQXADIGYEYBJEI-DJFWLOJKSA-N 0.000 description 1
- OUUCIIJSBIBCHB-ZPFDUUQYSA-N Ile-Leu-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(O)=O OUUCIIJSBIBCHB-ZPFDUUQYSA-N 0.000 description 1
- HPCFRQWLTRDGHT-AJNGGQMLSA-N Ile-Leu-Leu Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(C)C)C(O)=O HPCFRQWLTRDGHT-AJNGGQMLSA-N 0.000 description 1
- IOVUXUSIGXCREV-DKIMLUQUSA-N Ile-Leu-Phe Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 IOVUXUSIGXCREV-DKIMLUQUSA-N 0.000 description 1
- PNTWNAXGBOZMBO-MNXVOIDGSA-N Ile-Lys-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N PNTWNAXGBOZMBO-MNXVOIDGSA-N 0.000 description 1
- IALVDKNUFSTICJ-GMOBBJLQSA-N Ile-Met-Asp Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(=O)O)C(=O)O)N IALVDKNUFSTICJ-GMOBBJLQSA-N 0.000 description 1
- IITVUURPOYGCTD-NAKRPEOUSA-N Ile-Pro-Ala Chemical compound CC[C@H](C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O IITVUURPOYGCTD-NAKRPEOUSA-N 0.000 description 1
- BATWGBRIZANGPN-ZPFDUUQYSA-N Ile-Pro-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(=O)N)C(=O)O)N BATWGBRIZANGPN-ZPFDUUQYSA-N 0.000 description 1
- CZWANIQKACCEKW-CYDGBPFRSA-N Ile-Pro-Met Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCSC)C(=O)O)N CZWANIQKACCEKW-CYDGBPFRSA-N 0.000 description 1
- PXKACEXYLPBMAD-JBDRJPRFSA-N Ile-Ser-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)O)N PXKACEXYLPBMAD-JBDRJPRFSA-N 0.000 description 1
- WCNWGAUZWWSYDG-SVSWQMSJSA-N Ile-Thr-Ser Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)O)N WCNWGAUZWWSYDG-SVSWQMSJSA-N 0.000 description 1
- DZMWFIRHFFVBHS-ZEWNOJEFSA-N Ile-Tyr-Phe Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC2=CC=CC=C2)C(=O)O)N DZMWFIRHFFVBHS-ZEWNOJEFSA-N 0.000 description 1
- YJRSIJZUIUANHO-NAKRPEOUSA-N Ile-Val-Ala Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](C)C(=O)O)N YJRSIJZUIUANHO-NAKRPEOUSA-N 0.000 description 1
- BCISUQVFDGYZBO-QSFUFRPTSA-N Ile-Val-Asp Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O BCISUQVFDGYZBO-QSFUFRPTSA-N 0.000 description 1
- NJGXXYLPDMMFJB-XUXIUFHCSA-N Ile-Val-Lys Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCCCN)C(=O)O)N NJGXXYLPDMMFJB-XUXIUFHCSA-N 0.000 description 1
- RQZFWBLDTBDEOF-RNJOBUHISA-N Ile-Val-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N RQZFWBLDTBDEOF-RNJOBUHISA-N 0.000 description 1
- QSXSHZIRKTUXNG-STECZYCISA-N Ile-Val-Tyr Chemical compound CC[C@H](C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC1=CC=C(O)C=C1 QSXSHZIRKTUXNG-STECZYCISA-N 0.000 description 1
- 108060003951 Immunoglobulin Proteins 0.000 description 1
- 102000017727 Immunoglobulin Variable Region Human genes 0.000 description 1
- 108010067060 Immunoglobulin Variable Region Proteins 0.000 description 1
- 238000012404 In vitro experiment Methods 0.000 description 1
- 102000003746 Insulin Receptor Human genes 0.000 description 1
- 108010001127 Insulin Receptor Proteins 0.000 description 1
- 102000004901 Iron regulatory protein 1 Human genes 0.000 description 1
- 108090001025 Iron regulatory protein 1 Proteins 0.000 description 1
- SITWEMZOJNKJCH-UHFFFAOYSA-N L-alanine-L-arginine Natural products CC(N)C(=O)NC(C(O)=O)CCCNC(N)=N SITWEMZOJNKJCH-UHFFFAOYSA-N 0.000 description 1
- OUYCCCASQSFEME-QMMMGPOBSA-N L-tyrosine Chemical compound OC(=O)[C@@H](N)CC1=CC=C(O)C=C1 OUYCCCASQSFEME-QMMMGPOBSA-N 0.000 description 1
- 102000007330 LDL Lipoproteins Human genes 0.000 description 1
- 108010007622 LDL Lipoproteins Proteins 0.000 description 1
- KWTVLKBOQATPHJ-SRVKXCTJSA-N Leu-Ala-Lys Chemical compound C[C@@H](C(=O)N[C@@H](CCCCN)C(=O)O)NC(=O)[C@H](CC(C)C)N KWTVLKBOQATPHJ-SRVKXCTJSA-N 0.000 description 1
- BQSLGJHIAGOZCD-CIUDSAMLSA-N Leu-Ala-Ser Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CO)C(O)=O BQSLGJHIAGOZCD-CIUDSAMLSA-N 0.000 description 1
- KSZCCRIGNVSHFH-UWVGGRQHSA-N Leu-Arg-Gly Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O KSZCCRIGNVSHFH-UWVGGRQHSA-N 0.000 description 1
- FJUKMPUELVROGK-IHRRRGAJSA-N Leu-Arg-His Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N FJUKMPUELVROGK-IHRRRGAJSA-N 0.000 description 1
- CLVUXCBGKUECIT-HJGDQZAQSA-N Leu-Asp-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O CLVUXCBGKUECIT-HJGDQZAQSA-N 0.000 description 1
- PNUCWVAGVNLUMW-CIUDSAMLSA-N Leu-Cys-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(=O)N[C@@H](CO)C(O)=O PNUCWVAGVNLUMW-CIUDSAMLSA-N 0.000 description 1
- CQGSYZCULZMEDE-SRVKXCTJSA-N Leu-Gln-Pro Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCC(N)=O)C(=O)N1CCC[C@H]1C(O)=O CQGSYZCULZMEDE-SRVKXCTJSA-N 0.000 description 1
- CQGSYZCULZMEDE-UHFFFAOYSA-N Leu-Gln-Pro Natural products CC(C)CC(N)C(=O)NC(CCC(N)=O)C(=O)N1CCCC1C(O)=O CQGSYZCULZMEDE-UHFFFAOYSA-N 0.000 description 1
- KGCLIYGPQXUNLO-IUCAKERBSA-N Leu-Gly-Glu Chemical compound CC(C)C[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCC(O)=O KGCLIYGPQXUNLO-IUCAKERBSA-N 0.000 description 1
- UCDHVOALNXENLC-KBPBESRZSA-N Leu-Gly-Tyr Chemical compound CC(C)C[C@H]([NH3+])C(=O)NCC(=O)N[C@H](C([O-])=O)CC1=CC=C(O)C=C1 UCDHVOALNXENLC-KBPBESRZSA-N 0.000 description 1
- YWYQSLOTVIRCFE-SRVKXCTJSA-N Leu-His-Asp Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(O)=O)C(O)=O YWYQSLOTVIRCFE-SRVKXCTJSA-N 0.000 description 1
- CSFVADKICPDRRF-KKUMJFAQSA-N Leu-His-Leu Chemical compound CC(C)C[C@H]([NH3+])C(=O)N[C@H](C(=O)N[C@@H](CC(C)C)C([O-])=O)CC1=CN=CN1 CSFVADKICPDRRF-KKUMJFAQSA-N 0.000 description 1
- OMHLATXVNQSALM-FQUUOJAGSA-N Leu-Ile-Pro Chemical compound CC[C@H](C)[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC(C)C)N OMHLATXVNQSALM-FQUUOJAGSA-N 0.000 description 1
- HRTRLSRYZZKPCO-BJDJZHNGSA-N Leu-Ile-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O HRTRLSRYZZKPCO-BJDJZHNGSA-N 0.000 description 1
- DSFYPIUSAMSERP-IHRRRGAJSA-N Leu-Leu-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@H](C(O)=O)CCCN=C(N)N DSFYPIUSAMSERP-IHRRRGAJSA-N 0.000 description 1
- IFMPDNRWZZEZSL-SRVKXCTJSA-N Leu-Leu-Cys Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CS)C(O)=O IFMPDNRWZZEZSL-SRVKXCTJSA-N 0.000 description 1
- XVZCXCTYGHPNEM-UHFFFAOYSA-N Leu-Leu-Pro Natural products CC(C)CC(N)C(=O)NC(CC(C)C)C(=O)N1CCCC1C(O)=O XVZCXCTYGHPNEM-UHFFFAOYSA-N 0.000 description 1
- BGZCJDGBBUUBHA-KKUMJFAQSA-N Leu-Lys-Leu Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC(C)C)C(O)=O BGZCJDGBBUUBHA-KKUMJFAQSA-N 0.000 description 1
- QNTJIDXQHWUBKC-BZSNNMDCSA-N Leu-Lys-Phe Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O QNTJIDXQHWUBKC-BZSNNMDCSA-N 0.000 description 1
- WMIOEVKKYIMVKI-DCAQKATOSA-N Leu-Pro-Ala Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O WMIOEVKKYIMVKI-DCAQKATOSA-N 0.000 description 1
- VULJUQZPSOASBZ-SRVKXCTJSA-N Leu-Pro-Glu Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O VULJUQZPSOASBZ-SRVKXCTJSA-N 0.000 description 1
- MUCIDQMDOYQYBR-IHRRRGAJSA-N Leu-Pro-His Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC2=CN=CN2)C(=O)O)N MUCIDQMDOYQYBR-IHRRRGAJSA-N 0.000 description 1
- XXXXOVFBXRERQL-ULQDDVLXSA-N Leu-Pro-Phe Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@H](C(O)=O)CC1=CC=CC=C1 XXXXOVFBXRERQL-ULQDDVLXSA-N 0.000 description 1
- DPURXCQCHSQPAN-AVGNSLFASA-N Leu-Pro-Pro Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(O)=O)CCC1 DPURXCQCHSQPAN-AVGNSLFASA-N 0.000 description 1
- CHJKEDSZNSONPS-DCAQKATOSA-N Leu-Pro-Ser Chemical compound [H]N[C@@H](CC(C)C)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O CHJKEDSZNSONPS-DCAQKATOSA-N 0.000 description 1
- PWPBLZXWFXJFHE-RHYQMDGZSA-N Leu-Pro-Thr Chemical compound CC(C)C[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H]([C@@H](C)O)C(O)=O PWPBLZXWFXJFHE-RHYQMDGZSA-N 0.000 description 1
- IRMLZWSRWSGTOP-CIUDSAMLSA-N Leu-Ser-Ala Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O IRMLZWSRWSGTOP-CIUDSAMLSA-N 0.000 description 1
- KZZCOWMDDXDKSS-CIUDSAMLSA-N Leu-Ser-Asn Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(O)=O KZZCOWMDDXDKSS-CIUDSAMLSA-N 0.000 description 1
- PPGBXYKMUMHFBF-KATARQTJSA-N Leu-Ser-Thr Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O PPGBXYKMUMHFBF-KATARQTJSA-N 0.000 description 1
- ZDJQVSIPFLMNOX-RHYQMDGZSA-N Leu-Thr-Arg Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCCN=C(N)N ZDJQVSIPFLMNOX-RHYQMDGZSA-N 0.000 description 1
- URHJPNHRQMQGOZ-RHYQMDGZSA-N Leu-Thr-Met Chemical compound [H]N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCSC)C(O)=O URHJPNHRQMQGOZ-RHYQMDGZSA-N 0.000 description 1
- WGAZVKFCPHXZLO-SZMVWBNQSA-N Leu-Trp-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N WGAZVKFCPHXZLO-SZMVWBNQSA-N 0.000 description 1
- CGHXMODRYJISSK-NHCYSSNCSA-N Leu-Val-Asp Chemical compound CC(C)C[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CC(O)=O CGHXMODRYJISSK-NHCYSSNCSA-N 0.000 description 1
- FDBTVENULFNTAL-XQQFMLRXSA-N Leu-Val-Pro Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N1CCC[C@@H]1C(=O)O)N FDBTVENULFNTAL-XQQFMLRXSA-N 0.000 description 1
- 102100024103 Leucine-rich repeat and immunoglobulin-like domain-containing nogo receptor-interacting protein 2 Human genes 0.000 description 1
- FZIJIFCXUCZHOL-CIUDSAMLSA-N Lys-Ala-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN FZIJIFCXUCZHOL-CIUDSAMLSA-N 0.000 description 1
- MPGHETGWWWUHPY-CIUDSAMLSA-N Lys-Ala-Asp Chemical compound OC(=O)C[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN MPGHETGWWWUHPY-CIUDSAMLSA-N 0.000 description 1
- KCXUCYYZNZFGLL-SRVKXCTJSA-N Lys-Ala-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](C)C(=O)N[C@@H](CC(C)C)C(O)=O KCXUCYYZNZFGLL-SRVKXCTJSA-N 0.000 description 1
- UWKNTTJNVSYXPC-CIUDSAMLSA-N Lys-Ala-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN UWKNTTJNVSYXPC-CIUDSAMLSA-N 0.000 description 1
- VHXMZJGOKIMETG-CQDKDKBSSA-N Lys-Ala-Tyr Chemical compound C[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)O)NC(=O)[C@H](CCCCN)N VHXMZJGOKIMETG-CQDKDKBSSA-N 0.000 description 1
- IRNSXVOWSXSULE-DCAQKATOSA-N Lys-Ala-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C)NC(=O)[C@@H](N)CCCCN IRNSXVOWSXSULE-DCAQKATOSA-N 0.000 description 1
- YNNPKXBBRZVIRX-IHRRRGAJSA-N Lys-Arg-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC(C)C)C(O)=O YNNPKXBBRZVIRX-IHRRRGAJSA-N 0.000 description 1
- SJNZALDHDUYDBU-IHRRRGAJSA-N Lys-Arg-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CCCCN)C(O)=O SJNZALDHDUYDBU-IHRRRGAJSA-N 0.000 description 1
- YKIRNDPUWONXQN-GUBZILKMSA-N Lys-Asn-Gln Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N YKIRNDPUWONXQN-GUBZILKMSA-N 0.000 description 1
- HQVDJTYKCMIWJP-YUMQZZPRSA-N Lys-Asn-Gly Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(N)=O)C(=O)NCC(O)=O HQVDJTYKCMIWJP-YUMQZZPRSA-N 0.000 description 1
- IBQMEXQYZMVIFU-SRVKXCTJSA-N Lys-Asp-His Chemical compound C1=C(NC=N1)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@H](CCCCN)N IBQMEXQYZMVIFU-SRVKXCTJSA-N 0.000 description 1
- IWWMPCPLFXFBAF-SRVKXCTJSA-N Lys-Asp-Leu Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O IWWMPCPLFXFBAF-SRVKXCTJSA-N 0.000 description 1
- XTONYTDATVADQH-CIUDSAMLSA-N Lys-Cys-Asn Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(N)=O)C(O)=O XTONYTDATVADQH-CIUDSAMLSA-N 0.000 description 1
- LPAJOCKCPRZEAG-MNXVOIDGSA-N Lys-Glu-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CCCCN LPAJOCKCPRZEAG-MNXVOIDGSA-N 0.000 description 1
- WGLAORUKDGRINI-WDCWCFNPSA-N Lys-Glu-Thr Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O WGLAORUKDGRINI-WDCWCFNPSA-N 0.000 description 1
- FHIAJWBDZVHLAH-YUMQZZPRSA-N Lys-Gly-Ser Chemical compound NCCCC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O FHIAJWBDZVHLAH-YUMQZZPRSA-N 0.000 description 1
- QOJDBRUCOXQSSK-AJNGGQMLSA-N Lys-Ile-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CCCCN)C(O)=O QOJDBRUCOXQSSK-AJNGGQMLSA-N 0.000 description 1
- PFZWARWVRNTPBR-IHPCNDPISA-N Lys-Leu-Trp Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](CCCCN)N PFZWARWVRNTPBR-IHPCNDPISA-N 0.000 description 1
- BOJYMMBYBNOOGG-DCAQKATOSA-N Lys-Pro-Ala Chemical compound [H]N[C@@H](CCCCN)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O BOJYMMBYBNOOGG-DCAQKATOSA-N 0.000 description 1
- WQDKIVRHTQYJSN-DCAQKATOSA-N Lys-Ser-Arg Chemical compound C(CCN)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N WQDKIVRHTQYJSN-DCAQKATOSA-N 0.000 description 1
- ZUGVARDEGWMMLK-SRVKXCTJSA-N Lys-Ser-Lys Chemical compound NCCCC[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCCCN ZUGVARDEGWMMLK-SRVKXCTJSA-N 0.000 description 1
- SQXZLVXQXWILKW-KKUMJFAQSA-N Lys-Ser-Phe Chemical compound [H]N[C@@H](CCCCN)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(O)=O SQXZLVXQXWILKW-KKUMJFAQSA-N 0.000 description 1
- WZVSHTFTCYOFPL-GARJFASQSA-N Lys-Ser-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CO)NC(=O)[C@H](CCCCN)N)C(=O)O WZVSHTFTCYOFPL-GARJFASQSA-N 0.000 description 1
- 239000004472 Lysine Substances 0.000 description 1
- 229930195725 Mannitol Natural products 0.000 description 1
- OLWAOWXIADGIJG-AVGNSLFASA-N Met-Arg-Lys Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCCCN)C(O)=O OLWAOWXIADGIJG-AVGNSLFASA-N 0.000 description 1
- ZAJNRWKGHWGPDQ-SDDRHHMPSA-N Met-Arg-Pro Chemical compound CSCC[C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N1CCC[C@@H]1C(=O)O)N ZAJNRWKGHWGPDQ-SDDRHHMPSA-N 0.000 description 1
- YLLWCSDBVGZLOW-CIUDSAMLSA-N Met-Gln-Ala Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](C)C(O)=O YLLWCSDBVGZLOW-CIUDSAMLSA-N 0.000 description 1
- OOSPRDCGTLQLBP-NHCYSSNCSA-N Met-Glu-Val Chemical compound [H]N[C@@H](CCSC)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C(C)C)C(O)=O OOSPRDCGTLQLBP-NHCYSSNCSA-N 0.000 description 1
- FYRUJIJAUPHUNB-IUCAKERBSA-N Met-Gly-Arg Chemical compound CSCC[C@H](N)C(=O)NCC(=O)N[C@H](C(O)=O)CCCNC(N)=N FYRUJIJAUPHUNB-IUCAKERBSA-N 0.000 description 1
- UZWMJZSOXGOVIN-LURJTMIESA-N Met-Gly-Gly Chemical compound CSCC[C@H](N)C(=O)NCC(=O)NCC(O)=O UZWMJZSOXGOVIN-LURJTMIESA-N 0.000 description 1
- AWGBEIYZPAXXSX-RWMBFGLXSA-N Met-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CCSC)N AWGBEIYZPAXXSX-RWMBFGLXSA-N 0.000 description 1
- USBFEVBHEQBWDD-AVGNSLFASA-N Met-Leu-Val Chemical compound CSCC[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C(C)C)C(O)=O USBFEVBHEQBWDD-AVGNSLFASA-N 0.000 description 1
- SPSSJSICDYYTQN-HJGDQZAQSA-N Met-Thr-Gln Chemical compound CSCC[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CCC(N)=O SPSSJSICDYYTQN-HJGDQZAQSA-N 0.000 description 1
- 102000010645 MutS Proteins Human genes 0.000 description 1
- 108010038272 MutS Proteins Proteins 0.000 description 1
- 102100030330 Myosin regulatory light chain 12B Human genes 0.000 description 1
- WUGMRIBZSVSJNP-UHFFFAOYSA-N N-L-alanyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)C(N)C)C(O)=O)=CNC2=C1 WUGMRIBZSVSJNP-UHFFFAOYSA-N 0.000 description 1
- XMBSYZWANAQXEV-UHFFFAOYSA-N N-alpha-L-glutamyl-L-phenylalanine Natural products OC(=O)CCC(N)C(=O)NC(C(O)=O)CC1=CC=CC=C1 XMBSYZWANAQXEV-UHFFFAOYSA-N 0.000 description 1
- AJHCSUXXECOXOY-UHFFFAOYSA-N N-glycyl-L-tryptophan Natural products C1=CC=C2C(CC(NC(=O)CN)C(O)=O)=CNC2=C1 AJHCSUXXECOXOY-UHFFFAOYSA-N 0.000 description 1
- 108010087066 N2-tryptophyllysine Proteins 0.000 description 1
- 206010028980 Neoplasm Diseases 0.000 description 1
- 102100040288 Netrin receptor UNC5A Human genes 0.000 description 1
- 102000003683 Neurotrophin-4 Human genes 0.000 description 1
- PVNIIMVLHYAWGP-UHFFFAOYSA-N Niacin Chemical compound OC(=O)C1=CC=CN=C1 PVNIIMVLHYAWGP-UHFFFAOYSA-N 0.000 description 1
- 108020004711 Nucleic Acid Probes Proteins 0.000 description 1
- 102100034208 Otolin-1 Human genes 0.000 description 1
- 241000282579 Pan Species 0.000 description 1
- 206010034719 Personality change Diseases 0.000 description 1
- MPGJIHFJCXTVEX-KKUMJFAQSA-N Phe-Arg-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O MPGJIHFJCXTVEX-KKUMJFAQSA-N 0.000 description 1
- KKYHKZCMETTXEO-AVGNSLFASA-N Phe-Cys-Glu Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N KKYHKZCMETTXEO-AVGNSLFASA-N 0.000 description 1
- LLGTYVHITPVGKR-RYUDHWBXSA-N Phe-Gln-Gly Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(N)=O)C(=O)NCC(O)=O LLGTYVHITPVGKR-RYUDHWBXSA-N 0.000 description 1
- CDQCFGOQNYOICK-IHRRRGAJSA-N Phe-Glu-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 CDQCFGOQNYOICK-IHRRRGAJSA-N 0.000 description 1
- KJJROSNFBRWPHS-JYJNAYRXSA-N Phe-Glu-Leu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O KJJROSNFBRWPHS-JYJNAYRXSA-N 0.000 description 1
- JWQWPTLEOFNCGX-AVGNSLFASA-N Phe-Glu-Ser Chemical compound OC[C@@H](C(O)=O)NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)CC1=CC=CC=C1 JWQWPTLEOFNCGX-AVGNSLFASA-N 0.000 description 1
- QPVFUAUFEBPIPT-CDMKHQONSA-N Phe-Gly-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)NCC(=O)N[C@@H]([C@@H](C)O)C(O)=O QPVFUAUFEBPIPT-CDMKHQONSA-N 0.000 description 1
- ISYSEOWLRQKQEQ-JYJNAYRXSA-N Phe-His-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CCC(O)=O)C(O)=O ISYSEOWLRQKQEQ-JYJNAYRXSA-N 0.000 description 1
- KXUZHWXENMYOHC-QEJZJMRPSA-N Phe-Leu-Ala Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](C)C(O)=O KXUZHWXENMYOHC-QEJZJMRPSA-N 0.000 description 1
- KZRQONDKKJCAOL-DKIMLUQUSA-N Phe-Leu-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O KZRQONDKKJCAOL-DKIMLUQUSA-N 0.000 description 1
- OSBADCBXAMSPQD-YESZJQIVSA-N Phe-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CC=CC=C2)N OSBADCBXAMSPQD-YESZJQIVSA-N 0.000 description 1
- INHMISZWLJZQGH-ULQDDVLXSA-N Phe-Leu-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H](N)CC1=CC=CC=C1 INHMISZWLJZQGH-ULQDDVLXSA-N 0.000 description 1
- PEFJUUYFEGBXFA-BZSNNMDCSA-N Phe-Lys-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CC1=CC=CC=C1 PEFJUUYFEGBXFA-BZSNNMDCSA-N 0.000 description 1
- RYQWALWYQWBUKN-FHWLQOOXSA-N Phe-Phe-Glu Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CCC(O)=O)C(O)=O RYQWALWYQWBUKN-FHWLQOOXSA-N 0.000 description 1
- AAERWTUHZKLDLC-IHRRRGAJSA-N Phe-Pro-Asp Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC(O)=O)C(O)=O AAERWTUHZKLDLC-IHRRRGAJSA-N 0.000 description 1
- IPFXYNKCXYGSSV-KKUMJFAQSA-N Phe-Ser-Lys Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N IPFXYNKCXYGSSV-KKUMJFAQSA-N 0.000 description 1
- IAOZOFPONWDXNT-IXOXFDKPSA-N Phe-Ser-Thr Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(O)=O IAOZOFPONWDXNT-IXOXFDKPSA-N 0.000 description 1
- YFXXRYFWJFQAFW-JHYOHUSXSA-N Phe-Thr-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CC1=CC=CC=C1)N)O YFXXRYFWJFQAFW-JHYOHUSXSA-N 0.000 description 1
- NHHZWPNMYQUNEH-ACRUOGEOSA-N Phe-Tyr-His Chemical compound C1=CC=C(C=C1)C[C@@H](C(=O)N[C@@H](CC2=CC=C(C=C2)O)C(=O)N[C@@H](CC3=CN=CN3)C(=O)O)N NHHZWPNMYQUNEH-ACRUOGEOSA-N 0.000 description 1
- MMPBPRXOFJNCCN-ZEWNOJEFSA-N Phe-Tyr-Ile Chemical compound [H]N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(O)=O MMPBPRXOFJNCCN-ZEWNOJEFSA-N 0.000 description 1
- ABLZXFCXXLZCGV-UHFFFAOYSA-N Phosphorous acid Chemical group OP(O)=O ABLZXFCXXLZCGV-UHFFFAOYSA-N 0.000 description 1
- 102100022033 Presenilin-1 Human genes 0.000 description 1
- 102100022036 Presenilin-2 Human genes 0.000 description 1
- 241000288906 Primates Species 0.000 description 1
- AJLVKXCNXIJHDV-CIUDSAMLSA-N Pro-Ala-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C)C(=O)N[C@@H](CCC(N)=O)C(O)=O AJLVKXCNXIJHDV-CIUDSAMLSA-N 0.000 description 1
- KIZQGKLMXKGDIV-BQBZGAKWSA-N Pro-Ala-Gly Chemical compound OC(=O)CNC(=O)[C@H](C)NC(=O)[C@@H]1CCCN1 KIZQGKLMXKGDIV-BQBZGAKWSA-N 0.000 description 1
- CGBYDGAJHSOGFQ-LPEHRKFASA-N Pro-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@@H]2CCCN2 CGBYDGAJHSOGFQ-LPEHRKFASA-N 0.000 description 1
- ICTZKEXYDDZZFP-SRVKXCTJSA-N Pro-Arg-Pro Chemical compound N([C@@H](CCCN=C(N)N)C(=O)N1[C@@H](CCC1)C(O)=O)C(=O)[C@@H]1CCCN1 ICTZKEXYDDZZFP-SRVKXCTJSA-N 0.000 description 1
- CYQQWUPHIZVCNY-GUBZILKMSA-N Pro-Arg-Ser Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CO)C(O)=O CYQQWUPHIZVCNY-GUBZILKMSA-N 0.000 description 1
- AMBLXEMWFARNNQ-DCAQKATOSA-N Pro-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@@H]1CCCN1 AMBLXEMWFARNNQ-DCAQKATOSA-N 0.000 description 1
- UTAUEDINXUMHLG-FXQIFTODSA-N Pro-Asp-Ala Chemical compound C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)O)NC(=O)[C@@H]1CCCN1 UTAUEDINXUMHLG-FXQIFTODSA-N 0.000 description 1
- PZSCUPVOJGKHEP-CIUDSAMLSA-N Pro-Gln-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O PZSCUPVOJGKHEP-CIUDSAMLSA-N 0.000 description 1
- XZONQWUEBAFQPO-HJGDQZAQSA-N Pro-Gln-Thr Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O XZONQWUEBAFQPO-HJGDQZAQSA-N 0.000 description 1
- PULPZRAHVFBVTO-DCAQKATOSA-N Pro-Glu-Arg Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O PULPZRAHVFBVTO-DCAQKATOSA-N 0.000 description 1
- MGDFPGCFVJFITQ-CIUDSAMLSA-N Pro-Glu-Asp Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O MGDFPGCFVJFITQ-CIUDSAMLSA-N 0.000 description 1
- NXEYSLRNNPWCRN-SRVKXCTJSA-N Pro-Glu-Leu Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(C)C)C(O)=O NXEYSLRNNPWCRN-SRVKXCTJSA-N 0.000 description 1
- LGSANCBHSMDFDY-GARJFASQSA-N Pro-Glu-Pro Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N2CCC[C@@H]2C(=O)O LGSANCBHSMDFDY-GARJFASQSA-N 0.000 description 1
- ZTVCLZLGHZXLOT-ULQDDVLXSA-N Pro-Glu-Trp Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O ZTVCLZLGHZXLOT-ULQDDVLXSA-N 0.000 description 1
- AQSMZTIEJMZQEC-DCAQKATOSA-N Pro-His-Ser Chemical compound C1C[C@H](NC1)C(=O)N[C@@H](CC2=CN=CN2)C(=O)N[C@@H](CO)C(=O)O AQSMZTIEJMZQEC-DCAQKATOSA-N 0.000 description 1
- RUDOLGWDSKQQFF-DCAQKATOSA-N Pro-Leu-Asn Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CC(N)=O)C(O)=O RUDOLGWDSKQQFF-DCAQKATOSA-N 0.000 description 1
- NTXFLJULRHQMDC-GUBZILKMSA-N Pro-Met-Asp Chemical compound CSCC[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)O)NC(=O)[C@@H]1CCCN1 NTXFLJULRHQMDC-GUBZILKMSA-N 0.000 description 1
- AUYKOPJPKUCYHE-SRVKXCTJSA-N Pro-Met-Val Chemical compound CC(C)[C@@H](C(=O)O)NC(=O)[C@H](CCSC)NC(=O)[C@@H]1CCCN1 AUYKOPJPKUCYHE-SRVKXCTJSA-N 0.000 description 1
- RFWXYTJSVDUBBZ-DCAQKATOSA-N Pro-Pro-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 RFWXYTJSVDUBBZ-DCAQKATOSA-N 0.000 description 1
- CGSOWZUPLOKYOR-AVGNSLFASA-N Pro-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 CGSOWZUPLOKYOR-AVGNSLFASA-N 0.000 description 1
- AJNGQVUFQUVRQT-JYJNAYRXSA-N Pro-Pro-Tyr Chemical compound C([C@@H](C(=O)O)NC(=O)[C@H]1N(CCC1)C(=O)[C@H]1NCCC1)C1=CC=C(O)C=C1 AJNGQVUFQUVRQT-JYJNAYRXSA-N 0.000 description 1
- KBUAPZAZPWNYSW-SRVKXCTJSA-N Pro-Pro-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@H]1NCCC1 KBUAPZAZPWNYSW-SRVKXCTJSA-N 0.000 description 1
- JXVXYRZQIUPYSA-NHCYSSNCSA-N Pro-Val-Gln Chemical compound [H]N1CCC[C@H]1C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O JXVXYRZQIUPYSA-NHCYSSNCSA-N 0.000 description 1
- FHJQROWZEJFZPO-SRVKXCTJSA-N Pro-Val-Val Chemical compound CC(C)[C@@H](C(O)=O)NC(=O)[C@H](C(C)C)NC(=O)[C@@H]1CCCN1 FHJQROWZEJFZPO-SRVKXCTJSA-N 0.000 description 1
- 108010076504 Protein Sorting Signals Proteins 0.000 description 1
- 102100028033 Putative STAG3-like protein 4 Human genes 0.000 description 1
- 239000012980 RPMI-1640 medium Substances 0.000 description 1
- 238000011529 RT qPCR Methods 0.000 description 1
- 102000004278 Receptor Protein-Tyrosine Kinases Human genes 0.000 description 1
- 108090000873 Receptor Protein-Tyrosine Kinases Proteins 0.000 description 1
- 241000219061 Rheum Species 0.000 description 1
- 108091028664 Ribonucleotide Proteins 0.000 description 1
- PYMYPHUHKUWMLA-LMVFSUKVSA-N Ribose Natural products OC[C@@H](O)[C@@H](O)[C@@H](O)C=O PYMYPHUHKUWMLA-LMVFSUKVSA-N 0.000 description 1
- 241000283984 Rodentia Species 0.000 description 1
- BRKHVZNDAOMAHX-BIIVOSGPSA-N Ser-Ala-Pro Chemical compound C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N BRKHVZNDAOMAHX-BIIVOSGPSA-N 0.000 description 1
- JJKSSJVYOVRJMZ-FXQIFTODSA-N Ser-Arg-Cys Chemical compound C(C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N)CN=C(N)N JJKSSJVYOVRJMZ-FXQIFTODSA-N 0.000 description 1
- YUSRGTQIPCJNHQ-CIUDSAMLSA-N Ser-Arg-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CCC(O)=O)C(O)=O YUSRGTQIPCJNHQ-CIUDSAMLSA-N 0.000 description 1
- HQTKVSCNCDLXSX-BQBZGAKWSA-N Ser-Arg-Gly Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)NCC(O)=O HQTKVSCNCDLXSX-BQBZGAKWSA-N 0.000 description 1
- OYEDZGNMSBZCIM-XGEHTFHBSA-N Ser-Arg-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H]([C@@H](C)O)C(O)=O OYEDZGNMSBZCIM-XGEHTFHBSA-N 0.000 description 1
- ZXLUWXWISXIFIX-ACZMJKKPSA-N Ser-Asn-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZXLUWXWISXIFIX-ACZMJKKPSA-N 0.000 description 1
- UGJRQLURDVGULT-LKXGYXEUSA-N Ser-Asn-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H]([C@@H](C)O)C(O)=O UGJRQLURDVGULT-LKXGYXEUSA-N 0.000 description 1
- OHKLFYXEOGGGCK-ZLUOBGJFSA-N Ser-Asp-Asn Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](CC(N)=O)C(O)=O OHKLFYXEOGGGCK-ZLUOBGJFSA-N 0.000 description 1
- BYIROAKULFFTEK-CIUDSAMLSA-N Ser-Asp-Lys Chemical compound NCCCC[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CO BYIROAKULFFTEK-CIUDSAMLSA-N 0.000 description 1
- GHPQVUYZQQGEDA-BIIVOSGPSA-N Ser-Asp-Pro Chemical compound C1C[C@@H](N(C1)C(=O)[C@H](CC(=O)O)NC(=O)[C@H](CO)N)C(=O)O GHPQVUYZQQGEDA-BIIVOSGPSA-N 0.000 description 1
- TUYBIWUZWJUZDD-ACZMJKKPSA-N Ser-Cys-Gln Chemical compound OC[C@H](N)C(=O)N[C@@H](CS)C(=O)N[C@H](C(O)=O)CCC(N)=O TUYBIWUZWJUZDD-ACZMJKKPSA-N 0.000 description 1
- MPPHJZYXDVDGOF-BWBBJGPYSA-N Ser-Cys-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)[C@H](CS)NC(=O)[C@@H](N)CO MPPHJZYXDVDGOF-BWBBJGPYSA-N 0.000 description 1
- SMIDBHKWSYUBRZ-ACZMJKKPSA-N Ser-Glu-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](C)C(O)=O SMIDBHKWSYUBRZ-ACZMJKKPSA-N 0.000 description 1
- HJEBZBMOTCQYDN-ACZMJKKPSA-N Ser-Glu-Asp Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CC(O)=O)C(O)=O HJEBZBMOTCQYDN-ACZMJKKPSA-N 0.000 description 1
- BPMRXBZYPGYPJN-WHFBIAKZSA-N Ser-Gly-Asn Chemical compound [H]N[C@@H](CO)C(=O)NCC(=O)N[C@@H](CC(N)=O)C(O)=O BPMRXBZYPGYPJN-WHFBIAKZSA-N 0.000 description 1
- GZFAWAQTEYDKII-YUMQZZPRSA-N Ser-Gly-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO GZFAWAQTEYDKII-YUMQZZPRSA-N 0.000 description 1
- UIGMAMGZOJVTDN-WHFBIAKZSA-N Ser-Gly-Ser Chemical compound OC[C@H](N)C(=O)NCC(=O)N[C@@H](CO)C(O)=O UIGMAMGZOJVTDN-WHFBIAKZSA-N 0.000 description 1
- SFTZWNJFZYOLBD-ZDLURKLDSA-N Ser-Gly-Thr Chemical compound C[C@@H](O)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)CO SFTZWNJFZYOLBD-ZDLURKLDSA-N 0.000 description 1
- CXBFHZLODKPIJY-AAEUAGOBSA-N Ser-Gly-Trp Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)O)NC(=O)CNC(=O)[C@H](CO)N CXBFHZLODKPIJY-AAEUAGOBSA-N 0.000 description 1
- ZOPISOXXPQNOCO-SVSWQMSJSA-N Ser-Ile-Thr Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H]([C@@H](C)O)C(=O)O)NC(=O)[C@H](CO)N ZOPISOXXPQNOCO-SVSWQMSJSA-N 0.000 description 1
- IAORETPTUDBBGV-CIUDSAMLSA-N Ser-Leu-Cys Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CS)C(=O)O)NC(=O)[C@H](CO)N IAORETPTUDBBGV-CIUDSAMLSA-N 0.000 description 1
- ZIFYDQAFEMIZII-GUBZILKMSA-N Ser-Leu-Glu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O ZIFYDQAFEMIZII-GUBZILKMSA-N 0.000 description 1
- VMLONWHIORGALA-SRVKXCTJSA-N Ser-Leu-Leu Chemical compound CC(C)C[C@@H](C([O-])=O)NC(=O)[C@H](CC(C)C)NC(=O)[C@@H]([NH3+])CO VMLONWHIORGALA-SRVKXCTJSA-N 0.000 description 1
- KCGIREHVWRXNDH-GARJFASQSA-N Ser-Leu-Pro Chemical compound CC(C)C[C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N KCGIREHVWRXNDH-GARJFASQSA-N 0.000 description 1
- GVIGVIOEYBOTCB-XIRDDKMYSA-N Ser-Leu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)CO)CC(C)C)C(O)=O)=CNC2=C1 GVIGVIOEYBOTCB-XIRDDKMYSA-N 0.000 description 1
- XUDRHBPSPAPDJP-SRVKXCTJSA-N Ser-Lys-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@H](CCCCN)NC(=O)[C@@H](N)CO XUDRHBPSPAPDJP-SRVKXCTJSA-N 0.000 description 1
- LRZLZIUXQBIWTB-KATARQTJSA-N Ser-Lys-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)N[C@@H]([C@@H](C)O)C(O)=O LRZLZIUXQBIWTB-KATARQTJSA-N 0.000 description 1
- XNXRTQZTFVMJIJ-DCAQKATOSA-N Ser-Met-Leu Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](CC(C)C)C(O)=O XNXRTQZTFVMJIJ-DCAQKATOSA-N 0.000 description 1
- MQUZANJDFOQOBX-SRVKXCTJSA-N Ser-Phe-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CO)C(O)=O MQUZANJDFOQOBX-SRVKXCTJSA-N 0.000 description 1
- ZKBKUWQVDWWSRI-BZSNNMDCSA-N Ser-Phe-Tyr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(O)=O ZKBKUWQVDWWSRI-BZSNNMDCSA-N 0.000 description 1
- WNDUPCKKKGSKIQ-CIUDSAMLSA-N Ser-Pro-Gln Chemical compound OC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(N)=O)C(O)=O WNDUPCKKKGSKIQ-CIUDSAMLSA-N 0.000 description 1
- BSXKBOUZDAZXHE-CIUDSAMLSA-N Ser-Pro-Glu Chemical compound [H]N[C@@H](CO)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CCC(O)=O)C(O)=O BSXKBOUZDAZXHE-CIUDSAMLSA-N 0.000 description 1
- FKYWFUYPVKLJLP-DCAQKATOSA-N Ser-Pro-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H]1CCCN1C(=O)[C@@H](N)CO FKYWFUYPVKLJLP-DCAQKATOSA-N 0.000 description 1
- HHJFMHQYEAAOBM-ZLUOBGJFSA-N Ser-Ser-Ala Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C)C(O)=O HHJFMHQYEAAOBM-ZLUOBGJFSA-N 0.000 description 1
- VGQVAVQWKJLIRM-FXQIFTODSA-N Ser-Ser-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(O)=O VGQVAVQWKJLIRM-FXQIFTODSA-N 0.000 description 1
- ZSDXEKUKQAKZFE-XAVMHZPKSA-N Ser-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CO)N)O ZSDXEKUKQAKZFE-XAVMHZPKSA-N 0.000 description 1
- BDMWLJLPPUCLNV-XGEHTFHBSA-N Ser-Thr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(O)=O BDMWLJLPPUCLNV-XGEHTFHBSA-N 0.000 description 1
- HAYADTTXNZFUDM-IHRRRGAJSA-N Ser-Tyr-Val Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(O)=O HAYADTTXNZFUDM-IHRRRGAJSA-N 0.000 description 1
- LLSLRQOEAFCZLW-NRPADANISA-N Ser-Val-Gln Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CCC(N)=O)C(O)=O LLSLRQOEAFCZLW-NRPADANISA-N 0.000 description 1
- JGUWRQWULDWNCM-FXQIFTODSA-N Ser-Val-Ser Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(O)=O JGUWRQWULDWNCM-FXQIFTODSA-N 0.000 description 1
- SIEBDTCABMZCLF-XGEHTFHBSA-N Ser-Val-Thr Chemical compound [H]N[C@@H](CO)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O SIEBDTCABMZCLF-XGEHTFHBSA-N 0.000 description 1
- XUIMIQQOPSSXEZ-UHFFFAOYSA-N Silicon Chemical compound [Si] XUIMIQQOPSSXEZ-UHFFFAOYSA-N 0.000 description 1
- FAPWRFPIFSIZLT-UHFFFAOYSA-M Sodium chloride Chemical compound [Na+].[Cl-] FAPWRFPIFSIZLT-UHFFFAOYSA-M 0.000 description 1
- 238000002105 Southern blotting Methods 0.000 description 1
- 108010090804 Streptavidin Proteins 0.000 description 1
- NJEMRSFGDNECGF-GCJQMDKQSA-N Thr-Ala-Asp Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@H](C(O)=O)CC(O)=O NJEMRSFGDNECGF-GCJQMDKQSA-N 0.000 description 1
- JMQUAZXYFAEOIH-XGEHTFHBSA-N Thr-Arg-Cys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCCN=C(N)N)C(=O)N[C@@H](CS)C(=O)O)N)O JMQUAZXYFAEOIH-XGEHTFHBSA-N 0.000 description 1
- OJRNZRROAIAHDL-LKXGYXEUSA-N Thr-Asn-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(N)=O)C(=O)N[C@@H](CO)C(O)=O OJRNZRROAIAHDL-LKXGYXEUSA-N 0.000 description 1
- JXKMXEBNZCKSDY-JIOCBJNQSA-N Thr-Asp-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N1CCC[C@@H]1C(=O)O)N)O JXKMXEBNZCKSDY-JIOCBJNQSA-N 0.000 description 1
- KWQBJOUOSNJDRR-XAVMHZPKSA-N Thr-Cys-Pro Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N1CCC[C@@H]1C(=O)O)N)O KWQBJOUOSNJDRR-XAVMHZPKSA-N 0.000 description 1
- UZJDBCHMIQXLOQ-HEIBUPTGSA-N Thr-Cys-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O UZJDBCHMIQXLOQ-HEIBUPTGSA-N 0.000 description 1
- KGKWKSSSQGGYAU-SUSMZKCASA-N Thr-Gln-Thr Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H]([C@@H](C)O)C(=O)O)N)O KGKWKSSSQGGYAU-SUSMZKCASA-N 0.000 description 1
- CQNFRKAKGDSJFR-NUMRIWBASA-N Thr-Glu-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O CQNFRKAKGDSJFR-NUMRIWBASA-N 0.000 description 1
- ONNSECRQFSTMCC-XKBZYTNZSA-N Thr-Glu-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CCC(O)=O)C(=O)N[C@@H](CO)C(O)=O ONNSECRQFSTMCC-XKBZYTNZSA-N 0.000 description 1
- JKGGPMOUIAAJAA-YEPSODPASA-N Thr-Gly-Val Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)NCC(=O)N[C@@H](C(C)C)C(O)=O JKGGPMOUIAAJAA-YEPSODPASA-N 0.000 description 1
- AYCQVUUPIJHJTA-IXOXFDKPSA-N Thr-His-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC=N1)C(=O)N[C@@H](CC(C)C)C(O)=O AYCQVUUPIJHJTA-IXOXFDKPSA-N 0.000 description 1
- FQPDRTDDEZXCEC-SVSWQMSJSA-N Thr-Ile-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H](CO)C(O)=O FQPDRTDDEZXCEC-SVSWQMSJSA-N 0.000 description 1
- XYFISNXATOERFZ-OSUNSFLBSA-N Thr-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H]([C@@H](C)O)N XYFISNXATOERFZ-OSUNSFLBSA-N 0.000 description 1
- VTVVYQOXJCZVEB-WDCWCFNPSA-N Thr-Leu-Glu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CCC(O)=O)C(O)=O VTVVYQOXJCZVEB-WDCWCFNPSA-N 0.000 description 1
- KZURUCDWKDEAFZ-XVSYOHENSA-N Thr-Phe-Asn Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CC=CC=C1)C(=O)N[C@@H](CC(=O)N)C(=O)O)N)O KZURUCDWKDEAFZ-XVSYOHENSA-N 0.000 description 1
- DNCUODYZAMHLCV-XGEHTFHBSA-N Thr-Pro-Cys Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@H]1C(=O)N[C@@H](CS)C(=O)O)N)O DNCUODYZAMHLCV-XGEHTFHBSA-N 0.000 description 1
- KERCOYANYUPLHJ-XGEHTFHBSA-N Thr-Pro-Ser Chemical compound C[C@@H](O)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CO)C(O)=O KERCOYANYUPLHJ-XGEHTFHBSA-N 0.000 description 1
- IWAVRIPRTCJAQO-HSHDSVGOSA-N Thr-Pro-Trp Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N1CCC[C@H]1C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O IWAVRIPRTCJAQO-HSHDSVGOSA-N 0.000 description 1
- XHWCDRUPDNSDAZ-XKBZYTNZSA-N Thr-Ser-Glu Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCC(=O)O)C(=O)O)N)O XHWCDRUPDNSDAZ-XKBZYTNZSA-N 0.000 description 1
- SGAOHNPSEPVAFP-ZDLURKLDSA-N Thr-Ser-Gly Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)NCC(O)=O SGAOHNPSEPVAFP-ZDLURKLDSA-N 0.000 description 1
- AHERARIZBPOMNU-KATARQTJSA-N Thr-Ser-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CC(C)C)C(O)=O AHERARIZBPOMNU-KATARQTJSA-N 0.000 description 1
- XZUBGOYOGDRYFC-XGEHTFHBSA-N Thr-Ser-Met Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(O)=O XZUBGOYOGDRYFC-XGEHTFHBSA-N 0.000 description 1
- WPSKTVVMQCXPRO-BWBBJGPYSA-N Thr-Ser-Ser Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CO)C(=O)N[C@@H](CO)C(O)=O WPSKTVVMQCXPRO-BWBBJGPYSA-N 0.000 description 1
- AAZOYLQUEQRUMZ-GSSVUCPTSA-N Thr-Thr-Asn Chemical compound C[C@@H](O)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@H](C(O)=O)CC(N)=O AAZOYLQUEQRUMZ-GSSVUCPTSA-N 0.000 description 1
- BBPCSGKKPJUYRB-UVOCVTCTSA-N Thr-Thr-Leu Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC(C)C)C(O)=O BBPCSGKKPJUYRB-UVOCVTCTSA-N 0.000 description 1
- MYNYCUXMIIWUNW-IEGACIPQSA-N Thr-Trp-Lys Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CCCCN)C(=O)O)N)O MYNYCUXMIIWUNW-IEGACIPQSA-N 0.000 description 1
- ZEJBJDHSQPOVJV-UAXMHLISSA-N Thr-Trp-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ZEJBJDHSQPOVJV-UAXMHLISSA-N 0.000 description 1
- KZTLZZQTJMCGIP-ZJDVBMNYSA-N Thr-Val-Thr Chemical compound [H]N[C@@H]([C@@H](C)O)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O KZTLZZQTJMCGIP-ZJDVBMNYSA-N 0.000 description 1
- 108010033576 Transferrin Receptors Proteins 0.000 description 1
- 102000007238 Transferrin Receptors Human genes 0.000 description 1
- 102000008817 Trefoil Factor-1 Human genes 0.000 description 1
- 108010088412 Trefoil Factor-1 Proteins 0.000 description 1
- CDPXXGFRDZVVGF-OYDLWJJNSA-N Trp-Arg-Trp Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](CC1=CNC2=C1C=CC=C2)C(O)=O CDPXXGFRDZVVGF-OYDLWJJNSA-N 0.000 description 1
- UKINEYBQXPMOJO-UBHSHLNASA-N Trp-Asn-Ser Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)N[C@@H](CO)C(=O)O)N UKINEYBQXPMOJO-UBHSHLNASA-N 0.000 description 1
- RWAYYYOZMHMEGD-XIRDDKMYSA-N Trp-Leu-Ser Chemical compound C1=CC=C2C(C[C@H](N)C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C(O)=O)=CNC2=C1 RWAYYYOZMHMEGD-XIRDDKMYSA-N 0.000 description 1
- NFVQCNMGJILYMI-SZMVWBNQSA-N Trp-Met-Val Chemical compound [H]N[C@@H](CC1=CNC2=C1C=CC=C2)C(=O)N[C@@H](CCSC)C(=O)N[C@@H](C(C)C)C(O)=O NFVQCNMGJILYMI-SZMVWBNQSA-N 0.000 description 1
- UJGDFQRPYGJBEH-AAEUAGOBSA-N Trp-Ser-Gly Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)NCC(=O)O)N UJGDFQRPYGJBEH-AAEUAGOBSA-N 0.000 description 1
- WSMVEHPVOYXPAQ-XIRDDKMYSA-N Trp-Ser-Lys Chemical compound C1=CC=C2C(=C1)C(=CN2)C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCCCN)C(=O)O)N WSMVEHPVOYXPAQ-XIRDDKMYSA-N 0.000 description 1
- GSCPHMSPGQSZJT-JYBASQMISA-N Trp-Ser-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CO)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N)O GSCPHMSPGQSZJT-JYBASQMISA-N 0.000 description 1
- ZZDFLJFVSNQINX-HWHUXHBOSA-N Trp-Thr-Pro Chemical compound C[C@H]([C@@H](C(=O)N1CCC[C@@H]1C(=O)O)NC(=O)[C@H](CC2=CNC3=CC=CC=C32)N)O ZZDFLJFVSNQINX-HWHUXHBOSA-N 0.000 description 1
- BABINGWMZBWXIX-BPUTZDHNSA-N Trp-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)O)NC(=O)[C@H](CC1=CNC2=CC=CC=C21)N BABINGWMZBWXIX-BPUTZDHNSA-N 0.000 description 1
- 102100039257 Type II inositol 1,4,5-trisphosphate 5-phosphatase Human genes 0.000 description 1
- HSVPZJLMPLMPOX-BPNCWPANSA-N Tyr-Arg-Ala Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](CCCNC(N)=N)C(=O)N[C@@H](C)C(O)=O HSVPZJLMPLMPOX-BPNCWPANSA-N 0.000 description 1
- GAYLGYUVTDMLKC-UWJYBYFXSA-N Tyr-Asp-Ala Chemical compound OC(=O)[C@H](C)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 GAYLGYUVTDMLKC-UWJYBYFXSA-N 0.000 description 1
- NLMXVDDEQFKQQU-CFMVVWHZSA-N Tyr-Asp-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CC(O)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 NLMXVDDEQFKQQU-CFMVVWHZSA-N 0.000 description 1
- FFCRCJZJARTYCG-KKUMJFAQSA-N Tyr-Cys-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CCCCN)C(=O)O)N)O FFCRCJZJARTYCG-KKUMJFAQSA-N 0.000 description 1
- IYHNBRUWVBIVJR-IHRRRGAJSA-N Tyr-Gln-Glu Chemical compound OC(=O)CC[C@@H](C(O)=O)NC(=O)[C@H](CCC(N)=O)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 IYHNBRUWVBIVJR-IHRRRGAJSA-N 0.000 description 1
- WZQZUVWEPMGIMM-JYJNAYRXSA-N Tyr-Gln-Lys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N)O WZQZUVWEPMGIMM-JYJNAYRXSA-N 0.000 description 1
- FMOSEWZYZPMJAL-KKUMJFAQSA-N Tyr-Glu-Met Chemical compound CSCC[C@@H](C(=O)O)NC(=O)[C@H](CCC(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N FMOSEWZYZPMJAL-KKUMJFAQSA-N 0.000 description 1
- AXWBYOVVDRBOGU-SIUGBPQLSA-N Tyr-Ile-Gln Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](CC1=CC=C(C=C1)O)N AXWBYOVVDRBOGU-SIUGBPQLSA-N 0.000 description 1
- BXPOOVDVGWEXDU-WZLNRYEVSA-N Tyr-Ile-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H]([C@@H](C)CC)C(=O)N[C@@H]([C@@H](C)O)C(O)=O BXPOOVDVGWEXDU-WZLNRYEVSA-N 0.000 description 1
- KWKJGBHDYJOVCR-SRVKXCTJSA-N Tyr-Ser-Cys Chemical compound C1=CC(=CC=C1C[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N)O KWKJGBHDYJOVCR-SRVKXCTJSA-N 0.000 description 1
- QPOUERMDWKKZEG-HJPIBITLSA-N Tyr-Ser-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)[C@H](CO)NC(=O)[C@@H](N)CC1=CC=C(O)C=C1 QPOUERMDWKKZEG-HJPIBITLSA-N 0.000 description 1
- ABSXSJZNRAQDDI-KJEVXHAQSA-N Tyr-Val-Thr Chemical compound [H]N[C@@H](CC1=CC=C(O)C=C1)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H]([C@@H](C)O)C(O)=O ABSXSJZNRAQDDI-KJEVXHAQSA-N 0.000 description 1
- 102000056723 UBE3C Human genes 0.000 description 1
- 101150065336 Unc5c gene Proteins 0.000 description 1
- DDRBQONWVBDQOY-GUBZILKMSA-N Val-Ala-Arg Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C)C(=O)N[C@@H](CCCN=C(N)N)C(O)=O DDRBQONWVBDQOY-GUBZILKMSA-N 0.000 description 1
- YFOCMOVJBQDBCE-NRPADANISA-N Val-Ala-Glu Chemical compound C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N YFOCMOVJBQDBCE-NRPADANISA-N 0.000 description 1
- VJOWWOGRNXRQMF-UVBJJODRSA-N Val-Ala-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](C)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 VJOWWOGRNXRQMF-UVBJJODRSA-N 0.000 description 1
- PFNZJEPSCBAVGX-CYDGBPFRSA-N Val-Arg-Ile Chemical compound CC[C@H](C)[C@@H](C(=O)O)NC(=O)[C@H](CCCN=C(N)N)NC(=O)[C@H](C(C)C)N PFNZJEPSCBAVGX-CYDGBPFRSA-N 0.000 description 1
- UDNYEPLJTRDMEJ-RCOVLWMOSA-N Val-Asn-Gly Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)N)C(=O)NCC(=O)O)N UDNYEPLJTRDMEJ-RCOVLWMOSA-N 0.000 description 1
- LNYOXPDEIZJDEI-NHCYSSNCSA-N Val-Asn-Leu Chemical compound CC(C)C[C@@H](C(=O)O)NC(=O)[C@H](CC(=O)N)NC(=O)[C@H](C(C)C)N LNYOXPDEIZJDEI-NHCYSSNCSA-N 0.000 description 1
- XQVRMLRMTAGSFJ-QXEWZRGKSA-N Val-Asp-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC(=O)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N XQVRMLRMTAGSFJ-QXEWZRGKSA-N 0.000 description 1
- HHSILIQTHXABKM-YDHLFZDLSA-N Val-Asp-Phe Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CC(O)=O)C(=O)N[C@@H](Cc1ccccc1)C(O)=O HHSILIQTHXABKM-YDHLFZDLSA-N 0.000 description 1
- PFMAFMPJJSHNDW-ZKWXMUAHSA-N Val-Cys-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](CC(=O)N)C(=O)O)N PFMAFMPJJSHNDW-ZKWXMUAHSA-N 0.000 description 1
- XJFXZQKJQGYFMM-GUBZILKMSA-N Val-Cys-Val Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CS)C(=O)N[C@@H](C(C)C)C(=O)O)N XJFXZQKJQGYFMM-GUBZILKMSA-N 0.000 description 1
- ZEVNVXYRZRIRCH-GVXVVHGQSA-N Val-Gln-Lys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)N[C@@H](CCCCN)C(=O)O)N ZEVNVXYRZRIRCH-GVXVVHGQSA-N 0.000 description 1
- GBESYURLQOYWLU-LAEOZQHASA-N Val-Glu-Asp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)N[C@@H](CC(=O)O)C(=O)O)N GBESYURLQOYWLU-LAEOZQHASA-N 0.000 description 1
- RKIGNDAHUOOIMJ-BQFCYCMXSA-N Val-Glu-Trp Chemical compound C1=CC=C2C(C[C@H](NC(=O)[C@H](CCC(O)=O)NC(=O)[C@@H](N)C(C)C)C(O)=O)=CNC2=C1 RKIGNDAHUOOIMJ-BQFCYCMXSA-N 0.000 description 1
- OXGVAUFVTOPFFA-XPUUQOCRSA-N Val-Gly-Cys Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CS)C(=O)O)N OXGVAUFVTOPFFA-XPUUQOCRSA-N 0.000 description 1
- GMOLURHJBLOBFW-ONGXEEELSA-N Val-Gly-His Chemical compound CC(C)[C@@H](C(=O)NCC(=O)N[C@@H](CC1=CN=CN1)C(=O)O)N GMOLURHJBLOBFW-ONGXEEELSA-N 0.000 description 1
- PMDOQZFYGWZSTK-LSJOCFKGSA-N Val-Gly-Ile Chemical compound CC[C@H](C)[C@@H](C(O)=O)NC(=O)CNC(=O)[C@@H](N)C(C)C PMDOQZFYGWZSTK-LSJOCFKGSA-N 0.000 description 1
- OPGWZDIYEYJVRX-AVGNSLFASA-N Val-His-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N OPGWZDIYEYJVRX-AVGNSLFASA-N 0.000 description 1
- SDSCOOZQQGUQFC-GVXVVHGQSA-N Val-His-Gln Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CCC(=O)N)C(=O)O)N SDSCOOZQQGUQFC-GVXVVHGQSA-N 0.000 description 1
- KVRLNEILGGVBJX-IHRRRGAJSA-N Val-His-Leu Chemical compound CC(C)C[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CN=CN1 KVRLNEILGGVBJX-IHRRRGAJSA-N 0.000 description 1
- MJXNDRCLGDSBBE-FHWLQOOXSA-N Val-His-Trp Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CN=CN1)C(=O)N[C@@H](CC2=CNC3=CC=CC=C32)C(=O)O)N MJXNDRCLGDSBBE-FHWLQOOXSA-N 0.000 description 1
- CPGJELLYDQEDRK-NAKRPEOUSA-N Val-Ile-Ala Chemical compound CC[C@H](C)[C@H](NC(=O)[C@@H](N)C(C)C)C(=O)N[C@@H](C)C(O)=O CPGJELLYDQEDRK-NAKRPEOUSA-N 0.000 description 1
- DJQIUOKSNRBTSV-CYDGBPFRSA-N Val-Ile-Val Chemical compound CC[C@H](C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)O)NC(=O)[C@H](C(C)C)N DJQIUOKSNRBTSV-CYDGBPFRSA-N 0.000 description 1
- HGJRMXOWUWVUOA-GVXVVHGQSA-N Val-Leu-Gln Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)N)C(=O)O)NC(=O)[C@H](C(C)C)N HGJRMXOWUWVUOA-GVXVVHGQSA-N 0.000 description 1
- LYERIXUFCYVFFX-GVXVVHGQSA-N Val-Leu-Glu Chemical compound CC(C)C[C@@H](C(=O)N[C@@H](CCC(=O)O)C(=O)O)NC(=O)[C@H](C(C)C)N LYERIXUFCYVFFX-GVXVVHGQSA-N 0.000 description 1
- BTWMICVCQLKKNR-DCAQKATOSA-N Val-Leu-Ser Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](CC(C)C)C(=O)N[C@@H](CO)C([O-])=O BTWMICVCQLKKNR-DCAQKATOSA-N 0.000 description 1
- SYSWVVCYSXBVJG-RHYQMDGZSA-N Val-Leu-Thr Chemical compound C[C@H]([C@@H](C(=O)O)NC(=O)[C@H](CC(C)C)NC(=O)[C@H](C(C)C)N)O SYSWVVCYSXBVJG-RHYQMDGZSA-N 0.000 description 1
- XBJKAZATRJBDCU-GUBZILKMSA-N Val-Pro-Ala Chemical compound CC(C)[C@H](N)C(=O)N1CCC[C@H]1C(=O)N[C@@H](C)C(O)=O XBJKAZATRJBDCU-GUBZILKMSA-N 0.000 description 1
- JQTYTBPCSOAZHI-FXQIFTODSA-N Val-Ser-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CS)C(=O)O)N JQTYTBPCSOAZHI-FXQIFTODSA-N 0.000 description 1
- VIKZGAUAKQZDOF-NRPADANISA-N Val-Ser-Glu Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](CO)C(=O)N[C@H](C(O)=O)CCC(O)=O VIKZGAUAKQZDOF-NRPADANISA-N 0.000 description 1
- DLLRRUDLMSJTMB-GUBZILKMSA-N Val-Ser-Met Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CO)C(=O)N[C@@H](CCSC)C(=O)O)N DLLRRUDLMSJTMB-GUBZILKMSA-N 0.000 description 1
- YQYFYUSYEDNLSD-YEPSODPASA-N Val-Thr-Gly Chemical compound CC(C)[C@H](N)C(=O)N[C@@H]([C@@H](C)O)C(=O)NCC(O)=O YQYFYUSYEDNLSD-YEPSODPASA-N 0.000 description 1
- LCHZBEUVGAVMKS-RHYQMDGZSA-N Val-Thr-Leu Chemical compound CC(C)C[C@H](NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)[C@@H](C)O)C(O)=O LCHZBEUVGAVMKS-RHYQMDGZSA-N 0.000 description 1
- UEXPMFIAZZHEAD-HSHDSVGOSA-N Val-Thr-Trp Chemical compound C[C@H]([C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)O)NC(=O)[C@H](C(C)C)N)O UEXPMFIAZZHEAD-HSHDSVGOSA-N 0.000 description 1
- SVLAAUGFIHSJPK-JYJNAYRXSA-N Val-Trp-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CNC2=CC=CC=C21)C(=O)N[C@@H](CO)C(=O)O)N SVLAAUGFIHSJPK-JYJNAYRXSA-N 0.000 description 1
- JXCOEPXCBVCTRD-JYJNAYRXSA-N Val-Tyr-Arg Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CCCN=C(N)N)C(=O)O)N JXCOEPXCBVCTRD-JYJNAYRXSA-N 0.000 description 1
- MIAZWUMFUURQNP-YDHLFZDLSA-N Val-Tyr-Asn Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CC(=O)N)C(=O)O)N MIAZWUMFUURQNP-YDHLFZDLSA-N 0.000 description 1
- CFIBZQOLUDURST-IHRRRGAJSA-N Val-Tyr-Cys Chemical compound CC(C)[C@@H](C(=O)N[C@@H](CC1=CC=C(C=C1)O)C(=O)N[C@@H](CS)C(=O)O)N CFIBZQOLUDURST-IHRRRGAJSA-N 0.000 description 1
- DOBHJKVVACOQTN-DZKIICNBSA-N Val-Tyr-Gln Chemical compound NC(=O)CC[C@@H](C(O)=O)NC(=O)[C@@H](NC(=O)[C@@H](N)C(C)C)CC1=CC=C(O)C=C1 DOBHJKVVACOQTN-DZKIICNBSA-N 0.000 description 1
- ZHWZDZFWBXWPDW-GUBZILKMSA-N Val-Val-Cys Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CS)C(O)=O ZHWZDZFWBXWPDW-GUBZILKMSA-N 0.000 description 1
- VVIZITNVZUAEMI-DLOVCJGASA-N Val-Val-Gln Chemical compound CC(C)[C@H](N)C(=O)N[C@@H](C(C)C)C(=O)N[C@H](C(O)=O)CCC(N)=O VVIZITNVZUAEMI-DLOVCJGASA-N 0.000 description 1
- AEFJNECXZCODJM-UWVGGRQHSA-N Val-Val-Gly Chemical compound CC(C)[C@H]([NH3+])C(=O)N[C@@H](C(C)C)C(=O)NCC([O-])=O AEFJNECXZCODJM-UWVGGRQHSA-N 0.000 description 1
- LLJLBRRXKZTTRD-GUBZILKMSA-N Val-Val-Ser Chemical compound CC(C)[C@@H](C(=O)N[C@@H](C(C)C)C(=O)N[C@@H](CO)C(=O)O)N LLJLBRRXKZTTRD-GUBZILKMSA-N 0.000 description 1
- 241000269368 Xenopus laevis Species 0.000 description 1
- 239000003070 absorption delaying agent Substances 0.000 description 1
- 239000002253 acid Substances 0.000 description 1
- 150000007513 acids Chemical class 0.000 description 1
- NIXOWILDQLNWCW-UHFFFAOYSA-N acrylic acid group Chemical group C(C=C)(=O)O NIXOWILDQLNWCW-UHFFFAOYSA-N 0.000 description 1
- 230000002411 adverse Effects 0.000 description 1
- 230000009824 affinity maturation Effects 0.000 description 1
- 108010008685 alanyl-glutamyl-aspartic acid Proteins 0.000 description 1
- 108010086434 alanyl-seryl-glycine Proteins 0.000 description 1
- 108010047495 alanylglycine Proteins 0.000 description 1
- 108010070944 alanylhistidine Proteins 0.000 description 1
- 125000003342 alkenyl group Chemical group 0.000 description 1
- 125000000217 alkyl group Chemical group 0.000 description 1
- 239000002168 alkylating agent Substances 0.000 description 1
- 229940100198 alkylating agent Drugs 0.000 description 1
- HMFHBZSHGGEWLO-UHFFFAOYSA-N alpha-D-Furanose-Ribose Natural products OCC1OC(O)C(O)C1O HMFHBZSHGGEWLO-UHFFFAOYSA-N 0.000 description 1
- 150000001412 amines Chemical class 0.000 description 1
- 125000000539 amino acid group Chemical group 0.000 description 1
- 230000006986 amnesia Effects 0.000 description 1
- 210000004381 amniotic fluid Anatomy 0.000 description 1
- 230000000049 anti-anxiety effect Effects 0.000 description 1
- 230000000844 anti-bacterial effect Effects 0.000 description 1
- 230000003466 anti-cipated effect Effects 0.000 description 1
- 229940125713 antianxiety drug Drugs 0.000 description 1
- 229940088710 antibiotic agent Drugs 0.000 description 1
- 239000003146 anticoagulant agent Substances 0.000 description 1
- 229940127219 anticoagulant drug Drugs 0.000 description 1
- 229940005513 antidepressants Drugs 0.000 description 1
- 229940121375 antifungal agent Drugs 0.000 description 1
- 239000003429 antifungal agent Substances 0.000 description 1
- 239000000427 antigen Substances 0.000 description 1
- 108091007433 antigens Proteins 0.000 description 1
- 102000036639 antigens Human genes 0.000 description 1
- 229940005530 anxiolytics Drugs 0.000 description 1
- 238000003782 apoptosis assay Methods 0.000 description 1
- 230000005756 apoptotic signaling Effects 0.000 description 1
- PYMYPHUHKUWMLA-WDCZJNDASA-N arabinose Chemical compound OC[C@@H](O)[C@@H](O)[C@H](O)C=O PYMYPHUHKUWMLA-WDCZJNDASA-N 0.000 description 1
- 108010009111 arginyl-glycyl-glutamic acid Proteins 0.000 description 1
- 108010018691 arginyl-threonyl-arginine Proteins 0.000 description 1
- 108010068380 arginylarginine Proteins 0.000 description 1
- 125000003118 aryl group Chemical group 0.000 description 1
- 210000003567 ascitic fluid Anatomy 0.000 description 1
- 108010010430 asparagine-proline-alanine Proteins 0.000 description 1
- 108010069205 aspartyl-phenylalanine Proteins 0.000 description 1
- 108010038633 aspartylglutamate Proteins 0.000 description 1
- 108010047857 aspartylglycine Proteins 0.000 description 1
- 208000006673 asthma Diseases 0.000 description 1
- 210000003050 axon Anatomy 0.000 description 1
- 230000004888 barrier function Effects 0.000 description 1
- 239000011324 bead Substances 0.000 description 1
- 239000011230 binding agent Substances 0.000 description 1
- 230000033228 biological regulation Effects 0.000 description 1
- 230000005540 biological transmission Effects 0.000 description 1
- 239000012503 blood component Substances 0.000 description 1
- 210000001124 body fluid Anatomy 0.000 description 1
- 239000010839 body fluid Substances 0.000 description 1
- 229910052796 boron Inorganic materials 0.000 description 1
- QXZGBUJJYSLZLT-FDISYFBBSA-N bradykinin Chemical compound NC(=N)NCCC[C@H](N)C(=O)N1CCC[C@H]1C(=O)N1[C@H](C(=O)NCC(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CO)C(=O)N2[C@@H](CCC2)C(=O)N[C@@H](CC=2C=CC=CC=2)C(=O)N[C@@H](CCCNC(N)=N)C(O)=O)CCC1 QXZGBUJJYSLZLT-FDISYFBBSA-N 0.000 description 1
- 210000004781 brain capillary Anatomy 0.000 description 1
- 210000005013 brain tissue Anatomy 0.000 description 1
- 210000004899 c-terminal region Anatomy 0.000 description 1
- 238000005251 capillar electrophoresis Methods 0.000 description 1
- 125000002837 carbocyclic group Chemical group 0.000 description 1
- 125000004432 carbon atom Chemical group C* 0.000 description 1
- 230000001364 causal effect Effects 0.000 description 1
- 230000024245 cell differentiation Effects 0.000 description 1
- 230000010261 cell growth Effects 0.000 description 1
- 230000001413 cellular effect Effects 0.000 description 1
- 210000003710 cerebral cortex Anatomy 0.000 description 1
- 239000002738 chelating agent Substances 0.000 description 1
- 238000007385 chemical modification Methods 0.000 description 1
- 238000006243 chemical reaction Methods 0.000 description 1
- 239000002975 chemoattractant Substances 0.000 description 1
- 230000001684 chronic effect Effects 0.000 description 1
- 238000010367 cloning Methods 0.000 description 1
- 238000000576 coating method Methods 0.000 description 1
- 208000010877 cognitive disease Diseases 0.000 description 1
- 230000001149 cognitive effect Effects 0.000 description 1
- 238000002648 combination therapy Methods 0.000 description 1
- 238000004891 communication Methods 0.000 description 1
- 238000002591 computed tomography Methods 0.000 description 1
- 208000029078 coronary artery disease Diseases 0.000 description 1
- 230000008878 coupling Effects 0.000 description 1
- 238000010168 coupling process Methods 0.000 description 1
- 238000005859 coupling reaction Methods 0.000 description 1
- 210000004748 cultured cell Anatomy 0.000 description 1
- 125000000392 cycloalkenyl group Chemical group 0.000 description 1
- 125000000753 cycloalkyl group Chemical group 0.000 description 1
- 108010060199 cysteinylproline Proteins 0.000 description 1
- 238000007405 data analysis Methods 0.000 description 1
- 238000002716 delivery method Methods 0.000 description 1
- 239000005547 deoxyribonucleotide Substances 0.000 description 1
- 125000002637 deoxyribonucleotide group Chemical group 0.000 description 1
- 230000008021 deposition Effects 0.000 description 1
- 238000013461 design Methods 0.000 description 1
- VGONTNSXDCQUGY-UHFFFAOYSA-N desoxyinosine Natural products C1C(O)C(CO)OC1N1C(NC=NC2=O)=C2N=C1 VGONTNSXDCQUGY-UHFFFAOYSA-N 0.000 description 1
- 238000010586 diagram Methods 0.000 description 1
- NAGJZTKCGNOGPW-UHFFFAOYSA-K dioxido-sulfanylidene-sulfido-$l^{5}-phosphane Chemical compound [O-]P([O-])([S-])=S NAGJZTKCGNOGPW-UHFFFAOYSA-K 0.000 description 1
- FSXRLASFHBWESK-UHFFFAOYSA-N dipeptide phenylalanyl-tyrosine Natural products C=1C=C(O)C=CC=1CC(C(O)=O)NC(=O)C(N)CC1=CC=CC=C1 FSXRLASFHBWESK-UHFFFAOYSA-N 0.000 description 1
- 210000001840 diploid cell Anatomy 0.000 description 1
- 239000002612 dispersion medium Substances 0.000 description 1
- 238000009826 distribution Methods 0.000 description 1
- 238000013399 early diagnosis Methods 0.000 description 1
- 230000005520 electrodynamics Effects 0.000 description 1
- 230000002996 emotional effect Effects 0.000 description 1
- 230000008497 endothelial barrier function Effects 0.000 description 1
- 108091007231 endothelial receptors Proteins 0.000 description 1
- 238000005516 engineering process Methods 0.000 description 1
- 238000011156 evaluation Methods 0.000 description 1
- 210000003722 extracellular fluid Anatomy 0.000 description 1
- 239000000945 filler Substances 0.000 description 1
- 229940014144 folate Drugs 0.000 description 1
- OVBPIULPVIDEAO-LBPRGKRZSA-N folic acid Chemical compound C=1N=C2NC(N)=NC(=O)C2=NC=1CNC1=CC=C(C(=O)N[C@@H](CCC(O)=O)C(O)=O)C=C1 OVBPIULPVIDEAO-LBPRGKRZSA-N 0.000 description 1
- 235000019152 folic acid Nutrition 0.000 description 1
- 239000011724 folic acid Substances 0.000 description 1
- 108010063718 gamma-glutamylaspartic acid Proteins 0.000 description 1
- 238000001415 gene therapy Methods 0.000 description 1
- 238000010353 genetic engineering Methods 0.000 description 1
- 210000004602 germ cell Anatomy 0.000 description 1
- 229940084910 gliadel Drugs 0.000 description 1
- 108010078144 glutaminyl-glycine Proteins 0.000 description 1
- 108010037389 glutamyl-cysteinyl-lysine Proteins 0.000 description 1
- VPZXBVLAVMBEQI-UHFFFAOYSA-N glycyl-DL-alpha-alanine Natural products OC(=O)C(C)NC(=O)CN VPZXBVLAVMBEQI-UHFFFAOYSA-N 0.000 description 1
- XBGGUPMXALFZOT-UHFFFAOYSA-N glycyl-L-tyrosine hemihydrate Natural products NCC(=O)NC(C(O)=O)CC1=CC=C(O)C=C1 XBGGUPMXALFZOT-UHFFFAOYSA-N 0.000 description 1
- 108010000434 glycyl-alanyl-leucine Proteins 0.000 description 1
- 108010027668 glycyl-alanyl-valine Proteins 0.000 description 1
- 108010084264 glycyl-glycyl-cysteine Proteins 0.000 description 1
- 108010028188 glycyl-histidyl-serine Proteins 0.000 description 1
- 108010079413 glycyl-prolyl-glutamic acid Proteins 0.000 description 1
- 108010082286 glycyl-seryl-alanine Proteins 0.000 description 1
- 108010074027 glycyl-seryl-phenylalanine Proteins 0.000 description 1
- 108010084389 glycyltryptophan Proteins 0.000 description 1
- 108010087823 glycyltyrosine Proteins 0.000 description 1
- 230000009931 harmful effect Effects 0.000 description 1
- 230000036541 health Effects 0.000 description 1
- 238000010438 heat treatment Methods 0.000 description 1
- 238000004128 high performance liquid chromatography Methods 0.000 description 1
- 210000001320 hippocampus Anatomy 0.000 description 1
- 108010092114 histidylphenylalanine Proteins 0.000 description 1
- 102000052623 human IL6R Human genes 0.000 description 1
- 102000044215 human UNC5C Human genes 0.000 description 1
- 230000028993 immune response Effects 0.000 description 1
- 230000036039 immunity Effects 0.000 description 1
- 238000003119 immunoblot Methods 0.000 description 1
- 102000018358 immunoglobulin Human genes 0.000 description 1
- 239000012133 immunoprecipitate Substances 0.000 description 1
- 238000002513 implantation Methods 0.000 description 1
- 239000004615 ingredient Substances 0.000 description 1
- 230000000977 initiatory effect Effects 0.000 description 1
- 230000003993 interaction Effects 0.000 description 1
- 229940100601 interleukin-6 Drugs 0.000 description 1
- 108040006858 interleukin-6 receptor activity proteins Proteins 0.000 description 1
- 238000001361 intraarterial administration Methods 0.000 description 1
- 238000007918 intramuscular administration Methods 0.000 description 1
- 238000007912 intraperitoneal administration Methods 0.000 description 1
- 238000001990 intravenous administration Methods 0.000 description 1
- 108010078274 isoleucylvaline Proteins 0.000 description 1
- 239000007951 isotonicity adjuster Substances 0.000 description 1
- 210000003734 kidney Anatomy 0.000 description 1
- 108010053037 kyotorphin Proteins 0.000 description 1
- 108010030617 leucyl-phenylalanyl-valine Proteins 0.000 description 1
- 108010073472 leucyl-prolyl-proline Proteins 0.000 description 1
- 108010012058 leucyltyrosine Proteins 0.000 description 1
- 238000007834 ligase chain reaction Methods 0.000 description 1
- 230000000670 limiting effect Effects 0.000 description 1
- 238000012417 linear regression Methods 0.000 description 1
- 230000033001 locomotion Effects 0.000 description 1
- 230000007774 longterm Effects 0.000 description 1
- 108010089256 lysyl-aspartyl-glutamyl-leucine Proteins 0.000 description 1
- 108010009298 lysylglutamic acid Proteins 0.000 description 1
- 108010038320 lysylphenylalanine Proteins 0.000 description 1
- 238000002595 magnetic resonance imaging Methods 0.000 description 1
- 238000012423 maintenance Methods 0.000 description 1
- 239000000594 mannitol Substances 0.000 description 1
- 235000010355 mannitol Nutrition 0.000 description 1
- 238000000816 matrix-assisted laser desorption--ionisation Methods 0.000 description 1
- 239000002609 medium Substances 0.000 description 1
- 230000006386 memory function Effects 0.000 description 1
- 230000006996 mental state Effects 0.000 description 1
- YACKEPLHDIMKIO-UHFFFAOYSA-N methylphosphonic acid Chemical compound CP(O)(O)=O YACKEPLHDIMKIO-UHFFFAOYSA-N 0.000 description 1
- 230000033607 mismatch repair Effects 0.000 description 1
- 238000010369 molecular cloning Methods 0.000 description 1
- 230000036651 mood Effects 0.000 description 1
- 239000013642 negative control Substances 0.000 description 1
- 210000004126 nerve fiber Anatomy 0.000 description 1
- 230000006855 networking Effects 0.000 description 1
- 230000004770 neurodegeneration Effects 0.000 description 1
- 208000015122 neurodegenerative disease Diseases 0.000 description 1
- 238000002610 neuroimaging Methods 0.000 description 1
- 230000016273 neuron death Effects 0.000 description 1
- 230000014511 neuron projection development Effects 0.000 description 1
- 230000006576 neuronal survival Effects 0.000 description 1
- 230000007935 neutral effect Effects 0.000 description 1
- 229960003512 nicotinic acid Drugs 0.000 description 1
- 235000001968 nicotinic acid Nutrition 0.000 description 1
- 239000011664 nicotinic acid Substances 0.000 description 1
- 229920001220 nitrocellulos Polymers 0.000 description 1
- 239000002687 nonaqueous vehicle Substances 0.000 description 1
- 231100000252 nontoxic Toxicity 0.000 description 1
- 230000003000 nontoxic effect Effects 0.000 description 1
- 239000000346 nonvolatile oil Substances 0.000 description 1
- 238000007899 nucleic acid hybridization Methods 0.000 description 1
- 239000002853 nucleic acid probe Substances 0.000 description 1
- 239000002777 nucleoside Substances 0.000 description 1
- 150000003833 nucleoside derivatives Chemical class 0.000 description 1
- 235000015097 nutrients Nutrition 0.000 description 1
- 230000003204 osmotic effect Effects 0.000 description 1
- 108010040377 otolin-1 Proteins 0.000 description 1
- 230000001590 oxidative effect Effects 0.000 description 1
- 229940055726 pantothenic acid Drugs 0.000 description 1
- 235000019161 pantothenic acid Nutrition 0.000 description 1
- 239000011713 pantothenic acid Substances 0.000 description 1
- 230000036961 partial effect Effects 0.000 description 1
- 239000002245 particle Substances 0.000 description 1
- 230000001717 pathogenic effect Effects 0.000 description 1
- 230000007170 pathology Effects 0.000 description 1
- 230000037361 pathway Effects 0.000 description 1
- 238000012510 peptide mapping method Methods 0.000 description 1
- 230000002093 peripheral effect Effects 0.000 description 1
- 210000002856 peripheral neuron Anatomy 0.000 description 1
- 239000000546 pharmaceutical excipient Substances 0.000 description 1
- 108010064486 phenylalanyl-leucyl-valine Proteins 0.000 description 1
- 108010089198 phenylalanyl-prolyl-arginine Proteins 0.000 description 1
- 125000002467 phosphate group Chemical group [H]OP(=O)(O[H])O[*] 0.000 description 1
- 108010025488 pinealon Proteins 0.000 description 1
- 238000002264 polyacrylamide gel electrophoresis Methods 0.000 description 1
- 238000006116 polymerization reaction Methods 0.000 description 1
- 102000054765 polymorphisms of proteins Human genes 0.000 description 1
- 239000013641 positive control Substances 0.000 description 1
- 230000003389 potentiating effect Effects 0.000 description 1
- 230000035935 pregnancy Effects 0.000 description 1
- 238000002360 preparation method Methods 0.000 description 1
- 210000004986 primary T-cell Anatomy 0.000 description 1
- 230000005522 programmed cell death Effects 0.000 description 1
- 230000035755 proliferation Effects 0.000 description 1
- 108700042769 prolyl-leucyl-glycine Proteins 0.000 description 1
- 108010087846 prolyl-prolyl-glycine Proteins 0.000 description 1
- 230000004853 protein function Effects 0.000 description 1
- 230000006337 proteolytic cleavage Effects 0.000 description 1
- 238000003908 quality control method Methods 0.000 description 1
- 230000008707 rearrangement Effects 0.000 description 1
- 238000011084 recovery Methods 0.000 description 1
- 230000010076 replication Effects 0.000 description 1
- 108091008146 restriction endonucleases Proteins 0.000 description 1
- 238000004366 reverse phase liquid chromatography Methods 0.000 description 1
- 239000002336 ribonucleotide Substances 0.000 description 1
- 125000002652 ribonucleotide group Chemical group 0.000 description 1
- 108010048818 seryl-histidine Proteins 0.000 description 1
- 108010048397 seryl-lysyl-leucine Proteins 0.000 description 1
- FZHAPNGMFPVSLP-UHFFFAOYSA-N silanamine Chemical compound [SiH3]N FZHAPNGMFPVSLP-UHFFFAOYSA-N 0.000 description 1
- 229910052709 silver Inorganic materials 0.000 description 1
- 239000004332 silver Substances 0.000 description 1
- 238000002603 single-photon emission computed tomography Methods 0.000 description 1
- 150000003384 small molecules Chemical class 0.000 description 1
- 239000011780 sodium chloride Substances 0.000 description 1
- 239000002904 solvent Substances 0.000 description 1
- 230000000392 somatic effect Effects 0.000 description 1
- 238000000527 sonication Methods 0.000 description 1
- 108010005652 splenotritin Proteins 0.000 description 1
- 239000003381 stabilizer Substances 0.000 description 1
- 210000000130 stem cell Anatomy 0.000 description 1
- 150000003431 steroids Chemical class 0.000 description 1
- 238000007920 subcutaneous administration Methods 0.000 description 1
- 238000011477 surgical intervention Methods 0.000 description 1
- 102000013498 tau Proteins Human genes 0.000 description 1
- 108010026424 tau Proteins Proteins 0.000 description 1
- 230000002123 temporal effect Effects 0.000 description 1
- 101150065190 term gene Proteins 0.000 description 1
- 238000011285 therapeutic regimen Methods 0.000 description 1
- RYYWUUFWQRZTIU-UHFFFAOYSA-K thiophosphate Chemical compound [O-]P([O-])([O-])=S RYYWUUFWQRZTIU-UHFFFAOYSA-K 0.000 description 1
- 108010033670 threonyl-aspartyl-tyrosine Proteins 0.000 description 1
- 108010072986 threonyl-seryl-lysine Proteins 0.000 description 1
- 239000003053 toxin Substances 0.000 description 1
- 231100000765 toxin Toxicity 0.000 description 1
- 238000011277 treatment modality Methods 0.000 description 1
- 102000015534 trkB Receptor Human genes 0.000 description 1
- 108010064880 trkB Receptor Proteins 0.000 description 1
- 108010078580 tyrosylleucine Proteins 0.000 description 1
- 210000002700 urine Anatomy 0.000 description 1
- 108010015385 valyl-prolyl-proline Proteins 0.000 description 1
- 108010073969 valyllysine Proteins 0.000 description 1
- 108010009962 valyltyrosine Proteins 0.000 description 1
- 230000002792 vascular Effects 0.000 description 1
- 208000002670 vitamin B12 deficiency Diseases 0.000 description 1
- 235000012431 wafers Nutrition 0.000 description 1
- 239000011534 wash buffer Substances 0.000 description 1
- XLYOFNOQVPJJNP-UHFFFAOYSA-N water Substances O XLYOFNOQVPJJNP-UHFFFAOYSA-N 0.000 description 1
- 108010027345 wheylin-1 peptide Proteins 0.000 description 1
Images







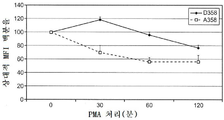
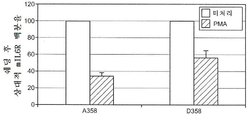
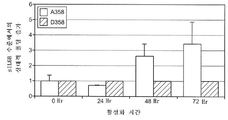
Classifications
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6813—Hybridisation assays
- C12Q1/6827—Hybridisation assays for detection of mutation or polymorphism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6844—Nucleic acid amplification reactions
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6876—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes
- C12Q1/6883—Nucleic acid products used in the analysis of nucleic acids, e.g. primers or probes for diseases caused by alterations of genetic material
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/179—Receptors; Cell surface antigens; Cell surface determinants for growth factors; for growth regulators
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/177—Receptors; Cell surface antigens; Cell surface determinants
- A61K38/1793—Receptors; Cell surface antigens; Cell surface determinants for cytokines; for lymphokines; for interferons
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61K—PREPARATIONS FOR MEDICAL, DENTAL OR TOILETRY PURPOSES
- A61K38/00—Medicinal preparations containing peptides
- A61K38/16—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof
- A61K38/17—Peptides having more than 20 amino acids; Gastrins; Somatostatins; Melanotropins; Derivatives thereof from animals; from humans
- A61K38/18—Growth factors; Growth regulators
- A61K38/1883—Neuregulins, e.g.. p185erbB2 ligands, glial growth factor, heregulin, ARIA, neu differentiation factor
-
- A—HUMAN NECESSITIES
- A61—MEDICAL OR VETERINARY SCIENCE; HYGIENE
- A61P—SPECIFIC THERAPEUTIC ACTIVITY OF CHEMICAL COMPOUNDS OR MEDICINAL PREPARATIONS
- A61P25/00—Drugs for disorders of the nervous system
- A61P25/28—Drugs for disorders of the nervous system for treating neurodegenerative disorders of the central nervous system, e.g. nootropic agents, cognition enhancers, drugs for treating Alzheimer's disease or other forms of dementia
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q1/00—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions
- C12Q1/68—Measuring or testing processes involving enzymes, nucleic acids or microorganisms; Compositions therefor; Processes of preparing such compositions involving nucleic acids
- C12Q1/6869—Methods for sequencing
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N33/00—Investigating or analysing materials by specific methods not covered by groups G01N1/00 - G01N31/00
- G01N33/48—Biological material, e.g. blood, urine; Haemocytometers
- G01N33/50—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing
- G01N33/68—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids
- G01N33/6893—Chemical analysis of biological material, e.g. blood, urine; Testing involving biospecific ligand binding methods; Immunological testing involving proteins, peptides or amino acids related to diseases not provided for elsewhere
- G01N33/6896—Neurological disorders, e.g. Alzheimer's disease
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/106—Pharmacogenomics, i.e. genetic variability in individual responses to drugs and drug metabolism
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/118—Prognosis of disease development
-
- C—CHEMISTRY; METALLURGY
- C12—BIOCHEMISTRY; BEER; SPIRITS; WINE; VINEGAR; MICROBIOLOGY; ENZYMOLOGY; MUTATION OR GENETIC ENGINEERING
- C12Q—MEASURING OR TESTING PROCESSES INVOLVING ENZYMES, NUCLEIC ACIDS OR MICROORGANISMS; COMPOSITIONS OR TEST PAPERS THEREFOR; PROCESSES OF PREPARING SUCH COMPOSITIONS; CONDITION-RESPONSIVE CONTROL IN MICROBIOLOGICAL OR ENZYMOLOGICAL PROCESSES
- C12Q2600/00—Oligonucleotides characterized by their use
- C12Q2600/156—Polymorphic or mutational markers
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/46—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans from vertebrates
- G01N2333/47—Assays involving proteins of known structure or function as defined in the subgroups
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/475—Assays involving growth factors
- G01N2333/4756—Neuregulins, i.e. p185erbB2 ligands, glial growth factor, heregulin, ARIA, neu differentiation factor
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/71—Assays involving receptors, cell surface antigens or cell surface determinants for growth factors; for growth regulators
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2333/00—Assays involving biological materials from specific organisms or of a specific nature
- G01N2333/435—Assays involving biological materials from specific organisms or of a specific nature from animals; from humans
- G01N2333/705—Assays involving receptors, cell surface antigens or cell surface determinants
- G01N2333/715—Assays involving receptors, cell surface antigens or cell surface determinants for cytokines; for lymphokines; for interferons
- G01N2333/7155—Assays involving receptors, cell surface antigens or cell surface determinants for cytokines; for lymphokines; for interferons for interleukins [IL]
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2800/00—Detection or diagnosis of diseases
- G01N2800/28—Neurological disorders
- G01N2800/2814—Dementia; Cognitive disorders
- G01N2800/2821—Alzheimer
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2800/00—Detection or diagnosis of diseases
- G01N2800/50—Determining the risk of developing a disease
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2800/00—Detection or diagnosis of diseases
- G01N2800/52—Predicting or monitoring the response to treatment, e.g. for selection of therapy based on assay results in personalised medicine; Prognosis
-
- G—PHYSICS
- G01—MEASURING; TESTING
- G01N—INVESTIGATING OR ANALYSING MATERIALS BY DETERMINING THEIR CHEMICAL OR PHYSICAL PROPERTIES
- G01N2800/00—Detection or diagnosis of diseases
- G01N2800/60—Complex ways of combining multiple protein biomarkers for diagnosis
Landscapes
- Life Sciences & Earth Sciences (AREA)
- Health & Medical Sciences (AREA)
- Chemical & Material Sciences (AREA)
- Engineering & Computer Science (AREA)
- Proteomics, Peptides & Aminoacids (AREA)
- Organic Chemistry (AREA)
- Zoology (AREA)
- Immunology (AREA)
- Wood Science & Technology (AREA)
- General Health & Medical Sciences (AREA)
- Bioinformatics & Cheminformatics (AREA)
- Analytical Chemistry (AREA)
- Molecular Biology (AREA)
- Genetics & Genomics (AREA)
- Microbiology (AREA)
- Physics & Mathematics (AREA)
- Biochemistry (AREA)
- Biotechnology (AREA)
- Biomedical Technology (AREA)
- Biophysics (AREA)
- General Engineering & Computer Science (AREA)
- Medicinal Chemistry (AREA)
- Pathology (AREA)
- Urology & Nephrology (AREA)
- Cell Biology (AREA)
- Animal Behavior & Ethology (AREA)
- Public Health (AREA)
- Veterinary Medicine (AREA)
- Hematology (AREA)
- Pharmacology & Pharmacy (AREA)
- Neurology (AREA)
- Neurosurgery (AREA)
- Gastroenterology & Hepatology (AREA)
- Epidemiology (AREA)
- General Physics & Mathematics (AREA)
- Food Science & Technology (AREA)
- Chemical Kinetics & Catalysis (AREA)
- Hospice & Palliative Care (AREA)
- Psychiatry (AREA)
- Nuclear Medicine, Radiotherapy & Molecular Imaging (AREA)
Abstract
본 발명은 피험체로부터의 샘플 내 하나 이상의 유전적 변이의 존재 또는 부재를 검출하는 단계를 포함하는 피험체에서 알츠하이머병(AD)의 진단 및 예후의 방법을 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다. AD의 치료를 위한 치료제에 대한 피험체의 반응을 예측하는 방법이 또한 제공된다.
Description
AD의 특정 하위표현형을 포함하는 알츠하이머병(Alzheimer's Disease: AD)의 확인, 진단 및 진단 방법뿐만 아니라 환자의 특정 하위집단을 포함하는 AD의 치료방법이 제공된다. 또한 효과적인 AD 치료제를 확인하고, AD 치료제에 대한 반응을 예측하는 방법이 제공된다.
알츠하이머병(AD)은 인지 및 기억 기능의 진행성 상실 및 궁극적으로는 치매와 관련된 중추신경계의 신경퇴행성 질병이다. AD는 개발도상국에서 가장 중요하고 흔한 치매의 원인이며, 모든 치매 경우의 60%이상을 차지한다. 검시에서 AD 환자에서 2가지 병리학적 특징이 관찰된다: 해마, 대뇌피질 및 인지기능에 필수적인 다른 뇌 영역에서 세포밖 플라크 및 세포내 매듭. 플라크는 주로 아밀로이드 전구체 단백질(amyloid precursor protein: APP)로부터 유래된 펩타이드인 아밀로이드 β(Aβ)의 침착으로부터 형성된다.
AD의 빈도는 성인 삶의 각 십 년에 따라 증가되며, 85세 이상의 집단에서 20 내지 40%에 이른다. 점점 더 많은 사람들이 80대 및 90대에 생존할 것이기 때문에, 환자 수는 다음 20년에 걸쳐 3배가 될 것으로 예상된다. 미국에서 5 백만명 이상의 사람들이 AD를 겪고 있으며, 해마다 800,000건의 사망이 AD와 관련된다. 2011년에, AD 환자를 돌보는 비용은 전체 1천 8백 3십억 달러가 되는 것으로 추정된다. AD는 또한 가족 구성원 및 간호자에 대해 굉장한 감정적 느끼게 한다: 미국에서 약 1천 4백 9십 만명의 사람이 AD 환자를 돌본다. AD 환자는 진단 후 평균 7 내지 10년 동안 생존하며, 가정에서 또는 요양원에서 보살핌 하에 평균 5년을 소비한다.
조발성 알츠하이머병(Early-onset Alzheimer's disease: EOAD)은 개체가 65세 전에 알츠하이머병으로 진단된 드문 형태의 알츠하이머병이다. 모든 알츠하이머병 환자의 10% 미만은 EOAD를 가진다. EOAD 경우의 대략 절반은 가족성인데, 질병 유전은 상염색체 우성형태에 따른다. 분명한 유전형태가 발견되지 않는 AD 경우는 "산발성"으로 칭해진다. 지금까지, 염색체 21에 대한 아밀로이드 전구체 단백질(amyloid precursor protein: APP), 염색체 14 상의 프리세닐린 1(PSEN1) 및 염색체 1 상의 프리세닐린 2(PSEN2)를 포함하는 3가지 유전자에서 돌연변이는 가족성 EOAD를 지니는 가족에서 확인되었다. APP 및 프리세닐린 유전자에서 대부분의 병원성 돌연변이는 비정상적 APP처리와 관련되는데, 이는 아밀로이드 플라크에서 주된 성분인 Aβ42의 생성에서의 증가를 야기한다.
후발성 알츠하이머병(Late-onset Alzheimer's disease: LOAD)은 약 90%를 차지하고, 보통 65세 후 생기는 가장 흔한 형태의 알츠하이머병이다. LOAD는 85세를 초과하는 모든 개체의 거의 절반에서 발생하며, 전형적으로 산발성이다. 쌍둥이 연구를 기반으로, 질병에 대한 유전율은 79%로 추정되었으며, 출현율 또는 유전율에서 남성과 여성 간의 차이는 없었다(연령에 대한 통제 후)(Gatz, et al., Arch. Gen. Psychiatry, 63:168-74 (2006)). 지금까지 조발성 알츠하이머병과 관련되는 것으로 확인된 단일 유전자 돌연변이는 후발성 알츠하이머병에 연루되는 것으로 보이지 않는다.
후발성 형태의 AD를 야기하는 특이적 유전자는 발견되지 않았지만, 질병이 발생할 사람의 위험을 증가시키는 하나의 유전적 위험인자는 염색체 19에서 발견된 아폴리포단백질 E(apolipoprotein: APOE) 유전자에 관련된다. AD의 조기 유전적 연구는 APOE 유전자를 함유하는 염색체 19 상의 동일 영역에 결합 및 연결을 보여주었다(Schellenberg, et al., J. Neurogenet., 4:97-108 (1987); Pericak-Vance, et al., Am. J. Hum. Gen., 48:1034-1050 (1991)). APOE 유전자는 ε2, ε3 및 ε4로 지정되는 3가지 흔한 대립유전자를 가진다. 보통의 ε3 대립유전자에 비해, ε4 대립유전자는 AD의 위험을 증가시키는 반면, ε2 대립유전자는 AD 위험을 감소시킨다(Corder, et al. (1993) Science, 281:921-923; Corder et al. (1994) Nat. Genet. 7: 180-184). 일반 집단에 대해 85세까지 AD의 수명위험(lifetime risk: LTR)은 11% 내지 14%인 반면, LTR은 APOE 3/4 보유자에 대해 23% 내지 35%로 상승되었고, APOE 4/4 보유자에 대해 51% 내지 68%로 상승되었다(Genin et al. (2011) Molecular Psychiatry 16: 903-907). APOE 2/4 보유자에 대한 AD 위험은 중성 유전자형 APOE 3/3을 갖는 피험체에 대해서와 동일한 반면, APOE 2/3 보유자는 감소된 위험을 가진다. AD 환자의 40% 내지 65%는 APOE-ε4 대립유전자 중 적어도 하나의 복제물을 가지지만, APOE-ε4는 질병의 필요한 결정요인이 아니며, 즉, AD를 지니는 환자의 적어도 1/3은 APOE-ε4 음성이고, 일부 APOE-ε4 동형접합체는 질병이 결코 발생하지 않는다. 따라서, 이 대립유전자는 그 자체가 AD의 진단에 충분하지 않다(Ertekin-Taner (2007) Neurol. Clin. 25: 811).
현재, AD를 진단하는 주된 방법은 상세한 환자 이력을 취하는 단계, 기억 및 심리학적 시험을 실시하는 단계, 및 일시적(예를 들어, 우울증 또는 비타민 B12 결핍증) 또는 영구적(예를 들어, 뇌졸중) 질병을 포함하는 기억상실의 다른 설명을 제외하는 단계를 수반한다. 이 접근 하에, 검시가 환자 뇌에서 질병의 특징적 아밀로이드 플라크 및 신경섬유매듭을 나타낼 때, AD는 사망 후까지 확정적으로 진단될 수 없다. 추가로, 임상적 진단 절차는 환자가 유의하고, 비정상적인 기억 상실 또는 성격 변화를 나타내기 시작한 후에만 도움이 된다. 그때까지, 환자는 수년 동안 AD를 가질 가능성이 있다. 예를 들어 의사가 질병과정에서 조기에 AD를 확인하거나 또는 질병이 진행할 고위험에 있는 개체를 확인하게 할 수 있는 진단 시험은 질병 과정에서 조기 단계에 개입되는 선택사항을 제공할 것이다. 질병 과정에서의 조기 개입은 이후의 개입에 비해 질병 개시 또는 진행을 지연시킴으로써 더 양호한 치료 결과를 초래한다. 따라서, AD를 진단하고, 진단을 보조하는 다른 방법에 대한 필요가 있다.
본 발명은 피험체로부터의 샘플 내 하나 이상의 유전적 변이의 존재 또는 부재를 검출하는 단계를 포함하는, 피험체에서 알츠하이머병(AD)의 진단 및 예후 방법을 제공하되, 유전적 변이의 존재는 피험체가 본 명세서에 개시된 바와 같은 AD로 고통받는지 또는 진행될 위험에 있는지를 나타낸다.
실시형태에서, 본 발명은 APOE-ε4 대립유전자를 갖는 피험체에서 AD 발생에 대해 해로운 또는 유리한 효과를 갖는 유전적 변이체에 대한 스크리닝 방법을 제공하며, 해당 방법은 AD가 없으면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 75세 초과의 대조군 피험체에 비해, AD를 가지면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 65세 미만의 피험체에서 증가되거나 또는 감소된 빈도로 존재하는 유전적 변이체를 확인하는 단계를 포함하되, 대조군 피험체에 비해 AD를 갖는 피험체에서 증가된 빈도는 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 해로운 효과와 관련된다는 것을 나타내며, 대조군 피험체에 비해 AD를 갖는 피험체에서 감소된 빈도는 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 유리한 효과와 관련된다는 것을 나타낸다. 일부 실시형태에서, 유전적 변이는 게놈-와이드(genome-wide) 관련 스캔을 사용하여 확인된다.
본 발명은 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 AD의 발생에 대해 해로운 또는 유리한 효과를 갖는 유전적 변이체에 대한 스크리닝 방법을 추가로 제공하며, 해당 방법은 (a) AD를 가지면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 65세 미만의 다수의 피험체의 하나 이상의 유전자 좌위에서 유전자형을 결정하는 단계; (b) AD가 없으면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 75세 초과의 다수의 대조군 피험체의 하나 이상의 유전자 좌위에서 유전자형을 결정하는 단계; 및 (c) 대조군 피험체에 비해 AD를 갖는 피험체에서 증가되거나 또는 감소된 빈도에서 존재하는 유전적 변이체를 확인하는 단계를 포함하되, 대조군 피험체에 비해 AD를 갖는 피험체에서 증가된 빈도는 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 해로운 효과와 관련된다는 것을 나타내고, 대조군 피험체에 비해 AD를 갖는 피험체에서 감소된 빈도는 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 유리한 효과와 관련된다는 것을 나타낸다.
이들 스크리닝 방법의 일부 실시형태에서, 해로운 효과는 AD가 발생할 증가된 위험이다. 일부 실시형태에서, 해로운 효과는 더 낮은 연령의 AD 개시이다. 일부 실시형태에서, 유리한 효과는 AD가 발생할 감소된 위험이다. 일부 실시형태에서, 유리한 효과는 후발 연령의 AD 개시이다.
실시형태에서, 본 발명은 (a) IL6R, NTF4 및 UNC5C를 암호화하는 유전자 또는 이들의 유전자 산물로부터 선택된 유전자에서 유전적 변이의 존재 또는 부재를 검출할 수 있는 시약과 피험체로부터의 샘플을 접촉시키는 단계; 및 (b) 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하는, 피험체에서 알츠하이머병(AD)을 나타내는 유전적 변이의 존재 또는 부재를 검출하는 방법을 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 발생될 위험에 있다는 것을 나타낸다.
다양한 실시형태에서, 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(single nucleotide polymorphism: SNP), 대립유전자, 단상형, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 SNP이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs2228145에서 'C' 대립유전자이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs121918427에서 'T' 대립유전자이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈에서 G를 A로 치환하는 SNP이다.
다른 실시형태에서, 적어도 하나의 유전적 변이는 아미노산 치환, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 아미노산 치환이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M이다.
해당 방법의 일부 실시형태에서, 시약은 올리고뉴클레오타이드, DNA 프로브, RNA 프로브 및 리보자임으로부터 선택된다. 다른 실시형태에서, 시약은 유전적 변이를 포함하는 단백질에 특이적으로 결합되는 항체이다. 일부 실시형태에서, 시약은 표지된다.
해당 방법의 일부 실시형태에서, 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된다.
실시형태에서, 해당 방법은 단계 (b)의 결과를 기반으로 AD에 대해 피험체를 치료하는 단계를 추가로 포함한다. 실시형태에서, 해당 방법은 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 존재를 검출하는 단계를 추가로 포함한다. 실시형태에서, 적어도 하나의 APOE-ε4 대립유전자의 존재와 함께 적어도 하나의 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 가지고, 적어도 하나의 유전적 변이 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타낸다.
본 발명은 IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자에서 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하는, 피험체에서 알츠하이머병(AD)을 나타내는 유전적 변이를 검출하는 방법을 추가로 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다.
다양한 실시형태에서, 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(SNP), 대립유전자, 단상형, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 SNP이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs2228145에서 'C' 대립유전자이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs121918427에서 'T' 대립유전자이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈에서 G를 A로 치환하는 SNP이다.
다른 실시형태에서, 적어도 하나의 유전적 변이는 아미노산 치환, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 아미노산 치환이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M이다.
해당 방법의 다양한 실시형태에서, 하나 이상의 유전적 변이의 존재 검출은 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 대립유전자-특이적 뉴클레오타이드 포함, 5' 뉴클레아제 분해, 분자 비콘(molecular beacon) 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석, 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행된다. 일부 실시형태에서, 샘플로부터의 핵산은 하나 이상의 유전적 변이의 존재를 결정하기 전에 증폭된다.
해당 방법의 다른 실시형태에서, 단백질 내 하나 이상의 유전적 변이의 존재 검출은 전기영동, 크로마토그래피, 질량 분석법, 단백질 분해, 단백질 시퀀싱, 면역친화도 분석, 또는 이들의 조합으로부터 선택된 공정에 의해 수행된다. 일부 실시형태에서, 샘플로부터의 단백질은 하나 이상의 유전적 변이의 존재를 결정하기 전에 단백질에 결합되는 항체 또는 펩타이드를 사용하여 정제된다.
해당 방법의 일부 실시형태에서, 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된다.
실시형태에서, 해당 방법은 단계 (b)의 결과를 기반으로 AD에 대해 피험체를 치료하는 단계를 추가로 포함한다. 실시형태에서, 해당 방법은 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 존재를 검출하는 단계를 추가로 포함한다. 실시형태에서, 적어도 하나의 APOE-ε4 대립유전자의 존재와 함께 적어도 하나의 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 가지고, 적어도 하나의 유전적 마커의 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타낸다.
본 발명은 (a) IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자에서 유전적 변이의 존재 또는 부재를 검출할 수 있는 시약과 피험체로부터의 샘플을 접촉시키는 단계; 및 (b) 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하는, 피험체에서 AD를 진단하거나 또는 예후하기 위한 방법을 추가로 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다.
다양한 실시형태에서, 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(SNP), 대립유전자, 단상형, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 SNP이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs2228145에서 'C' 대립유전자이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs121918427에서 'T' 대립유전자이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈에서 G를 A로 치환하는 SNP이다.
다른 실시형태에서, 적어도 하나의 유전적 변이는 아미노산 치환, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 아미노산 치환이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M이다.
해당 방법의 일부 실시형태에서, 시약은 올리고뉴클레오타이드, DNA 프로브, RNA 프로브 및 리보자임으로부터 선택된다. 다른 실시형태에서, 시약은 유전적 변이를 포함하는 단백질에 특이적으로 결합되는 항체이다. 일부 실시형태에서, 시약은 표지된다.
해당 방법의 일부 실시형태에서, 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된다.
실시형태에서, 해당 방법은 단계 (b)의 결과를 기반으로 AD에 대해 피험체를 치료하는 단계를 추가로 포함한다. 실시형태에서, 해당 방법은 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 존재를 검출하는 단계를 추가로 포함한다. 실시형태에서, 적어도 하나의 APOE-ε4 대립유전자의 존재와 함께 적어도 하나의 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 갖고, 적어도 하나의 유전적 마커의 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타낸다.
일부 실시형태에서, 해당 방법은 하나 이상의 추가적인 유전적 마커를 스크리닝하는 단계, 정신상태 검사를 실시하는 단계 또는 피험체에 영상화 절차를 실시하는 단계로 이루어진 군으로부터 선택된 AD에 대한 하나 이상의 추가적인 진단 시험을 피험체에 실시하는 단계를 추가로 포함한다.
일부 실시형태에서, 해당 방법은 샘플을 분석하여 APOE 변형제인 적어도 하나의 추가적인 유전적 마커의 존재를 검출하는 단계를 추가로 포함하되, 적어도 하나의 추가적인 유전적 마커는 IL6R을 암호화하는 유전자, NTF4를 암호화하는 유전자, UNC5C를 암호화하는 유전자, 및 표 3에 열거된 유전자로부터 선택된 유전자이다. 다양한 실시형태에서, 적어도 하나의 추가적인 유전적 마커는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP, NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W을 초래하는 SNP, UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835W을 초래하는 SNP, 또는 표 3에 열거된 SNP이다.
본 발명은 피험체로부터의 생물학적 샘플에서 IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자에서 유전자 변이의 존재 또는 부재를 결정하는 단계를 포함하는, 피험체에서 AD를 진단하거나 또는 예후하기 위한 방법을 추가로 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다.
다양한 실시형태에서, 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(SNP), 대립유전자, 단상형, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 SNP이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A을 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs2228145에서 'C' 대립유전자이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W을 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs121918427에서 'T' 대립유전자이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈에서 G를 A로 치환하는 SNP이다.
다른 실시형태에서, 적어도 하나의 유전적 변이는 아미노산 치환, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 아미노산 치환이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M이다.
해당 방법의 다양한 실시형태에서, 하나 이상의 유전적 변이의 존재 검출은 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 대립유전자-특이적 뉴클레오타이드 포함, 5' 뉴클레아제 분해, 분자 비콘 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석, 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행된다. 일부 실시형태에서, 샘플로부터의 핵산은 하나 이상의 유전적 변이의 존재를 결정하기 전에 증폭된다.
해당 방법의 다른 실시형태에서, 단백질 내 하나 이상의 유전적 변이의 존재 검출은 전기영동, 크로마토그래피, 질량 분석법, 단백질 분해, 단백질 시퀀싱, 면역친화도 분석, 또는 이들의 조합으로부터 선택된 과정에 의해 수행된다. 일부 실시형태에서, 샘플로부터의 단백질은 하나 이상의 유전적 변이의 존재를 결정하기 전에 단백질과 결합되는 항체 또는 펩타이드를 사용하여 정제된다.
해당 방법의 일부 실시형태에서, 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된다.
실시형태에서, 해당 방법은 단계 (b)의 결과를 기반으로 AD에 대한 피험체를 치료하는 단계를 추가로 포함한다. 실시형태에서, 해당 방법은 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 존재를 검출하는 단계를 추가로 포함한다. 실시형태에서, 적어도 하나의 APOE-ε4 대립유전자의 존재와 함께 적어도 하나의 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 가지고, 적어도 하나의 유전적 마커의 존재를 결여하는 피험체에 비해, 더 조기 연령의 AD 진단의 증가된 위험을 나타낸다.
일부 실시형태에서, 해당 방법은 APOE 변형제인 적어도 하나의 추가적인 유전적 마커의 존재를 검출하기 위한 샘플을 분석하는 단계를 추가로 포함하되, 적어도 하나의 추가적인 유전적 마커는 IL6R을 암호화하는 유전자, NTF4를 암호화하는 유전자, UNC5C를 암호화하는 유전자, 및 표 3에 열거된 유전자로부터 선택된 유전자이다. 다양한 실시형태에서, 적어도 하나의 추가적인 유전적 마커는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP, NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP, UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835W를 초래하는 SNP, 또는 표 3에 열거된 SNP이다.
본 발명은 (a) 피험체로부터의 생물학적 샘플에서 IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 결정하는 단계; 및 (b) 적어도 하나의 APOE-ε4 대립유전자의 존재 또는 부재를 결정하는 단계를 포함하는 더 조기 연령의 AD의 개시의 증가된 위험을 갖는 피험체를 확인하는 방법을 추가로 제공하되, 유전적 변이 및 적어도 하나의 APOE-ε4 대립유전자의 존재는 피험체가 유전적 변이 및 적어도 하나의 APOE-ε4 대립유전자의 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 가진다는 것을 나타낸다.
다양한 실시형태에서, 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(SNP), 대립유전자, 단상형, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 SNP이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs2228145에서 'C' 대립유전자이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 rs121918427에서 'T' 대립유전자이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP이다. 추가 실시형태에서, 유전적 변이는 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈에서 G를 A로 치환하는 SNP이다.
다른 실시형태에서, 적어도 하나의 유전적 변이는 아미노산 치환, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 아미노산 치환이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2) 내 아미노산 치환 R206W이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3) 내 아미노산 치환 T835M이다.
해당 방법의 다양한 실시형태에서, 하나 이상의 유전적 변이의 존재 검출은 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 대립유전자-특이적 뉴클레오타이드 포함, 5' 뉴클레아제 분해, 분자 비콘 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행된다. 일부 실시형태에서, 샘플로부터의 핵산은 하나 이상의 유전적 변이의 존재를 결정하기 전에 증폭된다.
해당 방법의 다른 실시형태에서, 단백질 내 하나 이상의 유전적 변이의 존재 검출은 전기영동, 크로마토그래피, 질량 분석법, 단백질 분해, 단백질 시퀀싱, 면역친화도 분석, 또는 이들의 조합으로부터 선택된 과정에 의해 수행된다. 일부 실시형태에서, 샘플로부터의 단백질은 하나 이상의 유전적 변이의 존재를 결정하기 전에 단백질과 결합되는 항체 또는 펩타이드를 사용하여 정제된다.
해당 방법의 일부 실시형태에서, 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된다.
본 발명은 피험체에서 AD의 하위표현형의 진단을 보조하는 방법을 추가로 제공하며, 해당 방법은 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP의 존재를 피험체로부터 유래된 생물학적 샘플에서 검출하는 단계를 포함하되, AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 가용성 IL6R의 증가된 수준을 특징으로 한다.
본 발명은 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP를 피험체로부터 얻은 생물학적 샘플에서 검출하는 단계를 포함하는, IL6R을 표적화하는 AD 치료제에 대한 피험체의 반응을 예측하는 방법을 추가로 제공하되, SNP의 존재는 IL6R을 표적화하는 치료제에 대한 반응을 표시한다. 실시형태에서, 치료제는 항-IL6R 항체이다.
본 발명은 피험체에서 AD의 하위표현형의 진단을 보조하는 방법을 추가로 제공하며, 해당 방법은 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP의 존재를 피험체로부터 유래된 생물학적 샘플에서 검출하는 단계를 포함하되, AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 TrkB의 감소된 활성화를 특징으로 한다.
본 발명은 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP를 피험체로부터 얻은 생물학적 샘플에서 검출하는 단계를 포함하는, TrkB를 표적화하는 AD 치료제에 대한 피험체의 반응을 예측하는 방법을 추가로 제공하되, SNP의 존재는 TrkB를 표적화하는 치료제에 대한 반응을 나타낸다. 실시형태에서, 치료제는 TrkB 작용물질이다.
본 발명은 피험체에서 AD의 하위표현형의 진단을 보조하는 방법을 추가로 제공하며, 해당 방법은 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP의 존재를 피험체로부터 유래된 생물학적 샘플에서 검출하는 단계를 포함하되, AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 UNC5C의 아포토시스 활성을 특징으로 한다.
본 발명은 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP를 피험체로부터 얻은 생물학적 샘플에서 검출하는 단계를 포함하는, UNC5C를 표적화하는 AD 치료제에 대한 피험체의 반응을 예측하는 방법을 추가로 제공하되, SNP의 존재는 UNC5C를 표적화하는 치료제에 대한 반응을 나타낸다. 실시형태에서, 치료제는 UNC5C 죽음 도메인을 표적화한다.
본 발명은 (a) IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP, NTF4의 아미노산 서열에서 아미노산 치환 R206W를 초래하는 SNP, 및 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP로 이루어진 군으로부터 선택된 하나 이상의 SNP의 존재 또는 부재를 검출할 수 있는 시약과 피험체로부터의 샘플을 접촉시키는 단계, 및 (b) 상기 하나 이상의 SNP의 존재를 검출하기 위한 샘플을 분석하는 단계를 포함하는, 피험체에서 알츠하이머병(AD)의 진단 또는 예후 방법을 추가로 제공하되, 샘플 내 하나 이상의 SNP의 존재는 피험체가 AD로 고통받거나 또는 AD가 발생될 위험에 있다는 것을 나타낸다. 실시형태에서, 해당 방법은 표 3에 열거된 SNP로부터 선택된 하나 이상의 SNP를 검출하는 단계를 추가로 포함한다.
본 발명은 적어도 하나의 올리고뉴클레오타이드 검출 시약을 포함하는, 해당 방법을 수행하기 위한 키트를 제공하되, 올리고뉴클레오타이드 검출 시약은 하나 이상의 SNP에서 적어도 2종의 상이한 대립유전자의 각각을 구별한다. 다양한 실시형태에서, 검출 단계는 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 시퀀싱, 5' 뉴클레아제 분해, 분자 비콘 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행된다.
실시형태에서, 올리고뉴클레오타이드 검출 시약은 기판에 고정된다. 추가 실시형태에서, 올리고뉴클레오타이드 검출 시약은 어레이 상에 배열된다.
본 발명은 (a) IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A, NTF4의 아미노산 서열에서 아미노산 치환 R206W 및 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M으로 이루어진 군으로부터 선택된 하나 이상의 아미노산 치환의 존재 또는 부재를 검출할 수 있는 시약과 피험체로부터의 샘플을 접촉시키는 단계, 및 (b) 상기 하나 이상의 아미노산 치환의 존재를 검출하기 위한 샘플을 분석하는 단계를 포함하는, 피험체에서 알츠하이머병(AD)의 진단 또는 예후 방법을 추가로 제공하되, 샘플 내 하나 이상의 아미노산 치환의 존재는 피험체가 AD로 고통받거나 또는 AD가 발생될 위험에 있다는 것을 나타낸다.
본 발명은 적어도 하나의 항체 검출 시약을 포함하는, 해당 방법에 의해 수행을 위한 키트를 추가로 제공하되, 항체 검출 시약은 하나 이상의 아미노산 치환에서 적어도 2종의 상이한 아미노산의 각각을 구별한다. 본 발명은 적어도 하나의 펩타이드 검출 시약을 포함하는, 해당 방법에 의해 수행을 위한 키트를 추가로 제공하되, 펩타이드 검출 시약은 하나 이상의 아미노산 치환에서 적어도 2종의 상이한 아미노산의 각각을 구별한다.
본 발명은 AD의 치료를 위한 치료적 표적을 추가로 제공하되, 치료적 표적은 IL6R, NTF4 및 UNC5C로부터 선택된 유전자에 의해 암호화된 단백질 중 하나 또는 조합이다.
본 발명은 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP, NTF4의 아미노산 서열에서 아미노산 치환 R206W를 초래하는 SNP, 및 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP를 포함하는 군으로부터 선택된 적어도 2종의 마커에서 직접적으로 또는 간접적으로 검출할 수 있는 적어도 2개의 프로브를 포함하는 AD의 진단 또는 예후를 위한 분자 프로브의 세트를 추가로 제공하되, 상기 분자 프로브는 1000개 초과의 구성요소의 마이크로어레이와 결합되지 않는다. 실시형태에서, 분자 프로브의 세트는 표 3에 열거된 SNP로부터 선택된 적어도 2종의 마커에서 직접적으로 또는 간접적으로 검출할 수 있는 하나 이상의 프로브를 추가로 포함한다.
도 1은 APOE 변형제 스크린에서 사용되는 전략을 도시하는 도면.
도 2는 상위 대조군에 대한 AD 사례 샘플에서 유전적 변이체 간의 통계적으로 유의한 차이가 있는 경우 인간 염색체 1의 부분을 가로지르는 위치를 나타내는 맨해튼(Manhattan) 플롯을 도시한 도면. p-값이 낮을수록, 관계는 더 강하다.
도 3은 NIA/LOAD 연구로부터의 미선택 알츠하이머병 사례(N = 932 개체) 및 대조군(N = 832 개체)에서 rs4129267의 T 대립유전자, rs2228145의 C 대립유전자의 프록시의 빈도를 도시한 도면. 부수적 대립유전자의 빈도는 AD 사례에서 개시 연령 및 대조군에서의 연령에 의해 계층화된다.
도 4는 TGEN 프로젝트(Webster et al. (2009) Am. J. Hum. Genet. 84: 445-458)로부터의 데이터 분석을 도시한 도면. AD(AD)를 지니는 피험체의 뇌에서 결합된 막과 가용성 IL6R의 발현 수준을 IL6R의 막 결합형태만을 검출하는 프로브(NM_000565) 또는 막 결합과 sIL6R을 둘 다 포획하는 프로브(NM_181359) 중 하나를 사용하여, 대조군(CN)과 비교하였다.
도 5는 LO1 가계도에서 비모수 결합 분석 결과를 도시한 도면.
도 6은 아미노산 잔기 T853의 보존을 나타내는, UNC5 패밀리 구성원의 아미노산 배열의 제공을 도시한 도면.
도 7은 뇌척수액에서 유전적 변이체와 가용성 IL6R의 수준 사이의 통계적으로 유의한 관계가 있는 경우, 인간 염색체 1의 일부를 가로지르는 위치를 나타내는 맨해튼 플롯을 도시한 도면. p-값이 낮을수록, 관계는 더 강하다.
도 8은 IL6R의 D358 또는 A358 작제물로 형질감염되고, 0, 30, 60 또는 120분 동안 100nM 포볼 미리스테이트 아세테이트(phorbol myristate acetate: PMA)로 처리한 293T 세포에서 IL6R의 상대적 막 결합 백분율을 도시한 도면. 세포를 치료 후 채취하였고, IL6R-PE 항체로 염색하였으며, 막 결합 IL6R을 FACS에 의해 분석하였다.
도 9는 60분 동안 100nM PMA으로 처리 전 및 처리 후 D358 또는 A358 중 하나에 대해 동형접합적인 연령, 성별 및 인종적으로 매칭된 공여체로부터의 CD4+ T 세포에서 막 결합 IL6R의 백분율을 도시한 도면. 세포를 처리 후 곧 채취하였고, IL6R-PE 항체로 염색하였으며, 막 결합 IL6R을 FACS에 의해 분석하였다.
도 10은 D358 또는 A358 중 하나에 대해 동형접합적인 연령, 성별 및 인종적으로 매칭된 공여체로부터 인간 CD4+ T 세포에 대한 가용성 IL6R을 도시한 도면. CD4+ T 세포를 항-CD3/항-CD28 상에 플레이팅하였고, 전체 RNA 추출을 위해 24, 48 및 72시간 후 채취하였으며, 상청액을 수집하여 ELISA에 의한 sIL6R 수준을 결정하였다. 그래프는 각 시점에 D358에 대해 A358에 대한 가용성 IL6R에서 폴딩 증가를 나타낸다.
도 2는 상위 대조군에 대한 AD 사례 샘플에서 유전적 변이체 간의 통계적으로 유의한 차이가 있는 경우 인간 염색체 1의 부분을 가로지르는 위치를 나타내는 맨해튼(Manhattan) 플롯을 도시한 도면. p-값이 낮을수록, 관계는 더 강하다.
도 3은 NIA/LOAD 연구로부터의 미선택 알츠하이머병 사례(N = 932 개체) 및 대조군(N = 832 개체)에서 rs4129267의 T 대립유전자, rs2228145의 C 대립유전자의 프록시의 빈도를 도시한 도면. 부수적 대립유전자의 빈도는 AD 사례에서 개시 연령 및 대조군에서의 연령에 의해 계층화된다.
도 4는 TGEN 프로젝트(Webster et al. (2009) Am. J. Hum. Genet. 84: 445-458)로부터의 데이터 분석을 도시한 도면. AD(AD)를 지니는 피험체의 뇌에서 결합된 막과 가용성 IL6R의 발현 수준을 IL6R의 막 결합형태만을 검출하는 프로브(NM_000565) 또는 막 결합과 sIL6R을 둘 다 포획하는 프로브(NM_181359) 중 하나를 사용하여, 대조군(CN)과 비교하였다.
도 5는 LO1 가계도에서 비모수 결합 분석 결과를 도시한 도면.
도 6은 아미노산 잔기 T853의 보존을 나타내는, UNC5 패밀리 구성원의 아미노산 배열의 제공을 도시한 도면.
도 7은 뇌척수액에서 유전적 변이체와 가용성 IL6R의 수준 사이의 통계적으로 유의한 관계가 있는 경우, 인간 염색체 1의 일부를 가로지르는 위치를 나타내는 맨해튼 플롯을 도시한 도면. p-값이 낮을수록, 관계는 더 강하다.
도 8은 IL6R의 D358 또는 A358 작제물로 형질감염되고, 0, 30, 60 또는 120분 동안 100nM 포볼 미리스테이트 아세테이트(phorbol myristate acetate: PMA)로 처리한 293T 세포에서 IL6R의 상대적 막 결합 백분율을 도시한 도면. 세포를 치료 후 채취하였고, IL6R-PE 항체로 염색하였으며, 막 결합 IL6R을 FACS에 의해 분석하였다.
도 9는 60분 동안 100nM PMA으로 처리 전 및 처리 후 D358 또는 A358 중 하나에 대해 동형접합적인 연령, 성별 및 인종적으로 매칭된 공여체로부터의 CD4+ T 세포에서 막 결합 IL6R의 백분율을 도시한 도면. 세포를 처리 후 곧 채취하였고, IL6R-PE 항체로 염색하였으며, 막 결합 IL6R을 FACS에 의해 분석하였다.
도 10은 D358 또는 A358 중 하나에 대해 동형접합적인 연령, 성별 및 인종적으로 매칭된 공여체로부터 인간 CD4+ T 세포에 대한 가용성 IL6R을 도시한 도면. CD4+ T 세포를 항-CD3/항-CD28 상에 플레이팅하였고, 전체 RNA 추출을 위해 24, 48 및 72시간 후 채취하였으며, 상청액을 수집하여 ELISA에 의한 sIL6R 수준을 결정하였다. 그래프는 각 시점에 D358에 대해 A358에 대한 가용성 IL6R에서 폴딩 증가를 나타낸다.
정의
본 명세서에서 상호호환적으로 사용되는 용어 "폴리뉴클레오타이드" 또는 "핵산"은 임의의 길이의 뉴클레오타이드의 중합체를 지칭하며, DNA 및 RNA를 포함한다. 뉴클레오타이드는 데옥시리보뉴클레오타이드, 리보뉴클레오타이드, 변형된 뉴클레오타이드 또는 염기, 및/또는 이들의 유사체 또는 DNA 또는 RNA 폴리머라제에 의해 중합체 내로 포함될 수 있는 임의의 기질일 수 있다. 폴리뉴클레오타이드는 변형된 뉴클레오타이드, 예컨대 메틸화된 뉴클레오타이드 및 그것의 유사체를 포함할 수 있다. 존재한다면, 뉴클레오타이드 구조에 대한 변형은 중합체의 조립 전 또는 후에 부여될 수 있다. 뉴클레오타이드의 서열은 비뉴클레오타이드 성분에 의해 방해된다. 폴리뉴클레오타이드는 중합 후, 예컨대 표지 성분과 컨쥬게이션에 의해 추가로 변형될 수 있다. 다른 유형의 변형은, 예를 들어 "캡", 자연적으로 생기는 뉴클레오타이드 중 하나 이상의 유사체로 치환, 예를 들어 비하전 결합(예를 들어, 메틸 포스포네이트, 포스포트라이에스터, 포스포아미데이트, 카바메이트 등) 및 하전 결합(예를 들어, 포스포로티오에이트, 포스포로다이티오에이트 등)을 지니는 것, 예를 들어 단백질(예를 들어, 뉴클레아제, 독소, 항체, 신호 펩타이드, 폴리-L-리신 등)과 같은 현수 모이어티를 함유하는 것, 삽입제(예를 들어, 아크리딘, 프소랄렌 등)를 지니는 것, 킬레이터를 함유하는 것(예를 들어, 금속, 방사성 금속, 붕소, 산화적 금속 등), 알킬화제를 함유하는 것, 변형된 결합(예를 들어, 알파 아노머 핵산 등)을 지니는 것과 같은 뉴클레오타이드간 변형뿐만 아니라 미변형된 형태의 폴리뉴클레오타이드(들)를 포함한다. 추가로, 보통 당에 존재하는 하이드록실기 중 어떤 것은, 예를 들어 추가적인 뉴클레오타이드에 추가적인 연결을 제공하도록 표준 보호기에 의해 보호되거나 활성화된 포스포네이트기, 포스페이트기로 대체될 수 있거나, 또는 고체 지지체에 컨쥬게이트될 수 있다. 5' 및 3' 말단 OH는 아민 또는 1 내지 20개의 탄소 원자로부터의 유기 캡핑 모이어티로 치환되거나 또는 포스포릴화될 수 있다. 다른 하이드록실은 또한 표준 보호기로 유도체화될 수 있다. 폴리뉴클레오타이드는 또한, 예를 들어, 2'-O-메틸-2'-O-알릴, 2'-플루오로- 또는 2'-아지도-리보스, 카보사이클릭 당 유사체, .알파.-아노머당, 에피머 당, 예컨대 아라비노스, 자일로스 또는 릭소스, 피라노스 당, 푸라노스 당, 세도펩툴로스, 아크릴 유사체 및 비염기성 뉴클레오사이드 유사체, 예컨대 메틸 리보사이드를 포함하는 당업계에 일반적으로 공지된 리보스 또는 데옥시리보스 당의 유사한 형태를 함유할 수 있다. 하나 이상의 포스포다이에스터 결합은 대안의 연결기에 의해 대체될 수 있다. 이들 대안의 연결기는 실시형태를 포함하지만, 이들로 제한되지 않으며, 포스페이트는 P(O)S("티오에이트"), P(S)S("다이티오에이트"), "(O)NR2("아미데이트"), P(O)R, P(O)OR', CO 또는 CH2("포름아세탈")에 의해 대체되며, 이때 각각의 R 또는 R'는 독립적으로 에터(--O--) 결합, 아릴, 알케닐, 사이클로알킬, 사이클로알케닐 또는 아랄딜을 선택적으로 함유하는 치환된 또는 미치환된 알킬(1-20C) 또는 H이다. 필요한 폴리뉴클레오타이드 내 모든 결합이 동일하지는 않다. 앞서 언급한 설명은 RNA 및 DNA를 포함하는 본 명세서에서 지칭되는 모든 폴리뉴클레오타이드에 적용된다.
본 명세서에 사용되는 바와 같은 "올리고뉴클레오타이드"는 길이로 적어도 약 7개 뉴클레오타이드 및 길이로 약 250개 미만의 뉴클레오타이드인 짧은, 단일 가닥 폴리뉴클레오타이드를 지칭한다. 올리고뉴클레오타이드는 합성일 수 있다. 용어 "올리고뉴클레오타이드" 및 "폴리뉴클레오타이드"는 상호 간에 배타적이지 않다. 폴리뉴클레오타이드에 대한 상기 기재는 올리고뉴클레오타이드에 대해 동일하고 완전하다.
용어 "프라이머"는 일반적으로 유리 3'--OH를 제공함으로써 핵산에 혼성화될 수 있고, 상보적 핵산을 중합할 수 있게 하는 단일 가닥 폴리뉴클레오타이드를 지칭한다.
본 명세서에서 사용되는 바와 같은 용어 "유전자"는 특이적 펩타이드, 폴리펩타이드 또는 단백질의 아미노산 특징의 서열을 DNA 주형 또는 메신저 RNA를 통해 암호화하는 DNA 서열을 지칭한다. 용어 "유전자"는 또한 RNA 산물을 암호화하는 DNA 서열을 지칭한다. 게놈 DNA와 관련하여 본 명세서에서 사용되는 용어 유전자는 개재, 비암호 영역뿐만 아니라 조절 영역을 포함하고, 5' 및 3' 말단을 포함할 수 있다.
용어 "유전적 변이" 또는 "뉴클레오타이드 변이"는 기준 서열(예를 들어, 보통 발견된/되거나 야생형 서열, 및/또는 주요 대립유전자의 서열)에 대해 뉴클레오타이드 서열에서의 변화(예를 들어, 하나 이상의 뉴클레오타이드의 삽입, 결실, 역위, 또는 치환, 예컨대 단일 뉴클레오타이드 다형성(SNP)의 변화를 지칭한다. 용어는 또한 달리 표시되지 않는다면, 뉴클레오타이드 서열의 보체의 대응되는 변화를 포함한다. 일 실시형태에서, 유전적 변이는 체세포 다형성이다. 일 실시형태에서, 유전적 변이는 생식계열 다형성이다.
"단일 뉴클레오타이드 다형성" 또는 "SNP"는 상이한 대립유전자 또는 대안의 뉴클레오타이드가 집단 내에 존재하는 DNA에서 단일 염기 위치를 지칭한다. SNP 위치는 보통 앞에 있으며, 뒤에 고도로 보존된 대립유전자의 서열(예를 들어 집단 구성원의 1/100 또는 1/1000 미만으로 다른 서열)이 있다. 개개는 각 SNP 위치에서 대립유전자에 대해 동형접합적 또는 이형접합적일 수 있다.
용어 "아미노산 변이"는 기준 서열에 대한 아미노산 서열 내 변화(예를 들어, 하나 이상의 아미노산 삽입, 치환, 또는 결실, 예컨대 내부 결실 또는 N- 또는 C-말단 절단)를 지칭한다.
용어 "변이"는 뉴클레오타이드 변이 또는 아미노산 변이를 지칭한다.
용어 "SNP에 대응되는 뉴클레오타이드 위치에서 유전적 변이", "SNP에 대응되는 뉴클레오타이드 위치에서 뉴클레오타이드 변이" 및 이들의 문법적 변형은 게놈 내 상기 SNP에 의해 점유되는 상대적인 대응되는 DNA에서 폴리뉴클레오타이드 서열 내 뉴클레오타이드 변이를 지칭한다. 용어는 또한 달리 표시되지 않는다면, 뉴클레오타이드 서열의 보체에서 대응되는 변이를 포함한다.
본 명세서에 사용되는 바와 같은 용어 "대립유전자"는 염색체 내 주어진 좌위에서 생기는 유전자 또는 비유전자 영역 형태의 쌍 또는 계열 중 하나를 지칭한다. 정상 2배체 세포에서, 상동 염색체 상에서 동일한 상대적 위치(좌위)를 점유하는 어느 하나의 유전자 중 2개의 대립유전자가 있다(각 모체로부터 하나). 집단 내에서, 2개 초과의 대립유전자의 유전자가 있을 수 있다. SNP는 또한 대립유전자, 즉, SNP를 특성규명하는 2(이상의) 뉴클레오타이드를 가진다.
본 명세서에 사용되는 바와 같은 용어 "연관불평형" 또는 "LD"는 2 이상의 좌위에 대한 대립유전자가 그것의 개개 대립유전자 빈도의 산물에 의해 예측된 빈도에서 집단으로부터 샘플링된 개체에서 함께 생기지 않는 상황을 지칭한다. LD에 있는 마커는 독립적 무작위 분리의 멘델의 제2 법칙을 따르지 않는다. LD는 몇몇 인구통계학적 또는 집단적 인공산물 중 어떤 것에 의할 뿐만 아니라 마커 간 유전적 결합의 존재에 의해 야기될 수 있다. 그러나, 이들 인공산물은 LD의 공급원으로서 제어되고, 제거된 다음, 관련된 좌위가 동일 염색체 상에서 서로 가깝게 위치되고, 따라서 상이한 마커(단상형)에 대한 대립 유전자의 특이적 조합이 함께 유전된다는 사실로부터 직접적으로 초래된다. 높은 LD에 있는 마커는 서로 가깝게 위치되는 것으로 추정될 수 있으며, 유전적 특성을 지니는 높은 LD에 있는 마커 또는 단상형은 해당 특성에 영향을 미치는 유전자 근처에 위치되는 것으로 추정될 수 있다.
본 명세서에 사용되는 바와 같은 용어 "좌위"는 염색체 또는 DNA 서열을 따라 특이적 위치를 지칭한다. 내용에 따라서, 좌위는 하나 이상의 뉴클레오타이드의 유전자, 마커, 염색체 밴드 또는 특이적 서열일 수 있었다.
용어 "어레이" 또는 "마이크로어레이"는 기판 상의 혼성가능한 어레이 구성요소, 바람직하게는 폴리뉴클레오타이드 프로브(예를 들어, 올리고뉴클레오타이드)의 정돈된 배열을 지칭한다. 기판은 고체 기판, 예컨대 유리 슬라이드 또는 반고체 기판, 예컨대 나이트로셀룰로스 막일 수 있다.
용어 "증폭"은 기준 핵산 서열 또는 그것의 보체의 하나 이상의 복제물을 생성하는 과정을 지칭한다. 증폭은 선형 또는 기하급수적일 수 있다(예를 들어, 폴리머라제 연쇄 반응(polymerase chain reaction: PCR)). "복제물"은 주형 서열에 대한 완전한 서열 상보성 또는 동일성을 반드시 의미하지는 않는다. 예를 들어, 복제물은 뉴클레오타이드 유사체, 예컨대 데옥시이노신, 의도적 서열 변경(예컨대 혼성화가능하지만, 주형에 대해 완전히 상보적이지 않은 서열을 포함하는 프라이머를 통해 도입된 서열 변경) 및/또는 증폭 동안 생기는 서열 오류를 포함할 수 있다.
용어 "대립유전자-특이적 올리고뉴클레오타이드"는 뉴클레오타이드 변이(종종 치환)를 포함하는 표적 핵산의 영역에 혼성화되는 올리고뉴클레오타이드를 지칭한다. "대립유전자-특이적 혼성화"는 대립유전자-특이적 올리고뉴클레오타이드가 그것의 표적 핵산에 혼성화될 때, 대립유전자-특이적 올리고뉴클레오타이드 내 뉴클레오타이드가 뉴클레오타이드 변이를 지니는 염기쌍에 특이적으로 결합되는 것을 의미한다. 특정 뉴클레오타이드 변이에 대해 대립유전자-특이적 혼성화될 수 있는 대립유전자-특이적 올리고뉴클레오타이드는 해당 변이"에 대해 특이적"인 것으로 언급된다.
용어 "대립유전자-특이적 프라이머"는 프라이머인 대립유전자-특이적 올리고뉴클레오타이드를 지칭한다.
용어 "프라이머 신장 분석"은 뉴클레오타이드가 핵산에 첨가되고, 직접적으로 또는 간접적으로 검출되는 더 긴 핵산 또는 "신장 산물"을 초래하는 분석을 지칭한다. 뉴클레오타이드는 핵산의 5' 또는 3' 말단을 신장시키도록 첨가될 수 있다.
용어 "대립유전자-특이적 뉴클레오타이드 포함 분석"은 프라이머가 (a) 뉴클레오타이드 변이의 3' 또는 5'인 영역에서 표적 핵산에 혼성화되고, (b) 폴리머라제에 의해 신장됨으로써 뉴클레오타이드 변이에 상보적인 뉴클레오타이드인 신장 산물 내로 포함되는 프라이머 신장 분석을 지칭한다.
용어 "대립유전자-특이적 프라이머 신장 분석"은 대립유전자-특이적 프라이머가 표적 핵산에 혼성화되고, 신장되는 프라이머 신장 분석을 지칭한다.
용어 "대립유전자-특이적 올리고뉴클레오타이드 혼성화 분석"은 (a) 대립유전자-특이적 올리고뉴클레오타이드가 표적 핵산에 혼성화되고, (b) 혼성화가 직접적으로 또는 간접적으로 검출되는 분석을 지칭한다.
용어 "5' 뉴클레아제 분석"은 표적 핵산에 대한 대립유전자-특이적 올리고뉴클레오타이드의 혼성화가 혼성화된 프로브를 핵산분해적으로 절단시키고, 검출가능한 신호를 야기하는 분석을 지칭한다.
용어 "분자 비콘을 사용하는 분석"은 표적 핵산에 대한 대립유전자-특이적 올리고뉴클레오타이드의 혼성화가 유리 올리고뉴클레오타이드에 의해 방출되는 검출가능한 신호 수준보다 더 높은 검출가능한 신호 수준을 야기하는 분석을 지칭한다.
용어 "올리고뉴클레오타이드 결찰 분석"은 대립유전자-특이적 올리고뉴클레오타이드 및 제2 올리고뉴클레오타이드가 표적 핵산 상에서 서로 인접하게 혼성화되고 함께 결찰되며(개재 뉴클레오타이드를 통해 직접적으로 또는 간접적으로), 결찰 산물이 직접적으로 또는 간접적으로 검출되는 분석을 지칭한다.
용어 "표적 서열", "표적 핵산" 또는 "표적 핵산 서열"은 일반적으로, 증폭에 의해 만들어진 이러한 표적 핵산의 복제물을 포함하는 뉴클레오타이드 변이가 의심되거나 또는 존재하는 것으로 알려진 관심 대상의 폴리뉴클레오타이드 서열을 지칭한다.
용어 "검출"은 직접적 및 간접적 검출을 포함하는 어떤 검출 수단을 포함한다.
용어 "IL6R"은 인터류킨-6 수용체를 지칭하기 위해 사용되며, 또한 IL-6R1, IL-6RA, IL-6R 알파, 인터류킨-6 수용체 서브유닛 알파, 및 CD126으로서 알려져 있다. 용어 "전장"은 미처리 IL6R뿐만 아니라 세포 내 처리로부터 초래되는 어떤 IL6R 형태를 포함한다. 용어는 또한 IL6R의 자연적으로 생기는 변이체, 예를 들어 스플라이스 변이체 또는 대립유전자 변이체를 포함한다. 예시적인 인간 IL6R의 아미노산 서열은 서열번호 1에 나타낸다:

용어 "NTF4"는 또한 뉴로트로핀 5, 뉴로트로핀 인자 4, 뉴로트로핀 인자 5, NT4, NT5, NT-4, NT-5, NTF5, GLC10 및 NT-4/5로서 알려진 뉴로트로핀 4를 지칭하기 위해 사용된다. 해당 용어는 "전장", 미처리 NTF4뿐만 아니라 세포 내 처리로부터 초래되는 NTF4의 임의의 형태를 포함한다. 해당 용어는 또한 NTF4의 자연적으로 생기는 변이체, 예를 들어 스플라이스 변이체 또는 대립유전자 변이체를 포함한다. 예시적인 인간 NTF4의 아미노산 서열은 서열번호 2에 나타낸다:

용어 "UNC5C"는 또한 UNC-5 상동체 3, UNC-5 상동체 C, 및 UNC5H3으로서 알려진 네트린 수용체 UNC5C를 지칭하기 위해 사용된다. 해당 용어는 "전장" 미처리 UNC5C뿐만 아니라 세포 내 처리로부터 초래되는 UNC5C의 어떤 형태를 포함한다. 해당 용어는 또한 UNC5C의 자연적으로 생기는 변이체, 예를 들어 스플라이스 변이체 또는 대립유전자 변이체를 포함한다. 예시적인 인간 UNC5C의 아미노산 서열은 서열번호 3에 나타낸다:

본 명세서에 사용되는 바와 같은 용어 "알츠하이머병"(AD)은 조발성 AD와 후발성 AD 둘 다뿐만 아니라, 가족성과 산발성 형태의 AD를 지칭한다.
본 명세서에 사용되는 바와 같은 알츠하이머병이 발생할 "위험에 있는" 피험체는 검출가능한 질병 또는 질병 증상을 가질 수도 있고, 가지지 않을 수도 있으며, 본 명세서에 기재된 치료 방법 전에 검출가능한 질병 또는 질병의 증상을 나타낼 수도 있거나 또는 나타내지 않을 수도 있다. "위험에 있는"은 본 명세서에 기재되고 당업계에 공지된 바와 같은 알츠하이머병의 진행과 관련된 측정가능한 변수인 피험체가 하나 이상의 위험 인자를 가지는 것을 의미한다. 이들 위험 인자 중 하나 이상을 갖는 피험체는 이들 위험 인자(들) 중 하나 이상이 없는 피험체보다 알츠하이머병이 진행될 더 높은 가능성을 가진다.
용어 "진단"은 분자적 또는 병리학적 상태, 질병 또는 질환, 예를 들어 AD의 확인 또는 분류를 지칭하기 위해 본 명세서에서 사용된다. "진단"은 또한, 예를 들어 분자적 특징에 의한 특정 하위유형의 AD의 분류(예를 들어, 특정 유전자 또는 핵산 영역에서 유전적 변이(들)를 특징으로 하는 환자 하위집단)를 지칭한다.
용어 "진단을 보조하는"은 특정 유형의 AD의 증상 또는 질환의 존재 또는 특성에 관해 임상적 결정요인을 만드는 것을 보조하는 방법을 지칭하기 위해 본 명세서에서 사용된다. 예를 들어, AD의 진단을 보존하는 방법은 개체로부터의 생물학적 샘플에서 AD를 나타내거나 또는 AD를 갖는 증가된 위험을 나타내는 하나 이상의 유전적 마커의 존재 또는 부재를 측정하는 단계를 포함할 수 있다.
용어 "예후"는, 예를 들어 기억 상실 및 치매를 포함하는 AD의 증상이 발생될 가능성의 예측을 지칭하기 위해 본 명세서에서 사용된다. 용어 "예측"은 환자가 약물 또는 약물 세트에 유리하게 또는 불리하게 반응할 가능성을 지칭하기 위해 본 명세서에서 사용된다. 일 실시형태에서, 예측은 해당 반응의 정도에 관한 것이다. 일 실시형태에서, 예측은 환자가 치료, 예를 들어 특정 치료제에 의한 치료 후 및 질병 재발이 없는 특정 시간 기간 동안 생존하거나 또는 개선되는지 여부 및/또는 가능성에 관한 것이다. 본 발명의 예측적 방법은 임의의 특정 환자에 대해 가장 적절한 치료 양상을 선택함으로써 치료 결정을 만들도록 임상적으로 사용될 수 있다. 본 발명의 예측적 방법은 환자가, 예를 들어 주어진 치료제 또는 조합물의 투여, 수술적 개입, 스테로이드 치료 등을 포함하는 주어진 치료요법과 같은 치료 요법에 대해 유리하게 반응될 가능성이 있는지 여부, 또는 치료요법 후 환자의 장기간 생존이 가능한지 여부를 예측하는데 가치 있는 도구이다.
본 명세서에서 사용되는 "치료"는 치료되는 개체 또는 세포의 자연적 과정을 변경시키는 시도에서 임상적 개입를 지칭하며, 임상적 병리 과정 전 또는 동안 수행될 수 있다. 바람직한 치료 효과는 질병 또는 질환 또는 이들의 증상의 발생 또는 재발을 예방하는 것, 질환 또는 질병의 증상을 완화시키는 것, 질병의 어떤 직접적 또는 간접적 병리학적 결과를 감소시키는 것, 질병 진행속도를 감소시키는 것, 질병 상태를 개선하거나 또는 완화시키는 것, 및 관해 또는 개선된 예후를 달성하는 것을 포함한다. 일부 실시형태에서, 본 발명의 방법 및 조성물은 질병 또는 장애의 발생을 지연시키기 위한 시도에서 유용하다.
본 명세서에서 사용되는 "AD 치료제", "AD를 치료하는데 효과적인 치료제", 미치 이들의 문법적 변형은 유효량이 제공될 때 AD를 갖는 피험체에서 치료적 이점을 제공하는 것으로 알려지거나, 임상적으로 나타나거나 또는 의사에 의해 예상되는 작용제를 지칭한다. 일 실시형태에서, 어구는 유효량으로 제공될 때 AD를 갖는 피험체에서 치료적 효과를 제공할 것으로 예상되는 임상적으로 허용가능한 작용제로서 제조업자에 의해 시판되거나 또는 자격 있는 의사에 의해 달리 사용되는 어떤 작용제를 포함한다. 다양한 비제한적 실시형태에서, AD 치료제는 콜린에스터라제 저해제, 메만틴, 항-불안 의약, 항-우울제, 불안제거제, 또는 아밀로이드 전구체 단백질, 아밀로이드 베타, 아밀로이드 플라크를 표적화하는 화합물, 또는 알파-세크레타제, 베타-세크레타제 및 감마-세크레타제를 포함하지만, 이들로 제한되지 않는 아밀로이드 전구체 단백질을 절단하는 어떤 효소를 포함한다.
용어 "약제학적 제형"은 그것에 함유된 활성 성분의 생물학적 활성을 허용하고, 제형이 투여되는 피험체에 대해 허용가능하지 않게 독성인 추가적인 성분을 함유하지 않는 그러한 형태의 제제를 지칭한다.
"약제학적으로 허용가능한 담체"는 피험체에 대해 비독성인 활성 성분 이외에 약제학적 제형 내 성분을 지칭한다. 약제학적으로 허용가능한 담체는 완충제, 부형제, 안정제 또는 보존제를 포함하지만, 이들로 제한되지 않는다.
"치료적 효과"는 장애를 겪지 않는 개체에서 평균 또는 정상 상태보다 양호한 상태의 생성(즉, 고통이 없거나 또는 무증상인 피험체에서 정상 또는 평균 상태에 비해 개선된 인지, 기억, 기분 또는 CNS의 기능에 적어도 부분적으로 기인하는 피험체에서의 다른 특징)을 지칭한다.
"유효량"은 원하는 치료적 또는 예방적 결과를 달성하기 위해 필요한 투약량 또는 시간 기간을 위해 유효한 양을 지칭한다. 치료제의 "치료적 유효량"은 개체의 질병 상태, 연령, 성별 및 체중 및 개체에서 원하는 반응을 유발하기 위한 항체의 능력과 같은 인자에 따라 다를 수 있다. 치료적 유효량은 또한 치료제의 임의의 독성 또는 해로운 효과가 치료적으로 유리한 효과에 의해 능가되는 치료적 유효량이다. "예방적 유효량"은 원하는 예방적 결과를 달성하는데 필요한 투약량에서 및 시간 기간 동안 유효한 양을 지칭한다. 전형적으로 필요하지는 않지만, 예방적 용량은 피험체에서 질병 전에 또는 질병의 조기 단계에서 사용되기 때문에, 예방적 유효량은 치료적 유효량 미만일 것이다.
"개체", "피험체" 또는 "환자"는 척추 동물이다. 특정 실시형태에서, 척추 동물은 포유류이다. 포유류는 영장류(인간 및 비인간 영장류를 포함) 및 설치류(예를 들어, 마우스 및 래트)를 포함하지만, 이들로 제한되지 않는다. 특정 실시형태에서, 포유류는 인간이다.
본 명세서에서 사용되는 바와 같은 "인간 하위집단" 및 이의 변형은 그것이 속하는 더 넓은 질병 범주에서 다른 것으로부터 인간 서브세트를 구별하는 하나 이상의 특유의 측정가능하고/하거나 확인가능한 특징을 갖는 것으로 특성규명된 인간 서브세트를 지칭한다. 이러한 특징은 하위범주, 성별, 생활방식, 건강 이력, 관련된 기관/조직, 치료 이력 등을 포함한다. 일 실시형태에서, 환자 하위집단은 특히 뉴클레오타이드 위치 및/또는 영역(예컨대 SNP)을 포함하는 유전적 특징을 특징으로 한다.
"대조군 피험체"는 AD를 갖는 것으로 진단된 적이 없고, AD와 관련된 어떤 징후 또는 증상으로 고통받지 않는 건강한 피험체를 지칭한다.
본 명세서에 사용되는 바와 같은 용어 "샘플"은, 예를 들어 신체적, 생화학적, 화학적 및/또는 생리학적 특징을 기반으로 특성규명되고/되거나 확인되는 세포 및/또는 다른 분자 독립체를 함유하는 관심대상의 피험체로부터 얻거나 또는 유래된 조성물을 지칭한다. 예를 들어, 어구 "질병 샘플" 및 이의 변형은 특성규명된 세포 및/또는 분자 독립체를 함유하는 것으로 예상되거나 또는 알려진 관심대상의 피험체로부터 얻은 임의의 샘플을 지칭한다.
"조직 또는 세포 샘플"은 피험체 또는 환자의 조직으로부터 얻은 유사한 세포의 수집을 의미한다. 조직 또는 세포 샘플의 공급원은 신선, 냉동 및/또는 보존된 기관 또는 조직 샘플 또는 생검 또는 흡입물로부터의 고체 조직; 혈액 또는 임의의 혈액 구성성분; 뇌척수액, 양수, 복막액 또는 세포간질액과 같은 체액; 피험체의 임신 또는 발생에서 임의의 시간으로부터의 세포일 수 있다. 조직 샘플은 1차 또는 배양된 세포 또는 세포주일 수 있다. 선택적으로, 조직 또는 세포 샘플은 질병 조직/기관으로부터 얻어진다. 조직 샘플은 보존제, 항응고제, 완충제, 정착액, 영양소, 항생제 등과 같은 자연에서 조직과 자연적으로 혼합되지 않는 화합물을 함유할 수 있다. 본 명세서에 사용되는 바와 같은 "기준 샘플", "기준 세포", "기준 조직", "대조군 샘플", "대조군 세포" 또는 "대조군 조직"은 본 발명의 방법 또는 조성물이 확인을 위해 사용되는 질병 또는 질환으로 고통받지 않는 것으로 알려지거나 또는 믿어지는 공급원으로부터 얻어진 샘플, 세포 또는 조직을 지칭한다. 일 실시형태에서, 기준 샘플, 기준 세포, 기준 조직, 대조군 샘플, 대조군 세포 또는 대조군 조직은 질병 또는 질환이 본 발명의 조성물 또는 방법을 사용하여 확인되는 동일한 피험체 또는 환자의 신체의 건강한 부분으로부터 얻어진다. 일 실시형태에서, 기준 샘플, 기준 세포, 기준 조직, 대조군 샘플, 대조군 세포 또는 대조군 조직은 질병 또는 질환이 본 발명의 조성물 또는 방법을 사용하여 확인되는 피험체 또는 환자가 아닌 개체의 신체의 건강한 부분으로부터 얻어진다.
본 명세서의 목적을 위해, 조직 샘플의 "절편"은 조직 샘플의 단일 부분 또는 조각, 예를 들어 조직의 얇은 슬라이스 또는 조직 샘플로부터 절단된 세포를 의미한다. 조직 샘플의 다수의 절편은 본 발명의 본 발명에 따른 분석이 취해지고, 실시될 수 있다는 것이 이해되며, 단, 본 발명은 조직 샘플의 동일 부분이 형태학적이며 분자적 수준 둘 다에서 분석되거나 또는 단백질과 핵산 둘 다에 대해 분석되는 방법을 포함하는 것이 이해된다.
"상호 관련되다" 또는 "상호 관련되는"은 어떤 방법에서 제1 분석 또는 프로토콜의 수행 및/또는 결과를 제2 분석 또는 프로토콜의 수행 및/또는 결과와 비교하는 것을 의미한다. 예를 들어, 제2 프로토콜을 수행하는데 제1 분석 또는 프로토콜의 결과를 사용할 수 있으며/있거나 제2 분석 또는 프로토콜이 수행되어야 하는지 여부를 결정하기 위한 제1 분석 또는 프로토콜의 결과를 사용할 수 있다. 유전자 발현 분석 또는 프로토콜의 실시형태에 대해, 구체적 치료요법이 수행되어야 하는지 여부를 결정하기 위한 유전자 발현 분석 또는 프로토콜의 결과를 사용할 수 있다.
용어 "항체" 및 "면역글로뷸린"은 가장 넓은 의미에서 상호 호환적으로 사용되며, 단클론성 항체(예를 들어, 전장 또는 무결함 단클론성 항체), 다클론성 항체, 1가 항체, 다가 항체, 다중 특이적 항체(예를 들어, 그것들이 원하는 생물학적 활성을 나타낸다면 이중특이성 항체)를 포함하고, 또한 특정 항체 단편을 포함할 수 있다(본 명세서에서 추가로 상세하게 설명됨). 항체는 키메라, 인간, 인간화된/되거나 친화도 성숙될 수 있다. "항체 단편"은 무결함 항체의 부분을 포함하며, 바람직하게는 이의 항원 결합 영역을 포함한다. 항체 단편의 예는 Fab, Fab', F(ab')2, 및 Fv 단편; 다이아바디; 선형 항체; 단일쇄 항체 분자; 및 항체 단편으로부터 형성된 다중특이성 항체를 포함한다.
"소분자" 또는 "소 유기분자"는 본 명세서에서 약 500 달톤 미만의 분자량을 갖는 유기 분자로서 정의된다.
본 명세서에서 사용될 때 단어 "표지"는 검출가능한 화합물 또는 조성물을 지칭한다. 표지는 그것만으로 검출가능할 수 있고(예를 들어, 방사성 동위원소 표지 또는 형광 표지) 또는 효소적 표지의 경우에 검출가능한 산물을 초래하는 기질 화합물 또는 조성물의 화학적 변경을 촉매할 수 있다. 검출가능한 표지로서 작용할 수 있는 방사성핵종은, 예를 들어 I-131, I-123, I-125, Y-90, Re-188, Re-186, At-211, Cu-67, Bi-212 및 Pd-109를 포함한다.
"약"에 대해서, 본 명세서의 수치 또는 변수는 그 자체의 해당 값 또는 변수와 관련되는 실시형태를 포함한다(기재한다). 예를 들어, "약 X"를 지칭하는 설명은 "X"의 설명을 포함한다.
용어 "포장 삽입물"은 이러한 치료적 제품의 사용에 관한 지시사항, 용법, 용량, 투여, 조합치료, 사용금지사유 및/또는 경고에 관한 정보를 함유하는 치료적 제품의 상업적 포장에 관례적으로 포함되는 설명서를 지칭하는데 사용된다.
본 발명의 조성물 및 방법
유전적 변이
일 양태에서, 본 발명은 피험체로부터의 샘플에서 알츠하이머병(AD)과 관련된 유전적 변이의 존재 또는 부재를 검출하는 방법뿐만 아니라 피험체로부터의 샘플에서 이들 유전적 변이 중 하나 이상의 존재 또는 부재를 검출함으로써 AD를 진단하고, 예측하는 방법을 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다. AD와 관련된 유전적 변이는 게놈-와이드 관련 연구, 변형제 스크린 및 가족 기반 스크리닝을 포함하는 전략을 사용하여 확인되었다.
본 발명의 방법에서 사용을 위한 유전적 변이는 인터류킨-6 수용체(IL6R) 내 유전적 변이, 뉴로트로핀 인자 4(NTF4) 및 UNC5C, 또는 이들 단백질을 암호화하는 유전자뿐만 아니라 표 3에 열거된 유전자 중 어떤 것 또는 그것들이 암호화하는 단백질을 포함한다. 일부 실시형태에서, 유전적 변이는 유전자(또는 그것의 조절 영역)를 암호화하는 게놈 DNA에 있되, 유전자는 인터류킨-6 수용체(IL6R)에 대해 암호화하는 유전자, 뉴로트로핀 인자 4(NTF4) 및 UNC5C, 및 표 3에 열거된 유전자 중 어떤 것으로부터 선택된다. 다양한 실시형태에서, 유전적 변이는 SNP, 대립유전자, 단상형, IL6R, NTF4 및 UNC5C에 대해 암호화하는 유전자로부터 선택된 하나 이상의 유전자 내 삽입 또는 결실, 및 표 3에 열거된 유전자 중 어떤 것이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP이다. 실시형태에서, 유전적 변이는 rs2228145에서 'C' 대립유전자이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W을 초래하는 SNP이다. 실시형태에서, 유전적 변이는 rs121918427에서 'T' 대립유전자이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP이다. 실시형태에서, 유전적 변이는 표 3에 열거된 것으로부터 선택된 유전자 내 SNP이다. 실시형태에서, 유전적 변이는 rs12733578, rs4658945, rs1478161, rs1024591, rs7799010, rs10969475 및 rs12961250로부터 선택된 SNP이다. 다양한 실시형태에서, 적어도 하나의 유전적 변이는 IL6R, NTF4 또는 UNC5C 내 아미노산 치환, 삽입 또는 결실이다. 일부 실시형태에서, 유전적 변이는 아미노산 치환이다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2) 내 아미노산 치환 R206W이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3) 내 아미노산 치환 T835M이다.
유전적 변이의 검출
본 명세서에 기재된 어떤 검출 방법에서 사용되는 바와 같은 핵산은 게놈 DNA; 게놈 DNA로부터 전사된 RNA; 또는 RNA로부터 만들어진 cDNA일 수 있다. 핵산은 척추 동물, 예를 들어, 포유류로부터 유래될 수 있다. 핵산은 그것이 해당 공급원으로부터 직접 얻어지거나 또는 그것이 해당 공급원에서 발견되는 핵산의 복제물이라면, 특정 공급원"으로부터 유래되는" 것으로 언급된다.
핵산은 핵산의 복제물, 예를 들어 증폭으로부터 초래되는 복제물을 포함한다. 증폭은, 예를 들어 검출가능한 변형을 위한 물질의 원하는 양을 얻기 위해 특정 예에서 바람직할 수 있다. 그 다음에 변형이 앰플리콘 내에 존재하는지 여부를 결정하기 위해 앰플리콘에 이하에 기재된 것과 같은 변형 검출 방법이 실시될 수 있다.
유전적 변이는 당업자에게 알려진 특정 방법에 의해 검출될 수 있다. 이러한 방법은 DNA 시퀀싱; 대립유전자-특이적 뉴클레오타이드 포함 분석 및 대립유전자-특이적 프라이머 신장 분석(예를 들어, 대립유전자-특이적 PCR, 대립유전자-특이적 결찰 연쇄반응(ligation chain reaction: LCR), 및 갭-LCR)을 포함하는 프라이머 신장 분석; 대립유전자-특이적 올리고뉴클레오타이드 혼성화 분석(예를 들어, 올리고뉴클레오타이드 결찰 분석); 절단 보호 분석(절단 작용제로부터의 보호는 핵산 듀플렉스 내 미스매칭된 염기를 검출하기 위해 사용됨); MutS 단백질 결합의 분석; 변이체 및 야생형 핵산 분자의 이동성을 비교하는 전기영동 분석; 변성 구배 겔 전기영동(예를 들어, 문헌[Myers et al. (1985) Nature 313:495]에서와 같은 Denaturing Gradient Gel Electrophoresis: DGGE); 미스매칭된 염기쌍에서 RNAase 절단의 분석; 이형이중가닥 DNA의 화학적 또는 효소적 절단의 분석; 질량 분석법(예를 들어, MALDI-TOF); 유전자 비트 분석(genetic bit analysis: GBA); 5' 뉴클레아제 분석(예를 들어, TaqMan(상표명)); 및 분자 비콘을 사용하는 분석을 포함하지만, 이들로 제한되지 않는다. 이들 방법 중 어떤 것은 이하에서 추가로 상세하게 논의된다.
표적 핵산에서 변이의 검출은 당업계에 잘 공지된 기법을 사용하여 표적 핵산의 분자 클로닝 및 시퀀싱에 의해 수행될 수 있다. 대안적으로, 폴리머라제 연쇄 반응(PCR)과 같은 증폭 기법은 종양 조직으로부터의 게놈 DNA 제조로부터 직접적으로 표적 핵산 서열을 증폭하는데 사용될 수 있다. 그 다음에 증폭된 서열의 핵산 서열은 결정될 수 있고, 그것으로부터 변이가 확인된다. 증폭 기법은 당업계에 잘 공지되어 있으며, 예를 들어, 폴리머라제 연쇄 반응은 문헌[Saiki et al., Science 239:487, 1988]; 미국특허 제 4,683,203호 및 제4,683,195호에 기재되어 있다.
당업계에 공지된 리가제 연쇄반응은 또한 표적 핵산 서열을 증폭하기 위해 사용될 수 있다. 예를 들어, 문헌[Wu et al., Genomics 4:560-569 (1989)] 참조. 추가로, 대립유전자-특이적 PCR로서 공지된 기법은 또한 변이를 검출하는데 사용될 수 있다(예를 들어, 치환). 예를 들어, 문헌[Ruano and Kidd (1989) Nucleic Acids Research 17:8392; McClay et al. (2002) Analytical Biochem. 301:200-206] 참조. 이 기법의 특정 실시형태에서, 대립유전자-특이적 프라이머가 사용되되, 프라이머의 3' 말단 뉴클레오타이드는 표적 핵산에서 특정 변이에 상보적이다(즉, 특이적으로 염기쌍형성을 할 수 있음). 특정 변이가 존재하지 않는다면, 증폭 산물은 관찰되지 않는다. 증폭 불응 돌연변이계(Amplification Refractory Mutation System: ARMS)가 또한 변이(예를 들어, 치환)를 검출하는데 사용될 수 있다. ARMS는, 예를 들어 유럽 특허 출원 공개 제0332435호 및 문헌[Newton et al., Nucleic Acids Research, 17:7, 1989]에 기재되어 있다.
변이(예를 들어, 치환)를 검출하는데 유용한 다른 방법은 (1) 대립유전자-특이적 뉴클레오타이드 포함 분석, 예컨대 단일 염기 신장 분석(예를 들어, 문헌[Chen et al. (2000) Genome Res. 10:549-557; Fan et al. (2000) Genome Res. 10:853-860; Pastinen et al. (1997) Genome Res. 7:606-614; 및 Ye et al. (2001) Hum. Mut. 17:305-316] 참조); (2) 대립유전자-특이적 PCR을 포함하는, 대립유전자-특이적 프라이머 신장 분석(예를 들어, 문헌[Ye et al. (2001) Hum. Mut. 17:305-316; 및 Shen et al. Genetic Engineering News, vol. 23, Mar. 15, 2003] 참조); (3) 5' 뉴클레아제 분석(예를 들어, 문헌[De La Vega et al. (2002) BioTechniques 32:S48-S54 (TaqMan.RTM. 분석을 기재함); Ranade et al. (2001) Genome Res. 11:1262-1268; 및 Shi (2001) Clin. Chem. 47:164-172]); (4) 분자 비콘을 사용하는 분석(예를 들어, 문헌[Tyagi et al. (1998) Nature Biotech. 16:49-53; 및 Mhlanga et al. (2001) Methods 25:463-71] 참조); 및 (5) 올리고뉴클레오타이드 결찰 분석(예를 들어, 문헌[Grossman et al. (1994) Nuc. Acids Res. 22:4527-4534]; 특허 출원 공개 번호 제US 2003/0119004 A1호; PCT 국제특허 공개 제WO 01/92579 A2호; 및 미국특허 제6,027,889호 참조)를 포함하지만, 이들로 제한되지 않는다.
변이는 또한 미스매치 검출 방법에 의해 검출될 수 있다. 미스매치는 100% 상보성이 아닌 혼성화된 핵산 듀플렉스이다. 전체 상보성의 결여는 결실, 삽입, 역위 또는 치환에 기인할 수 있다. 미스매치 검출 방법의 일 예는, 예를 들어 문헌[Faham et al., Proc. Natl. Acad. Sci. USA 102:14717-14722 (2005) 및 Faham et al., Hum. Mol. Genet. 10:1657-1664 (2001)]에 기재된 미스매치 수선 검출(Mismatch Repair Detection: MRD)이다. 미스매치 절단 기법의 다른 예는 문헌[Winter et al., Proc. Natl. Acad. Sci. USA, 82:7575, 1985, 및 Myers et al., Science 230:1242, 1985]에서 상세하게 설명되는 RNase 보호 방법이다. 예를 들어, 본 발명의 방법은 인간 야생형 표적 핵산에 상보적인 표지된 리보프로브의 사용과 관련될 수 있다. 표적 샘플로부터 유래된 리보프로브 및 표적 핵산은 함께 어닐링(혼성화)되며, 후속적으로 듀플렉스 RNA 구조에서 일부 미스매치를 검출할 수 있는 효소 RNase A에 의해 분해된다. 미스매치가 RNase A에 의해 검출된다면, 이는 미스매치 부위에서 절단된다. 따라서, 어닐링된 RNA 제제가 전기영동 겔 매트릭스 상에서 분리될 때, 미스매치가 검출되고 RNase A에 의해 절단된다면, 리보프로브 및 mRNA 또는 DNA에 대한 전장 듀플렉스 RNA보다 더 작은 RNA 산물이 보일 것이다. 리보프로브가 표적 핵산의 전장일 필요는 없지만, 표적 핵산의 일부일 수 있고, 단, 이는 변이를 갖는 것으로 의심되는 위치를 포함한다.
유사한 방식에서, DNA 프로브는, 예를 들어 효소적 또는 화학적 절단을 통해 미스매치를 검출하는데 사용될 수 있다. 예를 들어, 문헌[Cotton et al., Proc. Natl. Acad. Sci. USA, 85:4397, 1988; 및 Shenk et al., Proc. Natl. Acad. Sci. USA, 72:989, 1975] 참조. 대안적으로, 미스매치는 매치된 듀플렉스에 대해 미스매칭된 듀플렉스의 전기영동적 이동성에서의 이동에 의해 검출될 수 있다. 예를 들어, 문헌[Cariello, Human Genetics, 42:726, 1988] 참조. 리보프로브 또는 DNA 프로브에 의해, 변이를 포함하는 것으로 의심되는 표적 핵산은 혼성화전 증폭될 수 있다. 표적 핵산에서의 변화는 또한, 특히 변화가 전체 재배열, 예컨대 결실 및 삽입이라면, 사우던 혼성화를 사용하여 검출될 수 있다.
표적 핵산 또는 주변의 마커 유전자에 대한 제한효소 단편길이 다형성(Restriction fragment length polymorphism: RFLP) 프로브가 변이, 예를 들어 삽입 또는 결실을 검출하는데 사용될 수 있다. 삽입 및 결실은 또한 표적 핵산의 클로닝, 시퀀싱 및 증폭에 의해 검출될 수 있다. 단일 가닥 구조 다형성(Single stranded conformation polymorphism: SSCP) 분석은 대립유전자의 염기 변화 변이체를 검출하는데 사용될 수 있다. 예를 들어, 문헌[Orita et al., Proc. Natl. Acad. Sci. USA 86:2766-2770, 1989, 및 Genomics, 5:874-879, 1989] 참조. SSCP는 단일 가닥 PCR 산물의 전기영동적 이동에서의 변경에 의해 염기 차이를 확인한다. 단일 가닥 PCR 산물은 이중 가닥 PCR 산물을 가열하거나 또는 다르게 변성시킴으로써 만들어질 수 있다. 단일 가닥 핵산은 재폴딩되거나 또는 염기 서열에 부분적으로 의존하는 2차 구조를 형성할 수 있다. 단일 가닥 증폭 산물의 상이한 전기영동적 이동성은 SNP 위치에서 염기서열 차이와 관련된다. 변성 구배 겔 전기영동(DGGE)은 다형성 DNA에 고유한 상이한 서열 의존적 안정성 및 용융 특성 및 변성 구배 겔 내 전기영동적 이동 패턴에서의 대응되는 차이를 기반으로 SNP 대립유전자를 구별한다.
유전적 변이는 또한 마이크로어레이의 사용에 의해 검출될 수 있다. 마이크로어레이는, 예를 들어 고도 엄격 조건 하에 cDNA 또는 cRNA 샘플과 혼성화되는 배열된 일련의 수천 개의 핵산 프로브를 전형적으로 사용하는 다중 기법이다. 프로브 표적 혼성화는 표적에서 핵산 서열의 상대적 존재도를 결정하기 위해 형광단-, 은- 또는 화학발광-표지된 표적의 검출에 의해 전형적으로 검출되고 정량화된다. 전형적인 마이크로어레이에서, 프로브는 화학적 매트릭스에 대한 공유 결합에 의해 고체 표면에 부착된다(에폭시 실란, 아미노-실란, 리신, 폴리아크릴아마이드 또는 기타를 통해). 고체 표면은, 예를 들어 유리, 실리콘 칩 또는 미시적 비드이다. 예를 들어, 애피메트릭스 인코포레이티드(Affymetrix, Inc) 및 일루미나 인코포레이티드(Illumina, Inc)에 의해 제조되는 것을 포함하는 다양한 마이크로어레이가 상업적으로 입수가능하다.
SNP 게노타이핑(genotyping)을 위한 다른 방법은 질량 분석법에 기반한다. 질량 분석법은 DNA의 4개의 뉴클레오타이드의 각각의 독특한 질량의 이점을 취한다. SNP는 대안의 SNP 대립유전자를 갖는 핵산의 질량에서 차이를 측정함으로써 질량 분석법에 의해 분명하게 유전자형으로 될 수 있다. MALDI-TOF(매트릭스 보조 레이저 탈착 이온화-비행시간(Matrix Assisted Laser Desorption Ionization-Time of Flight)) 질량 분석 기법은 SNP와 같은 분자 질량의 극도로 정확한 결정을 위해 유용하다. SNP 분석에 대한 수많은 접근은 질량 분석법을 기반으로 개발되었다. SNP 게노타이핑의 예시적인 질량 분석법-기반 방법은 프라이머 신장 분석을 포함하는데, 이는 전통적인 겔기반 형식 및 마이크로어레이와 같은 다른 접근과 조합되어 이용될 수 있다.
서열-특이적 리보자임(미국특허 제5,498,531호)은 리보자임 절단 부위의 발생 또는 손실에 기반하여 SNP를 스코어링하는데 사용될 수 있다. 완벽하게 매칭된 서열은 뉴클레아제 절단 분해 분석에 의해 또는 용융 온도에서의 차이에 의해 미스매칭된 서열로부터 구별될 수 있다. SNP가 제한 효소 절단 부위에 영향을 미친다면, SNP는 제한 효소 분해 패턴에서 변경 및 겔 전기영동에 의해 결정된 핵산 단편 길이에서 대응되는 변화에 의해 확인될 수 있다.
본 발명의 다른 실시형태에서, 단백질 기반 검출 기법은 본 명세서에 개시된 바와 같은 유전적 변이를 갖는 유전자에 의해 암호화된 변이체 단백질을 검출하는데 사용된다. 단백질의 변이체 형태의 존재 결정은 당업계에 공지된 어떤 적합한 기법, 예를 들어, 전기영동(예를 들어, 변성 또는 비변성 폴리아크릴아마이드 겔 전기영동, 2-이차원 겔 전기영동, 모세관 전기영동, 및 등전기초점화), 크로마토그래피(예를 들어, 크기 크로마토그래피, 고성능 액체 크로마토그래피(HPLC), 및 양이온 교환 HPLC), 및 질량 분석법(예를 들어, MALDI-TOF 질량 분석법, 전기분무 이온화(ESI) 질량 분석법, 및 탠덤 질량 분석법)을 사용하여 수행될 수 있다. 예를 들어, 문헌[Ahrer and Jungabauer (2006) J. Chromatog. B. Analyt. Technol. Biomed. Life Sci. 841: 110-122; 및 Wada (2002) J. Chromatog. B. 781: 291-301)] 참조. 적합한 기법은 검출되는 변이의 특성에 부분적으로 기반하여 선택될 수 있다. 예를 들어, 치환된 아미노산이 본래 아미노산과 상이한 전하를 가지는 경우 아미노산 치환을 초래하는 변이는 등전점 전기영동에 의해 검출될 수 있다. 고전압에서 pH 구배를 갖는 겔을 통한 폴리펩타이드의 등전점 전기영동은 그것의 pI에 의해 단백질을 분리시킨다. pH 구배 겔은 야생형 단백질을 함유하는 동시 실행 겔과 비교될 수 있다. 변이가 새로운 단백질 분해 절단 부위의 생성 또는 기존 것의 폐지를 초래하는 경우, 샘플은 단백질 분해 다음에 적절한 전기영동, 크로마토그래피 또는 질량분석 기법을 사용하는 펩타이드 맵핑이 실시될 수 있다. 변이의 존재는 또한 에드먼(Edman) 분해 또는 특정 형태의 질량 분석법과 같은 단백질 시퀀싱 기법을 사용하여 검출될 수 있다.
이들 기법의 조합을 사용하는 당업계에 공지된 방법이 또한 사용될 수 있다. 예를 들어, HPLC-현미경 탠덤 질량 분석 기법에서, 단백질 분해는 단백질 상에서 수행되고, 얻어진 펩타이드 혼합물은 역상 크로마토그래피 분리에 의해 분리된다. 그 다음에 탠덤 질량 분석법이 수행되고, 그것으로부터 수집된 데이터는 분석된다.(Gatlin et al. (2000) Anal. Chem., 72:757-763). 다른 예에서, 미변성 겔 전기영동은 MALDI 질량 분석법과 조합된다(Mathew et al. (2011) Anal. Biochem. 416: 135-137).
일부 실시형태에서, 단백질은 단백질에 특이적으로 결합되는 항체 또는 펩타이드와 같은 시약을 사용하여 샘플로부터 단리될 수 있고, 그 다음에 상기 개시된 기법 중 어떤 것을 사용하여 유전적 변이의 존재 또는 부재를 결정하도록 추가로 분석될 수 있다.
대안적으로, 샘플 내 변이체 단백질의 존재는 본 발명에 따른 유전적 변이를 갖는 단백질에 특이적인 항체, 즉, 변이를 갖는 단백질에 특이적으로 결합되지만, 변이가 없는 단백질 형태에는 결합되지 않는 항체에 기반한 면역친화도 분석에 의해 검출될 수 있다. 이러한 항체는 당업계에 공지된 임의의 적합한 기법에 의해 생성될 수 있다. 용액 샘플로부터 특이적 단백질을 면역침전시키기 위해 또는, 예를 들어 폴리아크릴아마이드 겔에 의해 분리되는 단백질을 면역블롯팅하기 위해 항체가 사용될 수 있다. 조직 또는 세포에서 특이적 단백질 변이체를 검출하는데 면역 세포 화학적 방법이 또한 사용될 수 있다. 다른 잘 공지된 항체 기반 기법이 또한 사용될 수 있다. 예를 들어, 효소결합 면역흡착 분석(enzyme-linked immunosorbent assay: ELISA), 방사 면역 분석(radioimmuno-assay: RIA), 면역방사능 분석(immunoradiometric assay: IRMA) 및 단클론성 또는 다클론성 항체를 사용하는 샌드위치 분석을 포함하는 면역효소 분석(immunoenzymatic assay: IEMA)을 포함하는, 다수의 잘 공지된 항체 기반 기법이 또한 사용될 수 있다. 예를 들어, 미국특허 제4,376,110호 및 제4,486,530호 참조.
추가적인 유전적
마커의
확인
개시된 유전적 마커는 AD의 발생과 관련된 추가적인 유전적 마커를 확인하는데 유용하다. 예를 들어, 본 명세서에 개시된 SNP는 연관불평형인 추가적인 SNP를 확인하는데 사용될 수 있다. 사실, AD와 관련된 제1 SNP를 지니는 연관불평형에서의 어떤 SNP는 AD와 관련될 것이다. 일단 주어진 SNP와 AD 사이에 관련이 증명된다면, AD와 관련된 추가적인 SNP의 발견은 이 특정 영역에서 SNP의 밀도를 증가시키기 위한 큰 관심 대상을 가질 수 있다.
추가적인 SNP를 확인하고, 연관불평형 분석을 수행하는 방법은 당업계에 잘 공지되어 있다. 예를 들어, 본 명세서에 개시된 SNP를 지니는 연관불평형에서 추가적인 SNP의 식별은 (a) 다수의 개체로부터 제1 SNP를 포함하거나 또는 둘러싸는 게놈 영역으로부터 단편을 증폭시키는 단계; (b) 상기 제1 SNP를 은닉하거나 또는 둘러싸는 게놈 영역에서 제2 SNP를 확인하는 단계; (c) 상기 제1 SNP와 제2 SNP 간의 연관불평형 분석을 수행하는 단계; 및 (d) 상기 제1 마커를 지니는 연관불평형에서와 같이 상기 제2 SNP를 선택하는 단계를 수반할 수 있다.
조합에서 사용을 위한 추가적인 진단 방법
개시된 유전적 마커의 검출은 AD를 가지거나 또는 AD가 발생될 증가된 위험을 가지는 피험체를 확인하기 위한 하나 이상의 추가적인 진단적 접근과 조합되어 사용될 수 있다. 예를 들어, 피험체는 본 명세서에 개시된 유전적 마커에 더하여 추가적인 유전적 마커에 대해 스크리닝 될 수 있다. 피험체로부터의 뇌척수액은 AD의 특징인 아밀로이드 베타 또는 타우 단백질의 증가된 수준에 대해 분석될 수 있다. 피험체는 또한 간이 정신상태 검사(Mini Mental State Exam: MMSE) 와 같은 정신상태 검사가 실시되어, 기억, 집중 및 다른 인지 기능이 평가될 수 있다. 피험체에 또한 CT 스캔, MRI, SPECT 스캔 또는 PET 스캔과 같은 영상화 절차가 실시되어 알츠하이머병을 나타내는 뇌 구조 또는 크기의 변화를 확인할 수 있다.
알츠하이머병의 진단, 예후 및 치료
본 발명은 본 명세서에 개시된 바와 같은 AD와 관련된 하나 이상의 유전적 변이의 피험체로부터의 샘플에서 존재를 검출함으로써 피험체에서 AD의 진단 또는 예후를 위한 방법을 제공한다. 본 발명의 실시형태에서, 하나 이상의 유전적 변이는 인터류킨-6 수용체(IL6R)에 대해 암호화하는 유전자, 뉴로트로핀 인자 4(NTF4) 및 UNC5C, 및 표 3에 열거된 어떤 유전자로부터 선택된 유전자에 있다. 일부 실시형태에서, 유전적 변이는 유전자를 암호화하는 게놈 DNA(또는 그것의 조절 역)에 있되, 유전자는 인터류킨-6 수용체(IL6R)에 대해 암호화하는 유전자, 뉴로트로핀 인자 4(NTF4) 및 UNC5C, 및 표 3에 열거된 어떤 유전자로부터 선택된다. 다양한 실시형태에서, 유전적 변이는 인터류킨-6 수용체(IL6R)에 대해 암호화하는 유전자, 뉴로트로핀 인자 4(NTF4) 및 UNC5C, 및 표 3에 열거된 어떤 유전자로부터 선택된 하나 이상의 유전자에서 SNP, 대립유전자, 단상형, 삽입 또는 결실로부터 선택된 하나 이상의 유전자에 있다. 실시형태에서, 유전적 변이는 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP이다. 실시형태에서, 유전적 변이는 rs2228145에서 'C' 대립유전자이다. 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W이다. 실시형태에서, 유전적 변이는 rs121918427에서 'T' 대립유전자이다. 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP이다. 실시형태에서, 유전적 변이 표 3에 열거된 것으로부터 선택된 유전자 내 SNP이다. 실시형태에서, 유전적 변이는 rs12733578, rs4658945, rs1478161, rs1024591, rs7799010, rs10969475 및 rs12961250으로부터 선택된 SNP이다. 이들 유전적 변이 중 어느 하나 이상은 이하에 기재된 검출, 진단 및 예후 방법 중 어떤 것에서 사용될 수 있다.
실시형태에서, 본 발명은 (a) IL6R, NTF4 및 UNC5C를 암호화하는 유전자로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 검출할 수 있는 시약과 피험체로부터의 샘플을 접촉시키는 단계; 및 (b) 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하는, 피험체에서 알츠하이머병(AD)을 나타내는 유전적 변이의 존재 또는 부재를 검출하기 위한 방법을 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다.
해당 방법에서 사용을 위한 시약은 올리고뉴클레오타이드, DNA 프로브, RNA 프로브 및 리보자임일 수 있다. 일부 실시형태에서, 시약은 표지된다. 표지는, 예를 들어 방사성동위원소 표지, 형광 표지, 생물발광 표지 또는 효소적 표지를 포함할 수 있다. 검출할 수 있는 표지로서 작용할 수 있는 방사성핵종은, 예를 들어, I-131, I-123, I-125, Y-90, Re-188, Re-186, At-211, Cu-67, Bi-212 및 Pd-109를 포함한다.
또한 피험체로부터의 생물학적 샘플 내 IL6R, NTF4 및 UNC5C를 암호화하는 유전자로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하는, 피험체에서 알츠하이머병(AD)을 나타내는 유전적 변이를 검출하기 위한 방법이 제공되되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다. 해당 방법의 다양한 실시형태에서, 하나 이상의 유전적 변이의 존재의 검출은 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 대립유전자-특이적 뉴클레오타이드 포함, 5' 뉴클레아제 분해, 분자 비콘 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행된다. 일부 실시형태에서, 샘플로부터의 핵산은 하나 이상의 유전적 변이의 존재를 결정하기 전에 증폭된다.
본 발명은 (a) IL6R, NTF4 및 UNC5C를 암호화하는 유전자로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 검출할 수 있는 시약과 피험체로부터의 샘플을 접촉시키는 단계; 및 (b) 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하는 피험체에서 AD를 진단하거나 또는 예후하기 위한 방법을 추가로 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다.
본 발명은 피험체로부터의 생물학적 샘플 내 IL6R, NTF4 및 UNC5C를 암호화하는 유전자로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하는, 피험체에서 AD를 진단하거나 또는 예후하기 위한 방법을 추가로 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다.
본 발명은 또한 (a) 피험체로부터 핵산 함유 샘플을 얻는 단계, 및 (b) IL6R, NTF4 및 UNC5C를 암호화하는 유전자로부터 선택된 유전자 내 적어도 하나의 유전적 변이의 존재를 검출하기 위한 샘플을 분석하는 단계를 포함하는 피험체에서 AD를 진단하거나 또는 예후하기 위한 방법을 제공하되, 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타낸다.
일부 실시형태에서, 해당 방법은 피험체에 AD에 대한 하나 이상의 추가적인 진단적 시험을 실시하는 단계, 예를 들어 하나 이상의 추가적인 유전적 마커에 대한 스크리닝 단계, 정신상태 검사를 실시하는 단계 또는 피험체에 영상화 절차를 실시하는 단계를 추가로 포함한다. 일부 실시형태에서, 해당 방법은 APOE 변형제인 적어도 하나의 추가적인 유전적 마커의 존재를 검출하기 위한 샘플을 분석하는 단계를 추가로 포함하되, 적어도 하나의 추가적인 유전적 마커는 IL6R을 암호화하는 유전자, NTF4를 암호화하는 유전자, UNC5C를 암호화하는 유전자, 및 표 3에 열거된 유전자로부터 선택된 유전자 내에 있다.
상기 방법 중 어떤 것이 해당 방법의 결과를 기반으로 AD에 대해 피험체를 치료하는 단계를 추가로 포함할 수 있다. 일부 실시형태에서, 상기 방법은 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 존재를 검출하는 단계를 추가로 포함한다. 실시형태에서, 적어도 하나의 APOE-ε4 대립유전자의 존재와 함께 적어도 하나의 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 가지면서 적어도 하나의 유전적 마커의 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타낸다.
또한 AD의 더 조기 연령의 AD 진단의 증가된 위험을 갖는 피험체를 확인하는 방법이 제공되되, (a) 피험체로부터의 생물학적 샘플 내 IL6R, NTF4 및 UNC5C를 암호화하는 유전자로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 결정하는 단계; 및 (b) 적어도 하나의 APOE-ε4 대립유전자의 존재 또는 부재를 결정하는 단계를 포함하되, 유전적 변이 및 적어도 하나의 APOE-ε4 대립유전자의 존재는 유전적 변이 및 적어도 하나의 APOE-ε4 대립유전자의 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 가진다는 것을 나타낸다.
또한 피험체에서 AD의 하위표현형의 진단을 보조하는 방법이 제공되되, 해당 방법은 피험체로부터 유래된 생물학적 샘플에서 IL6R, NTF4 또는 UNC5C을 암호화하는 유전자에서 유전적 변이체의 존재를 검출하는 단계를 포함한다. 실시형태에서, 유전적 변이체는 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP이며, AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 가용성 IL6R의 증가된 수준을 특징으로 한다. 다른 실시형태에서, 유전적 변이는 NTF4의 아미노산 서열(서열번호 2) 내 아미노산 치환 R206W를 초래하는 SNP이며, AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 TrkB의 감소된 활성화를 특징으로 한다. 다른 실시형태에서, 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3) 내 아미노산 치환 T835M을 초래하는 SNP이며, AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 UNC5C의 증가된 아포토시스 활성을 특징으로 한다.
본 발명은 피험체로부터 얻은 생물학적 샘플에서 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP를 검출하는 단계를 포함하는, IL6R을 표적화하는 AD 치료제에 대한 피험체의 반응을 예측하는 방법을 추가로 제공하되, SNP의 존재는 IL6R을 표적화하는 치료제에 대한 반응을 나타낸다. 실시형태에서, 치료제는 IL6R 길항물질 또는 결합제, 예를 들어, 항-IL6R 항체이다.
본 발명은 피험체로부터 얻은 생물학적 샘플에서 NTF4의 아미노산 서열(서열번호 2) 내 아미노산 치환 R206W를 초래하는 SNP를 검출하는 단계를 포함하는 TrkB를 표적화하는 AD 치료제에 대한 피험체의 반응을 예측하는 방법을 추가로 제공하되, SNP의 존재는 TrkB를 표적화하는 치료제에 대한 반응을 나타낸다. 실시형태에서, 치료제는 TrkB 작용물질, 예를 들어 TrkB 작용물질 항체이다.
본 발명은 피험체로부터 얻은 생물학적 샘플에서 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP를 검출하는 단계를 포함하는, UNC5C를 표적화하는 AD 치료제에 대한 피험체의 반응을 예측하는 방법을 추가로 제공하되, SNP의 존재는 UNC5C를 표적화하는 치료제에 대한 반응을 나타낸다. 실시형태에서, 치료제는 UNC5C 죽음 도메인을 표적화한다.
상기 기재된 방법 중 어떤 것에서 사용을 위한 생물학적 샘플은 당업자에게 공지된 특정 방법을 사용하여 얻어질 수 있다. 생물학적 샘플은 척추 동물, 특히 포유류에서 얻어질 수 있다. 특정 실시형태에서, 생물학적 샘플은 세포 또는 조직, 예컨대 뇌척수액, 신경 세포, 또는 뇌 조직을 포함한다. 표적 핵산(또는 암호화된 폴리펩타이드) 내 변이는 조직 샘플로부터 또는 다른 신체 샘플, 예컨대 뇌척수액, 혈액, 혈청, 소변, 가래, 타액, 점막의 찰과표본, 눈물 분비물, 또는 땀으로부터 검출될 수 있다. 이러한 신체 샘플을 스크리닝함으로써, AD와 같은 질병에 대해 단순한 조기 진단이 달성될 수 있다. 추가로, 치료 과정은 표적 핵산(또는 암호화된 폴리펩타이드) 내 변이에 대해 이러한 신체 샘플을 시험함으로써 더 용이하게 모니터링될 수 있다. 일부 실시형태에서, 생물학적 샘플은 AD를 가질 것으로 의심되는 개체로부터 얻어진다.
피험체 또는 피험체로부터 얻은 생물학적 샘플이 본 명세서에 개시된 유전적 변이를 포함한다는 결정에 후속하여, 적절한 AD 치료제의 유효량이 피험체에서 AD를 치료하기 위해 피험체에 투여될 수 있는 것으로 생각된다.
상기 기재된 방법에 따라 또한 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자, 또는 표 3에 열거된 유전자 중 어느 하나 이상에서 유전적 변이를 포함하는 핵산 내 하나 이상의 변이의 존재를 검출함으로써 포유류에서 AD 진단을 보조하기 위한 방법이 제공된다.
다른 실시형태에서, 방법은 AD를 지니는 피험체가 상기 기재된 방법에 따라 본 명세서에 개시된 바와 같은 IL6R, NTF4, 또는 UNC5C를 암호화하는 유전자, 또는 표 3에 열거된 유전자 중 하나 이상에서 변이를 포함하는지 여부를 결정함으로써 치료제에 반응하는지 여부를 예측하는 방법이 제공된다.
또한 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자 또는 표 3에 열거된 유전자 중 하나 이상에서 변이의 피험체 내 존재 또는 부재를 검출함으로써 AD가 발생한 피험체의 소인을 평가하기 위한 방법이 제공된다.
또한 포유류에서 AD를 하위 분류하는 방법이 제공되며, 해당 방법은 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자 또는 표 3에 열거된 유전자 중 어느 하나 이상에서 유전적 변이의 존재를 검출하는 단계를 포함한다.
또한 환자 하위집단에서 AD를 치료하는데 효과적인 치료제를 확인하는 방법이 제공되며, 해당 방법은 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자 또는 표 3에 열거된 유전자 중 어느 하나 이상에서의 SNP에 대응되는 뉴클레오타이드 위치에서 유전적 변이의 존재와 작용제의 효능을 상호 관련짓는 단계를 포함한다.
추가적인 방법은 적절하다면, 적절한 임상적 개입 단계를 결정하는데 유용한 정보를 제공한다. 따라서, 본 발명의 방법의 일 실시형태에서, 해당 방법은 본 명세서에 개시된 바와 같은 AD와 관련된 유전자에서 변이의 존재 또는 부재의 평가 결과를 기반으로 임상적 개입 단계를 추가로 포함한다. 예를 들어, 적절한 개입은 본 발명의 방법에 의해 얻어지는 유전적 정보를 기반으로 예방적 및 치료 단계 또는 어떤 그 다음의 기존의 예방적 또는 치료 단계의 조절(들)을 수반할 수 있다.
당업자에게 명백할 바와 같이, 본 명세서에 기재된 어떤 방법에서, 변이 존재의 검출은 질병의 특징(예를 들어, 질병의 존재 또는 하위유형)을 양성으로 나타내지만, 변이의 미검출은 또한 질병의 상호간 특징을 제공함으로써 유용하게 된다.
또한 추가적인 방법은 포유류로부터 생물학적 샘플을 얻는 단계, 본 명세서에 개시된 바와 같은 변이의 존재 또는 부재에 대해 생물학적 샘플을 시험하는 단계, 상기 조직 또는 세포 샘플에서 변이의 존재 또는 부재를 결정하는 단계, 상기 포유류에 적절한 치료제의 유효량을 투여하는 단계를 포함하는, 포유류에서 AD를 치료하는 방법을 포함한다. 선택적으로, 해당 방법은 상기 포유류에 표적화된 AD 치료제의 유효량을 투여하는 단계를 포함한다.
또한 유전적 변이가 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자, 또는 표 3에 열거된 유전자 중 어느 하나 이상에서의 SNP에 대응되는 뉴클레오타이드 위치에서 존재하는 것으로 알려진 피험체에서 AD를 치료하는 방법이 제공되며, 해당 방법은 질환을 치료하는데 효과적인 치료제를 피험체에 투여하는 단계를 포함한다.
또한 AD를 갖는 피험체를 치료하는 방법이 제공되며, 해당 방법은 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자, 또는 표 3에 열거된 유전자 중 어느 하나 이상에서의 SNP에 대응되는 뉴클레오타이드 위치에서 유전적 변이를 갖는 피험체에서 질환을 치료하는데 효과적인 것으로 알려진 피험체에 투여하는 단계를 포함한다.
또한 AD를 갖는 피험체를 치료하는 방법이 제공되며, 해당 방법은 적어도 하나의 임상 연구에서 상기 질환을 치료하는데 효과적인 것으로 이전에 나타난 치료제를 피험체에 투여하는 단계를 포함하되, 작용제는 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자 또는 표 3에 열거된 유전자 중 어느 하나 이상에서의 SNP에 대응되는 뉴클레오타이드 위치에서 각각 유전적 변이를 갖는 적어도 5명의 인간 피험체에 투여된다. 일 실시형태에서, 적어도 5명의 피험체는 적어도 5명의 피험체의 그룹에 대해 전체적으로 2이상의 상이한 SNP를 가진다. 일 실시형태에서, 적어도 5명의 피험체는 적어도 5명의 피험체의 전체 그룹에 대해 동일한 SNP를 가진다.
또한 하위집단에 대해 치료제로서 승인된 치료제의 유효량을 피험체에 투여하는 단계를 포함하는, 특이적 AD 환자 하위집단을 가지는 AD 피험체를 치료하는 방법이 제공되되, 하위집단은 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자 또는 표 3에 열거된 유전자 중 어느 하나 이상에서의 SNP에 대응되는 뉴클레오타이드 위치에서 적어도 부분적으로 유전적 변이와 관련을 특징으로 한다.
일 실시형태에서, 하위집단은 유럽인 혈통이다. 일 실시형태에서, 본 발명은 AD 치료제를 제조하는 단계 및 AD를 가지거나 또는 갖는 것으로 믿어지는 피험체 또는 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자 또는 표 3에 열거된 유전자 중 어느 하나 이상에서의 SNP에 대응되는 위치에서 유전적 변이를 갖는 피험체에 작용제를 투여하기 위한 설명서와 함께 작용제를 포장하는 단계를 포함하는 방법을 제공한다.
또한 본 명세서에 개시된 바와 같은 IL6R, NTF4 또는 UNC5C를 암호화하는 유전자 또는 표 3에 열거된 유전자 중 어느 하나에서의 SNP에 대응되는 뉴클레오타이드 위치에서 유전적 변이의 존재를 검출하는 단계를 포함하는, AD 치료제에 의한 치료를 위해 AD로 고통받는 환자를 선택하기 위한 방법이 제공된다.
AD의 치료를 위한 치료제는 일부 실시형태에서 약제학적 사용에 적합한 조성물에 포함될 수 있다. 이러한 조성물은 전형적으로 펩타이드 또는 폴리펩타이드, 및 허용가능한 담체, 예를 들어 약제학적으로 허용가능한 것을 포함한다. "약제학적으로 허용가능한 담체"는 약제학적 투여와 양립가능한 임의의 및 모든 용매, 분산 매질, 코팅, 항박테리아제 및 항진균제, 등장 및 흡수 지연제 등을 포함한다(Gennaro, Remington: The science and practice of pharmacy. Lippincott, Williams & Wilkins, Philadelphia, Pa. (2000)). 이러한 담체 또는 희석제의 예는 물, 식염수, 링거액, 덱스트로스 용액 및 5% 인간 혈청 알부민을 포함하지만, 이들로 제한되지 않는다. 리포좀 및 비수성 비히클, 예컨대 고정유가 또한 사용될 수 있다. 통상적인 매질 또는 작용제가 활성 화합물과 양립불가능할 때를 제외하고, 이들 조성물의 사용이 고려된다. 보충 활성 화합물은 또한 조성물 내로 포함될 수 있다.
본 발명의 치료제(및 AD의 치료를 위한 임의의 추가적인 치료제)는 비경구, 폐내, 척추강내 및 비강내 및 원한다면 국소 치료를 위해 장애내 투여를 포함하는 임의의 적합한 수단에 의해 투여될 수 있다. 비경구 주입은, 예를 들어 근육내, 정맥내, 동맥내, 복강내, 또는 피하 투여를 포함한다. 투약은 부분적으로 투여가 간단한지 또는 만성인지 여부에 따라서 임의의 적합한 경로, 예를 들어 주사에 의할 수 있다. 1회 또는 다양한 시점에 걸친 다회 투여, 볼루스 투여 및 펄스 주입을 포함하지만, 이들로 제한되지 않는 다양한 투약 스케줄이 본 명세서에서 생각된다.
본 발명의 특정 실시형태는 혈액뇌 장벽을 횡단하는 AD 치료제를 제공한다. 몇몇 당업계에 공지된 접근은 생리적 방법, 지질기반 방법 및 수용체 및 채널기반 방법을 포함하지만, 이들로 제한되지 않는 혈액뇌 장벽을 횡단하는 분자를 수송하기 위해 존재한다.
혈액뇌 장벽을 횡단하는 AD 치료제를 수송하기 위한 생리적 방법은, 혈액뇌 장벽을 완전히 우회하거나 또는 혈액뇌장벽의 개방을 만드는 것을 포함한다. 우회 방법은 뇌 내로 직접 주사(예를 들어, 문헌[Papanastassiou et al ., Gene Therapy 9: 398-406 (2002)] 참조) 및 뇌에 전달 장치의 이식(예를 들어, 문헌[Gill et al., Nature Med . 9: 589-595 (2003); 및 Gliadel Wafers™, Guildford Pharmaceutical] 참조)을 포함하지만, 이들로 제한되지 않는다. 장벽 내 개방을 만드는 방법은 초음파(예를 들어, 미국특허 공개 제2002/0038086호 참조), 삼투압(예를 들어, 고장성 만니톨의 투여에 의해(Neuwelt, E. A., Implication of the Blood-Brain Barrier and its Manipulation, Vols 1 & 2, Plenum Press, N.Y. (1989))), 예를 들어, 브래디키닌 또는 투과기 A-7에 의한 투과(예를 들어, 미국특허 제5,112,596호, 제5,268,164호, 제5,506,206호 및 제5,686,416호 참조), 및 혈액뇌 장벽을 가로지르는 뉴런의 항체를 암호화하는 유전자 또는 이의 단편을 함유하는 벡터에 의한 형질감염(예를 들어, 미국특허 공개 제2003/0083299호 참조)을 포함하지만, 이들로 제한되지 않는다.
혈액뇌 장벽을 가로지르는 AD 치료제를 수송하는 지질기반 방법은 혈액뇌 장벽의 혈관 내피 상의 수용체에 결합되는 항체 결합 단편에 결합되는 리포좀에서 AD 치료제를 캡슐화하는 단계(예를 들어, 미국특허 출원 공개 제20020025313호 참조), 및 저밀도 리포단백질 입자(예를 들어, 미국특허 출원 공개 제20040204354호 참조) 또는 아폴리포단백질 E(예를 들어, 미국특허 출원 공개 제20040131692호 참조)에서 AD 치료제를 코팅하는 단계를 포함하지만, 이들로 제한되지 않는다.
혈액-뇌 장벽을 가로지르는 AD 치료제를 운송하는 수용체 기반 방법은 그것이 수용체 매개 트랜스사이토시스 후 혈액-뇌 장벽을 가로질러 운반되도록 야기하는 혈액-뇌 장벽에서 발현되는 수용체를 인식하는 리간드에 AD 치료제의 컨쥬게이션을 포함하지만, 이것으로 제한되지 않는다(Gabathuler (2010) Neurobiology of Disease 37; 48-57). 이들 리간드는 트랜스페린 수용체에 또는 인슐린 수용체, 히스톤, 바이오틴, 폴레이트, 나이아신, 판토텐산 또는 글라이코펩타이드에 단클론성 항체와 같은 뇌 모세관 내피 수용체를 포함하지만, 이들로 제한되지 않는 리간드를 포함한다.
AD 치료제를 투여하기 위한 효과적인 투약량 및 스케줄은 경험적으로 결정될 수 있으며, 이러한 결정을 하는 것은 당업자의 능력 내에 있다. 1회 또는 다회 투약량이 사용될 수 있다. AD 치료제의 생체내 투여가 사용될 때, 정상 투약량은 투여 경로에 따라서 1일 당 약 10ng/㎏ 내지 100㎎/kg까지의 포유류 체중 이상, 바람직하게는 약 1 ㎍/kg/일 내지 10㎎/kg/일로 다를 수 있다. 특정 투약량 및 전달 방법에 대한 지침은 문헌에서 제공된다; 예를 들어, 미국특허 제4,657,760호; 제 5,206,344호; 또는 제5,225,212호 참조.
또한 추가적인 치료가 해당 방법에서 사용될 수 있는 것으로 생각된다. 하나 이상의 다른 치료는 추가적인 AD 치료제, 예컨대 콜린에스터라제 저해제, 메만틴, 항-불안 의약, 항-우울제, 불안제거제, 또는 아밀로이드 전구체 단백질, 아밀로이드 베타, 아밀로이드 플라크를 표적화하는 화합물, 또는 알파-세크레타제, 베타-세크레타제 및 감마-세크레타제를 포함하지만, 이들로 제한되지 않는 아밀로이드 전구체 단백질을 절단하는 어떤 효소의 투여를 포함할 수 있지만, 이들로 제한되지 않는다.
키트
본 명세서에 기재되거나 또는 제시된 적용에서 사용을 위해, 키트 또는 제조물품이 또한 제공된다. 이러한 키트는 밀폐에서 바이알, 관 등과 같은 하나 이상의 용기 수단을 수용하도록 구획화된 운반체 수단을 포함할 수 있으며, 각각의 용기 수단은 해당 방법에서 사용되는 별개의 용기 중 하나를 포함한다. 예를 들어, 용기 수단 중 하나는 검출가능하게 표지되거나 또는 표지될 수 있는 프로브를 포함할 수 있다. 이러한 프로브는 본 명세서에 개시된 바와 같이 AD와 관련된 유전적 변이체를 포함하는 폴리뉴클레오타이드에 특이적인 폴리뉴클레오타이드일 수 있다. 키트가 표적 핵산을 검출하도록 핵산 혼성화를 이용하는 경우, 키트는 표적 핵산 서열의 증폭을 위한 뉴클레오타이드(들)를 함유하는 용기 및/또는 수용체 수단, 예컨대 효소적, 형광 또는 방사성동위원소 표지와 같은 수용체 분자에 결합된 바이오틴-결합 단백질, 예컨대 아비딘 또는 스트렙타비딘을 포함하는 용기를 가질 수 있다.
다른 실시형태에서, 키트는 본 명세서에 개시된 바와 같은 AD와 관련된 유전적 변이체를 포함하는 폴리펩타이드를 검출할 수 있는 표지 작용제를 포함할 수 있다. 이러한 작용제는 폴리펩타이드에 결합되는 항체일 수 있다. 이러한 작용제는 폴리펩타이드에 결합되는 펩타이드일 수 있다. 키트는, 예를 들어 본 명세서에 개시된 바와 같은 유전적 변이체를 포함하는 폴리펩타이드에 결합되는 제1 항체(예를 들어, 고체 지지체에 부착됨); 및 선택적으로 폴리펩타이드 또는 제1 항체에 결합되고, 검출가능한 표지에 컨쥬게이트되는 제2의 상이한 항체를 포함할 수 있다.
키트는 전형적으로 완충제, 희석제, 충전제, 바늘, 주사기 및 포장 삽입물을 포함하는 상업적 및 사용자 견지로부터 바람직한 재료를 사용을 위한 설명서와 함께 포함하는 상기 기재한 용기 및 하나 이상의 다른 용기를 포함할 것이다. 표지는 조성물이 특이적 치료 또는 비치료 적용을 위해 사용된다는 것을 나타내도록 용기 상에 제공될 수 있고, 또한 상기 기재한 것과 같은 생체내 또는 시험관내 사용을 위한 방향을 나타낼 수 있다. 키트 내 다른 선택적 성분은 하나 이상의 완충제(예를 들어, 차단 완충제, 세척 완충제, 기질 완충제 등), 효소적 표지, 에피토프 회복 용액, 대조군 샘플(양성 및/또는 음성 대조군), 대조군 슬라이드(들) 등에 의해 화학적으로 변경되는 다른 시약을 포함한다.
판매방법
본 명세서의 발명은 또한 표적 집단에 대한 광고, 지시 및/또는 명시를 포함하는 AD의 진단 또는 예후의 개시된 방법을 판매하기 위한 방법, 개시된 방법의 사용을 포함한다.
판매는 일반적으로 스폰서가 확인되고, 메시지가 통제되는 비인간 매체를 통해 유료 커뮤니케이션이다. 본 명세서의 목적을 위한 판매는 대중성, 공공관계, 간접광고, 후원, 인수 등을 포함한다. 이 용어는 또한 인쇄 전달 매체 중 어떤 것에서 나타나는 후원된 정보의 공고를 포함한다.
본 명세서의 진단 방법의 판매는 어떤 수단에 의해 달성될 수 있다. 이들 메시지를 전달하기 위해 사용되는 판매 매체의 예는 방송 매체에서 나타나는 메시지인 광고를 포함하여 텔레비전, 라디오, 영화, 잡지, 신문, 인터넷 및 옥외 광고판을 포함한다.
사용되는 판매 유형은 다수의 인자, 예를 들어 도달되는 표적 집단의 특성, 예를 들어 병원, 보험회사, 의원, 의사, 간호사 및 환자뿐만 아니라 비용의 고려 및 관계 사법당국의 법 및 의약 판매의 규제기관 및 진단에 의존할 것이다. 판매는 서비스 상호작용 및/또는 사용자 인구통계 및 지리적 위치와 같은 다른 데이터에 의해 정해지는 사용자의 특징을 기반으로 개별화되거나 또는 주문제작될 수 있다.
다음은 본 발명의 방법 및 조성물의 예이다. 상기 제공된 일반적 설명이 주어지는 다양한 다른 실시형태가 실행될 수 있는 것으로 이해된다.
실시예
실시예 1: APOE 변형제 스크리닝
알츠하이머병(AD)의 개발에 대해 APOE 효과를 변형시키는 변이체를 확인하는 연구를 설계하였다. 연구 설계를 도 1에 도시한다. 65세 미만이며 AD를 갖는 피험체로부터 단리하고, 따라서 위험 대립유전자에 대해 추정적으로 풍부한 DNA("사례")를 AD가 없고 신경학적 시험에 의해 정상 인식을 지니는 75세 또는 80세 초과의 피험체로부터 단리하며, 따라서 보호적 대립유전자가 추정적으로 풍부한 DNA("상위 대조군")와 비교하였다. 유럽 혈통의 미국 거주인 후손인 모든 피험체는 APOE E4 대립유전자에 대해 동형접합적(E4/E4) 또는 이형접합적(E3/E4)이었고, 알츠하이머병의 국립 세포 저장소(National Cell Repository of Alzheimer's Disease: NCRAD)로부터 얻었다. 표 1에 나타내는 바와 같이, 코호트 1에 대한 사례는 < 65세 및 >55세 연령의 치매 개시 연령에 의해 전체 31명의 미관련 E4/E4 동형접합체 및 50명 E3/E4 알츠하이머 사례를 포함하였다. 사례의 대략 1/3에 대해 AD 진단을 검시에 의해 확인하였다. 코호트 1에 대한 상위 대조군은 80세 초과에서 19명의 E3/E4 이형접합체 및 75세 초과에서 50명의 E4/E4 동형접합체를 포함하였다. 대조군은 모두 0과 동일한 임상치매척도(Clinical Dementia Rating: CDR)를 가지는데, 이는 최종 방문에서 인지 손상의 증거를 나타내지 않았다. 샘플의 APOE 대립유전자를 전체 게놈 시퀀싱에 의해(이형접합체에 대해) 또는 엑솜 시퀀싱에 의해(동형접합체에 대해) 확인하였다.
| 코호트 1* | ||
| APOE 대립유전자 | 사례(N) | 상위 대조군(N) |
| APOE-ε4/ APOE-ε4 | 31 | 19 |
| APOE-ε4/ APOE-ε3 | 50 | 50 |
| * 미국 국립 노화 연구소(National Institute on Aging: NIA)에 의해 수여된 협동 협약서승인(U24 AG21886) 하에 정부 지원을 받은 알츠하이머병에 대한 국립 세포 저장소(NCRAD)로부터의 샘플을 이 연구에서 사용하였다. 본 발명자들은 이 연구에서 사용한 샘플을 수집한 알츠하이머병 센터를 포함하는 기부자뿐만 아니라 이 작업이 가능하도록 도와주고 참여한 환자 및 그들의 가족에게 감사를 표한다. | ||
APOE 위험의 흔한 변형제
APOE를 변형시키는 흔한 변이체를 확인하기 위해 코호트 1에서 게놈 와이드 관련 스캔을 수행하였다. 일루미나(Illumina) 1M SNP 어레이를 사용하여 코호트 1의 피험체를 게노타이핑하였다. 게노타이핑 데이터에 대한 품질 대조군을 문헌[Gateva et al. (2009) Nat. Genet. 2009 Nov;41(11):1228-1233]에 기재된 바와 같이 수행하였다. 발견 단계에 대해 코호트 1(표 1)을 사용하였다. 인간 염색체 1 상의 IL6R/SHE/TDR10에서 흔한 변이체는 81 E4+ 사례 대 코호트 1의 68 E4+ 대조군에서 유의한 관련을 나타내었다(도 2).
미국 국립 노화 연구소에 대한 미국 국가생물공학센터(National Center for Biotechnology Information: NCBI)의 웹사이트에서 입수가능한 유전자형 및 표현형(dbGAP)의 데이터베이스로부터 복제 데이터 설정을 얻었다 - 후발성 알츠하이머병 패밀리 연구: 감수성 유전자좌위에 대한 게놈-와이드 관련 연구(dbGAP 연구 ID: phs000168.v1.p1). NIA/LOAD 연구는 일루미나 610K SNP 어레이에 대해 유전자형화된 932명의 AD 사례 및 836명의 유럽-미국 혈통 대조군으로 이루어졌다. <65세의 진단 연령을 지니는 200명의 E4 이형접합체 및 동형접합체 사례 및 최종 방문시 >=75세의 연령을 지니는 144명의 E4 이형접합체 및 동형접합체 대조군을 선택하였다.
표 2에서 나타내는 바와 같이, IL6R을 암호화하는 유전자 내 SNP(rs2228154)는 발견과 복제 코호트 둘 다에서 AD와 유의하게 관련되는 것을 확인하였다. 다형성 부위에서 C를 갖는 SNP rs2228145의 변이체("C 대립유전자")는 대조군에 비해 AD 사례에서 우선적으로 발견되었다. 이 대립유전자는 IL6R에서 아미노산 치환 D358A를 포함한다.
| 발견: 81명 < 65세 피험체 ALZ E4+ 사례 대 68명 > 80세 피험체 E4+ 대조군 | |||||||||
| 염색체 | SNP | 대립유전자 | 오즈비 | P | |||||
| 1 | rs2228154 | C | 1.738 | 0.0087 | |||||
| C 대립유전자: 사례에서 47%, 대조군에서 31% | |||||||||
| 복제: 200명 < 65세 피험체 ALZ E4+ 사례 대 144명 > 75세 피험체 E4+ 대조군 | |||||||||
| 염색체 | SNP | 대립유전자 | 오즈비 | P | |||||
| 1 | rs2228154 | C | 1.642 | 0.0017 | |||||
| C 대립유전자: 사례에서 46%, 대조군에서 33% 메타 P 값은 4.7 x 10-5이었다. |
|||||||||
IL6R의 A358 변이체 대립유전자의 분포를 NIA/LOAD 연구로부터 932명의 미선택 AD 사례 및 836명의 대조군에서 시험하였다. NIA/LOAD 피험체에서 APOE 다형체의 임상적 평가 및 게노타이핑은 문헌[Lee et al., (2008) Arch Neurol. 65: 1518-1526]에 기재되어 있다. 도 3은 AD 사례에서 개시 연령 및 대조군에서 연령에 의해 계층화되는 바와 같이 NIA/LOAD 연구로부터 미선택 AD 사례 및 대조군에서 rs4129267의 T 대립유전자, rs2228145의 C 대립유전자의 프록시의 빈도를 나타낸다. A358 변이체 대립유전자는 대조군에 비해 조발성 사례에서 더 빈번하게 존재하였지만, 대조군에 비해 후발성에서 덜 빈번하게 존재하였고, 이는 질량 변화 변이체와 일치된다.
인터류킨-6 수용체(IL6R)는 세포 성장 및 분화를 조절하고, 면역 반응에서 중요한 역할을 하는 강력한 다면발현 사이토카인인 사이토카인 인터류킨 6(IL-6)에 대한 수용체이다. IL6R A358은 증가된 혈청 IL6R 수준과 관련된 흔한 변이체 대립유전자이다(Galicia et al. (2004) Genes & Immunity 5:513; Marinou et al. (2010) Ann. Rheum. Dis. 69: 1191). A358 변이체 대립유전자는 감소된 CRP 순환 수준 및 관상심장병의 감소된 위험(Elliott et al. (2009) JAMA 302: 37-48)뿐만 아니라 증가된 천식 위험(Ferreira et al. (2011) Lancet 378: 1006-1014)과 관련되었다.
IL6R mRNA 발현이 AD에서 상승되고/되거나 위치 358에서 유전자형에 의해 영향받는지 여부를 시험하기 위해, TGEN 프로젝트로부터의 데이터(Webster et al. (2009) Am. J. Hum. Genet. 84: 445-458)를 대조군에 비해 AD를 지니는 피험체의 뇌에서 막결합과 가용성 IL6R의 발현 수준을 비교하도록 분석하였다. IL6R(NM_000565)의 막 결합 형태만을 검출한 프로브를 사용하여, AD에서 또는 위치 358에서 유전자형에 의한 풍부를 관찰하지 못하였다. 그러나, 막결합과 sIL6R(NM_181359) mRNA를 둘 다 포획하는 프로브를 사용할 때, 뇌의 측두부에서 및 위치 358에서 유전자형에 의해, 대조군에 비해 AD 사례에서 유의한 풍부함을 관찰하였다(도 4).
IL6R 영역에 추가적으로, 표 3에 열거한 영역은 코호트 1 및 NIA/LOAD 데이터베이스에서 유의한 관계를 나타내었는데, 이는 이들 좌위가 APOE 위험의 추가적인 흔한 변형제일 수 있다는 것을 시사한다.
| 코호트 1 및 NIA/LOAD 연구에서 APOE 위험과 관련된 영역 | ||||||||||
| 코호트 1(81명 사례 대 68명 대조군) | NIA/LOAD(200명 사례 대 144명 대조군) | |||||||||
| SNP | 유전자 | 빈도_A | 빈도_U | OR | P | 빈도_A | 빈도_U | OR | P | |
| rs12733578 | INPP5B | 0.19 | 0.36 | 0.45 | 0.00044 | 0.28 | 0.38 | 0.66 | 0.013 | |
| rs4658945 | DISC1 | 0.37 | 0.24 | 1.83 | 0.0058 | 0.30 | 0.22 | 1.46 | 0.037 | |
| rs1478161 | OTOLIN1 | 0.21 | 0.34 | 0.48 | 0.0023 | 0.26 | 0.34 | 0.70 | 0.035 | |
| rs1024591 | STAG3L4 | 0.48 | 0.34 | 1.82 | 0.0032 | 0.49 | 0.39 | 1.53 | 0.0093 | |
| rs7799010 | UBE3C/ MINX1 |
0.50 | 0.37 | 1.78 | 0.0074 | 0.48 | 0.40 | 1.40 | 0.035 | |
| rs10969475 | LINGO2/ ACO1 |
0.52 | 0.37 | 1.87 | 0.0024 | 0.50 | 0.41 | 1.44 | 0.026 | |
| rs12961250 | MRLC2 | 0.40 | 0.27 | 1.99 | 0.0023 | 0.41 | 0.33 | 1.38 | 0.050 | |
| rs225359 | TFF1 | 0.25 | 0.43 | 0.44 | 0.00022 | 0.30 | 0.41 | 0.64 | 0.0054 | |
APOE 변형제 스크린에서 희귀 변이체
뉴로트로핀 4(
NTF4
)
상기 개시한 흔한 변이체에 추가로, APOE 변형제 스크린은 또한 AD와 관련된 희귀 변이체의 확인을 초래하였다. 전체 집단에서 2% 미만의 대립유전자 빈도를 갖는 이들 희귀 변이체는 NTF4의 R206W 변이체를 포함하였다. NTF4의 R206W 변이체는 AD 사례의 78명 중 2명(2.6%) 및 상위대조군의 67명 중 0명(0.0%)에서 발견되었다. 추가로, NHLBI 엑솜 시퀀싱 프로젝트(Exome Sequencing Project: ESP) 엑솜 변이체 공급자로부터 얻은 데이터를 사용하는 샘플 수집 시간에 AD를 갖지 않는 1300명 엑속-시퀀싱 유럽-미국인(P =1.87 x10-9)에서 R206W 변이체는 관찰되지 않았다.
NTF4의 R206W 변이체는 염색체 19 상의 SNP rs121918427 부위에서 C에서 T로 치환을 초래한다. 뉴로트로핀 4는 포유류 뉴런의 생존 및 분화를 제어하는 뉴로트로핀 인자 패밀리의 구성원인 뉴로트로핀(NT)이다. 뉴로트로핀은 특이적 티로신 키나제 수용체인 Trk를 함유하는 뉴런의 서브세트의 유지, 증식 및 분화를 초래한다. NT에 의한 Trk 활성화는 프로그래밍된 세포사의 부정을 통해 생존 뉴런을 촉진한다(Robinson et al. (1999) Protein Sci. 8: 2589-2597). NTF4는 말초 및 주변 뉴런의 생존을 촉진하며, Trk와 TrkB를 둘 다 활성화시킨다(Berkemeier et al. (1991) Neuron 7: 857-866).
NTF4 R206W 변이체는 대조군에 비해 녹내장을 지니는 피험체에서 과제공되는 것으로 이전에 보고되었다((Passuto et al. (2009) Am. J. Hum. Genet. 85: 447-456); Liu et al. (2010) Am. J. Hum. Genet. 86: 498-499). 변성된 잔기는 침팬지, 개, 마우스 및 래트에서 오솔로그(ortholog) 중에서 고도로 보존되며, TrkB 결합 부위에 위치된다. 변이체 단백질은 TrkB를 활성화하는 능력이 감소되었고, 신경돌기 곁가지에서 약화된 기능을 보여준다. 따라서 변이체 단백질은 뉴런 생존에 대한 효과를 가지는 것으로 예측된다(Passuto et al., supra).
NTF4의 이런 약화된 기능의 R206W 변이체와 APOE4 보유자에서 조발성 AD의 이런 새로 확인된 관련은 NTF4 경로의 활성화가 AD의 발생에 대해 보호적일 수 있으며, TrkB 수용체의 작용물질이 AD의 치료를 위한 잠재적 치료제일 수 있다는 것을 시사한다.
실시예 2: 가족 기반 스크리닝
앨리슨 고트(Alison Goate)(워싱턴 유니버시티)와 협력을 통해 LO1 가계도를 얻었다. LO1 가계도는 AD의 우성 유전을 시사하는 형태를 나타내었다. 발단자는 5명의 형제자매 중 한명이었는데 이들 중 2명은 또한 AD를 가지는 한편, 다른 형제자며의 AD 상태는 결정되지 않았다. 발단자의 어머니는 AD를 가졌고, 아버지는 그렇지 않았다. 발단자의 절반의 형제자매인 다른 배우자에 의한 발단자 아버지의 자녀는 AD를 가지지 않았다. 발단자 및 형제자매의 자녀 중에서, 4명이 AD를 가졌다. 가족 구성원에서 AD 개시 연령은 58세 내지 87세의 범위에 있었다. LO1 가계도의 16명 구성원으로부터 얻은 일루미나 결합 어레이를 사용하여 수집한 유전자형 데이터를 사용하여 비모수 결합 분석을 수행하였다. QCed 데이터세트를 사용하는 MERLIN 소프트웨어를 사용하여 NPL 결합을 실행하였다. LO1 계통도에서 비모수 결합 분석의 결과는 도 5에 나타내며, >1.5의 NPL 로드 스코어를 지니는 3개 영역을 관찰하였다. 3개 결합 간격 내에서 잠재적인 인과관계 대립유전자를 확인하기 위해, 발단자에 대해 엑솜 시퀀싱을 수행하였고(일루미나 샷 판독 기법), 1.5 초과의 LOD 스코어를 갖는 NPL 결합 피크에 대해 분석을 제한하였다. 얻어진 4,153 변이체를 새로움(dbSNP 또는 1000 게놈 프로젝트 데이터 내 존재로서 정함), 이형접합성 및 추정 기능을 기준으로 랭킹하였다. 다른 AD 사례의 유전자형인 발단자의 조카딸을 완전 게놈 시퀀싱(complete genome sequencing: CGI)을 사용하여 결정하였고, 상위 5위에 랭크된 변이체의 존재 또는 부재를 결정하였다. 이 과정에 의해 단일 변이체를 확인하였고, 염색체 4에 위치된다. 이 변이체의 존재 또는 부재를 발단자, 발단자의 어머니, 3명의 형제자매 및 발단자 및 모든 형제자매의 자녀를 포함하는 LO1 계통도의 19명 구성원에 대해 결정하였다. 11명의 보유자 중에서 8명이 AD를 가지는 한편, 나머지의 질병 상태는 알려지지 않았다. 2명의 남은 보유자는 AD를 가지지 않았지만, 75세 미만이었다. 변이체가 없는 8명의 가족 구성원은 AD를 가졌다.
변이체는 염색체 4에서 G에서 A로 치환되는 것으로 발견되었는데, 이는 UNC5C를 암호화하는 유전자에서 아미노산 치환 T835M을 초래한다. UNC5C는 네트린 수용체의 UNC5 패밀리의 구성원이며, 네트린 1에 대한 수용체이다. UNC5C는 해마 뉴런에서 고도로 발현된다. UNC5A, B 및 C는 특이적 축삭 상에서 네트린 1의 화학반발적 효과를 매개한다. 이들 수용체는 또한 그것의 네트린 1 리간드에 미결합일 때 아포토시스를 유발하는 의존 수용체이다. 이들 수용체의 아포토시스전 활성은 카스파제에 의한 수용체의 절단 및 세포내 도메인의 C-말단에서 보존된 죽음 도메인의 존재에 의존한다.
SIFT 프로그램(Ng and Henikoff (2003) Nucleic Acids Res. 31: 3812-3814)을 사용하여 이 아미노산 치환이 단백질 기능에 영향을 미치는 것으로 예상되는지 여부를 예측하였다. 0.05 미만의 SIFT 스코어는 해로운 치환을 나타낸다. T835M 변이체의 SIFT 스코어는 0.01이었고, 이는 이 변이체가 해롭게 되는 높은 가능성을 가진다는 것을 나타낸다. 다른 UNC5 패밀리 구성원에 대한 정렬(도 6)은 이 변이체가 보존된 모티프에 존재한다는 것을 나타낸다. UNC5 단백질의 구조에 기반하여, 이 변이체는 죽음 도메인과 ZU5 도메인 사이의 힌지 영역, 아포토시스의 하류 조절자와 상호작용하는 영역에 있다(Williams et al. (2003) J. Biol. Chem. 278: 17483-17490). 네트린 수용체로서 UNC5C의 기능 및 해마 뉴런에서 그것의 높은 발현이 주어지면, T835M 변이체는 UNC5C 신호처리에 영향을 미칠 수 있으므로, UNC5C의 죽음 도메인은 개방, 활성화된 상태에서 우선적으로 발견되고, 이는 증가된 아포토시스 전 신호처리 및 뉴런 세포사를 초래한다. UNC5C의 T835M 변이체와 AD의 이런 새로 확인된 관계는 이 UNC5C 변이체의 비정상적 아포토시스 신호처리를 차단하는 것이 AD 치료를 위한 잠재적 치료적 접근일 수 있다는 것을 시사한다.
실시예 1에 기재한 APOE 변형제 스크린으로부터의 데이터를 UNC5C의 T385M 변이체의 존재에 대해 평가하였다. UNC5C의 T835M 변이체를 2/78 AD 사례 및 1/67 대조군에서 관찰하였다. >6,000 추가적인 대조군의 게노타이핑으로 유럽-미국인 집단에서 T825M의 집단 대립 유전자 빈도가 0.00071(T835M에 대해 이형접합적인 9/6315 개체)(표 4)이 되는 것 및 AD 사례 빈도가 0.013(P=1.5x10-7)인 것을 확고히 하였다. 이 데이터는 T835M이 AD 위험이 증가된 희귀 변이체라는 것을 시사한다.
| 연구 | AD 사례 | 대립유전자 빈도 | 대조군 | 대립유전자 빈도 |
| APOE 변형제 스크리닝 | 2/78 | 0.013 | 1/67 | 0.0074 |
| NF1,MADGC | 0/200 | 0.0 | ||
| AREDS | 6/2763 | 0.00011 | ||
| 결장직장암 | 0/235 | 0.0 | ||
| EVS(WashU) | 1/1350 | 0.00037 | ||
| NYCP | 1/1700 | |||
| 합계 | 2/78 | 0.013 | 9/6315 | 0.000712 |
실시예 3: A358와 증가된 가용성 IL6R 수준의 관계
알츠하이머 신경촬영법 계획(Alzheimer's Disease Neuroimaging Initiative: ADNI; Weiner, M.W. et al. (2010) Alzheimer's & Dementia 6: 202-211)으로부터의 291개 샘플에 대한 데이터에서 뇌척수액(CSF) 내 가용성 IL6R(sIL6R) 수준과 IL6R 유전자 영역 내 SNP에서 유전자형 사이의 관계에 대해 시험을 수행하였다. 일루미나의 Human610Quad 게놈-와이드 SNP 분석을 사용하여 피험체를 게노타이핑하였고, 규칙 기반 의학(Rules Based Medicine: MyriadRBM)에 의해 개발한 루미넥스(Luminex) 면역분석 기법에 기반한 면역분석 패널을 사용하여 sIL6R을 측정하였다. 각각의 SNP에서, 추가 방식에서 SNP 유전자형(0, 1 또는 2개의 돌연변이체 대립유전자)에 대해 log(sIL6R)의 선형 회귀를 수행하였고, 유전자형의 효과 크기가 0이 된다는 귀무가설을 시험하였다. IL6R 유전자 내 변이체는 CSF에서 증가된 sIL6R 수준(도 7), SNP rs4129267과 유의한 관계를 나타내었고, rs2228145의 프록시와 가장 강한 관계를 나타내었다.
상기 논의한 바와 같이, SNP rs2228145의 변이체는 IL6R에서 아미노산 치환 D358A를 초래하였다. 표 5에 나타낸 바와 같이, 위치 358에서 IL6R 유전자형은 CSF에서 가용성 IL6R 수준과 상호 관련되었고, A358 변이체 대립유전자의 존재는 더 높은 수준의 CSF sIL6R과 관련되었다.
| IL6R 유전자형 | CSF sIL6R (평균) | N |
| D/D 358 | 0.85ng/㎖ | 99 |
| D/A 358 | 1.19ng/㎖ | 138 |
| A/A 358 | 1.43ng/㎖ | 38 |
IL6R 쉐딩(shedding)에 대한 IL6R에서 A358의 존재 효과를 시험관내와 생체내 둘 다에서 시험하였다. 시험관내 실험을 위해, 293T 세포를 IL6R의 D358 또는 A358 작제물로 형질감염시켰다. 형질감염의 48시간 후, 배지를 변화시켰고, 세포를 100nM 포볼 미리스테이트 아세테이트(PMA)로 0, 30, 60 및 120분 동안 처리하였다. 처리 후 세포를 채취하였고, IL6R-PE 항체(BD 파밍겐(BD Pharmingen), 카탈로그 번호 No-551850)로 염색하였다. 막 결합 IL6R을 FACS에 의해 분석하였다. 도 8은 PMA로 처리 후 연속 시점에서 0분 시점에 대한 평균 형광 강도(mean fluorescence intensity: MFI) 백분율을 나타낸다. 이 데이터는 세포 결합 IL6R의 양이 야생형 D358-함유 샘플에서 검출된 것과 대조적으로 변이체 A358-함유 샘플에서 현저하게 감소되었기 때문에, A358 변이체가 293T 세포에서 IL6R의 증가된 쉐딩을 야기한다는 것을 보여준다.
또한 IL6R 내 A358 변이체 대립유전자의 존재가 1차 T 세포에서 IL6R의 증가된 쉐딩을 야기하는지 여부를 결정하기 위한 실험을 수행하였다. 어플라이드 바이오시스템즈(Applied Biosystems)로부터의 분석 ID C_16170664_10인 TaqMan SNP 게노타이핑 분석을 사용하여 실시간 정량적 PCR에 의해 IL6R SNP rs2228145에 대해 강한 인간 자원자를 게노타이핑하였다. 연령, 성별 및 인종적으로 매칭한 동형접합적 공여체의 쌍(각각 유전자형 AA 및 CC를 지니는 것)으로부터의 피콜(Ficol) 구배에 의해 말초 혈액 단핵세포(Peripheral blood mononuclear cell: PBMC)를 얻었다. 제조업자에 의해 추천되는 바와 같은 스템셀 테크놀로지즈(STEMCELL Technologies)제의 EasySep CD4+T 세포 풍부 키트(카탈로그 번호 19052)를 사용하는 음성 선택에 의해 PBMC로부터 CD4+T 세포를 정제하였다. 그 다음에 CD4+ T 세포를 RPMI 1640+10% FBS + 2-머캅토에탄올 중에서 72시간 동안 배양시켰고, 100nM PMA로 60분 동안 처리하였다. 처리 바로 후 세포를 채취하였고, IL6R-PE 항체(BD 파밍겐, 카탈로그 번호-551850)로 염색하였다. 막 결합 IL6R을 FACS에 의해 분석하였다. 도 9는 IL6R의 막 결합 분획이 PMA에 의한 활성화 후 야생형 D358 IL6R과 대조적으로 A358 돌연변이를 지니는 IL6R을 운반하는 CD4+T 세포에서 더 낮다는 것을 나타내는데, 이는 A358 세포에서 증가된 쉐딩을 나타낸다.
다른 실험에서, CD4+T 세포를 플레이트 결합 항 hCD3(BD 파밍겐, 카탈로그 번호-555329, 10㎎/㎖) 및 항 hCD28(BD-카탈로그 번호-555725, 5㎎/㎖) 또는 동위원소 대조군(BD Pharmingen, 카탈로그 번호 554721-15㎎/㎖)에 의해 활성화시켰다. 그 다음에 전체 RNA 추출 후 24, 48 및 72시간 후 세포를 채취하였고, 상청액을 수집하여 IL-6R 알파 퀀티카인(Quantikine) ELISA 키트(알앤디 시스템즈(R&D Systems), 카탈로그 번호 DR600)를 사용하는 ELISA에 의한 sIL6R 수준을 결정하였다. 도 10은 각 시점에 D358에 비해 A358에 대해 가용성 IL6R에서 폴딩 증가를 나타낸다. 가용성 IL6R의 양은 D358에 대한 시간을 거쳐서 거의 일정하게 남아있었지만, 실험 과정을 거쳐서 A358에 대해 4배 증가되었다.
SEQUENCE LISTING
<110> Behrens, Timothy W.
Graham, Robert R.
and Bhangale, Tushar
<120> METHODS FOR TREATING, DIAGNOSING AND MONITORING
ALZHEIMER'S DISEASE
<130> P4780R1 WO
<150> US 61/671,531
<151> 2012-07-13
<150> US 61/558,197
<151> 2011-11-10
<160> 18
<210> 1
<211> 468
<212> PRT
<213> Homo sapiens
<400> 1
Met Leu Ala Val Gly Cys Ala Leu Leu Ala Ala Leu Leu Ala Ala
1 5 10 15
Pro Gly Ala Ala Leu Ala Pro Arg Arg Cys Pro Ala Gln Glu Val
20 25 30
Ala Arg Gly Val Leu Thr Ser Leu Pro Gly Asp Ser Val Thr Leu
35 40 45
Thr Cys Pro Gly Val Glu Pro Glu Asp Asn Ala Thr Val His Trp
50 55 60
Val Leu Arg Lys Pro Ala Ala Gly Ser His Pro Ser Arg Trp Ala
65 70 75
Gly Met Gly Arg Arg Leu Leu Leu Arg Ser Val Gln Leu His Asp
80 85 90
Ser Gly Asn Tyr Ser Cys Tyr Arg Ala Gly Arg Pro Ala Gly Thr
95 100 105
Val His Leu Leu Val Asp Val Pro Pro Glu Glu Pro Gln Leu Ser
110 115 120
Cys Phe Arg Lys Ser Pro Leu Ser Asn Val Val Cys Glu Trp Gly
125 130 135
Pro Arg Ser Thr Pro Ser Leu Thr Thr Lys Ala Val Leu Leu Val
140 145 150
Arg Lys Phe Gln Asn Ser Pro Ala Glu Asp Phe Gln Glu Pro Cys
155 160 165
Gln Tyr Ser Gln Glu Ser Gln Lys Phe Ser Cys Gln Leu Ala Val
170 175 180
Pro Glu Gly Asp Ser Ser Phe Tyr Ile Val Ser Met Cys Val Ala
185 190 195
Ser Ser Val Gly Ser Lys Phe Ser Lys Thr Gln Thr Phe Gln Gly
200 205 210
Cys Gly Ile Leu Gln Pro Asp Pro Pro Ala Asn Ile Thr Val Thr
215 220 225
Ala Val Ala Arg Asn Pro Arg Trp Leu Ser Val Thr Trp Gln Asp
230 235 240
Pro His Ser Trp Asn Ser Ser Phe Tyr Arg Leu Arg Phe Glu Leu
245 250 255
Arg Tyr Arg Ala Glu Arg Ser Lys Thr Phe Thr Thr Trp Met Val
260 265 270
Lys Asp Leu Gln His His Cys Val Ile His Asp Ala Trp Ser Gly
275 280 285
Leu Arg His Val Val Gln Leu Arg Ala Gln Glu Glu Phe Gly Gln
290 295 300
Gly Glu Trp Ser Glu Trp Ser Pro Glu Ala Met Gly Thr Pro Trp
305 310 315
Thr Glu Ser Arg Ser Pro Pro Ala Glu Asn Glu Val Ser Thr Pro
320 325 330
Met Gln Ala Leu Thr Thr Asn Lys Asp Asp Asp Asn Ile Leu Phe
335 340 345
Arg Asp Ser Ala Asn Ala Thr Ser Leu Pro Val Gln Asp Ser Ser
350 355 360
Ser Val Pro Leu Pro Thr Phe Leu Val Ala Gly Gly Ser Leu Ala
365 370 375
Phe Gly Thr Leu Leu Cys Ile Ala Ile Val Leu Arg Phe Lys Lys
380 385 390
Thr Trp Lys Leu Arg Ala Leu Lys Glu Gly Lys Thr Ser Met His
395 400 405
Pro Pro Tyr Ser Leu Gly Gln Leu Val Pro Glu Arg Pro Arg Pro
410 415 420
Thr Pro Val Leu Val Pro Leu Ile Ser Pro Pro Val Ser Pro Ser
425 430 435
Ser Leu Gly Ser Asp Asn Thr Ser Ser His Asn Arg Pro Asp Ala
440 445 450
Arg Asp Pro Arg Ser Pro Tyr Asp Ile Ser Asn Thr Asp Tyr Phe
455 460 465
Phe Pro Arg
<210> 2
<211> 210
<212> PRT
<213> Homo sapiens
<400> 2
Met Leu Pro Leu Pro Ser Cys Ser Leu Pro Ile Leu Leu Leu Phe
1 5 10 15
Leu Leu Pro Ser Val Pro Ile Glu Ser Gln Pro Pro Pro Ser Thr
20 25 30
Leu Pro Pro Phe Leu Ala Pro Glu Trp Asp Leu Leu Ser Pro Arg
35 40 45
Val Val Leu Ser Arg Gly Ala Pro Ala Gly Pro Pro Leu Leu Phe
50 55 60
Leu Leu Glu Ala Gly Ala Phe Arg Glu Ser Ala Gly Ala Pro Ala
65 70 75
Asn Arg Ser Arg Arg Gly Val Ser Glu Thr Ala Pro Ala Ser Arg
80 85 90
Arg Gly Glu Leu Ala Val Cys Asp Ala Val Ser Gly Trp Val Thr
95 100 105
Asp Arg Arg Thr Ala Val Asp Leu Arg Gly Arg Glu Val Glu Val
110 115 120
Leu Gly Glu Val Pro Ala Ala Gly Gly Ser Pro Leu Arg Gln Tyr
125 130 135
Phe Phe Glu Thr Arg Cys Lys Ala Asp Asn Ala Glu Glu Gly Gly
140 145 150
Pro Gly Ala Gly Gly Gly Gly Cys Arg Gly Val Asp Arg Arg His
155 160 165
Trp Val Ser Glu Cys Lys Ala Lys Gln Ser Tyr Val Arg Ala Leu
170 175 180
Thr Ala Asp Ala Gln Gly Arg Val Gly Trp Arg Trp Ile Arg Ile
185 190 195
Asp Thr Ala Cys Val Cys Thr Leu Leu Ser Arg Thr Gly Arg Ala
200 205 210
<210> 3
<211> 931
<212> PRT
<213> Homo sapiens
<400> 3
Met Arg Lys Gly Leu Arg Ala Thr Ala Ala Arg Cys Gly Leu Gly
1 5 10 15
Leu Gly Tyr Leu Leu Gln Met Leu Val Leu Pro Ala Leu Ala Leu
20 25 30
Leu Ser Ala Ser Gly Thr Gly Ser Ala Ala Gln Asp Asp Asp Phe
35 40 45
Phe His Glu Leu Pro Glu Thr Phe Pro Ser Asp Pro Pro Glu Pro
50 55 60
Leu Pro His Phe Leu Ile Glu Pro Glu Glu Ala Tyr Ile Val Lys
65 70 75
Asn Lys Pro Val Asn Leu Tyr Cys Lys Ala Ser Pro Ala Thr Gln
80 85 90
Ile Tyr Phe Lys Cys Asn Ser Glu Trp Val His Gln Lys Asp His
95 100 105
Ile Val Asp Glu Arg Val Asp Glu Thr Ser Gly Leu Ile Val Arg
110 115 120
Glu Val Ser Ile Glu Ile Ser Arg Gln Gln Val Glu Glu Leu Phe
125 130 135
Gly Pro Glu Asp Tyr Trp Cys Gln Cys Val Ala Trp Ser Ser Ala
140 145 150
Gly Thr Thr Lys Ser Arg Lys Ala Tyr Val Arg Ile Ala Tyr Leu
155 160 165
Arg Lys Thr Phe Glu Gln Glu Pro Leu Gly Lys Glu Val Ser Leu
170 175 180
Glu Gln Glu Val Leu Leu Gln Cys Arg Pro Pro Glu Gly Ile Pro
185 190 195
Val Ala Glu Val Glu Trp Leu Lys Asn Glu Asp Ile Ile Asp Pro
200 205 210
Val Glu Asp Arg Asn Phe Tyr Ile Thr Ile Asp His Asn Leu Ile
215 220 225
Ile Lys Gln Ala Arg Leu Ser Asp Thr Ala Asn Tyr Thr Cys Val
230 235 240
Ala Lys Asn Ile Val Ala Lys Arg Lys Ser Thr Thr Ala Thr Val
245 250 255
Ile Val Tyr Val Asn Gly Gly Trp Ser Thr Trp Thr Glu Trp Ser
260 265 270
Val Cys Asn Ser Arg Cys Gly Arg Gly Tyr Gln Lys Arg Thr Arg
275 280 285
Thr Cys Thr Asn Pro Ala Pro Leu Asn Gly Gly Ala Phe Cys Glu
290 295 300
Gly Gln Ser Val Gln Lys Ile Ala Cys Thr Thr Leu Cys Pro Val
305 310 315
Asp Gly Arg Trp Thr Pro Trp Ser Lys Trp Ser Thr Cys Gly Thr
320 325 330
Glu Cys Thr His Trp Arg Arg Arg Glu Cys Thr Ala Pro Ala Pro
335 340 345
Lys Asn Gly Gly Lys Asp Cys Asp Gly Leu Val Leu Gln Ser Lys
350 355 360
Asn Cys Thr Asp Gly Leu Cys Met Gln Thr Ala Pro Asp Ser Asp
365 370 375
Asp Val Ala Leu Tyr Val Gly Ile Val Ile Ala Val Ile Val Cys
380 385 390
Leu Ala Ile Ser Val Val Val Ala Leu Phe Val Tyr Arg Lys Asn
395 400 405
His Arg Asp Phe Glu Ser Asp Ile Ile Asp Ser Ser Ala Leu Asn
410 415 420
Gly Gly Phe Gln Pro Val Asn Ile Lys Ala Ala Arg Gln Asp Leu
425 430 435
Leu Ala Val Pro Pro Asp Leu Thr Ser Ala Ala Ala Met Tyr Arg
440 445 450
Gly Pro Val Tyr Ala Leu His Asp Val Ser Asp Lys Ile Pro Met
455 460 465
Thr Asn Ser Pro Ile Leu Asp Pro Leu Pro Asn Leu Lys Ile Lys
470 475 480
Val Tyr Asn Thr Ser Gly Ala Val Thr Pro Gln Asp Asp Leu Ser
485 490 495
Glu Phe Thr Ser Lys Leu Ser Pro Gln Met Thr Gln Ser Leu Leu
500 505 510
Glu Asn Glu Ala Leu Ser Leu Lys Asn Gln Ser Leu Ala Arg Gln
515 520 525
Thr Asp Pro Ser Cys Thr Ala Phe Gly Ser Phe Asn Ser Leu Gly
530 535 540
Gly His Leu Ile Val Pro Asn Ser Gly Val Ser Leu Leu Ile Pro
545 550 555
Ala Gly Ala Ile Pro Gln Gly Arg Val Tyr Glu Met Tyr Val Thr
560 565 570
Val His Arg Lys Glu Thr Met Arg Pro Pro Met Asp Asp Ser Gln
575 580 585
Thr Leu Leu Thr Pro Val Val Ser Cys Gly Pro Pro Gly Ala Leu
590 595 600
Leu Thr Arg Pro Val Val Leu Thr Met His His Cys Ala Asp Pro
605 610 615
Asn Thr Glu Asp Trp Lys Ile Leu Leu Lys Asn Gln Ala Ala Gln
620 625 630
Gly Gln Trp Glu Asp Val Val Val Val Gly Glu Glu Asn Phe Thr
635 640 645
Thr Pro Cys Tyr Ile Gln Leu Asp Ala Glu Ala Cys His Ile Leu
650 655 660
Thr Glu Asn Leu Ser Thr Tyr Ala Leu Val Gly His Ser Thr Thr
665 670 675
Lys Ala Ala Ala Lys Arg Leu Lys Leu Ala Ile Phe Gly Pro Leu
680 685 690
Cys Cys Ser Ser Leu Glu Tyr Ser Ile Arg Val Tyr Cys Leu Asp
695 700 705
Asp Thr Gln Asp Ala Leu Lys Glu Ile Leu His Leu Glu Arg Gln
710 715 720
Met Gly Gly Gln Leu Leu Glu Glu Pro Lys Ala Leu His Phe Lys
725 730 735
Gly Ser Thr His Asn Leu Arg Leu Ser Ile His Asp Ile Ala His
740 745 750
Ser Leu Trp Lys Ser Lys Leu Leu Ala Lys Tyr Gln Glu Ile Pro
755 760 765
Phe Tyr His Val Trp Ser Gly Ser Gln Arg Asn Leu His Cys Thr
770 775 780
Phe Thr Leu Glu Arg Phe Ser Leu Asn Thr Val Glu Leu Val Cys
785 790 795
Lys Leu Cys Val Arg Gln Val Glu Gly Glu Gly Gln Ile Phe Gln
800 805 810
Leu Asn Cys Thr Val Ser Glu Glu Pro Thr Gly Ile Asp Leu Pro
815 820 825
Leu Leu Asp Pro Ala Asn Thr Ile Thr Thr Val Thr Gly Pro Ser
830 835 840
Ala Phe Ser Ile Pro Leu Pro Ile Arg Gln Lys Leu Cys Ser Ser
845 850 855
Leu Asp Ala Pro Gln Thr Arg Gly His Asp Trp Arg Met Leu Ala
860 865 870
His Lys Leu Asn Leu Asp Arg Tyr Leu Asn Tyr Phe Ala Thr Lys
875 880 885
Ser Ser Pro Thr Gly Val Ile Leu Asp Leu Trp Glu Ala Gln Asn
890 895 900
Phe Pro Asp Gly Asn Leu Ser Met Leu Ala Ala Val Leu Glu Glu
905 910 915
Met Gly Arg His Glu Thr Val Val Ser Leu Ala Ala Glu Gly Gln
920 925 930
Tyr
<210> 4
<211> 83
<212> PRT
<213> Rattus norvegicus
<400> 4
His Cys Thr Phe Thr Leu Glu Arg His Ser Leu Ala Ser Thr Glu
1 5 10 15
Phe Thr Cys Lys Val Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu His Thr Thr Leu Ala Glu Thr Pro Ala Gly Ser
35 40 45
Leu Asp Ala Leu Cys Ser Ala Pro Gly Asn Ala Ala Thr Thr Gln
50 55 60
Leu Gly Pro Tyr Ala Phe Lys Ile Pro Leu Ser Ile Arg Gln Lys
65 70 75
Ile Cys Asn Ser Leu Asp Ala Pro
80
<210> 5
<211> 83
<212> PRT
<213> Homo sapiens
<400> 5
His Cys Thr Phe Thr Leu Glu Arg His Ser Leu Ala Ser Thr Glu
1 5 10 15
Leu Thr Cys Lys Ile Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu His Thr Thr Leu Ala Glu Thr Pro Ala Gly Ser
35 40 45
Leu Asp Thr Ile Cys Ser Ala Pro Gly Ser Thr Val Thr Thr Gln
50 55 60
Leu Gly Pro Tyr Ala Phe Lys Ile Pro Leu Ser Ile Arg Gln Lys
65 70 75
Ile Cys Asn Ser Leu Asp Ala Pro
80
<210> 6
<211> 83
<212> PRT
<213> Mus musculus
<400> 6
His Cys Thr Phe Thr Leu Glu Arg His Ser Leu Ala Ser Thr Glu
1 5 10 15
Phe Thr Cys Lys Val Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu His Thr Thr Leu Ala Glu Thr Pro Ala Gly Ser
35 40 45
Leu Asp Ala Leu Cys Ser Ala Pro Gly Asn Ala Ile Thr Thr Gln
50 55 60
Leu Gly Pro Tyr Ala Phe Lys Ile Pro Leu Ser Ile Arg Gln Lys
65 70 75
Ile Cys Ser Ser Leu Asp Ala Pro
80
<210> 7
<211> 82
<212> PRT
<213> Xenopus Laevis
<400> 7
His Cys Thr Phe Thr Leu Glu Arg Tyr Ser Leu Ala Ala Thr Glu
1 5 10 15
Leu Thr Cys Lys Ile Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu His Thr Leu Leu Glu Glu Asn Val Lys Ser Phe
35 40 45
Asp Pro Phe Cys Ser Gln Ala Glu Asn Ser Val Thr Thr His Leu
50 55 60
Gly Pro Tyr Ala Phe Lys Ile Pro Phe Ser Ile Arg Gln Lys Ile
65 70 75
Cys Asn Ser Leu Asp Ala Pro
80
<210> 8
<211> 82
<212> PRT
<213> Rattus norvegicus
<400> 8
His Cys Thr Phe Thr Leu Glu Arg Ile Asn Ala Ser Thr Ser Asp
1 5 10 15
Leu Ala Cys Lys Val Trp Val Trp Gln Val Glu Gly Asp Gly Gln
20 25 30
Ser Phe Asn Ile Asn Phe Asn Ile Thr Lys Asp Thr Arg Phe Ala
35 40 45
Glu Leu Leu Ala Leu Glu Ser Glu Gly Gly Val Pro Ala Leu Val
50 55 60
Gly Pro Ser Ala Phe Lys Ile Pro Phe Leu Ile Arg Gln Lys Ile
65 70 75
Ile Ala Ser Leu Asp Pro Pro
80
<210> 9
<211> 82
<212> PRT
<213> Homo sapiens
<400> 9
His Cys Thr Phe Thr Leu Glu Arg Val Ser Pro Ser Thr Ser Asp
1 5 10 15
Leu Ala Cys Lys Leu Trp Val Trp Gln Val Glu Gly Asp Gly Gln
20 25 30
Ser Phe Ser Ile Asn Phe Asn Ile Thr Lys Asp Thr Arg Phe Ala
35 40 45
Glu Leu Leu Ala Leu Glu Ser Glu Ala Gly Val Pro Ala Leu Val
50 55 60
Gly Pro Ser Ala Phe Lys Ile Pro Phe Leu Ile Arg Gln Lys Ile
65 70 75
Ile Ser Ser Leu Asp Pro Pro
80
<210> 10
<211> 82
<212> PRT
<213> Mus musculus
<400> 10
His Cys Thr Phe Thr Leu Glu Arg Val Asn Ala Ser Thr Ser Asp
1 5 10 15
Leu Ala Cys Lys Val Trp Val Trp Gln Val Glu Gly Asp Gly Gln
20 25 30
Ser Phe Asn Ile Asn Phe Asn Ile Thr Lys Asp Thr Arg Phe Ala
35 40 45
Glu Met Leu Ala Leu Glu Ser Glu Gly Gly Val Pro Ala Leu Val
50 55 60
Gly Pro Ser Ala Phe Lys Ile Pro Phe Leu Ile Arg Gln Lys Ile
65 70 75
Ile Thr Ser Leu Asp Pro Pro
80
<210> 11
<211> 82
<212> PRT
<213> Rattus norvegicus
<400> 11
His Cys Thr Phe Thr Leu Glu Arg Leu Ser Leu Asn Thr Val Glu
1 5 10 15
Leu Val Cys Lys Leu Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu Asn Cys Thr Val Ser Glu Glu Pro Thr Gly Ile
35 40 45
Asp Leu Pro Leu Leu Asp Pro Ala Ser Thr Ile Thr Thr Val Thr
50 55 60
Gly Pro Ser Ala Phe Ser Ile Pro Leu Pro Ile Arg Gln Lys Leu
65 70 75
Cys Ser Ser Leu Asp Ala Pro
80
<210> 12
<211> 82
<212> PRT
<213> Homo sapiens
<400> 12
His Cys Thr Phe Thr Leu Glu Arg Phe Ser Leu Asn Thr Val Glu
1 5 10 15
Leu Val Cys Lys Leu Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu Asn Cys Thr Val Ser Glu Glu Pro Thr Gly Ile
35 40 45
Phe Leu Pro Leu Leu Asp Pro Ala Asn Thr Ile Thr Thr Val Thr
50 55 60
Gly Pro Ser Ala Phe Ser Ile Pro Leu Pro Ile Arg Gln Lys Leu
65 70 75
Cys Ser Ser Leu Asp Ala Pro
80
<210> 13
<211> 82
<212> PRT
<213> Mus musculus
<400> 13
His Cys Thr Phe Thr Leu Glu Arg Leu Ser Leu Asn Thr Val Glu
1 5 10 15
Leu Val Cys Lys Leu Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu Asn Cys Thr Val Ser Glu Glu Pro Thr Gly Ile
35 40 45
Asp Leu Pro Leu Leu Asp Pro Ala Ser Thr Ile Thr Thr Val Thr
50 55 60
Gly Pro Ser Ala Phe Ser Ile Pro Leu Pro Ile Arg Gln Lys Leu
65 70 75
Cys Ser Ser Leu Asp Ala Pro
80
<210> 14
<211> 82
<212> PRT
<213> Gallus gallus
<400> 14
His Cys Thr Phe Thr Leu Glu Arg Phe Ser Leu Asn Thr Leu Glu
1 5 10 15
Leu Val Cys Lys Leu Cys Val Arg Gln Val Glu Gly Glu Gly Gln
20 25 30
Ile Phe Gln Leu Asn Cys Ser Val Ser Glu Glu Pro Thr Gly Ile
35 40 45
Asp Tyr Pro Ile Met Asp Ser Ala Gly Ser Ile Thr Thr Ile Val
50 55 60
Gly Pro Asn Ala Phe Ser Ile Pro Leu Pro Ile Arg Gln Lys Leu
65 70 75
Cys Ser Ser Leu Asp Ala Pro
80
<210> 15
<211> 82
<212> PRT
<213> Homo sapiens
<400> 15
His Cys Ala Phe Ser Leu Glu Arg Tyr Thr Pro Thr Thr Thr Gln
1 5 10 15
Leu Ser Cys Lys Ile Cys Ile Arg Gln Leu Lys Gly His Glu Gln
20 25 30
Ile Leu Gln Val Gln Thr Ser Ile Leu Glu Ser Glu Arg Glu Thr
35 40 45
Ile Thr Phe Phe Ala Gln Glu Asp Ser Thr Phe Pro Ala Gln Thr
50 55 60
Gly Pro Lys Ala Phe Lys Ile Pro Tyr Ser Ile Arg Gln Arg Ile
65 70 75
Cys Ala Thr Phe Asp Thr Pro
80
<210> 16
<211> 82
<212> PRT
<213> Mus musculus
<400> 16
His Cys Ala Phe Ser Leu Glu Arg Tyr Thr Pro Thr Thr Thr Gln
1 5 10 15
Leu Ser Cys Lys Ile Cys Ile Arg Gln Leu Lys Gly His Glu Gln
20 25 30
Ile Leu Gln Val Gln Thr Ser Ile Leu Glu Ser Glu Arg Glu Thr
35 40 45
Ile Thr Phe Phe Ala Gln Glu Asp Ser Thr Phe Pro Ala Gln Thr
50 55 60
Gly Pro Lys Ala Phe Lys Ile Pro Tyr Ser Ile Arg Gln Arg Ile
65 70 75
Cys Ala Thr Phe Asp Thr Pro
80
<210> 17
<211> 76
<212> PRT
<213> Caenorhabditis elegans
<400> 17
His Cys Ser Leu Lys Phe Arg Pro Lys Glu Ile Asn Gly Ser Gln
1 5 10 15
Phe Ser Thr Arg Val Ile Val Tyr Gln Lys Ala Ser Ser Thr Glu
20 25 30
Pro Met Val Met Glu Val Ser Asn Glu Pro Glu Leu Tyr Asp Ala
35 40 45
Thr Ser Glu Glu Arg Glu Lys Gly Ser Val Cys Val Glu Phe Arg
50 55 60
Leu Pro Phe Gly Val Lys Asp Glu Leu Ala Arg Leu Leu Asp Met
65 70 75
Pro
<210> 18
<211> 86
<212> PRT
<213> Camelus dromedarius
<400> 18
His Cys Glu Phe Ser Leu Arg Arg Gln Asp Gln Asn Ser Leu Cys
1 5 10 15
Val Asp Phe Gly Gln Gly Ser Glu Asp Asp Tyr Tyr Thr Phe Asn
20 25 30
Ile Pro Ala His Ser Met Ser Gly Ser Ala Glu Glu Leu Ala Ser
35 40 45
Thr Thr Asn Thr Thr Ile Ser Ile Asp Arg Gln Gly Asn Tyr Val
50 55 60
Asn Glu Ser Cys Val Met Asp Phe Val Gln Leu Pro His Ala Thr
65 70 75
Lys Arg Leu Ile Cys Gly Ala Leu Asp Pro Pro
80 85
Claims (98)
- 피험체에서 알츠하이머병(AD)을 나타내는 유전적 변이의 존재 또는 부재를 검출하는 방법으로서,
(a) IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자에서 상기 유전적 변이의 존재 또는 부재를 검출할 수 있는 시약과 상기 피험체로부터의 샘플을 접촉시키는 단계; 및
(b) 상기 유전적 변이의 상기 존재 또는 부재를 결정하는 단계를 포함하되,
상기 유전적 변이의 존재는 상기 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타내는 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법. - 제1항에 있어서, 상기 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(single nucleotide polymorphism: SNP), 대립유전자, 단상형, 삽입 또는 결실인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제2항에 있어서, 상기 유전적 변이는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제3항에 있어서, 상기 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제4항에 있어서, 상기 유전적 변이는 rs2228145에서 'C' 대립유전자인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제3항에 있어서, 상기 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제6항에 있어서, 상기 유전적 변이는 rs121918427에서 'T' 대립유전자인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제3항에 있어서, 상기 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제8항에 있어서, 상기 유전적 변이는 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈 내 G를 A로 치환하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제1항에 있어서, 상기 시약은 올리고뉴클레오타이드, DNA 프로브, RNA 프로브 및 리보자임으로부터 선택된 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제10항에 있어서, 상기 시약은 표지된 것인, 알츠하이머병을 나타내는 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제1항에 있어서, 상기 적어도 하나의 유전적 변이는 IL6R, NTF4 및 UNC5C로부터 선택된 단백질에서 아미노산 치환, 삽입 또는 결실인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제12항에 있어서, 상기 적어도 하나의 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1)에서 D358A, 상기 NTF4의 아미노산 서열(서열번호 2)에서 R206W 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 T835M으로부터 선택된 아미노산 치환인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제12항에 있어서, 상기 시약은 상기 유전적 변이를 포함하는 단백질에 특이적으로 결합되는 항체인 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제1항에 있어서, 상기 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제1항에 있어서, 단계 (b)의 결과를 기반으로 AD에 대해 상기 피험체를 치료하는 단계를 더 포함하는, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제1항에 있어서, 상기 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 존재를 검출하는 단계를 더 포함하는, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 제17항에 있어서, 적어도 하나의 APOE-ε4 대립유전자의 존재와 함께 적어도 하나의 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 가지면서 상기 적어도 하나의 유전적 마커의 상기 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타내는 것인, 알츠하이머병을 나타내는 유전적 변이의 존재 또는 부재의 검출 방법.
- 피험체에서 알츠하이머병(AD)을 나타내는 유전적 변이를 검출하는 방법으로서,
피험체로부터의 생물학적 샘플에서 IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 결정하는 단계를 포함하되, 상기 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타내는 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법. - 제19항에 있어서, 상기 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(SNP), 대립유전자, 단상형, 삽입 또는 결실인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제20항에 있어서, 상기 유전적 변이는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제21항에 있어서, 상기 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제22항에 있어서, 상기 유전적 변이는 rs2228145에서 'C' 대립유전자인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제21항에 있어서, 상기 유전적 변이는 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제24항에 있어서, 상기 유전적 변이는 rs121918427에서 'T' 대립유전자인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제21항에 있어서, 상기 유전적 변이는 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제26항에 있어서, 상기 유전적 변이는 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈 내 G를 A로 치환하는 SNP인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제19항에 있어서, 상기 하나 이상의 유전적 변이의 상기 존재는 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 대립유전자-특이적 뉴클레오타이드 포함, 5' 뉴클레아제 분해, 분자 비콘 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행되는 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제25항에 있어서, 상기 샘플로부터의 핵산은 상기 하나 이상의 유전적 변이의 상기 존재를 결정하기 전에 증폭된 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제19항에 있어서, 상기 적어도 하나의 유전적 변이는 IL6R, NTF4 및 UNC5C로부터 선택된 단백질 내 아미노산 치환, 삽입 또는 결실인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제30항에 있어서, 상기 적어도 하나의 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1)에서 D358A, 상기 NTF4의 아미노산 서열(서열번호 2)에서 R206W 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 T835M으로부터 선택된 아미노산 치환인 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제19항에 있어서, 상기 하나 이상의 유전적 변이의 상기 존재는 전기영동, 크로마토그래피, 질량 분석법, 단백질 분해, 단백질 시퀀싱, 면역친화도 분석, 또는 이들의 조합으로부터 선택된 과정에 의해 수행되는 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제25항에 있어서, 상기 샘플로부터의 단백질은 상기 하나 이상의 유전적 변이의 상기 존재를 결정하기 전에 상기 단백질에 결합되는 항체 또는 펩타이드를 사용하여 정제되는 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제19항에 있어서, 상기 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제19항에 있어서, 상기 하나 이상의 유전적 변이의 상기 존재를 기반으로 AD에 대해 상기 피험체를 치료하는 단계를 더 포함하는, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제19항에 있어서, 상기 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 상기 존재를 검출하는 단계를 더 포함하는, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 제36항에 있어서, 적어도 하나의 APOE-ε4 대립유전자의 존재와 함께 상기 적어도 하나의 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 가지고, 상기 적어도 하나의 유전적 마커의 상기 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타내는 것인, 알츠하이머병을 나타내는 유전적 변이의 검출 방법.
- 피험체에서 AD의 진단 또는 예후 방법으로서,
(a) IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 검출할 수 있는 시약과 상기 피험체로부터의 샘플을 접촉시키는 단계; 및
(b) 상기 유전적 변이의 상기 존재 또는 부재를 결정하는 단계를 포함하되,
상기 유전적 변이의 존재는 상기 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타내는 것인, AD의 진단 또는 예후 방법. - 제38항에 있어서, 상기 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(SNP), 대립유전자, 단상형, 삽입 또는 결실인 것인, AD의 진단 또는 예후 방법.
- 제39항에 있어서, 상기 유전적 변이는 SNP인 것인, AD의 진단 또는 예후 방법.
- 제40항에 있어서, 상기 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1)에서 D358A를 초래하는 SNP, 상기 NTF4의 아미노산 서열(서열번호 2)에서 R206W를 초래하는 SNP 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 T835M을 초래하는 SNP로 이루어진 군으로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제34항에 있어서, 상기 유전적 변이는 rs2228145에서 'C' 대립유전자, rs121918427에서 'T' 대립유전자 및 UNC5C의 위치 835(서열번호 3)에서 상기 아미노산을 암호화하는 코돈에서 G를 A로 치환하는 SNP로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제38항에 있어서, 상기 시약은 올리고뉴클레오타이드, DNA 프로브, RNA 프로브 및 리보자임으로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제43항에 있어서, 상기 시약은 표지된 것인, AD의 진단 또는 예후 방법.
- 제38항에 있어서, 상기 적어도 하나의 유전적 변이는 IL6R, NTF4 및 UNC5C로부터 선택된 단백질 내 아미노산 치환, 삽입 또는 결실인 것인, AD의 진단 또는 예후 방법.
- 제45항에 있어서, 상기 적어도 하나의 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1)에서 D358A, 상기 NTF4의 아미노산 서열(서열번호 2)에서 R206W 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 T835M으로 이루어진 군으로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제45항에 있어서, 상기 시약은 상기 유전적 변이를 포함하는 단백질에 특이적으로 결합된 항체인 것인, AD의 진단 또는 예후 방법.
- 제38항에 있어서, 상기 샘플은 뇌척수액, 혈액, 혈청, 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제38항에 있어서, 단계 (b)의 결과를 기반으로 AD에 대해 상기 피험체를 치료하는 단계를 더 포함하는, 진단 또는 예후 방법.
- 제38항에 있어서, 상기 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 상기 존재를 검출하는 단계를 더 포함하는, AD의 진단 또는 예후 방법.
- 제50항에 있어서, 적어도 하나의 APOE-ε4 대립유전자의 상기 존재와 함께 적어도 하나의 유전적 변이의 존재는 상기 적어도 하나의 APOE-ε4 대립유전자를 가지면서 상기 적어도 하나의 유전적 마커의 상기 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타내는 것인, AD의 진단 또는 예후 방법.
- 제38항에 있어서, 하나 이상의 추가적인 유전적 마커를 스크리닝하는 단계, 정신상태 검사를 실시하는 단계 또는 피험체에 영상화 절차를 실시하는 단계로 이루어진 군으로부터 선택된 AD에 대한 하나 이상의 추가적인 진단 시험을 상기 피험체에 실시하는 단계를 더 포함하는, AD의 진단 또는 예후 방법.
- 제38항에 있어서, APOE 변형제인 적어도 하나의 추가적인 유전적 마커의 상기 존재를 검출하기 위해 상기 샘플을 분석하는 단계를 더 포함하되, 상기 적어도 하나의 추가적인 유전적 마커는 상기 IL6R을 암호화하는 유전자, 상기 NTF4를 암호화하는 유전자, 상기 UNC5C를 암호화하는 유전자 및 표 3에 열거된 유전자로부터 선택된 유전자에 있는 것인, AD의 진단 또는 예후 방법.
- 제53항에 있어서, 상기 적어도 하나의 추가적인 유전적 마커는 상기 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP, 상기 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835W을 초래하는 SNP 또는 표 3에 열거된 SNP인 것인, AD의 진단 또는 예후 방법.
- 피험체에서 AD의 진단 또는 예후 방법으로서,
상기 IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자 내 유전적 변이의 상기 존재 또는 부재를 결정하는 단계를 포함하되, 상기 유전적 변이의 존재는 피험체가 AD로 고통받거나 또는 AD가 진행될 위험에 있다는 것을 나타내는 것인, AD의 진단 또는 예후 방법. - 제55항에 있어서, 상기 적어도 하나의 유전적 변이는 단일 뉴클레오타이드 다형성(SNP), 대립유전자, 단상형, 삽입 또는 결실인 것인, AD의 진단 또는 예후 방법.
- 제56항에 있어서, 상기 유전적 변이는 SNP인 것인, AD의 진단 또는 예후 방법.
- 제57항에 있어서, 상기 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP, 상기 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M을 초래하는 SNP로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제57항에 있어서, 상기 유전적 변이는 rs2228145에서 'C' 대립유전자, rs121918427에서 'T' 대립유전자 및 UNC5C의 위치 835(서열번호 3)에서 아미노산을 암호화하는 코돈에서 G를 A로 치환하는 SNP로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제55항에 있어서, 상기 하나 이상의 유전적 변이의 상기 존재는, 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 대립유전자-특이적 뉴클레오타이드 포함, 5' 뉴클레아제 분해, 분자 비콘 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행되는 것인, AD의 진단 또는 예후 방법.
- 제60항에 있어서, 상기 샘플로부터의 핵산은 하나 이상의 유전적 변이의 존재를 결정하기 전에 증폭되는 것인, AD의 진단 또는 예후 방법.
- 제55항에 있어서, 상기 적어도 하나의 유전적 변이는 IL6R, NTF4 및 UNC5C로부터 선택된 단백질 내 아미노산 치환, 삽입 또는 결실인 것인, AD의 진단 또는 예후 방법.
- 제62항에 있어서, 상기 적어도 하나의 유전적 변이는 상기 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A, 상기 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835M으로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제55항에 있어서, 상기 하나 이상의 유전적 변이 내 상기 존재는 전기영동, 크로마토그래피, 질량 분석법, 단백질 분해, 단백질 시퀀싱, 면역친화도 분석, 또는 이들의 조합으로부터 선택된 과정에 의해 수행되는 것인, AD의 진단 또는 예후 방법.
- 제64항에 있어서, 상기 샘플로부터의 단백질은 하나 이상의 유전적 변이의 존재를 결정하기 전에 단백질에 결합된 항체 또는 펩타이드를 사용하여 정제된 것인, AD의 진단 또는 예후 방법.
- 제55항에 있어서, 상기 샘플은 뇌척수액, 혈액, 혈청 가래, 타액, 점막의 찰과표본, 조직생검, 눈물 분비물, 정액 또는 땀 중 하나로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 제55항에 있어서, 상기 하나 이상의 유전적 변이의 상기 존재를 기반으로 한 AD에 대해 상기 피험체를 치료하는 단계를 더 포함하는, AD의 진단 또는 예후 방법.
- 제55항에 있어서, 상기 샘플에서 적어도 하나의 APOE-ε4 대립유전자의 상기 존재를 검출하는 단계를 더 포함하는, AD의 진단 또는 예후 방법.
- 제68항에 있어서, 적어도 하나의 APOE-ε4 대립유전자의 상기 존재와 함께 적어도 하나의 상기 유전적 변이의 존재는, 적어도 하나의 APOE-ε4 대립유전자를 가지면서 상기 적어도 하나의 유전적 마커의 상기 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 나타내는 것인, AD의 진단 또는 예후 방법.
- 제55항에 있어서, 하나 이상의 추가적인 유전적 마커를 스크리닝하는 단계, 정신상태 검사를 실시하는 단계 또는 피험체에 영상화 절차를 실시하는 단계로 이루어진 군으로부터 선택된 AD에 대한 하나 이상의 추가적인 진단 시험을 상기 피험체에 실시하는 단계를 더 포함하는, AD의 진단 또는 예후 방법..
- 제55항에 있어서, APOE 변형제인 적어도 하나의 추가적인 유전적 마커의 상기 존재를 검출하기 위해 상기 샘플을 분석하는 단계를 더 포함하되, 상기 적어도 하나의 추가적인 유전적 마커는 상기 IL6R을 암호화하는 유전자, 상기 NTF4를 암호화하는 유전자, 상기 UNC5C를 암호화하는 유전자 및 표 3에 열거된 유전자로부터 선택된 유전자에 있는 것인, AD의 진단 또는 예후 방법.
- 제71항에 있어서, 상기 적어도 하나의 추가적인 유전적 마커는 상기 IL6R의 아미노산 서열(서열번호 1)에서 아미노산 치환 D358A를 초래하는 SNP, 상기 NTF4의 아미노산 서열(서열번호 2)에서 아미노산 치환 R206W를 초래하는 SNP 및 상기 UNC5C의 아미노산 서열(서열번호 3)에서 아미노산 치환 T835W를 초래하는 SNP 또는 표 3에 열거된 SNP로부터 선택된 것인, AD의 진단 또는 예후 방법.
- 더 조기 연령의 AD 진단의 증가된 위험을 갖는 피험체의 확인방법으로서,
피험체로부터의 생물학적 샘플에서 IL6R, NTF4 및 UNC5C를 암호화하는 유전자, 또는 이들의 유전자 산물로부터 선택된 유전자 내 유전적 변이의 존재 또는 부재를 결정하는 단계, 및
적어도 하나의 APOE-ε4 대립유전자의 존재 또는 부재를 결정하는 단계를 포함하되,
상기 유전적 변이 및 적어도 하나의 APOE-ε4 대립유전자의 상기 존재는 상기 피험체가 상기 유전적 변이 및 적어도 하나의 APOE-ε4 대립유전자의 상기 존재가 없는 피험체에 비해 더 조기 연령의 AD 진단의 증가된 위험을 가진다는 것을 나타내는 것인, 확인방법. - 피험체에서 AD의 하위표현형의 진단 보조방법으로서, 상기 방법은 피험체로부터 유래된 생물학적 샘플에서 상기 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP의 상기 존재를 검출하는 단계를 포함하되, 상기 AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 상기 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 가용성 IL6R의 증가된 수준을 특징으로 하는 것인, AD의 하위표현형의 진단 보조방법.
- IL6R을 표적화하는 AD 치료제에 대한 피험체의 반응 예측방법으로서, 상기 피험체로부터 얻은 생물학적 샘플에서 상기 IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP를 검출하는 단계를 포함하되, 상기 SNP의 상기 존재는 IL6R을 표적화하는 치료제에 대한 반응을 표시하는 것인, 반응 예측방법.
- 제75항에 있어서, 상기 치료제는 항-IL6R 항체인 것인, 반응 예측방법.
- 피험체에서 AD의 하위표현형의 진단 보조방법으로서, 상기 방법은 상기 피험체로부터 유래된 생물학적 샘플에서 NTF4의 아미노산 서열(서열번호 2) 내 상기 아미노산 치환 R206W를 초래하는 SNP의 상기 존재를 검출하는 단계를 포함하되, 상기 AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 TrkB의 적어도 부분적으로 감소된 활성화를 특징으로 하는 것인, 진단 보조방법.
- TrkB를 표적화하는 AD 치료제에 대한 피험체의 반응 예측방법으로서, 상기 피험체로부터 얻은 생물학적 샘플에서 NTF4의 아미노산 서열(서열번호 2) 내 아미노산 치환 R206W을 초래하는 SNP를 검출하는 단계를 포함하되, 상기 SNP의 존재는 TrkB를 표적화하는 치료제에 대한 반응을 나타내는 것인, 반응 예측방법.
- 제78항에 있어서, 상기 치료제는 TrkB 작용물질인 것인, 반응 예측방법.
- 피험체에서 AD의 하위표현형의 진단 보조방법으로서, 상기 방법은 피험체로부터 유래된 생물학적 샘플에서 UNC5C의 아미노산 서열(서열번호 3) 내 상기 아미노산 치환 T835M을 초래하는 SNP의 상기 존재를 검출하는 단계를 포함하되, 상기 AD의 하위표현형은 하나 이상의 대조군 피험체에 비해 피험체로부터 유래된 생물학적 샘플에서 적어도 부분적으로 UNC5C의 증가된 아포토시스 활성을 특징으로 하는 것인, 진단 보조방법.
- UNC5C를 표적화하는 AD 치료제에 대한 피험체의 반응 예측방법으로서, 상기 피험체로부터 얻은 생물학적 샘플에서 UNC5C의 아미노산 서열(서열번호 3) 내 아미노산 치환 T835M을 초래하는 SNP를 검출하는 단계를 포함하되, 상기 SNP의 존재는 UNC5C를 표적화하는 치료제에 대한 반응을 나타내는 것인, 반응 예측방법.
- 제81항에 있어서, 상기 치료제는 UNC5C 죽음 도메인을 표적화하는 것인, 반응 예측방법.
- 피험체에서 알츠하이머병(AD)의 진단 또는 예후 방법으로서,
(a) IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP, NTF4의 아미노산 서열 내 아미노산 치환 R206W를 초래하는 SNP 및 UNC5C의 아미노산 서열(서열번호 3) 내 아미노산 치환 T835M을 초래하는 SNP로 이루어진 군으로부터 선택된 하나 이상의 SNP의 존재 또는 부재를 검출할 수 있는 시약과 피험체로부터의 샘플을 접촉시키는 단계, 및
(b) 상기 하나 이상의 SNP의 상기 존재를 검출하기 위해 상기 샘플을 분석하는 단계를 포함하되, 상기 샘플 내 상기 하나 이상의 SNP의 상기 존재는 피험체가 AD로 고통받거나 또는 AD가 발생될 위험에 있다는 것을 나타내는 것인, 알츠하이머병의 진단 또는 예후 방법. - 제85항에 있어서, 표 3에 열거된 SNP로부터 선택된 하나 이상의 SNP를 검출하는 단계를 더 포함하는, 알츠하이머병의 진단 또는 예후 방법.
- 제83항의 방법을 수행하기 위한 키트로서, 적어도 하나의 올리고뉴클레오타이드 검출 시약을 포함하되, 상기 올리고뉴클레오타이드 검출 시약은 상기 하나 이상의 SNP에서 적어도 2종의 상이한 대립유전자의 각각을 구별하는 것인 키트.
- 제85항에 있어서, 상기 검출은 직접 시퀀싱, 대립유전자-특이적 프로브 혼성화, 대립유전자-특이적 프라이머 신장, 대립유전자-특이적 증폭, 시퀀싱, 5' 뉴클레아제 분해, 분자 비콘 분석, 올리고뉴클레오타이드 결찰 분석, 크기 분석, 및 단일 가닥 구조 다형성으로 이루어진 군으로부터 선택된 과정에 의해 수행되는 것인 키트.
- 제85항에 있어서, 상기 올리고뉴클레오타이드 검출 시약은 기판에 고정된 것인 키트.
- 제87항에 있어서, 상기 올리고뉴클레오타이드 검출 시약은 어레이 상에 배열된 것인 키트.
- 피험체에서 알츠하이머병(AD)의 진단 또는 예후 방법으로서,
(a) IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A, NTF4의 아미노산 서열 내 아미노산 치환 R206W 및 UNC5C의 아미노산 서열(서열번호 3) 내 아미노산 치환 T835M으로 이루어진 군으로부터 선택된 하나 이상의 아미노산 치환의 존재 또는 부재를 검출할 수 있는 시약과 상기 피험체로부터의 샘플을 접촉시키는 단계, 및
(b) 상기 하나 이상의 아미노산 치환의 존재를 검출하기 위해 상기 샘플을 분석하는 단계를 포함하되,
상기 샘플 내 상기 하나 이상의 아미노산 치환의 상기 존재는 피험체가 AD로 고통받거나 또는 AD가 발생될 위험에 있다는 것을 나타내는 것인, AD의 진단 또는 예후 방법. - 제89항의 방법을 수행하기 위한 키트로서, 적어도 하나의 항체 검출 시약을 포함하되, 상기 항체 검출 시약은 상기 하나 이상의 아미노산 치환에서 적어도 2종의 상이한 아미노산의 각각을 구별하는 것인 키트.
- AD의 치료를 위한 치료적 표적으로서, 상기 치료적 표적은 IL6R, NTF4 및 UNC5C로부터 선택된 유전자에 의해 암호화된 단백질 중 하나 또는 조합인 것인 치료적 표적.
- AD의 진단 또는 예후를 위한 분자 프로브의 세트로서, IL6R의 아미노산 서열(서열번호 1) 내 아미노산 치환 D358A를 초래하는 SNP, NTF4의 아미노산 서열 내 아미노산 치환 R206W를 초래하는 SNP, 및 UNC5C의 아미노산 서열(서열번호 3) 내 아미노산 치환 T835M을 초래하는 SNP를 포함하는 군으로부터 선택된 적어도 2종의 마커를 직접적으로 또는 간접적으로 검출할 수 있는 적어도 2종의 프로브를 포함하되, 상기 분자 프로브는 1000개 초과의 구성요소의 마이크로어레이와 결합되지 않는 것인 분자 프로브 세트.
- 제92항에 있어서, 표 3에 열거된 SNP로부터 선택된 적어도 2종의 마커를 직접적으로 또는 간접적으로 검출할 수 있는 하나 이상의 프로브를 더 포함하는 분자 프로브 세트.
- 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 AD의 발생에 대해 해로운 또는 유리한 효과를 갖는 유전적 변이체의 스크리닝 방법으로서, 상기 방법은, AD가 없으면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 75세 초과의 대조군 피험체에 비해 AD를 가지면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 65세 미만의 피험체에서 증가되거나 또는 감소된 빈도에서 존재하는 유전적 변이체를 확인하는 단계를 포함하되, 대조군 피험체에 비해 AD를 갖는 피험체에서 증가된 빈도는 상기 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 해로운 효과와 관련된다는 것을 나타내고, 대조군 피험체에 비해 AD를 갖는 피험체에서 감소된 빈도는 상기 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 유리한 효과와 관련된다는 것을 나타내는 것인, 유전적 변이체의 스크리닝 방법.
- 제94항에 있어서, 상기 유전적 변이는 게놈-와이드 관련 스캔을 사용하여 확인되는 것인, 유전적 변이체의 스크리닝 방법.
- 제94항에 있어서, 상기 해로운 효과는 AD가 발생할 증가된 위험 또는 더 낮은 연령의 AD 개시인 것인, 유전적 변이체의 스크리닝 방법.
- 제94항에 있어서, 상기 유리한 효과는 AD가 발생할 감소된 위험 또는 더 후기 연령의 AD 개시인 것인, 유전적 변이체의 스크리닝 방법.
- 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 AD의 발생에 대해 해로운 또는 유리한 효과를 갖는 유전적 변이체에 대한 스크리닝 방법으로서, 상기 방법은,
(a) AD를 가지면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 65세 미만의 다수의 피험체의 하나 이상의 유전자 좌위에서 유전자형을 결정하는 단계;
(b) AD가 없으면서 적어도 하나의 APOE-ε4 대립유전자를 갖는 75세 초과의 다수의 대조군 피험체의 하나 이상의 유전자 좌위에서 상기 유전자형을 결정하는 단계; 및
(c) 대조군 피험체에 비해 AD를 갖는 피험체에서 증가된 또는 감소된 빈도에서 존재하는 유전적 변이체를 확인하는 단계를 포함하되,
대조군 피험체에 비해 AD를 갖는 피험체에서 증가된 빈도는 상기 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 해로운 효과와 관련된다는 것을 나타내고, 대조군 피험체에 비해 AD를 갖는 피험체에서 감소된 효과는 상기 유전적 변이가 적어도 하나의 APOE-ε4 대립유전자를 갖는 피험체에서 유리한 효과와 관련된다는 것을 나타내는 것인, 유전적 변이체에 대한 스크리닝 방법.
Applications Claiming Priority (5)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US201161558197P | 2011-11-10 | 2011-11-10 | |
| US61/558,197 | 2011-11-10 | ||
| US201261671531P | 2012-07-13 | 2012-07-13 | |
| US61/671,531 | 2012-07-13 | ||
| PCT/US2012/064466 WO2013071119A2 (en) | 2011-11-10 | 2012-11-09 | Methods for treating, diagnosing and monitoring alzheimer's disease |
Publications (1)
| Publication Number | Publication Date |
|---|---|
| KR20140089384A true KR20140089384A (ko) | 2014-07-14 |
Family
ID=47222323
Family Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020147014033A Withdrawn KR20140089384A (ko) | 2011-11-10 | 2012-11-09 | 알츠하이머병의 치료, 진단 및 모니터링 방법 |
Country Status (12)
| Country | Link |
|---|---|
| US (1) | US20140371094A1 (ko) |
| EP (1) | EP2776582A2 (ko) |
| JP (2) | JP6338530B2 (ko) |
| KR (1) | KR20140089384A (ko) |
| CN (3) | CN106011243A (ko) |
| AR (1) | AR088827A1 (ko) |
| BR (1) | BR112014011127A2 (ko) |
| CA (1) | CA2854779A1 (ko) |
| HK (1) | HK1214631A1 (ko) |
| MX (1) | MX2014005683A (ko) |
| RU (1) | RU2014123511A (ko) |
| WO (1) | WO2013071119A2 (ko) |
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020231081A1 (ko) * | 2019-05-10 | 2020-11-19 | 주식회사 엠제이브레인바이오 | Top3b 유전자 변이 기반 치매 진단방법 |
Families Citing this family (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US7702468B2 (en) | 2006-05-03 | 2010-04-20 | Population Diagnostics, Inc. | Evaluating genetic disorders |
| US10522240B2 (en) | 2006-05-03 | 2019-12-31 | Population Bio, Inc. | Evaluating genetic disorders |
| CN103392182B (zh) | 2010-08-02 | 2017-07-04 | 众有生物有限公司 | 用于发现遗传疾病中致病突变的系统和方法 |
| CA2851388C (en) | 2011-10-10 | 2023-11-21 | The Hospital For Sick Children | Methods and compositions for screening and treating developmental disorders |
| WO2013067451A2 (en) * | 2011-11-04 | 2013-05-10 | Population Diagnostics Inc. | Methods and compositions for diagnosing, prognosing, and treating neurological conditions |
| US10407724B2 (en) | 2012-02-09 | 2019-09-10 | The Hospital For Sick Children | Methods and compositions for screening and treating developmental disorders |
| EP2895621B1 (en) | 2012-09-14 | 2020-10-21 | Population Bio, Inc. | Methods and compositions for diagnosing, prognosing, and treating neurological conditions |
| US10233495B2 (en) | 2012-09-27 | 2019-03-19 | The Hospital For Sick Children | Methods and compositions for screening and treating developmental disorders |
| US9782075B2 (en) | 2013-03-15 | 2017-10-10 | I2Dx, Inc. | Electronic delivery of information in personalized medicine |
| US11089959B2 (en) | 2013-03-15 | 2021-08-17 | I2Dx, Inc. | Electronic delivery of information in personalized medicine |
| EP3077533B1 (en) * | 2013-12-06 | 2019-04-24 | Life & Brain GmbH | Methods for establishing a clinical prognosis of diseases associated with the formation of aggregates of abeta1-42 |
| GB2558326B (en) | 2014-09-05 | 2021-01-20 | Population Bio Inc | Methods and compositions for inhibiting and treating neurological conditions |
| WO2016050111A1 (en) * | 2014-09-30 | 2016-04-07 | Bgi Shenzhen | Biomarkers for rheumatoid arthritis and usage thereof |
| JP6991134B2 (ja) * | 2015-10-09 | 2022-01-12 | ガーダント ヘルス, インコーポレイテッド | 無細胞dnaを使用する集団ベースの処置レコメンダ |
| JP2017189121A (ja) * | 2016-04-11 | 2017-10-19 | 国立大学法人旭川医科大学 | 抗TNFα抗体適応疾患の治療における抗TNFα抗体投与時反応の発症リスクを判定する方法、並びに該判定用オリゴヌクレオチドキット |
| KR102024862B1 (ko) * | 2016-10-19 | 2019-09-25 | 삼성디스플레이 주식회사 | 표시 장치 |
| US11725232B2 (en) | 2016-10-31 | 2023-08-15 | The Hong Kong University Of Science And Technology | Compositions, methods and kits for detection of genetic variants for alzheimer's disease |
| US10240205B2 (en) | 2017-02-03 | 2019-03-26 | Population Bio, Inc. | Methods for assessing risk of developing a viral disease using a genetic test |
| JP7399465B2 (ja) * | 2017-05-15 | 2023-12-18 | インフォメディテック・カンパニー,リミテッド | アルツハイマー病の危険性と関連するapoeプロモーターの一塩基多型およびその使用 |
| WO2019178167A1 (en) * | 2018-03-13 | 2019-09-19 | I2Dx, Inc. | Electronic delivery of information in personalized medicine |
| CN108753954B (zh) * | 2018-06-26 | 2022-11-18 | 中南大学湘雅医院 | 痴呆相关基因的捕获探针组、试剂盒、文库构建方法和用途 |
| DE24173683T1 (de) | 2018-08-08 | 2024-11-07 | Pml Screening, Llc | Verfahren zur beurteilung des risikos der entwicklung einer viruserkrankung unter verwendung eines genetischen tests |
| WO2020143044A1 (zh) * | 2019-01-11 | 2020-07-16 | 深圳市双科生物科技有限公司 | 一种双质控检测方法 |
| WO2021037027A1 (en) * | 2019-08-29 | 2021-03-04 | The Hong Kong University Of Science And Technology | Genetic variants for diagnosis of alzheimer's disease |
| GB202004832D0 (en) * | 2020-04-01 | 2020-05-13 | Instituto De Medicina Molecular Faculdade De Medicina Univ De Lisboa | Therapeutic agaents, pharmaceutical compositions, and associated biomarkers |
| KR102561438B1 (ko) * | 2020-11-04 | 2023-07-28 | 사회복지법인 삼성생명공익재단 | 뇌 아밀로이드 베타 축적 가능성을 예측하는 방법 |
| CN112980954B (zh) * | 2021-03-03 | 2022-02-25 | 首都医科大学宣武医院 | 一种预测神经退行性疾病风险的试剂盒及其用途 |
| CR20250274A (es) * | 2023-01-09 | 2025-09-16 | Lilly Co Eli | Anticuerpos ANTI-UNC5C |
| CN117230184B (zh) * | 2023-11-13 | 2024-03-19 | 深圳康美生物科技股份有限公司 | 基于飞行时间核酸质谱技术检测阿尔兹海默病基因的核酸组合及应用 |
| WO2025125898A1 (en) * | 2023-12-15 | 2025-06-19 | Alchemab Therapeutics Ltd | Anti-unc5c antibodies and uses thereof |
Family Cites Families (21)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US4657760A (en) | 1979-03-20 | 1987-04-14 | Ortho Pharmaceutical Corporation | Methods and compositions using monoclonal antibody to human T cells |
| US4486530A (en) | 1980-08-04 | 1984-12-04 | Hybritech Incorporated | Immunometric assays using monoclonal antibodies |
| US4376110A (en) | 1980-08-04 | 1983-03-08 | Hybritech, Incorporated | Immunometric assays using monoclonal antibodies |
| US4683203A (en) | 1984-04-14 | 1987-07-28 | Redco N.V. | Immobilized enzymes, processes for preparing same, and use thereof |
| US4683195A (en) | 1986-01-30 | 1987-07-28 | Cetus Corporation | Process for amplifying, detecting, and/or-cloning nucleic acid sequences |
| US5206344A (en) | 1985-06-26 | 1993-04-27 | Cetus Oncology Corporation | Interleukin-2 muteins and polymer conjugation thereof |
| IE61148B1 (en) | 1988-03-10 | 1994-10-05 | Ici Plc | Method of detecting nucleotide sequences |
| US5225212A (en) | 1989-10-20 | 1993-07-06 | Liposome Technology, Inc. | Microreservoir liposome composition and method |
| US5112596A (en) | 1990-04-23 | 1992-05-12 | Alkermes, Inc. | Method for increasing blood-brain barrier permeability by administering a bradykinin agonist of blood-brain barrier permeability |
| US5268164A (en) | 1990-04-23 | 1993-12-07 | Alkermes, Inc. | Increasing blood-brain barrier permeability with permeabilizer peptides |
| ATE191853T1 (de) | 1992-07-27 | 2000-05-15 | Us Health | Zielgerichte liposome zur blut-hirne schranke |
| US5498531A (en) | 1993-09-10 | 1996-03-12 | President And Fellows Of Harvard College | Intron-mediated recombinant techniques and reagents |
| EP1736554B1 (en) | 1996-05-29 | 2013-10-09 | Cornell Research Foundation, Inc. | Detection of nucleic acid sequence differences using coupled ligase detection and polymerase chain reactions |
| EP1313880A2 (en) | 2000-05-30 | 2003-05-28 | PE Corporation (NY) | Methods for detecting target nucleic acids using coupled ligation and amplification |
| US6514221B2 (en) | 2000-07-27 | 2003-02-04 | Brigham And Women's Hospital, Inc. | Blood-brain barrier opening |
| US20030083299A1 (en) | 2000-11-04 | 2003-05-01 | Ferguson Ian A. | Non-invasive delivery of polypeptides through the blood-brain barrier |
| DE10121982B4 (de) | 2001-05-05 | 2008-01-24 | Lts Lohmann Therapie-Systeme Ag | Nanopartikel aus Protein mit gekoppeltem Apolipoprotein E zur Überwindung der Blut-Hirn-Schranke und Verfahren zu ihrer Herstellung |
| US20030119004A1 (en) | 2001-12-05 | 2003-06-26 | Wenz H. Michael | Methods for quantitating nucleic acids using coupled ligation and amplification |
| CN101284136A (zh) | 2002-12-03 | 2008-10-15 | 布朗歇特洛克菲勒神经科学研究所 | 传输物质穿过血脑屏障的人工低密度脂蛋白载体 |
| EA019571B1 (ru) * | 2008-04-29 | 2014-04-30 | Фарнекст | Применение сульфизоксазола для лечения болезни альцгеймера |
| CN101812525A (zh) * | 2010-04-09 | 2010-08-25 | 南通大学 | 与ad发病相关的基因网络通路分析模型的建立方法 |
-
2012
- 2012-11-09 KR KR1020147014033A patent/KR20140089384A/ko not_active Withdrawn
- 2012-11-09 CN CN201610369743.5A patent/CN106011243A/zh active Pending
- 2012-11-09 CN CN201280055180.2A patent/CN103930568A/zh active Pending
- 2012-11-09 EP EP12791045.3A patent/EP2776582A2/en not_active Withdrawn
- 2012-11-09 JP JP2014541330A patent/JP6338530B2/ja not_active Expired - Fee Related
- 2012-11-09 CN CN201510445488.3A patent/CN105063186A/zh active Pending
- 2012-11-09 MX MX2014005683A patent/MX2014005683A/es unknown
- 2012-11-09 US US14/357,192 patent/US20140371094A1/en not_active Abandoned
- 2012-11-09 RU RU2014123511/10A patent/RU2014123511A/ru unknown
- 2012-11-09 CA CA2854779A patent/CA2854779A1/en not_active Abandoned
- 2012-11-09 WO PCT/US2012/064466 patent/WO2013071119A2/en not_active Ceased
- 2012-11-09 AR ARP120104237A patent/AR088827A1/es unknown
- 2012-11-09 BR BR112014011127A patent/BR112014011127A2/pt not_active IP Right Cessation
-
2014
- 2014-08-06 HK HK16102579.7A patent/HK1214631A1/zh unknown
-
2018
- 2018-05-08 JP JP2018090050A patent/JP2018166507A/ja active Pending
Cited By (1)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| WO2020231081A1 (ko) * | 2019-05-10 | 2020-11-19 | 주식회사 엠제이브레인바이오 | Top3b 유전자 변이 기반 치매 진단방법 |
Also Published As
| Publication number | Publication date |
|---|---|
| JP2018166507A (ja) | 2018-11-01 |
| BR112014011127A2 (pt) | 2017-05-16 |
| CN105063186A (zh) | 2015-11-18 |
| RU2014123511A (ru) | 2015-12-20 |
| JP6338530B2 (ja) | 2018-06-06 |
| WO2013071119A2 (en) | 2013-05-16 |
| CN106011243A (zh) | 2016-10-12 |
| CN103930568A (zh) | 2014-07-16 |
| EP2776582A2 (en) | 2014-09-17 |
| HK1214631A1 (zh) | 2016-07-29 |
| JP2014533949A (ja) | 2014-12-18 |
| CA2854779A1 (en) | 2013-05-16 |
| WO2013071119A3 (en) | 2013-07-11 |
| MX2014005683A (es) | 2015-01-22 |
| US20140371094A1 (en) | 2014-12-18 |
| AR088827A1 (es) | 2014-07-10 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| JP6338530B2 (ja) | アルツハイマー病を治療、診断、および監視するための方法 | |
| Brouwers et al. | Alzheimer risk associated with a copy number variation in the complement receptor 1 increasing C3b/C4b binding sites | |
| EP3202914B2 (en) | Method for treating a neurodegenerative disease | |
| Yu et al. | Implication of CLU gene polymorphisms in Chinese patients with Alzheimer's disease | |
| US20210388444A1 (en) | Fus/tls-based compounds and methods for diagnosis, treatment and prevention of amyotrophic lateral sclerosis and related motor neuron diseases | |
| EP1473367B1 (en) | Means and methods for diagnosing and treating affective disorders | |
| Rinaldi et al. | Relevance of CCM gene polymorphisms for clinical management of sporadic cerebral cavernous malformations | |
| Bucossi et al. | Association between the c. 2495 A> G ATP7B Polymorphism and Sporadic Alzheimer′ s Disease | |
| US20040076953A1 (en) | Detection of antidepressant induced mania | |
| Balabas et al. | Novel germline mutations in BRCA2 gene among breast and breast-ovarian cancer families from Poland | |
| HK1195587A (en) | Methods for treating, diagnosing and monitoring alzheimer's disease | |
| Alfimova et al. | Assessment of effects of the OPRD1 and OPRM1 genes encoding opioid receptors on apathy in schizophrenia | |
| HK1226781A (en) | Methods for treating, diagnosing and monitoring alzheimer's disease | |
| HK1226781A1 (en) | Methods for treating, diagnosing and monitoring alzheimer's disease | |
| CA2344093C (en) | Detection of antidepressant induced mania | |
| JP2026032559A (ja) | Il33にリスクアレルを有する対象を治療するための治療方法 | |
| JP5422805B2 (ja) | 新規糖尿病性腎症感受性遺伝子 | |
| da Silva Santos et al. | Association of the Polymorphism of GSTP1 with the Susceptibility to the Development of Schizophrenia | |
| Bucossi et al. | Research Article Association between the c. 2495 A> G ATP7B Polymorphism and Sporadic Alzheimer’s Disease | |
| WO2006136791A1 (en) | Polymorphisms and haplotypes in p2x7 gene and their use in determining susceptibility for atherosclerosis-mediated diseases |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| PA0105 | International application |
Patent event date: 20140526 Patent event code: PA01051R01D Comment text: International Patent Application |
|
| PG1501 | Laying open of application | ||
| PC1203 | Withdrawal of no request for examination | ||
| WITN | Application deemed withdrawn, e.g. because no request for examination was filed or no examination fee was paid |