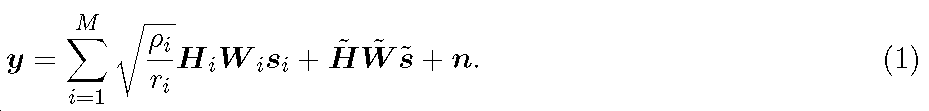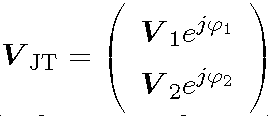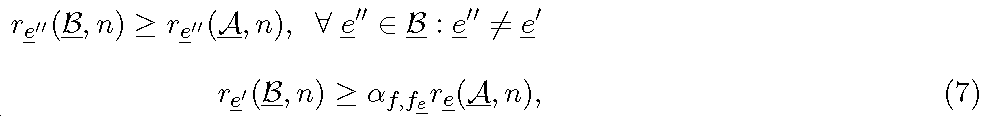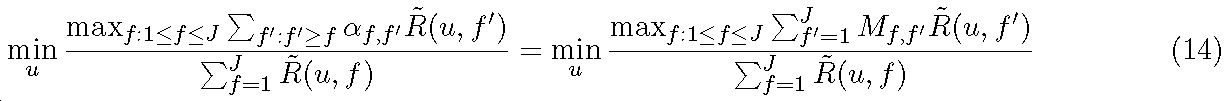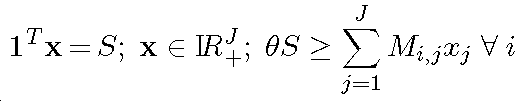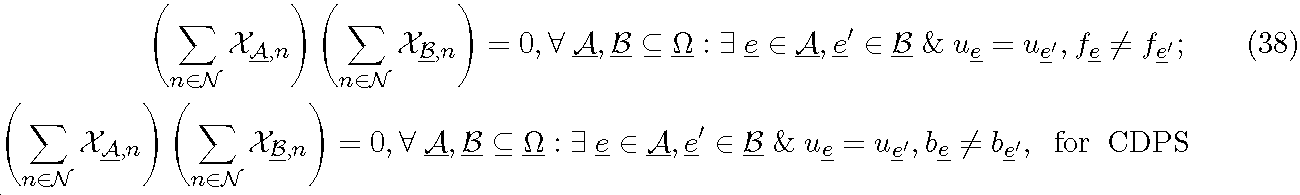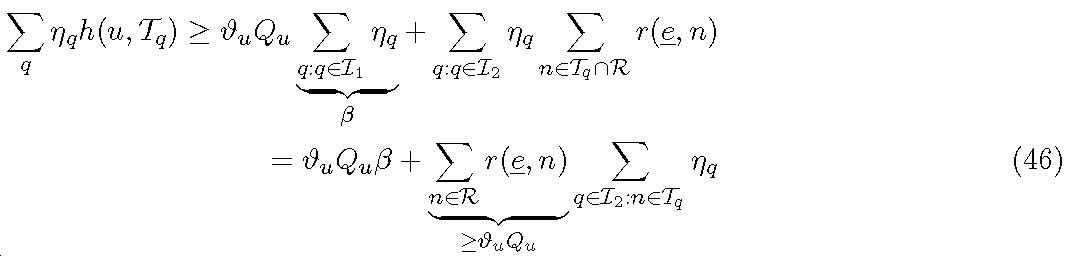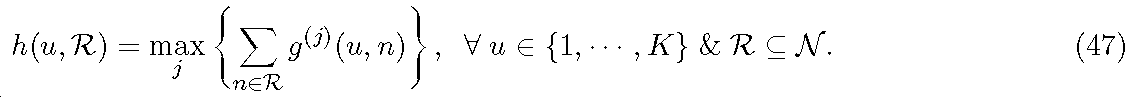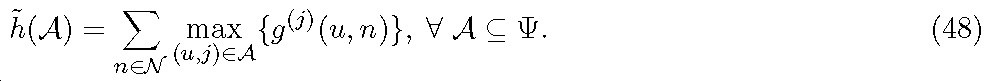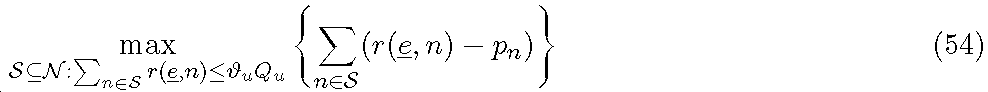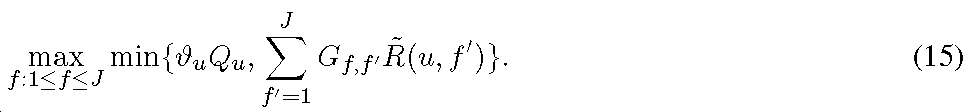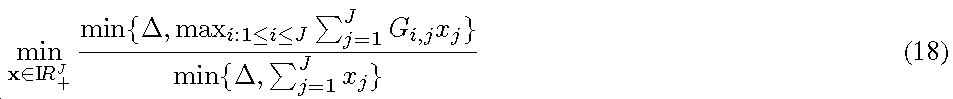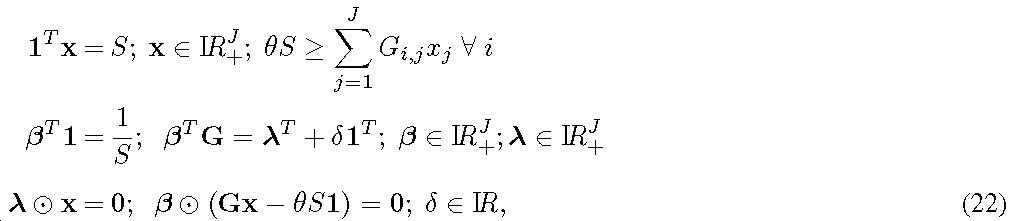1 시스템 설명
M개의 전송 포인트(Transmission Point: TP)로 구성되는 클러스터를 고려한다. 각 TP는 매크로셀(Macro-Cell) 기지국(Base Station; BS) 또는 저전력 원격 라디오 헤드(Remote Radio Head; RRH)일 수 있다. 따라서, CoMP 네트워크는, 모두 매크로셀 BS로 구성되는 동종 네트워크, 즉 도 1에 나타낸 동종 네트워크(100), 또는 도 2에 나타낸 매크로셀 BS과 저전력 RRH가 혼합된 이종 네트워크(HetNet)일 수 있다. 타겟 사용자 장비(User Equipment; UE)에 데이터가 전송되는 리소스 엘리먼트(Resource Element; RE)에서의 해당 UE를 위한 수신 신호는, 다음 식 (1)로 주어진다.
여기에서,
(i=1,...,M)는 해당 CoMP 세트 내의 i 번째 전송 포인트로부터의 UE가 보는 채널을 나타내며, CoMP 세트의 조합은 롱텀 신호대간섭 플러스 노이즈(signal-to-interference-plus-noise; SINR) 비율 측정에 기초하여 네트워크 컨트롤러에 의해 반정적 방식(semi-static manner)으로 결정되며 다수의 서브프레임에 걸쳐 고정 유지되고;
는 i 번째 전송 포인트에 의해 사용되는 전송 파워 또는 리소스 엘리먼트마다의 에너지(energy per resource element; EPRE)이고;
및
는 i 번째 전송 포인트에 의해 전송되는 프리코딩 매트릭스(
열을 가짐) 및 데이터 심볼 벡터이고;
, 및
는 UE의 CoMP 세트 외부의 모든 다른 전송 포인트에 의해 전송되는 합성 채널 매트릭스, 프리코딩 매트릭스, 및 데이터 심볼 벡터이다. 이어서, UE가 m 번째 전송 포인트의 j 번째 레이어만을 따라 송신되는 데이터 스트림을 수신하면, UE에서 해당 스트림에 대응하는 수신 SINR은 다음 식 (2)로 주어진다.
여기에서
F mj는 m 번째 전송 포인트의 j 번째 레이어로부터의 신호 s
mj를 취득하기 위한 수신 필터이고,
R은 CoMP 세트 외부의 간섭 + 노이즈의 공분산(covariance), 즉
이다. 그리고, 대응하는 정보 레이트는 다음의 식 (3)이다.
범용성을 잃지 않는다면, 전송 포인트 1은, (CoMP 없이) 종래의 단일 셀 전송을 위해 데이터 심볼뿐만 아니라 제어 시그널링을 UE에 송신하는 것으로 상정되어 있는 서빙 셀(serving cell)이며, UE가 업링크 채널에서 해당 CSI 피드백을 보고하는 TP인 것으로 가정한다. 따라서 CoMP가 없는 경우, SINR은
이며, 여기서 S
1은 이 UE를 대상으로 하는 레이어의 세트이다. 그리고 관심 UE에 대한 총 레이트는
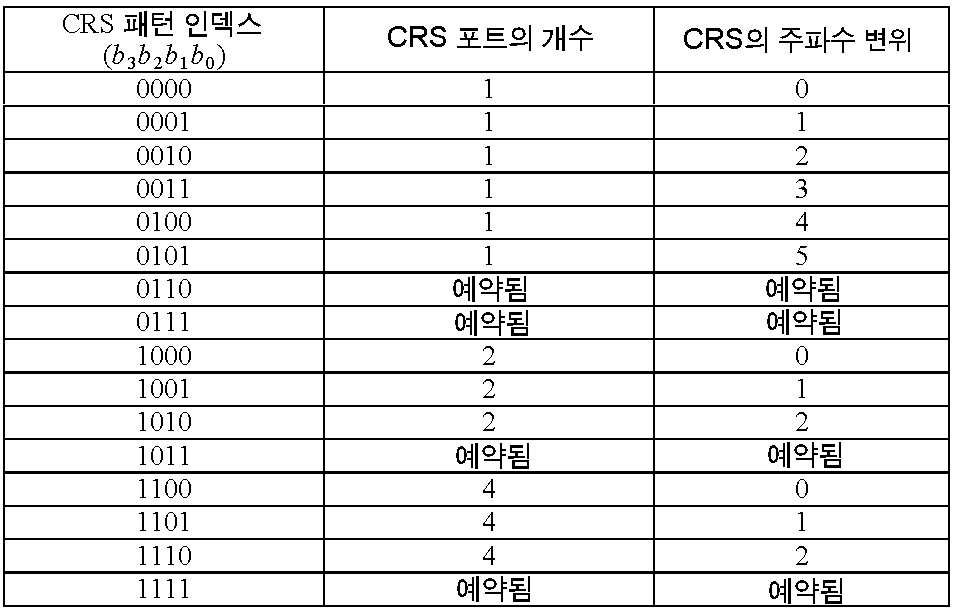
로 주어진다. 모든 CSI가, CoMP 네트워크의 네트워크 컨트롤러에 전달될 수 있고 이어서 네트워크 컨트롤러가 스케줄링을 하게 됨을 유념한다.
CS/CB CoMP 전송 방식에서, 데이터는 여전히 서빙 셀(또는 대등하게는, 앵커 셀(anchor cell)(앵커 셀로부터 제어 시그널링이 수신됨))로부터 전송된다. SINR이 여전히 식 (2)(m=1)에서 주어진 바와 같이
이지만, 전송 프리코딩 매트릭스
W i(i=1,...,M)는 CoMP 세트내(intra-CoMP set) 간섭이 감소되도록 공동으로 최적화된다.
DPS 방식에서, 모든 UE로부터의 CSI 피드백에 의거하여, 네트워크 컨트롤러는 시스템의 가중 합 레이트(weighted sum rate)가 최대가 되도록, 각 UE를 위한 전송 포인트를 선택한다. m
*이 UE를 위해 네트워크 컨트롤러에 의해 선택된 전송 포인트인 것으로 가정한다. 그러면 j 번째 레이어에 대응하는 SINR은
이고 전송 레이트는
이다.
한편 JT 방식에서는, 동일한 데이터 심볼은 CoMP 세트 내의 다수의, 즉 M
JT 전송 포인트를 통해 전송된다. JT를 위한 전송 포인트의 세트를
로 나타내며, 여기에서
⊆{1,...,M}이고, 그 여집합(complement set)을
로 나타낸다. 편의상
내의 모든 TP가 리소스 블록(resource block)을 통해 관심 UE에만 서빙하는 것으로 상정한다. 그러면, 식 (1)에서의 신호 모델을 다음 식과 같이 다시 쓸 수 있다.
여기에서,
는 코히어런트 JT를 위해 SINR을 향상시키는 코히어런트 위상 보정(coherent phase adjustment)이다. 인덱스 1을 갖는 서빙 셀 BS는 JT를 위한
내에 항상 존재하는 것으로 가정한다. 그리고
으로 고정한다. 넌코히어런트 JT에서,
에 대한 피드백은 필요하지 않으며, 즉,
이 적용된다. JT를 위해, 모든
에 대해 공통 전송 랭크(rank) r이 채용되고 있음을 알 수 있다.
을 정의한다. j 번째 레이어에 대한 SINR은 다음 식 (5)로 주어진다.
여기에서
는 CoMP JT 전송을 위한 식 (4)에서의 신호에 대한 수신 필터를 나타낸다. 그리고, CoMP JT 전송을 위한 해당 레이트는
이다.
2
CoMP
를 위한 CSI 피드백
이제 CoMP 방식을 위한 CSI 피드백을 고려한다. JT, CS/CB, 및 DPS를 포함하여 모든 합의된 CoMP 전송 방식을 지원하기 위해, 지난 몇 번의 3GPP-RAN1 미팅 동안 일반적 CSI 피드백 프레임워크가 논의되었다. CoMP 세트 내의 각 전송 포인트의 적어도 하나의 포트로부터, UE로 하여금 해당 TP의 해당 포트로부터의 채널을 추정하도록 참조 신호(RS)가 하나 이상의 리소스 엘리먼트(그 위치는 사전에 네트워크에 의해 UE에 전해짐)에서 송신된다.
H i를 i 번째 TP의 모든 포트에 대응하는, UE에 의해 추정된 채널 매트릭스라고 한다. 릴리스-10 및 그 이전 레거시 시스템에서, 인접한 리소스 블록(RB)(연속하는 서브-캐리어 및 OFDM 심볼의 세트로 구성되는 시간-주파수 리소스에 매핑됨)의 세트에 대한 CSI 피드백은, UE에 의해 추정되는 본질적으로 양자화된 SINR인 최대 두 개의 채널 품질 인덱스(channel quality indices; CQI)와 함께, 우선 순위의 프리코더 매트릭스
를 지시하는 와이드밴드 우선 순위의 프리코딩 매트릭스 인덱스(precoding matrix index; PMI), 와이드밴드 랭크 인덱스(Rank Index; RI)
로 구성되도록, 내재적(implicit) CSI 피드백이 채택된다. CB/CS 및 DPS에 대해 섹션 1로부터 알 수 있는 바와 같이, CoMP 세트 내의 각 전송 포인트에 대한 UE로부터 그 앵커 BS에의 CSI 피드백은, UE를 위한 적절한 변조 및 코딩 방식(modulation and coding scheme; MCS)을 할당할 수 있도록 컨트롤러가 (필요한 경우 각 서브밴드에서) UE에의 전송을 위한 하나의 TP를 선택하여 양호한 SINR 추정을 얻을 수 있게 하므로, 충분하다. 그러나, JT를 위해, 집합적(aggregated) SINR(CQI) 피드백이 CoMP에 의한 성능 이득(performance gain)을 실현하는 데 필수적이다. 코히어런트 JT를 위해, CSI-RS 리소스간 위상 정보(resourse phase information)의 피드백이 또한 필수적이다. 다음에서는 TP마다 및 CSI-RS마다 리소스를 상호 교환적으로 사용할 것이다. RAN1 #67 미팅에서, 다음의 합의에 이르렀다[2].
ㆍCoMP를 위한 CSI 피드백은 적어도 CSI-RS-리소스마다의 피드백을 사용한다.
그러나 이 CSI-RS-리소스마다의 피드백의 내용은 아직 결정되지 않았다.
이 합의에 의거하여, 이하 CoMP CSI 피드백을 위한 효율적인 접근법을 제공한다. 우선 공통 랭크 제한이 있는 또는 없는 CSI-RS 리소스마다의 피드백에 대한 택일적 솔루션에 대해 논의하고, 또한 CSI-RS-리소스간(inter-CSI-RS-resource) 피드백에 대한 옵션을 논의한다. 추후 CoMP를 위한 베트스-
CSI 피드백 방식을 제안한다.
2.1 공통
랭크
제한이 없는
CSI
-
RS
리소스마다의
피드백(
Per
CSI
-
RS
Resource
Feedback
without
Common
Rank
Restriction
)
퍼-CSI-RS-피드백이 모든 CoMP 전송 방식에 필수적이라고 합의되었으므로, 각 전송 포인트마다의 랭크 피드백에 대한 문제가 제기된다. CoMP 세트 내의 모든 전송 포인트에 대해 공통 랭크 피드백을 강제할지의 여부는 아직 결정되어 있지 않다. 우선 공통 랭크 제한이 없는 CoMP를 위한 퍼-CSI-RS-피드백 기반의 피드백 방식에 대한 장단점에 대해 논의하고 솔루션을 제공한다.
CSI-RS 리소스마다의 피드백에서, 각 UE는 CoMP 세트 내의 각 전송 포인트에 대한 CSI 피드백을 송신하며, 이는 단일 포인트 전송 가설을 가정하여 계산된다. 따라서, 서로 다른 전송 포인트에 대해 계산된 CSI 피드백에서는 우선 순위의 랭크가 변할 가능성이 있다. 이 옵션에서, UE는 각 전송 포인트에 대한 최선의 랭크(best rank)를, 대응하는 PMI/CQI와 함께 BS에 보내는 것이 가능할 수 있다.
CS/CB 및 DPS CoMP 전송 방식에서, UE에의 전송은 (스케줄링된 경우라면) 하나의 CSI-RS 리소스에 대응하는 (할당된 RB 각각에서) CoMP 세트 내의 하나의 전송 포인트로부터 행해진다. 와이드밴드 DPS(이하, DPS-w라 함)에 대해, 각 UE는 할당된 모든 RB에서 하나의 TP에 의해 서빙받을 수 있으나, 서브밴드 DPS(DPS-s)에 대해서는, UE는 할당된 각 RB에서 서로 다른 TP에 의해 서빙받을 수 있다. 따라서, DPS-w에 대해, 우선 순위의 랭크를 사용하여 계산된 각 TP에 대한 CSI 피드백을 컨트롤러가 이용할 수 있으므로, 공통 랭크 제한 없이 보다 높은 CoMP 성능 이득을 달성할 수 있다. 다음으로, CoMP 세트 내의 다른 TP가 사일런트(또는 뮤팅)이라는 가정에 의거하여 CSI-RS 피드백이 결정되는 것을 상정하면, 스케줄링의 결과에서의 다른 TP로부터의 간섭이, 다른 TP에 대응하는 CSI-RS 리소스 피드백을 사용하여 컨트롤러에 의해 근사될 수 있다. 또한 추후 논의될 다른 TP로부터의 간섭에 대한 서로 다른 가정에서도, 컨트롤러는 선택된 TP에 대한 포스트-스케줄링 SINR을 상당히 잘 추정할 수 있다. 따라서, 공통 랭크가 없는 CSI-RS-리소스마다의 피드백은 DPS-w에 적합한 것으로 보인다. 마찬가지로 CS/CB에 대해서, 각 UE가 미리 결정된 앵커 또는 서빙 셀 TP에 의해서만 데이터를 서빙받을 경우, 각 UE는 각각의 우선 순위의 랭크를 사용하여 다른 전송 포인트에 대한 보다 정확한 CSI를 보고하므로 성능 저하가 두드러지지 않는다. 이러한 옵션은 또한 CoMP로부터 비-CoMP 단일-셀 전송에의 폴백(fallback)을 용이하게 한다.
그러나, JT를 위해 공통 UE마다의 전송 랭크(common per-UE transmission rank)를 강제하는 것은 UE가 CoMP 세트 내의 서로 다른 전송 포인트에 대한 서로 다른 랭크를 보고할 때 랭크-오버라이드(rank-override)이 불가피하다. 또한 이 경우에, 다른 중요한 문제는 공통 랭크 제한이 없을 경우 다수의 CSI-RS 리소스에 걸친 CSI-RS 리소스간 피드백 또는 집합적 피드백을 보내기 위한 메커니즘이다.
CoMP JT 방식을 도입하기 위해, 이하 공통 피드백 랭크 제한이 없을 경우에 대한 다음의 솔루션을 제안한다.
솔루션 1: 서로 다른 CSI-RS 리소스에 대해 우선 순위의 랭크가 상이할 경우, CSI-RS 리소스간 피드백 또는 집합적 피드백이 모든 우선 순위의 랭크 중에서 최하위 랭크에 기초하여 계산된다. 최하위 랭크를
라 가정하면, 보고되는 각 프리코딩 매트릭스에서
최고 강한 SINR에 대응하는 열(column) 서브세트가 결정된다. CSI-RS 리소스간 위상 피드백 또는 집합적 피드백은 이 프리코딩 매트릭스 열 서브세트에 기초하여 계산되며 이 서브세트는 전송 프리코더를 설계하는 데 사용된다.
CoMP 세트가 두 개의 전송 포인트를 갖는 예를 고려한다. 3개 이상의 전송 포인트를 갖는 경우에 대해서는, 이하에서 논의되는 결과들이 마찬가지로 적용될 수 있다. 전송 포인트 1(TP1) 및 TP2에 대해, 우선 순위의 프리코딩 매트릭스, 양자화된 SINR(CQI를 사용한 피드백), 및 랭크 인덱스를 포함하는 CSI 피드백은 각각
및
이다. 이어서 UE는 랭크
를 선택한다. 그리고, CoMP JT에서 사용되는 프리코딩 매트릭스
V 1이
최고 강한 SINR에 대응하는
의
열을 이용하여 형성되는 것으로 가정된다. 동일한 SINR CQI 인덱스를 갖는 두 개 이상의 레이어가 있을 경우, (모든 UE 및 TP에 알려져 있는) 미리 결정된 규칙이 열 서브세트 선택을 위해 적용될 수 있다. 이어서, 프리코딩 매트릭스
도 마찬가지로 형성될 수 있다. CSI-RS 리소스간 위상
에서, 합성 프리코딩 매트릭스가
로서 형성된다. CSI-RS 리소스간 위상 피드백은, 합성 프리코딩 매트릭스
가 CoMP JT를 위해 채용된 것으로 가정하여 미리 결정된 세트로부터 최선의
를 찾음으로써 결정된다. 범용성을 잃지 않는다면,
을 설정함으로써
만이 보고될 필요가 있도록 한다.
마찬가지로, 집합적 SINR 또는 집합적 CQI 피드백은,
를 갖는 코히어런트 CoMP JT 또는 넌코히어런트 CoMP JT를 위해
가 채용되는 것을 가정하여 계산된다.
상술한 바와 같이, 솔루션 1에서, JT의 경우에 랭크 오버라이드(override)가 필요해진다. 솔루션 1에서, 보다 양호한 DPS-w 및 CS/CB 성능이 달성될 수 있다. JT의 성능은, 합성 채널의 처음 소수의 우세 우특이 벡터(dominant right singular vector)가 컨트롤러에서 정확하게 이용 가능하지 않음으로 저하될 것이다. 또한, UE가 서로 다른 할당 RB에서 서로 다른 TP(UE가 서로 다른 랭크를 보고했음)에 의해 서빙받을 경우, 이 경우에 랭크 오버라이드가 필수적이므로, 공통 랭크 피드백이 DPS-s에 보다 적합하다.
피드백 오버헤드에 대해, 서브밴드 CQI 피드백과 함께, 3-1과 유사한 피드백 모드, 즉 와이드밴드 PMI 피드백를 가정하면, 각 CSI-RS 리소스 피드백은 하나의 RI(예를 들면 랭크, 소위 r을 지시함), 및 하나의 PMI, 및 N min{2,r} CQI로 구성되며, 여기서 N은 UE가 보고하도록 설정된 서브밴드의 개수이다. 따라서 솔루션 1에서, M개의 CSI-RS 리소스로 CSI-RS 리소스마다의 피드백에 대한 총 피드백은
이며, 여기서
및
는 각각 CQI, RI 및 PMI의 피드백마다의 비트의 개수이다. 여기에서, N개의 서브밴드 리소스에 대한 CQI의 세트가 CSI-RS 리소스마다 반환되는 것을 가정한다. JP CoMP의 경우에 서브밴드마다의 포인트간 위상 및/또는 집합 CQI(들)가 또한 보고될 필요가 있을 수 있음을 유념한다. CQI 피드백에 제한을 둠으로써 이러한 오버헤드가 감소될 수 있으며, 이에 대해서는 후술할 것이다.
UE가 CSI-RS 리소스의 서브세트에 대한 피드백을 보고할 수 있을 경우, 다음의 솔루션을 제안한다.
솔루션 2: 표준은 CSI-RS 리소스마다의 피드백에 대해 공통 랭크 제한을 명시하고 있지 않다. UE 중심 CSI 피드백으로, UE는 우선 순위의 CoMP 방식을 결정한다. UE가 JT CoMP 방식에 우선 순위를 둘 경우, UE는 다수의 CSI-RS 리소스에 대해 공통 또는 동일 랭크를 갖는 CSI-RS 리소스마다의 피드백을, 가능하다면 집합 CQI 피드백(모든 CSI-RS 리소스에 걸쳐 집합됨) 및/또는 CSI-RS 리소스간 위상 피드백과 함께, 송신한다. UE가 DPS-w 또는 CB/CS에 우선 순위를 두면, CSI-RS 리소스마다의 피드백은 공통 랭크 제한 없이 송신된다. 또한 UE가 DPS-s에 우선 순위를 두면, UE는 공통 랭크를 갖는 CSI-RS 리소스마다의 피드백을 보낸다. 그러나, 이러한 피드백 방식이 컨트롤러가 사용할 CoMP 방식을 한정하는 것은 아니다.
솔루션 2에서, 랭크 오버라이드가 JT 및 DPS-s에 대해 필수적인 것은 아님을 알 수 있다. 또한 BS가, UE의 CSI 피드백에서 지시되는 바와 같이 UE가 우선 순위를 두는 CoMP 방식을 채용할 경우, 시스템은 UE에 대해 최대 이득을 달성할 수 있다. 우선 순위의 CoMP 방식을 지시하는 데는 추가적인 피드백이 필요하다. 그러나 이러한 피드백 오버헤드는 아주 작다. UE가 보고하도록 설정된 모든 서브밴드에 걸쳐 공통인 하나의 우선 순위의 CoMP 방식의 와이드밴드 지시를 가정했음을 유념한다. 이것은 시그널링 오버헤드를 감소시키며 성능 저하는 극히 작다. 또한, 오버헤드를 줄이기 위한 옵션으로서, 시스템은 DPS-s 및 DPS-w 중 단 하나만을 허용하는 것을 반정적(semi-static) 방식으로 결정할 수 있다.
솔루션 2에 대한 피드백 오버헤드가 다음과 같이 논의된다.
ㆍJT에 있어서, 총 피드백 오버헤드는
이며, 여기에서
은 UE에 의해 선택된 동일 랭크이다. 집합적 CQI 피드백 및/또는 CSI-RS 리소스간 위상 피드백에는 추가적인 오버헤드가 요구된다.
ㆍCB/CB 및 DPS-w에 있어서, 최대 오버헤드는
이며, 이는 솔루션 1의 것과 동일하다. 그러나, UE 중심 CSI 측정에서 UE는 M개의 CSI-RS 리소스의 서브세트에 대해서만 CSI를 측정할 수 있으므로, 최대 오버헤드는 줄어들 수 있다. 특히, DPS에 대해, UE는 앵커 포인트에 대한 하나의 CSI 피드백 및 최대 우선 순위의 TP에 대한 하나의 CSI 피드백에 대해서만 피드백할 필요가 있을 수 있다. 따라서, DPS-w의 경우에, 우선 순위의 TP를 지시하는 데 필요한 하나의 와이드밴드 지시가 있는 반면, DPS-s에 대해서는 서브밴드마다 하나의 지시가 필요하다. 이 접근법을 확장하여, UE가 (DPS-s에 대한 서브밴드마다) 최대 우선 순위의 TP에 대해서만 CSI를 피드백하도록 할 수도 있다. 이 대안에서는, 오버헤드가 감소하는 한편 스케줄링 이득 또한 감소할 수 있으며, 이는, 스케줄링될 경우 해당 UE로의 전송에 UE 우선 순위의 TP를 이용하도록 네트워크가 강제될 것이기 때문이다. 또한, CB/CS에 있어서, 시스템은, 각 사용자가 서빙 TP와는 상이한 CoMP 세트 내의 각 TP에 대한 CSI의 피드백에서 특정 랭크를 사용하도록 강제할 수 있다. 이는 랭크 지시 오버헤드를 감소시키고 비-서빙 TP에 대한 PMI의 UE 판정을 단순화할 수 있다. 이 특정 랭크는 네트워크에 의해 반정적 방식으로 UE에 전해질 수 있다. 옵션으로, 특정 랭크가 모든 다른 비-서빙 TP에 대해 동일할 수 있다(예를 들면 랭크-1).
단일 셀 전송에의 폴백에 대한 성능 손실을 줄이기 위해, 또한 JT를 위한 다음의 CoMP CSI 피드백 솔루션을 제안한다.
ㆍUE는 단일 TP 전송 가설 하에서 서빙 TP에 대한 CSI 피드백을 송신한다. CoMP를 위해, UE는 또한, 단일 서빙 셀 전송에 대해 보고되는 랭크와는 상이할 수 있는 동일 랭크를 갖는 서빙 TP를 포함하는 각 CSI-RS 리소스에 대한 와이드밴드 PMI를, CoMP JT를 위한 집합적 CQI 및/또는 CSI-RS간 위상 피드백과 함께 보고한다.
2.2 공통
랭크
제한이 있는
CSI
-
RS
리소스마다의
피드백(
Per
CSI
-
RS
Resource
Feedback
with
Common
Rank
Restriction
)
UE가 CSI-RS 리소스마다의 피드백을 송신할 때 공통 랭크가 채용되는 것을 보장하도록, 공통 랭크 제한을 특정할 수 있다. CSI-RS 리소스마다의 피드백에 대한 공통 랭크 제한을 갖고, BS에서 DPS-w 또는 CB/CS CoMP 방식이 채용되면, 우선 순위의 프리코딩 및 랭크가, 네트워크가 최종적으로 이용하는 전송 포인트에 최선이 아닐 수 있으므로, 성능 저하가 있을 수 있다. 또한 시스템이 이 UE에 대해 단일 셀(서빙 TP) 전송으로 폴백하는 경우 성능 저하가 있을 수 있다. 이하 이 가능한 성능 손실을 완화할 수 있는 UE 중심 CSI 피드백에 기반하는 다음의 솔루션을 제안한다.
솔루션 3: 표준은 CSI-RS 리소스마다의 피드백을 위해 공통 랭크 제한을 명시하고 있지만 어느 랭크를 사용할 것인지는 명시하지 않고 있다. UE 중심 CSI 피드백에서, UE가 JT CoMP 또는 CS/CB에 우선 순위를 두고 지시할 경우, UE는 CSI-RS 리소스의 서브세트에 대해 동일한 랭크를 갖는 CSI-RS 리소스마다의 피드백을 (JT CoMP의 경우, 가능한 한 CSI-RS 리소스간 피드백 및/또는 집합적 CQI 피드백과 함께) 송신할 수 있다. 이러한 유연성으로, DPS-w(DPS-s)가 UE에 의해 지시될 경우, UE는 공통 랭크를 갖는 서빙 셀 및 우선 순위의 전송 포인트(서브밴드마다의 우선 순위의 TP)에 대한 CSI 피드백을 보낼 수 있다. UE는 또한 서빙 셀에 대해서만 CSI 피드백을 송신할 수 있으며 UE가 단일 셀 전송에의 폴백에 우선 순위를 두는 것을 지시할 수 있다.
이 접근법에서, DPS-w 및 단일 셀 전송에의 폴백으로 인한 성능 저하가 감소될 수 있다.
오버헤드를 줄이기 위한 옵션으로서, JT 및/또는 CS-CB가 우선 순위가 되는 경우 시스템은 반정적 방식으로 솔루션 3에 대해 공통 랭크를 1로 보다 제한할 수 있다. 그 이유는 다음과 같다. JT에서, 코히어런트 위상 결합을 통한 CoMP 성능 이득은 주로 랭크-1 전송에 대해 달성된다. 또한 공통 랭크-1 피드백에서 UE는 (서브밴드마다) 하나의 집합 CQI만 피드백할 필요가 있다. CB/CB에 대해, 랭크-1 채널 피드백에서, 협력 BS가 CoMP 세트내 간섭(intra CoMP set interference)을 줄이기 위해 서로 다른 TP에 대해 프리코딩 빔을 제어하는 것이 보다 용이하다.
UE 중심 피드백에서, UE는 우선 순위의 CSI 피드백 방식을 선택할 수 있다. 하나의 간단한 경우로는, UE는, 두 개, 즉
및
하에서 얻을 수 있는 것으로 간주되는 유효 레이트를 비교함으로써, 보다 작은 랭크를 갖는 JT CoMP CSI 피드백, 예를 들면 집합적 CQI 피드백을 갖는 랭크-1 피드백, 또는 보다 큰 랭크를 갖는 단일 서빙 TP을 위한 CSI 피드백, 예를 들면 랭크 2(오버헤드가 작음) 사이에서 선택할 수 있으며, 여기에서
는 JT를 위해 UE에 의해 고려되는 TP의 세트이다. 보다 높은 레이트에 대응하는 것이, UE가 우선 순위를 두고 이에 따라 CSI 피드백을 보내는 전송 방식의 유형(CoMP 또는 단일 서빙 TP에의 폴백)이다. 그러나, 이 비교가 특정 UE에 대해 CSI 피드백을 선택하는 최상의 접근법임에도 불구하고 시스템 효율 면에서는 좋은 선택이 아니며, 이는 UE가 단일 서빙 TP에의 폴백을 선택하면, BS는 다른 TP에서 일부 데이터 전송을 스케줄링할 수 있기 때문이다. 다른 TP에서 잠재적으로 스케줄링되는 UE를 수용하기 위해, 다음의 세 가지의 대안적 접근법을 제안한다.
대안 1: i 번째 TP에 대해 오프셋
이 부여되어 반정적 방식으로 UE에 시그널링된다. 따라서 UE는, UE에 대해 단일 TP를 가정한 합산 레이트
와 CoMP 레이트
를 비교하여, 우선 순위의 전송 방식을 선택하고 이에 따라 CSI 피드백을 송신한다. 값
은 TP i로부터의 평균 단일 셀 전송 레이트일 수 있다.
대안 2: UE가 CoMP CQI를 계산할 때 부분적(fractional) EPRE 또는 파워
를 가정하여, UE에 의해 계산되는 CoMP JT에 대한 레이트를 스케일링한다(또는 이에 대등하게, 각 TP i에 대해 UE가 인자
에 의해 파워
를 포함하는 그 유효 추정 채널을 스케일링한다). 스케일링 인자
(UE 특정일 수 있음)는 네트워크에 의해 UE에 반정적으로 시그널링될 수 있다. 이어서 UE는 식 (5)에 따르지만 스케일링된 파워
으로 CoMP SINR을 계산하여 CoMP 레이트
을 획득한다. 레이트 비교는
와
간이다. 분수 거듭제곱 및 알고 있는
에 기초한 SINR(CQI) 피드백에서, BS는 적절한 MCS 할당을 위해 SINR을 다시 재스케일링할 수 있다. 이
의 역할은 UE가 선택하는 데 편중을 주는 것임에 유념한다. 보다 미세하게 제어하기 위해, 각
(TP마다 기초로)는 세트
의 서로 다른 카디널러티(cardinality)에 대해 상이하거나, 및/또는 서로 다른 랭크 가설에 대해 상이할 수 있다.
대안 3: UE는 각 전송 포인트로부터의 레이트
를 계산하고, 합산 레이트
를 CoMP JT의 레이트
와 비교하며, 여기에서
는 BS에 의해 반정적 방식으로 통지될 수 있는 스케일링 인자이다.
=0일 경우, 단일 서빙 TP 전송 레이트와 CoMP JT 레이트 간의 원래의 비교로 감소한다.
2.3
베스트
-
CSI
피드백(
Best
-
CSI
Feedback
)
일반적으로, BS는 CSI 피드백 송신하는 UE를 위한 특정 업링크(UL) 리소스를 사전에 할당한다. CSI-RS 리소스마다의 피드백이 모든 CoMP 방식을 지원하도록 합의되어 있으므로, 최악 경우, 즉 각 스트림에 대해 N개의 CQI와 함께 각 TP에 대한 최고 전송 랭크(랭크 2 이상에 대해 최대 2 데이터 스트림)를 수용할 수 있도록, 많은 수의 UL 피드백 리소스가 사전에 할당되어야 한다. 실질적 피드백 비트가 상당히 적을 수 있는 UE 중심 CSI 피드백에서도, UL 피드백 리소스가 사전에 할당되므로 여전히 시그널링 오버헤드를 줄일 수 없을 수 있다. 이하 소위 베스트-
CSI 피드백 방식을 제안하고, 두 개의 대안적 접근법을 제공한다. 이 방식은 공통 랭크 제한이 있는 또는 없는 시스템에 적용될 수 있다.
대안 1: BS는
의 신호를 설정하여 반정적으로 송신하고, UE가
, CSI-RS 리소스 또는 TP를 선택하여 각 리소스마다 CSI 피드백을 송신하도록 요청한다. 따라서 BS는
CSI-RS 리소스 또는 TP에 대한 CSI 피드백을 수용하도록 할 수 있는 UL 피드백 채널을 사전에 할당한다. 집합적 CQI 또는 CSI-RS 리소스간 위상 피드백이 특정되면, 이 피드백을 위한 추가적 UL 피드백 리소스가 또한 할당된다. UE는 우선 순위의
TP를 선택하며 이에 따라 CSI 피드백을 송신할 수 있다. 어느 CSI-RS 리소스 또는 TP에 대응하는 CSI 피드백에 대한 추가적인 시그널링이 필요하다.
은 UE 특정이거나 모든 UE에 대해 동일할 수 있다.
상술한 접근법에서, 시그널링 오버헤드는
일 때 상당히 감소됨을 알 수 있다. 이 이유는, CoMP 클러스터가 복수의 다수 UE로 구성되지만, 특정 UE에 대해, 유효한 협력 TP의 개수는 단지 두 개 또는 최대 세 개일 수 있기 때문이다. 도 1에 나타난 바와 같이, CoMP 세트는 3개의 TP로 구성된다. 그러나, UE1-UE3에 대해서는, 협력에 단지 두 개의 유효 TP가 존재한다. UE4에 대해서는, 3개의 협력 TP 중 베스트
=2를 선택함으로써 어떠한 현저한 성능 저하는 없을 것이다. UE가
미만의 CSI-RS 리소스 또는 TP에 대해 CSI 피드백을 송신할 수 있음은 물론이다.
상술한 접근법이 피드백 오버헤드를 현저하게 줄임에도 불구하고, CSI 피드백, 특히 CQI 피드백에 대한 최악의 시나리오는 UL 피드백 리소스, 즉 CoMP 세트 내의 TP 또는 CSI-RS 리소스에 대해 최대 랭크를 할당할 경우로 간주된다. 이 시나리오는 공통 제한 없는 경우 및 공통 랭크 제한이 있지만 어느 랭크를 사용할지를 명시하지는 않은 경우 모두에 대한 것이다. 따라서, 불필요한 피드백 리소스 할당을 보다 감소시키기 위해 다음의 접근법을 제안한다.
대안 2: BS는
의 신호를 설정하여 반정적으로 송신하고, UE가 CSI-RS 리소스 또는 TP를 선택하여 총
데이터 스트림에 대한 CSI 피드백을 송신하도록 요청한다. 따라서 BS는
데이터 스트림에 대한 CSI 피드백을 수용할 수 있는 UL 피드백 채널을 사전에 할당한다. 집합적 CQI 또는 CSI-RS 리소스간 위상 피드백이 특정되면, 이 피드백에 대한 추가적 UL 피드백 리소스가 또한 할당된다. UE는 이
데이터 스트림 제한으로 우선 순위의 TP 및 각 TP에 대한 랭크 또는 선택된 모든 TP에 대한 공통 랭크를 선택할 수 있다.
대안-2 접근법에서, UE는 CQI 피드백 세트의 총 개수를
이 되게 하여 TP를 선택할 수 있다. 예를 들면, UE는, 공유 랭크가 2 이상일 경우
/2 TP에 대해, 또는 공통 랭크가 1일 경우
의 TP에 대해, 또는 공통 랭크 제한이 없는 경우
을 만족하는 임의 개수의 TP에 대해 CSI 피드백을 송신할 수 있다.
상술한 대안-2 방식의 일 변형은, CQI 피드백의
세트의 제한이 집합적 CQI를 포함하는 것이다. UE는 집합 CQI가 필요한지의 여부를 선택하고 피드백 리소스를 확보하여 보다 적은 CSI-RS 리소스마다의 CSI 피드백이 보고되도록 할 수 있다.
2.4
CoMP
피드백 포맷(
CoMP
Feedback
Format
)
상술한 바와 같이, CSI-RS 리소스마다의 피드백에서, 각 UE는 CoMP 세트 내의 각 전송 포인트에 대한 CSI 피드백을 송신하며, 이 CSI-RS 리소스마다의 피드백은 단일 포인트 전송 가설(즉, 해당 CSI-RS 리소스에 대응하는 TP로부터만 전송)을 가정하여 계산된다. 따라서, 서로 다른 전송 포인트에 대해 계산된 CSI 피드백에서 우선 순위의 랭크가 달라질 수 있다. 이 옵션에서, UE는 각 전송 포인트에 대한 베스트 랭크를, 대응하는 PMI/CQI와 함께 서빙 TP로 송신하게 할 수 있다.
네트워크 컨트롤러가 UE의 CSI-RS 리소스마다의 피드백을 제어할 수 있는 간단한 방식은, UE의 CoMP 세트(일명, CoMP 측정 세트) 내의 각 TP에 대해 별개의 코드북 서브세트 제한을 채용하는 것이다. 환언하면 컨트롤러는 각 UE에게 CoMP 세트 내의 각 TP에 대해 채용해야 할 코드북 서브세트에 대해 반정적 방식으로 통지할 수 있으며, 따라서 UE는 CoMP 세트 내의 각 TP에 대응하는 해당 서브세트에서만 프리코더를 검색하여 보고할 수 있다. 이는 컨트롤러가 수신하는 CSI-RS 리소스마다의 피드백을 조정하도록 하며, 예를 들면 컨트롤러는 CS/CB를 보다 바람직한 방식이라 결정한 경우 UE의 CoMP 세트 내의 모든 비-서빙 TP에 대응하는 서브세트를 랭크-1 프리코딩 벡터만을 포함하도록 구성할 수 있다. 이에 따라 우세 간섭 방향(dominant interfering directions)의 보다 양호한 양자화 및 특히 CS/CB에 유용한 빔 조정이 가능해진다.
추가적으로, 옵션으로서 컨트롤러는 또한 UE에 의해 그 CoMP 세트 내의 각 TP에 대해 보고될 수 있는 랭크에 대해 별개의 최대 랭크 한계를 설정하고, 이 최대 랭크 한계를 UE에 반정적 방식으로 전할 수 있다. 이것은 코드북 서브세트 제한을 통해서도 달성될 수 있음과 함께, 별개의 최대 랭크 한계를 설정하는 것은 피드백 로드를 감소시킬 수 있다. 예를 들면, TP가 4개의 전송 안테나를 가질 경우, 코드북 서브세트 제한으로 피드백 오버헤드가 감소될 필요가 없으며, 이는 최대 서브세트 크기를 수용하도록 설계되어야 하기 때문이고, 이 경우 6 비트, 즉 랭크(최대 랭크 4)에 대해 2 비트 및 랭크마다 PMI에 대해 4 비트로 변환된다. 한편, 최대 랭크 한계를 2로 부여함으로써, 오버헤드는 5 비트, 즉 랭크(최대 랭크 2)에 대해 1 비트 및 랭크마다 PMI에 대해 4 비트이다. 코드북 서브세트 제한이 최대 랭크 한계와 함께 사용될 수 있음을 유념한다.
옵션으로, 네트워크는 또한 UE에 의해 보고되는 CSI-RS 리소스마다의 피드백 각각에 대해 별개의 피드백 모드를 반정적으로 설정할 능력을 가질 수 있다. 예를 들면 네트워크는 UE로 하여금 그 서빙-TP에 대해 서브밴드마다 PMI 및 CQI(들)를 보고하도록 하는 피드백 모드, 및 그 CoMP 세트 내의 일부 또는 모든 다른 TP에 대해 서브밴드마다 CQI(들)와 함께 와이드밴드 PMI를 보고하도록 하는 모드를 사용하도록 설정할 수 있다. 이에 따라, 컨트롤러가 성능에 있어 현저한 저하 없이 전체적인 CoMP 피드백 로드를 감소시키도록 할 수 있다.
CoMP 피드백 포맷으로서 포인트간 위상 리소스(들) 또는 추가적인 집합 CQI(들) 및 CoMP 세트 내의 모든 TP에 대한 공통 랭크 보고 등의 제한을 포함할 수 있는 CSI-RS 리소스마다의 피드백 모드의 특정 선택을 위해 UE로부터의 전체적 CoMP CSI 피드백을 나타내기로 한다. CoMP CSI 피드백 방식의 설계에 있어서의 중요 장애물은, 특정 CoMP 피드백 포맷을 보고하는 데 사용되는 UL 리소스의 크기가 사전에 할당되어야 하며 최악 경우의 로드를 수용하도록 설계되어야 한다는 것이다. 이는, 피드백을 수신하는 TP가 피드백의 디코딩을 위해서는 UE 피드백에 사용된 물리적 레이어 리소스 및 속성을 알아야 하기 때문이다. 따라서, UE가 허용 가능한 포맷의 세트로부터 피드백 포맷을 동적으로 선택할 수 있게 하면, 그 피드백을 수신하는 TP는 UE에 의해 사용된 포맷과 그 내부의 컨텐트를 함께 결정하기 위해서 블라인드 디코딩(blind decoding)을 채용해야할 것이다. 이러한 블라인드 디코딩은 복잡도를 증가시키며 이에 따라 허용 가능한 CoMP 피드백 포맷의 세트에 대해 단지 작은 카디널러티만이, 말하자면 2 정도만 허용하는 것이 바람직하다. 보다 간단한 다른 솔루션은, 컨트롤러가 반정적으로 UE를 위한 피드백 포맷을 설정하고 UE가 CSI 피드백을 위한 이 포맷을 네트워크에 의해 재구성될 때까지 채용하는 것이다.
이하 CoMP 피드백 포맷 설계를 위한 몇 가지 유용한 가이드라인을 제공한다.
1. CoMP 세트 크기 의존 피드백 포맷: UE를 위한 CoMP 세트는 네트워크에 의해 설정된다. 따라서 CoMP 클러스터에서의 가능한 모든 CoMP 세트 크기마다 하나의 피드백 포맷이 정의될 수 있다. 그러나, 단순한 네트워크 설계는 또한 적은 개수의 피드백 포맷을 요구한다. CoMP 세트 크기의 전형적인 가능한 값은 세트 크기 2 및 세트 크기 3이다. 따라서 크기 2에 대한 별개의 피드백 포맷 및 크기 3에 대한 다른 피드백 포맷을 정의할 수 있다. 추가적으로, 옵션으로서 3보다 큰 모든 크기에 대해 공통인 하나의 다른 포맷이 정의될 수 있다. 또는, 네트워크는 각 UE에 대해 크기가 3보다 작은 CoMP 세트를 설정하도록 자신을 제한할 수 있고, 이에 따라 이 추가적인 포맷을 정의할 필요는 없다. UE는 CoMP 세트의 크기에 대응하는 포맷을 사용할 것이다. 따라서 이러한 포맷 각각은 별도로 설계될 수 있고, 활용할 수 있는 중요 아이디어는, 주어진 피드백 로드에 대해 보다 작은 세트 크기에 대한 포맷이 CoMP 세트 내의 TP에 관한 보다 많은 정보를 전할 수 있다는 것이다.
2. 각 CoMP 피드백 포맷에서 CQI 피드백: 서브밴드마다 적어도 하나의 CQI가, UE에 의해 CoMP 세트 내의 각 TP에 대해(또는 CoMP 세트 크기가 크고 UE가, CoMP 세트의 (설정된 카디널러티의) 임의의 서브세트일 수 있는 우선 순위의 TP 세트에 대해서만 CSI를 보고하도록 설정되었을 경우, TP의 우선 순위의 세트 내의 각 TP에 대해) 보고되어야 함을 유념한다. CQI 피드백을 설정하기 위한 몇 가지 접근법을 강조한다. 단순화를 위해 UE가 CoMP 세트 내의 각 TP에 대해 서브밴드마다 적어도 하나의 CQI를 보고해야 하는 경우를 고려한다. 다른 경우가 간단한 변경 후 이어진다.
ㆍUE는 CoMP 세트 내의 각 TP에 대해 서브밴드마다 하나 또는 최대 2 개의 CQI(들)를 보고하도록 설정될 수 있다. 이 CQI(들) 각각은, CoMP 세트 내의 다른 TP가 뮤팅되어서 외부 CoMP 세트 간섭만이 이 CQI(들)에서 포착된다는 가정 하에 계산된다. 따라서, 컨트롤러는, 해당 보고된 PMI 및 CQI(들)를 사용하여 각 서브밴드에서 각 TP로부터 사용자에의 화이트닝(whitened) 다운링크 채널을 근사시킬 수 있으며, 즉 식 (1)의 모델을 참조하면 i 번째 TP로부터 사용자에의 화이트닝 채널은
이며, 이는
로서 TP i에 대응하는 보고된 PMI 및 CQI(들)를 사용하여 근사된다. 이어서 컨트롤러는 스케줄링의 결과로 사용자에 의해 수신되는 신호를 다음 식과 같이 모델링할 수 있다.
는
을 갖는 추가적 노이즈이다. 식 (6)에서의 모델을 사용하여 컨트롤러는 전송 프리코더를 설계하고 전송 프리코더의 각 선택 및 CoMP 전송 방식, 즉 CS/CB 또는 DPS 또는 JT 중의 선택에 대해 수신 SINR의 추정을 얻을 수 있다. 이에 따라 컨트롤러는 적절한 전송 방식을 선택할 수 있다. 이 CQI(들) 이외에도, UE는 또한 서브밴드마다 서빙 TP에 대해서만 "폴백(fallback)" CQI(들)를 보고할 수 있다. 이 CQI(들)는, CoMP 세트 내의 모든 다른 TP뿐만 아니라 CoMP 세트 외부의 TP로부터의 UE에 의해 측정된 간섭을 통합한 후에 서빙 셀에 대해 보고되는 PMI를 사용하여 계산된다. 이 CQI(들)를 서빙 셀에 대해 보고되는 PMI와 함께 사용하여, 컨트롤러는 우선 각 서브밴드에서 서빙 TP로부터 사용자에의 화이트닝 다운링크 채널을 근사하고(화이트닝은 현재 CoMP 세트 내 및 CoMP 세트 외부 간섭 모두에 대해서임) 이어서 스케줄링의 결과로서 사용자에 의해 수신되는 신호를 다음과 같이 모델링할 수 있다.
여기에서 다시
이다. 식 (7)의 모델을 사용하여 컨트롤러는 사용자를 종래의 단일 셀 사용자로서 스케줄링할 수 있다. 이에 따라 단일 셀 폴백 스케줄링이 가능하다. 또한, 옵션으로서, 네트워크는 또한 각 UE가 서브밴드마다 집합 CQI(들)를 보고하도록 설정할 수 있으며, 집합 CQI(들)를 계산하기 위해 UE에 의해 사용되는 CoMP 세트로부터의 TP의 세트는 네트워크(일명, 컨트롤러)에 의해 설정된다. 집합 CQI(들)는 TP의 세트(CoMP 세트 내의 다른 TP(있을 경우)는 사일런트라고 가정됨)로부터의 공동 전송을 가정하여 계산됨을 상기한다. 식 (6)의 모델은 JT 하에서 포스트-스케줄링 SINR 추정의 획득을 가능하게 하는 한편, 이렇게 획득된 SINR은 양호한 JT 이득을 위해 충분히 정확할 필요는 없다. 집합 CQI(들)를 사용하여 획득된 SINR 추정은 보다 양호한 링크 적응을 가능하게 하고, 이에 따라 공동 전송을 통해 보다 큰 이득을 가능하게 한다. 또는, 이 집합 CQI(들)를 서브밴드마다에 기초하여 보고하는 대신에, 베스트 M 서브밴드에 대해서만(해당 서브밴드의 인덱스와 함께) 보고될 수 있으며, M은 네트워크에 의해 설정된다. 또한, 옵션으로서, 네트워크는 이 집합 CQI(들)가 설정 가능한 최대 랭크 한계에 따라 계산되도록 강제할 수도 있다. 예를 들면, 네트워크가 상기 한계를 하나로 설정할 경우, 단 하나의 집합 CQI가 서브밴드마다 보고되며, 이는, 집합 CQI를 계산하는 TP에 대응하는 CSI 리소스마다의 피드백에서 UE에 의해 결정된 PMI 각각으로부터의 베스트(가장 강한) 열을 사용하여 계산된다. 보다 높은 최대 랭크 한계의 경우에, 두 개의 집합 CQI는 서브밴드마다 보고되며, 또한 공통 랭크 제한이 없는 JT를 위한 CSI 피드백에 대해 전술된 과정을 통해 결정될 수 있는 베스트(가장 강한) 열 서브세트를 사용하여 계산된다.
ㆍ UE는 그 CoMP 세트 내의 각 TP에 대해 서브밴드마다 하나 또는 최대 두 개의 CQI(들) 보고하도록 구성될 수 있다. CQI(들) 각각은, CoMP 세트 내의 다른 모든 TP뿐만 아니라 CoMP 세트 외부의 TP로부터의 UE에 의해 측정된 간섭을 통합한 후에 계산된다. UE에 대한 서빙 데이터가 아닌, CoMP 세트 내의 TP로부터 UE가 보게 될 포스트-스케줄링 간섭은 이 TP에 할당되는 전송 프리코더에 의존하게 됨을 유념한다. 그리고, 컨트롤러는 또한, UE가 CQI(들)를 계산한 서브프레임에서 UE의 CoMP 세트 내의 TP에 의해 사용된 특정 전송 프리코더의 지식을 이용할 수도 있다. 이에 따라 컨트롤러는 보고된 CQI를 변형하여 포스트-스케줄링 SINR에 대한 추정을 획득할 수 있다. 이 변형은, CQI 산출시 사용되었고 네트워크가 채용하고자 하는 전송 프리코더의 선택을 고려한 적절한 임의의 규칙을 사용하여 행해질 수 있다. 이러한 SINR 추정은 CS/CB 또는 DPS가 사용될 때 합리적인 CoMP 이득을 제공할 수 있다. 이 CQI가 이미 서빙 TP에 대해 보고되었으므로 추가적인 폴백 CQI는 필요하지 않음을 유념한다. 그러나 JT 이득은 부정확한 링크 적응으로 인해 떨어질 수 있다. 이전 경우에 대해 논의된 바와 같이, 옵션으로서 UE는 JT CoMP 이득을 이네이블하도록 추가적인 집합 CQI(들)를 보고하도록 설정될 수 있다. 이 집합 CQI(들)는 CoMP 세트 내의 다른 TP(있을 경우)로부터 간섭을 통합한 TP의 (설정) 세트로부터의 공동 전송을 가정하여 계산된다.
이하 CoMP 피드백 포맷 설계에서 채용될 수 있는 몇 가지 추가 변형예를 고려한다.
1. 랭크 보고에서의 서로 다른 유연성 정도: 이전에 논한 두 가지 경우는, 하나는 별개의 랭크 보고(최대 랭크 한계가 있거나 또는 없음)가 CoMP 세트 내의 각 TP에 대해 보고될 수 있는 점에서 최대 유연성이 허용되는 경우이다. 다른 하나는 CoMP 세트 내의 모든 TP에 대해 공통 랭크가 보고되어야만 하는 경우이다. 이 두 가지 옵션 사이에서 유연성 정도를 갖는 다른 가능성은, 별개의 랭크가, CoMP 세트 내의 다른 비-서빙 TP 모두에 대해 공통인 하나의 다른 별개의 랭크와 함께 서빙 TP에 대해 보고될 수 있는 것이다. 또한, 별개의 최대 랭크 제한이 이 두 개의 랭크 보고에 대해 부여될 수 있다. 이 옵션은 최대 유연성 경우에 비해 낮은 피드백을 갖고, CoMP 세트 내의 모든 TP에 대해 공통 랭크가 보고되어야 하는 경우에 비해 보다 정확하게 CSI를 전할 수 있음을 유념한다.
2.5
CoMP
피드백 포맷:
CoMP
측정 세트 크기 2 또는 3(
CoMP
Feedback
Format:
CoMP
Measurement
Set
Size
2
or
3)
본 섹션에서, 측정 세트 크기 2 및 3에 초점을 맞춰 피드백 포맷 설계를 보다 구체적으로 기술할 것이다. 이하 각 CSI-RS가 TP에 매핑(또는 대응)될 수 있는 것으로 가정할 것이다. 이들 원리는, CSI-RS가 다수의 TP로부터의 안테나 포트에 의해 형성된 가상 TP에 대응하는 경우로 간단하게 확장될 수 있다. 우선 측정 크기가 2인 것을 고려한다. 이하에 다양한 대안들을 열거한다.
ㆍ측정 세트에 대해 설정된 두 개의 CSI-RS 리소스 각각에 대한 포인트마다의 CSI-RS 리소스 피드백. 이러한 피드백 각각은, 나머지 TP(다른 CSI-RS 리소스에 대응함)가 사일런트이며 해당 CSI-RS 리소스에 대응하는 TP로부터의 단일 포인트 전송을 가정하여 산출된 PMI/CAI(들)를 포함하며, 이하 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백이라 한다. 포인트마다의 CSI-RS 리소스 피드백에서 사용자에 의해 송신되는 PMI 및 CQI(들)의 주파수 입도(granularity)는 네트워크에 의해 반정적 방식으로 별개로 독립적으로 설정될 수 있다. 예를 들면, 사용자는, 하나의 포인트마다의 CSI-RS 리소스 피드백에서 서브밴드마다의 CQI(들) 및 와이드밴드 PMI를 송신함과 함께 다른 포인트마다의 CSI-RS 리소스 피드백에서 서브밴드마다의 CQI(들) 및 서브밴드마다의 PMI를 보고하도록 설정될 수 있다.
ㆍ두 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 추가적으로, 별개의 폴백(fallback) PMI/CQI(들)(이하 폴백 CSI라 함)가 또한 보고된다. 이 폴백 CSI는, 서빙 TP로부터의 단일 포인트 전송 및 CoMP 세트 내의 다른 비-서빙 TP로부터의 간섭뿐만 아니라 CoMP 세트 외부의 모든 TP로부터의 간섭의 가정 하에 계산된다. 단순화 및 추가적 시그널링 오버헤드의 회피를 위해, 폴백 CSI에서의 PMI 및 CQI(들)의 주파수 입도는 서빙 TP에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백에서의 대응부의 주파수 입도와 동일하게 유지될 수 있다. 모든 다른 TP로부터의 간섭에 대한 공분산 매트릭스는 네트워크에 의해 해당 목적을 위해 설정된 리소스 엘리먼트를 이용하여 UE에 의해 추정될 수 있음을 유념한다. 또는, UE는, 특정 리소스 엘리먼트를 사용하여 CoMP 세트 외부로부터의 간섭에 대한 공분산 매트릭스를 추정하도록 네트워크에 의해 설정될 수 있다. 그리고, 사용자가 CoMP 세트 내의 다른 TP로부터의 비-프리코딩(unprecoded) 다운링크 채널 매트릭스를 이미 추정한 사실을 이용하도록 할 수 있다. 이 채널 추정을 사용하여 UE는 스케일링된 단위 매트릭스(identity matrix)가 다른 TP에 의해 사용되는 프리코더인 것으로 가정하여 공분산 매트릭스를 계산할 수 있고, 이어서 CoMP 세트 외부에 대해 계산된 공분산 매트릭스에 합산될 수 있다. 이어서, 합산 공분산 매트릭스는 폴백 PMI를 결정하고 연관된 폴백 SINR 및 폴백 CQI를 계산하는 데 사용된다. 스케일링된 단위 프리코더의 스케일링 인자는 UE에게 반정적 방식으로 통지될 수 있으며, (네트워크에 알려진) 다른 TP에 의해 서빙되는 평균 트래픽 로드와 같은 인자에 기반할 수 있음을 유념한다. 보다 높은 스칼라(scalar)는 보다 높은 트래픽 로드에 대응한다. 마찬가지로, 다른 TP에 대한 공분산 매트릭스는 또한 다른 TP를 위한 프리코더가 스케일링된 코드워드 매트릭스임을 가정하여 UE에 의해 계산될 수 있으며, 코드워드는 코드북 서브세트로부터 동일하게 유도될 수 있다. 서브세트 및 스케일링 인자의 선택은 네트워크에 의해 UE에 반정적 방식으로 전해질 수 있다.
ㆍ두 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 시그널링 오버헤드를 줄이기 위해, 폴백 CSI에서 폴백 CQI(들)만이 보고되며, 각 서브밴드에서 이 CQI(들)는, 해당 서브밴드 및 상술한 과정에 대응하는 서빙 TP에 대해 (뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백에서) 보고된 PMI를 사용하여 산출된다. 또는, 뮤팅 하에서 서빙 TP에 대해 보고된 랭크는 폴백에 대한 공격적인 선택일 수 있으므로(폴백은 또한 다른 TP로부터의 간섭을 가정함을 상기함), 별도의 랭크 지시자가 폴백을 위해 허용될 수 있다. 구체적으로, UE는 뮤팅 하에 서빙 TP에 대해 보고된 것보다 작거나 동일한 임의의 랭크 R을 선택 및 지시할 수 있다. 따라서 (뮤팅 하에 연관 CQI(들)로부터 복구된 R 최고 SINR에 대응하는) 서빙 TP에 대해 보고된 PMI의 R 열이 얻어진다. 이어서 폴백 CQI(들)가 이 열 서브세트를 사용하여 계산된다.
ㆍ두 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 네트워크는, UE가 폴백 CQI(들) 계산을 위한 서빙 TP인 것으로 가정해야하는 TP를 반정적 방식으로 설정할 수 있다. 이에 따라 나머지 TP는 간섭자로 취급되며 상술한 절차가 채용된다.
ㆍ두 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. UE는 폴백 CQI(들)를 산출하기 위한 서빙 TP를 동적으로 선택한다. 따라서 나머지 TP는 간섭자로 취급되며 상술한 절차가 채용된다. 폴백 계산을 위한 서빙 TP의 선택은 뮤팅 하에 계산된 CQI(들)에 따라 보다 높은 레이트를 제공하는 것으로 설정될 수 있다. 이 경우, 선택은 뮤팅 하에 계산된 CQI(들)를 통해 네트워크에 내재적으로 전해지므로 명시적으로 지시될 필요가 없음을 유념한다. 또한, 선택은 서브밴드마다의 CQI(들)에 기초하여 서브밴드에 걸쳐 변할 수 있다. 그러나, 보다 단순한 폴백 작업이 가능하게 하기 위해, UE는, 모든 서브밴드에 걸친 합산 레이트에 의거하여 와이드밴드 선택을 결정하며 이 경우에도 상기 선택이 내재적으로 전해지도록 설정될 수 있다. 또는, UE가 와이드밴드 기반이지만 임의로 선택을 결정할 수 있게 하는 선택을 UE가 지시하게 할 수 있도록, 별개의 와이드밴드 지시자가 채용될 수 있다.
ㆍ두 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 두 개의 CSI-RS 리소스 피드백에 대한 공통 랭크 제한이, 단 하나의 랭크 지시자만이 보고될 필요가 있도록 강제된다. 옵션으로, 위에서 열거된 옵션 중 어느 하나에 따른 폴백 CSI가 또한 보고된다. 또한 옵션으로, 두 개의 PMI(뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백에 대해 결정됨)를 사용하여 계산된 집합 CQI(들)가 또한 보고된다.
이하 측정 세트 크기 3을 고려한다. 이하에 다양한 대안을 열거한다.
ㆍ세 개의 CSI-RS 리소스 각각에 대해 포인트마다의 CSI-RS 리소스 피드백. 이러한 피드백 각각은, 나머지 TP(다른 두 개의 CSI-RS 리소스에 대응)가 사일런트이고(이하, 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백이라 함) 해당 CSI-RS 리소스에 대응하는 TP로부터의 단일 포인트 전송 가설을 가정하여 산출된 PMI/CQI(들)를 포함한다. 포인트마다의 CSI-RS 리소스 피드백에서 사용자에 의해 송신되는 PMI 및 CQI(들)의 주파수 입도(granularity)는 네트워크에 의해 반정적 방식으로 별개로 독립적으로 설정될 수 있음을 유념한다. 이 설정은, 사용자의 CoMP 세트 내의 서로 다른 TP에 대해 상이할 수 있다.
ㆍ세 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 또한, 별개의 폴백(fallback) PMI/CQI(들)(이하 폴백 CSI라 함)가 또한 보고된다. 이 CQI(들)는 서빙 TP로부터의 단일 포인트 전송 및 CoMP 세트 내의 다른 TP로부터의 간섭뿐만 아니라 CoMP 세트 외부의 모든 TP로부터의 간섭을 가정한다. 모든 다른 TP로부터의 간섭에 대한 공분산 매트릭스는 네트워크에 의해 해당 목적을 위해 설정된 리소스 엘리먼트를 사용하여 UE에 의해 추정될 수 있음을 유념한다. 또는, UE는, 특정 리소스 엘리먼트를 사용하여 CoMP 세트 외부로부터의 간섭에 대한 공분산 매트릭스를 추정하도록 네트워크에 의해 설정될 수 있다. 그리고, 사용자가 CoMP 세트의 다른 TP 각각으로부터 비-프리코딩(unprecoded) 다운링크 채널 매트릭스를 이미 추정했다는 사실을 이용하게 할 수 있다. 이 채널 추정을 사용하여 UE는 다른 TP 각각에 대해 스케일링된 단위 프리코더(identity precoder)를 가정하여 각각의 공분산 매트릭스를 계산할 수 있고, 이어서 CoMP 세트 외부에 대해 산출된 공분산 매트릭스와 함께 합산될 수 있다. 합산 공분산 매트릭스는 이어서 폴백 SINR 및 폴백 CQI를 계산하는 데 사용된다. 스케일링된 단위 프리코더 내의 스케일링 인자는 각각 UE에 반정적 방식으로 통지될 수 있으며, (네트워크에 알려진) 다른 TP에 의해 서빙되는 평균 트래픽 로드 등의 인자에 기초할 수 있음을 유념한다. 보다 높은 스칼라는 보다 높은 트래픽 로드에 대응한다. 마찬가지로, 다른 TP에 대한 공분산 매트릭스는, 각각의 다른 TP에 대한 프리코더가, 코드워드가 코드북 서브세트로부터 동일하게 유도될 수 있는 스케일링된 코드워드 매트릭스임을 가정하고 UE에 의해 계산될 수 있다. (다른 TP 각각과 연관된) 서브세트 및 스케일링 인자의 선택은 네트워크에 의해 반정적 방식으로 UE에 전해질 수 있다.
ㆍ세 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 시그널링 오버헤드를 줄이기 위해, 폴백 CSI에서 폴백 CQI(들)만이 보고되며, 이 CQI(들)는, 서빙 TP에 대해 보고되는 PMI 및 상술한 절차를 이용하여 계산된다. 또는, 뮤팅 하에서 서빙 TP에 대해 보고되는 랭크는 폴백에 대한 공격적인 선택일 수 있으므로(폴백은 또한 다른 TP로부터의 간섭을 가정함을 상기함) 폴백에 별개의 랭크 지시자를 허용될 수 있다. 구체적으로 UE는 뮤팅 하에서 서빙 TP에 대해 보고된 것보다 작거나 동일한 임의의 랭크 R을 선택할 수 있다. 이어서, (뮤팅 하에 연관 CQI(들)로부터 복구된 R 최상의 SINR에 대응하는) 서빙 TP에 대해 보고된 PMI의 R열이 얻어진다. 이어서 폴백 CQI(들)가 이 열 서브세트를 사용하여 계산된다.
ㆍ세 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 네트워크는, UE가 폴백 CQI(들)의 계산을 위한 서빙 TP인 것으로 가정해야 하는 TP를 반정적 방식으로 설정할 수 있다. 나머지 TP는 이에 따라 간섭자로 취급되며 상술한 절차가 채용된다. 또는, 간섭자로 취급되는 두 개의 다른 나머지 TP 중의 서브세트도 네트워크에 의해 반정적 방식으로 UE로에 전해질 수 있다. 서브세트 내가 아닌 TP(존재할 경우)는 CQI(들)를 계산하는 동안 사일런트로 가정된다. 서빙 및 간섭 TP의 설정된 폴백 선택에 의존하여 폴백 CQI(들)가 계산될 수 있는 다수의 가설이 있음을 유념한다. 하나의 피드백 실시예에서, 다수의 이러한 선택에 대응하는 폴백 CQI(들)가 동시에 보고될 수 있다. 또는, 이들은 피드백 오버헤드를 줄이기 위해 시간 다중화 방식으로 보고될 수 있다. 특히, 사용자는, 시퀀스의 각 보고가 서빙 및 간섭 TP의 특정 선택에 따라 계산된 폴백 CQI(들)를 포함하는 보고의 시퀀스를 따르도록 구성될 수 있다. 시퀀스 설정은 네트워크에 의해 반정적 방식으로 행해질 수 있다.
ㆍ세 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. UE는 폴백 CQI(들)를 계산하기 위한 서빙 TP를 동적으로 선택한다. 따라서 나머지 TP는 간섭자로 취급되고 상술한 절차가 채용된다. 서빙 TP의 선택은 뮤팅 하에 계산되는 CQI(들)에 따라 최상의 레이트를 제공하는 것으로 설정될 수 있다. 이 경우, 선택은 뮤팅 하에 계산된 CQI(들)를 통해 네트워크에 내재적으로 전해지며 따라서 명시적으로 지시될 필요가 없음을 유념한다. 또한, 선택은 서브밴드마다 CQI(들)에 기초하여 서브밴드에 걸쳐 변할 수 있다. 그러나, 보다 단순한 폴백 작업이 가능하도록 하기 위해, UE는 모든 서브밴드들에 걸친 합산 레이트에 의거하여 와이드밴드 선택을 결정하도록 설정될 수 있으며, 이 경우에도 선택이 내재적으로 전송된다. 또는, UE가 와이드밴드 기반일지라도 그 선택을 임의로 결정할 수 있게 하는 선택을 UE가 지시하게 할 수 있도록 별개의 와이드밴드 지시자가 채용될 수 있다.
ㆍ세 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 세 개의 CSI-RS 리소스 피드백에 대한 공통 랭크 제한이 강제된다. 옵션으로, 추가적으로 상기 열거된 옵션 중 임의의 하나에 따른 폴백 CSI가 보고될 수도 있다. 또한 옵션으로, 세 개의 모든 TP로부터의 공동 전송을 가정하여 세 개의 PMI(뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백에 대해 결정된)를 사용하여 계산된 집합 CQI(들)가 또한 보고된다.
ㆍ세 개의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백. 세 개의 CSI-RS 리소스 피드백에 대한 공통 랭크 제한이 강제된다. 나머지 TP가 사일런트이고 대응하는 두 개의 TP로부터의 공동 전송을 가정하여 서빙 PMI 및 하나의 다른 PMI(모두 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백에 대해 결정됨)를 사용하여 계산된 집합 CQI(들)가 또한 보고된다. 다른 TP의 와이드밴드 선택이 또한 지시된다. 옵션으로, 추가적으로 위에서 열거된 옵션 중 임의의 하나에 따른 폴백 CSI가 또한 보고될 수 있다.
이하, 측정 세트 크기 2 및 3에 대한 CoMP 피드백 포맷 설계에서 채용될 수 있는 일부 추가적인 변형을 고려한다.
ㆍ측정 세트 크기 2 및 3에 대해, 논의한 하나의 옵션은 별개의 폴백 CSI와 함께 측정 세트 내의 CSI-RS 리소스 각각에 대해 뮤팅을 갖는 포인트마다의 CSI-RS 리소스 피드백이고, 여기서 모든 보고되는 피드백에 대해 공통 랭크 제한을 부여할 수 있다. 여기에서, 이 공통 랭크 제한을 부여하는 접근법(또는 절차)을 개략적으로 설명한다. 이 접근법에서, UE는 우선 폴백 CSI(현재 PMI/CQI(들) 및 랭크 지시자를 포함함)를 계산하고, 이어서 각각의 포인트마다의 CSI-RS 리소스 피드백에서 이용되는 양자화 코드북의 랭크가 폴백 CSI에서의 것과 동일하다는 제한 하에 다른 포인트마다의 CSI-RS 리소스 폴백을 계산한다. 이에 따라 단 하나의 랭크 지시자만이 시그널링될 필요가 있다.
표 1: 폴백 랭크 제한을 갖는(RR=1), 또한 갖지 않는(RR=0) CoMP 방식의 스펙트럼 효율(bps/Hz)
폴백 랭크 제한을 부여함으로써, CoMP UE(즉, 측정 세트 내의 하나 이상의 TP를 갖는 사용자)가 랭크가 낮은 포인트마다의 CSI를 보고하는 것을 편중하여 설명한다. 이는, 폴백 CSI가 모든 비 서빙 TP로부터의 간섭을 가정하여 계산되고 이에 따라 낮은 랭크를 선택할 것이기 때문이다. 환언하면, CoMP 사용자는 폴백 단일-포인트 스케줄링 하의 셀 에지 사용자일 수 있고, 이에 따라 낮은 랭크를 지원할 것이다. 모든 포인트마다의 CSI에 이 폴백 랭크 제한을 둠으로 인해 CoMP 사용자에 대한 높은 랭크 전송을 디스에이블하게 되며, 이는 잠재적으로 레이트를 낮출 것임이 분명하다. 그러나, 그것은 또한 주요 이점을 갖는다. 각 포인트마다의 CSI에 대한 랭크 제한 하에서, 사용자는 본질적으로 우선 주어진 랭크의 최적의 비양자화 채널 근사를 결정하고, 이어서 양자화함을 유념한다. 이어서, 중요한 사실은 고정된 양자화 로드(코드북 사이즈에 의해 결정됨)를 고려할 경우, 양자화 에러는 낮은 랭크에 대해 보다 낮아진다는 점이다. 이것의 순 효과는, 대응하는 특이 값과 함께 제 1의 소수 우세 특이 벡터(우선 순위의 방향을 나타냄)가, 나머지 것을 보고하는 것을 전혀 감수하지 않고 사용자에 의해 보다 정확하게 보고된다는 점이다. 랭크 제한이 없을 경우에, 사용자는 일반적으로 보다 큰 특이 벡터의 세트를 선택해서 양자화한다. 이에 따라 중앙 스케줄러는 보다 성기지만(coarsely) 많은 방향 및 연관 이득을 알게 된다.
표 1에 이 폴백 랭크 제한의 영향을 강조하는 결과를 제공한다. 간략화를 위해, 두 가지 CoMP 방식 및 적절한 COMP 스케줄링 알고리즘을 고려한다. 이 결과로부터, 폴백 랭크 제한으로 인한 성능 저하가 거의 없게 됨을 알 수 있으며, 이는, 각 CoMP 사용자로부터의 보다 적은 방향을 정확하게 아는 것이 네트워크가 간섭을 보다 양호하게 관리할 수 있게 하고, 이에 따라 해당 사용자에의 상위 랭크 전송을 디스에이블하는 것으로 인한 손실을 상쇄시킬 수 있음을 제안한다. 따라서, 폴백 랭크 제한은 제한된 양자화 로드 하에서의 유용한 피드백 감소 전략일 수 있다.
ㆍ 피드백 가설의 동적 피드포워드 지시
폴백 CQI(들)가 서빙 및 간섭 TP의 설정 폴백 선택에 의존하여 계산될 수 있고 외부 CoMP 세트로부터의 간섭이 항상 포함되는 다수의 가설을 논했음을 상기한다. 일반적으로, 각각의 가설을 CSI 프로세스라고 할 수 있으며, 이 CSI 프로세스는, 서빙 TP(또는 이에 대등하게 어느 채널 추정이 얻어질 수 있는 것을 이용하는 그 측정 세트 내의 비-제로 파워(NZP) CSI-RS 리소스)의 선택을 나타내는 하나의 "채널 부분" 및 하나의 "간섭 부분"과 연관된다. 이 간섭 부분은 결과적으로 RE(간섭 측정 리소스(IMR)라고 하는 제로 파워(ZP) CSI-RS 리소스)의 세트와 연관될 수 있다. 앞서 설명한 바와 같이, UE는 해당 RE에서 간섭(간략화를 위해 이하 용어 "공분산 매트릭스"를 빼고 "간섭 측정/추정"만을 사용함)의 공분산을 직접 측정 또는 추정하도록 간단히 지시받을 수 있고, 컨트롤러는 UE가 측정할 간섭을 해당 RE에서 설정한다. 또는, UE는 IMR에서 간섭(예를 들면 외부 CoMP 세트로부터의 간섭)을 측정하고, 또한 전술한 바와 같이 스케일링된 단위 프리코더와 함께, 대응하는 NZP CSI-RS 리소스로부터 해당 TP에 대해 판정된 채널 추정을 이용하여 그 CoMP 내의 TP의 서브세트로부터의 추가적인 간섭을 에뮬레이션하도록 구성될 수 있다. 최대 CoMP 이득을 달성하기 위해, 네트워크는, 각각의 간섭의 에뮬레이션을 위해 서로 다른 IMR 및/또는 서로 다른 NZP CSI-RS 리소스와 함께, 서로 다른 CSI-프로세스가 UE에 대해 설정 가능해야함을 유념한다. 분명히, (집합 CQI(들)를 포함하는 것을 제외한) 전술한 모든 피드백 포맷 설계는 다수의 CSI-프로세스를 설정하는 측면에서 대신 설명할 수 있다. 예를 들면, 전술한 각 포인트마다의 CSI-RS 리소스 피드백은, UE가 외부 CoMP 세트 간섭을 측정하도록 IMR이 설정되고 UE가 대응하는 TP로부터의 채널 추정을 얻을 수 있게 하도록 NZP-CSI-RS 리소스가 설정되는 단순한 CSI 프로세스이다.
오버헤드 및 복잡도를 제한하기 위해, UE에 대해 설정될 수 있는 별개의 CSI 프로세스의 개수에 제한을 부여할 수 있다. 또한, CSI-프로세스의 세트로 구성되는 CSI 패턴의 개념을 정의할 수 있다. 이러한 패턴의 코드북은 반정적 방식으로 정의되어 UE에 공개될 수 있다. 이어서, 컨트롤러는 코드북으로부터의 인덱스를 패턴을 식별하는 UE에 동적으로 시그널링할 수 있다. 이어서, UE는 해당 패턴에서의 각 CSI-프로세스에 따라 CSI를 계산하고 이를 반환할 수 있다.
오버헤드를 감소시키기 위해, 패턴을 정의하면서, 하나 이상의 CSI 프로세스가 CQI만으로 표시되며, 즉 UE는 이 CSI 프로세스에 대해 계산되는 CSI에서 PMI/RI를 계산하지 않는다. 대신, 이러한 각각의 프로세스마다, CQI만으로 표시되지 않고 동일한 "채널 부분"(즉, NZP-CSI-RS 리소스)을 갖는 해당 패턴에서 다른 프로세스의 PMI를 사용하여 표시된 프로세스와 관련된 CQI(들)를 계산한다. PMI가 사용되는 프로세스는 또한 이러한 각 CQI만 표시되는 각각의 프로세스에 대해 별개로 고정된다. 또한, 일부 프로세스는 와이드밴드 PMI 및/또는 와이드밴드 CQI(들)를 필요로 하는 것으로 표시될 수 있으며, UE는 이러한 프로세스에 대해 와이드밴드 PMI 및/또는 와이드밴드 CQI(들)를 단지 계산 및 보고할 것이다. 추가적으로, 각각의 프로세스에 별개의 코드북 서브세트 제한을 부여할 수 있거나, 및/또는 각 프로세스에 별개의 최대 랭크 제한을 부여할 수 있다. 옵션으로, 패턴의 모든 프로세스에 대해 공통 랭크 제한을 부여할 수 있다. 또한, 이 제한을 특수화하여, 패턴의 CSI 프로세스는, UE가 우선 해당 프로세스에 대한 CSI(RI를 포함함)를 계산하여 나머지 모든 프로세스에 대해 계산된 RI를 사용하는 것을 지시하도록 표시될 수 있다. 이러한 모든 최적화는 코드북을 정의하면서 반정적으로 행해지고, 코드북 및 코드북의 각 패턴에서 각 프로세스의 코드북 및 속성(또는 마킹)은 UE에 반정적으로 전해질 수 있다. 이어서, 패턴의 인덱스가 동적인 방식으로 전해질 수 있고 UE는 인덱싱된 패턴 및 구성 CSI 프로세스의 속성에 따라 CSI를 보고할 것이다. 코드북은 UE 특정 방식으로 정의될 수 있음을 유념한다. 또는, 코드북은, 각 UE가 그 설정된 측정 세트에 의거하여 코드북을 알 수 있도록, 각각의 가능한 측정 세트에 대해 정의될 수 있다.
CoMP 측정 세트가 TP 0, 1, 2에 의해 형성되는 UE를 고려함으로써 패턴의 코드북의 특정 예를 고려한다. 이어서, TP 0, 1, 및 2와 각각 연관된 "채널 부분"에 대해 NZP-CSI-RS0, NZP-CSI-RS1, NZP-CSI-RS2로 표시되는 3개의 NZP-CSI-RS 리소스를 이용한다. CoMP 측정 세트 외부의 간섭을 측정하기 위한 IMR은 IMR012로 표시된다. 또한, CSI0, CSI1, 및 CSI2를, NZP-CSI-RS0, NZP-CSI-RS1, 및 NZP-CSI-RS2로부터 "채널 부분"이 결정되는 것으로 CSI 프로세스로 정의하고, 간섭 부분은 I0, I1, 및 I2로 각각 나타내고, 여기서 I0는 우선 IMR012에 대해 직접적으로 간섭을 측정/추정하고, 이어서 TP1 및 TP2로부터의 간섭을 에뮬레이션하고, 그들을 합산함으로써 계산된다. TP 1(TP 2)로부터의 간섭의 에뮬레이션은 NZP-CSI-RS1(NZP-CSI-RS2)로부터 추정된 채널 및 스케일링된 단위 프리코더(또는 설정된 프리코더 코드북 서브세트에 대한 평균)를 이용하여 행해진다. I1 및 I2는 IMR012에서의 간섭을 직접 추정하고, (NZP-CSI-RS0 및 NZP-CSI-RS-2) 및 (NZP-CSI-RS0 및 NZP-CSI-RS-1)을 이용하여 간섭을 에뮬레이션 및 가산함으로써 유사하게 각각 계산된다. 마지막으로, CSIij를 정의하기로 하며, 여기서 i 및 j는 {0, 1, 2} 내에 놓이고, 채널 부분은 NZP-CSI-RSi를 이용하여 결정되고 간섭은 직접 IMR012에 대한 간섭을 측정/추정하고 대응하는 NZPCSI-RS 리소스를 이용하여 세트 {0, 1, 2}\{i, j}의 TP로부터의 간섭을 에뮬레이션 및 가산함으로써 산출된다. 이어서, 코드북은 (CSI0, CSI1, CSI01, CSI10)을 포함하는 것 및 (CSI0, CSI2, CSI02, CSI20)로 구성된 다른 패턴을 포함하는 것으로서 정의될 수 있다. 동적으로, 컨트롤러는 이 2 개의 패턴 중 어느 하나에 대응하는 인덱스를 UE에 시그널링할 수 있다. 또한, 피드백 오버헤드를 줄이기 위한 옵션으로서, 패턴(CSI0, CSI1, CSI01, CSI10)에서 CSI01 및 CSI10이 CQI만으로 표시될 수 있으며, 여기서 CQI는 각각 CSI0 및 CSI1에 대해 결정된 PMI를 사용하여 계산되어야 한다. 마찬가지로, 패턴(CSI0, CSI2, CSI02, CSI20)에서 CSI02 및 CSI20은 CQI만으로 표시될 수 있으며, CQI는 각각 CSI0 및 CSI2에 대해 결정된 PMI를 이용하여 각각 계산되어야 한다.
또 다른 예에서, 코드북은 다음의 예외를 갖고 앞서와 같이 정의될 수 있다. 패턴(CSI0, CSI2, CSI02, CSI20)에서, 프로세스 CSI02에 대한 CSI는 이전과 같이 NZP-CSI-RS0를 이용하여 결정된 채널 부분을 이용하여 계산되지만, 간섭은, 이 IMR을 통해 UE에 지시된 RE에서 CoMP 세트 및 TP1 외부로부터의 간섭을 UE가 직접 측정/추정할 수 있도록 TP0 및 TP2가 사일런트로 유지될 것을 컨트롤러가 보장하는 것을 나타내는 IMR02에 대해, 직접 측정된다. 마찬가지로, 프로세스 CSI20에 대한 CSI는 NZP-CSI-RS2를 이용하여 결정된 채널 부분을 이용하여 계산되고, 간섭은 IMR02에 대해 직접 측정된다. 한편, 프로세스 CSI0에 대한 CSI는 NZP-CSI-RS0를 이용하여 결정된 채널 부분 및 IMR02에 대해 직접 측정된 간섭 + NZP-CSI-RS2를 이용하여 에뮬레이션된 간섭을 이용하여 계산되는 반면, 프로세스 CSI2에 대한 CSI는 NZP-CSI-RS2을 사용하여 판정된 채널 부분 및 IMR02에 대해 직접 측정된 간섭 + NZP-CSI-RS0을 이용하여 에뮬레이션된 간섭을 이용하여 계산된다. 패턴(CSI0, CSI1, CSI01, CSI10)에 대해 UE가 따라야 하는 CSI 계산 절차는, UE가 CoMP 세트 외부 및 TP2 외부로부터의 간섭을 UE가 직접 측정/추정할 수 있도록 이 IMR을 통해 UE에 지시된 RE에서 TP0 및 TP1이 사일런트로 유지될 것을 컨트롤러가 보장할 것을 나타내는 IMR01을 이용하여 마찬가지로 명시될 수 있다. 제 2 코드북에서, 하나의 추가의 IMR을 필요로 하지만, UE는 제 1 코드북에 비해 더 적은 간섭을 에뮬레이션하는 것이 필요하다.
따라서, 패턴 및 패턴의 CSI 계산 절차를 적절하게 정의함으로써, 컨트롤러는 (UE 특정 방식으로 IMR에 대해 RE를 예약하는 측면에서) 오버헤드 및 UE에서의 간섭 에뮬레이션의 복잡도를 제어할 수 있다. UE에서의 간섭 에뮬레이션의 복잡도는 직접 측정/추정에 비해 현저히 높지 않을 필요가 있음을 유념한다. 에뮬레이션에서, UE는 추정된 채널 및 미리 계산된 "대표" 프리코더를 이용하여(예를 들면 프리코더 코드북 서브세트에 걸친 아이소트로픽 또는 평균) 간섭 공분산 매트릭스를 계산한다. 심지어 간섭의 직접 측정에서도 공분산 추정 알고리즘을 구현할 필요가 있어서, 큰 복잡도 저감이 있을 필요는 없다. 또한, 직접 측정은 측정 시간 동안 간섭 TP에 의해 프리코더의 특정 선택이 채용되는 것에 기인한 간섭을 실제 측정한다. 스케줄링의 결과로 UE에 야기되는 간섭은 서로 다른 프리코더의 선택에 기인할 가능성이 가장 크다. 컨트롤러는 이 불일치를 감안하여 일부 보상을 할 수 있지만, UE에 의해 직접 추정을 하기 위해 채택된 알고리즘을 알지 못한다는 사실에 의해 복잡화된다. 이를 고려하면, 에뮬레이션 방법은 랜덤 또는 평균 프리코더를 가정하므로 편중이 덜한 것으로 보인다.
3
CoMP
에서의
PDSCH
매핑(
PDSCH
Mapping
in
CoMP
)
3.1
CoMP
에서의
PDSCH
매핑의
문제점
3.1.1
CRS
-
PDSCH
충돌 문제
레거시(릴리스 8) UE를 지원하기 위해, CRS는 주기적으로 송신되어야 한다[3]. 3GPP LTE 셀룰러 시스템은 CRS를 최대 4개의 안테나 포트까지 지원한다. CRS는 RE에서 셀 특정 주파수 변위를 갖고 위치된다. 따라서, CRS가 서브프레임에서 전송될 경우, 셀 특정 주파수 변위 및 CRS 포트의 개수는 이 서브프레임에서 모든 CRS RS 위치를 특정한다. 따라서, 서로 다른 셀 ID를 갖는 셀 또는 TP에 대해, CRS RE 위치는 상이하다. 이로 인해 CoMP 전송에 대해 PDSCH에서 데이터 심볼이 전송됨에 있어 충돌이 일어난다. 2 개의 CoMP TP의 예가 도 3에 나타나 있다. CoMP JT에서, 데이터는 2 개의 TP를 통해 전송되어야 한다. 이에 따라, 어느 TP에 따라 PDSCH 맵핑이 네트워크에 의해 설정되고 UE에 의해 가정되어야 하는지 의문이 있다. 한편, DPS에서, CoMP 전송이 UE에 대해 투명성(transparent)이 있으므로, UE는 그를 서빙하기 위해 어느 TP가 최종적으로 채용되었는지 알지 못한다. 따라서, UE는 이 TP로부터 송신되는 정확한 CRS RE 위치의 정보를 갖지 않는다. 다시 말해, DPS에서, UE가 제어 시그널링을 수신하는 서빙 TP에 의거하여 CRS 위치를 여전히 가정할 수는 있지만, 데이터 심볼과 CRS 신호 간의 불일치는 성능 저하를 야기할 것이다. 이는, 충돌 RE에서의 모든 데이터 심볼이 검출에 누락되어, JT에서의 문제에 비해 더욱 심각해 보인다. CS/CB에서는 전송이 항상 서빙 TP로부터 수행되므로, CoMP CS/CB 전송 방식에서는 이러한 충돌 문제가 없다.
이러한 충돌 문제는 또한 동일한 셀 ID를 갖는 CoMP TP에 대해서도 발생한다. 동일한 셀 ID를 갖는 모든 TP 간에서 안테나 포트의 개수가 동일할 때에는, CRS 위치가 모든 TP에 대해 정확히 동일하므로 문제가 없다. 그러나, 일부 경우, 예를 들면 HetNet에 있어서, 안테나 포트의 개수가 협력 TP 간에 상이할 수 있다. 예를 들면 저전력 노드는 매크로 기지국보다 적은 수의 안테나를 구비할 수 있다. 동일한 셀 ID를 갖지만 서로 다른 안테나 포트의 개수를 갖는, 즉 비대칭(asymmetric) 안테나 설정을 갖는 CoMP TP에서, 더 많은 안테나 포트를 갖는 TP에 대한 CRS는 더 적은 안테나 포트를 갖는 TP에 대한 PDSCH와 충돌할 것이다. 도 4에 일례가 도시되며, 여기에서 우측의 TP는 4개의 안테나 포트를 갖고 좌측의 TP는 2 개의 안테나 포트를 갖는다. 4개의 안테나 포트를 갖는 TP는 데이터 RE에서 2 개의 안테나 포트를 갖는 TP와 충돌하는 4개의 CRS RE를 가짐을 알 수 있다. 비대칭 안테나 설정은 서로 다른 셀 ID를 갖는 CoMP TP에 대해서도 존재함을 유념한다. 코딩된 QAM 변조 시퀀스는 PDSCH RE 리소스에 순차적으로 매핑되므로, CRS RE의 개수가 상이하면, UE는 QAM 심볼 시퀀스의 변위로 인해 상기 시퀀스를 전혀 디코딩할 수 없을 것이다. 이는 CRS 간섭보다 더욱 심각하다. 해당 TP에 대한 물리적 안테나의 개수가 상이할 경우에도 CRS 포트의 개수가 동일한 셀 ID를 갖는 클러스터 내의 서로 다른 TP에 대해 동일하도록 고정될 경우, 충돌 문제는 없다. 그러나, CRS 기반의 채널 추정은 일부 성능 저하가 있을 것이다.
DL 전송에서, MBSFN 서브프레임(MBSFN는 단일 주파수 네트워크에서의 멀티캐스트/브로드캐스트를 나타냄)으로서 설정되는 일부 서브프레임이 있다. CRS는 해당 MBSFN 서브프레임에서 전송된다. 그러므로, CoMP TP가 동일한 MBSFN 서브프레임 설정을 갖지 않을 경우, CRS-PDSCH 충돌이 또한 일어날 것이다. 예를 들면, 어느 시간 인스턴스에서, 하나의 TP는 일부 RE에서 전송되는 CRS를 갖는 비 MBSFN 서브프레임 상에 있는 한편, 동시에 측정 세트 내의 다른 TP는 MBSFN 서브프레임에 있다. 따라서, 이 서브프레임에서 이 2 개의 TP에 대해 PDSCH 맵핑이 상이하다. CoMP JT 또는 DPS가 이들 2 개의 TP 간에 실현될 경우, CRS-PDSCH 충돌이 일어난다.
3.1.2
PDSCH
개시점
서브프레임에서, 처음 복수의 OFDM 심볼은 제어 시그널링을 송신하는 데, 즉 LTE 및 LTE-A 시스템에서 PDCCH에 할당된다. 데이터 채널 PDSCH는 PDCCH에 이어서 다음 OFDM 심볼로부터 시작한다. 서로 다른 전송 포인트에서, PDCCH 전송을 위한 OFDM 심볼의 개수는 상이할 수 있다. 이에 따라, PDSCH에 대한 개시점이 상이할 수 있다. 환언하면, 코딩된 QAM 시퀀스가 PDSCH RE 리소스에 순차적으로 매핑되므로, CoMP 세트 내의 TP 간의 PDSCH 개시점의 불일치는, UE가 PDSCH의 개시점을 모른다면, CoMP 전송에서 JT 및 DPS 모두에 문제를 야기할 것이다. 일례를 도 5에 나타낸다.
3.2
CoMP
에서의
PDSCH
매핑
CoMP에서의 PDSCH RE 매핑의 상술한 문제로 인해, LTE-A 시스템에서 CoMP가 적절하게 작용하기 위해 일부 가정이 이루어지거나, 문제을 해결하기 위해 시그널링이 필요함을 알 수 있다. 이하 CoMP에서의 PDSCH 매핑에 대한 다음의 대안을 고려한다.
3.2.1
서빙
셀과의
정합
서빙 셀의 모든 정보 및 시그널링은 UE에 알려져 있다. 따라서, 추가적인 시그널링이 없는 단순한 솔루션이 다음과 같이 설명된다.
·CoMP UE는, PDSCH 매핑이 PDSCH 개시점 및 CRS RE 위치를 포함하는 서빙 셀에서의 매핑과 항상 정합되어 있는 것으로 가정한다. 네트워크는 이러한 가정에 따라 CoMP 전송을 위한 PDSCH 매핑을 수행한다. UE는 단일-셀 비-CoMP 전송에서의 PDSCH 매핑을 항상 가정함에 따라 추가적인 제어 신호가 필요하지 않다. 그러나, 이 상호간의 가정은 CoMP JT 또는 DPS 전송이 스케줄링될 때, QAM 데이터 심볼을 할당하는 PDSCH 매핑에 대한 이 원칙을 네트워크가 따르도록 특정할 필요가 있을 수 있으며, 이는 단일-셀 비-CoMP 전송과는 상이하다.
CoMP JT에서, (서빙 셀 이외의) 공동-스케줄링된 CoMP TP로부터의 PDCCH 영역(PDCCH를 위한 OFDM 심볼의 개수)은 서빙 셀에서의 것보다 더 클 경우, 상기 PDSCH 매핑 접근법에서, PDCCH 불일치 영역에서의 PDSCH 데이터 심볼은 서빙 셀로부터만 전송되며, 즉 비-CoMP 전송이고, 이 공동-스케줄링된 CoMP TP로부터의 PDCCH 신호로부터 간섭을 겪을 것이다. (서빙 셀 이외의) 공동-스케줄링된 CoMP TP로부터의 PDCCH 영역이 서빙 셀에서의 것보다 작으면, 공동-스케줄링된 CoMP TP에서 PDCCH 불일치 영역의 PDSCH RE에서 데이터는 전송되지 않을 것이다. 이러한 RE는 뮤팅될 수 있다.
DPS CoMP 방식에서, 전송을 위해 선택되는 TP가 서빙 셀 TP이면, PDCCH(또는 PDSCH 개시점) 불일치는 없다. 따라서 스펙트럼 효율 손실은 없다. 선택된 TP의 PDCCH 영역이 서빙 셀의 것보다 크면, PDSCH 매핑은 여전히 서빙 셀의 것으로서 설정되지만, PDCCH 불일치 영역에서의 QAM 심볼은 펑쳐링된다. 선택된 전송 TP가 UE에 대해 투명성이 있고 UE가 PDCCH 불일치 영역에서 QAM 심볼이 펑쳐링된 것을 알지 못하므로, UE는 RE 위치에서 전혀 관련없는 PDCCH 신호를 수신하여 디코딩한다. 선택된 TP의 PDCCH 영역이 서빙 셀의 것보다 작으면, UE는 PDSCH 매핑이 서빙 셀과 정합되는 것으로 가정하므로, 서빙 셀의 PDCCH 영역과 충돌하는 선택된 TP의 PDCCH 다음의 OFDM 심볼 또는 심볼들은 데이터 전송에 사용되지 않을 것이다. 네트워크는 서빙 TP와 동일하게 선택된 전송 TP의 PDSCH 개시점을 설정할 것이다.
마찬가지로, CRS/PDSCH 충돌 경우에 대해서. CoMP JT에서, 서빙 셀 이외의 전송 TP의 모든 CRS RE 위치에서, 모든 CoMP 전송 TP 간의 완전한 CoMP 공동 전송은 달성될 수 없다. 단지 TP 서브세트에서의 JT가 가능하다. 이 RE 위치에서의 데이터 심볼은 CoMP 전송 세트의 다른 TP에서의 CRS 전송으로부터 간섭을 받을 것이다. 서빙 셀의 CRS RE 위치에서, UE가 이 RE가 CRS라고 가정하므로 CoMP 세트 내의 다른 TP에서 데이터는 전송되지 않을 것이다. CoMP DPS에서, 선택된 전송 TP가 서빙 셀과 상이하면, 네트워크는 선택된 TP의 CRS 위치에서 심볼을 펑쳐링하고(전송하지 않고) 데이터 심볼에 대한 서빙 셀의 CRS RE 위치인 RE를 건너뛸(skip) 것이다.
이 접근법은 추가적 신호를 초래하지 않으므로 최소 표준 영향을 가짐을 알 수 있다. 그러나, 가능한 리소스 낭비 및 CRS-PDSCH RE 충돌 영역에서의 강한 간섭으로 인해 스펙트럼 효율은 낮다.
3.2.2 반정적
시그널링으로
충돌 회피
CRS/PDSCH 충돌 문제를 해결하기 위한 복수의 방법이 [4]에 정리되어 있다. [4]에 설명되어 있는 투명성 있는 접근법 중, 일 방식은 CRS 전송이 없는 MBSFM 서브프레임에서 CoMP UE에 대해 데이터를 전송하는 것이다. 이러한 제한은 CoMP 전송을 위한 리소스 활용을 제한한다. 두 번째 솔루션은 CRS OFDM 심볼에 대한 데이터를 전혀 전송하지 않는 것으로, 이는 CoMP 세트 내의 임의의 TP에 대한 CRS를 포함하는 전체 OFDM 심볼이, CoMP 시스템에서의 데이터 전송에 대해 제외되는 것을 의미한다. 이 접근법은 리소스를 낭비하고 CoMP에 대한 스펙트럼 효율 성능을 저하시키는 것이 명백하다. 다른 투명성 솔루션은 그저 동일한 셀 ID를 갖는 TP에 대해서 CoMP를 수행하는 것이다. 그러나, CoMP 전송은 서로 다른 셀 ID를 갖는 셀에 대해 수행될 수 있음이 합의되어 있다. 또한 상술한 바와 같이, 단일 셀 ID CoMP는 안테나 포트의 개수가 서로 다른 CoMP TP에 대해서 충돌 문제를 해결하지 못한다. 상술한 모든 방법들이 효과적이지 못함을 알 수 있다. 또한 다른 비투명성(non-transparent) 접근법으로서 예를 들면 UE에 CoMP 전송 TP 또는 TP들(DPS 또는 JT를 위해)을 시그널링하여 UE가 활성 TP 세트를 알 수 있게 하여 데이터가 충돌없이 RE에 할당될 수 있도록 하는 접근법이 있다. 다른 비투명성 접근법은 동적 또는 반정적 CRS 매핑 패턴 시그널링이 있다. 또한 CoMP 전송이 동적으로 스케줄링되고 UE 특정이므로, 활성 CoMP TP 세트 또는 CRS 매핑 패턴의 시그널링은 DL 시그널링 오버헤드를 상당히 증가시킬 것이다.
이하 CRS/PDSCH 충돌 문제를 다루기 위한 일부 효율적인 CoMP 투명성 있는 솔루션을 제공한다. CoMP 시스템에서, 네트워크가 설정하여 UE가 채널을 측정하는 TP 세트를 UE에 시그널링하는 것이 알려져 있다. 이러한 TP 세트를 측정 세트라고 한다. CoMP 전송 TP 또는 TP들은 측정 세트로부터 선택될 것이다. 우선, UE가 측정 세트 내의 각 TP에 대한 CRS 안테나 포트의 개수를 알고 있는 것으로 가정하여 다음의 리소스 매핑 접근법을 제공한다.
ㆍCoMP UE의 측정 세트 내의 TP에 대해 CRS 전송을 위해 할당된 RE의 조합은 이 UE를 위한 PDSCH에서 CoMP(JT 또는 DPS) 데이터 전송을 위한 리소스 매핑으로부터 배제된다. 다시 말해, CoMP UE를 위한 PDSCH에서의 리소스 매핑은, 이 UE를 위한 측정 세트 내의 임의의 TP에서의 CRS 전송을 위해 할당된 임의의 RE 위치를 회피할 것이다.
CoMP UE가 측정 세트 내의 TP의 CRS 정보를 이미 알고 있을 경우, CRS RE 위치의 조합은 UE에 알려져 있다. 따라서 RB에서의 리소스 매핑은 전송 및 검출 모두를 위해 네트워크 및 UE 양쪽에 알려져 있다. 또한 측정 세트는 보통 작으므로, CRS RE 위치의 조합은, 임의의 TP에 대한 CRS를 포함하는 OFDM 심볼에 대한 RE의 개수보다 적다. 따라서, 제안된 투명성 있는 접근법은 기존의 접근법에 비해 더 효율적이다. 그러나 이 리소스 매핑은 사용자 특정이지만, 네트워크가 이미 사용자 특정 CoMP 전송을 동적으로 관리하고 있으므로, 네트워크 측에 복잡도를 많이 증가시키지 않는다. 또한, 상기 제안된 접근법은 서로 다른 셀 ID 및 동일한 셀 ID를 갖지만 비대칭 안테나 설정을 갖는 충돌 경우 모두에 적용될 수 있다. 예로서 도 3 및 도 4에 도시된 리소스 매핑 솔루션이 도 6의 좌측부 및 우측부에 각각 도시된다. 각 예에서 측정 세트 내에 단 두 개의 TP가 존재하는 것으로 가정한다. 도 6의 좌측 도시에서, 서로 다른 셀 ID를 갖는 두 개의 TP로부터의 PDSCH에서의 CRS RE 위치의 조합은 데이터 매핑에서 제외됨을 알 수 있다. 우측에서, 데이터 전송으로부터 제외되는 CRS RE 위치의 조합은 4개의 안테나 포트를 갖는 TP를 위한 CRS RE와 본질적으로 동일하다. 따라서, 동일한 셀 ID를 갖는 TP에서, 솔루션이 다음과 같이 다시 설명될 수 있다.
ㆍ동일한 셀 ID를 갖는 CoMP TP에서, CoMP UE에 대한 PDSCH에서의 JT 또는 DPS CoMP 데이터 전송을 위한 리소스 매핑은 이 UE의 측정 세트 내의 최대 개수의 CRS 안테나 포트를 갖는 TP의 리소스 매핑에 따른다.
제안된 방식의 변형은, CoMP 클러스터, 즉 네트워크 배치(CoMP 측정 세트는 CoMP 클러스터 내의 TP의 UE 특정 서브세트임)에 기반한 CoMP 네트워크에 대한 최대 TP 세트 내의 모든 TP에 대한 셀 ID 또는 CRS RE 위치의 주파수 변위, 및 CRS 안테나 포트 개수를 포함할 수 있는 CRS 패턴 정보를 네트워크가 브로드캐스팅하는 것이다. 동일한 셀 ID를 갖는 CoMP 클러스터에서, 셀 ID가 UE에게 알려져 있으므로, CRS 안테나 포트의 최대 개수만이 CoMP 클러스터에 의해 서빙되는 모든 UE에 브로드캐스팅된다. 따라서 모든 CoMP UE을 위한 모든 리소스 매핑은, 서로 다른 셀 ID를 갖는 CoMP 클러스터 내의 모든 TP에 대한 CRS RE 위치, 또는 최대 개수의 안테나 포트를 갖는 TP에 따른 CRS RE 위치의 조합을 피할 것이다. 이 접근법은 UE 특정이 아니며, 따라서 네트워크 측에 리소스 매핑에 대한 복잡도를 더하지 않는다. 그러나, 이 접근법은, 배제된 RE 위치가 CRS 안테나 포트의 가능한 최대 개수, 즉 4에 대응하는 것일 뿐이므로 동일한 셀 ID CoMP의 시나리오에만 적합할 수 있다. 서로 다른 셀 ID를 갖는 CoMP 클러스터에 대해서는, CoMP 클러스터의 크기가 보통 UE 특정 CoMP 측정 세트의 크기보다 훨씬 크므로 이 접근법은 효율적이지 않다. 큰 크기의 CoMP 클러스터에서, 이 접근법은 일부 TP를 위한 CRS RE를 포함하는 임의의 OFDM 심볼을 결국 배제할 수 있다.
CRS는 주로 LTE(릴리스 8) UE에 대해 채널 추정과 데이터 심볼 검출을 위해 사용된다. LTE 어드밴스드(릴리스 10 또는 후속) 시스템에서, UE는 채널 추정에 CSI-RS를 사용한다. UE가 CRS를 모니터 또는 검출하지 못할 수 있다. 따라서, UE는, 측정 세트 내의 TP에 대해, CRS 위치의 주파수 변위 또는 CRS 안테나 포트의 개수, 결과적으로는 CRS RE 매핑 패턴을 알지못할 수 있다. 이 경우를 위해, 다음의 대안을 제안한다.
(Alt-CRS-1.1) 네트워크는 UE에, 각 TP에 대한 CRS 주파수 변위 및 UE의 측정 세트 내의 TP의 CRS 안테나 포트의 최대 개수를 반정적으로 시그널링한다. 이어서, UE는 각 TP에 대한 CRS 패턴이 CRS 안테나 포트의 최대 개수에 대응하는 CRS 위치를 따르는 것으로 가정한다. 따라서, CoMP 데이터 전송을 위한 기지국에서의 PDSCH 매핑은 이 CoMP UE에 대한 CRS 위치의 조합의 가정 또는 서빙 셀의 PDSCH 매핑(UE에 반정적으로 시그널링된 지시자로 알려짐)에 따른다.
(Alt-CRS-1.2) 네트워크는 UE에, UE의 측정 세트 내의 각 TP에 대한 CRS 주파수 변위 및 CRS 안테나 포트의 개수를 반정적으로 시그널링한다. 이에 따라 UE는 측정 세트 내의 각 TP에 대한 CRS 패턴을 얻을 수 있다. 따라서, CoMP 데이터 전송을 위한 기지국에서의 PDSCH 매핑은 이 CoMP UE에 대한 CRS 위치의 조합의 동일한 가정 또는 서빙 셀의 PDSCH 매핑에 따른다.
(Alt-CRS-1.3) 네트워크는 UE에, 측정 세트 내의 각 TP에 대해 셀 ID 및 CRS 안테나 포트의 개수를 반정적으로 시그널링한다. 이에 따라 UE는 측정 세트 내의 각 TP에 대한 CRS 패턴을 얻을 수 있다. 따라서, CoMP 데이터 전송을 위한 기지국에서의 PDSCH 매핑은 이 CoMP UE에 대한 CRS 위치의 조합의 가정 또는 서빙 셀의 PDSCH 매핑에 따른다.
CRS 주파수 변위 및 CRS 안테나 포트의 개수에 대한 인지로, UE는 CRS 패턴 또는 RE 위치를 안다. 또한 적은 수의 안테나 포트에 대한 CRS RE 위치는 보다 많은 수의 안테나 포트의 것의 서브세트이다. 측정 세트 내의 각 TP의 셀 ID 및 CRS 패턴을 알고 있으므로, CoMP 세트 내의 다른 TP에서 CRS RE와 충돌하는 하나의 TP에서의 일부 PDSCH RE에서 일부 데이터가 전송될 경우, UE는 CRS 신호를 검출하고 이어서 간섭 해소를 수행하여 수신기 성능을 향상시킬 수 있다. 측정 세트 내의 각 TP에서, MBSFN 서브프레임, MBSFN 서브프레임 설정의 정보는 또한 CoMP UE에 반정적으로 시그널링될 수 있다. 상술한 세 가지 대안에서, 뮤팅되는 CRS RE의 개수를 저감하며, 결과적으로 PDSCH 매핑으로부터 비 MBSFN 서브프레임에 있는 측정 중에 있는 TP의 CRS RE의 조합을 배제하는 것만으로 스펙트럼 효율을 향상시킬 수 있다.
CoMP UE에서 CRS 패턴의 조합을 얻기 위해, 네트워크는 우선, 상술한 Alt-CRS-1.2에서와 같이 측정 세트 내의 M개의 TP에 대해 주파수 변위
, 및 CRS 포트의 개수
을 반정적으로 시그널링한다(m=1, …,M). 측정 세트 내의 m 번째 TP의 CRS RE 위치의 세트로서 세트
를 표시한다. 측정 세트 내의 모든 CRS RE의 조합은
에 의해 주어진다. Alt-CRS-1.1에서, 측정 세트 내의 TP의 CRS 안테나 포트의 최대 개수
가 UE에 시그널링된다. 이어서 UE에서 가정된 TP-m에 대한 CRS RE의 세트는
이다.
임을 유념한다. 이어서 Alt-CRS-1.1에서,
에서의 모든 CRS RE는 PDSCH 매핑으로부터 배제된다. Alt-CRS-1.3에서, CoMP 세트 내의 TP의 셀 ID가 UE에 시그널링될 경우, UE는 CRS 주파수 변위
를 추정할 수 있다. CRS 포트의 개수 또는 CRS 포트의 최대 개수가 UE에 통지되어, Alt-CRS-1.3에서의 PDSCH 매핑은 ALT-CRS-1.2 또는 Alt-CRS-1.1에서와 같이 CRS RE의 조합, 즉
또는
을 다시 피하게 된다. 측정 세트 내의 m 번째 TP에 대한 t 번째 서브프레임에서 MBSFN 서브프레임의 지시자로서
로 표시하며, 즉
은 TP-m의 서브프레임 t가 MBSFN 서브프레임을 지시하며, 그렇지 않을 경우
이다. MBSFN 서브프레임 구성이 CoMP UE에 시그널링될 경우, UE는
를 얻을 수 있다. 이어서, 서브프레임 t에서의 CRS RE의 조합,
은 ALT-CRS-1.1, Alt-CRS-1.2, 또는 Alt-CRS-1.3에서 t 번째 서브프레임에서의 PDSCH RE 매핑으로부터 배제된다.
표 2: 반정적 시그널링만을 갖는 CoMP PDSCH RE 매핑(1비트)
PDSCH 매핑이 앵커 서빙 셀에 대한 것에 따라 설정되는 CoMP CS/CB 전송을 또한 지원하기 위해, 표 2에 나타난 바와 같이, UE에의 CRS RE 패턴의 신호와 함께 하나의 추가적인 비트를 사용하여, PDSCH RE 매핑이 서빙 셀 또는 측정 세트 내의 모든 CRS 위치에 대한 따름을 지시한다. 측정 세트 내의 TP의 MBSFN 서브프레임 설정이 UE에게 알려져 있을 경우, CRS RE의 조합은 서브프레임 내의 기존 CRS RE의 조합임을 유념한다.
이하 앵커 서빙 셀의 PDSCH 매핑을 항상 가정하는 디폴트 접근법과 비교해 상술한 반정적 접근법의 이점을 논한다. 디폴트 접근법에서는, eNB는 서빙 셀에 대한 것으로서 임의의 전송 TP에 대한 PDSCH RE 매핑을 구성한다. DPS에서, 측정 세트 내의 서빙 TP 이외의 TP가 전송하고 있을 경우, 이 TP를 위한 CRS 위치에서의 PDSCH는 데이터 전송에 사용되지 않을 것이다. UE가 서빙 셀 PDSCH 매핑을 가정할 경우, 실제로 어떠한 데이터 정보도 반송하지 않는 이들 CRS 위치에서의 데이터를 여전히 디코딩하려고 하므로, 일부 노이즈 신호, 소위 더티 데이터/비트를 수신하게 된다. 이어서, 이 시나리오의 성능을 평가하기 위해, 간단한 시뮬레이션을 행한다. 길이 576 정보 비트가 1/2 레이트의 LTE 터보 코드를 이용하여 인코딩된다. CRS/PDSCH 충돌의 영향을 받은 총 5% 코딩 비트가 존재한다고 가정한다. 펑쳐링 5% 코딩 비트(PDSCH 뮤팅), 5% 더티 수신 데이터(순수 노이즈), 및 2.5%의 펑쳐링 + 2.5% 더티 데이터를 갖는 AWGN 채널에서의 이 1/2 레이트 코드의 성능을 비교한다. 펑쳐링 또는 뮤팅 5% 코딩 비트는 충돌 RE에서의 전송을 피하는 상기의 접근법을 나타낸다. 2.5% 펑쳐링 비트 + 2.5%의 더티 데이터의 경우는 디폴트 PDSCH 매핑을 갖는 DPS를 나타낸다. 5% 더티 데이터의 경우는, 서빙 TP 이외의 TP가 비 MBSFN 서브프레임에서 전송되고 서빙 TP가 MBSFN 서브프레임에 있는 DPS 시나리오를 나타낸다. 이 경우의 블록 에러 레이트(BLER)를 도 9에 나타낸다. 5% 더티 비트에서 상당한 성능 저하가 있음을 알 수 있다. 충돌 RE 위치에서 절반의 더티 비트에 있어, RE 뮤팅에 비해 현저한 성능 저하가 여전히 존재한다.
이하 CRS/PDSCH 충돌 회피를 갖는 제안된 리소스 매핑을 위한 데이터 심볼 시퀀스 매핑 또는 할당을 고려한다. CRS/PDSCH 충돌 회피를 갖는 임의의 방법에서, CoMP 데이터 전송을 위한 RB에서의 RE의 개수는 종래의 단일 셀 또는 CoMP CS/CB 전송을 위한 것보다 적을 것이다. 이어서, 동일한 변조 및 코딩 방식(MCS)에 대해 동일한 유효 데이터 레이트를 유지하도록 데이터 전송을 위해 이용 가능한 RE의 변화에 대응하여 할당된 전송 블록 크기(TBS)가 변화되어야 한다. 그러나, CRS/PDSCH 충돌 회피를 위한 제안된 방식에 대해 할당 TBS의 변화를 수용하기 위해서는, [5]에서 전체 TBS 표를 변경할 필요가 있으며 결과적으로 사양에 큰 영향을 미칠 것이다. 따라서, 다음의 접근법을 제안한다. TBS 할당은 여전히 [5]의 동일 TBS 표를 따르며, 동일한 데이터 심볼 시퀀스, 예를 들면 S0, S1,…을 얻는다. 예로서 도 3의 경우를 든다. 먼저 도 7의 좌측 부분에 나타낸 바와 같이 서빙 셀 또는 TP에서의 데이터 전송에 따라 UE를 위한 데이터 심볼을 할당한다. CRS/PDSCH 충돌 회피를 갖는 리소스 맵핑을 위해, 도 7의 우측 부분에 나타낸 바와 같이, 네트워크 또는 CoMP 활성 TP 또는 TP들은 단순히 펑쳐링하여 이 UE의 CoMP 측정 세트 내의 다른 TP에서의 CRS RE 위치와 충돌하는 원래 할당된 데이터 심볼을 전송하지 않는다. CRS/PDSCH 충돌 회피를 위한 제안된 리소스 매핑은 데이터 전송에 많은 RE를 배제하는 것이 아니므로, 최종 유효 전송 레이트의 약간의 증가는 수신기 성능에 거의 영향을 주지 않을 것이다.
대안적 접근법이 도 8의 우측에 나타나 있으며, 여기에서 네트워크는 충돌 RE에는 어떠한 심볼도 부여하지 않고 RE에 데이터 심볼을 순차적으로 할당한다. 이어서, 이러한 접근법에서, 심볼 시퀀스의 말미의 일부 데이터 심볼은 할당 또는 전송되지 않을 것이다. 최종 유효 정보 레이트가 이전 접근법에서의 것과 동일하지만, 서브 블록 인터리빙으로 인해, 시퀀스의 말미의 연속하는 데이터 심볼의 펑쳐링은 비교적 큰 성능 저하를 초래할 수 있다.
PDSCH 개시점은 반정적으로 UE에 시그널링될 필요가 있을 수 있다. 따라서, 다음의 방식은 필요할 경우 PDSCH의 개시점에 주의한다.
·네트워크는 UE에, UE의 CoMP 측정 세트 내의 CRS RE 위치의 조합을 반정적으로 통보한다. 네트워크는 또한 반정적으로 설정하여 UE에 PDSCH의 개시점을 시그널링한다. 이어서, 네트워크는 설정된 반정적 PDSCH 개시점으로부터 PDSCH RE 매핑에 대한 QAM 심볼을 설정한다. 이어서 네트워크는 PDSCH RE 매핑에의 순차적 QAM 심볼에 대한 서빙 셀 CRS 패턴을 따르거나, CoMP 측정 세트 내의 CRS 위치의 조합을 피하기 위해 PDSCH RE 매핑에의 QAM 심볼을 순차적으로 행한다.
·네트워크는 CRS 위치의 주파수 변위 또는 셀 ID 중 어느 하나, 및 UE의 CoMP 측정 세트 내의 각 TP에 대한 안테나 포트의 개수를, UE에 반정적으로 통지한다. 네트워크는 또한 반정적으로 설정하여 UE에 PDSCH의 개시점을 시그널링한다. 이어서, 네트워크는 반정적으로 설정된 PDSCH 개시점에 따라 PDSCH RE 매핑에 대한 QAM 심볼을 설정한다. 그리고 네트워크는 PDSCH RE 매핑에 대한 순차적 QAM 심볼에 대한 서빙 셀 CRS 패턴을 따르거나, CoMP 측정 세트 내의 CRS 위치의 조합을 피하는 순서의 PDSCH RE 매핑에 대한 QAM 심볼을 설정한다.
상술한 접근법에서, PDSCH 개시점이 UE에 별도로 시그널링된다고 가정함을 유념한다. 또한, 2 비트 지시자를 갖는 다음의 반정적 접근법을 고려할 수 있다. 이어서 PDSCH 개시점의 반정적 시그널링이, CoMP PDSCH 매핑 지시자를 위한 비트의 개수를 증가시키지 않고 이 접근법에 포함될 수 있다.
·네트워크는 CRS 위치의 주파수 변위 또는 셀 ID 중 어느 하나, 및 UE의 CoMP 측정 세트 내의 각 TP에 대한 CRS 포트의 개수를, UE에 반정적으로 통지한다. 네트워크는 또한, 반정적으로 구성하여 PDSCH의 개시점 및 PDSCH 매핑을 위한 어느 CRS 패턴을 UE에 시그널링한다. 이어서, 네트워크는, 네트워크로부터 반정적으로 시그널링되는 지시자가 UE에 통지되는 해당 서브프레임에서 측정 세트 내의 TP의 CRS RE 위치의 조합을 배제함으로써 PDSCH 매핑 또는 하나의 TP의 PDSCH 매핑에 따른 PDSCH RE 매핑에의 QAM 심볼을 구성한다. 또한, 네트워크는 동일한 지시자가 UE에 알려지며 필요할 경우 반정적으로 설정된 PDSCH 개시점에 따라 PDSCH 매핑을 설정한다.
이것은 CRS 정보 및 PDSCH 개시점을 TP 인덱스로 태그하여 구현될 수 있다. 이어서 네트워크는, 네트워크가 PDSCH 매핑을 구성할 TP의 인덱스를 지시하는 것을 UE에 시그널링한다. 현재의 표준에서 CoMP 측정 세트 내에는 최대 3개의 TP가 있으므로, 이러한 정보를 반송하는 데 2 비트 지시자이면 충분하다. 또한, 표 3에 나타낸 바와 같이, 서브프레임 내의 모든 CRS RE에 대한 PDSCH 매핑의 옵션을 포함할 수 있다. 이러한 접근법은, 네트워크가 DL 데이터 전송을 위해 매크로 셀 eNB를 항상 설정할 수 있는 HetNet 시나리오에서의 일부 UE에 셀 범위 확장이 적용될 때 특히 유용하다. 전술한 바와 같이, 상기 표에서의 지시자는 CRS/PDSCH 충돌만을 피하도록 PDSCH RE 매핑에 적용되거나, PDSCH의 개시점을 포함할 수도 있다. 지시자가 11인 경우에, PDSCH 개시점은 측정 세트 내의 TP의 것 중에서 최대 수 또는 최소 수의 PDSCH 개시점일 수 있다.
표 3: 반정적 시그널링만을 갖는 CoMP PDSCH RE 매핑 지시(2비트)
3.2.3
PDSCH
매핑의
동적
시그널링
네트워크는 PDSCH 개시점을 UE에 반정적으로 통지할 수 있지만, DPS에 대해, CoMP 측정 세트 내의 TP에 대해 PDSCH 개시점 간의 불일치가 있을 경우, 스펙트럼 효율 손실 및 CoMP의 성능 이득을 감소시킬 것이다. CoMP 성능을 향상시키기 위해, 개시점 및 CRS 패턴을 포함하는 PDSCH 매핑 정보가 동적으로 UE에 전해질 수 있다. 이 목표를 달성하고 신호 오버헤드가 작은 모든 CoMP 전송 방식을 지원하는 다음의 대안을 열거한다.
(Alt-CRS-2.1) 네트워크는 CRS 위치의 주파수 변위 또는 셀 ID 중 어느 하나, 및 UE의 CoMP 측정 세트 내의 각 TP에 대한 CRS 안테나 포트의 개수를 UE에 반정적으로 통지한다. 이어서 네트워크는 PDSCH 매핑을 위해 설정될 PDSCH 개시점을 UE에 동적으로 시그널링한다. 이어서 네트워크는 설정된 PDSCH 개시점으로부터 PDSCH RE 매핑에 대한 QAM 심볼을 설정한다. 그리고 네트워크는 PDSCH RE 매핑에 대한 순차적 QAM 심볼에 대한 서빙 셀 CRS 패턴을 따르거나 CoMP 측정 세트 내의 CRS 위치의 조합을 피하기 위한 순차적 PDSCH RE 매핑에 대한 QAM 심볼을 설정한다.
(Alt-CRS-2.2) 네트워크는 CRS 위치의 주파수 변위 또는 셀 ID 중 어느 하나, 및 UE의 CoMP 측정 세트 내의 각 TP에 대한 CRS 안테나 포트의 개수를 UE에 반정적으로 통지한다. 네트워크는 또한, PDSCH 매핑을 위한 어느 TP 또는 어느 CRS 패턴을 UE에 반정적으로 시그널링한다. 이어서 네트워크는 PDSCH 매핑을 위해 설정될 PDSCH 개시점을 UE에 동적으로 시그널링한다. 이어서, 네트워크는 동적으로 설정된 PDSCH 개시점으로부터 개시되는 PDSCH RE 매핑 및 PDSCH 매핑을 위한 반정적으로 설정된 CRS 패턴 또는 TP에 따른 순차적 PDSCH 매핑에의 QAM 심볼을 설정한다.
(Alt-CRS-2.3) 네트워크는 CRS 위치의 주파수 변위 또는 셀 ID 중 어느 하나, 및 UE의 CoMP 측정 세트 내의 각 TP에 대한 CRS 안테나 포트의 개수를 UE에 반정적으로 통지한다. 이어서 네트워크는 PDSCH 매핑을 위해 설정될 PDSCH 개시점 및 PDSCH 매핑을 위한 어느 TP 또는 어느 CRS 패턴을 UE에 동적으로 시그널링한다. PDSCH에 대한 CRS 패턴은 UE에 반정적으로 시그널링된 CoMP 측정 세트 내의 CRS 패턴 또는 TP의 인덱스와 함께 UE에 동적으로 전해질 수 있다. 이어서 네트워크는 동적으로 설정된 PDSCH 개시점으로부터 개시되는 PDSCH RE 매핑 및 PDSCH 매핑을 위한 동적으로 설정된 CRS 패턴 또는 TP에 따른 순차적 PDSCH 매핑에의 QAM 심볼을 설정한다.
접근법 Alt-CRS-2.1은 1비트 지시자가 UE에 동적으로 송신되는 이전 반정적 접근법의 단순한 확장이다. 접근법 Alt-CRS-2.2에서, CRS에 대한 PDSCH RE 매핑은 여전히 반정적 접근법을 따르고 있지만, PDSCH 개시점은 UE에 동적으로 시그널링된다. 접근법 Alt-CRS-2.3은 표 3의 2 비트 지시자가 UE에 동적으로 시그널링되는 반정적 접근법의 확장이다. 그러나, 동적 시그널링에 있어서, Alt-CRS-2.3에서, 반정적 접근법에 대해 표 3의 경우와 마찬가지로 지시자가 11일 경우 동일한 PDSCH 매핑을 구성하는 것은 효율적이지 않다. 표 3에서의 처음 3개의 지시자 값, 즉 지시자가 00, 01, 10인 경우, DPS에 대한 PDSCH 매핑 문제는 이미 처리되어 있다. CoMP TP를 위한 매핑 문제만이 남아 있으며, 하나의 이상의 TP가 전송에 관여될 것이다. 이 경우에, 셀 내의 모든 TP에 대한 CRS 위치를 피하는 매핑을 대신하여 동적 시그널링이 이용 가능한 하이브리드 접근법에서, 모든 가능한 RE를 순차적으로 점유하는 PDSCH RE 매핑을 행하는 것이 좋다. 다만 충돌 CRS RE에서, (3TP JT를 위해) 오직 단일 TP 또는 TP의 서브세트가 전송에 관여된다. 이어서, 다음의 대안 방식이 있다.
(ALT-CRS-2.3A) 네트워크는 CRS 위치의 주파수 변위 또는 셀 ID 중 어느 하나, 및 UE의 CoMP 측정 세트 내의 각 TP에 대한 CRS 안테나 포트의 개수를 UE에 반정적으로 통지한다. 이어서, 네트워크는, 해당 인덱스를 전하거나, (1) 해당 서브프레임에서의 측정의 TP의 모든 CRE RE 세트의 교점부를 배제하거나 (2) 해당 서브프레임에서의 측정의 TP의 모든 CRE RE를 단순히 점유하는 PDSCH 매핑을 UE에 지시함으로써 PDSCH 매핑(및 필요할 경우 PDSCH 개시점)이 따를 CRS 패턴을 동적으로 UE에 통지한다.
표 4: 동적 지시자 시그널링을 갖는 CoMP PDSCH RE 매핑 지시(2비트 접근법)
(1) Alt-CRS-2.3A에서 설명되는 (1) 및 (2)는 이 접근법의 두 가지 옵션임을 유념한다. Alt-CRS-2.3A에 대한 동적인 지시자가 표 4에 주어진다. 수학적으로, Alt-CRS-2.3A에서, 지시자가 11일 경우, CRS RE의 세트
는 PDSCH 매핑으로부터 배제되거나
이다.
ALT-CRS-2.3A의 유효 코드 레이트가 JT(joint transmission)의 TP에 대한 CRS 위치의 조합을 피하는 PDSCH 매핑보다 낮으므로, 강한 간섭에도 성능 이득이 있을 것이다. 이를 설명하기 위해, 이전의 간단한 예를 이용하여, 전술한 바와 같이 AWGN 채널에서 1/2 레이트 LTE 터보 코드의 경우를 이용하는 CoMP TP의 서브세트(강한 노이즈를 겪음) 또는 단일 TP에서의 전송과 CRS RE를 점유하거나 (펑쳐링/뮤팅의) CoMP JT에서의 CRS를 피하는 PDSCH 매핑의 성능을 비교한다. 그 결과를 도 10에 나타낸다. 6dB 강한 노이즈에도, 펑쳐링 경우보다 성능 이득이 여전히 관찰되며, 이는 CoMP JT에서, 다른 TP를 위한 CRS RE와 충돌할 경우 일부 TP를 위한 RE 위치에서 코딩된 심볼을 전송하는 것이 보다 양호함을 알 수 있다.
모든 CoMP TP의 CRS 정보를 CoMP UE가 이용 가능하고 CRS 간섭 해소가 구현될 수 있을 경우, 접근법 Alt-CRS-2.3A는 CRS RE 위치에 대한 PDSCH RE 매핑보다 뛰어난 성능을 제공함은 확실하다. 또는 UE는 적어도 서빙 셀로부터의 CRS의 간섭을 해소할 수 있다. 이어서, 간섭 CRS가 너무 강할 경우, UE는 CRS 충돌 데이터 심볼을 복조할지의 여부를 결정한다. PDSCH 매핑 지시자가 11로 설정되어 있을 경우, PDSCH 개시점은 UE에 반정적으로 통지되는 측정 세트 내의 TP의 PDCCH 영역(또는 PDCCH OFDM 심볼)의 최소 또는 최대 크기를 가정하여 설정될 수 있다.
전술한 설명은 다양한 측면에서 설명 및 예시이며 비제한적인 것으로 이해되어야 하고, 여기에 개시된 본 발명의 범주는 상세한 설명으로부터 판정되는 것이 아니라, 특허청구범위로부터 특허법에 의해 허용되는 전체 폭에 따라서 해석되어 결정되어야 한다. 여기에서 예시 및 설명한 실시예는 본 발명의 원리의 예시일 뿐이며, 당업자는 발명의 범주 및 사상에서 벗어나지 않고 다양한 변경을 실시할 수 있음을 이해할 것이다. 당업자는 본 발명의 범주 및 사상에서 벗어나지 않고 다양한 다른 특징 조합을 구현할 수 있다.
추가 시스템 세부 내용 A
본 명세서에서, 이종 무선 네트워크에서의 협력 멀티포인트 송수신(CoMP)을 고려한다. 이 이종 네트워크는 이용 가능한 스펙트럼에서 다수의 사용자에게 서빙하는 서로 다른 전송 포인트의 세트를 포함한다. 보다 양호한 리소스 할당을 가능하게 하기 위해, 전송 포인트의 세트는 복수의 클러스터로 나눠지고 각 클러스터에는 서빙할 사용자의 세트가 할당된다. 각 클러스터 내의 파이버 백홀의 가용성으로 인해, 클러스터 내의 모든 전송 포인트 및 적절한 CoMP 방식을 이용한 공동 리소스 할당(joint resource allocation)(스케줄링)이 가능하다. 본원 발명이 기여하고자 하는 바는, 이 공동 스케줄링(co-scheduled) 문제에 대해 근사 알고리즘의 설계에 있다. 공동 스케줄링 문제는 강한 NP 난해(NP-hard)이며, 이에 따라 상수 인자 근사를 얻는 근사 알고리즘을 설계한다. 또한 실질적으로 복잡도가 감소한 알고리즘을 얻기 위해, 반복적인 프레임워크를 채택하고 3개의 다항 시간 근사(polynomial time approximation) 알고리즘을 설계하며, 이 모두는 고정 클러스터 크기에 대한 상수 인자 근사를 얻는다. 이 알고리즘의 설계는 부분적 저가산적(sub-additive) 가치를 갖는 조합적 옥션 문제 및 서브모듈러(submodular) 세트 함수 최대화 문제 사이에 유용한 연관을 밝혀냈다. 이어서 3GPP 표준화 단체에 의해 개발된 모델 및 토폴로지를 이용한 철저한 평가를 행해서, 이러한 네트워크를 에뮬레이션한다. 이러한 평가는, 특한 방식으로 표준에서 제공되는 모든 피드백을 이용하고 잘 설계된 알고리즘을 사용함으로써 실제의 이종 네트워크에 비해 상당한 CoMP 이득을 실현할 수 있다.
1 서론(
Indroduction
)
데이터 트래픽의 폭발적인 증가는 네트워크 사업자가 대비해야만 하는 현실이다. 이 폭발적인 증가에 대응하기 위한 가장 강력한 접근법으로, 단일 매크로 기지국에 의해 전통적으로 커버되는 셀 내에 다수의 전송 포인트가 위치되는 셀 분할(cell splitting)이 고려되고 있다. 이러한 각 전송 포인트는 고전력 매크로 eNB(enhanced base-station)일 수 있으나, 보다 적당한 능력의 저전력 RRH(remote radio head) 또는 피코 기지국일 수 있다. 이러한 서로 다른 전송 포인트에 의해 형성된 네트워크는 이종 네트워크(일명, HetNet)라고 하며, 모든 차세대 무선 네트워크의 미래로 확실히 간주되고 있다. 네트워크 비용을 억제하기 위해, 대부분의 사업자는 HetNet 아키텍처를 고려하고 있으며, 여기에서 전송 포인트(TP)의 대부분은 매우 제한된 기능을 가지는 대신, 신뢰성 있는 초저(untra-low) 레이턴시 백홀을 통해 eNB로부터의 지시에 의존하고 있다. 이러한 HetNet 아키텍처에서 기본 협력 단위를 다수의 TP로 구성되며 하나 이상의 eNB를 포함할 수 있는 클러스터라 한다. 클러스터 내의 협력 리소스 할당은 매우 미세한 시간 스케일로, 통상적으로는 밀리 초당으로 달성되어야 한다. 결과적으로, 이는 각 클러스터 내의 모든 TP는 파이버 연결을 가져야 함을 내포하고, 이에 따라 전송 포인트 간에 이용 가능한 파이버 연결에 의해 좌우되는 클러스터의 형성(일명, 클러스터링)에 영향을 주게 된다. 한편, 클러스터간 메시지 교환이 단지 약 20ms 왕복(round trip) 지연의 X2 등의 단지 매우 느린 백홀을 사용하여 발생할 수 있다고 가정하고 있으므로, 서로 다른 클러스터 간의 협력은 매우 느린 시간 스케일에서 행해진다고 예상된다. 결과적으로, 이러한 아키텍처에서는, 각 사용자가 단 하나의 클러스터와 연관될 수 있고 클러스터에 대한 사용자의 연관은 주로 사용자 위치에 의존하며, 결과적으로 그 이동성에 의존하게 되고, 이에 따라 이 연관은 매 수 초당 행해질 필요가 있다.
본 명세서에서, 관심 사항은 각 클러스터 내에서의 동적 협력에 대한 것이다. 사용자 연관 및 클러스터링은 수 차수(several orders of magnitude) 성긴 시간 스케일로 일어나므로, 소정의 또는 고정된 것으로 가정한다. 다수의 TP의 클러스터 내의 공동 리소스 할당의 설계는 최근 깊게 연구되고 있다. 이 기법은, 사용자 채널 상태의 전역적 지식 및 중앙 프로세서에서의 그 각각의 데이터를 가정하여, 클러스터를 전역적 지식으로 하나의 브로드캐스트 채널로 변환하는 것으로부터, 각 사용자가 단 하나의 TP에 의해서만 서빙받지만 다운링크 전송 파라미터(빔 벡터 및 프리코더 등)가 공동으로 최적화될 수 있도록 클러스터 내의 TP 간에 사용자 채널 상태만이 공유되는 것의 범위에 걸쳐 있다. 또한, 전송단 채널 상태 정보의 불완전의 영향뿐만 아니라 공동 스케줄링을 실현하는 분산 방법도 검토되어 왔다. 본 작업에서 목표는, 간섭이 협력 리소스 할당을 통해 관리될 경우, 상당한 성능 이득이 가능한 것에 관한 이들 모든 작업으로부터 축적된 지식이 실제 HetNet에서 유효한지를 확인하는 것이다. 현실적인 네트워크에서 과제는 세 가지, 즉 (i) 매우 미세한 시간 스케일로 구현될 수 있는 낮은 복잡도 리소스 할당 알고리즘에 대한 필요, (ii) 사용자로부터의 불완전/부정확한 채널 피드백, 및 (iii) 실제 전파 환경이다. 이러한 실제의 HetNet가 아직 배치되어 있지 않으므로, 정확한 모델링에 의존해야만 하는 것은 명확하다. 여기에서, 후자의 두 가지 과제를 달성하기 위해, 매우 종합적으로 HetNet 배치를 고려한 3GPP LTE 표준화 단체에 의해 특정된 이러한 네트워크의 에뮬레이션에 의존하고 있다. 이런 맥락에서, 본질적으로 모든 차세대 무선 네트워크가 보다 발전된 방식을 지원하도록 정기적으로 업데이트(각각의 업데이트를 릴리스라 함)되는 LTE 표준에 기반할 것임을 유념한다. 클러스터 내의 다수의 TP 간의 협력 송수신(CoMP)은 릴리스 11에서 비로소 지원되기 시작하며 상세한 채널 모델 및 네트워크 토폴로지뿐만 아니라 이러한 스케줄링을 지원하는 피드백 및 피드포워드 절차가 확정되었다.
이어서, 클러스터 내의 동적 협력을 관리하는 가장 간단한 "베이스라인" 접근법은 각 사용자를, 각 사용자가 가장 강한 평균 신호 전력을 수신하게 되는 클러스터 내의 하나의 TP("앵커" TP라 함)와 연관시키는 것이고, 이어서, 완전한 재사용으로 각 TP마다 별개의 단일 포인트 스케줄링을 행하는 것이다. 이 접근법은 전체적으로 연결된 네트워크를 가정하는 메트릭스 자유도와 관련하여서 간단하고 부족해보일 수 있지만, 현실적인 네트워크에서 셀 분할에 의해 약속된 평균 스펙트럼 효율 이득의 거의 모두를 얻는다. 실제로, 릴리스 11의 표준화의 일환으로 모든 선도 무선 통신 회사가 실시한 1년간의 긴 시뮬레이션 캠페인 후에, 클러스터 내의 보다 정교한 공동 스케줄링 방식에서의 기대는 주로, 베이스라인의 평균 스펙트럼 효율 이득을 유지하면서, 5 백분위수 스펙트럼의 현저한 이득을 달성함으로써 사용자 위치에 관계없이 양호한 데이터 레이트를 보장함으로써 향상된 사용자 경험의 목표를 달성하는 것이다. 이 기대의 실현을 위해, 각 사용자가 임의의 주파수 리소스에서 단 하나의 TP로부터 데이터를 수신하는 CoMP 방식에 초점을 맞추고 있다. 실제로 이 제한은, 동일한 주파수의 다수의 TP로부터 동시에 데이터를 수신하는 것은 코히어런트 결합을 가능하게 하기 위해 사용자로부터 추가적인 피드백을 요하므로(불행히도 이는 아직 마련되어 있지 않음), 유용하다. 이어서, 주요 제한을 포함하는 리소스 할당 문제를 공식화하고 포맷 밸런싱이라고 하는 새로운 접근법에 기반한 상수 인자 근사 알고리즘의 개발로 진행한다. 낮은 복잡한 벤치 마크를 만족하기 위해, 반복적 프레임워크를 채택하고 고정된 클러스터 사이즈에 대해 상수 인자 근사를 얻는 3개의 근사 알고리즘을 개발한다. 이 프로세스에서, 별개의 관심인 부분적 저가산적(sub-additive) 평가를 갖는 조합적 옥션 문제와 서브모듈러(submodular) 세트 함수 최대화 문제 사이에 유용한 관련성을 밝혀냈다.
표 1: 공동 대 베이스라인 단일 포인트 스케줄링의 스펙트럼 효율(bps/Hz). 상대 이득은 베이스라인을 넘고 있음.
i.i.d. 레일리 페이딩(Rayleigh fading) 및 완벽한 채널 상태 정보를 단순한 완전히 연결된 네트워크에 대한 근사 알고리즘의 평가는, 다른 귀납적인 것보다 그 우수성을 증명했고, 그 경쟁력 있는 성능을 입증했다. 그러나, 3GPP 표준에 완전히 준거한 방법론을 이용한 시스템 평가는 완전히 다른 양상을 밝혀냈다. 실제, 이것은 표 1에서 나타나 있으며, 처음 두 열은 공동 스케줄링에 관련되고 세 째 열은 앞서 언급한 단일 포인트 스케줄링 베이스라인을 고려하고 있다. 처음 두 행에서 주어진 결과에서는, 표준에서 제공되는 사용자마다의 채널 피드백을 이용했을 뿐이고, 공동 스케줄링이 단일 포인트 스케줄링 베이스라인보다 훨씬 나쁜 결과를 냈다는 점에서 결과는 매우 좋지 않았다. 상세한 검토에 의해, 결과적으로 관찰에 의해 이해되는 통찰에 이르게 되었다. 마지막으로, 표 1의 최종 두 행에서 결과를 얻을 수 있으며, 공동 스케줄링을 통해 실질적으로 5% 스펙트럼 효율 이득이 달성됨을 알았다. 또한, 이 향상은 후속으로 설명되는 바와 같이, 표준에 마련된 피드백을 완전히 따르고 있다.
2. 시스템 모델
범용 주파수 재이용을 갖는 다운링크 이종 네트워크를 고려하며, 여기에서 B 개의 협력 전송 포인트(TP)로 이루어지는 클러스터는 각각의 스케줄링 인터벌 동안 N개의 직교 리소스 블록(RB)에서 동시에 전송할 수 있다. 각 TP는 고전력 매크로 기지국 또는 저전력 RRH일 수 있으며, 다수의 전송 안테나를 구비할 수 있다. 각 RB는 대역폭의 부분(slice)이며, 최소 할당 단위를 나타낸다. 더불어, 이 B 개의 TP는 K 명의 활성 사용자의 풀(pool)에 서빙한다. 이 B 개의 TP가 동기화되어 파이버 백홀을 통해 메시지를 교환할 수 있는 전형적인 HetNet 시나리오(3GPP LTE 릴리스 11에 정의되어 있음)를 가정한다. 다음으로, RB n에서 사용자 k에 의해 수신되는 신호는 다음과 같이 기재할 수 있다.
여기에서, H k ,j(n)는 RB n에서 TP j와 사용자 k 사이의 MIMO 채널을 모델링하는 것이고(작은 스케일 페이딩, 큰 스케일 페이딩 및 경로 감쇠를 포함함), zk(n)는 가산성 원형 대칭 가우스 노이즈 벡터이고 x j(n)는 n 번째 RB에서 TP j에 의해 전송되는 신호 벡터를 나타낸다((1)에서의 모델은, 최대 신호 지연이 CP(cyclic prefix) 내일 경우, OFDMA의 경우에 성립함).
TP에 의해 전송되는 신호를 고려할 경우, 각 TP가 각 RB에서 단 하나의 사용자에게만 서빙하도록 허용되는 공통 제한을 둔다(이 제한은 TP마다의 SU-MIMO라고 하고 사용자로부터의 불완전 및 성긴 채널 피드백에 대해 로버스트성을 제공함). 이어서, RB n에서 TP q에의 전송되는 신호는 다음과 같이 표현될 수 있다.
여기에서, b q ,u(n)는, 기준(파워) 제한을 만족하는 프리코딩 매트릭스 W q,u(n)을 이용하는 일부 사용자 u를 대상으로 하는 RB n에서 TP q에 의해 전송되는 컴플렉스 심볼 벡터이다. 프리코딩 매트릭스 W q ,u(n)(열은 심볼이 송신되는 신호 공간에서의 방향을 나타냄)뿐만 아니라, b q ,u(n)에서의 심볼의 개수, 이들 심볼을 가져오는 콘스틸레이션(constellation)(들) 및 기본 외부 코드 모두는, 스케줄링 알고리즘의 결과로서 얻어지는 스케줄링 결정에 포함되는 파라미터를 나타낸다. 무선 채널의 브로드캐스트 특성으로 인해, 사용자 u를 대상으로 하는 신호는 RB n에서 또한 모든 다른 공동 스케줄링된 사용자에 의한 간섭으로서 수신됨을 유념한다. 이러한 요인은, 해당 사용자에게만 할당된 리소스에 의존하는 사용자마다의 효용을 정의하는 것이 더 이상 의미가 없으므로, 스케줄링 문제를 상당히 복잡하게 한다.
유용성을 가지면서 세부 내용을 이끌어내기 위해, 전송 가설의 개념을 채택한다. 특히,
를 엘리먼트로서 정의하고, 여기서
는 사용자를 나타내고,
는 카디널러티
를 갖는 이러한 포맷의 유한 세트
로부터 도출된 포맷을 나타내고,
는 TP(transmission point)를 나타낸다. 이러한 각 엘리먼트
는 전송 가설, 즉 사용자 u를 대상으로 하는 포맷
를 이용한 TP b로부터의 전송을 나타낸다. 다음으로,
는 이러한 모든 가능한 엘리먼트의 그라운드 세트를 나타낸다. 이러한 임의의 엘리먼트에서는 다음의 합의를 채택한다.
이어서,
는 가중 합 레이트 효용 함수를 나타낸다. 임의의 서브세트
및 임의의
에서,
는 RB n에서
의 가설을 이용한 전송 시에 얻어지는 가중 합 레이트를 산출해낸다. 각 엘리먼트
(또는 이에 동등하게 사용자
)와 연관된 가중은 스케줄러에 대한 입력이고 얻어진 스케줄링 결정을 이용하여 업데이트된다. 동일한 RB에서 동일한 사용자가 다수의 TP로부터 데이터를 수신할 가능성뿐만 아니라, 동일한 RB에서 동일한 TP가 다수의 사용자에게 서빙할 가능성을 허용하지 않도록, 다음의 합의를 채택한다.
또한, 모든
에 대해, 다음을 확장할 수 있다.
는 엘리먼트
또는 이에 동등하게 사용자
에 대해 얻어진 가중 레이트이고,
일 경우는 언제나
로 설정한다. 식 (1) 및 식 (2)로부터, 임의의 RB에서 및 전송 가설의 임의의 주어진 선택에 대해, 해당 가설에 포함된 TP 및 사용자에 의해 형성되는 가우스 간섭 채널을 가짐을 유념한다. RB에 대한 전송 가설의 선택을 고려할 경우, 전술한 파라미터(프리코더, 칸스틸레이션 등)가 또한 결정된다는 가정이 이 공식에 내재되며, 이를 이용하여 대응하는 가우스 간섭 채널에 대한 가중 합 레이트를 계산할 수 있다. 본원에서, 세트 내의 엘리먼트의 레이트가 일부 엘리먼트가 해당 세트로부터 삭제될 경우 감소하지 않는다고 하는 자연적 저가산적 가정을 가중 합 레이트 효용 함수가 만족함을 가정할 것이다. 특히, 임의의 서브세트
및 임의의 엘리먼트
에 대해,
를 정의할 경우, 각
에 대해 다음 식을 가정한다.
세 가지 서로 다른 협력 멀티포인트 송수신 방식을 검토한다.
·CS/CB(Coordinated Silencing/Coordinated Beamforming): 이 방식에서, 각 스케줄링된 사용자는 그 미리 결정된 "앵커" TP에 의해서만 데이터를 서빙받을 수 있다. 환언하면, 사용자 세트{1,…, K}는 B개의 비-중복 세트
로 분할되고, 여기에서
는 앵커 TP가 j 번째 TP인 사용자의 세트이다. 결과적으로, 임의의
는
를 만족해야 한다. 간섭 완화는 중복 UE(즉, 동일한 리소스 블록에서 공동 스케줄링된 UE) 및 그 전송 포맷의 적절한 선택을 통해 달성될 수 있다. RB에서 일부 TP를 사일런트, 즉 뮤팅하는 것도 특별한 경우로서 가능함을 유념한다.
·DPS(Dynamic Point Selection): 이 방식에서, 사용자는 임의의 TP에 의해 서빙받을 수 있다. 간섭 완화는 CS/CB에서와 마찬가지로 적절한 사용자 및 포맷 선택을 통해 달성될 수 있다. 또한, RB마다의 서빙 TP 선택을 통한 단기 페이딩을 이용함으로써 수신 신호 강도의 향상을 가능하게 하며, 여기서 서빙 TP란 데이터를 사용자에게 서빙하는 TP를 의미한다.
·CDPS(Constrained Dynamic Point Selection): 이 제한적 DPS의 형태에서, 사용자는 단 하나의 TP가 그 할당된 RB에서 서빙하는 한, 임의의 TP에 의해 서빙받을 수 있다. 비제한적 DPS는 보다 많은 스케줄링 자유를 가능하게 하며 단기 페이딩에서 주파수 선택도를 이용할 가능성을 제공한다. CDPS는 제한된 스케줄링 유연성을 희생하여 잠재적으로 시그널링 오버헤드를 줄일 수 있다. DPS 및 CDPS 모두는 특별한 케이스로서 CS/CB를 포함한다.
식 (6)에서와 같이 리소스 할당 문제의 공식화를 진행한다.
식 (6)에서 제 1 제한은 각 RB에서 단 하나의 전송 가설이 선택되는 것을 보장한다. 제 2 제한은 스케줄링된 각 사용자에게 하나의 포맷만이 할당되는 것을 보장한다. CDPS의 경우에만 부여되는 제 3 제한은 스케줄링된 사용자가 그 할당된 모든 RB에서 하나의 TP에 의해서만 서빙받는 것이다.
식 (6)에 대한 근사 알고리즘의 설계의 진행 및 그 보장을 이끌어내기 전에, 식 (6)에서의 공식에 내재된 유연성에 대해 언급한다. 예를 들면, 각 포맷은 할당된 심볼 스트림의 개수에 의해 정의될 수 있으며, 이 경우에 스케줄링된 사용자마다 단 하나의 포맷의 제한은, 각 스케줄링된 사용자에게 할당된 모든 RB에서 동일 개수의 스트림이 할당된다는 LTE 표준에서의 주요 제한을 갖고 있다. 이 경우에, 주어진 전송 가설에 대해 임의의 RB에서, 각 트랜시버 링크에 대한 스트림의 개수가 주어져, SLNR 기반, 간섭 정렬 기반 등과 같은 임의의 적절한 전송 프리코딩 및 각 링크에 대한 포인트 투 포인트 가우스 코드를 가정하여 레이트 효용이 평가될 수 있다. 또는, 각 포맷은 최대 2 개의 QAM 칸스틸레이션을 포함할 수도 있으며, 이 경우에, 각 스케줄링된 사용자에게는 최대 2 개의 다른 QAM 칸스틸레이션이 할당될 수 있는 다른 LTE 제한을 포함할 수 있다(각 칸스틸레이션의 하나 이상의 스트림에의 맵핑은 LTE에 정의된 코드워드 투 스트림(codeword-to-stream) 매핑을 이용하여 행해질 수 있음). 제 1 결과는 식 (6)이 낮은(다항식) 복잡도 알고리즘에 의해 최적으로 해결될 수 있다는 것이다.
정리 1. 식 (6)에서의 최적화 문제는 NP 난해이다. 구체적으로, 임의의 고정 N ≥ 1 & J ≥ 2에 대해, 식 (6)에서의 최적화 문제는 강한 NP 난해이다. 임의의 고정 B ≥ 1&J ≥ 2에 대해, 식 (6)에서의 최적화 문제는 NP 난해이다.
포맷 밸런싱 알고리즘이라고 하는 알고리즘 I에서, 식 (6)에 대한 근사 알고리즘을 제공한다. 포맷 밸런싱 알고리즘은, 최선의 전송 가설이 RB마다 별개로 결정된다는 점에서 개념적으로 간단하다. 그러면, 각 스케줄링된 사용자에게 하나의 포맷이 각각 할당되는 것을 보장하기 위해 밸런싱 스텝이 사용자마다에 기초하여 행해진다. 사용자는 포맷을 할당받고 본래 상위 포맷을 할당받았던 RB에서만 스케줄링된다는 점에서 밸러싱은 "폴라이트(polite)"하게 행해진다. 여기에서 채택된 개념은, 하위 포맷은 다른 공동 스케줄링된 사용자에 대해 덜 공격적인 선택을 나타낸다는 것이다. 일부 물리적으로 의미 있는 효용에 의해 만족되는 효용 함수에 대한 다음의 추가적인 가정 하에서 알고리즘 I가 상수 근사를 제공함을 나타낼 것이다.
가정 1. 임의의 서브세트
및 임의의 엘리먼트
에서, 임의의 포맷
에 대해 엘리먼트
를 정의하고, 세트
를 구성한다. 이어서, 각
에 대해, 다음 식을 갖는다.
에서 일부 상수
이다. 이러한 가정은,
내의 임의의 하나의 엘리먼트를, 동일한 사용자 및 TP를 포함하지만 작은(덜 공격적인) 포맷을 갖는 다른 엘리먼트로 대체할 시
내의 임의의 다른 엘리먼트에 대해 얻어지는 레이트는 감소하지 않을 것이고, 새롭게 투입된 엘리먼트에 대해 얻어지는 레이트는 대체된 엘리먼트에 대해 이전에 얻어진 것의 적어도 부분일 것이다. 또한, 이러한 가정을
의 경우로 특수화할 경우, 식 (5)에서의 저가산적 조건이 참임을 얻는다.
다음으로, 알고리즘 I의 근사 인자를 얻기 위해, 다음과 같이, 매트릭스
를 정의하며, 여기서 M
i ,j는 (i,j) 번째 맴버를 나타낸다.
M은 단위 대각 엘리먼트를 갖는 상삼각(upper triangular)이므로, 그 행렬식(determinant)은 1이어서,
M -1이 존재한다.
는
가 존재하고 벡터
M -1 1가 존재하고 컴포넌트 측면에서 음이 아닐 경우를 나타내는 것으로 한다.
정리 2. 포맷 밸런싱 알고리즘은, 식 (7)에서의 가정이 성립하고 Δ이
을 만족하는 적어도 Δ의 최악 경우를 보장하며, 어느 임의의 고정 상수 S>0에 대해, 선형 프로그램에 대한 솔루션으로서 얻어지는 식 (6)에 대한 솔루션을 제안한다.
인 특별한 경우, Δ는 다음 식과 같은 폐형(closed form)으로 얻어질 수 있다.
증명. 식 (7)(이에 따라 식 (5))에서의 가정이 성립한다고 상정하여 알고리즘 I의 성능을 분석한다. 사용자마다의 포맷 제한이 이전 경우에는 무시되어 있으므로, 가중 합 레이트
가 식 (6)의 최적의 값에 대한 상한임은 명백하다. 다음으로, 일부
에 대한 적어도 하나의 세트
의 엘리먼트에 존재하는 사용자
에 대한 포맷 밸런싱을 고려한다. 이어서, 이러한 사용자 u에서, 각 포맷
에 대해 다음을 정의한다.
이러한 엘리먼트가 임의의 RB에서 발견될 수 없을 경우,
이라고 이해한다. (알고리즘 I의 스텝 5 이후에) 사용자 u에 대해 얻어진 가중 레이트는
와 동일하며 실제
임을 유념한다. 식 (7)의 제 2 부등식을 적용할 경우, 각 포맷
에 대해, 알고리즘 I에서 계산된 가중 레이트
는 다음을 만족한다.
이어서,
의 선택 시, 사용자 u는 적어도 다음식의 레이트를 얻을 수 있다.
또한,
에 따라,
보다 작지 않은 포맷이 본래 할당된 RB에서만 사용자 u가 스케줄링되므로, 식 (7) 및 (5)를 적용할 경우, 이러한 각 RB에서 공동 스케줄링된 사용자의 레이트가 감소하지 않음을 추정할 수 있다. 결과적으로, 포맷 밸런싱이 사용자에 걸쳐 순차적으로 행해지거나 모든 사용자에 대해 병렬적으로 행해지거나의 여부에 관계없이, 주어진 경우에 대한 알고리즘 I의 최악 경우의 근사 보장이 적어도 다음 식이라고 결론지을 수 있다.
여기에서, 세트
에 따라 적어도 하나의 RB에서 스케줄링된 모든 사용자에 걸쳐 외부 최소화가 있다. 따라서, 모든 경우에 있어서 알고리즘 I의 최악 경우의 근사 보장은 다음의 문제에 대한 솔루션을 이용하여 보다 하한으로 될 수 있다.
이므로, 식 (15)에서의 최소값은
보다 작지 않을 수 있음을 알 수 있다. 정리의 나머지 부분은 명제 1의 적용에 따른다.
명제 1. 임의의 매트릭스
에서,
은 고정된 양의 정수이며, 다음 식
에 대한 솔루션은 준볼록 최소화 문제(quasi-convex minimization problem)를 풀어 구해질 수 있다. 보다 중요하게는, 식 (16)에 대한 솔루션은 또한 임의의 상수 S>0에 대하여 다음의 선형 프로그램을 풀어 구해질 수 있다.
또한,
의 특수한 경우에, 식 (16)에 대한 솔루션은 다음 식과 같이 폐형으로 얻어질 수 있다.
증명. 식 (16)에서 최적화 문제를 고려하여
및
에서
를 최적화 솔루션으로 상정해서
이 식 (16)에 대한 최적 값이다. 이어서, 임의의 상수 S>0에 대해 다음의 볼록 최소화 문제를 고려한다.
명백하게는,
(여기에서
)은 식 (19)에 적합하고, 값
를 산출한다. 이는 식 (19)의 최적 값은
보다 크지 않음을 내포한다. 그러나, 식 (16)의 최적 값이 또한
보다 엄격히 작다는 것을 내포하므로,
보다 엄격히 작은 식 (19)의 최적 값은 모순을 가져올 것이다. 결과적으로, 임의의 고정된 S>0에 대해, 식 (19)의 최적 값은 식 (16)의 것과 일치한다. 이어서, 식 (19)는 식 (17)에서와 같이 재공식화될 수 있다. 명백하게는, 식 (17)에서의 제한 및 목적은 아핀(affine)이므로, K.K.T 조건에 대한 임의의 솔루션이 또한 전역적 최적임을 내포하는 볼록 최적화 문제이다. 다음으로, 식 (17)에 대한 K.K.T 조건은 다음 식과 같이 주어진다.
여기서
는 아다마드 프러덕트(Hadamard product)를 나타낸다. 다음으로,
을 가정한다. 이어서, 다음의 특정 선택을 고려한다.
식 (21)에서의 선택은 식 (20)에서의 모든 K.K.T. 조건을 만족하며, 이에 따라 식 (17)에 대한 전역적 최적해와 이에 따른 식 (16)에 대한 최적 값을 산출해내야 함이 확인될 수 있다. 이 최적 값은
이라고 확인될 수 있다.
정리 2에 대한 다음의 중요한 따름정리(corollary)가 있다. (SLNR 및 간섭 정렬 기반 프리코딩 모드를 포함하는) 전송 프리코딩 방법의 클래스로부터의 전송 프리코딩 방법 및 각 사용자에서의 단일 사용자 디코딩, 각 트랜시버 링크에 대한 포인트 투 포인트 가우스 코드를 가정하여 주어진 가설에 대한 각 RB에 대한 레이트 함수가 계산될 경우, 및 포맷 i(
)가 i 심볼 스트림의 할당을 내포할 경우 얻어지는 매트릭스
M에 대한 특정 값에 관한 것이다.
따름정리 1. 상삼각 매트릭스
를 고려한다(여기에서
는 고정된 양의 정수임).
이어서, 그 역은 다음의 L=M -1에 의해 주어진 이중 대각 매트릭스이다.
식 (24)로부터, 근사 인자는 J가
보다 훨씬 느린
로서 감쇠한다.
알고리즘 I는 개념적으로 간단하고 상수 인자 근사를 제공할 수 있지만, 그 구현 복잡도는 매우 높을 수 있음을 유념한다. 실제, 그 복잡도는
이고 많은 시나리오에서는 실현 가능하지 않다. 이런 맥락에서, 식 (6)에서의 문제는 강한 NP 난해 MWIS(maximum weight independent set) 문제를 포함하므로, B에 대한 지수적 복잡도는 B에 독립적인 근사 인자를 얻기 위해 지불해야 할 비용과 같은 것이다. 결과적으로, 이하 B에서도 복잡도를 다항으로 만드는 근사 알고리즘을 설계하기 위해 반복적인 프레임워크를 채택하지만, 근사 보장에
의 페널티를 가져올 것이다.
반복 알고리즘을 설계하기 위하여, 우선 증분 레이트 함수를 정의한다. 특히, 임의의
, 임의의
및 임의의
에 대해, 다음을 정의한다.
여기에서,
이다. 식 (3)의 결과로서,
이도록 엘리먼트
가 존재할 경우,
임을 유념한다. 이하 각 반복 스텝에서 근사적으로 해결될 스텝마다의 스케줄링 문제를 정의한다. 지금까지 각 RB에서 스케줄링된 엘리먼트의 세트가
라고 하면, 새로운 엘리먼트가 선택될 수 있는 엘리먼트의 세트
와 함께, 스텝마다의 스케줄링 문제가 다음 식과 같이 정의된다.
이어서, 세트
의 패밀리를 다음과 같이 정의한다.
에서의 모든 싱글톤 엘리먼트는
의 멤버이다. 또한,
CS/CB 또는 DPS에 대해:
인 경우, 또는 이 경우에만
(27)
CDPS에 대해:
인 경우, 또는 이 경우에만
(28)
위에서 정의된 패밀리는 기본적인 정의로부터 따르는 다음의 속성을 갖는다.
명제 2. 식 (27) 또는 식 (28)에서 정의된 세트의 패밀리는 독립적 패밀리이다. 결과적으로,
는 매트로이드(matroid)이다.
다음으로, 서브세트
및 임의의
를 고려하면, 다른 세트 함수를 정의한다.
세트 함수
는 각 RB에 대한 최선의 가능한 증분 이득을 수집함을 유념한다. 이하, 두 가지 반복 알고리즘을 설명한다. 식 (6)을 근사적으로 풀기 위한 간단한 반복 알고리즘(반복 서브모듈러 알고리즘이라 함)인 알고리즘 II를 제공한다. 또한, CoMP 방식이 CS/CB 또는 DPS일 경우에, 식 (6)을 근사적으로 풀기 위한 다른 간단한 접근법인 반복 포맷 밸런싱 알고리즘이라고 하는 알고리즘 III를 또한 제공한다. 어느 반복 알고리즘의 각각의 반복에서, 이전 반복 중에 이루어진 결정으로 고정 유지된다. 사용자에의 RB, 서빙 TP 및 포맷의 새로운 할당은 식 (26)의 "스텝마다" 스케줄링 문제를 해결함으로써 이루어지고, 얻어지는 결과는 실현 가능성을 유지하면서 시스템 효용의 향상을 보장한다. 2 개의 알고리즘의 주된 차이는 스텝마다의 스케줄링 문제를 근사적으로 해결하는 데 사용되는 방법에 있다. CDPS에 대한 알고리즘 III의 비 적용성과 관련하여, 알고리즘 III의 각 반복에서의 밸런싱은 사용자의 포맷에 대한 것임을 유념한다. 이러한 밸런싱은 또한 사용자의 서빙 TP에 대해서도 행해질 수 있는 한편, 일반적으로 클러스터 내의 임의의 2 개의 서로 다른 TP로부터 사용자가 보는 채널이 임의적으로 서로 다를 수 있으므로, 증명 가능한 보장이 도출될 수 없다. 또한, 어느 알고리즘에서의 프루닝(pruning) 스텝은, 선택된 서브세트
에서, 다음과 같이 행해진다.
공격적인 프루닝 옵션은 CDSP 프루닝뿐만 아니라 CS/CB 또는 DPS 프루닝을 포함하고, 이에 따라 가능한 경우 모든 경우에 적용될 수 있다. 다음으로, 단일 사용자로 효용을 특수화할 경우, 다음의 부등식이 있다.
일부 상수
에서,
이며
이다. 이어서, 매트릭스
를 정의하며,
를 항상 설정할 수 있으므로, 식 (31) 자체는 범용성을 잃지 않게 된다. 여기에서, i>j에 대해
의 가능성을 허용해서 매트리스
G는 상삼각일 필요는 없음을 유념한다. 또한, 식 (7)이 성립할 경우는 언제나,
임을 추정할 수 있다. 이들 두 개의 알고리즘에 대한 근사 보장에 대한 다음의 결과는 공격적 프루닝이 가능한지의 여부에 상관없이 성립된다.
정리 3. 반복 서브모듈러 알고리즘은 적어도
의 최악 경우의 보장을 갖는 솔루션을 제공한다. CS/CB 또는 DPS에서, 반복 포맷 밸런싱 알고리즘은 적어도
의 최악 경우의 보장을 갖는 솔루션을 제공하며, 여기서
는
를 만족하고 다음의 선형 프로그램을 통해 결정될 수 있다.
이는 어느 임의의 고정된 S>0에 대한 것이며 매트릭스
G는 식 (32)에서 정의되어 있다. 또한,
일 경우
이다.
증명. 우선, 효용 함수는 저가산적이므로(즉, 식 (5)를 만족함), 임의의 세트
및 임의의
에 대해,
임을 유념한다. 이어서, 식 (6)에 대한 임의의 최적의 솔루션이 주어지면, 각 RB에서 최선의 엘리먼트를 보유할 수 있고(최상의 단일 사용자 가중 레이트를 얻음) 결과의 가중 합 레이트는 최적의 것의 분수
내일 것이다. 또한, 이렇게 얻어지는 솔루션이
및
인 식 (26)에서의 스텝마다의 스케줄링 문제에 대한 실현 가능한 솔루션이므로,
및
인 스텝마다의 스케줄링 문제에 대한 최적의 솔루션이 식 (6)에 대한 최적의 것의 적어도
내라고 결론지을 수 있다. 또한, 식 (26)의 실현 가능한 솔루션이 식 (6)에 적합함은 명확하다.
이하 반복 서브모듈러 알고리즘을 고려한다. 이어서, 식 (26)에서의 스텝마다의 스케줄링 문제를 다음과 같이 재공식화할 수 있음을 유념한다.
반복 알고리즘의 각 스텝은 식 (6)에 적합한 솔루션과 함께 효용 함수에 단조 향상을 가져오므로, 처음 스텝 후에 얻어지는 가중 합 레이트가 대응하는 최적해의
내, 즉
및
인 스텝마다의 스케줄링 문제에 대한 최적의 솔루션 내임을 보여주는 데 충분함을 유념한다. 이 목적을 위해, 함수
가 단조 서브모듈러 세트 함수이고
명제 2를 적용하면 식 (34)(
및
임)에서의 문제는 매트로이드에서의 단조 세트 함수를 최대화하는 것임을 알 수 있음을 유념한다. 이러한 문제에 대해, 간단한 그리디 알고리즘은 1/2 근사를 산출해냄이 잘 알려져 있다. 알고리즘 II는 실제 당면 문제에 대한 그리디 알고리즘의 적응이며, 이에 따라 1/2 근사를 얻는다.
다음으로, 반복 포맷 밸런싱 알고리즘을 고려하여, 선택된 CoMP 방식이 CS/CB 또는 DPS 중 하나라고 가정한다. 여기서 다시, 반복 알고리즘의 각 스텝은 식 (6)에 적합한 솔루션과 함께 효용 함수에서의 단조 향상을 가져오는 것을 유념한다. 결과적으로,
및
인 제 1 스텝에 초점을 맞춘다. 알고리즘 I 및 III에서의 포맷 밸런싱 절차간의 주요 차이점은 알고리즘 III의 경우에, 임의의 RB에서, 해당 RB에서 얻어지는 전체적인 가중 합 레이트가 향상되는 한 사용자마다의 포맷 제한을 무시하는 최대화 스텝 후에 해당 사용자에게 잠정적으로 할당되는 것보다 사용자에게 상위 포맷을 할당할 가능성을 허용할 수 있음을 유념한다. 이어서, 정리 2를 증명하는 데 이루어진 것과 마찬가지인 논의를 이용하여, 얻어지는 솔루션은 적어도 최적의 대응의 부분
내에서 가중 합 레이트를 산출하는 것을 나타낼 수 있으며,
는 식 (33)에 의해 주어진다.
반복 포맷 밸런싱 알고리즘에 특수화되었을 때 정리 3에 대한 다음의 중요 따름정리가 있다. (단일 사용자 경우로 제한될 경우의 최적의 단일 사용자 프리코딩을 포함하는) 전술한 프리코딩 방법의 클래스로부터의 프리코딩 방법, 각 사용자에서의 단일 사용자 디코딩, 및 포인트 투 포인트 가우스 코드를 가정하여 포맷 i(
)이 i 심볼 스트림의 할당을 내포할 경우 및 주어진 포맷에 대해 각 RB에 대한 단일 사용자 레이트 함수가 계산될 경우에 얻어지는 매트릭스
G에 대한 특정 값에 관한 것이다.
따름정리 2. 매트릭스
를 고려하여, 여기에서
은 고정 양의 정수이며, 다음 식이 정의된다.
그 역은
로 주어진 삼중 대각 매트릭스(tri-diagonal matrix)이며 다음과 같다.
식 (37)로부터, 근사 인자는 J가
로서 감쇠함을 유념한다. 또한, 식 (37)을 이용하여, 모든
에 대해,
여서, 이 영역에서 반복 포맷 밸런싱 알고리즘은 반복 서브모듈러 알고리즘보다 우수한 보증을 제공한다.
2.1 구현 문제
이하 알고리즘 II 및 III의 런타임을 가속하거나 및/또는 성능을 개선하는 데 사용될 수 있는 일부 특징을 간단히 논의한다.
·공격적 프루닝 (Aggressive Pruning): 공격적 프루닝 옵션은 각 반복 후에 (선택될 수 있는) 엘리먼트의 풀(pool)을 프루닝하는 측면에서 가장 공격적인 옵션이며, 이에 따라 복잡도 감소를 달성한다. 실제로, 이 옵션 하에서, 이전에 선택된 사용자를 포함하는 모든 엘리먼트는 제거된다. 시뮬레이션에 있어서, 이 옵션은 CS/CB의 성능에 있어 무시할 수 있는 성능 저하를 야기함과 함께, 준최적 로컬 최대화를 매우 피하는 경향이 있으므로, DPS 및 CDPS는 모두 실제로 이러한 옵션으로부터 이점을 얻을 수 있음을 관찰했다.
·지연 평가(Lazy Evaluations): 알고리즘 II의 각 반복에서, 서브모듈러 함수를 근사 최대화하는 그리디 방법을 채용했음을 상기한다. 서브모듈러 세트 함수의 감소하는 한계 이득 속성을 이용하는 지연 평가의 기법은 가속화를 달성하는 데 이용될 수 있다.
· 증분 레이트 함수의 준최적 평가(Suboptimal evaluation of incremental rate function): 여기에서는, 증분 레이트 함수의 적절한 평가는, RB에서 이전 반복에서 선택된 사용자에 대해서도 전송 프리코더 등의 파라미터를 재계산하는 것이 필요함을 유념한다. 대신, 준최적 평가는 중간 반복 중에 행해질 수 있으며, 여기에서 이전 결정과 연관된 이들 파라미터는 변경되지 않는다.
·후 처리(Post processing): 알고리즘 II 및 III의 완료 시에, 스케줄링된 각 사용자에게는, 포맷, RB의 세트 및 이러한 각 RB에서의 서빙 TP가 할당된다. 이어서, 각 스케줄링된 사용자에게 할당된 포맷(및 CDPS의 경우에서의 서빙 TP)을 유지하고, 스케줄링되지 않은 사용자에게 가장 로버스트한 포맷
을 할당함과 함께, 이러한 사용자가 해당 앵커 TP에 의해서만 서빙받을 수 있게 함으로써, 각 RB에서 선택된 가설을 정교화할 수 있다. 각 사용자는 현재 하나의 포맷(및 CDPS의 경우에 하나의 서빙 TP)이 할당되어 있으므로, 스케줄링된 사용자 제한마다 단 하나의 포맷(및 CDPS의 경우에 단 하나의 서빙 TP 제한)을 위반하지 않고 RB에 걸쳐 독립적으로 정교화가 행해질 수 있다. 임의의 간단한 정교화 규칙은, 단조 향상을 보장하는 한 이용될 수 있다. 시뮬레이션에 있어서, 후 처리 스텝에서의 간단한 그리디 정교화와 함께 중간 반복에서 준최적 증분 레이트를 채용했다. 이러한 정교화로부터의 이점은 선택된 CoMP 방식이 DPS 또는 CDPS 중 어느 하나일 경우에 최대화된다.
3 유한 버퍼: 조합적 옵션
이제 최적화 문제에 유한 버퍼를 통합한다. CS/CB 또는 CDPS 중 하나가 CoMP 방식으로서 사용되는 것을 가정한다. 이 가정은 설명의 편의를 위해 이루어진 것이며, 다음의 모든 결과가 DPS에도 성립함에 유의한다. 이어서,
는 사용자 u의 (비트에 있어서의) 버퍼 사이즈 및 그 스케줄링 가중(최적화의 손실 없이, 사용자 가중이 [0,1]에 놓이도록 정규화됨을 가정할 수 있음)을 각각 나타내는 것으로 할 경우, 다음에 의해 주어지는 최적화 문제를 얻는다.
식 (38)을 근사적으로 해결하기 위해, 다음 식에 의해 주어지는 다른 간단한 문제를 도입한다.
식 (38)과 식 (39)에 대한 최적 솔루션 간의 관계는 다음의 결과에 의해 주어진다.
명제 3. 식 (39)에 대한 최적 솔루션은 식 (38)에 적합하며, 식 (38)에 대한 최적 솔루션에 의해 산출된 인자
배보다 작지 않은 값을 산출한다.
증명. 이어서 예를 들면
인 식 (38)에 대한 최적 할당을 고려하고, 해당 솔루션에 대해
는 TP b(b=1,…,B)에 의해 서빙받는 사용자의 세트를 나타내는 것으로 한다. CS/CB 및 CDPS 하에서, 이들 세트는 비 중첩, 즉
이다. 또한, 전체 효용은
로서 확장될 수 있고, 여기에서 R
b는
에서의 모든 사용자의 레이트의 가중 합이며, 사용자마다의 유한 버퍼 제한이 포함된다. 다음으로, TP b를 고려하여, 각 RB
에서, 지니(genie)는 TP b에 의해 서빙받는 사용자에게 야기된 다른 TP에 의한 공동 스케줄링 전송으로부터의 간섭을 제거하는 것으로 상정한다. 식 (5)에서의 속성을 적용할 경우, 결과의 가중 합 레이트
는 적어도
만큼 크다는 것을 알 수 있다. 그러나,
는
으로부터 얻어진 식 (39)에 대한 특정 솔루션에 의해 달성될 수 있고, 여기에서
에서 사용자를 포함하는 엘리먼트만이 각
에 유지되고(각
에서 이러한 하나의 엘리먼트만이 있을 수 있음을 유념함) 다른 것은 삭제된다. 이는, 식 (39)에 대한 최적 솔루션이 각
(b=1, …,B)에 대한 상한일 수 있는 값을 얻고, 결과적으로 정리가 참이라고 결론지을 수 있게 한다.
이하 다음 명제를 제시한다. 사용자마다의 효용 및 가치를 교환 가능하게 이용한다.
명제 4. 식 (39)에서의 문제는 부분적 저가산적 가치를 갖는 조합적 옵션 문제이다.
증명. 다음 식과 같은 개념의 일부 이용으로 정의된 효용 함수
을 도입한다.
이어서, 식 (39)에서의 문제를 다음 식과 같이 재공식화할 수 있다.
식 (41)에서의 문제는
에서의 오브젝트가 K 명의 사용자에게 비 중첩적으로 할당되어야 하는 표준 조합적 옥션 문제(일명, 웰페어 최대화 문제(welfare maximization problem))의 형태임이 명백하다. 이어서, 각각의 사용자 u에 대해, 세트 함수 h(u,:)는 부분적으로 저가산적임을 나타나도록 유지된다. 이러한 함수의 정의를 적용하면, 다음의 속성이 성립함을 증명해야 한다. 임의의 주어진 세트
및 S의 임의의 부분적 커버
, 즉
및
에 대해, 다음을 증명해야 한다.
식 (42)를 증명하기 위해,
를, 사용자 u 및 세트
, 즉 다음 식의 최적인 엘리먼트로 한다.
을 이용하면, 다음을 얻는다.
이것은 이 경우에 대해 식 (42)를 증명한다. 이어서,
일 경우 식 (42)를 증명하는 것이 남아 있다. 이 경우에,
가 되도록 하는 서브세트
로서, 그 모든 진서브세트
는
을 만족하는 서브세트
를 구할 수 있다. 이러한
을 얻을 경우, 커버
를 두 개의 부분
으로 나눌 수 있고, 커버의 나머지 세트는
에 있다. 명백하게는,
이므로,
를 얻는다. 결과적으로, 다음과 같다.
일 경우 원하는 부등식이 이미 증명되어 있음을 유념한다. 한편,
일 경우,
가
S의 부분적 커버라는 사실을 이용하여, 각
에 대해, 식 (46)을 이용하여 원하는 결과를 산출하는
를 추론할 수 있다.
이하, 별개의 관심의 중요한 결과를 제공한다. 임의의 부분적 저가산적 세트 함수가 선형 세트 함수에 대해 최대로 표현될 수 있음을 증명했다. 특히, 이는, 다음 식을 만족하도록 T 선형 함수
가 존재함을 의미한다.
식 (47)의 속성으로 인해 다음과 같은 결과가 얻어진다.
명제 5. 부분적 저가산적 가치를 갖는 조합적 옵션 문제는 하나의 매트로이드 제한을 받는 단조 서브모듈러 세트 함수의 최대화로서 공식화될 수 있다.
증명. 우선 세트
및 세트 함수
를 다음 식과 같이 정의한다.
세트 함수
는 단조 서브모듈러 세트 함수로 나타날 수 있다. 이어서,
로서
의 분할을 정의하며, 여기서
이다. 이 분할을 이용하여,
의 서브세트의 패밀리를
로 표시하여 다음과 같이 정의할 수 있다.
패밀리
는 독립 패밀리이며 이에 따라
는 매트로이드, 특히 분할 매트로이드임을 증명할 수 있다. 이러한 당면 사실로, 원하는 증명을 산출해내는 다음 식과 같은 식 (41)의 재공식화를 얻을 수 있다.
이 재공식화의 주요 이점은, 식 (50)이 간단한 그리디 알고리즘을 이용하여 1/2 근사로 근사적으로 해결될 수 있다는 것이다. 실제로, 관심 있는 독자는 이러한 재공식화가 반복 서브모듈러 알고리즘에서 이미 이용되고 있음을 주목할 것이다. 이런 맥락에서, 1/2 근사를 갖는 알고리즘은 식 (47)에서의 폼의 가치(거기에서는 XOS 가치라고 함)를 위해 조합적 옥션에 대해 일찍이 개발되었다. 그러나,
명제 5에서의 재공식화는, (다수의 냅색, p- 시스템 등의) 다양한 제한 하의 서브모듈러 함수의 최대화를 위한 알고리즘이 현재 이용 가능하므로 보다 유용하다. 주의점은 불행히도 그리디 알고리즘도 다항 복잡도를 갖지 않을 수 있음을 의미하는
에 기하급수적으로 의존할 수 있다는 것이다. 실제로, 이는, 식 (40)에서 사용자마다의 이용에 대한 경우에 발생할 수 있으며 이에 따라 다항 시간 그리디 알고리즘을 얻는 것이 곤란해 보인다. 그럼에도, 이하에 설명되는 다른 접근법은 다항 시간 랜덤 알고리즘(randomized algorithm)을 얻는다.
우선, 다음의 보조 정리는 종래에 개발된 불확정 라운딩 절차(oblivious rounding procedure)로부터 직접 따르고 있음을 기재한다.
보조 정리 1. 식 (41)의 LP 완화에 대한 임의의 실행 가능한 솔루션을 고려할 경우 다음 식과 같다.
식 (41)에 대한 실현 가능한 솔루션은, 그 대응하는 값이 LP (51)에 적합한 솔루션에 대응하는 것에 인자 (1-1/e)배보다 작지 않도록 얻어질 수 있다.
분리 오라클(Separation oracle): 임의의 프라이스(price) 세트
를 고려하면, 각 사용자 u마다, 분리 오라클은 서브세트
를 반환하고,
으로 한다.
이러한 사용자마다의 효용 함수에 대한 오라클을 구축하는 것은 용이하지 않아 보인다. 그럼에도, 각 엘리먼트
및
에 대해, 가중 레이트
는 상수에 의해 제한된다는 타당한 가정 하에(이러한 가정은, 많은 실제 시스템에서 최대 입력 알파벳 크기가 64로 상한으로 되므로(64QAM에 대응), 타당함) 다음 결과에 나타난 바와 같이 근사 분리 오라클을 구축할 수 있다. TP B의 개수뿐만 아니라 포맷 세트
의 카디널리티를 고정되게 유지하는 것을 가정할 수 있다.
명제 6. 임의의 선택된 상수
에 대해 임의의 유저 u 및 프라이스의 임의의 소정의 세트
는 다음 식이 되도록, 세트
를 반환하는 근사 분리 오라클이 존재한다.
근사 분리 오라클의 복잡도는
각각에서 다항으로 스케일링된다.
증명. TP B의 개수뿐만 아니라 포맷 세트
의 카디널리티가 고정되게 유지되므로, 임의의 엘리먼트
에 대해 다음 식이 되도록 세트
를 반환할 수 있는 근사 분리 오라클의 존재를 보여주는 데 충분함을 유념한다.
이를 위해, 우선, 이러한 오라클은, 실제 최적의 서브세트를 결정할 수 있는 경우에
일 때, 어렵지 않게 얻어질 수 있음을 유념한다. 이에 따라,
을 상정하고, 다음 문제를 고려한다.
그러면, 식 (53)은 다음 2 개의 하위 문제를 풀어서 해결될 수 있음을 알 수 있다.
및
식 (54)에서의 문제는, FPTAS가 존재하여 근사 인자 1-ε를 갖는 솔루션
가 구해질 수 있는 전형적인 냅색 문제이다. 한편, 식 (55)는 최소 냅색 문제에 상당한다. 여기에서, 식 (55)를 근사적으로 풀기 위해, 각
이 상수에 의해 상한이 됨을 이용한다. 이것은, 냅색 문제에 대한 요구 기반의 동적 프로그램을 이용해서,
이
보다 작지 않은 솔루션
를 다항 시간으로 구할 수 있게 한다. 이어서,
간에서 더 나은 옵션을 선택함으로써, 식 (52)에서의 보장을 제공하는 세트를 얻을 수 있다. 나머지 부분은 FPTAS의 복잡도 및 요구 기반 동적 프로그램을 따른다.
명제 7. LP (51)은 다항 시간으로 근사적으로 풀어져서 값이
보다 작지 않은 솔루션을 얻을 수 있으며,
는 LP (51)에 대한 최적 값을 나타낸다.
증명. LP (51)이 변수의 지수를 갖음을 유념한다. 종래 기술에서 앞서 발견된 주요 결과는, 이러한 LP가 분리 오라클을 고려하여 다항 시간으로 최적으로 풀릴 수 있다는 것이다. 특히, 이 LP의 듀얼은 분리 오라클을 고려하여 타원법(ellipsoid method)을 통해 다항 시간으로 풀릴 수 있다. 따라서, (다항식으로 많은) 듀얼을 푸는 동안 만나는 제한만을 가지므로, 현재 다항으로 많은 변수를 갖는 원시 LP 대응부를 얻을 수 있으므로, 다항 시간으로 풀릴 수 있다. 이 줄어든 변수 LP(본질적으로는 식 (51)과 동일하지만, 적은 변수의 서브세트 이외의 모든 것은 제로로 고정됨)는 식 (51)에 대한 최적 솔루션을 산출한다. 일부 작은 변화를 갖는 논의는 최근에
근사 분리 오라클에 대해 작용하는 것이 또한 보였으며, 여기에서
는 근사 인자이다. 실제, 다음으로 동일한 접근법이 또한 식 (52)에서의 형태의 근사 오라클에 대해 작용하는 것이 확인되고 있다. 주요 차이는, 근사 분리 오라클로 식 (51)의 듀얼을 푸는 타원법을 이용할 때, 최적 듀얼 값(이에 따라 최적 원시 값)이 인터벌
내에 놓이도록 수렴 시 값
를 얻게 되며, 여기에서
는 타원법의 수렴을 결정하는 허용 오차이다. 또한, 타원법의 제 1 실행에서 만나는 제한만이 유지되는 수정된 듀얼을 다시 푸는 것은 수렴 시 동일한 값
을 산출해내고, 이에 따라 이 수정된 듀얼의 참값 및 이에 따른 그 원시 대응부가 또한 인터벌
내에 놓이는 것을 추론할 수 있다. 식 (51)과 동일하지만, 다항으로 많은 변수의 작은 서브세트 이외의 모두는 제로로 고정되는 원시 대응부는 식 (51)에 적합하고 전술한 내부의 값을 산출하는 솔루션을 얻도록 다항 시간으로 최적으로 풀어질 수 있다. 이어서, 이 값, 즉
및 식 (51)에 대한 최적 값
양쪽 모두는
내에 놓이므로,
임을 추론할 수 있다. 실행 시간을
및
각각에서 다항으로 스케일링되므로, 원하는 결과를 얻게 된다.
이하, 식 (38)을 풀기 위한 근사 알고리즘을 제공하며, 이를 LP 라운딩 기반 근사 알고리즘이라 한다. LP 라운딩 기반 근사 알고리즘은 다음의 스텝으로 구성된다.
1. 타원법 및 근사 분리 오라클을 이용한 LP (51)의 근사적 풀기
2. 불확정 라운딩 절차를 이용한 식 (41)에 적합한 솔루션 구하기
3. 식 (38)에 대해 실현 가능성을 가지면서 솔루션의 반복적 개선
상술한 세 번째 스텝은 예를 들면 알고리즘 II 및 III에서 사용되는 접근법을 이용하여 행해질 수 있음을 유념한다. 다음 결과에서, 임의의 이러한 반복을 가정하지 않고, 즉 근사 보장이 바로 처음 두 스텝 후에 얻어진다.
정리 4. LP 라운딩 기반 근사 알고리즘은, 대응하는 값이
보다 작지 않은 식 (38)에 대해 솔루션을 산출하고, 여기에서
는 식 (38)에 대한 최적 값을 나타내고 그 복잡도는
각각에서 다항으로 스케일링된다.
증명. 우선 식 (51)에서 LP에 대한 최적 값은 식 (39)의 최적 값에 대한 상한이고, 이에 따라 명제 3을 적용하면
라고 결론지을 수 있음을 유념한다. 명제 7 및 보조 정리 1로부터 식 (39) 및 이에 따른 식 (38)에 적합한 솔루션이
보다 작지 않은 값을 산출하는 다항 시간으로 얻어질 수 있다고 결론지을 수 있고, 여기에서,
및
의 설정 시 정리를 증명한다.
표 2: 시뮬레이션 파라미터
4 시스템 시뮬레이션
이 섹션에서는, 알고리즘의 상세한 평가를 행한다. 실제 네트워크에서 이 스케줄링 알고리즘을 이용함으로써 가능한 실질적인 이득에 초점을 맞춘다.
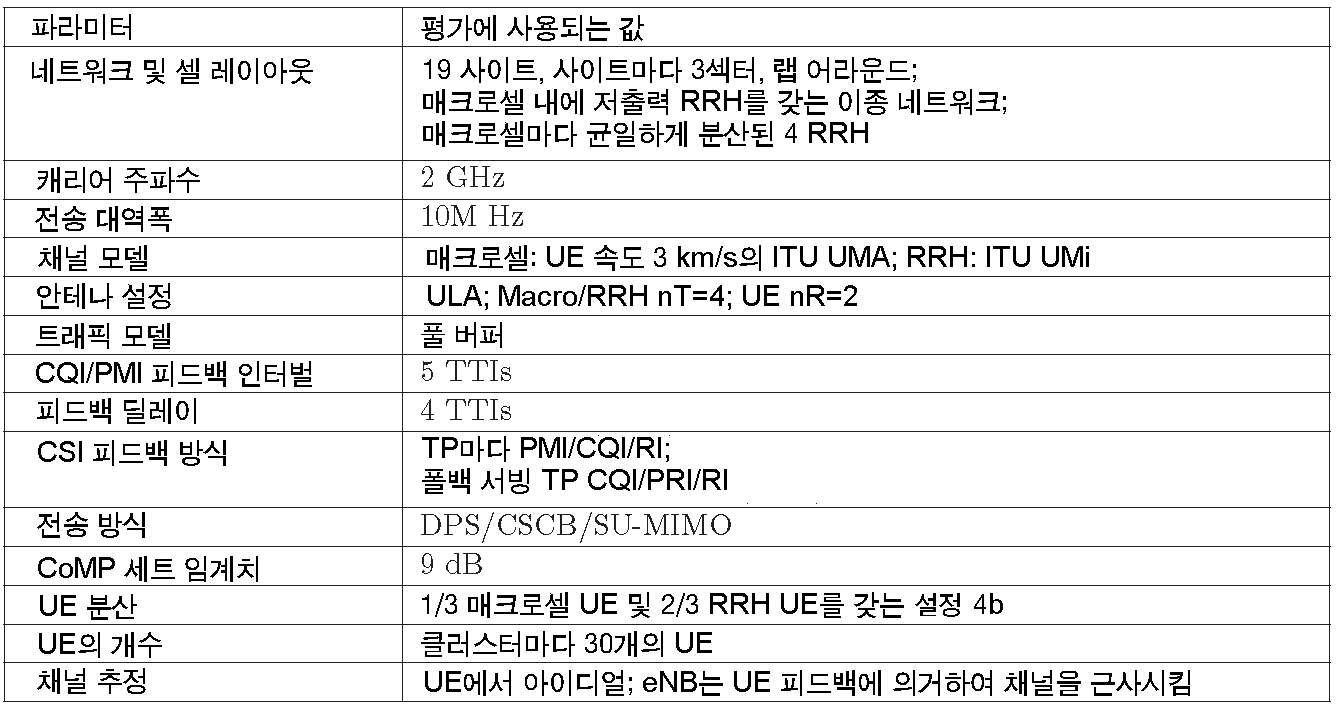
다음의 시뮬레이션 세트에서, 특히 협력 스케줄링에 이바지하는 CoMP 시나리오 4b를 고려했다. 여기에서 57개의 셀이 (랩어라운드로) 에뮬레이션되고 각 셀에서 하나의 매크로 기지국 및 4개의 RRH(remote radio head)가 배치된다. 각 클러스터는 셀을 커버하고 이에 따라 M=5 TP로 구성된다. 평균 30명의 사용자는 특정 분산을 이용하여 각 클러스터(셀)에 드롭된다. 주요 시뮬레이션의 가정을 표 2에 정리한다. 풀 버퍼 트래픽 모델에 대한 시뮬레이션이 실시되었고 그 결과는 NTTI=500 TTI에서 얻어지고, 각 TTI는 스케줄링 인터벌을 나타낸다.
4.1 채널 피드백
FDD 시스템에서, 중앙 스케줄러는, 그 각각의 다운 링크 채널의 추정 또는 근사를 얻기 위해 사용자로부터의 피드백에 의존해야 한다. 이러한 피드백에 이용 가능한 업링크 리소스는 한정되어 있으므로, 다음의 낮은 오버헤드 피드백 시그널링 방식이 지원된다.
· {1,…,M}의 임의의 서브세트인 TP의 측정 세트는 경로 손실, 쉐도잉 등의 느리게 변하는 큰 스케일의 페이딩 파라미터에 의거하여 각 사용자에 대해 별개로 설정된다. 각 사용자는 측정 세트 내의 TP로부터만 채널을 추정하는 반면, 그 측정 세트 내가 아닌 TP는 클러스터 외부의 것과 함께 간섭 또는 비협력 TP로 처리된다. 이 아이디어는 그 위치에 의존하여 사용자가 클러스터 내의 소수의 TP로부터만 (설정 가능한 임계값을 초과하는) 유용한 신호 강도를 수신할 수 있다는 것이다.
· 해당 측정 세트 내의 각 TP에 대해, 사용자는 다음과 같이 연관된 포인트마다의 CSI(channel state information)를 계산한다. 우선, (결과적으로 연속적인 RB의 세트로 구성되는) 각 서브밴드에서 해당 채널을 추정하고, 이어서 이를 "화이트닝"한다. 이 화이트닝은 간섭 공분산을 사용하여 얻어지는 선형 필터를 통해 행해지고 사용자가 비협력 TP로부터 보게 되는 간섭을 처리한다.
· 각 화이트닝 채널 매트릭스는 이득의 세트 및 프리코딩 코드북으로부터 도출된 매트릭스를 이용한 양호 방향의 세트로 양자화된다. 방향의 개수(또는 매트릭스에서의 열)를 랭크라고 하고 모든 서브밴드에 걸쳐 불변이다. 이어서 사용자는 해당 TP에 대한 포인트마다의 CSI를 함께 구성하는 서브밴드마다의 이득과 함께 서브밴드마다의 선택 매트릭스, 랭크를 보고한다.
· 추가적으로, 사용자는 앵커 TP로부터의 채널을 추정하고 다른 모든 TP로부터의 간섭을 고려한 후 화이트닝함으로써 계산된 "폴백" CSI를 또한 보고한다. 이 폴백 CSI는 간단한 비협력 포인트마다의 스케줄링을 가능하게 하기 위해 제공된다. 여기에서 검토되고 있는 피드백을 줄이기 위한 하나의 접근법은 모든 TP에 걸쳐 공통 랭크 제한을 부여하는 것이며, 사용자는 우선 폴백 CSI를 계산하고, 이어서 각 포인트마다의 CSI에 포함된 랭크가 폴백 CSI의 랭크와 동일하다는 제한 하에서 다른 포인트마다의 CSI를 계산한다.
서브밴드의 크기(주파수 입도) 및 피드백의 주기(시간 입도)는 설정 가능한 파라미터이다. 5개의 RB의 서브밴드의 크기 및 4ms의 주기를 설정함으로써 매우 미세한 입도를 가정했다. 중앙 스케줄러는 보고되는 모든 피드백을 수집하고 이를 이용하여 채널 근사를 구성한다. 특히, 각 사용자마다, 그 사용자의 측정 세트 내의 각 TP마다 및 각 서브밴드마다, 중앙 스케줄러는 대각 매트릭스
D에서의 해당하는 보고 이득을 수집하고 연관된 프리코더 매트릭스, 즉
V를 이용하여 채널을
로서 근사시킨다. 여기에서,
V는 반유니타리(semi-unitary)
여서
V의
i 번째 열을 따라 전송되는 심볼은 d
i의 이득을 볼 것이다. 이 채널 근사는 해당 서브밴드 내의 모든 RB에 이용된다. 사용자의 측정 세트 내가 아닌 모든 TP로부터의 채널은 제로로 가정된다. 강조될 필요가 있는 다른 하나의 측면은 각 사용자에서의 수신기의 선택이며, 이는 CoMP 방식을 통해 달성될 수 있는 이득에 영향을 주기 때문이다. 다만 간섭 공분산 추정을 대각 매트릭스인 것으로 제한하는 것에 상당하는 수신 안테나마다의 간섭 전력을 측정함으로써 간섭 공분산이 추정되는 각 사용자에서의 간단한 수신기를 우선 가정한다. 이 수신기는 표준에서 MMSE 옵션-1 수신기라 하며 모든 평가에서 베이스라인 수신기로서 이용된다. 후에 보다 개선된 수신기를 가정할 것이다. 다음의 모든 시뮬레이션에서, 포인트마다의 스케줄링 방식은, 알고리즘 II를 하나의 반복 및 단일 TP로 특수화함으로써 얻어지는 알고리즘 및 폴백 CSI를 이용하여 각 TP마다 스케줄링이 별개로 행해지는 베이스라인으로서 이용된다. 또한, 알고리즘 II 및 III에서의 공격적인 프루닝이 모든 케이스에 대해 이용되었다.
4.2 결과 및 관찰
협력 스케줄링을 위해 반복 서브모듈러 알고리즘 및 반복 포맷 밸런싱 알고리즘을 각각 채용하여 표 3 및 표 4에 처음 결과를 나타낸다. 선택된 CoMP 방식이 CDPS일 경우, 알고리즘 III에 서빙 TP 밸런싱 스텝이 또한 포함됨을 유념한다. 각각의 경우에, 상대적인 퍼센티지 이득이 베이스라인을 초과한다. 표 3 및 표 4로부터, CoMP 방식은 베이스라인 포인트마다의 스케줄링에 비해 엄청난 성능 저하를 초래하는 것으로 보인다. CoMP 방식을 가능하게 하도록 사용자로부터의 추가적인 피드백을 제공함에도 불구하고, 시스템이 매우 바람직하지 못한 손실을 입는 것으로 보인다.
관찰 1. CoMP 방식의 성능은 사용자로부터 수신된 피드백의 품질에 매우 민감하다.
다행히도, 다른 피드백의 형태는 각 사용자로부터 수신된 ACK/NACK 피드백의 형태로 또한 이용 가능하다. 이 피드백은 기존의 단일 셀 스케줄링에 성공적으로 사용되어 왔다.
표 3: 반복 서브모듈러 알고리즘을 갖는 CoMP 방식의 스펙트럼 효율(bps/Hz)
표 4: 반복 포맷 밸런싱 알고리즘을 갖는 CoMP 방식의 스펙트럼 효율(bps/Hz)
이 피드백을 활용하여 다음의 방식으로 중앙 스케줄러에서 채널 근사를 정교화한다. 각 사용자 k 및 사용자 k에 관련된 소정의 전송 가설에 대해, 그 측정 세트 내의 TP로부터 사용자 k가 보는 모든 채널의 근사가 이전과 같이 얻어진다. 이어서, (주어진 가설 하에서 있을 경우) 각 서브밴드에서 사용자 k에의 서빙 데이터와 관련된 TP에 대응하는 채널 근사가, 사용자 k와 연관된 수정 인자를 나타내는 인자 ck에 의해 스케일링된다. 이 스케일링 인자는 해당 사용자로부터 수신되는 일련의 ACK/NACK에 기초하여 지속적으로 업데이트된다. 업데이트 절차가 독점적인 동안, 모든 ACK는 인자를 증가시키는 반면 모든 NACK는 감소시키는 원리를 따르고 있다.
표 5 및 표 6의 ACK/NACK 기반의 정교화를 도입한 결과를 제공한다.
표 5 및 표 6으로부터, ACK/NACK 기반의 정교화로 인해 CoMP 방식의 성능이 비약적으로 향상되며, 보다 중요하게는, CoMP 방식이 현재 약속된 셀 에지 이득을 내고 있음을 알게 된다. 실제, 매우 상당한 셀 에지 이득이 세 가지 모든 CoMP 방식에 의해 얻어지면서 DPS 및 CDPS 이득이 현저해진다. 후자의 두 가지 방식에서, 빈(또는 뮤팅된) RB 비율이 높고, 이는 이들 방식이 RB 사일런싱(또는 뮤팅)을 더 공격적으로 사용하여 간섭을 줄임을 의미한다.
관찰 2. 채널 근사를 정교화하기 위한 ACK/NACK 피드백의 이용은 많은 이점을 주며 CoMP 이득을 실현할 필요가 있다.
이후, 달리 명시하지 않는 한, 다음의 시뮬레이션에서는 ACK/NACK 피드백을 이용한다.
표 5: 반복적 서브모듈러 알고리즘 및 ACK/NACK 정교화를 갖는 CoMP 방식의 스펙트럼 효율(bps/Hz).
표 6: 반복 포맷 밸런싱 알고리즘 및 ACK/NACK 정교화를 갖는 CoMP 방식의 스펙트럼 효율(bps/Hz).
이하, 공통 폴백 랭크 제한이 제거된 보다 확장된 피드백 방식을 검토한다. 폴백 랭크 제한을 부여해서 CoMP UE(즉, 그 측정 세트에서 하나보다 많은 TP를 갖는 사용자)가 랭크가 낮은 포인트마다의 CSI를 보고하도록 편중시켜서 설명한다. 이는, 폴백 CSI가 모든 비앵커 TP로부터의 간섭 가정 하에 계산되기 때문에 낮은 랭크를 선택할 것이다. 환언하면, CoMP 사용자는 폴백 단일 포인트 스케줄링 하의 셀 에지 사용자일 수 있으므로 낮은 랭크를 지원할 것이다. 모든 포인트마다의 CSI에 폴백 랭크 제한을 부여하는 것은 CoMP 사용자에 대해 상위 랭크 전송을 디세이블해서, 잠재적으로 레이트를 낮출 수 있음은 분명하다. 그러나, 그것은 또한 중요 이점을 갖는다. 각 포인트마다의 CSI에 대한 랭크 제한 하에서 사용자는 우선 주어진 랭크의 최적의 비양자화 채널 근사를 결정하고 나서 이를 양자화함을 유념한다. 그리고, 중요한 사실은 (코드북 크기에 의해 결정되는) 고정 양자화 부하를 고려하면 양자화 에러는 낮은 랭크에 대해 보다 작다는 것이다. 이것의 순 효과는 (우선 순위의 방향을 나타내는) 제 1의 소수의 지배적 특이 벡터가 대응하는 특이 값과 함께 나머지 것을 보고하는 것을 전혀 감수하지 않고 보다 정확하게 사용자에 의해 보고된다는 것이다. 랭크 제한이 없을 경우, 사용자는 일반적으로 양자화를 위해 보다 큰 특이 벡터의 세트를 선택할 것이다. 이것은 중앙 스케줄러가 더 성기기는 하지만, 보다 많은 방향 및 연관 이득을 알게 한다.
표 7에서 랭크 제한의 영향을 강조하는 결과를 제공한다. 간결성을 위해, 두 가지 CoMP 방식 및 반복 서브모듈러 알고리즘을 고려한다. 그 결과로부터, 폴백 랭크 제한으로 인해 각 CoMP 사용자로부터의 보다 적은 방향을 정확하게 아는 것은 네트워크가 간섭을 보다 양호하게 관리할 수 있게 하여 해당 사용자에의 상위 랭크 전송을 디스에이블시 손실을 상쇄하게 함을 제시하는 거의 저하 없음을 알 수 있다.
표 7: 반복 서브모듈러 알고리즘, ACK/NACK 정교화를 갖고, 랭크 제한 있음(RR=1) 또한 없음(RR=0)의 CoMP 방식의 스펙트럼 효율(bps/Hz).
표 8: 반복 서브모듈러 알고리즘, ACK/NACK 정교화, 랭크 제한 및 MMSE-IRC 수신기를 갖는 CoMP 방식의 스펙트럼 효율(bps/Hz).
관찰 3. 랭크 제한은 제한된 양자화 로드 하에서 유용한 피드백 감소 전략이다.
지금까지 각 사용자에서의 간단한 수신기를 가정하고 있었음을 상기한다. 이하, 어떠한 제한 없이 간섭 공분산이 추정되는 각 사용자에서의 보다 개선된 수신기를 고려한다. 이러한 결과의 수신기를 MMSE-IRC 수신기라 한다. 그 결과는, ACK/NACK 기반의 정교화 및 랭크 제한 모두가 부여되고 있음을 주목하는 표 8 및 표 9에 보고되어 있다. 흥미로운 관찰 사항은, 모든 방식의 성능이 표 5 및 표 6에서의 대응부와 비교하여 상당히 개선되어 있는 반면, 베이스라인 포인트마다의 스케줄링을 초과하는 상대 이득은 감소하고 있다는 것이다. 이는, 포인트마다의 스케줄링을 초과하는 큰 CoMP 이득에 유리한 시나리오는, 중앙 스케줄러가 양호한 네트워크 CSI를 갖지만 사용자 수신기가 제한된 간섭 거부 능력을 갖는다는 사실에 기인한 것이다. 한편, 최악의 시나리오는 스케줄러에서의 네트워크 CSI가 나쁘지만 사용자가 강력한 수신기를 갖는 것으로 이 경우 CoMP 방식이 유익하지 않을 것이다. 표 8 및 표 9에서 에뮬레이션된 시나리오는 후자의 경우에 더 가까우며, 이는 표 5 및 표 6의 것과 비교하여 총 피드백 오버헤드는 동일하지만 수신기가 보다 로버스트하기 때문이다. 따라서, 다음의 관찰을 갖는다.
표 9: 반복 포맷 밸런싱 알고리즘, ACK/NACK 정교화, 랭크 제한 및 MMSE-IRC 수신기를 갖는 CoMP 방식의 스펙트럼 효율(bps/Hz).
표 10: 반복 서브모듈러 알고리즘, MMSE-IRC 수신기, ACK/NACK 정교화를 갖고, 랭크 제한 있음(RR=1) 및 없음(RR=0)의 CoMP 방식의 스펙트럼 효율(bps/Hz).
관찰 4. 사용자 수신기를 CSI 피드백에서 상응하는 강화 없이 개선하는 것은 CoMP 이득의 감소로 이어진다.
표 10에서, ACK/NACK 기반의 정교화가 없는 시나리오를 시뮬레이션한다. 그 결과는 ACK/NACK 기반의 정교화가 실제 필요하며 이에 따라 관찰 2는 보다 강력한 사용자 수신기여도 참임을 입증하고 있다.
마지막으로, 표 11에서, ACK/NACK 기반의 정교화를 유지하지만 랭크 제한은 제거한다. 관찰 3은 해당 로버스트한 수신기에 대해서도 참임을 알게 된다.
표 11: 반복 서브모듈러 알고리즘, MMSE-IRC 수신기, 및 랭크 제한을 갖지만 ACK/NACK 정교화를 갖지 않는 CoMP 방식의 스펙트럼 효율(bps/Hz).
추가적인 시스템 세부 사항 B
I. 서론
데이터 트래픽의 폭발적인 성장에 대응하기 위해, 네트워크 운영자는 점차 셀 분할에 의존하고 있으며, 여기에서는 다수의 전송 포인트(TP)가 전통적으로 단일 매크로 기지국이 커버하는 셀에 위치된다. 이러한 각 전송 포인트는 고전력 매크로 강화 기지국이지만, 다소 적당한 성능을 갖는 저전력 RRH(remote radio head)일 수 있다. 이러한 서로 다른 전송 포인트에 의해 형성되는 네트워크를 이종 네트워크(일명, HetNet)라고 하며 바로 모든 차세대 무선 네트워크의 미래로 간주되고 있다. HetNet 아키텍처에서, 기본 협력 단위를 다수의 TP로 구성되는 클러스터라 한다. 클러스터 내에서의 협력 리소스 할당은 매우 미세한 시간 스케일, 전형적으로는 밀리 초당으로 달성되어야 한다. 결과적으로, 이것은 각 클러스터 내의 모든 TP가 파이버 연결을 가져야 하고, 이에 따라 클러스터의 형성(일명, 클러스터링)은 TP 간에 이용 가능한 파이버 연결에 의해 좌우됨을 의미한다. 한편, 서로 다른 클러스터간의 협력은 매우 느린 시간 스케일로 행해진다고 예상된다. 결과적으로, 각 사용자는 하나의 클러스터와만 연관될 수 있고 사용자의 클러스터에의 연관은 수 초당으로 행해질 필요가 있다.
본 명세서에서, 관심 사항은 각 클러스터 내에서의 동적 협력에 대한 것이다. 사용자 연관 및 클러스터링은 수 차수(several orders of magnitude) 성긴 시간 스케일로 일어나므로, 소정의 또는 고정된 것으로 가정한다. 다수의 TP의 클러스터 내에서의 공동 리소스 할당의 설계는 최근 깊게 연구되고 있다. 이 기법은, 사용자 채널 상태의 전역적 지식 및 중앙 프로세서에서의 그 각각의 데이터를 가정하여, 클러스터를 전역적 지식으로 하나의 브로드캐스트 채널로 변환하는 것으로부터, 각 사용자가 단 하나의 TP에 의해서만 서빙받지만 다운링크 전송 파라미터(빔 벡터 및 프리코더 등)가 여전히 공동으로 최적화될 수 있도록 클러스터 내의 TP 간에 사용자 채널 상태만이 공유되는 것까지의 범위에 걸쳐 있다. 본 작업에서 우리의 목표는, 간섭이 협력 리소스 할당을 통해 관리될 경우, 상당한 성능 이득이 가능한 것에 대한 이들 모든 작업으로부터 축적된 지식이 실제 HetNet에서 유효한지를 확인하는 것이다. 현실적인 네트워크에서의 과제는 세 가지, 즉 (i) 매우 미세한 시간 스케일로 구현될 수 있는 낮은 복잡도 리소스 할당 알고리즘에 대한 필요, (ii) 사용자로부터의 불완전/부정확한 채널 피드백, 및 (iii) 실제 전파 환경이다. 이러한 실제의 HetNet가 아직 배치되어 있지 않으므로, 정확한 모델링에 의존해야만 하는 것은 명확하다. 여기에서, 후자의 두 가지 과제를 달성하기 위해, 매우 종합적으로 HetNet 배치를 고려해 온 3GPP LTE 표준화 단체에 의해 특정된 이러한 네트워크의 에뮬레이션에 의존하고 있다. 이어서, 클러스터 내에서의 동적 협력을 관리하는 가장 간단한 "베이스라인" 접근법은 각 사용자를, 가장 강한 평균 신호 출력을 수신하는 클러스터 내의 하나의 TP("앵커" TP라 함)와 연관시키는 것이고, 이어서, 전체적으로 재사용하여 각 TP마다 별개의 단일 포인트 스케줄링을 행하는 것이다. 이 접근법은 메트릭스 자유도와 관련하여 간단하고 부족해보일 수 있지만, 현실적인 네트워크에서 셀 분할에 의해 약속된 평균 스펙트럼 효율 이득의 거의 모두를 얻는다. 실제로, 클러스터 내의 보다 정교한 공동 스케줄링 방식에서 기대하는 것은 주로, 베이스라인의 평균 스펙트럼 효율 이득을 유지하면서, 5 백분위수 스펙트럼 효율의 현저한 이득을 달성하는 것이다. 이 기대의 실현을 위해, 공동 리소스 할당 문제를 공식화하고, 서브모듈러 웰페어 최대화와 포맷 밸런싱이라고 하는 기법을 조합하는 신규한 접근법에 의거하여 상수-인자 근사 알고리즘의 개발로 진행되어 있다. 주요 측면은, 공식화된 리소스 할당 문제가 중요한 실제적 제한 및 전송 파라미터의 특정 선택을 포함하는 것이다. 결과적으로, 설계된 알고리즘은 실제적 중요 시나리오에 바로 적용 가능하고 실제 현실적 조건 하에 평가될 경우 기대되는 이득을 나타낸다.
II
. 시스템 모델
범용 주파수 재이용을 갖는 HetNet에서의 다운링크를 고려하여, 각각의 스케줄링 인터벌 동안 N개의 직교 리소스 블록(RB)에서 동시에 전송할 수 있는 B 개의 협력 TP의 클러스터에 초점을 맞춘다. 각 RB는 대역폭 부분이며, 최소 할당 단위를 나타낸다. 더불어, 이 B 개의 TP는 K 명의 활성 사용자의 풀에 서빙한다. 각 사용자뿐만 아니라 각 TP는 다수의 안테나를 구비할 수 있다. 이 B 개의 TP가 동기화되어 파이버 백홀을 통해 메시지를 교환할 수 있는 전형적인 HetNet 시나리오(3GPP LTE 릴리스 11에 정의되어 있음)를 가정한다. 다음으로, RB n에서 사용자 k에 의해 수신된 신호는 다음과 같이 기재될 수 있다.
여기에서, H k ,j(n)는 RB n에서 TP j와 사용자 k 사이의 MIMO 채널을 모델링하고(작은 스케일 페이딩, 큰 스케일 페이딩 및 경로 감쇠를 포함함), zk(n)는 가산성 원형 대칭 가우스 노이즈 벡터이고 x j(n)는 n 번째 RB에서 TP j에 의해 전송되는 신호 벡터를 나타낸다(최대 신호 전달 지연이 CP(cyclic prefix) 이내이면, 식 (1)에서의 모델은 OFDMA의 경우에도 성립함). TP에 의해 전송되는 신호를 고려할 경우, 각 TP가 각 RB에서 단 하나의 사용자에게만 서빙하도록 허용되는 공통 제한을 부여한다. 이 제한은 TP마다의 사용자로부터의 불완전 및 성긴 채널 피드백에 대한 로버스트성을 제공한다. 이어서, RB n에서 TP q에 의해 전송되는 신호는 다음과 같이 표현될 수 있다.
여기에서, b q ,u(n)는, 기준(파워) 제한을 만족하는 프리코딩 매트릭스 W q ,u(n)을 이용하여 일부 사용자 u를 대상으로 하는 RB n에서 TP q에 의해 전송되는 컴플렉스 심볼 벡터이다. 무선 채널의 브로드캐스트 특성으로 인해, RB에서 일부 TP에의해 전송되는 사용자를 대상으로 하는 신호는 RB에서 모든 다른 공동 스케줄링된 사용자에 의해서 간섭으로서 수신됨을 유념한다. 이러한 요인은, 해당 사용자에만 단독으로 할당된 리소스에 의존하는 사용자마다의 효용을 정의하는 것이 더 이상 의미가 없으므로, 스케줄링 문제를 상당히 복잡하게 한다.
유용성을 가지면서 세부 내용을 이끌어내기 위해, 전송 가설의 개념을 채택한다. 특히,
를 엘리먼트로서 정의하고, 여기서
는 사용자를 나타내고,
는 카디널러티
를 갖는 이러한 포맷의 유한 세트
로부터 도출된 포맷을 나타내고,
는 TP(transmission point)를 나타낸다. 이러한 각 엘리먼트
는 전송 가설, 즉 사용자 u를 대상으로 하는 포맷
를 이용한 TP b로부터의 전송을 나타낸다. 다음으로,
는 이러한 모든 가능한 엘리먼트의 그라운드 세트를 나타낸다. 이러한 임의의 엘리먼트에 대해서 다음의 합의를 채택한다.
이어서,
는 RB의 세트를 나타내고
는 가중 합 레이트 효용 함수를 나타낸다. 임의의 서브세트
및 임의의
에서,
는 RB n에서
의 가설을 이용한 전송 시에 얻어지는 가중 합 레이트를 얻는다.
에서의 가설은 다수의 가설을 포함할 수 있으며, 예를 들면 RB n에서
를 선택하는 것은 RB n에서 TP
가 포맷
를 사용하여 사용자
를 대상으로 하는 신호를 전송할 것이고, 동시에 TP
는 포맷
를 사용하여 사용자
를 대상으로 하는 신호를 전송할 것임을 내포한다. 각 엘리먼트
(또는 이에 대등하게 사용자
)와 연관된 가중이 스케줄러에 대한 입력이고 결과의 스케줄링 결정을 이용하여 차례로 업데이트된다. 동일한 RB에서 동일한 사용자가 다수의 TP로부터 데이터를 수신할 가능성뿐만 아니라(동일한 주파수에서 다수의 TP로부터의 동시 데이터의 수신을 인에이블하는 것은 코히어런트 결합을 가능하게 하기 위해 사용자로부터의 추가적인 피드백을 요할 수 있지만 가능하지 않을 수 있으므로, 이 후자 제한이 필요함), 동일한 RB에서 동일한 TP가 다수의 사용자에게 서빙할 가능성을 허용하지 않도록, 다음의 합의를 채택한다.
또한, 임의의
에 대해, 다음을 확장할 수 있다.
여기에서
는 RB n에서
의 가설을 이용하여 엘리먼트
또는 이에 대등하게 사용자
에 대해 얻어진 가중 레이트이고,
일 경우는 언제나
로 설정한다. RB n에서
의 임의의 가설의 선택 시, 해당 가설에 포함되는 TP 및 사용자에 의해 형성된 간섭 채널을 가짐을 유념한다. 이어서, 가중 합 레이트를 계산하는 임의의 미리 결정된 규칙을 이용할 수 있다. 본 명세서에서, 일부 엘리먼트가 해당 세트로부터 삭제될 경우 세트 내의 엘리먼트의 레이트는 감소하지 않는다고 하는 특성의 저가산적 가정을 가중 합 레이트 효용 함수가 만족한다고 가정할 것이다. 특히, 임의의 서브세트
및 임의의 엘리먼트
에 대해,
를 정의할 경우, 각
에 대해 다음을 가정한다.
다음의 두 가지 CoMP 방식의 어느 하나가 각 사용자에 대해 선택됨을 가정한다. 사용자와 CoMP 방식의 연관은 사전 결정 및 고정됨을 강조한다.
·CS/CB(Coordinated Silencing/Coordinated Beamforming ): 이 방식과 연관된 사용자는 미리 결정된 "앵커" TP에 의해서만 데이터를 서빙받을 수 있어서, TP 간의 사용자 데이터의 실시간 공유는 필요하지 않다. 따라서, CS/CB 사용자 u에 대해,
인 임의의
는 TP
가 u의 앵커 TP임을 만족해야 한다.
· DPS (Dynamic Point Selection): 이 방식과 연관된 사용자는 임의의 RB에서 임의의 TP에 의해 서빙받을 수 있다. 양쪽 CoMP 방식에서 간섭 완화는 적절한 사용자 및 포맷 선택을 통해 달성될 수 있음을 유념한다. 또한, DPS는 RB마다의 서빙 TP 선택을 통해 단기 페이딩을 이용함으로써 수신 신호 강도의 향상을 가능하게 하며, 여기서 서빙 TP란 데이터를 사용자에게 서빙하는 TP를 의미한다. 이어서,
는 각각 사용자 u의 (비트에서의) 버퍼 사이즈 및 그 스케줄링 가중(최적화 손실이 없을 경우, 사용자 가중은 [0,1] 내에 놓이도록 정규화되는 것으로 가정할 수 있음)을 표시하는 것으로 하며, 식 (6)에 의해 주어진 최적화 문제를 공식화한다.
식 (6)에서, 목적 함수는 유한 버퍼 제한를 포함하지만, 제 1 제한은 각 RB에서 단 하나의 전송 가설이 선택되는 것을 보장한다. 제 2 제한은 스케줄링된 각 사용자에게 하나의 포맷만이 할당되는 것을 보장한다. 소정 수의 사용자(K), TP(B), RB(N) 및 포맷(J)에 대해, 식 (6)의 인스턴스는, 모든 RB에서 모든 가능한 가설에 대한 모든 가중 합 레이트 효용 값의 세트와 함께, 버퍼 사이즈
및 사용자 가중의 세트이다. 식 (6)에 대한 근사 알고리즘의 설계의 진행에 앞서, 포맷의 특정 예를 가중 합 레이트를 계산하는 규칙과 함께 고려한다. 포맷은, 예를 들면 할당된 심볼 스트림의 개수에 의해 정의될 수 있으며, 이 경우에 임의의 RB에서 주어진 전송 가설에 대해, 각 트랜시버 링크의 스트림의 개수가 현재 주어져 있는 간섭 채널을 갖는다. 이어서, 가중 합 레이트를 평가하는 규칙은 각 트랜시버 링크마다 가우스 입력 알파벳을 가정하는 것 및 간섭 정렬에 의거한 것과 같은 전송 프리코딩 방법일 수 있다. 이어서 스케줄링된 사용자마다 단 하나의 포맷의 제한은, 각 스케줄링된 사용자에게 모든 할당된 RB에서 동일 개수의 스트림이 할당되는 것인 LTE 표준의 주요 제한을 갖는다. 제 1 결과는, 식 (6)이 낮은 (다항) 복잡도 알고리즘에 의해 최적으로 해결될 수 없다는 것이다. 이어서, 식 (6)을 두 가지 특수한 경우로 추리고 그 알려진 하드니스를 이용한다.
정리 1. 식 (6)에서의 최적화 문제는 NP 난해이다. 구체적으로, 임의의 고정 N ≥ 1 & J ≥ 2에 대해, 식 (6)은 강한 NP 난해이다. 임의의 고정 B ≥ 1&J ≥ 1에 대해, 식 (6)은 APX 난해이다.
정리 1은 식 (6)에 대한 효율적인 최적 알고리즘의 존재는 매우 가능성이 낮고, B에 대한 지수적 복잡도는 B에 독립적인 근사 인자를 얻기 위해 치뤄야할 대가일 수 있다. 여기에서, 반복적 프레임워크를 채택하여, B에서도 복잡도를 다항으로 만들지만 근사 보장에서 1/B의 페널티를 가져오는 근사 알고리즘을 설계한다. 따라서, 식 (7)에 의해 주어지는 다른 간단한 문제를 가져온다. 식 (6) 및 식 (7)에 대한 최적 솔루션을 이용하여 얻어지는 가중 합 레이트 간의 관계는 다음 결과로 주어진다.
명제 1. 식 (7)에 대한 최적 솔루션은 식 (6)에 적합하며, 식 (6)에 대한 최적 솔루션에 의해 얻어지는 것의 인자
배보다 작지 않은 값을 산출한다.
증명: 우선, 모든 사용자와 연관된 CoMP 방식이 CS/CB라고 가정한다. 이어서, 식 (6)에 대한 최적 솔루션, 즉
을 고려하여, 그 솔루션에 대해,
는 TP b(b = 1,…,B)에 의해 서빙받는 사용자의 세트를 나타낸다. CS/CB는 모든 사용자에 대해 사용되므로, 이들 세트는 비 중첩, 즉
임을 추정할 수 있다. 또한, 전체 효용이
로서 확장될 수 있고, 여기에서, R
b는
에서 모든 사용자의 레이트의 가중 합이고, 사용자마다의 유한 버퍼 제한이 포함된다. 다음으로, TP b를 고려하여, 각 RB
에서 지니가, 다른 TP에 의해 공동 스케줄링된 전송으로부터 TP b에 의해 서빙받는 사용자에게 야기된 간섭을 제거한다. 식 (5)의 속성을 적용하면, 결과의 가중 합 레이트
가 적어도 R
b만큼임을 알 수 있다. 그러나,
는
으로부터 얻어진 식 (7)에 대한 특정 솔루션에 의해 얻어질 수 있으며, 여기에서
의 사용자를 포함하는 엘리먼트만 각
에 유지되고(각
에 하나의 이러한 엘리먼트만이 있을 수 있음을 유념함) 다른 것은 제거된다. 이것은 식 (7)에 대한 최적 솔루션이 각
(b = 1,…,B)에 대한 상한인 값을 산출함을 내포하고, 결과적으로 정리가 참이라 결론지을 수 있게 한다. 이하, 일부 사용자에게는 CoMP 방식으로서 DPS가 채택되는 반면, 나머지 사용자에게는 CS/CB가 채택되는 일반적인 경우를 고려한다. 이 경우에, 각 DPS 사용자 u를 동일한 가중, 채널, 및 큐 크기를 갖는 B 명의 사용자 u
(i)(i = 1,…,B)로 나누고, 또한 이러한 i 번째 사용자는 앵커가 TP i여서 TP i에 의해서만 데이터를 서빙받을 수 있는 CS/CB 사용자라고 이해하기로 한다. 이 확장된
사용자의 풀을 수집하고 이 큰 풀에 대해 식 (6)에서의 문제를 부여하고, 모든 사용자는 CS/CB 사용자이고 버퍼 제한은 각 사용자에게 별개로 부여되는 것으로 한다. 후자의 문제의 최적 값은 K 명의 사용자를 갖는 원래의 것에 대한 상한임이 명확하다. 또한, 각 TP가 확장된 풀로부터 K 명의 사용자보다 많지 않은 앵커임을 통지하고 이전에 이루어진 논의를 적용할 때, 식 (7)의 최적 값은 후자의 문제의 것보다 1/B배 작지 않은 것임을 주장할 수 있으며, 이는 원하는 결과이다.
임의의 주어진 세트
, 임의의 엘리먼트
, 임의의 RB
, 및 임의의 비 음(non-negative)의 스칼라
에 대해, 스칼라
와 함께, 다음을 정의한다.
여기에서,
는,
내의 엘리먼트가 해당 RB에서 이미 스케줄링되어 있다고 가정할 경우, RB n에서 스케줄링 엘리먼트
에 의해 얻어지는 전체 증분 가중 레이트 이득(또는 손실)을 나타낸다. 또한, 이 증분 레이트를 정의할 때,
를 가중 레이트 마진으로 사용하며, 즉 사용자
에 대해 얻어진 가중 레이트 이득은
를 초과할 수 없다. 이 마진의 목적은, 사용자
가 다른 RB에서 스케줄링되는 결과로서
의 가중 레이트를 이미 얻었음을 조건으로 사용자
에 버퍼 제한을 강제하기 위한 것이다. 또한, 스칼라
는 다시 버퍼 제한을 포함하는 데 사용되는 디스카운트 인자이다. 예를 들면, 항
는 추가적인 엘리먼트
의 스케줄링으로부터 일어나는 증가된 간섭으로 인한 사용자
의 가중 레이트에서의 손실을 나타낸다. 그러나, 이 손실은
에 대한 버퍼 제한이 비활성일 경우에만 일어나는 최대 가능한 손실이다. (
에 할당된 모든 RB의 결과로서) 해당 사용자에 대한 버퍼 제한이 활성일 경우, 인자
에 의한 손실을 디스카운트한다. 이하에서는, 식 (6)을 근사적으로 풀기 위한 알고리즘 I를 제공하도록 진행한다. 이 알고리즘은 반복적 프레임워크를 채택함을 유념한다. (외부 Repeat-Until 루프 내의 모든 스텝으로 구성되는) 알고리즘의 외부 반복 각각에서, 이전 반복에서 이루어진 결정은 고정 유지된다. RB, 서빙 TP 및 포맷의 사용자에의 새로운 할당은 우선 단 하나의 포맷 사용자마다의 제한을 무시하면서, (내부 While-Do 루프 내의 모든 스텝으로 구성되는) 간단한 그리디 접근법을 이용함으로써 먼저 이루어진다. 이어서, 사용자의 포맷에 대해 밸런싱 스텝이 행해져서, 사용자가 하나의 포맷만으로 스케줄링되는 것을 보장한다. 얻어진 결과는 실현 가능성을 유지하면서 시스템 효용의 향상을 보장한다. 사용자
에 대한 알고리즘 I의 스텝 16에서의 포맷 밸런싱 루틴은 다음과 같이 구현된다. 주어진 서브세트
및
에 대해, 각각의 포맷
을 고려하여 식 (8)에서의 문제를 풀고, 여기에서
이다. 식 (8)은 다수의 선택 냅색 문제이며, 이에 따라 예를 들면 동적 프로그래밍을 통해 또는 효율적인 근사 알고리즘을 이용하여 풀릴 수 있음을 유념한다. 다음으로,
는, 연관된 솔루션이 식 (8)에 대해 최고의 목적 함수 값이 되게 하는 포맷을 나타내는 것으로 한다.
는
와 연관된 솔루션에 할당된 RB의 세트를 나타내고
는 대응하는 엘리먼트인 것으로 한다. 이어서,
및
이도록
및 엘리먼트
가 존재하는지의 여부를 더 체크한다. 이들 두 가지 조건이 만족되지 않을 경우, 포맷 밸런싱 솔루션으로서
을 반환한다. 그렇지 않으면, 포맷 밸런싱 솔루션으로서
을 반환하기 전에
에
을 가산하고
을 설정한다. 마지막으로, 선택 서브세트
가 주어지면 프루닝 스텝이 다음과 같이 행해진다.
공격적 프루닝 옵션은 다른 옵션을 포함함을 유념한다. 이하에서 얻어진 성능 보장은 두 가지 프루닝 옵션 모두에 유효하다. 알고리즘 I의 반복마다의 복잡도는
이다.
이하, 알고리즘 I에 대한 근사 보장을 얻는 것으로 진행한다. 이를 위해, 단일 사용자 경우로 효용을 특수화할 경우 다음의 가벼운 부등식이
인 일부 상수
에 대해 성립한다고 가정한다.
이어서, 매트릭스
를 정의한다. 세트
를 항상 설정할 수 있으므로, 식 (9) 자체는 범용성을 잃지 않게 된다. 그러나,
는, j에서 i로의 포맷 변경이 모든 RB에서 및 모든 인스턴스 내에서, 모든 사용자에 대해 원래의 가중 레이트의 분수 G
i ,j보다 큰 가중 레이트를 보장함을 의미한다. 이전에 제시된 포맷 예에 대해서는,
임을 유념한다.
정리 2. 알고리즘 I는 적어도
의 최악 경우의 보장을 갖는 식 (6)에 대한 솔루션을 제공하고, 즉 그에 의해 얻어진 솔루션을 이용하여 얻어진 가중 합 레이트 값은 식 (6)의 최적 솔루션을 이용하여 얻어진 것의
배보다 작지 않다. 또한,
는
을 만족하고 어느 임의의 고정
에 대하여 다음 LP를 통해 결정될 수 있다.
증명: 식 (7)의 최적 값을
로 표시한다. (
및
로 초기화된) 알고리즘 I의 제 1 외부 반복을 고려하여 제 1 반복 자체 후에 얻어지는 시스템 가중 합 레이트 값은 적어도 인자
×
임을 나타낸다. 이것은, 알고리즘 I의 각각의 반복으로 인해 시스템 효용이 향상된다는 사실과 더불어, 명제 I와 함께 정리를 증명한다.
여기에서
이고
이다. 제 1 관찰은, 임의의 유저 u에 대해, 세트 함수
는 단조 서브모듈러 세트 함수이며, 즉 임의의
및 임의의 n∈
에 대해,
및 다음을 얻는다.
다음으로, 다음의 문제를 고려한다.
식 (12)에서의 문제는 단조 서브모듈러 사용자마다의 효용 또는 가치를 갖는 조합적 옥션 문제(일명, 웰페어 최대화 문제)이다. 식 (12)에서 사용자마다의 포맷 제한이 드롭되므로, 그 최적 값은
에 대한 상한임을 유념한다. 보다 중요하게는, 단조 서브모듈러 가치를 갖는 임의의 조합적 옵션 문제는 그리디 알고리즘을 통해 근사적으로(1/2 근사로) 풀릴 수 있다. 실제, 내부 While-Do 루프는 그러한 그리디 루틴을 구현하고, 그 스텝 14 후의 결과로서
및 다음 식을 얻는다.
이하, 사용자 u:
에 대한 포맷 밸런싱 루틴을 고려한다. 이러한 사용자 u 및 각각의 포맷
에 대해, 임의의
에서 이러한 엘리먼트를 발견할 수 없을 경우
이라는 조건으로 다음 식을 정의한다.
이어서, (알고리즘 I의 스텝 14 후에) 사용자 u에 대해 얻어지는 가중 레이트는 min
와 동일하고 실제
와 동일함을 유념한다. 이어서, 상술한 포맷 밸런싱 방법에 따라
를 선택하고 식 (9)의 부등식을 적용하여, 사용자 u가 적어도 다음의 레이트를 얻는 것을 보장할 수 있다.
또한, 사용자에게 비 중첩 RB가 할당되므로, 주어진 인스턴스에 대해 포맷 밸런싱 루틴의 최악 경우의 근사 보장은 적어도 다음이라고 결론지을 수 있다.
외부 최소화는 모든 사용자
에 걸쳐 있다. 이어서, 모든 인스턴스에 걸쳐 최악 경우의 근사 보장은
만큼 하한으로 될 수 있으며, 이는 문제에 대한 솔루션이다.
이므로, 식 (16)에서의 최소 값은
보다 작지 않을 수 있음을 알게 됨은 명확하다. 정리의 나머지 부분은 부기 A에서 증명된 명제 2를 적용할 때 따라온다.
표 I 및 II에서, 알고리즘 I에 대한 평가 결과를 제공하며, 여기에서 평가는 HetNet를 에뮬레이션하는 완전히 조정된 시스템 시뮬레이터에서 행해졌다(시나리오 4b). 특히, 19 셀-사이트(랩어라운드를 가짐) 및 셀-사이트마다 3개의 섹터를 갖는 HetNet를 에뮬레이션하고, 각 섹터는 각각 4개의 전송 안테나를 갖는 4개의 저전력 무선 헤드 및 하나의 매크로 기지국의 5개의 TP로 구성되는 클러스터를 나타낸다. 각 섹터는 평균 10명의 사용자(각각 2 개의 수신 안테나를 가짐)에게 서빙하고 풀 버퍼 모델이 가정된다. 표 I에서, 각 사용자는 ICI(inter-cell interference) 거부 능력이 없는 간단한 수신기를 채용하는 반면, 표 II에서는 보다 로버스트한 MMSE-IRC 수신기를 채용하는 것으로 가정한다. 각 경우에, 모든 사용자가 DPS 사용자 또는 CS/CB 사용자 중 어느 하나임을 상정한다. 또한, 각 사용자로부터 얻어진 피드백은 ACK/NACK 피드백을 사용하여 정교화되고 제공된 피드백만이 채용되는 것을 추가하는 것을 신속히 한다. 표에서, 퍼센티지 이득이 베이스라인 단일 포인트 스케줄링을 초과할 경우, 공동 스케줄링을 통해 5% 스펙트럼 효율(SE)의 현저한 이득이 얻어질 수 있음을 알 수 있다. 결과적으로, 이는 베이스라인에 의해 얻어졌던 셀 분할 평균 SE 이득의 대부분을 유지하면서, 위치에 관계없이 사용자 경험의 개선을 보장한다. 또한, 네트워크 지원 협력 전송이 ICI를 관리하는 데 보다 필요하므로, 보다 간단한 수신기를 사용할 경우 이득이 보다 양호해진다.
III. 결론
HetNet에서의 리소스 할당을 고려했다. 세부적인 분석 및 시스템 평가는, 특정 방식으로 이용 가능한 모든 피드백을 이용하고 잘 설계된 알고리즘을 이용함으로써, 실제 현저한 이득이 실제의 HetNet에 대해 실현될 수 있음을 나타내고 있다.
부기
A. 부기: 명제 2 및 증명
명제 2. 임의의 매트릭스
에 대해,
는 고정된 양의 정수이고, 임의의
이고,
에 대한 솔루션은 임의의 상수 S>0에 대해 다음의 선형 프로그램을 풀어서 구할 수 있다.
또한,
인 특수한 경우에, 식 (18)에 대한 솔루션은
와 같이 폐형으로 구해질 수 있다.
증명: 식 (18)의 최적 값을
로 표시한다. 이어서, 임의의 상수
를 이용하여 다음과 같이 상한으로 될 수 있다.
또한, 다음을 알게 된다.
이하,
를 식 (21)의 RHS에 대한 최적 솔루션이며,
및
이어서
는 식 (21)의 RHS에 대한 최적 값이라 상정한다. 이어서, 임의의 상수 S>0에 대해 식 (20)의 RHS에서의 볼록 최소화 문제를 고려한다.
인
는 식 (20)의 RHS에 적합하고 값
을 산출해냄은 명확하다. 이것은 식 (20)의 RHS의 최적 값이
보다 크지 않음을 내포한다. 그러나, 식 (21)의 RHS의 최적 값이 또한
보다 엄격히 작음을 내포하므로
보다 엄격히 작은 식 (20)의 RHS의 최적 값은 모순이 된다. 결과적으로, 임의적으로 고정된 S>0에 대해, 식 (20)의 RHS의 최적 값은 식 (21)의 RHS의 것과 동일하며, 이는 이 값이
와 동일함을 내포한다. 이어서, 식 (20)은 식 (19)에서와 같이 재공식화될 수 있다. 식 (19)에서의 제한 및 목적은 아핀이므로, K.K.T 조건에 대한 임의의 솔루션이 또한 전역적으로 최적임을 내포하는 볼록 최적화 문제임은 명확하다. 다음으로, 식 (19)에 대한 K.K.T 조건이 다음과 같이 주어진다.
표 I
간단한 수신기를 통한 스펙트럼 효율(BPS/Hz)
표 II
MMSE-IRC 수신기를 통한 스펙트럼 효율(BPS/Hz)
여기에서
는 아다마르 프러덕트를 나타낸다. 다음으로
를 상정한다. 이어서, 다음 식의 특정 선택을 고려한다.
식 (23)에서의 선택은 식 (22)에서의 모든 K.K.T. 조건을 만족하므로 식 (19)에 대해 전역적 최적해, 및 이에 따른 식 (18)에 대한 최적 값을 산출해야 함을 확인할 수 있다. 이 최적 값은
라고 확인될 수 있다.
추가 시스템 세부 사항 C
1 서론
릴리스-11[6]에서는, 세 가지 CoMP 방식, 즉 JT(joint transmission), CS/CB(coordinated scheduling and beamforming), 및 DPS(dynamic point selection)이 지원되는 것이 합의되었다. CoMP CS/CB에서, 종래의 단일 셀(CoMP가 없음) 시스템에서의 경우와 마찬가지로, 서빙 셀의 TP(transmission point)를 통해 데이터가 전송될 것이다. 따라서, CoMP CS/CB에 대한 PDSCH 매핑에는 문제가 없다. 그러나, CoMP JT 및 DPS에서는, 상기 TP 또는 서빙 셀 이외의 TP가 데이터 전송에 관여될 수 있다. 이 경우에, PDSCH(Physical Downlink Shared Channel) RE(resource element) 매핑에서 서로 다른 시그널링 구조로 인해 일부 문제, 예를 들면 서로 다른 TP에 대응하는 CRS RE 위치에 대한 서로 다른 주파수 변위, 및 서로 다른 TP에 대한 PDCCH 영역의 서로 다른 크기로 인해 PDSCH 개시점으로 인한 CRS/PDSCH 충돌이 일어난다. 이 문제는 현실화되어 CoMP 연구 항목 스테이지 자체에서 논의되었으며, CoMP WI[6][7]에 포함되어 있다.
RAN1#69에서, CoMP에서의 PDSCH RE 매핑 문제를 해결하기 위한 방법이 논의되었고, 이들 문제를 해결하기 위해 추가적인 다운링크 제어 시그널링이 필요할 수 있다. RAN1#69 미팅에서 다음이 합의되었다.
·PDSCH 전송이 일어날 수 있는 적어도 하나의 셀의 CRS 위치를 지시하는 시그널링을 제공함
°시그널링은 적어도 주파수 변위를 식별함
°CRS 안테나 포트의 개수에 대한 FFS
°MBSFN 서브프레임에 대한 FFS
·시그널링이 전송될 경우, PDSCH는 단일 셀의 지시된 CRS에 대해 릴리스-10 레이트 매칭에 따르며, 그렇지 않을 경우 UE는 서빙 셀의 CRS 위치를 가정한다.
°RAN1#70까지 PDSCH가 레이트 매칭되는 조합된 CRS 패턴에 관해 최대 3개의 셀까지 시그널링이 또한 지시할 수 있는지의 여부를 FFS
반정적 또는 동적으로, CoMP PDSCH 매핑을 위한 DL 제어 신호에 대해 [8]에서 몇 가지 대안이 도입되었다. 서로 다른 대안 및 이 방식에 대한 논의를 위한 몇 가지 구체적인 신호 설계를 제공한다.
2
CoMP
에서의
PDSCH
매핑
작업
2.1 CoMP에서의 PDSCH 매핑 문제
CoMP JT 및 DPS 전송에서, 서빙 셀 이외의 전송 포인트가 실제 데이터 전송에 관여하므로, 특정 가정 또는 추가 DL 제어 신호가 특정되지 않을 경우, UE는 정확한 PDSCH RE 매핑의 지식을 갖지 못한다. CoMP JT 및 DPS에 대한 PDSCH 매핑은 다음 문제가 있다.
·PDSCH 전송을 위한 전송 포인트의 CRS 위치 또는 CRS/PDSCH 충돌.
·PDCCH 영역의 크기가 다름으로 인한 PDSCH의 개시점(OFDM 심볼).
·MBSFN 서브프레임의 정보.
[8]에서 이 문제의 세부 내용이 논의되었고 몇 가지 대안의 솔루션이 제공되었다. PDSCH RE 매핑 솔루션 및 이에 필요한 DL 제어 시그널링을 더 논의한다.
2.2
CoMP
에서의
PDSCH
RE
매핑
솔루션
CoMP JT 및 DPS를 위한 디폴트 PDSCH 매핑 접근법은, PDSCH 매핑이 PDSCH 개시점을 포함하는 서빙 셀의 매핑 및 및 CRS RE 위치에 대한 가정에 맞춰 항상 조정된다. 이 디폴트 접근법은 추가 DL 시그널링을 도입할 필요가 없으며, 따라서 표준에의 영향이 최소화된다. 그러나, 불일치 PDCCH 영역 및 CRS/PDSCH 충돌로 인해, 일부 RE 리소스는 낭비되거나 다른 셀의 CRS 신호로부터의 강한 간섭을 겪을 수 있다. 따라서, 이러한 디폴트 접근법은 스펙트럼 효율에 큰 CoMP 성능 저하를 초래할 수 있다.
CoMP에서의 CRS/PDSCH 충돌 문제를 해결하기 위한 몇 가지 잠재적인 솔루션이 [4]에 정리되어 있으며, 예를 들면 [9]에서도 제안된 바와 같이, CRS RE를 포함하는 어떠한 OFDM 심볼도 사용하지 않거나, CRS가 없는 CoMP JT 또는 DPS 전송을 위한 MBSFN 서브프레임만을 사용한다. 그러나, 이러한 접근법은 스펙트럼적으로 효율적이지 않거나 일부 특정 설정에 제한된다. [9]에서는, MBSFN을 이용하는 접근법이, CoMP가 로드가 높은 경우에 주로 유용하다는 의미에서, 여전히 스펙트럼적으로 효율적이다라고 논하고 있다. 그러나, 시스템 부하가 낮을 경우에는 CoMP JT가 셀 에지에서 큰 이득을 주는 것으로 알려져 있다. 일부 기업은 또한, eNB가 동일한 CRS 주파수 변위를 설정함으로써 CoMP 좌표 세트 내의 TP에 대한 CRS 위치를 조정하는 것을 제안했다. 그러나, 이 접근법은 eNB에서 구현 가능할 경우, eNB의 복잡도를 상당히 증가시킨다. 한편, 2 개의 TP가 CRS 포트의 개수가 상이할 경우 문제를 해결하지 못한다.
[8]에서는 PDSCH 매핑 문제를 해결하기 위해 몇 가지 대안이 제공되었다. CRS/PDSCH 충돌 문제를 처리하기 위한 제 1 접근법은 PDSCH 뮤팅에 기반한 것, 즉 다른 TP로부터의 CRS RE와 충돌하는 RE에서 데이터 심볼을 전송하지 않는 것이다. 이어서, PDSCH RE 뮤팅을 갖는 PDSCH 매핑 정보는 CoMP UE에 시그널링될 수 있다. CoMP UE에 정확한 PDSCH 매핑을 동적으로 송신할 경우, CoMP DPS에는 PDSCH RE 뮤팅이 필요하지 않을 수 있다. 그러나, 정확한 PDSCH 매핑을 동적으로 전송하는 것은 큰 시그널링 오버헤드를 요한다. 따라서, 동적 시그널링이 수용될 수 없는 경우에는, CoMP 측정 세트에 기반한 PDSCH 뮤팅은 유망한 대안 솔루션으로 보인다. 여기에서 CoMP 측정 세트 내의 대응하는 CSI-RS 리소스를 갖는 임의의 다른 TP로부터의 CRS RE와 충돌하는 모든 PDSCH RE는 데이터 전송에 대해 뮤팅된다. 측정 세트가 반정적으로 설정되므로, 뮤팅을 갖는 PDSCH 매핑은 UE에 반정적으로 시그널링될 수 있다. 또한, CoMP 측정 크기의 최대 크기가 3으로 합의되어 있다. 따라서, 측정 세트에 기반한 PDSCH 뮤팅은 스펙트럼 효율 성능을 크게 저하시키지 않을 것이다.
대안 1:
CoMP
JT
또는
DPS
를 위해, 네트워크는 반정적으로
CoMP
UE
에, 해당 UE에의
PDSCH
에서의 데이터 전송으로부터 배제되는
UE
의
CoMP
측정 세트 내의 CSI-
RS
리소스
또는 TP에 대한 CRS RE 패턴의 조합을 통지한다.
UE CoMP에 CRS RE 패턴의 조합을 시그널링하도록, 측정 세트 내의 M개의 TP에 대해 주파수 변위 v, 및 CRS의 포트의 개수 p를, 즉 (vm,pm)(m=1,…,M)을 반정적으로 시그널링할 수 있다. 측정 세트 내의 각 TP로부터의 MBSFN 서브프레임의 정보는 반정적으로 CoMP UE에 시그널링될 수도 있다.
또한, 서빙 셀에 따라 PDSCH 매핑이 설정되는 CoMP CS/CB 전송을 수용하도록, UE에 대한 CRS RE 패턴의 신호와 함께 1 개의 추가 비트를 사용하여, 표 1에 나타낸 바와 같이 서빙 셀 또는 측정 세트 내의 모든 주변 CRS 위치에 따름을 지시한다. CRS RE의 조합은 해당 서브프레임 내의 기존 CRS RE의 조합임을 유념한다. MBSFN 서브프레임 설정이 CoMP UE에 시그널링될 경우, CRS RE의 조합은 MBSFN 서브프레임에 있으면 TP에 대한 CRS RE 패턴을 포함하지 않는다.
표 1. 대안 1에 대한 CoMP PDSCH RE 매핑 지시
이 반정적 접근법이 디폴트 접근법보다 더 좋은지에 대해 의문이 제기될 수 있다. 디폴트 접근법에서, eNB는 서빙 셀에 대한 것과 같이 임의의 전송 TP에 대한 PDSCH RE 매핑을 설정할 수 있다. DPS에서, 측정 세트 내의 서빙 TP 이외의 TP가 전송할 경우, 이 TP에 대해 CRS 위치에서의 PDSCH는 데이터 전송에 사용되지 않을 것이다. UE가 서빙 셀 PDSCH 매핑을 가정하고 있으므로, 더티 데이터/비트라고 불리는 실제 어떠한 데이터 정보도 반송하지 않는 이들 CRS 위치에서의 데이터의 디코딩을 시도할 것이다. 이들 시나리오의 성능을 평가하기 위해 간단한 시뮬레이션을 행한다. 길이 576 정보 비트가 1/2 레이트의 LTE 터보 코드를 이용하여 인코딩된다. CRS/PDSCH 충돌의 영향을 받는 총 5% 코딩 비트가 존재한다고 가정한다. 펑쳐링 5% 코딩 비트(PDSCH 뮤팅), 5% 더티 수신 데이터(순수 노이즈), 및 2.5% 펑쳐링 + 2.5% 더티 데이터를 갖는 AWGN 채널에서의 이 1/2 레이트 코드의 성능을 비교한다. 이 결과를 도 9에 나타낸다. 5% 더티 비트에서, 상당한 성능 저하가 있음을 알 수 있다. 충돌 RE 위치에서 절반의 더티 비트여도, 여전히 RE 뮤팅에 비해 눈에 띄는 성능 손실이 있다.
디폴트 접근법보다 성능 이득을 향상시키기 위해, 다음의 반정적 접근법을 고려할 수 있다.
대안 2:
CoMP
JT
또는
DPS
를 위해, 네트워크는 반정적으로
CoMP
UE
에, 해당
UE
의
CoMP
측정 세트 내의 각 TP에 대한 CRS 정보, 및 네트워크가 해당
UE
에
서빙하기
위해 따를
PDSCH
매핑을
통지한다.
이 접근법에서, 우선 대안 1에서와 같이 측정 세트 내의 각 TP에 대해 CRS 포트의 개수 및 CRS의 주파수 변위를 UE에 반정적으로 시그널링할 수 있다. 또한, CRS 정보는 TP 인덱스로 태그된다. 이어서, eNB가 PDSCH 매핑을 설정할 TP 인덱스에 대한 지시자를 UE에 시그널링한다. CoMP 측정 세트 내에 최대 3개의 CRS-RS 리소스가 있으므로, 2 비트 지시자이면 정보를 반송하는 데 충분하다. 표 2에 나타난 바와 같이, 서브프레임에서 모든 CRS RE 주변의 PDSCH 매핑의 옵션을 또한 포함할 수 있다. 이 접근법은 HetNet 시나리오에서 일부 UE에 셀 레인지 확장이 적용될 경우 특히 유용하며, 이 경우에 네트워크는 DL 데이터 전송을 위해 매크로 셀 eNB를 항상 설정할 수 있다.
표 2. 대안 2에 대한 CoMP PDSCH RE 매핑 지시
CRS 주파수 변위 또는 CRS 포트의 개수 대신, 측정 세트 내의 TP의 셀 ID의 리스트 및 연관된 CRS 포트의 개수를 UE에 시그널링할 수 있음을 유념한다. 측정 세트 내의 셀 ID가 CoMP UE에 시그널링될 경우, UE는 CoMP 측정 세트 내의 모든 CRS 신호를 디코딩할 수 있으므로, 간섭 해소가 실현될 수 있다. 또한, FeICIC에 대한 논의에서, 강한 CRS 간섭의 리스트가 UE에 시그널링되어서 UE가 간섭 해소를 행할 수 있는 것이 합의되었음을 유념한다. 아마도 측정 세트 내의 서빙 TP 이외의 TP가 이 리스트에 포함되어 있으므로, CoMP PDSCH 매핑을 위해 이 리스트를 재사용하여 신호 오버헤드를 줄이는 것이 가능하다. 네트워크는 또한, 반정적으로 UE에 PDSCH 개시점을 통지할 수 있다. 그러나, DPS에 대해, CoMP 측정 세트 내의 TP에 대한 PDSCH 개시점 사이에 불일치가 있을 경우, 스펙트럼 효율 손실이 야기될 것이다. 이하, PDSCH 매핑 정보를 동적으로 전하기 위해 다음의 하이브리드 접근법을 고려한다.
대안 3:
CoMP
JT
및
DPS
를 위해, 네트워크는, 해당
UE
의
CoMP
측정 세트 내의 각 TP에 대해
PDSCH
개시점
및 CRS 정보를
CoMP
UE
에 어떤 순서로 반정적으로 통지한다. 이어서, 네트워크는 대응하는 인덱스를 전함으로써
PDSCH
매핑이
따를 CRS 패턴 및
PDSCH
개시점을
UE
에 동적으로 통지한다.
이러한 접근법에서, 네트워크는, 우선 대안 1 또는 대안 2에서와 같이 측정 세트 내의 각 TP마다의 CRS 정보뿐만 아니라, PDCCH 영역이 반정적으로 변할 경우 각 TP에 대한 PDSCH 개시점을 UE에 반정적으로 시그널링한다. 이어서, 네트워크는 개시점을 포함하여 PDSCH 매핑이 따르는 TP의 인덱스를 동적으로 시그널링한다. 이러한 동적 신호는 추가적인 신호 필드를 도입하여 DCI에 특정될 수 있다. 신호는 CRS RE의 조합에서 뮤팅을 위한 인덱스가 필요하지 않은 점을 제외하고 표 2와 유사하다. PDSCH의 개시점이 측정 세트 내의 각 TP에 동적으로 설정될 경우, 또한 PDSCH 개시점을 보다 양호하게 동적으로 시그널링할 수 있다.
CoMP JT를 위해, 하나 이상의 TP가 전송에 관여될 것이다. 이 경우, 동적 시그널링이 이용 가능한 하이브리드 접근법에서, 셀 내의 모든 TP에 대한 CRS 위치를 피하는 매핑 대신, 모든 CRS RE를 순차적으로 점유하는 PDSCH RE 매핑을 제안하며, 이는 바로 충돌 CRS RE에서, MBSFN 서브프레임에서 모두 스케줄링되지 않았을 경우 단일 TP 또는 TP의 서브세트(3TP JT를 위해)가 단일 전송을 위해 할당될 수 있다는 것이다. 이어서, 다음의 대안 방식이 있다.
대안 4:
CoMP
JT
및
DPS
를 위해, 네트워크는 어느 순서로, 해당
UE
의 CoMP 측정 세트 내의 각 TP에 대한 CRS 정보를
CoMP
UE
에 반정적으로 통지한다. 이어서, 네트워크는, 대응하는 인덱스를 전하거나
UE
에 (CRS가 없다고 가정하는) 모든 CRS RE 위치를 점유하는
PDSCH
매핑을
지시함으로써
PDSCH
매핑이
따르는 CRS 패턴을
UE
에 동적으로 통지한다.
이어서, 표 3에 매핑 지시자에 대한 동적 신호가 주어져 있다. PDSCH 매핑 지시자가 11로 설정될 경우, PDSCH 개시점은, UE에 반정적으로 통지되는 측정 세트 내의 TP의 PDCCH 영역(또는 PDCCH OFDM 심볼)의 최소 또는 최대 크기를 가정하여 설정될 수 있다.
표 3. 대안 3, 4에 대한 CoMP PDSCH RE 매핑 지시
표 3에서의 처음 세 경우(00, 01, 10)는, 비 MBSFN 서브프레임에서 대응 지시된 TP 및 MBSFN 서브프레임에서 다른 TP로 JT에 적용될 수 있고, 이는 11로 지시될 수도 있다. CRS JT가 MBSFN 경우에 행해지지 않거나, 때때로 eNB를 이용하여 부분적 JT에 대한 보상을 실현할 수 있다. 표 3에서 마지막 경우 (11), 즉 CRS가 없다고 가정한 것에 대해, JT는 MBSFN 경우에 행해질 수 있다. 그러나, 때때로 eNB를 이용하여 부분적 JT에 대한 보상, 즉 단일 TP 또는 TP의 서브세트를 통한 전송(3TP JT를 위해)에 대한 보상을 실현할 수 있다. 또한, CRS가 없다고 가정한 PDSCH RE 매핑이 CRS 포트의 개수가 0인 패턴에서와 같이 포함될 수 있다.
UE는 프리코딩된 복조 참조 신호(DMRS)로 채널을 추정할 수 있고, 이어서 이러한 추정된 채널을 이용하여 리소스 블록 또는 리소스 그룹 내의 모든 데이터 심볼에 대한 데이터 심볼을 복조/검출한다. 모든 설정된 JT TP를 이용하여 일반 TP에 대한 것과 동일한 프리코딩으로, TP의 서브세트의 데이터 심볼을 전송할 경우, 복조 성능을 저하시킬 수 있는 채널 불일치가 있을 것이다. 일부 RE에서 부분적 JT를 행하고 UE가 다른 RE에서 일반 JT로서 복조를 위한 유사한 결합된 채널을 알 수 있도록, 부분적 JT에서 TP의 서브세트의 서로 다른 프리코딩을 이용하는 것을 고려할 수 있다. 이하, 설정 2TP JT를 위한 부분적 JT의 경우를 고려한다. 충돌 RE에서의 단일 TP의 전송을 위한 프리코딩은 다음과 같이 얻어질 수 있다. U1 및 U2는 JT에서 2 개의 TP에 채용되는 2 개의 프리코딩 매트릭스라고 가정한다. UE에서 보는 수신 신호는 다음과 같이 기재될 수 있다.
1-TP에서 데이터가 전송되는 부분적 JT에서, 범용성을 잃지 않는다면, TP-2를 가정하면, 다음을 얻는다.
UE가 동일한 결합 채널을 아는 것을 보장하도록, 다음 식과 같이 하며,
여기에서, H
2 - 1는 H
2의 우역원(right inverse), 즉
를 표시한다.
를 표기하고, 여기서
는 i 번째 TP(CSI-RS 리소스) 및 j 번째 레이어에 대한 SINR 피드백(예를 들면, 양자화 형태 CQI)이며 랭크 r의 바람직한 프리코딩 G
i를 수반한다. JT를 위한 2 개의 TP에서 공통 랭크를 가정한다. 네트워크는
로서 채널을 근사화할 수 있다.
이 얻어지며, 이 경우 다음 식과 같다.
상기 프리코딩 방식은 일반적인 경우, 즉 TP의 서브세트, 말하자면
의 일반 JT에 대한 m TP를 이용한 부분적 JT로 쉽게 확장될 수 있다.
이어서, 정규화된 U는 TP-2를 위한 프리코딩 매트릭스로서 채용될 수 있다. U가 정규화/스케일링되므로, eNB는 이 스케일링 결과가 허용 가능한 성능으로 되는지의 여부를 결정할 수 있다.
CRS 포트의 개수 및 그 주파수 변위(셀 ID를 대신함)를 이용하여 UE 측정 세트 내의 각 TP에 대해 CRS 패턴을 반정적으로 시그널링하기 위해, 표 4에는 CRS 패턴에 대한 4비트 인덱스가 정리되어 있다. 이 설정에서, CRS 패턴 인덱스의 MSB b3은 CRS 포트의 개수가 M=1(b3=0) 또는 M>1(b3=1)인지의 여부를 정의한다. b3=0일 경우, 나머지 3 비트(b2b1b0)는 주파수 변위를 지시한다. b3=1일 경우, 두 번째 MSB b2는 M=2(b2=0) 또는 M=4(b2=1)를 구분하는 데 사용되며, 나머지 2 비트(b1b0)는 주파수 변위(2진 표현)를 지시한다. 표 4에서의 인덱싱으로, CRS의 주파수 변위에 명시적으로 인덱스의 복수의 비트(1 개의 CRS 포트에 대해 3 비트, 2 또는 4 개의 CRS 포트에 대해 2 비트)가 항상 매핑되게 함을 알 수 있다. CRS가 없을 경우(CRS 포트의 개수=0)가 CRS 패턴의 하나로서 또한 반정적으로 시그널링될 필요가 있을 경우, 예약된 인덱스 중 하나, 예를 들면 b3b2b1b0=1111을 이용하여 이 정보를 전할 수 있다.
표 4. CRS 패턴 인덱스
이상의 논의에 의거하여, 반정적 접근법에 대해서, 대안 2는, 하나의 추가 비트 신호 오버헤드가 반정적 시그널링에 치명적이지는 않으므로 더 양호하게 보인다. 따라서 반정적 접근법에 대해, 다음을 제안한다.
제안 1:
CoMP
에서의
PDSCH
매핑을
위해, 네트워크는, 그
CoMP
측정 세트 내의 각 TP의 CRS 정보, 및 해당
UE
에
서빙하기
위해 네트워크가 따를
CoMP
측정 세트로부터의 TP의
PDSCH
매핑
또는
CoMP
측정 세트 내의 모든 TP의 CRS RE의 조합을 배제한
PDSCH
매핑
중 어느 하나의 지시자
를
,
CoMP UE에 반정적으로
통지한다.
PDSCH 매핑 문제를 처리하기 위해 일부 동적 시그널링(예를 들면, DCI 내의 2 비트)이 도입될 수 있는 경우, 대안-4가 바람직하다. 따라서, 표 3에 주어진 동적 시그널링을 갖는 하이브리드 접근법에 대해 다음을 제안한다.
제안 2:
CoMP
에서의
PDSCH
매핑을
위해, 네트워크는 그
CoMP
측정 세트 내의 각 TP의 CRS 정보를
CoMP
UE
에 반정적으로 통지한다. 이어서, 네트워크는, 식별용 인덱스를 전하거나,
PDSCH
매핑이
모든 CRS RE 위치를 점유할 것을 UE에 지시함으로써,
PDSCH
매핑이
따를 CRS 패턴을
UE
에 동적으로 통지한다.
식 (1)에서 제시된 프리코딩 방식은, JT CoMP 전송에 있어서 일부 RE에서 JT TP의 서브세트로부터 일부 데이터 심볼을 전송할 경우, 부분적 JT에 효율적 구현일 수 있다.
3. 결론
본 명세서에서, CoMP JT 및 DPS를 위한 PDSCH 매핑 문제를 논의했다. CoMP에서의 PDSCH 매핑을 위해 다음 두 가지 대안을 고려한다(하나는 반정적 시그널링만을 갖는 것 및 다른 하나는 동적 시그널링을 갖는 것).
제안 1:
CoMP
에서의
PDSCH
매핑을
위해, 네트워크는, 그
CoMP
측정 세트 내의 각 TP의 CRS 정보, 및 해당
UE
에
서빙하기
위해 네트워크가 따를
CoMP
측정 세트로부터의 TP의
PDSCH
매핑
또는
CoMP
측정 세트 내의 모든 TP의 CRS RE의 조합을 배제한
PDSCH
매핑
중 어느 하나의 지시자를,
CoMP
UE
에 반정적으로 통지한다.
제안 2:
CoMP
에서의
PDSCH
매핑을
위해, 네트워크는 그
CoMP
측정 세트 내의 각 TP의 CRS 정보를
CoMP
UE
에 반정적으로 통지한다. 이어서, 네트워크는, 식별용 인덱스를 전하거나,
PDSCH
매핑이
모든 CRS RE 위치를 점유함을
UE
에 지시함으로써,
PDSCH
매핑이
따를 CRS 패턴을
UE
에 동적으로 통지한다.
식 (1)에서 제시된 프리코딩 방식은, JT CoMP 전송에 있어서 일부 RE에서 JT TP의 서브세트로부터 일부 데이터 심볼을 전송할 경우, 부분적 JT에 효율적 구현일 수 있다. 또한, 표 4에서 제안된 CRS 패턴 인덱싱은, CRS의 주파수 변위에 인덱스의 복수의 비트가 명시적으로 매핑된다는 이점을 갖는다(1 개의 CRS 포트에 3 비트, 2 또는 4 개의 CRS 포트에 2 비트).
추가 시스템 세부 사항 D
1 서론
릴리스-11[6]에서는, 세 가지 CoMP 방식, 즉 JT(joint transmission), CS/CB(coordinated scheduling and beamforming), 및 DPS(dynamic point selection)이 지원되는 것이 합의되었다. CoMP CS/CB에서는, 종래의 단일 셀(CoMP가 없음) 시스템에서의 경우와 마찬가지로, 서빙 셀의 TP(transmission point)를 통해 데이터가 전송될 것이다. 따라서, CoMP CS/CB에 대한 PDSCH 매핑에는 문제가 없다. 그러나, CoMP JT 및 DPS에서는, 상기 TP 또는 서빙 셀 이외의 TP는 데이터 전송에 관여될 수 있다. 이 경우에, PDSCH RE 매핑에서 서로 다른 시그널링 구조로 인해 일부 문제, 예를 들면 서로 다른 TP에 대응하는 CRS RE 위치에 대한 서로 다른 주파수 변위, 및 서로 다른 TP에 대한 PDCCH 영역의 서로 다른 크기로 인해 PDSCH 개시점으로 인한 CRS/PDSCH 충돌이 일어난다. 이 문제는 현실화되어 CoMP 연구 항목 스테이지 자체에서 논의되었으며, CoMP WI[6][7]에 포함되어 있다.
RAN1#69에서, CoMP에서의 PDSCH RE 매핑 문제를 해결하기 위한 방법이 논의되었고, 이들 문제를 해결하기 위해 추가적인 다운링크 제어 시그널링이 필요할 수 있다. RAN1#69 미팅에서 다음이 합의되었다.
·PDSCH 전송이 일어날 수 있는 적어도 하나의 셀의 CRS 위치를 지시하는 시그널링을 제공함
°시그널링은 적어도 주파수 변위를 식별함
°CRS 안테나 포트의 개수에 대해 FFS
°MBSFN 서브프레임에 대해 FFS
·시그널링이 전송될 경우, PDSCH는 단일 셀의 지시된 CRS 주변의 릴리스 10 레이트 매칭을 따르며, 그렇지 않을 경우 UE는 서빙 셀의 CRS 위치를 가정한다.
°RAN1#70까지 PDSCH가 레이트 매칭되는 조합되는 CRS 패턴에 대해 최대 3개의 셀까지를 시그널링이 또한 지시할 수 있는지의 여부를 FFS
후보 접근법에 대해 더 논의하며 일부 세부적인 신호 설계를 제공한다.
2 논의
2.1
CoMP
에서의
PDSCH
매핑
문제
CoMP JT 및 DPS 전송에서, 서빙 셀 이외의 전송 포인트가 실제 데이터 전송에 관여하므로, 특정 가정 또는 추가 DL 제어 신호가 특정되지 않을 경우, UE는 정확한 PDSCH RE 매핑의 지식을 갖지 못한다. CoMP JT 및 DPS를 위한 PDSCH 매핑은 다음 문제가 있다.
·PDSCH 전송을 위한 전송 포인트의 CRS 위치 또는 CRS/PDSCH 충돌
·PDCCH 영역의 크기가 다른 것에 기인한 PDSCH의 개시점(OFDM 심볼).
·MBSFN 서브프레임의 정보.
2.2
CoMP
에서의
PDSCH
RE
매핑
솔루션
상기 동적 시그널링 대안의 논의에 앞서, 우선 가능한 반정적 접근법을 정리한다. 동적 접근법은 추가적인 신호 오버헤드로 현저한 성능 이득을 제공하지 않을 경우, 반정적 접근법은 트레이드오프 솔루션일 수 있다. 반정적 접근법에서, CRS 충돌 RE에서 PDSCH 뮤팅을 고려하며, 즉 CoMP 측정 세트 내의 대응하는 CSI-RE 리소스로 임의의 다른 TP로부터의 CRS RE와 충돌하는 PDSCH RE는 데이터 전송에 뮤팅된다. 측정 세트가 반정적으로 설정되므로, 뮤팅을 갖는 PDSCH 매핑이 UE에 반정적으로 시그널링될 수 있다. 또한, CoMP 측정 크기의 최대 크기가 3으로 합의되어 있다. 따라서, 측정 세트에 기반한 PDSCH 뮤팅은 스펙트럼 효율 성능을 크게 저하시키지는 않는다.
대안 1:
CoMP
JT
또는
DPS
를 위해, 네트워크는,
PDSCH
에서 해당
UE
에의 데이터 전송으로부터 배제되는
UE
의
CoMP
측정 세트 내의 CSI-
RS
리소스
또는 TP에 대한 CRS RE 패턴의 조합을,
CoMP
UE
에 반정적으로 통지한다.
UE CoMP에 CRS RE 패턴의 조합을 시그널링하기 위해, 측정 세트 내의 M개의 TP에 대해 주파수 변위 v, 및 CRS의 포트의 개수 p를, 즉 (vm,pm)(m=1,…,M)을 반정적으로 시그널링할 수 있다. 측정 세트 내의 각 TP로부터의 MBSFN 서브프레임의 정보가 또한 반정적으로 CoMP UE에 시그널링될 수 있다.
또한, 서빙 셀에 따라 PDSCH 매핑이 설정되는 CoMP CS/CB 전송을 수용하기 위해, UE에 대해 CRS RE 패턴의 신호와 함께 1 개의 추가 비트를 사용하여, 표 1에 나타낸 바와 같이 서빙 셀에 따름을 또는 측정 세트 내의 모든 CRS 위치 주변임을 지시한다. CRS RE의 조합은 해당 서브프레임 내의 기존 CRS RE의 조합임을 유념한다. MBSFN 서브프레임 설정이 CoMP UE에 시그널링될 경우, CRS RE의 조합은 그 MBSFN 서브프레임에 있으면 TP에 대한 CRS RE 패턴을 포함하지 않는다.
표 1. 대안 1에 대한 CoMP PDSCH RE 매핑 지시
디폴트 접근법보다 성능 이득을 향상시키기 위해, 다음의 반정적 접근법을 고려할 수 있다.
대안 2:
CoMP
JT
또는
DPS
를 위해, 네트워크는, 해당
UE
의
CoMP
측정 세트 내의 각 TP에 대한 CRS 정보, 및 네트워크가 해당
UE
를
서빙하기
위해 따를
PDSCH
매
핑을,
CoMP UE에 반정적으로
통지한다.
이 접근법에서, 우선 대안 1에서와 같이 측정 세트 내의 각 TP에 대한 CRS 포트의 개수 및 CRS의 주파수 변위를 UE에 반정적으로 시그널링할 수 있다. 또한, CRS 정보는 TP 인덱스로 태그된다. 이어서, eNB가 PDSCH 매핑을 설정할 TP 인덱스에 대한 지시자를 UE에 시그널링한다. CoMP 측정 세트 내에 최대 3개의 CRS-RS 리소스가 있으므로, 2 비트 지시자이면 정보를 반송하는 데 충분하다. 표 2에 나타난 서브프레임에서의 모든 CRS RE 주변의 PDSCH 매핑의 옵션을 또한 포함할 수 있다. 이 접근법은 HetNet 시나리오에서 일부 UE에 셀 레인지 확장이 적용될 경우 특히 유용하며, 이 경우에 네트워크는 DL 데이터 전송을 위해 매크로 셀 eNB를 항상 설정할 수 있다.
표 2. 대안 2에 대한 CoMP PDSCH RE 매핑 지시
CRS 주파수 변위 또는 CRS 포트의 개수 대신, 측정 세트 내의 TP의 셀 ID의 리스트 및 연관 CRS 포트의 개수를 UE에 시그널링할 수 있음을 유념한다. 측정 세트 내의 셀 ID가 CoMP UE에 시그널링될 경우, UE는 CoMP 측정 세트 내의 모든 CRS 신호를 디코딩할 수 있으므로, 간섭 해소가 실현될 수 있다. 또한, FeICIC에 대한 논의에서, 강한 CRS 간섭의 리스트가 UE에 시그널링되는 것이 UE가 간섭 해소를 행하도록 합의되어 있다. 아마도 측정 세트 내의 서빙 TP 이외의 TP가 이 리스트에 포함되어 있으므로, CoMP PDSCH 매핑에 이 리스트를 재사용하여 신호 오버헤드를 줄이는 것이 가능하다.
네트워크는 또한, 반정적으로 UE에 PDSCH 개시점을 통지할 수 있다. 그러나, DPS에 대해, CoMP 측정 세트 내의 TP에 대한 PDSCH 개시점 사이에 불일치가 있을 경우, 스펙트럼 효율 손실을 야기한다.
상술한 반정적 접근법에서, 제 4 상태에서, 데이터는 측정 세트 내의 CRS RE의 조합에서 전송되지 않는다. 보다 많은 지시 비트가 할당될 수 있을 경우, CoMP 측정 세트 내의 CRS RE의 조합의 측면에서 보다 많은 조합을 포함할 수 있다. 예를 들면, 3 비트 지시, 즉 8 스테이트에서, (최대 크기 3을 갖는) 측정 세트 내의 TP의 임의의 조합에 대한 CRS RE의 조합이 수용될 수 있다. 이어서 3 비트 지시자에 의해 UE에 전해지는 CRS RE 패턴의 조합을 배제하여 PDSCH RE 매핑을 따른다.
이 반정적 접근법은, CoMP 클러스터 외부의 강한 간섭 CRS의 정보가 FeICIC의 특징으로서 UE에게 이용 가능할 경우, 일반적인 경우로 더 확장될 수 있다. 일부 UE가 CoMP 클러스터의 경계에 위치하고 있음을 알고 있다. 따라서, 해당 UE에 대한 강한 간섭은 CoMP 클러스터 외부의 일부 TP로부터 오고 있는 한편, UE의 CoMP 측정 세트 내의 TP는 그에 필적하는 간섭 강도를 갖지 않을 수 있다. 간섭 CRS 리스트에 의거하여, UE는 CRS 간섭을 제거하는 간섭 해소를 행해 디코딩 성능을 향상시킬지라도, 이러한 특징을 포함하기 위해 UE에 추가적인 복잡성이 초래된다. UE 복잡도를 저감하기 위해, 하나의 솔루션은, 심지어 CoMP 외부의 TP에 의해 간섭되는 RE에서 데이터를 전송하지 않는 것이다. 이에 따라, UE는 간섭 해소를 하거나 이러한 특징을 가질 필요가 없다. 따라서, PDSCH 매핑은, CRS RE의 조합이 CoMP 외부의 TP를 포함하는 것을 피할 수 있다. 따라서, CRS RE의 조합은, CoMP 측정 세트 내 또는 CoMP 측정 세트 외부 및/또는 CoMP 클러스터의 TP 모두를 포함하는 리스트에서의 CRS RE 패턴의 임의의 조합일 수 있다.
이하, PDSCH 매핑 정보의 동적 시그널링을 갖는 하이브리드 접근법을 논의한다.
전술한 Alt-2는 1 비트를 사용하여, 단지 2 개의 CRS 패턴만을 포함할 수 있는 PDSCH 매핑 정보의 두 가지 상태를 지시한다. UE에 대한 CoMP 측정 세트의 최대 크기가 3이므로, 1 비트는 CRS 패턴 및 MBSFN 서브프레임 정보를 전하는 데 충분하지 않다. 높은 가능성으로 CoMP 측정 세트의 크기가 3이지만, CoMP 측정 세트 크기가 하나일 경우가 무시될 수는 없다. 따라서, 2 비트 동적 시그널링을 우선으로 한다.
이하, 다음의 접근법을 제시한다.
대안 3:
CoMP
JT
및
DPS
를 위해, 네트워크는, 해당
UE
의
CoMP
측정 세트 내의 각 TP에 대해
PDSCH
개시점
및
CRS
정보를
CoMP
UE
에 어떤 순서로 통지한다. 이어서, 네트워크는 대응하는 인덱스를 전함으로써
PDSCH
매핑이
따를
CRS
패턴 및 PDSCH
개시점을
UE
에 동적으로 통지한다.
이러한 접근법으로, 네트워크는, 우선 대안 1 또는 대안 2에서와 같이 측정 세트 내의 각 TP에 대한 CRS 정보뿐만 아니라, PDCCH 영역이 반정적으로 변할 경우 각 TP에 대한 PDSCH 개시점을 UE에 반정적으로 시그널링한다. 이어서, 네트워크는 개시점을 가능한 포함하여 PDSCH 매핑이 따르는 TP의 인덱스를 동적으로 시그널링한다. 이러한 동적 신호는 추가적인 신호 필드로 DCI에 특정될 수 있다. 2 비트 동적 신호는 CRS RE의 조합에서 뮤팅에 대한 상태가 필요하지 않은 점을 제외하고 표 2와 유사하다. PDSCH 개시점이 측정 세트 내의 각 TP에 대해 동적으로 설정될 수 있다. 이 접근법에서, MBSFN 서브프레임 설정은 또한 UE에 반정적으로 통지되고 하나의 TP 또는 하나의 CSI-RS 리소스에 연관된다. 또한, 2 비트 DCI는 지시된 TP 또는 CSI-RS 리소스를 따르는 의사 동일 위치 가정을 지시할 수도 있다.
표 3. 대안 3에 대한 CoMP PDSCH RE 매핑 지시
표 3에서의 세 가지 상태(00, 01, 10)는 비 MBSFN 서브프레임에서의 대응 지시된 TP 및 해당 MBSFN 서브프레임에서의 다른 TP의 JT에도 적용될 수 있다. CRS가 없음을 나타내는 제 4 상태(또는 동등하게는 CRS 안테나 포트 0)를 사용하여 모든 TP에 대해 MBSFN에서 JT CoMP를 지시할 수 있다. 이러한 접근법으로, MBSFN 서브프레임 설정의 반정적 시그널링은, MBSFN에서의 임의의 전송에 대해 이러한 지시에 상태-11을 이용할 수 있으므로, 필요하지 않을 수 있다. 그러나, 상태-11을 이용하여 MBSFN 설정의 반정적 정보 없이 MBSFN 서브프레임에서 PDSCH 매핑을 시그널링하는 것의 한 가지 문제는, 2 비트 DCI로 의사 동일 위치 지시를 지원하지 않는다는 것이다.
여기에서, MBSFN 서브프레임 설정이 반정적으로 전해진다면, CRS가 없다고 가정한 PDSCH 매핑을 지시하는 상태-11이 필요할지의 여부에 대한 의문이 있다. 그것이 여전히 유용하다고 생각된다. 예를 들면, JT가 2개 또는 3 개의 TP 또는 MBSFN 서브프레임 전체에서 스케줄링될 경우, 상태-11이 없다면, 처음 3개의 상태 중 하나의 상태가 UE에 시그널링되며, 이는 UE가 어느 TP를 따라 의사 동일 위치를 가정해야함을 의미한다. 마찬가지로, 주파수 선택 DPS에서, 서로 다른 주파수 리소스 블록에서가 아닌 동일한 서브프레임에서 서로 다른 TP를 따라 신호가 전송될 수 있다. 그러나, CoMP JT 또는 주파수 선택 DPS에 대해, 하나의 TP에 따른 이러한 부분적 의사 동일 위치 지시는 시스템 성능을 저하시키는 가능성이 있다. 따라서, 하나의 상태, 예를 들면 2 비트 DCI의 상태-11을 이용하여 CRS가 없음 및 의사 동일 위치 가정이 없음을 가정하는 PDSCH RE 매핑을 지시하는 것을 제안한다.
대안 4:
CoMP
에서의
PDSCH
매핑을
위해, 네트워크는, 해당
CoMP
측정 세트 내의 각 TP의 가능한 의사 동일 위치 정보 및 CRS 정보를 포함하는 속성을 CoMP
UE
에 반정적으로 통지한다. 이어서, 네트워크는 이를 식별하는 인덱스를 전함으로써 CRS 패턴 및 다른 속성을
UE
에 동적으로 통지하거나,
PDSCH
매핑이
(CRS 없음, 예를 들면
MBSFN
서브프레임을 가정하여) 모든 CRS RE 위치를 점유하고 의사 동일 위치 가정이 이루어질 필요가 없음을
UE
에 지시한다.
표 4에는 지시자를 매핑하기 위한 동적 신호가 주어져 있다. PDSCH 개시점 및 CRS 정보 및 의사 동일 위치 등과 같은 다른 속성이 표의 엔트리와 반정적으로 연관될 수 있다.
표 4. 대안 4에 대한 CoMP PDSCH RE 매핑 지시
CRS 포트의 개수 및 그 주파수 변위(셀 ID 대신)를 이용하여 UE 측정 세트 내의 각 TP에 대해 CRS 패턴을 반정적으로 시그널링하기 위해, 표 4에는 CRS 패턴에 대한 4비트 인덱스가 정리되어 있다. 이 설정으로, CRS 패턴 인덱스의 MSB b3은 CRS 포트의 개수가 M=1(b3=0) 또는 M>1(b3=1)인지의 여부를 정의한다. b3=0일 경우, 나머지 3 비트(b2b1b0)는 주파수 변위를 지시한다. b3=1일 경우, 두 번째 MSB b2는 M=2(b2=0) 또는 M=4(b2=1)를 구분하는 데 사용되며, 나머지 2 비트(b1b0)는 주파수 변위를 지시한다. CRS가 없는 경우(CRS 포트의 개수=0)가 또한 시그널링될 필요가 있을 경우, 예약된 인덱스 중 하나, 예를 들면 b3b2b1b0=1111을 이용하여 이 정보를 전할 수 있다.
표 5. CRS 패턴
하나의 중요한 관찰은, 시스템 설계를 만족하면서 모든 CoMP 사용자에 대해 표 4에서와 같이 공통 표를 이용하는 것이 리소스의 시그널링에 최선의 이용이 아니라는 점이다.
예를 들면, CoMP 측정 세트 사이즈가 2인 사용자를 고려한다. 이어서, 이 사용자에 대해, 표 4를 이용하는 것은, 10에 대응하는 엔트리가 결코 사용되지 않으므로 최적의 선택이 아닐 것이다.
따라서, 하나의 대안은, CoMP 측정 세트 사이즈가 2인 모든 사용자를 커버하는 1 비트를 이용하는 다른 표를 설계하는 것이다. 사용자의 CoMP 측정 세트만이 반정적으로 변하므로, 사용되는 표의 선택은 CoMP 측정 세트와 함께 단지 반정적으로 설정될 필요가 있다.
다른 대안은 2 비트의 공통 크기를 갖지만, CoMP 측정 세트 크기에 의존적인 매핑 지시(즉, 표 내의 엔트리)를 해석하는 것이다. 이 방식으로, 표 4로 가능한 것보다 CoMP 측정 세트 사이즈가 2인 사용자에 대해 보다 많은 정보가 전해질 수 있다.
이 접근법의 예는 다음의 표 4b이다. 여기에서, 엔트리 10은 CRS 없음을 가정하여 PDSCH 매핑이 행해지고, 또한 사용자는 TP-1의 의사 동일 위치를 가정해야함을 사용자(CoMP 측정 세트 사이즈가 2임)에게 전한다. 이는 TP-1의 MBSFN 정보가 사용자에 대해 반정적으로 설정되지 않았다면 유익하다. 따라서, 사용자가 MBSFN 서브프레임에서 TP-1에 의해 데이터를 서빙받도록 스케줄링될 경우, 사용자는 엔트리 10을 이용하여 통지받아서, 사용자는 그를 위한 PDSCH 매핑이 CRS 없음을 가정하여 행해짐을 알게 되며 TP-1에 대한 CSI-RS 동안 추정된 파라미터를 이용하여 DMRS 기반의 추정기를 초기화하고, 이에 따라 향상된 성능을 달성하게 된다. 유사한 사실이 TP-2와 관련하여 엔트리 11에 대해 성립한다.
표 4b. CoMP PDSCH RE 매핑 지시
이 아이디어를 확장하여, 사용자에 대해, TP-1의 MBSFN 정보가 반정적으로 설정되지만 TP-2의 MBSFN 정보는 설정되지 않은 경우를 상정한다. 이어서, 네트워크는 다음의 표 4c를 채용할 수 있다.
표 4c. CoMP PDSCH RE 매핑 지시
여기에서, OO이 지시될 때마다, CRS 없음이 가정될 경우 TP-1의 MBSFN을 제외하고 TP-1의 CRS를 가정하여 사용자를 위한 PDSCH 매핑이 행해져 있음을 사용자는 알게 된다. 이제 사용자는 프레임이 TP-1을 위한 MBSFN인지의 여부를 판정하는 능력을 앞서 갖게 된다. 결과적으로, 표 4c에서와 같이, 엔트리 10의 사용이 불필요해진다. 따라서, 표 4c에서, 엔트리 10을 이용하여 사용자에게, 자신을 위한 PDSCH 매핑이 CRS가 없음을 가정하고 또한 임의의 의사 동일 위치 정보를 사용하지 않고 행해져 있음을 통지한다. 이는, 사용자가 서로 다른 의사 동일 위치 관련 파라미터를 갖는 2 개의 TP에 의해 서빙받는 일부 경우, 및 하나의 TP의 부분적 의사 동일 위치 정보를 사용자에게 지시하는 데 적합하지 않은 일부 경우를 커버한다.
다음으로, TP-1 및 TP-2 양쪽의 MBSFN 정보가 반정적으로 설정된 것을 상정한다. 여기에서, 표 설계의 예는 표 4d일 수 있다.
표 4d. CoMP PDSCHE RE 매핑 지시
여기에서, 엔트리 11을 이용하여, 양쪽 TP의 CRS 위치가 동일하고(양쪽 TP에 대해 동일한 셀 ID를 갖고 동일한 포트의 개수를 갖는 시나리오와 마찬가지임), 서로 다른 의사 동일 위치 관련 파라미터를 가지는 양쪽 TP에 의해 사용자가 서빙받고, 부분 의사 동일 위치 정보를 사용자에게 지시하는 데 적합하지 않은 경우를 커버한다.
유사한 방식으로, CoMP 세트 크기가 1인 사용자는 레거시 포맷을 이용하여 서빙받을 수 있다. 또는, 2 또는 1 비트 동적 지시 필드를 갖지만, 대응하는 표 내의 엔트리가 CoMP 측정 세트 크기 1에 대한 규칙에 따라 재해석되는 DCI를 이용하여 서빙될 수 있다.
예를 들면, 이 경우에, 데이터 서빙 TP는 항상 고정되므로, CRS 위치 및 MBSFN 정보가 이미 사용자에게 알려져 있을 경우, 엔트리는 서빙 TP의 CRS 및 강한 간섭자의 CRS의 조합의 배제를 가정하는 PDSCH 매핑을 지시하는 데 사용될 수 있다. 여기에서, 간섭자의 리스트 및 그 속성의 일부(CRS 위치 등)는 네트워크와 사용자 간에서 일부 반정적 설정 메커니즘을 통해 알려짐을 가정한다. 다음의 표를 고려한다.
표 4e. CoMP PDSCH RE 매핑 지시
표 4e에서, 예를 들면 엔트리 01은, TP-1의 CRS 위치 및 가장 강한 제 1 간섭자의 조합에 의해 커버되는 RE 위치를 제외한 PDSCH 매핑을 가정함을 사용자에게 전한다. 이 방식으로, 복잡도로 인한, 또는 이 해소에 필요한 파라미터를 정확하게 추정하는 데 있어서의 무능력으로 인한 CRS 간섭 해소를 행할 수 없는 사용자는 강한 간섭을 갖는 위치에서 데이터를 디코딩을 시도하지 않으므로 이점이 있을 수 있다.
표 4e에서의 지시자는 1 비트 지시자가 채택될 경우 처음 두 가지 상태만을 전하도록 축소될 수 있음을 유념한다.
마지막으로, 각 CoMP 측정 세트 크기에 대해, 표의 코드북이 정의될 수 있다. 그리고, 네트워크가 사용할 표의 코드북으로부터의 테이블의 선택은 반정적으로, 또한 사용자 특정 방식으로 설정될 수 있다.