KR20160010652A - 불충분한 탐색 콘텐츠 식별 - Google Patents
불충분한 탐색 콘텐츠 식별 Download PDFInfo
- Publication number
- KR20160010652A KR20160010652A KR1020167000665A KR20167000665A KR20160010652A KR 20160010652 A KR20160010652 A KR 20160010652A KR 1020167000665 A KR1020167000665 A KR 1020167000665A KR 20167000665 A KR20167000665 A KR 20167000665A KR 20160010652 A KR20160010652 A KR 20160010652A
- Authority
- KR
- South Korea
- Prior art keywords
- topic
- search
- corpus
- measure
- serviced
- Prior art date
- Legal status (The legal status is an assumption and is not a legal conclusion. Google has not performed a legal analysis and makes no representation as to the accuracy of the status listed.)
- Granted
Links
Images


Classifications
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F17/00—Digital computing or data processing equipment or methods, specially adapted for specific functions
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/953—Querying, e.g. by the use of web search engines
- G06F16/9532—Query formulation
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/40—Information retrieval; Database structures therefor; File system structures therefor of multimedia data, e.g. slideshows comprising image and additional audio data
- G06F16/41—Indexing; Data structures therefor; Storage structures
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06F—ELECTRIC DIGITAL DATA PROCESSING
- G06F16/00—Information retrieval; Database structures therefor; File system structures therefor
- G06F16/90—Details of database functions independent of the retrieved data types
- G06F16/95—Retrieval from the web
- G06F16/951—Indexing; Web crawling techniques
-
- G06F17/3002—
-
- G06F17/30864—
-
- G—PHYSICS
- G06—COMPUTING OR CALCULATING; COUNTING
- G06Q—INFORMATION AND COMMUNICATION TECHNOLOGY [ICT] SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES; SYSTEMS OR METHODS SPECIALLY ADAPTED FOR ADMINISTRATIVE, COMMERCIAL, FINANCIAL, MANAGERIAL OR SUPERVISORY PURPOSES, NOT OTHERWISE PROVIDED FOR
- G06Q30/00—Commerce
- G06Q30/02—Marketing; Price estimation or determination; Fundraising
Landscapes
- Engineering & Computer Science (AREA)
- Theoretical Computer Science (AREA)
- Physics & Mathematics (AREA)
- Databases & Information Systems (AREA)
- General Physics & Mathematics (AREA)
- Business, Economics & Management (AREA)
- General Engineering & Computer Science (AREA)
- Data Mining & Analysis (AREA)
- Development Economics (AREA)
- Strategic Management (AREA)
- Finance (AREA)
- Accounting & Taxation (AREA)
- Game Theory and Decision Science (AREA)
- Entrepreneurship & Innovation (AREA)
- Economics (AREA)
- Marketing (AREA)
- General Business, Economics & Management (AREA)
- Software Systems (AREA)
- Mathematical Physics (AREA)
- Multimedia (AREA)
- Information Retrieval, Db Structures And Fs Structures Therefor (AREA)
Abstract
색인어
토픽, 코퍼스, 탐색, 엔진, 통계, 분석, 수집, 랭크, 관련도, 분배
Description
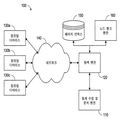
도2는 콘텐츠 생성자에게 토픽을 제안하는 시스템을 구비한 네트워크 환경의 블록도이다.
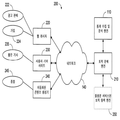
도3은 시스템 내에서 불충분한 웹 콘텐츠를 확인하기 위한 데이터 흐름을 예시하는 블록도이다.
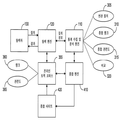
도4는 시스템 내에서 부적절하게 서비스되는 것으로 확인된 토픽에 관련된 웹 콘텐츠를 수집하는 데이터 흐름을 예시하는 블록도이다.
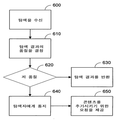
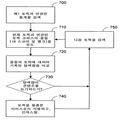
도5~7은 불충분한 웹 콘텐츠를 확인하는 예시적 방법을 나타내는 흐름도이다.
Claims (21)
- 컴퓨터에 의해 구현되는 방법(computer-implemented method)으로서,
데이터 프로세싱 디바이스가 사용자에 의해 제출된 탐색 질의(search query)를 명시하는(specifying) 데이터를 수신하는 단계와;
데이터 프로세싱 디바이스가 상기 탐색 질의가 속하는 특정한 탐색 토픽(search topic)을 결정하는 단계와;
데이터 프로세싱 디바이스가 상기 탐색 질의가 속하는 상기 특정한 탐색 토픽이 불충분 서비스된 토픽(underserved topic)으로서 분류됨을 결정하는 단계와,
여기서 상기 불충분 서비스된 토픽은 상대적인 토픽 코퍼스 품질 측정치(relative topic corpus quality measure)가 임계값(threshold value)보다 낮은탐색 토픽이고,
상기 상대적인 토픽 코퍼스 품질 측정치는 상기 탐색 토픽에 속하는 것으로서 식별된 질의들에 대한 질의 탐색량 값(query search volume value)에 상대적인 상기 탐색 토픽에 대한 토픽 코퍼스에 포함된 문서들에 대한 관련도 측정치(relevance measure)이고,
상기 질의 탐색량은 상기 탐색 질의가 수신된 횟수에 비례하는 값이며; 그리고
데이터 프로세싱 장치가 상기 탐색 질의를 수신하는 것에 응답하여, 상기 탐색 질의가 불충분 서비스된 토픽에 속한다는 통지를 표시하도록 하는 데이터를 제공하는 단계를 포함하는 것을 특징으로 하는 컴퓨터에 의해 구현되는 방법. - 제 1항에 있어서,
상기 불충분 서비스된 토픽에 대해 새로운 컨텐츠를 수신하는 단계와;
상기 새로운 컨텐츠가 상기 불충분 서비스된 토픽에 대한 상대적인 토픽 코퍼스 품질 측정치를 증가시킴을 결정하는 단계와; 그리고
상기 상대적인 토픽 코퍼스 품질 측정치에 대한 증가에 기초해서 상기 새로운 컨텐츠의 제공자에게 보상하는 단계를 더 포함하는 것을 특징으로 하는 컴퓨터에 의해 구현되는 방법. - 제 2항에 있어서,
상기 새로운 컨텐츠가 상기 상대적인 토픽 코퍼스 품질 측정치를 증가시킴을 결정하는 단계는 상기 새로운 컨텐츠가 상기 불충분 서비스된 토픽에 대한 토픽 코퍼스에 포함된 문서들에 대한 상기 관련도 측정치를 증가시킴을 결정하는 것을 포함하는 것을 특징으로 하는 컴퓨터에 의해 구현되는 방법. - 제 2항에 있어서,
상기 제공자에 대한 보상의 값(value of the compensation)을 결정하는 단계를 더 포함하며, 상기 보상의 값은 상기 불충분 서비스된 토픽에 대한 수요(demand)와 상기 불충분 서비스된 토픽의 토픽 코퍼스 품질 측정치에 기초해서 결정되는 것을 특징으로 하는 컴퓨터에 의해 구현되는 방법. - 제 1항에 있어서,
토픽 코퍼스의 상기 특정한 탐색 토픽에 대한 관련도의 측정치를 획득하는 단계와;
상기 특정한 탐색 토픽에 대한 토픽 탐색량 값을 획득하는 단계와, 상기 토픽 탐색량 값은 상기 특정한 탐색 토픽에 대응하는 수신된 탐색 질의들의 횟수를 표시하는 값이며;
상기 관련도의 측정치 및 상기 토픽 탐색량 값에 기초해서 상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치를 계산하는 단계와;
상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치가 상기 임계값보다 낮음을 결정하는 단계와; 그리고
상기 특정한 탐색 토픽을 불충분 서비스된 토픽으로서 분류하는 단계를 더 포함하는 것을 특징으로 하는 컴퓨터에 의해 구현되는 방법. - 제 5항에 있어서,
상기 특정한 탐색 토픽에 대한 토픽 탐색량의 임계값 내에 있는 토픽 탐색량들을 갖는 다른 탐색 토픽들에 대한 토픽 코퍼스 품질 측정치들을 획득하는 단계와; 그리고
상기 다른 탐색 토픽들에 대한 토픽 코퍼스 품질 측정치들에 기초해서 상기 임계값을 결정하는 단계를 더 포함하는 것을 특징으로 하는 컴퓨터에 의해 구현되는 방법. - 제 5항에 있어서,
토픽 코퍼스의 상기 특정한 탐색 토픽에 대한 관련도의 측정치를 획득하는 단계와;
상기 특정한 탐색 토픽에 대한 토픽 탐색량 값을 획득하는 단계와, 상기 토픽 탐색량 값은 상기 특정한 탐색 토픽에 대응하는 수신된 탐색 질의들의 횟수를 표시하는 값이며;
상기 관련도의 측정치 및 상기 토픽 탐색량 값에 기초해서 상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치를 계산하는 단계와;
상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치의 임계값 내에 있는 토픽 코퍼스 품질 측정치를 갖는 다른 탐색 토픽들에 대한 토픽 탐색량 값들을 획득하는 단계와;
상기 다른 탐색 토픽들에 대한 탐색량 값들에 기초해서 임계 탐색량 값을 결정하는 단계와;
상기 특정한 탐색 토픽에 대한 토픽 탐색량이 상기 임계 탐색량 값을 초과함을 결정하는 단계와;
상기 특정한 탐색 토픽을 불충분 서비스된 토픽으로서 분류하는 단계를 더 포함하는 것을 특징으로 하는 컴퓨터에 의해 구현되는 방법. - 시스템으로서,
불충분 서비스된 토픽들과 상기 불충분 서비스된 토픽들에 속하는 것으로서 식별된 탐색 질의들을 표시하는 불충분 서비스된 토픽 데이터(underserved topic data)를 저장하는 데이터 저장소와,
여기서 불충분 서비스된 토픽은 상대적인 토픽 코퍼스 품질 측정치가 임계값보다 낮은 탐색 토픽이고,
상기 상대적인 토픽 코퍼스 품질 측정치는 상기 탐색 토픽에 속하는 것으로서 식별된 질의들에 대한 질의 탐색량 값에 상대적인 상기 탐색 토픽에 대한 토픽 코퍼스에 포함된 문서들에 대한 관련도 측정치이고,
상기 질의 탐색량은 상기 탐색 질의가 수신된 횟수에 비례하는 값이며;
상기 데이터 저장소와 인터렉션(interaction)하도록 구성된 하나 이상의 컴퓨터들을 포함하며, 상기 하나 이상의 컴퓨터들은:
사용자에 의해 제출된 탐색 질의를 명시하는 데이터를 수신하는 동작과;
상기 불충분 서비스된 토픽 데이터에 적어도 부분적으로 기초해서, 상기 탐색 질의가 특정한 불충분 서비스된 토픽에 속함을 결정하는 동작과; 그리고
상기 탐색 질의를 수신함에 응답하여, 상기 탐색 질의가 불충분 서비스된 토픽에 속한다는 통지를 표시하도록 하는 데이터를 제공하는 동작을 포함하는 동작들을 수행하도록 더 구성되는 것을 특징으로 하는 시스템. - 제 8항에 있어서,
상기 하나 이상의 컴퓨터들은:
상기 특정한 불충분 서비스된 토픽에 대한 새로운 컨텐츠를 수신하는 동작과;
상기 새로운 컨텐츠가 상기 특정한 불충분 서비스된 토픽에 대한 상기 상대적인 토픽 코퍼스 품질 측정치를 증가시킴을 결정하는 동작과; 그리고
상기 상대적인 토픽 코퍼스 품질 측정치에 대한 증가에 기초해서 상기 새로운 컨텐츠의 제공자에게 보상하는 동작을 포함하는 동작들을 수행하도록 더 구성되는 것을 특징으로 하는 시스템. - 제 9항에 있어서,
상기 새로운 컨텐츠가 상기 상대적인 토픽 코퍼스 품질 측정치를 증가시킴을 결정하는 동작은 상기 새로운 컨텐츠가 상기 특정한 불충분 서비스된 토픽에 대한 토픽 코퍼스에 포함된 문서들에 대한 상기 관련도 측정치를 증가시킴을 결정하는 것을 포함하는 것을 특징으로 하는 시스템. - 제 9항에 있어서,
상기 하나 이상의 컴퓨터들은 상기 제공자에 대한 보상의 값을 결정하는 동작을 포함하는 동작들을 수행하도록 더 구성되며, 상기 보상의 값은 상기 특정한 불충분 서비스된 토픽에 대한 수요와 상기 특정한 불충분 서비스된 토픽의 토픽 코퍼스 품질 측정치에 기초해서 결정되는 것을 특징으로 하는 시스템. - 제 8항에 있어서,
상기 하나 이상의 컴퓨터들은:
특정한 탐색 토픽에 대한 토픽 코퍼스의 관련도의 측정치를 획득하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 탐색량 값을 획득하는 동작과, 상기 토픽 탐색량 값은 상기 특정한 탐색 토픽에 대응하는 수신된 탐색 질의들의 횟수를 표시하는 값이며;
상기 관련도의 측정치 및 상기 토픽 탐색량 값에 기초해서 상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치를 계산하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치가 상기 임계값보다 낮음을 결정하는 동작과; 그리고
상기 특정한 탐색 토픽을 불충분 서비스된 토픽으로서 분류하는 동작을 포함하는 동작들을 수행하도록 더 구성되는 것을 특징으로 하는 시스템. - 제 12항에 있어서,
상기 특정한 탐색 토픽에 대한 토픽 탐색량의 임계값 내에 있는 토픽 탐색량들을 갖는 다른 탐색 토픽들에 대한 토픽 코퍼스 품질 측정치들을 획득하는 동작과; 그리고
상기 다른 탐색 토픽들에 대한 토픽 코퍼스 품질 측정치들에 기초해서 상기 임계값을 결정하는 동작을 더 포함하는 것을 특징으로 하는 시스템. - 제 12항에 있어서,
상기 특정한 탐색 토픽에 대한 토픽 코퍼스의 관련도의 측정치를 획득하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 탐색량 값을 획득하는 동작과, 상기 토픽 탐색량 값은 상기 특정한 탐색 토픽에 대응하는 수신된 탐색 질의들의 횟수를 표시하는 값이며;
상기 관련도의 측정치 및 상기 토픽 탐색량 값에 기초해서 상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치를 계산하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치의 임계값 내에 있는 토픽 코퍼스 품질 측정치들을 갖는 다른 탐색 토픽들에 대한 토픽 탐색량 값들을 획득하는 동작과;
상기 다른 탐색 토픽들에 대한 탐색량 값들에 기초해서 임계 탐색량 값을 결정하는 동작과;
상기 특정한 탐색 토픽에 대한 상기 토픽 탐색량 값이 상기 임계 탐색량 값을 초과함을 결정하는 동작과; 그리고
상기 특정한 탐색 토픽을 불충분 서비스된 토픽으로서 분류하는 동작을 더 포함하는 것을 특징으로 하는 시스템. - 실행시에 하나 이상의 컴퓨터들로 하여금 동작들을 수행하도록 하는 명령어들을 포함하는 컴퓨터 프로그램이 수록된 메모리 디바이스(memory device)로서, 상기 동작들은:
데이터 프로세싱 디바이스가 사용자에 의해 제출된 탐색 질의를 명시하는 데이터를 수신하는 동작과;
데이터 프로세싱 디바이스가 상기 탐색 질의가 속하는 특정한 탐색 토픽을 결정하는 동작과;
데이터 프로세싱 디바이스가 상기 탐색 질의가 속하는 특정한 탐색 토픽이 불충분 서비스된 토픽으로서 분류됨을 결정하는 동작과,
상기 불충분 서비스된 토픽은 상대적인 토픽 코퍼스 품질 측정치가 임계값보다 낮은 탐색 토픽이고,
상기 상대적인 토픽 코퍼스 품질 측정치는 상기 탐색 토픽에 속하는 것으로서 식별된 질의들에 대한 질의 탐색량 값에 상대적인 상기 탐색 토픽에 대한 토픽 코퍼스에 포함된 문서들의 관련도 측정치이고,
상기 질의 탐색량 값은 상기 탐색 질의가 수신된 횟수에 비례하는 값이며; 그리고
데이터 프로세싱 디바이스가 상기 탐색 질의를 수신함에 응답하여, 상기 탐색 질의가 불충분 서비스된 토픽에 속한다는 통지를 표시하도록 하는 데이터를 제공하는 동작을 포함하는 것을 특징으로 하는 메모리 디바이스. - 제 15항에 있어서,
상기 하나 이상의 컴퓨터들로 하여금:
상기 불충분 서비스된 토픽에 대한 새로운 컨텐츠를 수신하는 동작과;
상기 새로운 컨텐츠가 상기 불충분 서비스된 토픽에 대한 상기 상대적인 토픽 코퍼스 품질 측정치를 증가시킴을 결정하는 동작과; 그리고
상기 상대적인 토픽 코퍼스 품질 측정치에 대한 증가에 기초해서 상기 새로운 컨텐츠의 제공자에게 보상하는 동작을 포함하는 동작들을 수행하도록 하는 명령어들을 더 포함하는 것을 특징으로 하는 메모리 디바이스. - 제 16항에 있어서,
상기 새로운 컨텐츠가 상기 상대적인 토픽 코퍼스 품질 측정치를 증가시킴을 결정하는 동작은 상기 새로운 컨텐츠가 상기 불충분 서비스된 토픽에 대한 토픽 코퍼스에 포함된 문서들에 대한 관련도 측정치를 증가시킴을 결정하는 것을 포함하는 것을 특징으로 하는 메모리 디바이스. - 제 16항에 있어서,
상기 하나 이상의 컴퓨터들로 하여금:
상기 제공자에 대한 보상의 값을 결정하는 동작을 포함하는 동작들을 수행하도록 하는 명령어들을 더 포함하며, 상기 보상의 값은 상기 불충분 서비스된 토픽에 대한 수요 및 상기 불충분 서비스된 토픽의 토픽 코퍼스 품질 측정치에 기초해서 결정되는 것을 특징으로 하는 메모리 디바이스. - 제 15항에 있어서,
상기 하나 이상의 컴퓨터들로 하여금:
상기 특정한 탐색 토픽에 대한 토픽 코퍼스의 관련도의 측정치를 획득하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 탐색량 값을 획득하는 동작과, 상기 토픽 탐색량 값은 상기 특정한 탐색 토픽에 대응하는 수신된 탐색 질의들의 횟수를 표시하는 값이며;
상기 관련도의 측정치 및 상기 토픽 탐색량 값에 기초해서 상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치를 계산하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치가 상기 임계값보다 낮음을 결정하는 동작과; 그리고
상기 특정한 탐색 토픽을 불충분 서비스된 토픽으로서 분류하는 동작을 포함하는 동작들을 수행하도록 하는 명령어들을 더 포함하는 것을 특징으로 하는 메모리 디바이스. - 제 19항에 있어서,
상기 하나 이상의 컴퓨터들로 하여금:
상기 특정한 탐색 토픽에 대한 토픽 탐색량의 임계값 내에 있는 토픽 탐색량들을 갖는 다른 탐색 토픽들에 대한 토픽 코퍼스 품질 측정치들을 획득하는 동작과;
상기 다른 탐색 토픽들에 대한 토픽 코퍼스 품질 측정치들에 기초해서 상기 임계값을 결정하는 동작을 포함하는 동작들을 수행하도록 하는 명령어들을 더 포함하는 것을 특징으로 하는 메모리 디바이스. - 제 19항에 있어서,
상기 하나 이상의 컴퓨터들로 하여금:
상기 특정한 탐색 토픽에 대한 토픽 코퍼스의 관련도의 측정치를 획득하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 탐색량 값을 획득하는 동작과, 상기 토픽 탐색량 값은 상기 특정한 탐색 토픽에 대응하는 수신된 탐색 질의들의 횟수를 표시하는 값이며;
상기 관련도의 측정치 및 상기 토픽 탐색량 값에 기초해서 상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치를 계산하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 코퍼스 품질 측정치의 임계값 내에 있는 토픽 코퍼스 품질 측정치들을 갖는 다른 탐색 토픽들에 대한 토픽 탐색량 값들을 획득하는 동작과;
상기 다른 탐색 토픽들에 대한 탐색량 값들에 기초해서 임계 탐색량 값을 결정하는 동작과;
상기 특정한 탐색 토픽에 대한 토픽 탐색량이 상기 임계 탐색량 값을 초과함을 결정하는 동작과; 그리고
상기 특정한 탐색 토픽을 불충분 서비스된 토픽으로서 분류하는 동작을 포함하는 동작들을 수행하도록 하는 명령어들을 더 포함하는 것을 특징으로 하는 메모리 디바이스.
Applications Claiming Priority (3)
| Application Number | Priority Date | Filing Date | Title |
|---|---|---|---|
| US11/695,725 | 2007-04-03 | ||
| US11/695,725 US7668823B2 (en) | 2007-04-03 | 2007-04-03 | Identifying inadequate search content |
| PCT/US2008/059303 WO2008124531A1 (en) | 2007-04-03 | 2008-04-03 | Identifying inadequate search content |
Related Parent Applications (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020097023002A Division KR101587966B1 (ko) | 2007-04-03 | 2008-04-03 | 불충분한 탐색 콘텐츠 식별 |
Publications (2)
| Publication Number | Publication Date |
|---|---|
| KR20160010652A true KR20160010652A (ko) | 2016-01-27 |
| KR101639773B1 KR101639773B1 (ko) | 2016-07-15 |
Family
ID=39827730
Family Applications (2)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020097023002A Expired - Fee Related KR101587966B1 (ko) | 2007-04-03 | 2008-04-03 | 불충분한 탐색 콘텐츠 식별 |
| KR1020167000665A Expired - Fee Related KR101639773B1 (ko) | 2007-04-03 | 2008-04-03 | 불충분한 탐색 콘텐츠 식별 |
Family Applications Before (1)
| Application Number | Title | Priority Date | Filing Date |
|---|---|---|---|
| KR1020097023002A Expired - Fee Related KR101587966B1 (ko) | 2007-04-03 | 2008-04-03 | 불충분한 탐색 콘텐츠 식별 |
Country Status (5)
| Country | Link |
|---|---|
| US (3) | US7668823B2 (ko) |
| EP (1) | EP2145262A4 (ko) |
| KR (2) | KR101587966B1 (ko) |
| CN (1) | CN101681352B (ko) |
| WO (1) | WO2008124531A1 (ko) |
Families Citing this family (46)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US8126874B2 (en) * | 2006-05-09 | 2012-02-28 | Google Inc. | Systems and methods for generating statistics from search engine query logs |
| US7668823B2 (en) | 2007-04-03 | 2010-02-23 | Google Inc. | Identifying inadequate search content |
| US7672937B2 (en) * | 2007-04-11 | 2010-03-02 | Yahoo, Inc. | Temporal targeting of advertisements |
| US8311996B2 (en) * | 2008-01-18 | 2012-11-13 | Microsoft Corporation | Generating content to satisfy underserved search queries |
| US8001131B2 (en) | 2008-12-17 | 2011-08-16 | Demand Media Inc. | Method and system for ranking of keywords for profitability |
| US20100223093A1 (en) * | 2009-02-27 | 2010-09-02 | Hubbard Robert B | System and method for intelligently monitoring subscriber's response to multimedia content |
| US8145623B1 (en) * | 2009-05-01 | 2012-03-27 | Google Inc. | Query ranking based on query clustering and categorization |
| US8572109B1 (en) | 2009-05-15 | 2013-10-29 | Google Inc. | Query translation quality confidence |
| US8577910B1 (en) | 2009-05-15 | 2013-11-05 | Google Inc. | Selecting relevant languages for query translation |
| US8577909B1 (en) | 2009-05-15 | 2013-11-05 | Google Inc. | Query translation using bilingual search refinements |
| US8538957B1 (en) * | 2009-06-03 | 2013-09-17 | Google Inc. | Validating translations using visual similarity between visual media search results |
| US8356047B2 (en) * | 2009-10-01 | 2013-01-15 | International Business Machines Corporation | Intelligent event-based data mining of unstructured information |
| US8954404B2 (en) * | 2010-02-24 | 2015-02-10 | Demand Media, Inc. | Rule-based system and method to associate attributes to text strings |
| US8825648B2 (en) | 2010-04-15 | 2014-09-02 | Microsoft Corporation | Mining multilingual topics |
| US8909623B2 (en) | 2010-06-29 | 2014-12-09 | Demand Media, Inc. | System and method for evaluating search queries to identify titles for content production |
| AU2011291544B2 (en) * | 2010-08-19 | 2015-03-26 | Google Llc | Predictive query completion and predictive search results |
| US20120158765A1 (en) * | 2010-12-15 | 2012-06-21 | Microsoft Corporation | User Interface for Interactive Query Reformulation |
| US9251185B2 (en) * | 2010-12-15 | 2016-02-02 | Girish Kumar | Classifying results of search queries |
| US8799297B2 (en) | 2011-03-21 | 2014-08-05 | Aol Inc. | Evaluating supply of electronic content relating to keywords |
| US8510285B1 (en) * | 2011-08-18 | 2013-08-13 | Google Inc. | Using pre-search triggers |
| CN102662957B (zh) * | 2012-03-02 | 2015-02-18 | 百度在线网络技术(北京)有限公司 | 用于优化浏览器的搜索结果页面的装置及方法 |
| US9165053B2 (en) * | 2013-03-15 | 2015-10-20 | Xerox Corporation | Multi-source contextual information item grouping for document analysis |
| US9400840B2 (en) * | 2013-03-25 | 2016-07-26 | Salesforce.Com, Inc. | Combining topic suggestions from different topic sources to assign to textual data items |
| US9405803B2 (en) * | 2013-04-23 | 2016-08-02 | Google Inc. | Ranking signals in mixed corpora environments |
| US9626438B2 (en) | 2013-04-24 | 2017-04-18 | Leaf Group Ltd. | Systems and methods for determining content popularity based on searches |
| US9275115B2 (en) | 2013-07-16 | 2016-03-01 | International Business Machines Corporation | Correlating corpus/corpora value from answered questions |
| US10063450B2 (en) * | 2013-07-26 | 2018-08-28 | Opentv, Inc. | Measuring response trends in a digital television network |
| US11004139B2 (en) | 2014-03-31 | 2021-05-11 | Monticello Enterprises LLC | System and method for providing simplified in store purchases and in-app purchases using a use-interface-based payment API |
| US12008629B2 (en) | 2014-03-31 | 2024-06-11 | Monticello Enterprises LLC | System and method for providing a social media shopping experience |
| US11080777B2 (en) * | 2014-03-31 | 2021-08-03 | Monticello Enterprises LLC | System and method for providing a social media shopping experience |
| US10511580B2 (en) | 2014-03-31 | 2019-12-17 | Monticello Enterprises LLC | System and method for providing a social media shopping experience |
| US11915303B2 (en) | 2014-03-31 | 2024-02-27 | Monticello Enterprises LLC | System and method for providing a social media shopping experience |
| US9754207B2 (en) | 2014-07-28 | 2017-09-05 | International Business Machines Corporation | Corpus quality analysis |
| CN105786936A (zh) | 2014-12-23 | 2016-07-20 | 阿里巴巴集团控股有限公司 | 用于对搜索数据进行处理的方法及设备 |
| US11042591B2 (en) | 2015-06-23 | 2021-06-22 | Splunk Inc. | Analytical search engine |
| US10866994B2 (en) * | 2015-06-23 | 2020-12-15 | Splunk Inc. | Systems and methods for instant crawling, curation of data sources, and enabling ad-hoc search |
| CN106936778B (zh) * | 2015-12-29 | 2020-05-05 | 北京国双科技有限公司 | 网站流量异常的检测方法和装置 |
| US10409818B1 (en) * | 2016-08-04 | 2019-09-10 | Google Llc | Populating streams of content |
| US10423614B2 (en) | 2016-11-08 | 2019-09-24 | International Business Machines Corporation | Determining the significance of an event in the context of a natural language query |
| US10459960B2 (en) * | 2016-11-08 | 2019-10-29 | International Business Machines Corporation | Clustering a set of natural language queries based on significant events |
| US10977242B2 (en) * | 2017-09-07 | 2021-04-13 | Atlassian Pty Ltd. | Systems and methods for managing designated content items |
| US11461340B2 (en) * | 2018-01-16 | 2022-10-04 | Sony Interactive Entertainment LLC | Adaptive search using social graph information |
| US12047373B2 (en) | 2019-11-05 | 2024-07-23 | Salesforce.Com, Inc. | Monitoring resource utilization of an online system based on browser attributes collected for a session |
| US11368464B2 (en) * | 2019-11-28 | 2022-06-21 | Salesforce.Com, Inc. | Monitoring resource utilization of an online system based on statistics describing browser attributes |
| US11238052B2 (en) | 2020-06-08 | 2022-02-01 | International Business Machines Corporation | Refining a search request to a content provider |
| US12423371B2 (en) * | 2022-05-02 | 2025-09-23 | Adobe Inc. | Utilizing machine learning models to process low-results web queries and generate web item deficiency predictions and corresponding user interfaces |
Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060044525A (ko) * | 2004-03-22 | 2006-05-16 | 마이크로소프트 코포레이션 | 검색 결과 관련성의 자동화된 최적화를 위한 시스템 및방법 |
| KR20060044299A (ko) * | 2004-03-09 | 2006-05-16 | 마이크로소프트 코포레이션 | 사용자의 검색 의도를 결정하기 위한 시스템, 방법 및 컴퓨터 판독 가능 매체 |
| KR20060050484A (ko) * | 2004-09-20 | 2006-05-19 | 마이크로소프트 코포레이션 | 지식 교환 질의를 수신하고 그에 응답하기 위한 방법,시스템 및 장치 |
| KR20060050486A (ko) * | 2004-09-20 | 2006-05-19 | 마이크로소프트 코포레이션 | 지식 교환 프로파일을 생성하기 위한 방법, 시스템 및 장치 |
Family Cites Families (30)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| US5469354A (en) * | 1989-06-14 | 1995-11-21 | Hitachi, Ltd. | Document data processing method and apparatus for document retrieval |
| US5694546A (en) * | 1994-05-31 | 1997-12-02 | Reisman; Richard R. | System for automatic unattended electronic information transport between a server and a client by a vendor provided transport software with a manifest list |
| US6460036B1 (en) * | 1994-11-29 | 2002-10-01 | Pinpoint Incorporated | System and method for providing customized electronic newspapers and target advertisements |
| US6029195A (en) * | 1994-11-29 | 2000-02-22 | Herz; Frederick S. M. | System for customized electronic identification of desirable objects |
| US5915249A (en) * | 1996-06-14 | 1999-06-22 | Excite, Inc. | System and method for accelerated query evaluation of very large full-text databases |
| US7050992B1 (en) * | 1998-03-03 | 2006-05-23 | Amazon.Com, Inc. | Identifying items relevant to a current query based on items accessed in connection with similar queries |
| US7076504B1 (en) * | 1998-11-19 | 2006-07-11 | Accenture Llp | Sharing a centralized profile |
| US7275061B1 (en) * | 2000-04-13 | 2007-09-25 | Indraweb.Com, Inc. | Systems and methods for employing an orthogonal corpus for document indexing |
| US6901402B1 (en) * | 1999-06-18 | 2005-05-31 | Microsoft Corporation | System for improving the performance of information retrieval-type tasks by identifying the relations of constituents |
| US7181438B1 (en) * | 1999-07-21 | 2007-02-20 | Alberti Anemometer, Llc | Database access system |
| US6519586B2 (en) * | 1999-08-06 | 2003-02-11 | Compaq Computer Corporation | Method and apparatus for automatic construction of faceted terminological feedback for document retrieval |
| US6691108B2 (en) * | 1999-12-14 | 2004-02-10 | Nec Corporation | Focused search engine and method |
| US20040205065A1 (en) * | 2000-02-10 | 2004-10-14 | Petras Gregory J. | System for creating and maintaining a database of information utilizing user opinions |
| US7080073B1 (en) * | 2000-08-18 | 2006-07-18 | Firstrain, Inc. | Method and apparatus for focused crawling |
| US6795820B2 (en) | 2001-06-20 | 2004-09-21 | Nextpage, Inc. | Metasearch technique that ranks documents obtained from multiple collections |
| KR100509276B1 (ko) | 2001-08-20 | 2005-08-22 | 엔에이치엔(주) | 웹페이지별 방문인기도에 기반한 웹페이지 검색방법 및 그장치 |
| US8180784B2 (en) * | 2003-03-28 | 2012-05-15 | Oracle International Corporation | Method and system for improving performance of counting hits in a search |
| US7685117B2 (en) | 2003-06-05 | 2010-03-23 | Hayley Logistics Llc | Method for implementing search engine |
| US7577655B2 (en) * | 2003-09-16 | 2009-08-18 | Google Inc. | Systems and methods for improving the ranking of news articles |
| US7277884B2 (en) * | 2004-02-17 | 2007-10-02 | Microsoft Corporation | Method and system for generating help files based on user queries |
| KR20050104713A (ko) | 2004-04-29 | 2005-11-03 | 엔에이치엔(주) | 지역의 인기 정보를 제공하는 방법 및 지역 인기 정보제공 시스템 |
| US20060074843A1 (en) * | 2004-09-30 | 2006-04-06 | Pereira Luis C | World wide web directory for providing live links |
| KR100599450B1 (ko) * | 2004-12-21 | 2006-07-12 | 한국전자통신연구원 | 질의응답시스템에서의 정답색인 시스템 및 방법 |
| US7962510B2 (en) * | 2005-02-11 | 2011-06-14 | Microsoft Corporation | Using content analysis to detect spam web pages |
| US20070130112A1 (en) * | 2005-06-30 | 2007-06-07 | Intelligentek Corp. | Multimedia conceptual search system and associated search method |
| US20070016545A1 (en) | 2005-07-14 | 2007-01-18 | International Business Machines Corporation | Detection of missing content in a searchable repository |
| US20070106685A1 (en) * | 2005-11-09 | 2007-05-10 | Podzinger Corp. | Method and apparatus for updating speech recognition databases and reindexing audio and video content using the same |
| WO2007067703A2 (en) * | 2005-12-08 | 2007-06-14 | Intelligent Search Technologies | Search engine with increased performance and specificity |
| US20070294240A1 (en) * | 2006-06-07 | 2007-12-20 | Microsoft Corporation | Intent based search |
| US7668823B2 (en) * | 2007-04-03 | 2010-02-23 | Google Inc. | Identifying inadequate search content |
-
2007
- 2007-04-03 US US11/695,725 patent/US7668823B2/en active Active
-
2008
- 2008-04-03 WO PCT/US2008/059303 patent/WO2008124531A1/en not_active Ceased
- 2008-04-03 KR KR1020097023002A patent/KR101587966B1/ko not_active Expired - Fee Related
- 2008-04-03 EP EP08745042A patent/EP2145262A4/en not_active Ceased
- 2008-04-03 KR KR1020167000665A patent/KR101639773B1/ko not_active Expired - Fee Related
- 2008-04-03 CN CN2008800181298A patent/CN101681352B/zh not_active Expired - Fee Related
-
2010
- 2010-02-03 US US12/699,418 patent/US8037063B2/en not_active Expired - Fee Related
-
2011
- 2011-09-23 US US13/242,517 patent/US9020933B2/en active Active
Patent Citations (4)
| Publication number | Priority date | Publication date | Assignee | Title |
|---|---|---|---|---|
| KR20060044299A (ko) * | 2004-03-09 | 2006-05-16 | 마이크로소프트 코포레이션 | 사용자의 검색 의도를 결정하기 위한 시스템, 방법 및 컴퓨터 판독 가능 매체 |
| KR20060044525A (ko) * | 2004-03-22 | 2006-05-16 | 마이크로소프트 코포레이션 | 검색 결과 관련성의 자동화된 최적화를 위한 시스템 및방법 |
| KR20060050484A (ko) * | 2004-09-20 | 2006-05-19 | 마이크로소프트 코포레이션 | 지식 교환 질의를 수신하고 그에 응답하기 위한 방법,시스템 및 장치 |
| KR20060050486A (ko) * | 2004-09-20 | 2006-05-19 | 마이크로소프트 코포레이션 | 지식 교환 프로파일을 생성하기 위한 방법, 시스템 및 장치 |
Also Published As
| Publication number | Publication date |
|---|---|
| KR20100016192A (ko) | 2010-02-12 |
| WO2008124531A1 (en) | 2008-10-16 |
| US20120016887A1 (en) | 2012-01-19 |
| KR101639773B1 (ko) | 2016-07-15 |
| US9020933B2 (en) | 2015-04-28 |
| EP2145262A4 (en) | 2012-08-01 |
| KR101587966B1 (ko) | 2016-01-22 |
| US20080249786A1 (en) | 2008-10-09 |
| US7668823B2 (en) | 2010-02-23 |
| EP2145262A1 (en) | 2010-01-20 |
| US8037063B2 (en) | 2011-10-11 |
| US20100138421A1 (en) | 2010-06-03 |
| CN101681352B (zh) | 2012-04-25 |
| CN101681352A (zh) | 2010-03-24 |
Similar Documents
| Publication | Publication Date | Title |
|---|---|---|
| KR101639773B1 (ko) | 불충분한 탐색 콘텐츠 식별 | |
| US8090621B1 (en) | Method and system for associating feedback with recommendation rules | |
| US9792332B2 (en) | Mining of user event data to identify users with common interests | |
| Kim et al. | A scientometric review of emerging trends and new developments in recommendation systems | |
| US8494897B1 (en) | Inferring profiles of network users and the resources they access | |
| CA2634918C (en) | Analyzing content to determine context and serving relevant content based on the context | |
| US7574426B1 (en) | Efficiently identifying the items most relevant to a current query based on items selected in connection with similar queries | |
| US20100030647A1 (en) | Advertisement selection for internet search and content pages | |
| US20110066615A1 (en) | Personalization engine for building a user profile | |
| US20130046584A1 (en) | Page reporting | |
| US20110040604A1 (en) | Systems and Methods for Providing Targeted Content | |
| JP2002157394A (ja) | ネットワークマーケティングシステム | |
| US10013699B1 (en) | Reverse associate website discovery | |
| Ashkan et al. | Impact of query intent and search context on clickthrough behavior in sponsored search | |
| WO2010087882A1 (en) | Personalization engine for building a user profile | |
| Ashkan et al. | Estimating ad clickthrough rate through query intent analysis | |
| Thor et al. | AWESOME: a data warehouse-based system for adaptive website recommendations | |
| Franke et al. | Recommender services in scientific digital libraries | |
| KR20030063275A (ko) | 인터넷 상에서의 타겟팅 광고를 위한 광고 시스템 및 방법 | |
| HK1142702A (en) | Identifying inadequate search content | |
| Ashkan | Characterizing User Search Intent and Behavior for Click Analysis in Sponsored Search | |
| Thor et al. | AWESOME–A Data Warehouse-based System for Adaptive | |
| Vattikonda | An Advertiser Centered Approach to Improve Sponsored Search Effectiveness |
Legal Events
| Date | Code | Title | Description |
|---|---|---|---|
| A107 | Divisional application of patent | ||
| A201 | Request for examination | ||
| PA0104 | Divisional application for international application |
St.27 status event code: A-0-1-A10-A16-div-PA0104 St.27 status event code: A-0-1-A10-A18-div-PA0104 |
|
| PA0201 | Request for examination |
St.27 status event code: A-1-2-D10-D11-exm-PA0201 |
|
| PG1501 | Laying open of application |
St.27 status event code: A-1-1-Q10-Q12-nap-PG1501 |
|
| E902 | Notification of reason for refusal | ||
| PE0902 | Notice of grounds for rejection |
St.27 status event code: A-1-2-D10-D21-exm-PE0902 |
|
| E13-X000 | Pre-grant limitation requested |
St.27 status event code: A-2-3-E10-E13-lim-X000 |
|
| P11-X000 | Amendment of application requested |
St.27 status event code: A-2-2-P10-P11-nap-X000 |
|
| P13-X000 | Application amended |
St.27 status event code: A-2-2-P10-P13-nap-X000 |
|
| E701 | Decision to grant or registration of patent right | ||
| PE0701 | Decision of registration |
St.27 status event code: A-1-2-D10-D22-exm-PE0701 |
|
| GRNT | Written decision to grant | ||
| PR0701 | Registration of establishment |
St.27 status event code: A-2-4-F10-F11-exm-PR0701 |
|
| PR1002 | Payment of registration fee |
Fee payment year number: 1 St.27 status event code: A-2-2-U10-U12-oth-PR1002 |
|
| PG1601 | Publication of registration |
St.27 status event code: A-4-4-Q10-Q13-nap-PG1601 |
|
| PN2301 | Change of applicant |
St.27 status event code: A-5-5-R10-R11-asn-PN2301 St.27 status event code: A-5-5-R10-R13-asn-PN2301 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-4-4-P10-P22-nap-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-4-4-P10-P22-nap-X000 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-4-4-P10-P22-nap-X000 |
|
| FPAY | Annual fee payment |
Payment date: 20190627 Year of fee payment: 4 |
|
| PR1001 | Payment of annual fee |
Fee payment year number: 4 St.27 status event code: A-4-4-U10-U11-oth-PR1001 |
|
| PR1001 | Payment of annual fee |
Fee payment year number: 5 St.27 status event code: A-4-4-U10-U11-oth-PR1001 |
|
| P22-X000 | Classification modified |
St.27 status event code: A-4-4-P10-P22-nap-X000 |
|
| PR1001 | Payment of annual fee |
Fee payment year number: 6 St.27 status event code: A-4-4-U10-U11-oth-PR1001 |
|
| PR1001 | Payment of annual fee |
Fee payment year number: 7 St.27 status event code: A-4-4-U10-U11-oth-PR1001 |
|
| PC1903 | Unpaid annual fee |
Not in force date: 20230709 Payment event data comment text: Termination Category : DEFAULT_OF_REGISTRATION_FEE St.27 status event code: A-4-4-U10-U13-oth-PC1903 |
|
| PC1903 | Unpaid annual fee |
Ip right cessation event data comment text: Termination Category : DEFAULT_OF_REGISTRATION_FEE Not in force date: 20230709 St.27 status event code: N-4-6-H10-H13-oth-PC1903 |